
repo_name
stringlengths 9
75
| topic
stringclasses 30
values | issue_number
int64 1
203k
| title
stringlengths 1
976
| body
stringlengths 0
254k
| state
stringclasses 2
values | created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| url
stringlengths 38
105
| labels
sequencelengths 0
9
| user_login
stringlengths 1
39
| comments_count
int64 0
452
|
|---|---|---|---|---|---|---|---|---|---|---|---|
python-restx/flask-restx | api | 356 | Can not install Flask-Restx in ARM | ## Description:
I am trying to create a docker image in a RaspberryPi which runs `aarch64`, but when the Docker image starts installing the Flask-Restx package, it fails.
!!**This was working correctly 4 months ago because that was the day of my last build.**
## **Environment**
RaspberryPi 4
```commandline
$ uname -a
Linux RPi 5.10.10-1-ARCH #1 SMP Sat Jan 23 16:26:04 MST 2021 aarch64 GNU/Linux
$ docker --version
Docker version 20.10.2, build 2291f610ae
```
## **requirements.txt**
```text
flask-restx==0.4.0
```
## **Dockerfile**
```dockerfile
# Build
FROM python:3.9 as build
COPY requirements.txt /
WORKDIR /pip-packages
RUN pip download -r /requirements.txt --no-input
# Prod
FROM python:3.9
COPY --from=build /pip-packages/ /pip-packages/
RUN pip install --no-index --find-links=/pip-packages/ /pip-packages/*
RUN pip list
```
## **Expected Behavior**
Docker image can be built correctly.
## **Actual Behavior**
Docker image fails when building.
## **Error Messages/Stack Trace**
### **Message Error**
```text
ERROR: Command errored out with exit status 1:
command: /usr/local/bin/python /usr/local/lib/python3.9/site-packages/pip install --ignore-installed --no-user --prefix /tmp/pip-build-env-qf_d47c3/overlay --no-warn-script-location --no-binary :none: --only-binary :none: --no-index --find-links /pip-packages/ -- 'setuptools>=42' wheel
cwd: None
Complete output (4 lines):
Looking in links: /pip-packages/
Processing /pip-packages/setuptools-57.2.0-py3-none-any.whl
ERROR: Could not find a version that satisfies the requirement wheel
ERROR: No matching distribution found for wheel
----------------------------------------
WARNING: Discarding file:///pip-packages/pyrsistent-0.18.0.tar.gz. Command errored out with exit status 1: /usr/local/bin/python /usr/local/lib/python3.9/site-packages/pip install --ignore-installed --no-user --prefix /tmp/pip-build-env-qf_d47c3/overlay --no-warn-script-location --no-binary :none: --only-binary :none: --no-index --find-links /pip-packages/ -- 'setuptools>=42' wheel Check the logs for full command output.
ERROR: Command errored out with exit status 1: /usr/local/bin/python /usr/local/lib/python3.9/site-packages/pip install --ignore-installed --no-user --prefix /tmp/pip-build-env-qf_d47c3/overlay --no-warn-script-location --no-binary :none: --only-binary :none: --no-index --find-links /pip-packages/ -- 'setuptools>=42' wheel Check the logs for full command output.
The command '/bin/sh -c pip install --no-index --find-links=/pip-packages/ /pip-packages/*' returned a non-zero code: 1
```
### Docker build output
```commandLine
$ docker build --tag docker-arm-poc-3:latest --no-cache .
```
```text
Sending build context to Docker daemon 5.12kB
Step 1/8 : FROM python:3.9 as build
---> 8ff7a2865c18
Step 2/8 : COPY requirements.txt /
---> 1f6972b1b83d
Step 3/8 : WORKDIR /pip-packages
---> Running in 4d614d4db71b
Removing intermediate container 4d614d4db71b
---> 45d2797d6000
Step 4/8 : RUN pip download -r /requirements.txt --no-input
---> Running in 53c81d589f32
Collecting flask-restx==0.4.0
Downloading flask_restx-0.4.0-py2.py3-none-any.whl (5.3 MB)
Collecting six>=1.3.0
Downloading six-1.16.0-py2.py3-none-any.whl (11 kB)
Collecting Flask<2.0.0,>=0.8
Downloading Flask-1.1.4-py2.py3-none-any.whl (94 kB)
Collecting werkzeug<2.0.0
Downloading Werkzeug-1.0.1-py2.py3-none-any.whl (298 kB)
Collecting jsonschema
Downloading jsonschema-3.2.0-py2.py3-none-any.whl (56 kB)
Collecting pytz
Downloading pytz-2021.1-py2.py3-none-any.whl (510 kB)
Collecting aniso8601>=0.82
Downloading aniso8601-9.0.1-py2.py3-none-any.whl (52 kB)
Collecting itsdangerous<2.0,>=0.24
Downloading itsdangerous-1.1.0-py2.py3-none-any.whl (16 kB)
Collecting Jinja2<3.0,>=2.10.1
Downloading Jinja2-2.11.3-py2.py3-none-any.whl (125 kB)
Collecting click<8.0,>=5.1
Downloading click-7.1.2-py2.py3-none-any.whl (82 kB)
Collecting MarkupSafe>=0.23
Downloading MarkupSafe-2.0.1-cp39-cp39-manylinux2014_aarch64.whl (31 kB)
Collecting setuptools
Downloading setuptools-57.2.0-py3-none-any.whl (818 kB)
Collecting pyrsistent>=0.14.0
Downloading pyrsistent-0.18.0.tar.gz (104 kB)
Installing build dependencies: started
Installing build dependencies: finished with status 'done'
Getting requirements to build wheel: started
Getting requirements to build wheel: finished with status 'done'
Preparing wheel metadata: started
Preparing wheel metadata: finished with status 'done'
Collecting attrs>=17.4.0
Downloading attrs-21.2.0-py2.py3-none-any.whl (53 kB)
Saved ./flask_restx-0.4.0-py2.py3-none-any.whl
Saved ./aniso8601-9.0.1-py2.py3-none-any.whl
Saved ./Flask-1.1.4-py2.py3-none-any.whl
Saved ./click-7.1.2-py2.py3-none-any.whl
Saved ./itsdangerous-1.1.0-py2.py3-none-any.whl
Saved ./Jinja2-2.11.3-py2.py3-none-any.whl
Saved ./MarkupSafe-2.0.1-cp39-cp39-manylinux2014_aarch64.whl
Saved ./six-1.16.0-py2.py3-none-any.whl
Saved ./Werkzeug-1.0.1-py2.py3-none-any.whl
Saved ./jsonschema-3.2.0-py2.py3-none-any.whl
Saved ./attrs-21.2.0-py2.py3-none-any.whl
Saved ./pyrsistent-0.18.0.tar.gz
Saved ./pytz-2021.1-py2.py3-none-any.whl
Saved ./setuptools-57.2.0-py3-none-any.whl
Successfully downloaded flask-restx aniso8601 Flask click itsdangerous Jinja2 MarkupSafe six werkzeug jsonschema attrs pyrsistent pytz setuptools
WARNING: You are using pip version 21.0.1; however, version 21.1.3 is available.
You should consider upgrading via the '/usr/local/bin/python -m pip install --upgrade pip' command.
Removing intermediate container 53c81d589f32
---> 1467b30d43ef
Step 5/8 : FROM python:3.9
---> 8ff7a2865c18
Step 6/8 : COPY --from=build /pip-packages/ /pip-packages/
---> 89c8bfc9a430
Step 7/8 : RUN pip install --no-index --find-links=/pip-packages/ /pip-packages/*
---> Running in a10bdd1551cb
Looking in links: /pip-packages/
Processing /pip-packages/Flask-1.1.4-py2.py3-none-any.whl
Processing /pip-packages/Jinja2-2.11.3-py2.py3-none-any.whl
Processing /pip-packages/MarkupSafe-2.0.1-cp39-cp39-manylinux2014_aarch64.whl
Processing /pip-packages/Werkzeug-1.0.1-py2.py3-none-any.whl
Processing /pip-packages/aniso8601-9.0.1-py2.py3-none-any.whl
Processing /pip-packages/attrs-21.2.0-py2.py3-none-any.whl
Processing /pip-packages/click-7.1.2-py2.py3-none-any.whl
Processing /pip-packages/flask_restx-0.4.0-py2.py3-none-any.whl
Processing /pip-packages/itsdangerous-1.1.0-py2.py3-none-any.whl
Processing /pip-packages/jsonschema-3.2.0-py2.py3-none-any.whl
Processing /pip-packages/pyrsistent-0.18.0.tar.gz
Installing build dependencies: started
Installing build dependencies: finished with status 'error'
ERROR: Command errored out with exit status 1:
command: /usr/local/bin/python /usr/local/lib/python3.9/site-packages/pip install --ignore-installed --no-user --prefix /tmp/pip-build-env-qf_d47c3/overlay --no-warn-script-location --no-binary :none: --only-binary :none: --no-index --find-links /pip-packages/ -- 'setuptools>=42' wheel
cwd: None
Complete output (4 lines):
Looking in links: /pip-packages/
Processing /pip-packages/setuptools-57.2.0-py3-none-any.whl
ERROR: Could not find a version that satisfies the requirement wheel
ERROR: No matching distribution found for wheel
----------------------------------------
WARNING: Discarding file:///pip-packages/pyrsistent-0.18.0.tar.gz. Command errored out with exit status 1: /usr/local/bin/python /usr/local/lib/python3.9/site-packages/pip install --ignore-installed --no-user --prefix /tmp/pip-build-env-qf_d47c3/overlay --no-warn-script-location --no-binary :none: --only-binary :none: --no-index --find-links /pip-packages/ -- 'setuptools>=42' wheel Check the logs for full command output.
ERROR: Command errored out with exit status 1: /usr/local/bin/python /usr/local/lib/python3.9/site-packages/pip install --ignore-installed --no-user --prefix /tmp/pip-build-env-qf_d47c3/overlay --no-warn-script-location --no-binary :none: --only-binary :none: --no-index --find-links /pip-packages/ -- 'setuptools>=42' wheel Check the logs for full command output.
The command '/bin/sh -c pip install --no-index --find-links=/pip-packages/ /pip-packages/*' returned a non-zero code: 1
``` | closed | 2021-07-17T17:33:33Z | 2021-07-18T01:57:15Z | https://github.com/python-restx/flask-restx/issues/356 | [
"bug"
] | FernandoArteaga | 3 |
exaloop/codon | numpy | 130 | How to uninstall it? | I'm trying to test this package but not good for my project.
And this package needs comercial license, so I want to remove it all.
How can I uninstall it?
| closed | 2022-12-25T23:56:09Z | 2022-12-26T15:46:34Z | https://github.com/exaloop/codon/issues/130 | [] | Laser-Cho | 1 |
Avaiga/taipy | automation | 1,522 | [🐛 BUG] Lambda expression not working with new line | ### What went wrong? 🤔
Lambda expressions are not working for no reason.
The second selector is not working.

### Expected Behavior
It should work.
### Steps to Reproduce Issue
```python
from taipy.gui import Gui
import taipy.gui.builder as tgb
value: int = 10
value_selector = 10
def get_list(value):
return [str(i) for i in range(value)]
with tgb.Page() as page:
# Works
tgb.selector(value="{value_selector}", lov=lambda value: get_list(value))
# don't work
tgb.selector(value="{value_selector}",
lov=lambda value: get_list(value))
Gui(page=page).run(title="Frontend Demo")
```
### Browsers
Chrome
### OS
Windows
### Version of Taipy
develop - 7/15/24
### Acceptance Criteria
- [ ] Ensure new code is unit tested, and check code coverage is at least 90%.
- [ ] Create related issue in taipy-doc for documentation and Release Notes.
### Code of Conduct
- [X] I have checked the [existing issues](https://github.com/Avaiga/taipy/issues?q=is%3Aissue+).
- [ ] I am willing to work on this issue (optional) | closed | 2024-07-15T19:39:46Z | 2024-07-16T13:14:16Z | https://github.com/Avaiga/taipy/issues/1522 | [
"🖰 GUI",
"💥Malfunction",
"🟧 Priority: High"
] | FlorianJacta | 1 |
serengil/deepface | machine-learning | 1,147 | [Question] Face verification does not meet expectations | I am very thankful for this open source project, it solved my immediate problem.
I am trying to accomplish the task of face comparison with yolov8n-face and Facenet512. But for some samples, the results are not too good.
I tried to replace the face detection with a paid api and this is my test result:
|Face detection type|x|y|w|h|left eye|right eye|Facenet512 cosine distance |
|---|---|---|---|---|---|---|---|
|yolov8n-face.pt img1|43|167|242|334|(99, 288)|(216, 290)| 0.2299605098248957|
|yolov8n-face.pt img2|170|165|405|541|(280, 377)|(457, 372)| |
|yolov8n-face.onnx img1|43|166|241|333|(99, 289)|(216, 291)|0.22794579406637527 |
|yolov8n-face.onnx img2|168|160|401|544|(278, 380)|(456, 376)| |
|payment api img1|44|229|245|271|(100, 284)|(220, 283)| 0.3275035163254295|
|payment api img2|169|307|385|414|(279, 376)|(453, 362)| |
On the left is the yolov8 detection area and on the right is the paid api detection area:

Now I'm confused. Based on the recommended threshold (0.3), the face region obtained from the paid api seems to be better suited to accomplish the face matching task. So should I find a way to shrink the face region or should I find a more suitable threshold based on my actual usage scenario?
Can you provide optimization suggestions?
| closed | 2024-03-28T08:11:07Z | 2024-03-28T08:20:11Z | https://github.com/serengil/deepface/issues/1147 | [
"question"
] | invokerbyxv | 1 |
dpgaspar/Flask-AppBuilder | rest-api | 1,803 | Multiple authentication methods enabled | Hi, is it possible to have multiple authentication methods enabled at the same time? I noticed that if I set
`AUTH_TYPE = AUTH_LDAP`
DB authentication does not work anymore. | closed | 2022-02-10T18:54:21Z | 2022-02-15T13:29:52Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1803 | [] | enribar | 1 |
FactoryBoy/factory_boy | django | 681 | Provide some basic Django Auth Factories (User, Group, Permission...) | #### The problem
Any project who uses `django.contrib.auth` and/or `django.contrib.contenttypes` now has to create the factories for User, Group, Permission, ContentType for using them in his tests, right?
Why we do not provide related Factories for them as they are very basic models...
#### Proposed solution
Something similar to:
```
import factory
import factory.fuzzy
from django.contrib.auth import get_user_model
from django.contrib.auth.models import Group, Permission
from django.contrib.contenttypes.models import ContentType
from factory.django import DjangoModelFactory
class ContentTypeFactory(factory.django.DjangoModelFactory):
class Meta:
model = ContentType
django_get_or_create = ('app_label', 'model')
app_label = factory.Faker("word")
model = factory.Faker("word")
class PermissionFactory(DjangoModelFactory):
class Meta:
model = Permission
django_get_or_create = ("name",)
name = factory.Faker("name")
content_type = factory.SubFactory(ContentTypeFactory)
class GroupFactory(DjangoModelFactory):
class Meta:
model = Group
django_get_or_create = ("name",)
name = factory.Faker("name")
class UserFactory(DjangoModelFactory):
username = factory.Faker("user_name")
email = factory.Faker("email")
password = factory.Faker("password")
is_active = True
is_staff = False
is_superuser = False
class Meta:
model = get_user_model()
django_get_or_create = ("username",)
@classmethod
def _create(cls, model_class, *args, **kwargs):
"""Override the default ``_create`` with our custom call."""
manager = cls._get_manager(model_class)
# Some support to generate auth users....
if kwargs.get("is_superuser"):
return manager.create_superuser(*args, **kwargs)
return manager.create_user(*args, **kwargs)
@factory.post_generation
def groups(self, create, extracted, **kwargs):
if not create:
# Simple build, do nothing.
return
if extracted:
# A list of groups were passed in, use them
for group in extracted:
self.groups.add(Group.objects.get_or_create(name=group)[0])
@factory.post_generation
def user_permissions(self, create, extracted, **kwargs):
if not create:
# Simple build, do nothing.
return
if extracted:
# A list of tuple (ModelClass, "my_permission")
for model, permission in extracted:
content_type = ContentType.objects.get_for_model(model)
self.user_permissions.add(
Permission.objects.get_or_create(
codename=permission, content_type=content_type
)[0]
)
```
#### Extra notes
Please, notice this is only a draft... I have to refine them :)
If could be interesting I can set up a PR draft :)
| closed | 2020-01-06T17:12:16Z | 2020-02-04T14:21:06Z | https://github.com/FactoryBoy/factory_boy/issues/681 | [] | estyxx | 1 |
nschloe/tikzplotlib | matplotlib | 181 | Escape special characters | matplotlib2tikz does not correctly escape special or accented characters in plots. Specifically, including characters such as the percent sign (%) in labels or captions causes a `Extra }, or forgotten \endgroup. \end{tikzpicture}` error; on the other hand, including accented characters such as á, é, and the like causes an inpuntenc error `Package inputenc Error: Unicode char ícu (U+E5)(inputenc) not set up for use with LaTeX. \end{axis}`
**(Not-so Minimal) Working Example:**
**Python code:**
```Python
def vehicles_vs_time():
cols = ['nvhcs', 't', 'demand', 'runID']
df = pandas.read_csv('NVeh_vs_T.csv', encoding='ISO-8859-1', sep=';')
df.columns = cols
df['nvhcs'] = pandas.to_numeric(df['nvhcs'])
df['t'] = pandas.to_numeric(df['t'])
df['runID'] = pandas.to_numeric(df['runID'])
df['demand'] = df['demand'].map(lambda x: float(x.strip('%')) / 100)
df100 = df.loc[df['demand'] == 1.00]
df75 = df.loc[df['demand'] == 0.75]
df50 = df.loc[df['demand'] == 0.50]
df25 = df.loc[df['demand'] == 0.25]
mean_df = pandas.DataFrame(columns=['demand', 'mean_vhcs', 'mean_time'])
mean_df.loc[0] = [1.00, df100['nvhcs'].mean(), df100['t'].mean()]
mean_df.loc[1] = [0.75, df75['nvhcs'].mean(), df75['t'].mean()]
mean_df.loc[2] = [0.50, df50['nvhcs'].mean(), df50['t'].mean()]
mean_df.loc[3] = [0.25, df25['nvhcs'].mean(), df25['t'].mean()]
# from this point onward, plot
fig, ax = pyplot.subplots()
ax.set_facecolor('white')
ax.grid(color='#a1a1a1', linestyle='-', alpha=0.1)
pyplot.xlim([df['nvhcs'].min() - 50, df['nvhcs'].max() + 50])
pyplot.ylim(0, df['t'].max() + 120)
yticks_mins = numpy.arange(0, df['t'].max() + 120, 120)
yticks_10secs = numpy.arange(0, df['t'].max() + 120, 60)
xticks = numpy.arange(200, 1500, 100)
xticks_minor = numpy.arange(150, 1500, 10)
ax.set_yticks(yticks_mins)
ax.set_yticks(yticks_10secs, minor=True)
ax.set_xticks(xticks)
ax.set_xticks(xticks_minor, minor=True)
# trendline
z = numpy.polyfit(df['nvhcs'], df['t'], 2)
p = numpy.poly1d(z)
nx = range(0, int(df['nvhcs'].max()) + 200)
ax.plot(nx, p(nx), '-.', alpha=0.3, label='Ajuste polinomial', color='#F06449')
# scatter
ax.plot(df100['nvhcs'], df100['t'], 'o', color='#17BEBB', label='Factor de demanda 100%')
ax.plot(df75['nvhcs'], df75['t'], 'o', color='#EF2D56', label='Factor de demanda 75%')
ax.plot(df50['nvhcs'], df50['t'], 'o', color='#8CD867', label='Factor de demanda 50%')
ax.plot(df25['nvhcs'], df25['t'], 'o', color='#2F243A', label='Factor de demanda 25%')
ax.legend(loc='upper left')
pyplot.ylabel('Tiempo (MM:SS)')
formatter = matplotlib.ticker.FuncFormatter(to_min_secs)
ax.yaxis.set_major_formatter(formatter)
pyplot.xlabel('Cantidad promedio vehículos en simulación')
# pyplot.title('Scatterplot: Cantidad promedio de vehículos vs duración en tiempo real de simulación')
# pyplot.savefig('n_vhcs_vs_time.pgf')
# pyplot.show()
tikz_save('n_vhcs_vs_time.tex',
figureheight='\\figureheight',
figurewidth='\\figurewidth')
```
**Generated output (note the labels and legends):**
```Latex
% This file was created by matplotlib2tikz v0.6.10.
\begin{tikzpicture}
\definecolor{color0}{rgb}{0.941176470588235,0.392156862745098,0.286274509803922}
\definecolor{color1}{rgb}{0.0901960784313725,0.745098039215686,0.733333333333333}
\definecolor{color2}{rgb}{0.937254901960784,0.176470588235294,0.337254901960784}
\definecolor{color3}{rgb}{0.549019607843137,0.847058823529412,0.403921568627451}
\definecolor{color4}{rgb}{0.184313725490196,0.141176470588235,0.227450980392157}
\begin{axis}[
xlabel={Cantidad promedio vehículos en simulación},
ylabel={Tiempo (MM:SS)},
xmin=150, xmax=1490,
ymin=0, ymax=1713,
width=\figurewidth,
height=\figureheight,
tick align=outside,
tick pos=left,
xmajorgrids,
x grid style={lightgray!84.183006535947712!black},
ymajorgrids,
y grid style={lightgray!84.183006535947712!black},
axis line style={white},
legend style={at={(0.03,0.97)}, anchor=north west, draw=white!80.0!black, fill=white!89.803921568627459!black},
legend cell align={left},
legend entries={{Ajuste polinomial},{Factor de demanda 100%},{Factor de demanda 75%},{Factor de demanda 50%},{Factor de demanda 25%}}
]
\addplot [semithick, color0, opacity=0.3, dash pattern=on 1pt off 3pt on 3pt off 3pt]
table {%
0 6.3172112993997
1 6.57640934437459
2 6.83677322746044
3 7.09830294865727
% ...
% ... lots of points
% ...
1611 1935.80824515293
1612 1937.94560839468
1613 1940.08413747453
1614 1942.2238323925
};
\addplot [semithick, color1, mark=*, mark size=3, mark options={solid}, only marks]
table {%
1398.4 1593
1351.4 1439
1354.67 1388
1415.13 1466
};
\addplot [semithick, color2, mark=*, mark size=3, mark options={solid}, only marks]
table {%
870.2 660
872.27 664
842.13 703
890.4 707
};
\addplot [semithick, color3, mark=*, mark size=3, mark options={solid}, only marks]
table {%
521.13 281
504.4 268
512.2 272
520.6 282
};
\addplot [semithick, color4, mark=*, mark size=3, mark options={solid}, only marks]
table {%
249.67 118
254.8 122
240.87 113
240.93 100
};
\end{axis}
\end{tikzpicture}
```
**Expected (and working!) output:**
```Latex
% This file was created by matplotlib2tikz v0.6.10.
\begin{tikzpicture}
\definecolor{color0}{rgb}{0.941176470588235,0.392156862745098,0.286274509803922}
\definecolor{color1}{rgb}{0.0901960784313725,0.745098039215686,0.733333333333333}
\definecolor{color2}{rgb}{0.937254901960784,0.176470588235294,0.337254901960784}
\definecolor{color3}{rgb}{0.549019607843137,0.847058823529412,0.403921568627451}
\definecolor{color4}{rgb}{0.184313725490196,0.141176470588235,0.227450980392157}
\begin{axis}[
xlabel={Cantidad promedio veh\'iculos en simulaci\'on},
ylabel={Tiempo (MM:SS)},
xmin=150, xmax=1490,
ymin=0, ymax=1713,
width=\figurewidth,
height=\figureheight,
tick align=outside,
tick pos=left,
xmajorgrids,
x grid style={lightgray!84.183006535947712!black},
ymajorgrids,
y grid style={lightgray!84.183006535947712!black},
axis line style={white},
legend style={at={(0.03,0.97)}, anchor=north west, draw=white!80.0!black, fill=white!89.803921568627459!black},
legend cell align={left},
legend entries={{Ajuste polinomial},{Factor de demanda 100\%},{Factor de demanda 75\%},{Factor de demanda 50\%},{Factor de demanda 25\%}}
]
\addplot [semithick, color0, opacity=0.3, dash pattern=on 1pt off 3pt on 3pt off 3pt]
table {%
0 6.3172112993997
1 6.57640934437459
2 6.83677322746044
3 7.09830294865727
% ...
% ... lots of points
% ...
1611 1935.80824515293
1612 1937.94560839468
1613 1940.08413747453
1614 1942.2238323925
};
\addplot [semithick, color1, mark=*, mark size=3, mark options={solid}, only marks]
table {%
1398.4 1593
1351.4 1439
1354.67 1388
1415.13 1466
};
\addplot [semithick, color2, mark=*, mark size=3, mark options={solid}, only marks]
table {%
870.2 660
872.27 664
842.13 703
890.4 707
};
\addplot [semithick, color3, mark=*, mark size=3, mark options={solid}, only marks]
table {%
521.13 281
504.4 268
512.2 272
520.6 282
};
\addplot [semithick, color4, mark=*, mark size=3, mark options={solid}, only marks]
table {%
249.67 118
254.8 122
240.87 113
240.93 100
};
\end{axis}
\end{tikzpicture}
```
| closed | 2017-06-15T15:44:06Z | 2017-06-15T16:00:37Z | https://github.com/nschloe/tikzplotlib/issues/181 | [] | molguin92 | 1 |
django-oscar/django-oscar | django | 3,581 | Add attachment to order_placed email | I need to add an attachment to the `order_placed` email. I see the function I would ideally hook into. The `Checkout.mixins.OrderPlacementMixin` there is a function called `send_order_placed_email`.
So would I fork the whole Checkout app? And add my own `mixins.py` and override the `OrderPlacementMixin`? | closed | 2020-11-28T15:58:17Z | 2020-11-30T04:58:23Z | https://github.com/django-oscar/django-oscar/issues/3581 | [] | ladrua | 1 |
neuml/txtai | nlp | 201 | Add social preview image for documentation | Reference: https://squidfunk.github.io/mkdocs-material/setup/setting-up-social-cards/#meta-tags | closed | 2022-01-22T11:05:56Z | 2022-01-22T11:09:30Z | https://github.com/neuml/txtai/issues/201 | [] | davidmezzetti | 0 |
geopandas/geopandas | pandas | 2,490 | BUG: Exporting df as a ESRI shapefile error: Object of type 'float' has no len() | - [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the latest version of geopandas.
- [x] (optional) I have confirmed this bug exists on the main branch of geopandas.
---
#### Code Sample, a copy-pastable example
```python
# Your code here
df.to_file(filename="test.shp", driver="ESRI Shapefile")
```
#### Problem description
The problem is occurred when the column name is an `float` type. Below is the Traceback,
```python
Traceback (most recent call last):
File "/opt/sdss/django/sdss/exposure/views.py", line 353, in downloadExposureResult
df.to_file(filename=shp_path, driver='ESRI Shapefile')
File "/home/sdss/.virtualenvs/sdss/lib/python3.8/site-packages/geopandas/geodataframe.py", line 1114, in to_file
_to_file(self, filename, driver, schema, index, **kwargs)
File "/home/sdss/.virtualenvs/sdss/lib/python3.8/site-packages/geopandas/io/file.py", line 376, in _to_file
if driver == "ESRI Shapefile" and any([len(c) > 10 for c in df.columns.tolist()]):
File "/home/sdss/.virtualenvs/sdss/lib/python3.8/site-packages/geopandas/io/file.py", line 376, in <listcomp>
if driver == "ESRI Shapefile" and any([len(c) > 10 for c in df.columns.tolist()]):
TypeError: object of type 'float' has no len()
```
#### Expected Output
It should write df into the shapefile.
#### Output of ``geopandas.show_versions()``
0.10.2
[paste the output of ``geopandas.show_versions()`` here leaving a blank line after the details tag]
</details>
| open | 2022-07-11T02:55:19Z | 2023-01-04T09:07:19Z | https://github.com/geopandas/geopandas/issues/2490 | [
"bug"
] | iamtekson | 5 |
ets-labs/python-dependency-injector | flask | 834 | WiringConfiguration(packages=[top_level_package]) affect subpackages only if they have __init__.py | Hello folks! I'm just started to learn dependency-injector.
I was following this public template [https://github.com/teamhide/fastapi-boilerplate](https://github.com/teamhide/fastapi-boilerplate) and found that WiringConfiguration can be affect subpackages of designated top level package only if all of paths have __init__.py.
I understand that from Python 3.6 we don't necessarily need to use __init__.py not if in some of situation but i believe this might not be one of the those cases.
**app.container.py**
```python
from dependency_injector.containers import DeclarativeContainer, WiringConfiguration
from dependency_injector.providers import Factory, Singleton
from app.auth.application.service.jwt import JwtService
from app.user.adapter.output.persistence.repository_adapter import UserRepositoryAdapter
from app.user.adapter.output.persistence.sqlalchemy.user import UserSQLAlchemyRepo
from app.user.application.service.user import UserService
class Container(DeclarativeContainer):
wiring_config = WiringConfiguration(packages=["app"])
user_repo = Singleton(UserSQLAlchemyRepo)
user_repo_adapter = Factory(UserRepositoryAdapter, user_repo=user_repo)
user_service = Factory(UserService, repository=user_repo_adapter)
jwt_service = Factory(JwtService)
``` | open | 2024-12-05T01:55:50Z | 2024-12-05T01:55:50Z | https://github.com/ets-labs/python-dependency-injector/issues/834 | [] | hagd0520 | 0 |
plotly/dash-core-components | dash | 167 | dcc.Graph shouldn't require an `id` | closed | 2018-02-25T23:19:48Z | 2018-11-29T20:18:00Z | https://github.com/plotly/dash-core-components/issues/167 | [
"help wanted",
"dash-meta-good_first_issue"
] | chriddyp | 1 |
|
twopirllc/pandas-ta | pandas | 506 | ATRTS not included in df.ta.study("volatility") | Using the latest version of develop, `Average True Range Trailing Stop: atrts`, isn't included in `df.ta.study("volatility")`. To be honest, I'm not entirely sure why. Things appears to be set up right.
```python
Python 3.8.13 (default, Mar 18 2022, 02:13:38)
[GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas_ta as ta
>>> print(ta.version)
0.3.59b0
>>> import talib
>>> import pytz
>>> from datetime import datetime
>>> from config import OUTPUT_DIR
>>> import numpy as np
>>> timezone = pytz.utc
>>> date_range = ["20200801", "20200901"]
>>> start_date = timezone.localize(datetime.strptime(date_range[0], "%Y%m%d"))
>>> end_date = timezone.localize(datetime.strptime(date_range[1], "%Y%m%d"))
>>> data = pd.read_feather(f"{OUTPUT_DIR}/BTC.feather")
>>> df = data[data["Datetime"].between(left=start_date, right=end_date, inclusive="both")]
>>> df.set_index(pd.DatetimeIndex(df["Datetime"]), inplace=True)
>>> df.ta.study("volatility")
>>> df.columns
Index(['Datetime', 'Open', 'High', 'Low', 'Close', 'Volume', 'ABER_ZG_5_15',
'ABER_SG_5_15', 'ABER_XG_5_15', 'ABER_ATR_5_15', 'ACCBL_20', 'ACCBM_20',
'ACCBU_20', 'ATRr_14', 'BBL_5_2.0', 'BBM_5_2.0', 'BBU_5_2.0',
'BBB_5_2.0', 'BBP_5_2.0', 'DCL_20_20', 'DCM_20_20', 'DCU_20_20',
'HWM_1', 'HWU_1', 'HWL_1', 'KCLe_20_2', 'KCBe_20_2', 'KCUe_20_2',
'MASSI_9_25', 'NATR_14', 'PDIST', 'RVI_14', 'THERMO_20_2_0.5',
'THERMOma_20_2_0.5', 'THERMOl_20_2_0.5', 'THERMOs_20_2_0.5',
'TRUERANGE_1', 'UI_14'],
dtype='object')``` | closed | 2022-03-27T00:15:48Z | 2022-04-05T03:18:22Z | https://github.com/twopirllc/pandas-ta/issues/506 | [
"bug"
] | CMobley7 | 3 |
Yorko/mlcourse.ai | data-science | 761 | The dataset for lecture 5 practical is not available | I was watching practical of lecture 5 and I like to code along the video, but the dataset used in the video is not available anywhere. Its not present in your kaggle nor in the github repo.
Would humbly request you to upload the same | closed | 2024-06-19T05:17:00Z | 2024-06-25T12:09:46Z | https://github.com/Yorko/mlcourse.ai/issues/761 | [] | Arnax308 | 1 |
WZMIAOMIAO/deep-learning-for-image-processing | deep-learning | 348 | 为了得到你的许可 | 非常抱歉打扰您,由于不知道您的联系方式,只能以这样的方式来征得您的同意。我写的论文里用了您的SSD和Faster rcnn代码做实验,我将在我的代码里公开我的代码与我的实验数据。代码链接会放您的。非常感谢您的代码以及视频讲解,帮助我很多。希望你能同意。谢谢你(哔哩哔哩也有私信过您)。如果您同意的话,请记得回复我一下。再次感谢您。
| closed | 2021-09-06T03:59:31Z | 2021-09-06T07:51:05Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/348 | [] | Saya520r | 14 |
gradio-app/gradio | deep-learning | 10,764 | Stop automatically sorting `gr.Barplot` labels alphabetically | It seems that the `gr.Barplot` component ignores the actual order of the labels in your dataframe and instead sorts the x values alphabetically / numerically? It should respect the order of values in your dataframe:
<img width="1237" alt="Image" src="https://github.com/user-attachments/assets/1b825a1c-61fa-4feb-9c14-1f5b5d414c92" />
See [playground link](https://www.gradio.app/playground?demo=Hello_World&code=aW1wb3J0IGdyYWRpbyBhcyBncgppbXBvcnQgcGFuZGFzIGFzIHBkCmltcG9ydCBudW1weSBhcyBucAoKIyBHZW5lcmF0ZSByYW5kb20gZGF0YSBmb3IgdGhlIGJhciBwbG90CmRhdGEgPSB7CiAgICAnQ2F0ZWdvcnknOiBbJ0YnLCAnRScsICdDJywgJ0InLCAnQUFBQUEnXSwKICAgICdWYWx1ZSc6IG5wLnJhbmRvbS5yYW5kaW50KDEsIDEwMCwgNSkKfQpkZiA9IHBkLkRhdGFGcmFtZShkYXRhKQoKIyBEZWZpbmUgdGhlIGZ1bmN0aW9uIHRvIGNyZWF0ZSB0aGUgYmFyIHBsb3QKZGVmIGNyZWF0ZV9iYXJfcGxvdCgpOgogICAgcmV0dXJuIGRmCgojIENyZWF0ZSB0aGUgR3JhZGlvIGludGVyZmFjZQp3aXRoIGdyLkJsb2NrcygpIGFzIGRlbW86CiAgICAjIENyZWF0ZSBhIEJhclBsb3QgY29tcG9uZW50CiAgICBiYXJfcGxvdCA9IGdyLkJhclBsb3QoCiAgICAgICAgdmFsdWU9Y3JlYXRlX2Jhcl9wbG90LAogICAgICAgIHg9IkNhdGVnb3J5IiwKICAgICAgICB5PSJWYWx1ZSIsCiAgICApCgojIExhdW5jaCB0aGUgaW50ZXJmYWNlCmRlbW8ubGF1bmNoKHNob3dfZXJyb3I9VHJ1ZSk%3D&reqs=cGFuZGFzCm51bXB5) | open | 2025-03-08T11:34:43Z | 2025-03-24T14:47:08Z | https://github.com/gradio-app/gradio/issues/10764 | [
"bug"
] | abidlabs | 1 |
chiphuyen/stanford-tensorflow-tutorials | tensorflow | 151 | Will there be a newer version of this course with TF 2.0 ? | open | 2019-11-14T22:38:24Z | 2019-11-14T22:38:24Z | https://github.com/chiphuyen/stanford-tensorflow-tutorials/issues/151 | [] | piyushghai | 0 |
|
autogluon/autogluon | data-science | 4,424 | [tabular] Speed-up learning-curve unit tests | Currently learning curve unit tests (introduced in #4411) take a long time (~25+ minutes). They comprise of 380 unit tests that each fit a model and evaluate it, which is time consuming.
We should either speed up these unit tests or disable the majority of them and only run the disabled ones prior to release. | closed | 2024-08-23T22:42:11Z | 2024-10-24T17:24:28Z | https://github.com/autogluon/autogluon/issues/4424 | [
"module: tabular",
"code cleanup"
] | Innixma | 0 |
encode/databases | sqlalchemy | 285 | Any support return dict from fetch? | In many synchronous IO libraries, cursor.fetch_all() is allowed to return a sequence of dictionaries. Do databases consider similar implementations?
Just like:
```python
rows: List[Dict[str, Any]] = await database.fetch_all(query=query, include_field_name=True)
``` | closed | 2021-02-03T05:05:10Z | 2021-02-03T06:32:59Z | https://github.com/encode/databases/issues/285 | [] | abersheeran | 1 |
aminalaee/sqladmin | fastapi | 688 | Document `column_default_sort` requires strings | ### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
The examples in the [documentation](https://aminalaee.dev/sqladmin/configurations/#list-page) show `column_default_sort` as accepting class attributes. However, since https://github.com/aminalaee/sqladmin/commit/8f9d07d0705b241490a1f55fc69115ef598b8c50 `split()` is being called on them, and that fails unless they are strings
### Steps to reproduce the bug
Visit an admin page with default sort defined via class attributes:
```python
class UserAdmin(ModelView, model=User):
...
column_default_sort = [(User.email, True), (User.name, False)]
```
### Expected behavior
The default sort is applied as defined
### Actual behavior
The server crashes because it can't `split()` class attributes
### Debugging material
_No response_
### Environment
Ubuntu 22.04, Python 3.11
### Additional context
`column_default_sort = [("email", True), ("name", False)]` works as expected | closed | 2024-01-04T02:31:35Z | 2024-02-18T09:46:18Z | https://github.com/aminalaee/sqladmin/issues/688 | [] | jerivas | 3 |
Yorko/mlcourse.ai | plotly | 679 | Improve translation in part 6 on feature selection | [A comment on Kaggle](https://www.kaggle.com/kashnitsky/topic-6-feature-engineering-and-feature-selection/comments#1149832) | closed | 2021-01-19T12:20:06Z | 2021-12-22T17:50:48Z | https://github.com/Yorko/mlcourse.ai/issues/679 | [
"minor_fix"
] | Yorko | 0 |
aidlearning/AidLearning-FrameWork | jupyter | 193 | sh: /usr/bin/dotnet: 权限不够 | 想要执行 dotnet core 5 ,提示 sh: /usr/bin/dotnet: 权限不够。
目录下执行也类似:sh: ./dotnet: 权限不够 | closed | 2021-10-20T12:52:18Z | 2021-10-23T11:16:44Z | https://github.com/aidlearning/AidLearning-FrameWork/issues/193 | [
"enhancement"
] | xulei-Itachi | 1 |
healthchecks/healthchecks | django | 966 | Feature: Filtering Rule for HTTP requests payload (like on emails) | Hi,
I'd like to see it possible to filter the HTTP request for a specific value, as it's currently possible with emails.
I've not spotted this in the current solution.
I'm using a solution where I can create a webhook, but not control other than "on job run". So I'd like to use healthcheck to filter the content, on basis of the payload (like if it contains "success" or similar).
I would be great to see a JSON parsed, however, using plain-text should possibly also work :)
Thank you for making this. I actually enjoy how simple it is it work with.
## Example data
Here's one Request Body for the application I'm trying to Filter (JSON formatted for easier reading).
The first one are the "job done" post, where I'd like to look to match the `params.vms.id` and `result`.
Solution one would be to look after `VM_ID_I_NEED_TO_MATCH_GOES_HERE` in the text, **and** `"result":true` in the text, too (so more than one check), or have the JSON parsed, and define the `result` nested_key, including a `mandatory` information to be part of the payload, before healthchecks will acknowledge the requests as related to the current `check`.
### Example for "Job Done", I need to acknowledge as a success
Requirements:
- `VM_ID_I_NEED_TO_MATCH_GOES_HERE` needs to be part of the payload
- Result should be `true`
For both requirements, it should be possible to just cheat the payload as a string, without having to use a JSON parser or similar. But two different requirements need to be allowed as a user-input (or a regex sting, maybe?... I mean.. Keep is simpel stupid, if that's the easiest thing to do).
```json
{
"callId":"CALL_ID_GOES_HERE",
"method":"backupNg.runJob",
"params":{
"id":"SECRET_ID_GOES_HERE",
"schedule":"SCHEDULER_ID_GOES_HERE",
"settings":{
"SETTINGS_ID_GOES_HERE":{
"snapshotRetention":5
}
},
"vms":{
"id":"VM_ID_I_NEED_TO_MATCH_GOES_HERE"
}
},
"timestamp":1709391402615,
"userId":"USER_ID_GOES_HERE",
"userName":"admin",
"result":true,
"duration":15735,
"type":"post"
}
```
Here's another example. Note the difference in the `vms` "array", which looks a bit odd, but, that's how it's reported.
Therefore, the plain-text validator are OK with me, I guess.
Again, more real-world like data. I've just replaced letters and stuff like that.
```json
{
"callId":"222h2akasaa",
"method":"backupNg.runJob",
"params":{
"id":"fccd0fbb-5ba8-47fd-9e44-401a1f10c474",
"schedule":"2a029a93-0f6d-4a10-891f-0a891041eeec",
"settings":{
"6d564d15-3d24-40e4-aa81-5c7df522def9":{
"exportRetention":1
}
},
"vms":{
"id":{
"__or":[
"bcdff841-c452-4eee-af61-5b8fddc3318b",
"083ac012-06ea-44f8-96e4-93b4731328e4",
"2c1ed51f-67bc-4306-b8f6-c080ee9221d9",
"8577151d-c758-49ce-a177-ad29d3e5fec2",
"f3c60996-418a-41f3-a246-aad3731e5c84",
"25d04cd3-292e-430d-85db-c67f1ecc45b0"
]
}
}
},
"timestamp":1709396008102,
"userId":"9a9758c5-233d-4a69-84e6-7b62ba522895",
"userName":"admin",
"result":true,
"duration":4645273,
"type":"post"
}
```
### Another example
Here's another example, which I'd need to maybe acknowledge,or maybe ignore, on basis of the "result" value, and the
params.id value (`a22aa300-2310-11dd-a222-2201aa1101b1`) value.
```json
{
"callId":"CALL_ID_GOES_HERE",
"userId":"USER_ID_GOES_HERE",
"userName":"admin",
"userIp":"::USER_IP_GOES_HERE",
"method":"backupNg.runJob",
"params":{
"id":"ID_GOES_HERE",
"schedule":"SCHDEULE_ID_GOES_HERE"
},
"timestamp":1709391402650,
"duration":15776,
"result":true,
"type":"post"
}
```
With more "real world" data:
```json
{
"callId":"1ab2abcdaa2a",
"userId":"USER_ID_GOES_HERE",
"userName":"admin",
"userIp":"::REMOVED",
"method":"backupNg.runJob",
"params":{
"id":"a22aa300-2310-11dd-a222-2201aa1101b1",
"schedule":"a3cfd101-faaa-12c2-bbd1-12b22c22eaa1"
},
"timestamp":1709396008114,
"duration":4645290,
"result":true,
"type":"post"
} | closed | 2024-03-02T14:47:39Z | 2024-03-15T10:52:23Z | https://github.com/healthchecks/healthchecks/issues/966 | [] | exetico | 1 |
pallets-eco/flask-wtf | flask | 95 | New release? | Hi, could you please make a new release on pypi? I'd like my deploy systems to grab the new fixes and it would probably be a nice idea to also have the updated author on there.
| closed | 2013-09-30T10:43:38Z | 2021-05-29T01:16:10Z | https://github.com/pallets-eco/flask-wtf/issues/95 | [] | svenstaro | 1 |
docarray/docarray | pydantic | 918 | docs: code snippet needed: DocumentArray construct | In [this section](https://docarray.jina.ai/fundamentals/documentarray/construct/#construct-from-local-files) there's no snippet for `read_mode`.
Note: Please leave snippet as comment, don't fix directly. I'm working on docs right now and don't want merge conflicts. | closed | 2022-12-08T13:40:08Z | 2023-04-22T09:38:35Z | https://github.com/docarray/docarray/issues/918 | [] | alexcg1 | 0 |
vllm-project/vllm | pytorch | 15,356 | [Bug]: Executor performance degradation | ### Your current environment
<details>
<summary>The output of `python collect_env.py`</summary>
```text
Versions of relevant libraries:
[pip3] numpy==1.26.4
[pip3] nvidia-cublas-cu12==12.1.3.1
[pip3] nvidia-cuda-cupti-cu12==12.1.105
[pip3] nvidia-cuda-nvrtc-cu12==12.1.105
[pip3] nvidia-cuda-runtime-cu12==12.1.105
[pip3] nvidia-cudnn-cu12==9.1.0.70
[pip3] nvidia-cufft-cu12==11.0.2.54
[pip3] nvidia-curand-cu12==10.3.2.106
[pip3] nvidia-cusolver-cu12==11.4.5.107
[pip3] nvidia-cusparse-cu12==12.1.0.106
[pip3] nvidia-ml-py==12.560.30
[pip3] nvidia-nccl-cu12==2.20.5
[pip3] nvidia-nvjitlink-cu12==12.6.85
[pip3] nvidia-nvtx-cu12==12.1.105
[pip3] pyzmq==26.2.0
[pip3] torch==2.4.0
[pip3] torch_tensor_module==0.0.0
[pip3] torchvision==0.19.0
[pip3] transformers==4.47.0
[pip3] triton==3.0.0
[conda] numpy 1.26.4 pypi_0 pypi
[conda] nvidia-cublas-cu12 12.1.3.1 pypi_0 pypi
[conda] nvidia-cuda-cupti-cu12 12.1.105 pypi_0 pypi
[conda] nvidia-cuda-nvrtc-cu12 12.1.105 pypi_0 pypi
[conda] nvidia-cuda-runtime-cu12 12.1.105 pypi_0 pypi
[conda] nvidia-cudnn-cu12 9.1.0.70 pypi_0 pypi
[conda] nvidia-cufft-cu12 11.0.2.54 pypi_0 pypi
[conda] nvidia-curand-cu12 10.3.2.106 pypi_0 pypi
[conda] nvidia-cusolver-cu12 11.4.5.107 pypi_0 pypi
[conda] nvidia-cusparse-cu12 12.1.0.106 pypi_0 pypi
[conda] nvidia-ml-py 12.560.30 pypi_0 pypi
[conda] nvidia-nccl-cu12 2.20.5 pypi_0 pypi
[conda] nvidia-nvjitlink-cu12 12.6.85 pypi_0 pypi
[conda] nvidia-nvtx-cu12 12.1.105 pypi_0 pypi
[conda] pyzmq 26.2.0 pypi_0 pypi
[conda] torch 2.4.0 pypi_0 pypi
[conda] torch-tensor-module 0.0.0 pypi_0 pypi
[conda] torchvision 0.19.0 pypi_0 pypi
[conda] transformers 4.47.0 pypi_0 pypi
[conda] triton 3.0.0 pypi_0 pypi
ROCM Version: Could not collect
Neuron SDK Version: N/A
vLLM Version: 0.6.3.post1
```
</details>
### 🐛 Describe the bug
I am currently using `vllm serve` to create an online server and using this server as a Scheduler to send and execute `ExecuteModelRequest` to one `LLM` instances created with `self.llm = LLM(model=self.model, gpu_memory_utilization=self.gpu_memory_utilization, enforce_eager=self.enforce_eager, tensor_parallel_size=self.tp_size)`. The inference is then performed by calling `self.llm.llm_engine.model_executor.execute_model(req)`. However, when I test using `vllm/benchmarks/benchmark_serving.py`, I notice a significant drop in inference performance, with both TTFT and TPOT increasing substantially, while directly using `vllm serve` for inference does not exhibit this issue. Is it possible that `vllm` has implemented some caching or optimizations above the Executor layer in the `LLMEngine`?
### Before submitting a new issue...
- [x] Make sure you already searched for relevant issues, and asked the chatbot living at the bottom right corner of the [documentation page](https://docs.vllm.ai/en/latest/), which can answer lots of frequently asked questions. | closed | 2025-03-23T13:23:30Z | 2025-03-24T13:26:03Z | https://github.com/vllm-project/vllm/issues/15356 | [
"bug"
] | Ltryxcy | 0 |
keras-team/autokeras | tensorflow | 961 | AutoKeras with tensorflow.dataset gives TypeError: 'PrefetchDataset' object does not support indexing |
### Bug Description
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-18-e8d1a7f824a0> in <module>
1 # Feed the image classifier with training data.
----> 2 clf.fit(train_ds[0], train_ds[1])
TypeError: 'PrefetchDataset' object does not support indexing
### Reproducing Steps
Following the steps for creating a tf.dataset from: https://www.tensorflow.org/tutorials/load_data/images
I encountered an issue with AutoModel when calling:
clf.fit(train_ds[0], train_ds[1])
and
clf.fit(next(iter(train_ds))[0], next(iter(train_ds))[1])
gives :
TypeError: Expect the data to ImageInput to be numpy.ndarray or tf.data.Dataset, but got <class 'tensorflow.python.framework.ops.EagerTensor'>.
### Expected Behavior
I expect to be able to use AutoKeras with imagesets that are too large to fit in memory.
| closed | 2020-02-12T16:21:07Z | 2020-04-20T07:53:20Z | https://github.com/keras-team/autokeras/issues/961 | [
"bug report",
"wontfix"
] | seanreynoldscs | 2 |
Aeternalis-Ingenium/FastAPI-Backend-Template | pytest | 26 | TYPO | Astounding and Great Template for SQL-based Project with FastAPI.
There's a small typo with `USERNAME` here: https://github.com/Aeternalis-Ingenium/FastAPI-Backend-Template/blob/571981c3d6af5feccb90de25a81e82442c22b40f/backend/src/config/settings/base.py#L35C11-L35C11
Consider making this for NoSQL-based aswell as it seems really becoming "Convention" to startup on any project! | open | 2023-10-29T10:55:25Z | 2023-10-29T10:55:25Z | https://github.com/Aeternalis-Ingenium/FastAPI-Backend-Template/issues/26 | [] | MistaIA | 0 |
pytest-dev/pytest-html | pytest | 849 | Missing data in HTML report table after upgrading to pytest-html 4.1.1 |
Hi Team,
I'm currently encountering a problem with pytest-html after upgrading from version 3.2.0 to 4.1.1. My HTML reports are now empty when running tagged tests, although untagged tests generate reports correctly.
Environment: Python version: 3.10 pytest version: 7.4.4 pytest-html version: 4.1.1 (previously 3.2.0)
I'm suspecting since pytest_html_results_table_header hook is not invoking in pytest-html 4.1.1 when running tests with tags. With pytest_html_results_table_header hook I’m trying to insert a snapshot column for failed test , since the table is not properly customized I'm getting an empty report. This hook was invoked in the previous version and is still invoking in 4.1.1 when running tests without tags. The lack of this hook prevents proper table customization, resulting in an empty table.
Observed Behavior: The HTML report's results table is empty when running the tests with tags.

Expected Behavior: The results table should display all test results (name, outcome, duration), including the newer column 'snapshot' when running the tests with tags.
If you have a moment, I'd appreciate your help. | open | 2024-11-22T06:20:27Z | 2024-11-26T15:14:18Z | https://github.com/pytest-dev/pytest-html/issues/849 | [] | Ramya2801 | 5 |
huggingface/datasets | numpy | 7,049 | Save nparray as list | ### Describe the bug
When I use the `map` function to convert images into features, datasets saves nparray as a list. Some people use the `set_format` function to convert the column back, but doesn't this lose precision?
### Steps to reproduce the bug
the map function
```python
def convert_image_to_features(inst, processor, image_dir):
image_file = inst["image_url"]
file = image_file.split("/")[-1]
image_path = os.path.join(image_dir, file)
image = Image.open(image_path)
image = image.convert("RGBA")
inst["pixel_values"] = processor(images=image, return_tensors="np")["pixel_values"]
return inst
```
main function
```python
map_fun = partial(
convert_image_to_features, processor=processor, image_dir=image_dir
)
ds = ds.map(map_fun, batched=False, num_proc=20)
print(type(ds[0]["pixel_values"])
```
### Expected behavior
(type < list>)
### Environment info
- `datasets` version: 2.16.1
- Platform: Linux-4.19.91-009.ali4000.alios7.x86_64-x86_64-with-glibc2.35
- Python version: 3.11.5
- `huggingface_hub` version: 0.23.4
- PyArrow version: 14.0.2
- Pandas version: 2.1.4
- `fsspec` version: 2023.10.0 | closed | 2024-07-15T11:36:11Z | 2024-07-18T11:33:34Z | https://github.com/huggingface/datasets/issues/7049 | [] | Sakurakdx | 5 |
sanic-org/sanic | asyncio | 2,925 | Documentation Hidden by Menu | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Describe the bug
When scrolling and zooming on sanic.dev via safari on OSX (is it MacOS now?) half the documentation gets obscured and it is not possible to correct it without a refresh.
<img width="979" alt="Screenshot 2024-03-13 at 17 07 46" src="https://github.com/sanic-org/sanic/assets/159023003/fdd4c1aa-2e17-418d-9658-f10e0645326a">
### Code snippet
_No response_
### Expected Behavior
The documentation is not obscured.
### How do you run Sanic?
As a module
### Operating System
MacOS
### Sanic Version
current
### Additional context
_No response_ | open | 2024-03-13T17:09:29Z | 2024-11-23T23:11:16Z | https://github.com/sanic-org/sanic/issues/2925 | [
"bug"
] | cdelaney-global | 3 |
art049/odmantic | pydantic | 456 | Custom fields serialisation & deserialisation | Hi,
I am trying to create a custom field to implement client side encryption. I am able to perform serialisation during save, however I dont see a way to deserialise the data after a find (decrypt it). Is this possible by some means?
This is how I created the custom field
`class EncryptedFieldType(str):
@classmethod
def __get_validators__(cls):
yield cls.validate
@classmethod
def validate(cls, v):
if isinstance(v, bytes): # Handle data coming from MongoDB
print("In isinstance(v, bytes) ...")
return "hello"
if not isinstance(v, str):
raise TypeError("string required")
if not v.isascii():
raise ValueError("Only ascii characters are allowed")
return v
@classmethod
def __bson__(cls, v) -> str:
print("In __bson__")
return "*******"
class CollectionWithEncField(Model):
encrypted_field: EncryptedFieldType` | open | 2024-04-23T13:07:08Z | 2024-04-23T16:44:19Z | https://github.com/art049/odmantic/issues/456 | [] | nikhildigde | 1 |
DistrictDataLabs/yellowbrick | scikit-learn | 433 | Doc error: on Docs » Visualizers and API » Feature Analysis Visualizers » PCA Projection "principle component analysis" should be "principal component analysis" | In http://www.scikit-yb.org/en/latest/api/features/pca.html
the phrase "principle component analysis" should be "principal component analysis" | closed | 2018-05-15T20:56:11Z | 2018-06-14T19:29:54Z | https://github.com/DistrictDataLabs/yellowbrick/issues/433 | [] | jibols | 1 |
d2l-ai/d2l-en | machine-learning | 1,807 | Tokenization in 8.2.2 | I think in tokenize function, if it's tokenizing words, it should add space_character to tokens too. Otherwise, in predict function, it will assume '<unk>' for spaces and the predictions doesn't have spaces between them (which can be solved by manipulating the predict function to this line: `return ''.join([vocab.idx_to_token[i] + ' ' for i in outputs])`)
I think tokenized should change like this:
`[line.split() for line in lines] + [[' ']]`
If I'm right, I can make a pr for both tokenize and predict funcs. (although for predict I might have to change inputs of function as well to recognize if it's a char level or word lever rnn) | closed | 2021-06-22T07:53:02Z | 2022-12-16T00:24:13Z | https://github.com/d2l-ai/d2l-en/issues/1807 | [] | armingh2000 | 2 |
RomelTorres/alpha_vantage | pandas | 128 | API Calls not working | I am not getting the expected response from Alpha Vantage APIs. The following are the details, could someone help?
Infrastructure - GCP Windows server
GCP Region: asia-south1-c
Error - { "Note": "Thank you for using Alpha Vantage! Our standard API call frequency is 5 calls per minute and 500 calls per day. Please visit https://www.alphavantage.co/premium/ if you would like to target a higher API call frequency." }
Key - Free trial keys
Pls note our url /python code works well to fetch the details however through GCP infrastructure is not working.
Code:
def __init__(self, api_key, part_url, query, function, exchange, symbol, interval, format):
self.api_key = api_key
self.part_url = part_url
self.query = query
self.function = function
self.exchange = exchange
self.symbol = symbol
self.interval = interval
self.format = format
def get_data(self):
#data_url = 'https://www.alphavantage.co/query?function=TIME_SERIES_INTRADAY&symbol=NSE:TATAMOTORS&interval=1min&apikey=STPO0LS61SH9DZ0J&datatype=csv'
data_url = self.part_url + self.query + self.function + '&symbol' + '=' + self.exchange + ':' + self.symbol + '&' + 'interval=' + self.interval + '&apikey=' + self.api_key + '&datatype=' + self.format
print (data_url)
try:
data=requests.get(data_url)
except Exception as e:
print ("Failed with error {0}".format(e))
raise SystemExit
| closed | 2019-05-10T09:31:49Z | 2019-09-12T01:48:22Z | https://github.com/RomelTorres/alpha_vantage/issues/128 | [] | rajvirkaushal | 1 |
JaidedAI/EasyOCR | deep-learning | 570 | Detected short number | Hello. I have image:

but easyOCR do not work.
I try use `detect` with diferrent parameters, but method return empty.
then i tried to make my simple-detector:
```
def recognition_number(self, img: np.ndarray) -> str:
image = self._filtration(img)
thresh = cv2.adaptiveThreshold(image, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 3, 1)
cnts, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
ox = [i[0][0] for i in cnts[0]]
oy = [i[0][1] for i in cnts[0]]
data = self.reader.recognize(image, horizontal_list=[[min(ox), max(ox), min(oy), max(oy)]], free_list=[], allowlist="1234567890.,")
return "".join([el[1] for el in data])
```
this solved the problem and now the number is recognized.
is it possible to do something with a easyOCR `detect`? | closed | 2021-10-18T12:39:08Z | 2021-10-19T09:02:56Z | https://github.com/JaidedAI/EasyOCR/issues/570 | [] | sas9mba | 2 |
dynaconf/dynaconf | django | 1,130 | [RFC]typed: Turn typed.Dynaconf into a class (currently it is just a constructor) | Current implementation of `typed.Dynaconf` is just a pass-through constructor, this class intercepts passed arguments and then created an instance of `LazySettings` with `cast`ed type annotation for auto complete.
## Proposal
- Turn that class into a real class with a `__init__` method, that will perform all the processes currently performed on `__new__` but instead of returning a `LazySettings` will instantiate `self` and assign `self._dynaconf_instance = LazySettings(...)`
- Stop inheriting from `BaseSettings`
- Implement attribute and method `stubs` that will feed the type check and auto completion
- Implement lookup for missing keys on the `self._dynaconf_instance`
The advantages will be:
- Expose only selected attributes for type annotation
- cache the values on the instance itself, after the first access, assign the value to the instance
- LazySettings will be just the `settings storage backend` that will eventually be replaced
| open | 2024-07-06T14:40:01Z | 2024-07-08T18:37:58Z | https://github.com/dynaconf/dynaconf/issues/1130 | [
"Not a Bug",
"RFC",
"typed_dynaconf"
] | rochacbruno | 1 |
man-group/arctic | pandas | 655 | [ChunkStore] Decompression error on concurrent read & write | #### Arctic Version
```
1.70.0
```
#### Arctic Store
```
ChunkStore
```
#### Platform and version
CentOS 7.2
#### Description of problem and/or code sample that reproduces the issue
I'm getting an error when I have two threads simultaneously reading and writing from one symbol. The reading thread will periodically throw a LZ4BlockError:
```LZ4BlockError: Decompression failed: corrupt input or insufficient space in destination buffer. Error code: 24049```
Here is the code to reproduce it:
```
def get_library():
return Arctic('some_host:1234').get_library(LIB_NAME)
def write_loop():
library = get_library()
while True:
data = create_data(100) # Creates 100 rows of random data
library.append('SYMBOL', data)
def read_loop():
library = get_library()
while True:
df = library.read('SYMBOL')
proc = mp.Process(target=write_loop)
proc.start()
try:
read_loop()
finally:
proc.terminate()
```
From a quick check, it seems that the data being passed to decompress(_str) in _compression.py is not valid lz4 - could the the block metadata and data be out of sync? | open | 2018-11-12T02:22:58Z | 2021-05-11T18:44:55Z | https://github.com/man-group/arctic/issues/655 | [
"enhancement",
"ChunkStore"
] | ddebie | 34 |
pydantic/logfire | pydantic | 300 | FastAPI integration error | ### Description
I apologize if this belongs in the FastAPI issues instead of logfire. I'm not really sure who is the culprit here.
I'm attaching a [sample project](https://github.com/user-attachments/files/16090524/example.zip) to demonstrate an error when `logfire[fastapi]` is added to a FastAPI project.
> **Note:** forcing a downgrade to pydantic v1 fixes the issue _(or removing logfire all together)_
### Error Reproduction
A simple API without any input works:
```shell
curl "http://localhost:8000/hello/"
```
Calling an API with a pydantic model as input fails:
```shell
curl -X POST "http://localhost:8000/test/" -H "Content-Type: application/json" -d '{"name": "test"}'
````
Error log:
```
INFO: 127.0.0.1:58776 - "POST /test/ HTTP/1.1" 500 Internal Server Error
ERROR: Exception in ASGI application
Traceback (most recent call last):
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/uvicorn/protocols/http/httptools_impl.py", line 399, in run_asgi
result = await app( # type: ignore[func-returns-value]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/uvicorn/middleware/proxy_headers.py", line 70, in __call__
return await self.app(scope, receive, send)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/fastapi/applications.py", line 1054, in __call__
await super().__call__(scope, receive, send)
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/starlette/applications.py", line 123, in __call__
await self.middleware_stack(scope, receive, send)
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/starlette/middleware/errors.py", line 186, in __call__
raise exc
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/starlette/middleware/errors.py", line 164, in __call__
await self.app(scope, receive, _send)
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/opentelemetry/instrumentation/asgi/__init__.py", line 631, in __call__
await self.app(scope, otel_receive, otel_send)
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/starlette/middleware/exceptions.py", line 65, in __call__
await wrap_app_handling_exceptions(self.app, conn)(scope, receive, send)
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/starlette/_exception_handler.py", line 64, in wrapped_app
raise exc
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/starlette/_exception_handler.py", line 53, in wrapped_app
await app(scope, receive, sender)
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/starlette/routing.py", line 756, in __call__
await self.middleware_stack(scope, receive, send)
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/starlette/routing.py", line 776, in app
await route.handle(scope, receive, send)
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/starlette/routing.py", line 297, in handle
await self.app(scope, receive, send)
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/starlette/routing.py", line 77, in app
await wrap_app_handling_exceptions(app, request)(scope, receive, send)
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/starlette/_exception_handler.py", line 64, in wrapped_app
raise exc
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/starlette/_exception_handler.py", line 53, in wrapped_app
await app(scope, receive, sender)
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/starlette/routing.py", line 72, in app
response = await func(request)
^^^^^^^^^^^^^^^^^^^
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/fastapi/routing.py", line 269, in app
solved_result = await solve_dependencies(
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/logfire/_internal/integrations/fastapi.py", line 111, in patched_solve_dependencies
return await instrumentation.solve_dependencies(request, original)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/logfire/_internal/integrations/fastapi.py", line 173, in solve_dependencies
result = await original
^^^^^^^^^^^^^^
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/fastapi/dependencies/utils.py", line 628, in solve_dependencies
) = await request_body_to_args( # body_params checked above
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/fastapi/dependencies/utils.py", line 758, in request_body_to_args
v_, errors_ = field.validate(value, values, loc=loc)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/fastapi/_compat.py", line 127, in validate
self._type_adapter.validate_python(value, from_attributes=True),
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/pydantic/type_adapter.py", line 142, in wrapped
return func(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/pydantic/type_adapter.py", line 373, in validate_python
return self.validator.validate_python(object, strict=strict, from_attributes=from_attributes, context=context)
^^^^^^^^^^^^^^
File "/Users/mcantrell/.pyenv/versions/3.11.9/lib/python3.11/functools.py", line 1001, in __get__
val = self.func(instance)
^^^^^^^^^^^^^^^^^^^
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/pydantic/type_adapter.py", line 142, in wrapped
return func(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/acme/fastapi-pydantic-error/.venv/lib/python3.11/site-packages/pydantic/type_adapter.py", line 318, in validator
assert isinstance(self._validator, SchemaValidator)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AssertionError
```
To fix the problem, either remove logfire completely or downgrade pydantic to v1.
### Python, Logfire & OS Versions, related packages (not required)
```TOML
requests="2.32.3"
pydantic="2.8.0"
fastapi="0.111.0"
protobuf="4.25.3"
rich="13.7.1"
executing="2.0.1"
opentelemetry-api="1.25.0"
opentelemetry-exporter-otlp-proto-common="1.25.0"
opentelemetry-exporter-otlp-proto-http="1.25.0"
opentelemetry-instrumentation="0.46b0"
opentelemetry-instrumentation-asgi="0.46b0"
opentelemetry-instrumentation-fastapi="0.46b0"
opentelemetry-proto="1.25.0"
opentelemetry-sdk="1.25.0"
opentelemetry-semantic-conventions="0.46b0"
opentelemetry-util-http="0.46b0"
```
| closed | 2024-07-03T20:07:53Z | 2024-07-04T10:33:35Z | https://github.com/pydantic/logfire/issues/300 | [
"bug"
] | mcantrell | 4 |
gee-community/geemap | jupyter | 1,293 | geemap.ee_to_geopandas allow more than 5,000 features | It seems that it is not possible to convert from EE to geopandas using the geemap.ee_to_geopandas function if there are more than 5,000 features. If so it fails with:
Exception: Collection query aborted after accumulating over 5000 elements.
Is it possible to allow more than 5,000 features?
| closed | 2022-10-15T22:49:09Z | 2022-10-16T00:34:39Z | https://github.com/gee-community/geemap/issues/1293 | [
"Feature Request"
] | sm-potter | 1 |
ResidentMario/geoplot | matplotlib | 46 | Suppress Matplotlib 2.0 warning | cf. #45 | closed | 2017-10-24T12:30:20Z | 2017-12-23T21:58:38Z | https://github.com/ResidentMario/geoplot/issues/46 | [
"enhancement"
] | ResidentMario | 4 |
wger-project/wger | django | 1,017 | Set video to main video in edit screen throws: 'File' object has no attribute 'content_type' | ## Steps to Reproduce
<!-- Please include as many steps to reproduce so that we can replicate the problem. -->
1. Upload a video without setting it as main video
2. Edit the uploaded video
3. set it as main video
4. get this error message
whole error message in html:
[AttributeError at _de_exercise_video_677_1_edit.html.txt](https://github.com/wger-project/wger/files/8497979/AttributeError.at._de_exercise_video_677_1_edit.html.txt)
PS: Aren't this too much sensible informations for a productivity error page?
EDIT: I don't choose an video for replacing the old one. | closed | 2022-04-15T19:48:51Z | 2022-11-30T13:35:45Z | https://github.com/wger-project/wger/issues/1017 | [
"bug"
] | DunklerPhoenix | 1 |
pyjanitor-devs/pyjanitor | pandas | 760 | Latest requirements.txt seems to be over-specifying dependencies | This is the latest version requirements.txt file:
```
black>=19.3b0
darglint
hypothesis>=4.4.0
interrogate
ipykernel
isort>=4.3.18
jupyter_client
lxml
natsort
nbsphinx>=0.4.2
pandas-flavor
pandas-vet
pre-commit
pyspark
pytest-azurepipelines
pytest-cov
pytest>=3.4.2
scikit-learn
seaborn
setuptools>=38.5.2
sphinxcontrib-fulltoc==1.2.0
unyt
xarray
```
Those are inject in the setup.py as mandatory dependencies but a lot in there looks like docs, dev, or optional. Is pyjanitor really require all that at run time? | closed | 2020-10-03T21:58:40Z | 2020-10-26T12:01:52Z | https://github.com/pyjanitor-devs/pyjanitor/issues/760 | [] | ocefpaf | 6 |
pywinauto/pywinauto | automation | 926 | Request/Guidance - HowTo make using pywinauto easy | **This is not an issue - but a request**
I'm a novice in python, perhaps I was still able to use pywinauto and do a good set of automation in the Unified Service Desk of Dynamics 365.
Now that I struggle a lot to progress quickly to cover more scenarios, I was looking for the below:
- A good tutorial with examples on how to use pywinauto libraries including how to use the uia_control wrappers
- A utility similar to inpect.exe but generates the pywinauto code to the action that we do on the uia control
- The same utility to give the hierarchical path of the uia control. because using the print_control_identifiers output to navigate the controls is way too difficult in complex application like USD
- How to switch between wpf controls and html components
@vasily-v-ryabov @airelil @enjoysmath | closed | 2020-04-27T14:07:41Z | 2020-05-14T23:40:03Z | https://github.com/pywinauto/pywinauto/issues/926 | [
"question"
] | jjbright | 11 |
PokeAPI/pokeapi | api | 503 | Where are natures of pokemons? | not able to find nature a pokemon in the pokemon endpoint
| closed | 2020-06-29T12:09:52Z | 2020-06-29T13:27:34Z | https://github.com/PokeAPI/pokeapi/issues/503 | [] | FirezTheGreat | 1 |
ni1o1/transbigdata | data-visualization | 63 | 【百度深度学习开源平台飞桨合作】 | 您好,我是百度飞桨的产品经理施依欣,看到transbigdata提供了较丰富的交通时空大数据分析能力,飞桨作为国内首个开源的深度学习平台,希望能不断深耕各行各业,因此想要和您进一步沟通,看看是否能够有深入结合/合作的机会,如果您方便的话可以添加我的微信(同电话):18108656919
期待您的回复~
施依欣 | 百度飞桨产品经理 | closed | 2022-10-08T03:03:50Z | 2022-10-10T00:32:33Z | https://github.com/ni1o1/transbigdata/issues/63 | [] | YixinKristy | 0 |
nltk/nltk | nlp | 3,084 | Texttiling and paragraphs | Hello.
I have a block of text that I want to segment. However I found out that the texttiling implementation requires that the input text is split into paragraphs. My questions is why does this happen? Doesn't the algorithm create pseudosentences and blocks on its own? After all, Hearst didn't rely on sentences and paragraphs to segment text. | closed | 2022-12-13T12:30:13Z | 2023-11-03T12:10:41Z | https://github.com/nltk/nltk/issues/3084 | [
"tokenizer"
] | markdimi | 7 |
mljar/mercury | jupyter | 44 | Add support to Julia notebooks | Please add option to convert Julia notebooks into standalone web apps. | closed | 2022-02-15T08:46:33Z | 2023-02-15T10:06:33Z | https://github.com/mljar/mercury/issues/44 | [
"enhancement",
"help wanted"
] | pplonski | 1 |
lepture/authlib | django | 178 | broken with httpx 0.10 | **Describe the bug**
authlib uses old classes of httpx. New version of httpx 0.10 removed `AsyncRequest` `AsyncResponse` and also there's no middleware.
**Environment:**
- OS: Linux
- Python Version: 3.7
- Authlib Version: 0.13
| closed | 2020-01-04T07:08:41Z | 2020-02-11T10:59:21Z | https://github.com/lepture/authlib/issues/178 | [
"bug"
] | kesavkolla | 8 |
Kanaries/pygwalker | plotly | 400 | [BUG] ERROR: Failed building wheel for duckdb | **Describe the bug**
When attempting to install via `pip install pygwalker` I receive the following errors:
`ERROR: Failed building wheel for duckdb`
`ERROR: Could not build wheels for duckdb, which is required to install pyproject.toml-based projects`
**To Reproduce**
Steps to reproduce the behavior:
1. Run ` pip install pygwalker `
2. See error
**Expected behavior**
The library should install without issue.
**Screenshots**
<img width="1513" alt="Screenshot 2024-01-19 at 8 06 33 PM" src="https://github.com/Kanaries/pygwalker/assets/7577457/65938774-af79-4325-a1b6-1aa4c1ee888f">
**Versions**
- pygwalker version: 0.4.2
- python version: 3.12.1 | closed | 2024-01-20T04:08:07Z | 2024-03-12T04:24:56Z | https://github.com/Kanaries/pygwalker/issues/400 | [
"bug"
] | jshuadvd | 6 |
Avaiga/taipy | automation | 2,261 | [🐛 BUG] Problem of intercompability between environment Docker/Un*x and Windows for path | ### What went wrong? 🤔
First, create a storage folder, ".taipy", built when running Taipy with Windows.
Then, try to run your code in a Linux-based Docker with this ".taipy".
This will create an issue for File Based Datanodes.
```
Traceback (most recent call last):
File "/app/main.py", line 20, in <module>
print(scenario.data.read())
^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/taipy/core/data/data_node.py", line 411, in read
return self.read_or_raise()
^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/taipy/core/data/data_node.py", line 402, in read_or_raise
return self._read()
^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/taipy/core/data/pickle.py", line 99, in _read
return self._read_from_path()
^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/taipy/core/data/pickle.py", line 105, in _read_from_path
with open(path, "rb") as pf:
^^^^^^^^^^^^^^^^
FileNotFoundError: [Errno 2] No such file or directory: 'user_data\\pickles\\DATANODE_data_dec56298-e438-4fcd-a1d9-313ad7bfa33e.p'
```
### Expected Behavior
This should work on all supported versions of Taipy.
### How to reproduce
Dockerfile
```
# Copyright 2021-2024 Avaiga Private Limited
#
# Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
# an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
# specific language governing permissions and limitations under the License.
FROM python:3.11
WORKDIR /app
# Install application dependencies.
COPY src/requirements.txt .
RUN pip install -r requirements.txt
# Copy the application source code.
COPY src .
CMD ["taipy", "run", "--no-debug", "--no-reloader", "main.py", "--host", "0.0.0.0", "-P", "5000", "--experiment", "1", "--force"]
```
src/requirements.txt
```
taipy==4.0.1
```
src/main.py
```python
import taipy as tp
from taipy import Config, Scope
data_cfg = Config.configure_data_node(
id="data", storage_type="pickle", scope=Scope.GLOBAL, default_data=1
)
scenario_cfg = Config.configure_scenario(
id="scenario",
additional_data_node_configs=[data_cfg],
)
if __name__ == "__main__":
tp.Orchestrator().run()
scenarios = tp.get_scenarios()
if len(scenarios) == 0:
scenario = tp.create_scenario(scenario_cfg)
else:
scenario = scenarios[0]
print(scenario.data.read())
```
Go into `src` and run the main.py locally (Windows) with :
```
taipy run main.py --experiment 1 --force
```
This will create the `.taipy` and `user_data` folders inside of src.
Then, go in the root folder and build and run the docker:
```bash
docker build -t issue2261 .
docker run -it -p 5000:5000issue2261
```
Here is the error raised:
```
(dev) PS C:\Users\jacta\OneDrive\Bureau\taipy\Code\basic-demo> docker run -it -p 5000:5000 issue
[2024-11-21 09:02:51.005][Taipy][INFO] Updating configuration with command-line arguments...
[2024-11-21 09:02:51.005][Taipy][INFO] Managing application's version...
[2024-11-21 09:02:51.014][Taipy][INFO] Checking application's version...
[2024-11-21 09:02:51.015][Taipy][WARNING] tasks field of ScenarioConfig `scenario` is empty.
[2024-11-21 09:02:51.015][Taipy][INFO] Blocking configuration update...
[2024-11-21 09:02:51.015][Taipy][INFO] Starting job dispatcher...
[2024-11-21 09:02:51.016][Taipy][INFO] Orchestrator service has been started.
Traceback (most recent call last):
File "/app/main.py", line 20, in <module>
print(scenario.data.read())
^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/taipy/core/data/data_node.py", line 411, in read
return self.read_or_raise()
^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/taipy/core/data/data_node.py", line 402, in read_or_raise
return self._read()
^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/taipy/core/data/pickle.py", line 99, in _read
return self._read_from_path()
^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/taipy/core/data/pickle.py", line 105, in _read_from_path
with open(path, "rb") as pf:
^^^^^^^^^^^^^^^^
FileNotFoundError: [Errno 2] No such file or directory: 'user_data\\pickles\\DATANODE_data_dec56298-e438-4fcd-a1d9-313ad7bfa33e.p'
```
### Version of Taipy
4.0.1
### Acceptance Criteria
- [x] A unit test reproducing the bug is added.
- [x] Any new code is covered by a unit tested.
- [x] Check code coverage is at least 90%.
- [ ] The bug reporter validated the fix.
- [ ] Related issue(s) in taipy-doc are created for documentation and Release Notes are updated.
### Code of Conduct
- [X] I have checked the [existing issues](https://github.com/Avaiga/taipy/issues?q=is%3Aissue+).
- [ ] I am willing to work on this issue (optional) | closed | 2024-11-19T17:08:28Z | 2024-12-23T12:19:18Z | https://github.com/Avaiga/taipy/issues/2261 | [
"Core",
"💥Malfunction",
"🟨 Priority: Medium",
"🔒 Staff only",
"Core: 📁 Data node"
] | FlorianJacta | 9 |
strawberry-graphql/strawberry | graphql | 3,568 | From future import annotations breaks lazy types | ## Describe the Bug
`from __future__ import annotations` breaks type resolver which results in `TypeError: Model fields cannot be resolved. Unexpected type 'typing.Any'`
I did not manage to track down what exactly causes this issue, but whenever I add `from __future__ import annotations` to the top of the file with strawberry types - strawberry type resolver breaks
<!-- A clear and concise description of what the bug is. -->
## System Information
- Operating system:
- Strawberry version (if applicable): 0.235.2
## Additional Context
<!-- Add any other relevant information about the problem here. --> | open | 2024-07-11T12:00:04Z | 2025-03-20T15:56:48Z | https://github.com/strawberry-graphql/strawberry/issues/3568 | [
"bug"
] | dartt0n | 7 |
scikit-image/scikit-image | computer-vision | 7,742 | Add intensity_median to regionprops | ### Description:
We have `intensity_min`, `intensity_mean` and `intensity_max` in `regionprops` already:
https://github.com/scikit-image/scikit-image/blob/5305ae2ae1fa5d8c01a45e77bb0c44cbabfe1102/skimage/measure/_regionprops.py#L573-L585
What about adding `intensity_median` as well, backed by `np.median` in a similar way as the other props?
I can open a pull request if there are no general objections against this idea. | open | 2025-03-06T14:25:47Z | 2025-03-11T15:38:46Z | https://github.com/scikit-image/scikit-image/issues/7742 | [
":pray: Feature request"
] | imagejan | 2 |
vllm-project/vllm | pytorch | 14,975 | [Bug][V1]: allenai/OLMo-2-0325-32B-Instruct - unexpected keyword argument 'inputs_embeds' | ### Your current environment
<details>
INFO 03-17 17:57:21 [__init__.py:256] Automatically detected platform cuda.
Collecting environment information...
PyTorch version: 2.5.1+cu124
Is debug build: False
CUDA used to build PyTorch: 12.4
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.4 LTS (x86_64)
GCC version: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Clang version: 14.0.0-1ubuntu1.1
CMake version: version 3.30.4
Libc version: glibc-2.35
Python version: 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0] (64-bit runtime)
Python platform: Linux-6.5.0-35-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 12.5.82
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA H100 80GB HBM3
GPU 1: NVIDIA H100 80GB HBM3
GPU 2: NVIDIA H100 80GB HBM3
GPU 3: NVIDIA H100 80GB HBM3
GPU 4: NVIDIA H100 80GB HBM3
GPU 5: NVIDIA H100 80GB HBM3
GPU 6: NVIDIA H100 80GB HBM3
GPU 7: NVIDIA H100 80GB HBM3
Nvidia driver version: 555.42.02
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.9.2.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv.so.9.2.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn.so.9.2.1
/usr/lib/x86_64-linux-gnu/libcudnn_engines_precompiled.so.9.2.1
/usr/lib/x86_64-linux-gnu/libcudnn_engines_runtime_compiled.so.9.2.1
/usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9.2.1
/usr/lib/x86_64-linux-gnu/libcudnn_heuristic.so.9.2.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops.so.9.2.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) Platinum 8462Y+
CPU family: 6
Model: 143
Thread(s) per core: 2
Core(s) per socket: 32
Socket(s): 2
Stepping: 8
CPU max MHz: 4100.0000
CPU min MHz: 800.0000
BogoMIPS: 5600.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cat_l2 cdp_l3 invpcid_single intel_ppin cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local split_lock_detect avx_vnni avx512_bf16 wbnoinvd dtherm ida arat pln pts hfi vnmi avx512vbmi umip pku ospke waitpkg avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg tme avx512_vpopcntdq la57 rdpid bus_lock_detect cldemote movdiri movdir64b enqcmd fsrm md_clear serialize tsxldtrk pconfig arch_lbr ibt amx_bf16 avx512_fp16 amx_tile amx_int8 flush_l1d arch_capabilities
Virtualization: VT-x
L1d cache: 3 MiB (64 instances)
L1i cache: 2 MiB (64 instances)
L2 cache: 128 MiB (64 instances)
L3 cache: 120 MiB (2 instances)
NUMA node(s): 2
NUMA node0 CPU(s): 0-31,64-95
NUMA node1 CPU(s): 32-63,96-127
Vulnerability Gather data sampling: Not affected
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec rstack overflow: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced / Automatic IBRS; IBPB conditional; RSB filling; PBRSB-eIBRS SW sequence; BHI BHI_DIS_S
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] mypy==1.11.1
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.26.4
[pip3] nvidia-cublas-cu12==12.4.5.8
[pip3] nvidia-cuda-cupti-cu12==12.4.127
[pip3] nvidia-cuda-nvrtc-cu12==12.4.127
[pip3] nvidia-cuda-runtime-cu12==12.4.127
[pip3] nvidia-cudnn-cu12==9.1.0.70
[pip3] nvidia-cufft-cu12==11.2.1.3
[pip3] nvidia-curand-cu12==10.3.5.147
[pip3] nvidia-cusolver-cu12==11.6.1.9
[pip3] nvidia-cusparse-cu12==12.3.1.170
[pip3] nvidia-ml-py==12.560.30
[pip3] nvidia-nccl-cu12==2.21.5
[pip3] nvidia-nvjitlink-cu12==12.4.127
[pip3] nvidia-nvtx-cu12==12.4.127
[pip3] onnx==1.14.1
[pip3] onnxruntime==1.18.1
[pip3] pyzmq==26.2.1
[pip3] sentence-transformers==3.2.1
[pip3] torch==2.5.1
[pip3] torchaudio==2.5.1
[pip3] torchvision==0.20.1
[pip3] transformers==4.48.3
[pip3] transformers-stream-generator==0.0.5
[pip3] triton==3.1.0
[pip3] tritonclient==2.51.0
[pip3] vector-quantize-pytorch==1.21.2
[conda] Could not collect
ROCM Version: Could not collect
Neuron SDK Version: N/A
vLLM Version: 0.7.4.dev448+g977a16772.d20250314
vLLM Build Flags:
CUDA Archs: Not Set; ROCm: Disabled; Neuron: Disabled
GPU Topology:
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 NIC0 NIC1 NIC2 NIC3 NIC4 NIC5 NIC6 NIC7 CPU AffinityNUMA Affinity GPU NUMA ID
GPU0 X NV18 NV18 NV18 NV18 NV18 NV18 NV18 PIX NODE NODE NODE SYS SYS SYS SYS 0-31,64-95 0 N/A
GPU1 NV18 X NV18 NV18 NV18 NV18 NV18 NV18 NODE PIX NODE NODE SYS SYS SYS SYS 0-31,64-95 0 N/A
GPU2 NV18 NV18 X NV18 NV18 NV18 NV18 NV18 NODE NODE PIX NODE SYS SYS SYS SYS 0-31,64-95 0 N/A
GPU3 NV18 NV18 NV18 X NV18 NV18 NV18 NV18 NODE NODE NODE PIX SYS SYS SYS SYS 0-31,64-95 0 N/A
GPU4 NV18 NV18 NV18 NV18 X NV18 NV18 NV18 SYS SYS SYS SYS PIX NODE NODE NODE 32-63,96-127 1 N/A
GPU5 NV18 NV18 NV18 NV18 NV18 X NV18 NV18 SYS SYS SYS SYS NODE PIX NODE NODE 32-63,96-127 1 N/A
GPU6 NV18 NV18 NV18 NV18 NV18 NV18 X NV18 SYS SYS SYS SYS NODE NODE PIX NODE 32-63,96-127 1 N/A
GPU7 NV18 NV18 NV18 NV18 NV18 NV18 NV18 X SYS SYS SYS SYS NODE NODE NODE PIX 32-63,96-127 1 N/A
NIC0 PIX NODE NODE NODE SYS SYS SYS SYS X NODE NODE NODE SYS SYS SYS SYS
NIC1 NODE PIX NODE NODE SYS SYS SYS SYS NODE X NODE NODE SYS SYS SYS SYS
NIC2 NODE NODE PIX NODE SYS SYS SYS SYS NODE NODE X NODE SYS SYS SYS SYS
NIC3 NODE NODE NODE PIX SYS SYS SYS SYS NODE NODE NODE X SYS SYS SYS SYS
NIC4 SYS SYS SYS SYS PIX NODE NODE NODE SYS SYS SYS SYS X NODE NODE NODE
NIC5 SYS SYS SYS SYS NODE PIX NODE NODE SYS SYS SYS SYS NODE X NODE NODE
NIC6 SYS SYS SYS SYS NODE NODE PIX NODE SYS SYS SYS SYS NODE NODE X NODE
NIC7 SYS SYS SYS SYS NODE NODE NODE PIX SYS SYS SYS SYS NODE NODE NODE X
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
NIC Legend:
NIC0: mlx5_0
NIC1: mlx5_1
NIC2: mlx5_2
NIC3: mlx5_3
NIC4: mlx5_4
NIC5: mlx5_5
NIC6: mlx5_6
NIC7: mlx5_7
CUDA_HOME=/usr/local/cuda
CUDA_HOME=/usr/local/cuda
CUDA_TOOLKIT_ROOT_DIR=/usr/local/cuda
LD_LIBRARY_PATH=:/usr/local/cuda/lib64
NCCL_CUMEM_ENABLE=0
TORCHINDUCTOR_COMPILE_THREADS=1
CUDA_MODULE_LOADING=LAZY
</details>
### 🐛 Describe the bug
I am hitting the following
```
ERROR 03-17 17:56:39 [core.py:340] TypeError: Olmo2ForCausalLM.forward() got an unexpected keyword argument 'inputs_embeds'
```
When running `vllm serve allenai/OLMo-2-0325-32B-Instruct --tensor-parallel-size 2` in V1. V0 is fine:
```
ERROR 03-17 17:56:39 [core.py:340] EngineCore hit an exception: Traceback (most recent call last):
ERROR 03-17 17:56:39 [core.py:340] File "/home/tms/vllm/vllm/v1/engine/core.py", line 332, in run_engine_core
ERROR 03-17 17:56:39 [core.py:340] engine_core = EngineCoreProc(*args, **kwargs)
ERROR 03-17 17:56:39 [core.py:340] File "/home/tms/vllm/vllm/v1/engine/core.py", line 287, in __init__
ERROR 03-17 17:56:39 [core.py:340] super().__init__(vllm_config, executor_class, log_stats)
ERROR 03-17 17:56:39 [core.py:340] File "/home/tms/vllm/vllm/v1/engine/core.py", line 62, in __init__
ERROR 03-17 17:56:39 [core.py:340] num_gpu_blocks, num_cpu_blocks = self._initialize_kv_caches(
ERROR 03-17 17:56:39 [core.py:340] File "/home/tms/vllm/vllm/v1/engine/core.py", line 121, in _initialize_kv_caches
ERROR 03-17 17:56:39 [core.py:340] available_gpu_memory = self.model_executor.determine_available_memory()
ERROR 03-17 17:56:39 [core.py:340] File "/home/tms/vllm/vllm/v1/executor/abstract.py", line 66, in determine_available_memory
ERROR 03-17 17:56:39 [core.py:340] output = self.collective_rpc("determine_available_memory")
ERROR 03-17 17:56:39 [core.py:340] File "/home/tms/vllm/vllm/v1/executor/multiproc_executor.py", line 133, in collective_rpc
ERROR 03-17 17:56:39 [core.py:340] raise e
ERROR 03-17 17:56:39 [core.py:340] File "/home/tms/vllm/vllm/v1/executor/multiproc_executor.py", line 122, in collective_rpc
ERROR 03-17 17:56:39 [core.py:340] raise result
ERROR 03-17 17:56:39 [core.py:340] TypeError: Olmo2ForCausalLM.forward() got an unexpected keyword argument 'inputs_embeds'
ERROR 03-17 17:56:39 [core.py:340]
CRITICAL 03-17 17:56:39 [core_client.py:269] Got fatal signal from worker processes, shutting down. See stack trace above for root cause issue.
```
### Before submitting a new issue...
- [x] Make sure you already searched for relevant issues, and asked the chatbot living at the bottom right corner of the [documentation page](https://docs.vllm.ai/en/latest/), which can answer lots of frequently asked questions. | closed | 2025-03-17T17:58:06Z | 2025-03-17T18:26:39Z | https://github.com/vllm-project/vllm/issues/14975 | [
"bug"
] | tlrmchlsmth | 0 |
davidsandberg/facenet | computer-vision | 1,253 | Latest version of Facenet | Hi everyone
I need a newer version of this facenet model. is there anyone who can refer such model?
so much appreciated. thanks
ps: I want to extract face features from human face image. | open | 2024-06-25T09:31:08Z | 2024-06-25T09:31:08Z | https://github.com/davidsandberg/facenet/issues/1253 | [] | jasuriy | 0 |
HumanSignal/labelImg | deep-learning | 189 | QString' object has no attribute 'rfind' | Ubuntu 16.04
python 2.7
qt4
when I load the image, the terminal show that "QString' object has no attribute 'rfind'.So ,I can't create the rectbox.
| closed | 2017-10-31T07:47:32Z | 2017-11-03T09:58:51Z | https://github.com/HumanSignal/labelImg/issues/189 | [] | zhoupan9109 | 1 |
nschloe/tikzplotlib | matplotlib | 108 | Use of matplotlib's colormap viridis | When I use matplotlibs new colormap _viridis_ and add a colorbar in a figure, matplotlib2tikz returns an AssertionError, because _viridis_ is not an linear-segemented-colormap.
``` python
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import matplotlib2tikz
x, y = np.meshgrid(np.linspace(0, 1), np.linspace(0, 1))
z = x**2 - y**2
plt.pcolormesh(x, y, z, cmap=cm.viridis)
plt.colorbar()
matplotlib2tikz.save('test.tex')
```
Is it possible to use pgfplots built-in colormap viridis for the colorbar specification with `colormap/viridis`, `point meta min=x` and `point meta max=y` in the axis options or is there a problem with different colormap-calculations/-interpolations?
| closed | 2016-09-04T11:31:00Z | 2016-09-08T07:27:49Z | https://github.com/nschloe/tikzplotlib/issues/108 | [] | m-rossi | 0 |
Lightning-AI/pytorch-lightning | pytorch | 19,618 | Validation runs during overfit, even when turned off | ### Bug description
I am attempting to overfit a model for demonstration. I am using the CLI and I am using trainer.overfit_batches=.125 and trainer.limit_val_batches=0.
If trainer.limit_val_batches=0 is run without the overfit_batches, the desired effect of turning off the validation dataloader and epoch is achieved.
### What version are you seeing the problem on?
v2.1
### How to reproduce the bug
```python
python cli.py fit -c config.yaml --trainer.limit_val_batches=0 --trainer.overfit_batches=.125
```
```
### Error messages and logs
```
No error message, undesired behavior
```
### Environment
<details>
<summary>Current environment</summary>
```
#- Lightning Component (e.g. Trainer, LightningModule, LightningApp, LightningWork, LightningFlow):
#- PyTorch Lightning Version (e.g., 1.5.0): 2.1
#- Lightning App Version (e.g., 0.5.2): N/A
#- PyTorch Version (e.g., 2.0):2.1
#- Python version (e.g., 3.9): 3.10
#- OS (e.g., Linux): Linux
#- CUDA/cuDNN version: 12.1
#- GPU models and configuration: A100
#- How you installed Lightning(`conda`, `pip`, source): PIP
#- Running environment of LightningApp (e.g. local, cloud): SLURM
```
</details>
### More info
_No response_
cc @borda @justusschock @awaelchli | closed | 2024-03-12T14:27:16Z | 2024-03-13T21:47:57Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19618 | [
"help wanted",
"docs",
"working as intended",
"trainer",
"ver: 2.1.x"
] | tkella47 | 2 |
dsdanielpark/Bard-API | nlp | 71 | Pre prompt like GPT | Just like OPENAI library has parameters like prompt where we put instruction to it. For example: Act like a mychatbot who's name is Toranto. so it will act like Toranto. Can't we do the same with bardapi? | closed | 2023-06-21T10:46:23Z | 2023-06-21T16:21:16Z | https://github.com/dsdanielpark/Bard-API/issues/71 | [] | Ali-Shahab | 3 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 141 | 获取用户的粉丝数等数据 | 期望提供一个获取用户的粉丝数等数据的接口,谢谢大佬
<img width="499" alt="image" src="https://user-images.githubusercontent.com/16174533/211499289-88218d27-b738-449f-957c-39ea9436c617.png">
| closed | 2023-01-10T08:26:38Z | 2023-02-06T03:32:44Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/141 | [
"enhancement"
] | ludasky | 4 |
Farama-Foundation/Gymnasium | api | 775 | [Proposal] Allowing environments with different Box action/observation space limits in a vector environment | ### Proposal
https://github.com/Farama-Foundation/Gymnasium/blob/8333df8666811d1d0f87f1ca71803cc58bcf09c6/gymnasium/vector/sync_vector_env.py#L251-L266
https://github.com/Farama-Foundation/Gymnasium/blob/8333df8666811d1d0f87f1ca71803cc58bcf09c6/gymnasium/vector/async_vector_env.py#L576-L596
Currently, these methods checks if all the observation and action spaces in a vector environment are identical, and raises an error if they are not. I'm assuming this is the case because we want to ensure that we can stack the observations and actions into one numpy array. I'm proposing a change to allow differences in the observation and action spaces as long as the shapes are consistent (e.g. the values in the `low` and `high` portions of a Box space).
The change can be implemented with an optional parameter to enable/disable it when creating the vector environments to preserve current default behaviours for now.
### Motivation
I want to vectorize environments with different action space boundaries but the current implementation of vector environments does not allow for that.
### Pitch
_No response_
### Alternatives
_No response_
### Additional context
_No response_
### Checklist
- [ ] I have checked that there is no similar [issue](https://github.com/Farama-Foundation/Gymnasium/issues) in the repo
| open | 2023-11-13T21:31:40Z | 2024-07-04T23:52:47Z | https://github.com/Farama-Foundation/Gymnasium/issues/775 | [
"enhancement"
] | howardh | 4 |
mwaskom/seaborn | pandas | 3,227 | seaborn objects scale with two visualisations with same kwargs? | Hello,
I ran into a problem with scale, when I'm trying to display two visualizations with color mapped by column.
I'm trying to create bar plot with labels on bars. Position of labels and color of labels depends on column of dataframe. Also, I would like to color bars by column.
here is my question on stack overflow: https://stackoverflow.com/questions/75161245/how-to-use-seaborn-objects-scale-with-two-visualisations-with-same-kwargs
Is there a way to do this?
Thank you for answer | closed | 2023-01-19T11:30:20Z | 2023-01-20T00:30:28Z | https://github.com/mwaskom/seaborn/issues/3227 | [] | vorel99 | 1 |
allenai/allennlp | nlp | 5,721 | Is it possible to load my own quantized model from local | Here is the code I tried for the coreference resolution
```
from allennlp.predictors.predictor import Predictor
model_url = 'https://storage.googleapis.com/pandora-intelligence/models/crosslingual-coreference/minilm/model.tar.gz'
predictor = Predictor.from_path(model_url)
text = "Eva and Martha didn't want their friend Jenny \
to feel lonely so they invited her to the party."
prediction = predictor.predict(document=text)
print(prediction['clusters'])
print(predictor.coref_resolved(text))
```
And it worked well I got the output with solved coreference. like below
```
Eva and Martha didn't want Eva and Martha's friend Jenny to feel lonely so Eva and Martha invited their friend Jenny to the party.
```
Now I have quantized the model used here (https://storage.googleapis.com/pandora-intelligence/models/crosslingual-coreference/minilm/model.tar.gz) and the new quantized model is stored in a specific path in my local machine.
Shall I use that customized(quantized) model from my local path in ```model_url``` value and use this prediction command like below?
```
model_url = <Path to the quantized model in my local machine>
predictor = Predictor.from_path(model_url)
```
| closed | 2022-10-19T12:00:29Z | 2022-11-14T18:53:33Z | https://github.com/allenai/allennlp/issues/5721 | [
"question"
] | pradeepdev-1995 | 3 |
Asabeneh/30-Days-Of-Python | pandas | 434 | Day 10 Exercises level 3 | I'm trying to solve exercise number 3, but I can't iterate through the file: `countries_data.py` I got this error message: `non iterable value is used in an iterating context` any ideas that could help me to solve this issue? and also How can I iterate a list of dictionaries like the one in `countries_data.py`. Thanks in advance! | open | 2023-08-17T18:20:50Z | 2023-08-27T23:17:27Z | https://github.com/Asabeneh/30-Days-Of-Python/issues/434 | [] | parzival-p1 | 2 |
STVIR/pysot | computer-vision | 69 | can I run the code in windows and without GPU | can I run the code in windows and without GPU? | closed | 2019-06-20T14:34:18Z | 2019-07-05T03:23:37Z | https://github.com/STVIR/pysot/issues/69 | [] | markofan | 2 |
jina-ai/serve | machine-learning | 5,448 | generate random ports for multiple protocols in gateway | generate random ports for multiple protocols in gateway.
This will entail the following changes:
parser ports default to None
in flow constructor, and gateway config, we generate ports up to the number of protocols
in jina gateway cli, when displaying pod settings, we will be printing None instead of the random port
| closed | 2022-11-25T10:11:13Z | 2022-11-28T13:05:41Z | https://github.com/jina-ai/serve/issues/5448 | [] | alaeddine-13 | 0 |
proplot-dev/proplot | matplotlib | 398 | Can not add patch in every axes | <!-- Thanks for helping us make proplot a better package! If this is a bug report, please use the template provided below. If this is a feature request, you can delete the template text (just try to be descriptive with your request). -->
### Description
I try to draw the Nino3 area in every axes, BUT here it is the Error:"ValueError: Can not reset the axes. You are probably trying to re-use an artist in more than one Axes which is not supported". The nino3 area is only drawn on the first axs. so How can i fix this?
Thanks a lot.

Here is the code for add patch:
```
from matplotlib.path import Path
from matplotlib.patches import PathPatch
codes = [Path.MOVETO] + [Path.LINETO]*3 + [Path.CLOSEPOLY]
vertices = [(210,-5), (210,5), (270,5), (270,-5), (0, 0)]
path = Path(vertices, codes)
pathpatch = PathPatch(path, facecolor='none', edgecolor='k',lw=1.5,label='Nino3',transform = ccrs.PlateCarree(),alpha = 0.6)
axs[0].add_patch(pathpatch)
axs[1].add_patch(pathpatch)
axs[2].add_patch(pathpatch)
```
### Proplot version
0.9.5.post332
| closed | 2022-11-15T07:31:17Z | 2023-03-29T10:01:32Z | https://github.com/proplot-dev/proplot/issues/398 | [
"support",
"external issue"
] | jwy-wbe | 5 |
LAION-AI/Open-Assistant | machine-learning | 3,339 | enable internet checkbox missing | enable internet checkbox missing
i think i have seen it earlier | closed | 2023-06-09T11:25:02Z | 2023-06-09T11:29:32Z | https://github.com/LAION-AI/Open-Assistant/issues/3339 | [] | SasiKiranK | 0 |
OpenInterpreter/open-interpreter | python | 637 | token streaming to stdout | ### Describe the bug
versions after 0.16 verbose streaming
> hi
```
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": ""
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": "Hello"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": "!"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": " How"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": " can"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": " I"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": " assist"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": " you"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": " today"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {
"content": "?"
},
"finish_reason": null
}
]
}
stream result: {
"id": "chatcmpl-897VdZUcQblQ4J5aHRIPfxQLk7Q0K",
"object": "chat.completion.chunk",
"created": 1697184509,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"delta": {},
"finish_reason": "stop"
}
]
}
```
Hello! How can I assist you today?
### Reproduce
install latest version
### Expected behavior
no streaming jsons
### Screenshots
_No response_
### Open Interpreter version
>=0.1.7
### Python version
3.11.6
### Operating System name and version
Windows 11
### Additional context
_No response_ | closed | 2023-10-13T08:16:12Z | 2023-10-24T16:14:10Z | https://github.com/OpenInterpreter/open-interpreter/issues/637 | [
"Bug"
] | veonua | 15 |
Zeyi-Lin/HivisionIDPhotos | fastapi | 187 | upgrade to gradio 5.0 | gradio 5.0 is out, see: https://huggingface.co/blog/gradio-5 | open | 2024-10-10T22:33:46Z | 2024-10-30T00:26:06Z | https://github.com/Zeyi-Lin/HivisionIDPhotos/issues/187 | [] | AK391 | 0 |
pydantic/pydantic-ai | pydantic | 837 | context_length_exceeded error | I think the message history keeps building up when running the agent over a large loop like:
```
for keyword in keywords:
result = lead_generation_agent.run_sync(user_promt, deps=keyword)
```
because the first iteration runs just fine but after dozen I get this error, why and how can I fix it?
File "/Users/UA/.venv/lib/python3.13/site-packages/openai/_base_client.py", line 1638, in _request
raise self._make_status_error_from_response(err.response) from None
openai.OpenAIError: Error code: 400 - {'error': {'message': "This model's maximum context length is 128000 tokens. However, your messages resulted in 136707 tokens (136367 in the messages, 340 in the functions). Please reduce the length of the messages or functions.", 'type': 'invalid_request_error', 'param': 'messages', 'code': 'context_length_exceeded'}}
How `Agent` class works, why does it pass the history messages to the next iteration of the for loop? | closed | 2025-02-01T12:22:10Z | 2025-02-16T14:00:46Z | https://github.com/pydantic/pydantic-ai/issues/837 | [
"question",
"Stale"
] | infinitivebyte | 16 |
huggingface/transformers | pytorch | 36,815 | Gemma3 | ### System Info
After installing the latest Transformers and reasoning about Gemma 3 video understanding, this error is reported
pip install -q git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3
# -*- coding: utf-8 -*-
"""Let's load the model."""
import torch
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
ckpt = "google/gemma-3-4b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
ckpt, device_map="auto", torch_dtype=torch.bfloat16,
)
processor = AutoProcessor.from_pretrained(ckpt)
"""Download the video and downsample the frames from the video."""
import cv2
from PIL import Image
import numpy as np
def downsample_video(video_path):
vidcap = cv2.VideoCapture(video_path)
total_frames = int(vidcap.get(cv2.CAP_PROP_FRAME_COUNT))
fps = vidcap.get(cv2.CAP_PROP_FPS)
frames = []
frame_indices = np.linspace(0, total_frames - 1, 10, dtype=int)
for i in frame_indices:
vidcap.set(cv2.CAP_PROP_POS_FRAMES, i)
success, image = vidcap.read()
if success:
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # Convert from BGR to RGB
pil_image = Image.fromarray(image)
timestamp = round(i / fps, 2)
frames.append((pil_image, timestamp))
vidcap.release()
return frames
frames = downsample_video("30515642-b6d9-11ef-b24f-fa163ea3a38d_zip.mp4")
frames
"""Here's our system prompt and the instruction. We will add frames and images on top of it."""
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "text", "text": f"What is happening in this video? Summarize the events."}]
}
]
messages[1]["content"][0]
for frame in frames:
image, timestamp = frame
messages[1]["content"].append({"type": "text", "text": f"Frame {timestamp}:"})
image.save(f"image_{timestamp}.png")
messages[1]["content"].append({"type": "image", "url": f"image_{timestamp}.png"})
messages
"""Preprocess our input and infer."""
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device)
processed_chat = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
video_fps=32,
video_load_backend="decord",
)
input_len = inputs["input_ids"].shape[-1]
generation = model.generate(**inputs, max_new_tokens=500, do_sample=True)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)
Traceback (most recent call last):
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/Gemma_3_for_Video_Understanding.py", line 89, in <module>
generation = model.generate(**inputs, max_new_tokens=500, do_sample=True)
File "/usr/local/lib/python3.10/dist-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/generation/utils.py", line 2314, in generate
result = self._sample(
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/generation/utils.py", line 3294, in _sample
outputs = model_forward(**model_inputs, return_dict=True)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1553, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1562, in _call_impl
return forward_call(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/utils/deprecation.py", line 172, in wrapped_func
return func(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/models/gemma3/modeling_gemma3.py", line 1352, in forward
outputs = self.language_model(
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1553, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1562, in _call_impl
return forward_call(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/utils/deprecation.py", line 172, in wrapped_func
return func(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/models/gemma3/modeling_gemma3.py", line 976, in forward
outputs = self.model(
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1553, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1562, in _call_impl
return forward_call(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/models/gemma3/modeling_gemma3.py", line 754, in forward
layer_outputs = decoder_layer(
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1553, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1562, in _call_impl
return forward_call(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/models/gemma3/modeling_gemma3.py", line 443, in forward
hidden_states, self_attn_weights = self.self_attn(
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1553, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1562, in _call_impl
return forward_call(*args, **kwargs)
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/models/gemma3/modeling_gemma3.py", line 365, in forward
attn_output, attn_weights = attention_interface(
File "/picassox/intelligence-sfs-turbo-cv/fc3/work/transformers/src/transformers/integrations/sdpa_attention.py", line 54, in sdpa_attention_forward
attn_output = torch.nn.functional.scaled_dot_product_attention(
RuntimeError: p.attn_bias_ptr is not correctly aligned
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
test
### Expected behavior
bug | open | 2025-03-19T08:27:45Z | 2025-03-20T00:03:02Z | https://github.com/huggingface/transformers/issues/36815 | [
"bug"
] | fuchao01 | 5 |
huggingface/peft | pytorch | 2,307 | The provided `peft_type` 'PROMPT_TUNING' is not compatible with the `PeftMixedModel`. | ### Feature request
PROMPT_TUNING is an useful adapter and it would be great if we can combine it with LORA.
### Motivation
Lots of finetunes on consumer grade hardware leverage lora. It would be great we can mix prompt tuning with lora as plug and play.
### Your contribution
I would like to submit a PR if there is interest. | closed | 2025-01-07T01:46:18Z | 2025-02-14T15:04:03Z | https://github.com/huggingface/peft/issues/2307 | [] | Radu1999 | 4 |
Esri/arcgis-python-api | jupyter | 1,689 | GitHub Action fails when loading arcgis package on subprocess | **Describe the bug**
I am getting a subprocess error when trying to run arcgis 2.1.0
Most likely I am doing something wrong within my set-up, any suggestions? It looks to be locked up on gssapi or krb5
error:
```python
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> [21 lines of output]
/bin/sh: 1: krb5-config: not found
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.9.18/x64/lib/python3.9/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 353, in <module>
main()
File "/opt/hostedtoolcache/Python/3.9.18/x64/lib/python3.9/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 335, in main
json_out['return_val'] = hook(**hook_input['kwargs'])
File "/opt/hostedtoolcache/Python/3.9.18/x64/lib/python3.9/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 118, in get_requires_for_build_wheel
return hook(config_settings)
File "/tmp/pip-build-env-ilhbhnfb/overlay/lib/python3.9/site-packages/setuptools/build_meta.py", line 355, in get_requires_for_build_wheel
return self._get_build_requires(config_settings, requirements=['wheel'])
File "/tmp/pip-build-env-ilhbhnfb/overlay/lib/python3.9/site-packages/setuptools/build_meta.py", line 325, in _get_build_requires
self.run_setup()
File "/tmp/pip-build-env-ilhbhnfb/overlay/lib/python3.9/site-packages/setuptools/build_meta.py", line 341, in run_setup
exec(code, locals())
File "<string>", line 109, in <module>
File "<string>", line 22, in get_output
File "/opt/hostedtoolcache/Python/3.9.18/x64/lib/python3.9/subprocess.py", line 424, in check_output
return run(*popenargs, stdout=PIPE, timeout=timeout, check=True,
File "/opt/hostedtoolcache/Python/3.9.18/x64/lib/python3.9/subprocess.py", line 528, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command 'krb5-config --libs gssapi' returned non-zero exit status 127.
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
```
My .yml file:
```
name: run script
on:
workflow_dispatch:
jobs:
run-python-script:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.9'
- name: Install dependencies
run: pip install -r requirements.txt
- name: Set environment variables from secrets
env:
AGOL_URL: ${{ secrets.AGOL_URL }}
AGOL_USERNAME: ${{ secrets.AGOL_USERNAME }}
AGOL_PASSWORD: ${{ secrets.AGOL_PASSWORD }}
run: echo Setting environment variables
- name: Run main.py
run: python main.py
```
| closed | 2023-10-10T21:14:12Z | 2023-10-13T18:00:41Z | https://github.com/Esri/arcgis-python-api/issues/1689 | [
"bug"
] | EricSamson-Tract | 1 |
jina-ai/serve | fastapi | 5,748 | Warnings about wrong grpc options | **Describe the bug**
<!-- A clear and concise description of what the bug is. -->
```python
Client(host="grpcs://someflow-somens-grpc.wolf.jina.ai").post(on='/', inputs=...)
```
```
E0308 16:59:23.961063922 551261 channel_args.cc:374] grpc.max_send_message_length ignored: it must be >= -1
E0308 16:59:23.961081461 551261 channel_args.cc:374] grpc.max_receive_message_length ignored: it must be >= -1
E0308 16:59:23.961096321 551261 channel_args.cc:374] grpc.max_receive_message_length ignored: it must be >= -1
```
**Describe how you solve it**
<!-- copy past your code/pull request link -->
Change these values in utils to >=-1
https://github.com/jina-ai/jina/blob/8b983a49be3289193e3a0ec768f24b22bc690fb3/jina/serve/networking/utils.py#L219-L221
| closed | 2023-03-08T12:00:29Z | 2023-03-09T09:51:44Z | https://github.com/jina-ai/serve/issues/5748 | [] | deepankarm | 2 |
developmentseed/lonboard | data-visualization | 80 | Private code to generate test data for geoarrow/deck.gl-layers | There's so much helper code here to create geoarrow-formatted data and validate other attributes, that it would be nice to have a private method to export for test data for the JS lib | closed | 2023-10-11T22:15:30Z | 2023-10-21T02:34:47Z | https://github.com/developmentseed/lonboard/issues/80 | [] | kylebarron | 0 |
Evil0ctal/Douyin_TikTok_Download_API | api | 143 | 请问可否出一个相对简单的使用教程? | closed | 2023-01-12T02:15:17Z | 2024-05-05T11:04:34Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/143 | [
"enhancement"
] | chenkongming | 4 |
|
mljar/mljar-supervised | scikit-learn | 411 | Dependencies too strict for numpy and scipy | **Issue**
I have a request regarding the dependencies for `mljar-supervised = "0.10.4"`. In particular, my question is whether it would be possible to allow for older versions of `numpy` and `scipy` (maybe in future releases).
I am currently trying to install `mljar-supervised = "0.10.4"` along with `tensorflow = "^2.2"`. It seems to me that these two dependencies should definitely be compatible in one application. However, this is not possible due to the following reason: `because mljar-supervised (0.10.4) depends on both numpy (>=1.20.0) and scipy (1.6.1), mljar-supervised (0.10.4) is incompatible with tensorflow (>=2.2,<3.0)`
**Full dependency issue**
```shell
Because no versions of tensorflow match >2.2,<2.2.1 || >2.2.1,<2.2.2 || >2.2.2,<2.3.0 || >2.3.0,<2.3.1 || >2.3.1,<2.3.2 || >2.3.2,<2.4.0 || >2.4.0,<2.4.1 || >2.4.1,<2.5.0 || >2.5.0,<3.0
and tensorflow (2.2.0) depends on scipy (1.4.1), tensorflow (>=2.2,<2.2.1 || >2.2.1,<2.2.2 || >2.2.2,<2.3.0 || >2.3.0,<2.3.1 || >2.3.1,<2.3.2 || >2.3.2,<2.4.0 || >2.4.0,<2.4.1 || >2.4.1,<2.5.0 || >2.5.0,<3.0) requires scipy (1.4.1).
And because tensorflow (2.2.1) depends on numpy (>=1.16.0,<1.19.0)
and tensorflow (2.2.2) depends on numpy (>=1.16.0,<1.19.0), tensorflow (>=2.2,<2.3.0 || >2.3.0,<2.3.1 || >2.3.1,<2.3.2 || >2.3.2,<2.4.0 || >2.4.0,<2.4.1 || >2.4.1,<2.5.0 || >2.5.0,<3.0) requires scipy (1.4.1) or numpy (>=1.16.0,<1.19.0).
And because tensorflow (2.3.0) depends on scipy (1.4.1)
and tensorflow (2.3.1) depends on numpy (>=1.16.0,<1.19.0), tensorflow (>=2.2,<2.3.2 || >2.3.2,<2.4.0 || >2.4.0,<2.4.1 || >2.4.1,<2.5.0 || >2.5.0,<3.0) requires scipy (1.4.1) or numpy (>=1.16.0,<1.19.0).
And because tensorflow (2.3.2) depends on numpy (>=1.16.0,<1.19.0)
and tensorflow (2.4.0) depends on numpy (>=1.19.2,<1.20.0), tensorflow (>=2.2,<2.4.1 || >2.4.1,<2.5.0 || >2.5.0,<3.0) requires scipy (1.4.1) or numpy (>=1.16.0,<1.19.0 || >=1.19.2,<1.20.0).
And because tensorflow (2.4.1) depends on numpy (>=1.19.2,<1.20.0)
and tensorflow (2.5.0) depends on numpy (>=1.19.2,<1.20.0), tensorflow (>=2.2,<3.0) requires numpy (>=1.16.0,<1.19.0 || >=1.19.2,<1.20.0) or scipy (1.4.1).
And because mljar-supervised (0.10.4) depends on both numpy (>=1.20.0) and scipy (1.6.1), mljar-supervised (0.10.4) is incompatible with tensorflow (>=2.2,<3.0).
So, because property-prediction-challenge depends on both tensorflow (^2.2) and mljar-supervised (0.10.4), version solving failed.
```
**Reproducible example**
- Step 1: Install poetry dependency management package with `pip install poetry==1.1.6`
- Step 2: Create a new folder and put the following into a new file `pyproject.toml`.
```shell
[tool.poetry]
name = "Dependency issues."
version = "0.1.0"
description = "Investigate dependency issues."
authors = ["nobody"]
[tool.poetry.dependencies]
python = "3.8.x"
tensorflow = "^2.2"
mljar-supervised = "0.10.4"
```
- Step 3: cd into the new folder and run `poetry install` | closed | 2021-06-13T17:20:56Z | 2021-09-02T11:33:54Z | https://github.com/mljar/mljar-supervised/issues/411 | [
"dependencies"
] | juliuskittler | 9 |
deepset-ai/haystack | nlp | 9,093 | Agent support multiple exit conditions | **Is your feature request related to a problem? Please describe.**
I'm testing out the new experimental Agent implementation, which feels great (I'm not sure if I should create these issues here or in the haystack-experimental repository).
In my use case, In addition to the text responses, I also have multiple tool exit conditions, not just one. For example, think of an AI bot that can render different UI elements. Each UI element is a separate tool for the Agent. (same way as [Vercel's AI SDK generative UI](https://sdk.vercel.ai/docs/ai-sdk-ui/generative-user-interfaces) works).
**Describe the solution you'd like**
The agent could take a list of `exit_conditions` rather than only one. It could include `text` but also multiple tools that should end the loop. This way, the Agent could answer text (for example, ask a question from the user) or trigger one of the many UI tools.
Especially after [the latest change](https://github.com/deepset-ai/haystack-experimental/pull/245) on how the Agent is implemented, I see this could be trivial to implement. Change the `exit_condition` to a list of str and check if the tool is in the list (or if the bot decided to answer text and if the `exit_condition` includes `text`).
**Additional context**
- The latest update to Agent impl. https://github.com/deepset-ai/haystack-experimental/pull/245
- Example feature in Vercel SDK https://sdk.vercel.ai/docs/ai-sdk-ui/generative-user-interfaces
| open | 2025-03-22T05:26:39Z | 2025-03-24T09:19:04Z | https://github.com/deepset-ai/haystack/issues/9093 | [
"P1"
] | ernoaapa | 0 |
mwaskom/seaborn | data-science | 3,405 | Allow violinplot areas to be scaled by count | Currently there are 3 methods to scale a violinplot:
> scale : _{“area”, “count”, “width”}, optional_
> The method used to scale the width of each violin. If `area`, each violin will have the same area. If `count`, the **width** of the violins will be scaled by the number of observations in that bin. If `width`, each violin will have the same width.
The count option is only able to scale the **width** by number of observations, but cannot scale the area by the number of observations. This means that if you have 3 violins, where the first two violins have 10 datapoints each and the 3rd violin has all 20 datapoints contained in the first two violins, you cannot make the area of the third violin equal to the sum of the area of the first two violins. Instead, using count will make the third violin double as wide as a 10 point violin, as is explained in the violinplot documentation.
In the following code, you can see that count scales the width, but I would like a version of count that can scale the area.
```python
import matplotlib.pyplot as plt
import seaborn as sns
one = [0.01*i for i in range(10)]
two = [0.3+0.03*i for i in range(10)]
data = [one, two, one+two]
fig = sns.violinplot(data=data, scale="count")
fig.set_xticklabels(['10 datapoints', 'another 10 datapoints\n(area should be equal\nto first violin)', '20 datapoints\n(area should be sum\nof first two violins)'])
plt.title('Violin Plot')
plt.show()
```

Here is the seaborn code:
```python
if np.isnan(peak_density):
span = 1
elif density_norm == "area":
span = data["density"] / max_density[norm_key]
elif density_norm == "count":
count = len(violin["observations"])
span = data["density"] / peak_density * (count / max_count[norm_key])
elif density_norm == "width":
span = data["density"] / peak_density
```
I would like it to be changed to something like:
<pre>
if np.isnan(peak_density):
span = 1
elif density_norm == "area":
span = data["density"] / max_density[norm_key]
</pre>
```diff
+ elif density_norm == "count_area":
+ count = len(violin["observations"])
+ span = data["density"] / max_density[norm_key] * (count / max_count[norm_key])
```
<pre>
elif density_norm == "width":
span = data["density"] / peak_density
elif density_norm == "count" or density_norm == "count_width":
count = len(violin["observations"])
span = data["density"] / peak_density * (count / max_count[norm_key])
</pre>
Also, the old "count" could be changed to "count_width". You could leave in "count" for backwards compatibility. | closed | 2023-06-27T08:36:35Z | 2024-12-16T20:41:11Z | https://github.com/mwaskom/seaborn/issues/3405 | [
"wishlist"
] | Matt-Schmitz | 3 |
ipython/ipython | data-science | 14,314 | Create a `_process_emscripten.py` | See https://github.com/ipython/ipython/issues/14312#issuecomment-1918742541_
It would be good to have a test that check we don't have regression or prevent importing on emscripten
| closed | 2024-01-31T09:44:49Z | 2024-02-13T09:00:04Z | https://github.com/ipython/ipython/issues/14314 | [] | Carreau | 2 |
jumpserver/jumpserver | django | 14,626 | [Bug] v4.4.0版本,前端不能滚动问题 | ### Product Version
v4.4.0
### Product Edition
- [X] Community Edition
- [ ] Enterprise Edition
- [ ] Enterprise Trial Edition
### Installation Method
- [ ] Online Installation (One-click command installation)
- [ ] Offline Package Installation
- [X] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] Source Code
### Environment Information

如图,下面明明还有数据,但是滚动条却无法继续滚动了,缩小网页尺寸可以看到下面的内容

### 🐛 Bug Description

如图,下面明明还有数据,但是滚动条却无法继续滚动了,缩小网页尺寸可以看到下面的内容

### Recurrence Steps
将每页显示数量调整到一页显示不全需要滚动的情况下就会复现
### Expected Behavior
_No response_
### Additional Information
_No response_
### Attempted Solutions
_No response_ | closed | 2024-12-10T07:48:15Z | 2024-12-11T07:45:52Z | https://github.com/jumpserver/jumpserver/issues/14626 | [
"🐛 Bug"
] | wppzxc | 6 |
opengeos/leafmap | plotly | 500 | Add support for Earthformer | https://github.com/amazon-science/earth-forecasting-transformer | closed | 2023-07-26T03:19:01Z | 2024-02-06T15:30:08Z | https://github.com/opengeos/leafmap/issues/500 | [
"Feature Request"
] | giswqs | 1 |
deezer/spleeter | deep-learning | 698 | [Bug] Cannot install, spleeter wants llvmlite 0.36.0 while pulling in numba that wants llvmlite 0.37.0 | - [X] I didn't find a similar issue already open.
- [ ] I read the documentation (README AND Wiki)
- [X] I have installed FFMpeg
- [X] My problem is related to Spleeter only, not a derivative product (such as Webapplication, or GUI provided by others)
## Description
```
$ python3.7 -m spleeter separate -p spleeter:2stems -o output inneruniverse.mp3
Traceback (most recent call last):
File "/usr/lib64/python3.7/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/lib64/python3.7/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/usr/local/lib/python3.7/site-packages/spleeter/__main__.py", line 262, in <module>
entrypoint()
File "/usr/local/lib/python3.7/site-packages/spleeter/__main__.py", line 256, in entrypoint
spleeter()
File "/usr/local/lib/python3.7/site-packages/typer/main.py", line 214, in __call__
return get_command(self)(*args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/click/core.py", line 829, in __call__
return self.main(*args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/click/core.py", line 782, in main
rv = self.invoke(ctx)
File "/usr/local/lib/python3.7/site-packages/click/core.py", line 1259, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/usr/local/lib/python3.7/site-packages/click/core.py", line 1066, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/usr/local/lib/python3.7/site-packages/click/core.py", line 610, in invoke
return callback(*args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/typer/main.py", line 497, in wrapper
return callback(**use_params) # type: ignore
File "/usr/local/lib/python3.7/site-packages/spleeter/__main__.py", line 114, in separate
from .separator import Separator
File "/usr/local/lib/python3.7/site-packages/spleeter/separator.py", line 27, in <module>
from librosa.core import istft, stft
File "/usr/local/lib/python3.7/site-packages/librosa/__init__.py", line 211, in <module>
from . import core
File "/usr/local/lib/python3.7/site-packages/librosa/core/__init__.py", line 5, in <module>
from .convert import * # pylint: disable=wildcard-import
File "/usr/local/lib/python3.7/site-packages/librosa/core/convert.py", line 7, in <module>
from . import notation
File "/usr/local/lib/python3.7/site-packages/librosa/core/notation.py", line 8, in <module>
from ..util.exceptions import ParameterError
File "/usr/local/lib/python3.7/site-packages/librosa/util/__init__.py", line 83, in <module>
from .utils import * # pylint: disable=wildcard-import
File "/usr/local/lib/python3.7/site-packages/librosa/util/utils.py", line 10, in <module>
import numba
File "/usr/local/lib64/python3.7/site-packages/numba/__init__.py", line 197, in <module>
_ensure_llvm()
File "/usr/local/lib64/python3.7/site-packages/numba/__init__.py", line 109, in _ensure_llvm
raise ImportError(msg)
ImportError: Numba requires at least version 0.37.0 of llvmlite.
Installed version is 0.36.0.
Please update llvmlite.
```
```
$ sudo python3.7 -m pip install -U llvmlite==0.37.0
Collecting llvmlite==0.37.0
Downloading https://files.pythonhosted.org/packages/55/21/f7df5d35f3f5d0637d64a89f6b0461f2adf78e22916d6372486f8fc2193d/llvmlite-0.37.0.tar.gz (125kB)
97% |███████████████████████████████▏| 122kB 49kB/s eta 0:00 100% |████████████████████████████████| 133kB 49kB/s
Building wheels for collected packages: llvmlite
Building wheel for llvmlite (setup.py) ... error
Complete output from command /usr/bin/python3.7 -u -c "import setuptools, tokenize;__file__='/tmp/pip-install-7r17xd2s/llvmlite/setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" bdist_wheel -d /tmp/pip-wheel-m1g2weyd --python-tag cp37:
running bdist_wheel
/usr/bin/python3.7 /tmp/pip-install-7r17xd2s/llvmlite/ffi/build.py
LLVM version... Traceback (most recent call last):
File "/tmp/pip-install-7r17xd2s/llvmlite/ffi/build.py", line 220, in <module>
main()
File "/tmp/pip-install-7r17xd2s/llvmlite/ffi/build.py", line 210, in main
main_posix('linux', '.so')
File "/tmp/pip-install-7r17xd2s/llvmlite/ffi/build.py", line 134, in main_posix
raise RuntimeError(msg) from None
RuntimeError: Could not find a `llvm-config` binary. There are a number of reasons this could occur, please see: https://llvmlite.readthedocs.io/en/latest/admin-guide/install.html#using-pip for help.
error: command '/usr/bin/python3.7' failed with exit status 1
----------------------------------------
Failed building wheel for llvmlite
Running setup.py clean for llvmlite
Failed to build llvmlite
spleeter 2.3.0 has requirement llvmlite<0.37.0,>=0.36.0, but you'll have llvmlite 0.37.0 which is incompatible.
```
## Step to reproduce
<!-- Indicates clearly steps to reproduce the behavior: -->
1. Install using `python3.7 -m pip` on Fedora 35
2. End up with above
## Environment
<!-- Fill the following table -->
| | |
| ----------------- | ------------------------------- |
| OS | Fedora Linux 35 |
| Installation type | pip |
| RAM available | |
| Hardware spec | skylake laptop cpu |
## Additional context
<!-- Add any other context about the problem here, references, cites, etc.. -->
| closed | 2021-12-25T15:04:05Z | 2022-01-07T10:58:31Z | https://github.com/deezer/spleeter/issues/698 | [
"bug",
"invalid"
] | ell1e | 3 |
flavors/django-graphql-jwt | graphql | 185 | set jwt_cookie on signup | First of all, thank you for the lib.
In my case, I need to set the `jwt_cookie` right after the signup. I've already read the docs and the issues too, so I know about the `get_token` decorator but I need a solution to be able to set the cookie.
is there any way to `authenticate` the user in a func, so the necessary tasks get done automatically? (including `jwt_cookie setup`)
if no, is it alright to set up the cookie manually? | open | 2020-03-31T12:31:29Z | 2020-04-10T08:22:36Z | https://github.com/flavors/django-graphql-jwt/issues/185 | [] | drippypale | 1 |
autogluon/autogluon | computer-vision | 4,355 | [tabular] Add target encoding preprocessing option | Add target encoding preprocessing option. Likely best as a toggle for models, such as `"ag.target_encoding": True`.
Examples of target encoding getting performance improvements:
1. Kaggle Playground Series: https://www.kaggle.com/code/theoviel/explaining-and-accelerating-target-encoding
2. Nested K-Fold: https://github.com/rapidsai/deeplearning/blob/main/RecSys2020Tutorial/03_3_TargetEncoding.ipynb
3. category_encoders package: https://contrib.scikit-learn.org/category_encoders/index.html | open | 2024-07-30T18:07:42Z | 2024-11-25T22:47:12Z | https://github.com/autogluon/autogluon/issues/4355 | [
"enhancement",
"module: tabular",
"priority: 1"
] | Innixma | 0 |
huggingface/datasets | machine-learning | 7,189 | Audio preview in dataset viewer for audio array data without a path/filename | ### Feature request
Huggingface has quite a comprehensive set of guides for [audio datasets](https://huggingface.co/docs/datasets/en/audio_dataset). It seems, however, all these guides assume the audio array data to be decoded/inserted into a HF dataset always originates from individual files. The [Audio-dataclass](https://github.com/huggingface/datasets/blob/3.0.1/src/datasets/features/audio.py#L20) appears designed with this assumption in mind. Looking at its source code it returns a dictionary with the keys `path`, `array` and `sampling_rate`.
However, sometimes users may have different pipelines where they themselves decode the audio array. This feature request has to do with wishing some clarification in guides on whether it is possible, and in such case how users can insert already decoded audio array data into datasets (pandas DataFrame, HF dataset or whatever) that are later saved as parquet, and still get a functioning audio preview in the dataset viewer.
Do I perhaps need to write a tempfile of my audio array slice to wav and capture the bytes object with `io.BytesIO` and pass that to `Audio()`?
### Motivation
I'm working with large audio datasets, and my pipeline reads (decodes) audio from larger files, and slices the relevant portions of audio from that larger file based on metadata I have available.
The pipeline is designed this way to avoid having to store multiple copies of data, and to avoid having to store tens of millions of small files.
I tried [test-uploading parquet files](https://huggingface.co/datasets/Lauler/riksdagen_test) where I store the audio array data of decoded slices of audio in an `audio` column with a dictionary with the keys `path`, `array` and `sampling_rate`. But I don't know the secret sauce of what the Huggingface Hub expects and requires to be able to display audio previews correctly.
### Your contribution
I could contribute a tool agnostic guide of creating HF audio datasets directly as parquet to the HF documentation if there is an interest. Provided you help me figure out the secret sauce of what the dataset viewer expects to display the preview correctly. | open | 2024-10-02T16:38:38Z | 2024-10-02T17:01:40Z | https://github.com/huggingface/datasets/issues/7189 | [
"enhancement"
] | Lauler | 0 |
neuml/txtai | nlp | 57 | Add example notebook that adds semantic search to existing system | Use similarity pipeline to add semantic search to Elasticsearch | closed | 2021-01-13T01:15:41Z | 2021-05-13T15:05:41Z | https://github.com/neuml/txtai/issues/57 | [] | davidmezzetti | 0 |
microsoft/nni | data-science | 4,948 | 要是有能支持list为参数的_type就好了 | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
**Why is this needed**:比如在多层卷积网络中设计卷积通道数,希望一次设计多层,而不是单个层的通道数设计,因为这样会产生很多冗余的不想要的没有价值的参数组合。这样一来,就需要一系列的list来表达这些设计方案。

这个batch tuner的办法似乎可以,但是又不支持普通的参数输入了。
**Without this feature, how does current nni work**:
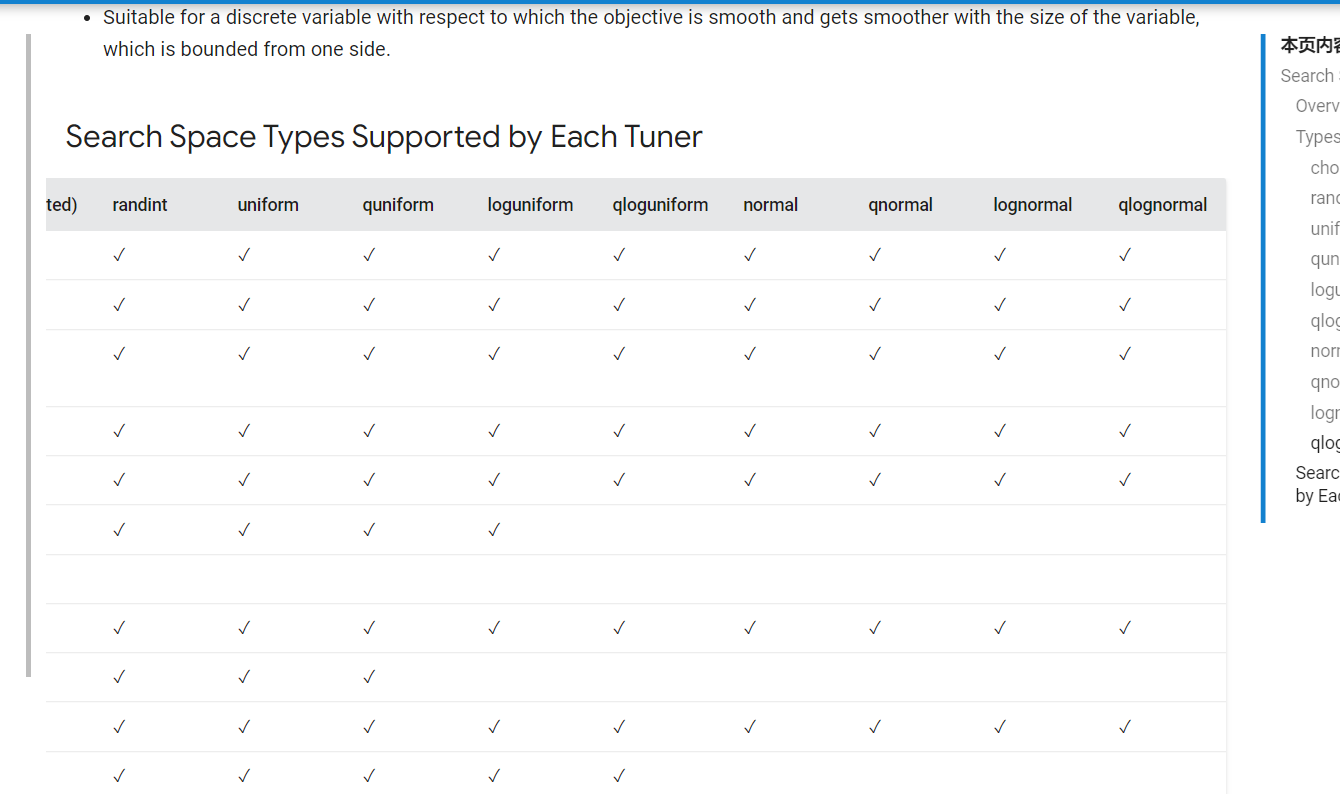
现有的所有seach space的type全都是标量
**Components that may involve changes**:
_type
**Brief description of your proposal if any**:
暂时没有 | closed | 2022-06-19T08:39:42Z | 2022-06-29T02:14:16Z | https://github.com/microsoft/nni/issues/4948 | [
"new feature",
"user raised",
"HPO"
] | BraveDrXuTF | 1 |
jschneier/django-storages | django | 544 | django-storages, boto3, and django-progressbarupload | I'm building a small app that stores whalesong. I've got my forms uploading to an S3 via boto3 and django-storages. I've also installed the development version of django-progressbarupload and am running django 2.0.6
django-progressbarupload gets it's progress data via
```
$.getJSON(upload_progress_url, {'X-Progress-ID': uuid}, function(data, status){
```
upload_progress_url is 'progressbarupload/upload_progress'. but the progress data just returns success / the full file size right away, even though the file is still uploading to S3. I'm not sure how these two components interact but thought perhaps django-storages isn't reporting upload progress in a way that django-progressbarupload expects.
Project Here:
https://github.com/kidconcept/whalejams
Video Here
https://tinytake.s3.amazonaws.com/pulse/elpulpo/attachments/8400940/TinyTake29-07-2018-11-47-06.mp4 | closed | 2018-08-03T09:18:23Z | 2018-08-06T18:21:46Z | https://github.com/jschneier/django-storages/issues/544 | [
"question"
] | kidconcept | 2 |
Josh-XT/AGiXT | automation | 917 | streamlit DuplicateWidgetID websearch = st.checkbox("Enable websearch") | ### Description
I was trying to modify chain Smart Instruct.
```
agixt-streamlit-1 | File "/app/components/selectors.py", line 73, in prompt_options
agixt-streamlit-1 | websearch = st.checkbox("Enable websearch")
agixt-streamlit-1 | File "/usr/local/lib/python3.10/site-packages/streamlit/runtime/metrics_util.py", line 356, in wrapped_func
agixt-streamlit-1 | result = non_optional_func(*args, **kwargs)
agixt-streamlit-1 | File "/usr/local/lib/python3.10/site-packages/streamlit/elements/checkbox.py", line 137, in checkbox
agixt-streamlit-1 | return self._checkbox(
agixt-streamlit-1 | File "/usr/local/lib/python3.10/site-packages/streamlit/elements/checkbox.py", line 181, in _checkbox
agixt-streamlit-1 | checkbox_state = register_widget(
agixt-streamlit-1 | File "/usr/local/lib/python3.10/site-packages/streamlit/runtime/state/widgets.py", line 164, in register_widget
agixt-streamlit-1 | return register_widget_from_metadata(metadata, ctx, widget_func_name, element_type)
agixt-streamlit-1 | File "/usr/local/lib/python3.10/site-packages/streamlit/runtime/state/widgets.py", line 209, in register_widget_from_metadata
agixt-streamlit-1 | raise DuplicateWidgetID(
agixt-streamlit-1 | streamlit.errors.DuplicateWidgetID: There are multiple identical `st.checkbox` widgets with the
agixt-streamlit-1 | same generated key.
agixt-streamlit-1 |
agixt-streamlit-1 | When a widget is created, it's assigned an internal key based on
agixt-streamlit-1 | its structure. Multiple widgets with an identical structure will
agixt-streamlit-1 | result in the same internal key, which causes this error.
agixt-streamlit-1 |
agixt-streamlit-1 | To fix this error, please pass a unique `key` argument to
agixt-streamlit-1 | `st.checkbox`.
agixt-streamlit-1 |
```
### Steps to Reproduce the Bug
1. Chain Management
2. Select Modify chain
3. Select Smart Instruct
4. For 1st step, check "Show Advanced Options" and check "Enable websearch".
5. Press Modify step
6. Scrolling down to 2nd step, and do the same.
### Expected Behavior
to run w/o error
### Operating System
- [X] Linux
- [ ] Microsoft Windows
- [ ] Apple MacOS
- [ ] Android
- [ ] iOS
- [ ] Other
### Python Version
- [ ] Python <= 3.9
- [X] Python 3.10
- [ ] Python 3.11
### Environment Type - Connection
- [X] Local - You run AGiXT in your home network
- [ ] Remote - You access AGiXT through the internet
### Runtime environment
- [X] Using docker compose
- [ ] Using local
- [ ] Custom setup (please describe above!)
### Acknowledgements
- [X] I have searched the existing issues to make sure this bug has not been reported yet.
- [X] I am using the latest version of AGiXT.
- [X] I have provided enough information for the maintainers to reproduce and diagnose the issue. | closed | 2023-08-14T11:14:11Z | 2023-08-15T17:53:53Z | https://github.com/Josh-XT/AGiXT/issues/917 | [
"type | report | bug",
"needs triage"
] | mongolu | 1 |
ultralytics/yolov5 | machine-learning | 12,582 | Engine crashes | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and found no similar bug report.
### YOLOv5 Component
Training
### Bug

### Environment
I have tried the old version and the new version of yolov5 6.2 and 7.0, and the situation is the same. I also found a lot of information and changed the parameters in export.py, but it still doesn't work.
### Minimal Reproducible Example
_No response_
### Additional
_No response_
### Are you willing to submit a PR?
- [X] Yes I'd like to help by submitting a PR! | closed | 2024-01-04T09:17:15Z | 2024-10-20T19:36:11Z | https://github.com/ultralytics/yolov5/issues/12582 | [
"bug",
"Stale"
] | 215561238 | 3 |
onnx/onnx | machine-learning | 6,649 | [Feature request] Can SpaceToDepth also add mode attribute? | ### System information
ONNX 1.17
### What is the problem that this feature solves?
Current SpaceToDepth Op https://github.com/onnx/onnx/blob/main/docs/Operators.md#spacetodepth doesn't have attributes to assign the DCR/CRD, and can only supports CRD in computation.
But the DepthToSpace Op https://github.com/onnx/onnx/blob/main/docs/Operators.md#depthtospace has such mode attributes, and is more flexible in supporting models conversion from tensorflow.
### Alternatives considered
_No response_
### Describe the feature
_No response_
### Will this influence the current api (Y/N)?
_No response_
### Feature Area
_No response_
### Are you willing to contribute it (Y/N)
None
### Notes
_No response_ | open | 2025-01-22T03:33:51Z | 2025-02-20T03:56:36Z | https://github.com/onnx/onnx/issues/6649 | [
"module: spec"
] | vera121 | 0 |
cookiecutter/cookiecutter-django | django | 4,768 | Add Hadolint | ## Description
Adding hadolint to pre-commit
## Rationale
Linting Dockerfile. Current lint warnings:
```
Lint Dockerfiles.........................................................Failed
- hook id: hadolint-docker
- exit code: 1
compose/local/django/Dockerfile:10 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
compose/local/django/Dockerfile:17 DL3045 warning: `COPY` to a relative destination without `WORKDIR` set.
compose/local/django/Dockerfile:38 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
compose/local/django/Dockerfile:38 DL3009 info: Delete the apt-get lists after installing something
compose/local/django/Dockerfile:49 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
compose/local/django/Dockerfile:68 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/local/django/Dockerfile:72 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/local/django/Dockerfile:77 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/local/django/Dockerfile:81 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/local/django/Dockerfile:85 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/local/docs/Dockerfile:10 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
compose/local/docs/Dockerfile:35 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
compose/local/docs/Dockerfile:55 DL3042 warning: Avoid use of cache directory with pip. Use `pip install --no-cache-dir <package>`
compose/local/docs/Dockerfile:60 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/production/django/Dockerfile:11 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
compose/production/django/Dockerfile:18 DL3045 warning: `COPY` to a relative destination without `WORKDIR` set.
compose/production/django/Dockerfile:42 DL3008 warning: Pin versions in apt get install. Instead of `apt-get install <package>` use `apt-get install <package>=<version>`
compose/production/django/Dockerfile:62 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/production/django/Dockerfile:67 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/production/django/Dockerfile:70 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/production/django/Dockerfile:75 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
compose/production/django/Dockerfile:80 DL3059 info: Multiple consecutive `RUN` instructions. Consider consolidation.
``` | open | 2023-12-31T20:36:46Z | 2024-05-27T18:30:56Z | https://github.com/cookiecutter/cookiecutter-django/issues/4768 | [
"enhancement"
] | Andrew-Chen-Wang | 2 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,505 | GPU not using more than 2 | Hi. I am trying to train the model.
Currently, I am training the model with the following configurations :
num_threads = 64
batch_size = 2
load_size = 1024
crop_size = 512
In this setting, it only uses 2 gpus.
If I increase the batch size, the number of GPU usage increases accordingly.
That is, batch size of 4 results to using 4 GPUs, batch size of 8 results to using 8 GPUs and etc.
However, if I increase the batch size more than 2, CUDA out of memory error pops out.
How can I increase the batch size? is decreasing the load_size only option?
Thank you
| open | 2022-11-11T12:08:10Z | 2023-07-21T07:28:08Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1505 | [] | stevekangLunit | 5 |
serengil/deepface | machine-learning | 777 | Age Prediction being either 0 or 90+ | I am currently working on a school project and I have taken deepface's code and compacted the code to only the stuff I needed to predict Age, Gender and Race.
my current code is working fine for Gender and Race, but my age is either 0 or 90+ most of the time, please advise on what I am doing wrong, thank you for your time! (Source Code is pasted below for demonstration video, click [here](https://1drv.ms/f/s!AkXMBs0vVpo9kIZt6gcGCyZ3OvITXw?e=Sus8eo))
```py
import os
import cv2
import sys
import time
import math
import gdown
import warnings
import tensorflow
import numpy as np
import pandas as pd
from numba import jit
import seaborn as sns
from PIL import Image
import tensorflow as tf
from glob import glob, iglob
from tqdm.notebook import tqdm
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
if tf_version == 1:
from keras.models import Model, Sequential
from keras.layers import (
Convolution2D,
ZeroPadding2D,
MaxPooling2D,
Flatten,
Dropout,
Activation,
)
else:
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.layers import (
Convolution2D,
ZeroPadding2D,
MaxPooling2D,
Flatten,
Dropout,
Activation,
)
class VGGface:
def __init__(self):
self.home = os.getcwd() + "\deepface"
print("Loading VGG Face Model . . .")
self.VGGfaceModel = Sequential()
self.VGGfaceModel.add(ZeroPadding2D((1, 1), input_shape=(224, 224, 3)))
self.VGGfaceModel.add(Convolution2D(64, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(64, (3, 3), activation="relu"))
self.VGGfaceModel.add(MaxPooling2D((2, 2), strides=(2, 2)))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(128, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(128, (3, 3), activation="relu"))
self.VGGfaceModel.add(MaxPooling2D((2, 2), strides=(2, 2)))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(256, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(256, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(256, (3, 3), activation="relu"))
self.VGGfaceModel.add(MaxPooling2D((2, 2), strides=(2, 2)))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(512, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(512, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(512, (3, 3), activation="relu"))
self.VGGfaceModel.add(MaxPooling2D((2, 2), strides=(2, 2)))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(512, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(512, (3, 3), activation="relu"))
self.VGGfaceModel.add(ZeroPadding2D((1, 1)))
self.VGGfaceModel.add(Convolution2D(512, (3, 3), activation="relu"))
self.VGGfaceModel.add(MaxPooling2D((2, 2), strides=(2, 2)))
self.VGGfaceModel.add(Convolution2D(4096, (7, 7), activation="relu"))
self.VGGfaceModel.add(Dropout(0.5))
self.VGGfaceModel.add(Convolution2D(4096, (1, 1), activation="relu"))
self.VGGfaceModel.add(Dropout(0.5))
self.VGGfaceModel.add(Convolution2D(2622, (1, 1)))
self.VGGfaceModel.add(Flatten())
self.VGGfaceModel.add(Activation("softmax"))
# -----------------------------------
output = self.home + "/.deepface/weights/vgg_face_weights.h5"
if os.path.isfile(output) != True:
print("vgg_face_weights.h5 will be downloaded...")
gdown.download("https://github.com/serengil/deepface_models/releases/download/v1.0/vgg_face_weights.h5", output, quiet=False)
# -----------------------------------
self.VGGfaceModel.load_weights(output)
# -----------------------------------
# TO-DO: why?
self.vgg_face_descriptor = Model(inputs=self.VGGfaceModel.layers[0].input, outputs=self.VGGfaceModel.layers[-2].output)
def AgeDetectionModel(self):
model = self.VGGfaceModel
# --------------------------
classes = 101
base_model_output = Sequential()
base_model_output = Convolution2D(classes, (1, 1), name="predictions")(model.layers[-4].output)
base_model_output = Flatten()(base_model_output)
base_model_output = Activation("softmax")(base_model_output)
# --------------------------
age_model = Model(inputs=model.input, outputs=base_model_output)
# --------------------------
# load weights
if os.path.isfile(self.home + "/.deepface/weights/age_model_weights.h5") != True:
print("age_model_weights.h5 will be downloaded...")
output = self.home + "/.deepface/weights/age_model_weights.h5"
gdown.download("https://github.com/serengil/deepface_models/releases/download/v1.0/age_model_weights.h5", output, quiet=False)
age_model.load_weights(self.home + "/.deepface/weights/age_model_weights.h5")
return age_model
def GenderDetectionModel(self):
model = self.VGGfaceModel
# --------------------------
classes = 2
base_model_output = Sequential()
base_model_output = Convolution2D(classes, (1, 1), name="predictions")(model.layers[-4].output)
base_model_output = Flatten()(base_model_output)
base_model_output = Activation("softmax")(base_model_output)
# --------------------------
gender_model = Model(inputs=model.input, outputs=base_model_output)
# --------------------------
# load weights
if os.path.isfile(self.home + "/.deepface/weights/gender_model_weights.h5") != True:
print("gender_model_weights.h5 will be downloaded...")
output = self.home + "/.deepface/weights/gender_model_weights.h5"
gdown.download("https://github.com/serengil/deepface_models/releases/download/v1.0/gender_model_weights.h5", output, quiet=False)
gender_model.load_weights(self.home + "/.deepface/weights/gender_model_weights.h5")
return gender_model
def RaceDetectionModel(self):
model = self.VGGfaceModel
# --------------------------
classes = 6
base_model_output = Sequential()
base_model_output = Convolution2D(classes, (1, 1), name="predictions")(model.layers[-4].output)
base_model_output = Flatten()(base_model_output)
base_model_output = Activation("softmax")(base_model_output)
# --------------------------
race_model = Model(inputs=model.input, outputs=base_model_output)
# --------------------------
# load weights
if os.path.isfile(self.home + "/.deepface/weights/race_model_single_batch.h5") != True:
print("race_model_single_batch.h5 will be downloaded...")
output = self.home + "/.deepface/weights/race_model_single_batch.h5"
gdown.download("https://github.com/serengil/deepface_models/releases/download/v1.0/race_model_single_batch.h5", output, quiet=False)
race_model.load_weights(self.home + "/.deepface/weights/race_model_single_batch.h5")
return race_model
def results2StringLabel_DeepFace(self, genderArray:np.ndarray, raceArray:np.ndarray, ageArray:np.ndarray):
genderLabels = ("woman", "man")
raceLabels = ("asian", "indian", "black", "white", "middle eastern", "latino hispanic")
# Evaluate Gender Label
for index, boolean in enumerate(genderArray[0]):
if boolean:
gender = genderLabels[index]
# Evaluate Race Label
for index, boolean in enumerate(raceArray[0]):
if boolean:
race = raceLabels[index]
# Turn Age into Integer
output_indexes = np.array(list(range(0, 101)))
apparent_age = np.sum(ageArray * output_indexes)
age = int(apparent_age)
return age, gender, race
def loadModels(self):
print("Loading Age Detection Model")
self.ageDetection = self.AgeDetectionModel()
print("Loading Gender Detection Model")
self.genderDetection = self.GenderDetectionModel()
print("Loading Race Detection Model")
self.raceDetection = self.RaceDetectionModel()
print("Model Loading Complete!")
def predict(self, image:np.ndarray):
image = cv2.resize(image, (224,224))
image = np.reshape(image, (-1,224,224,3))
ageResult = self.ageDetection.predict(image)
genderResult = self.genderDetection.predict(image)
raceResult = self.raceDetection.predict(image)
age, gender, race = self.results2StringLabel_DeepFace(genderArray=genderResult,\
raceArray=raceResult,\
ageArray=ageResult)
return age, gender, race
# OpenCV backend for deepface Face Detection
class OpenCV_FaceDetector:
def __init__(self) -> None:
# Get OpenCV Path.
opencv_home = cv2.__file__
folders = opencv_home.split(os.path.sep)[0:-1]
self.opencv_path = "\\".join(folders)
"""
path = folders[0]
for folder in folders[1:]:
self.opencv_path = path + "/" + folder
- Windows Design only huh
"""
# Initiate the detector dict. and build cascades to save on processing time later (hopefully)
self.detector = {}
self.detector["face_detector"] = self.build_cascade("haarcascade")
self.detector["eye_detector"] = self.build_cascade("haarcascade_eye")
def build_cascade(self, model_name="haarcascade"):
if model_name == "haarcascade":
face_detector_path = self.opencv_path + "\\data\\haarcascade_frontalface_default.xml"
if os.path.isfile(face_detector_path) != True:
raise ValueError(
"Confirm that opencv is installed on your environment! Expected path ",
face_detector_path,
" violated.",
)
detector = cv2.CascadeClassifier(face_detector_path)
elif model_name == "haarcascade_eye":
eye_detector_path = self.opencv_path + "\\data\\haarcascade_eye.xml"
if os.path.isfile(eye_detector_path) != True:
raise ValueError(
"Confirm that opencv is installed on your environment! Expected path ",
eye_detector_path,
" violated.",
)
detector = cv2.CascadeClassifier(eye_detector_path)
else:
raise ValueError(f"unimplemented model_name for build_cascade - {model_name}")
return detector
def detect_face(self, img, align=True):
responses = []
detected_face = None
img_region = [0, 0, img.shape[1], img.shape[0]]
faces = []
try:
# faces = detector["face_detector"].detectMultiScale(img, 1.3, 5)
# note that, by design, opencv's haarcascade scores are >0 but not capped at 1
faces, _, scores = self.detector["face_detector"].detectMultiScale3(
img, 1.1, 10, outputRejectLevels=True
)
except:
pass
if len(faces) > 0:
for (x, y, w, h), confidence in zip(faces, scores):
detected_face = img[int(y) : int(y + h), int(x) : int(x + w)]
if align:
detected_face = self.align_face(self.detector["eye_detector"], detected_face)
img_region = [x, y, w, h]
responses.append((detected_face, img_region, confidence))
return responses
def align_face(self,eye_detector, img):
detected_face_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # eye detector expects gray scale image
# eyes = eye_detector.detectMultiScale(detected_face_gray, 1.3, 5)
eyes = eye_detector.detectMultiScale(detected_face_gray, 1.1, 10)
# ----------------------------------------------------------------
# opencv eye detectin module is not strong. it might find more than 2 eyes!
# besides, it returns eyes with different order in each call (issue 435)
# this is an important issue because opencv is the default detector and ssd also uses this
# find the largest 2 eye. Thanks to @thelostpeace
eyes = sorted(eyes, key=lambda v: abs(v[2] * v[3]), reverse=True)
# ----------------------------------------------------------------
if len(eyes) >= 2:
# decide left and right eye
eye_1 = eyes[0]
eye_2 = eyes[1]
if eye_1[0] < eye_2[0]:
left_eye = eye_1
right_eye = eye_2
else:
left_eye = eye_2
right_eye = eye_1
# -----------------------
# find center of eyes
left_eye = (int(left_eye[0] + (left_eye[2] / 2)), int(left_eye[1] + (left_eye[3] / 2)))
right_eye = (int(right_eye[0] + (right_eye[2] / 2)), int(right_eye[1] + (right_eye[3] / 2)))
img = self.alignment_procedure(img, left_eye, right_eye)
return img # return img anyway
def alignment_procedure(self, img, left_eye, right_eye):
# this function aligns given face in img based on left and right eye coordinates
left_eye_x, left_eye_y = left_eye
right_eye_x, right_eye_y = right_eye
# -----------------------
# find rotation direction
if left_eye_y > right_eye_y:
point_3rd = (right_eye_x, left_eye_y)
direction = -1 # rotate same direction to clock
else:
point_3rd = (left_eye_x, right_eye_y)
direction = 1 # rotate inverse direction of clock
# -----------------------
# find length of triangle edges
a = self.findEuclideanDistance(np.array(left_eye), np.array(point_3rd))
b = self.findEuclideanDistance(np.array(right_eye), np.array(point_3rd))
c = self.findEuclideanDistance(np.array(right_eye), np.array(left_eye))
# -----------------------
# apply cosine rule
if b != 0 and c != 0: # this multiplication causes division by zero in cos_a calculation
cos_a = (b * b + c * c - a * a) / (2 * b * c)
angle = np.arccos(cos_a) # angle in radian
angle = (angle * 180) / math.pi # radian to degree
# -----------------------
# rotate base image
if direction == -1:
angle = 90 - angle
img = Image.fromarray(img)
img = np.array(img.rotate(direction * angle))
# -----------------------
return img # return img anyway
def findEuclideanDistance(self, source_representation, test_representation):
if isinstance(source_representation, list):
source_representation = np.array(source_representation)
if isinstance(test_representation, list):
test_representation = np.array(test_representation)
euclidean_distance = source_representation - test_representation
euclidean_distance = np.sum(np.multiply(euclidean_distance, euclidean_distance))
euclidean_distance = np.sqrt(euclidean_distance)
return euclidean_distance
```
The code that is interfacing with my class. Above code is in a file named 'operations.py'
```py
from operations import VGGface, OpenCV_FaceDetector
from glob import glob
import numpy as np
import cv2
VGGface = VGGface()
VGGface.loadModels()
faceDetector = OpenCV_FaceDetector()
"""
testImage = cv2.imread("UTKFace\\InTheWild_part1\\10_0_0_20170103233459275.jpg")
faces = faceDetector.detect_face(img=testImage,align=True)
# [<Detection Index>][<0:Detection Image, 1:Detection Cordinates>]
testImage1 = faces[0][0]
print(testImage)
print(type(testImage))
age, gender, race = VGG.predict(testImage1)
print(age,gender, race)
# Using cv2.imshow() method
# Displaying the image
cv2.imshow("test", testImage)
# waits for user to press any key
# (this is necessary to avoid Python kernel form crashing)
cv2.waitKey(0)
# closing all open windows
cv2.destroyAllWindows()
"""
print(glob("Videos\\DEMO_*_*_NG.mp4"))
for file in glob("Videos\\DEMO_*_*_NG.mp4"):
# Create an object to read
# from File
VideoFile_path = file
video = cv2.VideoCapture(file)
# We need to check if File
# is opened previously or not
if (video.isOpened() == False):
print("Error reading video file")
# We need to set resolutions.
# so, convert them from float to integer.
size = (int(video.get(3)), int(video.get(4)))
print(size)
# Below VideoWriter object will create
# a frame of above defined The output
# is stored in '*.mp4' file.
result = cv2.VideoWriter(f'{file[:-4]}_preds.mp4',\
cv2.VideoWriter_fourcc(*'mp4v'),\
20.0, size)
while(True):
ret, frame = video.read()
if ret == True:
# Process the frame with bounding boxes
processingFrame = faceDetector.detect_face(img=frame,align=True)
# [<Detection Index>][<0:Detection Image, 1:Detection Cordinates>]
for detection in processingFrame:
predictedAge, predictedGender, predictedRace = VGGface.predict(detection[0])
text_size, _ = cv2.getTextSize(f"Age: {predictedAge} | Gender: {predictedGender} | Race: {predictedRace}", cv2.FONT_HERSHEY_SIMPLEX, 1, 2)
rectangle_width = text_size[0] + 10
rectangle_height = text_size[1] + 40
print(detection[1])
# Draw Bounding boxes and display predictions
# x1,y1 = start_point
# y1 + x2,y1 + y2 = end_point
# frame x1 y1 x2 y2 B G R line Thickness
frame = cv2.rectangle(frame, (detection[1][0], detection[1][1]), (detection[1][0] + detection[1][2], detection[1][1] + detection[1][3]), (255, 0, 0), 2)
# Draw Bounding Boxes Around text
frame = cv2.rectangle(frame, (detection[1][0], detection[1][1]),\
(detection[1][0] + rectangle_width, detection[1][1] - rectangle_height), (255, 0, 0), -1)
# Displaying Text
frame = cv2.putText(frame, f"Age: {predictedAge} | Gender: {predictedGender} | Race: {predictedRace}",\
(detection[1][0], detection[1][1] - 20),\
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
# Display the frames
# saved in the file
cv2.imshow('Frame', frame)
# Write the frame into the
# file '*.mp4'
result.write(frame)
# Press S on keyboard
# to stop the process
if cv2.waitKey(1) & 0xFF == ord('s'):
break
# Break the loop
else:
break
# When everything done, release
# the video capture and video
# write objects
video.release()
result.release()
# Closes all the frames
cv2.destroyAllWindows()
print(f"The video {VideoFile_path} was successfully saved")
```
Any and all help will be appreciated. | closed | 2023-06-12T12:25:30Z | 2023-06-14T08:14:39Z | https://github.com/serengil/deepface/issues/777 | [
"question"
] | DrPlanecraft | 5 |
Lightning-AI/pytorch-lightning | pytorch | 20,274 | `strict = False` does not work when the checkpoint is distributed | ### Bug description
When loading a sharded checkpoint with:
```python
fabric.load(ckpt_path, state, strict = False)
```
the `_distributed_checkpoint_load` function called in the `FSDPStrategy` will raise an error if a checkpoint misses a key from the model in `state`, which should not be the case as `strict = False`.
A fix could be to take advantage of the [DefaultLoadPlanner](https://pytorch.org/docs/stable/distributed.checkpoint.html#torch.distributed.checkpoint.DefaultLoadPlanner) in `torch.distributed.checkpoint.load`, setting the `allow_partial_load` argument to the opposite of `strict`.
### What version are you seeing the problem on?
v2.4
### How to reproduce the bug
_No response_
### Error messages and logs
```
[rank7]: Traceback (most recent call last):
[rank7]: File "my_codebase/train_fabric.py", line 226, in <module>
[rank7]: main(**vars(args))
[rank7]: File "my_codebase/train_fabric.py", line 148, in main
[rank7]: fabric.load(ckpt_path, state, strict = strict_mode)
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/lightning/fabric/fabric.py", line 773, in load
[rank7]: remainder = self._strategy.load_checkpoint(path=path, state=unwrapped_state, strict=strict)
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/lightning/fabric/strategies/fsdp.py", line 570, in load_checkpoint
[rank7]: _distributed_checkpoint_load(module_state, path)
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/lightning/fabric/strategies/fsdp.py", line 886, in _distributed_checkpoint_load
[rank7]: load(module_state, checkpoint_id=path)
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/logger.py", line 66, in wrapper
[rank7]: result = func(*args, **kwargs)
[rank7]: ^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/utils.py", line 434, in inner_func
[rank7]: return func(*args, **kwargs)
[rank7]: ^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/state_dict_loader.py", line 168, in load
[rank7]: _load_state_dict(
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/state_dict_loader.py", line 220, in _load_state_dict
[rank7]: central_plan: LoadPlan = distW.reduce_scatter("plan", local_step, global_step)
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/utils.py", line 192, in reduce_scatter
[rank7]: raise result
[rank7]: torch.distributed.checkpoint.api.CheckpointException: CheckpointException ranks:dict_keys([0, 1, 2, 3, 4, 5, 6, 7])
[rank7]: Traceback (most recent call last): (RANK 0)
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/utils.py", line 165, in reduce_scatter
[rank7]: local_data = map_fun()
[rank7]: ^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/logger.py", line 66, in wrapper
[rank7]: result = func(*args, **kwargs)
[rank7]: ^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/state_dict_loader.py", line 209, in local_step
[rank7]: local_plan = planner.create_local_plan()
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/default_planner.py", line 197, in create_local_plan
[rank7]: return create_default_local_load_plan(
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/default_planner.py", line 316, in create_default_local_load_plan
[rank7]: raise RuntimeError(f"Missing key in checkpoint state_dict: {fqn}.")
[rank7]: RuntimeError: Missing key in checkpoint state_dict: model.lm_model.lm_head.weight.
[rank7]: Traceback (most recent call last): (RANK 1)
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/utils.py", line 165, in reduce_scatter
[rank7]: local_data = map_fun()
[rank7]: ^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/logger.py", line 66, in wrapper
[rank7]: result = func(*args, **kwargs)
[rank7]: ^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/state_dict_loader.py", line 209, in local_step
[rank7]: local_plan = planner.create_local_plan()
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/default_planner.py", line 197, in create_local_plan
[rank7]: return create_default_local_load_plan(
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/default_planner.py", line 316, in create_default_local_load_plan
[rank7]: raise RuntimeError(f"Missing key in checkpoint state_dict: {fqn}.")
[rank7]: RuntimeError: Missing key in checkpoint state_dict: model.lm_model.lm_head.weight.
[rank7]: Traceback (most recent call last): (RANK 2)
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/utils.py", line 165, in reduce_scatter
[rank7]: local_data = map_fun()
[rank7]: ^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/logger.py", line 66, in wrapper
[rank7]: result = func(*args, **kwargs)
[rank7]: ^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/state_dict_loader.py", line 209, in local_step
[rank7]: local_plan = planner.create_local_plan()
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/default_planner.py", line 197, in create_local_plan
[rank7]: return create_default_local_load_plan(
[rank7]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank7]: File "my_codebase/my-venv/lib/python3.11/site-packages/torch/distributed/checkpoint/default_planner.py", line 316, in create_default_local_load_plan
[rank7]: raise RuntimeError(f"Missing key in checkpoint state_dict: {fqn}.")
[rank7]: RuntimeError: Missing key in checkpoint state_dict: model.my_key.
```
### Environment
<details>
<summary>Current environment</summary>
```
#- PyTorch Lightning Version (e.g., 2.4.0): 2.4.0
#- PyTorch Version (e.g., 2.4): 2.4.0+rocm6.0
#- Python version (e.g., 3.12): 3.11
</details>
### More info
_No response_ | open | 2024-09-11T16:36:26Z | 2024-10-10T01:50:05Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20274 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | NathanGodey | 1 |
jupyter/nbviewer | jupyter | 484 | Jupyter>>nbviewer slides Fail, notebook view fine | When using the web based iPython Notebook/Jupyter capability, i created a notebook with markdown cells of text and code cells to display the code and plots for matplotlib and bokeh. I then download that as .ipynb open with sublime, copy and paste to git, then access it on nbviewer through my git account. When looking at it here:
http://nbviewer.ipython.org/github/angisgrate/test/blob/master/pyohio3.ipynb
in notebook view, it works fine. the markdown, code, and plot steps are all there.
When switching to slides view, the intent of the creation needed for the presentation, this code blocks occurs first, blocking out the first 10 markdown steps and all the matplotlib steps, rendering this weird code without the plots:
http://nbviewer.ipython.org/format/slides/github/angisgrate/test/blob/master/pyohio3.ipynb
How can i fix this asap?? I've looked through and there was a similar problem in 2014 with slides, but it yielded an actual "Error" that i'm not seeing, just this contorted view
| closed | 2015-07-30T19:45:30Z | 2015-08-30T03:18:01Z | https://github.com/jupyter/nbviewer/issues/484 | [
"type:Bug",
"tag:Format"
] | angisgrate | 17 |
jmcnamara/XlsxWriter | pandas | 959 | question: trendline equation | ### Question
Is it possible to extract trendline equation from chart? | closed | 2023-03-01T22:17:12Z | 2023-03-01T22:51:57Z | https://github.com/jmcnamara/XlsxWriter/issues/959 | [
"question"
] | dsulot | 1 |
django-import-export/django-import-export | django | 2,002 | MultiselectField is not working (with xlsx format) | **Describe the bug**
In our Django project, we have a model with Multiselectfield, when we import an export from this model, we see that these fields are not loaded.
https://pypi.org/project/django-multiselectfield/
**To Reproduce**
1. Create a model with a MultiSelectField. (for example:
```python
class SampleStudent:
name= models.CharField(max_length=128, null=True, blank=True)
countries = MultiSelectField(
choices=COUNTRY_CODE_CHOICES,
null=True,
blank=True
)
```
2. Generate a few random rows.
3. export as xlsx
4. try to import related file
**Versions (please complete the following information):**
- Django Import Export: 4.2.0
- Python 3.11
- Django 4.2.13
**Expected behavior**
What should happen is that MultiSelectField should be exported correctly and imported correctly. | closed | 2024-11-13T15:06:48Z | 2025-01-16T14:24:40Z | https://github.com/django-import-export/django-import-export/issues/2002 | [
"bug"
] | Natgho | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.