LLM Course documentation
Creare il proprio dataset
Creare il proprio dataset

A volte il dataset che ti serve per la tua applicazione NLP non esiste, per cui dovrai crearlo da te. In questa sezione ti mostreremo come creare un corpus di issue da GitHub, usate solitamente per tenere traccia dei bug e delle feature nelle repository su GitHub. Questo corpus può essere usato in diversi modi, ad esempio:
- Esplorare il tempo impiegato per chiudere un issue, o per effettuare dei pull
- Addestrare un classificatore multiclasse che assegna a ogni issue dei metadati sulla base della descrizione dell’issue (ad esempio, “bug”, “enhancement”, “question”)
- Creare un motore di ricerca semantico per trovare quale issue corrisponde a una richiesta dell’utente
Ci focalizzeremo sulla creazione del corpus, e nella prossima sezione affronteremo la creazione di un motore di ricerca semantico. Useremo gli issue GitHub associate a un progetto open source molto popolare: 🤗 Datasets! Diamo un’occhiata a come recuperare i dati e come esplorare le informazioni contenute negli issue.
Recuperare i dati
Puoi trovare tutte gli issue in 🤗 Datasets navigando nella sezione Issues della repository. Come si vede dallo screenshot, al momento della scrittura c’erano 331 issue aperti e 668 issue chiusi.

Se clicchi su una di questi issue vedrai che contiene un titolo, una descrizione, e un set di etichette che caratterizzano l’issue. Un esempio è mostrato nello screenshot successivo.

Per scaricare gli issue della repository, useremo la REST API di GitHub per interrogare l’endpoint Issues. Questo endpoint restituisce una lista di oggetti JSON, e ogni oggetto contiene un gran numero di campi, tra cui il titolo e la descrizione, così come dei metadati circo lo status dell’issue e altro ancora.
Una maniera conveniente di scaricare gli issue è attraverso la libreria requests, che rappresenta il metodo standard di fare richieste HTTP su Python. Puoi installa la libreria attraverso il codice:
!pip install requests
Una volta che la libreria è stata installata, puoi effettuare una richiesta GET all’endpoint Issues utilizzando la funzione requests.get(). Ad esempio, puoi eseguire il comando mostrato di seguito per recuperare il primo issue nella prima pagina:
import requests
url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=1"
response = requests.get(url)L’oggetto response contiene un sacco di informazioni utili sulla richiesta, compreso il codice di stato HTTP:
response.status_code
200Lo status 200 indica che la richiesta ha avuto buon fine (puoi trovare una lista di codici di stato HTTTP qui). Ma ciò che ci interessa davvero è il payload, a cui è possibile accedere utilizzando diversi formati come byte, stringh, o JSON. Visto che sappiamo che i nostri issue sono in formato JSON, diamo un’occhiata al payload come segue:
response.json()
[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'repository_url': 'https://api.github.com/repos/huggingface/datasets',
'labels_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/labels{/name}',
'comments_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/comments',
'events_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/events',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'id': 968650274,
'node_id': 'MDExOlB1bGxSZXF1ZXN0NzEwNzUyMjc0',
'number': 2792,
'title': 'Update GooAQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'labels': [],
'state': 'open',
'locked': False,
'assignee': None,
'assignees': [],
'milestone': None,
'comments': 1,
'created_at': '2021-08-12T11:40:18Z',
'updated_at': '2021-08-12T12:31:17Z',
'closed_at': None,
'author_association': 'CONTRIBUTOR',
'active_lock_reason': None,
'pull_request': {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/2792',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'diff_url': 'https://github.com/huggingface/datasets/pull/2792.diff',
'patch_url': 'https://github.com/huggingface/datasets/pull/2792.patch'},
'body': '[GooAQ](https://github.com/allenai/gooaq) dataset was recently updated after splits were added for the same. This PR contains new updated GooAQ with train/val/test splits and updated README as well.',
'performed_via_github_app': None}]Wow, quante informazioni! Possiamo vedere alcuni campi utili come title, body e number che descrivono l’issue, così come informazioni sull’utente che l’ha aperto.
✏️ Prova tu! Clicca su alcuni degli URL nel payload JSON per farti un’idea del tipo di informazione a cui è collegato ogni issue GitHub.
Come descritto nella documentazione di GitHub, le richieste senza autenticazione sono limitate a 60 ogni ora. Benché possiamo aumentare il parametro della query per_page per ridurre il numero di richieste, raggiungerai comunque il limite su qualunque repository che ha qualche migliaio di issue. Quindi, dovresti seguire le istruzioni su come creare un token di accesso personale così che puoi aumentare il limite a 5.000 richieste ogni ora. Una volta che hai ottenuto il tuo token, puoi includerlo come parte dell’header della richiesta:
GITHUB_TOKEN = xxx # inserisci qui il tuo token GitHub
headers = {"Authorization": f"token {GITHUB_TOKEN}"}⚠️ Fai attenzione a non condividere un notebook con il tuo GITHUB_TOKEN al suo interno. Ti consigliamo di cancellare l’ultima cella una volta che l’hai eseguita per evitare di far trapelare quest’informazione accidentalmente. Meglio ancora, salva il tuo token in un file .env e usa la libreria python-dotenv per caricarlo automaticamente come una variabile d’ambiente.
Ora che abbiamo il nostro token di accesso, creiamo una funzione che scarichi tutti gli issue da una repository GitHub:
import time
import math
from pathlib import Path
import pandas as pd
from tqdm.notebook import tqdm
def fetch_issues(
owner="huggingface",
repo="datasets",
num_issues=10_000,
rate_limit=5_000,
issues_path=Path("."),
):
if not issues_path.is_dir():
issues_path.mkdir(exist_ok=True)
batch = []
all_issues = []
per_page = 100 # Numero di issue da restituire per pagina
num_pages = math.ceil(num_issues / per_page)
base_url = "https://api.github.com/repos"
for page in tqdm(range(num_pages)):
# La query ha state=all per ottenere sia gli issue aperti che quelli chiusi
query = f"issues?page={page}&per_page={per_page}&state=all"
issues = requests.get(f"{base_url}/{owner}/{repo}/{query}", headers=headers)
batch.extend(issues.json())
if len(batch) > rate_limit and len(all_issues) < num_issues:
all_issues.extend(batch)
batch = [] # puliamo la batch per il termine successivo
print(f"Reached GitHub rate limit. Sleeping for one hour ...")
time.sleep(60 * 60 + 1)
all_issues.extend(batch)
df = pd.DataFrame.from_records(all_issues)
df.to_json(f"{issues_path}/{repo}-issues.jsonl", orient="records", lines=True)
print(
f"Downloaded all the issues for {repo}! Dataset stored at {issues_path}/{repo}-issues.jsonl"
)Ora quando eseguiremo fetch_issues(), scaricherà tutti gli issue in batch per evitare di superare il limite di GitHub del numero di richieste per ora; il risultato sarà conservato in un file repository_name-issues.jsonl, in cui ogni linea è un oggetto JSON che rappresenta un issue. Usiamo questa funzione per recuperare tutti gli issue da 🤗 Datasets:
# A seconda della tua connessione internet, ci potrebbe volere qualche secondo...
fetch_issues()Una volta che gli issue sono stati scaricati, possiamo caricarli in locale usando le nuove abilità imparate nella sezione 2:
issues_dataset = load_dataset("json", data_files="datasets-issues.jsonl", split="train")
issues_datasetDataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'timeline_url', 'performed_via_github_app'],
num_rows: 3019
})Benissimo, abbiamo creato il nostro primo dataset da zero! Ma perché ci sono migliaia di issue quando la sezione Issues della repository 🤗 Datasets mostra circa 1,000 issue in totale 🤔? Come indicato nella documentazione di GitHub, è perché abbiamo scaricato anche le richieste di pull:
GitHub’s REST API v3 considers every pull request an issue, but not every issue is a pull request. For this reason, “Issues” endpoints may return both issues and pull requests in the response. You can identify pull requests by the
pull_requestkey. Be aware that theidof a pull request returned from “Issues” endpoints will be an issue id.
(La REST API v3 di GitHub considera ogni richiesta di pull un issue, ma non ogni issue è una richiesta di pull. Per questa ragione, gli endpoint “Issues” potrebbe tornare sia gli issue che le richieste di pull. È possibile identificare le richieste di pull utilizzando la chiave pull_request. Tieni presente che l’id di una richiesta di pull resituita dagli endpoint Issues sarà un id di un issue.)
Poichè i contenuti degli issue e delle richieste di pull sono molto diversi, facciamo un po’ di preprocessing per permetterci di distinguere tra i due.
Pulire i dati
Il frammento precedente della documentazione di GitHub ci dice che la colonna pull_request può essere utilizzata per distinguere gli issue e le richieste di pull. Diamo uno sguardo a un esempio casuale per vedere qual è la differenza. Come abbiamo fatto nella sezione 3, concateneremo Dataset.shuffle() e Dataset.select() per creare un campione random, e poi zipperemo le colonne html_url e pull_request così da poter paragonare i diversi URL:
sample = issues_dataset.shuffle(seed=666).select(range(3))
# Stampiamo le entrate `URL` e `pull_request`
for url, pr in zip(sample["html_url"], sample["pull_request"]):
print(f">> URL: {url}")
print(f">> Pull request: {pr}\n")>> URL: https://github.com/huggingface/datasets/pull/850
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/850', 'html_url': 'https://github.com/huggingface/datasets/pull/850', 'diff_url': 'https://github.com/huggingface/datasets/pull/850.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/850.patch'}
>> URL: https://github.com/huggingface/datasets/issues/2773
>> Pull request: None
>> URL: https://github.com/huggingface/datasets/pull/783
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/783', 'html_url': 'https://github.com/huggingface/datasets/pull/783', 'diff_url': 'https://github.com/huggingface/datasets/pull/783.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/783.patch'}Possiamo vedere che ogni richiesta di pull è associata a diversi URL, mentre i comuni issue hanno un’entrata None. Possiamo usare questa distinzione per crare una nuova colonna is_pull_request che controlla se il campo pull_request sia None o meno:
issues_dataset = issues_dataset.map(
lambda x: {"is_pull_request": False if x["pull_request"] is None else True}
)✏️ Prova tu! Calcola il tempo medio che ci vuole a chiudere un issue su 🤗 Datasets. Potrebbe essere utile usare la funzione Dataset.filter() per eliminare le richieste di pull e gli issue aperti, e puoi usare la funzione Dataset.set_format() per convertire il dataset in un DataFrame così che puoi facilmente manipolare i timestamp created_at e closed_at. Per dei punti bonus, calcola il tempo medio che ci vuole a chiudere le richieste di pull.
Benché potremmo procedere e pulire ulteriormente il dataset eliminando o rinominando alcune colonne, è solitamente buona prassi lasciare il dataset quando più intatto è possibile in questo stadio, così che può essere utilizzato facilmente in più applicazioni.
Prima di caricare il nostro dataset sull’Hub Hugging Face, dobbiamo occuparci di una cosa che manca: i commenti associati a ogni issue e richiesta di pull. Hai indovinato, li aggiungeremo utilizzando la REST API di GitHub!
Estendere il dataset
Come mostrato negli screenshot di seguito, i commenti associati a un issue o una richiesta di pull offrono una fonte molto ricca di informazioni, soprattutto se siamo interessati a costruire un motore di ricerca per rispondere alle richieste degli utenti sulla libreria.

La REST API di GitHub offre un endpoint Comments che restituisce tutti i commenti associati con un numero di issue. Testiamo quest’endpoint per vedere cosa restituisce:
issue_number = 2792
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
response.json()[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/comments/897594128',
'html_url': 'https://github.com/huggingface/datasets/pull/2792#issuecomment-897594128',
'issue_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'id': 897594128,
'node_id': 'IC_kwDODunzps41gDMQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'created_at': '2021-08-12T12:21:52Z',
'updated_at': '2021-08-12T12:31:17Z',
'author_association': 'CONTRIBUTOR',
'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
'performed_via_github_app': None}]Possiamo vedere che il commento è archiviato nel campo body, quindi possiamo scvrivere una semplice funzione che restituisce tutti i commenti associati con un issue estraendo i contenuti di body per ogni elemento in response.json():
def get_comments(issue_number):
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
return [r["body"] for r in response.json()]
# Testiamo la nostra funzione
get_comments(2792)["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]Sembra andar bene, quindi possiamo usare Dataset.map() per aggiungere una nuova colonna comments a ogni usse nel nostro dataset:
# A seconda della tua connessione, potrebbe volerci qualche secondo...
issues_with_comments_dataset = issues_dataset.map(
lambda x: {"comments": get_comments(x["number"])}
)Come passaggio finale, salviamo il dataset esteso assieme ai nostri dati non processati, così da poter caricare entrambi sull’Hub:
issues_with_comments_dataset.to_json("issues-datasets-with-comments.jsonl")Caricare il dataset sull’Hub Hugging Face
Ora che abbiamo il nostro dataset esteso, è arrivato il momento di caricarlo sull’Hub, così da poterlo condividere con la community! Per caricare il dataset useremo la libreria 🤗 Hub, che ci permette di interagire con l’Hub di Hugging Face attraverso un’API di Python. 🤗 Hub è preinstallato con 🤗 Transformers, così possiamo usarlo da subito. Ad esempio, possiamo usare la funzione list_datastes() per avere informazioni su tutti i dataset pubblici attualmente presenti sull’Hub:
from huggingface_hub import list_datasets
all_datasets = list_datasets()
print(f"Number of datasets on Hub: {len(all_datasets)}")
print(all_datasets[0])Number of datasets on Hub: 1487
Dataset Name: acronym_identification, Tags: ['annotations_creators:expert-generated', 'language_creators:found', 'languages:en', 'licenses:mit', 'multilinguality:monolingual', 'size_categories:10K<n<100K', 'source_datasets:original', 'task_categories:structure-prediction', 'task_ids:structure-prediction-other-acronym-identification']Possiamo vedere che al momento ci sono circa 1.500 dataset sull’Hub, e la funzione list_datasets() inoltre permette di avere alcuni metadati su ciascuna repository.
Per ciò che ci riguarda, la prima cosa che dobbiamo fare è crare una nuova repository nell’Hub. Per far ciò abbiamo bisogno di un token di autentificazione, che pouò essere ottenuto effettuando l’accesso nell’Hub Hugging Face con la funzione notebook_login():
from huggingface_hub import notebook_login
notebook_login()Questo creerà un widget in cui puoi inserire il tuo username e la tua password, e un token API verrà salvato in ~/.huggingface/token. Se stai eseguendo il codice in un terminale, puoi effettuare l’accesso attraverso il comando:
huggingface-cli login
Una volta fatto questo, possiamo crare una nuova repository con la funzione create_repo():
from huggingface_hub import create_repo
repo_url = create_repo(name="github-issues", repo_type="dataset")
repo_url'https://huggingface.co/datasets/lewtun/github-issues'In quest’esempio, abbiamo creato una repository vuota chiamata github-issues con l’username lewtun (l’username dovrebbe essere quello del tuo account Hub quando esegui questo codice!).
✏️ Prova tu! Usa le tue credenziali dell’Hub Hugging Face per ottenere un token e creare una repository vuota chiamata github-issues. Ricordati di non salvere mai le tue credenziali su Colab o qualunque altra repository, perché potrebbero essere recuperate da malintenzionati.
Ora, cloniamo la repository dall’Hub alla nostra macchina e copiamo al suo interno i file del nostro dataset. 🤗 Hub contiene una classe Repository che ha al suo interno molti dei comandi più comuni di Git, per cui per clonare la repository in remoto dobbiamo semplicemente fornire l’URL e il percorso locale in cui desideriamo clonare:
from huggingface_hub import Repository
repo = Repository(local_dir="github-issues", clone_from=repo_url)
!cp issues-datasets-with-comments.jsonl github-issues/Di default, diverse estensioni file (ad esempio .bin, .gz e .zip) sono registrate da Git LFS, così che i file di grandi dimensioni possono essere gestiti all’interno dello stesso workflow. Puoi trovare una lista delle estensioni di file monitorati nel file .gitattributes della repository. Per includere il formato JSON Lines a questa lista, possiamo utilizzare il comando:
repo.lfs_track("*.jsonl")Ora possiamo usare Repository.push_to_hub() per caricare il dataset sull’Hub:
repo.push_to_hub()
Se navighiamo fino all’URL contenuto in repo_url, vedremo che il file del nostro dataset è stato caricato.
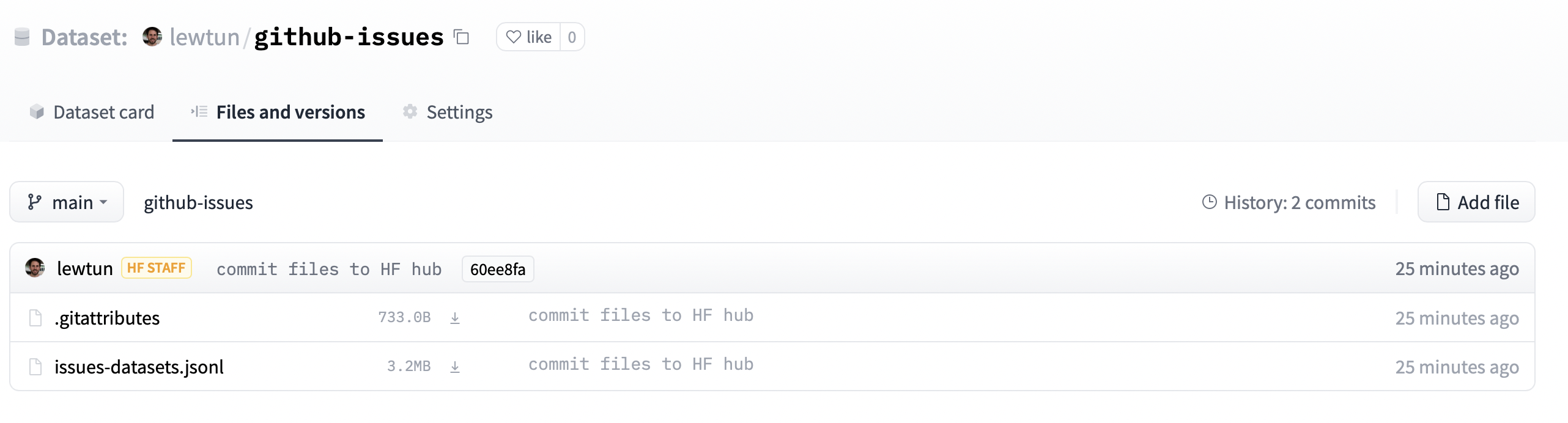
Da qui, chiunque può scaricare il dataset semplicemente inserendo l’ID della repository come argomento path di load_dataset():
remote_dataset = load_dataset("lewtun/github-issues", split="train")
remote_datasetDataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 2855
})Bene, abbiamo caricato il nostro dataset sull’Hub, e può essere utilizzato da tutti! C’è un’altra cosa importante che dobbiamo fare: aggiungere una dataset card che spiega come è stato creato il corpus, e offre altre informazioni utili per la community.
💡 Puoi caricare un dataset nell’Hub di Hugging Face anche direttamente dal terminale usando huggingface-cli e un po’ di magia Git. La guida a 🤗 Datasets spiega come farlo.
Creare una dataset card
I dataset ben-documentati sono più utili agli altri utenti (compreso il futuro te!), poiché spiegano il contesto per permettere agli utenti di decidere se un dataset può essere utile, e valutare gli eventuali bias o rischi associati nell’utilizzo del dataset.
Sull’Hug di Hugging Face, queste informazioni si trovano nel file README.md della repository. Ci sono due passaggi principali che dovresti seguire prima di creare questo file:
- Usa l’applicatione
datasets-taggingper creare tag di metadati in formato YAML. Questi tag sono usato per una serie di funzioni di ricerca sull’Hub di Hugging Face, e assicurano che il tuo dataset possa essere facilmente trovato dai membri della community. Poichè abbiamo creato un nostro dataset, dovrai clonare la repositorydatasets-tagging, ed eseguire l’applicazione in locale. Ecco com’è l’interfaccia:

- Leggi la guida 🤗 Datasets sulla creazione di dataset card informative, e usala come template.
Puoi creare il file README.md direttamente sull’Hub, e puoi trovare un modello per una dataset card nella repository lewtun/github-issues. Di seguito è mostrato uno screenshot di una dataset card già compilata.

✏️ Prova tu! Usa l’applicazione dataset-tagging e la guida 🤗 Datasets per completare il file README.md per il tuo dataset di issue di GitHub.
È tutto! Abbiamo visto in questa sezione che creare un buon dataset può essere un’impresa, ma per fortuna caricarlo e condividerlo con la community è molto più semplice. Nella prossima sezione useremo il nostro nuovo dataset per creare un motore di ricerca semantico con 🤗 Datasets, che abbina alle domande gli issue e i commenti più rilevanti.
✏️ Prova tu! Segui i passi che abbiamo eseguito in questa sezione per creare un dataset di issue GitHub per la tua libreria open source preferita (ovviamente scegli qualcosa di diverso da 🤗 Datasets!). Per punti bonus, esegui il fine-tuning di un classificatore multiclasse per predirre i tag presenti nel campo labels.