
repo_name
stringlengths 9
75
| topic
stringclasses 30
values | issue_number
int64 1
203k
| title
stringlengths 1
976
| body
stringlengths 0
254k
| state
stringclasses 2
values | created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| url
stringlengths 38
105
| labels
listlengths 0
9
| user_login
stringlengths 1
39
| comments_count
int64 0
452
|
|---|---|---|---|---|---|---|---|---|---|---|---|
mkhorasani/Streamlit-Authenticator
|
streamlit
| 182 |
Error Username/password is incorrect
|
I try using the demo app and also locally with my code. Even if the user is in the config.yaml file, it does not log in.

|
closed
|
2024-07-30T09:56:35Z
|
2024-08-01T13:42:52Z
|
https://github.com/mkhorasani/Streamlit-Authenticator/issues/182
|
[
"help wanted"
] |
vladyskai
| 6 |
K3D-tools/K3D-jupyter
|
jupyter
| 212 |
Usage in The Littlest JupyterHub
|
I'm new to hosting JupyterHub online in general. I followed the tutorial [here](http://tljh.jupyter.org/en/latest/install/google.html) to install JupyterHub on Google Cloud. I then installed k3d using pip. However, the widget doesn't show up in a notebook. This seems to only apply to k3d widgets, as other ipywidgets like the Buttons work fine. Any thought on what might cause this?
|
closed
|
2020-03-25T04:25:52Z
|
2020-03-26T17:28:51Z
|
https://github.com/K3D-tools/K3D-jupyter/issues/212
|
[] |
panangam
| 2 |
saulpw/visidata
|
pandas
| 2,162 |
Odd fuzzy matching in command palette
|
I love the command palette! 🙂
Why is it when I type "open" and "open file" `open-file` is **not** suggested -- but it is for "file"?
|
open
|
2023-12-07T21:57:46Z
|
2025-01-08T04:56:57Z
|
https://github.com/saulpw/visidata/issues/2162
|
[
"bug"
] |
reagle
| 4 |
ScrapeGraphAI/Scrapegraph-ai
|
machine-learning
| 285 |
Subprocess-exited-with-error
|
**Describe the bug**
When I attempt to pip install the package I get the following error.
register_finder(pkgutil.ImpImporter, find_on_path)
^^^^^^^^^^^^^^^^^^^
note: This error originates from a subprocess, and is likely not a problem with pip.
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> See above for output.
**To Reproduce**
Steps to reproduce the behavior:
- Type pip install scrapegraph-ai
- See error
**Expected behavior**
I excpeted the python package to be installed
**Desktop (please complete the following information):**
- OS: Windows (WSL)
|
closed
|
2024-05-22T16:11:07Z
|
2024-05-26T07:26:05Z
|
https://github.com/ScrapeGraphAI/Scrapegraph-ai/issues/285
|
[] |
jondoescoding
| 6 |
mljar/mljar-supervised
|
scikit-learn
| 268 |
Add more eval metrics
|
Please add support for more eval metrics.
|
closed
|
2020-12-09T09:39:11Z
|
2021-04-07T15:29:40Z
|
https://github.com/mljar/mljar-supervised/issues/268
|
[
"enhancement",
"help wanted"
] |
pplonski
| 6 |
QuivrHQ/quivr
|
api
| 2,731 |
Remove URL crawling and pywright to separate service
|
closed
|
2024-06-25T13:07:59Z
|
2024-09-28T20:06:17Z
|
https://github.com/QuivrHQ/quivr/issues/2731
|
[
"enhancement",
"Stale"
] |
linear[bot]
| 2 |
|
inventree/InvenTree
|
django
| 8,530 |
[FR] Add labor time for build orders
|
### Please verify that this feature request has NOT been suggested before.
- [x] I checked and didn't find a similar feature request
### Problem statement
Time is money. When building thinks the cost of time will add to the cost of the bought components. To get a good inside to the real cost of the product, it is essential to involve its build time as well and accumulate it over the whole project.
### Suggested solution
We can add values of time spend when we complete a build output. When the build is done there will be a total build time. Finally it can be average or range for each part. Same as the cost component.
Now we have a good price in indication for the bought components, but the build time is as much of a value as the money we spent on the components we bought.
### Describe alternatives you've considered
Now we have a good price in indication for the bought components, but the build time is as much of a value as the money we spent on the components we bought.
### Examples of other systems
_No response_
### Do you want to develop this?
- [ ] I want to develop this.
|
open
|
2024-11-20T07:55:45Z
|
2024-12-01T19:55:23Z
|
https://github.com/inventree/InvenTree/issues/8530
|
[
"enhancement",
"pricing",
"roadmap",
"feature"
] |
MIOsystems
| 6 |
Lightning-AI/LitServe
|
rest-api
| 275 |
Add Support to Huggingface Diffusers!
|
Add real-time support for serving diffusion models via the Hugging Face `diffusers` library.
https://huggingface.co/docs/diffusers/en/index
|
closed
|
2024-09-08T14:22:52Z
|
2024-09-08T15:08:25Z
|
https://github.com/Lightning-AI/LitServe/issues/275
|
[
"enhancement",
"help wanted"
] |
KaifAhmad1
| 2 |
slackapi/python-slack-sdk
|
asyncio
| 899 |
Happy Holidays! The team is taking a break until January 4th
|
## Happy Holidays! ❄️ ⏳
The maintainers are taking a break for the holidays and will be back to help with all your questions, issues, and feature requests in the new year. We hope you also find some time to relax and recharge. If you open an issue, please be patient and rest assured that the team will respond as soon as we can after we're back.
|
closed
|
2020-12-21T21:52:14Z
|
2021-01-05T03:03:07Z
|
https://github.com/slackapi/python-slack-sdk/issues/899
|
[
"discussion"
] |
aoberoi
| 0 |
gee-community/geemap
|
streamlit
| 1,174 |
Down image bug
|
<!-- Please search existing issues to avoid creating duplicates. -->
### Environment Information
- geemap version:0.15.4
- Python version:3.7
- Operating System:windows
### Description
When I execute the code to download the image, the downloaded image will appear empty. I downloaded the same image on gee. The image itself is OK. So i think, maybe geeemap have some bug? Thank you
Code:
image_t0=ee.Image("LANDSAT/LC08/C02/T1_L2/LC08_122026_20220106").select(['SR_B4', 'SR_B3', 'SR_B2'])
geemap.download_ee_image(image_t0, "image_t0_122026.tif", scale=30)
### What I Did
```
Paste the command(s) you ran and the output.
If there was a crash, please include the traceback here.
```
|
closed
|
2022-08-02T12:49:40Z
|
2022-08-03T21:50:48Z
|
https://github.com/gee-community/geemap/issues/1174
|
[
"bug"
] |
kgju
| 1 |
jacobgil/pytorch-grad-cam
|
computer-vision
| 49 |
how to visual the specific channels of feature?
|
good work! i have question about how to visual the specific of feature?
Like this, visual the first channel to third channel

|
closed
|
2020-10-27T13:21:38Z
|
2021-04-26T05:09:12Z
|
https://github.com/jacobgil/pytorch-grad-cam/issues/49
|
[] |
lao-ling-jie
| 10 |
wkentaro/labelme
|
computer-vision
| 870 |
how to create the chinese exe
|
how to create the chinese file, which file need to modify
|
closed
|
2021-05-26T02:41:07Z
|
2021-05-27T02:37:35Z
|
https://github.com/wkentaro/labelme/issues/870
|
[] |
Enn29
| 7 |
Evil0ctal/Douyin_TikTok_Download_API
|
web-scraping
| 78 |
修改了config.ini使用自己的服务器,开放了2333端口,docker部署的使用api没法请求到接口
|
网页端是正常..
|
closed
|
2022-09-17T01:09:20Z
|
2022-11-09T21:07:15Z
|
https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/78
|
[
"help wanted"
] |
zeku2022
| 9 |
iperov/DeepFaceLab
|
machine-learning
| 554 |
Traininig uses CPU not GPU. Is it how its supposed to be?
|
THIS IS NOT TECH SUPPORT FOR NEWBIE FAKERS
POST ONLY ISSUES RELATED TO BUGS OR CODE
## Expected behavior
I want to run the program with my GPU, i bought a new graphic card for this, but it is not using GPU while training.
## Actual behavior
firstly, before i write here, i searched every topics.
When i run the Train SAEHD, it first says this error (photo 1):

tensorflow/stream_executor/cuda/cuda_driver.cc806] failed to allocate 2.43 G (2608267264 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY: out of memory
and i get rid of this error doing these-unfortunately it just helps the erase the error, nothing more.(before that photo, train was also not work, reducing batch size helped to work but..):
https://github.com/iperov/DeepFaceLab/issues/369#issuecomment-524539937
> try batch size of 2, dims 128
----
> Try lowering the batch size, i.e start from 4 and double until you get the error.
>
> If this doesn't work, changing line 144 in `nnlib.py` to `config.gpu_options.allow_growth = False` seemed to stop this error appearing for me."
Train model is working but it's not using my GPU now. It uses RAM and CPU. Is it should be like this or how can i work my GPU? This is how i train now;
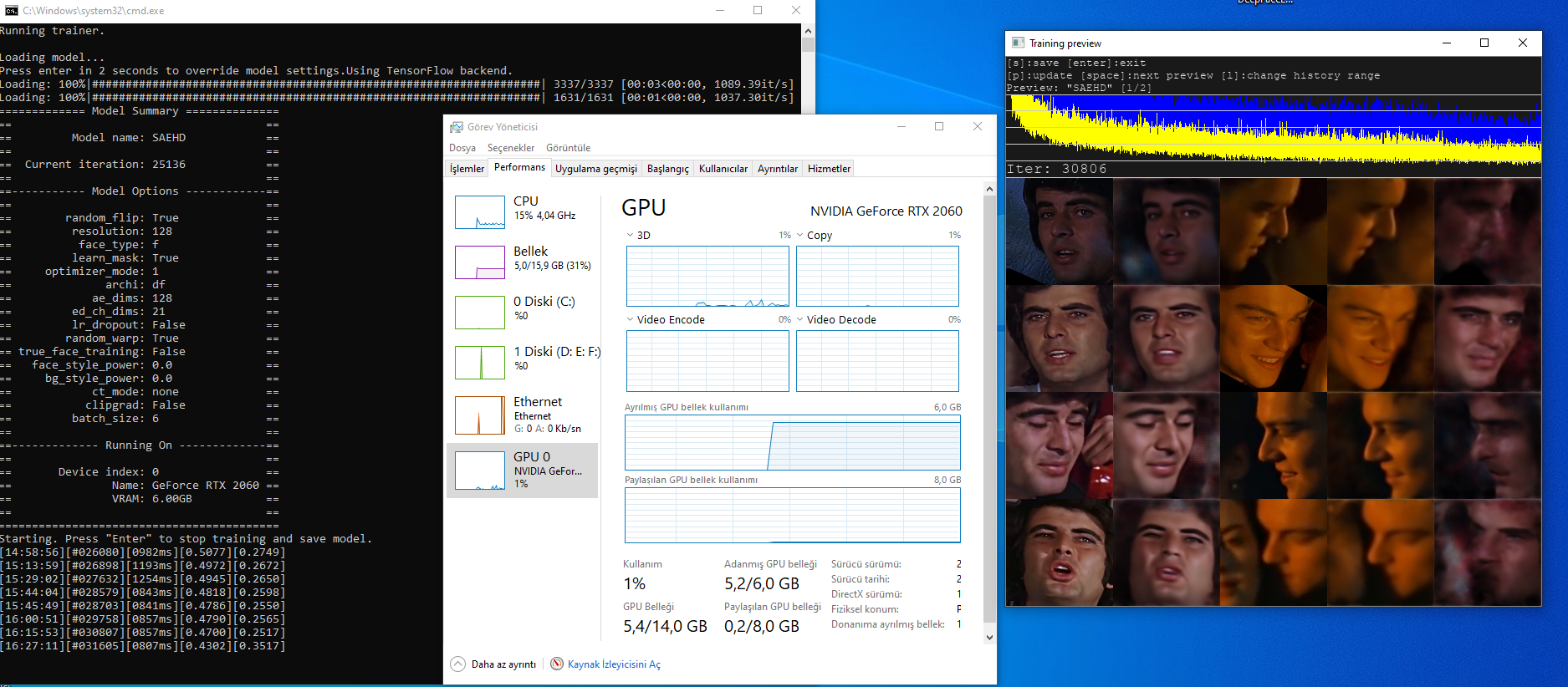
IT uses shared GPU Ram but not processor. Also not actual G-RAM it uses from my normal RAM.
## Other relevant information
Batch size=6
**Operating system and version:**
AMD Ryzen 3600 processor
Nvidia RTX 2060 6GB Graphic card
DFL build is the latest one (10.1)
Windows 10 64-bit, (i formatted several days ago, is it possible any other driver or program missing?)
**Python version:**
Python 3.8 64 bit.
|
closed
|
2020-01-13T14:42:35Z
|
2020-03-28T05:42:18Z
|
https://github.com/iperov/DeepFaceLab/issues/554
|
[] |
Glaewion
| 1 |
reloadware/reloadium
|
pandas
| 134 |
Does it support hot reloading of third-party libraries when using pycharm+pytest?
|
The reloadable paths is configured on the reloadium pycharm plugin.
When pytest is used to execute a testcase and a third-party library file is modified, but hot reloading cannot be performed. The following information is displayed:
```shell
xxx has been modified but is not loaded yet
Hot reloading not needed.
```
|
closed
|
2023-04-14T00:47:17Z
|
2023-04-14T11:00:52Z
|
https://github.com/reloadware/reloadium/issues/134
|
[] |
god-chaos
| 1 |
fastapi-users/fastapi-users
|
fastapi
| 1,466 |
Make user router flexible enough to pick few routes only
|
Hi 👋🏻
I was using fastapi users in one of my project and tried my best to customize according to requirement however I now come to deadend where `fastapi_users.get_users_router` includes multiple routes and we can't pick from one of the route or exlucde some of them.
In my case, I would like to change dependency of user patch route `PATCH /users/{id}` to change from superuser to authenticated user but I can't change that and also can't exclude that specific route while including router.
|
open
|
2024-11-15T08:29:48Z
|
2025-01-19T12:25:02Z
|
https://github.com/fastapi-users/fastapi-users/issues/1466
|
[
"bug"
] |
jd-solanki
| 5 |
Farama-Foundation/PettingZoo
|
api
| 480 |
[Proposal] Depend on OpenSpiel for Classic environment internals
|
OpenSpiels implementations of classic environments are all written in C and are dramatically faster than hours (and in some cases are better tested). They also have C implementations of most PettingZoo's classic environments. We would accordingly like to replace these with OpenSpiels over time.
|
closed
|
2021-09-11T21:36:07Z
|
2023-09-27T18:18:21Z
|
https://github.com/Farama-Foundation/PettingZoo/issues/480
|
[
"enhancement"
] |
jkterry1
| 2 |
pytest-dev/pytest-django
|
pytest
| 449 |
Fix building the docs on RTD
|
The building of the docs is currently broken: https://github.com/pytest-dev/pytest-django/pull/447#issuecomment-273681521
|
closed
|
2017-01-19T19:38:03Z
|
2017-01-28T23:16:56Z
|
https://github.com/pytest-dev/pytest-django/issues/449
|
[] |
blueyed
| 6 |
gradio-app/gradio
|
data-science
| 10,736 |
Nested functions with generic type annotations using python 3.12 syntax is not supported
|
### Describe the bug
The easiest way to explain this issue is with an example of a concrete failing function:
```python
def confirmation_harness[T](x: T) -> Callable[..., T]:
def _wrapped_fn() -> T:
return x
return _wrapped_fn
```
In this case gradio errors out with `NameError: name 'T' is not defined` because the occurrence of T in the inner function is not recognized.
A workaround is to use the old pre-3.12 way where `T` is defined as a stand alone variable like this:
````python
....
T = TypeVar('T')
def confirmation_harness(x: T) -> Callable[..., T]:
def _wrapped_fn() -> T:
return x
return _wrapped_fn
````
while this works it is not the recommended way of defining generics anymore, so I think the new way should be supported
### Have you searched existing issues? 🔎
- [x] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
```
### Screenshot
_No response_
### Logs
```shell
Traceback (most recent call last):
File "C:\Users\Jacki\repositories\ultimate-rvc\src\ultimate_rvc\web\main.py", line 452, in <module>
app = render_app()
^^^^^^^^^^^^
File "C:\Users\Jacki\repositories\ultimate-rvc\src\ultimate_rvc\web\main.py", line 403, in render_app
render_manage_audio_tab(
File "C:\Users\Jacki\repositories\ultimate-rvc\src\ultimate_rvc\web\tabs\manage\audio.py", line 294, in render
all_audio_click = all_audio_btn.click(
^^^^^^^^^^^^^^^^^^^^
File "C:\Users\Jacki\repositories\ultimate-rvc\uv\.venv\Lib\site-packages\gradio\events.py", line 670, in event_trigger
dep, dep_index = root_block.set_event_trigger(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\Jacki\repositories\ultimate-rvc\uv\.venv\Lib\site-packages\gradio\blocks.py", line 803, in set_event_trigger
check_function_inputs_match(fn, inputs, inputs_as_dict)
File "C:\Users\Jacki\repositories\ultimate-rvc\uv\.venv\Lib\site-packages\gradio\utils.py", line 1007, in check_function_inputs_match
parameter_types = get_type_hints(fn)
^^^^^^^^^^^^^^^^^^
File "C:\Users\Jacki\repositories\ultimate-rvc\uv\.venv\Lib\site-packages\gradio\utils.py", line 974, in get_type_hints
return typing.get_type_hints(fn)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\Jacki\AppData\Local\Programs\Python\Python312\Lib\typing.py", line 2310, in get_type_hints
hints[name] = _eval_type(value, globalns, localns, type_params)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\Jacki\AppData\Local\Programs\Python\Python312\Lib\typing.py", line 415, in _eval_type
return t._evaluate(globalns, localns, type_params, recursive_guard=recursive_guard)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\Jacki\AppData\Local\Programs\Python\Python312\Lib\typing.py", line 947, in _evaluate
eval(self.__forward_code__, globalns, localns),
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<string>", line 1, in <module>
NameError: name 'T' is not defined
```
### System Info
```shell
windows 11
python 3.12
gradio 5.20.0
```
### Severity
I can work around it
|
open
|
2025-03-05T22:32:29Z
|
2025-03-05T22:32:29Z
|
https://github.com/gradio-app/gradio/issues/10736
|
[
"bug"
] |
JackismyShephard
| 0 |
huggingface/datasets
|
computer-vision
| 6,622 |
multi-GPU map does not work
|
### Describe the bug
Here is the code for single-GPU processing: https://pastebin.com/bfmEeK2y
Here is the code for multi-GPU processing: https://pastebin.com/gQ7i5AQy
Here is the video showing that the multi-GPU mapping does not work as expected (there are so many things wrong here, it's better to watch the 3-minute video than explain here):
https://youtu.be/RNbdPkSppc4
### Steps to reproduce the bug
-
### Expected behavior
-
### Environment info
x2 RTX A4000
|
closed
|
2024-01-27T20:06:08Z
|
2024-02-08T11:18:21Z
|
https://github.com/huggingface/datasets/issues/6622
|
[] |
kopyl
| 1 |
OpenInterpreter/open-interpreter
|
python
| 1,168 |
Improve mouse movement and OCR speed
|
### Is your feature request related to a problem? Please describe.
When selecting a button or text, the mouse moves very slowly. Like in pyautogui, you can increase the speed to about 0.1seconds.
OI doesn't allow it which I'm aware of.
Also for OCR, It takes a long time before I can select a button or field.
I'm currently automating the generation of coupons on Kajabi. I need it to be faster than my employee
Also, how does OI decide which text to click on in the case when there are 2 or more texts that have the same text. For example, a button that says 'coupon' versus a label that says 'coupon'.
### Describe the solution you'd like
Have a duration field for mouse movement and click to improve the mouse movement speed
Improve screen-shot+ OCR speed. - To speed it up, we could in python specify the approximate location Region of interest, rather than screen capture the entire screen then run OCR.
### Describe alternatives you've considered
_No response_
### Additional context
_No response_
|
open
|
2024-04-03T14:37:20Z
|
2024-04-03T14:37:20Z
|
https://github.com/OpenInterpreter/open-interpreter/issues/1168
|
[] |
augmentedstartups
| 0 |
CorentinJ/Real-Time-Voice-Cloning
|
deep-learning
| 613 |
is there a way to configure it so that, rather than differentiate voices by speakers, it creates a composite voice trained on a few different speakers?
|
ive spent the last week or so having a ton of fun with this project and ive noticed that if you continuously train the encoder on one speaker it will tend to make any future attempts at voice cloning sound closer to the original voice it was trained on.
im a brainless monkey though and have no idea what im doing so im wondering if anyone else here has attempted this.
|
closed
|
2020-12-04T00:04:48Z
|
2020-12-05T08:03:04Z
|
https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/613
|
[] |
austin23cook
| 1 |
collerek/ormar
|
pydantic
| 415 |
Database transaction is not rollbacked
|
```python
async with transponder_.Meta.database.transaction():
sub_ = await Fusion.objects.create(
...
)
raise Exception("hello")
```
After the above code is executed, I still create a Fusion record in mysql
|
closed
|
2021-11-08T06:33:52Z
|
2021-11-15T11:47:18Z
|
https://github.com/collerek/ormar/issues/415
|
[
"bug"
] |
tufbel
| 1 |
matplotlib/matplotlib
|
data-visualization
| 28,794 |
[Doc]: Frame grabbing docs outdated?
|
### Documentation Link
https://matplotlib.org/stable/gallery/animation/frame_grabbing_sgskip.html
### Problem
An API part that used to accept scalars now expects a sequence.
Running:
``` python
import numpy as np
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.animation import FFMpegWriter
# Fixing random state for reproducibility
np.random.seed(19680801)
metadata = dict(title='Movie Test', artist='Matplotlib',
comment='Movie support!')
writer = FFMpegWriter(fps=15, metadata=metadata)
fig = plt.figure()
l, = plt.plot([], [], 'k-o')
plt.xlim(-5, 5)
plt.ylim(-5, 5)
x0, y0 = 0, 0
with writer.saving(fig, "writer_test.mp4", 100):
for i in range(100):
x0 += 0.1 * np.random.randn()
y0 += 0.1 * np.random.randn()
l.set_data(x0, y0)
writer.grab_frame()
```
from https://matplotlib.org/stable/gallery/animation/frame_grabbing_sgskip.html
Used to work, but now it produces:
``` bash
RuntimeError Traceback (most recent call last)
Cell In[1], line 30
28 x0 += 0.1 * np.random.randn()
29 y0 += 0.1 * np.random.randn()
---> 30 l.set_data(x0, y0)
31 writer.grab_frame()
File ~/miniconda3/envs/pytorch/lib/python3.12/site-packages/matplotlib/lines.py:665, in Line2D.set_data(self, *args)
662 else:
663 x, y = args
--> 665 self.set_xdata(x)
666 self.set_ydata(y)
File ~/miniconda3/envs/pytorch/lib/python3.12/site-packages/matplotlib/lines.py:1289, in Line2D.set_xdata(self, x)
1276 """
1277 Set the data array for x.
1278
(...)
1286 set_ydata
1287 """
1288 if not np.iterable(x):
-> 1289 raise RuntimeError('x must be a sequence')
1290 self._xorig = copy.copy(x)
1291 self._invalidx = True
RuntimeError: x must be a sequence
```
Which was not a problem in some previous versions.
### Suggested improvement
* We should update the docs with an example illustrating how people should use the new implementation of `FFMpegWriter` .
|
closed
|
2024-09-09T13:34:51Z
|
2024-09-12T09:29:50Z
|
https://github.com/matplotlib/matplotlib/issues/28794
|
[
"Documentation"
] |
v0lta
| 9 |
Lightning-AI/pytorch-lightning
|
pytorch
| 20,603 |
Progress bar is broken when loading trainer state from checkpoint
|
### Bug description
I am using lightning in conjunction with the mosaicML streaming library, which allows for stateful dataloaders for resumption of mid-epoch training. I am therefor passing in train/validation dataloaders manually to the trainer, as opposed to a datamodule. That said, as I am also looking to resume with optimizer state etc., I also pass in the checkpoint. Therefor my training is run as:
```
trainer.fit(
model=lightning_model,
train_dataloaders=train_dataloader,
val_dataloaders=validation_dataloader,
ckpt_path=args.ckpt
)
```
Note that at this stage, if resuming, I have already loaded my dataloader and updated with their state dict.
I have confirmed that the dataloader is still returning len(dataloader) correctly, indicating exactly how many steps are in the epoch.
But, when calling with resume logic, for example resuming from step n. 25 I will see the following in progress bar:
`25/?`
So, it seems that the trainer has (correctly) deduced that the checkpoint is resuming from a global step of 25, but is not calling len(dataloader) anymore to verify how many steps remain.
### What version are you seeing the problem on?
v2.5
### How to reproduce the bug
```python
```
### Error messages and logs
_No response_
### Environment
_No response_
### More info
_No response_
|
open
|
2025-02-25T20:41:58Z
|
2025-02-25T20:42:11Z
|
https://github.com/Lightning-AI/pytorch-lightning/issues/20603
|
[
"bug",
"needs triage",
"ver: 2.5.x"
] |
JLenzy
| 0 |
tensorpack/tensorpack
|
tensorflow
| 673 |
Infinite loop with MultiProcessMapDataZMQ
|
There is an infinite loop with the following code:
```
from tensorpack.dataflow import MultiProcessMapDataZMQ, FakeData
ds = FakeData(((50, 50, 3), (1,)))
import numpy as np
def proc(dp):
img = np.random.randint(0, 255, size=(1012, 1012, 3))
img[img < 120] = 0
return dp
mp_ds = MultiProcessMapDataZMQ(ds, map_func=proc, nr_proc=10, strict=True)
mp_ds.reset_state()
for i, (_, _) in enumerate(mp_ds.get_data()):
if i % 100 == 0:
print(i, end=" . ", flush=True)
```
Important part is `strict=True` and small size of `FakeData`. If change size to (512, 512, 3), then loop ends properly. Probably, there is something with buffer filling and dequeing...
Execution stucks [here](https://github.com/ppwwyyxx/tensorpack/blob/master/tensorpack/dataflow/parallel_map.py#L81).
|
closed
|
2018-02-25T22:58:10Z
|
2018-05-30T20:59:38Z
|
https://github.com/tensorpack/tensorpack/issues/673
|
[
"bug"
] |
vfdev-5
| 11 |
dask/dask
|
scikit-learn
| 11,016 |
Minimal dd.to_datetime to convert a string column no longer works
|
**Describe the issue**:
I feel like I must be do something wrong as this seems like a fairly simple example but I *think* it's an actual bug? (appologies if there's something really obvious in the below example that I'm missing)
**Minimal Complete Verifiable Example**:
```python
import dask.dataframe as dd
df = dd.from_dict(
{
"a": [1, 2, 3],
"dt": [
"2023-01-04T00:00:00",
"2023-04-02T00:00:00",
"2023-01-01T00:00:00",
],
},
npartitions=1,
)
dd.to_datetime(
df["dt"],
format="%Y-%m-%dT%H:%M:%S",
) # <- this throws a ValueError
```
Full error stack:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/ben/Documents/dask-issue/.venv/lib/python3.10/site-packages/dask_expr/_collection.py", line 427, in __repr__
return _str_fmt.format(
File "/home/ben/Documents/dask-issue/.venv/lib/python3.10/site-packages/dask_expr/_core.py", line 71, in __str__
s = ", ".join(
File "/home/ben/Documents/dask-issue/.venv/lib/python3.10/site-packages/dask_expr/_core.py", line 74, in <genexpr>
if isinstance(operand, Expr) or operand != self._defaults.get(param)
File "/home/ben/Documents/dask-issue/.venv/lib/python3.10/site-packages/pandas/core/generic.py", line 1576, in __nonzero__
raise ValueError(
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
>>> dd.to_datetime(df["dt"], format="%Y-%m-%dT%H:%M:%S")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/ben/Documents/dask-issue/.venv/lib/python3.10/site-packages/dask_expr/_collection.py", line 427, in __repr__
return _str_fmt.format(
File "/home/ben/Documents/dask-issue/.venv/lib/python3.10/site-packages/dask_expr/_core.py", line 71, in __str__
s = ", ".join(
File "/home/ben/Documents/dask-issue/.venv/lib/python3.10/site-packages/dask_expr/_core.py", line 74, in <genexpr>
if isinstance(operand, Expr) or operand != self._defaults.get(param)
File "/home/ben/Documents/dask-issue/.venv/lib/python3.10/site-packages/pandas/core/generic.py", line 1576, in __nonzero__
raise ValueError(
ValueError: the truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
```
**Environment**:
Dask version: 2024.3.1
Python version: 3.10.13
Operating System: Linux (Ubuntu)
Install method (conda, pip, source): pip
|
closed
|
2024-03-22T13:41:28Z
|
2024-03-22T17:00:02Z
|
https://github.com/dask/dask/issues/11016
|
[
"needs triage"
] |
benrutter
| 0 |
MaartenGr/BERTopic
|
nlp
| 1,893 |
list index out of range error in topic reduction
|
I am using the following code for topic modelling with bertopic version 0.16.0 and getting list index out of range error in topic reduction


|
open
|
2024-03-28T00:32:19Z
|
2024-03-29T07:27:42Z
|
https://github.com/MaartenGr/BERTopic/issues/1893
|
[] |
akalra03
| 1 |
errbotio/errbot
|
automation
| 1,298 |
Plugin config through chat cannot contain a line break after the plugin name
|
### I am...
* [x] Reporting a bug
* [ ] Suggesting a new feature
* [ ] Requesting help with running my bot
* [ ] Requesting help writing plugins
* [ ] Here about something else
### I am running...
* Errbot version: 5.1.1
* OS version: Ubuntu 18.04.1
* Python version: 3.6.6
* Using a virtual environment: yes/no
### Issue description
When running `!plugin config <plugin-name>`, you get a help message:
>Default configuration for this plugin (you can copy and paste this directly as a command):
When configuring a plugin through chat (Slack backend), there can't be a line break after `!plugin config <plugin-name>`. This means that, because it contains a line break, you cannot copy and paste the default configuration template as the message suggests. If you put the configuration dict on the same line, all works fine; if you put the config on new line, you get:
>Unknown plugin or the plugin could not load \<plugin-name\>.
### Steps to reproduce
Configure a plugin from chat using the Slack backend (I'm not sure if applies to all backends), making sure to include a line break between the plugin name and config dict, like:
```
!plugin config foobar
{...}
```
You will get an error: `Unknown plugin or the plugin could not load <plugin-name>`.
Now remove the line break and try configuring again:
```
!plugin config foobar {...}
```
The configuration will succeed.
|
open
|
2019-02-26T14:54:38Z
|
2019-06-18T06:10:18Z
|
https://github.com/errbotio/errbot/issues/1298
|
[
"type: bug"
] |
sheluchin
| 0 |
graphistry/pygraphistry
|
pandas
| 202 |
[BUG] as_files consistency checking
|
When using `as_files=True`:
* should compare settings
* should check for use-after-delete
|
open
|
2021-01-27T01:07:27Z
|
2021-07-16T19:47:53Z
|
https://github.com/graphistry/pygraphistry/issues/202
|
[
"bug"
] |
lmeyerov
| 1 |
postmanlabs/httpbin
|
api
| 47 |
Create a "Last-Modified" endpoint
|
Create an endpoint that allows you to specify a date/time, and will respond with a `Last-Modified` header containing that date.
If the request is sent with an `If-Modified-Since` header, a `304 Not Modified` response should be returned.
Does this sound like something that could be useful?
|
closed
|
2012-05-18T15:18:37Z
|
2018-04-26T17:50:56Z
|
https://github.com/postmanlabs/httpbin/issues/47
|
[
"feature-request"
] |
johtso
| 0 |
babysor/MockingBird
|
pytorch
| 183 |
用colab和谷歌云服务器预处理时,出现了AssertionError
|
~/MockingBird$ python pre.py dateAISHELL3 -d aishell3
Traceback (most recent call last):
File "pre.py", line 57, in <module>
assert args.datasets_root.exists()
AssertionError
colab和谷歌云都出现了相同的错误,版本都是用git clone 抓取的最新版
|
closed
|
2021-10-31T10:03:31Z
|
2021-12-26T03:23:50Z
|
https://github.com/babysor/MockingBird/issues/183
|
[] |
kulu2001
| 2 |
bmoscon/cryptofeed
|
asyncio
| 814 |
Add Kucoin L3 feed support
|
Kucoin supports L3 feed according to docs https://github.com/Kucoin-academy/best-practice/blob/master/README_EN.md
Would be nice to get it as not many exchanges support L3 data
|
closed
|
2022-03-28T17:57:52Z
|
2022-03-28T19:09:46Z
|
https://github.com/bmoscon/cryptofeed/issues/814
|
[
"Feature Request"
] |
anovv
| 1 |
gevent/gevent
|
asyncio
| 1,792 |
arm64 crossompile error
|
checking build system type... x86_64-pc-linux-gnu
checking host system type... Invalid configuration `aarch64-openwrt-linux': machine `aarch64-openwrt' not recognized
is there any solution from cross compilation ?
|
closed
|
2021-05-20T12:55:12Z
|
2021-05-21T11:23:33Z
|
https://github.com/gevent/gevent/issues/1792
|
[] |
erdoukki
| 5 |
allenai/allennlp
|
nlp
| 4,739 |
Potential bug: The maxpool in cnn_encoder can be triggered by pad tokens.
|
## Description
When using a text_field_embedder -> cnn_encoder (without seq2seq_encoder), the output of the embedder (and mask) get fed directly into the cnn_encoder. The pad tokens will get masked (set to 0), but it's still possible that after applying the mask followed by the CNN, the PAD tokens are those with highest activations. This could lead to the same exact datapoint getting different predictions if's part of a batch vs single prediction.
## Related issues or possible duplicates
- None
## Environment
OS: NA
Python version: NA
## Steps to reproduce
This can be reproduced by replacing
https://github.com/allenai/allennlp/blob/00bb6c59b3ac8fdc78dfe8d5b9b645ce8ed085c0/allennlp/modules/seq2vec_encoders/cnn_encoder.py#L113
```
filter_outputs.append(self._activation(convolution_layer(tokens)).max(dim=2)[0])
```
with
```
activated_outputs, max_indices = self._activation(convolution_layer(tokens)).max(dim=2)
```
and checking the indices for the same example inside of a batch vs unpadded.
## Possible solution:
We could resolve this by adding a large negative value to all CNN outputs for masked tokens, similarly to what they do in the transformers library (https://github.com/huggingface/transformers/issues/542, https://github.com/huggingface/transformers/blob/c912ba5f69a47396244c64deada5c2b8a258e2b8/src/transformers/modeling_bert.py#L262), but I have not been able to figure out how to do this efficiently.
|
closed
|
2020-10-19T23:30:31Z
|
2020-11-05T23:50:04Z
|
https://github.com/allenai/allennlp/issues/4739
|
[
"bug"
] |
MichalMalyska
| 6 |
JaidedAI/EasyOCR
|
machine-learning
| 377 |
How to train on custom data set?
|
Please reply.
Thanks in advance.
|
closed
|
2021-02-16T08:44:08Z
|
2021-07-02T08:54:30Z
|
https://github.com/JaidedAI/EasyOCR/issues/377
|
[] |
fahimnawaz7
| 1 |
inducer/pudb
|
pytest
| 477 |
Console history across sessions
|
Is it possible to record the python console history when in the debugger, so as to make it accessible accross sessions?
So if it run pudb once and input `a + b` and then restart the debugger in a new session I can press Ctrl + P and find `a + b` there?
I currently use my own fork of ipdb with certain modifications to make this happen (since ipdb as of right now does not support history across sessions), but I find pudb to be a lot nicer. So I was wondering if the addition of this functionality is being considered?
Thanks in advance for your help!!
|
closed
|
2021-10-22T12:40:10Z
|
2021-11-02T21:42:30Z
|
https://github.com/inducer/pudb/issues/477
|
[] |
dvd42
| 4 |
kizniche/Mycodo
|
automation
| 982 |
Atlas Gravity Analog pH Sensor Calibration
|
Hi Kyle
Huge fan.
Is it possible to calibrate or add calibration for the Atlas Analog probes?
Regards
Todd
|
closed
|
2021-04-15T14:58:05Z
|
2021-04-15T15:03:09Z
|
https://github.com/kizniche/Mycodo/issues/982
|
[] |
cactuscrawford
| 2 |
plotly/dash
|
flask
| 3,004 |
dropdowns ignore values when options are not set
|
Thank you so much for helping improve the quality of Dash!
We do our best to catch bugs during the release process, but we rely on your help to find the ones that slip through.
**Describe your context**
dash==2.18.1
dash-bootstrap-components==1.6.0
dash-extensions==1.0.15
dash-cytoscape==1.0.1
plotly==5.24.1
- replace the result of `pip list | grep dash` below
```
dash 2.18.1
dash-bootstrap-components 1.6.0
dash-core-components 2.0.0
dash_cytoscape 1.0.1
dash_dangerously_set_inner_html 0.0.2
dash-extensions 1.0.15
dash-html-components 2.0.0
dash-leaflet 1.0.15
dash-mantine-components 0.12.1
dash-quill 0.0.4
dash-svg 0.0.12
dash-table 5.0.0
```
- if frontend related, tell us your Browser, Version and OS
- OS: Windows
- Browser: Edge
- Version: 128.0.2739.67
**Describe the bug**
On my dashboard I use dropdowns where the options are dynamically updated based on the underlying dataset. In order to facilitate quick links throughout the site, I use URL params to pre-set the dropdowns to certain values.
It has been a very simple solution for me for years now.
Up to dash 2.16.1, this all works fine. On any higher versions the pre-set value is ignored.
**Expected behavior**
I am able to set the value of a dropdown without an options set, and once the options are updated, the pre-set value shows up as selected if it is part of the options set.
**Minimal Example***
```
from dash import Dash, dcc, html, Input, Output, callback
preset_value = 'NYC' # from url params
app = Dash(__name__)
app.layout = html.Div([
dcc.Store(id='demo-store'),
dcc.Interval(id='demo-interval', interval=1000, n_intervals=0),
dcc.Dropdown(
value=preset_value,
options=[],
id='demo-dropdown'
),
])
@callback(
Output('demo-store', 'data'),
Input('demo-interval', 'n_intervals')
)
def update_output(n):
return [{'label': i, 'value': i} for i in ['NYC', 'MTL', 'LA']]
@callback(
Output('demo-dropdown', 'options'),
Input('demo-store', 'data')
)
def update_output(data):
return data
if __name__ == '__main__':
app.run(debug=True)
```
|
closed
|
2024-09-15T10:28:32Z
|
2024-09-17T12:18:57Z
|
https://github.com/plotly/dash/issues/3004
|
[
"bug",
"P3"
] |
areed145
| 2 |
FujiwaraChoki/MoneyPrinterV2
|
automation
| 33 |
Macbook cannot find .model.js
|
When I run the project using my MacBook, I found that the output address was [/MoneyPrinterV2/venv**\\**Lib**\\**site-packages/TTS/.models.json] ,this Path is not supported in Mac, so I can't locate the real address.
This piece of code might need some adjustments.
```
# Path to the .models.json file
models_json_path = os.path.join(
ROOT_DIR,
venv_site_packages,
"TTS",
".models.json",
)
```
|
closed
|
2024-02-22T06:46:30Z
|
2024-02-22T09:05:13Z
|
https://github.com/FujiwaraChoki/MoneyPrinterV2/issues/33
|
[] |
NicholasChong
| 1 |
TvoroG/pytest-lazy-fixture
|
pytest
| 63 |
Inquiry about the status of pytest-lazy-fixture and offering assistance
|
Hey @TvoroG,
I hope you're doing well. I really find pytest-lazy-fixture a great pytest plugin, but I noticed that it hasn't had a release since 2020, and there are some open issues and pull requests that seem to be unattended.
For this reason, I wonder if the project is abandoned, or if it's still supported.
Specifically, I think that https://github.com/TvoroG/pytest-lazy-fixture/pull/62 is really something worth considering and that would make the project even more useful. I use that approach in pytest-factoryboy, but this project is way more advanced in the way it handles the pytest internals for lazy fixtures.
As an active user and maintainer of pytest-bdd and pytest-factoryboy, I would be interested in contributing to the project's maintenance and further development, including reviewing PRs, keeping the CI up to date with the latest pytests and python versions, making releases, etc.
Would that be something you can consider?
Thanks for your time, and I'm looking forward to your response.
Best regards,
Alessio
|
open
|
2023-07-30T10:19:40Z
|
2025-03-10T16:04:07Z
|
https://github.com/TvoroG/pytest-lazy-fixture/issues/63
|
[] |
youtux
| 10 |
aiortc/aiortc
|
asyncio
| 232 |
Using STUN and TURN Server at the same time
|
Hi,
I am currently trying to define add a stun and a turn server to my configuration, but it seems like it is using only the turn server:
```
pc = RTCPeerConnection(
configuration=RTCConfiguration([
RTCIceServer("stun:stun.l.google:19302"),
RTCIceServer("turn:turnserver.cidaas.de:3478?transport=udp", "user", "pw"),
]))
```
When I am behind a firewall which is blocking the turn server ports I receive the following error:
```
Error handling request
Traceback (most recent call last):
File "/home/tanja/venvs/cidaas/id-services-aggregator/lib/python3.7/site-packages/aiohttp/web_protocol.py", line 418, in start
resp = await task
File "/home/tanja/venvs/cidaas/id-services-aggregator/lib/python3.7/site-packages/aiohttp/web_app.py", line 458, in _handle
resp = await handler(request)
File "/home/tanja/git/cidaas/id-card-utility-backend/server.py", line 104, in offer
await pc.setLocalDescription(answer)
File "/home/tanja/venvs/cidaas/id-services-aggregator/lib/python3.7/site-packages/aiortc/rtcpeerconnection.py", line 666, in setLocalDescription
await self.__gather()
File "/home/tanja/venvs/cidaas/id-services-aggregator/lib/python3.7/site-packages/aiortc/rtcpeerconnection.py", line 865, in __gather
await asyncio.gather(*coros)
File "/home/tanja/venvs/cidaas/id-services-aggregator/lib/python3.7/site-packages/aiortc/rtcicetransport.py", line 174, in gather
await self._connection.gather_candidates()
File "/home/tanja/venvs/cidaas/id-services-aggregator/lib/python3.7/site-packages/aioice/ice.py", line 362, in gather_candidates
addresses=addresses)
File "/home/tanja/venvs/cidaas/id-services-aggregator/lib/python3.7/site-packages/aioice/ice.py", line 749, in get_component_candidates
transport=self.turn_transport)
File "/home/tanja/venvs/cidaas/id-services-aggregator/lib/python3.7/site-packages/aioice/turn.py", line 301, in create_turn_endpoint
await transport._connect()
File "/home/tanja/venvs/cidaas/id-services-aggregator/lib/python3.7/site-packages/aioice/turn.py", line 272, in _connect
self.__relayed_address = await self.__inner_protocol.connect()
File "/home/tanja/venvs/cidaas/id-services-aggregator/lib/python3.7/site-packages/aioice/turn.py", line 80, in connect
response, _ = await self.request(request)
File "/home/tanja/venvs/cidaas/id-services-aggregator/lib/python3.7/site-packages/aioice/turn.py", line 173, in request
return await transaction.run()
File "/home/tanja/venvs/cidaas/id-services-aggregator/lib/python3.7/site-packages/aioice/stun.py", line 250, in run
return await self.__future
aioice.exceptions.TransactionTimeout: STUN transaction timed out
```
when using the following configuration it works:
```
pc = RTCPeerConnection(
configuration=RTCConfiguration([
RTCIceServer("stun:stun.l.google:19302"),
]))
```
But when I use a mobile device using the configuration from above (turn + stun) it works (as the turn server connection is not blocked)
Any idea why it is not possible to use either stun or turn server, depending on which one is possible to use. Or is that expected behavior, if yes, what is the purpos of allowing muliple Server configuration? Shouldn't it give some kind of warning, that stun will not be used?
Or am I missing out some important config parameters?
Best Regards,
Tanja
|
closed
|
2019-12-03T16:06:16Z
|
2019-12-04T09:14:41Z
|
https://github.com/aiortc/aiortc/issues/232
|
[] |
TanjaBayer
| 4 |
deepinsight/insightface
|
pytorch
| 1,812 |
DeprecationWarning : np.float` is a deprecated alias for the builtin `float`.
|
`DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
eps=np.finfo(np.float).eps, random_state=None,`
|
open
|
2021-11-03T07:30:15Z
|
2021-11-03T07:30:15Z
|
https://github.com/deepinsight/insightface/issues/1812
|
[] |
HenryBao91
| 0 |
Avaiga/taipy
|
data-visualization
| 1,826 |
Customized labels for Boolean values in tables
|
### Description
Tables represent Boolean values with a switch component.
The labels are True and False, which makes a lot of sense.
It would be nice to allow for specifying these labels using a control's property.
I can think of 0/1, Off/On, Bad/Good, Male/Female, Disagree/Agree... and plenty of use cases where the UI would help providing semantic support.
### Acceptance Criteria
- [ ] Ensure new code is unit tested, and check code coverage is at least 90%.
- [ ] Create related issue in taipy-doc for documentation and Release Notes.
- [ ] Check if a new demo could be provided based on this, or if legacy demos could be benefit from it.
- [ ] Ensure any change is well documented.
### Code of Conduct
- [X] I have checked the [existing issues](https://github.com/Avaiga/taipy/issues?q=is%3Aissue+).
- [ ] I am willing to work on this issue (optional)
|
closed
|
2024-09-23T15:06:05Z
|
2024-09-24T12:03:10Z
|
https://github.com/Avaiga/taipy/issues/1826
|
[
"🖰 GUI",
"🟨 Priority: Medium",
"✨New feature"
] |
FabienLelaquais
| 0 |
TracecatHQ/tracecat
|
automation
| 653 |
No error handeling in env.sh if openssl is not installed
|
**Lacking error handeling**
A clean fedora 41 workstation install does not have openssl installed.
As the env.sh script assumes this is available and does not check you will get the error message:
_Generating new service key and signing secret...
./env.sh: line 60: openssl: command not found
./env.sh: line 61: openssl: command not found
Generating a Fernet encryption key for the database...
Creating new .env from .env.example..._
**To Reproduce**
Install clean _Fedora-Workstation-Live-x86_64-41-1.4.iso_.
Follow [Docker Compose](https://docs.tracecat.com/self-hosting/deployment-options/docker-compose)
Notice when running script you will get error message command not found.
**Expected behavior**
A clear error message and canceled creation of the .env file.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Environment (please complete the following information):**
- OS: Fedora Workstation 41 x86.
|
closed
|
2024-12-21T23:56:30Z
|
2024-12-27T00:28:29Z
|
https://github.com/TracecatHQ/tracecat/issues/653
|
[
"bug",
"documentation",
"build"
] |
FestHesten
| 0 |
Evil0ctal/Douyin_TikTok_Download_API
|
api
| 550 |
现在获取单个作品数据接口不行了吗
|

我本地测试报错,Cookie和User-Agent换过

报错信息如下

|
closed
|
2025-02-12T06:28:51Z
|
2025-02-14T02:41:17Z
|
https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/550
|
[] |
lao-wen
| 4 |
junyanz/pytorch-CycleGAN-and-pix2pix
|
computer-vision
| 1,044 |
Will training the discriminator model alone help improve my model performance?
|
Currently, I'm doing a task of image to image translation with the following dataset using pix2pix model. The task is to enhance the contrast between the text. I have very less such images and its label pairs. I am getting decent results with 300 manually annotated images. But it is not feasible to generate more image pairs.
Also it is very difficult to create the image pairs. I have created two more different datasets from the above large original image.
**Pixel wise paired dataset**
I have cropped various characters present in the image dataset and created pairs.
**Word pair dataset**
I trained with all three datasets together. It was worsening the performance compared to model trained with full image dataset.
Is it possible to train only the discriminator with the pixelwise and word wise dataset and train the generator and discriminator with the full image dataset?
What do you think will improve the performance in my case? Thanks in advance.
|
closed
|
2020-05-25T10:22:34Z
|
2020-06-01T10:37:42Z
|
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1044
|
[] |
kalai2033
| 6 |
pytorch/vision
|
computer-vision
| 8,820 |
Feature extraction blocks
|
deleted!
|
closed
|
2024-12-20T13:19:01Z
|
2025-01-09T18:21:15Z
|
https://github.com/pytorch/vision/issues/8820
|
[] |
jawi289o
| 1 |
RobertCraigie/prisma-client-py
|
asyncio
| 257 |
Support for using within a standalone package
|
## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
It is difficult to use Prisma Client Python in a CLI that will be installed by users as the generation step needs to be ran.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Provide a helper method for running a prisma command and reloading the generated modules, e.g.
```py
import prisma
# from prisma import Client would raise an ImportError here
prisma.run('db', 'push')
from prisma import Client
```
However you would not want to run this every time, we should provide mechanisms for running the command based on a condition. A potential problem with this is managing versions, if you update the schema and release a new version, anyone already using the old version wouldn't have their database updated. A potential solution for this could be hashing the schema and comparing hashes.
|
open
|
2022-01-30T21:45:55Z
|
2022-02-01T18:20:14Z
|
https://github.com/RobertCraigie/prisma-client-py/issues/257
|
[
"kind/feature",
"priority/medium",
"level/unknown"
] |
RobertCraigie
| 0 |
jupyter/nbgrader
|
jupyter
| 942 |
Jupyter/nbgrader learning analytics dashboard?
|
<!--
Thanks for helping to improve nbgrader!
If you are submitting a bug report or looking for support, please use the below
template so we can efficiently solve the problem.
If you are requesting a new feature, feel free to remove irrelevant pieces of
the issue template.
-->
I am curious as to whether there exists, or there are thoughts to develop, a learning analytics dashboard for use with Jupyter and nbgrader in the classroom? For example, if you have students working on a specific notebook during a class/tutorial that has several questions - could one probe how many questions students had answered and, if those questions were autogradable, what the mean/median grades were. Perhaps there is an existing tool in the Jupyter ecosystem but I have not yet come across one (and if there is, please point me in that direction).
If this may be possible and but does not yet exist, I would be more than happy to contribute to the creation of such a tool.
|
open
|
2018-03-14T22:49:01Z
|
2018-04-22T11:28:00Z
|
https://github.com/jupyter/nbgrader/issues/942
|
[
"enhancement"
] |
ttimbers
| 1 |
amidaware/tacticalrmm
|
django
| 1,461 |
Entering a comma in the hours number in the download agent dialog generates an error
|
**Server Info (please complete the following information):**
- OS: Ubuntu 20.04.4 LTS
- Browser: Firefox 110.0 (64-bit)
- RMM Version (as shown in top left of web UI): v0.15.7
**Installation Method:**
- [x] Standard
- [ ] Docker
**Agent Info (please complete the following information):**
- Agent version (as shown in the 'Summary' tab of the agent from web UI): v2.4.4
- Agent OS: Windows 10 Pro, 64 bit v21H2 (build 19044.2728)
**Describe the bug**
The "time expiration (hours)" field expects a number but does not accept numbers with a comma.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to Agents > Install Agent
2. Enter a number with a comma in the token expiration field.
3. Click "Generate and Download exe" and you'll get an error.
**Expected behavior**
I would expect the system to accept numbers with commas. Ideally, this should also be locale aware with the possibility of accepting periods instead of commas.
**Screenshots**
N/A
**Additional context**
The POST request does not have the token value. This implies the frontend is invalidating the input.
POST sent to `https://api.a8n.tools/agents/installer/`:
```json
{
"agenttype": "workstation",
"api": "https://api.a8n.tools",
"client": 6,
"expires": "",
"fileName": "trmm-help-onboarding-workstation-amd64.exe",
"goarch": "amd64",
"installMethod": "exe",
"ping": 0,
"plat": "windows",
"power": 0,
"rdp": 0,
"site": 9
}
```
Stack trace from `/rmm/api/tacticalrmm/tacticalrmm/private/log/django_debug.log`:
```text
[23/Mar/2023 18:57:25] ERROR [django.request:241] Internal Server Error: /agents/installer/
Traceback (most recent call last):
File "/rmm/api/env/lib/python3.10/site-packages/django/core/handlers/exception.py", line 55, in inner
response = get_response(request)
File "/rmm/api/env/lib/python3.10/site-packages/django/core/handlers/base.py", line 197, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/rmm/api/env/lib/python3.10/site-packages/django/views/decorators/csrf.py", line 54, in wrapped_view
return view_func(*args, **kwargs)
File "/rmm/api/env/lib/python3.10/site-packages/django/views/generic/base.py", line 103, in view
return self.dispatch(request, *args, **kwargs)
File "/rmm/api/env/lib/python3.10/site-packages/rest_framework/views.py", line 509, in dispatch
response = self.handle_exception(exc)
File "/rmm/api/env/lib/python3.10/site-packages/rest_framework/views.py", line 469, in handle_exception
self.raise_uncaught_exception(exc)
File "/rmm/api/env/lib/python3.10/site-packages/rest_framework/views.py", line 480, in raise_uncaught_exception
raise exc
File "/rmm/api/env/lib/python3.10/site-packages/rest_framework/views.py", line 506, in dispatch
response = handler(request, *args, **kwargs)
File "/rmm/api/env/lib/python3.10/site-packages/rest_framework/decorators.py", line 50, in handler
return func(*args, **kwargs)
File "/rmm/api/tacticalrmm/agents/views.py", line 563, in install_agent
user=installer_user, expiry=dt.timedelta(hours=request.data["expires"])
TypeError: unsupported type for timedelta hours component: str
```
|
closed
|
2023-03-23T19:11:24Z
|
2023-03-23T19:44:14Z
|
https://github.com/amidaware/tacticalrmm/issues/1461
|
[] |
NiceGuyIT
| 1 |
microsoft/MMdnn
|
tensorflow
| 420 |
I tried to convert tf frozen model to ir, but it failed.
|
Platform (like ubuntu 16.04/win10):
docker image mmdnn/mmdnn:cpu.small
Python version:
python 3.5
Source framework with version (like Tensorflow 1.4.1 with GPU):
tf 1.7 with GPU optimized by tensorRT, not very sure the version of tf
Destination framework with version (like CNTK 2.3 with GPU):
I want to convert the frozen pb to ir first, then convert it to saved model for tensorflow serving
Pre-trained model path (webpath or webdisk path):
https://developer.download.nvidia.com/devblogs/tftrt_sample.tar.xz
Running scripts:
```
mmtoir -f tensorflow --frozen_pb resnetV150_TRTFP32.pb --inNodeName input --inputShape 224 224 3 --dstNodeName dstNode -o resnet150-ir
```
> Traceback (most recent call last):
File "/usr/local/bin/mmtoir", line 11, in <module>
sys.exit(_main())
File "/usr/local/lib/python3.5/dist-packages/mmdnn/conversion/_script/convertToIR.py", line 184, in _main
ret = _convert(args)
File "/usr/local/lib/python3.5/dist-packages/mmdnn/conversion/_script/convertToIR.py", line 48, in _convert
parser = TensorflowParser2(args.frozen_pb, args.inputShape, args.inNodeName, args.dstNodeName)
File "/usr/local/lib/python3.5/dist-packages/mmdnn/conversion/tensorflow/tensorflow_frozenparser.py", line 108, in __init__
placeholder_type_enum = dtypes.float32.as_datatype_enum)
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/tools/strip_unused_lib.py", line 86, in strip_unused
output_node_names)
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/framework/graph_util_impl.py", line 174, in extract_sub_graph
_assert_nodes_are_present(name_to_node, dest_nodes)
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/framework/graph_util_impl.py", line 133, in _assert_nodes_are_present
assert d in name_to_node, "%s is not in graph" % d
AssertionError: dstNode is not in graph
Any ideas? Or does mmdnn support converting tensorRT optimized tf frozen model?
Thanks.
|
closed
|
2018-09-20T02:22:23Z
|
2018-09-25T08:20:11Z
|
https://github.com/microsoft/MMdnn/issues/420
|
[] |
elvys-zhang
| 7 |
yt-dlp/yt-dlp
|
python
| 11,875 |
support for 360research / motilaloswal.com
|
### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [X] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
### Checklist
- [X] I'm reporting a new site support request
- [X] I've verified that I have **updated yt-dlp to nightly or master** ([update instructions](https://github.com/yt-dlp/yt-dlp#update-channels))
- [X] I've checked that all provided URLs are playable in a browser with the same IP and same login details
- [X] I've checked that none of provided URLs [violate any copyrights](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#is-the-website-primarily-used-for-piracy) or contain any [DRM](https://en.wikipedia.org/wiki/Digital_rights_management) to the best of my knowledge
- [X] I've searched [known issues](https://github.com/yt-dlp/yt-dlp/issues/3766) and the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues **including closed ones**. DO NOT post duplicates
- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)
- [X] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and am willing to share it if required
### Region
_No response_
### Example URLs
https://prd.motilaloswal.com/edumo/videos/webinar/154
### Provide a description that is worded well enough to be understood
i want to download videos from the website called 360research(link is pasted above with the desired video that i want to download) the website is like you have to make an account pay a certain amount to access the course and watch it online only but i want to download it to i can refer later on and they(360research website doesnt have an download option) i have tried installing yt dlp and tried downloading using "yt-dlp https://prd.motilaloswal.com/edumo/videos/webinar/154" in the terminal and it shows it is an unsupported URL...
### Provide verbose output that clearly demonstrates the problem
- [X] Run **your** yt-dlp command with **-vU** flag added (`yt-dlp -vU <your command line>`)
- [X] If using API, add `'verbose': True` to `YoutubeDL` params instead
- [X] Copy the WHOLE output (starting with `[debug] Command-line config`) and insert it below
### Complete Verbose Output
```shell
[debug] Command-line config: ['-vU', 'yt-dlp', 'https://prd.motilaloswal.com/edumo/videos/webinar/154']
[debug] Encodings: locale UTF-8, fs utf-8, pref UTF-8, out utf-8, error utf-8, screen utf-8
[debug] yt-dlp version stable@2024.12.13 from yt-dlp/yt-dlp [542166962] (pip)
[debug] Python 3.13.1 (CPython x86_64 64bit) - macOS-14.6.1-x86_64-i386-64bit-Mach-O (OpenSSL 3.4.0 22 Oct 2024)
[debug] exe versions: ffmpeg 7.1 (setts), ffprobe 7.1
[debug] Optional libraries: Cryptodome-3.21.0, brotli-1.1.0, certifi-2024.12.14, mutagen-1.47.0, requests-2.32.3, sqlite3-3.47.2, urllib3-2.2.3, websockets-14.1
[debug] Proxy map: {}
[debug] Request Handlers: urllib, requests, websockets
[debug] Loaded 1837 extractors
[debug] Fetching release info: https://api.github.com/repos/yt-dlp/yt-dlp/releases/latest
Latest version: stable@2024.12.13 from yt-dlp/yt-dlp
yt-dlp is up to date (stable@2024.12.13 from yt-dlp/yt-dlp)
[CommonMistakes] Extracting URL: yt-dlp
ERROR: [CommonMistakes] You've asked yt-dlp to download the URL "yt-dlp". That doesn't make any sense. Simply remove the parameter in your command or configuration.
File "/usr/local/Cellar/yt-dlp/2024.12.13/libexec/lib/python3.13/site-packages/yt_dlp/extractor/common.py", line 742, in extract
ie_result = self._real_extract(url)
File "/usr/local/Cellar/yt-dlp/2024.12.13/libexec/lib/python3.13/site-packages/yt_dlp/extractor/commonmistakes.py", line 25, in _real_extract
raise ExtractorError(msg, expected=True)
[generic] Extracting URL: https://prd.motilaloswal.com/edumo/videos/webinar/154
[generic] 154: Downloading webpage
WARNING: [generic] Falling back on generic information extractor
[generic] 154: Extracting information
[debug] Looking for embeds
ERROR: Unsupported URL: https://prd.motilaloswal.com/edumo/videos/webinar/154
Traceback (most recent call last):
File "/usr/local/Cellar/yt-dlp/2024.12.13/libexec/lib/python3.13/site-packages/yt_dlp/YoutubeDL.py", line 1624, in wrapper
return func(self, *args, **kwargs)
File "/usr/local/Cellar/yt-dlp/2024.12.13/libexec/lib/python3.13/site-packages/yt_dlp/YoutubeDL.py", line 1759, in __extract_info
ie_result = ie.extract(url)
File "/usr/local/Cellar/yt-dlp/2024.12.13/libexec/lib/python3.13/site-packages/yt_dlp/extractor/common.py", line 742, in extract
ie_result = self._real_extract(url)
File "/usr/local/Cellar/yt-dlp/2024.12.13/libexec/lib/python3.13/site-packages/yt_dlp/extractor/generic.py", line 2553, in _real_extract
raise UnsupportedError(url)
yt_dlp.utils.UnsupportedError: Unsupported URL: https://prd.motilaloswal.com/edumo/videos/webinar/154
```
|
open
|
2024-12-22T16:04:42Z
|
2024-12-26T14:07:45Z
|
https://github.com/yt-dlp/yt-dlp/issues/11875
|
[
"site-request",
"account-needed",
"triage",
"can-share-account"
] |
panwariojpg
| 3 |
streamlit/streamlit
|
python
| 10,446 |
Clicking on a cell in a DatetimeColumn produces "This error should never happen. Please report this bug."
|
### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
Using a data editor with DatetimeColumns and creating a new row produces a "This error should never happen. Please report this bug." error (see screenshot below). Happens on every new row created.
### Reproducible Code Example
```Python
from typing import Final
import pandas as pd
import streamlit as st
TOTAL: Final = "total"
user_constraints = pd.DataFrame(
columns=[
"start_time",
"end_time",
"time_unit_in_min",
"departures",
"arrivals",
TOTAL,
],
data={
"start_time": pd.Series(
[],
dtype="datetime64[ns, UTC]",
),
"end_time": pd.Series(
[],
dtype="datetime64[ns, UTC]",
),
"time_unit_in_min": pd.Series([], dtype=int),
"departures": pd.Series([], dtype=int),
"arrivals": pd.Series([], dtype=int),
TOTAL: pd.Series([], dtype=int),
},
)
@st.fragment
def show_user_constraint() -> None:
"""
Displays user-defined capacity constraints for each time segment.
Returns:
None
"""
with st.expander("Capacity constraints"):
inputed_constraints = st.data_editor(
user_constraints,
hide_index=True,
num_rows="dynamic",
column_config={
"start_time": st.column_config.DatetimeColumn(
"Start time",
format="YYYY-MM-DD HH:mm",
width="medium",
timezone="Europe/Helsinki",
),
"end_time": st.column_config.DatetimeColumn(
"End time",
format="YYYY-MM-DD HH:mm",
width="medium",
timezone="Europe/Helsinki",
),
"time_unit_in_min": st.column_config.NumberColumn(
"Time unit in min",
default=60,
),
"departures": st.column_config.NumberColumn(
"Allowed departures",
default=0,
),
"arrivals": st.column_config.NumberColumn(
"Allowed arrivals",
default=0,
),
TOTAL: st.column_config.NumberColumn("Total allowed", default=0),
},
)
if not inputed_constraints.empty and inputed_constraints.notnull().all().all():
st.session_state.capacity_constraint_df = inputed_constraints
```
### Steps To Reproduce
1. Run the app
2. Click on a new row in the "Start time" column.
3. View the problem.
### Expected Behavior
Not to see the popup?
### Current Behavior

### Is this a regression?
~- [ ] Yes, this used to work in a previous version.~
Unsure, can't say for sure.
### Debug info
- Streamlit version: 1.42.0
- Python version: cpython@3.12.8
- Operating System: macOS Sequoia 15.3 (24D60)
- Browser: Happens of Safari and Chrome at least, I think also on Edge but unable to test currently
### Additional Information
Suddenly, I have been experiencing the following issue this issue. I am unsure when this has started happening, but _at least_ after updating to 1.42.0. There seems to be no obvious reason, nothing is logged to the console, only this small box that can be seen in the screenshot. I am also unsure how to reproduce it, but the code I have is provided. I have not tried to make a minimum reproducible example.
|
closed
|
2025-02-19T12:28:03Z
|
2025-02-19T12:46:39Z
|
https://github.com/streamlit/streamlit/issues/10446
|
[
"type:bug",
"status:needs-triage"
] |
christiansegercrantz
| 3 |
dynaconf/dynaconf
|
flask
| 261 |
[RFC] Method or property listing all defined environments
|
**Is your feature request related to a problem? Please describe.**
I'm trying to build a argparse argument that has a list of the available environments as choices to the argument. But I don't see any way to get this at the moment.
**Describe the solution you'd like**
I am proposing 2 features closely related to help with environment choices as a list and to validate that the environment was defined (not just that it is used with defaults or globals).
The first would be a way to get a list of defined environments minus `default` and global. This would make it easy to add to argparse as an argument to choices. I imagine a method or property such as `settings.available_environments` or `settings.defined_environments`.
The second feature would be a method to check if the environment is defined in settings. This could be used for checks in cases you don't use argparse or want to avoid selecting a non-existent environment. Maybe `settings.is_defined_environment('qa')` or similar.
**Describe alternatives you've considered**
I'm currently parsing my settings file keys outside of Dynaconf and discarding `default` and `global`. But this feels hacky.
**Additional context**
Since the environment is lazy loaded I wonder if this would be considered too expensive to do at load time. Maybe it makes sense as a utility outside of the `settings` object? Maybe there is a good way to do this without the feature? Maybe I shouldn't be doing this at all? :thinking:
|
open
|
2019-11-14T05:46:51Z
|
2024-02-05T21:17:08Z
|
https://github.com/dynaconf/dynaconf/issues/261
|
[
"hacktoberfest",
"Not a Bug",
"RFC"
] |
andyshinn
| 4 |
dbfixtures/pytest-postgresql
|
pytest
| 1,061 |
Connect pre-commit.ci
|
Connect pre-commit.ci to the repository
|
closed
|
2025-01-17T12:18:57Z
|
2025-01-17T15:19:20Z
|
https://github.com/dbfixtures/pytest-postgresql/issues/1061
|
[] |
fizyk
| 1 |
marcomusy/vedo
|
numpy
| 158 |
Boolean example
|
Hi everyone,
I have a question regarding one of the capabilities shown in the example galery:
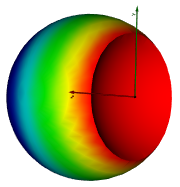
I could not find more detailed information on the Boolean operation between 3d meshes. My first question is, on which geometrical kernel is vtkplotter relying to perform this operation?
Does anyone know if the boolean between two unstructured triangle meshes (mesh origianly coming from a point cloud + delaunay triangulation) would work?
Thanks in advance!
|
closed
|
2020-06-10T08:50:55Z
|
2020-06-18T10:47:52Z
|
https://github.com/marcomusy/vedo/issues/158
|
[] |
pempmu
| 1 |
nteract/papermill
|
jupyter
| 583 |
How do we reuse engines across executions
|
Apologies if this is a duplicate.
I need to execute multiple notebooks in which each notebook is lightweight.
Think of this as a problem of drawing M notebooks from an N-notebook library, and executing the M notebooks.
I am running into two problems:
1. engine startup time is very high relative to notebook execution time
2. the libraries within the notebook cache content from databases that could be shared across notebook executions
It appears that each notebook execution creates a separate thread. Is this correct?
It would be great to be able to instantiate an engine and then feed it notebooks for processing to address the two issues raised. Is this possible today? If not, what would be involved in making it so?
Alternatively, it would be great to send papermill a list of notebooks and have each one processed with the same kernel.
|
closed
|
2021-03-04T21:54:23Z
|
2021-03-11T17:17:43Z
|
https://github.com/nteract/papermill/issues/583
|
[] |
ddreyfus
| 3 |
deepset-ai/haystack
|
pytorch
| 8,760 |
Support for o1-like reasoning model (LRMs)
|
It seems like we will need separation of reasoning content and the actual text completions to better manage multi-round conversations with reasoning (for example: https://api-docs.deepseek.com/guides/reasoning_model). This may have impact on the current structure and functionality of `ChatMessage`, `StreamingChunk` and generators.
My current purposal is to add a new boolean flag or type in both `TextContent` and `StreamingChunk` to indicate if this is a part of the reasoning steps. `ChatMessage.text` should point to the first non-reasoning text content, and we will need to add a new property for `ChatMessage.reasoning`.
For example, this is how the streaming chunks will be like from a reasoning model:
```
StreamingChunk(content: <reasoning-delta1>, is_reasoning: true)
StreamingChunk(content: <reasoning-delta2>, is_reasoning: true)
StreamingChunk(content: <completion-delta1>, is_reasoning: false)
StreamingChunk(content: <completion-delta2>, is_reasoning: false)
```
And user can access the reasoning and completions part using `chat_message.reasoning[s]` and `chat_message.text[s]` respectively from the generator output.
The other option is to have a separate `reasoning_content` field in `StreamingChunk` and `ReasoningContent` class in `ChatMessage._contents`. This is more aligned with the current deepseek-reasoner API but I feel like it is slightly overcomplicated. But I am not exactly sure whether both `reasoning_content` and `content` can appear in one SSE chunk.
I did some research today but there are few reasoning models/APIs available to reach a consensus on what reasoning should be like. I feel like it is probably better to start a discussion thread somewhere and explore the options.
|
open
|
2025-01-22T10:06:45Z
|
2025-02-26T03:47:05Z
|
https://github.com/deepset-ai/haystack/issues/8760
|
[
"P3"
] |
LastRemote
| 12 |
hzwer/ECCV2022-RIFE
|
computer-vision
| 36 |
Not the fastest for multi-frame interpolation
|
Hi,
Thanks for open sourcing the code and contributing to the video frame interpolation community.
In the paper, it mentioned: "Coupled with the large complexity in the bi-directional flow estimation, none of these methods can achieve real-time speed"
I believe that might be inappropriate to say, as the recent published paper (https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123720103.pdf) targets efficient multi-frame interpolation.
It utilizes bi-directional flow estimation as well, but it generates 7 frames for 0.12 second. where your method requires 0.036 * 7 = 0.252 seconds.
And the model from that paper is compact, which consists of only ~2M parameters, where your fast model has ~10M parameters.
|
closed
|
2020-11-25T15:36:37Z
|
2020-12-30T10:06:44Z
|
https://github.com/hzwer/ECCV2022-RIFE/issues/36
|
[] |
mrchizx
| 13 |
TencentARC/GFPGAN
|
deep-learning
| 313 |
[question] the effect of param tile and tile-pad
|
the more tile i set, the more __ i will get ?
the more tile-pad i set, the more __ i will get ?
such as Quality / Speed / Memory
|
open
|
2022-12-12T13:36:03Z
|
2022-12-12T15:50:14Z
|
https://github.com/TencentARC/GFPGAN/issues/313
|
[] |
wangping886
| 1 |
axnsan12/drf-yasg
|
django
| 242 |
Get view_method params in `swagger_auto_schema`?
|
How can I get the `class_name` or function arguments in the decorator?
|
closed
|
2018-11-01T09:40:54Z
|
2018-11-01T09:45:20Z
|
https://github.com/axnsan12/drf-yasg/issues/242
|
[] |
prafulbagai
| 0 |
Kav-K/GPTDiscord
|
asyncio
| 242 |
.txt support in conversations
|
Given the longer context limits gpt4 has and the current limitations we have surrounding the character limits of discord messages, we should let people upload .txt files, which can be read natively in discord by users so you can still read the conversation.
The .txt files can be read in and added in it's entirety as the user's message, with whatever is in the text field and uploaded with the file being added before the file.
Example
Would give the message content
```
Test\n\n{message.txt}
```
Doing this means we can avoid splitting messages up into multiple ones and feeding it to the bot one at a time.
There should probably be some sort of limit on the length of the file or we can run into the problem that the singular message in the history is bigger than the model can handle or saturates it too much, then no amount of embeddings will help. An option could be to split the contents into multiple chat entries instead so each one is smaller if it goes past a certain token amount depending on model context limits.
|
closed
|
2023-03-21T20:05:37Z
|
2023-11-24T22:15:25Z
|
https://github.com/Kav-K/GPTDiscord/issues/242
|
[
"enhancement"
] |
cherryroots
| 2 |
littlecodersh/ItChat
|
api
| 194 |
求助版主如何实现发送图片功能
|
求助版主如何实现发送图片功能
我自己写的机器人 发送图片一直失败失败失败,,跪求版主帮帮忙
|
closed
|
2016-12-31T09:44:18Z
|
2016-12-31T16:46:18Z
|
https://github.com/littlecodersh/ItChat/issues/194
|
[
"question"
] |
dakulzhan
| 1 |
ymcui/Chinese-LLaMA-Alpaca
|
nlp
| 10 |
再请教一下您对预训练阶段所起作用的见解
|
我通过lora方式进行fine-tune llama的时候发现,如果我给一些事实性的样本进行fine-tune,模型并不会学到事实,您是否认为事实性的学习发生于预训练阶段而SFT仅能做对齐提高模型的理解表达能力,不能增加事实知识(亦或是lora仅在attention层嵌入adapter导致无法新增事实性的内容)?
|
closed
|
2023-03-30T04:05:19Z
|
2023-03-30T05:30:58Z
|
https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/10
|
[] |
songbaiTalk
| 1 |
unit8co/darts
|
data-science
| 1,943 |
NBEATS and NBEATSx handling exogenous variables
|
I am quite new and I am still trying to understand how NBEATS is handling exogenous variables, I know the architecture is not designed for that, and this issue is overcome in NBEATx
How are handled in Darts NBEATS version external variables/covariates?
> In addition to the univariate version presented in the paper, our implementation also supports multivariate series (and covariates) by flattening the model inputs to a 1-D series and reshaping the outputs to a tensor of appropriate dimensions. Furthermore, it also supports producing probabilistic forecasts (by specifying a likelihood parameter).
Are you planning to implement NBEATSx?
Here NBEATSx Paper: [https://arxiv.org/pdf/2104.05522.pdf)](https://arxiv.org/pdf/2104.05522.pdf)
Here a Python implementation: [https://github.com/cchallu/nbeatsx/blob/main/nbeatsx_example.ipynb](https://github.com/cchallu/nbeatsx/blob/main/nbeatsx_example.ipynb)
|
open
|
2023-08-09T09:40:38Z
|
2023-08-09T15:42:30Z
|
https://github.com/unit8co/darts/issues/1943
|
[
"improvement",
"new model"
] |
uomodellamansarda
| 2 |
Gozargah/Marzban
|
api
| 946 |
مشکل لینک ساب
|
سلام . عرض ادب
ضمن تشکر بابت زحماتی که میکشید
و این پنل بی نطیر
از دیشب لینک ساب موقعی که تولید میشه و کپی میکنی کار نمیکنه و صرفا با یکبار رفرش کردن صفحه لینک ساب جدیدی جایگزین میشه که کار میکنه
ممنون از زحمات شما
|
closed
|
2024-04-16T11:15:35Z
|
2024-04-17T06:00:20Z
|
https://github.com/Gozargah/Marzban/issues/946
|
[
"Bug"
] |
sfeorg
| 3 |
ResidentMario/missingno
|
pandas
| 2 |
Option to remove the sparkline
|
Hi,
Many thanks for the awesome work! When the number of rows is large, the sparkline looks less useful (more difficult) to visually understand the #features available just looking at it. Wondering if an option to toggle the sparkline off could be added.
|
closed
|
2016-03-30T05:46:47Z
|
2016-04-08T05:29:41Z
|
https://github.com/ResidentMario/missingno/issues/2
|
[
"enhancement"
] |
nipunbatra
| 3 |
unionai-oss/pandera
|
pandas
| 838 |
hypothesis.errors.Unsatisfiable on Schema.to_schema().example() when SchemaModel has more than 38 fields
|
**Describe the bug**
If a SchemaModel contains more than 38 fields, SchemaModel.to_schema().example() throws an error:
```
hypothesis.errors.Unsatisfiable: Unable to satisfy assumptions of example_generating_inner_function
```
- [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the latest version of pandera.
- [ ] (optional) I have confirmed this bug exists on the master branch of pandera.
**Note**: Please read [this guide](https://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports) detailing how to provide the necessary information for us to reproduce your bug.
#### Code Sample, a copy-pastable example
- Running the below as-is throws an error.
- But runs successfully if `field39` and `field40` are commented out
```python
import pandera as pa
from pandera.typing import Series
class MyBaseSchema(pa.SchemaModel):
field1: Series[str] = pa.Field()
field2: Series[str] = pa.Field()
field3: Series[str] = pa.Field()
field4: Series[str] = pa.Field()
field5: Series[str] = pa.Field()
field6: Series[str] = pa.Field()
field7: Series[str] = pa.Field()
field8: Series[str] = pa.Field()
field9: Series[str] = pa.Field()
field10: Series[str] = pa.Field()
field11: Series[str] = pa.Field()
field12: Series[str] = pa.Field()
field13: Series[str] = pa.Field()
field14: Series[str] = pa.Field()
field15: Series[str] = pa.Field()
field16: Series[str] = pa.Field()
field17: Series[str] = pa.Field()
field18: Series[str] = pa.Field()
field19: Series[str] = pa.Field()
field20: Series[str] = pa.Field()
field21: Series[str] = pa.Field()
field22: Series[str] = pa.Field()
field23: Series[str] = pa.Field()
field24: Series[str] = pa.Field()
field25: Series[str] = pa.Field()
field26: Series[str] = pa.Field()
field27: Series[str] = pa.Field()
field28: Series[str] = pa.Field()
field29: Series[str] = pa.Field()
field30: Series[str] = pa.Field()
field31: Series[str] = pa.Field()
field32: Series[str] = pa.Field()
field33: Series[str] = pa.Field()
field34: Series[str] = pa.Field()
field35: Series[str] = pa.Field()
field36: Series[str] = pa.Field()
field37: Series[str] = pa.Field()
field38: Series[str] = pa.Field()
field39: Series[str] = pa.Field()
field40: Series[str] = pa.Field()
if __name__ == "__main__":
dataframe = MyBaseSchema.to_schema().example(1)
print(dataframe)
```
#### Expected behavior
Don't throw an error, generate an example for the SchemaModel.
#### Desktop (please complete the following information):
- OS: OSX
- Python version: 3.9.12
- pandera version: 0.10.1
- hypothesis version: 6.44.0
|
closed
|
2022-04-21T21:09:02Z
|
2022-11-03T18:00:04Z
|
https://github.com/unionai-oss/pandera/issues/838
|
[
"bug",
"help wanted"
] |
g-simmons
| 3 |
lux-org/lux
|
pandas
| 235 |
Add option for sort/unsorted bar chart
|
We currently sort bar charts based on highest to lowest bars if there are more than 5 bars. If there are less than five bars, the bars are unsorted to enable comparison. However, this is not always ideal, especially for ordinal data types. We should add an option to allow users to "turn off" sorting, either through code or UI.
```python
df = pd.read_csv("../lux-datasets/data/absenteeism.csv")
df.intent=["Pet"]
df
```
|
open
|
2021-01-18T09:27:14Z
|
2021-01-18T09:27:14Z
|
https://github.com/lux-org/lux/issues/235
|
[
"enhancement"
] |
dorisjlee
| 0 |
lukas-blecher/LaTeX-OCR
|
pytorch
| 220 |
zsh: no matches found: pix2tex[gui]
|
I have a problem in the installation process. I already have the requirements, but when I try to run the command pip install pix2tex[gui] I get this error zsh: no matches found: pix2tex[gui]
|
closed
|
2022-11-28T13:33:46Z
|
2023-01-31T10:20:02Z
|
https://github.com/lukas-blecher/LaTeX-OCR/issues/220
|
[
"linux"
] |
turexx
| 1 |
LAION-AI/Open-Assistant
|
machine-learning
| 3,320 |
About pretrain data size in sft-8-datasets.
|
Hi, i noticed that in the config of sft-8-datasets, 5% red_pajama are added in sft training.
So there are 3 question i was confused:
1. Will the pretrain data size be more larger and the instruction data size?
2. Will this situation affect the effect of SFT training?
3. How you guys pick the fraction of pretrain data?
|
closed
|
2023-06-07T07:56:59Z
|
2023-06-09T11:21:45Z
|
https://github.com/LAION-AI/Open-Assistant/issues/3320
|
[
"ml",
"question"
] |
fengyh3
| 2 |
JaidedAI/EasyOCR
|
deep-learning
| 968 |
Unable to use Char and number togeather.
|
Hi,
I am trying to run OCR for the attached image, but not getting the text. Any setting I need to change? any help?
<img width="381" alt="Screenshot 2023-03-19 at 11 59 33 AM" src="https://user-images.githubusercontent.com/3765085/226158299-26e15f3f-fe21-4ce4-b8de-b1bc7f6e8e31.png">

Thanks,
Sabari.
|
open
|
2023-03-19T06:32:10Z
|
2023-03-19T06:32:10Z
|
https://github.com/JaidedAI/EasyOCR/issues/968
|
[] |
ksabariraj
| 0 |
pytest-dev/pytest-xdist
|
pytest
| 419 |
Access a list of test IDs after master performs a sanity check of IDs returned by workers
|
Greetings,
Step 3 of execution flow [overview](https://github.com/pytest-dev/pytest-xdist/blob/master/OVERVIEW.md) indicates that after workers return collected tests IDs back master does checks and creates a list of tests ID. Is there a hook, that could be used to return this list after sanity check passes?
Thank you
|
open
|
2019-02-26T18:41:55Z
|
2019-02-26T18:41:55Z
|
https://github.com/pytest-dev/pytest-xdist/issues/419
|
[] |
apankov1
| 0 |
python-arq/arq
|
asyncio
| 265 |
Redis TimeoutError when using multiple workers
|
Hi there,
I am using your wonderful library for quite some time already. Right now I'm working on a tool which requires multiple workers to run, as roughly 900 jobs need to run in parallel. One task basically queues all the jobs (each job can take up to 20 seconds) and the 6 works work on them.
What I now see is that some of the workers (currently all running locally on my PC using a local Redis instance) execute a few jobs, and then all of the sudden stop working with a Redis Timeout error. See the below logs from one of the workers:
```
(venv) ➜ asa-rule-checker arq worker.WorkerSettings
11:08:44: Starting worker for 6 functions: sync_firewalls_cmdb, parse_connected_routes, parse_static_routes, sync_all_routes, sync_firewall_routes, cron:sync_all_routes
11:08:44: redis_version=6.2.5 mem_usage=2.68M clients_connected=1 db_keys=1833
11:09:00: 1.01s → cron:sync_all_routes()
asarulechecker-worker 2021-10-04 11:09:00,247 INFO route_sync.py:sync_all_routes Starting route sync for all firewalls
asarulechecker-worker 2021-10-04 11:09:00,341 INFO route_sync.py:sync_all_routes Found 916 firewalls to process
11:09:00: 0.36s → 64cccb63b63949b090b6fcd74157930e:sync_firewall_routes(10, 8, 916)
asarulechecker-worker 2021-10-04 11:09:00,746 INFO route_sync.py:sync_firewall_routes [8/916] Processing firewall xxx on management ip x
11:09:13: 13.04s ← 64cccb63b63949b090b6fcd74157930e:sync_firewall_routes ●
11:09:13: 13.39s → 3d65075291cb4a1e904305e3c04429f5:sync_firewall_routes(21, 19, 916) delayed=13.39s
asarulechecker-worker 2021-10-04 11:09:13,806 INFO route_sync.py:sync_firewall_routes [19/916] Processing firewall xxx on management ip x
11:09:19: 5.35s ← 3d65075291cb4a1e904305e3c04429f5:sync_firewall_routes ●
11:09:19: 18.75s → 28921985985046a4b73609e34bf2d9af:sync_firewall_routes(22, 20, 916) delayed=18.75s
asarulechecker-worker 2021-10-04 11:09:19,168 INFO route_sync.py:sync_firewall_routes [20/916] Processing firewall xxx on management ip x
asarulechecker-worker 2021-10-04 11:09:23,406 ERROR route_sync.py:sync_firewall_routes Unable to connect to firewall x: Invalid credentials
11:09:23: 4.27s ← 28921985985046a4b73609e34bf2d9af:sync_firewall_routes ●
[... a few are running in the meantime]
11:11:09: 129.36s → 27f0bfaff1f84c7c8aafe82992838a78:sync_firewall_routes(100, 98, 916) delayed=129.36s
asarulechecker-worker 2021-10-04 11:11:09,966 INFO route_sync.py:sync_firewall_routes [98/916] Processing firewall xxx on management ip x
11:11:14: 4.34s ← 27f0bfaff1f84c7c8aafe82992838a78:sync_firewall_routes ●
11:11:16: 135.93s ← cron:sync_all_routes ●
Traceback (most recent call last):
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/bin/arq", line 8, in <module>
sys.exit(cli())
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/click/core.py", line 829, in __call__
return self.main(*args, **kwargs)
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/click/core.py", line 782, in main
rv = self.invoke(ctx)
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/click/core.py", line 1066, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/click/core.py", line 610, in invoke
return callback(*args, **kwargs)
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/arq/cli.py", line 48, in cli
run_worker(worker_settings_, **kwargs)
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/arq/worker.py", line 756, in run_worker
worker.run()
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/arq/worker.py", line 256, in run
self.loop.run_until_complete(self.main_task)
File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/asyncio/base_events.py", line 616, in run_until_complete
return future.result()
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/arq/worker.py", line 308, in main
await self._poll_iteration()
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/arq/worker.py", line 346, in _poll_iteration
t.result()
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/arq/worker.py", line 419, in run_job
v, job_try, _ = await asyncio.gather(*coros)
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/aioredis/util.py", line 59, in wait_convert
result = await fut
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/aioredis/pool.py", line 257, in _wait_execute
conn = await self.acquire(command, args)
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/aioredis/pool.py", line 324, in acquire
await self._fill_free(override_min=True)
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/aioredis/pool.py", line 398, in _fill_free
conn = await self._create_new_connection(self._address)
File "/Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/aioredis/connection.py", line 111, in create_connection
reader, writer = await asyncio.wait_for(open_connection(
File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/asyncio/tasks.py", line 501, in wait_for
raise exceptions.TimeoutError()
asyncio.exceptions.TimeoutError
Task was destroyed but it is pending!
task: <Task pending name='Task-22' coro=<RedisConnection._read_data() running at /Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/aioredis/connection.py:186> wait_for=<Future pending cb=[<TaskWakeupMethWrapper object at 0x105818f10>()]> cb=[RedisConnection.__init__.<locals>.<lambda>() at /Users/<user>/<company>/PythonProjects/asa-rule-checker/venv/lib/python3.8/site-packages/aioredis/connection.py:168]>
```
3 workers have failed with the error message above after running roughly 10-15 jobs, the other 3 workers are still working fine.
Arq version is:
```
arq -V
arq, version 0.22
```
|
closed
|
2021-10-04T09:18:44Z
|
2023-04-04T17:48:28Z
|
https://github.com/python-arq/arq/issues/265
|
[] |
waza-ari
| 2 |
nvbn/thefuck
|
python
| 1,239 |
fuck gets killed immediately
|
I've been using thefuck for a while now, today it suddenly started getting killed immediately no matter what I do.
Tried reinstalling, tried debugging, tried resetting the configuration directory, nothing worked...
The output of `thefuck --version` (something like `The Fuck 3.1 using Python
3.5.0 and Bash 4.4.12(1)-release`):
[1] 10081 killed thefuck --version
Your system (Debian 7, ArchLinux, Windows, etc.):
MacOS Big Sur 11.6
How to reproduce the bug:
Simply use fuck
The output of The Fuck with `THEFUCK_DEBUG=true` exported (typically execute `export THEFUCK_DEBUG=true` in your shell before The Fuck):
[1] 10136 killed fuck
Anything else you think is relevant:
As I've said, worked fine until today, can't think of anything relevant I could've done...
|
closed
|
2021-09-30T13:01:33Z
|
2022-06-14T08:45:33Z
|
https://github.com/nvbn/thefuck/issues/1239
|
[] |
Aransh
| 4 |
huggingface/datasets
|
machine-learning
| 6,457 |
`TypeError`: huggingface_hub.hf_file_system.HfFileSystem.find() got multiple values for keyword argument 'maxdepth'
|
### Describe the bug
Please see https://github.com/huggingface/huggingface_hub/issues/1872
### Steps to reproduce the bug
Please see https://github.com/huggingface/huggingface_hub/issues/1872
### Expected behavior
Please see https://github.com/huggingface/huggingface_hub/issues/1872
### Environment info
Please see https://github.com/huggingface/huggingface_hub/issues/1872
|
closed
|
2023-11-29T01:57:36Z
|
2023-11-29T15:39:03Z
|
https://github.com/huggingface/datasets/issues/6457
|
[] |
wasertech
| 5 |
roboflow/supervision
|
pytorch
| 789 |
[ByteTrack] - add a method to reset the state of the tracker
|
### Description
Let's add a method to reset the state of the tracker - particularly useful when we want to process multiple videos one after another. Currently, part of the state is held in global variables, and even reinitializing the tracker doesn't help. It is necessary to kill the entire Python environment.
Pay attention to [`ByteTrack.tracked_tracks`](https://github.com/roboflow/supervision/blob/3024ddca83ad837651e59d040e2a5ac5b2b4f00f/supervision/tracker/byte_tracker/core.py#L197), [`ByteTrack.lost_tracks`](https://github.com/roboflow/supervision/blob/3024ddca83ad837651e59d040e2a5ac5b2b4f00f/supervision/tracker/byte_tracker/core.py#L198), [`ByteTrack.removed_tracks`](https://github.com/roboflow/supervision/blob/3024ddca83ad837651e59d040e2a5ac5b2b4f00f/supervision/tracker/byte_tracker/core.py#L199), and [`BaseTrack._count`](https://github.com/roboflow/supervision/blob/3024ddca83ad837651e59d040e2a5ac5b2b4f00f/supervision/tracker/byte_tracker/basetrack.py#L38). It may turn out that other places will also require changes.
### Additional
- Note: Please share a Google Colab with minimal code to test the new feature. We know it's additional work, but it will definitely speed up the review process. Each change must be tested by the reviewer. Setting up a local environment to do this is time-consuming. Please ensure that Google Colab can be accessed without any issues (make it public). Thank you! 🙏🏻
|
closed
|
2024-01-26T12:45:15Z
|
2024-03-28T11:46:47Z
|
https://github.com/roboflow/supervision/issues/789
|
[
"enhancement",
"api:tracker",
"Q1.2024"
] |
SkalskiP
| 3 |
ymcui/Chinese-LLaMA-Alpaca-2
|
nlp
| 2 |
赞!动作真快!能否直接上 plus 版本?
|
closed
|
2023-07-19T02:13:40Z
|
2023-07-22T04:03:14Z
|
https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/issues/2
|
[] |
jamesljl
| 3 |
|
open-mmlab/mmdetection
|
pytorch
| 11,738 |
RuntimeError: sigmoid_focal_loss_forward_impl: implementation for device cuda:0 not found.
|
I didn't have a problem with cpu training, but I ran into this problem with GPU training using the following commands:
``` python ../tools/train.py ./checkpoints/solov2_test.py ```
Here is my output:
[info.txt](https://github.com/open-mmlab/mmdetection/files/15426721/info.txt)
I tried setting the FORCE_CUDA and MMCV_WITH_OPS before installing mmcv but it didn't work.
How can I solve this problem, thank you very much.
|
closed
|
2024-05-24T02:51:05Z
|
2024-08-22T08:54:49Z
|
https://github.com/open-mmlab/mmdetection/issues/11738
|
[] |
miaomaomiaomaoda
| 2 |
StackStorm/st2
|
automation
| 5,803 |
Able to export/import objects for easy migration
|
To easy to deploy across regions or backup/restore, suggest to add feature to be able to export and import the rules/actions/triggers etc for easy migration.
We know that StackStorm uses packs as deployment unit and objects are loaded to MongoDB, but it's good to provide export/import capability to migrate objects instead of depending on MongoDB migration.
Thanks.
|
open
|
2022-11-11T10:20:02Z
|
2022-11-11T18:39:25Z
|
https://github.com/StackStorm/st2/issues/5803
|
[] |
yypptest
| 1 |
agronholm/anyio
|
asyncio
| 601 |
running blocking code in to_thread.run_sync does not honor move_on_after
|
### Things to check first
- [X] I have searched the existing issues and didn't find my bug already reported there
- [X] I have checked that my bug is still present in the latest release
### AnyIO version
3.7.1
### Python version
3.10.8
### What happened?
Expect to be able to time out a blocking function running within a thread when run inside a move_on_after block. However it seems the blocking function running inside the thread does not honor the move_on_after context manager:
The following shows that when the cancel has been called, 5 seconds have passed. I would expect the cancel to be called after 1 second and the underlying thread to carry on in the background. Here is the stdout from the below program:
```
started at 2023-08-10 08:09:46.229488
sleeping...
awake
cancelled at 2023-08-10 08:09:51.235228
```
### How can we reproduce the bug?
```
import datetime
import anyio
import time
def sleeper():
print('sleeping...')
time.sleep(5)
print('awake')
async def main():
start = datetime.datetime.utcnow()
print(f'started at {start}')
with anyio.move_on_after(1) as scope:
await anyio.to_thread.run_sync(sleeper)
end = datetime.datetime.utcnow()
if scope.cancel_called:
print(f"cancelled at {end}")
if __name__ == '__main__':
anyio.run(main)
```
|
closed
|
2023-08-10T08:12:32Z
|
2023-08-10T08:17:57Z
|
https://github.com/agronholm/anyio/issues/601
|
[
"bug"
] |
laker-93
| 1 |
voxel51/fiftyone
|
computer-vision
| 4,981 |
[FR] Visualize `ArrayField` (e.g. context RGB image)
|
### Instructions
### Proposal Summary
Given a simple RGB `Sample` Image, I can add several [Labels](https://docs.voxel51.com/user_guide/using_datasets.html#labels) to it.
To add e.g. a context RGB image to it, I couldn't find a corresponding label, but found that this works:
```
sample["contxt_image"] = rng.integers(0,255,(1024,1024,3),dtype=np.uint8)
```
However, could I visualize such a context image, too?
### What areas of FiftyOne does this feature affect?
- [x] App: FiftyOne application
- [x] Core: Core `fiftyone` Python library
- [ ] Server: FiftyOne server
### Willingness to contribute
The FiftyOne Community welcomes contributions! Would you or another member of your organization be willing to contribute an implementation of this feature?
- [ ] Yes. I can contribute this feature independently
- [x] Yes. I would be willing to contribute this feature with guidance from the FiftyOne community
- [ ] No. I cannot contribute this feature at this time
|
open
|
2024-10-24T15:51:35Z
|
2024-10-24T16:12:50Z
|
https://github.com/voxel51/fiftyone/issues/4981
|
[
"feature"
] |
cgebbe
| 1 |
ray-project/ray
|
data-science
| 51,532 |
[data] Remove dependency on `pytest_lazyfixture`
|
### Description
It's an unmaintained package, and will prevent us from upgrading pytest later on. Most of the community seems to have moved on to using native pytest features or new packages.
https://github.com/TvoroG/pytest-lazy-fixture/issues/65
### Use case
_No response_
|
open
|
2025-03-19T19:49:10Z
|
2025-03-19T19:49:10Z
|
https://github.com/ray-project/ray/issues/51532
|
[
"enhancement",
"P3",
"data"
] |
richardliaw
| 0 |
noirbizarre/flask-restplus
|
api
| 666 |
String field with enum option does not marshal the data to only enum choices
|
Using this example:
```python
from flask_restplus import Namespace, fields, marshal
def main():
api = Namespace("example", validate=True)
my_model = api.model("MyModel", {
"name": fields.String(enum=("FOO", "BAR"))
})
data = {
"name": "QUUX",
}
marshalled = marshal(data, my_model)
print(marshalled) # {'name': 'QUUX'}
if __name__ == "__main__":
main()
```
I would expect `name` to be _only_ `FOO`, `BAR`, or perhaps even `None`, but not the invalid value `QUUX`.
|
closed
|
2019-07-12T09:39:51Z
|
2019-07-12T15:26:31Z
|
https://github.com/noirbizarre/flask-restplus/issues/666
|
[] |
Drarok
| 1 |
dmlc/gluon-cv
|
computer-vision
| 1,264 |
can't open hyper link of 'shell script' or 'trainning log'
|
'https://raw.githubusercontent.com/dmlc/web-data/master/gluoncv/logs/classification/imagenet/resnet18_v1.log'
can't find service ip address of ' raw.githubusercontent.com'
|
closed
|
2020-04-22T02:33:15Z
|
2020-05-28T06:29:39Z
|
https://github.com/dmlc/gluon-cv/issues/1264
|
[] |
ritaiask
| 2 |
CorentinJ/Real-Time-Voice-Cloning
|
python
| 942 |
Pretrained Models link is dead
|
https://github.com/CorentinJ/Real-Time-Voice-Cloning/wiki/Pretrained-models
The download links on this page are giving me page not found errors.
This link is specifically dead - https://github.com/blue-fish/Real-Time-Voice-Cloning/releases/download/v1.0/pretrained.zip
|
closed
|
2021-12-08T03:21:53Z
|
2021-12-28T12:34:19Z
|
https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/942
|
[] |
DimensionWarped
| 7 |
pallets/flask
|
python
| 4,900 |
JavaScript file upload
|
Hello,
I'm trying to upload files to Flask using Javascript. On [this page](https://flask.palletsprojects.com/en/2.2.x/patterns/fileuploads/) I can read how to do that with an HTML form. However I'm not able to do the same with pure JavaScript.
To replicate:
```
const form = new FormData();
const files = document.getElementById('media-files').files;
for (let i = 0; i < files.length; i++) {
form.append(`file[${i}]`, files[i]);
}
await fetch('/api/v1/media', {
method: 'POST',
body: form,
headers: {'Content-Type': 'multipart/form-data'}
});
```
In Flask `request.data` is not empty. But `request.files` and `request.form` are.
Any help would be greatly appreciated.
Environment:
- Python version: 3.11
- Flask version: 2.2.2
|
closed
|
2022-12-06T18:01:46Z
|
2022-12-06T18:06:45Z
|
https://github.com/pallets/flask/issues/4900
|
[] |
stanmertens
| 1 |
autokey/autokey
|
automation
| 317 |
Moving multiple files in GTK GUI deletes half of them
|
## Classification: Bug / UI/Usability
## Reproducibility: Always
## Version
AutoKey version: 0.95.1
Used GUI: GTK
Installed via: PPA
Linux Distribution: Ubuntu 18.04
## Summary
Ctrl+Selecting multiple files deletes around half of the files selected, without warning, and rarely, but sometimes moves about a quarter to the desired location, rest is unmoved.
## Steps to Reproduce (if applicable)
1. Create 10 new files and 1 folder
1. Ctrl+Select all the new files
1. While still holding Ctrl, drag any of the selected files to the newly created folder
1. Panic because you just lost about half of your hotkeys/scripts
## Expected Results
All the selected files should move to the desired folder
## Actual Results
Half of the files are deleted without warning
[debug log](https://termbin.com/zewb)
## Notes
Workaround with GTK is to go into the default folder in a file explorer/terminal and move the files there.
Qt does not have this problem. I have switched to that now as it is more responsive and looks better.
|
open
|
2019-11-05T07:50:03Z
|
2019-12-08T13:37:44Z
|
https://github.com/autokey/autokey/issues/317
|
[
"bug",
"autokey-gtk"
] |
dovry
| 5 |
vprusso/youtube_tutorials
|
web-scraping
| 2 |
Not really an issue, but i found no other way to contact you
|
I really didn't understand because there was a part in your video where you attempted to print(buyers) however it printed the elements, not the exact element. Later in the video you printed it as buyers[i].text and the program stopped printing elements. Could you please explain to me how .text stops the program from printing elements, and also how to print something without printing any elements, without using a for loop like in the video. Thanks in advance
|
closed
|
2018-10-05T18:06:01Z
|
2018-10-05T18:07:58Z
|
https://github.com/vprusso/youtube_tutorials/issues/2
|
[] |
dagnyforhust
| 1 |
aiortc/aiortc
|
asyncio
| 518 |
send continuous image
|
Hi,
I will read frame from a web camera, and then do some image processing. I then send the processed image to browser in real time.
Here are the steps I take:
<pre>
step 1: read frame(image) from camera
step 2: process the image
step 3: send the processed image to browser
step 4: repeat step 1
</pre>
my questions are:
1) I could send each image as xxx.jpg to browser. but image is not encoded, the size of the image might be much big. is this the best solution?
2) If I use FFMPEG or webrtc to encode the image but not continuous images(all images are separate image but not video stream), how to do this? is the encoding effective?
3) do you have good solution for my case?
|
closed
|
2021-03-31T08:03:02Z
|
2021-04-02T10:08:28Z
|
https://github.com/aiortc/aiortc/issues/518
|
[
"question"
] |
ardeal
| 4 |
3b1b/manim
|
python
| 1,199 |
The shaders branch is creating a lot of npy files in manim directory
|
Hi,
I am using the shaders branch of manim in order to utilize the GPU on my PC to quickly render videos. It runs without any error but there are two issues that I am facing:
1. When I run the same scene file through both the `regular` manim and `shaders` manim. The text rendered by `shaders` manim is always bolder than the text rendered by `regular` manim.
2. The shaders version of manim also seems to create a lot of files with names like `d0589a9c57b0acc0.npy` inside the manim directory. Usually, these "helper" files with `.svg` extension are created inside the Media directory under "Tex" folder.
There are no files with `.npy` extension created by the `regular` manim version.
Is the `shaders` branch supposed to create these `.npy` files directly inside the `manim` directory?
If `yes`, then how do I get rid of these `.npy` files or move them somewhere else like the `media` directory? About 100 of them are created even for very basic scenes. My main manim directory is now cluttered with these files.
|
open
|
2020-08-04T14:13:20Z
|
2020-08-04T14:13:20Z
|
https://github.com/3b1b/manim/issues/1199
|
[] |
baljeetrathi
| 0 |
dynaconf/dynaconf
|
flask
| 1,141 |
[RFC]Generate Schema from runtime Dynaconf Instance
|
Given a runtime untyped dynaconf instance with all its validators set and data loaded:
```python
settings=Dynaconf(
settings_file="x.toml",
envvar_prefix="APP",
validators=[Validator("name", ne="admin")]
)
```
```toml
# x.toml
name = "Bruno"
age = 16
colors = ["red", "green", "blue"]
profile = {"username": "rocha"}
```
on CLI
```console
$ dynaconf -i config.settigns generate-schema --set-defaults > schema.py
```
```py
from dynaconf.typed import Dynaconf, Validator, Options, DictValue
class Profile(DictValue):
username: str = "rocha"
class Settings(Dynaconf):
dynaconf_options = Options(settings_file="x.toml", envvar_prefix="APP")
name: Annotated[str, Validator(ne="admin")] = "Bruno"
age: int = 16
colors: list[str] = ["red", "green", "blue"]
profile: Profile
settings = Settings()
```
|
open
|
2024-07-07T14:19:36Z
|
2024-07-08T18:38:21Z
|
https://github.com/dynaconf/dynaconf/issues/1141
|
[
"Not a Bug",
"RFC",
"typed_dynaconf"
] |
rochacbruno
| 0 |
man-group/arctic
|
pandas
| 806 |
VersionStore: DataFrame with tzinfo fails to serialize with Pandas >= 0.24
|
#### Arctic Version
```
1.79.2
```
#### Arctic Store
```
VersionStore
```
#### Platform and version
```
pandas >= 0.24
```
#### Description of problem and/or code sample that reproduces the issue
```
from arctic import Arctic
import pandas as pd
a = Arctic("localhost")
a.initialize_library("vstore")
lib = a["vstore"]
df = pd.DataFrame({"a": [1]}, index=[pd.Timestamp.utcnow()])
written = lib.write('test', df)
```
works fine with pandas 0.23.2, but with pandas >=0.24.0 the tzinfo cannot be serialized for mongodb:
```
File "/Applications/PyCharm.app/Contents/helpers/pydev/_pydev_imps/_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "/Users/meatz/tmp/arctic_timezone/bug.py", line 62, in <module>
written = lib.write('test', df)
File "/Users/meatz/miniconda3/envs/arctic_test/lib/python3.6/site-packages/arctic/decorators.py", line 49, in f_retry
return f(*args, **kwargs)
File "/Users/meatz/miniconda3/envs/arctic_test/lib/python3.6/site-packages/arctic/store/version_store.py", line 664, in write
self._insert_version(version)
File "/Users/meatz/miniconda3/envs/arctic_test/lib/python3.6/site-packages/arctic/store/version_store.py", line 529, in _insert_version
mongo_retry(self._versions.insert_one)(version)
File "/Users/meatz/miniconda3/envs/arctic_test/lib/python3.6/site-packages/arctic/decorators.py", line 49, in f_retry
return f(*args, **kwargs)
File "/Users/meatz/miniconda3/envs/arctic_test/lib/python3.6/site-packages/pymongo/collection.py", line 700, in insert_one
session=session),
File "/Users/meatz/miniconda3/envs/arctic_test/lib/python3.6/site-packages/pymongo/collection.py", line 614, in _insert
bypass_doc_val, session)
File "/Users/meatz/miniconda3/envs/arctic_test/lib/python3.6/site-packages/pymongo/collection.py", line 602, in _insert_one
acknowledged, _insert_command, session)
File "/Users/meatz/miniconda3/envs/arctic_test/lib/python3.6/site-packages/pymongo/mongo_client.py", line 1280, in _retryable_write
return self._retry_with_session(retryable, func, s, None)
File "/Users/meatz/miniconda3/envs/arctic_test/lib/python3.6/site-packages/pymongo/mongo_client.py", line 1233, in _retry_with_session
return func(session, sock_info, retryable)
File "/Users/meatz/miniconda3/envs/arctic_test/lib/python3.6/site-packages/pymongo/collection.py", line 597, in _insert_command
retryable_write=retryable_write)
File "/Users/meatz/miniconda3/envs/arctic_test/lib/python3.6/site-packages/pymongo/pool.py", line 589, in command
self._raise_connection_failure(error)
File "/Users/meatz/miniconda3/envs/arctic_test/lib/python3.6/site-packages/pymongo/pool.py", line 750, in _raise_connection_failure
raise error
File "/Users/meatz/miniconda3/envs/arctic_test/lib/python3.6/site-packages/pymongo/pool.py", line 584, in command
user_fields=user_fields)
File "/Users/meatz/miniconda3/envs/arctic_test/lib/python3.6/site-packages/pymongo/network.py", line 121, in command
codec_options, ctx=compression_ctx)
File "/Users/meatz/miniconda3/envs/arctic_test/lib/python3.6/site-packages/pymongo/message.py", line 678, in _op_msg
flags, command, identifier, docs, check_keys, opts)
bson.errors.InvalidDocument: cannot encode object: <UTC>, of type: <class 'pytz.UTC'>
Process finished with exit code 1
```
|
closed
|
2019-07-19T09:22:24Z
|
2023-03-09T18:10:18Z
|
https://github.com/man-group/arctic/issues/806
|
[] |
grawinkel
| 2 |
tqdm/tqdm
|
jupyter
| 889 |
Multiprocessing example in docs doesn't work.
|
- [ ] I have marked all applicable categories:
+ [ ] exception-raising bug
+ [ x] visual output bug
+ [ ] documentation request (i.e. "X is missing from the documentation." If instead I want to ask "how to use X?" I understand [StackOverflow#tqdm] is more appropriate)
+ [ ] new feature request
- [ x] I have visited the [source website], and in particular
read the [known issues]
- [ x] I have searched through the [issue tracker] for duplicates
- [ x] I have mentioned version numbers, operating system and
environment, where applicable:
```python
import tqdm, sys
print(tqdm.__version__, sys.version, sys.platform)
```
I want to use `tqdm` to show multiple concurrent progress bars similar to how `docker pull` shows the progress of parallel downloads concurrently. However, the simple multiprocessing example in the docs is buggy. Specifically, the `position` argument is not honored. The bars are first printed in correct order, and then re-printed in reverse order.
Here's the code i'm running
```
$ cat foo.py
from time import sleep
from tqdm import trange, tqdm
from multiprocessing import Pool, freeze_support
L = list(range(9))
def progresser(n):
interval = 0.001 / (n + 2)
total = 5000
text = "#{}, est. {:<04.2}s".format(n, interval * total)
for _ in trange(total, desc=text, position=n):
sleep(interval)
if __name__ == '__main__':
freeze_support() # for Windows support
p = Pool(initializer=tqdm.set_lock, initargs=(tqdm.get_lock(),))
p.map(progresser, L)
$
```
Here are some screenshots to demonstrate.
<img width="1920" alt="Screen Shot 2020-02-05 at 5 42 09 PM (2)" src="https://user-images.githubusercontent.com/7637700/73898808-5d14b880-483f-11ea-87f4-3b0c22422081.png">
<img width="1920" alt="Screen Shot 2020-02-05 at 5 42 10 PM (2)" src="https://user-images.githubusercontent.com/7637700/73898819-6736b700-483f-11ea-84d4-b9a95246cc2d.png">
<img width="1920" alt="Screen Shot 2020-02-05 at 5 42 11 PM (2)" src="https://user-images.githubusercontent.com/7637700/73898826-6e5dc500-483f-11ea-8dfe-15eeec5b553a.png">
|
open
|
2020-02-06T01:46:54Z
|
2021-06-29T15:18:53Z
|
https://github.com/tqdm/tqdm/issues/889
|
[] |
apengwin
| 3 |
graphql-python/gql
|
graphql
| 468 |
Request/Response payloads logged at level INFO
|
**Common problems**
My applications log is filled with the payload of every request/response. For example
```
INFO:gql.transport.requests:>>> {"query": "query IntrospectionQuery {\n __schema {\n queryType {\n name\n }\n mutationType {\n name\n }\n subscriptionType {\n name\n }\n types {\n ...FullType\n }\n directives {\n name\n description\n locations\n args {\n ...InputValue\n }\n }\n }\n}\n\nfragment FullType on __Type {\n kind\n name\n description\n fields(includeDeprecated: true) {\n name\n description\n args {\n ...InputValue\n }\n type {\n ...TypeRef\n }\n isDeprecated\n deprecationReason\n }\n inputFields {\n ...InputValue\n }\n interfaces {\n ...TypeRef\n }\n enumValues(includeDeprecated: true) {\n name\n description\n isDeprecated\n deprecationReason\n }\n possibleTypes {\n ...TypeRef\n }\n}\n\nfragment InputValue on __InputValue {\n name\n description\n type {\n ...TypeRef\n }\n defaultValue\n}\n\nfragment TypeRef on __Type {\n kind\n name\n ofType {\n kind\n name\n ofType {\n kind\n name\n ofType {\n kind\n name\n ofType {\n kind\n name\n ofType {\n kind\n name\n ofType {\n kind\n name\n ofType {\n kind\n name\n }\n }\n }\n }\n }\n }\n }\n}"}
INFO:gql.transport.requests:<<< {"data":{"__schema":{"queryType":{"name":"QueryRoot"},"mutationType":null,"subscriptionType":null,"types":[{"kind":"SCALAR","name":"Boolean","description":null,"fields":null,"inputFields":null,"interfaces":null,"enumValues":null,"possibleTypes":null}
```
Note this is at log level INFO, specifically https://github.com/graphql-python/gql/blob/48bb94cc4fc0755419c9edc7e8ef1470036c193d/gql/transport/requests.py#L234-L235
**Describe the bug**
Debug messages should not be logged at INFO level
**To Reproduce**
Set log level to INFO
**Expected behavior**
If required this should be logged at DEBUG lebel
**System info (please complete the following information):**
- OS: Ubuntu
- Python version: 3.10
- gql version: 3.5.0
- graphql-core version: 3.2.3
|
closed
|
2024-02-14T04:49:22Z
|
2024-03-28T00:31:35Z
|
https://github.com/graphql-python/gql/issues/468
|
[
"type: duplicate"
] |
david-waterworth
| 5 |
open-mmlab/mmdetection
|
pytorch
| 11,120 |
TwoStageDetector's code logic error ?
|
The description is `tuple: A tuple of features from ``rpn_head`` and ``roi_head`` forward.`, but I find there is no `rpn_head` in return.
The code `results = results + (roi_outs,)` may could be repeat by `results = (roi_outs,)`, because tuple `results` is always none.
Is it a code logic error ?
version: 3.2.0 ,file: two_stage.py
```python
def _forward(self, batch_inputs: Tensor,
batch_data_samples: SampleList) -> tuple:
"""Network forward process. Usually includes backbone, neck and head
forward without any post-processing.
Args:
batch_inputs (Tensor): Inputs with shape (N, C, H, W).
batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
the meta information of each image and corresponding
annotations.
Returns:
tuple: A tuple of features from ``rpn_head`` and ``roi_head``
forward.
"""
results = ()
x = self.extract_feat(batch_inputs)
if self.with_rpn:
rpn_results_list = self.rpn_head.predict(
x, batch_data_samples, rescale=False)
else:
assert batch_data_samples[0].get('proposals', None) is not None
rpn_results_list = [
data_sample.proposals for data_sample in batch_data_samples
]
roi_outs = self.roi_head.forward(x, rpn_results_list,
batch_data_samples)
results = results + (roi_outs,)
return results
```
|
open
|
2023-11-02T15:13:59Z
|
2023-11-02T15:14:25Z
|
https://github.com/open-mmlab/mmdetection/issues/11120
|
[] |
YChienHung
| 0 |
voila-dashboards/voila
|
jupyter
| 600 |
[master] nbconvert errors in the base template
|
I am seeing the following exception when using voilà master
```
HTTPServerRequest(protocol='http', host='localhost:8866', method='GET', uri='/', version='HTTP/1.1', remote_ip='::1')
Traceback (most recent call last):
File "/home/sylvain/miniconda3/lib/python3.7/site-packages/tornado/web.py", line 1703, in _execute
result = await result
File "/home/sylvain/miniconda3/lib/python3.7/site-packages/voila/handler.py", line 107, in get
async for html_snippet, resources in self.exporter.generate_from_notebook_node(self.notebook, resources=resources, extra_context=extra_context):
File "/home/sylvain/miniconda3/lib/python3.7/site-packages/voila/exporter.py", line 102, in generate_from_notebook_node
async for output in self.template.generate_async(nb=nb_copy, resources=resources, **extra_context):
File "/home/sylvain/miniconda3/lib/python3.7/site-packages/jinja2/asyncsupport.py", line 35, in generate_async
yield self.environment.handle_exception()
File "/home/sylvain/miniconda3/lib/python3.7/site-packages/jinja2/environment.py", line 832, in handle_exception
reraise(*rewrite_traceback_stack(source=source))
File "/home/sylvain/miniconda3/lib/python3.7/site-packages/jinja2/_compat.py", line 28, in reraise
raise value.with_traceback(tb)
File "/home/sylvain/miniconda3/share/jupyter/voila/templates/default/nbconvert_templates/voila.tpl", line 2, in top-level template code
{% import "spinner.tpl" as spinner %}
File "/home/sylvain/miniconda3/share/jupyter/voila/templates/default/nbconvert_templates/base.tpl", line 1, in top-level template code
{%- extends 'lab.tpl' -%}
File "/home/sylvain/miniconda3/share/jupyter/voila/templates/default/nbconvert_templates/lab.tpl", line 223, in top-level template code
{% set div_id = uuid4() %}
File "/home/sylvain/miniconda3/share/jupyter/nbconvert/templates/compatibility/display_priority.tpl", line 1, in top-level template code
{%- extends 'base/display_priority.j2' -%}
File "/home/sylvain/miniconda3/share/jupyter/nbconvert/templates/base/display_priority.j2", line 1, in top-level template code
{%- extends 'null.j2' -%}
File "/home/sylvain/miniconda3/share/jupyter/nbconvert/templates/base/null.j2", line 26, in top-level template code
{%- block body -%}
File "/home/sylvain/miniconda3/share/jupyter/voila/templates/default/nbconvert_templates/voila.tpl", line 63, in block "body"
{%- block body_loop -%}
File "/home/sylvain/miniconda3/share/jupyter/voila/templates/default/nbconvert_templates/voila.tpl", line 82, in block "body_loop"
{%- block any_cell scoped -%}
File "/home/sylvain/miniconda3/share/jupyter/voila/templates/default/nbconvert_templates/voila.tpl", line 84, in block "any_cell"
{{ super() }}
File "/home/sylvain/miniconda3/lib/python3.7/site-packages/jinja2/asyncsupport.py", line 174, in auto_await
return await value
File "/home/sylvain/miniconda3/lib/python3.7/site-packages/jinja2/asyncsupport.py", line 25, in concat_async
await collect()
File "/home/sylvain/miniconda3/lib/python3.7/site-packages/jinja2/asyncsupport.py", line 22, in collect
async for event in async_gen:
File "/home/sylvain/miniconda3/share/jupyter/nbconvert/templates/base/null.j2", line 95, in block "any_cell"
{%- if resources.global_content_filter.include_unknown and not cell.get("transient",{}).get("remove_source", false) -%}
jinja2.exceptions.UndefinedError: 'tuple object' has no attribute 'get'
```
|
closed
|
2020-05-15T17:26:02Z
|
2020-12-23T10:13:32Z
|
https://github.com/voila-dashboards/voila/issues/600
|
[] |
SylvainCorlay
| 2 |
developmentseed/lonboard
|
jupyter
| 764 |
Update traitlets version
|
https://github.com/developmentseed/lonboard/blob/510af74c550eced13a79d80f16cee38b98df69b7/pyproject.toml#L11-L13
It looks like colab has been updating packages recently https://github.com/googlecolab/colabtools/issues/2230#issuecomment-2691314734
|
open
|
2025-02-28T19:45:05Z
|
2025-02-28T19:45:05Z
|
https://github.com/developmentseed/lonboard/issues/764
|
[] |
kylebarron
| 0 |
mobarski/ask-my-pdf
|
streamlit
| 42 |
Storage/cache mode does not work when local/disk
|
Hi,
no problem running your demo but something on my side went wrong when trying to setup in run.sh these parameters:
STORAGE_MODE=LOCAL and CACHE_MODE=DISK.
No data is saved under cache/storage folder on disk.
Same problems on REDIS but maybe is something linked to issues above.
Any idea?
Thank you
|
open
|
2023-03-21T15:28:14Z
|
2023-03-21T15:28:14Z
|
https://github.com/mobarski/ask-my-pdf/issues/42
|
[] |
liucoj
| 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.