
Upload 01_how_to_train.ipynb
Browse files- 01_how_to_train.ipynb +1565 -0
01_how_to_train.ipynb
ADDED
|
@@ -0,0 +1,1565 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"nbformat": 4,
|
| 3 |
+
"nbformat_minor": 0,
|
| 4 |
+
"metadata": {
|
| 5 |
+
"colab": {
|
| 6 |
+
"name": "01_how-to-train.ipynb",
|
| 7 |
+
"provenance": [],
|
| 8 |
+
"collapsed_sections": [],
|
| 9 |
+
"toc_visible": true,
|
| 10 |
+
"machine_shape": "hm",
|
| 11 |
+
"include_colab_link": true
|
| 12 |
+
},
|
| 13 |
+
"kernelspec": {
|
| 14 |
+
"name": "python3",
|
| 15 |
+
"display_name": "Python 3"
|
| 16 |
+
},
|
| 17 |
+
"accelerator": "GPU",
|
| 18 |
+
"widgets": {
|
| 19 |
+
"application/vnd.jupyter.widget-state+json": {
|
| 20 |
+
"a58a66392b644b1384661e850c077a6c": {
|
| 21 |
+
"model_module": "@jupyter-widgets/controls",
|
| 22 |
+
"model_name": "HBoxModel",
|
| 23 |
+
"state": {
|
| 24 |
+
"_view_name": "HBoxView",
|
| 25 |
+
"_dom_classes": [],
|
| 26 |
+
"_model_name": "HBoxModel",
|
| 27 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 28 |
+
"_model_module_version": "1.5.0",
|
| 29 |
+
"_view_count": null,
|
| 30 |
+
"_view_module_version": "1.5.0",
|
| 31 |
+
"box_style": "",
|
| 32 |
+
"layout": "IPY_MODEL_a491e8caa0a048beb3b5259f14eb233f",
|
| 33 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 34 |
+
"children": [
|
| 35 |
+
"IPY_MODEL_837c9ddc3d594e088891874560c646b8",
|
| 36 |
+
"IPY_MODEL_dbf50873d62c4ba39321faefbed0cca5"
|
| 37 |
+
]
|
| 38 |
+
}
|
| 39 |
+
},
|
| 40 |
+
"a491e8caa0a048beb3b5259f14eb233f": {
|
| 41 |
+
"model_module": "@jupyter-widgets/base",
|
| 42 |
+
"model_name": "LayoutModel",
|
| 43 |
+
"state": {
|
| 44 |
+
"_view_name": "LayoutView",
|
| 45 |
+
"grid_template_rows": null,
|
| 46 |
+
"right": null,
|
| 47 |
+
"justify_content": null,
|
| 48 |
+
"_view_module": "@jupyter-widgets/base",
|
| 49 |
+
"overflow": null,
|
| 50 |
+
"_model_module_version": "1.2.0",
|
| 51 |
+
"_view_count": null,
|
| 52 |
+
"flex_flow": null,
|
| 53 |
+
"width": null,
|
| 54 |
+
"min_width": null,
|
| 55 |
+
"border": null,
|
| 56 |
+
"align_items": null,
|
| 57 |
+
"bottom": null,
|
| 58 |
+
"_model_module": "@jupyter-widgets/base",
|
| 59 |
+
"top": null,
|
| 60 |
+
"grid_column": null,
|
| 61 |
+
"overflow_y": null,
|
| 62 |
+
"overflow_x": null,
|
| 63 |
+
"grid_auto_flow": null,
|
| 64 |
+
"grid_area": null,
|
| 65 |
+
"grid_template_columns": null,
|
| 66 |
+
"flex": null,
|
| 67 |
+
"_model_name": "LayoutModel",
|
| 68 |
+
"justify_items": null,
|
| 69 |
+
"grid_row": null,
|
| 70 |
+
"max_height": null,
|
| 71 |
+
"align_content": null,
|
| 72 |
+
"visibility": null,
|
| 73 |
+
"align_self": null,
|
| 74 |
+
"height": null,
|
| 75 |
+
"min_height": null,
|
| 76 |
+
"padding": null,
|
| 77 |
+
"grid_auto_rows": null,
|
| 78 |
+
"grid_gap": null,
|
| 79 |
+
"max_width": null,
|
| 80 |
+
"order": null,
|
| 81 |
+
"_view_module_version": "1.2.0",
|
| 82 |
+
"grid_template_areas": null,
|
| 83 |
+
"object_position": null,
|
| 84 |
+
"object_fit": null,
|
| 85 |
+
"grid_auto_columns": null,
|
| 86 |
+
"margin": null,
|
| 87 |
+
"display": null,
|
| 88 |
+
"left": null
|
| 89 |
+
}
|
| 90 |
+
},
|
| 91 |
+
"837c9ddc3d594e088891874560c646b8": {
|
| 92 |
+
"model_module": "@jupyter-widgets/controls",
|
| 93 |
+
"model_name": "FloatProgressModel",
|
| 94 |
+
"state": {
|
| 95 |
+
"_view_name": "ProgressView",
|
| 96 |
+
"style": "IPY_MODEL_40bf955ba0284e84b198da6be8654219",
|
| 97 |
+
"_dom_classes": [],
|
| 98 |
+
"description": "Epoch: 100%",
|
| 99 |
+
"_model_name": "FloatProgressModel",
|
| 100 |
+
"bar_style": "success",
|
| 101 |
+
"max": 1,
|
| 102 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 103 |
+
"_model_module_version": "1.5.0",
|
| 104 |
+
"value": 1,
|
| 105 |
+
"_view_count": null,
|
| 106 |
+
"_view_module_version": "1.5.0",
|
| 107 |
+
"orientation": "horizontal",
|
| 108 |
+
"min": 0,
|
| 109 |
+
"description_tooltip": null,
|
| 110 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 111 |
+
"layout": "IPY_MODEL_fe20a8dae6e84628b5076d02183090f5"
|
| 112 |
+
}
|
| 113 |
+
},
|
| 114 |
+
"dbf50873d62c4ba39321faefbed0cca5": {
|
| 115 |
+
"model_module": "@jupyter-widgets/controls",
|
| 116 |
+
"model_name": "HTMLModel",
|
| 117 |
+
"state": {
|
| 118 |
+
"_view_name": "HTMLView",
|
| 119 |
+
"style": "IPY_MODEL_93b3f9eae3cb4e3e859cf456e3547c6d",
|
| 120 |
+
"_dom_classes": [],
|
| 121 |
+
"description": "",
|
| 122 |
+
"_model_name": "HTMLModel",
|
| 123 |
+
"placeholder": "",
|
| 124 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 125 |
+
"_model_module_version": "1.5.0",
|
| 126 |
+
"value": " 1/1 [2:46:46<00:00, 10006.17s/it]",
|
| 127 |
+
"_view_count": null,
|
| 128 |
+
"_view_module_version": "1.5.0",
|
| 129 |
+
"description_tooltip": null,
|
| 130 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 131 |
+
"layout": "IPY_MODEL_6feb10aeb43147e6aba028d065947ae8"
|
| 132 |
+
}
|
| 133 |
+
},
|
| 134 |
+
"40bf955ba0284e84b198da6be8654219": {
|
| 135 |
+
"model_module": "@jupyter-widgets/controls",
|
| 136 |
+
"model_name": "ProgressStyleModel",
|
| 137 |
+
"state": {
|
| 138 |
+
"_view_name": "StyleView",
|
| 139 |
+
"_model_name": "ProgressStyleModel",
|
| 140 |
+
"description_width": "initial",
|
| 141 |
+
"_view_module": "@jupyter-widgets/base",
|
| 142 |
+
"_model_module_version": "1.5.0",
|
| 143 |
+
"_view_count": null,
|
| 144 |
+
"_view_module_version": "1.2.0",
|
| 145 |
+
"bar_color": null,
|
| 146 |
+
"_model_module": "@jupyter-widgets/controls"
|
| 147 |
+
}
|
| 148 |
+
},
|
| 149 |
+
"fe20a8dae6e84628b5076d02183090f5": {
|
| 150 |
+
"model_module": "@jupyter-widgets/base",
|
| 151 |
+
"model_name": "LayoutModel",
|
| 152 |
+
"state": {
|
| 153 |
+
"_view_name": "LayoutView",
|
| 154 |
+
"grid_template_rows": null,
|
| 155 |
+
"right": null,
|
| 156 |
+
"justify_content": null,
|
| 157 |
+
"_view_module": "@jupyter-widgets/base",
|
| 158 |
+
"overflow": null,
|
| 159 |
+
"_model_module_version": "1.2.0",
|
| 160 |
+
"_view_count": null,
|
| 161 |
+
"flex_flow": null,
|
| 162 |
+
"width": null,
|
| 163 |
+
"min_width": null,
|
| 164 |
+
"border": null,
|
| 165 |
+
"align_items": null,
|
| 166 |
+
"bottom": null,
|
| 167 |
+
"_model_module": "@jupyter-widgets/base",
|
| 168 |
+
"top": null,
|
| 169 |
+
"grid_column": null,
|
| 170 |
+
"overflow_y": null,
|
| 171 |
+
"overflow_x": null,
|
| 172 |
+
"grid_auto_flow": null,
|
| 173 |
+
"grid_area": null,
|
| 174 |
+
"grid_template_columns": null,
|
| 175 |
+
"flex": null,
|
| 176 |
+
"_model_name": "LayoutModel",
|
| 177 |
+
"justify_items": null,
|
| 178 |
+
"grid_row": null,
|
| 179 |
+
"max_height": null,
|
| 180 |
+
"align_content": null,
|
| 181 |
+
"visibility": null,
|
| 182 |
+
"align_self": null,
|
| 183 |
+
"height": null,
|
| 184 |
+
"min_height": null,
|
| 185 |
+
"padding": null,
|
| 186 |
+
"grid_auto_rows": null,
|
| 187 |
+
"grid_gap": null,
|
| 188 |
+
"max_width": null,
|
| 189 |
+
"order": null,
|
| 190 |
+
"_view_module_version": "1.2.0",
|
| 191 |
+
"grid_template_areas": null,
|
| 192 |
+
"object_position": null,
|
| 193 |
+
"object_fit": null,
|
| 194 |
+
"grid_auto_columns": null,
|
| 195 |
+
"margin": null,
|
| 196 |
+
"display": null,
|
| 197 |
+
"left": null
|
| 198 |
+
}
|
| 199 |
+
},
|
| 200 |
+
"93b3f9eae3cb4e3e859cf456e3547c6d": {
|
| 201 |
+
"model_module": "@jupyter-widgets/controls",
|
| 202 |
+
"model_name": "DescriptionStyleModel",
|
| 203 |
+
"state": {
|
| 204 |
+
"_view_name": "StyleView",
|
| 205 |
+
"_model_name": "DescriptionStyleModel",
|
| 206 |
+
"description_width": "",
|
| 207 |
+
"_view_module": "@jupyter-widgets/base",
|
| 208 |
+
"_model_module_version": "1.5.0",
|
| 209 |
+
"_view_count": null,
|
| 210 |
+
"_view_module_version": "1.2.0",
|
| 211 |
+
"_model_module": "@jupyter-widgets/controls"
|
| 212 |
+
}
|
| 213 |
+
},
|
| 214 |
+
"6feb10aeb43147e6aba028d065947ae8": {
|
| 215 |
+
"model_module": "@jupyter-widgets/base",
|
| 216 |
+
"model_name": "LayoutModel",
|
| 217 |
+
"state": {
|
| 218 |
+
"_view_name": "LayoutView",
|
| 219 |
+
"grid_template_rows": null,
|
| 220 |
+
"right": null,
|
| 221 |
+
"justify_content": null,
|
| 222 |
+
"_view_module": "@jupyter-widgets/base",
|
| 223 |
+
"overflow": null,
|
| 224 |
+
"_model_module_version": "1.2.0",
|
| 225 |
+
"_view_count": null,
|
| 226 |
+
"flex_flow": null,
|
| 227 |
+
"width": null,
|
| 228 |
+
"min_width": null,
|
| 229 |
+
"border": null,
|
| 230 |
+
"align_items": null,
|
| 231 |
+
"bottom": null,
|
| 232 |
+
"_model_module": "@jupyter-widgets/base",
|
| 233 |
+
"top": null,
|
| 234 |
+
"grid_column": null,
|
| 235 |
+
"overflow_y": null,
|
| 236 |
+
"overflow_x": null,
|
| 237 |
+
"grid_auto_flow": null,
|
| 238 |
+
"grid_area": null,
|
| 239 |
+
"grid_template_columns": null,
|
| 240 |
+
"flex": null,
|
| 241 |
+
"_model_name": "LayoutModel",
|
| 242 |
+
"justify_items": null,
|
| 243 |
+
"grid_row": null,
|
| 244 |
+
"max_height": null,
|
| 245 |
+
"align_content": null,
|
| 246 |
+
"visibility": null,
|
| 247 |
+
"align_self": null,
|
| 248 |
+
"height": null,
|
| 249 |
+
"min_height": null,
|
| 250 |
+
"padding": null,
|
| 251 |
+
"grid_auto_rows": null,
|
| 252 |
+
"grid_gap": null,
|
| 253 |
+
"max_width": null,
|
| 254 |
+
"order": null,
|
| 255 |
+
"_view_module_version": "1.2.0",
|
| 256 |
+
"grid_template_areas": null,
|
| 257 |
+
"object_position": null,
|
| 258 |
+
"object_fit": null,
|
| 259 |
+
"grid_auto_columns": null,
|
| 260 |
+
"margin": null,
|
| 261 |
+
"display": null,
|
| 262 |
+
"left": null
|
| 263 |
+
}
|
| 264 |
+
},
|
| 265 |
+
"0989d41a4da24e9ebff377e02127642c": {
|
| 266 |
+
"model_module": "@jupyter-widgets/controls",
|
| 267 |
+
"model_name": "HBoxModel",
|
| 268 |
+
"state": {
|
| 269 |
+
"_view_name": "HBoxView",
|
| 270 |
+
"_dom_classes": [],
|
| 271 |
+
"_model_name": "HBoxModel",
|
| 272 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 273 |
+
"_model_module_version": "1.5.0",
|
| 274 |
+
"_view_count": null,
|
| 275 |
+
"_view_module_version": "1.5.0",
|
| 276 |
+
"box_style": "",
|
| 277 |
+
"layout": "IPY_MODEL_42c6061ef7e44f179db5a6e3551c0f17",
|
| 278 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 279 |
+
"children": [
|
| 280 |
+
"IPY_MODEL_d295dd80550447d88da0f04ce36a22ff",
|
| 281 |
+
"IPY_MODEL_04e7e6d291da49d5816dc98a2904e95c"
|
| 282 |
+
]
|
| 283 |
+
}
|
| 284 |
+
},
|
| 285 |
+
"42c6061ef7e44f179db5a6e3551c0f17": {
|
| 286 |
+
"model_module": "@jupyter-widgets/base",
|
| 287 |
+
"model_name": "LayoutModel",
|
| 288 |
+
"state": {
|
| 289 |
+
"_view_name": "LayoutView",
|
| 290 |
+
"grid_template_rows": null,
|
| 291 |
+
"right": null,
|
| 292 |
+
"justify_content": null,
|
| 293 |
+
"_view_module": "@jupyter-widgets/base",
|
| 294 |
+
"overflow": null,
|
| 295 |
+
"_model_module_version": "1.2.0",
|
| 296 |
+
"_view_count": null,
|
| 297 |
+
"flex_flow": null,
|
| 298 |
+
"width": null,
|
| 299 |
+
"min_width": null,
|
| 300 |
+
"border": null,
|
| 301 |
+
"align_items": null,
|
| 302 |
+
"bottom": null,
|
| 303 |
+
"_model_module": "@jupyter-widgets/base",
|
| 304 |
+
"top": null,
|
| 305 |
+
"grid_column": null,
|
| 306 |
+
"overflow_y": null,
|
| 307 |
+
"overflow_x": null,
|
| 308 |
+
"grid_auto_flow": null,
|
| 309 |
+
"grid_area": null,
|
| 310 |
+
"grid_template_columns": null,
|
| 311 |
+
"flex": null,
|
| 312 |
+
"_model_name": "LayoutModel",
|
| 313 |
+
"justify_items": null,
|
| 314 |
+
"grid_row": null,
|
| 315 |
+
"max_height": null,
|
| 316 |
+
"align_content": null,
|
| 317 |
+
"visibility": null,
|
| 318 |
+
"align_self": null,
|
| 319 |
+
"height": null,
|
| 320 |
+
"min_height": null,
|
| 321 |
+
"padding": null,
|
| 322 |
+
"grid_auto_rows": null,
|
| 323 |
+
"grid_gap": null,
|
| 324 |
+
"max_width": null,
|
| 325 |
+
"order": null,
|
| 326 |
+
"_view_module_version": "1.2.0",
|
| 327 |
+
"grid_template_areas": null,
|
| 328 |
+
"object_position": null,
|
| 329 |
+
"object_fit": null,
|
| 330 |
+
"grid_auto_columns": null,
|
| 331 |
+
"margin": null,
|
| 332 |
+
"display": null,
|
| 333 |
+
"left": null
|
| 334 |
+
}
|
| 335 |
+
},
|
| 336 |
+
"d295dd80550447d88da0f04ce36a22ff": {
|
| 337 |
+
"model_module": "@jupyter-widgets/controls",
|
| 338 |
+
"model_name": "FloatProgressModel",
|
| 339 |
+
"state": {
|
| 340 |
+
"_view_name": "ProgressView",
|
| 341 |
+
"style": "IPY_MODEL_e7d8c3a4fecd40778e32966b29ea65a1",
|
| 342 |
+
"_dom_classes": [],
|
| 343 |
+
"description": "Iteration: 100%",
|
| 344 |
+
"_model_name": "FloatProgressModel",
|
| 345 |
+
"bar_style": "success",
|
| 346 |
+
"max": 15228,
|
| 347 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 348 |
+
"_model_module_version": "1.5.0",
|
| 349 |
+
"value": 15228,
|
| 350 |
+
"_view_count": null,
|
| 351 |
+
"_view_module_version": "1.5.0",
|
| 352 |
+
"orientation": "horizontal",
|
| 353 |
+
"min": 0,
|
| 354 |
+
"description_tooltip": null,
|
| 355 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 356 |
+
"layout": "IPY_MODEL_016d7c8318f742c1943464b08232a510"
|
| 357 |
+
}
|
| 358 |
+
},
|
| 359 |
+
"04e7e6d291da49d5816dc98a2904e95c": {
|
| 360 |
+
"model_module": "@jupyter-widgets/controls",
|
| 361 |
+
"model_name": "HTMLModel",
|
| 362 |
+
"state": {
|
| 363 |
+
"_view_name": "HTMLView",
|
| 364 |
+
"style": "IPY_MODEL_8388e9da9da4492c98c19235ca5fc1b5",
|
| 365 |
+
"_dom_classes": [],
|
| 366 |
+
"description": "",
|
| 367 |
+
"_model_name": "HTMLModel",
|
| 368 |
+
"placeholder": "",
|
| 369 |
+
"_view_module": "@jupyter-widgets/controls",
|
| 370 |
+
"_model_module_version": "1.5.0",
|
| 371 |
+
"value": " 15228/15228 [2:46:46<00:00, 1.52it/s]",
|
| 372 |
+
"_view_count": null,
|
| 373 |
+
"_view_module_version": "1.5.0",
|
| 374 |
+
"description_tooltip": null,
|
| 375 |
+
"_model_module": "@jupyter-widgets/controls",
|
| 376 |
+
"layout": "IPY_MODEL_39c23c6a972b419eb2eeeebafeaedc22"
|
| 377 |
+
}
|
| 378 |
+
},
|
| 379 |
+
"e7d8c3a4fecd40778e32966b29ea65a1": {
|
| 380 |
+
"model_module": "@jupyter-widgets/controls",
|
| 381 |
+
"model_name": "ProgressStyleModel",
|
| 382 |
+
"state": {
|
| 383 |
+
"_view_name": "StyleView",
|
| 384 |
+
"_model_name": "ProgressStyleModel",
|
| 385 |
+
"description_width": "initial",
|
| 386 |
+
"_view_module": "@jupyter-widgets/base",
|
| 387 |
+
"_model_module_version": "1.5.0",
|
| 388 |
+
"_view_count": null,
|
| 389 |
+
"_view_module_version": "1.2.0",
|
| 390 |
+
"bar_color": null,
|
| 391 |
+
"_model_module": "@jupyter-widgets/controls"
|
| 392 |
+
}
|
| 393 |
+
},
|
| 394 |
+
"016d7c8318f742c1943464b08232a510": {
|
| 395 |
+
"model_module": "@jupyter-widgets/base",
|
| 396 |
+
"model_name": "LayoutModel",
|
| 397 |
+
"state": {
|
| 398 |
+
"_view_name": "LayoutView",
|
| 399 |
+
"grid_template_rows": null,
|
| 400 |
+
"right": null,
|
| 401 |
+
"justify_content": null,
|
| 402 |
+
"_view_module": "@jupyter-widgets/base",
|
| 403 |
+
"overflow": null,
|
| 404 |
+
"_model_module_version": "1.2.0",
|
| 405 |
+
"_view_count": null,
|
| 406 |
+
"flex_flow": null,
|
| 407 |
+
"width": null,
|
| 408 |
+
"min_width": null,
|
| 409 |
+
"border": null,
|
| 410 |
+
"align_items": null,
|
| 411 |
+
"bottom": null,
|
| 412 |
+
"_model_module": "@jupyter-widgets/base",
|
| 413 |
+
"top": null,
|
| 414 |
+
"grid_column": null,
|
| 415 |
+
"overflow_y": null,
|
| 416 |
+
"overflow_x": null,
|
| 417 |
+
"grid_auto_flow": null,
|
| 418 |
+
"grid_area": null,
|
| 419 |
+
"grid_template_columns": null,
|
| 420 |
+
"flex": null,
|
| 421 |
+
"_model_name": "LayoutModel",
|
| 422 |
+
"justify_items": null,
|
| 423 |
+
"grid_row": null,
|
| 424 |
+
"max_height": null,
|
| 425 |
+
"align_content": null,
|
| 426 |
+
"visibility": null,
|
| 427 |
+
"align_self": null,
|
| 428 |
+
"height": null,
|
| 429 |
+
"min_height": null,
|
| 430 |
+
"padding": null,
|
| 431 |
+
"grid_auto_rows": null,
|
| 432 |
+
"grid_gap": null,
|
| 433 |
+
"max_width": null,
|
| 434 |
+
"order": null,
|
| 435 |
+
"_view_module_version": "1.2.0",
|
| 436 |
+
"grid_template_areas": null,
|
| 437 |
+
"object_position": null,
|
| 438 |
+
"object_fit": null,
|
| 439 |
+
"grid_auto_columns": null,
|
| 440 |
+
"margin": null,
|
| 441 |
+
"display": null,
|
| 442 |
+
"left": null
|
| 443 |
+
}
|
| 444 |
+
},
|
| 445 |
+
"8388e9da9da4492c98c19235ca5fc1b5": {
|
| 446 |
+
"model_module": "@jupyter-widgets/controls",
|
| 447 |
+
"model_name": "DescriptionStyleModel",
|
| 448 |
+
"state": {
|
| 449 |
+
"_view_name": "StyleView",
|
| 450 |
+
"_model_name": "DescriptionStyleModel",
|
| 451 |
+
"description_width": "",
|
| 452 |
+
"_view_module": "@jupyter-widgets/base",
|
| 453 |
+
"_model_module_version": "1.5.0",
|
| 454 |
+
"_view_count": null,
|
| 455 |
+
"_view_module_version": "1.2.0",
|
| 456 |
+
"_model_module": "@jupyter-widgets/controls"
|
| 457 |
+
}
|
| 458 |
+
},
|
| 459 |
+
"39c23c6a972b419eb2eeeebafeaedc22": {
|
| 460 |
+
"model_module": "@jupyter-widgets/base",
|
| 461 |
+
"model_name": "LayoutModel",
|
| 462 |
+
"state": {
|
| 463 |
+
"_view_name": "LayoutView",
|
| 464 |
+
"grid_template_rows": null,
|
| 465 |
+
"right": null,
|
| 466 |
+
"justify_content": null,
|
| 467 |
+
"_view_module": "@jupyter-widgets/base",
|
| 468 |
+
"overflow": null,
|
| 469 |
+
"_model_module_version": "1.2.0",
|
| 470 |
+
"_view_count": null,
|
| 471 |
+
"flex_flow": null,
|
| 472 |
+
"width": null,
|
| 473 |
+
"min_width": null,
|
| 474 |
+
"border": null,
|
| 475 |
+
"align_items": null,
|
| 476 |
+
"bottom": null,
|
| 477 |
+
"_model_module": "@jupyter-widgets/base",
|
| 478 |
+
"top": null,
|
| 479 |
+
"grid_column": null,
|
| 480 |
+
"overflow_y": null,
|
| 481 |
+
"overflow_x": null,
|
| 482 |
+
"grid_auto_flow": null,
|
| 483 |
+
"grid_area": null,
|
| 484 |
+
"grid_template_columns": null,
|
| 485 |
+
"flex": null,
|
| 486 |
+
"_model_name": "LayoutModel",
|
| 487 |
+
"justify_items": null,
|
| 488 |
+
"grid_row": null,
|
| 489 |
+
"max_height": null,
|
| 490 |
+
"align_content": null,
|
| 491 |
+
"visibility": null,
|
| 492 |
+
"align_self": null,
|
| 493 |
+
"height": null,
|
| 494 |
+
"min_height": null,
|
| 495 |
+
"padding": null,
|
| 496 |
+
"grid_auto_rows": null,
|
| 497 |
+
"grid_gap": null,
|
| 498 |
+
"max_width": null,
|
| 499 |
+
"order": null,
|
| 500 |
+
"_view_module_version": "1.2.0",
|
| 501 |
+
"grid_template_areas": null,
|
| 502 |
+
"object_position": null,
|
| 503 |
+
"object_fit": null,
|
| 504 |
+
"grid_auto_columns": null,
|
| 505 |
+
"margin": null,
|
| 506 |
+
"display": null,
|
| 507 |
+
"left": null
|
| 508 |
+
}
|
| 509 |
+
}
|
| 510 |
+
}
|
| 511 |
+
}
|
| 512 |
+
},
|
| 513 |
+
"cells": [
|
| 514 |
+
{
|
| 515 |
+
"cell_type": "markdown",
|
| 516 |
+
"metadata": {
|
| 517 |
+
"id": "view-in-github",
|
| 518 |
+
"colab_type": "text"
|
| 519 |
+
},
|
| 520 |
+
"source": [
|
| 521 |
+
"<a href=\"https://colab.research.google.com/github/huggingface/blog/blob/notebook_update_may15/notebooks/01_how_to_train.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
|
| 522 |
+
]
|
| 523 |
+
},
|
| 524 |
+
{
|
| 525 |
+
"cell_type": "code",
|
| 526 |
+
"metadata": {
|
| 527 |
+
"id": "e67Ut53QYEdU",
|
| 528 |
+
"colab_type": "code",
|
| 529 |
+
"cellView": "form",
|
| 530 |
+
"outputId": "437871b8-b8ac-4eaf-c2e1-61d801c5e6b2",
|
| 531 |
+
"colab": {
|
| 532 |
+
"base_uri": "https://localhost:8080/",
|
| 533 |
+
"height": 100
|
| 534 |
+
}
|
| 535 |
+
},
|
| 536 |
+
"source": [
|
| 537 |
+
"#@title\n",
|
| 538 |
+
"%%html\n",
|
| 539 |
+
"<div style=\"background-color: pink;\">\n",
|
| 540 |
+
" Notebook written in collaboration with <a href=\"https://github.com/aditya-malte\">Aditya Malte</a>.\n",
|
| 541 |
+
" <br>\n",
|
| 542 |
+
" The Notebook is on GitHub, so contributions are more than welcome.\n",
|
| 543 |
+
"</div>\n",
|
| 544 |
+
"<br>\n",
|
| 545 |
+
"<div style=\"background-color: yellow;\">\n",
|
| 546 |
+
" Aditya wrote another notebook with a slightly different use case and methodology, please check it out.\n",
|
| 547 |
+
" <br>\n",
|
| 548 |
+
" <a target=\"_blank\" href=\"https://gist.github.com/aditya-malte/2d4f896f471be9c38eb4d723a710768b\">\n",
|
| 549 |
+
" https://gist.github.com/aditya-malte/2d4f896f471be9c38eb4d723a710768b\n",
|
| 550 |
+
" </a>\n",
|
| 551 |
+
"</div>\n"
|
| 552 |
+
],
|
| 553 |
+
"execution_count": 0,
|
| 554 |
+
"outputs": [
|
| 555 |
+
{
|
| 556 |
+
"output_type": "display_data",
|
| 557 |
+
"data": {
|
| 558 |
+
"text/html": [
|
| 559 |
+
"<div style=\"background-color: pink;\">\n",
|
| 560 |
+
" Notebook written in collaboration with <a href=\"https://github.com/aditya-malte\">Aditya Malte</a>.\n",
|
| 561 |
+
" <br>\n",
|
| 562 |
+
" The Notebook is on GitHub, so contributions are more than welcome.\n",
|
| 563 |
+
"</div>\n",
|
| 564 |
+
"<br>\n",
|
| 565 |
+
"<div style=\"background-color: yellow;\">\n",
|
| 566 |
+
" Aditya wrote another notebook with a slightly different use case and methodology, please check it out.\n",
|
| 567 |
+
" <br>\n",
|
| 568 |
+
" <a target=\"_blank\" href=\"https://gist.github.com/aditya-malte/2d4f896f471be9c38eb4d723a710768b\">\n",
|
| 569 |
+
" https://gist.github.com/aditya-malte/2d4f896f471be9c38eb4d723a710768b\n",
|
| 570 |
+
" </a>\n",
|
| 571 |
+
"</div>"
|
| 572 |
+
],
|
| 573 |
+
"text/plain": [
|
| 574 |
+
"<IPython.core.display.HTML object>"
|
| 575 |
+
]
|
| 576 |
+
},
|
| 577 |
+
"metadata": {
|
| 578 |
+
"tags": []
|
| 579 |
+
}
|
| 580 |
+
}
|
| 581 |
+
]
|
| 582 |
+
},
|
| 583 |
+
{
|
| 584 |
+
"cell_type": "markdown",
|
| 585 |
+
"metadata": {
|
| 586 |
+
"id": "M1oqh0F6W3ad",
|
| 587 |
+
"colab_type": "text"
|
| 588 |
+
},
|
| 589 |
+
"source": [
|
| 590 |
+
"# How to train a new language model from scratch using Transformers and Tokenizers\n",
|
| 591 |
+
"\n",
|
| 592 |
+
"### Notebook edition (link to blogpost [link](https://huggingface.co/blog/how-to-train)). Last update May 15, 2020\n",
|
| 593 |
+
"\n",
|
| 594 |
+
"\n",
|
| 595 |
+
"Over the past few months, we made several improvements to our [`transformers`](https://github.com/huggingface/transformers) and [`tokenizers`](https://github.com/huggingface/tokenizers) libraries, with the goal of making it easier than ever to **train a new language model from scratch**.\n",
|
| 596 |
+
"\n",
|
| 597 |
+
"In this post we’ll demo how to train a “small” model (84 M parameters = 6 layers, 768 hidden size, 12 attention heads) – that’s the same number of layers & heads as DistilBERT – on **Esperanto**. We’ll then fine-tune the model on a downstream task of part-of-speech tagging.\n"
|
| 598 |
+
]
|
| 599 |
+
},
|
| 600 |
+
{
|
| 601 |
+
"cell_type": "markdown",
|
| 602 |
+
"metadata": {
|
| 603 |
+
"id": "oK7PPVm2XBgr",
|
| 604 |
+
"colab_type": "text"
|
| 605 |
+
},
|
| 606 |
+
"source": [
|
| 607 |
+
"## 1. Find a dataset\n",
|
| 608 |
+
"\n",
|
| 609 |
+
"First, let us find a corpus of text in Esperanto. Here we’ll use the Esperanto portion of the [OSCAR corpus](https://traces1.inria.fr/oscar/) from INRIA.\n",
|
| 610 |
+
"OSCAR is a huge multilingual corpus obtained by language classification and filtering of [Common Crawl](https://commoncrawl.org/) dumps of the Web.\n",
|
| 611 |
+
"\n",
|
| 612 |
+
"<img src=\"https://huggingface.co/blog/assets/01_how-to-train/oscar.png\" style=\"margin: auto; display: block; width: 260px;\">\n",
|
| 613 |
+
"\n",
|
| 614 |
+
"The Esperanto portion of the dataset is only 299M, so we’ll concatenate with the Esperanto sub-corpus of the [Leipzig Corpora Collection](https://wortschatz.uni-leipzig.de/en/download), which is comprised of text from diverse sources like news, literature, and wikipedia.\n",
|
| 615 |
+
"\n",
|
| 616 |
+
"The final training corpus has a size of 3 GB, which is still small – for your model, you will get better results the more data you can get to pretrain on. \n",
|
| 617 |
+
"\n"
|
| 618 |
+
]
|
| 619 |
+
},
|
| 620 |
+
{
|
| 621 |
+
"cell_type": "code",
|
| 622 |
+
"metadata": {
|
| 623 |
+
"id": "HOk4iZ9YZvec",
|
| 624 |
+
"colab_type": "code",
|
| 625 |
+
"colab": {}
|
| 626 |
+
},
|
| 627 |
+
"source": [
|
| 628 |
+
"# in this notebook we'll only get one of the files (the Oscar one) for the sake of simplicity and performance\n",
|
| 629 |
+
"!wget -c https://cdn-datasets.huggingface.co/EsperBERTo/data/oscar.eo.txt"
|
| 630 |
+
],
|
| 631 |
+
"execution_count": 0,
|
| 632 |
+
"outputs": []
|
| 633 |
+
},
|
| 634 |
+
{
|
| 635 |
+
"cell_type": "markdown",
|
| 636 |
+
"metadata": {
|
| 637 |
+
"id": "G-kkz81OY6xH",
|
| 638 |
+
"colab_type": "text"
|
| 639 |
+
},
|
| 640 |
+
"source": [
|
| 641 |
+
"## 2. Train a tokenizer\n",
|
| 642 |
+
"\n",
|
| 643 |
+
"We choose to train a byte-level Byte-pair encoding tokenizer (the same as GPT-2), with the same special tokens as RoBERTa. Let’s arbitrarily pick its size to be 52,000.\n",
|
| 644 |
+
"\n",
|
| 645 |
+
"We recommend training a byte-level BPE (rather than let’s say, a WordPiece tokenizer like BERT) because it will start building its vocabulary from an alphabet of single bytes, so all words will be decomposable into tokens (no more `<unk>` tokens!).\n"
|
| 646 |
+
]
|
| 647 |
+
},
|
| 648 |
+
{
|
| 649 |
+
"cell_type": "code",
|
| 650 |
+
"metadata": {
|
| 651 |
+
"id": "5duRggBRZKvP",
|
| 652 |
+
"colab_type": "code",
|
| 653 |
+
"colab": {}
|
| 654 |
+
},
|
| 655 |
+
"source": [
|
| 656 |
+
"# We won't need TensorFlow here\n",
|
| 657 |
+
"!pip uninstall -y tensorflow\n",
|
| 658 |
+
"# Install `transformers` from master\n",
|
| 659 |
+
"!pip install git+https://github.com/huggingface/transformers\n",
|
| 660 |
+
"!pip list | grep -E 'transformers|tokenizers'\n",
|
| 661 |
+
"# transformers version at notebook update --- 2.11.0\n",
|
| 662 |
+
"# tokenizers version at notebook update --- 0.8.0rc1"
|
| 663 |
+
],
|
| 664 |
+
"execution_count": 0,
|
| 665 |
+
"outputs": []
|
| 666 |
+
},
|
| 667 |
+
{
|
| 668 |
+
"cell_type": "code",
|
| 669 |
+
"metadata": {
|
| 670 |
+
"id": "IMnymRDLe0hi",
|
| 671 |
+
"colab_type": "code",
|
| 672 |
+
"outputId": "4d26476f-e6b5-475a-a0c1-41b6fcdc041a",
|
| 673 |
+
"colab": {
|
| 674 |
+
"base_uri": "https://localhost:8080/",
|
| 675 |
+
"height": 52
|
| 676 |
+
}
|
| 677 |
+
},
|
| 678 |
+
"source": [
|
| 679 |
+
"%%time \n",
|
| 680 |
+
"from pathlib import Path\n",
|
| 681 |
+
"\n",
|
| 682 |
+
"from tokenizers import ByteLevelBPETokenizer\n",
|
| 683 |
+
"\n",
|
| 684 |
+
"paths = [str(x) for x in Path(\".\").glob(\"**/*.txt\")]\n",
|
| 685 |
+
"\n",
|
| 686 |
+
"# Initialize a tokenizer\n",
|
| 687 |
+
"tokenizer = ByteLevelBPETokenizer()\n",
|
| 688 |
+
"\n",
|
| 689 |
+
"# Customize training\n",
|
| 690 |
+
"tokenizer.train(files=paths, vocab_size=52_000, min_frequency=2, special_tokens=[\n",
|
| 691 |
+
" \"<s>\",\n",
|
| 692 |
+
" \"<pad>\",\n",
|
| 693 |
+
" \"</s>\",\n",
|
| 694 |
+
" \"<unk>\",\n",
|
| 695 |
+
" \"<mask>\",\n",
|
| 696 |
+
"])"
|
| 697 |
+
],
|
| 698 |
+
"execution_count": 3,
|
| 699 |
+
"outputs": [
|
| 700 |
+
{
|
| 701 |
+
"output_type": "stream",
|
| 702 |
+
"text": [
|
| 703 |
+
"CPU times: user 4min, sys: 3min 7s, total: 7min 7s\n",
|
| 704 |
+
"Wall time: 2min 25s\n"
|
| 705 |
+
],
|
| 706 |
+
"name": "stdout"
|
| 707 |
+
}
|
| 708 |
+
]
|
| 709 |
+
},
|
| 710 |
+
{
|
| 711 |
+
"cell_type": "markdown",
|
| 712 |
+
"metadata": {
|
| 713 |
+
"id": "6Ei7bqpRf1LH",
|
| 714 |
+
"colab_type": "text"
|
| 715 |
+
},
|
| 716 |
+
"source": [
|
| 717 |
+
"Now let's save files to disk"
|
| 718 |
+
]
|
| 719 |
+
},
|
| 720 |
+
{
|
| 721 |
+
"cell_type": "code",
|
| 722 |
+
"metadata": {
|
| 723 |
+
"id": "EIS-irI0f32P",
|
| 724 |
+
"colab_type": "code",
|
| 725 |
+
"outputId": "e86c4a24-eb65-4f0a-aa58-ed1931a05ac9",
|
| 726 |
+
"colab": {
|
| 727 |
+
"base_uri": "https://localhost:8080/",
|
| 728 |
+
"height": 34
|
| 729 |
+
}
|
| 730 |
+
},
|
| 731 |
+
"source": [
|
| 732 |
+
"!mkdir EsperBERTo\n",
|
| 733 |
+
"tokenizer.save_model(\"EsperBERTo\")"
|
| 734 |
+
],
|
| 735 |
+
"execution_count": 4,
|
| 736 |
+
"outputs": [
|
| 737 |
+
{
|
| 738 |
+
"output_type": "execute_result",
|
| 739 |
+
"data": {
|
| 740 |
+
"text/plain": [
|
| 741 |
+
"['EsperBERTo/vocab.json', 'EsperBERTo/merges.txt']"
|
| 742 |
+
]
|
| 743 |
+
},
|
| 744 |
+
"metadata": {
|
| 745 |
+
"tags": []
|
| 746 |
+
},
|
| 747 |
+
"execution_count": 4
|
| 748 |
+
}
|
| 749 |
+
]
|
| 750 |
+
},
|
| 751 |
+
{
|
| 752 |
+
"cell_type": "markdown",
|
| 753 |
+
"metadata": {
|
| 754 |
+
"id": "lOOfYSuQhSqT",
|
| 755 |
+
"colab_type": "text"
|
| 756 |
+
},
|
| 757 |
+
"source": [
|
| 758 |
+
"🔥🔥 Wow, that was fast! ⚡️🔥\n",
|
| 759 |
+
"\n",
|
| 760 |
+
"We now have both a `vocab.json`, which is a list of the most frequent tokens ranked by frequency, and a `merges.txt` list of merges.\n",
|
| 761 |
+
"\n",
|
| 762 |
+
"```json\n",
|
| 763 |
+
"{\n",
|
| 764 |
+
"\t\"<s>\": 0,\n",
|
| 765 |
+
"\t\"<pad>\": 1,\n",
|
| 766 |
+
"\t\"</s>\": 2,\n",
|
| 767 |
+
"\t\"<unk>\": 3,\n",
|
| 768 |
+
"\t\"<mask>\": 4,\n",
|
| 769 |
+
"\t\"!\": 5,\n",
|
| 770 |
+
"\t\"\\\"\": 6,\n",
|
| 771 |
+
"\t\"#\": 7,\n",
|
| 772 |
+
"\t\"$\": 8,\n",
|
| 773 |
+
"\t\"%\": 9,\n",
|
| 774 |
+
"\t\"&\": 10,\n",
|
| 775 |
+
"\t\"'\": 11,\n",
|
| 776 |
+
"\t\"(\": 12,\n",
|
| 777 |
+
"\t\")\": 13,\n",
|
| 778 |
+
"\t# ...\n",
|
| 779 |
+
"}\n",
|
| 780 |
+
"\n",
|
| 781 |
+
"# merges.txt\n",
|
| 782 |
+
"l a\n",
|
| 783 |
+
"Ġ k\n",
|
| 784 |
+
"o n\n",
|
| 785 |
+
"Ġ la\n",
|
| 786 |
+
"t a\n",
|
| 787 |
+
"Ġ e\n",
|
| 788 |
+
"Ġ d\n",
|
| 789 |
+
"Ġ p\n",
|
| 790 |
+
"# ...\n",
|
| 791 |
+
"```\n",
|
| 792 |
+
"\n",
|
| 793 |
+
"What is great is that our tokenizer is optimized for Esperanto. Compared to a generic tokenizer trained for English, more native words are represented by a single, unsplit token. Diacritics, i.e. accented characters used in Esperanto – `ĉ`, `ĝ`, `ĥ`, `ĵ`, `ŝ`, and `ŭ` – are encoded natively. We also represent sequences in a more efficient manner. Here on this corpus, the average length of encoded sequences is ~30% smaller as when using the pretrained GPT-2 tokenizer.\n",
|
| 794 |
+
"\n",
|
| 795 |
+
"Here’s how you can use it in `tokenizers`, including handling the RoBERTa special tokens – of course, you’ll also be able to use it directly from `transformers`.\n"
|
| 796 |
+
]
|
| 797 |
+
},
|
| 798 |
+
{
|
| 799 |
+
"cell_type": "code",
|
| 800 |
+
"metadata": {
|
| 801 |
+
"id": "tKVWB8WShT-z",
|
| 802 |
+
"colab_type": "code",
|
| 803 |
+
"colab": {}
|
| 804 |
+
},
|
| 805 |
+
"source": [
|
| 806 |
+
"from tokenizers.implementations import ByteLevelBPETokenizer\n",
|
| 807 |
+
"from tokenizers.processors import BertProcessing\n",
|
| 808 |
+
"\n",
|
| 809 |
+
"\n",
|
| 810 |
+
"tokenizer = ByteLevelBPETokenizer(\n",
|
| 811 |
+
" \"./EsperBERTo/vocab.json\",\n",
|
| 812 |
+
" \"./EsperBERTo/merges.txt\",\n",
|
| 813 |
+
")"
|
| 814 |
+
],
|
| 815 |
+
"execution_count": 0,
|
| 816 |
+
"outputs": []
|
| 817 |
+
},
|
| 818 |
+
{
|
| 819 |
+
"cell_type": "code",
|
| 820 |
+
"metadata": {
|
| 821 |
+
"id": "hO5M3vrAhcuj",
|
| 822 |
+
"colab_type": "code",
|
| 823 |
+
"colab": {}
|
| 824 |
+
},
|
| 825 |
+
"source": [
|
| 826 |
+
"tokenizer._tokenizer.post_processor = BertProcessing(\n",
|
| 827 |
+
" (\"</s>\", tokenizer.token_to_id(\"</s>\")),\n",
|
| 828 |
+
" (\"<s>\", tokenizer.token_to_id(\"<s>\")),\n",
|
| 829 |
+
")\n",
|
| 830 |
+
"tokenizer.enable_truncation(max_length=512)"
|
| 831 |
+
],
|
| 832 |
+
"execution_count": 0,
|
| 833 |
+
"outputs": []
|
| 834 |
+
},
|
| 835 |
+
{
|
| 836 |
+
"cell_type": "code",
|
| 837 |
+
"metadata": {
|
| 838 |
+
"id": "E3Ye27nchfzq",
|
| 839 |
+
"colab_type": "code",
|
| 840 |
+
"outputId": "b9812ed2-1ecd-4e1b-d9bd-7de581955e70",
|
| 841 |
+
"colab": {
|
| 842 |
+
"base_uri": "https://localhost:8080/",
|
| 843 |
+
"height": 34
|
| 844 |
+
}
|
| 845 |
+
},
|
| 846 |
+
"source": [
|
| 847 |
+
"tokenizer.encode(\"Mi estas Julien.\")"
|
| 848 |
+
],
|
| 849 |
+
"execution_count": 0,
|
| 850 |
+
"outputs": [
|
| 851 |
+
{
|
| 852 |
+
"output_type": "execute_result",
|
| 853 |
+
"data": {
|
| 854 |
+
"text/plain": [
|
| 855 |
+
"Encoding(num_tokens=7, attributes=[ids, type_ids, tokens, offsets, attention_mask, special_tokens_mask, overflowing])"
|
| 856 |
+
]
|
| 857 |
+
},
|
| 858 |
+
"metadata": {
|
| 859 |
+
"tags": []
|
| 860 |
+
},
|
| 861 |
+
"execution_count": 10
|
| 862 |
+
}
|
| 863 |
+
]
|
| 864 |
+
},
|
| 865 |
+
{
|
| 866 |
+
"cell_type": "code",
|
| 867 |
+
"metadata": {
|
| 868 |
+
"id": "X8ya5_7rhjKS",
|
| 869 |
+
"colab_type": "code",
|
| 870 |
+
"outputId": "e9e08ded-1081-4823-dd81-9d6be1255385",
|
| 871 |
+
"colab": {
|
| 872 |
+
"base_uri": "https://localhost:8080/",
|
| 873 |
+
"height": 34
|
| 874 |
+
}
|
| 875 |
+
},
|
| 876 |
+
"source": [
|
| 877 |
+
"tokenizer.encode(\"Mi estas Julien.\").tokens"
|
| 878 |
+
],
|
| 879 |
+
"execution_count": 0,
|
| 880 |
+
"outputs": [
|
| 881 |
+
{
|
| 882 |
+
"output_type": "execute_result",
|
| 883 |
+
"data": {
|
| 884 |
+
"text/plain": [
|
| 885 |
+
"['<s>', 'Mi', 'Ġestas', 'ĠJuli', 'en', '.', '</s>']"
|
| 886 |
+
]
|
| 887 |
+
},
|
| 888 |
+
"metadata": {
|
| 889 |
+
"tags": []
|
| 890 |
+
},
|
| 891 |
+
"execution_count": 11
|
| 892 |
+
}
|
| 893 |
+
]
|
| 894 |
+
},
|
| 895 |
+
{
|
| 896 |
+
"cell_type": "markdown",
|
| 897 |
+
"metadata": {
|
| 898 |
+
"id": "WQpUC_CDhnWW",
|
| 899 |
+
"colab_type": "text"
|
| 900 |
+
},
|
| 901 |
+
"source": [
|
| 902 |
+
"## 3. Train a language model from scratch\n",
|
| 903 |
+
"\n",
|
| 904 |
+
"**Update:** This section follows along the [`run_language_modeling.py`](https://github.com/huggingface/transformers/blob/master/examples/legacy/run_language_modeling.py) script, using our new [`Trainer`](https://github.com/huggingface/transformers/blob/master/src/transformers/trainer.py) directly. Feel free to pick the approach you like best.\n",
|
| 905 |
+
"\n",
|
| 906 |
+
"> We’ll train a RoBERTa-like model, which is a BERT-like with a couple of changes (check the [documentation](https://huggingface.co/transformers/model_doc/roberta.html) for more details).\n",
|
| 907 |
+
"\n",
|
| 908 |
+
"As the model is BERT-like, we’ll train it on a task of *Masked language modeling*, i.e. the predict how to fill arbitrary tokens that we randomly mask in the dataset. This is taken care of by the example script.\n"
|
| 909 |
+
]
|
| 910 |
+
},
|
| 911 |
+
{
|
| 912 |
+
"cell_type": "code",
|
| 913 |
+
"metadata": {
|
| 914 |
+
"id": "kD140sFjh0LQ",
|
| 915 |
+
"colab_type": "code",
|
| 916 |
+
"outputId": "0bab1f9e-bf7a-4f13-82d3-07fe5866ce78",
|
| 917 |
+
"colab": {
|
| 918 |
+
"base_uri": "https://localhost:8080/",
|
| 919 |
+
"height": 318
|
| 920 |
+
}
|
| 921 |
+
},
|
| 922 |
+
"source": [
|
| 923 |
+
"# Check that we have a GPU\n",
|
| 924 |
+
"!nvidia-smi"
|
| 925 |
+
],
|
| 926 |
+
"execution_count": 5,
|
| 927 |
+
"outputs": [
|
| 928 |
+
{
|
| 929 |
+
"output_type": "stream",
|
| 930 |
+
"text": [
|
| 931 |
+
"Fri May 15 21:17:12 2020 \n",
|
| 932 |
+
"+-----------------------------------------------------------------------------+\n",
|
| 933 |
+
"| NVIDIA-SMI 440.82 Driver Version: 418.67 CUDA Version: 10.1 |\n",
|
| 934 |
+
"|-------------------------------+----------------------+----------------------+\n",
|
| 935 |
+
"| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |\n",
|
| 936 |
+
"| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |\n",
|
| 937 |
+
"|===============================+======================+======================|\n",
|
| 938 |
+
"| 0 Tesla P100-PCIE... Off | 00000000:00:04.0 Off | 0 |\n",
|
| 939 |
+
"| N/A 38C P0 26W / 250W | 0MiB / 16280MiB | 0% Default |\n",
|
| 940 |
+
"+-------------------------------+----------------------+----------------------+\n",
|
| 941 |
+
" \n",
|
| 942 |
+
"+-----------------------------------------------------------------------------+\n",
|
| 943 |
+
"| Processes: GPU Memory |\n",
|
| 944 |
+
"| GPU PID Type Process name Usage |\n",
|
| 945 |
+
"|=============================================================================|\n",
|
| 946 |
+
"| No running processes found |\n",
|
| 947 |
+
"+-----------------------------------------------------------------------------+\n"
|
| 948 |
+
],
|
| 949 |
+
"name": "stdout"
|
| 950 |
+
}
|
| 951 |
+
]
|
| 952 |
+
},
|
| 953 |
+
{
|
| 954 |
+
"cell_type": "code",
|
| 955 |
+
"metadata": {
|
| 956 |
+
"id": "VNZZs-r6iKAV",
|
| 957 |
+
"colab_type": "code",
|
| 958 |
+
"outputId": "c8404d6c-7662-4240-c8da-ee89edfaf51b",
|
| 959 |
+
"colab": {
|
| 960 |
+
"base_uri": "https://localhost:8080/",
|
| 961 |
+
"height": 34
|
| 962 |
+
}
|
| 963 |
+
},
|
| 964 |
+
"source": [
|
| 965 |
+
"# Check that PyTorch sees it\n",
|
| 966 |
+
"import torch\n",
|
| 967 |
+
"torch.cuda.is_available()"
|
| 968 |
+
],
|
| 969 |
+
"execution_count": 6,
|
| 970 |
+
"outputs": [
|
| 971 |
+
{
|
| 972 |
+
"output_type": "execute_result",
|
| 973 |
+
"data": {
|
| 974 |
+
"text/plain": [
|
| 975 |
+
"True"
|
| 976 |
+
]
|
| 977 |
+
},
|
| 978 |
+
"metadata": {
|
| 979 |
+
"tags": []
|
| 980 |
+
},
|
| 981 |
+
"execution_count": 6
|
| 982 |
+
}
|
| 983 |
+
]
|
| 984 |
+
},
|
| 985 |
+
{
|
| 986 |
+
"cell_type": "markdown",
|
| 987 |
+
"metadata": {
|
| 988 |
+
"id": "u0qQzgrBi1OX",
|
| 989 |
+
"colab_type": "text"
|
| 990 |
+
},
|
| 991 |
+
"source": [
|
| 992 |
+
"### We'll define the following config for the model"
|
| 993 |
+
]
|
| 994 |
+
},
|
| 995 |
+
{
|
| 996 |
+
"cell_type": "code",
|
| 997 |
+
"metadata": {
|
| 998 |
+
"id": "LTXXutqeDzPi",
|
| 999 |
+
"colab_type": "code",
|
| 1000 |
+
"colab": {}
|
| 1001 |
+
},
|
| 1002 |
+
"source": [
|
| 1003 |
+
"from transformers import RobertaConfig\n",
|
| 1004 |
+
"\n",
|
| 1005 |
+
"config = RobertaConfig(\n",
|
| 1006 |
+
" vocab_size=52_000,\n",
|
| 1007 |
+
" max_position_embeddings=514,\n",
|
| 1008 |
+
" num_attention_heads=12,\n",
|
| 1009 |
+
" num_hidden_layers=6,\n",
|
| 1010 |
+
" type_vocab_size=1,\n",
|
| 1011 |
+
")"
|
| 1012 |
+
],
|
| 1013 |
+
"execution_count": 0,
|
| 1014 |
+
"outputs": []
|
| 1015 |
+
},
|
| 1016 |
+
{
|
| 1017 |
+
"cell_type": "markdown",
|
| 1018 |
+
"metadata": {
|
| 1019 |
+
"id": "yAwQ82JiE5pi",
|
| 1020 |
+
"colab_type": "text"
|
| 1021 |
+
},
|
| 1022 |
+
"source": [
|
| 1023 |
+
"Now let's re-create our tokenizer in transformers"
|
| 1024 |
+
]
|
| 1025 |
+
},
|
| 1026 |
+
{
|
| 1027 |
+
"cell_type": "code",
|
| 1028 |
+
"metadata": {
|
| 1029 |
+
"id": "4keFBUjQFOD1",
|
| 1030 |
+
"colab_type": "code",
|
| 1031 |
+
"colab": {}
|
| 1032 |
+
},
|
| 1033 |
+
"source": [
|
| 1034 |
+
"from transformers import RobertaTokenizerFast\n",
|
| 1035 |
+
"\n",
|
| 1036 |
+
"tokenizer = RobertaTokenizerFast.from_pretrained(\"./EsperBERTo\", max_len=512)"
|
| 1037 |
+
],
|
| 1038 |
+
"execution_count": 0,
|
| 1039 |
+
"outputs": []
|
| 1040 |
+
},
|
| 1041 |
+
{
|
| 1042 |
+
"cell_type": "markdown",
|
| 1043 |
+
"metadata": {
|
| 1044 |
+
"id": "6yNCw-3hFv9h",
|
| 1045 |
+
"colab_type": "text"
|
| 1046 |
+
},
|
| 1047 |
+
"source": [
|
| 1048 |
+
"Finally let's initialize our model.\n",
|
| 1049 |
+
"\n",
|
| 1050 |
+
"**Important:**\n",
|
| 1051 |
+
"\n",
|
| 1052 |
+
"As we are training from scratch, we only initialize from a config, not from an existing pretrained model or checkpoint."
|
| 1053 |
+
]
|
| 1054 |
+
},
|
| 1055 |
+
{
|
| 1056 |
+
"cell_type": "code",
|
| 1057 |
+
"metadata": {
|
| 1058 |
+
"id": "BzMqR-dzF4Ro",
|
| 1059 |
+
"colab_type": "code",
|
| 1060 |
+
"colab": {}
|
| 1061 |
+
},
|
| 1062 |
+
"source": [
|
| 1063 |
+
"from transformers import RobertaForMaskedLM\n",
|
| 1064 |
+
"\n",
|
| 1065 |
+
"model = RobertaForMaskedLM(config=config)"
|
| 1066 |
+
],
|
| 1067 |
+
"execution_count": 0,
|
| 1068 |
+
"outputs": []
|
| 1069 |
+
},
|
| 1070 |
+
{
|
| 1071 |
+
"cell_type": "code",
|
| 1072 |
+
"metadata": {
|
| 1073 |
+
"id": "jU6JhBSTKiaM",
|
| 1074 |
+
"colab_type": "code",
|
| 1075 |
+
"outputId": "35879a60-2915-4894-f702-2d649cfa398a",
|
| 1076 |
+
"colab": {
|
| 1077 |
+
"base_uri": "https://localhost:8080/",
|
| 1078 |
+
"height": 34
|
| 1079 |
+
}
|
| 1080 |
+
},
|
| 1081 |
+
"source": [
|
| 1082 |
+
"model.num_parameters()\n",
|
| 1083 |
+
"# => 84 million parameters"
|
| 1084 |
+
],
|
| 1085 |
+
"execution_count": 10,
|
| 1086 |
+
"outputs": [
|
| 1087 |
+
{
|
| 1088 |
+
"output_type": "execute_result",
|
| 1089 |
+
"data": {
|
| 1090 |
+
"text/plain": [
|
| 1091 |
+
"84095008"
|
| 1092 |
+
]
|
| 1093 |
+
},
|
| 1094 |
+
"metadata": {
|
| 1095 |
+
"tags": []
|
| 1096 |
+
},
|
| 1097 |
+
"execution_count": 10
|
| 1098 |
+
}
|
| 1099 |
+
]
|
| 1100 |
+
},
|
| 1101 |
+
{
|
| 1102 |
+
"cell_type": "markdown",
|
| 1103 |
+
"metadata": {
|
| 1104 |
+
"id": "jBtUHRMliOLM",
|
| 1105 |
+
"colab_type": "text"
|
| 1106 |
+
},
|
| 1107 |
+
"source": [
|
| 1108 |
+
"### Now let's build our training Dataset\n",
|
| 1109 |
+
"\n",
|
| 1110 |
+
"We'll build our dataset by applying our tokenizer to our text file.\n",
|
| 1111 |
+
"\n",
|
| 1112 |
+
"Here, as we only have one text file, we don't even need to customize our `Dataset`. We'll just use the `LineByLineDataset` out-of-the-box."
|
| 1113 |
+
]
|
| 1114 |
+
},
|
| 1115 |
+
{
|
| 1116 |
+
"cell_type": "code",
|
| 1117 |
+
"metadata": {
|
| 1118 |
+
"id": "GlvP_A-THEEl",
|
| 1119 |
+
"colab_type": "code",
|
| 1120 |
+
"outputId": "e0510a33-7937-4a04-fa1c-d4e20b758bb2",
|
| 1121 |
+
"colab": {
|
| 1122 |
+
"base_uri": "https://localhost:8080/",
|
| 1123 |
+
"height": 52
|
| 1124 |
+
}
|
| 1125 |
+
},
|
| 1126 |
+
"source": [
|
| 1127 |
+
"%%time\n",
|
| 1128 |
+
"from transformers import LineByLineTextDataset\n",
|
| 1129 |
+
"\n",
|
| 1130 |
+
"dataset = LineByLineTextDataset(\n",
|
| 1131 |
+
" tokenizer=tokenizer,\n",
|
| 1132 |
+
" file_path=\"./oscar.eo.txt\",\n",
|
| 1133 |
+
" block_size=128,\n",
|
| 1134 |
+
")"
|
| 1135 |
+
],
|
| 1136 |
+
"execution_count": 11,
|
| 1137 |
+
"outputs": [
|
| 1138 |
+
{
|
| 1139 |
+
"output_type": "stream",
|
| 1140 |
+
"text": [
|
| 1141 |
+
"CPU times: user 4min 54s, sys: 2.98 s, total: 4min 57s\n",
|
| 1142 |
+
"Wall time: 1min 37s\n"
|
| 1143 |
+
],
|
| 1144 |
+
"name": "stdout"
|
| 1145 |
+
}
|
| 1146 |
+
]
|
| 1147 |
+
},
|
| 1148 |
+
{
|
| 1149 |
+
"cell_type": "markdown",
|
| 1150 |
+
"metadata": {
|
| 1151 |
+
"id": "hDLs73HcIHk5",
|
| 1152 |
+
"colab_type": "text"
|
| 1153 |
+
},
|
| 1154 |
+
"source": [
|
| 1155 |
+
"Like in the [`run_language_modeling.py`](https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_language_modeling.py) script, we need to define a data_collator.\n",
|
| 1156 |
+
"\n",
|
| 1157 |
+
"This is just a small helper that will help us batch different samples of the dataset together into an object that PyTorch knows how to perform backprop on."
|
| 1158 |
+
]
|
| 1159 |
+
},
|
| 1160 |
+
{
|
| 1161 |
+
"cell_type": "code",
|
| 1162 |
+
"metadata": {
|
| 1163 |
+
"id": "zTgWPa9Dipk2",
|
| 1164 |
+
"colab_type": "code",
|
| 1165 |
+
"colab": {}
|
| 1166 |
+
},
|
| 1167 |
+
"source": [
|
| 1168 |
+
"from transformers import DataCollatorForLanguageModeling\n",
|
| 1169 |
+
"\n",
|
| 1170 |
+
"data_collator = DataCollatorForLanguageModeling(\n",
|
| 1171 |
+
" tokenizer=tokenizer, mlm=True, mlm_probability=0.15\n",
|
| 1172 |
+
")"
|
| 1173 |
+
],
|
| 1174 |
+
"execution_count": 0,
|
| 1175 |
+
"outputs": []
|
| 1176 |
+
},
|
| 1177 |
+
{
|
| 1178 |
+
"cell_type": "markdown",
|
| 1179 |
+
"metadata": {
|
| 1180 |
+
"id": "ri2BIQKqjfHm",
|
| 1181 |
+
"colab_type": "text"
|
| 1182 |
+
},
|
| 1183 |
+
"source": [
|
| 1184 |
+
"### Finally, we are all set to initialize our Trainer"
|
| 1185 |
+
]
|
| 1186 |
+
},
|
| 1187 |
+
{
|
| 1188 |
+
"cell_type": "code",
|
| 1189 |
+
"metadata": {
|
| 1190 |
+
"id": "YpvnFFmZJD-N",
|
| 1191 |
+
"colab_type": "code",
|
| 1192 |
+
"colab": {}
|
| 1193 |
+
},
|
| 1194 |
+
"source": [
|
| 1195 |
+
"from transformers import Trainer, TrainingArguments\n",
|
| 1196 |
+
"\n",
|
| 1197 |
+
"training_args = TrainingArguments(\n",
|
| 1198 |
+
" output_dir=\"./EsperBERTo\",\n",
|
| 1199 |
+
" overwrite_output_dir=True,\n",
|
| 1200 |
+
" num_train_epochs=1,\n",
|
| 1201 |
+
" per_gpu_train_batch_size=64,\n",
|
| 1202 |
+
" save_steps=10_000,\n",
|
| 1203 |
+
" save_total_limit=2,\n",
|
| 1204 |
+
" prediction_loss_only=True,\n",
|
| 1205 |
+
")\n",
|
| 1206 |
+
"\n",
|
| 1207 |
+
"trainer = Trainer(\n",
|
| 1208 |
+
" model=model,\n",
|
| 1209 |
+
" args=training_args,\n",
|
| 1210 |
+
" data_collator=data_collator,\n",
|
| 1211 |
+
" train_dataset=dataset,\n",
|
| 1212 |
+
")"
|
| 1213 |
+
],
|
| 1214 |
+
"execution_count": 0,
|
| 1215 |
+
"outputs": []
|
| 1216 |
+
},
|
| 1217 |
+
{
|
| 1218 |
+
"cell_type": "markdown",
|
| 1219 |
+
"metadata": {
|
| 1220 |
+
"id": "o6sASa36Nf-N",
|
| 1221 |
+
"colab_type": "text"
|
| 1222 |
+
},
|
| 1223 |
+
"source": [
|
| 1224 |
+
"### Start training"
|
| 1225 |
+
]
|
| 1226 |
+
},
|
| 1227 |
+
{
|
| 1228 |
+
"cell_type": "code",
|
| 1229 |
+
"metadata": {
|
| 1230 |
+
"id": "VmaHZXzmkNtJ",
|
| 1231 |
+
"colab_type": "code",
|
| 1232 |
+
"outputId": "a19880cb-bcc6-4885-bf24-c2c6d0f56d1e",
|
| 1233 |
+
"colab": {
|
| 1234 |
+
"base_uri": "https://localhost:8080/",
|
| 1235 |
+
"height": 738,
|
| 1236 |
+
"referenced_widgets": [
|
| 1237 |
+
"a58a66392b644b1384661e850c077a6c",
|
| 1238 |
+
"a491e8caa0a048beb3b5259f14eb233f",
|
| 1239 |
+
"837c9ddc3d594e088891874560c646b8",
|
| 1240 |
+
"dbf50873d62c4ba39321faefbed0cca5",
|
| 1241 |
+
"40bf955ba0284e84b198da6be8654219",
|
| 1242 |
+
"fe20a8dae6e84628b5076d02183090f5",
|
| 1243 |
+
"93b3f9eae3cb4e3e859cf456e3547c6d",
|
| 1244 |
+
"6feb10aeb43147e6aba028d065947ae8",
|
| 1245 |
+
"0989d41a4da24e9ebff377e02127642c",
|
| 1246 |
+
"42c6061ef7e44f179db5a6e3551c0f17",
|
| 1247 |
+
"d295dd80550447d88da0f04ce36a22ff",
|
| 1248 |
+
"04e7e6d291da49d5816dc98a2904e95c",
|
| 1249 |
+
"e7d8c3a4fecd40778e32966b29ea65a1",
|
| 1250 |
+
"016d7c8318f742c1943464b08232a510",
|
| 1251 |
+
"8388e9da9da4492c98c19235ca5fc1b5",
|
| 1252 |
+
"39c23c6a972b419eb2eeeebafeaedc22"
|
| 1253 |
+
]
|
| 1254 |
+
}
|
| 1255 |
+
},
|
| 1256 |
+
"source": [
|
| 1257 |
+
"%%time\n",
|
| 1258 |
+
"trainer.train()"
|
| 1259 |
+
],
|
| 1260 |
+
"execution_count": 18,
|
| 1261 |
+
"outputs": [
|
| 1262 |
+
{
|
| 1263 |
+
"output_type": "display_data",
|
| 1264 |
+
"data": {
|
| 1265 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 1266 |
+
"model_id": "a58a66392b644b1384661e850c077a6c",
|
| 1267 |
+
"version_minor": 0,
|
| 1268 |
+
"version_major": 2
|
| 1269 |
+
},
|
| 1270 |
+
"text/plain": [
|
| 1271 |
+
"HBox(children=(FloatProgress(value=0.0, description='Epoch', max=1.0, style=ProgressStyle(description_width='i…"
|
| 1272 |
+
]
|
| 1273 |
+
},
|
| 1274 |
+
"metadata": {
|
| 1275 |
+
"tags": []
|
| 1276 |
+
}
|
| 1277 |
+
},
|
| 1278 |
+
{
|
| 1279 |
+
"output_type": "display_data",
|
| 1280 |
+
"data": {
|
| 1281 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 1282 |
+
"model_id": "0989d41a4da24e9ebff377e02127642c",
|
| 1283 |
+
"version_minor": 0,
|
| 1284 |
+
"version_major": 2
|
| 1285 |
+
},
|
| 1286 |
+
"text/plain": [
|
| 1287 |
+
"HBox(children=(FloatProgress(value=0.0, description='Iteration', max=15228.0, style=ProgressStyle(description_…"
|
| 1288 |
+
]
|
| 1289 |
+
},
|
| 1290 |
+
"metadata": {
|
| 1291 |
+
"tags": []
|
| 1292 |
+
}
|
| 1293 |
+
},
|
| 1294 |
+
{
|
| 1295 |
+
"output_type": "stream",
|
| 1296 |
+
"text": [
|
| 1297 |
+
"{\"loss\": 7.152712148666382, \"learning_rate\": 4.8358287365379566e-05, \"epoch\": 0.03283425269240872, \"step\": 500}\n",
|
| 1298 |
+
"{\"loss\": 6.928811420440674, \"learning_rate\": 4.671657473075913e-05, \"epoch\": 0.06566850538481744, \"step\": 1000}\n",
|
| 1299 |
+
"{\"loss\": 6.789419063568115, \"learning_rate\": 4.5074862096138694e-05, \"epoch\": 0.09850275807722617, \"step\": 1500}\n",
|
| 1300 |
+
"{\"loss\": 6.688932447433472, \"learning_rate\": 4.343314946151826e-05, \"epoch\": 0.1313370107696349, \"step\": 2000}\n",
|
| 1301 |
+
"{\"loss\": 6.595982004165649, \"learning_rate\": 4.179143682689782e-05, \"epoch\": 0.1641712634620436, \"step\": 2500}\n",
|
| 1302 |
+
"{\"loss\": 6.545944199562073, \"learning_rate\": 4.0149724192277385e-05, \"epoch\": 0.19700551615445233, \"step\": 3000}\n",
|
| 1303 |
+
"{\"loss\": 6.4864857263565066, \"learning_rate\": 3.850801155765695e-05, \"epoch\": 0.22983976884686105, \"step\": 3500}\n",
|
| 1304 |
+
"{\"loss\": 6.412427802085876, \"learning_rate\": 3.686629892303651e-05, \"epoch\": 0.2626740215392698, \"step\": 4000}\n",
|
| 1305 |
+
"{\"loss\": 6.363630670547486, \"learning_rate\": 3.522458628841608e-05, \"epoch\": 0.29550827423167847, \"step\": 4500}\n",
|
| 1306 |
+
"{\"loss\": 6.273832890510559, \"learning_rate\": 3.358287365379564e-05, \"epoch\": 0.3283425269240872, \"step\": 5000}\n",
|
| 1307 |
+
"{\"loss\": 6.197585330963134, \"learning_rate\": 3.1941161019175205e-05, \"epoch\": 0.3611767796164959, \"step\": 5500}\n",
|
| 1308 |
+
"{\"loss\": 6.097779376983643, \"learning_rate\": 3.029944838455477e-05, \"epoch\": 0.39401103230890466, \"step\": 6000}\n",
|
| 1309 |
+
"{\"loss\": 5.985456382751464, \"learning_rate\": 2.8657735749934332e-05, \"epoch\": 0.42684528500131336, \"step\": 6500}\n",
|
| 1310 |
+
"{\"loss\": 5.8448616371154785, \"learning_rate\": 2.70160231153139e-05, \"epoch\": 0.4596795376937221, \"step\": 7000}\n",
|
| 1311 |
+
"{\"loss\": 5.692522863388062, \"learning_rate\": 2.5374310480693457e-05, \"epoch\": 0.4925137903861308, \"step\": 7500}\n",
|
| 1312 |
+
"{\"loss\": 5.562082152366639, \"learning_rate\": 2.3732597846073024e-05, \"epoch\": 0.5253480430785396, \"step\": 8000}\n",
|
| 1313 |
+
"{\"loss\": 5.457240365982056, \"learning_rate\": 2.2090885211452588e-05, \"epoch\": 0.5581822957709482, \"step\": 8500}\n",
|
| 1314 |
+
"{\"loss\": 5.376953645706177, \"learning_rate\": 2.0449172576832152e-05, \"epoch\": 0.5910165484633569, \"step\": 9000}\n",
|
| 1315 |
+
"{\"loss\": 5.298609251022339, \"learning_rate\": 1.8807459942211716e-05, \"epoch\": 0.6238508011557657, \"step\": 9500}\n",
|
| 1316 |
+
"{\"loss\": 5.225468152046203, \"learning_rate\": 1.716574730759128e-05, \"epoch\": 0.6566850538481744, \"step\": 10000}\n",
|
| 1317 |
+
"{\"loss\": 5.174519973754883, \"learning_rate\": 1.5524034672970843e-05, \"epoch\": 0.6895193065405831, \"step\": 10500}\n",
|
| 1318 |
+
"{\"loss\": 5.113943946838379, \"learning_rate\": 1.3882322038350407e-05, \"epoch\": 0.7223535592329918, \"step\": 11000}\n",
|
| 1319 |
+
"{\"loss\": 5.08140989112854, \"learning_rate\": 1.2240609403729971e-05, \"epoch\": 0.7551878119254006, \"step\": 11500}\n",
|
| 1320 |
+
"{\"loss\": 5.072491912841797, \"learning_rate\": 1.0598896769109535e-05, \"epoch\": 0.7880220646178093, \"step\": 12000}\n",
|
| 1321 |
+
"{\"loss\": 5.012459496498108, \"learning_rate\": 8.957184134489099e-06, \"epoch\": 0.820856317310218, \"step\": 12500}\n",
|
| 1322 |
+
"{\"loss\": 4.999591351509094, \"learning_rate\": 7.315471499868663e-06, \"epoch\": 0.8536905700026267, \"step\": 13000}\n",
|
| 1323 |
+
"{\"loss\": 4.994838352203369, \"learning_rate\": 5.673758865248227e-06, \"epoch\": 0.8865248226950354, \"step\": 13500}\n",
|
| 1324 |
+
"{\"loss\": 4.955870885848999, \"learning_rate\": 4.032046230627791e-06, \"epoch\": 0.9193590753874442, \"step\": 14000}\n",
|
| 1325 |
+
"{\"loss\": 4.941655583381653, \"learning_rate\": 2.390333596007355e-06, \"epoch\": 0.9521933280798529, \"step\": 14500}\n",
|
| 1326 |
+
"{\"loss\": 4.931783639907837, \"learning_rate\": 7.486209613869189e-07, \"epoch\": 0.9850275807722616, \"step\": 15000}\n",
|
| 1327 |
+
"\n",
|
| 1328 |
+
"\n",
|
| 1329 |
+
"CPU times: user 1h 43min 36s, sys: 1h 3min 28s, total: 2h 47min 4s\n",
|
| 1330 |
+
"Wall time: 2h 46min 46s\n"
|
| 1331 |
+
],
|
| 1332 |
+
"name": "stdout"
|
| 1333 |
+
},
|
| 1334 |
+
{
|
| 1335 |
+
"output_type": "execute_result",
|
| 1336 |
+
"data": {
|
| 1337 |
+
"text/plain": [
|
| 1338 |
+
"TrainOutput(global_step=15228, training_loss=5.762423221226405)"
|
| 1339 |
+
]
|
| 1340 |
+
},
|
| 1341 |
+
"metadata": {
|
| 1342 |
+
"tags": []
|
| 1343 |
+
},
|
| 1344 |
+
"execution_count": 18
|
| 1345 |
+
}
|
| 1346 |
+
]
|
| 1347 |
+
},
|
| 1348 |
+
{
|
| 1349 |
+
"cell_type": "markdown",
|
| 1350 |
+
"metadata": {
|
| 1351 |
+
"id": "_ZkooHz1-_2h",
|
| 1352 |
+
"colab_type": "text"
|
| 1353 |
+
},
|
| 1354 |
+
"source": [
|
| 1355 |
+
"#### 🎉 Save final model (+ tokenizer + config) to disk"
|
| 1356 |
+
]
|
| 1357 |
+
},
|
| 1358 |
+
{
|
| 1359 |
+
"cell_type": "code",
|
| 1360 |
+
"metadata": {
|
| 1361 |
+
"id": "QDNgPls7_l13",
|
| 1362 |
+
"colab_type": "code",
|
| 1363 |
+
"colab": {}
|
| 1364 |
+
},
|
| 1365 |
+
"source": [
|
| 1366 |
+
"trainer.save_model(\"./EsperBERTo\")"
|
| 1367 |
+
],
|
| 1368 |
+
"execution_count": 0,
|
| 1369 |
+
"outputs": []
|
| 1370 |
+
},
|
| 1371 |
+
{
|
| 1372 |
+
"cell_type": "markdown",
|
| 1373 |
+
"metadata": {
|
| 1374 |
+
"id": "d0caceCy_p1-",
|
| 1375 |
+
"colab_type": "text"
|
| 1376 |
+
},
|
| 1377 |
+
"source": [
|
| 1378 |
+
"## 4. Check that the LM actually trained"
|
| 1379 |
+
]
|
| 1380 |
+
},
|
| 1381 |
+
{
|
| 1382 |
+
"cell_type": "markdown",
|
| 1383 |
+
"metadata": {
|
| 1384 |
+
"id": "iIQJ8ND_AEhl",
|
| 1385 |
+
"colab_type": "text"
|
| 1386 |
+
},
|
| 1387 |
+
"source": [
|
| 1388 |
+
"Aside from looking at the training and eval losses going down, the easiest way to check whether our language model is learning anything interesting is via the `FillMaskPipeline`.\n",
|
| 1389 |
+
"\n",
|
| 1390 |
+
"Pipelines are simple wrappers around tokenizers and models, and the 'fill-mask' one will let you input a sequence containing a masked token (here, `<mask>`) and return a list of the most probable filled sequences, with their probabilities.\n",
|
| 1391 |
+
"\n"
|
| 1392 |
+
]
|
| 1393 |
+
},
|
| 1394 |
+
{
|
| 1395 |
+
"cell_type": "code",
|
| 1396 |
+
"metadata": {
|
| 1397 |
+
"id": "ltXgXyCbAJLY",
|
| 1398 |
+
"colab_type": "code",
|
| 1399 |
+
"colab": {}
|
| 1400 |
+
},
|
| 1401 |
+
"source": [
|
| 1402 |
+
"from transformers import pipeline\n",
|
| 1403 |
+
"\n",
|
| 1404 |
+
"fill_mask = pipeline(\n",
|
| 1405 |
+
" \"fill-mask\",\n",
|
| 1406 |
+
" model=\"./EsperBERTo\",\n",
|
| 1407 |
+
" tokenizer=\"./EsperBERTo\"\n",
|
| 1408 |
+
")"
|
| 1409 |
+
],
|
| 1410 |
+
"execution_count": 0,
|
| 1411 |
+
"outputs": []
|
| 1412 |
+
},
|
| 1413 |
+
{
|
| 1414 |
+
"cell_type": "code",
|
| 1415 |
+
"metadata": {
|
| 1416 |
+
"id": "UIvgZ3S6AO0z",
|
| 1417 |
+
"colab_type": "code",
|
| 1418 |
+
"colab": {
|
| 1419 |
+
"base_uri": "https://localhost:8080/",
|
| 1420 |
+
"height": 283
|
| 1421 |
+
},
|
| 1422 |
+
"outputId": "5f3d2f00-abdc-44a9-9c1b-75e3ec328576"
|
| 1423 |
+
},
|
| 1424 |
+
"source": [
|
| 1425 |
+
"# The sun <mask>.\n",
|
| 1426 |
+
"# =>\n",
|
| 1427 |
+
"\n",
|
| 1428 |
+
"fill_mask(\"La suno <mask>.\")"
|
| 1429 |
+
],
|
| 1430 |
+
"execution_count": 36,
|
| 1431 |
+
"outputs": [
|
| 1432 |
+
{
|
| 1433 |
+
"output_type": "execute_result",
|
| 1434 |
+
"data": {
|
| 1435 |
+
"text/plain": [
|
| 1436 |
+
"[{'score': 0.02119220793247223,\n",
|
| 1437 |
+
" 'sequence': '<s> La suno estas.</s>',\n",
|
| 1438 |
+
" 'token': 316},\n",
|
| 1439 |
+
" {'score': 0.012403824366629124,\n",
|
| 1440 |
+
" 'sequence': '<s> La suno situas.</s>',\n",
|
| 1441 |
+
" 'token': 2340},\n",
|
| 1442 |
+
" {'score': 0.011061107739806175,\n",
|
| 1443 |
+
" 'sequence': '<s> La suno estis.</s>',\n",
|
| 1444 |
+
" 'token': 394},\n",
|
| 1445 |
+
" {'score': 0.008284995332360268,\n",
|
| 1446 |
+
" 'sequence': '<s> La suno de.</s>',\n",
|
| 1447 |
+
" 'token': 274},\n",
|
| 1448 |
+
" {'score': 0.006471084896475077,\n",
|
| 1449 |
+
" 'sequence': '<s> La suno akvo.</s>',\n",
|
| 1450 |
+
" 'token': 1833}]"
|
| 1451 |
+
]
|
| 1452 |
+
},
|
| 1453 |
+
"metadata": {
|
| 1454 |
+
"tags": []
|
| 1455 |
+
},
|
| 1456 |
+
"execution_count": 36
|
| 1457 |
+
}
|
| 1458 |
+
]
|
| 1459 |
+
},
|
| 1460 |
+
{
|
| 1461 |
+
"cell_type": "markdown",
|
| 1462 |
+
"metadata": {
|
| 1463 |
+
"id": "i0qCyyhNAWZi",
|
| 1464 |
+
"colab_type": "text"
|
| 1465 |
+
},
|
| 1466 |
+
"source": [
|
| 1467 |
+
"Ok, simple syntax/grammar works. Let’s try a slightly more interesting prompt:\n",
|
| 1468 |
+
"\n"
|
| 1469 |
+
]
|
| 1470 |
+
},
|
| 1471 |
+
{
|
| 1472 |
+
"cell_type": "code",
|
| 1473 |
+
"metadata": {
|
| 1474 |
+
"id": "YZ9HSQxAAbme",
|
| 1475 |
+
"colab_type": "code",
|
| 1476 |
+
"colab": {
|
| 1477 |
+
"base_uri": "https://localhost:8080/",
|
| 1478 |
+
"height": 283
|
| 1479 |
+
},
|
| 1480 |
+
"outputId": "aabfeedc-b1d0-4837-b01d-cd42726a5a3d"
|
| 1481 |
+
},
|
| 1482 |
+
"source": [
|
| 1483 |
+
"fill_mask(\"Jen la komenco de bela <mask>.\")\n",
|
| 1484 |
+
"\n",
|
| 1485 |
+
"# This is the beginning of a beautiful <mask>.\n",
|
| 1486 |
+
"# =>"
|
| 1487 |
+
],
|
| 1488 |
+
"execution_count": 37,
|
| 1489 |
+
"outputs": [
|
| 1490 |
+
{
|
| 1491 |
+
"output_type": "execute_result",
|
| 1492 |
+
"data": {
|
| 1493 |
+
"text/plain": [
|
| 1494 |
+
"[{'score': 0.01814725436270237,\n",
|
| 1495 |
+
" 'sequence': '<s> Jen la komenco de bela urbo.</s>',\n",
|
| 1496 |
+
" 'token': 871},\n",
|
| 1497 |
+
" {'score': 0.015888698399066925,\n",
|
| 1498 |
+
" 'sequence': '<s> Jen la komenco de bela vivo.</s>',\n",
|
| 1499 |
+
" 'token': 1160},\n",
|
| 1500 |
+
" {'score': 0.015662025660276413,\n",
|
| 1501 |
+
" 'sequence': '<s> Jen la komenco de bela tempo.</s>',\n",
|
| 1502 |
+
" 'token': 1021},\n",
|
| 1503 |
+
" {'score': 0.015555007383227348,\n",
|
| 1504 |
+
" 'sequence': '<s> Jen la komenco de bela mondo.</s>',\n",
|
| 1505 |
+
" 'token': 945},\n",
|
| 1506 |
+
" {'score': 0.01412549614906311,\n",
|
| 1507 |
+
" 'sequence': '<s> Jen la komenco de bela tago.</s>',\n",
|
| 1508 |
+
" 'token': 1633}]"
|
| 1509 |
+
]
|
| 1510 |
+
},
|
| 1511 |
+
"metadata": {
|
| 1512 |
+
"tags": []
|
| 1513 |
+
},
|
| 1514 |
+
"execution_count": 37
|
| 1515 |
+
}
|
| 1516 |
+
]
|
| 1517 |
+
},
|
| 1518 |
+
{
|
| 1519 |
+
"cell_type": "markdown",
|
| 1520 |
+
"metadata": {
|
| 1521 |
+
"id": "6RsGaD1qAfLP",
|
| 1522 |
+
"colab_type": "text"
|
| 1523 |
+
},
|
| 1524 |
+
"source": [
|
| 1525 |
+
"## 5. Share your model 🎉"
|
| 1526 |
+
]
|
| 1527 |
+
},
|
| 1528 |
+
{
|
| 1529 |
+
"cell_type": "markdown",
|
| 1530 |
+
"metadata": {
|
| 1531 |
+
"id": "5oESe8djApQw",
|
| 1532 |
+
"colab_type": "text"
|
| 1533 |
+
},
|
| 1534 |
+
"source": [
|
| 1535 |
+
"Finally, when you have a nice model, please think about sharing it with the community:\n",
|
| 1536 |
+
"\n",
|
| 1537 |
+
"- upload your model using the CLI: `transformers-cli upload`\n",
|
| 1538 |
+
"- write a README.md model card and add it to the repository under `model_cards/`. Your model card should ideally include:\n",
|
| 1539 |
+
" - a model description,\n",
|
| 1540 |
+
" - training params (dataset, preprocessing, hyperparameters), \n",
|
| 1541 |
+
" - evaluation results,\n",
|
| 1542 |
+
" - intended uses & limitations\n",
|
| 1543 |
+
" - whatever else is helpful! 🤓\n",
|
| 1544 |
+
"\n",
|
| 1545 |
+
"### **TADA!**\n",
|
| 1546 |
+
"\n",
|
| 1547 |
+
"➡️ Your model has a page on http://huggingface.co/models and everyone can load it using `AutoModel.from_pretrained(\"username/model_name\")`.\n",
|
| 1548 |
+
"\n",
|
| 1549 |
+
"[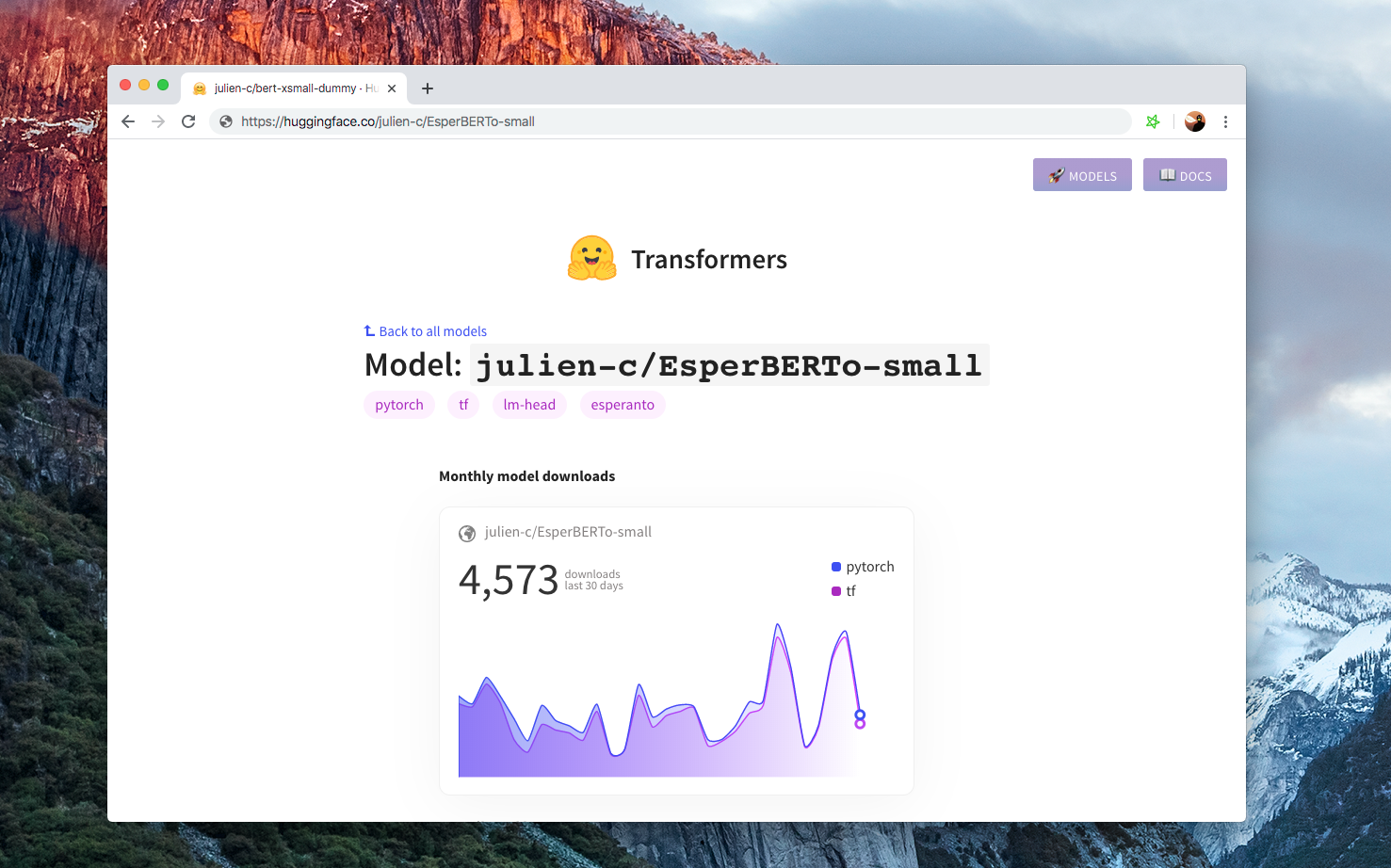](https://huggingface.co/julien-c/EsperBERTo-small)\n"
|
| 1550 |
+
]
|
| 1551 |
+
},
|
| 1552 |
+
{
|
| 1553 |
+
"cell_type": "markdown",
|
| 1554 |
+
"metadata": {
|
| 1555 |
+
"id": "aw9ifsgqBI2o",
|
| 1556 |
+
"colab_type": "text"
|
| 1557 |
+
},
|
| 1558 |
+
"source": [
|
| 1559 |
+
"If you want to take a look at models in different languages, check https://huggingface.co/models\n",
|
| 1560 |
+
"\n",
|
| 1561 |
+
"[](https://huggingface.co/models)\n"
|
| 1562 |
+
]
|
| 1563 |
+
}
|
| 1564 |
+
]
|
| 1565 |
+
}
|