

import from zenodo
Browse files- README.md +50 -0
- exp/tts_stats_raw_phn_jaconv_pyopenjtalk_accent/train/feats_stats.npz +0 -0
- exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/config.yaml +254 -0
- exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/attn_loss.png +0 -0
- exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/backward_time.png +0 -0
- exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/bce_loss.png +0 -0
- exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/forward_time.png +0 -0
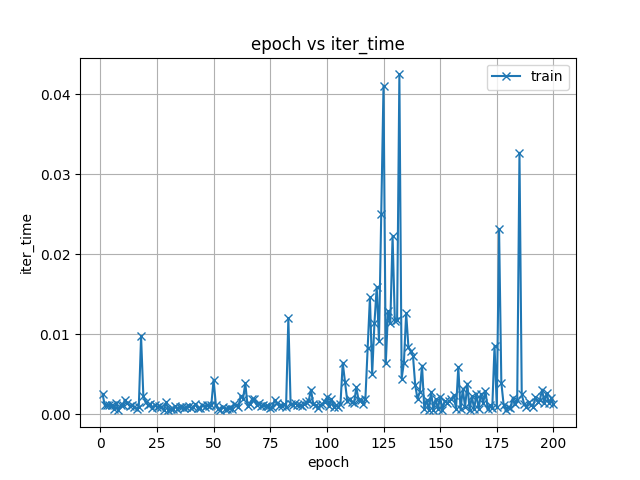
- exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/iter_time.png +0 -0
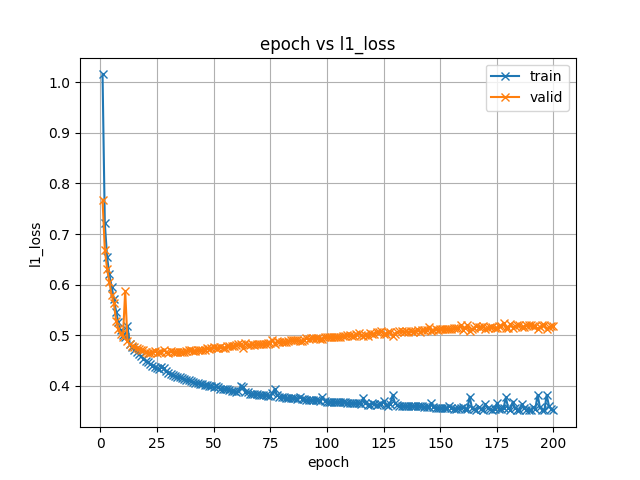
- exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/l1_loss.png +0 -0
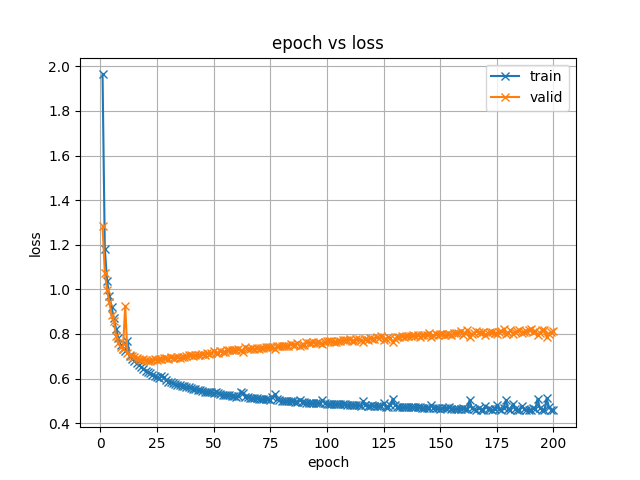
- exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/loss.png +0 -0
- exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/lr_0.png +0 -0
- exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/mse_loss.png +0 -0
- exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/optim_step_time.png +0 -0
- exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/train_time.png +0 -0
- exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/train.loss.ave_5best.pth +3 -0
- meta.yaml +8 -0
README.md
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tags:
|
| 3 |
+
- espnet
|
| 4 |
+
- audio
|
| 5 |
+
- text-to-speech
|
| 6 |
+
language: ja
|
| 7 |
+
datasets:
|
| 8 |
+
- jsut
|
| 9 |
+
license: cc-by-4.0
|
| 10 |
+
---
|
| 11 |
+
## Example ESPnet2 TTS model
|
| 12 |
+
### `kan-bayashi/jsut_tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent_train.loss.ave`
|
| 13 |
+
♻️ Imported from https://zenodo.org/record/4381098/
|
| 14 |
+
|
| 15 |
+
This model was trained by kan-bayashi using jsut/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
|
| 16 |
+
### Demo: How to use in ESPnet2
|
| 17 |
+
```python
|
| 18 |
+
# coming soon
|
| 19 |
+
```
|
| 20 |
+
### Citing ESPnet
|
| 21 |
+
```BibTex
|
| 22 |
+
@inproceedings{watanabe2018espnet,
|
| 23 |
+
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
|
| 24 |
+
title={{ESPnet}: End-to-End Speech Processing Toolkit},
|
| 25 |
+
year={2018},
|
| 26 |
+
booktitle={Proceedings of Interspeech},
|
| 27 |
+
pages={2207--2211},
|
| 28 |
+
doi={10.21437/Interspeech.2018-1456},
|
| 29 |
+
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
|
| 30 |
+
}
|
| 31 |
+
@inproceedings{hayashi2020espnet,
|
| 32 |
+
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
|
| 33 |
+
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
|
| 34 |
+
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
|
| 35 |
+
pages={7654--7658},
|
| 36 |
+
year={2020},
|
| 37 |
+
organization={IEEE}
|
| 38 |
+
}
|
| 39 |
+
```
|
| 40 |
+
or arXiv:
|
| 41 |
+
```bibtex
|
| 42 |
+
@misc{watanabe2018espnet,
|
| 43 |
+
title={ESPnet: End-to-End Speech Processing Toolkit},
|
| 44 |
+
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
|
| 45 |
+
year={2018},
|
| 46 |
+
eprint={1804.00015},
|
| 47 |
+
archivePrefix={arXiv},
|
| 48 |
+
primaryClass={cs.CL}
|
| 49 |
+
}
|
| 50 |
+
```
|
exp/tts_stats_raw_phn_jaconv_pyopenjtalk_accent/train/feats_stats.npz
ADDED
|
Binary file (1.4 kB). View file
|
exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/config.yaml
ADDED
|
@@ -0,0 +1,254 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
config: conf/tuning/train_tacotron2.yaml
|
| 2 |
+
print_config: false
|
| 3 |
+
log_level: INFO
|
| 4 |
+
dry_run: false
|
| 5 |
+
iterator_type: sequence
|
| 6 |
+
output_dir: exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent
|
| 7 |
+
ngpu: 1
|
| 8 |
+
seed: 0
|
| 9 |
+
num_workers: 1
|
| 10 |
+
num_att_plot: 3
|
| 11 |
+
dist_backend: nccl
|
| 12 |
+
dist_init_method: env://
|
| 13 |
+
dist_world_size: null
|
| 14 |
+
dist_rank: null
|
| 15 |
+
local_rank: 0
|
| 16 |
+
dist_master_addr: null
|
| 17 |
+
dist_master_port: null
|
| 18 |
+
dist_launcher: null
|
| 19 |
+
multiprocessing_distributed: false
|
| 20 |
+
cudnn_enabled: true
|
| 21 |
+
cudnn_benchmark: false
|
| 22 |
+
cudnn_deterministic: true
|
| 23 |
+
collect_stats: false
|
| 24 |
+
write_collected_feats: false
|
| 25 |
+
max_epoch: 200
|
| 26 |
+
patience: null
|
| 27 |
+
val_scheduler_criterion:
|
| 28 |
+
- valid
|
| 29 |
+
- loss
|
| 30 |
+
early_stopping_criterion:
|
| 31 |
+
- valid
|
| 32 |
+
- loss
|
| 33 |
+
- min
|
| 34 |
+
best_model_criterion:
|
| 35 |
+
- - valid
|
| 36 |
+
- loss
|
| 37 |
+
- min
|
| 38 |
+
- - train
|
| 39 |
+
- loss
|
| 40 |
+
- min
|
| 41 |
+
keep_nbest_models: 5
|
| 42 |
+
grad_clip: 1.0
|
| 43 |
+
grad_clip_type: 2.0
|
| 44 |
+
grad_noise: false
|
| 45 |
+
accum_grad: 1
|
| 46 |
+
no_forward_run: false
|
| 47 |
+
resume: true
|
| 48 |
+
train_dtype: float32
|
| 49 |
+
use_amp: false
|
| 50 |
+
log_interval: null
|
| 51 |
+
unused_parameters: false
|
| 52 |
+
use_tensorboard: true
|
| 53 |
+
use_wandb: false
|
| 54 |
+
wandb_project: null
|
| 55 |
+
wandb_id: null
|
| 56 |
+
pretrain_path: null
|
| 57 |
+
init_param: []
|
| 58 |
+
num_iters_per_epoch: 500
|
| 59 |
+
batch_size: 20
|
| 60 |
+
valid_batch_size: null
|
| 61 |
+
batch_bins: 3750000
|
| 62 |
+
valid_batch_bins: null
|
| 63 |
+
train_shape_file:
|
| 64 |
+
- exp/tts_stats_raw_phn_jaconv_pyopenjtalk_accent/train/text_shape.phn
|
| 65 |
+
- exp/tts_stats_raw_phn_jaconv_pyopenjtalk_accent/train/speech_shape
|
| 66 |
+
valid_shape_file:
|
| 67 |
+
- exp/tts_stats_raw_phn_jaconv_pyopenjtalk_accent/valid/text_shape.phn
|
| 68 |
+
- exp/tts_stats_raw_phn_jaconv_pyopenjtalk_accent/valid/speech_shape
|
| 69 |
+
batch_type: numel
|
| 70 |
+
valid_batch_type: null
|
| 71 |
+
fold_length:
|
| 72 |
+
- 150
|
| 73 |
+
- 240000
|
| 74 |
+
sort_in_batch: descending
|
| 75 |
+
sort_batch: descending
|
| 76 |
+
multiple_iterator: false
|
| 77 |
+
chunk_length: 500
|
| 78 |
+
chunk_shift_ratio: 0.5
|
| 79 |
+
num_cache_chunks: 1024
|
| 80 |
+
train_data_path_and_name_and_type:
|
| 81 |
+
- - dump/raw/tr_no_dev/text
|
| 82 |
+
- text
|
| 83 |
+
- text
|
| 84 |
+
- - dump/raw/tr_no_dev/wav.scp
|
| 85 |
+
- speech
|
| 86 |
+
- sound
|
| 87 |
+
valid_data_path_and_name_and_type:
|
| 88 |
+
- - dump/raw/dev/text
|
| 89 |
+
- text
|
| 90 |
+
- text
|
| 91 |
+
- - dump/raw/dev/wav.scp
|
| 92 |
+
- speech
|
| 93 |
+
- sound
|
| 94 |
+
allow_variable_data_keys: false
|
| 95 |
+
max_cache_size: 0.0
|
| 96 |
+
max_cache_fd: 32
|
| 97 |
+
valid_max_cache_size: null
|
| 98 |
+
optim: adam
|
| 99 |
+
optim_conf:
|
| 100 |
+
lr: 0.001
|
| 101 |
+
eps: 1.0e-06
|
| 102 |
+
weight_decay: 0.0
|
| 103 |
+
scheduler: null
|
| 104 |
+
scheduler_conf: {}
|
| 105 |
+
token_list:
|
| 106 |
+
- <blank>
|
| 107 |
+
- <unk>
|
| 108 |
+
- '1'
|
| 109 |
+
- '2'
|
| 110 |
+
- '0'
|
| 111 |
+
- '3'
|
| 112 |
+
- '4'
|
| 113 |
+
- '-1'
|
| 114 |
+
- '5'
|
| 115 |
+
- a
|
| 116 |
+
- o
|
| 117 |
+
- '-2'
|
| 118 |
+
- i
|
| 119 |
+
- '-3'
|
| 120 |
+
- u
|
| 121 |
+
- e
|
| 122 |
+
- k
|
| 123 |
+
- n
|
| 124 |
+
- t
|
| 125 |
+
- '6'
|
| 126 |
+
- r
|
| 127 |
+
- '-4'
|
| 128 |
+
- s
|
| 129 |
+
- N
|
| 130 |
+
- m
|
| 131 |
+
- '7'
|
| 132 |
+
- sh
|
| 133 |
+
- d
|
| 134 |
+
- g
|
| 135 |
+
- w
|
| 136 |
+
- '8'
|
| 137 |
+
- U
|
| 138 |
+
- '-5'
|
| 139 |
+
- I
|
| 140 |
+
- cl
|
| 141 |
+
- h
|
| 142 |
+
- y
|
| 143 |
+
- b
|
| 144 |
+
- '9'
|
| 145 |
+
- j
|
| 146 |
+
- ts
|
| 147 |
+
- ch
|
| 148 |
+
- '-6'
|
| 149 |
+
- z
|
| 150 |
+
- p
|
| 151 |
+
- '-7'
|
| 152 |
+
- f
|
| 153 |
+
- ky
|
| 154 |
+
- ry
|
| 155 |
+
- '-8'
|
| 156 |
+
- gy
|
| 157 |
+
- '-9'
|
| 158 |
+
- hy
|
| 159 |
+
- ny
|
| 160 |
+
- '-10'
|
| 161 |
+
- by
|
| 162 |
+
- my
|
| 163 |
+
- '-11'
|
| 164 |
+
- '-12'
|
| 165 |
+
- '-13'
|
| 166 |
+
- py
|
| 167 |
+
- '-14'
|
| 168 |
+
- '-15'
|
| 169 |
+
- v
|
| 170 |
+
- '10'
|
| 171 |
+
- '-16'
|
| 172 |
+
- '-17'
|
| 173 |
+
- '11'
|
| 174 |
+
- '-21'
|
| 175 |
+
- '-20'
|
| 176 |
+
- '12'
|
| 177 |
+
- '-19'
|
| 178 |
+
- '13'
|
| 179 |
+
- '-18'
|
| 180 |
+
- '14'
|
| 181 |
+
- dy
|
| 182 |
+
- '15'
|
| 183 |
+
- ty
|
| 184 |
+
- '-22'
|
| 185 |
+
- '16'
|
| 186 |
+
- '18'
|
| 187 |
+
- '19'
|
| 188 |
+
- '17'
|
| 189 |
+
- <sos/eos>
|
| 190 |
+
odim: null
|
| 191 |
+
model_conf: {}
|
| 192 |
+
use_preprocessor: true
|
| 193 |
+
token_type: phn
|
| 194 |
+
bpemodel: null
|
| 195 |
+
non_linguistic_symbols: null
|
| 196 |
+
cleaner: jaconv
|
| 197 |
+
g2p: pyopenjtalk_accent
|
| 198 |
+
feats_extract: fbank
|
| 199 |
+
feats_extract_conf:
|
| 200 |
+
fs: 24000
|
| 201 |
+
fmin: 80
|
| 202 |
+
fmax: 7600
|
| 203 |
+
n_mels: 80
|
| 204 |
+
hop_length: 300
|
| 205 |
+
n_fft: 2048
|
| 206 |
+
win_length: 1200
|
| 207 |
+
normalize: global_mvn
|
| 208 |
+
normalize_conf:
|
| 209 |
+
stats_file: exp/tts_stats_raw_phn_jaconv_pyopenjtalk_accent/train/feats_stats.npz
|
| 210 |
+
tts: tacotron2
|
| 211 |
+
tts_conf:
|
| 212 |
+
embed_dim: 512
|
| 213 |
+
elayers: 1
|
| 214 |
+
eunits: 512
|
| 215 |
+
econv_layers: 3
|
| 216 |
+
econv_chans: 512
|
| 217 |
+
econv_filts: 5
|
| 218 |
+
atype: location
|
| 219 |
+
adim: 512
|
| 220 |
+
aconv_chans: 32
|
| 221 |
+
aconv_filts: 15
|
| 222 |
+
cumulate_att_w: true
|
| 223 |
+
dlayers: 2
|
| 224 |
+
dunits: 1024
|
| 225 |
+
prenet_layers: 2
|
| 226 |
+
prenet_units: 256
|
| 227 |
+
postnet_layers: 5
|
| 228 |
+
postnet_chans: 512
|
| 229 |
+
postnet_filts: 5
|
| 230 |
+
output_activation: null
|
| 231 |
+
use_batch_norm: true
|
| 232 |
+
use_concate: true
|
| 233 |
+
use_residual: false
|
| 234 |
+
dropout_rate: 0.5
|
| 235 |
+
zoneout_rate: 0.1
|
| 236 |
+
reduction_factor: 1
|
| 237 |
+
spk_embed_dim: null
|
| 238 |
+
use_masking: true
|
| 239 |
+
bce_pos_weight: 5.0
|
| 240 |
+
use_guided_attn_loss: true
|
| 241 |
+
guided_attn_loss_sigma: 0.4
|
| 242 |
+
guided_attn_loss_lambda: 1.0
|
| 243 |
+
pitch_extract: null
|
| 244 |
+
pitch_extract_conf: {}
|
| 245 |
+
pitch_normalize: null
|
| 246 |
+
pitch_normalize_conf: {}
|
| 247 |
+
energy_extract: null
|
| 248 |
+
energy_extract_conf: {}
|
| 249 |
+
energy_normalize: null
|
| 250 |
+
energy_normalize_conf: {}
|
| 251 |
+
required:
|
| 252 |
+
- output_dir
|
| 253 |
+
- token_list
|
| 254 |
+
distributed: false
|
exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/attn_loss.png
ADDED
|
exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/backward_time.png
ADDED
|
exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/bce_loss.png
ADDED
|
exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/forward_time.png
ADDED
|
exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/iter_time.png
ADDED
|
exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/l1_loss.png
ADDED
|
exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/loss.png
ADDED
|
exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/lr_0.png
ADDED
|
exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/mse_loss.png
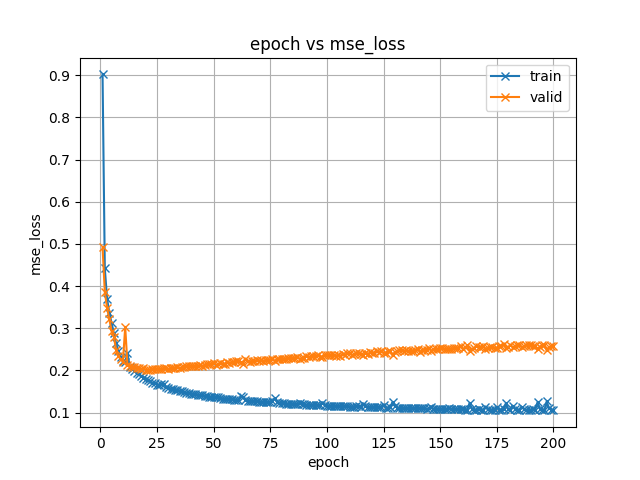
ADDED
|
exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/optim_step_time.png
ADDED
|
exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/images/train_time.png
ADDED
|
exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/train.loss.ave_5best.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:41d4eb5fcf0ef907b671f58dac8bee386ccd2b2f1525c81814b885d17adab515
|
| 3 |
+
size 107022094
|
meta.yaml
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
espnet: 0.8.0
|
| 2 |
+
files:
|
| 3 |
+
model_file: exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/train.loss.ave_5best.pth
|
| 4 |
+
python: "3.7.3 (default, Mar 27 2019, 22:11:17) \n[GCC 7.3.0]"
|
| 5 |
+
timestamp: 1608519878.710133
|
| 6 |
+
torch: 1.5.1
|
| 7 |
+
yaml_files:
|
| 8 |
+
train_config: exp/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_accent/config.yaml
|