

Update README.md
Browse files
README.md
CHANGED
|
@@ -1,16 +1,157 @@
|
|
| 1 |
---
|
| 2 |
-
|
|
|
|
|
|
|
| 3 |
tags:
|
| 4 |
- text-to-image
|
| 5 |
-
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
-
### leaf on Stable Diffusion via Dreambooth
|
| 8 |
-
#### model by mjbuehler
|
| 9 |
|
| 10 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
|
| 12 |
-
|
| 13 |
|
| 14 |
-
Here are the images used for training this concept:
|
| 15 |
|
| 16 |
-
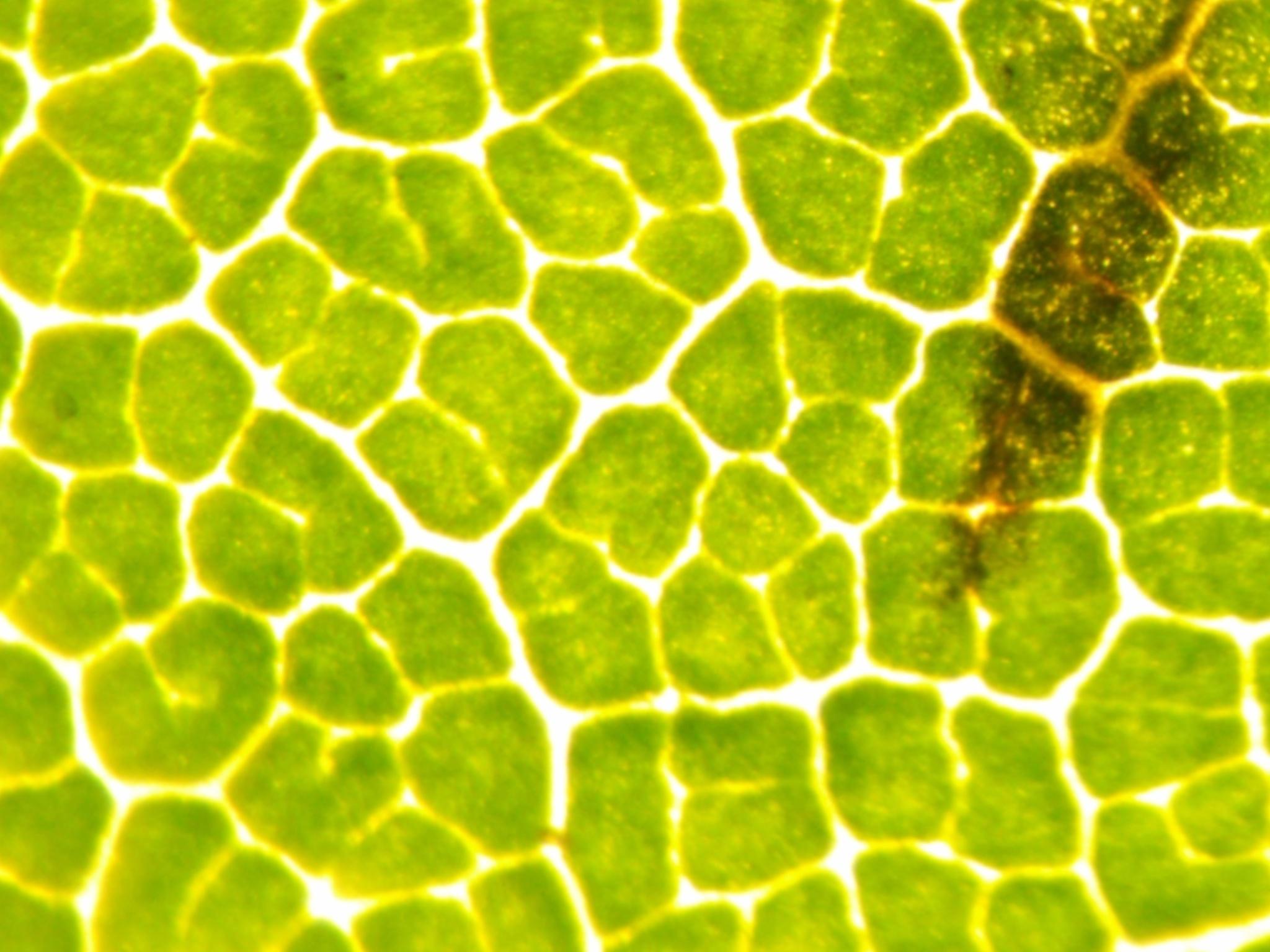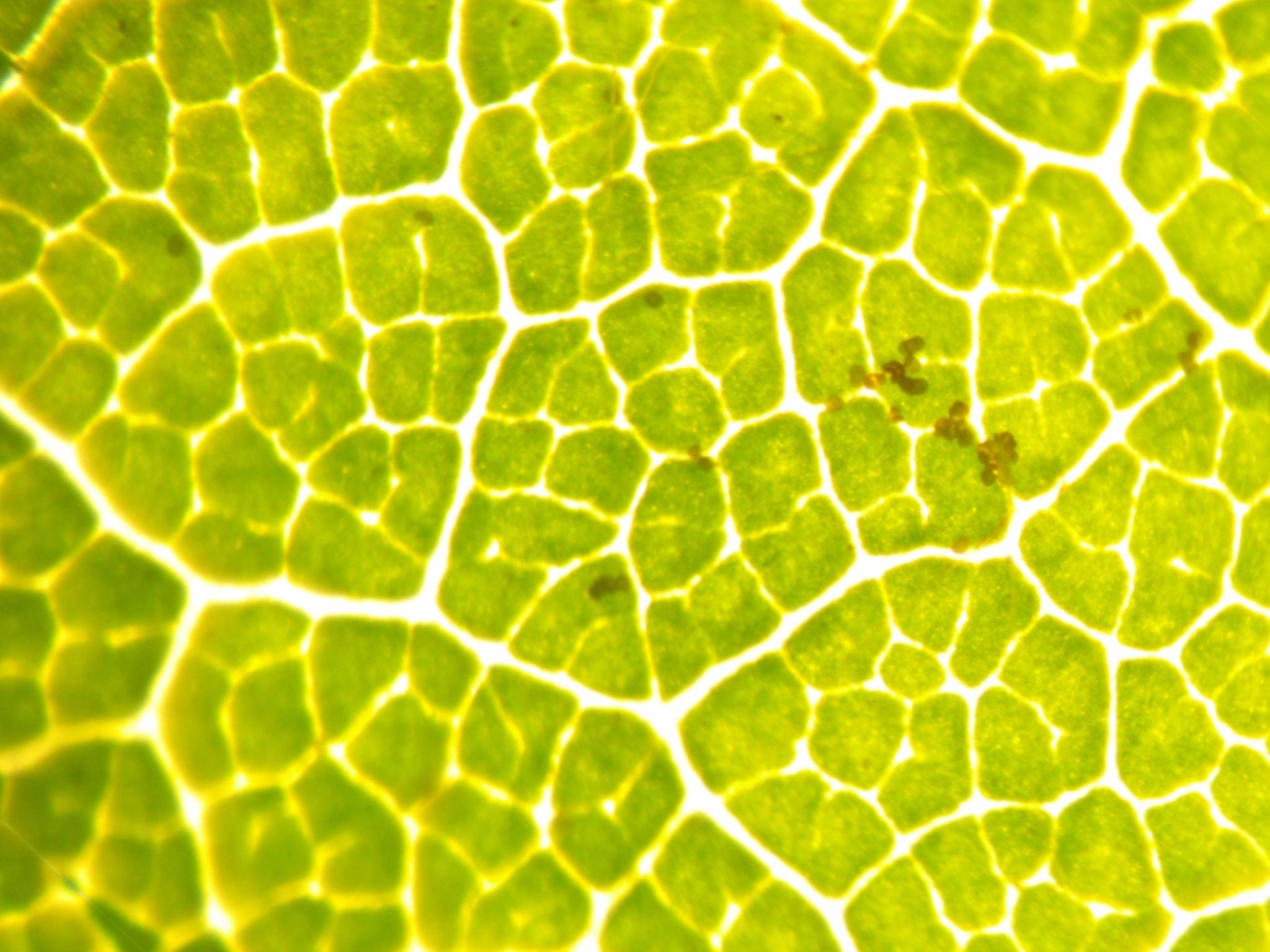
|
|
|
|
| 1 |
---
|
| 2 |
+
base_model: stabilityai/stable-diffusion-xl-base-1.0
|
| 3 |
+
library_name: diffusers
|
| 4 |
+
license: openrail++
|
| 5 |
tags:
|
| 6 |
- text-to-image
|
| 7 |
+
- text-to-image
|
| 8 |
+
- diffusers-training
|
| 9 |
+
- diffusers
|
| 10 |
+
- stable-diffusion-2
|
| 11 |
+
- stable-diffusion-2-diffusers
|
| 12 |
+
instance_prompt: <leaf microstructure>
|
| 13 |
+
widget: []
|
| 14 |
---
|
|
|
|
|
|
|
| 15 |
|
| 16 |
+
# Stable Diffusion 2.x Fine-tuned with Leaf Images
|
| 17 |
+
|
| 18 |
+
## Model description
|
| 19 |
+
|
| 20 |
+
These are fine-tuned weights for the ```stabilityai/stable-diffusion-2``` model. This is a full fine-tune of the model using DreamBooth.
|
| 21 |
+
|
| 22 |
+
## Trigger keywords
|
| 23 |
+
|
| 24 |
+
The following image were used during fine-tuning using the keyword \<leaf microstructure\>:
|
| 25 |
+
|
| 26 |
+

|
| 27 |
+
|
| 28 |
+
You should use <leaf microstructure> to trigger the image generation.
|
| 29 |
+
|
| 30 |
+
## How to use
|
| 31 |
+
|
| 32 |
+
Defining some helper functions:
|
| 33 |
+
|
| 34 |
+
```python
|
| 35 |
+
from diffusers import DiffusionPipeline
|
| 36 |
+
import torch
|
| 37 |
+
import os
|
| 38 |
+
from datetime import datetime
|
| 39 |
+
from PIL import Image
|
| 40 |
+
|
| 41 |
+
def generate_filename(base_name, extension=".png"):
|
| 42 |
+
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
|
| 43 |
+
return f"{base_name}_{timestamp}{extension}"
|
| 44 |
+
|
| 45 |
+
def save_image(image, directory, base_name="image_grid"):
|
| 46 |
+
|
| 47 |
+
filename = generate_filename(base_name)
|
| 48 |
+
file_path = os.path.join(directory, filename)
|
| 49 |
+
image.save(file_path)
|
| 50 |
+
print(f"Image saved as {file_path}")
|
| 51 |
+
|
| 52 |
+
def image_grid(imgs, rows, cols, save=True, save_dir='generated_images', base_name="image_grid",
|
| 53 |
+
save_individual_files=False):
|
| 54 |
+
|
| 55 |
+
if not os.path.exists(save_dir):
|
| 56 |
+
os.makedirs(save_dir)
|
| 57 |
+
|
| 58 |
+
assert len(imgs) == rows * cols
|
| 59 |
+
|
| 60 |
+
w, h = imgs[0].size
|
| 61 |
+
grid = Image.new('RGB', size=(cols * w, rows * h))
|
| 62 |
+
grid_w, grid_h = grid.size
|
| 63 |
+
|
| 64 |
+
for i, img in enumerate(imgs):
|
| 65 |
+
grid.paste(img, box=(i % cols * w, i // cols * h))
|
| 66 |
+
if save_individual_files:
|
| 67 |
+
save_image(img, save_dir, base_name=base_name+f'_{i}-of-{len(imgs)}_')
|
| 68 |
+
|
| 69 |
+
if save and save_dir:
|
| 70 |
+
save_image(grid, save_dir, base_name)
|
| 71 |
+
|
| 72 |
+
return grid
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
### Text-to-image
|
| 76 |
+
|
| 77 |
+
Model loading:
|
| 78 |
+
|
| 79 |
+
```python
|
| 80 |
+
|
| 81 |
+
import torch
|
| 82 |
+
from diffusers import DPMSolverMultistepScheduler
|
| 83 |
+
|
| 84 |
+
repo_id='lamm-mit/SD2x-leaf-inspired'
|
| 85 |
+
|
| 86 |
+
pipe = StableDiffusionPipeline.from_pretrained(repo_id,
|
| 87 |
+
scheduler = DPMSolverMultistepScheduler.from_pretrained(args.output_dir, subfolder="scheduler"),
|
| 88 |
+
torch_dtype=torch.float16,
|
| 89 |
+
).to("cuda")
|
| 90 |
+
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
Image generation:
|
| 94 |
+
|
| 95 |
+
```python
|
| 96 |
+
prompt = "a vase that resembles a <leaf microstructure>, high quality"
|
| 97 |
+
num_samples = 4
|
| 98 |
+
num_rows = 4
|
| 99 |
+
|
| 100 |
+
all_images = []
|
| 101 |
+
for _ in range(num_rows):
|
| 102 |
+
images = pipe(prompt, num_images_per_prompt=num_samples, num_inference_steps=50, guidance_scale=15).images
|
| 103 |
+
all_images.extend(images)
|
| 104 |
+
|
| 105 |
+
grid = image_grid(all_images, num_rows, num_samples)
|
| 106 |
+
grid
|
| 107 |
+
```
|
| 108 |
+

|
| 109 |
+
|
| 110 |
+
## Fine-tuning script
|
| 111 |
+
|
| 112 |
+
Download this script: [SD2x DreamBooth-Fine-Tune.ipynb](https://huggingface.co/lamm-mit/SDXL-leaf-inspired/resolve/main/SDXL_DreamBooth_LoRA_Fine-Tune.ipynb)
|
| 113 |
+
|
| 114 |
+
You need to create a local folder ```leaf_concept_dir``` and add the leaf images (provided in this repository, see subfolder), like so:
|
| 115 |
+
|
| 116 |
+
```python
|
| 117 |
+
save_path='leaf_concept_dir'
|
| 118 |
+
urls = [
|
| 119 |
+
"https://www.dropbox.com/scl/fi/4s09djm4nqxmq6vhvv9si/13_.jpg?rlkey=3m2f90pjofljmlqg5uc722i6y&dl=1",
|
| 120 |
+
"https://www.dropbox.com/scl/fi/w4jsrf0qmrcro37nxutbx/25_.jpg?rlkey=e52gnoqaar33kwrd01h1mwcnk&dl=1",
|
| 121 |
+
"https://www.dropbox.com/scl/fi/x0xgavduor4cbxz0sdcd2/33_.jpg?rlkey=5htaicapahhn66wnsr23v1nxz&dl=1",
|
| 122 |
+
"https://www.dropbox.com/scl/fi/2grt40acypah9h9ok607q/72_.jpg?rlkey=bl6vfv0rcas2ygsz6o3behlst&dl=1",
|
| 123 |
+
"https://www.dropbox.com/scl/fi/ecaf9agzdj2cawspmyt5i/117_.jpg?rlkey=oqxyk9i1wtu1wtkqadd6ylyjj&dl=1",
|
| 124 |
+
"https://www.dropbox.com/scl/fi/gw3p73r99fleozr6ckfa3/126_.jpg?rlkey=6n7kqaklczshht1ntyqunh2lt&dl=1",
|
| 125 |
+
## You can add additional images here
|
| 126 |
+
]
|
| 127 |
+
images = list(filter(None,[download_image(url) for url in urls]))
|
| 128 |
+
|
| 129 |
+
if not os.path.exists(save_path):
|
| 130 |
+
os.mkdir(save_path)
|
| 131 |
+
|
| 132 |
+
[image.save(f"{save_path}/{i}.jpeg") for i, image in enumerate(images)]
|
| 133 |
+
image_grid(images, 1, len(images))
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
The training script is included in the Jupyter notebook.
|
| 137 |
+
|
| 138 |
+
## More examples
|
| 139 |
+
|
| 140 |
+

|
| 141 |
+
|
| 142 |
+
|
| 143 |
+

|
| 144 |
+
|
| 145 |
+
|
| 146 |
+

|
| 147 |
+
|
| 148 |
+
|
| 149 |
+

|
| 150 |
+
|
| 151 |
+
|
| 152 |
+

|
| 153 |
+
|
| 154 |
|
| 155 |
+

|
| 156 |
|
|
|
|
| 157 |
|
|
|