
游雁
commited on
Commit
·
cee38ea
1
Parent(s):
5c2da43
add
Browse files- README.md +293 -3
- am.mvn +8 -0
- config.yaml +56 -0
- configuration.json +13 -0
- fig/struct.png +0 -0
- model.pt +3 -0
README.md
CHANGED
|
@@ -1,5 +1,295 @@
|
|
| 1 |
---
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
tasks:
|
| 3 |
+
- voice-activity-detection
|
| 4 |
+
domain:
|
| 5 |
+
- audio
|
| 6 |
+
model-type:
|
| 7 |
+
- VAD model
|
| 8 |
+
frameworks:
|
| 9 |
+
- pytorch
|
| 10 |
+
backbone:
|
| 11 |
+
- fsmn
|
| 12 |
+
metrics:
|
| 13 |
+
- f1_score
|
| 14 |
+
license: Apache License 2.0
|
| 15 |
+
language:
|
| 16 |
+
- cn
|
| 17 |
+
tags:
|
| 18 |
+
- FunASR
|
| 19 |
+
- FSMN
|
| 20 |
+
- Alibaba
|
| 21 |
+
- Online
|
| 22 |
+
datasets:
|
| 23 |
+
train:
|
| 24 |
+
- 20,000 hour industrial Mandarin task
|
| 25 |
+
test:
|
| 26 |
+
- 20,000 hour industrial Mandarin task
|
| 27 |
+
widgets:
|
| 28 |
+
- task: voice-activity-detection
|
| 29 |
+
inputs:
|
| 30 |
+
- type: audio
|
| 31 |
+
name: input
|
| 32 |
+
title: 音频
|
| 33 |
+
examples:
|
| 34 |
+
- name: 1
|
| 35 |
+
title: 示例1
|
| 36 |
+
inputs:
|
| 37 |
+
- name: input
|
| 38 |
+
data: git://example/vad_example.wav
|
| 39 |
+
inferencespec:
|
| 40 |
+
cpu: 1 #CPU数量
|
| 41 |
+
memory: 4096
|
| 42 |
---
|
| 43 |
+
|
| 44 |
+
# FSMN-Monophone VAD 模型介绍
|
| 45 |
+
|
| 46 |
+
[//]: # (FSMN-Monophone VAD 模型)
|
| 47 |
+
|
| 48 |
+
## Highlight
|
| 49 |
+
- 16k中文通用VAD模型:可用于检测长语音片段中有效语音的起止时间点。
|
| 50 |
+
- 基于[Paraformer-large长音频模型](https://www.modelscope.cn/models/damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch/summary)场景的使用
|
| 51 |
+
- 基于[FunASR框架](https://github.com/alibaba-damo-academy/FunASR),可进行ASR,VAD,[中文标点](https://www.modelscope.cn/models/damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/summary)的自由组合
|
| 52 |
+
- 基于音频数据的有效语音片段起止时间点检测
|
| 53 |
+
|
| 54 |
+
## <strong>[FunASR开源项目介绍](https://github.com/alibaba-damo-academy/FunASR)</strong>
|
| 55 |
+
<strong>[FunASR](https://github.com/alibaba-damo-academy/FunASR)</strong>希望在语音识别的学术研究和工业应用之间架起一座桥梁。通过发布工业级语音识别模型的训练和微调,研究人员和开发人员可以更方便地进行语音识别模型的研究和生产,并推动语音识别生态的发展。让语音识别更有趣!
|
| 56 |
+
|
| 57 |
+
[**github仓库**](https://github.com/alibaba-damo-academy/FunASR)
|
| 58 |
+
| [**最新动态**](https://github.com/alibaba-damo-academy/FunASR#whats-new)
|
| 59 |
+
| [**环境安装**](https://github.com/alibaba-damo-academy/FunASR#installation)
|
| 60 |
+
| [**服务部署**](https://www.funasr.com)
|
| 61 |
+
| [**模型库**](https://github.com/alibaba-damo-academy/FunASR/tree/main/model_zoo)
|
| 62 |
+
| [**联系我们**](https://github.com/alibaba-damo-academy/FunASR#contact)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
## 模型原理介绍
|
| 66 |
+
|
| 67 |
+
FSMN-Monophone VAD是达摩院语音团队提出的高效语音端点检测模型,用于检测输入音频中有效语音的起止时间点信息,并将检测出来的有效音频片段输入识别引擎进行识别,减少无效语音带来的识别错误。
|
| 68 |
+
|
| 69 |
+
<p align="center">
|
| 70 |
+
<img src="fig/struct.png" alt="VAD模型结构" width="500" />
|
| 71 |
+
|
| 72 |
+
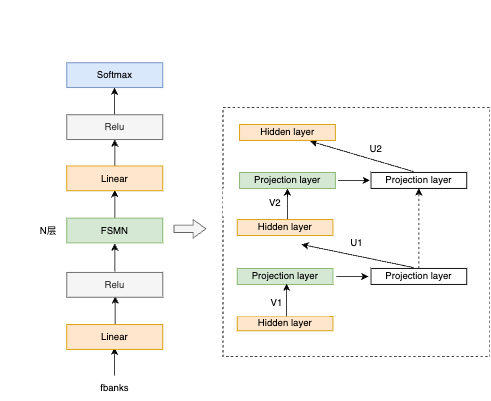
FSMN-Monophone VAD模型结构如上图所示:模型结构层面,FSMN模型结构建模时可考虑上下文信息,训练和推理速度快,且时延可控;同时根据VAD模型size以及低时延的要求,对FSMN的网络结构、右看帧数进行了适配。在建模单元层面,speech信息比较丰富,仅用单类来表征学习能力有限,我们将单一speech类升级为Monophone。建模单元细分,可以避免参数平均,抽象学习能力增强,区分性更好。
|
| 73 |
+
|
| 74 |
+
## 基于ModelScope进行推理
|
| 75 |
+
|
| 76 |
+
- 推理支持音频格式如下:
|
| 77 |
+
- wav文件路径,例如:data/test/audios/vad_example.wav
|
| 78 |
+
- wav文件url,例如:https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.wav
|
| 79 |
+
- wav二进制数据,格式bytes,例如:用户直接从文件里读出bytes数据或者是麦克风录出bytes数据。
|
| 80 |
+
- 已解析的audio音频,例如:audio, rate = soundfile.read("vad_example_zh.wav"),类型为numpy.ndarray或者torch.Tensor。
|
| 81 |
+
- wav.scp文件,需符合如下要求:
|
| 82 |
+
|
| 83 |
+
```sh
|
| 84 |
+
cat wav.scp
|
| 85 |
+
vad_example1 data/test/audios/vad_example1.wav
|
| 86 |
+
vad_example2 data/test/audios/vad_example2.wav
|
| 87 |
+
...
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
- 若输入格式wav文件url,api调用方式可参考如下范例:
|
| 91 |
+
|
| 92 |
+
```python
|
| 93 |
+
from modelscope.pipelines import pipeline
|
| 94 |
+
from modelscope.utils.constant import Tasks
|
| 95 |
+
|
| 96 |
+
inference_pipeline = pipeline(
|
| 97 |
+
task=Tasks.voice_activity_detection,
|
| 98 |
+
model='iic/speech_fsmn_vad_zh-cn-16k-common-pytorch',
|
| 99 |
+
model_revision="v2.0.4",
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
segments_result = inference_pipeline(input='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.wav')
|
| 103 |
+
print(segments_result)
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
- 输入音频为pcm格式,调用api时需要传入音频采样率参数fs,例如:
|
| 107 |
+
|
| 108 |
+
```python
|
| 109 |
+
segments_result = inference_pipeline(input='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.pcm', fs=16000)
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
- 若输入格式为文件wav.scp(注:文件名需要以.scp结尾),可添加 output_dir 参数将识别结果写入文件中,参考示例如下:
|
| 113 |
+
|
| 114 |
+
```python
|
| 115 |
+
inference_pipeline(input="wav.scp", output_dir='./output_dir')
|
| 116 |
+
```
|
| 117 |
+
识别结果输出路径结构如下:
|
| 118 |
+
|
| 119 |
+
```sh
|
| 120 |
+
tree output_dir/
|
| 121 |
+
output_dir/
|
| 122 |
+
└── 1best_recog
|
| 123 |
+
└── text
|
| 124 |
+
|
| 125 |
+
1 directory, 1 files
|
| 126 |
+
```
|
| 127 |
+
text:VAD检测语音起止时间点结果文件(单位:ms)
|
| 128 |
+
|
| 129 |
+
- 若输入音频为已解析的audio音频,api调用方式可参考如下范例:
|
| 130 |
+
|
| 131 |
+
```python
|
| 132 |
+
import soundfile
|
| 133 |
+
|
| 134 |
+
waveform, sample_rate = soundfile.read("vad_example_zh.wav")
|
| 135 |
+
segments_result = inference_pipeline(input=waveform)
|
| 136 |
+
print(segments_result)
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
- VAD常用参数调整说明(参考:vad.yaml文件):
|
| 140 |
+
- max_end_silence_time:尾部连续检测到多长时间静音进行尾点判停,参数范围500ms~6000ms,默认值800ms(该值过低容易出现语音提前截断的情况)。
|
| 141 |
+
- speech_noise_thres:speech的得分减去noise的得分大于此值则判断为speech,参数范围:(-1,1)
|
| 142 |
+
- 取值越趋于-1,噪音被误判定为语音的概率越大,FA越高
|
| 143 |
+
- 取值越趋于+1,语音被误判定为噪音的概率越大,Pmiss越高
|
| 144 |
+
- 通常情况下,该值会根据当前模型在长语音测试集上的效果取balance
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
## 基于FunASR进行推理
|
| 150 |
+
|
| 151 |
+
下面为快速上手教程,测试音频([中文](https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.wav),[英文](https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_en.wav))
|
| 152 |
+
|
| 153 |
+
### 可执行命令行
|
| 154 |
+
在命令行终端执行:
|
| 155 |
+
|
| 156 |
+
```shell
|
| 157 |
+
funasr ++model=paraformer-zh ++vad_model="fsmn-vad" ++punc_model="ct-punc" ++input=vad_example.wav
|
| 158 |
+
```
|
| 159 |
+
|
| 160 |
+
注:支持单条音频文件识别,也支持文件列表,列表为kaldi风格wav.scp:`wav_id wav_path`
|
| 161 |
+
|
| 162 |
+
### python示例
|
| 163 |
+
#### 非实时语音识别
|
| 164 |
+
```python
|
| 165 |
+
from funasr import AutoModel
|
| 166 |
+
# paraformer-zh is a multi-functional asr model
|
| 167 |
+
# use vad, punc, spk or not as you need
|
| 168 |
+
model = AutoModel(model="paraformer-zh", model_revision="v2.0.4",
|
| 169 |
+
vad_model="fsmn-vad", vad_model_revision="v2.0.4",
|
| 170 |
+
punc_model="ct-punc-c", punc_model_revision="v2.0.4",
|
| 171 |
+
# spk_model="cam++", spk_model_revision="v2.0.2",
|
| 172 |
+
)
|
| 173 |
+
res = model.generate(input=f"{model.model_path}/example/asr_example.wav",
|
| 174 |
+
batch_size_s=300,
|
| 175 |
+
hotword='魔搭')
|
| 176 |
+
print(res)
|
| 177 |
+
```
|
| 178 |
+
注:`model_hub`:表示模型仓库,`ms`为选择modelscope下载,`hf`为选择huggingface下载。
|
| 179 |
+
|
| 180 |
+
#### 实时语音识别
|
| 181 |
+
|
| 182 |
+
```python
|
| 183 |
+
from funasr import AutoModel
|
| 184 |
+
|
| 185 |
+
chunk_size = [0, 10, 5] #[0, 10, 5] 600ms, [0, 8, 4] 480ms
|
| 186 |
+
encoder_chunk_look_back = 4 #number of chunks to lookback for encoder self-attention
|
| 187 |
+
decoder_chunk_look_back = 1 #number of encoder chunks to lookback for decoder cross-attention
|
| 188 |
+
|
| 189 |
+
model = AutoModel(model="paraformer-zh-streaming", model_revision="v2.0.4")
|
| 190 |
+
|
| 191 |
+
import soundfile
|
| 192 |
+
import os
|
| 193 |
+
|
| 194 |
+
wav_file = os.path.join(model.model_path, "example/asr_example.wav")
|
| 195 |
+
speech, sample_rate = soundfile.read(wav_file)
|
| 196 |
+
chunk_stride = chunk_size[1] * 960 # 600ms
|
| 197 |
+
|
| 198 |
+
cache = {}
|
| 199 |
+
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
|
| 200 |
+
for i in range(total_chunk_num):
|
| 201 |
+
speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]
|
| 202 |
+
is_final = i == total_chunk_num - 1
|
| 203 |
+
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size, encoder_chunk_look_back=encoder_chunk_look_back, decoder_chunk_look_back=decoder_chunk_look_back)
|
| 204 |
+
print(res)
|
| 205 |
+
```
|
| 206 |
+
|
| 207 |
+
注:`chunk_size`为流式延时配置,`[0,10,5]`表示上屏实时出字粒度为`10*60=600ms`,未来信息为`5*60=300ms`。每次推理输入为`600ms`(采样点数为`16000*0.6=960`),输出为对应文字,最后一个语音片段输入需要设置`is_final=True`来强制输出最后一个字。
|
| 208 |
+
|
| 209 |
+
#### 语音端点检测(非实时)
|
| 210 |
+
```python
|
| 211 |
+
from funasr import AutoModel
|
| 212 |
+
|
| 213 |
+
model = AutoModel(model="fsmn-vad", model_revision="v2.0.4")
|
| 214 |
+
|
| 215 |
+
wav_file = f"{model.model_path}/example/asr_example.wav"
|
| 216 |
+
res = model.generate(input=wav_file)
|
| 217 |
+
print(res)
|
| 218 |
+
```
|
| 219 |
+
|
| 220 |
+
#### 语音端点检测(实时)
|
| 221 |
+
```python
|
| 222 |
+
from funasr import AutoModel
|
| 223 |
+
|
| 224 |
+
chunk_size = 200 # ms
|
| 225 |
+
model = AutoModel(model="fsmn-vad", model_revision="v2.0.4")
|
| 226 |
+
|
| 227 |
+
import soundfile
|
| 228 |
+
|
| 229 |
+
wav_file = f"{model.model_path}/example/vad_example.wav"
|
| 230 |
+
speech, sample_rate = soundfile.read(wav_file)
|
| 231 |
+
chunk_stride = int(chunk_size * sample_rate / 1000)
|
| 232 |
+
|
| 233 |
+
cache = {}
|
| 234 |
+
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
|
| 235 |
+
for i in range(total_chunk_num):
|
| 236 |
+
speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]
|
| 237 |
+
is_final = i == total_chunk_num - 1
|
| 238 |
+
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size)
|
| 239 |
+
if len(res[0]["value"]):
|
| 240 |
+
print(res)
|
| 241 |
+
```
|
| 242 |
+
|
| 243 |
+
#### 标点恢复
|
| 244 |
+
```python
|
| 245 |
+
from funasr import AutoModel
|
| 246 |
+
|
| 247 |
+
model = AutoModel(model="ct-punc", model_revision="v2.0.4")
|
| 248 |
+
|
| 249 |
+
res = model.generate(input="那今天的会就到这里吧 happy new year 明年见")
|
| 250 |
+
print(res)
|
| 251 |
+
```
|
| 252 |
+
|
| 253 |
+
#### 时间戳预测
|
| 254 |
+
```python
|
| 255 |
+
from funasr import AutoModel
|
| 256 |
+
|
| 257 |
+
model = AutoModel(model="fa-zh", model_revision="v2.0.4")
|
| 258 |
+
|
| 259 |
+
wav_file = f"{model.model_path}/example/asr_example.wav"
|
| 260 |
+
text_file = f"{model.model_path}/example/text.txt"
|
| 261 |
+
res = model.generate(input=(wav_file, text_file), data_type=("sound", "text"))
|
| 262 |
+
print(res)
|
| 263 |
+
```
|
| 264 |
+
|
| 265 |
+
更多详细用法([示例](https://github.com/alibaba-damo-academy/FunASR/tree/main/examples/industrial_data_pretraining))
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
## 微调
|
| 269 |
+
|
| 270 |
+
详细用法([示例](https://github.com/alibaba-damo-academy/FunASR/tree/main/examples/industrial_data_pretraining))
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
## 使用方式以及适用范围
|
| 277 |
+
|
| 278 |
+
运行范围
|
| 279 |
+
- 支持Linux-x86_64、Mac和Windows运行。
|
| 280 |
+
|
| 281 |
+
使用方式
|
| 282 |
+
- 直接推理:可以直接对长语音数据进行计算,有效语音片段的起止时间点信息(单位:ms)。
|
| 283 |
+
|
| 284 |
+
## 相关论文以及引用信息
|
| 285 |
+
|
| 286 |
+
```BibTeX
|
| 287 |
+
@inproceedings{zhang2018deep,
|
| 288 |
+
title={Deep-FSMN for large vocabulary continuous speech recognition},
|
| 289 |
+
author={Zhang, Shiliang and Lei, Ming and Yan, Zhijie and Dai, Lirong},
|
| 290 |
+
booktitle={2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
|
| 291 |
+
pages={5869--5873},
|
| 292 |
+
year={2018},
|
| 293 |
+
organization={IEEE}
|
| 294 |
+
}
|
| 295 |
+
```
|
am.mvn
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<Nnet>
|
| 2 |
+
<Splice> 400 400
|
| 3 |
+
[ 0 ]
|
| 4 |
+
<AddShift> 400 400
|
| 5 |
+
<LearnRateCoef> 0 [ -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 ]
|
| 6 |
+
<Rescale> 400 400
|
| 7 |
+
<LearnRateCoef> 0 [ 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 ]
|
| 8 |
+
</Nnet>
|
config.yaml
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
frontend: WavFrontendOnline
|
| 2 |
+
frontend_conf:
|
| 3 |
+
fs: 16000
|
| 4 |
+
window: hamming
|
| 5 |
+
n_mels: 80
|
| 6 |
+
frame_length: 25
|
| 7 |
+
frame_shift: 10
|
| 8 |
+
dither: 0.0
|
| 9 |
+
lfr_m: 5
|
| 10 |
+
lfr_n: 1
|
| 11 |
+
|
| 12 |
+
model: FsmnVADStreaming
|
| 13 |
+
model_conf:
|
| 14 |
+
sample_rate: 16000
|
| 15 |
+
detect_mode: 1
|
| 16 |
+
snr_mode: 0
|
| 17 |
+
max_end_silence_time: 800
|
| 18 |
+
max_start_silence_time: 3000
|
| 19 |
+
do_start_point_detection: True
|
| 20 |
+
do_end_point_detection: True
|
| 21 |
+
window_size_ms: 200
|
| 22 |
+
sil_to_speech_time_thres: 150
|
| 23 |
+
speech_to_sil_time_thres: 150
|
| 24 |
+
speech_2_noise_ratio: 1.0
|
| 25 |
+
do_extend: 1
|
| 26 |
+
lookback_time_start_point: 200
|
| 27 |
+
lookahead_time_end_point: 100
|
| 28 |
+
max_single_segment_time: 60000
|
| 29 |
+
snr_thres: -100.0
|
| 30 |
+
noise_frame_num_used_for_snr: 100
|
| 31 |
+
decibel_thres: -100.0
|
| 32 |
+
speech_noise_thres: 0.6
|
| 33 |
+
fe_prior_thres: 0.0001
|
| 34 |
+
silence_pdf_num: 1
|
| 35 |
+
sil_pdf_ids: [0]
|
| 36 |
+
speech_noise_thresh_low: -0.1
|
| 37 |
+
speech_noise_thresh_high: 0.3
|
| 38 |
+
output_frame_probs: False
|
| 39 |
+
frame_in_ms: 10
|
| 40 |
+
frame_length_ms: 25
|
| 41 |
+
|
| 42 |
+
encoder: FSMN
|
| 43 |
+
encoder_conf:
|
| 44 |
+
input_dim: 400
|
| 45 |
+
input_affine_dim: 140
|
| 46 |
+
fsmn_layers: 4
|
| 47 |
+
linear_dim: 250
|
| 48 |
+
proj_dim: 128
|
| 49 |
+
lorder: 20
|
| 50 |
+
rorder: 0
|
| 51 |
+
lstride: 1
|
| 52 |
+
rstride: 0
|
| 53 |
+
output_affine_dim: 140
|
| 54 |
+
output_dim: 248
|
| 55 |
+
|
| 56 |
+
|
configuration.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"framework": "pytorch",
|
| 3 |
+
"task" : "voice-activity-detection",
|
| 4 |
+
"pipeline": {"type":"funasr-pipeline"},
|
| 5 |
+
"model": {"type" : "funasr"},
|
| 6 |
+
"file_path_metas": {
|
| 7 |
+
"init_param":"model.pt",
|
| 8 |
+
"config":"config.yaml",
|
| 9 |
+
"frontend_conf":{"cmvn_file": "am.mvn"}},
|
| 10 |
+
"model_name_in_hub": {
|
| 11 |
+
"ms":"iic/speech_fsmn_vad_zh-cn-16k-common-pytorch",
|
| 12 |
+
"hf":""}
|
| 13 |
+
}
|
fig/struct.png
ADDED
|
model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b3be75be477f0780277f3bae0fe489f48718f585f3a6e45d7dd1fbb1a4255fc5
|
| 3 |
+
size 1721366
|