
Upload folder using huggingface_hub
Browse files- .gitattributes +1 -0
- README.md +941 -0
- added_tokens.json +11 -0
- config.json +144 -0
- configuration_intern_vit.py +119 -0
- configuration_internlm2.py +150 -0
- configuration_internvl_chat.py +96 -0
- conversation.py +393 -0
- examples/image1.jpg +0 -0
- examples/image2.jpg +0 -0
- examples/index.html +17 -0
- examples/red-panda.mp4 +3 -0
- generation_config.json +4 -0
- index.html +37 -0
- model-00001-of-00004.safetensors +3 -0
- model-00002-of-00004.safetensors +3 -0
- model-00003-of-00004.safetensors +3 -0
- model-00004-of-00004.safetensors +3 -0
- model.safetensors.index.json +580 -0
- modeling_intern_vit.py +435 -0
- modeling_internlm2.py +1415 -0
- modeling_internvl_chat.py +361 -0
- preprocessor_config.json +19 -0
- special_tokens_map.json +47 -0
- tokenization_internlm2.py +235 -0
- tokenization_internlm2_fast.py +211 -0
- tokenizer.model +3 -0
- tokenizer_config.json +179 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
examples/red-panda.mp4 filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,941 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
pipeline_tag: image-text-to-text
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
# InternVL2-8B
|
| 7 |
+
|
| 8 |
+
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[🆕 Blog\]](https://internvl.github.io/blog/) [\[📜 InternVL 1.0 Paper\]](https://arxiv.org/abs/2312.14238) [\[📜 InternVL 1.5 Report\]](https://arxiv.org/abs/2404.16821)
|
| 9 |
+
|
| 10 |
+
[\[🗨️ Chat Demo\]](https://internvl.opengvlab.com/) [\[🤗 HF Demo\]](https://huggingface.co/spaces/OpenGVLab/InternVL) [\[🚀 Quick Start\]](#quick-start) [\[📖 中文解读\]](https://zhuanlan.zhihu.com/p/706547971) \[🌟 [魔搭社区](https://modelscope.cn/organization/OpenGVLab) | [教程](https://mp.weixin.qq.com/s/OUaVLkxlk1zhFb1cvMCFjg) \]
|
| 11 |
+
|
| 12 |
+
[切换至中文版](#简介)
|
| 13 |
+
|
| 14 |
+
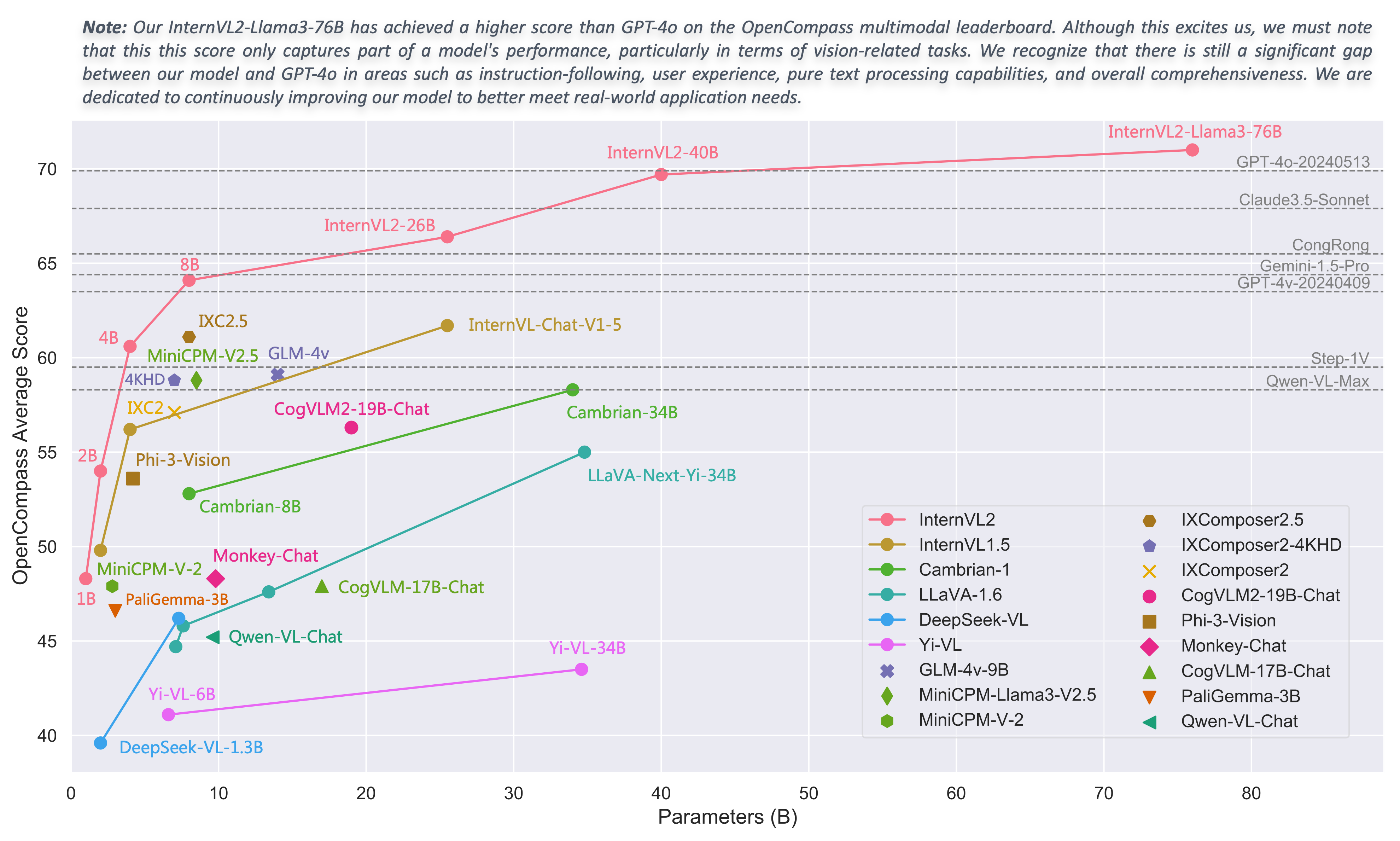
|
| 15 |
+
|
| 16 |
+
## Introduction
|
| 17 |
+
|
| 18 |
+
We are excited to announce the release of InternVL 2.0, the latest addition to the InternVL series of multimodal large language models. InternVL 2.0 features a variety of **instruction-tuned models**, ranging from 1 billion to 108 billion parameters. This repository contains the instruction-tuned InternVL2-8B model.
|
| 19 |
+
|
| 20 |
+
Compared to the state-of-the-art open-source multimodal large language models, InternVL 2.0 surpasses most open-source models. It demonstrates competitive performance on par with proprietary commercial models across various capabilities, including document and chart comprehension, infographics QA, scene text understanding and OCR tasks, scientific and mathematical problem solving, as well as cultural understanding and integrated multimodal capabilities.
|
| 21 |
+
|
| 22 |
+
InternVL 2.0 is trained with an 8k context window and utilizes training data consisting of long texts, multiple images, and videos, significantly improving its ability to handle these types of inputs compared to InternVL 1.5. For more details, please refer to our blog and GitHub.
|
| 23 |
+
|
| 24 |
+
| Model Name | Vision Part | Language Part | HF Link | MS Link |
|
| 25 |
+
| :------------------: | :---------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------: | :--------------------------------------------------------------: | :--------------------------------------------------------------------: |
|
| 26 |
+
| InternVL2-1B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-1B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-1B) |
|
| 27 |
+
| InternVL2-2B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [internlm2-chat-1_8b](https://huggingface.co/internlm/internlm2-chat-1_8b) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-2B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-2B) |
|
| 28 |
+
| InternVL2-4B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [Phi-3-mini-128k-instruct](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-4B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-4B) |
|
| 29 |
+
| InternVL2-8B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-8B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-8B) |
|
| 30 |
+
| InternVL2-26B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [internlm2-chat-20b](https://huggingface.co/internlm/internlm2-chat-20b) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-26B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-26B) |
|
| 31 |
+
| InternVL2-40B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [Nous-Hermes-2-Yi-34B](https://huggingface.co/NousResearch/Nous-Hermes-2-Yi-34B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-40B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-40B) |
|
| 32 |
+
| InternVL2-Llama3-76B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [Hermes-2-Theta-Llama-3-70B](https://huggingface.co/NousResearch/Hermes-2-Theta-Llama-3-70B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-Llama3-76B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-Llama3-76B) |
|
| 33 |
+
|
| 34 |
+
## Model Details
|
| 35 |
+
|
| 36 |
+
InternVL 2.0 is a multimodal large language model series, featuring models of various sizes. For each size, we release instruction-tuned models optimized for multimodal tasks. InternVL2-8B consists of [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px), an MLP projector, and [internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat).
|
| 37 |
+
|
| 38 |
+
## Performance
|
| 39 |
+
|
| 40 |
+
### Image Benchmarks
|
| 41 |
+
|
| 42 |
+
| Benchmark | MiniCPM-Llama3-V-2_5 | InternVL-Chat-V1-5 | InternVL2-8B |
|
| 43 |
+
| :--------------------------: | :------------------: | :----------------: | :----------: |
|
| 44 |
+
| Model Size | 8.5B | 25.5B | 8.1B |
|
| 45 |
+
| | | | |
|
| 46 |
+
| DocVQA<sub>test</sub> | 84.8 | 90.9 | 91.6 |
|
| 47 |
+
| ChartQA<sub>test</sub> | - | 83.8 | 83.3 |
|
| 48 |
+
| InfoVQA<sub>test</sub> | - | 72.5 | 74.8 |
|
| 49 |
+
| TextVQA<sub>val</sub> | 76.6 | 80.6 | 77.4 |
|
| 50 |
+
| OCRBench | 725 | 724 | 794 |
|
| 51 |
+
| MME<sub>sum</sub> | 2024.6 | 2187.8 | 2210.3 |
|
| 52 |
+
| RealWorldQA | 63.5 | 66.0 | 64.4 |
|
| 53 |
+
| AI2D<sub>test</sub> | 78.4 | 80.7 | 83.8 |
|
| 54 |
+
| MMMU<sub>val</sub> | 45.8 | 45.2 / 46.8 | 49.3 / 51.2 |
|
| 55 |
+
| MMBench-EN<sub>test</sub> | 77.2 | 82.2 | 81.7 |
|
| 56 |
+
| MMBench-CN<sub>test</sub> | 74.2 | 82.0 | 81.2 |
|
| 57 |
+
| CCBench<sub>dev</sub> | 45.9 | 69.8 | 75.9 |
|
| 58 |
+
| MMVet<sub>GPT-4-0613</sub> | - | 62.8 | 60.0 |
|
| 59 |
+
| MMVet<sub>GPT-4-Turbo</sub> | 52.8 | 55.4 | 54.2 |
|
| 60 |
+
| SEED-Image | 72.3 | 76.0 | 76.2 |
|
| 61 |
+
| HallBench<sub>avg</sub> | 42.4 | 49.3 | 45.2 |
|
| 62 |
+
| MathVista<sub>testmini</sub> | 54.3 | 53.5 | 58.3 |
|
| 63 |
+
| OpenCompass<sub>avg</sub> | 58.8 | 61.7 | 64.1 |
|
| 64 |
+
|
| 65 |
+
- We simultaneously use InternVL and VLMEvalKit repositories for model evaluation. Specifically, the results reported for DocVQA, ChartQA, InfoVQA, TextVQA, MME, AI2D, MMBench, CCBench, MMVet, and SEED-Image were tested using the InternVL repository. OCRBench, RealWorldQA, HallBench, and MathVista were evaluated using the VLMEvalKit.
|
| 66 |
+
|
| 67 |
+
- For MMMU, we report both the original scores (left side: evaluated using the InternVL codebase for InternVL series models, and sourced from technical reports or webpages for other models) and the VLMEvalKit scores (right side: collected from the OpenCompass leaderboard).
|
| 68 |
+
|
| 69 |
+
- Please note that evaluating the same model using different testing toolkits like InternVL and VLMEvalKit can result in slight differences, which is normal. Updates to code versions and variations in environment and hardware can also cause minor discrepancies in results.
|
| 70 |
+
|
| 71 |
+
### Video Benchmarks
|
| 72 |
+
|
| 73 |
+
| Benchmark | VideoChat2-HD-Mistral | Video-CCAM-9B | InternVL2-4B | InternVL2-8B |
|
| 74 |
+
| :-------------------------: | :-------------------: | :-----------: | :----------: | :----------: |
|
| 75 |
+
| Model Size | 7B | 9B | 4.2B | 8.1B |
|
| 76 |
+
| | | | | |
|
| 77 |
+
| MVBench | 60.4 | 60.7 | 63.7 | 66.4 |
|
| 78 |
+
| MMBench-Video<sub>8f</sub> | - | - | 1.10 | 1.19 |
|
| 79 |
+
| MMBench-Video<sub>16f</sub> | - | - | 1.18 | 1.28 |
|
| 80 |
+
| Video-MME<br>w/o subs | 42.3 | 50.6 | 51.4 | 54.0 |
|
| 81 |
+
| Video-MME<br>w subs | 54.6 | 54.9 | 53.4 | 56.9 |
|
| 82 |
+
|
| 83 |
+
- We evaluate our models on MVBench and Video-MME by extracting 16 frames from each video, and each frame was resized to a 448x448 image.
|
| 84 |
+
|
| 85 |
+
### Grounding Benchmarks
|
| 86 |
+
|
| 87 |
+
| Model | avg. | RefCOCO<br>(val) | RefCOCO<br>(testA) | RefCOCO<br>(testB) | RefCOCO+<br>(val) | RefCOCO+<br>(testA) | RefCOCO+<br>(testB) | RefCOCO‑g<br>(val) | RefCOCO‑g<br>(test) |
|
| 88 |
+
| :----------------------------: | :--: | :--------------: | :----------------: | :----------------: | :---------------: | :-----------------: | :-----------------: | :----------------: | :-----------------: |
|
| 89 |
+
| UNINEXT-H<br>(Specialist SOTA) | 88.9 | 92.6 | 94.3 | 91.5 | 85.2 | 89.6 | 79.8 | 88.7 | 89.4 |
|
| 90 |
+
| | | | | | | | | | |
|
| 91 |
+
| Mini-InternVL-<br>Chat-2B-V1-5 | 75.8 | 80.7 | 86.7 | 72.9 | 72.5 | 82.3 | 60.8 | 75.6 | 74.9 |
|
| 92 |
+
| Mini-InternVL-<br>Chat-4B-V1-5 | 84.4 | 88.0 | 91.4 | 83.5 | 81.5 | 87.4 | 73.8 | 84.7 | 84.6 |
|
| 93 |
+
| InternVL‑Chat‑V1‑5 | 88.8 | 91.4 | 93.7 | 87.1 | 87.0 | 92.3 | 80.9 | 88.5 | 89.3 |
|
| 94 |
+
| | | | | | | | | | |
|
| 95 |
+
| InternVL2‑1B | 79.9 | 83.6 | 88.7 | 79.8 | 76.0 | 83.6 | 67.7 | 80.2 | 79.9 |
|
| 96 |
+
| InternVL2‑2B | 77.7 | 82.3 | 88.2 | 75.9 | 73.5 | 82.8 | 63.3 | 77.6 | 78.3 |
|
| 97 |
+
| InternVL2‑4B | 84.4 | 88.5 | 91.2 | 83.9 | 81.2 | 87.2 | 73.8 | 84.6 | 84.6 |
|
| 98 |
+
| InternVL2‑8B | 82.9 | 87.1 | 91.1 | 80.7 | 79.8 | 87.9 | 71.4 | 82.7 | 82.7 |
|
| 99 |
+
| InternVL2‑26B | 88.5 | 91.2 | 93.3 | 87.4 | 86.8 | 91.0 | 81.2 | 88.5 | 88.6 |
|
| 100 |
+
| InternVL2‑40B | 90.3 | 93.0 | 94.7 | 89.2 | 88.5 | 92.8 | 83.6 | 90.3 | 90.6 |
|
| 101 |
+
| InternVL2-<br>Llama3‑76B | 90.0 | 92.2 | 94.8 | 88.4 | 88.8 | 93.1 | 82.8 | 89.5 | 90.3 |
|
| 102 |
+
|
| 103 |
+
- We use the following prompt to evaluate InternVL's grounding ability: `Please provide the bounding box coordinates of the region this sentence describes: <ref>{}</ref>`
|
| 104 |
+
|
| 105 |
+
Limitations: Although we have made efforts to ensure the safety of the model during the training process and to encourage the model to generate text that complies with ethical and legal requirements, the model may still produce unexpected outputs due to its size and probabilistic generation paradigm. For example, the generated responses may contain biases, discrimination, or other harmful content. Please do not propagate such content. We are not responsible for any consequences resulting from the dissemination of harmful information.
|
| 106 |
+
|
| 107 |
+
### Invitation to Evaluate InternVL
|
| 108 |
+
|
| 109 |
+
We welcome MLLM benchmark developers to assess our InternVL1.5 and InternVL2 series models. If you need to add your evaluation results here, please contact me at [wztxy89@163.com](mailto:wztxy89@163.com).
|
| 110 |
+
|
| 111 |
+
## Quick Start
|
| 112 |
+
|
| 113 |
+
We provide an example code to run InternVL2-8B using `transformers`.
|
| 114 |
+
|
| 115 |
+
We also welcome you to experience the InternVL2 series models in our [online demo](https://internvl.opengvlab.com/).
|
| 116 |
+
|
| 117 |
+
> Please use transformers==4.37.2 to ensure the model works normally.
|
| 118 |
+
|
| 119 |
+
### Model Loading
|
| 120 |
+
|
| 121 |
+
#### 16-bit (bf16 / fp16)
|
| 122 |
+
|
| 123 |
+
```python
|
| 124 |
+
import torch
|
| 125 |
+
from transformers import AutoTokenizer, AutoModel
|
| 126 |
+
path = "OpenGVLab/InternVL2-8B"
|
| 127 |
+
model = AutoModel.from_pretrained(
|
| 128 |
+
path,
|
| 129 |
+
torch_dtype=torch.bfloat16,
|
| 130 |
+
low_cpu_mem_usage=True,
|
| 131 |
+
trust_remote_code=True).eval().cuda()
|
| 132 |
+
```
|
| 133 |
+
|
| 134 |
+
#### BNB 8-bit Quantization
|
| 135 |
+
|
| 136 |
+
```python
|
| 137 |
+
import torch
|
| 138 |
+
from transformers import AutoTokenizer, AutoModel
|
| 139 |
+
path = "OpenGVLab/InternVL2-8B"
|
| 140 |
+
model = AutoModel.from_pretrained(
|
| 141 |
+
path,
|
| 142 |
+
torch_dtype=torch.bfloat16,
|
| 143 |
+
load_in_8bit=True,
|
| 144 |
+
low_cpu_mem_usage=True,
|
| 145 |
+
trust_remote_code=True).eval()
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
+
#### BNB 4-bit Quantization
|
| 149 |
+
|
| 150 |
+
```python
|
| 151 |
+
import torch
|
| 152 |
+
from transformers import AutoTokenizer, AutoModel
|
| 153 |
+
path = "OpenGVLab/InternVL2-8B"
|
| 154 |
+
model = AutoModel.from_pretrained(
|
| 155 |
+
path,
|
| 156 |
+
torch_dtype=torch.bfloat16,
|
| 157 |
+
load_in_4bit=True,
|
| 158 |
+
low_cpu_mem_usage=True,
|
| 159 |
+
trust_remote_code=True).eval()
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
#### Multiple GPUs
|
| 163 |
+
|
| 164 |
+
The reason for writing the code this way is to avoid errors that occur during multi-GPU inference due to tensors not being on the same device. By ensuring that the first and last layers of the large language model (LLM) are on the same device, we prevent such errors.
|
| 165 |
+
|
| 166 |
+
```python
|
| 167 |
+
import math
|
| 168 |
+
import torch
|
| 169 |
+
from transformers import AutoTokenizer, AutoModel
|
| 170 |
+
|
| 171 |
+
def split_model(model_name):
|
| 172 |
+
device_map = {}
|
| 173 |
+
world_size = torch.cuda.device_count()
|
| 174 |
+
num_layers = {
|
| 175 |
+
'InternVL2-1B': 24, 'InternVL2-2B': 24, 'InternVL2-4B': 32, 'InternVL2-8B': 32,
|
| 176 |
+
'InternVL2-26B': 48, 'InternVL2-40B': 60, 'InternVL2-Llama3-76B': 80}[model_name]
|
| 177 |
+
# Since the first GPU will be used for ViT, treat it as half a GPU.
|
| 178 |
+
num_layers_per_gpu = math.ceil(num_layers / (world_size - 0.5))
|
| 179 |
+
num_layers_per_gpu = [num_layers_per_gpu] * world_size
|
| 180 |
+
num_layers_per_gpu[0] = math.ceil(num_layers_per_gpu[0] * 0.5)
|
| 181 |
+
layer_cnt = 0
|
| 182 |
+
for i, num_layer in enumerate(num_layers_per_gpu):
|
| 183 |
+
for j in range(num_layer):
|
| 184 |
+
device_map[f'language_model.model.layers.{layer_cnt}'] = i
|
| 185 |
+
layer_cnt += 1
|
| 186 |
+
device_map['vision_model'] = 0
|
| 187 |
+
device_map['mlp1'] = 0
|
| 188 |
+
device_map['language_model.model.tok_embeddings'] = 0
|
| 189 |
+
device_map['language_model.model.embed_tokens'] = 0
|
| 190 |
+
device_map['language_model.output'] = 0
|
| 191 |
+
device_map['language_model.model.norm'] = 0
|
| 192 |
+
device_map['language_model.lm_head'] = 0
|
| 193 |
+
device_map[f'language_model.model.layers.{num_layers - 1}'] = 0
|
| 194 |
+
|
| 195 |
+
return device_map
|
| 196 |
+
|
| 197 |
+
path = "OpenGVLab/InternVL2-8B"
|
| 198 |
+
device_map = split_model('InternVL2-8B')
|
| 199 |
+
model = AutoModel.from_pretrained(
|
| 200 |
+
path,
|
| 201 |
+
torch_dtype=torch.bfloat16,
|
| 202 |
+
low_cpu_mem_usage=True,
|
| 203 |
+
trust_remote_code=True,
|
| 204 |
+
device_map=device_map).eval()
|
| 205 |
+
```
|
| 206 |
+
|
| 207 |
+
### Inference with Transformers
|
| 208 |
+
|
| 209 |
+
```python
|
| 210 |
+
import numpy as np
|
| 211 |
+
import torch
|
| 212 |
+
import torchvision.transforms as T
|
| 213 |
+
from decord import VideoReader, cpu
|
| 214 |
+
from PIL import Image
|
| 215 |
+
from torchvision.transforms.functional import InterpolationMode
|
| 216 |
+
from transformers import AutoModel, AutoTokenizer
|
| 217 |
+
|
| 218 |
+
IMAGENET_MEAN = (0.485, 0.456, 0.406)
|
| 219 |
+
IMAGENET_STD = (0.229, 0.224, 0.225)
|
| 220 |
+
|
| 221 |
+
def build_transform(input_size):
|
| 222 |
+
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
|
| 223 |
+
transform = T.Compose([
|
| 224 |
+
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
|
| 225 |
+
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
|
| 226 |
+
T.ToTensor(),
|
| 227 |
+
T.Normalize(mean=MEAN, std=STD)
|
| 228 |
+
])
|
| 229 |
+
return transform
|
| 230 |
+
|
| 231 |
+
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
|
| 232 |
+
best_ratio_diff = float('inf')
|
| 233 |
+
best_ratio = (1, 1)
|
| 234 |
+
area = width * height
|
| 235 |
+
for ratio in target_ratios:
|
| 236 |
+
target_aspect_ratio = ratio[0] / ratio[1]
|
| 237 |
+
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
|
| 238 |
+
if ratio_diff < best_ratio_diff:
|
| 239 |
+
best_ratio_diff = ratio_diff
|
| 240 |
+
best_ratio = ratio
|
| 241 |
+
elif ratio_diff == best_ratio_diff:
|
| 242 |
+
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
|
| 243 |
+
best_ratio = ratio
|
| 244 |
+
return best_ratio
|
| 245 |
+
|
| 246 |
+
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
|
| 247 |
+
orig_width, orig_height = image.size
|
| 248 |
+
aspect_ratio = orig_width / orig_height
|
| 249 |
+
|
| 250 |
+
# calculate the existing image aspect ratio
|
| 251 |
+
target_ratios = set(
|
| 252 |
+
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
|
| 253 |
+
i * j <= max_num and i * j >= min_num)
|
| 254 |
+
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
|
| 255 |
+
|
| 256 |
+
# find the closest aspect ratio to the target
|
| 257 |
+
target_aspect_ratio = find_closest_aspect_ratio(
|
| 258 |
+
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
|
| 259 |
+
|
| 260 |
+
# calculate the target width and height
|
| 261 |
+
target_width = image_size * target_aspect_ratio[0]
|
| 262 |
+
target_height = image_size * target_aspect_ratio[1]
|
| 263 |
+
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
|
| 264 |
+
|
| 265 |
+
# resize the image
|
| 266 |
+
resized_img = image.resize((target_width, target_height))
|
| 267 |
+
processed_images = []
|
| 268 |
+
for i in range(blocks):
|
| 269 |
+
box = (
|
| 270 |
+
(i % (target_width // image_size)) * image_size,
|
| 271 |
+
(i // (target_width // image_size)) * image_size,
|
| 272 |
+
((i % (target_width // image_size)) + 1) * image_size,
|
| 273 |
+
((i // (target_width // image_size)) + 1) * image_size
|
| 274 |
+
)
|
| 275 |
+
# split the image
|
| 276 |
+
split_img = resized_img.crop(box)
|
| 277 |
+
processed_images.append(split_img)
|
| 278 |
+
assert len(processed_images) == blocks
|
| 279 |
+
if use_thumbnail and len(processed_images) != 1:
|
| 280 |
+
thumbnail_img = image.resize((image_size, image_size))
|
| 281 |
+
processed_images.append(thumbnail_img)
|
| 282 |
+
return processed_images
|
| 283 |
+
|
| 284 |
+
def load_image(image_file, input_size=448, max_num=12):
|
| 285 |
+
image = Image.open(image_file).convert('RGB')
|
| 286 |
+
transform = build_transform(input_size=input_size)
|
| 287 |
+
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
|
| 288 |
+
pixel_values = [transform(image) for image in images]
|
| 289 |
+
pixel_values = torch.stack(pixel_values)
|
| 290 |
+
return pixel_values
|
| 291 |
+
|
| 292 |
+
# If you want to load a model using multiple GPUs, please refer to the `Multiple GPUs` section.
|
| 293 |
+
path = 'OpenGVLab/InternVL2-8B'
|
| 294 |
+
model = AutoModel.from_pretrained(
|
| 295 |
+
path,
|
| 296 |
+
torch_dtype=torch.bfloat16,
|
| 297 |
+
low_cpu_mem_usage=True,
|
| 298 |
+
trust_remote_code=True).eval().cuda()
|
| 299 |
+
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
|
| 300 |
+
|
| 301 |
+
# set the max number of tiles in `max_num`
|
| 302 |
+
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 303 |
+
generation_config = dict(max_new_tokens=1024, do_sample=False)
|
| 304 |
+
|
| 305 |
+
# pure-text conversation (纯文本对话)
|
| 306 |
+
question = 'Hello, who are you?'
|
| 307 |
+
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
|
| 308 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 309 |
+
|
| 310 |
+
question = 'Can you tell me a story?'
|
| 311 |
+
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
|
| 312 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 313 |
+
|
| 314 |
+
# single-image single-round conversation (单图单轮对话)
|
| 315 |
+
question = '<image>\nPlease describe the image shortly.'
|
| 316 |
+
response = model.chat(tokenizer, pixel_values, question, generation_config)
|
| 317 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 318 |
+
|
| 319 |
+
# single-image multi-round conversation (单图多轮对话)
|
| 320 |
+
question = '<image>\nPlease describe the image in detail.'
|
| 321 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
|
| 322 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 323 |
+
|
| 324 |
+
question = 'Please write a poem according to the image.'
|
| 325 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
|
| 326 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 327 |
+
|
| 328 |
+
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
|
| 329 |
+
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 330 |
+
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 331 |
+
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
|
| 332 |
+
|
| 333 |
+
question = '<image>\nDescribe the two images in detail.'
|
| 334 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 335 |
+
history=None, return_history=True)
|
| 336 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 337 |
+
|
| 338 |
+
question = 'What are the similarities and differences between these two images.'
|
| 339 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 340 |
+
history=history, return_history=True)
|
| 341 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 342 |
+
|
| 343 |
+
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
|
| 344 |
+
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 345 |
+
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 346 |
+
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
|
| 347 |
+
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
|
| 348 |
+
|
| 349 |
+
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
|
| 350 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 351 |
+
num_patches_list=num_patches_list,
|
| 352 |
+
history=None, return_history=True)
|
| 353 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 354 |
+
|
| 355 |
+
question = 'What are the similarities and differences between these two images.'
|
| 356 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 357 |
+
num_patches_list=num_patches_list,
|
| 358 |
+
history=history, return_history=True)
|
| 359 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 360 |
+
|
| 361 |
+
# batch inference, single image per sample (单图批处理)
|
| 362 |
+
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 363 |
+
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 364 |
+
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
|
| 365 |
+
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
|
| 366 |
+
|
| 367 |
+
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
|
| 368 |
+
responses = model.batch_chat(tokenizer, pixel_values,
|
| 369 |
+
num_patches_list=num_patches_list,
|
| 370 |
+
questions=questions,
|
| 371 |
+
generation_config=generation_config)
|
| 372 |
+
for question, response in zip(questions, responses):
|
| 373 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 374 |
+
|
| 375 |
+
# video multi-round conversation (视频多轮对话)
|
| 376 |
+
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
|
| 377 |
+
if bound:
|
| 378 |
+
start, end = bound[0], bound[1]
|
| 379 |
+
else:
|
| 380 |
+
start, end = -100000, 100000
|
| 381 |
+
start_idx = max(first_idx, round(start * fps))
|
| 382 |
+
end_idx = min(round(end * fps), max_frame)
|
| 383 |
+
seg_size = float(end_idx - start_idx) / num_segments
|
| 384 |
+
frame_indices = np.array([
|
| 385 |
+
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
|
| 386 |
+
for idx in range(num_segments)
|
| 387 |
+
])
|
| 388 |
+
return frame_indices
|
| 389 |
+
|
| 390 |
+
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
|
| 391 |
+
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
|
| 392 |
+
max_frame = len(vr) - 1
|
| 393 |
+
fps = float(vr.get_avg_fps())
|
| 394 |
+
|
| 395 |
+
pixel_values_list, num_patches_list = [], []
|
| 396 |
+
transform = build_transform(input_size=input_size)
|
| 397 |
+
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
|
| 398 |
+
for frame_index in frame_indices:
|
| 399 |
+
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
|
| 400 |
+
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
|
| 401 |
+
pixel_values = [transform(tile) for tile in img]
|
| 402 |
+
pixel_values = torch.stack(pixel_values)
|
| 403 |
+
num_patches_list.append(pixel_values.shape[0])
|
| 404 |
+
pixel_values_list.append(pixel_values)
|
| 405 |
+
pixel_values = torch.cat(pixel_values_list)
|
| 406 |
+
return pixel_values, num_patches_list
|
| 407 |
+
|
| 408 |
+
video_path = './examples/red-panda.mp4'
|
| 409 |
+
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
|
| 410 |
+
pixel_values = pixel_values.to(torch.bfloat16).cuda()
|
| 411 |
+
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
|
| 412 |
+
question = video_prefix + 'What is the red panda doing?'
|
| 413 |
+
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
|
| 414 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 415 |
+
num_patches_list=num_patches_list, history=None, return_history=True)
|
| 416 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 417 |
+
|
| 418 |
+
question = 'Describe this video in detail. Don\'t repeat.'
|
| 419 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 420 |
+
num_patches_list=num_patches_list, history=history, return_history=True)
|
| 421 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 422 |
+
```
|
| 423 |
+
|
| 424 |
+
#### Streaming output
|
| 425 |
+
|
| 426 |
+
Besides this method, you can also use the following code to get streamed output.
|
| 427 |
+
|
| 428 |
+
```python
|
| 429 |
+
from transformers import TextIteratorStreamer
|
| 430 |
+
from threading import Thread
|
| 431 |
+
|
| 432 |
+
# Initialize the streamer
|
| 433 |
+
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
|
| 434 |
+
# Define the generation configuration
|
| 435 |
+
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
|
| 436 |
+
# Start the model chat in a separate thread
|
| 437 |
+
thread = Thread(target=model.chat, kwargs=dict(
|
| 438 |
+
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
|
| 439 |
+
history=None, return_history=False, generation_config=generation_config,
|
| 440 |
+
))
|
| 441 |
+
thread.start()
|
| 442 |
+
|
| 443 |
+
# Initialize an empty string to store the generated text
|
| 444 |
+
generated_text = ''
|
| 445 |
+
# Loop through the streamer to get the new text as it is generated
|
| 446 |
+
for new_text in streamer:
|
| 447 |
+
if new_text == model.conv_template.sep:
|
| 448 |
+
break
|
| 449 |
+
generated_text += new_text
|
| 450 |
+
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
|
| 451 |
+
```
|
| 452 |
+
|
| 453 |
+
## Finetune
|
| 454 |
+
|
| 455 |
+
SWIFT from ModelScope community has supported the fine-tuning (Image/Video) of InternVL, please check [this link](https://github.com/modelscope/swift/blob/main/docs/source_en/Multi-Modal/internvl-best-practice.md) for more details.
|
| 456 |
+
|
| 457 |
+
## Deployment
|
| 458 |
+
|
| 459 |
+
### LMDeploy
|
| 460 |
+
|
| 461 |
+
LMDeploy is a toolkit for compressing, deploying, and serving LLM, developed by the MMRazor and MMDeploy teams.
|
| 462 |
+
|
| 463 |
+
```sh
|
| 464 |
+
pip install lmdeploy
|
| 465 |
+
```
|
| 466 |
+
|
| 467 |
+
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
|
| 468 |
+
|
| 469 |
+
#### A 'Hello, world' example
|
| 470 |
+
|
| 471 |
+
```python
|
| 472 |
+
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
|
| 473 |
+
from lmdeploy.vl import load_image
|
| 474 |
+
|
| 475 |
+
model = 'OpenGVLab/InternVL2-8B'
|
| 476 |
+
system_prompt = '我是书生·万象,英文名是InternVL,是由上海人工智能实验室及多家合作单位联合开发的多模态大语言模型。'
|
| 477 |
+
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
|
| 478 |
+
chat_template_config = ChatTemplateConfig('internvl-internlm2')
|
| 479 |
+
chat_template_config.meta_instruction = system_prompt
|
| 480 |
+
pipe = pipeline(model, chat_template_config=chat_template_config,
|
| 481 |
+
backend_config=TurbomindEngineConfig(session_len=8192))
|
| 482 |
+
response = pipe(('describe this image', image))
|
| 483 |
+
print(response.text)
|
| 484 |
+
```
|
| 485 |
+
|
| 486 |
+
If `ImportError` occurs while executing this case, please install the required dependency packages as prompted.
|
| 487 |
+
|
| 488 |
+
#### Multi-images inference
|
| 489 |
+
|
| 490 |
+
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
|
| 491 |
+
|
| 492 |
+
> Warning: Due to the scarcity of multi-image conversation data, the performance on multi-image tasks may be unstable, and it may require multiple attempts to achieve satisfactory results.
|
| 493 |
+
|
| 494 |
+
```python
|
| 495 |
+
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
|
| 496 |
+
from lmdeploy.vl import load_image
|
| 497 |
+
from lmdeploy.vl.constants import IMAGE_TOKEN
|
| 498 |
+
|
| 499 |
+
model = 'OpenGVLab/InternVL2-8B'
|
| 500 |
+
system_prompt = '我是书生·万象,英文名是InternVL,是由上海人工智能实验室及多家合��单位联合开发的多模态大语言模型。'
|
| 501 |
+
chat_template_config = ChatTemplateConfig('internvl-internlm2')
|
| 502 |
+
chat_template_config.meta_instruction = system_prompt
|
| 503 |
+
pipe = pipeline(model, chat_template_config=chat_template_config,
|
| 504 |
+
backend_config=TurbomindEngineConfig(session_len=8192))
|
| 505 |
+
|
| 506 |
+
image_urls=[
|
| 507 |
+
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
|
| 508 |
+
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
|
| 509 |
+
]
|
| 510 |
+
|
| 511 |
+
images = [load_image(img_url) for img_url in image_urls]
|
| 512 |
+
# Numbering images improves multi-image conversations
|
| 513 |
+
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
|
| 514 |
+
print(response.text)
|
| 515 |
+
```
|
| 516 |
+
|
| 517 |
+
#### Batch prompts inference
|
| 518 |
+
|
| 519 |
+
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
|
| 520 |
+
|
| 521 |
+
```python
|
| 522 |
+
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
|
| 523 |
+
from lmdeploy.vl import load_image
|
| 524 |
+
|
| 525 |
+
model = 'OpenGVLab/InternVL2-8B'
|
| 526 |
+
system_prompt = '我是书生·万象,英文名是InternVL,是由上海人工智能实验室及多家合作单位联合开发的多模态大语言模型。'
|
| 527 |
+
chat_template_config = ChatTemplateConfig('internvl-internlm2')
|
| 528 |
+
chat_template_config.meta_instruction = system_prompt
|
| 529 |
+
pipe = pipeline(model, chat_template_config=chat_template_config,
|
| 530 |
+
backend_config=TurbomindEngineConfig(session_len=8192))
|
| 531 |
+
|
| 532 |
+
image_urls=[
|
| 533 |
+
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
|
| 534 |
+
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
|
| 535 |
+
]
|
| 536 |
+
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
|
| 537 |
+
response = pipe(prompts)
|
| 538 |
+
print(response)
|
| 539 |
+
```
|
| 540 |
+
|
| 541 |
+
#### Multi-turn conversation
|
| 542 |
+
|
| 543 |
+
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
|
| 544 |
+
|
| 545 |
+
```python
|
| 546 |
+
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig, GenerationConfig
|
| 547 |
+
from lmdeploy.vl import load_image
|
| 548 |
+
|
| 549 |
+
model = 'OpenGVLab/InternVL2-8B'
|
| 550 |
+
system_prompt = '我是书生·万象,英文名是InternVL,是由上海人工智能实验室及多家合作单位联合开发的多模态大语言模型。'
|
| 551 |
+
chat_template_config = ChatTemplateConfig('internvl-internlm2')
|
| 552 |
+
chat_template_config.meta_instruction = system_prompt
|
| 553 |
+
pipe = pipeline(model, chat_template_config=chat_template_config,
|
| 554 |
+
backend_config=TurbomindEngineConfig(session_len=8192))
|
| 555 |
+
|
| 556 |
+
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
|
| 557 |
+
gen_config = GenerationConfig(top_k=40, top_p=0.8, temperature=0.8)
|
| 558 |
+
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
|
| 559 |
+
print(sess.response.text)
|
| 560 |
+
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
|
| 561 |
+
print(sess.response.text)
|
| 562 |
+
```
|
| 563 |
+
|
| 564 |
+
#### Service
|
| 565 |
+
|
| 566 |
+
To deploy InternVL2 as an API, please configure the chat template config first. Create the following JSON file `chat_template.json`.
|
| 567 |
+
|
| 568 |
+
```json
|
| 569 |
+
{
|
| 570 |
+
"model_name":"internvl-internlm2",
|
| 571 |
+
"meta_instruction":"我是书生·万象,英文名是InternVL,是由上海人工智能实验室及多家合作单位联合开发的多模态大语言模型。",
|
| 572 |
+
"stop_words":["<|im_start|>", "<|im_end|>"]
|
| 573 |
+
}
|
| 574 |
+
```
|
| 575 |
+
|
| 576 |
+
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
|
| 577 |
+
|
| 578 |
+
```shell
|
| 579 |
+
lmdeploy serve api_server OpenGVLab/InternVL2-8B --model-name InternVL2-8B --backend turbomind --server-port 23333 --chat-template chat_template.json
|
| 580 |
+
```
|
| 581 |
+
|
| 582 |
+
To use the OpenAI-style interface, you need to install OpenAI:
|
| 583 |
+
|
| 584 |
+
```shell
|
| 585 |
+
pip install openai
|
| 586 |
+
```
|
| 587 |
+
|
| 588 |
+
Then, use the code below to make the API call:
|
| 589 |
+
|
| 590 |
+
```python
|
| 591 |
+
from openai import OpenAI
|
| 592 |
+
|
| 593 |
+
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
|
| 594 |
+
model_name = client.models.list().data[0].id
|
| 595 |
+
response = client.chat.completions.create(
|
| 596 |
+
model="InternVL2-8B",
|
| 597 |
+
messages=[{
|
| 598 |
+
'role':
|
| 599 |
+
'user',
|
| 600 |
+
'content': [{
|
| 601 |
+
'type': 'text',
|
| 602 |
+
'text': 'describe this image',
|
| 603 |
+
}, {
|
| 604 |
+
'type': 'image_url',
|
| 605 |
+
'image_url': {
|
| 606 |
+
'url':
|
| 607 |
+
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
|
| 608 |
+
},
|
| 609 |
+
}],
|
| 610 |
+
}],
|
| 611 |
+
temperature=0.8,
|
| 612 |
+
top_p=0.8)
|
| 613 |
+
print(response)
|
| 614 |
+
```
|
| 615 |
+
|
| 616 |
+
### vLLM
|
| 617 |
+
|
| 618 |
+
TODO
|
| 619 |
+
|
| 620 |
+
### Ollama
|
| 621 |
+
|
| 622 |
+
TODO
|
| 623 |
+
|
| 624 |
+
## License
|
| 625 |
+
|
| 626 |
+
This project is released under the MIT license, while InternLM is licensed under the Apache-2.0 license.
|
| 627 |
+
|
| 628 |
+
## Citation
|
| 629 |
+
|
| 630 |
+
If you find this project useful in your research, please consider citing:
|
| 631 |
+
|
| 632 |
+
```BibTeX
|
| 633 |
+
@article{chen2023internvl,
|
| 634 |
+
title={InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks},
|
| 635 |
+
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and Li, Bin and Luo, Ping and Lu, Tong and Qiao, Yu and Dai, Jifeng},
|
| 636 |
+
journal={arXiv preprint arXiv:2312.14238},
|
| 637 |
+
year={2023}
|
| 638 |
+
}
|
| 639 |
+
@article{chen2024far,
|
| 640 |
+
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
|
| 641 |
+
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
|
| 642 |
+
journal={arXiv preprint arXiv:2404.16821},
|
| 643 |
+
year={2024}
|
| 644 |
+
}
|
| 645 |
+
```
|
| 646 |
+
|
| 647 |
+
## 简介
|
| 648 |
+
|
| 649 |
+
我们很高兴宣布 InternVL 2.0 的发布,这是 InternVL 系列多模态大语言模型的最新版本。InternVL 2.0 提供了多种**指令微调**的模型,参数从 10 亿到 1080 亿不等。此仓库包含经过指令微调的 InternVL2-8B 模型。
|
| 650 |
+
|
| 651 |
+
与最先进的开源多模态大语言模型相比,InternVL 2.0 超越了大多数开源模型。它在各种能力上表现出与闭源商业模型相媲美的竞争力,包括文档和图表理解、信息图表问答、场景文本理解和 OCR 任务、科学和数学问题解决,以及文化理解和综合多模态能力。
|
| 652 |
+
|
| 653 |
+
InternVL 2.0 使用 8k 上下文窗口进行训练,训练数据包含长文本、多图和视频数据,与 InternVL 1.5 相比,其处理这些类型输入的能力显著提高。更多详细信息,请参阅我们的博客和 GitHub。
|
| 654 |
+
|
| 655 |
+
| 模型名称 | 视觉部分 | 语言部分 | HF 链接 | MS 链接 |
|
| 656 |
+
| :------------------: | :---------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------: | :--------------------------------------------------------------: | :--------------------------------------------------------------------: |
|
| 657 |
+
| InternVL2-1B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-1B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-1B) |
|
| 658 |
+
| InternVL2-2B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [internlm2-chat-1_8b](https://huggingface.co/internlm/internlm2-chat-1_8b) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-2B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-2B) |
|
| 659 |
+
| InternVL2-4B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [Phi-3-mini-128k-instruct](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-4B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-4B) |
|
| 660 |
+
| InternVL2-8B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-8B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-8B) |
|
| 661 |
+
| InternVL2-26B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [internlm2-chat-20b](https://huggingface.co/internlm/internlm2-chat-20b) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-26B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-26B) |
|
| 662 |
+
| InternVL2-40B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [Nous-Hermes-2-Yi-34B](https://huggingface.co/NousResearch/Nous-Hermes-2-Yi-34B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-40B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-40B) |
|
| 663 |
+
| InternVL2-Llama3-76B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [Hermes-2-Theta-Llama-3-70B](https://huggingface.co/NousResearch/Hermes-2-Theta-Llama-3-70B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-Llama3-76B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-Llama3-76B) |
|
| 664 |
+
|
| 665 |
+
## 模型细节
|
| 666 |
+
|
| 667 |
+
InternVL 2.0 是一个多模态大语言模型系列,包含各种规模的模型。对于每个规模的模型,我们都会发布针对多模态任务优化的指令微调模型。InternVL2-8B 包含 [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px)、一个 MLP 投影器和 [internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat)。
|
| 668 |
+
|
| 669 |
+
## 性能测试
|
| 670 |
+
|
| 671 |
+
### 图像相关评测
|
| 672 |
+
|
| 673 |
+
| 评测数据集 | MiniCPM-Llama3-V-2_5 | InternVL-Chat-V1-5 | InternVL2-8B |
|
| 674 |
+
| :--------------------------: | :------------------: | :----------------: | :----------: |
|
| 675 |
+
| 模型大小 | 8.5B | 25.5B | 8.1B |
|
| 676 |
+
| | | | |
|
| 677 |
+
| DocVQA<sub>test</sub> | 84.8 | 90.9 | 91.6 |
|
| 678 |
+
| ChartQA<sub>test</sub> | - | 83.8 | 83.3 |
|
| 679 |
+
| InfoVQA<sub>test</sub> | - | 72.5 | 74.8 |
|
| 680 |
+
| TextVQA<sub>val</sub> | 76.6 | 80.6 | 77.4 |
|
| 681 |
+
| OCRBench | 725 | 724 | 794 |
|
| 682 |
+
| MME<sub>sum</sub> | 2024.6 | 2187.8 | 2210.3 |
|
| 683 |
+
| RealWorldQA | 63.5 | 66.0 | 64.4 |
|
| 684 |
+
| AI2D<sub>test</sub> | 78.4 | 80.7 | 83.8 |
|
| 685 |
+
| MMMU<sub>val</sub> | 45.8 | 45.2 / 46.8 | 49.3 / 51.2 |
|
| 686 |
+
| MMBench-EN<sub>test</sub> | 77.2 | 82.2 | 81.7 |
|
| 687 |
+
| MMBench-CN<sub>test</sub> | 74.2 | 82.0 | 81.2 |
|
| 688 |
+
| CCBench<sub>dev</sub> | 45.9 | 69.8 | 75.9 |
|
| 689 |
+
| MMVet<sub>GPT-4-0613</sub> | - | 62.8 | 60.0 |
|
| 690 |
+
| MMVet<sub>GPT-4-Turbo</sub> | 52.8 | 55.4 | 54.2 |
|
| 691 |
+
| SEED-Image | 72.3 | 76.0 | 76.2 |
|
| 692 |
+
| HallBench<sub>avg</sub> | 42.4 | 49.3 | 45.2 |
|
| 693 |
+
| MathVista<sub>testmini</sub> | 54.3 | 53.5 | 58.3 |
|
| 694 |
+
| OpenCompass<sub>avg</sub> | 58.8 | 61.7 | 64.1 |
|
| 695 |
+
|
| 696 |
+
- 我们同时使用 InternVL 和 VLMEvalKit 仓库进行模型评估。具体来说,DocVQA、ChartQA、InfoVQA、TextVQA、MME、AI2D、MMBench、CCBench、MMVet 和 SEED-Image 的结果是使用 InternVL 仓库测试的。OCRBench、RealWorldQA、HallBench 和 MathVista 是使用 VLMEvalKit 进行评估的。
|
| 697 |
+
|
| 698 |
+
- 对于MMMU,我们报告了原始分数(左侧:InternVL系列模型使用InternVL代码库评测,其他模型的分数来自其技术报告或网页)和VLMEvalKit分数(右侧:从OpenCompass排行榜收集)。
|
| 699 |
+
|
| 700 |
+
- 请注意,使用不同的测试工具包(如 InternVL 和 VLMEvalKit)评估同一模型可能会导致细微差异,这是正常的。代码版本的更新、环境和硬件的变化也可能导致结果的微小差异。
|
| 701 |
+
|
| 702 |
+
### 视频相关评测
|
| 703 |
+
|
| 704 |
+
| 评测数据集 | VideoChat2-HD-Mistral | Video-CCAM-9B | InternVL2-4B | InternVL2-8B |
|
| 705 |
+
| :-------------------------: | :-------------------: | :-----------: | :----------: | :----------: |
|
| 706 |
+
| 模型大小 | 7B | 9B | 4.2B | 8.1B |
|
| 707 |
+
| | | | | |
|
| 708 |
+
| MVBench | 60.4 | 60.7 | 63.7 | 66.4 |
|
| 709 |
+
| MMBench-Video<sub>8f</sub> | - | - | 1.10 | 1.19 |
|
| 710 |
+
| MMBench-Video<sub>16f</sub> | - | - | 1.18 | 1.28 |
|
| 711 |
+
| Video-MME<br>w/o subs | 42.3 | 50.6 | 51.4 | 54.0 |
|
| 712 |
+
| Video-MME<br>w subs | 54.6 | 54.9 | 53.4 | 56.9 |
|
| 713 |
+
|
| 714 |
+
- 我们通过从每个视频中提取 16 帧来评估我们的模型在 MVBench 和 Video-MME 上的性能,每个视频帧被调整为 448x448 的图像。
|
| 715 |
+
|
| 716 |
+
### 定位相关评测
|
| 717 |
+
|
| 718 |
+
| 模型 | avg. | RefCOCO<br>(val) | RefCOCO<br>(testA) | RefCOCO<br>(testB) | RefCOCO+<br>(val) | RefCOCO+<br>(testA) | RefCOCO+<br>(testB) | RefCOCO‑g<br>(val) | RefCOCO‑g<br>(test) |
|
| 719 |
+
| :----------------------------: | :--: | :--------------: | :----------------: | :----------------: | :---------------: | :-----------------: | :-----------------: | :----------------: | :-----------------: |
|
| 720 |
+
| UNINEXT-H<br>(Specialist SOTA) | 88.9 | 92.6 | 94.3 | 91.5 | 85.2 | 89.6 | 79.8 | 88.7 | 89.4 |
|
| 721 |
+
| | | | | | | | | | |
|
| 722 |
+
| Mini-InternVL-<br>Chat-2B-V1-5 | 75.8 | 80.7 | 86.7 | 72.9 | 72.5 | 82.3 | 60.8 | 75.6 | 74.9 |
|
| 723 |
+
| Mini-InternVL-<br>Chat-4B-V1-5 | 84.4 | 88.0 | 91.4 | 83.5 | 81.5 | 87.4 | 73.8 | 84.7 | 84.6 |
|
| 724 |
+
| InternVL‑Chat‑V1‑5 | 88.8 | 91.4 | 93.7 | 87.1 | 87.0 | 92.3 | 80.9 | 88.5 | 89.3 |
|
| 725 |
+
| | | | | | | | | | |
|
| 726 |
+
| InternVL2‑1B | 79.9 | 83.6 | 88.7 | 79.8 | 76.0 | 83.6 | 67.7 | 80.2 | 79.9 |
|
| 727 |
+
| InternVL2‑2B | 77.7 | 82.3 | 88.2 | 75.9 | 73.5 | 82.8 | 63.3 | 77.6 | 78.3 |
|
| 728 |
+
| InternVL2‑4B | 84.4 | 88.5 | 91.2 | 83.9 | 81.2 | 87.2 | 73.8 | 84.6 | 84.6 |
|
| 729 |
+
| InternVL2‑8B | 82.9 | 87.1 | 91.1 | 80.7 | 79.8 | 87.9 | 71.4 | 82.7 | 82.7 |
|
| 730 |
+
| InternVL2‑26B | 88.5 | 91.2 | 93.3 | 87.4 | 86.8 | 91.0 | 81.2 | 88.5 | 88.6 |
|
| 731 |
+
| InternVL2‑40B | 90.3 | 93.0 | 94.7 | 89.2 | 88.5 | 92.8 | 83.6 | 90.3 | 90.6 |
|
| 732 |
+
| InternVL2-<br>Llama3‑76B | 90.0 | 92.2 | 94.8 | 88.4 | 88.8 | 93.1 | 82.8 | 89.5 | 90.3 |
|
| 733 |
+
|
| 734 |
+
- 我们使用以下 Prompt 来评测 InternVL 的 Grounding 能力: `Please provide the bounding box coordinates of the region this sentence describes: <ref>{}</ref>`
|
| 735 |
+
|
| 736 |
+
限制:尽管在训练过程中我们非常注重模型的安全性,尽力促使模型输出符合伦理和法律要求的文本,但受限于模型大小以及概率生成范式,模型可能会产生各种不符合预期的输出,例如回复内容包含偏见、歧视等有害内容,请勿传播这些内容。由于传播不良信息导致的任何后果,本项目不承担责任。
|
| 737 |
+
|
| 738 |
+
### 邀请评测 InternVL
|
| 739 |
+
|
| 740 |
+
我们欢迎各位 MLLM benchmark 的开发者对我们的 InternVL1.5 以及 InternVL2 系列模型进行评测。如果需要在此处添加评测结果,请与我联系([wztxy89@163.com](mailto:wztxy89@163.com))。
|
| 741 |
+
|
| 742 |
+
## 快速启动
|
| 743 |
+
|
| 744 |
+
我们提供了一个示例代码,用于使用 `transformers` 运行 InternVL2-8B。
|
| 745 |
+
|
| 746 |
+
我们也欢迎你在我们的[在线demo](https://internvl.opengvlab.com/)中体验InternVL2的系列模型。
|
| 747 |
+
|
| 748 |
+
> 请使用 transformers==4.37.2 以确保模型正常运行。
|
| 749 |
+
|
| 750 |
+
示例代码请[点击这里](#quick-start)。
|
| 751 |
+
|
| 752 |
+
## 微调
|
| 753 |
+
|
| 754 |
+
来自ModelScope社区的SWIFT已经支持对InternVL进行微调(图像/视频),详情请查看[此链接](https://github.com/modelscope/swift/blob/main/docs/source_en/Multi-Modal/internvl-best-practice.md)。
|
| 755 |
+
|
| 756 |
+
## 部署
|
| 757 |
+
|
| 758 |
+
### LMDeploy
|
| 759 |
+
|
| 760 |
+
LMDeploy 是由 MMRazor 和 MMDeploy 团队开发的用于压缩、部署和服务大语言模型(LLM)的工具包。
|
| 761 |
+
|
| 762 |
+
```sh
|
| 763 |
+
pip install lmdeploy
|
| 764 |
+
```
|
| 765 |
+
|
| 766 |
+
LMDeploy 将多模态视觉-语言模型(VLM)的复杂推理过程抽象为一个易于使用的管道,类似于大语言模型(LLM)的推理管道。
|
| 767 |
+
|
| 768 |
+
#### 一个“你好,世界”示例
|
| 769 |
+
|
| 770 |
+
```python
|
| 771 |
+
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
|
| 772 |
+
from lmdeploy.vl import load_image
|
| 773 |
+
|
| 774 |
+
model = 'OpenGVLab/InternVL2-8B'
|
| 775 |
+
system_prompt = '我是书生·万象,英文名是InternVL,是由上海人工智能实验室及多家合作单位联合开发的多模态大语言模型。'
|
| 776 |
+
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
|
| 777 |
+
chat_template_config = ChatTemplateConfig('internvl-internlm2')
|
| 778 |
+
chat_template_config.meta_instruction = system_prompt
|
| 779 |
+
pipe = pipeline(model, chat_template_config=chat_template_config,
|
| 780 |
+
backend_config=TurbomindEngineConfig(session_len=8192))
|
| 781 |
+
response = pipe(('describe this image', image))
|
| 782 |
+
print(response.text)
|
| 783 |
+
```
|
| 784 |
+
|
| 785 |
+
如果在执行此示例时出现 `ImportError`,请按照提示安装所需的依赖包。
|
| 786 |
+
|
| 787 |
+
#### 多图像推理
|
| 788 |
+
|
| 789 |
+
在处理多张图像时,可以将它们全部放入一个列表中。请注意,多张图像会导致输入 token 数量增加,因此通常需要增加上下文窗口的大小。
|
| 790 |
+
|
| 791 |
+
```python
|
| 792 |
+
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
|
| 793 |
+
from lmdeploy.vl import load_image
|
| 794 |
+
from lmdeploy.vl.constants import IMAGE_TOKEN
|
| 795 |
+
|
| 796 |
+
model = 'OpenGVLab/InternVL2-8B'
|
| 797 |
+
system_prompt = '我是书生·万象,英文名是InternVL,是由上海人工智能实验室及多家合作单位联合开发的多模态大语言模型。'
|
| 798 |
+
chat_template_config = ChatTemplateConfig('internvl-internlm2')
|
| 799 |
+
chat_template_config.meta_instruction = system_prompt
|
| 800 |
+
pipe = pipeline(model, chat_template_config=chat_template_config,
|
| 801 |
+
backend_config=TurbomindEngineConfig(session_len=8192))
|
| 802 |
+
|
| 803 |
+
image_urls=[
|
| 804 |
+
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
|
| 805 |
+
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
|
| 806 |
+
]
|
| 807 |
+
|
| 808 |
+
images = [load_image(img_url) for img_url in image_urls]
|
| 809 |
+
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
|
| 810 |
+
print(response.text)
|
| 811 |
+
```
|
| 812 |
+
|
| 813 |
+
#### 批量Prompt推理
|
| 814 |
+
|
| 815 |
+
使用批量Prompt进行推理非常简单;只需将它们放在一个列表结构中:
|
| 816 |
+
|
| 817 |
+
```python
|
| 818 |
+
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
|
| 819 |
+
from lmdeploy.vl import load_image
|
| 820 |
+
|
| 821 |
+
model = 'OpenGVLab/InternVL2-8B'
|
| 822 |
+
system_prompt = '我是书生·万象,英文名是InternVL,是由上海人工智能实验室及多家合作单位联合开发的多模态大语言模型。'
|
| 823 |
+
chat_template_config = ChatTemplateConfig('internvl-internlm2')
|
| 824 |
+
chat_template_config.meta_instruction = system_prompt
|
| 825 |
+
pipe = pipeline(model, chat_template_config=chat_template_config,
|
| 826 |
+
backend_config=TurbomindEngineConfig(session_len=8192))
|
| 827 |
+
|
| 828 |
+
image_urls=[
|
| 829 |
+
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
|
| 830 |
+
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
|
| 831 |
+
]
|
| 832 |
+
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
|
| 833 |
+
response = pipe(prompts)
|
| 834 |
+
print(response)
|
| 835 |
+
```
|
| 836 |
+
|
| 837 |
+
#### 多轮对话
|
| 838 |
+
|
| 839 |
+
使用管道进行多轮对话有两种方法。一种是根据 OpenAI 的格式构建消息并使用上述方法,另一种是使用 `pipeline.chat` 接口。
|
| 840 |
+
|
| 841 |
+
```python
|
| 842 |
+
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig, GenerationConfig
|
| 843 |
+
from lmdeploy.vl import load_image
|
| 844 |
+
|
| 845 |
+
model = 'OpenGVLab/InternVL2-8B'
|
| 846 |
+
system_prompt = '我是书生·万象,英文名是InternVL,是由上海人工智能实验室及多家合作单位联合开发的多模态大语言模型。'
|
| 847 |
+
chat_template_config = ChatTemplateConfig('internvl-internlm2')
|
| 848 |
+
chat_template_config.meta_instruction = system_prompt
|
| 849 |
+
pipe = pipeline(model, chat_template_config=chat_template_config,
|
| 850 |
+
backend_config=TurbomindEngineConfig(session_len=8192))
|
| 851 |
+
|
| 852 |
+
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
|
| 853 |
+
gen_config = GenerationConfig(top_k=40, top_p=0.8, temperature=0.8)
|
| 854 |
+
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
|
| 855 |
+
print(sess.response.text)
|
| 856 |
+
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
|
| 857 |
+
print(sess.response.text)
|
| 858 |
+
```
|
| 859 |
+
|
| 860 |
+
#### API部署
|
| 861 |
+
|
| 862 |
+
为了将InternVL2部署成API,请先配置聊天模板配置文件。创建如下的 JSON 文件 `chat_template.json`。
|
| 863 |
+
|
| 864 |
+
```json
|
| 865 |
+
{
|
| 866 |
+
"model_name":"internvl-internlm2",
|
| 867 |
+
"meta_instruction":"我是书生·万象,英文名是InternVL,是由上海人工智能实验室及多家合作单位联合开发的多模态大语言模型。",
|
| 868 |
+
"stop_words":["<|im_start|>", "<|im_end|>"]
|
| 869 |
+
}
|
| 870 |
+
```
|
| 871 |
+
|
| 872 |
+
LMDeploy 的 `api_server` 使模型能够通过一个命令轻松打包成服务。提供的 RESTful API 与 OpenAI 的接口兼容。以下是服务启动的示例:
|
| 873 |
+
|
| 874 |
+
```shell
|
| 875 |
+
lmdeploy serve api_server OpenGVLab/InternVL2-8B --model-name InternVL2-8B --backend turbomind --server-port 23333 --chat-template chat_template.json
|
| 876 |
+
```
|
| 877 |
+
|
| 878 |
+
为了使用OpenAI风格的API接口,您需要安装OpenAI:
|
| 879 |
+
|
| 880 |
+
```shell
|
| 881 |
+
pip install openai
|
| 882 |
+
```
|
| 883 |
+
|
| 884 |
+
然后,使用下面的代码进行API调用:
|
| 885 |
+
|
| 886 |
+
```python
|
| 887 |
+
from openai import OpenAI
|
| 888 |
+
|
| 889 |
+
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
|
| 890 |
+
model_name = client.models.list().data[0].id
|
| 891 |
+
response = client.chat.completions.create(
|
| 892 |
+
model="InternVL2-8B",
|
| 893 |
+
messages=[{
|
| 894 |
+
'role':
|
| 895 |
+
'user',
|
| 896 |
+
'content': [{
|
| 897 |
+
'type': 'text',
|
| 898 |
+
'text': 'describe this image',
|
| 899 |
+
}, {
|
| 900 |
+
'type': 'image_url',
|
| 901 |
+
'image_url': {
|
| 902 |
+
'url':
|
| 903 |
+
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
|
| 904 |
+
},
|
| 905 |
+
}],
|
| 906 |
+
}],
|
| 907 |
+
temperature=0.8,
|
| 908 |
+
top_p=0.8)
|
| 909 |
+
print(response)
|
| 910 |
+
```
|
| 911 |
+
|
| 912 |
+
### vLLM
|
| 913 |
+
|
| 914 |
+
TODO
|
| 915 |
+
|
| 916 |
+
### Ollama
|
| 917 |
+
|
| 918 |
+
TODO
|
| 919 |
+
|
| 920 |
+
## 开源许可证
|
| 921 |
+
|
| 922 |
+
该项目采用 MIT 许可证发布,而 InternLM 则采用 Apache-2.0 许可证。
|
| 923 |
+
|
| 924 |
+
## 引用
|
| 925 |
+
|
| 926 |
+
如果您发现此项目对您的研究有用,可以考虑引用我们的论文:
|
| 927 |
+
|
| 928 |
+
```BibTeX
|
| 929 |
+
@article{chen2023internvl,
|
| 930 |
+
title={InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks},
|
| 931 |
+
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and Li, Bin and Luo, Ping and Lu, Tong and Qiao, Yu and Dai, Jifeng},
|
| 932 |
+
journal={arXiv preprint arXiv:2312.14238},
|
| 933 |
+
year={2023}
|
| 934 |
+
}
|
| 935 |
+
@article{chen2024far,
|
| 936 |
+
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
|
| 937 |
+
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
|
| 938 |
+
journal={arXiv preprint arXiv:2404.16821},
|
| 939 |
+
year={2024}
|
| 940 |
+
}
|
| 941 |
+
```
|
added_tokens.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</box>": 92552,
|
| 3 |
+
"</img>": 92545,
|
| 4 |
+
"</quad>": 92548,
|
| 5 |
+
"</ref>": 92550,
|
| 6 |
+
"<IMG_CONTEXT>": 92546,
|
| 7 |
+
"<box>": 92551,
|
| 8 |
+
"<img>": 92544,
|
| 9 |
+
"<quad>": 92547,
|
| 10 |
+
"<ref>": 92549
|
| 11 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_commit_hash": null,
|
| 3 |
+
"architectures": [
|
| 4 |
+
"InternVLChatModel"
|
| 5 |
+
],
|
| 6 |
+
"auto_map": {
|
| 7 |
+
"AutoConfig": "configuration_internvl_chat.InternVLChatConfig",
|
| 8 |
+
"AutoModel": "modeling_internvl_chat.InternVLChatModel",
|
| 9 |
+
"AutoModelForCausalLM": "modeling_internvl_chat.InternVLChatModel"
|
| 10 |
+
},
|
| 11 |
+
"downsample_ratio": 0.5,
|
| 12 |
+
"dynamic_image_size": true,
|
| 13 |
+
"force_image_size": 448,
|
| 14 |
+
"llm_config": {
|
| 15 |
+
"_name_or_path": "internlm/internlm2_5-7b-chat",
|
| 16 |
+
"add_cross_attention": false,
|
| 17 |
+
"architectures": [
|
| 18 |
+
"InternLM2ForCausalLM"
|
| 19 |
+
],
|
| 20 |
+
"attn_implementation": "flash_attention_2",
|
| 21 |
+
"auto_map": {
|
| 22 |
+
"AutoConfig": "configuration_internlm2.InternLM2Config",
|
| 23 |
+
"AutoModel": "modeling_internlm2.InternLM2ForCausalLM",
|
| 24 |
+
"AutoModelForCausalLM": "modeling_internlm2.InternLM2ForCausalLM"
|
| 25 |
+
},
|
| 26 |
+
"bad_words_ids": null,
|
| 27 |
+
"begin_suppress_tokens": null,
|
| 28 |
+
"bias": false,
|
| 29 |
+
"bos_token_id": 1,
|
| 30 |
+
"chunk_size_feed_forward": 0,
|
| 31 |
+
"cross_attention_hidden_size": null,
|
| 32 |
+
"decoder_start_token_id": null,
|
| 33 |
+
"diversity_penalty": 0.0,
|
| 34 |
+
"do_sample": false,
|
| 35 |
+
"early_stopping": false,
|
| 36 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 37 |
+
"eos_token_id": 2,
|
| 38 |
+
"exponential_decay_length_penalty": null,
|
| 39 |
+
"finetuning_task": null,
|
| 40 |
+
"forced_bos_token_id": null,
|
| 41 |
+
"forced_eos_token_id": null,
|
| 42 |
+
"hidden_act": "silu",
|
| 43 |
+
"hidden_size": 4096,
|
| 44 |
+
"id2label": {
|
| 45 |
+
"0": "LABEL_0",
|
| 46 |
+
"1": "LABEL_1"
|
| 47 |
+
},
|
| 48 |
+
"initializer_range": 0.02,
|
| 49 |
+
"intermediate_size": 14336,
|
| 50 |
+
"is_decoder": false,
|
| 51 |
+
"is_encoder_decoder": false,
|
| 52 |
+
"label2id": {
|
| 53 |
+
"LABEL_0": 0,
|
| 54 |
+
"LABEL_1": 1
|
| 55 |
+
},
|
| 56 |
+
"length_penalty": 1.0,
|
| 57 |
+
"max_length": 20,
|
| 58 |
+
"max_position_embeddings": 32768,
|
| 59 |
+
"min_length": 0,
|
| 60 |
+
"model_type": "internlm2",
|
| 61 |
+
"no_repeat_ngram_size": 0,
|
| 62 |
+
"num_attention_heads": 32,
|
| 63 |
+
"num_beam_groups": 1,
|
| 64 |
+
"num_beams": 1,
|
| 65 |
+
"num_hidden_layers": 32,
|
| 66 |
+
"num_key_value_heads": 8,
|
| 67 |
+
"num_return_sequences": 1,
|
| 68 |
+
"output_attentions": false,
|
| 69 |
+
"output_hidden_states": false,
|
| 70 |
+
"output_scores": false,
|
| 71 |
+
"pad_token_id": 2,
|
| 72 |
+
"prefix": null,
|
| 73 |
+
"pretraining_tp": 1,
|
| 74 |
+
"problem_type": null,
|
| 75 |
+
"pruned_heads": {},
|
| 76 |
+
"remove_invalid_values": false,
|
| 77 |
+
"repetition_penalty": 1.0,
|
| 78 |
+
"return_dict": true,
|
| 79 |
+
"return_dict_in_generate": false,
|
| 80 |
+
"rms_norm_eps": 1e-05,
|
| 81 |
+
"rope_scaling": {
|
| 82 |
+
"factor": 2.0,
|
| 83 |
+
"type": "dynamic"
|
| 84 |
+
},
|
| 85 |
+
"rope_theta": 1000000,
|
| 86 |
+
"sep_token_id": null,
|
| 87 |
+
"suppress_tokens": null,
|
| 88 |
+
"task_specific_params": null,
|
| 89 |
+
"temperature": 1.0,
|
| 90 |
+
"tf_legacy_loss": false,
|
| 91 |
+
"tie_encoder_decoder": false,
|
| 92 |
+
"tie_word_embeddings": false,
|
| 93 |
+
"tokenizer_class": null,
|
| 94 |
+
"top_k": 50,
|
| 95 |
+
"top_p": 1.0,
|
| 96 |
+
"torch_dtype": "bfloat16",
|
| 97 |
+
"torchscript": false,
|
| 98 |
+
"transformers_version": "4.37.2",
|
| 99 |
+
"typical_p": 1.0,
|
| 100 |
+
"use_bfloat16": true,
|
| 101 |
+
"use_cache": true,
|
| 102 |
+
"vocab_size": 92553
|
| 103 |
+
},
|
| 104 |
+
"max_dynamic_patch": 12,
|
| 105 |
+
"min_dynamic_patch": 1,
|
| 106 |
+
"model_type": "internvl_chat",
|
| 107 |
+
"ps_version": "v2",
|
| 108 |
+
"select_layer": -1,
|
| 109 |
+
"template": "internlm2-chat",
|
| 110 |
+
"torch_dtype": "bfloat16",
|
| 111 |
+
"use_backbone_lora": 0,
|
| 112 |
+
"use_llm_lora": 0,
|
| 113 |
+
"use_thumbnail": true,
|
| 114 |
+
"vision_config": {
|
| 115 |
+
"architectures": [
|
| 116 |
+
"InternVisionModel"
|
| 117 |
+
],
|
| 118 |
+
"attention_dropout": 0.0,
|
| 119 |
+
"drop_path_rate": 0.0,
|
| 120 |
+
"dropout": 0.0,
|
| 121 |
+
"hidden_act": "gelu",
|
| 122 |
+
"hidden_size": 1024,
|
| 123 |
+
"image_size": 448,
|
| 124 |
+
"initializer_factor": 1.0,
|
| 125 |
+
"initializer_range": 0.02,
|
| 126 |
+
"intermediate_size": 4096,
|
| 127 |
+
"layer_norm_eps": 1e-06,
|
| 128 |
+
"model_type": "intern_vit_6b",
|
| 129 |
+
"norm_type": "layer_norm",
|
| 130 |
+
"num_attention_heads": 16,
|
| 131 |
+
"num_channels": 3,
|
| 132 |
+
"num_hidden_layers": 24,
|
| 133 |
+
"output_attentions": false,
|
| 134 |
+
"output_hidden_states": false,
|
| 135 |
+
"patch_size": 14,
|
| 136 |
+
"qk_normalization": false,
|
| 137 |
+
"qkv_bias": true,
|
| 138 |
+
"return_dict": true,
|
| 139 |
+
"torch_dtype": "bfloat16",
|
| 140 |
+
"transformers_version": "4.37.2",
|
| 141 |
+
"use_bfloat16": true,
|
| 142 |
+
"use_flash_attn": true
|
| 143 |
+
}
|
| 144 |
+
}
|
configuration_intern_vit.py
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
import os
|
| 7 |
+
from typing import Union
|
| 8 |
+
|
| 9 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 10 |
+
from transformers.utils import logging
|
| 11 |
+
|
| 12 |
+
logger = logging.get_logger(__name__)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class InternVisionConfig(PretrainedConfig):
|
| 16 |
+
r"""
|
| 17 |
+
This is the configuration class to store the configuration of a [`InternVisionModel`]. It is used to
|
| 18 |
+
instantiate a vision encoder according to the specified arguments, defining the model architecture.
|
| 19 |
+
|
| 20 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 21 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 22 |
+
|
| 23 |
+
Args:
|
| 24 |
+
num_channels (`int`, *optional*, defaults to 3):
|
| 25 |
+
Number of color channels in the input images (e.g., 3 for RGB).
|
| 26 |
+
patch_size (`int`, *optional*, defaults to 14):
|
| 27 |
+
The size (resolution) of each patch.
|
| 28 |
+
image_size (`int`, *optional*, defaults to 224):
|
| 29 |
+
The size (resolution) of each image.
|
| 30 |
+
qkv_bias (`bool`, *optional*, defaults to `False`):
|
| 31 |
+
Whether to add a bias to the queries and values in the self-attention layers.
|
| 32 |
+
hidden_size (`int`, *optional*, defaults to 3200):
|
| 33 |
+
Dimensionality of the encoder layers and the pooler layer.
|
| 34 |
+
num_attention_heads (`int`, *optional*, defaults to 25):
|
| 35 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 36 |
+
intermediate_size (`int`, *optional*, defaults to 12800):
|
| 37 |
+
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
|
| 38 |
+
qk_normalization (`bool`, *optional*, defaults to `True`):
|
| 39 |
+
Whether to normalize the queries and keys in the self-attention layers.
|
| 40 |
+
num_hidden_layers (`int`, *optional*, defaults to 48):
|
| 41 |
+
Number of hidden layers in the Transformer encoder.
|
| 42 |
+
use_flash_attn (`bool`, *optional*, defaults to `True`):
|
| 43 |
+
Whether to use flash attention mechanism.
|
| 44 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
|
| 45 |
+
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
|
| 46 |
+
`"relu"`, `"selu"` and `"gelu_new"` ``"gelu"` are supported.
|
| 47 |
+
layer_norm_eps (`float`, *optional*, defaults to 1e-6):
|
| 48 |
+
The epsilon used by the layer normalization layers.
|
| 49 |
+
dropout (`float`, *optional*, defaults to 0.0):
|
| 50 |
+
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
|
| 51 |
+
drop_path_rate (`float`, *optional*, defaults to 0.0):
|
| 52 |
+
Dropout rate for stochastic depth.
|
| 53 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 54 |
+
The dropout ratio for the attention probabilities.
|
| 55 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 56 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 57 |
+
initializer_factor (`float`, *optional*, defaults to 0.1):
|
| 58 |
+
A factor for layer scale.
|
| 59 |
+
"""
|
| 60 |
+
|
| 61 |
+
model_type = 'intern_vit_6b'
|
| 62 |
+
|
| 63 |
+
def __init__(
|
| 64 |
+
self,
|
| 65 |
+
num_channels=3,
|
| 66 |
+
patch_size=14,
|
| 67 |
+
image_size=224,
|
| 68 |
+
qkv_bias=False,
|
| 69 |
+
hidden_size=3200,
|
| 70 |
+
num_attention_heads=25,
|
| 71 |
+
intermediate_size=12800,
|
| 72 |
+
qk_normalization=True,
|
| 73 |
+
num_hidden_layers=48,
|
| 74 |
+
use_flash_attn=True,
|
| 75 |
+
hidden_act='gelu',
|
| 76 |
+
norm_type='rms_norm',
|
| 77 |
+
layer_norm_eps=1e-6,
|
| 78 |
+
dropout=0.0,
|
| 79 |
+
drop_path_rate=0.0,
|
| 80 |
+
attention_dropout=0.0,
|
| 81 |
+
initializer_range=0.02,
|
| 82 |
+
initializer_factor=0.1,
|
| 83 |
+
**kwargs,
|
| 84 |
+
):
|
| 85 |
+
super().__init__(**kwargs)
|
| 86 |
+
|
| 87 |
+
self.hidden_size = hidden_size
|
| 88 |
+
self.intermediate_size = intermediate_size
|
| 89 |
+
self.dropout = dropout
|
| 90 |
+
self.drop_path_rate = drop_path_rate
|
| 91 |
+
self.num_hidden_layers = num_hidden_layers
|
| 92 |
+
self.num_attention_heads = num_attention_heads
|
| 93 |
+
self.num_channels = num_channels
|
| 94 |
+
self.patch_size = patch_size
|
| 95 |
+
self.image_size = image_size
|
| 96 |
+
self.initializer_range = initializer_range
|
| 97 |
+
self.initializer_factor = initializer_factor
|
| 98 |
+
self.attention_dropout = attention_dropout
|
| 99 |
+
self.layer_norm_eps = layer_norm_eps
|
| 100 |
+
self.hidden_act = hidden_act
|
| 101 |
+
self.norm_type = norm_type
|
| 102 |
+
self.qkv_bias = qkv_bias
|
| 103 |
+
self.qk_normalization = qk_normalization
|
| 104 |
+
self.use_flash_attn = use_flash_attn
|
| 105 |
+
|
| 106 |
+
@classmethod
|
| 107 |
+
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> 'PretrainedConfig':
|
| 108 |
+
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
|
| 109 |
+
|
| 110 |
+
if 'vision_config' in config_dict:
|
| 111 |
+
config_dict = config_dict['vision_config']
|
| 112 |
+
|
| 113 |
+
if 'model_type' in config_dict and hasattr(cls, 'model_type') and config_dict['model_type'] != cls.model_type:
|
| 114 |
+
logger.warning(
|
| 115 |
+
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
|
| 116 |
+
f'{cls.model_type}. This is not supported for all configurations of models and can yield errors.'
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
return cls.from_dict(config_dict, **kwargs)
|
configuration_internlm2.py
ADDED
|
@@ -0,0 +1,150 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) The InternLM team and The HuggingFace Inc. team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# This code is based on transformers/src/transformers/models/llama/configuration_llama.py
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
""" InternLM2 model configuration"""
|
| 17 |
+
|
| 18 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 19 |
+
from transformers.utils import logging
|
| 20 |
+
|
| 21 |
+
logger = logging.get_logger(__name__)
|
| 22 |
+
|
| 23 |
+
INTERNLM2_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
# Modified from transformers.model.llama.configuration_llama.LlamaConfig
|
| 27 |
+
class InternLM2Config(PretrainedConfig):
|
| 28 |
+
r"""
|
| 29 |
+
This is the configuration class to store the configuration of a [`InternLM2Model`]. It is used to instantiate
|
| 30 |
+
an InternLM2 model according to the specified arguments, defining the model architecture. Instantiating a
|
| 31 |
+
configuration with the defaults will yield a similar configuration to that of the InternLM2-7B.
|
| 32 |
+
|
| 33 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 34 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
Args:
|
| 38 |
+
vocab_size (`int`, *optional*, defaults to 32000):
|
| 39 |
+
Vocabulary size of the InternLM2 model. Defines the number of different tokens that can be represented by the
|
| 40 |
+
`inputs_ids` passed when calling [`InternLM2Model`]
|
| 41 |
+
hidden_size (`int`, *optional*, defaults to 4096):
|
| 42 |
+
Dimension of the hidden representations.
|
| 43 |
+
intermediate_size (`int`, *optional*, defaults to 11008):
|
| 44 |
+
Dimension of the MLP representations.
|
| 45 |
+
num_hidden_layers (`int`, *optional*, defaults to 32):
|
| 46 |
+
Number of hidden layers in the Transformer encoder.
|
| 47 |
+
num_attention_heads (`int`, *optional*, defaults to 32):
|
| 48 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 49 |
+
num_key_value_heads (`int`, *optional*):
|
| 50 |
+
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
| 51 |
+
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
| 52 |
+
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
|
| 53 |
+
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
|
| 54 |
+
by meanpooling all the original heads within that group. For more details checkout [this
|
| 55 |
+
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
|
| 56 |
+
`num_attention_heads`.
|
| 57 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
| 58 |
+
The non-linear activation function (function or string) in the decoder.
|
| 59 |
+
max_position_embeddings (`int`, *optional*, defaults to 2048):
|
| 60 |
+
The maximum sequence length that this model might ever be used with. Typically set this to something large
|
| 61 |
+
just in case (e.g., 512 or 1024 or 2048).
|
| 62 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 63 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 64 |
+
rms_norm_eps (`float`, *optional*, defaults to 1e-12):
|
| 65 |
+
The epsilon used by the rms normalization layers.
|
| 66 |
+
use_cache (`bool`, *optional*, defaults to `True`):
|
| 67 |
+
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
| 68 |
+
relevant if `config.is_decoder=True`.
|
| 69 |
+
tie_word_embeddings(`bool`, *optional*, defaults to `False`):
|
| 70 |
+
Whether to tie weight embeddings
|
| 71 |
+
Example:
|
| 72 |
+
|
| 73 |
+
"""
|
| 74 |
+
model_type = 'internlm2'
|
| 75 |
+
_auto_class = 'AutoConfig'
|
| 76 |
+
|
| 77 |
+
def __init__( # pylint: disable=W0102
|
| 78 |
+
self,
|
| 79 |
+
vocab_size=103168,
|
| 80 |
+
hidden_size=4096,
|
| 81 |
+
intermediate_size=11008,
|
| 82 |
+
num_hidden_layers=32,
|
| 83 |
+
num_attention_heads=32,
|
| 84 |
+
num_key_value_heads=None,
|
| 85 |
+
hidden_act='silu',
|
| 86 |
+
max_position_embeddings=2048,
|
| 87 |
+
initializer_range=0.02,
|
| 88 |
+
rms_norm_eps=1e-6,
|
| 89 |
+
use_cache=True,
|
| 90 |
+
pad_token_id=0,
|
| 91 |
+
bos_token_id=1,
|
| 92 |
+
eos_token_id=2,
|
| 93 |
+
tie_word_embeddings=False,
|
| 94 |
+
bias=True,
|
| 95 |
+
rope_theta=10000,
|
| 96 |
+
rope_scaling=None,
|
| 97 |
+
attn_implementation='eager',
|
| 98 |
+
**kwargs,
|
| 99 |
+
):
|
| 100 |
+
self.vocab_size = vocab_size
|
| 101 |
+
self.max_position_embeddings = max_position_embeddings
|
| 102 |
+
self.hidden_size = hidden_size
|
| 103 |
+
self.intermediate_size = intermediate_size
|
| 104 |
+
self.num_hidden_layers = num_hidden_layers
|
| 105 |
+
self.num_attention_heads = num_attention_heads
|
| 106 |
+
self.bias = bias
|
| 107 |
+
|
| 108 |
+
if num_key_value_heads is None:
|
| 109 |
+
num_key_value_heads = num_attention_heads
|
| 110 |
+
self.num_key_value_heads = num_key_value_heads
|
| 111 |
+
|
| 112 |
+
self.hidden_act = hidden_act
|
| 113 |
+
self.initializer_range = initializer_range
|
| 114 |
+
self.rms_norm_eps = rms_norm_eps
|
| 115 |
+
self.use_cache = use_cache
|
| 116 |
+
self.rope_theta = rope_theta
|
| 117 |
+
self.rope_scaling = rope_scaling
|
| 118 |
+
self._rope_scaling_validation()
|
| 119 |
+
|
| 120 |
+
self.attn_implementation = attn_implementation
|
| 121 |
+
if self.attn_implementation is None:
|
| 122 |
+
self.attn_implementation = 'eager'
|
| 123 |
+
super().__init__(
|
| 124 |
+
pad_token_id=pad_token_id,
|
| 125 |
+
bos_token_id=bos_token_id,
|
| 126 |
+
eos_token_id=eos_token_id,
|
| 127 |
+
tie_word_embeddings=tie_word_embeddings,
|
| 128 |
+
**kwargs,
|
| 129 |
+
)
|
| 130 |
+
|
| 131 |
+
def _rope_scaling_validation(self):
|
| 132 |
+
"""
|
| 133 |
+
Validate the `rope_scaling` configuration.
|
| 134 |
+
"""
|
| 135 |
+
if self.rope_scaling is None:
|
| 136 |
+
return
|
| 137 |
+
|
| 138 |
+
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
|
| 139 |
+
raise ValueError(
|
| 140 |
+
'`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, '
|
| 141 |
+
f'got {self.rope_scaling}'
|
| 142 |
+
)
|
| 143 |
+
rope_scaling_type = self.rope_scaling.get('type', None)
|
| 144 |
+
rope_scaling_factor = self.rope_scaling.get('factor', None)
|
| 145 |
+
if rope_scaling_type is None or rope_scaling_type not in ['linear', 'dynamic']:
|
| 146 |
+
raise ValueError(
|
| 147 |
+
f"`rope_scaling`'s type field must be one of ['linear', 'dynamic'], got {rope_scaling_type}"
|
| 148 |
+
)
|
| 149 |
+
if rope_scaling_factor is None or not isinstance(rope_scaling_factor, float) or rope_scaling_factor < 1.0:
|
| 150 |
+
raise ValueError(f"`rope_scaling`'s factor field must be a float >= 1, got {rope_scaling_factor}")
|
configuration_internvl_chat.py
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
import copy
|
| 8 |
+
|
| 9 |
+
from transformers import AutoConfig, LlamaConfig
|
| 10 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 11 |
+
from transformers.utils import logging
|
| 12 |
+
|
| 13 |
+
from .configuration_intern_vit import InternVisionConfig
|
| 14 |
+
from .configuration_internlm2 import InternLM2Config
|
| 15 |
+
|
| 16 |
+
logger = logging.get_logger(__name__)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class InternVLChatConfig(PretrainedConfig):
|
| 20 |
+
model_type = 'internvl_chat'
|
| 21 |
+
is_composition = True
|
| 22 |
+
|
| 23 |
+
def __init__(
|
| 24 |
+
self,
|
| 25 |
+
vision_config=None,
|
| 26 |
+
llm_config=None,
|
| 27 |
+
use_backbone_lora=0,
|
| 28 |
+
use_llm_lora=0,
|
| 29 |
+
select_layer=-1,
|
| 30 |
+
force_image_size=None,
|
| 31 |
+
downsample_ratio=0.5,
|
| 32 |
+
template=None,
|
| 33 |
+
dynamic_image_size=False,
|
| 34 |
+
use_thumbnail=False,
|
| 35 |
+
ps_version='v1',
|
| 36 |
+
min_dynamic_patch=1,
|
| 37 |
+
max_dynamic_patch=6,
|
| 38 |
+
**kwargs):
|
| 39 |
+
super().__init__(**kwargs)
|
| 40 |
+
|
| 41 |
+
if vision_config is None:
|
| 42 |
+
vision_config = {}
|
| 43 |
+
logger.info('vision_config is None. Initializing the InternVisionConfig with default values.')
|
| 44 |
+
|
| 45 |
+
if llm_config is None:
|
| 46 |
+
llm_config = {}
|
| 47 |
+
logger.info('llm_config is None. Initializing the LlamaConfig config with default values (`LlamaConfig`).')
|
| 48 |
+
|
| 49 |
+
self.vision_config = InternVisionConfig(**vision_config)
|
| 50 |
+
if llm_config['architectures'][0] == 'LlamaForCausalLM':
|
| 51 |
+
self.llm_config = LlamaConfig(**llm_config)
|
| 52 |
+
elif llm_config['architectures'][0] == 'InternLM2ForCausalLM':
|
| 53 |
+
self.llm_config = InternLM2Config(**llm_config)
|
| 54 |
+
else:
|
| 55 |
+
raise ValueError('Unsupported architecture: {}'.format(llm_config['architectures'][0]))
|
| 56 |
+
self.use_backbone_lora = use_backbone_lora
|
| 57 |
+
self.use_llm_lora = use_llm_lora
|
| 58 |
+
self.select_layer = select_layer
|
| 59 |
+
self.force_image_size = force_image_size
|
| 60 |
+
self.downsample_ratio = downsample_ratio
|
| 61 |
+
self.template = template
|
| 62 |
+
self.dynamic_image_size = dynamic_image_size
|
| 63 |
+
self.use_thumbnail = use_thumbnail
|
| 64 |
+
self.ps_version = ps_version # pixel shuffle version
|
| 65 |
+
self.min_dynamic_patch = min_dynamic_patch
|
| 66 |
+
self.max_dynamic_patch = max_dynamic_patch
|
| 67 |
+
|
| 68 |
+
logger.info(f'vision_select_layer: {self.select_layer}')
|
| 69 |
+
logger.info(f'ps_version: {self.ps_version}')
|
| 70 |
+
logger.info(f'min_dynamic_patch: {self.min_dynamic_patch}')
|
| 71 |
+
logger.info(f'max_dynamic_patch: {self.max_dynamic_patch}')
|
| 72 |
+
|
| 73 |
+
def to_dict(self):
|
| 74 |
+
"""
|
| 75 |
+
Serializes this instance to a Python dictionary. Override the default [`~PretrainedConfig.to_dict`].
|
| 76 |
+
|
| 77 |
+
Returns:
|
| 78 |
+
`Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
|
| 79 |
+
"""
|
| 80 |
+
output = copy.deepcopy(self.__dict__)
|
| 81 |
+
output['vision_config'] = self.vision_config.to_dict()
|
| 82 |
+
output['llm_config'] = self.llm_config.to_dict()
|
| 83 |
+
output['model_type'] = self.__class__.model_type
|
| 84 |
+
output['use_backbone_lora'] = self.use_backbone_lora
|
| 85 |
+
output['use_llm_lora'] = self.use_llm_lora
|
| 86 |
+
output['select_layer'] = self.select_layer
|
| 87 |
+
output['force_image_size'] = self.force_image_size
|
| 88 |
+
output['downsample_ratio'] = self.downsample_ratio
|
| 89 |
+
output['template'] = self.template
|
| 90 |
+
output['dynamic_image_size'] = self.dynamic_image_size
|
| 91 |
+
output['use_thumbnail'] = self.use_thumbnail
|
| 92 |
+
output['ps_version'] = self.ps_version
|
| 93 |
+
output['min_dynamic_patch'] = self.min_dynamic_patch
|
| 94 |
+
output['max_dynamic_patch'] = self.max_dynamic_patch
|
| 95 |
+
|
| 96 |
+
return output
|
conversation.py
ADDED
|
@@ -0,0 +1,393 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Conversation prompt templates.
|
| 3 |
+
|
| 4 |
+
We kindly request that you import fastchat instead of copying this file if you wish to use it.
|
| 5 |
+
If you have changes in mind, please contribute back so the community can benefit collectively and continue to maintain these valuable templates.
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import dataclasses
|
| 9 |
+
from enum import IntEnum, auto
|
| 10 |
+
from typing import Any, Dict, List, Tuple, Union
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class SeparatorStyle(IntEnum):
|
| 14 |
+
"""Separator styles."""
|
| 15 |
+
|
| 16 |
+
ADD_COLON_SINGLE = auto()
|
| 17 |
+
ADD_COLON_TWO = auto()
|
| 18 |
+
ADD_COLON_SPACE_SINGLE = auto()
|
| 19 |
+
NO_COLON_SINGLE = auto()
|
| 20 |
+
NO_COLON_TWO = auto()
|
| 21 |
+
ADD_NEW_LINE_SINGLE = auto()
|
| 22 |
+
LLAMA2 = auto()
|
| 23 |
+
CHATGLM = auto()
|
| 24 |
+
CHATML = auto()
|
| 25 |
+
CHATINTERN = auto()
|
| 26 |
+
DOLLY = auto()
|
| 27 |
+
RWKV = auto()
|
| 28 |
+
PHOENIX = auto()
|
| 29 |
+
ROBIN = auto()
|
| 30 |
+
FALCON_CHAT = auto()
|
| 31 |
+
CHATGLM3 = auto()
|
| 32 |
+
INTERNVL_ZH = auto()
|
| 33 |
+
MPT = auto()
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
@dataclasses.dataclass
|
| 37 |
+
class Conversation:
|
| 38 |
+
"""A class that manages prompt templates and keeps all conversation history."""
|
| 39 |
+
|
| 40 |
+
# The name of this template
|
| 41 |
+
name: str
|
| 42 |
+
# The template of the system prompt
|
| 43 |
+
system_template: str = '{system_message}'
|
| 44 |
+
# The system message
|
| 45 |
+
system_message: str = ''
|
| 46 |
+
# The names of two roles
|
| 47 |
+
roles: Tuple[str] = ('USER', 'ASSISTANT')
|
| 48 |
+
# All messages. Each item is (role, message).
|
| 49 |
+
messages: List[List[str]] = ()
|
| 50 |
+
# The number of few shot examples
|
| 51 |
+
offset: int = 0
|
| 52 |
+
# The separator style and configurations
|
| 53 |
+
sep_style: SeparatorStyle = SeparatorStyle.ADD_COLON_SINGLE
|
| 54 |
+
sep: str = '\n'
|
| 55 |
+
sep2: str = None
|
| 56 |
+
# Stop criteria (the default one is EOS token)
|
| 57 |
+
stop_str: Union[str, List[str]] = None
|
| 58 |
+
# Stops generation if meeting any token in this list
|
| 59 |
+
stop_token_ids: List[int] = None
|
| 60 |
+
|
| 61 |
+
def get_prompt(self) -> str:
|
| 62 |
+
"""Get the prompt for generation."""
|
| 63 |
+
system_prompt = self.system_template.format(system_message=self.system_message)
|
| 64 |
+
if self.sep_style == SeparatorStyle.ADD_COLON_SINGLE:
|
| 65 |
+
ret = system_prompt + self.sep
|
| 66 |
+
for role, message in self.messages:
|
| 67 |
+
if message:
|
| 68 |
+
ret += role + ': ' + message + self.sep
|
| 69 |
+
else:
|
| 70 |
+
ret += role + ':'
|
| 71 |
+
return ret
|
| 72 |
+
elif self.sep_style == SeparatorStyle.ADD_COLON_TWO:
|
| 73 |
+
seps = [self.sep, self.sep2]
|
| 74 |
+
ret = system_prompt + seps[0]
|
| 75 |
+
for i, (role, message) in enumerate(self.messages):
|
| 76 |
+
if message:
|
| 77 |
+
ret += role + ': ' + message + seps[i % 2]
|
| 78 |
+
else:
|
| 79 |
+
ret += role + ':'
|
| 80 |
+
return ret
|
| 81 |
+
elif self.sep_style == SeparatorStyle.ADD_COLON_SPACE_SINGLE:
|
| 82 |
+
ret = system_prompt + self.sep
|
| 83 |
+
for role, message in self.messages:
|
| 84 |
+
if message:
|
| 85 |
+
ret += role + ': ' + message + self.sep
|
| 86 |
+
else:
|
| 87 |
+
ret += role + ': ' # must be end with a space
|
| 88 |
+
return ret
|
| 89 |
+
elif self.sep_style == SeparatorStyle.ADD_NEW_LINE_SINGLE:
|
| 90 |
+
ret = '' if system_prompt == '' else system_prompt + self.sep
|
| 91 |
+
for role, message in self.messages:
|
| 92 |
+
if message:
|
| 93 |
+
ret += role + '\n' + message + self.sep
|
| 94 |
+
else:
|
| 95 |
+
ret += role + '\n'
|
| 96 |
+
return ret
|
| 97 |
+
elif self.sep_style == SeparatorStyle.NO_COLON_SINGLE:
|
| 98 |
+
ret = system_prompt
|
| 99 |
+
for role, message in self.messages:
|
| 100 |
+
if message:
|
| 101 |
+
ret += role + message + self.sep
|
| 102 |
+
else:
|
| 103 |
+
ret += role
|
| 104 |
+
return ret
|
| 105 |
+
elif self.sep_style == SeparatorStyle.NO_COLON_TWO:
|
| 106 |
+
seps = [self.sep, self.sep2]
|
| 107 |
+
ret = system_prompt
|
| 108 |
+
for i, (role, message) in enumerate(self.messages):
|
| 109 |
+
if message:
|
| 110 |
+
ret += role + message + seps[i % 2]
|
| 111 |
+
else:
|
| 112 |
+
ret += role
|
| 113 |
+
return ret
|
| 114 |
+
elif self.sep_style == SeparatorStyle.RWKV:
|
| 115 |
+
ret = system_prompt
|
| 116 |
+
for i, (role, message) in enumerate(self.messages):
|
| 117 |
+
if message:
|
| 118 |
+
ret += (
|
| 119 |
+
role
|
| 120 |
+
+ ': '
|
| 121 |
+
+ message.replace('\r\n', '\n').replace('\n\n', '\n')
|
| 122 |
+
)
|
| 123 |
+
ret += '\n\n'
|
| 124 |
+
else:
|
| 125 |
+
ret += role + ':'
|
| 126 |
+
return ret
|
| 127 |
+
elif self.sep_style == SeparatorStyle.LLAMA2:
|
| 128 |
+
seps = [self.sep, self.sep2]
|
| 129 |
+
if self.system_message:
|
| 130 |
+
ret = system_prompt
|
| 131 |
+
else:
|
| 132 |
+
ret = '[INST] '
|
| 133 |
+
for i, (role, message) in enumerate(self.messages):
|
| 134 |
+
tag = self.roles[i % 2]
|
| 135 |
+
if message:
|
| 136 |
+
if i == 0:
|
| 137 |
+
ret += message + ' '
|
| 138 |
+
else:
|
| 139 |
+
ret += tag + ' ' + message + seps[i % 2]
|
| 140 |
+
else:
|
| 141 |
+
ret += tag
|
| 142 |
+
return ret
|
| 143 |
+
elif self.sep_style == SeparatorStyle.CHATGLM:
|
| 144 |
+
# source: https://huggingface.co/THUDM/chatglm-6b/blob/1d240ba371910e9282298d4592532d7f0f3e9f3e/modeling_chatglm.py#L1302-L1308
|
| 145 |
+
# source2: https://huggingface.co/THUDM/chatglm2-6b/blob/e186c891cf64310ac66ef10a87e6635fa6c2a579/modeling_chatglm.py#L926
|
| 146 |
+
round_add_n = 1 if self.name == 'chatglm2' else 0
|
| 147 |
+
if system_prompt:
|
| 148 |
+
ret = system_prompt + self.sep
|
| 149 |
+
else:
|
| 150 |
+
ret = ''
|
| 151 |
+
|
| 152 |
+
for i, (role, message) in enumerate(self.messages):
|
| 153 |
+
if i % 2 == 0:
|
| 154 |
+
ret += f'[Round {i//2 + round_add_n}]{self.sep}'
|
| 155 |
+
|
| 156 |
+
if message:
|
| 157 |
+
ret += f'{role}:{message}{self.sep}'
|
| 158 |
+
else:
|
| 159 |
+
ret += f'{role}:'
|
| 160 |
+
return ret
|
| 161 |
+
elif self.sep_style == SeparatorStyle.CHATML:
|
| 162 |
+
ret = '' if system_prompt == '' else system_prompt + self.sep + '\n'
|
| 163 |
+
for role, message in self.messages:
|
| 164 |
+
if message:
|
| 165 |
+
ret += role + '\n' + message + self.sep + '\n'
|
| 166 |
+
else:
|
| 167 |
+
ret += role + '\n'
|
| 168 |
+
return ret
|
| 169 |
+
elif self.sep_style == SeparatorStyle.CHATGLM3:
|
| 170 |
+
ret = ''
|
| 171 |
+
if self.system_message:
|
| 172 |
+
ret += system_prompt
|
| 173 |
+
for role, message in self.messages:
|
| 174 |
+
if message:
|
| 175 |
+
ret += role + '\n' + ' ' + message
|
| 176 |
+
else:
|
| 177 |
+
ret += role
|
| 178 |
+
return ret
|
| 179 |
+
elif self.sep_style == SeparatorStyle.CHATINTERN:
|
| 180 |
+
# source: https://huggingface.co/internlm/internlm-chat-7b-8k/blob/bd546fa984b4b0b86958f56bf37f94aa75ab8831/modeling_internlm.py#L771
|
| 181 |
+
seps = [self.sep, self.sep2]
|
| 182 |
+
ret = system_prompt
|
| 183 |
+
for i, (role, message) in enumerate(self.messages):
|
| 184 |
+
# if i % 2 == 0:
|
| 185 |
+
# ret += "<s>"
|
| 186 |
+
if message:
|
| 187 |
+
ret += role + ':' + message + seps[i % 2] + '\n'
|
| 188 |
+
else:
|
| 189 |
+
ret += role + ':'
|
| 190 |
+
return ret
|
| 191 |
+
elif self.sep_style == SeparatorStyle.DOLLY:
|
| 192 |
+
seps = [self.sep, self.sep2]
|
| 193 |
+
ret = system_prompt
|
| 194 |
+
for i, (role, message) in enumerate(self.messages):
|
| 195 |
+
if message:
|
| 196 |
+
ret += role + ':\n' + message + seps[i % 2]
|
| 197 |
+
if i % 2 == 1:
|
| 198 |
+
ret += '\n\n'
|
| 199 |
+
else:
|
| 200 |
+
ret += role + ':\n'
|
| 201 |
+
return ret
|
| 202 |
+
elif self.sep_style == SeparatorStyle.PHOENIX:
|
| 203 |
+
ret = system_prompt
|
| 204 |
+
for role, message in self.messages:
|
| 205 |
+
if message:
|
| 206 |
+
ret += role + ': ' + '<s>' + message + '</s>'
|
| 207 |
+
else:
|
| 208 |
+
ret += role + ': ' + '<s>'
|
| 209 |
+
return ret
|
| 210 |
+
elif self.sep_style == SeparatorStyle.ROBIN:
|
| 211 |
+
ret = system_prompt + self.sep
|
| 212 |
+
for role, message in self.messages:
|
| 213 |
+
if message:
|
| 214 |
+
ret += role + ':\n' + message + self.sep
|
| 215 |
+
else:
|
| 216 |
+
ret += role + ':\n'
|
| 217 |
+
return ret
|
| 218 |
+
elif self.sep_style == SeparatorStyle.FALCON_CHAT:
|
| 219 |
+
ret = ''
|
| 220 |
+
if self.system_message:
|
| 221 |
+
ret += system_prompt + self.sep
|
| 222 |
+
for role, message in self.messages:
|
| 223 |
+
if message:
|
| 224 |
+
ret += role + ': ' + message + self.sep
|
| 225 |
+
else:
|
| 226 |
+
ret += role + ':'
|
| 227 |
+
|
| 228 |
+
return ret
|
| 229 |
+
elif self.sep_style == SeparatorStyle.INTERNVL_ZH:
|
| 230 |
+
seps = [self.sep, self.sep2]
|
| 231 |
+
ret = self.system_message + seps[0]
|
| 232 |
+
for i, (role, message) in enumerate(self.messages):
|
| 233 |
+
if message:
|
| 234 |
+
ret += role + ': ' + message + seps[i % 2]
|
| 235 |
+
else:
|
| 236 |
+
ret += role + ':'
|
| 237 |
+
return ret
|
| 238 |
+
elif self.sep_style == SeparatorStyle.MPT:
|
| 239 |
+
ret = system_prompt + self.sep
|
| 240 |
+
for role, message in self.messages:
|
| 241 |
+
if message:
|
| 242 |
+
if type(message) is tuple:
|
| 243 |
+
message, _, _ = message
|
| 244 |
+
ret += role + message + self.sep
|
| 245 |
+
else:
|
| 246 |
+
ret += role
|
| 247 |
+
return ret
|
| 248 |
+
else:
|
| 249 |
+
raise ValueError(f'Invalid style: {self.sep_style}')
|
| 250 |
+
|
| 251 |
+
def set_system_message(self, system_message: str):
|
| 252 |
+
"""Set the system message."""
|
| 253 |
+
self.system_message = system_message
|
| 254 |
+
|
| 255 |
+
def append_message(self, role: str, message: str):
|
| 256 |
+
"""Append a new message."""
|
| 257 |
+
self.messages.append([role, message])
|
| 258 |
+
|
| 259 |
+
def update_last_message(self, message: str):
|
| 260 |
+
"""Update the last output.
|
| 261 |
+
|
| 262 |
+
The last message is typically set to be None when constructing the prompt,
|
| 263 |
+
so we need to update it in-place after getting the response from a model.
|
| 264 |
+
"""
|
| 265 |
+
self.messages[-1][1] = message
|
| 266 |
+
|
| 267 |
+
def to_gradio_chatbot(self):
|
| 268 |
+
"""Convert the conversation to gradio chatbot format."""
|
| 269 |
+
ret = []
|
| 270 |
+
for i, (role, msg) in enumerate(self.messages[self.offset :]):
|
| 271 |
+
if i % 2 == 0:
|
| 272 |
+
ret.append([msg, None])
|
| 273 |
+
else:
|
| 274 |
+
ret[-1][-1] = msg
|
| 275 |
+
return ret
|
| 276 |
+
|
| 277 |
+
def to_openai_api_messages(self):
|
| 278 |
+
"""Convert the conversation to OpenAI chat completion format."""
|
| 279 |
+
ret = [{'role': 'system', 'content': self.system_message}]
|
| 280 |
+
|
| 281 |
+
for i, (_, msg) in enumerate(self.messages[self.offset :]):
|
| 282 |
+
if i % 2 == 0:
|
| 283 |
+
ret.append({'role': 'user', 'content': msg})
|
| 284 |
+
else:
|
| 285 |
+
if msg is not None:
|
| 286 |
+
ret.append({'role': 'assistant', 'content': msg})
|
| 287 |
+
return ret
|
| 288 |
+
|
| 289 |
+
def copy(self):
|
| 290 |
+
return Conversation(
|
| 291 |
+
name=self.name,
|
| 292 |
+
system_template=self.system_template,
|
| 293 |
+
system_message=self.system_message,
|
| 294 |
+
roles=self.roles,
|
| 295 |
+
messages=[[x, y] for x, y in self.messages],
|
| 296 |
+
offset=self.offset,
|
| 297 |
+
sep_style=self.sep_style,
|
| 298 |
+
sep=self.sep,
|
| 299 |
+
sep2=self.sep2,
|
| 300 |
+
stop_str=self.stop_str,
|
| 301 |
+
stop_token_ids=self.stop_token_ids,
|
| 302 |
+
)
|
| 303 |
+
|
| 304 |
+
def dict(self):
|
| 305 |
+
return {
|
| 306 |
+
'template_name': self.name,
|
| 307 |
+
'system_message': self.system_message,
|
| 308 |
+
'roles': self.roles,
|
| 309 |
+
'messages': self.messages,
|
| 310 |
+
'offset': self.offset,
|
| 311 |
+
}
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
# A global registry for all conversation templates
|
| 315 |
+
conv_templates: Dict[str, Conversation] = {}
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
def register_conv_template(template: Conversation, override: bool = False):
|
| 319 |
+
"""Register a new conversation template."""
|
| 320 |
+
if not override:
|
| 321 |
+
assert (
|
| 322 |
+
template.name not in conv_templates
|
| 323 |
+
), f'{template.name} has been registered.'
|
| 324 |
+
|
| 325 |
+
conv_templates[template.name] = template
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
def get_conv_template(name: str) -> Conversation:
|
| 329 |
+
"""Get a conversation template."""
|
| 330 |
+
return conv_templates[name].copy()
|
| 331 |
+
|
| 332 |
+
|
| 333 |
+
# Both Hermes-2 and internlm2-chat are chatml-format conversation templates. The difference
|
| 334 |
+
# is that during training, the preprocessing function for the Hermes-2 template doesn't add
|
| 335 |
+
# <s> at the beginning of the tokenized sequence, while the internlm2-chat template does.
|
| 336 |
+
# Therefore, they are completely equivalent during inference.
|
| 337 |
+
register_conv_template(
|
| 338 |
+
Conversation(
|
| 339 |
+
name='Hermes-2',
|
| 340 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 341 |
+
# note: The new system prompt was not used here to avoid changes in benchmark performance.
|
| 342 |
+
# system_message='我是书生·万象,英文名是InternVL,是由上海人工智能实验室及多家合作单位联合开发的多模态大语言模型。',
|
| 343 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 344 |
+
roles=('<|im_start|>user\n', '<|im_start|>assistant\n'),
|
| 345 |
+
sep_style=SeparatorStyle.MPT,
|
| 346 |
+
sep='<|im_end|>',
|
| 347 |
+
stop_token_ids=[
|
| 348 |
+
2,
|
| 349 |
+
6,
|
| 350 |
+
7,
|
| 351 |
+
8,
|
| 352 |
+
],
|
| 353 |
+
stop_str='<|endoftext|>',
|
| 354 |
+
)
|
| 355 |
+
)
|
| 356 |
+
|
| 357 |
+
|
| 358 |
+
register_conv_template(
|
| 359 |
+
Conversation(
|
| 360 |
+
name='internlm2-chat',
|
| 361 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 362 |
+
# note: The new system prompt was not used here to avoid changes in benchmark performance.
|
| 363 |
+
# system_message='我是书生·万象,英文名是InternVL,是由上海人工智能实验室及多家合作单位联合开发的多模态大语言模型。',
|
| 364 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 365 |
+
roles=('<|im_start|>user\n', '<|im_start|>assistant\n'),
|
| 366 |
+
sep_style=SeparatorStyle.MPT,
|
| 367 |
+
sep='<|im_end|>',
|
| 368 |
+
stop_token_ids=[
|
| 369 |
+
2,
|
| 370 |
+
92543,
|
| 371 |
+
92542
|
| 372 |
+
]
|
| 373 |
+
)
|
| 374 |
+
)
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
register_conv_template(
|
| 378 |
+
Conversation(
|
| 379 |
+
name='phi3-chat',
|
| 380 |
+
system_template='<|system|>\n{system_message}',
|
| 381 |
+
# note: The new system prompt was not used here to avoid changes in benchmark performance.
|
| 382 |
+
# system_message='我是书生·万象,英文名是InternVL,是由上海人工智能实验室及多家合作单位联合开发的多模态大语言模型。',
|
| 383 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 384 |
+
roles=('<|user|>\n', '<|assistant|>\n'),
|
| 385 |
+
sep_style=SeparatorStyle.MPT,
|
| 386 |
+
sep='<|end|>',
|
| 387 |
+
stop_token_ids=[
|
| 388 |
+
2,
|
| 389 |
+
32000,
|
| 390 |
+
32007
|
| 391 |
+
]
|
| 392 |
+
)
|
| 393 |
+
)
|
examples/image1.jpg
ADDED

|
examples/image2.jpg
ADDED

|
examples/index.html
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
|
| 2 |
+
<html>
|
| 3 |
+
<head>
|
| 4 |
+
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
|
| 5 |
+
<title>Directory listing for /share_internvl/InternVL2-8B/examples/</title>
|
| 6 |
+
</head>
|
| 7 |
+
<body>
|
| 8 |
+
<h1>Directory listing for /share_internvl/InternVL2-8B/examples/</h1>
|
| 9 |
+
<hr>
|
| 10 |
+
<ul>
|
| 11 |
+
<li><a href="image1.jpg">image1.jpg</a></li>
|
| 12 |
+
<li><a href="image2.jpg">image2.jpg</a></li>
|
| 13 |
+
<li><a href="red-panda.mp4">red-panda.mp4</a></li>
|
| 14 |
+
</ul>
|
| 15 |
+
<hr>
|
| 16 |
+
</body>
|
| 17 |
+
</html>
|
examples/red-panda.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d921c07bb97224d65a37801541d246067f0d506f08723ffa1ad85c217907ccb8
|
| 3 |
+
size 1867237
|
generation_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"transformers_version": "4.37.2"
|
| 4 |
+
}
|
index.html
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
|
| 2 |
+
<html>
|
| 3 |
+
<head>
|
| 4 |
+
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
|
| 5 |
+
<title>Directory listing for /share_internvl/InternVL2-8B/</title>
|
| 6 |
+
</head>
|
| 7 |
+
<body>
|
| 8 |
+
<h1>Directory listing for /share_internvl/InternVL2-8B/</h1>
|
| 9 |
+
<hr>
|
| 10 |
+
<ul>
|
| 11 |
+
<li><a href="added_tokens.json">added_tokens.json</a></li>
|
| 12 |
+
<li><a href="config.json">config.json</a></li>
|
| 13 |
+
<li><a href="configuration_intern_vit.py">configuration_intern_vit.py</a></li>
|
| 14 |
+
<li><a href="configuration_internlm2.py">configuration_internlm2.py</a></li>
|
| 15 |
+
<li><a href="configuration_internvl_chat.py">configuration_internvl_chat.py</a></li>
|
| 16 |
+
<li><a href="conversation.py">conversation.py</a></li>
|
| 17 |
+
<li><a href="examples/">examples/</a></li>
|
| 18 |
+
<li><a href="generation_config.json">generation_config.json</a></li>
|
| 19 |
+
<li><a href="model-00001-of-00004.safetensors">model-00001-of-00004.safetensors</a></li>
|
| 20 |
+
<li><a href="model-00002-of-00004.safetensors">model-00002-of-00004.safetensors</a></li>
|
| 21 |
+
<li><a href="model-00003-of-00004.safetensors">model-00003-of-00004.safetensors</a></li>
|
| 22 |
+
<li><a href="model-00004-of-00004.safetensors">model-00004-of-00004.safetensors</a></li>
|
| 23 |
+
<li><a href="model.safetensors.index.json">model.safetensors.index.json</a></li>
|
| 24 |
+
<li><a href="modeling_intern_vit.py">modeling_intern_vit.py</a></li>
|
| 25 |
+
<li><a href="modeling_internlm2.py">modeling_internlm2.py</a></li>
|
| 26 |
+
<li><a href="modeling_internvl_chat.py">modeling_internvl_chat.py</a></li>
|
| 27 |
+
<li><a href="preprocessor_config.json">preprocessor_config.json</a></li>
|
| 28 |
+
<li><a href="README.md">README.md</a></li>
|
| 29 |
+
<li><a href="special_tokens_map.json">special_tokens_map.json</a></li>
|
| 30 |
+
<li><a href="tokenization_internlm2.py">tokenization_internlm2.py</a></li>
|
| 31 |
+
<li><a href="tokenization_internlm2_fast.py">tokenization_internlm2_fast.py</a></li>
|
| 32 |
+
<li><a href="tokenizer.model">tokenizer.model</a></li>
|
| 33 |
+
<li><a href="tokenizer_config.json">tokenizer_config.json</a></li>
|
| 34 |
+
</ul>
|
| 35 |
+
<hr>
|
| 36 |
+
</body>
|
| 37 |
+
</html>
|
model-00001-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3a18c6c843dd1c046a7052129ac7ff5d3fa38e95149ea6ee763066dc1cc6579c
|
| 3 |
+
size 4939944336
|
model-00002-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e1967d2442fe5a38aba96e7ad7a18459962171591e5b7438aa0efa15db93b375
|
| 3 |
+
size 4915914584
|
model-00003-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9d31a1bd34e26858251c02741d450f64937b59bf3e45a2efede61a10c2086768
|
| 3 |
+
size 4915914592
|
model-00004-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5f20c98a99d6fcf5c01b70194b80984ad0b49220f365f7c415af7629743a5397
|
| 3 |
+
size 1379026920
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,580 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 16150730752
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"language_model.model.layers.0.attention.wo.weight": "model-00001-of-00004.safetensors",
|
| 7 |
+
"language_model.model.layers.0.attention.wqkv.weight": "model-00001-of-00004.safetensors",
|
| 8 |
+
"language_model.model.layers.0.attention_norm.weight": "model-00001-of-00004.safetensors",
|
| 9 |
+
"language_model.model.layers.0.feed_forward.w1.weight": "model-00001-of-00004.safetensors",
|
| 10 |
+
"language_model.model.layers.0.feed_forward.w2.weight": "model-00001-of-00004.safetensors",
|
| 11 |
+
"language_model.model.layers.0.feed_forward.w3.weight": "model-00001-of-00004.safetensors",
|
| 12 |
+
"language_model.model.layers.0.ffn_norm.weight": "model-00001-of-00004.safetensors",
|
| 13 |
+
"language_model.model.layers.1.attention.wo.weight": "model-00001-of-00004.safetensors",
|
| 14 |
+
"language_model.model.layers.1.attention.wqkv.weight": "model-00001-of-00004.safetensors",
|
| 15 |
+
"language_model.model.layers.1.attention_norm.weight": "model-00001-of-00004.safetensors",
|
| 16 |
+
"language_model.model.layers.1.feed_forward.w1.weight": "model-00001-of-00004.safetensors",
|
| 17 |
+
"language_model.model.layers.1.feed_forward.w2.weight": "model-00001-of-00004.safetensors",
|
| 18 |
+
"language_model.model.layers.1.feed_forward.w3.weight": "model-00001-of-00004.safetensors",
|
| 19 |
+
"language_model.model.layers.1.ffn_norm.weight": "model-00001-of-00004.safetensors",
|
| 20 |
+
"language_model.model.layers.10.attention.wo.weight": "model-00002-of-00004.safetensors",
|
| 21 |
+
"language_model.model.layers.10.attention.wqkv.weight": "model-00002-of-00004.safetensors",
|
| 22 |
+
"language_model.model.layers.10.attention_norm.weight": "model-00002-of-00004.safetensors",
|
| 23 |
+
"language_model.model.layers.10.feed_forward.w1.weight": "model-00002-of-00004.safetensors",
|
| 24 |
+
"language_model.model.layers.10.feed_forward.w2.weight": "model-00002-of-00004.safetensors",
|
| 25 |
+
"language_model.model.layers.10.feed_forward.w3.weight": "model-00002-of-00004.safetensors",
|
| 26 |
+
"language_model.model.layers.10.ffn_norm.weight": "model-00002-of-00004.safetensors",
|
| 27 |
+
"language_model.model.layers.11.attention.wo.weight": "model-00002-of-00004.safetensors",
|
| 28 |
+
"language_model.model.layers.11.attention.wqkv.weight": "model-00002-of-00004.safetensors",
|
| 29 |
+
"language_model.model.layers.11.attention_norm.weight": "model-00002-of-00004.safetensors",
|
| 30 |
+
"language_model.model.layers.11.feed_forward.w1.weight": "model-00002-of-00004.safetensors",
|
| 31 |
+
"language_model.model.layers.11.feed_forward.w2.weight": "model-00002-of-00004.safetensors",
|
| 32 |
+
"language_model.model.layers.11.feed_forward.w3.weight": "model-00002-of-00004.safetensors",
|
| 33 |
+
"language_model.model.layers.11.ffn_norm.weight": "model-00002-of-00004.safetensors",
|
| 34 |
+
"language_model.model.layers.12.attention.wo.weight": "model-00002-of-00004.safetensors",
|
| 35 |
+
"language_model.model.layers.12.attention.wqkv.weight": "model-00002-of-00004.safetensors",
|
| 36 |
+
"language_model.model.layers.12.attention_norm.weight": "model-00002-of-00004.safetensors",
|
| 37 |
+
"language_model.model.layers.12.feed_forward.w1.weight": "model-00002-of-00004.safetensors",
|
| 38 |
+
"language_model.model.layers.12.feed_forward.w2.weight": "model-00002-of-00004.safetensors",
|
| 39 |
+
"language_model.model.layers.12.feed_forward.w3.weight": "model-00002-of-00004.safetensors",
|
| 40 |
+
"language_model.model.layers.12.ffn_norm.weight": "model-00002-of-00004.safetensors",
|
| 41 |
+
"language_model.model.layers.13.attention.wo.weight": "model-00002-of-00004.safetensors",
|
| 42 |
+
"language_model.model.layers.13.attention.wqkv.weight": "model-00002-of-00004.safetensors",
|
| 43 |
+
"language_model.model.layers.13.attention_norm.weight": "model-00002-of-00004.safetensors",
|
| 44 |
+
"language_model.model.layers.13.feed_forward.w1.weight": "model-00002-of-00004.safetensors",
|
| 45 |
+
"language_model.model.layers.13.feed_forward.w2.weight": "model-00002-of-00004.safetensors",
|
| 46 |
+
"language_model.model.layers.13.feed_forward.w3.weight": "model-00002-of-00004.safetensors",
|
| 47 |
+
"language_model.model.layers.13.ffn_norm.weight": "model-00002-of-00004.safetensors",
|
| 48 |
+
"language_model.model.layers.14.attention.wo.weight": "model-00002-of-00004.safetensors",
|
| 49 |
+
"language_model.model.layers.14.attention.wqkv.weight": "model-00002-of-00004.safetensors",
|
| 50 |
+
"language_model.model.layers.14.attention_norm.weight": "model-00002-of-00004.safetensors",
|
| 51 |
+
"language_model.model.layers.14.feed_forward.w1.weight": "model-00002-of-00004.safetensors",
|
| 52 |
+
"language_model.model.layers.14.feed_forward.w2.weight": "model-00002-of-00004.safetensors",
|
| 53 |
+
"language_model.model.layers.14.feed_forward.w3.weight": "model-00002-of-00004.safetensors",
|
| 54 |
+
"language_model.model.layers.14.ffn_norm.weight": "model-00002-of-00004.safetensors",
|
| 55 |
+
"language_model.model.layers.15.attention.wo.weight": "model-00002-of-00004.safetensors",
|
| 56 |
+
"language_model.model.layers.15.attention.wqkv.weight": "model-00002-of-00004.safetensors",
|
| 57 |
+
"language_model.model.layers.15.attention_norm.weight": "model-00002-of-00004.safetensors",
|
| 58 |
+
"language_model.model.layers.15.feed_forward.w1.weight": "model-00002-of-00004.safetensors",
|
| 59 |
+
"language_model.model.layers.15.feed_forward.w2.weight": "model-00002-of-00004.safetensors",
|
| 60 |
+
"language_model.model.layers.15.feed_forward.w3.weight": "model-00002-of-00004.safetensors",
|
| 61 |
+
"language_model.model.layers.15.ffn_norm.weight": "model-00002-of-00004.safetensors",
|
| 62 |
+
"language_model.model.layers.16.attention.wo.weight": "model-00002-of-00004.safetensors",
|
| 63 |
+
"language_model.model.layers.16.attention.wqkv.weight": "model-00002-of-00004.safetensors",
|
| 64 |
+
"language_model.model.layers.16.attention_norm.weight": "model-00002-of-00004.safetensors",
|
| 65 |
+
"language_model.model.layers.16.feed_forward.w1.weight": "model-00002-of-00004.safetensors",
|
| 66 |
+
"language_model.model.layers.16.feed_forward.w2.weight": "model-00002-of-00004.safetensors",
|
| 67 |
+
"language_model.model.layers.16.feed_forward.w3.weight": "model-00002-of-00004.safetensors",
|
| 68 |
+
"language_model.model.layers.16.ffn_norm.weight": "model-00002-of-00004.safetensors",
|
| 69 |
+
"language_model.model.layers.17.attention.wo.weight": "model-00002-of-00004.safetensors",
|
| 70 |
+
"language_model.model.layers.17.attention.wqkv.weight": "model-00002-of-00004.safetensors",
|
| 71 |
+
"language_model.model.layers.17.attention_norm.weight": "model-00002-of-00004.safetensors",
|
| 72 |
+
"language_model.model.layers.17.feed_forward.w1.weight": "model-00002-of-00004.safetensors",
|
| 73 |
+
"language_model.model.layers.17.feed_forward.w2.weight": "model-00002-of-00004.safetensors",
|
| 74 |
+
"language_model.model.layers.17.feed_forward.w3.weight": "model-00002-of-00004.safetensors",
|
| 75 |
+
"language_model.model.layers.17.ffn_norm.weight": "model-00002-of-00004.safetensors",
|
| 76 |
+
"language_model.model.layers.18.attention.wo.weight": "model-00002-of-00004.safetensors",
|
| 77 |
+
"language_model.model.layers.18.attention.wqkv.weight": "model-00002-of-00004.safetensors",
|
| 78 |
+
"language_model.model.layers.18.attention_norm.weight": "model-00002-of-00004.safetensors",
|
| 79 |
+
"language_model.model.layers.18.feed_forward.w1.weight": "model-00002-of-00004.safetensors",
|
| 80 |
+
"language_model.model.layers.18.feed_forward.w2.weight": "model-00002-of-00004.safetensors",
|
| 81 |
+
"language_model.model.layers.18.feed_forward.w3.weight": "model-00002-of-00004.safetensors",
|
| 82 |
+
"language_model.model.layers.18.ffn_norm.weight": "model-00002-of-00004.safetensors",
|
| 83 |
+
"language_model.model.layers.19.attention.wo.weight": "model-00002-of-00004.safetensors",
|
| 84 |
+
"language_model.model.layers.19.attention.wqkv.weight": "model-00002-of-00004.safetensors",
|
| 85 |
+
"language_model.model.layers.19.attention_norm.weight": "model-00003-of-00004.safetensors",
|
| 86 |
+
"language_model.model.layers.19.feed_forward.w1.weight": "model-00002-of-00004.safetensors",
|
| 87 |
+
"language_model.model.layers.19.feed_forward.w2.weight": "model-00003-of-00004.safetensors",
|
| 88 |
+
"language_model.model.layers.19.feed_forward.w3.weight": "model-00003-of-00004.safetensors",
|
| 89 |
+
"language_model.model.layers.19.ffn_norm.weight": "model-00003-of-00004.safetensors",
|
| 90 |
+
"language_model.model.layers.2.attention.wo.weight": "model-00001-of-00004.safetensors",
|
| 91 |
+
"language_model.model.layers.2.attention.wqkv.weight": "model-00001-of-00004.safetensors",
|
| 92 |
+
"language_model.model.layers.2.attention_norm.weight": "model-00001-of-00004.safetensors",
|
| 93 |
+
"language_model.model.layers.2.feed_forward.w1.weight": "model-00001-of-00004.safetensors",
|
| 94 |
+
"language_model.model.layers.2.feed_forward.w2.weight": "model-00001-of-00004.safetensors",
|
| 95 |
+
"language_model.model.layers.2.feed_forward.w3.weight": "model-00001-of-00004.safetensors",
|
| 96 |
+
"language_model.model.layers.2.ffn_norm.weight": "model-00001-of-00004.safetensors",
|
| 97 |
+
"language_model.model.layers.20.attention.wo.weight": "model-00003-of-00004.safetensors",
|
| 98 |
+
"language_model.model.layers.20.attention.wqkv.weight": "model-00003-of-00004.safetensors",
|
| 99 |
+
"language_model.model.layers.20.attention_norm.weight": "model-00003-of-00004.safetensors",
|
| 100 |
+
"language_model.model.layers.20.feed_forward.w1.weight": "model-00003-of-00004.safetensors",
|
| 101 |
+
"language_model.model.layers.20.feed_forward.w2.weight": "model-00003-of-00004.safetensors",
|
| 102 |
+
"language_model.model.layers.20.feed_forward.w3.weight": "model-00003-of-00004.safetensors",
|
| 103 |
+
"language_model.model.layers.20.ffn_norm.weight": "model-00003-of-00004.safetensors",
|
| 104 |
+
"language_model.model.layers.21.attention.wo.weight": "model-00003-of-00004.safetensors",
|
| 105 |
+
"language_model.model.layers.21.attention.wqkv.weight": "model-00003-of-00004.safetensors",
|
| 106 |
+
"language_model.model.layers.21.attention_norm.weight": "model-00003-of-00004.safetensors",
|
| 107 |
+
"language_model.model.layers.21.feed_forward.w1.weight": "model-00003-of-00004.safetensors",
|
| 108 |
+
"language_model.model.layers.21.feed_forward.w2.weight": "model-00003-of-00004.safetensors",
|
| 109 |
+
"language_model.model.layers.21.feed_forward.w3.weight": "model-00003-of-00004.safetensors",
|
| 110 |
+
"language_model.model.layers.21.ffn_norm.weight": "model-00003-of-00004.safetensors",
|
| 111 |
+
"language_model.model.layers.22.attention.wo.weight": "model-00003-of-00004.safetensors",
|
| 112 |
+
"language_model.model.layers.22.attention.wqkv.weight": "model-00003-of-00004.safetensors",
|
| 113 |
+
"language_model.model.layers.22.attention_norm.weight": "model-00003-of-00004.safetensors",
|
| 114 |
+
"language_model.model.layers.22.feed_forward.w1.weight": "model-00003-of-00004.safetensors",
|
| 115 |
+
"language_model.model.layers.22.feed_forward.w2.weight": "model-00003-of-00004.safetensors",
|
| 116 |
+
"language_model.model.layers.22.feed_forward.w3.weight": "model-00003-of-00004.safetensors",
|
| 117 |
+
"language_model.model.layers.22.ffn_norm.weight": "model-00003-of-00004.safetensors",
|
| 118 |
+
"language_model.model.layers.23.attention.wo.weight": "model-00003-of-00004.safetensors",
|
| 119 |
+
"language_model.model.layers.23.attention.wqkv.weight": "model-00003-of-00004.safetensors",
|
| 120 |
+
"language_model.model.layers.23.attention_norm.weight": "model-00003-of-00004.safetensors",
|
| 121 |
+
"language_model.model.layers.23.feed_forward.w1.weight": "model-00003-of-00004.safetensors",
|
| 122 |
+
"language_model.model.layers.23.feed_forward.w2.weight": "model-00003-of-00004.safetensors",
|
| 123 |
+
"language_model.model.layers.23.feed_forward.w3.weight": "model-00003-of-00004.safetensors",
|
| 124 |
+
"language_model.model.layers.23.ffn_norm.weight": "model-00003-of-00004.safetensors",
|
| 125 |
+
"language_model.model.layers.24.attention.wo.weight": "model-00003-of-00004.safetensors",
|
| 126 |
+
"language_model.model.layers.24.attention.wqkv.weight": "model-00003-of-00004.safetensors",
|
| 127 |
+
"language_model.model.layers.24.attention_norm.weight": "model-00003-of-00004.safetensors",
|
| 128 |
+
"language_model.model.layers.24.feed_forward.w1.weight": "model-00003-of-00004.safetensors",
|
| 129 |
+
"language_model.model.layers.24.feed_forward.w2.weight": "model-00003-of-00004.safetensors",
|
| 130 |
+
"language_model.model.layers.24.feed_forward.w3.weight": "model-00003-of-00004.safetensors",
|
| 131 |
+
"language_model.model.layers.24.ffn_norm.weight": "model-00003-of-00004.safetensors",
|
| 132 |
+
"language_model.model.layers.25.attention.wo.weight": "model-00003-of-00004.safetensors",
|
| 133 |
+
"language_model.model.layers.25.attention.wqkv.weight": "model-00003-of-00004.safetensors",
|
| 134 |
+
"language_model.model.layers.25.attention_norm.weight": "model-00003-of-00004.safetensors",
|
| 135 |
+
"language_model.model.layers.25.feed_forward.w1.weight": "model-00003-of-00004.safetensors",
|
| 136 |
+
"language_model.model.layers.25.feed_forward.w2.weight": "model-00003-of-00004.safetensors",
|
| 137 |
+
"language_model.model.layers.25.feed_forward.w3.weight": "model-00003-of-00004.safetensors",
|
| 138 |
+
"language_model.model.layers.25.ffn_norm.weight": "model-00003-of-00004.safetensors",
|
| 139 |
+
"language_model.model.layers.26.attention.wo.weight": "model-00003-of-00004.safetensors",
|
| 140 |
+
"language_model.model.layers.26.attention.wqkv.weight": "model-00003-of-00004.safetensors",
|
| 141 |
+
"language_model.model.layers.26.attention_norm.weight": "model-00003-of-00004.safetensors",
|
| 142 |
+
"language_model.model.layers.26.feed_forward.w1.weight": "model-00003-of-00004.safetensors",
|
| 143 |
+
"language_model.model.layers.26.feed_forward.w2.weight": "model-00003-of-00004.safetensors",
|
| 144 |
+
"language_model.model.layers.26.feed_forward.w3.weight": "model-00003-of-00004.safetensors",
|
| 145 |
+
"language_model.model.layers.26.ffn_norm.weight": "model-00003-of-00004.safetensors",
|
| 146 |
+
"language_model.model.layers.27.attention.wo.weight": "model-00003-of-00004.safetensors",
|
| 147 |
+
"language_model.model.layers.27.attention.wqkv.weight": "model-00003-of-00004.safetensors",
|
| 148 |
+
"language_model.model.layers.27.attention_norm.weight": "model-00003-of-00004.safetensors",
|
| 149 |
+
"language_model.model.layers.27.feed_forward.w1.weight": "model-00003-of-00004.safetensors",
|
| 150 |
+
"language_model.model.layers.27.feed_forward.w2.weight": "model-00003-of-00004.safetensors",
|
| 151 |
+
"language_model.model.layers.27.feed_forward.w3.weight": "model-00003-of-00004.safetensors",
|
| 152 |
+
"language_model.model.layers.27.ffn_norm.weight": "model-00003-of-00004.safetensors",
|
| 153 |
+
"language_model.model.layers.28.attention.wo.weight": "model-00003-of-00004.safetensors",
|
| 154 |
+
"language_model.model.layers.28.attention.wqkv.weight": "model-00003-of-00004.safetensors",
|
| 155 |
+
"language_model.model.layers.28.attention_norm.weight": "model-00003-of-00004.safetensors",
|
| 156 |
+
"language_model.model.layers.28.feed_forward.w1.weight": "model-00003-of-00004.safetensors",
|
| 157 |
+
"language_model.model.layers.28.feed_forward.w2.weight": "model-00003-of-00004.safetensors",
|
| 158 |
+
"language_model.model.layers.28.feed_forward.w3.weight": "model-00003-of-00004.safetensors",
|
| 159 |
+
"language_model.model.layers.28.ffn_norm.weight": "model-00003-of-00004.safetensors",
|
| 160 |
+
"language_model.model.layers.29.attention.wo.weight": "model-00003-of-00004.safetensors",
|
| 161 |
+
"language_model.model.layers.29.attention.wqkv.weight": "model-00003-of-00004.safetensors",
|
| 162 |
+
"language_model.model.layers.29.attention_norm.weight": "model-00003-of-00004.safetensors",
|
| 163 |
+
"language_model.model.layers.29.feed_forward.w1.weight": "model-00003-of-00004.safetensors",
|
| 164 |
+
"language_model.model.layers.29.feed_forward.w2.weight": "model-00003-of-00004.safetensors",
|
| 165 |
+
"language_model.model.layers.29.feed_forward.w3.weight": "model-00003-of-00004.safetensors",
|
| 166 |
+
"language_model.model.layers.29.ffn_norm.weight": "model-00003-of-00004.safetensors",
|
| 167 |
+
"language_model.model.layers.3.attention.wo.weight": "model-00001-of-00004.safetensors",
|
| 168 |
+
"language_model.model.layers.3.attention.wqkv.weight": "model-00001-of-00004.safetensors",
|
| 169 |
+
"language_model.model.layers.3.attention_norm.weight": "model-00001-of-00004.safetensors",
|
| 170 |
+
"language_model.model.layers.3.feed_forward.w1.weight": "model-00001-of-00004.safetensors",
|
| 171 |
+
"language_model.model.layers.3.feed_forward.w2.weight": "model-00001-of-00004.safetensors",
|
| 172 |
+
"language_model.model.layers.3.feed_forward.w3.weight": "model-00001-of-00004.safetensors",
|
| 173 |
+
"language_model.model.layers.3.ffn_norm.weight": "model-00001-of-00004.safetensors",
|
| 174 |
+
"language_model.model.layers.30.attention.wo.weight": "model-00003-of-00004.safetensors",
|
| 175 |
+
"language_model.model.layers.30.attention.wqkv.weight": "model-00003-of-00004.safetensors",
|
| 176 |
+
"language_model.model.layers.30.attention_norm.weight": "model-00004-of-00004.safetensors",
|
| 177 |
+
"language_model.model.layers.30.feed_forward.w1.weight": "model-00003-of-00004.safetensors",
|
| 178 |
+
"language_model.model.layers.30.feed_forward.w2.weight": "model-00004-of-00004.safetensors",
|
| 179 |
+
"language_model.model.layers.30.feed_forward.w3.weight": "model-00003-of-00004.safetensors",
|
| 180 |
+
"language_model.model.layers.30.ffn_norm.weight": "model-00004-of-00004.safetensors",
|
| 181 |
+
"language_model.model.layers.31.attention.wo.weight": "model-00004-of-00004.safetensors",
|
| 182 |
+
"language_model.model.layers.31.attention.wqkv.weight": "model-00004-of-00004.safetensors",
|
| 183 |
+
"language_model.model.layers.31.attention_norm.weight": "model-00004-of-00004.safetensors",
|
| 184 |
+
"language_model.model.layers.31.feed_forward.w1.weight": "model-00004-of-00004.safetensors",
|
| 185 |
+
"language_model.model.layers.31.feed_forward.w2.weight": "model-00004-of-00004.safetensors",
|
| 186 |
+
"language_model.model.layers.31.feed_forward.w3.weight": "model-00004-of-00004.safetensors",
|
| 187 |
+
"language_model.model.layers.31.ffn_norm.weight": "model-00004-of-00004.safetensors",
|
| 188 |
+
"language_model.model.layers.4.attention.wo.weight": "model-00001-of-00004.safetensors",
|
| 189 |
+
"language_model.model.layers.4.attention.wqkv.weight": "model-00001-of-00004.safetensors",
|
| 190 |
+
"language_model.model.layers.4.attention_norm.weight": "model-00001-of-00004.safetensors",
|
| 191 |
+
"language_model.model.layers.4.feed_forward.w1.weight": "model-00001-of-00004.safetensors",
|
| 192 |
+
"language_model.model.layers.4.feed_forward.w2.weight": "model-00001-of-00004.safetensors",
|
| 193 |
+
"language_model.model.layers.4.feed_forward.w3.weight": "model-00001-of-00004.safetensors",
|
| 194 |
+
"language_model.model.layers.4.ffn_norm.weight": "model-00001-of-00004.safetensors",
|
| 195 |
+
"language_model.model.layers.5.attention.wo.weight": "model-00001-of-00004.safetensors",
|
| 196 |
+
"language_model.model.layers.5.attention.wqkv.weight": "model-00001-of-00004.safetensors",
|
| 197 |
+
"language_model.model.layers.5.attention_norm.weight": "model-00001-of-00004.safetensors",
|
| 198 |
+
"language_model.model.layers.5.feed_forward.w1.weight": "model-00001-of-00004.safetensors",
|
| 199 |
+
"language_model.model.layers.5.feed_forward.w2.weight": "model-00001-of-00004.safetensors",
|
| 200 |
+
"language_model.model.layers.5.feed_forward.w3.weight": "model-00001-of-00004.safetensors",
|
| 201 |
+
"language_model.model.layers.5.ffn_norm.weight": "model-00001-of-00004.safetensors",
|
| 202 |
+
"language_model.model.layers.6.attention.wo.weight": "model-00001-of-00004.safetensors",
|
| 203 |
+
"language_model.model.layers.6.attention.wqkv.weight": "model-00001-of-00004.safetensors",
|
| 204 |
+
"language_model.model.layers.6.attention_norm.weight": "model-00001-of-00004.safetensors",
|
| 205 |
+
"language_model.model.layers.6.feed_forward.w1.weight": "model-00001-of-00004.safetensors",
|
| 206 |
+
"language_model.model.layers.6.feed_forward.w2.weight": "model-00001-of-00004.safetensors",
|
| 207 |
+
"language_model.model.layers.6.feed_forward.w3.weight": "model-00001-of-00004.safetensors",
|
| 208 |
+
"language_model.model.layers.6.ffn_norm.weight": "model-00001-of-00004.safetensors",
|
| 209 |
+
"language_model.model.layers.7.attention.wo.weight": "model-00001-of-00004.safetensors",
|
| 210 |
+
"language_model.model.layers.7.attention.wqkv.weight": "model-00001-of-00004.safetensors",
|
| 211 |
+
"language_model.model.layers.7.attention_norm.weight": "model-00001-of-00004.safetensors",
|
| 212 |
+
"language_model.model.layers.7.feed_forward.w1.weight": "model-00001-of-00004.safetensors",
|
| 213 |
+
"language_model.model.layers.7.feed_forward.w2.weight": "model-00001-of-00004.safetensors",
|
| 214 |
+
"language_model.model.layers.7.feed_forward.w3.weight": "model-00001-of-00004.safetensors",
|
| 215 |
+
"language_model.model.layers.7.ffn_norm.weight": "model-00001-of-00004.safetensors",
|
| 216 |
+
"language_model.model.layers.8.attention.wo.weight": "model-00001-of-00004.safetensors",
|
| 217 |
+
"language_model.model.layers.8.attention.wqkv.weight": "model-00001-of-00004.safetensors",
|
| 218 |
+
"language_model.model.layers.8.attention_norm.weight": "model-00002-of-00004.safetensors",
|
| 219 |
+
"language_model.model.layers.8.feed_forward.w1.weight": "model-00002-of-00004.safetensors",
|
| 220 |
+
"language_model.model.layers.8.feed_forward.w2.weight": "model-00002-of-00004.safetensors",
|
| 221 |
+
"language_model.model.layers.8.feed_forward.w3.weight": "model-00002-of-00004.safetensors",
|
| 222 |
+
"language_model.model.layers.8.ffn_norm.weight": "model-00002-of-00004.safetensors",
|
| 223 |
+
"language_model.model.layers.9.attention.wo.weight": "model-00002-of-00004.safetensors",
|
| 224 |
+
"language_model.model.layers.9.attention.wqkv.weight": "model-00002-of-00004.safetensors",
|
| 225 |
+
"language_model.model.layers.9.attention_norm.weight": "model-00002-of-00004.safetensors",
|
| 226 |
+
"language_model.model.layers.9.feed_forward.w1.weight": "model-00002-of-00004.safetensors",
|
| 227 |
+
"language_model.model.layers.9.feed_forward.w2.weight": "model-00002-of-00004.safetensors",
|
| 228 |
+
"language_model.model.layers.9.feed_forward.w3.weight": "model-00002-of-00004.safetensors",
|
| 229 |
+
"language_model.model.layers.9.ffn_norm.weight": "model-00002-of-00004.safetensors",
|
| 230 |
+
"language_model.model.norm.weight": "model-00004-of-00004.safetensors",
|
| 231 |
+
"language_model.model.tok_embeddings.weight": "model-00001-of-00004.safetensors",
|
| 232 |
+
"language_model.output.weight": "model-00004-of-00004.safetensors",
|
| 233 |
+
"mlp1.0.bias": "model-00004-of-00004.safetensors",
|
| 234 |
+
"mlp1.0.weight": "model-00004-of-00004.safetensors",
|
| 235 |
+
"mlp1.1.bias": "model-00004-of-00004.safetensors",
|
| 236 |
+
"mlp1.1.weight": "model-00004-of-00004.safetensors",
|
| 237 |
+
"mlp1.3.bias": "model-00004-of-00004.safetensors",
|
| 238 |
+
"mlp1.3.weight": "model-00004-of-00004.safetensors",
|
| 239 |
+
"vision_model.embeddings.class_embedding": "model-00001-of-00004.safetensors",
|
| 240 |
+
"vision_model.embeddings.patch_embedding.bias": "model-00001-of-00004.safetensors",
|
| 241 |
+
"vision_model.embeddings.patch_embedding.weight": "model-00001-of-00004.safetensors",
|
| 242 |
+
"vision_model.embeddings.position_embedding": "model-00001-of-00004.safetensors",
|
| 243 |
+
"vision_model.encoder.layers.0.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 244 |
+
"vision_model.encoder.layers.0.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 245 |
+
"vision_model.encoder.layers.0.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 246 |
+
"vision_model.encoder.layers.0.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 247 |
+
"vision_model.encoder.layers.0.ls1": "model-00001-of-00004.safetensors",
|
| 248 |
+
"vision_model.encoder.layers.0.ls2": "model-00001-of-00004.safetensors",
|
| 249 |
+
"vision_model.encoder.layers.0.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 250 |
+
"vision_model.encoder.layers.0.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 251 |
+
"vision_model.encoder.layers.0.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 252 |
+
"vision_model.encoder.layers.0.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 253 |
+
"vision_model.encoder.layers.0.norm1.bias": "model-00001-of-00004.safetensors",
|
| 254 |
+
"vision_model.encoder.layers.0.norm1.weight": "model-00001-of-00004.safetensors",
|
| 255 |
+
"vision_model.encoder.layers.0.norm2.bias": "model-00001-of-00004.safetensors",
|
| 256 |
+
"vision_model.encoder.layers.0.norm2.weight": "model-00001-of-00004.safetensors",
|
| 257 |
+
"vision_model.encoder.layers.1.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 258 |
+
"vision_model.encoder.layers.1.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 259 |
+
"vision_model.encoder.layers.1.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 260 |
+
"vision_model.encoder.layers.1.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 261 |
+
"vision_model.encoder.layers.1.ls1": "model-00001-of-00004.safetensors",
|
| 262 |
+
"vision_model.encoder.layers.1.ls2": "model-00001-of-00004.safetensors",
|
| 263 |
+
"vision_model.encoder.layers.1.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 264 |
+
"vision_model.encoder.layers.1.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 265 |
+
"vision_model.encoder.layers.1.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 266 |
+
"vision_model.encoder.layers.1.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 267 |
+
"vision_model.encoder.layers.1.norm1.bias": "model-00001-of-00004.safetensors",
|
| 268 |
+
"vision_model.encoder.layers.1.norm1.weight": "model-00001-of-00004.safetensors",
|
| 269 |
+
"vision_model.encoder.layers.1.norm2.bias": "model-00001-of-00004.safetensors",
|
| 270 |
+
"vision_model.encoder.layers.1.norm2.weight": "model-00001-of-00004.safetensors",
|
| 271 |
+
"vision_model.encoder.layers.10.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 272 |
+
"vision_model.encoder.layers.10.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 273 |
+
"vision_model.encoder.layers.10.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 274 |
+
"vision_model.encoder.layers.10.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 275 |
+
"vision_model.encoder.layers.10.ls1": "model-00001-of-00004.safetensors",
|
| 276 |
+
"vision_model.encoder.layers.10.ls2": "model-00001-of-00004.safetensors",
|
| 277 |
+
"vision_model.encoder.layers.10.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 278 |
+
"vision_model.encoder.layers.10.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 279 |
+
"vision_model.encoder.layers.10.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 280 |
+
"vision_model.encoder.layers.10.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 281 |
+
"vision_model.encoder.layers.10.norm1.bias": "model-00001-of-00004.safetensors",
|
| 282 |
+
"vision_model.encoder.layers.10.norm1.weight": "model-00001-of-00004.safetensors",
|
| 283 |
+
"vision_model.encoder.layers.10.norm2.bias": "model-00001-of-00004.safetensors",
|
| 284 |
+
"vision_model.encoder.layers.10.norm2.weight": "model-00001-of-00004.safetensors",
|
| 285 |
+
"vision_model.encoder.layers.11.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 286 |
+
"vision_model.encoder.layers.11.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 287 |
+
"vision_model.encoder.layers.11.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 288 |
+
"vision_model.encoder.layers.11.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 289 |
+
"vision_model.encoder.layers.11.ls1": "model-00001-of-00004.safetensors",
|
| 290 |
+
"vision_model.encoder.layers.11.ls2": "model-00001-of-00004.safetensors",
|
| 291 |
+
"vision_model.encoder.layers.11.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 292 |
+
"vision_model.encoder.layers.11.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 293 |
+
"vision_model.encoder.layers.11.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 294 |
+
"vision_model.encoder.layers.11.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 295 |
+
"vision_model.encoder.layers.11.norm1.bias": "model-00001-of-00004.safetensors",
|
| 296 |
+
"vision_model.encoder.layers.11.norm1.weight": "model-00001-of-00004.safetensors",
|
| 297 |
+
"vision_model.encoder.layers.11.norm2.bias": "model-00001-of-00004.safetensors",
|
| 298 |
+
"vision_model.encoder.layers.11.norm2.weight": "model-00001-of-00004.safetensors",
|
| 299 |
+
"vision_model.encoder.layers.12.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 300 |
+
"vision_model.encoder.layers.12.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 301 |
+
"vision_model.encoder.layers.12.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 302 |
+
"vision_model.encoder.layers.12.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 303 |
+
"vision_model.encoder.layers.12.ls1": "model-00001-of-00004.safetensors",
|
| 304 |
+
"vision_model.encoder.layers.12.ls2": "model-00001-of-00004.safetensors",
|
| 305 |
+
"vision_model.encoder.layers.12.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 306 |
+
"vision_model.encoder.layers.12.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 307 |
+
"vision_model.encoder.layers.12.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 308 |
+
"vision_model.encoder.layers.12.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 309 |
+
"vision_model.encoder.layers.12.norm1.bias": "model-00001-of-00004.safetensors",
|
| 310 |
+
"vision_model.encoder.layers.12.norm1.weight": "model-00001-of-00004.safetensors",
|
| 311 |
+
"vision_model.encoder.layers.12.norm2.bias": "model-00001-of-00004.safetensors",
|
| 312 |
+
"vision_model.encoder.layers.12.norm2.weight": "model-00001-of-00004.safetensors",
|
| 313 |
+
"vision_model.encoder.layers.13.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 314 |
+
"vision_model.encoder.layers.13.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 315 |
+
"vision_model.encoder.layers.13.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 316 |
+
"vision_model.encoder.layers.13.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 317 |
+
"vision_model.encoder.layers.13.ls1": "model-00001-of-00004.safetensors",
|
| 318 |
+
"vision_model.encoder.layers.13.ls2": "model-00001-of-00004.safetensors",
|
| 319 |
+
"vision_model.encoder.layers.13.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 320 |
+
"vision_model.encoder.layers.13.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 321 |
+
"vision_model.encoder.layers.13.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 322 |
+
"vision_model.encoder.layers.13.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 323 |
+
"vision_model.encoder.layers.13.norm1.bias": "model-00001-of-00004.safetensors",
|
| 324 |
+
"vision_model.encoder.layers.13.norm1.weight": "model-00001-of-00004.safetensors",
|
| 325 |
+
"vision_model.encoder.layers.13.norm2.bias": "model-00001-of-00004.safetensors",
|
| 326 |
+
"vision_model.encoder.layers.13.norm2.weight": "model-00001-of-00004.safetensors",
|
| 327 |
+
"vision_model.encoder.layers.14.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 328 |
+
"vision_model.encoder.layers.14.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 329 |
+
"vision_model.encoder.layers.14.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 330 |
+
"vision_model.encoder.layers.14.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 331 |
+
"vision_model.encoder.layers.14.ls1": "model-00001-of-00004.safetensors",
|
| 332 |
+
"vision_model.encoder.layers.14.ls2": "model-00001-of-00004.safetensors",
|
| 333 |
+
"vision_model.encoder.layers.14.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 334 |
+
"vision_model.encoder.layers.14.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 335 |
+
"vision_model.encoder.layers.14.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 336 |
+
"vision_model.encoder.layers.14.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 337 |
+
"vision_model.encoder.layers.14.norm1.bias": "model-00001-of-00004.safetensors",
|
| 338 |
+
"vision_model.encoder.layers.14.norm1.weight": "model-00001-of-00004.safetensors",
|
| 339 |
+
"vision_model.encoder.layers.14.norm2.bias": "model-00001-of-00004.safetensors",
|
| 340 |
+
"vision_model.encoder.layers.14.norm2.weight": "model-00001-of-00004.safetensors",
|
| 341 |
+
"vision_model.encoder.layers.15.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 342 |
+
"vision_model.encoder.layers.15.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 343 |
+
"vision_model.encoder.layers.15.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 344 |
+
"vision_model.encoder.layers.15.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 345 |
+
"vision_model.encoder.layers.15.ls1": "model-00001-of-00004.safetensors",
|
| 346 |
+
"vision_model.encoder.layers.15.ls2": "model-00001-of-00004.safetensors",
|
| 347 |
+
"vision_model.encoder.layers.15.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 348 |
+
"vision_model.encoder.layers.15.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 349 |
+
"vision_model.encoder.layers.15.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 350 |
+
"vision_model.encoder.layers.15.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 351 |
+
"vision_model.encoder.layers.15.norm1.bias": "model-00001-of-00004.safetensors",
|
| 352 |
+
"vision_model.encoder.layers.15.norm1.weight": "model-00001-of-00004.safetensors",
|
| 353 |
+
"vision_model.encoder.layers.15.norm2.bias": "model-00001-of-00004.safetensors",
|
| 354 |
+
"vision_model.encoder.layers.15.norm2.weight": "model-00001-of-00004.safetensors",
|
| 355 |
+
"vision_model.encoder.layers.16.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 356 |
+
"vision_model.encoder.layers.16.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 357 |
+
"vision_model.encoder.layers.16.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 358 |
+
"vision_model.encoder.layers.16.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 359 |
+
"vision_model.encoder.layers.16.ls1": "model-00001-of-00004.safetensors",
|
| 360 |
+
"vision_model.encoder.layers.16.ls2": "model-00001-of-00004.safetensors",
|
| 361 |
+
"vision_model.encoder.layers.16.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 362 |
+
"vision_model.encoder.layers.16.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 363 |
+
"vision_model.encoder.layers.16.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 364 |
+
"vision_model.encoder.layers.16.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 365 |
+
"vision_model.encoder.layers.16.norm1.bias": "model-00001-of-00004.safetensors",
|
| 366 |
+
"vision_model.encoder.layers.16.norm1.weight": "model-00001-of-00004.safetensors",
|
| 367 |
+
"vision_model.encoder.layers.16.norm2.bias": "model-00001-of-00004.safetensors",
|
| 368 |
+
"vision_model.encoder.layers.16.norm2.weight": "model-00001-of-00004.safetensors",
|
| 369 |
+
"vision_model.encoder.layers.17.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 370 |
+
"vision_model.encoder.layers.17.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 371 |
+
"vision_model.encoder.layers.17.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 372 |
+
"vision_model.encoder.layers.17.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 373 |
+
"vision_model.encoder.layers.17.ls1": "model-00001-of-00004.safetensors",
|
| 374 |
+
"vision_model.encoder.layers.17.ls2": "model-00001-of-00004.safetensors",
|
| 375 |
+
"vision_model.encoder.layers.17.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 376 |
+
"vision_model.encoder.layers.17.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 377 |
+
"vision_model.encoder.layers.17.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 378 |
+
"vision_model.encoder.layers.17.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 379 |
+
"vision_model.encoder.layers.17.norm1.bias": "model-00001-of-00004.safetensors",
|
| 380 |
+
"vision_model.encoder.layers.17.norm1.weight": "model-00001-of-00004.safetensors",
|
| 381 |
+
"vision_model.encoder.layers.17.norm2.bias": "model-00001-of-00004.safetensors",
|
| 382 |
+
"vision_model.encoder.layers.17.norm2.weight": "model-00001-of-00004.safetensors",
|
| 383 |
+
"vision_model.encoder.layers.18.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 384 |
+
"vision_model.encoder.layers.18.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 385 |
+
"vision_model.encoder.layers.18.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 386 |
+
"vision_model.encoder.layers.18.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 387 |
+
"vision_model.encoder.layers.18.ls1": "model-00001-of-00004.safetensors",
|
| 388 |
+
"vision_model.encoder.layers.18.ls2": "model-00001-of-00004.safetensors",
|
| 389 |
+
"vision_model.encoder.layers.18.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 390 |
+
"vision_model.encoder.layers.18.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 391 |
+
"vision_model.encoder.layers.18.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 392 |
+
"vision_model.encoder.layers.18.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 393 |
+
"vision_model.encoder.layers.18.norm1.bias": "model-00001-of-00004.safetensors",
|
| 394 |
+
"vision_model.encoder.layers.18.norm1.weight": "model-00001-of-00004.safetensors",
|
| 395 |
+
"vision_model.encoder.layers.18.norm2.bias": "model-00001-of-00004.safetensors",
|
| 396 |
+
"vision_model.encoder.layers.18.norm2.weight": "model-00001-of-00004.safetensors",
|
| 397 |
+
"vision_model.encoder.layers.19.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 398 |
+
"vision_model.encoder.layers.19.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 399 |
+
"vision_model.encoder.layers.19.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 400 |
+
"vision_model.encoder.layers.19.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 401 |
+
"vision_model.encoder.layers.19.ls1": "model-00001-of-00004.safetensors",
|
| 402 |
+
"vision_model.encoder.layers.19.ls2": "model-00001-of-00004.safetensors",
|
| 403 |
+
"vision_model.encoder.layers.19.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 404 |
+
"vision_model.encoder.layers.19.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 405 |
+
"vision_model.encoder.layers.19.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 406 |
+
"vision_model.encoder.layers.19.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 407 |
+
"vision_model.encoder.layers.19.norm1.bias": "model-00001-of-00004.safetensors",
|
| 408 |
+
"vision_model.encoder.layers.19.norm1.weight": "model-00001-of-00004.safetensors",
|
| 409 |
+
"vision_model.encoder.layers.19.norm2.bias": "model-00001-of-00004.safetensors",
|
| 410 |
+
"vision_model.encoder.layers.19.norm2.weight": "model-00001-of-00004.safetensors",
|
| 411 |
+
"vision_model.encoder.layers.2.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 412 |
+
"vision_model.encoder.layers.2.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 413 |
+
"vision_model.encoder.layers.2.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 414 |
+
"vision_model.encoder.layers.2.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 415 |
+
"vision_model.encoder.layers.2.ls1": "model-00001-of-00004.safetensors",
|
| 416 |
+
"vision_model.encoder.layers.2.ls2": "model-00001-of-00004.safetensors",
|
| 417 |
+
"vision_model.encoder.layers.2.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 418 |
+
"vision_model.encoder.layers.2.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 419 |
+
"vision_model.encoder.layers.2.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 420 |
+
"vision_model.encoder.layers.2.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 421 |
+
"vision_model.encoder.layers.2.norm1.bias": "model-00001-of-00004.safetensors",
|
| 422 |
+
"vision_model.encoder.layers.2.norm1.weight": "model-00001-of-00004.safetensors",
|
| 423 |
+
"vision_model.encoder.layers.2.norm2.bias": "model-00001-of-00004.safetensors",
|
| 424 |
+
"vision_model.encoder.layers.2.norm2.weight": "model-00001-of-00004.safetensors",
|
| 425 |
+
"vision_model.encoder.layers.20.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 426 |
+
"vision_model.encoder.layers.20.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 427 |
+
"vision_model.encoder.layers.20.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 428 |
+
"vision_model.encoder.layers.20.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 429 |
+
"vision_model.encoder.layers.20.ls1": "model-00001-of-00004.safetensors",
|
| 430 |
+
"vision_model.encoder.layers.20.ls2": "model-00001-of-00004.safetensors",
|
| 431 |
+
"vision_model.encoder.layers.20.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 432 |
+
"vision_model.encoder.layers.20.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 433 |
+
"vision_model.encoder.layers.20.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 434 |
+
"vision_model.encoder.layers.20.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 435 |
+
"vision_model.encoder.layers.20.norm1.bias": "model-00001-of-00004.safetensors",
|
| 436 |
+
"vision_model.encoder.layers.20.norm1.weight": "model-00001-of-00004.safetensors",
|
| 437 |
+
"vision_model.encoder.layers.20.norm2.bias": "model-00001-of-00004.safetensors",
|
| 438 |
+
"vision_model.encoder.layers.20.norm2.weight": "model-00001-of-00004.safetensors",
|
| 439 |
+
"vision_model.encoder.layers.21.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 440 |
+
"vision_model.encoder.layers.21.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 441 |
+
"vision_model.encoder.layers.21.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 442 |
+
"vision_model.encoder.layers.21.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 443 |
+
"vision_model.encoder.layers.21.ls1": "model-00001-of-00004.safetensors",
|
| 444 |
+
"vision_model.encoder.layers.21.ls2": "model-00001-of-00004.safetensors",
|
| 445 |
+
"vision_model.encoder.layers.21.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 446 |
+
"vision_model.encoder.layers.21.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 447 |
+
"vision_model.encoder.layers.21.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 448 |
+
"vision_model.encoder.layers.21.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 449 |
+
"vision_model.encoder.layers.21.norm1.bias": "model-00001-of-00004.safetensors",
|
| 450 |
+
"vision_model.encoder.layers.21.norm1.weight": "model-00001-of-00004.safetensors",
|
| 451 |
+
"vision_model.encoder.layers.21.norm2.bias": "model-00001-of-00004.safetensors",
|
| 452 |
+
"vision_model.encoder.layers.21.norm2.weight": "model-00001-of-00004.safetensors",
|
| 453 |
+
"vision_model.encoder.layers.22.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 454 |
+
"vision_model.encoder.layers.22.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 455 |
+
"vision_model.encoder.layers.22.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 456 |
+
"vision_model.encoder.layers.22.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 457 |
+
"vision_model.encoder.layers.22.ls1": "model-00001-of-00004.safetensors",
|
| 458 |
+
"vision_model.encoder.layers.22.ls2": "model-00001-of-00004.safetensors",
|
| 459 |
+
"vision_model.encoder.layers.22.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 460 |
+
"vision_model.encoder.layers.22.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 461 |
+
"vision_model.encoder.layers.22.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 462 |
+
"vision_model.encoder.layers.22.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 463 |
+
"vision_model.encoder.layers.22.norm1.bias": "model-00001-of-00004.safetensors",
|
| 464 |
+
"vision_model.encoder.layers.22.norm1.weight": "model-00001-of-00004.safetensors",
|
| 465 |
+
"vision_model.encoder.layers.22.norm2.bias": "model-00001-of-00004.safetensors",
|
| 466 |
+
"vision_model.encoder.layers.22.norm2.weight": "model-00001-of-00004.safetensors",
|
| 467 |
+
"vision_model.encoder.layers.23.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 468 |
+
"vision_model.encoder.layers.23.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 469 |
+
"vision_model.encoder.layers.23.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 470 |
+
"vision_model.encoder.layers.23.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 471 |
+
"vision_model.encoder.layers.23.ls1": "model-00001-of-00004.safetensors",
|
| 472 |
+
"vision_model.encoder.layers.23.ls2": "model-00001-of-00004.safetensors",
|
| 473 |
+
"vision_model.encoder.layers.23.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 474 |
+
"vision_model.encoder.layers.23.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 475 |
+
"vision_model.encoder.layers.23.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 476 |
+
"vision_model.encoder.layers.23.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 477 |
+
"vision_model.encoder.layers.23.norm1.bias": "model-00001-of-00004.safetensors",
|
| 478 |
+
"vision_model.encoder.layers.23.norm1.weight": "model-00001-of-00004.safetensors",
|
| 479 |
+
"vision_model.encoder.layers.23.norm2.bias": "model-00001-of-00004.safetensors",
|
| 480 |
+
"vision_model.encoder.layers.23.norm2.weight": "model-00001-of-00004.safetensors",
|
| 481 |
+
"vision_model.encoder.layers.3.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 482 |
+
"vision_model.encoder.layers.3.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 483 |
+
"vision_model.encoder.layers.3.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 484 |
+
"vision_model.encoder.layers.3.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 485 |
+
"vision_model.encoder.layers.3.ls1": "model-00001-of-00004.safetensors",
|
| 486 |
+
"vision_model.encoder.layers.3.ls2": "model-00001-of-00004.safetensors",
|
| 487 |
+
"vision_model.encoder.layers.3.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 488 |
+
"vision_model.encoder.layers.3.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 489 |
+
"vision_model.encoder.layers.3.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 490 |
+
"vision_model.encoder.layers.3.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 491 |
+
"vision_model.encoder.layers.3.norm1.bias": "model-00001-of-00004.safetensors",
|
| 492 |
+
"vision_model.encoder.layers.3.norm1.weight": "model-00001-of-00004.safetensors",
|
| 493 |
+
"vision_model.encoder.layers.3.norm2.bias": "model-00001-of-00004.safetensors",
|
| 494 |
+
"vision_model.encoder.layers.3.norm2.weight": "model-00001-of-00004.safetensors",
|
| 495 |
+
"vision_model.encoder.layers.4.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 496 |
+
"vision_model.encoder.layers.4.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 497 |
+
"vision_model.encoder.layers.4.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 498 |
+
"vision_model.encoder.layers.4.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 499 |
+
"vision_model.encoder.layers.4.ls1": "model-00001-of-00004.safetensors",
|
| 500 |
+
"vision_model.encoder.layers.4.ls2": "model-00001-of-00004.safetensors",
|
| 501 |
+
"vision_model.encoder.layers.4.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 502 |
+
"vision_model.encoder.layers.4.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 503 |
+
"vision_model.encoder.layers.4.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 504 |
+
"vision_model.encoder.layers.4.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 505 |
+
"vision_model.encoder.layers.4.norm1.bias": "model-00001-of-00004.safetensors",
|
| 506 |
+
"vision_model.encoder.layers.4.norm1.weight": "model-00001-of-00004.safetensors",
|
| 507 |
+
"vision_model.encoder.layers.4.norm2.bias": "model-00001-of-00004.safetensors",
|
| 508 |
+
"vision_model.encoder.layers.4.norm2.weight": "model-00001-of-00004.safetensors",
|
| 509 |
+
"vision_model.encoder.layers.5.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 510 |
+
"vision_model.encoder.layers.5.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 511 |
+
"vision_model.encoder.layers.5.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 512 |
+
"vision_model.encoder.layers.5.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 513 |
+
"vision_model.encoder.layers.5.ls1": "model-00001-of-00004.safetensors",
|
| 514 |
+
"vision_model.encoder.layers.5.ls2": "model-00001-of-00004.safetensors",
|
| 515 |
+
"vision_model.encoder.layers.5.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 516 |
+
"vision_model.encoder.layers.5.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 517 |
+
"vision_model.encoder.layers.5.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 518 |
+
"vision_model.encoder.layers.5.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 519 |
+
"vision_model.encoder.layers.5.norm1.bias": "model-00001-of-00004.safetensors",
|
| 520 |
+
"vision_model.encoder.layers.5.norm1.weight": "model-00001-of-00004.safetensors",
|
| 521 |
+
"vision_model.encoder.layers.5.norm2.bias": "model-00001-of-00004.safetensors",
|
| 522 |
+
"vision_model.encoder.layers.5.norm2.weight": "model-00001-of-00004.safetensors",
|
| 523 |
+
"vision_model.encoder.layers.6.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 524 |
+
"vision_model.encoder.layers.6.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 525 |
+
"vision_model.encoder.layers.6.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 526 |
+
"vision_model.encoder.layers.6.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 527 |
+
"vision_model.encoder.layers.6.ls1": "model-00001-of-00004.safetensors",
|
| 528 |
+
"vision_model.encoder.layers.6.ls2": "model-00001-of-00004.safetensors",
|
| 529 |
+
"vision_model.encoder.layers.6.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 530 |
+
"vision_model.encoder.layers.6.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 531 |
+
"vision_model.encoder.layers.6.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 532 |
+
"vision_model.encoder.layers.6.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 533 |
+
"vision_model.encoder.layers.6.norm1.bias": "model-00001-of-00004.safetensors",
|
| 534 |
+
"vision_model.encoder.layers.6.norm1.weight": "model-00001-of-00004.safetensors",
|
| 535 |
+
"vision_model.encoder.layers.6.norm2.bias": "model-00001-of-00004.safetensors",
|
| 536 |
+
"vision_model.encoder.layers.6.norm2.weight": "model-00001-of-00004.safetensors",
|
| 537 |
+
"vision_model.encoder.layers.7.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 538 |
+
"vision_model.encoder.layers.7.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 539 |
+
"vision_model.encoder.layers.7.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 540 |
+
"vision_model.encoder.layers.7.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 541 |
+
"vision_model.encoder.layers.7.ls1": "model-00001-of-00004.safetensors",
|
| 542 |
+
"vision_model.encoder.layers.7.ls2": "model-00001-of-00004.safetensors",
|
| 543 |
+
"vision_model.encoder.layers.7.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 544 |
+
"vision_model.encoder.layers.7.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 545 |
+
"vision_model.encoder.layers.7.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 546 |
+
"vision_model.encoder.layers.7.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 547 |
+
"vision_model.encoder.layers.7.norm1.bias": "model-00001-of-00004.safetensors",
|
| 548 |
+
"vision_model.encoder.layers.7.norm1.weight": "model-00001-of-00004.safetensors",
|
| 549 |
+
"vision_model.encoder.layers.7.norm2.bias": "model-00001-of-00004.safetensors",
|
| 550 |
+
"vision_model.encoder.layers.7.norm2.weight": "model-00001-of-00004.safetensors",
|
| 551 |
+
"vision_model.encoder.layers.8.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 552 |
+
"vision_model.encoder.layers.8.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 553 |
+
"vision_model.encoder.layers.8.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 554 |
+
"vision_model.encoder.layers.8.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 555 |
+
"vision_model.encoder.layers.8.ls1": "model-00001-of-00004.safetensors",
|
| 556 |
+
"vision_model.encoder.layers.8.ls2": "model-00001-of-00004.safetensors",
|
| 557 |
+
"vision_model.encoder.layers.8.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 558 |
+
"vision_model.encoder.layers.8.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 559 |
+
"vision_model.encoder.layers.8.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 560 |
+
"vision_model.encoder.layers.8.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 561 |
+
"vision_model.encoder.layers.8.norm1.bias": "model-00001-of-00004.safetensors",
|
| 562 |
+
"vision_model.encoder.layers.8.norm1.weight": "model-00001-of-00004.safetensors",
|
| 563 |
+
"vision_model.encoder.layers.8.norm2.bias": "model-00001-of-00004.safetensors",
|
| 564 |
+
"vision_model.encoder.layers.8.norm2.weight": "model-00001-of-00004.safetensors",
|
| 565 |
+
"vision_model.encoder.layers.9.attn.proj.bias": "model-00001-of-00004.safetensors",
|
| 566 |
+
"vision_model.encoder.layers.9.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 567 |
+
"vision_model.encoder.layers.9.attn.qkv.bias": "model-00001-of-00004.safetensors",
|
| 568 |
+
"vision_model.encoder.layers.9.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 569 |
+
"vision_model.encoder.layers.9.ls1": "model-00001-of-00004.safetensors",
|
| 570 |
+
"vision_model.encoder.layers.9.ls2": "model-00001-of-00004.safetensors",
|
| 571 |
+
"vision_model.encoder.layers.9.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 572 |
+
"vision_model.encoder.layers.9.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 573 |
+
"vision_model.encoder.layers.9.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 574 |
+
"vision_model.encoder.layers.9.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 575 |
+
"vision_model.encoder.layers.9.norm1.bias": "model-00001-of-00004.safetensors",
|
| 576 |
+
"vision_model.encoder.layers.9.norm1.weight": "model-00001-of-00004.safetensors",
|
| 577 |
+
"vision_model.encoder.layers.9.norm2.bias": "model-00001-of-00004.safetensors",
|
| 578 |
+
"vision_model.encoder.layers.9.norm2.weight": "model-00001-of-00004.safetensors"
|
| 579 |
+
}
|
| 580 |
+
}
|
modeling_intern_vit.py
ADDED
|
@@ -0,0 +1,435 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
from typing import Optional, Tuple, Union
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
import torch.utils.checkpoint
|
| 11 |
+
from einops import rearrange
|
| 12 |
+
from timm.models.layers import DropPath
|
| 13 |
+
from torch import nn
|
| 14 |
+
from transformers.activations import ACT2FN
|
| 15 |
+
from transformers.modeling_outputs import (BaseModelOutput,
|
| 16 |
+
BaseModelOutputWithPooling)
|
| 17 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 18 |
+
from transformers.utils import logging
|
| 19 |
+
|
| 20 |
+
from .configuration_intern_vit import InternVisionConfig
|
| 21 |
+
|
| 22 |
+
try:
|
| 23 |
+
try: # v1
|
| 24 |
+
from flash_attn.flash_attn_interface import \
|
| 25 |
+
flash_attn_unpadded_qkvpacked_func
|
| 26 |
+
except: # v2
|
| 27 |
+
from flash_attn.flash_attn_interface import \
|
| 28 |
+
flash_attn_varlen_qkvpacked_func as flash_attn_unpadded_qkvpacked_func
|
| 29 |
+
|
| 30 |
+
from flash_attn.bert_padding import pad_input, unpad_input
|
| 31 |
+
|
| 32 |
+
has_flash_attn = True
|
| 33 |
+
except:
|
| 34 |
+
print('FlashAttention is not installed.')
|
| 35 |
+
has_flash_attn = False
|
| 36 |
+
|
| 37 |
+
logger = logging.get_logger(__name__)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class FlashAttention(nn.Module):
|
| 41 |
+
"""Implement the scaled dot product attention with softmax.
|
| 42 |
+
Arguments
|
| 43 |
+
---------
|
| 44 |
+
softmax_scale: The temperature to use for the softmax attention.
|
| 45 |
+
(default: 1/sqrt(d_keys) where d_keys is computed at
|
| 46 |
+
runtime)
|
| 47 |
+
attention_dropout: The dropout rate to apply to the attention
|
| 48 |
+
(default: 0.0)
|
| 49 |
+
"""
|
| 50 |
+
|
| 51 |
+
def __init__(self, softmax_scale=None, attention_dropout=0.0, device=None, dtype=None):
|
| 52 |
+
super().__init__()
|
| 53 |
+
self.softmax_scale = softmax_scale
|
| 54 |
+
self.dropout_p = attention_dropout
|
| 55 |
+
|
| 56 |
+
def forward(self, qkv, key_padding_mask=None, causal=False, cu_seqlens=None,
|
| 57 |
+
max_s=None, need_weights=False):
|
| 58 |
+
"""Implements the multihead softmax attention.
|
| 59 |
+
Arguments
|
| 60 |
+
---------
|
| 61 |
+
qkv: The tensor containing the query, key, and value. (B, S, 3, H, D) if key_padding_mask is None
|
| 62 |
+
if unpadded: (nnz, 3, h, d)
|
| 63 |
+
key_padding_mask: a bool tensor of shape (B, S)
|
| 64 |
+
"""
|
| 65 |
+
assert not need_weights
|
| 66 |
+
assert qkv.dtype in [torch.float16, torch.bfloat16]
|
| 67 |
+
assert qkv.is_cuda
|
| 68 |
+
|
| 69 |
+
if cu_seqlens is None:
|
| 70 |
+
batch_size = qkv.shape[0]
|
| 71 |
+
seqlen = qkv.shape[1]
|
| 72 |
+
if key_padding_mask is None:
|
| 73 |
+
qkv = rearrange(qkv, 'b s ... -> (b s) ...')
|
| 74 |
+
max_s = seqlen
|
| 75 |
+
cu_seqlens = torch.arange(0, (batch_size + 1) * seqlen, step=seqlen, dtype=torch.int32,
|
| 76 |
+
device=qkv.device)
|
| 77 |
+
output = flash_attn_unpadded_qkvpacked_func(
|
| 78 |
+
qkv, cu_seqlens, max_s, self.dropout_p if self.training else 0.0,
|
| 79 |
+
softmax_scale=self.softmax_scale, causal=causal
|
| 80 |
+
)
|
| 81 |
+
output = rearrange(output, '(b s) ... -> b s ...', b=batch_size)
|
| 82 |
+
else:
|
| 83 |
+
nheads = qkv.shape[-2]
|
| 84 |
+
x = rearrange(qkv, 'b s three h d -> b s (three h d)')
|
| 85 |
+
x_unpad, indices, cu_seqlens, max_s = unpad_input(x, key_padding_mask)
|
| 86 |
+
x_unpad = rearrange(x_unpad, 'nnz (three h d) -> nnz three h d', three=3, h=nheads)
|
| 87 |
+
output_unpad = flash_attn_unpadded_qkvpacked_func(
|
| 88 |
+
x_unpad, cu_seqlens, max_s, self.dropout_p if self.training else 0.0,
|
| 89 |
+
softmax_scale=self.softmax_scale, causal=causal
|
| 90 |
+
)
|
| 91 |
+
output = rearrange(pad_input(rearrange(output_unpad, 'nnz h d -> nnz (h d)'),
|
| 92 |
+
indices, batch_size, seqlen),
|
| 93 |
+
'b s (h d) -> b s h d', h=nheads)
|
| 94 |
+
else:
|
| 95 |
+
assert max_s is not None
|
| 96 |
+
output = flash_attn_unpadded_qkvpacked_func(
|
| 97 |
+
qkv, cu_seqlens, max_s, self.dropout_p if self.training else 0.0,
|
| 98 |
+
softmax_scale=self.softmax_scale, causal=causal
|
| 99 |
+
)
|
| 100 |
+
|
| 101 |
+
return output, None
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
class InternRMSNorm(nn.Module):
|
| 105 |
+
def __init__(self, hidden_size, eps=1e-6):
|
| 106 |
+
super().__init__()
|
| 107 |
+
self.weight = nn.Parameter(torch.ones(hidden_size))
|
| 108 |
+
self.variance_epsilon = eps
|
| 109 |
+
|
| 110 |
+
def forward(self, hidden_states):
|
| 111 |
+
input_dtype = hidden_states.dtype
|
| 112 |
+
hidden_states = hidden_states.to(torch.float32)
|
| 113 |
+
variance = hidden_states.pow(2).mean(-1, keepdim=True)
|
| 114 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
|
| 115 |
+
return self.weight * hidden_states.to(input_dtype)
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
try:
|
| 119 |
+
from apex.normalization import FusedRMSNorm
|
| 120 |
+
|
| 121 |
+
InternRMSNorm = FusedRMSNorm # noqa
|
| 122 |
+
|
| 123 |
+
logger.info('Discovered apex.normalization.FusedRMSNorm - will use it instead of InternRMSNorm')
|
| 124 |
+
except ImportError:
|
| 125 |
+
# using the normal InternRMSNorm
|
| 126 |
+
pass
|
| 127 |
+
except Exception:
|
| 128 |
+
logger.warning('discovered apex but it failed to load, falling back to InternRMSNorm')
|
| 129 |
+
pass
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
NORM2FN = {
|
| 133 |
+
'rms_norm': InternRMSNorm,
|
| 134 |
+
'layer_norm': nn.LayerNorm,
|
| 135 |
+
}
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
class InternVisionEmbeddings(nn.Module):
|
| 139 |
+
def __init__(self, config: InternVisionConfig):
|
| 140 |
+
super().__init__()
|
| 141 |
+
self.config = config
|
| 142 |
+
self.embed_dim = config.hidden_size
|
| 143 |
+
self.image_size = config.image_size
|
| 144 |
+
self.patch_size = config.patch_size
|
| 145 |
+
|
| 146 |
+
self.class_embedding = nn.Parameter(
|
| 147 |
+
torch.randn(1, 1, self.embed_dim),
|
| 148 |
+
)
|
| 149 |
+
|
| 150 |
+
self.patch_embedding = nn.Conv2d(
|
| 151 |
+
in_channels=3, out_channels=self.embed_dim, kernel_size=self.patch_size, stride=self.patch_size
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
self.num_patches = (self.image_size // self.patch_size) ** 2
|
| 155 |
+
self.num_positions = self.num_patches + 1
|
| 156 |
+
|
| 157 |
+
self.position_embedding = nn.Parameter(torch.randn(1, self.num_positions, self.embed_dim))
|
| 158 |
+
|
| 159 |
+
def _get_pos_embed(self, pos_embed, H, W):
|
| 160 |
+
target_dtype = pos_embed.dtype
|
| 161 |
+
pos_embed = pos_embed.float().reshape(
|
| 162 |
+
1, self.image_size // self.patch_size, self.image_size // self.patch_size, -1).permute(0, 3, 1, 2)
|
| 163 |
+
pos_embed = F.interpolate(pos_embed, size=(H, W), mode='bicubic', align_corners=False). \
|
| 164 |
+
reshape(1, -1, H * W).permute(0, 2, 1).to(target_dtype)
|
| 165 |
+
return pos_embed
|
| 166 |
+
|
| 167 |
+
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
|
| 168 |
+
target_dtype = self.patch_embedding.weight.dtype
|
| 169 |
+
patch_embeds = self.patch_embedding(pixel_values) # shape = [*, channel, width, height]
|
| 170 |
+
batch_size, _, height, width = patch_embeds.shape
|
| 171 |
+
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
|
| 172 |
+
class_embeds = self.class_embedding.expand(batch_size, 1, -1).to(target_dtype)
|
| 173 |
+
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
|
| 174 |
+
position_embedding = torch.cat([
|
| 175 |
+
self.position_embedding[:, :1, :],
|
| 176 |
+
self._get_pos_embed(self.position_embedding[:, 1:, :], height, width)
|
| 177 |
+
], dim=1)
|
| 178 |
+
embeddings = embeddings + position_embedding.to(target_dtype)
|
| 179 |
+
return embeddings
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
class InternAttention(nn.Module):
|
| 183 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 184 |
+
|
| 185 |
+
def __init__(self, config: InternVisionConfig):
|
| 186 |
+
super().__init__()
|
| 187 |
+
self.config = config
|
| 188 |
+
self.embed_dim = config.hidden_size
|
| 189 |
+
self.num_heads = config.num_attention_heads
|
| 190 |
+
self.use_flash_attn = config.use_flash_attn and has_flash_attn
|
| 191 |
+
if config.use_flash_attn and not has_flash_attn:
|
| 192 |
+
print('Warning: Flash Attention is not available, use_flash_attn is set to False.')
|
| 193 |
+
self.head_dim = self.embed_dim // self.num_heads
|
| 194 |
+
if self.head_dim * self.num_heads != self.embed_dim:
|
| 195 |
+
raise ValueError(
|
| 196 |
+
f'embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:'
|
| 197 |
+
f' {self.num_heads}).'
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
self.scale = self.head_dim ** -0.5
|
| 201 |
+
self.qkv = nn.Linear(self.embed_dim, 3 * self.embed_dim, bias=config.qkv_bias)
|
| 202 |
+
self.attn_drop = nn.Dropout(config.attention_dropout)
|
| 203 |
+
self.proj_drop = nn.Dropout(config.dropout)
|
| 204 |
+
|
| 205 |
+
self.qk_normalization = config.qk_normalization
|
| 206 |
+
|
| 207 |
+
if self.qk_normalization:
|
| 208 |
+
self.q_norm = InternRMSNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 209 |
+
self.k_norm = InternRMSNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 210 |
+
|
| 211 |
+
if self.use_flash_attn:
|
| 212 |
+
self.inner_attn = FlashAttention(attention_dropout=config.attention_dropout)
|
| 213 |
+
self.proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 214 |
+
|
| 215 |
+
def _naive_attn(self, x):
|
| 216 |
+
B, N, C = x.shape
|
| 217 |
+
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
|
| 218 |
+
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
|
| 219 |
+
|
| 220 |
+
if self.qk_normalization:
|
| 221 |
+
B_, H_, N_, D_ = q.shape
|
| 222 |
+
q = self.q_norm(q.transpose(1, 2).flatten(-2, -1)).view(B_, N_, H_, D_).transpose(1, 2)
|
| 223 |
+
k = self.k_norm(k.transpose(1, 2).flatten(-2, -1)).view(B_, N_, H_, D_).transpose(1, 2)
|
| 224 |
+
|
| 225 |
+
attn = ((q * self.scale) @ k.transpose(-2, -1))
|
| 226 |
+
attn = attn.softmax(dim=-1)
|
| 227 |
+
attn = self.attn_drop(attn)
|
| 228 |
+
|
| 229 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
|
| 230 |
+
x = self.proj(x)
|
| 231 |
+
x = self.proj_drop(x)
|
| 232 |
+
return x
|
| 233 |
+
|
| 234 |
+
def _flash_attn(self, x, key_padding_mask=None, need_weights=False):
|
| 235 |
+
qkv = self.qkv(x)
|
| 236 |
+
qkv = rearrange(qkv, 'b s (three h d) -> b s three h d', three=3, h=self.num_heads)
|
| 237 |
+
|
| 238 |
+
if self.qk_normalization:
|
| 239 |
+
q, k, v = qkv.unbind(2)
|
| 240 |
+
q = self.q_norm(q.flatten(-2, -1)).view(q.shape)
|
| 241 |
+
k = self.k_norm(k.flatten(-2, -1)).view(k.shape)
|
| 242 |
+
qkv = torch.stack([q, k, v], dim=2)
|
| 243 |
+
|
| 244 |
+
context, _ = self.inner_attn(
|
| 245 |
+
qkv, key_padding_mask=key_padding_mask, need_weights=need_weights, causal=False
|
| 246 |
+
)
|
| 247 |
+
outs = self.proj(rearrange(context, 'b s h d -> b s (h d)'))
|
| 248 |
+
outs = self.proj_drop(outs)
|
| 249 |
+
return outs
|
| 250 |
+
|
| 251 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 252 |
+
x = self._naive_attn(hidden_states) if not self.use_flash_attn else self._flash_attn(hidden_states)
|
| 253 |
+
return x
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
class InternMLP(nn.Module):
|
| 257 |
+
def __init__(self, config: InternVisionConfig):
|
| 258 |
+
super().__init__()
|
| 259 |
+
self.config = config
|
| 260 |
+
self.act = ACT2FN[config.hidden_act]
|
| 261 |
+
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
|
| 262 |
+
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
|
| 263 |
+
|
| 264 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 265 |
+
hidden_states = self.fc1(hidden_states)
|
| 266 |
+
hidden_states = self.act(hidden_states)
|
| 267 |
+
hidden_states = self.fc2(hidden_states)
|
| 268 |
+
return hidden_states
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
class InternVisionEncoderLayer(nn.Module):
|
| 272 |
+
def __init__(self, config: InternVisionConfig, drop_path_rate: float):
|
| 273 |
+
super().__init__()
|
| 274 |
+
self.embed_dim = config.hidden_size
|
| 275 |
+
self.intermediate_size = config.intermediate_size
|
| 276 |
+
self.norm_type = config.norm_type
|
| 277 |
+
|
| 278 |
+
self.attn = InternAttention(config)
|
| 279 |
+
self.mlp = InternMLP(config)
|
| 280 |
+
self.norm1 = NORM2FN[self.norm_type](self.embed_dim, eps=config.layer_norm_eps)
|
| 281 |
+
self.norm2 = NORM2FN[self.norm_type](self.embed_dim, eps=config.layer_norm_eps)
|
| 282 |
+
|
| 283 |
+
self.ls1 = nn.Parameter(config.initializer_factor * torch.ones(self.embed_dim))
|
| 284 |
+
self.ls2 = nn.Parameter(config.initializer_factor * torch.ones(self.embed_dim))
|
| 285 |
+
self.drop_path1 = DropPath(drop_path_rate) if drop_path_rate > 0. else nn.Identity()
|
| 286 |
+
self.drop_path2 = DropPath(drop_path_rate) if drop_path_rate > 0. else nn.Identity()
|
| 287 |
+
|
| 288 |
+
def forward(
|
| 289 |
+
self,
|
| 290 |
+
hidden_states: torch.Tensor,
|
| 291 |
+
) -> Tuple[torch.FloatTensor, Optional[torch.FloatTensor], Optional[Tuple[torch.FloatTensor]]]:
|
| 292 |
+
"""
|
| 293 |
+
Args:
|
| 294 |
+
hidden_states (`Tuple[torch.FloatTensor, Optional[torch.FloatTensor]]`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 295 |
+
"""
|
| 296 |
+
hidden_states = hidden_states + self.drop_path1(self.attn(self.norm1(hidden_states)) * self.ls1)
|
| 297 |
+
|
| 298 |
+
hidden_states = hidden_states + self.drop_path2(self.mlp(self.norm2(hidden_states)) * self.ls2)
|
| 299 |
+
|
| 300 |
+
return hidden_states
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
class InternVisionEncoder(nn.Module):
|
| 304 |
+
"""
|
| 305 |
+
Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
|
| 306 |
+
[`InternEncoderLayer`].
|
| 307 |
+
|
| 308 |
+
Args:
|
| 309 |
+
config (`InternConfig`):
|
| 310 |
+
The corresponding vision configuration for the `InternEncoder`.
|
| 311 |
+
"""
|
| 312 |
+
|
| 313 |
+
def __init__(self, config: InternVisionConfig):
|
| 314 |
+
super().__init__()
|
| 315 |
+
self.config = config
|
| 316 |
+
# stochastic depth decay rule
|
| 317 |
+
dpr = [x.item() for x in torch.linspace(0, config.drop_path_rate, config.num_hidden_layers)]
|
| 318 |
+
self.layers = nn.ModuleList([
|
| 319 |
+
InternVisionEncoderLayer(config, dpr[idx]) for idx in range(config.num_hidden_layers)])
|
| 320 |
+
self.gradient_checkpointing = True
|
| 321 |
+
|
| 322 |
+
def forward(
|
| 323 |
+
self,
|
| 324 |
+
inputs_embeds,
|
| 325 |
+
output_hidden_states: Optional[bool] = None,
|
| 326 |
+
return_dict: Optional[bool] = None,
|
| 327 |
+
) -> Union[Tuple, BaseModelOutput]:
|
| 328 |
+
r"""
|
| 329 |
+
Args:
|
| 330 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 331 |
+
Embedded representation of the inputs. Should be float, not int tokens.
|
| 332 |
+
output_hidden_states (`bool`, *optional*):
|
| 333 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
|
| 334 |
+
for more detail.
|
| 335 |
+
return_dict (`bool`, *optional*):
|
| 336 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 337 |
+
"""
|
| 338 |
+
output_hidden_states = (
|
| 339 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 340 |
+
)
|
| 341 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 342 |
+
|
| 343 |
+
encoder_states = () if output_hidden_states else None
|
| 344 |
+
hidden_states = inputs_embeds
|
| 345 |
+
|
| 346 |
+
for idx, encoder_layer in enumerate(self.layers):
|
| 347 |
+
if output_hidden_states:
|
| 348 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 349 |
+
if self.gradient_checkpointing and self.training:
|
| 350 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 351 |
+
encoder_layer,
|
| 352 |
+
hidden_states)
|
| 353 |
+
else:
|
| 354 |
+
layer_outputs = encoder_layer(
|
| 355 |
+
hidden_states,
|
| 356 |
+
)
|
| 357 |
+
hidden_states = layer_outputs
|
| 358 |
+
|
| 359 |
+
if output_hidden_states:
|
| 360 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 361 |
+
|
| 362 |
+
if not return_dict:
|
| 363 |
+
return tuple(v for v in [hidden_states, encoder_states] if v is not None)
|
| 364 |
+
return BaseModelOutput(
|
| 365 |
+
last_hidden_state=hidden_states, hidden_states=encoder_states
|
| 366 |
+
)
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
class InternVisionModel(PreTrainedModel):
|
| 370 |
+
main_input_name = 'pixel_values'
|
| 371 |
+
_supports_flash_attn_2 = True
|
| 372 |
+
config_class = InternVisionConfig
|
| 373 |
+
_no_split_modules = ['InternVisionEncoderLayer']
|
| 374 |
+
|
| 375 |
+
def __init__(self, config: InternVisionConfig):
|
| 376 |
+
super().__init__(config)
|
| 377 |
+
self.config = config
|
| 378 |
+
|
| 379 |
+
self.embeddings = InternVisionEmbeddings(config)
|
| 380 |
+
self.encoder = InternVisionEncoder(config)
|
| 381 |
+
|
| 382 |
+
def resize_pos_embeddings(self, old_size, new_size, patch_size):
|
| 383 |
+
pos_emb = self.embeddings.position_embedding
|
| 384 |
+
_, num_positions, embed_dim = pos_emb.shape
|
| 385 |
+
cls_emb = pos_emb[:, :1, :]
|
| 386 |
+
pos_emb = pos_emb[:, 1:, :].reshape(1, old_size // patch_size, old_size // patch_size, -1).permute(0, 3, 1, 2)
|
| 387 |
+
pos_emb = F.interpolate(pos_emb.float(), size=new_size // patch_size, mode='bicubic', align_corners=False)
|
| 388 |
+
pos_emb = pos_emb.to(cls_emb.dtype).reshape(1, embed_dim, -1).permute(0, 2, 1)
|
| 389 |
+
pos_emb = torch.cat([cls_emb, pos_emb], dim=1)
|
| 390 |
+
self.embeddings.position_embedding = nn.Parameter(pos_emb)
|
| 391 |
+
self.embeddings.image_size = new_size
|
| 392 |
+
logger.info('Resized position embeddings from {} to {}'.format(old_size, new_size))
|
| 393 |
+
|
| 394 |
+
def get_input_embeddings(self):
|
| 395 |
+
return self.embeddings
|
| 396 |
+
|
| 397 |
+
def forward(
|
| 398 |
+
self,
|
| 399 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 400 |
+
output_hidden_states: Optional[bool] = None,
|
| 401 |
+
return_dict: Optional[bool] = None,
|
| 402 |
+
pixel_embeds: Optional[torch.FloatTensor] = None,
|
| 403 |
+
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
| 404 |
+
output_hidden_states = (
|
| 405 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 406 |
+
)
|
| 407 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 408 |
+
|
| 409 |
+
if pixel_values is None and pixel_embeds is None:
|
| 410 |
+
raise ValueError('You have to specify pixel_values or pixel_embeds')
|
| 411 |
+
|
| 412 |
+
if pixel_embeds is not None:
|
| 413 |
+
hidden_states = pixel_embeds
|
| 414 |
+
else:
|
| 415 |
+
if len(pixel_values.shape) == 4:
|
| 416 |
+
hidden_states = self.embeddings(pixel_values)
|
| 417 |
+
else:
|
| 418 |
+
raise ValueError(f'wrong pixel_values size: {pixel_values.shape}')
|
| 419 |
+
encoder_outputs = self.encoder(
|
| 420 |
+
inputs_embeds=hidden_states,
|
| 421 |
+
output_hidden_states=output_hidden_states,
|
| 422 |
+
return_dict=return_dict,
|
| 423 |
+
)
|
| 424 |
+
last_hidden_state = encoder_outputs.last_hidden_state
|
| 425 |
+
pooled_output = last_hidden_state[:, 0, :]
|
| 426 |
+
|
| 427 |
+
if not return_dict:
|
| 428 |
+
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
|
| 429 |
+
|
| 430 |
+
return BaseModelOutputWithPooling(
|
| 431 |
+
last_hidden_state=last_hidden_state,
|
| 432 |
+
pooler_output=pooled_output,
|
| 433 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 434 |
+
attentions=encoder_outputs.attentions,
|
| 435 |
+
)
|
modeling_internlm2.py
ADDED
|
@@ -0,0 +1,1415 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) The InternLM team and The HuggingFace Inc. team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# This code is based on transformers/src/transformers/models/llama/modeling_llama.py
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
""" PyTorch InternLM2 model."""
|
| 17 |
+
import math
|
| 18 |
+
import queue
|
| 19 |
+
import threading
|
| 20 |
+
import warnings
|
| 21 |
+
from typing import List, Optional, Tuple, Union
|
| 22 |
+
|
| 23 |
+
import torch
|
| 24 |
+
import torch.nn.functional as F
|
| 25 |
+
import torch.utils.checkpoint
|
| 26 |
+
from einops import rearrange
|
| 27 |
+
from torch import nn
|
| 28 |
+
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
|
| 29 |
+
from transformers.activations import ACT2FN
|
| 30 |
+
from transformers.modeling_outputs import (BaseModelOutputWithPast,
|
| 31 |
+
CausalLMOutputWithPast,
|
| 32 |
+
SequenceClassifierOutputWithPast)
|
| 33 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 34 |
+
from transformers.utils import (add_start_docstrings,
|
| 35 |
+
add_start_docstrings_to_model_forward, logging,
|
| 36 |
+
replace_return_docstrings)
|
| 37 |
+
|
| 38 |
+
try:
|
| 39 |
+
from transformers.generation.streamers import BaseStreamer
|
| 40 |
+
except: # noqa # pylint: disable=bare-except
|
| 41 |
+
BaseStreamer = None
|
| 42 |
+
|
| 43 |
+
from .configuration_internlm2 import InternLM2Config
|
| 44 |
+
|
| 45 |
+
logger = logging.get_logger(__name__)
|
| 46 |
+
|
| 47 |
+
_CONFIG_FOR_DOC = 'InternLM2Config'
|
| 48 |
+
|
| 49 |
+
flash_attn_func, flash_attn_varlen_func = None, None
|
| 50 |
+
pad_input, index_first_axis, unpad_input = None, None, None
|
| 51 |
+
try:
|
| 52 |
+
from flash_attn import flash_attn_func as _flash_attn_func
|
| 53 |
+
from flash_attn import flash_attn_varlen_func as _flash_attn_varlen_func
|
| 54 |
+
from flash_attn.bert_padding import index_first_axis as _index_first_axis
|
| 55 |
+
from flash_attn.bert_padding import pad_input as _pad_input
|
| 56 |
+
from flash_attn.bert_padding import unpad_input as _unpad_input
|
| 57 |
+
|
| 58 |
+
flash_attn_func, flash_attn_varlen_func = _flash_attn_func, _flash_attn_varlen_func
|
| 59 |
+
pad_input, index_first_axis, unpad_input = _pad_input, _index_first_axis, _unpad_input
|
| 60 |
+
has_flash_attn = True
|
| 61 |
+
except:
|
| 62 |
+
has_flash_attn = False
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def _import_flash_attn():
|
| 66 |
+
global flash_attn_func, flash_attn_varlen_func
|
| 67 |
+
global pad_input, index_first_axis, unpad_input
|
| 68 |
+
try:
|
| 69 |
+
from flash_attn import flash_attn_func as _flash_attn_func
|
| 70 |
+
from flash_attn import \
|
| 71 |
+
flash_attn_varlen_func as _flash_attn_varlen_func
|
| 72 |
+
from flash_attn.bert_padding import \
|
| 73 |
+
index_first_axis as _index_first_axis
|
| 74 |
+
from flash_attn.bert_padding import pad_input as _pad_input
|
| 75 |
+
from flash_attn.bert_padding import unpad_input as _unpad_input
|
| 76 |
+
flash_attn_func, flash_attn_varlen_func = _flash_attn_func, _flash_attn_varlen_func
|
| 77 |
+
pad_input, index_first_axis, unpad_input = _pad_input, _index_first_axis, _unpad_input
|
| 78 |
+
except ImportError:
|
| 79 |
+
raise ImportError('flash_attn is not installed.')
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
|
| 83 |
+
def _get_unpad_data(attention_mask):
|
| 84 |
+
seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
|
| 85 |
+
indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
|
| 86 |
+
max_seqlen_in_batch = seqlens_in_batch.max().item()
|
| 87 |
+
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
|
| 88 |
+
return (
|
| 89 |
+
indices,
|
| 90 |
+
cu_seqlens,
|
| 91 |
+
max_seqlen_in_batch,
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
# Copied from transformers.models.bart.modeling_bart._make_causal_mask
|
| 96 |
+
def _make_causal_mask(
|
| 97 |
+
input_ids_shape: torch.Size, dtype: torch.dtype, device: torch.device, past_key_values_length: int = 0
|
| 98 |
+
):
|
| 99 |
+
"""
|
| 100 |
+
Make causal mask used for bi-directional self-attention.
|
| 101 |
+
"""
|
| 102 |
+
bsz, tgt_len = input_ids_shape
|
| 103 |
+
mask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min, device=device), device=device)
|
| 104 |
+
mask_cond = torch.arange(mask.size(-1), device=device)
|
| 105 |
+
mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
|
| 106 |
+
mask = mask.to(dtype)
|
| 107 |
+
|
| 108 |
+
if past_key_values_length > 0:
|
| 109 |
+
mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)
|
| 110 |
+
return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
# Copied from transformers.models.bart.modeling_bart._expand_mask
|
| 114 |
+
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
|
| 115 |
+
"""
|
| 116 |
+
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
| 117 |
+
"""
|
| 118 |
+
bsz, src_len = mask.size()
|
| 119 |
+
tgt_len = tgt_len if tgt_len is not None else src_len
|
| 120 |
+
|
| 121 |
+
expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
|
| 122 |
+
|
| 123 |
+
inverted_mask = 1.0 - expanded_mask
|
| 124 |
+
|
| 125 |
+
return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaRMSNorm with Llama->InternLM2
|
| 129 |
+
class InternLM2RMSNorm(nn.Module):
|
| 130 |
+
def __init__(self, hidden_size, eps=1e-6):
|
| 131 |
+
"""
|
| 132 |
+
InternLM2RMSNorm is equivalent to T5LayerNorm
|
| 133 |
+
"""
|
| 134 |
+
super().__init__()
|
| 135 |
+
self.weight = nn.Parameter(torch.ones(hidden_size))
|
| 136 |
+
self.variance_epsilon = eps
|
| 137 |
+
|
| 138 |
+
def forward(self, hidden_states):
|
| 139 |
+
input_dtype = hidden_states.dtype
|
| 140 |
+
hidden_states = hidden_states.to(torch.float32)
|
| 141 |
+
variance = hidden_states.pow(2).mean(-1, keepdim=True)
|
| 142 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
|
| 143 |
+
return self.weight * hidden_states.to(input_dtype)
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
# Copied from transformers.model.llama.modeling_llama.LlamaRotaryEmbedding with Llama->InternLM2
|
| 147 |
+
class InternLM2RotaryEmbedding(nn.Module):
|
| 148 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
|
| 149 |
+
super().__init__()
|
| 150 |
+
|
| 151 |
+
self.dim = dim
|
| 152 |
+
self.max_position_embeddings = max_position_embeddings
|
| 153 |
+
self.base = base
|
| 154 |
+
inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
|
| 155 |
+
self.register_buffer('inv_freq', inv_freq, persistent=False)
|
| 156 |
+
|
| 157 |
+
# Build here to make `torch.jit.trace` work.
|
| 158 |
+
self._set_cos_sin_cache(
|
| 159 |
+
seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype()
|
| 160 |
+
)
|
| 161 |
+
|
| 162 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 163 |
+
self.max_seq_len_cached = seq_len
|
| 164 |
+
t = torch.arange(self.max_seq_len_cached, device=device).to(dtype=self.inv_freq.dtype)
|
| 165 |
+
|
| 166 |
+
freqs = torch.einsum('i,j->ij', t, self.inv_freq)
|
| 167 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 168 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 169 |
+
self.register_buffer('cos_cached', emb.cos().to(dtype), persistent=False)
|
| 170 |
+
self.register_buffer('sin_cached', emb.sin().to(dtype), persistent=False)
|
| 171 |
+
|
| 172 |
+
def forward(self, x, seq_len=None):
|
| 173 |
+
# x: [bs, num_attention_heads, seq_len, head_size]
|
| 174 |
+
if seq_len > self.max_seq_len_cached:
|
| 175 |
+
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=torch.float32)
|
| 176 |
+
|
| 177 |
+
return (
|
| 178 |
+
self.cos_cached[:seq_len].to(dtype=x.dtype),
|
| 179 |
+
self.sin_cached[:seq_len].to(dtype=x.dtype),
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
# Copied from transformers.model.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding with Llama->InternLM2
|
| 184 |
+
class InternLM2LinearScalingRotaryEmbedding(InternLM2RotaryEmbedding):
|
| 185 |
+
"""InternLM2RotaryEmbedding extended with linear scaling. Credits to the Reddit user /u/kaiokendev"""
|
| 186 |
+
|
| 187 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
|
| 188 |
+
self.scaling_factor = scaling_factor
|
| 189 |
+
super().__init__(dim, max_position_embeddings, base, device)
|
| 190 |
+
|
| 191 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 192 |
+
self.max_seq_len_cached = seq_len
|
| 193 |
+
t = torch.arange(self.max_seq_len_cached, device=device).to(dtype=self.inv_freq.dtype)
|
| 194 |
+
t = t / self.scaling_factor
|
| 195 |
+
|
| 196 |
+
freqs = torch.einsum('i,j->ij', t, self.inv_freq)
|
| 197 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 198 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 199 |
+
self.register_buffer('cos_cached', emb.cos().to(dtype), persistent=False)
|
| 200 |
+
self.register_buffer('sin_cached', emb.sin().to(dtype), persistent=False)
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
# Copied from transformers.model.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->InternLM2
|
| 204 |
+
class InternLM2DynamicNTKScalingRotaryEmbedding(InternLM2RotaryEmbedding):
|
| 205 |
+
"""InternLM2RotaryEmbedding extended with Dynamic NTK scaling.
|
| 206 |
+
Credits to the Reddit users /u/bloc97 and /u/emozilla.
|
| 207 |
+
"""
|
| 208 |
+
|
| 209 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
|
| 210 |
+
self.scaling_factor = scaling_factor
|
| 211 |
+
super().__init__(dim, max_position_embeddings, base, device)
|
| 212 |
+
|
| 213 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 214 |
+
self.max_seq_len_cached = seq_len
|
| 215 |
+
|
| 216 |
+
if seq_len > self.max_position_embeddings:
|
| 217 |
+
base = self.base * (
|
| 218 |
+
(self.scaling_factor * seq_len / self.max_position_embeddings) - (self.scaling_factor - 1)
|
| 219 |
+
) ** (self.dim / (self.dim - 2))
|
| 220 |
+
inv_freq = 1.0 / (base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
|
| 221 |
+
self.register_buffer('inv_freq', inv_freq, persistent=False)
|
| 222 |
+
|
| 223 |
+
t = torch.arange(self.max_seq_len_cached, device=device).to(dtype=self.inv_freq.dtype)
|
| 224 |
+
|
| 225 |
+
freqs = torch.einsum('i,j->ij', t, self.inv_freq)
|
| 226 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 227 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 228 |
+
self.register_buffer('cos_cached', emb.cos().to(dtype), persistent=False)
|
| 229 |
+
self.register_buffer('sin_cached', emb.sin().to(dtype), persistent=False)
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
# Copied from transformers.model.llama.modeling_llama.rotate_half
|
| 233 |
+
def rotate_half(x):
|
| 234 |
+
"""Rotates half the hidden dims of the input."""
|
| 235 |
+
x1 = x[..., : x.shape[-1] // 2]
|
| 236 |
+
x2 = x[..., x.shape[-1] // 2 :]
|
| 237 |
+
return torch.cat((-x2, x1), dim=-1)
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
# Copied from transformers.model.llama.modeling_llama.apply_rotary_pos_emb
|
| 241 |
+
def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
|
| 242 |
+
"""Applies Rotary Position Embedding to the query and key tensors."""
|
| 243 |
+
cos = cos[position_ids].unsqueeze(unsqueeze_dim)
|
| 244 |
+
sin = sin[position_ids].unsqueeze(unsqueeze_dim)
|
| 245 |
+
q_embed = (q * cos) + (rotate_half(q) * sin)
|
| 246 |
+
k_embed = (k * cos) + (rotate_half(k) * sin)
|
| 247 |
+
return q_embed, k_embed
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
class InternLM2MLP(nn.Module):
|
| 251 |
+
def __init__(self, config):
|
| 252 |
+
super().__init__()
|
| 253 |
+
self.config = config
|
| 254 |
+
self.hidden_size = config.hidden_size
|
| 255 |
+
self.intermediate_size = config.intermediate_size
|
| 256 |
+
self.w1 = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 257 |
+
self.w3 = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 258 |
+
self.w2 = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
| 259 |
+
self.act_fn = ACT2FN[config.hidden_act]
|
| 260 |
+
|
| 261 |
+
def forward(self, x):
|
| 262 |
+
down_proj = self.w2(self.act_fn(self.w1(x)) * self.w3(x))
|
| 263 |
+
|
| 264 |
+
return down_proj
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
# Copied from transformers.model.llama.modeling_llama.repeat_kv
|
| 268 |
+
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
| 269 |
+
"""
|
| 270 |
+
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
| 271 |
+
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
| 272 |
+
"""
|
| 273 |
+
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
|
| 274 |
+
if n_rep == 1:
|
| 275 |
+
return hidden_states
|
| 276 |
+
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
|
| 277 |
+
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
# Modified from transformers.model.llama.modeling_llama.LlamaAttention
|
| 281 |
+
class InternLM2Attention(nn.Module):
|
| 282 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 283 |
+
|
| 284 |
+
def __init__(self, config: InternLM2Config):
|
| 285 |
+
super().__init__()
|
| 286 |
+
self.config = config
|
| 287 |
+
self.hidden_size = config.hidden_size
|
| 288 |
+
self.num_heads = config.num_attention_heads
|
| 289 |
+
self.head_dim = self.hidden_size // self.num_heads
|
| 290 |
+
self.num_key_value_heads = config.num_key_value_heads
|
| 291 |
+
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
|
| 292 |
+
self.max_position_embeddings = config.max_position_embeddings
|
| 293 |
+
self.is_causal = True
|
| 294 |
+
|
| 295 |
+
if (self.head_dim * self.num_heads) != self.hidden_size:
|
| 296 |
+
raise ValueError(
|
| 297 |
+
f'hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}'
|
| 298 |
+
f' and `num_heads`: {self.num_heads}).'
|
| 299 |
+
)
|
| 300 |
+
|
| 301 |
+
self.wqkv = nn.Linear(
|
| 302 |
+
self.hidden_size,
|
| 303 |
+
(self.num_heads + 2 * self.num_key_value_heads) * self.head_dim,
|
| 304 |
+
bias=config.bias,
|
| 305 |
+
)
|
| 306 |
+
|
| 307 |
+
self.wo = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=config.bias)
|
| 308 |
+
self._init_rope()
|
| 309 |
+
|
| 310 |
+
def _init_rope(self):
|
| 311 |
+
if self.config.rope_scaling is None:
|
| 312 |
+
self.rotary_emb = InternLM2RotaryEmbedding(
|
| 313 |
+
self.head_dim,
|
| 314 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 315 |
+
base=self.config.rope_theta,
|
| 316 |
+
)
|
| 317 |
+
else:
|
| 318 |
+
scaling_type = self.config.rope_scaling['type']
|
| 319 |
+
scaling_factor = self.config.rope_scaling['factor']
|
| 320 |
+
if scaling_type == 'dynamic':
|
| 321 |
+
self.rotary_emb = InternLM2DynamicNTKScalingRotaryEmbedding(
|
| 322 |
+
self.head_dim,
|
| 323 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 324 |
+
base=self.config.rope_theta,
|
| 325 |
+
scaling_factor=scaling_factor,
|
| 326 |
+
)
|
| 327 |
+
elif scaling_type == 'linear':
|
| 328 |
+
self.rotary_emb = InternLM2LinearScalingRotaryEmbedding(
|
| 329 |
+
self.head_dim,
|
| 330 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 331 |
+
base=self.config.rope_theta,
|
| 332 |
+
scaling_factor=scaling_factor,
|
| 333 |
+
)
|
| 334 |
+
else:
|
| 335 |
+
raise ValueError("Currently we only support rotary embedding's type being 'dynamic' or 'linear'.")
|
| 336 |
+
return self.rotary_emb
|
| 337 |
+
|
| 338 |
+
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 339 |
+
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
|
| 340 |
+
|
| 341 |
+
def forward(
|
| 342 |
+
self,
|
| 343 |
+
hidden_states: torch.Tensor,
|
| 344 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 345 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 346 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 347 |
+
output_attentions: bool = False,
|
| 348 |
+
use_cache: bool = False,
|
| 349 |
+
**kwargs,
|
| 350 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 351 |
+
if 'padding_mask' in kwargs:
|
| 352 |
+
warnings.warn(
|
| 353 |
+
'Passing `padding_mask` is deprecated and will be removed in v4.37. '
|
| 354 |
+
'Please make sure use `attention_mask` instead.`'
|
| 355 |
+
)
|
| 356 |
+
|
| 357 |
+
bsz, q_len, _ = hidden_states.size()
|
| 358 |
+
|
| 359 |
+
qkv_states = self.wqkv(hidden_states)
|
| 360 |
+
|
| 361 |
+
qkv_states = rearrange(
|
| 362 |
+
qkv_states,
|
| 363 |
+
'b q (h gs d) -> b q h gs d',
|
| 364 |
+
gs=2 + self.num_key_value_groups,
|
| 365 |
+
d=self.head_dim,
|
| 366 |
+
)
|
| 367 |
+
|
| 368 |
+
query_states = qkv_states[..., : self.num_key_value_groups, :]
|
| 369 |
+
query_states = rearrange(query_states, 'b q h gs d -> b q (h gs) d')
|
| 370 |
+
key_states = qkv_states[..., -2, :]
|
| 371 |
+
value_states = qkv_states[..., -1, :]
|
| 372 |
+
|
| 373 |
+
query_states = query_states.transpose(1, 2)
|
| 374 |
+
key_states = key_states.transpose(1, 2)
|
| 375 |
+
value_states = value_states.transpose(1, 2)
|
| 376 |
+
|
| 377 |
+
kv_seq_len = key_states.shape[-2]
|
| 378 |
+
if past_key_value is not None:
|
| 379 |
+
kv_seq_len += past_key_value[0].shape[-2]
|
| 380 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 381 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
| 382 |
+
|
| 383 |
+
if past_key_value is not None:
|
| 384 |
+
# reuse k, v, self_attention
|
| 385 |
+
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
| 386 |
+
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
| 387 |
+
|
| 388 |
+
past_key_value = (key_states, value_states) if use_cache else None
|
| 389 |
+
|
| 390 |
+
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
| 391 |
+
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
| 392 |
+
|
| 393 |
+
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
|
| 394 |
+
|
| 395 |
+
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
|
| 396 |
+
raise ValueError(
|
| 397 |
+
f'Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is'
|
| 398 |
+
f' {attn_weights.size()}'
|
| 399 |
+
)
|
| 400 |
+
|
| 401 |
+
if attention_mask is not None:
|
| 402 |
+
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
|
| 403 |
+
raise ValueError(
|
| 404 |
+
f'Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}'
|
| 405 |
+
)
|
| 406 |
+
attn_weights = attn_weights + attention_mask
|
| 407 |
+
|
| 408 |
+
# upcast attention to fp32
|
| 409 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
|
| 410 |
+
attn_output = torch.matmul(attn_weights, value_states)
|
| 411 |
+
|
| 412 |
+
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
|
| 413 |
+
raise ValueError(
|
| 414 |
+
f'`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is'
|
| 415 |
+
f' {attn_output.size()}'
|
| 416 |
+
)
|
| 417 |
+
|
| 418 |
+
attn_output = attn_output.transpose(1, 2).contiguous()
|
| 419 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
| 420 |
+
|
| 421 |
+
attn_output = self.wo(attn_output)
|
| 422 |
+
|
| 423 |
+
if not output_attentions:
|
| 424 |
+
attn_weights = None
|
| 425 |
+
|
| 426 |
+
return attn_output, attn_weights, past_key_value
|
| 427 |
+
|
| 428 |
+
|
| 429 |
+
# Modified from transformers.model.llama.modeling_llama.InternLM2FlashAttention2
|
| 430 |
+
class InternLM2FlashAttention2(InternLM2Attention):
|
| 431 |
+
"""
|
| 432 |
+
InternLM2 flash attention module. This module inherits from `InternLM2Attention` as the weights of the module stays
|
| 433 |
+
untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
|
| 434 |
+
flash attention and deal with padding tokens in case the input contains any of them.
|
| 435 |
+
"""
|
| 436 |
+
|
| 437 |
+
def forward(
|
| 438 |
+
self,
|
| 439 |
+
hidden_states: torch.Tensor,
|
| 440 |
+
attention_mask: Optional[torch.LongTensor] = None,
|
| 441 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 442 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 443 |
+
output_attentions: bool = False,
|
| 444 |
+
use_cache: bool = False,
|
| 445 |
+
**kwargs,
|
| 446 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 447 |
+
# InternLM2FlashAttention2 attention does not support output_attentions
|
| 448 |
+
if 'padding_mask' in kwargs:
|
| 449 |
+
warnings.warn(
|
| 450 |
+
'Passing `padding_mask` is deprecated and will be removed in v4.37. '
|
| 451 |
+
'Please make sure use `attention_mask` instead.`'
|
| 452 |
+
)
|
| 453 |
+
|
| 454 |
+
# overwrite attention_mask with padding_mask
|
| 455 |
+
attention_mask = kwargs.pop('padding_mask')
|
| 456 |
+
|
| 457 |
+
output_attentions = False
|
| 458 |
+
|
| 459 |
+
bsz, q_len, _ = hidden_states.size()
|
| 460 |
+
|
| 461 |
+
qkv_states = self.wqkv(hidden_states)
|
| 462 |
+
|
| 463 |
+
qkv_states = rearrange(
|
| 464 |
+
qkv_states,
|
| 465 |
+
'b q (h gs d) -> b q h gs d',
|
| 466 |
+
gs=2 + self.num_key_value_groups,
|
| 467 |
+
d=self.head_dim,
|
| 468 |
+
)
|
| 469 |
+
|
| 470 |
+
query_states = qkv_states[..., : self.num_key_value_groups, :]
|
| 471 |
+
query_states = rearrange(query_states, 'b q h gs d -> b q (h gs) d')
|
| 472 |
+
key_states = qkv_states[..., -2, :]
|
| 473 |
+
value_states = qkv_states[..., -1, :]
|
| 474 |
+
|
| 475 |
+
query_states = query_states.transpose(1, 2)
|
| 476 |
+
key_states = key_states.transpose(1, 2)
|
| 477 |
+
value_states = value_states.transpose(1, 2)
|
| 478 |
+
|
| 479 |
+
kv_seq_len = key_states.shape[-2]
|
| 480 |
+
if past_key_value is not None:
|
| 481 |
+
kv_seq_len += past_key_value[0].shape[-2]
|
| 482 |
+
|
| 483 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 484 |
+
|
| 485 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
| 486 |
+
|
| 487 |
+
if past_key_value is not None:
|
| 488 |
+
# reuse k, v, self_attention
|
| 489 |
+
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
| 490 |
+
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
| 491 |
+
|
| 492 |
+
past_key_value = (key_states, value_states) if use_cache else None
|
| 493 |
+
|
| 494 |
+
query_states = query_states.transpose(1, 2)
|
| 495 |
+
key_states = key_states.transpose(1, 2)
|
| 496 |
+
value_states = value_states.transpose(1, 2)
|
| 497 |
+
|
| 498 |
+
attn_output = self._flash_attention_forward(
|
| 499 |
+
query_states, key_states, value_states, attention_mask, q_len
|
| 500 |
+
)
|
| 501 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size).contiguous()
|
| 502 |
+
attn_output = self.wo(attn_output)
|
| 503 |
+
|
| 504 |
+
if not output_attentions:
|
| 505 |
+
attn_weights = None
|
| 506 |
+
|
| 507 |
+
return attn_output, attn_weights, past_key_value
|
| 508 |
+
|
| 509 |
+
def _flash_attention_forward(
|
| 510 |
+
self, query_states, key_states, value_states, attention_mask, query_length, dropout=0.0, softmax_scale=None
|
| 511 |
+
):
|
| 512 |
+
"""
|
| 513 |
+
Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
|
| 514 |
+
first unpad the input, then computes the attention scores and pad the final attention scores.
|
| 515 |
+
|
| 516 |
+
Args:
|
| 517 |
+
query_states (`torch.Tensor`):
|
| 518 |
+
Input query states to be passed to Flash Attention API
|
| 519 |
+
key_states (`torch.Tensor`):
|
| 520 |
+
Input key states to be passed to Flash Attention API
|
| 521 |
+
value_states (`torch.Tensor`):
|
| 522 |
+
Input value states to be passed to Flash Attention API
|
| 523 |
+
attention_mask (`torch.Tensor`):
|
| 524 |
+
The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
|
| 525 |
+
position of padding tokens and 1 for the position of non-padding tokens.
|
| 526 |
+
dropout (`int`, *optional*):
|
| 527 |
+
Attention dropout
|
| 528 |
+
softmax_scale (`float`, *optional*):
|
| 529 |
+
The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
|
| 530 |
+
"""
|
| 531 |
+
# Contains at least one padding token in the sequence
|
| 532 |
+
causal = self.is_causal and query_length != 1
|
| 533 |
+
if attention_mask is not None:
|
| 534 |
+
batch_size = query_states.shape[0]
|
| 535 |
+
query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._unpad_input(
|
| 536 |
+
query_states, key_states, value_states, attention_mask, query_length
|
| 537 |
+
)
|
| 538 |
+
|
| 539 |
+
cu_seqlens_q, cu_seqlens_k = cu_seq_lens
|
| 540 |
+
max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
|
| 541 |
+
|
| 542 |
+
attn_output_unpad = flash_attn_varlen_func(
|
| 543 |
+
query_states,
|
| 544 |
+
key_states,
|
| 545 |
+
value_states,
|
| 546 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 547 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 548 |
+
max_seqlen_q=max_seqlen_in_batch_q,
|
| 549 |
+
max_seqlen_k=max_seqlen_in_batch_k,
|
| 550 |
+
dropout_p=dropout,
|
| 551 |
+
softmax_scale=softmax_scale,
|
| 552 |
+
causal=causal,
|
| 553 |
+
)
|
| 554 |
+
|
| 555 |
+
attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
|
| 556 |
+
else:
|
| 557 |
+
attn_output = flash_attn_func(
|
| 558 |
+
query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal
|
| 559 |
+
)
|
| 560 |
+
|
| 561 |
+
return attn_output
|
| 562 |
+
|
| 563 |
+
def _unpad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
|
| 564 |
+
indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
|
| 565 |
+
batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
|
| 566 |
+
|
| 567 |
+
key_layer = index_first_axis(
|
| 568 |
+
key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 569 |
+
)
|
| 570 |
+
value_layer = index_first_axis(
|
| 571 |
+
value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 572 |
+
)
|
| 573 |
+
|
| 574 |
+
if query_length == kv_seq_len:
|
| 575 |
+
query_layer = index_first_axis(
|
| 576 |
+
query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k
|
| 577 |
+
)
|
| 578 |
+
cu_seqlens_q = cu_seqlens_k
|
| 579 |
+
max_seqlen_in_batch_q = max_seqlen_in_batch_k
|
| 580 |
+
indices_q = indices_k
|
| 581 |
+
elif query_length == 1:
|
| 582 |
+
max_seqlen_in_batch_q = 1
|
| 583 |
+
cu_seqlens_q = torch.arange(
|
| 584 |
+
batch_size + 1, dtype=torch.int32, device=query_layer.device
|
| 585 |
+
) # There is a memcpy here, that is very bad.
|
| 586 |
+
indices_q = cu_seqlens_q[:-1]
|
| 587 |
+
query_layer = query_layer.squeeze(1)
|
| 588 |
+
else:
|
| 589 |
+
# The -q_len: slice assumes left padding.
|
| 590 |
+
attention_mask = attention_mask[:, -query_length:]
|
| 591 |
+
query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
|
| 592 |
+
|
| 593 |
+
return (
|
| 594 |
+
query_layer,
|
| 595 |
+
key_layer,
|
| 596 |
+
value_layer,
|
| 597 |
+
indices_q.to(torch.int64),
|
| 598 |
+
(cu_seqlens_q, cu_seqlens_k),
|
| 599 |
+
(max_seqlen_in_batch_q, max_seqlen_in_batch_k),
|
| 600 |
+
)
|
| 601 |
+
|
| 602 |
+
|
| 603 |
+
INTERNLM2_ATTENTION_CLASSES = {
|
| 604 |
+
'eager': InternLM2Attention,
|
| 605 |
+
'flash_attention_2': InternLM2FlashAttention2,
|
| 606 |
+
}
|
| 607 |
+
|
| 608 |
+
|
| 609 |
+
# Modified from transformers.model.llama.modeling_llama.LlamaDecoderLayer
|
| 610 |
+
class InternLM2DecoderLayer(nn.Module):
|
| 611 |
+
def __init__(self, config: InternLM2Config):
|
| 612 |
+
super().__init__()
|
| 613 |
+
self.hidden_size = config.hidden_size
|
| 614 |
+
|
| 615 |
+
self.attention = INTERNLM2_ATTENTION_CLASSES[config.attn_implementation](config=config)
|
| 616 |
+
|
| 617 |
+
self.feed_forward = InternLM2MLP(config)
|
| 618 |
+
self.attention_norm = InternLM2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 619 |
+
self.ffn_norm = InternLM2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 620 |
+
|
| 621 |
+
def forward(
|
| 622 |
+
self,
|
| 623 |
+
hidden_states: torch.Tensor,
|
| 624 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 625 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 626 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 627 |
+
output_attentions: Optional[bool] = False,
|
| 628 |
+
use_cache: Optional[bool] = False,
|
| 629 |
+
**kwargs,
|
| 630 |
+
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
| 631 |
+
"""
|
| 632 |
+
Args:
|
| 633 |
+
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 634 |
+
attention_mask (`torch.FloatTensor`, *optional*):
|
| 635 |
+
attention mask of size `(batch_size, sequence_length)` if flash attention is used or `(batch_size, 1,
|
| 636 |
+
query_sequence_length, key_sequence_length)` if default attention is used.
|
| 637 |
+
output_attentions (`bool`, *optional*):
|
| 638 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 639 |
+
returned tensors for more detail.
|
| 640 |
+
use_cache (`bool`, *optional*):
|
| 641 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
|
| 642 |
+
(see `past_key_values`).
|
| 643 |
+
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
|
| 644 |
+
"""
|
| 645 |
+
if 'padding_mask' in kwargs:
|
| 646 |
+
warnings.warn(
|
| 647 |
+
'Passing `padding_mask` is deprecated and will be removed in v4.37. '
|
| 648 |
+
'Please make sure use `attention_mask` instead.`'
|
| 649 |
+
)
|
| 650 |
+
|
| 651 |
+
residual = hidden_states
|
| 652 |
+
|
| 653 |
+
hidden_states = self.attention_norm(hidden_states)
|
| 654 |
+
|
| 655 |
+
# Self Attention
|
| 656 |
+
hidden_states, self_attn_weights, present_key_value = self.attention(
|
| 657 |
+
hidden_states=hidden_states,
|
| 658 |
+
attention_mask=attention_mask,
|
| 659 |
+
position_ids=position_ids,
|
| 660 |
+
past_key_value=past_key_value,
|
| 661 |
+
output_attentions=output_attentions,
|
| 662 |
+
use_cache=use_cache,
|
| 663 |
+
**kwargs,
|
| 664 |
+
)
|
| 665 |
+
hidden_states = residual + hidden_states
|
| 666 |
+
|
| 667 |
+
# Fully Connected
|
| 668 |
+
residual = hidden_states
|
| 669 |
+
hidden_states = self.ffn_norm(hidden_states)
|
| 670 |
+
hidden_states = self.feed_forward(hidden_states)
|
| 671 |
+
hidden_states = residual + hidden_states
|
| 672 |
+
|
| 673 |
+
outputs = (hidden_states,)
|
| 674 |
+
|
| 675 |
+
if output_attentions:
|
| 676 |
+
outputs += (self_attn_weights,)
|
| 677 |
+
|
| 678 |
+
if use_cache:
|
| 679 |
+
outputs += (present_key_value,)
|
| 680 |
+
|
| 681 |
+
return outputs
|
| 682 |
+
|
| 683 |
+
|
| 684 |
+
InternLM2_START_DOCSTRING = r"""
|
| 685 |
+
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
|
| 686 |
+
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
|
| 687 |
+
etc.)
|
| 688 |
+
|
| 689 |
+
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
|
| 690 |
+
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
|
| 691 |
+
and behavior.
|
| 692 |
+
|
| 693 |
+
Parameters:
|
| 694 |
+
config ([`InternLM2Config`]):
|
| 695 |
+
Model configuration class with all the parameters of the model. Initializing with a config file does not
|
| 696 |
+
load the weights associated with the model, only the configuration. Check out the
|
| 697 |
+
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
| 698 |
+
"""
|
| 699 |
+
|
| 700 |
+
|
| 701 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaPreTrainedModel with Llama->InternLM2
|
| 702 |
+
@add_start_docstrings(
|
| 703 |
+
'The bare InternLM2 Model outputting raw hidden-states without any specific head on top.',
|
| 704 |
+
InternLM2_START_DOCSTRING,
|
| 705 |
+
)
|
| 706 |
+
class InternLM2PreTrainedModel(PreTrainedModel):
|
| 707 |
+
config_class = InternLM2Config
|
| 708 |
+
base_model_prefix = 'model'
|
| 709 |
+
supports_gradient_checkpointing = True
|
| 710 |
+
_no_split_modules = ['InternLM2DecoderLayer']
|
| 711 |
+
_skip_keys_device_placement = 'past_key_values'
|
| 712 |
+
_supports_flash_attn_2 = True
|
| 713 |
+
|
| 714 |
+
def _init_weights(self, module):
|
| 715 |
+
std = self.config.initializer_range
|
| 716 |
+
if isinstance(module, nn.Linear):
|
| 717 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 718 |
+
if module.bias is not None:
|
| 719 |
+
module.bias.data.zero_()
|
| 720 |
+
elif isinstance(module, nn.Embedding):
|
| 721 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 722 |
+
if module.padding_idx is not None:
|
| 723 |
+
module.weight.data[module.padding_idx].zero_()
|
| 724 |
+
|
| 725 |
+
|
| 726 |
+
InternLM2_INPUTS_DOCSTRING = r"""
|
| 727 |
+
Args:
|
| 728 |
+
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
| 729 |
+
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
| 730 |
+
it.
|
| 731 |
+
|
| 732 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 733 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 734 |
+
|
| 735 |
+
[What are input IDs?](../glossary#input-ids)
|
| 736 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 737 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 738 |
+
|
| 739 |
+
- 1 for tokens that are **not masked**,
|
| 740 |
+
- 0 for tokens that are **masked**.
|
| 741 |
+
|
| 742 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 743 |
+
|
| 744 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 745 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 746 |
+
|
| 747 |
+
If `past_key_values` is used, optionally only the last `input_ids` have to be input (see
|
| 748 |
+
`past_key_values`).
|
| 749 |
+
|
| 750 |
+
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
|
| 751 |
+
and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
|
| 752 |
+
information on the default strategy.
|
| 753 |
+
|
| 754 |
+
- 1 indicates the head is **not masked**,
|
| 755 |
+
- 0 indicates the head is **masked**.
|
| 756 |
+
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 757 |
+
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
| 758 |
+
config.n_positions - 1]`.
|
| 759 |
+
|
| 760 |
+
[What are position IDs?](../glossary#position-ids)
|
| 761 |
+
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or
|
| 762 |
+
when `config.use_cache=True`):
|
| 763 |
+
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
|
| 764 |
+
`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
|
| 765 |
+
`(batch_size, num_heads, decoder_sequence_length, embed_size_per_head)`.
|
| 766 |
+
|
| 767 |
+
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
|
| 768 |
+
blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
|
| 769 |
+
|
| 770 |
+
If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
|
| 771 |
+
have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
|
| 772 |
+
of shape `(batch_size, sequence_length)`.
|
| 773 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
|
| 774 |
+
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
|
| 775 |
+
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
|
| 776 |
+
model's internal embedding lookup matrix.
|
| 777 |
+
use_cache (`bool`, *optional*):
|
| 778 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
|
| 779 |
+
`past_key_values`).
|
| 780 |
+
output_attentions (`bool`, *optional*):
|
| 781 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 782 |
+
tensors for more detail.
|
| 783 |
+
output_hidden_states (`bool`, *optional*):
|
| 784 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 785 |
+
more detail.
|
| 786 |
+
return_dict (`bool`, *optional*):
|
| 787 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 788 |
+
"""
|
| 789 |
+
|
| 790 |
+
|
| 791 |
+
# Modified from transformers.model.llama.modeling_llama.LlamaModel
|
| 792 |
+
@add_start_docstrings(
|
| 793 |
+
'The bare InternLM2 Model outputting raw hidden-states without any specific head on top.',
|
| 794 |
+
InternLM2_START_DOCSTRING,
|
| 795 |
+
)
|
| 796 |
+
class InternLM2Model(InternLM2PreTrainedModel):
|
| 797 |
+
"""
|
| 798 |
+
Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`InternLM2DecoderLayer`]
|
| 799 |
+
|
| 800 |
+
Args:
|
| 801 |
+
config: InternLM2Config
|
| 802 |
+
"""
|
| 803 |
+
|
| 804 |
+
_auto_class = 'AutoModel'
|
| 805 |
+
|
| 806 |
+
def __init__(self, config: InternLM2Config):
|
| 807 |
+
super().__init__(config)
|
| 808 |
+
self.padding_idx = config.pad_token_id
|
| 809 |
+
self.vocab_size = config.vocab_size
|
| 810 |
+
self.config = config
|
| 811 |
+
if not has_flash_attn:
|
| 812 |
+
self.config.attn_implementation = 'eager'
|
| 813 |
+
print('Warning: Flash attention is not available, using eager attention instead.')
|
| 814 |
+
|
| 815 |
+
self.tok_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
| 816 |
+
|
| 817 |
+
self.layers = nn.ModuleList([InternLM2DecoderLayer(config) for _ in range(config.num_hidden_layers)])
|
| 818 |
+
self.norm = InternLM2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 819 |
+
|
| 820 |
+
self.gradient_checkpointing = False
|
| 821 |
+
# Initialize weights and apply final processing
|
| 822 |
+
self.post_init()
|
| 823 |
+
|
| 824 |
+
def get_input_embeddings(self):
|
| 825 |
+
return self.tok_embeddings
|
| 826 |
+
|
| 827 |
+
def set_input_embeddings(self, value):
|
| 828 |
+
self.tok_embeddings = value
|
| 829 |
+
|
| 830 |
+
def _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_embeds, past_key_values_length):
|
| 831 |
+
# create causal mask
|
| 832 |
+
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
| 833 |
+
combined_attention_mask = None
|
| 834 |
+
if input_shape[-1] > 1:
|
| 835 |
+
combined_attention_mask = _make_causal_mask(
|
| 836 |
+
input_shape,
|
| 837 |
+
inputs_embeds.dtype,
|
| 838 |
+
device=inputs_embeds.device,
|
| 839 |
+
past_key_values_length=past_key_values_length,
|
| 840 |
+
)
|
| 841 |
+
|
| 842 |
+
if attention_mask is not None:
|
| 843 |
+
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
| 844 |
+
expanded_attn_mask = _expand_mask(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]).to(
|
| 845 |
+
inputs_embeds.device
|
| 846 |
+
)
|
| 847 |
+
combined_attention_mask = (
|
| 848 |
+
expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask
|
| 849 |
+
)
|
| 850 |
+
|
| 851 |
+
return combined_attention_mask
|
| 852 |
+
|
| 853 |
+
@add_start_docstrings_to_model_forward(InternLM2_INPUTS_DOCSTRING)
|
| 854 |
+
def forward(
|
| 855 |
+
self,
|
| 856 |
+
input_ids: torch.LongTensor = None,
|
| 857 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 858 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 859 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 860 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 861 |
+
use_cache: Optional[bool] = None,
|
| 862 |
+
output_attentions: Optional[bool] = None,
|
| 863 |
+
output_hidden_states: Optional[bool] = None,
|
| 864 |
+
return_dict: Optional[bool] = None,
|
| 865 |
+
) -> Union[Tuple, BaseModelOutputWithPast]:
|
| 866 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 867 |
+
output_hidden_states = (
|
| 868 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 869 |
+
)
|
| 870 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 871 |
+
|
| 872 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 873 |
+
|
| 874 |
+
if self.config.attn_implementation == 'flash_attention_2':
|
| 875 |
+
_import_flash_attn()
|
| 876 |
+
|
| 877 |
+
# retrieve input_ids and inputs_embeds
|
| 878 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 879 |
+
raise ValueError('You cannot specify both input_ids and inputs_embeds at the same time')
|
| 880 |
+
elif input_ids is not None:
|
| 881 |
+
batch_size, seq_length = input_ids.shape[:2]
|
| 882 |
+
elif inputs_embeds is not None:
|
| 883 |
+
batch_size, seq_length = inputs_embeds.shape[:2]
|
| 884 |
+
else:
|
| 885 |
+
raise ValueError('You have to specify either input_ids or inputs_embeds')
|
| 886 |
+
|
| 887 |
+
seq_length_with_past = seq_length
|
| 888 |
+
past_key_values_length = 0
|
| 889 |
+
if past_key_values is not None:
|
| 890 |
+
past_key_values_length = past_key_values[0][0].shape[2]
|
| 891 |
+
seq_length_with_past = seq_length_with_past + past_key_values_length
|
| 892 |
+
|
| 893 |
+
if position_ids is None:
|
| 894 |
+
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
| 895 |
+
position_ids = torch.arange(
|
| 896 |
+
past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
|
| 897 |
+
)
|
| 898 |
+
position_ids = position_ids.unsqueeze(0)
|
| 899 |
+
|
| 900 |
+
if inputs_embeds is None:
|
| 901 |
+
inputs_embeds = self.tok_embeddings(input_ids)
|
| 902 |
+
|
| 903 |
+
if self.config.attn_implementation == 'flash_attention_2':
|
| 904 |
+
# 2d mask is passed through the layers
|
| 905 |
+
attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
|
| 906 |
+
else:
|
| 907 |
+
if attention_mask is None:
|
| 908 |
+
attention_mask = torch.ones(
|
| 909 |
+
(batch_size, seq_length_with_past), dtype=torch.bool, device=inputs_embeds.device
|
| 910 |
+
)
|
| 911 |
+
attention_mask = self._prepare_decoder_attention_mask(
|
| 912 |
+
attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
|
| 913 |
+
)
|
| 914 |
+
|
| 915 |
+
# embed positions
|
| 916 |
+
hidden_states = inputs_embeds
|
| 917 |
+
|
| 918 |
+
if self.gradient_checkpointing and self.training:
|
| 919 |
+
if use_cache:
|
| 920 |
+
logger.warning_once(
|
| 921 |
+
'`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...'
|
| 922 |
+
)
|
| 923 |
+
use_cache = False
|
| 924 |
+
|
| 925 |
+
# decoder layers
|
| 926 |
+
all_hidden_states = () if output_hidden_states else None
|
| 927 |
+
all_self_attns = () if output_attentions else None
|
| 928 |
+
next_decoder_cache = () if use_cache else None
|
| 929 |
+
|
| 930 |
+
for idx, decoder_layer in enumerate(self.layers):
|
| 931 |
+
if output_hidden_states:
|
| 932 |
+
all_hidden_states += (hidden_states,)
|
| 933 |
+
|
| 934 |
+
past_key_value = past_key_values[idx] if past_key_values is not None else None
|
| 935 |
+
|
| 936 |
+
if self.gradient_checkpointing and self.training:
|
| 937 |
+
|
| 938 |
+
def create_custom_forward(module):
|
| 939 |
+
def custom_forward(*inputs):
|
| 940 |
+
# None for past_key_value
|
| 941 |
+
return module(*inputs, output_attentions, None)
|
| 942 |
+
|
| 943 |
+
return custom_forward
|
| 944 |
+
|
| 945 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 946 |
+
create_custom_forward(decoder_layer),
|
| 947 |
+
hidden_states,
|
| 948 |
+
attention_mask,
|
| 949 |
+
position_ids,
|
| 950 |
+
None,
|
| 951 |
+
)
|
| 952 |
+
else:
|
| 953 |
+
layer_outputs = decoder_layer(
|
| 954 |
+
hidden_states,
|
| 955 |
+
attention_mask=attention_mask,
|
| 956 |
+
position_ids=position_ids,
|
| 957 |
+
past_key_value=past_key_value,
|
| 958 |
+
output_attentions=output_attentions,
|
| 959 |
+
use_cache=use_cache,
|
| 960 |
+
)
|
| 961 |
+
|
| 962 |
+
hidden_states = layer_outputs[0]
|
| 963 |
+
|
| 964 |
+
if use_cache:
|
| 965 |
+
next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
|
| 966 |
+
|
| 967 |
+
if output_attentions:
|
| 968 |
+
all_self_attns += (layer_outputs[1],)
|
| 969 |
+
|
| 970 |
+
hidden_states = self.norm(hidden_states)
|
| 971 |
+
|
| 972 |
+
# add hidden states from the last decoder layer
|
| 973 |
+
if output_hidden_states:
|
| 974 |
+
all_hidden_states += (hidden_states,)
|
| 975 |
+
|
| 976 |
+
next_cache = next_decoder_cache if use_cache else None
|
| 977 |
+
if not return_dict:
|
| 978 |
+
return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
|
| 979 |
+
return BaseModelOutputWithPast(
|
| 980 |
+
last_hidden_state=hidden_states,
|
| 981 |
+
past_key_values=next_cache,
|
| 982 |
+
hidden_states=all_hidden_states,
|
| 983 |
+
attentions=all_self_attns,
|
| 984 |
+
)
|
| 985 |
+
|
| 986 |
+
|
| 987 |
+
# Modified from transformers.model.llama.modeling_llama.LlamaForCausalLM
|
| 988 |
+
class InternLM2ForCausalLM(InternLM2PreTrainedModel):
|
| 989 |
+
_auto_class = 'AutoModelForCausalLM'
|
| 990 |
+
|
| 991 |
+
_tied_weights_keys = ['output.weight']
|
| 992 |
+
|
| 993 |
+
def __init__(self, config):
|
| 994 |
+
super().__init__(config)
|
| 995 |
+
self.model = InternLM2Model(config)
|
| 996 |
+
self.vocab_size = config.vocab_size
|
| 997 |
+
self.output = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 998 |
+
|
| 999 |
+
# Initialize weights and apply final processing
|
| 1000 |
+
self.post_init()
|
| 1001 |
+
|
| 1002 |
+
def get_input_embeddings(self):
|
| 1003 |
+
return self.model.tok_embeddings
|
| 1004 |
+
|
| 1005 |
+
def set_input_embeddings(self, value):
|
| 1006 |
+
self.model.tok_embeddings = value
|
| 1007 |
+
|
| 1008 |
+
def get_output_embeddings(self):
|
| 1009 |
+
return self.output
|
| 1010 |
+
|
| 1011 |
+
def set_output_embeddings(self, new_embeddings):
|
| 1012 |
+
self.output = new_embeddings
|
| 1013 |
+
|
| 1014 |
+
def set_decoder(self, decoder):
|
| 1015 |
+
self.model = decoder
|
| 1016 |
+
|
| 1017 |
+
def get_decoder(self):
|
| 1018 |
+
return self.model
|
| 1019 |
+
|
| 1020 |
+
@add_start_docstrings_to_model_forward(InternLM2_INPUTS_DOCSTRING)
|
| 1021 |
+
@replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
|
| 1022 |
+
def forward(
|
| 1023 |
+
self,
|
| 1024 |
+
input_ids: torch.LongTensor = None,
|
| 1025 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1026 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1027 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 1028 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1029 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1030 |
+
use_cache: Optional[bool] = None,
|
| 1031 |
+
output_attentions: Optional[bool] = None,
|
| 1032 |
+
output_hidden_states: Optional[bool] = None,
|
| 1033 |
+
return_dict: Optional[bool] = None,
|
| 1034 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 1035 |
+
r"""
|
| 1036 |
+
Args:
|
| 1037 |
+
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 1038 |
+
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
| 1039 |
+
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
| 1040 |
+
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
|
| 1041 |
+
|
| 1042 |
+
Returns:
|
| 1043 |
+
|
| 1044 |
+
Example:
|
| 1045 |
+
|
| 1046 |
+
```python
|
| 1047 |
+
>>> from transformers import AutoTokenizer, InternLM2ForCausalLM
|
| 1048 |
+
|
| 1049 |
+
>>> model = InternLM2ForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
|
| 1050 |
+
>>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
|
| 1051 |
+
|
| 1052 |
+
>>> prompt = "Hey, are you conscious? Can you talk to me?"
|
| 1053 |
+
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
| 1054 |
+
|
| 1055 |
+
>>> # Generate
|
| 1056 |
+
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
|
| 1057 |
+
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
| 1058 |
+
"Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
|
| 1059 |
+
```"""
|
| 1060 |
+
|
| 1061 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 1062 |
+
output_hidden_states = (
|
| 1063 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 1064 |
+
)
|
| 1065 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1066 |
+
|
| 1067 |
+
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
| 1068 |
+
outputs = self.model(
|
| 1069 |
+
input_ids=input_ids,
|
| 1070 |
+
attention_mask=attention_mask,
|
| 1071 |
+
position_ids=position_ids,
|
| 1072 |
+
past_key_values=past_key_values,
|
| 1073 |
+
inputs_embeds=inputs_embeds,
|
| 1074 |
+
use_cache=use_cache,
|
| 1075 |
+
output_attentions=output_attentions,
|
| 1076 |
+
output_hidden_states=output_hidden_states,
|
| 1077 |
+
return_dict=return_dict,
|
| 1078 |
+
)
|
| 1079 |
+
|
| 1080 |
+
hidden_states = outputs[0]
|
| 1081 |
+
logits = self.output(hidden_states)
|
| 1082 |
+
logits = logits.float()
|
| 1083 |
+
|
| 1084 |
+
loss = None
|
| 1085 |
+
if labels is not None:
|
| 1086 |
+
# Shift so that tokens < n predict n
|
| 1087 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 1088 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 1089 |
+
# Flatten the tokens
|
| 1090 |
+
loss_fct = CrossEntropyLoss()
|
| 1091 |
+
shift_logits = shift_logits.view(-1, self.config.vocab_size)
|
| 1092 |
+
shift_labels = shift_labels.view(-1)
|
| 1093 |
+
# Enable model parallelism
|
| 1094 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 1095 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 1096 |
+
|
| 1097 |
+
if not return_dict:
|
| 1098 |
+
output = (logits,) + outputs[1:]
|
| 1099 |
+
return (loss,) + output if loss is not None else output
|
| 1100 |
+
|
| 1101 |
+
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
| 1102 |
+
output = CausalLMOutputWithPast(
|
| 1103 |
+
loss=loss,
|
| 1104 |
+
logits=logits,
|
| 1105 |
+
past_key_values=outputs.past_key_values,
|
| 1106 |
+
hidden_states=outputs.hidden_states,
|
| 1107 |
+
attentions=outputs.attentions,
|
| 1108 |
+
)
|
| 1109 |
+
output['logits'] = output['logits'].to(device)
|
| 1110 |
+
return output
|
| 1111 |
+
|
| 1112 |
+
def prepare_inputs_for_generation(
|
| 1113 |
+
self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs
|
| 1114 |
+
):
|
| 1115 |
+
if past_key_values is not None:
|
| 1116 |
+
past_length = past_key_values[0][0].shape[2]
|
| 1117 |
+
|
| 1118 |
+
# Some generation methods already pass only the last input ID
|
| 1119 |
+
if input_ids.shape[1] > past_length:
|
| 1120 |
+
remove_prefix_length = past_length
|
| 1121 |
+
else:
|
| 1122 |
+
# Default to old behavior: keep only final ID
|
| 1123 |
+
remove_prefix_length = input_ids.shape[1] - 1
|
| 1124 |
+
|
| 1125 |
+
input_ids = input_ids[:, remove_prefix_length:]
|
| 1126 |
+
|
| 1127 |
+
position_ids = kwargs.get('position_ids', None)
|
| 1128 |
+
if attention_mask is not None and position_ids is None:
|
| 1129 |
+
# create position_ids on the fly for batch generation
|
| 1130 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 1131 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 1132 |
+
if past_key_values:
|
| 1133 |
+
position_ids = position_ids[:, -input_ids.shape[1] :]
|
| 1134 |
+
|
| 1135 |
+
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
| 1136 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 1137 |
+
model_inputs = {'inputs_embeds': inputs_embeds}
|
| 1138 |
+
else:
|
| 1139 |
+
model_inputs = {'input_ids': input_ids}
|
| 1140 |
+
|
| 1141 |
+
model_inputs.update(
|
| 1142 |
+
{
|
| 1143 |
+
'position_ids': position_ids,
|
| 1144 |
+
'past_key_values': past_key_values,
|
| 1145 |
+
'use_cache': kwargs.get('use_cache'),
|
| 1146 |
+
'attention_mask': attention_mask,
|
| 1147 |
+
}
|
| 1148 |
+
)
|
| 1149 |
+
return model_inputs
|
| 1150 |
+
|
| 1151 |
+
@staticmethod
|
| 1152 |
+
def _reorder_cache(past_key_values, beam_idx):
|
| 1153 |
+
reordered_past = ()
|
| 1154 |
+
for layer_past in past_key_values:
|
| 1155 |
+
reordered_past += (
|
| 1156 |
+
tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),
|
| 1157 |
+
)
|
| 1158 |
+
return reordered_past
|
| 1159 |
+
|
| 1160 |
+
def build_inputs(self, tokenizer, query: str, history: List[Tuple[str, str]] = [], meta_instruction=''):
|
| 1161 |
+
if tokenizer.add_bos_token:
|
| 1162 |
+
prompt = ''
|
| 1163 |
+
else:
|
| 1164 |
+
prompt = tokenizer.bos_token
|
| 1165 |
+
if meta_instruction:
|
| 1166 |
+
prompt += f"""<|im_start|>system\n{meta_instruction}<|im_end|>\n"""
|
| 1167 |
+
for record in history:
|
| 1168 |
+
prompt += f"""<|im_start|>user\n{record[0]}<|im_end|>\n<|im_start|>assistant\n{record[1]}<|im_end|>\n"""
|
| 1169 |
+
prompt += f"""<|im_start|>user\n{query}<|im_end|>\n<|im_start|>assistant\n"""
|
| 1170 |
+
return tokenizer([prompt], return_tensors='pt')
|
| 1171 |
+
|
| 1172 |
+
@torch.no_grad()
|
| 1173 |
+
def chat(
|
| 1174 |
+
self,
|
| 1175 |
+
tokenizer,
|
| 1176 |
+
query: str,
|
| 1177 |
+
history: List[Tuple[str, str]] = [],
|
| 1178 |
+
streamer: Optional[BaseStreamer] = None,
|
| 1179 |
+
max_new_tokens: int = 1024,
|
| 1180 |
+
do_sample: bool = True,
|
| 1181 |
+
temperature: float = 0.8,
|
| 1182 |
+
top_p: float = 0.8,
|
| 1183 |
+
meta_instruction: str = 'You are an AI assistant whose name is InternLM (书生·浦语).\n'
|
| 1184 |
+
'- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.\n'
|
| 1185 |
+
'- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.',
|
| 1186 |
+
**kwargs,
|
| 1187 |
+
):
|
| 1188 |
+
inputs = self.build_inputs(tokenizer, query, history, meta_instruction)
|
| 1189 |
+
inputs = {k: v.to(self.device) for k, v in inputs.items() if torch.is_tensor(v)}
|
| 1190 |
+
# also add end-of-assistant token in eos token id to avoid unnecessary generation
|
| 1191 |
+
eos_token_id = [tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids(['<|im_end|>'])[0]]
|
| 1192 |
+
outputs = self.generate(
|
| 1193 |
+
**inputs,
|
| 1194 |
+
streamer=streamer,
|
| 1195 |
+
max_new_tokens=max_new_tokens,
|
| 1196 |
+
do_sample=do_sample,
|
| 1197 |
+
temperature=temperature,
|
| 1198 |
+
top_p=top_p,
|
| 1199 |
+
eos_token_id=eos_token_id,
|
| 1200 |
+
**kwargs,
|
| 1201 |
+
)
|
| 1202 |
+
outputs = outputs[0].cpu().tolist()[len(inputs['input_ids'][0]) :]
|
| 1203 |
+
response = tokenizer.decode(outputs, skip_special_tokens=True)
|
| 1204 |
+
response = response.split('<|im_end|>')[0]
|
| 1205 |
+
history = history + [(query, response)]
|
| 1206 |
+
return response, history
|
| 1207 |
+
|
| 1208 |
+
@torch.no_grad()
|
| 1209 |
+
def stream_chat(
|
| 1210 |
+
self,
|
| 1211 |
+
tokenizer,
|
| 1212 |
+
query: str,
|
| 1213 |
+
history: List[Tuple[str, str]] = [],
|
| 1214 |
+
max_new_tokens: int = 1024,
|
| 1215 |
+
do_sample: bool = True,
|
| 1216 |
+
temperature: float = 0.8,
|
| 1217 |
+
top_p: float = 0.8,
|
| 1218 |
+
**kwargs,
|
| 1219 |
+
):
|
| 1220 |
+
"""
|
| 1221 |
+
Return a generator in format: (response, history)
|
| 1222 |
+
Eg.
|
| 1223 |
+
('你好,有什么可以帮助您的吗', [('你好', '你好,有什么可以帮助您的吗')])
|
| 1224 |
+
('你好,有什么可以帮助您的吗?', [('你好', '你好,有什么可以帮助您的吗?')])
|
| 1225 |
+
"""
|
| 1226 |
+
if BaseStreamer is None:
|
| 1227 |
+
raise ModuleNotFoundError(
|
| 1228 |
+
'The version of `transformers` is too low. Please make sure '
|
| 1229 |
+
'that you have installed `transformers>=4.28.0`.'
|
| 1230 |
+
)
|
| 1231 |
+
|
| 1232 |
+
response_queue = queue.Queue(maxsize=20)
|
| 1233 |
+
|
| 1234 |
+
class ChatStreamer(BaseStreamer):
|
| 1235 |
+
def __init__(self, tokenizer) -> None:
|
| 1236 |
+
super().__init__()
|
| 1237 |
+
self.tokenizer = tokenizer
|
| 1238 |
+
self.queue = response_queue
|
| 1239 |
+
self.query = query
|
| 1240 |
+
self.history = history
|
| 1241 |
+
self.response = ''
|
| 1242 |
+
self.cache = []
|
| 1243 |
+
self.received_inputs = False
|
| 1244 |
+
self.queue.put((self.response, history + [(self.query, self.response)]))
|
| 1245 |
+
|
| 1246 |
+
def put(self, value):
|
| 1247 |
+
if len(value.shape) > 1 and value.shape[0] > 1:
|
| 1248 |
+
raise ValueError('ChatStreamer only supports batch size 1')
|
| 1249 |
+
elif len(value.shape) > 1:
|
| 1250 |
+
value = value[0]
|
| 1251 |
+
|
| 1252 |
+
if not self.received_inputs:
|
| 1253 |
+
# The first received value is input_ids, ignore here
|
| 1254 |
+
self.received_inputs = True
|
| 1255 |
+
return
|
| 1256 |
+
|
| 1257 |
+
self.cache.extend(value.tolist())
|
| 1258 |
+
token = self.tokenizer.decode(self.cache, skip_special_tokens=True)
|
| 1259 |
+
if token.strip() != '<|im_end|>':
|
| 1260 |
+
self.response = self.response + token
|
| 1261 |
+
history = self.history + [(self.query, self.response)]
|
| 1262 |
+
self.queue.put((self.response, history))
|
| 1263 |
+
self.cache = []
|
| 1264 |
+
else:
|
| 1265 |
+
self.end()
|
| 1266 |
+
|
| 1267 |
+
def end(self):
|
| 1268 |
+
self.queue.put(None)
|
| 1269 |
+
|
| 1270 |
+
def stream_producer():
|
| 1271 |
+
return self.chat(
|
| 1272 |
+
tokenizer=tokenizer,
|
| 1273 |
+
query=query,
|
| 1274 |
+
streamer=ChatStreamer(tokenizer=tokenizer),
|
| 1275 |
+
history=history,
|
| 1276 |
+
max_new_tokens=max_new_tokens,
|
| 1277 |
+
do_sample=do_sample,
|
| 1278 |
+
temperature=temperature,
|
| 1279 |
+
top_p=top_p,
|
| 1280 |
+
**kwargs,
|
| 1281 |
+
)
|
| 1282 |
+
|
| 1283 |
+
def consumer():
|
| 1284 |
+
producer = threading.Thread(target=stream_producer)
|
| 1285 |
+
producer.start()
|
| 1286 |
+
while True:
|
| 1287 |
+
res = response_queue.get()
|
| 1288 |
+
if res is None:
|
| 1289 |
+
return
|
| 1290 |
+
yield res
|
| 1291 |
+
|
| 1292 |
+
return consumer()
|
| 1293 |
+
|
| 1294 |
+
|
| 1295 |
+
# Copied from transformers.model.llama.modeling_llama.LlamaForSequenceClassification with Llama->InternLM2
|
| 1296 |
+
@add_start_docstrings(
|
| 1297 |
+
"""
|
| 1298 |
+
The InternLM2 Model transformer with a sequence classification head on top (linear layer).
|
| 1299 |
+
|
| 1300 |
+
[`InternLM2ForSequenceClassification`] uses the last token in order to do the classification,
|
| 1301 |
+
as other causal models (e.g. GPT-2) do.
|
| 1302 |
+
|
| 1303 |
+
Since it does classification on the last token, it requires to know the position of the last token. If a
|
| 1304 |
+
`pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
|
| 1305 |
+
no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
|
| 1306 |
+
padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
|
| 1307 |
+
each row of the batch).
|
| 1308 |
+
""",
|
| 1309 |
+
InternLM2_START_DOCSTRING,
|
| 1310 |
+
)
|
| 1311 |
+
class InternLM2ForSequenceClassification(InternLM2PreTrainedModel):
|
| 1312 |
+
def __init__(self, config):
|
| 1313 |
+
super().__init__(config)
|
| 1314 |
+
self.num_labels = config.num_labels
|
| 1315 |
+
self.model = InternLM2Model(config)
|
| 1316 |
+
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
|
| 1317 |
+
|
| 1318 |
+
# Initialize weights and apply final processing
|
| 1319 |
+
self.post_init()
|
| 1320 |
+
|
| 1321 |
+
def get_input_embeddings(self):
|
| 1322 |
+
return self.model.tok_embeddings
|
| 1323 |
+
|
| 1324 |
+
def set_input_embeddings(self, value):
|
| 1325 |
+
self.model.tok_embeddings = value
|
| 1326 |
+
|
| 1327 |
+
@add_start_docstrings_to_model_forward(InternLM2_INPUTS_DOCSTRING)
|
| 1328 |
+
def forward(
|
| 1329 |
+
self,
|
| 1330 |
+
input_ids: torch.LongTensor = None,
|
| 1331 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1332 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1333 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 1334 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1335 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1336 |
+
use_cache: Optional[bool] = None,
|
| 1337 |
+
output_attentions: Optional[bool] = None,
|
| 1338 |
+
output_hidden_states: Optional[bool] = None,
|
| 1339 |
+
return_dict: Optional[bool] = None,
|
| 1340 |
+
) -> Union[Tuple, SequenceClassifierOutputWithPast]:
|
| 1341 |
+
r"""
|
| 1342 |
+
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 1343 |
+
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
| 1344 |
+
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
| 1345 |
+
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
| 1346 |
+
"""
|
| 1347 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1348 |
+
|
| 1349 |
+
transformer_outputs = self.model(
|
| 1350 |
+
input_ids,
|
| 1351 |
+
attention_mask=attention_mask,
|
| 1352 |
+
position_ids=position_ids,
|
| 1353 |
+
past_key_values=past_key_values,
|
| 1354 |
+
inputs_embeds=inputs_embeds,
|
| 1355 |
+
use_cache=use_cache,
|
| 1356 |
+
output_attentions=output_attentions,
|
| 1357 |
+
output_hidden_states=output_hidden_states,
|
| 1358 |
+
return_dict=return_dict,
|
| 1359 |
+
)
|
| 1360 |
+
hidden_states = transformer_outputs[0]
|
| 1361 |
+
logits = self.score(hidden_states)
|
| 1362 |
+
|
| 1363 |
+
if input_ids is not None:
|
| 1364 |
+
batch_size = input_ids.shape[0]
|
| 1365 |
+
else:
|
| 1366 |
+
batch_size = inputs_embeds.shape[0]
|
| 1367 |
+
|
| 1368 |
+
if self.config.pad_token_id is None and batch_size != 1:
|
| 1369 |
+
raise ValueError('Cannot handle batch sizes > 1 if no padding token is defined.')
|
| 1370 |
+
if self.config.pad_token_id is None:
|
| 1371 |
+
sequence_lengths = -1
|
| 1372 |
+
else:
|
| 1373 |
+
if input_ids is not None:
|
| 1374 |
+
sequence_lengths = (torch.eq(input_ids, self.config.pad_token_id).int().argmax(-1) - 1).to(
|
| 1375 |
+
logits.device
|
| 1376 |
+
)
|
| 1377 |
+
else:
|
| 1378 |
+
sequence_lengths = -1
|
| 1379 |
+
|
| 1380 |
+
pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
|
| 1381 |
+
|
| 1382 |
+
loss = None
|
| 1383 |
+
if labels is not None:
|
| 1384 |
+
labels = labels.to(logits.device)
|
| 1385 |
+
if self.config.problem_type is None:
|
| 1386 |
+
if self.num_labels == 1:
|
| 1387 |
+
self.config.problem_type = 'regression'
|
| 1388 |
+
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
|
| 1389 |
+
self.config.problem_type = 'single_label_classification'
|
| 1390 |
+
else:
|
| 1391 |
+
self.config.problem_type = 'multi_label_classification'
|
| 1392 |
+
|
| 1393 |
+
if self.config.problem_type == 'regression':
|
| 1394 |
+
loss_fct = MSELoss()
|
| 1395 |
+
if self.num_labels == 1:
|
| 1396 |
+
loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
|
| 1397 |
+
else:
|
| 1398 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1399 |
+
elif self.config.problem_type == 'single_label_classification':
|
| 1400 |
+
loss_fct = CrossEntropyLoss()
|
| 1401 |
+
loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
|
| 1402 |
+
elif self.config.problem_type == 'multi_label_classification':
|
| 1403 |
+
loss_fct = BCEWithLogitsLoss()
|
| 1404 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1405 |
+
if not return_dict:
|
| 1406 |
+
output = (pooled_logits,) + transformer_outputs[1:]
|
| 1407 |
+
return ((loss,) + output) if loss is not None else output
|
| 1408 |
+
|
| 1409 |
+
return SequenceClassifierOutputWithPast(
|
| 1410 |
+
loss=loss,
|
| 1411 |
+
logits=pooled_logits,
|
| 1412 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 1413 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1414 |
+
attentions=transformer_outputs.attentions,
|
| 1415 |
+
)
|
modeling_internvl_chat.py
ADDED
|
@@ -0,0 +1,361 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
import warnings
|
| 7 |
+
from typing import Any, List, Optional, Tuple, Union
|
| 8 |
+
|
| 9 |
+
import torch.utils.checkpoint
|
| 10 |
+
import transformers
|
| 11 |
+
from torch import nn
|
| 12 |
+
from torch.nn import CrossEntropyLoss
|
| 13 |
+
from transformers import (AutoModel, GenerationConfig, LlamaForCausalLM,
|
| 14 |
+
LlamaTokenizer)
|
| 15 |
+
from transformers.modeling_outputs import CausalLMOutputWithPast
|
| 16 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 17 |
+
from transformers.utils import ModelOutput, logging
|
| 18 |
+
|
| 19 |
+
from .configuration_internvl_chat import InternVLChatConfig
|
| 20 |
+
from .conversation import get_conv_template
|
| 21 |
+
from .modeling_intern_vit import InternVisionModel
|
| 22 |
+
from .modeling_internlm2 import InternLM2ForCausalLM
|
| 23 |
+
from peft import LoraConfig, get_peft_model
|
| 24 |
+
logger = logging.get_logger(__name__)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def version_cmp(v1, v2, op='eq'):
|
| 28 |
+
import operator
|
| 29 |
+
|
| 30 |
+
from packaging import version
|
| 31 |
+
op_func = getattr(operator, op)
|
| 32 |
+
return op_func(version.parse(v1), version.parse(v2))
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class InternVLChatModel(PreTrainedModel):
|
| 36 |
+
config_class = InternVLChatConfig
|
| 37 |
+
main_input_name = 'pixel_values'
|
| 38 |
+
_supports_flash_attn_2 = True
|
| 39 |
+
_no_split_modules = ['InternVisionModel', 'LlamaDecoderLayer', 'InternLM2DecoderLayer']
|
| 40 |
+
|
| 41 |
+
def __init__(self, config: InternVLChatConfig, vision_model=None, language_model=None):
|
| 42 |
+
super().__init__(config)
|
| 43 |
+
|
| 44 |
+
assert version_cmp(transformers.__version__, '4.36.2', 'ge')
|
| 45 |
+
image_size = config.force_image_size or config.vision_config.image_size
|
| 46 |
+
patch_size = config.vision_config.patch_size
|
| 47 |
+
self.patch_size = patch_size
|
| 48 |
+
self.select_layer = config.select_layer
|
| 49 |
+
self.template = config.template
|
| 50 |
+
self.num_image_token = int((image_size // patch_size) ** 2 * (config.downsample_ratio ** 2))
|
| 51 |
+
self.downsample_ratio = config.downsample_ratio
|
| 52 |
+
self.ps_version = config.ps_version
|
| 53 |
+
|
| 54 |
+
logger.info(f'num_image_token: {self.num_image_token}')
|
| 55 |
+
logger.info(f'ps_version: {self.ps_version}')
|
| 56 |
+
if vision_model is not None:
|
| 57 |
+
self.vision_model = vision_model
|
| 58 |
+
else:
|
| 59 |
+
self.vision_model = InternVisionModel(config.vision_config)
|
| 60 |
+
if language_model is not None:
|
| 61 |
+
self.language_model = language_model
|
| 62 |
+
else:
|
| 63 |
+
if config.llm_config.architectures[0] == 'LlamaForCausalLM':
|
| 64 |
+
self.language_model = LlamaForCausalLM(config.llm_config)
|
| 65 |
+
elif config.llm_config.architectures[0] == 'InternLM2ForCausalLM':
|
| 66 |
+
self.language_model = InternLM2ForCausalLM(config.llm_config)
|
| 67 |
+
else:
|
| 68 |
+
raise NotImplementedError(f'{config.llm_config.architectures[0]} is not implemented.')
|
| 69 |
+
|
| 70 |
+
vit_hidden_size = config.vision_config.hidden_size
|
| 71 |
+
llm_hidden_size = config.llm_config.hidden_size
|
| 72 |
+
|
| 73 |
+
self.mlp1 = nn.Sequential(
|
| 74 |
+
nn.LayerNorm(vit_hidden_size * int(1 / self.downsample_ratio) ** 2),
|
| 75 |
+
nn.Linear(vit_hidden_size * int(1 / self.downsample_ratio) ** 2, llm_hidden_size),
|
| 76 |
+
nn.GELU(),
|
| 77 |
+
nn.Linear(llm_hidden_size, llm_hidden_size)
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
self.img_context_token_id = None
|
| 81 |
+
self.conv_template = get_conv_template(self.template)
|
| 82 |
+
self.system_message = self.conv_template.system_message
|
| 83 |
+
|
| 84 |
+
def wrap_llm_lora(self, r=128, lora_alpha=256, lora_dropout=0.05):
|
| 85 |
+
# Determine the target modules based on the architecture of the language model
|
| 86 |
+
|
| 87 |
+
target_modules = ['attention.wqkv', 'attention.wo', 'feed_forward.w1', 'feed_forward.w2', 'feed_forward.w3']
|
| 88 |
+
|
| 89 |
+
lora_config = LoraConfig(
|
| 90 |
+
r=r,
|
| 91 |
+
target_modules=target_modules,
|
| 92 |
+
lora_alpha=lora_alpha,
|
| 93 |
+
lora_dropout=lora_dropout,
|
| 94 |
+
task_type='CAUSAL_LM'
|
| 95 |
+
)
|
| 96 |
+
self.language_model = get_peft_model(self.language_model, lora_config)
|
| 97 |
+
self.language_model.enable_input_require_grads()
|
| 98 |
+
self.language_model.print_trainable_parameters()
|
| 99 |
+
|
| 100 |
+
def forward(
|
| 101 |
+
self,
|
| 102 |
+
pixel_values: torch.FloatTensor,
|
| 103 |
+
input_ids: torch.LongTensor = None,
|
| 104 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 105 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 106 |
+
image_flags: Optional[torch.LongTensor] = None,
|
| 107 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 108 |
+
labels: Optional[torch.LongTensor] = None,
|
| 109 |
+
use_cache: Optional[bool] = None,
|
| 110 |
+
output_attentions: Optional[bool] = None,
|
| 111 |
+
output_hidden_states: Optional[bool] = None,
|
| 112 |
+
return_dict: Optional[bool] = None,
|
| 113 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 114 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 115 |
+
|
| 116 |
+
image_flags = image_flags.squeeze(-1)
|
| 117 |
+
input_embeds = self.language_model.get_input_embeddings()(input_ids)
|
| 118 |
+
|
| 119 |
+
vit_embeds = self.extract_feature(pixel_values)
|
| 120 |
+
vit_embeds = vit_embeds[image_flags == 1]
|
| 121 |
+
vit_batch_size = pixel_values.shape[0]
|
| 122 |
+
|
| 123 |
+
B, N, C = input_embeds.shape
|
| 124 |
+
input_embeds = input_embeds.reshape(B * N, C)
|
| 125 |
+
|
| 126 |
+
if torch.distributed.get_rank() == 0:
|
| 127 |
+
print(f'dynamic ViT batch size: {vit_batch_size}, images per sample: {vit_batch_size / B}, dynamic token length: {N}')
|
| 128 |
+
|
| 129 |
+
input_ids = input_ids.reshape(B * N)
|
| 130 |
+
selected = (input_ids == self.img_context_token_id)
|
| 131 |
+
try:
|
| 132 |
+
input_embeds[selected] = input_embeds[selected] * 0.0 + vit_embeds.reshape(-1, C)
|
| 133 |
+
except Exception as e:
|
| 134 |
+
vit_embeds = vit_embeds.reshape(-1, C)
|
| 135 |
+
print(f'warning: {e}, input_embeds[selected].shape={input_embeds[selected].shape}, '
|
| 136 |
+
f'vit_embeds.shape={vit_embeds.shape}')
|
| 137 |
+
n_token = selected.sum()
|
| 138 |
+
input_embeds[selected] = input_embeds[selected] * 0.0 + vit_embeds[:n_token]
|
| 139 |
+
|
| 140 |
+
input_embeds = input_embeds.reshape(B, N, C)
|
| 141 |
+
|
| 142 |
+
outputs = self.language_model(
|
| 143 |
+
inputs_embeds=input_embeds,
|
| 144 |
+
attention_mask=attention_mask,
|
| 145 |
+
position_ids=position_ids,
|
| 146 |
+
past_key_values=past_key_values,
|
| 147 |
+
use_cache=use_cache,
|
| 148 |
+
output_attentions=output_attentions,
|
| 149 |
+
output_hidden_states=output_hidden_states,
|
| 150 |
+
return_dict=return_dict,
|
| 151 |
+
)
|
| 152 |
+
logits = outputs.logits
|
| 153 |
+
|
| 154 |
+
loss = None
|
| 155 |
+
if labels is not None:
|
| 156 |
+
# Shift so that tokens < n predict n
|
| 157 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 158 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 159 |
+
# Flatten the tokens
|
| 160 |
+
loss_fct = CrossEntropyLoss()
|
| 161 |
+
shift_logits = shift_logits.view(-1, self.language_model.config.vocab_size)
|
| 162 |
+
shift_labels = shift_labels.view(-1)
|
| 163 |
+
# Enable model parallelism
|
| 164 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 165 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 166 |
+
|
| 167 |
+
if not return_dict:
|
| 168 |
+
output = (logits,) + outputs[1:]
|
| 169 |
+
return (loss,) + output if loss is not None else output
|
| 170 |
+
|
| 171 |
+
return CausalLMOutputWithPast(
|
| 172 |
+
loss=loss,
|
| 173 |
+
logits=logits,
|
| 174 |
+
past_key_values=outputs.past_key_values,
|
| 175 |
+
hidden_states=outputs.hidden_states,
|
| 176 |
+
attentions=outputs.attentions,
|
| 177 |
+
)
|
| 178 |
+
|
| 179 |
+
def pixel_shuffle(self, x, scale_factor=0.5):
|
| 180 |
+
n, w, h, c = x.size()
|
| 181 |
+
# N, W, H, C --> N, W, H * scale, C // scale
|
| 182 |
+
x = x.view(n, w, int(h * scale_factor), int(c / scale_factor))
|
| 183 |
+
# N, W, H * scale, C // scale --> N, H * scale, W, C // scale
|
| 184 |
+
x = x.permute(0, 2, 1, 3).contiguous()
|
| 185 |
+
# N, H * scale, W, C // scale --> N, H * scale, W * scale, C // (scale ** 2)
|
| 186 |
+
x = x.view(n, int(h * scale_factor), int(w * scale_factor),
|
| 187 |
+
int(c / (scale_factor * scale_factor)))
|
| 188 |
+
if self.ps_version == 'v1':
|
| 189 |
+
warnings.warn("In ps_version 'v1', the height and width have not been swapped back, "
|
| 190 |
+
'which results in a transposed image.')
|
| 191 |
+
else:
|
| 192 |
+
x = x.permute(0, 2, 1, 3).contiguous()
|
| 193 |
+
return x
|
| 194 |
+
|
| 195 |
+
def extract_feature(self, pixel_values):
|
| 196 |
+
if self.select_layer == -1:
|
| 197 |
+
vit_embeds = self.vision_model(
|
| 198 |
+
pixel_values=pixel_values,
|
| 199 |
+
output_hidden_states=False,
|
| 200 |
+
return_dict=True).last_hidden_state
|
| 201 |
+
else:
|
| 202 |
+
vit_embeds = self.vision_model(
|
| 203 |
+
pixel_values=pixel_values,
|
| 204 |
+
output_hidden_states=True,
|
| 205 |
+
return_dict=True).hidden_states[self.select_layer]
|
| 206 |
+
vit_embeds = vit_embeds[:, 1:, :]
|
| 207 |
+
|
| 208 |
+
h = w = int(vit_embeds.shape[1] ** 0.5)
|
| 209 |
+
vit_embeds = vit_embeds.reshape(vit_embeds.shape[0], h, w, -1)
|
| 210 |
+
vit_embeds = self.pixel_shuffle(vit_embeds, scale_factor=self.downsample_ratio)
|
| 211 |
+
vit_embeds = vit_embeds.reshape(vit_embeds.shape[0], -1, vit_embeds.shape[-1])
|
| 212 |
+
vit_embeds = self.mlp1(vit_embeds)
|
| 213 |
+
return vit_embeds
|
| 214 |
+
|
| 215 |
+
def batch_chat(self, tokenizer, pixel_values, questions, generation_config, num_patches_list=None,
|
| 216 |
+
history=None, return_history=False, IMG_START_TOKEN='<img>', IMG_END_TOKEN='</img>',
|
| 217 |
+
IMG_CONTEXT_TOKEN='<IMG_CONTEXT>', verbose=False, image_counts=None):
|
| 218 |
+
if history is not None or return_history:
|
| 219 |
+
print('Now multi-turn chat is not supported in batch_chat.')
|
| 220 |
+
raise NotImplementedError
|
| 221 |
+
|
| 222 |
+
if image_counts is not None:
|
| 223 |
+
num_patches_list = image_counts
|
| 224 |
+
print('Warning: `image_counts` is deprecated. Please use `num_patches_list` instead.')
|
| 225 |
+
|
| 226 |
+
img_context_token_id = tokenizer.convert_tokens_to_ids(IMG_CONTEXT_TOKEN)
|
| 227 |
+
self.img_context_token_id = img_context_token_id
|
| 228 |
+
|
| 229 |
+
if verbose and pixel_values is not None:
|
| 230 |
+
image_bs = pixel_values.shape[0]
|
| 231 |
+
print(f'dynamic ViT batch size: {image_bs}')
|
| 232 |
+
|
| 233 |
+
queries = []
|
| 234 |
+
for idx, num_patches in enumerate(num_patches_list):
|
| 235 |
+
question = questions[idx]
|
| 236 |
+
if pixel_values is not None and '<image>' not in question:
|
| 237 |
+
question = '<image>\n' + question
|
| 238 |
+
template = get_conv_template(self.template)
|
| 239 |
+
template.append_message(template.roles[0], question)
|
| 240 |
+
template.append_message(template.roles[1], None)
|
| 241 |
+
query = template.get_prompt()
|
| 242 |
+
|
| 243 |
+
image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * self.num_image_token * num_patches + IMG_END_TOKEN
|
| 244 |
+
query = query.replace('<image>', image_tokens, 1)
|
| 245 |
+
queries.append(query)
|
| 246 |
+
|
| 247 |
+
tokenizer.padding_side = 'left'
|
| 248 |
+
model_inputs = tokenizer(queries, return_tensors='pt', padding=True)
|
| 249 |
+
input_ids = model_inputs['input_ids'].cuda()
|
| 250 |
+
attention_mask = model_inputs['attention_mask'].cuda()
|
| 251 |
+
eos_token_id = tokenizer.convert_tokens_to_ids(template.sep)
|
| 252 |
+
generation_config['eos_token_id'] = eos_token_id
|
| 253 |
+
generation_output = self.generate(
|
| 254 |
+
pixel_values=pixel_values,
|
| 255 |
+
input_ids=input_ids,
|
| 256 |
+
attention_mask=attention_mask,
|
| 257 |
+
**generation_config
|
| 258 |
+
)
|
| 259 |
+
responses = tokenizer.batch_decode(generation_output, skip_special_tokens=True)
|
| 260 |
+
responses = [response.split(template.sep)[0].strip() for response in responses]
|
| 261 |
+
return responses
|
| 262 |
+
|
| 263 |
+
def chat(self, tokenizer, pixel_values, question, generation_config, history=None, return_history=False,
|
| 264 |
+
num_patches_list=None, IMG_START_TOKEN='<img>', IMG_END_TOKEN='</img>', IMG_CONTEXT_TOKEN='<IMG_CONTEXT>',
|
| 265 |
+
verbose=False):
|
| 266 |
+
|
| 267 |
+
if history is None and pixel_values is not None and '<image>' not in question:
|
| 268 |
+
question = '<image>\n' + question
|
| 269 |
+
|
| 270 |
+
if num_patches_list is None:
|
| 271 |
+
num_patches_list = [pixel_values.shape[0]] if pixel_values is not None else []
|
| 272 |
+
assert pixel_values is None or len(pixel_values) == sum(num_patches_list)
|
| 273 |
+
|
| 274 |
+
img_context_token_id = tokenizer.convert_tokens_to_ids(IMG_CONTEXT_TOKEN)
|
| 275 |
+
self.img_context_token_id = img_context_token_id
|
| 276 |
+
|
| 277 |
+
template = get_conv_template(self.template)
|
| 278 |
+
template.system_message = self.system_message
|
| 279 |
+
eos_token_id = tokenizer.convert_tokens_to_ids(template.sep)
|
| 280 |
+
|
| 281 |
+
history = [] if history is None else history
|
| 282 |
+
for (old_question, old_answer) in history:
|
| 283 |
+
template.append_message(template.roles[0], old_question)
|
| 284 |
+
template.append_message(template.roles[1], old_answer)
|
| 285 |
+
template.append_message(template.roles[0], question)
|
| 286 |
+
template.append_message(template.roles[1], None)
|
| 287 |
+
query = template.get_prompt()
|
| 288 |
+
|
| 289 |
+
if verbose and pixel_values is not None:
|
| 290 |
+
image_bs = pixel_values.shape[0]
|
| 291 |
+
print(f'dynamic ViT batch size: {image_bs}')
|
| 292 |
+
|
| 293 |
+
for num_patches in num_patches_list:
|
| 294 |
+
image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * self.num_image_token * num_patches + IMG_END_TOKEN
|
| 295 |
+
query = query.replace('<image>', image_tokens, 1)
|
| 296 |
+
|
| 297 |
+
model_inputs = tokenizer(query, return_tensors='pt')
|
| 298 |
+
input_ids = model_inputs['input_ids'].cuda()
|
| 299 |
+
attention_mask = model_inputs['attention_mask'].cuda()
|
| 300 |
+
generation_config['eos_token_id'] = eos_token_id
|
| 301 |
+
generation_output = self.generate(
|
| 302 |
+
pixel_values=pixel_values,
|
| 303 |
+
input_ids=input_ids,
|
| 304 |
+
attention_mask=attention_mask,
|
| 305 |
+
**generation_config
|
| 306 |
+
)
|
| 307 |
+
response = tokenizer.batch_decode(generation_output, skip_special_tokens=True)[0]
|
| 308 |
+
response = response.split(template.sep)[0].strip()
|
| 309 |
+
history.append((question, response))
|
| 310 |
+
if return_history:
|
| 311 |
+
return response, history
|
| 312 |
+
else:
|
| 313 |
+
query_to_print = query.replace(IMG_CONTEXT_TOKEN, '')
|
| 314 |
+
query_to_print = query_to_print.replace(f'{IMG_START_TOKEN}{IMG_END_TOKEN}', '<image>')
|
| 315 |
+
if verbose:
|
| 316 |
+
print(query_to_print, response)
|
| 317 |
+
return response
|
| 318 |
+
|
| 319 |
+
@torch.no_grad()
|
| 320 |
+
def generate(
|
| 321 |
+
self,
|
| 322 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 323 |
+
input_ids: Optional[torch.FloatTensor] = None,
|
| 324 |
+
attention_mask: Optional[torch.LongTensor] = None,
|
| 325 |
+
visual_features: Optional[torch.FloatTensor] = None,
|
| 326 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 327 |
+
output_hidden_states: Optional[bool] = None,
|
| 328 |
+
return_dict: Optional[bool] = None,
|
| 329 |
+
**generate_kwargs,
|
| 330 |
+
) -> torch.LongTensor:
|
| 331 |
+
|
| 332 |
+
assert self.img_context_token_id is not None
|
| 333 |
+
if pixel_values is not None:
|
| 334 |
+
if visual_features is not None:
|
| 335 |
+
vit_embeds = visual_features
|
| 336 |
+
else:
|
| 337 |
+
vit_embeds = self.extract_feature(pixel_values)
|
| 338 |
+
input_embeds = self.language_model.get_input_embeddings()(input_ids)
|
| 339 |
+
B, N, C = input_embeds.shape
|
| 340 |
+
input_embeds = input_embeds.reshape(B * N, C)
|
| 341 |
+
|
| 342 |
+
input_ids = input_ids.reshape(B * N)
|
| 343 |
+
selected = (input_ids == self.img_context_token_id)
|
| 344 |
+
assert selected.sum() != 0
|
| 345 |
+
input_embeds[selected] = vit_embeds.reshape(-1, C).to(input_embeds.device)
|
| 346 |
+
|
| 347 |
+
input_embeds = input_embeds.reshape(B, N, C)
|
| 348 |
+
else:
|
| 349 |
+
input_embeds = self.language_model.get_input_embeddings()(input_ids)
|
| 350 |
+
|
| 351 |
+
outputs = self.language_model.generate(
|
| 352 |
+
inputs_embeds=input_embeds,
|
| 353 |
+
attention_mask=attention_mask,
|
| 354 |
+
generation_config=generation_config,
|
| 355 |
+
output_hidden_states=output_hidden_states,
|
| 356 |
+
return_dict=return_dict,
|
| 357 |
+
use_cache=True,
|
| 358 |
+
**generate_kwargs,
|
| 359 |
+
)
|
| 360 |
+
|
| 361 |
+
return outputs
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"crop_size": 448,
|
| 3 |
+
"do_center_crop": true,
|
| 4 |
+
"do_normalize": true,
|
| 5 |
+
"do_resize": true,
|
| 6 |
+
"feature_extractor_type": "CLIPFeatureExtractor",
|
| 7 |
+
"image_mean": [
|
| 8 |
+
0.485,
|
| 9 |
+
0.456,
|
| 10 |
+
0.406
|
| 11 |
+
],
|
| 12 |
+
"image_std": [
|
| 13 |
+
0.229,
|
| 14 |
+
0.224,
|
| 15 |
+
0.225
|
| 16 |
+
],
|
| 17 |
+
"resample": 3,
|
| 18 |
+
"size": 448
|
| 19 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>",
|
| 5 |
+
"<|action_start|>",
|
| 6 |
+
"<|action_end|>",
|
| 7 |
+
"<|interpreter|>",
|
| 8 |
+
"<|plugin|>",
|
| 9 |
+
"<img>",
|
| 10 |
+
"</img>",
|
| 11 |
+
"<IMG_CONTEXT>",
|
| 12 |
+
"<quad>",
|
| 13 |
+
"</quad>",
|
| 14 |
+
"<ref>",
|
| 15 |
+
"</ref>",
|
| 16 |
+
"<box>",
|
| 17 |
+
"</box>"
|
| 18 |
+
],
|
| 19 |
+
"bos_token": {
|
| 20 |
+
"content": "<s>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false
|
| 25 |
+
},
|
| 26 |
+
"eos_token": {
|
| 27 |
+
"content": "</s>",
|
| 28 |
+
"lstrip": false,
|
| 29 |
+
"normalized": false,
|
| 30 |
+
"rstrip": false,
|
| 31 |
+
"single_word": false
|
| 32 |
+
},
|
| 33 |
+
"pad_token": {
|
| 34 |
+
"content": "</s>",
|
| 35 |
+
"lstrip": false,
|
| 36 |
+
"normalized": false,
|
| 37 |
+
"rstrip": false,
|
| 38 |
+
"single_word": false
|
| 39 |
+
},
|
| 40 |
+
"unk_token": {
|
| 41 |
+
"content": "<unk>",
|
| 42 |
+
"lstrip": false,
|
| 43 |
+
"normalized": false,
|
| 44 |
+
"rstrip": false,
|
| 45 |
+
"single_word": false
|
| 46 |
+
}
|
| 47 |
+
}
|
tokenization_internlm2.py
ADDED
|
@@ -0,0 +1,235 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) The InternLM team and The HuggingFace Inc. team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# This code is based on transformers/src/transformers/models/llama/tokenization_llama.py
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
|
| 17 |
+
"""Tokenization classes for InternLM."""
|
| 18 |
+
import os
|
| 19 |
+
from shutil import copyfile
|
| 20 |
+
from typing import Any, Dict, List, Optional, Tuple
|
| 21 |
+
|
| 22 |
+
import sentencepiece as spm
|
| 23 |
+
from transformers.tokenization_utils import PreTrainedTokenizer
|
| 24 |
+
from transformers.utils import logging
|
| 25 |
+
|
| 26 |
+
logger = logging.get_logger(__name__)
|
| 27 |
+
|
| 28 |
+
VOCAB_FILES_NAMES = {'vocab_file': './tokenizer.model'}
|
| 29 |
+
|
| 30 |
+
PRETRAINED_VOCAB_FILES_MAP = {}
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
# Modified from transformers.model.llama.tokenization_llama.LlamaTokenizer
|
| 34 |
+
class InternLM2Tokenizer(PreTrainedTokenizer):
|
| 35 |
+
"""
|
| 36 |
+
Construct a InternLM2 tokenizer. Based on byte-level Byte-Pair-Encoding.
|
| 37 |
+
|
| 38 |
+
Args:
|
| 39 |
+
vocab_file (`str`):
|
| 40 |
+
Path to the vocabulary file.
|
| 41 |
+
"""
|
| 42 |
+
|
| 43 |
+
vocab_files_names = VOCAB_FILES_NAMES
|
| 44 |
+
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
|
| 45 |
+
model_input_names = ['input_ids', 'attention_mask']
|
| 46 |
+
_auto_class = 'AutoTokenizer'
|
| 47 |
+
|
| 48 |
+
def __init__(
|
| 49 |
+
self,
|
| 50 |
+
vocab_file,
|
| 51 |
+
unk_token='<unk>',
|
| 52 |
+
bos_token='<s>',
|
| 53 |
+
eos_token='</s>',
|
| 54 |
+
pad_token='</s>',
|
| 55 |
+
sp_model_kwargs: Optional[Dict[str, Any]] = None,
|
| 56 |
+
add_bos_token=True,
|
| 57 |
+
add_eos_token=False,
|
| 58 |
+
decode_with_prefix_space=False,
|
| 59 |
+
clean_up_tokenization_spaces=False,
|
| 60 |
+
**kwargs,
|
| 61 |
+
):
|
| 62 |
+
self.sp_model_kwargs = {} if sp_model_kwargs is None else sp_model_kwargs
|
| 63 |
+
self.vocab_file = vocab_file
|
| 64 |
+
self.add_bos_token = add_bos_token
|
| 65 |
+
self.add_eos_token = add_eos_token
|
| 66 |
+
self.decode_with_prefix_space = decode_with_prefix_space
|
| 67 |
+
self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
|
| 68 |
+
self.sp_model.Load(vocab_file)
|
| 69 |
+
self._no_prefix_space_tokens = None
|
| 70 |
+
super().__init__(
|
| 71 |
+
bos_token=bos_token,
|
| 72 |
+
eos_token=eos_token,
|
| 73 |
+
unk_token=unk_token,
|
| 74 |
+
pad_token=pad_token,
|
| 75 |
+
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
|
| 76 |
+
**kwargs,
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
@property
|
| 80 |
+
def no_prefix_space_tokens(self):
|
| 81 |
+
if self._no_prefix_space_tokens is None:
|
| 82 |
+
vocab = self.convert_ids_to_tokens(list(range(self.vocab_size)))
|
| 83 |
+
self._no_prefix_space_tokens = {i for i, tok in enumerate(vocab) if not tok.startswith('▁')}
|
| 84 |
+
return self._no_prefix_space_tokens
|
| 85 |
+
|
| 86 |
+
@property
|
| 87 |
+
def vocab_size(self):
|
| 88 |
+
"""Returns vocab size"""
|
| 89 |
+
return self.sp_model.get_piece_size()
|
| 90 |
+
|
| 91 |
+
@property
|
| 92 |
+
def bos_token_id(self) -> Optional[int]:
|
| 93 |
+
return self.sp_model.bos_id()
|
| 94 |
+
|
| 95 |
+
@property
|
| 96 |
+
def eos_token_id(self) -> Optional[int]:
|
| 97 |
+
return self.sp_model.eos_id()
|
| 98 |
+
|
| 99 |
+
def get_vocab(self):
|
| 100 |
+
"""Returns vocab as a dict"""
|
| 101 |
+
vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
|
| 102 |
+
vocab.update(self.added_tokens_encoder)
|
| 103 |
+
return vocab
|
| 104 |
+
|
| 105 |
+
def _tokenize(self, text):
|
| 106 |
+
"""Returns a tokenized string."""
|
| 107 |
+
return self.sp_model.encode(text, out_type=str)
|
| 108 |
+
|
| 109 |
+
def _convert_token_to_id(self, token):
|
| 110 |
+
"""Converts a token (str) in an id using the vocab."""
|
| 111 |
+
return self.sp_model.piece_to_id(token)
|
| 112 |
+
|
| 113 |
+
def _convert_id_to_token(self, index):
|
| 114 |
+
"""Converts an index (integer) in a token (str) using the vocab."""
|
| 115 |
+
token = self.sp_model.IdToPiece(index)
|
| 116 |
+
return token
|
| 117 |
+
|
| 118 |
+
def _maybe_add_prefix_space(self, tokens, decoded):
|
| 119 |
+
if tokens and tokens[0] not in self.no_prefix_space_tokens:
|
| 120 |
+
return ' ' + decoded
|
| 121 |
+
else:
|
| 122 |
+
return decoded
|
| 123 |
+
|
| 124 |
+
def convert_tokens_to_string(self, tokens):
|
| 125 |
+
"""Converts a sequence of tokens (string) in a single string."""
|
| 126 |
+
current_sub_tokens = []
|
| 127 |
+
out_string = ''
|
| 128 |
+
prev_is_special = False
|
| 129 |
+
for token in tokens:
|
| 130 |
+
# make sure that special tokens are not decoded using sentencepiece model
|
| 131 |
+
if token in self.all_special_tokens:
|
| 132 |
+
if not prev_is_special:
|
| 133 |
+
out_string += ' '
|
| 134 |
+
out_string += self.sp_model.decode(current_sub_tokens) + token
|
| 135 |
+
prev_is_special = True
|
| 136 |
+
current_sub_tokens = []
|
| 137 |
+
else:
|
| 138 |
+
current_sub_tokens.append(token)
|
| 139 |
+
prev_is_special = False
|
| 140 |
+
out_string += self.sp_model.decode(current_sub_tokens)
|
| 141 |
+
out_string = self.clean_up_tokenization(out_string)
|
| 142 |
+
out_string = self._maybe_add_prefix_space(tokens=tokens, decoded=out_string)
|
| 143 |
+
return out_string[1:]
|
| 144 |
+
|
| 145 |
+
def save_vocabulary(self, save_directory, filename_prefix: Optional[str] = None) -> Tuple[str]:
|
| 146 |
+
"""
|
| 147 |
+
Save the vocabulary and special tokens file to a directory.
|
| 148 |
+
|
| 149 |
+
Args:
|
| 150 |
+
save_directory (`str`):
|
| 151 |
+
The directory in which to save the vocabulary.
|
| 152 |
+
|
| 153 |
+
Returns:
|
| 154 |
+
`Tuple(str)`: Paths to the files saved.
|
| 155 |
+
"""
|
| 156 |
+
if not os.path.isdir(save_directory):
|
| 157 |
+
logger.error(f'Vocabulary path ({save_directory}) should be a directory')
|
| 158 |
+
return
|
| 159 |
+
out_vocab_file = os.path.join(
|
| 160 |
+
save_directory, (filename_prefix + '-' if filename_prefix else '') + VOCAB_FILES_NAMES['vocab_file']
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file) and os.path.isfile(self.vocab_file):
|
| 164 |
+
copyfile(self.vocab_file, out_vocab_file)
|
| 165 |
+
elif not os.path.isfile(self.vocab_file):
|
| 166 |
+
with open(out_vocab_file, 'wb') as fi:
|
| 167 |
+
content_spiece_model = self.sp_model.serialized_model_proto()
|
| 168 |
+
fi.write(content_spiece_model)
|
| 169 |
+
|
| 170 |
+
return (out_vocab_file,)
|
| 171 |
+
|
| 172 |
+
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
|
| 173 |
+
if self.add_bos_token:
|
| 174 |
+
bos_token_ids = [self.bos_token_id]
|
| 175 |
+
else:
|
| 176 |
+
bos_token_ids = []
|
| 177 |
+
|
| 178 |
+
output = bos_token_ids + token_ids_0
|
| 179 |
+
|
| 180 |
+
if token_ids_1 is not None:
|
| 181 |
+
output = output + token_ids_1
|
| 182 |
+
|
| 183 |
+
if self.add_eos_token:
|
| 184 |
+
output = output + [self.eos_token_id]
|
| 185 |
+
|
| 186 |
+
return output
|
| 187 |
+
|
| 188 |
+
def get_special_tokens_mask(
|
| 189 |
+
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
|
| 190 |
+
) -> List[int]:
|
| 191 |
+
"""
|
| 192 |
+
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
|
| 193 |
+
special tokens using the tokenizer `prepare_for_model` method.
|
| 194 |
+
|
| 195 |
+
Args:
|
| 196 |
+
token_ids_0 (`List[int]`):
|
| 197 |
+
List of IDs.
|
| 198 |
+
token_ids_1 (`List[int]`, *optional*):
|
| 199 |
+
Optional second list of IDs for sequence pairs.
|
| 200 |
+
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
|
| 201 |
+
Whether or not the token list is already formatted with special tokens for the model.
|
| 202 |
+
|
| 203 |
+
Returns:
|
| 204 |
+
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
|
| 205 |
+
"""
|
| 206 |
+
if already_has_special_tokens:
|
| 207 |
+
return super().get_special_tokens_mask(
|
| 208 |
+
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
|
| 209 |
+
)
|
| 210 |
+
|
| 211 |
+
if token_ids_1 is None:
|
| 212 |
+
return [1] + ([0] * len(token_ids_0)) + [1]
|
| 213 |
+
return [1] + ([0] * len(token_ids_0)) + [1, 1] + ([0] * len(token_ids_1)) + [1]
|
| 214 |
+
|
| 215 |
+
def create_token_type_ids_from_sequences(
|
| 216 |
+
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
|
| 217 |
+
) -> List[int]:
|
| 218 |
+
"""
|
| 219 |
+
Create a mask from the two sequences passed to be used in a sequence-pair classification task. T5 does not make
|
| 220 |
+
use of token type ids, therefore a list of zeros is returned.
|
| 221 |
+
|
| 222 |
+
Args:
|
| 223 |
+
token_ids_0 (`List[int]`):
|
| 224 |
+
List of IDs.
|
| 225 |
+
token_ids_1 (`List[int]`, *optional*):
|
| 226 |
+
Optional second list of IDs for sequence pairs.
|
| 227 |
+
|
| 228 |
+
Returns:
|
| 229 |
+
`List[int]`: List of zeros.
|
| 230 |
+
"""
|
| 231 |
+
eos = [self.eos_token_id]
|
| 232 |
+
|
| 233 |
+
if token_ids_1 is None:
|
| 234 |
+
return len(token_ids_0 + eos) * [0]
|
| 235 |
+
return len(token_ids_0 + eos + token_ids_1 + eos) * [0]
|
tokenization_internlm2_fast.py
ADDED
|
@@ -0,0 +1,211 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) The InternLM team and The HuggingFace Inc. team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# This code is based on transformers/src/transformers/models/llama/tokenization_llama_fast.py
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
|
| 17 |
+
"""Tokenization Fast class for InternLM."""
|
| 18 |
+
import os
|
| 19 |
+
from shutil import copyfile
|
| 20 |
+
from typing import Any, Dict, Optional, Tuple
|
| 21 |
+
|
| 22 |
+
from tokenizers import Tokenizer, decoders, normalizers, processors
|
| 23 |
+
from tokenizers.models import BPE
|
| 24 |
+
from transformers.convert_slow_tokenizer import (SLOW_TO_FAST_CONVERTERS,
|
| 25 |
+
SentencePieceExtractor,
|
| 26 |
+
SpmConverter)
|
| 27 |
+
from transformers.tokenization_utils_fast import PreTrainedTokenizerFast
|
| 28 |
+
from transformers.utils import logging
|
| 29 |
+
|
| 30 |
+
from .tokenization_internlm2 import InternLM2Tokenizer
|
| 31 |
+
|
| 32 |
+
logger = logging.get_logger(__name__)
|
| 33 |
+
|
| 34 |
+
VOCAB_FILES_NAMES = {'vocab_file': './tokenizer.model'}
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
# Modified from transformers.convert_slow_tokenizer.LlamaConverter
|
| 38 |
+
class InternLM2Converter(SpmConverter):
|
| 39 |
+
handle_byte_fallback = True
|
| 40 |
+
|
| 41 |
+
def vocab(self, proto):
|
| 42 |
+
vocab = [
|
| 43 |
+
('<unk>', 0.0),
|
| 44 |
+
('<s>', 0.0),
|
| 45 |
+
('</s>', 0.0),
|
| 46 |
+
]
|
| 47 |
+
vocab += [(piece.piece, piece.score) for piece in proto.pieces[3:]]
|
| 48 |
+
return vocab
|
| 49 |
+
|
| 50 |
+
def unk_id(self, proto):
|
| 51 |
+
unk_id = 0
|
| 52 |
+
return unk_id
|
| 53 |
+
|
| 54 |
+
def decoder(self, replacement, add_prefix_space):
|
| 55 |
+
return decoders.Sequence(
|
| 56 |
+
[
|
| 57 |
+
decoders.Replace('▁', ' '),
|
| 58 |
+
decoders.ByteFallback(),
|
| 59 |
+
decoders.Fuse(),
|
| 60 |
+
decoders.Strip(content=' ', left=1),
|
| 61 |
+
]
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
def tokenizer(self, proto):
|
| 65 |
+
model_type = proto.trainer_spec.model_type
|
| 66 |
+
vocab_scores = self.vocab(proto)
|
| 67 |
+
# special tokens
|
| 68 |
+
added_tokens = self.original_tokenizer.added_tokens_decoder
|
| 69 |
+
for i in range(len(vocab_scores)):
|
| 70 |
+
piece, score = vocab_scores[i]
|
| 71 |
+
if i in added_tokens:
|
| 72 |
+
vocab_scores[i] = (added_tokens[i].content, score)
|
| 73 |
+
if model_type == 1:
|
| 74 |
+
raise RuntimeError('InternLM2 is supposed to be a BPE model!')
|
| 75 |
+
|
| 76 |
+
elif model_type == 2:
|
| 77 |
+
_, merges = SentencePieceExtractor(self.original_tokenizer.vocab_file).extract(vocab_scores)
|
| 78 |
+
bpe_vocab = {word: i for i, (word, _score) in enumerate(vocab_scores)}
|
| 79 |
+
tokenizer = Tokenizer(
|
| 80 |
+
BPE(bpe_vocab, merges, unk_token=proto.trainer_spec.unk_piece, fuse_unk=True, byte_fallback=True)
|
| 81 |
+
)
|
| 82 |
+
tokenizer.add_special_tokens(
|
| 83 |
+
[ added_token for index, added_token in added_tokens.items()]
|
| 84 |
+
)
|
| 85 |
+
else:
|
| 86 |
+
raise Exception(
|
| 87 |
+
"You're trying to run a `Unigram` model but you're file was trained with a different algorithm"
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
return tokenizer
|
| 91 |
+
|
| 92 |
+
def normalizer(self, proto):
|
| 93 |
+
normalizers_list = []
|
| 94 |
+
if proto.normalizer_spec.add_dummy_prefix:
|
| 95 |
+
normalizers_list.append(normalizers.Prepend(prepend='▁'))
|
| 96 |
+
normalizers_list.append(normalizers.Replace(pattern=' ', content='▁'))
|
| 97 |
+
return normalizers.Sequence(normalizers_list)
|
| 98 |
+
|
| 99 |
+
def pre_tokenizer(self, replacement, add_prefix_space):
|
| 100 |
+
return None
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
SLOW_TO_FAST_CONVERTERS['InternLM2Tokenizer'] = InternLM2Converter
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
# Modified from transformers.model.llama.tokenization_llama_fast.LlamaTokenizerFast -> InternLM2TokenizerFast
|
| 107 |
+
class InternLM2TokenizerFast(PreTrainedTokenizerFast):
|
| 108 |
+
vocab_files_names = VOCAB_FILES_NAMES
|
| 109 |
+
slow_tokenizer_class = InternLM2Tokenizer
|
| 110 |
+
padding_side = 'left'
|
| 111 |
+
model_input_names = ['input_ids', 'attention_mask']
|
| 112 |
+
_auto_class = 'AutoTokenizer'
|
| 113 |
+
|
| 114 |
+
def __init__(
|
| 115 |
+
self,
|
| 116 |
+
vocab_file,
|
| 117 |
+
unk_token='<unk>',
|
| 118 |
+
bos_token='<s>',
|
| 119 |
+
eos_token='</s>',
|
| 120 |
+
pad_token='</s>',
|
| 121 |
+
sp_model_kwargs: Optional[Dict[str, Any]] = None,
|
| 122 |
+
add_bos_token=True,
|
| 123 |
+
add_eos_token=False,
|
| 124 |
+
decode_with_prefix_space=False,
|
| 125 |
+
clean_up_tokenization_spaces=False,
|
| 126 |
+
**kwargs,
|
| 127 |
+
):
|
| 128 |
+
super().__init__(
|
| 129 |
+
vocab_file=vocab_file,
|
| 130 |
+
unk_token=unk_token,
|
| 131 |
+
bos_token=bos_token,
|
| 132 |
+
eos_token=eos_token,
|
| 133 |
+
pad_token=pad_token,
|
| 134 |
+
sp_model_kwargs=sp_model_kwargs,
|
| 135 |
+
add_bos_token=add_bos_token,
|
| 136 |
+
add_eos_token=add_eos_token,
|
| 137 |
+
decode_with_prefix_space=decode_with_prefix_space,
|
| 138 |
+
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
|
| 139 |
+
**kwargs,
|
| 140 |
+
)
|
| 141 |
+
self._add_bos_token = add_bos_token
|
| 142 |
+
self._add_eos_token = add_eos_token
|
| 143 |
+
self.update_post_processor()
|
| 144 |
+
self.vocab_file = vocab_file
|
| 145 |
+
|
| 146 |
+
@property
|
| 147 |
+
def can_save_slow_tokenizer(self) -> bool:
|
| 148 |
+
return os.path.isfile(self.vocab_file) if self.vocab_file else False
|
| 149 |
+
|
| 150 |
+
def update_post_processor(self):
|
| 151 |
+
"""
|
| 152 |
+
Updates the underlying post processor with the current `bos_token` and `eos_token`.
|
| 153 |
+
"""
|
| 154 |
+
bos = self.bos_token
|
| 155 |
+
bos_token_id = self.bos_token_id
|
| 156 |
+
if bos is None and self.add_bos_token:
|
| 157 |
+
raise ValueError('add_bos_token = True but bos_token = None')
|
| 158 |
+
|
| 159 |
+
eos = self.eos_token
|
| 160 |
+
eos_token_id = self.eos_token_id
|
| 161 |
+
if eos is None and self.add_eos_token:
|
| 162 |
+
raise ValueError('add_eos_token = True but eos_token = None')
|
| 163 |
+
|
| 164 |
+
single = f"{(bos+':0 ') if self.add_bos_token else ''}$A:0{(' '+eos+':0') if self.add_eos_token else ''}"
|
| 165 |
+
pair = f"{single}{(' '+bos+':1') if self.add_bos_token else ''} $B:1{(' '+eos+':1') if self.add_eos_token else ''}"
|
| 166 |
+
|
| 167 |
+
special_tokens = []
|
| 168 |
+
if self.add_bos_token:
|
| 169 |
+
special_tokens.append((bos, bos_token_id))
|
| 170 |
+
if self.add_eos_token:
|
| 171 |
+
special_tokens.append((eos, eos_token_id))
|
| 172 |
+
self._tokenizer.post_processor = processors.TemplateProcessing(
|
| 173 |
+
single=single, pair=pair, special_tokens=special_tokens
|
| 174 |
+
)
|
| 175 |
+
|
| 176 |
+
@property
|
| 177 |
+
def add_eos_token(self):
|
| 178 |
+
return self._add_eos_token
|
| 179 |
+
|
| 180 |
+
@property
|
| 181 |
+
def add_bos_token(self):
|
| 182 |
+
return self._add_bos_token
|
| 183 |
+
|
| 184 |
+
@add_eos_token.setter
|
| 185 |
+
def add_eos_token(self, value):
|
| 186 |
+
self._add_eos_token = value
|
| 187 |
+
self.update_post_processor()
|
| 188 |
+
|
| 189 |
+
@add_bos_token.setter
|
| 190 |
+
def add_bos_token(self, value):
|
| 191 |
+
self._add_bos_token = value
|
| 192 |
+
self.update_post_processor()
|
| 193 |
+
|
| 194 |
+
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
|
| 195 |
+
if not self.can_save_slow_tokenizer:
|
| 196 |
+
raise ValueError(
|
| 197 |
+
'Your fast tokenizer does not have the necessary information to save the vocabulary for a slow '
|
| 198 |
+
'tokenizer.'
|
| 199 |
+
)
|
| 200 |
+
|
| 201 |
+
if not os.path.isdir(save_directory):
|
| 202 |
+
logger.error(f'Vocabulary path ({save_directory}) should be a directory')
|
| 203 |
+
return
|
| 204 |
+
out_vocab_file = os.path.join(
|
| 205 |
+
save_directory, (filename_prefix + '-' if filename_prefix else '') + VOCAB_FILES_NAMES['vocab_file']
|
| 206 |
+
)
|
| 207 |
+
|
| 208 |
+
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file):
|
| 209 |
+
copyfile(self.vocab_file, out_vocab_file)
|
| 210 |
+
|
| 211 |
+
return (out_vocab_file,)
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f868398fc4e05ee1e8aeba95ddf18ddcc45b8bce55d5093bead5bbf80429b48b
|
| 3 |
+
size 1477754
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "<unk>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "<s>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "</s>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"92538": {
|
| 28 |
+
"content": "<|plugin|>",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"92539": {
|
| 36 |
+
"content": "<|interpreter|>",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
},
|
| 43 |
+
"92540": {
|
| 44 |
+
"content": "<|action_end|>",
|
| 45 |
+
"lstrip": false,
|
| 46 |
+
"normalized": false,
|
| 47 |
+
"rstrip": false,
|
| 48 |
+
"single_word": false,
|
| 49 |
+
"special": true
|
| 50 |
+
},
|
| 51 |
+
"92541": {
|
| 52 |
+
"content": "<|action_start|>",
|
| 53 |
+
"lstrip": false,
|
| 54 |
+
"normalized": false,
|
| 55 |
+
"rstrip": false,
|
| 56 |
+
"single_word": false,
|
| 57 |
+
"special": true
|
| 58 |
+
},
|
| 59 |
+
"92542": {
|
| 60 |
+
"content": "<|im_end|>",
|
| 61 |
+
"lstrip": false,
|
| 62 |
+
"normalized": false,
|
| 63 |
+
"rstrip": false,
|
| 64 |
+
"single_word": false,
|
| 65 |
+
"special": true
|
| 66 |
+
},
|
| 67 |
+
"92543": {
|
| 68 |
+
"content": "<|im_start|>",
|
| 69 |
+
"lstrip": false,
|
| 70 |
+
"normalized": false,
|
| 71 |
+
"rstrip": false,
|
| 72 |
+
"single_word": false,
|
| 73 |
+
"special": true
|
| 74 |
+
},
|
| 75 |
+
"92544": {
|
| 76 |
+
"content": "<img>",
|
| 77 |
+
"lstrip": false,
|
| 78 |
+
"normalized": false,
|
| 79 |
+
"rstrip": false,
|
| 80 |
+
"single_word": false,
|
| 81 |
+
"special": true
|
| 82 |
+
},
|
| 83 |
+
"92545": {
|
| 84 |
+
"content": "</img>",
|
| 85 |
+
"lstrip": false,
|
| 86 |
+
"normalized": false,
|
| 87 |
+
"rstrip": false,
|
| 88 |
+
"single_word": false,
|
| 89 |
+
"special": true
|
| 90 |
+
},
|
| 91 |
+
"92546": {
|
| 92 |
+
"content": "<IMG_CONTEXT>",
|
| 93 |
+
"lstrip": false,
|
| 94 |
+
"normalized": false,
|
| 95 |
+
"rstrip": false,
|
| 96 |
+
"single_word": false,
|
| 97 |
+
"special": true
|
| 98 |
+
},
|
| 99 |
+
"92547": {
|
| 100 |
+
"content": "<quad>",
|
| 101 |
+
"lstrip": false,
|
| 102 |
+
"normalized": false,
|
| 103 |
+
"rstrip": false,
|
| 104 |
+
"single_word": false,
|
| 105 |
+
"special": true
|
| 106 |
+
},
|
| 107 |
+
"92548": {
|
| 108 |
+
"content": "</quad>",
|
| 109 |
+
"lstrip": false,
|
| 110 |
+
"normalized": false,
|
| 111 |
+
"rstrip": false,
|
| 112 |
+
"single_word": false,
|
| 113 |
+
"special": true
|
| 114 |
+
},
|
| 115 |
+
"92549": {
|
| 116 |
+
"content": "<ref>",
|
| 117 |
+
"lstrip": false,
|
| 118 |
+
"normalized": false,
|
| 119 |
+
"rstrip": false,
|
| 120 |
+
"single_word": false,
|
| 121 |
+
"special": true
|
| 122 |
+
},
|
| 123 |
+
"92550": {
|
| 124 |
+
"content": "</ref>",
|
| 125 |
+
"lstrip": false,
|
| 126 |
+
"normalized": false,
|
| 127 |
+
"rstrip": false,
|
| 128 |
+
"single_word": false,
|
| 129 |
+
"special": true
|
| 130 |
+
},
|
| 131 |
+
"92551": {
|
| 132 |
+
"content": "<box>",
|
| 133 |
+
"lstrip": false,
|
| 134 |
+
"normalized": false,
|
| 135 |
+
"rstrip": false,
|
| 136 |
+
"single_word": false,
|
| 137 |
+
"special": true
|
| 138 |
+
},
|
| 139 |
+
"92552": {
|
| 140 |
+
"content": "</box>",
|
| 141 |
+
"lstrip": false,
|
| 142 |
+
"normalized": false,
|
| 143 |
+
"rstrip": false,
|
| 144 |
+
"single_word": false,
|
| 145 |
+
"special": true
|
| 146 |
+
}
|
| 147 |
+
},
|
| 148 |
+
"additional_special_tokens": [
|
| 149 |
+
"<|im_start|>",
|
| 150 |
+
"<|im_end|>",
|
| 151 |
+
"<|action_start|>",
|
| 152 |
+
"<|action_end|>",
|
| 153 |
+
"<|interpreter|>",
|
| 154 |
+
"<|plugin|>",
|
| 155 |
+
"<img>",
|
| 156 |
+
"</img>",
|
| 157 |
+
"<IMG_CONTEXT>",
|
| 158 |
+
"<quad>",
|
| 159 |
+
"</quad>",
|
| 160 |
+
"<ref>",
|
| 161 |
+
"</ref>",
|
| 162 |
+
"<box>",
|
| 163 |
+
"</box>"
|
| 164 |
+
],
|
| 165 |
+
"auto_map": {
|
| 166 |
+
"AutoTokenizer": [
|
| 167 |
+
"tokenization_internlm2.InternLM2Tokenizer",
|
| 168 |
+
null
|
| 169 |
+
]
|
| 170 |
+
},
|
| 171 |
+
"bos_token": "<s>",
|
| 172 |
+
"chat_template": "{{ bos_token }}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
| 173 |
+
"clean_up_tokenization_spaces": false,
|
| 174 |
+
"eos_token": "</s>",
|
| 175 |
+
"model_max_length": 8192,
|
| 176 |
+
"pad_token": "</s>",
|
| 177 |
+
"tokenizer_class": "InternLM2Tokenizer",
|
| 178 |
+
"unk_token": "<unk>"
|
| 179 |
+
}
|