Que faire lorsque vous obtenez une erreur
Dans cette section, nous allons examiner certaines erreurs courantes qui peuvent se produire lorsque vous essayez de générer des prédictions à partir de votre transformer fraîchement finetuné. Cela vous préparera pour la section 4 de ce chapitre où nous explorerons comment déboguer la phase d’entraînement elle-même.
Nous avons préparé un gabarit de dépôt de modèles pour cette section et si vous voulez exécuter le code de ce chapitre, vous devrez d’abord copier le modèle dans votre compte sur le Hub d’Hugging Face. Pour ce faire, connectez-vous d’abord en exécutant l’une ou l’autre des commandes suivantes dans un notebook Jupyter :
from huggingface_hub import notebook_login
notebook_login()ou ce qui suit dans votre terminal préféré :
huggingface-cli login
Cela vous demandera d’entrer votre nom d’utilisateur et votre mot de passe, et enregistrera un jeton sous ~/.cache/huggingface/. Une fois que vous vous êtes connecté, vous pouvez copier le gabarit du dépôt avec la fonction suivante :
from distutils.dir_util import copy_tree
from huggingface_hub import Repository, snapshot_download, create_repo, get_full_repo_name
def copy_repository_template():
# Cloner le dépôt et extraire le chemin local
template_repo_id = "lewtun/distilbert-base-uncased-finetuned-squad-d5716d28"
commit_hash = "be3eaffc28669d7932492681cd5f3e8905e358b4"
template_repo_dir = snapshot_download(template_repo_id, revision=commit_hash)
# Créer un dépôt vide sur le Hub
model_name = template_repo_id.split("/")[1]
create_repo(model_name, exist_ok=True)
# Cloner le dépôt vide
new_repo_id = get_full_repo_name(model_name)
new_repo_dir = model_name
repo = Repository(local_dir=new_repo_dir, clone_from=new_repo_id)
# Copier les fichiers
copy_tree(template_repo_dir, new_repo_dir)
# Pousser sur le Hub
repo.push_to_hub()Maintenant, lorsque vous appelez copy_repository_template(), cela va créer une copie du gabarit du dépôt sous votre compte.
Déboguer le pipeline à partir de 🤗 <i> Transformers </i>
Pour donner le coup d’envoi de notre voyage dans le monde merveilleux du débogage de transformers, considérez le scénario suivant : vous travaillez avec un collègue sur un projet de réponse à des questions pour aider les clients d’un site de commerce en ligne à trouver des réponses à des produits. Votre collègue vous envoie un message du genre :
Bonjour ! Je viens de réaliser une expérience en utilisant les techniques du chapitre 7 du cours d’Hugging Face et j’ai obtenu d’excellents résultats sur SQuAD ! Je pense que nous pouvons utiliser ce modèle comme point de départ pour notre projet. L’identifiant du modèle sur le Hub est “lewtun/distillbert-base-uncased-finetuned-squad-d5716d28”. N’hésite pas à le tester :)
et la première chose à laquelle on pense est de charger le modèle en utilisant le pipeline de 🤗 Transformers :
from transformers import pipeline
model_checkpoint = get_full_repo_name("distillbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""Oh non, quelque chose semble s’être mal passée ! Si vous êtes novice en programmation, ce genre d’erreurs peut sembler un peu cryptique au début (qu’est-ce qu’une OSError ?!). L’erreur affichée ici n’est que la dernière partie d’un rapport d’erreur beaucoup plus long appelé Python traceback (alias stack trace). Par exemple, si vous exécutez ce code sur Google Colab, vous devriez voir quelque chose comme la capture d’écran suivante :
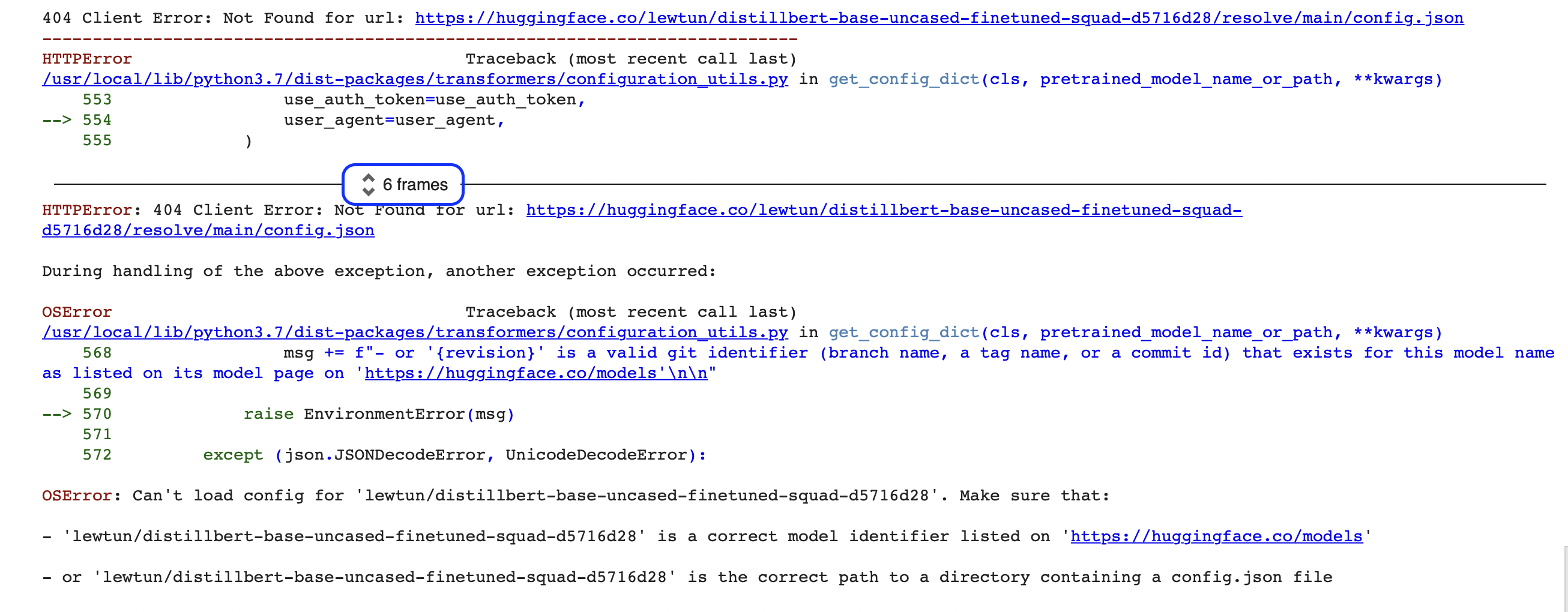
Il y a beaucoup d’informations dans ces rapports, nous allons donc en parcourir ensemble les éléments clés. La première chose à noter est que les tracebacks doivent être lus de bas en haut. Cela peut sembler bizarre si vous avez l’habitude de lire du texte français de haut en bas mais cela reflète le fait que le traceback montre la séquence d’appels de fonction que le pipeline fait lors du téléchargement du modèle et du tokenizer. Consultez le chapitre 2 pour plus de détails sur la façon dont le pipeline fonctionne sous le capot.
🚨 Vous voyez le cadre bleu autour de « 6 frames » dans le traceback de Google Colab ? Il s’agit d’une fonctionnalité spéciale de Colab qui compresse le traceback en frames. Si vous ne parvenez pas à trouver la source d’une erreur, déroulez le traceback en cliquant sur ces deux petites flèches.
Cela signifie que la dernière ligne du traceback indique le dernier message d’erreur et donne le nom de l’exception qui a été levée. Dans ce cas, le type d’exception est OSError, ce qui indique une erreur liée au système. Si nous lisons le message d’erreur qui l’accompagne, nous pouvons voir qu’il semble y avoir un problème avec le fichier config.json du modèle et deux suggestions nous sont données pour le résoudre :
"""
Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""💡 Si vous rencontrez un message d’erreur difficile à comprendre, copiez et collez le message dans Google ou sur Stack Overflow (oui, vraiment !). Il y a de fortes chances que vous ne soyez pas la première personne à rencontrer cette erreur et c’est un bon moyen de trouver des solutions que d’autres membres de la communauté ont publiées. Par exemple, en recherchant OSError : Can't load config for sur Stack Overflow donne plusieurs réponses qui peuvent être utilisées comme point de départ pour résoudre le problème.
La première suggestion nous demande de vérifier si l’identifiant du modèle est effectivement correct, la première chose à faire est donc de copier l’identifiant et de le coller dans la barre de recherche du Hub :

Hmm, il semble en effet que le modèle de notre collègue ne soit pas sur le Hub… Mais il y a une faute de frappe dans le nom du modèle ! DistilBERT n’a qu’un seul « l » dans son nom alors corrigeons cela et cherchons « lewtun/distilbert-base-uncased-finetuned-squad-d5716d28 » à la place :

Ok, ça a marché. Maintenant essayons de télécharger à nouveau le modèle avec le bon identifiant :
model_checkpoint = get_full_repo_name("distilbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""Argh, encore un échec. Bienvenue dans la vie quotidienne d’un ingénieur en apprentissage machine ! Puisque nous avons corrigé l’identifiant du modèle, le problème doit se situer dans le dépôt lui-même. Une façon rapide d’accéder au contenu d’un dépôt sur le 🤗 Hub est via la fonction list_repo_files() de la bibliothèque huggingface_hub :
from huggingface_hub import list_repo_files
list_repo_files(repo_id=model_checkpoint)['.gitattributes', 'README.md', 'pytorch_model.bin', 'special_tokens_map.json', 'tokenizer_config.json', 'training_args.bin', 'vocab.txt']Intéressant. Il ne semble pas y avoir de fichier config.json dans le dépôt ! Pas étonnant que notre pipeline n’ait pas pu charger le modèle. Notre collègue a dû oublier de pousser ce fichier vers le Hub après l’avoir finetuné. Dans ce cas, le problème semble assez simple à résoudre : nous pouvons lui demander d’ajouter le fichier, ou, puisque nous pouvons voir à partir de l’identifiant du modèle que le modèle pré-entraîné utilisé est distilbert-base-uncased, nous pouvons télécharger la configuration de ce modèle et la pousser dans notre dépôt pour voir si cela résout le problème. Essayons cela. En utilisant les techniques apprises dans le chapitre 2, nous pouvons télécharger la configuration du modèle avec la classe AutoConfig :
from transformers import AutoConfig
pretrained_checkpoint = "distilbert-base-uncased"
config = AutoConfig.from_pretrained(pretrained_checkpoint)🚨 L’approche que nous adoptons ici n’est pas infaillible puisque notre collègue peut avoir modifié la configuration de distilbert-base-uncased avant de finetuner le modèle. Dans la vie réelle, nous voudrions vérifier avec lui d’abord, mais pour les besoins de cette section nous supposerons qu’il a utilisé la configuration par défaut.
Nous pouvons ensuite le pousser vers notre dépôt de modèles avec la fonction push_to_hub() de la configuration :
config.push_to_hub(model_checkpoint, commit_message="Add config.json")Maintenant, nous pouvons tester si cela a fonctionné en chargeant le modèle depuis le dernier commit de la branche main :
reader = pipeline("question-answering", model=model_checkpoint, revision="main")
context = r"""
Extractive Question Answering is the task of extracting an answer from a text
given a question. An example of a question answering dataset is the SQuAD
dataset, which is entirely based on that task. If you would like to fine-tune a
model on a SQuAD task, you may leverage the
examples/pytorch/question-answering/run_squad.py script.
🤗 Transformers is interoperable with the PyTorch, TensorFlow, and JAX
frameworks, so you can use your favourite tools for a wide variety of tasks!
"""
context_fr = r"""
La réponse à des questions consiste à extraire une réponse d'un texte
à partir d'une question. Un exemple de jeu de données de réponse aux questions est le
jeu de données SQuAD qui est entièrement basé sur cette tâche. Si vous souhaitez finetuner
un modèle sur une tâche SQuAD, vous pouvez utiliser le fichier
exemples/pytorch/question-answering/run_squad.py.
🤗 Transformers est interopérable avec les frameworks PyTorch, TensorFlow et JAX.
de sorte que vous pouvez utiliser vos outils préférés pour une grande variété de tâches !
"""
question = "What is extractive question answering?"
# Qu'est-ce que la réponse extractive aux questions ?
reader(question=question, context=context){'score': 0.38669535517692566,
'start': 34,
'end': 95,
'answer': 'the task of extracting an answer from a text given a question'}
# la tâche consistant à extraire une réponse d'un texte à partir d'une question.Woohoo, ça a marché ! Récapitulons ce que vous venez d’apprendre :
- les messages d’erreur en Python sont appelés tracebacks et sont lus de bas en haut. La dernière ligne du message d’erreur contient généralement les informations dont vous avez besoin pour localiser la source du problème,
- si la dernière ligne ne contient pas suffisamment d’informations, remontez dans le traceback et voyez si vous pouvez identifier où l’erreur se produit dans le code source,
- si aucun des messages d’erreur ne peut vous aider à déboguer le problème, essayez de rechercher en ligne une solution à un problème similaire,
- l’
huggingface_hubfournit une suite d’outils que vous pouvez utiliser pour interagir avec et déboguer les dépôts sur le Hub.
Maintenant que vous savez comment déboguer un pipeline, examinons un exemple plus délicat dans la passe avant du modèle lui-même.
Déboguer la passe avant de votre modèle
Bien que le pipeline soit parfait pour la plupart des applications où vous devez générer rapidement des prédictions, vous aurez parfois besoin d’accéder aux logits du modèle (par exemple si vous avez un post-traitement personnalisé que vous souhaitez appliquer). Pour voir ce qui peut mal tourner dans ce cas, commençons par récupérer le modèle et le tokenizer de notre pipeline :
tokenizer = reader.tokenizer model = reader.model
Ensuite, nous avons besoin d’une question, alors voyons si nos frameworks préférés sont supportés :
question = "Which frameworks can I use?" # Quel frameworks puis-je utiliser ?Comme nous l’avons vu dans le chapitre 7, les étapes habituelles que nous devons suivre sont la tokénisation des entrées, l’extraction des logits des tokens de début et de fin, puis le décodage de l’étendue de la réponse :
import torch
inputs = tokenizer(question, context, add_special_tokens=True)
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Pour obtenir le début de réponse le plus probable avec l'argmax du score
answer_start = torch.argmax(answer_start_scores)
# Pour obtenir la fin de réponse la plus probable avec l'argmax du score
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/var/folders/28/k4cy5q7s2hs92xq7_h89_vgm0000gn/T/ipykernel_75743/2725838073.py in <module>
1 inputs = tokenizer(question, text, add_special_tokens=True)
2 input_ids = inputs["input_ids"]
----> 3 outputs = model(**inputs)
4 answer_start_scores = outputs.start_logits
5 answer_end_scores = outputs.end_logits
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, start_positions, end_positions, output_attentions, output_hidden_states, return_dict)
723 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
724
--> 725 distilbert_output = self.distilbert(
726 input_ids=input_ids,
727 attention_mask=attention_mask,
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'
"""Il semble que nous ayons un bug dans notre code ! Mais il ne nous fait pas peur. Nous pouvons utiliser le débogueur Python dans un notebook :
ou dans un terminal :
Ici, la lecture du message d’erreur nous indique que l’objet 'list' n'a pas d'attribut 'size', et nous pouvons voir une flèche --> pointant vers la ligne où le problème a été soulevé dans model(**inputs). Vous pouvez déboguer ceci de manière interactive en utilisant le débogueur Python, mais pour l’instant nous allons simplement imprimer une tranche de inputs pour voir ce que nous avons :
inputs["input_ids"][:5][101, 2029, 7705, 2015, 2064]Cela ressemble certainement à une list ordinaire en Python mais vérifions le type :
type(inputs["input_ids"])listOui, c’est bien une list Python. Alors, qu’est-ce qui a mal tourné ? Rappelez-vous que dans le chapitre 2 nous avons vu que les classes AutoModelForXxx opèrent sur des tenseurs (soit dans PyTorch ou TensorFlow) et qu’une opération commune est d’extraire les dimensions d’un tenseur en utilisant Tensor.size(). Jetons un autre coup d’oeil au traceback pour voir quelle ligne a déclenché l’exception :
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'Il semble que notre code ait essayé d’appeler input_ids.size(), mais cela ne fonctionne clairement pas pour une list Python qui est juste un conteneur. Comment pouvons-nous résoudre ce problème ? La recherche du message d’erreur sur Stack Overflow donne quelques réponses pertinentes. En cliquant sur la première, une question similaire à la nôtre s’affiche, avec la réponse indiquée dans la capture d’écran ci-dessous :
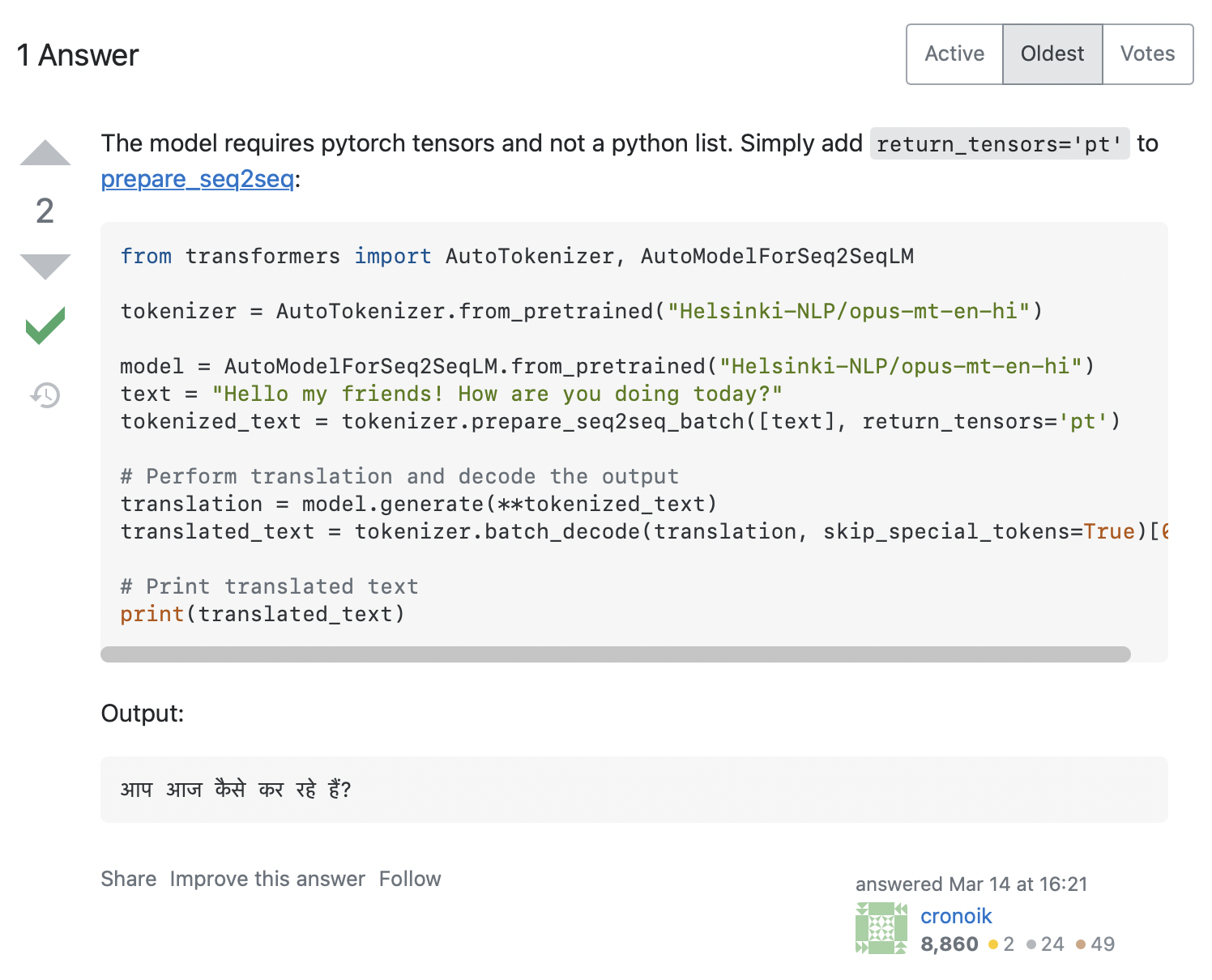
La réponse recommande d’ajouter return_tensors='pt' au tokenizer, voyons donc si cela fonctionne pour nous :
inputs = tokenizer(question, context, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Pour obtenir le début de réponse le plus probable avec l'argmax du score
answer_start = torch.argmax(answer_start_scores)
# Pour obtenir la fin de réponse la plus probable avec l'argmax du score
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
Question: Which frameworks can I use? # Quels frameworks puis-je utiliser ?
Answer: pytorch, tensorflow, and jax # pytorch, tensorflow et jax
"""Super, ça a marché ! Voilà un excellent exemple de l’utilité de Stack Overflow : en identifiant un problème similaire, nous avons pu bénéficier de l’expérience d’autres membres de la communauté. Cependant, une recherche de ce type ne donne pas toujours une réponse pertinente. Que faire alors dans ce cas ? Heureusement, il existe une communauté accueillante de développeurs sur le forum d’Hugging Face qui peut vous aider ! Dans la prochaine section, nous verrons comment rédiger de bonnes questions sur les forums pour avoir de bonnes chances d’obtenir une réponse.
< > Update on GitHub