

Commit
•
0198c1c
1
Parent(s):
e000016
Update README.md
Browse files
README.md
CHANGED
|
@@ -23,35 +23,82 @@ Paper: [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1
|
|
| 23 |
|
| 24 |
Authors: *Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler*
|
| 25 |
|
| 26 |
-
#
|
| 27 |
|
| 28 |
-
The
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 36 |
|
| 37 |
## Fine-tuning
|
| 38 |
|
| 39 |
The model was continously fine-tuned after N pretraining steps where N is typically from 50k to 100k.
|
| 40 |
-
In other words, after each Nk steps of pretraining,
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
In total, the model was trained for 2.65 million steps where as
|
| 45 |
|
| 46 |
-
**Important**: For more details, please see sections 5.2.1 and 5.2.2 of the paper.
|
| 47 |
|
| 48 |
## Contribution
|
| 49 |
|
| 50 |
-
This model was contributed by [Daniel Hesslow](https://huggingface.co/Seledorn)
|
| 51 |
|
| 52 |
## Examples
|
| 53 |
|
| 54 |
-
|
|
|
|
|
|
|
| 55 |
|
| 56 |
```python
|
| 57 |
from transformers import T5ForConditionalGeneration, AutoTokenizer
|
| 23 |
|
| 24 |
Authors: *Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler*
|
| 25 |
|
| 26 |
+
# Training
|
| 27 |
|
| 28 |
+
The checkpoint was iteratively pre-trained on C4 and fine-tuned on a variety of datasets
|
| 29 |
+
|
| 30 |
+
## PreTraining
|
| 31 |
+
|
| 32 |
+
The model is pretrained on the C4 corpus. For pretraining, the model is trained on a total of 1 trillion tokens on C4 (2 million steps)
|
| 33 |
+
with a batch size of 1024. The sequence length is set to 512/512 for inputs and targets.
|
| 34 |
+
Dropout is set to 0 during pretraining. Pre-training took slightly more than one month for about 1 trillion
|
| 35 |
+
tokens. The model has 32 encoder layers and 32 decoder layers, `dmodel` of 4096 and `df` of 16384.
|
| 36 |
+
The dimension of each head is 256 for a total of 16 heads. Our model uses a model parallelism of 8.
|
| 37 |
+
The same same sentencepiece tokenizer as T5 of vocab size 32000 is used (click [here](https://huggingface.co/docs/transformers/v4.20.0/en/model_doc/t5#transformers.T5Tokenizer) for more information about the T5 tokenizer).
|
| 38 |
+
|
| 39 |
+
UL-20B can be interpreted as a model that is quite similar to T5 but trained with a different objective and slightly different scaling knobs.
|
| 40 |
+
UL-20B was trained using the [Jax](https://github.com/google/jax) and [T5X](https://github.com/google-research/t5x) infrastructure.
|
| 41 |
+
|
| 42 |
+
The training objective during pretraining is a mixture of different denoising strategies that are explained in the following:
|
| 43 |
+
|
| 44 |
+
## Mixture of Denoisers
|
| 45 |
+
|
| 46 |
+
To quote the paper:
|
| 47 |
+
> We conjecture that a strong universal model has to be exposed to solving diverse set of problems
|
| 48 |
+
> during pre-training. Given that pre-training is done using self-supervision, we argue that such diversity
|
| 49 |
+
> should be injected to the objective of the model, otherwise the model might suffer from lack a certain
|
| 50 |
+
> ability, like long-coherent text generation.
|
| 51 |
+
> Motivated by this, as well as current class of objective functions, we define three main paradigms that
|
| 52 |
+
> are used during pre-training:
|
| 53 |
+
|
| 54 |
+
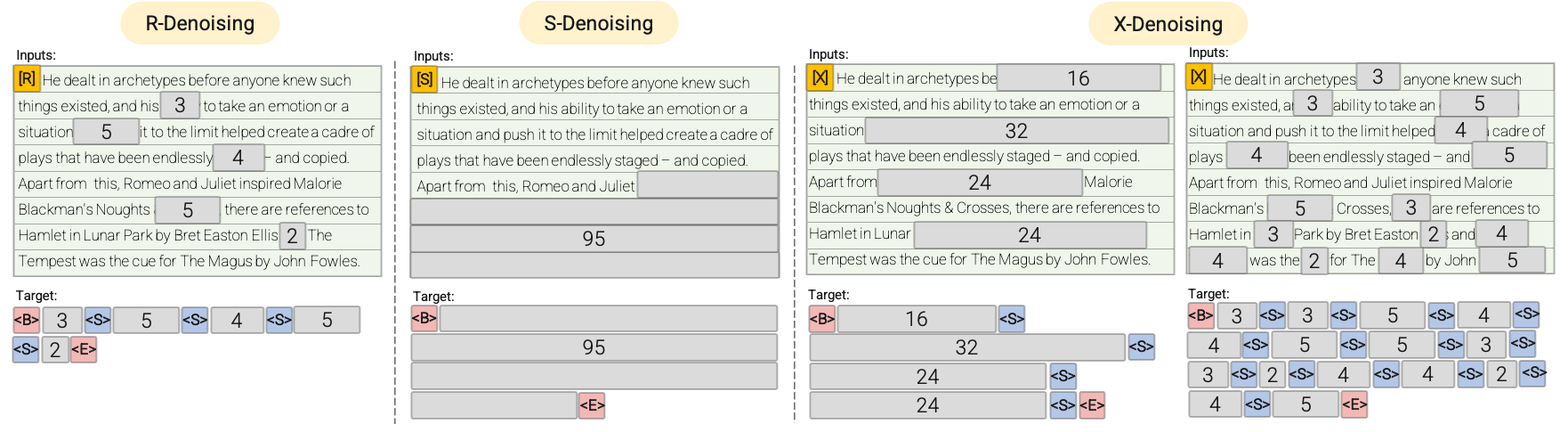
- **R-Denoiser**: The regular denoising is the standard span corruption introduced in [T5](https://huggingface.co/docs/transformers/v4.20.0/en/model_doc/t5)
|
| 55 |
+
that uses a range of 2 to 5 tokens as the span length, which masks about 15% of
|
| 56 |
+
input tokens. These spans are short and potentially useful to acquire knowledge instead of
|
| 57 |
+
learning to generate fluent text.
|
| 58 |
+
|
| 59 |
+
- **S-Denoiser**: A specific case of denoising where we observe a strict sequential order when
|
| 60 |
+
framing the inputs-to-targets task, i.e., prefix language modeling. To do so, we simply
|
| 61 |
+
partition the input sequence into two sub-sequences of tokens as context and target such that
|
| 62 |
+
the targets do not rely on future information. This is unlike standard span corruption where
|
| 63 |
+
there could be a target token with earlier position than a context token. Note that similar to
|
| 64 |
+
the Prefix-LM setup, the context (prefix) retains a bidirectional receptive field. We note that
|
| 65 |
+
S-Denoising with very short memory or no memory is in similar spirit to standard causal
|
| 66 |
+
language modeling.
|
| 67 |
+
|
| 68 |
+
- **X-Denoiser**: An extreme version of denoising where the model must recover a large part
|
| 69 |
+
of the input, given a small to moderate part of it. This simulates a situation where a model
|
| 70 |
+
needs to generate long target from a memory with relatively limited information. To do
|
| 71 |
+
so, we opt to include examples with aggressive denoising where approximately 50% of the
|
| 72 |
+
input sequence is masked. This is by increasing the span length and/or corruption rate. We
|
| 73 |
+
consider a pre-training task to be extreme if it has a long span (e.g., ≥ 12 tokens) or have
|
| 74 |
+
a large corruption rate (e.g., ≥ 30%). X-denoising is motivated by being an interpolation
|
| 75 |
+
between regular span corruption and language model like objectives.
|
| 76 |
+
|
| 77 |
+
See the following diagram for a more visual explanation:
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
**Important**: For more details, please see sections 3.1.2 of the [paper](https://arxiv.org/pdf/2205.05131v1.pdf).
|
| 82 |
|
| 83 |
## Fine-tuning
|
| 84 |
|
| 85 |
The model was continously fine-tuned after N pretraining steps where N is typically from 50k to 100k.
|
| 86 |
+
In other words, after each Nk steps of pretraining, the model is finetuned on each downstream task. See section 5.2.2 of [paper](https://arxiv.org/pdf/2205.05131v1.pdf) to get an overview of all datasets that were used for fine-tuning).
|
| 87 |
+
|
| 88 |
+
As the model is continuously finetuned, finetuning is stopped on a task once it has reached state-of-the-art to save compute.
|
| 89 |
+
In total, the model was trained for 2.65 million steps.
|
|
|
|
| 90 |
|
| 91 |
+
**Important**: For more details, please see sections 5.2.1 and 5.2.2 of the [paper](https://arxiv.org/pdf/2205.05131v1.pdf).
|
| 92 |
|
| 93 |
## Contribution
|
| 94 |
|
| 95 |
+
This model was contributed by [Daniel Hesslow](https://huggingface.co/Seledorn).
|
| 96 |
|
| 97 |
## Examples
|
| 98 |
|
| 99 |
+
The following shows how one can predict masked passages using the different denoising strategies.
|
| 100 |
+
|
| 101 |
+
|
| 102 |
|
| 103 |
```python
|
| 104 |
from transformers import T5ForConditionalGeneration, AutoTokenizer
|