
Eyüp İpler
commited on
Commit
•
a4d3600
1
Parent(s):
d08596f
Update README.md
Browse files
README.md
CHANGED
|
@@ -40,161 +40,298 @@ tags:
|
|
| 40 |
|
| 41 |
### Direct Use
|
| 42 |
|
| 43 |
-
|
| 44 |
|
| 45 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 46 |
|
| 47 |
-
|
| 48 |
|
| 49 |
-
|
| 50 |
|
| 51 |
-
|
| 52 |
|
| 53 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 54 |
|
| 55 |
-
|
| 56 |
|
| 57 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 58 |
|
| 59 |
-
|
| 60 |
|
| 61 |
-
|
| 62 |
|
| 63 |
-
|
| 64 |
|
| 65 |
-
|
|
|
|
| 66 |
|
| 67 |
-
|
|
|
|
| 68 |
|
| 69 |
-
|
|
|
|
|
|
|
|
|
|
| 70 |
|
| 71 |
-
|
|
|
|
|
|
|
| 72 |
|
| 73 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 74 |
|
| 75 |
-
|
|
|
|
|
|
|
| 76 |
|
| 77 |
-
|
| 78 |
|
| 79 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 80 |
|
| 81 |
-
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
|
| 82 |
|
| 83 |
-
|
|
|
|
|
|
|
|
|
|
| 84 |
|
| 85 |
-
|
| 86 |
|
| 87 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 88 |
|
| 89 |
-
#### Preprocessing [optional]
|
| 90 |
|
| 91 |
-
|
|
|
|
|
|
|
| 92 |
|
|
|
|
| 93 |
|
| 94 |
-
|
|
|
|
|
|
|
| 95 |
|
| 96 |
-
|
|
|
|
|
|
|
| 97 |
|
| 98 |
-
|
|
|
|
| 99 |
|
| 100 |
-
|
| 101 |
|
| 102 |
-
[
|
|
|
|
|
|
|
| 103 |
|
| 104 |
-
|
| 105 |
|
| 106 |
-
|
|
|
|
| 107 |
|
| 108 |
-
|
|
|
|
|
|
|
| 109 |
|
| 110 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 111 |
|
| 112 |
-
|
|
|
|
|
|
|
|
|
|
| 113 |
|
| 114 |
-
|
|
|
|
| 115 |
|
| 116 |
-
|
|
|
|
| 117 |
|
| 118 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 119 |
|
| 120 |
-
|
|
|
|
|
|
|
|
|
|
| 121 |
|
| 122 |
-
|
|
|
|
| 123 |
|
| 124 |
-
|
| 125 |
|
| 126 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 127 |
|
| 128 |
-
### Results
|
| 129 |
|
| 130 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 131 |
|
| 132 |
-
|
| 133 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 134 |
|
|
|
|
|
|
|
| 135 |
|
| 136 |
-
|
| 137 |
|
| 138 |
-
|
| 139 |
|
| 140 |
-
|
|
|
|
| 141 |
|
| 142 |
-
|
|
|
|
|
|
|
| 143 |
|
| 144 |
-
|
|
|
|
| 145 |
|
| 146 |
-
|
|
|
|
|
|
|
| 147 |
|
| 148 |
-
|
| 149 |
-
- **Hours used:** [More Information Needed]
|
| 150 |
-
- **Cloud Provider:** [More Information Needed]
|
| 151 |
-
- **Compute Region:** [More Information Needed]
|
| 152 |
-
- **Carbon Emitted:** [More Information Needed]
|
| 153 |
|
| 154 |
-
|
|
|
|
|
|
|
| 155 |
|
| 156 |
-
|
|
|
|
|
|
|
| 157 |
|
| 158 |
-
[More Information Needed]
|
| 159 |
|
| 160 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 161 |
|
| 162 |
-
|
|
|
|
|
|
|
|
|
|
| 163 |
|
| 164 |
-
|
| 165 |
|
| 166 |
-
|
| 167 |
|
| 168 |
-
|
|
|
|
|
|
|
| 169 |
|
| 170 |
-
|
| 171 |
|
| 172 |
-
|
|
|
|
|
|
|
| 173 |
|
| 174 |
-
|
| 175 |
|
| 176 |
-
|
| 177 |
|
| 178 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 179 |
|
| 180 |
-
|
| 181 |
|
| 182 |
-
|
|
|
|
|
|
|
| 183 |
|
| 184 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 185 |
|
| 186 |
-
|
| 187 |
|
| 188 |
-
|
| 189 |
|
| 190 |
-
## More Information
|
| 191 |
|
| 192 |
-
|
| 193 |
|
| 194 |
## Model Card Authors [optional]
|
| 195 |
|
| 196 |
-
|
| 197 |
|
| 198 |
## Model Card Contact
|
| 199 |
|
| 200 |
-
|
|
|
|
| 40 |
|
| 41 |
### Direct Use
|
| 42 |
|
| 43 |
+
**Classical Use:**
|
| 44 |
|
| 45 |
+
```python
|
| 46 |
+
import numpy as np
|
| 47 |
+
import pandas as pd
|
| 48 |
+
from sklearn.preprocessing import StandardScaler
|
| 49 |
+
from tensorflow.keras.models import load_model
|
| 50 |
+
import matplotlib.pyplot as plt
|
| 51 |
|
| 52 |
+
model_path = 'model-path'
|
| 53 |
|
| 54 |
+
model = load_model(model_path)
|
| 55 |
|
| 56 |
+
model_name = model_path.split('/')[-1].split('.')[0]
|
| 57 |
|
| 58 |
+
plt.figure(figsize=(10, 6))
|
| 59 |
+
plt.title(f'Duygu Tahmini ({model_name})')
|
| 60 |
+
plt.xlabel('Zaman')
|
| 61 |
+
plt.ylabel('Sınıf')
|
| 62 |
+
plt.legend(loc='upper right')
|
| 63 |
+
plt.grid(True)
|
| 64 |
+
plt.show()
|
| 65 |
+
model.summary()
|
| 66 |
+
```
|
| 67 |
|
| 68 |
+
**Prediction Test:**
|
| 69 |
|
| 70 |
+
```python
|
| 71 |
+
import numpy as np
|
| 72 |
+
import pandas as pd
|
| 73 |
+
from sklearn.preprocessing import StandardScaler
|
| 74 |
+
from tensorflow.keras.models import load_model
|
| 75 |
|
| 76 |
+
model_path = 'model-path'
|
| 77 |
|
| 78 |
+
model = load_model(model_path)
|
| 79 |
|
| 80 |
+
scaler = StandardScaler()
|
| 81 |
|
| 82 |
+
predictions = model.predict(X_new_reshaped)
|
| 83 |
+
predicted_labels = np.argmax(predictions, axis=1)
|
| 84 |
|
| 85 |
+
label_mapping = {'NEGATIVE': 0, 'NEUTRAL': 1, 'POSITIVE': 2}
|
| 86 |
+
label_mapping_reverse = {v: k for k, v in label_mapping.items()}
|
| 87 |
|
| 88 |
+
#new_input = np.array([[23, 465, 12, 9653] * 637])
|
| 89 |
+
new_input = np.random.rand(1, 2548) # 1 sample and 2548 features
|
| 90 |
+
new_input_scaled = scaler.fit_transform(new_input)
|
| 91 |
+
new_input_reshaped = new_input_scaled.reshape((new_input_scaled.shape[0], 1, new_input_scaled.shape[1]))
|
| 92 |
|
| 93 |
+
new_prediction = model.predict(new_input_reshaped)
|
| 94 |
+
predicted_label = np.argmax(new_prediction, axis=1)[0]
|
| 95 |
+
predicted_emotion = label_mapping_reverse[predicted_label]
|
| 96 |
|
| 97 |
+
# TR Lang
|
| 98 |
+
if predicted_emotion == 'NEGATIVE':
|
| 99 |
+
predicted_emotion = 'Negatif'
|
| 100 |
+
elif predicted_emotion == 'NEUTRAL':
|
| 101 |
+
predicted_emotion = 'Nötr'
|
| 102 |
+
elif predicted_emotion == 'POSITIVE':
|
| 103 |
+
predicted_emotion = 'Pozitif'
|
| 104 |
|
| 105 |
+
print(f'Input Data: {new_input}')
|
| 106 |
+
print(f'Predicted Emotion: {predicted_emotion}')
|
| 107 |
+
```
|
| 108 |
|
| 109 |
+
**Realtime Use (EEG Monitoring without AI Model):**
|
| 110 |
|
| 111 |
+
```python
|
| 112 |
+
import sys
|
| 113 |
+
import pyaudio
|
| 114 |
+
import numpy as np
|
| 115 |
+
import matplotlib.pyplot as plt
|
| 116 |
+
from matplotlib.lines import Line2D
|
| 117 |
+
from PyQt5.QtWidgets import QApplication, QMainWindow, QPushButton, QVBoxLayout, QWidget
|
| 118 |
+
from PyQt5.QtCore import QTimer
|
| 119 |
+
from PyQt5.QtGui import QIcon
|
| 120 |
+
from matplotlib.backends.backend_qt5agg import FigureCanvasQTAgg as FigureCanvas
|
| 121 |
+
from matplotlib.backends.backend_qt5agg import NavigationToolbar2QT as NavigationToolbar
|
| 122 |
|
|
|
|
| 123 |
|
| 124 |
+
CHUNK = 1000 # Chunk size
|
| 125 |
+
FORMAT = pyaudio.paInt16 # Data type (16-bit PCM)
|
| 126 |
+
CHANNELS = 1 # (Mono)
|
| 127 |
+
RATE = 2000 # Sample rate (Hz)
|
| 128 |
|
| 129 |
+
p = pyaudio.PyAudio()
|
| 130 |
|
| 131 |
+
stream = p.open(format=FORMAT,
|
| 132 |
+
channels=CHANNELS,
|
| 133 |
+
rate=RATE,
|
| 134 |
+
input=True,
|
| 135 |
+
frames_per_buffer=CHUNK)
|
| 136 |
|
|
|
|
| 137 |
|
| 138 |
+
class MainWindow(QMainWindow):
|
| 139 |
+
def __init__(self):
|
| 140 |
+
super().__init__()
|
| 141 |
|
| 142 |
+
self.initUI()
|
| 143 |
|
| 144 |
+
self.timer = QTimer()
|
| 145 |
+
self.timer.timeout.connect(self.update_plot)
|
| 146 |
+
self.timer.start(1)
|
| 147 |
|
| 148 |
+
def initUI(self):
|
| 149 |
+
self.setWindowTitle('EEG Monitoring by Neurazum')
|
| 150 |
+
self.setWindowIcon(QIcon('/neurazumicon.ico'))
|
| 151 |
|
| 152 |
+
self.central_widget = QWidget()
|
| 153 |
+
self.setCentralWidget(self.central_widget)
|
| 154 |
|
| 155 |
+
self.layout = QVBoxLayout(self.central_widget)
|
| 156 |
|
| 157 |
+
self.fig, (self.ax1, self.ax2) = plt.subplots(2, 1, figsize=(12, 8), gridspec_kw={'height_ratios': [9, 1]})
|
| 158 |
+
self.fig.tight_layout()
|
| 159 |
+
self.canvas = FigureCanvas(self.fig)
|
| 160 |
|
| 161 |
+
self.layout.addWidget(self.canvas)
|
| 162 |
|
| 163 |
+
self.toolbar = NavigationToolbar(self.canvas, self)
|
| 164 |
+
self.layout.addWidget(self.toolbar)
|
| 165 |
|
| 166 |
+
self.x = np.arange(0, 2 * CHUNK, 2)
|
| 167 |
+
self.line1, = self.ax1.plot(self.x, np.random.rand(CHUNK))
|
| 168 |
+
self.line2, = self.ax2.plot(self.x, np.random.rand(CHUNK))
|
| 169 |
|
| 170 |
+
self.legend_elements = [
|
| 171 |
+
Line2D([0, 4], [0], color='yellow', lw=4, label='DELTA (0hz-4hz)'),
|
| 172 |
+
Line2D([4, 7], [0], color='blue', lw=4, label='THETA (4hz-7hz)'),
|
| 173 |
+
Line2D([8, 12], [0], color='green', lw=4, label='ALPHA (8hz-12hz)'),
|
| 174 |
+
Line2D([12, 30], [0], color='red', lw=4, label='BETA (12hz-30hz)'),
|
| 175 |
+
Line2D([30, 100], [0], color='purple', lw=4, label='GAMMA (30hz-100hz)')
|
| 176 |
+
]
|
| 177 |
|
| 178 |
+
def update_plot(self):
|
| 179 |
+
data = np.frombuffer(stream.read(CHUNK), dtype=np.int16)
|
| 180 |
+
data = np.abs(data)
|
| 181 |
+
voltage_data = data * (3.3 / 1024) # Voltage to "mV"
|
| 182 |
|
| 183 |
+
self.line1.set_ydata(data)
|
| 184 |
+
self.line2.set_ydata(voltage_data)
|
| 185 |
|
| 186 |
+
for coll in self.ax1.collections:
|
| 187 |
+
coll.remove()
|
| 188 |
|
| 189 |
+
self.ax1.fill_between(self.x, data, where=((self.x >= 0) & (self.x <= 4)), color='yellow', alpha=1)
|
| 190 |
+
self.ax1.fill_between(self.x, data, where=((self.x >= 4) & (self.x <= 7)), color='blue', alpha=1)
|
| 191 |
+
self.ax1.fill_between(self.x, data, where=((self.x >= 8) & (self.x <= 12)), color='green', alpha=1)
|
| 192 |
+
self.ax1.fill_between(self.x, data, where=((self.x >= 12) & (self.x <= 30)), color='red', alpha=1)
|
| 193 |
+
self.ax1.fill_between(self.x, data, where=((self.x >= 30) & (self.x <= 100)), color='purple', alpha=1)
|
| 194 |
|
| 195 |
+
self.ax1.legend(handles=self.legend_elements, loc='upper right')
|
| 196 |
+
self.ax1.set_ylabel('Value (dB)')
|
| 197 |
+
self.ax1.set_xlabel('Frequency (Hz)')
|
| 198 |
+
self.ax1.set_title('Frequency and mV')
|
| 199 |
|
| 200 |
+
self.ax2.set_ylabel('Voltage (mV)')
|
| 201 |
+
self.ax2.set_xlabel('Time')
|
| 202 |
|
| 203 |
+
self.canvas.draw()
|
| 204 |
|
| 205 |
+
def close_application(self):
|
| 206 |
+
self.timer.stop()
|
| 207 |
+
stream.stop_stream()
|
| 208 |
+
stream.close()
|
| 209 |
+
p.terminate()
|
| 210 |
+
sys.exit(app.exec_())
|
| 211 |
|
|
|
|
| 212 |
|
| 213 |
+
if __name__ == '__main__':
|
| 214 |
+
app = QApplication(sys.argv)
|
| 215 |
+
mainWin = MainWindow()
|
| 216 |
+
mainWin.show()
|
| 217 |
+
sys.exit(app.exec_())
|
| 218 |
+
```
|
| 219 |
|
| 220 |
+
**Emotion Dataset Prediction Use:**
|
| 221 |
|
| 222 |
+
```python
|
| 223 |
+
import numpy as np
|
| 224 |
+
import pandas as pd
|
| 225 |
+
from sklearn.preprocessing import StandardScaler
|
| 226 |
+
from tensorflow.keras.models import load_model
|
| 227 |
|
| 228 |
+
model_path = 'model-path'
|
| 229 |
+
new_data_path = 'dataset-path'
|
| 230 |
|
| 231 |
+
model = load_model(model_path)
|
| 232 |
|
| 233 |
+
new_data = pd.read_csv(new_data_path)
|
| 234 |
|
| 235 |
+
X_new = new_data.drop('label', axis=1)
|
| 236 |
+
y_new = new_data['label']
|
| 237 |
|
| 238 |
+
scaler = StandardScaler()
|
| 239 |
+
X_new_scaled = scaler.fit_transform(X_new)
|
| 240 |
+
X_new_reshaped = X_new_scaled.reshape((X_new_scaled.shape[0], 1, X_new_scaled.shape[1]))
|
| 241 |
|
| 242 |
+
predictions = model.predict(X_new_reshaped)
|
| 243 |
+
predicted_labels = np.argmax(predictions, axis=1)
|
| 244 |
|
| 245 |
+
label_mapping = {'NEGATIVE': 0, 'NEUTRAL': 1, 'POSITIVE': 2}
|
| 246 |
+
label_mapping_reverse = {v: k for k, v in label_mapping.items()}
|
| 247 |
+
actual_labels = y_new.replace(label_mapping).values
|
| 248 |
|
| 249 |
+
accuracy = np.mean(predicted_labels == actual_labels)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 250 |
|
| 251 |
+
new_input = np.random.rand(2548, 2548) # 1 sample and 2548 features
|
| 252 |
+
new_input_scaled = scaler.transform(new_input)
|
| 253 |
+
new_input_reshaped = new_input_scaled.reshape((new_input_scaled.shape[0], 1, new_input_scaled.shape[1]))
|
| 254 |
|
| 255 |
+
new_prediction = model.predict(new_input_reshaped)
|
| 256 |
+
predicted_label = np.argmax(new_prediction, axis=1)[0]
|
| 257 |
+
predicted_emotion = label_mapping_reverse[predicted_label]
|
| 258 |
|
|
|
|
| 259 |
|
| 260 |
+
# TR Lang
|
| 261 |
+
if predicted_emotion == 'NEGATIVE':
|
| 262 |
+
predicted_emotion = 'Negatif'
|
| 263 |
+
elif predicted_emotion == 'NEUTRAL':
|
| 264 |
+
predicted_emotion = 'Nötr'
|
| 265 |
+
elif predicted_emotion == 'POSITIVE':
|
| 266 |
+
predicted_emotion = 'Pozitif'
|
| 267 |
|
| 268 |
+
print(f'Inputs: {new_input}')
|
| 269 |
+
print(f'Predicted Emotion: {predicted_emotion}')
|
| 270 |
+
print(f'Accuracy: %{accuracy * 100:.5f}')
|
| 271 |
+
```
|
| 272 |
|
| 273 |
+
## Bias, Risks, and Limitations
|
| 274 |
|
| 275 |
+
**bai Models;**
|
| 276 |
|
| 277 |
+
- _The biggest risk is wrong prediction :),_
|
| 278 |
+
- _It does not contain any restrictions in any area (for now),_
|
| 279 |
+
- _Data from brain signals do not contain personal information (because they are only mV values). Therefore, every guess made by bai is only a "GUESS"._
|
| 280 |
|
| 281 |
+
### Recommendations
|
| 282 |
|
| 283 |
+
- _Do not experience too many mood changes,_
|
| 284 |
+
- _Do not take thoughts/decisions with too many different qualities,_
|
| 285 |
+
- _When he/she makes a lot of mistakes, do not think that he/she gave the wrong answer (think of it as giving the correct answer),_
|
| 286 |
|
| 287 |
+
**Note: These items are only recommendations for better operation of the model. They do not carry any risk.**
|
| 288 |
|
| 289 |
+
## How to Get Started with the Model
|
| 290 |
|
| 291 |
+
- ```bash
|
| 292 |
+
pip install -r requirements.txt
|
| 293 |
+
```
|
| 294 |
+
- Place the path of the model in the example uses.
|
| 295 |
+
- And run the file.
|
| 296 |
|
| 297 |
+
## Evaluation
|
| 298 |
|
| 299 |
+
- bai-2.0 (Accuracy very high = 97%, 93621013133208)(EMOTIONAL CLASSIFICATION) (AUTONOMOUS MODEL) (High probability of OVERFITTING)
|
| 300 |
+
- bai-2.1 (Accuracy very high = 97%, 93621013133208)(EMOTIONAL CLASSIFICATION) (AUTONOMOUS MODEL) (Low probability of OVERFITTING)
|
| 301 |
+
- bai-2.2 (Accuracy very high = 94%, 8874296435272)(EMOTIONAL CLASSIFICATION) (AUTONOMOUS MODEL) (Low probability of OVERFITTING)
|
| 302 |
|
| 303 |
+
### Results
|
| 304 |
+
|
| 305 |
+
[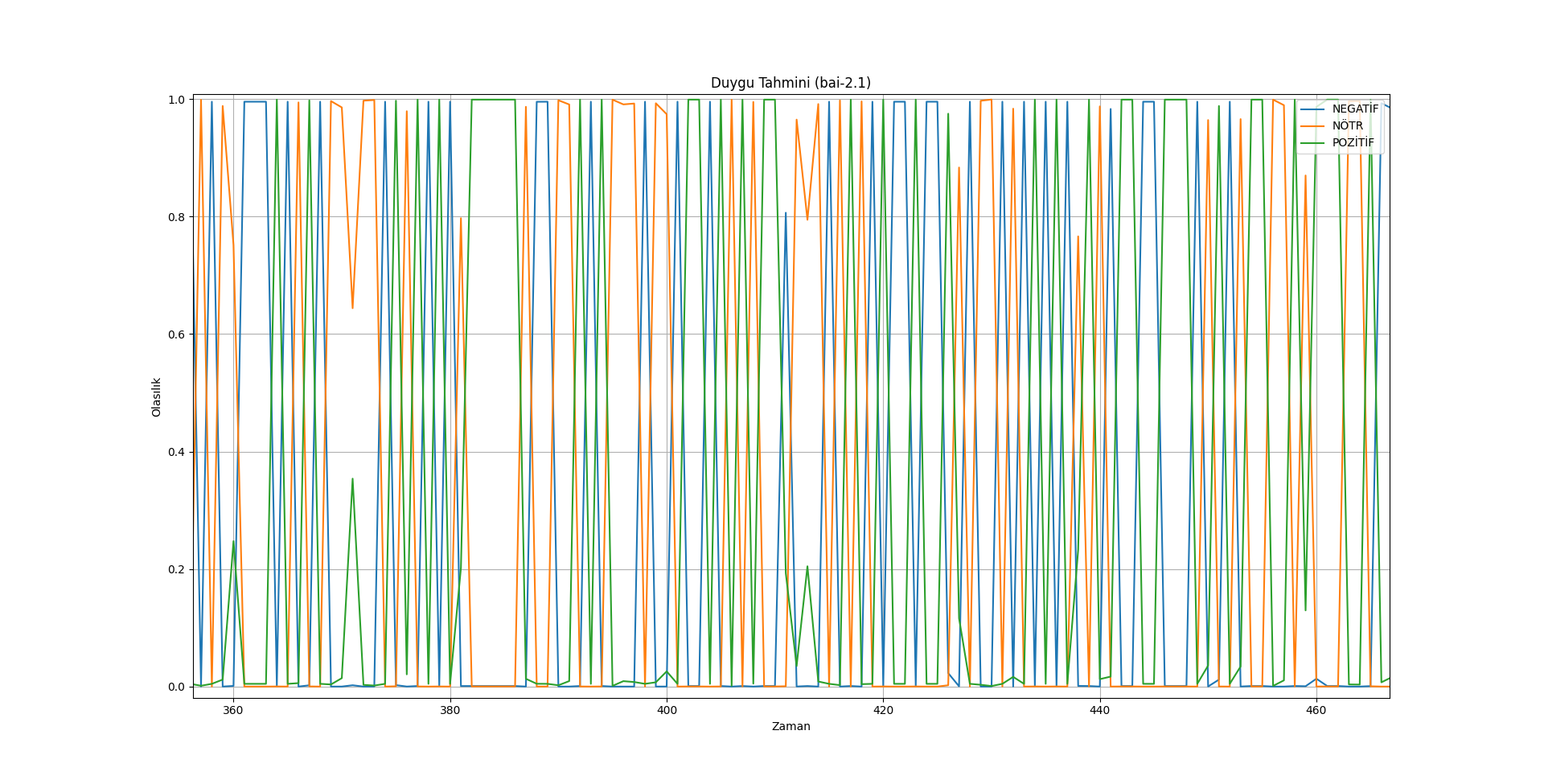](https://resimlink.com/O7GyMoQL)
|
| 306 |
+
|
| 307 |
+
[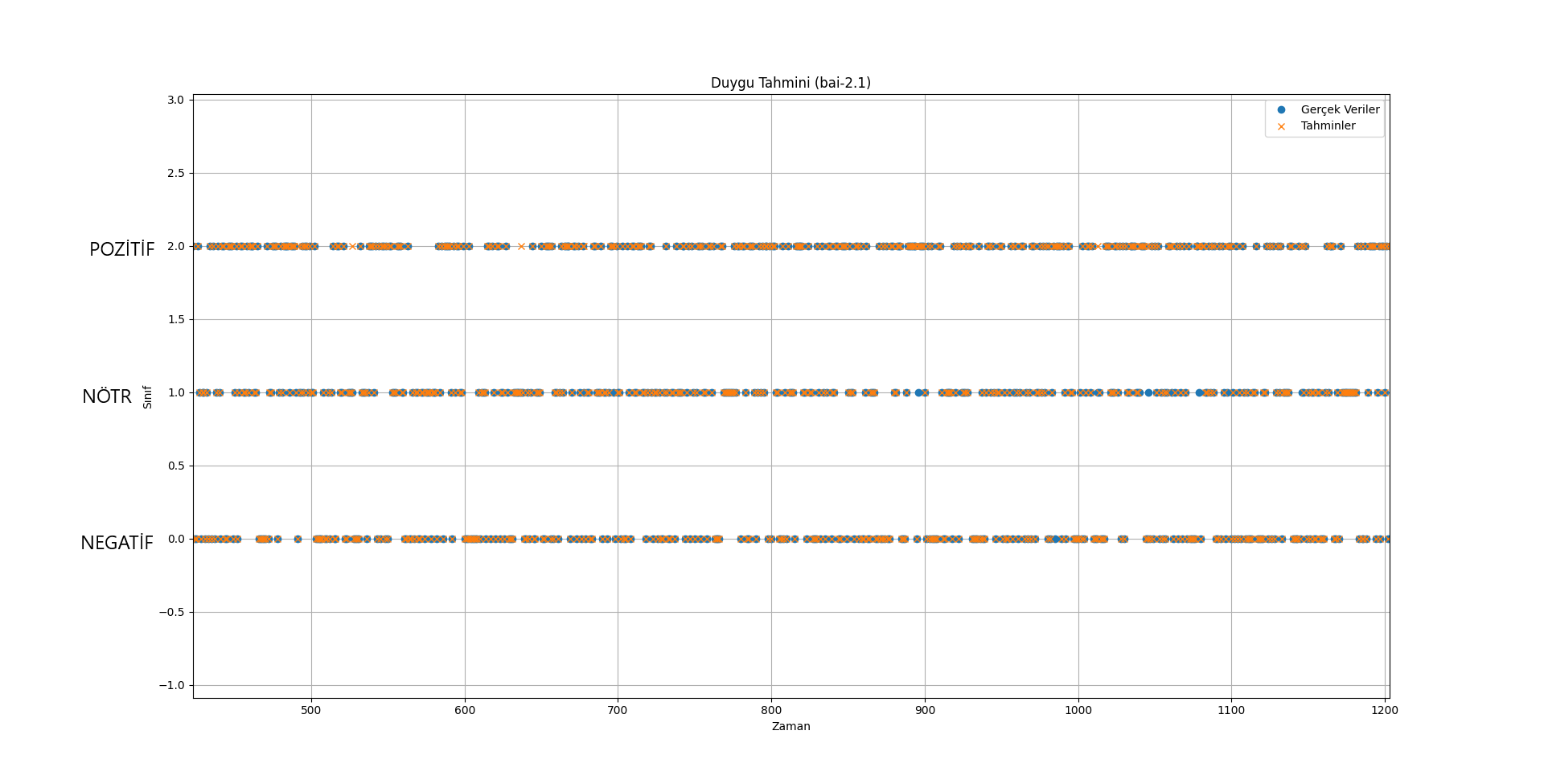](https://resimlink.com/gdyCW3RP)
|
| 308 |
+
|
| 309 |
+
[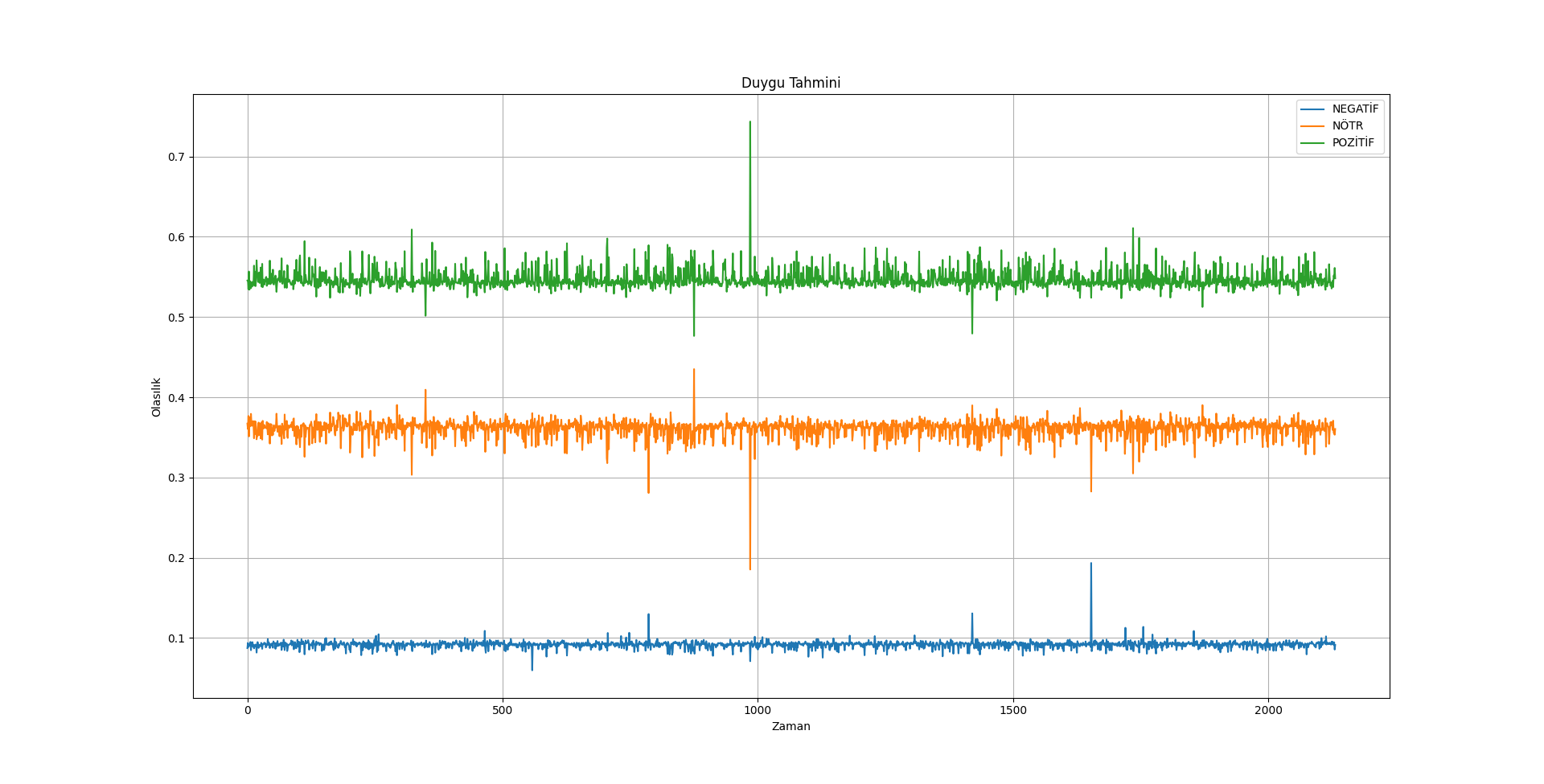](https://resimlink.com/MpH9XS_0E)
|
| 310 |
+
|
| 311 |
+
[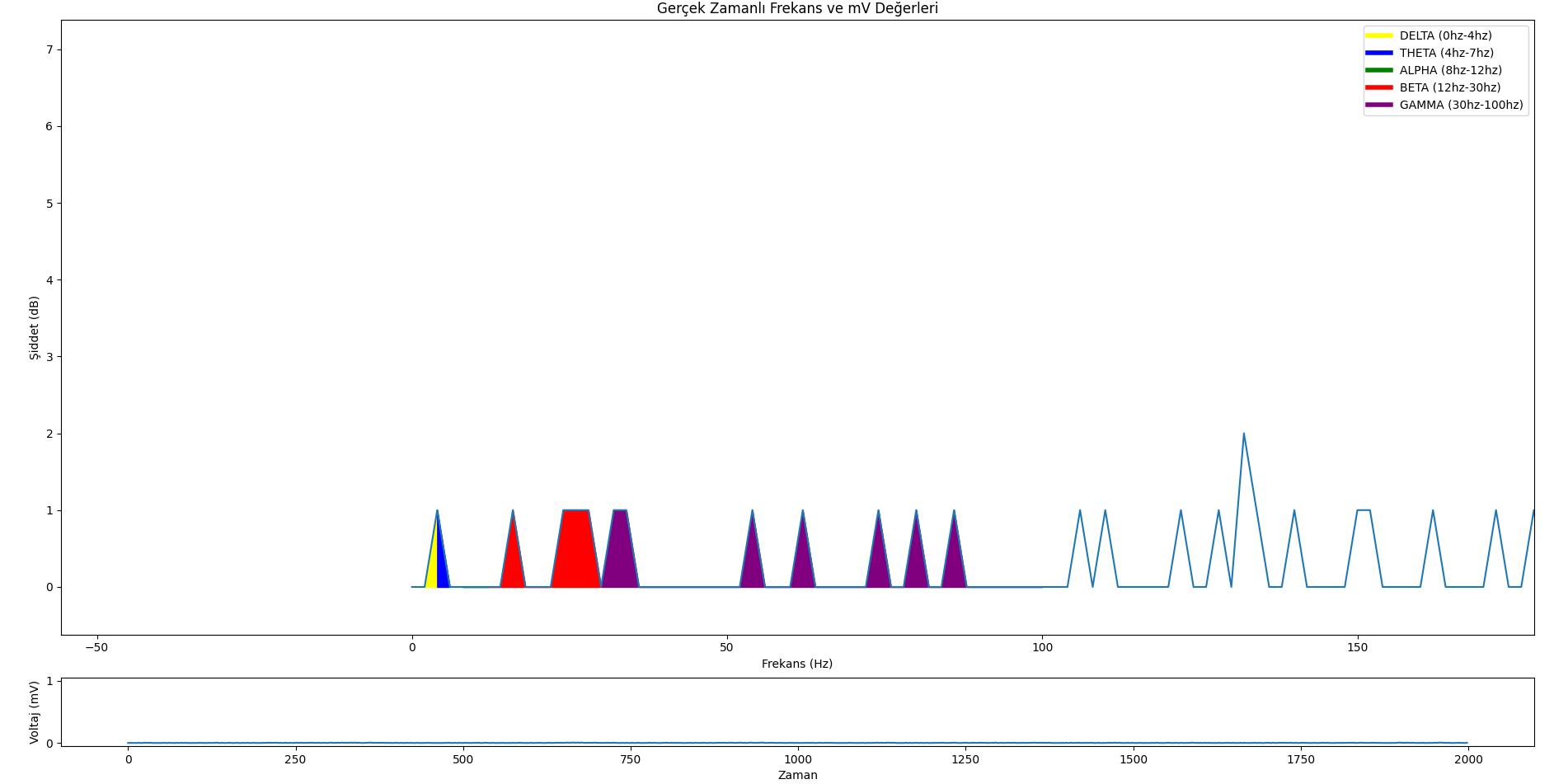](https://resimlink.com/vsyYqJnQ4k)
|
| 312 |
+
|
| 313 |
+
#### Summary
|
| 314 |
+
|
| 315 |
+
In summary, bai models continue to be developed to learn about and predict a person's thoughts and emotions.
|
| 316 |
+
|
| 317 |
+
#### Hardware
|
| 318 |
+
|
| 319 |
+
The EEG is the only hardware!
|
| 320 |
+
|
| 321 |
+
#### Software
|
| 322 |
|
| 323 |
+
You can then operate this EEG device (for the time being only with audio input) with the real-time data monitoring application we have published.
|
| 324 |
|
| 325 |
+
GitHub: https://github.com/neurazum/Realtime-EEG-Monitoring
|
| 326 |
|
| 327 |
+
## More Information
|
| 328 |
|
| 329 |
+
LinkedIn: https://www.linkedin.com/company/neurazum
|
| 330 |
|
| 331 |
## Model Card Authors [optional]
|
| 332 |
|
| 333 |
+
Eyüp İpler - https://www.linkedin.com/in/eyupipler/
|
| 334 |
|
| 335 |
## Model Card Contact
|
| 336 |
|
| 337 |
+
neurazum@gmail.com
|