
Upload 88 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- .gitignore +132 -0
- DATA_LICENSE +407 -0
- LICENSE +201 -0
- README.md +201 -0
- alpaca_data.json +0 -0
- assets/alpaca_main.jpg +0 -0
- assets/alpaca_right_email.png +0 -0
- assets/alpaca_right_llama.png +0 -0
- assets/alpaca_wrong_42.png +0 -0
- assets/alpaca_wrong_capital.png +0 -0
- assets/logo.png +0 -0
- assets/parse_analysis.png +0 -0
- cog.yaml +16 -0
- datasheet.md +102 -0
- generate_instruction.py +217 -0
- model_card.md +52 -0
- predict.py +63 -0
- prompt.txt +14 -0
- requirements.txt +9 -0
- seed_tasks.jsonl +0 -0
- train.py +247 -0
- train_model.sh +23 -0
- unconverted-weights/7B/.gitattributes +35 -0
- unconverted-weights/7B/LICENSE.txt +201 -0
- unconverted-weights/7B/README.md +126 -0
- unconverted-weights/7B/checklist.chk +2 -0
- unconverted-weights/7B/config.json +22 -0
- unconverted-weights/7B/consolidated.00.pth +3 -0
- unconverted-weights/7B/generation_config.json +7 -0
- unconverted-weights/7B/open_llama_7b_preview_300bt_easylm +3 -0
- unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/config.json +22 -0
- unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/generation_config.json +7 -0
- unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00001-of-00002.bin +3 -0
- unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00002-of-00002.bin +3 -0
- unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model.bin.index.json +330 -0
- unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/special_tokens_map.json +1 -0
- unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer.model +3 -0
- unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer_config.json +1 -0
- unconverted-weights/7B/params.json +1 -0
- unconverted-weights/7B/pytorch_model-00001-of-00002.bin +3 -0
- unconverted-weights/7B/pytorch_model-00002-of-00002.bin +3 -0
- unconverted-weights/7B/pytorch_model.bin.index.json +330 -0
- unconverted-weights/7B/special_tokens_map.json +1 -0
- unconverted-weights/7B/tokenizer.model +3 -0
- unconverted-weights/7B/tokenizer.vocab +0 -0
- unconverted-weights/7B/tokenizer_config.json +1 -0
- unconverted-weights/tokenizer.model +3 -0
- unconverted-weights/tokenizer_checklist.chk +1 -0
- utils.py +173 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
unconverted-weights/7B/open_llama_7b_preview_300bt_easylm filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
pip-wheel-metadata/
|
| 24 |
+
share/python-wheels/
|
| 25 |
+
*.egg-info/
|
| 26 |
+
.installed.cfg
|
| 27 |
+
*.egg
|
| 28 |
+
MANIFEST
|
| 29 |
+
|
| 30 |
+
# PyInstaller
|
| 31 |
+
# Usually these files are written by a python script from a template
|
| 32 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 33 |
+
*.manifest
|
| 34 |
+
*.spec
|
| 35 |
+
|
| 36 |
+
# Installer logs
|
| 37 |
+
pip-log.txt
|
| 38 |
+
pip-delete-this-directory.txt
|
| 39 |
+
|
| 40 |
+
# Unit test / coverage reports
|
| 41 |
+
htmlcov/
|
| 42 |
+
.tox/
|
| 43 |
+
.nox/
|
| 44 |
+
.coverage
|
| 45 |
+
.coverage.*
|
| 46 |
+
.cache
|
| 47 |
+
nosetests.xml
|
| 48 |
+
coverage.xml
|
| 49 |
+
*.cover
|
| 50 |
+
*.py,cover
|
| 51 |
+
.hypothesis/
|
| 52 |
+
.pytest_cache/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
target/
|
| 76 |
+
|
| 77 |
+
# Jupyter Notebook
|
| 78 |
+
.ipynb_checkpoints
|
| 79 |
+
|
| 80 |
+
# IPython
|
| 81 |
+
profile_default/
|
| 82 |
+
ipython_config.py
|
| 83 |
+
|
| 84 |
+
# pyenv
|
| 85 |
+
.python-version
|
| 86 |
+
|
| 87 |
+
# pipenv
|
| 88 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 89 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 90 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 91 |
+
# install all needed dependencies.
|
| 92 |
+
#Pipfile.lock
|
| 93 |
+
|
| 94 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 95 |
+
__pypackages__/
|
| 96 |
+
|
| 97 |
+
# Celery stuff
|
| 98 |
+
celerybeat-schedule
|
| 99 |
+
celerybeat.pid
|
| 100 |
+
|
| 101 |
+
# SageMath parsed files
|
| 102 |
+
*.sage.py
|
| 103 |
+
|
| 104 |
+
# Environments
|
| 105 |
+
.env
|
| 106 |
+
.venv
|
| 107 |
+
env/
|
| 108 |
+
venv/
|
| 109 |
+
ENV/
|
| 110 |
+
env.bak/
|
| 111 |
+
venv.bak/
|
| 112 |
+
|
| 113 |
+
# Spyder project settings
|
| 114 |
+
.spyderproject
|
| 115 |
+
.spyproject
|
| 116 |
+
|
| 117 |
+
# Rope project settings
|
| 118 |
+
.ropeproject
|
| 119 |
+
|
| 120 |
+
# mkdocs documentation
|
| 121 |
+
/site
|
| 122 |
+
|
| 123 |
+
# mypy
|
| 124 |
+
.mypy_cache/
|
| 125 |
+
.dmypy.json
|
| 126 |
+
dmypy.json
|
| 127 |
+
|
| 128 |
+
# Pyre type checker
|
| 129 |
+
.pyre/
|
| 130 |
+
|
| 131 |
+
.DS_Store
|
| 132 |
+
.idea
|
DATA_LICENSE
ADDED
|
@@ -0,0 +1,407 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Attribution-NonCommercial 4.0 International
|
| 2 |
+
|
| 3 |
+
=======================================================================
|
| 4 |
+
|
| 5 |
+
Creative Commons Corporation ("Creative Commons") is not a law firm and
|
| 6 |
+
does not provide legal services or legal advice. Distribution of
|
| 7 |
+
Creative Commons public licenses does not create a lawyer-client or
|
| 8 |
+
other relationship. Creative Commons makes its licenses and related
|
| 9 |
+
information available on an "as-is" basis. Creative Commons gives no
|
| 10 |
+
warranties regarding its licenses, any material licensed under their
|
| 11 |
+
terms and conditions, or any related information. Creative Commons
|
| 12 |
+
disclaims all liability for damages resulting from their use to the
|
| 13 |
+
fullest extent possible.
|
| 14 |
+
|
| 15 |
+
Using Creative Commons Public Licenses
|
| 16 |
+
|
| 17 |
+
Creative Commons public licenses provide a standard set of terms and
|
| 18 |
+
conditions that creators and other rights holders may use to share
|
| 19 |
+
original works of authorship and other material subject to copyright
|
| 20 |
+
and certain other rights specified in the public license below. The
|
| 21 |
+
following considerations are for informational purposes only, are not
|
| 22 |
+
exhaustive, and do not form part of our licenses.
|
| 23 |
+
|
| 24 |
+
Considerations for licensors: Our public licenses are
|
| 25 |
+
intended for use by those authorized to give the public
|
| 26 |
+
permission to use material in ways otherwise restricted by
|
| 27 |
+
copyright and certain other rights. Our licenses are
|
| 28 |
+
irrevocable. Licensors should read and understand the terms
|
| 29 |
+
and conditions of the license they choose before applying it.
|
| 30 |
+
Licensors should also secure all rights necessary before
|
| 31 |
+
applying our licenses so that the public can reuse the
|
| 32 |
+
material as expected. Licensors should clearly mark any
|
| 33 |
+
material not subject to the license. This includes other CC-
|
| 34 |
+
licensed material, or material used under an exception or
|
| 35 |
+
limitation to copyright. More considerations for licensors:
|
| 36 |
+
wiki.creativecommons.org/Considerations_for_licensors
|
| 37 |
+
|
| 38 |
+
Considerations for the public: By using one of our public
|
| 39 |
+
licenses, a licensor grants the public permission to use the
|
| 40 |
+
licensed material under specified terms and conditions. If
|
| 41 |
+
the licensor's permission is not necessary for any reason--for
|
| 42 |
+
example, because of any applicable exception or limitation to
|
| 43 |
+
copyright--then that use is not regulated by the license. Our
|
| 44 |
+
licenses grant only permissions under copyright and certain
|
| 45 |
+
other rights that a licensor has authority to grant. Use of
|
| 46 |
+
the licensed material may still be restricted for other
|
| 47 |
+
reasons, including because others have copyright or other
|
| 48 |
+
rights in the material. A licensor may make special requests,
|
| 49 |
+
such as asking that all changes be marked or described.
|
| 50 |
+
Although not required by our licenses, you are encouraged to
|
| 51 |
+
respect those requests where reasonable. More considerations
|
| 52 |
+
for the public:
|
| 53 |
+
wiki.creativecommons.org/Considerations_for_licensees
|
| 54 |
+
|
| 55 |
+
=======================================================================
|
| 56 |
+
|
| 57 |
+
Creative Commons Attribution-NonCommercial 4.0 International Public
|
| 58 |
+
License
|
| 59 |
+
|
| 60 |
+
By exercising the Licensed Rights (defined below), You accept and agree
|
| 61 |
+
to be bound by the terms and conditions of this Creative Commons
|
| 62 |
+
Attribution-NonCommercial 4.0 International Public License ("Public
|
| 63 |
+
License"). To the extent this Public License may be interpreted as a
|
| 64 |
+
contract, You are granted the Licensed Rights in consideration of Your
|
| 65 |
+
acceptance of these terms and conditions, and the Licensor grants You
|
| 66 |
+
such rights in consideration of benefits the Licensor receives from
|
| 67 |
+
making the Licensed Material available under these terms and
|
| 68 |
+
conditions.
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
Section 1 -- Definitions.
|
| 72 |
+
|
| 73 |
+
a. Adapted Material means material subject to Copyright and Similar
|
| 74 |
+
Rights that is derived from or based upon the Licensed Material
|
| 75 |
+
and in which the Licensed Material is translated, altered,
|
| 76 |
+
arranged, transformed, or otherwise modified in a manner requiring
|
| 77 |
+
permission under the Copyright and Similar Rights held by the
|
| 78 |
+
Licensor. For purposes of this Public License, where the Licensed
|
| 79 |
+
Material is a musical work, performance, or sound recording,
|
| 80 |
+
Adapted Material is always produced where the Licensed Material is
|
| 81 |
+
synched in timed relation with a moving image.
|
| 82 |
+
|
| 83 |
+
b. Adapter's License means the license You apply to Your Copyright
|
| 84 |
+
and Similar Rights in Your contributions to Adapted Material in
|
| 85 |
+
accordance with the terms and conditions of this Public License.
|
| 86 |
+
|
| 87 |
+
c. Copyright and Similar Rights means copyright and/or similar rights
|
| 88 |
+
closely related to copyright including, without limitation,
|
| 89 |
+
performance, broadcast, sound recording, and Sui Generis Database
|
| 90 |
+
Rights, without regard to how the rights are labeled or
|
| 91 |
+
categorized. For purposes of this Public License, the rights
|
| 92 |
+
specified in Section 2(b)(1)-(2) are not Copyright and Similar
|
| 93 |
+
Rights.
|
| 94 |
+
d. Effective Technological Measures means those measures that, in the
|
| 95 |
+
absence of proper authority, may not be circumvented under laws
|
| 96 |
+
fulfilling obligations under Article 11 of the WIPO Copyright
|
| 97 |
+
Treaty adopted on December 20, 1996, and/or similar international
|
| 98 |
+
agreements.
|
| 99 |
+
|
| 100 |
+
e. Exceptions and Limitations means fair use, fair dealing, and/or
|
| 101 |
+
any other exception or limitation to Copyright and Similar Rights
|
| 102 |
+
that applies to Your use of the Licensed Material.
|
| 103 |
+
|
| 104 |
+
f. Licensed Material means the artistic or literary work, database,
|
| 105 |
+
or other material to which the Licensor applied this Public
|
| 106 |
+
License.
|
| 107 |
+
|
| 108 |
+
g. Licensed Rights means the rights granted to You subject to the
|
| 109 |
+
terms and conditions of this Public License, which are limited to
|
| 110 |
+
all Copyright and Similar Rights that apply to Your use of the
|
| 111 |
+
Licensed Material and that the Licensor has authority to license.
|
| 112 |
+
|
| 113 |
+
h. Licensor means the individual(s) or entity(ies) granting rights
|
| 114 |
+
under this Public License.
|
| 115 |
+
|
| 116 |
+
i. NonCommercial means not primarily intended for or directed towards
|
| 117 |
+
commercial advantage or monetary compensation. For purposes of
|
| 118 |
+
this Public License, the exchange of the Licensed Material for
|
| 119 |
+
other material subject to Copyright and Similar Rights by digital
|
| 120 |
+
file-sharing or similar means is NonCommercial provided there is
|
| 121 |
+
no payment of monetary compensation in connection with the
|
| 122 |
+
exchange.
|
| 123 |
+
|
| 124 |
+
j. Share means to provide material to the public by any means or
|
| 125 |
+
process that requires permission under the Licensed Rights, such
|
| 126 |
+
as reproduction, public display, public performance, distribution,
|
| 127 |
+
dissemination, communication, or importation, and to make material
|
| 128 |
+
available to the public including in ways that members of the
|
| 129 |
+
public may access the material from a place and at a time
|
| 130 |
+
individually chosen by them.
|
| 131 |
+
|
| 132 |
+
k. Sui Generis Database Rights means rights other than copyright
|
| 133 |
+
resulting from Directive 96/9/EC of the European Parliament and of
|
| 134 |
+
the Council of 11 March 1996 on the legal protection of databases,
|
| 135 |
+
as amended and/or succeeded, as well as other essentially
|
| 136 |
+
equivalent rights anywhere in the world.
|
| 137 |
+
|
| 138 |
+
l. You means the individual or entity exercising the Licensed Rights
|
| 139 |
+
under this Public License. Your has a corresponding meaning.
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
Section 2 -- Scope.
|
| 143 |
+
|
| 144 |
+
a. License grant.
|
| 145 |
+
|
| 146 |
+
1. Subject to the terms and conditions of this Public License,
|
| 147 |
+
the Licensor hereby grants You a worldwide, royalty-free,
|
| 148 |
+
non-sublicensable, non-exclusive, irrevocable license to
|
| 149 |
+
exercise the Licensed Rights in the Licensed Material to:
|
| 150 |
+
|
| 151 |
+
a. reproduce and Share the Licensed Material, in whole or
|
| 152 |
+
in part, for NonCommercial purposes only; and
|
| 153 |
+
|
| 154 |
+
b. produce, reproduce, and Share Adapted Material for
|
| 155 |
+
NonCommercial purposes only.
|
| 156 |
+
|
| 157 |
+
2. Exceptions and Limitations. For the avoidance of doubt, where
|
| 158 |
+
Exceptions and Limitations apply to Your use, this Public
|
| 159 |
+
License does not apply, and You do not need to comply with
|
| 160 |
+
its terms and conditions.
|
| 161 |
+
|
| 162 |
+
3. Term. The term of this Public License is specified in Section
|
| 163 |
+
6(a).
|
| 164 |
+
|
| 165 |
+
4. Media and formats; technical modifications allowed. The
|
| 166 |
+
Licensor authorizes You to exercise the Licensed Rights in
|
| 167 |
+
all media and formats whether now known or hereafter created,
|
| 168 |
+
and to make technical modifications necessary to do so. The
|
| 169 |
+
Licensor waives and/or agrees not to assert any right or
|
| 170 |
+
authority to forbid You from making technical modifications
|
| 171 |
+
necessary to exercise the Licensed Rights, including
|
| 172 |
+
technical modifications necessary to circumvent Effective
|
| 173 |
+
Technological Measures. For purposes of this Public License,
|
| 174 |
+
simply making modifications authorized by this Section 2(a)
|
| 175 |
+
(4) never produces Adapted Material.
|
| 176 |
+
|
| 177 |
+
5. Downstream recipients.
|
| 178 |
+
|
| 179 |
+
a. Offer from the Licensor -- Licensed Material. Every
|
| 180 |
+
recipient of the Licensed Material automatically
|
| 181 |
+
receives an offer from the Licensor to exercise the
|
| 182 |
+
Licensed Rights under the terms and conditions of this
|
| 183 |
+
Public License.
|
| 184 |
+
|
| 185 |
+
b. No downstream restrictions. You may not offer or impose
|
| 186 |
+
any additional or different terms or conditions on, or
|
| 187 |
+
apply any Effective Technological Measures to, the
|
| 188 |
+
Licensed Material if doing so restricts exercise of the
|
| 189 |
+
Licensed Rights by any recipient of the Licensed
|
| 190 |
+
Material.
|
| 191 |
+
|
| 192 |
+
6. No endorsement. Nothing in this Public License constitutes or
|
| 193 |
+
may be construed as permission to assert or imply that You
|
| 194 |
+
are, or that Your use of the Licensed Material is, connected
|
| 195 |
+
with, or sponsored, endorsed, or granted official status by,
|
| 196 |
+
the Licensor or others designated to receive attribution as
|
| 197 |
+
provided in Section 3(a)(1)(A)(i).
|
| 198 |
+
|
| 199 |
+
b. Other rights.
|
| 200 |
+
|
| 201 |
+
1. Moral rights, such as the right of integrity, are not
|
| 202 |
+
licensed under this Public License, nor are publicity,
|
| 203 |
+
privacy, and/or other similar personality rights; however, to
|
| 204 |
+
the extent possible, the Licensor waives and/or agrees not to
|
| 205 |
+
assert any such rights held by the Licensor to the limited
|
| 206 |
+
extent necessary to allow You to exercise the Licensed
|
| 207 |
+
Rights, but not otherwise.
|
| 208 |
+
|
| 209 |
+
2. Patent and trademark rights are not licensed under this
|
| 210 |
+
Public License.
|
| 211 |
+
|
| 212 |
+
3. To the extent possible, the Licensor waives any right to
|
| 213 |
+
collect royalties from You for the exercise of the Licensed
|
| 214 |
+
Rights, whether directly or through a collecting society
|
| 215 |
+
under any voluntary or waivable statutory or compulsory
|
| 216 |
+
licensing scheme. In all other cases the Licensor expressly
|
| 217 |
+
reserves any right to collect such royalties, including when
|
| 218 |
+
the Licensed Material is used other than for NonCommercial
|
| 219 |
+
purposes.
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
Section 3 -- License Conditions.
|
| 223 |
+
|
| 224 |
+
Your exercise of the Licensed Rights is expressly made subject to the
|
| 225 |
+
following conditions.
|
| 226 |
+
|
| 227 |
+
a. Attribution.
|
| 228 |
+
|
| 229 |
+
1. If You Share the Licensed Material (including in modified
|
| 230 |
+
form), You must:
|
| 231 |
+
|
| 232 |
+
a. retain the following if it is supplied by the Licensor
|
| 233 |
+
with the Licensed Material:
|
| 234 |
+
|
| 235 |
+
i. identification of the creator(s) of the Licensed
|
| 236 |
+
Material and any others designated to receive
|
| 237 |
+
attribution, in any reasonable manner requested by
|
| 238 |
+
the Licensor (including by pseudonym if
|
| 239 |
+
designated);
|
| 240 |
+
|
| 241 |
+
ii. a copyright notice;
|
| 242 |
+
|
| 243 |
+
iii. a notice that refers to this Public License;
|
| 244 |
+
|
| 245 |
+
iv. a notice that refers to the disclaimer of
|
| 246 |
+
warranties;
|
| 247 |
+
|
| 248 |
+
v. a URI or hyperlink to the Licensed Material to the
|
| 249 |
+
extent reasonably practicable;
|
| 250 |
+
|
| 251 |
+
b. indicate if You modified the Licensed Material and
|
| 252 |
+
retain an indication of any previous modifications; and
|
| 253 |
+
|
| 254 |
+
c. indicate the Licensed Material is licensed under this
|
| 255 |
+
Public License, and include the text of, or the URI or
|
| 256 |
+
hyperlink to, this Public License.
|
| 257 |
+
|
| 258 |
+
2. You may satisfy the conditions in Section 3(a)(1) in any
|
| 259 |
+
reasonable manner based on the medium, means, and context in
|
| 260 |
+
which You Share the Licensed Material. For example, it may be
|
| 261 |
+
reasonable to satisfy the conditions by providing a URI or
|
| 262 |
+
hyperlink to a resource that includes the required
|
| 263 |
+
information.
|
| 264 |
+
|
| 265 |
+
3. If requested by the Licensor, You must remove any of the
|
| 266 |
+
information required by Section 3(a)(1)(A) to the extent
|
| 267 |
+
reasonably practicable.
|
| 268 |
+
|
| 269 |
+
4. If You Share Adapted Material You produce, the Adapter's
|
| 270 |
+
License You apply must not prevent recipients of the Adapted
|
| 271 |
+
Material from complying with this Public License.
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
Section 4 -- Sui Generis Database Rights.
|
| 275 |
+
|
| 276 |
+
Where the Licensed Rights include Sui Generis Database Rights that
|
| 277 |
+
apply to Your use of the Licensed Material:
|
| 278 |
+
|
| 279 |
+
a. for the avoidance of doubt, Section 2(a)(1) grants You the right
|
| 280 |
+
to extract, reuse, reproduce, and Share all or a substantial
|
| 281 |
+
portion of the contents of the database for NonCommercial purposes
|
| 282 |
+
only;
|
| 283 |
+
|
| 284 |
+
b. if You include all or a substantial portion of the database
|
| 285 |
+
contents in a database in which You have Sui Generis Database
|
| 286 |
+
Rights, then the database in which You have Sui Generis Database
|
| 287 |
+
Rights (but not its individual contents) is Adapted Material; and
|
| 288 |
+
|
| 289 |
+
c. You must comply with the conditions in Section 3(a) if You Share
|
| 290 |
+
all or a substantial portion of the contents of the database.
|
| 291 |
+
|
| 292 |
+
For the avoidance of doubt, this Section 4 supplements and does not
|
| 293 |
+
replace Your obligations under this Public License where the Licensed
|
| 294 |
+
Rights include other Copyright and Similar Rights.
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
Section 5 -- Disclaimer of Warranties and Limitation of Liability.
|
| 298 |
+
|
| 299 |
+
a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
|
| 300 |
+
EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
|
| 301 |
+
AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
|
| 302 |
+
ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
|
| 303 |
+
IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
|
| 304 |
+
WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
|
| 305 |
+
PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
|
| 306 |
+
ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
|
| 307 |
+
KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
|
| 308 |
+
ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
|
| 309 |
+
|
| 310 |
+
b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
|
| 311 |
+
TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
|
| 312 |
+
NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
|
| 313 |
+
INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
|
| 314 |
+
COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
|
| 315 |
+
USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
|
| 316 |
+
ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
|
| 317 |
+
DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
|
| 318 |
+
IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
|
| 319 |
+
|
| 320 |
+
c. The disclaimer of warranties and limitation of liability provided
|
| 321 |
+
above shall be interpreted in a manner that, to the extent
|
| 322 |
+
possible, most closely approximates an absolute disclaimer and
|
| 323 |
+
waiver of all liability.
|
| 324 |
+
|
| 325 |
+
|
| 326 |
+
Section 6 -- Term and Termination.
|
| 327 |
+
|
| 328 |
+
a. This Public License applies for the term of the Copyright and
|
| 329 |
+
Similar Rights licensed here. However, if You fail to comply with
|
| 330 |
+
this Public License, then Your rights under this Public License
|
| 331 |
+
terminate automatically.
|
| 332 |
+
|
| 333 |
+
b. Where Your right to use the Licensed Material has terminated under
|
| 334 |
+
Section 6(a), it reinstates:
|
| 335 |
+
|
| 336 |
+
1. automatically as of the date the violation is cured, provided
|
| 337 |
+
it is cured within 30 days of Your discovery of the
|
| 338 |
+
violation; or
|
| 339 |
+
|
| 340 |
+
2. upon express reinstatement by the Licensor.
|
| 341 |
+
|
| 342 |
+
For the avoidance of doubt, this Section 6(b) does not affect any
|
| 343 |
+
right the Licensor may have to seek remedies for Your violations
|
| 344 |
+
of this Public License.
|
| 345 |
+
|
| 346 |
+
c. For the avoidance of doubt, the Licensor may also offer the
|
| 347 |
+
Licensed Material under separate terms or conditions or stop
|
| 348 |
+
distributing the Licensed Material at any time; however, doing so
|
| 349 |
+
will not terminate this Public License.
|
| 350 |
+
|
| 351 |
+
d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
|
| 352 |
+
License.
|
| 353 |
+
|
| 354 |
+
|
| 355 |
+
Section 7 -- Other Terms and Conditions.
|
| 356 |
+
|
| 357 |
+
a. The Licensor shall not be bound by any additional or different
|
| 358 |
+
terms or conditions communicated by You unless expressly agreed.
|
| 359 |
+
|
| 360 |
+
b. Any arrangements, understandings, or agreements regarding the
|
| 361 |
+
Licensed Material not stated herein are separate from and
|
| 362 |
+
independent of the terms and conditions of this Public License.
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
Section 8 -- Interpretation.
|
| 366 |
+
|
| 367 |
+
a. For the avoidance of doubt, this Public License does not, and
|
| 368 |
+
shall not be interpreted to, reduce, limit, restrict, or impose
|
| 369 |
+
conditions on any use of the Licensed Material that could lawfully
|
| 370 |
+
be made without permission under this Public License.
|
| 371 |
+
|
| 372 |
+
b. To the extent possible, if any provision of this Public License is
|
| 373 |
+
deemed unenforceable, it shall be automatically reformed to the
|
| 374 |
+
minimum extent necessary to make it enforceable. If the provision
|
| 375 |
+
cannot be reformed, it shall be severed from this Public License
|
| 376 |
+
without affecting the enforceability of the remaining terms and
|
| 377 |
+
conditions.
|
| 378 |
+
|
| 379 |
+
c. No term or condition of this Public License will be waived and no
|
| 380 |
+
failure to comply consented to unless expressly agreed to by the
|
| 381 |
+
Licensor.
|
| 382 |
+
|
| 383 |
+
d. Nothing in this Public License constitutes or may be interpreted
|
| 384 |
+
as a limitation upon, or waiver of, any privileges and immunities
|
| 385 |
+
that apply to the Licensor or You, including from the legal
|
| 386 |
+
processes of any jurisdiction or authority.
|
| 387 |
+
|
| 388 |
+
=======================================================================
|
| 389 |
+
|
| 390 |
+
Creative Commons is not a party to its public
|
| 391 |
+
licenses. Notwithstanding, Creative Commons may elect to apply one of
|
| 392 |
+
its public licenses to material it publishes and in those instances
|
| 393 |
+
will be considered the “Licensor.” The text of the Creative Commons
|
| 394 |
+
public licenses is dedicated to the public domain under the CC0 Public
|
| 395 |
+
Domain Dedication. Except for the limited purpose of indicating that
|
| 396 |
+
material is shared under a Creative Commons public license or as
|
| 397 |
+
otherwise permitted by the Creative Commons policies published at
|
| 398 |
+
creativecommons.org/policies, Creative Commons does not authorize the
|
| 399 |
+
use of the trademark "Creative Commons" or any other trademark or logo
|
| 400 |
+
of Creative Commons without its prior written consent including,
|
| 401 |
+
without limitation, in connection with any unauthorized modifications
|
| 402 |
+
to any of its public licenses or any other arrangements,
|
| 403 |
+
understandings, or agreements concerning use of licensed material. For
|
| 404 |
+
the avoidance of doubt, this paragraph does not form part of the
|
| 405 |
+
public licenses.
|
| 406 |
+
|
| 407 |
+
Creative Commons may be contacted at creativecommons.org.
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright 2023 Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.md
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
<p align="center" width="100%">
|
| 3 |
+
<a href="https://crfm.stanford.edu/alpaca/" target="_blank"><img src="assets/logo.png" alt="Stanford-Alpaca" style="width: 50%; min-width: 300px; display: block; margin: auto;"></a>
|
| 4 |
+
</p>
|
| 5 |
+
|
| 6 |
+
# Stanford Alpaca: An Instruction-following LLaMA Model
|
| 7 |
+
[](https://github.com/tatsu-lab/stanford_alpaca/blob/main/LICENSE)
|
| 8 |
+
[](https://www.python.org/downloads/release/python-390/)
|
| 9 |
+
[](https://github.com/psf/black)
|
| 10 |
+
|
| 11 |
+
This is the repo for the Stanford Alpaca project, which aims to build and share an instruction-following LLaMA model. The repo contains:
|
| 12 |
+
- A [**web demo**](https://crfm.stanford.edu/alpaca/) to interact with our Alpaca model
|
| 13 |
+
- The [52K data](#data-release) used for fine-tuning the model
|
| 14 |
+
- The code for [generating the data](#data-generation-process)
|
| 15 |
+
|
| 16 |
+
## Overview
|
| 17 |
+
|
| 18 |
+
The current Alpaca model is fine-tuned from a 7B LLaMA model [1] on 52K instruction-following data generated by the techniques in the Self-Instruct [2] paper, with some modifications that we discuss in the next section.
|
| 19 |
+
In a preliminary human evaluation, we found that the Alpaca 7B model behaves similarly to the `text-davinci-003` model on the Self-Instruct instruction-following evaluation suite [2].
|
| 20 |
+
|
| 21 |
+
Alpaca is still under development, and there are many limitations that have to be addressed.
|
| 22 |
+
Importantly, we have not yet fine-tuned the Alpaca model to be safe and harmless.
|
| 23 |
+
We thus encourage users to be cautious when interacting with Alpaca, and to report any concerning behavior to help improve the safety and ethical considerations of the model.
|
| 24 |
+
|
| 25 |
+
Our initial release contains the data generation procedure, dataset, and training recipe. We intend to release the model weights if we are given permission to do so by the creators of LLaMA. For now, we have chosen to host a live demo to help readers better understand the capabilities and limits of Alpaca, as well as a way to help us better evaluate Alpaca's performance on a broader audience.
|
| 26 |
+
|
| 27 |
+
**Please read our release [blog post](https://crfm.stanford.edu/2023/03/13/alpaca.html) for more details about the model, our discussion of the potential harm and limitations of Alpaca models, and our thought process for releasing a reproducible model.**
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
[1]: LLaMA: Open and Efficient Foundation Language Models. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. https://arxiv.org/abs/2302.13971v1
|
| 31 |
+
|
| 32 |
+
[2]: Self-Instruct: Aligning Language Model with Self Generated Instructions. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishirzi. https://arxiv.org/abs/2212.10560
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
## Data Release
|
| 36 |
+
[`alpaca_data.json`](./alpaca_data.json) contains 52K instruction-following data we used for fine-tuning the Alpaca model.
|
| 37 |
+
This JSON file is a list of dictionaries, each dictionary contains the following fields:
|
| 38 |
+
- `instruction`: `str`, describes the task the model should perform. Each of the 52K instructions is unique.
|
| 39 |
+
- `input`: `str`, optional context or input for the task. For example, when the instruction is "Summarize the following article", the input is the article. Around 40% of the examples have an input.
|
| 40 |
+
- `output`: `str`, the answer to the instruction as generated by `text-davinci-003`.
|
| 41 |
+
|
| 42 |
+
We used the following prompts for fine-tuning the Alpaca model:
|
| 43 |
+
- for examples with a non-empty input field:
|
| 44 |
+
```
|
| 45 |
+
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
|
| 46 |
+
|
| 47 |
+
### Instruction:
|
| 48 |
+
{instruction}
|
| 49 |
+
|
| 50 |
+
### Input:
|
| 51 |
+
{input}
|
| 52 |
+
|
| 53 |
+
### Response:
|
| 54 |
+
```
|
| 55 |
+
- for examples with an empty input field:
|
| 56 |
+
```
|
| 57 |
+
Below is an instruction that describes a task. Write a response that appropriately completes the request.
|
| 58 |
+
|
| 59 |
+
### Instruction:
|
| 60 |
+
{instruction}
|
| 61 |
+
|
| 62 |
+
### Response:
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
During inference (eg for the web demo), we use the user instruction with an empty input field (second option).
|
| 66 |
+
|
| 67 |
+
## Data Generation Process
|
| 68 |
+
|
| 69 |
+
<details>
|
| 70 |
+
<summary> <strong> Running the code </strong> </summary>
|
| 71 |
+
|
| 72 |
+
1. Set environment variables `OPENAI_API_KEY` to your OpenAI API key.
|
| 73 |
+
2. Install the dependencies with `pip install -r requirements.txt`.
|
| 74 |
+
3. Run `python -m generate_instruction generate_instruction_following_data` to generate the data.
|
| 75 |
+
|
| 76 |
+
</details>
|
| 77 |
+
|
| 78 |
+
We built on the data generation pipeline from [self-instruct](https://github.com/yizhongw/self-instruct) and made the following modifications:
|
| 79 |
+
- We used `text-davinci-003` to generate the instruction data instead of `davinci`.
|
| 80 |
+
- We wrote a new prompt (`prompt.txt`) that explicitly gave the requirement of instruction generation to `text-davinci-003`. Note: there is a slight error in the prompt we used, and future users should incorporate the edit in https://github.com/tatsu-lab/stanford_alpaca/pull/24
|
| 81 |
+
- We adopted much more aggressive batch decoding, i.e., generating 20 instructions at once, which significantly reduced the cost of data generation.
|
| 82 |
+
- We simplified the data generation pipeline by discarding the difference between classification and non-classification instructions.
|
| 83 |
+
- We only generated a single instance for each instruction, instead of 2 to 3 instances as in [1].
|
| 84 |
+
|
| 85 |
+
This produced an instruction-following dataset with 52K examples obtained at a much lower cost (less than $500).
|
| 86 |
+
In a preliminary study, we also find our 52K generated data to be much more diverse than the data released by [self-instruct](https://github.com/yizhongw/self-instruct/blob/main/data/seed_tasks.jsonl).
|
| 87 |
+
We plot the below figure (in the style of Figure 2 in the [self-instruct paper](https://arxiv.org/abs/2212.10560) to demonstrate the diversity of our data.
|
| 88 |
+
The inner circle of the plot represents the root verb of the instructions, and the outer circle represents the direct objects.
|
| 89 |
+
|
| 90 |
+
[//]: # ()
|
| 91 |
+
[<img src="assets/parse_analysis.png" width="750" />](./assets/parse_analysis.png)
|
| 92 |
+
|
| 93 |
+
## Fine-tuning
|
| 94 |
+
We fine-tune our models using standard Hugging Face training code with the following hyperparameters:
|
| 95 |
+
|
| 96 |
+
| Hyperparameter | Value |
|
| 97 |
+
|----------------|-------|
|
| 98 |
+
| Batch size | 128 |
|
| 99 |
+
| Learning rate | 2e-5 |
|
| 100 |
+
| Epochs | 3 |
|
| 101 |
+
| Max length | 512 |
|
| 102 |
+
| Weight decay | 0 |
|
| 103 |
+
|
| 104 |
+
Given Hugging Face hasn't officially supported the LLaMA models, we fine-tuned LLaMA with Hugging Face's transformers library by installing it from a particular fork (i.e. this [PR](https://github.com/huggingface/transformers/pull/21955) to be merged).
|
| 105 |
+
The hash of the specific commit we installed was `68d640f7c368bcaaaecfc678f11908ebbd3d6176`.
|
| 106 |
+
|
| 107 |
+
To reproduce our fine-tuning runs for LLaMA, first install the requirements
|
| 108 |
+
```bash
|
| 109 |
+
pip install -r requirements.txt
|
| 110 |
+
```
|
| 111 |
+
Then, install the particular fork of Hugging Face's transformers library.
|
| 112 |
+
|
| 113 |
+
Below is a command that fine-tunes LLaMA-7B with our dataset on a machine with 4 A100 80G GPUs in FSDP `full_shard` mode.
|
| 114 |
+
We were able to reproduce a model of similar quality as the one we hosted in our demo with the following command using **Python 3.10**.
|
| 115 |
+
Replace `<your_random_port>` with a port of your own, `<your_path_to_hf_converted_llama_ckpt_and_tokenizer>` with the
|
| 116 |
+
path to your converted checkpoint and tokenizer (following instructions in the PR), and `<your_output_dir>` with where you want to store your outputs.
|
| 117 |
+
|
| 118 |
+
```bash
|
| 119 |
+
torchrun --nproc_per_node=4 --master_port=<your_random_port> train.py \
|
| 120 |
+
--model_name_or_path <your_path_to_hf_converted_llama_ckpt_and_tokenizer> \
|
| 121 |
+
--data_path ./alpaca_data.json \
|
| 122 |
+
--bf16 True \
|
| 123 |
+
--output_dir <your_output_dir> \
|
| 124 |
+
--num_train_epochs 3 \
|
| 125 |
+
--per_device_train_batch_size 4 \
|
| 126 |
+
--per_device_eval_batch_size 4 \
|
| 127 |
+
--gradient_accumulation_steps 8 \
|
| 128 |
+
--evaluation_strategy "no" \
|
| 129 |
+
--save_strategy "steps" \
|
| 130 |
+
--save_steps 2000 \
|
| 131 |
+
--save_total_limit 1 \
|
| 132 |
+
--learning_rate 2e-5 \
|
| 133 |
+
--weight_decay 0. \
|
| 134 |
+
--warmup_ratio 0.03 \
|
| 135 |
+
--lr_scheduler_type "cosine" \
|
| 136 |
+
--logging_steps 1 \
|
| 137 |
+
--fsdp "full_shard auto_wrap" \
|
| 138 |
+
--fsdp_transformer_layer_cls_to_wrap 'LLaMADecoderLayer' \
|
| 139 |
+
--tf32 True
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
The same script also works for OPT fine-tuning. Here's an example for fine-tuning OPT-6.7B
|
| 143 |
+
|
| 144 |
+
```bash
|
| 145 |
+
torchrun --nproc_per_node=4 --master_port=<your_random_port> train.py \
|
| 146 |
+
--model_name_or_path "facebook/opt-6.7b" \
|
| 147 |
+
--data_path ./alpaca_data.json \
|
| 148 |
+
--bf16 True \
|
| 149 |
+
--output_dir <your_output_dir> \
|
| 150 |
+
--num_train_epochs 3 \
|
| 151 |
+
--per_device_train_batch_size 4 \
|
| 152 |
+
--per_device_eval_batch_size 4 \
|
| 153 |
+
--gradient_accumulation_steps 8 \
|
| 154 |
+
--evaluation_strategy "no" \
|
| 155 |
+
--save_strategy "steps" \
|
| 156 |
+
--save_steps 2000 \
|
| 157 |
+
--save_total_limit 1 \
|
| 158 |
+
--learning_rate 2e-5 \
|
| 159 |
+
--weight_decay 0. \
|
| 160 |
+
--warmup_ratio 0.03 \
|
| 161 |
+
--lr_scheduler_type "cosine" \
|
| 162 |
+
--logging_steps 1 \
|
| 163 |
+
--fsdp "full_shard auto_wrap" \
|
| 164 |
+
--fsdp_transformer_layer_cls_to_wrap 'OPTDecoderLayer' \
|
| 165 |
+
--tf32 True
|
| 166 |
+
```
|
| 167 |
+
|
| 168 |
+
Note the given training script is meant to be simple and easy to use, and is not particularly optimized.
|
| 169 |
+
To run on more gpus, you may prefer to turn down `gradient_accumulation_steps` to keep a global batch size of 128. Global batch size has not been tested for optimality.
|
| 170 |
+
|
| 171 |
+
### Authors
|
| 172 |
+
All grad students below contributed equally and the order is determined by random draw.
|
| 173 |
+
|
| 174 |
+
- [Rohan Taori](https://www.rohantaori.com/)
|
| 175 |
+
- [Ishaan Gulrajani](https://ishaan.io/)
|
| 176 |
+
- [Tianyi Zhang](https://tiiiger.github.io/)
|
| 177 |
+
- [Yann Dubois](https://yanndubs.github.io/)
|
| 178 |
+
- [Xuechen Li](https://www.lxuechen.com/)
|
| 179 |
+
|
| 180 |
+
All advised by [Tatsunori B. Hashimoto](https://thashim.github.io/). Yann is also advised by [Percy Liang](https://cs.stanford.edu/~pliang/) and Xuechen is also advised by [Carlos Guestrin](https://guestrin.su.domains/).
|
| 181 |
+
|
| 182 |
+
### Citation
|
| 183 |
+
|
| 184 |
+
Please cite the repo if you use the data or code in this repo.
|
| 185 |
+
```
|
| 186 |
+
@misc{alpaca,
|
| 187 |
+
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
|
| 188 |
+
title = {Stanford Alpaca: An Instruction-following LLaMA model},
|
| 189 |
+
year = {2023},
|
| 190 |
+
publisher = {GitHub},
|
| 191 |
+
journal = {GitHub repository},
|
| 192 |
+
howpublished = {\url{https://github.com/tatsu-lab/stanford_alpaca}},
|
| 193 |
+
}
|
| 194 |
+
```
|
| 195 |
+
|
| 196 |
+
Naturally, you should also cite the original LLaMA paper [1] and the Self-Instruct paper [2].
|
| 197 |
+
|
| 198 |
+
### Acknowledgements
|
| 199 |
+
|
| 200 |
+
We thank Yizhong Wang for his help in explaining the data generation pipeline in Self-Instruct and providing the code for the parse analysis plot.
|
| 201 |
+
We thank Yifan Mai for helpful support, and members of the Stanford NLP Group as well as the Center for Research on Foundation Models (CRFM) for their helpful feedback.
|
alpaca_data.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
assets/alpaca_main.jpg
ADDED

|
assets/alpaca_right_email.png
ADDED

|
assets/alpaca_right_llama.png
ADDED

|
assets/alpaca_wrong_42.png
ADDED

|
assets/alpaca_wrong_capital.png
ADDED

|
assets/logo.png
ADDED
|
|
assets/parse_analysis.png
ADDED
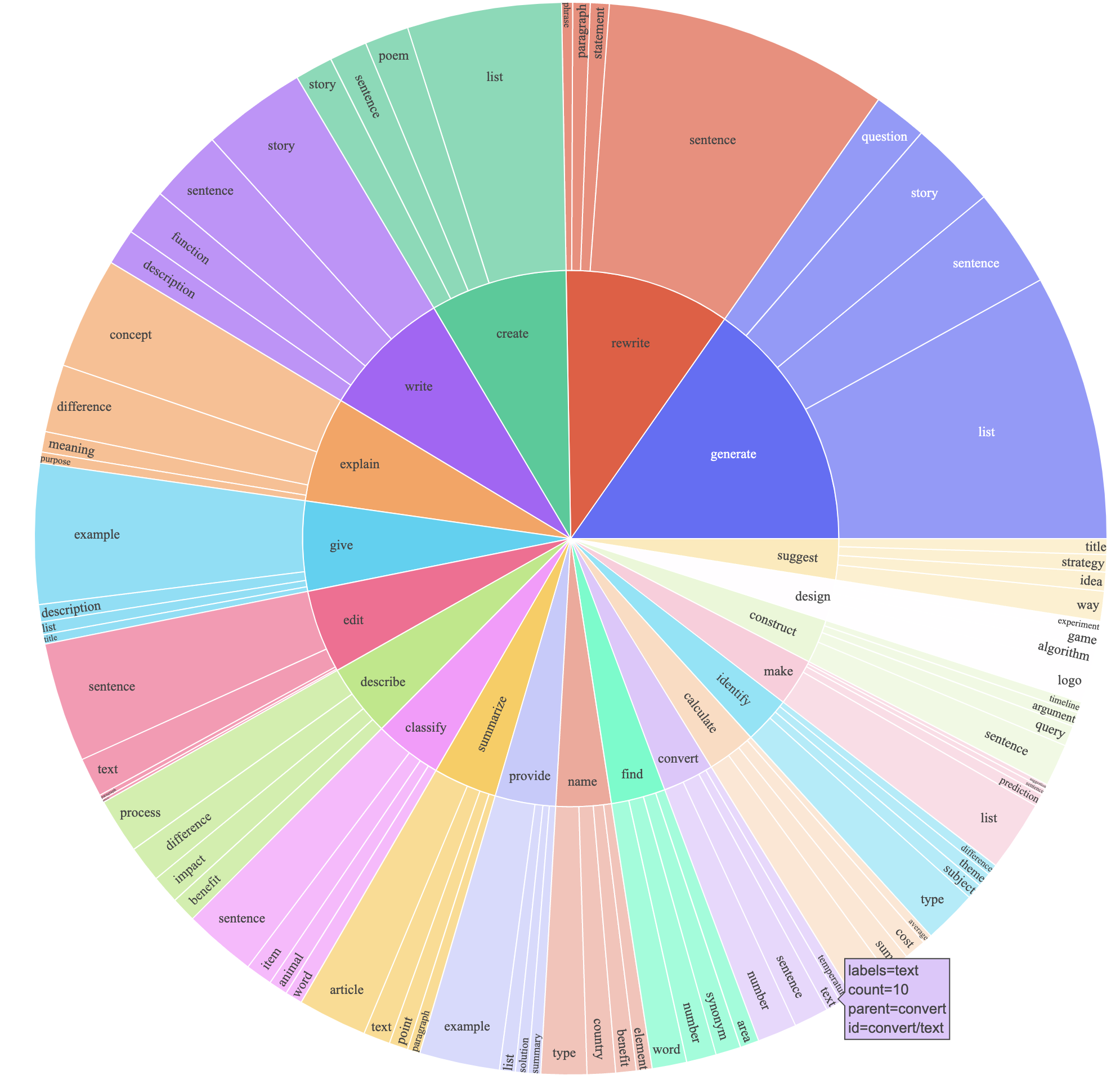
|
cog.yaml
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Configuration for Cog ⚙️
|
| 2 |
+
# Reference: https://github.com/replicate/cog/blob/main/docs/yaml.md
|
| 3 |
+
|
| 4 |
+
build:
|
| 5 |
+
gpu: true
|
| 6 |
+
python_version: "3.10"
|
| 7 |
+
cuda: "11.6"
|
| 8 |
+
python_packages:
|
| 9 |
+
- "torch==1.13.1"
|
| 10 |
+
- "sentencepiece==0.1.97"
|
| 11 |
+
- "accelerate==0.16.0"
|
| 12 |
+
|
| 13 |
+
run:
|
| 14 |
+
- "pip install git+https://github.com/huggingface/transformers.git@c3dc391da81e6ed7efce42be06413725943b3920"
|
| 15 |
+
|
| 16 |
+
predict: "predict.py:Predictor"
|
datasheet.md
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Alpaca Instruction Following Dataset
|
| 2 |
+
|
| 3 |
+
## Motivation
|
| 4 |
+
### For what purpose was the dataset created?
|
| 5 |
+
To enable more open-source research on instruction following large language models, we use generate 52K instruction-followng demonstrations using OpenAI's text-davinci-003 model.
|
| 6 |
+
|
| 7 |
+
### Who created the dataset
|
| 8 |
+
- [Rohan Taori](https://www.rohantaori.com/)
|
| 9 |
+
- [Ishaan Gulrajani](https://ishaan.io/)
|
| 10 |
+
- [Tianyi Zhang](https://tiiiger.github.io/)
|
| 11 |
+
- [Yann Dubois](https://yanndubs.github.io/)
|
| 12 |
+
- [Xuechen Li](https://www.lxuechen.com/)
|
| 13 |
+
- [Carlos Guestrin](https://guestrin.su.domains/)
|
| 14 |
+
- [Percy Liang](https://cs.stanford.edu/~pliang/)
|
| 15 |
+
- [Tatsunori B. Hashimoto](https://thashim.github.io/)
|
| 16 |
+
|
| 17 |
+
## Composition
|
| 18 |
+
|
| 19 |
+
### What do the instances that comprise the dataset represent (e.g., documents, photos, people, countries)?
|
| 20 |
+
The instruction following demonstrations are bootstrapped by following the [seed set](https://github.com/yizhongw/self-instruct/blob/main/data/seed_tasks.jsonl) released from the self-instruct project.
|
| 21 |
+
Given that the dataset is generated, it is difficult to pinpoint who/what the instances represent.
|
| 22 |
+
|
| 23 |
+
### How many instances are there in total
|
| 24 |
+
In total, there are 52,002 instances in the dataset.
|
| 25 |
+
|
| 26 |
+
### Does the dataset contain all possible instances or is it a sample (not necessarily random) of instances from a larger set?
|
| 27 |
+
not applicable.
|
| 28 |
+
|
| 29 |
+
### What data does each instance consist of?
|
| 30 |
+
|
| 31 |
+
- `instruction`: `str`, describes the task the model should perform. Each of the 52K instructions is unique.
|
| 32 |
+
- `input`: `str`, optional context or input for the task. For example, when the instruction is "Summarize the following article", the input is the article. Around 40% of the examples have an input.
|
| 33 |
+
- `output`: `str`, the answer to the instruction as generated by `text-davinci-003`.
|
| 34 |
+
|
| 35 |
+
### Is any information missing from individual instances?
|
| 36 |
+
no.
|
| 37 |
+
|
| 38 |
+
### Are relationships between individual instances made explicit (e.g., users’ movie ratings, social network links)?
|
| 39 |
+
not applicable.
|
| 40 |
+
|
| 41 |
+
### Is there a label or target associated with each instance?
|
| 42 |
+
the finetuning target is the response generated by `text-davinci-003`.
|
| 43 |
+
|
| 44 |
+
### Are there recommended data splits (e.g., training, development/validation, testing)?
|
| 45 |
+
The Alpaca models (both demo and the ones that will be released) are trained on all 52K data.
|
| 46 |
+
There is no recommended data split for the dataset.
|
| 47 |
+
|
| 48 |
+
### Are there any errors, sources of noise, or redundancies in the dataset?
|
| 49 |
+
All 52k instructions are unique. However, some generated instructions may not be sensible, i.e., there may not exist any good response to the instruction.
|
| 50 |
+
|
| 51 |
+
### Is the dataset self-contained, or does it link to or otherwise rely on external resources (e.g., websites, tweets, other datasets)?
|
| 52 |
+
the dataset is self-contained.
|
| 53 |
+
|
| 54 |
+
### Does the dataset contain data that might be considered confidential (e.g., data that is protected by legal privilege or by doctor-patient confidentiality, data that includes the content of individuals’ non-public communications)?
|
| 55 |
+
no.
|
| 56 |
+
|
| 57 |
+
### Does the dataset contain data that, if viewed directly, might be offensive, insulting, threatening, or might otherwise cause anxiety?
|
| 58 |
+
The generated may contain a few inappropriate responses. In our preliminary testing, we have not encountered any offensive responses.
|
| 59 |
+
|
| 60 |
+
## Collection process
|
| 61 |
+
The [Github repository](https://github.com/tatsu-lab/stanford_alpaca) contains the code to generate the dataset.
|
| 62 |
+
|
| 63 |
+
## Uses
|
| 64 |
+
|
| 65 |
+
### Has the dataset been used for any tasks already?
|
| 66 |
+
The dataset is used to train the Alpaca models that are both used for the demo and released.
|
| 67 |
+
|
| 68 |
+
### Is there a repository that links to any or all papers or systems that use the dataset?
|
| 69 |
+
Please see https://github.com/tatsu-lab/stanford_alpaca
|
| 70 |
+
|
| 71 |
+
### Is there anything about the composition of the dataset or the way it was collected and preprocessed/cleaned/labeled that might impact future uses?
|
| 72 |
+
This dataset is generated by using the OpenAI's API. Therefore, this dataset cannot be used for commerical usage that compete with OpenAI.
|
| 73 |
+
|
| 74 |
+
### Are there tasks for which the dataset should not be used?
|
| 75 |
+
The dataset should not be used for commerical usage that compete with OpenAI.
|
| 76 |
+
|
| 77 |
+
## Distribution
|
| 78 |
+
### Will the dataset be distributed to third parties outside of the entity (e.g., company, institution, organization) on behalf of which the dataset was created?
|
| 79 |
+
The dataset can be freely downloaded.
|
| 80 |
+
|
| 81 |
+
### How will the dataset will be distributed (e.g., tarball on website, API, GitHub)?
|
| 82 |
+
The dataset can be downloaded from the [Github repository](https://github.com/tatsu-lab/stanford_alpaca) as a json file.
|
| 83 |
+
|
| 84 |
+
### Will the dataset be distributed under a copyright or other intellectual property (IP) license, and/or under applicable terms of use (ToU)?
|
| 85 |
+
This dataset is distributed under [the ODC-By license](https://opendatacommons.org/licenses/by/1-0/).
|
| 86 |
+
|
| 87 |
+
### Have any third parties imposed IP-based or other restrictions on the data associated with the instances?
|
| 88 |
+
no
|
| 89 |
+
|
| 90 |
+
### Do any export controls or other regulatory restrictions apply to the dataset or to individual instances?
|
| 91 |
+
no
|
| 92 |
+
|
| 93 |
+
## Maintenance
|
| 94 |
+
|
| 95 |
+
### Who is supporting/hosting/maintaining the dataset?
|
| 96 |
+
The dataset is hosted on github and the Github repository is maintained by Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li.
|
| 97 |
+
|
| 98 |
+
### How can the owner/curator/manager of the dataset be contacted (e.g., email address)?
|
| 99 |
+
Please open an issue in the [Github repository](https://github.com/tatsu-lab/stanford_alpaca)
|
| 100 |
+
|
| 101 |
+
### Will the dataset be updated (e.g., to correct labeling errors, add new instances, delete instances)?
|
| 102 |
+
We do not have plan to update the dataset.
|
generate_instruction.py
ADDED
|
@@ -0,0 +1,217 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
batch_selfinstruct_generate.py
|
| 3 |
+
|
| 4 |
+
run:
|
| 5 |
+
python -m generate_instruction generate_instruction_following_data \
|
| 6 |
+
--output_dir ./ \
|
| 7 |
+
--num_instructions_to_generate 10 \
|
| 8 |
+
--model_name="text-davinci-003" \
|
| 9 |
+
"""
|
| 10 |
+
import time
|
| 11 |
+
import json
|
| 12 |
+
import os
|
| 13 |
+
import random
|
| 14 |
+
import re
|
| 15 |
+
import string
|
| 16 |
+
from functools import partial
|
| 17 |
+
from multiprocessing import Pool
|
| 18 |
+
|
| 19 |
+
import numpy as np
|
| 20 |
+
import tqdm
|
| 21 |
+
from rouge_score import rouge_scorer
|
| 22 |
+
import utils
|
| 23 |
+
|
| 24 |
+
import fire
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def encode_prompt(prompt_instructions):
|
| 28 |
+
"""Encode multiple prompt instructions into a single string."""
|
| 29 |
+
prompt = open("./prompt.txt").read() + "\n"
|
| 30 |
+
|
| 31 |
+
for idx, task_dict in enumerate(prompt_instructions):
|
| 32 |
+
(instruction, input, output) = task_dict["instruction"], task_dict["input"], task_dict["output"]
|
| 33 |
+
instruction = re.sub(r"\s+", " ", instruction).strip().rstrip(":")
|
| 34 |
+
input = "<noinput>" if input.lower() == "" else input
|
| 35 |
+
prompt += f"###\n"
|
| 36 |
+
prompt += f"{idx + 1}. Instruction: {instruction}\n"
|
| 37 |
+
prompt += f"{idx + 1}. Input:\n{input}\n"
|
| 38 |
+
prompt += f"{idx + 1}. Output:\n{output}\n"
|
| 39 |
+
prompt += f"###\n"
|
| 40 |
+
prompt += f"{idx + 2}. Instruction:"
|
| 41 |
+
return prompt
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def post_process_gpt3_response(num_prompt_instructions, response):
|
| 45 |
+
if response is None:
|
| 46 |
+
return []
|
| 47 |
+
raw_instructions = f"{num_prompt_instructions+1}. Instruction:" + response["text"]
|
| 48 |
+
raw_instructions = re.split("###", raw_instructions)
|
| 49 |
+
instructions = []
|
| 50 |
+
for idx, inst in enumerate(raw_instructions):
|
| 51 |
+
# if the decoding stops due to length, the last example is likely truncated so we discard it
|
| 52 |
+
if idx == len(raw_instructions) - 1 and response["finish_reason"] == "length":
|
| 53 |
+
continue
|
| 54 |
+
idx += num_prompt_instructions + 1
|
| 55 |
+
splitted_data = re.split(f"{idx}\.\s+(Instruction|Input|Output):", inst)
|
| 56 |
+
if len(splitted_data) != 7:
|
| 57 |
+
continue
|
| 58 |
+
else:
|
| 59 |
+
inst = splitted_data[2].strip()
|
| 60 |
+
input = splitted_data[4].strip()
|
| 61 |
+
input = "" if input.lower() == "<noinput>" else input
|
| 62 |
+
output = splitted_data[6].strip()
|
| 63 |
+
# filter out too short or too long instructions
|
| 64 |
+
if len(inst.split()) <= 3 or len(inst.split()) > 150:
|
| 65 |
+
continue
|
| 66 |
+
# filter based on keywords that are not suitable for language models.
|
| 67 |
+
blacklist = [
|
| 68 |
+
"image",
|
| 69 |
+
"images",
|
| 70 |
+
"graph",
|
| 71 |
+
"graphs",
|
| 72 |
+
"picture",
|
| 73 |
+
"pictures",
|
| 74 |
+
"file",
|
| 75 |
+
"files",
|
| 76 |
+
"map",
|
| 77 |
+
"maps",
|
| 78 |
+
"draw",
|
| 79 |
+
"plot",
|
| 80 |
+
"go to",
|
| 81 |
+
"video",
|
| 82 |
+
"audio",
|
| 83 |
+
"music",
|
| 84 |
+
"flowchart",
|
| 85 |
+
"diagram",
|
| 86 |
+
]
|
| 87 |
+
blacklist += []
|
| 88 |
+
if any(find_word_in_string(word, inst) for word in blacklist):
|
| 89 |
+
continue
|
| 90 |
+
# We found that the model tends to add "write a program" to some existing instructions, which lead to a lot of such instructions.
|
| 91 |
+
# And it's a bit comfusing whether the model need to write a program or directly output the result.
|
| 92 |
+
# Here we filter them out.
|
| 93 |
+
# Note this is not a comprehensive filtering for all programming instructions.
|
| 94 |
+
if inst.startswith("Write a program"):
|
| 95 |
+
continue
|
| 96 |
+
# filter those starting with punctuation
|
| 97 |
+
if inst[0] in string.punctuation:
|
| 98 |
+
continue
|
| 99 |
+
# filter those starting with non-english character
|
| 100 |
+
if not inst[0].isascii():
|
| 101 |
+
continue
|
| 102 |
+
instructions.append({"instruction": inst, "input": input, "output": output})
|
| 103 |
+
return instructions
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def find_word_in_string(w, s):
|
| 107 |
+
return re.compile(r"\b({0})\b".format(w), flags=re.IGNORECASE).search(s)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def generate_instruction_following_data(
|
| 111 |
+
output_dir="./",
|
| 112 |
+
seed_tasks_path="./seed_tasks.jsonl",
|
| 113 |
+
num_instructions_to_generate=100,
|
| 114 |
+
model_name="text-davinci-003",
|
| 115 |
+
num_prompt_instructions=3,
|
| 116 |
+
request_batch_size=5,
|
| 117 |
+
temperature=1.0,
|
| 118 |
+
top_p=1.0,
|
| 119 |
+
num_cpus=16,
|
| 120 |
+
):
|
| 121 |
+
seed_tasks = [json.loads(l) for l in open(seed_tasks_path, "r")]
|
| 122 |
+
seed_instruction_data = [
|
| 123 |
+
{"instruction": t["instruction"], "input": t["instances"][0]["input"], "output": t["instances"][0]["output"]}
|
| 124 |
+
for t in seed_tasks
|
| 125 |
+
]
|
| 126 |
+
print(f"Loaded {len(seed_instruction_data)} human-written seed instructions")
|
| 127 |
+
|
| 128 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 129 |
+
request_idx = 0
|
| 130 |
+
# load the LM-generated instructions
|
| 131 |
+
machine_instruction_data = []
|
| 132 |
+
if os.path.exists(os.path.join(output_dir, "regen.json")):
|
| 133 |
+
machine_instruction_data = utils.jload(os.path.join(output_dir, "regen.json"))
|
| 134 |
+
print(f"Loaded {len(machine_instruction_data)} machine-generated instructions")
|
| 135 |
+
|
| 136 |
+
# similarities = {}
|
| 137 |
+
scorer = rouge_scorer.RougeScorer(["rougeL"], use_stemmer=False)
|
| 138 |
+
|
| 139 |
+
# now let's generate new instructions!
|
| 140 |
+
progress_bar = tqdm.tqdm(total=num_instructions_to_generate)
|
| 141 |
+
if machine_instruction_data:
|
| 142 |
+
progress_bar.update(len(machine_instruction_data))
|
| 143 |
+
|
| 144 |
+
# first we tokenize all the seed instructions and generated machine instructions
|
| 145 |
+
all_instructions = [d["instruction"] for d in seed_instruction_data] + [
|
| 146 |
+
d["instruction"] for d in machine_instruction_data
|
| 147 |
+
]
|
| 148 |
+
all_instruction_tokens = [scorer._tokenizer.tokenize(inst) for inst in all_instructions]
|
| 149 |
+
|
| 150 |
+
while len(machine_instruction_data) < num_instructions_to_generate:
|
| 151 |
+
request_idx += 1
|
| 152 |
+
|
| 153 |
+
batch_inputs = []
|
| 154 |
+
for _ in range(request_batch_size):
|
| 155 |
+
# only sampling from the seed tasks
|
| 156 |
+
prompt_instructions = random.sample(seed_instruction_data, num_prompt_instructions)
|
| 157 |
+
prompt = encode_prompt(prompt_instructions)
|
| 158 |
+
batch_inputs.append(prompt)
|
| 159 |
+
decoding_args = utils.OpenAIDecodingArguments(
|
| 160 |
+
temperature=temperature,
|
| 161 |
+
n=1,
|
| 162 |
+
max_tokens=3072, # hard-code to maximize the length. the requests will be automatically adjusted
|
| 163 |
+
top_p=top_p,
|
| 164 |
+
stop=["\n20", "20.", "20."],
|
| 165 |
+
)
|
| 166 |
+
request_start = time.time()
|
| 167 |
+
results = utils.openai_completion(
|
| 168 |
+
prompts=batch_inputs,
|
| 169 |
+
model_name=model_name,
|
| 170 |
+
batch_size=request_batch_size,
|
| 171 |
+
decoding_args=decoding_args,
|
| 172 |
+
logit_bias={"50256": -100}, # prevent the <|endoftext|> token from being generated
|
| 173 |
+
)
|
| 174 |
+
request_duration = time.time() - request_start
|
| 175 |
+
|
| 176 |
+
process_start = time.time()
|
| 177 |
+
instruction_data = []
|
| 178 |
+
for result in results:
|
| 179 |
+
new_instructions = post_process_gpt3_response(num_prompt_instructions, result)
|
| 180 |
+
instruction_data += new_instructions
|
| 181 |
+
|
| 182 |
+
total = len(instruction_data)
|
| 183 |
+
keep = 0
|
| 184 |
+
for instruction_data_entry in instruction_data:
|
| 185 |
+
# computing similarity with the pre-tokenzied instructions
|
| 186 |
+
new_instruction_tokens = scorer._tokenizer.tokenize(instruction_data_entry["instruction"])
|
| 187 |
+
with Pool(num_cpus) as p:
|
| 188 |
+
rouge_scores = p.map(
|
| 189 |
+
partial(rouge_scorer._score_lcs, new_instruction_tokens),
|
| 190 |
+
all_instruction_tokens,
|
| 191 |
+
)
|
| 192 |
+
rouge_scores = [score.fmeasure for score in rouge_scores]
|
| 193 |
+
most_similar_instructions = {
|
| 194 |
+
all_instructions[i]: rouge_scores[i] for i in np.argsort(rouge_scores)[-10:][::-1]
|
| 195 |
+
}
|
| 196 |
+
if max(rouge_scores) > 0.7:
|
| 197 |
+
continue
|
| 198 |
+
else:
|
| 199 |
+
keep += 1
|
| 200 |
+
instruction_data_entry["most_similar_instructions"] = most_similar_instructions
|
| 201 |
+
instruction_data_entry["avg_similarity_score"] = float(np.mean(rouge_scores))
|
| 202 |
+
machine_instruction_data.append(instruction_data_entry)
|
| 203 |
+
all_instructions.append(instruction_data_entry["instruction"])
|
| 204 |
+
all_instruction_tokens.append(new_instruction_tokens)
|
| 205 |
+
progress_bar.update(1)
|
| 206 |
+
process_duration = time.time() - process_start
|
| 207 |
+
print(f"Request {request_idx} took {request_duration:.2f}s, processing took {process_duration:.2f}s")
|
| 208 |
+
print(f"Generated {total} instructions, kept {keep} instructions")
|
| 209 |
+
utils.jdump(machine_instruction_data, os.path.join(output_dir, "regen.json"))
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
def main(task, **kwargs):
|
| 213 |
+
globals()[task](**kwargs)
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
if __name__ == "__main__":
|
| 217 |
+
fire.Fire(main)
|
model_card.md
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
# Alpaca Model Card
|
| 3 |
+
|
| 4 |
+
## Model details
|
| 5 |
+
**Organization developing the model**
|
| 6 |
+
Stanford Hashimoto Group
|
| 7 |
+
|
| 8 |
+
**Model date**
|
| 9 |
+
Alpaca was trained in March 2023
|
| 10 |
+
|
| 11 |
+
**Model version**
|
| 12 |
+
This is version 1 of the model.
|
| 13 |
+
|
| 14 |
+
**Model type**
|
| 15 |
+
Alpaca models are instruction-following models finetuned from LLaMA models.
|
| 16 |
+
|
| 17 |
+
**More information**
|
| 18 |
+
Please see our blog post at `link` for more information.
|
| 19 |
+
|
| 20 |
+
**Citations details**
|
| 21 |
+
Please cite the [github repo](https://github.com/tatsu-lab/stanford_alpaca) if you use the data or code in this repo.
|
| 22 |
+
|
| 23 |
+
**License**
|
| 24 |
+
Code and data are licensed under the Apache 2.0 license.
|
| 25 |
+
|
| 26 |
+
**Where to send questions or comments about the model**
|
| 27 |
+
Questions and comments about LLaMA can be sent via the [GitHub repository](https://github.com/tatsu-lab/stanford_alpaca) of the project, by opening an issue.
|
| 28 |
+
|
| 29 |
+
## Intended use
|
| 30 |
+
**Primary intended uses**
|
| 31 |
+
The primary use of Alpaca is research on instruction following large language models.
|
| 32 |
+
|
| 33 |
+
**Primary intended users**
|
| 34 |
+
The primary intended users of the model are researchers in natural language processing, machine learning and artificial intelligence.
|
| 35 |
+
|
| 36 |
+
**Out-of-scope use cases**
|
| 37 |
+
Alpaca models are not finetuned with human feedback and are not intended for use in production systems.
|
| 38 |
+
Alpaca models are trained from data generated using the OpenAI API and thus any usage must not be competing with the OpenAI API.
|
| 39 |
+
|
| 40 |
+
## Metrics
|
| 41 |
+
**Model performance measures**
|
| 42 |
+
the Alpaca 7B model has been evaluated using blinded pairwise comparison with OpenAI's text-davinci-003 on the self-instruct evaluation set.
|
| 43 |
+
Our student authors have judged the Alpaca 7B model to be on par with text-davinci-003, with a win rate around 50%.
|
| 44 |
+
|
| 45 |
+
**Approaches to uncertainty and variability**
|
| 46 |
+
We have only finetuned a single Alpaca model at each model size, and thus we do not have a good sense of the variability of the model.
|
| 47 |
+
|
| 48 |
+
## Evaluation datasets
|
| 49 |
+
The model was evaluated on the self-instruct evaluation set.
|
| 50 |
+
|
| 51 |
+
## Training dataset
|
| 52 |
+
The model was trained on 52K instruction following data, which is release in the [Github repository](https://github.com/tatsu-lab/stanford_alpaca).
|
predict.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Optional
|
| 2 |
+
from cog import BasePredictor, Input
|
| 3 |
+
from transformers import LLaMAForCausalLM, LLaMATokenizer
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
from train import PROMPT_DICT
|
| 7 |
+
PROMPT = PROMPT_DICT['prompt_no_input']
|
| 8 |
+
|
| 9 |
+
CACHE_DIR = 'alpaca_out'
|
| 10 |
+
|
| 11 |
+
class Predictor(BasePredictor):
|
| 12 |
+
def setup(self):
|
| 13 |
+
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 14 |
+
self.model = LLaMAForCausalLM.from_pretrained("alpaca_out", cache_dir=CACHE_DIR, local_files_only=True)
|
| 15 |
+
self.model = self.model
|
| 16 |
+
self.model.to(self.device)
|
| 17 |
+
self.tokenizer = LLaMATokenizer.from_pretrained("alpaca_out", cache_dir=CACHE_DIR, local_files_only=True)
|
| 18 |
+
|
| 19 |
+
def predict(
|
| 20 |
+
self,
|
| 21 |
+
prompt: str = Input(description=f"Prompt to send to LLaMA."),
|
| 22 |
+
n: int = Input(description="Number of output sequences to generate", default=1, ge=1, le=5),
|
| 23 |
+
total_tokens: int = Input(
|
| 24 |
+
description="Maximum number of tokens for input + generation. A word is generally 2-3 tokens",
|
| 25 |
+
ge=1,
|
| 26 |
+
default=2000
|
| 27 |
+
),
|
| 28 |
+
temperature: float = Input(
|
| 29 |
+
description="Adjusts randomness of outputs, greater than 1 is random and 0 is deterministic, 0.75 is a good starting value.",
|
| 30 |
+
ge=0.01,
|
| 31 |
+
le=5,
|
| 32 |
+
default=0.75,
|
| 33 |
+
),
|
| 34 |
+
top_p: float = Input(
|
| 35 |
+
description="When decoding text, samples from the top p percentage of most likely tokens; lower to ignore less likely tokens",
|
| 36 |
+
ge=0.01,
|
| 37 |
+
le=1.0,
|
| 38 |
+
default=1.0
|
| 39 |
+
),
|
| 40 |
+
repetition_penalty: float = Input(
|
| 41 |
+
description="Penalty for repeated words in generated text; 1 is no penalty, values greater than 1 discourage repetition, less than 1 encourage it.",
|
| 42 |
+
ge=0.01,
|
| 43 |
+
le=5,
|
| 44 |
+
default=1
|
| 45 |
+
)
|
| 46 |
+
) -> List[str]:
|
| 47 |
+
format_prompt = PROMPT.format_map({'instruction': prompt})
|
| 48 |
+
input = self.tokenizer(format_prompt, return_tensors="pt").input_ids.to(self.device)
|
| 49 |
+
|
| 50 |
+
outputs = self.model.generate(
|
| 51 |
+
input,
|
| 52 |
+
num_return_sequences=n,
|
| 53 |
+
max_length=total_tokens,
|
| 54 |
+
do_sample=True,
|
| 55 |
+
temperature=temperature,
|
| 56 |
+
top_p=top_p,
|
| 57 |
+
repetition_penalty=repetition_penalty
|
| 58 |
+
)
|
| 59 |
+
out = self.tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
| 60 |
+
# removing prompt b/c it's returned with every input
|
| 61 |
+
out = [val.split('Response:')[1] for val in out]
|
| 62 |
+
return out
|
| 63 |
+
|
prompt.txt
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
You are asked to come up with a set of 20 diverse task instructions. These task instructions will be given to a GPT model and we will evaluate the GPT model for completing the instructions.
|
| 2 |
+
|
| 3 |
+
Here are the requirements:
|
| 4 |
+
1. Try not to repeat the verb for each instruction to maximize diversity.
|
| 5 |
+
2. The language used for the instruction also should be diverse. For example, you should combine questions with imperative instrucitons.
|
| 6 |
+
3. The type of instructions should be diverse. The list should include diverse types of tasks like open-ended generation, classification, editing, etc.
|
| 7 |
+
2. A GPT language model should be able to complete the instruction. For example, do not ask the assistant to create any visual or audio output. For another example, do not ask the assistant to wake you up at 5pm or set a reminder because it cannot perform any action.
|
| 8 |
+
3. The instructions should be in English.
|
| 9 |
+
4. The instructions should be 1 to 2 sentences long. Either an imperative sentence or a question is permitted.
|
| 10 |
+
5. You should generate an appropriate input to the instruction. The input field should contain a specific example provided for the instruction. It should involve realistic data and should not contain simple placeholders. The input should provide substantial content to make the instruction challenging but should ideally not exceed 100 words.
|
| 11 |
+
6. Not all instructions require input. For example, when a instruction asks about some general information, "what is the highest peak in the world", it is not necssary to provide a specific context. In this case, we simply put "<noinput>" in the input field.
|
| 12 |
+
7. The output should be an appropriate response to the instruction and the input. Make sure the output is less than 100 words.
|
| 13 |
+
|
| 14 |
+
List of 20 tasks:
|
requirements.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
numpy
|
| 2 |
+
rouge_score
|
| 3 |
+
fire
|
| 4 |
+
openai
|
| 5 |
+
transformers>=4.26.1
|
| 6 |
+
torch
|
| 7 |
+
sentencepiece
|
| 8 |
+
tokenizers==0.12.1
|
| 9 |
+
wandb
|
seed_tasks.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
train.py
ADDED
|
@@ -0,0 +1,247 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
import copy
|
| 16 |
+
import logging
|
| 17 |
+
import io
|
| 18 |
+
import json
|
| 19 |
+
from dataclasses import dataclass, field
|
| 20 |
+
from typing import Optional, Dict, Sequence
|
| 21 |
+
|
| 22 |
+
import torch
|
| 23 |
+
import transformers
|
| 24 |
+
from torch.utils.data import Dataset
|
| 25 |
+
from transformers import Trainer
|
| 26 |
+
|
| 27 |
+
IGNORE_INDEX = -100
|
| 28 |
+
DEFAULT_PAD_TOKEN = "[PAD]"
|
| 29 |
+
DEFAULT_EOS_TOKEN = "</s>"
|
| 30 |
+
DEFAULT_BOS_TOKEN = "</s>"
|
| 31 |
+
DEFAULT_UNK_TOKEN = "</s>"
|
| 32 |
+
PROMPT_DICT = {
|
| 33 |
+
"prompt_input": (
|
| 34 |
+
"Below is an instruction that describes a task, paired with an input that provides further context. "
|
| 35 |
+
"Write a response that appropriately completes the request.\n\n"
|
| 36 |
+
"### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:"
|
| 37 |
+
),
|
| 38 |
+
"prompt_no_input": (
|
| 39 |
+
"Below is an instruction that describes a task. "
|
| 40 |
+
"Write a response that appropriately completes the request.\n\n"
|
| 41 |
+
"### Instruction:\n{instruction}\n\n### Response:"
|
| 42 |
+
),
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def _make_r_io_base(f, mode: str):
|
| 47 |
+
if not isinstance(f, io.IOBase):
|
| 48 |
+
f = open(f, mode=mode)
|
| 49 |
+
return f
|
| 50 |
+
|
| 51 |
+
def jload(f, mode="r"):
|
| 52 |
+
"""Load a .json file into a dictionary."""
|
| 53 |
+
f = _make_r_io_base(f, mode)
|
| 54 |
+
jdict = json.load(f)
|
| 55 |
+
f.close()
|
| 56 |
+
return jdict
|
| 57 |
+
|
| 58 |
+
@dataclass
|
| 59 |
+
class ModelArguments:
|
| 60 |
+
model_name_or_path: Optional[str] = field(default="facebook/opt-125m")
|
| 61 |
+
tokenizer_name_or_path: Optional[str] = field(default="facebook/opt-125m")
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
@dataclass
|
| 65 |
+
class DataArguments:
|
| 66 |
+
data_path: str = field(default=None, metadata={"help": "Path to the training data."})
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
@dataclass
|
| 70 |
+
class TrainingArguments(transformers.TrainingArguments):
|
| 71 |
+
cache_dir: Optional[str] = field(default=None)
|
| 72 |
+
optim: str = field(default="adamw_torch")
|
| 73 |
+
fsdp_transformer_layer_cls_to_wrap: str = field(default=None)
|
| 74 |
+
model_max_length: int = field(
|
| 75 |
+
default=512,
|
| 76 |
+
metadata={"help": "Maximum sequence length. Sequences will be right padded (and possibly truncated)."},
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def safe_save_model_for_hf_trainer(trainer: transformers.Trainer, output_dir: str):
|
| 81 |
+
"""Collects the state dict and dump to disk."""
|
| 82 |
+
state_dict = trainer.model.state_dict()
|
| 83 |
+
if trainer.args.should_save:
|
| 84 |
+
cpu_state_dict = {key: value.cpu() for key, value in state_dict.items()}
|
| 85 |
+
del state_dict
|
| 86 |
+
trainer._save(output_dir, state_dict=cpu_state_dict) # noqa
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def smart_tokenizer_and_embedding_resize(
|
| 90 |
+
special_tokens_dict: Dict,
|
| 91 |
+
tokenizer: transformers.PreTrainedTokenizer,
|
| 92 |
+
model: transformers.PreTrainedModel,
|
| 93 |
+
):
|
| 94 |
+
"""Resize tokenizer and embedding.
|
| 95 |
+
|
| 96 |
+
Note: This is the unoptimized version that may make your embedding size not be divisible by 64.
|
| 97 |
+
"""
|
| 98 |
+
num_new_tokens = tokenizer.add_special_tokens(special_tokens_dict)
|
| 99 |
+
model.resize_token_embeddings(len(tokenizer))
|
| 100 |
+
|
| 101 |
+
if num_new_tokens > 0:
|
| 102 |
+
input_embeddings = model.get_input_embeddings().weight.data
|
| 103 |
+
output_embeddings = model.get_output_embeddings().weight.data
|
| 104 |
+
|
| 105 |
+
input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(dim=0, keepdim=True)
|
| 106 |
+
output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(dim=0, keepdim=True)
|
| 107 |
+
|
| 108 |
+
input_embeddings[-num_new_tokens:] = input_embeddings_avg
|
| 109 |
+
output_embeddings[-num_new_tokens:] = output_embeddings_avg
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def _tokenize_fn(strings: Sequence[str], tokenizer: transformers.PreTrainedTokenizer) -> Dict:
|
| 113 |
+
"""Tokenize a list of strings."""
|
| 114 |
+
tokenized_list = [
|
| 115 |
+
tokenizer(
|
| 116 |
+
text,
|
| 117 |
+
return_tensors="pt",
|
| 118 |
+
padding="longest",
|
| 119 |
+
max_length=tokenizer.model_max_length,
|
| 120 |
+
truncation=True,
|
| 121 |
+
)
|
| 122 |
+
for text in strings
|
| 123 |
+
]
|
| 124 |
+
input_ids = labels = [tokenized.input_ids[0] for tokenized in tokenized_list]
|
| 125 |
+
input_ids_lens = labels_lens = [
|
| 126 |
+
tokenized.input_ids.ne(tokenizer.pad_token_id).sum().item() for tokenized in tokenized_list
|
| 127 |
+
]
|
| 128 |
+
return dict(
|
| 129 |
+
input_ids=input_ids,
|
| 130 |
+
labels=labels,
|
| 131 |
+
input_ids_lens=input_ids_lens,
|
| 132 |
+
labels_lens=labels_lens,
|
| 133 |
+
)
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def preprocess(
|
| 137 |
+
sources: Sequence[str],
|
| 138 |
+
targets: Sequence[str],
|
| 139 |
+
tokenizer: transformers.PreTrainedTokenizer,
|
| 140 |
+
) -> Dict:
|
| 141 |
+
"""Preprocess the data by tokenizing."""
|
| 142 |
+
examples = [s + t for s, t in zip(sources, targets)]
|
| 143 |
+
examples_tokenized, sources_tokenized = [_tokenize_fn(strings, tokenizer) for strings in (examples, sources)]
|
| 144 |
+
input_ids = examples_tokenized["input_ids"]
|
| 145 |
+
labels = copy.deepcopy(input_ids)
|
| 146 |
+
for label, source_len in zip(labels, sources_tokenized["input_ids_lens"]):
|
| 147 |
+
label[:source_len] = IGNORE_INDEX
|
| 148 |
+
return dict(input_ids=input_ids, labels=labels)
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
class SupervisedDataset(Dataset):
|
| 152 |
+
"""Dataset for supervised fine-tuning."""
|
| 153 |
+
|
| 154 |
+
def __init__(self, data_path: str, tokenizer: transformers.PreTrainedTokenizer):
|
| 155 |
+
super(SupervisedDataset, self).__init__()
|
| 156 |
+
logging.warning("Loading data...")
|
| 157 |
+
list_data_dict = jload(data_path)
|
| 158 |
+
|
| 159 |
+
logging.warning("Formatting inputs...")
|
| 160 |
+
prompt_input, prompt_no_input = PROMPT_DICT["prompt_input"], PROMPT_DICT["prompt_no_input"]
|
| 161 |
+
sources = [
|
| 162 |
+
prompt_input.format_map(example) if example.get("input", "") != "" else prompt_no_input.format_map(example)
|
| 163 |
+
for example in list_data_dict
|
| 164 |
+
]
|
| 165 |
+
targets = [f"{example['output']}{tokenizer.eos_token}" for example in list_data_dict]
|
| 166 |
+
|
| 167 |
+
logging.warning("Tokenizing inputs... This may take some time...")
|
| 168 |
+
data_dict = preprocess(sources, targets, tokenizer)
|
| 169 |
+
|
| 170 |
+
self.input_ids = data_dict["input_ids"]
|
| 171 |
+
self.labels = data_dict["labels"]
|
| 172 |
+
|
| 173 |
+
def __len__(self):
|
| 174 |
+
return len(self.input_ids)
|
| 175 |
+
|
| 176 |
+
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
|
| 177 |
+
return dict(input_ids=self.input_ids[i], labels=self.labels[i])
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
@dataclass
|
| 181 |
+
class DataCollatorForSupervisedDataset(object):
|
| 182 |
+
"""Collate examples for supervised fine-tuning."""
|
| 183 |
+
|
| 184 |
+
tokenizer: transformers.PreTrainedTokenizer
|
| 185 |
+
|
| 186 |
+
def __call__(self, instances: Sequence[Dict]) -> Dict[str, torch.Tensor]:
|
| 187 |
+
input_ids, labels = tuple([instance[key] for instance in instances] for key in ("input_ids", "labels"))
|
| 188 |
+
input_ids = torch.nn.utils.rnn.pad_sequence(
|
| 189 |
+
input_ids, batch_first=True, padding_value=self.tokenizer.pad_token_id
|
| 190 |
+
)
|
| 191 |
+
labels = torch.nn.utils.rnn.pad_sequence(labels, batch_first=True, padding_value=IGNORE_INDEX)
|
| 192 |
+
return dict(
|
| 193 |
+
input_ids=input_ids,
|
| 194 |
+
labels=labels,
|
| 195 |
+
attention_mask=input_ids.ne(self.tokenizer.pad_token_id),
|
| 196 |
+
)
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
def make_supervised_data_module(tokenizer: transformers.PreTrainedTokenizer, data_args) -> Dict:
|
| 200 |
+
"""Make dataset and collator for supervised fine-tuning."""
|
| 201 |
+
train_dataset = SupervisedDataset(tokenizer=tokenizer, data_path=data_args.data_path)
|
| 202 |
+
data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
|
| 203 |
+
return dict(train_dataset=train_dataset, eval_dataset=None, data_collator=data_collator)
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
def train():
|
| 207 |
+
parser = transformers.HfArgumentParser((ModelArguments, DataArguments, TrainingArguments))
|
| 208 |
+
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
|
| 209 |
+
print(training_args)
|
| 210 |
+
print(model_args)
|
| 211 |
+
print(data_args)
|
| 212 |
+
model = transformers.AutoModelForCausalLM.from_pretrained(
|
| 213 |
+
model_args.model_name_or_path,
|
| 214 |
+
cache_dir=training_args.cache_dir,
|
| 215 |
+
)
|
| 216 |
+
|
| 217 |
+
tokenizer = transformers.AutoTokenizer.from_pretrained(
|
| 218 |
+
"facebook/opt-125m",
|
| 219 |
+
cache_dir=None,
|
| 220 |
+
model_max_length=512,
|
| 221 |
+
padding_side="right",
|
| 222 |
+
use_fast=False,
|
| 223 |
+
)
|
| 224 |
+
if tokenizer.pad_token is None:
|
| 225 |
+
smart_tokenizer_and_embedding_resize(
|
| 226 |
+
special_tokens_dict=dict(pad_token=DEFAULT_PAD_TOKEN),
|
| 227 |
+
tokenizer=tokenizer,
|
| 228 |
+
model=model,
|
| 229 |
+
)
|
| 230 |
+
if "llama" in model_args.model_name_or_path:
|
| 231 |
+
tokenizer.add_special_tokens(
|
| 232 |
+
{
|
| 233 |
+
"eos_token": DEFAULT_EOS_TOKEN,
|
| 234 |
+
"bos_token": DEFAULT_BOS_TOKEN,
|
| 235 |
+
"unk_token": DEFAULT_UNK_TOKEN,
|
| 236 |
+
}
|
| 237 |
+
)
|
| 238 |
+
|
| 239 |
+
data_module = make_supervised_data_module(tokenizer=tokenizer, data_args=data_args)
|
| 240 |
+
trainer = Trainer(model=model, tokenizer=tokenizer, args=training_args, **data_module)
|
| 241 |
+
trainer.train()
|
| 242 |
+
trainer.save_state()
|
| 243 |
+
safe_save_model_for_hf_trainer(trainer=trainer, output_dir=training_args.output_dir)
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
if __name__ == "__main__":
|
| 247 |
+
train()
|
train_model.sh
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
torchrun --nproc_per_node=1 --master_port=9292 train.py \
|
| 4 |
+
--tokenizer_name_or_path /src/weights/tokenizer \
|
| 5 |
+
--data_path ./alpaca_data.json \
|
| 6 |
+
--model_name_or_path /src/weights/llama-7b \
|
| 7 |
+
--bf16 True \
|
| 8 |
+
--output_dir alpaca_out \
|
| 9 |
+
--num_train_epochs 3 \
|
| 10 |
+
--per_device_train_batch_size 4 \
|
| 11 |
+
--per_device_eval_batch_size 4 \
|
| 12 |
+
--gradient_accumulation_steps 8 \
|
| 13 |
+
--evaluation_strategy "no" \
|
| 14 |
+
--save_strategy "steps" \
|
| 15 |
+
--save_steps 2000 \
|
| 16 |
+
--learning_rate 2e-5 \
|
| 17 |
+
--weight_decay 0. \
|
| 18 |
+
--warmup_ratio 0.03 \
|
| 19 |
+
--lr_scheduler_type "cosine" \
|
| 20 |
+
--logging_steps 1 \
|
| 21 |
+
--fsdp "full_shard auto_wrap" \
|
| 22 |
+
--fsdp_transformer_layer_cls_to_wrap 'LLaMADecoderLayer' \
|
| 23 |
+
--tf32 True \
|
unconverted-weights/7B/.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
open_llama_7b_preview_300bt_easylm filter=lfs diff=lfs merge=lfs -text
|
unconverted-weights/7B/LICENSE.txt
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
unconverted-weights/7B/README.md
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
datasets:
|
| 4 |
+
- togethercomputer/RedPajama-Data-1T
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
# OpenLLaMA: An Open Reproduction of LLaMA
|
| 9 |
+
|
| 10 |
+
In this repo, we release a permissively licensed open source reproduction of Meta AI's [LLaMA](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/) large language model. In this release, we're releasing a public preview of the 7B OpenLLaMA model that has been trained with 200 billion tokens. We provide PyTorch and Jax weights of pre-trained OpenLLaMA models, as well as evaluation results and comparison against the original LLaMA models. Stay tuned for our updates.
|
| 11 |
+
|
| 12 |
+
**JAX and PyTorch Weights on Huggingface Hub**
|
| 13 |
+
- [200B Checkpoint](https://huggingface.co/openlm-research/open_llama_7b_preview_200bt)
|
| 14 |
+
- [300B Checkpoint](https://huggingface.co/openlm-research/open_llama_7b_preview_300bt)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
## Update 5/3/2023
|
| 18 |
+
We have released a new checkpoint of OpenLLaMA 7B trained on 300B tokens. In communicating
|
| 19 |
+
with our users, we have realized that many existing implementations of LLaMA does not
|
| 20 |
+
prepend the BOS token (id=1) at generation time. Our 200B checkpoint is sensitive
|
| 21 |
+
to this and may produce degraded results without BOS token at the beginning. Hence,
|
| 22 |
+
we recommend always prepending the BOS token when using our 200B checkpoint.
|
| 23 |
+
|
| 24 |
+
In an effort to make our model boradly compatible with existing implementations, we have now
|
| 25 |
+
released a new 300B checkpoint, which is less sensitive to BOS token and can be used
|
| 26 |
+
either way.
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
## Dataset and Training
|
| 30 |
+
|
| 31 |
+
We train our models on the [RedPajama](https://www.together.xyz/blog/redpajama) dataset released by [Together](https://www.together.xyz/), which is a reproduction of the LLaMA training dataset containing over 1.2 trillion tokens. We follow the exactly same preprocessing steps and training hyperparameters as the original LLaMA paper, including model architecture, context length, training steps, learning rate schedule, and optimizer. The only difference between our setting and the original one is the dataset used: OpenLLaMA employs the RedPajama dataset rather than the one utilized by the original LLaMA.
|
| 32 |
+
|
| 33 |
+
We train the models on cloud TPU-v4s using [EasyLM](https://github.com/young-geng/EasyLM), a JAX based training pipeline we developed for training and fine-tuning language model. We employ a combination of normal data parallelism and [fully sharded data parallelism (also know as ZeRO stage 3)](https://engineering.fb.com/2021/07/15/open-source/fsdp/) to balance the training throughput and memory usage. Overall we reach a throughput of over 1900 tokens / second / TPU-v4 chip in our training run.
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
## Evaluation
|
| 37 |
+
|
| 38 |
+
We evaluated OpenLLaMA on a wide range of tasks using [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness). The LLaMA results are generated by running the original LLaMA model on the same evaluation metrics. We note that our results for the LLaMA model differ slightly from the original LLaMA paper, which we believe is a result of different evaluation protocols. Similar differences have been reported in [this issue of lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness/issues/443). Additionally, we present the results of GPT-J, a 6B parameter model trained on the [Pile](https://pile.eleuther.ai/) dataset by [EleutherAI](https://www.eleuther.ai/).
|
| 39 |
+
|
| 40 |
+
The original LLaMA model was trained for 1 trillion tokens and GPT-J was trained for 500 billion tokens, whereas OpenLLaMA was trained on 200 billion tokens. We present the results in the table below. OpenLLaMA exhibits comparable performance to the original LLaMA and GPT-J across a majority of tasks, and outperforms them in some tasks. We expect that the performance of OpenLLaMA, after completing its training on 1 trillion tokens, will be enhanced even further.
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
| **Task/Metric** | **GPT-J 6B** | **LLaMA 7B** | **Open LLaMA 7B Preview 200B Tokens** |
|
| 44 |
+
| ---------------------- | ------------ | ------------ | ------------------------------------- |
|
| 45 |
+
| anli_r1/acc | 0.32 | 0.35 | 0.34 |
|
| 46 |
+
| anli_r2/acc | 0.34 | 0.34 | 0.35 |
|
| 47 |
+
| anli_r3/acc | 0.35 | 0.37 | 0.34 |
|
| 48 |
+
| arc_challenge/acc | 0.34 | 0.39 | 0.31 |
|
| 49 |
+
| arc_challenge/acc_norm | 0.37 | 0.41 | 0.34 |
|
| 50 |
+
| arc_easy/acc | 0.67 | 0.68 | 0.66 |
|
| 51 |
+
| arc_easy/acc_norm | 0.62 | 0.52 | 0.59 |
|
| 52 |
+
| boolq/acc | 0.66 | 0.75 | 0.67 |
|
| 53 |
+
| cb/acc | 0.36 | 0.36 | 0.38 |
|
| 54 |
+
| cb/f1 | 0.26 | 0.24 | 0.29 |
|
| 55 |
+
| hellaswag/acc | 0.50 | 0.56 | 0.47 |
|
| 56 |
+
| hellaswag/acc_norm | 0.66 | 0.73 | 0.63 |
|
| 57 |
+
| openbookqa/acc | 0.29 | 0.29 | 0.26 |
|
| 58 |
+
| openbookqa/acc_norm | 0.38 | 0.41 | 0.37 |
|
| 59 |
+
| piqa/acc | 0.75 | 0.78 | 0.74 |
|
| 60 |
+
| piqa/acc_norm | 0.76 | 0.78 | 0.74 |
|
| 61 |
+
| record/em | 0.88 | 0.91 | 0.87 |
|
| 62 |
+
| record/f1 | 0.89 | 0.91 | 0.88 |
|
| 63 |
+
| rte/acc | 0.54 | 0.56 | 0.53 |
|
| 64 |
+
| truthfulqa_mc/mc1 | 0.20 | 0.21 | 0.21 |
|
| 65 |
+
| truthfulqa_mc/mc2 | 0.36 | 0.34 | 0.34 |
|
| 66 |
+
| wic/acc | 0.50 | 0.50 | 0.50 |
|
| 67 |
+
| winogrande/acc | 0.64 | 0.68 | 0.62 |
|
| 68 |
+
| wsc/acc | 0.37 | 0.35 | 0.57 |
|
| 69 |
+
| Average | 0.50 | 0.52 | 0.50 |
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
## Preview Weights Release and Usage
|
| 75 |
+
|
| 76 |
+
To encourage the feedback from the community, we release a preview checkpoint of our weights. The checkpoint can be downloaded from [HuggingFace Hub](https://huggingface.co/openlm-research/open_llama_7b_preview_200bt). We release the weights in two formats: an EasyLM format to be use with our [EasyLM framework](https://github.com/young-geng/EasyLM), and a PyTorch format to be used with the [Huggingface Transformers](https://huggingface.co/docs/transformers/index) library.
|
| 77 |
+
|
| 78 |
+
For using the weights in our EasyLM framework, please refer to the [LLaMA documentation of EasyLM](https://github.com/young-geng/EasyLM/blob/main/docs/llama.md). Note that unlike the original LLaMA model, our OpenLLaMA tokenizer and weights are trained completely from scratch so it is no longer needed to obtain the original LLaMA tokenizer and weights. For using the weights in the transformers library, please follow the [transformers LLaMA documentation](https://huggingface.co/docs/transformers/main/model_doc/llama). Note that we use BOS (beginning of sentence) token (id=1) during training, so it is important to prepend this token for best performance during few-shot evaluation.
|
| 79 |
+
|
| 80 |
+
Both our training framework EasyLM and the preview checkpoint weights are licensed permissively under the Apache 2.0 license.
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
## Future Plans
|
| 84 |
+
|
| 85 |
+
The current release is only a preview of what the complete OpenLLaMA release will offer. We are currently focused on completing the training process on the entire RedPajama dataset. This can gives us a good apple-to-apple comparison between the original LLaMA and our OpenLLaMA. Other than the 7B model, we are also training a smaller 3B model in hope of facilitating language model usage in low resource use cases. Please stay tuned for our upcoming releases.
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
## Contact
|
| 90 |
+
|
| 91 |
+
We would love to get feedback from the community. If you have any questions, please open an issue or contact us.
|
| 92 |
+
|
| 93 |
+
OpenLLaMA is developed by:
|
| 94 |
+
[Xinyang Geng](https://young-geng.xyz/)* and [Hao Liu](https://www.haoliu.site/)* from Berkeley AI Research.
|
| 95 |
+
*Equal Contribution
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
## Reference
|
| 99 |
+
|
| 100 |
+
If you found OpenLLaMA useful in your research or applications, please cite using the following BibTeX:
|
| 101 |
+
```
|
| 102 |
+
@software{openlm2023openllama,
|
| 103 |
+
author = {Geng, Xinyang and Liu, Hao},
|
| 104 |
+
title = {OpenLLaMA: An Open Reproduction of LLaMA},
|
| 105 |
+
month = May,
|
| 106 |
+
year = 2023,
|
| 107 |
+
url = {https://github.com/openlm-research/open_llama}
|
| 108 |
+
}
|
| 109 |
+
```
|
| 110 |
+
```
|
| 111 |
+
@software{together2023redpajama,
|
| 112 |
+
author = {Together Computer},
|
| 113 |
+
title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
|
| 114 |
+
month = April,
|
| 115 |
+
year = 2023,
|
| 116 |
+
url = {https://github.com/togethercomputer/RedPajama-Data}
|
| 117 |
+
}
|
| 118 |
+
```
|
| 119 |
+
```
|
| 120 |
+
@article{touvron2023llama,
|
| 121 |
+
title={Llama: Open and efficient foundation language models},
|
| 122 |
+
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{\'e}e and Rozi{\`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
|
| 123 |
+
journal={arXiv preprint arXiv:2302.13971},
|
| 124 |
+
year={2023}
|
| 125 |
+
}
|
| 126 |
+
```
|
unconverted-weights/7B/checklist.chk
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
6efc8dab194ab59e49cd24be5574d85e consolidated.00.pth
|
| 2 |
+
7596560e011154b90eb51a1b15739763 params.json
|
unconverted-weights/7B/config.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"LlamaForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"bos_token_id": 1,
|
| 6 |
+
"eos_token_id": 2,
|
| 7 |
+
"hidden_act": "silu",
|
| 8 |
+
"hidden_size": 4096,
|
| 9 |
+
"initializer_range": 0.02,
|
| 10 |
+
"intermediate_size": 11008,
|
| 11 |
+
"max_position_embeddings": 2048,
|
| 12 |
+
"model_type": "llama",
|
| 13 |
+
"num_attention_heads": 32,
|
| 14 |
+
"num_hidden_layers": 32,
|
| 15 |
+
"pad_token_id": 0,
|
| 16 |
+
"rms_norm_eps": 1e-06,
|
| 17 |
+
"tie_word_embeddings": false,
|
| 18 |
+
"torch_dtype": "float16",
|
| 19 |
+
"transformers_version": "4.28.0.dev0",
|
| 20 |
+
"use_cache": true,
|
| 21 |
+
"vocab_size": 32000
|
| 22 |
+
}
|
unconverted-weights/7B/consolidated.00.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:700df0d3013b703a806d2ae7f1bfb8e59814e3d06ae78be0c66368a50059f33d
|
| 3 |
+
size 13476939516
|
unconverted-weights/7B/generation_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"pad_token_id": 0,
|
| 6 |
+
"transformers_version": "4.28.0.dev0"
|
| 7 |
+
}
|
unconverted-weights/7B/open_llama_7b_preview_300bt_easylm
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:63ab9d652aaf4e0e47f1d9a0321ef565b62c02921ce0b18a781ba0daac2ebb98
|
| 3 |
+
size 13476851687
|
unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/config.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"LlamaForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"bos_token_id": 1,
|
| 6 |
+
"eos_token_id": 2,
|
| 7 |
+
"hidden_act": "silu",
|
| 8 |
+
"hidden_size": 4096,
|
| 9 |
+
"initializer_range": 0.02,
|
| 10 |
+
"intermediate_size": 11008,
|
| 11 |
+
"max_position_embeddings": 2048,
|
| 12 |
+
"model_type": "llama",
|
| 13 |
+
"num_attention_heads": 32,
|
| 14 |
+
"num_hidden_layers": 32,
|
| 15 |
+
"pad_token_id": 0,
|
| 16 |
+
"rms_norm_eps": 1e-06,
|
| 17 |
+
"tie_word_embeddings": false,
|
| 18 |
+
"torch_dtype": "float16",
|
| 19 |
+
"transformers_version": "4.28.0.dev0",
|
| 20 |
+
"use_cache": true,
|
| 21 |
+
"vocab_size": 32000
|
| 22 |
+
}
|
unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/generation_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"pad_token_id": 0,
|
| 6 |
+
"transformers_version": "4.28.0.dev0"
|
| 7 |
+
}
|
unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00001-of-00002.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:adce75e45dbad20967c0e96a83b318720a767e4b8f77aabcd01cd2b38e8f0b2e
|
| 3 |
+
size 9976634558
|
unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00002-of-00002.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a80d748a6ab528f0db2249013a5d3fea17e039ad9fa1bf3e170e9070ec30f938
|
| 3 |
+
size 3500315539
|
unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model.bin.index.json
ADDED
|
@@ -0,0 +1,330 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 13476839424
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "pytorch_model-00002-of-00002.bin",
|
| 7 |
+
"model.embed_tokens.weight": "pytorch_model-00001-of-00002.bin",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 14 |
+
"model.layers.0.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 15 |
+
"model.layers.0.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 16 |
+
"model.layers.0.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 17 |
+
"model.layers.0.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 18 |
+
"model.layers.1.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 19 |
+
"model.layers.1.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 20 |
+
"model.layers.1.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 21 |
+
"model.layers.1.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 22 |
+
"model.layers.1.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 23 |
+
"model.layers.1.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 24 |
+
"model.layers.1.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 25 |
+
"model.layers.1.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 26 |
+
"model.layers.1.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 27 |
+
"model.layers.1.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 28 |
+
"model.layers.10.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 29 |
+
"model.layers.10.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 30 |
+
"model.layers.10.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 31 |
+
"model.layers.10.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 32 |
+
"model.layers.10.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 33 |
+
"model.layers.10.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 34 |
+
"model.layers.10.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 35 |
+
"model.layers.10.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 36 |
+
"model.layers.10.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 37 |
+
"model.layers.10.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 38 |
+
"model.layers.11.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 39 |
+
"model.layers.11.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 40 |
+
"model.layers.11.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 41 |
+
"model.layers.11.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 42 |
+
"model.layers.11.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 43 |
+
"model.layers.11.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 44 |
+
"model.layers.11.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 45 |
+
"model.layers.11.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 46 |
+
"model.layers.11.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 47 |
+
"model.layers.11.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 48 |
+
"model.layers.12.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 49 |
+
"model.layers.12.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 50 |
+
"model.layers.12.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 51 |
+
"model.layers.12.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 52 |
+
"model.layers.12.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 53 |
+
"model.layers.12.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 54 |
+
"model.layers.12.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 55 |
+
"model.layers.12.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 56 |
+
"model.layers.12.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 57 |
+
"model.layers.12.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 58 |
+
"model.layers.13.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 59 |
+
"model.layers.13.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 60 |
+
"model.layers.13.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 61 |
+
"model.layers.13.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 62 |
+
"model.layers.13.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 63 |
+
"model.layers.13.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 64 |
+
"model.layers.13.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 65 |
+
"model.layers.13.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 66 |
+
"model.layers.13.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 67 |
+
"model.layers.13.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 68 |
+
"model.layers.14.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 69 |
+
"model.layers.14.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 70 |
+
"model.layers.14.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 71 |
+
"model.layers.14.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 72 |
+
"model.layers.14.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 73 |
+
"model.layers.14.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 74 |
+
"model.layers.14.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 75 |
+
"model.layers.14.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 76 |
+
"model.layers.14.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 77 |
+
"model.layers.14.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 78 |
+
"model.layers.15.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 79 |
+
"model.layers.15.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 80 |
+
"model.layers.15.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 81 |
+
"model.layers.15.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 82 |
+
"model.layers.15.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 83 |
+
"model.layers.15.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 84 |
+
"model.layers.15.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 85 |
+
"model.layers.15.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 86 |
+
"model.layers.15.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 87 |
+
"model.layers.15.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 88 |
+
"model.layers.16.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 89 |
+
"model.layers.16.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 90 |
+
"model.layers.16.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 91 |
+
"model.layers.16.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 92 |
+
"model.layers.16.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 93 |
+
"model.layers.16.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 94 |
+
"model.layers.16.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 95 |
+
"model.layers.16.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 96 |
+
"model.layers.16.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 97 |
+
"model.layers.16.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 98 |
+
"model.layers.17.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 99 |
+
"model.layers.17.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 100 |
+
"model.layers.17.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 101 |
+
"model.layers.17.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 102 |
+
"model.layers.17.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 103 |
+
"model.layers.17.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 104 |
+
"model.layers.17.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 105 |
+
"model.layers.17.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 106 |
+
"model.layers.17.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 107 |
+
"model.layers.17.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 108 |
+
"model.layers.18.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 109 |
+
"model.layers.18.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 110 |
+
"model.layers.18.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 111 |
+
"model.layers.18.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 112 |
+
"model.layers.18.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 113 |
+
"model.layers.18.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 114 |
+
"model.layers.18.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 115 |
+
"model.layers.18.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 116 |
+
"model.layers.18.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 117 |
+
"model.layers.18.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 118 |
+
"model.layers.19.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 119 |
+
"model.layers.19.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 120 |
+
"model.layers.19.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 121 |
+
"model.layers.19.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 122 |
+
"model.layers.19.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 123 |
+
"model.layers.19.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 124 |
+
"model.layers.19.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 125 |
+
"model.layers.19.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 126 |
+
"model.layers.19.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 127 |
+
"model.layers.19.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 128 |
+
"model.layers.2.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 129 |
+
"model.layers.2.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 130 |
+
"model.layers.2.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 131 |
+
"model.layers.2.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 132 |
+
"model.layers.2.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 133 |
+
"model.layers.2.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 134 |
+
"model.layers.2.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 135 |
+
"model.layers.2.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 136 |
+
"model.layers.2.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 137 |
+
"model.layers.2.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 138 |
+
"model.layers.20.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 139 |
+
"model.layers.20.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 140 |
+
"model.layers.20.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 141 |
+
"model.layers.20.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 142 |
+
"model.layers.20.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 143 |
+
"model.layers.20.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 144 |
+
"model.layers.20.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 145 |
+
"model.layers.20.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 146 |
+
"model.layers.20.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 147 |
+
"model.layers.20.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 148 |
+
"model.layers.21.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 149 |
+
"model.layers.21.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 150 |
+
"model.layers.21.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 151 |
+
"model.layers.21.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 152 |
+
"model.layers.21.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 153 |
+
"model.layers.21.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 154 |
+
"model.layers.21.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 155 |
+
"model.layers.21.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 156 |
+
"model.layers.21.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 157 |
+
"model.layers.21.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 158 |
+
"model.layers.22.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 159 |
+
"model.layers.22.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 160 |
+
"model.layers.22.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 161 |
+
"model.layers.22.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 162 |
+
"model.layers.22.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 163 |
+
"model.layers.22.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 164 |
+
"model.layers.22.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 165 |
+
"model.layers.22.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 166 |
+
"model.layers.22.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 167 |
+
"model.layers.22.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 168 |
+
"model.layers.23.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 169 |
+
"model.layers.23.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 170 |
+
"model.layers.23.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 171 |
+
"model.layers.23.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 172 |
+
"model.layers.23.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 173 |
+
"model.layers.23.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 174 |
+
"model.layers.23.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 175 |
+
"model.layers.23.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 176 |
+
"model.layers.23.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 177 |
+
"model.layers.23.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 178 |
+
"model.layers.24.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 179 |
+
"model.layers.24.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 180 |
+
"model.layers.24.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 181 |
+
"model.layers.24.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 182 |
+
"model.layers.24.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 183 |
+
"model.layers.24.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 184 |
+
"model.layers.24.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 185 |
+
"model.layers.24.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 186 |
+
"model.layers.24.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 187 |
+
"model.layers.24.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 188 |
+
"model.layers.25.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 189 |
+
"model.layers.25.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 190 |
+
"model.layers.25.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 191 |
+
"model.layers.25.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 192 |
+
"model.layers.25.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 193 |
+
"model.layers.25.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 194 |
+
"model.layers.25.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 195 |
+
"model.layers.25.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 196 |
+
"model.layers.25.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 197 |
+
"model.layers.25.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 198 |
+
"model.layers.26.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 199 |
+
"model.layers.26.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 200 |
+
"model.layers.26.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 201 |
+
"model.layers.26.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 202 |
+
"model.layers.26.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 203 |
+
"model.layers.26.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 204 |
+
"model.layers.26.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 205 |
+
"model.layers.26.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 206 |
+
"model.layers.26.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 207 |
+
"model.layers.26.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 208 |
+
"model.layers.27.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 209 |
+
"model.layers.27.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 210 |
+
"model.layers.27.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 211 |
+
"model.layers.27.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 212 |
+
"model.layers.27.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 213 |
+
"model.layers.27.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 214 |
+
"model.layers.27.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 215 |
+
"model.layers.27.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 216 |
+
"model.layers.27.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 217 |
+
"model.layers.27.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 218 |
+
"model.layers.28.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 219 |
+
"model.layers.28.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 220 |
+
"model.layers.28.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 221 |
+
"model.layers.28.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 222 |
+
"model.layers.28.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 223 |
+
"model.layers.28.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 224 |
+
"model.layers.28.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 225 |
+
"model.layers.28.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 226 |
+
"model.layers.28.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 227 |
+
"model.layers.28.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 228 |
+
"model.layers.29.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 229 |
+
"model.layers.29.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 230 |
+
"model.layers.29.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 231 |
+
"model.layers.29.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 232 |
+
"model.layers.29.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 233 |
+
"model.layers.29.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 234 |
+
"model.layers.29.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 235 |
+
"model.layers.29.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 236 |
+
"model.layers.29.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 237 |
+
"model.layers.29.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 238 |
+
"model.layers.3.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 239 |
+
"model.layers.3.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 240 |
+
"model.layers.3.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 241 |
+
"model.layers.3.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 242 |
+
"model.layers.3.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 243 |
+
"model.layers.3.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 244 |
+
"model.layers.3.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 245 |
+
"model.layers.3.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 246 |
+
"model.layers.3.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 247 |
+
"model.layers.3.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 248 |
+
"model.layers.30.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 249 |
+
"model.layers.30.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 250 |
+
"model.layers.30.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 251 |
+
"model.layers.30.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 252 |
+
"model.layers.30.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 253 |
+
"model.layers.30.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 254 |
+
"model.layers.30.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 255 |
+
"model.layers.30.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 256 |
+
"model.layers.30.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 257 |
+
"model.layers.30.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 258 |
+
"model.layers.31.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 259 |
+
"model.layers.31.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 260 |
+
"model.layers.31.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 261 |
+
"model.layers.31.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 262 |
+
"model.layers.31.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 263 |
+
"model.layers.31.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 264 |
+
"model.layers.31.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 265 |
+
"model.layers.31.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 266 |
+
"model.layers.31.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 267 |
+
"model.layers.31.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 268 |
+
"model.layers.4.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 269 |
+
"model.layers.4.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 270 |
+
"model.layers.4.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 271 |
+
"model.layers.4.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 272 |
+
"model.layers.4.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 273 |
+
"model.layers.4.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 274 |
+
"model.layers.4.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 275 |
+
"model.layers.4.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 276 |
+
"model.layers.4.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 277 |
+
"model.layers.4.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 278 |
+
"model.layers.5.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 279 |
+
"model.layers.5.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 280 |
+
"model.layers.5.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 281 |
+
"model.layers.5.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 282 |
+
"model.layers.5.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 283 |
+
"model.layers.5.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 284 |
+
"model.layers.5.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 285 |
+
"model.layers.5.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 286 |
+
"model.layers.5.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 287 |
+
"model.layers.5.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 288 |
+
"model.layers.6.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 289 |
+
"model.layers.6.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 290 |
+
"model.layers.6.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 291 |
+
"model.layers.6.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 292 |
+
"model.layers.6.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 293 |
+
"model.layers.6.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 294 |
+
"model.layers.6.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 295 |
+
"model.layers.6.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 296 |
+
"model.layers.6.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 297 |
+
"model.layers.6.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 298 |
+
"model.layers.7.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 299 |
+
"model.layers.7.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 300 |
+
"model.layers.7.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 301 |
+
"model.layers.7.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 302 |
+
"model.layers.7.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 303 |
+
"model.layers.7.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 304 |
+
"model.layers.7.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 305 |
+
"model.layers.7.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 306 |
+
"model.layers.7.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 307 |
+
"model.layers.7.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 308 |
+
"model.layers.8.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 309 |
+
"model.layers.8.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 310 |
+
"model.layers.8.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 311 |
+
"model.layers.8.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 312 |
+
"model.layers.8.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 313 |
+
"model.layers.8.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 314 |
+
"model.layers.8.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 315 |
+
"model.layers.8.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 316 |
+
"model.layers.8.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 317 |
+
"model.layers.8.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 318 |
+
"model.layers.9.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 319 |
+
"model.layers.9.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 320 |
+
"model.layers.9.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 321 |
+
"model.layers.9.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 322 |
+
"model.layers.9.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 323 |
+
"model.layers.9.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 324 |
+
"model.layers.9.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 325 |
+
"model.layers.9.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 326 |
+
"model.layers.9.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 327 |
+
"model.layers.9.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 328 |
+
"model.norm.weight": "pytorch_model-00002-of-00002.bin"
|
| 329 |
+
}
|
| 330 |
+
}
|
unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/special_tokens_map.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{}
|
unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bc820fc43f4173d6362c16658c409ed423929a807e55a984af96cce1277d39a4
|
| 3 |
+
size 772031
|
unconverted-weights/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"bos_token": "", "eos_token": "", "model_max_length": 1000000000000000019884624838656, "tokenizer_class": "LlamaTokenizer", "unk_token": ""}
|
unconverted-weights/7B/params.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"dim": 4096, "multiple_of": 256, "n_heads": 32, "n_layers": 32, "norm_eps": 1e-06, "vocab_size": -1}
|
unconverted-weights/7B/pytorch_model-00001-of-00002.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:adce75e45dbad20967c0e96a83b318720a767e4b8f77aabcd01cd2b38e8f0b2e
|
| 3 |
+
size 9976634558
|
unconverted-weights/7B/pytorch_model-00002-of-00002.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a80d748a6ab528f0db2249013a5d3fea17e039ad9fa1bf3e170e9070ec30f938
|
| 3 |
+
size 3500315539
|
unconverted-weights/7B/pytorch_model.bin.index.json
ADDED
|
@@ -0,0 +1,330 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 13476839424
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "pytorch_model-00002-of-00002.bin",
|
| 7 |
+
"model.embed_tokens.weight": "pytorch_model-00001-of-00002.bin",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 14 |
+
"model.layers.0.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 15 |
+
"model.layers.0.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 16 |
+
"model.layers.0.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 17 |
+
"model.layers.0.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 18 |
+
"model.layers.1.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 19 |
+
"model.layers.1.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 20 |
+
"model.layers.1.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 21 |
+
"model.layers.1.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 22 |
+
"model.layers.1.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 23 |
+
"model.layers.1.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 24 |
+
"model.layers.1.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 25 |
+
"model.layers.1.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 26 |
+
"model.layers.1.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 27 |
+
"model.layers.1.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 28 |
+
"model.layers.10.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 29 |
+
"model.layers.10.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 30 |
+
"model.layers.10.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 31 |
+
"model.layers.10.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 32 |
+
"model.layers.10.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 33 |
+
"model.layers.10.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 34 |
+
"model.layers.10.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 35 |
+
"model.layers.10.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 36 |
+
"model.layers.10.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 37 |
+
"model.layers.10.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 38 |
+
"model.layers.11.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 39 |
+
"model.layers.11.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 40 |
+
"model.layers.11.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 41 |
+
"model.layers.11.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 42 |
+
"model.layers.11.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 43 |
+
"model.layers.11.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 44 |
+
"model.layers.11.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 45 |
+
"model.layers.11.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 46 |
+
"model.layers.11.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 47 |
+
"model.layers.11.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 48 |
+
"model.layers.12.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 49 |
+
"model.layers.12.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 50 |
+
"model.layers.12.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 51 |
+
"model.layers.12.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 52 |
+
"model.layers.12.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 53 |
+
"model.layers.12.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 54 |
+
"model.layers.12.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 55 |
+
"model.layers.12.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 56 |
+
"model.layers.12.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 57 |
+
"model.layers.12.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 58 |
+
"model.layers.13.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 59 |
+
"model.layers.13.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 60 |
+
"model.layers.13.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 61 |
+
"model.layers.13.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 62 |
+
"model.layers.13.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 63 |
+
"model.layers.13.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 64 |
+
"model.layers.13.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 65 |
+
"model.layers.13.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 66 |
+
"model.layers.13.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 67 |
+
"model.layers.13.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 68 |
+
"model.layers.14.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 69 |
+
"model.layers.14.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 70 |
+
"model.layers.14.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 71 |
+
"model.layers.14.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 72 |
+
"model.layers.14.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 73 |
+
"model.layers.14.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 74 |
+
"model.layers.14.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 75 |
+
"model.layers.14.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 76 |
+
"model.layers.14.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 77 |
+
"model.layers.14.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 78 |
+
"model.layers.15.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 79 |
+
"model.layers.15.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 80 |
+
"model.layers.15.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 81 |
+
"model.layers.15.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 82 |
+
"model.layers.15.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 83 |
+
"model.layers.15.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 84 |
+
"model.layers.15.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 85 |
+
"model.layers.15.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 86 |
+
"model.layers.15.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 87 |
+
"model.layers.15.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 88 |
+
"model.layers.16.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 89 |
+
"model.layers.16.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 90 |
+
"model.layers.16.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 91 |
+
"model.layers.16.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 92 |
+
"model.layers.16.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 93 |
+
"model.layers.16.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 94 |
+
"model.layers.16.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 95 |
+
"model.layers.16.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 96 |
+
"model.layers.16.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 97 |
+
"model.layers.16.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 98 |
+
"model.layers.17.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 99 |
+
"model.layers.17.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 100 |
+
"model.layers.17.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 101 |
+
"model.layers.17.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 102 |
+
"model.layers.17.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 103 |
+
"model.layers.17.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 104 |
+
"model.layers.17.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 105 |
+
"model.layers.17.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 106 |
+
"model.layers.17.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 107 |
+
"model.layers.17.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 108 |
+
"model.layers.18.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 109 |
+
"model.layers.18.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 110 |
+
"model.layers.18.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 111 |
+
"model.layers.18.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 112 |
+
"model.layers.18.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 113 |
+
"model.layers.18.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 114 |
+
"model.layers.18.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 115 |
+
"model.layers.18.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 116 |
+
"model.layers.18.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 117 |
+
"model.layers.18.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 118 |
+
"model.layers.19.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 119 |
+
"model.layers.19.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 120 |
+
"model.layers.19.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 121 |
+
"model.layers.19.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 122 |
+
"model.layers.19.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 123 |
+
"model.layers.19.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 124 |
+
"model.layers.19.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 125 |
+
"model.layers.19.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 126 |
+
"model.layers.19.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 127 |
+
"model.layers.19.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 128 |
+
"model.layers.2.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 129 |
+
"model.layers.2.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 130 |
+
"model.layers.2.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 131 |
+
"model.layers.2.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 132 |
+
"model.layers.2.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 133 |
+
"model.layers.2.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 134 |
+
"model.layers.2.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 135 |
+
"model.layers.2.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 136 |
+
"model.layers.2.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 137 |
+
"model.layers.2.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 138 |
+
"model.layers.20.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 139 |
+
"model.layers.20.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 140 |
+
"model.layers.20.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 141 |
+
"model.layers.20.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 142 |
+
"model.layers.20.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 143 |
+
"model.layers.20.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 144 |
+
"model.layers.20.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 145 |
+
"model.layers.20.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 146 |
+
"model.layers.20.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 147 |
+
"model.layers.20.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 148 |
+
"model.layers.21.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 149 |
+
"model.layers.21.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 150 |
+
"model.layers.21.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 151 |
+
"model.layers.21.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 152 |
+
"model.layers.21.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 153 |
+
"model.layers.21.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 154 |
+
"model.layers.21.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 155 |
+
"model.layers.21.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 156 |
+
"model.layers.21.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 157 |
+
"model.layers.21.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 158 |
+
"model.layers.22.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 159 |
+
"model.layers.22.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 160 |
+
"model.layers.22.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 161 |
+
"model.layers.22.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 162 |
+
"model.layers.22.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 163 |
+
"model.layers.22.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 164 |
+
"model.layers.22.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 165 |
+
"model.layers.22.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 166 |
+
"model.layers.22.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 167 |
+
"model.layers.22.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 168 |
+
"model.layers.23.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 169 |
+
"model.layers.23.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 170 |
+
"model.layers.23.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 171 |
+
"model.layers.23.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 172 |
+
"model.layers.23.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 173 |
+
"model.layers.23.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 174 |
+
"model.layers.23.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 175 |
+
"model.layers.23.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 176 |
+
"model.layers.23.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 177 |
+
"model.layers.23.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 178 |
+
"model.layers.24.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 179 |
+
"model.layers.24.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 180 |
+
"model.layers.24.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 181 |
+
"model.layers.24.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 182 |
+
"model.layers.24.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 183 |
+
"model.layers.24.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 184 |
+
"model.layers.24.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 185 |
+
"model.layers.24.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 186 |
+
"model.layers.24.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 187 |
+
"model.layers.24.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 188 |
+
"model.layers.25.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 189 |
+
"model.layers.25.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 190 |
+
"model.layers.25.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 191 |
+
"model.layers.25.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 192 |
+
"model.layers.25.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 193 |
+
"model.layers.25.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 194 |
+
"model.layers.25.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 195 |
+
"model.layers.25.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 196 |
+
"model.layers.25.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 197 |
+
"model.layers.25.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 198 |
+
"model.layers.26.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 199 |
+
"model.layers.26.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 200 |
+
"model.layers.26.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 201 |
+
"model.layers.26.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 202 |
+
"model.layers.26.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 203 |
+
"model.layers.26.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 204 |
+
"model.layers.26.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 205 |
+
"model.layers.26.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 206 |
+
"model.layers.26.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 207 |
+
"model.layers.26.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 208 |
+
"model.layers.27.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 209 |
+
"model.layers.27.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 210 |
+
"model.layers.27.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 211 |
+
"model.layers.27.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 212 |
+
"model.layers.27.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 213 |
+
"model.layers.27.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 214 |
+
"model.layers.27.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 215 |
+
"model.layers.27.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 216 |
+
"model.layers.27.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 217 |
+
"model.layers.27.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 218 |
+
"model.layers.28.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 219 |
+
"model.layers.28.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 220 |
+
"model.layers.28.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 221 |
+
"model.layers.28.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 222 |
+
"model.layers.28.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 223 |
+
"model.layers.28.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 224 |
+
"model.layers.28.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 225 |
+
"model.layers.28.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 226 |
+
"model.layers.28.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 227 |
+
"model.layers.28.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 228 |
+
"model.layers.29.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 229 |
+
"model.layers.29.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 230 |
+
"model.layers.29.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 231 |
+
"model.layers.29.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 232 |
+
"model.layers.29.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 233 |
+
"model.layers.29.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 234 |
+
"model.layers.29.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 235 |
+
"model.layers.29.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 236 |
+
"model.layers.29.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 237 |
+
"model.layers.29.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 238 |
+
"model.layers.3.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 239 |
+
"model.layers.3.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 240 |
+
"model.layers.3.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 241 |
+
"model.layers.3.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 242 |
+
"model.layers.3.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 243 |
+
"model.layers.3.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 244 |
+
"model.layers.3.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 245 |
+
"model.layers.3.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 246 |
+
"model.layers.3.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 247 |
+
"model.layers.3.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 248 |
+
"model.layers.30.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 249 |
+
"model.layers.30.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 250 |
+
"model.layers.30.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 251 |
+
"model.layers.30.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 252 |
+
"model.layers.30.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 253 |
+
"model.layers.30.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 254 |
+
"model.layers.30.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 255 |
+
"model.layers.30.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 256 |
+
"model.layers.30.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 257 |
+
"model.layers.30.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 258 |
+
"model.layers.31.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 259 |
+
"model.layers.31.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 260 |
+
"model.layers.31.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 261 |
+
"model.layers.31.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 262 |
+
"model.layers.31.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 263 |
+
"model.layers.31.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 264 |
+
"model.layers.31.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 265 |
+
"model.layers.31.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 266 |
+
"model.layers.31.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 267 |
+
"model.layers.31.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 268 |
+
"model.layers.4.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 269 |
+
"model.layers.4.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 270 |
+
"model.layers.4.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 271 |
+
"model.layers.4.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 272 |
+
"model.layers.4.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 273 |
+
"model.layers.4.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 274 |
+
"model.layers.4.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 275 |
+
"model.layers.4.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 276 |
+
"model.layers.4.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 277 |
+
"model.layers.4.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 278 |
+
"model.layers.5.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 279 |
+
"model.layers.5.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 280 |
+
"model.layers.5.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 281 |
+
"model.layers.5.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 282 |
+
"model.layers.5.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 283 |
+
"model.layers.5.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 284 |
+
"model.layers.5.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 285 |
+
"model.layers.5.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 286 |
+
"model.layers.5.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 287 |
+
"model.layers.5.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 288 |
+
"model.layers.6.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 289 |
+
"model.layers.6.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 290 |
+
"model.layers.6.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 291 |
+
"model.layers.6.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 292 |
+
"model.layers.6.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 293 |
+
"model.layers.6.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 294 |
+
"model.layers.6.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 295 |
+
"model.layers.6.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 296 |
+
"model.layers.6.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 297 |
+
"model.layers.6.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 298 |
+
"model.layers.7.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 299 |
+
"model.layers.7.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 300 |
+
"model.layers.7.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 301 |
+
"model.layers.7.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 302 |
+
"model.layers.7.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 303 |
+
"model.layers.7.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 304 |
+
"model.layers.7.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 305 |
+
"model.layers.7.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 306 |
+
"model.layers.7.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 307 |
+
"model.layers.7.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 308 |
+
"model.layers.8.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 309 |
+
"model.layers.8.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 310 |
+
"model.layers.8.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 311 |
+
"model.layers.8.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 312 |
+
"model.layers.8.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 313 |
+
"model.layers.8.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 314 |
+
"model.layers.8.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 315 |
+
"model.layers.8.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 316 |
+
"model.layers.8.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 317 |
+
"model.layers.8.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 318 |
+
"model.layers.9.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 319 |
+
"model.layers.9.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 320 |
+
"model.layers.9.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 321 |
+
"model.layers.9.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 322 |
+
"model.layers.9.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 323 |
+
"model.layers.9.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 324 |
+
"model.layers.9.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 325 |
+
"model.layers.9.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 326 |
+
"model.layers.9.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 327 |
+
"model.layers.9.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 328 |
+
"model.norm.weight": "pytorch_model-00002-of-00002.bin"
|
| 329 |
+
}
|
| 330 |
+
}
|
unconverted-weights/7B/special_tokens_map.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{}
|
unconverted-weights/7B/tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bc820fc43f4173d6362c16658c409ed423929a807e55a984af96cce1277d39a4
|
| 3 |
+
size 772031
|
unconverted-weights/7B/tokenizer.vocab
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
unconverted-weights/7B/tokenizer_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"bos_token": "", "eos_token": "", "model_max_length": 1000000000000000019884624838656, "tokenizer_class": "LlamaTokenizer", "unk_token": ""}
|
unconverted-weights/tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e556afd44213b6bd1be2b850ebbbd98f5481437a8021afaf58ee7fb1818d347
|
| 3 |
+
size 499723
|
unconverted-weights/tokenizer_checklist.chk
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
eeec4125e9c7560836b4873b6f8e3025 tokenizer.model
|
utils.py
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import dataclasses
|
| 2 |
+
import logging
|
| 3 |
+
import math
|
| 4 |
+
import os
|
| 5 |
+
import io
|
| 6 |
+
import sys
|
| 7 |
+
import time
|
| 8 |
+
import json
|
| 9 |
+
from typing import Optional, Sequence, Union
|
| 10 |
+
|
| 11 |
+
import openai
|
| 12 |
+
import tqdm
|
| 13 |
+
from openai import openai_object
|
| 14 |
+
import copy
|
| 15 |
+
|
| 16 |
+
StrOrOpenAIObject = Union[str, openai_object.OpenAIObject]
|
| 17 |
+
|
| 18 |
+
openai_org = os.getenv("OPENAI_ORG")
|
| 19 |
+
if openai_org is not None:
|
| 20 |
+
openai.organization = openai_org
|
| 21 |
+
logging.warning(f"Switching to organization: {openai_org} for OAI API key.")
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
@dataclasses.dataclass
|
| 25 |
+
class OpenAIDecodingArguments(object):
|
| 26 |
+
max_tokens: int = 1800
|
| 27 |
+
temperature: float = 0.2
|
| 28 |
+
top_p: float = 1.0
|
| 29 |
+
n: int = 1
|
| 30 |
+
stream: bool = False
|
| 31 |
+
stop: Optional[Sequence[str]] = None
|
| 32 |
+
presence_penalty: float = 0.0
|
| 33 |
+
frequency_penalty: float = 0.0
|
| 34 |
+
suffix: Optional[str] = None
|
| 35 |
+
logprobs: Optional[int] = None
|
| 36 |
+
echo: bool = False
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def openai_completion(
|
| 40 |
+
prompts: Union[str, Sequence[str], Sequence[dict[str, str]], dict[str, str]],
|
| 41 |
+
decoding_args: OpenAIDecodingArguments,
|
| 42 |
+
model_name="text-davinci-003",
|
| 43 |
+
sleep_time=2,
|
| 44 |
+
batch_size=1,
|
| 45 |
+
max_instances=sys.maxsize,
|
| 46 |
+
max_batches=sys.maxsize,
|
| 47 |
+
return_text=False,
|
| 48 |
+
**decoding_kwargs,
|
| 49 |
+
) -> Union[Union[StrOrOpenAIObject], Sequence[StrOrOpenAIObject], Sequence[Sequence[StrOrOpenAIObject]],]:
|
| 50 |
+
"""Decode with OpenAI API.
|
| 51 |
+
|
| 52 |
+
Args:
|
| 53 |
+
prompts: A string or a list of strings to complete. If it is a chat model the strings should be formatted
|
| 54 |
+
as explained here: https://github.com/openai/openai-python/blob/main/chatml.md. If it is a chat model
|
| 55 |
+
it can also be a dictionary (or list thereof) as explained here:
|
| 56 |
+
https://github.com/openai/openai-cookbook/blob/main/examples/How_to_format_inputs_to_ChatGPT_models.ipynb
|
| 57 |
+
decoding_args: Decoding arguments.
|
| 58 |
+
model_name: Model name. Can be either in the format of "org/model" or just "model".
|
| 59 |
+
sleep_time: Time to sleep once the rate-limit is hit.
|
| 60 |
+
batch_size: Number of prompts to send in a single request. Only for non chat model.
|
| 61 |
+
max_instances: Maximum number of prompts to decode.
|
| 62 |
+
max_batches: Maximum number of batches to decode. This argument will be deprecated in the future.
|
| 63 |
+
return_text: If True, return text instead of full completion object (which contains things like logprob).
|
| 64 |
+
decoding_kwargs: Additional decoding arguments. Pass in `best_of` and `logit_bias` if you need them.
|
| 65 |
+
|
| 66 |
+
Returns:
|
| 67 |
+
A completion or a list of completions.
|
| 68 |
+
Depending on return_text, return_openai_object, and decoding_args.n, the completion type can be one of
|
| 69 |
+
- a string (if return_text is True)
|
| 70 |
+
- an openai_object.OpenAIObject object (if return_text is False)
|
| 71 |
+
- a list of objects of the above types (if decoding_args.n > 1)
|
| 72 |
+
"""
|
| 73 |
+
is_single_prompt = isinstance(prompts, (str, dict))
|
| 74 |
+
if is_single_prompt:
|
| 75 |
+
prompts = [prompts]
|
| 76 |
+
|
| 77 |
+
if max_batches < sys.maxsize:
|
| 78 |
+
logging.warning(
|
| 79 |
+
"`max_batches` will be deprecated in the future, please use `max_instances` instead."
|
| 80 |
+
"Setting `max_instances` to `max_batches * batch_size` for now."
|
| 81 |
+
)
|
| 82 |
+
max_instances = max_batches * batch_size
|
| 83 |
+
|
| 84 |
+
prompts = prompts[:max_instances]
|
| 85 |
+
num_prompts = len(prompts)
|
| 86 |
+
prompt_batches = [
|
| 87 |
+
prompts[batch_id * batch_size : (batch_id + 1) * batch_size]
|
| 88 |
+
for batch_id in range(int(math.ceil(num_prompts / batch_size)))
|
| 89 |
+
]
|
| 90 |
+
|
| 91 |
+
completions = []
|
| 92 |
+
for batch_id, prompt_batch in tqdm.tqdm(
|
| 93 |
+
enumerate(prompt_batches),
|
| 94 |
+
desc="prompt_batches",
|
| 95 |
+
total=len(prompt_batches),
|
| 96 |
+
):
|
| 97 |
+
batch_decoding_args = copy.deepcopy(decoding_args) # cloning the decoding_args
|
| 98 |
+
|
| 99 |
+
while True:
|
| 100 |
+
try:
|
| 101 |
+
shared_kwargs = dict(
|
| 102 |
+
model=model_name,
|
| 103 |
+
**batch_decoding_args.__dict__,
|
| 104 |
+
**decoding_kwargs,
|
| 105 |
+
)
|
| 106 |
+
completion_batch = openai.Completion.create(prompt=prompt_batch, **shared_kwargs)
|
| 107 |
+
choices = completion_batch.choices
|
| 108 |
+
|
| 109 |
+
for choice in choices:
|
| 110 |
+
choice["total_tokens"] = completion_batch.usage.total_tokens
|
| 111 |
+
completions.extend(choices)
|
| 112 |
+
break
|
| 113 |
+
except openai.error.OpenAIError as e:
|
| 114 |
+
logging.warning(f"OpenAIError: {e}.")
|
| 115 |
+
if "Please reduce your prompt" in str(e):
|
| 116 |
+
batch_decoding_args.max_tokens = int(batch_decoding_args.max_tokens * 0.8)
|
| 117 |
+
logging.warning(f"Reducing target length to {batch_decoding_args.max_tokens}, Retrying...")
|
| 118 |
+
else:
|
| 119 |
+
logging.warning("Hit request rate limit; retrying...")
|
| 120 |
+
time.sleep(sleep_time) # Annoying rate limit on requests.
|
| 121 |
+
|
| 122 |
+
if return_text:
|
| 123 |
+
completions = [completion.text for completion in completions]
|
| 124 |
+
if decoding_args.n > 1:
|
| 125 |
+
# make completions a nested list, where each entry is a consecutive decoding_args.n of original entries.
|
| 126 |
+
completions = [completions[i : i + decoding_args.n] for i in range(0, len(completions), decoding_args.n)]
|
| 127 |
+
if is_single_prompt:
|
| 128 |
+
# Return non-tuple if only 1 input and 1 generation.
|
| 129 |
+
(completions,) = completions
|
| 130 |
+
return completions
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def _make_w_io_base(f, mode: str):
|
| 134 |
+
if not isinstance(f, io.IOBase):
|
| 135 |
+
f_dirname = os.path.dirname(f)
|
| 136 |
+
if f_dirname != "":
|
| 137 |
+
os.makedirs(f_dirname, exist_ok=True)
|
| 138 |
+
f = open(f, mode=mode)
|
| 139 |
+
return f
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def _make_r_io_base(f, mode: str):
|
| 143 |
+
if not isinstance(f, io.IOBase):
|
| 144 |
+
f = open(f, mode=mode)
|
| 145 |
+
return f
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
def jdump(obj, f, mode="w", indent=4, default=str):
|
| 149 |
+
"""Dump a str or dictionary to a file in json format.
|
| 150 |
+
|
| 151 |
+
Args:
|
| 152 |
+
obj: An object to be written.
|
| 153 |
+
f: A string path to the location on disk.
|
| 154 |
+
mode: Mode for opening the file.
|
| 155 |
+
indent: Indent for storing json dictionaries.
|
| 156 |
+
default: A function to handle non-serializable entries; defaults to `str`.
|
| 157 |
+
"""
|
| 158 |
+
f = _make_w_io_base(f, mode)
|
| 159 |
+
if isinstance(obj, (dict, list)):
|
| 160 |
+
json.dump(obj, f, indent=indent, default=default)
|
| 161 |
+
elif isinstance(obj, str):
|
| 162 |
+
f.write(obj)
|
| 163 |
+
else:
|
| 164 |
+
raise ValueError(f"Unexpected type: {type(obj)}")
|
| 165 |
+
f.close()
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
def jload(f, mode="r"):
|
| 169 |
+
"""Load a .json file into a dictionary."""
|
| 170 |
+
f = _make_r_io_base(f, mode)
|
| 171 |
+
jdict = json.load(f)
|
| 172 |
+
f.close()
|
| 173 |
+
return jdict
|