

truncation = true
Browse files- .gitignore +1 -0
- README.md +180 -1
- config.json +45 -0
- create_handler.ipynb +223 -0
- handler.py +64 -0
- invoice_example.png +0 -0
- output_form_lower.jpg +0 -0
- preprocessor_config.json +9 -0
- pytorch_model.bin +3 -0
- special_tokens_map.json +7 -0
- tokenizer.json +0 -0
- tokenizer_config.json +39 -0
- training_args.bin +3 -0
- vocab.txt +0 -0
.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
checkpoint-*/
|
README.md
CHANGED
|
@@ -1,3 +1,182 @@
|
|
| 1 |
---
|
| 2 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
tags:
|
| 3 |
+
- generated_from_trainer
|
| 4 |
+
- endpoints-template
|
| 5 |
+
library_name: generic
|
| 6 |
+
datasets:
|
| 7 |
+
- funsd
|
| 8 |
+
model-index:
|
| 9 |
+
- name: layoutlm-funsd
|
| 10 |
+
results: []
|
| 11 |
+
pipeline_tag: other
|
| 12 |
---
|
| 13 |
+
|
| 14 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 15 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 16 |
+
|
| 17 |
+
# layoutlm-funsd
|
| 18 |
+
|
| 19 |
+
This model is a fine-tuned version of [microsoft/layoutlm-base-uncased](https://huggingface.co/microsoft/layoutlm-base-uncased) on the funsd dataset.
|
| 20 |
+
It achieves the following results on the evaluation set:
|
| 21 |
+
- Loss: 1.0045
|
| 22 |
+
- Answer: {'precision': 0.7348314606741573, 'recall': 0.8084054388133498, 'f1': 0.7698646262507357, 'number': 809}
|
| 23 |
+
- Header: {'precision': 0.44285714285714284, 'recall': 0.5210084033613446, 'f1': 0.47876447876447875, 'number': 119}
|
| 24 |
+
- Question: {'precision': 0.8211009174311926, 'recall': 0.8403755868544601, 'f1': 0.8306264501160092, 'number': 1065}
|
| 25 |
+
- Overall Precision: 0.7599
|
| 26 |
+
- Overall Recall: 0.8083
|
| 27 |
+
- Overall F1: 0.7866
|
| 28 |
+
- Overall Accuracy: 0.8106
|
| 29 |
+
|
| 30 |
+
### Training hyperparameters
|
| 31 |
+
|
| 32 |
+
The following hyperparameters were used during training:
|
| 33 |
+
- learning_rate: 3e-05
|
| 34 |
+
- train_batch_size: 16
|
| 35 |
+
- eval_batch_size: 8
|
| 36 |
+
- seed: 42
|
| 37 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 38 |
+
- lr_scheduler_type: linear
|
| 39 |
+
- num_epochs: 15
|
| 40 |
+
- mixed_precision_training: Native AMP
|
| 41 |
+
|
| 42 |
+
## Deploy Model with Inference Endpoints
|
| 43 |
+
|
| 44 |
+
Before we can get started, make sure you meet all of the following requirements:
|
| 45 |
+
|
| 46 |
+
1. An Organization/User with an active plan and *WRITE* access to the model repository.
|
| 47 |
+
2. Can access the UI: [https://ui.endpoints.huggingface.co](https://ui.endpoints.huggingface.co/endpoints)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
### 1. Deploy LayoutLM and Send requests
|
| 52 |
+
|
| 53 |
+
In this tutorial, you will learn how to deploy a [LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm) to [Hugging Face Inference Endpoints](https://huggingface.co/inference-endpoints) and how you can integrate it via an API into your products.
|
| 54 |
+
|
| 55 |
+
This tutorial is not covering how you create the custom handler for inference. If you want to learn how to create a custom Handler for Inference Endpoints, you can either checkout the [documentation](https://huggingface.co/docs/inference-endpoints/guides/custom_handler) or go through [“Custom Inference with Hugging Face Inference Endpoints”](https://www.philschmid.de/custom-inference-handler)
|
| 56 |
+
|
| 57 |
+
We are going to deploy [philschmid/layoutlm-funsd](https://huggingface.co/philschmid/layoutlm-funsd) which implements the following `handler.py`
|
| 58 |
+
|
| 59 |
+
```python
|
| 60 |
+
from typing import Dict, List, Any
|
| 61 |
+
from transformers import LayoutLMForTokenClassification, LayoutLMv2Processor
|
| 62 |
+
import torch
|
| 63 |
+
from subprocess import run
|
| 64 |
+
|
| 65 |
+
# install tesseract-ocr and pytesseract
|
| 66 |
+
run("apt install -y tesseract-ocr", shell=True, check=True)
|
| 67 |
+
run("pip install pytesseract", shell=True, check=True)
|
| 68 |
+
|
| 69 |
+
# helper function to unnormalize bboxes for drawing onto the image
|
| 70 |
+
def unnormalize_box(bbox, width, height):
|
| 71 |
+
return [
|
| 72 |
+
width * (bbox[0] / 1000),
|
| 73 |
+
height * (bbox[1] / 1000),
|
| 74 |
+
width * (bbox[2] / 1000),
|
| 75 |
+
height * (bbox[3] / 1000),
|
| 76 |
+
]
|
| 77 |
+
|
| 78 |
+
# set device
|
| 79 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 80 |
+
|
| 81 |
+
class EndpointHandler:
|
| 82 |
+
def __init__(self, path=""):
|
| 83 |
+
# load model and processor from path
|
| 84 |
+
self.model = LayoutLMForTokenClassification.from_pretrained(path).to(device)
|
| 85 |
+
self.processor = LayoutLMv2Processor.from_pretrained(path)
|
| 86 |
+
|
| 87 |
+
def __call__(self, data: Dict[str, bytes]) -> Dict[str, List[Any]]:
|
| 88 |
+
"""
|
| 89 |
+
Args:
|
| 90 |
+
data (:obj:):
|
| 91 |
+
includes the deserialized image file as PIL.Image
|
| 92 |
+
"""
|
| 93 |
+
# process input
|
| 94 |
+
image = data.pop("inputs", data)
|
| 95 |
+
|
| 96 |
+
# process image
|
| 97 |
+
encoding = self.processor(image, return_tensors="pt")
|
| 98 |
+
|
| 99 |
+
# run prediction
|
| 100 |
+
with torch.inference_mode():
|
| 101 |
+
outputs = self.model(
|
| 102 |
+
input_ids=encoding.input_ids.to(device),
|
| 103 |
+
bbox=encoding.bbox.to(device),
|
| 104 |
+
attention_mask=encoding.attention_mask.to(device),
|
| 105 |
+
token_type_ids=encoding.token_type_ids.to(device),
|
| 106 |
+
)
|
| 107 |
+
predictions = outputs.logits.softmax(-1)
|
| 108 |
+
|
| 109 |
+
# post process output
|
| 110 |
+
result = []
|
| 111 |
+
for item, inp_ids, bbox in zip(
|
| 112 |
+
predictions.squeeze(0).cpu(), encoding.input_ids.squeeze(0).cpu(), encoding.bbox.squeeze(0).cpu()
|
| 113 |
+
):
|
| 114 |
+
label = self.model.config.id2label[int(item.argmax().cpu())]
|
| 115 |
+
if label == "O":
|
| 116 |
+
continue
|
| 117 |
+
score = item.max().item()
|
| 118 |
+
text = self.processor.tokenizer.decode(inp_ids)
|
| 119 |
+
bbox = unnormalize_box(bbox.tolist(), image.width, image.height)
|
| 120 |
+
result.append({"label": label, "score": score, "text": text, "bbox": bbox})
|
| 121 |
+
return {"predictions": result}
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
### 2. Send HTTP request using Python
|
| 125 |
+
|
| 126 |
+
Hugging Face Inference endpoints can directly work with binary data, this means that we can directly send our image from our document to the endpoint. We are going to use `requests` to send our requests. (make your you have it installed `pip install requests`)
|
| 127 |
+
|
| 128 |
+
```python
|
| 129 |
+
import json
|
| 130 |
+
import requests as r
|
| 131 |
+
import mimetypes
|
| 132 |
+
|
| 133 |
+
ENDPOINT_URL="" # url of your endpoint
|
| 134 |
+
HF_TOKEN="" # organization token where you deployed your endpoint
|
| 135 |
+
|
| 136 |
+
def predict(path_to_image:str=None):
|
| 137 |
+
with open(path_to_image, "rb") as i:
|
| 138 |
+
b = i.read()
|
| 139 |
+
headers= {
|
| 140 |
+
"Authorization": f"Bearer {HF_TOKEN}",
|
| 141 |
+
"Content-Type": mimetypes.guess_type(path_to_image)[0]
|
| 142 |
+
}
|
| 143 |
+
response = r.post(ENDPOINT_URL, headers=headers, data=b)
|
| 144 |
+
return response.json()
|
| 145 |
+
|
| 146 |
+
prediction = predict(path_to_image="path_to_your_image.png")
|
| 147 |
+
|
| 148 |
+
print(prediction)
|
| 149 |
+
# {'predictions': [{'label': 'I-ANSWER', 'score': 0.4823932945728302, 'text': '[CLS]', 'bbox': [0.0, 0.0, 0.0, 0.0]}, {'label': 'B-HEADER', 'score': 0.992474377155304, 'text': 'your', 'bbox': [1712.529, 181.203, 1859.949, 228.88799999999998]},
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
### 3. Draw result on image
|
| 154 |
+
|
| 155 |
+
To get a better understanding of what the model predicted you can also draw the predictions on the provided image.
|
| 156 |
+
|
| 157 |
+
```python
|
| 158 |
+
from PIL import Image, ImageDraw, ImageFont
|
| 159 |
+
|
| 160 |
+
# draw results on image
|
| 161 |
+
def draw_result(path_to_image,result):
|
| 162 |
+
image = Image.open(path_to_image)
|
| 163 |
+
label2color = {
|
| 164 |
+
"B-HEADER": "blue",
|
| 165 |
+
"B-QUESTION": "red",
|
| 166 |
+
"B-ANSWER": "green",
|
| 167 |
+
"I-HEADER": "blue",
|
| 168 |
+
"I-QUESTION": "red",
|
| 169 |
+
"I-ANSWER": "green",
|
| 170 |
+
}
|
| 171 |
+
|
| 172 |
+
# draw predictions over the image
|
| 173 |
+
draw = ImageDraw.Draw(image)
|
| 174 |
+
font = ImageFont.load_default()
|
| 175 |
+
for res in result:
|
| 176 |
+
draw.rectangle(res["bbox"], outline="black")
|
| 177 |
+
draw.rectangle(res["bbox"], outline=label2color[res["label"]])
|
| 178 |
+
draw.text((res["bbox"][0] + 10, res["bbox"][1] - 10), text=res["label"], fill=label2color[res["label"]], font=font)
|
| 179 |
+
return image
|
| 180 |
+
|
| 181 |
+
draw_result("path_to_your_image.png", prediction["predictions"])
|
| 182 |
+
```
|
config.json
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "microsoft/layoutlm-base-uncased",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"LayoutLMForTokenClassification"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"classifier_dropout": null,
|
| 8 |
+
"hidden_act": "gelu",
|
| 9 |
+
"hidden_dropout_prob": 0.1,
|
| 10 |
+
"hidden_size": 768,
|
| 11 |
+
"id2label": {
|
| 12 |
+
"0": "O",
|
| 13 |
+
"1": "B-HEADER",
|
| 14 |
+
"2": "I-HEADER",
|
| 15 |
+
"3": "B-QUESTION",
|
| 16 |
+
"4": "I-QUESTION",
|
| 17 |
+
"5": "B-ANSWER",
|
| 18 |
+
"6": "I-ANSWER"
|
| 19 |
+
},
|
| 20 |
+
"initializer_range": 0.02,
|
| 21 |
+
"intermediate_size": 3072,
|
| 22 |
+
"label2id": {
|
| 23 |
+
"B-ANSWER": 5,
|
| 24 |
+
"B-HEADER": 1,
|
| 25 |
+
"B-QUESTION": 3,
|
| 26 |
+
"I-ANSWER": 6,
|
| 27 |
+
"I-HEADER": 2,
|
| 28 |
+
"I-QUESTION": 4,
|
| 29 |
+
"O": 0
|
| 30 |
+
},
|
| 31 |
+
"layer_norm_eps": 1e-12,
|
| 32 |
+
"max_2d_position_embeddings": 1024,
|
| 33 |
+
"max_position_embeddings": 512,
|
| 34 |
+
"model_type": "layoutlm",
|
| 35 |
+
"num_attention_heads": 12,
|
| 36 |
+
"num_hidden_layers": 12,
|
| 37 |
+
"output_past": true,
|
| 38 |
+
"pad_token_id": 0,
|
| 39 |
+
"position_embedding_type": "absolute",
|
| 40 |
+
"torch_dtype": "float32",
|
| 41 |
+
"transformers_version": "4.21.2",
|
| 42 |
+
"type_vocab_size": 2,
|
| 43 |
+
"use_cache": true,
|
| 44 |
+
"vocab_size": 30522
|
| 45 |
+
}
|
create_handler.ipynb
ADDED
|
@@ -0,0 +1,223 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"## 1. Setup & Installation"
|
| 8 |
+
]
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
"cell_type": "code",
|
| 12 |
+
"execution_count": null,
|
| 13 |
+
"metadata": {},
|
| 14 |
+
"outputs": [],
|
| 15 |
+
"source": [
|
| 16 |
+
"!apt install -y tesseract-ocr\n",
|
| 17 |
+
"pip install pytesseract"
|
| 18 |
+
]
|
| 19 |
+
},
|
| 20 |
+
{
|
| 21 |
+
"cell_type": "markdown",
|
| 22 |
+
"metadata": {},
|
| 23 |
+
"source": [
|
| 24 |
+
"## 2. Create Custom Handler for Inference Endpoints\n"
|
| 25 |
+
]
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"cell_type": "code",
|
| 29 |
+
"execution_count": 20,
|
| 30 |
+
"metadata": {},
|
| 31 |
+
"outputs": [
|
| 32 |
+
{
|
| 33 |
+
"name": "stdout",
|
| 34 |
+
"output_type": "stream",
|
| 35 |
+
"text": [
|
| 36 |
+
"Overwriting handler.py\n"
|
| 37 |
+
]
|
| 38 |
+
}
|
| 39 |
+
],
|
| 40 |
+
"source": [
|
| 41 |
+
"%%writefile handler.py\n",
|
| 42 |
+
"from typing import Dict, List, Any\n",
|
| 43 |
+
"from transformers import LayoutLMForTokenClassification, LayoutLMv2Processor\n",
|
| 44 |
+
"import torch\n",
|
| 45 |
+
"from subprocess import run\n",
|
| 46 |
+
"\n",
|
| 47 |
+
"# install tesseract-ocr and pytesseract\n",
|
| 48 |
+
"run(\"apt install -y tesseract-ocr\", shell=True, check=True)\n",
|
| 49 |
+
"run(\"pip install pytesseract\", shell=True, check=True)\n",
|
| 50 |
+
"\n",
|
| 51 |
+
"# helper function to unnormalize bboxes for drawing onto the image\n",
|
| 52 |
+
"def unnormalize_box(bbox, width, height):\n",
|
| 53 |
+
" return [\n",
|
| 54 |
+
" width * (bbox[0] / 1000),\n",
|
| 55 |
+
" height * (bbox[1] / 1000),\n",
|
| 56 |
+
" width * (bbox[2] / 1000),\n",
|
| 57 |
+
" height * (bbox[3] / 1000),\n",
|
| 58 |
+
" ]\n",
|
| 59 |
+
"\n",
|
| 60 |
+
"\n",
|
| 61 |
+
"# set device\n",
|
| 62 |
+
"device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n",
|
| 63 |
+
"\n",
|
| 64 |
+
"\n",
|
| 65 |
+
"class EndpointHandler:\n",
|
| 66 |
+
" def __init__(self, path=\"\"):\n",
|
| 67 |
+
" # load model and processor from path\n",
|
| 68 |
+
" self.model = LayoutLMForTokenClassification.from_pretrained(\"philschmid/layoutlm-funsd\").to(device)\n",
|
| 69 |
+
" self.processor = LayoutLMv2Processor.from_pretrained(\"philschmid/layoutlm-funsd\")\n",
|
| 70 |
+
"\n",
|
| 71 |
+
" def __call__(self, data: Dict[str, bytes]) -> Dict[str, List[Any]]:\n",
|
| 72 |
+
" \"\"\"\n",
|
| 73 |
+
" Args:\n",
|
| 74 |
+
" data (:obj:):\n",
|
| 75 |
+
" includes the deserialized image file as PIL.Image\n",
|
| 76 |
+
" \"\"\"\n",
|
| 77 |
+
" # process input\n",
|
| 78 |
+
" image = data.pop(\"inputs\", data)\n",
|
| 79 |
+
"\n",
|
| 80 |
+
" # process image\n",
|
| 81 |
+
" encoding = self.processor(image, return_tensors=\"pt\")\n",
|
| 82 |
+
"\n",
|
| 83 |
+
" # run prediction\n",
|
| 84 |
+
" with torch.inference_mode():\n",
|
| 85 |
+
" outputs = self.model(\n",
|
| 86 |
+
" input_ids=encoding.input_ids.to(device),\n",
|
| 87 |
+
" bbox=encoding.bbox.to(device),\n",
|
| 88 |
+
" attention_mask=encoding.attention_mask.to(device),\n",
|
| 89 |
+
" token_type_ids=encoding.token_type_ids.to(device),\n",
|
| 90 |
+
" )\n",
|
| 91 |
+
" predictions = outputs.logits.softmax(-1)\n",
|
| 92 |
+
"\n",
|
| 93 |
+
" # post process output\n",
|
| 94 |
+
" result = []\n",
|
| 95 |
+
" for item, inp_ids, bbox in zip(\n",
|
| 96 |
+
" predictions.squeeze(0).cpu(), encoding.input_ids.squeeze(0).cpu(), encoding.bbox.squeeze(0).cpu()\n",
|
| 97 |
+
" ):\n",
|
| 98 |
+
" label = self.model.config.id2label[int(item.argmax().cpu())]\n",
|
| 99 |
+
" if label == \"O\":\n",
|
| 100 |
+
" continue\n",
|
| 101 |
+
" score = item.max().item()\n",
|
| 102 |
+
" text = self.processor.tokenizer.decode(inp_ids)\n",
|
| 103 |
+
" bbox = unnormalize_box(bbox.tolist(), image.width, image.height)\n",
|
| 104 |
+
" result.append({\"label\": label, \"score\": score, \"text\": text, \"bbox\": bbox})\n",
|
| 105 |
+
" return {\"predictions\": result}\n"
|
| 106 |
+
]
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"cell_type": "markdown",
|
| 110 |
+
"metadata": {},
|
| 111 |
+
"source": [
|
| 112 |
+
"test custom pipeline"
|
| 113 |
+
]
|
| 114 |
+
},
|
| 115 |
+
{
|
| 116 |
+
"cell_type": "code",
|
| 117 |
+
"execution_count": 2,
|
| 118 |
+
"metadata": {},
|
| 119 |
+
"outputs": [],
|
| 120 |
+
"source": [
|
| 121 |
+
"from handler import EndpointHandler\n",
|
| 122 |
+
"\n",
|
| 123 |
+
"my_handler = EndpointHandler(\".\")"
|
| 124 |
+
]
|
| 125 |
+
},
|
| 126 |
+
{
|
| 127 |
+
"cell_type": "code",
|
| 128 |
+
"execution_count": 13,
|
| 129 |
+
"metadata": {},
|
| 130 |
+
"outputs": [
|
| 131 |
+
{
|
| 132 |
+
"name": "stdout",
|
| 133 |
+
"output_type": "stream",
|
| 134 |
+
"text": [
|
| 135 |
+
"huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
|
| 136 |
+
"To disable this warning, you can either:\n",
|
| 137 |
+
"\t- Avoid using `tokenizers` before the fork if possible\n",
|
| 138 |
+
"\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n"
|
| 139 |
+
]
|
| 140 |
+
}
|
| 141 |
+
],
|
| 142 |
+
"source": [
|
| 143 |
+
"import base64\n",
|
| 144 |
+
"from PIL import Image\n",
|
| 145 |
+
"from io import BytesIO\n",
|
| 146 |
+
"import json\n",
|
| 147 |
+
"\n",
|
| 148 |
+
"# read image from disk\n",
|
| 149 |
+
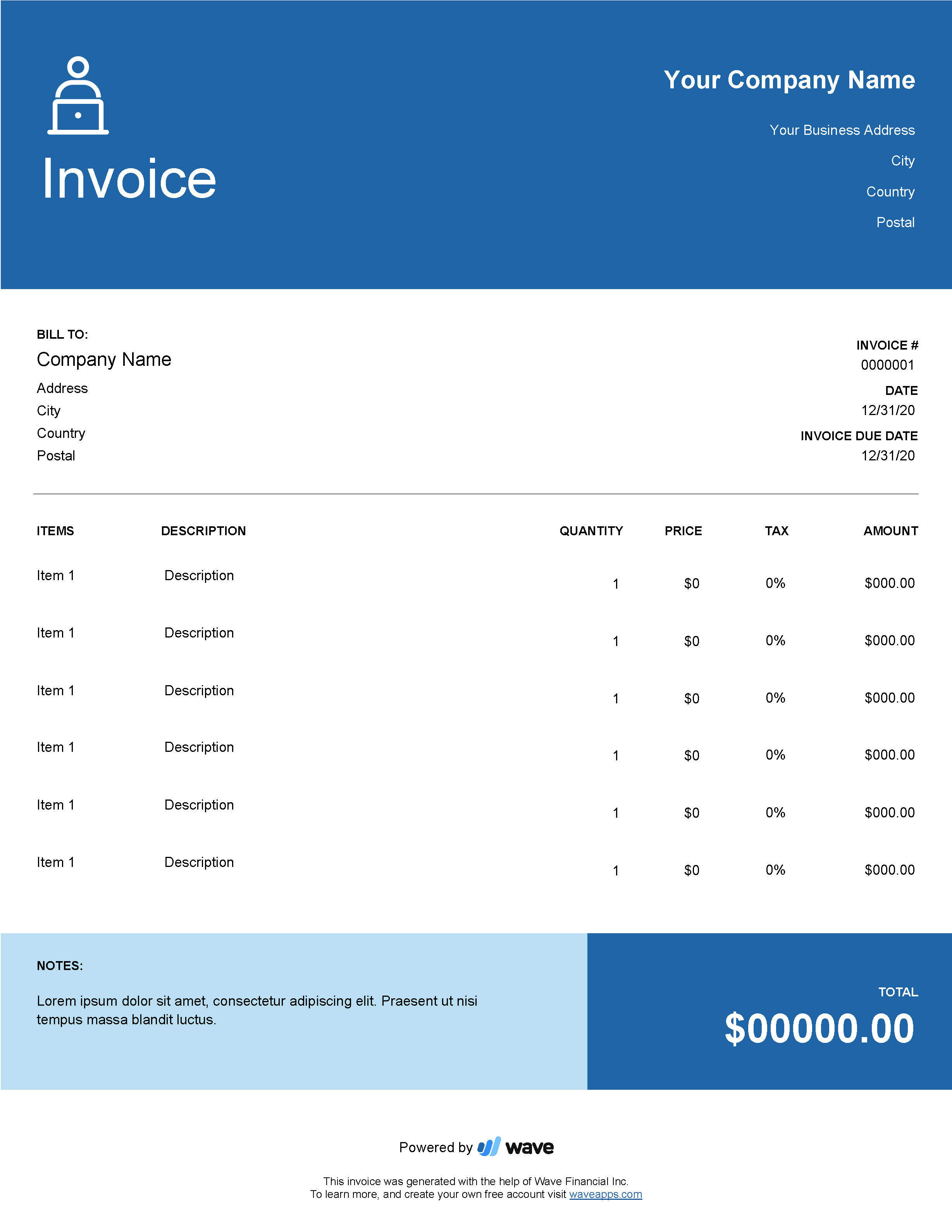
"image = Image.open(\"invoice_example.png\")\n",
|
| 150 |
+
"request = {\"inputs\":image }\n",
|
| 151 |
+
"\n",
|
| 152 |
+
"# test the handler\n",
|
| 153 |
+
"pred = my_handler(request)"
|
| 154 |
+
]
|
| 155 |
+
},
|
| 156 |
+
{
|
| 157 |
+
"cell_type": "code",
|
| 158 |
+
"execution_count": 16,
|
| 159 |
+
"metadata": {},
|
| 160 |
+
"outputs": [],
|
| 161 |
+
"source": [
|
| 162 |
+
"from PIL import Image, ImageDraw, ImageFont\n",
|
| 163 |
+
"\n",
|
| 164 |
+
"\n",
|
| 165 |
+
"def draw_result(image,result):\n",
|
| 166 |
+
" label2color = {\n",
|
| 167 |
+
" \"B-HEADER\": \"blue\",\n",
|
| 168 |
+
" \"B-QUESTION\": \"red\",\n",
|
| 169 |
+
" \"B-ANSWER\": \"green\",\n",
|
| 170 |
+
" \"I-HEADER\": \"blue\",\n",
|
| 171 |
+
" \"I-QUESTION\": \"red\",\n",
|
| 172 |
+
" \"I-ANSWER\": \"green\",\n",
|
| 173 |
+
" }\n",
|
| 174 |
+
"\n",
|
| 175 |
+
"\n",
|
| 176 |
+
" # draw predictions over the image\n",
|
| 177 |
+
" draw = ImageDraw.Draw(image)\n",
|
| 178 |
+
" font = ImageFont.load_default()\n",
|
| 179 |
+
" for res in result:\n",
|
| 180 |
+
" draw.rectangle(res[\"bbox\"], outline=\"black\")\n",
|
| 181 |
+
" draw.rectangle(res[\"bbox\"], outline=label2color[res[\"label\"]])\n",
|
| 182 |
+
" draw.text((res[\"bbox\"][0] + 10, res[\"bbox\"][1] - 10), text=res[\"label\"], fill=label2color[res[\"label\"]], font=font)\n",
|
| 183 |
+
" return image\n",
|
| 184 |
+
"\n",
|
| 185 |
+
"draw_result(image,pred[\"predictions\"])"
|
| 186 |
+
]
|
| 187 |
+
},
|
| 188 |
+
{
|
| 189 |
+
"cell_type": "code",
|
| 190 |
+
"execution_count": null,
|
| 191 |
+
"metadata": {},
|
| 192 |
+
"outputs": [],
|
| 193 |
+
"source": []
|
| 194 |
+
}
|
| 195 |
+
],
|
| 196 |
+
"metadata": {
|
| 197 |
+
"kernelspec": {
|
| 198 |
+
"display_name": "Python 3.9.13 ('dev': conda)",
|
| 199 |
+
"language": "python",
|
| 200 |
+
"name": "python3"
|
| 201 |
+
},
|
| 202 |
+
"language_info": {
|
| 203 |
+
"codemirror_mode": {
|
| 204 |
+
"name": "ipython",
|
| 205 |
+
"version": 3
|
| 206 |
+
},
|
| 207 |
+
"file_extension": ".py",
|
| 208 |
+
"mimetype": "text/x-python",
|
| 209 |
+
"name": "python",
|
| 210 |
+
"nbconvert_exporter": "python",
|
| 211 |
+
"pygments_lexer": "ipython3",
|
| 212 |
+
"version": "3.9.13"
|
| 213 |
+
},
|
| 214 |
+
"orig_nbformat": 4,
|
| 215 |
+
"vscode": {
|
| 216 |
+
"interpreter": {
|
| 217 |
+
"hash": "f6dd96c16031089903d5a31ec148b80aeb0d39c32affb1a1080393235fbfa2fc"
|
| 218 |
+
}
|
| 219 |
+
}
|
| 220 |
+
},
|
| 221 |
+
"nbformat": 4,
|
| 222 |
+
"nbformat_minor": 2
|
| 223 |
+
}
|
handler.py
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Dict, List, Any
|
| 2 |
+
from transformers import LayoutLMForTokenClassification, LayoutLMv2Processor
|
| 3 |
+
import torch
|
| 4 |
+
from subprocess import run
|
| 5 |
+
|
| 6 |
+
# install tesseract-ocr and pytesseract
|
| 7 |
+
run("apt install -y tesseract-ocr", shell=True, check=True)
|
| 8 |
+
run("pip install pytesseract", shell=True, check=True)
|
| 9 |
+
|
| 10 |
+
# helper function to unnormalize bboxes for drawing onto the image
|
| 11 |
+
def unnormalize_box(bbox, width, height):
|
| 12 |
+
return [
|
| 13 |
+
width * (bbox[0] / 1000),
|
| 14 |
+
height * (bbox[1] / 1000),
|
| 15 |
+
width * (bbox[2] / 1000),
|
| 16 |
+
height * (bbox[3] / 1000),
|
| 17 |
+
]
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
# set device
|
| 21 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class EndpointHandler:
|
| 25 |
+
def __init__(self, path=""):
|
| 26 |
+
# load model and processor from path
|
| 27 |
+
self.model = LayoutLMForTokenClassification.from_pretrained(path).to(device)
|
| 28 |
+
self.processor = LayoutLMv2Processor.from_pretrained(path)
|
| 29 |
+
|
| 30 |
+
def __call__(self, data: Dict[str, bytes]) -> Dict[str, List[Any]]:
|
| 31 |
+
"""
|
| 32 |
+
Args:
|
| 33 |
+
data (:obj:):
|
| 34 |
+
includes the deserialized image file as PIL.Image
|
| 35 |
+
"""
|
| 36 |
+
# process input
|
| 37 |
+
image = data.pop("inputs", data)
|
| 38 |
+
|
| 39 |
+
# process image
|
| 40 |
+
encoding = self.processor(image, return_tensors="pt", truncation=True)
|
| 41 |
+
|
| 42 |
+
# run prediction
|
| 43 |
+
with torch.inference_mode():
|
| 44 |
+
outputs = self.model(
|
| 45 |
+
input_ids=encoding.input_ids.to(device),
|
| 46 |
+
bbox=encoding.bbox.to(device),
|
| 47 |
+
attention_mask=encoding.attention_mask.to(device),
|
| 48 |
+
token_type_ids=encoding.token_type_ids.to(device),
|
| 49 |
+
)
|
| 50 |
+
predictions = outputs.logits.softmax(-1)
|
| 51 |
+
|
| 52 |
+
# post process output
|
| 53 |
+
result = []
|
| 54 |
+
for item, inp_ids, bbox in zip(
|
| 55 |
+
predictions.squeeze(0).cpu(), encoding.input_ids.squeeze(0).cpu(), encoding.bbox.squeeze(0).cpu()
|
| 56 |
+
):
|
| 57 |
+
label = self.model.config.id2label[int(item.argmax().cpu())]
|
| 58 |
+
if label == "O":
|
| 59 |
+
continue
|
| 60 |
+
score = item.max().item()
|
| 61 |
+
text = self.processor.tokenizer.decode(inp_ids)
|
| 62 |
+
bbox = unnormalize_box(bbox.tolist(), image.width, image.height)
|
| 63 |
+
result.append({"label": label, "score": score, "text": text, "bbox": bbox})
|
| 64 |
+
return {"predictions": result}
|
invoice_example.png
ADDED
|
output_form_lower.jpg
ADDED

|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"apply_ocr": true,
|
| 3 |
+
"do_resize": true,
|
| 4 |
+
"feature_extractor_type": "LayoutLMv2FeatureExtractor",
|
| 5 |
+
"ocr_lang": null,
|
| 6 |
+
"processor_class": "LayoutLMv2Processor",
|
| 7 |
+
"resample": 2,
|
| 8 |
+
"size": 224
|
| 9 |
+
}
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4f31380262cd4f276be211189196f190c0268e9cece977d500886a4e4c16fc07
|
| 3 |
+
size 450606565
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": "[CLS]",
|
| 3 |
+
"mask_token": "[MASK]",
|
| 4 |
+
"pad_token": "[PAD]",
|
| 5 |
+
"sep_token": "[SEP]",
|
| 6 |
+
"unk_token": "[UNK]"
|
| 7 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": null,
|
| 3 |
+
"apply_ocr": false,
|
| 4 |
+
"cls_token": "[CLS]",
|
| 5 |
+
"cls_token_box": [
|
| 6 |
+
0,
|
| 7 |
+
0,
|
| 8 |
+
0,
|
| 9 |
+
0
|
| 10 |
+
],
|
| 11 |
+
"do_basic_tokenize": true,
|
| 12 |
+
"do_lower_case": true,
|
| 13 |
+
"mask_token": "[MASK]",
|
| 14 |
+
"model_max_length": 512,
|
| 15 |
+
"name_or_path": "microsoft/layoutlmv2-base-uncased",
|
| 16 |
+
"never_split": null,
|
| 17 |
+
"only_label_first_subword": true,
|
| 18 |
+
"pad_token": "[PAD]",
|
| 19 |
+
"pad_token_box": [
|
| 20 |
+
0,
|
| 21 |
+
0,
|
| 22 |
+
0,
|
| 23 |
+
0
|
| 24 |
+
],
|
| 25 |
+
"pad_token_label": -100,
|
| 26 |
+
"processor_class": "LayoutLMv2Processor",
|
| 27 |
+
"sep_token": "[SEP]",
|
| 28 |
+
"sep_token_box": [
|
| 29 |
+
1000,
|
| 30 |
+
1000,
|
| 31 |
+
1000,
|
| 32 |
+
1000
|
| 33 |
+
],
|
| 34 |
+
"special_tokens_map_file": null,
|
| 35 |
+
"strip_accents": null,
|
| 36 |
+
"tokenize_chinese_chars": true,
|
| 37 |
+
"tokenizer_class": "LayoutLMv2Tokenizer",
|
| 38 |
+
"unk_token": "[UNK]"
|
| 39 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c56fc4a68a8102016f0d13df85e3cef173b08bfd50400f2f88c520a325d11676
|
| 3 |
+
size 3375
|
vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|