
Commit
•
4794c8c
1
Parent(s):
f6d1e58
Update README.md
Browse files
README.md
CHANGED
|
@@ -5,10 +5,11 @@ The dataset was constructed using documents from [the Pile](https://pile.eleuthe
|
|
| 5 |
The procedure was the following:
|
| 6 |
1. A chunk of the Pile (3%, 7m documents) was scored using the Perspective API.
|
| 7 |
1. The first half of this dataset is [tomekkorbak/pile-toxic-chunk-0](https://huggingface.co/datasets/tomekkorbak/pile-toxic-chunk-0), 100k *most* toxic documents of the scored chunk
|
| 8 |
-
2. The first half of this dataset is [tomekkorbak/pile-nontoxic-chunk-0](https://huggingface.co/datasets/tomekkorbak/pile-nontoxic-chunk-0), 100k most *least* documents of the scored chunk
|
| 9 |
3. Then, the dataset was shuffled and a 9:1 train-test split was done
|
| 10 |
|
| 11 |
## Basic stats
|
| 12 |
|
| 13 |
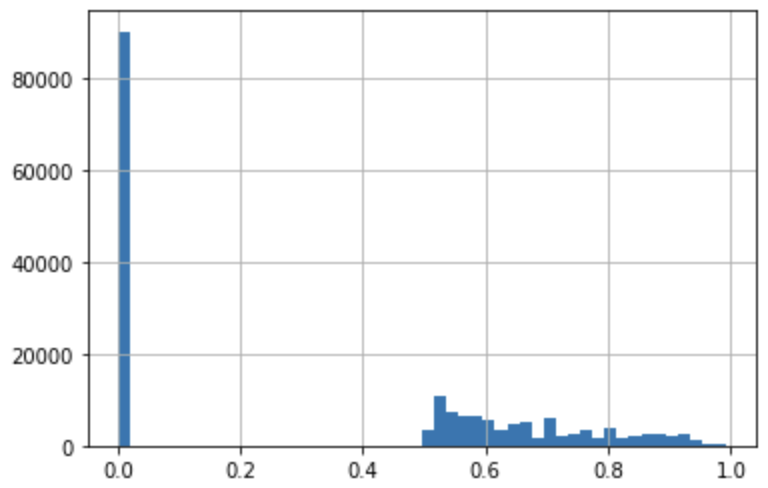
The average scores of the good and bad half are 0.0014 and 0.67, respectively. The average score of the whole dataset is 0.33; the median is 0.51.
|
| 14 |
|
|
|
|
|
|
| 5 |
The procedure was the following:
|
| 6 |
1. A chunk of the Pile (3%, 7m documents) was scored using the Perspective API.
|
| 7 |
1. The first half of this dataset is [tomekkorbak/pile-toxic-chunk-0](https://huggingface.co/datasets/tomekkorbak/pile-toxic-chunk-0), 100k *most* toxic documents of the scored chunk
|
| 8 |
+
2. The first half of this dataset is [tomekkorbak/pile-nontoxic-chunk-0](https://huggingface.co/datasets/tomekkorbak/pile-nontoxic-chunk-0), 100k most *least* toxic documents of the scored chunk
|
| 9 |
3. Then, the dataset was shuffled and a 9:1 train-test split was done
|
| 10 |
|
| 11 |
## Basic stats
|
| 12 |
|
| 13 |
The average scores of the good and bad half are 0.0014 and 0.67, respectively. The average score of the whole dataset is 0.33; the median is 0.51.
|
| 14 |
|
| 15 |
+
|