
repo_name
stringlengths 9
75
| topic
stringclasses 30
values | issue_number
int64 1
203k
| title
stringlengths 1
976
| body
stringlengths 0
254k
| state
stringclasses 2
values | created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| url
stringlengths 38
105
| labels
listlengths 0
9
| user_login
stringlengths 1
39
| comments_count
int64 0
452
|
|---|---|---|---|---|---|---|---|---|---|---|---|
Evil0ctal/Douyin_TikTok_Download_API
|
web-scraping
| 513 |
[BUG] bilibili 获取指定用户的信息 一直返回风控校验失败
|
平台: bilibili
使用接口:api/bilibili/web/fetch_user_profile 获取指定用户的信息
接口返回: {
"code": -352,
"message": "风控校验失败",
"ttl": 1,
"data": {
"v_voucher": "voucher_f7a432cb-91fb-467e-a9a3-3e861aac9478"
}
}
错误描述: 已经更新过config.yaml内的cookie,使用 【获取用户发布的视频数据】接口就可以正常返回数据。但是使用【获取指定用户的信息】,就返回【风控校验失败】。
|
open
|
2024-11-28T10:52:56Z
|
2024-11-28T10:57:11Z
|
https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/513
|
[
"BUG"
] |
sukris
| 0 |
jupyterhub/repo2docker
|
jupyter
| 1,131 |
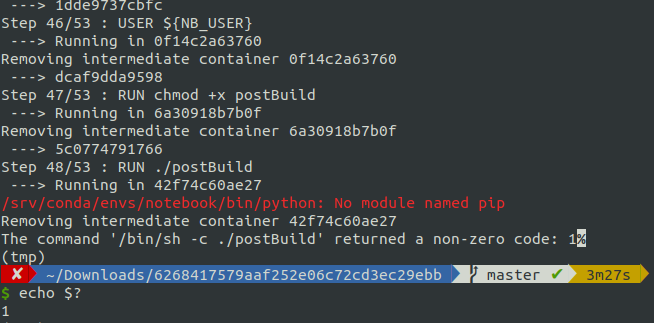
/srv/conda/envs/notebook/bin/python: No module named pip
|
<!-- Thank you for contributing. These HTML commments will not render in the issue, but you can delete them once you've read them if you prefer! -->
### Bug description
Opening a new issue as a follow-up to the comment posted in https://github.com/jupyterhub/repo2docker/pull/1062#issuecomment-1023073794.
Using the latest `repo2docker` (with `python -m pip install https://github.com/jupyterhub/repo2docker/archive/main.zip`), (existing) repos that have a custom `environment.yml` don't seem to be able to invoke `pip`, for example with `python -m pip`.
#### Expected behaviour
Running arbitrary `python -m pip install .` or similar should still be supported in a `postBuild` file.
#### Actual behaviour
Getting the following error:
```
/srv/conda/envs/notebook/bin/python: No module named pip
```
### How to reproduce
**With Binder**
Using the test gist: https://gist.github.com/jtpio/6268417579aaf252e06c72cd3ec29ebb
With `postBuild`:
```
python -m pip --help
```
And `environment.yml`:
```yaml
name: test
channels:
- conda-forge
dependencies:
- python >=3.10,<3.11
```

**Locally with repo2docker**
```
mamba create -n tmp -c conda-forge python=3.10 -y
conda activate tmp
python -m pip install https://github.com/jupyterhub/repo2docker/archive/main.zip
jupyter-repo2docker https://gist.github.com/jtpio/6268417579aaf252e06c72cd3ec29ebb
```
### Your personal set up
Using this gist on mybinder.org: https://gist.github.com/jtpio/6268417579aaf252e06c72cd3ec29ebb
|
closed
|
2022-01-28T16:35:33Z
|
2022-02-01T10:48:39Z
|
https://github.com/jupyterhub/repo2docker/issues/1131
|
[] |
jtpio
| 6 |
inducer/pudb
|
pytest
| 449 |
Internal shell height should be saved in the settings
|
I think the default height of internal shell is too small.
Thx~
|
closed
|
2021-05-09T09:41:15Z
|
2021-07-13T11:53:25Z
|
https://github.com/inducer/pudb/issues/449
|
[] |
sisrfeng
| 3 |
timkpaine/lantern
|
plotly
| 165 |
add "email notebook" to GUI
|
closed
|
2018-06-05T04:27:27Z
|
2018-08-07T14:13:28Z
|
https://github.com/timkpaine/lantern/issues/165
|
[
"feature"
] |
timkpaine
| 1 |
|
smarie/python-pytest-cases
|
pytest
| 238 |
Setting `ids` in `@parametrize` leads to "ValueError: Only one of ids and idgen should be provided"
|
Using `ids` without setting `idgen` to None explicitly leads to this error.
```python
from pytest_cases import parametrize, parametrize_with_cases
class Person:
def __init__(self, name):
self.name = name
def get_tasks():
return [Person("joe"), Person("ana")]
class CasesFoo:
@parametrize(task=get_tasks(), ids=lambda task: task.name)
def case_task(self, task):
return task
@parametrize_with_cases("task", cases=CasesFoo)
def test_foo(task):
print(task)
```
A workaround is to set `idgen=None` too: `@parametrize(task=get_tasks(), ids=lambda task: task.name, idgen=None)`
See also #237
|
closed
|
2021-11-24T09:19:47Z
|
2022-01-07T13:40:25Z
|
https://github.com/smarie/python-pytest-cases/issues/238
|
[] |
smarie
| 0 |
deepinsight/insightface
|
pytorch
| 2,374 |
Failed in downloading one of the facial analysis model
|
RuntimeError: Failed downloading url http://insightface.cn-sh2.ufileos.com/models/buffalo_l.zip
Reproduce:
model = FaceAnalysis(name='buffalo_l')
|
closed
|
2023-07-17T14:12:24Z
|
2023-07-17T14:58:26Z
|
https://github.com/deepinsight/insightface/issues/2374
|
[] |
amztc34283
| 1 |
gradio-app/gradio
|
data-visualization
| 9,956 |
[Gradio 5] - Gallery with two "X" close button
|
### Describe the bug
I have noticed that the gallery in the latest version of Gradio is showing 2 buttons to close the gallery image, and the button on top is interfering with the selection of the buttons below. This happens when I am in preview mode, either starting in preview mode or after clicking on the image to preview.
### Have you searched existing issues? 🔎
- [X] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
with gr.Blocks(analytics_enabled=False) as app:
gallery = gr.Gallery(label="Generated Images", interactive=True, show_label=True, preview=True, allow_preview=True)
app.launch(inbrowser=True)
```
### Screenshot

### Logs
```shell
N/A
```
### System Info
```shell
Gradio Environment Information:
------------------------------
Operating System: Windows
gradio version: 5.5.0
gradio_client version: 1.4.2
------------------------------------------------
gradio dependencies in your environment:
aiofiles: 23.2.1
anyio: 4.4.0
audioop-lts is not installed.
fastapi: 0.115.4
ffmpy: 0.4.0
gradio-client==1.4.2 is not installed.
httpx: 0.27.0
huggingface-hub: 0.25.2
jinja2: 3.1.3
markupsafe: 2.1.5
numpy: 1.26.3
orjson: 3.10.6
packaging: 24.1
pandas: 2.2.2
pillow: 10.2.0
pydantic: 2.8.2
pydub: 0.25.1
python-multipart==0.0.12 is not installed.
pyyaml: 6.0.1
ruff: 0.5.6
safehttpx: 0.1.1
semantic-version: 2.10.0
starlette: 0.41.2
tomlkit==0.12.0 is not installed.
typer: 0.12.3
typing-extensions: 4.12.2
urllib3: 2.2.2
uvicorn: 0.30.5
authlib; extra == 'oauth' is not installed.
itsdangerous; extra == 'oauth' is not installed.
gradio_client dependencies in your environment:
fsspec: 2024.2.0
httpx: 0.27.0
huggingface-hub: 0.25.2
packaging: 24.1
typing-extensions: 4.12.2
websockets: 12.0
```
### Severity
I can work around it
|
closed
|
2024-11-13T23:25:20Z
|
2024-11-25T17:13:39Z
|
https://github.com/gradio-app/gradio/issues/9956
|
[
"bug"
] |
elismasilva
| 9 |
gradio-app/gradio
|
machine-learning
| 10,738 |
gradio canvas won't accept images bigger then 600 x 600 on forgewebui
|
### Describe the bug
I think it's a gradio problem since the problem started today and forge hasn't updated anything
### Have you searched existing issues? 🔎
- [x] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
```
### Screenshot
_No response_
### Logs
```shell
```
### System Info
```shell
colab on forgewebui
```
### Severity
I can work around it
|
closed
|
2025-03-06T02:57:40Z
|
2025-03-06T15:21:24Z
|
https://github.com/gradio-app/gradio/issues/10738
|
[
"bug",
"pending clarification"
] |
Darknessssenkrad
| 13 |
serengil/deepface
|
machine-learning
| 709 |
How to avoid black padding pixels?
|
Thanks for the great work! I have a question about the face detector module.
The README.md mentions that
> To avoid deformation, deepface adds black padding pixels according to the target size argument after detection and alignment.
If I don't want any padding pixels, what pre-processing steps should I do? Or is there any requirement on the shape if I want to skip the padding?
|
closed
|
2023-04-02T11:59:30Z
|
2023-04-02T14:53:28Z
|
https://github.com/serengil/deepface/issues/709
|
[] |
xjtupanda
| 1 |
moshi4/pyCirclize
|
data-visualization
| 84 |
Auto annotation for sectors in chord diagram
|
> Annotation plotting is a feature added in v1.9.0 (python>=3.9). It is not available in v1.8.0.
_Originally posted by @moshi4 in [#83](https://github.com/moshi4/pyCirclize/issues/83#issuecomment-2658729865)_
upgraded to v1.9.0 still it is not changing.
```
from pycirclize import Circos, config
from pycirclize.parser import Matrix
config.ann_adjust.enable = True
circos = Circos.chord_diagram(
matrix,
cmap= sector_color_dict,
link_kws=dict(direction=0, ec="black", lw=0.5, fc="black", alpha=0.5),
link_kws_handler = link_kws_handler_overall,
order = country_order_list,
# label_kws = dict(orientation = 'vertical', r=115)
)
```
While in the documentation track.annotate is used. However I am using from to matrix and updates aren't happing still. Do you have any suggestions.
full pseudocode:
```
country_order_list = sorted(list(set(edge_list['source']).union(set(edge_list['target']))))
for country in country_order_list:
cnt = country.split('_')[0]
if country not in country_color_dict.keys():
sector_color_dict[cnt] = 'red'
else:
sector_color_dict[cnt] = country_color_dict[cnt]
from_to_table_df = edge_list.groupby(['source', 'target']).size().reset_index(name='count')[['source', 'target', 'count']]
matrix = Matrix.parse_fromto_table(from_to_table_df)
from_to_table_df['year'] = year
from_to_table_overall = pd.concat([from_to_table_overall, from_to_table_df])
circos = Circos.chord_diagram(
matrix,
cmap= sector_color_dict,
link_kws=dict(direction=0, ec="black", lw=0.5, fc="black", alpha=0.5),
link_kws_handler = link_kws_handler_overall,
order = country_order_list,
# label_kws = dict(orientation = 'vertical', r=115)
)
circos.plotfig()
plt.show()
plt.title(f'{year}_overall')
plt.close()
```
|
closed
|
2025-02-14T09:41:38Z
|
2025-02-21T09:36:39Z
|
https://github.com/moshi4/pyCirclize/issues/84
|
[
"question"
] |
jishnu-lab
| 7 |
autokey/autokey
|
automation
| 728 |
Key capture seems broken on Ubuntu 22.04
|
### Has this issue already been reported?
- [X] I have searched through the existing issues.
### Is this a question rather than an issue?
- [X] This is not a question.
### What type of issue is this?
Bug
### Which Linux distribution did you use?
I've been using AutoKey on Ubuntu 20.04 LTS for months now with this setup and it worked perfectly. Since updating to 22.04 LTS AutoKey no longer captures keys properly.
### Which AutoKey GUI did you use?
GTK
### Which AutoKey version did you use?
Autokey-gtk 0.95.10 from apt.
### How did you install AutoKey?
Distro's repository, didn't change anything during upgrade to 22.04LTS.
### Can you briefly describe the issue?
AutoKey no longer seems to capture keys reliably.
My old scripts are set up like: ALT+A = ä, ALT+SHIFT+A = Ä, ALT+S=ß etc. This worked perfectly on 20.04LTS across multiple machines.
Since the update to 22.04LTS, these scripts only work sporadically, and only in some apps.
Firefox (Snap):
ALT+A works in Firefox if pressed slowly.
ALT+SHIFT+A produces the same output as ALT+A in Firefox if pressed slowly.
If combination is pressed quickly while typing a word, such as "ändern", Firefox will capture the release of the ALT key and send the letters "ndern" to the menu, triggering EDIT=>SETTINGS.
Geany (text editor): ALT key is immediately captured by the menu
Gedit (text editor): ALT key is immediately captured by the menu
Setting hotkeys in AutoKey-GTK itself also doesn't seem to work any more. If I click "Press to Set" the program no longer recognizes any keypresses, hanging on "press a key..." indefinitely.

My scripts are set up as follows:

### Can the issue be reproduced?
Sometimes
### What are the steps to reproduce the issue?
I've reproduced this on two different machines, both of which were upgraded from 20.04LTS to 22.04LTS and run the same script files.
### What should have happened?
Same perfect performance as on 20.04LTS
### What actually happened?
See issue description. AutoKey seems to no longer be capturing the keys properly, or rather the foreground app is grabbing them before AutoKey has a chance to do so.
### Do you have screenshots?
_No response_
### Can you provide the output of the AutoKey command?
_No response_
### Anything else?
_No response_
|
closed
|
2022-08-31T16:58:57Z
|
2022-08-31T22:00:24Z
|
https://github.com/autokey/autokey/issues/728
|
[
"invalid",
"installation/configuration"
] |
sbroenner
| 4 |
AntonOsika/gpt-engineer
|
python
| 679 |
Sweep: add test coverage badge to github project
|
<details open>
<summary>Checklist</summary>
- [X] `.github/workflows/python-app.yml`
> • Add a new step to run tests with coverage using pytest-cov. This step should be added after the step where the tests are currently being run.
> • In the new step, use the command `pytest --cov=./` to run the tests with coverage.
> • Add another step to send the coverage report to Codecov. This can be done using the codecov/codecov-action GitHub Action. The step should look like this:
> - name: Upload coverage to Codecov
> uses: codecov/codecov-action@v1
- [X] `README.md`
> • Add the Codecov badge to the top of the README file. The markdown for the badge can be obtained from the settings page of the repository on Codecov. It should look something like this: `[](https://codecov.io/gh/AntonOsika/gpt-engineer)`
</details>
|
closed
|
2023-09-06T17:47:51Z
|
2023-09-15T07:56:56Z
|
https://github.com/AntonOsika/gpt-engineer/issues/679
|
[
"enhancement",
"sweep"
] |
ATheorell
| 1 |
jupyter-book/jupyter-book
|
jupyter
| 1,919 |
Add on page /lectures/big-o.html
|
closed
|
2023-02-02T16:38:30Z
|
2023-02-12T12:47:28Z
|
https://github.com/jupyter-book/jupyter-book/issues/1919
|
[] |
js-uri
| 1 |
|
apache/airflow
|
python
| 48,083 |
xmlsec==1.3.15 update on March 11/2025 breaks apache-airflow-providers-amazon builds in Ubuntu running Python 3.11+
|
### Apache Airflow Provider(s)
amazon
### Versions of Apache Airflow Providers
Looks like a return of https://github.com/apache/airflow/issues/39437
```
uname -a
Linux airflow-worker-qg8nn 6.1.123+ #1 SMP PREEMPT_DYNAMIC Sun Jan 12 17:02:52 UTC 2025 x86_64 x86_64 x86_64 GNU/Linux
airflow@airflow-worker-qg8nn:~$ cat /etc/issue
Ubuntu 24.04.2 LTS \n \l
```
When installing apache-airflow-providers-amazon
`
********************************************************************************
Please consider removing the following classifiers in favor of a SPDX license expression:
License :: OSI Approved :: MIT License
See https://packaging.python.org/en/latest/guides/writing-pyproject-toml/#license for details.
********************************************************************************
!!
self._finalize_license_expression()
running bdist_wheel
running build
running build_py
creating build/lib.linux-x86_64-cpython-311/xmlsec
copying src/xmlsec/__init__.pyi -> build/lib.linux-x86_64-cpython-311/xmlsec
copying src/xmlsec/template.pyi -> build/lib.linux-x86_64-cpython-311/xmlsec
copying src/xmlsec/tree.pyi -> build/lib.linux-x86_64-cpython-311/xmlsec
copying src/xmlsec/constants.pyi -> build/lib.linux-x86_64-cpython-311/xmlsec
copying src/xmlsec/py.typed -> build/lib.linux-x86_64-cpython-311/xmlsec
running build_ext
error: xmlsec1 is not installed or not in path.
[end of output]
```
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for xmlsec
Building wheel for pyhive (setup.py): started
Building wheel for pyhive (setup.py): finished with status 'done'
Created wheel for pyhive: filename=PyHive-0.7.0-py3-none-any.whl size=53933 sha256=3db46c1d80f77ee8782f517987a0c1fc898576faf2efc3842475b53df6630d2f
Stored in directory: /tmp/pip-ephem-wheel-cache-nnezwghj/wheels/11/32/63/d1d379f01c15d6488b22ed89d257b613494e4595ed9b9c7f1c
Successfully built maxminddb-geolite2 thrift pure-sasl pyhive
Failed to build xmlsec
ERROR: Could not build wheels for xmlsec, which is required to install pyproject.toml-based projects
```
Pinning pip install xmlsec==1.3.14 resolve the issue
### Apache Airflow version
2.10.5
### Operating System
Ubuntu 24.04.2
### Deployment
Google Cloud Composer
### Deployment details
_No response_
### What happened
_No response_
### What you think should happen instead
_No response_
### How to reproduce
pip install apache-airflow-providers-amazon
### Anything else
_No response_
### Are you willing to submit PR?
- [ ] Yes I am willing to submit a PR!
### Code of Conduct
- [x] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)
|
closed
|
2025-03-21T21:24:51Z
|
2025-03-23T20:02:27Z
|
https://github.com/apache/airflow/issues/48083
|
[
"kind:bug",
"area:providers",
"area:dependencies",
"needs-triage"
] |
kmarutya
| 4 |
exaloop/codon
|
numpy
| 558 |
Error:Tuple from_py overload match problem
|
The following code snippet will result in a compilation error
```python
@python
def t3() -> tuple[pyobj, pyobj, pyobj]:
return (1, 2, 3)
@python
def t2() -> tuple[pyobj, pyobj]:
return (1, 2)
@python
def t33() -> tuple[pyobj, pyobj, pyobj]:
return (1, 3, 5)
def test1(a, b, c):
return a + b + c
def test2(a, b):
return a + b
print(test1(*t3()))
print(test2(*t2()))
print(test1(*t33()))
```
```
test_py_dec.py:10:1-41: error: 'Tuple[pyobj,pyobj,pyobj]' does not match expected type 'Tuple[T1,T2]'
╰─ test_py_dec.py:21:14-17: error: during the realization of t33()
```
|
closed
|
2024-05-10T12:26:40Z
|
2024-11-10T19:20:26Z
|
https://github.com/exaloop/codon/issues/558
|
[
"bug"
] |
victor3d
| 2 |
huggingface/datasets
|
deep-learning
| 6,441 |
Trouble Loading a Gated Dataset For User with Granted Permission
|
### Describe the bug
I have granted permissions to several users to access a gated huggingface dataset. The users accepted the invite and when trying to load the dataset using their access token they get
`FileNotFoundError: Couldn't find a dataset script at .....` . Also when they try to click the url link for the dataset they get a 404 error.
### Steps to reproduce the bug
1. Grant access to gated dataset for specific users
2. Users accept invitation
3. Users login to hugging face hub using cli login
4. Users run load_dataset
### Expected behavior
Dataset is loaded normally for users who were granted access to the gated dataset.
### Environment info
datasets==2.15.0
|
closed
|
2023-11-21T19:24:36Z
|
2023-12-13T08:27:16Z
|
https://github.com/huggingface/datasets/issues/6441
|
[] |
e-trop
| 3 |
miguelgrinberg/python-socketio
|
asyncio
| 443 |
python-socketio bridge with ws4py
|
what i need.
client-machine (python-socketio-client) -> server-1 (python-socketio-server also ws4py-client) -> server-2(ws4py-server)
currently 2 websocket connections exists
from client to server-1 (socketio)
from server-1 to server-2(ws4py)
what i hold is server-1.
server-2(ws4py) is from a third party service provider.
i want to get data from client -> receive it on my server-1 thru websocket running on socketio -> send this data to server-2 thru websocket running on ws4py.
What i have currently built.
socketio client and server-1 = working fine
ws4py server-1 to server-2 = working fine
what i want
get the event or class object of that connected client from socketio and send that directly to ws4py.
Can someone guide me on this.
|
closed
|
2020-03-20T10:20:56Z
|
2020-03-20T14:52:10Z
|
https://github.com/miguelgrinberg/python-socketio/issues/443
|
[
"question"
] |
Geo-Joy
| 6 |
jina-ai/clip-as-service
|
pytorch
| 310 |
Suggestions for building semantic search engine
|
Hello! I'm looking for suggestions of using BERT (and BERT-as-service) in my case. Sorry if such is off-topic here. I'm building kind of information retrieval system and trying to use BERT as semantic search engine. In my DB I have objects with descriptions like "pizza", "falafel", "Chinese restaurant", "I bake pies", "Chocolate Factory Roshen" and I want all these objects to be retrieved by a search query "food" or "I'm hungry" - with some score of semantic relatedness, of course.
First of all, does it look like semantic sentence similarity task or more like word similarity? I expect max_seq_len to be 10-15, on average up to 5. So that, should I look into fine-tuning and if yes, on what task? GLUE? Or maybe on my own data creating dataset like STS-B? Or maybe it's better to extract ELMo-like contextual word embedding and then average them?
Really appreciate any suggestion. Thanks in advance!
**Prerequisites**
> Please fill in by replacing `[ ]` with `[x]`.
* [x] Are you running the latest `bert-as-service`?
* [x] Did you follow [the installation](https://github.com/hanxiao/bert-as-service#install) and [the usage](https://github.com/hanxiao/bert-as-service#usage) instructions in `README.md`?
* [x] Did you check the [FAQ list in `README.md`](https://github.com/hanxiao/bert-as-service#speech_balloon-faq)?
* [x] Did you perform [a cursory search on existing issues](https://github.com/hanxiao/bert-as-service/issues)?
|
open
|
2019-04-04T11:57:14Z
|
2019-07-26T16:09:51Z
|
https://github.com/jina-ai/clip-as-service/issues/310
|
[] |
realsergii
| 2 |
kensho-technologies/graphql-compiler
|
graphql
| 904 |
Remove cached-property dependency
|
I think we should remove our dependency on `cached-property`, for a few reasons:
- We use a very minimal piece of functionality we can easily replicate and improve upon ourselves.
- It isn't type-hinted, and the open issue for it is over a year old with no activity: https://github.com/pydanny/cached-property/issues/172
- The lack of type hints means that we have to always suppress `mypy`'s `disallow_untyped_decorators` rule. It also means that `@cached_property` properties return type `Any`, which makes `mypy` even less useful.
- `@cached_property` doesn't inherit from `@property`, causing a number of other type issues. Here's the tracking issue for it, which has also been inactive in many years: https://github.com/pydanny/cached-property/issues/26
|
closed
|
2020-08-13T21:52:34Z
|
2020-08-14T18:22:20Z
|
https://github.com/kensho-technologies/graphql-compiler/issues/904
|
[] |
obi1kenobi
| 0 |
graphql-python/gql
|
graphql
| 206 |
gql-cli pagination
|
Looks like https://gql.readthedocs.io/en/latest/gql-cli/intro.html doesn't support pagination, which is necessary to get all results from API calls like GitLab https://docs.gitlab.com/ee/api/graphql/getting_started.html#pagination in one go.
Are there any plans to add it?
|
closed
|
2021-05-08T09:33:19Z
|
2021-08-24T15:00:39Z
|
https://github.com/graphql-python/gql/issues/206
|
[
"type: invalid",
"type: question or discussion"
] |
abitrolly
| 13 |
microsoft/unilm
|
nlp
| 900 |
Layoutlmv3 for RE
|
**Describe**
when i use layoutlmv3 to do RE task on XFUND_zh dataset, the result is 'eval_precision': 0.5283, 'eval_recall': 0.4392.
i do not konw the reason of the bad result. maybe there is something wrong with my RE task code? maybe i need more data for training? is there some suggestions for me to improve the result?
Dose anyone meet the same problem?
|
open
|
2022-10-25T10:00:19Z
|
2022-12-05T03:01:29Z
|
https://github.com/microsoft/unilm/issues/900
|
[] |
SuXuping
| 3 |
flairNLP/flair
|
nlp
| 3,487 |
[Bug]: GPU memory leak in TextPairRegressor when embed_separately is set to `False`
|
### Describe the bug
When training a `TextPairRegressor` model with `embed_separately=False` (the default), via e.g. `ModelTrainer.fine_tune`, the GPU memory slowly creeps up with each batch, eventually causing an OOM even when the model and a single batch fits easily in GPU memory.
The function `store_embeddings` is supposed to clear any embeddings of each DataPoint. For this model, the type of data point is `TextPair`. It actually does seem to handle clearing `text_pair.first` and `.second` when `embed_separately=True`, because it runs embed for each sentence (see `TextPairRegressor._get_embedding_for_data_point`), and that embedding is attached to each sentence so it can be referenced via the sentence.
However, the default setting is `False`; in that case, to embed the pair, it concatenates the text of both sentences (adding a separator), creates a new sentence, embeds that sentence, and then returns that embedding. Since it's never attached to the `DataPoint` object, `clear_embeddings` doesn't find it when you iterate over the data points. The function `identify_dynamic_embeddings` also always comes up empty
### To Reproduce
```python
import flair
from flair.data import DataPairCorpus
from flair.models import TextPairRegressor
search_rel_corpus = DataPairCorpus(Path('text_pair_dataset'), train_file='train.tsv', test_file='test.tsv', dev_file='dev.tsv', label_type='relevance', in_memory=False)
text_pair_regressor = TextPairRegressor(embeddings=embeddings, label_type='relevance')
embeddings = TransformerDocumentEmbeddings(
model='xlm-roberta-base',
layers="-1",
subtoken_pooling='first',
fine_tune=True,
use_context=True,
is_word_embedding=True,
)
trainer = ModelTrainer(text_pair_regressor, search_rel_corpus)
trainer.fine_tune(
"relevance_regressor",
learning_rate=1e-5,
epoch=0,
max_epochs=5,
mini_batch_size=4,
save_optimizer_state=True,
save_model_each_k_epochs=1,
use_amp=True, # aka Automatic Mixed Precision, e.g. float16
)
```
### Expected behavior
The memory should remain relatively flat with each epoch of training if memory is cleared correctly. In other training, such as for a `TextClassifier`, it stays roughly the same after each mini-batch,
### Logs and Stack traces
```stacktrace
OutOfMemoryError Traceback (most recent call last)
Cell In[15], line 1
----> 1 final_score = trainer.fine_tune(
2 "relevance_regressor",
3 learning_rate=1e-5,
4 epoch=0,
5 max_epochs=5,
6 mini_batch_size=4,
7 save_optimizer_state=True,
8 save_model_each_k_epochs=1,
9 use_amp=True, # aka Automatic Mixed Precision, e.g. float16
10 )
11 final_score
File /pyzr/active_venv/lib/python3.10/site-packages/flair/trainers/trainer.py:253, in ModelTrainer.fine_tune(self, base_path, warmup_fraction, learning_rate, decoder_learning_rate, mini_batch_size, eval_batch_size, mini_batch_chunk_size, max_epochs, optimizer, train_with_dev, train_with_test, reduce_transformer_vocab, main_evaluation_metric, monitor_test, monitor_train_sample, use_final_model_for_eval, gold_label_dictionary_for_eval, exclude_labels, sampler, shuffle, shuffle_first_epoch, embeddings_storage_mode, epoch, save_final_model, save_optimizer_state, save_model_each_k_epochs, create_file_logs, create_loss_file, write_weights, use_amp, plugins, attach_default_scheduler, **kwargs)
250 if attach_default_scheduler:
251 plugins.append(LinearSchedulerPlugin(warmup_fraction=warmup_fraction))
--> 253 return self.train_custom(
254 base_path=base_path,
255 # training parameters
256 learning_rate=learning_rate,
257 decoder_learning_rate=decoder_learning_rate,
258 mini_batch_size=mini_batch_size,
259 eval_batch_size=eval_batch_size,
260 mini_batch_chunk_size=mini_batch_chunk_size,
261 max_epochs=max_epochs,
262 optimizer=optimizer,
263 train_with_dev=train_with_dev,
264 train_with_test=train_with_test,
265 reduce_transformer_vocab=reduce_transformer_vocab,
266 # evaluation and monitoring
267 main_evaluation_metric=main_evaluation_metric,
268 monitor_test=monitor_test,
269 monitor_train_sample=monitor_train_sample,
270 use_final_model_for_eval=use_final_model_for_eval,
271 gold_label_dictionary_for_eval=gold_label_dictionary_for_eval,
272 exclude_labels=exclude_labels,
273 # sampling and shuffling
274 sampler=sampler,
275 shuffle=shuffle,
276 shuffle_first_epoch=shuffle_first_epoch,
277 # evaluation and monitoring
278 embeddings_storage_mode=embeddings_storage_mode,
279 epoch=epoch,
280 # when and what to save
281 save_final_model=save_final_model,
282 save_optimizer_state=save_optimizer_state,
283 save_model_each_k_epochs=save_model_each_k_epochs,
284 # logging parameters
285 create_file_logs=create_file_logs,
286 create_loss_file=create_loss_file,
287 write_weights=write_weights,
288 # amp
289 use_amp=use_amp,
290 # plugins
291 plugins=plugins,
292 **kwargs,
293 )
File /pyzr/active_venv/lib/python3.10/site-packages/flair/trainers/trainer.py:624, in ModelTrainer.train_custom(self, base_path, learning_rate, decoder_learning_rate, mini_batch_size, eval_batch_size, mini_batch_chunk_size, max_epochs, optimizer, train_with_dev, train_with_test, max_grad_norm, reduce_transformer_vocab, main_evaluation_metric, monitor_test, monitor_train_sample, use_final_model_for_eval, gold_label_dictionary_for_eval, exclude_labels, sampler, shuffle, shuffle_first_epoch, embeddings_storage_mode, epoch, save_final_model, save_optimizer_state, save_model_each_k_epochs, create_file_logs, create_loss_file, write_weights, use_amp, plugins, **kwargs)
622 gradient_norm = None
623 scale_before = scaler.get_scale()
--> 624 scaler.step(self.optimizer)
625 scaler.update()
626 scale_after = scaler.get_scale()
File /pyzr/active_venv/lib/python3.10/site-packages/torch/cuda/amp/grad_scaler.py:370, in GradScaler.step(self, optimizer, *args, **kwargs)
366 self.unscale_(optimizer)
368 assert len(optimizer_state["found_inf_per_device"]) > 0, "No inf checks were recorded for this optimizer."
--> 370 retval = self._maybe_opt_step(optimizer, optimizer_state, *args, **kwargs)
372 optimizer_state["stage"] = OptState.STEPPED
374 return retval
File /pyzr/active_venv/lib/python3.10/site-packages/torch/cuda/amp/grad_scaler.py:290, in GradScaler._maybe_opt_step(self, optimizer, optimizer_state, *args, **kwargs)
288 retval = None
289 if not sum(v.item() for v in optimizer_state["found_inf_per_device"].values()):
--> 290 retval = optimizer.step(*args, **kwargs)
291 return retval
File /pyzr/active_venv/lib/python3.10/site-packages/torch/optim/lr_scheduler.py:69, in LRScheduler.__init__.<locals>.with_counter.<locals>.wrapper(*args, **kwargs)
67 instance._step_count += 1
68 wrapped = func.__get__(instance, cls)
---> 69 return wrapped(*args, **kwargs)
File /pyzr/active_venv/lib/python3.10/site-packages/torch/optim/optimizer.py:280, in Optimizer.profile_hook_step.<locals>.wrapper(*args, **kwargs)
276 else:
277 raise RuntimeError(f"{func} must return None or a tuple of (new_args, new_kwargs),"
278 f"but got {result}.")
--> 280 out = func(*args, **kwargs)
281 self._optimizer_step_code()
283 # call optimizer step post hooks
File /pyzr/active_venv/lib/python3.10/site-packages/torch/optim/optimizer.py:33, in _use_grad_for_differentiable.<locals>._use_grad(self, *args, **kwargs)
31 try:
32 torch.set_grad_enabled(self.defaults['differentiable'])
---> 33 ret = func(self, *args, **kwargs)
34 finally:
35 torch.set_grad_enabled(prev_grad)
File /pyzr/active_venv/lib/python3.10/site-packages/torch/optim/adamw.py:171, in AdamW.step(self, closure)
158 beta1, beta2 = group["betas"]
160 self._init_group(
161 group,
162 params_with_grad,
(...)
168 state_steps,
169 )
--> 171 adamw(
172 params_with_grad,
173 grads,
174 exp_avgs,
175 exp_avg_sqs,
176 max_exp_avg_sqs,
177 state_steps,
178 amsgrad=amsgrad,
179 beta1=beta1,
180 beta2=beta2,
181 lr=group["lr"],
182 weight_decay=group["weight_decay"],
183 eps=group["eps"],
184 maximize=group["maximize"],
185 foreach=group["foreach"],
186 capturable=group["capturable"],
187 differentiable=group["differentiable"],
188 fused=group["fused"],
189 grad_scale=getattr(self, "grad_scale", None),
190 found_inf=getattr(self, "found_inf", None),
191 )
193 return loss
File /pyzr/active_venv/lib/python3.10/site-packages/torch/optim/adamw.py:321, in adamw(params, grads, exp_avgs, exp_avg_sqs, max_exp_avg_sqs, state_steps, foreach, capturable, differentiable, fused, grad_scale, found_inf, amsgrad, beta1, beta2, lr, weight_decay, eps, maximize)
318 else:
319 func = _single_tensor_adamw
--> 321 func(
322 params,
323 grads,
324 exp_avgs,
325 exp_avg_sqs,
326 max_exp_avg_sqs,
327 state_steps,
328 amsgrad=amsgrad,
329 beta1=beta1,
330 beta2=beta2,
331 lr=lr,
332 weight_decay=weight_decay,
333 eps=eps,
334 maximize=maximize,
335 capturable=capturable,
336 differentiable=differentiable,
337 grad_scale=grad_scale,
338 found_inf=found_inf,
339 )
File /pyzr/active_venv/lib/python3.10/site-packages/torch/optim/adamw.py:566, in _multi_tensor_adamw(params, grads, exp_avgs, exp_avg_sqs, max_exp_avg_sqs, state_steps, grad_scale, found_inf, amsgrad, beta1, beta2, lr, weight_decay, eps, maximize, capturable, differentiable)
564 exp_avg_sq_sqrt = torch._foreach_sqrt(device_exp_avg_sqs)
565 torch._foreach_div_(exp_avg_sq_sqrt, bias_correction2_sqrt)
--> 566 denom = torch._foreach_add(exp_avg_sq_sqrt, eps)
568 torch._foreach_addcdiv_(device_params, device_exp_avgs, denom, step_size)
OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 15.78 GiB total capacity; 14.06 GiB already allocated; 12.00 MiB free; 14.90 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
```
### Screenshots
_No response_
### Additional Context
I printed out the GPU usage in an altered `train_custom`:
```
def print_gpu_usage(entry=None):
allocated_memory = torch.cuda.memory_allocated(0)
reserved_memory = torch.cuda.memory_reserved(0)
print(f"{entry}\t{allocated_memory:<15,} / {reserved_memory:<15,}")
```
I saw that when training a `TextClassifier`, the memory usage goes back down to the value at the beginning of a batch after `store_embeddings` is called. In `TextPairRegressor`, the memory does not go down at all after `store_embeddings` is called.
### Environment
#### Versions:
##### Flair
0.13.1
##### Pytorch
2.3.1+cu121
##### Transformers
4.31.0
#### GPU
True
|
closed
|
2024-07-03T18:26:59Z
|
2024-07-24T06:24:40Z
|
https://github.com/flairNLP/flair/issues/3487
|
[
"bug"
] |
MattGPT-ai
| 0 |
python-restx/flask-restx
|
api
| 141 |
How do I programmatically access the sample requests from the generated swagger UI
|
**Ask a question**
For a given restx application, I can see a rich set of details contained in the generated Swagger UI, for example for each endpoint, I can see sample requests populated with default values from the restx `fields` I created to serve as the components when defining the endpoints. These show up as example `curl` commands that I can copy/paste into a shell (as well as being executed from the 'Try it out' button).
However, I want to access this data programmatically from the app client itself. Suppose I load and run the app in a standalone Python program and have a handle to the Flask `app` object. I can see attributes such as `api.application.blueprints['restx_doc']` to get a handle to the `Apidoc` object.
But I cannot find out where this object stores all the information I need to programmatically reconstruct valid requests to the service's endpoint.
|
open
|
2020-05-23T19:46:12Z
|
2020-05-23T19:46:12Z
|
https://github.com/python-restx/flask-restx/issues/141
|
[
"question"
] |
espears1
| 0 |
darrenburns/posting
|
automation
| 48 |
Request body is saved in a non human-readable format when it contains special characters
|
Hello and thank you for creating this tool, it looks very promising! The overall experience has been good so far, but I did notice an issue that's a bit inconvenient.
I've created a `POST` request which contains letters with diacritics in the body, such as this one:
```json
{
"Hello": "There",
"Hi": "Čau"
}
```
If I save the request into a yaml file, the body will be saved in a hard to read format:
```yaml
name: Test
method: POST
url: https://example.org/test
body:
content: "{\n \"Hello\": \"There\",\n \"Hi\": \"\u010Cau\"\n}"
```
If I replace the `Č` with a regular `C`, the resulting yaml file will have the format that I expect:
```yaml
name: Test
method: POST
url: https://example.org/test
body:
content: |-
{
"Hello": "There",
"Hi": "Cau"
}
```
Is it possible to fix this? The current behavior complicates manual editing and version control diffs, so I think it might be worth looking into.
I'm using `posting` `1.7.0`
Thanks!
|
closed
|
2024-07-19T08:54:53Z
|
2024-07-19T20:02:11Z
|
https://github.com/darrenburns/posting/issues/48
|
[] |
MilanVasko
| 0 |
voila-dashboards/voila
|
jupyter
| 1,447 |
Voila not displaying Canvas from IpyCanvas
|
<!--
Welcome! Before creating a new issue please search for relevant issues and recreate the issue in a fresh environment.
-->
## Description
When executing the Jupyter Notebook, the canvas appears and works as intended, but when executing with Voila, its a blank canvas
<!--Describe the bug clearly and concisely. Include screenshots/gifs if possible-->


Empty...
|
closed
|
2024-02-25T16:34:54Z
|
2024-02-27T19:21:16Z
|
https://github.com/voila-dashboards/voila/issues/1447
|
[
"bug"
] |
Voranto
| 5 |
tflearn/tflearn
|
tensorflow
| 275 |
Error when loading multiple models - Tensor name not found
|
In my code, I'm loading two DNN models. Model A is a normal DNN with fully-connected layers, and Model B is a Convolutional Neural Network similar to the one used in the MNIST example.
Individually, they both work just fine - they train properly, they save properly, they load properly, and predict properly. However, when loading both neural networks, tflearn crashes with an error that seems to indicate `"Tensor name 'example_name' not found in checkpoint files..."`
This error will be thrown for whatever model is loaded second (i.e. Model A will load and run correctly but Model B will not, and if the order is switched, then vice-versa). This happens even when the models are saved in and loaded from completely different directories. I'm guessing it's some sort of internal caching problem with the checkpoint files. Any solutions?
Here's some more of the stack trace, if it helps
```
File "/usr/local/lib/python2.7/site-packages/tflearn/models/dnn.py", line 227, in load
self.trainer.restore(model_file)
File "/usr/local/lib/python2.7/site-packages/tflearn/helpers/trainer.py", line 379, in restore
self.restorer.restore(self.session, model_file)
File "/usr/local/lib/python2.7/site-packages/tensorflow/python/training/saver.py", line 1105, in restore
{self.saver_def.filename_tensor_name: save_path})
File "/usr/local/lib/python2.7/site-packages/tensorflow/python/client/session.py", line 372, in run
run_metadata_ptr)
File "/usr/local/lib/python2.7/site-packages/tensorflow/python/client/session.py", line 636, in _run
feed_dict_string, options, run_metadata)
File "/usr/local/lib/python2.7/site-packages/tensorflow/python/client/session.py", line 708, in _do_run
target_list, options, run_metadata)
File "/usr/local/lib/python2.7/site-packages/tensorflow/python/client/session.py", line 728, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors.NotFoundError: Tensor name "Accuracy/Mean/moving_avg_1" not found in checkpoint files classification_classifier.tfl
[[Node: save_5/restore_slice_1 = RestoreSlice[dt=DT_FLOAT, preferred_shard=-1, _device="/job:localhost/replica:0/task:0/cpu:0"](_recv_save_5/Const_0, save_5/restore_slice_1/tensor_name, save_5/restore_slice_1/shape_and_slice)]]
Caused by op u'save_5/restore_slice_1', defined at:
```
|
open
|
2016-08-12T07:31:03Z
|
2020-11-19T10:46:14Z
|
https://github.com/tflearn/tflearn/issues/275
|
[] |
samvaran
| 8 |
ploomber/ploomber
|
jupyter
| 726 |
Programmatically create tasks based on the product of the task executed in the previous pipeline step
|
I would like to understand how to programmatically create tasks based on the product of the task executed in the previous pipeline step.
For example, `get_data` creates csv-file and I want to create tasks for each row of csv: `process_row_1`, `process_row_2`, .... Accordingly, I have code using the python api that reads a csv-file -- how do I indicate that this csv-file is the product of another task?
So how do I use the upstream idiom (`upstream['get_data']`)?
I formulate the question a brief, assuming that my case is quite typical. If this assumption of mine is incorrect, then I am ready to supplement the issue with code that more clearly illustrates my request.
|
closed
|
2022-04-25T12:32:48Z
|
2024-04-01T05:09:19Z
|
https://github.com/ploomber/ploomber/issues/726
|
[] |
theotheo
| 5 |
litestar-org/litestar
|
api
| 3,995 |
Bug: `Unsupported type: <class 'msgspec._core.StructMeta'>`
|
### Description
Visiting /schema when a route contains a request struct that utilizes a `msgspec` Struct via default factory is raising the error `Unsupported type: <class 'msgspec._core.StructMeta'>`.
Essentially, if I have a struct like this:
```
class Stuff(msgspec.Struct):
foo: list = msgspec.field(default=list)
```
And I use that struct as my request and then I visit `/schema`, I will get the error `Unsupported type: <class 'msgspec._core.StructMeta'>`.
### URL to code causing the issue
_No response_
### MCVE
```python
# Your MCVE code here
```
### Steps to reproduce
```bash
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
```
### Screenshots
```bash
""
```
### Logs
```bash
```
### Litestar Version
2.13.0 final
### Platform
- [x] Linux
- [ ] Mac
- [ ] Windows
- [ ] Other (Please specify in the description above)
|
closed
|
2025-02-13T09:32:13Z
|
2025-02-13T11:35:31Z
|
https://github.com/litestar-org/litestar/issues/3995
|
[
"Bug :bug:"
] |
umarbutler
| 3 |
holoviz/panel
|
plotly
| 7,264 |
Bokeh: BokehJS was loaded multiple times but one version failed to initialize.
|
Hi team, thanks for your hard work. If possible, can we put a high priority on this fix? It's quite damaging to user experience.
#### ALL software version info
(this library, plus any other relevant software, e.g. bokeh, python, notebook, OS, browser, etc should be added within the dropdown below.)
<details>
<summary>Software Version Info</summary>
```plaintext
acryl-datahub==0.10.5.5
aiohappyeyeballs==2.4.0
aiohttp==3.10.5
aiosignal==1.3.1
alembic==1.13.2
ansi2html==1.9.2
anyio==4.4.0
argon2-cffi==23.1.0
argon2-cffi-bindings==21.2.0
arrow==1.3.0
asttokens==2.4.1
async-generator==1.10
async-lru==2.0.4
attrs==24.2.0
autograd==1.7.0
autograd-gamma==0.5.0
avro==1.10.2
avro-gen3==0.7.10
awscli==1.33.27
babel==2.16.0
backports.tarfile==1.2.0
beautifulsoup4==4.12.3
black==24.8.0
bleach==6.1.0
blinker==1.8.2
bokeh==3.4.2
bokehtools==0.46.2
boto3==1.34.76
botocore==1.34.145
bouncer-client==0.4.1
cached-property==1.5.2
certifi==2024.7.4
certipy==0.1.3
cffi==1.17.0
charset-normalizer==3.3.2
click==8.1.7
click-default-group==1.2.4
click-spinner==0.1.10
cloudpickle==3.0.0
colorama==0.4.6
colorcet==3.0.1
comm==0.2.2
contourpy==1.3.0
cryptography==43.0.0
cycler==0.12.1
dash==2.17.1
dash-core-components==2.0.0
dash-html-components==2.0.0
dash-table==5.0.0
dask==2024.8.1
datashader==0.16.3
datatank-client==2.1.10.post12049
dataworks-common==2.1.10.post12049
debugpy==1.8.5
decorator==5.1.1
defusedxml==0.7.1
Deprecated==1.2.14
directives-client==0.4.4
docker==7.1.0
docutils==0.16
entrypoints==0.4
executing==2.0.1
expandvars==0.12.0
fastjsonschema==2.20.0
Flask==3.0.3
fonttools==4.53.1
formulaic==1.0.2
fqdn==1.5.1
frozenlist==1.4.1
fsspec==2024.6.1
future==1.0.0
gitdb==4.0.11
GitPython==3.1.43
greenlet==3.0.3
h11==0.14.0
holoviews==1.19.0
httpcore==1.0.5
httpx==0.27.2
humanfriendly==10.0
hvplot==0.10.0
idna==3.8
ijson==3.3.0
importlib-metadata==4.13.0
interface-meta==1.3.0
ipykernel==6.29.5
ipython==8.18.0
ipython-genutils==0.2.0
ipywidgets==8.1.5
isoduration==20.11.0
isort==5.13.2
itsdangerous==2.2.0
jaraco.classes==3.4.0
jaraco.context==6.0.1
jaraco.functools==4.0.2
jedi==0.19.1
jeepney==0.8.0
Jinja2==3.1.4
jira==3.2.0
jmespath==1.0.1
json5==0.9.25
jsonpointer==3.0.0
jsonref==1.1.0
jsonschema==4.17.3
jsonschema-specifications==2023.12.1
jupyter==1.0.0
jupyter-console==6.6.3
jupyter-dash==0.4.2
jupyter-events==0.10.0
jupyter-lsp==2.2.5
jupyter-resource-usage==1.1.0
jupyter-server-mathjax==0.2.6
jupyter-telemetry==0.1.0
jupyter_bokeh==4.0.5
jupyter_client==8.6.2
jupyter_core==5.7.2
jupyter_server==2.14.2
jupyter_server_proxy==4.3.0
jupyter_server_terminals==0.5.3
jupyterhub==4.1.4
jupyterlab==4.2.5
jupyterlab-vim==4.1.3
jupyterlab_code_formatter==3.0.2
jupyterlab_git==0.50.1
jupyterlab_pygments==0.3.0
jupyterlab_server==2.27.3
jupyterlab_templates==0.5.2
jupyterlab_widgets==3.0.13
keyring==25.3.0
kiwisolver==1.4.5
lckr_jupyterlab_variableinspector==3.2.1
lifelines==0.29.0
linkify-it-py==2.0.3
llvmlite==0.43.0
locket==1.0.0
Mako==1.3.5
Markdown==3.3.7
markdown-it-py==3.0.0
MarkupSafe==2.1.5
matplotlib==3.9.2
matplotlib-inline==0.1.7
mdit-py-plugins==0.4.1
mdurl==0.1.2
mistune==3.0.2
mixpanel==4.10.1
more-itertools==10.4.0
multidict==6.0.5
multipledispatch==1.0.0
mypy-extensions==1.0.0
nbclassic==1.1.0
nbclient==0.10.0
nbconvert==7.16.4
nbdime==4.0.1
nbformat==5.10.4
nbgitpuller==1.2.1
nest-asyncio==1.6.0
notebook==7.2.2
notebook_shim==0.2.4
numba==0.60.0
numpy==1.26.4
oauthlib==3.2.2
overrides==7.7.0
packaging==24.1
pamela==1.2.0
pandas==2.1.4
pandocfilters==1.5.1
panel==1.4.4
param==2.1.1
parso==0.8.4
partd==1.4.2
pathspec==0.12.1
pexpect==4.9.0
pillow==10.4.0
platformdirs==4.2.2
plotly==5.23.0
progressbar2==4.5.0
prometheus_client==0.20.0
prompt-toolkit==3.0.38
psutil==5.9.8
psycopg2-binary==2.9.9
ptyprocess==0.7.0
pure_eval==0.2.3
pyarrow==15.0.2
pyasn1==0.6.0
pycparser==2.22
pyct==0.5.0
pydantic==1.10.18
Pygments==2.18.0
PyHive==0.7.0
PyJWT==2.9.0
pymssql==2.3.0
PyMySQL==1.1.1
pyodbc==5.1.0
pyOpenSSL==24.2.1
pyparsing==3.1.4
pyrsistent==0.20.0
pyspork==2.24.0
python-dateutil==2.9.0.post0
python-json-logger==2.0.7
python-utils==3.8.2
pytz==2024.1
pyviz_comms==3.0.3
PyYAML==6.0.1
pyzmq==26.2.0
qtconsole==5.5.2
QtPy==2.4.1
ratelimiter==1.2.0.post0
redis==3.5.3
referencing==0.35.1
requests==2.32.3
requests-file==2.1.0
requests-oauthlib==2.0.0
requests-toolbelt==1.0.0
retrying==1.3.4
rfc3339-validator==0.1.4
rfc3986-validator==0.1.1
rpds-py==0.20.0
rsa==4.7.2
ruamel.yaml==0.17.40
ruamel.yaml.clib==0.2.8
ruff==0.6.2
s3transfer==0.10.2
scipy==1.13.0
SecretStorage==3.3.3
Send2Trash==1.8.3
sentry-sdk==2.13.0
simpervisor==1.0.0
six==1.16.0
smmap==5.0.1
sniffio==1.3.1
soupsieve==2.6
SQLAlchemy==1.4.52
sqlparse==0.4.4
stack-data==0.6.3
structlog==22.1.0
tabulate==0.9.0
tenacity==9.0.0
termcolor==2.4.0
terminado==0.18.1
tesladex-client==0.9.0
tinycss2==1.3.0
toml==0.10.2
toolz==0.12.1
tornado==6.4.1
tqdm==4.66.4
traitlets==5.14.3
types-python-dateutil==2.9.0.20240821
typing-inspect==0.9.0
typing_extensions==4.5.0
tzdata==2024.1
tzlocal==5.2
uc-micro-py==1.0.3
uri-template==1.3.0
urllib3==1.26.19
wcwidth==0.2.13
webcolors==24.8.0
webencodings==0.5.1
websocket-client==1.8.0
Werkzeug==3.0.4
widgetsnbextension==4.0.13
wrapt==1.16.0
xarray==2024.7.0
xyzservices==2024.6.0
yapf==0.32.0
yarl==1.9.4
zipp==3.20.1
```
</details>
#### Description of expected behavior and the observed behavior
I should be able to use panel in 2 notebooks simultaneously, but if I save my changes and reload the page, the error will show.
#### Complete, minimal, self-contained example code that reproduces the issue
Steps to reproduce:
1. create 2 notebooks with the following content
```python
# notebook 1
import panel as pn
pn.extension()
pn.Column('hi')
```
```python
# notebook 2 (open in another jupyterlab tab)
import panel as pn
pn.extension()
pn.Column('hi')
```
2. Run both notebooks
3. Save both notebooks
4. Reload your page
5. Try to run either of the notebooks and you'll see the error.
#### Stack traceback and/or browser JavaScript console output
(Ignore 'set_log_level` error. I think it's unrelated.)

|
closed
|
2024-09-12T16:03:33Z
|
2024-09-13T17:34:46Z
|
https://github.com/holoviz/panel/issues/7264
|
[] |
tomascsantos
| 4 |
jupyterhub/repo2docker
|
jupyter
| 1,295 |
--base-image not recognise as valid argument
|
Related with https://github.com/jupyterhub/repo2docker/issues/487
https://github.com/jupyterhub/repo2docker/blob/247e9535b167112cabf69eed59a6947e4af1ee34/repo2docker/app.py#L450 should make `--base-image` a valid argument for `repo2docker` but I'm getting
```
repo2docker: error: unrecognized arguments: --base-image
```
with
```
$ repo2docker --version
2023.06.0
```
|
closed
|
2023-07-12T16:05:50Z
|
2023-07-13T07:47:53Z
|
https://github.com/jupyterhub/repo2docker/issues/1295
|
[] |
rgaiacs
| 2 |
coqui-ai/TTS
|
pytorch
| 3,017 |
[Bug] pip install TTS failure: pip._vendor.resolvelib.resolvers.ResolutionTooDeep: 200000
|
### Describe the bug
Can't make pip installation
### To Reproduce
**1. Run the following command:** `pip install TTS`
```
C:>C:\Python38\scripts\pip install TTS
```
**2. Wait:**
```
Collecting TTS
Downloading TTS-0.14.3.tar.gz (1.5 MB)
---------------------------------------- 1.5/1.5 MB 1.7 MB/s eta 0:00:00
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing metadata (pyproject.toml) ... done
Collecting cython==0.29.28 (from TTS)
Using cached Cython-0.29.28-py2.py3-none-any.whl (983 kB)
Requirement already satisfied: scipy>=1.4.0 in C:\python38\lib\site-packages (from TTS) (1.7.1)
Collecting torch>=1.7 (from TTS)
Downloading torch-2.0.1-cp38-cp38-win_amd64.whl (172.4 MB)
---------------------------------------- 172.4/172.4 MB ? eta 0:00:00
Collecting torchaudio (from TTS)
Downloading torchaudio-2.0.2-cp38-cp38-win_amd64.whl (2.1 MB)
---------------------------------------- 2.1/2.1 MB 3.6 MB/s eta 0:00:00
Collecting soundfile (from TTS)
Downloading soundfile-0.12.1-py2.py3-none-win_amd64.whl (1.0 MB)
---------------------------------------- 1.0/1.0 MB 5.8 MB/s eta 0:00:00
Collecting librosa==0.10.0.* (from TTS)
Downloading librosa-0.10.0.post2-py3-none-any.whl (253 kB)
---------------------------------------- 253.0/253.0 kB 15.2 MB/s eta 0:00:00
Collecting inflect==5.6.0 (from TTS)
Downloading inflect-5.6.0-py3-none-any.whl (33 kB)
Requirement already satisfied: tqdm in C:\python38\lib\site-packages (from TTS) (4.60.0)
Collecting anyascii (from TTS)
Downloading anyascii-0.3.2-py3-none-any.whl (289 kB)
---------------------------------------- 289.9/289.9 kB 9.0 MB/s eta 0:00:00
Requirement already satisfied: pyyaml in C:\python38\lib\site-packages (from TTS) (5.4.1)
Requirement already satisfied: fsspec>=2021.04.0 in C:\python38\lib\site-packages (from TTS) (2022.3.0)
Requirement already satisfied: aiohttp in C:\python38\lib\site-packages (from TTS) (3.7.3)
Requirement already satisfied: packaging in C:\python38\lib\site-packages (from TTS) (23.0)
Collecting flask (from TTS)
Downloading flask-2.3.3-py3-none-any.whl (96 kB)
---------------------------------------- 96.1/96.1 kB 5.4 MB/s eta 0:00:00
Collecting pysbd (from TTS)
Downloading pysbd-0.3.4-py3-none-any.whl (71 kB)
---------------------------------------- 71.1/71.1 kB 2.0 MB/s eta 0:00:00
Collecting umap-learn==0.5.1 (from TTS)
Downloading umap-learn-0.5.1.tar.gz (80 kB)
---------------------------------------- 80.9/80.9 kB 4.7 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Requirement already satisfied: pandas in C:\python38\lib\site-packages (from TTS) (1.5.1)
Requirement already satisfied: matplotlib in C:\python38\lib\site-packages (from TTS) (3.6.3)
Collecting trainer==0.0.20 (from TTS)
Downloading trainer-0.0.20-py3-none-any.whl (45 kB)
---------------------------------------- 45.2/45.2 kB 1.1 MB/s eta 0:00:00
Collecting coqpit>=0.0.16 (from TTS)
Downloading coqpit-0.0.17-py3-none-any.whl (13 kB)
Collecting jieba (from TTS)
Downloading jieba-0.42.1.tar.gz (19.2 MB)
---------------------------------------- 19.2/19.2 MB 2.0 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Collecting pypinyin (from TTS)
Downloading pypinyin-0.49.0-py2.py3-none-any.whl (1.4 MB)
---------------------------------------- 1.4/1.4 MB 3.2 MB/s eta 0:00:00
Collecting mecab-python3==1.0.5 (from TTS)
Downloading mecab_python3-1.0.5-cp38-cp38-win_amd64.whl (500 kB)
---------------------------------------- 500.8/500.8 kB 6.3 MB/s eta 0:00:00
Collecting unidic-lite==1.0.8 (from TTS)
Downloading unidic-lite-1.0.8.tar.gz (47.4 MB)
---------------------------------------- 47.4/47.4 MB 1.8 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Collecting gruut[de,es,fr]==2.2.3 (from TTS)
Downloading gruut-2.2.3.tar.gz (73 kB)
---------------------------------------- 73.5/73.5 kB 213.1 kB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Collecting jamo (from TTS)
Downloading jamo-0.4.1-py3-none-any.whl (9.5 kB)
Collecting nltk (from TTS)
Downloading nltk-3.8.1-py3-none-any.whl (1.5 MB)
---------------------------------------- 1.5/1.5 MB 3.4 MB/s eta 0:00:00
Collecting g2pkk>=0.1.1 (from TTS)
Downloading g2pkk-0.1.2-py3-none-any.whl (25 kB)
Collecting bangla==0.0.2 (from TTS)
Downloading bangla-0.0.2-py2.py3-none-any.whl (6.2 kB)
Collecting bnnumerizer (from TTS)
Downloading bnnumerizer-0.0.2.tar.gz (4.7 kB)
Preparing metadata (setup.py) ... done
Collecting bnunicodenormalizer==0.1.1 (from TTS)
Downloading bnunicodenormalizer-0.1.1.tar.gz (38 kB)
Preparing metadata (setup.py) ... done
Collecting k-diffusion (from TTS)
Downloading k_diffusion-0.1.0-py3-none-any.whl (33 kB)
Collecting einops (from TTS)
Downloading einops-0.6.1-py3-none-any.whl (42 kB)
---------------------------------------- 42.2/42.2 kB 1.0 MB/s eta 0:00:00
Collecting transformers (from TTS)
Downloading transformers-4.33.3-py3-none-any.whl (7.6 MB)
---------------------------------------- 7.6/7.6 MB 3.1 MB/s eta 0:00:00
Collecting numpy==1.21.6 (from TTS)
Using cached numpy-1.21.6-cp38-cp38-win_amd64.whl (14.0 MB)
Collecting numba==0.55.1 (from TTS)
Downloading numba-0.55.1-cp38-cp38-win_amd64.whl (2.4 MB)
---------------------------------------- 2.4/2.4 MB 4.1 MB/s eta 0:00:00
Requirement already satisfied: Babel<3.0.0,>=2.8.0 in C:\python38\lib\site-packages (from gruut[de,es,fr]==2.2.3->TT
Collecting dateparser~=1.1.0 (from gruut[de,es,fr]==2.2.3->TTS)
Downloading dateparser-1.1.8-py2.py3-none-any.whl (293 kB)
---------------------------------------- 293.8/293.8 kB 4.6 MB/s eta 0:00:00
Collecting gruut-ipa<1.0,>=0.12.0 (from gruut[de,es,fr]==2.2.3->TTS)
Downloading gruut-ipa-0.13.0.tar.gz (101 kB)
---------------------------------------- 101.6/101.6 kB ? eta 0:00:00
Preparing metadata (setup.py) ... done
Collecting gruut_lang_en~=2.0.0 (from gruut[de,es,fr]==2.2.3->TTS)
Downloading gruut_lang_en-2.0.0.tar.gz (15.2 MB)
---------------------------------------- 15.2/15.2 MB 3.5 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Collecting jsonlines~=1.2.0 (from gruut[de,es,fr]==2.2.3->TTS)
Downloading jsonlines-1.2.0-py2.py3-none-any.whl (7.6 kB)
Requirement already satisfied: networkx<3.0.0,>=2.5.0 in C:\python38\lib\site-packages (from gruut[de,es,fr]==2.2.3-
Collecting num2words<1.0.0,>=0.5.10 (from gruut[de,es,fr]==2.2.3->TTS)
Downloading num2words-0.5.12-py3-none-any.whl (125 kB)
---------------------------------------- 125.2/125.2 kB 7.2 MB/s eta 0:00:00
Collecting python-crfsuite~=0.9.7 (from gruut[de,es,fr]==2.2.3->TTS)
Downloading python_crfsuite-0.9.9-cp38-cp38-win_amd64.whl (138 kB)
---------------------------------------- 138.9/138.9 kB 4.2 MB/s eta 0:00:00
Requirement already satisfied: importlib_resources in C:\python38\lib\site-packages (from gruut[de,es,fr]==2.2.3->TT
Collecting gruut_lang_es~=2.0.0 (from gruut[de,es,fr]==2.2.3->TTS)
Downloading gruut_lang_es-2.0.0.tar.gz (31.4 MB)
---------------------------------------- 31.4/31.4 MB 2.8 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Collecting gruut_lang_fr~=2.0.0 (from gruut[de,es,fr]==2.2.3->TTS)
Downloading gruut_lang_fr-2.0.2.tar.gz (10.9 MB)
---------------------------------------- 10.9/10.9 MB 3.8 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Collecting gruut_lang_de~=2.0.0 (from gruut[de,es,fr]==2.2.3->TTS)
Downloading gruut_lang_de-2.0.0.tar.gz (18.1 MB)
---------------------------------------- 18.1/18.1 MB 3.9 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Collecting audioread>=2.1.9 (from librosa==0.10.0.*->TTS)
Downloading audioread-3.0.1-py3-none-any.whl (23 kB)
Requirement already satisfied: scikit-learn>=0.20.0 in C:\python38\lib\site-packages (from librosa==0.10.0.*->TTS) (
Requirement already satisfied: joblib>=0.14 in C:\python38\lib\site-packages (from librosa==0.10.0.*->TTS) (1.0.1)
Requirement already satisfied: decorator>=4.3.0 in C:\python38\lib\site-packages (from librosa==0.10.0.*->TTS) (4.4.
Collecting pooch<1.7,>=1.0 (from librosa==0.10.0.*->TTS)
Downloading pooch-1.6.0-py3-none-any.whl (56 kB)
---------------------------------------- 56.3/56.3 kB 51.7 kB/s eta 0:00:00
Collecting soxr>=0.3.2 (from librosa==0.10.0.*->TTS)
Downloading soxr-0.3.6-cp38-cp38-win_amd64.whl (185 kB)
---------------------------------------- 185.1/185.1 kB 431.8 kB/s eta 0:00:00
Requirement already satisfied: typing-extensions>=4.1.1 in C:\python38\lib\site-packages (from librosa==0.10.0.*->TT
Collecting lazy-loader>=0.1 (from librosa==0.10.0.*->TTS)
Downloading lazy_loader-0.3-py3-none-any.whl (9.1 kB)
Collecting msgpack>=1.0 (from librosa==0.10.0.*->TTS)
Downloading msgpack-1.0.7-cp38-cp38-win_amd64.whl (222 kB)
---------------------------------------- 222.8/222.8 kB 1.4 MB/s eta 0:00:00
Collecting llvmlite<0.39,>=0.38.0rc1 (from numba==0.55.1->TTS)
Downloading llvmlite-0.38.1-cp38-cp38-win_amd64.whl (23.2 MB)
---------------------------------------- 23.2/23.2 MB 917.7 kB/s eta 0:00:00
Requirement already satisfied: setuptools in C:\python38\lib\site-packages (from numba==0.55.1->TTS) (67.6.1)
Requirement already satisfied: psutil in C:\python38\lib\site-packages (from trainer==0.0.20->TTS) (5.8.0)
Collecting tensorboardX (from trainer==0.0.20->TTS)
Downloading tensorboardX-2.6.2.2-py2.py3-none-any.whl (101 kB)
---------------------------------------- 101.7/101.7 kB 1.9 MB/s eta 0:00:00
Requirement already satisfied: protobuf<3.20,>=3.9.2 in C:\python38\lib\site-packages (from trainer==0.0.20->TTS) (3
Collecting pynndescent>=0.5 (from umap-learn==0.5.1->TTS)
Downloading pynndescent-0.5.10.tar.gz (1.1 MB)
---------------------------------------- 1.1/1.1 MB 3.3 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Requirement already satisfied: cffi>=1.0 in C:\python38\lib\site-packages (from soundfile->TTS) (1.14.5)
Requirement already satisfied: filelock in C:\python38\lib\site-packages (from torch>=1.7->TTS) (3.0.12)
Requirement already satisfied: sympy in C:\python38\lib\site-packages (from torch>=1.7->TTS) (1.11.1)
Requirement already satisfied: jinja2 in C:\python38\lib\site-packages (from torch>=1.7->TTS) (3.0.1)
Requirement already satisfied: attrs>=17.3.0 in C:\python38\lib\site-packages (from aiohttp->TTS) (21.2.0)
Requirement already satisfied: chardet<4.0,>=2.0 in C:\python38\lib\site-packages (from aiohttp->TTS) (3.0.4)
Requirement already satisfied: multidict<7.0,>=4.5 in C:\python38\lib\site-packages (from aiohttp->TTS) (5.1.0)
Requirement already satisfied: async-timeout<4.0,>=3.0 in C:\python38\lib\site-packages (from aiohttp->TTS) (3.0.1)
Requirement already satisfied: yarl<2.0,>=1.0 in C:\python38\lib\site-packages (from aiohttp->TTS) (1.6.3)
Collecting Werkzeug>=2.3.7 (from flask->TTS)
Downloading werkzeug-2.3.7-py3-none-any.whl (242 kB)
---------------------------------------- 242.2/242.2 kB 1.5 MB/s eta 0:00:00
Collecting jinja2 (from torch>=1.7->TTS)
Downloading Jinja2-3.1.2-py3-none-any.whl (133 kB)
---------------------------------------- 133.1/133.1 kB 7.7 MB/s eta 0:00:00
Requirement already satisfied: itsdangerous>=2.1.2 in C:\python38\lib\site-packages (from flask->TTS) (2.1.2)
Requirement already satisfied: click>=8.1.3 in C:\python38\lib\site-packages (from flask->TTS) (8.1.7)
Collecting blinker>=1.6.2 (from flask->TTS)
Downloading blinker-1.6.2-py3-none-any.whl (13 kB)
Requirement already satisfied: importlib-metadata>=3.6.0 in C:\python38\lib\site-packages (from flask->TTS) (6.0.0)
Collecting accelerate (from k-diffusion->TTS)
Downloading accelerate-0.23.0-py3-none-any.whl (258 kB)
---------------------------------------- 258.1/258.1 kB 4.0 MB/s eta 0:00:00
Collecting clean-fid (from k-diffusion->TTS)
Downloading clean_fid-0.1.35-py3-none-any.whl (26 kB)
Collecting clip-anytorch (from k-diffusion->TTS)
Downloading clip_anytorch-2.5.2-py3-none-any.whl (1.4 MB)
---------------------------------------- 1.4/1.4 MB 3.1 MB/s eta 0:00:00
Collecting dctorch (from k-diffusion->TTS)
Downloading dctorch-0.1.2-py3-none-any.whl (2.3 kB)
Collecting jsonmerge (from k-diffusion->TTS)
Downloading jsonmerge-1.9.2-py3-none-any.whl (19 kB)
Collecting kornia (from k-diffusion->TTS)
Downloading kornia-0.7.0-py2.py3-none-any.whl (705 kB)
---------------------------------------- 705.7/705.7 kB 3.0 MB/s eta 0:00:00
Requirement already satisfied: Pillow in C:\python38\lib\site-packages (from k-diffusion->TTS) (9.5.0)
Collecting rotary-embedding-torch (from k-diffusion->TTS)
Downloading rotary_embedding_torch-0.3.0-py3-none-any.whl (4.9 kB)
Collecting safetensors (from k-diffusion->TTS)
Downloading safetensors-0.3.3-cp38-cp38-win_amd64.whl (266 kB)
---------------------------------------- 266.3/266.3 kB 1.6 MB/s eta 0:00:00
Collecting scikit-image (from k-diffusion->TTS)
Downloading scikit_image-0.21.0-cp38-cp38-win_amd64.whl (22.7 MB)
---------------------------------------- 22.7/22.7 MB 944.0 kB/s eta 0:00:00
Collecting torchdiffeq (from k-diffusion->TTS)
Downloading torchdiffeq-0.2.3-py3-none-any.whl (31 kB)
Collecting torchsde (from k-diffusion->TTS)
Downloading torchsde-0.2.6-py3-none-any.whl (61 kB)
---------------------------------------- 61.2/61.2 kB ? eta 0:00:00
Collecting torchvision (from k-diffusion->TTS)
Downloading torchvision-0.15.2-cp38-cp38-win_amd64.whl (1.2 MB)
---------------------------------------- 1.2/1.2 MB 6.3 MB/s eta 0:00:00
Collecting wandb (from k-diffusion->TTS)
Downloading wandb-0.15.11-py3-none-any.whl (2.1 MB)
---------------------------------------- 2.1/2.1 MB 2.8 MB/s eta 0:00:00
Requirement already satisfied: contourpy>=1.0.1 in C:\python38\lib\site-packages (from matplotlib->TTS) (1.0.7)
Requirement already satisfied: cycler>=0.10 in C:\python38\lib\site-packages (from matplotlib->TTS) (0.10.0)
Requirement already satisfied: fonttools>=4.22.0 in C:\python38\lib\site-packages (from matplotlib->TTS) (4.38.0)
Requirement already satisfied: kiwisolver>=1.0.1 in C:\python38\lib\site-packages (from matplotlib->TTS) (1.3.1)
Requirement already satisfied: pyparsing>=2.2.1 in C:\python38\lib\site-packages (from matplotlib->TTS) (2.4.7)
Requirement already satisfied: python-dateutil>=2.7 in C:\python38\lib\site-packages (from matplotlib->TTS) (2.8.2)
Collecting regex>=2021.8.3 (from nltk->TTS)
Downloading regex-2023.8.8-cp38-cp38-win_amd64.whl (268 kB)
---------------------------------------- 268.3/268.3 kB 4.2 MB/s eta 0:00:00
Requirement already satisfied: pytz>=2020.1 in C:\python38\lib\site-packages (from pandas->TTS) (2021.1)
Collecting huggingface-hub<1.0,>=0.15.1 (from transformers->TTS)
Downloading huggingface_hub-0.17.3-py3-none-any.whl (295 kB)
---------------------------------------- 295.0/295.0 kB 1.1 MB/s eta 0:00:00
Requirement already satisfied: requests in C:\python38\lib\site-packages (from transformers->TTS) (2.31.0)
Collecting tokenizers!=0.11.3,<0.14,>=0.11.1 (from transformers->TTS)
Downloading tokenizers-0.13.3-cp38-cp38-win_amd64.whl (3.5 MB)
---------------------------------------- 3.5/3.5 MB 4.7 MB/s eta 0:00:00
Requirement already satisfied: pycparser in C:\python38\lib\site-packages (from cffi>=1.0->soundfile->TTS) (2.20)
Requirement already satisfied: colorama in C:\python38\lib\site-packages (from click>=8.1.3->flask->TTS) (0.4.6)
Requirement already satisfied: six in C:\python38\lib\site-packages (from cycler>=0.10->matplotlib->TTS) (1.15.0)
Requirement already satisfied: tzlocal in C:\python38\lib\site-packages (from dateparser~=1.1.0->gruut[de,es,fr]==2.
Requirement already satisfied: zipp>=0.5 in C:\python38\lib\site-packages (from importlib-metadata>=3.6.0->flask->TT
Requirement already satisfied: MarkupSafe>=2.0 in C:\python38\lib\site-packages (from jinja2->torch>=1.7->TTS) (2.0.
Collecting docopt>=0.6.2 (from num2words<1.0.0,>=0.5.10->gruut[de,es,fr]==2.2.3->TTS)
Downloading docopt-0.6.2.tar.gz (25 kB)
Preparing metadata (setup.py) ... done
Requirement already satisfied: appdirs>=1.3.0 in C:\python38\lib\site-packages (from pooch<1.7,>=1.0->librosa==0.10.
Requirement already satisfied: charset-normalizer<4,>=2 in C:\python38\lib\site-packages (from requests->transformer
Requirement already satisfied: idna<4,>=2.5 in C:\python38\lib\site-packages (from requests->transformers->TTS) (2.1
Requirement already satisfied: urllib3<3,>=1.21.1 in C:\python38\lib\site-packages (from requests->transformers->TTS
Requirement already satisfied: certifi>=2017.4.17 in C:\python38\lib\site-packages (from requests->transformers->TTS
Requirement already satisfied: threadpoolctl>=2.0.0 in C:\python38\lib\site-packages (from scikit-learn>=0.20.0->lib
Collecting MarkupSafe>=2.0 (from jinja2->torch>=1.7->TTS)
Downloading MarkupSafe-2.1.3-cp38-cp38-win_amd64.whl (17 kB)
Collecting ftfy (from clip-anytorch->k-diffusion->TTS)
Downloading ftfy-6.1.1-py3-none-any.whl (53 kB)
---------------------------------------- 53.1/53.1 kB 2.7 MB/s eta 0:00:00
INFO: pip is looking at multiple versions of dctorch to determine which version is compatible with other requirements. This could take a while.
Collecting dctorch (from k-diffusion->TTS)
Downloading dctorch-0.1.1-py3-none-any.whl (2.3 kB)
Downloading dctorch-0.1.0-py3-none-any.whl (2.3 kB)
Collecting clean-fid (from k-diffusion->TTS)
Downloading clean_fid-0.1.34-py3-none-any.whl (26 kB)
Collecting requests (from transformers->TTS)
Using cached requests-2.25.1-py2.py3-none-any.whl (61 kB)
Collecting clean-fid (from k-diffusion->TTS)
Downloading clean_fid-0.1.33-py3-none-any.whl (25 kB)
INFO: pip is looking at multiple versions of dctorch to determine which version is compatible with other requirements. This could take a while.
Downloading clean_fid-0.1.32-py3-none-any.whl (26 kB)
Downloading clean_fid-0.1.31-py3-none-any.whl (24 kB)
INFO: This is taking longer than usual. You might need to provide the dependency resolver with stricter constraints to reduce runtime. See https://pip.pypa.io
u want to abort this run, press Ctrl + C.
Downloading clean_fid-0.1.30-py3-none-any.whl (24 kB)
Downloading clean_fid-0.1.29-py3-none-any.whl (24 kB)
Downloading clean_fid-0.1.28-py3-none-any.whl (23 kB)
Downloading clean_fid-0.1.26-py3-none-any.whl (23 kB)
Downloading clean_fid-0.1.25-py3-none-any.whl (23 kB)
Downloading clean_fid-0.1.24-py3-none-any.whl (23 kB)
Downloading clean_fid-0.1.23-py3-none-any.whl (23 kB)
Downloading clean_fid-0.1.22-py3-none-any.whl (23 kB)
Downloading clean_fid-0.1.21-py3-none-any.whl (23 kB)
Downloading clean_fid-0.1.19-py3-none-any.whl (23 kB)
Downloading clean_fid-0.1.18-py3-none-any.whl (23 kB)
Downloading clean_fid-0.1.17-py3-none-any.whl (23 kB)
Downloading clean_fid-0.1.16-py3-none-any.whl (22 kB)
Downloading clean_fid-0.1.15-py3-none-any.whl (22 kB)
Downloading clean_fid-0.1.14-py3-none-any.whl (22 kB)
Downloading clean_fid-0.1.13-py3-none-any.whl (19 kB)
Downloading clean_fid-0.1.12-py3-none-any.whl (19 kB)
Downloading clean_fid-0.1.11-py3-none-any.whl (19 kB)
Downloading clean_fid-0.1.10-py3-none-any.whl (16 kB)
Downloading clean_fid-0.1.9-py3-none-any.whl (15 kB)
Downloading clean_fid-0.1.8-py3-none-any.whl (16 kB)
Downloading clean_fid-0.1.6-py3-none-any.whl (15 kB)
Collecting accelerate (from k-diffusion->TTS)
Downloading accelerate-0.22.0-py3-none-any.whl (251 kB)
---------------------------------------- 251.2/251.2 kB 15.1 MB/s eta 0:00:00
Downloading accelerate-0.21.0-py3-none-any.whl (244 kB)
---------------------------------------- 244.2/244.2 kB 7.3 MB/s eta 0:00:00
Downloading accelerate-0.20.3-py3-none-any.whl (227 kB)
---------------------------------------- 227.6/227.6 kB 6.8 MB/s eta 0:00:00
Downloading accelerate-0.20.2-py3-none-any.whl (227 kB)
---------------------------------------- 227.5/227.5 kB 2.8 MB/s eta 0:00:00
Downloading accelerate-0.20.1-py3-none-any.whl (227 kB)
---------------------------------------- 227.5/227.5 kB 2.8 MB/s eta 0:00:00
Downloading accelerate-0.20.0-py3-none-any.whl (227 kB)
---------------------------------------- 227.4/227.4 kB 7.0 MB/s eta 0:00:00
Downloading accelerate-0.19.0-py3-none-any.whl (219 kB)
---------------------------------------- 219.1/219.1 kB 13.1 MB/s eta 0:00:00
Downloading accelerate-0.18.0-py3-none-any.whl (215 kB)
---------------------------------------- 215.3/215.3 kB 3.3 MB/s eta 0:00:00
Downloading accelerate-0.17.1-py3-none-any.whl (212 kB)
---------------------------------------- 212.8/212.8 kB 13.5 MB/s eta 0:00:00
Downloading accelerate-0.17.0-py3-none-any.whl (212 kB)
---------------------------------------- 212.8/212.8 kB 6.5 MB/s eta 0:00:00
Downloading accelerate-0.16.0-py3-none-any.whl (199 kB)
---------------------------------------- 199.7/199.7 kB 11.8 MB/s eta 0:00:00
Downloading accelerate-0.15.0-py3-none-any.whl (191 kB)
---------------------------------------- 191.5/191.5 kB 12.1 MB/s eta 0:00:00
Downloading accelerate-0.14.0-py3-none-any.whl (175 kB)
---------------------------------------- 176.0/176.0 kB 11.1 MB/s eta 0:00:00
Downloading accelerate-0.13.2-py3-none-any.whl (148 kB)
---------------------------------------- 148.8/148.8 kB 4.5 MB/s eta 0:00:00
Downloading accelerate-0.13.1-py3-none-any.whl (148 kB)
---------------------------------------- 148.8/148.8 kB 9.2 MB/s eta 0:00:00
Downloading accelerate-0.13.0-py3-none-any.whl (148 kB)
---------------------------------------- 148.8/148.8 kB 2.9 MB/s eta 0:00:00
Downloading accelerate-0.12.0-py3-none-any.whl (143 kB)
---------------------------------------- 144.0/144.0 kB 8.9 MB/s eta 0:00:00
Downloading accelerate-0.11.0-py3-none-any.whl (123 kB)
---------------------------------------- 123.1/123.1 kB 7.1 MB/s eta 0:00:00
Downloading accelerate-0.10.0-py3-none-any.whl (117 kB)
---------------------------------------- 117.1/117.1 kB ? eta 0:00:00
Downloading accelerate-0.9.0-py3-none-any.whl (106 kB)
---------------------------------------- 106.8/106.8 kB 3.1 MB/s eta 0:00:00
Downloading accelerate-0.8.0-py3-none-any.whl (114 kB)
---------------------------------------- 114.5/114.5 kB 6.5 MB/s eta 0:00:00
Downloading accelerate-0.7.1-py3-none-any.whl (79 kB)
---------------------------------------- 79.9/79.9 kB 2.2 MB/s eta 0:00:00
Downloading accelerate-0.7.0-py3-none-any.whl (79 kB)
---------------------------------------- 79.8/79.8 kB 4.3 MB/s eta 0:00:00
Downloading accelerate-0.6.2-py3-none-any.whl (65 kB)
---------------------------------------- 65.9/65.9 kB ? eta 0:00:00
Downloading accelerate-0.6.1-py3-none-any.whl (65 kB)
---------------------------------------- 65.9/65.9 kB 1.8 MB/s eta 0:00:00
Downloading accelerate-0.6.0-py3-none-any.whl (65 kB)
---------------------------------------- 65.8/65.8 kB 3.5 MB/s eta 0:00:00
Downloading accelerate-0.5.1-py3-none-any.whl (58 kB)
---------------------------------------- 58.0/58.0 kB 1.5 MB/s eta 0:00:00
Downloading accelerate-0.5.0-py3-none-any.whl (57 kB)
---------------------------------------- 58.0/58.0 kB 757.7 kB/s eta 0:00:00
Downloading accelerate-0.4.0-py3-none-any.whl (55 kB)
---------------------------------------- 55.3/55.3 kB 221.9 kB/s eta 0:00:00
Collecting soxr>=0.3.2 (from librosa==0.10.0.*->TTS)
Downloading soxr-0.3.5-cp38-cp38-win_amd64.whl (184 kB)
---------------------------------------- 184.4/184.4 kB 11.6 MB/s eta 0:00:00
Downloading soxr-0.3.4-cp38-cp38-win_amd64.whl (184 kB)
---------------------------------------- 184.8/184.8 kB 3.8 MB/s eta 0:00:00
Downloading soxr-0.3.3-cp38-cp38-win_amd64.whl (176 kB)
---------------------------------------- 176.7/176.7 kB 11.1 MB/s eta 0:00:00
Downloading soxr-0.3.2-cp38-cp38-win_amd64.whl (176 kB)
---------------------------------------- 176.7/176.7 kB ? eta 0:00:00
Collecting scikit-learn>=0.20.0 (from librosa==0.10.0.*->TTS)
Downloading scikit_learn-1.3.1-cp38-cp38-win_amd64.whl (9.3 MB)
---------------------------------------- 9.3/9.3 MB 3.5 MB/s eta 0:00:00
Collecting joblib>=0.14 (from librosa==0.10.0.*->TTS)
Downloading joblib-1.3.2-py3-none-any.whl (302 kB)
---------------------------------------- 302.2/302.2 kB 6.2 MB/s eta 0:00:00
Collecting scikit-learn>=0.20.0 (from librosa==0.10.0.*->TTS)
Downloading scikit_learn-1.3.0-cp38-cp38-win_amd64.whl (9.2 MB)
---------------------------------------- 9.2/9.2 MB 2.1 MB/s eta 0:00:00
Downloading scikit_learn-1.2.2-cp38-cp38-win_amd64.whl (8.3 MB)
---------------------------------------- 8.3/8.3 MB 2.6 MB/s eta 0:00:00
Downloading scikit_learn-1.2.1-cp38-cp38-win_amd64.whl (8.3 MB)
---------------------------------------- 8.3/8.3 MB 2.6 MB/s eta 0:00:00
Downloading scikit_learn-1.2.0-cp38-cp38-win_amd64.whl (8.2 MB)
---------------------------------------- 8.2/8.2 MB 4.1 MB/s eta 0:00:00
Downloading scikit_learn-1.1.3-cp38-cp38-win_amd64.whl (7.5 MB)
---------------------------------------- 7.5/7.5 MB 4.5 MB/s eta 0:00:00
Downloading scikit_learn-1.1.2-cp38-cp38-win_amd64.whl (7.3 MB)
---------------------------------------- 7.3/7.3 MB 3.9 MB/s eta 0:00:00
Downloading scikit_learn-1.1.1-cp38-cp38-win_amd64.whl (7.3 MB)
---------------------------------------- 7.3/7.3 MB 3.5 MB/s eta 0:00:00
Downloading scikit_learn-1.1.0-cp38-cp38-win_amd64.whl (7.3 MB)
---------------------------------------- 7.3/7.3 MB 3.3 MB/s eta 0:00:00
Using cached scikit_learn-1.0.2-cp38-cp38-win_amd64.whl (7.2 MB)
Downloading scikit_learn-1.0.1-cp38-cp38-win_amd64.whl (7.2 MB)
---------------------------------------- 7.2/7.2 MB 4.0 MB/s eta 0:00:00
Downloading scikit_learn-1.0-cp38-cp38-win_amd64.whl (7.2 MB)
---------------------------------------- 7.2/7.2 MB 4.2 MB/s eta 0:00:00
Downloading scikit_learn-0.24.2-cp38-cp38-win_amd64.whl (6.9 MB)
---------------------------------------- 6.9/6.9 MB 2.6 MB/s eta 0:00:00
Downloading scikit_learn-0.24.1-cp38-cp38-win_amd64.whl (6.9 MB)
---------------------------------------- 6.9/6.9 MB 4.2 MB/s eta 0:00:00
Downloading scikit_learn-0.24.0-cp38-cp38-win_amd64.whl (6.9 MB)
---------------------------------------- 6.9/6.9 MB 3.1 MB/s eta 0:00:00
Downloading scikit_learn-0.23.2-cp38-cp38-win_amd64.whl (6.8 MB)
---------------------------------------- 6.8/6.8 MB 2.7 MB/s eta 0:00:00
Downloading scikit_learn-0.23.1-cp38-cp38-win_amd64.whl (6.8 MB)
---------------------------------------- 6.8/6.8 MB 3.7 MB/s eta 0:00:00
Downloading scikit_learn-0.23.0-cp38-cp38-win_amd64.whl (6.8 MB)
---------------------------------------- 6.8/6.8 MB 4.3 MB/s eta 0:00:00
Downloading scikit_learn-0.22.2.post1-cp38-cp38-win_amd64.whl (6.6 MB)
---------------------------------------- 6.6/6.6 MB 4.0 MB/s eta 0:00:00
Downloading scikit_learn-0.22.2-cp38-cp38-win_amd64.whl (6.6 MB)
---------------------------------------- 6.6/6.6 MB 2.9 MB/s eta 0:00:00
Downloading scikit_learn-0.22.1-cp38-cp38-win_amd64.whl (6.4 MB)
---------------------------------------- 6.4/6.4 MB 3.0 MB/s eta 0:00:00
Downloading scikit_learn-0.22-cp38-cp38-win_amd64.whl (6.3 MB)
---------------------------------------- 6.3/6.3 MB 3.5 MB/s eta 0:00:00
Collecting pynndescent>=0.5 (from umap-learn==0.5.1->TTS)
Downloading pynndescent-0.5.9.tar.gz (1.1 MB)
---------------------------------------- 1.1/1.1 MB 3.4 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Collecting contourpy>=1.0.1 (from matplotlib->TTS)
Downloading contourpy-1.1.1-cp38-cp38-win_amd64.whl (477 kB)
---------------------------------------- 477.9/477.9 kB 7.4 MB/s eta 0:00:00
Downloading contourpy-1.1.0-cp38-cp38-win_amd64.whl (470 kB)
---------------------------------------- 470.4/470.4 kB 7.3 MB/s eta 0:00:00
Using cached contourpy-1.0.7-cp38-cp38-win_amd64.whl (162 kB)
Downloading contourpy-1.0.6-cp38-cp38-win_amd64.whl (163 kB)
---------------------------------------- 163.5/163.5 kB 2.5 MB/s eta 0:00:00
Downloading contourpy-1.0.5-cp38-cp38-win_amd64.whl (164 kB)
---------------------------------------- 164.0/164.0 kB 5.0 MB/s eta 0:00:00
Downloading contourpy-1.0.4-cp38-cp38-win_amd64.whl (162 kB)
---------------------------------------- 162.5/162.5 kB 9.5 MB/s eta 0:00:00
Downloading contourpy-1.0.3-cp38-cp38-win_amd64.whl (159 kB)
---------------------------------------- 159.8/159.8 kB 9.3 MB/s eta 0:00:00
Downloading contourpy-1.0.2-cp38-cp38-win_amd64.whl (158 kB)
---------------------------------------- 158.1/158.1 kB 9.9 MB/s eta 0:00:00
Downloading contourpy-1.0.1-cp38-cp38-win_amd64.whl (158 kB)
---------------------------------------- 158.1/158.1 kB 9.2 MB/s eta 0:00:00
Collecting transformers (from TTS)
Downloading transformers-4.33.2-py3-none-any.whl (7.6 MB)
---------------------------------------- 7.6/7.6 MB 3.4 MB/s eta 0:00:00
Downloading transformers-4.33.1-py3-none-any.whl (7.6 MB)
---------------------------------------- 7.6/7.6 MB 3.5 MB/s eta 0:00:00
Downloading transformers-4.33.0-py3-none-any.whl (7.6 MB)
---------------------------------------- 7.6/7.6 MB 4.6 MB/s eta 0:00:00
Downloading transformers-4.32.1-py3-none-any.whl (7.5 MB)
---------------------------------------- 7.5/7.5 MB 2.6 MB/s eta 0:00:00
Downloading transformers-4.32.0-py3-none-any.whl (7.5 MB)
---------------------------------------- 7.5/7.5 MB 3.5 MB/s eta 0:00:00
Downloading transformers-4.31.0-py3-none-any.whl (7.4 MB)
---------------------------------------- 7.4/7.4 MB 3.6 MB/s eta 0:00:00
Downloading transformers-4.30.2-py3-none-any.whl (7.2 MB)
---------------------------------------- 7.2/7.2 MB 3.5 MB/s eta 0:00:00
Downloading transformers-4.30.1-py3-none-any.whl (7.2 MB)
---------------------------------------- 7.2/7.2 MB 4.3 MB/s eta 0:00:00
Downloading transformers-4.30.0-py3-none-any.whl (7.2 MB)
---------------------------------------- 7.2/7.2 MB 3.7 MB/s eta 0:00:00
Downloading transformers-4.29.2-py3-none-any.whl (7.1 MB)
---------------------------------------- 7.1/7.1 MB 4.5 MB/s eta 0:00:00
Downloading transformers-4.29.1-py3-none-any.whl (7.1 MB)
---------------------------------------- 7.1/7.1 MB 2.4 MB/s eta 0:00:00
Downloading transformers-4.29.0-py3-none-any.whl (7.1 MB)
---------------------------------------- 7.1/7.1 MB 4.0 MB/s eta 0:00:00
Downloading transformers-4.28.1-py3-none-any.whl (7.0 MB)
---------------------------------------- 7.0/7.0 MB 3.3 MB/s eta 0:00:00
Downloading transformers-4.28.0-py3-none-any.whl (7.0 MB)
---------------------------------------- 7.0/7.0 MB 4.1 MB/s eta 0:00:00
Downloading transformers-4.27.4-py3-none-any.whl (6.8 MB)
---------------------------------------- 6.8/6.8 MB 2.8 MB/s eta 0:00:00
Downloading transformers-4.27.3-py3-none-any.whl (6.8 MB)
---------------------------------------- 6.8/6.8 MB 3.8 MB/s eta 0:00:00
Downloading transformers-4.27.2-py3-none-any.whl (6.8 MB)
---------------------------------------- 6.8/6.8 MB 3.2 MB/s eta 0:00:00
Downloading transformers-4.27.1-py3-none-any.whl (6.7 MB)
---------------------------------------- 6.7/6.7 MB 3.7 MB/s eta 0:00:00
Downloading transformers-4.27.0-py3-none-any.whl (6.8 MB)
---------------------------------------- 6.8/6.8 MB 4.7 MB/s eta 0:00:00
Downloading transformers-4.26.1-py3-none-any.whl (6.3 MB)
---------------------------------------- 6.3/6.3 MB 3.6 MB/s eta 0:00:00
Downloading transformers-4.26.0-py3-none-any.whl (6.3 MB)
---------------------------------------- 6.3/6.3 MB 4.5 MB/s eta 0:00:00
Downloading transformers-4.25.1-py3-none-any.whl (5.8 MB)
---------------------------------------- 5.8/5.8 MB 4.6 MB/s eta 0:00:00
Downloading transformers-4.24.0-py3-none-any.whl (5.5 MB)
---------------------------------------- 5.5/5.5 MB 3.5 MB/s eta 0:00:00
Downloading transformers-4.23.1-py3-none-any.whl (5.3 MB)
---------------------------------------- 5.3/5.3 MB 2.5 MB/s eta 0:00:00
Downloading transformers-4.23.0-py3-none-any.whl (5.3 MB)
---------------------------------------- 5.3/5.3 MB 2.6 MB/s eta 0:00:00
Downloading transformers-4.22.2-py3-none-any.whl (4.9 MB)
---------------------------------------- 4.9/4.9 MB 4.3 MB/s eta 0:00:00
Collecting tokenizers!=0.11.3,<0.13,>=0.11.1 (from transformers->TTS)
Downloading tokenizers-0.12.1-cp38-cp38-win_amd64.whl (3.3 MB)
---------------------------------------- 3.3/3.3 MB 3.3 MB/s eta 0:00:00
Collecting transformers (from TTS)
Downloading transformers-4.22.1-py3-none-any.whl (4.9 MB)
---------------------------------------- 4.9/4.9 MB 3.5 MB/s eta 0:00:00
Downloading transformers-4.22.0-py3-none-any.whl (4.9 MB)
---------------------------------------- 4.9/4.9 MB 2.4 MB/s eta 0:00:00
Downloading transformers-4.21.3-py3-none-any.whl (4.7 MB)
---------------------------------------- 4.7/4.7 MB 3.9 MB/s eta 0:00:00
Downloading transformers-4.21.2-py3-none-any.whl (4.7 MB)
---------------------------------------- 4.7/4.7 MB 2.6 MB/s eta 0:00:00
Downloading transformers-4.21.1-py3-none-any.whl (4.7 MB)
---------------------------------------- 4.7/4.7 MB 4.0 MB/s eta 0:00:00
Downloading transformers-4.21.0-py3-none-any.whl (4.7 MB)
---------------------------------------- 4.7/4.7 MB 4.4 MB/s eta 0:00:00
Downloading transformers-4.20.1-py3-none-any.whl (4.4 MB)
---------------------------------------- 4.4/4.4 MB 2.9 MB/s eta 0:00:00
Downloading transformers-4.20.0-py3-none-any.whl (4.4 MB)
---------------------------------------- 4.4/4.4 MB 3.9 MB/s eta 0:00:00
Downloading transformers-4.19.4-py3-none-any.whl (4.2 MB)
---------------------------------------- 4.2/4.2 MB 3.1 MB/s eta 0:00:00
Downloading transformers-4.19.3-py3-none-any.whl (4.2 MB)
---------------------------------------- 4.2/4.2 MB 2.8 MB/s eta 0:00:00
Downloading transformers-4.19.2-py3-none-any.whl (4.2 MB)
---------------------------------------- 4.2/4.2 MB 3.6 MB/s eta 0:00:00
Downloading transformers-4.19.1-py3-none-any.whl (4.2 MB)
---------------------------------------- 4.2/4.2 MB 3.4 MB/s eta 0:00:00
Downloading transformers-4.19.0-py3-none-any.whl (4.2 MB)
---------------------------------------- 4.2/4.2 MB 3.9 MB/s eta 0:00:00
Downloading transformers-4.18.0-py3-none-any.whl (4.0 MB)
---------------------------------------- 4.0/4.0 MB 3.8 MB/s eta 0:00:00
Collecting sacremoses (from transformers->TTS)
Downloading sacremoses-0.0.53.tar.gz (880 kB)
---------------------------------------- 880.6/880.6 kB 5.1 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Collecting transformers (from TTS)
Downloading transformers-4.17.0-py3-none-any.whl (3.8 MB)
---------------------------------------- 3.8/3.8 MB 4.4 MB/s eta 0:00:00
Collecting tokenizers!=0.11.3,>=0.11.1 (from transformers->TTS)
Downloading tokenizers-0.14.0-cp38-none-win_amd64.whl (2.2 MB)
---------------------------------------- 2.2/2.2 MB 3.6 MB/s eta 0:00:00
Collecting transformers (from TTS)
Downloading transformers-4.16.2-py3-none-any.whl (3.5 MB)
---------------------------------------- 3.5/3.5 MB 4.4 MB/s eta 0:00:00
Downloading transformers-4.16.1-py3-none-any.whl (3.5 MB)
---------------------------------------- 3.5/3.5 MB 2.5 MB/s eta 0:00:00
Downloading transformers-4.16.0-py3-none-any.whl (3.5 MB)
---------------------------------------- 3.5/3.5 MB 3.5 MB/s eta 0:00:00
Downloading transformers-4.15.0-py3-none-any.whl (3.4 MB)
---------------------------------------- 3.4/3.4 MB 2.8 MB/s eta 0:00:00
Collecting tokenizers<0.11,>=0.10.1 (from transformers->TTS)
Downloading tokenizers-0.10.3-cp38-cp38-win_amd64.whl (2.0 MB)
---------------------------------------- 2.0/2.0 MB 4.1 MB/s eta 0:00:00
Collecting transformers (from TTS)
Downloading transformers-4.14.1-py3-none-any.whl (3.4 MB)
---------------------------------------- 3.4/3.4 MB 2.8 MB/s eta 0:00:00
Downloading transformers-4.13.0-py3-none-any.whl (3.3 MB)
---------------------------------------- 3.3/3.3 MB 4.0 MB/s eta 0:00:00
Downloading transformers-4.12.5-py3-none-any.whl (3.1 MB)
---------------------------------------- 3.1/3.1 MB 3.3 MB/s eta 0:00:00
Downloading transformers-4.12.4-py3-none-any.whl (3.1 MB)
---------------------------------------- 3.1/3.1 MB 2.4 MB/s eta 0:00:00
Downloading transformers-4.12.3-py3-none-any.whl (3.1 MB)
---------------------------------------- 3.1/3.1 MB 3.7 MB/s eta 0:00:00
Downloading transformers-4.12.2-py3-none-any.whl (3.1 MB)
---------------------------------------- 3.1/3.1 MB 3.0 MB/s eta 0:00:00
Downloading transformers-4.12.1-py3-none-any.whl (3.1 MB)
---------------------------------------- 3.1/3.1 MB 3.0 MB/s eta 0:00:00
Downloading transformers-4.12.0-py3-none-any.whl (3.1 MB)
---------------------------------------- 3.1/3.1 MB 2.9 MB/s eta 0:00:00
Downloading transformers-4.11.3-py3-none-any.whl (2.9 MB)
---------------------------------------- 2.9/2.9 MB 2.9 MB/s eta 0:00:00
Downloading transformers-4.11.2-py3-none-any.whl (2.9 MB)
---------------------------------------- 2.9/2.9 MB 3.1 MB/s eta 0:00:00
Downloading transformers-4.11.1-py3-none-any.whl (2.9 MB)
---------------------------------------- 2.9/2.9 MB 4.3 MB/s eta 0:00:00
Downloading transformers-4.11.0-py3-none-any.whl (2.9 MB)
---------------------------------------- 2.9/2.9 MB 3.0 MB/s eta 0:00:00
Downloading transformers-4.10.3-py3-none-any.whl (2.8 MB)
---------------------------------------- 2.8/2.8 MB 2.2 MB/s eta 0:00:00
Downloading transformers-4.10.2-py3-none-any.whl (2.8 MB)
---------------------------------------- 2.8/2.8 MB 2.8 MB/s eta 0:00:00
Downloading transformers-4.10.1-py3-none-any.whl (2.8 MB)
---------------------------------------- 2.8/2.8 MB 3.4 MB/s eta 0:00:00
Downloading transformers-4.10.0-py3-none-any.whl (2.8 MB)
---------------------------------------- 2.8/2.8 MB 3.2 MB/s eta 0:00:00
Downloading transformers-4.9.2-py3-none-any.whl (2.6 MB)
---------------------------------------- 2.6/2.6 MB 4.0 MB/s eta 0:00:00
Collecting huggingface-hub==0.0.12 (from transformers->TTS)
Downloading huggingface_hub-0.0.12-py3-none-any.whl (37 kB)
Collecting transformers (from TTS)
Downloading transformers-4.9.1-py3-none-any.whl (2.6 MB)
---------------------------------------- 2.6/2.6 MB 4.1 MB/s eta 0:00:00
Downloading transformers-4.9.0-py3-none-any.whl (2.6 MB)
---------------------------------------- 2.6/2.6 MB 4.4 MB/s eta 0:00:00
Downloading transformers-4.8.2-py3-none-any.whl (2.5 MB)
---------------------------------------- 2.5/2.5 MB 3.2 MB/s eta 0:00:00
Downloading transformers-4.8.1-py3-none-any.whl (2.5 MB)
---------------------------------------- 2.5/2.5 MB 2.6 MB/s eta 0:00:00
Downloading transformers-4.8.0-py3-none-any.whl (2.5 MB)
---------------------------------------- 2.5/2.5 MB 2.9 MB/s eta 0:00:00
Downloading transformers-4.7.0-py3-none-any.whl (2.5 MB)
---------------------------------------- 2.5/2.5 MB 4.2 MB/s eta 0:00:00
Collecting huggingface-hub==0.0.8 (from transformers->TTS)
Downloading huggingface_hub-0.0.8-py3-none-any.whl (34 kB)
Collecting transformers (from TTS)
Downloading transformers-4.6.1-py3-none-any.whl (2.2 MB)
---------------------------------------- 2.2/2.2 MB 4.1 MB/s eta 0:00:00
Downloading transformers-4.6.0-py3-none-any.whl (2.3 MB)
---------------------------------------- 2.3/2.3 MB 4.5 MB/s eta 0:00:00
Downloading transformers-4.5.1-py3-none-any.whl (2.1 MB)
---------------------------------------- 2.1/2.1 MB 4.1 MB/s eta 0:00:00
Downloading transformers-4.5.0-py3-none-any.whl (2.1 MB)
---------------------------------------- 2.1/2.1 MB 2.9 MB/s eta 0:00:00
Downloading transformers-4.4.2-py3-none-any.whl (2.0 MB)
---------------------------------------- 2.0/2.0 MB 2.4 MB/s eta 0:00:00
Downloading transformers-4.4.1-py3-none-any.whl (2.1 MB)
---------------------------------------- 2.1/2.1 MB 3.3 MB/s eta 0:00:00
Downloading transformers-4.4.0-py3-none-any.whl (2.1 MB)
---------------------------------------- 2.1/2.1 MB 1.9 MB/s eta 0:00:00
Downloading transformers-4.3.3-py3-none-any.whl (1.9 MB)
---------------------------------------- 1.9/1.9 MB 3.3 MB/s eta 0:00:00
Downloading transformers-4.3.2-py3-none-any.whl (1.8 MB)
---------------------------------------- 1.8/1.8 MB 3.8 MB/s eta 0:00:00
Downloading transformers-4.3.1-py3-none-any.whl (1.8 MB)
---------------------------------------- 1.8/1.8 MB 4.1 MB/s eta 0:00:00
ERROR: Exception:
Traceback (most recent call last):
File "C:\Python38\lib\site-packages\pip\_internal\cli\base_command.py", line 169, in exc_logging_wrapper
status = run_func(*args)
File "C:\Python38\lib\site-packages\pip\_internal\cli\req_command.py", line 248, in wrapper
return func(self, options, args)
File "C:\Python38\lib\site-packages\pip\_internal\commands\install.py", line 377, in run
requirement_set = resolver.resolve(
File "C:\Python38\lib\site-packages\pip\_internal\resolution\resolvelib\resolver.py", line 92, in resolve
result = self._result = resolver.resolve(
File "C:\Python38\lib\site-packages\pip\_vendor\resolvelib\resolvers.py", line 546, in resolve
state = resolution.resolve(requirements, max_rounds=max_rounds)
File "C:\Python38\lib\site-packages\pip\_vendor\resolvelib\resolvers.py", line 457, in resolve
raise ResolutionTooDeep(max_rounds)
pip._vendor.resolvelib.resolvers.ResolutionTooDeep: 200000
```
**3. See error message:** `pip._vendor.resolvelib.resolvers.ResolutionTooDeep: 200000`
### Expected behavior
_No response_
### Logs
_No response_
### Environment
```shell
nothing installed yet, just trying to do it on Windows 7, Python 3.8
```
### Additional context
_No response_
|
closed
|
2023-09-30T15:39:23Z
|
2023-10-09T10:08:26Z
|
https://github.com/coqui-ai/TTS/issues/3017
|
[
"bug"
] |
abubelinha
| 4 |
hbldh/bleak
|
asyncio
| 599 |
BleakDotNetTaskError Could not get GATT characteristics AccessDenied
|
* bleak version: 0.12.1
* Python version: 3.9
* Operating System: Win 10 [Version 10.0.19042.1083]
* BlueZ version (`bluetoothctl -v`) in case of Linux:
* Bluetooth Firmware Version: HCI 8.256 / LMP 8.256
### Description
Similar to Issue #257 #222 From what I understand
I am trying to connect to a BLE Device using example code and get exceptions.
For reference I have previously interfaced with the device using closed source software without issues with the same hardware.
Noteworthy is that the device contains three characteristics with the same UUIDs related to the HID Service since the HID service seems to be the thing causing trouble.
### What I Did
Running the example code for Services I get the following output:
```
Traceback (most recent call last):
File "C:\Users\HP\PycharmProjects\Measure\venv\BLE-test3.py", line 32, in <module>
loop.run_until_complete(print_services(ADDRESS))
File "C:\Users\HP\AppData\Local\Programs\Python\Python39\lib\asyncio\base_events.py", line 642, in run_until_complete
return future.result()
File "C:\Users\HP\PycharmProjects\Measure\venv\BLE-test3.py", line 24, in print_services
async with BleakClient(mac_addr) as client:
File "C:\Users\HP\PycharmProjects\Measure\venv\lib\site-packages\bleak\backends\client.py", line 61, in __aenter__
await self.connect()
File "C:\Users\HP\PycharmProjects\Measure\venv\lib\site-packages\bleak\backends\winrt\client.py", line 227, in connect
await self.get_services(use_cached=use_cached)
File "C:\Users\HP\PycharmProjects\Measure\venv\lib\site-packages\bleak\backends\winrt\client.py", line 449, in get_services
raise BleakDotNetTaskError(
bleak.exc.BleakDotNetTaskError: Could not get GATT characteristics for <_winrt_Windows_Devices_Bluetooth_GenericAttributeProfile.GattDeviceService object at 0x000001A15CF7F290>: AccessDenied
```
By commenting out the ``` raise BleakDotNetTaskError( ``` in the file [winrt\client.py](https://github.com/hbldh/bleak/blob/7e0fdae6c0f6a78713e5984c2840666e0c38c3f3/bleak/backends/winrt/client.py#L449-L454) that the traceback is refering to, Bleak seems to work fairly normal, with the exception that the HID service has no characteristics.
|
closed
|
2021-07-15T13:28:36Z
|
2021-10-08T16:58:10Z
|
https://github.com/hbldh/bleak/issues/599
|
[
"Backend: pythonnet"
] |
ertex
| 1 |
hankcs/HanLP
|
nlp
| 1,449 |
hanlp+jupyter的docker镜像
|
**Describe the feature and the current behavior/state.**
目前官方文档里没有提供更快上手HanLP 的方式,所以我做了一个HanLP + Jupyter 的Docker镜像,可以帮助感兴趣的人更快上手体验。
walterinsh/hanlp:2.0.0a41-jupyter
[https://github.com/WalterInSH/hanlp-jupyter-docker](https://github.com/WalterInSH/hanlp-jupyter-docker)
如果满足你们的期望,可以加在文档里。
**Will this change the current api? How?**
No
**Who will benefit with this feature?**
会使用docker,期望快速尝试的人
**Are you willing to contribute it (Yes/No):**
yes
**System information**
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Debian
- Python version: 3.6
- HanLP version: 2.0.0a41
**Any other info**
* [x] I've carefully completed this form.
|
closed
|
2020-04-07T11:51:00Z
|
2020-04-09T11:42:18Z
|
https://github.com/hankcs/HanLP/issues/1449
|
[
"feature request"
] |
WalterInSH
| 1 |
QingdaoU/OnlineJudge
|
django
| 385 |
新增swift语言时候出现的问题。
|
在languages内添加了
_swift_lang_config = {
"run": {
"exe_name": "t.swift",
"command": "/usr/bin/swift {exe_path}",
"seccomp_rule": None,
}
}
并且在JudgeServer 容器内安装了swift环境,并且在容器内可运行swift代码。(swift也无需编译可运行)
但是最终在项目中运行时,会出现运行时错误。
最终在此次运行的文件地址(在挂载的judege_server/run/run的目标文件中),寻找到一个错误。1.out文件内显示:<unknown>:0: error: unable to open output file '/home/code/.cache/clang/ModuleCache/VXKMIN1Y83K6/SwiftShims-1KFO504FT44T.pcm': 'No such file or directory'
<unknown>:0: error: could not build C module 'SwiftShims'。
请问,该如何解决此项问题?
|
closed
|
2021-09-22T05:39:29Z
|
2021-09-22T09:26:50Z
|
https://github.com/QingdaoU/OnlineJudge/issues/385
|
[] |
metaire
| 3 |
waditu/tushare
|
pandas
| 1,645 |
installer 打包时候会提示错误
|
1.2.62可以打包成功,但是在请求数据的时候会报403错误
1.2.84打包的时候报错
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd7 in position 2556: invalid continuation byte
|
closed
|
2022-04-19T05:36:22Z
|
2022-04-20T09:13:47Z
|
https://github.com/waditu/tushare/issues/1645
|
[] |
jianyuanyang
| 3 |
piccolo-orm/piccolo
|
fastapi
| 317 |
Improve tests for `piccolo asgi new`
|
We have a basic test for `piccolo asgi new`:
https://github.com/piccolo-orm/piccolo/blob/master/tests/apps/asgi/commands/test_new.py
It can definitely be improved though. As a minimum, we should read the generated file contents, and use `ast.parse(file_contents)` to make sure the file is valid Python code. We use a similar approach here:
https://github.com/piccolo-orm/piccolo/blob/e0f04a40e868e9fa3c4f6bb9ebb1128f74180b07/tests/apps/schema/commands/test_generate.py#L91
Even better, we would try and run the app to make sure it works, but this might be too tricky.
|
closed
|
2021-10-29T18:33:28Z
|
2021-12-04T09:40:28Z
|
https://github.com/piccolo-orm/piccolo/issues/317
|
[
"enhancement",
"good first issue"
] |
dantownsend
| 3 |
pyeve/eve
|
flask
| 889 |
Docs are not clear about installation requirements
|
The docs say:
> Eve is powered by Flask, Redis, Cerberus, Events
but it does not indicate if all of those are required.
Specifically, I have failed to find anywhere in the docs if Redis is an optional dependency.
Looking into the requirements.txt and reading usage samples of Redis, `app = Eve()` vs `app = Eve(redis=r)` also suggests Redis is optional.
However, that is too many hoops for those new to Eve to conclude about Redis requirement - many may give up having no option to host Redis. For example, PythonAnywhere users: [I couldn't tell from their docs whether redis is a hard requirement or something that you can use for some features](https://www.pythonanywhere.com/forums/topic/3730/#id_post_18968)).
|
closed
|
2016-08-04T08:01:03Z
|
2016-08-07T15:14:40Z
|
https://github.com/pyeve/eve/issues/889
|
[
"documentation"
] |
mloskot
| 2 |
miLibris/flask-rest-jsonapi
|
sqlalchemy
| 187 |
Preventing useless queries when listing entities
|
Hello,
On an application with about 100k entries, listing them takes minutes. This surprised me because listing entries should be fairly quick, even if there are many of them. It appears that **for each entry** it produces a query to **each** relationship. This makes a huge number of queries. To understand if I did something wrong, I started from your own example in the documentation. I created 100 computers and 100 persons, related to a computer.
Then I listed all the computers (with `/computers?page[size]=0`) and I asked SQLAlchemy to log every query. This confirmed that I had one `SELECT` on the `computer` table and as many `SELECT` on the `person` table as there are owner of a computer. For instance, one of them:
```
INFO:sqlalchemy.engine.base.Engine:SELECT person.id AS person_id, person.name AS person_name, person.email AS person_email, person.birth_date AS person_birth_date, person.password AS person_password
FROM person
WHERE person.id = ?
INFO:sqlalchemy.engine.base.Engine:(19,)
```
First: why is this query necessary? I mean the listing doesn't provide the detail of the person, so why retrieving this data? How could we prevent Flask-REST-JSONAPI from retrieving it?
Second: if this query is necessary, why don't you have a join?
Third: can I prevent this from happening to prevent huge efficiency losses?
Thanks a lot!
|
closed
|
2020-02-20T18:32:57Z
|
2020-04-09T14:01:59Z
|
https://github.com/miLibris/flask-rest-jsonapi/issues/187
|
[] |
mikael-s
| 4 |
hankcs/HanLP
|
nlp
| 1,819 |
在使用文本相似度比较时,两个字符串交换一下位置,得出来的文本相似度不一样
|
<!--
感谢找出bug,请认真填写下表:
-->
**Describe the bug**
在使用文本相似度比较时,两个字符串交换一下位置,得出来的文本相似度不一样
**Code to reproduce the issue**

```python
```
**Describe the current behavior**
点击运行后,发现文本相似度的值不同
**Expected behavior**
交换字符串的位置,应该得到的文本相似度是一样的。
**System information**
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):
- Python version:
- HanLP version:
**Other info / logs**
Include any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.
* [x] I've completed this form and searched the web for solutions.
<!-- ⬆️此处务必勾选,否则你的issue会被机器人自动删除! -->
<!-- ⬆️此处务必勾选,否则你的issue会被机器人自动删除! -->
<!-- ⬆️此处务必勾选,否则你的issue会被机器人自动删除! -->
|
closed
|
2023-05-06T06:21:39Z
|
2023-05-07T16:53:38Z
|
https://github.com/hankcs/HanLP/issues/1819
|
[
"feature request"
] |
callmebyZJ
| 1 |
nolar/kopf
|
asyncio
| 243 |
[PR] Fix an issue with mistakenly added Bearer auth in addition to Basic auth
|
> <a href="https://github.com/nolar"><img align="left" height="50" src="https://avatars0.githubusercontent.com/u/544296?v=4"></a> A pull request by [nolar](https://github.com/nolar) at _2019-11-19 22:31:04+00:00_
> Original URL: https://github.com/zalando-incubator/kopf/pull/243
> Merged by [nolar](https://github.com/nolar) at _2019-11-19 23:55:13+00:00_
> Issue : #242
## Description
`Authorization: Bearer` header was sent (without a token!) because there was a schema defined by default (`"Bearer"`), which should not be there (`None`).
This caused problems when Basic auth (username+password) was used — it could not co-exist with `Authorization: Bearer` header.
## Types of Changes
- Bug fix (non-breaking change which fixes an issue)
---
> <a href="https://github.com/dneuhaeuser-zalando"><img align="left" height="30" src="https://avatars2.githubusercontent.com/u/37899626?v=4"></a> Commented by [dneuhaeuser-zalando](https://github.com/dneuhaeuser-zalando) at _2019-11-19 23:12:50+00:00_
>
Approved because I understand it's somewhat urgent but ideally this should have a test, to ensure this fixes the problem and to prevent a regression.
---
> <a href="https://github.com/nolar"><img align="left" height="30" src="https://avatars0.githubusercontent.com/u/544296?v=4"></a> Commented by [nolar](https://github.com/nolar) at _2019-11-20 01:01:26+00:00_
>
The tests for this case are added post-factum in #244 (with other auth/ssl tests).
|
closed
|
2020-08-18T20:01:38Z
|
2020-08-23T20:52:21Z
|
https://github.com/nolar/kopf/issues/243
|
[
"bug",
"archive"
] |
kopf-archiver[bot]
| 0 |
ray-project/ray
|
pytorch
| 51,086 |
[core] Guard ray C++ code quality via unit test
|
### Description
Ray core C++ components are not properly unit tested:
- As people left, it's less confident to guard against improper code change with missing context;
- Sanitizer on CI is only triggered on unit test;
- Unit test coverage is a good indicator of code quality (i.e. 85% branch coverage).
### Use case
_No response_
|
open
|
2025-03-05T02:20:07Z
|
2025-03-05T02:20:34Z
|
https://github.com/ray-project/ray/issues/51086
|
[
"enhancement",
"P2",
"core",
"help-wanted"
] |
dentiny
| 1 |
noirbizarre/flask-restplus
|
api
| 378 |
Namespace expect without model
|
@ns.expect(someModel)
def get(self):
pass
Instead of having a model passed to expect decorator, can I have a custom JSON? No model required in the application.
|
open
|
2018-01-06T05:01:59Z
|
2018-01-06T05:01:59Z
|
https://github.com/noirbizarre/flask-restplus/issues/378
|
[] |
VinayakBagaria
| 0 |
widgetti/solara
|
fastapi
| 737 |
`Card` component's `ma-{margin}` class takes precedence to `classes`
|
The view below does not seem to respect my CSS class, at least not my `margin-bottom: ... !important` property.
I see that `Card` prepends `ma-{margin}` to the class order. On inspection, I see that `ma-0` is applied as `.v-application .ma-0`, which applies a `margin: # !important` property.
Two things:
1. Does `v-application` overrides precedence somehow? There are several `v-application` nested classes throughout. I take it this is `vuetify`? Is their higher precedence by design?
2. The issue really is the `!important` flag on the `ma` class. It effectively blocks any user styles. Can this be modified?
```python
with Card(
margin=0,
classes=["container node-card"],
):
...
```
|
closed
|
2024-08-16T14:22:07Z
|
2024-08-20T04:38:38Z
|
https://github.com/widgetti/solara/issues/737
|
[] |
edan-bainglass
| 5 |
babysor/MockingBird
|
pytorch
| 554 |
pre.py 改进建议
|
**Summary[问题简述(一句话)]**
使用 `pre.py` 时如何暂停以及开始
**Env & To Reproduce[复现与环境]**
各依赖环境正常
使用 `pre.py` 开始训练后,无法停止
按 `Ctrl + C` 后报错,但计算未停止
看了一下 `pre.py` 源码,应该是 `multiprocessing` 的问题,其进程实例需人为停止
可以考虑使用 :
`p.terminate()`
`p.join()`
|
open
|
2022-05-15T11:04:47Z
|
2022-05-15T12:02:52Z
|
https://github.com/babysor/MockingBird/issues/554
|
[] |
tomcup
| 1 |
ray-project/ray
|
python
| 51,574 |
[CG, Core] Add Ascend NPU Support for RCCL and CG
|
### Description
This RFC proposes to provide initial support for RCCL and CG on Ascend NPU.
Original work by [@Bye-legumes](https://github.com/ray-project/ray/pull/47658) and [@hipudding](https://github.com/ray-project/ray/pull/51032).
However, we need to decouple them into several PRs with minor modifications and set an example for further hardware support.
## Notes:
- I previously submitted a PR in September 2024 to support HCCL and refactor NCCL into a communicator, but the feedback was that it was too large and complicated and we should decouple into some PR with minor modification.
- We should avoid adding additional C code into Ray, as that would influence the build stage.
## Plan for Decoupling into Several Stages:
### **PR1: Support RCCL on NPU**
Ray Core supports scheduling on Ascend NPU devices, but the Ray Collective API does not yet support communication between NPUs using HCCL.
🔗 [PR #50790](https://github.com/ray-project/ray/pull/50790)
👤 @liuxsh9
### **PR2: Refactor CG to Support Multiple Devices**
We can refer to [this PR](https://github.com/ray-project/ray/pull/44086) to decouple device-related modules.
Move cupy dependency, support rank mapping or different progress group.
👤 @hipudding
### **PR3: CG Support for NPU**
CG support will be added after RCCL is merged, utilizing the RCCL API from [PR #47658](https://github.com/ray-project/ray/pull/47658).
👤 @Bye-legumes
### **Merge Strategy**
- PR2 and PR3 can be merged independently.
- PR3 will adjust accordingly based on PR2.
### CANN+torch Version
Based on vLLM or latest?
### Use case
Support vllm-ascend https://github.com/vllm-project/vllm-ascend
|
open
|
2025-03-21T02:09:40Z
|
2025-03-21T23:37:13Z
|
https://github.com/ray-project/ray/issues/51574
|
[
"enhancement",
"core",
"compiled-graphs"
] |
Bye-legumes
| 0 |
koxudaxi/datamodel-code-generator
|
pydantic
| 1,436 |
Field names which begins and ends with underscores being prefixed with `field`
|
**Describe the bug**
There was a PR some time ago: https://github.com/koxudaxi/datamodel-code-generator/pull/962
It restricts usage of protected and private variables, but it doesn't consider variables with double-underscores on both sides, e.g. `__version__`.
Such variables are supported by pydantic and you can access them without any problems.
**To Reproduce**
Example schema:
```json
{
"title": "Event",
"properties": {
"__version__": {
"type": "string",
"title": "Event version"
}
}
}
```
Used commandline:
```
$ datamodel-codegen --input event.json --output event.py
```
** Actual behavior **
```python
class Event(BaseModel):
field__version__: Optional[str] = Field(
None, alias='__version__', title='Event version'
)
```
**Expected behavior**
```python
class Event(BaseModel):
__version__: Optional[str] = Field(
None, alias='__version__', title='Event version'
)
```
**Version:**
- OS: MacOS
- Python version: 3.11
- datamodel-code-generator version: 0.21.1
|
closed
|
2023-07-20T11:01:10Z
|
2024-02-13T14:12:01Z
|
https://github.com/koxudaxi/datamodel-code-generator/issues/1436
|
[
"bug"
] |
parikls
| 1 |
mwaskom/seaborn
|
pandas
| 3,000 |
Release v0.12.0
|
Release tracker issue for v0.12.0.
Mostly opening so that it gets issue #3000, which is satisfying.
|
closed
|
2022-09-05T16:53:42Z
|
2022-09-06T22:24:08Z
|
https://github.com/mwaskom/seaborn/issues/3000
|
[] |
mwaskom
| 2 |
openapi-generators/openapi-python-client
|
rest-api
| 202 |
Use httpx.Client Directly
|
As of version 0.6.1, the generated `Client` is somewhat configurable - headers, cookies, and timeout. However, these are all abstractions which have to then be handled explicitly within each generated API method.
Would it be simpler to just make calls using an `httpx.Client` or `httpx.AsyncClient` instance, and allow consumers to configure that directly? Advantages:
- Multiple versions of `httpx` can be supported, and there's less likelihood that you'll have to change your package due to changes or new features in `httpx`.
- It's more efficient than direct calls to `httpx.get` etc, and explicitly what `httpx` recommends in [its documentation](https://www.python-httpx.org/advanced/):
> If you do anything more than experimentation, one-off scripts, or prototypes, then you should use a Client instance.
of course, this package _does_ use the context manager within API operations, but that doesn't allow _multiple calls_ to share the same client and thus connection.
- Everything else good in that documentation, like the ability to use the generated client package as a WSGI test client
- [Event hooks](https://www.python-httpx.org/advanced/#event-hooks) will allow consumers to implement our own global retry logic (like refreshing authentication tokens) prior to official retry support from `httpx` itself.
- `AuthenticatedClient` and `Client` can just each just become an `httpx.Client` configured with different headers.
**tl;dr**: it decreases coupling between the two packages and lets you worry less about the client configuration and how to abstract it. More `httpx` functionality will be directly available to consumers, so you'll get fewer (actionable) feature requests. Future breaking changes here will be less likely. Seems like this alone would allow closing a couple currently pending issues (retries, different auth methods, response mimetypes), by putting them entirely in the hands of the consumer.
**Describe the solution you'd like**
There are a few options.
1. The `httpx.Client` could be used directly (i.e. replace `client.py` entirely). API methods would just accept the client and use it directly, and it would be up to the caller to configure and manage it. This is the simplest for sure, and meets the current use case. This is what I'd recommend.
```python
def sync_detailed(
*,
client: httpx.Client,
json_body: CreateUserRequest,
) -> Response[Union[User, Error]]:
kwargs = _get_kwargs(
client=client,
json_body=json_body,
)
response = client.post(
**kwargs,
)
return _build_response(response=response)
```
2. The `Client` could wrap an `httpx.Client` which allows you to add convenience methods as needed, and stay in control of the `Client` object itself. This abstraction layer offers protected variation, but wouldn't be used for anything right now - headers, timeouts, and cookies can all be configured directly on an `httpx.Client`. _However_ this need could also be met with configuration values passed directly to each API operation.
```python
def sync_detailed(
*,
client: Client,
json_body: CreateUserRequest,
) -> Response[Union[User, Error]]:
kwargs = _get_kwargs(
client=client.httpx_client,
json_body=json_body,
)
response = client.httpx_client.post(
**kwargs,
)
return _build_response(response=response)
```
3. Keep the `Client` and proxy calls (with `__getattr__`) to an inner client, _or_ typecheck `client` on each API operation to see if you've got a `Client` or `httpx.Client`. This allows them to be used interchangeably in API operations. This one's the most fragile and doesn't offer any advantages at the moment.
Of course, this would all apply to `AsyncClient` for the `asyncio` calls.
**Additional context**
Happy to send a PR, can do it pretty quickly. Am looking to use this in production, and would love to stay on (and contribute to) mainline rather than a fork!
|
closed
|
2020-09-30T03:46:15Z
|
2023-07-23T19:38:25Z
|
https://github.com/openapi-generators/openapi-python-client/issues/202
|
[
"✨ enhancement"
] |
kalzoo
| 7 |
babysor/MockingBird
|
pytorch
| 28 |
RuntimeError: CUDA error: CUBLAS_STATUS_INTERNAL_ERROR when calling `cublasSgemm( handle, opa, opb, m, n, k, &alpha, a, lda, b, ldb, &beta, c, ldc)`
|

训练一半后出现这个,谁能解决help
|
closed
|
2021-08-22T00:09:53Z
|
2021-10-16T08:52:18Z
|
https://github.com/babysor/MockingBird/issues/28
|
[] |
wangkewk
| 4 |
biosustain/potion
|
sqlalchemy
| 130 |
Move Model documents to different files (MongoEngine) Example
|
I am trying to figure out how I can create the `MongoEngine.Document` classes in separate files and still use the instance variable here:
https://github.com/biosustain/potion/blob/dc71f4954422f6edfde5bfa86f65dd622a35fdea/examples/mongoengine_simple.py#L12
Is there a good way of doing this so I can create a connection to the database and pass that mongo engine object around when i define my class modules in separate files?
|
closed
|
2018-02-12T19:42:11Z
|
2018-02-13T09:46:21Z
|
https://github.com/biosustain/potion/issues/130
|
[] |
wbashir
| 1 |
noirbizarre/flask-restplus
|
api
| 30 |
Refactor tests
|
Test files starts to be too dense.
Refactor to split into more files.
|
closed
|
2015-03-18T18:26:05Z
|
2015-11-04T15:39:06Z
|
https://github.com/noirbizarre/flask-restplus/issues/30
|
[
"technical"
] |
noirbizarre
| 1 |
pytest-dev/pytest-qt
|
pytest
| 394 |
Apparent leaks between tests with (customised) qapp
|
The [pytest-qt documentation](https://pytest-qt.readthedocs.io/en/latest/qapplication.html#testing-custom-qapplications) explains how to create a `QApplication` subclass from your own project which will then take the place of the default fixture `qapp` used to make a default `QApplication`. It tells you to put that in the conftest.py file in the relevant testing directory, and to give it "session" scope. From my experience any other scope causes horrendous crashes.
But what this means is that this fixture is only run once in your whole test session. `qapp` appears to be a strange beast, because you can add attributes to it, get your application code to change these attributes, etc. So... it's kind of half an object and half a function (which is only called once).
Dealing with the above wouldn't be that hard: you can prefer methods to attributes (e.g. `MyApp.set_version(...)` rather than `MyApp.version = ...`).
But there's a bigger problem I've just experienced: apparent leaking of patches between tests. This test, which checks that `setWindowTitle` is set on `app.main_window`, passes OK when run on its own:
```
def test_window_title_updated_on_new_doc(request, qapp):
t_logger.info(f'\n>>>>>> test name: {request.node.originalname}')
qapp.main_window = main_window.AutoTransMainWindow()
with unittest.mock.patch.object(qapp.main_window, 'setWindowTitle') as mock_set_wt:
qapp.try_to_create_new_doc()
mock_set_wt.assert_called_once()
```
... but there is another method before this:
```
@pytest.mark.parametrize('close_result', [True, False])
def test_try_to_create_new_doc_returns_expected_result(request, close_result, qapp):
t_logger.info(f'\n>>>>>> test name: {request.node.originalname}, close_result {close_result}')
with unittest.mock.patch.object(qapp, 'main_window'):
qapp.open_document = project.Project()
with unittest.mock.patch.object(qapp, 'try_to_close_curr_doc') as mock_try:
mock_try.return_value = close_result
create_result = qapp.try_to_create_new_doc()
assert close_result == create_result
```
... this tests that `app.try_to_create_new_doc` returns the same boolean value as `try_to_close_curr_doc`. This method passes with `close_result` as both `True` and `False`.
When both tests are run in the same `pytest` command, however, I get the following error on the *second* test (i.e. `test_window_updated_on_new_doc`):
```
E AssertionError: Expected 'setWindowTitle' to have been called once. Called 2 times.
E Calls: [call('Auto_trans 0.0.1 - No projects open'),
E call('Auto_trans 0.0.1 - Project: Not yet saved')].
```
These calls happened during the *first* test, i.e. `test_try_to_create_new_doc_returns_expected_result`, something which I've been able to verify, but they get reported as fails during the *second* test!
Does anyone know what to do about this?
|
closed
|
2021-11-09T21:16:14Z
|
2021-11-10T07:52:32Z
|
https://github.com/pytest-dev/pytest-qt/issues/394
|
[] |
Mrodent
| 2 |
sloria/TextBlob
|
nlp
| 240 |
No module named 'textblob'
|
Hi there,
I am a starter of Python and I would like to use 'textblob'. I am a MacOS High Sierra user.
What I tried is to install textblob on a new anaconda environment by `conda install -c conda-forge textblob` and `conda install -c conda-forge/label/gcc7 textblob`. It gets installed and then I check on the conda list and textblob is there. However, when I am running `from textblob import TextBlob` on Python I get an error: **No module named 'textblob'**
How can I resolve this? Thank you in advance
|
closed
|
2018-12-13T13:54:29Z
|
2018-12-24T13:50:07Z
|
https://github.com/sloria/TextBlob/issues/240
|
[] |
VickyVouk
| 3 |
comfyanonymous/ComfyUI
|
pytorch
| 7,020 |
Wan2.1 result is black, when using --use-sage-attention and setting weight_dtype to fp8_e4m3fn.
|
When using --use-sage-attention and setting weight_dtype to fp8_e4m3fn, the result is black,
Using --use-sage-attention, --force-upcast-attention and setting weight_dtype to fp8_e4m3fn, the result is still black.
|
open
|
2025-02-28T16:15:21Z
|
2025-03-12T21:40:16Z
|
https://github.com/comfyanonymous/ComfyUI/issues/7020
|
[] |
TangYanxin
| 6 |
coqui-ai/TTS
|
deep-learning
| 3,114 |
[Bug] xtts OrderedVocab problem
|
### Describe the bug
> TRAINING (2023-10-28 18:37:37)
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
### To Reproduce
training xtts with standard recipe
### Expected behavior
_No response_
### Logs
```shell
python finetunextts.py
>> DVAE weights restored from: C:\Users\someone\Desktop\xtts/run\training\XTTS_v1.1_original_model_files/dvae.pth
| > Found 489 files in C:\Users\someone\Desktop\xtts
fatal: not a git repository (or any of the parent directories): .git
fatal: not a git repository (or any of the parent directories): .git
> Training Environment:
| > Current device: 0
| > Num. of GPUs: 1
| > Num. of CPUs: 12
| > Num. of Torch Threads: 1
| > Torch seed: 1
| > Torch CUDNN: True
| > Torch CUDNN deterministic: False
| > Torch CUDNN benchmark: False
> Start Tensorboard: tensorboard --logdir=C:\Users\someone\Desktop\xtts/run\training\GPT_XTTS_LJSpeech_FT-October-27-2023_10+56PM-0000000
> Model has 543985103 parameters
> EPOCH: 0/1000
--> C:\Users\someone\Desktop\xtts/run\training\GPT_XTTS_LJSpeech_FT-October-27-2023_10+56PM-0000000
> Filtering invalid eval samples!!
> Total eval samples after filtering: 4
> EVALUATION
| > Synthesizing test sentences.
--> EVAL PERFORMANCE
| > avg_loader_time: 0.01900 (+0.00000)
| > avg_loss_text_ce: 0.04067 (+0.00000)
| > avg_loss_mel_ce: 4.33739 (+0.00000)
| > avg_loss: 4.37806 (+0.00000)
> BEST MODEL : C:\Users\someone\Desktop\xtts/run\training\GPT_XTTS_LJSpeech_FT-October-27-2023_10+56PM-0000000\best_model_0.pth
> EPOCH: 1/1000
--> C:\Users\someone\Desktop\xtts/run\training\GPT_XTTS_LJSpeech_FT-October-27-2023_10+56PM-0000000
> Sampling by language: dict_keys(['en'])
> TRAINING (2023-10-27 22:57:08)
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5024, your vocabulary could be corrupted !
The OrderedVocab you are attempting to save contains a hole for index 5025, your vocabulary could be corrupted !
--> STEP: 0/243 -- GLOBAL_STEP: 0
| > loss_text_ce: 0.04536 (0.04536)
| > loss_mel_ce: 4.79820 (4.79820)
| > loss: 4.84356 (4.84356)
| > current_lr: 0.00001
| > step_time: 0.88430 (0.88431)
| > loader_time: 70.14840 (70.14841)
--> STEP: 50/243 -- GLOBAL_STEP: 50
| > loss_text_ce: 0.04994 (0.04525)
| > loss_mel_ce: 5.39171 (4.74854)
| > loss: 5.44165 (4.79379)
| > current_lr: 0.00001
| > step_time: 0.66870 (1.54556)
| > loader_time: 0.01600 (0.01624)
--> STEP: 100/243 -- GLOBAL_STEP: 100
| > loss_text_ce: 0.04045 (0.04345)
| > loss_mel_ce: 3.84910 (4.67366)
| > loss: 3.88955 (4.71711)
| > current_lr: 0.00001
| > step_time: 1.74700 (1.66512)
| > loader_time: 0.01520 (0.01434)
--> STEP: 150/243 -- GLOBAL_STEP: 150
| > loss_text_ce: 0.05477 (0.04379)
| > loss_mel_ce: 5.39814 (4.72587)
| > loss: 5.45292 (4.76966)
| > current_lr: 0.00001
| > step_time: 2.80970 (1.85835)
| > loader_time: 0.01400 (0.01352)
--> STEP: 200/243 -- GLOBAL_STEP: 200
| > loss_text_ce: 0.03867 (0.04367)
| > loss_mel_ce: 4.21473 (4.71702)
| > loss: 4.25340 (4.76068)
| > current_lr: 0.00001
| > step_time: 3.30200 (2.20536)
| > loader_time: 0.00500 (0.01207)
> Filtering invalid eval samples!!
> Total eval samples after filtering: 4
> EVALUATION
| > Synthesizing test sentences.
--> EVAL PERFORMANCE
| > avg_loader_time: 0.01202 (-0.00698)
| > avg_loss_text_ce: 0.03961 (-0.00106)
| > avg_loss_mel_ce: 4.15599 (-0.18140)
| > avg_loss: 4.19560 (-0.18246)
> BEST MODEL : C:\Users\someone\Desktop\xtts/run\training\GPT_XTTS_LJSpeech_FT-October-27-2023_10+56PM-0000000\best_model_243.pth
```
### Environment
```shell
{
"CUDA": {
"GPU": [
"NVIDIA GeForce RTX 3060"
],
"available": true,
"version": "11.7"
},
"Packages": {
"PyTorch_debug": false,
"PyTorch_version": "2.0.1",
"TTS": "0.19.0",
"numpy": "1.22.0"
},
"System": {
"OS": "Windows",
"architecture": [
"64bit",
"WindowsPE"
],
"processor": "AMD64 Family 25 Model 80 Stepping 0, AuthenticAMD",
"python": "3.9.13",
"version": "10.0.22621"
}
}
```
### Additional context
_No response_
|
closed
|
2023-10-28T07:48:53Z
|
2023-10-28T08:31:28Z
|
https://github.com/coqui-ai/TTS/issues/3114
|
[
"bug"
] |
jazza420
| 1 |
sinaptik-ai/pandas-ai
|
pandas
| 920 |
Error in exe file which made by Pyinstaller
|
### System Info
python = 3.11.7
pandasai = 1.15.8
openai = 1.10.0
I made executable file by pyinstaller using following code.
=============================================================================
import pandas as pd
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
llm = OpenAI(api_token="", model = 'gpt-4')
df = pd.DataFrame({
"country": ["United States", "United Kingdom", "France", "Germany", "Italy", "Spain", "Canada", "Australia", "Japan", "China"],
"gdp": [19294482071552, 2891615567872, 2411255037952, 3435817336832, 1745433788416, 1181205135360, 1607402389504, 1490967855104, 4380756541440, 14631844184064],
"happiness_index": [6.94, 7.16, 6.66, 7.07, 6.38, 6.4, 7.23, 7.22, 5.87, 5.12]
})
df = SmartDataframe(df, config={"llm": llm})
print(df.chat('Which are the 5 happiest countries?'))
============================================================================
### 🐛 Describe the bug
If I run this exe file, I got following error
===========================================================================
Unfortunately, I was not able to answer your question, because of the following error:
'help'
===========================================================================
|
closed
|
2024-02-02T01:43:27Z
|
2024-06-01T00:20:24Z
|
https://github.com/sinaptik-ai/pandas-ai/issues/920
|
[] |
beysoftceo
| 2 |
vitalik/django-ninja
|
django
| 1,375 |
[BUG] AttributeError: 'method' object has no attribute '_ninja_operation'
|
**Describe the bug**
When I'm trying to create a class-based router using the ApiRouter class as a base class, I receive this error at the time of self.add_api_operations:
```
view_func._ninja_operation = operation # type: ignore
^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: 'method' object has no attribute '_ninja_operation'
```
When I comment out this line in the source code for django-ninja my project works absolutely correctly.
Code snippet:
```
class TestRouter(Router):
def __init__(self: Self) -> None:
super().__init__()
self.tags = ["Router"]
self.add_api_operation(
methods=["POST"],
path="/asd",
view_func=self.hello,
)
def hello(self: Self, request: WSGIRequest) -> str:
return "ok"
```
**Versions (please complete the following information):**
- Python version: 3.12.3
Note you can quickly get this by runninng in `./manage.py shell` this line:
```
>>> import django; import pydantic; import ninja; django.__version__; ninja.__version__; pydantic.__version__
'5.1.3'
'1.3.0'
'2.10.4'
```
|
closed
|
2024-12-30T02:03:26Z
|
2025-01-03T11:25:54Z
|
https://github.com/vitalik/django-ninja/issues/1375
|
[] |
shrpow
| 2 |
desec-io/desec-stack
|
rest-api
| 119 |
expose domain limit through API
|
There is a user-specific limit on how many domains can be registered. We need to expose this limit through the API so that GUIs can display it.
|
closed
|
2018-09-10T20:52:49Z
|
2018-09-20T11:12:38Z
|
https://github.com/desec-io/desec-stack/issues/119
|
[
"enhancement",
"api",
"prio: medium",
"easy"
] |
peterthomassen
| 0 |
aiortc/aiortc
|
asyncio
| 324 |
Make media codecs optional
|
For some use-cases, I think that media codecs are not required. For example, I am just interested in data channels.
Would you accept a PR that moves `av` to [extra_require](https://setuptools.readthedocs.io/en/latest/setuptools.html#declaring-extras-optional-features-with-their-own-dependencies) and make the `mediastreams` module optional?
|
closed
|
2020-03-23T01:24:04Z
|
2020-03-23T18:05:41Z
|
https://github.com/aiortc/aiortc/issues/324
|
[] |
DurandA
| 1 |
Significant-Gravitas/AutoGPT
|
python
| 9,079 |
Create Exa.ai "Get Contents" and "Find Similar" Blocks
|
Following up from [https://github.com/Significant-Gravitas/AutoGPT/pull/8835](https://github.com/Significant-Gravitas/AutoGPT/pull/8835)**<br>**<br>Now that we have Exa Search on the platform, let's add support for their Get Contents and Find Similar endpoints.<br><br>[https://docs.exa.ai/reference/get-contents](https://docs.exa.ai/reference/get-contents)<br><br>[https://docs.exa.ai/reference/find-similar-links](https://docs.exa.ai/reference/find-similar-links)
|
closed
|
2024-12-19T12:56:29Z
|
2024-12-29T18:40:24Z
|
https://github.com/Significant-Gravitas/AutoGPT/issues/9079
|
[
"good first issue",
"platform/blocks"
] |
Torantulino
| 0 |
HumanSignal/labelImg
|
deep-learning
| 979 |
BUG: GUI silently crashes if `classes.txt` is not found
|
When a folder is opened in `labelImg` GUI that doesn't have `classes.txt`, the GUI silently crashes without showing any error popup.
### Steps to Reproduce
- Put some images and corresponding annotation text files in a test folder.
- DON'T create `classes.txt`.
- Start `labelImg` GUI, and open the test folder using *Open Directory*.
- `labelImg` tries to read `classes.txt` in the test folder, and prints `FileNotFound` error to the console.
- **No error popup is shown in the GUI** and the program crashes after a few moments.
### Environment
- **OS:** Windows 11
- **PyQt version:** 5.5.19
- **Python version:** 3.11
|
open
|
2023-02-22T11:44:51Z
|
2023-02-22T11:44:51Z
|
https://github.com/HumanSignal/labelImg/issues/979
|
[] |
sohang3112
| 0 |
huggingface/datasets
|
machine-learning
| 6,584 |
np.fromfile not supported
|
How to do np.fromfile to use it like np.load
```python
def xnumpy_fromfile(filepath_or_buffer, *args, download_config: Optional[DownloadConfig] = None, **kwargs):
import numpy as np
if hasattr(filepath_or_buffer, "read"):
return np.fromfile(filepath_or_buffer, *args, **kwargs)
else:
filepath_or_buffer = str(filepath_or_buffer)
return np.fromfile(xopen(filepath_or_buffer, "rb", download_config=download_config).read(), *args, **kwargs)
```
this is not work
|
open
|
2024-01-12T09:46:17Z
|
2024-01-15T05:20:50Z
|
https://github.com/huggingface/datasets/issues/6584
|
[] |
d710055071
| 6 |
sunscrapers/djoser
|
rest-api
| 649 |
Search filter for Djoser auth/users view ?
|
Hi,
Is there a way to add a search filter (https://www.django-rest-framework.org/api-guide/filtering/#searchfilter) to the `auth/users/` GET endpoint of Djoser ?
I would like to add a username filter without having to use an extra endpoint.
Would it make sense to create a pull request to add a setting to specify some custom filters on the views ?
|
open
|
2022-01-14T18:58:11Z
|
2024-05-26T15:13:47Z
|
https://github.com/sunscrapers/djoser/issues/649
|
[] |
ahermant
| 1 |
miguelgrinberg/Flask-SocketIO
|
flask
| 1,266 |
How to unit test the application without a create_app function due to known bug with socketio
|
Hello, I'm struggling to unit test my application because I don't have a create_app() function which I think I need for the unit tests. I heard it was a known bug with socketio that you can't use a create_app() function and then use flask run. How do you unit test an application otherwise? Or is the bug fixed perchance?
My app code is as follows:
```
#!/usr/bin/python3
# maybe delete above line
# app.py
from flask import Flask, session
from flask_sqlalchemy import SQLAlchemy
from flask_login import LoginManager
import configparser
from flask_socketio import SocketIO, emit, send, join_room, leave_room
config = configparser.ConfigParser()
config.read("../settings.conf")
app = Flask(__name__)
# Ignores slashes on the end of URLs.
app.url_map.strict_slashes = False
app.config['SECRET_KEY'] = config.get('SQLALCHEMY','secret_key')
app.config['SQLALCHEMY_DATABASE_URI'] = config.get('SQLALCHEMY','sqlalchemy_database_uri')
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
# init SQLAlchemy so we can use it later
db = SQLAlchemy(app)
socketio = SocketIO()
socketio.init_app(app)
login_manager = LoginManager()
login_manager.login_view = 'auth.login'
login_manager.init_app(app)
import models
@login_manager.user_loader
def load_user(user_id):
return models.User.query.get(int(user_id))
# blueprint for auth routes in our app
from controllers.auth import auth as auth_blueprint
app.register_blueprint(auth_blueprint)
# blueprint for non-auth parts of app
from controllers.main import main as main_blueprint
app.register_blueprint(main_blueprint)
# blueprint for chase_the_ace parts of app
from controllers.games.chase_the_ace import chase_the_ace as chase_the_ace_blueprint
app.register_blueprint(chase_the_ace_blueprint)
# blueprint for shed parts of app
from controllers.games.shed import shed as shed_blueprint
app.register_blueprint(shed_blueprint)
# Game sockets import game mechanics and socketio listeners.
from controllers.games import chase_the_ace_gameplay
@socketio.on('connect')
def handle_my_connect_event():
print('connected')
@socketio.on('disconnect')
def handle_my_disconnect_event():
print('disconnected')
# If running app.py, then run app itself.
if __name__ == '__main__':
socketio.run(app)
```
Models:
```# models.py
from flask_login import UserMixin
from app import db
class User(UserMixin, db.Model):
id = db.Column(db.Integer, primary_key = True)
email = db.Column(db.String(100), unique = True)
username = db.Column(db.String(50), unique = True)
password = db.Column(db.String(50))
firstName = db.Column(db.String(50))
lastName = db.Column(db.String(50))
chaseTheAceWins = db.Column(db.Integer)
class Player(db.Model):
id = db.Column(db.Integer, primary_key = True)
userId = db.Column(db.Integer)
roomId = db.Column(db.Integer)
generatedPlayerId = db.Column(db.String(100), unique = True)
name = db.Column(db.String(100))
card = db.Column(db.String(10))
lives = db.Column(db.Integer)
outOfGame = db.Column(db.Boolean)
class Room(db.Model):
id = db.Column(db.Integer, primary_key = True)
roomId = db.Column(db.Integer, unique = True)
gameType = db.Column(db.String(20))
hostPlayerId = db.Column(db.String(100))
currentPlayerId = db.Column(db.String(100))
dealerPlayerId = db.Column(db.String(100))
locked = db.Column(db.Boolean)
```
Is there anything in my app that I'm doing wrong?
|
closed
|
2020-04-30T10:26:29Z
|
2020-10-09T19:05:40Z
|
https://github.com/miguelgrinberg/Flask-SocketIO/issues/1266
|
[
"question"
] |
Ash4669
| 4 |
cobrateam/splinter
|
automation
| 632 |
Browser opens but no further actions
|
Just opens the browser and sits there with both Firefox and Chrome
Browsers - Firefox ESR & Chromium 68.0.3440.75
This is in the geckodriver.log
[Child 2489] ###!!! ABORT: Aborting on channel error.: file /build/firefox-esr-TVuMhV/firefox-esr-52.9.0esr/ipc/glue/MessageChannel.cpp, line 2152
|
closed
|
2018-09-05T15:02:11Z
|
2020-02-29T15:16:48Z
|
https://github.com/cobrateam/splinter/issues/632
|
[] |
impshum
| 6 |
babysor/MockingBird
|
deep-learning
| 81 |
载入文件失败,载入的是mp3格式的,但是没有反应。
|


如图,载入了跟没载入差不多。
然后我这自己录的合成出来的声音有点像外国人学中文说话,哈哈。
|
closed
|
2021-09-10T09:58:04Z
|
2021-10-12T09:20:27Z
|
https://github.com/babysor/MockingBird/issues/81
|
[] |
luosaidage
| 11 |
pytorch/pytorch
|
numpy
| 148,874 |
`torch.device.__enter__` does not affect `get_default_device` despite taking precedence over `set_default_device`
|
### 🐛 Describe the bug
Using a `torch.device` as a context manager takes precedence over `set_default_device`, but this isn't reflected by the return value of `get_default_device`.
```python
import torch
import torch.utils._device
torch.set_default_device("cuda:1")
with torch.device("cuda:0"):
print(f"get_default_device(): {torch.get_default_device()}")
print(f"CURRENT_DEVICE: {torch.utils._device.CURRENT_DEVICE}")
print(f"actual current device: {torch.tensor(()).device}")
```
```
get_default_device(): cuda:1
CURRENT_DEVICE: cuda:1
actual current device: cuda:0
```
I feel like calling `__enter__` on the `DeviceContext` created in `torch.device`'s C++ `__enter__` implementation and `__exit__` in the C++ `__exit__` implementation might be a solution.
https://github.com/pytorch/pytorch/blob/00199acdb85a4355612bff28e1018b035e0e46b9/torch/csrc/Device.cpp#L179-L197
https://github.com/pytorch/pytorch/blob/00199acdb85a4355612bff28e1018b035e0e46b9/torch/utils/_device.py#L100-L104
https://github.com/pytorch/pytorch/blob/00199acdb85a4355612bff28e1018b035e0e46b9/torch/__init__.py#L1134-L1147
cc: @ezyang
### Versions
torch==2.6.0
cc @albanD
|
open
|
2025-03-10T07:52:08Z
|
2025-03-10T19:56:44Z
|
https://github.com/pytorch/pytorch/issues/148874
|
[
"triaged",
"module: python frontend"
] |
ringohoffman
| 1 |
mlflow/mlflow
|
machine-learning
| 14,709 |
[FR] Update Anthropic tracing to handle thinking blocks for claude-3.7-sonnet
|
### Willingness to contribute
Yes. I can contribute this feature independently.
### Proposal Summary
The current MLflow integration for Anthropic doesn't properly handle the new "thinking" feature in Claude Sonnet. When thinking is enabled, Claude returns content with specialized ThinkingBlock and TextBlock objects, but these aren't correctly processed in the message conversion function. As a result, the chat messages aren't properly captured during MLflow tracing, leading to incomplete traces (missing "chat" tab).
<img width="880" alt="Image" src="https://github.com/user-attachments/assets/a203b644-6f7d-403f-8023-365a145b7a50" />
I propose updating the implementation to check for the `thinking` block type and filter it out in the `convert_message_to_mlflow_chat` function, which restores the chat tab. The thinking contents are still captured in the inputs/outputs tab.
A more comprehensive handling of this issue would involve adding a `thinking` type to the chat section and would likely involve updates to multiple providers that now support thinking.
### Motivation
> #### What is the use case for this feature?
Working with the new `claude-3-7-sonnet-20250219` model with thinking enabled.
> #### Why is this use case valuable to support for MLflow users in general?
`claude-3-7-sonnet-20250219` is the latest and most capable claude model and will likely see substantial usage.
> #### Why is this use case valuable to support for your project(s) or organization?
this will address a limitation in the tracing handling of `claude-3-7-sonnet-20250219`
> #### Why is it currently difficult to achieve this use case?
(see above)
### Details
Proposed simple fix here:
https://github.com/mlflow/mlflow/blob/9cf17478518f632004ae062e87224fea0f704b45/mlflow/anthropic/chat.py#L50
```python
for content_block in content:
# Skip ThinkingBlock objects
if hasattr(content_block, "type") and getattr(content_block, "type") == "thinking":
continue
# Handle TextBlock objects directly
if hasattr(content_block, "type") and getattr(content_block, "type") == "text":
if hasattr(content_block, "text"):
contents.append(TextContentPart(text=getattr(content_block, "text"), type="text"))
continue
```
### What component(s) does this bug affect?
- [ ] `area/artifacts`: Artifact stores and artifact logging
- [ ] `area/build`: Build and test infrastructure for MLflow
- [ ] `area/deployments`: MLflow Deployments client APIs, server, and third-party Deployments integrations
- [ ] `area/docs`: MLflow documentation pages
- [ ] `area/examples`: Example code
- [ ] `area/model-registry`: Model Registry service, APIs, and the fluent client calls for Model Registry
- [x] `area/models`: MLmodel format, model serialization/deserialization, flavors
- [ ] `area/recipes`: Recipes, Recipe APIs, Recipe configs, Recipe Templates
- [ ] `area/projects`: MLproject format, project running backends
- [ ] `area/scoring`: MLflow Model server, model deployment tools, Spark UDFs
- [ ] `area/server-infra`: MLflow Tracking server backend
- [ ] `area/tracking`: Tracking Service, tracking client APIs, autologging
### What interface(s) does this bug affect?
- [ ] `area/uiux`: Front-end, user experience, plotting, JavaScript, JavaScript dev server
- [ ] `area/docker`: Docker use across MLflow's components, such as MLflow Projects and MLflow Models
- [ ] `area/sqlalchemy`: Use of SQLAlchemy in the Tracking Service or Model Registry
- [ ] `area/windows`: Windows support
### What language(s) does this bug affect?
- [ ] `language/r`: R APIs and clients
- [ ] `language/java`: Java APIs and clients
- [ ] `language/new`: Proposals for new client languages
### What integration(s) does this bug affect?
- [ ] `integrations/azure`: Azure and Azure ML integrations
- [ ] `integrations/sagemaker`: SageMaker integrations
- [ ] `integrations/databricks`: Databricks integrations
|
closed
|
2025-02-24T20:57:00Z
|
2025-03-16T09:43:48Z
|
https://github.com/mlflow/mlflow/issues/14709
|
[
"enhancement",
"area/models"
] |
djliden
| 4 |
RobertCraigie/prisma-client-py
|
pydantic
| 1,073 |
Deprecation of the Python client
|
Hello everyone, it's been long time coming but I'm officially stopping development of the Prisma Python Client.
This is for a couple of reasons:
- I originally built the client just for fun while I was a student, nowadays I don't have enough free time to properly maintain it.
- Prisma are rewriting their [core from Rust to TypeScript](https://www.prisma.io/blog/from-rust-to-typescript-a-new-chapter-for-prisma-orm). Unfortunately, adapting Prisma Client Python to this new architecture would require a ground up rewrite of our internals with significantly increased complexity as we would have to provide our own query interpreters and database drivers which is not something I'm interested in working on.
While it's certainly not impossible for community clients to exist in this new world, it is a *lot* more work. The [Go](https://github.com/steebchen/prisma-client-go/issues/1542), [Rust](https://github.com/Brendonovich/prisma-client-rust/discussions/476), and [Dart](https://github.com/medz/prisma-dart/issues/471) clients have similarly all been deprecated.
I greatly appreciate everyone who has supported the project over these last few years.
|
open
|
2025-03-23T17:40:06Z
|
2025-03-23T17:40:06Z
|
https://github.com/RobertCraigie/prisma-client-py/issues/1073
|
[] |
RobertCraigie
| 0 |
tensorflow/tensor2tensor
|
deep-learning
| 1,603 |
Getting duplicate logs with t2t_trainer,t2t_decoder,t2t_eval
|
I am getting duplicate logs for each t2t command. How can I avoid that?Like While I run t2t_eval script., It evals on eval dataset and then again starts eval and logs same as previous logs.
|
open
|
2019-06-14T07:11:55Z
|
2019-06-14T07:11:55Z
|
https://github.com/tensorflow/tensor2tensor/issues/1603
|
[] |
ashu5644
| 0 |
pyjanitor-devs/pyjanitor
|
pandas
| 489 |
[DOC] We need release notes!
|
This one is definitely on me. Starting with version 0.18.1, we should start collecting release notes in CHANGELOG.rst.
|
closed
|
2019-07-21T01:33:29Z
|
2019-07-21T19:50:35Z
|
https://github.com/pyjanitor-devs/pyjanitor/issues/489
|
[
"docfix",
"being worked on",
"high priority"
] |
ericmjl
| 0 |
gee-community/geemap
|
streamlit
| 2,213 |
[bug] Opacity parameter not working in geemap.deck Layer API
|
### Environment Information
Tue Jan 28 16:21:45 2025 UTC
--
OS | Linux (Ubuntu 22.04) | CPU(s) | 2 | Machine | x86_64
Architecture | 64bit | RAM | 12.7 GiB | Environment | IPython
Python 3.11.11 (main, Dec 4 2024, 08:55:07) [GCC 11.4.0]
geemap | 0.35.1 | ee | 1.4.6 | ipyleaflet | 0.19.2
folium | 0.19.4 | jupyterlab | Module not found | notebook | 6.5.5
ipyevents | 2.0.2 | geopandas | 1.0.1 | |
### Description
Trying to draw an EE layer with transparency (partial opacity) using the `geemap.deck` extension module.
The [geemap.deck.Layer.add_ee_layer](https://geemap.org/deck/#geemap.deck.Map.add_ee_layer) method’s documentation includes an `opacity` keyword argument which should allow setting the layer’s opacity. This is often useful when there is a need for transparency to ensure a new layer doesn’t completely occlude other layers or the base map itself.
However, this argument is currently [ignored in the implementation](https://github.com/gee-community/geemap/blob/824e4e5/geemap/deck.py#L103-L187) which can cause confusion for the user.
### What I Did
As an _undocumented_ workaround, I set the `opacity` within the `vis_params` dictionary explicitly to get the opacity to work.
```python
import geemap.deck as gmd
image_collection = ee.ImageCollection(...)
vis_params = {
"min": -40.0,
"max": 35.0,
"palette": ["blue", "purple", "cyan", "green", "yellow", "red"],
# set within vis parameters instead of the add_ee_layer_kwarg
"opacity": 0.2,
}
view_state = pdk.ViewState(,,,)
m = gmd.Map(initial_view_state=view_state)
# NOTE: opacity kwarg is not recognized. rely on vis_params instead
m.add_ee_layer(image_collection, vis_params=vis_params, ...)
m.show()
```
~It would be a trivial fix to simply do this automatically within `add_ee_layer` to set the `opacity` within the `vis_params` dictionary if this kwarg is not `None`.~
|
closed
|
2025-01-28T16:32:56Z
|
2025-02-02T13:41:06Z
|
https://github.com/gee-community/geemap/issues/2213
|
[
"bug"
] |
bijanvakili
| 4 |
xinntao/Real-ESRGAN
|
pytorch
| 712 |
TFlite version?
|
Do we have a mobile version of the Real-ESRGAN (.tflite version)?
If not, would it be straightforward to convert the model (.pth file) to .tflite?
|
open
|
2023-10-24T20:32:15Z
|
2024-10-07T07:18:14Z
|
https://github.com/xinntao/Real-ESRGAN/issues/712
|
[] |
arianaa30
| 4 |
ets-labs/python-dependency-injector
|
asyncio
| 61 |
Review docs: Feedback
|
closed
|
2015-05-08T15:40:47Z
|
2015-05-13T15:42:25Z
|
https://github.com/ets-labs/python-dependency-injector/issues/61
|
[
"docs"
] |
rmk135
| 0 |
|
satwikkansal/wtfpython
|
python
| 38 |
"Let's make a giant string!" code example is not representative
|
`add_string_with_plus()` and `add_string_with_join()` take the same time in the example. It implies that CPython's `+=` optimization is in effect (unrelated to the example in the very next section with a possibly misleading title: ["String concatenation interpreter optimizations"](https://github.com/satwikkansal/wtfpython#string-concatenation-interpreter-optimizations) -- the example is more about string interning, string *literals* than string concatination -- the linked StackOverflow [answer](https://stackoverflow.com/a/24245514/4279) explains it quite well).
The explanation in ["Let's make a giant string!"](https://github.com/satwikkansal/wtfpython#lets-make-a-giant-string) claims *quadratic* behavior for `str + str + str + ...` in Python (correct) but the example `add_string_with_plus()` uses CPython `+= ` optimizations -- the actual times are *linear* on my machine (in theory the worst case is still O(n<sup>2</sup>) -- it depends on `realloc()` being O(n) in the worst case on the given platform -- unlike for Python lists x1.125 overallocation (`add_string_with_join()` is linear) is not used for str):
```
In [2]: %timeit add_string_with_plus(10000)
1000 loops, best of 3: 1.1 ms per loop
In [3]: %timeit add_string_with_format(10000)
1000 loops, best of 3: 539 µs per loop
In [4]: %timeit add_string_with_join(10000)
1000 loops, best of 3: 1.1 ms per loop
In [5]: L = ["xyz"]*10000
In [6]: %timeit convert_list_to_string(L, 10000)
10000 loops, best of 3: 118 µs per loop
In [7]: %timeit add_string_with_plus(100000)
100 loops, best of 3: 11.9 ms per loop
In [8]: %timeit add_string_with_join(100000)
100 loops, best of 3: 11.8 ms per loop
In [9]: %timeit add_string_with_plus(1000000)
10 loops, best of 3: 121 ms per loop
In [10]: %timeit add_string_with_join(1000000)
10 loops, best of 3: 116 ms per loop
```
Increasing `iters` x10, increases the time x10 -- *linear* behavior.
If you try the same code with `bytes` on Python 3; you get *quadratic* behavior (increasing x10 leads to x100 time) -- no optimization:
```
In [11]: def add_bytes_with_plus(n):
...: s = b""
...: for _ in range(n):
...: s += b"abc"
...: assert len(s) == 3*n
...:
In [12]: %timeit add_bytes_with_plus(10000)
100 loops, best of 3: 10.8 ms per loop
In [13]: %timeit add_bytes_with_plus(100000)
1 loop, best of 3: 1.26 s per loop
In [14]: %timeit add_bytes_with_plus(1000000)
1 loop, best of 3: 2min 37s per loop
```
[Here's a detailed explanation in Russian](https://ru.stackoverflow.com/a/710403/23044) (look at the timings, follow the links in the answer).
|
closed
|
2017-09-07T18:46:13Z
|
2017-10-11T13:25:23Z
|
https://github.com/satwikkansal/wtfpython/issues/38
|
[
"enhancement",
"Hacktoberfest"
] |
zed
| 2 |
dask/dask
|
pandas
| 11,691 |
Errors with Zarr v3 and da.to_zarr()
|
I'm having various issues and errors with `da.to_zarr()` using:
```
dask==2025.1.0
zarr==3.0.1
fsspec==2024.12.0
```
```
from skimage import data
import dask.array as da
import zarr
dask_data = da.from_array(data.coins(), chunks=(64, 64))
da.to_zarr(dask_data, "test_dask_to_zarr.zarr", compute=True, storage_options={"chunks": (64, 64)})
# Traceback (most recent call last):
# File "/Users/wmoore/Desktop/python-scripts/zarr_scripts/test_dask_to_zarr.py", line 7, in <module>
# da.to_zarr(dask_data, "test_dask_to_zarr.zarr", compute=True, storage_options={"chunks": (64, 64)})
# File "/Users/wmoore/opt/anaconda3/envs/zarrv3_py312/lib/python3.12/site-packages/dask/array/core.py", line 3891, in to_zarr
# store = zarr.storage.FsspecStore.from_url(
# ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
# File "/Users/wmoore/opt/anaconda3/envs/zarrv3_py312/lib/python3.12/site-packages/zarr/storage/_fsspec.py", line 182, in from_url
# return cls(fs=fs, path=path, read_only=read_only, allowed_exceptions=allowed_exceptions)
# ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
# File "/Users/wmoore/opt/anaconda3/envs/zarrv3_py312/lib/python3.12/site-packages/zarr/storage/_fsspec.py", line 96, in __init__
# raise TypeError("Filesystem needs to support async operations.")
# TypeError: Filesystem needs to support async operations.
```
Trying to use a local store has a different error:
```
store = zarr.storage.LocalStore("test_dask_to_zarr.zarr", read_only=False)
da.to_zarr(dask_data, store, compute=True, storage_options={"chunks": (64, 64)})
# File "/Users/wmoore/Desktop/python-scripts/zarr_scripts/test_dask_to_zarr.py", line 46, in <module>
# da.to_zarr(dask_data, store, compute=True, storage_options={"chunks": (64, 64)})
# File "/Users/wmoore/opt/anaconda3/envs/zarrv3_py312/lib/python3.12/site-packages/dask/array/core.py", line 3891, in to_zarr
# store = zarr.storage.FsspecStore.from_url(
# ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
# File "/Users/wmoore/opt/anaconda3/envs/zarrv3_py312/lib/python3.12/site-packages/zarr/storage/_fsspec.py", line 174, in from_url
# fs, path = url_to_fs(url, **opts)
# ^^^^^^^^^^^^^^^^^^^^^^
# File "/Users/wmoore/opt/anaconda3/envs/zarrv3_py312/lib/python3.12/site-packages/fsspec/core.py", line 403, in url_to_fs
# chain = _un_chain(url, kwargs)
# ^^^^^^^^^^^^^^^^^^^^^^
# File "/Users/wmoore/opt/anaconda3/envs/zarrv3_py312/lib/python3.12/site-packages/fsspec/core.py", line 335, in _un_chain
# if "::" in path:
# ^^^^^^^^^^^^
# TypeError: argument of type 'LocalStore' is not iterable
```
And also tried with FsspecStore:
```
store = zarr.storage.FsspecStore("test_dask_to_zarr.zarr", read_only=False)
da.to_zarr(dask_data, store, compute=True, storage_options={"chunks": (64, 64)})
# Traceback (most recent call last):
# File "/Users/wmoore/Desktop/python-scripts/zarr_scripts/test_dask_to_zarr.py", line 32, in <module>
# store = zarr.storage.FsspecStore("test_dask_to_zarr_v3.zarr", read_only=False)
# ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
# File "/Users/wmoore/opt/anaconda3/envs/zarrv3_py312/lib/python3.12/site-packages/zarr/storage/_fsspec.py", line 95, in __init__
# if not self.fs.async_impl:
# ^^^^^^^^^^^^^^^^^^
# AttributeError: 'str' object has no attribute 'async_impl'
```
Many thanks for your help
|
closed
|
2025-01-23T10:44:50Z
|
2025-03-13T07:20:46Z
|
https://github.com/dask/dask/issues/11691
|
[
"needs triage"
] |
will-moore
| 4 |
ResidentMario/missingno
|
pandas
| 44 |
Cite SciPy family of packages and seaborn
|
The final sentence of your paper states:
> The underlying packages involved (numpy, pandas, scipy, matplotlib, and seaborn) are familiar parts of the core scientific Python ecosystem, and hence very learnable and extensible. missingno works "out of the box" with a variety of data types and formats, and provides an extremely compact API.
The packages numpy, pandas, scipy, matplotlib, and seaborn should be cited. You can use this link to find the appropriate citation methods: https://scipy.org/citing.html (for all but seaborn).
|
closed
|
2018-01-29T15:24:27Z
|
2018-02-06T20:02:40Z
|
https://github.com/ResidentMario/missingno/issues/44
|
[] |
zkamvar
| 2 |
ScrapeGraphAI/Scrapegraph-ai
|
machine-learning
| 9 |
add security policy
|
closed
|
2024-02-05T08:16:58Z
|
2024-02-07T15:46:54Z
|
https://github.com/ScrapeGraphAI/Scrapegraph-ai/issues/9
|
[] |
VinciGit00
| 0 |
|
ray-project/ray
|
pytorch
| 50,947 |
Release test microbenchmark.aws failed
|
Release test **microbenchmark.aws** failed. See https://buildkite.com/ray-project/release/builds/34295#01954658-83ea-482b-b817-7731040b6ee1 for more details.
Managed by OSS Test Policy
|
closed
|
2025-02-27T08:16:23Z
|
2025-02-28T05:24:59Z
|
https://github.com/ray-project/ray/issues/50947
|
[
"bug",
"P0",
"triage",
"core",
"release-test",
"jailed-test",
"ray-test-bot",
"weekly-release-blocker",
"stability"
] |
can-anyscale
| 5 |
ned2/slapdash
|
dash
| 3 |
datatable_experiments does not display
|
Love the boilerplate mate! Keep up with the good work.
I am trying to implement one of the datatables (via import dash_table_experiments ) but they do not seem to work. Take the code from this [example](https://github.com/plotly/dash-recipes/blob/master/dash-datatable-filter.py):
```python
_pages.py_
import dash
import dash_core_components as dcc
import dash_html_components as html
import dash_table_experiments as dt
import pandas as pd
import json
import pandas as pd
import plotly
from .components import Col, Row
page1 = html.Div([
dt.DataTable(
id='datatable',
rows=[
{'x': 1, 'y': 3},
{'x': 2, 'y': 10}
],
columns=['x'],
filterable=True,
filters={
"x": {
"column": {
"sortable": True,
"name": "x",
"filterable": True,
"editable": True,
"width": 673,
"rowType": "filter",
"key": "x",
"left": 673
},
"filterTerm": "2"
}
}
),
html.Div(id='content')
])
```
```python
_callbacks.py_
@app.callback(Output('content', 'children'), [Input('datatable', 'filters')])
def display_filters(filters):
return html.Pre(json.dumps(filters, indent=2))
```
When I run this, I not seem to get any errors but it doesnt display the table as it should. Could you perhaps have a quick look?
|
closed
|
2018-08-17T08:26:12Z
|
2018-08-20T05:20:21Z
|
https://github.com/ned2/slapdash/issues/3
|
[] |
markofferman
| 5 |
xuebinqin/U-2-Net
|
computer-vision
| 350 |
Cannot Import U2NET
|
I am trying to ```from model import U2NET`` but its not working. Module "model" does not exist. How to fix it?
|
open
|
2023-01-22T18:23:01Z
|
2023-01-22T18:23:01Z
|
https://github.com/xuebinqin/U-2-Net/issues/350
|
[] |
FASTANDEXTREME
| 0 |
graphistry/pygraphistry
|
jupyter
| 62 |
Add a .register() option to accept self-signed certificates (no validation)
|
closed
|
2016-04-20T22:10:27Z
|
2016-05-07T20:41:17Z
|
https://github.com/graphistry/pygraphistry/issues/62
|
[
"enhancement"
] |
thibaudh
| 0 |
|
pydantic/pydantic-ai
|
pydantic
| 495 |
Test
|
Test for @samuelcolvin
|
closed
|
2024-12-19T11:59:44Z
|
2024-12-19T11:59:51Z
|
https://github.com/pydantic/pydantic-ai/issues/495
|
[] |
tomhamiltonstubber
| 0 |
jupyter-book/jupyter-book
|
jupyter
| 1,966 |
A content in `extra_navbar` is no longer shown after updating to 0.15.0
|
### Describe the bug
**context**
A content in `extra_navbar` for `html` in `_config.yml` is no longer shown after updating to 0.15.0
**expectation**
I expected the content to be shown.
**bug**
No error message.
### Reproduce the bug
Update to 0.15.0 and build the book.
### List your environment
Jupyter Book : 0.15.0
External ToC : 0.3.1
MyST-Parser : 0.18.1
MyST-NB : 0.17.1
Sphinx Book Theme : 1.0.0
Jupyter-Cache : 0.5.0
NbClient : 0.5.13
|
open
|
2023-03-09T14:31:42Z
|
2023-04-17T12:30:40Z
|
https://github.com/jupyter-book/jupyter-book/issues/1966
|
[
"bug"
] |
spring-haru
| 1 |
allenai/allennlp
|
data-science
| 5,430 |
MultiLabelField not being indexed correctly with pre-trained transformer
|
This is probably a user error but I cannot find a jsonl vocab constructor which works correctly with a MultiLabelField (i.e. a multi-label classifier).
I need to set the vocabs `unk` and `pad` token as I'm using a huggingface transformer, and of course, I need to index the labels.
When I use `from_pretrained_transformer` to construct my vocabulary there are two issues, first, when `MultiLabelField.index` is called, the vocab only contains a tokens namespace, no labels. This causes 'index' to crash - oddly `vocab.get_token_index(label, self._label_namespace)` returns 1 (one) for every label despite the namespace not existing, should it not return an error?
vocabulary: {
type: "from_pretrained_transformer",
model_name: "models/transformer",
}
Also inspecting the vocab object I'm seeing
_oov_token:'\<unk\>'
_padding_token:'@@PADDING@@'
So it's failed to infer the padding token. From what I can see the from_pretrained_transformer has no `padding_token` argument?
If I use 'from_instances' it indexes the labels correctly but afaik it's reindexing the original vocab but it's out of alignment.
My model is
vocabulary: {
type: "from_pretrained_transformer",
model_name: "models/transformer",
},
dataset_reader: {
type: "multi_label",
tokenizer: {
type: "pretrained_transformer",
model_name: "models/transformer"
},
token_indexers: {
tokens: {
type: "pretrained_transformer",
model_name: "models/transformer",
namespace: "tokens"
},
},
},
model: {
type: "multi_label",
text_field_embedder: {
token_embedders: {
tokens: {
type: "pretrained_transformer",
model_name: "models/transformer"
}
},
},
seq2vec_encoder: {
type: "bert_pooler",
pretrained_model: "models/transformer",
dropout: 0.1,
},
},
|
closed
|
2021-10-05T04:22:16Z
|
2021-10-15T04:13:00Z
|
https://github.com/allenai/allennlp/issues/5430
|
[
"bug"
] |
david-waterworth
| 1 |
horovod/horovod
|
pytorch
| 3,294 |
Building `horovod-cpu` image failed with cmake errors
|
**Environment:**
1. Framework: TensorFlow, PyTorch, MXNet
2. Framework version: 2.5.0, 1.8.1, 1.8.0.post0
3. Horovod version: v0.23.0
4. MPI version: 3.0.0
5. CUDA version: None
6. NCCL version: None
7. Python version: 3.7
8. Spark / PySpark version: 3.1.1
9. Ray version: None
10. OS and version: Ubuntu 18.04
11. GCC version: 7.5.0
12. CMake version: 3.10.2
**Checklist:**
1. Did you search issues to find if somebody asked this question before? Yes
2. If your question is about hang, did you read [this doc](https://github.com/horovod/horovod/blob/master/docs/running.rst)?
3. If your question is about docker, did you read [this doc](https://github.com/horovod/horovod/blob/master/docs/docker.rst)? Yes
4. Did you check if you question is answered in the [troubleshooting guide](https://github.com/horovod/horovod/blob/master/docs/troubleshooting.rst)? Yes
**Bug report:**
I was trying to build a horovod-cpu image locally using this [provided Dockerfile](https://github.com/horovod/horovod/blob/v0.23.0/docker/horovod-cpu/Dockerfile) and with command
```
docker build -f docker/horovod-cpu/Dockerfile .
```
however the build failed with the following errors:
```
#22 48.71 running build_ext
#22 48.76 -- Could not find CCache. Consider installing CCache to speed up compilation.
#22 48.90 -- The CXX compiler identification is GNU 7.5.0
#22 48.90 -- Check for working CXX compiler: /usr/bin/c++
#22 49.00 -- Check for working CXX compiler: /usr/bin/c++ -- works
#22 49.00 -- Detecting CXX compiler ABI info
#22 49.10 -- Detecting CXX compiler ABI info - done
#22 49.11 -- Detecting CXX compile features
#22 49.56 -- Detecting CXX compile features - done
#22 49.58 -- Build architecture flags: -mf16c -mavx -mfma
#22 49.58 -- Using command /usr/bin/python
#22 49.97 -- Found MPI_CXX: /usr/local/lib/libmpi.so (found version "3.1")
#22 49.97 -- Found MPI: TRUE (found version "3.1")
#22 49.97 -- Could NOT find NVTX (missing: NVTX_INCLUDE_DIR)
#22 49.97 CMake Error at CMakeLists.txt:265 (add_subdirectory):
#22 49.97 add_subdirectory given source "third_party/gloo" which is not an existing
#22 49.98 directory.
#22 49.98
#22 49.98
#22 49.98 CMake Error at CMakeLists.txt:267 (target_compile_definitions):
#22 49.98 Cannot specify compile definitions for target "gloo" which is not built by
#22 49.98 this project.
#22 49.98
#22 49.98
#22 52.34 Tensorflow_LIBRARIES := -L/usr/local/lib/python3.7/dist-packages/tensorflow -l:libtensorflow_framework.so.2
#22 52.35 -- Found Tensorflow: -L/usr/local/lib/python3.7/dist-packages/tensorflow -l:libtensorflow_framework.so.2 (found suitable version "2.5.0", minimum required is "1.15.0")
#22 53.16 -- Found Pytorch: 1.8.1+cu102 (found suitable version "1.8.1+cu102", minimum required is "1.2.0")
#22 59.99 -- Found Mxnet: /usr/local/lib/python3.7/dist-packages/mxnet/libmxnet.so (found suitable version "1.8.0", minimum required is "1.4.0")
#22 61.13 CMake Error at CMakeLists.txt:327 (file):
#22 61.13 file COPY cannot find "/tmp/pip-req-build-s0z_ufky/third_party/gloo".
#22 61.13
#22 61.13
#22 61.13 CMake Error at CMakeLists.txt:328 (file):
#22 61.13 file failed to open for reading (No such file or directory):
#22 61.13
#22 61.13 /tmp/pip-req-build-s0z_ufky/third_party/compatible_gloo/gloo/CMakeLists.txt
#22 61.13
#22 61.13
#22 61.13 CMake Error at CMakeLists.txt:331 (add_subdirectory):
#22 61.13 The source directory
#22 61.13
#22 61.13 /tmp/pip-req-build-s0z_ufky/third_party/compatible_gloo
#22 61.13
#22 61.13 does not contain a CMakeLists.txt file.
#22 61.13
#22 61.13
#22 61.13 CMake Error at CMakeLists.txt:332 (target_compile_definitions):
#22 61.13 Cannot specify compile definitions for target "compatible_gloo" which is
#22 61.13 not built by this project.
#22 61.13
#22 61.13
#22 61.13 CMake Error: The following variables are used in this project, but they are set to NOTFOUND.
#22 61.13 Please set them or make sure they are set and tested correctly in the CMake files:
#22 61.13 /tmp/pip-req-build-s0z_ufky/horovod/mxnet/TF_FLATBUFFERS_INCLUDE_PATH
#22 61.13 used as include directory in directory /tmp/pip-req-build-s0z_ufky/horovod/mxnet
#22 61.13 /tmp/pip-req-build-s0z_ufky/horovod/tensorflow/TF_FLATBUFFERS_INCLUDE_PATH
#22 61.13 used as include directory in directory /tmp/pip-req-build-s0z_ufky/horovod/tensorflow
#22 61.13 /tmp/pip-req-build-s0z_ufky/horovod/torch/TF_FLATBUFFERS_INCLUDE_PATH
#22 61.13 used as include directory in directory /tmp/pip-req-build-s0z_ufky/horovod/torch
#22 61.13
#22 61.13 -- Configuring incomplete, errors occurred!
#22 61.13 See also "/tmp/pip-req-build-s0z_ufky/build/temp.linux-x86_64-3.7/RelWithDebInfo/CMakeFiles/CMakeOutput.log".
#22 61.14 Traceback (most recent call last):
#22 61.14 File "<string>", line 1, in <module>
#22 61.14 File "/tmp/pip-req-build-s0z_ufky/setup.py", line 211, in <module>
#22 61.14 'horovodrun = horovod.runner.launch:run_commandline'
#22 61.14 File "/usr/local/lib/python3.7/dist-packages/setuptools/__init__.py", line 153, in setup
#22 61.14 return distutils.core.setup(**attrs)
#22 61.14 File "/usr/lib/python3.7/distutils/core.py", line 148, in setup
#22 61.14 dist.run_commands()
#22 61.14 File "/usr/lib/python3.7/distutils/dist.py", line 966, in run_commands
#22 61.14 self.run_command(cmd)
#22 61.14 File "/usr/lib/python3.7/distutils/dist.py", line 985, in run_command
#22 61.14 cmd_obj.run()
#22 61.14 File "/usr/local/lib/python3.7/dist-packages/wheel/bdist_wheel.py", line 299, in run
#22 61.14 self.run_command('build')
#22 61.14 File "/usr/lib/python3.7/distutils/cmd.py", line 313, in run_command
#22 61.14 self.distribution.run_command(command)
#22 61.14 File "/usr/lib/python3.7/distutils/dist.py", line 985, in run_command
#22 61.14 cmd_obj.run()
#22 61.14 File "/usr/lib/python3.7/distutils/command/build.py", line 135, in run
#22 61.14 self.run_command(cmd_name)
#22 61.14 File "/usr/lib/python3.7/distutils/cmd.py", line 313, in run_command
#22 61.14 self.distribution.run_command(command)
#22 61.15 File "/usr/lib/python3.7/distutils/dist.py", line 985, in run_command
#22 61.15 cmd_obj.run()
#22 61.15 File "/usr/local/lib/python3.7/dist-packages/setuptools/command/build_ext.py", line 79, in run
#22 61.15 _build_ext.run(self)
#22 61.15 File "/usr/lib/python3.7/distutils/command/build_ext.py", line 340, in run
#22 61.15 self.build_extensions()
#22 61.15 File "/tmp/pip-req-build-s0z_ufky/setup.py", line 99, in build_extensions
#22 61.15 cwd=cmake_build_dir)
#22 61.15 File "/usr/lib/python3.7/subprocess.py", line 363, in check_call
#22 61.15 raise CalledProcessError(retcode, cmd)
#22 61.15 subprocess.CalledProcessError: Command '['cmake', '/tmp/pip-req-build-s0z_ufky', '-DCMAKE_BUILD_TYPE=RelWithDebInfo', '-DCMAKE_LIBRARY_OUTPUT_DIRECTORY_RELWITHDEBINFO=/tmp/pip-req-build-s0z_ufky/build/lib.linux-x86_64-3.7', '-DPYTHON_EXECUTABLE:FILEPATH=/usr/bin/python']' returned non-zero exit status 1.
#22 61.17 Building wheel for horovod (setup.py): finished with status 'error'
#22 61.17 ERROR: Failed building wheel for horovod
#22 61.17 Running setup.py clean for horovod
#22 61.17 Running command /usr/bin/python -u -c 'import io, os, sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-req-build-s0z_ufky/setup.py'"'"'; __file__='"'"'/tmp/pip-req-build-s0z_ufky/setup.py'"'"';f = getattr(tokenize, '"'"'open'"'"', open)(__file__) if os.path.exists(__file__) else io.StringIO('"'"'from setuptools import setup; setup()'"'"');code = f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' clean --all
#22 61.43 running clean
#22 61.43 removing 'build/temp.linux-x86_64-3.7' (and everything under it)
#22 61.44 removing 'build/lib.linux-x86_64-3.7' (and everything under it)
#22 61.44 'build/bdist.linux-x86_64' does not exist -- can't clean it
#22 61.44 'build/scripts-3.7' does not exist -- can't clean it
#22 61.44 removing 'build'
#22 61.46 Failed to build horovod
#22 62.05 Installing collected packages: pytz, python-dateutil, pyrsistent, pycparser, importlib-resources, deprecated, redis, pyzmq, pyarrow, psutil, pandas, msgpack, jsonschema, hiredis, filelock, diskcache, dill, cloudpickle, click, cffi, ray, petastorm, horovod, h5py, aioredis
#22 63.76 changing mode of /usr/local/bin/plasma_store to 755
#22 67.56 changing mode of /usr/local/bin/jsonschema to 755
#22 70.60 changing mode of /usr/local/bin/ray to 755
#22 70.60 changing mode of /usr/local/bin/ray-operator to 755
#22 70.60 changing mode of /usr/local/bin/rllib to 755
#22 70.60 changing mode of /usr/local/bin/serve to 755
#22 70.60 changing mode of /usr/local/bin/tune to 755
#22 70.79 changing mode of /usr/local/bin/petastorm-copy-dataset.py to 755
#22 70.79 changing mode of /usr/local/bin/petastorm-generate-metadata.py to 755
#22 70.79 changing mode of /usr/local/bin/petastorm-throughput.py to 755
#22 70.80 Running setup.py install for horovod: started
#22 70.80 Running command /usr/bin/python -u -c 'import io, os, sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-req-build-s0z_ufky/setup.py'"'"'; __file__='"'"'/tmp/pip-req-build-s0z_ufky/setup.py'"'"';f = getattr(tokenize, '"'"'open'"'"', open)(__file__) if os.path.exists(__file__) else io.StringIO('"'"'from setuptools import setup; setup()'"'"');code = f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /tmp/pip-record-2urw0_at/install-record.txt --single-version-externally-managed --compile --install-headers /usr/local/include/python3.7/horovod
#22 71.08 running install
#22 71.08 /usr/local/lib/python3.7/dist-packages/setuptools/command/install.py:37: SetuptoolsDeprecationWarning: setup.py install is deprecated. Use build and pip and other standards-based tools.
#22 71.08 setuptools.SetuptoolsDeprecationWarning,
#22 71.08 running build
#22 71.08 running build_py
#22 71.08 creating build
#22 71.08 creating build/lib.linux-x86_64-3.7
#22 71.08 creating build/lib.linux-x86_64-3.7/horovod
#22 71.08 copying horovod/__init__.py -> build/lib.linux-x86_64-3.7/horovod
#22 71.08 creating build/lib.linux-x86_64-3.7/horovod/spark
#22 71.08 copying horovod/spark/runner.py -> build/lib.linux-x86_64-3.7/horovod/spark
#22 71.08 copying horovod/spark/gloo_run.py -> build/lib.linux-x86_64-3.7/horovod/spark
#22 71.08 copying horovod/spark/conf.py -> build/lib.linux-x86_64-3.7/horovod/spark
#22 71.08 copying horovod/spark/mpi_run.py -> build/lib.linux-x86_64-3.7/horovod/spark
#22 71.09 copying horovod/spark/__init__.py -> build/lib.linux-x86_64-3.7/horovod/spark
#22 71.09 creating build/lib.linux-x86_64-3.7/horovod/keras
#22 71.09 copying horovod/keras/elastic.py -> build/lib.linux-x86_64-3.7/horovod/keras
#22 71.09 copying horovod/keras/callbacks.py -> build/lib.linux-x86_64-3.7/horovod/keras
#22 71.09 copying horovod/keras/__init__.py -> build/lib.linux-x86_64-3.7/horovod/keras
#22 71.09 creating build/lib.linux-x86_64-3.7/horovod/tensorflow
#22 71.09 copying horovod/tensorflow/elastic.py -> build/lib.linux-x86_64-3.7/horovod/tensorflow
#22 71.09 copying horovod/tensorflow/mpi_ops.py -> build/lib.linux-x86_64-3.7/horovod/tensorflow
#22 71.09 copying horovod/tensorflow/sync_batch_norm.py -> build/lib.linux-x86_64-3.7/horovod/tensorflow
#22 71.09 copying horovod/tensorflow/functions.py -> build/lib.linux-x86_64-3.7/horovod/tensorflow
#22 71.09 copying horovod/tensorflow/gradient_aggregation.py -> build/lib.linux-x86_64-3.7/horovod/tensorflow
#22 71.09 copying horovod/tensorflow/__init__.py -> build/lib.linux-x86_64-3.7/horovod/tensorflow
#22 71.09 copying horovod/tensorflow/util.py -> build/lib.linux-x86_64-3.7/horovod/tensorflow
#22 71.09 copying horovod/tensorflow/compression.py -> build/lib.linux-x86_64-3.7/horovod/tensorflow
#22 71.09 copying horovod/tensorflow/gradient_aggregation_eager.py -> build/lib.linux-x86_64-3.7/horovod/tensorflow
#22 71.09 creating build/lib.linux-x86_64-3.7/horovod/data
#22 71.09 copying horovod/data/__init__.py -> build/lib.linux-x86_64-3.7/horovod/data
#22 71.09 copying horovod/data/data_loader_base.py -> build/lib.linux-x86_64-3.7/horovod/data
#22 71.10 creating build/lib.linux-x86_64-3.7/horovod/_keras
#22 71.10 copying horovod/_keras/elastic.py -> build/lib.linux-x86_64-3.7/horovod/_keras
#22 71.10 copying horovod/_keras/callbacks.py -> build/lib.linux-x86_64-3.7/horovod/_keras
#22 71.10 copying horovod/_keras/__init__.py -> build/lib.linux-x86_64-3.7/horovod/_keras
#22 71.10 creating build/lib.linux-x86_64-3.7/horovod/common
#22 71.10 copying horovod/common/elastic.py -> build/lib.linux-x86_64-3.7/horovod/common
#22 71.10 copying horovod/common/basics.py -> build/lib.linux-x86_64-3.7/horovod/common
#22 71.10 copying horovod/common/process_sets.py -> build/lib.linux-x86_64-3.7/horovod/common
#22 71.10 copying horovod/common/__init__.py -> build/lib.linux-x86_64-3.7/horovod/common
#22 71.10 copying horovod/common/exceptions.py -> build/lib.linux-x86_64-3.7/horovod/common
#22 71.10 copying horovod/common/util.py -> build/lib.linux-x86_64-3.7/horovod/common
#22 71.10 creating build/lib.linux-x86_64-3.7/horovod/mxnet
#22 71.10 copying horovod/mxnet/mpi_ops.py -> build/lib.linux-x86_64-3.7/horovod/mxnet
#22 71.10 copying horovod/mxnet/functions.py -> build/lib.linux-x86_64-3.7/horovod/mxnet
#22 71.10 copying horovod/mxnet/__init__.py -> build/lib.linux-x86_64-3.7/horovod/mxnet
#22 71.10 copying horovod/mxnet/compression.py -> build/lib.linux-x86_64-3.7/horovod/mxnet
#22 71.10 creating build/lib.linux-x86_64-3.7/horovod/runner
#22 71.10 copying horovod/runner/task_fn.py -> build/lib.linux-x86_64-3.7/horovod/runner
#22 71.10 copying horovod/runner/launch.py -> build/lib.linux-x86_64-3.7/horovod/runner
#22 71.10 copying horovod/runner/run_task.py -> build/lib.linux-x86_64-3.7/horovod/runner
#22 71.10 copying horovod/runner/gloo_run.py -> build/lib.linux-x86_64-3.7/horovod/runner
#22 71.10 copying horovod/runner/js_run.py -> build/lib.linux-x86_64-3.7/horovod/runner
#22 71.10 copying horovod/runner/mpi_run.py -> build/lib.linux-x86_64-3.7/horovod/runner
#22 71.10 copying horovod/runner/__init__.py -> build/lib.linux-x86_64-3.7/horovod/runner
#22 71.10 creating build/lib.linux-x86_64-3.7/horovod/torch
#22 71.10 copying horovod/torch/optimizer.py -> build/lib.linux-x86_64-3.7/horovod/torch
#22 71.10 copying horovod/torch/mpi_ops.py -> build/lib.linux-x86_64-3.7/horovod/torch
#22 71.10 copying horovod/torch/sync_batch_norm.py -> build/lib.linux-x86_64-3.7/horovod/torch
#22 71.10 copying horovod/torch/functions.py -> build/lib.linux-x86_64-3.7/horovod/torch
#22 71.11 copying horovod/torch/__init__.py -> build/lib.linux-x86_64-3.7/horovod/torch
#22 71.11 copying horovod/torch/compression.py -> build/lib.linux-x86_64-3.7/horovod/torch
#22 71.11 creating build/lib.linux-x86_64-3.7/horovod/ray
#22 71.11 copying horovod/ray/runner.py -> build/lib.linux-x86_64-3.7/horovod/ray
#22 71.11 copying horovod/ray/elastic.py -> build/lib.linux-x86_64-3.7/horovod/ray
#22 71.11 copying horovod/ray/worker.py -> build/lib.linux-x86_64-3.7/horovod/ray
#22 71.11 copying horovod/ray/strategy.py -> build/lib.linux-x86_64-3.7/horovod/ray
#22 71.11 copying horovod/ray/driver_service.py -> build/lib.linux-x86_64-3.7/horovod/ray
#22 71.11 copying horovod/ray/ray_logger.py -> build/lib.linux-x86_64-3.7/horovod/ray
#22 71.11 copying horovod/ray/__init__.py -> build/lib.linux-x86_64-3.7/horovod/ray
#22 71.11 copying horovod/ray/utils.py -> build/lib.linux-x86_64-3.7/horovod/ray
#22 71.11 creating build/lib.linux-x86_64-3.7/horovod/spark/keras
#22 71.11 copying horovod/spark/keras/optimizer.py -> build/lib.linux-x86_64-3.7/horovod/spark/keras
#22 71.11 copying horovod/spark/keras/tensorflow.py -> build/lib.linux-x86_64-3.7/horovod/spark/keras
#22 71.11 copying horovod/spark/keras/__init__.py -> build/lib.linux-x86_64-3.7/horovod/spark/keras
#22 71.11 copying horovod/spark/keras/bare.py -> build/lib.linux-x86_64-3.7/horovod/spark/keras
#22 71.11 copying horovod/spark/keras/remote.py -> build/lib.linux-x86_64-3.7/horovod/spark/keras
#22 71.11 copying horovod/spark/keras/util.py -> build/lib.linux-x86_64-3.7/horovod/spark/keras
#22 71.11 copying horovod/spark/keras/estimator.py -> build/lib.linux-x86_64-3.7/horovod/spark/keras
#22 71.11 creating build/lib.linux-x86_64-3.7/horovod/spark/lightning
#22 71.11 copying horovod/spark/lightning/datamodule.py -> build/lib.linux-x86_64-3.7/horovod/spark/lightning
#22 71.11 copying horovod/spark/lightning/legacy.py -> build/lib.linux-x86_64-3.7/horovod/spark/lightning
#22 71.11 copying horovod/spark/lightning/__init__.py -> build/lib.linux-x86_64-3.7/horovod/spark/lightning
#22 71.11 copying horovod/spark/lightning/remote.py -> build/lib.linux-x86_64-3.7/horovod/spark/lightning
#22 71.11 copying horovod/spark/lightning/util.py -> build/lib.linux-x86_64-3.7/horovod/spark/lightning
#22 71.11 copying horovod/spark/lightning/estimator.py -> build/lib.linux-x86_64-3.7/horovod/spark/lightning
#22 71.11 creating build/lib.linux-x86_64-3.7/horovod/spark/data_loaders
#22 71.11 copying horovod/spark/data_loaders/pytorch_data_loaders.py -> build/lib.linux-x86_64-3.7/horovod/spark/data_loaders
#22 71.11 copying horovod/spark/data_loaders/__init__.py -> build/lib.linux-x86_64-3.7/horovod/spark/data_loaders
#22 71.12 creating build/lib.linux-x86_64-3.7/horovod/spark/task
#22 71.12 copying horovod/spark/task/gloo_exec_fn.py -> build/lib.linux-x86_64-3.7/horovod/spark/task
#22 71.12 copying horovod/spark/task/__init__.py -> build/lib.linux-x86_64-3.7/horovod/spark/task
#22 71.12 copying horovod/spark/task/task_info.py -> build/lib.linux-x86_64-3.7/horovod/spark/task
#22 71.12 copying horovod/spark/task/task_service.py -> build/lib.linux-x86_64-3.7/horovod/spark/task
#22 71.12 copying horovod/spark/task/mpirun_exec_fn.py -> build/lib.linux-x86_64-3.7/horovod/spark/task
#22 71.12 creating build/lib.linux-x86_64-3.7/horovod/spark/driver
#22 71.12 copying horovod/spark/driver/driver_service.py -> build/lib.linux-x86_64-3.7/horovod/spark/driver
#22 71.12 copying horovod/spark/driver/host_discovery.py -> build/lib.linux-x86_64-3.7/horovod/spark/driver
#22 71.12 copying horovod/spark/driver/__init__.py -> build/lib.linux-x86_64-3.7/horovod/spark/driver
#22 71.12 copying horovod/spark/driver/rendezvous.py -> build/lib.linux-x86_64-3.7/horovod/spark/driver
#22 71.12 copying horovod/spark/driver/job_id.py -> build/lib.linux-x86_64-3.7/horovod/spark/driver
#22 71.12 copying horovod/spark/driver/mpirun_rsh.py -> build/lib.linux-x86_64-3.7/horovod/spark/driver
#22 71.12 copying horovod/spark/driver/rsh.py -> build/lib.linux-x86_64-3.7/horovod/spark/driver
#22 71.12 creating build/lib.linux-x86_64-3.7/horovod/spark/common
#22 71.12 copying horovod/spark/common/serialization.py -> build/lib.linux-x86_64-3.7/horovod/spark/common
#22 71.12 copying horovod/spark/common/cache.py -> build/lib.linux-x86_64-3.7/horovod/spark/common
#22 71.12 copying horovod/spark/common/backend.py -> build/lib.linux-x86_64-3.7/horovod/spark/common
#22 71.12 copying horovod/spark/common/_namedtuple_fix.py -> build/lib.linux-x86_64-3.7/horovod/spark/common
#22 71.12 copying horovod/spark/common/constants.py -> build/lib.linux-x86_64-3.7/horovod/spark/common
#22 71.12 copying horovod/spark/common/__init__.py -> build/lib.linux-x86_64-3.7/horovod/spark/common
#22 71.12 copying horovod/spark/common/util.py -> build/lib.linux-x86_64-3.7/horovod/spark/common
#22 71.12 copying horovod/spark/common/params.py -> build/lib.linux-x86_64-3.7/horovod/spark/common
#22 71.13 copying horovod/spark/common/store.py -> build/lib.linux-x86_64-3.7/horovod/spark/common
#22 71.13 copying horovod/spark/common/estimator.py -> build/lib.linux-x86_64-3.7/horovod/spark/common
#22 71.13 creating build/lib.linux-x86_64-3.7/horovod/spark/torch
#22 71.13 copying horovod/spark/torch/__init__.py -> build/lib.linux-x86_64-3.7/horovod/spark/torch
#22 71.13 copying horovod/spark/torch/remote.py -> build/lib.linux-x86_64-3.7/horovod/spark/torch
#22 71.13 copying horovod/spark/torch/util.py -> build/lib.linux-x86_64-3.7/horovod/spark/torch
#22 71.13 copying horovod/spark/torch/estimator.py -> build/lib.linux-x86_64-3.7/horovod/spark/torch
#22 71.13 creating build/lib.linux-x86_64-3.7/horovod/tensorflow/keras
#22 71.13 copying horovod/tensorflow/keras/elastic.py -> build/lib.linux-x86_64-3.7/horovod/tensorflow/keras
#22 71.13 copying horovod/tensorflow/keras/callbacks.py -> build/lib.linux-x86_64-3.7/horovod/tensorflow/keras
#22 71.13 copying horovod/tensorflow/keras/__init__.py -> build/lib.linux-x86_64-3.7/horovod/tensorflow/keras
#22 71.13 creating build/lib.linux-x86_64-3.7/horovod/runner/util
#22 71.13 copying horovod/runner/util/cache.py -> build/lib.linux-x86_64-3.7/horovod/runner/util
#22 71.13 copying horovod/runner/util/threads.py -> build/lib.linux-x86_64-3.7/horovod/runner/util
#22 71.13 copying horovod/runner/util/__init__.py -> build/lib.linux-x86_64-3.7/horovod/runner/util
#22 71.13 copying horovod/runner/util/lsf.py -> build/lib.linux-x86_64-3.7/horovod/runner/util
#22 71.13 copying horovod/runner/util/remote.py -> build/lib.linux-x86_64-3.7/horovod/runner/util
#22 71.13 copying horovod/runner/util/streams.py -> build/lib.linux-x86_64-3.7/horovod/runner/util
#22 71.13 copying horovod/runner/util/network.py -> build/lib.linux-x86_64-3.7/horovod/runner/util
#22 71.13 creating build/lib.linux-x86_64-3.7/horovod/runner/http
#22 71.13 copying horovod/runner/http/http_server.py -> build/lib.linux-x86_64-3.7/horovod/runner/http
#22 71.13 copying horovod/runner/http/__init__.py -> build/lib.linux-x86_64-3.7/horovod/runner/http
#22 71.13 copying horovod/runner/http/http_client.py -> build/lib.linux-x86_64-3.7/horovod/runner/http
#22 71.13 creating build/lib.linux-x86_64-3.7/horovod/runner/task
#22 71.13 copying horovod/runner/task/__init__.py -> build/lib.linux-x86_64-3.7/horovod/runner/task
#22 71.13 copying horovod/runner/task/task_service.py -> build/lib.linux-x86_64-3.7/horovod/runner/task
#22 71.13 creating build/lib.linux-x86_64-3.7/horovod/runner/driver
#22 71.13 copying horovod/runner/driver/driver_service.py -> build/lib.linux-x86_64-3.7/horovod/runner/driver
#22 71.13 copying horovod/runner/driver/__init__.py -> build/lib.linux-x86_64-3.7/horovod/runner/driver
#22 71.13 creating build/lib.linux-x86_64-3.7/horovod/runner/common
#22 71.13 copying horovod/runner/common/__init__.py -> build/lib.linux-x86_64-3.7/horovod/runner/common
#22 71.13 creating build/lib.linux-x86_64-3.7/horovod/runner/elastic
#22 71.14 copying horovod/runner/elastic/worker.py -> build/lib.linux-x86_64-3.7/horovod/runner/elastic
#22 71.14 copying horovod/runner/elastic/driver.py -> build/lib.linux-x86_64-3.7/horovod/runner/elastic
#22 71.14 copying horovod/runner/elastic/registration.py -> build/lib.linux-x86_64-3.7/horovod/runner/elastic
#22 71.14 copying horovod/runner/elastic/constants.py -> build/lib.linux-x86_64-3.7/horovod/runner/elastic
#22 71.14 copying horovod/runner/elastic/settings.py -> build/lib.linux-x86_64-3.7/horovod/runner/elastic
#22 71.14 copying horovod/runner/elastic/__init__.py -> build/lib.linux-x86_64-3.7/horovod/runner/elastic
#22 71.14 copying horovod/runner/elastic/rendezvous.py -> build/lib.linux-x86_64-3.7/horovod/runner/elastic
#22 71.14 copying horovod/runner/elastic/discovery.py -> build/lib.linux-x86_64-3.7/horovod/runner/elastic
#22 71.14 creating build/lib.linux-x86_64-3.7/horovod/runner/common/util
#22 71.14 copying horovod/runner/common/util/secret.py -> build/lib.linux-x86_64-3.7/horovod/runner/common/util
#22 71.14 copying horovod/runner/common/util/host_hash.py -> build/lib.linux-x86_64-3.7/horovod/runner/common/util
#22 71.14 copying horovod/runner/common/util/settings.py -> build/lib.linux-x86_64-3.7/horovod/runner/common/util
#22 71.14 copying horovod/runner/common/util/tiny_shell_exec.py -> build/lib.linux-x86_64-3.7/horovod/runner/common/util
#22 71.14 copying horovod/runner/common/util/__init__.py -> build/lib.linux-x86_64-3.7/horovod/runner/common/util
#22 71.14 copying horovod/runner/common/util/config_parser.py -> build/lib.linux-x86_64-3.7/horovod/runner/common/util
#22 71.14 copying horovod/runner/common/util/env.py -> build/lib.linux-x86_64-3.7/horovod/runner/common/util
#22 71.14 copying horovod/runner/common/util/hosts.py -> build/lib.linux-x86_64-3.7/horovod/runner/common/util
#22 71.14 copying horovod/runner/common/util/timeout.py -> build/lib.linux-x86_64-3.7/horovod/runner/common/util
#22 71.14 copying horovod/runner/common/util/network.py -> build/lib.linux-x86_64-3.7/horovod/runner/common/util
#22 71.14 copying horovod/runner/common/util/safe_shell_exec.py -> build/lib.linux-x86_64-3.7/horovod/runner/common/util
#22 71.14 copying horovod/runner/common/util/codec.py -> build/lib.linux-x86_64-3.7/horovod/runner/common/util
#22 71.14 creating build/lib.linux-x86_64-3.7/horovod/runner/common/service
#22 71.14 copying horovod/runner/common/service/driver_service.py -> build/lib.linux-x86_64-3.7/horovod/runner/common/service
#22 71.14 copying horovod/runner/common/service/__init__.py -> build/lib.linux-x86_64-3.7/horovod/runner/common/service
#22 71.14 copying horovod/runner/common/service/task_service.py -> build/lib.linux-x86_64-3.7/horovod/runner/common/service
#22 71.14 creating build/lib.linux-x86_64-3.7/horovod/torch/mpi_lib
#22 71.14 copying horovod/torch/mpi_lib/__init__.py -> build/lib.linux-x86_64-3.7/horovod/torch/mpi_lib
#22 71.14 creating build/lib.linux-x86_64-3.7/horovod/torch/mpi_lib_impl
#22 71.14 copying horovod/torch/mpi_lib_impl/__init__.py -> build/lib.linux-x86_64-3.7/horovod/torch/mpi_lib_impl
#22 71.14 creating build/lib.linux-x86_64-3.7/horovod/torch/elastic
#22 71.14 copying horovod/torch/elastic/state.py -> build/lib.linux-x86_64-3.7/horovod/torch/elastic
#22 71.14 copying horovod/torch/elastic/__init__.py -> build/lib.linux-x86_64-3.7/horovod/torch/elastic
#22 71.15 copying horovod/torch/elastic/sampler.py -> build/lib.linux-x86_64-3.7/horovod/torch/elastic
#22 71.15 running build_ext
#22 71.16 -- Could not find CCache. Consider installing CCache to speed up compilation.
#22 71.23 -- The CXX compiler identification is GNU 7.5.0
#22 71.24 -- Check for working CXX compiler: /usr/bin/c++
#22 71.34 -- Check for working CXX compiler: /usr/bin/c++ -- works
#22 71.34 -- Detecting CXX compiler ABI info
#22 71.43 -- Detecting CXX compiler ABI info - done
#22 71.45 -- Detecting CXX compile features
#22 71.91 -- Detecting CXX compile features - done
#22 71.92 -- Build architecture flags: -mf16c -mavx -mfma
#22 71.92 -- Using command /usr/bin/python
#22 72.31 -- Found MPI_CXX: /usr/local/lib/libmpi.so (found version "3.1")
#22 72.31 -- Found MPI: TRUE (found version "3.1")
#22 72.31 -- Could NOT find NVTX (missing: NVTX_INCLUDE_DIR)
#22 72.31 CMake Error at CMakeLists.txt:265 (add_subdirectory):
#22 72.31 add_subdirectory given source "third_party/gloo" which is not an existing
#22 72.31 directory.
#22 72.31
#22 72.31
#22 72.31 CMake Error at CMakeLists.txt:267 (target_compile_definitions):
#22 72.31 Cannot specify compile definitions for target "gloo" which is not built by
#22 72.32 this project.
#22 72.32
#22 72.32
#22 73.91 Tensorflow_LIBRARIES := -L/usr/local/lib/python3.7/dist-packages/tensorflow -l:libtensorflow_framework.so.2
#22 73.91 -- Found Tensorflow: -L/usr/local/lib/python3.7/dist-packages/tensorflow -l:libtensorflow_framework.so.2 (found suitable version "2.5.0", minimum required is "1.15.0")
#22 74.42 -- Found Pytorch: 1.8.1+cu102 (found suitable version "1.8.1+cu102", minimum required is "1.2.0")
#22 81.17 -- Found Mxnet: /usr/local/lib/python3.7/dist-packages/mxnet/libmxnet.so (found suitable version "1.8.0", minimum required is "1.4.0")
#22 82.47 CMake Error at CMakeLists.txt:327 (file):
#22 82.47 file COPY cannot find "/tmp/pip-req-build-s0z_ufky/third_party/gloo".
#22 82.47
#22 82.47
#22 82.47 CMake Error at CMakeLists.txt:331 (add_subdirectory):
#22 82.47 The source directory
#22 82.47
#22 82.47 /tmp/pip-req-build-s0z_ufky/third_party/compatible_gloo
#22 82.47
#22 82.47 does not contain a CMakeLists.txt file.
#22 82.47
#22 82.47
#22 82.47 CMake Error at CMakeLists.txt:332 (target_compile_definitions):
#22 82.47 Cannot specify compile definitions for target "compatible_gloo" which is
#22 82.47 not built by this project.
#22 82.47
#22 82.47
#22 82.47 CMake Error: The following variables are used in this project, but they are set to NOTFOUND.
#22 82.47 Please set them or make sure they are set and tested correctly in the CMake files:
#22 82.47 /tmp/pip-req-build-s0z_ufky/horovod/mxnet/TF_FLATBUFFERS_INCLUDE_PATH
#22 82.47 used as include directory in directory /tmp/pip-req-build-s0z_ufky/horovod/mxnet
#22 82.47 /tmp/pip-req-build-s0z_ufky/horovod/tensorflow/TF_FLATBUFFERS_INCLUDE_PATH
#22 82.47 used as include directory in directory /tmp/pip-req-build-s0z_ufky/horovod/tensorflow
#22 82.47 /tmp/pip-req-build-s0z_ufky/horovod/torch/TF_FLATBUFFERS_INCLUDE_PATH
#22 82.47 used as include directory in directory /tmp/pip-req-build-s0z_ufky/horovod/torch
#22 82.47
#22 82.47 -- Configuring incomplete, errors occurred!
#22 82.48 See also "/tmp/pip-req-build-s0z_ufky/build/temp.linux-x86_64-3.7/RelWithDebInfo/CMakeFiles/CMakeOutput.log".
#22 82.48 Traceback (most recent call last):
#22 82.48 File "<string>", line 1, in <module>
#22 82.48 File "/tmp/pip-req-build-s0z_ufky/setup.py", line 211, in <module>
#22 82.48 'horovodrun = horovod.runner.launch:run_commandline'
#22 82.48 File "/usr/local/lib/python3.7/dist-packages/setuptools/__init__.py", line 153, in setup
#22 82.48 return distutils.core.setup(**attrs)
#22 82.48 File "/usr/lib/python3.7/distutils/core.py", line 148, in setup
#22 82.48 dist.run_commands()
#22 82.48 File "/usr/lib/python3.7/distutils/dist.py", line 966, in run_commands
#22 82.48 self.run_command(cmd)
#22 82.48 File "/usr/lib/python3.7/distutils/dist.py", line 985, in run_command
#22 82.49 cmd_obj.run()
#22 82.49 File "/usr/local/lib/python3.7/dist-packages/setuptools/command/install.py", line 68, in run
#22 82.49 return orig.install.run(self)
#22 82.49 File "/usr/lib/python3.7/distutils/command/install.py", line 589, in run
#22 82.49 self.run_command('build')
#22 82.49 File "/usr/lib/python3.7/distutils/cmd.py", line 313, in run_command
#22 82.49 self.distribution.run_command(command)
#22 82.49 File "/usr/lib/python3.7/distutils/dist.py", line 985, in run_command
#22 82.49 cmd_obj.run()
#22 82.49 File "/usr/lib/python3.7/distutils/command/build.py", line 135, in run
#22 82.49 self.run_command(cmd_name)
#22 82.49 File "/usr/lib/python3.7/distutils/cmd.py", line 313, in run_command
#22 82.49 self.distribution.run_command(command)
#22 82.49 File "/usr/lib/python3.7/distutils/dist.py", line 985, in run_command
#22 82.49 cmd_obj.run()
#22 82.49 File "/usr/local/lib/python3.7/dist-packages/setuptools/command/build_ext.py", line 79, in run
#22 82.49 _build_ext.run(self)
#22 82.49 File "/usr/lib/python3.7/distutils/command/build_ext.py", line 340, in run
#22 82.49 self.build_extensions()
#22 82.49 File "/tmp/pip-req-build-s0z_ufky/setup.py", line 99, in build_extensions
#22 82.50 cwd=cmake_build_dir)
#22 82.50 File "/usr/lib/python3.7/subprocess.py", line 363, in check_call
#22 82.50 raise CalledProcessError(retcode, cmd)
#22 82.50 subprocess.CalledProcessError: Command '['cmake', '/tmp/pip-req-build-s0z_ufky', '-DCMAKE_BUILD_TYPE=RelWithDebInfo', '-DCMAKE_LIBRARY_OUTPUT_DIRECTORY_RELWITHDEBINFO=/tmp/pip-req-build-s0z_ufky/build/lib.linux-x86_64-3.7', '-DPYTHON_EXECUTABLE:FILEPATH=/usr/bin/python']' returned non-zero exit status 1.
#22 82.52 Running setup.py install for horovod: finished with status 'error'
#22 82.52 ERROR: Command errored out with exit status 1: /usr/bin/python -u -c 'import io, os, sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-req-build-s0z_ufky/setup.py'"'"'; __file__='"'"'/tmp/pip-req-build-s0z_ufky/setup.py'"'"';f = getattr(tokenize, '"'"'open'"'"', open)(__file__) if os.path.exists(__file__) else io.StringIO('"'"'from setuptools import setup; setup()'"'"');code = f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /tmp/pip-record-2urw0_at/install-record.txt --single-version-externally-managed --compile --install-headers /usr/local/include/python3.7/horovod Check the logs for full command output.
------
executor failed running [/bin/bash -cu python setup.py sdist && bash -c "HOROVOD_WITH_TENSORFLOW=1 HOROVOD_WITH_PYTORCH=1 HOROVOD_WITH_MXNET=1 pip install --no-cache-dir -v $(ls /horovod/dist/horovod-*.tar.gz)[spark,ray]" && horovodrun --check-build]: exit code: 1
```
Thank you.
|
closed
|
2021-11-30T00:24:39Z
|
2021-11-30T17:42:08Z
|
https://github.com/horovod/horovod/issues/3294
|
[
"question"
] |
jizezhang
| 2 |
Nemo2011/bilibili-api
|
api
| 814 |
[提问] {获取弹幕的时候,现在报错KeyError: 'total'}
|
**Python 版本:** 3.12
**模块版本:** x.y.z
**运行环境:** Linux
这个还在维护嘛
---------------------------------------------------------------------------
# 这是我的代码
# 获取rank排行 实时查询查询在线观看人数 收集弹幕
import asyncio
from bilibili_api import video
# 实例化
v = video.Video(bvid="BV15EtgeUEaD")
# 获取在线人数
print(sync(v.get_online()))
print(sync(v.get_danmakus())) #此处会报错
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[43], line 10
7 # 获取在线人数
8 print(sync(v.get_online()))
---> 10 print(sync(v.get_danmakus()))
File ~/anaconda3/lib/python3.12/site-packages/bilibili_api/utils/sync.py:33, in sync(coroutine)
31 __ensure_event_loop()
32 loop = asyncio.get_event_loop()
---> 33 return loop.run_until_complete(coroutine)
File ~/anaconda3/lib/python3.12/site-packages/nest_asyncio.py:98, in _patch_loop.<locals>.run_until_complete(self, future)
95 if not f.done():
96 raise RuntimeError(
97 'Event loop stopped before Future completed.')
---> 98 return f.result()
File ~/anaconda3/lib/python3.12/asyncio/futures.py:203, in Future.result(self)
201 self.__log_traceback = False
202 if self._exception is not None:
--> 203 raise self._exception.with_traceback(self._exception_tb)
204 return self._result
File ~/anaconda3/lib/python3.12/asyncio/tasks.py:314, in Task.__step_run_and_handle_result(***failed resolving arguments***)
310 try:
311 if exc is None:
312 # We use the `send` method directly, because coroutines
313 # don't have `__iter__` and `__next__` methods.
--> 314 result = coro.send(None)
315 else:
316 result = coro.throw(exc)
File ~/anaconda3/lib/python3.12/site-packages/bilibili_api/video.py:883, in Video.get_danmakus(self, page_index, date, cid, from_seg, to_seg)
881 if to_seg == None:
882 view = await self.get_danmaku_view(cid=cid)
--> 883 to_seg = view["dm_seg"]["total"] - 1
885 danmakus = []
887 for seg in range(from_seg, to_seg + 1):
KeyError: 'total'
Selection deleted
|
open
|
2024-09-18T07:42:27Z
|
2024-10-29T10:37:31Z
|
https://github.com/Nemo2011/bilibili-api/issues/814
|
[
"question"
] |
Sukang1002
| 1 |
pallets-eco/flask-sqlalchemy
|
sqlalchemy
| 918 |
RuntimeError During Pytest Collection Because no App Context is Set Up Yet
|
## Current Behavior
My application uses the factory method for setting up the application, so I use a pattern similar to the following:
```python
# ./api/__init__.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
def create_app():
app = Flask(__name__)
db.init_app(app)
```
When collecting tests, pytest imports the test files as defined by in the pytest settings (in my case, the `pytest.ini` specifies that all `test_*` files in the directory `./tests` are collected). During the collection, the test files are imported before any of the fixtures are set up. I have a file which defines a model which is subclassed from `api.db.Model`. My test makes use of this model by using sqlalchemy to scan the database to evaluate the precondition. Something like this:
```python
from api.models import User
def it_creates_a_user(self, session):
# GIVEN there is no existing user
assert session.query(User).count() == 0
```
So when this file is imported, the `api.models.__init__.py` file is imported which, in turn, imports `api.models.user.User` which has a definition similar to the following:
```python
from api import db
class User(db.Model):
# columns
```
Again, when this import happens, pytest has not yet created the app fixture where I push the app_context, which means flask_sqlalchemy does not know which app the db is bound to and so it raises a `RuntimeError`:
```
RuntimeError: No application found. Either work inside a view function or push an application context. See http://flask-sqlalchemy.pocoo.org/contexts/.
```
This perplexed me greatly at first since I definitely am pushing an application context in my app fixture:
```python
@pytest.fixture(scope="session", autouse=True)
def app():
logger.info("Creating test application")
test_app = create_app()
with test_app.app_context():
yield test_app
```
It wasn't until I thought to run `pytest --continue-on-collection-errors` that I found that the tests all run and pass just fine after the RuntimeError is raised during the collection phase. It was then that it dawned on me what the cause of the issue was. I have worked around this issue by pushing the context in my `tests/__init__.py` file:
```python
# ./tests/__init__.py
from api import create_app
"""
This is a workaround for pytest collection of flask-sqlalchemy models.
When running tests, the first thing that pytest does is to collect the
tests by importing all the test files. If a test file imports a model,
as they will surely do, then the model tries to use the api.db before
the app has been created. Doing this makes flask-sqlalchemy raise a
RuntimeError saying that there is no application found. The following
code only exists to set the app context during test import to avoid
this RuntimeError. The tests will us the app fixture which sets up the
context and so this has no effect on the tests when they are run.
"""
app = create_app()
app.app_context().push()
```
This feels a little dirty and I'm hopeful that there is a way for this issue to be solved.
### Relevant Code
```toml
# pyproject.toml
# Unrelated items
[tool.pytest.ini_options]
minversion = "6.0"
log_auto_indent = true
log_cli = true
log_cli_format = "%(levelname)-5.5s [%(name)s] %(message)s"
testpaths = ["tests"]
python_functions = ["test_*", "it_*"]
```
```python
# api/__init__.py
import os
import shlex
import subprocess
from dotenv import load_dotenv
from flask import Flask
from flask_marshmallow import Marshmallow
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
ma = Marshmallow()
def create_app(test_config=None):
app = Flask(__name__, instance_relative_config=True)
if test_config is None:
app.config.from_object(os.getenv("APP_SETTINGS"))
else:
app.config.from_mapping(test_config)
db.init_app(app)
ma.init_app(app)
# a simple page that says hello
@app.route("/health-check")
def health_check(): # pragma: no cover
cmd = "git describe --always"
current_rev = subprocess.check_output(shlex.split(cmd)).strip()
return current_rev
return app
```
```python
# ./app/models/__init__.py
from .user import User
```
```python
# ./api/models/user.py
from uuid import uuid4
from sqlalchemy_utils import EmailType, UUIDType
from api import db
class User(db.Model):
id = db.Column(UUIDType, primary_key=True, default=uuid4)
email = db.Column(EmailType, nullable=False)
def __repr__(self):
return f"<User: {self.email}>"
```
```python
# ./tests/unit/models/test_user.py
import logging
import pytest
import sqlalchemy
from api.models import User # pytest imports this line before it sets up any fixtures
logger = logging.getLogger(__name__)
class TestUserModel:
class TestNormalCase:
def it_creates_a_user(self, session):
# GIVEN No user exists in our database
assert session.query(User).count() == 0
# WHEN we add a new user
test_user = User(email="test@testing.com")
session.add(test_user)
session.commit()
# THEN the user is persisted in the database
actual_user = session.query(User).get(test_user.id)
assert actual_user == test_user
assert repr(actual_user) == f"<User: {test_user.email}>"
class TestErrorCase:
def it_requires_a_user_email(self, session):
with pytest.raises(sqlalchemy.exc.IntegrityError):
test_user = User()
session.add(test_user)
session.commit()
```
```python
# ./tests/conftest.py
# other stuff here, just showing that I am using the context in my app fixture
@pytest.fixture(scope="session", autouse=True)
def app():
logger.info("Creating test application")
test_app = create_app()
with test_app.app_context():
yield test_app
```
Environment:
- Python version: `3.9.1`
- Flask-SQLAlchemy version: `2.4.4`
- SQLAlchemy version: `1.3.23`
|
closed
|
2021-02-23T03:05:53Z
|
2021-03-10T00:34:05Z
|
https://github.com/pallets-eco/flask-sqlalchemy/issues/918
|
[] |
mikelane
| 1 |
nonebot/nonebot2
|
fastapi
| 2,674 |
Plugin: 三爻易数
|
### PyPI 项目名
nonebot-plugin-sanyao
### 插件 import 包名
nonebot_plugin_sanyao
### 标签
[{"label":"占卜","color":"#415656"}]
### 插件配置项
_No response_
|
closed
|
2024-04-21T16:37:31Z
|
2024-04-23T04:36:38Z
|
https://github.com/nonebot/nonebot2/issues/2674
|
[
"Plugin"
] |
afterow
| 7 |
microsoft/nni
|
tensorflow
| 4,803 |
Error: PolicyBasedRL
|
**Describe the issue**:
I tried running the the following models space with PolicyBasedRL and I will also put in the experiment configuration:
#BASELINE NAS USING v2.7
from nni.retiarii.serializer import model_wrapper
import torch.nn.functional as F
import nni.retiarii.nn.pytorch as nn
class Block1(nn.Module):
def __init__(self, layer_size):
super().__init__()
self.conv1 = nn.Conv2d(3, layer_size*2, 3, stride=1,padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(layer_size*2, layer_size*8, 3, stride=1, padding=1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(x)
x = F.relu(self.conv2(x))
x = self.pool(x)
return x
class Block2(nn.Module):
def __init__(self, layer_size):
super().__init__()
self.conv1 = nn.Conv2d(3, layer_size, 3, stride=1,padding=1)
self.conv2 = nn.Conv2d(layer_size, layer_size*2, 3, stride=1,padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv3 = nn.Conv2d(layer_size*2, layer_size*8, 3, stride=1,padding=1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = self.pool(x)
x = F.relu(self.conv3(x))
x = self.pool(x)
return x
class Block3(nn.Module):
def __init__(self, layer_size):
super().__init__()
self.conv1 = nn.Conv2d(3, layer_size, 3, stride=1,padding=1)
self.conv2 = nn.Conv2d(layer_size, layer_size*2, 3, stride=1,padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv3 = nn.Conv2d(layer_size*2, layer_size*4, 3, stride=1,padding=1)
self.conv4 = nn.Conv2d(layer_size*4, layer_size*8, 3, stride=1, padding=1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = self.pool(x)
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = self.pool(x)
return x
@model_wrapper
class Net(nn.Module):
def __init__(self):
super().__init__()
rand_var = nn.ValueChoice([32,64])
self.conv1 = nn.LayerChoice([Block1(rand_var),Block2(rand_var),Block3(rand_var)])
self.conv2 = nn.Conv2d(rand_var*8,rand_var*16 , 3, stride=1, padding=1)
self.fc1 = nn.Linear(rand_var*16*8*8, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(self.conv2(x))
x = x.reshape(x.shape[0],-1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
model = Net()
from nni.retiarii.experiment.pytorch import RetiariiExeConfig, RetiariiExperiment
exp = RetiariiExperiment(model, trainer, [], RL_strategy)
exp_config = RetiariiExeConfig('local')
exp_config.experiment_name = '5%_RL_10_epochs_64_batch'
exp_config.trial_concurrency = 2
exp_config.max_trial_number = 100
#exp_config.trial_gpu_number = 2
exp_config.max_experiment_duration = '660m'
exp_config.execution_engine = 'base'
exp_config.training_service.use_active_gpu = False
--> This led to the following error:
[2022-04-24 23:49:22] ERROR (nni.runtime.msg_dispatcher_base/Thread-5) 3
Traceback (most recent call last):
File "/Users/sh/opt/anaconda3/lib/python3.7/site-packages/nni/runtime/msg_dispatcher_base.py", line 88, in command_queue_worker
self.process_command(command, data)
File "/Users/sh/opt/anaconda3/lib/python3.7/site-packages/nni/runtime/msg_dispatcher_base.py", line 147, in process_command
command_handlers[command](data)
File "/Users/sh/opt/anaconda3/lib/python3.7/site-packages/nni/retiarii/integration.py", line 170, in handle_report_metric_data
self._process_value(data['value']))
File "/Users/sh/opt/anaconda3/lib/python3.7/site-packages/nni/retiarii/execution/base.py", line 111, in _intermediate_metric_callback
model = self._running_models[trial_id]
KeyError: 3
What does this error mean/ why does it occur/ how can I fix it?
Thanks for your help!
**Environment**:
- NNI version:
- Training service (local|remote|pai|aml|etc):
- Client OS:
- Server OS (for remote mode only):
- Python version:
- PyTorch/TensorFlow version:
- Is conda/virtualenv/venv used?:
- Is running in Docker?:
**Configuration**:
- Experiment config (remember to remove secrets!):
- Search space:
**Log message**:
- nnimanager.log:
- dispatcher.log:
- nnictl stdout and stderr:
<!--
Where can you find the log files:
LOG: https://github.com/microsoft/nni/blob/master/docs/en_US/Tutorial/HowToDebug.md#experiment-root-director
STDOUT/STDERR: https://github.com/microsoft/nni/blob/master/docs/en_US/Tutorial/Nnictl.md#nnictl%20log%20stdout
-->
**How to reproduce it?**:
|
open
|
2022-04-25T09:36:27Z
|
2023-04-25T13:28:22Z
|
https://github.com/microsoft/nni/issues/4803
|
[] |
NotSure2732
| 2 |
benbusby/whoogle-search
|
flask
| 877 |
[BUG] Whoogle personal cloud docker instance suddenly showing arabic and right to left layout
|
I setup an instance of whoogle on a ubuntu oracle cloud server last week. I used docker to get the latest version of whoogle and have been using it on my fedora laptop and my Pixel 6 phone. It's been working fine and the results have always been in English with the interface showing English too. Unfortunately about 1 or 2 hours ago I noticed I was getting search results in English but with the display showing right to left and the interface language showing in Arabic This happened on both my laptop and my phone. I actually thought someone had hacked my instance so deleted the docker instance and tried again but am still getting the issue.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to 'my whoogle instance url' - I don't want to share the url as I want to keep it personal
2. Click on 'search box and enter search term then return'
3. See error = search results shown in English with right to left formatting and the interface (like NEXT) showing in Arabic
**Deployment Method**
- [ ] Heroku (one-click deploy)
- [x] Docker
- [ ] `run` executable
- [ ] pip/pipx
- [ ] Other: [describe setup]
**Version of Whoogle Search**
- [x] Latest build from [source] (i.e. GitHub, Docker Hub, pip, etc)
- [ ] Version [version number]
- [ ] Not sure
**Desktop (please complete the following information):**
- OS: [e.g. iOS] Fedora Silverblue on laptop and
- Browser [e.g. chrome, safari] Firefox
- Version [e.g. 22] 105.1
**Smartphone (please complete the following information):**
- Device: [e.g. iPhone6] Pixel 6
- OS: [e.g. iOS8.1] Android 13
- Browser [e.g. stock browser, safari] Bromite
- Version [e.g. 22] 106
**Additional context**
I tired setting the additional env variables for language and I seem to have fixed the mobile version with these additional settings but the desktop version is still showing the issues.
added env:
-e WHOOGLE_CONFIG_LANGUAGE=lang_en \
-e WHOOGLE_CONFIG_SEARCH_LANGUAGE=lang_en \
docker command:
docker run --restart=always --publish 5000:5000 --detach --name whoogle-search \
-e WHOOGLE_CONFIG_URL=https://xxx.xxx.xx\
-e WHOOGLE_CONFIG_THEME=system \
-e WHOOGLE_CONFIG_DISABLE=1\
-e WHOOGLE_CONFIG_ALTS=1 \
-e WHOOGLE_ALT_TW=xxx.xxx.xxx \
-e WHOOGLE_ALT_YT=xxx.xxx.xxx \
-e WHOOGLE_ALT_RD=xxx.xxx.xxx \
-e WHOOGLE_ALT_TL=xxx.xxx.xxx\
-e WHOOGLE_ALT_WIKI=xxx.xxx.xxx \
-e WHOOGLE_CONFIG_NEW_TAB=1 \
-e WHOOGLE_RESULTS_PER_PAGE=30 \
-e WHOOGLE_CONFIG_GET_ONLY=1 \
-e WHOOGLE_CONFIG_LANGUAGE=lang_en \
-e WHOOGLE_CONFIG_SEARCH_LANGUAGE=lang_en \
benbusby/whoogle-search:latest
Happy to share my personal URL with support for help with troubleshooting. I just don't want to post it publicly.
|
closed
|
2022-11-03T15:10:34Z
|
2022-12-05T20:38:11Z
|
https://github.com/benbusby/whoogle-search/issues/877
|
[
"bug"
] |
Rochey
| 3 |
ultralytics/ultralytics
|
pytorch
| 19,640 |
I try use one backbone and neck to achieve a multitask model (include pose and seg)
|
### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
I have already reviewed the related topics in the issue and Repositories .
**Such as:**
https://github.com/ultralytics/ultralytics/issues/6949
https://github.com/ultralytics/ultralytics/pull/5219
https://github.com/ultralytics/ultralytics/issues/5073
https://github.com/yermandy/ultralytics/tree/multi-task-model
https://github.com/stedavkle/ultralytics/tree/multitask
https://github.com/JiayuanWang-JW/YOLOv8-multi-task
My `PoSeg` Repositories base on https://github.com/stedavkle/ultralytics/tree/multitask **(Thank stedavkle)**
Now My model has some error:
During the training process, the accuracy for both keypoints and segmentation masks is 0, as follows:
``` shell
Epoch GPU_mem box_loss pose_loss seg_loss kobj_loss cls_loss dfl_loss Instances Size
19/20 0G 3.686 9.066 5.869 4.282 1.412 0.7072 55 640: 100%|██████████| 2/2 [00:04<00:00, 2.05s/it]
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:00<00:00, 3.59it/s]
all 4 15 0 0 0 0 0 0 0 0 0 0 0 0
Epoch GPU_mem box_loss pose_loss seg_loss kobj_loss cls_loss dfl_loss Instances Size
20/20 0G 3.689 10.34 5.701 4.333 1.571 0.7128 83 640: 100%|██████████| 2/2 [00:04<00:00, 2.12s/it]
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:00<00:00, 3.54it/s]
all 4 15 0 0 0 0 0 0 0 0 0 0 0 0
```
I am not sure which part has gone wrong, leading to the inference accuracy being 0 for all parts
My yolo-poSeg address : https://github.com/Mosazh/yolo-poSeg
### Additional
_No response_
|
open
|
2025-03-11T09:47:40Z
|
2025-03-17T23:23:41Z
|
https://github.com/ultralytics/ultralytics/issues/19640
|
[
"question",
"segment",
"pose"
] |
Mosazh
| 10 |
GibbsConsulting/django-plotly-dash
|
plotly
| 241 |
Bad dependencies in v1.3.0
|
The packaged v1.3.0 has a dependency of >=2, < 3 for Django version.
This should be relaxed to be >=2 in `setup.py` to match `requirements.txt`
In addition, whilst it requires Dash < 1.11 it doesn't constrain dash-core-components (1.9.0) or dash-renderer (1.3.0) which also leads to errors on installation.
|
closed
|
2020-04-16T21:35:03Z
|
2020-04-17T03:57:51Z
|
https://github.com/GibbsConsulting/django-plotly-dash/issues/241
|
[
"bug"
] |
GibbsConsulting
| 1 |
deeppavlov/DeepPavlov
|
nlp
| 1,122 |
building go-bot in russian
|
Good day!
I want to build a go-bot using DeepPavlov in russian language (on example of this [notebook](https://colab.research.google.com/github/deepmipt/DeepPavlov/blob/master/examples/gobot_extended_tutorial.ipynb)).
I created dataset by DSTC2 format. Now i want add NER training in go bot config pipline. Because my dataset includes **_names_** and **_phones_**. All possible variants i **can't** include in slot_vals.json
It is possible to implement on DeepPavlov?
|
closed
|
2020-01-23T12:43:24Z
|
2020-05-21T10:04:10Z
|
https://github.com/deeppavlov/DeepPavlov/issues/1122
|
[] |
Grossmend
| 1 |
graphdeco-inria/gaussian-splatting
|
computer-vision
| 943 |
jlvbl
|
closed
|
2024-08-22T19:42:26Z
|
2024-08-22T19:42:35Z
|
https://github.com/graphdeco-inria/gaussian-splatting/issues/943
|
[] |
jb-ye
| 0 |
|
junyanz/pytorch-CycleGAN-and-pix2pix
|
computer-vision
| 706 |
Training with various input sizes?
|
I have various photographs of different sizes that I am trying to train and I keep getting errors similar to `RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 1. Got 16 and 17 in dimension 3`
I've tried setting `--preprocess` to either `none` or `scale_width` and I have tried setting the `batch_size` to 1. Is it possible to input images of different rectangular sizes for training and testing?
|
open
|
2019-07-16T23:40:27Z
|
2019-07-17T18:50:16Z
|
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/706
|
[] |
0003mg
| 1 |
litestar-org/polyfactory
|
pydantic
| 115 |
Factories cannot randomly generate missing parameters for child factories if all params passed on higher level
|
When at least one field doesn't passed in nested objects all child objects created right way:
```python
from pydantic_factories import ModelFactory
from pydantic import BaseModel
class A(BaseModel):
name: str
age: int
class B(BaseModel):
a: A
name: str # THIS LINE DIFFERENT TO NEXT EXAMPLE
class C(BaseModel):
b: B
name: str
class CFactory(ModelFactory):
__model__ = C
CFactory.build(**{'b': {'a': {'name': 'test'}}})
# C(b=B(a=A(name='test', age=8345), name='dLiQxkFuLvlMINwbCkbp'), name='uWGxEDUWlAejTgMePGXZ')
```
However if we pass all fields in nested objects then nested objects creation ignored:
```python
from pydantic_factories import ModelFactory
from pydantic import BaseModel
class A(BaseModel):
name: str
age: int
class B(BaseModel):
a: A
# name: str # THIS LINE DIFFERENT TO PREV EXAMPLE
class C(BaseModel):
b: B
name: str
class CFactory(ModelFactory):
__model__ = C
CFactory.build(**{'b': {'a': {'name': 'test'}}})
```
```
---------------------------------------------------------------------------
ValidationError Traceback (most recent call last)
Cell In [19], line 1
----> 1 CFactory.build(**{'b': {'a': {'name': 'test'}}})
File ./venv/lib/python3.10/site-packages/pydantic_factories/factory.py:724, in ModelFactory.build(cls, factory_use_construct, **kwargs)
721 return cast("T", cls.__model__.construct(**kwargs))
722 raise ConfigurationError("factory_use_construct requires a pydantic model as the factory's __model__")
--> 724 return cast("T", cls.__model__(**kwargs))
File ./venv/lib/python3.10/site-packages/pydantic/main.py:342, in BaseModel.__init__(__pydantic_self__, **data)
340 values, fields_set, validation_error = validate_model(__pydantic_self__.__class__, data)
341 if validation_error:
--> 342 raise validation_error
343 try:
344 object_setattr(__pydantic_self__, '__dict__', values)
ValidationError: 1 validation error for C
b -> a -> age
field required (type=value_error.missing)
```
that explained by next logic https://github.com/starlite-api/pydantic-factories/blob/main/pydantic_factories/factory.py#L200
expected that child objects created in both cases
|
closed
|
2022-11-07T22:06:41Z
|
2022-11-21T14:29:21Z
|
https://github.com/litestar-org/polyfactory/issues/115
|
[
"bug"
] |
tbicr
| 2 |
xinntao/Real-ESRGAN
|
pytorch
| 122 |
Strange margin in the Mesh-ish material.
|


Using realesrgan-x4plus-anime. The slice of the input and outpt is above.
|
open
|
2021-10-11T14:11:58Z
|
2022-01-25T16:07:54Z
|
https://github.com/xinntao/Real-ESRGAN/issues/122
|
[
"hard-samples reported"
] |
ChiseHatori
| 2 |
wkentaro/labelme
|
computer-vision
| 750 |
[Feature] Add Key-value attributes/properties
|
**Is your feature request related to a problem? Please describe.**
For a data set which is going to be used for instance segmentation, I want to add for each annotation certain properties with non-discrete values. For example I have dataset of objects and I want to add a mass attribute and add a ground-truth mass (which is a floating number) to the annotated object. In this case the current labelflags doesn't suffice in this case.
**Describe the solution you'd like**
Each time you have to choose a label for the annotation, you also have the option to select a certain attribute, and for a selected attribute you have to fill in a number, string or whatever.
|
closed
|
2020-08-12T17:50:51Z
|
2022-06-25T04:57:52Z
|
https://github.com/wkentaro/labelme/issues/750
|
[] |
MennoK
| 1 |
Evil0ctal/Douyin_TikTok_Download_API
|
fastapi
| 540 |
[BUG] 抖音-获取指定视频的评论回复数据 返回400
|
大佬你好, 拉去项目后,测试 抖音-获取指定视频的评论回复数据 返回400
之后仔细查看文档,并在你的在线接口测试同样也返回400
https://douyin.wtf/docs#/Douyin-Web-API/fetch_video_comments_reply_api_douyin_web_fetch_video_comment_replies_get

|
closed
|
2025-01-17T09:47:12Z
|
2025-02-14T09:04:35Z
|
https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/540
|
[
"BUG"
] |
yumingzhu
| 4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.