

Commit
·
0efa21a
1
Parent(s):
29af53e
feat: init
Browse files- NuZero_token_token_metrics.txt +35 -0
- README.md +108 -0
- gliner_config.json +27 -0
- pytorch_model.bin +3 -0
- zero_shot_performance_unzero_token.png +0 -0
NuZero_token_token_metrics.txt
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
##############################################
|
| 2 |
+
step: final
|
| 3 |
+
Table for all datasets except crossNER
|
| 4 |
+
ACE 2004 : 38.5%
|
| 5 |
+
ACE 2005 : 39.6%
|
| 6 |
+
AnatEM : 48.8%
|
| 7 |
+
Broad Tweet Corpus : 64.5%
|
| 8 |
+
CoNLL 2003 : 66.0%
|
| 9 |
+
FabNER : 35.8%
|
| 10 |
+
FindVehicle : 48.8%
|
| 11 |
+
GENIA_NER : 59.4%
|
| 12 |
+
HarveyNER : 28.0%
|
| 13 |
+
MultiNERD : 61.8%
|
| 14 |
+
Ontonotes : 39.7%
|
| 15 |
+
PolyglotNER : 48.5%
|
| 16 |
+
TweetNER7 : 52.3%
|
| 17 |
+
WikiANN en : 69.6%
|
| 18 |
+
WikiNeural : 75.0%
|
| 19 |
+
bc2gm : 64.6%
|
| 20 |
+
bc4chemd : 64.6%
|
| 21 |
+
bc5cdr : 74.1%
|
| 22 |
+
ncbi : 74.9%
|
| 23 |
+
Average : 55.5%
|
| 24 |
+
|
| 25 |
+
Table for zero-shot benchmark
|
| 26 |
+
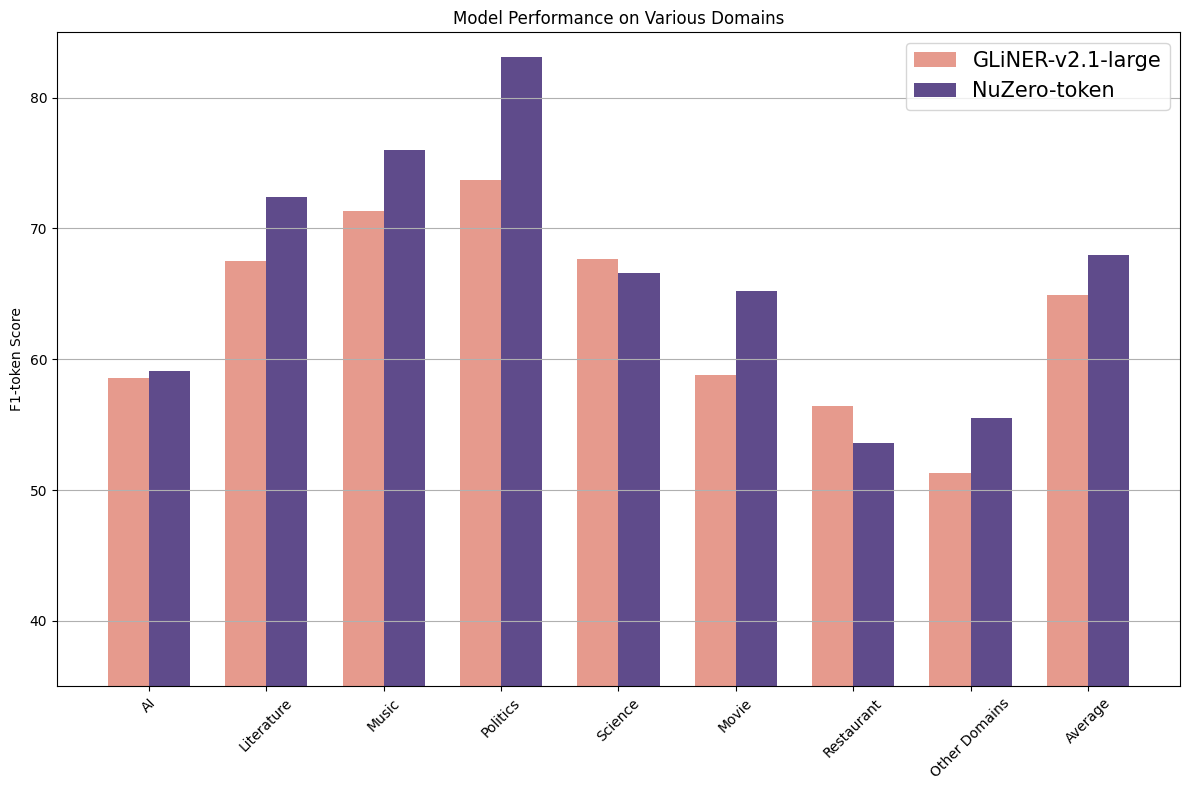
CrossNER_AI : 59.1%
|
| 27 |
+
CrossNER_literature : 72.4%
|
| 28 |
+
CrossNER_music : 76.0%
|
| 29 |
+
CrossNER_politics : 83.1%
|
| 30 |
+
CrossNER_science : 66.6%
|
| 31 |
+
mit-movie : 65.2%
|
| 32 |
+
mit-restaurant : 53.6%
|
| 33 |
+
Average : 68.0%
|
| 34 |
+
##############################################
|
| 35 |
+
|
README.md
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
datasets:
|
| 4 |
+
- numind/NuNER
|
| 5 |
+
library_name: gliner
|
| 6 |
+
language:
|
| 7 |
+
- en
|
| 8 |
+
pipeline_tag: token-classification
|
| 9 |
+
tags:
|
| 10 |
+
- entity recognition
|
| 11 |
+
- NER
|
| 12 |
+
- named entity recognition
|
| 13 |
+
- zero shot
|
| 14 |
+
- zero-shot
|
| 15 |
+
---
|
| 16 |
+
|
| 17 |
+
NuNER Zero is a zero-shot Named Entity Recognition (NER) Model. (Check [NuNER](https://huggingface.co/collections/numind/nuner-token-classification-and-ner-backbones-65e1f6e14639e2a465af823b) for the few-shot setting).
|
| 18 |
+
|
| 19 |
+
NuNER Zero uses the [GLiNER](https://huggingface.co/papers/2311.08526) architecture: its input should be a concatenation of entity types and text.
|
| 20 |
+
|
| 21 |
+
Unlike GliNER, NuNER Zero is a token classifier, which allows detect arbitrary long entities.
|
| 22 |
+
|
| 23 |
+
NuNER Zero was trained on [NuNER v2.0](https://huggingface.co/numind/NuNER-v2.0) dataset, which combines subsets of Pile and C4 annotated via LLMs using [NuNER's procedure](https://huggingface.co/papers/2402.15343).
|
| 24 |
+
|
| 25 |
+
NuNER Zero is (at the time of its release) the best compact zero-shot NER model (+3.1% token-level F1-Score over GLiNER-large-v2.1 on GLiNERS's benchmark)
|
| 26 |
+
|
| 27 |
+
<p align="left">
|
| 28 |
+
<img src="zero_shot_performance_unzero_token.png" width="600">
|
| 29 |
+
</p>
|
| 30 |
+
|
| 31 |
+
## Installation & Usage
|
| 32 |
+
|
| 33 |
+
```
|
| 34 |
+
!pip install gliner
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
**NuZero requires labels to be lower-cased**
|
| 38 |
+
|
| 39 |
+
```python
|
| 40 |
+
from gliner import GLiNER
|
| 41 |
+
|
| 42 |
+
def merge_entities(entities):
|
| 43 |
+
if not entities:
|
| 44 |
+
return []
|
| 45 |
+
merged = []
|
| 46 |
+
current = entities[0]
|
| 47 |
+
for next_entity in entities[1:]:
|
| 48 |
+
if next_entity['label'] == current['label'] and (next_entity['start'] == current['end'] + 1 or next_entity['start'] == current['end']):
|
| 49 |
+
current['text'] = text[current['start']: next_entity['end']].strip()
|
| 50 |
+
current['end'] = next_entity['end']
|
| 51 |
+
else:
|
| 52 |
+
merged.append(current)
|
| 53 |
+
current = next_entity
|
| 54 |
+
# Append the last entity
|
| 55 |
+
merged.append(current)
|
| 56 |
+
return merged
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
model = GLiNER.from_pretrained("numind/NuNerZero")
|
| 60 |
+
|
| 61 |
+
# NuZero requires labels to be lower-cased!
|
| 62 |
+
labels = ["organization", "initiative", "project"]
|
| 63 |
+
labels = [l.lower() for l in labels]
|
| 64 |
+
|
| 65 |
+
text = "At the annual technology summit, the keynote address was delivered by a senior member of the Association for Computing Machinery Special Interest Group on Algorithms and Computation Theory, which recently launched an expansive initiative titled 'Quantum Computing and Algorithmic Innovations: Shaping the Future of Technology'. This initiative explores the implications of quantum mechanics on next-generation computing and algorithm design and is part of a broader effort that includes the 'Global Computational Science Advancement Project'. The latter focuses on enhancing computational methodologies across scientific disciplines, aiming to set new benchmarks in computational efficiency and accuracy."
|
| 66 |
+
|
| 67 |
+
entities = model.predict_entities(text, labels)
|
| 68 |
+
|
| 69 |
+
entities = merge_entities(entities)
|
| 70 |
+
|
| 71 |
+
for entity in entities:
|
| 72 |
+
print(entity["text"], "=>", entity["label"])
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
```
|
| 76 |
+
Association for Computing Machinery Special Interest Group on Algorithms and Computation Theory => organization
|
| 77 |
+
Quantum Computing and Algorithmic Innovations: Shaping the Future of Technology => initiative
|
| 78 |
+
Global Computational Science Advancement Project => project
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
## Fine-tuning
|
| 82 |
+
|
| 83 |
+
A fine-tuning script can be found [here](https://colab.research.google.com/drive/1-hk5AIdX-TZdyes1yx-0qzS34YYEf3d2?usp=sharing).
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
## Citation
|
| 87 |
+
### This work
|
| 88 |
+
```bibtex
|
| 89 |
+
@misc{bogdanov2024nuner,
|
| 90 |
+
title={NuNER: Entity Recognition Encoder Pre-training via LLM-Annotated Data},
|
| 91 |
+
author={Sergei Bogdanov and Alexandre Constantin and Timothée Bernard and Benoit Crabbé and Etienne Bernard},
|
| 92 |
+
year={2024},
|
| 93 |
+
eprint={2402.15343},
|
| 94 |
+
archivePrefix={arXiv},
|
| 95 |
+
primaryClass={cs.CL}
|
| 96 |
+
}
|
| 97 |
+
```
|
| 98 |
+
### Previous work
|
| 99 |
+
```bibtex
|
| 100 |
+
@misc{zaratiana2023gliner,
|
| 101 |
+
title={GLiNER: Generalist Model for Named Entity Recognition using Bidirectional Transformer},
|
| 102 |
+
author={Urchade Zaratiana and Nadi Tomeh and Pierre Holat and Thierry Charnois},
|
| 103 |
+
year={2023},
|
| 104 |
+
eprint={2311.08526},
|
| 105 |
+
archivePrefix={arXiv},
|
| 106 |
+
primaryClass={cs.CL}
|
| 107 |
+
}
|
| 108 |
+
```
|
gliner_config.json
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"lr_encoder": "1e-5",
|
| 3 |
+
"lr_others": "5e-5",
|
| 4 |
+
"num_steps": 60000,
|
| 5 |
+
"warmup_ratio": 0.1,
|
| 6 |
+
"train_batch_size": 4,
|
| 7 |
+
"gradient_accumulation_steps": 2,
|
| 8 |
+
"eval_every": 2500,
|
| 9 |
+
"max_width": 1,
|
| 10 |
+
"model_name": "microsoft/deberta-v3-large",
|
| 11 |
+
"fine_tune": true,
|
| 12 |
+
"subtoken_pooling": "first",
|
| 13 |
+
"hidden_size": 768,
|
| 14 |
+
"span_mode": "marker",
|
| 15 |
+
"dropout": 0.4,
|
| 16 |
+
"root_dir": "ablation_backbone",
|
| 17 |
+
"train_data": "NuMinds_custom_data_mix.json",
|
| 18 |
+
"prev_path": "none",
|
| 19 |
+
"size_sup": -1,
|
| 20 |
+
"max_types": 25,
|
| 21 |
+
"shuffle_types": true,
|
| 22 |
+
"random_drop": true,
|
| 23 |
+
"max_neg_type_ratio": 1,
|
| 24 |
+
"max_len": 384,
|
| 25 |
+
"name": "large",
|
| 26 |
+
"log_dir": "logs"
|
| 27 |
+
}
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:96a89110ff7d5d029a1b1bc1236dc46b9e01202ca807a8d319fd4fe3009403f5
|
| 3 |
+
size 1795685762
|
zero_shot_performance_unzero_token.png
ADDED
|