Cosa fare quando si riceve un errore

In questa sezione esamineremo alcuni errori comuni che possono verificarsi quando si cerca di generare previsioni dal modello Transformer appena affinato. Questo ti preparerà alla sezione 4, in cui esploreremo come eseguire il debug della fase di training.
Per questa sezione, abbiamo preparato un template repository del modello e, se vuoi eseguire il codice di questo capitolo, dovrai prima copiare il modello nel tuo account su Hugging Face Hub. Per farlo, occorre innanzitutto effettuare il login eseguendo una delle seguenti operazioni in un Jupyter notebook:
from huggingface_hub import notebook_login
notebook_login()o il seguente nel tuo terminale preferito:
huggingface-cli login
Questo chiederà di inserire il nome utente e la password e salverà un token in ~/.cache/huggingface/. Una volta effettuato l’accesso, è possibile copiare il template repository con la seguente funzione:
from distutils.dir_util import copy_tree
from huggingface_hub import Repository, snapshot_download, create_repo, get_full_repo_name
def copy_repository_template():
# Clone the repo and extract the local path
template_repo_id = "lewtun/distilbert-base-uncased-finetuned-squad-d5716d28"
commit_hash = "be3eaffc28669d7932492681cd5f3e8905e358b4"
template_repo_dir = snapshot_download(template_repo_id, revision=commit_hash)
# Create an empty repo on the Hub
model_name = template_repo_id.split("/")[1]
create_repo(model_name, exist_ok=True)
# Clone the empty repo
new_repo_id = get_full_repo_name(model_name)
new_repo_dir = model_name
repo = Repository(local_dir=new_repo_dir, clone_from=new_repo_id)
# Copy files
copy_tree(template_repo_dir, new_repo_dir)
# Push to Hub
repo.push_to_hub()A questo punto, quando si esegue copy_repository_template(), verrà creata una copia del template repository nel proprio account.
Fare il debug della pipeline di 🤗 Transformers
Per iniziare il nostro viaggio nel fantastico mondo del debug dei modelli Transformer, considera lo scenario seguente: stai lavorando con un/a collega a un progetto di risposta alle domande per aiutare i clienti di un sito web di e-commerce a trovare risposte sui prodotti di consumo. Il/La collega ti invia un messaggio del tipo:
Ciao! Ho appena fatto un esperimento utilizzando le tecniche del Capitolo 7 del corso di Hugging Face e ho ottenuto ottimi risultati su SQuAD! Penso che possiamo usare questo modello come punto di partenza per il nostro progetto. L’ID del modello sull’Hub è “lewtun/distillbert-base-uncased-finetuned-squad-d5716d28”. Provalo pure :)
e la prima cosa che pensi è di caricare il modello usando la pipeline di 🤗 Transformers:
from transformers import pipeline
model_checkpoint = get_full_repo_name("distillbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""Oh no, sembra che qualcosa sia andato storto! Se sei alle prime armi con la programmazione, questo tipo di errori può sembrare un po’ criptico all’inizio (cos’è un OSError?!). L’errore visualizzato qui è solo l’ultima parte di un messaggio di errore molto più ampio, chiamato Python traceback (anche detto stack trace). Per esempio, se si esegue questo codice su Google Colab, si dovrebbe vedere qualcosa di simile alla seguente schermata:
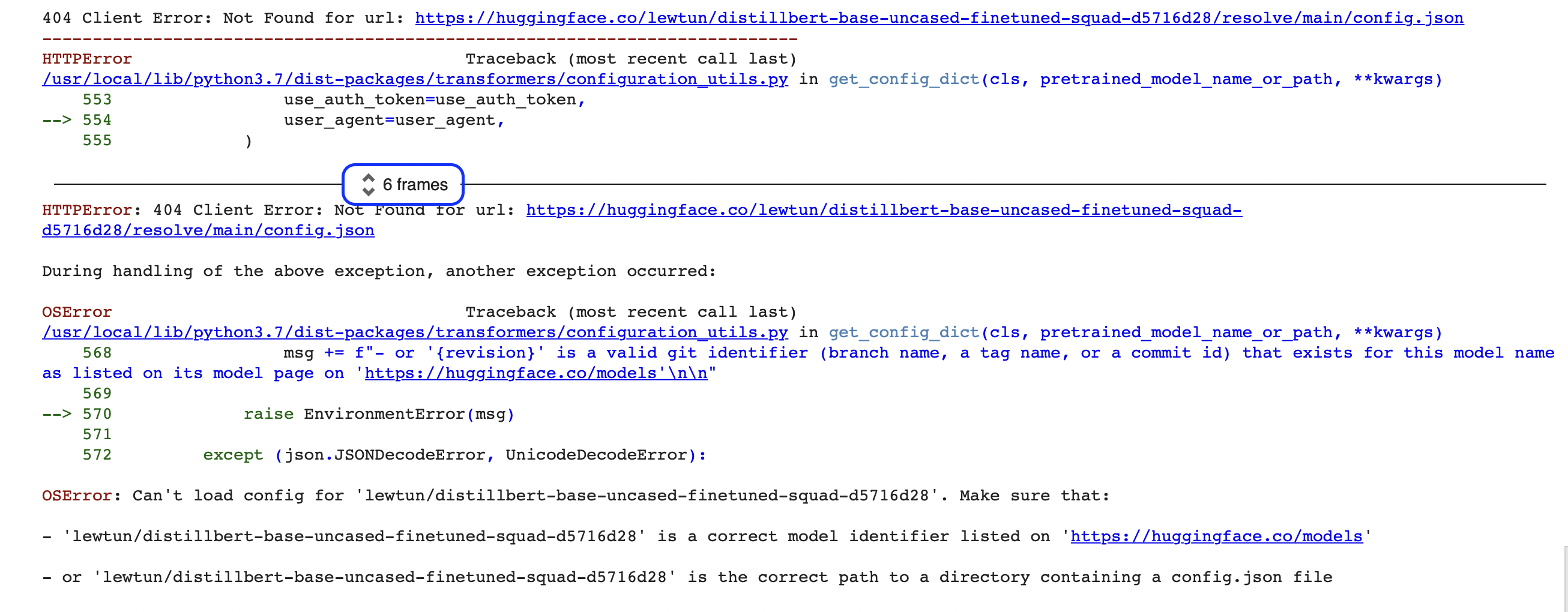
Questi messaggi contengono molte informazioni, quindi analizziamo insieme le parti principali. La prima cosa da notare è che i traceback devono essere letti dal basso verso l’alto. Questo può sembrare strano se si è abituati a leggere dall’alto verso il basso, ma riflette il fatto che il traceback mostra la sequenza di chiamate delle funzioni che la pipeline effettua quando scarica il modello e il tokenizer. (Dai un’occhiata al Capitolo 2 per maggiori dettagli su come funziona la pipeline.)
🚨 Hai notato quel riquadro blu intorno a “6 frames” nel traceback di Google Colab? È una funzionalità speciale di Colab, che comprime il traceback in “frame”. Se non riesci a trovare l’origine di un errore, assicurati di espandere l’intero traceback facendo clic su quelle due piccole frecce.
Ciò significa che l’ultima riga del traceback indica l’ultimo messaggio di errore e fornisce il nome dell’eccezione sollevata. In questo caso, il tipo di eccezione è OSError, che indica un errore legato al sistema. Leggendo il messaggio di errore, si può notare che sembra esserci un problema con il file config.json del modello e vengono forniti due suggerimenti per risolverlo:
"""
Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""💡 Se vedi un messaggio di errore che è difficile da capire, copia e incolla il messaggio nella barra di ricerca di Google o di Stack Overflow (sì, davvero!). C’è una buona probabilità che non sei la prima persona a riscontrare l’errore, e questo è un buon modo per trovare le soluzioni pubblicate da altri utenti della community. Ad esempio, cercando OSError: Can't load config for su Stack Overflow si ottengono diversi risultati che possono essere usati come punto di partenza per risolvere il problema.
Il primo suggerimento ci chiede di verificare se l’ID del modello è effettivamente corretto, quindi la prima cosa da fare è copiare l’identificativo e incollarlo nella barra di ricerca dell’Hub:

Mmm, sembra proprio che il modello del/la nostro/a collega non sia sull’Hub… aha, ma c’è un errore di battitura nel nome del modello! DistilBERT ha solo una “l” nel suo nome, quindi correggiamolo e cerchiamo invece “lewtun/distilbert-base-uncased-finetuned-squad-d5716d28”:

Ok, questo c’è. Ora proviamo a scaricare di nuovo il modello con l’ID corretto:
model_checkpoint = get_full_repo_name("distilbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""Argh, è fallito ancora - benvenuti nella routine quotidiana di un machine learning engineer! Poiché abbiamo aggiustato l’ID del modello, il problema deve essere nel repository stesso. Un modo rapido per accedere al contenuto di un repository sul 🤗 Hub è la funzione list_repo_files() della libreria huggingface_hub:
from huggingface_hub import list_repo_files
list_repo_files(repo_id=model_checkpoint)['.gitattributes', 'README.md', 'pytorch_model.bin', 'special_tokens_map.json', 'tokenizer_config.json', 'training_args.bin', 'vocab.txt']Interessante: non sembra esserci un file config.json nel repository! Non c’è da stupirsi che la nostra pipeline non riesca a caricare il modello; il/la nostro/a collega deve aver dimenticato di inserire questo file nell’Hub dopo averlo affinato. In questo caso, il problema sembra abbastanza semplice da risolvere: potremmo chiedere loro di aggiungere il file, oppure, dato che possiamo vedere dall’ID del modello che il modello pre-addestrato usato è distilbert-base-uncased, possiamo scaricare la configurazione di questo modello e inserirla nel nostro repository per vedere se questo risolve il problema. Proviamo. Utilizzando le tecniche apprese nel Capitolo 2, possiamo scaricare la configurazione del modello con la classe AutoConfig:
from transformers import AutoConfig
pretrained_checkpoint = "distilbert-base-uncased"
config = AutoConfig.from_pretrained(pretrained_checkpoint)🚨 L’approccio che stiamo adottando non è infallibile, poiché il/la nostro/a collega potrebbe aver modificato la configurazione di distilbert-base-uncased prima di affinare il modello. Nella vita reale, dovremmo verificare prima con loro, ma per lo scopo di questa sezione assumeremo che abbiano usato la configurazione predefinita.
Possiamo quindi inviarlo al nostro repository del modello con la funzione push_to_hub() della configurazione:
config.push_to_hub(model_checkpoint, commit_message="Add config.json")Ora possiamo verificare se ha funzionato, caricando il modello dall’ultimo commit del ramo main:
reader = pipeline("question-answering", model=model_checkpoint, revision="main")
context = r"""
Extractive Question Answering is the task of extracting an answer from a text
given a question. An example of a question answering dataset is the SQuAD
dataset, which is entirely based on that task. If you would like to fine-tune a
model on a SQuAD task, you may leverage the
examples/pytorch/question-answering/run_squad.py script.
🤗 Transformers is interoperable with the PyTorch, TensorFlow, and JAX
frameworks, so you can use your favourite tools for a wide variety of tasks!
"""
question = "What is extractive question answering?"
reader(question=question, context=context){'score': 0.38669535517692566,
'start': 34,
'end': 95,
'answer': 'the task of extracting an answer from a text given a question'}Woohoo, ha funzionato! Riassumiamo quello che hai appena imparato:
- I messaggi di errore in Python sono noti come traceback e vengono letti dal basso verso l’alto. L’ultima riga del messaggio di errore di solito contiene le informazioni necessarie per individuare l’origine del problema.
- Se l’ultima riga non contiene informazioni sufficienti, risali il traceback e vedi se riesci a identificare in quale punto del codice sorgente si verifica l’errore.
- Se nessuno dei messaggi di errore può aiutare a individuare il problema, provare a cercare online una soluzione a un problema simile.
- Il `huggingface_hub’ // 🤗 Hub? fornisce una serie di strumenti che si possono usare per interagire e fare il debug dei repository su Hub.
Ora che sappiamo come eseguire il debug di una pipeline, diamo un’occhiata a un esempio più complicato nel forward pass del modello stesso.
Debug del forward pass del modello
Sebbene la pipeline sia ottima per la maggior parte delle applicazioni in cui è necessario generare previsioni rapidamente, a volte è necessario accedere ai logit del modello (ad esempio, se si desidera applicare un post-processing personalizzato). Per vedere cosa potrebbe andare storto in questo caso, iniziamo prendendo il modello e il tokenizer dalla nostra pipeline:
tokenizer = reader.tokenizer model = reader.model
Poi abbiamo bisogno di una domanda, quindi vediamo se i nostri framework preferiti sono supportati:
question = "Which frameworks can I use?"Come abbiamo visto nel Capitolo 7, i passaggi tipici da svolgere sono la tokenizzazione degli input, l’estrazione dei logit dei token iniziali e finali e la decodifica dell’intervallo di risposta:
import torch
inputs = tokenizer(question, context, add_special_tokens=True)
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Get the most likely beginning of answer with the argmax of the score
answer_start = torch.argmax(answer_start_scores)
# Get the most likely end of answer with the argmax of the score
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/var/folders/28/k4cy5q7s2hs92xq7_h89_vgm0000gn/T/ipykernel_75743/2725838073.py in <module>
1 inputs = tokenizer(question, text, add_special_tokens=True)
2 input_ids = inputs["input_ids"]
----> 3 outputs = model(**inputs)
4 answer_start_scores = outputs.start_logits
5 answer_end_scores = outputs.end_logits
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, start_positions, end_positions, output_attentions, output_hidden_states, return_dict)
723 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
724
--> 725 distilbert_output = self.distilbert(
726 input_ids=input_ids,
727 attention_mask=attention_mask,
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'
"""Oh cielo, sembra che ci sia un bug nel nostro codice! Ma non avere paura di un po’ di debug. Puoi usare il debugger di Python in un notebook:
o dal terminale:
Qui, leggendo il messaggio di errore vediamo che l’oggetto 'list' non ha attributo 'size', e possiamo vedere una --> freccia che punta alla riga in cui il problema è stato sollevato in model(**inputs). Possiamo eseguire il debug interattivo utilizzando il debugger di Python, ma per ora ci limiteremo a stampare una parte di input per vedere cosa abbiamo:
inputs["input_ids"][:5][101, 2029, 7705, 2015, 2064]Questo sembra certamente una normale list di Python, ma ricontrolliamo il type:
type(inputs["input_ids"])listSì, questa è sicuramente una list di Python. Cos’è andato storto? Ricordiamo dal Capitolo 2 che le classi AutoModelForXxx in 🤗 Transformers operano su tensori (sia in PyTorch che in TensorFlow), e un’operazione comune è quella di estrarre le dimensioni di un tensore usando Tensor.size() in PyTorch, per esempio. Diamo un’altra occhiata al traceback, per vedere quale riga ha causato l’eccezione:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'Sembra che il nostro codice abbia provato a chiamare input_ids.size(), ma questo chiaramente non funziona per una listdi Python, che è solo un container. Come possiamo risolvere questo problema? Cercando il messaggio di errore su Stack Overflow si ottengono alcuni risultati pertinenti. Cliccando sul primo, viene visualizzata una domanda simile alla nostra, con la risposta mostrata nello screenshot seguente:
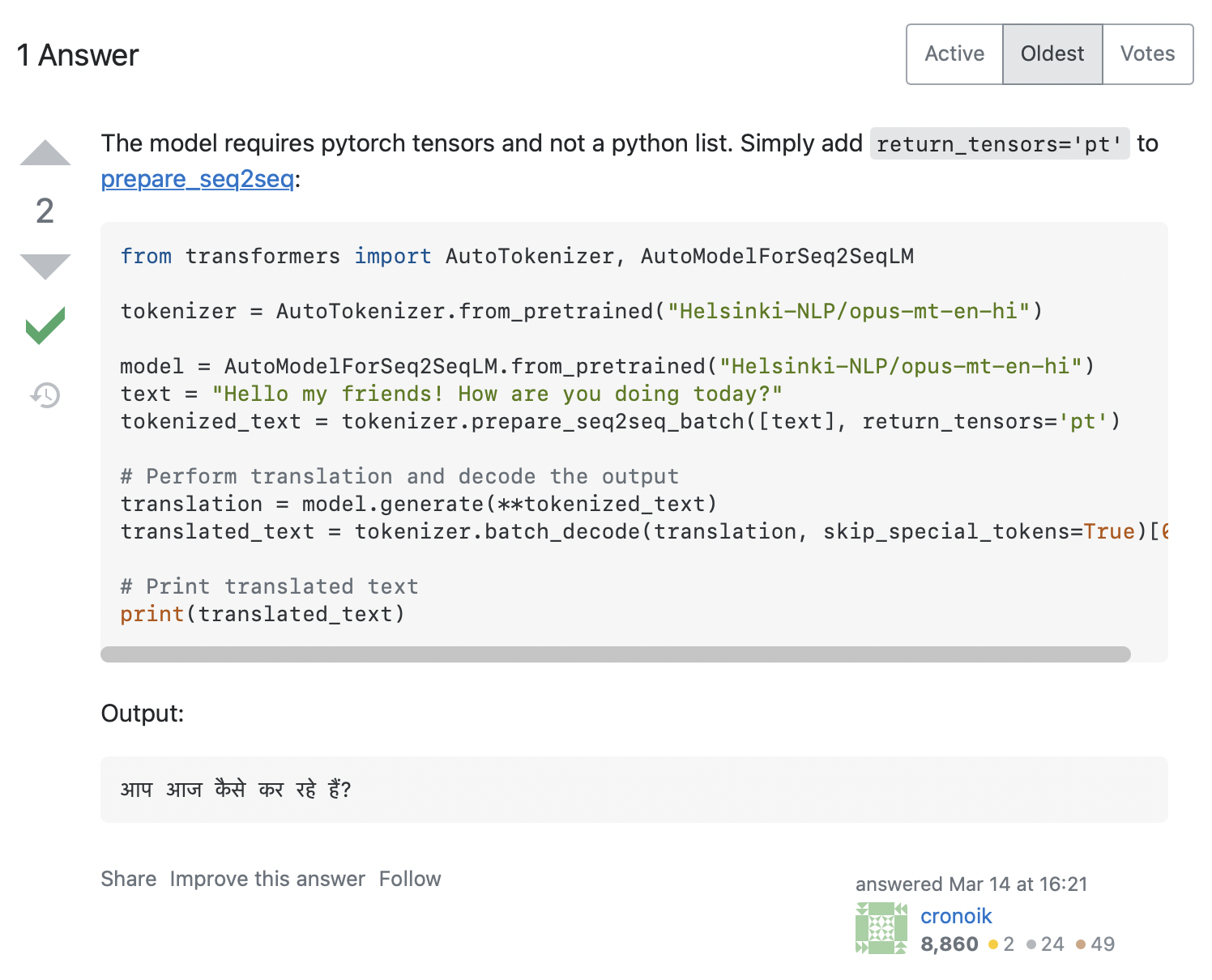
La risposta raccomanda di aggiungere return_tensors='pt' al tokenizer, quindi proviamo se funziona:
inputs = tokenizer(question, context, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Get the most likely beginning of answer with the argmax of the score
answer_start = torch.argmax(answer_start_scores)
# Get the most likely end of answer with the argmax of the score
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
Question: Which frameworks can I use?
Answer: pytorch, tensorflow, and jax
"""Bene, ha funzionato! Questo è un ottimo esempio di quanto possa essere utile Stack Overflow: identificando un problema simile, abbiamo potuto beneficiare dell’esperienza di altri membri della community. Tuttavia, una ricerca come questa non sempre produce una risposta pertinente, quindi cosa si può fare in questi casi? Fortunatamente, sul forum di Hugging Face c’è un’accogliente community di sviluppatori che può aiutarti! Nella prossima sezione, vedremo come creare bene delle domande sul forum che abbiano buona probabilità di ricevere una risposta.
< > Update on GitHub