¿Qué hacer cuando se produce un error?

En esta sección veremos algunos errores comunes que pueden ocurrir cuando intentas generar predicciones a partir de tu modelo Transformer recién afinado. Esto te preparará para la sección 4, en la que exploraremos cómo depurar (debug) la fase de entrenamiento.
Hemos preparado un repositorio de un modelo de ejemplo para esta sección, por lo que si deseas ejecutar el código en este capítulo, primero necesitarás copiar el modelo a tu cuenta en el Hub de Hugging Face. Para ello, primero inicia sesión (log in) ejecutando lo siguiente en una Jupyter notebook:
from huggingface_hub import notebook_login
notebook_login()o puedes ejecutar lo siguiente en tu terminal favorita:
huggingface-cli login
Esto te pedirá que introduzcas tu nombre de usuario y contraseña, y guardará un token en ~/.cache/huggingface/. Una vez que hayas iniciado sesión, puedes copiar el repositorio de ejemplo con la siguiente función:
from distutils.dir_util import copy_tree
from huggingface_hub import Repository, snapshot_download, create_repo, get_full_repo_name
def copy_repository_template():
# Clona el repo y extrae la ruta local
template_repo_id = "lewtun/distilbert-base-uncased-finetuned-squad-d5716d28"
commit_hash = "be3eaffc28669d7932492681cd5f3e8905e358b4"
template_repo_dir = snapshot_download(template_repo_id, revision=commit_hash)
# Crea un repo vacío en el Hub
model_name = template_repo_id.split("/")[1]
create_repo(model_name, exist_ok=True)
# Clona el repo vacío
new_repo_id = get_full_repo_name(model_name)
new_repo_dir = model_name
repo = Repository(local_dir=new_repo_dir, clone_from=new_repo_id)
# Copia los archivos
copy_tree(template_repo_dir, new_repo_dir)
# Envia (push) al Hub
repo.push_to_hub()Ahora cuando llames a la función copy_repository_template(), esta creará una copia del repositorio de ejemplo en tu cuenta.
Depurando el pipeline de 🤗 Transformers
Para iniciar nuestro viaje hacia el maravilloso mundo de la depuración de modelos de Transformers, imagina lo siguiente: estás trabajando con un compañero en un proyecto de respuesta a preguntas (question answering) para ayudar a los clientes de un sitio web de comercio electrónico a encontrar respuestas sobre productos de consumo. Tu compañero te envía el siguiente mensaje:
¡Buen día! Acabo de lanzar un experimento usando las técnicas del Capitulo 7 del curso de Hugging Face y ¡obtuvo unos buenos resultados con el conjunto de datos SQuAD! Creo que podemos usar este modelo como punto de partida para nuestro proyecto. El identificador del modelo en el Hub es “lewtun/distillbert-base-uncased-finetuned-squad-d5716d28”. No dudes en probarlo :)
y en lo primero que piensas es en cargar el modelo usando el pipeline de la librería 🤗 Transformers:
from transformers import pipeline
model_checkpoint = get_full_repo_name("distillbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""¡Oh no, algo parece estar mal! Si eres nuevo en programación, este tipo de errores pueden parecer un poco crípticos al inicio (¿qué es un OSError?). El error mostrado aquí es solo la última parte de un reporte de errores mucho más largo llamado Python traceback (o stack trace). Por ejemplo, si estás ejecutando este código en Google Colab, podrías ver algo parecido como la siguiente captura:
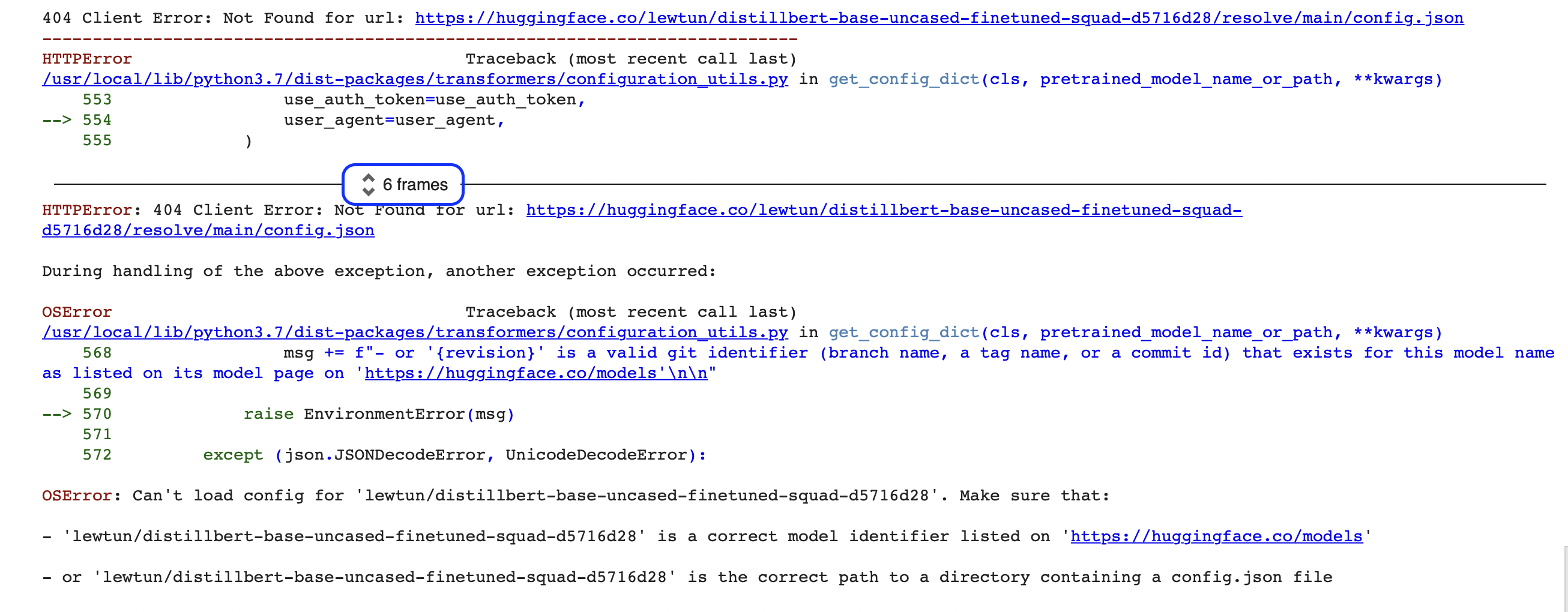
Hay mucha información contenida en estos reportes, así que vamos a repasar juntos las partes clave. La primera cosa que notamos es que el traceback debería ser leído de abajo hacia arriba. Esto puede sonar extraño si estás acostumbrado a leer en español de arriba hacia abajo, pero refleja el hecho de que el traceback muestra la secuencia de funciones llamadas que el pipeline realiza al descargar el modelo y el tokenizador. (Ve al Capítulo 2 para más detalles sobre cómo funciona el pipeline bajo el capó)
🚨 ¿Ves el cuadro azul alrededor de “6 frames” en el traceback de Google Colab? Es una característica especial de Colab, que comprime el traceback en “frames”. Si no puedes encontrar el origen de un error, asegúrate de ampliar el traceback completo haciendo clic en esas dos flechitas.
Esto significa que la última línea del traceback indica el último mensaje de error y nos da el nombre de la excepción (exception) que se ha generado. En este caso, el tipo de excepción es OSError, lo que indica un error relacionado con el sistema. Si leemos el mensaje de error que lo acompaña, podemos ver que parece haber un problema con el archivo config.json del modelo, y nos da dos sugerencias para solucionarlo:
"""
Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""💡 Si te encuentras con un mensaje de error difícil de entender, simplemente copia y pega el mensaje en la barra de búsqueda de Google o de Stack Overflow (¡sí, en serio!). Es muy posible que no seas la primera persona en encontrar el error, y esta es una buena forma de hallar soluciones que otros miembros de la comunidad han publicado. Por ejemplo, al buscar OSError: Can't load config for en Stack Overflow se obtienen varios resultados que pueden ser utilizados como punto de partida para resolver el problema.
La primera sugerencia nos pide que comprobemos si el identificador del modelo es realmente correcto, así que lo primero es copiar el identificador y pegarlo en la barra de búsqueda del Hub:

Hmm, efectivamente parece que el modelo de nuestro compañero no está en el Hub… ¡pero hay una errata en el nombre del modelo! DistilBERT solo tiene una “l” en el nombre, así que vamos a corregirlo y a buscar “lewtun/distilbert-base-uncased-finetuned-squad-d5716d28” en su lugar:

Bien, esto dio resultado. Ahora vamos a intentar descargar el modelo de nuevo con el identificador correcto:
model_checkpoint = get_full_repo_name("distilbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""Argh, falló de nuevo, ¡bienvenido al día a día de un ingeniero de machine learning! Dado que arreglamos el identificador del modelo, el problema debe estar en el repositorio. Una manera rápida de acceder a los contenidos de un repositorio en el 🤗 Hub es por medio de la función list_repo_files() de la librería de huggingface_hub:
from huggingface_hub import list_repo_files
list_repo_files(repo_id=model_checkpoint)['.gitattributes', 'README.md', 'pytorch_model.bin', 'special_tokens_map.json', 'tokenizer_config.json', 'training_args.bin', 'vocab.txt']Interesante. ¡No parece haber un archivo config.json en el repositorio! No es de extrañar que nuestro pipeline no pudiera cargar el modelo; nuestro compañero debe haberse olvidado de enviar este archivo al Hub después de ajustarlo (fine-tuned). En este caso, el problema parece bastante simple de resolver: podemos pedirle a nuestro compañero que añada el archivo, o, ya que podemos ver en el identificador del modelo que el modelo preentrenado fue distilbert-base-uncased, podemos descargar la configuración para este modelo y enviarla a nuestro repositorio para ver si eso resuelve el problema. Intentemos esto. Usando las técnicas que aprendimos en el Capítulo 2, podemos descargar la configuración del modelo con la clase AutoConfig:
from transformers import AutoConfig
pretrained_checkpoint = "distilbert-base-uncased"
config = AutoConfig.from_pretrained(pretrained_checkpoint)🚨 El enfoque que tomamos aquí no es infalible, ya que nuestro compañero puede haber cambiado la configuración de distilbert-base-uncased antes de ajustar (fine-tuning) el modelo. En la vida real, nos gustaría consultar con él primero, pero para los fines de esta sección asumiremos que usó la configuración predeterminada.
Luego podemos enviar esto a nuestro repositorio del modelo con la función de configuración push_to_hub():
config.push_to_hub(model_checkpoint, commit_message="Add config.json")Ahora podemos probar si esto funciona cargando el modelo desde el último commit de la rama main:
reader = pipeline("question-answering", model=model_checkpoint, revision="main")
context = r"""
Extractive Question Answering is the task of extracting an answer from a text
given a question. An example of a question answering dataset is the SQuAD
dataset, which is entirely based on that task. If you would like to fine-tune a
model on a SQuAD task, you may leverage the
examples/pytorch/question-answering/run_squad.py script.
🤗 Transformers is interoperable with the PyTorch, TensorFlow, and JAX
frameworks, so you can use your favourite tools for a wide variety of tasks!
"""
context_es = r"""
La respuesta a preguntas es la extracción de una respuesta textual a partir de
una pregunta. Un ejemplo de conjunto de datos de respuesta a preguntas es el
dataset SQuAD, que se basa por completo en esta tarea. Si deseas afinar un modelo
en una tarea SQuAD, puedes aprovechar el script
examples/pytorch/question-answering/run_squad.py
🤗 Transformers es interoperable con los frameworks PyTorch, TensorFlow y JAX,
así que ¡puedes utilizar tus herramientas favoritas para una gran variedad de tareas!
"""
question = "What is extractive question answering?"
# ¿Qué es la respuesta extractiva a preguntas?
reader(question=question, context=context){'score': 0.38669535517692566,
'start': 34,
'end': 95,
'answer': 'the task of extracting an answer from a text given a question'}
# la tarea de extraer una respuesta de un texto a una pregunta dada¡Yuju, funcionó! Recapitulemos lo que acabas de aprender:
- Los mensajes de error en Python son conocidos como tracebacks y se leen de abajo hacia arriba. La última línea del mensaje de error generalmente contiene la información que necesitas para ubicar la fuente del problema.
- Si la última línea no contiene suficiente información, sigue el traceback y mira si puedes identificar en qué parte del código fuente se produce el error.
- Si ninguno de los mensajes de error te ayuda a depurar el problema, trata de buscar en internet una solución a un problema similar.
- El 🤗
huggingface_hubde la librería proporciona un conjunto de herramientas que puedes utilizar para interactuar y depurar los repositorios en el Hub.
Ahora que sabes cómo depurar un pipeline, vamos a ver un ejemplo más complicado en la pasada hacia delante (forward pass) del propio modelo.
Depurando la pasada hacia delante (forward pass) de tu modelo
Aunque el pipeline es estupendo para la mayoría de las aplicaciones en las que necesitas generar predicciones rápidamente, a veces necesitarás acceder a los logits del modelo (por ejemplo, si tienes algún postprocesamiento personalizado que te gustaría aplicar). Para ver lo que puede salir mal en este caso, vamos a coger primero el modelo y el tokenizador de nuestro pipeline:
tokenizer = reader.tokenizer model = reader.model
A continuación, necesitamos una pregunta, así que veamos si nuestros frameworks son compatibles:
question = "Which frameworks can I use?" # ¿Qué frameworks puedo usar?Como vimos en el Capítulo 7, los pasos habituales que debemos seguir son tokenizar los inputs, extraer los logits de los tokens de inicio y fin y luego decodificar el intervalo de la respuesta:
import torch
inputs = tokenizer(question, context, add_special_tokens=True)
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Obtiene el comienzo más probable de la respuesta con el argmax de la puntuación
answer_start = torch.argmax(answer_start_scores)
# Obtiene el final más probable de la respuesta con el argmax de la puntuación
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/var/folders/28/k4cy5q7s2hs92xq7_h89_vgm0000gn/T/ipykernel_75743/2725838073.py in <module>
1 inputs = tokenizer(question, text, add_special_tokens=True)
2 input_ids = inputs["input_ids"]
----> 3 outputs = model(**inputs)
4 answer_start_scores = outputs.start_logits
5 answer_end_scores = outputs.end_logits
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, start_positions, end_positions, output_attentions, output_hidden_states, return_dict)
723 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
724
--> 725 distilbert_output = self.distilbert(
726 input_ids=input_ids,
727 attention_mask=attention_mask,
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'
"""Vaya, parece que tenemos un bug en nuestro código. Pero no nos asusta un poco de depuración. Puedes usar el depurador de Python en una notebook:
o en una terminal:
Aquí la lectura del mensaje de error nos dice que el objeto 'list' no tiene atributo 'size', y podemos ver una flecha --> apuntando a la línea donde el problema se originó en model(**inputs). Puedes depurar esto interactivamente usando el debugger de Python, pero por ahora simplemente imprimiremos un fragmento de inputs para ver qué obtenemos:
inputs["input_ids"][:5][101, 2029, 7705, 2015, 2064]Esto sin duda parece una lista ordinaria de Python, pero vamos a comprobar el tipo:
type(inputs["input_ids"])listSí, es una lista de Python. Entonces, ¿qué salió mal? Recordemos del Capítulo 2 que las clases AutoModelForXxx en 🤗 Transformers operan con tensores (tanto en PyTorch como en TensorFlow), y una operación común es extraer las dimensiones de un tensor usando Tensor.size() en, por ejemplo, PyTorch. Volvamos a echar un vistazo al traceback, para ver qué línea desencadenó la excepción:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'Parece que nuestro código trata de llamar a la función input_ids.size(), pero esta claramente no funcionará con una lista de Python, la cual solo es un contenedor. ¿Cómo podemos resolver este problema? La búsqueda del mensaje de error en Stack Overflow da bastantes resultados relevantes. Al hacer clic en el primero, aparece una pregunta similar a la nuestra, con la respuesta que se muestra en la siguiente captura de pantalla:
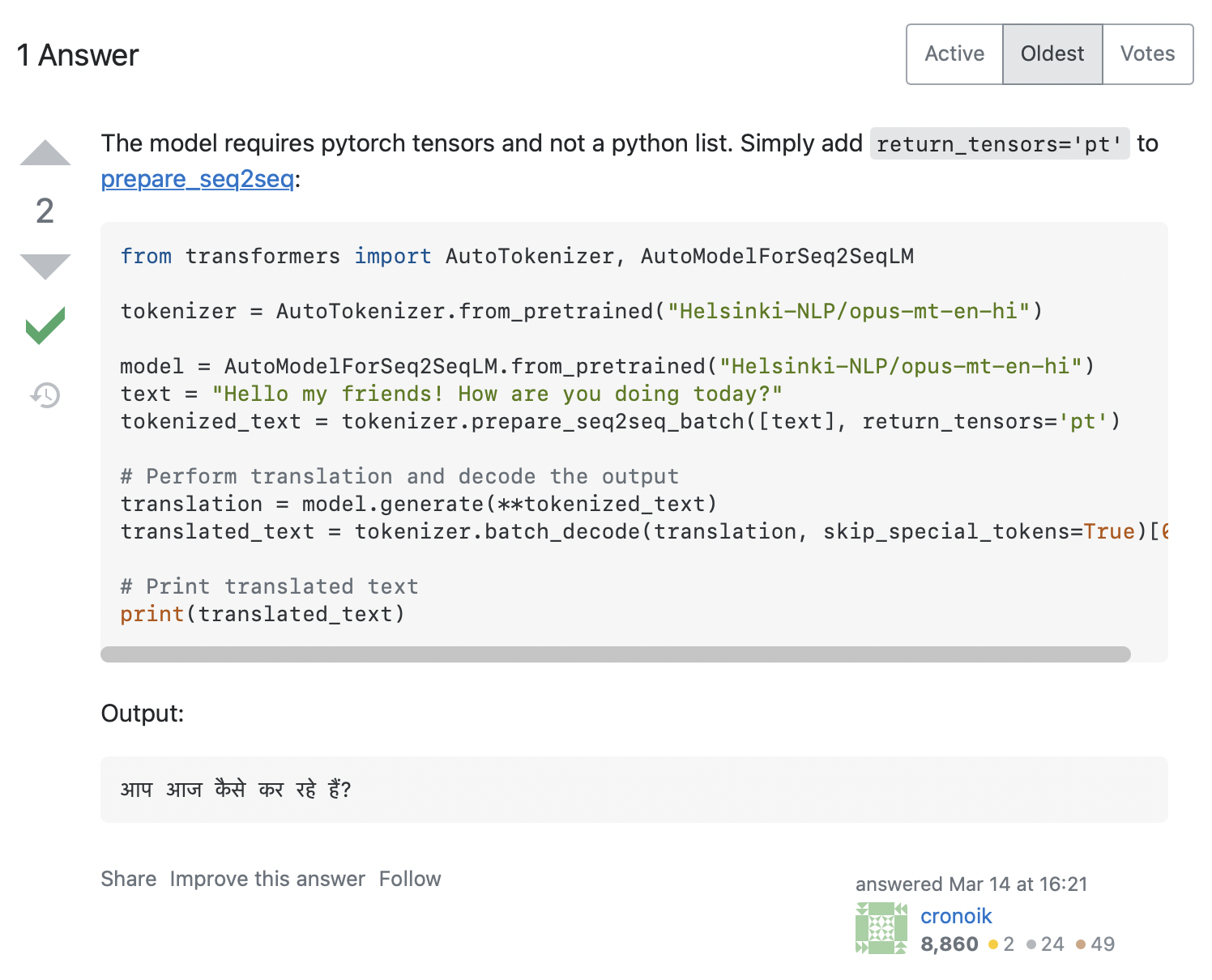
La respuesta recomienda que adicionemos return_tensors='pt' al tokenizador, así que veamos si esto nos funciona:
inputs = tokenizer(question, context, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Obtiene el comienzo más probable de la respuesta con el argmax de la puntuación
answer_start = torch.argmax(answer_start_scores)
# Obtiene el final más probable de la respuesta con el argmax de la puntuación
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
Question: Which frameworks can I use? # ¿Qué frameworks puedo usar?
Answer: pytorch, tensorflow, and jax
"""¡Excelente, funcionó! Este en un gran ejemplo de lo útil que puede ser Stack Overflow: al identificar un problema similar, fuimos capaces de beneficiarnos de la experiencia de otros en la comunidad. Sin embargo, una búsqueda como esta no siempre dará una respuesta relevante, así que ¿qué podemos hacer en esos casos? Afortunadamente hay una comunidad acogedora de desarrolladores en los foros de Hugging Face que pueden ayudarte. En la siguiente sección, veremos cómo elaborar buenas preguntas en el foro que tengan posibilidades de ser respondidas.
< > Update on GitHub