エラーを見つけた時に最初にすること

このセクションでは、新しくチューニングされたTransformerモデルから予測を生成しようとするときに起こる事ができる、いくつかの一般的なエラーについて見ていきましょう。これはセクション4の準備となり、学習段階をデバッグする方法を見ていきましょう。
この章の為にテンプレートレポジトリーを用意しました。この章のコードを実行したい場合は、まずモデルをハギングフェイスハブ(Hugging Face Hub)のアカウントにコピーする必要があります。まずJupyterNotebookでログインしましょう
from huggingface_hub import notebook_login
notebook_login()それとも、ターミナルを使いながら:
huggingface-cli login
ユーザー名とパスワードを入力する画面が表示されます。Authentification token が ~/.cache/huggingface/の中にセーブされます。ログインした後に以下の機能でテンプレートリポジトリをコピーすることができます
from distutils.dir_util import copy_tree
from huggingface_hub import Repository, snapshot_download, create_repo, get_full_repo_name
def copy_repository_template():
# Clone the repo and extract the local path
template_repo_id = "lewtun/distilbert-base-uncased-finetuned-squad-d5716d28"
commit_hash = "be3eaffc28669d7932492681cd5f3e8905e358b4"
template_repo_dir = snapshot_download(template_repo_id, revision=commit_hash)
# Create an empty repo on the Hub
model_name = template_repo_id.split("/")[1]
create_repo(model_name, exist_ok=True)
# Clone the empty repo
new_repo_id = get_full_repo_name(model_name)
new_repo_dir = model_name
repo = Repository(local_dir=new_repo_dir, clone_from=new_repo_id)
# Copy files
copy_tree(template_repo_dir, new_repo_dir)
# Push to Hub
repo.push_to_hub()copy_repository_template()機能はテンプレートレポジトリーをアカウントにコピーします。
🤗 Transformers パイプラインのデバグ
Transformerモデルとパイプラインのデバッグという素晴らしい世界への旅を始めるにあたり、次のようなシナリオを考えてみましょう。あなたは同僚と一緒に、あるeコマースサイトに関するお客さんの答えを見つけられるように、‘Question Answering’のプロジェクトに取り組んでいます。あなたの同僚はこんなメッセージを送りました。
どうも! 先ほど、【第7章】(/course/chapter7/7) のテクニックを使って実験をしたところ、SQuADデータセットで素晴らしい結果が得られました!Hub上のモデルIDは”lewtun/distilbert-base-uncased-finetuned-squad-d5716d28”です。このモデルをぜひテストしてみましょう!
さて、🤗 Transformers でモデルをロードするために pipeline を使いましょう!
from transformers import pipeline
model_checkpoint = get_full_repo_name("distillbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""残念!どうしてもエラーが発生しました。プログラミングが初めての方はこんなメッセージは怖そうに見えます。(OSErrorは何?)。このようなエラーは、Python traceback と呼ばれる、より大きなエラーレポートの最後の部分です。このエラーは、Google Colabで実行した場合には、次のような画像が表示されます。
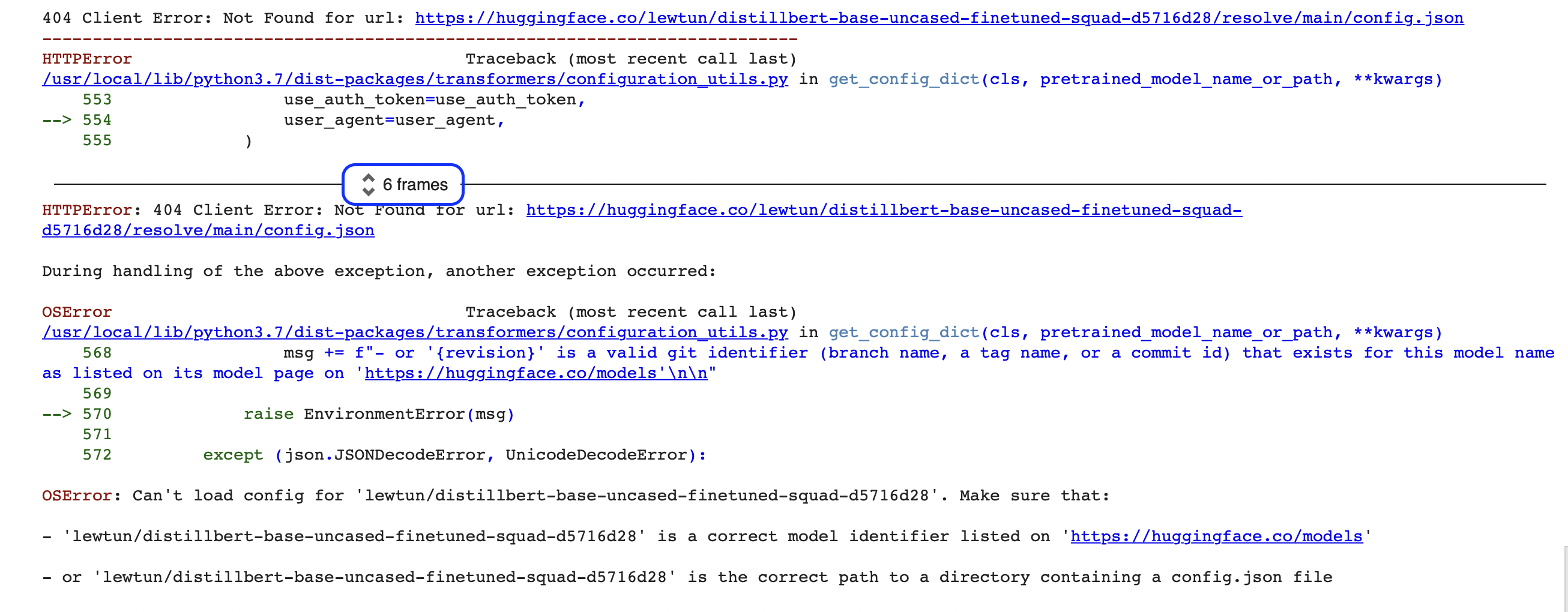
このレポートには多くの情報が含まれているので、主要な部分を一緒に見ていきましょう。まず注意すべきは、トレースバックは下から上へ読むということです(日本語の逆の読み方ですね!)。これは、エラートレースバックが、モデルとトークナイザーをダウンロードするときに pipeline が行う一連の関数呼び出しを反映していますいます(詳しくは第2章)をご覧下さい。
🚨 Google Colabのトレースバックで、「6frames」のあたりに青い枠があるのが見えますか?これはColabの特別な機能で、トレースバックを “フレーム “に圧縮しているのです。もしエラーの原因が詳しく見つからないようであれば、この2つの小さな矢印をクリックして、トレースバックの全容を拡大してみてください。
これは、トレースバックの最後の行が、発生したエラーの名前を与えることをします。エラーのタイプは OSError で、これはシステム関連のエラーを示しています。付属のエラーメッセージを読むと、モデルの config.json ファイルに問題があるようで、それを修正するための2つの提案を与えられています。
"""
Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""💡 理解しがたいエラーメッセージが表示された場合は、そのメッセージをコピーしてGoogle または Stack Overflow の検索バーに貼り付けてください! そのエラーに遭遇したのはあなたが初めてではない可能性が高いですし、コミュニティの他の人が投稿した解決策を見つける良い方法です。例えば、OSError: Can't load config for を Stack Overflow で検索すると、いくつかの ヒント が見付けられます。これは、問題解決の出発点として使うことができます。
最初の提案は、モデルIDが実際に正しいかどうかを確認するよう求めているので、まず、識別子をコピーしてHubの検索バーに貼り付けましょう。

うーん、確かに同僚のモデルはハブにないようだ…しかし、モデルの名前にタイプミスがある! DistilBERTの名前には「l」が1つしかないので、それを直して、代わりに「lewtun/distilbert-base-uncased-finetuned-squad-d5716d28」を探そう!

さて、これでヒットしました。では、正しいモデルIDで再度ダウンロードをしてみましょう。
model_checkpoint = get_full_repo_name("distilbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""ああ、また失敗だ。機械学習エンジニアの日常へようこそ! モデルIDは修正できたので、問題はリポジトリ自体にあるはずです。🤗 Hub上のリポジトリの内容にアクセスする簡単な方法は、huggingface_hubライブラリの list_repo_files() 関数を使用することです。
from huggingface_hub import list_repo_files
list_repo_files(repo_id=model_checkpoint)['.gitattributes', 'README.md', 'pytorch_model.bin', 'special_tokens_map.json', 'tokenizer_config.json', 'training_args.bin', 'vocab.txt']リポジトリには config.json ファイルがないようです! どうりで pipeline がモデルを読み込めないわけです。同僚がこのファイルをHubにプッシュするのを忘れたに違いありません。この場合、問題を解決するのは簡単です。ファイルを追加するように依頼するか、モデルIDから使用された事前学習済みモデルがdistilbert-base-uncasedであることがわかるので、そのモデルのconfig(設定)をダウンロードし、我々のリポジトリにプッシュして問題が解決するか確認することができます。それでは試してみましょう。第2章で学んだテクニックを使って、AutoConfigクラスでモデルの設定をダウンロードすることができます。
from transformers import AutoConfig
pretrained_checkpoint = "distilbert-base-uncased"
config = AutoConfig.from_pretrained(pretrained_checkpoint)🚨 同僚は distilbert-base-uncased の設定を間違えていじったかもしれないです。実際のところ、私たちはまず彼らに確認したいところですが、このセクションの目的では、彼らがデフォルトの設定を使用したと仮定することにします。
それでpush_to_hub() 機能でモデルの設定をリポジトリにプッシュすることができます。
config.push_to_hub(model_checkpoint, commit_message="Add config.json")そしては、最新のコミットを main ブランチから読み込こんでみましょう。
reader = pipeline("question-answering", model=model_checkpoint, revision="main")
context = r"""
Extractive Question Answering is the task of extracting an answer from a text
given a question. An example of a question answering dataset is the SQuAD
dataset, which is entirely based on that task. If you would like to fine-tune a
model on a SQuAD task, you may leverage the
examples/pytorch/question-answering/run_squad.py script.
🤗 Transformers is interoperable with the PyTorch, TensorFlow, and JAX
frameworks, so you can use your favourite tools for a wide variety of tasks!
"""
question = "What is extractive question answering?"
reader(question=question, context=context){'score': 0.38669535517692566,
'start': 34,
'end': 95,
'answer': 'the task of extracting an answer from a text given a question'}やったね! これで、お疲れ様でした。今までのことを一緒に振り返ってみましょう。
- Pythonのエラーメッセージは traceback と呼ばれ、下から上へと読み上げられます。エラーメッセージの最後の行は一番必要な情報を含んでいます。
- エラーメッセージが複雑な場合は、traceback を読み上げながらエラーが発生したソースコードファイル名や行番号を指定して、エラーの原因を読み取ることができます。
- その場合でもデバグすることができないなら、インターネット上にを検索してみましょう。
huggingface_hubライブラリは、Hubのリポジトリを使用するため一連のツールを提供します。デバッグするために使用できるのツールも含めています。
パイプラインのデバッグ方法がわかったところで、モデルのフォワードパスで難しい例を見てみましょう。
モデルのフォワードパスをデバッグ
時にはモデルのロジットにアクセスする必要があります(例えば、カスタムなパイプラインを使いたい場合で)。このような場合、何が問題になるかを知るために、まず pipeline からモデルとトークナイザーを取得してみましょう。
tokenizer = reader.tokenizer model = reader.model
次に必要なのは、お気に入りのフレームワークがサポートされているかどうかという質問です。
question = "Which frameworks can I use?"第7章で見たように、通常必要なステップは、入力のトークン、開始と終了トークンのロジット、そして解答スパンのデコードです。
import torch
inputs = tokenizer(question, context, add_special_tokens=True)
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Get the most likely beginning of answer with the argmax of the score
answer_start = torch.argmax(answer_start_scores)
# Get the most likely end of answer with the argmax of the score
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/var/folders/28/k4cy5q7s2hs92xq7_h89_vgm0000gn/T/ipykernel_75743/2725838073.py in <module>
1 inputs = tokenizer(question, text, add_special_tokens=True)
2 input_ids = inputs["input_ids"]
----> 3 outputs = model(**inputs)
4 answer_start_scores = outputs.start_logits
5 answer_end_scores = outputs.end_logits
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, start_positions, end_positions, output_attentions, output_hidden_states, return_dict)
723 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
724
--> 725 distilbert_output = self.distilbert(
726 input_ids=input_ids,
727 attention_mask=attention_mask,
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'
"""おやおや、どうやらコードにバグがあるようですね。でも、ちょっとしたデバッグは怖くありません。Pythonのデバッガをノートブックで使うことができるのです。
それとも、ターミナルでデバッグを行うことができます:
エラーメッセージを読むと、 'list' object has no attribute 'size' と、 --> 矢印が model(**inputs) の中で問題が発生した行を指していることが分かります。Pythonデバッガを使ってインタラクティブにデバッグできますが、今は単に inputs のスライスを表示して何があるか見てみましょう。
inputs["input_ids"][:5][101, 2029, 7705, 2015, 2064]これは確かに普通のPythonの list のように見えますが、再確認してみましょう。
type(inputs["input_ids"])listこれは確かにPythonのlistですね。では何がいけなかったのか?第2章で、🤗 Transformersの AutoModelForXxx クラスは tensor (PyTorch または TensorFlow のいずれか)を使いながら、例えばPyTorchの Tensor.size()機能を呼び出しています。トレースバックをもう一度見て、どの行で例外が発生したかを確認しましょう。
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'私たちのコードは input_ids.size() を呼び出そうとしたようですが、これは明らかにPythonの list に対して動作しません。どうすればこの問題を解決できるでしょうか?Stack Overflowでエラーメッセージを検索すると、関連するヒント がかなり見つかります。
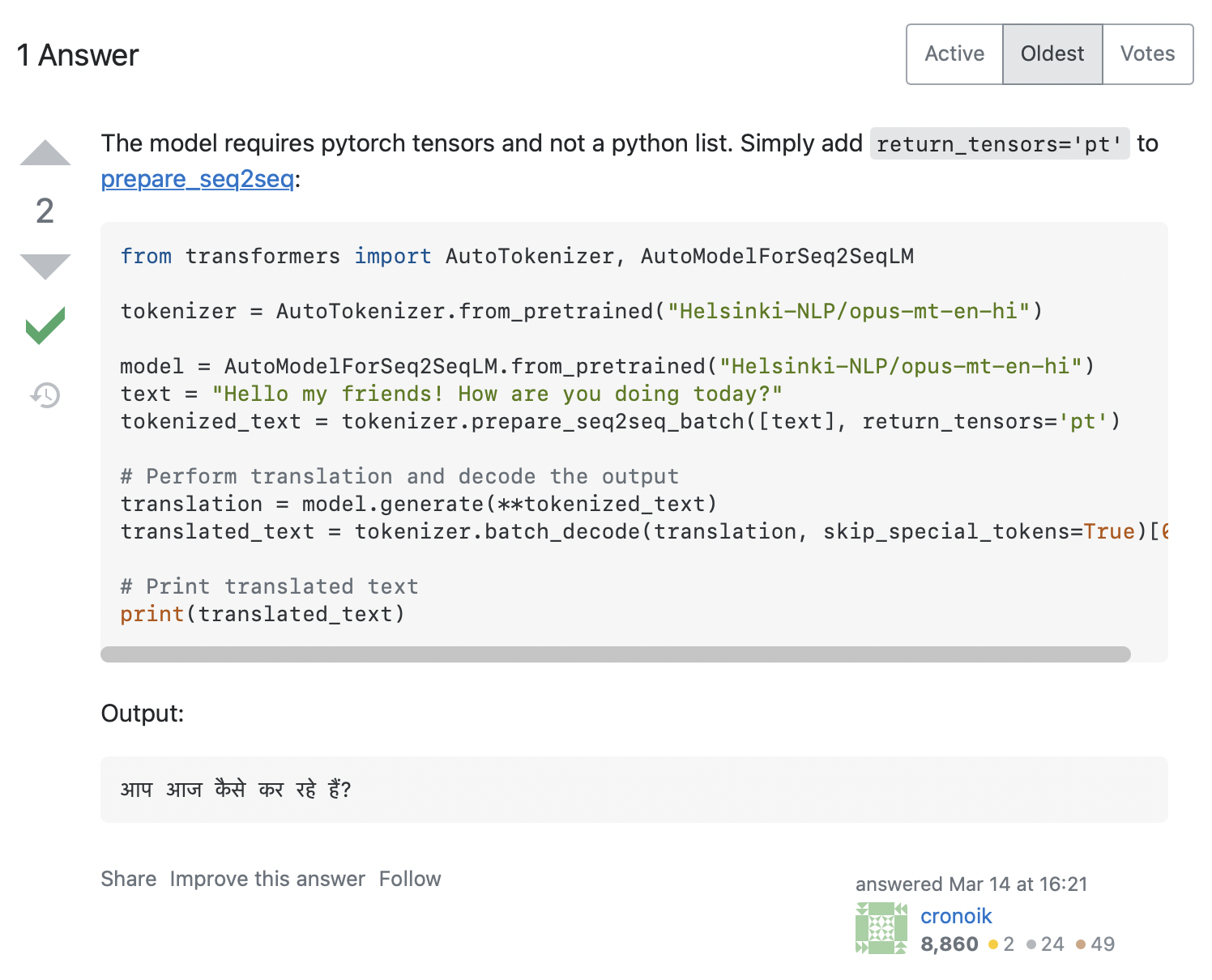
回答では、トークナイザーに return_tensors='pt' を追加することが推奨されているので、これがうまくいくかどうか見てみましょう。
inputs = tokenizer(question, context, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Get the most likely beginning of answer with the argmax of the score
answer_start = torch.argmax(answer_start_scores)
# Get the most likely end of answer with the argmax of the score
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
Question: Which frameworks can I use?
Answer: pytorch, tensorflow, and jax
"""Stack Overflowがいかに有用であるかを示す素晴らしい例です。同様の問題を特定することで、コミュニティの他の人々の経験から恩恵を受けることができました。しかし、このような検索では、常に適切な回答が得られるとは限りません。では、このような場合、どうすればいいのでしょうか?幸い、ハギングフェイスフォーラム(Hugging Face forums)には、開発者たちの歓迎するコミュニティがあり、あなたを助けてくれるでしょう。次のセクションでは、回答が得られる可能性の高い、良いフォーラムの質問を作成する方法を見ていきます。