
Commit
•
3ca532e
1
Parent(s):
df8d078
Upload 4 files
Browse files- Model_Evaluation_UdacityGenAIAWS.ipynb +307 -0
- Model_FineTuning.ipynb +875 -0
- Screenshot 2024-05-22 164003.png +0 -0
- Screenshot 2024-05-22 171622.png +0 -0
Model_Evaluation_UdacityGenAIAWS.ipynb
ADDED
|
@@ -0,0 +1,307 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"#### Step 3: LLM Model Evaluation"
|
| 8 |
+
]
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
"cell_type": "markdown",
|
| 12 |
+
"metadata": {},
|
| 13 |
+
"source": [
|
| 14 |
+
"In this notebook, you'll deploy the Meta Llama 2 7B model and evaluate it's text generation capabilities and domain knowledge. You'll use the SageMaker Python SDK for Foundation Models and deploy the model for inference. \n",
|
| 15 |
+
"\n",
|
| 16 |
+
"The Llama 2 7B Foundation model performs the task of text generation. It takes a text string as input and predicts next words in the sequence. "
|
| 17 |
+
]
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"cell_type": "markdown",
|
| 21 |
+
"metadata": {},
|
| 22 |
+
"source": [
|
| 23 |
+
"#### Set Up\n",
|
| 24 |
+
"There are some initial steps required for setup. If you recieve warnings after running these cells, you can ignore them as they won't impact the code running in the notebook. Run the cell below to ensure you're using the latest version of the Sagemaker Python client library. Restart the Kernel after you run this cell. "
|
| 25 |
+
]
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"cell_type": "code",
|
| 29 |
+
"execution_count": 1,
|
| 30 |
+
"metadata": {
|
| 31 |
+
"tags": []
|
| 32 |
+
},
|
| 33 |
+
"outputs": [],
|
| 34 |
+
"source": [
|
| 35 |
+
"!pip install ipywidgets==7.0.0 --quiet\n",
|
| 36 |
+
"!pip install --upgrade sagemaker datasets --quiet"
|
| 37 |
+
]
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"cell_type": "markdown",
|
| 41 |
+
"metadata": {},
|
| 42 |
+
"source": [
|
| 43 |
+
"***! Restart the notebook kernel now after running the above cell and before you run any cells below !*** "
|
| 44 |
+
]
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"cell_type": "markdown",
|
| 48 |
+
"metadata": {},
|
| 49 |
+
"source": [
|
| 50 |
+
"To deploy the model on Amazon Sagemaker, we need to setup and authenticate the use of AWS services. Yo'll uuse the execution role associated with the current notebook instance as the AWS account role with SageMaker access. Validate your role is the Sagemaker IAM role you created for the project by running the next cell. "
|
| 51 |
+
]
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"cell_type": "code",
|
| 55 |
+
"execution_count": 1,
|
| 56 |
+
"metadata": {
|
| 57 |
+
"tags": []
|
| 58 |
+
},
|
| 59 |
+
"outputs": [
|
| 60 |
+
{
|
| 61 |
+
"name": "stdout",
|
| 62 |
+
"output_type": "stream",
|
| 63 |
+
"text": [
|
| 64 |
+
"sagemaker.config INFO - Not applying SDK defaults from location: /etc/xdg/sagemaker/config.yaml\n",
|
| 65 |
+
"sagemaker.config INFO - Not applying SDK defaults from location: /home/ec2-user/.config/sagemaker/config.yaml\n",
|
| 66 |
+
"arn:aws:iam::558778471579:role/service-role/SageMaker-ProjectSagemakerRole\n",
|
| 67 |
+
"us-west-2\n",
|
| 68 |
+
"<sagemaker.session.Session object at 0x7ff7ca50a530>\n"
|
| 69 |
+
]
|
| 70 |
+
}
|
| 71 |
+
],
|
| 72 |
+
"source": [
|
| 73 |
+
"import sagemaker, boto3, json\n",
|
| 74 |
+
"from sagemaker.session import Session\n",
|
| 75 |
+
"\n",
|
| 76 |
+
"sagemaker_session = Session()\n",
|
| 77 |
+
"aws_role = sagemaker_session.get_caller_identity_arn()\n",
|
| 78 |
+
"aws_region = boto3.Session().region_name\n",
|
| 79 |
+
"sess = sagemaker.Session()\n",
|
| 80 |
+
"print(aws_role)\n",
|
| 81 |
+
"print(aws_region)\n",
|
| 82 |
+
"print(sess)"
|
| 83 |
+
]
|
| 84 |
+
},
|
| 85 |
+
{
|
| 86 |
+
"cell_type": "markdown",
|
| 87 |
+
"metadata": {},
|
| 88 |
+
"source": [
|
| 89 |
+
"## 2. Select Text Generation Model Meta Llama 2 7B\n",
|
| 90 |
+
"Run the next cell to set variables that contain the values of the name of the model we want to load and the version of the model ."
|
| 91 |
+
]
|
| 92 |
+
},
|
| 93 |
+
{
|
| 94 |
+
"cell_type": "code",
|
| 95 |
+
"execution_count": 3,
|
| 96 |
+
"metadata": {
|
| 97 |
+
"tags": []
|
| 98 |
+
},
|
| 99 |
+
"outputs": [],
|
| 100 |
+
"source": [
|
| 101 |
+
"(model_id, model_version,) = (\"meta-textgeneration-llama-2-7b\",\"2.*\",)"
|
| 102 |
+
]
|
| 103 |
+
},
|
| 104 |
+
{
|
| 105 |
+
"cell_type": "markdown",
|
| 106 |
+
"metadata": {},
|
| 107 |
+
"source": [
|
| 108 |
+
"Running the next cell deploys the model\n",
|
| 109 |
+
"This Python code is used to deploy a machine learning model using Amazon SageMaker's JumpStart library. \n",
|
| 110 |
+
"\n",
|
| 111 |
+
"1. Import the `JumpStartModel` class from the `sagemaker.jumpstart.model` module.\n",
|
| 112 |
+
"\n",
|
| 113 |
+
"2. Create an instance of the `JumpStartModel` class using the `model_id` and `model_version` variables created in the previous cell. This object represents the machine learning model you want to deploy.\n",
|
| 114 |
+
"\n",
|
| 115 |
+
"3. Call the `deploy` method on the `JumpStartModel` instance. This method deploys the model on Amazon SageMaker and returns a `Predictor` object.\n",
|
| 116 |
+
"\n",
|
| 117 |
+
"The `Predictor` object (`predictor`) can be used to make predictions with the deployed model. The `deploy` method will automatically choose an endpoint name, instance type, and other deployment parameters. If you want to specify these parameters, you can pass them as arguments to the `deploy` method.\n",
|
| 118 |
+
"\n",
|
| 119 |
+
"**The next cell will take some time to run.** It is deploying a large language model, and that takes time. You'll see dashes (--) while it is being deployed. Please be patient! You'll see an exclamation point at the end of the dashes (---!) when the model is deployed and then you can continue running the next cells. \n",
|
| 120 |
+
"\n",
|
| 121 |
+
"You might see a warning \"For forward compatibility, pin to model_version...\" You can ignore this warning, just wait for the model to deploy. \n"
|
| 122 |
+
]
|
| 123 |
+
},
|
| 124 |
+
{
|
| 125 |
+
"cell_type": "code",
|
| 126 |
+
"execution_count": 4,
|
| 127 |
+
"metadata": {
|
| 128 |
+
"tags": []
|
| 129 |
+
},
|
| 130 |
+
"outputs": [
|
| 131 |
+
{
|
| 132 |
+
"name": "stderr",
|
| 133 |
+
"output_type": "stream",
|
| 134 |
+
"text": [
|
| 135 |
+
"For forward compatibility, pin to model_version='2.*' in your JumpStartModel or JumpStartEstimator definitions. Note that major version upgrades may have different EULA acceptance terms and input/output signatures.\n",
|
| 136 |
+
"Using vulnerable JumpStart model 'meta-textgeneration-llama-2-7b' and version '2.1.8'.\n",
|
| 137 |
+
"Using model 'meta-textgeneration-llama-2-7b' with wildcard version identifier '2.*'. You can pin to version '2.1.8' for more stable results. Note that models may have different input/output signatures after a major version upgrade.\n"
|
| 138 |
+
]
|
| 139 |
+
},
|
| 140 |
+
{
|
| 141 |
+
"name": "stdout",
|
| 142 |
+
"output_type": "stream",
|
| 143 |
+
"text": [
|
| 144 |
+
"----------------!"
|
| 145 |
+
]
|
| 146 |
+
}
|
| 147 |
+
],
|
| 148 |
+
"source": [
|
| 149 |
+
"from sagemaker.jumpstart.model import JumpStartModel\n",
|
| 150 |
+
"\n",
|
| 151 |
+
"model = JumpStartModel(model_id=model_id, model_version=model_version, instance_type=\"ml.g5.2xlarge\")\n",
|
| 152 |
+
"predictor = model.deploy()\n"
|
| 153 |
+
]
|
| 154 |
+
},
|
| 155 |
+
{
|
| 156 |
+
"cell_type": "markdown",
|
| 157 |
+
"metadata": {},
|
| 158 |
+
"source": [
|
| 159 |
+
"#### Invoke the endpoint, query and parse response\n",
|
| 160 |
+
"The next step is to invoke the model endpoint, send a query to the endpoint, and recieve a response from the model. \n",
|
| 161 |
+
"\n",
|
| 162 |
+
"Running the next cell defines a function that will be used to parse and print the response from the model. "
|
| 163 |
+
]
|
| 164 |
+
},
|
| 165 |
+
{
|
| 166 |
+
"cell_type": "code",
|
| 167 |
+
"execution_count": 5,
|
| 168 |
+
"metadata": {
|
| 169 |
+
"tags": []
|
| 170 |
+
},
|
| 171 |
+
"outputs": [],
|
| 172 |
+
"source": [
|
| 173 |
+
"def print_response(payload, response):\n",
|
| 174 |
+
" print(payload[\"inputs\"])\n",
|
| 175 |
+
" print(f\"> {response[0]['generation']}\")\n",
|
| 176 |
+
" print(\"\\n==================================\\n\")"
|
| 177 |
+
]
|
| 178 |
+
},
|
| 179 |
+
{
|
| 180 |
+
"cell_type": "markdown",
|
| 181 |
+
"metadata": {},
|
| 182 |
+
"source": [
|
| 183 |
+
"The model takes a text string as input and predicts next words in the sequence, the input we send it is the prompt. \n",
|
| 184 |
+
"\n",
|
| 185 |
+
"The prompt we send the model should relate to the domain we'd like to fine-tune the model on. This way we'll identify the model's domain knowledge before it's fine-tuned, and then we can run the same prompts on the fine-tuned model. \n",
|
| 186 |
+
"\n",
|
| 187 |
+
"**Replace \"inputs\"** in the next cell with the input to send the model based on the domain you've chosen. \n",
|
| 188 |
+
"\n",
|
| 189 |
+
"**For financial domain:**\n",
|
| 190 |
+
"\n",
|
| 191 |
+
" \"inputs\": \"Replace with sentence below\" \n",
|
| 192 |
+
"- \"The investment tests performed indicate\"\n",
|
| 193 |
+
"- \"the relative volume for the long out of the money options, indicates\"\n",
|
| 194 |
+
"- \"The results for the short in the money options\"\n",
|
| 195 |
+
"- \"The results are encouraging for aggressive investors\"\n",
|
| 196 |
+
"\n",
|
| 197 |
+
"**For medical domain:** \n",
|
| 198 |
+
"\n",
|
| 199 |
+
" \"inputs\": \"Replace with sentence below\" \n",
|
| 200 |
+
"- \"Myeloid neoplasms and acute leukemias derive from\"\n",
|
| 201 |
+
"- \"Genomic characterization is essential for\"\n",
|
| 202 |
+
"- \"Certain germline disorders may be associated with\"\n",
|
| 203 |
+
"- \"In contrast to targeted approaches, genome-wide sequencing\"\n",
|
| 204 |
+
"\n",
|
| 205 |
+
"**For IT domain:** \n",
|
| 206 |
+
"\n",
|
| 207 |
+
" \"inputs\": \"Replace with sentence below\" \n",
|
| 208 |
+
"- \"Traditional approaches to data management such as\"\n",
|
| 209 |
+
"- \"A second important aspect of ubiquitous computing environments is\"\n",
|
| 210 |
+
"- \"because ubiquitous computing is intended to\" \n",
|
| 211 |
+
"- \"outline the key aspects of ubiquitous computing from a data management perspective.\""
|
| 212 |
+
]
|
| 213 |
+
},
|
| 214 |
+
{
|
| 215 |
+
"cell_type": "code",
|
| 216 |
+
"execution_count": 6,
|
| 217 |
+
"metadata": {
|
| 218 |
+
"tags": []
|
| 219 |
+
},
|
| 220 |
+
"outputs": [
|
| 221 |
+
{
|
| 222 |
+
"name": "stdout",
|
| 223 |
+
"output_type": "stream",
|
| 224 |
+
"text": [
|
| 225 |
+
"outline the key aspects of ubiquitous computing from a data management perspective.\n",
|
| 226 |
+
"> The data management aspects of ubiquitous computing are classified into three categories: (1) data management in ubiquitous environments, (2) data management in ubiquitous applications, and (3) data management in ubiquitous services. We discuss the data management aspects of each of these\n",
|
| 227 |
+
"\n",
|
| 228 |
+
"==================================\n",
|
| 229 |
+
"\n"
|
| 230 |
+
]
|
| 231 |
+
}
|
| 232 |
+
],
|
| 233 |
+
"source": [
|
| 234 |
+
"payload = {\n",
|
| 235 |
+
" \"inputs\": \"outline the key aspects of ubiquitous computing from a data management perspective.\",\n",
|
| 236 |
+
" \"parameters\": {\n",
|
| 237 |
+
" \"max_new_tokens\": 64,\n",
|
| 238 |
+
" \"top_p\": 0.9,\n",
|
| 239 |
+
" \"temperature\": 0.6,\n",
|
| 240 |
+
" \"return_full_text\": False,\n",
|
| 241 |
+
" },\n",
|
| 242 |
+
"}\n",
|
| 243 |
+
"try:\n",
|
| 244 |
+
" response = predictor.predict(payload, custom_attributes=\"accept_eula=true\")\n",
|
| 245 |
+
" print_response(payload, response)\n",
|
| 246 |
+
"except Exception as e:\n",
|
| 247 |
+
" print(e)"
|
| 248 |
+
]
|
| 249 |
+
},
|
| 250 |
+
{
|
| 251 |
+
"cell_type": "markdown",
|
| 252 |
+
"metadata": {},
|
| 253 |
+
"source": [
|
| 254 |
+
"The prompt is related to the domain you want to fine-tune your model on. You will see the outputs from the model without fine-tuning are limited in providing insightful or relevant content.\n",
|
| 255 |
+
"\n",
|
| 256 |
+
"**Use the output from this notebook to fill out the \"model evaluation\" section of the project documentation report**\n",
|
| 257 |
+
"\n",
|
| 258 |
+
"Take a screenshot of this file with the cell output for your project documentation report. Download it with cell output by making sure you used Save on the notebook before downloading \n",
|
| 259 |
+
"\n",
|
| 260 |
+
"**After you've filled out the report, run the cells below to delete the model deployment** \n",
|
| 261 |
+
"\n",
|
| 262 |
+
"`IF YOU FAIL TO RUN THE CELLS BELOW YOU WILL RUN OUT OF BUDGET TO COMPLETE THE PROJECT`"
|
| 263 |
+
]
|
| 264 |
+
},
|
| 265 |
+
{
|
| 266 |
+
"cell_type": "code",
|
| 267 |
+
"execution_count": null,
|
| 268 |
+
"metadata": {
|
| 269 |
+
"tags": []
|
| 270 |
+
},
|
| 271 |
+
"outputs": [],
|
| 272 |
+
"source": [
|
| 273 |
+
"# Delete the SageMaker endpoint and the attached resources\n",
|
| 274 |
+
"predictor.delete_model()\n",
|
| 275 |
+
"predictor.delete_endpoint()"
|
| 276 |
+
]
|
| 277 |
+
},
|
| 278 |
+
{
|
| 279 |
+
"cell_type": "markdown",
|
| 280 |
+
"metadata": {},
|
| 281 |
+
"source": [
|
| 282 |
+
"Verify your model endpoint was deleted by visiting the Sagemaker dashboard and choosing `endpoints` under 'Inference' in the left navigation menu. If you see your endpoint still there, choose the endpoint, and then under \"Actions\" select **Delete**"
|
| 283 |
+
]
|
| 284 |
+
}
|
| 285 |
+
],
|
| 286 |
+
"metadata": {
|
| 287 |
+
"kernelspec": {
|
| 288 |
+
"display_name": "conda_pytorch_p310",
|
| 289 |
+
"language": "python",
|
| 290 |
+
"name": "conda_pytorch_p310"
|
| 291 |
+
},
|
| 292 |
+
"language_info": {
|
| 293 |
+
"codemirror_mode": {
|
| 294 |
+
"name": "ipython",
|
| 295 |
+
"version": 3
|
| 296 |
+
},
|
| 297 |
+
"file_extension": ".py",
|
| 298 |
+
"mimetype": "text/x-python",
|
| 299 |
+
"name": "python",
|
| 300 |
+
"nbconvert_exporter": "python",
|
| 301 |
+
"pygments_lexer": "ipython3",
|
| 302 |
+
"version": "3.10.14"
|
| 303 |
+
}
|
| 304 |
+
},
|
| 305 |
+
"nbformat": 4,
|
| 306 |
+
"nbformat_minor": 4
|
| 307 |
+
}
|
Model_FineTuning.ipynb
ADDED
|
@@ -0,0 +1,875 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"#### Step 3: Model Fine-tuning\n",
|
| 8 |
+
"In this notebook, you'll fine-tune the Meta Llama 2 7B large language model, deploy the fine-tuned model, and test it's text generation and domain knowledge capabilities. \n",
|
| 9 |
+
"\n",
|
| 10 |
+
"Fine-tuning refers to the process of taking a pre-trained language model and retraining it for a different but related task using specific data. This approach is also known as transfer learning, which involves transferring the knowledge learned from one task to another. Large language models (LLMs) like Llama 2 7B are trained on massive amounts of unlabeled data and can be fine-tuned on domain domain datasets, making the model perform better on that specific domain.\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"Input: A train and an optional validation directory. Each directory contains a CSV/JSON/TXT file.\n",
|
| 13 |
+
"For CSV/JSON files, the train or validation data is used from the column called 'text' or the first column if no column called 'text' is found.\n",
|
| 14 |
+
"The number of files under train and validation should equal to one.\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"- **You'll choose your dataset below based on the domain you've chosen**\n",
|
| 17 |
+
"\n",
|
| 18 |
+
"Output: A trained model that can be deployed for inference.\\\n",
|
| 19 |
+
"After you've fine-tuned the model, you'll evaluate it with the same input you used in project step 2: model evaluation. \n",
|
| 20 |
+
"\n",
|
| 21 |
+
"---"
|
| 22 |
+
]
|
| 23 |
+
},
|
| 24 |
+
{
|
| 25 |
+
"cell_type": "markdown",
|
| 26 |
+
"metadata": {},
|
| 27 |
+
"source": [
|
| 28 |
+
"#### Set up\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"---\n",
|
| 31 |
+
"Install and import the necessary packages. Restart the kernel after executing the cell below. \n",
|
| 32 |
+
"\n",
|
| 33 |
+
"---"
|
| 34 |
+
]
|
| 35 |
+
},
|
| 36 |
+
{
|
| 37 |
+
"cell_type": "code",
|
| 38 |
+
"execution_count": 1,
|
| 39 |
+
"metadata": {
|
| 40 |
+
"tags": []
|
| 41 |
+
},
|
| 42 |
+
"outputs": [
|
| 43 |
+
{
|
| 44 |
+
"name": "stdout",
|
| 45 |
+
"output_type": "stream",
|
| 46 |
+
"text": [
|
| 47 |
+
"Requirement already satisfied: sagemaker in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (2.219.0)\n",
|
| 48 |
+
"Collecting sagemaker\n",
|
| 49 |
+
" Using cached sagemaker-2.221.0-py3-none-any.whl.metadata (14 kB)\n",
|
| 50 |
+
"Collecting datasets\n",
|
| 51 |
+
" Using cached datasets-2.19.1-py3-none-any.whl.metadata (19 kB)\n",
|
| 52 |
+
"Requirement already satisfied: attrs<24,>=23.1.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (23.2.0)\n",
|
| 53 |
+
"Requirement already satisfied: boto3<2.0,>=1.33.3 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (1.34.101)\n",
|
| 54 |
+
"Requirement already satisfied: cloudpickle==2.2.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (2.2.1)\n",
|
| 55 |
+
"Requirement already satisfied: google-pasta in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (0.2.0)\n",
|
| 56 |
+
"Requirement already satisfied: numpy<2.0,>=1.9.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (1.22.4)\n",
|
| 57 |
+
"Requirement already satisfied: protobuf<5.0,>=3.12 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (4.25.3)\n",
|
| 58 |
+
"Requirement already satisfied: smdebug-rulesconfig==1.0.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (1.0.1)\n",
|
| 59 |
+
"Requirement already satisfied: importlib-metadata<7.0,>=1.4.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (6.11.0)\n",
|
| 60 |
+
"Requirement already satisfied: packaging>=20.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (21.3)\n",
|
| 61 |
+
"Requirement already satisfied: pandas in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (2.2.1)\n",
|
| 62 |
+
"Requirement already satisfied: pathos in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (0.3.2)\n",
|
| 63 |
+
"Requirement already satisfied: schema in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (0.7.7)\n",
|
| 64 |
+
"Requirement already satisfied: PyYAML~=6.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (6.0.1)\n",
|
| 65 |
+
"Requirement already satisfied: jsonschema in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (4.21.1)\n",
|
| 66 |
+
"Requirement already satisfied: platformdirs in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (4.2.0)\n",
|
| 67 |
+
"Requirement already satisfied: tblib<4,>=1.7.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (3.0.0)\n",
|
| 68 |
+
"Requirement already satisfied: urllib3<3.0.0,>=1.26.8 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (2.2.1)\n",
|
| 69 |
+
"Requirement already satisfied: requests in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (2.31.0)\n",
|
| 70 |
+
"Requirement already satisfied: docker in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (6.1.3)\n",
|
| 71 |
+
"Requirement already satisfied: tqdm in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (4.66.2)\n",
|
| 72 |
+
"Requirement already satisfied: psutil in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from sagemaker) (5.9.8)\n",
|
| 73 |
+
"Requirement already satisfied: filelock in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from datasets) (3.13.3)\n",
|
| 74 |
+
"Requirement already satisfied: pyarrow>=12.0.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from datasets) (15.0.2)\n",
|
| 75 |
+
"Requirement already satisfied: pyarrow-hotfix in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from datasets) (0.6)\n",
|
| 76 |
+
"Requirement already satisfied: dill<0.3.9,>=0.3.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from datasets) (0.3.8)\n",
|
| 77 |
+
"Collecting xxhash (from datasets)\n",
|
| 78 |
+
" Using cached xxhash-3.4.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (12 kB)\n",
|
| 79 |
+
"Requirement already satisfied: multiprocess in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from datasets) (0.70.16)\n",
|
| 80 |
+
"Requirement already satisfied: fsspec<=2024.3.1,>=2023.1.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from fsspec[http]<=2024.3.1,>=2023.1.0->datasets) (2024.3.1)\n",
|
| 81 |
+
"Requirement already satisfied: aiohttp in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from datasets) (3.9.3)\n",
|
| 82 |
+
"Collecting huggingface-hub>=0.21.2 (from datasets)\n",
|
| 83 |
+
" Using cached huggingface_hub-0.23.1-py3-none-any.whl.metadata (12 kB)\n",
|
| 84 |
+
"Requirement already satisfied: botocore<1.35.0,>=1.34.101 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from boto3<2.0,>=1.33.3->sagemaker) (1.34.101)\n",
|
| 85 |
+
"Requirement already satisfied: jmespath<2.0.0,>=0.7.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from boto3<2.0,>=1.33.3->sagemaker) (1.0.1)\n",
|
| 86 |
+
"Requirement already satisfied: s3transfer<0.11.0,>=0.10.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from boto3<2.0,>=1.33.3->sagemaker) (0.10.1)\n",
|
| 87 |
+
"Requirement already satisfied: aiosignal>=1.1.2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from aiohttp->datasets) (1.3.1)\n",
|
| 88 |
+
"Requirement already satisfied: frozenlist>=1.1.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from aiohttp->datasets) (1.4.1)\n",
|
| 89 |
+
"Requirement already satisfied: multidict<7.0,>=4.5 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from aiohttp->datasets) (6.0.5)\n",
|
| 90 |
+
"Requirement already satisfied: yarl<2.0,>=1.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from aiohttp->datasets) (1.9.4)\n",
|
| 91 |
+
"Requirement already satisfied: async-timeout<5.0,>=4.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from aiohttp->datasets) (4.0.3)\n",
|
| 92 |
+
"Requirement already satisfied: typing-extensions>=3.7.4.3 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from huggingface-hub>=0.21.2->datasets) (4.10.0)\n",
|
| 93 |
+
"Requirement already satisfied: zipp>=0.5 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from importlib-metadata<7.0,>=1.4.0->sagemaker) (3.17.0)\n",
|
| 94 |
+
"Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from packaging>=20.0->sagemaker) (3.1.2)\n",
|
| 95 |
+
"Requirement already satisfied: charset-normalizer<4,>=2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from requests->sagemaker) (3.3.2)\n",
|
| 96 |
+
"Requirement already satisfied: idna<4,>=2.5 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from requests->sagemaker) (3.6)\n",
|
| 97 |
+
"Requirement already satisfied: certifi>=2017.4.17 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from requests->sagemaker) (2024.2.2)\n",
|
| 98 |
+
"Requirement already satisfied: websocket-client>=0.32.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from docker->sagemaker) (1.7.0)\n",
|
| 99 |
+
"Requirement already satisfied: six in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from google-pasta->sagemaker) (1.16.0)\n",
|
| 100 |
+
"Requirement already satisfied: jsonschema-specifications>=2023.03.6 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from jsonschema->sagemaker) (2023.12.1)\n",
|
| 101 |
+
"Requirement already satisfied: referencing>=0.28.4 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from jsonschema->sagemaker) (0.34.0)\n",
|
| 102 |
+
"Requirement already satisfied: rpds-py>=0.7.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from jsonschema->sagemaker) (0.18.0)\n",
|
| 103 |
+
"Requirement already satisfied: python-dateutil>=2.8.2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from pandas->sagemaker) (2.9.0)\n",
|
| 104 |
+
"Requirement already satisfied: pytz>=2020.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from pandas->sagemaker) (2024.1)\n",
|
| 105 |
+
"Requirement already satisfied: tzdata>=2022.7 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from pandas->sagemaker) (2024.1)\n",
|
| 106 |
+
"Requirement already satisfied: ppft>=1.7.6.8 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from pathos->sagemaker) (1.7.6.8)\n",
|
| 107 |
+
"Requirement already satisfied: pox>=0.3.4 in /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages (from pathos->sagemaker) (0.3.4)\n",
|
| 108 |
+
"Using cached sagemaker-2.221.0-py3-none-any.whl (1.5 MB)\n",
|
| 109 |
+
"Using cached datasets-2.19.1-py3-none-any.whl (542 kB)\n",
|
| 110 |
+
"Using cached huggingface_hub-0.23.1-py3-none-any.whl (401 kB)\n",
|
| 111 |
+
"Using cached xxhash-3.4.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (194 kB)\n",
|
| 112 |
+
"Installing collected packages: xxhash, huggingface-hub, datasets, sagemaker\n",
|
| 113 |
+
" Attempting uninstall: sagemaker\n",
|
| 114 |
+
" Found existing installation: sagemaker 2.219.0\n",
|
| 115 |
+
" Uninstalling sagemaker-2.219.0:\n",
|
| 116 |
+
" Successfully uninstalled sagemaker-2.219.0\n",
|
| 117 |
+
"Successfully installed datasets-2.19.1 huggingface-hub-0.23.1 sagemaker-2.221.0 xxhash-3.4.1\n"
|
| 118 |
+
]
|
| 119 |
+
}
|
| 120 |
+
],
|
| 121 |
+
"source": [
|
| 122 |
+
"!pip install --upgrade sagemaker datasets"
|
| 123 |
+
]
|
| 124 |
+
},
|
| 125 |
+
{
|
| 126 |
+
"cell_type": "markdown",
|
| 127 |
+
"metadata": {},
|
| 128 |
+
"source": [
|
| 129 |
+
"Select the model to fine-tune"
|
| 130 |
+
]
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"cell_type": "code",
|
| 134 |
+
"execution_count": 2,
|
| 135 |
+
"metadata": {
|
| 136 |
+
"tags": []
|
| 137 |
+
},
|
| 138 |
+
"outputs": [],
|
| 139 |
+
"source": [
|
| 140 |
+
"model_id, model_version = \"meta-textgeneration-llama-2-7b\", \"2.*\""
|
| 141 |
+
]
|
| 142 |
+
},
|
| 143 |
+
{
|
| 144 |
+
"cell_type": "markdown",
|
| 145 |
+
"metadata": {},
|
| 146 |
+
"source": [
|
| 147 |
+
"In the cell below, choose the training dataset text for the domain you've chosen and update the code in the cell below: \n",
|
| 148 |
+
"\n",
|
| 149 |
+
"To create a finance domain expert model: \n",
|
| 150 |
+
"\n",
|
| 151 |
+
"- `\"training\": f\"s3://genaiwithawsproject2024/training-datasets/finance\"`\n",
|
| 152 |
+
"\n",
|
| 153 |
+
"To create a medical domain expert model: \n",
|
| 154 |
+
"\n",
|
| 155 |
+
"- `\"training\": f\"s3://genaiwithawsproject2024/training-datasets/medical\"`\n",
|
| 156 |
+
"\n",
|
| 157 |
+
"To create an IT domain expert model: \n",
|
| 158 |
+
"\n",
|
| 159 |
+
"- `\"training\": f\"s3://genaiwithawsproject2024/training-datasets/it\"`"
|
| 160 |
+
]
|
| 161 |
+
},
|
| 162 |
+
{
|
| 163 |
+
"cell_type": "code",
|
| 164 |
+
"execution_count": null,
|
| 165 |
+
"metadata": {
|
| 166 |
+
"tags": []
|
| 167 |
+
},
|
| 168 |
+
"outputs": [
|
| 169 |
+
{
|
| 170 |
+
"name": "stdout",
|
| 171 |
+
"output_type": "stream",
|
| 172 |
+
"text": [
|
| 173 |
+
"sagemaker.config INFO - Not applying SDK defaults from location: /etc/xdg/sagemaker/config.yaml\n",
|
| 174 |
+
"sagemaker.config INFO - Not applying SDK defaults from location: /home/ec2-user/.config/sagemaker/config.yaml\n"
|
| 175 |
+
]
|
| 176 |
+
},
|
| 177 |
+
{
|
| 178 |
+
"name": "stderr",
|
| 179 |
+
"output_type": "stream",
|
| 180 |
+
"text": [
|
| 181 |
+
"Using model 'meta-textgeneration-llama-2-7b' with wildcard version identifier '*'. You can pin to version '4.1.0' for more stable results. Note that models may have different input/output signatures after a major version upgrade.\n",
|
| 182 |
+
"INFO:sagemaker:Creating training-job with name: meta-textgeneration-llama-2-7b-2024-05-22-11-21-47-115\n"
|
| 183 |
+
]
|
| 184 |
+
},
|
| 185 |
+
{
|
| 186 |
+
"name": "stdout",
|
| 187 |
+
"output_type": "stream",
|
| 188 |
+
"text": [
|
| 189 |
+
"2024-05-22 11:21:47 Starting - Starting the training job...\n",
|
| 190 |
+
"2024-05-22 11:22:06 Pending - Training job waiting for capacity...\n",
|
| 191 |
+
"2024-05-22 11:22:20 Pending - Preparing the instances for training...\n",
|
| 192 |
+
"2024-05-22 11:22:51 Downloading - Downloading input data.....................\n",
|
| 193 |
+
"2024-05-22 11:27:42 Training - Training image download completed. Training in progress..\u001b[34mbash: cannot set terminal process group (-1): Inappropriate ioctl for device\u001b[0m\n",
|
| 194 |
+
"\u001b[34mbash: no job control in this shell\u001b[0m\n",
|
| 195 |
+
"\u001b[34m2024-05-22 11:27:44,151 sagemaker-training-toolkit INFO Imported framework sagemaker_pytorch_container.training\u001b[0m\n",
|
| 196 |
+
"\u001b[34m2024-05-22 11:27:44,169 sagemaker-training-toolkit INFO No Neurons detected (normal if no neurons installed)\u001b[0m\n",
|
| 197 |
+
"\u001b[34m2024-05-22 11:27:44,178 sagemaker_pytorch_container.training INFO Block until all host DNS lookups succeed.\u001b[0m\n",
|
| 198 |
+
"\u001b[34m2024-05-22 11:27:44,181 sagemaker_pytorch_container.training INFO Invoking user training script.\u001b[0m\n",
|
| 199 |
+
"\u001b[34m2024-05-22 11:27:53,654 sagemaker-training-toolkit INFO Installing dependencies from requirements.txt:\u001b[0m\n",
|
| 200 |
+
"\u001b[34m/opt/conda/bin/python3.10 -m pip install -r requirements.txt\u001b[0m\n",
|
| 201 |
+
"\u001b[34mProcessing ./lib/accelerate/accelerate-0.21.0-py3-none-any.whl (from -r requirements.txt (line 1))\u001b[0m\n",
|
| 202 |
+
"\u001b[34mProcessing ./lib/bitsandbytes/bitsandbytes-0.39.1-py3-none-any.whl (from -r requirements.txt (line 2))\u001b[0m\n",
|
| 203 |
+
"\u001b[34mProcessing ./lib/black/black-23.7.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (from -r requirements.txt (line 3))\u001b[0m\n",
|
| 204 |
+
"\u001b[34mProcessing ./lib/brotli/Brotli-1.0.9-cp310-cp310-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_12_x86_64.manylinux2010_x86_64.whl (from -r requirements.txt (line 4))\u001b[0m\n",
|
| 205 |
+
"\u001b[34mProcessing ./lib/datasets/datasets-2.14.1-py3-none-any.whl (from -r requirements.txt (line 5))\u001b[0m\n",
|
| 206 |
+
"\u001b[34mProcessing ./lib/docstring-parser/docstring_parser-0.16-py3-none-any.whl (from -r requirements.txt (line 6))\u001b[0m\n",
|
| 207 |
+
"\u001b[34mProcessing ./lib/fire/fire-0.5.0.tar.gz\u001b[0m\n",
|
| 208 |
+
"\u001b[34mPreparing metadata (setup.py): started\u001b[0m\n",
|
| 209 |
+
"\u001b[34mPreparing metadata (setup.py): finished with status 'done'\u001b[0m\n",
|
| 210 |
+
"\u001b[34mProcessing ./lib/huggingface-hub/huggingface_hub-0.20.3-py3-none-any.whl (from -r requirements.txt (line 8))\u001b[0m\n",
|
| 211 |
+
"\u001b[34mProcessing ./lib/inflate64/inflate64-0.3.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (from -r requirements.txt (line 9))\u001b[0m\n",
|
| 212 |
+
"\u001b[34mProcessing ./lib/loralib/loralib-0.1.1-py3-none-any.whl (from -r requirements.txt (line 10))\u001b[0m\n",
|
| 213 |
+
"\u001b[34mProcessing ./lib/multivolumefile/multivolumefile-0.2.3-py3-none-any.whl (from -r requirements.txt (line 11))\u001b[0m\n",
|
| 214 |
+
"\u001b[34mProcessing ./lib/mypy-extensions/mypy_extensions-1.0.0-py3-none-any.whl (from -r requirements.txt (line 12))\u001b[0m\n",
|
| 215 |
+
"\u001b[34mProcessing ./lib/nvidia-cublas-cu12/nvidia_cublas_cu12-12.1.3.1-py3-none-manylinux1_x86_64.whl (from -r requirements.txt (line 13))\u001b[0m\n",
|
| 216 |
+
"\u001b[34mProcessing ./lib/nvidia-cuda-cupti-cu12/nvidia_cuda_cupti_cu12-12.1.105-py3-none-manylinux1_x86_64.whl (from -r requirements.txt (line 14))\u001b[0m\n",
|
| 217 |
+
"\u001b[34mProcessing ./lib/nvidia-cuda-nvrtc-cu12/nvidia_cuda_nvrtc_cu12-12.1.105-py3-none-manylinux1_x86_64.whl (from -r requirements.txt (line 15))\u001b[0m\n",
|
| 218 |
+
"\u001b[34mProcessing ./lib/nvidia-cuda-runtime-cu12/nvidia_cuda_runtime_cu12-12.1.105-py3-none-manylinux1_x86_64.whl (from -r requirements.txt (line 16))\u001b[0m\n",
|
| 219 |
+
"\u001b[34mProcessing ./lib/nvidia-cudnn-cu12/nvidia_cudnn_cu12-8.9.2.26-py3-none-manylinux1_x86_64.whl (from -r requirements.txt (line 17))\u001b[0m\n",
|
| 220 |
+
"\u001b[34mProcessing ./lib/nvidia-cufft-cu12/nvidia_cufft_cu12-11.0.2.54-py3-none-manylinux1_x86_64.whl (from -r requirements.txt (line 18))\u001b[0m\n",
|
| 221 |
+
"\u001b[34mProcessing ./lib/nvidia-curand-cu12/nvidia_curand_cu12-10.3.2.106-py3-none-manylinux1_x86_64.whl (from -r requirements.txt (line 19))\u001b[0m\n",
|
| 222 |
+
"\u001b[34mProcessing ./lib/nvidia-cusolver-cu12/nvidia_cusolver_cu12-11.4.5.107-py3-none-manylinux1_x86_64.whl (from -r requirements.txt (line 20))\u001b[0m\n",
|
| 223 |
+
"\u001b[34mProcessing ./lib/nvidia-cusparse-cu12/nvidia_cusparse_cu12-12.1.0.106-py3-none-manylinux1_x86_64.whl (from -r requirements.txt (line 21))\u001b[0m\n",
|
| 224 |
+
"\u001b[34mProcessing ./lib/nvidia-nccl-cu12/nvidia_nccl_cu12-2.19.3-py3-none-manylinux1_x86_64.whl (from -r requirements.txt (line 22))\u001b[0m\n",
|
| 225 |
+
"\u001b[34mProcessing ./lib/nvidia-nvjitlink-cu12/nvidia_nvjitlink_cu12-12.3.101-py3-none-manylinux1_x86_64.whl (from -r requirements.txt (line 23))\u001b[0m\n",
|
| 226 |
+
"\u001b[34mProcessing ./lib/nvidia-nvtx-cu12/nvidia_nvtx_cu12-12.1.105-py3-none-manylinux1_x86_64.whl (from -r requirements.txt (line 24))\u001b[0m\n",
|
| 227 |
+
"\u001b[34mProcessing ./lib/pathspec/pathspec-0.11.1-py3-none-any.whl (from -r requirements.txt (line 25))\u001b[0m\n",
|
| 228 |
+
"\u001b[34mProcessing ./lib/peft/peft-0.4.0-py3-none-any.whl (from -r requirements.txt (line 26))\u001b[0m\n",
|
| 229 |
+
"\u001b[34mProcessing ./lib/py7zr/py7zr-0.20.5-py3-none-any.whl (from -r requirements.txt (line 27))\u001b[0m\n",
|
| 230 |
+
"\u001b[34mProcessing ./lib/pybcj/pybcj-1.0.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (from -r requirements.txt (line 28))\u001b[0m\n",
|
| 231 |
+
"\u001b[34mProcessing ./lib/pycryptodomex/pycryptodomex-3.18.0-cp35-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (from -r requirements.txt (line 29))\u001b[0m\n",
|
| 232 |
+
"\u001b[34mProcessing ./lib/pyppmd/pyppmd-1.0.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (from -r requirements.txt (line 30))\u001b[0m\n",
|
| 233 |
+
"\u001b[34mProcessing ./lib/pyzstd/pyzstd-0.15.9-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (from -r requirements.txt (line 31))\u001b[0m\n",
|
| 234 |
+
"\u001b[34mProcessing ./lib/safetensors/safetensors-0.4.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (from -r requirements.txt (line 32))\u001b[0m\n",
|
| 235 |
+
"\u001b[34mProcessing ./lib/scipy/scipy-1.11.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (from -r requirements.txt (line 33))\u001b[0m\n",
|
| 236 |
+
"\u001b[34mProcessing ./lib/shtab/shtab-1.7.1-py3-none-any.whl (from -r requirements.txt (line 34))\u001b[0m\n",
|
| 237 |
+
"\u001b[34mProcessing ./lib/termcolor/termcolor-2.3.0-py3-none-any.whl (from -r requirements.txt (line 35))\u001b[0m\n",
|
| 238 |
+
"\u001b[34mProcessing ./lib/texttable/texttable-1.6.7-py2.py3-none-any.whl (from -r requirements.txt (line 36))\u001b[0m\n",
|
| 239 |
+
"\u001b[34mProcessing ./lib/tokenize-rt/tokenize_rt-5.1.0-py2.py3-none-any.whl (from -r requirements.txt (line 37))\u001b[0m\n",
|
| 240 |
+
"\u001b[34mProcessing ./lib/tokenizers/tokenizers-0.15.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (from -r requirements.txt (line 38))\u001b[0m\n",
|
| 241 |
+
"\u001b[34mProcessing ./lib/torch/torch-2.2.0-cp310-cp310-manylinux1_x86_64.whl (from -r requirements.txt (line 39))\u001b[0m\n",
|
| 242 |
+
"\u001b[34mProcessing ./lib/transformers/transformers-4.38.0-py3-none-any.whl (from -r requirements.txt (line 40))\u001b[0m\n",
|
| 243 |
+
"\u001b[34mProcessing ./lib/triton/triton-2.2.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (from -r requirements.txt (line 41))\u001b[0m\n",
|
| 244 |
+
"\u001b[34mProcessing ./lib/trl/trl-0.8.1-py3-none-any.whl (from -r requirements.txt (line 42))\u001b[0m\n",
|
| 245 |
+
"\u001b[34mProcessing ./lib/typing-extensions/typing_extensions-4.8.0-py3-none-any.whl (from -r requirements.txt (line 43))\u001b[0m\n",
|
| 246 |
+
"\u001b[34mProcessing ./lib/tyro/tyro-0.7.3-py3-none-any.whl (from -r requirements.txt (line 44))\u001b[0m\n",
|
| 247 |
+
"\u001b[34mProcessing ./lib/sagemaker_jumpstart_script_utilities/sagemaker_jumpstart_script_utilities-1.1.9-py2.py3-none-any.whl (from -r requirements.txt (line 45))\u001b[0m\n",
|
| 248 |
+
"\u001b[34mProcessing ./lib/sagemaker_jumpstart_huggingface_script_utilities/sagemaker_jumpstart_huggingface_script_utilities-1.2.3-py2.py3-none-any.whl (from -r requirements.txt (line 46))\u001b[0m\n",
|
| 249 |
+
"\u001b[34mRequirement already satisfied: numpy>=1.17 in /opt/conda/lib/python3.10/site-packages (from accelerate==0.21.0->-r requirements.txt (line 1)) (1.24.4)\u001b[0m\n",
|
| 250 |
+
"\u001b[34mRequirement already satisfied: packaging>=20.0 in /opt/conda/lib/python3.10/site-packages (from accelerate==0.21.0->-r requirements.txt (line 1)) (23.1)\u001b[0m\n",
|
| 251 |
+
"\u001b[34mRequirement already satisfied: psutil in /opt/conda/lib/python3.10/site-packages (from accelerate==0.21.0->-r requirements.txt (line 1)) (5.9.5)\u001b[0m\n",
|
| 252 |
+
"\u001b[34mRequirement already satisfied: pyyaml in /opt/conda/lib/python3.10/site-packages (from accelerate==0.21.0->-r requirements.txt (line 1)) (6.0)\u001b[0m\n",
|
| 253 |
+
"\u001b[34mRequirement already satisfied: click>=8.0.0 in /opt/conda/lib/python3.10/site-packages (from black==23.7.0->-r requirements.txt (line 3)) (8.1.4)\u001b[0m\n",
|
| 254 |
+
"\u001b[34mRequirement already satisfied: platformdirs>=2 in /opt/conda/lib/python3.10/site-packages (from black==23.7.0->-r requirements.txt (line 3)) (3.8.1)\u001b[0m\n",
|
| 255 |
+
"\u001b[34mRequirement already satisfied: tomli>=1.1.0 in /opt/conda/lib/python3.10/site-packages (from black==23.7.0->-r requirements.txt (line 3)) (2.0.1)\u001b[0m\n",
|
| 256 |
+
"\u001b[34mRequirement already satisfied: pyarrow>=8.0.0 in /opt/conda/lib/python3.10/site-packages (from datasets==2.14.1->-r requirements.txt (line 5)) (14.0.2)\u001b[0m\n",
|
| 257 |
+
"\u001b[34mRequirement already satisfied: dill<0.3.8,>=0.3.0 in /opt/conda/lib/python3.10/site-packages (from datasets==2.14.1->-r requirements.txt (line 5)) (0.3.6)\u001b[0m\n",
|
| 258 |
+
"\u001b[34mRequirement already satisfied: pandas in /opt/conda/lib/python3.10/site-packages (from datasets==2.14.1->-r requirements.txt (line 5)) (2.0.3)\u001b[0m\n",
|
| 259 |
+
"\u001b[34mRequirement already satisfied: requests>=2.19.0 in /opt/conda/lib/python3.10/site-packages (from datasets==2.14.1->-r requirements.txt (line 5)) (2.31.0)\u001b[0m\n",
|
| 260 |
+
"\u001b[34mRequirement already satisfied: tqdm>=4.62.1 in /opt/conda/lib/python3.10/site-packages (from datasets==2.14.1->-r requirements.txt (line 5)) (4.65.0)\u001b[0m\n",
|
| 261 |
+
"\u001b[34mRequirement already satisfied: xxhash in /opt/conda/lib/python3.10/site-packages (from datasets==2.14.1->-r requirements.txt (line 5)) (3.4.1)\u001b[0m\n",
|
| 262 |
+
"\u001b[34mRequirement already satisfied: multiprocess in /opt/conda/lib/python3.10/site-packages (from datasets==2.14.1->-r requirements.txt (line 5)) (0.70.14)\u001b[0m\n",
|
| 263 |
+
"\u001b[34mRequirement already satisfied: fsspec>=2021.11.1 in /opt/conda/lib/python3.10/site-packages (from fsspec[http]>=2021.11.1->datasets==2.14.1->-r requirements.txt (line 5)) (2023.6.0)\u001b[0m\n",
|
| 264 |
+
"\u001b[34mRequirement already satisfied: aiohttp in /opt/conda/lib/python3.10/site-packages (from datasets==2.14.1->-r requirements.txt (line 5)) (3.9.3)\u001b[0m\n",
|
| 265 |
+
"\u001b[34mRequirement already satisfied: six in /opt/conda/lib/python3.10/site-packages (from fire==0.5.0->-r requirements.txt (line 7)) (1.16.0)\u001b[0m\n",
|
| 266 |
+
"\u001b[34mRequirement already satisfied: filelock in /opt/conda/lib/python3.10/site-packages (from huggingface-hub==0.20.3->-r requirements.txt (line 8)) (3.12.2)\u001b[0m\n",
|
| 267 |
+
"\u001b[34mRequirement already satisfied: sympy in /opt/conda/lib/python3.10/site-packages (from torch==2.2.0->-r requirements.txt (line 39)) (1.12)\u001b[0m\n",
|
| 268 |
+
"\u001b[34mRequirement already satisfied: networkx in /opt/conda/lib/python3.10/site-packages (from torch==2.2.0->-r requirements.txt (line 39)) (3.1)\u001b[0m\n",
|
| 269 |
+
"\u001b[34mRequirement already satisfied: jinja2 in /opt/conda/lib/python3.10/site-packages (from torch==2.2.0->-r requirements.txt (line 39)) (3.1.2)\u001b[0m\n",
|
| 270 |
+
"\u001b[34mRequirement already satisfied: regex!=2019.12.17 in /opt/conda/lib/python3.10/site-packages (from transformers==4.38.0->-r requirements.txt (line 40)) (2023.12.25)\u001b[0m\n",
|
| 271 |
+
"\u001b[34mRequirement already satisfied: rich>=11.1.0 in /opt/conda/lib/python3.10/site-packages (from tyro==0.7.3->-r requirements.txt (line 44)) (13.4.2)\u001b[0m\n",
|
| 272 |
+
"\u001b[34mRequirement already satisfied: aiosignal>=1.1.2 in /opt/conda/lib/python3.10/site-packages (from aiohttp->datasets==2.14.1->-r requirements.txt (line 5)) (1.3.1)\u001b[0m\n",
|
| 273 |
+
"\u001b[34mRequirement already satisfied: attrs>=17.3.0 in /opt/conda/lib/python3.10/site-packages (from aiohttp->datasets==2.14.1->-r requirements.txt (line 5)) (23.1.0)\u001b[0m\n",
|
| 274 |
+
"\u001b[34mRequirement already satisfied: frozenlist>=1.1.1 in /opt/conda/lib/python3.10/site-packages (from aiohttp->datasets==2.14.1->-r requirements.txt (line 5)) (1.4.1)\u001b[0m\n",
|
| 275 |
+
"\u001b[34mRequirement already satisfied: multidict<7.0,>=4.5 in /opt/conda/lib/python3.10/site-packages (from aiohttp->datasets==2.14.1->-r requirements.txt (line 5)) (6.0.5)\u001b[0m\n",
|
| 276 |
+
"\u001b[34mRequirement already satisfied: yarl<2.0,>=1.0 in /opt/conda/lib/python3.10/site-packages (from aiohttp->datasets==2.14.1->-r requirements.txt (line 5)) (1.9.4)\u001b[0m\n",
|
| 277 |
+
"\u001b[34mRequirement already satisfied: async-timeout<5.0,>=4.0 in /opt/conda/lib/python3.10/site-packages (from aiohttp->datasets==2.14.1->-r requirements.txt (line 5)) (4.0.3)\u001b[0m\n",
|
| 278 |
+
"\u001b[34mRequirement already satisfied: charset-normalizer<4,>=2 in /opt/conda/lib/python3.10/site-packages (from requests>=2.19.0->datasets==2.14.1->-r requirements.txt (line 5)) (3.1.0)\u001b[0m\n",
|
| 279 |
+
"\u001b[34mRequirement already satisfied: idna<4,>=2.5 in /opt/conda/lib/python3.10/site-packages (from requests>=2.19.0->datasets==2.14.1->-r requirements.txt (line 5)) (3.4)\u001b[0m\n",
|
| 280 |
+
"\u001b[34mRequirement already satisfied: urllib3<3,>=1.21.1 in /opt/conda/lib/python3.10/site-packages (from requests>=2.19.0->datasets==2.14.1->-r requirements.txt (line 5)) (1.26.15)\u001b[0m\n",
|
| 281 |
+
"\u001b[34mRequirement already satisfied: certifi>=2017.4.17 in /opt/conda/lib/python3.10/site-packages (from requests>=2.19.0->datasets==2.14.1->-r requirements.txt (line 5)) (2024.2.2)\u001b[0m\n",
|
| 282 |
+
"\u001b[34mRequirement already satisfied: markdown-it-py>=2.2.0 in /opt/conda/lib/python3.10/site-packages (from rich>=11.1.0->tyro==0.7.3->-r requirements.txt (line 44)) (3.0.0)\u001b[0m\n",
|
| 283 |
+
"\u001b[34mRequirement already satisfied: pygments<3.0.0,>=2.13.0 in /opt/conda/lib/python3.10/site-packages (from rich>=11.1.0->tyro==0.7.3->-r requirements.txt (line 44)) (2.15.1)\u001b[0m\n",
|
| 284 |
+
"\u001b[34mRequirement already satisfied: MarkupSafe>=2.0 in /opt/conda/lib/python3.10/site-packages (from jinja2->torch==2.2.0->-r requirements.txt (line 39)) (2.1.3)\u001b[0m\n",
|
| 285 |
+
"\u001b[34mRequirement already satisfied: python-dateutil>=2.8.2 in /opt/conda/lib/python3.10/site-packages (from pandas->datasets==2.14.1->-r requirements.txt (line 5)) (2.8.2)\u001b[0m\n",
|
| 286 |
+
"\u001b[34mRequirement already satisfied: pytz>=2020.1 in /opt/conda/lib/python3.10/site-packages (from pandas->datasets==2.14.1->-r requirements.txt (line 5)) (2023.3)\u001b[0m\n",
|
| 287 |
+
"\u001b[34mRequirement already satisfied: tzdata>=2022.1 in /opt/conda/lib/python3.10/site-packages (from pandas->datasets==2.14.1->-r requirements.txt (line 5)) (2023.3)\u001b[0m\n",
|
| 288 |
+
"\u001b[34mRequirement already satisfied: mpmath>=0.19 in /opt/conda/lib/python3.10/site-packages (from sympy->torch==2.2.0->-r requirements.txt (line 39)) (1.3.0)\u001b[0m\n",
|
| 289 |
+
"\u001b[34mRequirement already satisfied: mdurl~=0.1 in /opt/conda/lib/python3.10/site-packages (from markdown-it-py>=2.2.0->rich>=11.1.0->tyro==0.7.3->-r requirements.txt (line 44)) (0.1.0)\u001b[0m\n",
|
| 290 |
+
"\u001b[34mhuggingface-hub is already installed with the same version as the provided wheel. Use --force-reinstall to force an installation of the wheel.\u001b[0m\n",
|
| 291 |
+
"\u001b[34mscipy is already installed with the same version as the provided wheel. Use --force-reinstall to force an installation of the wheel.\u001b[0m\n",
|
| 292 |
+
"\u001b[34mBuilding wheels for collected packages: fire\u001b[0m\n",
|
| 293 |
+
"\u001b[34mBuilding wheel for fire (setup.py): started\u001b[0m\n",
|
| 294 |
+
"\u001b[34mBuilding wheel for fire (setup.py): finished with status 'done'\u001b[0m\n",
|
| 295 |
+
"\u001b[34mCreated wheel for fire: filename=fire-0.5.0-py2.py3-none-any.whl size=116932 sha256=2a5173559197e576b1fab65e23e1fe5c01dd107705a98910c658104e3f10f8da\u001b[0m\n",
|
| 296 |
+
"\u001b[34mStored in directory: /root/.cache/pip/wheels/db/3d/41/7e69dca5f61e37d109a4457082ffc5c6edb55ab633bafded38\u001b[0m\n",
|
| 297 |
+
"\u001b[34mSuccessfully built fire\u001b[0m\n",
|
| 298 |
+
"\u001b[34mInstalling collected packages: texttable, Brotli, bitsandbytes, typing-extensions, triton, tokenize-rt, termcolor, shtab, sagemaker-jumpstart-script-utilities, sagemaker-jumpstart-huggingface-script-utilities, safetensors, pyzstd, pyppmd, pycryptodomex, pybcj, pathspec, nvidia-nvtx-cu12, nvidia-nvjitlink-cu12, nvidia-nccl-cu12, nvidia-curand-cu12, nvidia-cufft-cu12, nvidia-cuda-runtime-cu12, nvidia-cuda-nvrtc-cu12, nvidia-cuda-cupti-cu12, nvidia-cublas-cu12, mypy-extensions, multivolumefile, loralib, inflate64, docstring-parser, py7zr, nvidia-cusparse-cu12, nvidia-cudnn-cu12, fire, black, tyro, tokenizers, nvidia-cusolver-cu12, transformers, torch, datasets, accelerate, trl, peft\u001b[0m\n",
|
| 299 |
+
"\u001b[34mAttempting uninstall: typing-extensions\u001b[0m\n",
|
| 300 |
+
"\u001b[34mFound existing installation: typing_extensions 4.7.1\u001b[0m\n",
|
| 301 |
+
"\u001b[34mUninstalling typing_extensions-4.7.1:\u001b[0m\n",
|
| 302 |
+
"\u001b[34mSuccessfully uninstalled typing_extensions-4.7.1\u001b[0m\n",
|
| 303 |
+
"\u001b[34mAttempting uninstall: triton\u001b[0m\n",
|
| 304 |
+
"\u001b[34mFound existing installation: triton 2.0.0.dev20221202\u001b[0m\n",
|
| 305 |
+
"\u001b[34mUninstalling triton-2.0.0.dev20221202:\u001b[0m\n",
|
| 306 |
+
"\u001b[34mSuccessfully uninstalled triton-2.0.0.dev20221202\u001b[0m\n",
|
| 307 |
+
"\u001b[34mAttempting uninstall: tokenizers\u001b[0m\n",
|
| 308 |
+
"\u001b[34mFound existing installation: tokenizers 0.13.3\u001b[0m\n",
|
| 309 |
+
"\u001b[34mUninstalling tokenizers-0.13.3:\u001b[0m\n",
|
| 310 |
+
"\u001b[34mSuccessfully uninstalled tokenizers-0.13.3\u001b[0m\n",
|
| 311 |
+
"\u001b[34mAttempting uninstall: transformers\u001b[0m\n",
|
| 312 |
+
"\u001b[34mFound existing installation: transformers 4.28.1\u001b[0m\n",
|
| 313 |
+
"\u001b[34mUninstalling transformers-4.28.1:\u001b[0m\n",
|
| 314 |
+
"\u001b[34mSuccessfully uninstalled transformers-4.28.1\u001b[0m\n",
|
| 315 |
+
"\u001b[34mAttempting uninstall: torch\u001b[0m\n",
|
| 316 |
+
"\u001b[34mFound existing installation: torch 2.0.0\u001b[0m\n",
|
| 317 |
+
"\u001b[34mUninstalling torch-2.0.0:\u001b[0m\n",
|
| 318 |
+
"\u001b[34mSuccessfully uninstalled torch-2.0.0\u001b[0m\n",
|
| 319 |
+
"\u001b[34mAttempting uninstall: datasets\u001b[0m\n",
|
| 320 |
+
"\u001b[34mFound existing installation: datasets 2.16.1\u001b[0m\n",
|
| 321 |
+
"\u001b[34mUninstalling datasets-2.16.1:\u001b[0m\n",
|
| 322 |
+
"\u001b[34mSuccessfully uninstalled datasets-2.16.1\u001b[0m\n",
|
| 323 |
+
"\u001b[34mAttempting uninstall: accelerate\u001b[0m\n",
|
| 324 |
+
"\u001b[34mFound existing installation: accelerate 0.19.0\u001b[0m\n",
|
| 325 |
+
"\u001b[34mUninstalling accelerate-0.19.0:\u001b[0m\n",
|
| 326 |
+
"\u001b[34mSuccessfully uninstalled accelerate-0.19.0\u001b[0m\n",
|
| 327 |
+
"\u001b[34mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\u001b[0m\n",
|
| 328 |
+
"\u001b[34mfastai 2.7.12 requires torch<2.1,>=1.7, but you have torch 2.2.0 which is incompatible.\u001b[0m\n",
|
| 329 |
+
"\u001b[34mSuccessfully installed Brotli-1.0.9 accelerate-0.21.0 bitsandbytes-0.39.1 black-23.7.0 datasets-2.14.1 docstring-parser-0.16 fire-0.5.0 inflate64-0.3.1 loralib-0.1.1 multivolumefile-0.2.3 mypy-extensions-1.0.0 nvidia-cublas-cu12-12.1.3.1 nvidia-cuda-cupti-cu12-12.1.105 nvidia-cuda-nvrtc-cu12-12.1.105 nvidia-cuda-runtime-cu12-12.1.105 nvidia-cudnn-cu12-8.9.2.26 nvidia-cufft-cu12-11.0.2.54 nvidia-curand-cu12-10.3.2.106 nvidia-cusolver-cu12-11.4.5.107 nvidia-cusparse-cu12-12.1.0.106 nvidia-nccl-cu12-2.19.3 nvidia-nvjitlink-cu12-12.3.101 nvidia-nvtx-cu12-12.1.105 pathspec-0.11.1 peft-0.4.0 py7zr-0.20.5 pybcj-1.0.1 pycryptodomex-3.18.0 pyppmd-1.0.0 pyzstd-0.15.9 safetensors-0.4.2 sagemaker-jumpstart-huggingface-script-utilities-1.2.3 sagemaker-jumpstart-script-utilities-1.1.9 shtab-1.7.1 termcolor-2.3.0 texttable-1.6.7 tokenize-rt-5.1.0 tokenizers-0.15.2 torch-2.2.0 transformers-4.38.0 triton-2.2.0 trl-0.8.1 typing-extensions-4.8.0 tyro-0.7.3\u001b[0m\n",
|
| 330 |
+
"\u001b[34mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv\u001b[0m\n",
|
| 331 |
+
"\u001b[34m2024-05-22 11:29:09,303 sagemaker-training-toolkit INFO Waiting for the process to finish and give a return code.\u001b[0m\n",
|
| 332 |
+
"\u001b[34m2024-05-22 11:29:09,303 sagemaker-training-toolkit INFO Done waiting for a return code. Received 0 from exiting process.\u001b[0m\n",
|
| 333 |
+
"\u001b[34m2024-05-22 11:29:09,342 sagemaker-training-toolkit INFO No Neurons detected (normal if no neurons installed)\u001b[0m\n",
|
| 334 |
+
"\u001b[34m2024-05-22 11:29:09,372 sagemaker-training-toolkit INFO No Neurons detected (normal if no neurons installed)\u001b[0m\n",
|
| 335 |
+
"\u001b[34m2024-05-22 11:29:09,401 sagemaker-training-toolkit INFO No Neurons detected (normal if no neurons installed)\u001b[0m\n",
|
| 336 |
+
"\u001b[34m2024-05-22 11:29:09,412 sagemaker-training-toolkit INFO Invoking user script\u001b[0m\n",
|
| 337 |
+
"\u001b[34mTraining Env:\u001b[0m\n",
|
| 338 |
+
"\u001b[34m{\n",
|
| 339 |
+
" \"additional_framework_parameters\": {},\n",
|
| 340 |
+
" \"channel_input_dirs\": {\n",
|
| 341 |
+
" \"code\": \"/opt/ml/input/data/code\",\n",
|
| 342 |
+
" \"training\": \"/opt/ml/input/data/training\"\n",
|
| 343 |
+
" },\n",
|
| 344 |
+
" \"current_host\": \"algo-1\",\n",
|
| 345 |
+
" \"current_instance_group\": \"homogeneousCluster\",\n",
|
| 346 |
+
" \"current_instance_group_hosts\": [\n",
|
| 347 |
+
" \"algo-1\"\n",
|
| 348 |
+
" ],\n",
|
| 349 |
+
" \"current_instance_type\": \"ml.g5.2xlarge\",\n",
|
| 350 |
+
" \"distribution_hosts\": [],\n",
|
| 351 |
+
" \"distribution_instance_groups\": [],\n",
|
| 352 |
+
" \"framework_module\": \"sagemaker_pytorch_container.training:main\",\n",
|
| 353 |
+
" \"hosts\": [\n",
|
| 354 |
+
" \"algo-1\"\n",
|
| 355 |
+
" ],\n",
|
| 356 |
+
" \"hyperparameters\": {\n",
|
| 357 |
+
" \"add_input_output_demarcation_key\": \"True\",\n",
|
| 358 |
+
" \"chat_dataset\": \"False\",\n",
|
| 359 |
+
" \"enable_fsdp\": \"True\",\n",
|
| 360 |
+
" \"epoch\": \"5\",\n",
|
| 361 |
+
" \"instruction_tuned\": \"False\",\n",
|
| 362 |
+
" \"int8_quantization\": \"False\",\n",
|
| 363 |
+
" \"learning_rate\": \"0.0001\",\n",
|
| 364 |
+
" \"lora_alpha\": \"32\",\n",
|
| 365 |
+
" \"lora_dropout\": \"0.05\",\n",
|
| 366 |
+
" \"lora_r\": \"8\",\n",
|
| 367 |
+
" \"max_input_length\": \"-1\",\n",
|
| 368 |
+
" \"max_train_samples\": \"-1\",\n",
|
| 369 |
+
" \"max_val_samples\": \"-1\",\n",
|
| 370 |
+
" \"per_device_eval_batch_size\": \"1\",\n",
|
| 371 |
+
" \"per_device_train_batch_size\": \"4\",\n",
|
| 372 |
+
" \"preprocessing_num_workers\": \"None\",\n",
|
| 373 |
+
" \"seed\": \"10\",\n",
|
| 374 |
+
" \"target_modules\": \"q_proj,v_proj\",\n",
|
| 375 |
+
" \"train_data_split_seed\": \"0\",\n",
|
| 376 |
+
" \"validation_split_ratio\": \"0.2\"\n",
|
| 377 |
+
" },\n",
|
| 378 |
+
" \"input_config_dir\": \"/opt/ml/input/config\",\n",
|
| 379 |
+
" \"input_data_config\": {\n",
|
| 380 |
+
" \"code\": {\n",
|
| 381 |
+
" \"TrainingInputMode\": \"File\",\n",
|
| 382 |
+
" \"S3DistributionType\": \"FullyReplicated\",\n",
|
| 383 |
+
" \"RecordWrapperType\": \"None\"\n",
|
| 384 |
+
" },\n",
|
| 385 |
+
" \"training\": {\n",
|
| 386 |
+
" \"TrainingInputMode\": \"File\",\n",
|
| 387 |
+
" \"S3DistributionType\": \"FullyReplicated\",\n",
|
| 388 |
+
" \"RecordWrapperType\": \"None\"\n",
|
| 389 |
+
" }\n",
|
| 390 |
+
" },\n",
|
| 391 |
+
" \"input_dir\": \"/opt/ml/input\",\n",
|
| 392 |
+
" \"instance_groups\": [\n",
|
| 393 |
+
" \"homogeneousCluster\"\n",
|
| 394 |
+
" ],\n",
|
| 395 |
+
" \"instance_groups_dict\": {\n",
|
| 396 |
+
" \"homogeneousCluster\": {\n",
|
| 397 |
+
" \"instance_group_name\": \"homogeneousCluster\",\n",
|
| 398 |
+
" \"instance_type\": \"ml.g5.2xlarge\",\n",
|
| 399 |
+
" \"hosts\": [\n",
|
| 400 |
+
" \"algo-1\"\n",
|
| 401 |
+
" ]\n",
|
| 402 |
+
" }\n",
|
| 403 |
+
" },\n",
|
| 404 |
+
" \"is_hetero\": false,\n",
|
| 405 |
+
" \"is_master\": true,\n",
|
| 406 |
+
" \"is_modelparallel_enabled\": null,\n",
|
| 407 |
+
" \"is_smddpmprun_installed\": true,\n",
|
| 408 |
+
" \"job_name\": \"meta-textgeneration-llama-2-7b-2024-05-22-11-21-47-115\",\n",
|
| 409 |
+
" \"log_level\": 20,\n",
|
| 410 |
+
" \"master_hostname\": \"algo-1\",\n",
|
| 411 |
+
" \"model_dir\": \"/opt/ml/model\",\n",
|
| 412 |
+
" \"module_dir\": \"/opt/ml/input/data/code/sourcedir.tar.gz\",\n",
|
| 413 |
+
" \"module_name\": \"transfer_learning\",\n",
|
| 414 |
+
" \"network_interface_name\": \"eth0\",\n",
|
| 415 |
+
" \"num_cpus\": 8,\n",
|
| 416 |
+
" \"num_gpus\": 1,\n",
|
| 417 |
+
" \"num_neurons\": 0,\n",
|
| 418 |
+
" \"output_data_dir\": \"/opt/ml/output/data\",\n",
|
| 419 |
+
" \"output_dir\": \"/opt/ml/output\",\n",
|
| 420 |
+
" \"output_intermediate_dir\": \"/opt/ml/output/intermediate\",\n",
|
| 421 |
+
" \"resource_config\": {\n",
|
| 422 |
+
" \"current_host\": \"algo-1\",\n",
|
| 423 |
+
" \"current_instance_type\": \"ml.g5.2xlarge\",\n",
|
| 424 |
+
" \"current_group_name\": \"homogeneousCluster\",\n",
|
| 425 |
+
" \"hosts\": [\n",
|
| 426 |
+
" \"algo-1\"\n",
|
| 427 |
+
" ],\n",
|
| 428 |
+
" \"instance_groups\": [\n",
|
| 429 |
+
" {\n",
|
| 430 |
+
" \"instance_group_name\": \"homogeneousCluster\",\n",
|
| 431 |
+
" \"instance_type\": \"ml.g5.2xlarge\",\n",
|
| 432 |
+
" \"hosts\": [\n",
|
| 433 |
+
" \"algo-1\"\n",
|
| 434 |
+
" ]\n",
|
| 435 |
+
" }\n",
|
| 436 |
+
" ],\n",
|
| 437 |
+
" \"network_interface_name\": \"eth0\"\n",
|
| 438 |
+
" },\n",
|
| 439 |
+
" \"user_entry_point\": \"transfer_learning.py\"\u001b[0m\n",
|
| 440 |
+
"\u001b[34m}\u001b[0m\n",
|
| 441 |
+
"\u001b[34mEnvironment variables:\u001b[0m\n",
|
| 442 |
+
"\u001b[34mSM_HOSTS=[\"algo-1\"]\u001b[0m\n",
|
| 443 |
+
"\u001b[34mSM_NETWORK_INTERFACE_NAME=eth0\u001b[0m\n",
|
| 444 |
+
"\u001b[34mSM_HPS={\"add_input_output_demarcation_key\":\"True\",\"chat_dataset\":\"False\",\"enable_fsdp\":\"True\",\"epoch\":\"5\",\"instruction_tuned\":\"False\",\"int8_quantization\":\"False\",\"learning_rate\":\"0.0001\",\"lora_alpha\":\"32\",\"lora_dropout\":\"0.05\",\"lora_r\":\"8\",\"max_input_length\":\"-1\",\"max_train_samples\":\"-1\",\"max_val_samples\":\"-1\",\"per_device_eval_batch_size\":\"1\",\"per_device_train_batch_size\":\"4\",\"preprocessing_num_workers\":\"None\",\"seed\":\"10\",\"target_modules\":\"q_proj,v_proj\",\"train_data_split_seed\":\"0\",\"validation_split_ratio\":\"0.2\"}\u001b[0m\n",
|
| 445 |
+
"\u001b[34mSM_USER_ENTRY_POINT=transfer_learning.py\u001b[0m\n",
|
| 446 |
+
"\u001b[34mSM_FRAMEWORK_PARAMS={}\u001b[0m\n",
|
| 447 |
+
"\u001b[34mSM_RESOURCE_CONFIG={\"current_group_name\":\"homogeneousCluster\",\"current_host\":\"algo-1\",\"current_instance_type\":\"ml.g5.2xlarge\",\"hosts\":[\"algo-1\"],\"instance_groups\":[{\"hosts\":[\"algo-1\"],\"instance_group_name\":\"homogeneousCluster\",\"instance_type\":\"ml.g5.2xlarge\"}],\"network_interface_name\":\"eth0\"}\u001b[0m\n",
|
| 448 |
+
"\u001b[34mSM_INPUT_DATA_CONFIG={\"code\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"},\"training\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"}}\u001b[0m\n",
|
| 449 |
+
"\u001b[34mSM_OUTPUT_DATA_DIR=/opt/ml/output/data\u001b[0m\n",
|
| 450 |
+
"\u001b[34mSM_CHANNELS=[\"code\",\"training\"]\u001b[0m\n",
|
| 451 |
+
"\u001b[34mSM_CURRENT_HOST=algo-1\u001b[0m\n",
|
| 452 |
+
"\u001b[34mSM_CURRENT_INSTANCE_TYPE=ml.g5.2xlarge\u001b[0m\n",
|
| 453 |
+
"\u001b[34mSM_CURRENT_INSTANCE_GROUP=homogeneousCluster\u001b[0m\n",
|
| 454 |
+
"\u001b[34mSM_CURRENT_INSTANCE_GROUP_HOSTS=[\"algo-1\"]\u001b[0m\n",
|
| 455 |
+
"\u001b[34mSM_INSTANCE_GROUPS=[\"homogeneousCluster\"]\u001b[0m\n",
|
| 456 |
+
"\u001b[34mSM_INSTANCE_GROUPS_DICT={\"homogeneousCluster\":{\"hosts\":[\"algo-1\"],\"instance_group_name\":\"homogeneousCluster\",\"instance_type\":\"ml.g5.2xlarge\"}}\u001b[0m\n",
|
| 457 |
+
"\u001b[34mSM_DISTRIBUTION_INSTANCE_GROUPS=[]\u001b[0m\n",
|
| 458 |
+
"\u001b[34mSM_IS_HETERO=false\u001b[0m\n",
|
| 459 |
+
"\u001b[34mSM_MODULE_NAME=transfer_learning\u001b[0m\n",
|
| 460 |
+
"\u001b[34mSM_LOG_LEVEL=20\u001b[0m\n",
|
| 461 |
+
"\u001b[34mSM_FRAMEWORK_MODULE=sagemaker_pytorch_container.training:main\u001b[0m\n",
|
| 462 |
+
"\u001b[34mSM_INPUT_DIR=/opt/ml/input\u001b[0m\n",
|
| 463 |
+
"\u001b[34mSM_INPUT_CONFIG_DIR=/opt/ml/input/config\u001b[0m\n",
|
| 464 |
+
"\u001b[34mSM_OUTPUT_DIR=/opt/ml/output\u001b[0m\n",
|
| 465 |
+
"\u001b[34mSM_NUM_CPUS=8\u001b[0m\n",
|
| 466 |
+
"\u001b[34mSM_NUM_GPUS=1\u001b[0m\n",
|
| 467 |
+
"\u001b[34mSM_NUM_NEURONS=0\u001b[0m\n",
|
| 468 |
+
"\u001b[34mSM_MODEL_DIR=/opt/ml/model\u001b[0m\n",
|
| 469 |
+
"\u001b[34mSM_MODULE_DIR=/opt/ml/input/data/code/sourcedir.tar.gz\u001b[0m\n",
|
| 470 |
+
"\u001b[34mSM_TRAINING_ENV={\"additional_framework_parameters\":{},\"channel_input_dirs\":{\"code\":\"/opt/ml/input/data/code\",\"training\":\"/opt/ml/input/data/training\"},\"current_host\":\"algo-1\",\"current_instance_group\":\"homogeneousCluster\",\"current_instance_group_hosts\":[\"algo-1\"],\"current_instance_type\":\"ml.g5.2xlarge\",\"distribution_hosts\":[],\"distribution_instance_groups\":[],\"framework_module\":\"sagemaker_pytorch_container.training:main\",\"hosts\":[\"algo-1\"],\"hyperparameters\":{\"add_input_output_demarcation_key\":\"True\",\"chat_dataset\":\"False\",\"enable_fsdp\":\"True\",\"epoch\":\"5\",\"instruction_tuned\":\"False\",\"int8_quantization\":\"False\",\"learning_rate\":\"0.0001\",\"lora_alpha\":\"32\",\"lora_dropout\":\"0.05\",\"lora_r\":\"8\",\"max_input_length\":\"-1\",\"max_train_samples\":\"-1\",\"max_val_samples\":\"-1\",\"per_device_eval_batch_size\":\"1\",\"per_device_train_batch_size\":\"4\",\"preprocessing_num_workers\":\"None\",\"seed\":\"10\",\"target_modules\":\"q_proj,v_proj\",\"train_data_split_seed\":\"0\",\"validation_split_ratio\":\"0.2\"},\"input_config_dir\":\"/opt/ml/input/config\",\"input_data_config\":{\"code\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"},\"training\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"}},\"input_dir\":\"/opt/ml/input\",\"instance_groups\":[\"homogeneousCluster\"],\"instance_groups_dict\":{\"homogeneousCluster\":{\"hosts\":[\"algo-1\"],\"instance_group_name\":\"homogeneousCluster\",\"instance_type\":\"ml.g5.2xlarge\"}},\"is_hetero\":false,\"is_master\":true,\"is_modelparallel_enabled\":null,\"is_smddpmprun_installed\":true,\"job_name\":\"meta-textgeneration-llama-2-7b-2024-05-22-11-21-47-115\",\"log_level\":20,\"master_hostname\":\"algo-1\",\"model_dir\":\"/opt/ml/model\",\"module_dir\":\"/opt/ml/input/data/code/sourcedir.tar.gz\",\"module_name\":\"transfer_learning\",\"network_interface_name\":\"eth0\",\"num_cpus\":8,\"num_gpus\":1,\"num_neurons\":0,\"output_data_dir\":\"/opt/ml/output/data\",\"output_dir\":\"/opt/ml/output\",\"output_intermediate_dir\":\"/opt/ml/output/intermediate\",\"resource_config\":{\"current_group_name\":\"homogeneousCluster\",\"current_host\":\"algo-1\",\"current_instance_type\":\"ml.g5.2xlarge\",\"hosts\":[\"algo-1\"],\"instance_groups\":[{\"hosts\":[\"algo-1\"],\"instance_group_name\":\"homogeneousCluster\",\"instance_type\":\"ml.g5.2xlarge\"}],\"network_interface_name\":\"eth0\"},\"user_entry_point\":\"transfer_learning.py\"}\u001b[0m\n",
|
| 471 |
+
"\u001b[34mSM_USER_ARGS=[\"--add_input_output_demarcation_key\",\"True\",\"--chat_dataset\",\"False\",\"--enable_fsdp\",\"True\",\"--epoch\",\"5\",\"--instruction_tuned\",\"False\",\"--int8_quantization\",\"False\",\"--learning_rate\",\"0.0001\",\"--lora_alpha\",\"32\",\"--lora_dropout\",\"0.05\",\"--lora_r\",\"8\",\"--max_input_length\",\"-1\",\"--max_train_samples\",\"-1\",\"--max_val_samples\",\"-1\",\"--per_device_eval_batch_size\",\"1\",\"--per_device_train_batch_size\",\"4\",\"--preprocessing_num_workers\",\"None\",\"--seed\",\"10\",\"--target_modules\",\"q_proj,v_proj\",\"--train_data_split_seed\",\"0\",\"--validation_split_ratio\",\"0.2\"]\u001b[0m\n",
|
| 472 |
+
"\u001b[34mSM_OUTPUT_INTERMEDIATE_DIR=/opt/ml/output/intermediate\u001b[0m\n",
|
| 473 |
+
"\u001b[34mSM_CHANNEL_CODE=/opt/ml/input/data/code\u001b[0m\n",
|
| 474 |
+
"\u001b[34mSM_CHANNEL_TRAINING=/opt/ml/input/data/training\u001b[0m\n",
|
| 475 |
+
"\u001b[34mSM_HP_ADD_INPUT_OUTPUT_DEMARCATION_KEY=True\u001b[0m\n",
|
| 476 |
+
"\u001b[34mSM_HP_CHAT_DATASET=False\u001b[0m\n",
|
| 477 |
+
"\u001b[34mSM_HP_ENABLE_FSDP=True\u001b[0m\n",
|
| 478 |
+
"\u001b[34mSM_HP_EPOCH=5\u001b[0m\n",
|
| 479 |
+
"\u001b[34mSM_HP_INSTRUCTION_TUNED=False\u001b[0m\n",
|
| 480 |
+
"\u001b[34mSM_HP_INT8_QUANTIZATION=False\u001b[0m\n",
|
| 481 |
+
"\u001b[34mSM_HP_LEARNING_RATE=0.0001\u001b[0m\n",
|
| 482 |
+
"\u001b[34mSM_HP_LORA_ALPHA=32\u001b[0m\n",
|
| 483 |
+
"\u001b[34mSM_HP_LORA_DROPOUT=0.05\u001b[0m\n",
|
| 484 |
+
"\u001b[34mSM_HP_LORA_R=8\u001b[0m\n",
|
| 485 |
+
"\u001b[34mSM_HP_MAX_INPUT_LENGTH=-1\u001b[0m\n",
|
| 486 |
+
"\u001b[34mSM_HP_MAX_TRAIN_SAMPLES=-1\u001b[0m\n",
|
| 487 |
+
"\u001b[34mSM_HP_MAX_VAL_SAMPLES=-1\u001b[0m\n",
|
| 488 |
+
"\u001b[34mSM_HP_PER_DEVICE_EVAL_BATCH_SIZE=1\u001b[0m\n",
|
| 489 |
+
"\u001b[34mSM_HP_PER_DEVICE_TRAIN_BATCH_SIZE=4\u001b[0m\n",
|
| 490 |
+
"\u001b[34mSM_HP_PREPROCESSING_NUM_WORKERS=None\u001b[0m\n",
|
| 491 |
+
"\u001b[34mSM_HP_SEED=10\u001b[0m\n",
|
| 492 |
+
"\u001b[34mSM_HP_TARGET_MODULES=q_proj,v_proj\u001b[0m\n",
|
| 493 |
+
"\u001b[34mSM_HP_TRAIN_DATA_SPLIT_SEED=0\u001b[0m\n",
|
| 494 |
+
"\u001b[34mSM_HP_VALIDATION_SPLIT_RATIO=0.2\u001b[0m\n",
|
| 495 |
+
"\u001b[34mPYTHONPATH=/opt/ml/code:/opt/conda/bin:/opt/conda/lib/python310.zip:/opt/conda/lib/python3.10:/opt/conda/lib/python3.10/lib-dynload:/opt/conda/lib/python3.10/site-packages\u001b[0m\n",
|
| 496 |
+
"\u001b[34mInvoking script with the following command:\u001b[0m\n",
|
| 497 |
+
"\u001b[34m/opt/conda/bin/python3.10 transfer_learning.py --add_input_output_demarcation_key True --chat_dataset False --enable_fsdp True --epoch 5 --instruction_tuned False --int8_quantization False --learning_rate 0.0001 --lora_alpha 32 --lora_dropout 0.05 --lora_r 8 --max_input_length -1 --max_train_samples -1 --max_val_samples -1 --per_device_eval_batch_size 1 --per_device_train_batch_size 4 --preprocessing_num_workers None --seed 10 --target_modules q_proj,v_proj --train_data_split_seed 0 --validation_split_ratio 0.2\u001b[0m\n",
|
| 498 |
+
"\u001b[34m2024-05-22 11:29:09,452 sagemaker-training-toolkit INFO Exceptions not imported for SageMaker TF as Tensorflow is not installed.\u001b[0m\n",
|
| 499 |
+
"\u001b[34m===================================BUG REPORT===================================\u001b[0m\n",
|
| 500 |
+
"\u001b[34mWelcome to bitsandbytes. For bug reports, please run\u001b[0m\n",
|
| 501 |
+
"\u001b[34mpython -m bitsandbytes\n",
|
| 502 |
+
" and submit this information together with your error trace to: https://github.com/TimDettmers/bitsandbytes/issues\u001b[0m\n",
|
| 503 |
+
"\u001b[34m================================================================================\u001b[0m\n",
|
| 504 |
+
"\u001b[34mbin /opt/conda/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda118.so\u001b[0m\n",
|
| 505 |
+
"\u001b[34m/opt/conda/lib/python3.10/site-packages/bitsandbytes/cuda_setup/main.py:149: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/usr/local/nvidia/lib'), PosixPath('/usr/local/nvidia/lib64')}\n",
|
| 506 |
+
" warn(msg)\u001b[0m\n",
|
| 507 |
+
"\u001b[34mCUDA SETUP: CUDA runtime path found: /opt/conda/lib/libcudart.so\u001b[0m\n",
|
| 508 |
+
"\u001b[34mCUDA SETUP: Highest compute capability among GPUs detected: 8.6\u001b[0m\n",
|
| 509 |
+
"\u001b[34mCUDA SETUP: Detected CUDA version 118\u001b[0m\n",
|
| 510 |
+
"\u001b[34mCUDA SETUP: Loading binary /opt/conda/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda118.so...\u001b[0m\n",
|
| 511 |
+
"\u001b[34mINFO:root:Using pre-trained artifacts in SAGEMAKER_ADDITIONAL_S3_DATA_PATH=/opt/ml/additonals3data\u001b[0m\n",
|
| 512 |
+
"\u001b[34mINFO:root:Identify file serving.properties in the un-tar directory /opt/ml/additonals3data. Copying it over to /opt/ml/model for model deployment after training is finished.\u001b[0m\n",
|
| 513 |
+
"\u001b[34mINFO:root:Invoking the training command ['torchrun', '--nnodes', '1', '--nproc_per_node', '1', 'llama_finetuning.py', '--model_name', '/opt/ml/additonals3data', '--num_gpus', '1', '--pure_bf16', '--dist_checkpoint_root_folder', 'model_checkpoints', '--dist_checkpoint_folder', 'fine-tuned', '--batch_size_training', '4', '--micro_batch_size', '4', '--train_file', '/opt/ml/input/data/training', '--lr', '0.0001', '--do_train', '--output_dir', 'saved_peft_model', '--num_epochs', '5', '--use_peft', '--peft_method', 'lora', '--max_train_samples', '-1', '--max_val_samples', '-1', '--seed', '10', '--per_device_eval_batch_size', '1', '--max_input_length', '-1', '--preprocessing_num_workers', '--None', '--validation_split_ratio', '0.2', '--train_data_split_seed', '0', '--num_workers_dataloader', '0', '--weight_decay', '0.1', '--lora_r', '8', '--lora_alpha', '32', '--lora_dropout', '0.05', '--target_modules', 'q_proj,v_proj', '--enable_fsdp', '--add_input_output_demarcation_key'].\u001b[0m\n",
|
| 514 |
+
"\u001b[34m===================================BUG REPORT===================================\u001b[0m\n",
|
| 515 |
+
"\u001b[34mWelcome to bitsandbytes. For bug reports, please run\u001b[0m\n",
|
| 516 |
+
"\u001b[34mpython -m bitsandbytes\n",
|
| 517 |
+
" and submit this information together with your error trace to: https://github.com/TimDettmers/bitsandbytes/issues\u001b[0m\n",
|
| 518 |
+
"\u001b[34m================================================================================\u001b[0m\n",
|
| 519 |
+
"\u001b[34mbin /opt/conda/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda118.so\u001b[0m\n",
|
| 520 |
+
"\u001b[34m/opt/conda/lib/python3.10/site-packages/bitsandbytes/cuda_setup/main.py:149: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/usr/local/nvidia/lib'), PosixPath('/usr/local/nvidia/lib64')}\n",
|
| 521 |
+
" warn(msg)\u001b[0m\n",
|
| 522 |
+
"\u001b[34mCUDA SETUP: CUDA runtime path found: /opt/conda/lib/libcudart.so.11.0\u001b[0m\n",
|
| 523 |
+
"\u001b[34mCUDA SETUP: Highest compute capability among GPUs detected: 8.6\u001b[0m\n",
|
| 524 |
+
"\u001b[34mCUDA SETUP: Detected CUDA version 118\u001b[0m\n",
|
| 525 |
+
"\u001b[34mCUDA SETUP: Loading binary /opt/conda/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda118.so...\u001b[0m\n",
|
| 526 |
+
"\u001b[34mINFO:root:Local rank is 0. Rank is 0\u001b[0m\n",
|
| 527 |
+
"\u001b[34mINFO:root:Setting torch device = 0\u001b[0m\n",
|
| 528 |
+
"\u001b[34mINFO:root:Loading the tokenizer.\u001b[0m\n",
|
| 529 |
+
"\u001b[34m--> Running with torch dist debug set to detail\u001b[0m\n",
|
| 530 |
+
"\u001b[34mINFO:root:Loading the data.\u001b[0m\n",
|
| 531 |
+
"\u001b[34mINFO:root:Both instruction_tuned and chat_dataset are set to False.Assuming domain adaptation dataset format.\u001b[0m\n",
|
| 532 |
+
"\u001b[34mDownloading data files: 0%| | 0/1 [00:00<?, ?it/s]\u001b[0m\n",
|
| 533 |
+
"\u001b[34mDownloading data files: 100%|██████████| 1/1 [00:00<00:00, 11748.75it/s]\u001b[0m\n",
|
| 534 |
+
"\u001b[34mExtracting data files: 0%| | 0/1 [00:00<?, ?it/s]\u001b[0m\n",
|
| 535 |
+
"\u001b[34mExtracting data files: 100%|██████████| 1/1 [00:00<00:00, 674.43it/s]\u001b[0m\n",
|
| 536 |
+
"\u001b[34mGenerating train split: 0 examples [00:00, ? examples/s]\u001b[0m\n",
|
| 537 |
+
"\u001b[34mGenerating train split: 342 examples [00:00, 127620.28 examples/s]\u001b[0m\n",
|
| 538 |
+
"\u001b[34mINFO:jumpstart:Training data is identified. The corresponded column names are ['text'].\u001b[0m\n",
|
| 539 |
+
"\u001b[34mWARNING:jumpstart:The tokenizer picked has a `model_max_length` (1000000000000000019884624838656) larger than maximum input length cap 1024. Picking 1024 instead.\u001b[0m\n",
|
| 540 |
+
"\u001b[34mINFO:jumpstart:The max sequence length is set as 1024.\u001b[0m\n",
|
| 541 |
+
"\u001b[34mRunning tokenizer on dataset: 0%| | 0/342 [00:00<?, ? examples/s]\u001b[0m\n",
|
| 542 |
+
"\u001b[34mRunning tokenizer on dataset: 100%|██████████| 342/342 [00:00<00:00, 32597.48 examples/s]\u001b[0m\n",
|
| 543 |
+
"\u001b[34mGrouping texts in chunks of 1024: 0%| | 0/342 [00:00<?, ? examples/s]\u001b[0m\n",
|
| 544 |
+
"\u001b[34mGrouping texts in chunks of 1024: 100%|██████████| 342/342 [00:00<00:00, 18777.27 examples/s]\u001b[0m\n",
|
| 545 |
+
"\u001b[34mINFO:jumpstart:Test data is not identified. Split the data into train and test data respectively.\u001b[0m\n",
|
| 546 |
+
"\u001b[34mINFO:root:Loading the pre-trained model.\u001b[0m\n",
|
| 547 |
+
"\u001b[34mLoading checkpoint shards: 0%| | 0/2 [00:00<?, ?it/s]\u001b[0m\n",
|
| 548 |
+
"\u001b[34mLoading checkpoint shards: 50%|█████ | 1/2 [00:27<00:27, 27.86s/it]\u001b[0m\n",
|
| 549 |
+
"\u001b[34mLoading checkpoint shards: 100%|██████████| 2/2 [00:38<00:00, 17.66s/it]\u001b[0m\n",
|
| 550 |
+
"\u001b[34mLoading checkpoint shards: 100%|██████████| 2/2 [00:38<00:00, 19.19s/it]\u001b[0m\n",
|
| 551 |
+
"\u001b[34m--> Model /opt/ml/additonals3data\u001b[0m\n",
|
| 552 |
+
"\u001b[34m--> /opt/ml/additonals3data has 6738.415616 Million params\u001b[0m\n",
|
| 553 |
+
"\u001b[34mtrainable params: 4,194,304 || all params: 6,742,609,920 || trainable%: 0.06220594176090199\u001b[0m\n",
|
| 554 |
+
"\u001b[34mbFloat16 enabled for mixed precision - using bfSixteen policy\u001b[0m\n",
|
| 555 |
+
"\u001b[34m--> applying fsdp activation checkpointing...\u001b[0m\n",
|
| 556 |
+
"\u001b[34mINFO:root:--> Training Set Length = 4\u001b[0m\n",
|
| 557 |
+
"\u001b[34mINFO:root:--> Validation Set Length = 1\u001b[0m\n",
|
| 558 |
+
"\u001b[34m/opt/conda/lib/python3.10/site-packages/torch/cuda/memory.py:330: FutureWarning: torch.cuda.reset_max_memory_allocated now calls torch.cuda.reset_peak_memory_stats, which resets /all/ peak memory stats.\n",
|
| 559 |
+
" warnings.warn(\u001b[0m\n",
|
| 560 |
+
"\u001b[34mTraining Epoch0: 0%|#033[34m #033[0m| 0/1 [00:00<?, ?it/s]\u001b[0m\n",
|
| 561 |
+
"\u001b[34m`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`.\u001b[0m\n",
|
| 562 |
+
"\u001b[34mNCCL version 2.19.3+cuda12.3\u001b[0m\n",
|
| 563 |
+
"\u001b[34malgo-1:51:73 [0] nccl_net_ofi_init:1444 NCCL WARN NET/OFI Only EFA provider is supported\u001b[0m\n",
|
| 564 |
+
"\u001b[34malgo-1:51:73 [0] nccl_net_ofi_init:1483 NCCL WARN NET/OFI aws-ofi-nccl initialization failed\u001b[0m\n",
|
| 565 |
+
"\u001b[34mstep 0 is completed and loss is 3.9553062915802\u001b[0m\n",
|
| 566 |
+
"\u001b[34mTraining Epoch0: 100%|#033[34m██████████#033[0m| 1/1 [00:05<00:00, 5.97s/it]\u001b[0m\n",
|
| 567 |
+
"\u001b[34mTraining Epoch0: 100%|#033[34m██████████#033[0m| 1/1 [00:05<00:00, 5.97s/it]\u001b[0m\n",
|
| 568 |
+
"\u001b[34mMax CUDA memory allocated was 16 GB\u001b[0m\n",
|
| 569 |
+
"\u001b[34mMax CUDA memory reserved was 17 GB\u001b[0m\n",
|
| 570 |
+
"\u001b[34mPeak active CUDA memory was 16 GB\u001b[0m\n",
|
| 571 |
+
"\u001b[34mCuda Malloc retires : 0\u001b[0m\n",
|
| 572 |
+
"\u001b[34mCPU Total Peak Memory consumed during the train (max): 1 GB\u001b[0m\n",
|
| 573 |
+
"\u001b[34mevaluating Epoch: 0%|#033[32m #033[0m| 0/1 [00:00<?, ?it/s]\u001b[0m\n",
|
| 574 |
+
"\u001b[34mevaluating Epoch: 100%|#033[32m██████████#033[0m| 1/1 [00:00<00:00, 2.93it/s]\u001b[0m\n",
|
| 575 |
+
"\u001b[34mevaluating Epoch: 100%|#033[32m██████████#033[0m| 1/1 [00:00<00:00, 2.93it/s]\u001b[0m\n",
|
| 576 |
+
"\u001b[34meval_ppl=tensor(47.9821, device='cuda:0') eval_epoch_loss=tensor(3.8708, device='cuda:0')\u001b[0m\n",
|
| 577 |
+
"\u001b[34mwe are about to save the PEFT modules\u001b[0m\n",
|
| 578 |
+
"\u001b[34mPEFT modules are saved in saved_peft_model directory\u001b[0m\n",
|
| 579 |
+
"\u001b[34mbest eval loss on epoch 0 is 3.87082839012146\u001b[0m\n",
|
| 580 |
+
"\u001b[34mEpoch 1: train_perplexity=52.2117, train_epoch_loss=3.9553, epcoh time 6.363337319999971s\u001b[0m\n",
|
| 581 |
+
"\u001b[34mTraining Epoch1: 0%|#033[34m #033[0m| 0/1 [00:00<?, ?it/s]\u001b[0m\n",
|
| 582 |
+
"\u001b[34mstep 0 is completed and loss is 3.9068057537078857\u001b[0m\n",
|
| 583 |
+
"\u001b[34mTraining Epoch1: 100%|#033[34m██████████#033[0m| 1/1 [00:04<00:00, 4.35s/it]\u001b[0m\n",
|
| 584 |
+
"\u001b[34mTraining Epoch1: 100%|#033[34m██████████#033[0m| 1/1 [00:04<00:00, 4.35s/it]\u001b[0m\n",
|
| 585 |
+
"\u001b[34mMax CUDA memory allocated was 16 GB\u001b[0m\n",
|
| 586 |
+
"\u001b[34mMax CUDA memory reserved was 18 GB\u001b[0m\n",
|
| 587 |
+
"\u001b[34mPeak active CUDA memory was 16 GB\u001b[0m\n",
|
| 588 |
+
"\u001b[34mCuda Malloc retires : 61\u001b[0m\n",
|
| 589 |
+
"\u001b[34mCPU Total Peak Memory consumed during the train (max): 2 GB\u001b[0m\n",
|
| 590 |
+
"\u001b[34mevaluating Epoch: 0%|#033[32m #033[0m| 0/1 [00:00<?, ?it/s]\u001b[0m\n",
|
| 591 |
+
"\u001b[34mevaluating Epoch: 100%|#033[32m██████████#033[0m| 1/1 [00:00<00:00, 2.96it/s]\u001b[0m\n",
|
| 592 |
+
"\u001b[34mevaluating Epoch: 100%|#033[32m██████████#033[0m| 1/1 [00:00<00:00, 2.95it/s]\u001b[0m\n",
|
| 593 |
+
"\u001b[34meval_ppl=tensor(45.8683, device='cuda:0') eval_epoch_loss=tensor(3.8258, device='cuda:0')\u001b[0m\n",
|
| 594 |
+
"\u001b[34mwe are about to save the PEFT modules\u001b[0m\n",
|
| 595 |
+
"\u001b[34mPEFT modules are saved in saved_peft_model directory\u001b[0m\n",
|
| 596 |
+
"\u001b[34mbest eval loss on epoch 1 is 3.825774669647217\u001b[0m\n",
|
| 597 |
+
"\u001b[34mEpoch 2: train_perplexity=49.7398, train_epoch_loss=3.9068, epcoh time 4.903923768000027s\u001b[0m\n",
|
| 598 |
+
"\u001b[34mTraining Epoch2: 0%|#033[34m #033[0m| 0/1 [00:00<?, ?it/s]\u001b[0m\n",
|
| 599 |
+
"\u001b[34mstep 0 is completed and loss is 3.851773738861084\u001b[0m\n",
|
| 600 |
+
"\u001b[34mTraining Epoch2: 100%|#033[34m██████████#033[0m| 1/1 [00:04<00:00, 4.33s/it]\u001b[0m\n",
|
| 601 |
+
"\u001b[34mTraining Epoch2: 100%|#033[34m██████████#033[0m| 1/1 [00:04<00:00, 4.34s/it]\u001b[0m\n",
|
| 602 |
+
"\u001b[34mMax CUDA memory allocated was 16 GB\u001b[0m\n",
|
| 603 |
+
"\u001b[34mMax CUDA memory reserved was 18 GB\u001b[0m\n",
|
| 604 |
+
"\u001b[34mPeak active CUDA memory was 16 GB\u001b[0m\n",
|
| 605 |
+
"\u001b[34mCuda Malloc retires : 122\u001b[0m\n",
|
| 606 |
+
"\u001b[34mCPU Total Peak Memory consumed during the train (max): 2 GB\u001b[0m\n",
|
| 607 |
+
"\u001b[34mevaluating Epoch: 0%|#033[32m #033[0m| 0/1 [00:00<?, ?it/s]\u001b[0m\n",
|
| 608 |
+
"\u001b[34mevaluating Epoch: 100%|#033[32m██████████#033[0m| 1/1 [00:00<00:00, 2.96it/s]\u001b[0m\n",
|
| 609 |
+
"\u001b[34mevaluating Epoch: 100%|#033[32m██████████#033[0m| 1/1 [00:00<00:00, 2.96it/s]\u001b[0m\n",
|
| 610 |
+
"\u001b[34meval_ppl=tensor(43.5456, device='cuda:0') eval_epoch_loss=tensor(3.7738, device='cuda:0')\u001b[0m\n",
|
| 611 |
+
"\u001b[34mwe are about to save the PEFT modules\u001b[0m\n",
|
| 612 |
+
"\u001b[34mPEFT modules are saved in saved_peft_model directory\u001b[0m\n",
|
| 613 |
+
"\u001b[34mbest eval loss on epoch 2 is 3.7738089561462402\u001b[0m\n",
|
| 614 |
+
"\u001b[34mEpoch 3: train_perplexity=47.0765, train_epoch_loss=3.8518, epcoh time 4.8904556350000234s\u001b[0m\n",
|
| 615 |
+
"\u001b[34mTraining Epoch3: 0%|#033[34m #033[0m| 0/1 [00:00<?, ?it/s]\u001b[0m\n",
|
| 616 |
+
"\u001b[34mstep 0 is completed and loss is 3.7955386638641357\u001b[0m\n",
|
| 617 |
+
"\u001b[34mTraining Epoch3: 100%|#033[34m██████████#033[0m| 1/1 [00:04<00:00, 4.33s/it]\u001b[0m\n",
|
| 618 |
+
"\u001b[34mTraining Epoch3: 100%|#033[34m██████████#033[0m| 1/1 [00:04<00:00, 4.33s/it]\u001b[0m\n",
|
| 619 |
+
"\u001b[34mMax CUDA memory allocated was 16 GB\u001b[0m\n",
|
| 620 |
+
"\u001b[34mMax CUDA memory reserved was 18 GB\u001b[0m\n",
|
| 621 |
+
"\u001b[34mPeak active CUDA memory was 16 GB\u001b[0m\n",
|
| 622 |
+
"\u001b[34mCuda Malloc retires : 183\u001b[0m\n",
|
| 623 |
+
"\u001b[34mCPU Total Peak Memory consumed during the train (max): 2 GB\u001b[0m\n",
|
| 624 |
+
"\u001b[34mevaluating Epoch: 0%|#033[32m #033[0m| 0/1 [00:00<?, ?it/s]\u001b[0m\n",
|
| 625 |
+
"\u001b[34mevaluating Epoch: 100%|#033[32m██████████#033[0m| 1/1 [00:00<00:00, 2.96it/s]\u001b[0m\n",
|
| 626 |
+
"\u001b[34mevaluating Epoch: 100%|#033[32m██████████#033[0m| 1/1 [00:00<00:00, 2.95it/s]\u001b[0m\n",
|
| 627 |
+
"\u001b[34meval_ppl=tensor(41.6456, device='cuda:0') eval_epoch_loss=tensor(3.7292, device='cuda:0')\u001b[0m\n",
|
| 628 |
+
"\u001b[34mwe are about to save the PEFT modules\u001b[0m\n",
|
| 629 |
+
"\u001b[34mPEFT modules are saved in saved_peft_model directory\u001b[0m\n",
|
| 630 |
+
"\u001b[34mbest eval loss on epoch 3 is 3.729196310043335\u001b[0m\n",
|
| 631 |
+
"\u001b[34mEpoch 4: train_perplexity=44.5022, train_epoch_loss=3.7955, epcoh time 4.880903646999968s\u001b[0m\n",
|
| 632 |
+
"\u001b[34mTraining Epoch4: 0%|#033[34m #033[0m| 0/1 [00:00<?, ?it/s]\u001b[0m\n",
|
| 633 |
+
"\u001b[34mstep 0 is completed and loss is 3.7404911518096924\u001b[0m\n",
|
| 634 |
+
"\u001b[34mTraining Epoch4: 100%|#033[34m██████████#033[0m| 1/1 [00:04<00:00, 4.33s/it]\u001b[0m\n",
|
| 635 |
+
"\u001b[34mTraining Epoch4: 100%|#033[34m██████████#033[0m| 1/1 [00:04<00:00, 4.33s/it]\u001b[0m\n",
|
| 636 |
+
"\u001b[34mMax CUDA memory allocated was 16 GB\u001b[0m\n",
|
| 637 |
+
"\u001b[34mMax CUDA memory reserved was 18 GB\u001b[0m\n",
|
| 638 |
+
"\u001b[34mPeak active CUDA memory was 16 GB\u001b[0m\n",
|
| 639 |
+
"\u001b[34mCuda Malloc retires : 244\u001b[0m\n",
|
| 640 |
+
"\u001b[34mCPU Total Peak Memory consumed during the train (max): 2 GB\u001b[0m\n",
|
| 641 |
+
"\u001b[34mevaluating Epoch: 0%|#033[32m #033[0m| 0/1 [00:00<?, ?it/s]\u001b[0m\n",
|
| 642 |
+
"\u001b[34mevaluating Epoch: 100%|#033[32m██████████#033[0m| 1/1 [00:00<00:00, 2.95it/s]\u001b[0m\n",
|
| 643 |
+
"\u001b[34mevaluating Epoch: 100%|#033[32m██████████#033[0m| 1/1 [00:00<00:00, 2.95it/s]\u001b[0m\n",
|
| 644 |
+
"\u001b[34meval_ppl=tensor(39.8134, device='cuda:0') eval_epoch_loss=tensor(3.6842, device='cuda:0')\u001b[0m\n",
|
| 645 |
+
"\u001b[34mwe are about to save the PEFT modules\u001b[0m\n",
|
| 646 |
+
"\u001b[34mPEFT modules are saved in saved_peft_model directory\u001b[0m\n",
|
| 647 |
+
"\u001b[34mbest eval loss on epoch 4 is 3.6842031478881836\u001b[0m\n",
|
| 648 |
+
"\u001b[34mEpoch 5: train_perplexity=42.1187, train_epoch_loss=3.7405, epcoh time 4.888503620999984s\u001b[0m\n",
|
| 649 |
+
"\u001b[34mINFO:root:Key: avg_train_prep, Value: 47.1297721862793\u001b[0m\n",
|
| 650 |
+
"\u001b[34mINFO:root:Key: avg_train_loss, Value: 3.8499832153320312\u001b[0m\n",
|
| 651 |
+
"\u001b[34mINFO:root:Key: avg_eval_prep, Value: 43.7710075378418\u001b[0m\n",
|
| 652 |
+
"\u001b[34mINFO:root:Key: avg_eval_loss, Value: 3.7767624855041504\u001b[0m\n",
|
| 653 |
+
"\u001b[34mINFO:root:Key: avg_epoch_time, Value: 5.185424798199994\u001b[0m\n",
|
| 654 |
+
"\u001b[34mINFO:root:Key: avg_checkpoint_time, Value: 0.7955098424000198\u001b[0m\n",
|
| 655 |
+
"\u001b[34mINFO:root:Combining pre-trained base model with the PEFT adapter module.\u001b[0m\n",
|
| 656 |
+
"\u001b[34mLoading checkpoint shards: 0%| | 0/2 [00:00<?, ?it/s]\u001b[0m\n",
|
| 657 |
+
"\u001b[34mLoading checkpoint shards: 50%|█████ | 1/2 [00:29<00:29, 29.79s/it]\u001b[0m\n",
|
| 658 |
+
"\u001b[34mLoading checkpoint shards: 100%|██████████| 2/2 [00:35<00:00, 15.64s/it]\u001b[0m\n",
|
| 659 |
+
"\u001b[34mLoading checkpoint shards: 100%|██████████| 2/2 [00:35<00:00, 17.76s/it]\u001b[0m\n",
|
| 660 |
+
"\u001b[34mINFO:root:Saving the combined model in safetensors format.\u001b[0m\n",
|
| 661 |
+
"\u001b[34mINFO:root:Saving complete.\u001b[0m\n",
|
| 662 |
+
"\u001b[34mINFO:root:Copying tokenizer to the output directory.\u001b[0m\n",
|
| 663 |
+
"\u001b[34mINFO:root:Putting inference code with the fine-tuned model directory.\u001b[0m\n",
|
| 664 |
+
"\u001b[34m2024-05-22 11:33:18,933 sagemaker-training-toolkit INFO Waiting for the process to finish and give a return code.\u001b[0m\n",
|
| 665 |
+
"\u001b[34m2024-05-22 11:33:18,933 sagemaker-training-toolkit INFO Done waiting for a return code. Received 0 from exiting process.\u001b[0m\n",
|
| 666 |
+
"\u001b[34m2024-05-22 11:33:18,934 sagemaker-training-toolkit INFO Reporting training SUCCESS\u001b[0m\n",
|
| 667 |
+
"\n",
|
| 668 |
+
"2024-05-22 11:33:43 Uploading - Uploading generated training model\n",
|
| 669 |
+
"2024-05-22 11:34:26 Completed - Training job completed\n",
|
| 670 |
+
"Training seconds: 696\n",
|
| 671 |
+
"Billable seconds: 696\n"
|
| 672 |
+
]
|
| 673 |
+
}
|
| 674 |
+
],
|
| 675 |
+
"source": [
|
| 676 |
+
"from sagemaker.jumpstart.estimator import JumpStartEstimator\n",
|
| 677 |
+
"import boto3\n",
|
| 678 |
+
"\n",
|
| 679 |
+
"estimator = JumpStartEstimator(model_id=model_id, environment={\"accept_eula\": \"true\"},instance_type = \"ml.g5.2xlarge\") \n",
|
| 680 |
+
"\n",
|
| 681 |
+
"estimator.set_hyperparameters(instruction_tuned=\"False\", epoch=\"5\")\n",
|
| 682 |
+
"\n",
|
| 683 |
+
"#Fill in the code below with the dataset you want to use from above \n",
|
| 684 |
+
"#example: estimator.fit({\"training\": f\"s3://genaiwithawsproject2024/training-datasets/finance\"})\n",
|
| 685 |
+
"estimator.fit({ \"training\": f\"s3://genaiwithawsproject2024/training-datasets/it\" })"
|
| 686 |
+
]
|
| 687 |
+
},
|
| 688 |
+
{
|
| 689 |
+
"cell_type": "markdown",
|
| 690 |
+
"metadata": {},
|
| 691 |
+
"source": [
|
| 692 |
+
"#### Deploy the fine-tuned model\n",
|
| 693 |
+
"---\n",
|
| 694 |
+
"Next, we deploy the domain fine-tuned model. We will compare the performance of the fine-tuned and pre-trained model.\n",
|
| 695 |
+
"\n",
|
| 696 |
+
"---"
|
| 697 |
+
]
|
| 698 |
+
},
|
| 699 |
+
{
|
| 700 |
+
"cell_type": "code",
|
| 701 |
+
"execution_count": 4,
|
| 702 |
+
"metadata": {
|
| 703 |
+
"tags": []
|
| 704 |
+
},
|
| 705 |
+
"outputs": [
|
| 706 |
+
{
|
| 707 |
+
"name": "stderr",
|
| 708 |
+
"output_type": "stream",
|
| 709 |
+
"text": [
|
| 710 |
+
"No instance type selected for inference hosting endpoint. Defaulting to ml.g5.2xlarge.\n",
|
| 711 |
+
"INFO:sagemaker.jumpstart:No instance type selected for inference hosting endpoint. Defaulting to ml.g5.2xlarge.\n",
|
| 712 |
+
"INFO:sagemaker:Creating model with name: meta-textgeneration-llama-2-7b-2024-05-22-11-34-38-062\n",
|
| 713 |
+
"INFO:sagemaker:Creating endpoint-config with name meta-textgeneration-llama-2-7b-2024-05-22-11-34-38-056\n",
|
| 714 |
+
"INFO:sagemaker:Creating endpoint with name meta-textgeneration-llama-2-7b-2024-05-22-11-34-38-056\n"
|
| 715 |
+
]
|
| 716 |
+
},
|
| 717 |
+
{
|
| 718 |
+
"name": "stdout",
|
| 719 |
+
"output_type": "stream",
|
| 720 |
+
"text": [
|
| 721 |
+
"----------!"
|
| 722 |
+
]
|
| 723 |
+
}
|
| 724 |
+
],
|
| 725 |
+
"source": [
|
| 726 |
+
"finetuned_predictor = estimator.deploy()"
|
| 727 |
+
]
|
| 728 |
+
},
|
| 729 |
+
{
|
| 730 |
+
"cell_type": "markdown",
|
| 731 |
+
"metadata": {},
|
| 732 |
+
"source": [
|
| 733 |
+
"#### Evaluate the pre-trained and fine-tuned model\n",
|
| 734 |
+
"---\n",
|
| 735 |
+
"Next, we use the same input from the model evaluation step to evaluate the performance of the fine-tuned model and compare it with the base pre-trained model. \n",
|
| 736 |
+
"\n",
|
| 737 |
+
"---"
|
| 738 |
+
]
|
| 739 |
+
},
|
| 740 |
+
{
|
| 741 |
+
"cell_type": "markdown",
|
| 742 |
+
"metadata": {},
|
| 743 |
+
"source": [
|
| 744 |
+
"Create a function to print the response from the model"
|
| 745 |
+
]
|
| 746 |
+
},
|
| 747 |
+
{
|
| 748 |
+
"cell_type": "code",
|
| 749 |
+
"execution_count": 5,
|
| 750 |
+
"metadata": {
|
| 751 |
+
"tags": []
|
| 752 |
+
},
|
| 753 |
+
"outputs": [],
|
| 754 |
+
"source": [
|
| 755 |
+
"def print_response(payload, response):\n",
|
| 756 |
+
" print(payload[\"inputs\"])\n",
|
| 757 |
+
" print(f\"> {response}\")\n",
|
| 758 |
+
" print(\"\\n==================================\\n\")"
|
| 759 |
+
]
|
| 760 |
+
},
|
| 761 |
+
{
|
| 762 |
+
"cell_type": "markdown",
|
| 763 |
+
"metadata": {},
|
| 764 |
+
"source": [
|
| 765 |
+
"Now we can run the same prompts on the fine-tuned model to evaluate it's domain knowledge. \n",
|
| 766 |
+
"\n",
|
| 767 |
+
"**Replace \"inputs\"** in the next cell with the input to send the model based on the domain you've chosen. \n",
|
| 768 |
+
"\n",
|
| 769 |
+
"**For financial domain:**\n",
|
| 770 |
+
"\n",
|
| 771 |
+
" \"inputs\": \"Replace with sentence below from text\" \n",
|
| 772 |
+
"- \"The investment tests performed indicate\"\n",
|
| 773 |
+
"- \"the relative volume for the long out of the money options, indicates\"\n",
|
| 774 |
+
"- \"The results for the short in the money options\"\n",
|
| 775 |
+
"- \"The results are encouraging for aggressive investors\"\n",
|
| 776 |
+
"\n",
|
| 777 |
+
"**For medical domain:** \n",
|
| 778 |
+
"\n",
|
| 779 |
+
" \"inputs\": \"Replace with sentence below from text\" \n",
|
| 780 |
+
"- \"Myeloid neoplasms and acute leukemias derive from\"\n",
|
| 781 |
+
"- \"Genomic characterization is essential for\"\n",
|
| 782 |
+
"- \"Certain germline disorders may be associated with\"\n",
|
| 783 |
+
"- \"In contrast to targeted approaches, genome-wide sequencing\"\n",
|
| 784 |
+
"\n",
|
| 785 |
+
"**For IT domain:** \n",
|
| 786 |
+
"\n",
|
| 787 |
+
" \"inputs\": \"Replace with sentence below from text\" \n",
|
| 788 |
+
"- \"Traditional approaches to data management such as\"\n",
|
| 789 |
+
"- \"A second important aspect of ubiquitous computing environments is\"\n",
|
| 790 |
+
"- \"because ubiquitous computing is intended to\" \n",
|
| 791 |
+
"- \"outline the key aspects of ubiquitous computing from a data management perspective.\""
|
| 792 |
+
]
|
| 793 |
+
},
|
| 794 |
+
{
|
| 795 |
+
"cell_type": "code",
|
| 796 |
+
"execution_count": 12,
|
| 797 |
+
"metadata": {
|
| 798 |
+
"tags": []
|
| 799 |
+
},
|
| 800 |
+
"outputs": [
|
| 801 |
+
{
|
| 802 |
+
"name": "stdout",
|
| 803 |
+
"output_type": "stream",
|
| 804 |
+
"text": [
|
| 805 |
+
"outline the key aspects of ubiquitous computing from a data management perspective.\n",
|
| 806 |
+
"> [{'generated_text': '\\nUbiquitous computing is a vision for the future in which computers are embedded in everyday objects and become invisible. As a result, users will be able to interact with their environment in a natural and seamless way.\\nThis book provides an overview of the key aspects of ubiquitous computing'}]\n",
|
| 807 |
+
"\n",
|
| 808 |
+
"==================================\n",
|
| 809 |
+
"\n"
|
| 810 |
+
]
|
| 811 |
+
}
|
| 812 |
+
],
|
| 813 |
+
"source": [
|
| 814 |
+
"payload = {\n",
|
| 815 |
+
" \"inputs\": \"outline the key aspects of ubiquitous computing from a data management perspective.\",\n",
|
| 816 |
+
" \"parameters\": {\n",
|
| 817 |
+
" \"max_new_tokens\": 64,\n",
|
| 818 |
+
" \"top_p\": 0.9,\n",
|
| 819 |
+
" \"temperature\": 0.6,\n",
|
| 820 |
+
" \"return_full_text\": False,\n",
|
| 821 |
+
" },\n",
|
| 822 |
+
"}\n",
|
| 823 |
+
"try:\n",
|
| 824 |
+
" response = finetuned_predictor.predict(payload, custom_attributes=\"accept_eula=true\")\n",
|
| 825 |
+
" print_response(payload, response)\n",
|
| 826 |
+
"except Exception as e:\n",
|
| 827 |
+
" print(e)"
|
| 828 |
+
]
|
| 829 |
+
},
|
| 830 |
+
{
|
| 831 |
+
"cell_type": "markdown",
|
| 832 |
+
"metadata": {},
|
| 833 |
+
"source": [
|
| 834 |
+
"Do the outputs from the fine-tuned model provide domain-specific insightful and relevant content? You can continue experimenting with the inputs of the model to test it's domain knowledge. \n",
|
| 835 |
+
"\n",
|
| 836 |
+
"**Use the output from this notebook to fill out the \"model fine-tuning\" section of the project documentation report**\n",
|
| 837 |
+
"\n",
|
| 838 |
+
"**After you've filled out the report, run the cells below to delete the model deployment** \n",
|
| 839 |
+
"\n",
|
| 840 |
+
"`IF YOU FAIL TO RUN THE CELLS BELOW YOU WILL RUN OUT OF BUDGET TO COMPLETE THE PROJECT`"
|
| 841 |
+
]
|
| 842 |
+
},
|
| 843 |
+
{
|
| 844 |
+
"cell_type": "code",
|
| 845 |
+
"execution_count": null,
|
| 846 |
+
"metadata": {},
|
| 847 |
+
"outputs": [],
|
| 848 |
+
"source": [
|
| 849 |
+
"finetuned_predictor.delete_model()\n",
|
| 850 |
+
"finetuned_predictor.delete_endpoint()"
|
| 851 |
+
]
|
| 852 |
+
}
|
| 853 |
+
],
|
| 854 |
+
"metadata": {
|
| 855 |
+
"kernelspec": {
|
| 856 |
+
"display_name": "conda_python3",
|
| 857 |
+
"language": "python",
|
| 858 |
+
"name": "conda_python3"
|
| 859 |
+
},
|
| 860 |
+
"language_info": {
|
| 861 |
+
"codemirror_mode": {
|
| 862 |
+
"name": "ipython",
|
| 863 |
+
"version": 3
|
| 864 |
+
},
|
| 865 |
+
"file_extension": ".py",
|
| 866 |
+
"mimetype": "text/x-python",
|
| 867 |
+
"name": "python",
|
| 868 |
+
"nbconvert_exporter": "python",
|
| 869 |
+
"pygments_lexer": "ipython3",
|
| 870 |
+
"version": "3.10.14"
|
| 871 |
+
}
|
| 872 |
+
},
|
| 873 |
+
"nbformat": 4,
|
| 874 |
+
"nbformat_minor": 4
|
| 875 |
+
}
|
Screenshot 2024-05-22 164003.png
ADDED
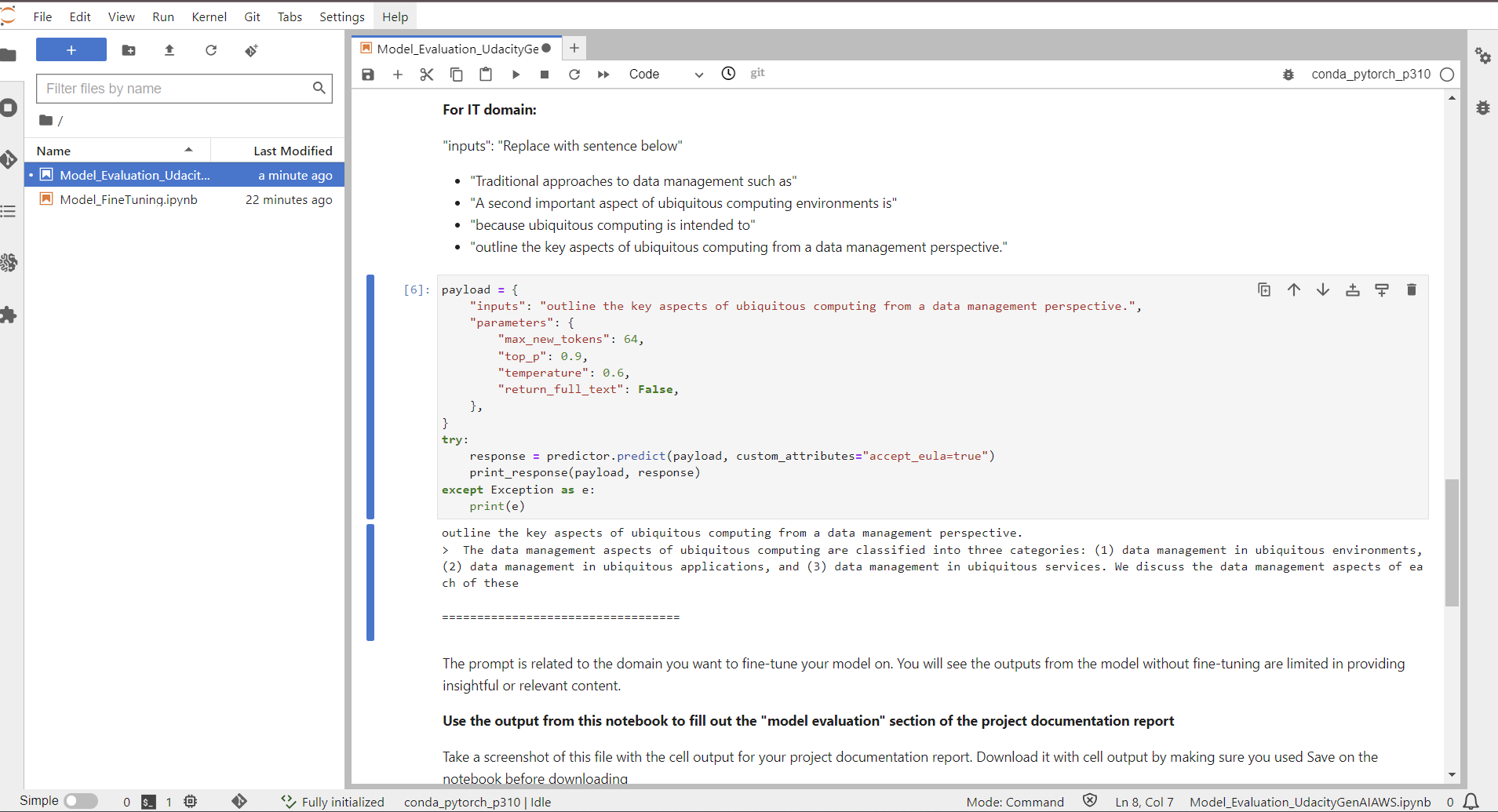
|
Screenshot 2024-05-22 171622.png
ADDED
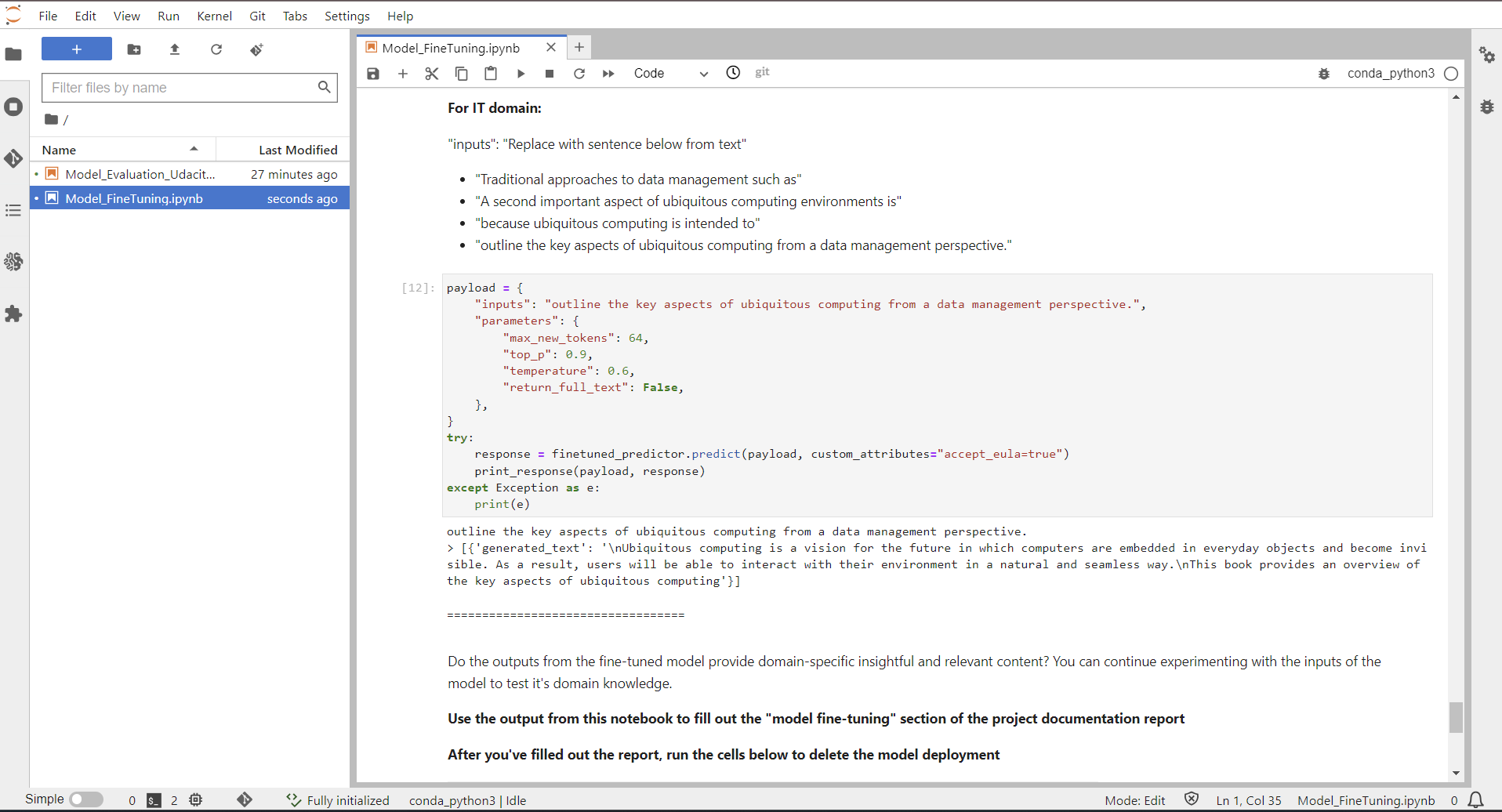
|