
feat: v1 model
Browse files- .idea/csv-editor.xml +16 -0
- .idea/misc.xml +1 -1
- .idea/trocr-handwritten-mathematical-expressions.iml +4 -2
- dataset/annotations.csv +23 -0
- dataset/images/0001.png +0 -0
- dataset/images/0002.png +0 -0
- dataset/images/0003.png +0 -0
- dataset/images/0004.png +0 -0
- dataset/images/0005.png +0 -0
- dataset/images/0006.png +0 -0
- dataset/images/0007.png +0 -0
- dataset/images/0008.png +0 -0
- dataset/images/0009.png +0 -0
- dataset/images/0010.png +0 -0
- dataset/images/0011.png +0 -0
- dataset/images/0012.png +0 -0
- dataset/images/0013.png +0 -0
- dataset/images/0014.png +0 -0
- dataset/images/0015.png +0 -0
- dataset/images/0016.png +0 -0
- dataset/images/0017.png +0 -0
- dataset/images/0018.png +0 -0
- dataset/images/0019.png +0 -0
- dataset/images/0020.png +0 -0
- dataset/images/0021.png +0 -0
- dataset/images/0022.png +0 -0
- model/checkpoint-500/config.json +171 -0
- model/checkpoint-500/generation_config.json +9 -0
- model/checkpoint-500/model.safetensors +3 -0
- model/checkpoint-500/optimizer.pt +3 -0
- model/checkpoint-500/rng_state.pth +3 -0
- model/checkpoint-500/scheduler.pt +3 -0
- model/checkpoint-500/trainer_state.json +321 -0
- model/checkpoint-500/training_args.bin +3 -0
- requirements.txt +6 -0
- train.py +87 -0
.idea/csv-editor.xml
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<project version="4">
|
| 3 |
+
<component name="CsvFileAttributes">
|
| 4 |
+
<option name="attributeMap">
|
| 5 |
+
<map>
|
| 6 |
+
<entry key="\dataset\annotations.csv">
|
| 7 |
+
<value>
|
| 8 |
+
<Attribute>
|
| 9 |
+
<option name="separator" value="," />
|
| 10 |
+
</Attribute>
|
| 11 |
+
</value>
|
| 12 |
+
</entry>
|
| 13 |
+
</map>
|
| 14 |
+
</option>
|
| 15 |
+
</component>
|
| 16 |
+
</project>
|
.idea/misc.xml
CHANGED
|
@@ -3,5 +3,5 @@
|
|
| 3 |
<component name="Black">
|
| 4 |
<option name="sdkName" value="Python 3.10 (Задачи на семинар 8. Ответы)" />
|
| 5 |
</component>
|
| 6 |
-
<component name="ProjectRootManager" version="2" project-jdk-name="Python 3.
|
| 7 |
</project>
|
|
|
|
| 3 |
<component name="Black">
|
| 4 |
<option name="sdkName" value="Python 3.10 (Задачи на семинар 8. Ответы)" />
|
| 5 |
</component>
|
| 6 |
+
<component name="ProjectRootManager" version="2" project-jdk-name="Python 3.12 (trocr-handwritten-mathematical-expressions)" project-jdk-type="Python SDK" />
|
| 7 |
</project>
|
.idea/trocr-handwritten-mathematical-expressions.iml
CHANGED
|
@@ -1,8 +1,10 @@
|
|
| 1 |
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
<module type="PYTHON_MODULE" version="4">
|
| 3 |
<component name="NewModuleRootManager">
|
| 4 |
-
<content url="file://$MODULE_DIR$"
|
| 5 |
-
|
|
|
|
|
|
|
| 6 |
<orderEntry type="sourceFolder" forTests="false" />
|
| 7 |
</component>
|
| 8 |
</module>
|
|
|
|
| 1 |
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
<module type="PYTHON_MODULE" version="4">
|
| 3 |
<component name="NewModuleRootManager">
|
| 4 |
+
<content url="file://$MODULE_DIR$">
|
| 5 |
+
<excludeFolder url="file://$MODULE_DIR$/venv" />
|
| 6 |
+
</content>
|
| 7 |
+
<orderEntry type="jdk" jdkName="Python 3.12 (trocr-handwritten-mathematical-expressions)" jdkType="Python SDK" />
|
| 8 |
<orderEntry type="sourceFolder" forTests="false" />
|
| 9 |
</component>
|
| 10 |
</module>
|
dataset/annotations.csv
CHANGED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
filename,expression
|
| 2 |
+
./dataset/images/0001.png,0.9 + 0.1
|
| 3 |
+
./dataset/images/0002.png,1 + 1
|
| 4 |
+
./dataset/images/0003.png,2 + 2 * 2
|
| 5 |
+
./dataset/images/0004.png,13 / 3 + 3^2
|
| 6 |
+
./dataset/images/0005.png,26 * 3
|
| 7 |
+
./dataset/images/0006.png,52 + 100
|
| 8 |
+
./dataset/images/0007.png,6.5 * 9
|
| 9 |
+
./dataset/images/0008.png,89 * 9
|
| 10 |
+
./dataset/images/0009.png,46 - 2
|
| 11 |
+
./dataset/images/0010.png,28 - 9
|
| 12 |
+
./dataset/images/0011.png,4^3 / 7
|
| 13 |
+
./dataset/images/0012.png,73 / 4 + (3 * 3)
|
| 14 |
+
./dataset/images/0013.png,0.123 + 0
|
| 15 |
+
./dataset/images/0014.png,1.34 + 5.67
|
| 16 |
+
./dataset/images/0015.png,123 - 49 + 7
|
| 17 |
+
./dataset/images/0016.png,1426 = 62x
|
| 18 |
+
./dataset/images/0017.png,103 = a + 91
|
| 19 |
+
./dataset/images/0018.png,799x + 22 = 426688
|
| 20 |
+
./dataset/images/0019.png,901 + 315 = 302a - 274027
|
| 21 |
+
./dataset/images/0020.png,20(58x + 78) = 115240
|
| 22 |
+
./dataset/images/0021.png,46(4c + 2) = -4508 / 2
|
| 23 |
+
./dataset/images/0022.png,65 = 5915 / x
|
dataset/images/0001.png
ADDED
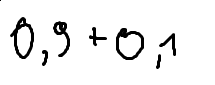
|
dataset/images/0002.png
ADDED
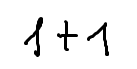
|
dataset/images/0003.png
ADDED
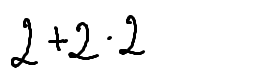
|
dataset/images/0004.png
ADDED
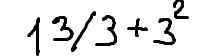
|
dataset/images/0005.png
ADDED
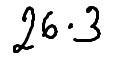
|
dataset/images/0006.png
ADDED

|
dataset/images/0007.png
ADDED

|
dataset/images/0008.png
ADDED
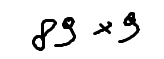
|
dataset/images/0009.png
ADDED
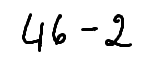
|
dataset/images/0010.png
ADDED
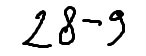
|
dataset/images/0011.png
ADDED

|
dataset/images/0012.png
ADDED
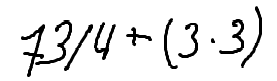
|
dataset/images/0013.png
ADDED

|
dataset/images/0014.png
ADDED

|
dataset/images/0015.png
ADDED

|
dataset/images/0016.png
ADDED
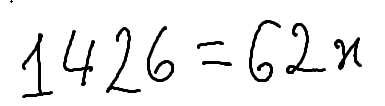
|
dataset/images/0017.png
ADDED
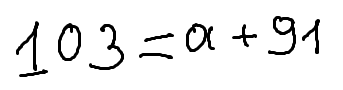
|
dataset/images/0018.png
ADDED

|
dataset/images/0019.png
ADDED
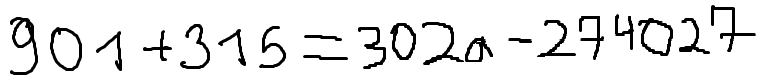
|
dataset/images/0020.png
ADDED
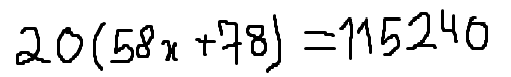
|
dataset/images/0021.png
ADDED
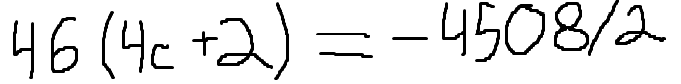
|
dataset/images/0022.png
ADDED

|
model/checkpoint-500/config.json
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "microsoft/trocr-base-handwritten",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"VisionEncoderDecoderModel"
|
| 5 |
+
],
|
| 6 |
+
"decoder": {
|
| 7 |
+
"_name_or_path": "",
|
| 8 |
+
"activation_dropout": 0.0,
|
| 9 |
+
"activation_function": "gelu",
|
| 10 |
+
"add_cross_attention": true,
|
| 11 |
+
"architectures": null,
|
| 12 |
+
"attention_dropout": 0.0,
|
| 13 |
+
"bad_words_ids": null,
|
| 14 |
+
"begin_suppress_tokens": null,
|
| 15 |
+
"bos_token_id": 0,
|
| 16 |
+
"chunk_size_feed_forward": 0,
|
| 17 |
+
"classifier_dropout": 0.0,
|
| 18 |
+
"cross_attention_hidden_size": 768,
|
| 19 |
+
"d_model": 1024,
|
| 20 |
+
"decoder_attention_heads": 16,
|
| 21 |
+
"decoder_ffn_dim": 4096,
|
| 22 |
+
"decoder_layerdrop": 0.0,
|
| 23 |
+
"decoder_layers": 12,
|
| 24 |
+
"decoder_start_token_id": 2,
|
| 25 |
+
"diversity_penalty": 0.0,
|
| 26 |
+
"do_sample": false,
|
| 27 |
+
"dropout": 0.1,
|
| 28 |
+
"early_stopping": false,
|
| 29 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 30 |
+
"eos_token_id": 2,
|
| 31 |
+
"exponential_decay_length_penalty": null,
|
| 32 |
+
"finetuning_task": null,
|
| 33 |
+
"forced_bos_token_id": null,
|
| 34 |
+
"forced_eos_token_id": null,
|
| 35 |
+
"id2label": {
|
| 36 |
+
"0": "LABEL_0",
|
| 37 |
+
"1": "LABEL_1"
|
| 38 |
+
},
|
| 39 |
+
"init_std": 0.02,
|
| 40 |
+
"is_decoder": true,
|
| 41 |
+
"is_encoder_decoder": false,
|
| 42 |
+
"label2id": {
|
| 43 |
+
"LABEL_0": 0,
|
| 44 |
+
"LABEL_1": 1
|
| 45 |
+
},
|
| 46 |
+
"layernorm_embedding": true,
|
| 47 |
+
"length_penalty": 1.0,
|
| 48 |
+
"max_length": 20,
|
| 49 |
+
"max_position_embeddings": 512,
|
| 50 |
+
"min_length": 0,
|
| 51 |
+
"model_type": "trocr",
|
| 52 |
+
"no_repeat_ngram_size": 0,
|
| 53 |
+
"num_beam_groups": 1,
|
| 54 |
+
"num_beams": 1,
|
| 55 |
+
"num_return_sequences": 1,
|
| 56 |
+
"output_attentions": false,
|
| 57 |
+
"output_hidden_states": false,
|
| 58 |
+
"output_scores": false,
|
| 59 |
+
"pad_token_id": 1,
|
| 60 |
+
"prefix": null,
|
| 61 |
+
"problem_type": null,
|
| 62 |
+
"pruned_heads": {},
|
| 63 |
+
"remove_invalid_values": false,
|
| 64 |
+
"repetition_penalty": 1.0,
|
| 65 |
+
"return_dict": true,
|
| 66 |
+
"return_dict_in_generate": false,
|
| 67 |
+
"scale_embedding": false,
|
| 68 |
+
"sep_token_id": null,
|
| 69 |
+
"suppress_tokens": null,
|
| 70 |
+
"task_specific_params": null,
|
| 71 |
+
"temperature": 1.0,
|
| 72 |
+
"tf_legacy_loss": false,
|
| 73 |
+
"tie_encoder_decoder": false,
|
| 74 |
+
"tie_word_embeddings": true,
|
| 75 |
+
"tokenizer_class": null,
|
| 76 |
+
"top_k": 50,
|
| 77 |
+
"top_p": 1.0,
|
| 78 |
+
"torch_dtype": null,
|
| 79 |
+
"torchscript": false,
|
| 80 |
+
"typical_p": 1.0,
|
| 81 |
+
"use_bfloat16": false,
|
| 82 |
+
"use_cache": false,
|
| 83 |
+
"use_learned_position_embeddings": true,
|
| 84 |
+
"vocab_size": 50265
|
| 85 |
+
},
|
| 86 |
+
"decoder_start_token_id": 0,
|
| 87 |
+
"encoder": {
|
| 88 |
+
"_name_or_path": "",
|
| 89 |
+
"add_cross_attention": false,
|
| 90 |
+
"architectures": null,
|
| 91 |
+
"attention_probs_dropout_prob": 0.0,
|
| 92 |
+
"bad_words_ids": null,
|
| 93 |
+
"begin_suppress_tokens": null,
|
| 94 |
+
"bos_token_id": null,
|
| 95 |
+
"chunk_size_feed_forward": 0,
|
| 96 |
+
"cross_attention_hidden_size": null,
|
| 97 |
+
"decoder_start_token_id": null,
|
| 98 |
+
"diversity_penalty": 0.0,
|
| 99 |
+
"do_sample": false,
|
| 100 |
+
"early_stopping": false,
|
| 101 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 102 |
+
"encoder_stride": 16,
|
| 103 |
+
"eos_token_id": null,
|
| 104 |
+
"exponential_decay_length_penalty": null,
|
| 105 |
+
"finetuning_task": null,
|
| 106 |
+
"forced_bos_token_id": null,
|
| 107 |
+
"forced_eos_token_id": null,
|
| 108 |
+
"hidden_act": "gelu",
|
| 109 |
+
"hidden_dropout_prob": 0.0,
|
| 110 |
+
"hidden_size": 768,
|
| 111 |
+
"id2label": {
|
| 112 |
+
"0": "LABEL_0",
|
| 113 |
+
"1": "LABEL_1"
|
| 114 |
+
},
|
| 115 |
+
"image_size": 384,
|
| 116 |
+
"initializer_range": 0.02,
|
| 117 |
+
"intermediate_size": 3072,
|
| 118 |
+
"is_decoder": false,
|
| 119 |
+
"is_encoder_decoder": false,
|
| 120 |
+
"label2id": {
|
| 121 |
+
"LABEL_0": 0,
|
| 122 |
+
"LABEL_1": 1
|
| 123 |
+
},
|
| 124 |
+
"layer_norm_eps": 1e-12,
|
| 125 |
+
"length_penalty": 1.0,
|
| 126 |
+
"max_length": 20,
|
| 127 |
+
"min_length": 0,
|
| 128 |
+
"model_type": "vit",
|
| 129 |
+
"no_repeat_ngram_size": 0,
|
| 130 |
+
"num_attention_heads": 12,
|
| 131 |
+
"num_beam_groups": 1,
|
| 132 |
+
"num_beams": 1,
|
| 133 |
+
"num_channels": 3,
|
| 134 |
+
"num_hidden_layers": 12,
|
| 135 |
+
"num_return_sequences": 1,
|
| 136 |
+
"output_attentions": false,
|
| 137 |
+
"output_hidden_states": false,
|
| 138 |
+
"output_scores": false,
|
| 139 |
+
"pad_token_id": null,
|
| 140 |
+
"patch_size": 16,
|
| 141 |
+
"prefix": null,
|
| 142 |
+
"problem_type": null,
|
| 143 |
+
"pruned_heads": {},
|
| 144 |
+
"qkv_bias": false,
|
| 145 |
+
"remove_invalid_values": false,
|
| 146 |
+
"repetition_penalty": 1.0,
|
| 147 |
+
"return_dict": true,
|
| 148 |
+
"return_dict_in_generate": false,
|
| 149 |
+
"sep_token_id": null,
|
| 150 |
+
"suppress_tokens": null,
|
| 151 |
+
"task_specific_params": null,
|
| 152 |
+
"temperature": 1.0,
|
| 153 |
+
"tf_legacy_loss": false,
|
| 154 |
+
"tie_encoder_decoder": false,
|
| 155 |
+
"tie_word_embeddings": true,
|
| 156 |
+
"tokenizer_class": null,
|
| 157 |
+
"top_k": 50,
|
| 158 |
+
"top_p": 1.0,
|
| 159 |
+
"torch_dtype": null,
|
| 160 |
+
"torchscript": false,
|
| 161 |
+
"typical_p": 1.0,
|
| 162 |
+
"use_bfloat16": false
|
| 163 |
+
},
|
| 164 |
+
"is_encoder_decoder": true,
|
| 165 |
+
"model_type": "vision-encoder-decoder",
|
| 166 |
+
"pad_token_id": 1,
|
| 167 |
+
"processor_class": "TrOCRProcessor",
|
| 168 |
+
"tie_word_embeddings": false,
|
| 169 |
+
"torch_dtype": "float32",
|
| 170 |
+
"transformers_version": "4.37.2"
|
| 171 |
+
}
|
model/checkpoint-500/generation_config.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 0,
|
| 4 |
+
"decoder_start_token_id": 2,
|
| 5 |
+
"eos_token_id": 2,
|
| 6 |
+
"pad_token_id": 1,
|
| 7 |
+
"transformers_version": "4.37.2",
|
| 8 |
+
"use_cache": false
|
| 9 |
+
}
|
model/checkpoint-500/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b40685900fc767af31aef4a3a62d0f2fc964f910e9d5d6eb3a6accc9c83324f2
|
| 3 |
+
size 1335747032
|
model/checkpoint-500/optimizer.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:277ee31979f928e16dacf35727b361540431efc2179066178de8aff98fade57e
|
| 3 |
+
size 2667050412
|
model/checkpoint-500/rng_state.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ae815a4262cf019aa02c8291a4c9c2a2b22f9c4534ccef44ebbef7835c2c5e48
|
| 3 |
+
size 14244
|
model/checkpoint-500/scheduler.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d02c16cc82c2dd3c41a58b5d09ae955539e7b9165124433ee976a0bb0323a2ee
|
| 3 |
+
size 1064
|
model/checkpoint-500/trainer_state.json
ADDED
|
@@ -0,0 +1,321 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 100.0,
|
| 5 |
+
"eval_steps": 500,
|
| 6 |
+
"global_step": 500,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 2.0,
|
| 13 |
+
"learning_rate": 9.8e-05,
|
| 14 |
+
"loss": 8.2056,
|
| 15 |
+
"step": 10
|
| 16 |
+
},
|
| 17 |
+
{
|
| 18 |
+
"epoch": 4.0,
|
| 19 |
+
"learning_rate": 9.6e-05,
|
| 20 |
+
"loss": 4.4086,
|
| 21 |
+
"step": 20
|
| 22 |
+
},
|
| 23 |
+
{
|
| 24 |
+
"epoch": 6.0,
|
| 25 |
+
"learning_rate": 9.4e-05,
|
| 26 |
+
"loss": 3.1851,
|
| 27 |
+
"step": 30
|
| 28 |
+
},
|
| 29 |
+
{
|
| 30 |
+
"epoch": 8.0,
|
| 31 |
+
"learning_rate": 9.200000000000001e-05,
|
| 32 |
+
"loss": 3.2542,
|
| 33 |
+
"step": 40
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
"epoch": 10.0,
|
| 37 |
+
"learning_rate": 9e-05,
|
| 38 |
+
"loss": 2.6913,
|
| 39 |
+
"step": 50
|
| 40 |
+
},
|
| 41 |
+
{
|
| 42 |
+
"epoch": 12.0,
|
| 43 |
+
"learning_rate": 8.800000000000001e-05,
|
| 44 |
+
"loss": 2.3765,
|
| 45 |
+
"step": 60
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"epoch": 14.0,
|
| 49 |
+
"learning_rate": 8.6e-05,
|
| 50 |
+
"loss": 2.2853,
|
| 51 |
+
"step": 70
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"epoch": 16.0,
|
| 55 |
+
"learning_rate": 8.4e-05,
|
| 56 |
+
"loss": 2.3182,
|
| 57 |
+
"step": 80
|
| 58 |
+
},
|
| 59 |
+
{
|
| 60 |
+
"epoch": 18.0,
|
| 61 |
+
"learning_rate": 8.2e-05,
|
| 62 |
+
"loss": 2.156,
|
| 63 |
+
"step": 90
|
| 64 |
+
},
|
| 65 |
+
{
|
| 66 |
+
"epoch": 20.0,
|
| 67 |
+
"learning_rate": 8e-05,
|
| 68 |
+
"loss": 1.9019,
|
| 69 |
+
"step": 100
|
| 70 |
+
},
|
| 71 |
+
{
|
| 72 |
+
"epoch": 22.0,
|
| 73 |
+
"learning_rate": 7.800000000000001e-05,
|
| 74 |
+
"loss": 1.8288,
|
| 75 |
+
"step": 110
|
| 76 |
+
},
|
| 77 |
+
{
|
| 78 |
+
"epoch": 24.0,
|
| 79 |
+
"learning_rate": 7.6e-05,
|
| 80 |
+
"loss": 1.7968,
|
| 81 |
+
"step": 120
|
| 82 |
+
},
|
| 83 |
+
{
|
| 84 |
+
"epoch": 26.0,
|
| 85 |
+
"learning_rate": 7.4e-05,
|
| 86 |
+
"loss": 1.6366,
|
| 87 |
+
"step": 130
|
| 88 |
+
},
|
| 89 |
+
{
|
| 90 |
+
"epoch": 28.0,
|
| 91 |
+
"learning_rate": 7.2e-05,
|
| 92 |
+
"loss": 1.5084,
|
| 93 |
+
"step": 140
|
| 94 |
+
},
|
| 95 |
+
{
|
| 96 |
+
"epoch": 30.0,
|
| 97 |
+
"learning_rate": 7e-05,
|
| 98 |
+
"loss": 1.3425,
|
| 99 |
+
"step": 150
|
| 100 |
+
},
|
| 101 |
+
{
|
| 102 |
+
"epoch": 32.0,
|
| 103 |
+
"learning_rate": 6.800000000000001e-05,
|
| 104 |
+
"loss": 1.3157,
|
| 105 |
+
"step": 160
|
| 106 |
+
},
|
| 107 |
+
{
|
| 108 |
+
"epoch": 34.0,
|
| 109 |
+
"learning_rate": 6.6e-05,
|
| 110 |
+
"loss": 1.1184,
|
| 111 |
+
"step": 170
|
| 112 |
+
},
|
| 113 |
+
{
|
| 114 |
+
"epoch": 36.0,
|
| 115 |
+
"learning_rate": 6.400000000000001e-05,
|
| 116 |
+
"loss": 0.8982,
|
| 117 |
+
"step": 180
|
| 118 |
+
},
|
| 119 |
+
{
|
| 120 |
+
"epoch": 38.0,
|
| 121 |
+
"learning_rate": 6.2e-05,
|
| 122 |
+
"loss": 0.7471,
|
| 123 |
+
"step": 190
|
| 124 |
+
},
|
| 125 |
+
{
|
| 126 |
+
"epoch": 40.0,
|
| 127 |
+
"learning_rate": 6e-05,
|
| 128 |
+
"loss": 0.7546,
|
| 129 |
+
"step": 200
|
| 130 |
+
},
|
| 131 |
+
{
|
| 132 |
+
"epoch": 42.0,
|
| 133 |
+
"learning_rate": 5.8e-05,
|
| 134 |
+
"loss": 0.5103,
|
| 135 |
+
"step": 210
|
| 136 |
+
},
|
| 137 |
+
{
|
| 138 |
+
"epoch": 44.0,
|
| 139 |
+
"learning_rate": 5.6000000000000006e-05,
|
| 140 |
+
"loss": 0.4532,
|
| 141 |
+
"step": 220
|
| 142 |
+
},
|
| 143 |
+
{
|
| 144 |
+
"epoch": 46.0,
|
| 145 |
+
"learning_rate": 5.4000000000000005e-05,
|
| 146 |
+
"loss": 0.4687,
|
| 147 |
+
"step": 230
|
| 148 |
+
},
|
| 149 |
+
{
|
| 150 |
+
"epoch": 48.0,
|
| 151 |
+
"learning_rate": 5.2000000000000004e-05,
|
| 152 |
+
"loss": 0.4073,
|
| 153 |
+
"step": 240
|
| 154 |
+
},
|
| 155 |
+
{
|
| 156 |
+
"epoch": 50.0,
|
| 157 |
+
"learning_rate": 5e-05,
|
| 158 |
+
"loss": 0.5488,
|
| 159 |
+
"step": 250
|
| 160 |
+
},
|
| 161 |
+
{
|
| 162 |
+
"epoch": 52.0,
|
| 163 |
+
"learning_rate": 4.8e-05,
|
| 164 |
+
"loss": 0.5888,
|
| 165 |
+
"step": 260
|
| 166 |
+
},
|
| 167 |
+
{
|
| 168 |
+
"epoch": 54.0,
|
| 169 |
+
"learning_rate": 4.600000000000001e-05,
|
| 170 |
+
"loss": 0.3194,
|
| 171 |
+
"step": 270
|
| 172 |
+
},
|
| 173 |
+
{
|
| 174 |
+
"epoch": 56.0,
|
| 175 |
+
"learning_rate": 4.4000000000000006e-05,
|
| 176 |
+
"loss": 0.47,
|
| 177 |
+
"step": 280
|
| 178 |
+
},
|
| 179 |
+
{
|
| 180 |
+
"epoch": 58.0,
|
| 181 |
+
"learning_rate": 4.2e-05,
|
| 182 |
+
"loss": 0.2736,
|
| 183 |
+
"step": 290
|
| 184 |
+
},
|
| 185 |
+
{
|
| 186 |
+
"epoch": 60.0,
|
| 187 |
+
"learning_rate": 4e-05,
|
| 188 |
+
"loss": 0.2798,
|
| 189 |
+
"step": 300
|
| 190 |
+
},
|
| 191 |
+
{
|
| 192 |
+
"epoch": 62.0,
|
| 193 |
+
"learning_rate": 3.8e-05,
|
| 194 |
+
"loss": 0.322,
|
| 195 |
+
"step": 310
|
| 196 |
+
},
|
| 197 |
+
{
|
| 198 |
+
"epoch": 64.0,
|
| 199 |
+
"learning_rate": 3.6e-05,
|
| 200 |
+
"loss": 0.1707,
|
| 201 |
+
"step": 320
|
| 202 |
+
},
|
| 203 |
+
{
|
| 204 |
+
"epoch": 66.0,
|
| 205 |
+
"learning_rate": 3.4000000000000007e-05,
|
| 206 |
+
"loss": 0.1222,
|
| 207 |
+
"step": 330
|
| 208 |
+
},
|
| 209 |
+
{
|
| 210 |
+
"epoch": 68.0,
|
| 211 |
+
"learning_rate": 3.2000000000000005e-05,
|
| 212 |
+
"loss": 0.1246,
|
| 213 |
+
"step": 340
|
| 214 |
+
},
|
| 215 |
+
{
|
| 216 |
+
"epoch": 70.0,
|
| 217 |
+
"learning_rate": 3e-05,
|
| 218 |
+
"loss": 0.1404,
|
| 219 |
+
"step": 350
|
| 220 |
+
},
|
| 221 |
+
{
|
| 222 |
+
"epoch": 72.0,
|
| 223 |
+
"learning_rate": 2.8000000000000003e-05,
|
| 224 |
+
"loss": 0.1098,
|
| 225 |
+
"step": 360
|
| 226 |
+
},
|
| 227 |
+
{
|
| 228 |
+
"epoch": 74.0,
|
| 229 |
+
"learning_rate": 2.6000000000000002e-05,
|
| 230 |
+
"loss": 0.1441,
|
| 231 |
+
"step": 370
|
| 232 |
+
},
|
| 233 |
+
{
|
| 234 |
+
"epoch": 76.0,
|
| 235 |
+
"learning_rate": 2.4e-05,
|
| 236 |
+
"loss": 0.1531,
|
| 237 |
+
"step": 380
|
| 238 |
+
},
|
| 239 |
+
{
|
| 240 |
+
"epoch": 78.0,
|
| 241 |
+
"learning_rate": 2.2000000000000003e-05,
|
| 242 |
+
"loss": 0.1241,
|
| 243 |
+
"step": 390
|
| 244 |
+
},
|
| 245 |
+
{
|
| 246 |
+
"epoch": 80.0,
|
| 247 |
+
"learning_rate": 2e-05,
|
| 248 |
+
"loss": 0.103,
|
| 249 |
+
"step": 400
|
| 250 |
+
},
|
| 251 |
+
{
|
| 252 |
+
"epoch": 82.0,
|
| 253 |
+
"learning_rate": 1.8e-05,
|
| 254 |
+
"loss": 0.0907,
|
| 255 |
+
"step": 410
|
| 256 |
+
},
|
| 257 |
+
{
|
| 258 |
+
"epoch": 84.0,
|
| 259 |
+
"learning_rate": 1.6000000000000003e-05,
|
| 260 |
+
"loss": 0.0909,
|
| 261 |
+
"step": 420
|
| 262 |
+
},
|
| 263 |
+
{
|
| 264 |
+
"epoch": 86.0,
|
| 265 |
+
"learning_rate": 1.4000000000000001e-05,
|
| 266 |
+
"loss": 0.0874,
|
| 267 |
+
"step": 430
|
| 268 |
+
},
|
| 269 |
+
{
|
| 270 |
+
"epoch": 88.0,
|
| 271 |
+
"learning_rate": 1.2e-05,
|
| 272 |
+
"loss": 0.0757,
|
| 273 |
+
"step": 440
|
| 274 |
+
},
|
| 275 |
+
{
|
| 276 |
+
"epoch": 90.0,
|
| 277 |
+
"learning_rate": 1e-05,
|
| 278 |
+
"loss": 0.0753,
|
| 279 |
+
"step": 450
|
| 280 |
+
},
|
| 281 |
+
{
|
| 282 |
+
"epoch": 92.0,
|
| 283 |
+
"learning_rate": 8.000000000000001e-06,
|
| 284 |
+
"loss": 0.0763,
|
| 285 |
+
"step": 460
|
| 286 |
+
},
|
| 287 |
+
{
|
| 288 |
+
"epoch": 94.0,
|
| 289 |
+
"learning_rate": 6e-06,
|
| 290 |
+
"loss": 0.0714,
|
| 291 |
+
"step": 470
|
| 292 |
+
},
|
| 293 |
+
{
|
| 294 |
+
"epoch": 96.0,
|
| 295 |
+
"learning_rate": 4.000000000000001e-06,
|
| 296 |
+
"loss": 0.0736,
|
| 297 |
+
"step": 480
|
| 298 |
+
},
|
| 299 |
+
{
|
| 300 |
+
"epoch": 98.0,
|
| 301 |
+
"learning_rate": 2.0000000000000003e-06,
|
| 302 |
+
"loss": 0.0601,
|
| 303 |
+
"step": 490
|
| 304 |
+
},
|
| 305 |
+
{
|
| 306 |
+
"epoch": 100.0,
|
| 307 |
+
"learning_rate": 0.0,
|
| 308 |
+
"loss": 0.0731,
|
| 309 |
+
"step": 500
|
| 310 |
+
}
|
| 311 |
+
],
|
| 312 |
+
"logging_steps": 10,
|
| 313 |
+
"max_steps": 500,
|
| 314 |
+
"num_input_tokens_seen": 0,
|
| 315 |
+
"num_train_epochs": 100,
|
| 316 |
+
"save_steps": 500,
|
| 317 |
+
"total_flos": 1.4217418628923392e+18,
|
| 318 |
+
"train_batch_size": 2,
|
| 319 |
+
"trial_name": null,
|
| 320 |
+
"trial_params": null
|
| 321 |
+
}
|
model/checkpoint-500/training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:04deb0d096a36c5f7da938e19ec51b9bd341c0c139090e278562f90413d3087e
|
| 3 |
+
size 4664
|
requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
transformers
|
| 2 |
+
torch # pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
|
| 3 |
+
pandas
|
| 4 |
+
pillow
|
| 5 |
+
scikit-learn
|
| 6 |
+
accelerate
|
train.py
CHANGED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.utils.data import Dataset
|
| 2 |
+
from transformers import TrOCRProcessor, VisionEncoderDecoderModel, Trainer, TrainingArguments
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import pandas as pd
|
| 5 |
+
from sklearn.model_selection import train_test_split
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class HandwrittenMathDataset(Dataset):
|
| 9 |
+
"""
|
| 10 |
+
Initialize the class with the provided annotations file, image directory, and processor.
|
| 11 |
+
|
| 12 |
+
Parameters:
|
| 13 |
+
annotations_file (str): The file path to the annotations file.
|
| 14 |
+
img_dir (str): The directory path to the images.
|
| 15 |
+
processor: The processor object to be used for image processing.
|
| 16 |
+
"""
|
| 17 |
+
def __init__(self, annotations_file, img_dir, processor, subset="train"):
|
| 18 |
+
self.img_labels = pd.read_csv(annotations_file)
|
| 19 |
+
self.train_data, self.test_data = train_test_split(self.img_labels, test_size=0.1, random_state=42)
|
| 20 |
+
self.data = self.train_data if subset == "train" else self.test_data
|
| 21 |
+
self.img_dir = img_dir
|
| 22 |
+
self.processor = processor
|
| 23 |
+
|
| 24 |
+
def __len__(self):
|
| 25 |
+
return len(self.data)
|
| 26 |
+
|
| 27 |
+
def __getitem__(self, idx):
|
| 28 |
+
img_path = self.data.iloc[idx, 0]
|
| 29 |
+
image = Image.open(img_path).convert("RGB")
|
| 30 |
+
# Ensure the image is processed correctly
|
| 31 |
+
pixel_values = self.processor(images=image, return_tensors="pt").pixel_values
|
| 32 |
+
label = self.data.iloc[idx, 1]
|
| 33 |
+
# Process labels correctly
|
| 34 |
+
labels = self.processor.tokenizer(label, padding="max_length", max_length=128, truncation=True,
|
| 35 |
+
return_tensors="pt").input_ids
|
| 36 |
+
# Replace -100 in the labels as they are not to be computed for loss
|
| 37 |
+
labels[labels == self.processor.tokenizer.pad_token_id] = -100
|
| 38 |
+
|
| 39 |
+
return {"pixel_values": pixel_values.squeeze(), "labels": labels.squeeze()}
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def main():
|
| 43 |
+
"""
|
| 44 |
+
A function to train a model for handwritten text recognition using TrOCRProcessor and VisionEncoderDecoderModel.
|
| 45 |
+
"""
|
| 46 |
+
annotations_file = './dataset/annotations.csv'
|
| 47 |
+
img_dir = './dataset/images/'
|
| 48 |
+
model_id = 'microsoft/trocr-base-handwritten'
|
| 49 |
+
|
| 50 |
+
processor = TrOCRProcessor.from_pretrained(model_id)
|
| 51 |
+
model = VisionEncoderDecoderModel.from_pretrained(model_id).to("cuda")
|
| 52 |
+
|
| 53 |
+
# Set the decoder_start_token_id
|
| 54 |
+
model.config.decoder_start_token_id = processor.tokenizer.cls_token_id
|
| 55 |
+
model.config.pad_token_id = processor.tokenizer.pad_token_id
|
| 56 |
+
|
| 57 |
+
train_dataset = HandwrittenMathDataset(annotations_file=annotations_file, img_dir=img_dir, processor=processor,
|
| 58 |
+
subset="train")
|
| 59 |
+
test_dataset = HandwrittenMathDataset(annotations_file=annotations_file, img_dir=img_dir, processor=processor,
|
| 60 |
+
subset="test")
|
| 61 |
+
|
| 62 |
+
training_args = TrainingArguments(
|
| 63 |
+
output_dir='./model',
|
| 64 |
+
per_device_train_batch_size=2,
|
| 65 |
+
num_train_epochs=100,
|
| 66 |
+
logging_dir='./training_logs',
|
| 67 |
+
logging_steps=10,
|
| 68 |
+
save_strategy="epoch",
|
| 69 |
+
save_total_limit=1,
|
| 70 |
+
weight_decay=0.01,
|
| 71 |
+
learning_rate=1e-4,
|
| 72 |
+
gradient_checkpointing=True,
|
| 73 |
+
gradient_accumulation_steps=2
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
trainer = Trainer(
|
| 77 |
+
model=model,
|
| 78 |
+
args=training_args,
|
| 79 |
+
train_dataset=train_dataset,
|
| 80 |
+
eval_dataset=test_dataset
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
trainer.train()
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
if __name__ == '__main__':
|
| 87 |
+
main()
|