
repo_name
stringlengths 9
75
| topic
stringclasses 30
values | issue_number
int64 1
203k
| title
stringlengths 1
976
| body
stringlengths 0
254k
| state
stringclasses 2
values | created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| url
stringlengths 38
105
| labels
sequencelengths 0
9
| user_login
stringlengths 1
39
| comments_count
int64 0
452
|
|---|---|---|---|---|---|---|---|---|---|---|---|
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 3,250 | "BAD signature" for Debian bulleys | gpg --verify Release.gpg globaleaks_4.9.9_all.deb
gpg: Signature made Thu 30 Jun 2022 08:35:21 AM UTC
gpg: using RSA key B353922AE4457748559E777832E6792624045008
gpg: BAD signature from "GlobaLeaks software signing key <info@globaleaks.org>" [unknown]
from my machine
lsb_release -a
No LSB modules are available.
Distributor ID: Debian
Description: Debian GNU/Linux 11 (bullseye)
Release: 11
Codename: bullseye
**Additional context**
I'm new! I think the signature for the debian bulleys has not be updated. but I dont know.
| closed | 2022-07-20T00:19:11Z | 2022-08-10T21:45:14Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/3250 | [] | ship3262 | 4 |
jofpin/trape | flask | 186 | Can't find Google Maps and Goo.Gl APIs | Ngrok token can be found in free but google map ali is not grtting in free qnd goo.gl is no longer available | open | 2019-11-07T04:32:13Z | 2019-11-07T04:32:13Z | https://github.com/jofpin/trape/issues/186 | [] | mr-sparx | 0 |
2noise/ChatTTS | python | 794 | 在运行官方给的Advanced Usage示例时报错 | 运行Basic Usage没有问题,但运行Advanced Usage时出现以下报错
Traceback (most recent call last):
File "xxx/test1.py", line 10, in <module>
rand_spk = chat.sample_random_speaker()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "xxx/ChatTTS/ChatTTS/core.py", line 160, in sample_random_speaker
return self.speaker.sample_random()
^^^^^^^^^^^^
AttributeError: 'Chat' object has no attribute 'speaker'
 | closed | 2024-10-21T07:51:17Z | 2024-10-29T14:24:51Z | https://github.com/2noise/ChatTTS/issues/794 | [] | AstronautBase | 3 |
apragacz/django-rest-registration | rest-api | 186 | Setting to disable new user registration (the `/register` endpoint) | ### Checklist
* [x] I read [Contribution Guidelines](https://github.com/apragacz/django-rest-registration/blob/master/CONTRIBUTING.md#issues)
* [x] I searched [the documentation](https://django-rest-registration.readthedocs.io/) to ensure that the requested feature is not already implemented and described
* [x] I searched existing issues before opening this one
### Is your feature request related to a problem? Please describe.
Sometimes, we need to stop new users from registering, while still continuing to provide the rest of the functionalities from this library to existing users.
### Describe the solution you'd like
I would like to be able to disable registration of new users (the `/register` endpoint) based on a [setting](https://django-rest-registration.readthedocs.io/en/latest/detailed_configuration/all_settings.html).
### Describe alternatives you've considered
Reading through the list of existing settings (and reading the code to make sure there isn't an undocumented setting), there doesn't seem to be any :upside_down_face:
The best I can come up with (but haven't had time to test yet) is to define a custom [`REGISTER_SERIALIZER_CLASS`](https://django-rest-registration.readthedocs.io/en/latest/detailed_configuration/all_settings.html#register-serializer-class) that would be a copy of [the one already provided](https://github.com/apragacz/django-rest-registration/blob/master/rest_registration/api/serializers.py#L96) with an added exception at the beginning of `validate()`, thrown based on a django setting. | closed | 2022-03-14T14:52:09Z | 2022-03-23T12:07:55Z | https://github.com/apragacz/django-rest-registration/issues/186 | [
"type:feature-request"
] | 1ace | 4 |
skypilot-org/skypilot | data-science | 4,915 | [k8s] Make `ports: ingress` reuse API server's nginx controller | Currently if users deploy the API server with our helm chart, we create an ingress controller and expose it through a NodePort svc (or optionally, LoadBalancer svc).
We can (and should) piggyback on this existing ingress controller for exposing ports via [`ports: ingress` mode](https://docs.skypilot.co/en/latest/reference/kubernetes/kubernetes-ports.html#nginx-ingress). This would eliminate the need for users to set up another nginx ingress controller and re-use the same public facing NodePort/LoadBalancer service. | open | 2025-03-07T19:54:58Z | 2025-03-10T05:11:51Z | https://github.com/skypilot-org/skypilot/issues/4915 | [
"k8s"
] | romilbhardwaj | 2 |
apache/airflow | data-science | 47,889 | OperatorExtra links xcom keys should be pushed to xcom db | ### Body
After #45481, we need to check if the operator extra links are being pushed to the right place and not to the custom xcom backend.
### Committer
- [x] I acknowledge that I am a maintainer/committer of the Apache Airflow project. | open | 2025-03-18T06:22:41Z | 2025-03-18T06:24:56Z | https://github.com/apache/airflow/issues/47889 | [
"area:core",
"area:core-operators",
"area:task-sdk"
] | amoghrajesh | 0 |
apache/airflow | data-science | 47,720 | Issue running task of an asset decorated dag | ### Apache Airflow version
main (development)
### If "Other Airflow 2 version" selected, which one?
_No response_
### What happened?
Serialisation issue is coming when triggering a dag which is asset decorated and decorator has name attribute.
<img width="1563" alt="Image" src="https://github.com/user-attachments/assets/7fa2ba1e-69a1-4d86-9254-149023331f38" />
```
INFO: 192.168.97.1:53086 - "GET /public/dags/abcd/dagRuns/manual__2025-03-13T10%3A58%3A38.178923%2B00%3A00_vNVGhOqs/taskInstances/__main__/-1 HTTP/1.1" 200 OK
/usr/local/lib/python3.9/site-packages/pydantic/type_adapter.py:527 UserWarning: Pydantic serializer warnings:
PydanticSerializationUnexpectedValue: Expected `StructuredLogMessage` but got `StructuredLogMessage` with value `StructuredLogMessage(time..._main__/attempt=1.log'])` - serialized value may not be as expected
PydanticSerializationUnexpectedValue: Expected `str` but got `StructuredLogMessage` with value `StructuredLogMessage(time..._main__/attempt=1.log'])` - serialized value may not be as expected
```
### What you think should happen instead?
The Dag should work fine and create an asset event.
### How to reproduce
Run the below DAG:
```python
@asset(uri="s3://bucket/asset1_producer", schedule=None)
def asset1_producer():
pass
@asset(name="abcd", uri="s3://bucket/object", schedule=None)
def asset2_producer(self, context, asset1_producer):
print(self)
print(context["inlet_events"][asset1_producer])
```
### Operating System
Linux
### Versions of Apache Airflow Providers
_No response_
### Deployment
Other
### Deployment details
_No response_
### Anything else?
_No response_
### Are you willing to submit PR?
- [ ] Yes I am willing to submit a PR!
### Code of Conduct
- [x] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)
| closed | 2025-03-13T11:06:19Z | 2025-03-18T08:58:36Z | https://github.com/apache/airflow/issues/47720 | [
"kind:bug",
"area:serialization",
"priority:high",
"area:core",
"area:datasets",
"affected_version:3.0.0beta"
] | atul-astronomer | 2 |
streamlit/streamlit | python | 10,615 | cache_data and cache_resource not working with DuckDB on Motherduck connection | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
I have this connections script that connects to DuckDB on Motherduck:
```python
import streamlit as st
import duckdb
from duckdb import DuckDBPyConnection
import polars as pl
import toml
@st.cache_resource
def motherduck_connection() -> DuckDBPyConnection:
with open("./secrets.toml", "r") as f:
secrets = toml.load(f)
motherduck_token = secrets["tokens"]["motherduck"]
conn = duckdb.connect(f"md:nba_data?motherduck_token={motherduck_token}")
return conn
@st.cache_data(ttl=600)
def standings_table_connection(conn: DuckDBPyConnection) -> pl.DataFrame:
standings_dataframe = pl.from_arrow(
conn.sql("SELECT * FROM nba_data_staging.teams")
)
return standings_dataframe
```
when running the streamlit app:
```python
import streamlit as st
from streamlit_components.standings_section import StandingsSection
from streamlit_components.connections import (
motherduck_connection,
standings_table_connection
)
conn = motherduck_connection()
standings_table = standings_table_connection(conn)
st.set_page_config(page_title="Streamlit: Premier League", layout="wide")
def app():
standings_section = StandingsSection(standings_table)
standings_section.display()
if __name__ == "__main__":
app()
```
Python unexpectedly quits with the error:
```bash
libc++abi: terminating due to uncaught exception of type std::runtime_error: instance allocation failed: new instance has no pybind11-registered base types
Abort trap: 6
```
when I remove the caching, it works.
### Reproducible Code Example
```Python
```
### Steps To Reproduce
_No response_
### Expected Behavior
_No response_
### Current Behavior
Error message:
```bash
libc++abi: terminating due to uncaught exception of type std::runtime_error: instance allocation failed: new instance has no pybind11-registered base types
Abort trap: 6
```
### Is this a regression?
- [ ] Yes, this used to work in a previous version.
### Debug info
- Streamlit version: `1.42.0`
- duckdb `1.2.0`
- polars `1.22.0`
- pyarrow `19.0.0`
- Python version: `3.12.2`
- Operating System: macOS - M3 chip
- Browser: Firefox
### Additional Information
_No response_ | closed | 2025-03-03T19:37:21Z | 2025-03-04T19:08:39Z | https://github.com/streamlit/streamlit/issues/10615 | [
"type:bug",
"status:won't-fix"
] | digitalghost-dev | 5 |
widgetti/solara | jupyter | 790 | VBox widget not scrollable | I am trying to build a custom widget class that I want to use for popups in a couple of ipyleaflet Markers. The custom widget consists of a main HBox, which itself contains two VBoxes.. something like this:

So far so good.. the smaller VBox on the left is meant to be scrollable. This screenshot was taken from a Jupyter notebook with the ipyleaflet Map as a solara component (see code below).
However, when I test the same code using solara, the left VBox is not scrollable and its elements are incomplete (e.g., you can't see the "C" item):

Here's the code:
```python
import solara
import markdown
import ipyleaflet
import ipywidgets as widgets
text = """## Test markdown
### Details
- **A**: a
- **B**: b
- **C**: c
"""
class Map(ipyleaflet.Map):
def __init__(self, **kwargs):
super().__init__(**kwargs)
marker = ipyleaflet.Marker(
location = (0,0),
draggable = False,
title = "My marker",
popup_max_width=1000,
popup_max_height=1000
)
self.add(marker)
main_box = widgets.HBox(
layout=widgets.Layout(
width='1000px',
height='480px',
justify_content='space-between',
)
)
panel_box = widgets.VBox(
layout = widgets.Layout(
width='25%',
height='100%',
border='solid 2px'
)
)
image_box = widgets.VBox(
layout = widgets.Layout(
width='65%',
height='100%',
border='solid 2px'
)
)
value = markdown.markdown(text)
description_box = widgets.HTML(
layout=widgets.Layout(
border='solid 1px',
flex_shrink=1
),
value=value,
)
panel_box.children = [
description_box,
description_box,
description_box,
description_box,
]
main_box.children=[
panel_box,
image_box
]
marker.popup = main_box
@solara.component
def Page():
with solara.Column() as main:
map = Map.element(
layout=widgets.Layout(height='800px')
)
return main
display(Page())
```
| open | 2024-09-16T10:40:21Z | 2024-09-18T08:36:22Z | https://github.com/widgetti/solara/issues/790 | [] | lopezvoliver | 5 |
xinntao/Real-ESRGAN | pytorch | 232 | error of processing all videos in upload folder | when running
`!python inference_realesrgan_video.py --input upload -n RealESRGANv2-animevideo-xsx2 -s 4 -v -a --half --suffix outx2
`
I'm getting :
```
Traceback (most recent call last):
File "inference_realesrgan_video.py", line 199, in <module>
main()
File "inference_realesrgan_video.py", line 108, in main
if mimetypes.guess_type(args.input)[0].startswith('video'): # is a video file
AttributeError: 'NoneType' object has no attribute 'startswith'
```
I'm unable to run the inference on the videos inside the upload folder one after the other.
Hope someone can help fix this issue. | closed | 2022-01-24T18:22:11Z | 2022-02-07T21:21:11Z | https://github.com/xinntao/Real-ESRGAN/issues/232 | [] | GeorvityLabs | 3 |
autogluon/autogluon | scikit-learn | 4,221 | Instance Segmentation | Are there any plans to add support for instance segmentation in the future? From what I understand it is currently not supported, correct? | closed | 2024-05-23T12:40:32Z | 2024-06-28T21:41:07Z | https://github.com/autogluon/autogluon/issues/4221 | [
"enhancement",
"module: multimodal"
] | serwansj | 1 |
marcomusy/vedo | numpy | 999 | Decimating a mesh with islands results in missing cells | `mesh.ncells` > `mesh.cells.shape[0]` after `mesh.decimate_pro().clean()`
This causes issues as `mesh.cell_centers()` matches the number of cells returned by `mesh.ncells`. Trying to use `mesh.cell_centers()` and `mesh.cells`. So it looks like `mesh.cells` is missing some cells.
I wasn't able to reproduce this with the typical bunny model but I found out it only occurs with a mesh that has both multiple regions and a face that is only connected to the rest of the mesh by one vertex. The issue is resolved after running `mesh = mesh.extract_largest_region()` and then `mesh.clean()`.
Maybe an error should raise if decimating a mesh with small islands? | open | 2023-12-21T22:33:40Z | 2023-12-23T23:01:01Z | https://github.com/marcomusy/vedo/issues/999 | [
"possible bug"
] | JeffreyWardman | 0 |
mljar/mercury | data-visualization | 66 | Unable to run docker container (missing ipython_genutils package) | @pplonski With a clone of the repo, I am unable to run a docker container containing the `mercury_demo` .
The message **Problem while loading notebooks. Please try again later or contact Mercury administrator.** displays
Steps to reproduce:
Clone `https://github.com/MarvinKweyu/mercury-docker-demo` and run the container
| closed | 2022-03-15T04:02:26Z | 2022-03-21T11:12:35Z | https://github.com/mljar/mercury/issues/66 | [
"bug"
] | MarvinKweyu | 16 |
zappa/Zappa | flask | 1,094 | Error: Warning! Status check on the deployed lambda failed. A GET request to '/' yielded a 502 response code. | <!--- Provide a general summary of the issue in the Title above -->
## Context
When im trying to deploy using _zappa update dev_ im getting this error:
Error: Warning! Status check on the deployed lambda failed. A GET request to '/' yielded a 502 response code.
## Expected Behavior
Could not get a valid link such as https://**********.execute-api.us-west-2.amazonaws.com/dev such as this
## Actual Behavior
`{'message': 'An uncaught exception happened while servicing this request. You can investigate this with the `zappa tail` command.', 'traceback': ['Traceback (most recent call last):', ' File /var/task/handler.py, line 540, in handler with Response.from_app(self.wsgi_app, environ) as response:', ' File /var/task/werkzeug/wrappers/base_response.py, line 287, in from_app return cls(*_run_wsgi_app(app, environ, buffered))', ' File /var/task/werkzeug/wrappers/base_response.py, line 26, in _run_wsgi_app return _run_wsgi_app(*args)', ' File /var/task/werkzeug/test.py, line 1119, in run_wsgi_app app_rv = app(environ, start_response)', TypeError: 'NoneType' object is not callable]}`
when im trying to access any endpoint from my application
## Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* Zappa 0.54.1
* Python version 3.7
* Zappa settings
{
"dev": {
"app_function": "app.app",
"aws_region": "us-west-2",
"profile_name": "default",
"project_name": "***************",
"runtime": "python3.7",
"s3_bucket": "zappa-*********"
}
}
| closed | 2021-12-21T04:46:07Z | 2022-08-17T06:20:54Z | https://github.com/zappa/Zappa/issues/1094 | [] | mathsmtnx | 5 |
hankcs/HanLP | nlp | 1,751 | 自己训练的pos.bin不能加载 | <!--
提问请上论坛,不要发这里!
提问请上论坛,不要发这里!
提问请上论坛,不要发这里!
以下必填,否则恕不受理。
-->
**Describe the bug**
自己训练的crf模型文件,pos.bin不能加载,但是同时生成的pos.bin.txt就可以加载成功。
**Code to reproduce the issue**
```java
CRFPOSTagger tagger = new CRFPOSTagger(null); // 创建空白标注器
// tagger = new CRFPOSTagger(PKU.POS_MODEL); // 加载
tagger = new CRFPOSTagger("/root/repo/hanlp-java/HanLP/data/test/pos.bin"); // 加载
System.out.println(Arrays.toString(tagger.tag("他", "的", "希望", "是", "希望", "上学"))); // 预测
AbstractLexicalAnalyzer analyzer = new AbstractLexicalAnalyzer(new PerceptronSegmenter(), tagger); // 构造词法分析器
System.out.println(analyzer.analyze("李狗蛋的希望是希望上学")); // 分词+词性标注
```
报错如下:
java.lang.ArrayIndexOutOfBoundsException: 1677721600
at com.hankcs.hanlp.model.perceptron.feature.FeatureMap.loadTagSet(FeatureMap.java:99)
at com.hankcs.hanlp.model.perceptron.feature.ImmutableFeatureMDatMap.load(ImmutableFeatureMDatMap.java:92)
at com.hankcs.hanlp.model.perceptron.model.LinearModel.load(LinearModel.java:421)
at com.hankcs.hanlp.model.crf.LogLinearModel.load(LogLinearModel.java:58)
at com.hankcs.hanlp.model.perceptron.model.LinearModel.load(LinearModel.java:388)
at com.hankcs.hanlp.model.crf.LogLinearModel.<init>(LogLinearModel.java:83)
at com.hankcs.hanlp.model.crf.CRFTagger.<init>(CRFTagger.java:41)
at com.hankcs.hanlp.model.crf.CRFPOSTagger.<init>(CRFPOSTagger.java:45)
at com.hankcs.hanlp.model.crf.CRFPOSTaggerTest.testTrain(CRFPOSTaggerTest.java:25)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at junit.framework.TestCase.runTest(TestCase.java:176)
at junit.framework.TestCase.runBare(TestCase.java:141)
at junit.framework.TestResult$1.protect(TestResult.java:122)
at junit.framework.TestResult.runProtected(TestResult.java:142)
at junit.framework.TestResult.run(TestResult.java:125)
at junit.framework.TestCase.run(TestCase.java:129)
at junit.framework.TestSuite.runTest(TestSuite.java:255)
at junit.framework.TestSuite.run(TestSuite.java:250)
at org.junit.internal.runners.JUnit38ClassRunner.run(JUnit38ClassRunner.java:84)
at org.junit.runner.JUnitCore.run(JUnitCore.java:160)
at com.intellij.junit4.JUnit4IdeaTestRunner.startRunnerWithArgs(JUnit4IdeaTestRunner.java:69)
at com.intellij.rt.junit.IdeaTestRunner$Repeater$1.execute(IdeaTestRunner.java:38)
at com.intellij.rt.execution.junit.TestsRepeater.repeat(TestsRepeater.java:11)
at com.intellij.rt.junit.IdeaTestRunner$Repeater.startRunnerWithArgs(IdeaTestRunner.java:35)
at com.intellij.rt.junit.JUnitStarter.prepareStreamsAndStart(JUnitStarter.java:235)
at com.intellij.rt.junit.JUnitStarter.main(JUnitStarter.java:54)
**Describe the current behavior**
100%出错
**Expected behavior**
能正常加载pos.bin
**System information**
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):
- Python version:
- jkd version:jdk 1.8
- HanLP version: 1.7.5 and 1.8.3
**Other info / logs**
Include any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.
* [x] I've completed this form and searched the web for solutions.
<!-- 发表前先搜索,此处一定要勾选! -->
<!-- 发表前先搜索,此处一定要勾选! -->
<!-- 发表前先搜索,此处一定要勾选! --> | closed | 2022-06-24T11:31:58Z | 2022-06-24T21:09:49Z | https://github.com/hankcs/HanLP/issues/1751 | [
"invalid"
] | tianjiangtao | 2 |
joouha/euporie | jupyter | 47 | Remove shadow | Please, how can I remove the shadow?

| closed | 2022-12-02T07:44:50Z | 2022-12-02T13:59:18Z | https://github.com/joouha/euporie/issues/47 | [] | ghost | 2 |
RobertCraigie/prisma-client-py | asyncio | 1,063 | Allow early commiting transaction from inside the context manager before raising an exception | ## Problem
Use case:
```python
async def get_transaction():
async with db.tx() as tx:
yield tx
@router.post("/")
async def endpoint(tx: Annotated[Prisma, Depends(get_transaction)]):
await tx.entity.delete_many()
if not_good:
raise HTTPException()
return "ok"
```
I require the removal of the `entity` to be committed, even though the function was interrupted with an exception.
## Suggested solution
Add a `commit` method to the `Prisma` class:
```python
class Prisma:
...
async def commit(self):
if self._tx_id:
await self._engine.commit_transaction(self._tx_id)
```
Similar function could be added for rollback.
Usage example:
```python
@router.post("/")
async def endpoint(tx: Annotated[Prisma, Depends(get_transaction)]):
await tx.entity.delete_many()
if not_good:
await tx.commit()
raise HTTPException()
return "ok"
```
## Alternatives
Instead of calling `commit_transaction` it may be possible to set an internal flag that will be consulted on the context exit.
## Additional context
Currently I am using this function to do what I want:
```python
async def early_commit(tx: prisma.Prisma):
if tx._tx_id: # pyright: ignore[reportPrivateUsage]
await tx._engine.commit_transaction( # pyright: ignore[reportPrivateUsage]
tx._tx_id # pyright: ignore[reportPrivateUsage]
)
``` | open | 2025-01-24T10:04:17Z | 2025-01-24T10:04:17Z | https://github.com/RobertCraigie/prisma-client-py/issues/1063 | [] | rijenkii | 0 |
ijl/orjson | numpy | 369 | Multithreading race condition when lazy loading NUMPY_TYPES | The following code crashes randomly with "Illegal instruction" (tested with orjson 3.8.7 and 3.8.8):
```
import orjson
import multiprocessing.pool
class X:
pass
def mydump(i):
orjson.dumps({'abc': X()}, option=orjson.OPT_SERIALIZE_NUMPY, default=lambda x: None)
# mydump(0)
with multiprocessing.pool.ThreadPool(processes=16) as pool:
pool.map(mydump, (i for i in range(0, 16)))
```
Commenting out the mydump(0) call circumvents the issue (with CPython 3.8.13). When building without --strip and with RUST_BACKTRACE=1, the following call stack can be seen:
```
thread '<unnamed>' panicked at 'Lazy instance has previously been poisoned', /usr/local/cargo/registry/src/github.com-1ecc6299db9ec823/once_cell-1.17.1/src/lib.rs:749:25
stack backtrace:
0: rust_begin_unwind
at /rustc/2c8cc343237b8f7d5a3c3703e3a87f2eb2c54a74/library/std/src/panicking.rs:575:5
1: core::panicking::panic_fmt
at /rustc/2c8cc343237b8f7d5a3c3703e3a87f2eb2c54a74/library/core/src/panicking.rs:64:14
2: orjson::serialize::numpy::is_numpy_scalar
3: orjson::serialize::serializer::pyobject_to_obtype_unlikely
4: <orjson::serialize::serializer::PyObjectSerializer as serde::ser::Serialize>::serialize
5: <orjson::serialize::dict::Dict as serde::ser::Serialize>::serialize
6: <orjson::serialize::serializer::PyObjectSerializer as serde::ser::Serialize>::serialize
7: dumps
8: cfunction_vectorcall_FASTCALL_KEYWORDS
at /Python-3.8.13/build_release/../Objects/methodobject.c:441:24
...
```
This happens no matter whether numpy is installed or not. | closed | 2023-03-27T13:30:08Z | 2023-03-28T15:16:00Z | https://github.com/ijl/orjson/issues/369 | [] | Matthias-Wagner | 2 |
marcomusy/vedo | numpy | 341 | Labelling while plotting time-series data over a network | Hi @marcomusy ,
This is related to the question that was posted [here](https://github.com/marcomusy/vedo/issues/183).
When I run the code below,
```
import networkx as nx
from vedo import *
G = nx.gnm_random_graph(n=10, m=15, seed=1)
nxpos = nx.spring_layout(G)
nxpts = [nxpos[pt] for pt in sorted(nxpos)]
nx_lines = [ (nxpts[i], nxpts[j]) for i, j in G.edges() ]
nx_pts = Points(nxpts, r=12)
nx_edg = Lines(nx_lines).lw(2)
# node values
values = [[1, .80, .10, .79, .70, .60, .75, .78, .65, .90],
[3, .80, .10, .79, .70, .60, .75, .78, .65, .10],
[1, .30, .10, .79, .70, .60, .75, .78, .65, .90]]
time = [0.0, 0.1, 0.2] # in seconds
for val,t in zip(values, time):
nx_pts.cmap('YlGn', val, vmin=0.1, vmax=3)
if t==0:
nx_pts.addScalarBar()
# make a plot title
x0, x1 = nx_pts.xbounds()
y0, y1 = nx_pts.ybounds()
t = Text('My μ-Graph at time='+str(t)+' seconds',
font='BPmonoItalics', justify='center', s=.07, c='lb')
t.pos((x0+x1)/2, y1*1.4)
show(nx_pts, nx_edg, nx_pts.labels('id',c='w'), t,
interactive=True, bg='black')
```
The `text` overlaps

I see this issue in the current version.
Could you please suggest how to update the `text` that corresponds to each time instant and remove the `text` of the previous time step?
| closed | 2021-03-14T06:41:17Z | 2021-03-24T16:35:12Z | https://github.com/marcomusy/vedo/issues/341 | [
"bug",
"fixed"
] | DeepaMahm | 1 |
QuivrHQ/quivr | api | 3,168 | Enabling data ingestion pipelines | For now, the ingestion of new data is managed in `backend/worker/quivr_worker/process/process_file.py` or in `backend/core/quivr_core/brain/brain.py` using the `get_processor_class` in `backend/core/quivr_core/processor/registry.py`.
This approach prevents the construction and use of more complex ingestion pipelines, for instance based on LangGraph.
We would need to restructure the code so that a Data Ingestion pipeline can be build and used by `backend/core/quivr_core/brain/brain.py` or by `backend/api/quivr_api/modules/upload/controller/upload_routes.py` | closed | 2024-09-06T14:41:33Z | 2024-09-06T15:08:03Z | https://github.com/QuivrHQ/quivr/issues/3168 | [
"area: backend"
] | jacopo-chevallard | 3 |
alteryx/featuretools | scikit-learn | 2,133 | Add the ability to specify custom feature column names and save/recreate them during serialization | - As a user, I wish I could use Featuretools to specify custom column names for the feature columns that are generated when a feature matrix is calculated. Column names are automatically generated based on a variety of factors including the primitive name, the base features and any parameters passed to the primitive, but it would be beneficial in some circumstances to allow users to easily override these names with a `Feature.set_feature_names` method to directly set the `Feature._names` attribute, rather than having the names generated.
This setter should include a simple check to confirm that the number of feature names provided matches the number of output columns for the feature. Optionally, the names could be serialized only in situations where the user has set custom names.
#### Code Example
```python
custom_feature_names = ["feat_col1", "feat_col2"]
my_feature.set_feature_names(custom_feature_names)
assert my_feature.get_feature_names == custom_feature_names
ft.save_features([my_feature], "features.json")
deserialized_features = ft.load_features("features.json")
assert deserialized_features[0].get_feature_names == custom_feature_names
```
| closed | 2022-06-22T22:49:49Z | 2022-06-28T15:36:57Z | https://github.com/alteryx/featuretools/issues/2133 | [
"new feature"
] | thehomebrewnerd | 0 |
LibrePhotos/librephotos | django | 631 | Sub folders are not indexed in Nextcloud watch folder |
## 📝 Description of issue:
My nextcloud watch folder contains many sub folders (organized by date, occasion, etc) and LibrePhotos are only importing a few of those folders. So if `/nextcloud` containers `/nextcloud/photoset1` `nextcloud/photoset2` `/nextcloud/photoset3` it is only importing the photos in photoset 1 and 3
## 🔁 How can we reproduce it:
1. connect nextcloud to librephotos
2. choose a scan directory that includes subfolders
3. click scan photos (nextcloud)
4. an incomplete number of folders/photos are infexed
## Please provide additional information:
- 💻 Operating system: Ubuntu 22.04 in a proxmox VM
- ⚙ Architecture (x86 or ARM): x86
- 🔢 Librephotos version:
- 📸 Librephotos installation method (Docker, Kubernetes, .deb, etc.):
* 🐋 If Docker or Kubernets, provide docker-compose image tag: `latest`
- 📁 How is you picture library mounted (Local file system (Type), NFS, SMB, etc.): SMB
- ☁ If you are virtualizing librephotos, Virtualization platform (Proxmox, Xen, HyperV, etc.): proxmox
| open | 2022-09-06T00:39:27Z | 2022-09-08T01:22:56Z | https://github.com/LibrePhotos/librephotos/issues/631 | [
"bug"
] | gdelosre91 | 2 |
skypilot-org/skypilot | data-science | 4,589 | [AZURE] Job and cluster terminated due to a Runtime error after 2 days running | **Versions:**
skypilot==0.7.0
skypilot-nightly==1.0.0.dev20250107
**Description:**
Job and cluster was terminated by Skypilot without any retry due to this runtime error. The controller free disk space, memory and CPU resources are fine.
`(noleak_yolov5mblob_150102025, pid=1267637) I 01-18 00:41:12 utils.py:95] === Checking the job status... ===
(noleak_yolov5mblob_150102025, pid=1267637) I 01-18 00:41:12 utils.py:101] Job status: JobStatus.RUNNING
(noleak_yolov5mblob_150102025, pid=1267637) I 01-18 00:41:12 utils.py:104] ==================================
(noleak_yolov5mblob_150102025, pid=1267637) W 01-18 00:41:43 common_utils.py:404] Caught Failed to parse status from Azure response: None.. Retrying.
(noleak_yolov5mblob_150102025, pid=1267637) W 01-18 00:42:21 common_utils.py:404] Caught Failed to parse status from Azure response: None.. Retrying.
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] Traceback (most recent call last):
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/skypilot-runtime/lib/python3.10/site-packages/sky/backends/backend_utils.py", line 1791, in _query_cluster_status_via_cloud_api
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] node_status_dict = provision_lib.query_instances(
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/skypilot-runtime/lib/python3.10/site-packages/sky/utils/common_utils.py", line 386, in _record
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] return f(*args, **kwargs)
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/skypilot-runtime/lib/python3.10/site-packages/sky/provision/__init__.py", line 52, in _wrapper
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] return impl(*args, **kwargs)
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/skypilot-runtime/lib/python3.10/site-packages/sky/utils/common_utils.py", line 400, in method_with_retries
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] return method(*args, **kwargs)
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/skypilot-runtime/lib/python3.10/site-packages/sky/provision/azure/instance.py", line 984, in query_instances
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] p.starmap(_fetch_and_map_status,
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/miniconda3/envs/skypilot-runtime/lib/python3.10/multiprocessing/pool.py", line 375, in starmap
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] return self._map_async(func, iterable, starmapstar, chunksize).get()
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/miniconda3/envs/skypilot-runtime/lib/python3.10/multiprocessing/pool.py", line 774, in get
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] raise self._value
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/miniconda3/envs/skypilot-runtime/lib/python3.10/multiprocessing/pool.py", line 125, in worker
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] result = (True, func(*args, **kwds))
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/miniconda3/envs/skypilot-runtime/lib/python3.10/multiprocessing/pool.py", line 51, in starmapstar
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] return list(itertools.starmap(args[0], args[1]))
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/skypilot-runtime/lib/python3.10/site-packages/sky/provision/azure/instance.py", line 976, in _fetch_and_map_status
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] status = _get_instance_status(compute_client, node, resource_group)
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/skypilot-runtime/lib/python3.10/site-packages/sky/provision/azure/instance.py", line 740, in _get_instance_status
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] return AzureInstanceStatus.from_raw_states(provisioning_state, None)
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/skypilot-runtime/lib/python3.10/site-packages/sky/provision/azure/instance.py", line 128, in from_raw_states
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] raise exceptions.ClusterStatusFetchingError(
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] sky.exceptions.ClusterStatusFetchingError: Failed to parse status from Azure response: None.
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394]
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] During handling of the above exception, another exception occurred:
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394]
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] Traceback (most recent call last):
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/skypilot-runtime/lib/python3.10/site-packages/sky/jobs/controller.py", line 369, in run
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] succeeded = self._run_one_task(task_id, task)
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/skypilot-runtime/lib/python3.10/site-packages/sky/jobs/controller.py", line 273, in _run_one_task
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] handle) = backend_utils.refresh_cluster_status_handle(
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/skypilot-runtime/lib/python3.10/site-packages/sky/utils/common_utils.py", line 386, in _record
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] return f(*args, **kwargs)
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/skypilot-runtime/lib/python3.10/site-packages/sky/backends/backend_utils.py", line 2328, in refresh_cluster_status_handle
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] record = refresh_cluster_record(
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/skypilot-runtime/lib/python3.10/site-packages/sky/backends/backend_utils.py", line 2290, in refresh_cluster_record
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] return _update_cluster_status_no_lock(cluster_name)
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/skypilot-runtime/lib/python3.10/site-packages/sky/backends/backend_utils.py", line 1959, in _update_cluster_status_no_lock
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] node_statuses = _query_cluster_status_via_cloud_api(handle)
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] File "/home/azureuser/skypilot-runtime/lib/python3.10/site-packages/sky/backends/backend_utils.py", line 1799, in _query_cluster_status_via_cloud_api
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] raise exceptions.ClusterStatusFetchingError(
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394] sky.exceptions.ClusterStatusFetchingError: Failed to query Azure cluster 'noleak-yolov5mblob-150-6l-73' status: [sky.exceptions.ClusterStatusFetchingError] Failed to parse status from Azure response: None.
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:394]
(noleak_yolov5mblob_150102025, pid=1267637) E 01-18 00:42:54 controller.py:397] Unexpected error occurred: [sky.exceptions.ClusterStatusFetchingError] Failed to query Azure cluster 'noleak-yolov5mblob-150-6l-73' status: [sky.exceptions.ClusterStatusFetchingError] Failed to parse status from Azure response: None.
(noleak_yolov5mblob_150102025, pid=1267637) I 01-18 00:42:54 state.py:480] Unexpected error occurred: [sky.exceptions.ClusterStatusFetchingError] Failed to query Azure cluster 'noleak-yolov5mblob-150-6l-73' status: [sky.exceptions.ClusterStatusFetchingError] Failed to parse status from Azure response: None.
(noleak_yolov5mblob_150102025, pid=1267637) I 01-18 00:42:56 controller.py:523] Killing controller process 1267707.
(noleak_yolov5mblob_150102025, pid=1267637) I 01-18 00:42:56 controller.py:531] Controller process 1267707 killed.
(noleak_yolov5mblob_150102025, pid=1267637) I 01-18 00:42:56 controller.py:533] Cleaning up any cluster for job 73.
(noleak_yolov5mblob_150102025, pid=1267637) I 01-18 00:43:01 storage.py:645] Verifying bucket for storage test-bucket
(noleak_yolov5mblob_150102025, pid=1267637) I 01-18 00:43:01 storage.py:997] Storage type StoreType.AZURE already exists under storage account 'sky63566309a1c8c949'.
(noleak_yolov5mblob_150102025, pid=1267637) W 01-18 00:43:06 task.py:153] Docker login configs SKYPILOT_DOCKER_PASSWORD, SKYPILOT_DOCKER_SERVER, SKYPILOT_DOCKER_USERNAME are provided, but no docker image is specified in `image_id`. The login configs will be ignored.
(noleak_yolov5mblob_150102025, pid=1267637) W 01-18 00:43:06 task.py:153] Docker login configs SKYPILOT_DOCKER_PASSWORD, SKYPILOT_DOCKER_SERVER, SKYPILOT_DOCKER_USERNAME are provided, but no docker image is specified in `image_id`. The login configs will be ignored.
(noleak_yolov5mblob_150102025, pid=1267637) W 01-18 00:43:06 task.py:153] Docker login configs SKYPILOT_DOCKER_PASSWORD, SKYPILOT_DOCKER_SERVER, SKYPILOT_DOCKER_USERNAME are provided, but no docker image is specified in `image_id`. The login configs will be ignored.
(noleak_yolov5mblob_150102025, pid=1267637) W 01-18 00:43:06 task.py:153] Docker login configs SKYPILOT_DOCKER_PASSWORD, SKYPILOT_DOCKER_SERVER, SKYPILOT_DOCKER_USERNAME are provided, but no docker image is specified in `image_id`. The login configs will be ignored.
(noleak_yolov5mblob_150102025, pid=1267637) W 01-18 00:43:06 task.py:153] Docker login configs SKYPILOT_DOCKER_PASSWORD, SKYPILOT_DOCKER_SERVER, SKYPILOT_DOCKER_USERNAME are provided, but no docker image is specified in `image_id`. The login configs will be ignored.
(noleak_yolov5mblob_150102025, pid=1267637) W 01-18 00:43:06 task.py:153] Docker login configs SKYPILOT_DOCKER_PASSWORD, SKYPILOT_DOCKER_SERVER, SKYPILOT_DOCKER_USERNAME are provided, but no docker image is specified in `image_id`. The login configs will be ignored.
(noleak_yolov5mblob_150102025, pid=1267637) W 01-18 00:43:06 task.py:153] Docker login configs SKYPILOT_DOCKER_PASSWORD, SKYPILOT_DOCKER_SERVER, SKYPILOT_DOCKER_USERNAME are provided, but no docker image is specified in `image_id`. The login configs will be ignored.
(noleak_yolov5mblob_150102025, pid=1267637) W 01-18 00:43:06 task.py:153] Docker login configs SKYPILOT_DOCKER_PASSWORD, SKYPILOT_DOCKER_SERVER, SKYPILOT_DOCKER_USERNAME are provided, but no docker image is specified in `image_id`. The login configs will be ignored.
(noleak_yolov5mblob_150102025, pid=1267637) W 01-18 00:43:06 task.py:153] Docker login configs SKYPILOT_DOCKER_PASSWORD, SKYPILOT_DOCKER_SERVER, SKYPILOT_DOCKER_USERNAME are provided, but no docker image is specified in `image_id`. The login configs will be ignored.
(noleak_yolov5mblob_150102025, pid=1267637) W 01-18 00:43:06 task.py:153] Docker login configs SKYPILOT_DOCKER_PASSWORD, SKYPILOT_DOCKER_SERVER, SKYPILOT_DOCKER_USERNAME are provided, but no docker image is specified in `image_id`. The login configs will be ignored.
(noleak_yolov5mblob_150102025, pid=1267637) W 01-18 00:43:06 task.py:153] Docker login configs SKYPILOT_DOCKER_PASSWORD, SKYPILOT_DOCKER_SERVER, SKYPILOT_DOCKER_USERNAME are provided, but no docker image is specified in `image_id`. The login configs will be ignored.
(noleak_yolov5mblob_150102025, pid=1267637) W 01-18 00:43:06 task.py:153] Docker login configs SKYPILOT_DOCKER_PASSWORD, SKYPILOT_DOCKER_SERVER, SKYPILOT_DOCKER_USERNAME are provided, but no docker image is specified in `image_id`. The login configs will be ignored.
(noleak_yolov5mblob_150102025, pid=1267637) I 01-18 00:43:19 controller.py:542] Cluster of managed job 73 has been cleaned up.
` | open | 2025-01-18T08:34:16Z | 2025-01-18T08:34:16Z | https://github.com/skypilot-org/skypilot/issues/4589 | [] | rafox2005 | 0 |
Miserlou/Zappa | flask | 1,490 | Allow setting of alias along with version, for use with rollback | ## Context
AWS lambdas allow you to set an `alias` along with `versions`, per the [documentation](https://docs.aws.amazon.com/lambda/latest/dg/aliases-intro.html). Although this may not be useful within the zappa_settings, having a switch like `--alias` during zappa deploy could allow a user to set this field, and reference said alias during a rollback. This could also allow for other useful features, like setting a `default` rollback, if a function fails, but for now, just being able to create the references would be useful.
## Use case
For our projects, I have been using AWS tags to create a tag for the function, setting it to the most current git commit hash, so we can compare the latest commit to the currently deployed commit. It allows us to reference it so that we can directly deploy any previous commit, without being tied to 'how many versions before'. Ideally, setting the aliases could be a better way of handling this use case.
## Optional use case
Regarding this use case, (this would be terribly specific), it could be useful to have aliases set by default to git commit hashes, so they could be referenced, and allow a different type of hash or naming mechanism in zappa_settings. Thus, we could rollback to specific commits by referencing aliases, while the 'versions back' ability would still remain. | open | 2018-04-25T18:31:04Z | 2018-04-25T22:57:25Z | https://github.com/Miserlou/Zappa/issues/1490 | [] | chiqomar | 1 |
plotly/plotly.py | plotly | 5,066 | Colorbar is not showing last tick | Hi,
I have added a horizontal colorbar to a heatmap figure and can't get the last tick to show. Here are some of things I tried and thought are the most logical:
```
colorbar= dict(
orientation='h',
y=1.01,
tickformat=".0%",
tickmode='array',
tickvals=[0, 0.25, 0.5, 0.75, 1],
showticksuffix='last',
),
```
and
```
colorbar= dict(
orientation='h',
y=1.01,
tickformat=".0%",
tickmode='linear',
tick0=0,
dtick=0.25,
nticks=5,
ticklabeloverflow="allow",
),
```
but both yield the same result:

I have also tried moving the bar around the x axis and played with labels and length, but it always seems missing.
Is this a bug?
Plotly: `5.24.1` and Python: `3.12.7` | open | 2025-03-06T11:36:48Z | 2025-03-10T09:19:24Z | https://github.com/plotly/plotly.py/issues/5066 | [
"bug",
"P2"
] | ccpjulia | 2 |
tflearn/tflearn | data-science | 525 | Demonstrate how to use the trained model with new data in examples | This is more of a feature request around examples.
It'd be very useful to extend the examples to demonstrate how one might use the trained models on new data. This is already done for the generative models such as the NLP City Name Generator but when it comes to the classifiers the examples are currently only concerned with creating networks and training. They never show how the model can be used on new data.
For example, the `lstm.py` currently finishes with the line where `mode.fit` is called. What I'm suggesting is to extend the example code to include a case where the model is used on new data.
````python
.....
# Training
model = tflearn.DNN(net, tensorboard_verbose=0)
model.fit(trainX, trainY, validation_set=(testX, testY), show_metric=True,
batch_size=32)
# Use
new_sentence = 'this is a new sentence to be analysed using the trained model`
# code to prepare the new string ....
predictions = model.predict(new_sentence)
print(predictions)
````
Same goes for the computer vision examples.
This can be particularly useful for people (like myself) who are new to machine learning. | open | 2016-12-17T21:10:09Z | 2017-07-02T07:58:21Z | https://github.com/tflearn/tflearn/issues/525 | [
"enhancement",
"contributions welcome"
] | zya | 2 |
httpie/cli | python | 835 | Punycode support | I wanted to use https://twitter.com/rfreebern/status/1214560971185778693 with httpie, alas,
```
» http 👻:6677
http: error: InvalidURL: Failed to parse: http://👻:6677
```
Should resolve to `http://xn--9q8h:6677` | open | 2020-01-10T20:25:26Z | 2021-12-28T12:13:09Z | https://github.com/httpie/cli/issues/835 | [
"enhancement",
"low-priority"
] | forivall | 1 |
davidsandberg/facenet | computer-vision | 411 | How to extract multiple faces in align_dataset_mtcnn.py | I execute:
python src/align/align_dataset_mtcnn.py input output --image_size 160 --margin 32 --random_order
And there are multiple faces in one of those images,but the result only shows one face in each image,how can i modify this code?
Please give me some tips~~~ | closed | 2017-08-06T06:23:22Z | 2017-12-27T00:37:42Z | https://github.com/davidsandberg/facenet/issues/411 | [] | Victoria2333 | 2 |
NullArray/AutoSploit | automation | 556 | Unhandled Exception (534dde169) | Autosploit version: `3.0`
OS information: `Linux-4.15.0-kali2-amd64-x86_64-with-Kali-kali-rolling-kali-rolling`
Running context: `autosploit.py -a -q ****** -C WORKSPACE LHOST 192.168.19.128 -e`
Error meesage: `'access_token'`
Error traceback:
```
Traceback (most recent call):
File "/root/AutoSploit/autosploit/main.py", line 110, in main
AutoSploitParser().single_run_args(opts, loaded_tokens, loaded_exploits)
File "/root/AutoSploit/lib/cmdline/cmd.py", line 207, in single_run_args
save_mode=search_save_mode
File "/root/AutoSploit/api_calls/zoomeye.py", line 88, in search
raise AutoSploitAPIConnectionError(str(e))
errors: 'access_token'
```
Metasploit launched: `False`
| closed | 2019-03-11T08:31:20Z | 2019-04-02T20:25:17Z | https://github.com/NullArray/AutoSploit/issues/556 | [] | AutosploitReporter | 0 |
Yorko/mlcourse.ai | plotly | 22 | Решение вопроса 5.11 не стабильно | Даже при выставленных random_state параметрах, best_score лучшей модели отличается от вариантов в ответах.
Подтверждено запуском несколькими участниками.
Возможно влияют конкретные версии пакетов на расчеты.
Могу приложить ipynb, на котором воспроизводится. | closed | 2017-04-03T08:43:37Z | 2017-04-03T08:52:22Z | https://github.com/Yorko/mlcourse.ai/issues/22 | [] | coodix | 2 |
SYSTRAN/faster-whisper | deep-learning | 989 | Duplicate sentences and missing sentences in large-v3 | Duplicate sentences and missing sentences in large-v3 | open | 2024-09-03T08:37:45Z | 2024-09-03T08:37:45Z | https://github.com/SYSTRAN/faster-whisper/issues/989 | [] | tuocheng0824 | 0 |
ipython/ipython | data-science | 14,719 | deprecated `def embed_kernel` whcih should use directly ipykernel | closed | 2025-02-04T10:47:20Z | 2025-02-12T10:33:58Z | https://github.com/ipython/ipython/issues/14719 | [] | Carreau | 0 |
|
plotly/dash-table | plotly | 379 | Table triggers render on mouse move | Since the tooltip feature addition, the table is re-rendering on each mouse move. While it's mostly cached an unexpensive vs. an actual full re-render, this still takes ~15ms and happens extremely often.
- there's no need to re-render the table when moving inside a cell, a normal debounce for activating the tooltip will do
- there's no need to do this if the table doesn't have tooltips (or better yet, if the cells involved do not have tooltips) | closed | 2019-02-16T11:29:39Z | 2019-07-09T17:38:20Z | https://github.com/plotly/dash-table/issues/379 | [
"dash-type-bug"
] | Marc-Andre-Rivet | 2 |
graphql-python/graphene-django | graphql | 547 | Retrieve object primary keys with Relay | Hello,
Using Relay, the `id` field is not the primary key of the ingredients objects in the database. Is there a way to get it back ?
```
query {
allIngredients {
edges {
node {
id,
name
}
}
}
}
```
Thanks, | closed | 2018-10-30T16:58:18Z | 2019-04-26T11:10:10Z | https://github.com/graphql-python/graphene-django/issues/547 | [] | JBPressac | 1 |
allenai/allennlp | nlp | 4,949 | Unexpected keyword arguments with textual entailment | Following the code sample at https://demo.allennlp.org/textual-entailment, I stumbled across an issue (discussed in #4192 ), but has not been solved:
```python
pip install allennlp==1.0.0 allennlp-models==1.0.0
from allennlp.predictors.predictor import Predictor
import allennlp_models.tagging
predictor = Predictor.from_path("https://storage.googleapis.com/allennlp-public-models/snli-roberta-2020-07-29.tar.gz")
predictor.predict(
premise="Two women are wandering along the shore drinking iced tea.",
hypothesis="Two women are sitting on a blanket near some rocks talking about politics."
)
```
And it returns an error:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-33-9b5a14a8a794> in <module>()
1 predictor.predict(
2 premise="Two women are wandering along the shore drinking iced tea.",
----> 3 hypothesis="Two women are sitting on a blanket near some rocks talking about politics."
4 )
TypeError: predict() got an unexpected keyword argument 'premise'
```
It should just return the values. | closed | 2021-02-01T13:58:03Z | 2021-04-02T17:06:31Z | https://github.com/allenai/allennlp/issues/4949 | [
"bug"
] | jackcrane | 12 |
strawberry-graphql/strawberry | graphql | 3,779 | Type-safe "optional-nullable" fields | ### Preface
it is a common practice in strawberry that when your data layer have
an optional field i.e
```py
class Person:
name: str
phone: str | None = None
```
and you want to update it you would use `UNSET` in the mutation input
in order to check whether this field provided by the client or not like so:
```py
@strawberry.input
class UpdatePersonInput:
id: strawberry.ID
name: str| None
phone: str | None = UNSET
@strawberry.mutation
def update_person(input: UpdatePersonInput) -> Person:
inst = service.get_person(input.id)
if name := input.name:
inst.name = name
if input.phone is not UNSET:
inst.phone = input.phone # ❌ not type safe
service.save(inst)
```
Note that this is not an optimization rather a business requirement.
if the user wants to nullify the phone it won't be possible other wise
OTOH you might nullify the phone unintentionally.
This approach can cause lots of bugs since you need to **remember** that you have
used `UNSET` and to handle this correspondingly.
Since strawberry claims to
> Strawberry leverages Python type hints to provide a great developer experience while creating GraphQL Libraries.
it is only natural for us to provide a typesafe way to mitigate this.
### Proposal
The `Option` type.which will require only this minimal implementation
```py
import dataclasses
@dataclasses.dataclass
class Some[T]:
value: T
def some(self) -> Some[T | None] | None:
return self
@dataclasses.dataclass
class Nothing[T]:
def some(self) -> Some[T | None] | None:
return None
Maybe[T] = Some[T] | Nothing[T]
```
and this is how you'd use it
```py
@strawberry.input
class UpdatePersonInput:
id: strawberry.ID
name: str| None
phone: Maybe[str | None]
@strawberry.mutation
def update_person(input: UpdatePersonInput) -> Person:
inst = service.get_person(input.id)
if name := input.name:
inst.name = name
if phone := input.phone.some():
inst.phone = phone.value # ✅ type safe
service.save(inst)
```
Currently if you want to know if a field was provided
### Backward compat
`UNSET` can remain as is for existing codebases.
`Option` would be handled separately.
### which `Option` library should we use?
1. **Don't use any library craft something minimal our own** as suggested above.
2. ** use something existing**
The sad truth is that there are no well-maintained libs in the ecosystem.
Never the less it is not hard to maintain something just for strawberry since the implementation
is rather straight forward and not much features are needed. we can fork either
- https://github.com/rustedpy/maybe
- https://github.com/MaT1g3R/option
and just forget about it.
3. **allow users to decide**
```py
# before anything
strawberry.register_option_type((MyOptionType, NOTHING))
```
then strawberry could use that and you could use whatever you want.
- [ ] Core functionality
- [ ] Alteration (enhancement/optimization) of existing feature(s)
- [x] New behavior
| open | 2025-02-12T06:43:17Z | 2025-03-23T13:31:33Z | https://github.com/strawberry-graphql/strawberry/issues/3779 | [] | nrbnlulu | 16 |
FactoryBoy/factory_boy | django | 446 | SelfAttributes Fail When Called Through PostGeneration functions | I have a simplified set of factory definitions below. If i try to create a WorkOrderKit object, via WorkOrderKitFactory(), it successfully generates a workorderkit with factory_boy 2.6.1 but fails with 2.9.2. I'm wondering if this is a bug or if it worked unintentionally before and this is the intended behavior. (If it is the intended behavior, do you have any suggestions on achieving this behavior now?)
The whole example django project: https://bitbucket.org/marky1991/factory-test/ .
If you would like to test it yourself, checkout the project, setup the database, run setup_db.psql, and then run factory_test/factory_test/factory_test_app/test.py.
Please let me know if anything is unclear or if you have any questions.
```python
import factory
from factory.declarations import SubFactory, SelfAttribute
from factory.fuzzy import FuzzyText, FuzzyChoice
from factory_test_app import models
class ItemFactory(factory.DjangoModelFactory):
class Meta:
model = models.Item
barcode = factory.fuzzy.FuzzyText(length=10)
class OrderHdrFactory(factory.DjangoModelFactory):
order_nbr = factory.fuzzy.FuzzyText(length=20)
class Meta:
model = models.OrderHdr
@factory.post_generation
def order_dtls(self, create, extracted, **kwargs):
if not create:
return
if extracted is not None:
for order_dtl in extracted:
order_dtl.order = self
author.save()
return
for _ in range(5):
OrderDtlFactory(order=self,
**kwargs)
class WorkOrderKitFactory(factory.DjangoModelFactory):
class Meta:
model = models.WorkOrderKit
work_order_nbr = factory.fuzzy.FuzzyText(length=20)
item = SubFactory(ItemFactory)
sales_order = SubFactory(OrderHdrFactory,
order_dtls__item=SelfAttribute("..item"))
class OrderDtlFactory(factory.DjangoModelFactory):
class Meta:
model = models.OrderDtl
order = SubFactory(OrderHdrFactory,
order_dtls=[])
item = SubFactory(ItemFactory)
```
The traceback in 2.9.1:
```
Traceback (most recent call last):
File "factory_test_app/test.py", line 8, in <module>
kit = WorkOrderKitFactory()
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/base.py", line 46, in __call__
return cls.create(**kwargs)
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/base.py", line 568, in create
return cls._generate(enums.CREATE_STRATEGY, kwargs)
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/base.py", line 505, in _generate
return step.build()
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/builder.py", line 275, in build
step.resolve(pre)
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/builder.py", line 224, in resolve
self.attributes[field_name] = getattr(self.stub, field_name)
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/builder.py", line 366, in __getattr__
extra=declaration.context,
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/declarations.py", line 306, in evaluate
return self.generate(step, defaults)
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/declarations.py", line 395, in generate
return step.recurse(subfactory, params, force_sequence=force_sequence)
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/builder.py", line 236, in recurse
return builder.build(parent_step=self, force_sequence=force_sequence)
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/builder.py", line 296, in build
context=postgen_context,
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/declarations.py", line 570, in call
instance, create, context.value, **context.extra)
File "/home/lgfdev/factory_test/factory_test/factory_test_app/factories.py", line 29, in order_dtls
**kwargs)
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/base.py", line 46, in __call__
return cls.create(**kwargs)
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/base.py", line 568, in create
return cls._generate(enums.CREATE_STRATEGY, kwargs)
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/base.py", line 505, in _generate
return step.build()
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/builder.py", line 275, in build
step.resolve(pre)
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/builder.py", line 224, in resolve
self.attributes[field_name] = getattr(self.stub, field_name)
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/builder.py", line 366, in __getattr__
extra=declaration.context,
File "/home/lgfdev/ve_factory_test/local/lib/python2.7/site-packages/factory/declarations.py", line 137, in evaluate
target = step.chain[self.depth - 1]
IndexError: tuple index out of range
``` | open | 2018-01-30T18:24:43Z | 2019-09-16T18:17:57Z | https://github.com/FactoryBoy/factory_boy/issues/446 | [
"Bug"
] | marky1991 | 8 |
WZMIAOMIAO/deep-learning-for-image-processing | pytorch | 747 | 高版本的torch报错未发现torch._six | **System information**
* Have I writtenTraceback (most recent call last):
File "C:\Work\Pycharm\faster_rcnn\train_mobilenetv2.py", line 11, in <module>
from train_utils import GroupedBatchSampler, create_aspect_ratio_groups
File "C:\Work\Pycharm\faster_rcnn\train_utils\__init__.py", line 4, in <module>
from .coco_eval import CocoEvaluator
File "C:\Work\Pycharm\faster_rcnn\train_utils\coco_eval.py", line 7, in <module>
import torch._six
ModuleNotFoundError: No module named 'torch._six'
我的torch版本是2.0.1
| open | 2023-07-18T08:18:50Z | 2023-08-11T14:25:40Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/747 | [] | water107 | 3 |
PaddlePaddle/ERNIE | nlp | 186 | window上用BERT在XNLI任务上Fine-tuning报错 | 在LARK/BERT目录中,执行python -u run_classifier.py --task_name XNLI --use_cuda true --do_train true --do_val true --do_test true --batch_size 8192 --in_tokens true --init_pretraining_params chinese_L-12_H-768_A-12/params --data_dir ./XNLI --checkpoints ./XNLI_checkpoints --save_steps 1000 --weight_decay 0.01 --warmup_proportion 0.0 --validation_steps 25 --epoch 1 --max_seq_len 512 --bert_config_path chinese_L-12_H-768_A-12/bert_config.json --learning_rate 1e-4 --skip_steps 10 --random_seed 1,使用BERT在NLP任务上Fine-tuning,报错信息如下:

| closed | 2019-07-01T12:49:30Z | 2020-05-28T12:53:02Z | https://github.com/PaddlePaddle/ERNIE/issues/186 | [
"wontfix"
] | JiaXiao243 | 3 |
capitalone/DataProfiler | pandas | 1,055 | Support for PySpark | **Is your feature request related to a problem? Please describe.**
Hello, I see that this package supports Pandas, but does it support pyspark? I'd like to use this on large datasets and pandas is insufficient for my use case.
**Describe the outcome you'd like:**
I'd like to be able to run this on large datasets over 10k+ rows. Do you think this would be possible?
| open | 2023-10-26T17:46:23Z | 2023-11-20T14:57:27Z | https://github.com/capitalone/DataProfiler/issues/1055 | [
"New Feature"
] | gracemiguel | 2 |
ymcui/Chinese-LLaMA-Alpaca-2 | nlp | 386 | 指令精调之后,除了指令里面的问题能回答,其他回答全是none | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 我已阅读[项目文档](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki)和[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案。
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.cpp)、[LangChain](https://github.com/hwchase17/langchain)、[text-generation-webui](https://github.com/oobabooga/text-generation-webui)等,同时建议到对应的项目中查找解决方案。
### 问题类型
模型训练与精调
### 基础模型
Chinese-Alpaca-2 (7B/13B)
### 操作系统
Linux
### 详细描述问题
对Chinese-llama-alpaca2-hf进行指令精调,后将得到的lora与Chinese-llama-alpaca2-hf进行合并,但只能回答指令精调中的内容,其他任何语句的回答均为none
```
# 请在此处粘贴运行代码(请粘贴在本代码块里)
``lr=1e-4
lora_rank=64
lora_alpha=128
lora_trainable="q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj"
modules_to_save="embed_tokens,lm_head"
lora_dropout=0.05
pretrained_model=/home/sensorweb/lijialin/llm_Chinese/Chinese-LLaMA-Alpaca-2/chinese-alpaca-2-7b-hf
chinese_tokenizer_path=/home/sensorweb/lijialin/llm_Chinese/Chinese-LLaMA-Alpaca-2/chinese-alpaca-2-7b-hf
dataset_dir=/home/sensorweb/lijialin/llm_Chinese/Chinese-LLaMA-Alpaca-2/data_final/train
per_device_train_batch_size=1
per_device_eval_batch_size=1
gradient_accumulation_steps=8
max_seq_length=512
output_dir=/home/sensorweb/lijialin/llm_Chinese/Chinese-LLaMA-Alpaca-2/base_sft/lora
peft_model=/home/sensorweb/lijialin/llm_Chinese/Chinese-LLaMA-Alpaca-2/chinese-alpaca-2-lora-7b
validation_file=/home/sensorweb/lijialin/llm_Chinese/Chinese-LLaMA-Alpaca-2/data_final/eval/eval.json
deepspeed_config_file=ds_zero2_no_offload.json
torchrun --nnodes 1 --nproc_per_node 1 run_clm_sft_with_peft.py \
--deepspeed ${deepspeed_config_file} \
--model_name_or_path ${pretrained_model} \
--tokenizer_name_or_path ${chinese_tokenizer_path} \
--dataset_dir ${dataset_dir} \
--per_device_train_batch_size ${per_device_train_batch_size} \
--per_device_eval_batch_size ${per_device_eval_batch_size} \
--do_train \
--do_eval \
--seed $RANDOM \
--fp16 \
--num_train_epochs 1 \
--lr_scheduler_type cosine \
--learning_rate ${lr} \
--warmup_ratio 0.03 \
--weight_decay 0 \
--logging_strategy steps \
--logging_steps 10 \
--save_strategy steps \
--save_total_limit 3 \
--evaluation_strategy steps \
--eval_steps 100 \
--save_steps 200 \
--gradient_accumulation_steps ${gradient_accumulation_steps} \
--preprocessing_num_workers 8 \
--max_seq_length ${max_seq_length} \
--output_dir ${output_dir} \
--overwrite_output_dir \
--ddp_timeout 30000 \
--logging_first_step True \
--torch_dtype float16 \
--validation_file ${validation_file} \
--peft_path ${peft_model} \
--load_in_kbits 16
### 依赖情况(代码类问题务必提供)
```
# 请在此处粘贴依赖情况(请粘贴在本代码块里)
```
### 运行日志或截图
```
# 请在此处粘贴运行日志(请粘贴在本代码块里)
```
history: [[ 'nihao', None]]Input length: 38 history: [['nihao', 'None' ],['*SBAS#InSAR可观测什么事件',"形变速率'],['事件',"滑坡形变特征']
| closed | 2023-11-02T12:58:57Z | 2023-11-28T08:42:55Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/issues/386 | [
"stale"
] | Rainlv | 7 |
slackapi/bolt-python | fastapi | 337 | How do I subscribe to block_action using bolt? | How do I subscribe to `block_action` using bolt?
I've found the decorator in the source code, but there are no comprehensive examples and the docs omit it. The decorator takes constrains argument, what do I pass there? I tried "button" and the value that I use for my action blocks, but nothing changes. I am just frustrated at this point.
What I am trying to do:
I am trying to open a modal when user clicks on a button in an ephemeral message.
| closed | 2021-05-11T02:37:46Z | 2021-05-12T22:07:00Z | https://github.com/slackapi/bolt-python/issues/337 | [
"question"
] | DataGreed | 6 |
autogluon/autogluon | scikit-learn | 4,095 | [BUG]ValueError: Model Dlinear is not supported yet. | **Bug Report Checklist**
<!-- Please ensure at least one of the following to help the developers troubleshoot the problem: -->
- [ ] I provided code that demonstrates a minimal reproducible example. <!-- Ideal, especially via source install -->
- [ ] I confirmed bug exists on the latest mainline of AutoGluon via source install. <!-- Preferred -->
- [ ] I confirmed bug exists on the latest stable version of AutoGluon. <!-- Unnecessary if prior items are checked -->
**Describe the bug**
ValueError: Model Dlinear is not supported yet.
**Expected behavior**
<!-- A clear and concise description of what you expected to happen. -->
**To Reproduce**
<!-- A minimal script to reproduce the issue. Links to Colab notebooks or similar tools are encouraged.
```
predictor = TimeSeriesPredictor(
quantile_levels=None,
prediction_length=prediction_length,
eval_metric="RMSE",
freq="15T",
path=f"{station}-{prediction_length}_ahead-15min/" + pd.Timestamp.now().strftime("%Y_%m_%d_%H_%M_%S"),
known_covariates_names=known_covariates_name,
target="power",
)
predictor.fit(
train_data,
# presets="best_quality",
hyperparameters={
"DlinearModel": {}
},
num_val_windows=3,
refit_every_n_windows=1,
refit_full=True,
)
```
**Screenshots / Logs**
<!-- If applicable, add screenshots or logs to help explain your problem. -->
**Installed Versions**
<!-- Please run the following code snippet: -->
gluonts 0.14.4
autogluon 1.0.0
autogluon.common 1.0.0
autogluon.core 1.0.0
autogluon.features 1.0.0
autogluon.multimodal 1.0.0
autogluon.tabular 1.0.0
autogluon.timeseries 1.0.0
Python 3.10.14
</details>
| closed | 2024-04-13T13:09:45Z | 2024-04-15T19:53:01Z | https://github.com/autogluon/autogluon/issues/4095 | [
"bug: unconfirmed",
"Needs Triage"
] | isCopyman | 2 |
zalandoresearch/fashion-mnist | computer-vision | 158 | Cant find the csv file of the data set | open | 2020-03-26T13:47:35Z | 2020-04-01T03:34:23Z | https://github.com/zalandoresearch/fashion-mnist/issues/158 | [] | jayanaubale633 | 2 |
|
horovod/horovod | tensorflow | 3,260 | Building Horovod 0.23.0 w HOROVOD_GPU=CUDA on a system with ROCM also installed-- Build tries to use ROCM too | **Environment:**
1. Framework: TensorFlow, PyTorch
2. Framework version: 2.7.0, 1.9.1
3. Horovod version: 0.23.0
4. MPI version: MPICH 3.4.2
5. CUDA version: 11.4.2
6. NCCL version: 2.11.4
7. Python version: 3.9.7
8. Spark / PySpark version: NA
9. Ray version: NA
10. OS and version: Ubuntu 20.04
11. GCC version: GCC 9.3.0
12. CMake version: 3.21.4
**Bug report:**
Trying to build Horovod w/ CUDA, on a system that also has ROCM 4.3.1 installed, and despite setting `HOROVOD_GPU=CUDA` it looks like the install is trying to build against ROCM too:
```
$> HOROVOD_WITH_TENSORFLOW=1 \
HOROVOD_WITH_PYTORCH=1 \
HOROVOD_WITH_MPI=1 \
HOROVOD_GPU_OPERATIONS=NCCL \
HOROVOD_BUILD_CUDA_CC_LIST=35,70,80 \
HOROVOD_BUILD_ARCH_FLAGS="-march=x86-64" \
HOROVOD_CUDA_HOME=/usr/local/cuda-11.4 \
HOROVOD_GPU=CUDA \
pip install horovod[tensorflow,pytorch]
...
[ 74%] Building CXX object horovod/torch/CMakeFiles/pytorch.dir/__/common/common.cc.o
cd /tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/build/temp.linux-x86_64-3.9/RelWithDebInfo/horovod/torch && /usr/bin/c++ -DEIGEN_MPL2_ONLY=1 -DHAVE_CUDA=1 -DHAVE_GLOO=1 -DHAVE_GPU=1 -DHAVE_MPI=1 -DHAVE_NCCL=1 -DHAVE_NVTX=1 -DHAVE_ROCM=1 -DHOROVOD_GPU_ALLGATHER=78 -DHOROVOD_GPU_ALLREDUCE=78 -DHOROVOD_GPU_ALLTOALL=78 -DHOROVOD_GPU_BROADCAST=78 -DTORCH_API_INCLUDE_EXTENSION_H=1 -DTORCH_VERSION=1009001000 -Dpytorch_EXPORTS -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/HTTPRequest/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/boost/assert/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/boost/config/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/boost/core/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/boost/detail/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/boost/iterator/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/boost/lockfree/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/boost/mpl/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/boost/parameter/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/boost/predef/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/boost/preprocessor/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/boost/static_assert/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/boost/type_traits/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/boost/utility/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/lbfgs/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/gloo -I/usr/local/miniconda3/envs/cuda/lib/python3.9/site-packages/tensorflow/include -I/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/third_party/flatbuffers/include -isystem /spack/opt/spack/linux-ubuntu20.04-x86_64/gcc-9.3.0/mpich-3.4.2-qfhacakdkcdmvjzstuukmphjr4khbdgn/include -isystem /usr/local/cuda-11.4/include -isystem /usr/local/miniconda3/envs/cuda/lib/python3.9/site-packages/torch/include -isystem /usr/local/miniconda3/envs/cuda/lib/python3.9/site-packages/torch/include/torch/csrc/api/include -isystem /usr/local/miniconda3/envs/cuda/lib/python3.9/site-packages/torch/include/TH -isystem /usr/local/miniconda3/envs/cuda/lib/python3.9/site-packages/torch/include/THC -isystem /usr/local/miniconda3/envs/cuda/include/python3.9 No ROCm runtime is found, using ROCM_HOME='/opt/rocm-4.3.1' -MD -MT horovod/torch/CMakeFiles/pytorch.dir/__/common/common.cc.o -MF CMakeFiles/pytorch.dir/__/common/common.cc.o.d -o CMakeFiles/pytorch.dir/__/common/common.cc.o -c /tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/horovod/common/common.cc
c++: error: No: No such file or directory
c++: error: ROCm: No such file or directory
c++: error: runtime: No such file or directory
c++: error: is: No such file or directory
c++: error: found,: No such file or directory
c++: error: using: No such file or directory
c++: error: ROCM_HOME=/opt/rocm-4.3.1: No such file or directory
make[2]: *** [horovod/torch/CMakeFiles/pytorch.dir/build.make:76: horovod/torch/CMakeFiles/pytorch.dir/__/common/common.cc.o] Error 1
make[2]: Leaving directory '/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/build/temp.linux-x86_64-3.9/RelWithDebInfo'
make[1]: *** [CMakeFiles/Makefile2:446: horovod/torch/CMakeFiles/pytorch.dir/all] Error 2
make[1]: Leaving directory '/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/build/temp.linux-x86_64-3.9/RelWithDebInfo'
make: *** [Makefile:136: all] Error 2
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/setup.py", line 167, in <module>
setup(name='horovod',
File "/usr/local/miniconda3/envs/cuda/lib/python3.9/site-packages/setuptools/__init__.py", line 153, in setup
return distutils.core.setup(**attrs)
File "/usr/local/miniconda3/envs/cuda/lib/python3.9/distutils/core.py", line 148, in setup
dist.run_commands()
File "/usr/local/miniconda3/envs/cuda/lib/python3.9/distutils/dist.py", line 966, in run_commands
self.run_command(cmd)
File "/usr/local/miniconda3/envs/cuda/lib/python3.9/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/usr/local/miniconda3/envs/cuda/lib/python3.9/site-packages/wheel/bdist_wheel.py", line 299, in run
self.run_command('build')
File "/usr/local/miniconda3/envs/cuda/lib/python3.9/distutils/cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "/usr/local/miniconda3/envs/cuda/lib/python3.9/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/usr/local/miniconda3/envs/cuda/lib/python3.9/distutils/command/build.py", line 135, in run
self.run_command(cmd_name)
File "/usr/local/miniconda3/envs/cuda/lib/python3.9/distutils/cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "/usr/local/miniconda3/envs/cuda/lib/python3.9/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/usr/local/miniconda3/envs/cuda/lib/python3.9/site-packages/setuptools/command/build_ext.py", line 79, in run
_build_ext.run(self)
File "/usr/local/miniconda3/envs/cuda/lib/python3.9/distutils/command/build_ext.py", line 340, in run
self.build_extensions()
File "/tmp/pip-install-bs7lwyxo/horovod_9543edab589b4acfbafcd2a92c02c4c3/setup.py", line 100, in build_extensions
subprocess.check_call([cmake_bin, '--build', '.'] + cmake_build_args,
File "/usr/local/miniconda3/envs/cuda/lib/python3.9/subprocess.py", line 373, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['cmake', '--build', '.', '--config', 'RelWithDebInfo', '--', 'VERBOSE=1']' returned non-zero exit status 2.
----------------------------------------
ERROR: Failed building wheel for horovod
Running setup.py clean for horovod
Failed to build horovod
...
```
| open | 2021-11-05T15:42:58Z | 2021-11-16T12:24:57Z | https://github.com/horovod/horovod/issues/3260 | [
"bug"
] | eugeneswalker | 1 |
zappa/Zappa | django | 397 | [Migrated] When no aws_environment_variables are defined in settings, a zappa update will delete any vars defined in the console | Originally from: https://github.com/Miserlou/Zappa/issues/1010 by [seanpaley](https://github.com/seanpaley)
<!--- Provide a general summary of the issue in the Title above -->
## Context
Title says it - when I have no aws_environment_variables in my zappa_settings.json, any env vars I set manually in the Lambda console disappear on zappa update. If I define one var in the aws_environment_variables dictionary, the vars I manually set persist after an update.
## Expected Behavior
Manually defined vars don't get deleted.
## Actual Behavior
They get deleted.
## Possible Fix
<!--- Not obligatory, but suggest a fix or reason for the bug -->
## Steps to Reproduce
<!--- Provide a link to a live example, or an unambiguous set of steps to -->
<!--- reproduce this bug include code to reproduce, if relevant -->
## Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* Zappa version used: 43.0
* Operating System and Python version: mac os, python 2.7.13
* The output of `pip freeze`:
argcomplete==1.8.2
base58==0.2.4
boto3==1.4.4
botocore==1.5.40
certifi==2017.4.17
chardet==3.0.4
click==6.7
docutils==0.13.1
durationpy==0.4
future==0.16.0
futures==3.1.1
hjson==2.0.7
idna==2.5
jmespath==0.9.3
kappa==0.6.0
lambda-packages==0.16.1
placebo==0.8.1
psycopg2==2.7.1
python-dateutil==2.6.1
python-slugify==1.2.4
PyYAML==3.12
requests==2.18.1
s3transfer==0.1.10
six==1.10.0
toml==0.9.2
tqdm==4.14.0
troposphere==1.9.4
Unidecode==0.4.21
urllib3==1.21.1
Werkzeug==0.12
wsgi-request-logger==0.4.6
zappa==0.43.0
* Your `zappa_settings.py`:
| closed | 2021-02-20T08:27:54Z | 2024-04-13T15:37:14Z | https://github.com/zappa/Zappa/issues/397 | [
"no-activity",
"auto-closed"
] | jneves | 2 |
Lightning-AI/pytorch-lightning | data-science | 20,511 | Cannot import OptimizerLRSchedulerConfig or OptimizerLRSchedulerConfigDict | ### Bug description
Since I bumped up `lightning` to `2.5.0`, the `configure_optimizers` has been failing the type checker. I saw that `OptimizerLRSchedulerConfig` had been replaced with `OptimizerLRSchedulerConfigDict`, but I cannot import any of them.
### What version are you seeing the problem on?
v2.5
### How to reproduce the bug
```python
import torch
import pytorch_lightning as pl
from lightning.pytorch.utilities.types import OptimizerLRSchedulerConfigDict
from torch.optim.lr_scheduler import ReduceLROnPlateau
class Model(pl.LightningModule):
...
def configure_optimizers(self) -> OptimizerLRSchedulerConfigDict:
optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
scheduler = ReduceLROnPlateau(
optimizer, mode="min", factor=0.1, patience=20, min_lr=1e-6
)
return {
"optimizer": optimizer,
"lr_scheduler": {
"scheduler": scheduler,
"monitor": "val_loss",
"interval": "epoch",
"frequency": 1,
},
}
```
### Error messages and logs
```
In [2]: import lightning
In [3]: lightning.__version__
Out[3]: '2.5.0'
In [4]: from lightning.pytorch.utilities.types import OptimizerLRSchedulerConfigDict
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
Cell In[4], line 1
----> 1 from lightning.pytorch.utilities.types import OptimizerLRSchedulerConfigDict
ImportError: cannot import name 'OptimizerLRSchedulerConfigDict' from 'lightning.pytorch.utilities.types' (/home/test/.venv/lib/python3.11/site-packages/lightning/pytorch/utilities/types.py)
In [5]: from lightning.pytorch.utilities.types import OptimizerLRSchedulerConfig
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
Cell In[5], line 1
----> 1 from lightning.pytorch.utilities.types import OptimizerLRSchedulerConfig
ImportError: cannot import name 'OptimizerLRSchedulerConfig' from 'lightning.pytorch.utilities.types' (/home/test/.venv/lib/python3.11/site-packages/lightning/pytorch/utilities/types.py)
```
### Environment
<details>
<summary>Current environment</summary>
```
#- PyTorch Lightning Version (e.g., 2.5.0):
#- PyTorch Version (e.g., 2.5):
#- Python version (e.g., 3.12):
#- OS (e.g., Linux):
#- CUDA/cuDNN version:
#- GPU models and configuration:
#- How you installed Lightning(`conda`, `pip`, source):
```
</details>
### More info
_No response_ | closed | 2024-12-20T15:18:27Z | 2024-12-21T01:42:58Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20511 | [
"bug",
"ver: 2.5.x"
] | zordi-youngsun | 4 |
alpacahq/alpaca-trade-api-python | rest-api | 465 | get_portfolio_history TypeError:: Cannot convert Float64Index to dtype datetime64[ns] | I've used this for months to check my account's current profit/loss % for the day:
```
# Connect to the Alpaca API
alpaca = tradeapi.REST(API_KEY, API_SECRET, APCA_API_BASE_URL, 'v2')
# Define our destination time zone
tz_dest = pytz.timezone('America/New_York')
# Get the current date
today = datetime.datetime.date(datetime.datetime.now(tz_dest))
# Get today's account history
history = alpaca.get_portfolio_history(date_start=today, timeframe = '1D', extended_hours = False).df
# Format profit/loss as a string and percent
profit_pct = str("{:.2%}".format(history.profit_loss_pct[0]))
```
As of today though, I'm getting this error when I try to put any date in the "date_start" command of the get_portfolio_history function. I haven't been able to find a date format it'll take yet. I keep hitting this error:
**TypeError: Cannot convert Float64Index to dtype datetime64[ns]; integer values are required for conversion**
It seems that the error from these two earlier issues has re-surfaced. Help?
https://github.com/alpacahq/alpaca-trade-api-python/issues/62#issue-422913769
https://github.com/alpacahq/alpaca-trade-api-python/issues/53#issue-405386294 | closed | 2021-07-07T16:08:37Z | 2022-01-04T02:15:12Z | https://github.com/alpacahq/alpaca-trade-api-python/issues/465 | [] | BradleyRR | 3 |
eamigo86/graphene-django-extras | graphql | 21 | How to add request.user to serializer? | The codes seems not passing context to serializer when it's called.
`serializer = cls._meta.serializer_class(data=new_obj)`
I would like to add `request.user` when it tries to save, I couldn't find a way to do it.
Anyone has done this before? | closed | 2018-01-26T09:54:55Z | 2018-01-29T18:45:43Z | https://github.com/eamigo86/graphene-django-extras/issues/21 | [] | legshort | 1 |
hbldh/bleak | asyncio | 1,076 | micro:bit disconnected after pairing (In JustWorks setting) and cannot connect to micro:bit again | * bleak version: 0.18.1
* Python version: 3.10.7
* Operating System: Windows10
### Description
I want to connect to micro:bit using bleak's api in windows 10 OS. And use the
> BleakClient.write_gatt_char
to send messge to the micro:bit Event Service (UUID: E95D93AF-251D-470A-A062-FA1922DFA9A8) (Which have Characteristic: 'E95D5404-251D-470A-A062-FA1922DFA9A8' to trigger the event I've been written and downloaded to micro:bit). Unfortunately I found out that I must paired with microbit in order to send message from my computer. So I used:
```
async with BleakClient(device,disconnected_callback=disconnected_callback,timeout=15.0) as client:
print("Pairing Client")
await client.pair()
....
codes that use to send message
```
to pair with micro:bit. I found out that micro:bit is successfully connect and pair with my computer. But after pairing finished, disconnected_callback called out (Though I saw it is still connected On Windows Bluetooth setting)

After that I add connect command after paired, and it always failed with **TimeoutError**:
```
async with BleakClient(device,disconnected_callback=disconnected_callback,timeout=15.0) as client:
print("Pairing Client")
await pairClient(client)
await asyncio.sleep(10)
print("Reconnecting")
print(f'is connect? {client.is_connected}')
if not client.is_connected:
await client.connect()
```
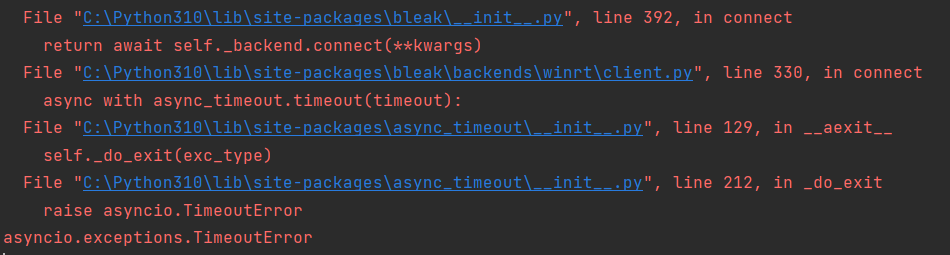
### What I Did
This is an example code that micro:bit used
https://makecode.microbit.org/_1yFbXM6TyPxT
This is an brief python code (minimal code that can run) that I used to connect and pair with micro:bit :
```
import time
import asyncio
import logging
from bleak import BleakClient, BLEDevice, BleakGATTCharacteristic
from bleak import BleakScanner
#device pair tag
deviceChar = "zipeg"
disconnected_event = asyncio.Event()
def disconnected_callback(client):
print("Disconnected callback called!")
disconnected_event.set()
async def scanWithNamePart(wanted_name_part):
'''
Find device by specific string
:param wanted_name_part:
:return:
'''
device = await BleakScanner.find_device_by_filter(
lambda d,ad: (wanted_name_part.lower() in d.name or wanted_name_part.lower() in d.name.lower()) if d.name is not None else False
)
print(device)
device_data = device
return device_data
async def mainCheck():
#main function
print("Discover device by name:")
device: BLEDevice = await scanWithNamePart(deviceChar)
if device is not None:
print("Device Found!")
else:
print(f"Failed to discover device with string: {deviceChar}")
return 0
async with BleakClient(device,disconnected_callback=disconnected_callback,timeout=15.0) as client:
print("Pairing Client")
await client.pair()
await asyncio.sleep(10)
print(f'is connect? {client.is_connected}')
if not client.is_connected:
print("Reconnecting")
await client.connect()
```
And the running result from Terminal:
'''
Discover device by name:
D1:09:0B:5C:D7:FC: BBC micro:bit [zipeg]
Device Found!
Pairing Client
INFO:bleak.backends.winrt.client:Services resolved for BleakClientWinRT (D1:09:0B:5C:D7:FC)
INFO:bleak.backends.winrt.client:Paired to device with protection level 1.
Disconnected callback called!
Reconnecting
is connect? False
Disconnected callback called!
Traceback (most recent call last):
File "C:\Python310\lib\site-packages\bleak\backends\winrt\client.py", line 331, in connect
await event.wait()
File "C:\Python310\lib\asyncio\locks.py", line 214, in wait
await fut
asyncio.exceptions.CancelledError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\...\microbit_control.py", line 271, in <module>
asyncio.run(mainCheck())
File "C:\Python310\lib\asyncio\runners.py", line 44, in run
return loop.run_until_complete(main)
File "C:\Python310\lib\asyncio\base_events.py", line 646, in run_until_complete
return future.result()
File "C:\...\microbit_control.py", line 221, in mainCheck
await client.connect()
File "C:\Python310\lib\site-packages\bleak\__init__.py", line 392, in connect
return await self._backend.connect(**kwargs)
File "C:\Python310\lib\site-packages\bleak\backends\winrt\client.py", line 330, in connect
async with async_timeout.timeout(timeout):
File "C:\Python310\lib\site-packages\async_timeout\__init__.py", line 129, in __aexit__
self._do_exit(exc_type)
File "C:\Python310\lib\site-packages\async_timeout\__init__.py", line 212, in _do_exit
raise asyncio.TimeoutError
asyncio.exceptions.TimeoutError
'''
### Logs
I opened Bleak_Logging andd this is the result:
```
Discover device by name:
2022-10-11 17:43:29,454 bleak.backends.winrt.scanner DEBUG: Received 7F:BA:14:5F:F8:35: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 7F:BA:14:5F:F8:35: Unknown.
2022-10-11 17:43:29,456 bleak.backends.winrt.scanner DEBUG: Received 7F:BA:14:5F:F8:35: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 7F:BA:14:5F:F8:35: Unknown.
2022-10-11 17:43:29,458 bleak.backends.winrt.scanner DEBUG: Received 4E:FB:74:B8:29:3C: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 4E:FB:74:B8:29:3C: Unknown.
2022-10-11 17:43:29,459 bleak.backends.winrt.scanner DEBUG: Received 4A:1E:A1:26:F4:50: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 4A:1E:A1:26:F4:50: Unknown.
2022-10-11 17:43:29,460 bleak.backends.winrt.scanner DEBUG: Received 4A:1E:A1:26:F4:50: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 4A:1E:A1:26:F4:50: Unknown.
2022-10-11 17:43:29,461 bleak.backends.winrt.scanner DEBUG: Received C0:00:00:11:40:7E: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received C0:00:00:11:40:7E: Unknown.
2022-10-11 17:43:29,464 bleak.backends.winrt.scanner DEBUG: Received 5C:A7:C9:C4:04:3A: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 5C:A7:C9:C4:04:3A: Unknown.
2022-10-11 17:43:29,465 bleak.backends.winrt.scanner DEBUG: Received 5C:A7:C9:C4:04:3A: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 5C:A7:C9:C4:04:3A: Unknown.
2022-10-11 17:43:29,467 bleak.backends.winrt.scanner DEBUG: Received 46:4F:18:B2:E4:CF: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 46:4F:18:B2:E4:CF: Unknown.
2022-10-11 17:43:29,469 bleak.backends.winrt.scanner DEBUG: Received 46:4F:18:B2:E4:CF: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 46:4F:18:B2:E4:CF: Unknown.
2022-10-11 17:43:29,470 bleak.backends.winrt.scanner DEBUG: Received 09:99:4B:01:CD:3C: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 09:99:4B:01:CD:3C: Unknown.
2022-10-11 17:43:29,472 bleak.backends.winrt.scanner DEBUG: Received 29:18:E2:EB:C9:7D: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 29:18:E2:EB:C9:7D: Unknown.
2022-10-11 17:43:29,473 bleak.backends.winrt.scanner DEBUG: Received 0F:E9:A6:AE:17:19: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 0F:E9:A6:AE:17:19: Unknown.
2022-10-11 17:43:29,475 bleak.backends.winrt.scanner DEBUG: Received 0B:16:3D:50:42:BD: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 0B:16:3D:50:42:BD: Unknown.
2022-10-11 17:43:29,476 bleak.backends.winrt.scanner DEBUG: Received 06:0B:51:37:3C:77: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 06:0B:51:37:3C:77: Unknown.
2022-10-11 17:43:29,481 bleak.backends.winrt.scanner DEBUG: Received C0:00:00:11:40:7E: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received C0:00:00:11:40:7E: Unknown.
2022-10-11 17:43:29,573 bleak.backends.winrt.scanner DEBUG: Received 61:FD:DA:F3:5B:5B: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 61:FD:DA:F3:5B:5B: Unknown.
2022-10-11 17:43:29,575 bleak.backends.winrt.scanner DEBUG: Received 61:FD:DA:F3:5B:5B: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 61:FD:DA:F3:5B:5B: Unknown.
2022-10-11 17:43:29,577 bleak.backends.winrt.scanner DEBUG: Received 0F:E9:A6:AE:17:19: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 0F:E9:A6:AE:17:19: Unknown.
2022-10-11 17:43:29,578 bleak.backends.winrt.scanner DEBUG: Received 29:18:E2:EB:C9:7D: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 29:18:E2:EB:C9:7D: Unknown.
2022-10-11 17:43:29,581 bleak.backends.winrt.scanner DEBUG: Received 75:A3:C8:DD:0B:24: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 75:A3:C8:DD:0B:24: Unknown.
2022-10-11 17:43:29,583 bleak.backends.winrt.scanner DEBUG: Received 06:0B:51:37:3C:77: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 06:0B:51:37:3C:77: Unknown.
2022-10-11 17:43:29,588 bleak.backends.winrt.scanner DEBUG: Received 6D:B2:A0:39:C6:93: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 6D:B2:A0:39:C6:93: Unknown.
2022-10-11 17:43:29,589 bleak.backends.winrt.scanner DEBUG: Received 6D:B2:A0:39:C6:93: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 6D:B2:A0:39:C6:93: Unknown.
2022-10-11 17:43:29,594 bleak.backends.winrt.scanner DEBUG: Received 4A:1E:A1:26:F4:50: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 4A:1E:A1:26:F4:50: Unknown.
2022-10-11 17:43:29,595 bleak.backends.winrt.scanner DEBUG: Received 4A:1E:A1:26:F4:50: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 4A:1E:A1:26:F4:50: Unknown.
2022-10-11 17:43:29,714 bleak.backends.winrt.scanner DEBUG: Received C0:00:00:11:40:7E: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received C0:00:00:11:40:7E: Unknown.
2022-10-11 17:43:29,716 bleak.backends.winrt.scanner DEBUG: Received 76:FD:EF:61:02:C4: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 76:FD:EF:61:02:C4: Unknown.
2022-10-11 17:43:29,718 bleak.backends.winrt.scanner DEBUG: Received E9:49:CE:EC:44:B3: mobike.
DEBUG:bleak.backends.winrt.scanner:Received E9:49:CE:EC:44:B3: mobike.
2022-10-11 17:43:29,719 bleak.backends.winrt.scanner DEBUG: Received 69:D2:4E:A9:07:BA: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 69:D2:4E:A9:07:BA: Unknown.
2022-10-11 17:43:29,720 bleak.backends.winrt.scanner DEBUG: Received 69:D2:4E:A9:07:BA: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 69:D2:4E:A9:07:BA: Unknown.
2022-10-11 17:43:29,753 bleak.backends.winrt.scanner DEBUG: Received 25:F3:1E:DF:34:0D: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 25:F3:1E:DF:34:0D: Unknown.
2022-10-11 17:43:29,757 bleak.backends.winrt.scanner DEBUG: Received 6F:CA:44:42:9A:FB: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 6F:CA:44:42:9A:FB: Unknown.
2022-10-11 17:43:29,759 bleak.backends.winrt.scanner DEBUG: Received CA:1D:25:29:E2:C7: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received CA:1D:25:29:E2:C7: Unknown.
2022-10-11 17:43:29,760 bleak.backends.winrt.scanner DEBUG: Received C0:00:00:11:40:7E: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received C0:00:00:11:40:7E: Unknown.
2022-10-11 17:43:29,803 bleak.backends.winrt.scanner DEBUG: Received 79:13:B2:67:E8:9E: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 79:13:B2:67:E8:9E: Unknown.
2022-10-11 17:43:29,810 bleak.backends.winrt.scanner DEBUG: Received C0:00:00:11:40:7E: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received C0:00:00:11:40:7E: Unknown.
2022-10-11 17:43:29,813 bleak.backends.winrt.scanner DEBUG: Received 46:4F:18:B2:E4:CF: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 46:4F:18:B2:E4:CF: Unknown.
2022-10-11 17:43:29,815 bleak.backends.winrt.scanner DEBUG: Received 46:4F:18:B2:E4:CF: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 46:4F:18:B2:E4:CF: Unknown.
2022-10-11 17:43:29,816 bleak.backends.winrt.scanner DEBUG: Received 69:90:EA:55:4C:CB: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 69:90:EA:55:4C:CB: Unknown.
2022-10-11 17:43:29,822 bleak.backends.winrt.scanner DEBUG: Received 12:76:BC:82:9C:33: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 12:76:BC:82:9C:33: Unknown.
2022-10-11 17:43:29,825 bleak.backends.winrt.scanner DEBUG: Received 7D:07:F2:06:19:E9: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 7D:07:F2:06:19:E9: Unknown.
2022-10-11 17:43:29,826 bleak.backends.winrt.scanner DEBUG: Received 7D:07:F2:06:19:E9: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 7D:07:F2:06:19:E9: Unknown.
2022-10-11 17:43:29,831 bleak.backends.winrt.scanner DEBUG: Received 7B:9D:B8:3D:F3:E4: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 7B:9D:B8:3D:F3:E4: Unknown.
2022-10-11 17:43:29,832 bleak.backends.winrt.scanner DEBUG: Received 22:F0:52:59:39:80: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 22:F0:52:59:39:80: Unknown.
2022-10-11 17:43:29,835 bleak.backends.winrt.scanner DEBUG: Received 10:6D:61:74:6F:3E: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 10:6D:61:74:6F:3E: Unknown.
2022-10-11 17:43:29,931 bleak.backends.winrt.scanner DEBUG: Received 76:FD:EF:61:02:C4: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 76:FD:EF:61:02:C4: Unknown.
2022-10-11 17:43:29,933 bleak.backends.winrt.scanner DEBUG: Received 52:11:FA:6D:49:99: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 52:11:FA:6D:49:99: Unknown.
2022-10-11 17:43:29,934 bleak.backends.winrt.scanner DEBUG: Received 52:11:FA:6D:49:99: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 52:11:FA:6D:49:99: Unknown.
2022-10-11 17:43:29,935 bleak.backends.winrt.scanner DEBUG: Received 7B:9D:B8:3D:F3:E4: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 7B:9D:B8:3D:F3:E4: Unknown.
2022-10-11 17:43:29,938 bleak.backends.winrt.scanner DEBUG: Received 2F:F3:72:2E:1D:B1: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 2F:F3:72:2E:1D:B1: Unknown.
2022-10-11 17:43:29,940 bleak.backends.winrt.scanner DEBUG: Received C0:00:00:11:40:7E: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received C0:00:00:11:40:7E: Unknown.
2022-10-11 17:43:29,941 bleak.backends.winrt.scanner DEBUG: Received 35:E5:49:CD:8F:64: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 35:E5:49:CD:8F:64: Unknown.
2022-10-11 17:43:29,944 bleak.backends.winrt.scanner DEBUG: Received 78:98:EA:20:D7:12: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 78:98:EA:20:D7:12: Unknown.
2022-10-11 17:43:30,038 bleak.backends.winrt.scanner DEBUG: Received 47:A7:E2:AB:31:15: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 47:A7:E2:AB:31:15: Unknown.
2022-10-11 17:43:30,039 bleak.backends.winrt.scanner DEBUG: Received 4F:23:8F:30:EA:37: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 4F:23:8F:30:EA:37: Unknown.
2022-10-11 17:43:30,042 bleak.backends.winrt.scanner DEBUG: Received 22:F0:52:59:39:80: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 22:F0:52:59:39:80: Unknown.
2022-10-11 17:43:30,045 bleak.backends.winrt.scanner DEBUG: Received 2D:85:E7:1C:7C:B1: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 2D:85:E7:1C:7C:B1: Unknown.
2022-10-11 17:43:30,048 bleak.backends.winrt.scanner DEBUG: Received 04:AA:82:2C:12:3A: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 04:AA:82:2C:12:3A: Unknown.
2022-10-11 17:43:30,050 bleak.backends.winrt.scanner DEBUG: Received 10:6D:61:74:6F:3E: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 10:6D:61:74:6F:3E: Unknown.
2022-10-11 17:43:30,059 bleak.backends.winrt.scanner DEBUG: Received 46:4F:18:B2:E4:CF: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 46:4F:18:B2:E4:CF: Unknown.
2022-10-11 17:43:30,063 bleak.backends.winrt.scanner DEBUG: Received 46:4F:18:B2:E4:CF: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 46:4F:18:B2:E4:CF: Unknown.
2022-10-11 17:43:30,064 bleak.backends.winrt.scanner DEBUG: Received C0:00:00:11:40:7E: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received C0:00:00:11:40:7E: Unknown.
2022-10-11 17:43:30,065 bleak.backends.winrt.scanner DEBUG: Received 25:F3:1E:DF:34:0D: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 25:F3:1E:DF:34:0D: Unknown.
2022-10-11 17:43:30,066 bleak.backends.winrt.scanner DEBUG: Received 0E:1D:AA:88:79:2E: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 0E:1D:AA:88:79:2E: Unknown.
2022-10-11 17:43:30,159 bleak.backends.winrt.scanner DEBUG: Received 47:2E:86:D2:79:57: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 47:2E:86:D2:79:57: Unknown.
2022-10-11 17:43:30,161 bleak.backends.winrt.scanner DEBUG: Received 47:2E:86:D2:79:57: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 47:2E:86:D2:79:57: Unknown.
2022-10-11 17:43:30,164 bleak.backends.winrt.scanner DEBUG: Received C0:00:00:11:40:7E: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received C0:00:00:11:40:7E: Unknown.
2022-10-11 17:43:30,165 bleak.backends.winrt.scanner DEBUG: Received D1:09:0B:5C:D7:FC: BBC micro:bit [zipeg].
DEBUG:bleak.backends.winrt.scanner:Received D1:09:0B:5C:D7:FC: BBC micro:bit [zipeg].
2022-10-11 17:43:30,166 bleak.backends.winrt.scanner DEBUG: Received D1:09:0B:5C:D7:FC: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received D1:09:0B:5C:D7:FC: Unknown.
2022-10-11 17:43:30,167 bleak.backends.winrt.scanner DEBUG: Received 25:F3:1E:DF:34:0D: Unknown.
DEBUG:bleak.backends.winrt.scanner:Received 25:F3:1E:DF:34:0D: Unknown.
2022-10-11 17:43:30,168 bleak.backends.winrt.scanner DEBUG: 38 devices found. Watcher status: 3.
DEBUG:bleak.backends.winrt.scanner:38 devices found. Watcher status: 3.
D1:09:0B:5C:D7:FC: BBC micro:bit [zipeg]
Device Found!
2022-10-11 17:43:30,172 bleak.backends.winrt.client DEBUG: Connecting to BLE device @ D1:09:0B:5C:D7:FC
DEBUG:bleak.backends.winrt.client:Connecting to BLE device @ D1:09:0B:5C:D7:FC
2022-10-11 17:43:31,187 bleak.backends.winrt.client DEBUG: session_status_changed_event_handler: id: <_bleak_winrt_Windows_Devices_Bluetooth.BluetoothDeviceId object at 0x000001F0226453F0>, error: BluetoothError.SUCCESS, status: GattSessionStatus.ACTIVE
DEBUG:bleak.backends.winrt.client:session_status_changed_event_handler: id: <_bleak_winrt_Windows_Devices_Bluetooth.BluetoothDeviceId object at 0x000001F0226453F0>, error: BluetoothError.SUCCESS, status: GattSessionStatus.ACTIVE
2022-10-11 17:43:31,190 bleak.backends.winrt.client DEBUG: Get Services...
DEBUG:bleak.backends.winrt.client:Get Services...
2022-10-11 17:43:34,525 bleak.backends.winrt.client INFO: Services resolved for BleakClientWinRT (D1:09:0B:5C:D7:FC)
INFO:bleak.backends.winrt.client:Services resolved for BleakClientWinRT (D1:09:0B:5C:D7:FC)
Pairing Client
2022-10-11 17:43:34,902 bleak.backends.winrt.client INFO: Paired to device with protection level 1.
INFO:bleak.backends.winrt.client:Paired to device with protection level 1.
2022-10-11 17:43:35,441 bleak.backends.winrt.client DEBUG: session_status_changed_event_handler: id: <_bleak_winrt_Windows_Devices_Bluetooth.BluetoothDeviceId object at 0x000001F022645430>, error: BluetoothError.SUCCESS, status: GattSessionStatus.CLOSED
DEBUG:bleak.backends.winrt.client:session_status_changed_event_handler: id: <_bleak_winrt_Windows_Devices_Bluetooth.BluetoothDeviceId object at 0x000001F022645430>, error: BluetoothError.SUCCESS, status: GattSessionStatus.CLOSED
Disconnected callback called!
Reconnecting
is connect? False
2022-10-11 17:43:44,908 bleak.backends.winrt.client DEBUG: Connecting to BLE device @ D1:09:0B:5C:D7:FC
DEBUG:bleak.backends.winrt.client:Connecting to BLE device @ D1:09:0B:5C:D7:FC
2022-10-11 17:44:00,038 bleak.backends.winrt.client DEBUG: Disconnecting from BLE device...
DEBUG:bleak.backends.winrt.client:Disconnecting from BLE device...
Traceback (most recent call last):
File "C:\Python310\lib\site-packages\bleak\backends\winrt\client.py", line 331, in connect
await event.wait()
File "C:\Python310\lib\asyncio\locks.py", line 214, in wait
await fut
asyncio.exceptions.CancelledError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\...\microbit_control.py", line 271, in <module>
asyncio.run(mainCheck())
File "C:\Python310\lib\asyncio\runners.py", line 44, in run
return loop.run_until_complete(main)
File "C:\Python310\lib\asyncio\base_events.py", line 646, in run_until_complete
return future.result()
File "C:\...\microbit_control.py", line 221, in mainCheck
await client.connect()
File "C:\Python310\lib\site-packages\bleak\__init__.py", line 392, in connect
return await self._backend.connect(**kwargs)
File "C:\Python310\lib\site-packages\bleak\backends\winrt\client.py", line 330, in connect
async with async_timeout.timeout(timeout):
File "C:\Python310\lib\site-packages\async_timeout\__init__.py", line 129, in __aexit__
self._do_exit(exc_type)
File "C:\Python310\lib\site-packages\async_timeout\__init__.py", line 212, in _do_exit
raise asyncio.TimeoutError
asyncio.exceptions.TimeoutError
```
I almost done with using computer to control micro:bit with BluetoothLE! I would be very happy if this problem is solved!
| closed | 2022-10-11T09:49:57Z | 2022-10-13T08:29:15Z | https://github.com/hbldh/bleak/issues/1076 | [
"Backend: WinRT"
] | BitaMatt | 6 |
plotly/dash | jupyter | 2,455 | [BUG] No dialog box for dcc.Download component in Edge browser | Thank you so much for helping improve the quality of Dash!
We do our best to catch bugs during the release process, but we rely on your help to find the ones that slip through.
**Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
- replace the result of `pip list | grep dash` below
```
dash 0.42.0
dash-core-components 0.47.0
dash-html-components 0.16.0
dash-renderer 0.23.0
dash-table 3.6.0
```
- if frontend related, tell us your Browser, Version and OS
- OS: [e.g. iOS]
- Browser [e.g. chrome, safari]
- Version [e.g. 22]
**Describe the bug**
A clear and concise description of what the bug is.
**Expected behavior**
A clear and concise description of what you expected to happen.
**Screenshots**
If applicable, add screenshots or screen recording to help explain your problem.
| closed | 2023-03-13T16:48:33Z | 2023-03-13T16:49:00Z | https://github.com/plotly/dash/issues/2455 | [] | Pomurnik | 0 |
Zeyi-Lin/HivisionIDPhotos | fastapi | 112 | ModuleNotFoundError: No module named 'PIL' | Traceback (most recent call last):
File "G:\HivisionIDPhotos\app.py", line 3, in <module>
from demo.processor import IDPhotoProcessor
File "G:\HivisionIDPhotos\demo\processor.py", line 2, in <module>
from hivision import IDCreator
File "G:\HivisionIDPhotos\hivision\__init__.py", line 1, in <module>
from .creator import IDCreator, Params as IDParams, Result as IDResult
File "G:\HivisionIDPhotos\hivision\creator\__init__.py", line 14, in <module>
from .human_matting import extract_human
File "G:\HivisionIDPhotos\hivision\creator\human_matting.py", line 11, in <module>
from PIL import Image
ModuleNotFoundError: No module named 'PIL' | closed | 2024-09-12T10:14:40Z | 2024-09-12T10:16:01Z | https://github.com/Zeyi-Lin/HivisionIDPhotos/issues/112 | [] | sunsetmuu | 0 |
huggingface/datasets | pytorch | 7,108 | website broken: Create a new dataset repository, doesn't create a new repo in Firefox | ### Describe the bug
This issue is also reported here:
https://discuss.huggingface.co/t/create-a-new-dataset-repository-broken-page/102644
This page is broken.
https://huggingface.co/new-dataset
I fill in the form with my text, and click `Create Dataset`.

Then the form gets wiped. And no repo got created. No error message visible in the developer console.
# Idea for improvement
For better UX, if the repo cannot be created, then show an error message, that something went wrong.
# Work around, that works for me
```python
from huggingface_hub import HfApi, HfFolder
repo_id = 'simon-arc-solve-fractal-v3'
api = HfApi()
username = api.whoami()['name']
repo_url = api.create_repo(repo_id=repo_id, exist_ok=True, private=True, repo_type="dataset")
```
### Steps to reproduce the bug
Go https://huggingface.co/new-dataset
Fill in the form.
Click `Create dataset`.
Now the form is cleared. And the page doesn't jump anywhere.
### Expected behavior
The moment the user clicks `Create dataset`, the repo gets created and the page jumps to the created repo.
### Environment info
Firefox 128.0.3 (64-bit)
macOS Sonoma 14.5
| closed | 2024-08-16T17:23:00Z | 2024-08-19T13:21:12Z | https://github.com/huggingface/datasets/issues/7108 | [] | neoneye | 4 |
MilesCranmer/PySR | scikit-learn | 758 | [BUG]: Custom loss function not working in multiprocessing-mode | ### What happened?
I'm having issues running PySR in multiprocessing mode when I use a custom loss function. My loss function looks like:
```
function eval_loss(tree, dataset::Dataset{T, L}, options::Options, idx)::L where {T, L}
# Extract data for the given indices
x = idx === nothing ? dataset.X : view(dataset.X, :, idx)
y = idx === nothing ? dataset.y : view(dataset.y, idx)
derivative_with_respect_to = 1
predicted, gradient, complete = eval_diff_tree_array(tree, x, options, derivative_with_respect_to)
if !complete
# encountered NaN/Inf, so return early
return L(Inf)
end
# loss components
positivity = sum(i -> gradient[i] > 0 ? L(0) : abs2(gradient[i]), eachindex(gradient))
scatter_loss = sum(i -> abs(log((abs(predicted[i])+1e-20) / (abs(y[i])+1e-20))), eachindex(predicted, y))
sign_loss = sum(i -> 10 * (sign(predicted[i]) - sign(y[i]))^2, eachindex(predicted, y))
beta = L(1e-3)
return (scatter_loss + sign_loss + beta*positivity) / length(y)
end
```
It works fine when I run it in multithreading mode, but it crashes when trying to use multiprocessing. Grateful for help!
### Version
1.0.0
### Operating System
macOS
### Package Manager
pip
### Interface
Script (i.e., `python my_script.py`)
### Relevant log output
```shell
Traceback (most recent call last):
File "/Users/isakbe/Dev/modelling/il-sr/il_sr/scripts/run_sr.py", line 32, in <module>
main()
File "/Users/isakbe/Dev/modelling/il-sr/il_sr/scripts/run_sr.py", line 23, in main
trainer.fit_expression()
File "/Users/isakbe/Dev/modelling/il-sr/il_sr/scripts/../src/sr_training.py", line 243, in fit_expression
self.model.fit(
File "/Users/isakbe/Library/Caches/pypoetry/virtualenvs/il-sr-9TFUWRsR-py3.11/lib/python3.11/site-packages/pysr/sr.py", line 2240, in fit
self._run(X, y, runtime_params, weights=weights, seed=seed, category=category)
File "/Users/isakbe/Library/Caches/pypoetry/virtualenvs/il-sr-9TFUWRsR-py3.11/lib/python3.11/site-packages/pysr/sr.py", line 2028, in _run
out = SymbolicRegression.equation_search(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/isakbe/.julia/packages/PythonCall/Nr75f/src/JlWrap/any.jl", line 258, in __call__
return self._jl_callmethod($(pyjl_methodnum(pyjlany_call)), args, kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
juliacall.JuliaError: On worker 2:
MethodError: no method matching eval_loss(::Node{Float32}, ::Dataset{Float32, Float32, Matrix{Float32}, Vector{Float32}, Nothing, @NamedTuple{}, Nothing, Nothing, Nothing, Nothing}, ::Options{SymbolicRegression.CoreModule.OptionsStructModule.ComplexityMapping{Int64, Int64}, DynamicExpressions.OperatorEnumModule.OperatorEnum, Node, Expression, @NamedTuple{}, MutationWeights, false, true, nothing, Nothing, 5})
Closest candidates are:
eval_loss(::Any, ::Dataset{T, L, AX} where AX<:AbstractMatrix{T}, ::Options, !Matched::Any) where {T, L}
@ Main none:1
Stacktrace:
[1] #9
@ /opt/homebrew/Cellar/julia/1.10.4/share/julia/stdlib/v1.10/Distributed/src/macros.jl:83
[2] #invokelatest#2
@ ./essentials.jl:892 [inlined]
[3] invokelatest
@ ./essentials.jl:889
[4] #107
@ /opt/homebrew/Cellar/julia/1.10.4/share/julia/stdlib/v1.10/Distributed/src/process_messages.jl:283
[5] run_work_thunk
@ /opt/homebrew/Cellar/julia/1.10.4/share/julia/stdlib/v1.10/Distributed/src/process_messages.jl:70
[6] run_work_thunk
@ /opt/homebrew/Cellar/julia/1.10.4/share/julia/stdlib/v1.10/Distributed/src/process_messages.jl:79
[7] #100
@ /opt/homebrew/Cellar/julia/1.10.4/share/julia/stdlib/v1.10/Distributed/src/process_messages.jl:88
Stacktrace:
[1] remotecall_fetch(f::Function, w::Distributed.Worker, args::Distributed.RRID; kwargs::@Kwargs{})
@ Distributed /opt/homebrew/Cellar/julia/1.10.4/share/julia/stdlib/v1.10/Distributed/src/remotecall.jl:465
[2] remotecall_fetch(f::Function, w::Distributed.Worker, args::Distributed.RRID)
@ Distributed /opt/homebrew/Cellar/julia/1.10.4/share/julia/stdlib/v1.10/Distributed/src/remotecall.jl:454
[3] remotecall_fetch
@ /opt/homebrew/Cellar/julia/1.10.4/share/julia/stdlib/v1.10/Distributed/src/remotecall.jl:492 [inlined]
[4] call_on_owner
@ /opt/homebrew/Cellar/julia/1.10.4/share/julia/stdlib/v1.10/Distributed/src/remotecall.jl:565 [inlined]
[5] fetch(r::Distributed.Future)
@ Distributed /opt/homebrew/Cellar/julia/1.10.4/share/julia/stdlib/v1.10/Distributed/src/remotecall.jl:619
[6] test_function_on_workers(example_inputs::Tuple{Node{Float32}, Dataset{Float32, Float32, Matrix{Float32}, Vector{Float32}, Nothing, @NamedTuple{}, Nothing, Nothing, Nothing, Nothing}, Options{SymbolicRegression.CoreModule.OptionsStructModule.ComplexityMapping{Int64, Int64}, DynamicExpressions.OperatorEnumModule.OperatorEnum, Node, Expression, @NamedTuple{}, MutationWeights, false, true, nothing, Nothing, 5}}, op::Function, procs::Vector{Int64})
@ SymbolicRegression ~/.julia/packages/SymbolicRegression/44X04/src/Configure.jl:206
[7] move_functions_to_workers(procs::Vector{Int64}, options::Options{SymbolicRegression.CoreModule.OptionsStructModule.ComplexityMapping{Int64, Int64}, DynamicExpressions.OperatorEnumModule.OperatorEnum, Node, Expression, @NamedTuple{}, MutationWeights, false, true, nothing, Nothing, 5}, dataset::Dataset{Float32, Float32, Matrix{Float32}, Vector{Float32}, Nothing, @NamedTuple{}, Nothing, Nothing, Nothing, Nothing}, verbosity::Int64)
@ SymbolicRegression ~/.julia/packages/SymbolicRegression/44X04/src/Configure.jl:180
[8] configure_workers(; procs::Nothing, numprocs::Int64, addprocs_function::typeof(Distributed.addprocs), options::Options{SymbolicRegression.CoreModule.OptionsStructModule.ComplexityMapping{Int64, Int64}, DynamicExpressions.OperatorEnumModule.OperatorEnum, Node, Expression, @NamedTuple{}, MutationWeights, false, true, nothing, Nothing, 5}, project_path::String, file::String, exeflags::Cmd, verbosity::Int64, example_dataset::Dataset{Float32, Float32, Matrix{Float32}, Vector{Float32}, Nothing, @NamedTuple{}, Nothing, Nothing, Nothing, Nothing}, runtests::Bool)
@ SymbolicRegression ~/.julia/packages/SymbolicRegression/44X04/src/Configure.jl:349
[9] _create_workers(datasets::Vector{Dataset{Float32, Float32, Matrix{Float32}, Vector{Float32}, Nothing, @NamedTuple{}, Nothing, Nothing, Nothing, Nothing}}, ropt::SymbolicRegression.SearchUtilsModule.RuntimeOptions{:multiprocessing, 1, true, SRLogger{TensorBoardLogger.TBLogger{String, IOStream}}}, options::Options{SymbolicRegression.CoreModule.OptionsStructModule.ComplexityMapping{Int64, Int64}, DynamicExpressions.OperatorEnumModule.OperatorEnum, Node, Expression, @NamedTuple{}, MutationWeights, false, true, nothing, Nothing, 5})
@ SymbolicRegression ~/.julia/packages/SymbolicRegression/44X04/src/SymbolicRegression.jl:597
[10] _equation_search(datasets::Vector{Dataset{Float32, Float32, Matrix{Float32}, Vector{Float32}, Nothing, @NamedTuple{}, Nothing, Nothing, Nothing, Nothing}}, ropt::SymbolicRegression.SearchUtilsModule.RuntimeOptions{:multiprocessing, 1, true, SRLogger{TensorBoardLogger.TBLogger{String, IOStream}}}, options::Options{SymbolicRegression.CoreModule.OptionsStructModule.ComplexityMapping{Int64, Int64}, DynamicExpressions.OperatorEnumModule.OperatorEnum, Node, Expression, @NamedTuple{}, MutationWeights, false, true, nothing, Nothing, 5}, saved_state::Nothing)
@ SymbolicRegression ~/.julia/packages/SymbolicRegression/44X04/src/SymbolicRegression.jl:532
[11] equation_search(datasets::Vector{Dataset{Float32, Float32, Matrix{Float32}, Vector{Float32}, Nothing, @NamedTuple{}, Nothing, Nothing, Nothing, Nothing}}; options::Options{SymbolicRegression.CoreModule.OptionsStructModule.ComplexityMapping{Int64, Int64}, DynamicExpressions.OperatorEnumModule.OperatorEnum, Node, Expression, @NamedTuple{}, MutationWeights, false, true, nothing, Nothing, 5}, saved_state::Nothing, runtime_options::Nothing, runtime_options_kws::@Kwargs{niterations::Int64, parallelism::String, numprocs::Int64, procs::Nothing, addprocs_function::Nothing, heap_size_hint_in_bytes::Nothing, runtests::Bool, return_state::Bool, run_id::String, verbosity::Int64, logger::SRLogger{TensorBoardLogger.TBLogger{String, IOStream}}, progress::Bool, v_dim_out::Val{1}})
@ SymbolicRegression ~/.julia/packages/SymbolicRegression/44X04/src/SymbolicRegression.jl:525
[12] equation_search
@ ~/.julia/packages/SymbolicRegression/44X04/src/SymbolicRegression.jl:506 [inlined]
[13] #equation_search#20
@ ~/.julia/packages/SymbolicRegression/44X04/src/SymbolicRegression.jl:476 [inlined]
[14] equation_search
@ ~/.julia/packages/SymbolicRegression/44X04/src/SymbolicRegression.jl:422 [inlined]
[15] #equation_search#21
@ ~/.julia/packages/SymbolicRegression/44X04/src/SymbolicRegression.jl:499 [inlined]
[16] pyjlany_call(self::typeof(equation_search), args_::Py, kwargs_::Py)
@ PythonCall.JlWrap ~/.julia/packages/PythonCall/Nr75f/src/JlWrap/any.jl:40
[17] _pyjl_callmethod(f::Any, self_::Ptr{PythonCall.C.PyObject}, args_::Ptr{PythonCall.C.PyObject}, nargs::Int64)
@ PythonCall.JlWrap ~/.julia/packages/PythonCall/Nr75f/src/JlWrap/base.jl:73
[18] _pyjl_callmethod(o::Ptr{PythonCall.C.PyObject}, args::Ptr{PythonCall.C.PyObject})
@ PythonCall.JlWrap.Cjl ~/.julia/packages/PythonCall/Nr75f/src/JlWrap/C.jl:63
```
### Extra Info
_No response_ | closed | 2024-12-02T12:04:54Z | 2024-12-02T13:59:36Z | https://github.com/MilesCranmer/PySR/issues/758 | [
"bug"
] | ibengtsson | 9 |
deezer/spleeter | deep-learning | 711 | Latest Python bricked Spleeter | - [x] I didn't find a similar issue already open.
- [x] I read the documentation (README AND Wiki)
- [x] I have installed FFMpeg
- [x] My problem is related to Spleeter only, not a derivative product (such as Webapplication, or GUI provided by others)
## Description
Hi there. I hate Python with a passion.
Now, they have decided to make an update that bricks a bunch of Spleeter dependencies. It also bricked Kodi for some reason.
I have had it up to here with Python.
And of course this isn't your fault. But do you think you could consider building Spleeter as a flatpak or appimage?
Or is there some other containerized solution I can try?
Thanks. | open | 2022-01-16T21:48:18Z | 2022-01-22T13:54:19Z | https://github.com/deezer/spleeter/issues/711 | [
"bug",
"invalid"
] | CHJ85 | 3 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 834 | an abnormal region in the generated image | Hi, Dr Zhu, Thank you for sharing the code of this excellent work.
I use your code for unsupervised image-to-image translation. The generated image looks good on the whole except for a small abnormal region in it. Each generated image contains an abnormal region, however, the other region looks good.
Did you run into this problem? Could you give me some suggestions, thanks. | open | 2019-11-10T10:06:32Z | 2019-11-13T18:04:45Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/834 | [] | DanChen001 | 1 |
PokeAPI/pokeapi | graphql | 743 | Error with trying to get the evolution chain | So Im trying to get the evolution chain for pokemon using this link:
https://pokeapi.co/api/v2/pokemon-species/2
But it keeps telling me KeyError
Im using discord.py to make this into a command btw | closed | 2022-08-07T00:34:21Z | 2022-08-07T04:03:22Z | https://github.com/PokeAPI/pokeapi/issues/743 | [] | Necrosis000 | 3 |
feature-engine/feature_engine | scikit-learn | 206 | add jupyter notebook examples for the SklearnTransformerWrapper | At the moment there is only 1 notebook showing how to wrap the one hot encoder, simple imputer and standard scaler from sklearn. I would like to separate each one of these in an individual notebook.
In addition, I would like to add notebooks demonstrating how to wrap for example the PowerTransformer, the FunctionTransformer and the Feature selection methods.
| closed | 2020-12-29T10:22:13Z | 2021-04-12T16:16:49Z | https://github.com/feature-engine/feature_engine/issues/206 | [
"jupyter notebook",
"priority"
] | solegalli | 6 |
httpie/cli | python | 1,442 | Test | closed | 2022-10-10T14:17:46Z | 2022-10-10T14:18:09Z | https://github.com/httpie/cli/issues/1442 | [] | AlphaMeta-max | 0 |
|
public-apis/public-apis | api | 3,703 | Hi community | Hi community
This message is to clarify and make transparent the current situation of Public APIs, in addition to demonstrating the frustration of us maintainers. So read this if you find it interesting, please.
Well, I keep the Public APIs project together with other 3 developers (@pawelborkar, @marekdano and @yannbertrand) for a long time.
1 year ago, the Public APIs project was dead, with over 300 open pull requests and dozens of unresolved issues. We started work and resolved all PRs and open issues in about 2 months. Since then, more than 1000 PRs have been resolved, dozens of issues resolved, several improvements to the project and a remarkable growth. So it's clear that we've revived and improved the project.
See more at: https://github.com/public-apis/public-apis/issues/1268
Over time, we had several other ideas to further improve the project for the community, but we encountered a number of problems that prevented us from executing them. Many of these issues are related to our access level in the public-apis organization/repository, as we needed to activate special features in the settings and create new repositories in the organization.
We started making attempts to communicate with people working at [APILayer](https://apilayer.com/) (current owner of the public-apis organization/project) to try to help us improve the project, but this proved extremely difficult.
I spoke with employees and ex-employees, but could not get help. I also spoke to [John Burr](https://www.linkedin.com/in/johnwburr/) (APILayer's General Manager) but he hasn't responded for many months.
I made several more attempts to communicate with [Julian Zehetmayr](https://www.linkedin.com/in/julianzehetmayr/) and [Paul Zehetmayr](https://www.linkedin.com/in/paulzehetmayr/) (co-founders and former CEOs of APILayer), but got no response. I believe they are very busy people.
See more at: https://github.com/public-apis/public-apis/issues/1268#issuecomment-793154290
Just trying to communicate with APILayer to help us improve the project and failing in almost every attempt is frustrating for us maintainers. In addition to other problems caused by the apilayer-admin user, who sometimes made undue modifications that caused all our tests and project policies to be broken.
See the history of apilayer-admin: https://github.com/public-apis/public-apis/commits?author=apilayer-admin
Also, we noticed that this week all of us maintainers had our access levels lowered without any communication, motivation or anything close to that. Now we don't even have access to the basic settings in the repository.
So realize how frustrating this is for us, but we're still trying because we believe it's important to the community.
We have no idea why APILayer is acting this way with us maintainers who help revive and improve the project. We just want help and collaboration so that everything works well without harming the community.
So, due to all these problems, I have indicated possible solutions to help us to APILayer representatives:
- APILayer add us as one of the owners or members of the public-apis organization with the necessary access to move forward with the project
- Or if APILayer is not interested in maintaining and helping to evolve the project (which we believe, given the whole situation), transfer it to one of us maintainers so that we can improve it. I believe that this is an adequate measure given everything I have described, and it would solve several communication problems that APILayer would not need to deal with, in addition, of course, to help an entire community to improve it all. Transferring projects is very well seen by the community, and this transfer to the right people who will maintain the project.
But again I didn't get any straight answer to that. Then notice how frustrating this is.
We greatly want APILayer's collaboration and understanding. We don't want the project to die again or be used in a way that harms the community with inappropriate additions. We just want to help.
---
@yannbertrand also wrote about the situation on his blog:
- https://dev.to/yannbertrand/public-apis-situation-4101
Other links that may be useful for more information:
- https://github.com/public-apis/public-apis/commits/master
- https://github.com/public-apis/public-apis/pulse/monthly
- https://github.com/public-apis/public-apis/graphs/commit-activity
- https://github.com/public-apis/public-apis/graphs/code-frequency
- https://github.com/public-apis/public-apis/graphs/contributors
- https://github.com/public-apis/public-apis/commits?author=matheusfelipeog
- https://github.com/public-apis/public-apis/commits?author=yannbertrand
- https://github.com/public-apis/public-apis/commits?author=pawelborkar
- https://github.com/public-apis/public-apis/commits?author=marekdano
- https://github.com/public-apis/public-apis/issues/1268
- https://github.com/public-apis/public-apis/issues/1932#issuecomment-989514138
- https://apilayer.com/
- https://www.linkedin.com/company/apilayer/
- https://github.com/apilayer/
- https://www.ideracorp.com/developertools/apilayer
---
If this issue is permanently deleted to hide what I've described, you can find a permanent record at:
**Wayback Machine:**
- Last capture: https://web.archive.org/web/20231114154916/https://github.com/public-apis/public-apis/issues/3104
- Capture history: https://web.archive.org/web/*/https://github.com/public-apis/public-apis/issues/3104
**archive.today:**
- Last capture: https://archive.is/S2vco
- Capture history: https://archive.is/https://github.com/public-apis/public-apis/issues/3104
_Originally posted by @matheusfelipeog in https://github.com/public-apis/public-apis/issues/3104_ | closed | 2023-11-20T00:47:01Z | 2023-11-20T01:06:51Z | https://github.com/public-apis/public-apis/issues/3703 | [] | Game77ok | 1 |
amisadmin/fastapi-amis-admin | fastapi | 94 | 无法创建管理员账户 | 参考了 #75,但依然无法新建。是否可以提供详细的例子?以下是代码
```python
# main.py
from fastapi import FastAPI, Request
from adminsite import site, async_database
from sqlmodel import SQLModel
from starlette.middleware.base import BaseHTTPMiddleware
app = FastAPI()
auth = site.auth
auth.backend.attach_middleware(app)
app.add_middleware(BaseHTTPMiddleware, dispatch=async_database.asgi_dispatch)
# 挂载后台管理系统
site.mount_app(app)
@app.on_event("startup")
async def startup():
await site.db.async_run_sync(SQLModel.metadata.create_all, is_session=False)
# Create default admin user,user name:admin,password:admin,please change it after login!!!
await auth.create_role_user('admin')
if __name__ == '__main__':
import uvicorn
uvicorn.run(app)
```
```python
# adminsite.py
from fastapi_user_auth.auth.backends.jwt import JwtTokenStore
from sqlalchemy.ext.asyncio import create_async_engine
from sqlalchemy_database import AsyncDatabase
from fastapi_user_auth.site import AuthAdminSite
from fastapi_user_auth.auth import Auth
from fastapi_amis_admin.admin.settings import Settings
async_db_url = (
"mysql+asyncmy://root:password@127.0.0.1:3306/admin"
)
engine = create_async_engine(
async_db_url,
pool_size=10,
max_overflow=20,
pool_pre_ping=True,
pool_recycle=3600,
pool_reset_on_return="rollback",
echo=False,
echo_pool=True,
future=True,
connect_args={"charset": "utf8mb4"},
)
async_database = AsyncDatabase(engine)
auth = Auth(
db=async_database,
token_store=JwtTokenStore(secret_key='06c17af47a244bfee96020e9de676d75a5b5fbe1994e342c0b4c03a14e5c197142bc0bcadc2f5f182fdb88e269b40ba3660d004f9d7673a7d9da86a4052b7b29')
)
site = AuthAdminSite(
settings=Settings(
site_title="后台管理系统",
language="zh_CN"
),
auth=auth,
engine=engine,
)
| closed | 2023-04-20T18:06:34Z | 2023-07-24T01:41:00Z | https://github.com/amisadmin/fastapi-amis-admin/issues/94 | [] | VXenomac | 1 |
nltk/nltk | nlp | 3,316 | punkt model for Arabic needed | Is arabic model not supported any more?
the latest punkt packages do not include arabic.
Is there anyway to get arabic back? | closed | 2024-08-29T09:28:20Z | 2024-10-19T10:39:53Z | https://github.com/nltk/nltk/issues/3316 | [] | snoucair | 2 |
fastapi/sqlmodel | pydantic | 64 | Convert all fields to optional | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X] I already read and followed all the tutorial in the docs and didn't find an answer.
- [X] I already checked if it is not related to SQLModel but to [Pydantic](https://github.com/samuelcolvin/pydantic).
- [X] I already checked if it is not related to SQLModel but to [SQLAlchemy](https://github.com/sqlalchemy/sqlalchemy).
### Commit to Help
- [X] I commit to help with one of those options 👆
### Example Code
```python
class HeroBase(SQLModel):
name: str
secret_name: str
age: Optional[int] = None
class HeroUpdate(HeroBase, all_optional=True):
pass
```
### Description
Is it possible to add the ability to modify the fields of a base class to convert them to all optional with a parameter like the table=True but in this case all_optional=True? This would help eliminate the duplication when creating a class for making updates.
### Wanted Solution
Set all base fields to Optional based on keyword argument.
### Wanted Code
```python
class HeroBase(SQLModel):
name: str
secret_name: str
age: Optional[int] = None
class HeroUpdate(HeroBase, all_optional=True):
pass
```
### Alternatives
_No response_
### Operating System
Linux, Windows
### Operating System Details
_No response_
### SQLModel Version
0.0.4
### Python Version
3.8.5
### Additional Context
_No response_ | open | 2021-08-31T20:03:37Z | 2024-02-23T00:15:21Z | https://github.com/fastapi/sqlmodel/issues/64 | [
"feature"
] | nickleman | 5 |
noirbizarre/flask-restplus | api | 482 | api.inherit() not working as intended Swagger allOf Feature | It seems like the api.inherit() / model.inherit() function does not seem perform the same affect on the Rest API as the Swagger allOf feature, which I believe is the intended functionality of the inherit function.
Specifically, I don't think the discriminator value works as Swagger docs intend it to.
Looking at swagger's documentation (https://swagger.io/docs/specification/data-models/oneof-anyof-allof-not/#allof), we see that when you specify allOf in a certain model that references a parent model, then the name of the child model is used as a reference for the discriminator value. In my flask-restplus implementation, the value of the discriminator field doesn't have any affect on the allowed fields. For example, if I had:
```
pet = api.model('Pet', {
'type': field.String(required=True, discriminator=True)
})
dog = api.inherit('Dog', pet, {
'dogType': field.String(required=True)
})
```
then the API would accept a request body like so: `{'type': 'Dog'}` even though it should respond that the `dogType` field is missing.
Also, it seems that in the example in the swagger dos, the discriminator value can only be either Cat or Dog and nothing else. However, in flask-restplus, I can set it equal to anything with no effect. For example, using the models above, the API would also accept something like `{'type': 'Toaster'}`. Is this supposed to be the intended functionality?
Flask-Restplus is really helpful for designing Swagger API's dynamically for Python, but the allOf description and the discriminator field are both really important features that I would like to make sure is working correct. If you can, could you please describe what you think about this? Thanks! | closed | 2018-06-28T17:30:45Z | 2022-08-26T02:55:05Z | https://github.com/noirbizarre/flask-restplus/issues/482 | [] | srilman | 1 |
aminalaee/sqladmin | sqlalchemy | 606 | relationship + search | ### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
I have a model in which there is a relationship to another model, if I just open the page, then everything is fine, if I add and start using it, then after the request I get
`sqlalchemy.orm.exc.DetachedInstanceError: Parent instance <x> is not bound to a Session; lazy load operation of attribute 'user' cannot proceed (Background on this error at: https://sqlalche.me/e/20/bhk3)`
### Steps to reproduce the bug
1. go to admin site
2. do search
3. get error
### Expected behavior
a normal page will be generated
### Actual behavior
`sqlalchemy.orm.exc.DetachedInstanceError: Parent instance <x> is not bound to a Session; lazy load operation of attribute 'user' cannot proceed (Background on this error at: https://sqlalche.me/e/20/bhk3)`
### Debugging material
```python
import asyncio
from uvicorn import Config, Server
from sqladmin import ModelView, Admin
from fastapi import FastAPI
from sqlalchemy import Select, select, BigInteger, String, ForeignKey
from sqlalchemy.ext.asyncio import create_async_engine, async_sessionmaker
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column, relationship
class Base(DeclarativeBase):
pass
class User(Base):
id: Mapped[int] = mapped_column(BigInteger, primary_key=True)
orders = relationship("OrderInfo", back_populates="user")
class OrderInfo(Base):
id: Mapped[str] = mapped_column(String, primary_key=True)
user_id: Mapped[int] = mapped_column(BigInteger, ForeignKey("users.id"))
user = relationship("User", back_populates="orders")
class OrderInfoModel(ModelView, model=OrderInfo):
column_list = [OrderInfo.id, OrderInfo.user]
column_searchable_list = [OrderInfo.user_id]
def search_placeholder(self) -> str:
return "User-Id"
def search_query(self, stmt: Select, term: str) -> Select:
return select(OrderInfo).where(OrderInfo.user_id == int(term))
async def main():
engine = create_async_engine(config.postgres.url)
session_maker = async_sessionmaker(engine, expire_on_commit=False)
app = FastAPI()
admin = Admin(
app=app,
session_maker=session_maker,
base_url="/admin",
)
admin.add_view(OrderInfoModel)
server_config = Config(
app=app,
host=config.app.host,
port=config.app.port,
)
server = Server(server_config)
await server.serve()
asyncio.run(main())
```
### Environment
python - 3.11
sqladmin - 0.14.1
### Additional context
_No response_ | closed | 2023-09-03T17:18:50Z | 2023-09-14T16:14:09Z | https://github.com/aminalaee/sqladmin/issues/606 | [] | sheldygg | 10 |
sanic-org/sanic | asyncio | 2,082 | RFC: Temporary config value overrides | Often times you may need to change a config value for a particular duration, or perhaps for a single route handler. There should be a simple API to manage that.
```python
with app.config.override(RESPONSE_TIMEOUT=99999):
do_something()
# or
app.route("/", config_override={"RESPONSE_TIMEOUT":99999 })(...)
```
A similar approach [can be found here](https://sanic-jwt.readthedocs.io/en/latest/pages/configuration.html#temporary-override). | closed | 2021-03-22T08:48:31Z | 2021-12-14T09:22:09Z | https://github.com/sanic-org/sanic/issues/2082 | [] | ahopkins | 10 |
ccxt/ccxt | api | 24,970 | MEXC wrong signature for broker endpoints | ### Operating System
_No response_
### Programming Languages
JavaScript
### CCXT Version
latest
### Description
There is some mistake in `sign` function for MEXC POST/PUT/DELETE private **broker** endpoints (https://mexcdevelop.github.io/apidocs/broker_en/#create-a-sub-account and others from this page). We need to put `timestamp/recvWindow/signature` parameters in URL however other parameters should be in Request body.
In the current implementation I get error:
```
fetch Request:
mexc POST https://api.mexc.com/api/v3/broker/sub-account/virtualSubAccount?subAccount=Test1test¬e=Test×tamp=1737462608011&recvWindow=5000&signature=xxx
RequestHeaders:
{
'X-MEXC-APIKEY': 'xxx',
source: 'CCXT',
'Content-Type': 'application/json'
}
RequestBody:
undefined
handleRestResponse:
mexc POST https://api.mexc.com/api/v3/broker/sub-account/virtualSubAccount?subAccount=Test1test¬e=Test×tamp=1737462608011&recvWindow=5000&signature=xxx
ResponseHeaders:
{
'Access-Control-Expose-Headers': 'x-cache',
'Akamai-Grn': 'xxx',
'Cache-Control': 'max-age=0, no-cache, no-store',
Connection: 'keep-alive',
'Content-Length': '81',
'Content-Type': 'application/json',
Date: 'Tue, 21 Jan 2025 12:30:08 GMT',
Expires: 'Tue, 21 Jan 2025 12:30:08 GMT',
Pragma: 'no-cache',
'Server-Timing': 'cdn-cache; desc=MISS, edge; dur=282, origin; dur=20, ak_p; desc="xxx";dur=1',
'Strict-Transport-Security': 'max-age=63072000; includeSubdomains; preload',
'X-Cache': 'NotCacheable from child'
}
ResponseBody:
{"success":false,"code":33333,"msg":"Parameter error","data":null,"_extend":null}
```
But it works fine if I put `subAccount` and `note` in request body (tested). Can you please fix it in a best way?
### Code
| closed | 2025-01-21T12:41:16Z | 2025-01-26T14:28:37Z | https://github.com/ccxt/ccxt/issues/24970 | [] | ndubel | 4 |
Tinche/aiofiles | asyncio | 84 | DeprecationWarning: "@coroutine" decorator is deprecated since Python 3.8, use "async def" instead | I'm getting the exception below on Python 3.8:
```
...lib/python3.8/site-packages/aiofiles/os.py:10: DeprecationWarning: "@coroutine" decorator is deprecated since Python 3.8, use "async def" instead
def run(*args, loop=None, executor=None, **kwargs):
```
```
In [2]: aiofiles.__version__
Out[2]: '0.5.0'
``` | closed | 2020-09-19T11:21:13Z | 2020-10-30T16:05:45Z | https://github.com/Tinche/aiofiles/issues/84 | [] | timkofu | 3 |
explosion/spaCy | machine-learning | 13,761 | Empty coarse-grained POS tags for number in the large Romanian model | Hi, I noticed that the coarse-grained POS tags for numbers in the large Romanian model (`ro_core_news_lg`) is empty rather than `X`. Is this the expected behavior?
## How to reproduce the behaviour
```
import spacy
nlp = spacy.load('ro_core_news_lg')
for token in nlp('2025'):
print(len(token.pos_), token.pos_)
print(len(token.tag_), token.tag_)
```
## Your Environment
* Operating System: Windows 11 x64
* Python Version Used: 3.11.9
* spaCy Version Used: 3.8.4
| open | 2025-02-28T14:39:49Z | 2025-02-28T14:39:49Z | https://github.com/explosion/spaCy/issues/13761 | [] | BLKSerene | 0 |
marcomusy/vedo | numpy | 257 | Unsupported gzip encoding for NRRD reader | I would like to open a volume and slice it with vedo using code example provided by Marco:
```
from vedo import load, show
from vedo.applications import Slicer
file_path = './average_template_100.nrrd'
vol = load(file_path)
plt = Slicer(vol, bg='white', bg2='lightblue', useSlider3D=False)
plt.show()
```
but the code fails with this error:
```
2020-12-01 22:41:59.342 ( 1.042s) [ 905B63] vtkNrrdReader.cxx:395 ERR| vtkNrrdReader (0x7fb2b8469d40): Unsupported encoding: gzip
2020-12-01 22:41:59.342 ( 1.043s) [ 905B63] vtkExecutive.cxx:753 ERR| vtkCompositeDataPipeline (0x7fb2b8445e70): Algorithm vtkNrrdReader(0x7fb2b8469d40) returned failure for request: vtkInformation (0x7fb2b55e4960)
Debug: Off
Modified Time: 159
Reference Count: 1
Registered Events: (none)
Request: REQUEST_INFORMATION
ALGORITHM_AFTER_FORWARD: 1
FORWARD_DIRECTION: 0
Slicer tool
2020-12-01 22:42:00.220 ( 1.920s) [ 905B63]vtkSmartVolumeMapper.cx:271 ERR| vtkSmartVolumeMapper (0x7fb2b8469fa0): Could not find the requested vtkDataArray! 0, 0, -1,
2020-12-01 22:42:00.249 ( 1.949s) [ 905B63]vtkSmartVolumeMapper.cx:271 ERR| vtkSmartVolumeMapper (0x7fb2b8469fa0): Could not find the requested vtkDataArray! 0, 0, -1,
```
I have loaded the same volume within Paraview (VTK) all fine.
Is it because of an older VTK version or because of how vtkNrrdReader is called? Or something else? | closed | 2020-12-02T09:24:23Z | 2020-12-18T07:47:22Z | https://github.com/marcomusy/vedo/issues/257 | [] | nantille | 10 |
jazzband/django-oauth-toolkit | django | 727 | User can delete other users' access tokens | ### Steps to reproduce ###
- Log in as two different users and take note of the access tokens
- Execute `curl -X POST -H 'Authorization: Bearer <access_token_of_user_1>' -H 'Content-Type: application/x-www-form-urlencoded' --data 'token=<access_token_of_user_2>&token_type_hint=access_token&client_id=<client_id>' http://your.host/oauth2/revoke_token/`
It's maybe very unlikely that anyone obtains other users' access token, but it still doesn't seem right to be able to terminate other users' session.
| open | 2019-07-31T18:57:44Z | 2020-10-23T09:54:42Z | https://github.com/jazzband/django-oauth-toolkit/issues/727 | [] | pasiorovuo | 3 |
mckinsey/vizro | pydantic | 390 | Add a tabbed navigation to move between `vizro-core` and `vizro-ai` docs | The Kedro docs (https://docs.kedro.org) has a tabbed navigation.
<img width="1089" alt="image" src="https://github.com/mckinsey/vizro/assets/5180475/5527861a-aba0-45d8-8d36-977226c098f8">
Why can't we have something similar? This shouldn't be a major piece of work and will simply enable users to move between https://vizro.readthedocs.io/en/stable/ and https://vizro.readthedocs.io/projects/vizro-ai/en/latest/ at a top level.
We did this in Kedro in the `layout.html` https://github.com/kedro-org/kedro/blob/main/docs/source/_templates/layout.html
Anyone better at front end design and development will be able to add to this ticket to explain how to make it work.
Ideally we should have some design input but I know we are already waiting on that for other tickets so perhaps we could mock this up in code and then add it to the queries we have for Design.
Suitable for help from anyone with front-end skills, no prior knowledge of Vizro is required, so I'm marking as "Help Wanted" and "Good First Issue" | closed | 2024-03-26T15:05:46Z | 2024-09-23T16:01:12Z | https://github.com/mckinsey/vizro/issues/390 | [
"Help Wanted :pray:",
"Docs :spiral_notepad:",
"Good first issue :baby_chick:"
] | stichbury | 3 |
sherlock-project/sherlock | python | 1,795 | Sherlock | <!--
######################################################################
WARNING!
IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE.
######################################################################
-->
## Checklist
<!--
Put x into all boxes (like this [x]) once you have completed what they say.
Make sure complete everything in the checklist.
-->
- [x] I'm asking a question regarding Sherlock
- [x] My question is not a tech support question.
**We are not your tech support**.
If you have questions related to `pip`, `git`, or something that is not related to Sherlock, please ask them on [Stack Overflow](https://stackoverflow.com/) or [r/learnpython](https://www.reddit.com/r/learnpython/)
## Question
ASK YOUR QUESTION HERE

This is issue i am facing in Sherlock
| closed | 2023-05-16T14:03:13Z | 2023-05-24T16:32:10Z | https://github.com/sherlock-project/sherlock/issues/1795 | [
"question"
] | Bhoomikak18 | 4 |
sanic-org/sanic | asyncio | 2,532 | app.create_server fails after version 21.6.2 | **Describe the bug**
Every version after 21.6.2 fails when running app with app.create_server. The error is
```
venv/lib/python3.9/site-packages/sanic/signals.py", line 73, in get
group, param_basket = self.find_route(
TypeError: 'NoneType' object is not callable
```
I realize this isn't the recommended way to run Sanic, but the web server is only part of my application, does not run on startup or continuously, and shares memory with other async code. This has worked very well for me so far.
Side node: I noticed while troubleshooting that the event loop is changed to uvloop just by importing sanic. I'm of the opinion that imports shouldn't "do things". Would it be better to set the event loop when the application starts?
**Code snippet**
```
import asyncio
from sanic import Sanic
import sanic.response
async def main():
app = Sanic('HelloWorld')
@app.get('/')
async def helloworld(request):
return sanic.response.text('hello world')
server = app.create_server(host='127.0.0.1', port=9999, return_asyncio_server=True)
asyncio.create_task(server)
await asyncio.sleep(30)
if __name__ == '__main__':
asyncio.run(main(), debug=True)
```
**Expected behavior**
successful http response
**Environment (please complete the following information):**
- OS: Pop!_OS 21.10
- Sanic Version: 21.9.0 (or later)
**Additional context**
Interesting bit in the status line:
`[2022-08-19 12:15:06 -0400] - (sanic.access)[INFO][UNKNOWN]: NONE http:///* 503 666`
| open | 2022-08-19T16:58:58Z | 2024-06-19T18:37:14Z | https://github.com/sanic-org/sanic/issues/2532 | [] | ironhacker | 2 |
allure-framework/allure-python | pytest | 67 | Add six dependency to allure-pytest | closed | 2017-06-27T16:10:02Z | 2017-06-28T16:06:55Z | https://github.com/allure-framework/allure-python/issues/67 | [
"bug"
] | sseliverstov | 0 |
|
AirtestProject/Airtest | automation | 677 | 我的页面有几个相同图像,能否指定区域进行touch呢 | 我是ui结合图像进行识别的,我的页面有几个相同图像,我能否根据ui进行指定一个区域范围,airtest就在我指定的区域寻找这个图像,进行touch呢
很多地方都需要指定区域进行touch,不然会错误点击其他的。
谢谢哈 | closed | 2020-01-12T12:11:44Z | 2021-02-27T08:32:14Z | https://github.com/AirtestProject/Airtest/issues/677 | [] | xiaoyuerrocketcat | 3 |
pydantic/pydantic-settings | pydantic | 535 | Don't spit env vars if env_nested_delimiter=None | By default `env_nested_delimiter=None` but this value is not special-cased, leading to surprising (if not ourtight buggy) behavior with `case_sensitive=True`:
```python
class Subsettings(BaseSettings):
foo: str
class Settings(BaseSettings):
subsettings: Subsettings
model_config = SettingsConfigDict(case_sensitive=True)
env.set('subsettingsNonefoo', 'abc')
s = Settings()
assert s.subsettings.foo == 'abc'
``` | closed | 2025-02-11T07:18:59Z | 2025-02-19T08:50:28Z | https://github.com/pydantic/pydantic-settings/issues/535 | [
"bug"
] | gsakkis | 1 |
flairNLP/flair | pytorch | 2,777 | How and where to add add_unk = True | Hello, I am training a ner model, apparently I have a wrong tag in my training corpus because during the training process I get this error.

I already checked the corpus several times and I can't find the error, so I want to do what the problem tells me to add add_unk = True, but I don't know where to add it, in what part of the code.
The code I am using is the following
```
from flair.data import Corpus
from flair.datasets import ColumnCorpus
from flair.embeddings import TransformerWordEmbeddings
from flair.models import SequenceTagger
from flair.trainers import ModelTrainer
with tf.device('/device:GPU:0'):
# 1. get the corpus
columns = {0:'text',1:'ner'}
data_folder = '/content/drive/MyDrive/corpus de prueba/entrenamiento1'
corpus: Corpus = ColumnCorpus(data_folder, columns,
train_file='train.txt',
test_file='test.txt',
dev_file='dev.txt')
print(len(corpus.train))
# 2. what label do we want to predict?
label_type = 'ner'
# 3. make the label dictionary from the corpus
label_dict = corpus.make_label_dictionary(label_type=label_type)
print("el diccionario de mi corpus contiene las etiquetas: ",label_dict)
# 4. initialize fine-tuneable transformer embeddings WITH document context
embeddings = TransformerWordEmbeddings(model='bert-base-multilingual-cased',
layers="-1",
subtoken_pooling="first",
fine_tune=True,
use_context=True,
)
# 5. initialize bare-bones sequence tagger (no CRF, no RNN, no reprojection)
tagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=label_dict,
tag_type='ner',
use_crf=False,
use_rnn=False,
reproject_embeddings=False,
)
# 6. initialize trainer
trainer = ModelTrainer(tagger, corpus)
# 7. run fine-tuning
trainer.fine_tune('resources/taggers/pruebatest',
learning_rate=5.0e-3,
mini_batch_size=2,
max_epochs=5,
#mini_batch_chunk_size=1, # remove this parameter to speed up computation if you have a big GPU
)
```
Thanks | closed | 2022-05-17T19:50:47Z | 2023-01-28T22:16:23Z | https://github.com/flairNLP/flair/issues/2777 | [
"question",
"wontfix"
] | fmafelipe | 5 |
piskvorky/gensim | machine-learning | 2,852 | Reduce gensim surface area | Are there subpackages/submodules that we're not maintaining anymore, and could remove?
- [x] summarization
- [x] HDP
- [x] wordrank
- [x] dependency on pattern
- [x] various wrappers (incl. sklearn) and others.
- [x] simserver documentation
- [x] viz
The goal is to reduce the maintenance burden of the project.
| closed | 2020-06-10T07:34:42Z | 2021-03-19T04:55:15Z | https://github.com/piskvorky/gensim/issues/2852 | [
"breaks backward-compatibility",
"impact HIGH",
"reach LOW",
"housekeeping"
] | mpenkov | 14 |
microsoft/unilm | nlp | 1,349 | FileNotFoundError: [Errno 2] No such file or directory: 'xxx/vqa.train.jsonl' | **Describe**
I am using Beit-3 but I have faced one problem I don't know how to create vqa.train.jsonl.
| open | 2023-11-01T12:11:25Z | 2023-11-03T07:23:45Z | https://github.com/microsoft/unilm/issues/1349 | [] | yanggoumao2 | 2 |
Anjok07/ultimatevocalremovergui | pytorch | 1,275 | My first use of this application got this error. | I tried to remove the vocals from dragonforce through the fire and flames music mp3.
Last Error Received:
Process: MDX-Net
If this error persists, please contact the developers with the error details.
Raw Error Details:
Fail: "[ONNXRuntimeError] : 1 : FAIL : bad allocation"
Traceback Error: "
File "UVR.py", line 6638, in process_start
File "separate.py", line 499, in seperate
File "separate.py", line 594, in demix
File "separate.py", line 635, in run_model
File "separate.py", line 491, in <lambda>
File "onnxruntime\capi\onnxruntime_inference_collection.py", line 192, in run
"
Error Time Stamp [2024-04-06 19:51:26]
Full Application Settings:
vr_model: Choose Model
aggression_setting: 5
window_size: 512
mdx_segment_size: 256
batch_size: Default
crop_size: 256
is_tta: False
is_output_image: False
is_post_process: False
is_high_end_process: False
post_process_threshold: 0.2
vr_voc_inst_secondary_model: No Model Selected
vr_other_secondary_model: No Model Selected
vr_bass_secondary_model: No Model Selected
vr_drums_secondary_model: No Model Selected
vr_is_secondary_model_activate: False
vr_voc_inst_secondary_model_scale: 0.9
vr_other_secondary_model_scale: 0.7
vr_bass_secondary_model_scale: 0.5
vr_drums_secondary_model_scale: 0.5
demucs_model: Choose Model
segment: Default
overlap: 0.25
overlap_mdx: Default
overlap_mdx23: 8
shifts: 2
chunks_demucs: Auto
margin_demucs: 44100
is_chunk_demucs: False
is_chunk_mdxnet: False
is_primary_stem_only_Demucs: False
is_secondary_stem_only_Demucs: False
is_split_mode: True
is_demucs_combine_stems: True
is_mdx23_combine_stems: True
demucs_voc_inst_secondary_model: No Model Selected
demucs_other_secondary_model: No Model Selected
demucs_bass_secondary_model: No Model Selected
demucs_drums_secondary_model: No Model Selected
demucs_is_secondary_model_activate: False
demucs_voc_inst_secondary_model_scale: 0.9
demucs_other_secondary_model_scale: 0.7
demucs_bass_secondary_model_scale: 0.5
demucs_drums_secondary_model_scale: 0.5
demucs_pre_proc_model: No Model Selected
is_demucs_pre_proc_model_activate: False
is_demucs_pre_proc_model_inst_mix: False
mdx_net_model: UVR-MDX-NET Inst HQ 3
chunks: Auto
margin: 44100
compensate: Auto
denoise_option: None
is_match_frequency_pitch: True
phase_option: Automatic
phase_shifts: None
is_save_align: False
is_match_silence: True
is_spec_match: False
is_mdx_c_seg_def: False
is_invert_spec: False
is_deverb_vocals: False
deverb_vocal_opt: Main Vocals Only
voc_split_save_opt: Lead Only
is_mixer_mode: False
mdx_batch_size: Default
mdx_voc_inst_secondary_model: No Model Selected
mdx_other_secondary_model: No Model Selected
mdx_bass_secondary_model: No Model Selected
mdx_drums_secondary_model: No Model Selected
mdx_is_secondary_model_activate: False
mdx_voc_inst_secondary_model_scale: 0.9
mdx_other_secondary_model_scale: 0.7
mdx_bass_secondary_model_scale: 0.5
mdx_drums_secondary_model_scale: 0.5
is_save_all_outputs_ensemble: True
is_append_ensemble_name: False
chosen_audio_tool: Manual Ensemble
choose_algorithm: Min Spec
time_stretch_rate: 2.0
pitch_rate: 2.0
is_time_correction: True
is_gpu_conversion: False
is_primary_stem_only: True
is_secondary_stem_only: False
is_testing_audio: False
is_auto_update_model_params: True
is_add_model_name: False
is_accept_any_input: False
is_task_complete: False
is_normalization: False
is_use_opencl: False
is_wav_ensemble: False
is_create_model_folder: False
mp3_bit_set: 320k
semitone_shift: 0
save_format: MP3
wav_type_set: PCM_16
device_set: Default
help_hints_var: True
set_vocal_splitter: No Model Selected
is_set_vocal_splitter: False
is_save_inst_set_vocal_splitter: False
model_sample_mode: False
model_sample_mode_duration: 30
demucs_stems: All Stems
mdx_stems: All Stems | closed | 2024-04-06T22:58:59Z | 2024-04-06T23:30:46Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1275 | [] | TheKenseiden | 0 |
tiangolo/uwsgi-nginx-flask-docker | flask | 218 | Compatibility of flash-admin url = / " | The relevant codes are as follows
https://github.com/jackadam1981/test_flask_admin.git
If flash-adimn is used, the user-defined URL address is url = '/',
It works well under windows and Linux.
The static file of flash-admin cannot be accessed normally in the container.
#admin = Admin(app,url='/')
admin = Admin(app)
Correct record
10.0.0.210 - - [14/Mar/2021:01:47:28 +0000] "GET /admin/static/bootstrap/bootstrap2/swatch/default/bootstrap.min.css?v=2.3.2 HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36" "-"
[pid: 16|app: 0|req: 3/5] 10.0.0.210 () {48 vars in 1001 bytes} [Sun Mar 14 01:47:28 2021] GET /admin/static/bootstrap/bootstrap2/swatch/default/bootstrap.min.css?v=2.3.2 => generated 0 bytes in 1 msecs (HTTP/1.1 304) 4 headers in 183 bytes (0 switches on core 0)
admin = Admin(app,url='/')
#admin = Admin(app)
Record of errors
2021/03/14 01:32:12 [error] 14#14: *3 open() "/app/static/admin/bootstrap/bootstrap2/js/bootstrap.min.js" failed (2: No such file or directory), client: 10.0.0.210, server: , request: "GET /static/admin/bootstrap/bootstrap2/js/bootstrap.min.js?v=2.3.2 HTTP/1.1", host: "10.0.0.10", referrer: "http://10.0.0.10/"
2021/03/14 01:32:12 [error] 14#14: *1 open() "/app/static/admin/vendor/moment.min.js" failed (2: No such file or directory), client: 10.0.0.210, server: , request: "GET /static/admin/vendor/moment.min.js?v=2.22.2 HTTP/1.1", host: "10.0.0.10", referrer: "http://10.0.0.10/"
| closed | 2021-03-14T01:50:02Z | 2024-08-29T00:16:57Z | https://github.com/tiangolo/uwsgi-nginx-flask-docker/issues/218 | [] | jackadam1981 | 2 |
pykaldi/pykaldi | numpy | 104 | sh: gmm-boost-silence: command not found when running gmm-aligner.py | pykaldi was installed and `python setup.py test` shows that it either skipped or passed all the tests. When I ran the example script examples/alignment/gmm-aligner.py I get the error below.
```
sh: gmm-boost-silence: command not found
ERROR ([5.5.195~1-9daa6]:ExpectToken():io-funcs.cc:203) Failed to read token [started at file position -1], expected <TransitionModel>
ERROR ([5.5.195~1-9daa6]:ExpectToken():io-funcs.cc:203) Failed to read token [started at file position -1], expected <TransitionModel>
WARNING ([5.5.195~1-9daa6]:Close():kaldi-io.cc:515) Pipe gmm-boost-silence --boost=1.0 1 final.mdl - | had nonzero return status 32512
Traceback (most recent call last):
File "/home/jpadmin/Desktop/pycharm-community-2018.1.4/helpers/pydev/pydevd.py", line 1664, in <module>
main()
File "/home/jpadmin/Desktop/pycharm-community-2018.1.4/helpers/pydev/pydevd.py", line 1658, in main
globals = debugger.run(setup['file'], None, None, is_module)
File "/home/jpadmin/Desktop/pycharm-community-2018.1.4/helpers/pydev/pydevd.py", line 1068, in run
pydev_imports.execfile(file, globals, locals) # execute the script
File "/media/jpadmin/c92d86f3-ed84-4b98-b4ca-3d7777aca034/kaldi/pykaldi/examples/alignment/gmm-aligner.py", line 13, in <module>
self_loop_scale=0.1)
File "/media/jpadmin/c92d86f3-ed84-4b98-b4ca-3d7777aca034/kaldi/pykaldi/kaldi/alignment.py", line 403, in from_files
transition_model, acoustic_model = cls.read_model(model_rxfilename)
File "/media/jpadmin/c92d86f3-ed84-4b98-b4ca-3d7777aca034/kaldi/pykaldi/kaldi/alignment.py", line 369, in read_model
ki.binary)
RuntimeError: C++ exception:
```
The strange thing is that I am able to run gmm-boost-slience from the terminal and `which` shows that it's pointing to the kaldi directory inside tools
>/media/jpadmin/c92d86f3-ed84-4b98-b4ca-3d7777aca034/kaldi/pykaldi/tools/kaldi/src/gmmbin/gmm-boost-silence
I have already added KALDI_ROOT to path in bashrc
```
export KALDI_ROOT='/media/jpadmin/c92d86f3-ed84-4b98-b4ca-3d7777aca034/kaldi/pykaldi/tools/kaldi'
export PATH=$KALDI_ROOT/src/bin:$KALDI_ROOT/tools/openfst/bin:$KALDI_ROOT/src/fstbin:$KALDI_ROOT/src/gmmbin:$KALDI_ROOT/src/featbin:$KALDI_ROOT/src/lmbin:$KALDI_ROOT/src/sgmm2bin:$KALDI_ROOT/src/fgmmbin:$KALDI_ROOT/src/latbin:$PATH
```
I am not sure why gmm-boost-silence is not being found within GmmAligner.from_files()
| closed | 2019-04-02T23:49:46Z | 2019-04-03T22:45:57Z | https://github.com/pykaldi/pykaldi/issues/104 | [] | kkawabat | 3 |
sloria/TextBlob | nlp | 329 | out of vocab words results in neutral sentiment | 
- death is definitely not positive, at least most of the cases the word death implies sad/ negative emotion
- Empathy is strong positive word, but Textblob predicts it as neutral.
| open | 2020-06-08T14:36:51Z | 2020-06-08T14:36:51Z | https://github.com/sloria/TextBlob/issues/329 | [] | preetham-salehundam | 0 |
2noise/ChatTTS | python | 539 | 多次合成音色不稳定 | 使用了固定的音色,也固定了seed,但多次合成音色很不问题。
一句话按标点分割后,分段流式合成,合成完之后听起来音色不够稳定。
```
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
spk = torch.load('****.pt', map_location=select_device()).detach()
params_infer_code = ChatTTS.Chat.InferCodeParams(
spk_emb=spk,
temperature=0.001
)
```
| closed | 2024-07-06T06:40:00Z | 2024-11-21T04:02:21Z | https://github.com/2noise/ChatTTS/issues/539 | [
"documentation",
"question",
"stale"
] | XiaolongJason | 3 |
docarray/docarray | fastapi | 1,475 | docs: hnswlib cosine distance | Specify in the documentation of the `HnswLibDocIndex` that 'cosine' refers to cosine distance, not cosine similarity.
In the hnswlib documentation they claim it to be similarity, but it actually is distance. I opened an [issue](https://github.com/nmslib/hnswlib/issues/456#issuecomment-1521118534) on their side, and they will change it in their documentation. | closed | 2023-04-28T07:46:49Z | 2023-04-28T08:57:18Z | https://github.com/docarray/docarray/issues/1475 | [] | anna-charlotte | 1 |
dropbox/PyHive | sqlalchemy | 160 | How to get the hive server error msg? | I have a bad sql like
`select * from log where concat_ws('-',year,month,day) between 2017-09-13 and 2017-09-19`
which should has _2017-09-13_ and _2017-09-19_ surrounded by ''.
In beeline, it will result the error msg like
> Error: Error while compiling statement: FAILED: ParseException line 2:0 missing EOF at 'select' near ']' (state=42000,code=40000)
but in PyHive, it goes normal with the empty result []. By the way, I am using it through sqlalchemy.
I've tried to use _echo=True_ in the _create_engine()_ function and _logging_ by
`import logging`
`logging.basicConfig()`
`logging.getLogger('sqlalchemy.engine').setLevel(logging.DEBUG)`
but both can not output the error msg.
> 2017-09-20 12:17:22,904 INFO sqlalchemy.engine.base.Engine select * from log where concat_ws('-',year,month,day) between 2017-09-13 and 2017-09-19
> INFO:sqlalchemy.engine.base.Engine:select * from log where concat_ws('-',year,month,day) between 2017-09-13 and 2017-09-19
> 2017-09-20 12:17:22,905 INFO sqlalchemy.engine.base.Engine {}
> INFO:sqlalchemy.engine.base.Engine:{}
So I wonder if there is a way to get the server side error, it will be convenient to debug. | closed | 2017-09-20T04:32:54Z | 2017-09-22T06:08:34Z | https://github.com/dropbox/PyHive/issues/160 | [] | petersunbag | 2 |
autokey/autokey | automation | 61 | Fatal error starting Autokey. 'utf-8' codec can't decode byte 0xd2 in position 0: invalid continuation byte | Classification: Bug
Reproducibility: Always
## Summary
Since this morning, starting autokey-py shows an error dialog and exits:
```
Fatal error starting AutoKey.
'utf-8' codec can't decode byte 0xd2 in position 0: invalid continuation byte
```
## Steps to Reproduce
1. Start autokey-py3.
## Expected Results
Autokey should start. :-)
## Actual Results
Apart from the error dialog, this is the output with `--verbose`:
```
$ autokey-gtk --verbose
Gtk-Message: GtkDialog mapped without a transient parent. This is discouraged.
2017-01-12 00:40:30,776 ERROR - root - Fatal error starting AutoKey: 'utf-8' codec can't decode byte 0xd2 in position 0: invalid continuation byte
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/autokey/gtkapp.py", line 77, in __init__
if self.__verifyNotRunning():
File "/usr/lib/python3/dist-packages/autokey/gtkapp.py", line 95, in __verifyNotRunning
with open(LOCK_FILE, 'r') as f: pid = f.read()
File "/usr/lib/python3.5/codecs.py", line 321, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd2 in position 0: invalid continuation byte
```
## Version
AutoKey-Py3 version 0.93.9-1 from the Ubuntu PPA. The master branch ( commit c0f5af1217589d970ef028c243f8bdd5fc9c111d) has the same problem.
Installed via: 0.93.9-1 from PPA, master branch using `python3 setup.py install`.
Distro: Ubuntu 16.04.
| closed | 2017-01-11T23:44:09Z | 2017-01-12T09:11:10Z | https://github.com/autokey/autokey/issues/61 | [] | jcassee | 2 |
xinntao/Real-ESRGAN | pytorch | 828 | 动漫视频 提取帧和合并帧时使用cpu | 您好,我在用 real 进行动漫视频画质修复的时候,在提取帧和合并帧的时候,电脑一直使用cpu(有核显)进行编码.
我也在网上进行了一下搜索看时候可以在这个时候不适用cpu来进行提取帧和合并帧指令.
我找到了-hwaccel cuvid -c:v h264_nvenc 网上说ffmpeg可以这样可以使用显卡来进行编码,但是这样使用后就会报错.

我也想问一下,能否可以在使用ffmpeg提取帧和合并帧的时候使用gpu(是否因为cpu有核显导致不能全程使用独立显卡)显卡支持加速,也安装了相应的cuda | open | 2024-07-19T06:24:45Z | 2024-07-19T06:34:59Z | https://github.com/xinntao/Real-ESRGAN/issues/828 | [] | XHBGDXX | 0 |
postmanlabs/httpbin | api | 593 | POSTing to the /redirect-to results in 500 internal server error | Reproduce either using httpbin's own UI or run `curl -X POST "http://httpbin.org/redirect-to" -H "accept: text/html" -H "Content-Type: application/x-www-form-urlencoded" -d "url=http%3A%2F%2Ffoo.bar&status_code=308"`
httpbin responds with
```
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
<title>500 Internal Server Error</title>
<h1>Internal Server Error</h1>
<p>The server encountered an internal error and was unable to complete your request. Either the server is overloaded or there is an error in the application.</p>
``` | open | 2020-01-20T12:10:31Z | 2021-04-20T23:55:39Z | https://github.com/postmanlabs/httpbin/issues/593 | [] | PerMalmberg | 1 |
nonebot/nonebot2 | fastapi | 2,451 | Plugin: DALL-E 3绘图 | ### PyPI 项目名
nonebot-plugin-bingimagecreator
### 插件 import 包名
nonebot_plugin_bingimagecreator
### 标签
[{"label":"AI","color":"#ea5252"},{"label":"绘图","color":"#ea5252"}]
### 插件配置项
```dotenv
BING_COOKIES=["cookies1","cookies2","cookies3"]
BING_PROXY="http://127.0.0.1:8001"
```
| closed | 2023-11-07T09:36:56Z | 2023-11-09T06:12:45Z | https://github.com/nonebot/nonebot2/issues/2451 | [
"Plugin"
] | Alpaca4610 | 2 |
littlecodersh/ItChat | api | 222 | 当注册群组为自己所发出的消息时,无法特定群id | 下面这段代码在消息为自己发送的时候无法正常工作。
原因是 msg['FromUserName']为自己的id。
不知道能否在msg增加专门的群id。
在其他一些场景中也遇到如果是自己发送的消息,msg会与别人发的msg信息有很大差别。不好区分的情况。
格式问题sorry。稍微美化了一下。。。。
```
@itchat.msg_register(itchat.content.TEXT,` isGroupChat=True)
def text_replys(msg):
taget_chatroom = itchat.search_chatrooms(CHATROOMNAME)
if taget_chatroom is None:
print(u'没有找到群聊:' + CHATROOMNAME)
chatroom_name = taget_chatroom[0]['UserName']
print(chatroom_name)
print(msg['FromUserName'])
if chatroom_name in msg['FromUserName']:
if str(msg['Text']) in [u'开始']:
itchat.send(u'输入 碰运气 看看 ,满分100', msg['FromUserName'])
``` | closed | 2017-02-01T12:49:19Z | 2019-07-03T03:06:31Z | https://github.com/littlecodersh/ItChat/issues/222 | [
"invalid"
] | yangjicai | 4 |
strawberry-graphql/strawberry | django | 3,149 | Automatically sort query/mutations for introspection and in exported GraphQL schema |
<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->
<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->
## Feature Request Type
- [ ] Core functionality
- [x] Alteration (enhancement/optimization) of existing feature(s)
- [ ] New behavior
## Description
By default, the GraphQL schema stawberry generates uses the same ordering as the order fields in which fields are defined. This makes the `/graphql` introspection UI hard to parse. As a consumer of this UI and the exported schema.graphql files, it's very hard to find all query fields associated with some concept (like `userBy...`) because these are not logically grouped together.
It would be amazing if stawberry could (either by default or as a configuration option) support running `lexicographicSortSchema` ([reference](https://graphql-js.org/api/function/lexicographicsortschema/)) on the schema. This would take care of updating both the introspection UI, and exported schema file.
### Current output

### Desired output
 | open | 2023-10-13T09:09:19Z | 2025-03-20T15:56:25Z | https://github.com/strawberry-graphql/strawberry/issues/3149 | [] | smhutch | 0 |
igorbenav/FastAPI-boilerplate | sqlalchemy | 68 | Remove `allow_reuse` | ```
PydanticDeprecatedSince20: `allow_reuse` is deprecated and will be ignored; it should no longer be necessary. Deprecated in Pydantic V2.0 to be removed in V3.0. See Pydantic V2 Migration Guide at https://errors.pydantic.dev/2.4/migration/
``` | closed | 2023-12-04T03:31:49Z | 2023-12-07T08:03:39Z | https://github.com/igorbenav/FastAPI-boilerplate/issues/68 | [
"bug"
] | igorbenav | 0 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,801 | Nodriver: memory leak on Chromium 122.0.6261.128 | The memory consumption increases over time through each URL until all memory (8GB) runs out, initially, my application only consumes around 500MB.
My machine: Raspberry Pi 4 with 8GB ram
OS: Ubuntu
Chromium version: 122.0.6261.128 | closed | 2024-03-22T02:49:51Z | 2024-03-25T13:26:03Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1801 | [] | nhanvu327 | 7 |
flairNLP/flair | pytorch | 3,124 | [Feature]: Class-dependent label noise simulation | ### Problem statement
Currently Flair allows to generate only uniform label noise, which does not account for any similarities between the data points in the dataset. Generating class-dependent label noise would allow for a more realistic scenario, in which models have to deal with labelling mistakes/inaccuracies.
### Solution
Extend the `_corrupt_labels()` method of the `Corpus` by allowing to pass a pre-defined noise transition matrix.
### Additional Context
_No response_ | closed | 2023-02-24T14:53:01Z | 2023-03-30T10:18:00Z | https://github.com/flairNLP/flair/issues/3124 | [
"feature"
] | aynetdia | 0 |
sloria/TextBlob | nlp | 411 | Errors occurred when using Naive Bayes for sentiment classification | 1. As the question, when I use the Bayesian classifier for emotion classification, due to the excessive amount of data, when the amount of data exceeds 10,000, it will be automatically killed by the system, and there is no problem when the amount of data is not large

2. How do you save a trained naïve Bayes model? | open | 2022-07-03T07:50:10Z | 2022-07-03T07:50:10Z | https://github.com/sloria/TextBlob/issues/411 | [] | yaoysyao | 0 |
developmentseed/lonboard | data-visualization | 425 | Support `__arrow_c_array__` in viz() | It would be nice to be able to visualize any array. Note that this should be before `__geo_interface__` in the conversion steps.
You might want to do something like the following to ensure the field metadata isn't lost if extension types aren't installed.
```py
if hasattr(obj, "__arrow_c_array__"):
schema, _ = obj.__arrow_c_array__()
class SchemaHolder:
def __init__(self, capsule) -> None:
self.capsule = capsule
def __arrow_c_schema__(self):
return self.capsule
pyarrow_field = pa.field(SchemaHolder(schema))
pyarrow_array = pa.array(obj)
``` | closed | 2024-03-20T20:02:58Z | 2024-03-25T16:29:23Z | https://github.com/developmentseed/lonboard/issues/425 | [] | kylebarron | 0 |
schemathesis/schemathesis | graphql | 1,753 | [BUG] --report flag without arguments is broken. | **Checklist**
- [x] I checked the [FAQ section](https://schemathesis.readthedocs.io/en/stable/faq.html#frequently-asked-questions) of the documentation
- [x] I looked for similar issues in the [issue tracker](https://github.com/schemathesis/schemathesis/issues)
**Describe the bug**
When running from the CLI with the --report flag an error is thrown. When adding any arguments like true or 1, a file with that name is created. I would like a report on schemathesis.io to be generated.
**To Reproduce**
Steps to reproduce the behavior:
Run a valid schemathesis command with the --report flag
The error received is the following:
```
Traceback (most recent call last):
File "/home/docker/.local/bin/st", line 8, in <module>
sys.exit(schemathesis())
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 1157, in __call__
return self.main(*args, **kwargs)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 1078, in main
rv = self.invoke(ctx)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 1686, in invoke
sub_ctx = cmd.make_context(cmd_name, args, parent=ctx)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 943, in make_context
self.parse_args(ctx, args)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 1408, in parse_args
value, args = param.handle_parse_result(ctx, opts, args)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 2400, in handle_parse_result
value = self.process_value(ctx, value)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 2356, in process_value
value = self.type_cast_value(ctx, value)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 2344, in type_cast_value
return convert(value)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 2316, in convert
return self.type(value, param=self, ctx=ctx)
File "/home/docker/.local/lib/python3.8/site-packages/click/types.py", line 83, in __call__
return self.convert(value, param, ctx)
File "/home/docker/.local/lib/python3.8/site-packages/click/types.py", line 712, in convert
lazy = self.resolve_lazy_flag(value)
File "/home/docker/.local/lib/python3.8/site-packages/click/types.py", line 694, in resolve_lazy_flag
if os.fspath(value) == "-":
TypeError: expected str, bytes or os.PathLike object, not object
```
**Expected behavior**
--report with no flags should upload a report to schemathesis.io
**Environment (please complete the following information):**
- OS: Debian WSL
- Python version: 3.8.10
- Schemathesis version: 3.19.5
- Spec version: 3.0.3
| closed | 2023-07-07T08:45:11Z | 2023-08-29T13:50:29Z | https://github.com/schemathesis/schemathesis/issues/1753 | [
"Priority: High",
"Type: Bug",
"Difficulty: Intermediate"
] | phknot | 3 |
nteract/papermill | jupyter | 616 | Reusing dedicated, initialized kernel | Apologies if this is in the wrong place—I wasn't quite sure where to ask a support question.
I'm using Papermill to render notebooks in real-time, and I would like to reduce the overhead involved in starting a new kernel every time I execute a notebook.
Is it possible to either (i) use the current Python session as the kernel, or (ii) connect to an already-running kernel?
Either way, my goal is to access variables in an already-running kernel / Python process, and use those in the course of executing a notebook. I have it in my head that this is similar to pasting a bunch of cells into an already-running notebook / kernel, and executing them in the existing runtime.
Thank you for any pointers or suggestions! | closed | 2021-06-23T17:31:46Z | 2021-08-09T14:37:28Z | https://github.com/nteract/papermill/issues/616 | [] | mhlinder | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.