
repo_name
stringlengths 9
75
| topic
stringclasses 30
values | issue_number
int64 1
203k
| title
stringlengths 1
976
| body
stringlengths 0
254k
| state
stringclasses 2
values | created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| url
stringlengths 38
105
| labels
sequencelengths 0
9
| user_login
stringlengths 1
39
| comments_count
int64 0
452
|
|---|---|---|---|---|---|---|---|---|---|---|---|
google-research/bert | nlp | 566 | What is BERT? | Hello,
I am hearing a lot that I should use BERT for applications instead of word embeddings, but I am not understanding what BERT is? Maybe becuase I do not know transformer.
Could anyone explain, what is BERT? How does it differ from word2vec, Glove and more importantly elmo.
How does bert differ from openai-gpt?
How can I adapt bert to a question-answering model or any classification task?
Any help is highly appreciated.
Thank you.
| open | 2019-04-09T00:39:53Z | 2019-04-09T10:10:11Z | https://github.com/google-research/bert/issues/566 | [] | ghost | 2 |
joke2k/django-environ | django | 17 | environ should be able to infer casting type from the default | If you have `DEBUG = env('DEBUG', default=False)`, having to also specify `env = environ.Env(DEBUG=(bool, False),)` seems redundant. For example, see http://tornado.readthedocs.org/en/latest/options.html#tornado.options.OptionParser.define
> If type is given (one of str, float, int, datetime, or timedelta) or can be inferred from the default, we parse the command line arguments based on the given type.
| closed | 2014-11-22T00:28:20Z | 2018-06-26T20:57:54Z | https://github.com/joke2k/django-environ/issues/17 | [
"enhancement"
] | crccheck | 1 |
3b1b/manim | python | 1,800 | Fullscreen mode leaves out a fully transparent bar at the bottom in Windows 10 | ### Describe the bug
When I use fullscreen mode with manimGL v1.6.1 on Windows 10 there is an empty bar at the bottom of the screen through which I can see whatever is behind the python fullscreen drawing area (i.e. it's not actually fullscreen). That is, if I have a browser open I can see the browser through the bottom bar, or if I have only the desktop, I can see it.
**Code**:
Any example in fullscreen, e.g. from the example_scenes.py.
**Wrong display or Error traceback**:
<!-- the wrong display result of the code you run, or the error Traceback -->
### Additional context
### Environment
**OS System**: Windows 10
**manim version**: master MagnimGL v1.6.1
**python version**: Python 3.9.6
| open | 2022-04-23T20:28:03Z | 2022-08-04T05:22:55Z | https://github.com/3b1b/manim/issues/1800 | [
"bug"
] | vchizhov | 3 |
amidaware/tacticalrmm | django | 1,538 | "Install software" is missing a package that appears at chocolatey.org | **Server Info (please complete the following information):**
- OS: Ubuntu 20.04
- Browser: firefox
- RMM Version (as shown in top left of web UI): v0.15.12
**Installation Method:**
- [X ] Standard
- [ ] Docker
**Agent Info (please complete the following information):**
- Agent version (as shown in the 'Summary' tab of the agent from web UI): Agent v2.4.9
- Agent OS: Win 10/11
**Describe the bug**
A package that appears on https://chocolatey.org/ is not available to install
**To Reproduce**
Steps to reproduce the behavior:
1. Go to software
2. Click on install
3. Search for remarkable
**Expected behavior**
I'd expect to see https://community.chocolatey.org/packages/remarkable
**Screenshots**

This package has only been on choco since Thursday, May 25, 2023 - do I need to refresh the choco package list somehow? | closed | 2023-06-14T12:02:59Z | 2023-12-20T05:02:24Z | https://github.com/amidaware/tacticalrmm/issues/1538 | [
"bug",
"enhancement"
] | moose999 | 12 |
2noise/ChatTTS | python | 400 | 参考 Readme 生成的是电流声 | commit id: e58fe48d2ee99310ce2066005c5108ac86942ad4
步骤
```
git clone https://github.com/2noise/ChatTTS
cd ChatTTS
conda create -n chattts
conda activate chattts
pip install -r requirements.txt
python examples/cmd/run.py "chat T T S is a text to speech model designed for dialogue applications."
```
生成的 `output_audio_0.wav`如下:
[output_audio_0.zip](https://github.com/user-attachments/files/15934697/output_audio_0.zip)
| open | 2024-06-22T01:31:49Z | 2024-06-22T05:28:08Z | https://github.com/2noise/ChatTTS/issues/400 | [
"bug",
"help wanted",
"question"
] | BUG1989 | 2 |
lanpa/tensorboardX | numpy | 392 | ImportError: cannot import name 'summary' | (n2n) [410@mu01 noise2noise-master]$ python config.py validate --dataset-dir=datasets/kodak --network-snapshot=results/network_final-gaussian-n2c.pickle
Traceback (most recent call last):
File "config.py", line 14, in <module>
import validation
File "/home/410/ysn/noise2noise-master/validation.py", line 16, in <module>
import dnnlib.tflib.tfutil as tfutil
File "/home/410/ysn/noise2noise-master/dnnlib/tflib/__init__.py", line 8, in <module>
from . import autosummary
File "/home/410/ysn/noise2noise-master/dnnlib/tflib/autosummary.py", line 28, in <module>
from tensorboard import summary as summary_lib
ImportError: cannot import name 'summary'
| closed | 2019-03-22T13:30:41Z | 2019-05-19T13:46:58Z | https://github.com/lanpa/tensorboardX/issues/392 | [] | YangSN0719 | 1 |
piskvorky/gensim | machine-learning | 2,758 | How to use LdaModel with Callback | <!--
**IMPORTANT**:
- Use the [Gensim mailing list](https://groups.google.com/forum/#!forum/gensim) to ask general or usage questions. Github issues are only for bug reports.
- Check [Recipes&FAQ](https://github.com/RaRe-Technologies/gensim/wiki/Recipes-&-FAQ) first for common answers.
Github bug reports that do not include relevant information and context will be closed without an answer. Thanks!
-->
#### Problem description
I wonder if I can implement early stopping while training LdaModel using Callbacks and throwing exception.
But when I try to use Callback class gensim throws an error about `logger` attribute. If I add `logger` it then requires `get_value` method, i.e. it treats Callback like it's a Metric class. So how do you use it correctly?
#### Steps/code/corpus to reproduce
```
from gensim import corpora, models
from gensim.models.callbacks import Callback
texts = [['Lorem ipsum dolor sit amet, consectetur adipiscing elit'],['sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ']]
bigram = models.Phrases(texts, min_count=5, threshold=100)
trigram = models.Phrases(bigram[texts], threshold=100)
bigram_mod = models.phrases.Phraser(bigram)
trigram_mod = models.phrases.Phraser(trigram)
dictionary = corpora.Dictionary(trigram_mod[bigram_mod[texts]])
corpus = [dictionary.doc2bow(text) for text in texts]
callback = Callback(metrics=['DiffMetric'])
lda_model = models.LdaModel(
corpus, num_topics=3, id2word=dictionary, callbacks=[callback] )
```
> ---------------------------------------------------------------------------
> AttributeError Traceback (most recent call last)
> <ipython-input-2-67d9133f842a> in <module>
> 13
> 14 lda_model = models.LdaModel(
> ---> 15 corpus, num_topics=3, id2word=dictionary, callbacks=[callback] )
>
> ~\Anaconda3\lib\site-packages\gensim\models\ldamodel.py in __init__(self, corpus, num_topics, id2word, distributed, chunksize, passes, update_every, alpha, eta, decay, offset, eval_every, iterations, gamma_threshold, minimum_probability, random_state, ns_conf, minimum_phi_value, per_word_topics, callbacks, dtype)
> 517 if corpus is not None:
> 518 use_numpy = self.dispatcher is not None
> --> 519 self.update(corpus, chunks_as_numpy=use_numpy)
> 520
> 521 def init_dir_prior(self, prior, name):
>
> ~\Anaconda3\lib\site-packages\gensim\models\ldamodel.py in update(self, corpus, chunksize, decay, offset, passes, update_every, eval_every, iterations, gamma_threshold, chunks_as_numpy)
> 945 # pass the list of input callbacks to Callback class
> 946 callback = Callback(self.callbacks)
> --> 947 callback.set_model(self)
> 948 # initialize metrics list to store metric values after every epoch
> 949 self.metrics = defaultdict(list)
>
> ~\Anaconda3\lib\site-packages\gensim\models\callbacks.py in set_model(self, model)
> 482 # store diff diagonals of previous epochs
> 483 self.diff_mat = Queue()
> --> 484 if any(metric.logger == "visdom" for metric in self.metrics):
> 485 if not VISDOM_INSTALLED:
> 486 raise ImportError("Please install Visdom for visualization")
>
> ~\Anaconda3\lib\site-packages\gensim\models\callbacks.py in <genexpr>(.0)
> 482 # store diff diagonals of previous epochs
> 483 self.diff_mat = Queue()
> --> 484 if any(metric.logger == "visdom" for metric in self.metrics):
> 485 if not VISDOM_INSTALLED:
> 486 raise ImportError("Please install Visdom for visualization")
>
> AttributeError: 'Callback' object has no attribute 'logger'
>
#### Versions
Windows-10-10.0.18362-SP0
Python 3.5.6 |Anaconda custom (64-bit)| (default, Aug 26 2018, 16:05:27) [MSC v.1900 64 bit (AMD64)]
NumPy 1.15.2
SciPy 1.1.0
gensim 3.8.1
FAST_VERSION 1 | open | 2020-02-22T13:54:00Z | 2023-06-22T06:07:25Z | https://github.com/piskvorky/gensim/issues/2758 | [] | hellpanderrr | 1 |
google-deepmind/graph_nets | tensorflow | 114 | hi,i want to know whether graph nets will add DropEdge in the future like https://github.com/DropEdge/DropEdge | closed | 2020-04-13T07:33:30Z | 2020-09-30T03:04:04Z | https://github.com/google-deepmind/graph_nets/issues/114 | [] | luyifanlu | 1 |
|
sinaptik-ai/pandas-ai | pandas | 671 | Conversational Answer won,t work | ### System Info
OS version: windows 10
Python version : 3.11
The current version of pandas ai
### 🐛 Describe the bug
In the current version of Pandas AI :
# Conversational Answer won,t work
# when I asked what is the GDP then answer Just 20,0000 But I need The GDP is 20,000 like this .. | closed | 2023-10-22T08:34:21Z | 2024-06-01T00:20:17Z | https://github.com/sinaptik-ai/pandas-ai/issues/671 | [] | Ridoy302583 | 2 |
ageitgey/face_recognition | machine-learning | 613 | Nameerror: pil_image is not defined | * face_recognition version:
* Python version:
* Operating System:
### Description
Describe what you were trying to get done.
Tell us what happened, what went wrong, and what you expected to happen.
IMPORTANT: If your issue is related to a specific picture, include it so others can reproduce the issue.
### What I Did
```
Paste the command(s) you ran and the output.
If there was a crash, please include the traceback here.
```
| closed | 2018-09-01T15:59:51Z | 2018-09-01T16:01:21Z | https://github.com/ageitgey/face_recognition/issues/613 | [] | multikillerr | 0 |
gradio-app/gradio | data-visualization | 10,201 | Accordion - Expanding vertically to the right | - [x] I have searched to see if a similar issue already exists.
I would really like to have the ability to place an accordion vertically and expand to the right. I have scenarios where this would be a better UI solution, as doing so would automatically push the other components to the right of it forward.
I have no idea how to tweak this in CSS to make it work. If you have a simple CSS solution I would appreciate it until we have this feature. I am actually developing something that would really need this feature.
I made this drawing of what it would be like.

| closed | 2024-12-14T23:51:34Z | 2024-12-16T16:46:38Z | https://github.com/gradio-app/gradio/issues/10201 | [] | elismasilva | 1 |
adbar/trafilatura | web-scraping | 604 | New port of readability.js? | The current implementation of `readability_lxml` and the original project [readability.js](https://github.com/mozilla/readability/tree/main) is out of sync, so it would make sense to update the `readability_lxml` implementation to benefit from potentially newer feature and fixes.
[readability.js](https://github.com/mozilla/readability/tree/main) has a big set of [test pages](https://github.com/mozilla/readability/tree/main/test/test-pages) with source.html and expected.html files. As a first step, we could test how `readability_lxml` compares against this test set?
Based on the results we could check if it's better to _fix_ the differences (if there aren't too many), or if a new port based on the current javascript implementation would make more sense. What do you think?
By the way, `readability_lxml` looks like it was first ported to ruby and then to python. Besides using `lxml`, were there any functions added specifically for trafilatura? | open | 2024-05-23T13:49:54Z | 2024-06-05T08:44:47Z | https://github.com/adbar/trafilatura/issues/604 | [
"question"
] | zirkelc | 4 |
miguelgrinberg/Flask-SocketIO | flask | 1,037 | connection refreshing automatically after emit event from Flask server. | I'm trying to create a simple chatroom style application with Flask and Flask-SocketIO. When users type messages and click 'submit' (submitting a form in html), it should create an unordered list of messages. The problem I'm facing is the message gets appended as list item but then after few seconds it disappears(it appears as though connection is refreshed). I want to turn off this behavior. Thanks in advance. :smile:
Here is code snippet :
Flask:
```
@socketio.on('send messages')
def vote(data):
messages = data['messages']
emit('announce messages', {"messages":messages}, broadcast=True)
```
JavaScript:
```
document.addEventListener('DOMContentLoaded', () => {
// Connect to websocket
var socket = io.connect(location.protocol + '//' + document.domain + ':' + location.port);
// When connected
socket.on('connect', () => {
document.querySelector('#form').onsubmit = () => {
const messages = document.querySelector('#messages').value;
socket.emit('send messages', {'messages': messages});
return false;
}
});
socket.on('announce messages', data => {
const li = document.createElement('li');
li.innerHTML = `${data.messages}`;
document.querySelector('#push').append(li);
return false;
});
});
``` | closed | 2019-08-14T06:33:32Z | 2019-08-14T09:03:33Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1037 | [
"question"
] | AkshayKumar007 | 2 |
MaartenGr/BERTopic | nlp | 2,189 | fit_transform tries to access embedding_model if representation_model is not None | ### Have you searched existing issues? 🔎
- [X] I have searched and found no existing issues
### Desribe the bug
I was using BERTopic on a cluster of queries with my own embeddings (computed on a model that is hard to pass as a parameter) and it was working as expected.
After trying to use `representation_model = KeyBERTInspired()` and adding ` representation_model=representation_model` to BERTopic as a parameter. I got this error :
```
AttributeError Traceback (most recent call last)
[1] representation_model = KeyBERTInspired()
[2] topic_model = BERTopic(
[3] calculate_probabilities=True,
[4] min_topic_size=1
[5] embedding_model=None,
[6] representation_model=representation_model,
[7] )
----> [8] topics, probs = topic_model.fit_transform(corpus, np.array(corpus_embeddings))
[9] topic_model.get_topic_info()
File ~/query_analysis/bertopic_env/lib/python3.11/site-packages/bertopic/_bertopic.py:493, in BERTopic.fit_transform(self, documents, embeddings, images, y)
[490] self._save_representative_docs(custom_documents)
[491] else:
[492] # Extract topics by calculating c-TF-IDF
--> [493] self._extract_topics(documents, embeddings=embeddings, verbose=self.verbose)
[495] # Reduce topics
[496] if self.nr_topics:
File ~/query_analysis/bertopic_env/lib/python3.11/site-packages/bertopic/_bertopic.py:3991, in BERTopic._extract_topics(self, documents, embeddings, mappings, verbose)
[3989] documents_per_topic = documents.groupby(["Topic"], as_index=False).agg({"Document": " ".join})
[3990] self.c_tf_idf_, words = self._c_tf_idf(documents_per_topic)
-> [3991] self.topic_representations_ = self._extract_words_per_topic(words, documents)
...
[3680] "Make sure to use an embedding model that can either embed documents"
[3681] "or images depending on which you want to embed."
[3682]
AttributeError: 'NoneType' object has no attribute 'embed_documents'
```
### Reproduction
```python
from query import Query
import json
import numpy as np
from sklearn.cluster import DBSCAN
from bertopic import BERTopic
from openai import OpenAI
from bertopic.representation import KeyBERTInspired
representation_model = KeyBERTInspired()
topic_model = BERTopic(
calculate_probabilities=True,
min_topic_size=15,
embedding_model=None,
representation_model=representation_model,
)
topics, probs = topic_model.fit_transform(corpus, np.array(corpus_embeddings))
topic_model.get_topic_info()
```
### BERTopic Version
0.16.4 | open | 2024-10-17T08:10:23Z | 2024-10-18T10:24:13Z | https://github.com/MaartenGr/BERTopic/issues/2189 | [
"bug"
] | rasantangelo | 1 |
Johnserf-Seed/TikTokDownload | api | 565 | 【使用】我想问下。这个在linux命令行下(debian)怎么使用 | 教程好像说的都是windows如何使用。但是我觉得这种会经常更新视频的东西。使用debian进行定时增量更新是更好的选择
但是不知道在debian下。这个程序应该怎么使用
| open | 2023-09-27T08:51:41Z | 2023-10-09T09:24:12Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/565 | [
"无效(invalid)"
] | Whichbfj28 | 10 |
apachecn/ailearning | python | 421 | ApacheCN | http://ailearning.apachecn.org/
ApacheCN 专注于优秀项目维护的开源组织 | closed | 2018-08-24T06:58:15Z | 2021-09-07T17:41:31Z | https://github.com/apachecn/ailearning/issues/421 | [
"Gitalk",
"6666cd76f96956469e7be39d750cc7d9"
] | jiangzhonglian | 2 |
chezou/tabula-py | pandas | 269 | consistency issues across similar pdfs | closed | 2020-11-09T14:33:41Z | 2020-11-09T14:34:28Z | https://github.com/chezou/tabula-py/issues/269 | [] | aestella | 1 |
|
huggingface/datasets | pytorch | 7,107 | load_dataset broken in 2.21.0 | ### Describe the bug
`eval_set = datasets.load_dataset("tatsu-lab/alpaca_eval", "alpaca_eval_gpt4_baseline", trust_remote_code=True)`
used to work till 2.20.0 but doesn't work in 2.21.0
In 2.20.0:

in 2.21.0:
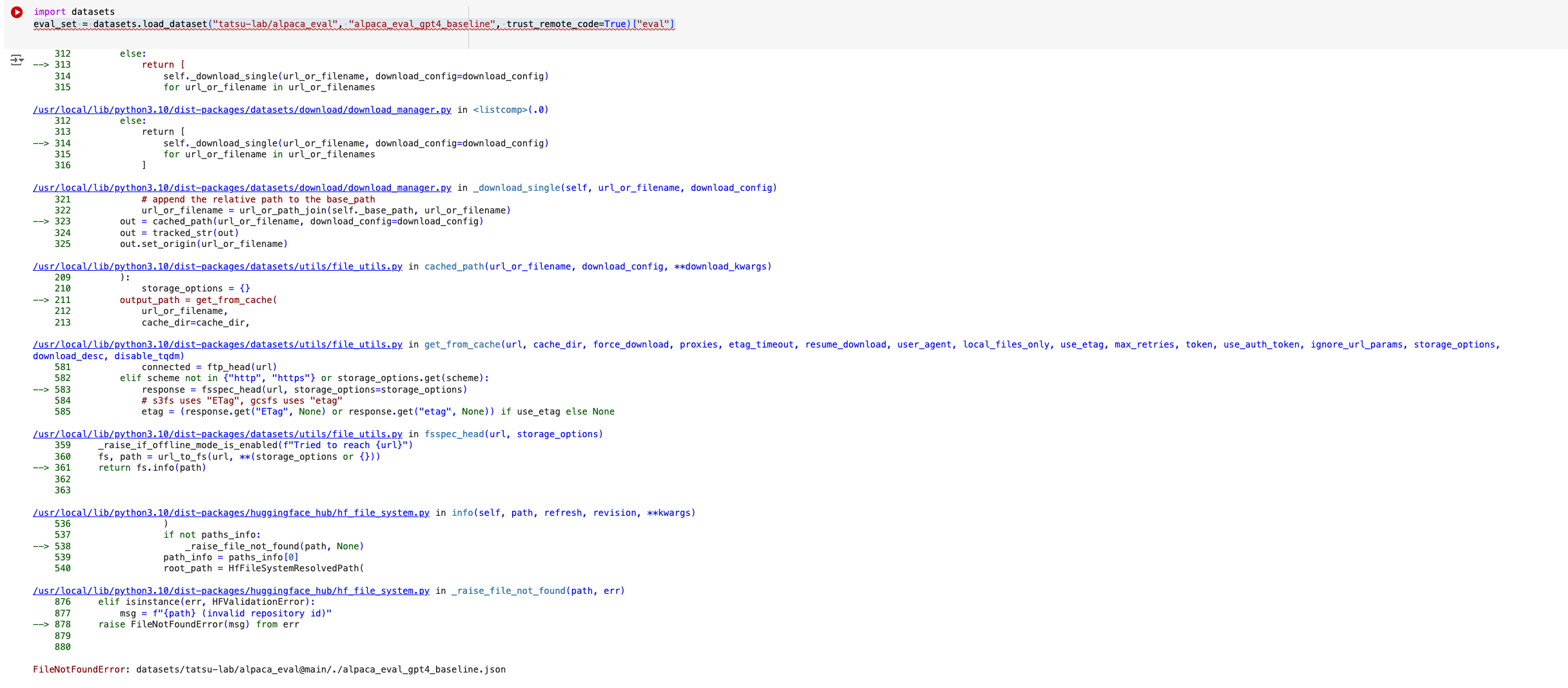
### Steps to reproduce the bug
1. Spin up a new google collab
2. `pip install datasets==2.21.0`
3. `import datasets`
4. `eval_set = datasets.load_dataset("tatsu-lab/alpaca_eval", "alpaca_eval_gpt4_baseline", trust_remote_code=True)`
5. Will throw an error.
### Expected behavior
Try steps 1-5 again but replace datasets version with 2.20.0, it will work
### Environment info
- `datasets` version: 2.21.0
- Platform: Linux-6.1.85+-x86_64-with-glibc2.35
- Python version: 3.10.12
- `huggingface_hub` version: 0.23.5
- PyArrow version: 17.0.0
- Pandas version: 2.1.4
- `fsspec` version: 2024.5.0
| closed | 2024-08-16T14:59:51Z | 2024-08-18T09:28:43Z | https://github.com/huggingface/datasets/issues/7107 | [] | anjor | 4 |
pyeve/eve | flask | 1,360 | Nested unique constraint doesn't work | ### Expected Behavior
The `unique` constraint does not work when is inside of a dict or a list, for example. The problem comes from [this line](https://github.com/pyeve/eve/blob/master/eve/io/mongo/validation.py#L95). The resulting query will find only properties in the root document.
The `unique` constraint won't work also when nested inside lists, as the query will try to find by a numeric index instead of the key of the parent schema.
```json
{
"dict_test": {
"type": "dict",
"schema": {
"string_attribute": {
"type": "string",
"unique": true
}
}
}
}
```
### Actual Behavior
You can create more than one resource of that schema with the same `string_attribute` value.
### Environment
* Python version: 3.7
* Eve version: 1.1
| closed | 2020-02-25T19:19:44Z | 2021-01-22T16:31:03Z | https://github.com/pyeve/eve/issues/1360 | [] | elias-garcia | 0 |
ClimbsRocks/auto_ml | scikit-learn | 4 | FUTURE: train regressors or classifiers | closed | 2016-08-08T00:16:30Z | 2016-08-12T06:12:57Z | https://github.com/ClimbsRocks/auto_ml/issues/4 | [] | ClimbsRocks | 1 |
|
AutoGPTQ/AutoGPTQ | nlp | 678 | How to install auto-gptq in GCC 8.5.0 environment? | I want to install auto-gptq package to finetune my LLM. But when I followed the README, it showed some error.
The error show that need GCC 9.0, but my environment only has GCC 8.5.0 and couldn't update to 5.0 in some reasons.
```
Looking in indexes: https://mirrors.aliyun.com/pypi/simple/
Processing /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ
Preparing metadata (setup.py) ... done
Requirement already satisfied: accelerate>=0.26.0 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from auto_gptq==0.8.0.dev0+cu118) (0.29.3)
Requirement already satisfied: datasets in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from auto_gptq==0.8.0.dev0+cu118) (2.18.0)
Collecting sentencepiece (from auto_gptq==0.8.0.dev0+cu118)
Using cached https://mirrors.aliyun.com/pypi/packages/4f/d2/18246f43ca730bb81918f87b7e886531eda32d835811ad9f4657c54eee35/sentencepiece-0.2.0-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.3 MB)
Requirement already satisfied: numpy in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from auto_gptq==0.8.0.dev0+cu118) (1.26.4)
Collecting rouge (from auto_gptq==0.8.0.dev0+cu118)
Using cached https://mirrors.aliyun.com/pypi/packages/32/7c/650ae86f92460e9e8ef969cc5008b24798dcf56a9a8947d04c78f550b3f5/rouge-1.0.1-py3-none-any.whl (13 kB)
Collecting gekko (from auto_gptq==0.8.0.dev0+cu118)
Using cached https://mirrors.aliyun.com/pypi/packages/3f/ed/960a6cec9e588b8c05e830dcb6789750ee88e791e9cd5467f85a12ee7f46/gekko-1.1.1-py3-none-any.whl (13.2 MB)
Requirement already satisfied: torch>=1.13.0 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from auto_gptq==0.8.0.dev0+cu118) (2.3.0+cu118)
Requirement already satisfied: safetensors in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from auto_gptq==0.8.0.dev0+cu118) (0.4.3)
Requirement already satisfied: transformers>=4.31.0 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from auto_gptq==0.8.0.dev0+cu118) (4.37.2)
Requirement already satisfied: peft>=0.5.0 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from auto_gptq==0.8.0.dev0+cu118) (0.7.1)
Requirement already satisfied: tqdm in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from auto_gptq==0.8.0.dev0+cu118) (4.66.2)
Requirement already satisfied: packaging>=20.0 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from accelerate>=0.26.0->auto_gptq==0.8.0.dev0+cu118) (23.2)
Requirement already satisfied: psutil in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from accelerate>=0.26.0->auto_gptq==0.8.0.dev0+cu118) (5.9.8)
Requirement already satisfied: pyyaml in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from accelerate>=0.26.0->auto_gptq==0.8.0.dev0+cu118) (6.0.1)
Requirement already satisfied: huggingface-hub in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from accelerate>=0.26.0->auto_gptq==0.8.0.dev0+cu118) (0.22.2)
Requirement already satisfied: filelock in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (3.13.4)
Requirement already satisfied: typing-extensions>=4.8.0 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (4.11.0)
Requirement already satisfied: sympy in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (1.12)
Requirement already satisfied: networkx in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (3.3)
Requirement already satisfied: jinja2 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (3.1.3)
Requirement already satisfied: fsspec in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (2024.2.0)
Requirement already satisfied: nvidia-cuda-nvrtc-cu11==11.8.89 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (11.8.89)
Requirement already satisfied: nvidia-cuda-runtime-cu11==11.8.89 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (11.8.89)
Requirement already satisfied: nvidia-cuda-cupti-cu11==11.8.87 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (11.8.87)
Requirement already satisfied: nvidia-cudnn-cu11==8.7.0.84 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (8.7.0.84)
Requirement already satisfied: nvidia-cublas-cu11==11.11.3.6 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (11.11.3.6)
Requirement already satisfied: nvidia-cufft-cu11==10.9.0.58 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (10.9.0.58)
Requirement already satisfied: nvidia-curand-cu11==10.3.0.86 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (10.3.0.86)
Requirement already satisfied: nvidia-cusolver-cu11==11.4.1.48 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (11.4.1.48)
Requirement already satisfied: nvidia-cusparse-cu11==11.7.5.86 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (11.7.5.86)
Requirement already satisfied: nvidia-nccl-cu11==2.20.5 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (2.20.5)
Requirement already satisfied: nvidia-nvtx-cu11==11.8.86 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (11.8.86)
Requirement already satisfied: regex!=2019.12.17 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from transformers>=4.31.0->auto_gptq==0.8.0.dev0+cu118) (2024.4.28)
Requirement already satisfied: requests in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from transformers>=4.31.0->auto_gptq==0.8.0.dev0+cu118) (2.31.0)
Requirement already satisfied: tokenizers<0.19,>=0.14 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from transformers>=4.31.0->auto_gptq==0.8.0.dev0+cu118) (0.15.2)
Requirement already satisfied: pyarrow>=12.0.0 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from datasets->auto_gptq==0.8.0.dev0+cu118) (16.0.0)
Requirement already satisfied: pyarrow-hotfix in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from datasets->auto_gptq==0.8.0.dev0+cu118) (0.6)
Requirement already satisfied: dill<0.3.9,>=0.3.0 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from datasets->auto_gptq==0.8.0.dev0+cu118) (0.3.8)
Requirement already satisfied: pandas in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from datasets->auto_gptq==0.8.0.dev0+cu118) (2.2.2)
Requirement already satisfied: xxhash in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from datasets->auto_gptq==0.8.0.dev0+cu118) (3.4.1)
Requirement already satisfied: multiprocess in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from datasets->auto_gptq==0.8.0.dev0+cu118) (0.70.16)
Requirement already satisfied: aiohttp in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from datasets->auto_gptq==0.8.0.dev0+cu118) (3.9.5)
Requirement already satisfied: six in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from rouge->auto_gptq==0.8.0.dev0+cu118) (1.16.0)
Requirement already satisfied: aiosignal>=1.1.2 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from aiohttp->datasets->auto_gptq==0.8.0.dev0+cu118) (1.3.1)
Requirement already satisfied: attrs>=17.3.0 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from aiohttp->datasets->auto_gptq==0.8.0.dev0+cu118) (23.2.0)
Requirement already satisfied: frozenlist>=1.1.1 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from aiohttp->datasets->auto_gptq==0.8.0.dev0+cu118) (1.4.1)
Requirement already satisfied: multidict<7.0,>=4.5 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from aiohttp->datasets->auto_gptq==0.8.0.dev0+cu118) (6.0.5)
Requirement already satisfied: yarl<2.0,>=1.0 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from aiohttp->datasets->auto_gptq==0.8.0.dev0+cu118) (1.9.4)
Requirement already satisfied: charset-normalizer<4,>=2 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from requests->transformers>=4.31.0->auto_gptq==0.8.0.dev0+cu118) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from requests->transformers>=4.31.0->auto_gptq==0.8.0.dev0+cu118) (3.7)
Requirement already satisfied: urllib3<3,>=1.21.1 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from requests->transformers>=4.31.0->auto_gptq==0.8.0.dev0+cu118) (2.2.1)
Requirement already satisfied: certifi>=2017.4.17 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from requests->transformers>=4.31.0->auto_gptq==0.8.0.dev0+cu118) (2024.2.2)
Requirement already satisfied: MarkupSafe>=2.0 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from jinja2->torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (2.1.5)
Requirement already satisfied: python-dateutil>=2.8.2 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from pandas->datasets->auto_gptq==0.8.0.dev0+cu118) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from pandas->datasets->auto_gptq==0.8.0.dev0+cu118) (2024.1)
Requirement already satisfied: tzdata>=2022.7 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from pandas->datasets->auto_gptq==0.8.0.dev0+cu118) (2024.1)
Requirement already satisfied: mpmath>=0.19 in /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages (from sympy->torch>=1.13.0->auto_gptq==0.8.0.dev0+cu118) (1.3.0)
Building wheels for collected packages: auto_gptq
Building wheel for auto_gptq (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py bdist_wheel did not run successfully.
│ exit code: 1
╰─> [285 lines of output]
conda_cuda_include_dir /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/nvidia/cuda_runtime/include
appending conda cuda include dir /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/nvidia/cuda_runtime/include
running bdist_wheel
running build
running build_py
creating build
creating build/lib.linux-x86_64-cpython-312
creating build/lib.linux-x86_64-cpython-312/auto_gptq
copying auto_gptq/__init__.py -> build/lib.linux-x86_64-cpython-312/auto_gptq
creating build/lib.linux-x86_64-cpython-312/tests
copying tests/__init__.py -> build/lib.linux-x86_64-cpython-312/tests
copying tests/bench_autoawq_autogptq.py -> build/lib.linux-x86_64-cpython-312/tests
copying tests/test_awq_compatibility_generation.py -> build/lib.linux-x86_64-cpython-312/tests
copying tests/test_peft_conversion.py -> build/lib.linux-x86_64-cpython-312/tests
copying tests/test_q4.py -> build/lib.linux-x86_64-cpython-312/tests
copying tests/test_quantization.py -> build/lib.linux-x86_64-cpython-312/tests
copying tests/test_repacking.py -> build/lib.linux-x86_64-cpython-312/tests
copying tests/test_serialization.py -> build/lib.linux-x86_64-cpython-312/tests
copying tests/test_sharded_loading.py -> build/lib.linux-x86_64-cpython-312/tests
copying tests/test_triton.py -> build/lib.linux-x86_64-cpython-312/tests
creating build/lib.linux-x86_64-cpython-312/auto_gptq/eval_tasks
copying auto_gptq/eval_tasks/__init__.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/eval_tasks
copying auto_gptq/eval_tasks/_base.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/eval_tasks
copying auto_gptq/eval_tasks/language_modeling_task.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/eval_tasks
copying auto_gptq/eval_tasks/sequence_classification_task.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/eval_tasks
copying auto_gptq/eval_tasks/text_summarization_task.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/eval_tasks
creating build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/__init__.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/_base.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/_const.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/_utils.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/auto.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/baichuan.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/bloom.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/codegen.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/cohere.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/decilm.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/gemma.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/gpt2.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/gpt_bigcode.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/gpt_neox.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/gptj.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/internlm.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/llama.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/longllama.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/mistral.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/mixtral.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/moss.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/mpt.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/opt.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/phi.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/qwen.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/qwen2.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/rw.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/stablelmepoch.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/starcoder2.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/xverse.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
copying auto_gptq/modeling/yi.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/modeling
creating build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules
copying auto_gptq/nn_modules/__init__.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules
copying auto_gptq/nn_modules/_fused_base.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules
copying auto_gptq/nn_modules/fused_gptj_attn.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules
copying auto_gptq/nn_modules/fused_llama_attn.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules
copying auto_gptq/nn_modules/fused_llama_mlp.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules
creating build/lib.linux-x86_64-cpython-312/auto_gptq/quantization
copying auto_gptq/quantization/__init__.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/quantization
copying auto_gptq/quantization/config.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/quantization
copying auto_gptq/quantization/gptq.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/quantization
copying auto_gptq/quantization/quantizer.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/quantization
creating build/lib.linux-x86_64-cpython-312/auto_gptq/utils
copying auto_gptq/utils/__init__.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/utils
copying auto_gptq/utils/accelerate_utils.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/utils
copying auto_gptq/utils/data_utils.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/utils
copying auto_gptq/utils/exllama_utils.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/utils
copying auto_gptq/utils/import_utils.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/utils
copying auto_gptq/utils/marlin_utils.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/utils
copying auto_gptq/utils/modeling_utils.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/utils
copying auto_gptq/utils/peft_utils.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/utils
copying auto_gptq/utils/perplexity_utils.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/utils
creating build/lib.linux-x86_64-cpython-312/auto_gptq/eval_tasks/_utils
copying auto_gptq/eval_tasks/_utils/__init__.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/eval_tasks/_utils
copying auto_gptq/eval_tasks/_utils/classification_utils.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/eval_tasks/_utils
copying auto_gptq/eval_tasks/_utils/generation_utils.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/eval_tasks/_utils
creating build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/qlinear
copying auto_gptq/nn_modules/qlinear/__init__.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/qlinear
copying auto_gptq/nn_modules/qlinear/qlinear_cuda.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/qlinear
copying auto_gptq/nn_modules/qlinear/qlinear_cuda_old.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/qlinear
copying auto_gptq/nn_modules/qlinear/qlinear_exllama.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/qlinear
copying auto_gptq/nn_modules/qlinear/qlinear_exllamav2.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/qlinear
copying auto_gptq/nn_modules/qlinear/qlinear_marlin.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/qlinear
copying auto_gptq/nn_modules/qlinear/qlinear_qigen.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/qlinear
copying auto_gptq/nn_modules/qlinear/qlinear_triton.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/qlinear
copying auto_gptq/nn_modules/qlinear/qlinear_tritonv2.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/qlinear
creating build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/triton_utils
copying auto_gptq/nn_modules/triton_utils/__init__.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/triton_utils
copying auto_gptq/nn_modules/triton_utils/custom_autotune.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/triton_utils
copying auto_gptq/nn_modules/triton_utils/dequant.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/triton_utils
copying auto_gptq/nn_modules/triton_utils/kernels.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/triton_utils
copying auto_gptq/nn_modules/triton_utils/mixin.py -> build/lib.linux-x86_64-cpython-312/auto_gptq/nn_modules/triton_utils
running build_ext
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/utils/cpp_extension.py:428: UserWarning: There are no g++ version bounds defined for CUDA version 11.8
warnings.warn(f'There are no {compiler_name} version bounds defined for CUDA version {cuda_str_version}')
building 'autogptq_cuda_64' extension
creating /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/build/temp.linux-x86_64-cpython-312
creating /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/build/temp.linux-x86_64-cpython-312/autogptq_extension
creating /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/build/temp.linux-x86_64-cpython-312/autogptq_extension/cuda_64
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/utils/cpp_extension.py:1967: UserWarning: TORCH_CUDA_ARCH_LIST is not set, all archs for visible cards are included for compilation.
If this is not desired, please set os.environ['TORCH_CUDA_ARCH_LIST'].
warnings.warn(
Emitting ninja build file /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/build/temp.linux-x86_64-cpython-312/build.ninja...
Compiling objects...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
[1/2] /usr/local/cuda/bin/nvcc --generate-dependencies-with-compile --dependency-output /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/build/temp.linux-x86_64-cpython-312/autogptq_extension/cuda_64/autogptq_cuda_kernel_64.o.d -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/api/include -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/TH -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/THC -I/usr/local/cuda/include -I/home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/autogptq_cuda -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/nvidia/cuda_runtime/include -I/home/dongna/.virtualenvs/Qwen-14B/include -I/usr/local/miniconda3/include/python3.12 -c -c /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/autogptq_extension/cuda_64/autogptq_cuda_kernel_64.cu -o /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/build/temp.linux-x86_64-cpython-312/autogptq_extension/cuda_64/autogptq_cuda_kernel_64.o -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr --compiler-options ''"'"'-fPIC'"'"'' -DTORCH_API_INCLUDE_EXTENSION_H '-DPYBIND11_COMPILER_TYPE="_gcc"' '-DPYBIND11_STDLIB="_libstdcpp"' '-DPYBIND11_BUILD_ABI="_cxxabi1011"' -DTORCH_EXTENSION_NAME=autogptq_cuda_64 -D_GLIBCXX_USE_CXX11_ABI=0 -gencode=arch=compute_89,code=compute_89 -gencode=arch=compute_89,code=sm_89 -ccbin g++ -std=c++17
FAILED: /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/build/temp.linux-x86_64-cpython-312/autogptq_extension/cuda_64/autogptq_cuda_kernel_64.o
/usr/local/cuda/bin/nvcc --generate-dependencies-with-compile --dependency-output /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/build/temp.linux-x86_64-cpython-312/autogptq_extension/cuda_64/autogptq_cuda_kernel_64.o.d -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/api/include -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/TH -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/THC -I/usr/local/cuda/include -I/home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/autogptq_cuda -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/nvidia/cuda_runtime/include -I/home/dongna/.virtualenvs/Qwen-14B/include -I/usr/local/miniconda3/include/python3.12 -c -c /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/autogptq_extension/cuda_64/autogptq_cuda_kernel_64.cu -o /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/build/temp.linux-x86_64-cpython-312/autogptq_extension/cuda_64/autogptq_cuda_kernel_64.o -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr --compiler-options ''"'"'-fPIC'"'"'' -DTORCH_API_INCLUDE_EXTENSION_H '-DPYBIND11_COMPILER_TYPE="_gcc"' '-DPYBIND11_STDLIB="_libstdcpp"' '-DPYBIND11_BUILD_ABI="_cxxabi1011"' -DTORCH_EXTENSION_NAME=autogptq_cuda_64 -D_GLIBCXX_USE_CXX11_ABI=0 -gencode=arch=compute_89,code=compute_89 -gencode=arch=compute_89,code=sm_89 -ccbin g++ -std=c++17
In file included from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/ATen/core/TensorBase.h:14,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/ATen/core/TensorBody.h:38,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/ATen/core/Tensor.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/ATen/Tensor.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/autograd/function_hook.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/autograd/cpp_hook.h:2,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/autograd/variable.h:6,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/autograd/autograd.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/api/include/torch/autograd.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/api/include/torch/all.h:7,
from /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/autogptq_extension/cuda_64/autogptq_cuda_kernel_64.cu:1:
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/util/C++17.h:13:2: error: #error "You're trying to build PyTorch with a too old version of GCC. We need GCC 9 or later."
#error \
^~~~~
[2/2] g++ -MMD -MF /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/build/temp.linux-x86_64-cpython-312/autogptq_extension/cuda_64/autogptq_cuda_64.o.d -fno-strict-overflow -DNDEBUG -O2 -Wall -fPIC -O2 -isystem /usr/local/miniconda3/include -fPIC -O2 -isystem /usr/local/miniconda3/include -fPIC -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/api/include -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/TH -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/THC -I/usr/local/cuda/include -I/home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/autogptq_cuda -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/nvidia/cuda_runtime/include -I/home/dongna/.virtualenvs/Qwen-14B/include -I/usr/local/miniconda3/include/python3.12 -c -c /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/autogptq_extension/cuda_64/autogptq_cuda_64.cpp -o /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/build/temp.linux-x86_64-cpython-312/autogptq_extension/cuda_64/autogptq_cuda_64.o -DTORCH_API_INCLUDE_EXTENSION_H '-DPYBIND11_COMPILER_TYPE="_gcc"' '-DPYBIND11_STDLIB="_libstdcpp"' '-DPYBIND11_BUILD_ABI="_cxxabi1011"' -DTORCH_EXTENSION_NAME=autogptq_cuda_64 -D_GLIBCXX_USE_CXX11_ABI=0 -std=c++17
FAILED: /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/build/temp.linux-x86_64-cpython-312/autogptq_extension/cuda_64/autogptq_cuda_64.o
g++ -MMD -MF /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/build/temp.linux-x86_64-cpython-312/autogptq_extension/cuda_64/autogptq_cuda_64.o.d -fno-strict-overflow -DNDEBUG -O2 -Wall -fPIC -O2 -isystem /usr/local/miniconda3/include -fPIC -O2 -isystem /usr/local/miniconda3/include -fPIC -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/api/include -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/TH -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/THC -I/usr/local/cuda/include -I/home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/autogptq_cuda -I/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/nvidia/cuda_runtime/include -I/home/dongna/.virtualenvs/Qwen-14B/include -I/usr/local/miniconda3/include/python3.12 -c -c /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/autogptq_extension/cuda_64/autogptq_cuda_64.cpp -o /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/build/temp.linux-x86_64-cpython-312/autogptq_extension/cuda_64/autogptq_cuda_64.o -DTORCH_API_INCLUDE_EXTENSION_H '-DPYBIND11_COMPILER_TYPE="_gcc"' '-DPYBIND11_STDLIB="_libstdcpp"' '-DPYBIND11_BUILD_ABI="_cxxabi1011"' -DTORCH_EXTENSION_NAME=autogptq_cuda_64 -D_GLIBCXX_USE_CXX11_ABI=0 -std=c++17
In file included from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/ATen/core/TensorBase.h:14,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/ATen/core/TensorBody.h:38,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/ATen/core/Tensor.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/ATen/Tensor.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/autograd/function_hook.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/autograd/cpp_hook.h:2,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/autograd/variable.h:6,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/autograd/autograd.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/api/include/torch/autograd.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/api/include/torch/all.h:7,
from /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/autogptq_extension/cuda_64/autogptq_cuda_64.cpp:1:
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/util/C++17.h:13:2: error: #error "You're trying to build PyTorch with a too old version of GCC. We need GCC 9 or later."
#error \
^~~~~
In file included from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/Backend.h:5,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/Layout.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/ATen/core/TensorBody.h:12,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/ATen/core/Tensor.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/ATen/Tensor.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/autograd/function_hook.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/autograd/cpp_hook.h:2,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/autograd/variable.h:6,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/autograd/autograd.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/api/include/torch/autograd.h:3,
from /home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/torch/csrc/api/include/torch/all.h:7,
from /home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/autogptq_extension/cuda_64/autogptq_cuda_64.cpp:1:
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:752:73: in ‘constexpr’ expansion of ‘c10::DispatchKeySet(AutogradCPU)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:236:42: in ‘constexpr’ expansion of ‘c10::toBackendComponent(k)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:752:73: error: overflow in constant expression [-fpermissive]
constexpr auto autograd_cpu_ks = DispatchKeySet(DispatchKey::AutogradCPU);
^
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:753:73: in ‘constexpr’ expansion of ‘c10::DispatchKeySet(AutogradIPU)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:236:42: in ‘constexpr’ expansion of ‘c10::toBackendComponent(k)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:753:73: error: overflow in constant expression [-fpermissive]
constexpr auto autograd_ipu_ks = DispatchKeySet(DispatchKey::AutogradIPU);
^
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:754:73: in ‘constexpr’ expansion of ‘c10::DispatchKeySet(AutogradXPU)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:236:42: in ‘constexpr’ expansion of ‘c10::toBackendComponent(k)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:754:73: error: overflow in constant expression [-fpermissive]
constexpr auto autograd_xpu_ks = DispatchKeySet(DispatchKey::AutogradXPU);
^
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:755:75: in ‘constexpr’ expansion of ‘c10::DispatchKeySet(AutogradCUDA)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:236:42: in ‘constexpr’ expansion of ‘c10::toBackendComponent(k)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:755:75: error: overflow in constant expression [-fpermissive]
constexpr auto autograd_cuda_ks = DispatchKeySet(DispatchKey::AutogradCUDA);
^
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:756:73: in ‘constexpr’ expansion of ‘c10::DispatchKeySet(AutogradXLA)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:236:42: in ‘constexpr’ expansion of ‘c10::toBackendComponent(k)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:756:73: error: overflow in constant expression [-fpermissive]
constexpr auto autograd_xla_ks = DispatchKeySet(DispatchKey::AutogradXLA);
^
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:757:75: in ‘constexpr’ expansion of ‘c10::DispatchKeySet(AutogradLazy)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:236:42: in ‘constexpr’ expansion of ‘c10::toBackendComponent(k)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:757:75: error: overflow in constant expression [-fpermissive]
constexpr auto autograd_lazy_ks = DispatchKeySet(DispatchKey::AutogradLazy);
^
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:758:75: in ‘constexpr’ expansion of ‘c10::DispatchKeySet(AutogradMeta)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:236:42: in ‘constexpr’ expansion of ‘c10::toBackendComponent(k)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:758:75: error: overflow in constant expression [-fpermissive]
constexpr auto autograd_meta_ks = DispatchKeySet(DispatchKey::AutogradMeta);
^
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:759:73: in ‘constexpr’ expansion of ‘c10::DispatchKeySet(AutogradMPS)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:236:42: in ‘constexpr’ expansion of ‘c10::toBackendComponent(k)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:759:73: error: overflow in constant expression [-fpermissive]
constexpr auto autograd_mps_ks = DispatchKeySet(DispatchKey::AutogradMPS);
^
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:760:73: in ‘constexpr’ expansion of ‘c10::DispatchKeySet(AutogradHPU)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:236:42: in ‘constexpr’ expansion of ‘c10::toBackendComponent(k)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:760:73: error: overflow in constant expression [-fpermissive]
constexpr auto autograd_hpu_ks = DispatchKeySet(DispatchKey::AutogradHPU);
^
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:762:52: in ‘constexpr’ expansion of ‘c10::DispatchKeySet(AutogradPrivateUse1)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:236:42: in ‘constexpr’ expansion of ‘c10::toBackendComponent(k)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:762:52: error: overflow in constant expression [-fpermissive]
DispatchKeySet(DispatchKey::AutogradPrivateUse1);
^
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:764:52: in ‘constexpr’ expansion of ‘c10::DispatchKeySet(AutogradPrivateUse2)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:236:42: in ‘constexpr’ expansion of ‘c10::toBackendComponent(k)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:764:52: error: overflow in constant expression [-fpermissive]
DispatchKeySet(DispatchKey::AutogradPrivateUse2);
^
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:766:52: in ‘constexpr’ expansion of ‘c10::DispatchKeySet(AutogradPrivateUse3)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:236:42: in ‘constexpr’ expansion of ‘c10::toBackendComponent(k)’
/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/include/c10/core/DispatchKeySet.h:766:52: error: overflow in constant expression [-fpermissive]
DispatchKeySet(DispatchKey::AutogradPrivateUse3);
^
ninja: build stopped: subcommand failed.
Traceback (most recent call last):
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/utils/cpp_extension.py", line 2107, in _run_ninja_build
subprocess.run(
File "/usr/local/miniconda3/lib/python3.12/subprocess.py", line 571, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command '['ninja', '-v']' returned non-zero exit status 1.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "<pip-setuptools-caller>", line 34, in <module>
File "/home/dongna/lsx-project/Qwen-14B/Qwen-main/AutoGPTQ/setup.py", line 247, in <module>
setup(
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/__init__.py", line 104, in setup
return distutils.core.setup(**attrs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/_distutils/core.py", line 184, in setup
return run_commands(dist)
^^^^^^^^^^^^^^^^^^
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/_distutils/core.py", line 200, in run_commands
dist.run_commands()
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/_distutils/dist.py", line 969, in run_commands
self.run_command(cmd)
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/dist.py", line 967, in run_command
super().run_command(command)
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/_distutils/dist.py", line 988, in run_command
cmd_obj.run()
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/wheel/bdist_wheel.py", line 368, in run
self.run_command("build")
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/_distutils/cmd.py", line 316, in run_command
self.distribution.run_command(command)
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/dist.py", line 967, in run_command
super().run_command(command)
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/_distutils/dist.py", line 988, in run_command
cmd_obj.run()
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/_distutils/command/build.py", line 132, in run
self.run_command(cmd_name)
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/_distutils/cmd.py", line 316, in run_command
self.distribution.run_command(command)
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/dist.py", line 967, in run_command
super().run_command(command)
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/_distutils/dist.py", line 988, in run_command
cmd_obj.run()
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/command/build_ext.py", line 91, in run
_build_ext.run(self)
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/_distutils/command/build_ext.py", line 359, in run
self.build_extensions()
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/utils/cpp_extension.py", line 870, in build_extensions
build_ext.build_extensions(self)
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/_distutils/command/build_ext.py", line 479, in build_extensions
self._build_extensions_serial()
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/_distutils/command/build_ext.py", line 505, in _build_extensions_serial
self.build_extension(ext)
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/command/build_ext.py", line 252, in build_extension
_build_ext.build_extension(self, ext)
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/setuptools/_distutils/command/build_ext.py", line 560, in build_extension
objects = self.compiler.compile(
^^^^^^^^^^^^^^^^^^^^^^
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/utils/cpp_extension.py", line 683, in unix_wrap_ninja_compile
_write_ninja_file_and_compile_objects(
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/utils/cpp_extension.py", line 1783, in _write_ninja_file_and_compile_objects
_run_ninja_build(
File "/home/dongna/.virtualenvs/Qwen-14B/lib/python3.12/site-packages/torch/utils/cpp_extension.py", line 2123, in _run_ninja_build
raise RuntimeError(message) from e
RuntimeError: Error compiling objects for extension
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for auto_gptq
Running setup.py clean for auto_gptq
Failed to build auto_gptq
ERROR: Could not build wheels for auto_gptq, which is required to install pyproject.toml-based projects
```
| closed | 2024-05-24T08:31:50Z | 2024-06-02T09:09:36Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/678 | [] | StephenSX66 | 0 |
hbldh/bleak | asyncio | 700 | WinRT: pairing crashes if accepting too soon | * bleak version: 0.13.0
* Python version: 3.8.2
* Operating System: Windows 10
### Description
Trying to pair and connect to the device, after accepting to pair on the OS pop-up, Bleak fails.
The device I am trying to connect to requires pairing.
If I accept pairing as soon as it pops up, the script fails. If I wait until after services discovery has finished, and only then accept the pairing, it will work OK.
### What I Did
With this code:
```python
# bleak_minimal_example.py
import asyncio
from bleak import BleakScanner
from bleak import BleakClient
address = "AA:AA:AA:AA:AA:AA"
# Characteristics UUIDs
NUM_SENSORS_UUID = "b9e634a8-57ef-11e9-8647-d663bd873d93"
# ===============================================================
# Connect and read
# ===============================================================
async def run_connection(address, debug=False):
async with BleakClient(address) as client:
print(" >> Please accept pairing")
await asyncio.sleep(5.0)
print(" >> Reading...")
num_sensors = await client.read_gatt_char(NUM_SENSORS_UUID, use_cached = True)
print(" Number of sensors: {0}".format(num_sensors.hex()))
# ===============================================================
# MAIN
# ===============================================================
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(run_connection(address))
print ('>> Goodbye!')
exit(0)
```
**Use case 1: fails**
Accepting the pairing before it finished discovering services - fails
1. the script calls BleakClient.connect()
2. connects to the device and Windows pop-up requests to pair
3. Bleak.connect() is still doing the discovery (and it takes long, because the device has many services with many chars.)
4. if I accept the pairing before it finished discovering it fails
The traceback of the error:
```
Traceback (most recent call last):
File "bleak_minimal_example.py", line 86, in <module>
loop.run_until_complete(run_connection(device_address))
File "C:\Program Files\Python38\lib\asyncio\base_events.py", line 616, in run_until_complete
return future.result()
File "bleak_minimal_example.py", line 50, in run_connection
async with BleakClient(address) as client:
File "C:\Program Files\Python38\lib\site-packages\bleak\backends\client.py", line 61, in __aenter__
await self.connect()
File "C:\Program Files\Python38\lib\site-packages\bleak\backends\winrt\client.py", line 258, in connect
await self.get_services()
File "C:\Program Files\Python38\lib\site-packages\bleak\backends\winrt\client.py", line 446, in get_services
await service.get_characteristics_async(
OSError: [WinError -2147418113] Catastrophic failure
```
**Use case 2: succeeds**
Waiting to accept pairing, then succeeds
1. the script calls BleakClient.connect()
2. connects to the device and Windows pop-up requests to pair
3. Bleak.connect() is still doing the discovery (and it takes long, because the device has many services with many chars.)
4. after connect returned I print ('Please accept pairing')
5. I accept the pairing
6. the script reads + writes... all good
### Alternative use of the API:
With the script modified to call pair() before connect():
```
# bleak_minimal_pair_example.py
import asyncio
from bleak import BleakScanner
from bleak import BleakClient
address = "AA:AA:AA:AA:AA:AA"
# Characteristics UUIDs
NUM_SENSORS_UUID = "b9e634a8-57ef-11e9-8647-d663bd873d93"
# ===============================================================
# Connect and read
# ===============================================================
async def run_connection(address, debug=False):
client = BleakClient(address)
if await client.pair():
pritnt("paired")
await client.connect()
print(" >> Reading...")
num_sensors = await client.read_gatt_char(NUM_SENSORS_UUID, use_cached = True)
print(" Number of sensors: {0}".format(num_sensors.hex()))
# ===============================================================
# MAIN
# ===============================================================
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(run_connection(address))
print ('>> Goodbye!')
exit(0)
```
The execution fails as follows:
The traceback of the error:
```
python bleak_minimal_pair_example.py
Traceback (most recent call last):
File "bleak_minimal_pair_example.py", line 47, in <module>
loop.run_until_complete(run_connection(address))
File "C:\Program Files\Python38\lib\asyncio\base_events.py", line 616, in run_until_complete
return future.result()
File "bleak_minimal_pair_example.py", line 31, in run_connection
if await client.pair():
File "C:\Program Files\Python38\lib\site-packages\bleak\backends\winrt\client.py", line 336, in pair
self._requester.device_information.pairing.can_pair
AttributeError: 'NoneType' object has no attribute 'device_information'
``` | open | 2021-12-27T19:17:45Z | 2022-11-22T14:03:54Z | https://github.com/hbldh/bleak/issues/700 | [
"Backend: WinRT"
] | marianacalzon | 2 |
piskvorky/gensim | data-science | 3,019 | can not import ENGLISH_CONNECTOR_WORDS from gensim.models.phrases | #### Problem description
When I try to load the gensim ENGLISH_CONNECTOR_WORDS, it seems to be missing in my current version. I am trying to use common stopwords in my Phrase detection training.
#### Steps/code/corpus to reproduce
Here is what I tried to do by following the [gensim Phrase Detection documnetation](https://radimrehurek.com/gensim/models/phrases.html).
```python
from gensim.models.phrases import Phrases, ENGLISH_CONNECTOR_WORDS
```
Here is the output:
```python
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
<ipython-input-5-f038e2aaf034> in <module>
----> 1 from gensim.models.phrases import Phrases, ENGLISH_CONNECTOR_WORDS
ImportError: cannot import name 'ENGLISH_CONNECTOR_WORDS' from 'gensim.models.phrases' (/project/venv/lib/python3.9/site-packages/gensim/models/phrases.py)
```
#### Versions
```python
macOS-10.15.7-x86_64-i386-64bit
Python 3.9.0 (default, Oct 30 2020, 16:46:27)
[Clang 12.0.0 (clang-1200.0.32.2)]
Bits 64
NumPy 1.19.4
SciPy 1.6.0
gensim 3.8.3
FAST_VERSION 0
```
| closed | 2021-01-06T02:20:05Z | 2021-01-06T11:08:57Z | https://github.com/piskvorky/gensim/issues/3019 | [] | syedarehaq | 1 |
Kanaries/pygwalker | pandas | 618 | [BUG] Memory growth when using PyGWalker with Streamlit | **Describe the bug**
I observe RAM growth when using PyGWalker with Streamlit framework. The RAM usage constantly grow on page reload (on every app run). When using Streamlit without PyGWalker, RAM usage remain constant (flat, does not grow). It seems like memory is never released, this was observed indirectly (we tracked growth locally, see reproduction below, but we also observe same issue in Azure web app and RAM usage never decline).
**To Reproduce**
We tracked down the issue with isolated Streamlit app with PyGwalker and memory profile (run with `python -m streamlit run app.py`):
```
# app.py
import numpy as np
np.random.seed(seed=1)
import pandas as pd
from memory_profiler import profile
from pygwalker.api.streamlit import StreamlitRenderer
@profile
def app():
# Create random dataframe
df = pd.DataFrame(np.random.randint(0, 100, size=(100, 4)), columns=list("ABCD"))
render = StreamlitRenderer(df)
render.explorer()
app()
```
Observed output for a few consequent reloads from browser (press `R`, rerun):
```
Line # Mem usage Increment Occurrences Line Contents
13 302.6 MiB 23.3 MiB 1 render.explorer()
13 315.4 MiB 23.3 MiB 1 render.explorer()
13 325.8 MiB 23.3 MiB 1 render.explorer()
```
**Expected behavior**
RAM usage to remain at constant level between app reruns.
**Screenshots**
On screenshot you may observe a user activity peaks (cause CPU usage) and growing RAM usage (memory set).

On this screenshot a debug app memory profiling is displayed.

**Versions**
streamlit 1.38.0
pygwalker 0.4.9.3
memory_profiler (latest)
python 3.9.10
browser: chrome 128.0.6613.138 (Official Build) (64-bit)
Tested locally on Windows 11
*Thanks for support!* | open | 2024-09-13T07:23:36Z | 2024-09-29T02:07:33Z | https://github.com/Kanaries/pygwalker/issues/618 | [
"bug",
"good first issue",
"P1"
] | ChrnyaevEK | 3 |
microsoft/MMdnn | tensorflow | 529 | Could not support Slice in pytorch to IR | Platform (like ubuntu 16.04/win10): ubuntu 16.04
Python version:3.6
Source framework with version (like Tensorflow 1.4.1 with GPU):pytorch0.4.0 with GPU
Destination framework with version (like CNTK 2.3 with GPU):caffe
| open | 2018-12-17T07:55:59Z | 2018-12-26T13:48:40Z | https://github.com/microsoft/MMdnn/issues/529 | [
"enhancement"
] | xiaoranchenwai | 1 |
davidsandberg/facenet | tensorflow | 510 | Hi,a question about export embeddings and labels | Hello, I have a quesion bout the labels by export_embeddings.py.
I think the 'label_list' is the same as 'classes'
So I can only ues the label_list to train my own model?
Looking farword your replying sincely
Thanks
@davidsandberg @cjekel
| closed | 2017-10-31T08:04:33Z | 2017-11-07T01:00:42Z | https://github.com/davidsandberg/facenet/issues/510 | [] | xvdehao | 1 |
tortoise/tortoise-orm | asyncio | 1,853 | IntField: constraints not taken into account | **Describe the bug**
The IntField has the property constraints. It contains the constraints `ge` and `le`. These constraints are not taken into account (in any place as far as I can tell) or they should be reflected by a validator.
**To Reproduce**
```py
from tortoise import models, fields, run_async
from tortoise.contrib.test import init_memory_sqlite
class Acc(models.Model):
id = fields.IntField(pk=True)
some = fields.IntField()
async def main():
constraints_id = Acc._meta.fields_map.get('id').constraints # {'ge': -2147483648, 'le': 2147483647}
too_high_id = constraints_id.get('le') + 1
constraints_some = Acc._meta.fields_map.get('some').constraints # {'ge': -2147483648, 'le': 2147483647}
too_low_some = constraints_some.get('ge') - 1
acc = Acc(id=too_high_id, some=too_low_some) # this should throw an error
await acc.save() # or maybe this
if __name__ == '__main__':
run_async(init_memory_sqlite(main)())
```
**Expected behavior**
Either the constraints should match the capabilities of the DB or the constraints should be checked beforehand. And an error should be thrown.
**Additional context**
The produced Pydantic Model by pydantic_model_creator would check those constraints.
| open | 2025-01-17T10:30:36Z | 2025-02-24T10:49:30Z | https://github.com/tortoise/tortoise-orm/issues/1853 | [
"enhancement"
] | markus-96 | 0 |
pallets/flask | flask | 4,569 | Move `redirect` to the `Flask` app object | Add a `redirect` method to the `Flask` app object. Similar to functions like `flask.json.dumps`, `flask.redirect` should look for a `current_app` and call its `redirect` method. This will allow applications to override the redirect behavior. | closed | 2022-05-02T14:41:29Z | 2022-05-26T00:06:04Z | https://github.com/pallets/flask/issues/4569 | [
"save-for-sprint"
] | davidism | 2 |
vllm-project/vllm | pytorch | 14,583 | [Bug]: ERROR 03-11 07:47:00 [engine.py:141] AttributeError: Invalid attention type encoder-only | ### Your current environment
<details>
<summary>The output of `python collect_env.py`</summary>
```text
Your output of `python collect_env.py` here
```
INFO 03-11 07:49:54 [__init__.py:256] Automatically detected platform rocm.
Collecting environment information...
PyTorch version: 2.7.0.dev20250309+rocm6.3
Is debug build: False
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: 6.3.42131-fa1d09cbd
OS: Fedora Linux 40 (Server Edition) (x86_64)
GCC version: (GCC) 14.2.1 20240912 (Red Hat 14.2.1-3)
Clang version: 18.0.0git (https://github.com/RadeonOpenCompute/llvm-project roc-6.3.3 25012 e5bf7e55c91490b07c49d8960fa7983d864936c4)
CMake version: version 3.31.2
Libc version: glibc-2.39
Python version: 3.12.8 | packaged by Anaconda, Inc. | (main, Dec 11 2024, 16:31:09) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-6.13.5-100.fc40.x86_64-x86_64-with-glibc2.39
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: AMD Instinct MI100 (gfx908:sramecc+:xnack-)
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: 6.3.42131
MIOpen runtime version: 3.3.0
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Vendor ID: AuthenticAMD
Model name: AMD EPYC 7C13 64-Core Processor
CPU family: 25
Model: 1
Thread(s) per core: 1
Core(s) per socket: 64
Socket(s): 2
Stepping: 1
Frequency boost: enabled
CPU(s) scaling MHz: 45%
CPU max MHz: 3720.0000
CPU min MHz: 400.0000
BogoMIPS: 4000.34
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 pcid sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate ssbd mba ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local user_shstk clzero irperf xsaveerptr rdpru wbnoinvd amd_ppin brs arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold v_vmsave_vmload vgif v_spec_ctrl umip pku ospke vaes vpclmulqdq rdpid overflow_recov succor smca fsrm debug_swap
Virtualization: AMD-V
L1d cache: 4 MiB (128 instances)
L1i cache: 4 MiB (128 instances)
L2 cache: 64 MiB (128 instances)
L3 cache: 512 MiB (16 instances)
NUMA node(s): 2
NUMA node0 CPU(s): 0-63
NUMA node1 CPU(s): 64-127
Vulnerability Gather data sampling: Not affected
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Reg file data sampling: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec rstack overflow: Mitigation; Safe RET
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines; IBPB conditional; IBRS_FW; STIBP disabled; RSB filling; PBRSB-eIBRS Not affected; BHI Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.26.4
[pip3] nvidia-cublas-cu12==12.4.5.8
[pip3] nvidia-cuda-cupti-cu12==12.4.127
[pip3] nvidia-cuda-nvrtc-cu12==12.4.127
[pip3] nvidia-cuda-runtime-cu12==12.4.127
[pip3] nvidia-cudnn-cu12==9.1.0.70
[pip3] nvidia-cufft-cu12==11.2.1.3
[pip3] nvidia-curand-cu12==10.3.5.147
[pip3] nvidia-cusolver-cu12==11.6.1.9
[pip3] nvidia-cusparse-cu12==12.3.1.170
[pip3] nvidia-cusparselt-cu12==0.6.2
[pip3] nvidia-ml-py==12.560.30
[pip3] nvidia-nccl-cu12==2.21.5
[pip3] nvidia-nvjitlink-cu12==12.4.127
[pip3] nvidia-nvtx-cu12==12.4.127
[pip3] optree==0.14.1
[pip3] pytorch-triton-rocm==3.2.0+git4b3bb1f8
[pip3] pyzmq==26.2.1
[pip3] torch==2.7.0.dev20250309+rocm6.3
[pip3] torchaudio==2.6.0.dev20250309+rocm6.3
[pip3] torchvision==0.22.0.dev20250309+rocm6.3
[pip3] transformers==4.49.0
[pip3] triton==3.0.0
[conda] numpy 1.26.4 pypi_0 pypi
[conda] nvidia-cublas-cu12 12.4.5.8 pypi_0 pypi
[conda] nvidia-cuda-cupti-cu12 12.4.127 pypi_0 pypi
[conda] nvidia-cuda-nvrtc-cu12 12.4.127 pypi_0 pypi
[conda] nvidia-cuda-runtime-cu12 12.4.127 pypi_0 pypi
[conda] nvidia-cudnn-cu12 9.1.0.70 pypi_0 pypi
[conda] nvidia-cufft-cu12 11.2.1.3 pypi_0 pypi
[conda] nvidia-curand-cu12 10.3.5.147 pypi_0 pypi
[conda] nvidia-cusolver-cu12 11.6.1.9 pypi_0 pypi
[conda] nvidia-cusparse-cu12 12.3.1.170 pypi_0 pypi
[conda] nvidia-cusparselt-cu12 0.6.2 pypi_0 pypi
[conda] nvidia-ml-py 12.560.30 pypi_0 pypi
[conda] nvidia-nccl-cu12 2.21.5 pypi_0 pypi
[conda] nvidia-nvjitlink-cu12 12.4.127 pypi_0 pypi
[conda] nvidia-nvtx-cu12 12.4.127 pypi_0 pypi
[conda] optree 0.14.1 pypi_0 pypi
[conda] pytorch-triton-rocm 3.2.0+git4b3bb1f8 pypi_0 pypi
[conda] pyzmq 26.2.1 pypi_0 pypi
[conda] torch 2.7.0.dev20250309+rocm6.3 pypi_0 pypi
[conda] torchaudio 2.6.0.dev20250309+rocm6.3 pypi_0 pypi
[conda] torchvision 0.22.0.dev20250309+rocm6.3 pypi_0 pypi
[conda] transformers 4.49.0 pypi_0 pypi
[conda] triton 3.0.0 pypi_0 pypi
ROCM Version: 6.3.42134-a9a80e791
Neuron SDK Version: N/A
vLLM Version: 0.7.4.dev340+gdc74613f.d20250310
vLLM Build Flags:
CUDA Archs: Not Set; ROCm: Disabled; Neuron: Disabled
GPU Topology:
============================ ROCm System Management Interface ============================
================================ Weight between two GPUs =================================
GPU0 GPU1
GPU0 0 40
GPU1 40 0
================================= Hops between two GPUs ==================================
GPU0 GPU1
GPU0 0 2
GPU1 2 0
=============================== Link Type between two GPUs ===============================
GPU0 GPU1
GPU0 0 PCIE
GPU1 PCIE 0
======================================= Numa Nodes =======================================
GPU[0] : (Topology) Numa Node: 1
GPU[0] : (Topology) Numa Affinity: 1
GPU[1] : (Topology) Numa Node: 1
GPU[1] : (Topology) Numa Affinity: 1
================================== End of ROCm SMI Log ===================================
PYTORCH_ROCM_ARCH=gfx908
VLLM_TARGET_DEVICE=rocm
LD_LIBRARY_PATH=/data01/anaconda3/envs/vllm/lib/python3.12/site-packages/cv2/../../lib64:/usr/lib64:/usr/local/lib:/opt/rocm-6.3.3/lib:
PYTORCH_ROCM_DISABLE_HIPBLASLT=1
VLLM_USE_TRITON_FLASH_ATTN=0
NCCL_CUMEM_ENABLE=0
TORCHINDUCTOR_COMPILE_THREADS=1
CUDA_MODULE_LOADING=LAZY
</details>
### 🐛 Describe the bug
ERROR 03-11 07:47:00 [engine.py:141] AttributeError('Invalid attention type encoder_only')
ERROR 03-11 07:47:00 [engine.py:141] Traceback (most recent call last):
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/engine/multiprocessing/engine.py", line 139, in start
ERROR 03-11 07:47:00 [engine.py:141] self.run_engine_loop()
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/engine/multiprocessing/engine.py", line 202, in run_engine_loop
ERROR 03-11 07:47:00 [engine.py:141] request_outputs = self.engine_step()
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/engine/multiprocessing/engine.py", line 228, in engine_step
ERROR 03-11 07:47:00 [engine.py:141] raise e
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/engine/multiprocessing/engine.py", line 211, in engine_step
ERROR 03-11 07:47:00 [engine.py:141] return self.engine.step()
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/engine/llm_engine.py", line 1407, in step
ERROR 03-11 07:47:00 [engine.py:141] outputs = self.model_executor.execute_model(
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/executor/executor_base.py", line 139, in execute_model
ERROR 03-11 07:47:00 [engine.py:141] output = self.collective_rpc("execute_model",
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/executor/uniproc_executor.py", line 56, in collective_rpc
ERROR 03-11 07:47:00 [engine.py:141] answer = run_method(self.driver_worker, method, args, kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/utils.py", line 2238, in run_method
ERROR 03-11 07:47:00 [engine.py:141] return func(*args, **kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/worker/worker_base.py", line 420, in execute_model
ERROR 03-11 07:47:00 [engine.py:141] output = self.model_runner.execute_model(
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/data01/anaconda3/envs/vllm/lib/python3.12/site-packages/torch/utils/_contextlib.py", line 116, in decorate_context
ERROR 03-11 07:47:00 [engine.py:141] return func(*args, **kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/worker/pooling_model_runner.py", line 111, in execute_model
ERROR 03-11 07:47:00 [engine.py:141] hidden_or_intermediate_states = model_executable(
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/data01/anaconda3/envs/vllm/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1751, in _wrapped_call_impl
ERROR 03-11 07:47:00 [engine.py:141] return self._call_impl(*args, **kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/data01/anaconda3/envs/vllm/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1762, in _call_impl
ERROR 03-11 07:47:00 [engine.py:141] return forward_call(*args, **kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/model_executor/models/bert.py", line 414, in forward
ERROR 03-11 07:47:00 [engine.py:141] return self.model(input_ids=input_ids,
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/data01/anaconda3/envs/vllm/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1751, in _wrapped_call_impl
ERROR 03-11 07:47:00 [engine.py:141] return self._call_impl(*args, **kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/data01/anaconda3/envs/vllm/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1762, in _call_impl
ERROR 03-11 07:47:00 [engine.py:141] return forward_call(*args, **kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/model_executor/models/bert.py", line 349, in forward
ERROR 03-11 07:47:00 [engine.py:141] return self.encoder(hidden_states)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/compilation/decorators.py", line 172, in __call__
ERROR 03-11 07:47:00 [engine.py:141] return self.forward(*args, **kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/model_executor/models/bert.py", line 119, in forward
ERROR 03-11 07:47:00 [engine.py:141] hidden_states = layer(hidden_states)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/data01/anaconda3/envs/vllm/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1751, in _wrapped_call_impl
ERROR 03-11 07:47:00 [engine.py:141] return self._call_impl(*args, **kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/data01/anaconda3/envs/vllm/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1762, in _call_impl
ERROR 03-11 07:47:00 [engine.py:141] return forward_call(*args, **kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/model_executor/models/bert.py", line 154, in forward
ERROR 03-11 07:47:00 [engine.py:141] attn_output = self.attention(hidden_states)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/data01/anaconda3/envs/vllm/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1751, in _wrapped_call_impl
ERROR 03-11 07:47:00 [engine.py:141] return self._call_impl(*args, **kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/data01/anaconda3/envs/vllm/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1762, in _call_impl
ERROR 03-11 07:47:00 [engine.py:141] return forward_call(*args, **kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/model_executor/models/bert.py", line 188, in forward
ERROR 03-11 07:47:00 [engine.py:141] self_output = self.self(hidden_states)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/data01/anaconda3/envs/vllm/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1751, in _wrapped_call_impl
ERROR 03-11 07:47:00 [engine.py:141] return self._call_impl(*args, **kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/data01/anaconda3/envs/vllm/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1762, in _call_impl
ERROR 03-11 07:47:00 [engine.py:141] return forward_call(*args, **kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/model_executor/models/bert.py", line 243, in forward
ERROR 03-11 07:47:00 [engine.py:141] output = self.attn(q, k, v)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/data01/anaconda3/envs/vllm/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1751, in _wrapped_call_impl
ERROR 03-11 07:47:00 [engine.py:141] return self._call_impl(*args, **kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/data01/anaconda3/envs/vllm/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1762, in _call_impl
ERROR 03-11 07:47:00 [engine.py:141] return forward_call(*args, **kwargs)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/attention/layer.py", line 225, in forward
ERROR 03-11 07:47:00 [engine.py:141] return torch.ops.vllm.unified_attention(
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/data01/anaconda3/envs/vllm/lib/python3.12/site-packages/torch/_ops.py", line 1158, in __call__
ERROR 03-11 07:47:00 [engine.py:141] return self._op(*args, **(kwargs or {}))
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/attention/layer.py", line 331, in unified_attention
ERROR 03-11 07:47:00 [engine.py:141] return self.impl.forward(self, query, key, value, kv_cache, attn_metadata)
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/attention/backends/rocm_flash_attn.py", line 667, in forward
ERROR 03-11 07:47:00 [engine.py:141] causal_mask) = _get_seq_len_block_table_args(
ERROR 03-11 07:47:00 [engine.py:141] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 03-11 07:47:00 [engine.py:141] File "/home/radmin/gitlab/vllm/vllm/attention/backends/rocm_flash_attn.py", line 421, in _get_seq_len_block_table_args
ERROR 03-11 07:47:00 [engine.py:141] raise AttributeError(f"Invalid attention type {str(attn_type)}")
ERROR 03-11 07:47:00 [engine.py:141] AttributeError: Invalid attention type encoder_only
...
INFO 03-11 07:47:00 [logger.py:39] Received request embd-57e89ad988d14a9894249ce553985904-0: prompt: 'Thaa های тоlen loten diている oड्या suaલા16 ju ме in ac4%õ gia למ செல்லጉ gia למDEESTAכך sind高ronani till els sua су 20 jaunung r habari:1000larирање í është nuóła tubuha බව tillσεa är dekora های то mássang ги habari:1000e pour X可 habari:1000í های4 ke And Gι-им under pesquisa گفتπληf το viva jenαць<pad> nu vi sua untuk Si като ж sunt r inteیل nu меня vi敬 çoxité í化 keLA video پاکستان2和城 З R-имego pesquisa گفتπληf το viva მაць<pad> nu vi sua untuk Si като ж sunt r inteیل nuadi ; vi敬 çox програм2和城 З 8 եւимവര് bod” روی τοва न ke Leroep degreette 8 bona敬tima2 15 למ estasге可五eσεa های то más MV nu viство dụnge ved Gο asi ke技术ı sua aðı可 frálar Д तक和 အ кога vi可 frá keимتى wyborબကိုS למDEnet pasJAड्या apstkelA pasJAड्या apqa pesquisa گفت eनेa پاکستان pesquisa گفت e Toaint bod eő://kel ಇಲ್ಲ 그第二 Glückמיילa hafaට preocupaמייל так Також e`a還有 még को retzaο Le vilበል una triება ihana ärı可 fráe ved сува más viим uygun”ʻ nu viим歐 wybor dari keyn vi suaى frá ke NUe Wij团a viимego pesquisa گفت” fånuಲಿ Fed vi NU 문제им не” nuим歐تtigeσεa های اصلی vi suangимego pesquisa گفت e To”نLAበል ärим не e tri”ება ihan’f τοابון2 lo काम Anton部署njanı vi fărălarand vi çox perheधे videotul програмovi นาย Glücka nhưngට preocupaA suaseid үндэсний many第二 Glückמיילa hafaට preocupaמייל так ta e tri://</s>եց всеот นาย Glücka nhưngට preocupaAEtgrip اشاره 그 นาย Glücka nhưngට preocupa دی', params: PoolingParams(additional_metadata=None), prompt_token_ids: [5971, 11, 584, 690, 1977, 459, 510, 45, 7826, 36, 50207, 1646, 9725, 2485, 1129, 3928, 23, 1030, 11267, 4340, 3529, 7183, 80472, 11959, 3529, 7183, 8399, 55669, 77432, 1276, 1395, 1900, 2628, 570, 1115, 1646, 649, 387, 33519, 449, 1690, 17508, 12, 14105, 320, 21470, 439, 1396, 315, 41050, 11, 13931, 11, 5099, 570, 5810, 11, 369, 40075, 11, 584, 690, 1005, 433, 449, 1670, 17508, 12, 14105, 13, 578, 1193, 1403, 17508, 12, 14105, 430, 584, 617, 311, 3493, 527, 1473, 9, 1595, 1379, 31639, 5228, 45722, 420, 374, 279, 330, 7349, 1445, 3321, 1, 315, 279, 1646, 482, 602, 1770, 2637, 1268, 1690, 892, 7504, 315, 3925, 279, 30828, 4009, 5097, 439, 1988, 311, 8356, 1202, 2612, 304, 264, 4741, 1522, 627, 9, 1595, 3081, 31639, 5228, 45722, 420, 374, 279, 330, 13741, 3321, 1, 315, 279, 1646, 482, 602, 1770, 2637, 1268, 1690, 892, 7504, 315, 3938, 2819, 279, 30828, 4009, 16674, 304, 264, 4741, 1522, 382, 791, 1595, 11719, 4486, 63, 5852, 374, 1120, 1618, 311, 636, 53823, 79385, 3135, 382, 13622, 30828, 14488, 304, 423, 7183, 1397, 1521, 1403, 5137, 13, 5810, 11, 584, 690, 1005, 66160, 315, 279, 3280, 2786, 13, 1226, 527, 1457, 5644, 311, 5052, 1057, 1646, 389, 1057, 1403, 4101, 320, 1729, 7231, 264, 1160, 8649, 279, 1403, 4101, 311, 1595, 6410, 55358, 7887, 1527, 294, 7183, 8399, 1179, 452, 11855, 50207, 1747, 271, 2590, 284, 452, 11855, 50207, 1747, 5498, 31639, 5228, 28, 1187, 11, 2612, 31639, 5228, 28, 717, 11, 4288, 4486, 28, 2983, 696, 2590, 21529, 2625, 10613, 51927, 62815, 11, 5542, 722, 34263, 62815, 1145, 40446, 28, 1135, 11, 14008, 3702, 629, 10267, 596, 1457, 636, 1063, 51165, 220, 1927, 4038, 8469, 11, 369, 1057, 1403, 4101, 13, 1226, 649, 1120, 1005, 279, 1595, 20473, 63, 5811, 315, 279, 1595, 35798, 55358, 734, 311, 3371, 279, 1646, 902, 4101, 311, 18057, 13, 13516, 18007, 11, 279, 1595, 3081, 31639, 5228, 63, 1587, 539, 6089, 80799, 279, 18057, 35174, 1595, 77, 63, 315, 1595, 35798, 368, 29687, 5810, 11, 584, 16572, 279, 1646, 449, 1595, 3081, 31639, 5228, 28, 717, 63, 323, 8356, 51165, 369, 1595, 77, 28, 1927, 63, 4038, 8469, 26, 420, 374, 5042, 2884, 304, 459, 3313, 33263, 49053, 1648, 4920, 279, 16451, 320, 2940, 279, 4009, 53947, 60606, 1202, 3766, 16674, 3677, 24361, 51927, 11, 4255, 722, 34263, 284, 1646, 24706, 71951, 5941, 10613, 51927, 62815, 11, 5542, 722, 34263, 62815, 1145, 308, 28, 1927, 696, 2, 5569, 1203, 512, 24361, 51927, 11, 4255, 722, 34263, 284, 69824, 77663, 18956, 2625, 24361, 51927, 11, 4255, 722, 34263, 2526], lora_request: None, prompt_adapter_request: None.
CRITICAL 03-11 07:47:00 [launcher.py:116] MQLLMEngine is already dead, terminating server process
INFO: 192.168.50.87:49810 - "POST /v1/embeddings HTTP/1.1" 500 Internal Server Error
### Before submitting a new issue...
- [x] Make sure you already searched for relevant issues, and asked the chatbot living at the bottom right corner of the [documentation page](https://docs.vllm.ai/en/latest/), which can answer lots of frequently asked questions. | closed | 2025-03-10T22:56:17Z | 2025-03-12T16:31:21Z | https://github.com/vllm-project/vllm/issues/14583 | [
"bug"
] | gigascake | 1 |
aio-libs-abandoned/aioredis-py | asyncio | 1,179 | "aioredis.exceptions.ConnectionError: max number of clients reached" When my website gets lots of requests | ### Describe the bug
When I dos my website I get this error `aioredis.exceptions.ConnectionError: max number of clients reached`. I do not get this error when using the non async redis library.
### To Reproduce
code : https://pastecord.com/pozywivufa.py
### Expected behavior
I would expect this to ratelimit the requests from the dos attack.
### Logs/tracebacks
```python-traceback
`Error handling request
Traceback (most recent call last):
File "C:\Users\fixin\PycharmProjects\aiohttp-ratelimiter\venv\lib\site-packages\aiohttp\web_protocol.py", line 422, in _handle_request
resp = await self._request_handler(request)
File "C:\Users\fixin\PycharmProjects\aiohttp-ratelimiter\venv\lib\site-packages\aiohttp\web_app.py", line 499, in _handle
resp = await handler(request)
File "C:\Users\fixin\PycharmProjects\aiohttp-ratelimiter\aiohttplimiter\redis_limiter.py", line 43, in wrapper
nc = await self.db.get(db_key)
File "C:\Users\fixin\PycharmProjects\aiohttp-ratelimiter\venv\lib\site-packages\aioredis\client.py", line 1061, in execute_command
conn = self.connection or await pool.get_connection(command_name, **options)
File "C:\Users\fixin\PycharmProjects\aiohttp-ratelimiter\venv\lib\site-packages\aioredis\connection.py", line 1359, in get_connection
await connection.connect()
File "C:\Users\fixin\PycharmProjects\aiohttp-ratelimiter\venv\lib\site-packages\aioredis\connection.py", line 661, in connect
await self.on_connect()
File "C:\Users\fixin\PycharmProjects\aiohttp-ratelimiter\venv\lib\site-packages\aioredis\connection.py", line 726, in on_connect
auth_response = await self.read_response()
File "C:\Users\fixin\PycharmProjects\aiohttp-ratelimiter\venv\lib\site-packages\aioredis\connection.py", line 854, in read_response
response = await self._parser.read_response()
File "C:\Users\fixin\PycharmProjects\aiohttp-ratelimiter\venv\lib\site-packages\aioredis\connection.py", line 383, in read_response
raise error
aioredis.exceptions.ConnectionError: max number of clients reached
`
```
### Python Version
```console
$ python --version
3.9.7
```
### aioredis Version
```console
$ python -m pip show aioredis
2.0
```
### Additional context
_No response_
### Code of Conduct
- [X] I agree to follow the aio-libs Code of Conduct | closed | 2021-10-20T19:20:49Z | 2022-02-14T14:26:16Z | https://github.com/aio-libs-abandoned/aioredis-py/issues/1179 | [
"bug"
] | Nebula1213 | 7 |
ploomber/ploomber | jupyter | 300 | Simplify logic to determine project root | Currently, ploomber sets the project root to a folder that has a requirements.txt or environment.yml. This was under the assumption that pipeline.yaml is always next to these files but that might not be the case.
We must simplify this logic to make it more intuitive and only rely on pipeline.yaml. This requires refactoring the logic to cover the case where the pipeline.yaml file is inside a package (e.g., src/package_name/pipeline.yaml). | closed | 2021-06-12T17:37:19Z | 2021-06-18T01:23:43Z | https://github.com/ploomber/ploomber/issues/300 | [] | edublancas | 0 |
BeanieODM/beanie | pydantic | 304 | Cyclic Relations | Will beanie support cyclic relations soon, or is that not a planned feature?
E.g.,
```python
from beanie import Document
class Employer(Document):
name: str
employees: Link['Employee']
class Employee(Document):
name: str
employer: Link[Employer]
``` | closed | 2022-07-14T22:23:54Z | 2023-01-06T02:35:05Z | https://github.com/BeanieODM/beanie/issues/304 | [
"Stale"
] | gncs | 6 |
seleniumbase/SeleniumBase | pytest | 2,249 | PSA: Check for duplicates before opening new tickets! | I'm starting to receive more than 20 GitHub notifications per day (plus more from other networks). I'm well aware of the sharp increase in visitors since releasing a popular new YouTube video a week ago on UC Mode (https://www.youtube.com/watch?v=5dMFI3e85ig), which is currently getting around 100 views per day. I'm doing my best to keep up with all your tickets, questions, issues, etc, but you can help out by making sure your questions weren't already answered. Be aware that I do have a full-time job outside of SeleniumBase. Many of your tickets require more than simple answers:
<img width="588" alt="Screenshot 2023-11-07 at 9 32 27 AM" src="https://github.com/seleniumbase/SeleniumBase/assets/6788579/48b65c6e-bad7-4244-8bb4-6ae86ffa4f54">
(That's just the notifications from GitHub!)
Getting through that many notifications in a timely fashion may require speeding through them with less-than-complete answers/solutions. This probably means I'll need to start prioritizing tickets when too many come in at once. If you want your tickets to be prioritized, be sure you have already given a **GitHub Star** (⭐) to SeleniumBase first. That shows you appreciate the work I do, and in return, your tickets get prioritized. | open | 2023-11-07T15:25:25Z | 2023-11-07T18:33:58Z | https://github.com/seleniumbase/SeleniumBase/issues/2249 | [
"News / Announcements"
] | mdmintz | 3 |
Yorko/mlcourse.ai | matplotlib | 680 | Assignment 2. Last question | The right answer is not 55. It's 54, according to the data:
[image](https://drive.google.com/file/d/1XQ7eWW4Wcn_3Uub3IOx_ZCMWmT5mJAZ0/view?usp=sharing)
This might as well be my mistake in rounding ages, but I've used the standard round() function for that.
`df['age_years'] = round(df['age'] / 30 / 12)`
(the result is practically the same on both cleaned and default datasets) | closed | 2021-02-10T18:54:54Z | 2021-02-10T19:14:28Z | https://github.com/Yorko/mlcourse.ai/issues/680 | [] | DablSi | 0 |
huggingface/datasets | tensorflow | 7,298 | loading dataset issue with load_dataset() when training controlnet | ### Describe the bug
i'm unable to load my dataset for [controlnet training](https://github.com/huggingface/diffusers/blob/074e12358bc17e7dbe111ea4f62f05dbae8a49d5/examples/controlnet/train_controlnet.py#L606) using load_dataset(). however, load_from_disk() seems to work?
would appreciate if someone can explain why that's the case here
1. for reference here's the structure of the original training files _before_ dataset creation -
```
- dir train
- dir A (illustrations)
- dir B (SignWriting)
- prompt.json containing:
{"source": "B/file.png", "target": "A/file.png", "prompt": "..."}
```
2. here are features _after_ dataset creation -
```
"features": {
"control_image": {
"_type": "Image"
},
"image": {
"_type": "Image"
},
"caption": {
"dtype": "string",
"_type": "Value"
}
```
3. I've also attempted to upload the dataset to huggingface with the same error output
### Steps to reproduce the bug
1. [dataset creation script](https://github.com/sign-language-processing/signwriting-illustration/blob/main/signwriting_illustration/controlnet_huggingface/dataset.py)
2. controlnet [training script](examples/controlnet/train_controlnet.py) used
3. training parameters -
! accelerate launch diffusers/examples/controlnet/train_controlnet.py \
--pretrained_model_name_or_path="stable-diffusion-v1-5/stable-diffusion-v1-5" \
--output_dir="$OUTPUT_DIR" \
--train_data_dir="$HF_DATASET_DIR" \
--conditioning_image_column=control_image \
--image_column=image \
--caption_column=caption \
--resolution=512\
--learning_rate=1e-5 \
--validation_image "./validation/0a4b3c71265bb3a726457837428dda78.png" "./validation/0a5922fe2c638e6776bd62f623145004.png" "./validation/1c9f1a53106f64c682cf5d009ee7156f.png" \
--validation_prompt "An illustration of a man with short hair" "An illustration of a woman with short hair" "An illustration of Barack Obama" \
--train_batch_size=4 \
--num_train_epochs=500 \
--tracker_project_name="sd-controlnet-signwriting-test" \
--hub_model_id="sarahahtee/signwriting-illustration-test" \
--checkpointing_steps=5000 \
--validation_steps=1000 \
--report_to wandb \
--push_to_hub
4. command -
` sbatch --export=HUGGINGFACE_TOKEN=hf_token,WANDB_API_KEY=api_key script.sh`
### Expected behavior
```
11/25/2024 17:12:18 - INFO - __main__ - Initializing controlnet weights from unet
Generating train split: 1 examples [00:00, 334.85 examples/s]
Traceback (most recent call last):
File "/data/user/user/signwriting_illustration/controlnet_huggingface/diffusers/examples/controlnet/train_controlnet.py", line 1189, in <module>
main(args)
File "/data/user/user/signwriting_illustration/controlnet_huggingface/diffusers/examples/controlnet/train_controlnet.py", line 923, in main
train_dataset = make_train_dataset(args, tokenizer, accelerator)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/user/user/signwriting_illustration/controlnet_huggingface/diffusers/examples/controlnet/train_controlnet.py", line 639, in make_train_dataset
raise ValueError(
ValueError: `--image_column` value 'image' not found in dataset columns. Dataset columns are: _data_files, _fingerprint, _format_columns, _format_kwargs, _format_type, _output_all_columns, _split
```
### Environment info
accelerate 1.1.1
huggingface-hub 0.26.2
python 3.11
torch 2.5.1
transformers 4.46.2 | open | 2024-11-26T10:50:18Z | 2024-11-26T10:50:18Z | https://github.com/huggingface/datasets/issues/7298 | [] | sarahahtee | 0 |
microsoft/nni | machine-learning | 5,533 | RuntimeError: max(): Expected reduction dim to be specified for input.numel() == 0. Specify the reduction dim with the 'dim' argument | **Describe the bug**:
- scheduler: AGP
- pruner: TaylorFO
- mode: global
- using evaluator (new api)
- torchvision resnet 18 model
- iterations: 10
**Environment**:
- NNI version: 2.10
- Training service (local|remote|pai|aml|etc): local
- Python version: Python 3.9.12
- PyTorch version: 1.12.0 py3.9_cuda11.3_cudnn8.3.2_0 pytorch
- torchvision: 0.13.0 py39_cu113 pytorch
- Cpu or cuda version: cuda
**Reproduce the problem**
- Code|Example:
| closed | 2023-04-26T23:05:45Z | 2023-05-10T10:44:34Z | https://github.com/microsoft/nni/issues/5533 | [] | kriteshg | 9 |
roboflow/supervision | machine-learning | 754 | [ByteTrack] - redesign `update_with_detections` to use IoU to match input `Detections` with `tracker_id` | ### Description
- Currently, `update_with_detections` returns the predicted position of boxes, not their actual coordinates received from the detector. Many users have complained about the deterioration of box quality when using ByteTrack. ([#743](https://github.com/roboflow/supervision/issues/743))
- `ByteTrack` does not work with segmentation models because masks are not transferred to the `update_with_detections` output.
- The `Detections.data field` is lost after passing through `update_with_detections`.
All these issues can be resolved by changing the logic in `update_with_detections`. Instead of mapping values obtained from `update_with_tensors` to new `Detections` objects, we should use IoU to map the results of `update_with_tensors` to input `Detections` objects. This way, the input `xyxy` coordinates and the input state of the `mask` and `data` fields will be preserved.
For this purpose, we can utilize the already existing function [`box_iou_batch`](https://github.com/roboflow/supervision/blob/3024ddca83ad837651e59d040e2a5ac5b2b4f00f/supervision/detection/utils.py#L31). The matching procedure has been demonstrated in [one](https://www.youtube.com/watch?v=OS5qI9YBkfk) of our videos on YouTube.
### Additional
- Note: Please share a Google Colab with minimal code to test the new feature. We know it's additional work, but it will definitely speed up the review process. Each change must be tested by the reviewer. Setting up a local environment to do this is time-consuming. Please ensure that Google Colab can be accessed without any issues (make it public). Thank you! 🙏🏻 | closed | 2024-01-18T21:16:44Z | 2024-03-25T15:20:26Z | https://github.com/roboflow/supervision/issues/754 | [
"enhancement",
"api:tracker",
"Q1.2024"
] | SkalskiP | 3 |
art049/odmantic | pydantic | 353 | Embedded Model Exclude None Not Functioning | # Bug
Using 'exclude_none' in .update function does not work for fields in embedded models
### Current Behavior
Create 'model' with embedded model in field. Use 'exclude_none' in 'model.update(*, exclude_none=True). Field with non-null value becomes null in embedded model.
### Expected behavior
Fields in embedded model should not change from a non-null value to a null if exclude_none is set to True.
### Environment
- ODMantic version: odmantic==0.8.0
| open | 2023-04-18T00:12:05Z | 2023-04-19T04:35:07Z | https://github.com/art049/odmantic/issues/353 | [
"bug"
] | pmcb99 | 1 |
onnx/onnx | pytorch | 6,104 | Clarification of Reshape semantics for attribute 'allowzero' NOT set, zero volume | # Ask a Question
### Question
The Reshape documentation is not clear on whether reshaping from [0,10] to new shape [0,1,-1] is legal when attribute 'allowzero' is NOT set.
The relevant sentence is:
> At most one dimension of the new shape can be -1. In this case, the value is inferred from the size of the tensor and the remaining dimensions.
In the example, the input volume is 0, and the first two dimensions of the output tensor are [0,1]. The output tensor thus has a volume of 0 for _any_ value inferred for the -1 wildcard. Thus by one reading of the documentation the example is illegal.
However, another interpretation would be that when an input dimension is forwarded (because the new shape specifies 0 and `allowzero` is not set), then the dimension is ignored for purposes of inferring the -1 wildcard. I.e., the inference question is treated as equivalent to inferring the -1 wildcard for reshaping [10] to [1,-1].
Which interpretation is intended? | open | 2024-04-29T15:02:27Z | 2024-05-06T21:53:42Z | https://github.com/onnx/onnx/issues/6104 | [
"question",
"topic: spec clarification"
] | ArchRobison | 3 |
nerfstudio-project/nerfstudio | computer-vision | 2,602 | Add Orthographic Rendering Support | **Is your feature request related to a problem? Please describe.**
At present, nerfstudio does not support orthographic renderring. However, generating orthographic images requires merely producing a set of parallel rays for rendering for NeRF. This capability is essential for various applications but is currently lacking in nerfstudio. I plan to submit a PR for this feature.
**Describe the solution you'd like**
I propose to extend the existing `Cameras` class by adding an orthographic camera model to `CameraType`. This model would accept the same camera parameters as the perspective camera model already present in nerfstudio, allowing users to easily switch between perspective and orthographic modes.
| open | 2023-11-13T07:53:09Z | 2024-10-07T15:15:43Z | https://github.com/nerfstudio-project/nerfstudio/issues/2602 | [] | LeaFendd | 16 |
biolab/orange3 | data-visualization | 7,016 | File does not always recognize datetime from Google Sheets, and, in such cases, won't allow reinterpretation of text as datetime. | <!--
Thanks for taking the time to report a bug!
If you're raising an issue about an add-on (i.e., installed via Options > Add-ons), raise an issue in the relevant add-on's issue tracker instead. See: https://github.com/biolab?q=orange3
To fix the bug, we need to be able to reproduce it. Please answer the following questions to the best of your ability.
-->
**What's wrong?**
File does not always recognize datetime from Google Sheets, and, in such cases, won't allow reinterpretation of text as datetime.
**How can we reproduce the problem?**
Put a File widget on the canvas, and put the following link in the URL field: https://tinyurl.com/5xsaaywz (or https://docs.google.com/spreadsheets/d/1bWFTDeoOZ8qOc18OrprhhuHemgLolV8N0RG601j52zw/edit?gid=644664737#gid=644664737, which is what the short link refers to).
The datetime "End of Ride" is properly ISO formatted, but as Type, only text and categorical can be selected.
It can be changed to datetime with Edit Domain downstream, though
**What's your environment?**
<!-- To find your Orange version, see "Help → About → Version" or `Orange.version.full_version` in code -->
- Operating system: Mac OS 15.3
- Orange version: 3.38.1
| closed | 2025-02-04T16:06:11Z | 2025-02-11T08:10:58Z | https://github.com/biolab/orange3/issues/7016 | [
"bug report"
] | wvdvegte | 2 |
noirbizarre/flask-restplus | flask | 314 | Propagating exceptions | Flask has a [handle_exception](https://github.com/pallets/flask/blob/0.12.2/flask/app.py#L1520) method which handles exceptions and[ propagates](https://github.com/pallets/flask/blob/0.12.2/flask/app.py#L580) them if necessary prior to making a call to [log_exception](https://github.com/pallets/flask/blob/0.12.2/flask/app.py#L15446). Re-raising exceptions can be extremely helpful for debugging purposes.
Flask RESTPlus explicitly [calls](https://github.com/noirbizarre/flask-restplus/blob/0.10.1/flask_restplus/api.py#L597) the same `log_exception` function but I was wondering whether i) it should call `handle_exception` instead or ii) it should also re-raise (propagate) exceptions in debug mode.
A temporary work around is something of the form,
```python
@api.errorhandler
def default_error_handler(error):
"""
Default error handler to make certain that non-exception specific error
handlers and non-HTTPException exceptions are re-raised to ensure that the
original Flask error handler in invoked, which handles propagation of
errors.
:param Exception error: The error
:raises Exception: Re-raises the exception
"""
raise error
```
which ensures that an exception is thrown causing the [orginal_handler](https://github.com/noirbizarre/flask-restplus/blob/master/flask_restplus/api.py#L567) to be called however the full stack trace is not present.
Note even with the workaround I cannot invoke the Flask interactive debugger. I'm unsure whether that is the expected behavior or not. | open | 2017-08-14T21:24:03Z | 2018-05-03T01:30:45Z | https://github.com/noirbizarre/flask-restplus/issues/314 | [] | john-bodley | 3 |
STVIR/pysot | computer-vision | 149 | AdjustLayer may cause non-symmetric cropping | in _pysot/models/neck/neck.py_ starting from line 21
```
if x.size(3) < 20:
l = 4
r = l + 7
x = x[:, :, l:r, l:r]
return x
```
The hard-coding of _l_ & _r_ may cause non-symmetric cropping.
| closed | 2019-08-04T14:29:47Z | 2019-08-06T11:58:47Z | https://github.com/STVIR/pysot/issues/149 | [] | MARMOTatZJU | 1 |
astrofrog/mpl-scatter-density | matplotlib | 7 | Examples do not work in the jupyter notebook | Very interesting mini module. Thank you for this.
Examples do not appear to work in the jupyter notebook. I had no problem executing them in the ipython shell
Here is the traceback (Jupyter 5.0.0, python 3.6.1, ipython 5.3.0):
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/usr/lib/python3.6/site-packages/IPython/core/formatters.py in __call__(self, obj)
305 pass
306 else:
--> 307 return printer(obj)
308 # Finally look for special method names
309 method = get_real_method(obj, self.print_method)
/usr/lib/python3.6/site-packages/IPython/core/pylabtools.py in <lambda>(fig)
238
239 if 'png' in formats:
--> 240 png_formatter.for_type(Figure, lambda fig: print_figure(fig, 'png', **kwargs))
241 if 'retina' in formats or 'png2x' in formats:
242 png_formatter.for_type(Figure, lambda fig: retina_figure(fig, **kwargs))
/usr/lib/python3.6/site-packages/IPython/core/pylabtools.py in print_figure(fig, fmt, bbox_inches, **kwargs)
122
123 bytes_io = BytesIO()
--> 124 fig.canvas.print_figure(bytes_io, **kw)
125 data = bytes_io.getvalue()
126 if fmt == 'svg':
/usr/lib/python3.6/site-packages/matplotlib/backend_bases.py in print_figure(self, filename, dpi, facecolor, edgecolor, orientation, format, **kwargs)
2208 bbox_filtered = []
2209 for a in bbox_artists:
-> 2210 bbox = a.get_window_extent(renderer)
2211 if a.get_clip_on():
2212 clip_box = a.get_clip_box()
/usr/lib/python3.6/site-packages/matplotlib/image.py in get_window_extent(self, renderer)
755
756 def get_window_extent(self, renderer=None):
--> 757 x0, x1, y0, y1 = self._extent
758 bbox = Bbox.from_extents([x0, y0, x1, y1])
759 return bbox.transformed(self.axes.transData)
TypeError: 'NoneType' object is not iterable
``` | closed | 2017-07-19T23:47:44Z | 2017-07-20T16:05:29Z | https://github.com/astrofrog/mpl-scatter-density/issues/7 | [
"bug"
] | lbignone | 4 |
microsoft/Bringing-Old-Photos-Back-to-Life | pytorch | 104 | How to activate multi-GPU mode? | Is the multi-GPU mode supported? How do I enable it?
Thank you in advance | closed | 2020-12-31T00:01:33Z | 2021-12-02T01:34:31Z | https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life/issues/104 | [] | Gegam | 3 |
jpadilla/django-rest-framework-jwt | django | 15 | Ability to refresh JWT token | I know this has been talked about a little, but the ability to refresh the JWT token would be a great feature. I have a Django app that communicates to the REST framework via JWT. I stick the JWT token in the apps session scope but I have no control on how to refresh the token if the use is not done and it expires. I'd rather not have to have them login again and obviously storing the user credentials defeats the purpose of using JTW.
| closed | 2014-03-18T22:58:57Z | 2014-08-30T11:57:03Z | https://github.com/jpadilla/django-rest-framework-jwt/issues/15 | [] | jmacul2 | 3 |
polakowo/vectorbt | data-visualization | 312 | portfolion records and stats mismatch | PnL in records does not match the ending balance in portfolio stats, not sure i am missing something here. There is ~ month worth of data but only one day traded, all trades are closed.
```
portfolio = vbt.Portfolio.from_orders(p, orders, freq="1Min",direction='longonly',init_cash=10000.0)
print(portfolio.trades.records_readable.to_string())
Exit Trade Id Column Size Entry Timestamp Avg Entry Price Entry Fees Exit Timestamp Avg Exit Price Exit Fees PnL Return Direction Status Position Id
0 0 TEAM 44.0 2021-06-04 13:31:00+00:00 225.4100 0.0 2021-06-04 19:58:00+00:00 225.77 0.0 15.840 0.001597 Long Closed 0
1 1 LULU 30.0 2021-06-04 13:31:00+00:00 326.9899 0.0 2021-06-04 19:58:00+00:00 329.50 0.0 75.303 0.007676 Long Closed 1
2 2 TSLA 17.0 2021-06-04 13:31:00+00:00 580.3300 0.0 2021-06-04 19:58:00+00:00 599.11 0.0 319.260 0.032361 Long Closed 2
3 3 NVDA 14.0 2021-06-04 13:31:00+00:00 692.2900 0.0 2021-06-04 19:58:00+00:00 702.36 0.0 140.980 0.014546 Long Closed 3
4 4 IDXX 17.0 2021-06-04 13:30:00+00:00 559.9600 0.0 2021-06-04 19:58:00+00:00 558.34 0.0 -27.540 -0.002893 Long Closed 4
```
`print(portfolio.stats())`
```
Start 2021-06-01 08:00:00+00:00
End 2021-07-01 23:59:00+00:00
Period 12 days 19:30:00
Start Value 10000.0
End Value 10032.740187
Total Return [%] 0.327402
Benchmark Return [%] 9.289643
Max Gross Exposure [%] 30.512039
Total Fees Paid 0.0
Max Drawdown [%] 1.33725
Max Drawdown Duration 10 days 19:55:24
Total Trades 0.3125
Total Closed Trades 0.3125
Total Open Trades 0.0
Open Trade PnL 0.0
Win Rate [%] 80.0
Best Trade [%] 1.065745
Worst Trade [%] 1.065745
Avg Winning Trade [%] 1.404507
Avg Losing Trade [%] -0.289306
Avg Winning Trade Duration 0 days 06:27:00
Avg Losing Trade Duration 0 days 06:28:00
Profit Factor inf
Expectancy 104.7686
Sharpe Ratio inf
Calmar Ratio 39.094083
Omega Ratio inf
Sortino Ratio inf
Name: agg_func_mean, dtype: object
``` | closed | 2021-12-29T22:39:03Z | 2021-12-29T22:58:32Z | https://github.com/polakowo/vectorbt/issues/312 | [] | asemx | 6 |
keras-team/keras | python | 21,052 | convert_to_tensor does not support torch tensors on "meta" device | I faced the same error then #19376 using the torch backend. While investigating, I found that the "root" issue comes from `convert_to_tensor` not supporting torch tensors defined on "meta" device.
## Way to reproduce
```python
import os
os.environ["KERAS_BACKEND"] = "torch"
import torch
from keras import ops
with torch.device('meta'):
x = torch.randn(5)
ops.convert_to_tensor(x)
```
Outputs
```python
NotImplementedError: Cannot copy out of meta tensor; no data!
```
## System version
```
3.12.9 | packaged by Anaconda, Inc. | (main, Feb 6 2025, 18:56:27) [GCC 11.2.0]
Linux-5.4.0-208-generic-x86_64-with-glibc2.31
Keras 3.9.0
torch 2.5.1
``` | closed | 2025-03-17T16:51:37Z | 2025-03-18T15:15:20Z | https://github.com/keras-team/keras/issues/21052 | [
"type:Bug"
] | rfezzani | 0 |
jschneier/django-storages | django | 549 | Add AWS_STORAGE_CLASS setting | And deprecate `AWS_REDUCED_REDUNDANCY`. The available values (pulled out of botocore) are:
"STANDARD",
"REDUCED_REDUNDANCY",
"GLACIER",
"STANDARD_IA",
"ONEZONE_IA", | closed | 2018-08-12T03:15:34Z | 2020-02-03T05:47:11Z | https://github.com/jschneier/django-storages/issues/549 | [
"s3boto"
] | jschneier | 0 |
holoviz/panel | matplotlib | 6,923 | FileInput default to higher websocket_max_message_size? | Currently, the default is 20 MBs, but this is pretty small for most use cases.
If it exceeds the 20 MBs, it silently disconnects the websocket (at least in notebook; when serving, it does show `2024-06-14 11:39:36,766 WebSocket connection closed: code=None, reason=None`). This leaves the user confused as to why nothing is happening (perhaps a separate issue).
Is there a good reason why the default is 20 MBs, or can we make it larger?
For reference:
https://discourse.holoviz.org/t/file-upload-is-uploading-the-file-but-the-value-is-always-none/7268/7 | closed | 2024-06-14T18:59:54Z | 2024-06-25T11:23:18Z | https://github.com/holoviz/panel/issues/6923 | [
"wontfix",
"type: discussion"
] | ahuang11 | 1 |
albumentations-team/albumentations | machine-learning | 2,353 | HueSaturationValue: whites don't remain white with increase in saturation | ## Describe the bug
Whites become blue with increase in saturation.
### To Reproduce
Steps to reproduce the behavior:
Environment:
```
Python 3.11.10
Ubuntu 22.04
opencv-python==4.11.0.86
albumentations==2.0.0
```
Code:
```python
!wget "https://i.pinimg.com/originals/56/ad/53/56ad5334915d999d8ecc6e503f14fb29.png" -O sat.jpg
from albumentations import HueSaturationValue
hsv_transform = HueSaturationValue(hue_shift_limit=0, sat_shift_limit=(255,255), val_shift_limit=0, p=1.0)
img = cv2.imread('sat.jpg') # Replace with a valid image path
plt.imshow(hsv_transform(image=img)["image"].astype(np.uint8))
plt.axis("off")
```
Also reproducible in Explore with the same arguments:
https://explore.albumentations.ai/transform/HueSaturationValue
### Expected behavior
Whites should remain white and unaffected by saturation changes.
### Actual behavior
Whites became bluer with increase in saturation.
### Screenshots
**Original**

**Shifted**

| closed | 2025-02-25T06:33:45Z | 2025-02-26T21:03:34Z | https://github.com/albumentations-team/albumentations/issues/2353 | [
"bug"
] | Y-T-G | 1 |
hankcs/HanLP | nlp | 887 | 关于能否客观统计出文章中各词语的出现的次数 | ## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检索功能](https://github.com/hankcs/HanLP/issues)搜索了我的问题,也没有找到答案。
* 我明白开源社区是出于兴趣爱好聚集起来的自由社区,不承担任何责任或义务。我会礼貌发言,向每一个帮助我的人表示感谢。
* [ √] 我在此括号内输入x打钩,代表上述事项确认完毕。
## 版本号
1.6.6
当前最新版本号是:1.6.6
我使用的版本是:1.6.6
## 我的问题
如何客观统计出文章中各词语的出现的次数。
例如:今天是星期天我狠开心,希望下个星期天我也依然开心。
以上:星期天:2次;开心:2次;今天:1次 等...
## 复现问题
无
### 步骤
无
### 触发代码
无
### 期望输出
无
### 实际输出
无
## 其他信息
无
| closed | 2018-07-16T08:02:59Z | 2018-07-16T08:29:45Z | https://github.com/hankcs/HanLP/issues/887 | [] | potenlife | 1 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 16,466 | [Bug]: TypeError: AsyncConnectionPool.__init__() got an unexpected keyword argument 'socket_options' | ### Checklist
- [ ] The issue exists after disabling all extensions
- [ ] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [ ] The issue exists in the current version of the webui
- [ ] The issue has not been reported before recently
- [ ] The issue has been reported before but has not been fixed yet
### What happened?
/content
env: TF_CPP_MIN_LOG_LEVEL=1
51 packages can be upgraded. Run 'apt list --upgradable' to see them.
W: Skipping acquire of configured file 'main/source/Sources' as repository 'https://r2u.stat.illinois.edu/ubuntu jammy InRelease' does not seem to provide it (sources.list entry misspelt?)
env: LD_PRELOAD=/content/libtcmalloc_minimal.so.4
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
libcairo2-dev is already the newest version (1.16.0-5ubuntu2).
pkg-config is already the newest version (0.29.2-1ubuntu3).
aria2 is already the newest version (1.36.0-1).
python3-dev is already the newest version (3.10.6-1~22.04.1).
0 upgraded, 0 newly installed, 0 to remove and 51 not upgraded.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path 'stable-diffusion-webui' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/embeddings/negative' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/models/Lora/positive' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
555fe1|OK | 0B/s|/content/stable-diffusion-webui/models/ESRGAN/4x-UltraSharp.pth
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
--2024-09-06 05:59:24-- https://raw.githubusercontent.com/camenduru/stable-diffusion-webui-scripts/main/run_n_times.py
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 533 [text/plain]
Saving to: ‘/content/stable-diffusion-webui/scripts/run_n_times.py’
/content/stable-dif 100%[===================>] 533 --.-KB/s in 0s
2024-09-06 05:59:24 (37.4 MB/s) - ‘/content/stable-diffusion-webui/scripts/run_n_times.py’ saved [533/533]
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/deforum-for-automatic1111-webui' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/stable-diffusion-webui-images-browser' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/stable-diffusion-webui-huggingface' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/sd-civitai-browser' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/sd-webui-additional-networks' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/sd-webui-controlnet' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/openpose-editor' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/sd-webui-depth-lib' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/posex' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/sd-webui-3d-open-pose-editor' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/sd-webui-tunnels' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/batchlinks-webui' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/stable-diffusion-webui-catppuccin' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/stable-diffusion-webui-rembg' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/stable-diffusion-webui-two-shot' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/sd-webui-aspect-ratio-helper' already exists and is not an empty directory.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: destination path '/content/stable-diffusion-webui/extensions/asymmetric-tiling-sd-webui' already exists and is not an empty directory.
/content/stable-diffusion-webui
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
HEAD is now at f865d3e1 add changelog for 1.4.1
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
HEAD is now at cf1d67a Update modelcard.md
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
1024ca|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11e_sd15_ip2p_fp16.safetensors
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
347dcb|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11e_sd15_shuffle_fp16.safetensors
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
cd5f42|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_canny_fp16.safetensors
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
ca2576|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11f1p_sd15_depth_fp16.safetensors
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
a48655|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_inpaint_fp16.safetensors
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
dfb597|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_lineart_fp16.safetensors
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
f22a80|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_mlsd_fp16.safetensors
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
397dc5|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_normalbae_fp16.safetensors
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
708b46|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_openpose_fp16.safetensors
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
7637f7|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_scribble_fp16.safetensors
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
f6a8a9|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_seg_fp16.safetensors
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
e6d27f|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_softedge_fp16.safetensors
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
aa348b|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15s2_lineart_anime_fp16.safetensors
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
8ac149|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11f1e_sd15_tile_fp16.safetensors
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
05a30c|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11e_sd15_ip2p_fp16.yaml
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
28a747|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11e_sd15_shuffle_fp16.yaml
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
3e8f60|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_canny_fp16.yaml
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
c2b50d|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11f1p_sd15_depth_fp16.yaml
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
e2c962|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_inpaint_fp16.yaml
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
7dcf73|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_lineart_fp16.yaml
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
45d18d|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_mlsd_fp16.yaml
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
b58cf9|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_normalbae_fp16.yaml
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
f50a20|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_openpose_fp16.yaml
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
035707|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_scribble_fp16.yaml
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
7dc879|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_seg_fp16.yaml
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
732b82|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15_softedge_fp16.yaml
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
59c20b|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11p_sd15s2_lineart_anime_fp16.yaml
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
57d782|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/control_v11f1e_sd15_tile_fp16.yaml
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
5215f9|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/t2iadapter_style_sd14v1.pth
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
b3f046|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/t2iadapter_sketch_sd14v1.pth
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
ee8964|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/t2iadapter_seg_sd14v1.pth
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
bebf0f|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/t2iadapter_openpose_sd14v1.pth
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
28d091|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/t2iadapter_keypose_sd14v1.pth
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
9a2864|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/t2iadapter_depth_sd14v1.pth
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
c2538a|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/t2iadapter_color_sd14v1.pth
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
3feadd|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/t2iadapter_canny_sd14v1.pth
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
e5199d|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/t2iadapter_canny_sd15v2.pth
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
aae782|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/t2iadapter_depth_sd15v2.pth
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
3bc04e|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/t2iadapter_sketch_sd15v2.pth
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
986c25|OK | 0B/s|/content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/t2iadapter_zoedepth_sd15v1.pth
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
8fea2c|OK | 0B/s|/content/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned-emaonly.ckpt
Status Legend:
(OK):download completed.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
fatal: No names found, cannot describe anything.
Python 3.10.12 (main, Jul 29 2024, 16:56:48) [GCC 11.4.0]
Version: ## 1.4.1
Commit hash: f865d3e11647dfd6c7b2cdf90dde24680e58acd8
Installing requirements
ControlNet init warning: Unable to install insightface automatically. Please try run `pip install insightface` manually.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
ERROR: ld.so: object '/content/libtcmalloc_minimal.so.4' from LD_PRELOAD cannot be preloaded (file too short): ignored.
Launching Web UI with arguments: --listen --xformers --enable-insecure-extension-access --theme dark --gradio-queue --multiple
2024-09-06 05:59:58.551432: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:485] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-09-06 05:59:58.589830: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:8454] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-09-06 05:59:58.600425: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1452] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2024-09-06 06:00:00.268915: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
Traceback (most recent call last):
File "/content/stable-diffusion-webui/launch.py", line 40, in <module>
main()
File "/content/stable-diffusion-webui/launch.py", line 36, in main
start()
File "/content/stable-diffusion-webui/modules/launch_utils.py", line 340, in start
import webui
File "/content/stable-diffusion-webui/webui.py", line 35, in <module>
import gradio
File "/usr/local/lib/python3.10/dist-packages/gradio/__init__.py", line 3, in <module>
import gradio.components as components
File "/usr/local/lib/python3.10/dist-packages/gradio/components.py", line 55, in <module>
from gradio import processing_utils, utils
File "/usr/local/lib/python3.10/dist-packages/gradio/utils.py", line 339, in <module>
class AsyncRequest:
File "/usr/local/lib/python3.10/dist-packages/gradio/utils.py", line 358, in AsyncRequest
client = httpx.AsyncClient()
File "/usr/local/lib/python3.10/dist-packages/httpx/_client.py", line 1397, in __init__
self._transport = self._init_transport(
File "/usr/local/lib/python3.10/dist-packages/httpx/_client.py", line 1445, in _init_transport
return AsyncHTTPTransport(
File "/usr/local/lib/python3.10/dist-packages/httpx/_transports/default.py", line 275, in __init__
self._pool = httpcore.AsyncConnectionPool(
TypeError: AsyncConnectionPool.__init__() got an unexpected keyword argument 'socket_options'
### Steps to reproduce the problem
TypeError: AsyncConnectionPool.__init__() got an unexpected keyword argument 'socket_options'
### What should have happened?
1
### What browsers do you use to access the UI ?
Google Chrome
### Sysinfo
1
### Console logs
```Shell
1
```
### Additional information
_No response_ | open | 2024-09-06T06:06:03Z | 2024-10-09T01:35:34Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16466 | [
"bug-report"
] | whenold | 3 |
python-restx/flask-restx | api | 142 | AttributeError: 'SchemaModel' object has no attribute 'items' | Hi,
I am trying to use @api.marshal_with a JSON schema but I get the following error: AttributeError: 'SchemaModel' object has no attribute 'items'
The schema is correct as it works with @api.response and the model is shown correctly in Swagger.
### **Code**
```python
downloadOrderResponse = api.schema_model('DownloadOrderResponse', {
'properties': {
'iccid': {
"type" : "string",
"pattern" : "^[0-9]{19}[0-9F]?$",
"description" : "ICCID as described in section 5.2.1"
}
},
'type': 'object'
})
@api.route('/downloadOrder')
class DownloadOrder(Resource):
@api.marshal_with(downloadOrderResponse, skip_none=True)
def post(self):
return {
"iccid": "01234567890123456789"
}
```
### **Expected Behavior**
Correct response marshalling using the JSON schema.
### **Actual Behavior**
Throws: AttributeError: 'SchemaModel' object has no attribute 'items'
### **Error Messages/Stack Trace**
Traceback (most recent call last):
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask/app.py", line 2464, in __call__
return self.wsgi_app(environ, start_response)
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask/app.py", line 2450, in wsgi_app
response = self.handle_exception(e)
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask_restx/api.py", line 638, in error_router
return original_handler(f)
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask/app.py", line 1867, in handle_exception
reraise(exc_type, exc_value, tb)
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask/_compat.py", line 39, in reraise
raise value
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask_restx/api.py", line 636, in error_router
return self.handle_error(e)
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask/app.py", line 2447, in wsgi_app
response = self.full_dispatch_request()
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask/app.py", line 1952, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask_restx/api.py", line 638, in error_router
return original_handler(f)
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask/app.py", line 1821, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask/_compat.py", line 39, in reraise
raise value
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask_restx/api.py", line 636, in error_router
return self.handle_error(e)
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask/app.py", line 1950, in full_dispatch_request
rv = self.dispatch_request()
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask/app.py", line 1936, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask_restx/api.py", line 375, in wrapper
resp = resource(*args, **kwargs)
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask/views.py", line 89, in view
return self.dispatch_request(*args, **kwargs)
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask_restx/resource.py", line 44, in dispatch_request
resp = meth(*args, **kwargs)
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask_restx/marshalling.py", line 269, in wrapper
resp, self.fields, self.envelope, self.skip_none, mask, self.ordered
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask_restx/marshalling.py", line 58, in marshal
out, has_wildcards = _marshal(data, fields, envelope, skip_none, mask, ordered)
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/flask_restx/marshalling.py", line 181, in _marshal
for k, v in iteritems(fields)
File "/Users/edwin/.local/share/virtualenvs/flask-test-BGYUVEN8/lib/python3.7/site-packages/six.py", line 589, in iteritems
return iter(d.items(**kw))
AttributeError: 'SchemaModel' object has no attribute 'items'
### **Environment**
- Python version: 3.7.4
- Flask version: 1.1.2
- Werkzeug version: 1.0.1
- Flask-RESTX version: 0.2.0
| open | 2020-05-24T11:59:27Z | 2024-06-02T07:32:26Z | https://github.com/python-restx/flask-restx/issues/142 | [
"bug"
] | edwinhaver | 8 |
encode/databases | asyncio | 535 | Support for psycopg3? | Has there been any discussion around support for [psycopg 3](https://www.psycopg.org/features/) (now just psycopg)? It is a complete rewrite of the project. It was implemented to support async from the start. Seems like a natural fit. | open | 2023-02-15T19:59:53Z | 2024-03-03T13:51:08Z | https://github.com/encode/databases/issues/535 | [] | ghost | 5 |
tableau/server-client-python | rest-api | 678 | deleting duplicate datasources using tableau sever client | i am trying to delete some duplicate data sources available on the server using tableau server client. the script i have will only delete all data sources, but i do have specific data source names i want to delete from the server | closed | 2020-08-27T00:36:51Z | 2020-09-15T04:59:47Z | https://github.com/tableau/server-client-python/issues/678 | [] | Segexy | 1 |
Miserlou/Zappa | flask | 1,984 | Upcoming changes in Lambda. Does it affect Zappa? | https://aws.amazon.com/es/blogs/compute/coming-soon-updated-lambda-states-lifecycle-for-vpc-networking/
I have seen this regarding function creation. Does it affect Zappa? | open | 2020-01-21T16:01:20Z | 2021-02-09T13:15:25Z | https://github.com/Miserlou/Zappa/issues/1984 | [] | soymonitus | 9 |
tensorlayer/TensorLayer | tensorflow | 1,166 | A error about Q_learning | _**_a = np.argmax(Q[s, :] + np.random.randn(1, env.action_space.n) * (1. / (i + 1)))
IndexError: only integers, slices (`:`), ellipsis (`...`), numpy.newaxis (`None`) and integer or boolean arrays are valid indices_**_
import argparse
import os
import time
import gym
import matplotlib.pyplot as plt
import numpy as np
parser = argparse.ArgumentParser()
parser.add_argument('--train', dest='train', action='store_true', default=True)
parser.add_argument('--test', dest='test', action='store_true', default=True)
parser.add_argument(
'--save_path', default=None, help='folder to save if mode == train else model path,'
'qnet will be saved once target net update'
)
parser.add_argument('--seed', help='random seed', type=int, default=0)
parser.add_argument('--env_id', default='FrozenLake-v1')
args = parser.parse_args()
## Load the environment
alg_name = 'Qlearning'
env_id = args.env_id
env = gym.make(env_id)
render = False # display the game environment
##================= Implement Q-Table learning algorithm =====================##
## Initialize table with all zeros
Q = np.zeros([env.observation_space.n, env.action_space.n])
## Set learning parameters
lr = .85 # alpha, if use value function approximation, we can ignore it
lambd = .99 # decay factor
num_episodes = 10000
t0 = time.time()
if args.train:
all_episode_reward = []
for i in range(num_episodes):
## Reset environment and get first new observation
s = env.reset()
rAll = 0
## The Q-Table learning algorithm
for j in range(99):
if render: env.render()
## Choose an action by greedily (with noise) picking from Q table
a = np.argmax(Q[s, :] + np.random.randn(1, env.action_space.n) * (1. / (i + 1)))
## Get new state and reward from environment
s1, r, d, _ = env.step(a)
## Update Q-Table with new knowledge
Q[s, a] = Q[s, a] + lr * (r + lambd * np.max(Q[s1, :]) - Q[s, a])
rAll += r
s = s1
if d is True:
break
print(
'Training | Episode: {}/{} | Episode Reward: {:.4f} | Running Time: {:.4f}'.format(
i + 1, num_episodes, rAll,
time.time() - t0
)
)
if i == 0:
all_episode_reward.append(rAll)
else:
all_episode_reward.append(all_episode_reward[-1] * 0.9 + rAll * 0.1)
# save
path = os.path.join('model', '_'.join([alg_name, env_id]))
if not os.path.exists(path):
os.makedirs(path)
np.save(os.path.join(path, 'Q_table.npy'), Q)
plt.plot(all_episode_reward)
if not os.path.exists('image'):
os.makedirs('image')
plt.savefig(os.path.join('image', '_'.join([alg_name, env_id])))
# print("Final Q-Table Values:/n %s" % Q)
if args.test:
path = os.path.join('model', '_'.join([alg_name, env_id]))
Q = np.load(os.path.join(path, 'Q_table.npy'))
for i in range(num_episodes):
## Reset environment and get first new observation
s = env.reset()
rAll = 0
## The Q-Table learning algorithm
for j in range(99):
## Choose an action by greedily (with noise) picking from Q table
a = np.argmax(Q[s, :])
## Get new state and reward from environment
s1, r, d, _ = env.step(a)
## Update Q-Table with new knowledge
rAll += r
s = s1
if d is True:
break
print(
'Testing | Episode: {}/{} | Episode Reward: {:.4f} | Running Time: {:.4f}'.format(
i + 1, num_episodes, rAll,
time.time() - t0
)
)
**a = np.argmax(Q[s, :] + np.random.randn(1, env.action_space.n) * (1. / (i + 1)))
IndexError: only integers, slices (`:`), ellipsis (`...`), numpy.newaxis (`None`) and integer or boolean arrays are valid indices** | open | 2024-10-19T07:17:48Z | 2024-10-19T07:18:33Z | https://github.com/tensorlayer/TensorLayer/issues/1166 | [] | guest-oo | 0 |
GibbsConsulting/django-plotly-dash | plotly | 461 | Make code robust against internal method name | As per #460 the 2.10 release of Dash appears to have changed the name of an internal method.
There is a quick fix - restrict the dash version - and a better fix that is to handle both variants of the name (or not depend on an internal API if possible)
| open | 2023-05-28T17:27:52Z | 2023-05-28T17:27:52Z | https://github.com/GibbsConsulting/django-plotly-dash/issues/461 | [
"bug"
] | GibbsConsulting | 0 |
miguelgrinberg/Flask-Migrate | flask | 384 | Flask db migrate/upgrade not responding | Hi, I deleted the migrations folder, then ran `flask db init`, then `flask db migrate -m 'Test'`, but nothing happened, only got some messages:
```
INFO [alembic.runtime.migration] Context impl MySQLImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
```
The command `flask db upgrade` also shows the same message but nothing else. | closed | 2021-02-08T00:26:37Z | 2024-02-27T18:18:42Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/384 | [
"question"
] | Victor7095 | 10 |
Lightning-AI/pytorch-lightning | pytorch | 20,604 | PyTorchProfiler does not profile GPU | ### Bug description
Using PyTorchProfiler I don't get GPU profiling in Tensorboard view, the logs indicate that GPU is being used.

### What version are you seeing the problem on?
v2.5
### How to reproduce the bug
```python
Conda env
name: lightning_tutorials
channels:
- conda-forge
dependencies:
- python=3.12
- lightning
- torchvision=0.21.0=cuda126_py312_h361dbbe_0
- tensorboard
- torch-tb-profiler
train.py
import lightning as L
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as data
import torchvision as tv
from lightning.pytorch.loggers import TensorBoardLogger
from lightning.pytorch.profilers import PyTorchProfiler
# --------------------------------
# Step 1: Define a LightningModule
# --------------------------------
# A LightningModule (nn.Module subclass) defines a full *system*
# (ie: an LLM, diffusion model, autoencoder, or simple image classifier).
class LitAutoEncoder(L.LightningModule):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 3)
)
self.decoder = nn.Sequential(
nn.Linear(3, 128), nn.ReLU(), nn.Linear(128, 28 * 28)
)
def forward(self, x):
# in lightning, forward defines the prediction/inference actions
embedding = self.encoder(x)
return embedding
def training_step(self, batch, batch_idx):
# training_step defines the train loop. It is independent of forward
x, _ = batch
x = x.view(x.size(0), -1)
z = self.encoder(x)
x_hat = self.decoder(z)
loss = F.mse_loss(x_hat, x)
self.log("train_loss", loss)
return loss
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
return optimizer
# -------------------
# Step 2: Define data
# -------------------
dataset = tv.datasets.MNIST(".", download=True, transform=tv.transforms.ToTensor())
train, val = data.random_split(dataset, [55000, 5000])
# -------------------
# Step 3: Train
# -------------------
autoencoder = LitAutoEncoder()
logger = TensorBoardLogger(save_dir="tb_logs")
profiler = PyTorchProfiler()
trainer = L.Trainer(logger=logger, profiler=profiler, max_epochs=2)
trainer.fit(autoencoder, data.DataLoader(train), data.DataLoader(val))
```
### Error messages and logs
```
(lightning_tutorials) PS C:\Users\anguzo\Projects\work\Machine-Learning-Collection> & C:/Users/anguzo/.local/share/mamba/envs/lightning_tutorials/python.exe "c:/Users/anguzo/Projects/work/Machine-Learning-Collection/ML/Pytorch/pytorch_lightning/9.1 Prof/train.py"
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
C:\Users\anguzo\.local\share\mamba\envs\lightning_tutorials\Lib\site-packages\lightning\pytorch\trainer\configuration_validator.py:68: You passed in a `val_dataloader` but have no `validation_step`. Skipping val loop.
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
-----------------------------------------------
0 | encoder | Sequential | 100 K | train
1 | decoder | Sequential | 101 K | train
-----------------------------------------------
202 K Trainable params
0 Non-trainable params
202 K Total params
0.810 Total estimated model params size (MB)
8 Modules in train mode
0 Modules in eval mode
C:\Users\anguzo\.local\share\mamba\envs\lightning_tutorials\Lib\site-packages\lightning\pytorch\trainer\connectors\data_connector.py:425: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=15` in the `DataLoader` to improve performance.
Epoch 0: 0%| | 4/55000 [00:00<39:03, 23.47it/s, v_num=0][W226 15:37:54.000000000 collection.cpp:647] Warning: Optimizer.step#Adam.step (function operator ())
Epoch 1: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 55000/55000 [03:34<00:00, 256.89it/s, v_num=0]`Trainer.fit` stopped: `max_epochs=2` reached.
Epoch 1: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 55000/55000 [03:34<00:00, 256.88it/s, v_num=0]
FIT Profiler Report
Profile stats for: records
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
ProfilerStep* 18.41% 10.089ms 60.02% 32.896ms 10.965ms 8.532ms 15.48% 32.903ms 10.968ms 3
[pl][profile]run_training_batch 0.22% 118.400us 27.99% 15.341ms 7.670ms 107.000us 0.19% 15.349ms 7.675ms 2
[pl][profile][LightningModule]LitAutoEncoder.optimiz... 0.13% 70.600us 27.77% 15.222ms 7.611ms 48.000us 0.09% 15.242ms 7.621ms 2
Optimizer.step#Adam.step 20.39% 11.178ms 27.64% 15.152ms 7.576ms 11.207ms 20.33% 15.194ms 7.597ms 2
[pl][profile][Strategy]SingleDeviceStrategy.backward... 19.32% 10.590ms 20.25% 11.099ms 3.700ms 10.435ms 18.93% 11.136ms 3.712ms 3
[pl][profile][Strategy]SingleDeviceStrategy.training... 3.26% 1.788ms 10.56% 5.790ms 1.930ms 1.524ms 2.77% 5.809ms 1.936ms 3
autograd::engine::evaluate_function: AddmmBackward0 1.48% 812.100us 5.97% 3.271ms 272.583us 473.000us 0.86% 3.406ms 283.833us 12
AddmmBackward0 1.47% 806.000us 4.16% 2.280ms 189.967us 578.000us 1.05% 2.577ms 214.750us 12
aten::t 1.95% 1.066ms 3.62% 1.986ms 34.840us 1.088ms 1.97% 2.560ms 44.912us 57
[pl][profile][_TrainingEpochLoop].train_dataloader_n... 0.21% 113.100us 3.95% 2.167ms 722.333us 94.000us 0.17% 2.214ms 738.000us 3
enumerate(DataLoader)#_SingleProcessDataLoaderIter._... 2.32% 1.273ms 3.75% 2.054ms 684.633us 924.000us 1.68% 2.120ms 706.667us 3
[pl][module]torch.nn.modules.container.Sequential: e... 0.58% 315.500us 3.02% 1.653ms 551.067us 300.000us 0.54% 1.691ms 563.667us 3
aten::transpose 1.61% 880.300us 1.68% 919.700us 16.135us 1.056ms 1.92% 1.472ms 25.825us 57
autograd::engine::evaluate_function: torch::autograd... 0.49% 267.800us 2.12% 1.161ms 48.367us 425.000us 0.77% 1.408ms 58.667us 24
aten::linear 0.42% 232.500us 2.34% 1.285ms 107.042us 233.000us 0.42% 1.398ms 116.500us 12
[pl][profile][Callback]TQDMProgressBar.on_train_batc... 2.27% 1.246ms 2.34% 1.284ms 427.967us 1.278ms 2.32% 1.333ms 444.333us 3
aten::item 1.50% 821.700us 1.53% 836.700us 16.406us 818.000us 1.48% 1.254ms 24.588us 51
[pl][module]torch.nn.modules.container.Sequential: d... 0.48% 265.400us 2.17% 1.191ms 397.033us 201.000us 0.36% 1.201ms 400.333us 3
aten::detach 1.34% 737.000us 1.46% 802.700us 17.838us 737.000us 1.34% 1.142ms 25.378us 45
aten::result_type 0.03% 14.100us 0.03% 14.100us 0.117us 997.000us 1.81% 997.000us 8.308us 120
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 54.812ms
Self CUDA time total: 55.115ms
```
### Environment
<details>
<summary>Current environment</summary>
* CUDA:
- GPU:
- NVIDIA GeForce GTX 1080
- available: True
- version: 12.6
* Lightning:
- lightning: 2.5.0.post0
- lightning-utilities: 0.12.0
- pytorch-lightning: 2.5.0.post0
- torch: 2.6.0
- torch-tb-profiler: 0.4.3
- torchmetrics: 1.6.1
- torchvision: 0.21.0
* Packages:
- absl-py: 2.1.0
- autocommand: 2.2.2
- backports.tarfile: 1.2.0
- brotli: 1.1.0
- certifi: 2025.1.31
- charset-normalizer: 3.4.1
- colorama: 0.4.6
- filelock: 3.17.0
- fsspec: 2025.2.0
- grpcio: 1.67.1
- idna: 3.10
- importlib-metadata: 8.6.1
- inflect: 7.3.1
- jaraco.collections: 5.1.0
- jaraco.context: 5.3.0
- jaraco.functools: 4.0.1
- jaraco.text: 3.12.1
- jinja2: 3.1.5
- lightning: 2.5.0.post0
- lightning-utilities: 0.12.0
- markdown: 3.6
- markupsafe: 3.0.2
- more-itertools: 10.3.0
- mpmath: 1.3.0
- networkx: 3.4.2
- numpy: 2.2.3
- optree: 0.14.0
- packaging: 24.2
- pandas: 2.2.3
- pillow: 11.1.0
- pip: 25.0.1
- platformdirs: 4.2.2
- protobuf: 5.28.3
- pybind11: 2.13.6
- pybind11-global: 2.13.6
- pysocks: 1.7.1
- python-dateutil: 2.9.0.post0
- pytorch-lightning: 2.5.0.post0
- pytz: 2024.1
- pyyaml: 6.0.2
- requests: 2.32.3
- setuptools: 75.8.0
- six: 1.17.0
- sympy: 1.13.3
- tensorboard: 2.19.0
- tensorboard-data-server: 0.7.0
- tomli: 2.0.1
- torch: 2.6.0
- torch-tb-profiler: 0.4.3
- torchmetrics: 1.6.1
- torchvision: 0.21.0
- tqdm: 4.67.1
- typeguard: 4.3.0
- typing-extensions: 4.12.2
- tzdata: 2025.1
- urllib3: 2.2.2
- werkzeug: 3.1.3
- wheel: 0.45.1
- win-inet-pton: 1.1.0
- zipp: 3.21.0
* System:
- OS: Windows
- architecture:
- 64bit
- WindowsPE
- processor: AMD64 Family 25 Model 116 Stepping 1, AuthenticAMD
- python: 3.12.9
- release: 11
- version: 10.0.22631
</details>
### More info
_No response_ | open | 2025-02-26T14:04:33Z | 2025-03-24T16:10:02Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20604 | [
"bug",
"needs triage",
"ver: 2.5.x"
] | anguzo | 1 |
Miserlou/Zappa | django | 1,896 | FastAPI incompatibility | ## Context
I get a 500 response code when I try to deploy a simple application.
```python
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
```
Zappa tail says `[1562665728357] __call__() missing 1 required positional argument: 'send'`.
When I go to the api gateway url, I see this message:
> "{'message': 'An uncaught exception happened while servicing this request. You can investigate this with the `zappa tail` command.', 'traceback': ['Traceback (most recent call last):\\n', ' File \"/var/task/handler.py\", line 531, in handler\\n with Response.from_app(self.wsgi_app, environ) as response:\\n', ' File \"/var/task/werkzeug/wrappers/base_response.py\", line 287, in from_app\\n return cls(*_run_wsgi_app(app, environ, buffered))\\n', ' File \"/var/task/werkzeug/test.py\", line 1119, in run_wsgi_app\\n app_rv = app(environ, start_response)\\n', ' File \"/var/task/zappa/middleware.py\", line 70, in __call__\\n response = self.application(environ, encode_response)\\n', \"TypeError: __call__() missing 1 required positional argument: 'send'\\n\"]}"
## Steps to Reproduce
```bash
zappa init
zappa deploy dev
# Error: Warning! Status check on the deployed lambda failed. A GET request to '/' yielded a 500 response code.
```
## Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* Zappa version used: 0.48.2
* Operating System and Python version: macOS Mojave | Python 3.6.5
* The output of `pip freeze`:
```
Package Version
------------------- ---------
aiofiles 0.4.0
aniso8601 6.0.0
argcomplete 1.9.3
boto3 1.9.184
botocore 1.12.184
certifi 2019.6.16
cfn-flip 1.2.1
chardet 3.0.4
Click 7.0
dataclasses 0.6
dnspython 1.16.0
docutils 0.14
durationpy 0.5
email-validator 1.0.4
fastapi 0.31.0
future 0.16.0
graphene 2.1.6
graphql-core 2.2
graphql-relay 0.4.5
h11 0.8.1
hjson 3.0.1
httptools 0.0.13
idna 2.8
itsdangerous 1.1.0
Jinja2 2.10.1
jmespath 0.9.3
kappa 0.6.0
lambda-packages 0.20.0
MarkupSafe 1.1.1
pip 19.1.1
placebo 0.9.0
promise 2.2.1
pydantic 0.29
python-dateutil 2.6.1
python-multipart 0.0.5
python-slugify 1.2.4
PyYAML 5.1.1
requests 2.22.0
Rx 1.6.1
s3transfer 0.2.1
setuptools 39.0.1
six 1.12.0
starlette 0.12.0
toml 0.10.0
tqdm 4.19.1
troposphere 2.4.9
ujson 1.35
Unidecode 1.1.1
urllib3 1.25.3
uvicorn 0.8.3
uvloop 0.12.2
websockets 7.0
Werkzeug 0.15.4
wheel 0.33.4
wsgi-request-logger 0.4.6
zappa 0.48.2
```
* Your `zappa_settings.py`:
```
{
"dev": {
"app_function": "app.main.app",
"aws_region": "ap-northeast-2",
"profile_name": "default",
"project_name": "myprojectname",
"runtime": "python3.6",
"s3_bucket": "mybucketname"
}
}
```
| open | 2019-07-09T10:06:07Z | 2020-02-09T21:40:56Z | https://github.com/Miserlou/Zappa/issues/1896 | [] | sunnysid3up | 11 |
LAION-AI/Open-Assistant | python | 3,131 | Chat plugin alignment | The text should be in the middle instead of top

| closed | 2023-05-11T23:35:21Z | 2023-05-15T07:07:30Z | https://github.com/LAION-AI/Open-Assistant/issues/3131 | [
"bug",
"website",
"good first issue",
"UI/UX"
] | notmd | 1 |
davidteather/TikTok-Api | api | 392 | [BUG] - TikTok sent invalid JSON back | # Read Below!!! If this doesn't fix your issue delete these two lines
**You may need to install chromedriver for your machine globally. Download it [here](https://sites.google.com/a/chromium.org/chromedriver/) and add it to your path.**
**Describe the bug**
TikTok sent invalid JSON back.
**The buggy code**
Please insert the code that is throwing errors or is giving you weird unexpected results.
```
from TikTokApi import TikTokApi
import random
import os
api = TikTokApi.get_instance(custom_verifyFp=os.environ.get("verifyFp", None))
did = str(random.randint(10000, 999999999))
t = api.byUsername('therock', did=did, custom_verifyFp='your_verify_fp')[0]
print(t)
v_bytes = api.get_Video_By_TikTok(t, did=did, custom_verifyFp='your_verify_fp')
with open("test.mp4", 'wb') as o:
o.write(v_bytes)
```
**Expected behavior**
A clear and concise description of what you expected to happen.
**Error Trace (if any)**
Put the error trace below if there's any error thrown.
```
# Error Trace Here
```
ERROR:root:TikTok response: illegal request...
ERROR:root:Converting response to JSON failed
ERROR:root:Expecting value: line 1 column 1 (char 0)
Traceback (most recent call last):
File "C:\Users\john\anaconda3\envs\tiktok_new\lib\site-packages\TikTokApi\tiktok.py", line 173, in getData
json = r.json()
File "C:\Users\john\anaconda3\envs\tiktok_new\lib\site-packages\requests\models.py", line 900, in json
return complexjson.loads(self.text, **kwargs)
File "C:\Users\john\anaconda3\envs\tiktok_new\lib\json\__init__.py", line 348, in loads
return _default_decoder.decode(s)
File "C:\Users\john\anaconda3\envs\tiktok_new\lib\json\decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "C:\Users\john\anaconda3\envs\tiktok_new\lib\json\decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "temp.py", line 6, in <module>
t = api.byUsername('therock', did=did, custom_verifyFp='your_verify_fp')[0]
File "C:\Users\john\anaconda3\envs\tiktok_new\lib\site-packages\TikTokApi\tiktok.py", line 493, in byUsername
**kwargs,
File "C:\Users\john\anaconda3\envs\tiktok_new\lib\site-packages\TikTokApi\tiktok.py", line 451, in userPosts
res = self.getData(url=api_url, **kwargs)
File "C:\Users\john\anaconda3\envs\tiktok_new\lib\site-packages\TikTokApi\tiktok.py", line 191, in getData
raise JSONDecodeFailure() from e
TikTokApi.exceptions.JSONDecodeFailure: TikTok sent invalid JSON back
**Desktop (please complete the following information):**
- OS: [e.g. Windows 10]
- TikTokApi Version [e.g. 3.3.1] - 3.8.1
**Additional context**
Referred to #374 for bugfix.
Add any other context about the problem here.
| closed | 2020-11-24T02:14:43Z | 2023-02-28T05:57:17Z | https://github.com/davidteather/TikTok-Api/issues/392 | [
"bug"
] | JohnTYH | 9 |
dfm/corner.py | data-visualization | 208 | multiple line style for quantiles | I want to thank the author first for the excellent tool, corner.py.
It does help me a lot plotting MCMC results.
I usually plot five quantiles: median, 1-sigma, and 2-sigma. So, it is not easy to catch the median immediately when seeing the histograms since all the quantiles are indicated with dashed lines.
It will be great if corner.py provides an option to set the line style of quantiles;
for example, quantiles=[0.16, 0.5, 0.84], q_ls=['dotted', 'dashed', 'dotted']
Thanks in advance for your consideration- | open | 2022-09-08T01:06:57Z | 2023-07-20T13:13:57Z | https://github.com/dfm/corner.py/issues/208 | [
"enhancement"
] | jhshinn | 2 |
recommenders-team/recommenders | data-science | 1,832 | [FEATURE] Test benchmark utils | ### Description
<!--- Describe your expected feature in detail -->
Related to https://github.com/microsoft/recommenders/pull/1831. We want to programmatically test the movielens benchmark
### Expected behavior with the suggested feature
<!--- For example: -->
<!--- *Adding algorithm xxx will help people understand more about xxx use case scenarios. -->
### Other Comments
branch: miguel/bench_tests | closed | 2022-10-20T09:59:43Z | 2022-11-17T10:13:21Z | https://github.com/recommenders-team/recommenders/issues/1832 | [
"enhancement"
] | miguelgfierro | 7 |
dmlc/gluon-cv | computer-vision | 1,759 | -+++++++++++++++++++++++ | closed | 2022-09-30T06:48:52Z | 2023-01-06T06:33:43Z | https://github.com/dmlc/gluon-cv/issues/1759 | [
"Stale"
] | mkkim007 | 1 |
|
exaloop/codon | numpy | 250 | When trying to run django's manage.py, get an indendation error | $ codon run manage.py
manage.py:10:1: error: unexpected indentation
This file is properly formatted according to normal python 🤷♂️ | closed | 2023-03-16T06:01:58Z | 2024-11-26T18:58:02Z | https://github.com/exaloop/codon/issues/250 | [] | TechNickAI | 1 |
dynaconf/dynaconf | flask | 761 | Question - Ability to Avoid Forced Upper Case Keys | Given an environment variable with a lower-case key like `TEST_my_key`, and a dynaconf `LazySettings` instance configured like `settings = LazySettings(ENVVAR_PREFIX='TEST')`, the result is that the key is converted to `MY_KEY` instead of `my_key`.
While this is fine in most situations due to being able to access both upper and lower case keys from the DynaConf instance, I am using it to parse and provide configuration for a tool that requires lower case config variables (celery specifically). So, is there some way to bypass/disable the case conversion that happens when DynaConf loads the values?
Also, I apologize in advance if this is in the docs, they are not currently accessible due to dynaconf.com being down. | open | 2022-06-23T23:20:35Z | 2024-07-09T18:17:30Z | https://github.com/dynaconf/dynaconf/issues/761 | [
"question",
"hacktoberfest",
"RFC",
"typed_dynaconf",
"4.0-breaking-change"
] | mrname | 9 |
encode/httpx | asyncio | 2,139 | Response not closed when timeout/cancel reading response stream, which cause RuntimeError: The connection pool was closed while 1 HTTP requests/responses were still in-flight. | Response not closed when timeout/cancel reading response stream, which cause `RuntimeError: The connection pool was closed while 1 HTTP requests/responses were still in-flight.`
#### Reproduce:
```python
import asyncio
import httpx
async def main():
url = "https://httpbin.org/drip?delay=0&duration=5"
# Or use local httpbin server:
# docker run -ti -p 8088:80 kennethreitz/httpbin:latest
url = "http://127.0.0.1:8088/drip?delay=0&duration=5"
async with httpx.AsyncClient(timeout=10, trust_env=False) as client:
try:
coro = client.get(url)
response = await asyncio.wait_for(coro, 3)
except Exception as ex:
print(type(ex), repr(ex))
else:
print(response)
if __name__ == "__main__":
asyncio.run(main())
```
#### Output:
```python
<class 'asyncio.exceptions.TimeoutError'> TimeoutError()
Traceback (most recent call last):
File "/Users/kk/dev/zhuwen/httpx/http_error2.py", line 22, in <module>
asyncio.run(main())
File "/Users/kk/.pyenv/versions/3.9.7/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/asyncio/runners.py", line 44, in run
return loop.run_until_complete(main)
File "/Users/kk/.pyenv/versions/3.9.7/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/asyncio/base_events.py", line 642, in run_until_complete
return future.result()
File "/Users/kk/dev/zhuwen/httpx/http_error2.py", line 18, in main
print(response)
File "/Users/kk/dev/zhuwen/httpx/httpx/_client.py", line 1978, in __aexit__
await self._transport.__aexit__(exc_type, exc_value, traceback)
File "/Users/kk/dev/zhuwen/httpx/httpx/_transports/default.py", line 332, in __aexit__
await self._pool.__aexit__(exc_type, exc_value, traceback)
File "/Users/kk/.pyenv/versions/3.9.7/envs/httpx/lib/python3.9/site-packages/httpcore/_async/connection_pool.py", line 326, in __aexit__
await self.aclose()
File "/Users/kk/.pyenv/versions/3.9.7/envs/httpx/lib/python3.9/site-packages/httpcore/_async/connection_pool.py", line 312, in aclose
raise RuntimeError(
RuntimeError: The connection pool was closed while 1 HTTP requests/responses were still in-flight.
```
#### Root cause:
It's because use `except Exception` in _client.py which will not catch asyncio CancelledError, so except branch will not executed. https://github.com/encode/httpx/blob/master/httpx/_client.py#L1604
```python
try:
if not stream:
await response.aread() # will raise CancelledError
return response
except Exception as exc: # pragma: no cover
await response.aclose() # will not executed
raise exc
```
Change all `except Exception` in _client.py to `except BaseException` can resolve the issue.
| closed | 2022-03-22T10:07:42Z | 2022-09-08T13:25:29Z | https://github.com/encode/httpx/issues/2139 | [
"bug"
] | guyskk | 9 |
sinaptik-ai/pandas-ai | data-science | 834 | Langchain LLM | ### System Info
Python: 3.10.6
Pandasai: 1.5.11
### 🐛 Describe the bug
I have to replace some log info for privacy reasons.
```py
from langchain.llms import OpenAI
custom_llm = OpenAI(model=<MODEL_NAME>",
api_key=<API KEY>",
base_url=<URL>,
verbose=True,
temperature=0.0)
df_smart = SmartDataframe('data2.csv', config={"llm":custom_llm,
"verbose":True})
response = df_smart.chat('Return maximal amount')
```
After this the log outputs
```
2023-12-22 08:41:32 [INFO] Question: Return maximal amount
2023-12-22 08:41:32 [INFO] Running PandasAI with langchain_openai LLM...
2023-12-22 08:41:32 [INFO] Prompt ID <ID>
2023-12-22 08:41:32 [INFO] Executing Step 0: CacheLookup
2023-12-22 08:41:32 [INFO] Using cached response
2023-12-22 08:41:32 [INFO] Executing Step 1: PromptGeneration
2023-12-22 08:41:32 [INFO] Executing Step 2: CodeGenerator
2023-12-22 08:41:32 [INFO] Executing Step 3: CachePopulation
2023-12-22 08:41:32 [INFO] Executing Step 4: CodeExecution
2023-12-22 08:41:32 [INFO] Saving charts to <PATH>
2023-12-22 08:41:32 [INFO]
Code running:
2023-12-22 08:41:32 [WARNING] Failed to execute code with a correction framework [retry number: 1]
2023-12-22 08:41:32 [ERROR] Failed with error: Traceback (most recent call last):
File "/opt/conda/lib/python3.10/site-packages/pandasai/pipelines/smart_datalake_chat/code_execution.py", line 46, in execute
result = pipeline_context.query_exec_tracker.execute_func(
File "/opt/conda/lib/python3.10/site-packages/pandasai/helpers/query_exec_tracker.py", line 128, in execute_func
result = function(*args, **kwargs)
File "/opt/conda/lib/python3.10/site-packages/pandasai/helpers/code_manager.py", line 212, in execute_code
raise NoResultFoundError("No result returned")
pandasai.exceptions.NoResultFoundError: No result returned
. Retrying
2023-12-22 08:41:32 [INFO] Using prompt: <dataframe>
The user asked the following question:
Q: Return maximal amount
You generated this python code:
# TODO: import the required dependencies
import pandas as pd
# Write code here
# Declare result var: type (possible value "string", "number", "dataframe", "plot"). Examples: { "type": "string", "value": f"The highest salary is {highest_salary}." } or { "type": "number", "value": 125 } or { "type": "dataframe", "value": pd.DataFrame({...}) } or { "type": "plot", "value": "temp_chart.png" }
It fails with the following error:
Traceback (most recent call last):
File "/opt/conda/lib/python3.10/site-packages/pandasai/pipelines/smart_datalake_chat/code_execution.py", line 46, in execute
result = pipeline_context.query_exec_tracker.execute_func(
File "/opt/conda/lib/python3.10/site-packages/pandasai/helpers/query_exec_tracker.py", line 128, in execute_func
result = function(*args, **kwargs)
File "/opt/conda/lib/python3.10/site-packages/pandasai/helpers/code_manager.py", line 212, in execute_code
raise NoResultFoundError("No result returned")
pandasai.exceptions.NoResultFoundError: No result returned
Fix the python code above and return the new python code:
2023-12-22 08:41:36 [INFO] HTTP Request: POST<LINK> "HTTP/1.1 200 OK"
2023-12-22 08:41:36 [ERROR] Pipeline failed on step 4: No code found in the response
``` | closed | 2023-12-22T08:44:30Z | 2024-06-01T00:20:20Z | https://github.com/sinaptik-ai/pandas-ai/issues/834 | [] | danielstankw | 2 |
tiangolo/uvicorn-gunicorn-fastapi-docker | fastapi | 55 | set root-path to uvicorn | I'm trying to set `root_path` to _uvicorn_ as suggested [1] using this image, but don't see any options to pass arguments:
uvicorn main:app --root-path /api/v1
How can I do it?
**Refs:**
1. https://fastapi.tiangolo.com/advanced/behind-a-proxy/#providing-the-root_path | closed | 2020-08-08T14:39:22Z | 2024-08-25T04:05:07Z | https://github.com/tiangolo/uvicorn-gunicorn-fastapi-docker/issues/55 | [
"investigate"
] | 0anton | 6 |
gradio-app/gradio | python | 10,052 | Edit: deleted - found the issue | Edit: deleted - found the issue | closed | 2024-11-27T15:32:19Z | 2024-11-27T15:40:53Z | https://github.com/gradio-app/gradio/issues/10052 | [
"bug"
] | GhostlyScript | 0 |
microsoft/unilm | nlp | 1,473 | E5 Base Model Can't Use GPU | **Describe the bug**
Model I am using (UniLM, MiniLM, LayoutLM ...): multilingual-e5-base
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
I would like to move e5 model to GPU but I get an error when I try to do that.
A clear and concise description of what the bug is.
**To Reproduce**
Steps to reproduce the behavior:

**Expected behavior**
A clear and concise description of what you expected to happen.
- Platform: Ubuntu/Google Colab
- Python version: 3.10.12
- PyTorch version (GPU?): 2.1.0+cu121
| closed | 2024-03-07T15:36:07Z | 2024-03-09T23:32:30Z | https://github.com/microsoft/unilm/issues/1473 | [] | lordsoffallen | 1 |
dpgaspar/Flask-AppBuilder | rest-api | 1,456 | [Question] pre_add/pre_update method exception should redirect to same page with filled form | Using Basic view create and edit form, I want to do some additional check before adding/updating entry to db. For this I am using `pre_add` or `pre_update` method. But exception raised from both of these method end up redirecting page back and showing flash error. I want to stay on the same page and show error, so that user can modify the form without re-entering all the details of Form.
### Environment
Flask-Appbuilder version:
Flask-AppBuilder==2.3.4
Python 3.7.5
Sorry for asking basic question, new to flask_appbuilder. Thanks in advance. | closed | 2020-08-20T14:33:22Z | 2020-12-04T22:01:19Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1456 | [
"stale"
] | aksswami | 1 |
ludwig-ai/ludwig | data-science | 3,583 | Out of Memory Error Running llama2_7b_finetuning_4bit Example | **Describe the bug**
Running the "Llama2-7b Fine-Tuning with 4bit Quantization" example notebook in Colab fails with the following error:
`OutOfMemoryError: CUDA out of memory. Tried to allocate 86.00 MiB (GPU 0; 14.75 GiB total capacity; 13.37 GiB already allocated; 80.81 MiB free; 13.79 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF`
I am new to Ludwig and AI in general so this may be user error.
**To Reproduce**
Steps to reproduce the behavior:
1. Open the notebook in Colab - https://colab.research.google.com/drive/1c3AO8l_H6V_x37RwQ8V7M6A-RmcBf2tG?usp=sharing
2. Add my HUGGING_FACE_HUB_TOKEN to code frame 2
3. Run the notebook
4. Run ends in error
```
INFO:ludwig.trainers.trainer:Starting with step 0, epoch: 0
Training: 18%|█▊ | 1935/10920 [17:45<1:13:32, 2.04it/s, loss=0.081]
---------------------------------------------------------------------------
OutOfMemoryError Traceback (most recent call last)
<ipython-input-4-f24794477812> in <cell line: 6>()
4
5 model = LudwigModel(config=config, logging_level=logging.INFO)
----> 6 results = model.train(dataset="ludwig://alpaca")
7 print(results)
27 frames
/usr/local/lib/python3.10/dist-packages/bitsandbytes/functional.py in dequantize_4bit(A, quant_state, absmax, out, blocksize, quant_type)
906
907 if out is None:
--> 908 out = torch.empty(shape, dtype=dtype, device=A.device)
909
910 n = out.numel()
OutOfMemoryError: CUDA out of memory. Tried to allocate 86.00 MiB (GPU 0; 14.75 GiB total capacity; 13.37 GiB already allocated; 80.81 MiB free; 13.79 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
```
After 3 runs in new Colab sessions it consistently fails at the same point.
```
INFO:ludwig.trainers.trainer:Starting with step 0, epoch: 0
Training: 18%|█▊ | 1935/10920
```
Running the [example notebook](https://ludwig.ai/latest/examples/llms/llm_finetuning/) out the box. No other changes were made to the notebook or config.
```
model_type: llm
base_model: meta-llama/Llama-2-7b-hf
quantization:
bits: 4
adapter:
type: lora
prompt:
template: |
### Instruction:
{instruction}
### Input:
{input}
### Response:
input_features:
- name: prompt
type: text
output_features:
- name: output
type: text
trainer:
type: finetune
learning_rate: 0.0001
batch_size: 1
gradient_accumulation_steps: 16
epochs: 3
learning_rate_scheduler:
warmup_fraction: 0.01
preprocessing:
sample_ratio: 0.1
```
**Expected behavior**
After watching [video](https://www.youtube.com/watch?v=g68qlo9Izf0) by Ludwig team that explained how to fine-tune Llama-2-7b on a single T4 GPU, I tried running the [example notebook](https://github.com/ludwig-ai/ludwig/tree/master/examples/llama2_7b_finetuning_4bit) linked in the Ludwig GitHub repository and expected the model to be fine-tuned for instruction on the Alpaca dataset.
*FYI, the notebook from the video worked fine for me, but it uses a smaller data set - https://colab.research.google.com/drive/1Ly01S--kUwkKQalE-75skalp-ftwl0fE?usp=sharing.*
**Environment (please complete the following information):**
- OS: Google Colab - Linux Ubuntu
- Python version: 3.10
- Ludwig version: 0.8.2
**Additional context**
Add any other context about the problem here.
- Random seed: 42
- Dataset: ludwig://alpaca
- Data format: ludwig
- Torch version: 2.0.1+cu118
- Compute:
- GPU Type: Tesla T4
- GPUs per node: 1
- Number of nodes: 1
- System RAM: 51.0 GB
- GPU RAM: 15.0 GB
- Disk: 166.8 GB | closed | 2023-09-03T23:26:57Z | 2023-10-23T23:17:58Z | https://github.com/ludwig-ai/ludwig/issues/3583 | [
"bug"
] | charleslbryant | 6 |
iperov/DeepFaceLab | machine-learning | 5,475 | RTM WF faceset | rtm wf faceset file does not open | closed | 2022-02-11T19:12:59Z | 2022-02-14T11:34:48Z | https://github.com/iperov/DeepFaceLab/issues/5475 | [] | notname956 | 0 |
sherlock-project/sherlock | python | 2,198 | Permission denied | ### Description
I had problems

### Code of Conduct
- [X] I agree to follow this project's Code of Conduct | closed | 2024-06-26T16:22:05Z | 2024-06-26T18:04:12Z | https://github.com/sherlock-project/sherlock/issues/2198 | [
"invalid"
] | Hjgkcgf35 | 2 |
pydantic/FastUI | fastapi | 218 | Unable to pass a BaseModel into component from subfolder (Pydantic V1 issue) | I was attempting to create a simple pydantic object as below
```
class User(BaseModel):
name: str = Field(title='Name', max_lengh=200)
```
But I face some issues:
### Scenario 1 - Having the Pydantic Base Model define on the same page as entry point (i.e. `main.py`)
In this scenario, the BaseModel is implemented on the same file as the entry point file as below:
```
component = [
# Blah, other components
c.ModelForm(model=User),
# Blah....
]
```
This works fine and it shows the form as expected on UI.
Here's the problem:
### Scenario 2 - The Pydantic object is imported from somewhere else
```
from model.blah import User
...
component = [
# Blah, other components
c.ModelForm(model=User),
# Blah....
]
```
When I run this, I receive an exception of
```
Input should be a subclass of BaseModel [type=is_subclass_of, input_value=<class 'model.blah.User'>, input_type=ModelMetaclass]
For further information visit https://errors.pydantic.dev/2.6/v/is_subclass_of
```
Not entirely sure what happened here, will continue to investigate but will raise this problem I bumped into. | closed | 2024-02-26T13:57:51Z | 2024-02-26T14:26:54Z | https://github.com/pydantic/FastUI/issues/218 | [] | edwardmfho | 2 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 817 | telling me to install pretrained models even tho i already have | i've extracted both versions of the pretrained .zip multiple times but it keeps telling me they arent there | closed | 2021-08-11T23:24:20Z | 2021-08-25T08:48:28Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/817 | [] | kneegobbler | 1 |
lk-geimfari/mimesis | pandas | 1,463 | Add please connected data support | # Feature request
I think it is needed to have related data during schema generation.
## Thesis
For example, we have simple schema
``` python
schema_definition = lambda: {
'full_name': field('name', gender=Gender.MALE),
'surname': field('person.surname', gender=Gender.MALE)
}
>>> {'full_name': 'Irvin Savage', 'surname': 'Delgado'}
```
## Reasoning
It would be better to have related data during schema generation process, when attribure **full_name** connected to **surname** and return the same data. In my example with full_name = 'Irvin Savage', surname should return 'Savage', not generated new value.
| open | 2024-01-11T11:30:41Z | 2024-03-31T09:08:38Z | https://github.com/lk-geimfari/mimesis/issues/1463 | [] | DarkwingDuck48 | 5 |
plotly/dash | dash | 3,094 | Allow_duplicate=True Fails with More Than Two Duplicate Callbacks | ## Bug Report: `allow_duplicate=True` Fails with More Than Two Duplicate Callbacks
**Description:**
The `allow_duplicate=True` parameter does not function correctly when there are more than two duplicate callbacks.
**Reproducible Example:**
The following examples demonstrate the issue:
**Working Examples (Two Duplicate Callbacks):**
```python
# Example 1: Works
Output("layout_ctx-train", "children")
Input('button1', 'n_clicks'),
...
Output("layout_ctx-train", "children", allow_duplicate=True)
Input('button2', 'n_clicks'),
...
```
```python
# Example 2: Works
Output("layout_ctx-train", "children", allow_duplicate=True)
Input('button1', 'n_clicks'),
...
Output("layout_ctx-train", "children")
Input('button2', 'n_clicks'),
...
```
```python
# Example 3: Works
Output("layout_ctx-train", "children", allow_duplicate=True)
Input('button1', 'n_clicks'),
...
Output("layout_ctx-train", "children", allow_duplicate=True)
Input('button2', 'n_clicks'),
...
```
**Failing Examples (More Than Two Duplicate Callbacks):**
```python
# Example 4: Fails
Output("layout_ctx-train", "children", allow_duplicate=True)
Input('button1', 'n_clicks'),
...
Output("layout_ctx-train", "children")
Input('button2', 'n_clicks'),
...
Output("layout_ctx-train", "children")
Input('button3', 'n_clicks'),
...
Output("layout_ctx-train", "children")
Input('button4', 'n_clicks'),
...
```
```python
# Example 5: Fails
Output("layout_ctx-train", "children")
Input('button1', 'n_clicks'),
...
Output("layout_ctx-train", "children")
Input('button2', 'n_clicks'),
...
Output("layout_ctx-train", "children")
Input('button3', 'n_clicks'),
...
Output("layout_ctx-train", "children", allow_duplicate=True)
Input('button4', 'n_clicks'),
...
```
```python
# Example 6: Fails
Output("layout_ctx-train", "children", allow_duplicate=True)
Input('button1', 'n_clicks'),
...
Output("layout_ctx-train", "children", allow_duplicate=True)
Input('button2', 'n_clicks'),
...
Output("layout_ctx-train", "children", allow_duplicate=True)
Input('button3', 'n_clicks'),
...
Output("layout_ctx-train", "children", allow_duplicate=True)
Input('button4', 'n_clicks'),
...
```
**Expected Behavior:**
Duplicate callbacks should function correctly when at least one of the components has `allow_duplicate=True` set.
**Additional Comments:**
This functionality worked correctly in Dash version 2.9.1 for more than two duplicate callbacks as long as `allow_duplicate=True` was present on all relevant components. The issue was encountered in Dash versions 2.17.1+. | closed | 2024-11-26T12:01:25Z | 2024-11-27T15:35:24Z | https://github.com/plotly/dash/issues/3094 | [
"bug",
"P2"
] | Kissabi | 1 |
Kanaries/pygwalker | pandas | 29 | HEX support | Hi magic people,
I don't know if it is up to the HEX developers or you, but it would be nice if the library could work on HEX notebooks as well. For now it only prints the following:

Thank you very much! | closed | 2023-02-22T15:49:14Z | 2023-04-11T04:36:05Z | https://github.com/Kanaries/pygwalker/issues/29 | [
"fixed but needs feedback"
] | giov-bs | 4 |
horovod/horovod | tensorflow | 3,670 | UnicodeDecodeError in horovod | **Environment:**
1. Framework: TensorFlow
2. Framework version: 2.7
3. Horovod version: 0.23
4. MPI version: None
5. CUDA version: 11.4
6. NCCL version: 11.4
7. Python version: 3.6.8
8. Spark / PySpark version:
9. Ray version:
10. OS and version:
11. GCC version: 8.3.1
12. CMake version: 3.23.3
**Bug report:**
When I run my model with horovodrun command I found this error:
Exception in thread Thread-5:
Traceback (most recent call last):
File "/usr/local/lib/python3.8/threading.py", line 932, in _bootstrap_inner
self.run()
File "/usr/local/lib/python3.8/threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "/usr/local/lib/python3.8/site-packages/horovod/runner/common/util/safe_shell_exec.py", line 126, in prefix_connection
text = decoder.decode(buf or b'', final=not buf)
File "/usr/local/lib/python3.8/codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8a in position 91: invalid start byte
File "/usr/local/lib/python3.8/site-packages/horovod/runner/common/util/safe_shell_exec.py", line 126 -- this is mentioned in https://github.com/horovod/horovod/issues/2367 and it is regarded as a solution.
how to solve this error?
| closed | 2022-08-27T11:21:05Z | 2022-08-29T17:54:53Z | https://github.com/horovod/horovod/issues/3670 | [
"bug"
] | yinciki | 0 |
pallets/quart | asyncio | 382 | Updated version Flask, error | In the library requirements new versions of Flask are allowed, so 2 days ago a new version was released that generates the following error.

To replicate this error, all you have to do is uninstall the Flask and Quart version and reinstall Quart and create an app.
Environment:
- Python version: 3.9
- Quart version: 0.19.6
| closed | 2024-11-15T07:41:10Z | 2024-11-15T14:03:12Z | https://github.com/pallets/quart/issues/382 | [] | DaniMunos95 | 1 |
coqui-ai/TTS | pytorch | 3,447 | [Feature request] Please Make an spacial android release for persian deafs | <!-- Welcome to the 🐸TTS project!
We are excited to see your interest, and appreciate your support! --->
**🚀 Feature Description**
Persian Deafs need your help to can speak with others.
we have not voice functionality in persian in apps like google translate and need your help to make an spacial model to persian language as android offline app.
<!--A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
**Solution**
I hope we have at the end an android app that we can load prebuild models for example for persian and than use it to generate persian voice from persian text
also we need an spacial model for persian language
<!-- A clear and concise description of what you want to happen. -->
**Alternative Solutions**
<!-- A clear and concise description of any alternative solutions or features you've considered. -->
**Additional context**
persian deaf need your help them cant speak and be social please help them.thanks
<!-- Add any other context or screenshots about the feature request here. -->
| closed | 2023-12-20T04:57:52Z | 2024-02-23T03:28:15Z | https://github.com/coqui-ai/TTS/issues/3447 | [
"wontfix",
"feature request"
] | mablue | 2 |
huggingface/peft | pytorch | 1,381 | wrong model loading after merge_and_unload + save_pretrained | ### System Info
running sagemaker on a g5.12xlarge machine
this is my requirements file:
```
autoawq @ git+https://github.com/casper-hansen/AutoAWQ
wandb==0.16.2
transformers==4.36.2
trl @ git+https://github.com/huggingface/trl.git
peft==0.7.1
accelerate==0.26.1
bitsandbytes==0.42.0
diffusers==0.24.0
```
### Who can help?
@pacman100 @younesbelkada @sayakpaul
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder
- [ ] My own task or dataset (give details below)
### Reproduction
I'm working with mistralai/Mixtral-8x7B-Instruct-v0.1.
I load up a model and train a lora adapter like:
```
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(
args.model_name,
trust_remote_code=True,
use_auth_token=True,
)
model = AutoModelForCausalLM.from_pretrained(
args.model_name,
device_map="auto",
use_auth_token=True,
trust_remote_code=True,
quantization_config=bnb_config,
use_cache=False if args.gradient_checkpointing else True,
)
peft_config = LoraConfig(
r=args.lora_r,
lora_alpha=args.lora_alpha,
target_modules=find_all_linear_names(model),
lora_dropout=0.1,
bias="none",
task_type=TaskType.CAUSAL_LM,
)
model = prepare_model_for_kbit_training(model)
if args.gradient_checkpointing:
model.gradient_checkpointing_enable()
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
output_dir = "/opt/ml/checkpoints/"
training_args = TrainingArguments(
do_eval=True,
bf16=args.bf16,
output_dir=output_dir,
max_steps=args.max_steps,
warmup_ratio=warmup_ratio,
eval_steps=args.eval_steps,
evaluation_strategy="steps",
learning_rate=learning_rate,
logging_steps=args.eval_steps,
num_train_epochs=args.n_epochs,
lr_scheduler_type=args.lr_scheduler_type,
auto_find_batch_size=auto_find_batch_size,
per_device_train_batch_size=args.train_batch_size,
gradient_checkpointing=args.gradient_checkpointing,
gradient_accumulation_steps=args.gradient_accumulation_steps,
logging_strategy="steps",
overwrite_output_dir=True,
logging_dir=f"{output_dir}/logs",
)
# Create Trainer instance
trainer = Trainer(
model=model,
args=training_args,
eval_dataset=dataset_test,
train_dataset=dataset_train,
compute_metrics=get_compute_metrics_fn(tokenizer),
data_collator=default_data_collator,
)
# pre-process the model by upcasting the layer norms in float 32
for name, module in model.named_modules():
if isinstance(module, LoraLayer):
if args.bf16:
module = module.to(torch.bfloat16)
if "norm" in name:
module = module.to(torch.float32)
if "lm_head" in name or "embed_tokens" in name:
if hasattr(module, "weight"):
if args.bf16 and module.weight.dtype == torch.float32:
module = module.to(torch.bfloat16)
# Start training
trainer.train()
```
then I need to save a 16 bit model with merged adapter, so
I save the adapter:
```
model.save_pretrained(output_dir)
```
then I reload the base 16 bit model, mount the adapter, merge_and_unload, and save the merged model:
```
del model
del trainer
model = AutoModelForCausalLM.from_pretrained(
args.model_name,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.bfloat16 if args.bf16 else torch.float16,
# use_auth_token=True,
)
model.eval()
model = PeftModel.from_pretrained(
model,
output_dir,
# use_auth_token=True,
)
merged_model = model.merge_and_unload()
merged_model.save_pretrained(f"{output_dir}_merged")
```
For debugging, here I print merged model and obtain the follwoing output:
```
print('#################################### merged_model ####################################')
print(merged_model)
```
```
#################################### merged_model ####################################
MixtralForCausalLM(
(model): MixtralModel(
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x MixtralDecoderLayer(
(self_attn): MixtralAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear(in_features=4096, out_features=1024, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): MixtralRotaryEmbedding()
)
(block_sparse_moe): MixtralSparseMoeBlock(
(gate): Linear(in_features=4096, out_features=8, bias=False)
(experts): ModuleList(
(0-7): 8 x MixtralBLockSparseTop2MLP(
(w1): Linear(in_features=4096, out_features=14336, bias=False)
(w2): Linear(in_features=14336, out_features=4096, bias=False)
(w3): Linear(in_features=4096, out_features=14336, bias=False)
(act_fn): SiLU()
)
)
)
(input_layernorm): MixtralRMSNorm()
(post_attention_layernorm): MixtralRMSNorm()
)
)
(norm): MixtralRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)
```
As you can see, the model seems to be correctly merged when I save it.
At a second time, I load back the model with from_pretrained from the directory I previously used
```
model = AutoModelForCausalLM.from_pretrained(
f"{output_dir}_merged",
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.bfloat16 if args.bf16 else torch.float16,
# use_auth_token=True,
)
print('#################################### reloaded merged MODEL #######')
print(model)
```
And when I print it, you can see the adapter was loaded back on!
```
#################################### reloaded merged MODEL ####################################
MixtralForCausalLM(
(model): MixtralModel(
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x MixtralDecoderLayer(
(self_attn): MixtralAttention(
(q_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(k_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(v_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(o_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(rotary_emb): MixtralRotaryEmbedding()
)
(block_sparse_moe): MixtralSparseMoeBlock(
(gate): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=8, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=8, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(experts): ModuleList(
(0-7): 8 x MixtralBLockSparseTop2MLP(
(w1): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=14336, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=14336, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(w2): lora.Linear(
(base_layer): Linear(in_features=14336, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=14336, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(w3): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=14336, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=14336, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(act_fn): SiLU()
)
)
)
(input_layernorm): MixtralRMSNorm()
(post_attention_layernorm): MixtralRMSNorm()
)
)
(norm): MixtralRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)
```
### Expected behavior
I consider this behaviour as totally unexpected, I wanted to save and load a merged model!
Could someone please help me out with this? | closed | 2024-01-22T13:23:21Z | 2025-03-19T09:06:53Z | https://github.com/huggingface/peft/issues/1381 | [] | sd3ntato | 6 |
clovaai/donut | computer-vision | 113 | Train donut on two different downstream tasks simultaneously | Is it possible to train donut on two downstream tasks simultaneously ? document parsing and classification for example. If yes, should the `{"class" : {class_name}}` inside `ground_truth_parse` when the `gt_parse` is as follows `{\"gt_parse\": {ground_truth_parse}}` ? | closed | 2022-12-27T14:37:51Z | 2023-02-05T09:39:23Z | https://github.com/clovaai/donut/issues/113 | [] | Rabie-H | 2 |
FactoryBoy/factory_boy | django | 517 | FactoryBoy recursive stubs (i.e. SubFactory stubbing) | #### The problem
Factory boy is very useful for creating structures with lots of fake data. A design pattern I like to use is to create the stubs, and then use the stubs for checking the resulting model instance at the end of the test. This is really handy for checking integration (e.g. I can convert this data from the stubs, pass into, say, an XML parser, then check the generated instance at the end against the original stubs).
The issue that I'm having is that the subfactories are not created as stubs, so I want to either recursively generate stubs, or exclude the subfactories entirely.
#### Proposed solution
Without knowing much about the factory boys internal, I don't know whether this would even be practical, let alone easy to implement. Even an option to just disable SubFactory and RelatedFactory would do the job as well. I might have a go at seeing if I can add a class override that will let me do this. It may not be too hard. Perhaps I could use the FACTORY_CLASS keyword argument to do some magic.
#### Extra notes
As stubbing is a strategy, this feature could perhaps deal with allowing recursive strategies in general. | closed | 2018-09-13T09:34:45Z | 2018-09-13T11:06:42Z | https://github.com/FactoryBoy/factory_boy/issues/517 | [] | chriswyatt | 1 |
apache/airflow | machine-learning | 47,789 | airflow_local_settings.py overriden as an empty string | ### Official Helm Chart version
1.15.0 (latest released)
### Apache Airflow version
v2.10.4
### Kubernetes Version
1.32.1
### Helm Chart configuration
```yaml
spec:
values:
webserverSecretKeySecretName: webserver-secret-key
```
### Docker Image customizations
```Dockerfile
FROM apache/airflow:2.10.4-python3.12
COPY airflow_local_settings.py $AIRFLOW_USER_HOME/config/airflow_local_settings.py
```
### What happened
The `airflow_local_config.py` file is is empty and e.g. cluster policies are not applied (since the file is empty).
### What you think should happen instead
Either, if the airflow_local_settings.py exists, it should not be overridden (by the empty configMap value)
Or this behavior should be documented and chart users should be able to disable the configMap mounting e.g.: by setting:
```yaml
spec:
values:
airflowLocalSettings: ~
```
### How to reproduce
I think the reason for that is the templating in the chart values.yaml:
```yaml
airflowLocalSettings: |-
{{- if semverCompare ">=2.2.0 <3.0.0" .Values.airflowVersion }}
{{- if not (or .Values.webserverSecretKey .Values.webserverSecretKeySecretName) }}
from airflow.www.utils import UIAlert
DASHBOARD_UIALERTS = [
UIAlert(
'Usage of a dynamic webserver secret key detected. We recommend a static webserver secret key instead.'
' See the <a href='
'"https://airflow.apache.org/docs/helm-chart/stable/production-guide.html#webserver-secret-key" '
'target="_blank" rel="noopener noreferrer">'
'Helm Chart Production Guide</a> for more details.',
category="warning",
roles=["Admin"],
html=True,
)
]
{{- end }}
{{- end }}
```
If `webserverSecretKey` or `webserverSecretKeySecretName` is defined, the local_airflow_settings.py will be overwritten by mounting an empty configMap.
This might be on purpose - in that case, I would extend the documentation to point out this caveat.
### Anything else
_No response_
### Are you willing to submit PR?
- [x] Yes I am willing to submit a PR!
### Code of Conduct
- [x] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)
| closed | 2025-03-14T14:49:01Z | 2025-03-19T14:55:33Z | https://github.com/apache/airflow/issues/47789 | [
"kind:bug",
"area:helm-chart",
"needs-triage"
] | timonviola | 2 |
2noise/ChatTTS | python | 107 | modelscope中缺少 spk_stat.pt | 改成从 modelscope下载模型后,下载成功运行时提示`AssertionError: Missing spk_stat.pt: **/pzc163/chatTTS/asset/spk_stat.pt`
从 https://huggingface.co/2Noise/ChatTTS/blob/main/asset/spk_stat.pt 下载 spk_stat.pt 复制到 asset 目录后问题解决 | closed | 2024-05-30T15:30:25Z | 2024-07-17T04:01:41Z | https://github.com/2noise/ChatTTS/issues/107 | [
"stale"
] | jianchang512 | 6 |
kornia/kornia | computer-vision | 2,534 | Allow different filling formats | ## 🚀 Feature
Warp operators (https://kornia.readthedocs.io/en/latest/geometry.transform.html#warp-operators) should allow fill values for different sizes. For example `warp_perspective` and `warp_affine` should allow filling values for one channel images.
## Motivation
Apply data augmentation in 1 channels images such as grayscale or IR.
## Pitch
Filling value should match the size of the channels rather than asking always to have size 3
| closed | 2023-08-31T10:17:28Z | 2023-09-25T12:40:16Z | https://github.com/kornia/kornia/issues/2534 | [
"help wanted"
] | priba | 2 |
pytorch/vision | computer-vision | 8,122 | Scheduled workflow failed | Oh no, something went wrong in the scheduled workflow tests/download.
Please look into it:
https://github.com/pytorch/vision/actions/runs/6919508562
Feel free to close this if this was just a one-off error.
cc @pmeier | closed | 2023-11-19T09:09:23Z | 2023-11-20T16:03:24Z | https://github.com/pytorch/vision/issues/8122 | [
"bug",
"module: datasets"
] | github-actions[bot] | 0 |
fastapi/sqlmodel | sqlalchemy | 10 | Unsure how to specify foreign keys when receiving AmbiguousForeignKeysError | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X] I already read and followed all the tutorial in the docs and didn't find an answer.
- [X] I already checked if it is not related to SQLModel but to [Pydantic](https://github.com/samuelcolvin/pydantic).
- [X] I already checked if it is not related to SQLModel but to [SQLAlchemy](https://github.com/sqlalchemy/sqlalchemy).
### Commit to Help
- [X] I commit to help with one of those options 👆
### Example Code
```python
from typing import Optional
from uuid import uuid4
from sqlmodel import Field, Session, SQLModel, create_engine, Relationship
class Account(SQLModel, table=True):
id: Optional[str] = Field(default=uuid4, primary_key=True)
institution_id: str
institution_name: str
class Transaction(SQLModel, table=True):
id: Optional[str] = Field(default=uuid4, primary_key=True)
from_account_id: Optional[str] = Field(default=None, foreign_key="account.id")
from_account: Account = Relationship()
to_account_id: Optional[str] = Field(default=None, foreign_key="account.id")
to_account: Account = Relationship()
amount: float
sqlite_file_name = "database.db"
sqlite_url = f"sqlite:///{sqlite_file_name}"
engine = create_engine(sqlite_url, echo=True)
SQLModel.metadata.create_all(engine)
account = Account(institution_id='1', institution_name='Account 1')
with Session(engine) as s:
s.add(account)
```
### Description
When creating a table with multiple relationships to another table I am receiving the AmbiguousForeignKeysError SQLAlchemy error. There doesn't appear to be a SQLModel argument for the foreign key on `Relationship`. I tried passing the following to SQLAlchemy using `Relationship(sa_relationship_kwargs={'foreign_keys':...})`, but neither are a SQLAlchemy `Column`
* the SQLModel/pydantic field (a `FieldInfo` object)
* that field's `field_name.sa_column` (a `PydanticUndefined` object at this point in initialization)
Not sure how else to pass the right foreign key (possibly using SQLAlchemy's Query API?). Hoping there's a cleaner SQLModel/pydantic way to do this!
### Operating System
macOS
### Operating System Details
_No response_
### SQLModel Version
0.0.3
### Python Version
3.9.5
### Additional Context
Full stack trace:
```
2021-08-24 22:28:57,351 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2021-08-24 22:28:57,352 INFO sqlalchemy.engine.Engine PRAGMA main.table_info("account")
2021-08-24 22:28:57,352 INFO sqlalchemy.engine.Engine [raw sql] ()
2021-08-24 22:28:57,352 INFO sqlalchemy.engine.Engine PRAGMA main.table_info("transaction")
2021-08-24 22:28:57,352 INFO sqlalchemy.engine.Engine [raw sql] ()
2021-08-24 22:28:57,352 INFO sqlalchemy.engine.Engine COMMIT
Traceback (most recent call last):
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/orm/relationships.py", line 2744, in _determine_joins
self.primaryjoin = join_condition(
File "<string>", line 2, in join_condition
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/sql/selectable.py", line 1184, in _join_condition
cls._joincond_trim_constraints(
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/sql/selectable.py", line 1305, in _joincond_trim_constraints
raise exc.AmbiguousForeignKeysError(
sqlalchemy.exc.AmbiguousForeignKeysError: Can't determine join between 'transaction' and 'account'; tables have more than one foreign key constraint relationship between them. Please specify the 'onclause' of this join explicitly.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/trippwickersham/Projects/village/gh_issue.py", line 27, in <module>
account = Account(institution_id='1', institution_name='Account 1')
File "<string>", line 4, in __init__
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/orm/state.py", line 474, in _initialize_instance
manager.dispatch.init(self, args, kwargs)
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/event/attr.py", line 343, in __call__
fn(*args, **kw)
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/orm/mapper.py", line 3565, in _event_on_init
instrumenting_mapper._check_configure()
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/orm/mapper.py", line 1873, in _check_configure
_configure_registries({self.registry}, cascade=True)
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/orm/mapper.py", line 3380, in _configure_registries
_do_configure_registries(registries, cascade)
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/orm/mapper.py", line 3419, in _do_configure_registries
mapper._post_configure_properties()
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/orm/mapper.py", line 1890, in _post_configure_properties
prop.init()
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/orm/interfaces.py", line 222, in init
self.do_init()
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/orm/relationships.py", line 2142, in do_init
self._setup_join_conditions()
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/orm/relationships.py", line 2238, in _setup_join_conditions
self._join_condition = jc = JoinCondition(
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/orm/relationships.py", line 2633, in __init__
self._determine_joins()
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/orm/relationships.py", line 2796, in _determine_joins
util.raise_(
File "/Users/trippwickersham/opt/miniconda3/envs/village/lib/python3.9/site-packages/sqlalchemy/util/compat.py", line 207, in raise_
raise exception
sqlalchemy.exc.AmbiguousForeignKeysError: Could not determine join condition between parent/child tables on relationship Transaction.from_account - there are multiple foreign key paths linking the tables. Specify the 'foreign_keys' argument, providing a list of those columns which should be counted as containing a foreign key reference to the parent table.
``` | open | 2021-08-25T05:48:09Z | 2024-12-06T17:29:27Z | https://github.com/fastapi/sqlmodel/issues/10 | [
"question"
] | trippersham | 21 |
python-restx/flask-restx | flask | 617 | __init__() I'm encountering an error: "got multiple values for argument 'X'" | I'm having trouble transitioning from flask_restful to flask_restx while using the add_resource() method. In flask_restful, everything was working fine, but I'm encountering issues with flask_restx.
A clear and concise question
Here are the relevant links to the documentation I’m following:
- [Flask-RESTx API Documentation](https://flask-restx.readthedocs.io/en/latest/quickstart.html?highlight=Namespace#order-preservation)
- [Flask-RESTx Example](https://flask-restx.readthedocs.io/en/latest/example.html)
I'm encountering an error: "got multiple values for argument 'rate_limiter'".
I have tried removing rate_limiter from resource_class_kwargs, but the error persists. it will then ask "got multiple values for argument 'authentication'".
Here’s the code snippet that is causing the issue:
```
from flask import Flask
from flask_restx import Api, Resource, reqparse
self.app = Flask(__name__)
self.api = Api(self.app, version='1.0', title='todo', description='todo')
self.products_namespace = self.api.namespace(
'api/products',
description='products endpoint'
)
self.products_namespace.add_resource(ProductManagement, '/products/management/<string:id>', resource_class_kwargs={
'rate_limiter': self.rate_limiter,
'authentication': self.authentication,
'product_controller': self.product_controller
})
class ProductManagement(Resource):
def __init__(self, rate_limiter, authentication, product_controller):
self.result = []
self.parser = reqparse.RequestParser()
self.parser.add_argument('company_id', type=str)
self.rate_limiter = rate_limiter
self.authentication = authentication
self.product_controller = product_controller
self.api.add_namespace(self.products_namespace)
``` | closed | 2024-09-04T10:58:52Z | 2024-09-04T11:31:26Z | https://github.com/python-restx/flask-restx/issues/617 | [
"question"
] | KeithYatco | 1 |
falconry/falcon | api | 1,596 | Improve docs re suffixed responders | - [x] Add an example to the `suffix` kwarg docstring for `add_route()`
- [x] Add a section about suffixed responders to the [routing](https://falcon.readthedocs.io/en/stable/api/routing.html) page | closed | 2019-10-29T05:48:49Z | 2021-03-06T19:55:16Z | https://github.com/falconry/falcon/issues/1596 | [
"documentation",
"good first issue"
] | kgriffs | 3 |
axnsan12/drf-yasg | django | 33 | OpenAPI 3 support | The latest version of the [OpenAPI specification](https://swagger.io/specification/) has some interesting new features and could be worth implementing. A great overview of new stuff can be found here: https://blog.readme.io/an-example-filled-guide-to-swagger-3-2/
It would enable support for some features we cannot currently represent:
* `write_only` and `allow_null` serializer fields via new [Schema properties](https://swagger.io/specification/#schemaObject)
* hostname versioning via [server variables](https://swagger.io/specification/#serverVariableObject)
* support for file types via [Encoding objects](https://swagger.io/specification/#encodingObject)
* support for more complex multipart/form parameters with the new [Parameter styles](https://swagger.io/specification/#parameterObject) and the new [RequestBody object](https://swagger.io/specification/#requestBodyObject)
There are also improvements like support for `anyOf` and `oneOf`, more complete [security schemes](https://swagger.io/specification/#securitySchemeObject), operation [links](https://swagger.io/specification/#linkObject) and other goodies.
On the other hand, there are some considerations:
1. it is significantly more complex than OpenAPI 2.0
1. it would require non-trivial changes to both public interfaces and internal code
1. supporting both 2.0 and 3.0 at the same time is a bit complicated, so 2.0 would probably have to be dropped
1. many tools do not yet support 3.0 - the spec itself was just released in September 2017
So, as of now, this is mostly a statement of intent and personal observations - I do not have any plans of starting work on this in the foreseeable future, and certainly not until the tooling situation improves. | open | 2018-01-02T14:32:34Z | 2025-03-09T10:41:50Z | https://github.com/axnsan12/drf-yasg/issues/33 | [
"help wanted",
"enhancement",
"2.x.x"
] | axnsan12 | 24 |
chaoss/augur | data-visualization | 2,648 | Bus factor metric API | The canonical definition is here: https://chaoss.community/?p=3944 | open | 2023-11-30T18:07:30Z | 2023-11-30T18:19:04Z | https://github.com/chaoss/augur/issues/2648 | [
"API",
"first-timers-only"
] | sgoggins | 0 |
ckan/ckan | api | 7,718 | wrong counts in group_list with include_dataset_count=True | ## CKAN version
all
## Describe the bug
Permission labels aren't checked for group or organization dataset counts leading to incorrect counts
### Steps to reproduce
Use an IPermissionLabels plugin or package collaborators to give permission to a dataset to a user that
wouldn't normally be able to view it. When that user views the group or organization page that dataset isn't
included in the package counts shown.
### Expected behavior
dataset counts in group_list (and by extension group and organization pages) should match the counts
on the dataset search pages
### Additional details
https://github.com/ckan/ckan/blob/9956f92925740957b119bd7c6719ee202eb51082/ckan/lib/dictization/model_dictize.py#L326-L333 is performing a solr query that mimics the one
in `package_search` but is incomplete. We're better off moving this up to the logic layer and calling
`package_search` so we're sure to get correct results.
| open | 2023-07-26T18:40:12Z | 2023-09-21T15:05:44Z | https://github.com/ckan/ckan/issues/7718 | [] | wardi | 0 |
django-cms/django-cms | django | 7,395 | Freenode URLs still lingering in markdown files / IRC | It appears that there used to be an IRC channel on #django-cms on Freenode at some point, and some of the documentation files still seem to mention Freenode, but not visibly. (e.g. https://github.com/django-cms/django-cms/blame/6e4841e4cadc9820b296bbe1b093497bcaf32b99/docs/contributing/code.rst#L203 and https://github.com/django-cms/django-cms/blame/2a19342613ab2ea5147afa1ca29d3af79027de0c/docs/contributing/development-policies.rst#L235 )
Has the project considered moving to or having a channel on libera.chat, where most of Freenode has moved after the network changed hands? | closed | 2022-09-16T18:47:29Z | 2022-10-23T17:20:16Z | https://github.com/django-cms/django-cms/issues/7395 | [
"component: documentation"
] | deliciouslytyped | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.