
Commit
•
3c6da53
1
Parent(s):
61e1a0b
First commit
Browse files- README.md +135 -3
- grad_norm.png +0 -0
- loss.png +0 -0
- lr.png +0 -0
- test-turkish-t5.ipynb +1 -0
README.md
CHANGED
|
@@ -1,3 +1,135 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Turkish Diacritization
|
| 2 |
+
The goal of this project is to present and introduce the processing of Turkish language, particularly in social media situations, by investigating the field of diacritization and developing techniques for adding diacritical marks to text in the future.
|
| 3 |
+
|
| 4 |
+
# Path Design
|
| 5 |
+
```
|
| 6 |
+
.
|
| 7 |
+
├── docs
|
| 8 |
+
│ ├── Project Proposal.pdf
|
| 9 |
+
├── ner
|
| 10 |
+
│ ├── new_df.csv
|
| 11 |
+
│ ├── process_data.ipynb
|
| 12 |
+
│ ├── named-entity-recognition.ipynb
|
| 13 |
+
│ ├── getting_B.py
|
| 14 |
+
├── plots
|
| 15 |
+
├── tools
|
| 16 |
+
│ ├── data_utils.py
|
| 17 |
+
├── test
|
| 18 |
+
│ ├── test-turkish-t5.ipynb
|
| 19 |
+
├── train
|
| 20 |
+
│ ├── llm-fine-tune-t5-transformer.ipynb
|
| 21 |
+
│ ├── llm-fine-tune.ipynb
|
| 22 |
+
├── README.md
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
# Dataset
|
| 26 |
+
|
| 27 |
+
[The original train dataset](https://drive.google.com/file/d/1nR-HvWjrqDT2Sf6O6ScTUSldszRW0Shm/view?usp=share_link), You can access the original train dataset from the link.
|
| 28 |
+
|
| 29 |
+
[The test dataset](https://drive.google.com/file/d/1EK5FbVii8fYmqzY2WdQ6qo7-YfQqf1a9/view?usp=sharing), You can access the test dataset from the link.
|
| 30 |
+
|
| 31 |
+
We generated negative sentences by using original sentences. Negative sentences are randomly mapping of some letters to another letter. We used this negative sentences to generate augmented dataset. We used this augmented dataset to train our model.
|
| 32 |
+
|
| 33 |
+
Character Mapping is as follows:
|
| 34 |
+
```python
|
| 35 |
+
character_mapping = {
|
| 36 |
+
'ı': 'i',
|
| 37 |
+
'i': 'ı',
|
| 38 |
+
'u': 'ü',
|
| 39 |
+
'ü': 'u',
|
| 40 |
+
'o': 'ö',
|
| 41 |
+
'ö': 'o',
|
| 42 |
+
'ç': 'c',
|
| 43 |
+
'c': 'ç',
|
| 44 |
+
'ğ': 'g',
|
| 45 |
+
'g': 'ğ',
|
| 46 |
+
's': 'ş',
|
| 47 |
+
'ş': 's'
|
| 48 |
+
}
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
You can see the dataset from the link [the augmented dataset](https://drive.google.com/file/d/1ndDUpLIm0G_BL-k1qsxpo21pS-EwnXLt/view?usp=sharing)
|
| 52 |
+
|
| 53 |
+
# NER
|
| 54 |
+
|
| 55 |
+
## Why NER?
|
| 56 |
+
|
| 57 |
+
After the diacritization process, when we look our result we saw that our model does not care about capital letter. So we decided to add additional NER layer to our transormer model. We will use BiLSTM-CRF NER model to detect the named entities and we will use this information to improve our diacritization model.
|
| 58 |
+
|
| 59 |
+
## Dataset
|
| 60 |
+
|
| 61 |
+
Firstly, we downloaded [2 Kaggle datasets](https://www.kaggle.com/datasets/cebeci/turkish-ner?select=Coarse_Grained_NER_No_NoiseReduction.csv) and process them to make appropriate for BiLSTM-CRF NER model. You can find the processed dataset from the link. [The processed NER dataset](https://drive.google.com/file/d/1v-Ye6aF8ruc-A7nq9BZZ2KOKE1qxqBPf/view?usp=sharing)
|
| 62 |
+
|
| 63 |
+
However, BiLSTM-CRF Model, that we trained, did not work well. We needed to use pretrained BERT Model.
|
| 64 |
+
|
| 65 |
+
## NER Model
|
| 66 |
+
|
| 67 |
+
Model is [Turkish Bert Classication Model](https://huggingface.co/akdeniz27/bert-base-turkish-cased-ner) which is trained on Turkish NER dataset. We used this model to detect named entities in our text.
|
| 68 |
+
|
| 69 |
+
# Model
|
| 70 |
+
|
| 71 |
+
In this project we tried two different tasks for transformers. One of them is Casual LM with BERT and other is Seq2Seq with T5. And we decided to continue with T5 model because of the better results.
|
| 72 |
+
|
| 73 |
+
## BERT Model
|
| 74 |
+
|
| 75 |
+
We used BERT model for casual language modeling. We designed our dataset according to this task and trained a pretrained BERT model. You can find the model in that link. [BERT Model](https://huggingface.co/dbmdz/bert-base-turkish-cased)
|
| 76 |
+
|
| 77 |
+
## T5 Model
|
| 78 |
+
|
| 79 |
+
We used T5 model for seq2seq task. We designed our dataset according to this task and trained a pretrained T5 model. You can find the model in that link. [T5 Model](https://huggingface.co/Turkish-NLP/t5-efficient-small-turkish). Our resulted model for T5 is on kaggle you can download two version of the model from that link. [T5 Model](https://www.kaggle.com/models/emirhangazi/turkish-t5).
|
| 80 |
+
|
| 81 |
+
### V1.0
|
| 82 |
+
|
| 83 |
+
This variation of model half trained with 1 million samples and without missing tokens. So we can say this model works well but there are some issues according to it's result due to missing tokens.
|
| 84 |
+
|
| 85 |
+
### V2.0
|
| 86 |
+
|
| 87 |
+
This variation of model trained with 2 million samples and with missing tokens. So we can say this model works very good but this model needs NER model to improve it's performance.
|
| 88 |
+
|
| 89 |
+
#### Training Arguments
|
| 90 |
+
|
| 91 |
+
We used the following training arguments for our model.
|
| 92 |
+
|
| 93 |
+
```python
|
| 94 |
+
training_args = transformers.TrainingArguments(
|
| 95 |
+
per_device_train_batch_size=25,
|
| 96 |
+
num_train_epochs=1,
|
| 97 |
+
warmup_steps=50,
|
| 98 |
+
weight_decay=0.01,
|
| 99 |
+
learning_rate=2e-3,
|
| 100 |
+
save_steps=10000,
|
| 101 |
+
logging_steps=10,
|
| 102 |
+
save_strategy='steps',
|
| 103 |
+
output_dir="/kaggle/working/turkish2",
|
| 104 |
+
lr_scheduler_type="cosine",
|
| 105 |
+
)
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
# Training Plots
|
| 109 |
+
|
| 110 |
+
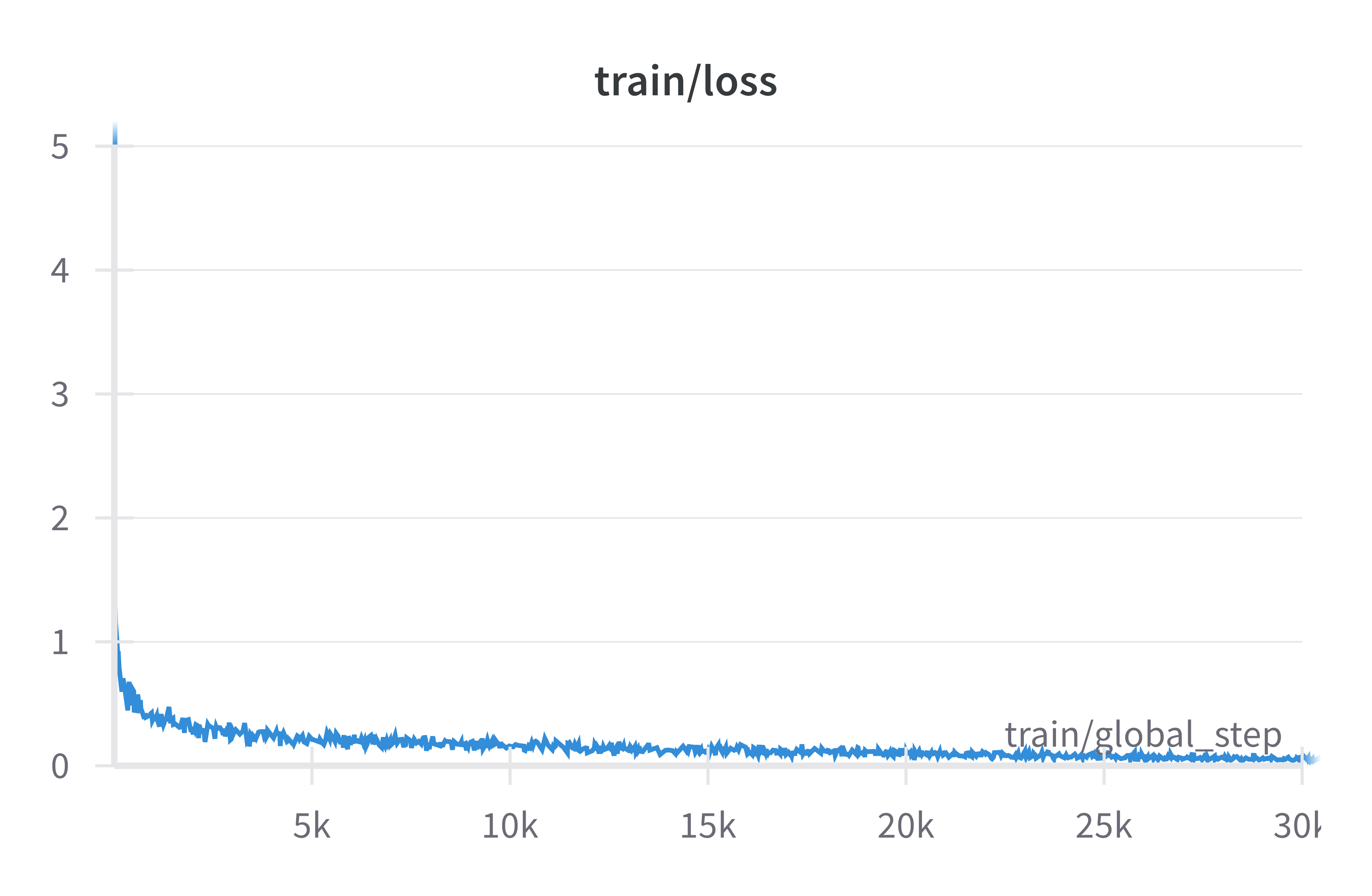
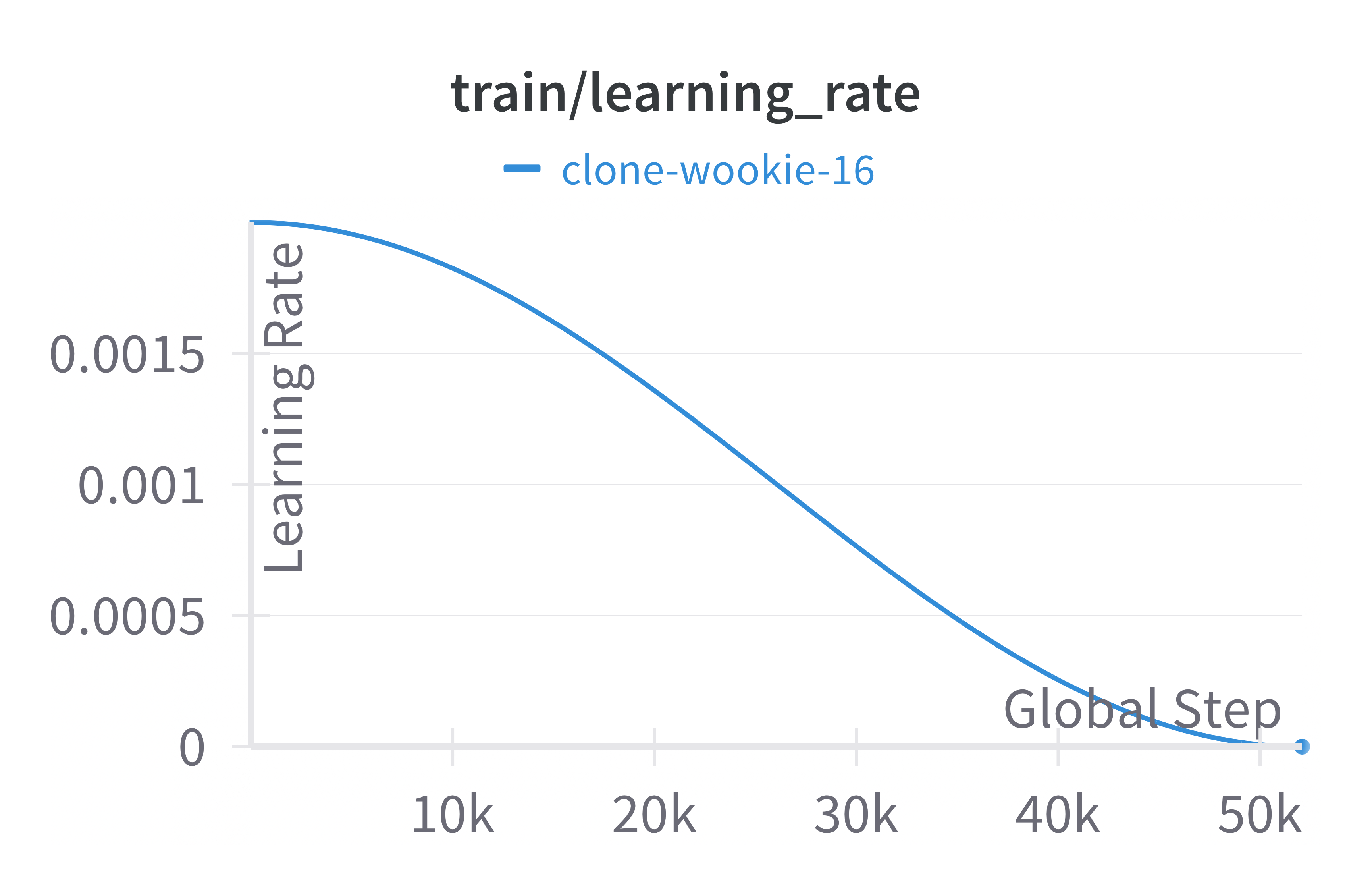
The loss and learning rate plots for the T5 model are given below.
|
| 111 |
+
|
| 112 |
+

|
| 113 |
+

|
| 114 |
+

|
| 115 |
+
|
| 116 |
+
# Model Evaluation
|
| 117 |
+
|
| 118 |
+
We evaluated our model with the provided test dataset. While we are testing our model, we also added NER model to our pipeline. We used NER model to detect named entities in our text and we used this information to improve our diacritization model. Evaluation function is given as follow:
|
| 119 |
+
|
| 120 |
+
```python
|
| 121 |
+
def acc_overall(test_result, testgold):
|
| 122 |
+
|
| 123 |
+
correct = 0
|
| 124 |
+
total = 0
|
| 125 |
+
# count number of correctly diacritized words
|
| 126 |
+
for i in range(len(testgold)):
|
| 127 |
+
for m in range(len(testgold[i].split())):
|
| 128 |
+
if test_result[i].split()[m] == testgold[i].split()[m]:
|
| 129 |
+
correct += 1
|
| 130 |
+
total +=1
|
| 131 |
+
|
| 132 |
+
return correct / total
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
Our model's accuracy on test dataset is <b>%94.03</b>. We can say that our model works well.
|
grad_norm.png
ADDED

|
loss.png
ADDED
|
lr.png
ADDED
|
test-turkish-t5.ipynb
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"cells":[{"cell_type":"markdown","metadata":{},"source":["# Evaluation of the Models"]},{"cell_type":"code","execution_count":73,"metadata":{"_cell_guid":"b1076dfc-b9ad-4769-8c92-a6c4dae69d19","_uuid":"8f2839f25d086af736a60e9eeb907d3b93b6e0e5","execution":{"iopub.execute_input":"2024-05-06T20:02:03.387301Z","iopub.status.busy":"2024-05-06T20:02:03.386545Z","iopub.status.idle":"2024-05-06T20:02:03.412072Z","shell.execute_reply":"2024-05-06T20:02:03.411093Z","shell.execute_reply.started":"2024-05-06T20:02:03.387269Z"},"trusted":true},"outputs":[{"name":"stdout","output_type":"stream","text":["/kaggle/input/nlp-project-test/test.csv\n","/kaggle/input/train-augmented/train_augmented.csv\n","/kaggle/input/turkish-t5/pytorch/v2.0/1/model-last/config.json\n","/kaggle/input/turkish-t5/pytorch/v2.0/1/model-last/training_args.bin\n","/kaggle/input/turkish-t5/pytorch/v2.0/1/model-last/model.safetensors\n","/kaggle/input/turkish-t5/pytorch/v2.0/1/model-last/generation_config.json\n","/kaggle/input/turkish-t5/pytorch/v1.1/1/model/config.json\n","/kaggle/input/turkish-t5/pytorch/v1.1/1/model/trainer_state.json\n","/kaggle/input/turkish-t5/pytorch/v1.1/1/model/training_args.bin\n","/kaggle/input/turkish-t5/pytorch/v1.1/1/model/scheduler.pt\n","/kaggle/input/turkish-t5/pytorch/v1.1/1/model/model.safetensors\n","/kaggle/input/turkish-t5/pytorch/v1.1/1/model/optimizer.pt\n","/kaggle/input/turkish-t5/pytorch/v1.1/1/model/rng_state.pth\n","/kaggle/input/turkish-t5/pytorch/v1.1/1/model/generation_config.json\n"]}],"source":["# # This Python 3 environment comes with many helpful analytics libraries installed\n","# # It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python\n","# # For example, here's several helpful packages to load\n","\n","# import numpy as np # linear algebra\n","# import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)\n","\n","# # Input data files are available in the read-only \"../input/\" directory\n","# # For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory\n","\n","# import os\n","# for dirname, _, filenames in os.walk('/kaggle/input'):\n","# for filename in filenames:\n","# print(os.path.join(dirname, filename))\n","\n","# # You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using \"Save & Run All\" \n","# # You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session"]},{"cell_type":"markdown","metadata":{},"source":["## Importing Libraries\n"]},{"cell_type":"code","execution_count":74,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:02:04.080878Z","iopub.status.busy":"2024-05-06T20:02:04.080233Z","iopub.status.idle":"2024-05-06T20:02:04.085997Z","shell.execute_reply":"2024-05-06T20:02:04.084835Z","shell.execute_reply.started":"2024-05-06T20:02:04.080846Z"},"trusted":true},"outputs":[],"source":["import torch\n","from transformers import (\n"," AutoTokenizer,\n"," AutoModelForSeq2SeqLM,\n"," AutoModelForTokenClassification,\n"," pipeline)\n","\n","import pandas as pd"]},{"cell_type":"markdown","metadata":{},"source":["## Uploading Pretrained NER Model"]},{"cell_type":"code","execution_count":75,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:02:04.491063Z","iopub.status.busy":"2024-05-06T20:02:04.490671Z","iopub.status.idle":"2024-05-06T20:02:05.746532Z","shell.execute_reply":"2024-05-06T20:02:05.745397Z","shell.execute_reply.started":"2024-05-06T20:02:04.491034Z"},"trusted":true},"outputs":[],"source":["ner_model = AutoModelForTokenClassification.from_pretrained(\"akdeniz27/bert-base-turkish-cased-ner\",device_map = \"cuda:0\") # pretrained ner model \n","ner_tokenizer = AutoTokenizer.from_pretrained(\"akdeniz27/bert-base-turkish-cased-ner\") # pretrained ner tokenizer\n","ner = pipeline('ner', model=ner_model, tokenizer=ner_tokenizer, aggregation_strategy=\"first\") # ner pipeline\n"]},{"cell_type":"code","execution_count":76,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:02:05.749750Z","iopub.status.busy":"2024-05-06T20:02:05.748895Z","iopub.status.idle":"2024-05-06T20:02:05.754301Z","shell.execute_reply":"2024-05-06T20:02:05.753358Z","shell.execute_reply.started":"2024-05-06T20:02:05.749713Z"},"trusted":true},"outputs":[],"source":["model_dir = \"/kaggle/input/turkish-t5/pytorch/v2.0/1/model-last\" # our model "]},{"cell_type":"code","execution_count":77,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:02:05.756941Z","iopub.status.busy":"2024-05-06T20:02:05.755806Z","iopub.status.idle":"2024-05-06T20:02:05.764492Z","shell.execute_reply":"2024-05-06T20:02:05.763371Z","shell.execute_reply.started":"2024-05-06T20:02:05.756876Z"},"trusted":true},"outputs":[],"source":["test_dataset_dir = \"/kaggle/input/nlp-project-test/test.csv\" # dataset location"]},{"cell_type":"code","execution_count":79,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:02:06.191431Z","iopub.status.busy":"2024-05-06T20:02:06.190727Z","iopub.status.idle":"2024-05-06T20:02:06.201149Z","shell.execute_reply":"2024-05-06T20:02:06.200218Z","shell.execute_reply.started":"2024-05-06T20:02:06.191389Z"},"trusted":true},"outputs":[],"source":["df_test = pd.read_csv(test_dataset_dir) # read dataset"]},{"cell_type":"markdown","metadata":{},"source":["## Testing NER Model Usage"]},{"cell_type":"code","execution_count":87,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:02:11.544600Z","iopub.status.busy":"2024-05-06T20:02:11.543964Z","iopub.status.idle":"2024-05-06T20:02:11.589457Z","shell.execute_reply":"2024-05-06T20:02:11.588309Z","shell.execute_reply.started":"2024-05-06T20:02:11.544567Z"},"trusted":true},"outputs":[{"data":{"text/plain":["[{'entity_group': 'LOC',\n"," 'score': 0.57057905,\n"," 'word': 'franken',\n"," 'start': 285,\n"," 'end': 292},\n"," {'entity_group': 'PER',\n"," 'score': 0.990382,\n"," 'word': 'Joe',\n"," 'start': 383,\n"," 'end': 386},\n"," {'entity_group': 'PER',\n"," 'score': 0.98566425,\n"," 'word': 'Marley',\n"," 'start': 415,\n"," 'end': 421},\n"," {'entity_group': 'LOC',\n"," 'score': 0.9250223,\n"," 'word': 'Roma´ya',\n"," 'start': 545,\n"," 'end': 552},\n"," {'entity_group': 'PER',\n"," 'score': 0.9943376,\n"," 'word': 'Sammy´nin',\n"," 'start': 612,\n"," 'end': 621},\n"," {'entity_group': 'LOC',\n"," 'score': 0.9336442,\n"," 'word': 'Istanbul',\n"," 'start': 717,\n"," 'end': 725},\n"," {'entity_group': 'PER',\n"," 'score': 0.9977376,\n"," 'word': 'Abraham Lincoln',\n"," 'start': 775,\n"," 'end': 790}]"]},"execution_count":87,"metadata":{},"output_type":"execute_result"}],"source":["ner(df_test['Sentence'].values[167]) # testing ner pipeline"]},{"cell_type":"markdown","metadata":{},"source":["## Uploading Our Fine-Tuned Transformers Model"]},{"cell_type":"code","execution_count":82,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:02:07.439647Z","iopub.status.busy":"2024-05-06T20:02:07.438955Z","iopub.status.idle":"2024-05-06T20:02:08.592399Z","shell.execute_reply":"2024-05-06T20:02:08.591574Z","shell.execute_reply.started":"2024-05-06T20:02:07.439616Z"},"trusted":true},"outputs":[],"source":["model = AutoModelForSeq2SeqLM.from_pretrained(model_dir, device_map=\"cuda:0\") # load model "]},{"cell_type":"code","execution_count":83,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:02:08.594453Z","iopub.status.busy":"2024-05-06T20:02:08.594143Z","iopub.status.idle":"2024-05-06T20:02:08.598606Z","shell.execute_reply":"2024-05-06T20:02:08.597684Z","shell.execute_reply.started":"2024-05-06T20:02:08.594427Z"},"trusted":true},"outputs":[],"source":["tokenizer_dir = \"Turkish-NLP/t5-efficient-small-turkish\" # tokenizer location "]},{"cell_type":"code","execution_count":84,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:02:08.600343Z","iopub.status.busy":"2024-05-06T20:02:08.600006Z","iopub.status.idle":"2024-05-06T20:02:08.608039Z","shell.execute_reply":"2024-05-06T20:02:08.606966Z","shell.execute_reply.started":"2024-05-06T20:02:08.600313Z"},"trusted":true},"outputs":[],"source":["device = torch.device('cuda:0') # device "]},{"cell_type":"code","execution_count":85,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:02:09.509859Z","iopub.status.busy":"2024-05-06T20:02:09.509503Z","iopub.status.idle":"2024-05-06T20:02:09.920290Z","shell.execute_reply":"2024-05-06T20:02:09.919467Z","shell.execute_reply.started":"2024-05-06T20:02:09.509822Z"},"trusted":true},"outputs":[],"source":["tokenizer = AutoTokenizer.from_pretrained(tokenizer_dir) # load tokenizer "]},{"cell_type":"markdown","metadata":{},"source":["## Adding the Special Tokens"]},{"cell_type":"code","execution_count":86,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:02:10.931548Z","iopub.status.busy":"2024-05-06T20:02:10.931164Z","iopub.status.idle":"2024-05-06T20:02:11.080444Z","shell.execute_reply":"2024-05-06T20:02:11.079391Z","shell.execute_reply.started":"2024-05-06T20:02:10.931519Z"},"trusted":true},"outputs":[{"name":"stdout","output_type":"stream","text":["q not in vocab\n","( not in vocab\n","° not in vocab\n","[ not in vocab\n","´ not in vocab\n","] not in vocab\n","{ not in vocab\n","} not in vocab\n","& not in vocab\n"]}],"source":["missing_tokens = [\"q\",\"(\",\"°\",\"[\",\"´\",\"]\",\"{\",\"}\",\"&\"] \n","for i in missing_tokens: \n"," if i not in tokenizer.vocab.keys():\n"," print(f\"{i} not in vocab\")"]},{"cell_type":"code","execution_count":89,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:02:17.127810Z","iopub.status.busy":"2024-05-06T20:02:17.126948Z","iopub.status.idle":"2024-05-06T20:02:17.133819Z","shell.execute_reply":"2024-05-06T20:02:17.132677Z","shell.execute_reply.started":"2024-05-06T20:02:17.127777Z"},"trusted":true},"outputs":[],"source":["for i in missing_tokens: \n"," tokenizer.add_tokens(i)"]},{"cell_type":"markdown","metadata":{},"source":["## Testing Function"]},{"cell_type":"code","execution_count":94,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:04:08.374259Z","iopub.status.busy":"2024-05-06T20:04:08.373829Z","iopub.status.idle":"2024-05-06T20:04:08.380610Z","shell.execute_reply":"2024-05-06T20:04:08.379473Z","shell.execute_reply.started":"2024-05-06T20:04:08.374218Z"},"trusted":true},"outputs":[],"source":["def generate_result(text):\n"," prefix = \"Correct diacritics for : \"\n"," postfix = \" </s>\"\n"," text = prefix + text + postfix\n"," \n"," tokenizer.truncation_side = \"left\"\n"," batch = tokenizer(text, return_tensors='pt', max_length = 64, truncation = False).to(device)\n"," result = model.generate(**batch, max_new_tokens = 128)\n"," result = tokenizer.batch_decode(result)\n"," \n"," return str(result[0])"]},{"cell_type":"markdown","metadata":{},"source":["## Processing Functions before Testing"]},{"cell_type":"code","execution_count":182,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:36:12.529255Z","iopub.status.busy":"2024-05-06T20:36:12.528564Z","iopub.status.idle":"2024-05-06T20:36:12.543577Z","shell.execute_reply":"2024-05-06T20:36:12.542475Z","shell.execute_reply.started":"2024-05-06T20:36:12.529220Z"},"trusted":true},"outputs":[],"source":["# json\n","import re \n","\n","def ner_predict_mapping(text, threshold=0.3):\n"," result = ner(text)\n"," if len(result) == 0:\n"," return []\n"," else:\n"," special_words = [result[\"word\"] for result in result if result[\"score\"] > threshold]\n"," special_words_ = []\n"," for word_ in special_words:\n"," if word_.lower()[0] == \"i\":\n"," word_ = word_.replace(\"I\",\"İ\")\n"," if len(word_.split()) > 1:\n"," special_words_.extend(word_.split())\n"," else:\n"," special_words_.append(word_)\n"," \n"," return special_words_\n"," \n","def split_text_into_n_worded_chunks(text, n):\n"," words = text.split()\n"," chunks = []\n"," for i in range(0, len(words), n):\n"," chunks.append(' '.join(words[i:i+n]))\n"," last_chunk_words = len(words) % n\n"," if last_chunk_words != 0:\n"," chunks[-1] = ' '.join(words[-last_chunk_words:])\n"," return chunks\n","\n","def chunk_2(text):\n"," chunks = split_text_into_n_worded_chunks(text, 2)\n"," processed_chunks = [re.sub(r'([\"q(°\\[\\]{}&´])\\s+', r'\\1',generate_result(chunk)) for chunk in chunks] \n"," result = ' '.join(processed_chunks)\n"," return result.replace(\"<pad>\",\"\").replace(\"</s>\",\"\").replace(\" \",\" \")\n","\n","def chunk_1(text): \n"," chunks = split_text_into_n_worded_chunks(text, 1)\n"," processed_chunks = [generate_result(chunk).replace(\" \",\"\") for chunk in chunks]\n"," result = ''.join(processed_chunks)\n"," return result.replace(\"<pad>\",\" \").replace(\"</s>\",\"\")\n","\n","def process_text(text):\n"," words = ner_predict_mapping(text)\n"," two_chunk = chunk_2(text)\n"," one_chunk = chunk_1(text)\n"," if len(one_chunk.split()) != len(two_chunk.split()):\n"," for word in words: \n"," one_chunk = one_chunk.replace(word.lower().replace('i̇',\"i\"),word)\n"," return one_chunk\n"," else: \n"," for word in words: \n"," two_chunk = two_chunk.replace(word.lower().replace('i̇',\"i\"),word)\n"," return two_chunk"]},{"cell_type":"code","execution_count":191,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:36:51.027557Z","iopub.status.busy":"2024-05-06T20:36:51.027167Z","iopub.status.idle":"2024-05-06T20:59:13.613401Z","shell.execute_reply":"2024-05-06T20:59:13.612486Z","shell.execute_reply.started":"2024-05-06T20:36:51.027527Z"},"trusted":true},"outputs":[],"source":["df_test[\"Result\"] = df_test[\"Sentence\"].apply(process_text) # apply preprocessing to the dataset"]},{"cell_type":"code","execution_count":192,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:59:21.080714Z","iopub.status.busy":"2024-05-06T20:59:21.080065Z","iopub.status.idle":"2024-05-06T20:59:21.099328Z","shell.execute_reply":"2024-05-06T20:59:21.098441Z","shell.execute_reply.started":"2024-05-06T20:59:21.080684Z"},"trusted":true},"outputs":[{"data":{"text/html":["<div>\n","<style scoped>\n"," .dataframe tbody tr th:only-of-type {\n"," vertical-align: middle;\n"," }\n","\n"," .dataframe tbody tr th {\n"," vertical-align: top;\n"," }\n","\n"," .dataframe thead th {\n"," text-align: right;\n"," }\n","</style>\n","<table border=\"1\" class=\"dataframe\">\n"," <thead>\n"," <tr style=\"text-align: right;\">\n"," <th></th>\n"," <th>ID</th>\n"," <th>Sentence</th>\n"," <th>Result</th>\n"," </tr>\n"," </thead>\n"," <tbody>\n"," <tr>\n"," <th>0</th>\n"," <td>0</td>\n"," <td>tr ekonomi ve politika haberleri turkiye nin ...</td>\n"," <td>tr ekonomi ve politika haberleri türkiye nin ...</td>\n"," </tr>\n"," <tr>\n"," <th>1</th>\n"," <td>1</td>\n"," <td>uye girisi</td>\n"," <td>üye girişi</td>\n"," </tr>\n"," <tr>\n"," <th>2</th>\n"," <td>2</td>\n"," <td>son guncelleme 12:12</td>\n"," <td>son güncelleme 12:12</td>\n"," </tr>\n"," <tr>\n"," <th>3</th>\n"," <td>3</td>\n"," <td>Imrali Mit gorusmesi ihtiyac duyuldukca oluyor</td>\n"," <td>imralı Mit görüşmesi ihtiyaç duyuldukça oluyor</td>\n"," </tr>\n"," <tr>\n"," <th>4</th>\n"," <td>4</td>\n"," <td>Suriye deki silahli selefi muhalifler yeni ku...</td>\n"," <td>Suriye deki silahlı selefi muhalifler yeni ku...</td>\n"," </tr>\n"," <tr>\n"," <th>...</th>\n"," <td>...</td>\n"," <td>...</td>\n"," <td>...</td>\n"," </tr>\n"," <tr>\n"," <th>1152</th>\n"," <td>1152</td>\n"," <td>Yuregir Adana ilimize ait sirin bir ilcedir</td>\n"," <td>yüreğir Adana ilimize ait şirin bir ilçedir</td>\n"," </tr>\n"," <tr>\n"," <th>1153</th>\n"," <td>1153</td>\n"," <td>yuze guluculugun at oynattigi bir aydinlar ort...</td>\n"," <td>yüze gülücülüğün at oynattığı bir aydınlar or...</td>\n"," </tr>\n"," <tr>\n"," <th>1154</th>\n"," <td>1154</td>\n"," <td>zavalli adami oracikta astilar ve hic kimse se...</td>\n"," <td>zavallı adamı oracıkta astılar ve hiç kimse s...</td>\n"," </tr>\n"," <tr>\n"," <th>1155</th>\n"," <td>1155</td>\n"," <td>zengin cocuklarina ariz munasebetsizlikler fak...</td>\n"," <td>zengin çocuklarına ariz münakaşsizlikler faki...</td>\n"," </tr>\n"," <tr>\n"," <th>1156</th>\n"," <td>1156</td>\n"," <td>senin acin hepimizin acisidir</td>\n"," <td>senin açın hepimizin acısıdır</td>\n"," </tr>\n"," </tbody>\n","</table>\n","<p>1157 rows × 3 columns</p>\n","</div>"],"text/plain":[" ID Sentence \\\n","0 0 tr ekonomi ve politika haberleri turkiye nin ... \n","1 1 uye girisi \n","2 2 son guncelleme 12:12 \n","3 3 Imrali Mit gorusmesi ihtiyac duyuldukca oluyor \n","4 4 Suriye deki silahli selefi muhalifler yeni ku... \n","... ... ... \n","1152 1152 Yuregir Adana ilimize ait sirin bir ilcedir \n","1153 1153 yuze guluculugun at oynattigi bir aydinlar ort... \n","1154 1154 zavalli adami oracikta astilar ve hic kimse se... \n","1155 1155 zengin cocuklarina ariz munasebetsizlikler fak... \n","1156 1156 senin acin hepimizin acisidir \n","\n"," Result \n","0 tr ekonomi ve politika haberleri türkiye nin ... \n","1 üye girişi \n","2 son güncelleme 12:12 \n","3 imralı Mit görüşmesi ihtiyaç duyuldukça oluyor \n","4 Suriye deki silahlı selefi muhalifler yeni ku... \n","... ... \n","1152 yüreğir Adana ilimize ait şirin bir ilçedir \n","1153 yüze gülücülüğün at oynattığı bir aydınlar or... \n","1154 zavallı adamı oracıkta astılar ve hiç kimse s... \n","1155 zengin çocuklarına ariz münakaşsizlikler faki... \n","1156 senin açın hepimizin acısıdır \n","\n","[1157 rows x 3 columns]"]},"execution_count":192,"metadata":{},"output_type":"execute_result"}],"source":["df_test"]},{"cell_type":"code","execution_count":193,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T20:59:27.981615Z","iopub.status.busy":"2024-05-06T20:59:27.981246Z","iopub.status.idle":"2024-05-06T20:59:28.001820Z","shell.execute_reply":"2024-05-06T20:59:28.000894Z","shell.execute_reply.started":"2024-05-06T20:59:27.981586Z"},"trusted":true},"outputs":[],"source":["df_test.to_csv(\"/kaggle/working/test_designed2.csv\") # save the result "]},{"cell_type":"code","execution_count":194,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T21:00:22.851347Z","iopub.status.busy":"2024-05-06T21:00:22.850931Z","iopub.status.idle":"2024-05-06T21:00:22.856811Z","shell.execute_reply":"2024-05-06T21:00:22.855676Z","shell.execute_reply.started":"2024-05-06T21:00:22.851317Z"},"trusted":true},"outputs":[],"source":["df_test['Sentence'] = df_test['Result'] # making the result the input for the competition"]},{"cell_type":"code","execution_count":195,"metadata":{"execution":{"iopub.execute_input":"2024-05-06T21:00:49.554221Z","iopub.status.busy":"2024-05-06T21:00:49.553096Z","iopub.status.idle":"2024-05-06T21:00:49.560833Z","shell.execute_reply":"2024-05-06T21:00:49.559888Z","shell.execute_reply.started":"2024-05-06T21:00:49.554186Z"},"trusted":true},"outputs":[],"source":["df_test = df_test.drop(columns= ['Result'])"]},{"cell_type":"markdown","metadata":{},"source":["## Saving the Test Results"]},{"cell_type":"code","execution_count":4,"metadata":{},"outputs":[],"source":["df_test.to_csv('testv3.csv', index = False) # save the result"]}],"metadata":{"kaggle":{"accelerator":"nvidiaTeslaT4","dataSources":[{"datasetId":4868624,"sourceId":8214383,"sourceType":"datasetVersion"},{"datasetId":4943387,"sourceId":8321889,"sourceType":"datasetVersion"},{"isSourceIdPinned":true,"modelInstanceId":36800,"sourceId":43823,"sourceType":"modelInstanceVersion"},{"isSourceIdPinned":true,"modelInstanceId":37084,"sourceId":44158,"sourceType":"modelInstanceVersion"}],"dockerImageVersionId":30699,"isGpuEnabled":true,"isInternetEnabled":true,"language":"python","sourceType":"notebook"},"kernelspec":{"display_name":"Python 3","language":"python","name":"python3"},"language_info":{"codemirror_mode":{"name":"ipython","version":3},"file_extension":".py","mimetype":"text/x-python","name":"python","nbconvert_exporter":"python","pygments_lexer":"ipython3","version":"3.8.19"}},"nbformat":4,"nbformat_minor":4}
|