
url
stringlengths 61
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 75
75
| comments_url
stringlengths 70
70
| events_url
stringlengths 68
68
| html_url
stringlengths 49
51
| id
int64 758M
1.95B
| node_id
stringlengths 18
32
| number
int64 1.2k
6.31k
| title
stringlengths 1
290
| user
dict | labels
listlengths 0
3
| state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
listlengths 0
4
| milestone
dict | comments
sequencelengths 0
30
| created_at
unknown | updated_at
unknown | closed_at
unknown | author_association
stringclasses 3
values | active_lock_reason
float64 | draft
float64 0
1
⌀ | pull_request
dict | body
stringlengths 0
36.2k
⌀ | reactions
dict | timeline_url
stringlengths 70
70
| performed_via_github_app
float64 | state_reason
stringclasses 3
values | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/2814 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2814/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2814/comments | https://api.github.com/repos/huggingface/datasets/issues/2814/events | https://github.com/huggingface/datasets/pull/2814 | 973,632,645 | MDExOlB1bGxSZXF1ZXN0NzE1MDUwODc4 | 2,814 | Bump tqdm version | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [] | "2021-08-18T12:51:29Z" | "2021-08-18T13:44:11Z" | "2021-08-18T13:39:50Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2814.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2814",
"merged_at": "2021-08-18T13:39:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2814.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2814"
} | The recently released tqdm 4.62.1 includes a fix for PermissionError on Windows (submitted by me in https://github.com/tqdm/tqdm/pull/1207), which means we can remove expensive `gc.collect` calls by bumping tqdm to that version. This PR does exactly that and, additionally, fixes a `disable_tqdm` definition that would previously, if used, raise a PermissionError on Windows. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2814/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2814/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3707 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3707/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3707/comments | https://api.github.com/repos/huggingface/datasets/issues/3707/events | https://github.com/huggingface/datasets/issues/3707 | 1,132,741,903 | I_kwDODunzps5DhEUP | 3,707 | `.select`: unexpected behavior with `indices` | {
"avatar_url": "https://avatars.githubusercontent.com/u/36087158?v=4",
"events_url": "https://api.github.com/users/gabegma/events{/privacy}",
"followers_url": "https://api.github.com/users/gabegma/followers",
"following_url": "https://api.github.com/users/gabegma/following{/other_user}",
"gists_url": "https://api.github.com/users/gabegma/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gabegma",
"id": 36087158,
"login": "gabegma",
"node_id": "MDQ6VXNlcjM2MDg3MTU4",
"organizations_url": "https://api.github.com/users/gabegma/orgs",
"received_events_url": "https://api.github.com/users/gabegma/received_events",
"repos_url": "https://api.github.com/users/gabegma/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gabegma/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gabegma/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gabegma"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
}
] | null | [
"Hi! Currently, we compute the final index as `index % len(dset)`. I agree this behavior is somewhat unexpected and that it would be more appropriate to raise an error instead (this is what `df.iloc` in Pandas does, for instance).\r\n\r\n@albertvillanova @lhoestq wdyt?",
"I agree. I think `index % len(dset)` was used to support negative indices.\r\n\r\nI think this needs to be fixed in `datasets.formatting.formatting._check_valid_index_key` if I'm not mistaken"
] | "2022-02-11T15:20:01Z" | "2022-02-14T19:19:21Z" | "2022-02-14T19:19:21Z" | NONE | null | null | null | ## Describe the bug
The `.select` method will not throw when sending `indices` bigger than the dataset length; `indices` will be wrapped instead. This behavior is not documented anywhere, and is not intuitive.
## Steps to reproduce the bug
```python
from datasets import Dataset
ds = Dataset.from_dict({"text": ["d", "e", "f"], "label": [4, 5, 6]})
res1 = ds.select([1, 2, 3])['text']
res2 = ds.select([1000])['text']
```
## Expected results
Both results should throw an `Error`.
## Actual results
`res1` will give `['e', 'f', 'd']`
`res2` will give `['e']`
## Environment info
Bug found from this environment:
- `datasets` version: 1.16.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.7
- PyArrow version: 6.0.1
It was also replicated on `master`.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3707/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3707/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1985 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1985/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1985/comments | https://api.github.com/repos/huggingface/datasets/issues/1985/events | https://github.com/huggingface/datasets/pull/1985 | 822,170,651 | MDExOlB1bGxSZXF1ZXN0NTg0ODM4NjIw | 1,985 | Optimize int precision | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"@lhoestq, are the tests OK? Some other cases I missed? Do you agree with this approach?",
"I just tested this and it works like a charm :) \r\n\r\nHowever tokenizing and then setting the format to \"torch\" to feed the tokens into a model doesn't seem to work anymore, since the pytorch tensors have the int32/int8 precisions instead of int64 that is required as model inputs.\r\n\r\nFor example:\r\n\r\n```python\r\nimport torch\r\nfrom datasets import Dataset\r\nfrom transformers import BertModel, BertTokenizer\r\n\r\ntorch.set_grad_enabled(False)\r\n\r\ntokenizer = BertTokenizer.from_pretrained(\"bert-base-uncased\")\r\nmodel = BertModel.from_pretrained(\"bert-base-uncased\")\r\n\r\ndataset = Dataset.from_dict({\"text\": [\"hello there !\"]})\r\ndataset = dataset.map(tokenizer, input_columns=\"text\", remove_columns=dataset.column_names)\r\ndataset = dataset.with_format(\"torch\")\r\n\r\nprint(dataset.features)\r\n# {'attention_mask': Sequence(feature=Value(dtype='int8', id=None), length=-1, id=None),\r\n# 'input_ids': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), # this should be int32 though\r\n# 'token_type_ids': Sequence(feature=Value(dtype='int8', id=None), length=-1, id=None)}\r\n\r\nmodel(**dataset[:1])\r\n# RuntimeError: Expected tensor for argument #1 'indices' to have scalar type Long; but got torch.CharTensor instead (while checking arguments for embedding)\r\n\r\ndataset = dataset.with_format(\"torch\", dtype=torch.int64)\r\n\r\nmodel(**dataset[:1])\r\n# works as expected\r\n```\r\n\r\nPinging @sgugger here to make sure we take the right decision here.\r\n\r\nDo we want the \"torch\" format to always return int64 ? Or does it have to keep the precision defined by the `dataset.features` \r\n and therefore we would need to specify \"torch\" with `dtype=torch.int64` ?",
"From a user perspective, I think it's fine if the \"torch\" format converts all ints types to `torch.int64` by default since it's what the model will need almost all the time. I don't see a case where you would want to keep the low precision at the top of my head, and one can always write a custom transform for an edge case.",
"Sounds good to me !\r\nFor consistency maybe we should make the float precision fixed as well (float32, I guess)",
"Yes, that would be the one used by default.",
"Do we have the same requirements for TensorFlow?",
"Yes I we should do the same for tensorflow as well since tf models would have the same issue\r\n\r\nThanks for adding this :)",
"@lhoestq I think this PR is ready... :)"
] | "2021-03-04T14:12:23Z" | "2021-03-22T12:04:40Z" | "2021-03-16T09:44:00Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1985.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1985",
"merged_at": "2021-03-16T09:44:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1985.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1985"
} | Optimize int precision to reduce dataset file size.
Close #1973, close #1825, close #861. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 3,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1985/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1985/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3548 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3548/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3548/comments | https://api.github.com/repos/huggingface/datasets/issues/3548/events | https://github.com/huggingface/datasets/issues/3548 | 1,096,409,512 | I_kwDODunzps5BWeGo | 3,548 | Specify the feature types of a dataset on the Hub without needing a dataset script | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gists_url": "https://api.github.com/users/abidlabs/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abidlabs",
"id": 1778297,
"login": "abidlabs",
"node_id": "MDQ6VXNlcjE3NzgyOTc=",
"organizations_url": "https://api.github.com/users/abidlabs/orgs",
"received_events_url": "https://api.github.com/users/abidlabs/received_events",
"repos_url": "https://api.github.com/users/abidlabs/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abidlabs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abidlabs/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abidlabs"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gists_url": "https://api.github.com/users/abidlabs/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abidlabs",
"id": 1778297,
"login": "abidlabs",
"node_id": "MDQ6VXNlcjE3NzgyOTc=",
"organizations_url": "https://api.github.com/users/abidlabs/orgs",
"received_events_url": "https://api.github.com/users/abidlabs/received_events",
"repos_url": "https://api.github.com/users/abidlabs/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abidlabs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abidlabs/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abidlabs"
}
] | null | [
"After looking into this, discovered that this is already supported if the `dataset_infos.json` file is configured correctly! Here is a working example: https://huggingface.co/datasets/abidlabs/test-audio-13\r\n\r\nThis should be probably be documented, though. "
] | "2022-01-07T15:17:06Z" | "2022-01-20T14:48:38Z" | "2022-01-20T14:48:38Z" | MEMBER | null | null | null | **Is your feature request related to a problem? Please describe.**
Currently if I upload a CSV with paths to audio files, the column type is string instead of Audio.
**Describe the solution you'd like**
I'd like to be able to specify the types of the column, so that when loading the dataset I directly get the features types I want.
The feature types could read from the `dataset_infos.json` for example.
**Describe alternatives you've considered**
Create a dataset script to specify the features, but that seems complicated for a simple thing.
cc @abidlabs | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3548/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3548/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4088 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4088/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4088/comments | https://api.github.com/repos/huggingface/datasets/issues/4088/events | https://github.com/huggingface/datasets/pull/4088 | 1,191,901,172 | PR_kwDODunzps41l4yE | 4,088 | Remove unused legacy Beam utils | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-04-04T14:43:51Z" | "2022-04-05T15:23:27Z" | "2022-04-05T15:17:41Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4088.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4088",
"merged_at": "2022-04-05T15:17:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4088.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4088"
} | This PR removes unused legacy custom `WriteToParquet`, once official Apache Beam includes the patch since version 2.22.0:
- Patch PR: https://github.com/apache/beam/pull/11699
- Issue: https://issues.apache.org/jira/browse/BEAM-10022
In relation with:
- #204 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4088/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4088/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4376 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4376/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4376/comments | https://api.github.com/repos/huggingface/datasets/issues/4376/events | https://github.com/huggingface/datasets/issues/4376 | 1,242,218,144 | I_kwDODunzps5KCr6g | 4,376 | irc_disentagle viewer error | {
"avatar_url": "https://avatars.githubusercontent.com/u/25671683?v=4",
"events_url": "https://api.github.com/users/labouz/events{/privacy}",
"followers_url": "https://api.github.com/users/labouz/followers",
"following_url": "https://api.github.com/users/labouz/following{/other_user}",
"gists_url": "https://api.github.com/users/labouz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/labouz",
"id": 25671683,
"login": "labouz",
"node_id": "MDQ6VXNlcjI1NjcxNjgz",
"organizations_url": "https://api.github.com/users/labouz/orgs",
"received_events_url": "https://api.github.com/users/labouz/received_events",
"repos_url": "https://api.github.com/users/labouz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/labouz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/labouz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/labouz"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"DUPLICATED comment from https://github.com/huggingface/datasets/issues/3807:\r\n\r\nmy code:\r\n```\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"irc_disentangle\", download_mode=\"force_redownload\")\r\n```\r\nhowever, it produces the same error\r\n```\r\n[38](file:///Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/datasets/utils/info_utils.py?line=37) if len(bad_urls) > 0:\r\n [39](file:///Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/datasets/utils/info_utils.py?line=38) error_msg = \"Checksums didn't match\" + for_verification_name + \":\\n\"\r\n---> [40](file:///Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/datasets/utils/info_utils.py?line=39) raise NonMatchingChecksumError(error_msg + str(bad_urls))\r\n [41](file:///Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/datasets/utils/info_utils.py?line=40) logger.info(\"All the checksums matched successfully\" + for_verification_name)\r\n\r\nNonMatchingChecksumError: Checksums didn't match for dataset source files:\r\n['https://github.com/jkkummerfeld/irc-disentanglement/tarball/master']\r\n```\r\nI attempted to use the `ignore_verifications' as such:\r\n\r\n```\r\nds = datasets.load_dataset('irc_disentangle', download_mode=\"force_redownload\", ignore_verifications=True)\r\n\r\nDownloading builder script: 12.0kB [00:00, 5.92MB/s] \r\nDownloading metadata: 7.58kB [00:00, 3.48MB/s] \r\nNo config specified, defaulting to: irc_disentangle/ubuntu\r\nDownloading and preparing dataset irc_disentangle/ubuntu (download: 112.98 MiB, generated: 60.05 MiB, post-processed: Unknown size, total: 173.03 MiB) to /Users/laylabouzoubaa/.cache/huggingface/datasets/irc_disentangle/ubuntu/1.0.0/0f24ab262a21d8c1d989fa53ed20caa928f5880be26c162bfbc02445dbade7e5...\r\nDownloading data: 118MB [00:09, 12.1MB/s] \r\n \r\nDataset irc_disentangle downloaded and prepared to /Users/laylabouzoubaa/.cache/huggingface/datasets/irc_disentangle/ubuntu/1.0.0/0f24ab262a21d8c1d989fa53ed20caa928f5880be26c162bfbc02445dbade7e5. Subsequent calls will reuse this data.\r\n100%|██████████| 3/3 [00:00<00:00, 675.38it/s]\r\n```\r\nbut, this returns an empty set?\r\n```\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['id', 'raw', 'ascii', 'tokenized', 'date', 'connections'],\r\n num_rows: 0\r\n })\r\n test: Dataset({\r\n features: ['id', 'raw', 'ascii', 'tokenized', 'date', 'connections'],\r\n num_rows: 0\r\n })\r\n validation: Dataset({\r\n features: ['id', 'raw', 'ascii', 'tokenized', 'date', 'connections'],\r\n num_rows: 0\r\n })\r\n})\r\n```\r\nnot sure what else to try at this point?\r\nThanks in advanced🤗",
"Thanks for reporting, @labouz. I'm addressing it. ",
"The issue with checksum and empty dataset has been fixed by:\r\n- #4377\r\n\r\nTo load the dataset, you should force the re-generation of the dataset from the downloaded file by passing `download_mode=\"reuse_cache_if_exists\"` to `load_dataset`.\r\n\r\nIn relation with the issue with the dataset viewer, first the dataset should be refactored to support streaming.",
"parfait!\r\nit works now, thank you 🙏 ",
"Hi there, \r\nI see this issue is closed, but I am wondering if there is any chance the source files have been moved since this fix? I am stumbling into the same NonMatchingChecksumError noted by lebouz's second post once 118MB of data has been downloaded, and have tried the solutions noted in the various fix checksum posts linked here and in other posts regarding passing in \"reuse_cache_if_exists\" to download_mode. Any suggestions? Thank you!\r\n\r\n"
] | "2022-05-19T19:15:16Z" | "2023-01-12T16:56:13Z" | "2022-06-02T08:20:00Z" | NONE | null | null | null | the dataviewer shows this message for "ubuntu" - "train", "test", and "validation" splits:
```
Server error
Status code: 400
Exception: ValueError
Message: Cannot seek streaming HTTP file
```
it appears to give the same message for the "channel_two" data as well.
I get a Checksums error when using `load_data()` with this dataset. Even with the `download_mode` and `ignore_verifications` options set. i referenced the issue here: https://github.com/huggingface/datasets/issues/3807 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4376/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4376/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1593 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1593/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1593/comments | https://api.github.com/repos/huggingface/datasets/issues/1593/events | https://github.com/huggingface/datasets/issues/1593 | 769,611,386 | MDU6SXNzdWU3Njk2MTEzODY= | 1,593 | Access to key in DatasetDict map | {
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url": "https://api.github.com/users/ZhaofengWu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ZhaofengWu",
"id": 11954789,
"login": "ZhaofengWu",
"node_id": "MDQ6VXNlcjExOTU0Nzg5",
"organizations_url": "https://api.github.com/users/ZhaofengWu/orgs",
"received_events_url": "https://api.github.com/users/ZhaofengWu/received_events",
"repos_url": "https://api.github.com/users/ZhaofengWu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ZhaofengWu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZhaofengWu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ZhaofengWu"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Indeed that would be cool\r\n\r\nAlso FYI right now the easiest way to do this is\r\n```python\r\ndataset_dict[\"train\"] = dataset_dict[\"train\"].map(my_transform_for_the_train_set)\r\ndataset_dict[\"test\"] = dataset_dict[\"test\"].map(my_transform_for_the_test_set)\r\n```",
"I don't feel like adding an extra param for this simple usage makes sense, considering how many args `map` already has. \r\n\r\n(Feel free to re-open this issue if you don't agree with me)",
"I still think this is useful, since it's common that the data processing is different for training/dev/testing. And I don't know if the fact that `map` currently takes many arguments is a good reason not to support a useful feature."
] | "2020-12-17T07:02:20Z" | "2022-10-05T13:47:28Z" | "2022-10-05T12:33:06Z" | NONE | null | null | null | It is possible that we want to do different things in the `map` function (and possibly other functions too) of a `DatasetDict`, depending on the key. I understand that `DatasetDict.map` is a really thin wrapper of `Dataset.map`, so it is easy to directly implement this functionality in the client code. Still, it'd be nice if there can be a flag, similar to `with_indices`, that allows the callable to know the key inside `DatasetDict`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1593/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1593/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6000 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6000/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6000/comments | https://api.github.com/repos/huggingface/datasets/issues/6000/events | https://github.com/huggingface/datasets/pull/6000 | 1,782,456,878 | PR_kwDODunzps5UU_FB | 6,000 | Pin `joblib` to avoid `joblibspark` test failures | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006722 / 0.011353 (-0.004631) | 0.004425 / 0.011008 (-0.006583) | 0.100850 / 0.038508 (0.062341) | 0.040816 / 0.023109 (0.017707) | 0.348823 / 0.275898 (0.072925) | 0.446285 / 0.323480 (0.122805) | 0.005738 / 0.007986 (-0.002247) | 0.003517 / 0.004328 (-0.000811) | 0.078824 / 0.004250 (0.074574) | 0.064695 / 0.037052 (0.027643) | 0.389894 / 0.258489 (0.131405) | 0.416107 / 0.293841 (0.122266) | 0.028850 / 0.128546 (-0.099696) | 0.009011 / 0.075646 (-0.066635) | 0.323117 / 0.419271 (-0.096154) | 0.049162 / 0.043533 (0.005629) | 0.340144 / 0.255139 (0.085005) | 0.382072 / 0.283200 (0.098872) | 0.023160 / 0.141683 (-0.118523) | 1.549218 / 1.452155 (0.097063) | 1.581266 / 1.492716 (0.088550) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.293360 / 0.018006 (0.275353) | 0.602189 / 0.000490 (0.601700) | 0.004608 / 0.000200 (0.004408) | 0.000082 / 0.000054 (0.000028) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028144 / 0.037411 (-0.009267) | 0.107088 / 0.014526 (0.092562) | 0.112188 / 0.176557 (-0.064369) | 0.174669 / 0.737135 (-0.562466) | 0.116359 / 0.296338 (-0.179980) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422911 / 0.215209 (0.207702) | 4.231524 / 2.077655 (2.153869) | 1.906711 / 1.504120 (0.402591) | 1.706841 / 1.541195 (0.165646) | 1.792066 / 1.468490 (0.323576) | 0.559221 / 4.584777 (-4.025556) | 3.434280 / 3.745712 (-0.311433) | 1.918714 / 5.269862 (-3.351148) | 1.073070 / 4.565676 (-3.492606) | 0.067891 / 0.424275 (-0.356384) | 0.011927 / 0.007607 (0.004320) | 0.530843 / 0.226044 (0.304799) | 5.309213 / 2.268929 (3.040285) | 2.439246 / 55.444624 (-53.005378) | 2.101245 / 6.876477 (-4.775231) | 2.177436 / 2.142072 (0.035363) | 0.672150 / 4.805227 (-4.133077) | 0.137571 / 6.500664 (-6.363093) | 0.068343 / 0.075469 (-0.007126) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.265262 / 1.841788 (-0.576525) | 14.988021 / 8.074308 (6.913713) | 13.611677 / 10.191392 (3.420285) | 0.171389 / 0.680424 (-0.509035) | 0.017681 / 0.534201 (-0.516520) | 0.377542 / 0.579283 (-0.201741) | 0.399475 / 0.434364 (-0.034889) | 0.469553 / 0.540337 (-0.070785) | 0.561888 / 1.386936 (-0.825048) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006782 / 0.011353 (-0.004571) | 0.004412 / 0.011008 (-0.006597) | 0.078594 / 0.038508 (0.040086) | 0.039930 / 0.023109 (0.016820) | 0.371879 / 0.275898 (0.095981) | 0.444910 / 0.323480 (0.121430) | 0.005707 / 0.007986 (-0.002279) | 0.003901 / 0.004328 (-0.000427) | 0.080125 / 0.004250 (0.075875) | 0.063977 / 0.037052 (0.026925) | 0.382781 / 0.258489 (0.124292) | 0.441791 / 0.293841 (0.147950) | 0.030428 / 0.128546 (-0.098118) | 0.009008 / 0.075646 (-0.066638) | 0.084447 / 0.419271 (-0.334824) | 0.044432 / 0.043533 (0.000899) | 0.365686 / 0.255139 (0.110547) | 0.394312 / 0.283200 (0.111113) | 0.024508 / 0.141683 (-0.117175) | 1.577020 / 1.452155 (0.124865) | 1.630259 / 1.492716 (0.137543) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.307960 / 0.018006 (0.289953) | 0.591473 / 0.000490 (0.590983) | 0.008098 / 0.000200 (0.007898) | 0.000110 / 0.000054 (0.000056) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029567 / 0.037411 (-0.007845) | 0.112773 / 0.014526 (0.098247) | 0.117362 / 0.176557 (-0.059194) | 0.174293 / 0.737135 (-0.562843) | 0.123156 / 0.296338 (-0.173182) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.457475 / 0.215209 (0.242266) | 4.599067 / 2.077655 (2.521412) | 2.262638 / 1.504120 (0.758518) | 2.124943 / 1.541195 (0.583748) | 2.339912 / 1.468490 (0.871422) | 0.566264 / 4.584777 (-4.018513) | 3.489261 / 3.745712 (-0.256451) | 1.925151 / 5.269862 (-3.344711) | 1.099389 / 4.565676 (-3.466287) | 0.068232 / 0.424275 (-0.356043) | 0.011660 / 0.007607 (0.004052) | 0.571227 / 0.226044 (0.345183) | 5.702059 / 2.268929 (3.433130) | 2.837701 / 55.444624 (-52.606924) | 2.605468 / 6.876477 (-4.271008) | 2.818396 / 2.142072 (0.676323) | 0.681856 / 4.805227 (-4.123371) | 0.141401 / 6.500664 (-6.359263) | 0.069728 / 0.075469 (-0.005741) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.354935 / 1.841788 (-0.486853) | 15.437404 / 8.074308 (7.363095) | 15.415193 / 10.191392 (5.223801) | 0.153459 / 0.680424 (-0.526964) | 0.017190 / 0.534201 (-0.517011) | 0.367256 / 0.579283 (-0.212027) | 0.392709 / 0.434364 (-0.041655) | 0.426125 / 0.540337 (-0.114213) | 0.522612 / 1.386936 (-0.864324) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009183 / 0.011353 (-0.002170) | 0.005232 / 0.011008 (-0.005776) | 0.120349 / 0.038508 (0.081841) | 0.044715 / 0.023109 (0.021606) | 0.361519 / 0.275898 (0.085621) | 0.463702 / 0.323480 (0.140223) | 0.005842 / 0.007986 (-0.002144) | 0.004041 / 0.004328 (-0.000288) | 0.096953 / 0.004250 (0.092703) | 0.070593 / 0.037052 (0.033540) | 0.409790 / 0.258489 (0.151301) | 0.477452 / 0.293841 (0.183611) | 0.045827 / 0.128546 (-0.082719) | 0.014038 / 0.075646 (-0.061608) | 0.421317 / 0.419271 (0.002045) | 0.065276 / 0.043533 (0.021743) | 0.360074 / 0.255139 (0.104935) | 0.409147 / 0.283200 (0.125947) | 0.032444 / 0.141683 (-0.109238) | 1.739257 / 1.452155 (0.287102) | 1.831408 / 1.492716 (0.338692) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.274852 / 0.018006 (0.256846) | 0.596320 / 0.000490 (0.595830) | 0.006399 / 0.000200 (0.006199) | 0.000133 / 0.000054 (0.000079) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031400 / 0.037411 (-0.006012) | 0.127052 / 0.014526 (0.112526) | 0.134269 / 0.176557 (-0.042288) | 0.225998 / 0.737135 (-0.511137) | 0.150019 / 0.296338 (-0.146319) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.654202 / 0.215209 (0.438993) | 6.216735 / 2.077655 (4.139081) | 2.440214 / 1.504120 (0.936094) | 2.150575 / 1.541195 (0.609380) | 2.124790 / 1.468490 (0.656300) | 0.923514 / 4.584777 (-3.661263) | 5.556924 / 3.745712 (1.811212) | 2.843886 / 5.269862 (-2.425975) | 1.834232 / 4.565676 (-2.731444) | 0.111735 / 0.424275 (-0.312540) | 0.014823 / 0.007607 (0.007216) | 0.820503 / 0.226044 (0.594459) | 7.887737 / 2.268929 (5.618809) | 3.120307 / 55.444624 (-52.324317) | 2.405856 / 6.876477 (-4.470621) | 2.411239 / 2.142072 (0.269167) | 1.071283 / 4.805227 (-3.733944) | 0.227738 / 6.500664 (-6.272926) | 0.073516 / 0.075469 (-0.001953) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.531806 / 1.841788 (-0.309982) | 18.547661 / 8.074308 (10.473353) | 21.083922 / 10.191392 (10.892530) | 0.241706 / 0.680424 (-0.438718) | 0.034169 / 0.534201 (-0.500032) | 0.497514 / 0.579283 (-0.081769) | 0.599801 / 0.434364 (0.165437) | 0.576465 / 0.540337 (0.036127) | 0.673509 / 1.386936 (-0.713427) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007558 / 0.011353 (-0.003795) | 0.005001 / 0.011008 (-0.006008) | 0.093809 / 0.038508 (0.055301) | 0.039792 / 0.023109 (0.016683) | 0.456869 / 0.275898 (0.180971) | 0.493370 / 0.323480 (0.169891) | 0.005561 / 0.007986 (-0.002424) | 0.003982 / 0.004328 (-0.000346) | 0.085421 / 0.004250 (0.081170) | 0.059817 / 0.037052 (0.022765) | 0.468040 / 0.258489 (0.209550) | 0.514853 / 0.293841 (0.221012) | 0.044267 / 0.128546 (-0.084279) | 0.012674 / 0.075646 (-0.062972) | 0.098324 / 0.419271 (-0.320948) | 0.056604 / 0.043533 (0.013071) | 0.432200 / 0.255139 (0.177061) | 0.459812 / 0.283200 (0.176612) | 0.033872 / 0.141683 (-0.107811) | 1.618576 / 1.452155 (0.166421) | 1.676562 / 1.492716 (0.183846) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230625 / 0.018006 (0.212619) | 0.600558 / 0.000490 (0.600068) | 0.003419 / 0.000200 (0.003219) | 0.000113 / 0.000054 (0.000059) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026916 / 0.037411 (-0.010496) | 0.103003 / 0.014526 (0.088478) | 0.117078 / 0.176557 (-0.059478) | 0.169359 / 0.737135 (-0.567776) | 0.120305 / 0.296338 (-0.176034) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.616877 / 0.215209 (0.401668) | 6.157232 / 2.077655 (4.079577) | 2.869219 / 1.504120 (1.365099) | 2.381410 / 1.541195 (0.840216) | 2.417357 / 1.468490 (0.948867) | 0.914947 / 4.584777 (-3.669830) | 5.718526 / 3.745712 (1.972814) | 2.757253 / 5.269862 (-2.512609) | 1.794122 / 4.565676 (-2.771554) | 0.108423 / 0.424275 (-0.315852) | 0.013378 / 0.007607 (0.005771) | 0.831067 / 0.226044 (0.605023) | 8.478946 / 2.268929 (6.210018) | 3.685937 / 55.444624 (-51.758687) | 2.867472 / 6.876477 (-4.009005) | 2.895975 / 2.142072 (0.753903) | 1.137547 / 4.805227 (-3.667681) | 0.213891 / 6.500664 (-6.286773) | 0.075825 / 0.075469 (0.000356) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.621193 / 1.841788 (-0.220594) | 17.322110 / 8.074308 (9.247802) | 21.804016 / 10.191392 (11.612624) | 0.243692 / 0.680424 (-0.436732) | 0.030331 / 0.534201 (-0.503870) | 0.492186 / 0.579283 (-0.087097) | 0.632583 / 0.434364 (0.198219) | 0.576265 / 0.540337 (0.035927) | 0.713165 / 1.386936 (-0.673771) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008916 / 0.011353 (-0.002437) | 0.004737 / 0.011008 (-0.006271) | 0.134271 / 0.038508 (0.095763) | 0.054472 / 0.023109 (0.031363) | 0.380942 / 0.275898 (0.105044) | 0.474138 / 0.323480 (0.150658) | 0.007917 / 0.007986 (-0.000068) | 0.003748 / 0.004328 (-0.000580) | 0.092765 / 0.004250 (0.088515) | 0.077873 / 0.037052 (0.040821) | 0.397533 / 0.258489 (0.139043) | 0.454737 / 0.293841 (0.160896) | 0.039901 / 0.128546 (-0.088645) | 0.010188 / 0.075646 (-0.065458) | 0.447312 / 0.419271 (0.028040) | 0.068684 / 0.043533 (0.025151) | 0.371554 / 0.255139 (0.116415) | 0.459655 / 0.283200 (0.176455) | 0.027157 / 0.141683 (-0.114526) | 1.874643 / 1.452155 (0.422488) | 2.014800 / 1.492716 (0.522083) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.227079 / 0.018006 (0.209073) | 0.483241 / 0.000490 (0.482751) | 0.012404 / 0.000200 (0.012204) | 0.000409 / 0.000054 (0.000354) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033135 / 0.037411 (-0.004277) | 0.137782 / 0.014526 (0.123257) | 0.142951 / 0.176557 (-0.033605) | 0.209825 / 0.737135 (-0.527311) | 0.152438 / 0.296338 (-0.143900) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.513066 / 0.215209 (0.297857) | 5.122776 / 2.077655 (3.045121) | 2.399270 / 1.504120 (0.895150) | 2.180143 / 1.541195 (0.638949) | 2.286395 / 1.468490 (0.817905) | 0.641866 / 4.584777 (-3.942911) | 4.694922 / 3.745712 (0.949210) | 2.543390 / 5.269862 (-2.726472) | 1.398592 / 4.565676 (-3.167084) | 0.088662 / 0.424275 (-0.335613) | 0.015854 / 0.007607 (0.008247) | 0.688891 / 0.226044 (0.462847) | 6.370148 / 2.268929 (4.101220) | 2.949974 / 55.444624 (-52.494650) | 2.538049 / 6.876477 (-4.338428) | 2.699380 / 2.142072 (0.557308) | 0.792670 / 4.805227 (-4.012557) | 0.169126 / 6.500664 (-6.331538) | 0.078511 / 0.075469 (0.003042) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.609119 / 1.841788 (-0.232669) | 18.785069 / 8.074308 (10.710761) | 16.670783 / 10.191392 (6.479391) | 0.213081 / 0.680424 (-0.467343) | 0.023904 / 0.534201 (-0.510296) | 0.567720 / 0.579283 (-0.011564) | 0.505806 / 0.434364 (0.071442) | 0.649466 / 0.540337 (0.109129) | 0.773174 / 1.386936 (-0.613762) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008036 / 0.011353 (-0.003317) | 0.004808 / 0.011008 (-0.006201) | 0.094316 / 0.038508 (0.055808) | 0.056174 / 0.023109 (0.033065) | 0.481618 / 0.275898 (0.205720) | 0.565300 / 0.323480 (0.241820) | 0.006339 / 0.007986 (-0.001646) | 0.003950 / 0.004328 (-0.000379) | 0.093389 / 0.004250 (0.089139) | 0.076163 / 0.037052 (0.039111) | 0.489013 / 0.258489 (0.230524) | 0.565451 / 0.293841 (0.271611) | 0.039392 / 0.128546 (-0.089155) | 0.010553 / 0.075646 (-0.065093) | 0.101406 / 0.419271 (-0.317865) | 0.062355 / 0.043533 (0.018822) | 0.470461 / 0.255139 (0.215322) | 0.502574 / 0.283200 (0.219375) | 0.030196 / 0.141683 (-0.111486) | 1.893926 / 1.452155 (0.441771) | 1.958902 / 1.492716 (0.466185) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.198074 / 0.018006 (0.180068) | 0.476828 / 0.000490 (0.476338) | 0.003457 / 0.000200 (0.003257) | 0.000105 / 0.000054 (0.000051) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.037576 / 0.037411 (0.000165) | 0.146663 / 0.014526 (0.132138) | 0.152969 / 0.176557 (-0.023588) | 0.218683 / 0.737135 (-0.518452) | 0.161552 / 0.296338 (-0.134786) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.525988 / 0.215209 (0.310779) | 5.234673 / 2.077655 (3.157018) | 2.571668 / 1.504120 (1.067548) | 2.339760 / 1.541195 (0.798565) | 2.422886 / 1.468490 (0.954395) | 0.651537 / 4.584777 (-3.933240) | 4.811148 / 3.745712 (1.065436) | 4.451165 / 5.269862 (-0.818697) | 2.016283 / 4.565676 (-2.549394) | 0.096393 / 0.424275 (-0.327882) | 0.015222 / 0.007607 (0.007615) | 0.739132 / 0.226044 (0.513087) | 6.813327 / 2.268929 (4.544399) | 3.169018 / 55.444624 (-52.275606) | 2.783120 / 6.876477 (-4.093356) | 2.918979 / 2.142072 (0.776907) | 0.797476 / 4.805227 (-4.007751) | 0.171038 / 6.500664 (-6.329626) | 0.079878 / 0.075469 (0.004409) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.595082 / 1.841788 (-0.246705) | 19.685844 / 8.074308 (11.611536) | 17.518989 / 10.191392 (7.327597) | 0.220015 / 0.680424 (-0.460409) | 0.026351 / 0.534201 (-0.507850) | 0.578977 / 0.579283 (-0.000306) | 0.549564 / 0.434364 (0.115200) | 0.667564 / 0.540337 (0.127227) | 0.802121 / 1.386936 (-0.584815) |\n\n</details>\n</details>\n\n\n"
] | "2023-06-30T12:36:54Z" | "2023-06-30T13:17:05Z" | "2023-06-30T13:08:27Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6000.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6000",
"merged_at": "2023-06-30T13:08:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6000.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6000"
} | `joblibspark` doesn't support the latest `joblib` release.
See https://github.com/huggingface/datasets/actions/runs/5401870932/jobs/9812337078 for the errors | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6000/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6000/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3003 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3003/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3003/comments | https://api.github.com/repos/huggingface/datasets/issues/3003/events | https://github.com/huggingface/datasets/pull/3003 | 1,014,137,933 | PR_kwDODunzps4smExP | 3,003 | common_language: Fix license in README.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/227350?v=4",
"events_url": "https://api.github.com/users/jimregan/events{/privacy}",
"followers_url": "https://api.github.com/users/jimregan/followers",
"following_url": "https://api.github.com/users/jimregan/following{/other_user}",
"gists_url": "https://api.github.com/users/jimregan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jimregan",
"id": 227350,
"login": "jimregan",
"node_id": "MDQ6VXNlcjIyNzM1MA==",
"organizations_url": "https://api.github.com/users/jimregan/orgs",
"received_events_url": "https://api.github.com/users/jimregan/received_events",
"repos_url": "https://api.github.com/users/jimregan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jimregan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jimregan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jimregan"
} | [] | closed | false | null | [] | null | [] | "2021-10-02T18:47:37Z" | "2021-10-04T09:27:01Z" | "2021-10-04T09:27:01Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3003.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3003",
"merged_at": "2021-10-04T09:27:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3003.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3003"
} | ...it's correct elsewhere | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3003/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3003/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3364 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3364/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3364/comments | https://api.github.com/repos/huggingface/datasets/issues/3364/events | https://github.com/huggingface/datasets/pull/3364 | 1,068,851,196 | PR_kwDODunzps4vRaxq | 3,364 | Use the Audio feature in the AutomaticSpeechRecognition template | {
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https://api.github.com/users/anton-l/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/anton-l",
"id": 26864830,
"login": "anton-l",
"node_id": "MDQ6VXNlcjI2ODY0ODMw",
"organizations_url": "https://api.github.com/users/anton-l/orgs",
"received_events_url": "https://api.github.com/users/anton-l/received_events",
"repos_url": "https://api.github.com/users/anton-l/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/anton-l/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anton-l/subscriptions",
"type": "User",
"url": "https://api.github.com/users/anton-l"
} | [] | closed | false | null | [] | null | [
"Cool !\r\n\r\nI noticed that you removed the `audio_file_path_column` field of the template, note that you also have to update all the dataset_infos.json file that still contain this outdated field. For example in the common_voice you can find this:\r\n```\r\n\"task_templates\": [{\"task\": \"automatic-speech-recognition\", \"audio_file_path_column\": \"path\", \"transcription_column\": \"sentence\"}]\r\n```",
"Yes, will do that. I'm just busy with the bigscience task.",
"After we merge this, we should also update the following dataset scripts: https://huggingface.co/datasets?task_ids=task_ids:automatic-speech-recognition",
"Closing in favor of https://github.com/huggingface/datasets/pull/4006"
] | "2021-12-01T20:42:26Z" | "2022-03-24T14:34:09Z" | "2022-03-24T14:34:08Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3364.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3364",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3364.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3364"
} | This updates the ASR template and all supported datasets to use the `Audio` feature | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3364/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3364/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4338 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4338/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4338/comments | https://api.github.com/repos/huggingface/datasets/issues/4338/events | https://github.com/huggingface/datasets/pull/4338 | 1,234,478,851 | PR_kwDODunzps43vwsm | 4,338 | Eval metadata Batch 4: Tweet Eval, Tweets Hate Speech Detection, VCTK, Weibo NER, Wisesight Sentiment, XSum, Yahoo Answers Topics, Yelp Polarity, Yelp Review Full | {
"avatar_url": "https://avatars.githubusercontent.com/u/14205986?v=4",
"events_url": "https://api.github.com/users/sashavor/events{/privacy}",
"followers_url": "https://api.github.com/users/sashavor/followers",
"following_url": "https://api.github.com/users/sashavor/following{/other_user}",
"gists_url": "https://api.github.com/users/sashavor/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sashavor",
"id": 14205986,
"login": "sashavor",
"node_id": "MDQ6VXNlcjE0MjA1OTg2",
"organizations_url": "https://api.github.com/users/sashavor/orgs",
"received_events_url": "https://api.github.com/users/sashavor/received_events",
"repos_url": "https://api.github.com/users/sashavor/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sashavor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sashavor/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sashavor"
} | [] | closed | false | null | [] | null | [
"Summary of CircleCI errors:\r\n\r\n- **XSum**: missing 6 required positional arguments: 'annotations_creators', 'language_creators', 'licenses', 'multilinguality', 'size_categories', and 'source_datasets'\r\n- **Yelp_polarity**: missing 8 required positional arguments: 'annotations_creators', 'language_creators', 'licenses', 'multilinguality', 'size_categories', 'source_datasets', 'task_categories', and 'task_ids'",
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-05-12T21:02:08Z" | "2022-05-16T15:51:02Z" | "2022-05-16T15:42:59Z" | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4338.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4338",
"merged_at": "2022-05-16T15:42:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4338.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4338"
} | Adding evaluation metadata for:
- Tweet Eval
- Tweets Hate Speech Detection
- VCTK
- Weibo NER
- Wisesight Sentiment
- XSum
- Yahoo Answers Topics
- Yelp Polarity
- Yelp Review Full | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4338/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4338/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1632 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1632/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1632/comments | https://api.github.com/repos/huggingface/datasets/issues/1632/events | https://github.com/huggingface/datasets/issues/1632 | 774,388,625 | MDU6SXNzdWU3NzQzODg2MjU= | 1,632 | SICK dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehk/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rabeehk",
"id": 6278280,
"login": "rabeehk",
"node_id": "MDQ6VXNlcjYyNzgyODA=",
"organizations_url": "https://api.github.com/users/rabeehk/orgs",
"received_events_url": "https://api.github.com/users/rabeehk/received_events",
"repos_url": "https://api.github.com/users/rabeehk/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rabeehk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehk/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rabeehk"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [] | "2020-12-24T12:40:14Z" | "2021-02-05T15:49:25Z" | "2021-02-05T15:49:25Z" | CONTRIBUTOR | null | null | null | Hi, this would be great to have this dataset included. I might be missing something, but I could not find it in the list of already included datasets. Thank you.
## Adding a Dataset
- **Name:** SICK
- **Description:** SICK consists of about 10,000 English sentence pairs that include many examples of the lexical, syntactic, and semantic phenomena.
- **Paper:** https://www.aclweb.org/anthology/L14-1314/
- **Data:** http://marcobaroni.org/composes/sick.html
- **Motivation:** This dataset is well-known in the NLP community used for recognizing entailment between sentences.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1632/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1632/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1941 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1941/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1941/comments | https://api.github.com/repos/huggingface/datasets/issues/1941/events | https://github.com/huggingface/datasets/issues/1941 | 815,985,167 | MDU6SXNzdWU4MTU5ODUxNjc= | 1,941 | Loading of FAISS index fails for index_name = 'exact' | {
"avatar_url": "https://avatars.githubusercontent.com/u/2992022?v=4",
"events_url": "https://api.github.com/users/mkserge/events{/privacy}",
"followers_url": "https://api.github.com/users/mkserge/followers",
"following_url": "https://api.github.com/users/mkserge/following{/other_user}",
"gists_url": "https://api.github.com/users/mkserge/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mkserge",
"id": 2992022,
"login": "mkserge",
"node_id": "MDQ6VXNlcjI5OTIwMjI=",
"organizations_url": "https://api.github.com/users/mkserge/orgs",
"received_events_url": "https://api.github.com/users/mkserge/received_events",
"repos_url": "https://api.github.com/users/mkserge/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mkserge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mkserge/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mkserge"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | [
"Thanks for reporting ! I'm taking a look",
"Index training was missing, I fixed it here: https://github.com/huggingface/datasets/commit/f5986c46323583989f6ed1dabaf267854424a521\r\n\r\nCan you try again please ?",
"Works great 👍 I just put a minor comment on the commit, I think you meant to pass the `train_size` from the one obtained from the config.\r\n\r\nThanks for a quick response!"
] | "2021-02-25T01:30:54Z" | "2021-02-25T14:28:46Z" | "2021-02-25T14:28:46Z" | CONTRIBUTOR | null | null | null | Hi,
It looks like loading of FAISS index now fails when using index_name = 'exact'.
For example, from the RAG [model card](https://huggingface.co/facebook/rag-token-nq?fbclid=IwAR3bTfhls5U_t9DqsX2Vzb7NhtRHxJxfQ-uwFT7VuCPMZUM2AdAlKF_qkI8#usage).
Running `transformers==4.3.2` and datasets installed from source on latest `master` branch.
```bash
(venv) sergey_mkrtchyan datasets (master) $ python
Python 3.8.6 (v3.8.6:db455296be, Sep 23 2020, 13:31:39)
[Clang 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration
>>> tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
>>> retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
Using custom data configuration dummy.psgs_w100.nq.no_index-dummy=True,with_index=False
Reusing dataset wiki_dpr (/Users/sergey_mkrtchyan/.cache/huggingface/datasets/wiki_dpr/dummy.psgs_w100.nq.no_index-dummy=True,with_index=False/0.0.0/8a97e0f4fa5bc46e179474db6a61b09d5d2419d2911835bd3f91d110c936d8bb)
Using custom data configuration dummy.psgs_w100.nq.exact-50b6cda57ff32ab4
Reusing dataset wiki_dpr (/Users/sergey_mkrtchyan/.cache/huggingface/datasets/wiki_dpr/dummy.psgs_w100.nq.exact-50b6cda57ff32ab4/0.0.0/8a97e0f4fa5bc46e179474db6a61b09d5d2419d2911835bd3f91d110c936d8bb)
0%| | 0/10 [00:00<?, ?it/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py", line 425, in from_pretrained
return cls(
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py", line 387, in __init__
self.init_retrieval()
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py", line 458, in init_retrieval
self.index.init_index()
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py", line 284, in init_index
self.dataset = load_dataset(
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/load.py", line 750, in load_dataset
ds = builder_instance.as_dataset(split=split, ignore_verifications=ignore_verifications, in_memory=keep_in_memory)
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/builder.py", line 734, in as_dataset
datasets = utils.map_nested(
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/utils/py_utils.py", line 195, in map_nested
return function(data_struct)
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/builder.py", line 769, in _build_single_dataset
post_processed = self._post_process(ds, resources_paths)
File "/Users/sergey_mkrtchyan/.cache/huggingface/modules/datasets_modules/datasets/wiki_dpr/8a97e0f4fa5bc46e179474db6a61b09d5d2419d2911835bd3f91d110c936d8bb/wiki_dpr.py", line 205, in _post_process
dataset.add_faiss_index("embeddings", custom_index=index)
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/arrow_dataset.py", line 2516, in add_faiss_index
super().add_faiss_index(
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/search.py", line 416, in add_faiss_index
faiss_index.add_vectors(self, column=column, train_size=train_size, faiss_verbose=faiss_verbose)
File "/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/search.py", line 281, in add_vectors
self.faiss_index.add(vecs)
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/faiss/__init__.py", line 104, in replacement_add
self.add_c(n, swig_ptr(x))
File "/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/faiss/swigfaiss.py", line 3263, in add
return _swigfaiss.IndexHNSW_add(self, n, x)
RuntimeError: Error in virtual void faiss::IndexHNSW::add(faiss::Index::idx_t, const float *) at /Users/runner/work/faiss-wheels/faiss-wheels/faiss/faiss/IndexHNSW.cpp:356: Error: 'is_trained' failed
>>>
```
The issue seems to be related to the scalar quantization in faiss added in this commit: 8c5220307c33f00e01c3bf7b8. Reverting it fixes the issue.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1941/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1941/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2727/comments | https://api.github.com/repos/huggingface/datasets/issues/2727/events | https://github.com/huggingface/datasets/issues/2727 | 955,812,149 | MDU6SXNzdWU5NTU4MTIxNDk= | 2,727 | Error in loading the Arabic Billion Words Corpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/9285264?v=4",
"events_url": "https://api.github.com/users/M-Salti/events{/privacy}",
"followers_url": "https://api.github.com/users/M-Salti/followers",
"following_url": "https://api.github.com/users/M-Salti/following{/other_user}",
"gists_url": "https://api.github.com/users/M-Salti/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/M-Salti",
"id": 9285264,
"login": "M-Salti",
"node_id": "MDQ6VXNlcjkyODUyNjQ=",
"organizations_url": "https://api.github.com/users/M-Salti/orgs",
"received_events_url": "https://api.github.com/users/M-Salti/received_events",
"repos_url": "https://api.github.com/users/M-Salti/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/M-Salti/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/M-Salti/subscriptions",
"type": "User",
"url": "https://api.github.com/users/M-Salti"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"I modified the dataset loading script to catch the `IndexError` and inspect the records at which the error is happening, and I found this:\r\nFor the `Techreen` config, the error happens in 36 records when trying to find the `Text` or `Dateline` tags. All these 36 records look something like:\r\n```\r\n<Techreen>\r\n <ID>TRN_ARB_0248167</ID>\r\n <URL>http://tishreen.news.sy/tishreen/public/read/248240</URL>\r\n <Headline>Removed, because the original articles was in English</Headline>\r\n</Techreen>\r\n```\r\n\r\nand all the 288 faulty records in the `Almustaqbal` config look like:\r\n```\r\n<Almustaqbal>\r\n <ID>MTL_ARB_0028398</ID>\r\n \r\n <URL>http://www.almustaqbal.com/v4/article.aspx?type=NP&ArticleID=179015</URL>\r\n <Headline> Removed because it is not available in the original site</Headline>\r\n</Almustaqbal>\r\n```\r\n\r\nso the error is happening because the articles were removed and so the associated records lack the `Text` tag.\r\n\r\nIn this case, I think we just need to catch the `IndexError` and ignore (pass) it.\r\n",
"Thanks @M-Salti for reporting this issue and for your investigation.\r\n\r\nIndeed, those `IndexError` should be catched and the corresponding record should be ignored.\r\n\r\nI'm opening a Pull Request to fix it."
] | "2021-07-29T12:53:09Z" | "2021-07-30T13:03:55Z" | "2021-07-30T13:03:55Z" | CONTRIBUTOR | null | null | null | ## Describe the bug
I get `IndexError: list index out of range` when trying to load the `Techreen` and `Almustaqbal` configs of the dataset.
## Steps to reproduce the bug
```python
load_dataset("arabic_billion_words", "Techreen")
load_dataset("arabic_billion_words", "Almustaqbal")
```
## Expected results
The datasets load succefully.
## Actual results
```python
_extract_tags(self, sample, tag)
139 if len(out) > 0:
140 break
--> 141 return out[0]
142
143 def _clean_text(self, text):
IndexError: list index out of range
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.10.2
- Platform: Ubuntu 18.04.5 LTS
- Python version: 3.7.11
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2727/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2727/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5191 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5191/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5191/comments | https://api.github.com/repos/huggingface/datasets/issues/5191/events | https://github.com/huggingface/datasets/pull/5191 | 1,433,191,658 | PR_kwDODunzps5CD0Qp | 5,191 | Make torch.Tensor and spacy models cacheable | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-11-02T13:56:18Z" | "2022-11-02T17:20:48Z" | "2022-11-02T17:18:42Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5191.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5191",
"merged_at": "2022-11-02T17:18:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5191.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5191"
} | Override `Pickler.save` to implement deterministic reduction (lazily registered; inspired by https://github.com/uqfoundation/dill/blob/master/dill/_dill.py#L343) functions for `torch.Tensor` and spaCy models.
Fix https://github.com/huggingface/datasets/issues/5170, fix https://github.com/huggingface/datasets/issues/3178
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5191/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5191/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1265 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1265/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1265/comments | https://api.github.com/repos/huggingface/datasets/issues/1265/events | https://github.com/huggingface/datasets/pull/1265 | 758,687,223 | MDExOlB1bGxSZXF1ZXN0NTMzODE4NjY0 | 1,265 | Add CovidQA dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4341867?v=4",
"events_url": "https://api.github.com/users/olinguyen/events{/privacy}",
"followers_url": "https://api.github.com/users/olinguyen/followers",
"following_url": "https://api.github.com/users/olinguyen/following{/other_user}",
"gists_url": "https://api.github.com/users/olinguyen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/olinguyen",
"id": 4341867,
"login": "olinguyen",
"node_id": "MDQ6VXNlcjQzNDE4Njc=",
"organizations_url": "https://api.github.com/users/olinguyen/orgs",
"received_events_url": "https://api.github.com/users/olinguyen/received_events",
"repos_url": "https://api.github.com/users/olinguyen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/olinguyen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/olinguyen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/olinguyen"
} | [] | closed | false | null | [] | null | [
"It seems to share the same name as this dataset: https://openreview.net/forum?id=JENSKEEzsoU",
"> It seems to share the same name as this dataset: https://openreview.net/forum?id=JENSKEEzsoU\r\n\r\nyou're right it can be confusing. I'll add the organization/research group for clarity: `covid_qa_castorini`. I added the dataset you shared as `covid_qa_deepset` in another PR (#1182) ",
"Thanks for avoiding the name collision !"
] | "2020-12-07T17:06:51Z" | "2020-12-08T17:02:26Z" | "2020-12-08T17:02:26Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1265.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1265",
"merged_at": "2020-12-08T17:02:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1265.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1265"
} | This PR adds CovidQA, a question answering dataset specifically designed for COVID-19, built by hand from knowledge gathered from Kaggle’s COVID-19 Open Research Dataset Challenge.
Link to the paper: https://arxiv.org/pdf/2004.11339.pdf
Link to the homepage: https://covidqa.ai | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1265/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1265/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2906 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2906/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2906/comments | https://api.github.com/repos/huggingface/datasets/issues/2906/events | https://github.com/huggingface/datasets/pull/2906 | 995,962,905 | PR_kwDODunzps4rulH- | 2,906 | feat: 🎸 add a function to get a dataset config's split names | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [] | closed | false | null | [] | null | [
"> Should I add a section in https://github.com/huggingface/datasets/blob/master/docs/source/load_hub.rst? (there is no section for get_dataset_infos)\r\n\r\nYes totally :) This tutorial should indeed mention this, given how fundamental it is"
] | "2021-09-14T12:31:22Z" | "2021-10-04T09:55:38Z" | "2021-10-04T09:55:37Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2906.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2906",
"merged_at": "2021-10-04T09:55:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2906.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2906"
} | Also: pass additional arguments (use_auth_token) to get private configs + info of private datasets on the hub
Questions:
- [x] I'm not sure how the versions work: I changed 1.12.1.dev0 to 1.12.1.dev1, was it correct?
-> no: reverted
- [x] Should I add a section in https://github.com/huggingface/datasets/blob/master/docs/source/load_hub.rst? (there is no section for get_dataset_infos)
-> yes: added | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2906/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2906/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4727/comments | https://api.github.com/repos/huggingface/datasets/issues/4727/events | https://github.com/huggingface/datasets/issues/4727 | 1,312,645,391 | I_kwDODunzps5OPWEP | 4,727 | Dataset Viewer issue for TheNoob3131/mosquito-data | {
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"events_url": "https://api.github.com/users/thenerd31/events{/privacy}",
"followers_url": "https://api.github.com/users/thenerd31/followers",
"following_url": "https://api.github.com/users/thenerd31/following{/other_user}",
"gists_url": "https://api.github.com/users/thenerd31/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thenerd31",
"id": 53668030,
"login": "thenerd31",
"node_id": "MDQ6VXNlcjUzNjY4MDMw",
"organizations_url": "https://api.github.com/users/thenerd31/orgs",
"received_events_url": "https://api.github.com/users/thenerd31/received_events",
"repos_url": "https://api.github.com/users/thenerd31/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thenerd31/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thenerd31/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thenerd31"
} | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | null | [
"The preview is working OK:\r\n\r\n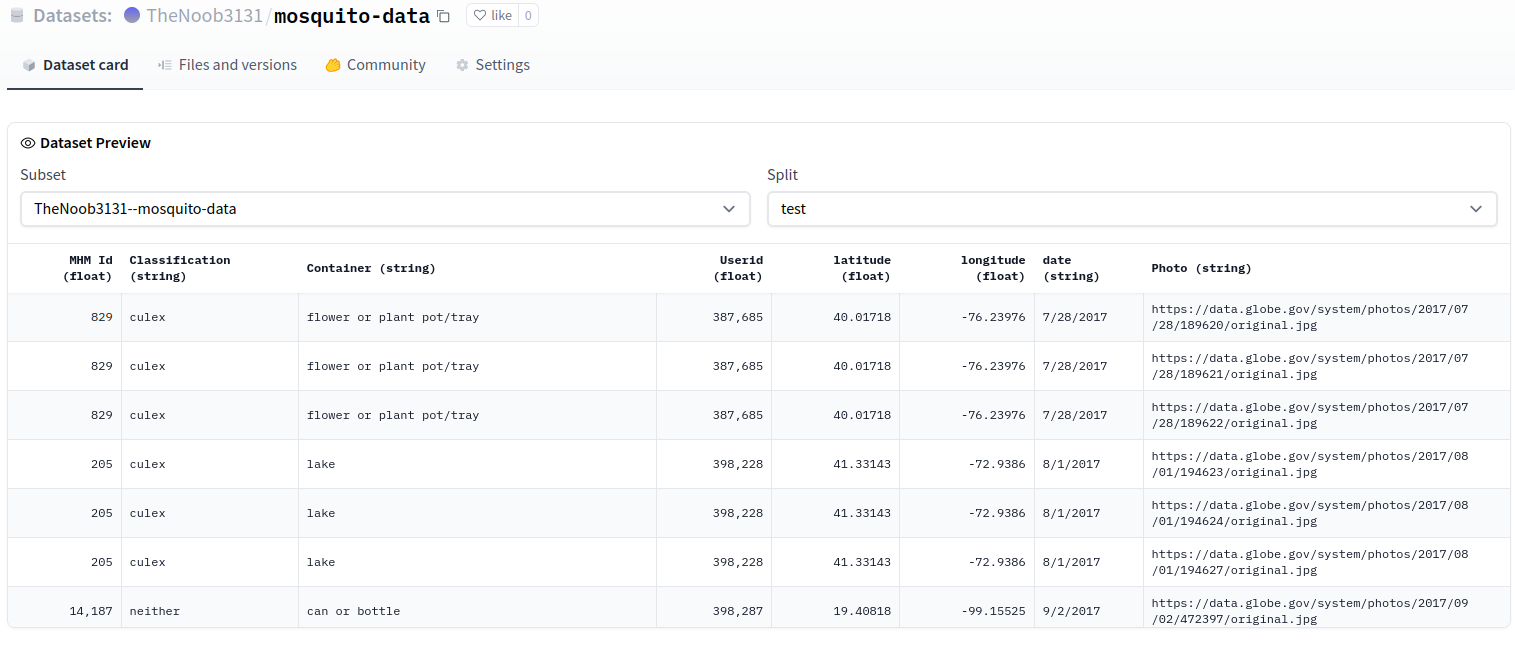\r\n\r\n"
] | "2022-07-21T05:24:48Z" | "2022-07-21T07:51:56Z" | "2022-07-21T07:45:01Z" | NONE | null | null | null | ### Link
https://huggingface.co/datasets/TheNoob3131/mosquito-data/viewer/TheNoob3131--mosquito-data/test
### Description
Dataset preview not showing with large files. Says 'split cache is empty' even though there are train and test splits.
### Owner
_No response_ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4727/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4727/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1240 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1240/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1240/comments | https://api.github.com/repos/huggingface/datasets/issues/1240/events | https://github.com/huggingface/datasets/pull/1240 | 758,355,523 | MDExOlB1bGxSZXF1ZXN0NTMzNTQxNjk5 | 1,240 | Multi Domain Sentiment Analysis Dataset (MDSA) | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user}",
"gists_url": "https://api.github.com/users/abhishekkrthakur/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abhishekkrthakur",
"id": 1183441,
"login": "abhishekkrthakur",
"node_id": "MDQ6VXNlcjExODM0NDE=",
"organizations_url": "https://api.github.com/users/abhishekkrthakur/orgs",
"received_events_url": "https://api.github.com/users/abhishekkrthakur/received_events",
"repos_url": "https://api.github.com/users/abhishekkrthakur/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abhishekkrthakur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhishekkrthakur/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abhishekkrthakur"
} | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"can you also run `make style` to format the code ?",
"I'll come back to this one in sometime :) @lhoestq ",
"Also if you would use `xml.etree.ElementTree` to parse the XML it would be awesome, because right now you're using an external dependency `xmltodict `",
"> Also if you would use xml.etree.ElementTree to parse the XML it would be awesome, because right now you're using an external dependency xmltodict\r\n\r\nIts pseudo xml so elementtree fails. xmltodict seems to be working quite good for this. do we have examples of pseudo xml datasets?",
"for the other pseudo xml the text is parsed manually",
"Can you add `xmltodict` to the test dependencies in setup.py please to fix the CI please ?",
"Also can you add the dataset card with the tags and run `make style` ?",
"Hi :) have you had a chance to fix the test dependency and apply `make style` ?\r\n\r\nFeel fee to ping me when it's ready for a review",
"Thanks for your contribution, @abhishekkrthakur. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] | "2020-12-07T09:57:15Z" | "2023-09-24T09:40:59Z" | "2022-10-03T09:39:43Z" | MEMBER | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1240.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1240",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1240.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1240"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1240/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1240/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4619 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4619/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4619/comments | https://api.github.com/repos/huggingface/datasets/issues/4619/events | https://github.com/huggingface/datasets/issues/4619 | 1,292,107,275 | I_kwDODunzps5NA_4L | 4,619 | np arrays get turned into native lists | {
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url": "https://api.github.com/users/ZhaofengWu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ZhaofengWu",
"id": 11954789,
"login": "ZhaofengWu",
"node_id": "MDQ6VXNlcjExOTU0Nzg5",
"organizations_url": "https://api.github.com/users/ZhaofengWu/orgs",
"received_events_url": "https://api.github.com/users/ZhaofengWu/received_events",
"repos_url": "https://api.github.com/users/ZhaofengWu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ZhaofengWu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZhaofengWu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ZhaofengWu"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"If you add the line `dataset2.set_format('np')` before calling `dataset2[0]['tmp']` it should return `np.ndarray`.\r\nI believe internally it will not store it as a list, it is only returning a list when you index it.\r\n\r\n```\r\nIn [1]: import datasets, numpy as np\r\nIn [2]: dataset = datasets.load_dataset(\"glue\", \"mrpc\")[\"validation\"]\r\nIn [3]: dataset2 = dataset.map(lambda x: {\"tmp\": np.array([0.5])}, batched=False)\r\nIn [4]: dataset2[0][\"tmp\"]\r\nOut[4]: [0.5]\r\n\r\nIn [5]: dataset2.set_format('np')\r\n\r\nIn [6]: dataset2[0][\"tmp\"]\r\nOut[6]: array([0.5])\r\n```",
"I see, thanks! Any idea if the default numpy → list conversion might cause precision loss?",
"I'm not super familiar with our datasets works internally, but I think your `np` array will be stored in a `pyarrow` format, and then you take a view of this as a python array. In which case, I think the precision should be preserved."
] | "2022-07-02T17:54:57Z" | "2022-07-03T20:27:07Z" | null | NONE | null | null | null | ## Describe the bug
When attaching an `np.array` field, it seems that it automatically gets turned into a list (see below). Why is this happening? Could it lose precision? Is there a way to make sure this doesn't happen?
## Steps to reproduce the bug
```python
>>> import datasets, numpy as np
>>> dataset = datasets.load_dataset("glue", "mrpc")["validation"]
Reusing dataset glue (...)
100%|███████████████████████████████████████████████| 3/3 [00:00<00:00, 1360.61it/s]
>>> dataset2 = dataset.map(lambda x: {"tmp": np.array([0.5])}, batched=False)
100%|██████████████████████████████████████████| 408/408 [00:00<00:00, 10819.97ex/s]
>>> dataset2[0]["tmp"]
[0.5]
>>> type(dataset2[0]["tmp"])
<class 'list'>
```
## Expected results
`dataset2[0]["tmp"]` should be an `np.ndarray`.
## Actual results
It's a list.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.3.2
- Platform: mac, though I'm pretty sure it happens on a linux machine too
- Python version: 3.9.7
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4619/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4619/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3599 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3599/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3599/comments | https://api.github.com/repos/huggingface/datasets/issues/3599/events | https://github.com/huggingface/datasets/issues/3599 | 1,108,111,607 | I_kwDODunzps5CDHD3 | 3,599 | The `add_column()` method does not work if used on dataset sliced with `select()` | {
"avatar_url": "https://avatars.githubusercontent.com/u/59422506?v=4",
"events_url": "https://api.github.com/users/ThGouzias/events{/privacy}",
"followers_url": "https://api.github.com/users/ThGouzias/followers",
"following_url": "https://api.github.com/users/ThGouzias/following{/other_user}",
"gists_url": "https://api.github.com/users/ThGouzias/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ThGouzias",
"id": 59422506,
"login": "ThGouzias",
"node_id": "MDQ6VXNlcjU5NDIyNTA2",
"organizations_url": "https://api.github.com/users/ThGouzias/orgs",
"received_events_url": "https://api.github.com/users/ThGouzias/received_events",
"repos_url": "https://api.github.com/users/ThGouzias/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ThGouzias/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ThGouzias/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ThGouzias"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
}
] | null | [
"similar #3611 "
] | "2022-01-19T13:36:50Z" | "2022-01-28T15:35:57Z" | "2022-01-28T15:35:57Z" | NONE | null | null | null | Hello, I posted this as a question on the forums ([here](https://discuss.huggingface.co/t/add-column-does-not-work-if-used-on-dataset-sliced-with-select/13893)):
I have a dataset with 2000 entries
> dataset = Dataset.from_dict({'colA': list(range(2000))})
and from which I want to extract the first one thousand rows, create a new dataset with these and also add a new column to it:
> dataset2 = dataset.select(list(range(1000)))
> final_dataset = dataset2.add_column('colB', list(range(1000)))
This gives an error
>ArrowInvalid: Added column's length must match table's length. Expected length 2000 but got length 1000
So it looks like even though it is a dataset with 1000 rows, it "remembers" the shape of the one it was sliced from.
## Actual results
```
ArrowInvalid Traceback (most recent call last)
<ipython-input-138-e806860f3ce3> in <module>
----> 1 final_dataset = dataset2.add_column('colB', list(range(1000)))
~/.local/lib/python3.8/site-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
468 }
469 # apply actual function
--> 470 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
471 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
472 # re-apply format to the output
~/.local/lib/python3.8/site-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
404 # Call actual function
405
--> 406 out = func(self, *args, **kwargs)
407
408 # Update fingerprint of in-place transforms + update in-place history of transforms
~/.local/lib/python3.8/site-packages/datasets/arrow_dataset.py in add_column(self, name, column, new_fingerprint)
3343 column_table = InMemoryTable.from_pydict({name: column})
3344 # Concatenate tables horizontally
-> 3345 table = ConcatenationTable.from_tables([self._data, column_table], axis=1)
3346 # Update features
3347 info = self.info.copy()
~/.local/lib/python3.8/site-packages/datasets/table.py in from_tables(cls, tables, axis)
729 table_blocks = to_blocks(table)
730 blocks = _extend_blocks(blocks, table_blocks, axis=axis)
--> 731 return cls.from_blocks(blocks)
732
733 @property
~/.local/lib/python3.8/site-packages/datasets/table.py in from_blocks(cls, blocks)
668 @classmethod
669 def from_blocks(cls, blocks: TableBlockContainer) -> "ConcatenationTable":
--> 670 blocks = cls._consolidate_blocks(blocks)
671 if isinstance(blocks, TableBlock):
672 table = blocks
~/.local/lib/python3.8/site-packages/datasets/table.py in _consolidate_blocks(cls, blocks)
664 return cls._merge_blocks(blocks, axis=0)
665 else:
--> 666 return cls._merge_blocks(blocks)
667
668 @classmethod
~/.local/lib/python3.8/site-packages/datasets/table.py in _merge_blocks(cls, blocks, axis)
650 merged_blocks += list(block_group)
651 else: # both
--> 652 merged_blocks = [cls._merge_blocks(row_block, axis=1) for row_block in blocks]
653 if all(len(row_block) == 1 for row_block in merged_blocks):
654 merged_blocks = cls._merge_blocks(
~/.local/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
650 merged_blocks += list(block_group)
651 else: # both
--> 652 merged_blocks = [cls._merge_blocks(row_block, axis=1) for row_block in blocks]
653 if all(len(row_block) == 1 for row_block in merged_blocks):
654 merged_blocks = cls._merge_blocks(
~/.local/lib/python3.8/site-packages/datasets/table.py in _merge_blocks(cls, blocks, axis)
647 for is_in_memory, block_group in groupby(blocks, key=lambda x: isinstance(x, InMemoryTable)):
648 if is_in_memory:
--> 649 block_group = [InMemoryTable(cls._concat_blocks(list(block_group), axis=axis))]
650 merged_blocks += list(block_group)
651 else: # both
~/.local/lib/python3.8/site-packages/datasets/table.py in _concat_blocks(blocks, axis)
626 else:
627 for name, col in zip(table.column_names, table.columns):
--> 628 pa_table = pa_table.append_column(name, col)
629 return pa_table
630 else:
~/.local/lib/python3.8/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.append_column()
~/.local/lib/python3.8/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.add_column()
~/.local/lib/python3.8/site-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()
~/.local/lib/python3.8/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowInvalid: Added column's length must match table's length. Expected length 2000 but got length 1000
```
A solution provided by @mariosasko is to use `dataset2.flatten_indices()` after the `select()` and before attempting to add the new column:
> dataset = Dataset.from_dict({'colA': list(range(2000))})
> dataset2 = dataset.select(list(range(1000)))
> dataset2 = dataset2.flatten_indices()
> final_dataset = dataset2.add_column('colB', list(range(1000)))
which works.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.13.2 (note: also checked with version 1.17.0, still the same error)
- Platform: Ubuntu 20.04.3
- Python version: 3.8.10
- PyArrow version: 6.0.0
| {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3599/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3599/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5349 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5349/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5349/comments | https://api.github.com/repos/huggingface/datasets/issues/5349/events | https://github.com/huggingface/datasets/pull/5349 | 1,487,396,780 | PR_kwDODunzps5E8N6G | 5,349 | Clean up remaining Main Classes docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-12-09T20:17:15Z" | "2022-12-12T17:27:17Z" | "2022-12-12T17:24:13Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5349.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5349",
"merged_at": "2022-12-12T17:24:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5349.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5349"
} | This PR cleans up the remaining docstrings in Main Classes (`IterableDataset`, `IterableDatasetDict`, and `Features`). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5349/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5349/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1978 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1978/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1978/comments | https://api.github.com/repos/huggingface/datasets/issues/1978/events | https://github.com/huggingface/datasets/pull/1978 | 820,956,806 | MDExOlB1bGxSZXF1ZXN0NTgzODI5Njgz | 1,978 | Adding ro sts dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/36982089?v=4",
"events_url": "https://api.github.com/users/lorinczb/events{/privacy}",
"followers_url": "https://api.github.com/users/lorinczb/followers",
"following_url": "https://api.github.com/users/lorinczb/following{/other_user}",
"gists_url": "https://api.github.com/users/lorinczb/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lorinczb",
"id": 36982089,
"login": "lorinczb",
"node_id": "MDQ6VXNlcjM2OTgyMDg5",
"organizations_url": "https://api.github.com/users/lorinczb/orgs",
"received_events_url": "https://api.github.com/users/lorinczb/received_events",
"repos_url": "https://api.github.com/users/lorinczb/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lorinczb/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lorinczb/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lorinczb"
} | [] | closed | false | null | [] | null | [
"@lhoestq thank you very much for the quick review and useful comments! \r\n\r\nI have tried to address them all, and a few comments that you left for ro_sts I have applied to the ro_sts_parallel as well (in read-me: fixed source_datasets, links to homepage, repository, leaderboard, thanks to me message, in ro_sts_parallel.py changed to camel case as well). In the ro_sts_parallel I have changed the order on the languages, also in the example, as you said order doesn't matter, but just to have them listed in the readme in the same order.\r\n\r\nI have commented above on why we would like to keep them as separate datasets, hope it makes sense.\r\n\r\nIf there is anything else I should change please let me know.\r\n\r\nThanks again!",
"@lhoestq I tried to adjust the ro_sts_parallel, locally when I run the tests they are passing, but somewhere it has the old name of rosts-parallel-ro-en which I am trying to change to ro_sts_parallel. I don't think I have left anything related to rosts-parallel-ro-en, but when the dataset_infos.json is regenerated it adds it. Could you please help me out, how can I fix this? Thanks in advance!",
"Great, thanks for all your help! "
] | "2021-03-03T10:08:53Z" | "2021-03-05T10:00:14Z" | "2021-03-05T09:33:55Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1978.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1978",
"merged_at": "2021-03-05T09:33:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1978.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1978"
} | Adding [RO-STS](https://github.com/dumitrescustefan/RO-STS) dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1978/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1978/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2806 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2806/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2806/comments | https://api.github.com/repos/huggingface/datasets/issues/2806/events | https://github.com/huggingface/datasets/pull/2806 | 971,625,449 | MDExOlB1bGxSZXF1ZXN0NzEzMzM5NDUw | 2,806 | Fix streaming tar files from canonical datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"In case it's relevant for this PR, I'm finding that I cannot stream the `bookcorpus` dataset (using the `master` branch of `datasets`), which is a `.tar.bz2` file:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nbooks_dataset_streamed = load_dataset(\"bookcorpus\", split=\"train\", streaming=True)\r\n# Throws a 404 HTTP error\r\nnext(iter(books_dataset_streamed))\r\n```\r\n\r\nThe full stack trace is:\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nClientResponseError Traceback (most recent call last)\r\n<ipython-input-11-5ebbbe110b13> in <module>()\r\n----> 1 next(iter(books_dataset_streamed))\r\n\r\n11 frames\r\n/usr/local/lib/python3.7/dist-packages/datasets/iterable_dataset.py in __iter__(self)\r\n 339 \r\n 340 def __iter__(self):\r\n--> 341 for key, example in self._iter():\r\n 342 if self.features:\r\n 343 # we encode the example for ClassLabel feature types for example\r\n\r\n/usr/local/lib/python3.7/dist-packages/datasets/iterable_dataset.py in _iter(self)\r\n 336 else:\r\n 337 ex_iterable = self._ex_iterable\r\n--> 338 yield from ex_iterable\r\n 339 \r\n 340 def __iter__(self):\r\n\r\n/usr/local/lib/python3.7/dist-packages/datasets/iterable_dataset.py in __iter__(self)\r\n 76 \r\n 77 def __iter__(self):\r\n---> 78 for key, example in self.generate_examples_fn(**self.kwargs):\r\n 79 yield key, example\r\n 80 \r\n\r\n/root/.cache/huggingface/modules/datasets_modules/datasets/bookcorpus/44662c4a114441c35200992bea923b170e6f13f2f0beb7c14e43759cec498700/bookcorpus.py in _generate_examples(self, directory)\r\n 98 for txt_file in files:\r\n 99 with open(txt_file, mode=\"r\", encoding=\"utf-8\") as f:\r\n--> 100 for line in f:\r\n 101 yield _id, {\"text\": line.strip()}\r\n 102 _id += 1\r\n\r\n/usr/local/lib/python3.7/dist-packages/fsspec/implementations/http.py in read(self, length)\r\n 496 else:\r\n 497 length = min(self.size - self.loc, length)\r\n--> 498 return super().read(length)\r\n 499 \r\n 500 async def async_fetch_all(self):\r\n\r\n/usr/local/lib/python3.7/dist-packages/fsspec/spec.py in read(self, length)\r\n 1481 # don't even bother calling fetch\r\n 1482 return b\"\"\r\n-> 1483 out = self.cache._fetch(self.loc, self.loc + length)\r\n 1484 self.loc += len(out)\r\n 1485 return out\r\n\r\n/usr/local/lib/python3.7/dist-packages/fsspec/caching.py in _fetch(self, start, end)\r\n 374 ):\r\n 375 # First read, or extending both before and after\r\n--> 376 self.cache = self.fetcher(start, bend)\r\n 377 self.start = start\r\n 378 elif start < self.start:\r\n\r\n/usr/local/lib/python3.7/dist-packages/fsspec/asyn.py in wrapper(*args, **kwargs)\r\n 86 def wrapper(*args, **kwargs):\r\n 87 self = obj or args[0]\r\n---> 88 return sync(self.loop, func, *args, **kwargs)\r\n 89 \r\n 90 return wrapper\r\n\r\n/usr/local/lib/python3.7/dist-packages/fsspec/asyn.py in sync(loop, func, timeout, *args, **kwargs)\r\n 67 raise FSTimeoutError\r\n 68 if isinstance(result[0], BaseException):\r\n---> 69 raise result[0]\r\n 70 return result[0]\r\n 71 \r\n\r\n/usr/local/lib/python3.7/dist-packages/fsspec/asyn.py in _runner(event, coro, result, timeout)\r\n 23 coro = asyncio.wait_for(coro, timeout=timeout)\r\n 24 try:\r\n---> 25 result[0] = await coro\r\n 26 except Exception as ex:\r\n 27 result[0] = ex\r\n\r\n/usr/local/lib/python3.7/dist-packages/fsspec/implementations/http.py in async_fetch_range(self, start, end)\r\n 535 # range request outside file\r\n 536 return b\"\"\r\n--> 537 r.raise_for_status()\r\n 538 if r.status == 206:\r\n 539 # partial content, as expected\r\n\r\n/usr/local/lib/python3.7/dist-packages/aiohttp/client_reqrep.py in raise_for_status(self)\r\n 1003 status=self.status,\r\n 1004 message=self.reason,\r\n-> 1005 headers=self.headers,\r\n 1006 )\r\n 1007 \r\n\r\nClientResponseError: 404, message='Not Found', url=URL('https://storage.googleapis.com/huggingface-nlp/datasets/bookcorpus/bookcorpus.tar.bz2/books_large_p1.txt')\r\n```\r\n\r\nLet me know if this is unrelated and I'll open a separate issue :)\r\n\r\nEnvironment info:\r\n\r\n```\r\n- `datasets` version: 1.11.1.dev0\r\n- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic\r\n- Python version: 3.7.11\r\n- PyArrow version: 3.0.0\r\n```",
"@lewtun: `.tar.compression-extension` files are not supported yet. That is the objective of this PR.",
"> @lewtun: `.tar.compression-extension` files are not supported yet. That is the objective of this PR.\r\n\r\nthanks for the context and the great work on the streaming features (right now i'm writing the streaming section of the HF course, so am acting like a beta tester 😄)",
"@lewtun this PR fixes previous issue with xjoin:\r\n\r\nGiven:\r\n```python\r\nxjoin(\r\n \"https://storage.googleapis.com/huggingface-nlp/datasets/bookcorpus/bookcorpus.tar.bz2\",\r\n \"books_large_p1.txt\"\r\n)\r\n```\r\n\r\n- Before it gave: \r\n `\"https://storage.googleapis.com/huggingface-nlp/datasets/bookcorpus/bookcorpus.tar.bz2/books_large_p1.txt\"`\r\n thus raising the 404 error\r\n\r\n- Now it gives:\r\n `tar://books_large_p1.txt::https://storage.googleapis.com/huggingface-nlp/datasets/bookcorpus/bookcorpus.tar.bz2`\r\n (this is the expected format for `fsspec`) and additionally passes the parameter `compression=\"bz2\"`.\r\n See: https://github.com/huggingface/datasets/pull/2806/files#diff-97bb2d08db65ce3b679aefc43cadad76d053c1e58ecc315e49b80873d0fbdabeR15",
"closing in favor of #3066 "
] | "2021-08-16T11:10:28Z" | "2021-10-13T09:04:03Z" | "2021-10-13T09:04:02Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2806.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2806",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2806.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2806"
} | Previous PR #2800 implemented support to stream remote tar files when passing the parameter `data_files`: they required a glob string `"*"`.
However, this glob string creates an error when streaming canonical datasets (with a `join` after the `open`).
This PR fixes this issue and allows streaming tar files both from:
- canonical datasets scripts and
- data files.
This PR also adds support for compressed tar files: `.tar.gz`, `.tar.bz2`,...
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2806/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2806/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1769 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1769/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1769/comments | https://api.github.com/repos/huggingface/datasets/issues/1769/events | https://github.com/huggingface/datasets/issues/1769 | 792,523,284 | MDU6SXNzdWU3OTI1MjMyODQ= | 1,769 | _pickle.PicklingError: Can't pickle typing.Union[str, NoneType]: it's not the same object as typing.Union when calling datasets.map with num_proc=2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/14048129?v=4",
"events_url": "https://api.github.com/users/shuaihuaiyi/events{/privacy}",
"followers_url": "https://api.github.com/users/shuaihuaiyi/followers",
"following_url": "https://api.github.com/users/shuaihuaiyi/following{/other_user}",
"gists_url": "https://api.github.com/users/shuaihuaiyi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shuaihuaiyi",
"id": 14048129,
"login": "shuaihuaiyi",
"node_id": "MDQ6VXNlcjE0MDQ4MTI5",
"organizations_url": "https://api.github.com/users/shuaihuaiyi/orgs",
"received_events_url": "https://api.github.com/users/shuaihuaiyi/received_events",
"repos_url": "https://api.github.com/users/shuaihuaiyi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shuaihuaiyi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shuaihuaiyi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shuaihuaiyi"
} | [] | closed | false | null | [] | null | [
"More information: `run_mlm.py` will raise same error when `data_args.line_by_line==True`\r\n\r\nhttps://github.com/huggingface/transformers/blob/9152f16023b59d262b51573714b40325c8e49370/examples/language-modeling/run_mlm.py#L300\r\n",
"Hi ! What version of python and datasets do you have ? And also what version of dill and pickle ?",
"> Hi ! What version of python and datasets do you have ? And also what version of dill and pickle ?\r\n\r\npython==3.6.10\r\ndatasets==1.2.1\r\ndill==0.3.2\r\npickle.format_version==4.0",
"Multiprocessing in python require all the functions to be picklable. More specifically, functions need to be picklable with `dill`.\r\n\r\nHowever objects like `typing.Union[str, NoneType]` are not picklable in python <3.7.\r\nCan you try to update your python version to python>=3.7 ?\r\n"
] | "2021-01-23T10:13:00Z" | "2022-10-05T12:38:51Z" | "2022-10-05T12:38:51Z" | NONE | null | null | null | It may be a bug of multiprocessing with Datasets, when I disable the multiprocessing by set num_proc to None, everything works fine.
The script I use is https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm_wwm.py
Script args:
```
--model_name_or_path
../../../model/chinese-roberta-wwm-ext
--train_file
/nfs/volume-377-2/bert/data/test/train.txt
--output_dir
test
--do_train
--per_device_train_batch_size
2
--gradient_accumulation_steps
2
--learning_rate
1e-4
--max_steps
1000
--warmup_steps
10
--save_steps
1000
--save_total_limit
1
--seed
23333
--max_seq_length
512
--preprocessing_num_workers
2
--cache_dir
/nfs/volume-377-2/bert/data/test/cache
```
Where the `/nfs/volume-377-2/bert/data/test/train.txt` is just a toy example with 10000 lines of random string, you should be able to reproduce this error esaily.
Full Traceback:
```
Traceback (most recent call last):
File "/nfs/volume-377-2/bert/transformers/examples/language-modeling/run_mlm_wwm.py", line 398, in <module>
main()
File "/nfs/volume-377-2/bert/transformers/examples/language-modeling/run_mlm_wwm.py", line 325, in main
load_from_cache_file=not data_args.overwrite_cache,
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/datasets/dataset_dict.py", line 303, in map
for k, dataset in self.items()
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/datasets/dataset_dict.py", line 303, in <dictcomp>
for k, dataset in self.items()
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/datasets/arrow_dataset.py", line 1318, in map
transformed_shards = [r.get() for r in results]
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/datasets/arrow_dataset.py", line 1318, in <listcomp>
transformed_shards = [r.get() for r in results]
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/multiprocess/pool.py", line 644, in get
raise self._value
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/multiprocess/pool.py", line 424, in _handle_tasks
put(task)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/multiprocess/connection.py", line 209, in send
self._send_bytes(_ForkingPickler.dumps(obj))
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/multiprocess/reduction.py", line 54, in dumps
cls(buf, protocol, *args, **kwds).dump(obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/dill/_dill.py", line 446, in dump
StockPickler.dump(self, obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 409, in dump
self.save(obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 751, in save_tuple
save(element)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/dill/_dill.py", line 933, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 821, in save_dict
self._batch_setitems(obj.items())
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 847, in _batch_setitems
save(v)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/dill/_dill.py", line 1438, in save_function
obj.__dict__, fkwdefaults), obj=obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 610, in save_reduce
save(args)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 751, in save_tuple
save(element)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 736, in save_tuple
save(element)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/dill/_dill.py", line 1170, in save_cell
pickler.save_reduce(_create_cell, (f,), obj=obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 610, in save_reduce
save(args)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 736, in save_tuple
save(element)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 521, in save
self.save_reduce(obj=obj, *rv)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 605, in save_reduce
save(cls)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/dill/_dill.py", line 1365, in save_type
obj.__bases__, _dict), obj=obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 610, in save_reduce
save(args)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 751, in save_tuple
save(element)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/dill/_dill.py", line 933, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 821, in save_dict
self._batch_setitems(obj.items())
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 847, in _batch_setitems
save(v)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/dill/_dill.py", line 933, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 821, in save_dict
self._batch_setitems(obj.items())
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 847, in _batch_setitems
save(v)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 507, in save
self.save_global(obj, rv)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 927, in save_global
(obj, module_name, name))
_pickle.PicklingError: Can't pickle typing.Union[str, NoneType]: it's not the same object as typing.Union
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1769/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1769/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5032 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5032/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5032/comments | https://api.github.com/repos/huggingface/datasets/issues/5032/events | https://github.com/huggingface/datasets/issues/5032 | 1,388,270,935 | I_kwDODunzps5Sv1VX | 5,032 | new dataset type: single-label and multi-label video classification | {
"avatar_url": "https://avatars.githubusercontent.com/u/34196005?v=4",
"events_url": "https://api.github.com/users/fcakyon/events{/privacy}",
"followers_url": "https://api.github.com/users/fcakyon/followers",
"following_url": "https://api.github.com/users/fcakyon/following{/other_user}",
"gists_url": "https://api.github.com/users/fcakyon/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/fcakyon",
"id": 34196005,
"login": "fcakyon",
"node_id": "MDQ6VXNlcjM0MTk2MDA1",
"organizations_url": "https://api.github.com/users/fcakyon/orgs",
"received_events_url": "https://api.github.com/users/fcakyon/received_events",
"repos_url": "https://api.github.com/users/fcakyon/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/fcakyon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fcakyon/subscriptions",
"type": "User",
"url": "https://api.github.com/users/fcakyon"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi ! You can in the `features` folder how we implemented the audio and image feature types.\r\n\r\nWe can have something similar to videos. What we need to decide:\r\n- the video loading library to use\r\n- the output format when a user accesses a video type object\r\n- what parameters a `Video()` feature type needs\r\n\r\nalso cc @nateraw who also took a look at what we can do for video",
"@lhoestq @nateraw is there any progress on adding video classification datasets? ",
"Hi ! I think we just missing which lib we're going to use to decode the videos + which parameters must go in the `Video` type",
"Hmm. `decord` could be nice but it's no longer maintained [it seems](https://github.com/dmlc/decord/issues/214). ",
"pytorchvideo uses [pyav](https://github.com/PyAV-Org/PyAV) as the default decoder: https://github.com/facebookresearch/pytorchvideo/blob/c8d23d8b7e597586a9e2d18f6ed31ad8aa379a7a/pytorchvideo/data/labeled_video_dataset.py#L37\r\n\r\nAlso it would be great if `optionally` audio can also be decoded from the video as in pytorchvideo: https://github.com/facebookresearch/pytorchvideo/blob/c8d23d8b7e597586a9e2d18f6ed31ad8aa379a7a/pytorchvideo/data/labeled_video_dataset.py#L35\r\n\r\nHere are the other decoders supported in pytorchvideo: https://github.com/facebookresearch/pytorchvideo/blob/c8d23d8b7e597586a9e2d18f6ed31ad8aa379a7a/pytorchvideo/data/encoded_video.py#L17\r\n",
"@sayakpaul I did do quite a bit of work on [this PR](https://github.com/huggingface/datasets/pull/4532) a while back to add a video feature. It's outdated, but uses my `encoded_video` [package](https://github.com/nateraw/encoded-video) under the hood, which is basically a wrapper around PyAV stolen from [pytorchvideo](https://github.com/facebookresearch/pytorchvideo/) that gets rid of the `torch` dependency. \r\n\r\nwould be really great to get something like this in...it's just a really tricky and time consuming feature to add. "
] | "2022-09-27T19:40:11Z" | "2022-11-02T19:10:13Z" | null | NONE | null | null | null | **Is your feature request related to a problem? Please describe.**
In my research, I am dealing with multi-modal (audio+text+frame sequence) video classification. It would be great if the datasets library supported generating multi-modal batches from a video dataset.
**Describe the solution you'd like**
Assume I have video files having single/multiple labels. I want to train a single/multi-label video classification model. I want datasets to support generating multi-modal batches (audio+frame sequence) from video files. Audio waveform and frame sequence can be extracted from each video clip then I can use any audio, image and video model from transformers library to extract features which will be fed into my model.
**Describe alternatives you've considered**
Currently, I am using https://github.com/facebookresearch/pytorchvideo dataloaders. There seems to be not much alternative.
**Additional context**
I am wiling to open a PR but don't know where to start.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5032/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5032/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3637 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3637/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3637/comments | https://api.github.com/repos/huggingface/datasets/issues/3637/events | https://github.com/huggingface/datasets/issues/3637 | 1,115,526,438 | I_kwDODunzps5CfZUm | 3,637 | [TypeError: Couldn't cast array of type] Cannot load dataset in v1.18 | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @lewtun!\r\n \r\nThis one was tricky to debug. Initially, I tought there is a bug in the recently-added (by @lhoestq ) `cast_array_to_feature` function because `git bisect` points to the https://github.com/huggingface/datasets/commit/6ca96c707502e0689f9b58d94f46d871fa5a3c9c commit. Then, I noticed that the feature tpye of the `dialogue` field is `list`, which explains why you didn't get an error in earlier versions. Is there a specific reason why you use `list` instead of `Sequence` in the script? Maybe to avoid turning list of dicts to dicts of lists as it's done by `Sequence` for compatibility with TFDS or for performance reasons? If the field was `Sequence`, you would get an error in `encode_nested_example` because **the scripts yields some additional (nested) columns which are not specified in the `features` dictionary**. Previously, these additional columns would've been ignored by PyArrow (1), but now we have a check for them (2).\r\n(1) See PyArrow behavior:\r\n```\r\n>>> pa.array([{\"a\": 2, \"b\": 3}], type=pa.struct({\"a\": pa.int32()})) # pyarrow ignores the extra column\r\n-- is_valid: all not null\r\n-- child 0 type: int32\r\n [\r\n 2\r\n ]\r\n ```\r\n\r\n(2) Check:\r\nhttps://github.com/huggingface/datasets/blob/4c417d52def6e20359ca16c6723e0a2855e5c3fd/src/datasets/table.py#L1059\r\n\r\nThe fix is very simple: just add the missing columns to the _EMPTY_BELIEF_STATE list:\r\n```python\r\n_EMPTY_BELIEF_STATE.extend(['通用-产品类别', '火车-舱位档次', '通用-系列', '通用-价格区间', '通用-品牌'])\r\n```",
"Hey @mariosasko, thank you so much for figuring this one out - it certainly looks like a tricky bug 😱 ! I don't think there's a specific reason to use `list` instead of `Sequence` with the script, but I'll let the dataset creators know to see if your suggestion is acceptable.\r\n\r\nThank you again!",
"Thanks, this was indeed the fix! Would it make sense to produce a more informative error message in such cases? \r\n\r\nThe issue can be closed. \r\n\r\n"
] | "2022-01-26T21:38:02Z" | "2022-02-09T16:15:53Z" | "2022-02-09T16:15:53Z" | MEMBER | null | null | null | ## Describe the bug
I am trying to load the [`GEM/RiSAWOZ` dataset](https://huggingface.co/datasets/GEM/RiSAWOZ) in `datasets` v1.18.1 and am running into a type error when casting the features. The strange thing is that I can load the dataset with v1.17.0. Note that the error is also present if I install from `master` too.
As far as I can tell, the dataset loading script is correct and the problematic features [here](https://huggingface.co/datasets/GEM/RiSAWOZ/blob/main/RiSAWOZ.py#L237) also look fine to me.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dset = load_dataset("GEM/RiSAWOZ")
```
## Expected results
I can load the dataset without error.
## Actual results
<details><summary>Traceback</summary>
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/builder.py in _prepare_split(self, split_generator)
1083 example = self.info.features.encode_example(record)
-> 1084 writer.write(example, key)
1085 finally:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in write(self, example, key, writer_batch_size)
445
--> 446 self.write_examples_on_file()
447
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in write_examples_on_file(self)
403 batch_examples[col] = [row[0][col] for row in self.current_examples]
--> 404 self.write_batch(batch_examples=batch_examples)
405 self.current_examples = []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in write_batch(self, batch_examples, writer_batch_size)
496 typed_sequence = OptimizedTypedSequence(batch_examples[col], type=col_type, try_type=col_try_type, col=col)
--> 497 arrays.append(pa.array(typed_sequence))
498 inferred_features[col] = typed_sequence.get_inferred_type()
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/pyarrow/array.pxi in pyarrow.lib.array()
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/pyarrow/array.pxi in pyarrow.lib._handle_arrow_array_protocol()
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in __arrow_array__(self, type)
204 # We only do it if trying_type is False - since this is what the user asks for.
--> 205 out = cast_array_to_feature(out, type, allow_number_to_str=not self.trying_type)
206 return out
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
919 else:
--> 920 return func(array, *args, **kwargs)
921
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1064 if isinstance(feature, list):
-> 1065 return pa.ListArray.from_arrays(array.offsets, _c(array.values, feature[0]))
1066 elif isinstance(feature, Sequence):
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
919 else:
--> 920 return func(array, *args, **kwargs)
921
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
919 else:
--> 920 return func(array, *args, **kwargs)
921
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
919 else:
--> 920 return func(array, *args, **kwargs)
921
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1086 return array_cast(array, feature(), allow_number_to_str=allow_number_to_str)
-> 1087 raise TypeError(f"Couldn't cast array of type\n{array.type}\nto\n{feature}")
1088
TypeError: Couldn't cast array of type
struct<医院-3.0T MRI: string, 医院-CT: string, 医院-DSA: string, 医院-公交线路: string, 医院-区域: string, 医院-名称: string, 医院-地址: string, 医院-地铁可达: string, 医院-地铁线路: string, 医院-性质: string, 医院-挂号时间: string, 医院-电话: string, 医院-等级: string, 医院-类别: string, 医院-重点科室: string, 医院-门诊时间: string, 天气-城市: string, 天气-天气: string, 天气-日期: string, 天气-温度: string, 天气-紫外线强度: string, 天气-风力风向: string, 旅游景点-区域: string, 旅游景点-名称: string, 旅游景点-地址: string, 旅游景点-开放时间: string, 旅游景点-是否地铁直达: string, 旅游景点-景点类型: string, 旅游景点-最适合人群: string, 旅游景点-消费: string, 旅游景点-特点: string, 旅游景点-电话号码: string, 旅游景点-评分: string, 旅游景点-门票价格: string, 汽车-价格(万元): string, 汽车-倒车影像: string, 汽车-动力水平: string, 汽车-厂商: string, 汽车-发动机排量(L): string, 汽车-发动机马力(Ps): string, 汽车-名称: string, 汽车-定速巡航: string, 汽车-巡航系统: string, 汽车-座位数: string, 汽车-座椅加热: string, 汽车-座椅通风: string, 汽车-所属价格区间: string, 汽车-油耗水平: string, 汽车-环保标准: string, 汽车-级别: string, 汽车-综合油耗(L/100km): string, 汽车-能源类型: string, 汽车-车型: string, 汽车-车系: string, 汽车-车身尺寸(mm): string, 汽车-驱动方式: string, 汽车-驾驶辅助影像: string, 火车-出发地: string, 火车-出发时间: string, 火车-到达时间: string, 火车-坐席: string, 火车-日期: string, 火车-时长: string, 火车-目的地: string, 火车-票价: string, 火车-舱位档次: string, 火车-车型: string, 火车-车次信息: string, 电影-主演: string, 电影-主演名单: string, 电影-具体上映时间: string, 电影-制片国家/地区: string, 电影-导演: string, 电影-年代: string, 电影-片名: string, 电影-片长: string, 电影-类型: string, 电影-豆瓣评分: string, 电脑-CPU: string, 电脑-CPU型号: string, 电脑-产品类别: string, 电脑-价格: string, 电脑-价格区间: string, 电脑-内存容量: string, 电脑-分类: string, 电脑-品牌: string, 电脑-商品名称: string, 电脑-屏幕尺寸: string, 电脑-待机时长: string, 电脑-显卡型号: string, 电脑-显卡类别: string, 电脑-游戏性能: string, 电脑-特性: string, 电脑-硬盘容量: string, 电脑-系列: string, 电脑-系统: string, 电脑-色系: string, 电脑-裸机重量: string, 电视剧-主演: string, 电视剧-主演名单: string, 电视剧-制片国家/地区: string, 电视剧-单集片长: string, 电视剧-导演: string, 电视剧-年代: string, 电视剧-片名: string, 电视剧-类型: string, 电视剧-豆瓣评分: string, 电视剧-集数: string, 电视剧-首播时间: string, 辅导班-上课方式: string, 辅导班-上课时间: string, 辅导班-下课时间: string, 辅导班-价格: string, 辅导班-区域: string, 辅导班-年级: string, 辅导班-开始日期: string, 辅导班-教室地点: string, 辅导班-教师: string, 辅导班-教师网址: string, 辅导班-时段: string, 辅导班-校区: string, 辅导班-每周: string, 辅导班-班号: string, 辅导班-科目: string, 辅导班-结束日期: string, 辅导班-课时: string, 辅导班-课次: string, 辅导班-课程网址: string, 辅导班-难度: string, 通用-产品类别: string, 通用-价格区间: string, 通用-品牌: string, 通用-系列: string, 酒店-价位: string, 酒店-停车场: string, 酒店-区域: string, 酒店-名称: string, 酒店-地址: string, 酒店-房型: string, 酒店-房费: string, 酒店-星级: string, 酒店-电话号码: string, 酒店-评分: string, 酒店-酒店类型: string, 飞机-准点率: string, 飞机-出发地: string, 飞机-到达时间: string, 飞机-日期: string, 飞机-目的地: string, 飞机-票价: string, 飞机-航班信息: string, 飞机-舱位档次: string, 飞机-起飞时间: string, 餐厅-人均消费: string, 餐厅-价位: string, 餐厅-区域: string, 餐厅-名称: string, 餐厅-地址: string, 餐厅-推荐菜: string, 餐厅-是否地铁直达: string, 餐厅-电话号码: string, 餐厅-菜系: string, 餐厅-营业时间: string, 餐厅-评分: string>
to
{'旅游景点-名称': Value(dtype='string', id=None), '旅游景点-区域': Value(dtype='string', id=None), '旅游景点-景点类型': Value(dtype='string', id=None), '旅游景点-最适合人群': Value(dtype='string', id=None), '旅游景点-消费': Value(dtype='string', id=None), '旅游景点-是否地铁直达': Value(dtype='string', id=None), '旅游景点-门票价格': Value(dtype='string', id=None), '旅游景点-电话号码': Value(dtype='string', id=None), '旅游景点-地址': Value(dtype='string', id=None), '旅游景点-评分': Value(dtype='string', id=None), '旅游景点-开放时间': Value(dtype='string', id=None), '旅游景点-特点': Value(dtype='string', id=None), '餐厅-名称': Value(dtype='string', id=None), '餐厅-区域': Value(dtype='string', id=None), '餐厅-菜系': Value(dtype='string', id=None), '餐厅-价位': Value(dtype='string', id=None), '餐厅-是否地铁直达': Value(dtype='string', id=None), '餐厅-人均消费': Value(dtype='string', id=None), '餐厅-地址': Value(dtype='string', id=None), '餐厅-电话号码': Value(dtype='string', id=None), '餐厅-评分': Value(dtype='string', id=None), '餐厅-营业时间': Value(dtype='string', id=None), '餐厅-推荐菜': Value(dtype='string', id=None), '酒店-名称': Value(dtype='string', id=None), '酒店-区域': Value(dtype='string', id=None), '酒店-星级': Value(dtype='string', id=None), '酒店-价位': Value(dtype='string', id=None), '酒店-酒店类型': Value(dtype='string', id=None), '酒店-房型': Value(dtype='string', id=None), '酒店-停车场': Value(dtype='string', id=None), '酒店-房费': Value(dtype='string', id=None), '酒店-地址': Value(dtype='string', id=None), '酒店-电话号码': Value(dtype='string', id=None), '酒店-评分': Value(dtype='string', id=None), '电脑-品牌': Value(dtype='string', id=None), '电脑-产品类别': Value(dtype='string', id=None), '电脑-分类': Value(dtype='string', id=None), '电脑-内存容量': Value(dtype='string', id=None), '电脑-屏幕尺寸': Value(dtype='string', id=None), '电脑-CPU': Value(dtype='string', id=None), '电脑-价格区间': Value(dtype='string', id=None), '电脑-系列': Value(dtype='string', id=None), '电脑-商品名称': Value(dtype='string', id=None), '电脑-系统': Value(dtype='string', id=None), '电脑-游戏性能': Value(dtype='string', id=None), '电脑-CPU型号': Value(dtype='string', id=None), '电脑-裸机重量': Value(dtype='string', id=None), '电脑-显卡类别': Value(dtype='string', id=None), '电脑-显卡型号': Value(dtype='string', id=None), '电脑-特性': Value(dtype='string', id=None), '电脑-色系': Value(dtype='string', id=None), '电脑-待机时长': Value(dtype='string', id=None), '电脑-硬盘容量': Value(dtype='string', id=None), '电脑-价格': Value(dtype='string', id=None), '火车-出发地': Value(dtype='string', id=None), '火车-目的地': Value(dtype='string', id=None), '火车-日期': Value(dtype='string', id=None), '火车-车型': Value(dtype='string', id=None), '火车-坐席': Value(dtype='string', id=None), '火车-车次信息': Value(dtype='string', id=None), '火车-时长': Value(dtype='string', id=None), '火车-出发时间': Value(dtype='string', id=None), '火车-到达时间': Value(dtype='string', id=None), '火车-票价': Value(dtype='string', id=None), '飞机-出发地': Value(dtype='string', id=None), '飞机-目的地': Value(dtype='string', id=None), '飞机-日期': Value(dtype='string', id=None), '飞机-舱位档次': Value(dtype='string', id=None), '飞机-航班信息': Value(dtype='string', id=None), '飞机-起飞时间': Value(dtype='string', id=None), '飞机-到达时间': Value(dtype='string', id=None), '飞机-票价': Value(dtype='string', id=None), '飞机-准点率': Value(dtype='string', id=None), '天气-城市': Value(dtype='string', id=None), '天气-日期': Value(dtype='string', id=None), '天气-天气': Value(dtype='string', id=None), '天气-温度': Value(dtype='string', id=None), '天气-风力风向': Value(dtype='string', id=None), '天气-紫外线强度': Value(dtype='string', id=None), '电影-制片国家/地区': Value(dtype='string', id=None), '电影-类型': Value(dtype='string', id=None), '电影-年代': Value(dtype='string', id=None), '电影-主演': Value(dtype='string', id=None), '电影-导演': Value(dtype='string', id=None), '电影-片名': Value(dtype='string', id=None), '电影-主演名单': Value(dtype='string', id=None), '电影-具体上映时间': Value(dtype='string', id=None), '电影-片长': Value(dtype='string', id=None), '电影-豆瓣评分': Value(dtype='string', id=None), '电视剧-制片国家/地区': Value(dtype='string', id=None), '电视剧-类型': Value(dtype='string', id=None), '电视剧-年代': Value(dtype='string', id=None), '电视剧-主演': Value(dtype='string', id=None), '电视剧-导演': Value(dtype='string', id=None), '电视剧-片名': Value(dtype='string', id=None), '电视剧-主演名单': Value(dtype='string', id=None), '电视剧-首播时间': Value(dtype='string', id=None), '电视剧-集数': Value(dtype='string', id=None), '电视剧-单集片长': Value(dtype='string', id=None), '电视剧-豆瓣评分': Value(dtype='string', id=None), '辅导班-班号': Value(dtype='string', id=None), '辅导班-难度': Value(dtype='string', id=None), '辅导班-科目': Value(dtype='string', id=None), '辅导班-年级': Value(dtype='string', id=None), '辅导班-区域': Value(dtype='string', id=None), '辅导班-校区': Value(dtype='string', id=None), '辅导班-上课方式': Value(dtype='string', id=None), '辅导班-开始日期': Value(dtype='string', id=None), '辅导班-结束日期': Value(dtype='string', id=None), '辅导班-每周': Value(dtype='string', id=None), '辅导班-上课时间': Value(dtype='string', id=None), '辅导班-下课时间': Value(dtype='string', id=None), '辅导班-时段': Value(dtype='string', id=None), '辅导班-课次': Value(dtype='string', id=None), '辅导班-课时': Value(dtype='string', id=None), '辅导班-教室地点': Value(dtype='string', id=None), '辅导班-教师': Value(dtype='string', id=None), '辅导班-价格': Value(dtype='string', id=None), '辅导班-课程网址': Value(dtype='string', id=None), '辅导班-教师网址': Value(dtype='string', id=None), '汽车-名称': Value(dtype='string', id=None), '汽车-车型': Value(dtype='string', id=None), '汽车-级别': Value(dtype='string', id=None), '汽车-座位数': Value(dtype='string', id=None), '汽车-车身尺寸(mm)': Value(dtype='string', id=None), '汽车-厂商': Value(dtype='string', id=None), '汽车-能源类型': Value(dtype='string', id=None), '汽车-发动机排量(L)': Value(dtype='string', id=None), '汽车-发动机马力(Ps)': Value(dtype='string', id=None), '汽车-驱动方式': Value(dtype='string', id=None), '汽车-综合油耗(L/100km)': Value(dtype='string', id=None), '汽车-环保标准': Value(dtype='string', id=None), '汽车-驾驶辅助影像': Value(dtype='string', id=None), '汽车-巡航系统': Value(dtype='string', id=None), '汽车-价格(万元)': Value(dtype='string', id=None), '汽车-车系': Value(dtype='string', id=None), '汽车-动力水平': Value(dtype='string', id=None), '汽车-油耗水平': Value(dtype='string', id=None), '汽车-倒车影像': Value(dtype='string', id=None), '汽车-定速巡航': Value(dtype='string', id=None), '汽车-座椅加热': Value(dtype='string', id=None), '汽车-座椅通风': Value(dtype='string', id=None), '汽车-所属价格区间': Value(dtype='string', id=None), '医院-名称': Value(dtype='string', id=None), '医院-等级': Value(dtype='string', id=None), '医院-类别': Value(dtype='string', id=None), '医院-性质': Value(dtype='string', id=None), '医院-区域': Value(dtype='string', id=None), '医院-地址': Value(dtype='string', id=None), '医院-电话': Value(dtype='string', id=None), '医院-挂号时间': Value(dtype='string', id=None), '医院-门诊时间': Value(dtype='string', id=None), '医院-公交线路': Value(dtype='string', id=None), '医院-地铁可达': Value(dtype='string', id=None), '医院-地铁线路': Value(dtype='string', id=None), '医院-重点科室': Value(dtype='string', id=None), '医院-CT': Value(dtype='string', id=None), '医院-3.0T MRI': Value(dtype='string', id=None), '医院-DSA': Value(dtype='string', id=None)}
During handling of the above exception, another exception occurred:
TypeError Traceback (most recent call last)
/var/folders/28/k4cy5q7s2hs92xq7_h89_vgm0000gn/T/ipykernel_44306/2896005239.py in <module>
----> 1 dset = load_dataset("GEM/RiSAWOZ")
2 dset
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, script_version, **config_kwargs)
1692
1693 # Download and prepare data
-> 1694 builder_instance.download_and_prepare(
1695 download_config=download_config,
1696 download_mode=download_mode,
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
593 logger.warning("HF google storage unreachable. Downloading and preparing it from source")
594 if not downloaded_from_gcs:
--> 595 self._download_and_prepare(
596 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
597 )
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
682 try:
683 # Prepare split will record examples associated to the split
--> 684 self._prepare_split(split_generator, **prepare_split_kwargs)
685 except OSError as e:
686 raise OSError(
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/builder.py in _prepare_split(self, split_generator)
1084 writer.write(example, key)
1085 finally:
-> 1086 num_examples, num_bytes = writer.finalize()
1087
1088 split_generator.split_info.num_examples = num_examples
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in finalize(self, close_stream)
525 # Re-intializing to empty list for next batch
526 self.hkey_record = []
--> 527 self.write_examples_on_file()
528 if self.pa_writer is None:
529 if self.schema:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in write_examples_on_file(self)
402 # Since current_examples contains (example, key) tuples
403 batch_examples[col] = [row[0][col] for row in self.current_examples]
--> 404 self.write_batch(batch_examples=batch_examples)
405 self.current_examples = []
406
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in write_batch(self, batch_examples, writer_batch_size)
495 col_try_type = try_features[col] if try_features is not None and col in try_features else None
496 typed_sequence = OptimizedTypedSequence(batch_examples[col], type=col_type, try_type=col_try_type, col=col)
--> 497 arrays.append(pa.array(typed_sequence))
498 inferred_features[col] = typed_sequence.get_inferred_type()
499 schema = inferred_features.arrow_schema if self.pa_writer is None else self.schema
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/pyarrow/array.pxi in pyarrow.lib.array()
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/pyarrow/array.pxi in pyarrow.lib._handle_arrow_array_protocol()
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/arrow_writer.py in __arrow_array__(self, type)
203 # Also, when trying type "string", we don't want to convert integers or floats to "string".
204 # We only do it if trying_type is False - since this is what the user asks for.
--> 205 out = cast_array_to_feature(out, type, allow_number_to_str=not self.trying_type)
206 return out
207 except (TypeError, pa.lib.ArrowInvalid) as e: # handle type errors and overflows
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
942 if pa.types.is_list(array.type) and config.PYARROW_VERSION < version.parse("4.0.0"):
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
946 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
918 return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
919 else:
--> 920 return func(array, *args, **kwargs)
921
922 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1063 # feature must be either [subfeature] or Sequence(subfeature)
1064 if isinstance(feature, list):
-> 1065 return pa.ListArray.from_arrays(array.offsets, _c(array.values, feature[0]))
1066 elif isinstance(feature, Sequence):
1067 if feature.length > -1:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
942 if pa.types.is_list(array.type) and config.PYARROW_VERSION < version.parse("4.0.0"):
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
946 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
918 return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
919 else:
--> 920 return func(array, *args, **kwargs)
921
922 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1058 }
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
1062 elif pa.types.is_list(array.type):
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
1058 }
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
1062 elif pa.types.is_list(array.type):
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
942 if pa.types.is_list(array.type) and config.PYARROW_VERSION < version.parse("4.0.0"):
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
946 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
918 return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
919 else:
--> 920 return func(array, *args, **kwargs)
921
922 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1058 }
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
1062 elif pa.types.is_list(array.type):
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
1058 }
1059 if isinstance(feature, dict) and set(field.name for field in array.type) == set(feature):
-> 1060 arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
1061 return pa.StructArray.from_arrays(arrays, names=list(feature))
1062 elif pa.types.is_list(array.type):
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
942 if pa.types.is_list(array.type) and config.PYARROW_VERSION < version.parse("4.0.0"):
943 array = _sanitize(array)
--> 944 return func(array, *args, **kwargs)
945
946 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in wrapper(array, *args, **kwargs)
918 return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
919 else:
--> 920 return func(array, *args, **kwargs)
921
922 return wrapper
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/datasets/table.py in cast_array_to_feature(array, feature, allow_number_to_str)
1085 elif not isinstance(feature, (Sequence, dict, list, tuple)):
1086 return array_cast(array, feature(), allow_number_to_str=allow_number_to_str)
-> 1087 raise TypeError(f"Couldn't cast array of type\n{array.type}\nto\n{feature}")
1088
1089
TypeError: Couldn't cast array of type
struct<医院-3.0T MRI: string, 医院-CT: string, 医院-DSA: string, 医院-公交线路: string, 医院-区域: string, 医院-名称: string, 医院-地址: string, 医院-地铁可达: string, 医院-地铁线路: string, 医院-性质: string, 医院-挂号时间: string, 医院-电话: string, 医院-等级: string, 医院-类别: string, 医院-重点科室: string, 医院-门诊时间: string, 天气-城市: string, 天气-天气: string, 天气-日期: string, 天气-温度: string, 天气-紫外线强度: string, 天气-风力风向: string, 旅游景点-区域: string, 旅游景点-名称: string, 旅游景点-地址: string, 旅游景点-开放时间: string, 旅游景点-是否地铁直达: string, 旅游景点-景点类型: string, 旅游景点-最适合人群: string, 旅游景点-消费: string, 旅游景点-特点: string, 旅游景点-电话号码: string, 旅游景点-评分: string, 旅游景点-门票价格: string, 汽车-价格(万元): string, 汽车-倒车影像: string, 汽车-动力水平: string, 汽车-厂商: string, 汽车-发动机排量(L): string, 汽车-发动机马力(Ps): string, 汽车-名称: string, 汽车-定速巡航: string, 汽车-巡航系统: string, 汽车-座位数: string, 汽车-座椅加热: string, 汽车-座椅通风: string, 汽车-所属价格区间: string, 汽车-油耗水平: string, 汽车-环保标准: string, 汽车-级别: string, 汽车-综合油耗(L/100km): string, 汽车-能源类型: string, 汽车-车型: string, 汽车-车系: string, 汽车-车身尺寸(mm): string, 汽车-驱动方式: string, 汽车-驾驶辅助影像: string, 火车-出发地: string, 火车-出发时间: string, 火车-到达时间: string, 火车-坐席: string, 火车-日期: string, 火车-时长: string, 火车-目的地: string, 火车-票价: string, 火车-舱位档次: string, 火车-车型: string, 火车-车次信息: string, 电影-主演: string, 电影-主演名单: string, 电影-具体上映时间: string, 电影-制片国家/地区: string, 电影-导演: string, 电影-年代: string, 电影-片名: string, 电影-片长: string, 电影-类型: string, 电影-豆瓣评分: string, 电脑-CPU: string, 电脑-CPU型号: string, 电脑-产品类别: string, 电脑-价格: string, 电脑-价格区间: string, 电脑-内存容量: string, 电脑-分类: string, 电脑-品牌: string, 电脑-商品名称: string, 电脑-屏幕尺寸: string, 电脑-待机时长: string, 电脑-显卡型号: string, 电脑-显卡类别: string, 电脑-游戏性能: string, 电脑-特性: string, 电脑-硬盘容量: string, 电脑-系列: string, 电脑-系统: string, 电脑-色系: string, 电脑-裸机重量: string, 电视剧-主演: string, 电视剧-主演名单: string, 电视剧-制片国家/地区: string, 电视剧-单集片长: string, 电视剧-导演: string, 电视剧-年代: string, 电视剧-片名: string, 电视剧-类型: string, 电视剧-豆瓣评分: string, 电视剧-集数: string, 电视剧-首播时间: string, 辅导班-上课方式: string, 辅导班-上课时间: string, 辅导班-下课时间: string, 辅导班-价格: string, 辅导班-区域: string, 辅导班-年级: string, 辅导班-开始日期: string, 辅导班-教室地点: string, 辅导班-教师: string, 辅导班-教师网址: string, 辅导班-时段: string, 辅导班-校区: string, 辅导班-每周: string, 辅导班-班号: string, 辅导班-科目: string, 辅导班-结束日期: string, 辅导班-课时: string, 辅导班-课次: string, 辅导班-课程网址: string, 辅导班-难度: string, 通用-产品类别: string, 通用-价格区间: string, 通用-品牌: string, 通用-系列: string, 酒店-价位: string, 酒店-停车场: string, 酒店-区域: string, 酒店-名称: string, 酒店-地址: string, 酒店-房型: string, 酒店-房费: string, 酒店-星级: string, 酒店-电话号码: string, 酒店-评分: string, 酒店-酒店类型: string, 飞机-准点率: string, 飞机-出发地: string, 飞机-到达时间: string, 飞机-日期: string, 飞机-目的地: string, 飞机-票价: string, 飞机-航班信息: string, 飞机-舱位档次: string, 飞机-起飞时间: string, 餐厅-人均消费: string, 餐厅-价位: string, 餐厅-区域: string, 餐厅-名称: string, 餐厅-地址: string, 餐厅-推荐菜: string, 餐厅-是否地铁直达: string, 餐厅-电话号码: string, 餐厅-菜系: string, 餐厅-营业时间: string, 餐厅-评分: string>
to
{'旅游景点-名称': Value(dtype='string', id=None), '旅游景点-区域': Value(dtype='string', id=None), '旅游景点-景点类型': Value(dtype='string', id=None), '旅游景点-最适合人群': Value(dtype='string', id=None), '旅游景点-消费': Value(dtype='string', id=None), '旅游景点-是否地铁直达': Value(dtype='string', id=None), '旅游景点-门票价格': Value(dtype='string', id=None), '旅游景点-电话号码': Value(dtype='string', id=None), '旅游景点-地址': Value(dtype='string', id=None), '旅游景点-评分': Value(dtype='string', id=None), '旅游景点-开放时间': Value(dtype='string', id=None), '旅游景点-特点': Value(dtype='string', id=None), '餐厅-名称': Value(dtype='string', id=None), '餐厅-区域': Value(dtype='string', id=None), '餐厅-菜系': Value(dtype='string', id=None), '餐厅-价位': Value(dtype='string', id=None), '餐厅-是否地铁直达': Value(dtype='string', id=None), '餐厅-人均消费': Value(dtype='string', id=None), '餐厅-地址': Value(dtype='string', id=None), '餐厅-电话号码': Value(dtype='string', id=None), '餐厅-评分': Value(dtype='string', id=None), '餐厅-营业时间': Value(dtype='string', id=None), '餐厅-推荐菜': Value(dtype='string', id=None), '酒店-名称': Value(dtype='string', id=None), '酒店-区域': Value(dtype='string', id=None), '酒店-星级': Value(dtype='string', id=None), '酒店-价位': Value(dtype='string', id=None), '酒店-酒店类型': Value(dtype='string', id=None), '酒店-房型': Value(dtype='string', id=None), '酒店-停车场': Value(dtype='string', id=None), '酒店-房费': Value(dtype='string', id=None), '酒店-地址': Value(dtype='string', id=None), '酒店-电话号码': Value(dtype='string', id=None), '酒店-评分': Value(dtype='string', id=None), '电脑-品牌': Value(dtype='string', id=None), '电脑-产品类别': Value(dtype='string', id=None), '电脑-分类': Value(dtype='string', id=None), '电脑-内存容量': Value(dtype='string', id=None), '电脑-屏幕尺寸': Value(dtype='string', id=None), '电脑-CPU': Value(dtype='string', id=None), '电脑-价格区间': Value(dtype='string', id=None), '电脑-系列': Value(dtype='string', id=None), '电脑-商品名称': Value(dtype='string', id=None), '电脑-系统': Value(dtype='string', id=None), '电脑-游戏性能': Value(dtype='string', id=None), '电脑-CPU型号': Value(dtype='string', id=None), '电脑-裸机重量': Value(dtype='string', id=None), '电脑-显卡类别': Value(dtype='string', id=None), '电脑-显卡型号': Value(dtype='string', id=None), '电脑-特性': Value(dtype='string', id=None), '电脑-色系': Value(dtype='string', id=None), '电脑-待机时长': Value(dtype='string', id=None), '电脑-硬盘容量': Value(dtype='string', id=None), '电脑-价格': Value(dtype='string', id=None), '火车-出发地': Value(dtype='string', id=None), '火车-目的地': Value(dtype='string', id=None), '火车-日期': Value(dtype='string', id=None), '火车-车型': Value(dtype='string', id=None), '火车-坐席': Value(dtype='string', id=None), '火车-车次信息': Value(dtype='string', id=None), '火车-时长': Value(dtype='string', id=None), '火车-出发时间': Value(dtype='string', id=None), '火车-到达时间': Value(dtype='string', id=None), '火车-票价': Value(dtype='string', id=None), '飞机-出发地': Value(dtype='string', id=None), '飞机-目的地': Value(dtype='string', id=None), '飞机-日期': Value(dtype='string', id=None), '飞机-舱位档次': Value(dtype='string', id=None), '飞机-航班信息': Value(dtype='string', id=None), '飞机-起飞时间': Value(dtype='string', id=None), '飞机-到达时间': Value(dtype='string', id=None), '飞机-票价': Value(dtype='string', id=None), '飞机-准点率': Value(dtype='string', id=None), '天气-城市': Value(dtype='string', id=None), '天气-日期': Value(dtype='string', id=None), '天气-天气': Value(dtype='string', id=None), '天气-温度': Value(dtype='string', id=None), '天气-风力风向': Value(dtype='string', id=None), '天气-紫外线强度': Value(dtype='string', id=None), '电影-制片国家/地区': Value(dtype='string', id=None), '电影-类型': Value(dtype='string', id=None), '电影-年代': Value(dtype='string', id=None), '电影-主演': Value(dtype='string', id=None), '电影-导演': Value(dtype='string', id=None), '电影-片名': Value(dtype='string', id=None), '电影-主演名单': Value(dtype='string', id=None), '电影-具体上映时间': Value(dtype='string', id=None), '电影-片长': Value(dtype='string', id=None), '电影-豆瓣评分': Value(dtype='string', id=None), '电视剧-制片国家/地区': Value(dtype='string', id=None), '电视剧-类型': Value(dtype='string', id=None), '电视剧-年代': Value(dtype='string', id=None), '电视剧-主演': Value(dtype='string', id=None), '电视剧-导演': Value(dtype='string', id=None), '电视剧-片名': Value(dtype='string', id=None), '电视剧-主演名单': Value(dtype='string', id=None), '电视剧-首播时间': Value(dtype='string', id=None), '电视剧-集数': Value(dtype='string', id=None), '电视剧-单集片长': Value(dtype='string', id=None), '电视剧-豆瓣评分': Value(dtype='string', id=None), '辅导班-班号': Value(dtype='string', id=None), '辅导班-难度': Value(dtype='string', id=None), '辅导班-科目': Value(dtype='string', id=None), '辅导班-年级': Value(dtype='string', id=None), '辅导班-区域': Value(dtype='string', id=None), '辅导班-校区': Value(dtype='string', id=None), '辅导班-上课方式': Value(dtype='string', id=None), '辅导班-开始日期': Value(dtype='string', id=None), '辅导班-结束日期': Value(dtype='string', id=None), '辅导班-每周': Value(dtype='string', id=None), '辅导班-上课时间': Value(dtype='string', id=None), '辅导班-下课时间': Value(dtype='string', id=None), '辅导班-时段': Value(dtype='string', id=None), '辅导班-课次': Value(dtype='string', id=None), '辅导班-课时': Value(dtype='string', id=None), '辅导班-教室地点': Value(dtype='string', id=None), '辅导班-教师': Value(dtype='string', id=None), '辅导班-价格': Value(dtype='string', id=None), '辅导班-课程网址': Value(dtype='string', id=None), '辅导班-教师网址': Value(dtype='string', id=None), '汽车-名称': Value(dtype='string', id=None), '汽车-车型': Value(dtype='string', id=None), '汽车-级别': Value(dtype='string', id=None), '汽车-座位数': Value(dtype='string', id=None), '汽车-车身尺寸(mm)': Value(dtype='string', id=None), '汽车-厂商': Value(dtype='string', id=None), '汽车-能源类型': Value(dtype='string', id=None), '汽车-发动机排量(L)': Value(dtype='string', id=None), '汽车-发动机马力(Ps)': Value(dtype='string', id=None), '汽车-驱动方式': Value(dtype='string', id=None), '汽车-综合油耗(L/100km)': Value(dtype='string', id=None), '汽车-环保标准': Value(dtype='string', id=None), '汽车-驾驶辅助影像': Value(dtype='string', id=None), '汽车-巡航系统': Value(dtype='string', id=None), '汽车-价格(万元)': Value(dtype='string', id=None), '汽车-车系': Value(dtype='string', id=None), '汽车-动力水平': Value(dtype='string', id=None), '汽车-油耗水平': Value(dtype='string', id=None), '汽车-倒车影像': Value(dtype='string', id=None), '汽车-定速巡航': Value(dtype='string', id=None), '汽车-座椅加热': Value(dtype='string', id=None), '汽车-座椅通风': Value(dtype='string', id=None), '汽车-所属价格区间': Value(dtype='string', id=None), '医院-名称': Value(dtype='string', id=None), '医院-等级': Value(dtype='string', id=None), '医院-类别': Value(dtype='string', id=None), '医院-性质': Value(dtype='string', id=None), '医院-区域': Value(dtype='string', id=None), '医院-地址': Value(dtype='string', id=None), '医院-电话': Value(dtype='string', id=None), '医院-挂号时间': Value(dtype='string', id=None), '医院-门诊时间': Value(dtype='string', id=None), '医院-公交线路': Value(dtype='string', id=None), '医院-地铁可达': Value(dtype='string', id=None), '医院-地铁线路': Value(dtype='string', id=None), '医院-重点科室': Value(dtype='string', id=None), '医院-CT': Value(dtype='string', id=None), '医院-3.0T MRI': Value(dtype='string', id=None), '医院-DSA': Value(dtype='string', id=None)}
```
</details>
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.10
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3637/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3637/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5858 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5858/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5858/comments | https://api.github.com/repos/huggingface/datasets/issues/5858/events | https://github.com/huggingface/datasets/issues/5858 | 1,709,332,632 | I_kwDODunzps5l4liY | 5,858 | Throw an error when dataset improperly indexed | {
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sarahwie",
"id": 8027676,
"login": "sarahwie",
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sarahwie"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Thanks for reporting, @sarahwie.\r\n\r\nPlease note that in `datasets` we do not have vectorized operation like `pandas`. Therefore, your equality comparisons above are `False`:\r\n- For example: `squad['question']` returns a `list`, and this list is not equal to `\"Who was the Norse leader?\"`\r\n\r\nThe `False` value is equivalent to `0` when indexing a dataset, thus the reason why you get the first element (with index 0): \r\n- For example: `squad[False]` is equivalent to `squad[0]`\r\n\r\nMaybe we should an exception instead of assuming that `False` is equivalent to `0` (and `True` is equivalent to `1`) in the context of indexing."
] | "2023-05-15T05:15:53Z" | "2023-05-25T16:23:19Z" | "2023-05-25T16:23:19Z" | NONE | null | null | null | ### Describe the bug
Pandas-style subset indexing on dataset does not throw an error, when maybe it should. Instead returns the first instance of the dataset regardless of index condition.
### Steps to reproduce the bug
Steps to reproduce the behavior:
1. `squad = datasets.load_dataset("squad_v2", split="validation")`
2. `item = squad[squad['question'] == "Who was the Norse leader?"]`
or `it = squad[squad['id'] == '56ddde6b9a695914005b962b']`
3. returns the first item in the dataset, which does not satisfy the above conditions:
`{'id': '56ddde6b9a695914005b9628', 'title': 'Normans', 'context': 'The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse ("Norman" comes from "Norseman") raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King Charles III of West Francia. Through generations of assimilation and mixing with the native Frankish and Roman-Gaulish populations, their descendants would gradually merge with the Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the Normans emerged initially in the first half of the 10th century, and it continued to evolve over the succeeding centuries.', 'question': 'In what country is Normandy located?', 'answers': {'text': ['France', 'France', 'France', 'France'], 'answer_start': [159, 159, 159, 159]}}`
### Expected behavior
Should either throw an error message, or return the dataset item that satisfies the condition.
### Environment info
- `datasets` version: 2.9.0
- Platform: macOS-13.3.1-arm64-arm-64bit
- Python version: 3.10.8
- PyArrow version: 10.0.1
- Pandas version: 1.5.3 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5858/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5858/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5691 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5691/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5691/comments | https://api.github.com/repos/huggingface/datasets/issues/5691/events | https://github.com/huggingface/datasets/pull/5691 | 1,649,737,526 | PR_kwDODunzps5NX08d | 5,691 | [docs] Compress data files | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"[Confirmed](https://huggingface.slack.com/archives/C02EMARJ65P/p1680541667004199) with the Hub team the file size limit for the Hugging Face Hub is 10MB :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006789 / 0.011353 (-0.004564) | 0.004935 / 0.011008 (-0.006073) | 0.096796 / 0.038508 (0.058288) | 0.032485 / 0.023109 (0.009376) | 0.335342 / 0.275898 (0.059444) | 0.354999 / 0.323480 (0.031519) | 0.005467 / 0.007986 (-0.002519) | 0.005267 / 0.004328 (0.000939) | 0.073988 / 0.004250 (0.069737) | 0.044402 / 0.037052 (0.007350) | 0.331156 / 0.258489 (0.072666) | 0.363595 / 0.293841 (0.069754) | 0.035301 / 0.128546 (-0.093245) | 0.012141 / 0.075646 (-0.063505) | 0.333164 / 0.419271 (-0.086107) | 0.048818 / 0.043533 (0.005286) | 0.331458 / 0.255139 (0.076319) | 0.343567 / 0.283200 (0.060367) | 0.094963 / 0.141683 (-0.046720) | 1.444383 / 1.452155 (-0.007772) | 1.520093 / 1.492716 (0.027377) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.212311 / 0.018006 (0.194305) | 0.436413 / 0.000490 (0.435923) | 0.000333 / 0.000200 (0.000133) | 0.000057 / 0.000054 (0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026670 / 0.037411 (-0.010742) | 0.105774 / 0.014526 (0.091248) | 0.115796 / 0.176557 (-0.060760) | 0.176504 / 0.737135 (-0.560631) | 0.121883 / 0.296338 (-0.174456) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.400783 / 0.215209 (0.185574) | 4.006608 / 2.077655 (1.928953) | 1.817659 / 1.504120 (0.313539) | 1.619777 / 1.541195 (0.078582) | 1.684247 / 1.468490 (0.215757) | 0.701116 / 4.584777 (-3.883661) | 3.684056 / 3.745712 (-0.061656) | 2.065258 / 5.269862 (-3.204603) | 1.425460 / 4.565676 (-3.140217) | 0.084519 / 0.424275 (-0.339757) | 0.011949 / 0.007607 (0.004342) | 0.496793 / 0.226044 (0.270749) | 4.978864 / 2.268929 (2.709935) | 2.303388 / 55.444624 (-53.141237) | 1.978341 / 6.876477 (-4.898135) | 2.055744 / 2.142072 (-0.086329) | 0.832022 / 4.805227 (-3.973206) | 0.164715 / 6.500664 (-6.335949) | 0.062701 / 0.075469 (-0.012768) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.178723 / 1.841788 (-0.663065) | 14.583986 / 8.074308 (6.509678) | 14.189402 / 10.191392 (3.998010) | 0.183867 / 0.680424 (-0.496557) | 0.017565 / 0.534201 (-0.516636) | 0.421345 / 0.579283 (-0.157938) | 0.420235 / 0.434364 (-0.014129) | 0.496758 / 0.540337 (-0.043580) | 0.591558 / 1.386936 (-0.795378) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007019 / 0.011353 (-0.004334) | 0.004996 / 0.011008 (-0.006012) | 0.073345 / 0.038508 (0.034836) | 0.033077 / 0.023109 (0.009968) | 0.335954 / 0.275898 (0.060056) | 0.372616 / 0.323480 (0.049136) | 0.005678 / 0.007986 (-0.002308) | 0.003906 / 0.004328 (-0.000423) | 0.072841 / 0.004250 (0.068591) | 0.046829 / 0.037052 (0.009777) | 0.335177 / 0.258489 (0.076688) | 0.382862 / 0.293841 (0.089021) | 0.038406 / 0.128546 (-0.090141) | 0.012110 / 0.075646 (-0.063536) | 0.085796 / 0.419271 (-0.333476) | 0.049896 / 0.043533 (0.006363) | 0.338232 / 0.255139 (0.083093) | 0.361054 / 0.283200 (0.077855) | 0.103171 / 0.141683 (-0.038512) | 1.556692 / 1.452155 (0.104538) | 1.540023 / 1.492716 (0.047306) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.223705 / 0.018006 (0.205699) | 0.438771 / 0.000490 (0.438282) | 0.002838 / 0.000200 (0.002639) | 0.000081 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028423 / 0.037411 (-0.008988) | 0.110560 / 0.014526 (0.096035) | 0.121629 / 0.176557 (-0.054928) | 0.173638 / 0.737135 (-0.563498) | 0.127062 / 0.296338 (-0.169277) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.425806 / 0.215209 (0.210597) | 4.251051 / 2.077655 (2.173397) | 2.059735 / 1.504120 (0.555615) | 1.864886 / 1.541195 (0.323692) | 1.941553 / 1.468490 (0.473063) | 0.700084 / 4.584777 (-3.884693) | 3.753150 / 3.745712 (0.007438) | 3.218606 / 5.269862 (-2.051256) | 1.439648 / 4.565676 (-3.126028) | 0.085239 / 0.424275 (-0.339037) | 0.012026 / 0.007607 (0.004419) | 0.521564 / 0.226044 (0.295520) | 5.217902 / 2.268929 (2.948973) | 2.557831 / 55.444624 (-52.886793) | 2.240223 / 6.876477 (-4.636254) | 2.364664 / 2.142072 (0.222591) | 0.825884 / 4.805227 (-3.979343) | 0.167800 / 6.500664 (-6.332864) | 0.063552 / 0.075469 (-0.011917) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.255532 / 1.841788 (-0.586256) | 14.747783 / 8.074308 (6.673475) | 14.352263 / 10.191392 (4.160871) | 0.143659 / 0.680424 (-0.536765) | 0.017517 / 0.534201 (-0.516684) | 0.419863 / 0.579283 (-0.159421) | 0.416674 / 0.434364 (-0.017690) | 0.485694 / 0.540337 (-0.054643) | 0.584810 / 1.386936 (-0.802126) |\n\n</details>\n</details>\n\n\n"
] | "2023-03-31T17:17:26Z" | "2023-04-19T13:37:32Z" | "2023-04-19T07:25:58Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5691.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5691",
"merged_at": "2023-04-19T07:25:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5691.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5691"
} | This PR addresses the comments in #5687 about compressing text file extensions before uploading to the Hub. Also clarified what "too large" means based on the GitLFS [docs](https://docs.github.com/en/repositories/working-with-files/managing-large-files/about-git-large-file-storage). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5691/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5691/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3323 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3323/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3323/comments | https://api.github.com/repos/huggingface/datasets/issues/3323/events | https://github.com/huggingface/datasets/pull/3323 | 1,064,660,452 | PR_kwDODunzps4vEZwq | 3,323 | Fix wrongly converted assert | {
"avatar_url": "https://avatars.githubusercontent.com/u/19492473?v=4",
"events_url": "https://api.github.com/users/eliasws/events{/privacy}",
"followers_url": "https://api.github.com/users/eliasws/followers",
"following_url": "https://api.github.com/users/eliasws/following{/other_user}",
"gists_url": "https://api.github.com/users/eliasws/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/eliasws",
"id": 19492473,
"login": "eliasws",
"node_id": "MDQ6VXNlcjE5NDkyNDcz",
"organizations_url": "https://api.github.com/users/eliasws/orgs",
"received_events_url": "https://api.github.com/users/eliasws/received_events",
"repos_url": "https://api.github.com/users/eliasws/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/eliasws/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eliasws/subscriptions",
"type": "User",
"url": "https://api.github.com/users/eliasws"
} | [] | closed | false | null | [] | null | [
"Closes #3327 "
] | "2021-11-26T16:05:39Z" | "2021-11-26T16:44:12Z" | "2021-11-26T16:44:11Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3323.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3323",
"merged_at": "2021-11-26T16:44:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3323.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3323"
} | Seems like this assertion was replaced by an exception but the condition got wrongly converted. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3323/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3323/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2818 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2818/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2818/comments | https://api.github.com/repos/huggingface/datasets/issues/2818/events | https://github.com/huggingface/datasets/issues/2818 | 974,552,009 | MDU6SXNzdWU5NzQ1NTIwMDk= | 2,818 | cannot load data from my loacal path | {
"avatar_url": "https://avatars.githubusercontent.com/u/46920280?v=4",
"events_url": "https://api.github.com/users/yang-collect/events{/privacy}",
"followers_url": "https://api.github.com/users/yang-collect/followers",
"following_url": "https://api.github.com/users/yang-collect/following{/other_user}",
"gists_url": "https://api.github.com/users/yang-collect/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yang-collect",
"id": 46920280,
"login": "yang-collect",
"node_id": "MDQ6VXNlcjQ2OTIwMjgw",
"organizations_url": "https://api.github.com/users/yang-collect/orgs",
"received_events_url": "https://api.github.com/users/yang-collect/received_events",
"repos_url": "https://api.github.com/users/yang-collect/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yang-collect/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yang-collect/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yang-collect"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! The `data_files` parameter must be a string, a list/tuple or a python dict.\r\n\r\nCan you check the type of your `config.train_path` please ? Or use `data_files=str(config.train_path)` ?"
] | "2021-08-19T11:13:30Z" | "2023-07-25T17:42:15Z" | "2023-07-25T17:42:15Z" | NONE | null | null | null | ## Describe the bug
I just want to directly load data from my local path,but find a bug.And I compare it with pandas to provide my local path is real.
here is my code
```python3
# print my local path
print(config.train_path)
# read data and print data length
tarin=pd.read_csv(config.train_path)
print(len(tarin))
# loading data by load_dataset
data = load_dataset('csv',data_files=config.train_path)
print(len(data))
```
## Steps to reproduce the bug
```python
C:\Users\wie\Documents\项目\文本分类\data\train.csv
7613
Traceback (most recent call last):
File "c:/Users/wie/Documents/项目/文本分类/lib/DataPrecess.py", line 17, in <module>
data = load_dataset('csv',data_files=config.train_path)
File "C:\Users\wie\Miniconda3\lib\site-packages\datasets\load.py", line 830, in load_dataset
**config_kwargs,
File "C:\Users\wie\Miniconda3\lib\site-packages\datasets\load.py", line 710, in load_dataset_builder
**config_kwargs,
File "C:\Users\wie\Miniconda3\lib\site-packages\datasets\builder.py", line 271, in __init__
**config_kwargs,
File "C:\Users\wie\Miniconda3\lib\site-packages\datasets\builder.py", line 386, in _create_builder_config
config_kwargs, custom_features=custom_features, use_auth_token=self.use_auth_token
File "C:\Users\wie\Miniconda3\lib\site-packages\datasets\builder.py", line 156, in create_config_id
raise ValueError("Please provide a valid `data_files` in `DatasetBuilder`")
ValueError: Please provide a valid `data_files` in `DatasetBuilder`
```
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.11.0
- Platform: win10
- Python version: 3.7.9
- PyArrow version: 5.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2818/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2818/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5023 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5023/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5023/comments | https://api.github.com/repos/huggingface/datasets/issues/5023/events | https://github.com/huggingface/datasets/issues/5023 | 1,385,881,112 | I_kwDODunzps5Smt4Y | 5,023 | Text strings are split into lists of characters in xcsr dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | "2022-09-26T11:11:50Z" | "2022-09-28T07:54:20Z" | "2022-09-28T07:54:20Z" | MEMBER | null | null | null | ## Describe the bug
Text strings are split into lists of characters.
Example for "X-CSQA-en":
```
{'id': 'd3845adc08414fda',
'lang': 'en',
'question': {'stem': ['T',
'h',
'e',
' ',
'd',
'e',
'n',
't',
'a',
'l',
' ',
'o',
'f',
'f',
'i',
'c',
'e',
' ',
'h',
'a',
'n',
'd',
'l',
'e',
'd',
' ',
'a',
' ',
'l',
'o',
't',
' ',
'o',
'f',
' ',
'p',
'a',
't',
'i',
'e',
'n',
't',
's',
' ',
'w',
'h',
'o',
' ',
'e',
'x',
'p',
'e',
'r',
'i',
'e',
'n',
'c',
'e',
'd',
' ',
't',
'r',
'a',
'u',
'm',
'a',
't',
'i',
'c',
' ',
'm',
'o',
'u',
't',
'h',
' ',
'i',
'n',
'j',
'u',
'r',
'y',
',',
' ',
'w',
'h',
'e',
'r',
'e',
' ',
'w',
'e',
'r',
'e',
' ',
't',
'h',
'e',
's',
'e',
' ',
'p',
'a',
't',
'i',
'e',
'n',
't',
's',
' ',
'c',
'o',
'm',
'i',
'n',
'g',
' ',
'f',
'r',
'o',
'm',
'?'],
'choices': [{'label': ['A'], 'text': ['t', 'o', 'w', 'n']},
{'label': ['B'], 'text': ['m', 'i', 'c', 'h', 'i', 'g', 'a', 'n']},
{'label': ['C'], 'text': ['h', 'o', 's', 'p', 'i', 't', 'a', 'l']},
{'label': ['D'], 'text': ['s', 'c', 'h', 'o', 'o', 'l', 's']},
{'label': ['E'],
'text': ['o',
'f',
'f',
'i',
'c',
'e',
' ',
'b',
'u',
'i',
'l',
'd',
'i',
'n',
'g']}]},
'answerKey': 'C'}
## Steps to reproduce the bug
```python
ds = load_dataset("datasets/xcsr", "X-CSQA-en", split="validation", streaming=True)
item = next(iter(ds))
item
```
## Expected results
```
{'id': 'd3845adc08414fda',
'lang': 'en',
'question': {'stem': 'The dental office handled a lot of patients who experienced traumatic mouth injury, where were these patients coming from?',
'choices': {'label': ['A', 'B', 'C', 'D', 'E'],
'text': ['town', 'michigan', 'hospital', 'schools', 'office building']}},
'answerKey': 'C'}
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5023/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5023/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3990 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3990/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3990/comments | https://api.github.com/repos/huggingface/datasets/issues/3990/events | https://github.com/huggingface/datasets/issues/3990 | 1,176,976,247 | I_kwDODunzps5GJzt3 | 3,990 | Improve AutomaticSpeechRecognition task template | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"There is an open PR to do that: #3364. I just haven't had time to finish it... ",
"> There is an open PR to do that: #3364. I just haven't had time to finish it...\r\n\r\n😬 thanks..."
] | "2022-03-22T15:41:08Z" | "2022-03-23T17:12:40Z" | "2022-03-23T17:12:40Z" | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
[AutomaticSpeechRecognition task template](https://github.com/huggingface/datasets/blob/master/src/datasets/tasks/automatic_speech_recognition.py) is outdated as it uses path to audiofile as an audio column instead of a Audio feature itself (I guess it's because Audio feature didn't exist at the time this template was created).
**Describe the solution you'd like**
Change audio columns from string path to Audio feature.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3990/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3990/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3958 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3958/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3958/comments | https://api.github.com/repos/huggingface/datasets/issues/3958/events | https://github.com/huggingface/datasets/pull/3958 | 1,172,657,981 | PR_kwDODunzps40nQU2 | 3,958 | Update Wikipedia metadata | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3958). All of your documentation changes will be reflected on that endpoint.",
"Once this last PR validated, I can take care of the integration of all the wikipedia update branch into master, @lhoestq. "
] | "2022-03-17T17:50:05Z" | "2022-03-21T12:26:48Z" | "2022-03-21T12:26:47Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3958.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3958",
"merged_at": "2022-03-21T12:26:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3958.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3958"
} | This PR updates:
- dataset card
- metadata JSON | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3958/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3958/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1730 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1730/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1730/comments | https://api.github.com/repos/huggingface/datasets/issues/1730/events | https://github.com/huggingface/datasets/pull/1730 | 784,617,525 | MDExOlB1bGxSZXF1ZXN0NTUzNzgxMDY0 | 1,730 | Add MNIST dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sgugger",
"id": 35901082,
"login": "sgugger",
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"repos_url": "https://api.github.com/users/sgugger/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sgugger"
} | [] | closed | false | null | [] | null | [] | "2021-01-12T21:48:02Z" | "2021-01-13T10:19:47Z" | "2021-01-13T10:19:46Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1730.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1730",
"merged_at": "2021-01-13T10:19:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1730.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1730"
} | This PR adds the MNIST dataset to the library. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1730/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1730/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2353 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2353/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2353/comments | https://api.github.com/repos/huggingface/datasets/issues/2353/events | https://github.com/huggingface/datasets/pull/2353 | 890,296,262 | MDExOlB1bGxSZXF1ZXN0NjQzMzM4MDcz | 2,353 | Update README vallidation rules | {
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gchhablani",
"id": 29076344,
"login": "gchhablani",
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gchhablani"
} | [] | closed | false | null | [] | null | [] | "2021-05-12T16:57:26Z" | "2021-05-14T08:56:06Z" | "2021-05-14T08:56:06Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2353.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2353",
"merged_at": "2021-05-14T08:56:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2353.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2353"
} | This PR allows unexpected subsections under third-level headings. All except `Contributions`.
@lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2353/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2353/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4973 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4973/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4973/comments | https://api.github.com/repos/huggingface/datasets/issues/4973/events | https://github.com/huggingface/datasets/pull/4973 | 1,371,600,074 | PR_kwDODunzps4-33JW | 4,973 | [GH->HF] Load datasets from the Hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Duplicate of:\r\n- #4059"
] | "2022-09-13T15:01:41Z" | "2023-09-24T10:06:02Z" | "2022-09-15T15:24:26Z" | MEMBER | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4973.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4973",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4973.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4973"
} | Currently datasets with no namespace (e.g. squad, glue) are loaded from github.
In this PR I changed this logic to use the Hugging Face Hub instead.
This is the first step in removing all the dataset scripts in this repository
related to discussions in https://github.com/huggingface/datasets/pull/4059 (I should have continued from this PR actually) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4973/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4973/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1336 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1336/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1336/comments | https://api.github.com/repos/huggingface/datasets/issues/1336/events | https://github.com/huggingface/datasets/pull/1336 | 759,706,932 | MDExOlB1bGxSZXF1ZXN0NTM0NjY0NjIw | 1,336 | Add dataset Yoruba BBC Topic Classification | {
"avatar_url": "https://avatars.githubusercontent.com/u/1858628?v=4",
"events_url": "https://api.github.com/users/michael-aloys/events{/privacy}",
"followers_url": "https://api.github.com/users/michael-aloys/followers",
"following_url": "https://api.github.com/users/michael-aloys/following{/other_user}",
"gists_url": "https://api.github.com/users/michael-aloys/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/michael-aloys",
"id": 1858628,
"login": "michael-aloys",
"node_id": "MDQ6VXNlcjE4NTg2Mjg=",
"organizations_url": "https://api.github.com/users/michael-aloys/orgs",
"received_events_url": "https://api.github.com/users/michael-aloys/received_events",
"repos_url": "https://api.github.com/users/michael-aloys/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/michael-aloys/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/michael-aloys/subscriptions",
"type": "User",
"url": "https://api.github.com/users/michael-aloys"
} | [] | closed | false | null | [] | null | [] | "2020-12-08T19:12:18Z" | "2020-12-10T11:27:41Z" | "2020-12-10T11:27:41Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1336.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1336",
"merged_at": "2020-12-10T11:27:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1336.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1336"
} | Added new dataset Yoruba BBC Topic Classification
Contains loading script as well as dataset card including YAML tags. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1336/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1336/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3329 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3329/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3329/comments | https://api.github.com/repos/huggingface/datasets/issues/3329/events | https://github.com/huggingface/datasets/issues/3329 | 1,065,096,971 | I_kwDODunzps4_fBcL | 3,329 | Map function: Type error on iter #999 | {
"avatar_url": "https://avatars.githubusercontent.com/u/52659318?v=4",
"events_url": "https://api.github.com/users/josephkready666/events{/privacy}",
"followers_url": "https://api.github.com/users/josephkready666/followers",
"following_url": "https://api.github.com/users/josephkready666/following{/other_user}",
"gists_url": "https://api.github.com/users/josephkready666/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/josephkready666",
"id": 52659318,
"login": "josephkready666",
"node_id": "MDQ6VXNlcjUyNjU5MzE4",
"organizations_url": "https://api.github.com/users/josephkready666/orgs",
"received_events_url": "https://api.github.com/users/josephkready666/received_events",
"repos_url": "https://api.github.com/users/josephkready666/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/josephkready666/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/josephkready666/subscriptions",
"type": "User",
"url": "https://api.github.com/users/josephkready666"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi, thanks for reporting.\r\n\r\nIt would be really helpful if you could provide the actual code of the `text_numbers_to_int` function so we can reproduce the error.",
"```\r\ndef text_numbers_to_int(text, column=\"\"):\r\n \"\"\"\r\n Convert text numbers to int.\r\n\r\n :param text: text numbers\r\n :return: int\r\n \"\"\"\r\n try:\r\n numbers = find_numbers(text)\r\n if not numbers:\r\n return text\r\n result = \"\"\r\n i, j = 0, 0\r\n while i < len(text):\r\n if j < len(numbers) and i == numbers[j][1]:\r\n n = int(numbers[j][0]) if numbers[j][0] % 1 == 0 else float(numbers[j][0])\r\n result += str(n)\r\n i = numbers[j][2] #end\r\n j += 1\r\n else:\r\n result += text[i]\r\n i += 1\r\n if column:\r\n return{column: result}\r\n else:\r\n return {column: result}\r\n except Exception as e:\r\n print(e)\r\n return {column: result}\r\n```",
"Maybe this is because of the `return text` line ? I think it should return a dictionary rather than a string",
"Yes that was it, good catch! Thanks"
] | "2021-11-27T17:53:05Z" | "2021-11-29T20:40:15Z" | "2021-11-29T20:40:15Z" | NONE | null | null | null | ## Describe the bug
Using the map function, it throws a type error on iter #999
Here is the code I am calling:
```
dataset = datasets.load_dataset('squad')
dataset['validation'].map(text_numbers_to_int, input_columns=['context'], fn_kwargs={'column': 'context'})
```
text_numbers_to_int returns the input text with numbers replaced in the format {'context': text}
It happens at
`
File "C:\Users\lonek\anaconda3\envs\ai\Lib\site-packages\datasets\arrow_writer.py", line 289, in <listcomp>
[row[0][col] for row in self.current_examples], type=col_type, try_type=col_try_type, col=col
`
The issue is that the list comprehension expects self.current_examples to be type tuple(dict, str), but for some reason 26 out of 1000 of the sefl.current_examples are type tuple(str, str)
Here is an example of what self.current_examples should be
({'context': 'Super Bowl 50 was an...merals 50.'}, '')
Here is an example of what self.current_examples are when it throws the error:
('The Panthers used th... Marriott.', '')
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3329/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3329/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2997 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2997/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2997/comments | https://api.github.com/repos/huggingface/datasets/issues/2997/events | https://github.com/huggingface/datasets/issues/2997 | 1,013,270,069 | I_kwDODunzps48ZUY1 | 2,997 | Dataset has incorrect labels | {
"avatar_url": "https://avatars.githubusercontent.com/u/63367770?v=4",
"events_url": "https://api.github.com/users/marshmellow77/events{/privacy}",
"followers_url": "https://api.github.com/users/marshmellow77/followers",
"following_url": "https://api.github.com/users/marshmellow77/following{/other_user}",
"gists_url": "https://api.github.com/users/marshmellow77/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/marshmellow77",
"id": 63367770,
"login": "marshmellow77",
"node_id": "MDQ6VXNlcjYzMzY3Nzcw",
"organizations_url": "https://api.github.com/users/marshmellow77/orgs",
"received_events_url": "https://api.github.com/users/marshmellow77/received_events",
"repos_url": "https://api.github.com/users/marshmellow77/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/marshmellow77/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/marshmellow77/subscriptions",
"type": "User",
"url": "https://api.github.com/users/marshmellow77"
} | [] | closed | false | null | [] | null | [
"Hi @marshmellow77, thanks for reporting.\r\n\r\nThat issue is fixed since `datasets` version 1.9.0 (see 16bc665f2753677c765011ef79c84e55486d4347).\r\n\r\nPlease, update `datasets` with: `pip install -U datasets`",
"Thanks. Please note that the dataset explorer (https://huggingface.co/datasets/viewer/?dataset=turkish_product_reviews) still shows the incorrect state. The sentiment for the first few customer reviews is actually negative and should be labelled with \"0\", see screenshot:\r\n\r\n\r\n\r\n\r\n",
"Thanks @marshmellow77, good catch! I'm transferring this issue to https://github.com/huggingface/datasets-viewer. "
] | "2021-10-01T12:09:06Z" | "2021-10-01T15:32:00Z" | "2021-10-01T13:54:34Z" | NONE | null | null | null | The dataset https://huggingface.co/datasets/turkish_product_reviews has incorrect labels - all reviews are labelled with "1" (positive sentiment). None of the reviews is labelled with "0". See screenshot attached:

| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2997/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2997/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1830 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1830/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1830/comments | https://api.github.com/repos/huggingface/datasets/issues/1830/events | https://github.com/huggingface/datasets/issues/1830 | 802,790,075 | MDU6SXNzdWU4MDI3OTAwNzU= | 1,830 | using map on loaded Tokenizer 10x - 100x slower than default Tokenizer? | {
"avatar_url": "https://avatars.githubusercontent.com/u/7662740?v=4",
"events_url": "https://api.github.com/users/wumpusman/events{/privacy}",
"followers_url": "https://api.github.com/users/wumpusman/followers",
"following_url": "https://api.github.com/users/wumpusman/following{/other_user}",
"gists_url": "https://api.github.com/users/wumpusman/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/wumpusman",
"id": 7662740,
"login": "wumpusman",
"node_id": "MDQ6VXNlcjc2NjI3NDA=",
"organizations_url": "https://api.github.com/users/wumpusman/orgs",
"received_events_url": "https://api.github.com/users/wumpusman/received_events",
"repos_url": "https://api.github.com/users/wumpusman/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/wumpusman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wumpusman/subscriptions",
"type": "User",
"url": "https://api.github.com/users/wumpusman"
} | [] | open | false | null | [] | null | [
"Hi @wumpusman \r\n`datasets` has a caching mechanism that allows to cache the results of `.map` so that when you want to re-run it later it doesn't recompute it again.\r\nSo when you do `.map`, what actually happens is:\r\n1. compute the hash used to identify your `map` for the cache\r\n2. apply your function on every batch\r\n\r\nThis can explain the time difference between your different experiments.\r\n\r\nThe hash computation time depends of how complex your function is. For a tokenizer, the hash computation scans the lists of the words in the tokenizer to identify this tokenizer. Usually it takes 2-3 seconds.\r\n\r\nAlso note that you can disable caching though using\r\n```python\r\nimport datasets\r\n\r\ndatasets.set_caching_enabled(False)\r\n```",
"Hi @lhoestq ,\r\n\r\nThanks for the reply. It's entirely possible that is the issue. Since it's a side project I won't be looking at it till later this week, but, I'll verify it by disabling caching and hopefully I'll see the same runtime. \r\n\r\nAppreciate the reference,\r\n\r\nMichael",
"I believe this is an actual issue, tokenizing a ~4GB txt file went from an hour and a half to ~10 minutes when I switched from my pre-trained tokenizer(on the same dataset) to the default gpt2 tokenizer.\r\nBoth were loaded using:\r\n```\r\nAutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)\r\n```\r\nI trained the tokenizer using ByteLevelBPETokenizer from the Tokenizers library and save it to a tokenizer.json file.\r\n\r\nI have tested the caching ideas above, changing the number of process, the TOKENIZERS_PARALLELISM env variable, keep_in_memory=True and batching with different sizes.\r\n\r\nApologies I can't really upload much code, but wanted to back up the finding and hopefully a fix/the problem can be found.\r\nI will comment back if I find a fix as well.",
"Hi @johncookds do you think this can come from one tokenizer being faster than the other one ? Can you try to compare their speed without using `datasets` just to make sure ?",
"Hi yes, I'm closing the loop here with some timings below. The issue seems to be at least somewhat/mainly with the tokenizer's themselves. Moreover legacy saves of the trainer tokenizer perform faster but differently than the new tokenizer.json saves(note nothing about the training process/adding of special tokens changed between the top two trained tokenizer tests, only the way it was saved). This is only a 3x slowdown vs like a 10x but I think the slowdown is most likely due to this.\r\n\r\n```\r\ntrained tokenizer - tokenizer.json save (same results for AutoTokenizer legacy_format=False):\r\nTokenizer time(seconds): 0.32767510414123535\r\nTokenized avg. length: 323.01\r\n\r\ntrained tokenizer - AutoTokenizer legacy_format=True:\r\nTokenizer time(seconds): 0.09258866310119629\r\nTokenized avg. length: 301.01\r\n\r\nGPT2 Tokenizer from huggingface\r\nTokenizer time(seconds): 0.1010282039642334\r\nTokenized avg. length: 461.21\r\n```",
"@lhoestq ,\r\n\r\nHi, which version of datasets has datasets.set_caching_enabled(False)? I get \r\nmodule 'datasets' has no attribute 'set_caching_enabled'. To hopefully get around this, I reran my code on a new set of data, and did so only once.\r\n\r\n@johncookds , thanks for chiming in, it looks this might be an issue of Tokenizer.\r\n\r\n**Tokenizer**: The runtime of GPT2TokenizerFast.from_pretrained(\"gpt2\") on 1000 chars is: **143 ms**\r\n**SlowTokenizer**: The runtime of a locally saved and loaded Tokenizer using the same vocab on 1000 chars is: **4.43 s**\r\n\r\nThat being said, I compared performance on the map function:\r\n\r\nRunning Tokenizer versus using it in the map function for 1000 chars goes from **141 ms** to **356 ms** \r\nRunning SlowTokenizer versus using it in the map function for 1000 chars with a single element goes from **4.43 s** to **9.76 s**\r\n\r\nI'm trying to figure out why the overhead of map would increase the time by double (figured it would be a fixed increase in time)? Though maybe this is expected behavior.\r\n\r\n@lhoestq, do you by chance know how I can redirect this issue to Tokenizer?\r\n\r\nRegards,\r\n\r\nMichael",
"Thanks for the experiments @johncookds and @wumpusman ! \r\n\r\n> Hi, which version of datasets has datasets.set_caching_enabled(False)?\r\n\r\nCurrently you have to install `datasets` from source to have this feature, but this will be available in the next release in a few days.\r\n\r\n> I'm trying to figure out why the overhead of map would increase the time by double (figured it would be a fixed increase in time)? Though maybe this is expected behavior.\r\n\r\nCould you also try with double the number of characters ? This should let us have an idea of the fixed cost (hashing) and the dynamic cost (actual tokenization, grows with the size of the input)\r\n\r\n> @lhoestq, do you by chance know how I can redirect this issue to Tokenizer?\r\n\r\nFeel free to post an issue on the `transformers` repo. Also I'm sure there should be related issues so you can also look for someone with the same concerns on the `transformers` repo.",
"@lhoestq,\r\n\r\nI just checked that previous run time was actually 3000 chars. I increased it to 6k chars, again, roughly double.\r\n\r\nSlowTokenizer **7.4 s** to **15.7 s**\r\nTokenizer: **276 ms** to **616 ms**\r\n\r\nI'll post this issue on Tokenizer, seems it hasn't quite been raised (albeit I noticed a similar issue that might relate).\r\n\r\nRegards,\r\n\r\nMichael",
"Hi, \r\nI'm following up here as I found my exact issue. It was with saving and re-loading the tokenizer. When I trained then processed the data without saving and reloading it, it was 10x-100x faster than when I saved and re-loaded it.\r\nBoth resulted in the exact same tokenized datasets as well. \r\nThere is additionally a bug where the older legacy tokenizer save does not preserve a learned tokenizing behavior if trained from scratch.\r\nUnderstand its not exactly Datasets related but hope it can help someone if they have the same issue.\r\nThanks!"
] | "2021-02-06T21:00:26Z" | "2021-02-24T21:56:14Z" | null | NONE | null | null | null | This could total relate to me misunderstanding particular call functions, but I added words to a GPT2Tokenizer, and saved it to disk (note I'm only showing snippets but I can share more) and the map function ran much slower:
````
def save_tokenizer(original_tokenizer,text,path="simpledata/tokenizer"):
words_unique = set(text.split(" "))
for i in words_unique:
original_tokenizer.add_tokens(i)
original_tokenizer.save_pretrained(path)
tokenizer2 = GPT2Tokenizer.from_pretrained(os.path.join(experiment_path,experiment_name,"tokenizer_squad"))
train_set_baby=Dataset.from_dict({"text":[train_set["text"][0][0:50]]})
````
I then applied the dataset map function on a fairly small set of text:
```
%%time
train_set_baby = train_set_baby.map(lambda d:tokenizer2(d["text"]),batched=True)
```
The run time for train_set_baby.map was 6 seconds, and the batch itself was 2.6 seconds
**100% 1/1 [00:02<00:00, 2.60s/ba] CPU times: user 5.96 s, sys: 36 ms, total: 5.99 s Wall time: 5.99 s**
In comparison using (even after adding additional tokens):
`
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")`
```
%%time
train_set_baby = train_set_baby.map(lambda d:tokenizer2(d["text"]),batched=True)
```
The time is
**100% 1/1 [00:00<00:00, 34.09ba/s] CPU times: user 68.1 ms, sys: 16 µs, total: 68.1 ms Wall time: 62.9 ms**
It seems this might relate to the tokenizer save or load function, however, the issue appears to come up when I apply the loaded tokenizer to the map function.
I should also add that playing around with the amount of words I add to the tokenizer before I save it to disk and load it into memory appears to impact the time it takes to run the map function.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1830/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1830/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1594/comments | https://api.github.com/repos/huggingface/datasets/issues/1594/events | https://github.com/huggingface/datasets/issues/1594 | 769,747,767 | MDU6SXNzdWU3Njk3NDc3Njc= | 1,594 | connection error | {
"avatar_url": "https://avatars.githubusercontent.com/u/73364383?v=4",
"events_url": "https://api.github.com/users/rabeehkarimimahabadi/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehkarimimahabadi/followers",
"following_url": "https://api.github.com/users/rabeehkarimimahabadi/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehkarimimahabadi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rabeehkarimimahabadi",
"id": 73364383,
"login": "rabeehkarimimahabadi",
"node_id": "MDQ6VXNlcjczMzY0Mzgz",
"organizations_url": "https://api.github.com/users/rabeehkarimimahabadi/orgs",
"received_events_url": "https://api.github.com/users/rabeehkarimimahabadi/received_events",
"repos_url": "https://api.github.com/users/rabeehkarimimahabadi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rabeehkarimimahabadi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehkarimimahabadi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rabeehkarimimahabadi"
} | [] | closed | false | null | [] | null | [
"This happen quite often when they are too many concurrent requests to github.\r\n\r\ni can understand it’s a bit cumbersome to handle on the user side. Maybe we should try a few times in the lib (eg with timeout) before failing, what do you think @lhoestq ?",
"Yes currently there's no retry afaik. We should add retries",
"Retries were added in #1603 :) \r\nIt will be available in the next release",
"Hi @lhoestq thank you for the modification, I will use`script_version=\"master\"` for now :), to my experience, also setting timeout to a larger number like 3*60 which I normally use helps a lot on this.\r\n"
] | "2020-12-17T09:18:34Z" | "2022-06-01T15:33:42Z" | "2022-06-01T15:33:41Z" | NONE | null | null | null | Hi
I am hitting to this error, thanks
```
> Traceback (most recent call last):
File "finetune_t5_trainer.py", line 379, in <module>
main()
File "finetune_t5_trainer.py", line 208, in main
if training_args.do_eval or training_args.evaluation_strategy != EvaluationStrategy.NO
File "finetune_t5_trainer.py", line 207, in <dictcomp>
for task in data_args.eval_tasks}
File "/workdir/seq2seq/data/tasks.py", line 70, in get_dataset
dataset = self.load_dataset(split=split)
File "/workdir/seq2seq/data/tasks.py", line 66, in load_dataset
return datasets.load_dataset(self.task.name, split=split, script_version="master")
File "/usr/local/lib/python3.6/dist-packages/datasets/load.py", line 589, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/usr/local/lib/python3.6/dist-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/usr/local/lib/python3.6/dist-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/usr/local/lib/python3.6/dist-packages/datasets/utils/file_utils.py", line 487, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/master/datasets/boolq/boolq.py
el/0 I1217 01:11:33.898849 354161 main shadow.py:210 Current job status: FINISHED
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1594/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1594/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5508 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5508/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5508/comments | https://api.github.com/repos/huggingface/datasets/issues/5508/events | https://github.com/huggingface/datasets/issues/5508 | 1,573,290,359 | I_kwDODunzps5dxoF3 | 5,508 | Saving a dataset after setting format to torch doesn't work, but only if filtering | {
"avatar_url": "https://avatars.githubusercontent.com/u/13984157?v=4",
"events_url": "https://api.github.com/users/joebhakim/events{/privacy}",
"followers_url": "https://api.github.com/users/joebhakim/followers",
"following_url": "https://api.github.com/users/joebhakim/following{/other_user}",
"gists_url": "https://api.github.com/users/joebhakim/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/joebhakim",
"id": 13984157,
"login": "joebhakim",
"node_id": "MDQ6VXNlcjEzOTg0MTU3",
"organizations_url": "https://api.github.com/users/joebhakim/orgs",
"received_events_url": "https://api.github.com/users/joebhakim/received_events",
"repos_url": "https://api.github.com/users/joebhakim/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/joebhakim/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/joebhakim/subscriptions",
"type": "User",
"url": "https://api.github.com/users/joebhakim"
} | [] | closed | false | null | [] | null | [
"Hey, I'm a research engineer working on language modelling wanting to contribute to open source. I was wondering if I could give it a shot?",
"Hi! This issue was fixed in https://github.com/huggingface/datasets/pull/4972, so please install `datasets>=2.5.0` to avoid it."
] | "2023-02-06T21:08:58Z" | "2023-02-09T14:55:26Z" | "2023-02-09T14:55:26Z" | NONE | null | null | null | ### Describe the bug
Saving a dataset after setting format to torch doesn't work, but only if filtering
### Steps to reproduce the bug
```
a = Dataset.from_dict({"b": [1, 2]})
a.set_format('torch')
a.save_to_disk("test_save") # saves successfully
a.filter(None).save_to_disk("test_save_filter") # does not
>> [...] TypeError: Provided `function` which is applied to all elements of table returns a `dict` of types [<class 'torch.Tensor'>]. When using `batched=True`, make sure provided `function` returns a `dict` of types like `(<class 'list'>, <class 'numpy.ndarray'>)`.
# note: skipping the format change to torch lets this work.
### Expected behavior
Saving to work
### Environment info
- `datasets` version: 2.4.0
- Platform: Linux-6.1.9-arch1-1-x86_64-with-glibc2.36
- Python version: 3.10.9
- PyArrow version: 9.0.0
- Pandas version: 1.4.4 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5508/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5508/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4374 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4374/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4374/comments | https://api.github.com/repos/huggingface/datasets/issues/4374/events | https://github.com/huggingface/datasets/issues/4374 | 1,241,860,535 | I_kwDODunzps5KBUm3 | 4,374 | extremely slow processing when using a custom dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/32235549?v=4",
"events_url": "https://api.github.com/users/StephennFernandes/events{/privacy}",
"followers_url": "https://api.github.com/users/StephennFernandes/followers",
"following_url": "https://api.github.com/users/StephennFernandes/following{/other_user}",
"gists_url": "https://api.github.com/users/StephennFernandes/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/StephennFernandes",
"id": 32235549,
"login": "StephennFernandes",
"node_id": "MDQ6VXNlcjMyMjM1NTQ5",
"organizations_url": "https://api.github.com/users/StephennFernandes/orgs",
"received_events_url": "https://api.github.com/users/StephennFernandes/received_events",
"repos_url": "https://api.github.com/users/StephennFernandes/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/StephennFernandes/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/StephennFernandes/subscriptions",
"type": "User",
"url": "https://api.github.com/users/StephennFernandes"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] | closed | false | null | [] | null | [
"Hi !\r\n\r\nMy guess is that some examples in your dataset are bigger than your RAM, and therefore loading them in RAM to pass them to `remove_non_indic_sentences` takes forever because it might use SWAP memory.\r\n\r\nMaybe several examples in your dataset are grouped together, can you check `len(lang_dataset[\"train\"])` and `lang_dataset[\"train\"].data.nbytes` of both datasets please ? It can also be helpful to check the distribution of lengths of each examples in your dataset.",
"Closing due to inactivity"
] | "2022-05-19T14:18:05Z" | "2023-07-25T15:07:17Z" | "2023-07-25T15:07:16Z" | NONE | null | null | null | ## processing a custom dataset loaded as .txt file is extremely slow, compared to a dataset of similar volume from the hub
I have a large .txt file of 22 GB which i load into HF dataset
`lang_dataset = datasets.load_dataset("text", data_files="hi.txt")`
further i use a pre-processing function to clean the dataset
`lang_dataset["train"] = lang_dataset["train"].map(
remove_non_indic_sentences, num_proc=12, batched=True, remove_columns=lang_dataset['train'].column_names), batch_size=64)`
the following processing takes astronomical time to process, while hoging all the ram.
similar dataset of same size that's available in the huggingface hub works completely fine. which runs the same processing function and has the same amount of data.
`lang_dataset = datasets.load_dataset("oscar-corpus/OSCAR-2109", "hi", use_auth_token=True)`
the hours predicted to preprocess are as follows:
huggingface hub dataset: 6.5 hrs
custom loaded dataset: 7000 hrs
note: both the datasets are almost actually same, just provided by different sources with has +/- some samples, only one is hosted on the HF hub and the other is downloaded in a text format.
## Steps to reproduce the bug
```
import datasets
import psutil
import sys
import glob
from fastcore.utils import listify
import re
import gc
def remove_non_indic_sentences(example):
tmp_ls = []
eng_regex = r'[. a-zA-Z0-9ÖÄÅöäå _.,!"\'\/$]*'
for e in listify(example['text']):
matches = re.findall(eng_regex, e)
for match in (str(match).strip() for match in matches if match not in [""," ", " ", ",", " ,", ", ", " , "]):
if len(list(match.split(" "))) > 2:
e = re.sub(match," ",e,count=1)
tmp_ls.append(e)
gc.collect()
example['clean_text'] = tmp_ls
return example
lang_dataset = datasets.load_dataset("text", data_files="hi.txt")
lang_dataset["train"] = lang_dataset["train"].map(
remove_non_indic_sentences, num_proc=12, batched=True, remove_columns=lang_dataset['train'].column_names), batch_size=64)
## same thing work much faster when loading similar dataset from hub
lang_dataset = datasets.load_dataset("oscar-corpus/OSCAR-2109", "hi", split="train", use_auth_token=True)
lang_dataset["train"] = lang_dataset["train"].map(
remove_non_indic_sentences, num_proc=12, batched=True, remove_columns=lang_dataset['train'].column_names), batch_size=64)
```
## Actual results
similar dataset of same size that's available in the huggingface hub works completely fine. which runs the same processing function and has the same amount of data.
`lang_dataset = datasets.load_dataset("oscar-corpus/OSCAR-2109", "hi", use_auth_token=True)
**the hours predicted to preprocess are as follows:**
huggingface hub dataset: 6.5 hrs
custom loaded dataset: 7000 hrs
**i even tried the following:**
- sharding the large 22gb text files into smaller files and loading
- saving the file to disk and then loading
- using lesser num_proc
- using smaller batch size
- processing without batches ie : without `batched=True`
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.2.2.dev0
- Platform: Ubuntu 20.04 LTS
- Python version: 3.9.7
- PyArrow version:8.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4374/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4374/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3234 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3234/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3234/comments | https://api.github.com/repos/huggingface/datasets/issues/3234/events | https://github.com/huggingface/datasets/pull/3234 | 1,047,634,236 | PR_kwDODunzps4uPHRk | 3,234 | Avoid PyArrow type optimization if it fails | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"That's good to have a way to disable this easily :)\r\nI just find it a bit unfortunate that users would have to experience the error once and then do `DISABLE_PYARROW_TYPES_OPTIMIZATION=1`. Do you know if there's a way to simply fallback on disabling it automatically when it fails ?",
"@lhoestq Actually, I agree a fallback makes more sense. The current approach is not very practical indeed and would require a mention in the docs.\r\n",
"Replaced the env variable with a fallback!",
"Hmm if the fallback automatically happens without the user knowing it, then I don't think we really need to mention it. But if you really wanted to, I think the [Improve performance](https://huggingface.co/docs/datasets/cache.html#improve-performance) section would be a great place for it! ",
"Yea I think this could just end up in a note that says that `datasets` automatically picks the most optimized integer precision for your tokenized text data to save you disk space. Maybe later if we have a page on text processing we can add this note, but for now I agree it doesn't fit well into the doc.\r\n\r\nIn particular in the \"Improve performance\" section we mention what users can do to speed up their computations, while this behavior is just some internal feature that users don't have control over anyway."
] | "2021-11-08T16:10:27Z" | "2021-11-10T12:04:29Z" | "2021-11-10T12:04:28Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3234.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3234",
"merged_at": "2021-11-10T12:04:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3234.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3234"
} | Adds a new variable, `DISABLE_PYARROW_TYPES_OPTIMIZATION`, to `config.py` for easier control of the Arrow type optimization.
Fix #2206 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3234/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3234/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3605 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3605/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3605/comments | https://api.github.com/repos/huggingface/datasets/issues/3605/events | https://github.com/huggingface/datasets/pull/3605 | 1,108,738,561 | PR_kwDODunzps4xS9rX | 3,605 | Adding Turkic X-WMT evaluation set for machine translation | {
"avatar_url": "https://avatars.githubusercontent.com/u/26018417?v=4",
"events_url": "https://api.github.com/users/mirzakhalov/events{/privacy}",
"followers_url": "https://api.github.com/users/mirzakhalov/followers",
"following_url": "https://api.github.com/users/mirzakhalov/following{/other_user}",
"gists_url": "https://api.github.com/users/mirzakhalov/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mirzakhalov",
"id": 26018417,
"login": "mirzakhalov",
"node_id": "MDQ6VXNlcjI2MDE4NDE3",
"organizations_url": "https://api.github.com/users/mirzakhalov/orgs",
"received_events_url": "https://api.github.com/users/mirzakhalov/received_events",
"repos_url": "https://api.github.com/users/mirzakhalov/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mirzakhalov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mirzakhalov/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mirzakhalov"
} | [] | closed | false | null | [] | null | [
"hi! Thank you for all the comments! I believe I addressed them all. Let me know if there is anything else",
"Hi there! I was wondering if there is anything else to change before this can be merged",
"@lhoestq Hi! Just a gentle reminder about the steps to merge this one! ",
"Thanks for the heads up ! I think I fixed the last issue with the YAML tags",
"The CI failure is unrelated to this PR and fixed on master, let's merge :)\r\n\r\nThanks a lot !"
] | "2022-01-20T01:40:29Z" | "2022-01-31T09:50:57Z" | "2022-01-31T09:50:57Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3605.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3605",
"merged_at": "2022-01-31T09:50:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3605.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3605"
} | This dataset is a human-translated evaluation set for MT crowdsourced and provided by the [Turkic Interlingua ](turkic-interlingua.org) community. It contains eval sets for 8 Turkic languages covering 88 language directions. Languages being covered are:
Azerbaijani (az)
Bashkir (ba)
English (en)
Karakalpak (kaa)
Kazakh (kk)
Kirghiz (ky)
Russian (ru)
Turkish (tr)
Sakha (sah)
Uzbek (uz)
More info about the corpus is here: [https://github.com/turkic-interlingua/til-mt/tree/master/xwmt](https://github.com/turkic-interlingua/til-mt/tree/master/xwmt)
A paper describing the test set is here: [https://arxiv.org/abs/2109.04593](https://arxiv.org/abs/2109.04593)
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3605/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3605/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5366 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5366/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5366/comments | https://api.github.com/repos/huggingface/datasets/issues/5366/events | https://github.com/huggingface/datasets/pull/5366 | 1,498,530,851 | PR_kwDODunzps5FjSFl | 5,366 | ExamplesIterable fixes | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-12-15T14:23:05Z" | "2022-12-15T14:44:47Z" | "2022-12-15T14:41:45Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5366.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5366",
"merged_at": "2022-12-15T14:41:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5366.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5366"
} | fix typing and ExamplesIterable.shard_data_sources | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5366/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5366/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4321 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4321/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4321/comments | https://api.github.com/repos/huggingface/datasets/issues/4321/events | https://github.com/huggingface/datasets/pull/4321 | 1,233,273,351 | PR_kwDODunzps43ryW7 | 4,321 | Adding dataset enwik8 | {
"avatar_url": "https://avatars.githubusercontent.com/u/22773355?v=4",
"events_url": "https://api.github.com/users/HallerPatrick/events{/privacy}",
"followers_url": "https://api.github.com/users/HallerPatrick/followers",
"following_url": "https://api.github.com/users/HallerPatrick/following{/other_user}",
"gists_url": "https://api.github.com/users/HallerPatrick/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/HallerPatrick",
"id": 22773355,
"login": "HallerPatrick",
"node_id": "MDQ6VXNlcjIyNzczMzU1",
"organizations_url": "https://api.github.com/users/HallerPatrick/orgs",
"received_events_url": "https://api.github.com/users/HallerPatrick/received_events",
"repos_url": "https://api.github.com/users/HallerPatrick/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/HallerPatrick/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HallerPatrick/subscriptions",
"type": "User",
"url": "https://api.github.com/users/HallerPatrick"
} | [] | closed | false | null | [] | null | [
"@lhoestq Thank you for the great feedback! Looks like all tests are passing now :)",
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-05-11T23:25:02Z" | "2022-06-01T14:27:30Z" | "2022-06-01T14:04:06Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4321.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4321",
"merged_at": "2022-06-01T14:04:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4321.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4321"
} | Because I regularly work with enwik8, I would like to contribute the dataset loader 🤗 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4321/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4321/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5528 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5528/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5528/comments | https://api.github.com/repos/huggingface/datasets/issues/5528/events | https://github.com/huggingface/datasets/pull/5528 | 1,582,195,085 | PR_kwDODunzps5J13wC | 5,528 | Push to hub in a pull request | {
"avatar_url": "https://avatars.githubusercontent.com/u/38854604?v=4",
"events_url": "https://api.github.com/users/AJDERS/events{/privacy}",
"followers_url": "https://api.github.com/users/AJDERS/followers",
"following_url": "https://api.github.com/users/AJDERS/following{/other_user}",
"gists_url": "https://api.github.com/users/AJDERS/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AJDERS",
"id": 38854604,
"login": "AJDERS",
"node_id": "MDQ6VXNlcjM4ODU0NjA0",
"organizations_url": "https://api.github.com/users/AJDERS/orgs",
"received_events_url": "https://api.github.com/users/AJDERS/received_events",
"repos_url": "https://api.github.com/users/AJDERS/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AJDERS/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AJDERS/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AJDERS"
} | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5528). All of your documentation changes will be reflected on that endpoint.",
"It seems that the parameter `create_pr` is available for [`0.8.0`](https://huggingface.co/docs/huggingface_hub/v0.8.1/en/package_reference/hf_api#huggingface_hub.HfApi.upload_file) (its not here: [`0.7.0`](https://huggingface.co/docs/huggingface_hub/v0.7.0.rc0/en/package_reference/hf_api#huggingface_hub.HfApi.upload_file)) and onwards. I included a warning, informing the user that no PR was created.",
"@nateraw you are completely right! Actually, the dataset shards is never added to the created pr, only the metadata, as the code is now. Ill look into you suggestion asap. Thank!",
"@nateraw Nothing more to add, that's a perfect usage of `huggingface_hub` as far as I can tell ! :fire: \r\n\r\nA very nit improvement would be to use the [for .. else ... python statement](https://book.pythontips.com/en/latest/for_-_else.html).\r\ni.e:\r\n\r\n```py\r\nif create_pr is True and revision is not None:\r\n for discussion in get_repo_discussions(repo_id, repo_type='dataset'):\r\n if discussion.is_pull_request and discussion.git_reference == revision:\r\n create_pr = False\r\n break\r\n else:\r\n raise ValueError(\"Provided revision not found\")\r\n```\r\nNo need for the `revision_found` temporary flag when do so. Yeah ok, it's niche :wink: ",
"I added the suggestions from @nateraw and @Wauplin .",
"> Thanks. Some comments/suggestions below...\r\n> \r\n> Why have you removed the test for create_pr? You could add it again and just add a pytest skipif when version of huggingface_hub is lower than 0.8.1.\r\n\r\nI have added the test again. I removed it because i kept getting errors when calling `create_pull_request` with `repo_id=ds_name` where `temporary_repo = ds_name`, and thought i might look more thoroughly at it later. I have added a test called `test_test` showing this, it gives:\r\n```\r\ntests/test_upstream_hub.py:360: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _\r\n.venv/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py:124: in _inner_fn\r\n return fn(*args, **kwargs)\r\n.venv/lib/python3.10/site-packages/huggingface_hub/hf_api.py:3451: in create_pull_request\r\n return self.create_discussion(\r\n.venv/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py:124: in _inner_fn\r\n return fn(*args, **kwargs)\r\n.venv/lib/python3.10/site-packages/huggingface_hub/hf_api.py:3393: in create_discussion\r\n hf_raise_for_status(resp)\r\n(...)\r\nE huggingface_hub.utils._errors.RepositoryNotFoundError: 401 Client Error. (Request ID: Root=1-63ecd2cb-2cf2557a332c86ad27f687b3)\r\nE \r\nE Repository Not Found for url: https://huggingface.co/api/models/__DUMMY_TRANSFORMERS_USER__/test-16764648321590/discussions.\r\nE Please make sure you specified the correct `repo_id` and `repo_type`.\r\nE If you are trying to access a private or gated repo, make sure you are authenticated.\r\nE Invalid username or password.\r\n```",
"> > Thanks. Some comments/suggestions below...\r\n> > Why have you removed the test for create_pr? You could add it again and just add a pytest skipif when version of huggingface_hub is lower than 0.8.1.\r\n> \r\n> I have added the test again. I removed it because i kept getting errors when calling `create_pull_request` with `repo_id=ds_name` where `temporary_repo = ds_name`, and thought i might look more thoroughly at it later. I have added a test called `test_test` showing this, it gives:\r\n> \r\n> ```\r\n> tests/test_upstream_hub.py:360: \r\n> _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _\r\n> .venv/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py:124: in _inner_fn\r\n> return fn(*args, **kwargs)\r\n> .venv/lib/python3.10/site-packages/huggingface_hub/hf_api.py:3451: in create_pull_request\r\n> return self.create_discussion(\r\n> .venv/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py:124: in _inner_fn\r\n> return fn(*args, **kwargs)\r\n> .venv/lib/python3.10/site-packages/huggingface_hub/hf_api.py:3393: in create_discussion\r\n> hf_raise_for_status(resp)\r\n> (...)\r\n> E huggingface_hub.utils._errors.RepositoryNotFoundError: 401 Client Error. (Request ID: Root=1-63ecd2cb-2cf2557a332c86ad27f687b3)\r\n> E \r\n> E Repository Not Found for url: https://huggingface.co/api/models/__DUMMY_TRANSFORMERS_USER__/test-16764648321590/discussions.\r\n> E Please make sure you specified the correct `repo_id` and `repo_type`.\r\n> E If you are trying to access a private or gated repo, make sure you are authenticated.\r\n> E Invalid username or password.\r\n> ```\r\n\r\n@albertvillanova, @lhoestq , FYI I have looked at this again, and i haven't figured it out, so the test`test_push_dataset_to_hub_with_pull_request` and the minimal example `test_test` are still failing locally, while the other tests succeed. Do you have any advice?",
"I tried to move all of the \"create pr safely\"-logic to a seperate function in `_hf_hub_fixes`. I looked at how the exceptions were raised before `huggingface_hub.utils.RepositoryNotFoundError`existed, and make changes accordingly. ",
"`create_pr` was set during `push_to_hub`, even though it was `None` from the outset, hence causing tests to fail for older versions of `huggingface_hub`. This is now fixed.\r\n\r\nWith the implementation of `_hf_hub_fixes.upload_file` the function call expected `commit_message`, `commit_description`. If these are not set we call the function without them, even though we are on a version of `huggingface_hub` where they are not available in `upload_file`.\r\n\r\nWhen `huggingface_hub < 0.5.0` we assume `repo_id` of them form `organisation/name`, so now that we are calling `create_repo` in the tests with `repo_id` not of this form, we need to handle this case, this is now done.\r\n\r\nMany tests failed for `dataset_dict` for the above reasons, so the fixes from `arrow_dataset.py` were also added to `dataset_dict.py`. \r\n\r\n**All tests are now passing locally for `huggingface_hub==0.2.0` and `huggingface_hub==0.12.1`…** Im sorry I should have downgraded and went through this a long time ago, but I didn’t realise the extend of these version fixes until recently…",
"Hi ! FYI bumped the `huggingface-hub` dependency to 0.11 and removed the `_hf_hub_fixes.py` - which should make this PR much easier",
"Just now finding this - seems like a cool issue to contribute to. If any more help is needed please ping me! @AJDERS "
] | "2023-02-13T11:43:47Z" | "2023-10-06T21:58:02Z" | null | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5528.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5528",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5528.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5528"
} | Fixes #5492.
Introduce new kwarg `create_pr` in `push_to_hub`, which is passed to `HFapi.upload_file`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5528/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5528/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5893 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5893/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5893/comments | https://api.github.com/repos/huggingface/datasets/issues/5893/events | https://github.com/huggingface/datasets/pull/5893 | 1,722,519,056 | PR_kwDODunzps5RK40K | 5,893 | Load cached dataset as iterable | {
"avatar_url": "https://avatars.githubusercontent.com/u/10278877?v=4",
"events_url": "https://api.github.com/users/mariusz-jachimowicz-83/events{/privacy}",
"followers_url": "https://api.github.com/users/mariusz-jachimowicz-83/followers",
"following_url": "https://api.github.com/users/mariusz-jachimowicz-83/following{/other_user}",
"gists_url": "https://api.github.com/users/mariusz-jachimowicz-83/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariusz-jachimowicz-83",
"id": 10278877,
"login": "mariusz-jachimowicz-83",
"node_id": "MDQ6VXNlcjEwMjc4ODc3",
"organizations_url": "https://api.github.com/users/mariusz-jachimowicz-83/orgs",
"received_events_url": "https://api.github.com/users/mariusz-jachimowicz-83/received_events",
"repos_url": "https://api.github.com/users/mariusz-jachimowicz-83/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariusz-jachimowicz-83/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariusz-jachimowicz-83/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariusz-jachimowicz-83"
} | [] | closed | false | null | [] | null | [
"@lhoestq Could you please look into that and review?",
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq I refactored the code. Could you please check is it what you requested?",
"@lhoestq Thanks for a review. Excellent tips. All tips applied. ",
"I think there is just PythonFormatter that needs to be imported in the test file and we should be good to merge",
"@lhoestq that is weird. I have linter error when I do it.",
"@lhoestq Now it should work properly.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006152 / 0.011353 (-0.005201) | 0.004169 / 0.011008 (-0.006839) | 0.097968 / 0.038508 (0.059460) | 0.028325 / 0.023109 (0.005216) | 0.308958 / 0.275898 (0.033060) | 0.341832 / 0.323480 (0.018352) | 0.005098 / 0.007986 (-0.002887) | 0.004721 / 0.004328 (0.000393) | 0.075067 / 0.004250 (0.070817) | 0.040514 / 0.037052 (0.003462) | 0.308355 / 0.258489 (0.049866) | 0.351063 / 0.293841 (0.057222) | 0.025261 / 0.128546 (-0.103285) | 0.008483 / 0.075646 (-0.067163) | 0.321219 / 0.419271 (-0.098052) | 0.058258 / 0.043533 (0.014725) | 0.312572 / 0.255139 (0.057433) | 0.330667 / 0.283200 (0.047467) | 0.091047 / 0.141683 (-0.050635) | 1.536541 / 1.452155 (0.084387) | 1.606566 / 1.492716 (0.113850) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.213234 / 0.018006 (0.195228) | 0.494801 / 0.000490 (0.494311) | 0.003764 / 0.000200 (0.003564) | 0.000074 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023653 / 0.037411 (-0.013758) | 0.097176 / 0.014526 (0.082650) | 0.102961 / 0.176557 (-0.073595) | 0.164285 / 0.737135 (-0.572851) | 0.107586 / 0.296338 (-0.188753) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421402 / 0.215209 (0.206193) | 4.195828 / 2.077655 (2.118174) | 1.884664 / 1.504120 (0.380544) | 1.679750 / 1.541195 (0.138556) | 1.719725 / 1.468490 (0.251235) | 0.552290 / 4.584777 (-4.032486) | 3.386337 / 3.745712 (-0.359375) | 1.771527 / 5.269862 (-3.498334) | 1.133327 / 4.565676 (-3.432349) | 0.067911 / 0.424275 (-0.356364) | 0.012572 / 0.007607 (0.004965) | 0.518004 / 0.226044 (0.291960) | 5.192381 / 2.268929 (2.923453) | 2.316032 / 55.444624 (-53.128592) | 1.993264 / 6.876477 (-4.883212) | 2.071009 / 2.142072 (-0.071063) | 0.655062 / 4.805227 (-4.150165) | 0.135488 / 6.500664 (-6.365177) | 0.067273 / 0.075469 (-0.008196) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.217731 / 1.841788 (-0.624056) | 13.812927 / 8.074308 (5.738619) | 13.137886 / 10.191392 (2.946494) | 0.143102 / 0.680424 (-0.537322) | 0.016884 / 0.534201 (-0.517317) | 0.370106 / 0.579283 (-0.209178) | 0.392349 / 0.434364 (-0.042015) | 0.424501 / 0.540337 (-0.115837) | 0.509830 / 1.386936 (-0.877106) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006210 / 0.011353 (-0.005142) | 0.004215 / 0.011008 (-0.006793) | 0.076129 / 0.038508 (0.037621) | 0.027825 / 0.023109 (0.004716) | 0.403973 / 0.275898 (0.128075) | 0.441089 / 0.323480 (0.117609) | 0.005420 / 0.007986 (-0.002566) | 0.004870 / 0.004328 (0.000542) | 0.075558 / 0.004250 (0.071308) | 0.039464 / 0.037052 (0.002411) | 0.404329 / 0.258489 (0.145840) | 0.447213 / 0.293841 (0.153372) | 0.025877 / 0.128546 (-0.102669) | 0.008660 / 0.075646 (-0.066987) | 0.081849 / 0.419271 (-0.337422) | 0.044551 / 0.043533 (0.001018) | 0.379102 / 0.255139 (0.123963) | 0.403104 / 0.283200 (0.119905) | 0.094754 / 0.141683 (-0.046929) | 1.460772 / 1.452155 (0.008617) | 1.569531 / 1.492716 (0.076815) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.183923 / 0.018006 (0.165917) | 0.420708 / 0.000490 (0.420219) | 0.002091 / 0.000200 (0.001891) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026180 / 0.037411 (-0.011231) | 0.101529 / 0.014526 (0.087003) | 0.108739 / 0.176557 (-0.067818) | 0.160702 / 0.737135 (-0.576433) | 0.111739 / 0.296338 (-0.184600) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.448671 / 0.215209 (0.233462) | 4.469287 / 2.077655 (2.391632) | 2.244335 / 1.504120 (0.740215) | 2.107495 / 1.541195 (0.566301) | 2.224763 / 1.468490 (0.756272) | 0.554006 / 4.584777 (-4.030771) | 3.390109 / 3.745712 (-0.355603) | 1.744189 / 5.269862 (-3.525673) | 1.008515 / 4.565676 (-3.557161) | 0.067904 / 0.424275 (-0.356371) | 0.012243 / 0.007607 (0.004636) | 0.557635 / 0.226044 (0.331590) | 5.610383 / 2.268929 (3.341454) | 2.687326 / 55.444624 (-52.757298) | 2.405262 / 6.876477 (-4.471214) | 2.527300 / 2.142072 (0.385227) | 0.662282 / 4.805227 (-4.142945) | 0.136225 / 6.500664 (-6.364439) | 0.068136 / 0.075469 (-0.007334) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.310791 / 1.841788 (-0.530997) | 14.370381 / 8.074308 (6.296072) | 14.122675 / 10.191392 (3.931283) | 0.152302 / 0.680424 (-0.528122) | 0.016624 / 0.534201 (-0.517577) | 0.359395 / 0.579283 (-0.219888) | 0.392131 / 0.434364 (-0.042233) | 0.423796 / 0.540337 (-0.116542) | 0.511387 / 1.386936 (-0.875549) |\n\n</details>\n</details>\n\n\n"
] | "2023-05-23T17:40:35Z" | "2023-06-01T11:58:24Z" | "2023-06-01T11:51:29Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5893.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5893",
"merged_at": "2023-06-01T11:51:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5893.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5893"
} | To be used to train models it allows to load an IterableDataset from the cached Arrow file.
See https://github.com/huggingface/datasets/issues/5481 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5893/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5893/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5224 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5224/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5224/comments | https://api.github.com/repos/huggingface/datasets/issues/5224/events | https://github.com/huggingface/datasets/issues/5224 | 1,443,640,867 | I_kwDODunzps5WDDYj | 5,224 | Seems to freeze when loading audio dataset with wav files from local folder | {
"avatar_url": "https://avatars.githubusercontent.com/u/45894267?v=4",
"events_url": "https://api.github.com/users/uriii3/events{/privacy}",
"followers_url": "https://api.github.com/users/uriii3/followers",
"following_url": "https://api.github.com/users/uriii3/following{/other_user}",
"gists_url": "https://api.github.com/users/uriii3/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/uriii3",
"id": 45894267,
"login": "uriii3",
"node_id": "MDQ6VXNlcjQ1ODk0MjY3",
"organizations_url": "https://api.github.com/users/uriii3/orgs",
"received_events_url": "https://api.github.com/users/uriii3/received_events",
"repos_url": "https://api.github.com/users/uriii3/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/uriii3/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/uriii3/subscriptions",
"type": "User",
"url": "https://api.github.com/users/uriii3"
} | [] | closed | false | null | [] | null | [
"I just tried to do the same but changing the `.wav` files to `.mp3` files and that doesn't fix it.",
"I don't know if anyone will ever read this but I've tried to upload the same dataset with google colab and the output seems more clarifying. I didn't specify the train/test split so the dataset wasn't fully uploaded (or that is what I understood, might be wrong!!).\r\n\r\nNow, including the `drop_metadata` flag I can load the dataset normally (at least with colab notebook):\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"audiofolder\", data_dir=\"../archive/Dataset\", , drop_metadata=True)\r\n```\r\n\r\nI'll close the issue.",
"@uriii3 Hello, I understand correctly that you converted your wav files to mp3?",
"Yes but it didn't matter. I don't remember which of them I ended up working with."
] | "2022-11-10T10:29:31Z" | "2023-04-25T09:54:05Z" | "2022-11-22T11:24:19Z" | NONE | null | null | null | ### Describe the bug
I'm following the instructions in [https://huggingface.co/docs/datasets/audio_load#audiofolder-with-metadata](url) to be able to load a dataset from a local folder.
I have everything into a folder, into a train folder and then the audios and csv. When I try to load the dataset and run from terminal, seems to work but then freezes with no apparent reason.
The metadata.csv file contains a few columns but the important ones, `file_name` with the filename and `transcription` with the transcription are okay.
The audios are `.wav` files, I don't know if that might be the problem (I will proceed to try to change them all to `.mp3` and try again).
### Steps to reproduce the bug
The code I'm using:
```python
from datasets import load_dataset
dataset = load_dataset("audiofolder", data_dir="../archive/Dataset")
dataset[0]["audio"]
```
The output I obtain:
```
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 311135.43it/s]
Using custom data configuration default-38d4546ffd010f3e
Downloading and preparing dataset audiofolder/default to /Users/mine/.cache/huggingface/datasets/audiofolder/default-38d4546ffd010f3e/0.0.0/6cbdd16f8688354c63b4e2a36e1585d05de285023ee6443ffd71c4182055c0fc...
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 166467.72it/s]
Using custom data configuration default-38d4546ffd010f3e
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 187772.74it/s]
Using custom data configuration default-38d4546ffd010f3e
Resolving data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 59623.71it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 138090.55it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 106065.64it/s]
Resolving data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 56036.38it/s]
Resolving data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 74004.24it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 162343.45it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 101881.23it/s]
Using custom data configuration default-38d4546ffd010f3e
Resolving data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 60145.67it/s]
Resolving data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 80890.02it/s]
Resolving data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 54036.67it/s]
Resolving data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 95851.09it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 155897.00it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 137656.96it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 439/439 [00:00<00:00, 131230.81it/s]
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
Using custom data configuration default-38d4546ffd010f3e
```
And then here it just freezes and nothing more happens.
### Expected behavior
Load the dataset.
### Environment info
Datasets version:
datasets 2.6.1 pypi_0 pypi
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5224/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5224/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5288 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5288/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5288/comments | https://api.github.com/repos/huggingface/datasets/issues/5288/events | https://github.com/huggingface/datasets/issues/5288 | 1,462,134,067 | I_kwDODunzps5XJmUz | 5,288 | Lossy json serialization - deserialization of dataset info | {
"avatar_url": "https://avatars.githubusercontent.com/u/57542204?v=4",
"events_url": "https://api.github.com/users/anuragprat1k/events{/privacy}",
"followers_url": "https://api.github.com/users/anuragprat1k/followers",
"following_url": "https://api.github.com/users/anuragprat1k/following{/other_user}",
"gists_url": "https://api.github.com/users/anuragprat1k/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/anuragprat1k",
"id": 57542204,
"login": "anuragprat1k",
"node_id": "MDQ6VXNlcjU3NTQyMjA0",
"organizations_url": "https://api.github.com/users/anuragprat1k/orgs",
"received_events_url": "https://api.github.com/users/anuragprat1k/received_events",
"repos_url": "https://api.github.com/users/anuragprat1k/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/anuragprat1k/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anuragprat1k/subscriptions",
"type": "User",
"url": "https://api.github.com/users/anuragprat1k"
} | [] | open | false | null | [] | null | [
"Hi ! JSON is a lossy format indeed. If you want to keep the feature types or other metadata I'd encourage you to store them as well. For example you can use `dataset.info.write_to_directory` and `DatasetInfo.from_directory` to store the feature types, split info, description, license etc."
] | "2022-11-23T17:20:15Z" | "2022-11-25T12:53:51Z" | null | NONE | null | null | null | ### Describe the bug
Saving a dataset to disk as json (using `to_json`) and then loading it again (using `load_dataset`) results in features whose labels are not type-cast correctly. In the code snippet below, `features.label` should have a label of type `ClassLabel` but has type `Value` instead.
### Steps to reproduce the bug
```
from datasets import load_dataset
def test_serdes_from_json(d):
dataset = load_dataset(d, split="train")
dataset.to_json('_test')
dataset_loaded = load_dataset("json", data_files='_test', split='train')
try:
assert dataset_loaded.info.features == dataset.info.features, "features unequal!"
except Exception as ex:
print(f'{ex}')
print(f'expected {dataset.info.features}, \nactual { dataset_loaded.info.features }')
test_serdes_from_json('rotten_tomatoes')
```
Output
```
features unequal!
expected {'text': Value(dtype='string', id=None), 'label': ClassLabel(names=['neg', 'pos'], id=None)},
actual {'text': Value(dtype='string', id=None), 'label': Value(dtype='int64', id=None)}
```
### Expected behavior
The deserialized `features.label` should have type `ClassLabel`.
### Environment info
- `datasets` version: 2.6.1
- Platform: Linux-5.10.144-127.601.amzn2.x86_64-x86_64-with-glibc2.17
- Python version: 3.7.13
- PyArrow version: 7.0.0
- Pandas version: 1.2.3 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5288/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5288/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3228 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3228/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3228/comments | https://api.github.com/repos/huggingface/datasets/issues/3228/events | https://github.com/huggingface/datasets/pull/3228 | 1,046,702,143 | PR_kwDODunzps4uMJ58 | 3,228 | Add CITATION file | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [] | "2021-11-07T09:40:19Z" | "2021-11-07T09:51:47Z" | "2021-11-07T09:51:46Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3228.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3228",
"merged_at": "2021-11-07T09:51:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3228.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3228"
} | Add CITATION file. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3228/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3228/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4778 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4778/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4778/comments | https://api.github.com/repos/huggingface/datasets/issues/4778/events | https://github.com/huggingface/datasets/pull/4778 | 1,324,928,750 | PR_kwDODunzps48dRPh | 4,778 | Update local loading script docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4778). All of your documentation changes will be reflected on that endpoint.",
"I would rather have a section in the docs that explains how to modify the script of an existing dataset (`inspect_dataset` + modification + `load_dataset`) instead of focusing on the GH datasets bundled with the source (only applicable for devs).",
"Good idea! I went with @mariosasko's suggestion to use `inspect_dataset` instead of cloning a dataset repository since it's a good opportunity to show off more of the library's lesser-known functions if that's ok with everyone :)",
"One advantage of cloning the repo is that it fetches potential data files referenced inside a script using relative paths, so if we decide to use `inspect_dataset`, we should at least add a tip to explain this limitation and how to circumvent it.",
"Oh you're right. Calling `load_dataset` on the modified script without having the files that come with it is not ideal. I agree it should be `git clone` instead - and inspect is for inspection only ^^'"
] | "2022-08-01T20:21:07Z" | "2022-08-23T16:32:26Z" | "2022-08-23T16:32:22Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4778.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4778",
"merged_at": "2022-08-23T16:32:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4778.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4778"
} | This PR clarifies the local loading script section to include how to load a dataset after you've modified the local loading script (closes #4732). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4778/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4778/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4326 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4326/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4326/comments | https://api.github.com/repos/huggingface/datasets/issues/4326/events | https://github.com/huggingface/datasets/pull/4326 | 1,233,818,489 | PR_kwDODunzps43tjWy | 4,326 | Fix type hint and documentation for `new_fingerprint` | {
"avatar_url": "https://avatars.githubusercontent.com/u/9808326?v=4",
"events_url": "https://api.github.com/users/fxmarty/events{/privacy}",
"followers_url": "https://api.github.com/users/fxmarty/followers",
"following_url": "https://api.github.com/users/fxmarty/following{/other_user}",
"gists_url": "https://api.github.com/users/fxmarty/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/fxmarty",
"id": 9808326,
"login": "fxmarty",
"node_id": "MDQ6VXNlcjk4MDgzMjY=",
"organizations_url": "https://api.github.com/users/fxmarty/orgs",
"received_events_url": "https://api.github.com/users/fxmarty/received_events",
"repos_url": "https://api.github.com/users/fxmarty/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/fxmarty/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fxmarty/subscriptions",
"type": "User",
"url": "https://api.github.com/users/fxmarty"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-05-12T11:05:08Z" | "2022-06-01T13:04:45Z" | "2022-06-01T12:56:18Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4326.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4326",
"merged_at": "2022-06-01T12:56:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4326.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4326"
} | Currently, there are no type hints nor `Optional` for the argument `new_fingerprint` in several methods of `datasets.arrow_dataset.Dataset`.
There was some documentation missing as well.
Note that pylance is happy with the type hints, but pyright does not detect that `new_fingerprint` is set within the decorator.
The modifications in this PR are fine since here https://github.com/huggingface/datasets/blob/aa743886221d76afb409d263e1b136e7a71fe2b4/src/datasets/fingerprint.py#L446-L454
for the non-inplace case we make sure to auto-generate a new fingerprint (as indicated in the doc). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4326/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4326/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6101 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6101/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6101/comments | https://api.github.com/repos/huggingface/datasets/issues/6101/events | https://github.com/huggingface/datasets/pull/6101 | 1,828,469,648 | PR_kwDODunzps5WwspW | 6,101 | Release 2.14.2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006543 / 0.011353 (-0.004810) | 0.003894 / 0.011008 (-0.007115) | 0.084742 / 0.038508 (0.046234) | 0.072942 / 0.023109 (0.049833) | 0.310722 / 0.275898 (0.034824) | 0.346806 / 0.323480 (0.023326) | 0.005373 / 0.007986 (-0.002613) | 0.003270 / 0.004328 (-0.001059) | 0.064379 / 0.004250 (0.060128) | 0.054876 / 0.037052 (0.017824) | 0.316794 / 0.258489 (0.058305) | 0.350353 / 0.293841 (0.056512) | 0.030683 / 0.128546 (-0.097863) | 0.008275 / 0.075646 (-0.067371) | 0.288747 / 0.419271 (-0.130525) | 0.051892 / 0.043533 (0.008359) | 0.315060 / 0.255139 (0.059921) | 0.331664 / 0.283200 (0.048464) | 0.023334 / 0.141683 (-0.118349) | 1.499734 / 1.452155 (0.047579) | 1.542006 / 1.492716 (0.049290) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.210488 / 0.018006 (0.192482) | 0.462187 / 0.000490 (0.461697) | 0.001280 / 0.000200 (0.001080) | 0.000076 / 0.000054 (0.000021) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027812 / 0.037411 (-0.009599) | 0.082492 / 0.014526 (0.067966) | 0.096504 / 0.176557 (-0.080053) | 0.158164 / 0.737135 (-0.578972) | 0.096678 / 0.296338 (-0.199661) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.403317 / 0.215209 (0.188108) | 4.008367 / 2.077655 (1.930713) | 2.033067 / 1.504120 (0.528947) | 1.869484 / 1.541195 (0.328290) | 1.947450 / 1.468490 (0.478960) | 0.494048 / 4.584777 (-4.090729) | 3.631673 / 3.745712 (-0.114039) | 5.322167 / 5.269862 (0.052306) | 3.125570 / 4.565676 (-1.440107) | 0.057341 / 0.424275 (-0.366934) | 0.007318 / 0.007607 (-0.000289) | 0.483990 / 0.226044 (0.257945) | 4.830573 / 2.268929 (2.561645) | 2.543267 / 55.444624 (-52.901358) | 2.217890 / 6.876477 (-4.658587) | 2.435111 / 2.142072 (0.293038) | 0.597920 / 4.805227 (-4.207307) | 0.132690 / 6.500664 (-6.367974) | 0.060160 / 0.075469 (-0.015309) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.247656 / 1.841788 (-0.594131) | 19.436984 / 8.074308 (11.362675) | 14.504249 / 10.191392 (4.312857) | 0.167444 / 0.680424 (-0.512980) | 0.018214 / 0.534201 (-0.515987) | 0.394790 / 0.579283 (-0.184493) | 0.413770 / 0.434364 (-0.020594) | 0.474290 / 0.540337 (-0.066048) | 0.646782 / 1.386936 (-0.740154) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006575 / 0.011353 (-0.004778) | 0.003924 / 0.011008 (-0.007084) | 0.064402 / 0.038508 (0.025893) | 0.072569 / 0.023109 (0.049460) | 0.361981 / 0.275898 (0.086083) | 0.398660 / 0.323480 (0.075180) | 0.005380 / 0.007986 (-0.002605) | 0.003355 / 0.004328 (-0.000974) | 0.065173 / 0.004250 (0.060923) | 0.057120 / 0.037052 (0.020067) | 0.366347 / 0.258489 (0.107858) | 0.402723 / 0.293841 (0.108882) | 0.031258 / 0.128546 (-0.097288) | 0.008499 / 0.075646 (-0.067147) | 0.070558 / 0.419271 (-0.348714) | 0.050089 / 0.043533 (0.006556) | 0.361280 / 0.255139 (0.106141) | 0.384497 / 0.283200 (0.101297) | 0.024789 / 0.141683 (-0.116893) | 1.492577 / 1.452155 (0.040422) | 1.572242 / 1.492716 (0.079525) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.228054 / 0.018006 (0.210048) | 0.448317 / 0.000490 (0.447828) | 0.000368 / 0.000200 (0.000168) | 0.000056 / 0.000054 (0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030575 / 0.037411 (-0.006836) | 0.088604 / 0.014526 (0.074078) | 0.099317 / 0.176557 (-0.077239) | 0.152455 / 0.737135 (-0.584680) | 0.100444 / 0.296338 (-0.195894) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.411876 / 0.215209 (0.196667) | 4.108187 / 2.077655 (2.030532) | 2.096371 / 1.504120 (0.592251) | 1.923532 / 1.541195 (0.382337) | 1.998345 / 1.468490 (0.529855) | 0.483853 / 4.584777 (-4.100924) | 3.622433 / 3.745712 (-0.123279) | 3.254430 / 5.269862 (-2.015431) | 2.044342 / 4.565676 (-2.521334) | 0.056756 / 0.424275 (-0.367519) | 0.007720 / 0.007607 (0.000113) | 0.487656 / 0.226044 (0.261612) | 4.882024 / 2.268929 (2.613096) | 2.585008 / 55.444624 (-52.859616) | 2.229251 / 6.876477 (-4.647225) | 2.408318 / 2.142072 (0.266246) | 0.617537 / 4.805227 (-4.187691) | 0.132102 / 6.500664 (-6.368562) | 0.061694 / 0.075469 (-0.013775) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.362077 / 1.841788 (-0.479711) | 19.750714 / 8.074308 (11.676406) | 14.545299 / 10.191392 (4.353907) | 0.168666 / 0.680424 (-0.511758) | 0.018606 / 0.534201 (-0.515595) | 0.394760 / 0.579283 (-0.184523) | 0.410030 / 0.434364 (-0.024334) | 0.464742 / 0.540337 (-0.075596) | 0.610881 / 1.386936 (-0.776055) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005836 / 0.011353 (-0.005517) | 0.003493 / 0.011008 (-0.007515) | 0.079877 / 0.038508 (0.041369) | 0.057299 / 0.023109 (0.034190) | 0.332945 / 0.275898 (0.057047) | 0.386615 / 0.323480 (0.063135) | 0.004437 / 0.007986 (-0.003548) | 0.002758 / 0.004328 (-0.001571) | 0.062668 / 0.004250 (0.058418) | 0.046135 / 0.037052 (0.009083) | 0.346160 / 0.258489 (0.087671) | 0.416720 / 0.293841 (0.122879) | 0.026678 / 0.128546 (-0.101868) | 0.007893 / 0.075646 (-0.067753) | 0.260427 / 0.419271 (-0.158845) | 0.044240 / 0.043533 (0.000707) | 0.328101 / 0.255139 (0.072963) | 0.380072 / 0.283200 (0.096872) | 0.020813 / 0.141683 (-0.120870) | 1.400202 / 1.452155 (-0.051952) | 1.475627 / 1.492716 (-0.017089) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.174479 / 0.018006 (0.156473) | 0.413810 / 0.000490 (0.413320) | 0.003059 / 0.000200 (0.002860) | 0.000212 / 0.000054 (0.000157) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023422 / 0.037411 (-0.013990) | 0.071519 / 0.014526 (0.056993) | 0.080555 / 0.176557 (-0.096001) | 0.143825 / 0.737135 (-0.593311) | 0.081182 / 0.296338 (-0.215157) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.406858 / 0.215209 (0.191648) | 4.161475 / 2.077655 (2.083820) | 1.991800 / 1.504120 (0.487680) | 1.811224 / 1.541195 (0.270030) | 1.828809 / 1.468490 (0.360318) | 0.504882 / 4.584777 (-4.079895) | 2.985010 / 3.745712 (-0.760703) | 3.984856 / 5.269862 (-1.285006) | 2.477936 / 4.565676 (-2.087740) | 0.057553 / 0.424275 (-0.366722) | 0.006436 / 0.007607 (-0.001172) | 0.488061 / 0.226044 (0.262016) | 4.805501 / 2.268929 (2.536573) | 2.446508 / 55.444624 (-52.998116) | 2.051406 / 6.876477 (-4.825071) | 2.177696 / 2.142072 (0.035623) | 0.588021 / 4.805227 (-4.217207) | 0.125118 / 6.500664 (-6.375546) | 0.060885 / 0.075469 (-0.014584) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.197130 / 1.841788 (-0.644658) | 17.867450 / 8.074308 (9.793142) | 13.536895 / 10.191392 (3.345503) | 0.137603 / 0.680424 (-0.542821) | 0.016706 / 0.534201 (-0.517495) | 0.327642 / 0.579283 (-0.251641) | 0.347201 / 0.434364 (-0.087163) | 0.379570 / 0.540337 (-0.160768) | 0.517825 / 1.386936 (-0.869111) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005769 / 0.011353 (-0.005584) | 0.003414 / 0.011008 (-0.007594) | 0.063198 / 0.038508 (0.024690) | 0.056020 / 0.023109 (0.032911) | 0.393333 / 0.275898 (0.117435) | 0.421166 / 0.323480 (0.097686) | 0.004360 / 0.007986 (-0.003626) | 0.002860 / 0.004328 (-0.001469) | 0.062712 / 0.004250 (0.058461) | 0.045363 / 0.037052 (0.008311) | 0.413156 / 0.258489 (0.154667) | 0.422897 / 0.293841 (0.129056) | 0.027092 / 0.128546 (-0.101455) | 0.007960 / 0.075646 (-0.067687) | 0.068531 / 0.419271 (-0.350740) | 0.041402 / 0.043533 (-0.002131) | 0.377008 / 0.255139 (0.121869) | 0.409142 / 0.283200 (0.125942) | 0.019707 / 0.141683 (-0.121976) | 1.440556 / 1.452155 (-0.011599) | 1.487403 / 1.492716 (-0.005314) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224355 / 0.018006 (0.206349) | 0.397855 / 0.000490 (0.397365) | 0.000363 / 0.000200 (0.000163) | 0.000056 / 0.000054 (0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025107 / 0.037411 (-0.012305) | 0.076404 / 0.014526 (0.061878) | 0.083194 / 0.176557 (-0.093362) | 0.135347 / 0.737135 (-0.601789) | 0.084786 / 0.296338 (-0.211553) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.433024 / 0.215209 (0.217815) | 4.323879 / 2.077655 (2.246224) | 2.263004 / 1.504120 (0.758884) | 2.072053 / 1.541195 (0.530858) | 2.113916 / 1.468490 (0.645426) | 0.502742 / 4.584777 (-4.082035) | 3.001716 / 3.745712 (-0.743996) | 2.777960 / 5.269862 (-2.491901) | 1.826514 / 4.565676 (-2.739162) | 0.057735 / 0.424275 (-0.366540) | 0.006671 / 0.007607 (-0.000937) | 0.503347 / 0.226044 (0.277303) | 5.037308 / 2.268929 (2.768380) | 2.679146 / 55.444624 (-52.765478) | 2.410899 / 6.876477 (-4.465577) | 2.467341 / 2.142072 (0.325268) | 0.589824 / 4.805227 (-4.215403) | 0.125529 / 6.500664 (-6.375135) | 0.061950 / 0.075469 (-0.013520) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.304128 / 1.841788 (-0.537659) | 17.950215 / 8.074308 (9.875907) | 13.673768 / 10.191392 (3.482376) | 0.129863 / 0.680424 (-0.550561) | 0.016720 / 0.534201 (-0.517481) | 0.329795 / 0.579283 (-0.249488) | 0.339057 / 0.434364 (-0.095307) | 0.382279 / 0.540337 (-0.158059) | 0.507337 / 1.386936 (-0.879599) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006199 / 0.011353 (-0.005154) | 0.003749 / 0.011008 (-0.007259) | 0.080600 / 0.038508 (0.042092) | 0.061017 / 0.023109 (0.037908) | 0.319966 / 0.275898 (0.044067) | 0.354937 / 0.323480 (0.031457) | 0.004854 / 0.007986 (-0.003131) | 0.002996 / 0.004328 (-0.001333) | 0.063100 / 0.004250 (0.058849) | 0.050063 / 0.037052 (0.013011) | 0.316744 / 0.258489 (0.058255) | 0.358001 / 0.293841 (0.064160) | 0.027503 / 0.128546 (-0.101043) | 0.007876 / 0.075646 (-0.067771) | 0.262211 / 0.419271 (-0.157060) | 0.045717 / 0.043533 (0.002184) | 0.317188 / 0.255139 (0.062049) | 0.342404 / 0.283200 (0.059205) | 0.020194 / 0.141683 (-0.121489) | 1.498672 / 1.452155 (0.046517) | 1.545479 / 1.492716 (0.052762) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.210985 / 0.018006 (0.192979) | 0.433592 / 0.000490 (0.433102) | 0.002864 / 0.000200 (0.002664) | 0.000079 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023463 / 0.037411 (-0.013948) | 0.073375 / 0.014526 (0.058850) | 0.083082 / 0.176557 (-0.093475) | 0.142583 / 0.737135 (-0.594552) | 0.084267 / 0.296338 (-0.212071) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.412890 / 0.215209 (0.197681) | 4.131421 / 2.077655 (2.053766) | 1.969164 / 1.504120 (0.465044) | 1.772379 / 1.541195 (0.231185) | 1.834154 / 1.468490 (0.365664) | 0.496290 / 4.584777 (-4.088487) | 3.056504 / 3.745712 (-0.689208) | 3.400962 / 5.269862 (-1.868900) | 2.120575 / 4.565676 (-2.445101) | 0.056932 / 0.424275 (-0.367343) | 0.006412 / 0.007607 (-0.001195) | 0.484521 / 0.226044 (0.258477) | 4.817474 / 2.268929 (2.548545) | 2.464075 / 55.444624 (-52.980549) | 2.085056 / 6.876477 (-4.791421) | 2.324516 / 2.142072 (0.182444) | 0.592013 / 4.805227 (-4.213214) | 0.132232 / 6.500664 (-6.368432) | 0.062825 / 0.075469 (-0.012645) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.228080 / 1.841788 (-0.613708) | 18.555385 / 8.074308 (10.481077) | 13.939565 / 10.191392 (3.748173) | 0.145979 / 0.680424 (-0.534445) | 0.016823 / 0.534201 (-0.517377) | 0.330569 / 0.579283 (-0.248714) | 0.358094 / 0.434364 (-0.076270) | 0.384642 / 0.540337 (-0.155696) | 0.518347 / 1.386936 (-0.868589) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006198 / 0.011353 (-0.005155) | 0.003670 / 0.011008 (-0.007338) | 0.062502 / 0.038508 (0.023994) | 0.064339 / 0.023109 (0.041229) | 0.428414 / 0.275898 (0.152516) | 0.463899 / 0.323480 (0.140420) | 0.005524 / 0.007986 (-0.002462) | 0.002915 / 0.004328 (-0.001413) | 0.062521 / 0.004250 (0.058270) | 0.051182 / 0.037052 (0.014130) | 0.431144 / 0.258489 (0.172655) | 0.469465 / 0.293841 (0.175624) | 0.027463 / 0.128546 (-0.101083) | 0.007974 / 0.075646 (-0.067673) | 0.068029 / 0.419271 (-0.351242) | 0.042123 / 0.043533 (-0.001409) | 0.428667 / 0.255139 (0.173528) | 0.455917 / 0.283200 (0.172717) | 0.023264 / 0.141683 (-0.118419) | 1.426986 / 1.452155 (-0.025168) | 1.500049 / 1.492716 (0.007332) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.207264 / 0.018006 (0.189258) | 0.440738 / 0.000490 (0.440248) | 0.000802 / 0.000200 (0.000602) | 0.000062 / 0.000054 (0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026245 / 0.037411 (-0.011166) | 0.078749 / 0.014526 (0.064223) | 0.087873 / 0.176557 (-0.088684) | 0.141518 / 0.737135 (-0.595617) | 0.089811 / 0.296338 (-0.206527) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418955 / 0.215209 (0.203746) | 4.177881 / 2.077655 (2.100226) | 2.162678 / 1.504120 (0.658558) | 1.998969 / 1.541195 (0.457775) | 2.066720 / 1.468490 (0.598230) | 0.496850 / 4.584777 (-4.087927) | 3.041179 / 3.745712 (-0.704534) | 4.126039 / 5.269862 (-1.143823) | 2.740507 / 4.565676 (-1.825169) | 0.058025 / 0.424275 (-0.366250) | 0.006846 / 0.007607 (-0.000761) | 0.493281 / 0.226044 (0.267237) | 4.930196 / 2.268929 (2.661268) | 2.685152 / 55.444624 (-52.759472) | 2.378247 / 6.876477 (-4.498230) | 2.469103 / 2.142072 (0.327031) | 0.585346 / 4.805227 (-4.219882) | 0.126099 / 6.500664 (-6.374565) | 0.062946 / 0.075469 (-0.012523) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.313892 / 1.841788 (-0.527896) | 19.177117 / 8.074308 (11.102809) | 14.081321 / 10.191392 (3.889929) | 0.133948 / 0.680424 (-0.546476) | 0.017128 / 0.534201 (-0.517073) | 0.332241 / 0.579283 (-0.247042) | 0.373218 / 0.434364 (-0.061145) | 0.395308 / 0.540337 (-0.145030) | 0.529883 / 1.386936 (-0.857053) |\n\n</details>\n</details>\n\n\n"
] | "2023-07-31T06:05:36Z" | "2023-07-31T06:33:00Z" | "2023-07-31T06:18:17Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6101.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6101",
"merged_at": "2023-07-31T06:18:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6101.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6101"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6101/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6101/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5672 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5672/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5672/comments | https://api.github.com/repos/huggingface/datasets/issues/5672/events | https://github.com/huggingface/datasets/issues/5672 | 1,641,005,322 | I_kwDODunzps5hz8EK | 5,672 | Pushing dataset to hub crash | {
"avatar_url": "https://avatars.githubusercontent.com/u/14275989?v=4",
"events_url": "https://api.github.com/users/tzvc/events{/privacy}",
"followers_url": "https://api.github.com/users/tzvc/followers",
"following_url": "https://api.github.com/users/tzvc/following{/other_user}",
"gists_url": "https://api.github.com/users/tzvc/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tzvc",
"id": 14275989,
"login": "tzvc",
"node_id": "MDQ6VXNlcjE0Mjc1OTg5",
"organizations_url": "https://api.github.com/users/tzvc/orgs",
"received_events_url": "https://api.github.com/users/tzvc/received_events",
"repos_url": "https://api.github.com/users/tzvc/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tzvc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tzvc/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tzvc"
} | [] | closed | false | null | [] | null | [
"Hi ! It's been fixed by https://github.com/huggingface/datasets/pull/5598. We're doing a new release tomorrow with the fix and you'll be able to push your 100k images ;)\r\n\r\nBasically `push_to_hub` used to fail if the remote repository already exists and has a README.md without dataset_info in the YAML tags.\r\n\r\nIn the meantime you can install datasets from source",
"Hi @lhoestq ,\r\n\r\nWhat version of datasets library fix this case? I am using the last `v2.10.1` and I get the same error.",
"We just released 2.11 which includes a fix :)"
] | "2023-03-26T17:42:13Z" | "2023-03-30T08:11:05Z" | "2023-03-30T08:11:05Z" | NONE | null | null | null | ### Describe the bug
Uploading a dataset with `push_to_hub()` fails without error description.
### Steps to reproduce the bug
Hey there,
I've built a image dataset of 100k images + text pair as described here https://huggingface.co/docs/datasets/image_dataset#imagefolder
Now I'm trying to push it to the hub but I'm running into issues. First, I tried doing it via git directly, I added all the files in git lfs and pushed but I got hit with an error saying huggingface only accept up to 10k files in a folder.
So I'm now trying with the `push_to_hub()` func as follow:
```python
from datasets import load_dataset
import os
dataset = load_dataset("imagefolder", data_dir="./data", split="train")
dataset.push_to_hub("tzvc/organization-logos", token=os.environ.get('HF_TOKEN'))
```
But again, this produces an error:
```
Resolving data files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 100212/100212 [00:00<00:00, 439108.61it/s]
Downloading and preparing dataset imagefolder/default to /home/contact_theochampion/.cache/huggingface/datasets/imagefolder/default-20567ffc703aa314/0.0.0/37fbb85cc714a338bea574ac6c7d0b5be5aff46c1862c1989b20e0771199e93f...
Downloading data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 100211/100211 [00:00<00:00, 149323.73it/s]
Downloading data files: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 15947.92it/s]
Extracting data files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 2245.34it/s]
Dataset imagefolder downloaded and prepared to /home/contact_theochampion/.cache/huggingface/datasets/imagefolder/default-20567ffc703aa314/0.0.0/37fbb85cc714a338bea574ac6c7d0b5be5aff46c1862c1989b20e0771199e93f. Subsequent calls will reuse this data.
Resuming upload of the dataset shards.
Pushing dataset shards to the dataset hub: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 14/14 [00:31<00:00, 2.24s/it]
Downloading metadata: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 118/118 [00:00<00:00, 225kB/s]
Traceback (most recent call last):
File "/home/contact_theochampion/organization-logos/push_to_hub.py", line 5, in <module>
dataset.push_to_hub("tzvc/organization-logos", token=os.environ.get('HF_TOKEN'))
File "/home/contact_theochampion/.local/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 5245, in push_to_hub
repo_info = dataset_infos[next(iter(dataset_infos))]
StopIteration
```
What could be happening here ?
### Expected behavior
The dataset is pushed to the hub
### Environment info
- `datasets` version: 2.10.1
- Platform: Linux-5.10.0-21-cloud-amd64-x86_64-with-glibc2.31
- Python version: 3.9.2
- PyArrow version: 11.0.0
- Pandas version: 1.5.3 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5672/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5672/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3758 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3758/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3758/comments | https://api.github.com/repos/huggingface/datasets/issues/3758/events | https://github.com/huggingface/datasets/issues/3758 | 1,143,366,393 | I_kwDODunzps5EJmL5 | 3,758 | head_qa file missing | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"We usually find issues with files hosted at Google Drive...\r\n\r\nIn this case we download the Google Drive Virus scan warning instead of the data file.",
"Fixed: https://huggingface.co/datasets/head_qa/viewer/en/train. Thanks\r\n\r\n<img width=\"1551\" alt=\"Capture d’écran 2022-02-28 à 15 29 04\" src=\"https://user-images.githubusercontent.com/1676121/156000224-fd3f62c6-8b54-4df1-8911-bdcb0bac3f1a.png\">\r\n"
] | "2022-02-18T16:32:43Z" | "2022-02-28T14:29:18Z" | "2022-02-21T14:39:19Z" | CONTRIBUTOR | null | null | null | ## Describe the bug
A file for the `head_qa` dataset is missing (https://drive.google.com/u/0/uc?export=download&id=1a_95N5zQQoUCq8IBNVZgziHbeM-QxG2t/HEAD_EN/train_HEAD_EN.json)
## Steps to reproduce the bug
```python
>>> from datasets import load_dataset
>>> load_dataset("head_qa", name="en")
```
## Expected results
The dataset should be loaded
## Actual results
```
Downloading and preparing dataset head_qa/en (download: 75.69 MiB, generated: 2.69 MiB, post-processed: Unknown size, total: 78.38 MiB) to /home/slesage/.cache/huggingface/datasets/head_qa/en/1.1.0/583ab408e8baf54aab378c93715fadc4d8aa51b393e27c3484a877e2ac0278e9...
Downloading data: 2.21kB [00:00, 2.05MB/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/load.py", line 1729, in load_dataset
builder_instance.download_and_prepare(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/builder.py", line 594, in download_and_prepare
self._download_and_prepare(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/builder.py", line 665, in _download_and_prepare
verify_checksums(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/utils/info_utils.py", line 40, in verify_checksums
raise NonMatchingChecksumError(error_msg + str(bad_urls))
datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://drive.google.com/u/0/uc?export=download&id=1a_95N5zQQoUCq8IBNVZgziHbeM-QxG2t']
```
## Environment info
- `datasets` version: 1.18.4.dev0
- Platform: Linux-5.11.0-1028-aws-x86_64-with-glibc2.31
- Python version: 3.9.6
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3758/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3758/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1821 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1821/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1821/comments | https://api.github.com/repos/huggingface/datasets/issues/1821/events | https://github.com/huggingface/datasets/issues/1821 | 801,747,647 | MDU6SXNzdWU4MDE3NDc2NDc= | 1,821 | Provide better exception message when one of many files results in an exception | {
"avatar_url": "https://avatars.githubusercontent.com/u/5028974?v=4",
"events_url": "https://api.github.com/users/david-waterworth/events{/privacy}",
"followers_url": "https://api.github.com/users/david-waterworth/followers",
"following_url": "https://api.github.com/users/david-waterworth/following{/other_user}",
"gists_url": "https://api.github.com/users/david-waterworth/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/david-waterworth",
"id": 5028974,
"login": "david-waterworth",
"node_id": "MDQ6VXNlcjUwMjg5NzQ=",
"organizations_url": "https://api.github.com/users/david-waterworth/orgs",
"received_events_url": "https://api.github.com/users/david-waterworth/received_events",
"repos_url": "https://api.github.com/users/david-waterworth/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/david-waterworth/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/david-waterworth/subscriptions",
"type": "User",
"url": "https://api.github.com/users/david-waterworth"
} | [] | closed | false | null | [] | null | [
"Hi!\r\n\r\nThank you for reporting this issue. I agree that the information about the exception should be more clear and explicit.\r\n\r\nI could take on this issue.\r\n\r\nOn the meantime, as you can see from the exception stack trace, HF Datasets uses pandas to read the CSV files. You can pass arguments to `pandas.read_csv` by passing additional keyword arguments to `load_dataset`. For example, you may find useful this argument:\r\n- `error_bad_lines` : bool, default True\r\n Lines with too many fields (e.g. a csv line with too many commas) will by default cause an exception to be raised, and no DataFrame will be returned. If False, then these “bad lines” will be dropped from the DataFrame that is returned.\r\n\r\nYou could try:\r\n```python\r\ndatasets = load_dataset(\"csv\", data_files=dict(train=train_files, validation=validation_files), error_bad_lines=False)\r\n```\r\n"
] | "2021-02-05T00:49:03Z" | "2021-02-09T17:39:27Z" | "2021-02-09T17:39:27Z" | NONE | null | null | null | I find when I process many files, i.e.
```
train_files = glob.glob('rain*.csv')
validation_files = glob.glob(validation*.csv')
datasets = load_dataset("csv", data_files=dict(train=train_files, validation=validation_files))
```
I sometimes encounter an error due to one of the files being misformed (i.e. no data, or a comma in a field that isn't quoted, etc).
For example, this is the tail of an exception which I suspect is due to a stray comma.
> File "pandas/_libs/parsers.pyx", line 756, in pandas._libs.parsers.TextReader.read
> File "pandas/_libs/parsers.pyx", line 783, in pandas._libs.parsers.TextReader._read_low_memory
> File "pandas/_libs/parsers.pyx", line 827, in pandas._libs.parsers.TextReader._read_rows
> File "pandas/_libs/parsers.pyx", line 814, in pandas._libs.parsers.TextReader._tokenize_rows
> File "pandas/_libs/parsers.pyx", line 1951, in pandas._libs.parsers.raise_parser_error
> pandas.errors.ParserError: Error tokenizing data. C error: Expected 2 fields in line 559, saw 3
It would be nice if the exception trace contained the name of the file being processed (I have 250 separate files!) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1821/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1821/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1313 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1313/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1313/comments | https://api.github.com/repos/huggingface/datasets/issues/1313/events | https://github.com/huggingface/datasets/pull/1313 | 759,536,512 | MDExOlB1bGxSZXF1ZXN0NTM0NTI1NjE3 | 1,313 | Add HateSpeech Corpus for Polish | {
"avatar_url": "https://avatars.githubusercontent.com/u/2649301?v=4",
"events_url": "https://api.github.com/users/kacperlukawski/events{/privacy}",
"followers_url": "https://api.github.com/users/kacperlukawski/followers",
"following_url": "https://api.github.com/users/kacperlukawski/following{/other_user}",
"gists_url": "https://api.github.com/users/kacperlukawski/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kacperlukawski",
"id": 2649301,
"login": "kacperlukawski",
"node_id": "MDQ6VXNlcjI2NDkzMDE=",
"organizations_url": "https://api.github.com/users/kacperlukawski/orgs",
"received_events_url": "https://api.github.com/users/kacperlukawski/received_events",
"repos_url": "https://api.github.com/users/kacperlukawski/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kacperlukawski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kacperlukawski/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kacperlukawski"
} | [] | closed | false | null | [] | null | [
"@lhoestq Do you think using the ClassLabel is correct if we don't know the meaning of them?",
"Once we find out the meanings we can still add them to the dataset card",
"Feel free to ping me when the PR is ready for the final review"
] | "2020-12-08T15:23:53Z" | "2020-12-16T16:48:45Z" | "2020-12-16T16:48:45Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1313.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1313",
"merged_at": "2020-12-16T16:48:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1313.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1313"
} | This PR adds a HateSpeech Corpus for Polish, containing offensive language examples.
- **Homepage:** http://zil.ipipan.waw.pl/HateSpeech
- **Paper:** http://www.qualitativesociologyreview.org/PL/Volume38/PSJ_13_2_Troszynski_Wawer.pdf | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1313/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1313/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1516 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1516/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1516/comments | https://api.github.com/repos/huggingface/datasets/issues/1516/events | https://github.com/huggingface/datasets/pull/1516 | 764,032,327 | MDExOlB1bGxSZXF1ZXN0NTM4MjkzOTMw | 1,516 | adding wrbsc | {
"avatar_url": "https://avatars.githubusercontent.com/u/15803781?v=4",
"events_url": "https://api.github.com/users/kldarek/events{/privacy}",
"followers_url": "https://api.github.com/users/kldarek/followers",
"following_url": "https://api.github.com/users/kldarek/following{/other_user}",
"gists_url": "https://api.github.com/users/kldarek/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kldarek",
"id": 15803781,
"login": "kldarek",
"node_id": "MDQ6VXNlcjE1ODAzNzgx",
"organizations_url": "https://api.github.com/users/kldarek/orgs",
"received_events_url": "https://api.github.com/users/kldarek/received_events",
"repos_url": "https://api.github.com/users/kldarek/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kldarek/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kldarek/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kldarek"
} | [] | closed | false | null | [] | null | [
"@lhoestq thanks for the comments! Should be fixed in the latest commit, I assume the CI errors are unrelated. ",
"merging since the CI is fixed on master"
] | "2020-12-12T16:38:40Z" | "2020-12-18T09:41:33Z" | "2020-12-18T09:41:33Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1516.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1516",
"merged_at": "2020-12-18T09:41:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1516.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1516"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1516/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1516/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/4881 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4881/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4881/comments | https://api.github.com/repos/huggingface/datasets/issues/4881/events | https://github.com/huggingface/datasets/issues/4881 | 1,348,495,777 | I_kwDODunzps5QYGmh | 4,881 | Language names and language codes: connecting to a big database (rather than slow enrichment of custom list) | {
"avatar_url": "https://avatars.githubusercontent.com/u/6072524?v=4",
"events_url": "https://api.github.com/users/alexis-michaud/events{/privacy}",
"followers_url": "https://api.github.com/users/alexis-michaud/followers",
"following_url": "https://api.github.com/users/alexis-michaud/following{/other_user}",
"gists_url": "https://api.github.com/users/alexis-michaud/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/alexis-michaud",
"id": 6072524,
"login": "alexis-michaud",
"node_id": "MDQ6VXNlcjYwNzI1MjQ=",
"organizations_url": "https://api.github.com/users/alexis-michaud/orgs",
"received_events_url": "https://api.github.com/users/alexis-michaud/received_events",
"repos_url": "https://api.github.com/users/alexis-michaud/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/alexis-michaud/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alexis-michaud/subscriptions",
"type": "User",
"url": "https://api.github.com/users/alexis-michaud"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Thanks for opening this discussion, @alexis-michaud.\r\n\r\nAs the language validation procedure is shared with other Hugging Face projects, I'm tagging them as well.\r\n\r\nCC: @huggingface/moon-landing ",
"on the Hub side, there is not fine grained validation we just check that `language:` contains an array of lowercase strings between 2 and 3 characters long =)\r\n\r\nand for `language_bcp47:` we just check it's an array of strings.\r\n\r\nThe only page where we have a hardcoded list of languages is https://huggingface.co/languages and I've been thinking of hooking that page on an external database of languages (so any suggestion is super interesting), but it's not used for validation.\r\n\r\nThat being said, in `datasets` this file https://github.com/huggingface/datasets/blob/main/src/datasets/utils/resources/languages.json is not really used no? Or just in the tagging tool? What about just removing it?\r\n\r\nalso cc'ing @lbourdois who's been active and helpful on those subjects in the past!",
"PS @alexis-michaud is there a DB of language codes you would recommend? That would contain all `ISO 639-1, 639-2 or 639-3 codes` and be kept up to date, and ideally that would be accessible as a Node.js npm package?\r\n\r\ncc @albertvillanova too",
"> PS @alexis-michaud is there a DB of language codes you would recommend? That would contain all `ISO 639-1, 639-2 or 639-3 codes` and be kept up to date, and ideally that would be accessible as a Node.js npm package?\r\n> \r\n> cc @albertvillanova too\r\n\r\nMany thanks for your answer! \r\n\r\nThe Glottolog database is kept up to date, and has information on the closest ISO code for each Glottocode. So providing a clean table with equivalences sounds (to me) like something perfectly reasonable to expect from their team. \r\nTo what extent would [pyglottolog](https://github.com/glottolog/pyglottolog) fit the bill / do the job? (API documentation [here](https://pyglottolog.readthedocs.io/en/latest/index.html)) I'm reaching my technical limitations here: I can't assess the distance between what they offer and what the HF team needs. \r\nI have opened an Issue in [their repo](https://github.com/glottolog/glottolog-cldf/issues/13). \r\n\r\nVery interested to see where it goes from there.",
"I just tried pyglottolog to generate a file with all the current IDs (first column).\r\n\r\n`glottolog languoids` inside the `glottolog` repository.\r\n\r\n[glottolog-languoids-v4.6-10-g5c66eec874.csv](https://github.com/huggingface/datasets/files/9417456/glottolog-languoids-v4.6-10-g5c66eec874.csv)\r\n\r\n",
"Greetings @alexis-michaud and others,\r\nI think perhaps a standards-based approach here would help everyone out both at the technical and social layers of technical innovations. \r\n\r\nLet me say a few things: \r\n1. there are multiple kinds of assets in AI that should have associated language codes. \r\n * AI Training Data sets\r\n * AI models\r\n * AI outputs\r\nThese are all distinct components which should be tagged for the language and encoding methods they operate on or enhance. For example, an AI based cross-language tool from French to English (UK variety) still needs to consider if it is operating on oral language speech or written text. This is where [IANA language sub-tags](https://www.iana.org/assignments/language-subtag-registry/language-subtag-registry) come in and are so important. I link to the official source. If one wants to use middleware such as a python package or npm package to manage strings then please make sure those packages are updating codes as they are being revised. I see that @julien-c mentioned BCP-47. BCP-47 is the current standard for language tagging. Following it will make the resources you create more findable and let future users better understand or expect any biases which may have been introduced in the different AI based products.\r\n2. BCP-47 is a technical read. However, you will notice that it identifies when to use an ISO 639-1, ISO 639-2, or ISO 639-3. code. This is important for interoperability with many systems. If you are using library systems then you should likely just stick with ISO 639-3 codes.\r\n3. If you are going to use Glottolog codes use them after an `-x-` tag in the BCP-47 format to maintain BCP-47 validity. \r\n4. You should source ISO 639-3 codes directly from the [ISO 639-3 registrar](https://iso639-3.sil.org/code_tables/639/data) as these codes are updated annually, usually in February or March. ISO 639-3 codes have multiple classes: `Active`, `Deprecated`, and `Unassigned`. This means that string length checking is not a sufficient strategy for validation.\r\n5. The names of smaller languages often change depending on the language used to describe them. The [ISO639-2 documentation](https://www.loc.gov/standards/iso639-2/php/code_list.php) has a list of language names for languages with smaller populations for languages in which descriptions about these languages are often written. For example, ISO 639-2's documentation contains the names of languages as they are used in French, German, and English. ISO 639-2 rarely is updated as it is now tied to ISO 639-3's evolution and modern systems should just use ISO 639-3, but these additional names of languages in other languages may not appear in the ISO 369-3 tables.\r\n6. Glottolog codes are also updated at least annually. Usually sometime after ISO 639-3 updates.\r\n7. Please, if the material is in a written mode, please indicate which script is used unless the IANA field has a `suppress script` value. Please use the script tag that BCP-47 calls for from [ISO 15924](https://unicode.org/iso15924/iso15924-codes.html). This also updates at least annually. \r\n8. Another great place to look for language names is the [Unicode CLDR database for locales](https://cldr.unicode.org/translation/displaynames/languagelocale-names). These ought to be congruent with ISO 639-3 but, sometimes CLDR has additional references to languages (such as the french name for a language) which is not contained in ISO 639-2 or ISO 639-3.\r\n9. Wikidata for language names is not always a great source of authoritative information. Language names are asymmetrical. Many times they are contrived because there is no actual name for the language in the language referring... e.g. French doesn't have a name for every language in the world, often they say something like: the language of 'x' people. — English does the same. When a language name standard does not have the best name for a language the best way to handle that is to make a change request with the standards registrar. Keeping track of the source list and the version of your source list for your language codes is very important. \r\n10. Finally, It would be a great service to technologist, minority language communities, and linguists if for all resources of the three types mentioned in number 1 above you added a record to [OLAC](http://www.language-archives.org/). — I can help you with that. OLAC is a search interface for language resources.\r\n",
"Hi everybody!\r\n\r\nAbout the point:\r\n> also cc'ing @lbourdois who's been active and helpful on those subjects in the past!\r\n\r\nDiscussions on the need to improve the Hub's tagging system (applying to both datasets and models) can be found in the following discussion: https://github.com/huggingface/hub-docs/issues/193\r\nOnce this system has been redone and satisfies the identified needs, a redesign of the [Languages page](https://huggingface.co/languages) would also be relevant: https://github.com/huggingface/hub-docs/issues/194. \r\nI invite you to read them. But as a quick summary, the exchanges were oriented towards the ISO standard (the first HF system was based on it and it is generally the standard indicated in AI/DL papers) by favouring ISO 639-1 if it exists, and fallback to ISO 639-2 or ISO 639-3 if it doesn't. In addition, it is possible to add BCP-47 tags to consider existing varieties/regionalisms within a language (https://huggingface.co/datasets/AmazonScience/massive/discussions/1). If a language does not belong to either of these two standards, then a request should be made to the HF team to add it manually.\r\n\r\n\r\nTo return to the present discussion, thank you for the various databases and methodologies you mention. It makes a big difference to have linguists in the loop 🚀.\r\n\r\nI have a couple of questions where I think an expert perspective would be appreciated:\r\n- Do you think it's possible to easily handle tags that have been deprecated potentially for decades?\r\nFor example (I'm taking the case of Hebrew but this has happened for other languages) I tagged Google models with the \"iw\" [tag](https://huggingface.co/models?language=iw&sort=downloads) because I based it on what the authors gave in their [paper](https://arxiv.org/pdf/2010.11934.pdf) see table 6 page 12). It turns out that this ISO tag has in fact been deprecated since 1989 in favour of the \"he\" tag. It would therefore be necessary to have a verification that transforms the old tags into the most recent ones.\r\n\r\n- When you look up a language on Wikipedia, it usually shows, in addition to the ISO standard, the codes in the Glottolog (which you have already mentioned), [ELP](https://www.endangeredlanguages.com/?hl=en) and [Linguasphere](http://www.linguasphere.info/jr/index.php?l1=home&l2=welcome) databases. Would you have any opinion about these two other databases?\r\n\r\n- On the Hub, there is the following dataset where French people speak in English: https://huggingface.co/datasets/Datatang/French_Speaking_English_Speech_Data_by_Mobile_Phone \r\nIs there a database to take this case into account? I have not found any code in the Glottolog database. If based on an IETF BCP-47 standard, I would tend to tag the dataset with \"en-fr\" but would this be something accepted by linguists?\r\nBased on the first post in this thread that there are about 8000 languages, if one considers that a given language can be pronounced by a speaker of the other 7999, that would theoretically make about 64 million BCP-47 language1-language2 codes existing. And even much more if we consider regionalists with language1_regionalism_x-language2_regionalism_y. I guess there is no such database.\r\n\r\n- Are there any databases that take into account all the existing sign languages in the world?\r\nIt would be nice to have them included on the Hub.\r\n\r\n- Is there an international classification of languages?\r\nA bit like the [International Classification of Diseases](https://en.wikipedia.org/wiki/International_Classification_of_Diseases) in medicine, which is established by the WHO and used as a reference throughout the world. The idea would be to have a precise number of languages to which we would then have to assign a unique tag in order to find them later. \r\n\r\n- Finally for the CNRS team, when can we expect to see all the datasets of [Pangloss](https://pangloss.cnrs.fr/) on HF? 👀 And I don't know if you have a way to help to add also the datasets of [CoCoON](https://cocoon.huma-num.fr/exist/crdo/).",
"> I invite you to read them. But as a quick summary, the exchanges were oriented towards the ISO standard (the first HF system was based on it and it is generally the standard indicated in AI/DL papers) by favouring ISO 639-1 if it exists, and fallback to ISO 639-2 or ISO 639-3 if it doesn't. In addition, it is possible to add BCP-47 tags to consider existing varieties/regionalisms within a language (https://huggingface.co/datasets/AmazonScience/massive/discussions/1). If a language does not belong to either of these two standards, then a request should be made to the HF team to add it manually.\r\n\r\nOne comment on this fall back system (which generally follows the BCP-47 process). ISO 639-2 has some codes which refer to a language ambiguously. For example, I believe code `ara` is used for arabic. In some contexts arabic is considered a single language, however, Egyptian Arabic is quite different from Moroccan Arabic, which are both considered separate languages. These ambiguous codes are valid ISO 639-3 codes but they have a special status. They are called `macro codes`. They exist inside the ISO 639-3 standard to provide absolute fallback compatibility between ISO 639-2 and ISO 639-3. However, when considering AI and MT applications with language data, the unforeseen potential applications and the potential for bias using macro codes should be avoided for new applications of language tags to resources. For historical cases where it is not clear what resources were used to create the AI tools or datasets then I understand the use of ambiguous tag uses. So for clarity in language tagging I suggest:\r\n\r\n1. Strictly following BCP-47\r\n2. Whenever possible avoid the use of macro tags in the ISO 639-3 standard. These are BCP-47 valid, but could introduce biases in the application of their use in society. (Generally there are more specific tags available to use in the ISO 639-3 standard.)",
"> * Are there any databases that take into account all the existing sign languages in the world?\r\n> It would be nice to have them included on the Hub.\r\n\r\nSign Languages present an interesting case. As I understand the situation. The identification of sign languages has been identified as a component of their endangerment. Some sign languages do exist in ISO 639-3. For further discussion on the issue I refer readers to the following publications: \r\n\r\n* https://doi.org/10.3390/languages7010049\r\n* https://www.academia.edu/35870983/The_ethics_of_of_language_identification_and_ISO_639\r\n\r\nOne way to be BCP-47 compliant and identify a sign language which is not identified in any of the BCP-47 referenced standards is to use the ISO 639-3 code for undetermined language `und` and then apply a custom suffix indicator (as explained in BCP-47) `-x-` and a custom code, such as the ones used in https://doi.org/10.3390/languages7010049",
"> * Is there an international classification of languages?\r\n> A bit like the [International Classification of Diseases](https://en.wikipedia.org/wiki/International_Classification_of_Diseases) in medicine, which is established by the WHO and used as a reference throughout the world. The idea would be to have a precise number of languages to which we would then have to assign a unique tag in order to find them later.\r\n\r\nYes that would be the function of ISO 639-3. It is the reference standard for languages. It includes a code and its name and the status of the code. Many technical metadata standards for file and computer interoperability reference it, many technical library metadata standards reference it. Some linguists use it. Many governments reference it. \r\n\r\nIndexing diseases are different from indexing languages in several ways, one way is that diseases are the impact of a pathogen not the pathogen itself. If we take COVID-19 as an example, there are many varieties of the pathogen but broadly speaking there is only one disease — with many symptoms.\r\n\r\n",
">* When you look up a language on Wikipedia, it usually shows, in addition to the ISO standard, the codes in the Glottolog (which you have already mentioned), [ELP](https://www.endangeredlanguages.com/?hl=en) and [Linguasphere](http://www.linguasphere.info/jr/index.php?l1=home&l2=welcome) databases. Would you have any opinion about these two other databases?\r\n\r\nWhile these do appear on wikipedia, I don't know of any information system which uses these codes. I do know that glottolog did import ELP data at one time and its database does contain ELP data I'm not sure if Glottolog regularly ingests new versions of ELP data. I suspect that the use of Linguasphere data may be relevant to users of wikidata as a linked data attribute but I haven't heard of any linked data projects using Linguasphere data for analysis or product development. My impression is that it is fairly unused.",
"> * Do you think it's possible to easily handle tags that have been deprecated potentially for decades?\r\n>For example (I'm taking the case of Hebrew but this has happened for other languages) I [tag](https://huggingface.co/models?language=iw&sort=downloads)ged Google models with the \"iw\" tag because I based it on what the authors gave in their [paper](https://arxiv.org/pdf/2010.11934.pdf) see table 6 page 12). It turns out that this ISO tag has in fact been deprecated since 1989 in favour of the \"he\" tag. It would therefore be necessary to have a verification that transforms the old tags into the most recent ones.\r\n\r\nYes. You can parse the IANA file linked to above (it is regularly updated). All deprecated tags are marked as such in that file. The new prefered tag if there is one, is indicated. ISO 639-3 also indicates a code's status but their list is relevant only codes within their domain (ISO 639-3).",
"> * On the Hub, there is the following dataset where French people speak in English: https://huggingface.co/datasets/Datatang/French_Speaking_English_Speech_Data_by_Mobile_Phone\r\nIs there a database to take this case into account? I have not found any code in the Glottolog database. If based on an IETF BCP-47 standard, I would tend to tag the dataset with \"en-fr\" but would this be something accepted by linguists?\r\n\r\nI would interpret `en-fr` as english as spoken in France. `fr`in this position refers to the geo-political entity not a second language. I see no reason that other linguists should have a different option after having read BCP-47 and understood how it works.\r\n\r\nThe functional goal here is to tag a language resource as being produced by nonnative speakers, while tagging both languages. There are several problems here. The first is that BCP-47 has no way explicit way to do this. One could use the sub code `x-` with a private use code to indicate a second language and infer some meaning as to that language's role. However, there is another problem here which complexifies the situation greatly... how do we know that those english speakers (in France, or from France, or who were native French speakers) were not speaking their third or fourth language rather than their second language. So to conceptualize a sub-tag which indicates the first language of a speech act for speakers in a second (or other) language would need to be carefully crafted. It might then be proposed to the appropriate authorities. For example three sub-tags exist.\r\n\r\nThere are three registered sub-tags out of a BCP-47 allowed 35. These are `x-`, `u-`, and `t-`. `u-` and `t-` are defined in [RFC6067 ](https://www.rfc-editor.org/rfc/rfc6067)and [RFC6497](https://www.rfc-editor.org/rfc/rfc6497) . For more information see the [Unicode CLDR documentation](https://cldr.unicode.org/index/bcp47-extension) where it says: \r\n\r\n\r\n>[IETF BCP 47 ](http://www.google.com/url?q=http%3A%2F%2Ftools.ietf.org%2Fhtml%2Fbcp47&sa=D&sntz=1&usg=AOvVaw1DoMN1IBGg-JHgECBvdW1t)[Tags for Identifying Languages](http://www.google.com/url?q=http%3A%2F%2Ftools.ietf.org%2Fhtml%2Fbcp47&sa=D&sntz=1&usg=AOvVaw1DoMN1IBGg-JHgECBvdW1t) defines the language identifiers (tags) used on the Internet and in many standards. It has an extension mechanism that allows additional information to be included. The Unicode Consortium is the maintainer of the extension ‘u’ for Locale Extensions, as described in [rfc6067](https://www.google.com/url?q=https%3A%2F%2Ftools.ietf.org%2Fhtml%2Frfc6067&sa=D&sntz=1&usg=AOvVaw0gGWi0EjHfy1WId8k8oKAi), and the extension 't' for Transformed Content, as described in [rfc6497](https://www.google.com/url?q=https%3A%2F%2Ftools.ietf.org%2Fhtml%2Frfc6497&sa=D&sntz=1&usg=AOvVaw0w-OUsFX1PtaKYIq31P64I).\r\n>\r\n>The subtags available for use in the 'u' extension provide language tag extensions that provide for additional information needed for identifying locales. The 'u' subtags consist of a set of keys and associated values (types). For example, a locale identifier for British English with numeric collation has the following form: en-GB-u-kn-true\r\n>\r\n>The subtags available for use in the 't' extension provide language tag extensions that provide for additional information needed for identifying transformed content, or a request to transform content in a certain way. For example, the language tag \"ja-Kana-t-it\" can be used as a content tag indicates Japanese Katakana transformed from Italian. It can also be used as a request for a given transformation.\r\n>\r\n>For more details on the valid subtags for these extensions, their syntax, and their meanings, see LDML Section 3.7 [Unicode BCP 47 Extension Data](http://www.google.com/url?q=http%3A%2F%2Fwww.unicode.org%2Freports%2Ftr35%2F%23Locale_Extension_Key_and_Type_Data&sa=D&sntz=1&usg=AOvVaw0lMthb9KbTJtoOd5mvv3Ha).",
"Hi @lbourdois ! Many thanks for the detailed information.\r\n\r\n> Discussions on the need to improve the Hub's tagging system (applying to both datasets and models) can be found in the following discussion: [huggingface/hub-docs#193](https://github.com/huggingface/hub-docs/issues/193) \r\nFascinating topic! To me, the following suggestion has a lot of appeal:\r\n\"if consider that it was necessary to create an ISO 639-3 because ISO 639-1 was deficient, it would be to do the reverse and thus convert the tags from ISO 639-1 to ISO 639-2 or 3 (https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes or https://iso639-3.sil.org/code_tables/639/data).\"\r\n\r\nYes, ISO 639-1 is unsuitable because it has so few codes: less than 200. To address linguistic diversity in 'unrestricted mode', a list of all languages is wanted. \r\n\r\nThe idea of letting people use their favourite nomenclature and automatically adding the ISO 639-3 three-letter code as a tag is appealing. Thus all the HF datasets would have three-letter language tags (handy for basic search), alongside the authors' preferred tags and language names (including Glottolog tags as well as ISO 639-{1, 2}, and all other options allowed by BCP-47). \r\n\r\nRetaining the authors' original tags and language names would be best. \r\n* For language names: some people favour one name over another and it is important to respect their choice. In the case of Yongning Na: alternative names include 'Mosuo', 'Narua', 'Eastern Naxi'... and the names carry implications: people have been reported to come to blows about the use of the term 'Mosuo'. \r\n* For language tags: Glottocodes can be more fine-grained than Ethnologue (ISO 639-3), and some colleagues feel strongly about those. \r\n\r\nThus there would be a BCP-47 tag (sounds like a solid technical choice, though not 'passer-by-friendly': requiring some expertise to interpret) **plus** an ISO 639-3 tag that could be grabbed easily, and (last but not least) language names spelled out in full. Searches would be easier. No information would be lost. \r\n\r\nAre industry practices so conservative that many people are happy with two-letter codes, and consider ISO 639-3 three-letter codes an unnecessary complication? That would be a pity, since there are so many advantages to using longer lists. (Somewhat like the transition to Unicode: sooo much better!) But maybe that conservative attitude _is_ widespread, and it would then need to be taken into account. In which case, one could consider offering two-letter codes as a search option. Internally, the search engine would look up the corresponding 3-letter codes, and produce the search results accordingly. \r\n\r\nNow to the other questions:\r\n\r\n> * Do you think it's possible to easily handle tags that have been deprecated potentially for decades?\r\n> For example (I'm taking the case of Hebrew but this has happened for other languages) I tagged Google models with the \"iw\" [tag](https://huggingface.co/models?language=iw&sort=downloads) because I based it on what the authors gave in their [paper](https://arxiv.org/pdf/2010.11934.pdf) see table 6 page 12). It turns out that this ISO tag has in fact been deprecated since 1989 in favour of the \"he\" tag. It would therefore be necessary to have a verification that transforms the old tags into the most recent ones.\r\nI guess that the above suggestion takes care of this case. The original tag (in this example, \"iw\") is retained (facilitating cross-reference with the published paper, and respecting the real: the way the dataset was originally tagged). This old tag goes into the `BCP-47` field of the dataset, which can handle quirks & oddities like this one. And a new tag is added in the `ISO 639-3` field: the 3-letter code \"heb\". \r\n\r\n> * When you look up a language on Wikipedia, it usually shows, in addition to the ISO standard, the codes in the Glottolog (which you have already mentioned), [ELP](https://www.endangeredlanguages.com/?hl=en) and [Linguasphere](http://www.linguasphere.info/jr/index.php?l1=home&l2=welcome) databases. Would you have any opinion about these two other databases?\r\n\r\nI'm afraid I never heard about Linguasphere. The [online register for Linguasphere (PDF)](http://www.linguasphere.info/jr/pdf/index/LS_index_n-n.pdf) seems to be from 1999-2000. It seems that the level of interoperability is not very high right now. (By contrast, Glottolog has [pyglottolog](https://github.com/glottolog/pyglottolog) and in my experience contacts flow well.) \r\n\r\nThe Endangered Languages Project is something Google started but initially did not 'push' very strongly, it seems. Just airing an opinion on the public Internet, it seems that the project is now solidly rooted at University of Hawaiʻi at Mānoa. It seems that they do not generate codes of their own. They refer to ISO 639-3 (Ethnologue) as a code authority when applicable, and otherwise provide comments in so many words, such as that language L currently lacks an Ethnologue code of its own (example [here](https://www.endangeredlanguages.com/lang/10624)). \r\n\r\n> * On the Hub, there is the following dataset where French people speak in English: https://huggingface.co/datasets/Datatang/French_Speaking_English_Speech_Data_by_Mobile_Phone\r\n> Is there a database to take this case into account? I have not found any code in the Glottolog database. If based on an IETF BCP-47 standard, I would tend to tag the dataset with \"en-fr\" but would this be something accepted by linguists?\r\n> Based on the first post in this thread that there are about 8000 languages, if one considers that a given language can be pronounced by a speaker of the other 7999, that would theoretically make about 64 million BCP-47 language1-language2 codes existing. And even much more if we consider regionalists with language1_regionalism_x-language2_regionalism_y. I guess there is no such database.\r\n\r\nYes, you noted the difficulty here: that there are so many possible situations. Eventually, each dataset would required descriptors of its own. @BenjaminGalliot points out that, in addition to specifying the speakers' native languages, the degree of language proficiency would also be relevant. How many years did the speakers spend in which area? Talking which languages? In what chronological order? Etc. The complexity defies encoding. The purpose of language codes is to allow for searches that group resources into sets that make sense. Additional information is very important, but would seem to be a matter for 'comments' fields. \r\n\r\n> * Is there an international classification of languages?\r\n> A bit like the [International Classification of Diseases](https://en.wikipedia.org/wiki/International_Classification_of_Diseases) in medicine, which is established by the WHO and used as a reference throughout the world. The idea would be to have a precise number of languages to which we would then have to assign a unique tag in order to find them later.\r\n\r\nAs I understand, Ethnologue and Glottolog both try to do that, each in its own way. The simile with diseases seems interesting, to some extent: in both cases it's about human classification of phenomena that have complexity (though some diseases are simpler than others, whereas all languages have much complexity, in different ways).\r\n\r\n> * Finally, when can we expect to see all the datasets of [Pangloss](https://pangloss.cnrs.fr/) on HF? eyes And I don't know if you have a way to help to add also the datasets of [CoCoON](https://cocoon.huma-num.fr/exist/crdo/).\r\n\r\nThree concerns: (i) Technical specifications: we have not yet received feedback on the Japhug and Na datasets in HF. There may be technical considerations that we have not yet thought of and that would need to be taken into account before 'bulk upload'. (ii) Would there be a way to automate the process? The way @BenjaminGalliot did it for Japhug and Na, there was a manual component involved, and doing it by hand for all 200 datasets would not be an ideal workflow, given that the metadata are all clearly arranged. (iii) Some datasets are currently under a 'No derivatives' CreativeCommons license. We could go back to the depositors and argue that the 'No derivatives' mention were best omitted (see [here a similar argument about publications](https://creativecommons.org/2020/04/21/academic-publications-under-no-derivatives-licenses-is-misguided/)): again, we'd want to be sure about the way forward before we set the process into motion.\r\n\r\nOur hope would be that some colleagues try out the [OutilsPangloss](https://gitlab.com/lacito/outilspangloss) download tool, assemble datasets from Pangloss/Cocoon as they wish, then deposit them to HF.",
"> The idea of letting people use their favourite nomenclature and automatically adding the ISO 639-3 three-letter code as a tag is appealing. Thus all the HF datasets would have three-letter language tags (handy for basic search), alongside the authors' preferred tags and language names (including Glottolog tags as well as ISO 639-{1, 2}, and all other options allowed by BCP-47).\r\n> \r\n> Retaining the authors' original tags and language names would be best.\r\n> \r\n> * For language names: some people favour one name over another and it is important to respect their choice. In the case of Yongning Na: alternative names include 'Mosuo', 'Narua', 'Eastern Naxi'... and the names carry implications: people have been reported to come to blows about the use of the term 'Mosuo'.\r\n> * For language tags: Glottocodes can be more fine-grained than Ethnologue (ISO 639-3), and some colleagues feel strongly about those.\r\n> \r\n> Thus there would be a BCP-47 tag (sounds like a solid technical choice, though not 'passer-by-friendly': requiring some expertise to interpret) **plus** an ISO 639-3 tag that could be grabbed easily, and (last but not least) language names spelled out in full. Searches would be easier. No information would be lost.\r\n\r\n@alexis-michaud raises an excellent point. Language Resource users have varying search habits (or approaches). This includes cases where two or more language names refer to a single language. A search utility/interface needs to be flexible and able to present results from various kinds of input in the search process. This could be like how the terms French/Français/Franzosisch (en/fr/de) are names for the same language or it could be a variety of the following: autoglottonyms (how the speakers of the language refer to their language), or exoglottonyms (how others refer to the language). Additionally, in web based searches I have also needed to implement diacritic sensitive and insensitive logic so that users can type with or without diacritics and not have results unnecessarily excluded. \r\n\r\nDepending on how detailed of a search problem HF seeks to solve. It may be better to off load complex search to search engines like OLAC which aggregate a lot of language resources. — as I mentioned above I can assist with the informatics on creating an OLAC feed.\r\n\r\nAbstracting search logic from actual metadata may prove a useful way to lower the technical debt overhead. Technical tools and library standards use ISO and BCP-47 Standards. So, from a bibliographic metadata perspective this seems to be the way forward with the widest set of use cases. ",
"To get a visual idea of these first exchanges, I coded a Streamlit app that I put online on Spaces: https://huggingface.co/spaces/lbourdois/Language-tags-demo. \r\nThe code is in Python so I don't know if it can be used by HF who seems to need something in Node.js but it serves as a proof of concept. The advantage is also that you can directly test ideas by enter things in a search bar and see what comes up. \r\n\r\nThis application is divided into 3 points:\r\n- The first is to enter a language in natural language to get its code which can then be filled in the YAML file of the README.MD files of the HF datasets or models in order to be referenced and found by everyone.\r\nIn practice, enter the language (e.g: `English`) you are interested in to get its associated tag (e.g: `en`). You can enter several languages by separating them with a comma (e.g `French,English,German`). You will be given priority to the ISO 639-3 code if it exists otherwise the Glottocode or the BCP47 code (for varieties in particular). If none of these codes are available, it links to a page where the user can contact HF to request to add this tag. \r\nIf you enter a BCP47 code, it must be entered as follows: `Language(Territory)`, for example `French(Canada)`. Attention! If you enter a BCP-47 language, it must be entered first, otherwise the plant code will be displayed. I have to fix this problem but I am moving to a new place, I don't have an internet connection when I want and I prefer to push this first version so that you can already test things now and not have to wait days or weeks.\r\nThis point is intended to simulate the user's side of the equation, which wonders which tag he should fill in for his language.\r\n\r\n\r\n- The second is to enter a language code to obtain the name of the language in natural language.\r\nIn practice, enter the tag (ISO 639-1/2/3, Glottolog or BCP-47) you are interested in (e.g: `fra`) to get its associated language (e.g: French). You can enter several languages by separating them with a comma (e.g `fra,eng,deu`). Attention! If you enter a BCP-47 code, it must be entered first, otherwise the plant code will be displayed. Same as the other bug above (it's actually the same one).\r\nThis point is intended to simulate the side of HF that for a given tag must return the correct language.\r\n\r\n\r\n\r\nTo code these two points, I tested two approaches. \r\n\r\n1. The first one (internal DB in the app) consists in querying a database that HF would have locally at their place. To create this database, I merged the ISO 639 database (https://iso639-3.sil.org/sites/iso639-3/files/downloads/iso-639-3.tab) and the Glottolog database (https://glottolog.org/meta/downloads). The result of this merge is visible in the 3rd point of the application qui is an overview of the database.\r\nIn the image below, on line 1 of the database, we can see that the Glottocode database gives an ISO 639-3 code (column ISO639P3code) but not the ISO 639 database (column 639-3). Do you have an explanation for this phenomenon?\r\n\r\n\r\n\r\nFor BCP 47 codes of the type `fr-CA`, I have retrieved the ISO-3166 alpha 1 codes of the territories (https://www.iso.org/iso-3166-country-codes.html).\r\nIn practice, what I do is if we enter `fr-CA` is that the letters before the `-` refer to a language in the `Name` column for a `639-1` == `fr` (`639-3` for `fra` or `fre`) in the base of my image above. Then I look at the letters after the `-` which refers to a territory. It comes out `French (Canada)`. I used https://cldr.unicode.org/translation/displaynames/languagelocale-name-patterns for the pattern that came up.\r\n\r\n\r\n2. The second approach (with langcodes lib in the app) consists in using the Python `langcodes` library (https://github.com/rspeer/langcodes) which offers a lot of features in ready-made functions. It manages for example deprecated codes, the validity of an entered code, gives languages from code in the language of your choice (by default in English, but also autoglottonyms), etc. I invite you to read the README of the library. The only negative point is that it hasn't been updated for 10 months so basing your tag system on an external tool that isn't necessarily up to date can cause problems in the long run. But it is certainly an interesting source.\r\n\r\nFinally, I have added some information on the number of people speaking/reading the language(s) searched (figures provided by langcodes which are based on those given by ISO). This is not relevant for our topic but it could be figures that could be added as information on the https://huggingface.co/languages page. \r\n\r\n\r\n\r\nWhat could be done to improve the app if I have time:\r\n- Write the text for the app's homepage to describe what it does. This could serve as a basis for a documentation that I think will be necessary to add somewhere on the HF website to explain how the language tagging system works.\r\n- Deal with the bug mentioned above\r\n- Integrate ISO 3166-1 alpha 2 territories (https://www.iso.org/obp/ui#iso:pub:PUB500001:en)? They offer a finer granularity than ISO 3166-1 alpha 1 which is limited to the country level, but they are very administrative (for French, ISO 3166-1 alpha 2 gives us the \"départements\" for example).\r\n- Add autoglottonyms? (I only handle English language names for the moment)\r\n- For each language indicate to which family it belongs, in practice this could help to make data augmentation, but especially to classify the languages and find them more easily on the page https://huggingface.co/languages.",
"Very impressive! Using the prompt 'Japhug' (a language name), the app finds the intended language:\r\n\r\n\r\nA first question: based on the Glottocode, would it be possible to grab the closest ISO639-3 code? In case there is no match for the exact language variety, one needs to explore the higher-level groupings, level by level. For this language (Japhug), the information provided in the extracted CSV file (`glottolog-languoids-v4.6.csv`) is: \r\n`sino1245/burm1265/naqi1236/qian1263/rgya1241/core1262/jiar1240` \r\nOne need not look further than the first higher-level grouping, [`jiar1240`](https://glottolog.org/resource/languoid/id/jiar1240), to get an ISO639-3 code, namely `jya`.\r\n\r\nThus users searching by language names would get ISO639-3 (often less fine-grained than Glottolog) as a bonus.\r\nIt might be possible to ask the Glottolog team to provide this piece of information as part of an export from their database.",
"> on line 1 of the database, we can see that the Glottocode database gives an ISO 639-3 code (column ISO639P3code) but not the ISO 639 database (column 639-3). Do you have an explanation for this phenomenon?\r\n\r\nThat is because the language name 'Aewa' is not found in the Ethnologue (ISO 639-3) export that you are using. [This export in table form](https://iso639-3.sil.org/sites/iso639-3/files/downloads/iso-639-3.tab) only has one reference name (`Ref_Name`). For the language at issue, it is not 'Aewa' but ['Awishira'](https://www.ethnologue.com/language/ash).\r\n\r\nBy contrast, the language on line 0 of the database is called 'Abinomn' by both Ethnologue and Glottolog, and accordingly, columns `ISO639P3code` and `639-3` both contain the ISO 639-3 code, `bsa`.\r\n \r\nThe full Ethnologue database records alternate names for each language, and I'd bet that 'Aewa' is recorded among alternate names for the 'Ashiwira' language. I can't check because the full Ethnologue database is paywalled. \r\n\r\n\r\n[Glottolog](https://glottolog.org/resource/languoid/id/abis1238) does provide the corresponding ISO 639-3 code for 'Aewa', `ash`, which is an exact match (it refers to the same variety as Glottolog `abis1238`).\r\nIn this specific case, Glottolog provides all the relevant information. I'd say that Glottolog can be trusted for all the codes they provide, including ISO 639-3 codes: they only include them when the match is good. \r\n\r\nSee previous comment about the cases where there is no exact match between Glottolog and ISO 639-3 (suggested workaround: look at a higher-level grouping to get an ISO 639-3 code).",
"I will add these two points to my TODO list.\r\n- Since Glottolog can be trust, I will add a condition to the code that if there is no ISO 639-3 code in the \"official\" database (https://iso639-3.sil.org/sites/iso639-3/files/downloads/iso-639-3.tab), look for it in the \"ISO639P3code\" column of Glottolog.\r\n- For the point of adding the closest ISO 639-3 code for a Glottolog code, what convention should be adopted for the output? Just the ISO 639-3 code, or the ISO 639-3 code - Glottolog code, or the ISO 639-3 code - language name?\r\nTo use the example of `Japhug` , should it be just `jya`, or `jya-japh1234` or `jya-Japhug`?",
"> * Integrate ISO 3166-1 alpha 2 territories (https://www.iso.org/obp/ui#iso:pub:PUB500001:en)? They offer a finer granularity than ISO 3166-1 alpha 1 which is limited to the country level, but they are very administrative (for French, ISO 3166-1 alpha 2 gives us the \"départements\" for example).\r\n\r\nI'm concerned with this sort of exploration. Not because I am against innovation. In fact this is an interesting thought exercise. However, to explore this thought further creates cognitive dissidence between BCP-47 authorized codes and other code sets which are not BP-47 compliant. For that reason, I think adding additional codes is a waste of time both for HF devs and for future users who get a confusing idea about language tagging. ",
"Good job for the application!\r\n\r\n> On the Hub, there is the following dataset where French people speak in English: https://huggingface.co/datasets/Datatang/French_Speaking_English_Speech_Data_by_Mobile_Phone\r\n Is there a database to take this case into account? I have not found any code in the Glottolog database. If based on an IETF BCP-47 standard, I would tend to tag the dataset with \"en-fr\" but would this be something accepted by linguists?\r\n Based on the first post in this thread that there are about 8000 languages, if one considers that a given language can be pronounced by a speaker of the other 7999, that would theoretically make about 64 million BCP-47 language1-language2 codes existing. And even much more if we consider regionalists with language1_regionalism_x-language2_regionalism_y. I guess there is no such database.\r\n\r\n> Yes, you noted the difficulty here: that there are so many possible situations. Eventually, each dataset would required descriptors of its own. @BenjaminGalliot points out that, in addition to specifying the speakers' native languages, the degree of language proficiency would also be relevant. How many years did the speakers spend in which area? Talking which languages? In what chronological order? Etc. The complexity defies encoding. The purpose of language codes is to allow for searches that group resources into sets that make sense. Additional information is very important, but would seem to be a matter for 'comments' fields.\r\n\r\nTo briefly complete what I said on this subject in a private discussion group, there is a lot of (meta)data associated with each element of a corpus (which language level, according to which criteria, knowing that even among native speakers there are differences, some of which may go beyond what seems obvious to us from a linguistic point of view, such as socio-professional category, life history, environment in the broad sense, etc.), which can be placed in ad-hoc columns, or more freely in a comment/note column. And it is the role of the researcher (in this case a linguist, in all likelihood) to do analyses (statistics...) to determine the relevant data, including criteria that may justify separating different languages (in the broad sense), making separate corpora, etc. Putting this information in the language code is in my opinion doing the job in the opposite and wrong direction, as well as bringing other problems, like where to stop in the list of multidimensional criteria to be integrated, so in my opinion, here, the minimum is the best (the important thing is in my opinion to have well-documented data, globally, by sub-corpus or by line)...\r\n\r\n> If you are going to use Glottolog codes use them after an -x- tag in the BCP-47 format to maintain BCP-47 validity.\r\n\r\nYes, for the current corpora, I have written:\r\n\r\n```\r\nlanguage:\r\n- jya\r\n- nru\r\nlanguage_bcp47:\r\n- x-japh1234\r\n- x-yong1288\r\n```\r\n\r\n> * Add autoglottonyms? (I only handle English language names for the moment)\r\n\r\nAutoglossonyms are useful (I use them prior to other glossonyms), but I'm not sure there is an easy way to retrieve them. We can find some of them in the \"Alternative Names\" panel of Glottolog, but even if we have an API to retrieve them easily, their associated language code will often not be the one we are in (hence the need to do several cycles to find one, which might not be the right one...). Maybe this problem needs more investigation...\r\n\r\n> For the point of adding the closest ISO 639-3 code for a Glottolog code, what convention should be adopted for the output? Just the ISO 639-3 code, or the ISO 639-3 code - Glottolog code, or the ISO 639-3 code - language name?\r\nTo use the example of Japhug , should it be just jya, or jya-japh1234 or jya-Japhug?\r\n\r\nI strongly insist not to add **a** language name after the code, it would restart a spiral of problems, notably the choice of the language in question:\r\n* the autoglossonym: in my opinion the best choice, but you have to know it…\r\n* the English name: iniquitous,\r\n* the name in the administratively/politically dominant language of the target language if it is relevant (strictly localized without overlapping, for example): iniquitous and tendentious (and in a way a special case of the previous one)...\r\n* etc.\r\n",
"> To get a visual idea of these first exchanges, I coded a Streamlit app that I put online on Spaces: https://huggingface.co/spaces/lbourdois/Language-tags-demo.\r\n> The code is in Python so I don't know if it can be used by HF who seems to need something in Node.js but it serves as a proof of concept. The advantage is also that you can directly test ideas by enter things in a search bar and see what comes up.\r\n\r\nThis is really great. You're doing a fantastic job. I love watching the creative process evolve. It is exciting. Let me provide some links to some search interfaces for further inspiration. I always find it helpful to know how others have approached a problem when figuring out my approach. I will link to three examples Glottolog, r12a's language sub-tag chooser, and the FLEx project builder wizard. The first two are online, but the last one is in an application which must be downloaded and works only on windows or linux. I have placed some notes on each of the screenshots.\r\n\r\n* **[Glottolog](https://glottolog.org/)** | [Search Query](https://glottolog.org/glottolog?name=en&namequerytype=part&multilingual=on#2/20.9/150.0) \r\n\r\n\r\n\r\n\r\n\r\n* **[r12a language sub-tag chooser](https://r12a.github.io/app-subtags/)** | [Code on github](https://github.com/r12a/app-subtags)\r\n\r\n\r\n\r\n\r\n* **FLEx Language Chooser** | [application page](https://software.sil.org/fieldworks/)\r\n\r\n\r\n",
"> In practice, what I do is if we enter `fr-CA` is that the letters before the `-` refer to a language in the `Name` column for a `639-1` == `fr` (`639-3` for `fra` or `fre`) in the base of my image above. Then I look at the letters after the `-` which refers to a territory. It comes out `French (Canada)`. I used https://cldr.unicode.org/translation/displaynames/languagelocale-name-patterns for the pattern that came up.\r\n\r\nWhat you are doing is looking at the algorithm for Locale generation rather than BCP-47's original documentation. I'm not sure there are difference, there might be. I know that locale IDs generally follow BCP-47 But I think there are some differences such as the use of `_` vs. `-`. ",
"> A first question: based on the Glottocode, would it be possible to grab the closest ISO639-3 code? In case there is no match for the exact language variety, one needs to explore the higher-level groupings, level by level. For this language (Japhug), the information provided in the extracted CSV file (`glottolog-languoids-v4.6.csv`) is: `sino1245/burm1265/naqi1236/qian1263/rgya1241/core1262/jiar1240` One need not look further than the first higher-level grouping, [`jiar1240`](https://glottolog.org/resource/languoid/id/jiar1240), to get an ISO639-3 code, namely `jya`.\r\n> \r\n> Thus users searching by language names would get ISO639-3 (often less fine-grained than Glottolog) as a bonus. It might be possible to ask the Glottolog team to provide this piece of information as part of an export from their database.\r\n\r\nThis is logical, but the fine grained assertions are not the same. That is just because they are in a hierarchical structure today doesn't mean they will be tomorrow. In some cases the glottolog is clearly referring to sub-language variants which will never receive full language status, whereas in other cases glottolog is referencing to unequal entities one or more of which should be a language. Many of the codes in glottolog have no associated documentation indicating what sort of speech variety they are. ",
"@lbourdois \r\n> * Since Glottolog can be trust, I will add a condition to the code that if there is no ISO 639-3 code in the \"official\" database (https://iso639-3.sil.org/sites/iso639-3/files/downloads/iso-639-3.tab), look for it in the \"ISO639P3code\" column of Glottolog.\r\n\r\nI'm confused here... if there is no ISO639-3 code in the official database from the registrar, why would you look for an \"unofficial\" code from someone else? What is the use case here?",
"> For the point of adding the closest ISO 639-3 code for a Glottolog code, what convention should be adopted for the output? Just the ISO 639-3 code, or the ISO 639-3 code - Glottolog code, or the ISO 639-3 code - language name?\r\nTo use the example of Japhug , should it be just jya, or jya-japh1234 or jya-Japhug?\r\n\r\n(answer edited in view of [Benjamin Galliot's comment](https://github.com/huggingface/datasets/issues/4881#issuecomment-1237420600) \r\nEasy part of the answer first: jya-Japhug is out, because, as @BenjaminGalliot pointed out above, mixing language names with language codes will make trouble. For Japhug, `jya-Japhug` looks rather good: the pair looks nice, the one (`jya`) packed together, the other (`Japhug`) good and complete while still pretty compact. But think about languages like 'Yongning Na' or 'Yucatán Maya': a code with a space in the middle, like `nru-Yongning Na`, is really unsightly and unwieldy, not?\r\n\r\nSome [principles for language naming in English](http://hdl.handle.net/10125/24725) have been put forward, with some linguistic arguments, but always supposing that such standardization is desirable, actual standardization of language names in English may well never happen.\r\n\r\nAs for `jya-japh1234`: again, at first sight it seems cute, combining two fierce competitors (Ethnologue and Glottolog) into something that gets the best of both worlds. \r\nBut @HughP has a point: _adding additional codes is a waste of time both for HF devs and for future users who get a confusing idea about language tagging_ Strong wording, for an important comment: better stick with BCP 47. \r\n\r\nSo the solution pointed out by Benjamin, from Frances Gillis-Webber and Sabine Tittel, looks attractive: \r\njya-x-japh1234\r\n\r\nOn the other hand, if the idea for HF Datasets is simply to add the closest ISO 639-3 code for a Glottolog code, maybe it could be provided simply in three letters: providing the 'raw' ISO 639-3 code `jya`. Availability of 'straight' ISO 639-3 codes could save trouble for some users, and those who want more detail could look at the rest of the metadata and general information associated with datasets.",
"The problem seems to have already been raised here: https://drops.dagstuhl.de/opus/volltexte/2019/10368/pdf/OASIcs-LDK-2019-4.pdf\r\n\r\nAn example can be seen here :\r\n\r\n> 3.1.2 The use of privateuse sub-tag\r\nIn light of unambiguous language codes being available for the two Khoisan varieties, we\r\npropose to combine the ISO 639-3 code for the parent language N‖ng, i.e., ‘ngh’, with the\r\nprivateuse sub-tag ‘x-’ and the respective Glottocodes stated above.\r\nThe language tags for N|uu and ‖’Au can then be defined accordingly:\r\nN|uu: ngh-x-nuuu1242\r\n‖’Au: ngh-x-auni1243\r\n\r\nBy the way, while searching for this, I came across this application: https://huggingface.co/spaces/cdleong/langcode-search",
"> > * Since Glottolog can be trust, I will add a condition to the code that if there is no ISO 639-3 code in the \"official\" database (https://iso639-3.sil.org/sites/iso639-3/files/downloads/iso-639-3.tab), look for it in the \"ISO639P3code\" column of Glottolog.\r\n> \r\n> I'm confused here... if there is no ISO639-3 code in the official database from the registrar, why would you look for an \"unofficial\" code from someone else? What is the use case here?\r\n\r\nHi @HughP, I'm happy to clear what confusion may exist here :innocent: Here is the use case. \r\nGuillaume Jacques (@rgyalrong) put together a sizeable corpus of the Japhug language. It is up on HF Datasets ([here](https://huggingface.co/datasets/Lacito/pangloss/viewer/japh1234)) as well as on Zenodo. \r\n\r\nZenodo is an all-purpose repository without adequate domain-specific metadata (\"[métadonnées métier](https://www.cines.fr/archivage/des-expertises/les-metadonnees/metadonnees-metier/)\"), and the deposits in there are not easy to locate. The Zenodo deposit is intended for a highly specific user case: someone reads about the dataset in a paper, goes to the address on Zenodo and grabs the dataset at one go. \r\n\r\nHF Datasets, on the other hand, allows users to look around among corpora. The Japhug corpus needs proper tagging so that HF Datasets users can find out about it. \r\nJaphug has an entry of its own in Glottolog, whereas it lacks an entry of its own in Ethnologue. Hence the practical usefulness of Glottolog. Ethnologue pools together, under the code `jya`, three different languages (Japhug, Tshobdun `tsho1240` and Zbu `zbua1234`). \r\n\r\nI hope that this helps.",
"> By the way, while searching for this, I came across this application: https://huggingface.co/spaces/cdleong/langcode-search\r\n\r\nReally relevant Space, so tagging its author @cdleong, just in case!",
"@cdleong A one-stop shop for language codes: terrific!\r\nHow do you feel about the use of Glottocodes? When searching the language names 'Japhug' and 'Yongning Na' (real examples, related to a HF Datasets deposit & various research projects), the relevant Glottocodes are retrieved, and that is great (and not that easy, notably with the space in the middle of 'Yongning Na'). But this positive result is 'hidden' in the results page. Specifically: \r\n\r\n- for Japhug: when searching by language name ('Japhug'), the result in big print is 'Failure', even though there is an available Glottocode (at bottom).\r\n\r\nWhen searching by Glottocode (japh1234), same outcome: 'Result: failure!' (even though this _is_ the right Glottocode\r\nWhen searching by x-japh1234 (Glottocode encapsulated in BCP 47 syntax), one gets the message \r\n\r\n> ''x-japh1234' parses meaningfully as a language tag according to IANA\"\r\n\r\nbut there is paradoxically no link provided to Glottolog: the 'Glottolog' part of the results page is empty\r\n\r\n\r\n- Yongning Na: the correct code is identified (yong1288) but instead of foregrounding this exact match, the first result that comes up is a completely different language, called 'Yong'. \r\n\r\nTrying to formulate a conclusion (admittedly, this note is not based on intensive testing, it is just feedback on initial contact): from a user perspective, it seems that the tool could make more extensive use of Glottolog. `langcode-search` does a great job querying Glottolog, why not make more extensive use of that information? (including: to arrive at the nearest ISO 639-3 code)"
] | "2022-08-23T20:14:24Z" | "2023-01-03T08:32:35Z" | null | NONE | null | null | null | **The problem:**
Language diversity is an important dimension of the diversity of datasets. To find one's way around datasets, being able to search by language name and by standardized codes appears crucial.
Currently the list of language codes is [here](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/resources/languages.json), right? At about 1,500 entries, it is roughly at 1/4th of the world's diversity of extant languages. (Probably less, as the list of 1,418 contains variants that are linguistically very close: 108 varieties of English, for instance.)
Looking forward to ever increasing coverage, how will the list of language names and language codes improve over time?
Enrichment of the custom list by HFT contributors (like [here](https://github.com/huggingface/datasets/pull/4880)) has several issues:
* progress is likely to be slow:

(input required from reviewers, etc.)
* the more contributors, the less consistency can be expected among contributions. No need to elaborate on how much confusion is likely to ensue as datasets accumulate.
* there is no information on which language relates with which: no encoding of the special closeness between the languages of the Northwestern Germanic branch (English+Dutch+German etc.), for instance. Information on phylogenetic closeness can be relevant to run experiments on transfer of technology from one language to its close relatives.
**A solution that seems desirable:**
Connecting to an established database that (i) aims at full coverage of the world's languages and (ii) has information on higher-level groupings, alternative names, etc.
It takes a lot of hard work to do such databases. Two important initiatives are [Ethnologue](https://www.ethnologue.com/) (ISO standard) and [Glottolog](https://glottolog.org/). Both have pros and cons. Glottolog contains references to Ethnologue identifiers, so adopting Glottolog entails getting the advantages of both sets of language codes.
Both seem technically accessible & 'developer-friendly'. Glottolog has a [GitHub repo](https://github.com/glottolog/glottolog). For Ethnologue, harvesting tools have been devised (see [here](https://github.com/lyy1994/ethnologue); I did not try it out).
In case a conversation with linguists seemed in order here, I'd be happy to participate ('pro bono', of course), & to rustle up more colleagues as useful, to help this useful development happen.
With appreciation of HFT, | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4881/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4881/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2954 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2954/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2954/comments | https://api.github.com/repos/huggingface/datasets/issues/2954/events | https://github.com/huggingface/datasets/pull/2954 | 1,003,904,803 | PR_kwDODunzps4sHa8O | 2,954 | Run tests in parallel | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"There is a speed up in Windows machines:\r\n- From `13m 52s` to `11m 10s`\r\n\r\nIn Linux machines, some workers crash with error message:\r\n```\r\nOSError: [Errno 12] Cannot allocate memory\r\n```",
"There is also a speed up in Linux machines:\r\n- From `7m 30s` to `5m 32s`"
] | "2021-09-22T07:00:44Z" | "2021-09-28T06:55:51Z" | "2021-09-28T06:55:51Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2954.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2954",
"merged_at": "2021-09-28T06:55:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2954.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2954"
} | Run CI tests in parallel to speed up the test suite.
Speed up results:
- Linux: from `7m 30s` to `5m 32s`
- Windows: from `13m 52s` to `11m 10s`
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2954/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2954/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3132 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3132/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3132/comments | https://api.github.com/repos/huggingface/datasets/issues/3132/events | https://github.com/huggingface/datasets/issues/3132 | 1,032,505,430 | I_kwDODunzps49ishW | 3,132 | Support Audio feature in streaming mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | "2021-10-21T13:32:18Z" | "2021-11-12T14:13:04Z" | "2021-11-12T14:13:04Z" | MEMBER | null | null | null | Currently, Audio feature is only supported for non-streaming datasets.
Due to the large size of many speech datasets, we should also support Audio feature in streaming mode.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3132/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3132/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1766 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1766/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1766/comments | https://api.github.com/repos/huggingface/datasets/issues/1766/events | https://github.com/huggingface/datasets/issues/1766 | 792,044,105 | MDU6SXNzdWU3OTIwNDQxMDU= | 1,766 | Issues when run two programs compute the same metrics | {
"avatar_url": "https://avatars.githubusercontent.com/u/8089862?v=4",
"events_url": "https://api.github.com/users/lamthuy/events{/privacy}",
"followers_url": "https://api.github.com/users/lamthuy/followers",
"following_url": "https://api.github.com/users/lamthuy/following{/other_user}",
"gists_url": "https://api.github.com/users/lamthuy/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lamthuy",
"id": 8089862,
"login": "lamthuy",
"node_id": "MDQ6VXNlcjgwODk4NjI=",
"organizations_url": "https://api.github.com/users/lamthuy/orgs",
"received_events_url": "https://api.github.com/users/lamthuy/received_events",
"repos_url": "https://api.github.com/users/lamthuy/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lamthuy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lamthuy/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lamthuy"
} | [] | closed | false | null | [] | null | [
"Hi ! To avoid collisions you can specify a `experiment_id` when instantiating your metric using `load_metric`. It will replace \"default_experiment\" with the experiment id that you provide in the arrow filename. \r\n\r\nAlso when two `experiment_id` collide we're supposed to detect it using our locking mechanism. Not sure why it didn't work in your case. Could you share some code that reproduces the issue ? This would help us investigate.",
"Thank you for your response. I fixed the issue by set \"keep_in_memory=True\" when load_metric. \r\nI cannot share the entire source code but below is the wrapper I wrote:\r\n\r\n```python\r\nclass Evaluation:\r\n def __init__(self, metric='sacrebleu'):\r\n # self.metric = load_metric(metric, keep_in_memory=True)\r\n self.metric = load_metric(metric)\r\n\r\n def add(self, predictions, references):\r\n self.metric.add_batch(predictions=predictions, references=references)\r\n\r\n def compute(self):\r\n return self.metric.compute()['score']\r\n```\r\n\r\nThen call the given wrapper as follows:\r\n\r\n```python\r\neval = Evaluation(metric='sacrebleu')\r\nfor query, candidates, labels in tqdm(dataset):\r\n predictions = net.generate(query)\r\n references = [[s] for s in labels]\r\n eval.add(predictions, references)\r\n if n % 100 == 0:\r\n bleu += eval.compute()\r\n eval = Evaluation(metric='sacrebleu')"
] | "2021-01-22T14:22:55Z" | "2021-02-02T10:38:06Z" | "2021-02-02T10:38:06Z" | NONE | null | null | null | I got the following error when running two different programs that both compute sacreblue metrics. It seems that both read/and/write to the same location (.cache/huggingface/metrics/sacrebleu/default/default_experiment-1-0.arrow) where it caches the batches:
```
File "train_matching_min.py", line 160, in <module>ch_9_label
avg_loss = valid(epoch, args.batch, args.validation, args.with_label)
File "train_matching_min.py", line 93, in valid
bleu += eval.compute()
File "/u/tlhoang/projects/seal/match/models/eval.py", line 23, in compute
return self.metric.compute()['score']
File "/dccstor/know/anaconda3/lib/python3.7/site-packages/datasets/metric.py", line 387, in compute
self._finalize()
File "/dccstor/know/anaconda3/lib/python3.7/site-packages/datasets/metric.py", line 355, in _finalize
self.data = Dataset(**reader.read_files([{"filename": f} for f in file_paths]))
File "/dccstor/know/anaconda3/lib/python3.7/site-packages/datasets/arrow_reader.py", line 231, in read_files
pa_table = self._read_files(files)
File "/dccstor/know/anaconda3/lib/python3.7/site-packages/datasets/arrow_reader.py", line 170, in _read_files
pa_table: pa.Table = self._get_dataset_from_filename(f_dict)
File "/dccstor/know/anaconda3/lib/python3.7/site-packages/datasets/arrow_reader.py", line 299, in _get_dataset_from_filename
pa_table = f.read_all()
File "pyarrow/ipc.pxi", line 481, in pyarrow.lib.RecordBatchReader.read_all
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Expected to read 1819307375 metadata bytes, but only read 454396
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1766/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1766/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2403 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2403/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2403/comments | https://api.github.com/repos/huggingface/datasets/issues/2403/events | https://github.com/huggingface/datasets/pull/2403 | 900,059,014 | MDExOlB1bGxSZXF1ZXN0NjUxNjcxMTMw | 2,403 | Free datasets with cache file in temp dir on exit | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [] | "2021-05-24T22:15:11Z" | "2021-05-26T17:25:19Z" | "2021-05-26T16:39:29Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2403.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2403",
"merged_at": "2021-05-26T16:39:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2403.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2403"
} | This PR properly cleans up the memory-mapped tables that reference the cache files inside the temp dir.
Since the built-in `_finalizer` of `TemporaryDirectory` can't be modified, this PR defines its own `TemporaryDirectory` class that accepts a custom clean-up function.
Fixes #2402 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2403/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2403/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5584 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5584/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5584/comments | https://api.github.com/repos/huggingface/datasets/issues/5584/events | https://github.com/huggingface/datasets/issues/5584 | 1,601,821,808 | I_kwDODunzps5fedxw | 5,584 | Unable to load coyo700M dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/3059998?v=4",
"events_url": "https://api.github.com/users/manuaero/events{/privacy}",
"followers_url": "https://api.github.com/users/manuaero/followers",
"following_url": "https://api.github.com/users/manuaero/following{/other_user}",
"gists_url": "https://api.github.com/users/manuaero/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/manuaero",
"id": 3059998,
"login": "manuaero",
"node_id": "MDQ6VXNlcjMwNTk5OTg=",
"organizations_url": "https://api.github.com/users/manuaero/orgs",
"received_events_url": "https://api.github.com/users/manuaero/received_events",
"repos_url": "https://api.github.com/users/manuaero/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/manuaero/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/manuaero/subscriptions",
"type": "User",
"url": "https://api.github.com/users/manuaero"
} | [] | closed | false | null | [] | null | [
"Hi @manuaero \r\n\r\nThank you for your interest in the COYO dataset.\r\n\r\nOur dataset provides the img-url and alt-text in the form of a parquet, so to utilize the coyo dataset you will need to download it directly.\r\n\r\nWe provide a [guide](https://github.com/kakaobrain/coyo-dataset/blob/main/download/README.md) to download, so check it out.\r\n\r\nThank you."
] | "2023-02-27T19:35:03Z" | "2023-02-28T07:27:59Z" | "2023-02-28T07:27:58Z" | NONE | null | null | null | ### Describe the bug
Seeing this error when downloading https://huggingface.co/datasets/kakaobrain/coyo-700m:
```ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.```
Full stack trace
```Downloading and preparing dataset parquet/kakaobrain--coyo-700m to /root/.cache/huggingface/datasets/kakaobrain___parquet/kakaobrain--coyo-700m-ae729692ae3e0073/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec...
Downloading data files: 100%
1/1 [00:00<00:00, 63.35it/s]
Extracting data files: 100%
1/1 [00:00<00:00, 5.00it/s]
---------------------------------------------------------------------------
ArrowInvalid Traceback (most recent call last)
[/usr/local/lib/python3.8/dist-packages/datasets/builder.py](https://localhost:8080/#) in _prepare_split_single(self, gen_kwargs, fpath, file_format, max_shard_size, job_id)
1859 _time = time.time()
-> 1860 for _, table in generator:
1861 if max_shard_size is not None and writer._num_bytes > max_shard_size:
9 frames
ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.
The above exception was the direct cause of the following exception:
DatasetGenerationError Traceback (most recent call last)
[/usr/local/lib/python3.8/dist-packages/datasets/builder.py](https://localhost:8080/#) in _prepare_split_single(self, gen_kwargs, fpath, file_format, max_shard_size, job_id)
1890 if isinstance(e, SchemaInferenceError) and e.__context__ is not None:
1891 e = e.__context__
-> 1892 raise DatasetGenerationError("An error occurred while generating the dataset") from e
1893
1894 yield job_id, True, (total_num_examples, total_num_bytes, writer._features, num_shards, shard_lengths)
DatasetGenerationError: An error occurred while generating the dataset```
### Steps to reproduce the bug
```
from datasets import load_dataset
hf_dataset = load_dataset("kakaobrain/coyo-700m")
```
### Expected behavior
The above commands load the dataset successfully. Or handles exception and continue loading the remainder.
### Environment info
colab. any | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5584/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5584/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6047 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6047/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6047/comments | https://api.github.com/repos/huggingface/datasets/issues/6047/events | https://github.com/huggingface/datasets/pull/6047 | 1,809,627,947 | PR_kwDODunzps5VxRLA | 6,047 | Bump dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6047). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006384 / 0.011353 (-0.004969) | 0.003872 / 0.011008 (-0.007136) | 0.083454 / 0.038508 (0.044946) | 0.069120 / 0.023109 (0.046011) | 0.312573 / 0.275898 (0.036675) | 0.345814 / 0.323480 (0.022334) | 0.005729 / 0.007986 (-0.002257) | 0.003225 / 0.004328 (-0.001103) | 0.063950 / 0.004250 (0.059700) | 0.053998 / 0.037052 (0.016946) | 0.316492 / 0.258489 (0.058003) | 0.350738 / 0.293841 (0.056897) | 0.030770 / 0.128546 (-0.097776) | 0.008474 / 0.075646 (-0.067173) | 0.286989 / 0.419271 (-0.132282) | 0.052473 / 0.043533 (0.008940) | 0.314361 / 0.255139 (0.059222) | 0.335170 / 0.283200 (0.051970) | 0.022885 / 0.141683 (-0.118798) | 1.465430 / 1.452155 (0.013275) | 1.527799 / 1.492716 (0.035083) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.209377 / 0.018006 (0.191371) | 0.455583 / 0.000490 (0.455094) | 0.003352 / 0.000200 (0.003152) | 0.000080 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026284 / 0.037411 (-0.011127) | 0.080710 / 0.014526 (0.066185) | 0.091741 / 0.176557 (-0.084816) | 0.147602 / 0.737135 (-0.589534) | 0.091173 / 0.296338 (-0.205166) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.386592 / 0.215209 (0.171383) | 3.856665 / 2.077655 (1.779011) | 1.835745 / 1.504120 (0.331625) | 1.671814 / 1.541195 (0.130619) | 1.711224 / 1.468490 (0.242734) | 0.484704 / 4.584777 (-4.100073) | 3.649239 / 3.745712 (-0.096473) | 3.784051 / 5.269862 (-1.485810) | 2.241195 / 4.565676 (-2.324482) | 0.056613 / 0.424275 (-0.367662) | 0.007140 / 0.007607 (-0.000467) | 0.464585 / 0.226044 (0.238540) | 4.616537 / 2.268929 (2.347609) | 2.371969 / 55.444624 (-53.072656) | 1.977754 / 6.876477 (-4.898723) | 2.083385 / 2.142072 (-0.058687) | 0.582330 / 4.805227 (-4.222897) | 0.132744 / 6.500664 (-6.367920) | 0.059822 / 0.075469 (-0.015647) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.259566 / 1.841788 (-0.582221) | 18.990166 / 8.074308 (10.915858) | 13.992069 / 10.191392 (3.800677) | 0.160001 / 0.680424 (-0.520423) | 0.018622 / 0.534201 (-0.515579) | 0.392921 / 0.579283 (-0.186362) | 0.418225 / 0.434364 (-0.016139) | 0.471252 / 0.540337 (-0.069086) | 0.653227 / 1.386936 (-0.733709) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006641 / 0.011353 (-0.004712) | 0.003738 / 0.011008 (-0.007271) | 0.064053 / 0.038508 (0.025545) | 0.069467 / 0.023109 (0.046357) | 0.360625 / 0.275898 (0.084727) | 0.394291 / 0.323480 (0.070811) | 0.005236 / 0.007986 (-0.002750) | 0.003304 / 0.004328 (-0.001024) | 0.064078 / 0.004250 (0.059827) | 0.054605 / 0.037052 (0.017552) | 0.374567 / 0.258489 (0.116078) | 0.411227 / 0.293841 (0.117386) | 0.031614 / 0.128546 (-0.096933) | 0.008323 / 0.075646 (-0.067324) | 0.070616 / 0.419271 (-0.348656) | 0.050077 / 0.043533 (0.006544) | 0.362229 / 0.255139 (0.107090) | 0.388310 / 0.283200 (0.105110) | 0.024053 / 0.141683 (-0.117630) | 1.508913 / 1.452155 (0.056759) | 1.562140 / 1.492716 (0.069423) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230172 / 0.018006 (0.212165) | 0.449363 / 0.000490 (0.448873) | 0.002374 / 0.000200 (0.002174) | 0.000097 / 0.000054 (0.000043) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029813 / 0.037411 (-0.007598) | 0.087298 / 0.014526 (0.072772) | 0.096712 / 0.176557 (-0.079845) | 0.152864 / 0.737135 (-0.584271) | 0.098204 / 0.296338 (-0.198135) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.408664 / 0.215209 (0.193455) | 4.075068 / 2.077655 (1.997414) | 2.096365 / 1.504120 (0.592245) | 1.936096 / 1.541195 (0.394901) | 1.961872 / 1.468490 (0.493382) | 0.483383 / 4.584777 (-4.101394) | 3.686926 / 3.745712 (-0.058787) | 4.798824 / 5.269862 (-0.471037) | 2.652279 / 4.565676 (-1.913398) | 0.056695 / 0.424275 (-0.367580) | 0.007592 / 0.007607 (-0.000016) | 0.484710 / 0.226044 (0.258665) | 4.842153 / 2.268929 (2.573225) | 2.636828 / 55.444624 (-52.807796) | 2.243666 / 6.876477 (-4.632811) | 2.375972 / 2.142072 (0.233899) | 0.578544 / 4.805227 (-4.226683) | 0.132579 / 6.500664 (-6.368085) | 0.061287 / 0.075469 (-0.014182) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.360287 / 1.841788 (-0.481501) | 19.464110 / 8.074308 (11.389802) | 14.530875 / 10.191392 (4.339483) | 0.149479 / 0.680424 (-0.530944) | 0.018471 / 0.534201 (-0.515730) | 0.395399 / 0.579283 (-0.183884) | 0.412897 / 0.434364 (-0.021467) | 0.465194 / 0.540337 (-0.075144) | 0.611752 / 1.386936 (-0.775184) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008986 / 0.011353 (-0.002367) | 0.005104 / 0.011008 (-0.005905) | 0.108371 / 0.038508 (0.069863) | 0.091655 / 0.023109 (0.068546) | 0.430183 / 0.275898 (0.154285) | 0.481387 / 0.323480 (0.157907) | 0.006662 / 0.007986 (-0.001324) | 0.004681 / 0.004328 (0.000353) | 0.089325 / 0.004250 (0.085075) | 0.065096 / 0.037052 (0.028044) | 0.435021 / 0.258489 (0.176532) | 0.478635 / 0.293841 (0.184794) | 0.047628 / 0.128546 (-0.080918) | 0.013496 / 0.075646 (-0.062150) | 0.389661 / 0.419271 (-0.029611) | 0.082260 / 0.043533 (0.038727) | 0.474165 / 0.255139 (0.219026) | 0.464877 / 0.283200 (0.181677) | 0.039784 / 0.141683 (-0.101899) | 1.874694 / 1.452155 (0.422539) | 1.980183 / 1.492716 (0.487467) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.254044 / 0.018006 (0.236038) | 0.631495 / 0.000490 (0.631005) | 0.000628 / 0.000200 (0.000428) | 0.000086 / 0.000054 (0.000032) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.038773 / 0.037411 (0.001362) | 0.103681 / 0.014526 (0.089156) | 0.125081 / 0.176557 (-0.051476) | 0.198345 / 0.737135 (-0.538790) | 0.122217 / 0.296338 (-0.174121) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.611677 / 0.215209 (0.396468) | 6.220790 / 2.077655 (4.143135) | 2.729858 / 1.504120 (1.225739) | 2.351944 / 1.541195 (0.810749) | 2.449137 / 1.468490 (0.980647) | 0.896842 / 4.584777 (-3.687935) | 5.537491 / 3.745712 (1.791778) | 8.480182 / 5.269862 (3.210320) | 5.251404 / 4.565676 (0.685728) | 0.100449 / 0.424275 (-0.323826) | 0.009008 / 0.007607 (0.001401) | 0.750060 / 0.226044 (0.524016) | 7.390940 / 2.268929 (5.122011) | 3.478256 / 55.444624 (-51.966369) | 2.883597 / 6.876477 (-3.992880) | 3.082256 / 2.142072 (0.940183) | 1.114339 / 4.805227 (-3.690889) | 0.225389 / 6.500664 (-6.275275) | 0.083972 / 0.075469 (0.008503) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.741522 / 1.841788 (-0.100266) | 25.674700 / 8.074308 (17.600392) | 24.324412 / 10.191392 (14.133020) | 0.257878 / 0.680424 (-0.422546) | 0.038384 / 0.534201 (-0.495817) | 0.508302 / 0.579283 (-0.070981) | 0.612979 / 0.434364 (0.178615) | 0.584366 / 0.540337 (0.044029) | 0.881115 / 1.386936 (-0.505821) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009114 / 0.011353 (-0.002239) | 0.005333 / 0.011008 (-0.005675) | 0.094944 / 0.038508 (0.056436) | 0.099178 / 0.023109 (0.076068) | 0.529813 / 0.275898 (0.253915) | 0.551282 / 0.323480 (0.227802) | 0.006442 / 0.007986 (-0.001543) | 0.004283 / 0.004328 (-0.000045) | 0.084257 / 0.004250 (0.080007) | 0.067557 / 0.037052 (0.030504) | 0.514733 / 0.258489 (0.256244) | 0.568200 / 0.293841 (0.274359) | 0.050969 / 0.128546 (-0.077577) | 0.014495 / 0.075646 (-0.061151) | 0.097089 / 0.419271 (-0.322182) | 0.063142 / 0.043533 (0.019609) | 0.513327 / 0.255139 (0.258188) | 0.520593 / 0.283200 (0.237394) | 0.036824 / 0.141683 (-0.104859) | 1.954875 / 1.452155 (0.502720) | 1.976307 / 1.492716 (0.483591) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.304070 / 0.018006 (0.286063) | 0.611073 / 0.000490 (0.610583) | 0.005027 / 0.000200 (0.004827) | 0.000113 / 0.000054 (0.000059) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.037993 / 0.037411 (0.000582) | 0.115876 / 0.014526 (0.101350) | 0.118087 / 0.176557 (-0.058469) | 0.186437 / 0.737135 (-0.550699) | 0.129883 / 0.296338 (-0.166456) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.658292 / 0.215209 (0.443083) | 6.618257 / 2.077655 (4.540602) | 3.203786 / 1.504120 (1.699667) | 2.858714 / 1.541195 (1.317519) | 2.940974 / 1.468490 (1.472484) | 0.856238 / 4.584777 (-3.728538) | 5.427708 / 3.745712 (1.681996) | 4.810048 / 5.269862 (-0.459813) | 3.120006 / 4.565676 (-1.445671) | 0.098098 / 0.424275 (-0.326177) | 0.010077 / 0.007607 (0.002470) | 0.790890 / 0.226044 (0.564845) | 7.956679 / 2.268929 (5.687750) | 3.955710 / 55.444624 (-51.488914) | 3.446419 / 6.876477 (-3.430057) | 3.541228 / 2.142072 (1.399156) | 1.013420 / 4.805227 (-3.791808) | 0.213741 / 6.500664 (-6.286923) | 0.080857 / 0.075469 (0.005388) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.813265 / 1.841788 (-0.028522) | 25.965199 / 8.074308 (17.890891) | 21.892761 / 10.191392 (11.701369) | 0.257843 / 0.680424 (-0.422580) | 0.029388 / 0.534201 (-0.504813) | 0.510609 / 0.579283 (-0.068674) | 0.626579 / 0.434364 (0.192215) | 0.576865 / 0.540337 (0.036528) | 0.826610 / 1.386936 (-0.560326) |\n\n</details>\n</details>\n\n\n"
] | "2023-07-18T10:15:39Z" | "2023-07-18T10:28:01Z" | "2023-07-18T10:15:52Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6047.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6047",
"merged_at": "2023-07-18T10:15:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6047.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6047"
} | workaround to fix an issue with transformers CI
https://github.com/huggingface/transformers/pull/24867#discussion_r1266519626 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6047/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6047/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5407 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5407/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5407/comments | https://api.github.com/repos/huggingface/datasets/issues/5407/events | https://github.com/huggingface/datasets/issues/5407 | 1,519,797,345 | I_kwDODunzps5alkRh | 5,407 | Datasets.from_sql() generates deprecation warning | {
"avatar_url": "https://avatars.githubusercontent.com/u/21002157?v=4",
"events_url": "https://api.github.com/users/msummerfield/events{/privacy}",
"followers_url": "https://api.github.com/users/msummerfield/followers",
"following_url": "https://api.github.com/users/msummerfield/following{/other_user}",
"gists_url": "https://api.github.com/users/msummerfield/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/msummerfield",
"id": 21002157,
"login": "msummerfield",
"node_id": "MDQ6VXNlcjIxMDAyMTU3",
"organizations_url": "https://api.github.com/users/msummerfield/orgs",
"received_events_url": "https://api.github.com/users/msummerfield/received_events",
"repos_url": "https://api.github.com/users/msummerfield/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/msummerfield/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/msummerfield/subscriptions",
"type": "User",
"url": "https://api.github.com/users/msummerfield"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Thanks for reporting @msummerfield. We are fixing it."
] | "2023-01-05T00:43:17Z" | "2023-01-06T10:59:14Z" | "2023-01-06T10:59:14Z" | NONE | null | null | null | ### Describe the bug
Calling `Datasets.from_sql()` generates a warning:
`.../site-packages/datasets/builder.py:712: FutureWarning: 'use_auth_token' was deprecated in version 2.7.1 and will be removed in 3.0.0. Pass 'use_auth_token' to the initializer/'load_dataset_builder' instead.`
### Steps to reproduce the bug
Any valid call to `Datasets.from_sql()` will produce the deprecation warning.
### Expected behavior
No warning.
The fix should be simply to remove the parameter `use_auth_token` from the call to `builder.download_and_prepare()` at line 43 of `io/sql.py` (it is set to `None` anyway, and is not needed).
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-4.15.0-169-generic-x86_64-with-glibc2.27
- Python version: 3.9.15
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5407/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5407/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3475 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3475/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3475/comments | https://api.github.com/repos/huggingface/datasets/issues/3475/events | https://github.com/huggingface/datasets/issues/3475 | 1,087,352,041 | I_kwDODunzps5Az6zp | 3,475 | The rotten_tomatoes dataset of movie reviews contains some reviews in Spanish | {
"avatar_url": "https://avatars.githubusercontent.com/u/17426779?v=4",
"events_url": "https://api.github.com/users/puzzler10/events{/privacy}",
"followers_url": "https://api.github.com/users/puzzler10/followers",
"following_url": "https://api.github.com/users/puzzler10/following{/other_user}",
"gists_url": "https://api.github.com/users/puzzler10/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/puzzler10",
"id": 17426779,
"login": "puzzler10",
"node_id": "MDQ6VXNlcjE3NDI2Nzc5",
"organizations_url": "https://api.github.com/users/puzzler10/orgs",
"received_events_url": "https://api.github.com/users/puzzler10/received_events",
"repos_url": "https://api.github.com/users/puzzler10/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/puzzler10/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/puzzler10/subscriptions",
"type": "User",
"url": "https://api.github.com/users/puzzler10"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"Hi @puzzler10, thanks for reporting.\r\n\r\nPlease note this dataset is not hosted on Hugging Face Hub. See: \r\nhttps://github.com/huggingface/datasets/blob/c8f914473b041833fd47178fa4373cdcb56ac522/datasets/rotten_tomatoes/rotten_tomatoes.py#L42\r\n\r\nIf there are issues with the source data of a dataset, you should contact the data owners/creators instead. In the homepage associated with this dataset (http://www.cs.cornell.edu/people/pabo/movie-review-data/), you can find the authors of the dataset and how to contact them:\r\n> If you have any questions or comments regarding this site, please send email to Bo Pang or Lillian Lee.\r\n\r\nP.S.: Please also note that the example you gave of non-English review is in Portuguese (not Spanish). ;)",
"Maybe best to just put a quick sentence in the dataset description that highlights this? "
] | "2021-12-23T03:56:43Z" | "2021-12-24T00:23:03Z" | null | NONE | null | null | null | ## Describe the bug
See title. I don't think this is intentional and they probably should be removed. If they stay the dataset description should be at least updated to make it clear to the user.
## Steps to reproduce the bug
Go to the [dataset viewer](https://huggingface.co/datasets/viewer/?dataset=rotten_tomatoes) for the dataset, set the offset to 4160 for the train dataset, and scroll through the results. I found ones at index 4166 and 4173. There's others too (e.g. index 2888) but those two are easy to find like that.
## Expected results
English movie reviews only.
## Actual results
Example of a Spanish movie review (4173):
> "É uma pena que , mais tarde , o próprio filme abandone o tom de paródia e passe a utilizar os mesmos clichês que havia satirizado "
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3475/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3475/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5716 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5716/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5716/comments | https://api.github.com/repos/huggingface/datasets/issues/5716/events | https://github.com/huggingface/datasets/issues/5716 | 1,658,613,092 | I_kwDODunzps5i3G1k | 5,716 | Handle empty audio | {
"avatar_url": "https://avatars.githubusercontent.com/u/38179632?v=4",
"events_url": "https://api.github.com/users/v-yunbin/events{/privacy}",
"followers_url": "https://api.github.com/users/v-yunbin/followers",
"following_url": "https://api.github.com/users/v-yunbin/following{/other_user}",
"gists_url": "https://api.github.com/users/v-yunbin/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/v-yunbin",
"id": 38179632,
"login": "v-yunbin",
"node_id": "MDQ6VXNlcjM4MTc5NjMy",
"organizations_url": "https://api.github.com/users/v-yunbin/orgs",
"received_events_url": "https://api.github.com/users/v-yunbin/received_events",
"repos_url": "https://api.github.com/users/v-yunbin/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/v-yunbin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/v-yunbin/subscriptions",
"type": "User",
"url": "https://api.github.com/users/v-yunbin"
} | [] | closed | false | null | [] | null | [
"Hi! Can you share one of the problematic audio files with us?\r\n\r\nI tried to reproduce the error with the following code: \r\n```python\r\nimport soundfile as sf\r\nimport numpy as np\r\nfrom datasets import Audio\r\n\r\nsf.write(\"empty.wav\", np.array([]), 16000)\r\nAudio(sampling_rate=24000).decode_example({\"path\": \"empty.wav\", \"bytes\": None})\r\n```\r\nBut without success.\r\n\r\nAlso, what version of `librosa` is installed in your env? (You can get this info with `python -c \"import librosa; print(librosa.__version__)`)\r\n\r\n",
"I'm closing this issue as the reproducer hasn't been provided."
] | "2023-04-07T09:51:40Z" | "2023-09-27T17:47:08Z" | "2023-09-27T17:47:08Z" | NONE | null | null | null | Some audio paths exist, but they are empty, and an error will be reported when reading the audio path.How to use the filter function to avoid the empty audio path?
when a audio is empty, when do resample , it will break:
`array, sampling_rate = sf.read(f) array = librosa.resample(array, orig_sr=sampling_rate, target_sr=self.sampling_rate)` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5716/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5716/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4657 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4657/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4657/comments | https://api.github.com/repos/huggingface/datasets/issues/4657/events | https://github.com/huggingface/datasets/issues/4657 | 1,296,743,133 | I_kwDODunzps5NSrrd | 4,657 | Add SQuAD2.0 Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_url": "https://api.github.com/users/omarespejel/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/omarespejel",
"id": 4755430,
"login": "omarespejel",
"node_id": "MDQ6VXNlcjQ3NTU0MzA=",
"organizations_url": "https://api.github.com/users/omarespejel/orgs",
"received_events_url": "https://api.github.com/users/omarespejel/received_events",
"repos_url": "https://api.github.com/users/omarespejel/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/omarespejel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/omarespejel/subscriptions",
"type": "User",
"url": "https://api.github.com/users/omarespejel"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [
"Hey, It's already present [here](https://huggingface.co/datasets/squad_v2) ",
"Hi! This dataset is indeed already available on the Hub. Closing."
] | "2022-07-07T03:19:36Z" | "2022-07-12T16:14:52Z" | "2022-07-12T16:14:52Z" | NONE | null | null | null | ## Adding a Dataset
- **Name:** *SQuAD2.0*
- **Description:** *Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.*
- **Paper:** *https://aclanthology.org/P18-2124.pdf*
- **Data:** *https://rajpurkar.github.io/SQuAD-explorer/*
- **Motivation:** *Dataset for training and evaluating models of conversational response*
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4657/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4657/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4015 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4015/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4015/comments | https://api.github.com/repos/huggingface/datasets/issues/4015/events | https://github.com/huggingface/datasets/issues/4015 | 1,180,510,856 | I_kwDODunzps5GXSqI | 4,015 | Can not correctly parse the classes with imagefolder | {
"avatar_url": "https://avatars.githubusercontent.com/u/21264909?v=4",
"events_url": "https://api.github.com/users/YiSyuanChen/events{/privacy}",
"followers_url": "https://api.github.com/users/YiSyuanChen/followers",
"following_url": "https://api.github.com/users/YiSyuanChen/following{/other_user}",
"gists_url": "https://api.github.com/users/YiSyuanChen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/YiSyuanChen",
"id": 21264909,
"login": "YiSyuanChen",
"node_id": "MDQ6VXNlcjIxMjY0OTA5",
"organizations_url": "https://api.github.com/users/YiSyuanChen/orgs",
"received_events_url": "https://api.github.com/users/YiSyuanChen/received_events",
"repos_url": "https://api.github.com/users/YiSyuanChen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/YiSyuanChen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/YiSyuanChen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/YiSyuanChen"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"I found that the problem arises because the image files in my folder are actually symbolic links (for my own reasons). After modifications, the classes can now be correctly parsed. Therefore, I close this issue.",
"HI, I have a question. How much time did you load the ImageNet data files? "
] | "2022-03-25T08:51:17Z" | "2022-03-28T01:02:03Z" | "2022-03-25T09:27:56Z" | NONE | null | null | null | ## Describe the bug
I try to load my own image dataset with imagefolder, but the parsing of classes is incorrect.
## Steps to reproduce the bug
I organized my dataset (ImageNet) in the following structure:
```
- imagenet/
- train/
- n01440764/
- ILSVRC2012_val_00000293.jpg
- ......
- n01695060/
- ......
- val/
- n01440764/
- n01695060/
- ......
```
At first, I followed the instructions from the Huggingface [example](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification#using-your-own-data) to load my data as:
```
from datasets import load_dataset
data_files = {'train': 'imagenet/train', 'val': 'imagenet/val'}
ds = load_dataset("nateraw/image-folder", data_files=data_files, task="image-classification")
```
but it resulted following error (I mask my personal path as <PERSONAL_PATH>):
```
FileNotFoundError: Unable to find 'https://huggingface.co/datasets/nateraw/image-folder/resolve/main/imagenet/train' at <PERSONAL_PATH>/ImageNet/https:/huggingface.co/datasets/nateraw/image-folder/resolve/main
```
Next, I followed a recent issue #3960 to load data as:
```
from datasets import load_dataset
data_files = {'train': ['imagenet/train/**'], 'val': ['imagenet/val/**']}
ds = load_dataset("imagefolder", data_files=data_files, task="image-classification")
```
and the data can be loaded without error as: (I copy val folder to train folder for illustration)
```
>>> ds
DatasetDict({
train: Dataset({
features: ['image', 'labels'],
num_rows: 50000
})
val: Dataset({
features: ['image', 'labels'],
num_rows: 50000
})
})
```
However, the parsed classes is wrong (should be 1000 classes):
```
>>> ds["train"].features
{'image': Image(decode=True, id=None), 'labels': ClassLabel(num_classes=1, names=['val'], id=None)}
```
## Expected results
I expect that the "labels" in ds["train"].features should contain 1000 classes.
## Actual results
The "labels" in ds["train"].features contains only 1 wrong class.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.0.0
- Platform: Ubuntu 18.04
- Python version: Python 3.7.12
- PyArrow version: 7.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4015/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4015/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6265 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6265/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6265/comments | https://api.github.com/repos/huggingface/datasets/issues/6265/events | https://github.com/huggingface/datasets/pull/6265 | 1,915,651,566 | PR_kwDODunzps5bWDfc | 6,265 | Remove `apache_beam` import in `BeamBasedBuilder._save_info` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005896 / 0.011353 (-0.005457) | 0.003642 / 0.011008 (-0.007366) | 0.081917 / 0.038508 (0.043409) | 0.059513 / 0.023109 (0.036404) | 0.341422 / 0.275898 (0.065524) | 0.359278 / 0.323480 (0.035798) | 0.004707 / 0.007986 (-0.003279) | 0.002938 / 0.004328 (-0.001390) | 0.063095 / 0.004250 (0.058845) | 0.051777 / 0.037052 (0.014725) | 0.321114 / 0.258489 (0.062625) | 0.363823 / 0.293841 (0.069982) | 0.027590 / 0.128546 (-0.100957) | 0.007846 / 0.075646 (-0.067800) | 0.261197 / 0.419271 (-0.158074) | 0.045812 / 0.043533 (0.002279) | 0.319787 / 0.255139 (0.064648) | 0.341839 / 0.283200 (0.058640) | 0.021913 / 0.141683 (-0.119770) | 1.397525 / 1.452155 (-0.054630) | 1.495902 / 1.492716 (0.003186) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224815 / 0.018006 (0.206809) | 0.425780 / 0.000490 (0.425290) | 0.006934 / 0.000200 (0.006734) | 0.000225 / 0.000054 (0.000171) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024342 / 0.037411 (-0.013070) | 0.073923 / 0.014526 (0.059398) | 0.082108 / 0.176557 (-0.094448) | 0.143017 / 0.737135 (-0.594119) | 0.083163 / 0.296338 (-0.213175) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.398244 / 0.215209 (0.183035) | 3.957688 / 2.077655 (1.880033) | 1.904615 / 1.504120 (0.400495) | 1.710353 / 1.541195 (0.169158) | 1.798980 / 1.468490 (0.330490) | 0.499307 / 4.584777 (-4.085470) | 3.026734 / 3.745712 (-0.718978) | 2.923940 / 5.269862 (-2.345922) | 1.831870 / 4.565676 (-2.733807) | 0.058551 / 0.424275 (-0.365724) | 0.006403 / 0.007607 (-0.001204) | 0.464164 / 0.226044 (0.238119) | 4.644556 / 2.268929 (2.375628) | 2.341455 / 55.444624 (-53.103169) | 2.004385 / 6.876477 (-4.872092) | 2.051819 / 2.142072 (-0.090253) | 0.585610 / 4.805227 (-4.219617) | 0.124735 / 6.500664 (-6.375929) | 0.061150 / 0.075469 (-0.014319) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.224665 / 1.841788 (-0.617122) | 17.476227 / 8.074308 (9.401919) | 13.867617 / 10.191392 (3.676225) | 0.144177 / 0.680424 (-0.536247) | 0.017045 / 0.534201 (-0.517156) | 0.337468 / 0.579283 (-0.241815) | 0.374476 / 0.434364 (-0.059888) | 0.393428 / 0.540337 (-0.146910) | 0.535335 / 1.386936 (-0.851601) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006208 / 0.011353 (-0.005145) | 0.003650 / 0.011008 (-0.007359) | 0.062843 / 0.038508 (0.024335) | 0.062272 / 0.023109 (0.039162) | 0.446336 / 0.275898 (0.170438) | 0.477476 / 0.323480 (0.153996) | 0.004862 / 0.007986 (-0.003124) | 0.002822 / 0.004328 (-0.001506) | 0.063427 / 0.004250 (0.059177) | 0.049023 / 0.037052 (0.011971) | 0.453633 / 0.258489 (0.195144) | 0.486494 / 0.293841 (0.192653) | 0.028634 / 0.128546 (-0.099912) | 0.008187 / 0.075646 (-0.067460) | 0.068846 / 0.419271 (-0.350425) | 0.041104 / 0.043533 (-0.002429) | 0.446646 / 0.255139 (0.191507) | 0.468860 / 0.283200 (0.185660) | 0.020980 / 0.141683 (-0.120703) | 1.455565 / 1.452155 (0.003410) | 1.511142 / 1.492716 (0.018426) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224242 / 0.018006 (0.206236) | 0.408483 / 0.000490 (0.407993) | 0.003495 / 0.000200 (0.003296) | 0.000076 / 0.000054 (0.000022) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027286 / 0.037411 (-0.010125) | 0.081151 / 0.014526 (0.066625) | 0.096598 / 0.176557 (-0.079959) | 0.146193 / 0.737135 (-0.590942) | 0.092213 / 0.296338 (-0.204125) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.463837 / 0.215209 (0.248628) | 4.636820 / 2.077655 (2.559165) | 2.576100 / 1.504120 (1.071980) | 2.396974 / 1.541195 (0.855779) | 2.461526 / 1.468490 (0.993036) | 0.502360 / 4.584777 (-4.082417) | 3.099973 / 3.745712 (-0.645739) | 2.937260 / 5.269862 (-2.332602) | 1.871274 / 4.565676 (-2.694402) | 0.057913 / 0.424275 (-0.366362) | 0.006511 / 0.007607 (-0.001096) | 0.536917 / 0.226044 (0.310873) | 5.396966 / 2.268929 (3.128038) | 3.015646 / 55.444624 (-52.428978) | 2.673793 / 6.876477 (-4.202684) | 2.712376 / 2.142072 (0.570304) | 0.591632 / 4.805227 (-4.213595) | 0.124872 / 6.500664 (-6.375792) | 0.061820 / 0.075469 (-0.013649) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.356828 / 1.841788 (-0.484960) | 18.076995 / 8.074308 (10.002687) | 15.116482 / 10.191392 (4.925090) | 0.151375 / 0.680424 (-0.529049) | 0.017867 / 0.534201 (-0.516334) | 0.335012 / 0.579283 (-0.244271) | 0.384137 / 0.434364 (-0.050226) | 0.397792 / 0.540337 (-0.142546) | 0.551521 / 1.386936 (-0.835415) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009418 / 0.011353 (-0.001935) | 0.005186 / 0.011008 (-0.005822) | 0.112270 / 0.038508 (0.073761) | 0.114856 / 0.023109 (0.091747) | 0.402267 / 0.275898 (0.126369) | 0.445213 / 0.323480 (0.121733) | 0.005588 / 0.007986 (-0.002398) | 0.004315 / 0.004328 (-0.000013) | 0.083561 / 0.004250 (0.079311) | 0.087319 / 0.037052 (0.050267) | 0.400989 / 0.258489 (0.142500) | 0.455636 / 0.293841 (0.161795) | 0.045168 / 0.128546 (-0.083378) | 0.010939 / 0.075646 (-0.064707) | 0.400120 / 0.419271 (-0.019151) | 0.071599 / 0.043533 (0.028066) | 0.418112 / 0.255139 (0.162973) | 0.443889 / 0.283200 (0.160690) | 0.032433 / 0.141683 (-0.109250) | 1.886313 / 1.452155 (0.434159) | 2.012909 / 1.492716 (0.520193) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.306991 / 0.018006 (0.288985) | 0.590426 / 0.000490 (0.589937) | 0.011811 / 0.000200 (0.011611) | 0.000596 / 0.000054 (0.000542) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.042520 / 0.037411 (0.005108) | 0.129808 / 0.014526 (0.115283) | 0.125481 / 0.176557 (-0.051075) | 0.199181 / 0.737135 (-0.537954) | 0.130426 / 0.296338 (-0.165913) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.526455 / 0.215209 (0.311246) | 5.213304 / 2.077655 (3.135649) | 2.643406 / 1.504120 (1.139286) | 2.611214 / 1.541195 (1.070019) | 2.586730 / 1.468490 (1.118240) | 0.639103 / 4.584777 (-3.945674) | 5.197421 / 3.745712 (1.451709) | 4.634642 / 5.269862 (-0.635220) | 2.741079 / 4.565676 (-1.824598) | 0.073064 / 0.424275 (-0.351211) | 0.009441 / 0.007607 (0.001834) | 0.635984 / 0.226044 (0.409940) | 6.283268 / 2.268929 (4.014339) | 3.337205 / 55.444624 (-52.107419) | 3.192362 / 6.876477 (-3.684114) | 2.910367 / 2.142072 (0.768294) | 0.767937 / 4.805227 (-4.037290) | 0.177467 / 6.500664 (-6.323198) | 0.081162 / 0.075469 (0.005693) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.803717 / 1.841788 (-0.038071) | 26.823235 / 8.074308 (18.748927) | 19.714471 / 10.191392 (9.523079) | 0.204048 / 0.680424 (-0.476376) | 0.025992 / 0.534201 (-0.508209) | 0.521438 / 0.579283 (-0.057845) | 0.596524 / 0.434364 (0.162160) | 0.600763 / 0.540337 (0.060425) | 0.945971 / 1.386936 (-0.440965) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009126 / 0.011353 (-0.002226) | 0.005109 / 0.011008 (-0.005899) | 0.083046 / 0.038508 (0.044538) | 0.115930 / 0.023109 (0.092821) | 0.534311 / 0.275898 (0.258413) | 0.552846 / 0.323480 (0.229366) | 0.007240 / 0.007986 (-0.000746) | 0.004617 / 0.004328 (0.000289) | 0.083927 / 0.004250 (0.079676) | 0.075926 / 0.037052 (0.038873) | 0.534750 / 0.258489 (0.276261) | 0.575122 / 0.293841 (0.281281) | 0.041001 / 0.128546 (-0.087545) | 0.010851 / 0.075646 (-0.064795) | 0.096574 / 0.419271 (-0.322697) | 0.063533 / 0.043533 (0.020001) | 0.546850 / 0.255139 (0.291711) | 0.547122 / 0.283200 (0.263922) | 0.032437 / 0.141683 (-0.109245) | 1.926191 / 1.452155 (0.474036) | 2.029841 / 1.492716 (0.537125) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.275582 / 0.018006 (0.257576) | 0.574212 / 0.000490 (0.573722) | 0.006863 / 0.000200 (0.006663) | 0.000236 / 0.000054 (0.000181) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.045340 / 0.037411 (0.007928) | 0.129196 / 0.014526 (0.114670) | 0.136637 / 0.176557 (-0.039920) | 0.200040 / 0.737135 (-0.537096) | 0.136328 / 0.296338 (-0.160011) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.612379 / 0.215209 (0.397170) | 5.874664 / 2.077655 (3.797010) | 3.070626 / 1.504120 (1.566506) | 2.999319 / 1.541195 (1.458124) | 3.000571 / 1.468490 (1.532081) | 0.732119 / 4.584777 (-3.852658) | 5.193226 / 3.745712 (1.447514) | 4.714571 / 5.269862 (-0.555291) | 2.870438 / 4.565676 (-1.695239) | 0.075793 / 0.424275 (-0.348482) | 0.009238 / 0.007607 (0.001631) | 0.695192 / 0.226044 (0.469148) | 6.897996 / 2.268929 (4.629067) | 3.923474 / 55.444624 (-51.521150) | 3.458326 / 6.876477 (-3.418151) | 3.331652 / 2.142072 (1.189579) | 0.821132 / 4.805227 (-3.984095) | 0.182252 / 6.500664 (-6.318412) | 0.084730 / 0.075469 (0.009260) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.919861 / 1.841788 (0.078073) | 27.437228 / 8.074308 (19.362920) | 21.109899 / 10.191392 (10.918507) | 0.245998 / 0.680424 (-0.434426) | 0.025817 / 0.534201 (-0.508384) | 0.517757 / 0.579283 (-0.061526) | 0.576375 / 0.434364 (0.142011) | 0.625283 / 0.540337 (0.084945) | 0.956877 / 1.386936 (-0.430059) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008099 / 0.011353 (-0.003254) | 0.004815 / 0.011008 (-0.006194) | 0.099657 / 0.038508 (0.061149) | 0.064737 / 0.023109 (0.041628) | 0.461773 / 0.275898 (0.185875) | 0.444810 / 0.323480 (0.121330) | 0.004247 / 0.007986 (-0.003739) | 0.004956 / 0.004328 (0.000628) | 0.068664 / 0.004250 (0.064414) | 0.052039 / 0.037052 (0.014986) | 0.406750 / 0.258489 (0.148261) | 0.452832 / 0.293841 (0.158991) | 0.044518 / 0.128546 (-0.084028) | 0.013220 / 0.075646 (-0.062426) | 0.317713 / 0.419271 (-0.101558) | 0.061897 / 0.043533 (0.018364) | 0.398664 / 0.255139 (0.143525) | 0.531494 / 0.283200 (0.248294) | 0.064033 / 0.141683 (-0.077650) | 1.590385 / 1.452155 (0.138231) | 1.769918 / 1.492716 (0.277202) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230795 / 0.018006 (0.212789) | 0.568797 / 0.000490 (0.568308) | 0.013498 / 0.000200 (0.013298) | 0.000448 / 0.000054 (0.000393) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028394 / 0.037411 (-0.009017) | 0.081973 / 0.014526 (0.067447) | 0.097623 / 0.176557 (-0.078934) | 0.158691 / 0.737135 (-0.578445) | 0.101548 / 0.296338 (-0.194791) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.574459 / 0.215209 (0.359249) | 5.709871 / 2.077655 (3.632217) | 2.521460 / 1.504120 (1.017340) | 2.239463 / 1.541195 (0.698268) | 2.195067 / 1.468490 (0.726577) | 0.792390 / 4.584777 (-3.792387) | 4.841665 / 3.745712 (1.095952) | 4.201620 / 5.269862 (-1.068241) | 2.664081 / 4.565676 (-1.901595) | 0.097661 / 0.424275 (-0.326614) | 0.008428 / 0.007607 (0.000821) | 0.698729 / 0.226044 (0.472684) | 6.908867 / 2.268929 (4.639939) | 3.247480 / 55.444624 (-52.197145) | 2.563921 / 6.876477 (-4.312556) | 2.738249 / 2.142072 (0.596177) | 0.972066 / 4.805227 (-3.833161) | 0.191196 / 6.500664 (-6.309468) | 0.064732 / 0.075469 (-0.010737) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.421910 / 1.841788 (-0.419877) | 20.633538 / 8.074308 (12.559230) | 18.054562 / 10.191392 (7.863170) | 0.194125 / 0.680424 (-0.486299) | 0.028097 / 0.534201 (-0.506104) | 0.417857 / 0.579283 (-0.161426) | 0.518758 / 0.434364 (0.084394) | 0.500199 / 0.540337 (-0.040138) | 0.754662 / 1.386936 (-0.632274) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008452 / 0.011353 (-0.002901) | 0.004646 / 0.011008 (-0.006362) | 0.077286 / 0.038508 (0.038778) | 0.072507 / 0.023109 (0.049398) | 0.439580 / 0.275898 (0.163682) | 0.506166 / 0.323480 (0.182686) | 0.006035 / 0.007986 (-0.001950) | 0.003886 / 0.004328 (-0.000442) | 0.075091 / 0.004250 (0.070841) | 0.063163 / 0.037052 (0.026110) | 0.468550 / 0.258489 (0.210061) | 0.523273 / 0.293841 (0.229432) | 0.048728 / 0.128546 (-0.079818) | 0.012991 / 0.075646 (-0.062655) | 0.087964 / 0.419271 (-0.331308) | 0.058920 / 0.043533 (0.015387) | 0.451247 / 0.255139 (0.196108) | 0.489827 / 0.283200 (0.206628) | 0.031164 / 0.141683 (-0.110519) | 1.675504 / 1.452155 (0.223349) | 1.806098 / 1.492716 (0.313382) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.253567 / 0.018006 (0.235561) | 0.508971 / 0.000490 (0.508481) | 0.010882 / 0.000200 (0.010682) | 0.000111 / 0.000054 (0.000057) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029490 / 0.037411 (-0.007921) | 0.090255 / 0.014526 (0.075729) | 0.110075 / 0.176557 (-0.066482) | 0.159375 / 0.737135 (-0.577760) | 0.109313 / 0.296338 (-0.187025) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.580252 / 0.215209 (0.365043) | 5.911741 / 2.077655 (3.834086) | 2.659405 / 1.504120 (1.155285) | 2.344943 / 1.541195 (0.803749) | 2.390748 / 1.468490 (0.922258) | 0.827823 / 4.584777 (-3.756954) | 4.973544 / 3.745712 (1.227832) | 4.300220 / 5.269862 (-0.969642) | 2.826181 / 4.565676 (-1.739495) | 0.101013 / 0.424275 (-0.323263) | 0.008025 / 0.007607 (0.000418) | 0.728414 / 0.226044 (0.502369) | 7.508045 / 2.268929 (5.239117) | 3.687627 / 55.444624 (-51.756997) | 2.902953 / 6.876477 (-3.973524) | 3.094624 / 2.142072 (0.952551) | 1.054696 / 4.805227 (-3.750531) | 0.212297 / 6.500664 (-6.288367) | 0.070211 / 0.075469 (-0.005258) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.567117 / 1.841788 (-0.274670) | 21.420746 / 8.074308 (13.346438) | 19.857467 / 10.191392 (9.666075) | 0.228554 / 0.680424 (-0.451870) | 0.032278 / 0.534201 (-0.501923) | 0.459966 / 0.579283 (-0.119317) | 0.541219 / 0.434364 (0.106855) | 0.549599 / 0.540337 (0.009261) | 0.731476 / 1.386936 (-0.655460) |\n\n</details>\n</details>\n\n\n"
] | "2023-09-27T13:56:34Z" | "2023-09-28T18:34:02Z" | "2023-09-28T18:23:35Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6265.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6265",
"merged_at": "2023-09-28T18:23:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6265.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6265"
} | ... to avoid an `ImportError` raised in `BeamBasedBuilder._save_info` when `apache_beam` is not installed (e.g., when downloading the processed version of a dataset from the HF GCS)
Fix https://github.com/huggingface/datasets/issues/6260 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6265/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6265/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1559 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1559/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1559/comments | https://api.github.com/repos/huggingface/datasets/issues/1559/events | https://github.com/huggingface/datasets/pull/1559 | 765,714,183 | MDExOlB1bGxSZXF1ZXN0NTM5MDQ5MTky | 1,559 | adding dataset card information to CONTRIBUTING.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite"
} | [] | closed | false | null | [] | null | [] | "2020-12-14T00:08:43Z" | "2020-12-14T17:55:03Z" | "2020-12-14T17:55:03Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1559.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1559",
"merged_at": "2020-12-14T17:55:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1559.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1559"
} | Added a documentation line and link to the full sprint guide in the "How to add a dataset" section, and a section on how to contribute to the dataset card of an existing dataset.
And a thank you note at the end :hugs: | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1559/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1559/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4545 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4545/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4545/comments | https://api.github.com/repos/huggingface/datasets/issues/4545/events | https://github.com/huggingface/datasets/pull/4545 | 1,280,899,028 | PR_kwDODunzps46KV-y | 4,545 | Make DuplicateKeysError more user friendly [For Issue #2556] | {
"avatar_url": "https://avatars.githubusercontent.com/u/20517962?v=4",
"events_url": "https://api.github.com/users/VijayKalmath/events{/privacy}",
"followers_url": "https://api.github.com/users/VijayKalmath/followers",
"following_url": "https://api.github.com/users/VijayKalmath/following{/other_user}",
"gists_url": "https://api.github.com/users/VijayKalmath/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/VijayKalmath",
"id": 20517962,
"login": "VijayKalmath",
"node_id": "MDQ6VXNlcjIwNTE3OTYy",
"organizations_url": "https://api.github.com/users/VijayKalmath/orgs",
"received_events_url": "https://api.github.com/users/VijayKalmath/received_events",
"repos_url": "https://api.github.com/users/VijayKalmath/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/VijayKalmath/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VijayKalmath/subscriptions",
"type": "User",
"url": "https://api.github.com/users/VijayKalmath"
} | [] | closed | false | null | [] | null | [
"> Nice thanks !\r\n> \r\n> After your changes feel free to mark this PR as \"ready for review\" ;)\r\n\r\nMarking PR ready for review.\r\n\r\n@lhoestq Let me know if there is anything else required or if we are good to go ahead and merge.",
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-06-22T21:01:34Z" | "2022-06-28T09:37:06Z" | "2022-06-28T09:26:04Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4545.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4545",
"merged_at": "2022-06-28T09:26:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4545.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4545"
} | # What does this PR do?
## Summary
*DuplicateKeysError error does not provide any information regarding the examples which have the same the key.*
*This information is very helpful for debugging the dataset generator script.*
## Additions
-
## Changes
- Changed `DuplicateKeysError Class` in `src/datasets/keyhash.py` to add current index and duplicate_key_indices to error message.
- Changed `check_duplicate_keys` function in `src/datasets/arrow_writer.py` to find indices of examples with duplicate hash if duplicate keys are found.
## Deletions
-
## To do :
- [x] Find way to find and print path `<Path to Dataset>` in Error message
## Issues Addressed :
Fixes #2556 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4545/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4545/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3784 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3784/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3784/comments | https://api.github.com/repos/huggingface/datasets/issues/3784/events | https://github.com/huggingface/datasets/issues/3784 | 1,150,057,955 | I_kwDODunzps5EjH3j | 3,784 | Unable to Download CNN-Dailymail Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/58678541?v=4",
"events_url": "https://api.github.com/users/AngadSethi/events{/privacy}",
"followers_url": "https://api.github.com/users/AngadSethi/followers",
"following_url": "https://api.github.com/users/AngadSethi/following{/other_user}",
"gists_url": "https://api.github.com/users/AngadSethi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AngadSethi",
"id": 58678541,
"login": "AngadSethi",
"node_id": "MDQ6VXNlcjU4Njc4NTQx",
"organizations_url": "https://api.github.com/users/AngadSethi/orgs",
"received_events_url": "https://api.github.com/users/AngadSethi/received_events",
"repos_url": "https://api.github.com/users/AngadSethi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AngadSethi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AngadSethi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AngadSethi"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/58678541?v=4",
"events_url": "https://api.github.com/users/AngadSethi/events{/privacy}",
"followers_url": "https://api.github.com/users/AngadSethi/followers",
"following_url": "https://api.github.com/users/AngadSethi/following{/other_user}",
"gists_url": "https://api.github.com/users/AngadSethi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AngadSethi",
"id": 58678541,
"login": "AngadSethi",
"node_id": "MDQ6VXNlcjU4Njc4NTQx",
"organizations_url": "https://api.github.com/users/AngadSethi/orgs",
"received_events_url": "https://api.github.com/users/AngadSethi/received_events",
"repos_url": "https://api.github.com/users/AngadSethi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AngadSethi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AngadSethi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AngadSethi"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/58678541?v=4",
"events_url": "https://api.github.com/users/AngadSethi/events{/privacy}",
"followers_url": "https://api.github.com/users/AngadSethi/followers",
"following_url": "https://api.github.com/users/AngadSethi/following{/other_user}",
"gists_url": "https://api.github.com/users/AngadSethi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AngadSethi",
"id": 58678541,
"login": "AngadSethi",
"node_id": "MDQ6VXNlcjU4Njc4NTQx",
"organizations_url": "https://api.github.com/users/AngadSethi/orgs",
"received_events_url": "https://api.github.com/users/AngadSethi/received_events",
"repos_url": "https://api.github.com/users/AngadSethi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AngadSethi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AngadSethi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AngadSethi"
}
] | null | [
"#self-assign",
"@AngadSethi thanks for reporting and thanks for your PR!",
"Glad to help @albertvillanova! Just fine-tuning the PR, will comment once I am able to get it up and running 😀",
"Fixed by:\r\n- #3787"
] | "2022-02-25T05:24:47Z" | "2022-03-03T14:05:17Z" | "2022-03-03T14:05:17Z" | NONE | null | null | null | ## Describe the bug
I am unable to download the CNN-Dailymail dataset. Upon closer investigation, I realised why this was happening:
- The dataset sits in Google Drive, and both the CNN and DM datasets are large.
- Google is unable to scan the folder for viruses, **so the link which would originally download the dataset, now downloads the source code of this web page:**

- **This leads to the following error**:
```python
NotADirectoryError: [Errno 20] Not a directory: '/root/.cache/huggingface/datasets/downloads/1bc05d24fa6dda2468e83a73cf6dc207226e01e3c48a507ea716dc0421da583b/cnn/stories'
```
## Steps to reproduce the bug
```python
import datasets
dataset = datasets.load_dataset("cnn_dailymail", "3.0.0", split="train")
```
## Expected results
That the dataset is downloaded and processed just like other datasets.
## Actual results
Hit with this error:
```python
NotADirectoryError: [Errno 20] Not a directory: '/root/.cache/huggingface/datasets/downloads/1bc05d24fa6dda2468e83a73cf6dc207226e01e3c48a507ea716dc0421da583b/cnn/stories'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3784/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3784/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3578 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3578/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3578/comments | https://api.github.com/repos/huggingface/datasets/issues/3578/events | https://github.com/huggingface/datasets/issues/3578 | 1,103,403,287 | I_kwDODunzps5BxJkX | 3,578 | label information get lost after parquet serialization | {
"avatar_url": "https://avatars.githubusercontent.com/u/56633664?v=4",
"events_url": "https://api.github.com/users/Tudyx/events{/privacy}",
"followers_url": "https://api.github.com/users/Tudyx/followers",
"following_url": "https://api.github.com/users/Tudyx/following{/other_user}",
"gists_url": "https://api.github.com/users/Tudyx/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Tudyx",
"id": 56633664,
"login": "Tudyx",
"node_id": "MDQ6VXNlcjU2NjMzNjY0",
"organizations_url": "https://api.github.com/users/Tudyx/orgs",
"received_events_url": "https://api.github.com/users/Tudyx/received_events",
"repos_url": "https://api.github.com/users/Tudyx/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Tudyx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Tudyx/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Tudyx"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! We did a release of `datasets` today that may fix this issue. Can you try updating `datasets` and trying again ?\r\n\r\nEDIT: the issue is still there actually\r\n\r\nI think we can fix that by storing the Features in the parquet schema metadata, and then reload them when loading the parquet file",
"This info is stored in the Parquet schema metadata as of https://github.com/huggingface/datasets/pull/5516"
] | "2022-01-14T10:10:38Z" | "2023-07-25T15:44:53Z" | "2023-07-25T15:44:53Z" | NONE | null | null | null | ## Describe the bug
In *dataset_info.json* file, information about the label get lost after the dataset serialization.
## Steps to reproduce the bug
```python
from datasets import load_dataset
# normal save
dataset = load_dataset('glue', 'sst2', split='train')
dataset.save_to_disk("normal_save")
# save after parquet serialization
dataset.to_parquet("glue-sst2-train.parquet")
dataset = load_dataset("parquet", data_files='glue-sst2-train.parquet')
dataset.save_to_disk("save_after_parquet")
```
## Expected results
I expected to keep label information in *dataset_info.json* file even after parquet serialization
## Actual results
In the normal serialization i got
```json
"label": {
"num_classes": 2,
"names": [
"negative",
"positive"
],
"names_file": null,
"id": null,
"_type": "ClassLabel"
},
```
And after parquet serialization i got
```json
"label": {
"dtype": "int64",
"id": null,
"_type": "Value"
},
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.0
- Platform: ubuntu 20.04
- Python version: 3.8.10
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3578/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3578/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2648 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2648/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2648/comments | https://api.github.com/repos/huggingface/datasets/issues/2648/events | https://github.com/huggingface/datasets/issues/2648 | 944,484,522 | MDU6SXNzdWU5NDQ0ODQ1MjI= | 2,648 | Add web_split dataset for Paraphase and Rephrase benchmark | {
"avatar_url": "https://avatars.githubusercontent.com/u/26653468?v=4",
"events_url": "https://api.github.com/users/bhadreshpsavani/events{/privacy}",
"followers_url": "https://api.github.com/users/bhadreshpsavani/followers",
"following_url": "https://api.github.com/users/bhadreshpsavani/following{/other_user}",
"gists_url": "https://api.github.com/users/bhadreshpsavani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bhadreshpsavani",
"id": 26653468,
"login": "bhadreshpsavani",
"node_id": "MDQ6VXNlcjI2NjUzNDY4",
"organizations_url": "https://api.github.com/users/bhadreshpsavani/orgs",
"received_events_url": "https://api.github.com/users/bhadreshpsavani/received_events",
"repos_url": "https://api.github.com/users/bhadreshpsavani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bhadreshpsavani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhadreshpsavani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bhadreshpsavani"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/26653468?v=4",
"events_url": "https://api.github.com/users/bhadreshpsavani/events{/privacy}",
"followers_url": "https://api.github.com/users/bhadreshpsavani/followers",
"following_url": "https://api.github.com/users/bhadreshpsavani/following{/other_user}",
"gists_url": "https://api.github.com/users/bhadreshpsavani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bhadreshpsavani",
"id": 26653468,
"login": "bhadreshpsavani",
"node_id": "MDQ6VXNlcjI2NjUzNDY4",
"organizations_url": "https://api.github.com/users/bhadreshpsavani/orgs",
"received_events_url": "https://api.github.com/users/bhadreshpsavani/received_events",
"repos_url": "https://api.github.com/users/bhadreshpsavani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bhadreshpsavani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhadreshpsavani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bhadreshpsavani"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/26653468?v=4",
"events_url": "https://api.github.com/users/bhadreshpsavani/events{/privacy}",
"followers_url": "https://api.github.com/users/bhadreshpsavani/followers",
"following_url": "https://api.github.com/users/bhadreshpsavani/following{/other_user}",
"gists_url": "https://api.github.com/users/bhadreshpsavani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bhadreshpsavani",
"id": 26653468,
"login": "bhadreshpsavani",
"node_id": "MDQ6VXNlcjI2NjUzNDY4",
"organizations_url": "https://api.github.com/users/bhadreshpsavani/orgs",
"received_events_url": "https://api.github.com/users/bhadreshpsavani/received_events",
"repos_url": "https://api.github.com/users/bhadreshpsavani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bhadreshpsavani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhadreshpsavani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bhadreshpsavani"
}
] | null | [
"#take"
] | "2021-07-14T14:24:36Z" | "2021-07-14T14:26:12Z" | null | CONTRIBUTOR | null | null | null | ## Describe:
For getting simple sentences from complex sentence there are dataset and task like wiki_split that is available in hugging face datasets. This web_split is a very similar dataset. There some research paper which states that by combining these two datasets we if we train the model it will yield better results on both tests data.
This dataset is made from web NLG data.
All the dataset related details are provided in the below repository
Github link: https://github.com/shashiongithub/Split-and-Rephrase
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2648/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2648/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1290 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1290/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1290/comments | https://api.github.com/repos/huggingface/datasets/issues/1290/events | https://github.com/huggingface/datasets/issues/1290 | 759,339,989 | MDU6SXNzdWU3NTkzMzk5ODk= | 1,290 | imdb dataset cannot be downloaded | {
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehk/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rabeehk",
"id": 6278280,
"login": "rabeehk",
"node_id": "MDQ6VXNlcjYyNzgyODA=",
"organizations_url": "https://api.github.com/users/rabeehk/orgs",
"received_events_url": "https://api.github.com/users/rabeehk/received_events",
"repos_url": "https://api.github.com/users/rabeehk/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rabeehk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehk/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rabeehk"
} | [] | closed | false | null | [] | null | [
"Hi @rabeehk , I am unable to reproduce your problem locally.\r\nCan you try emptying the cache (removing the content of `/idiap/temp/rkarimi/cache_home_1/datasets`) and retry ?",
"Hi,\r\nthanks, I did remove the cache and still the same error here\r\n\r\n```\r\n>>> a = datasets.load_dataset(\"imdb\", split=\"train\")\r\ncahce dir /idiap/temp/rkarimi/cache_home_1/datasets\r\ncahce dir /idiap/temp/rkarimi/cache_home_1/datasets\r\nDownloading and preparing dataset imdb/plain_text (download: 80.23 MiB, generated: 127.06 MiB, post-processed: Unknown size, total: 207.28 MiB) to /idiap/temp/rkarimi/cache_home_1/datasets/imdb/plain_text/1.0.0/90099cb476936b753383ba2ae6ab2eae419b2e87f71cd5189cb9c8e5814d12a3...\r\ncahce dir /idiap/temp/rkarimi/cache_home_1/datasets\r\ncahce dir /idiap/temp/rkarimi/cache_home_1/datasets/downloads\r\nTraceback (most recent call last): \r\n File \"<stdin>\", line 1, in <module>\r\n File \"/idiap/user/rkarimi/libs/anaconda3/envs/internship/lib/python3.7/site-packages/datasets/load.py\", line 611, in load_dataset\r\n ignore_verifications=ignore_verifications,\r\n File \"/idiap/user/rkarimi/libs/anaconda3/envs/internship/lib/python3.7/site-packages/datasets/builder.py\", line 476, in download_and_prepare\r\n dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs\r\n File \"/idiap/user/rkarimi/libs/anaconda3/envs/internship/lib/python3.7/site-packages/datasets/builder.py\", line 558, in _download_and_prepare\r\n verify_splits(self.info.splits, split_dict)\r\n File \"/idiap/user/rkarimi/libs/anaconda3/envs/internship/lib/python3.7/site-packages/datasets/utils/info_utils.py\", line 73, in verify_splits\r\n raise NonMatchingSplitsSizesError(str(bad_splits))\r\ndatasets.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='unsupervised', num_bytes=67125548, num_examples=50000, dataset_name='imdb'), 'recorded': SplitInfo(name='unsupervised', num_bytes=4902716, num_examples=3680, dataset_name='imdb')}]\r\n```\r\n\r\ndatasets version\r\n```\r\ndatasets 1.1.2 <pip>\r\ntensorflow-datasets 4.1.0 <pip>\r\n\r\n```",
"resolved with moving to version 1.1.3"
] | "2020-12-08T10:47:36Z" | "2020-12-24T17:38:09Z" | "2020-12-24T17:38:09Z" | CONTRIBUTOR | null | null | null | hi
please find error below getting imdb train spli:
thanks
`
datasets.load_dataset>>> datasets.load_dataset("imdb", split="train")`
errors
```
cahce dir /idiap/temp/rkarimi/cache_home_1/datasets
cahce dir /idiap/temp/rkarimi/cache_home_1/datasets
Downloading and preparing dataset imdb/plain_text (download: 80.23 MiB, generated: 127.06 MiB, post-processed: Unknown size, total: 207.28 MiB) to /idiap/temp/rkarimi/cache_home_1/datasets/imdb/plain_text/1.0.0/90099cb476936b753383ba2ae6ab2eae419b2e87f71cd5189cb9c8e5814d12a3...
cahce dir /idiap/temp/rkarimi/cache_home_1/datasets
cahce dir /idiap/temp/rkarimi/cache_home_1/datasets/downloads
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/idiap/user/rkarimi/libs/anaconda3/envs/internship/lib/python3.7/site-packages/datasets/load.py", line 611, in load_dataset
ignore_verifications=ignore_verifications,
File "/idiap/user/rkarimi/libs/anaconda3/envs/internship/lib/python3.7/site-packages/datasets/builder.py", line 476, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/idiap/user/rkarimi/libs/anaconda3/envs/internship/lib/python3.7/site-packages/datasets/builder.py", line 558, in _download_and_prepare
verify_splits(self.info.splits, split_dict)
File "/idiap/user/rkarimi/libs/anaconda3/envs/internship/lib/python3.7/site-packages/datasets/utils/info_utils.py", line 73, in verify_splits
raise NonMatchingSplitsSizesError(str(bad_splits))
datasets.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='unsupervised', num_bytes=67125548, num_examples=50000, dataset_name='imdb'), 'recorded': SplitInfo(name='unsupervised', num_bytes=7486451, num_examples=5628, dataset_name='imdb')}]
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1290/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1290/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3189 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3189/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3189/comments | https://api.github.com/repos/huggingface/datasets/issues/3189/events | https://github.com/huggingface/datasets/issues/3189 | 1,041,044,986 | I_kwDODunzps4-DRX6 | 3,189 | conll2003 incorrect label explanation | {
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/BramVanroy",
"id": 2779410,
"login": "BramVanroy",
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"type": "User",
"url": "https://api.github.com/users/BramVanroy"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @BramVanroy,\r\n\r\nsince these fields are of type `ClassLabel` (you can check this with `dset.features`), you can inspect the possible values with:\r\n```python\r\ndset.features[field_name].feature.names # .feature because it's a sequence of labels\r\n```\r\n\r\nand to find the mapping between names and integers, use: \r\n```python\r\ndset.features[field_name].feature.int2str(value_or_values_list) # map integer value to string value\r\n# or\r\ndset.features[field_name].feature.str2int(value_or_values_list) # map string value to integer value\r\n```\r\n\r\n"
] | "2021-11-01T11:03:30Z" | "2021-11-09T10:40:58Z" | "2021-11-09T10:40:58Z" | CONTRIBUTOR | null | null | null | In the [conll2003](https://huggingface.co/datasets/conll2003#data-fields) README, the labels are described as follows
> - `id`: a `string` feature.
> - `tokens`: a `list` of `string` features.
> - `pos_tags`: a `list` of classification labels, with possible values including `"` (0), `''` (1), `#` (2), `$` (3), `(` (4).
> - `chunk_tags`: a `list` of classification labels, with possible values including `O` (0), `B-ADJP` (1), `I-ADJP` (2), `B-ADVP` (3), `I-ADVP` (4).
> - `ner_tags`: a `list` of classification labels, with possible values including `O` (0), `B-PER` (1), `I-PER` (2), `B-ORG` (3), `I-ORG` (4) `B-LOC` (5), `I-LOC` (6) `B-MISC` (7), `I-MISC` (8).
First of all, it would be great if we can get a list of ALL possible pos_tags.
Second, the chunk tags labels cannot be correct. The description says the values go from 0 to 4 whereas the data shows values from at least 11 to 21 and 0.
EDIT: not really a bug, sorry for mistagging. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3189/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3189/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5958 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5958/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5958/comments | https://api.github.com/repos/huggingface/datasets/issues/5958/events | https://github.com/huggingface/datasets/pull/5958 | 1,757,265,971 | PR_kwDODunzps5TA3__ | 5,958 | set dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5958). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006232 / 0.011353 (-0.005121) | 0.003788 / 0.011008 (-0.007220) | 0.100014 / 0.038508 (0.061506) | 0.036488 / 0.023109 (0.013379) | 0.306255 / 0.275898 (0.030357) | 0.363337 / 0.323480 (0.039857) | 0.004765 / 0.007986 (-0.003221) | 0.002935 / 0.004328 (-0.001394) | 0.078897 / 0.004250 (0.074647) | 0.052221 / 0.037052 (0.015169) | 0.315169 / 0.258489 (0.056680) | 0.353050 / 0.293841 (0.059209) | 0.029059 / 0.128546 (-0.099488) | 0.008599 / 0.075646 (-0.067047) | 0.318770 / 0.419271 (-0.100502) | 0.046631 / 0.043533 (0.003098) | 0.303728 / 0.255139 (0.048589) | 0.332379 / 0.283200 (0.049180) | 0.021164 / 0.141683 (-0.120519) | 1.576963 / 1.452155 (0.124808) | 1.629575 / 1.492716 (0.136859) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.204246 / 0.018006 (0.186240) | 0.426600 / 0.000490 (0.426110) | 0.004336 / 0.000200 (0.004136) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024039 / 0.037411 (-0.013372) | 0.098240 / 0.014526 (0.083715) | 0.108889 / 0.176557 (-0.067668) | 0.170827 / 0.737135 (-0.566308) | 0.111288 / 0.296338 (-0.185051) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418103 / 0.215209 (0.202894) | 4.190759 / 2.077655 (2.113104) | 1.875978 / 1.504120 (0.371858) | 1.679198 / 1.541195 (0.138003) | 1.737965 / 1.468490 (0.269474) | 0.556660 / 4.584777 (-4.028117) | 3.413800 / 3.745712 (-0.331912) | 3.004999 / 5.269862 (-2.264862) | 1.464030 / 4.565676 (-3.101647) | 0.067338 / 0.424275 (-0.356937) | 0.011486 / 0.007607 (0.003879) | 0.522589 / 0.226044 (0.296544) | 5.214653 / 2.268929 (2.945724) | 2.316903 / 55.444624 (-53.127722) | 1.991941 / 6.876477 (-4.884536) | 2.110601 / 2.142072 (-0.031471) | 0.665400 / 4.805227 (-4.139828) | 0.135755 / 6.500664 (-6.364910) | 0.065980 / 0.075469 (-0.009489) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.197269 / 1.841788 (-0.644519) | 14.085205 / 8.074308 (6.010897) | 14.083360 / 10.191392 (3.891968) | 0.148054 / 0.680424 (-0.532369) | 0.016548 / 0.534201 (-0.517653) | 0.371538 / 0.579283 (-0.207745) | 0.391068 / 0.434364 (-0.043296) | 0.430589 / 0.540337 (-0.109748) | 0.529319 / 1.386936 (-0.857617) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006214 / 0.011353 (-0.005138) | 0.003846 / 0.011008 (-0.007162) | 0.078559 / 0.038508 (0.040051) | 0.037855 / 0.023109 (0.014745) | 0.437479 / 0.275898 (0.161581) | 0.497588 / 0.323480 (0.174108) | 0.003491 / 0.007986 (-0.004494) | 0.003900 / 0.004328 (-0.000428) | 0.078443 / 0.004250 (0.074193) | 0.048019 / 0.037052 (0.010967) | 0.452076 / 0.258489 (0.193587) | 0.494597 / 0.293841 (0.200756) | 0.028127 / 0.128546 (-0.100419) | 0.008549 / 0.075646 (-0.067098) | 0.082977 / 0.419271 (-0.336295) | 0.043133 / 0.043533 (-0.000400) | 0.441342 / 0.255139 (0.186203) | 0.464339 / 0.283200 (0.181139) | 0.020110 / 0.141683 (-0.121573) | 1.485181 / 1.452155 (0.033026) | 1.532019 / 1.492716 (0.039302) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.228014 / 0.018006 (0.210007) | 0.416887 / 0.000490 (0.416397) | 0.001133 / 0.000200 (0.000933) | 0.000108 / 0.000054 (0.000053) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026452 / 0.037411 (-0.010960) | 0.104328 / 0.014526 (0.089802) | 0.110045 / 0.176557 (-0.066511) | 0.164725 / 0.737135 (-0.572410) | 0.116348 / 0.296338 (-0.179990) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.483502 / 0.215209 (0.268293) | 4.829814 / 2.077655 (2.752159) | 2.505271 / 1.504120 (1.001151) | 2.305819 / 1.541195 (0.764624) | 2.348633 / 1.468490 (0.880143) | 0.562316 / 4.584777 (-4.022461) | 3.426425 / 3.745712 (-0.319287) | 1.737934 / 5.269862 (-3.531927) | 1.042616 / 4.565676 (-3.523061) | 0.068088 / 0.424275 (-0.356187) | 0.011735 / 0.007607 (0.004128) | 0.586339 / 0.226044 (0.360295) | 5.861283 / 2.268929 (3.592354) | 2.953956 / 55.444624 (-52.490668) | 2.626611 / 6.876477 (-4.249865) | 2.687978 / 2.142072 (0.545906) | 0.672748 / 4.805227 (-4.132479) | 0.137231 / 6.500664 (-6.363433) | 0.068149 / 0.075469 (-0.007320) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.323139 / 1.841788 (-0.518649) | 14.503102 / 8.074308 (6.428794) | 14.092102 / 10.191392 (3.900710) | 0.165395 / 0.680424 (-0.515028) | 0.016898 / 0.534201 (-0.517303) | 0.366905 / 0.579283 (-0.212378) | 0.396671 / 0.434364 (-0.037692) | 0.421831 / 0.540337 (-0.118506) | 0.514075 / 1.386936 (-0.872861) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007778 / 0.011353 (-0.003575) | 0.004624 / 0.011008 (-0.006384) | 0.123426 / 0.038508 (0.084918) | 0.052209 / 0.023109 (0.029100) | 0.341084 / 0.275898 (0.065186) | 0.421905 / 0.323480 (0.098425) | 0.005768 / 0.007986 (-0.002217) | 0.003647 / 0.004328 (-0.000682) | 0.085569 / 0.004250 (0.081319) | 0.070473 / 0.037052 (0.033421) | 0.356626 / 0.258489 (0.098136) | 0.407413 / 0.293841 (0.113572) | 0.038800 / 0.128546 (-0.089746) | 0.010289 / 0.075646 (-0.065357) | 0.462707 / 0.419271 (0.043436) | 0.060390 / 0.043533 (0.016858) | 0.349805 / 0.255139 (0.094666) | 0.355288 / 0.283200 (0.072088) | 0.025364 / 0.141683 (-0.116318) | 1.745720 / 1.452155 (0.293565) | 1.852764 / 1.492716 (0.360048) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.290582 / 0.018006 (0.272576) | 0.480044 / 0.000490 (0.479554) | 0.007658 / 0.000200 (0.007458) | 0.000100 / 0.000054 (0.000046) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031529 / 0.037411 (-0.005882) | 0.130441 / 0.014526 (0.115915) | 0.147653 / 0.176557 (-0.028904) | 0.215935 / 0.737135 (-0.521200) | 0.149871 / 0.296338 (-0.146467) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.461662 / 0.215209 (0.246453) | 4.570353 / 2.077655 (2.492698) | 2.104416 / 1.504120 (0.600297) | 1.936974 / 1.541195 (0.395779) | 2.139167 / 1.468490 (0.670677) | 0.645100 / 4.584777 (-3.939677) | 4.361536 / 3.745712 (0.615824) | 2.155960 / 5.269862 (-3.113902) | 1.207854 / 4.565676 (-3.357822) | 0.080162 / 0.424275 (-0.344113) | 0.014265 / 0.007607 (0.006658) | 0.606294 / 0.226044 (0.380250) | 5.928093 / 2.268929 (3.659165) | 2.701811 / 55.444624 (-52.742813) | 2.344490 / 6.876477 (-4.531987) | 2.435997 / 2.142072 (0.293925) | 0.761020 / 4.805227 (-4.044207) | 0.165860 / 6.500664 (-6.334804) | 0.075666 / 0.075469 (0.000197) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.427318 / 1.841788 (-0.414469) | 17.327468 / 8.074308 (9.253160) | 15.323065 / 10.191392 (5.131673) | 0.178518 / 0.680424 (-0.501905) | 0.020888 / 0.534201 (-0.513313) | 0.497891 / 0.579283 (-0.081393) | 0.487717 / 0.434364 (0.053353) | 0.581430 / 0.540337 (0.041093) | 0.703430 / 1.386936 (-0.683506) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007954 / 0.011353 (-0.003399) | 0.004442 / 0.011008 (-0.006566) | 0.090950 / 0.038508 (0.052442) | 0.054282 / 0.023109 (0.031173) | 0.424474 / 0.275898 (0.148576) | 0.531770 / 0.323480 (0.208290) | 0.004492 / 0.007986 (-0.003493) | 0.004745 / 0.004328 (0.000416) | 0.088213 / 0.004250 (0.083962) | 0.063967 / 0.037052 (0.026914) | 0.454256 / 0.258489 (0.195767) | 0.502870 / 0.293841 (0.209029) | 0.038203 / 0.128546 (-0.090343) | 0.010327 / 0.075646 (-0.065319) | 0.097809 / 0.419271 (-0.321463) | 0.062136 / 0.043533 (0.018604) | 0.426148 / 0.255139 (0.171009) | 0.467812 / 0.283200 (0.184612) | 0.029148 / 0.141683 (-0.112535) | 1.762307 / 1.452155 (0.310152) | 1.814238 / 1.492716 (0.321521) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.195676 / 0.018006 (0.177670) | 0.475382 / 0.000490 (0.474892) | 0.003070 / 0.000200 (0.002870) | 0.000112 / 0.000054 (0.000057) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033945 / 0.037411 (-0.003466) | 0.134666 / 0.014526 (0.120140) | 0.147585 / 0.176557 (-0.028971) | 0.209472 / 0.737135 (-0.527664) | 0.154471 / 0.296338 (-0.141867) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.518132 / 0.215209 (0.302923) | 5.103423 / 2.077655 (3.025768) | 2.565207 / 1.504120 (1.061087) | 2.389454 / 1.541195 (0.848259) | 2.391706 / 1.468490 (0.923216) | 0.606463 / 4.584777 (-3.978314) | 4.392227 / 3.745712 (0.646515) | 2.067121 / 5.269862 (-3.202741) | 1.217551 / 4.565676 (-3.348125) | 0.074304 / 0.424275 (-0.349971) | 0.013418 / 0.007607 (0.005811) | 0.623327 / 0.226044 (0.397282) | 6.340233 / 2.268929 (4.071304) | 3.153948 / 55.444624 (-52.290677) | 2.824548 / 6.876477 (-4.051929) | 2.938402 / 2.142072 (0.796329) | 0.774305 / 4.805227 (-4.030922) | 0.170681 / 6.500664 (-6.329983) | 0.075895 / 0.075469 (0.000426) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.473491 / 1.841788 (-0.368296) | 17.372294 / 8.074308 (9.297986) | 15.550201 / 10.191392 (5.358809) | 0.191402 / 0.680424 (-0.489022) | 0.021401 / 0.534201 (-0.512800) | 0.484377 / 0.579283 (-0.094906) | 0.488844 / 0.434364 (0.054480) | 0.563336 / 0.540337 (0.022999) | 0.694210 / 1.386936 (-0.692726) |\n\n</details>\n</details>\n\n\n"
] | "2023-06-14T16:26:34Z" | "2023-06-14T16:34:55Z" | "2023-06-14T16:26:51Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5958.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5958",
"merged_at": "2023-06-14T16:26:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5958.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5958"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5958/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5958/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2790 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2790/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2790/comments | https://api.github.com/repos/huggingface/datasets/issues/2790/events | https://github.com/huggingface/datasets/pull/2790 | 967,772,181 | MDExOlB1bGxSZXF1ZXN0NzA5OTI3NjM2 | 2,790 | Fix typo in test_dataset_common | {
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https://api.github.com/users/nateraw/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nateraw",
"id": 32437151,
"login": "nateraw",
"node_id": "MDQ6VXNlcjMyNDM3MTUx",
"organizations_url": "https://api.github.com/users/nateraw/orgs",
"received_events_url": "https://api.github.com/users/nateraw/received_events",
"repos_url": "https://api.github.com/users/nateraw/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nateraw/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nateraw/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nateraw"
} | [] | closed | false | null | [] | null | [] | "2021-08-12T01:10:29Z" | "2021-08-12T11:31:29Z" | "2021-08-12T11:31:29Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2790.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2790",
"merged_at": "2021-08-12T11:31:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2790.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2790"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2790/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2790/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5610/comments | https://api.github.com/repos/huggingface/datasets/issues/5610/events | https://github.com/huggingface/datasets/issues/5610 | 1,610,698,006 | I_kwDODunzps5gAU0W | 5,610 | use datasets streaming mode in trainer ddp mode cause memory leak | {
"avatar_url": "https://avatars.githubusercontent.com/u/15223544?v=4",
"events_url": "https://api.github.com/users/gromzhu/events{/privacy}",
"followers_url": "https://api.github.com/users/gromzhu/followers",
"following_url": "https://api.github.com/users/gromzhu/following{/other_user}",
"gists_url": "https://api.github.com/users/gromzhu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gromzhu",
"id": 15223544,
"login": "gromzhu",
"node_id": "MDQ6VXNlcjE1MjIzNTQ0",
"organizations_url": "https://api.github.com/users/gromzhu/orgs",
"received_events_url": "https://api.github.com/users/gromzhu/received_events",
"repos_url": "https://api.github.com/users/gromzhu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gromzhu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gromzhu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gromzhu"
} | [] | open | false | null | [] | null | [
"Same problem, \r\ntransformers 4.28.1\r\ndatasets 2.12.0\r\n\r\nleak around 100Mb per 10 seconds when use dataloader_num_werker > 0 in training argumennts for transformer train, possile bug in transformers repo, but still not found solution :(\r\n",
"found an article described a problem, may be helpful for somebody:\r\nhttps://ppwwyyxx.com/blog/2022/Demystify-RAM-Usage-in-Multiprocess-DataLoader/\r\nI confirm, it`s not memory leak, after some time memory growing has stopped"
] | "2023-03-06T05:26:49Z" | "2023-05-07T15:15:32Z" | null | NONE | null | null | null | ### Describe the bug
use datasets streaming mode in trainer ddp mode cause memory leak
### Steps to reproduce the bug
import os
import time
import datetime
import sys
import numpy as np
import random
import torch
from torch.utils.data import Dataset, DataLoader, random_split, RandomSampler, SequentialSampler,DistributedSampler,BatchSampler
torch.manual_seed(42)
from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config, GPT2Model,DataCollatorForLanguageModeling,AutoModelForCausalLM
from transformers import AdamW, get_linear_schedule_with_warmup
hf_model_path ='./Wenzhong-GPT2-110M'
tokenizer = GPT2Tokenizer.from_pretrained(hf_model_path)
tokenizer.add_special_tokens({'pad_token': '<|pad|>'})
from datasets import load_dataset
gpus=8
max_len = 576
batch_size_node = 17
save_step = 5000
gradient_accumulation = 2
dataloader_num = 4
max_step = 351000*1000//batch_size_node//gradient_accumulation//gpus
#max_step = -1
print("total_step:%d"%(max_step))
import datasets
datasets.version
dataset = load_dataset("text", data_files="./gpt_data_v1/*",split='train',cache_dir='./dataset_cache',streaming=True)
print('load over')
shuffled_dataset = dataset.shuffle(seed=42)
print('shuffle over')
def dataset_tokener(example,max_lenth=max_len):
example['text'] = list(map(lambda x : x.strip()+'<|endoftext|>',example['text'] ))
return tokenizer(example['text'], truncation=True, max_length=max_lenth, padding="longest")
new_new_dataset = shuffled_dataset.map(dataset_tokener, batched=True, remove_columns=["text"])
print('map over')
configuration = GPT2Config.from_pretrained(hf_model_path, output_hidden_states=False)
model = AutoModelForCausalLM.from_pretrained(hf_model_path)
model.resize_token_embeddings(len(tokenizer))
seed_val = 42
random.seed(seed_val)
np.random.seed(seed_val)
torch.manual_seed(seed_val)
torch.cuda.manual_seed_all(seed_val)
from transformers import Trainer,TrainingArguments
import os
print("strat train")
training_args = TrainingArguments(output_dir="./test_trainer",
num_train_epochs=1.0,
report_to="none",
do_train=True,
dataloader_num_workers=dataloader_num,
local_rank=int(os.environ.get('LOCAL_RANK', -1)),
overwrite_output_dir=True,
logging_strategy='steps',
logging_first_step=True,
logging_dir="./logs",
log_on_each_node=False,
per_device_train_batch_size=batch_size_node,
warmup_ratio=0.03,
save_steps=save_step,
save_total_limit=5,
gradient_accumulation_steps=gradient_accumulation,
max_steps=max_step,
disable_tqdm=False,
data_seed=42
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=new_new_dataset,
eval_dataset=None,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(tokenizer,mlm=False),
#compute_metrics=compute_metrics if training_args.do_eval and not is_torch_tpu_available() else None,
#preprocess_logits_for_metrics=preprocess_logits_for_metrics
#if training_args.do_eval and not is_torch_tpu_available()
#else None,
)
trainer.train(resume_from_checkpoint=True)
### Expected behavior
use the train code uppper
my dataset ./gpt_data_v1 have 1000 files, each file size is 120mb
start cmd is : python -m torch.distributed.launch --nproc_per_node=8 my_train.py
here is result:
here is memory usage monitor in 12 hours

every dataloader work allocate over 24gb cpu memory
according to memory usage monitor in 12 hours,sometime small memory releases, but total memory usage is increase.
i think datasets streaming mode should not used so much memery,so maybe somewhere has memory leak.
### Environment info
pytorch 1.11.0
py 3.8
cuda 11.3
transformers 4.26.1
datasets 2.9.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5610/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5610/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2053 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2053/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2053/comments | https://api.github.com/repos/huggingface/datasets/issues/2053/events | https://github.com/huggingface/datasets/pull/2053 | 831,151,728 | MDExOlB1bGxSZXF1ZXN0NTkyNTM4ODY2 | 2,053 | Add bAbI QA tasks | {
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gchhablani",
"id": 29076344,
"login": "gchhablani",
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gchhablani"
} | [] | closed | false | null | [] | null | [
"Hi @lhoestq,\r\n\r\nShould I remove the 160 configurations? Is it too much?\r\n\r\nEDIT:\r\nCan you also check the task category? I'm not sure if there is an appropriate tag for the same.",
"Thanks for the changes !\r\n\r\n> Should I remove the 160 configurations? Is it too much?\r\n\r\nYea 160 configuration is a lot.\r\nMaybe this dataset can work with parameters `type` and `task_no` ?\r\nYou can just remove the configuration in BUILDER_CONFIGS to only keep a few ones.\r\nAlso feel free to add an example in the dataset card of how to load the other configurations\r\n```\r\nload_dataset(\"babi_qa\", type=\"hn\", task_no=\"qa1\")\r\n```\r\nfor example, and with a list of the possible combinations.\r\n\r\n> Can you also check the task category? I'm not sure if there is an appropriate tag for the same.\r\n\r\nIt looks appropriate, thanks :)",
"Hi @lhoestq \r\n\r\nI'm unable to test it locally using:\r\n```python\r\nload_dataset(\"datasets/babi_qa\", type=\"hn\", task_no=\"qa1\")\r\n```\r\nIt raises an error:\r\n```python\r\nTypeError: __init__() got an unexpected keyword argument 'type'\r\n```\r\nWill this be possible only after merging? Or am I missing something here?",
"Can you try adding this class attribute to `BabiQa` ?\r\n```python\r\nBUILDER_CONFIG_CLASS = BabiQaConfig\r\n```\r\nThis should fix the TypeError issue you got",
"My bad. Thanks a lot!",
"Hi @lhoestq \r\n\r\nI have added the changes. Only the \"qa1\" task for each category is included. Also, I haven't removed the size categories and other description because I think it will still be useful. I have updated the line in README showing the example.\r\n\r\nThanks,\r\nGunjan",
"Hi @lhoestq,\r\n\r\nDoes this look good now?"
] | "2021-03-14T13:04:39Z" | "2021-03-29T12:41:48Z" | "2021-03-29T12:41:48Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2053.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2053",
"merged_at": "2021-03-29T12:41:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2053.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2053"
} | - **Name:** *The (20) QA bAbI tasks*
- **Description:** *The (20) QA bAbI tasks are a set of proxy tasks that evaluate reading comprehension via question answering. Our tasks measure understanding in several ways: whether a system is able to answer questions via chaining facts, simple induction, deduction and many more. The tasks are designed to be prerequisites for any system that aims to be capable of conversing with a human. The aim is to classify these tasks into skill sets,so that researchers can identify (and then rectify) the failings of their systems.*
- **Paper:** [arXiv](https://arxiv.org/pdf/1502.05698.pdf)
- **Data:** [Facebook Research Page](https://research.fb.com/downloads/babi/)
- **Motivation:** This is a unique dataset with story-based Question Answering. It is a part of the `bAbI` project by Facebook Research.
**Note**: I have currently added all the 160 configs. If this seems impractical, I can keep only a few. While each `dummy_data.zip` weighs a few KBs, overall it is around 1.3MB for all configurations. This is problematic. Let me know what is to be done.
Thanks :)
### Checkbox
- [x] Create the dataset script `/datasets/my_dataset/my_dataset.py` using the template
- [x] Fill the `_DESCRIPTION` and `_CITATION` variables
- [x] Implement `_infos()`, `_split_generators()` and `_generate_examples()`
- [x] Make sure that the `BUILDER_CONFIGS` class attribute is filled with the different configurations of the dataset and that the `BUILDER_CONFIG_CLASS` is specified if there is a custom config class.
- [x] Generate the metadata file `dataset_infos.json` for all configurations
- [x] Generate the dummy data `dummy_data.zip` files to have the dataset script tested and that they don't weigh too much (<50KB)
- [x] Add the dataset card `README.md` using the template : fill the tags and the various paragraphs
- [x] Both tests for the real data and the dummy data pass.
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2053/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2053/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6254 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6254/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6254/comments | https://api.github.com/repos/huggingface/datasets/issues/6254/events | https://github.com/huggingface/datasets/issues/6254 | 1,909,672,104 | I_kwDODunzps5x00io | 6,254 | Dataset.from_generator() cost much more time in vscode debugging mode then running mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/56437469?v=4",
"events_url": "https://api.github.com/users/dontnet-wuenze/events{/privacy}",
"followers_url": "https://api.github.com/users/dontnet-wuenze/followers",
"following_url": "https://api.github.com/users/dontnet-wuenze/following{/other_user}",
"gists_url": "https://api.github.com/users/dontnet-wuenze/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dontnet-wuenze",
"id": 56437469,
"login": "dontnet-wuenze",
"node_id": "MDQ6VXNlcjU2NDM3NDY5",
"organizations_url": "https://api.github.com/users/dontnet-wuenze/orgs",
"received_events_url": "https://api.github.com/users/dontnet-wuenze/received_events",
"repos_url": "https://api.github.com/users/dontnet-wuenze/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dontnet-wuenze/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dontnet-wuenze/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dontnet-wuenze"
} | [] | closed | false | null | [] | null | [
"Answered on the forum: https://discuss.huggingface.co/t/dataset-from-generator-cost-much-more-time-in-vscode-debugging-mode-then-running-mode/56005/2"
] | "2023-09-23T02:07:26Z" | "2023-10-03T14:42:53Z" | "2023-10-03T14:42:53Z" | NONE | null | null | null | ### Describe the bug
Hey there,
I’m using Dataset.from_generator() to convert a torch_dataset to the Huggingface Dataset.
However, when I debug my code on vscode, I find that it runs really slow on Dataset.from_generator() which may even 20 times longer then run the script on terminal.
### Steps to reproduce the bug
I write a simple test code :
```python
import os
from functools import partial
from typing import Callable
import torch
import time
from torch.utils.data import Dataset as TorchDataset
from datasets import load_from_disk, Dataset as HFDataset
import torch
from torch.utils.data import Dataset
class SimpleDataset(Dataset):
def __init__(self, data):
self.data = data
self.keys = list(data[0].keys())
def __len__(self):
return len(self.data)
def __getitem__(self, index):
sample = self.data[index]
return {key: sample[key] for key in self.keys}
def TorchDataset2HuggingfaceDataset(torch_dataset: TorchDataset, cache_dir: str = None
) -> HFDataset:
"""
convert torch dataset to huggingface dataset
"""
generator : Callable[[], TorchDataset] = lambda: (sample for sample in torch_dataset)
return HFDataset.from_generator(generator, cache_dir=cache_dir)
if __name__ == '__main__':
data = [
{'id': 1, 'name': 'Alice'},
{'id': 2, 'name': 'Bob'},
{'id': 3, 'name': 'Charlie'}
]
torch_dataset = SimpleDataset(data)
start_time = time.time()
huggingface_dataset = TorchDataset2HuggingfaceDataset(torch_dataset)
end_time = time.time()
print("time: ", end_time - start_time)
print(huggingface_dataset)
```
### Expected behavior
this test on my machine report that the running time on terminal is 0.086,
however the running time in debugging mode on vscode is 0.25, which I think is much longer than expected.
I’d like to know is the anything wrong in the code or just because of debugging?
I have traced the code and I find is this func which I get stuck.
```python
def create_config_id(
self,
config_kwargs: dict,
custom_features: Optional[Features] = None,
) -> str:
...
# stuck in this line
suffix = Hasher.hash(config_kwargs_to_add_to_suffix)
```
### Environment info
- `datasets` version: 2.12.0
- Platform: Linux-5.11.0-27-generic-x86_64-with-glibc2.31
- Python version: 3.11.3
- Huggingface_hub version: 0.17.2
- PyArrow version: 11.0.0
- Pandas version: 2.0.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6254/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6254/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5881 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5881/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5881/comments | https://api.github.com/repos/huggingface/datasets/issues/5881/events | https://github.com/huggingface/datasets/issues/5881 | 1,719,402,643 | I_kwDODunzps5mfACT | 5,881 | Split dataset by node: index error when sharding iterable dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sanchit-gandhi",
"id": 93869735,
"login": "sanchit-gandhi",
"node_id": "U_kgDOBZhWpw",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sanchit-gandhi"
} | [] | open | false | null | [] | null | [
"cc @lhoestq in case you have any ideas here! Might need a multi-host set-up to debug (can give you access to a JAX one if you need)"
] | "2023-05-22T10:36:13Z" | "2023-05-23T08:32:14Z" | null | CONTRIBUTOR | null | null | null | ### Describe the bug
Context: we're splitting an iterable dataset by node and then passing it to a torch data loader with multiple workers
When we iterate over it for 5 steps, we don't get an error
When we instead iterate over it for 8 steps, we get an `IndexError` when fetching the data if we have too many workers
### Steps to reproduce the bug
Here, we have 2 JAX processes (`jax.process_count() = 2`) which we split the dataset over. The dataset loading script can be found here: https://huggingface.co/datasets/distil-whisper/librispeech_asr/blob/c6a1e805cbfeed5057400ac5937327d7e30281b8/librispeech_asr.py#L310
<details>
<summary> Code to reproduce </summary>
```python
from datasets import load_dataset
import jax
from datasets.distributed import split_dataset_by_node
from torch.utils.data import DataLoader
from tqdm import tqdm
# load an example dataset (https://huggingface.co/datasets/distil-whisper/librispeech_asr)
dataset = load_dataset("distil-whisper/librispeech_asr", "all", split="train.clean.100", streaming=True)
# just keep the text column -> no need to define a collator
dataset_text = dataset.remove_columns(set(dataset.features.keys()) - {"text"})
# define some constants
batch_size = 256
num_examples = 5 # works for 5 examples, doesn't for 8
num_workers = dataset_text.n_shards
# try with multiple workers
dataloader = DataLoader(dataset_text, batch_size=batch_size, num_workers=num_workers, drop_last=True)
for i, batch in tqdm(enumerate(dataloader), total=num_examples, desc="Multiple workers"):
if i == num_examples:
break
# try splitting by node (we can't do this with `dataset_text` since `split_dataset_by_node` expects the Audio column for an ASR dataset)
dataset = split_dataset_by_node(dataset, rank=jax.process_index(), world_size=jax.process_count())
# remove the text column again
dataset_text = dataset.remove_columns(set(dataset.features.keys()) - {"text"})
dataloader = DataLoader(dataset_text, batch_size=16, num_workers=num_workers // 2, drop_last=True)
for i, batch in tqdm(enumerate(dataloader), total=num_examples, desc="Split by node"):
if i == num_examples:
break
# too many workers
dataloader = DataLoader(dataset_text, batch_size=256, num_workers=num_workers, drop_last=True)
for i, batch in tqdm(enumerate(dataloader), total=num_examples, desc="Too many workers"):
if i == num_examples:
break
```
</details>
<details>
<summary> With 5 examples: </summary>
```
Multiple workers: 100%|███████████████████████████████████████████████████████████████████| 5/5 [00:16<00:00, 3.33s/it]
Assigning 7 shards (or data sources) of the dataset to each node.
Split by node: 100%|██████████████████████████████████████████████████████████████████████| 5/5 [00:13<00:00, 2.76s/it]
Assigning 7 shards (or data sources) of the dataset to each node.
Too many dataloader workers: 14 (max is dataset.n_shards=7). Stopping 7 dataloader workers.
To parallelize data loading, we give each process some shards (or data sources) to process. Therefore it's unnecessary t
o have a number of workers greater than dataset.n_shards=7. To enable more parallelism, please split the dataset in more
files than 7.
Too many workers: 100%|███████████████████████████████████████████████████████████████████| 5/5 [00:15<00:00, 3.03s/it]
```
</details>
<details>
<summary> With 7 examples: </summary>
```
Multiple workers: 100%|███████████████████████████████████████████████████████████████████| 8/8 [00:13<00:00, 1.71s/it]
Assigning 7 shards (or data sources) of the dataset to each node.
Split by node: 100%|██████████████████████████████████████████████████████████████████████| 8/8 [00:11<00:00, 1.38s/it]
Assigning 7 shards (or data sources) of the dataset to each node.
Too many dataloader workers: 14 (max is dataset.n_shards=7). Stopping 7 dataloader workers.
To parallelize data loading, we give each process some shards (or data sources) to process. Therefore it's unnecessary to have a number of workers greater than dataset.n_shards=7. To enable more parallelism, please split the dataset in more files than 7.
Too many workers: 88%|██████████████████████████████████████████████████████████▋ | 7/8 [00:13<00:01, 1.89s/it]
Traceback (most recent call last):
File "distil-whisper/test_librispeech.py", line 36, in <module>
for i, batch in tqdm(enumerate(dataloader), total=num_examples, desc="Too many workers"):
File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/tqdm/std.py", line 1178, in __iter__
for obj in iterable:
File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 633, in __next__
data = self._next_data()
File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1325, in _next_data
return self._process_data(data)
File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1371, in _process_data
data.reraise()
File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/_utils.py", line 644, in reraise
raise exception
IndexError: Caught IndexError in DataLoader worker process 7.
Original Traceback (most recent call last):
File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/utils/data/_utils/worker.py", line 308, in _worker_loop
data = fetcher.fetch(index)
File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py", line 32, in fetch
data.append(next(self.dataset_iter))
File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 986, in __iter__
yield from self._iter_pytorch(ex_iterable)
File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 920, in _iter_pytorch
for key, example in ex_iterable.shard_data_sources(worker_info.id, worker_info.num_workers):
File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 540, in shard_data_sources
self.ex_iterable.shard_data_sources(worker_id, num_workers),
File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 796, in shard_data_sources
self.ex_iterable.shard_data_sources(worker_id, num_workers),
File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 126, in shard_data_sources
requested_gen_kwargs = _merge_gen_kwargs([gen_kwargs_list[i] for i in shard_indices])
File "/home/sanchitgandhi/datasets/src/datasets/utils/sharding.py", line 76, in _merge_gen_kwargs
for key in gen_kwargs_list[0]
IndexError: list index out of range
```
</details>
### Expected behavior
Should pass for both 5 and 7 examples
### Environment info
- `datasets` version: 2.12.1.dev0
- Platform: Linux-5.13.0-1023-gcp-x86_64-with-glibc2.29
- Python version: 3.8.10
- Huggingface_hub version: 0.14.1
- PyArrow version: 12.0.0
- Pandas version: 2.0.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5881/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5881/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/6271 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6271/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6271/comments | https://api.github.com/repos/huggingface/datasets/issues/6271/events | https://github.com/huggingface/datasets/issues/6271 | 1,920,420,295 | I_kwDODunzps5yd0nH | 6,271 | Overwriting Split overwrites data but not metadata, corrupting dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/13859249?v=4",
"events_url": "https://api.github.com/users/govindrai/events{/privacy}",
"followers_url": "https://api.github.com/users/govindrai/followers",
"following_url": "https://api.github.com/users/govindrai/following{/other_user}",
"gists_url": "https://api.github.com/users/govindrai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/govindrai",
"id": 13859249,
"login": "govindrai",
"node_id": "MDQ6VXNlcjEzODU5MjQ5",
"organizations_url": "https://api.github.com/users/govindrai/orgs",
"received_events_url": "https://api.github.com/users/govindrai/received_events",
"repos_url": "https://api.github.com/users/govindrai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/govindrai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/govindrai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/govindrai"
} | [] | closed | false | null | [] | null | [] | "2023-09-30T22:37:31Z" | "2023-10-16T13:30:50Z" | "2023-10-16T13:30:50Z" | NONE | null | null | null | ### Describe the bug
I want to be able to overwrite/update/delete splits in my dataset. Currently the only way to do is to manually go into the dataset and delete the split. If I try to overwrite programmatically I end up in an error state and (somewhat) corrupting the dataset. Read below.
**Current Behavior**
When I push to an existing split I get this error:
`ValueError: Split complexRoofLocation_01Apr2023_to_31May2023test already present`
This seems to suggest that the library doesn't support overwriting splits.
**Potential Bug**
What’s strange is that datasets, despite the operation erroring out with the ValueError above, does, in fact, overwrite the split:
`Pushing dataset shards to the dataset hub: 100% [.....................] 1/1 [00:00<00:00, 55.04it/s]`
Even though you got an error message and your code fails, your dataset is now changed. That seems like a bug. Either don't change the dataset, or don't throw the error and allow the script to proceed.
Additional Bug
While it overwrites the split, it doesn’t overwrite the split’s information. Because of this when you pull down the dataset you may end up getting a `NonMatchingSplitsSizesError` if the size of the dataset during the overwrite is different. For example, my original split had 5 rows, but on my overwrite, I only had 4. Then when I try to download the dataset, I get a `NonMatchingSplitsSizesError` because the dataset's data.json states there’s 5 but only 4 exist in the split.
Expected Behavior
This corrupts the dataset rendering it unusable (until you take manual intervention). Either the library should let the overwrite happen (which it does but should also update the metadata) or it shouldn’t do anything.
### Steps to reproduce the bug
[Colab Notebook](https://colab.research.google.com/drive/1bqVkD06Ngs9MQNdSk_ygCG6y1UqXA4pC?usp=sharing)
### Expected behavior
The split should be overwritten and I should be able to use the new version of the dataset without issue.
### Environment info
- `datasets` version: 2.14.5
- Platform: Linux-5.15.120+-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.17.3
- PyArrow version: 9.0.0
- Pandas version: 1.5.3
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6271/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6271/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2210 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2210/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2210/comments | https://api.github.com/repos/huggingface/datasets/issues/2210/events | https://github.com/huggingface/datasets/issues/2210 | 855,709,400 | MDU6SXNzdWU4NTU3MDk0MDA= | 2,210 | dataloading slow when using HUGE dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/29157715?v=4",
"events_url": "https://api.github.com/users/hwijeen/events{/privacy}",
"followers_url": "https://api.github.com/users/hwijeen/followers",
"following_url": "https://api.github.com/users/hwijeen/following{/other_user}",
"gists_url": "https://api.github.com/users/hwijeen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hwijeen",
"id": 29157715,
"login": "hwijeen",
"node_id": "MDQ6VXNlcjI5MTU3NzE1",
"organizations_url": "https://api.github.com/users/hwijeen/orgs",
"received_events_url": "https://api.github.com/users/hwijeen/received_events",
"repos_url": "https://api.github.com/users/hwijeen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hwijeen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hwijeen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hwijeen"
} | [] | closed | false | null | [] | null | [
"Hi ! Yes this is an issue with `datasets<=1.5.0`\r\nThis issue has been fixed by #2122 , we'll do a new release soon :)\r\nFor now you can test it on the `master` branch.",
"Hi, thank you for your answer. I did not realize that my issue stems from the same problem. "
] | "2021-04-12T08:33:02Z" | "2021-04-13T02:03:05Z" | "2021-04-13T02:03:05Z" | NONE | null | null | null | Hi,
When I use datasets with 600GB data, the dataloading speed increases significantly.
I am experimenting with two datasets, and one is about 60GB and the other 600GB.
Simply speaking, my code uses `datasets.set_format("torch")` function and let pytorch-lightning handle ddp training.
When looking at the pytorch-lightning supported profile of two different runs, I see that fetching a batch(`get_train_batch`) consumes an unreasonable amount of time when data is large. What could be the cause?
* 60GB data
```
Action | Mean duration (s) |Num calls | Total time (s) | Percentage % |
------------------------------------------------------------------------------------------------------------------------------------
Total | - |_ | 200.33 | 100 % |
------------------------------------------------------------------------------------------------------------------------------------
run_training_epoch | 71.994 |1 | 71.994 | 35.937 |
run_training_batch | 0.64373 |100 | 64.373 | 32.133 |
optimizer_step_and_closure_0 | 0.64322 |100 | 64.322 | 32.108 |
training_step_and_backward | 0.61004 |100 | 61.004 | 30.452 |
model_backward | 0.37552 |100 | 37.552 | 18.745 |
model_forward | 0.22813 |100 | 22.813 | 11.387 |
training_step | 0.22759 |100 | 22.759 | 11.361 |
get_train_batch | 0.066385 |100 | 6.6385 | 3.3138 |
```
* 600GB data
```
Action | Mean duration (s) |Num calls | Total time (s) | Percentage % |
------------------------------------------------------------------------------------------------------------------------------------
Total | - |_ | 3285.6 | 100 % |
------------------------------------------------------------------------------------------------------------------------------------
run_training_epoch | 1397.9 |1 | 1397.9 | 42.546 |
run_training_batch | 7.2596 |100 | 725.96 | 22.095 |
optimizer_step_and_closure_0 | 7.2589 |100 | 725.89 | 22.093 |
training_step_and_backward | 7.223 |100 | 722.3 | 21.984 |
model_backward | 6.9662 |100 | 696.62 | 21.202 |
get_train_batch | 6.322 |100 | 632.2 | 19.241 |
model_forward | 0.24902 |100 | 24.902 | 0.75789 |
training_step | 0.2485 |100 | 24.85 | 0.75633 |
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2210/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2210/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4868 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4868/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4868/comments | https://api.github.com/repos/huggingface/datasets/issues/4868/events | https://github.com/huggingface/datasets/pull/4868 | 1,345,191,322 | PR_kwDODunzps49gBk0 | 4,868 | adding mafand to datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/23586676?v=4",
"events_url": "https://api.github.com/users/dadelani/events{/privacy}",
"followers_url": "https://api.github.com/users/dadelani/followers",
"following_url": "https://api.github.com/users/dadelani/following{/other_user}",
"gists_url": "https://api.github.com/users/dadelani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dadelani",
"id": 23586676,
"login": "dadelani",
"node_id": "MDQ6VXNlcjIzNTg2Njc2",
"organizations_url": "https://api.github.com/users/dadelani/orgs",
"received_events_url": "https://api.github.com/users/dadelani/received_events",
"repos_url": "https://api.github.com/users/dadelani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dadelani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dadelani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dadelani"
} | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi @dadelani, thanks for your awesome contribution!!! :heart: \r\n\r\nHowever, now we are using the Hub to add new datasets, instead of this GitHub repo. \r\n\r\nYou could share this dataset under your Hub organization namespace: [Masakhane NLP](https://huggingface.co/masakhane). This way the dataset will be accessible using:\r\n```python\r\nds = load_dataset(\"masakhane/mafand\")\r\n```\r\n\r\nYou have the procedure documented in our online docs: \r\n- [Create a dataset loading script](https://huggingface.co/docs/datasets/dataset_script)\r\n- [Share](https://huggingface.co/docs/datasets/share)\r\n\r\nMoreover, datasets shared on the Hub no longer need the dummy data files.\r\n\r\nPlease, feel free to ping me if you need any further guidance/support.",
"thank you for the comment. I have moved it to the Hub https://huggingface.co/datasets/masakhane/mafand",
"Great job, @dadelani!!\r\n\r\nPlease, note that in the README.md file, the YAML tags should be preceded and followed by three dashes `---`, so that they are properly parsed. See, e.g.: https://raw.githubusercontent.com/huggingface/datasets/main/templates/README.md",
"Also you could replace the line:\r\n```\r\n# Dataset Card for [Needs More Information]\r\n```\r\nwith\r\n```\r\n# Dataset Card for MAFAND-MT\r\n```",
"Great, thank you for the feedback. I have fixed both issues."
] | "2022-08-20T15:26:14Z" | "2022-08-22T11:00:50Z" | "2022-08-22T08:52:23Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4868.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4868",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4868.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4868"
} | I'm addding the MAFAND dataset by Masakhane based on the paper/repository below:
Paper: https://aclanthology.org/2022.naacl-main.223/
Code: https://github.com/masakhane-io/lafand-mt
Please, help merge this
Everything works except for creating dummy data file | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4868/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4868/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5945 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5945/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5945/comments | https://api.github.com/repos/huggingface/datasets/issues/5945/events | https://github.com/huggingface/datasets/issues/5945 | 1,754,084,577 | I_kwDODunzps5ojTTh | 5,945 | Failing to upload dataset to the hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/77382661?v=4",
"events_url": "https://api.github.com/users/Ar770/events{/privacy}",
"followers_url": "https://api.github.com/users/Ar770/followers",
"following_url": "https://api.github.com/users/Ar770/following{/other_user}",
"gists_url": "https://api.github.com/users/Ar770/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Ar770",
"id": 77382661,
"login": "Ar770",
"node_id": "MDQ6VXNlcjc3MzgyNjYx",
"organizations_url": "https://api.github.com/users/Ar770/orgs",
"received_events_url": "https://api.github.com/users/Ar770/received_events",
"repos_url": "https://api.github.com/users/Ar770/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Ar770/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Ar770/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Ar770"
} | [] | closed | false | null | [] | null | [
"Hi ! Feel free to re-run your code later, it will resume automatically where you left",
"Tried many times in the last 2 weeks, problem remains.",
"Alternatively you can save your dataset in parquet files locally and upload them to the hub manually\r\n\r\n```python\r\nfrom tqdm import tqdm\r\nnum_shards = 60\r\nfor index in tqdm(range(num_shards)):\r\n ds.shard(num_shards=num_shards, index=index, contiguous=True).to_parquet(f\"{index:05d}.parquet\")\r\n````"
] | "2023-06-13T05:46:46Z" | "2023-07-24T11:56:40Z" | "2023-07-24T11:56:40Z" | NONE | null | null | null | ### Describe the bug
Trying to upload a dataset of hundreds of thousands of audio samples (the total volume is not very large, 60 gb) to the hub with push_to_hub, it doesn't work.
From time to time one piece of the data (parquet) gets pushed and then I get RemoteDisconnected even though my internet is stable.
Please help.
I'm trying to upload the dataset for almost a week.
Thanks
### Steps to reproduce the bug
not relevant
### Expected behavior
Be able to upload thedataset
### Environment info
python: 3.9 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5945/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5945/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3747 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3747/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3747/comments | https://api.github.com/repos/huggingface/datasets/issues/3747/events | https://github.com/huggingface/datasets/issues/3747 | 1,141,688,854 | I_kwDODunzps5EDMoW | 3,747 | Passing invalid subset should throw an error | {
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jxmorris12",
"id": 13238952,
"login": "jxmorris12",
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jxmorris12"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [] | "2022-02-17T18:16:11Z" | "2022-02-17T18:16:11Z" | null | CONTRIBUTOR | null | null | null | ## Describe the bug
Only some datasets have a subset (as in `load_dataset(name, subset)`). If you pass an invalid subset, an error should be thrown.
## Steps to reproduce the bug
```python
import datasets
datasets.load_dataset('rotten_tomatoes', 'asdfasdfa')
```
## Expected results
This should break, since `'asdfasdfa'` isn't a subset of the `rotten_tomatoes` dataset.
## Actual results
This API call silently succeeds. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3747/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3747/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4639 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4639/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4639/comments | https://api.github.com/repos/huggingface/datasets/issues/4639/events | https://github.com/huggingface/datasets/issues/4639 | 1,295,367,322 | I_kwDODunzps5NNbya | 4,639 | Add HaGRID -- HAnd Gesture Recognition Image Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_url": "https://api.github.com/users/osanseviero/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/osanseviero",
"id": 7246357,
"login": "osanseviero",
"node_id": "MDQ6VXNlcjcyNDYzNTc=",
"organizations_url": "https://api.github.com/users/osanseviero/orgs",
"received_events_url": "https://api.github.com/users/osanseviero/received_events",
"repos_url": "https://api.github.com/users/osanseviero/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/osanseviero/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/osanseviero/subscriptions",
"type": "User",
"url": "https://api.github.com/users/osanseviero"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | [] | null | [] | "2022-07-06T07:41:32Z" | "2022-07-06T07:41:32Z" | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** HaGRID -- HAnd Gesture Recognition Image Dataset
- **Description:** We introduce a large image dataset HaGRID (HAnd Gesture Recognition Image Dataset) for hand gesture recognition (HGR) systems. You can use it for image classification or image detection tasks. Proposed dataset allows to build HGR systems, which can be used in video conferencing services (Zoom, Skype, Discord, Jazz etc.), home automation systems, the automotive sector, etc.
- **Paper:** https://arxiv.org/abs/2206.08219
- **Data:** https://github.com/hukenovs/hagrid
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4639/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4639/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5053 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5053/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5053/comments | https://api.github.com/repos/huggingface/datasets/issues/5053/events | https://github.com/huggingface/datasets/issues/5053 | 1,393,739,882 | I_kwDODunzps5TEshq | 5,053 | Intermittent JSON parse error when streaming the Pile | {
"avatar_url": "https://avatars.githubusercontent.com/u/77788841?v=4",
"events_url": "https://api.github.com/users/neelnanda-io/events{/privacy}",
"followers_url": "https://api.github.com/users/neelnanda-io/followers",
"following_url": "https://api.github.com/users/neelnanda-io/following{/other_user}",
"gists_url": "https://api.github.com/users/neelnanda-io/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/neelnanda-io",
"id": 77788841,
"login": "neelnanda-io",
"node_id": "MDQ6VXNlcjc3Nzg4ODQx",
"organizations_url": "https://api.github.com/users/neelnanda-io/orgs",
"received_events_url": "https://api.github.com/users/neelnanda-io/received_events",
"repos_url": "https://api.github.com/users/neelnanda-io/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/neelnanda-io/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/neelnanda-io/subscriptions",
"type": "User",
"url": "https://api.github.com/users/neelnanda-io"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"Maybe #2838 can help. In this PR we allow to skip bad chunks of JSON data to not crash the training\r\n\r\nDid you have warning messages before the error ?\r\n\r\nsomething like this maybe ?\r\n```\r\n03/24/2022 02:19:46 - WARNING - datasets.utils.streaming_download_manager - Got disconnected from remote data host. Retrying in 5sec [1/20]\r\n03/24/2022 02:20:01 - WARNING - datasets.utils.streaming_download_manager - Got disconnected from remote data host. Retrying in 5sec [2/20]\r\n03/24/2022 02:20:09 - ERROR - datasets.packaged_modules.json.json - Failed to read file 'gzip://file-000000000007.json::https://huggingface.co/datasets/lvwerra/codeparrot-clean-train/resolve/1d740acb9d09cf7a3307553323e2c677a6535407/file-000000000007.json.gz' with error <class 'pyarrow.lib.ArrowInvalid'>: JSON parse error: Invalid value. in row 0\r\n```",
"Ah, thanks! I did get errors like that. Sad that PR wasn't merged in! \r\n\r\nI'm currently just downloading 200GB of the Pile locally to avoid streaming (I have space and it's faster anyway), but that's really useful! I can probably apply the dumb patch of just commenting out the bits that raise the JSON Parse Error lol, based on your code - if I continue the loop should it be fine?",
"Yup you can get some inspiration from this PR. It simply ignores the bad chunks (a chunk is ~a few MBs of data).\r\nWe'll try to merge this PR soon"
] | "2022-10-02T11:56:46Z" | "2022-10-04T17:59:03Z" | null | NONE | null | null | null | ## Describe the bug
I have an intermittent error when streaming the Pile, where I get a JSON parse error which causes my program to crash.
This is intermittent - when I rerun the program with the same random seed it does not crash in the same way. The exact point this happens also varied - it happened to me 11B tokens and 4 days into a training run, and now just happened 2 minutes into one, but I can't reliably reproduce it.
I'm using a remote machine with 8 A6000 GPUs via runpod.io
## Expected results
I have a DataLoader which can iterate through the whole Pile
## Actual results
Stack trace:
```
Failed to read file 'zstd://12.jsonl::https://the-eye.eu/public/AI/pile/train/12.jsonl.zst' with error <class 'pyarrow.lib.ArrowInvalid'>: JSON parse error: Invalid value. in row 0
```
I'm currently using HuggingFace accelerate, which also gave me the following stack trace, but I've also experienced this problem intermittently when using DataParallel, so I don't think it's to do with parallelisation
```
Traceback (most recent call last):
File "ddp_script.py", line 1258, in <module>
main()
File "ddp_script.py", line 1143, in main
for c, batch in tqdm.tqdm(enumerate(data_iter)):
File "/opt/conda/lib/python3.7/site-packages/tqdm/std.py", line 1195, in __iter__
for obj in iterable:
File "/opt/conda/lib/python3.7/site-packages/accelerate/data_loader.py", line 503, in __iter__
next_batch, next_batch_info, next_skip = self._fetch_batches(main_iterator)
File "/opt/conda/lib/python3.7/site-packages/accelerate/data_loader.py", line 454, in _fetch_batches
broadcast_object_list(batch_info)
File "/opt/conda/lib/python3.7/site-packages/accelerate/utils/operations.py", line 333, in broadcast_object_list
torch.distributed.broadcast_object_list(object_list, src=from_process)
File "/opt/conda/lib/python3.7/site-packages/torch/distributed/distributed_c10d.py", line 1900, in broadcast_object_list
object_list[i] = _tensor_to_object(obj_view, obj_size)
File "/opt/conda/lib/python3.7/site-packages/torch/distributed/distributed_c10d.py", line 1571, in _tensor_to_object
return _unpickler(io.BytesIO(buf)).load()
_pickle.UnpicklingError: invalid load key, '@'.
```
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset(
cfg["dataset_name"], streaming=True, split="train")
dataset = dataset.remove_columns("meta")
dataset = dataset.map(tokenize_and_concatenate, batched=True)
dataset = dataset.with_format(type="torch")
train_data_loader = DataLoader(
dataset, batch_size=cfg["batch_size"], num_workers=3)
for batch in train_data_loader:
continue
```
`tokenize_and_concatenate` is a custom tokenization function I defined on the GPT-NeoX tokenizer to tokenize the text, separated by endoftext tokens, and reshape to have length batch_size, I don't think this is related to tokenization:
```
import numpy as np
import einops
import torch
def tokenize_and_concatenate(examples):
texts = examples["text"]
full_text = tokenizer.eos_token.join(texts)
div = 20
length = len(full_text) // div
text_list = [full_text[i * length: (i + 1) * length]
for i in range(div)]
tokens = tokenizer(text_list, return_tensors="np", padding=True)[
"input_ids"
].flatten()
tokens = tokens[tokens != tokenizer.pad_token_id]
n = len(tokens)
curr_batch_size = n // (seq_len - 1)
tokens = tokens[: (seq_len - 1) * curr_batch_size]
tokens = einops.rearrange(
tokens,
"(batch_size seq) -> batch_size seq",
batch_size=curr_batch_size,
seq=seq_len - 1,
)
prefix = np.ones((curr_batch_size, 1), dtype=np.int64) * \
tokenizer.bos_token_id
return {
"text": np.concatenate([prefix, tokens], axis=1)
}
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.4.0
- Platform: Linux-5.4.0-105-generic-x86_64-with-debian-buster-sid
- Python version: 3.7.13
- PyArrow version: 9.0.0
- Pandas version: 1.3.5
ZStandard data:
Version: 0.18.0
Summary: Zstandard bindings for Python
Home-page: https://github.com/indygreg/python-zstandard
Author: Gregory Szorc
Author-email: gregory.szorc@gmail.com
License: BSD
Location: /opt/conda/lib/python3.7/site-packages
Requires:
Required-by: | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5053/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5053/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1297 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1297/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1297/comments | https://api.github.com/repos/huggingface/datasets/issues/1297/events | https://github.com/huggingface/datasets/pull/1297 | 759,404,103 | MDExOlB1bGxSZXF1ZXN0NTM0NDE1ODMx | 1,297 | OPUS Ted Talks 2013 | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user}",
"gists_url": "https://api.github.com/users/abhishekkrthakur/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abhishekkrthakur",
"id": 1183441,
"login": "abhishekkrthakur",
"node_id": "MDQ6VXNlcjExODM0NDE=",
"organizations_url": "https://api.github.com/users/abhishekkrthakur/orgs",
"received_events_url": "https://api.github.com/users/abhishekkrthakur/received_events",
"repos_url": "https://api.github.com/users/abhishekkrthakur/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abhishekkrthakur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhishekkrthakur/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abhishekkrthakur"
} | [] | closed | false | null | [] | null | [] | "2020-12-08T12:25:39Z" | "2023-09-24T09:51:49Z" | "2020-12-08T12:35:50Z" | MEMBER | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1297.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1297",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1297.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1297"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1297/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1297/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/3954 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3954/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3954/comments | https://api.github.com/repos/huggingface/datasets/issues/3954/events | https://github.com/huggingface/datasets/issues/3954 | 1,172,141,664 | I_kwDODunzps5F3XZg | 3,954 | The dataset preview is not available for tdklab/Hebrew_Squad_v1.1 dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/49593805?v=4",
"events_url": "https://api.github.com/users/MatanBenChorin/events{/privacy}",
"followers_url": "https://api.github.com/users/MatanBenChorin/followers",
"following_url": "https://api.github.com/users/MatanBenChorin/following{/other_user}",
"gists_url": "https://api.github.com/users/MatanBenChorin/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/MatanBenChorin",
"id": 49593805,
"login": "MatanBenChorin",
"node_id": "MDQ6VXNlcjQ5NTkzODA1",
"organizations_url": "https://api.github.com/users/MatanBenChorin/orgs",
"received_events_url": "https://api.github.com/users/MatanBenChorin/received_events",
"repos_url": "https://api.github.com/users/MatanBenChorin/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/MatanBenChorin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MatanBenChorin/subscriptions",
"type": "User",
"url": "https://api.github.com/users/MatanBenChorin"
} | [] | closed | false | null | [] | null | [
"Hi @MatanBenChorin, thanks for reporting.\r\n\r\nPlease, take into account that the preview may take some time until it properly renders (we are working to reduce this time).\r\n\r\nMaybe @severo can give more details on this.",
"Hi, \r\nThank you",
"Thanks for reporting. We are looking at it and will give updates here.",
"I imagine the dataset has been moved to https://huggingface.co/datasets/tdklab/Hebrew_Squad_v1, which still has an issue:\r\n\r\n```\r\nServer Error\r\n\r\nStatus code: 400\r\nException: NameError\r\nMessage: name 'HebrewSquad' is not defined\r\n```",
"The issue is not related to the dataset viewer but to the loading script (cc @albertvillanova @lhoestq @mariosasko)\r\n\r\n```python\r\n>>> import datasets as ds\r\n>>> hf_token = \"hf_...\" # <- required because the dataset is gated\r\n>>> d = ds.load_dataset('tdklab/Hebrew_Squad_v1', use_auth_token=hf_token)\r\n...\r\nNameError: name 'HebrewSquad' is not defined\r\n```",
"Yes indeed there is an error in [Hebrew_Squad_v1.py:L40](https://huggingface.co/datasets/tdklab/Hebrew_Squad_v1/blob/main/Hebrew_Squad_v1.py#L40)\r\n\r\nHere is the fix @MatanBenChorin :\r\n\r\n```diff\r\n- HebrewSquad(\r\n+ HebrewSquadConfig(\r\n```"
] | "2022-03-17T09:38:11Z" | "2022-04-20T12:39:07Z" | "2022-04-20T12:39:07Z" | NONE | null | null | null | ## Dataset viewer issue for 'tdklab/Hebrew_Squad_v1.1'
**Link:** https://huggingface.co/api/datasets/tdklab/Hebrew_Squad_v1.1?full=true
The dataset preview is not available for this dataset.
Am I the one who added this dataset ? Yes | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3954/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3954/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5316 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5316/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5316/comments | https://api.github.com/repos/huggingface/datasets/issues/5316/events | https://github.com/huggingface/datasets/issues/5316 | 1,470,115,681 | I_kwDODunzps5XoC9h | 5,316 | Bug in sample_by="paragraph" | {
"avatar_url": "https://avatars.githubusercontent.com/u/1243668?v=4",
"events_url": "https://api.github.com/users/adampauls/events{/privacy}",
"followers_url": "https://api.github.com/users/adampauls/followers",
"following_url": "https://api.github.com/users/adampauls/following{/other_user}",
"gists_url": "https://api.github.com/users/adampauls/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/adampauls",
"id": 1243668,
"login": "adampauls",
"node_id": "MDQ6VXNlcjEyNDM2Njg=",
"organizations_url": "https://api.github.com/users/adampauls/orgs",
"received_events_url": "https://api.github.com/users/adampauls/received_events",
"repos_url": "https://api.github.com/users/adampauls/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/adampauls/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adampauls/subscriptions",
"type": "User",
"url": "https://api.github.com/users/adampauls"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Thanks for reporting, @adampauls.\r\n\r\nWe are having a look at it. "
] | "2022-11-30T19:24:13Z" | "2022-12-01T15:19:02Z" | "2022-12-01T15:19:02Z" | NONE | null | null | null | ### Describe the bug
I think [this line](https://github.com/huggingface/datasets/blob/main/src/datasets/packaged_modules/text/text.py#L96) is wrong and should be `batch = f.read(self.config.chunksize)`. Otherwise it will never terminate because even when `f` is finished reading, `batch` will still be truthy from the last iteration.
### Steps to reproduce the bug
```
> cat test.txt
a b c
d e f
````
```python
>>> import datasets
>>> datasets.load_dataset("text", data_files={"train":"test.txt"}, sample_by="paragraph")
```
This will go on forever.
### Expected behavior
Terminates very quickly.
### Environment info
`version = "2.6.1"` but I think the bug is still there on main. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5316/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5316/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5323 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5323/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5323/comments | https://api.github.com/repos/huggingface/datasets/issues/5323/events | https://github.com/huggingface/datasets/issues/5323 | 1,471,518,803 | I_kwDODunzps5XtZhT | 5,323 | Duplicated Keys in Taskmaster-2 Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/52380283?v=4",
"events_url": "https://api.github.com/users/liaeh/events{/privacy}",
"followers_url": "https://api.github.com/users/liaeh/followers",
"following_url": "https://api.github.com/users/liaeh/following{/other_user}",
"gists_url": "https://api.github.com/users/liaeh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/liaeh",
"id": 52380283,
"login": "liaeh",
"node_id": "MDQ6VXNlcjUyMzgwMjgz",
"organizations_url": "https://api.github.com/users/liaeh/orgs",
"received_events_url": "https://api.github.com/users/liaeh/received_events",
"repos_url": "https://api.github.com/users/liaeh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/liaeh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/liaeh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/liaeh"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Thanks for reporting, @liaeh.\r\n\r\nWe are having a look at it. ",
"I have transferred the discussion to the Community tab of the dataset: https://huggingface.co/datasets/taskmaster2/discussions/1"
] | "2022-12-01T15:31:06Z" | "2022-12-01T16:26:06Z" | "2022-12-01T16:26:06Z" | NONE | null | null | null | ### Describe the bug
Loading certain splits () of the taskmaster-2 dataset fails because of a DuplicatedKeysError. This occurs for the following domains: `'hotels', 'movies', 'music', 'sports'`. The domains `'flights', 'food-ordering', 'restaurant-search'` load fine.
Output:
### Steps to reproduce the bug
```
from datasets import load_dataset
dataset = load_dataset("taskmaster2", "music")
```
Output:
```
---------------------------------------------------------------------------
DuplicatedKeysError Traceback (most recent call last)
File ~/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py:1532, in GeneratorBasedBuilder._prepare_split_single(self, arg)
[1531](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1530) example = self.info.features.encode_example(record) if self.info.features is not None else record
-> [1532](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1531) writer.write(example, key)
[1533](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1532) num_examples_progress_update += 1
File ~/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py:475, in ArrowWriter.write(self, example, key, writer_batch_size)
[474](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=473) if self._check_duplicates:
--> [475](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=474) self.check_duplicate_keys()
[476](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=475) # Re-intializing to empty list for next batch
File ~/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py:492, in ArrowWriter.check_duplicate_keys(self)
[486](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=485) duplicate_key_indices = [
[487](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=486) str(self._num_examples + index)
[488](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=487) for index, (duplicate_hash, _) in enumerate(self.hkey_record)
[489](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=488) if duplicate_hash == hash
[490](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=489) ]
--> [492](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=491) raise DuplicatedKeysError(key, duplicate_key_indices)
[493](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=492) else:
DuplicatedKeysError: Found multiple examples generated with the same key
The examples at index 858, 859 have the key dlg-89174425-d57a-4db7-a92b-165c3bff6735
During handling of the above exception, another exception occurred:
DuplicatedKeysError Traceback (most recent call last)
File ~/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py:1541, in GeneratorBasedBuilder._prepare_split_single(self, arg)
[1540](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1539) num_shards = shard_id + 1
-> [1541](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1540) num_examples, num_bytes = writer.finalize()
[1542](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1541) writer.close()
File ~/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py:563, in ArrowWriter.finalize(self, close_stream)
[562](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=561) if self._check_duplicates:
--> [563](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=562) self.check_duplicate_keys()
[564](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=563) # Re-intializing to empty list for next batch
File ~/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py:492, in ArrowWriter.check_duplicate_keys(self)
[486](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=485) duplicate_key_indices = [
[487](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=486) str(self._num_examples + index)
[488](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=487) for index, (duplicate_hash, _) in enumerate(self.hkey_record)
[489](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=488) if duplicate_hash == hash
[490](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=489) ]
--> [492](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=491) raise DuplicatedKeysError(key, duplicate_key_indices)
[493](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/arrow_writer.py?line=492) else:
DuplicatedKeysError: Found multiple examples generated with the same key
The examples at index 858, 859 have the key dlg-89174425-d57a-4db7-a92b-165c3bff6735
The above exception was the direct cause of the following exception:
DatasetGenerationError Traceback (most recent call last)
Cell In[23], line 1
----> 1 dataset = load_dataset("taskmaster2", "music")
File ~/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/load.py:1741, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, num_proc, **config_kwargs)
[1738](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/load.py?line=1737) try_from_hf_gcs = path not in _PACKAGED_DATASETS_MODULES
[1740](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/load.py?line=1739) # Download and prepare data
-> [1741](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/load.py?line=1740) builder_instance.download_and_prepare(
[1742](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/load.py?line=1741) download_config=download_config,
[1743](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/load.py?line=1742) download_mode=download_mode,
[1744](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/load.py?line=1743) ignore_verifications=ignore_verifications,
[1745](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/load.py?line=1744) try_from_hf_gcs=try_from_hf_gcs,
[1746](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/load.py?line=1745) use_auth_token=use_auth_token,
[1747](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/load.py?line=1746) num_proc=num_proc,
[1748](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/load.py?line=1747) )
[1750](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/load.py?line=1749) # Build dataset for splits
[1751](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/load.py?line=1750) keep_in_memory = (
[1752](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/load.py?line=1751) keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)
[1753](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/load.py?line=1752) )
File ~/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py:822, in DatasetBuilder.download_and_prepare(self, output_dir, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, num_proc, storage_options, **download_and_prepare_kwargs)
[820](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=819) if num_proc is not None:
[821](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=820) prepare_split_kwargs["num_proc"] = num_proc
--> [822](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=821) self._download_and_prepare(
[823](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=822) dl_manager=dl_manager,
[824](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=823) verify_infos=verify_infos,
[825](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=824) **prepare_split_kwargs,
[826](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=825) **download_and_prepare_kwargs,
[827](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=826) )
[828](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=827) # Sync info
[829](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=828) self.info.dataset_size = sum(split.num_bytes for split in self.info.splits.values())
File ~/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py:1555, in GeneratorBasedBuilder._download_and_prepare(self, dl_manager, verify_infos, **prepare_splits_kwargs)
[1554](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1553) def _download_and_prepare(self, dl_manager, verify_infos, **prepare_splits_kwargs):
-> [1555](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1554) super()._download_and_prepare(
[1556](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1555) dl_manager, verify_infos, check_duplicate_keys=verify_infos, **prepare_splits_kwargs
[1557](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1556) )
File ~/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py:913, in DatasetBuilder._download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
[909](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=908) split_dict.add(split_generator.split_info)
[911](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=910) try:
[912](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=911) # Prepare split will record examples associated to the split
--> [913](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=912) self._prepare_split(split_generator, **prepare_split_kwargs)
[914](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=913) except OSError as e:
[915](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=914) raise OSError(
[916](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=915) "Cannot find data file. "
[917](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=916) + (self.manual_download_instructions or "")
[918](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=917) + "\nOriginal error:\n"
[919](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=918) + str(e)
[920](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=919) ) from None
File ~/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py:1396, in GeneratorBasedBuilder._prepare_split(self, split_generator, check_duplicate_keys, file_format, num_proc, max_shard_size)
[1394](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1393) gen_kwargs = split_generator.gen_kwargs
[1395](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1394) job_id = 0
-> [1396](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1395) for job_id, done, content in self._prepare_split_single(
[1397](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1396) {"gen_kwargs": gen_kwargs, "job_id": job_id, **_prepare_split_args}
[1398](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1397) ):
[1399](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1398) if done:
[1400](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1399) result = content
File ~/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py:1550, in GeneratorBasedBuilder._prepare_split_single(self, arg)
[1548](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1547) if isinstance(e, SchemaInferenceError) and e.__context__ is not None:
[1549](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1548) e = e.__context__
-> [1550](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1549) raise DatasetGenerationError("An error occurred while generating the dataset") from e
[1552](file:///home/user/repos/tts-dataset/tts-dataset/venv/lib/python3.9/site-packages/datasets/builder.py?line=1551) yield job_id, True, (total_num_examples, total_num_bytes, writer._features, num_shards, shard_lengths)
DatasetGenerationError: An error occurred while generating the dataset
```
### Expected behavior
Loads the dataset
### Environment info
- `datasets` version: 2.7.1
- Platform: Linux-5.13.0-40-generic-x86_64-with-glibc2.31
- Python version: 3.9.7
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5323/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5323/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4090 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4090/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4090/comments | https://api.github.com/repos/huggingface/datasets/issues/4090/events | https://github.com/huggingface/datasets/pull/4090 | 1,191,956,734 | PR_kwDODunzps41mEs5 | 4,090 | Avoid writing empty license files | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-04-04T15:23:37Z" | "2022-04-07T12:46:45Z" | "2022-04-07T12:40:43Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4090.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4090",
"merged_at": "2022-04-07T12:40:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4090.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4090"
} | This PR avoids the creation of empty `LICENSE` files. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4090/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4090/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3941 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3941/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3941/comments | https://api.github.com/repos/huggingface/datasets/issues/3941/events | https://github.com/huggingface/datasets/issues/3941 | 1,171,132,709 | I_kwDODunzps5FzhEl | 3,941 | billsum dataset: Checksums didn't match for dataset source files: | {
"avatar_url": "https://avatars.githubusercontent.com/u/8507585?v=4",
"events_url": "https://api.github.com/users/XingxingZhang/events{/privacy}",
"followers_url": "https://api.github.com/users/XingxingZhang/followers",
"following_url": "https://api.github.com/users/XingxingZhang/following{/other_user}",
"gists_url": "https://api.github.com/users/XingxingZhang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/XingxingZhang",
"id": 8507585,
"login": "XingxingZhang",
"node_id": "MDQ6VXNlcjg1MDc1ODU=",
"organizations_url": "https://api.github.com/users/XingxingZhang/orgs",
"received_events_url": "https://api.github.com/users/XingxingZhang/received_events",
"repos_url": "https://api.github.com/users/XingxingZhang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/XingxingZhang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/XingxingZhang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/XingxingZhang"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @XingxingZhang, thanks for reporting.\r\n\r\nThis was due to a change in Google Drive service:\r\n- #3786 \r\n\r\nWe have already fixed it:\r\n- #3787\r\n\r\nYou should update `datasets` version to at least 1.18.4:\r\n```shell\r\npip install -U datasets\r\n```\r\nAnd then force the redownload:\r\n```python\r\nload_dataset(\"...\", download_mode=\"force_redownload\")\r\n```",
"thanks @albertvillanova "
] | "2022-03-16T14:52:08Z" | "2022-03-16T15:57:08Z" | "2022-03-16T15:46:44Z" | NONE | null | null | null | ## Describe the bug
When loading the `billsum` dataset, it throws the exception "Checksums didn't match for dataset source files"
```
File "virtualenv_projects/codex/lib/python3.7/site-packages/datasets/utils/info_utils.py", line 40, in verify_checksums
raise NonMatchingChecksumError(error_msg + str(bad_urls))
datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://drive.google.com/uc?export=download&id=1g89WgFHMRbr4QrvA0ngh26PY081Nv3lx']
```
## Steps to reproduce the bug
```python
import datasets
from datasets import load_dataset
print(datasets.__version__)
load_dataset('billsum')
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.17.0
- Platform: mac os
- Python version: Python 3.7.6
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3941/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3941/timeline | null | completed | false |