LLM Course documentation
Création de votre propre jeu de données
Création de votre propre jeu de données
Parfois, le jeu de données dont vous avez besoin pour créer une application de NLP n’existe pas. Vous devrez donc le créer vous-même. Dans cette section, nous allons vous montrer comment créer un corpus de problèmes GitHub, qui sont couramment utilisés pour suivre les bogues ou les fonctionnalités dans les dépôts GitHub. Ce corpus pourrait être utilisé à diverses fins, notamment :
- explorer combien de temps il faut pour fermer les problèmes ouverts ou les pull requests
- entraîner d’un classifieur multilabel capable d’étiqueter les problèmes avec des métadonnées basées sur la description du problème (par exemple : « bug », « amélioration » ou « question »)
- créer un moteur de recherche sémantique pour trouver les problèmes correspondant à la requête d’un utilisateur
Ici, nous nous concentrerons sur la création du corpus, et dans la section suivante, nous aborderons l’application de recherche sémantique. Pour garder les choses méta, nous utiliserons les problèmes GitHub associés à un projet open source populaire : 🤗 Datasets ! Voyons comment obtenir les données et explorons les informations contenues dans ces problèmes.
Obtenir les données
Vous pouvez trouver tous les problèmes dans 🤗 Datasets en accédant à l’onglet « Issues » du dépôt. Comme le montre la capture d’écran suivante, au moment de la rédaction, il y avait 331 problèmes ouverts et 668 problèmes fermés.

Si vous cliquez sur l’un de ces problèmes, vous constaterez qu’il contient un titre, une description et un ensemble d’étiquettes qui caractérisent le problème. Un exemple est montré dans la capture d’écran ci-dessous.

Pour télécharger tous les problèmes du dépôt, nous utilisons l’API REST GitHub pour interroger le point de terminaison Issues. Ce point de terminaison renvoie une liste d’objets JSON. Chaque objet contenant un grand nombre de champs qui incluent le titre et la description ainsi que des métadonnées sur l’état du problème, etc.
Un moyen pratique de télécharger les problèmes consiste à utiliser la bibliothèque requests, qui est la méthode standard pour effectuer des requêtes HTTP en Python. Vous pouvez installer la bibliothèque en exécutant :
!pip install requests
Une fois la bibliothèque installée, vous pouvez envoyer des requêtes GET au point de terminaison Issues en appelant la fonction requests.get(). Par exemple, vous pouvez exécuter la commande suivante pour récupérer le premier numéro sur la première page :
import requests
url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=1"
response = requests.get(url)L’objet response contient de nombreuses informations utiles sur la requête, y compris le code d’état HTTP :
response.status_code
200où un statut 200 signifie que la requête a réussi (vous pouvez trouver une liste des codes de statut HTTP possibles ici). Ce qui nous intéresse vraiment, cependant, c’est le payload, qui peut être consulté dans différents formats comme les octets, les chaînes ou JSON. Comme nous savons que nos problèmes sont au format JSON, examinons la charge utile comme suit :
response.json()
[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'repository_url': 'https://api.github.com/repos/huggingface/datasets',
'labels_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/labels{/name}',
'comments_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/comments',
'events_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/events',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'id': 968650274,
'node_id': 'MDExOlB1bGxSZXF1ZXN0NzEwNzUyMjc0',
'number': 2792,
'title': 'Update GooAQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'labels': [],
'state': 'open',
'locked': False,
'assignee': None,
'assignees': [],
'milestone': None,
'comments': 1,
'created_at': '2021-08-12T11:40:18Z',
'updated_at': '2021-08-12T12:31:17Z',
'closed_at': None,
'author_association': 'CONTRIBUTOR',
'active_lock_reason': None,
'pull_request': {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/2792',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'diff_url': 'https://github.com/huggingface/datasets/pull/2792.diff',
'patch_url': 'https://github.com/huggingface/datasets/pull/2792.patch'},
'body': '[GooAQ](https://github.com/allenai/gooaq) dataset was recently updated after splits were added for the same. This PR contains new updated GooAQ with train/val/test splits and updated README as well.',
'performed_via_github_app': None}]Waouh, ça fait beaucoup d’informations ! Nous pouvons voir des champs utiles comme title, body et number qui décrivent le problème, ainsi que des informations sur l’utilisateur GitHub qui a ouvert le problème.
✏️ Essayez ! Cliquez sur quelques-unes des URL pour avoir une idée du type d’informations auxquelles chaque problème GitHub est lié.
Comme décrit dans la documentation GitHub, les requêtes non authentifiées sont limitées à 60 requêtes par heure. Bien que vous puissiez augmenter le paramètre de requête per_page pour réduire le nombre de requêtes que vous effectuez, vous atteindrez toujours la limite de débit sur tout dépôt contenant des milliers de problèmes. Donc, à la place, vous devez suivre les instructions de GitHub sur la création d’un jeton d’accès personnel afin que vous peut augmenter la limite de débit à 5 000 requêtes par heure. Une fois que vous avez votre token, vous pouvez l’inclure dans l’en-tête de la requête :
GITHUB_TOKEN = xxx # Copiez votre jeton GitHub ici
headers = {"Authorization": f"token {GITHUB_TOKEN}"}⚠️ Ne partagez pas un notebook avec votre GITHUB_TOKEN collé dedans. Nous vous recommandons de supprimer la dernière cellule une fois que vous l’avez exécutée pour éviter de divulguer accidentellement ces informations. Mieux encore, stockez le jeton dans un fichier .env et utilisez la bibliothèque python-dotenv pour le charger automatiquement pour vous en tant que variable d’environnement.
Maintenant que nous avons notre jeton d’accès, créons une fonction qui peut télécharger tous les problèmes depuis un référentiel GitHub :
import time
import math
from pathlib import Path
import pandas as pd
from tqdm.notebook import tqdm
def fetch_issues(
owner="huggingface",
repo="datasets",
num_issues=10_000,
rate_limit=5_000,
issues_path=Path("."),
):
if not issues_path.is_dir():
issues_path.mkdir(exist_ok=True)
batch = []
all_issues = []
per_page = 100 # Nombre d'issues à retourner par page
num_pages = math.ceil(num_issues / per_page)
base_url = "https://api.github.com/repos"
for page in tqdm(range(num_pages)):
# Requête avec state=all pour obtenir les issues ouvertes et fermées
query = f"issues?page={page}&per_page={per_page}&state=all"
issues = requests.get(f"{base_url}/{owner}/{repo}/{query}", headers=headers)
batch.extend(issues.json())
if len(batch) > rate_limit and len(all_issues) < num_issues:
all_issues.extend(batch)
batch = [] # Vider le batch pour la période de temps suivante
print(f"Reached GitHub rate limit. Sleeping for one hour ...")
time.sleep(60 * 60 + 1)
all_issues.extend(batch)
df = pd.DataFrame.from_records(all_issues)
df.to_json(f"{issues_path}/{repo}-issues.jsonl", orient="records", lines=True)
print(
f"Downloaded all the issues for {repo}! Dataset stored at {issues_path}/{repo}-issues.jsonl"
)Désormais, lorsque nous appellerons fetch_issues(), tous les problèmes seront téléchargés par batchs pour éviter de dépasser la limite de GitHub sur le nombre de requêtes par heure. Le résultat sera stocké dans un fichier repository_name-issues.jsonl, où chaque ligne est un objet JSON qui représente un problème. Utilisons cette fonction pour saisir tous les problèmes de 🤗 Datasets :
# En fonction de votre connexion Internet, l'exécution peut prendre plusieurs minutes...
fetch_issues()Une fois les problèmes téléchargés, nous pouvons les charger localement en utilisant nos nouvelles compétences de section 2 :
issues_dataset = load_dataset("json", data_files="datasets-issues.jsonl", split="train")
issues_datasetDataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'timeline_url', 'performed_via_github_app'],
num_rows: 3019
})Génial, nous avons créé notre premier jeu de données à partir de rien ! Mais pourquoi y a-t-il plusieurs milliers de problèmes alors que l’onglet « Issues » de la librairie 🤗 Datasets n’affiche qu’environ 1 000 problèmes au total 🤔 ? Comme décrit dans la documentation GitHub, c’est parce que nous avons téléchargé toutes les pull requests également :
L’API REST v3 de GitHub considère chaque pull request comme un problème, mais chaque problème n’est pas une pull request. Pour cette raison, les points de terminaison « Issues » peuvent renvoyer à la fois des problèmes et des pull requests dans la réponse. Vous pouvez identifier les pull requests par la clé
pull_request. Sachez que l’identifiant d’une pull request renvoyée par les points de terminaison « Issues » sera un identifiant de problème.
Étant donné que le contenu des « Issues » et des pull request est assez différent, procédons à un prétraitement mineur pour nous permettre de les distinguer.
Nettoyer les données
L’extrait ci-dessus de la documentation de GitHub nous indique que la colonne pull_request peut être utilisée pour différencier les issues et les pull requests. Regardons un échantillon aléatoire pour voir quelle est la différence. Comme nous l’avons fait dans section 3, nous allons enchaîner Dataset.shuffle() et Dataset.select() pour créer un échantillon aléatoire, puis compresser html_url et pull_request afin que nous puissions comparer les différentes URL :
sample = issues_dataset.shuffle(seed=666).select(range(3))
# Afficher l'URL et les entrées de la PR
for url, pr in zip(sample["html_url"], sample["pull_request"]):
print(f">> URL: {url}")
print(f">> Pull request: {pr}\n")>> URL: https://github.com/huggingface/datasets/pull/850
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/850', 'html_url': 'https://github.com/huggingface/datasets/pull/850', 'diff_url': 'https://github.com/huggingface/datasets/pull/850.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/850.patch'}
>> URL: https://github.com/huggingface/datasets/issues/2773
>> Pull request: None
>> URL: https://github.com/huggingface/datasets/pull/783
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/783', 'html_url': 'https://github.com/huggingface/datasets/pull/783', 'diff_url': 'https://github.com/huggingface/datasets/pull/783.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/783.patch'}Ici, nous pouvons voir que chaque pull request est associée à diverses URL, tandis que les problèmes ordinaires ont une entrée None. Nous pouvons utiliser cette distinction pour créer une nouvelle colonne is_pull_request qui vérifie si le champ pull_request est None ou non :
issues_dataset = issues_dataset.map(
lambda x: {"is_pull_request": False if x["pull_request"] is None else True}
)✏️ Essayez ! Calculez le temps moyen nécessaire pour résoudre les problèmes dans 🤗 Datasets. Vous pouvez trouver la fonction Dataset.filter() utile pour filtrer les demandes d’extraction et les problèmes ouverts. Vous pouvez utiliser la fonction Dataset.set_format() pour convertir le jeu de données en un DataFrame afin que vous puissiez facilement manipuler les horodatages created_at et closed_at. Pour les points bonus, calculez le temps moyen nécessaire pour fermer les pull_requests.
Bien que nous puissions continuer à nettoyer davantage le jeu de données en supprimant ou en renommant certaines colonnes, il est généralement recommandé de le conserver aussi brut que possible à ce stade afin qu’il puisse être facilement utilisé dans plusieurs applications.
Avant de pousser notre jeu de données vers le Hub d’Hugging Face, traitons une chose manquante : les commentaires associés à chaque problème et pull requests. Nous les ajouterons ensuite avec l’API GitHub REST !
Enrichir le jeu de données
Comme le montre la capture d’écran suivante, les commentaires associés à un problème ou à une pull request fournissent une riche source d’informations, en particulier si nous souhaitons créer un moteur de recherche pour répondre aux requêtes des utilisateurs sur la bibliothèque.

L’API REST GitHub fournit un point de terminaison Comments qui renvoie tous les commentaires associés à un numéro de problème. Testons le point de terminaison pour voir ce qu’il renvoie :
issue_number = 2792
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
response.json()[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/comments/897594128',
'html_url': 'https://github.com/huggingface/datasets/pull/2792#issuecomment-897594128',
'issue_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'id': 897594128,
'node_id': 'IC_kwDODunzps41gDMQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'created_at': '2021-08-12T12:21:52Z',
'updated_at': '2021-08-12T12:31:17Z',
'author_association': 'CONTRIBUTOR',
'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
'performed_via_github_app': None}]Nous pouvons voir que le commentaire est stocké dans le champ body. Ecrivons donc une fonction simple qui renvoie tous les commentaires associés à un problème en sélectionnant le contenu body pour chaque élément dans response.json() :
def get_comments(issue_number):
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
return [r["body"] for r in response.json()]
# Tester notre fonction fonctionne comme prévu
get_comments(2792)["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]Cela a l’air bien. Utilisons Dataset.map() pour ajouter une nouvelle colonne comments à chaque problème de notre jeu de données :
# Selon votre connexion internet, cela peut prendre quelques minutes...
issues_with_comments_dataset = issues_dataset.map(
lambda x: {"comments": get_comments(x["number"])}
)La dernière étape consiste à enregistrer le jeu de données augmentées avec nos données brutes afin que nous puissions les pousser tous les deux vers le Hub :
issues_with_comments_dataset.to_json("issues-datasets-with-comments.jsonl")Téléchargement du jeu de données sur le <i> Hub </i>
Maintenant que nous avons notre jeu de données augmenté, il est temps de le pousser vers le Hub afin que nous puissions le partager avec la communauté ! Pour télécharger le jeu de données, nous utilisons la bibliothèque 🤗 Hub, qui nous permet d’interagir avec le Hub d’Hugging Face via une API Python. 🤗 Hub est préinstallé avec 🤗 Transformers, nous pouvons donc l’utiliser directement. Par exemple, nous pouvons utiliser la fonction list_datasets() pour obtenir des informations sur tous les ensembles de données publics actuellement hébergés sur le Hub:
from huggingface_hub import list_datasets
all_datasets = list_datasets()
print(f"Number of datasets on Hub: {len(all_datasets)}")
print(all_datasets[0])Number of datasets on Hub: 1487
Dataset Name: acronym_identification, Tags: ['annotations_creators:expert-generated', 'language_creators:found', 'languages:en', 'licenses:mit', 'multilinguality:monolingual', 'size_categories:10K<n<100K', 'source_datasets:original', 'task_categories:structure-prediction', 'task_ids:structure-prediction-other-acronym-identification']Nous pouvons voir qu’il y a actuellement près de 1 500 jeux de données sur le Hub et la fonction list_datasets() fournit également des métadonnées de base sur chaque dépôts de jeux de données.
Pour nos besoins, la première chose que nous devons faire est de créer un nouveau dépôt de jeux de données sur le Hub. Pour ce faire, nous avons besoin d’un jeton d’authentification, qui peut être obtenu en se connectant d’abord au Hub d’Hugging Face avec la fonction notebook_login() :
from huggingface_hub import notebook_login
notebook_login()Cela créé un widget dans lequel vous pouvez entrer votre nom d’utilisateur et votre mot de passe. Un jeton API sera enregistré dans ~/.huggingface/token. Si vous exécutez le code dans un terminal, vous pouvez vous connecter via la CLI à la place :
huggingface-cli login
Une fois que nous avons fait cela, nous pouvons créer un nouveau dépôt de jeux de données avec la fonction create_repo() :
from huggingface_hub import create_repo
repo_url = create_repo(name="github-issues", repo_type="dataset")
repo_url'https://huggingface.co/datasets/lewtun/github-issues'Dans cet exemple, nous avons créé un dépôt vide appelé github-issues sous le nom d’utilisateur lewtun (le nom d’utilisateur doit être votre nom d’utilisateur Hub lorsque vous exécutez ce code !).
✏️ Essayez ! Utilisez votre nom d’utilisateur et votre mot de passe Hugging Face pour obtenir un jeton et créer un dépôt vide appelé github-issues. N’oubliez pas de n’enregistrez jamais vos informations d’identification dans Colab ou tout autre référentiel car ces informations peuvent être exploitées par de mauvais individus.
Ensuite, clonons le dépôt du Hub sur notre machine locale et copions-y notre fichier jeu de données. 🤗 Hub fournit une classe Repository pratique qui encapsule de nombreuses commandes Git courantes. Donc pour cloner le dépôt distant, nous devons simplement fournir l’URL et le chemin local vers lesquels nous souhaitons cloner :
from huggingface_hub import Repository
repo = Repository(local_dir="github-issues", clone_from=repo_url)
!cp datasets-issues-with-comments.jsonl github-issues/Par défaut, diverses extensions de fichiers (telles que .bin, .gz et .zip) sont suivies avec Git LFS afin que les fichiers volumineux puissent être versionnés dans le même workflow Git. Vous pouvez trouver une liste des extensions de fichiers suivis dans le fichier .gitattributes du référentiel. Pour inclure le format JSON Lines dans la liste, nous pouvons exécuter la commande suivante :
repo.lfs_track("*.jsonl")Ensuite, nous pouvons utiliser Repository.push_to_hub() pour pousser le jeu de données vers le Hub :
repo.push_to_hub()
Si nous naviguons vers l’URL contenue dans repo_url, nous devrions maintenant voir que notre fichier de jeu de données a été téléchargé.
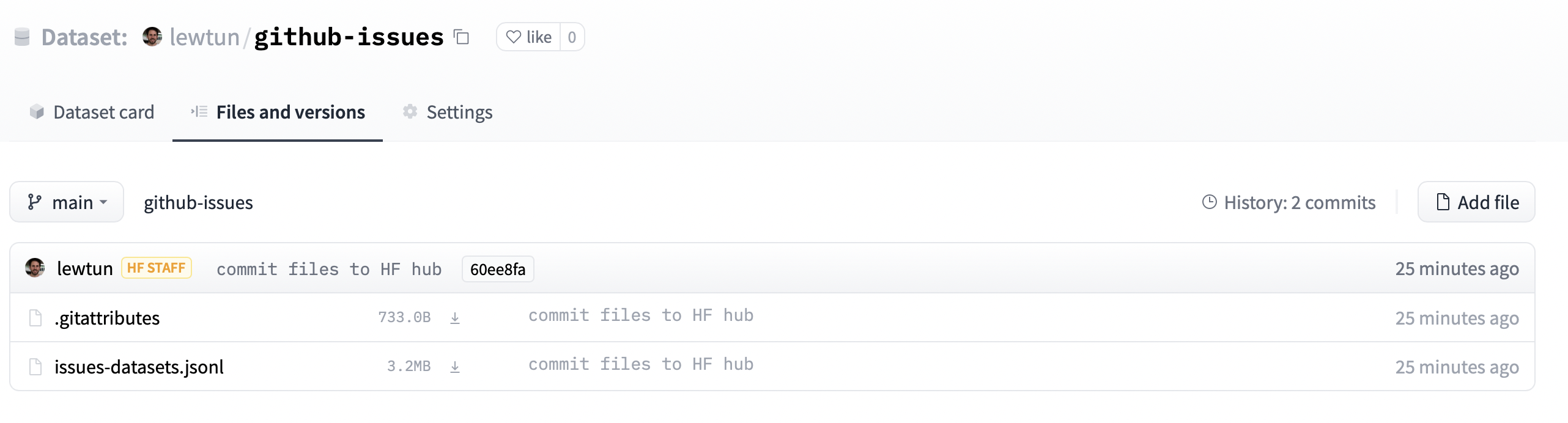
À partir de là, n’importe qui peut télécharger le jeu de données en fournissant simplement load_dataset() avec l’ID du référentiel comme argument path :
remote_dataset = load_dataset("lewtun/github-issues", split="train")
remote_datasetDataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 2855
})Cool, nous avons poussé notre jeu de données vers le Hub et il est disponible pour que d’autres puissent l’utiliser ! Il ne reste plus qu’une chose importante à faire : ajouter une carte de jeu de données qui explique comment le corpus a été créé et fournit d’autres informations utiles à la communauté.
💡 Vous pouvez également télécharger un jeu de données sur le Hub directement depuis le terminal en utilisant huggingface-cli et un peu de magie Git. Consultez le guide de 🤗 Datasets pour savoir comment procéder.
Création d’une carte pour un jeu de données
Des jeux de données bien documentés sont plus susceptibles d’être utiles aux autres (y compris à vous-même) car ils fournissent le contexte permettant aux utilisateurs de décider si le jeu de données est pertinent pour leur tâche et d’évaluer les biais potentiels ou les risques associés à l’utilisation du jeu de données.
Sur le Hub, ces informations sont stockées dans le fichier README.md de chaque dépôt de jeux de données. Il y a deux étapes principales que vous devez suivre avant de créer ce fichier :
- Utilisez l’application
datasets-taggingpour créer des balises de métadonnées au format YAML. Ces balises sont utilisées pour une variété de fonctionnalités de recherche sur le Hub d’Hugging Face et garantissent que votre jeu de données peut être facilement trouvé par les membres de la communauté. Puisque nous avons créé un jeu de données personnalisé ici, vous devrez cloner le référentieldatasets-tagginget exécuter l’application localement. Voici à quoi ressemble l’interface :

- Lisez le guide de 🤗 Datasets sur la création des cartes informatives des jeux de données et utilisez-le comme modèle.
Vous pouvez créer le fichier README.md directement sur le Hub et vous pouvez trouver un modèle de carte dans le dépot lewtun/github-issues. Une capture d’écran de la carte remplie est illustrée ci-dessous.

✏️ Essayez ! Utilisez l’application dataset-tagging et le guide de 🤗 Datasets pour compléter le fichier README.md de votre jeu de données de problèmes GitHub.
C’est tout ! Nous avons vu dans cette section que la création d’un bon jeu de données peut être assez complexe, mais heureusement, le télécharger et le partager avec la communauté ne l’est pas. Dans la section suivante, nous utiliserons notre nouveau jeu de données pour créer un moteur de recherche sémantique avec 🤗 Datasets qui peut faire correspondre les questions aux problèmes et commentaires les plus pertinents.
✏️ Essayez ! Suivez les étapes que nous avons suivies dans cette section pour créer un jeu de données de problèmes GitHub pour votre bibliothèque open source préférée (choisissez autre chose que 🤗 Datasets, bien sûr !). Pour obtenir des points bonus, finetunez un classifieur multilabel pour prédire les balises présentes dans le champ labels.