
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
(Gluon) SE-ResNeXt
**SE ResNeXt** is a variant of a [ResNext](https://www.paperswithcode.com/method/resnext) that employs [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block) to enable the network to perform dynamic channel-wise feature recalibration.
The weights from this model were ported from [Gluon](https://cv.gluon.ai/model_zoo/classification.html).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('gluon_seresnext101_32x4d', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `gluon_seresnext101_32x4d`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('gluon_seresnext101_32x4d', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{hu2019squeezeandexcitation,
title={Squeeze-and-Excitation Networks},
author={Jie Hu and Li Shen and Samuel Albanie and Gang Sun and Enhua Wu},
year={2019},
eprint={1709.01507},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Gloun SEResNeXt
Paper:
Title: Squeeze-and-Excitation Networks
URL: https://paperswithcode.com/paper/squeeze-and-excitation-networks
Models:
- Name: gluon_seresnext101_32x4d
In Collection: Gloun SEResNeXt
Metadata:
FLOPs: 10302923504
Parameters: 48960000
File Size: 196505510
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_seresnext101_32x4d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L219
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_seresnext101_32x4d-cf52900d.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.87%
Top 5 Accuracy: 95.29%
- Name: gluon_seresnext101_64x4d
In Collection: Gloun SEResNeXt
Metadata:
FLOPs: 19958950640
Parameters: 88230000
File Size: 353875948
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_seresnext101_64x4d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L229
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_seresnext101_64x4d-f9926f93.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.88%
Top 5 Accuracy: 95.31%
- Name: gluon_seresnext50_32x4d
In Collection: Gloun SEResNeXt
Metadata:
FLOPs: 5475179184
Parameters: 27560000
File Size: 110578827
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_seresnext50_32x4d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/gluon_resnet.py#L209
Weights: https://github.com/rwightman/pytorch-pretrained-gluonresnet/releases/download/v0.1/gluon_seresnext50_32x4d-90cf2d6e.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.92%
Top 5 Accuracy: 94.82%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/gloun-seresnext.mdx |
Getting Started with Repositories
This beginner-friendly guide will help you get the basic skills you need to create and manage your repository on the Hub. Each section builds on the previous one, so feel free to choose where to start!
## Requirements
This document shows how to handle repositories through the web interface as well as through the terminal. There are no requirements if working with the UI. If you want to work with the terminal, please follow these installation instructions.
If you do not have `git` available as a CLI command yet, you will need to [install Git](https://git-scm.com/downloads) for your platform. You will also need to [install Git LFS](https://git-lfs.github.com/), which will be used to handle large files such as images and model weights.
To be able to push your code to the Hub, you'll need to authenticate somehow. The easiest way to do this is by installing the [`huggingface_hub` CLI](https://huggingface.co/docs/huggingface_hub/index) and running the login command:
```bash
python -m pip install huggingface_hub
huggingface-cli login
```
**The content in the Getting Started section of this document is also available as a video!**
<iframe width="560" height="315" src="https://www.youtube-nocookie.com/embed/rkCly_cbMBk" title="Managing a repo" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
## Creating a repository
Using the Hub's web interface you can easily create repositories, add files (even large ones!), explore models, visualize diffs, and much more. There are three kinds of repositories on the Hub, and in this guide you'll be creating a **model repository** for demonstration purposes. For information on creating and managing models, datasets, and Spaces, refer to their respective documentation.
1. To create a new repository, visit [huggingface.co/new](http://huggingface.co/new):
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/new_repo.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/new_repo-dark.png"/>
</div>
2. Specify the owner of the repository: this can be either you or any of the organizations you’re affiliated with.
3. Enter your model’s name. This will also be the name of the repository.
4. Specify whether you want your model to be public or private.
5. Specify the license. You can leave the *License* field blank for now. To learn about licenses, visit the [**Licenses**](repositories-licenses) documentation.
After creating your model repository, you should see a page like this:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/empty_repo.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/empty_repo-dark.png"/>
</div>
Note that the Hub prompts you to create a *Model Card*, which you can learn about in the [**Model Cards documentation**](./model-cards). Including a Model Card in your model repo is best practice, but since we're only making a test repo at the moment we can skip this.
## Adding files to a repository (Web UI)
To add files to your repository via the web UI, start by selecting the **Files** tab, navigating to the desired directory, and then clicking **Add file**. You'll be given the option to create a new file or upload a file directly from your computer.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/repositories-add_file.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/repositories-add_file-dark.png"/>
</div>
### Creating a new file
Choosing to create a new file will take you to the following editor screen, where you can choose a name for your file, add content, and save your file with a message that summarizes your changes. Instead of directly committing the new file to your repo's `main` branch, you can select `Open as a pull request` to create a [Pull Request](./repositories-pull-requests-discussions).
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/repositories-create_file.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/repositories-create_file-dark.png"/>
</div>
### Uploading a file
If you choose _Upload file_ you'll be able to choose a local file to upload, along with a message summarizing your changes to the repo.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/repositories-upload_file.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/repositories-upload_file-dark.png"/>
</div>
As with creating new files, you can select `Open as a pull request` to create a [Pull Request](./repositories-pull-requests-discussions) instead of adding your changes directly to the `main` branch of your repo.
## Adding files to a repository (terminal)[[terminal]]
### Cloning repositories
Downloading repositories to your local machine is called *cloning*. You can use the following commands to load your repo and navigate to it:
```bash
git clone https://huggingface.co/<your-username>/<your-model-name>
cd <your-model-name>
```
You can clone over SSH with the following command:
```bash
git clone git@hf.co:<your-username>/<your-model-name>
cd <your-model-name>
```
You'll need to add your SSH public key to [your user settings](https://huggingface.co/settings/keys) to push changes or access private repositories.
### Set up
Now's the time, you can add any files you want to the repository! 🔥
Do you have files larger than 10MB? Those files should be tracked with `git-lfs`, which you can initialize with:
```bash
git lfs install
```
Note that if your files are larger than **5GB** you'll also need to run:
```bash
huggingface-cli lfs-enable-largefiles .
```
When you use Hugging Face to create a repository, Hugging Face automatically provides a list of common file extensions for common Machine Learning large files in the `.gitattributes` file, which `git-lfs` uses to efficiently track changes to your large files. However, you might need to add new extensions if your file types are not already handled. You can do so with `git lfs track "*.your_extension"`.
### Pushing files
You can use Git to save new files and any changes to already existing files as a bundle of changes called a *commit*, which can be thought of as a "revision" to your project. To create a commit, you have to `add` the files to let Git know that we're planning on saving the changes and then `commit` those changes. In order to sync the new commit with the Hugging Face Hub, you then `push` the commit to the Hub.
```bash
# Create any files you like! Then...
git add .
git commit -m "First model version" # You can choose any descriptive message
git push
```
And you're done! You can check your repository on Hugging Face with all the recently added files. For example, in the screenshot below the user added a number of files. Note that some files in this example have a size of `1.04 GB`, so the repo uses Git LFS to track it.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/repo_with_files.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/repo_with_files-dark.png"/>
</div>
## Viewing a repo's history
Every time you go through the `add`-`commit`-`push` cycle, the repo will keep track of every change you've made to your files. The UI allows you to explore the model files and commits and to see the difference (also known as *diff*) introduced by each commit. To see the history, you can click on the **History: X commits** link.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/repo_history.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/repo_history-dark.png"/>
</div>
You can click on an individual commit to see what changes that commit introduced:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/explore_history.gif"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/explore_history-dark.gif"/>
</div>
| huggingface/hub-docs/blob/main/docs/hub/repositories-getting-started.md |
Tests examples taken from the original great gltflib
Find the great gltflib by Lukas Shawford here: https://github.com/lukas-shawford/gltflib
| huggingface/simulate/blob/main/tests/test_gltflib/README.md |
RegNetX
**RegNetX** is a convolutional network design space with simple, regular models with parameters: depth \\( d \\), initial width \\( w\_{0} > 0 \\), and slope \\( w\_{a} > 0 \\), and generates a different block width \\( u\_{j} \\) for each block \\( j < d \\). The key restriction for the RegNet types of model is that there is a linear parameterisation of block widths (the design space only contains models with this linear structure):
\\( \\) u\_{j} = w\_{0} + w\_{a}\cdot{j} \\( \\)
For **RegNetX** we have additional restrictions: we set \\( b = 1 \\) (the bottleneck ratio), \\( 12 \leq d \leq 28 \\), and \\( w\_{m} \geq 2 \\) (the width multiplier).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('regnetx_002', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `regnetx_002`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('regnetx_002', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{radosavovic2020designing,
title={Designing Network Design Spaces},
author={Ilija Radosavovic and Raj Prateek Kosaraju and Ross Girshick and Kaiming He and Piotr Dollár},
year={2020},
eprint={2003.13678},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: RegNetX
Paper:
Title: Designing Network Design Spaces
URL: https://paperswithcode.com/paper/designing-network-design-spaces
Models:
- Name: regnetx_002
In Collection: RegNetX
Metadata:
FLOPs: 255276032
Parameters: 2680000
File Size: 10862199
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_002
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L337
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_002-e7e85e5c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 68.75%
Top 5 Accuracy: 88.56%
- Name: regnetx_004
In Collection: RegNetX
Metadata:
FLOPs: 510619136
Parameters: 5160000
File Size: 20841309
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_004
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L343
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_004-7d0e9424.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 72.39%
Top 5 Accuracy: 90.82%
- Name: regnetx_006
In Collection: RegNetX
Metadata:
FLOPs: 771659136
Parameters: 6200000
File Size: 24965172
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_006
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L349
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_006-85ec1baa.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 73.84%
Top 5 Accuracy: 91.68%
- Name: regnetx_008
In Collection: RegNetX
Metadata:
FLOPs: 1027038208
Parameters: 7260000
File Size: 29235944
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_008
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L355
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_008-d8b470eb.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.05%
Top 5 Accuracy: 92.34%
- Name: regnetx_016
In Collection: RegNetX
Metadata:
FLOPs: 2059337856
Parameters: 9190000
File Size: 36988158
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_016
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L361
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_016-65ca972a.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.95%
Top 5 Accuracy: 93.43%
- Name: regnetx_032
In Collection: RegNetX
Metadata:
FLOPs: 4082555904
Parameters: 15300000
File Size: 61509573
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_032
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L367
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_032-ed0c7f7e.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.15%
Top 5 Accuracy: 94.09%
- Name: regnetx_040
In Collection: RegNetX
Metadata:
FLOPs: 5095167744
Parameters: 22120000
File Size: 88844824
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_040
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L373
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_040-73c2a654.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.48%
Top 5 Accuracy: 94.25%
- Name: regnetx_064
In Collection: RegNetX
Metadata:
FLOPs: 8303405824
Parameters: 26210000
File Size: 105184854
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_064
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L379
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_064-29278baa.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.06%
Top 5 Accuracy: 94.47%
- Name: regnetx_080
In Collection: RegNetX
Metadata:
FLOPs: 10276726784
Parameters: 39570000
File Size: 158720042
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_080
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L385
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_080-7c7fcab1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.21%
Top 5 Accuracy: 94.55%
- Name: regnetx_120
In Collection: RegNetX
Metadata:
FLOPs: 15536378368
Parameters: 46110000
File Size: 184866342
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_120
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L391
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_120-65d5521e.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.61%
Top 5 Accuracy: 94.73%
- Name: regnetx_160
In Collection: RegNetX
Metadata:
FLOPs: 20491740672
Parameters: 54280000
File Size: 217623862
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_160
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L397
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_160-c98c4112.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.84%
Top 5 Accuracy: 94.82%
- Name: regnetx_320
In Collection: RegNetX
Metadata:
FLOPs: 40798958592
Parameters: 107810000
File Size: 431962133
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnetx_320
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L403
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnetx_320-8ea38b93.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.25%
Top 5 Accuracy: 95.03%
-->
| huggingface/pytorch-image-models/blob/main/hfdocs/source/models/regnetx.mdx |
Gradio Demo: titanic_survival
```
!pip install -q gradio scikit-learn numpy pandas
```
```
# Downloading files from the demo repo
import os
os.mkdir('files')
!wget -q -O files/titanic.csv https://github.com/gradio-app/gradio/raw/main/demo/titanic_survival/files/titanic.csv
```
```
import os
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import gradio as gr
current_dir = os.path.dirname(os.path.realpath(__file__))
data = pd.read_csv(os.path.join(current_dir, "files/titanic.csv"))
def encode_age(df):
df.Age = df.Age.fillna(-0.5)
bins = (-1, 0, 5, 12, 18, 25, 35, 60, 120)
categories = pd.cut(df.Age, bins, labels=False)
df.Age = categories
return df
def encode_fare(df):
df.Fare = df.Fare.fillna(-0.5)
bins = (-1, 0, 8, 15, 31, 1000)
categories = pd.cut(df.Fare, bins, labels=False)
df.Fare = categories
return df
def encode_df(df):
df = encode_age(df)
df = encode_fare(df)
sex_mapping = {"male": 0, "female": 1}
df = df.replace({"Sex": sex_mapping})
embark_mapping = {"S": 1, "C": 2, "Q": 3}
df = df.replace({"Embarked": embark_mapping})
df.Embarked = df.Embarked.fillna(0)
df["Company"] = 0
df.loc[(df["SibSp"] > 0), "Company"] = 1
df.loc[(df["Parch"] > 0), "Company"] = 2
df.loc[(df["SibSp"] > 0) & (df["Parch"] > 0), "Company"] = 3
df = df[
[
"PassengerId",
"Pclass",
"Sex",
"Age",
"Fare",
"Embarked",
"Company",
"Survived",
]
]
return df
train = encode_df(data)
X_all = train.drop(["Survived", "PassengerId"], axis=1)
y_all = train["Survived"]
num_test = 0.20
X_train, X_test, y_train, y_test = train_test_split(
X_all, y_all, test_size=num_test, random_state=23
)
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
predictions = clf.predict(X_test)
def predict_survival(passenger_class, is_male, age, company, fare, embark_point):
if passenger_class is None or embark_point is None:
return None
df = pd.DataFrame.from_dict(
{
"Pclass": [passenger_class + 1],
"Sex": [0 if is_male else 1],
"Age": [age],
"Fare": [fare],
"Embarked": [embark_point + 1],
"Company": [
(1 if "Sibling" in company else 0) + (2 if "Child" in company else 0)
]
}
)
df = encode_age(df)
df = encode_fare(df)
pred = clf.predict_proba(df)[0]
return {"Perishes": float(pred[0]), "Survives": float(pred[1])}
demo = gr.Interface(
predict_survival,
[
gr.Dropdown(["first", "second", "third"], type="index"),
"checkbox",
gr.Slider(0, 80, value=25),
gr.CheckboxGroup(["Sibling", "Child"], label="Travelling with (select all)"),
gr.Number(value=20),
gr.Radio(["S", "C", "Q"], type="index"),
],
"label",
examples=[
["first", True, 30, [], 50, "S"],
["second", False, 40, ["Sibling", "Child"], 10, "Q"],
["third", True, 30, ["Child"], 20, "S"],
],
live=True,
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/titanic_survival/run.ipynb |
Embed your Space in another website
Once your Space is up and running you might wish to embed it in a website or in your blog.
Embedding or sharing your Space is a great way to allow your audience to interact with your work and demonstrations without requiring any setup on their side.
To embed a Space its visibility needs to be public.
## Direct URL
A Space is assigned a unique URL you can use to share your Space or embed it in a website.
This URL is of the form: `"https://<space-subdomain>.hf.space"`. For instance, the Space [NimaBoscarino/hotdog-gradio](https://huggingface.co/spaces/NimaBoscarino/hotdog-gradio) has the corresponding URL of `"https://nimaboscarino-hotdog-gradio.hf.space"`. The subdomain is unique and only changes if you move or rename your Space.
Your space is always served from the root of this subdomain.
You can find the Space URL along with examples snippets of how to embed it directly from the options menu:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-embed-option.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-embed-option-dark.png"/>
</div>
## Embedding with IFrames
The default embedding method for a Space is using IFrames. Add in the HTML location where you want to embed your Space the following element:
```html
<iframe
src="https://<space-subdomain>.hf.space"
frameborder="0"
width="850"
height="450"
></iframe>
```
For instance using the [NimaBoscarino/hotdog-gradio](https://huggingface.co/spaces/NimaBoscarino/hotdog-gradio) Space:
<iframe src="https://nimaboscarino-hotdog-gradio.hf.space"frameborder="0"width="850"height="500" ></iframe>
## Embedding with WebComponents
If the Space you wish to embed is Gradio-based, you can use Web Components to embed your Space. WebComponents are faster than IFrames and automatically adjust to your web page so that you do not need to configure `width` or `height` for your element.
First, you need to import the Gradio JS library that corresponds to the Gradio version in the Space by adding the following script to your HTML.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-embed-gradio-module.png"/>
</div>
Then, add a `gradio-app` element where you want to embed your Space.
```html
<gradio-app src="https://<space-subdomain>.hf.space"></gradio-app>
```
Check out the [Gradio documentation](https://gradio.app/sharing_your_app/#embedding-hosted-spaces) for more details. | huggingface/hub-docs/blob/main/docs/hub/spaces-embed.md |
Tabby on Spaces
[Tabby](https://tabby.tabbyml.com) is an open-source, self-hosted AI coding assistant. With Tabby, every team can set up its own LLM-powered code completion server with ease.
In this guide, you will learn how to deploy your own Tabby instance and use it for development directly from the Hugging Face website.
## Your first Tabby Space
In this section, you will learn how to deploy a Tabby Space and use it for yourself or your orgnization.
### Deploy Tabby on Spaces
You can deploy Tabby on Spaces with just a few clicks:
[](https://huggingface.co/spaces/TabbyML/tabby-template-space?duplicate=true)
You need to define the Owner (your personal account or an organization), a Space name, and the Visibility. To secure the api endpoint, we're configuring the visibility as Private.
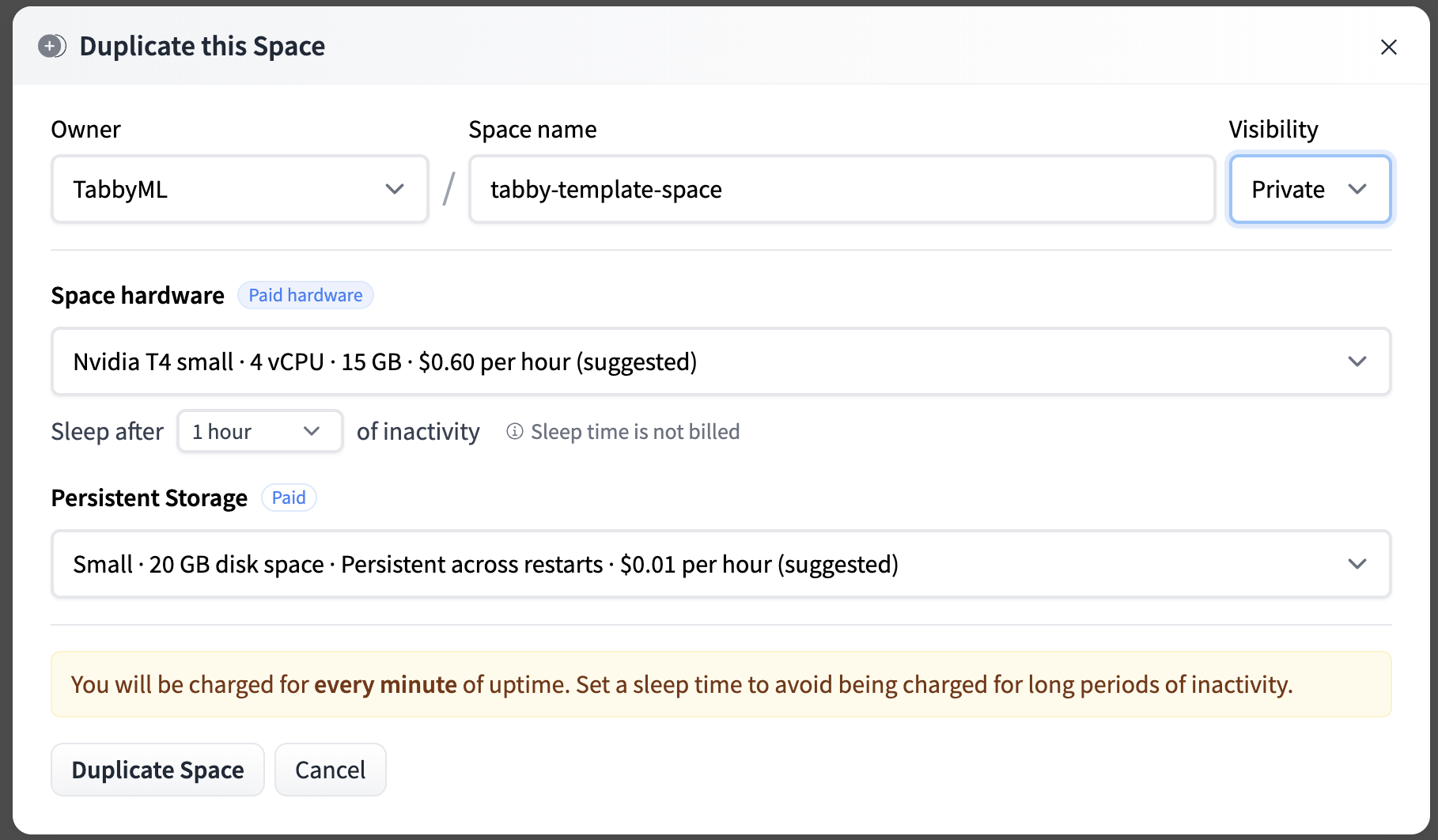
You’ll see the *Building status*. Once it becomes *Running*, your Space is ready to go. If you don’t see the Tabby Swagger UI, try refreshing the page.
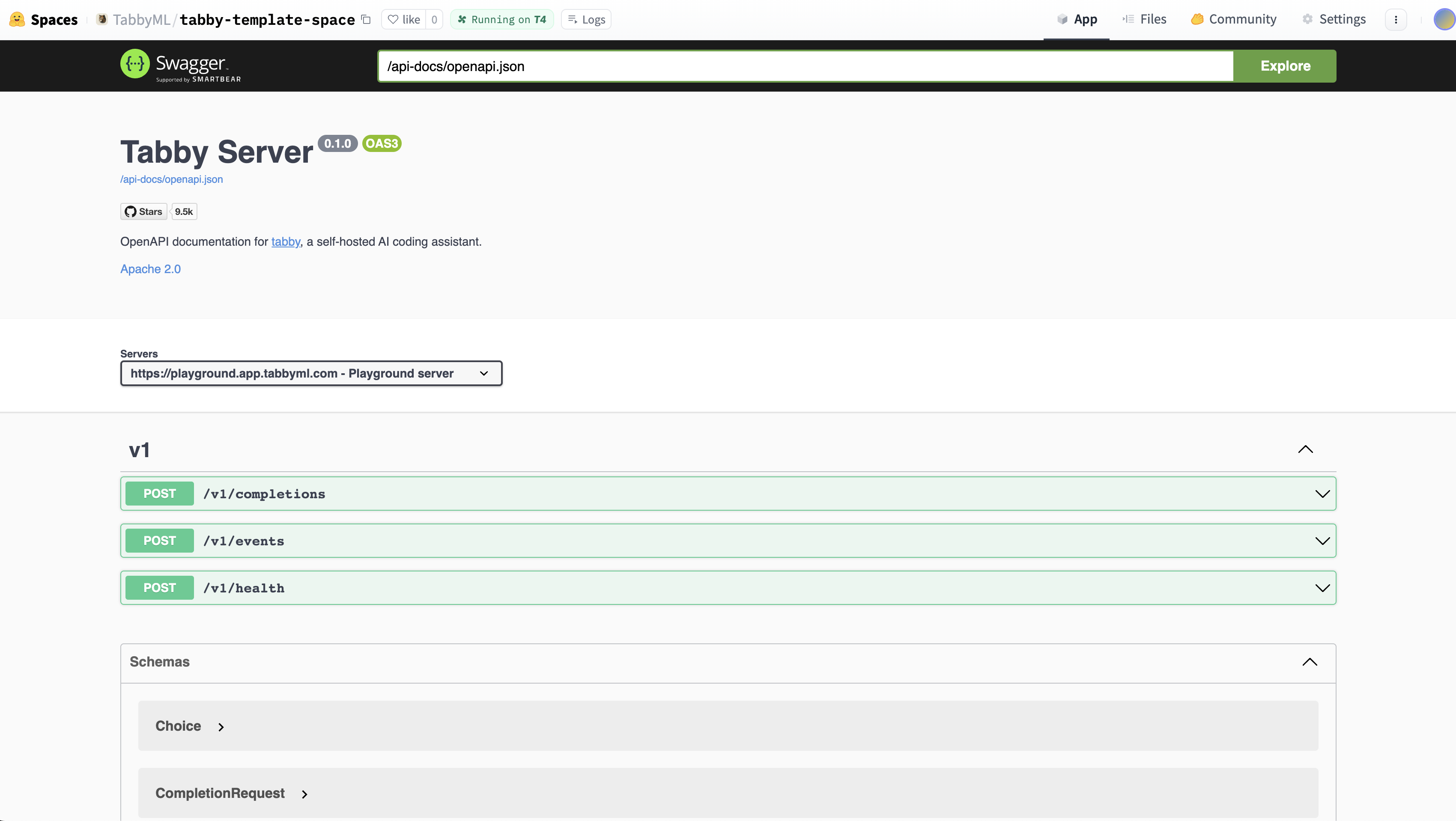
<Tip>
If you want to customize the title, emojis, and colors of your space, go to "Files and Versions" and edit the metadata of your README.md file.
</Tip>
### Your Tabby Space URL
Once Tabby is up and running, for a space link such as https://huggingface.com/spaces/TabbyML/tabby, the direct URL will be https://tabbyml-tabby.hf.space.
This URL provides access to a stable Tabby instance in full-screen mode and serves as the API endpoint for IDE/Editor Extensions to talk with.
### Connect VSCode Extension to Space backend
1. Install the [VSCode Extension](https://marketplace.visualstudio.com/items?itemName=TabbyML.vscode-tabby).
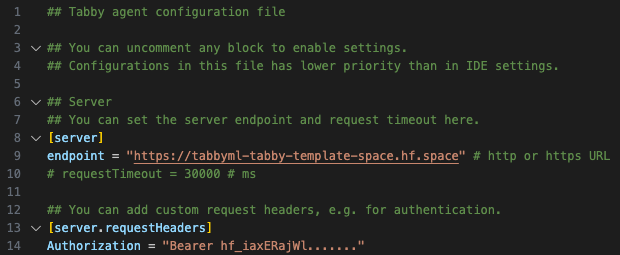
2. Open the file located at `~/.tabby-client/agent/config.toml`. Uncomment both the `[server]` section and the `[server.requestHeaders]` section.
* Set the endpoint to the Direct URL you found in the previous step, which should look something like `https://UserName-SpaceName.hf.space`.
* As the Space is set to **Private**, it is essential to configure the authorization header for accessing the endpoint. You can obtain a token from the [Access Tokens](https://huggingface.co/settings/tokens) page.
3. You'll notice a ✓ icon indicating a successful connection.
4. You've complete the setup, now enjoy tabing!
You can also utilize Tabby extensions in other IDEs, such as [JetBrains](https://plugins.jetbrains.com/plugin/22379-tabby).
## Feedback and support
If you have improvement suggestions or need specific support, please join [Tabby Slack community](https://join.slack.com/t/tabbycommunity/shared_invite/zt-1xeiddizp-bciR2RtFTaJ37RBxr8VxpA) or reach out on [Tabby’s GitHub repository](https://github.com/TabbyML/tabby).
| huggingface/hub-docs/blob/main/docs/hub/spaces-sdks-docker-tabby.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BigBirdPegasus
## Overview
The BigBird model was proposed in [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by
Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon,
Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others. BigBird, is a sparse-attention
based transformer which extends Transformer based models, such as BERT to much longer sequences. In addition to sparse
attention, BigBird also applies global attention as well as random attention to the input sequence. Theoretically, it
has been shown that applying sparse, global, and random attention approximates full attention, while being
computationally much more efficient for longer sequences. As a consequence of the capability to handle longer context,
BigBird has shown improved performance on various long document NLP tasks, such as question answering and
summarization, compared to BERT or RoBERTa.
The abstract from the paper is the following:
*Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP.
Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence
length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that
reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and
is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our
theoretical analysis reveals some of the benefits of having O(1) global tokens (such as CLS), that attend to the entire
sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to
8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context,
BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also
propose novel applications to genomics data.*
The original code can be found [here](https://github.com/google-research/bigbird).
## Usage tips
- For an in-detail explanation on how BigBird's attention works, see [this blog post](https://huggingface.co/blog/big-bird).
- BigBird comes with 2 implementations: **original_full** & **block_sparse**. For the sequence length < 1024, using
**original_full** is advised as there is no benefit in using **block_sparse** attention.
- The code currently uses window size of 3 blocks and 2 global blocks.
- Sequence length must be divisible by block size.
- Current implementation supports only **ITC**.
- Current implementation doesn't support **num_random_blocks = 0**.
- BigBirdPegasus uses the [PegasusTokenizer](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pegasus/tokenization_pegasus.py).
- BigBird is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## BigBirdPegasusConfig
[[autodoc]] BigBirdPegasusConfig
- all
## BigBirdPegasusModel
[[autodoc]] BigBirdPegasusModel
- forward
## BigBirdPegasusForConditionalGeneration
[[autodoc]] BigBirdPegasusForConditionalGeneration
- forward
## BigBirdPegasusForSequenceClassification
[[autodoc]] BigBirdPegasusForSequenceClassification
- forward
## BigBirdPegasusForQuestionAnswering
[[autodoc]] BigBirdPegasusForQuestionAnswering
- forward
## BigBirdPegasusForCausalLM
[[autodoc]] BigBirdPegasusForCausalLM
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/bigbird_pegasus.md |
`@gradio/uploadbutton`
```html
<script>
import { BaseUploadButton } from "@gradio/uploadbutton";
</script>
```
BaseUploadButton
```javascript
export let elem_id = "";
export let elem_classes: string[] = [];
export let visible = true;
export let label: string;
export let value: null | FileData | FileData[];
export let file_count: string;
export let file_types: string[] = [];
export let root: string;
export let size: "sm" | "lg" = "lg";
export let scale: number | null = null;
export let min_width: number | undefined = undefined;
export let variant: "primary" | "secondary" | "stop" = "secondary";
export let disabled = false;
``` | gradio-app/gradio/blob/main/js/uploadbutton/README.md |
Metric Card for SuperGLUE
## Metric description
This metric is used to compute the SuperGLUE evaluation metric associated to each of the subsets of the [SuperGLUE dataset](https://huggingface.co/datasets/super_glue).
SuperGLUE is a new benchmark styled after GLUE with a new set of more difficult language understanding tasks, improved resources, and a new public leaderboard.
## How to use
There are two steps: (1) loading the SuperGLUE metric relevant to the subset of the dataset being used for evaluation; and (2) calculating the metric.
1. **Loading the relevant SuperGLUE metric** : the subsets of SuperGLUE are the following: `boolq`, `cb`, `copa`, `multirc`, `record`, `rte`, `wic`, `wsc`, `wsc.fixed`, `axb`, `axg`.
More information about the different subsets of the SuperGLUE dataset can be found on the [SuperGLUE dataset page](https://huggingface.co/datasets/super_glue) and on the [official dataset website](https://super.gluebenchmark.com/).
2. **Calculating the metric**: the metric takes two inputs : one list with the predictions of the model to score and one list of reference labels. The structure of both inputs depends on the SuperGlUE subset being used:
Format of `predictions`:
- for `record`: list of question-answer dictionaries with the following keys:
- `idx`: index of the question as specified by the dataset
- `prediction_text`: the predicted answer text
- for `multirc`: list of question-answer dictionaries with the following keys:
- `idx`: index of the question-answer pair as specified by the dataset
- `prediction`: the predicted answer label
- otherwise: list of predicted labels
Format of `references`:
- for `record`: list of question-answers dictionaries with the following keys:
- `idx`: index of the question as specified by the dataset
- `answers`: list of possible answers
- otherwise: list of reference labels
```python
from datasets import load_metric
super_glue_metric = load_metric('super_glue', 'copa')
predictions = [0, 1]
references = [0, 1]
results = super_glue_metric.compute(predictions=predictions, references=references)
```
## Output values
The output of the metric depends on the SuperGLUE subset chosen, consisting of a dictionary that contains one or several of the following metrics:
`exact_match`: A given predicted string's exact match score is 1 if it is the exact same as its reference string, and is 0 otherwise. (See [Exact Match](https://huggingface.co/metrics/exact_match) for more information).
`f1`: the harmonic mean of the precision and recall (see [F1 score](https://huggingface.co/metrics/f1) for more information). Its range is 0-1 -- its lowest possible value is 0, if either the precision or the recall is 0, and its highest possible value is 1.0, which means perfect precision and recall.
`matthews_correlation`: a measure of the quality of binary and multiclass classifications (see [Matthews Correlation](https://huggingface.co/metrics/matthews_correlation) for more information). Its range of values is between -1 and +1, where a coefficient of +1 represents a perfect prediction, 0 an average random prediction and -1 an inverse prediction.
### Values from popular papers
The [original SuperGLUE paper](https://arxiv.org/pdf/1905.00537.pdf) reported average scores ranging from 47 to 71.5%, depending on the model used (with all evaluation values scaled by 100 to make computing the average possible).
For more recent model performance, see the [dataset leaderboard](https://super.gluebenchmark.com/leaderboard).
## Examples
Maximal values for the COPA subset (which outputs `accuracy`):
```python
from datasets import load_metric
super_glue_metric = load_metric('super_glue', 'copa') # any of ["copa", "rte", "wic", "wsc", "wsc.fixed", "boolq", "axg"]
predictions = [0, 1]
references = [0, 1]
results = super_glue_metric.compute(predictions=predictions, references=references)
print(results)
{'accuracy': 1.0}
```
Minimal values for the MultiRC subset (which outputs `pearson` and `spearmanr`):
```python
from datasets import load_metric
super_glue_metric = load_metric('super_glue', 'multirc')
predictions = [{'idx': {'answer': 0, 'paragraph': 0, 'question': 0}, 'prediction': 0}, {'idx': {'answer': 1, 'paragraph': 2, 'question': 3}, 'prediction': 1}]
references = [1,0]
results = super_glue_metric.compute(predictions=predictions, references=references)
print(results)
{'exact_match': 0.0, 'f1_m': 0.0, 'f1_a': 0.0}
```
Partial match for the COLA subset (which outputs `matthews_correlation`)
```python
from datasets import load_metric
super_glue_metric = load_metric('super_glue', 'axb')
references = [0, 1]
predictions = [1,1]
results = super_glue_metric.compute(predictions=predictions, references=references)
print(results)
{'matthews_correlation': 0.0}
```
## Limitations and bias
This metric works only with datasets that have the same format as the [SuperGLUE dataset](https://huggingface.co/datasets/super_glue).
The dataset also includes Winogender, a subset of the dataset that is designed to measure gender bias in coreference resolution systems. However, as noted in the SuperGLUE paper, this subset has its limitations: *"It offers only positive predictive value: A poor bias score is clear evidence that a model exhibits gender bias, but a good score does not mean that the model is unbiased.[...] Also, Winogender does not cover all forms of social bias, or even all forms of gender. For instance, the version of the data used here offers no coverage of gender-neutral they or non-binary pronouns."
## Citation
```bibtex
@article{wang2019superglue,
title={Super{GLUE}: A Stickier Benchmark for General-Purpose Language Understanding Systems},
author={Wang, Alex and Pruksachatkun, Yada and Nangia, Nikita and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R},
journal={arXiv preprint arXiv:1905.00537},
year={2019}
}
```
## Further References
- [SuperGLUE benchmark homepage](https://super.gluebenchmark.com/)
| huggingface/datasets/blob/main/metrics/super_glue/README.md |
--
title: "Introducing Decision Transformers on Hugging Face 🤗"
thumbnail: /blog/assets/58_decision-transformers/thumbnail.jpg
authors:
- user: edbeeching
- user: ThomasSimonini
---
# Introducing Decision Transformers on Hugging Face 🤗
At Hugging Face, we are contributing to the ecosystem for Deep Reinforcement Learning researchers and enthusiasts. Recently, we have integrated Deep RL frameworks such as [Stable-Baselines3](https://github.com/DLR-RM/stable-baselines3).
And today we are happy to announce that we integrated the [Decision Transformer](https://arxiv.org/abs/2106.01345), an Offline Reinforcement Learning method, into the 🤗 transformers library and the Hugging Face Hub. We have some exciting plans for improving accessibility in the field of Deep RL and we are looking forward to sharing them with you over the coming weeks and months.
- [What is Offline Reinforcement Learning?](#what-is-offline-reinforcement-learning?)
- [Introducing Decision Transformers](#introducing-decision-transformers)
- [Using the Decision Transformer in 🤗 Transformers](#using-the-decision-transformer-in--transformers)
- [Conclusion](#conclusion)
- [What's next?](#whats-next)
- [References](#references)
## What is Offline Reinforcement Learning?
Deep Reinforcement Learning (RL) is a framework to build decision-making agents. These agents aim to learn optimal behavior (policy) by interacting with the environment through trial and error and receiving rewards as unique feedback.
The agent’s goal is to maximize **its cumulative reward, called return.** Because RL is based on the reward hypothesis: **all goals can be described as the maximization of the expected cumulative reward.**
Deep Reinforcement Learning agents **learn with batches of experience.** The question is, how do they collect it?:

*A comparison between Reinforcement Learning in an Online and Offline setting, figure taken from [this post](https://offline-rl.github.io/)*
In online reinforcement learning, **the agent gathers data directly**: it collects a batch of experience by interacting with the environment. Then, it uses this experience immediately (or via some replay buffer) to learn from it (update its policy).
But this implies that either you train your agent directly in the real world or have a simulator. If you don’t have one, you need to build it, which can be very complex (how to reflect the complex reality of the real world in an environment?), expensive, and insecure since if the simulator has flaws, the agent will exploit them if they provide a competitive advantage.
On the other hand, in offline reinforcement learning, the agent only uses data collected from other agents or human demonstrations. **It does not interact with the environment**.
The process is as follows:
1. Create a dataset using one or more policies and/or human interactions.
2. Run offline RL on this dataset to learn a policy
This method has one drawback: the counterfactual queries problem. What do we do if our agent decides to do something for which we don’t have the data? For instance, turning right on an intersection but we don’t have this trajectory.
There’s already exists some solutions on this topic, but if you want to know more about offline reinforcement learning you can watch [this video](https://www.youtube.com/watch?v=k08N5a0gG0A)
## Introducing Decision Transformers
The Decision Transformer model was introduced by [“Decision Transformer: Reinforcement Learning via Sequence Modeling” by Chen L. et al](https://arxiv.org/abs/2106.01345). It abstracts Reinforcement Learning as a **conditional-sequence modeling problem**.
The main idea is that instead of training a policy using RL methods, such as fitting a value function, that will tell us what action to take to maximize the return (cumulative reward), we use a sequence modeling algorithm (Transformer) that, given a desired return, past states, and actions, will generate future actions to achieve this desired return. It’s an autoregressive model conditioned on the desired return, past states, and actions to generate future actions that achieve the desired return.
This is a complete shift in the Reinforcement Learning paradigm since we use generative trajectory modeling (modeling the joint distribution of the sequence of states, actions, and rewards) to replace conventional RL algorithms. It means that in Decision Transformers, we don’t maximize the return but rather generate a series of future actions that achieve the desired return.
The process goes this way:
1. We feed the last K timesteps into the Decision Transformer with 3 inputs:
- Return-to-go
- State
- Action
2. The tokens are embedded either with a linear layer if the state is a vector or CNN encoder if it’s frames.
3. The inputs are processed by a GPT-2 model which predicts future actions via autoregressive modeling.

*Decision Transformer architecture. States, actions, and returns are fed into modality specific linear embeddings and a positional episodic timestep encoding is added. Tokens are fed into a GPT architecture which predicts actions autoregressively using a causal self-attention mask. Figure from [1].*
## Using the Decision Transformer in 🤗 Transformers
The Decision Transformer model is now available as part of the 🤗 transformers library. In addition, we share [nine pre-trained model checkpoints for continuous control tasks in the Gym environment](https://huggingface.co/models?other=gym-continous-control).
<figure class="image table text-center m-0 w-full">
<video
alt="WalkerEd-expert"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="assets/58_decision-transformers/walker2d-expert.mp4" type="video/mp4">
</video>
</figure>
*An “expert” Decision Transformers model, learned using offline RL in the Gym Walker2d environment.*
### Install the package
`````python
pip install git+https://github.com/huggingface/transformers
`````
### Loading the model
Using the Decision Transformer is relatively easy, but as it is an autoregressive model, some care has to be taken in order to prepare the model’s inputs at each time-step. We have prepared both a [Python script](https://github.com/huggingface/transformers/blob/main/examples/research_projects/decision_transformer/run_decision_transformer.py) and a [Colab notebook](https://colab.research.google.com/drive/1K3UuajwoPY1MzRKNkONNRS3gS5DxZ-qF?usp=sharing) that demonstrates how to use this model.
Loading a pretrained Decision Transformer is simple in the 🤗 transformers library:
`````python
from transformers import DecisionTransformerModel
model_name = "edbeeching/decision-transformer-gym-hopper-expert"
model = DecisionTransformerModel.from_pretrained(model_name)
``````
### Creating the environment
We provide pretrained checkpoints for the Gym Hopper, Walker2D and Halfcheetah. Checkpoints for Atari environments will soon be available.
`````python
import gym
env = gym.make("Hopper-v3")
state_dim = env.observation_space.shape[0] # state size
act_dim = env.action_space.shape[0] # action size
``````
### Autoregressive prediction function
The model performs an [autoregressive prediction](https://en.wikipedia.org/wiki/Autoregressive_model); that is to say that predictions made at the current time-step **t** are sequentially conditioned on the outputs from previous time-steps. This function is quite meaty, so we will aim to explain it in the comments.
`````python
# Function that gets an action from the model using autoregressive prediction
# with a window of the previous 20 timesteps.
def get_action(model, states, actions, rewards, returns_to_go, timesteps):
# This implementation does not condition on past rewards
states = states.reshape(1, -1, model.config.state_dim)
actions = actions.reshape(1, -1, model.config.act_dim)
returns_to_go = returns_to_go.reshape(1, -1, 1)
timesteps = timesteps.reshape(1, -1)
# The prediction is conditioned on up to 20 previous time-steps
states = states[:, -model.config.max_length :]
actions = actions[:, -model.config.max_length :]
returns_to_go = returns_to_go[:, -model.config.max_length :]
timesteps = timesteps[:, -model.config.max_length :]
# pad all tokens to sequence length, this is required if we process batches
padding = model.config.max_length - states.shape[1]
attention_mask = torch.cat([torch.zeros(padding), torch.ones(states.shape[1])])
attention_mask = attention_mask.to(dtype=torch.long).reshape(1, -1)
states = torch.cat([torch.zeros((1, padding, state_dim)), states], dim=1).float()
actions = torch.cat([torch.zeros((1, padding, act_dim)), actions], dim=1).float()
returns_to_go = torch.cat([torch.zeros((1, padding, 1)), returns_to_go], dim=1).float()
timesteps = torch.cat([torch.zeros((1, padding), dtype=torch.long), timesteps], dim=1)
# perform the prediction
state_preds, action_preds, return_preds = model(
states=states,
actions=actions,
rewards=rewards,
returns_to_go=returns_to_go,
timesteps=timesteps,
attention_mask=attention_mask,
return_dict=False,)
return action_preds[0, -1]
``````
### Evaluating the model
In order to evaluate the model, we need some additional information; the mean and standard deviation of the states that were used during training. Fortunately, these are available for each of the checkpoint’s [model card](https://huggingface.co/edbeeching/decision-transformer-gym-hopper-expert) on the Hugging Face Hub!
We also need a target return for the model. This is the power of return conditioned Offline Reinforcement Learning: we can use the target return to control the performance of the policy. This could be really powerful in a multiplayer setting, where we would like to adjust the performance of an opponent bot to be at a suitable difficulty for the player. The authors show a great plot of this in their paper!

*Sampled (evaluation) returns accumulated by Decision Transformer when conditioned on
the specified target (desired) returns. Top: Atari. Bottom: D4RL medium-replay datasets. Figure from [1].*
``````python
TARGET_RETURN = 3.6 # This was normalized during training
MAX_EPISODE_LENGTH = 1000
state_mean = np.array(
[1.3490015, -0.11208222, -0.5506444, -0.13188992, -0.00378754, 2.6071432,
0.02322114, -0.01626922, -0.06840388, -0.05183131, 0.04272673,])
state_std = np.array(
[0.15980862, 0.0446214, 0.14307782, 0.17629202, 0.5912333, 0.5899924,
1.5405099, 0.8152689, 2.0173461, 2.4107876, 5.8440027,])
state_mean = torch.from_numpy(state_mean)
state_std = torch.from_numpy(state_std)
state = env.reset()
target_return = torch.tensor(TARGET_RETURN).float().reshape(1, 1)
states = torch.from_numpy(state).reshape(1, state_dim).float()
actions = torch.zeros((0, act_dim)).float()
rewards = torch.zeros(0).float()
timesteps = torch.tensor(0).reshape(1, 1).long()
# take steps in the environment
for t in range(max_ep_len):
# add zeros for actions as input for the current time-step
actions = torch.cat([actions, torch.zeros((1, act_dim))], dim=0)
rewards = torch.cat([rewards, torch.zeros(1)])
# predicting the action to take
action = get_action(model,
(states - state_mean) / state_std,
actions,
rewards,
target_return,
timesteps)
actions[-1] = action
action = action.detach().numpy()
# interact with the environment based on this action
state, reward, done, _ = env.step(action)
cur_state = torch.from_numpy(state).reshape(1, state_dim)
states = torch.cat([states, cur_state], dim=0)
rewards[-1] = reward
pred_return = target_return[0, -1] - (reward / scale)
target_return = torch.cat([target_return, pred_return.reshape(1, 1)], dim=1)
timesteps = torch.cat([timesteps, torch.ones((1, 1)).long() * (t + 1)], dim=1)
if done:
break
``````
You will find a more detailed example, with the creation of videos of the agent in our [Colab notebook](https://colab.research.google.com/drive/1K3UuajwoPY1MzRKNkONNRS3gS5DxZ-qF?usp=sharing).
## Conclusion
In addition to Decision Transformers, we want to support more use cases and tools from the Deep Reinforcement Learning community. Therefore, it would be great to hear your feedback on the Decision Transformer model, and more generally anything we can build with you that would be useful for RL. Feel free to **[reach out to us](mailto:thomas.simonini@huggingface.co)**.
## What’s next?
In the coming weeks and months, we plan on supporting other tools from the ecosystem:
- Integrating **[RL-baselines3-zoo](https://github.com/DLR-RM/rl-baselines3-zoo)**
- Uploading **[RL-trained-agents models](https://github.com/DLR-RM/rl-trained-agents)** into the Hub: a big collection of pre-trained Reinforcement Learning agents using stable-baselines3
- Integrating other Deep Reinforcement Learning libraries
- Implementing Convolutional Decision Transformers For Atari
- And more to come 🥳
The best way to keep in touch is to **[join our discord server](https://discord.gg/YRAq8fMnUG)** to exchange with us and with the community.
## References
[1] Chen, Lili, et al. "Decision transformer: Reinforcement learning via sequence modeling." *Advances in neural information processing systems* 34 (2021).
[2] Agarwal, Rishabh, Dale Schuurmans, and Mohammad Norouzi. "An optimistic perspective on offline reinforcement learning." *International Conference on Machine Learning*. PMLR, 2020.
### Acknowledgements
We would like to thank the paper’s first authors, Kevin Lu and Lili Chen, for their constructive conversations.
| huggingface/blog/blob/main/decision-transformers.md |
Gradio Demo: translation
### This translation demo takes in the text, source and target languages, and returns the translation. It uses the Transformers library to set up the model and has a title, description, and example.
```
!pip install -q gradio git+https://github.com/huggingface/transformers gradio torch
```
```
import gradio as gr
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, pipeline
import torch
# this model was loaded from https://hf.co/models
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M")
tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
device = 0 if torch.cuda.is_available() else -1
LANGS = ["ace_Arab", "eng_Latn", "fra_Latn", "spa_Latn"]
def translate(text, src_lang, tgt_lang):
"""
Translate the text from source lang to target lang
"""
translation_pipeline = pipeline("translation", model=model, tokenizer=tokenizer, src_lang=src_lang, tgt_lang=tgt_lang, max_length=400, device=device)
result = translation_pipeline(text)
return result[0]['translation_text']
demo = gr.Interface(
fn=translate,
inputs=[
gr.components.Textbox(label="Text"),
gr.components.Dropdown(label="Source Language", choices=LANGS),
gr.components.Dropdown(label="Target Language", choices=LANGS),
],
outputs=["text"],
examples=[["Building a translation demo with Gradio is so easy!", "eng_Latn", "spa_Latn"]],
cache_examples=False,
title="Translation Demo",
description="This demo is a simplified version of the original [NLLB-Translator](https://huggingface.co/spaces/Narrativaai/NLLB-Translator) space"
)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/translation/run.ipynb |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Distributed inference with multiple GPUs
On distributed setups, you can run inference across multiple GPUs with 🤗 [Accelerate](https://huggingface.co/docs/accelerate/index) or [PyTorch Distributed](https://pytorch.org/tutorials/beginner/dist_overview.html), which is useful for generating with multiple prompts in parallel.
This guide will show you how to use 🤗 Accelerate and PyTorch Distributed for distributed inference.
## 🤗 Accelerate
🤗 [Accelerate](https://huggingface.co/docs/accelerate/index) is a library designed to make it easy to train or run inference across distributed setups. It simplifies the process of setting up the distributed environment, allowing you to focus on your PyTorch code.
To begin, create a Python file and initialize an [`accelerate.PartialState`] to create a distributed environment; your setup is automatically detected so you don't need to explicitly define the `rank` or `world_size`. Move the [`DiffusionPipeline`] to `distributed_state.device` to assign a GPU to each process.
Now use the [`~accelerate.PartialState.split_between_processes`] utility as a context manager to automatically distribute the prompts between the number of processes.
```py
import torch
from accelerate import PartialState
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True
)
distributed_state = PartialState()
pipeline.to(distributed_state.device)
with distributed_state.split_between_processes(["a dog", "a cat"]) as prompt:
result = pipeline(prompt).images[0]
result.save(f"result_{distributed_state.process_index}.png")
```
Use the `--num_processes` argument to specify the number of GPUs to use, and call `accelerate launch` to run the script:
```bash
accelerate launch run_distributed.py --num_processes=2
```
<Tip>
To learn more, take a look at the [Distributed Inference with 🤗 Accelerate](https://huggingface.co/docs/accelerate/en/usage_guides/distributed_inference#distributed-inference-with-accelerate) guide.
</Tip>
## PyTorch Distributed
PyTorch supports [`DistributedDataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) which enables data parallelism.
To start, create a Python file and import `torch.distributed` and `torch.multiprocessing` to set up the distributed process group and to spawn the processes for inference on each GPU. You should also initialize a [`DiffusionPipeline`]:
```py
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from diffusers import DiffusionPipeline
sd = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True
)
```
You'll want to create a function to run inference; [`init_process_group`](https://pytorch.org/docs/stable/distributed.html?highlight=init_process_group#torch.distributed.init_process_group) handles creating a distributed environment with the type of backend to use, the `rank` of the current process, and the `world_size` or the number of processes participating. If you're running inference in parallel over 2 GPUs, then the `world_size` is 2.
Move the [`DiffusionPipeline`] to `rank` and use `get_rank` to assign a GPU to each process, where each process handles a different prompt:
```py
def run_inference(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
sd.to(rank)
if torch.distributed.get_rank() == 0:
prompt = "a dog"
elif torch.distributed.get_rank() == 1:
prompt = "a cat"
image = sd(prompt).images[0]
image.save(f"./{'_'.join(prompt)}.png")
```
To run the distributed inference, call [`mp.spawn`](https://pytorch.org/docs/stable/multiprocessing.html#torch.multiprocessing.spawn) to run the `run_inference` function on the number of GPUs defined in `world_size`:
```py
def main():
world_size = 2
mp.spawn(run_inference, args=(world_size,), nprocs=world_size, join=True)
if __name__ == "__main__":
main()
```
Once you've completed the inference script, use the `--nproc_per_node` argument to specify the number of GPUs to use and call `torchrun` to run the script:
```bash
torchrun run_distributed.py --nproc_per_node=2
```
| huggingface/diffusers/blob/main/docs/source/en/training/distributed_inference.md |
T2I-Adapter training example for Stable Diffusion XL (SDXL)
The `train_t2i_adapter_sdxl.py` script shows how to implement the [T2I-Adapter training procedure](https://hf.co/papers/2302.08453) for [Stable Diffusion XL](https://huggingface.co/papers/2307.01952).
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the `examples/t2i_adapter` folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell (e.g., a notebook)
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
## Circle filling dataset
The original dataset is hosted in the [ControlNet repo](https://huggingface.co/lllyasviel/ControlNet/blob/main/training/fill50k.zip). We re-uploaded it to be compatible with `datasets` [here](https://huggingface.co/datasets/fusing/fill50k). Note that `datasets` handles dataloading within the training script.
## Training
Our training examples use two test conditioning images. They can be downloaded by running
```sh
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_1.png
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_2.png
```
Then run `huggingface-cli login` to log into your Hugging Face account. This is needed to be able to push the trained T2IAdapter parameters to Hugging Face Hub.
```bash
export MODEL_DIR="stabilityai/stable-diffusion-xl-base-1.0"
export OUTPUT_DIR="path to save model"
accelerate launch train_t2i_adapter_sdxl.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--mixed_precision="fp16" \
--resolution=1024 \
--learning_rate=1e-5 \
--max_train_steps=15000 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--validation_steps=100 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--report_to="wandb" \
--seed=42 \
--push_to_hub
```
To better track our training experiments, we're using the following flags in the command above:
* `report_to="wandb` will ensure the training runs are tracked on Weights and Biases. To use it, be sure to install `wandb` with `pip install wandb`.
* `validation_image`, `validation_prompt`, and `validation_steps` to allow the script to do a few validation inference runs. This allows us to qualitatively check if the training is progressing as expected.
Our experiments were conducted on a single 40GB A100 GPU.
### Inference
Once training is done, we can perform inference like so:
```python
from diffusers import StableDiffusionXLAdapterPipeline, T2IAdapter, EulerAncestralDiscreteSchedulerTest
from diffusers.utils import load_image
import torch
base_model_path = "stabilityai/stable-diffusion-xl-base-1.0"
adapter_path = "path to adapter"
adapter = T2IAdapter.from_pretrained(adapter_path, torch_dtype=torch.float16)
pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
base_model_path, adapter=adapter, torch_dtype=torch.float16
)
# speed up diffusion process with faster scheduler and memory optimization
pipe.scheduler = EulerAncestralDiscreteSchedulerTest.from_config(pipe.scheduler.config)
# remove following line if xformers is not installed or when using Torch 2.0.
pipe.enable_xformers_memory_efficient_attention()
# memory optimization.
pipe.enable_model_cpu_offload()
control_image = load_image("./conditioning_image_1.png")
prompt = "pale golden rod circle with old lace background"
# generate image
generator = torch.manual_seed(0)
image = pipe(
prompt, num_inference_steps=20, generator=generator, image=control_image
).images[0]
image.save("./output.png")
```
## Notes
### Specifying a better VAE
SDXL's VAE is known to suffer from numerical instability issues. This is why we also expose a CLI argument namely `--pretrained_vae_model_name_or_path` that lets you specify the location of a better VAE (such as [this one](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix)).
| huggingface/diffusers/blob/main/examples/t2i_adapter/README_sdxl.md |
Using Hugging Face Integrations
Related spaces: https://huggingface.co/spaces/gradio/en2es
Tags: HUB, SPACES, EMBED
Contributed by <a href="https://huggingface.co/osanseviero">Omar Sanseviero</a> 🦙
## Introduction
The Hugging Face Hub is a central platform that has hundreds of thousands of [models](https://huggingface.co/models), [datasets](https://huggingface.co/datasets) and [demos](https://huggingface.co/spaces) (also known as Spaces).
Gradio has multiple features that make it extremely easy to leverage existing models and Spaces on the Hub. This guide walks through these features.
## Demos with the Hugging Face Inference API
Hugging Face has a free service called the [Inference API](https://huggingface.co/inference-api), which allows you to send HTTP requests to models in the Hub. For transformers or diffusers-based models, the API can be 2 to 10 times faster than running the inference yourself. The API is free (rate limited), and you can switch to dedicated [Inference Endpoints](https://huggingface.co/pricing) when you want to use it in production. Gradio integrates directly with the Hugging Face Inference API so that you can create a demo simply by specifying a model's name (e.g. `Helsinki-NLP/opus-mt-en-es`), like this:
```python
import gradio as gr
demo = gr.load("Helsinki-NLP/opus-mt-en-es", src="models")
demo.launch()
```
For any Hugging Face model supported in the Inference API, Gradio automatically infers the expected input and output and make the underlying server calls, so you don't have to worry about defining the prediction function.
Notice that we just put specify the model name and state that the `src` should be `models` (Hugging Face's Model Hub). There is no need to install any dependencies (except `gradio`) since you are not loading the model on your computer.
You might notice that the first inference takes about 20 seconds. This happens since the Inference API is loading the model in the server. You get some benefits afterward:
- The inference will be much faster.
- The server caches your requests.
- You get built-in automatic scaling.
## Hosting your Gradio demos on Spaces
[Hugging Face Spaces](https://hf.co/spaces) allows anyone to host their Gradio demos freely, and uploading your Gradio demos take a couple of minutes. You can head to [hf.co/new-space](https://huggingface.co/new-space), select the Gradio SDK, create an `app.py` file, and voila! You have a demo you can share with anyone else. To learn more, read [this guide how to host on Hugging Face Spaces using the website](https://huggingface.co/blog/gradio-spaces).
Alternatively, you can create a Space programmatically, making use of the [huggingface_hub client library](https://huggingface.co/docs/huggingface_hub/index) library. Here's an example:
```python
from huggingface_hub import (
create_repo,
get_full_repo_name,
upload_file,
)
create_repo(name=target_space_name, token=hf_token, repo_type="space", space_sdk="gradio")
repo_name = get_full_repo_name(model_id=target_space_name, token=hf_token)
file_url = upload_file(
path_or_fileobj="file.txt",
path_in_repo="app.py",
repo_id=repo_name,
repo_type="space",
token=hf_token,
)
```
Here, `create_repo` creates a gradio repo with the target name under a specific account using that account's Write Token. `repo_name` gets the full repo name of the related repo. Finally `upload_file` uploads a file inside the repo with the name `app.py`.
## Loading demos from Spaces
You can also use and remix existing Gradio demos on Hugging Face Spaces. For example, you could take two existing Gradio demos on Spaces and put them as separate tabs and create a new demo. You can run this new demo locally, or upload it to Spaces, allowing endless possibilities to remix and create new demos!
Here's an example that does exactly that:
```python
import gradio as gr
with gr.Blocks() as demo:
with gr.Tab("Translate to Spanish"):
gr.load("gradio/en2es", src="spaces")
with gr.Tab("Translate to French"):
gr.load("abidlabs/en2fr", src="spaces")
demo.launch()
```
Notice that we use `gr.load()`, the same method we used to load models using the Inference API. However, here we specify that the `src` is `spaces` (Hugging Face Spaces).
Note: loading a Space in this way may result in slight differences from the original Space. In particular, any attributes that apply to the entire Blocks, such as the theme or custom CSS/JS, will not be loaded. You can copy these properties from the Space you are loading into your own `Blocks` object.
## Demos with the `Pipeline` in `transformers`
Hugging Face's popular `transformers` library has a very easy-to-use abstraction, [`pipeline()`](https://huggingface.co/docs/transformers/v4.16.2/en/main_classes/pipelines#transformers.pipeline) that handles most of the complex code to offer a simple API for common tasks. By specifying the task and an (optional) model, you can build a demo around an existing model with few lines of Python:
```python
import gradio as gr
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-en-es")
def predict(text):
return pipe(text)[0]["translation_text"]
demo = gr.Interface(
fn=predict,
inputs='text',
outputs='text',
)
demo.launch()
```
But `gradio` actually makes it even easier to convert a `pipeline` to a demo, simply by using the `gradio.Interface.from_pipeline` methods, which skips the need to specify the input and output components:
```python
from transformers import pipeline
import gradio as gr
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-en-es")
demo = gr.Interface.from_pipeline(pipe)
demo.launch()
```
The previous code produces the following interface, which you can try right here in your browser:
<gradio-app space="gradio/en2es"></gradio-app>
## Recap
That's it! Let's recap the various ways Gradio and Hugging Face work together:
1. You can build a demo around the Inference API without having to load the model easily using `gr.load()`.
2. You host your Gradio demo on Hugging Face Spaces, either using the GUI or entirely in Python.
3. You can load demos from Hugging Face Spaces to remix and create new Gradio demos using `gr.load()`.
4. You can convert a `transformers` pipeline into a Gradio demo using `from_pipeline()`.
🤗
| gradio-app/gradio/blob/main/guides/06_integrating-other-frameworks/01_using-hugging-face-integrations.md |
Accelerated inference on AMD GPUs supported by ROCm
By default, ONNX Runtime runs inference on CPU devices. However, it is possible to place supported operations on an AMD Instinct GPU, while leaving any unsupported ones on CPU. In most cases, this allows costly operations to be placed on GPU and significantly accelerate inference.
Our testing involved AMD Instinct GPUs, and for specific GPU compatibility, please refer to the official support list of GPUs available [here](https://rocm.docs.amd.com/en/latest/release/gpu_os_support.html).
This guide will show you how to run inference on the `ROCMExecutionProvider` execution provider that ONNX Runtime supports for AMD GPUs.
## Installation
The following setup installs the ONNX Runtime support with ROCM Execution Provider with ROCm 5.7.
#### 1 ROCm Installation
Refer to the [ROCm installation guide](https://rocm.docs.amd.com/en/latest/deploy/linux/index.html) to install ROCm 5.7.
#### 2 Installing `onnxruntime-rocm`
Please use the provided [Dockerfile](https://github.com/huggingface/optimum-amd/blob/main/docker/onnx-runtime-amd-gpu/Dockerfile) example or do a local installation from source since pip wheels are currently unavailable.
**Docker Installation:**
```bash
docker build -f Dockerfile -t ort/rocm .
```
**Local Installation Steps:**
##### 2.1 PyTorch with ROCm Support
Optimum ONNX Runtime integration relies on some functionalities of Transformers that require PyTorch. For now, we recommend to use Pytorch compiled against RoCm 5.7, that can be installed following [PyTorch installation guide](https://pytorch.org/get-started/locally/):
```bash
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/rocm5.7
# Use 'rocm/pytorch:latest' as the preferred base image when using Docker for PyTorch installation.
```
##### 2.2 ONNX Runtime with ROCm Execution Provider
```bash
# pre-requisites
pip install -U pip
pip install cmake onnx
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
# Install ONNXRuntime from source
git clone --recursive https://github.com/ROCmSoftwarePlatform/onnxruntime.git
cd onnxruntime
git checkout rocm5.7_internal_testing_eigen-3.4.zip_hash
./build.sh --config Release --build_wheel --update --build --parallel --cmake_extra_defines ONNXRUNTIME_VERSION=$(cat ./VERSION_NUMBER) --use_rocm --rocm_home=/opt/rocm
pip install build/Linux/Release/dist/*
```
<Tip>
To avoid conflicts between `onnxruntime` and `onnxruntime-rocm`, make sure the package `onnxruntime` is not installed by running `pip uninstall onnxruntime` prior to installing `onnxruntime-rocm`.
</Tip>
### Checking the ROCm installation is successful
Before going further, run the following sample code to check whether the install was successful:
```python
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
>>> from transformers import AutoTokenizer
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(
... "philschmid/tiny-bert-sst2-distilled",
... export=True,
... provider="ROCMExecutionProvider",
... )
>>> tokenizer = AutoTokenizer.from_pretrained("philschmid/tiny-bert-sst2-distilled")
>>> inputs = tokenizer("expectations were low, actual enjoyment was high", return_tensors="pt", padding=True)
>>> outputs = ort_model(**inputs)
>>> assert ort_model.providers == ["ROCMExecutionProvider", "CPUExecutionProvider"]
```
In case this code runs gracefully, congratulations, the installation is successful! If you encounter the following error or similar,
```
ValueError: Asked to use ROCMExecutionProvider as an ONNX Runtime execution provider, but the available execution providers are ['CPUExecutionProvider'].
```
then something is wrong with the ROCM or ONNX Runtime installation.
## Use ROCM Execution Provider with ORT models
For ORT models, the use is straightforward. Simply specify the `provider` argument in the `ORTModel.from_pretrained()` method. Here's an example:
```python
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(
... "distilbert-base-uncased-finetuned-sst-2-english",
... export=True,
... provider="ROCMExecutionProvider",
... )
```
The model can then be used with the common 🤗 Transformers API for inference and evaluation, such as [pipelines](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/pipelines).
When using Transformers pipeline, note that the `device` argument should be set to perform pre- and post-processing on GPU, following the example below:
```python
>>> from optimum.pipelines import pipeline
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
>>> pipe = pipeline(task="text-classification", model=ort_model, tokenizer=tokenizer, device="cuda:0")
>>> result = pipe("Both the music and visual were astounding, not to mention the actors performance.")
>>> print(result) # doctest: +IGNORE_RESULT
# printing: [{'label': 'POSITIVE', 'score': 0.9997727274894c714}]
```
Additionally, you can pass the session option `log_severity_level = 0` (verbose), to check whether all nodes are indeed placed on the ROCM execution provider or not:
```python
>>> import onnxruntime
>>> session_options = onnxruntime.SessionOptions()
>>> session_options.log_severity_level = 0
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(
... "distilbert-base-uncased-finetuned-sst-2-english",
... export=True,
... provider="ROCMExecutionProvider",
... session_options=session_options
... )
```
## Observed time gains
Coming soon!
| huggingface/optimum/blob/main/docs/source/onnxruntime/usage_guides/amdgpu.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Automatic speech recognition
[[open-in-colab]]
<Youtube id="TksaY_FDgnk"/>
Automatic speech recognition (ASR) converts a speech signal to text, mapping a sequence of audio inputs to text outputs. Virtual assistants like Siri and Alexa use ASR models to help users everyday, and there are many other useful user-facing applications like live captioning and note-taking during meetings.
This guide will show you how to:
1. Finetune [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) on the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset to transcribe audio to text.
2. Use your finetuned model for inference.
<Tip>
The task illustrated in this tutorial is supported by the following model architectures:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [M-CTC-T](../model_doc/mctct), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm)
<!--End of the generated tip-->
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate jiwer
```
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load MInDS-14 dataset
Start by loading a smaller subset of the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset from the 🤗 Datasets library. This'll give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
```py
>>> from datasets import load_dataset, Audio
>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train[:100]")
```
Split the dataset's `train` split into a train and test set with the [`~Dataset.train_test_split`] method:
```py
>>> minds = minds.train_test_split(test_size=0.2)
```
Then take a look at the dataset:
```py
>>> minds
DatasetDict({
train: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 16
})
test: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 4
})
})
```
While the dataset contains a lot of useful information, like `lang_id` and `english_transcription`, you'll focus on the `audio` and `transcription` in this guide. Remove the other columns with the [`~datasets.Dataset.remove_columns`] method:
```py
>>> minds = minds.remove_columns(["english_transcription", "intent_class", "lang_id"])
```
Take a look at the example again:
```py
>>> minds["train"][0]
{'audio': {'array': array([-0.00024414, 0. , 0. , ..., 0.00024414,
0.00024414, 0.00024414], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 8000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
```
There are two fields:
- `audio`: a 1-dimensional `array` of the speech signal that must be called to load and resample the audio file.
- `transcription`: the target text.
## Preprocess
The next step is to load a Wav2Vec2 processor to process the audio signal:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base")
```
The MInDS-14 dataset has a sampling rate of 8000kHz (you can find this information in its [dataset card](https://huggingface.co/datasets/PolyAI/minds14)), which means you'll need to resample the dataset to 16000kHz to use the pretrained Wav2Vec2 model:
```py
>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
>>> minds["train"][0]
{'audio': {'array': array([-2.38064706e-04, -1.58618059e-04, -5.43987835e-06, ...,
2.78103951e-04, 2.38446111e-04, 1.18740834e-04], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 16000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
```
As you can see in the `transcription` above, the text contains a mix of upper and lowercase characters. The Wav2Vec2 tokenizer is only trained on uppercase characters so you'll need to make sure the text matches the tokenizer's vocabulary:
```py
>>> def uppercase(example):
... return {"transcription": example["transcription"].upper()}
>>> minds = minds.map(uppercase)
```
Now create a preprocessing function that:
1. Calls the `audio` column to load and resample the audio file.
2. Extracts the `input_values` from the audio file and tokenize the `transcription` column with the processor.
```py
>>> def prepare_dataset(batch):
... audio = batch["audio"]
... batch = processor(audio["array"], sampling_rate=audio["sampling_rate"], text=batch["transcription"])
... batch["input_length"] = len(batch["input_values"][0])
... return batch
```
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] function. You can speed up `map` by increasing the number of processes with the `num_proc` parameter. Remove the columns you don't need with the [`~datasets.Dataset.remove_columns`] method:
```py
>>> encoded_minds = minds.map(prepare_dataset, remove_columns=minds.column_names["train"], num_proc=4)
```
🤗 Transformers doesn't have a data collator for ASR, so you'll need to adapt the [`DataCollatorWithPadding`] to create a batch of examples. It'll also dynamically pad your text and labels to the length of the longest element in its batch (instead of the entire dataset) so they are a uniform length. While it is possible to pad your text in the `tokenizer` function by setting `padding=True`, dynamic padding is more efficient.
Unlike other data collators, this specific data collator needs to apply a different padding method to `input_values` and `labels`:
```py
>>> import torch
>>> from dataclasses import dataclass, field
>>> from typing import Any, Dict, List, Optional, Union
>>> @dataclass
... class DataCollatorCTCWithPadding:
... processor: AutoProcessor
... padding: Union[bool, str] = "longest"
... def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
... # split inputs and labels since they have to be of different lengths and need
... # different padding methods
... input_features = [{"input_values": feature["input_values"][0]} for feature in features]
... label_features = [{"input_ids": feature["labels"]} for feature in features]
... batch = self.processor.pad(input_features, padding=self.padding, return_tensors="pt")
... labels_batch = self.processor.pad(labels=label_features, padding=self.padding, return_tensors="pt")
... # replace padding with -100 to ignore loss correctly
... labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
... batch["labels"] = labels
... return batch
```
Now instantiate your `DataCollatorForCTCWithPadding`:
```py
>>> data_collator = DataCollatorCTCWithPadding(processor=processor, padding="longest")
```
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load a evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [word error rate](https://huggingface.co/spaces/evaluate-metric/wer) (WER) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
```py
>>> import evaluate
>>> wer = evaluate.load("wer")
```
Then create a function that passes your predictions and labels to [`~evaluate.EvaluationModule.compute`] to calculate the WER:
```py
>>> import numpy as np
>>> def compute_metrics(pred):
... pred_logits = pred.predictions
... pred_ids = np.argmax(pred_logits, axis=-1)
... pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
... pred_str = processor.batch_decode(pred_ids)
... label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
... wer = wer.compute(predictions=pred_str, references=label_str)
... return {"wer": wer}
```
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
## Train
<frameworkcontent>
<pt>
<Tip>
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
</Tip>
You're ready to start training your model now! Load Wav2Vec2 with [`AutoModelForCTC`]. Specify the reduction to apply with the `ctc_loss_reduction` parameter. It is often better to use the average instead of the default summation:
```py
>>> from transformers import AutoModelForCTC, TrainingArguments, Trainer
>>> model = AutoModelForCTC.from_pretrained(
... "facebook/wav2vec2-base",
... ctc_loss_reduction="mean",
... pad_token_id=processor.tokenizer.pad_token_id,
... )
```
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the WER and save the training checkpoint.
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_asr_mind_model",
... per_device_train_batch_size=8,
... gradient_accumulation_steps=2,
... learning_rate=1e-5,
... warmup_steps=500,
... max_steps=2000,
... gradient_checkpointing=True,
... fp16=True,
... group_by_length=True,
... evaluation_strategy="steps",
... per_device_eval_batch_size=8,
... save_steps=1000,
... eval_steps=1000,
... logging_steps=25,
... load_best_model_at_end=True,
... metric_for_best_model="wer",
... greater_is_better=False,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
... tokenizer=processor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
```py
>>> trainer.push_to_hub()
```
</pt>
</frameworkcontent>
<Tip>
For a more in-depth example of how to finetune a model for automatic speech recognition, take a look at this blog [post](https://huggingface.co/blog/fine-tune-wav2vec2-english) for English ASR and this [post](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for multilingual ASR.
</Tip>
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Load an audio file you'd like to run inference on. Remember to resample the sampling rate of the audio file to match the sampling rate of the model if you need to!
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", "en-US", split="train")
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> audio_file = dataset[0]["audio"]["path"]
```
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for automatic speech recognition with your model, and pass your audio file to it:
```py
>>> from transformers import pipeline
>>> transcriber = pipeline("automatic-speech-recognition", model="stevhliu/my_awesome_asr_minds_model")
>>> transcriber(audio_file)
{'text': 'I WOUD LIKE O SET UP JOINT ACOUNT WTH Y PARTNER'}
```
<Tip>
The transcription is decent, but it could be better! Try finetuning your model on more examples to get even better results!
</Tip>
You can also manually replicate the results of the `pipeline` if you'd like:
<frameworkcontent>
<pt>
Load a processor to preprocess the audio file and transcription and return the `input` as PyTorch tensors:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
```
Pass your inputs to the model and return the logits:
```py
>>> from transformers import AutoModelForCTC
>>> model = AutoModelForCTC.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits
```
Get the predicted `input_ids` with the highest probability, and use the processor to decode the predicted `input_ids` back into text:
```py
>>> import torch
>>> predicted_ids = torch.argmax(logits, dim=-1)
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription
['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
```
</pt>
</frameworkcontent> | huggingface/transformers/blob/main/docs/source/en/tasks/asr.md |
--
title: "Course Launch Community Event"
thumbnail: /blog/assets/34_course_launch/speakers_day1_thumb.png
authors:
- user: sgugger
---
# Course Launch Community Event
We are excited to share that after a lot of work from the Hugging Face team, part 2 of the [Hugging Face Course](https://hf.co/course) will be released on November 15th! Part 1 focused on teaching you how to use a pretrained model, fine-tune it on a text classification task then upload the result to the [Model Hub](https://hf.co/models). Part 2 will focus on all the other common NLP tasks: token classification, language modeling (causal and masked), translation, summarization and question answering. It will also take a deeper dive in the whole Hugging Face ecosystem, in particular [🤗 Datasets](https://github.com/huggingface/datasets) and [🤗 Tokenizers](https://github.com/huggingface/tokenizers).
To go with this release, we are organizing a large community event to which you are invited! The program includes two days of talks, then team projects focused on fine-tuning a model on any NLP task ending with live demos like [this one](https://huggingface.co/spaces/flax-community/chef-transformer). Those demos will go nicely in your portfolio if you are looking for a new job in Machine Learning. We will also deliver a certificate of completion to all the participants that achieve building one of them.
AWS is sponsoring this event by offering free compute to participants via [Amazon SageMaker](https://aws.amazon.com/sagemaker/).
<div class="flex justify-center">
<img src="/blog/assets/34_course_launch/amazon_logo_dark.png" width=30% class="hidden dark:block">
<img src="/blog/assets/34_course_launch/amazon_logo_white.png" width=30% class="dark:hidden">
</div>
To register, please fill out [this form](https://docs.google.com/forms/d/e/1FAIpQLSd17_u-wMCdO4fcOPOSMLKcJhuIcevJaOT8Y83Gs-H6KFF5ew/viewform). You will find below more details on the two days of talks.
## Day 1 (November 15th): A high-level view of Transformers and how to train them
The first day of talks will focus on a high-level presentation of Transformers models and the tools we can use to train or fine-tune them.
<div
class="container md:grid md:grid-cols-2 gap-2 max-w-7xl"
>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/thom_wolf.png" width=50% style="border-radius: 50%;">
<p><strong>Thomas Wolf: <em>Transfer Learning and the birth of the Transformers library</em></strong></p>
<p>Thomas Wolf is co-founder and Chief Science Officer of HuggingFace. The tools created by Thomas Wolf and the Hugging Face team are used across more than 5,000 research organisations including Facebook Artificial Intelligence Research, Google Research, DeepMind, Amazon Research, Apple, the Allen Institute for Artificial Intelligence as well as most university departments. Thomas Wolf is the initiator and senior chair of the largest research collaboration that has ever existed in Artificial Intelligence: <a href="https://bigscience.huggingface.co">“BigScience”</a>, as well as a set of widely used <a href="https://github.com/huggingface/">libraries and tools</a>. Thomas Wolf is also a prolific educator and a thought leader in the field of Artificial Intelligence and Natural Language Processing, a regular invited speaker to conferences all around the world (<a href="https://thomwolf.io">https://thomwolf.io</a>).</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/meg_mitchell.png" width=50% style="border-radius: 50%;">
<p><strong>Margaret Mitchell: <em>On Values in ML Development</em></strong></p>
<p>Margaret Mitchell is a researcher working on Ethical AI, currently focused on the ins and outs of ethics-informed AI development in tech. She has published over 50 papers on natural language generation, assistive technology, computer vision, and AI ethics, and holds multiple patents in the areas of conversation generation and sentiment classification. She previously worked at Google AI as a Staff Research Scientist, where she founded and co-led Google's Ethical AI group, focused on foundational AI ethics research and operationalizing AI ethics Google-internally. Before joining Google, she was a researcher at Microsoft Research, focused on computer vision-to-language generation; and was a postdoc at Johns Hopkins, focused on Bayesian modeling and information extraction. She holds a PhD in Computer Science from the University of Aberdeen and a Master's in computational linguistics from the University of Washington. While earning her degrees, she also worked from 2005-2012 on machine learning, neurological disorders, and assistive technology at Oregon Health and Science University. She has spearheaded a number of workshops and initiatives at the intersections of diversity, inclusion, computer science, and ethics. Her work has received awards from Secretary of Defense Ash Carter and the American Foundation for the Blind, and has been implemented by multiple technology companies. She likes gardening, dogs, and cats.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/jakob_uszkoreit.png" width=50% style="border-radius: 50%;">
<p><strong>Jakob Uszkoreit: <em>It Ain't Broke So <del>Don't Fix</del> Let's Break It</em></strong></p>
<p>Jakob Uszkoreit is the co-founder of Inceptive. Inceptive designs RNA molecules for vaccines and therapeutics using large-scale deep learning in a tight loop with high throughput experiments with the goal of making RNA-based medicines more accessible, more effective and more broadly applicable. Previously, Jakob worked at Google for more than a decade, leading research and development teams in Google Brain, Research and Search working on deep learning fundamentals, computer vision, language understanding and machine translation.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/jay_alammar.png" width=50% style="border-radius: 50%;">
<p><strong>Jay Alammar: <em>A gentle visual intro to Transformers models</em></strong></p>
<p>Jay Alammar, Cohere. Through his popular ML blog, Jay has helped millions of researchers and engineers visually understand machine learning tools and concepts from the basic (ending up in numPy, pandas docs) to the cutting-edge (Transformers, BERT, GPT-3).</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/matthew_watson.png" width=50% style="border-radius: 50%;">
<p><strong>Matthew Watson: <em>NLP workflows with Keras</em></strong></p>
<p>Matthew Watson is a machine learning engineer on the Keras team, with a focus on high-level modeling APIs. He studied Computer Graphics during undergrad and a Masters at Stanford University. An almost English major who turned towards computer science, he is passionate about working across disciplines and making NLP accessible to a wider audience.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/chen_qian.png" width=50% style="border-radius: 50%;">
<p><strong>Chen Qian: <em>NLP workflows with Keras</em></strong></p>
<p>Chen Qian is a software engineer from Keras team, with a focus on high-level modeling APIs. Chen got a Master degree of Electrical Engineering from Stanford University, and he is especially interested in simplifying code implementations of ML tasks and large-scale ML.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/mark_saroufim.png" width=50% style="border-radius: 50%;">
<p><strong>Mark Saroufim: <em>How to Train a Model with Pytorch</em></strong></p>
<p>Mark Saroufim is a Partner Engineer at Pytorch working on OSS production tools including TorchServe and Pytorch Enterprise. In his past lives, Mark was an Applied Scientist and Product Manager at Graphcore, <a href="http://yuri.ai/">yuri.ai</a>, Microsoft and NASA's JPL. His primary passion is to make programming more fun.</p>
</div>
</div>
## Day 2 (November 16th): The tools you will use
Day 2 will be focused on talks by the Hugging Face, [Gradio](https://www.gradio.app/), and [AWS](https://aws.amazon.com/) teams, showing you the tools you will use.
<div
class="container md:grid md:grid-cols-2 gap-2 max-w-7xl"
>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/lewis_tunstall.png" width=50% style="border-radius: 50%;">
<p><strong>Lewis Tunstall: <em>Simple Training with the 🤗 Transformers Trainer</em></strong></p>
<p>Lewis is a machine learning engineer at Hugging Face, focused on developing open-source tools and making them accessible to the wider community. He is also a co-author of an upcoming O’Reilly book on Transformers and you can follow him on Twitter (@_lewtun) for NLP tips and tricks!</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/matthew_carrigan.png" width=50% style="border-radius: 50%;">
<p><strong>Matthew Carrigan: <em>New TensorFlow Features for 🤗 Transformers and 🤗 Datasets</em></strong></p>
<p>Matt is responsible for TensorFlow maintenance at Transformers, and will eventually lead a coup against the incumbent PyTorch faction which will likely be co-ordinated via his Twitter account @carrigmat.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/lysandre_debut.png" width=50% style="border-radius: 50%;">
<p><strong>Lysandre Debut: <em>The Hugging Face Hub as a means to collaborate on and share Machine Learning projects</em></strong></p>
<p>Lysandre is a Machine Learning Engineer at Hugging Face where he is involved in many open source projects. His aim is to make Machine Learning accessible to everyone by developing powerful tools with a very simple API.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/sylvain_gugger.png" width=50% style="border-radius: 50%;">
<p><strong>Sylvain Gugger: <em>Supercharge your PyTorch training loop with 🤗 Accelerate</em></strong></p>
<p>Sylvain is a Research Engineer at Hugging Face and one of the core maintainers of 🤗 Transformers and the developer behind 🤗 Accelerate. He likes making model training more accessible.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/lucile_saulnier.png" width=50% style="border-radius: 50%;">
<p><strong>Lucile Saulnier: <em>Get your own tokenizer with 🤗 Transformers & 🤗 Tokenizers</em></strong></p>
<p>Lucile is a machine learning engineer at Hugging Face, developing and supporting the use of open source tools. She is also actively involved in many research projects in the field of Natural Language Processing such as collaborative training and BigScience.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/merve_noyan.png" width=50% style="border-radius: 50%;">
<p><strong>Merve Noyan: <em>Showcase your model demos with 🤗 Spaces</em></strong></p>
<p>Merve is a developer advocate at Hugging Face, working on developing tools and building content around them to democratize machine learning for everyone.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/abubakar_abid.png" width=50% style="border-radius: 50%;">
<p><strong>Abubakar Abid: <em>Building Machine Learning Applications Fast</em></strong></p>
<p>Abubakar Abid is the CEO of <a href="www.gradio.app">Gradio</a>. He received his Bachelor's of Science in Electrical Engineering and Computer Science from MIT in 2015, and his PhD in Applied Machine Learning from Stanford in 2021. In his role as the CEO of Gradio, Abubakar works on making machine learning models easier to demo, debug, and deploy.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/mathieu_desve.png" width=50% style="border-radius: 50%;">
<p><strong>Mathieu Desvé: <em>AWS ML Vision: Making Machine Learning Accessible to all Customers</em></strong></p>
<p>Technology enthusiast, maker on my free time. I like challenges and solving problem of clients and users, and work with talented people to learn every day. Since 2004, I work in multiple positions switching from frontend, backend, infrastructure, operations and managements. Try to solve commons technical and managerial issues in agile manner.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="/blog/assets/34_course_launch/philipp_schmid.png" width=50% style="border-radius: 50%;">
<p><strong>Philipp Schmid: <em>Managed Training with Amazon SageMaker and 🤗 Transformers</em></strong></p>
<p>Philipp Schmid is a Machine Learning Engineer and Tech Lead at Hugging Face, where he leads the collaboration with the Amazon SageMaker team. He is passionate about democratizing and productionizing cutting-edge NLP models and improving the ease of use for Deep Learning.</p>
</div>
</div>
| huggingface/blog/blob/main/course-launch-event.md |
Inference Endpoints Version
Hugging Face Inference Endpoints comes with a default serving container which is used for all [supported Transformers and Sentence-Transformers tasks](/docs/inference-endpoints/supported_tasks) and for [custom inference handler](/docs/inference-endpoints/guides/custom_handler) and implement batching.
Below you will find information about the installed packages and versions used.
You can always upgrade installed packages and a custom packages by adding a `requirements.txt` file to your model repository. Read more in [Add custom Dependencies](/docs/inference-endpoints/guides/custom_dependencies).
## Installed packages & version
The installed packages are split into `general`, `CPU` & `GPU` packages. The `general` packages are installed in all containers, the `CPU` and `GPU` packages are only installed in the corresponding containers.
The Hugging Face Inference Runtime has separate versions for `PyTorch` and `TensorFlow` for `CPU` and `GPU`, which are used based on the selected `framework` when creating an Inference Endpoint. The `TensorFlow` and `PyTorch` flavors are grouped together in the list below.
### General
- `Python`: `3.9.13`
### CPU
- `transformers[sklearn,sentencepiece,audio,vision]`: `4.27.2`
- `diffusers`: `0.14.0`
- `accelerate`: `0.17.1`
- `sentence_transformers`: `latest`
- `pandas`: `latest`
- `pytorch`: `1.13.1`
- `torchvision`: `0.14.1`
- `tensorflow`: `2.9.1`
### GPU
- `transformers[sklearn,sentencepiece,audio,vision]`: `4.27.2`
- `diffusers`: `0.14.0`
- `accelerate`: `0.17.1`
- `sentence_transformers`: `latest`
- `pandas`: `latest`
- `pytorch`: `1.13.1=py3.9_cuda11.8*`
- `torchvision`: `0.14.1`
- `tensorflow`: `2.9.1=*cuda112*py39*`
| huggingface/hf-endpoints-documentation/blob/main/docs/source/others/runtime.mdx |
使用 Gradio 块像函数一样
Tags: TRANSLATION, HUB, SPACES
**先决条件**: 本指南是在块介绍的基础上构建的。请确保[先阅读该指南](https://gradio.app/quickstart/#blocks-more-flexibility-and-control)。
## 介绍
你知道吗,除了作为一个全栈机器学习演示,Gradio 块应用其实也是一个普通的 Python 函数!?
这意味着如果你有一个名为 `demo` 的 Gradio 块(或界面)应用,你可以像使用任何 Python 函数一样使用 `demo`。
所以,像 `output = demo("Hello", "friend")` 这样的操作会在输入为 "Hello" 和 "friend" 的情况下运行 `demo` 中定义的第一个事件,并将其存储在变量 `output` 中。
如果以上内容让你打瞌睡 🥱,请忍耐一下!通过将应用程序像函数一样使用,你可以轻松地组合 Gradio 应用。
接下来的部分将展示如何实现。
## 将块视为函数
假设我们有一个将英文文本翻译为德文文本的演示块。
$code_english_translator
我已经将它托管在 Hugging Face Spaces 上的 [gradio/english_translator](https://huggingface.co/spaces/gradio/english_translator)。
你也可以在下面看到演示:
$demo_english_translator
现在,假设你有一个生成英文文本的应用程序,但你还想额外生成德文文本。
你可以选择:
1. 将我的英德翻译的源代码复制粘贴到你的应用程序中。
2. 在你的应用程序中加载我的英德翻译,并将其当作普通的 Python 函数处理。
选项 1 从技术上讲总是有效的,但它经常引入不必要的复杂性。
选项 2 允许你借用所需的功能,而不会过于紧密地耦合我们的应用程序。
你只需要在源文件中调用 `Blocks.load` 类方法即可。
之后,你就可以像使用普通的 Python 函数一样使用我的翻译应用程序了!
下面的代码片段和演示展示了如何使用 `Blocks.load`。
请注意,变量 `english_translator` 是我的英德翻译应用程序,但它在 `generate_text` 中像普通函数一样使用。
$code_generate_english_german
$demo_generate_english_german
## 如何控制使用应用程序中的哪个函数
如果你正在加载的应用程序定义了多个函数,你可以使用 `fn_index` 和 `api_name` 参数指定要使用的函数。
在英德演示的代码中,你会看到以下代码行:
translate_btn.click(translate, inputs=english, outputs=german, api_name="translate-to-german")
这个 `api_name` 在我们的应用程序中给这个函数一个唯一的名称。你可以使用这个名称告诉 Gradio 你想使用
上游空间中的哪个函数:
english_generator(text, api_name="translate-to-german")[0]["generated_text"]
你也可以使用 `fn_index` 参数。
假设我的应用程序还定义了一个英语到西班牙语的翻译函数。
为了在我们的文本生成应用程序中使用它,我们将使用以下代码:
english_generator(text, fn_index=1)[0]["generated_text"]
Gradio 空间中的函数是从零开始索引的,所以西班牙语翻译器将是我的空间中的第二个函数,
因此你会使用索引 1。
## 结语
我们展示了将块应用视为普通 Python 函数的方法,这有助于在不同的应用程序之间组合功能。
任何块应用程序都可以被视为一个函数,但一个强大的模式是在将其视为函数之前,
在[自己的应用程序中加载](https://huggingface.co/spaces)托管在[Hugging Face Spaces](https://huggingface.co/spaces)上的应用程序。
您也可以加载托管在[Hugging Face Model Hub](https://huggingface.co/models)上的模型——有关示例,请参阅[使用 Hugging Face 集成](/using_hugging_face_integrations)指南。
### 开始构建!⚒️
## Parting Remarks
我们展示了如何将 Blocks 应用程序视为常规 Python 函数,以便在不同的应用程序之间组合功能。
任何 Blocks 应用程序都可以被视为函数,但是一种有效的模式是在将其视为自己应用程序的函数之前,先`加载`托管在[Hugging Face Spaces](https://huggingface.co/spaces)上的应用程序。
您还可以加载托管在[Hugging Face Model Hub](https://huggingface.co/models)上的模型-请参见[使用 Hugging Face 集成指南](/using_hugging_face_integrations)中的示例。
### Happy building! ⚒️
| gradio-app/gradio/blob/main/guides/cn/03_building-with-blocks/05_using-blocks-like-functions.md |
Stream
Dataset streaming lets you work with a dataset without downloading it.
The data is streamed as you iterate over the dataset.
This is especially helpful when:
- You don't want to wait for an extremely large dataset to download.
- The dataset size exceeds the amount of available disk space on your computer.
- You want to quickly explore just a few samples of a dataset.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/streaming.gif"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/streaming-dark.gif"/>
</div>
For example, the English split of the [oscar-corpus/OSCAR-2201](https://huggingface.co/datasets/oscar-corpus/OSCAR-2201) dataset is 1.2 terabytes, but you can use it instantly with streaming. Stream a dataset by setting `streaming=True` in [`load_dataset`] as shown below:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset('oscar-corpus/OSCAR-2201', 'en', split='train', streaming=True)
>>> print(next(iter(dataset)))
{'id': 0, 'text': 'Founded in 2015, Golden Bees is a leading programmatic recruitment platform dedicated to employers, HR agencies and job boards. The company has developed unique HR-custom technologies and predictive algorithms to identify and attract the best candidates for a job opportunity.', ...
```
Dataset streaming also lets you work with a dataset made of local files without doing any conversion.
In this case, the data is streamed from the local files as you iterate over the dataset.
This is especially helpful when:
- You don't want to wait for an extremely large local dataset to be converted to Arrow.
- The converted files size would exceed the amount of available disk space on your computer.
- You want to quickly explore just a few samples of a dataset.
For example, you can stream a local dataset of hundreds of compressed JSONL files like [oscar-corpus/OSCAR-2201](https://huggingface.co/datasets/oscar-corpus/OSCAR-2201) to use it instantly:
```py
>>> from datasets import load_dataset
>>> data_files = {'train': 'path/to/OSCAR-2201/compressed/en_meta/*.jsonl.gz'}
>>> dataset = load_dataset('json', data_files=data_files, split='train', streaming=True)
>>> print(next(iter(dataset)))
{'id': 0, 'text': 'Founded in 2015, Golden Bees is a leading programmatic recruitment platform dedicated to employers, HR agencies and job boards. The company has developed unique HR-custom technologies and predictive algorithms to identify and attract the best candidates for a job opportunity.', ...
```
Loading a dataset in streaming mode creates a new dataset type instance (instead of the classic [`Dataset`] object), known as an [`IterableDataset`].
This special type of dataset has its own set of processing methods shown below.
<Tip>
An [`IterableDataset`] is useful for iterative jobs like training a model.
You shouldn't use a [`IterableDataset`] for jobs that require random access to examples because you have to iterate all over it using a for loop. Getting the last example in an iterable dataset would require you to iterate over all the previous examples.
You can find more details in the [Dataset vs. IterableDataset guide](./about_mapstyle_vs_iterable).
</Tip>
## Convert from a Dataset
If you have an existing [`Dataset`] object, you can convert it to an [`IterableDataset`] with the [`~Dataset.to_iterable_dataset`] function. This is actually faster than setting the `streaming=True` argument in [`load_dataset`] because the data is streamed from local files.
```py
>>> from datasets import load_dataset
# faster 🐇
>>> dataset = load_dataset("food101")
>>> iterable_dataset = dataset.to_iterable_dataset()
# slower 🐢
>>> iterable_dataset = load_dataset("food101", streaming=True)
```
The [`~Dataset.to_iterable_dataset`] function supports sharding when the [`IterableDataset`] is instantiated. This is useful when working with big datasets, and you'd like to shuffle the dataset or to enable fast parallel loading with a PyTorch DataLoader.
```py
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("food101")
>>> iterable_dataset = dataset.to_iterable_dataset(num_shards=64) # shard the dataset
>>> iterable_dataset = iterable_dataset.shuffle(buffer_size=10_000) # shuffles the shards order and use a shuffle buffer when you start iterating
dataloader = torch.utils.data.DataLoader(iterable_dataset, num_workers=4) # assigns 64 / 4 = 16 shards from the shuffled list of shards to each worker when you start iterating
```
## Shuffle
Like a regular [`Dataset`] object, you can also shuffle a [`IterableDataset`] with [`IterableDataset.shuffle`].
The `buffer_size` argument controls the size of the buffer to randomly sample examples from. Let's say your dataset has one million examples, and you set the `buffer_size` to ten thousand. [`IterableDataset.shuffle`] will randomly select examples from the first ten thousand examples in the buffer. Selected examples in the buffer are replaced with new examples. By default, the buffer size is 1,000.
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset('oscar', "unshuffled_deduplicated_en", split='train', streaming=True)
>>> shuffled_dataset = dataset.shuffle(seed=42, buffer_size=10_000)
```
<Tip>
[`IterableDataset.shuffle`] will also shuffle the order of the shards if the dataset is sharded into multiple files.
</Tip>
## Reshuffle
Sometimes you may want to reshuffle the dataset after each epoch. This will require you to set a different seed for each epoch. Use [`IterableDataset.set_epoch`] in between epochs to tell the dataset what epoch you're on.
Your seed effectively becomes: `initial seed + current epoch`.
```py
>>> for epoch in range(epochs):
... shuffled_dataset.set_epoch(epoch)
... for example in shuffled_dataset:
... ...
```
## Split dataset
You can split your dataset one of two ways:
- [`IterableDataset.take`] returns the first `n` examples in a dataset:
```py
>>> dataset = load_dataset('oscar', "unshuffled_deduplicated_en", split='train', streaming=True)
>>> dataset_head = dataset.take(2)
>>> list(dataset_head)
[{'id': 0, 'text': 'Mtendere Village was...'}, {'id': 1, 'text': 'Lily James cannot fight the music...'}]
```
- [`IterableDataset.skip`] omits the first `n` examples in a dataset and returns the remaining examples:
```py
>>> train_dataset = shuffled_dataset.skip(1000)
```
<Tip warning={true}>
`take` and `skip` prevent future calls to `shuffle` because they lock in the order of the shards. You should `shuffle` your dataset before splitting it.
</Tip>
<a id='interleave_datasets'></a>
## Interleave
[`interleave_datasets`] can combine an [`IterableDataset`] with other datasets. The combined dataset returns alternating examples from each of the original datasets.
```py
>>> from datasets import interleave_datasets
>>> en_dataset = load_dataset('oscar', "unshuffled_deduplicated_en", split='train', streaming=True, trust_remote_code=True)
>>> fr_dataset = load_dataset('oscar', "unshuffled_deduplicated_fr", split='train', streaming=True, trust_remote_code=True)
>>> multilingual_dataset = interleave_datasets([en_dataset, fr_dataset])
>>> list(multilingual_dataset.take(2))
[{'text': 'Mtendere Village was inspired by the vision...'}, {'text': "Média de débat d'idées, de culture et de littérature..."}]
```
Define sampling probabilities from each of the original datasets for more control over how each of them are sampled and combined. Set the `probabilities` argument with your desired sampling probabilities:
```py
>>> multilingual_dataset_with_oversampling = interleave_datasets([en_dataset, fr_dataset], probabilities=[0.8, 0.2], seed=42)
>>> list(multilingual_dataset_with_oversampling.take(2))
[{'text': 'Mtendere Village was inspired by the vision...'}, {'text': 'Lily James cannot fight the music...'}]
```
Around 80% of the final dataset is made of the `en_dataset`, and 20% of the `fr_dataset`.
You can also specify the `stopping_strategy`. The default strategy, `first_exhausted`, is a subsampling strategy, i.e the dataset construction is stopped as soon one of the dataset runs out of samples.
You can specify `stopping_strategy=all_exhausted` to execute an oversampling strategy. In this case, the dataset construction is stopped as soon as every samples in every dataset has been added at least once. In practice, it means that if a dataset is exhausted, it will return to the beginning of this dataset until the stop criterion has been reached.
Note that if no sampling probabilities are specified, the new dataset will have `max_length_datasets*nb_dataset samples`.
## Rename, remove, and cast
The following methods allow you to modify the columns of a dataset. These methods are useful for renaming or removing columns and changing columns to a new set of features.
### Rename
Use [`IterableDataset.rename_column`] when you need to rename a column in your dataset. Features associated with the original column are actually moved under the new column name, instead of just replacing the original column in-place.
Provide [`IterableDataset.rename_column`] with the name of the original column, and the new column name:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset('mc4', 'en', streaming=True, split='train', trust_remote_code=True)
>>> dataset = dataset.rename_column("text", "content")
```
### Remove
When you need to remove one or more columns, give [`IterableDataset.remove_columns`] the name of the column to remove. Remove more than one column by providing a list of column names:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset('mc4', 'en', streaming=True, split='train', trust_remote_code=True)
>>> dataset = dataset.remove_columns('timestamp')
```
### Cast
[`IterableDataset.cast`] changes the feature type of one or more columns. This method takes your new `Features` as its argument. The following sample code shows how to change the feature types of `ClassLabel` and `Value`:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset('glue', 'mrpc', split='train', streaming=True)
>>> dataset.features
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
'idx': Value(dtype='int32', id=None)}
>>> from datasets import ClassLabel, Value
>>> new_features = dataset.features.copy()
>>> new_features["label"] = ClassLabel(names=['negative', 'positive'])
>>> new_features["idx"] = Value('int64')
>>> dataset = dataset.cast(new_features)
>>> dataset.features
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['negative', 'positive'], names_file=None, id=None),
'idx': Value(dtype='int64', id=None)}
```
<Tip>
Casting only works if the original feature type and new feature type are compatible. For example, you can cast a column with the feature type `Value('int32')` to `Value('bool')` if the original column only contains ones and zeros.
</Tip>
Use [`IterableDataset.cast_column`] to change the feature type of just one column. Pass the column name and its new feature type as arguments:
```py
>>> dataset.features
{'audio': Audio(sampling_rate=44100, mono=True, id=None)}
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> dataset.features
{'audio': Audio(sampling_rate=16000, mono=True, id=None)}
```
## Map
Similar to the [`Dataset.map`] function for a regular [`Dataset`], 🤗 Datasets features [`IterableDataset.map`] for processing an [`IterableDataset`].
[`IterableDataset.map`] applies processing on-the-fly when examples are streamed.
It allows you to apply a processing function to each example in a dataset, independently or in batches. This function can even create new rows and columns.
The following example demonstrates how to tokenize a [`IterableDataset`]. The function needs to accept and output a `dict`:
```py
>>> def add_prefix(example):
... example['text'] = 'My text: ' + example['text']
... return example
```
Next, apply this function to the dataset with [`IterableDataset.map`]:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset('oscar', 'unshuffled_deduplicated_en', streaming=True, split='train', trust_remote_code=True)
>>> updated_dataset = dataset.map(add_prefix)
>>> list(updated_dataset.take(3))
[{'id': 0, 'text': 'My text: Mtendere Village was inspired by...'},
{'id': 1, 'text': 'My text: Lily James cannot fight the music...'},
{'id': 2, 'text': 'My text: "I\'d love to help kickstart...'}]
```
Let's take a look at another example, except this time, you will remove a column with [`IterableDataset.map`]. When you remove a column, it is only removed after the example has been provided to the mapped function. This allows the mapped function to use the content of the columns before they are removed.
Specify the column to remove with the `remove_columns` argument in [`IterableDataset.map`]:
```py
>>> updated_dataset = dataset.map(add_prefix, remove_columns=["id"])
>>> list(updated_dataset.take(3))
[{'text': 'My text: Mtendere Village was inspired by...'},
{'text': 'My text: Lily James cannot fight the music...'},
{'text': 'My text: "I\'d love to help kickstart...'}]
```
### Batch processing
[`IterableDataset.map`] also supports working with batches of examples. Operate on batches by setting `batched=True`. The default batch size is 1000, but you can adjust it with the `batch_size` argument. This opens the door to many interesting applications such as tokenization, splitting long sentences into shorter chunks, and data augmentation.
#### Tokenization
```py
>>> from datasets import load_dataset
>>> from transformers import AutoTokenizer
>>> dataset = load_dataset("mc4", "en", streaming=True, split="train", trust_remote_code=True)
>>> tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
>>> def encode(examples):
... return tokenizer(examples['text'], truncation=True, padding='max_length')
>>> dataset = dataset.map(encode, batched=True, remove_columns=["text", "timestamp", "url"])
>>> next(iter(dataset))
{'input_ids': [101, 8466, 1018, 1010, 4029, 2475, 2062, 18558, 3100, 2061, ...,1106, 3739, 102],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ..., 1, 1]}
```
<Tip>
See other examples of batch processing in the [batched map processing](./process#batch-processing) documentation. They work the same for iterable datasets.
</Tip>
### Filter
You can filter rows in the dataset based on a predicate function using [`Dataset.filter`]. It returns rows that match a specified condition:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset('oscar', 'unshuffled_deduplicated_en', streaming=True, split='train', trust_remote_code=True)
>>> start_with_ar = dataset.filter(lambda example: example['text'].startswith('Ar'))
>>> next(iter(start_with_ar))
{'id': 4, 'text': 'Are you looking for Number the Stars (Essential Modern Classics)?...'}
```
[`Dataset.filter`] can also filter by indices if you set `with_indices=True`:
```py
>>> even_dataset = dataset.filter(lambda example, idx: idx % 2 == 0, with_indices=True)
>>> list(even_dataset.take(3))
[{'id': 0, 'text': 'Mtendere Village was inspired by the vision of Chief Napoleon Dzombe, ...'},
{'id': 2, 'text': '"I\'d love to help kickstart continued development! And 0 EUR/month...'},
{'id': 4, 'text': 'Are you looking for Number the Stars (Essential Modern Classics)? Normally, ...'}]
```
## Stream in a training loop
[`IterableDataset`] can be integrated into a training loop. First, shuffle the dataset:
<frameworkcontent>
<pt>
```py
>>> seed, buffer_size = 42, 10_000
>>> dataset = dataset.shuffle(seed, buffer_size=buffer_size)
```
Lastly, create a simple training loop and start training:
```py
>>> import torch
>>> from torch.utils.data import DataLoader
>>> from transformers import AutoModelForMaskedLM, DataCollatorForLanguageModeling
>>> from tqdm import tqdm
>>> dataset = dataset.with_format("torch")
>>> dataloader = DataLoader(dataset, collate_fn=DataCollatorForLanguageModeling(tokenizer))
>>> device = 'cuda' if torch.cuda.is_available() else 'cpu'
>>> model = AutoModelForMaskedLM.from_pretrained("distilbert-base-uncased")
>>> model.train().to(device)
>>> optimizer = torch.optim.AdamW(params=model.parameters(), lr=1e-5)
>>> for epoch in range(3):
... dataset.set_epoch(epoch)
... for i, batch in enumerate(tqdm(dataloader, total=5)):
... if i == 5:
... break
... batch = {k: v.to(device) for k, v in batch.items()}
... outputs = model(**batch)
... loss = outputs[0]
... loss.backward()
... optimizer.step()
... optimizer.zero_grad()
... if i % 10 == 0:
... print(f"loss: {loss}")
```
</pt>
</frameworkcontent>
<!-- TODO: Write the TF content! -->
| huggingface/datasets/blob/main/docs/source/stream.mdx |
--
title: 'Accelerated Inference with Optimum and Transformers Pipelines'
thumbnail: /blog/assets/66_optimum_inference/thumbnail.png
authors:
- user: philschmid
---
# Accelerated Inference with Optimum and Transformers Pipelines
> Inference has landed in Optimum with support for Hugging Face Transformers pipelines, including text-generation using ONNX Runtime.
The adoption of BERT and Transformers continues to grow. Transformer-based models are now not only achieving state-of-the-art performance in Natural Language Processing but also for Computer Vision, Speech, and Time-Series. 💬 🖼 🎤 ⏳
Companies are now moving from the experimentation and research phase to the production phase in order to use Transformer models for large-scale workloads. But by default BERT and its friends are relatively slow, big, and complex models compared to traditional Machine Learning algorithms.
To solve this challenge, we created [Optimum](https://huggingface.co/blog/hardware-partners-program) – an extension of [Hugging Face Transformers](https://github.com/huggingface/transformers) to accelerate the training and inference of Transformer models like BERT.
In this blog post, you'll learn:
- [1. What is Optimum? An ELI5](#1-what-is-optimum-an-eli5)
- [2. New Optimum inference and pipeline features](#2-new-optimum-inference-and-pipeline-features)
- [3. End-to-End tutorial on accelerating RoBERTa for Question-Answering including quantization and optimization](#3-end-to-end-tutorial-on-accelerating-roberta-for-question-answering-including-quantization-and-optimization)
- [4. Current Limitations](#4-current-limitations)
- [5. Optimum Inference FAQ](#5-optimum-inference-faq)
- [6. What’s next?](#6-whats-next)
Let's get started! 🚀
## 1. What is Optimum? An ELI5
[Hugging Face Optimum](https://github.com/huggingface/optimum) is an open-source library and an extension of [Hugging Face Transformers](https://github.com/huggingface/transformers), that provides a unified API of performance optimization tools to achieve maximum efficiency to train and run models on accelerated hardware, including toolkits for optimized performance on [Graphcore IPU](https://github.com/huggingface/optimum-graphcore) and [Habana Gaudi](https://github.com/huggingface/optimum-habana). Optimum can be used for accelerated training, quantization, graph optimization, and now inference as well with support for [transformers pipelines](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#pipelines).
## 2. New Optimum inference and pipeline features
With [release](https://github.com/huggingface/optimum/releases/tag/v1.2.0) of Optimum 1.2, we are adding support for [inference](https://huggingface.co/docs/optimum/main/en/onnxruntime/modeling_ort) and [transformers pipelines](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#pipelines). This allows Optimum users to leverage the same API they are used to from transformers with the power of accelerated runtimes, like [ONNX Runtime](https://onnxruntime.ai/).
**Switching from Transformers to Optimum Inference**
The [Optimum Inference models](https://huggingface.co/docs/optimum/main/en/onnxruntime/modeling_ort) are API compatible with Hugging Face Transformers models. This means you can just replace your `AutoModelForXxx` class with the corresponding `ORTModelForXxx` class in Optimum. For example, this is how you can use a question answering model in Optimum:
```diff
from transformers import AutoTokenizer, pipeline
-from transformers import AutoModelForQuestionAnswering
+from optimum.onnxruntime import ORTModelForQuestionAnswering
-model = AutoModelForQuestionAnswering.from_pretrained("deepset/roberta-base-squad2") # pytorch checkpoint
+model = ORTModelForQuestionAnswering.from_pretrained("optimum/roberta-base-squad2") # onnx checkpoint
tokenizer = AutoTokenizer.from_pretrained("deepset/roberta-base-squad2")
optimum_qa = pipeline("question-answering", model=model, tokenizer=tokenizer)
question = "What's my name?"
context = "My name is Philipp and I live in Nuremberg."
pred = optimum_qa(question, context)
```
In the first release, we added [support for ONNX Runtime](https://huggingface.co/docs/optimum/main/en/onnxruntime/modeling_ort) but there is more to come!
These new `ORTModelForXX` can now be used with the [transformers pipelines](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#pipelines). They are also fully integrated into the [Hugging Face Hub](https://huggingface.co/models) to push and pull optimized checkpoints from the community. In addition to this, you can use the [ORTQuantizer](https://huggingface.co/docs/optimum/main/en/onnxruntime/quantization) and [ORTOptimizer](https://huggingface.co/docs/optimum/main/en/onnxruntime/optimization) to first quantize and optimize your model and then run inference on it.
Check out [End-to-End Tutorial on accelerating RoBERTa for question-answering including quantization and optimization](#3-end-to-end-tutorial-on-accelerating-roberta-for-question-answering-including-quantization-and-optimization) for more details.
## 3. End-to-End tutorial on accelerating RoBERTa for Question-Answering including quantization and optimization
In this End-to-End tutorial on accelerating RoBERTa for question-answering, you will learn how to:
1. Install `Optimum` for ONNX Runtime
2. Convert a Hugging Face `Transformers` model to ONNX for inference
3. Use the `ORTOptimizer` to optimize the model
4. Use the `ORTQuantizer` to apply dynamic quantization
5. Run accelerated inference using Transformers pipelines
6. Evaluate the performance and speed
Let’s get started 🚀
*This tutorial was created and run on an `m5.xlarge` AWS EC2 Instance.*
### 3.1 Install `Optimum` for Onnxruntime
Our first step is to install `Optimum` with the `onnxruntime` utilities.
```bash
pip install "optimum[onnxruntime]==1.2.0"
```
This will install all required packages for us including `transformers`, `torch`, and `onnxruntime`. If you are going to use a GPU you can install optimum with `pip install optimum[onnxruntime-gpu]`.
### 3.2 Convert a Hugging Face `Transformers` model to ONNX for inference**
Before we can start optimizing we need to convert our vanilla `transformers` model to the `onnx` format. To do this we will use the new [ORTModelForQuestionAnswering](https://huggingface.co/docs/optimum/main/en/onnxruntime/modeling_ort#optimum.onnxruntime.ORTModelForQuestionAnswering) class calling the `from_pretrained()` method with the `from_transformers` attribute. The model we are using is the [deepset/roberta-base-squad2](https://huggingface.co/deepset/roberta-base-squad2) a fine-tuned RoBERTa model on the SQUAD2 dataset achieving an F1 score of `82.91` and as the feature (task) `question-answering`.
```python
from pathlib import Path
from transformers import AutoTokenizer, pipeline
from optimum.onnxruntime import ORTModelForQuestionAnswering
model_id = "deepset/roberta-base-squad2"
onnx_path = Path("onnx")
task = "question-answering"
# load vanilla transformers and convert to onnx
model = ORTModelForQuestionAnswering.from_pretrained(model_id, from_transformers=True)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# save onnx checkpoint and tokenizer
model.save_pretrained(onnx_path)
tokenizer.save_pretrained(onnx_path)
# test the model with using transformers pipeline, with handle_impossible_answer for squad_v2
optimum_qa = pipeline(task, model=model, tokenizer=tokenizer, handle_impossible_answer=True)
prediction = optimum_qa(question="What's my name?", context="My name is Philipp and I live in Nuremberg.")
print(prediction)
# {'score': 0.9041663408279419, 'start': 11, 'end': 18, 'answer': 'Philipp'}
```
We successfully converted our vanilla transformers to `onnx` and used the model with the `transformers.pipelines` to run the first prediction. Now let's optimize it. 🏎
If you want to learn more about exporting transformers model check-out the documentation: [Export 🤗 Transformers Models](https://huggingface.co/docs/transformers/main/en/serialization)
### 3.3 Use the `ORTOptimizer` to optimize the model
After we saved our onnx checkpoint to `onnx/` we can now use the `ORTOptimizer` to apply graph optimization such as operator fusion and constant folding to accelerate latency and inference.
```python
from optimum.onnxruntime import ORTOptimizer
from optimum.onnxruntime.configuration import OptimizationConfig
# create ORTOptimizer and define optimization configuration
optimizer = ORTOptimizer.from_pretrained(model_id, feature=task)
optimization_config = OptimizationConfig(optimization_level=99) # enable all optimizations
# apply the optimization configuration to the model
optimizer.export(
onnx_model_path=onnx_path / "model.onnx",
onnx_optimized_model_output_path=onnx_path / "model-optimized.onnx",
optimization_config=optimization_config,
)
```
To test performance we can use the `ORTModelForQuestionAnswering` class again and provide an additional `file_name` parameter to load our optimized model. **(This also works for models available on the hub).**
```python
from optimum.onnxruntime import ORTModelForQuestionAnswering
# load quantized model
opt_model = ORTModelForQuestionAnswering.from_pretrained(onnx_path, file_name="model-optimized.onnx")
# test the quantized model with using transformers pipeline
opt_optimum_qa = pipeline(task, model=opt_model, tokenizer=tokenizer, handle_impossible_answer=True)
prediction = opt_optimum_qa(question="What's my name?", context="My name is Philipp and I live in Nuremberg.")
print(prediction)
# {'score': 0.9041663408279419, 'start': 11, 'end': 18, 'answer': 'Philipp'}
```
We will evaluate the performance changes in step [3.6 Evaluate the performance and speed](#36-evaluate-the-performance-and-speed) in detail.
### 3.4 Use the `ORTQuantizer` to apply dynamic quantization
After we have optimized our model we can accelerate it even more by quantizing it using the `ORTQuantizer`. The `ORTOptimizer` can be used to apply dynamic quantization to decrease the size of the model size and accelerate latency and inference.
*We use the `avx512_vnni` since the instance is powered by an intel cascade-lake CPU supporting avx512.*
```python
from optimum.onnxruntime import ORTQuantizer
from optimum.onnxruntime.configuration import AutoQuantizationConfig
# create ORTQuantizer and define quantization configuration
quantizer = ORTQuantizer.from_pretrained(model_id, feature=task)
qconfig = AutoQuantizationConfig.avx512_vnni(is_static=False, per_channel=True)
# apply the quantization configuration to the model
quantizer.export(
onnx_model_path=onnx_path / "model-optimized.onnx",
onnx_quantized_model_output_path=onnx_path / "model-quantized.onnx",
quantization_config=qconfig,
)
```
We can now compare this model size as well as some latency performance
```python
import os
# get model file size
size = os.path.getsize(onnx_path / "model.onnx")/(1024*1024)
print(f"Vanilla Onnx Model file size: {size:.2f} MB")
size = os.path.getsize(onnx_path / "model-quantized.onnx")/(1024*1024)
print(f"Quantized Onnx Model file size: {size:.2f} MB")
# Vanilla Onnx Model file size: 473.31 MB
# Quantized Onnx Model file size: 291.77 MB
```
<figure class="image table text-center m-0 w-full">
<img src="assets/66_optimum_inference/model_size.png" alt="Model size comparison"/>
</figure>
We decreased the size of our model by almost 50% from 473MB to 291MB. To run inference we can use the `ORTModelForQuestionAnswering` class again and provide an additional `file_name` parameter to load our quantized model. **(This also works for models available on the hub).**
```python
# load quantized model
quantized_model = ORTModelForQuestionAnswering.from_pretrained(onnx_path, file_name="model-quantized.onnx")
# test the quantized model with using transformers pipeline
quantized_optimum_qa = pipeline(task, model=quantized_model, tokenizer=tokenizer, handle_impossible_answer=True)
prediction = quantized_optimum_qa(question="What's my name?", context="My name is Philipp and I live in Nuremberg.")
print(prediction)
# {'score': 0.9246969819068909, 'start': 11, 'end': 18, 'answer': 'Philipp'}
```
Nice! The model predicted the same answer.
### 3.5 Run accelerated inference using Transformers pipelines
[Optimum](https://huggingface.co/docs/optimum/main/en/pipelines#optimizing-with-ortoptimizer) has built-in support for [transformers pipelines](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#pipelines). This allows us to leverage the same API that we know from using PyTorch and TensorFlow models. We have already used this feature in steps 3.2,3.3 & 3.4 to test our converted and optimized models. At the time of writing this, we are supporting [ONNX Runtime](https://onnxruntime.ai/) with more to come in the future. An example of how to use the [transformers pipelines](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#pipelines) can be found below.
```python
from transformers import AutoTokenizer, pipeline
from optimum.onnxruntime import ORTModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained(onnx_path)
model = ORTModelForQuestionAnswering.from_pretrained(onnx_path)
optimum_qa = pipeline("question-answering", model=model, tokenizer=tokenizer)
prediction = optimum_qa(question="What's my name?", context="My name is Philipp and I live in Nuremberg.")
print(prediction)
# {'score': 0.9041663408279419, 'start': 11, 'end': 18, 'answer': 'Philipp'}
```
In addition to this we added a `pipelines` API to Optimum to guarantee more safety for your accelerated models. Meaning if you are trying to use `optimum.pipelines` with an unsupported model or task you will see an error. You can use `optimum.pipelines` as a replacement for `transformers.pipelines`.
```python
from transformers import AutoTokenizer
from optimum.onnxruntime import ORTModelForQuestionAnswering
from optimum.pipelines import pipeline
tokenizer = AutoTokenizer.from_pretrained(onnx_path)
model = ORTModelForQuestionAnswering.from_pretrained(onnx_path)
optimum_qa = pipeline("question-answering", model=model, tokenizer=tokenizer, handle_impossible_answer=True)
prediction = optimum_qa(question="What's my name?", context="My name is Philipp and I live in Nuremberg.")
print(prediction)
# {'score': 0.9041663408279419, 'start': 11, 'end': 18, 'answer': 'Philipp'}
```
### 3.6 Evaluate the performance and speed
During this [End-to-End tutorial on accelerating RoBERTa for Question-Answering including quantization and optimization](#3-end-to-end-tutorial-on-accelerating-roberta-for-question-answering-including-quantization-and-optimization), we created 3 different models. A vanilla converted model, an optimized model, and a quantized model.
As the last step of the tutorial, we want to take a detailed look at the performance and accuracy of our model. Applying optimization techniques, like graph optimizations or quantization not only impact performance (latency) those also might have an impact on the accuracy of the model. So accelerating your model comes with a trade-off.
Let's evaluate our models. Our transformers model [deepset/roberta-base-squad2](https://huggingface.co/deepset/roberta-base-squad2) was fine-tuned on the SQUAD2 dataset. This will be the dataset we use to evaluate our models.
```python
from datasets import load_metric,load_dataset
metric = load_metric("squad_v2")
dataset = load_dataset("squad_v2")["validation"]
print(f"length of dataset {len(dataset)}")
#length of dataset 11873
```
We can now leverage the [map](https://huggingface.co/docs/datasets/v2.1.0/en/process#map) function of [datasets](https://huggingface.co/docs/datasets/index) to iterate over the validation set of squad 2 and run prediction for each data point. Therefore we write a `evaluate` helper method which uses our pipelines and applies some transformation to work with the [squad v2 metric.](https://huggingface.co/metrics/squad_v2)
*This can take quite a while (1.5h)*
```python
def evaluate(example):
default = optimum_qa(question=example["question"], context=example["context"])
optimized = opt_optimum_qa(question=example["question"], context=example["context"])
quantized = quantized_optimum_qa(question=example["question"], context=example["context"])
return {
'reference': {'id': example['id'], 'answers': example['answers']},
'default': {'id': example['id'],'prediction_text': default['answer'], 'no_answer_probability': 0.},
'optimized': {'id': example['id'],'prediction_text': optimized['answer'], 'no_answer_probability': 0.},
'quantized': {'id': example['id'],'prediction_text': quantized['answer'], 'no_answer_probability': 0.},
}
result = dataset.map(evaluate)
# COMMENT IN to run evaluation on 2000 subset of the dataset
# result = dataset.shuffle().select(range(2000)).map(evaluate)
```
Now lets compare the results
```python
default_acc = metric.compute(predictions=result["default"], references=result["reference"])
optimized = metric.compute(predictions=result["optimized"], references=result["reference"])
quantized = metric.compute(predictions=result["quantized"], references=result["reference"])
print(f"vanilla model: exact={default_acc['exact']}% f1={default_acc['f1']}%")
print(f"optimized model: exact={optimized['exact']}% f1={optimized['f1']}%")
print(f"quantized model: exact={quantized['exact']}% f1={quantized['f1']}%")
# vanilla model: exact=79.07858165585783% f1=82.14970024570314%
# optimized model: exact=79.07858165585783% f1=82.14970024570314%
# quantized model: exact=78.75010528088941% f1=81.82526107204629%
```
Our optimized & quantized model achieved an exact match of `78.75%` and an f1 score of `81.83%` which is `99.61%` of the original accuracy. Achieving `99%` of the original model is very good especially since we used dynamic quantization.
Okay, let's test the performance (latency) of our optimized and quantized model.
But first, let’s extend our context and question to a more meaningful sequence length of 128.
```python
context="Hello, my name is Philipp and I live in Nuremberg, Germany. Currently I am working as a Technical Lead at Hugging Face to democratize artificial intelligence through open source and open science. In the past I designed and implemented cloud-native machine learning architectures for fin-tech and insurance companies. I found my passion for cloud concepts and machine learning 5 years ago. Since then I never stopped learning. Currently, I am focusing myself in the area NLP and how to leverage models like BERT, Roberta, T5, ViT, and GPT2 to generate business value."
question="As what is Philipp working?"
```
To keep it simple, we are going to use a python loop and calculate the avg/mean latency for our vanilla model and for the optimized and quantized model.
```python
from time import perf_counter
import numpy as np
def measure_latency(pipe):
latencies = []
# warm up
for _ in range(10):
_ = pipe(question=question, context=context)
# Timed run
for _ in range(100):
start_time = perf_counter()
_ = pipe(question=question, context=context)
latency = perf_counter() - start_time
latencies.append(latency)
# Compute run statistics
time_avg_ms = 1000 * np.mean(latencies)
time_std_ms = 1000 * np.std(latencies)
return f"Average latency (ms) - {time_avg_ms:.2f} +\- {time_std_ms:.2f}"
print(f"Vanilla model {measure_latency(optimum_qa)}")
print(f"Optimized & Quantized model {measure_latency(quantized_optimum_qa)}")
# Vanilla model Average latency (ms) - 117.61 +\- 8.48
# Optimized & Quantized model Average latency (ms) - 64.94 +\- 3.65
```
<figure class="image table text-center m-0 w-full">
<img src="assets/66_optimum_inference/results.png" alt="Latency & F1 results"/>
</figure>
We managed to accelerate our model latency from `117.61ms` to `64.94ms` or roughly 2x while keeping `99.61%` of the accuracy. Something we should keep in mind is that we used a mid-performant CPU instance with 2 physical cores. By switching to GPU or a more performant CPU instance, e.g. [ice-lake powered you can decrease the latency number down to a few milliseconds.](https://huggingface.co/blog/bert-cpu-scaling-part-2#more-efficient-ai-processing-on-latest-intel-ice-lake-cpus)
## 4. Current Limitations
We just started supporting inference in [https://github.com/huggingface/optimum](https://github.com/huggingface/optimum) so we would like to share current limitations as well. All of those limitations are on the roadmap and will be resolved in the near future.
- **Remote Models > 2GB:** Currently, only models smaller than 2GB can be loaded from the [Hugging Face Hub](https://hf.co/). We are working on adding support for models > 2GB / multi-file models.
- **Seq2Seq tasks/model:** We don’t have support for seq2seq tasks, like summarization and models like T5 mostly due to the limitation of the single model support. But we are actively working to solve it, to provide you with the same experience you are familiar with in transformers.
- **Past key values:** Generation models like GPT-2 use something called past key values which are precomputed key-value pairs of the attention blocks and can be used to speed up decoding. Currently the ORTModelForCausalLM is not using past key values.
- **No cache:** Currently when loading an optimized model (*.onnx), it will not be cached locally.
## 5. Optimum Inference FAQ
**Which tasks are supported?**
You can find a list of all supported tasks in the [documentation](https://huggingface.co/docs/optimum/main/en/pipelines). Currently support pipelines tasks are `feature-extraction`, `text-classification`, `token-classification`, `question-answering`, `zero-shot-classification`, `text-generation`
**Which models are supported?**
Any model that can be exported with [transformers.onnx](https://huggingface.co/docs/transformers/serialization) and has a supported task can be used, this includes among others BERT, ALBERT, GPT2, RoBERTa, XLM-RoBERTa, DistilBERT ....
**Which runtimes are supported?**
Currently, ONNX Runtime is supported. We are working on adding more in the future. [Let us know](https://discuss.huggingface.co/c/optimum/59) if you are interested in a specific runtime.
**How can I use Optimum with Transformers?**
You can find an example and instructions in our [documentation](https://huggingface.co/docs/optimum/main/en/pipelines#transformers-pipeline-usage).
**How can I use GPUs?**
To be able to use GPUs you simply need to install `optimum[onnxruntine-gpu]` which will install the required GPU providers and use them by default.
**How can I use a quantized and optimized model with pipelines?**
You can load the optimized or quantized model using the new [ORTModelForXXX](https://huggingface.co/docs/optimum/main/en/onnxruntime/modeling_ort) classes using the [from_pretrained](https://huggingface.co/docs/optimum/main/en/onnxruntime/modeling_ort#optimum.onnxruntime.ORTModelForQuestionAnswering.forward.example) method. You can learn more about it in our [documentation](https://huggingface.co/docs/optimum/main/en/onnxruntime/modeling_ort#optimum-inference-with-onnx-runtime).
## 6. What’s next?
What’s next for Optimum you ask? A lot of things. We are focused on making Optimum the reference open-source toolkit to work with transformers for acceleration & optimization. To be able to achieve this we will solve the current limitations, improve the documentation, create more content and examples and push the limits for accelerating and optimizing transformers.
Some important features on the roadmap for Optimum amongst the [current limitations](#4-current-limitations) are:
- Support for speech models (Wav2vec2) and speech tasks (automatic speech recognition)
- Support for vision models (ViT) and vision tasks (image classification)
- Improve performance by adding support for [OrtValue](https://onnxruntime.ai/docs/api/python/api_summary.html#ortvalue) and [IOBinding](https://onnxruntime.ai/docs/api/python/api_summary.html#iobinding)
- Easier ways to evaluate accelerated models
- Add support for other runtimes and providers like TensorRT and AWS-Neuron
---
Thanks for reading! If you are as excited as I am about accelerating Transformers, make them efficient and scale them to billions of requests. You should apply, [we are hiring](https://apply.workable.com/huggingface/#jobs).🚀
If you have any questions, feel free to contact me, through [Github](https://github.com/huggingface/optimum/issues), or on the [forum](https://discuss.huggingface.co/c/optimum/59). You can also connect with me on [Twitter](https://twitter.com/_philschmid) or [LinkedIn](https://www.linkedin.com/in/philipp-schmid-a6a2bb196/). | huggingface/blog/blob/main/optimum-inference.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# PyTorch 2.0
🤗 Diffusers supports the latest optimizations from [PyTorch 2.0](https://pytorch.org/get-started/pytorch-2.0/) which include:
1. A memory-efficient attention implementation, scaled dot product attention, without requiring any extra dependencies such as xFormers.
2. [`torch.compile`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html), a just-in-time (JIT) compiler to provide an extra performance boost when individual models are compiled.
Both of these optimizations require PyTorch 2.0 or later and 🤗 Diffusers > 0.13.0.
```bash
pip install --upgrade torch diffusers
```
## Scaled dot product attention
[`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) (SDPA) is an optimized and memory-efficient attention (similar to xFormers) that automatically enables several other optimizations depending on the model inputs and GPU type. SDPA is enabled by default if you're using PyTorch 2.0 and the latest version of 🤗 Diffusers, so you don't need to add anything to your code.
However, if you want to explicitly enable it, you can set a [`DiffusionPipeline`] to use [`~models.attention_processor.AttnProcessor2_0`]:
```diff
import torch
from diffusers import DiffusionPipeline
+ from diffusers.models.attention_processor import AttnProcessor2_0
pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
+ pipe.unet.set_attn_processor(AttnProcessor2_0())
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
```
SDPA should be as fast and memory efficient as `xFormers`; check the [benchmark](#benchmark) for more details.
In some cases - such as making the pipeline more deterministic or converting it to other formats - it may be helpful to use the vanilla attention processor, [`~models.attention_processor.AttnProcessor`]. To revert to [`~models.attention_processor.AttnProcessor`], call the [`~UNet2DConditionModel.set_default_attn_processor`] function on the pipeline:
```diff
import torch
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
+ pipe.unet.set_default_attn_processor()
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
```
## torch.compile
The `torch.compile` function can often provide an additional speed-up to your PyTorch code. In 🤗 Diffusers, it is usually best to wrap the UNet with `torch.compile` because it does most of the heavy lifting in the pipeline.
```python
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
images = pipe(prompt, num_inference_steps=steps, num_images_per_prompt=batch_size).images[0]
```
Depending on GPU type, `torch.compile` can provide an *additional speed-up* of **5-300x** on top of SDPA! If you're using more recent GPU architectures such as Ampere (A100, 3090), Ada (4090), and Hopper (H100), `torch.compile` is able to squeeze even more performance out of these GPUs.
Compilation requires some time to complete, so it is best suited for situations where you prepare your pipeline once and then perform the same type of inference operations multiple times. For example, calling the compiled pipeline on a different image size triggers compilation again which can be expensive.
For more information and different options about `torch.compile`, refer to the [`torch_compile`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) tutorial.
## Benchmark
We conducted a comprehensive benchmark with PyTorch 2.0's efficient attention implementation and `torch.compile` across different GPUs and batch sizes for five of our most used pipelines. The code is benchmarked on 🤗 Diffusers v0.17.0.dev0 to optimize `torch.compile` usage (see [here](https://github.com/huggingface/diffusers/pull/3313) for more details).
Expand the dropdown below to find the code used to benchmark each pipeline:
<details>
### Stable Diffusion text-to-image
```python
from diffusers import DiffusionPipeline
import torch
path = "runwayml/stable-diffusion-v1-5"
run_compile = True # Set True / False
pipe = DiffusionPipeline.from_pretrained(path, torch_dtype=torch.float16, use_safetensors=True)
pipe = pipe.to("cuda")
pipe.unet.to(memory_format=torch.channels_last)
if run_compile:
print("Run torch compile")
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
prompt = "ghibli style, a fantasy landscape with castles"
for _ in range(3):
images = pipe(prompt=prompt).images
```
### Stable Diffusion image-to-image
```python
from diffusers import StableDiffusionImg2ImgPipeline
from diffusers.utils import load_image
import torch
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
init_image = load_image(url)
init_image = init_image.resize((512, 512))
path = "runwayml/stable-diffusion-v1-5"
run_compile = True # Set True / False
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(path, torch_dtype=torch.float16, use_safetensors=True)
pipe = pipe.to("cuda")
pipe.unet.to(memory_format=torch.channels_last)
if run_compile:
print("Run torch compile")
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
prompt = "ghibli style, a fantasy landscape with castles"
for _ in range(3):
image = pipe(prompt=prompt, image=init_image).images[0]
```
### Stable Diffusion inpainting
```python
from diffusers import StableDiffusionInpaintPipeline
from diffusers.utils import load_image
import torch
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
init_image = load_image(img_url).resize((512, 512))
mask_image = load_image(mask_url).resize((512, 512))
path = "runwayml/stable-diffusion-inpainting"
run_compile = True # Set True / False
pipe = StableDiffusionInpaintPipeline.from_pretrained(path, torch_dtype=torch.float16, use_safetensors=True)
pipe = pipe.to("cuda")
pipe.unet.to(memory_format=torch.channels_last)
if run_compile:
print("Run torch compile")
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
prompt = "ghibli style, a fantasy landscape with castles"
for _ in range(3):
image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
```
### ControlNet
```python
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
from diffusers.utils import load_image
import torch
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
init_image = load_image(url)
init_image = init_image.resize((512, 512))
path = "runwayml/stable-diffusion-v1-5"
run_compile = True # Set True / False
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
path, controlnet=controlnet, torch_dtype=torch.float16, use_safetensors=True
)
pipe = pipe.to("cuda")
pipe.unet.to(memory_format=torch.channels_last)
pipe.controlnet.to(memory_format=torch.channels_last)
if run_compile:
print("Run torch compile")
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
pipe.controlnet = torch.compile(pipe.controlnet, mode="reduce-overhead", fullgraph=True)
prompt = "ghibli style, a fantasy landscape with castles"
for _ in range(3):
image = pipe(prompt=prompt, image=init_image).images[0]
```
### DeepFloyd IF text-to-image + upscaling
```python
from diffusers import DiffusionPipeline
import torch
run_compile = True # Set True / False
pipe_1 = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-M-v1.0", variant="fp16", text_encoder=None, torch_dtype=torch.float16, use_safetensors=True)
pipe_1.to("cuda")
pipe_2 = DiffusionPipeline.from_pretrained("DeepFloyd/IF-II-M-v1.0", variant="fp16", text_encoder=None, torch_dtype=torch.float16, use_safetensors=True)
pipe_2.to("cuda")
pipe_3 = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-x4-upscaler", torch_dtype=torch.float16, use_safetensors=True)
pipe_3.to("cuda")
pipe_1.unet.to(memory_format=torch.channels_last)
pipe_2.unet.to(memory_format=torch.channels_last)
pipe_3.unet.to(memory_format=torch.channels_last)
if run_compile:
pipe_1.unet = torch.compile(pipe_1.unet, mode="reduce-overhead", fullgraph=True)
pipe_2.unet = torch.compile(pipe_2.unet, mode="reduce-overhead", fullgraph=True)
pipe_3.unet = torch.compile(pipe_3.unet, mode="reduce-overhead", fullgraph=True)
prompt = "the blue hulk"
prompt_embeds = torch.randn((1, 2, 4096), dtype=torch.float16)
neg_prompt_embeds = torch.randn((1, 2, 4096), dtype=torch.float16)
for _ in range(3):
image_1 = pipe_1(prompt_embeds=prompt_embeds, negative_prompt_embeds=neg_prompt_embeds, output_type="pt").images
image_2 = pipe_2(image=image_1, prompt_embeds=prompt_embeds, negative_prompt_embeds=neg_prompt_embeds, output_type="pt").images
image_3 = pipe_3(prompt=prompt, image=image_1, noise_level=100).images
```
</details>
The graph below highlights the relative speed-ups for the [`StableDiffusionPipeline`] across five GPU families with PyTorch 2.0 and `torch.compile` enabled. The benchmarks for the following graphs are measured in *number of iterations/second*.

To give you an even better idea of how this speed-up holds for the other pipelines, consider the following
graph for an A100 with PyTorch 2.0 and `torch.compile`:

In the following tables, we report our findings in terms of the *number of iterations/second*.
### A100 (batch size: 1)
| **Pipeline** | **torch 2.0 - <br>no compile** | **torch nightly - <br>no compile** | **torch 2.0 - <br>compile** | **torch nightly - <br>compile** |
|:---:|:---:|:---:|:---:|:---:|
| SD - txt2img | 21.66 | 23.13 | 44.03 | 49.74 |
| SD - img2img | 21.81 | 22.40 | 43.92 | 46.32 |
| SD - inpaint | 22.24 | 23.23 | 43.76 | 49.25 |
| SD - controlnet | 15.02 | 15.82 | 32.13 | 36.08 |
| IF | 20.21 / <br>13.84 / <br>24.00 | 20.12 / <br>13.70 / <br>24.03 | ❌ | 97.34 / <br>27.23 / <br>111.66 |
| SDXL - txt2img | 8.64 | 9.9 | - | - |
### A100 (batch size: 4)
| **Pipeline** | **torch 2.0 - <br>no compile** | **torch nightly - <br>no compile** | **torch 2.0 - <br>compile** | **torch nightly - <br>compile** |
|:---:|:---:|:---:|:---:|:---:|
| SD - txt2img | 11.6 | 13.12 | 14.62 | 17.27 |
| SD - img2img | 11.47 | 13.06 | 14.66 | 17.25 |
| SD - inpaint | 11.67 | 13.31 | 14.88 | 17.48 |
| SD - controlnet | 8.28 | 9.38 | 10.51 | 12.41 |
| IF | 25.02 | 18.04 | ❌ | 48.47 |
| SDXL - txt2img | 2.44 | 2.74 | - | - |
### A100 (batch size: 16)
| **Pipeline** | **torch 2.0 - <br>no compile** | **torch nightly - <br>no compile** | **torch 2.0 - <br>compile** | **torch nightly - <br>compile** |
|:---:|:---:|:---:|:---:|:---:|
| SD - txt2img | 3.04 | 3.6 | 3.83 | 4.68 |
| SD - img2img | 2.98 | 3.58 | 3.83 | 4.67 |
| SD - inpaint | 3.04 | 3.66 | 3.9 | 4.76 |
| SD - controlnet | 2.15 | 2.58 | 2.74 | 3.35 |
| IF | 8.78 | 9.82 | ❌ | 16.77 |
| SDXL - txt2img | 0.64 | 0.72 | - | - |
### V100 (batch size: 1)
| **Pipeline** | **torch 2.0 - <br>no compile** | **torch nightly - <br>no compile** | **torch 2.0 - <br>compile** | **torch nightly - <br>compile** |
|:---:|:---:|:---:|:---:|:---:|
| SD - txt2img | 18.99 | 19.14 | 20.95 | 22.17 |
| SD - img2img | 18.56 | 19.18 | 20.95 | 22.11 |
| SD - inpaint | 19.14 | 19.06 | 21.08 | 22.20 |
| SD - controlnet | 13.48 | 13.93 | 15.18 | 15.88 |
| IF | 20.01 / <br>9.08 / <br>23.34 | 19.79 / <br>8.98 / <br>24.10 | ❌ | 55.75 / <br>11.57 / <br>57.67 |
### V100 (batch size: 4)
| **Pipeline** | **torch 2.0 - <br>no compile** | **torch nightly - <br>no compile** | **torch 2.0 - <br>compile** | **torch nightly - <br>compile** |
|:---:|:---:|:---:|:---:|:---:|
| SD - txt2img | 5.96 | 5.89 | 6.83 | 6.86 |
| SD - img2img | 5.90 | 5.91 | 6.81 | 6.82 |
| SD - inpaint | 5.99 | 6.03 | 6.93 | 6.95 |
| SD - controlnet | 4.26 | 4.29 | 4.92 | 4.93 |
| IF | 15.41 | 14.76 | ❌ | 22.95 |
### V100 (batch size: 16)
| **Pipeline** | **torch 2.0 - <br>no compile** | **torch nightly - <br>no compile** | **torch 2.0 - <br>compile** | **torch nightly - <br>compile** |
|:---:|:---:|:---:|:---:|:---:|
| SD - txt2img | 1.66 | 1.66 | 1.92 | 1.90 |
| SD - img2img | 1.65 | 1.65 | 1.91 | 1.89 |
| SD - inpaint | 1.69 | 1.69 | 1.95 | 1.93 |
| SD - controlnet | 1.19 | 1.19 | OOM after warmup | 1.36 |
| IF | 5.43 | 5.29 | ❌ | 7.06 |
### T4 (batch size: 1)
| **Pipeline** | **torch 2.0 - <br>no compile** | **torch nightly - <br>no compile** | **torch 2.0 - <br>compile** | **torch nightly - <br>compile** |
|:---:|:---:|:---:|:---:|:---:|
| SD - txt2img | 6.9 | 6.95 | 7.3 | 7.56 |
| SD - img2img | 6.84 | 6.99 | 7.04 | 7.55 |
| SD - inpaint | 6.91 | 6.7 | 7.01 | 7.37 |
| SD - controlnet | 4.89 | 4.86 | 5.35 | 5.48 |
| IF | 17.42 / <br>2.47 / <br>18.52 | 16.96 / <br>2.45 / <br>18.69 | ❌ | 24.63 / <br>2.47 / <br>23.39 |
| SDXL - txt2img | 1.15 | 1.16 | - | - |
### T4 (batch size: 4)
| **Pipeline** | **torch 2.0 - <br>no compile** | **torch nightly - <br>no compile** | **torch 2.0 - <br>compile** | **torch nightly - <br>compile** |
|:---:|:---:|:---:|:---:|:---:|
| SD - txt2img | 1.79 | 1.79 | 2.03 | 1.99 |
| SD - img2img | 1.77 | 1.77 | 2.05 | 2.04 |
| SD - inpaint | 1.81 | 1.82 | 2.09 | 2.09 |
| SD - controlnet | 1.34 | 1.27 | 1.47 | 1.46 |
| IF | 5.79 | 5.61 | ❌ | 7.39 |
| SDXL - txt2img | 0.288 | 0.289 | - | - |
### T4 (batch size: 16)
| **Pipeline** | **torch 2.0 - <br>no compile** | **torch nightly - <br>no compile** | **torch 2.0 - <br>compile** | **torch nightly - <br>compile** |
|:---:|:---:|:---:|:---:|:---:|
| SD - txt2img | 2.34s | 2.30s | OOM after 2nd iteration | 1.99s |
| SD - img2img | 2.35s | 2.31s | OOM after warmup | 2.00s |
| SD - inpaint | 2.30s | 2.26s | OOM after 2nd iteration | 1.95s |
| SD - controlnet | OOM after 2nd iteration | OOM after 2nd iteration | OOM after warmup | OOM after warmup |
| IF * | 1.44 | 1.44 | ❌ | 1.94 |
| SDXL - txt2img | OOM | OOM | - | - |
### RTX 3090 (batch size: 1)
| **Pipeline** | **torch 2.0 - <br>no compile** | **torch nightly - <br>no compile** | **torch 2.0 - <br>compile** | **torch nightly - <br>compile** |
|:---:|:---:|:---:|:---:|:---:|
| SD - txt2img | 22.56 | 22.84 | 23.84 | 25.69 |
| SD - img2img | 22.25 | 22.61 | 24.1 | 25.83 |
| SD - inpaint | 22.22 | 22.54 | 24.26 | 26.02 |
| SD - controlnet | 16.03 | 16.33 | 17.38 | 18.56 |
| IF | 27.08 / <br>9.07 / <br>31.23 | 26.75 / <br>8.92 / <br>31.47 | ❌ | 68.08 / <br>11.16 / <br>65.29 |
### RTX 3090 (batch size: 4)
| **Pipeline** | **torch 2.0 - <br>no compile** | **torch nightly - <br>no compile** | **torch 2.0 - <br>compile** | **torch nightly - <br>compile** |
|:---:|:---:|:---:|:---:|:---:|
| SD - txt2img | 6.46 | 6.35 | 7.29 | 7.3 |
| SD - img2img | 6.33 | 6.27 | 7.31 | 7.26 |
| SD - inpaint | 6.47 | 6.4 | 7.44 | 7.39 |
| SD - controlnet | 4.59 | 4.54 | 5.27 | 5.26 |
| IF | 16.81 | 16.62 | ❌ | 21.57 |
### RTX 3090 (batch size: 16)
| **Pipeline** | **torch 2.0 - <br>no compile** | **torch nightly - <br>no compile** | **torch 2.0 - <br>compile** | **torch nightly - <br>compile** |
|:---:|:---:|:---:|:---:|:---:|
| SD - txt2img | 1.7 | 1.69 | 1.93 | 1.91 |
| SD - img2img | 1.68 | 1.67 | 1.93 | 1.9 |
| SD - inpaint | 1.72 | 1.71 | 1.97 | 1.94 |
| SD - controlnet | 1.23 | 1.22 | 1.4 | 1.38 |
| IF | 5.01 | 5.00 | ❌ | 6.33 |
### RTX 4090 (batch size: 1)
| **Pipeline** | **torch 2.0 - <br>no compile** | **torch nightly - <br>no compile** | **torch 2.0 - <br>compile** | **torch nightly - <br>compile** |
|:---:|:---:|:---:|:---:|:---:|
| SD - txt2img | 40.5 | 41.89 | 44.65 | 49.81 |
| SD - img2img | 40.39 | 41.95 | 44.46 | 49.8 |
| SD - inpaint | 40.51 | 41.88 | 44.58 | 49.72 |
| SD - controlnet | 29.27 | 30.29 | 32.26 | 36.03 |
| IF | 69.71 / <br>18.78 / <br>85.49 | 69.13 / <br>18.80 / <br>85.56 | ❌ | 124.60 / <br>26.37 / <br>138.79 |
| SDXL - txt2img | 6.8 | 8.18 | - | - |
### RTX 4090 (batch size: 4)
| **Pipeline** | **torch 2.0 - <br>no compile** | **torch nightly - <br>no compile** | **torch 2.0 - <br>compile** | **torch nightly - <br>compile** |
|:---:|:---:|:---:|:---:|:---:|
| SD - txt2img | 12.62 | 12.84 | 15.32 | 15.59 |
| SD - img2img | 12.61 | 12,.79 | 15.35 | 15.66 |
| SD - inpaint | 12.65 | 12.81 | 15.3 | 15.58 |
| SD - controlnet | 9.1 | 9.25 | 11.03 | 11.22 |
| IF | 31.88 | 31.14 | ❌ | 43.92 |
| SDXL - txt2img | 2.19 | 2.35 | - | - |
### RTX 4090 (batch size: 16)
| **Pipeline** | **torch 2.0 - <br>no compile** | **torch nightly - <br>no compile** | **torch 2.0 - <br>compile** | **torch nightly - <br>compile** |
|:---:|:---:|:---:|:---:|:---:|
| SD - txt2img | 3.17 | 3.2 | 3.84 | 3.85 |
| SD - img2img | 3.16 | 3.2 | 3.84 | 3.85 |
| SD - inpaint | 3.17 | 3.2 | 3.85 | 3.85 |
| SD - controlnet | 2.23 | 2.3 | 2.7 | 2.75 |
| IF | 9.26 | 9.2 | ❌ | 13.31 |
| SDXL - txt2img | 0.52 | 0.53 | - | - |
## Notes
* Follow this [PR](https://github.com/huggingface/diffusers/pull/3313) for more details on the environment used for conducting the benchmarks.
* For the DeepFloyd IF pipeline where batch sizes > 1, we only used a batch size of > 1 in the first IF pipeline for text-to-image generation and NOT for upscaling. That means the two upscaling pipelines received a batch size of 1.
*Thanks to [Horace He](https://github.com/Chillee) from the PyTorch team for their support in improving our support of `torch.compile()` in Diffusers.*
| huggingface/diffusers/blob/main/docs/source/en/optimization/torch2.0.md |
Data files Configuration
There are no constraints on how to structure dataset repositories.
However, if you want the Dataset Viewer to show certain data files, or to separate your dataset in train/validation/test splits, you need to structure your dataset accordingly.
Often it is as simple as naming your data files according to their split names, e.g. `train.csv` and `test.csv`.
## File names and splits
To structure your dataset by naming your data files or directories according to their split names, see the [File names and splits](./datasets-file-names-and-splits) documentation.
## Manual configuration
You can choose the data files to show in the Dataset Viewer for your dataset using YAML.
It is useful if you want to specify which file goes into which split manually.
You can also define multiple configurations (or subsets) for your dataset, and pass dataset building parameters (e.g. the separator to use for CSV files).
See the documentation on [Manual configuration](./datasets-manual-configuration) for more information.
## Image and Audio datasets
For image and audio classification datasets, you can also use directories to name the image and audio classes.
And if your images/audio files have metadata (e.g. captions, bounding boxes, transcriptions, etc.), you can have metadata files next to them.
We provide two guides that you can check out:
- [How to create an image dataset](./datasets-image)
- [How to create an audio dataset](https://huggingface.co/docs/datasets/audio_dataset)
| huggingface/hub-docs/blob/main/docs/hub/datasets-data-files-configuration.md |
(Tensorflow) EfficientNet
**EfficientNet** is a convolutional neural network architecture and scaling method that uniformly scales all dimensions of depth/width/resolution using a *compound coefficient*. Unlike conventional practice that arbitrary scales these factors, the EfficientNet scaling method uniformly scales network width, depth, and resolution with a set of fixed scaling coefficients. For example, if we want to use \\( 2^N \\) times more computational resources, then we can simply increase the network depth by \\( \alpha ^ N \\), width by \\( \beta ^ N \\), and image size by \\( \gamma ^ N \\), where \\( \alpha, \beta, \gamma \\) are constant coefficients determined by a small grid search on the original small model. EfficientNet uses a compound coefficient \\( \phi \\) to uniformly scales network width, depth, and resolution in a principled way.
The compound scaling method is justified by the intuition that if the input image is bigger, then the network needs more layers to increase the receptive field and more channels to capture more fine-grained patterns on the bigger image.
The base EfficientNet-B0 network is based on the inverted bottleneck residual blocks of [MobileNetV2](https://paperswithcode.com/method/mobilenetv2), in addition to [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block).
The weights from this model were ported from [Tensorflow/TPU](https://github.com/tensorflow/tpu).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('tf_efficientnet_b0', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `tf_efficientnet_b0`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('tf_efficientnet_b0', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{tan2020efficientnet,
title={EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks},
author={Mingxing Tan and Quoc V. Le},
year={2020},
eprint={1905.11946},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
Type: model-index
Collections:
- Name: TF EfficientNet
Paper:
Title: 'EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks'
URL: https://paperswithcode.com/paper/efficientnet-rethinking-model-scaling-for
Models:
- Name: tf_efficientnet_b0
In Collection: TF EfficientNet
Metadata:
FLOPs: 488688572
Parameters: 5290000
File Size: 21383997
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
Training Resources: TPUv3 Cloud TPU
ID: tf_efficientnet_b0
LR: 0.256
Epochs: 350
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 2048
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1241
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b0_aa-827b6e33.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.85%
Top 5 Accuracy: 93.23%
- Name: tf_efficientnet_b1
In Collection: TF EfficientNet
Metadata:
FLOPs: 883633200
Parameters: 7790000
File Size: 31512534
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b1
LR: 0.256
Epochs: 350
Crop Pct: '0.882'
Momentum: 0.9
Batch Size: 2048
Image Size: '240'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1251
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b1_aa-ea7a6ee0.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.84%
Top 5 Accuracy: 94.2%
- Name: tf_efficientnet_b2
In Collection: TF EfficientNet
Metadata:
FLOPs: 1234321170
Parameters: 9110000
File Size: 36797929
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b2
LR: 0.256
Epochs: 350
Crop Pct: '0.89'
Momentum: 0.9
Batch Size: 2048
Image Size: '260'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1261
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b2_aa-60c94f97.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.07%
Top 5 Accuracy: 94.9%
- Name: tf_efficientnet_b3
In Collection: TF EfficientNet
Metadata:
FLOPs: 2275247568
Parameters: 12230000
File Size: 49381362
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b3
LR: 0.256
Epochs: 350
Crop Pct: '0.904'
Momentum: 0.9
Batch Size: 2048
Image Size: '300'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1271
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b3_aa-84b4657e.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.65%
Top 5 Accuracy: 95.72%
- Name: tf_efficientnet_b4
In Collection: TF EfficientNet
Metadata:
FLOPs: 5749638672
Parameters: 19340000
File Size: 77989689
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
Training Resources: TPUv3 Cloud TPU
ID: tf_efficientnet_b4
LR: 0.256
Epochs: 350
Crop Pct: '0.922'
Momentum: 0.9
Batch Size: 2048
Image Size: '380'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1281
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b4_aa-818f208c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.03%
Top 5 Accuracy: 96.3%
- Name: tf_efficientnet_b5
In Collection: TF EfficientNet
Metadata:
FLOPs: 13176501888
Parameters: 30390000
File Size: 122403150
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b5
LR: 0.256
Epochs: 350
Crop Pct: '0.934'
Momentum: 0.9
Batch Size: 2048
Image Size: '456'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1291
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b5_ra-9a3e5369.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.81%
Top 5 Accuracy: 96.75%
- Name: tf_efficientnet_b6
In Collection: TF EfficientNet
Metadata:
FLOPs: 24180518488
Parameters: 43040000
File Size: 173232007
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b6
LR: 0.256
Epochs: 350
Crop Pct: '0.942'
Momentum: 0.9
Batch Size: 2048
Image Size: '528'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1301
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b6_aa-80ba17e4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.11%
Top 5 Accuracy: 96.89%
- Name: tf_efficientnet_b7
In Collection: TF EfficientNet
Metadata:
FLOPs: 48205304880
Parameters: 66349999
File Size: 266850607
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b7
LR: 0.256
Epochs: 350
Crop Pct: '0.949'
Momentum: 0.9
Batch Size: 2048
Image Size: '600'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1312
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b7_ra-6c08e654.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 84.93%
Top 5 Accuracy: 97.2%
- Name: tf_efficientnet_b8
In Collection: TF EfficientNet
Metadata:
FLOPs: 80962956270
Parameters: 87410000
File Size: 351379853
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Label Smoothing
- RMSProp
- Stochastic Depth
- Weight Decay
Training Data:
- ImageNet
ID: tf_efficientnet_b8
LR: 0.256
Epochs: 350
Crop Pct: '0.954'
Momentum: 0.9
Batch Size: 2048
Image Size: '672'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1323
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b8_ra-572d5dd9.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 85.35%
Top 5 Accuracy: 97.39%
- Name: tf_efficientnet_el
In Collection: TF EfficientNet
Metadata:
FLOPs: 9356616096
Parameters: 10590000
File Size: 42800271
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_el
Crop Pct: '0.904'
Image Size: '300'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1551
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_el-5143854e.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.45%
Top 5 Accuracy: 95.17%
- Name: tf_efficientnet_em
In Collection: TF EfficientNet
Metadata:
FLOPs: 3636607040
Parameters: 6900000
File Size: 27933644
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_em
Crop Pct: '0.882'
Image Size: '240'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1541
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_em-e78cfe58.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.71%
Top 5 Accuracy: 94.33%
- Name: tf_efficientnet_es
In Collection: TF EfficientNet
Metadata:
FLOPs: 2057577472
Parameters: 5440000
File Size: 22008479
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_es
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1531
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_es-ca1afbfe.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.28%
Top 5 Accuracy: 93.6%
- Name: tf_efficientnet_l2_ns_475
In Collection: TF EfficientNet
Metadata:
FLOPs: 217795669644
Parameters: 480310000
File Size: 1925950424
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- FixRes
- Label Smoothing
- Noisy Student
- RMSProp
- RandAugment
- Weight Decay
Training Data:
- ImageNet
- JFT-300M
Training Resources: TPUv3 Cloud TPU
ID: tf_efficientnet_l2_ns_475
LR: 0.128
Epochs: 350
Dropout: 0.5
Crop Pct: '0.936'
Momentum: 0.9
Batch Size: 2048
Image Size: '475'
Weight Decay: 1.0e-05
Interpolation: bicubic
RMSProp Decay: 0.9
Label Smoothing: 0.1
BatchNorm Momentum: 0.99
Stochastic Depth Survival: 0.8
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1509
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_l2_ns_475-bebbd00a.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 88.24%
Top 5 Accuracy: 98.55%
-->
| huggingface/pytorch-image-models/blob/main/hfdocs/source/models/tf-efficientnet.mdx |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# RoFormer
## Overview
The RoFormer model was proposed in [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
The abstract from the paper is the following:
*Position encoding in transformer architecture provides supervision for dependency modeling between elements at
different positions in the sequence. We investigate various methods to encode positional information in
transformer-based language models and propose a novel implementation named Rotary Position Embedding(RoPE). The
proposed RoPE encodes absolute positional information with rotation matrix and naturally incorporates explicit relative
position dependency in self-attention formulation. Notably, RoPE comes with valuable properties such as flexibility of
being expand to any sequence lengths, decaying inter-token dependency with increasing relative distances, and
capability of equipping the linear self-attention with relative position encoding. As a result, the enhanced
transformer with rotary position embedding, or RoFormer, achieves superior performance in tasks with long texts. We
release the theoretical analysis along with some preliminary experiment results on Chinese data. The undergoing
experiment for English benchmark will soon be updated.*
This model was contributed by [junnyu](https://huggingface.co/junnyu). The original code can be found [here](https://github.com/ZhuiyiTechnology/roformer).
## Usage tips
RoFormer is a BERT-like autoencoding model with rotary position embeddings. Rotary position embeddings have shown
improved performance on classification tasks with long texts.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## RoFormerConfig
[[autodoc]] RoFormerConfig
## RoFormerTokenizer
[[autodoc]] RoFormerTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## RoFormerTokenizerFast
[[autodoc]] RoFormerTokenizerFast
- build_inputs_with_special_tokens
<frameworkcontent>
<pt>
## RoFormerModel
[[autodoc]] RoFormerModel
- forward
## RoFormerForCausalLM
[[autodoc]] RoFormerForCausalLM
- forward
## RoFormerForMaskedLM
[[autodoc]] RoFormerForMaskedLM
- forward
## RoFormerForSequenceClassification
[[autodoc]] RoFormerForSequenceClassification
- forward
## RoFormerForMultipleChoice
[[autodoc]] RoFormerForMultipleChoice
- forward
## RoFormerForTokenClassification
[[autodoc]] RoFormerForTokenClassification
- forward
## RoFormerForQuestionAnswering
[[autodoc]] RoFormerForQuestionAnswering
- forward
</pt>
<tf>
## TFRoFormerModel
[[autodoc]] TFRoFormerModel
- call
## TFRoFormerForMaskedLM
[[autodoc]] TFRoFormerForMaskedLM
- call
## TFRoFormerForCausalLM
[[autodoc]] TFRoFormerForCausalLM
- call
## TFRoFormerForSequenceClassification
[[autodoc]] TFRoFormerForSequenceClassification
- call
## TFRoFormerForMultipleChoice
[[autodoc]] TFRoFormerForMultipleChoice
- call
## TFRoFormerForTokenClassification
[[autodoc]] TFRoFormerForTokenClassification
- call
## TFRoFormerForQuestionAnswering
[[autodoc]] TFRoFormerForQuestionAnswering
- call
</tf>
<jax>
## FlaxRoFormerModel
[[autodoc]] FlaxRoFormerModel
- __call__
## FlaxRoFormerForMaskedLM
[[autodoc]] FlaxRoFormerForMaskedLM
- __call__
## FlaxRoFormerForSequenceClassification
[[autodoc]] FlaxRoFormerForSequenceClassification
- __call__
## FlaxRoFormerForMultipleChoice
[[autodoc]] FlaxRoFormerForMultipleChoice
- __call__
## FlaxRoFormerForTokenClassification
[[autodoc]] FlaxRoFormerForTokenClassification
- __call__
## FlaxRoFormerForQuestionAnswering
[[autodoc]] FlaxRoFormerForQuestionAnswering
- __call__
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/roformer.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
### Translating the Diffusers documentation into your language
As part of our mission to democratize machine learning, we'd love to make the Diffusers library available in many more languages! Follow the steps below if you want to help translate the documentation into your language 🙏.
**🗞️ Open an issue**
To get started, navigate to the [Issues](https://github.com/huggingface/diffusers/issues) page of this repo and check if anyone else has opened an issue for your language. If not, open a new issue by selecting the "🌐 Translating a New Language?" from the "New issue" button.
Once an issue exists, post a comment to indicate which chapters you'd like to work on, and we'll add your name to the list.
**🍴 Fork the repository**
First, you'll need to [fork the Diffusers repo](https://docs.github.com/en/get-started/quickstart/fork-a-repo). You can do this by clicking on the **Fork** button on the top-right corner of this repo's page.
Once you've forked the repo, you'll want to get the files on your local machine for editing. You can do that by cloning the fork with Git as follows:
```bash
git clone https://github.com/<YOUR-USERNAME>/diffusers.git
```
**📋 Copy-paste the English version with a new language code**
The documentation files are in one leading directory:
- [`docs/source`](https://github.com/huggingface/diffusers/tree/main/docs/source): All the documentation materials are organized here by language.
You'll only need to copy the files in the [`docs/source/en`](https://github.com/huggingface/diffusers/tree/main/docs/source/en) directory, so first navigate to your fork of the repo and run the following:
```bash
cd ~/path/to/diffusers/docs
cp -r source/en source/<LANG-ID>
```
Here, `<LANG-ID>` should be one of the ISO 639-1 or ISO 639-2 language codes -- see [here](https://www.loc.gov/standards/iso639-2/php/code_list.php) for a handy table.
**✍️ Start translating**
The fun part comes - translating the text!
The first thing we recommend is translating the part of the `_toctree.yml` file that corresponds to your doc chapter. This file is used to render the table of contents on the website.
> 🙋 If the `_toctree.yml` file doesn't yet exist for your language, you can create one by copy-pasting from the English version and deleting the sections unrelated to your chapter. Just make sure it exists in the `docs/source/<LANG-ID>/` directory!
The fields you should add are `local` (with the name of the file containing the translation; e.g. `autoclass_tutorial`), and `title` (with the title of the doc in your language; e.g. `Load pretrained instances with an AutoClass`) -- as a reference, here is the `_toctree.yml` for [English](https://github.com/huggingface/diffusers/blob/main/docs/source/en/_toctree.yml):
```yaml
- sections:
- local: pipeline_tutorial # Do not change this! Use the same name for your .md file
title: Pipelines for inference # Translate this!
...
title: Tutorials # Translate this!
```
Once you have translated the `_toctree.yml` file, you can start translating the [MDX](https://mdxjs.com/) files associated with your docs chapter.
> 🙋 If you'd like others to help you with the translation, you should [open an issue](https://github.com/huggingface/diffusers/issues) and tag @patrickvonplaten.
| huggingface/diffusers/blob/main/docs/TRANSLATING.md |
Input Sequences
<tokenizerslangcontent>
<python>
These types represent all the different kinds of sequence that can be used as input of a Tokenizer.
Globally, any sequence can be either a string or a list of strings, according to the operating
mode of the tokenizer: `raw text` vs `pre-tokenized`.
## TextInputSequence[[tokenizers.TextInputSequence]]
<code>tokenizers.TextInputSequence</code>
A `str` that represents an input sequence
## PreTokenizedInputSequence[[tokenizers.PreTokenizedInputSequence]]
<code>tokenizers.PreTokenizedInputSequence</code>
A pre-tokenized input sequence. Can be one of:
- A `List` of `str`
- A `Tuple` of `str`
alias of `Union[List[str], Tuple[str]]`.
## InputSequence[[tokenizers.InputSequence]]
<code>tokenizers.InputSequence</code>
Represents all the possible types of input sequences for encoding. Can be:
- When `is_pretokenized=False`: [TextInputSequence](#tokenizers.TextInputSequence)
- When `is_pretokenized=True`: [PreTokenizedInputSequence](#tokenizers.PreTokenizedInputSequence)
alias of `Union[str, List[str], Tuple[str]]`.
</python>
<rust>
The Rust API Reference is available directly on the [Docs.rs](https://docs.rs/tokenizers/latest/tokenizers/) website.
</rust>
<node>
The node API has not been documented yet.
</node>
</tokenizerslangcontent> | huggingface/tokenizers/blob/main/docs/source-doc-builder/api/input-sequences.mdx |
``python
from transformers import AutoModelForSeq2SeqLM
import peft
from peft import get_peft_config, get_peft_model, get_peft_model_state_dict, IA3Config, TaskType
import torch
from datasets import load_dataset
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
from transformers import AutoTokenizer
from torch.utils.data import DataLoader
from transformers import default_data_collator, get_linear_schedule_with_warmup
from tqdm import tqdm
from datasets import load_dataset
device = "cuda"
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
checkpoint_name = "financial_sentiment_analysis_ia3_v1.pt"
text_column = "sentence"
label_column = "text_label"
max_length = 128
lr = 8e-3
num_epochs = 3
batch_size = 8
```
```python
import importlib
importlib.reload(peft)
```
```python
# creating model
peft_config = IA3Config(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, feedforward_modules=[])
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
```
```python
model
```
```python
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
model
```
```python
# loading dataset
dataset = load_dataset("financial_phrasebank", "sentences_allagree")
dataset = dataset["train"].train_test_split(test_size=0.1)
dataset["validation"] = dataset["test"]
del dataset["test"]
classes = dataset["train"].features["label"].names
dataset = dataset.map(
lambda x: {"text_label": [classes[label] for label in x["label"]]},
batched=True,
num_proc=1,
)
dataset["train"][0]
```
```python
# data preprocessing
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
def preprocess_function(examples):
inputs = examples[text_column]
targets = examples[label_column]
model_inputs = tokenizer(inputs, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt")
labels = tokenizer(targets, max_length=3, padding="max_length", truncation=True, return_tensors="pt")
labels = labels["input_ids"]
labels[labels == tokenizer.pad_token_id] = -100
model_inputs["labels"] = labels
return model_inputs
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["validation"]
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
```
```python
# optimizer and lr scheduler
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
```
```python
# training and evaluation
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
```
```python
# print accuracy
correct = 0
total = 0
for pred, true in zip(eval_preds, dataset["validation"]["text_label"]):
if pred.strip() == true.strip():
correct += 1
total += 1
accuracy = correct / total * 100
print(f"{accuracy=} % on the evaluation dataset")
print(f"{eval_preds[:10]=}")
print(f"{dataset['validation']['text_label'][:10]=}")
```
```python
# saving model
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
model.save_pretrained(peft_model_id)
```
```python
ckpt = f"{peft_model_id}/adapter_model.bin"
!du -h $ckpt
```
```python
from peft import PeftModel, PeftConfig
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)
```
```python
model.eval()
i = 13
inputs = tokenizer(dataset["validation"][text_column][i], return_tensors="pt")
print(dataset["validation"][text_column][i])
print(inputs)
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)
print(outputs)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
```
| huggingface/peft/blob/main/examples/conditional_generation/peft_ia3_seq2seq.ipynb |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLSR-Wav2Vec2
## Overview
The XLSR-Wav2Vec2 model was proposed in [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael
Auli.
The abstract from the paper is the following:
*This paper presents XLSR which learns cross-lingual speech representations by pretraining a single model from the raw
waveform of speech in multiple languages. We build on wav2vec 2.0 which is trained by solving a contrastive task over
masked latent speech representations and jointly learns a quantization of the latents shared across languages. The
resulting model is fine-tuned on labeled data and experiments show that cross-lingual pretraining significantly
outperforms monolingual pretraining. On the CommonVoice benchmark, XLSR shows a relative phoneme error rate reduction
of 72% compared to the best known results. On BABEL, our approach improves word error rate by 16% relative compared to
a comparable system. Our approach enables a single multilingual speech recognition model which is competitive to strong
individual models. Analysis shows that the latent discrete speech representations are shared across languages with
increased sharing for related languages. We hope to catalyze research in low-resource speech understanding by releasing
XLSR-53, a large model pretrained in 53 languages.*
The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
## Usage tips
- XLSR-Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- XLSR-Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be
decoded using [`Wav2Vec2CTCTokenizer`].
<Tip>
XLSR-Wav2Vec2's architecture is based on the Wav2Vec2 model, so one can refer to [Wav2Vec2's documentation page](wav2vec2).
</Tip>
| huggingface/transformers/blob/main/docs/source/en/model_doc/xlsr_wav2vec2.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Inpainting
The Stable Diffusion model can also be applied to inpainting which lets you edit specific parts of an image by providing a mask and a text prompt using Stable Diffusion.
## Tips
It is recommended to use this pipeline with checkpoints that have been specifically fine-tuned for inpainting, such
as [runwayml/stable-diffusion-inpainting](https://huggingface.co/runwayml/stable-diffusion-inpainting). Default
text-to-image Stable Diffusion checkpoints, such as
[runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) are also compatible but they might be less performant.
<Tip>
Make sure to check out the Stable Diffusion [Tips](overview#tips) section to learn how to explore the tradeoff between scheduler speed and quality, and how to reuse pipeline components efficiently!
If you're interested in using one of the official checkpoints for a task, explore the [CompVis](https://huggingface.co/CompVis), [Runway](https://huggingface.co/runwayml), and [Stability AI](https://huggingface.co/stabilityai) Hub organizations!
</Tip>
## StableDiffusionInpaintPipeline
[[autodoc]] StableDiffusionInpaintPipeline
- all
- __call__
- enable_attention_slicing
- disable_attention_slicing
- enable_xformers_memory_efficient_attention
- disable_xformers_memory_efficient_attention
- load_textual_inversion
- load_lora_weights
- save_lora_weights
## StableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
## FlaxStableDiffusionInpaintPipeline
[[autodoc]] FlaxStableDiffusionInpaintPipeline
- all
- __call__
## FlaxStableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/stable_diffusion/inpaint.md |
Single Sign-On (SSO)
<Tip warning={true}>
This feature is part of the <a href="https://huggingface.co/enterprise" target="_blank">Enterprise Hub</a>.
</Tip>
Read the [documentation for SSO under the Security section](./security-sso).
| huggingface/hub-docs/blob/main/docs/hub/enterprise-sso.md |
--
title: "Hugging Face Selected for the French Data Protection Agency Enhanced Support Program"
thumbnail: /blog/assets/146_cnil-accompaniment/logo.png
authors:
- user: yjernite
- user: julien-c
- user: annatrdj
- user: Ima1
---
# Hugging Face Selected for the French Data Protection Agency Enhanced Support Program
*This blog post was originally published on [LinkedIn on 05/15/2023](https://www.linkedin.com/pulse/accompagnement-renforc%25C3%25A9-de-la-cnil-et-protection-des-donn%25C3%25A9es/)*
We are happy to announce that Hugging Face has been selected by the [CNIL](https://www.cnil.fr/en/home) (French Data Protection Authority) to benefit from its [Enhanced Support program](https://www.cnil.fr/en/enhanced-support-cnil-selects-3-digital-companies-strong-potential)!
This new program picked three companies with “strong potential for economic development” out of over 40 candidates, who will receive support in understanding and implementing their duties with respect to data protection -
a daunting and necessary endeavor in the context of the rapidly evolving field of Artificial Intelligence.
When it comes to respecting people’s privacy rights, the recent developments in ML and AI pose new questions, and engender new challenges.
We have been particularly sensitive to these challenges in our own work at Hugging Face and in our collaborations.
The [BigScience Workshop](https://huggingface.co/bigscience) that we hosted in collaboration with hundreds of researchers from many different countries and institutions
was the first Large Language Model training effort to [visibly put privacy front and center](https://linc.cnil.fr/fr/bigscience-il-faut-promouvoir-linnovation-ouverte-et-bienveillante-pour-mettre-le-respect-de-la-vie),
through a multi-pronged approach covering [data selection and governance, data processing, and model sharing](https://montrealethics.ai/category/columns/social-context-in-llm-research/).
The more recent [BigCode project](https://huggingface.co/bigcode) co-hosted with [ServiceNow](https://huggingface.co/ServiceNow) also dedicated significant resources to [addressing privacy risks](https://huggingface.co/datasets/bigcode/governance-card#social-impact-dimensions-and-considerations),
creating [new tools to support pseudonymization](https://huggingface.co/bigcode/starpii) that will benefit other projects.
These efforts help us better understand what is technically necessary and feasible at various levels of the AI development process so we can better address legal requirements and risks tied to personal data.
The accompaniment program from the CNIL, benefiting from its expertise and role as France’s Data Protection Agency,
will play an instrumental role in supporting our broader efforts to push GDPR compliance forward and provide clarity for our community of users on questions of privacy and data protection.
We look forward to working together on addressing these questions with more foresight, and helping develop amazing new ML technology that does respect people’s data rights!
| huggingface/blog/blob/main/cnil.md |
(Legacy) SE-ResNet
**SE ResNet** is a variant of a [ResNet](https://www.paperswithcode.com/method/resnet) that employs [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block) to enable the network to perform dynamic channel-wise feature recalibration.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('legacy_seresnet101', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `legacy_seresnet101`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('legacy_seresnet101', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{hu2019squeezeandexcitation,
title={Squeeze-and-Excitation Networks},
author={Jie Hu and Li Shen and Samuel Albanie and Gang Sun and Enhua Wu},
year={2019},
eprint={1709.01507},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Legacy SE ResNet
Paper:
Title: Squeeze-and-Excitation Networks
URL: https://paperswithcode.com/paper/squeeze-and-excitation-networks
Models:
- Name: legacy_seresnet101
In Collection: Legacy SE ResNet
Metadata:
FLOPs: 9762614000
Parameters: 49330000
File Size: 197822624
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnet101
LR: 0.6
Epochs: 100
Layers: 101
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L426
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-cadene/se_resnet101-7e38fcc6.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.38%
Top 5 Accuracy: 94.26%
- Name: legacy_seresnet152
In Collection: Legacy SE ResNet
Metadata:
FLOPs: 14553578160
Parameters: 66819999
File Size: 268033864
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnet152
LR: 0.6
Epochs: 100
Layers: 152
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L433
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-cadene/se_resnet152-d17c99b7.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.67%
Top 5 Accuracy: 94.38%
- Name: legacy_seresnet18
In Collection: Legacy SE ResNet
Metadata:
FLOPs: 2328876024
Parameters: 11780000
File Size: 47175663
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnet18
LR: 0.6
Epochs: 100
Layers: 18
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L405
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnet18-4bb0ce65.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 71.74%
Top 5 Accuracy: 90.34%
- Name: legacy_seresnet34
In Collection: Legacy SE ResNet
Metadata:
FLOPs: 4706201004
Parameters: 21960000
File Size: 87958697
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnet34
LR: 0.6
Epochs: 100
Layers: 34
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L412
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnet34-a4004e63.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.79%
Top 5 Accuracy: 92.13%
- Name: legacy_seresnet50
In Collection: Legacy SE ResNet
Metadata:
FLOPs: 4974351024
Parameters: 28090000
File Size: 112611220
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnet50
LR: 0.6
Epochs: 100
Layers: 50
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '224'
Interpolation: bilinear
Minibatch Size: 1024
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L419
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-cadene/se_resnet50-ce0d4300.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.64%
Top 5 Accuracy: 93.74%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/legacy-se-resnet.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Load pipelines, models, and schedulers
[[open-in-colab]]
Having an easy way to use a diffusion system for inference is essential to 🧨 Diffusers. Diffusion systems often consist of multiple components like parameterized models, tokenizers, and schedulers that interact in complex ways. That is why we designed the [`DiffusionPipeline`] to wrap the complexity of the entire diffusion system into an easy-to-use API, while remaining flexible enough to be adapted for other use cases, such as loading each component individually as building blocks to assemble your own diffusion system.
Everything you need for inference or training is accessible with the `from_pretrained()` method.
This guide will show you how to load:
- pipelines from the Hub and locally
- different components into a pipeline
- checkpoint variants such as different floating point types or non-exponential mean averaged (EMA) weights
- models and schedulers
## Diffusion Pipeline
<Tip>
💡 Skip to the [DiffusionPipeline explained](#diffusionpipeline-explained) section if you are interested in learning in more detail about how the [`DiffusionPipeline`] class works.
</Tip>
The [`DiffusionPipeline`] class is the simplest and most generic way to load the latest trending diffusion model from the [Hub](https://huggingface.co/models?library=diffusers&sort=trending). The [`DiffusionPipeline.from_pretrained`] method automatically detects the correct pipeline class from the checkpoint, downloads, and caches all the required configuration and weight files, and returns a pipeline instance ready for inference.
```python
from diffusers import DiffusionPipeline
repo_id = "runwayml/stable-diffusion-v1-5"
pipe = DiffusionPipeline.from_pretrained(repo_id, use_safetensors=True)
```
You can also load a checkpoint with its specific pipeline class. The example above loaded a Stable Diffusion model; to get the same result, use the [`StableDiffusionPipeline`] class:
```python
from diffusers import StableDiffusionPipeline
repo_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(repo_id, use_safetensors=True)
```
A checkpoint (such as [`CompVis/stable-diffusion-v1-4`](https://huggingface.co/CompVis/stable-diffusion-v1-4) or [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5)) may also be used for more than one task, like text-to-image or image-to-image. To differentiate what task you want to use the checkpoint for, you have to load it directly with its corresponding task-specific pipeline class:
```python
from diffusers import StableDiffusionImg2ImgPipeline
repo_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(repo_id)
```
### Local pipeline
To load a diffusion pipeline locally, use [`git-lfs`](https://git-lfs.github.com/) to manually download the checkpoint (in this case, [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5)) to your local disk. This creates a local folder, `./stable-diffusion-v1-5`, on your disk:
```bash
git-lfs install
git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
```
Then pass the local path to [`~DiffusionPipeline.from_pretrained`]:
```python
from diffusers import DiffusionPipeline
repo_id = "./stable-diffusion-v1-5"
stable_diffusion = DiffusionPipeline.from_pretrained(repo_id, use_safetensors=True)
```
The [`~DiffusionPipeline.from_pretrained`] method won't download any files from the Hub when it detects a local path, but this also means it won't download and cache the latest changes to a checkpoint.
### Swap components in a pipeline
You can customize the default components of any pipeline with another compatible component. Customization is important because:
- Changing the scheduler is important for exploring the trade-off between generation speed and quality.
- Different components of a model are typically trained independently and you can swap out a component with a better-performing one.
- During finetuning, usually only some components - like the UNet or text encoder - are trained.
To find out which schedulers are compatible for customization, you can use the `compatibles` method:
```py
from diffusers import DiffusionPipeline
repo_id = "runwayml/stable-diffusion-v1-5"
stable_diffusion = DiffusionPipeline.from_pretrained(repo_id, use_safetensors=True)
stable_diffusion.scheduler.compatibles
```
Let's use the [`SchedulerMixin.from_pretrained`] method to replace the default [`PNDMScheduler`] with a more performant scheduler, [`EulerDiscreteScheduler`]. The `subfolder="scheduler"` argument is required to load the scheduler configuration from the correct [subfolder](https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main/scheduler) of the pipeline repository.
Then you can pass the new [`EulerDiscreteScheduler`] instance to the `scheduler` argument in [`DiffusionPipeline`]:
```python
from diffusers import DiffusionPipeline, EulerDiscreteScheduler
repo_id = "runwayml/stable-diffusion-v1-5"
scheduler = EulerDiscreteScheduler.from_pretrained(repo_id, subfolder="scheduler")
stable_diffusion = DiffusionPipeline.from_pretrained(repo_id, scheduler=scheduler, use_safetensors=True)
```
### Safety checker
Diffusion models like Stable Diffusion can generate harmful content, which is why 🧨 Diffusers has a [safety checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) to check generated outputs against known hardcoded NSFW content. If you'd like to disable the safety checker for whatever reason, pass `None` to the `safety_checker` argument:
```python
from diffusers import DiffusionPipeline
repo_id = "runwayml/stable-diffusion-v1-5"
stable_diffusion = DiffusionPipeline.from_pretrained(repo_id, safety_checker=None, use_safetensors=True)
"""
You have disabled the safety checker for <class 'diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline'> by passing `safety_checker=None`. Ensure that you abide by the conditions of the Stable Diffusion license and do not expose unfiltered results in services or applications open to the public. Both the diffusers team and Hugging Face strongly recommend keeping the safety filter enabled in all public-facing circumstances, disabling it only for use cases that involve analyzing network behavior or auditing its results. For more information, please have a look at https://github.com/huggingface/diffusers/pull/254 .
"""
```
### Reuse components across pipelines
You can also reuse the same components in multiple pipelines to avoid loading the weights into RAM twice. Use the [`~DiffusionPipeline.components`] method to save the components:
```python
from diffusers import StableDiffusionPipeline, StableDiffusionImg2ImgPipeline
model_id = "runwayml/stable-diffusion-v1-5"
stable_diffusion_txt2img = StableDiffusionPipeline.from_pretrained(model_id, use_safetensors=True)
components = stable_diffusion_txt2img.components
```
Then you can pass the `components` to another pipeline without reloading the weights into RAM:
```py
stable_diffusion_img2img = StableDiffusionImg2ImgPipeline(**components)
```
You can also pass the components individually to the pipeline if you want more flexibility over which components to reuse or disable. For example, to reuse the same components in the text-to-image pipeline, except for the safety checker and feature extractor, in the image-to-image pipeline:
```py
from diffusers import StableDiffusionPipeline, StableDiffusionImg2ImgPipeline
model_id = "runwayml/stable-diffusion-v1-5"
stable_diffusion_txt2img = StableDiffusionPipeline.from_pretrained(model_id, use_safetensors=True)
stable_diffusion_img2img = StableDiffusionImg2ImgPipeline(
vae=stable_diffusion_txt2img.vae,
text_encoder=stable_diffusion_txt2img.text_encoder,
tokenizer=stable_diffusion_txt2img.tokenizer,
unet=stable_diffusion_txt2img.unet,
scheduler=stable_diffusion_txt2img.scheduler,
safety_checker=None,
feature_extractor=None,
requires_safety_checker=False,
)
```
## Checkpoint variants
A checkpoint variant is usually a checkpoint whose weights are:
- Stored in a different floating point type for lower precision and lower storage, such as [`torch.float16`](https://pytorch.org/docs/stable/tensors.html#data-types), because it only requires half the bandwidth and storage to download. You can't use this variant if you're continuing training or using a CPU.
- Non-exponential mean averaged (EMA) weights, which shouldn't be used for inference. You should use these to continue fine-tuning a model.
<Tip>
💡 When the checkpoints have identical model structures, but they were trained on different datasets and with a different training setup, they should be stored in separate repositories instead of variations (for example, [`stable-diffusion-v1-4`] and [`stable-diffusion-v1-5`]).
</Tip>
Otherwise, a variant is **identical** to the original checkpoint. They have exactly the same serialization format (like [Safetensors](./using_safetensors)), model structure, and weights that have identical tensor shapes.
| **checkpoint type** | **weight name** | **argument for loading weights** |
|---------------------|-------------------------------------|----------------------------------|
| original | diffusion_pytorch_model.bin | |
| floating point | diffusion_pytorch_model.fp16.bin | `variant`, `torch_dtype` |
| non-EMA | diffusion_pytorch_model.non_ema.bin | `variant` |
There are two important arguments to know for loading variants:
- `torch_dtype` defines the floating point precision of the loaded checkpoints. For example, if you want to save bandwidth by loading a `fp16` variant, you should specify `torch_dtype=torch.float16` to *convert the weights* to `fp16`. Otherwise, the `fp16` weights are converted to the default `fp32` precision. You can also load the original checkpoint without defining the `variant` argument, and convert it to `fp16` with `torch_dtype=torch.float16`. In this case, the default `fp32` weights are downloaded first, and then they're converted to `fp16` after loading.
- `variant` defines which files should be loaded from the repository. For example, if you want to load a `non_ema` variant from the [`diffusers/stable-diffusion-variants`](https://huggingface.co/diffusers/stable-diffusion-variants/tree/main/unet) repository, you should specify `variant="non_ema"` to download the `non_ema` files.
```python
from diffusers import DiffusionPipeline
import torch
# load fp16 variant
stable_diffusion = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", variant="fp16", torch_dtype=torch.float16, use_safetensors=True
)
# load non_ema variant
stable_diffusion = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", variant="non_ema", use_safetensors=True
)
```
To save a checkpoint stored in a different floating-point type or as a non-EMA variant, use the [`DiffusionPipeline.save_pretrained`] method and specify the `variant` argument. You should try and save a variant to the same folder as the original checkpoint, so you can load both from the same folder:
```python
from diffusers import DiffusionPipeline
# save as fp16 variant
stable_diffusion.save_pretrained("runwayml/stable-diffusion-v1-5", variant="fp16")
# save as non-ema variant
stable_diffusion.save_pretrained("runwayml/stable-diffusion-v1-5", variant="non_ema")
```
If you don't save the variant to an existing folder, you must specify the `variant` argument otherwise it'll throw an `Exception` because it can't find the original checkpoint:
```python
# 👎 this won't work
stable_diffusion = DiffusionPipeline.from_pretrained(
"./stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True
)
# 👍 this works
stable_diffusion = DiffusionPipeline.from_pretrained(
"./stable-diffusion-v1-5", variant="fp16", torch_dtype=torch.float16, use_safetensors=True
)
```
<!--
TODO(Patrick) - Make sure to uncomment this part as soon as things are deprecated.
#### Using `revision` to load pipeline variants is deprecated
Previously the `revision` argument of [`DiffusionPipeline.from_pretrained`] was heavily used to
load model variants, e.g.:
```python
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", revision="fp16", use_safetensors=True)
```
However, this behavior is now deprecated since the "revision" argument should (just as it's done in GitHub) better be used to load model checkpoints from a specific commit or branch in development.
The above example is therefore deprecated and won't be supported anymore for `diffusers >= 1.0.0`.
<Tip warning={true}>
If you load diffusers pipelines or models with `revision="fp16"` or `revision="non_ema"`,
please make sure to update the code and use `variant="fp16"` or `variation="non_ema"` respectively
instead.
</Tip>
-->
## Models
Models are loaded from the [`ModelMixin.from_pretrained`] method, which downloads and caches the latest version of the model weights and configurations. If the latest files are available in the local cache, [`~ModelMixin.from_pretrained`] reuses files in the cache instead of re-downloading them.
Models can be loaded from a subfolder with the `subfolder` argument. For example, the model weights for `runwayml/stable-diffusion-v1-5` are stored in the [`unet`](https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main/unet) subfolder:
```python
from diffusers import UNet2DConditionModel
repo_id = "runwayml/stable-diffusion-v1-5"
model = UNet2DConditionModel.from_pretrained(repo_id, subfolder="unet", use_safetensors=True)
```
Or directly from a repository's [directory](https://huggingface.co/google/ddpm-cifar10-32/tree/main):
```python
from diffusers import UNet2DModel
repo_id = "google/ddpm-cifar10-32"
model = UNet2DModel.from_pretrained(repo_id, use_safetensors=True)
```
You can also load and save model variants by specifying the `variant` argument in [`ModelMixin.from_pretrained`] and [`ModelMixin.save_pretrained`]:
```python
from diffusers import UNet2DConditionModel
model = UNet2DConditionModel.from_pretrained(
"runwayml/stable-diffusion-v1-5", subfolder="unet", variant="non_ema", use_safetensors=True
)
model.save_pretrained("./local-unet", variant="non_ema")
```
## Schedulers
Schedulers are loaded from the [`SchedulerMixin.from_pretrained`] method, and unlike models, schedulers are **not parameterized** or **trained**; they are defined by a configuration file.
Loading schedulers does not consume any significant amount of memory and the same configuration file can be used for a variety of different schedulers.
For example, the following schedulers are compatible with [`StableDiffusionPipeline`], which means you can load the same scheduler configuration file in any of these classes:
```python
from diffusers import StableDiffusionPipeline
from diffusers import (
DDPMScheduler,
DDIMScheduler,
PNDMScheduler,
LMSDiscreteScheduler,
EulerAncestralDiscreteScheduler,
EulerDiscreteScheduler,
DPMSolverMultistepScheduler,
)
repo_id = "runwayml/stable-diffusion-v1-5"
ddpm = DDPMScheduler.from_pretrained(repo_id, subfolder="scheduler")
ddim = DDIMScheduler.from_pretrained(repo_id, subfolder="scheduler")
pndm = PNDMScheduler.from_pretrained(repo_id, subfolder="scheduler")
lms = LMSDiscreteScheduler.from_pretrained(repo_id, subfolder="scheduler")
euler_anc = EulerAncestralDiscreteScheduler.from_pretrained(repo_id, subfolder="scheduler")
euler = EulerDiscreteScheduler.from_pretrained(repo_id, subfolder="scheduler")
dpm = DPMSolverMultistepScheduler.from_pretrained(repo_id, subfolder="scheduler")
# replace `dpm` with any of `ddpm`, `ddim`, `pndm`, `lms`, `euler_anc`, `euler`
pipeline = StableDiffusionPipeline.from_pretrained(repo_id, scheduler=dpm, use_safetensors=True)
```
## DiffusionPipeline explained
As a class method, [`DiffusionPipeline.from_pretrained`] is responsible for two things:
- Download the latest version of the folder structure required for inference and cache it. If the latest folder structure is available in the local cache, [`DiffusionPipeline.from_pretrained`] reuses the cache and won't redownload the files.
- Load the cached weights into the correct pipeline [class](../api/pipelines/overview#diffusers-summary) - retrieved from the `model_index.json` file - and return an instance of it.
The pipelines' underlying folder structure corresponds directly with their class instances. For example, the [`StableDiffusionPipeline`] corresponds to the folder structure in [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5).
```python
from diffusers import DiffusionPipeline
repo_id = "runwayml/stable-diffusion-v1-5"
pipeline = DiffusionPipeline.from_pretrained(repo_id, use_safetensors=True)
print(pipeline)
```
You'll see pipeline is an instance of [`StableDiffusionPipeline`], which consists of seven components:
- `"feature_extractor"`: a [`~transformers.CLIPImageProcessor`] from 🤗 Transformers.
- `"safety_checker"`: a [component](https://github.com/huggingface/diffusers/blob/e55687e1e15407f60f32242027b7bb8170e58266/src/diffusers/pipelines/stable_diffusion/safety_checker.py#L32) for screening against harmful content.
- `"scheduler"`: an instance of [`PNDMScheduler`].
- `"text_encoder"`: a [`~transformers.CLIPTextModel`] from 🤗 Transformers.
- `"tokenizer"`: a [`~transformers.CLIPTokenizer`] from 🤗 Transformers.
- `"unet"`: an instance of [`UNet2DConditionModel`].
- `"vae"`: an instance of [`AutoencoderKL`].
```json
StableDiffusionPipeline {
"feature_extractor": [
"transformers",
"CLIPImageProcessor"
],
"safety_checker": [
"stable_diffusion",
"StableDiffusionSafetyChecker"
],
"scheduler": [
"diffusers",
"PNDMScheduler"
],
"text_encoder": [
"transformers",
"CLIPTextModel"
],
"tokenizer": [
"transformers",
"CLIPTokenizer"
],
"unet": [
"diffusers",
"UNet2DConditionModel"
],
"vae": [
"diffusers",
"AutoencoderKL"
]
}
```
Compare the components of the pipeline instance to the [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main) folder structure, and you'll see there is a separate folder for each of the components in the repository:
```
.
├── feature_extractor
│ └── preprocessor_config.json
├── model_index.json
├── safety_checker
│ ├── config.json
| ├── model.fp16.safetensors
│ ├── model.safetensors
│ ├── pytorch_model.bin
| └── pytorch_model.fp16.bin
├── scheduler
│ └── scheduler_config.json
├── text_encoder
│ ├── config.json
| ├── model.fp16.safetensors
│ ├── model.safetensors
│ |── pytorch_model.bin
| └── pytorch_model.fp16.bin
├── tokenizer
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
├── unet
│ ├── config.json
│ ├── diffusion_pytorch_model.bin
| |── diffusion_pytorch_model.fp16.bin
│ |── diffusion_pytorch_model.f16.safetensors
│ |── diffusion_pytorch_model.non_ema.bin
│ |── diffusion_pytorch_model.non_ema.safetensors
│ └── diffusion_pytorch_model.safetensors
|── vae
. ├── config.json
. ├── diffusion_pytorch_model.bin
├── diffusion_pytorch_model.fp16.bin
├── diffusion_pytorch_model.fp16.safetensors
└── diffusion_pytorch_model.safetensors
```
You can access each of the components of the pipeline as an attribute to view its configuration:
```py
pipeline.tokenizer
CLIPTokenizer(
name_or_path="/root/.cache/huggingface/hub/models--runwayml--stable-diffusion-v1-5/snapshots/39593d5650112b4cc580433f6b0435385882d819/tokenizer",
vocab_size=49408,
model_max_length=77,
is_fast=False,
padding_side="right",
truncation_side="right",
special_tokens={
"bos_token": AddedToken("<|startoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=True),
"eos_token": AddedToken("<|endoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=True),
"unk_token": AddedToken("<|endoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=True),
"pad_token": "<|endoftext|>",
},
clean_up_tokenization_spaces=True
)
```
Every pipeline expects a [`model_index.json`](https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/model_index.json) file that tells the [`DiffusionPipeline`]:
- which pipeline class to load from `_class_name`
- which version of 🧨 Diffusers was used to create the model in `_diffusers_version`
- what components from which library are stored in the subfolders (`name` corresponds to the component and subfolder name, `library` corresponds to the name of the library to load the class from, and `class` corresponds to the class name)
```json
{
"_class_name": "StableDiffusionPipeline",
"_diffusers_version": "0.6.0",
"feature_extractor": [
"transformers",
"CLIPImageProcessor"
],
"safety_checker": [
"stable_diffusion",
"StableDiffusionSafetyChecker"
],
"scheduler": [
"diffusers",
"PNDMScheduler"
],
"text_encoder": [
"transformers",
"CLIPTextModel"
],
"tokenizer": [
"transformers",
"CLIPTokenizer"
],
"unet": [
"diffusers",
"UNet2DConditionModel"
],
"vae": [
"diffusers",
"AutoencoderKL"
]
}
```
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/loading.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# ScoreSdeVpScheduler
`ScoreSdeVpScheduler` is a variance preserving stochastic differential equation (SDE) scheduler. It was introduced in the [Score-Based Generative Modeling through Stochastic Differential Equations](https://huggingface.co/papers/2011.13456) paper by Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, Ben Poole.
The abstract from the paper is:
*Creating noise from data is easy; creating data from noise is generative modeling. We present a stochastic differential equation (SDE) that smoothly transforms a complex data distribution to a known prior distribution by slowly injecting noise, and a corresponding reverse-time SDE that transforms the prior distribution back into the data distribution by slowly removing the noise. Crucially, the reverse-time SDE depends only on the time-dependent gradient field (\aka, score) of the perturbed data distribution. By leveraging advances in score-based generative modeling, we can accurately estimate these scores with neural networks, and use numerical SDE solvers to generate samples. We show that this framework encapsulates previous approaches in score-based generative modeling and diffusion probabilistic modeling, allowing for new sampling procedures and new modeling capabilities. In particular, we introduce a predictor-corrector framework to correct errors in the evolution of the discretized reverse-time SDE. We also derive an equivalent neural ODE that samples from the same distribution as the SDE, but additionally enables exact likelihood computation, and improved sampling efficiency. In addition, we provide a new way to solve inverse problems with score-based models, as demonstrated with experiments on class-conditional generation, image inpainting, and colorization. Combined with multiple architectural improvements, we achieve record-breaking performance for unconditional image generation on CIFAR-10 with an Inception score of 9.89 and FID of 2.20, a competitive likelihood of 2.99 bits/dim, and demonstrate high fidelity generation of 1024 x 1024 images for the first time from a score-based generative model.*
<Tip warning={true}>
🚧 This scheduler is under construction!
</Tip>
## ScoreSdeVpScheduler
[[autodoc]] schedulers.deprecated.scheduling_sde_vp.ScoreSdeVpScheduler
| huggingface/diffusers/blob/main/docs/source/en/api/schedulers/score_sde_vp.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Llama-Adapter
[Llama-Adapter](https://hf.co/papers/2303.16199) is a PEFT method specifically designed for turning Llama into an instruction-following model. The Llama model is frozen and only a set of adaptation prompts prefixed to the input instruction tokens are learned. Since randomly initialized modules inserted into the model can cause the model to lose some of its existing knowledge, Llama-Adapter uses zero-initialized attention with zero gating to progressively add the instructional prompts to the model.
The abstract from the paper is:
*We present LLaMA-Adapter, a lightweight adaption method to efficiently fine-tune LLaMA into an instruction-following model. Using 52K self-instruct demonstrations, LLaMA-Adapter only introduces 1.2M learnable parameters upon the frozen LLaMA 7B model, and costs less than one hour for fine-tuning on 8 A100 GPUs. Specifically, we adopt a set of learnable adaption prompts, and prepend them to the input text tokens at higher transformer layers. Then, a zero-init attention mechanism with zero gating is proposed, which adaptively injects the new instructional cues into LLaMA, while effectively preserves its pre-trained knowledge. With efficient training, LLaMA-Adapter generates high-quality responses, comparable to Alpaca with fully fine-tuned 7B parameters. Furthermore, our approach can be simply extended to multi-modal input, e.g., images, for image-conditioned LLaMA, which achieves superior reasoning capacity on ScienceQA. We release our code at https://github.com/ZrrSkywalker/LLaMA-Adapter*.
## AdaptionPromptConfig
[[autodoc]] tuners.adaption_prompt.config.AdaptionPromptConfig
## AdaptionPromptModel
[[autodoc]] tuners.adaption_prompt.model.AdaptionPromptModel | huggingface/peft/blob/main/docs/source/package_reference/llama_adapter.md |
--
title: Using Stable Diffusion with Core ML on Apple Silicon
thumbnail: /blog/assets/diffusers_coreml/thumbnail.png
authors:
- user: pcuenq
---
# Using Stable Diffusion with Core ML on Apple Silicon
Thanks to Apple engineers, you can now run Stable Diffusion on Apple Silicon using Core ML!
[This Apple repo](https://github.com/apple/ml-stable-diffusion) provides conversion scripts and inference code based on [🧨 Diffusers](https://github.com/huggingface/diffusers), and we love it! To make it as easy as possible for you, we converted the weights ourselves and put the Core ML versions of the models in [the Hugging Face Hub](https://hf.co/apple).
**Update**: some weeks after this post was written we created a native Swift app that you can use to run Stable Diffusion effortlessly on your own hardware. We released [an app in the Mac App Store](https://apps.apple.com/app/diffusers/id1666309574) as well as [the source code to allow other projects to use it](https://github.com/huggingface/swift-coreml-diffusers).
The rest of this post guides you on how to use the converted weights in your own code or convert additional weights yourself.
## Available Checkpoints
The official Stable Diffusion checkpoints are already converted and ready for use:
- Stable Diffusion v1.4: [converted](https://hf.co/apple/coreml-stable-diffusion-v1-4) [original](https://hf.co/CompVis/stable-diffusion-v1-4)
- Stable Diffusion v1.5: [converted](https://hf.co/apple/coreml-stable-diffusion-v1-5) [original](https://hf.co/runwayml/stable-diffusion-v1-5)
- Stable Diffusion v2 base: [converted](https://hf.co/apple/coreml-stable-diffusion-2-base) [original](https://huggingface.co/stabilityai/stable-diffusion-2-base)
- Stable Diffusion v2.1 base: [converted](https://hf.co/apple/coreml-stable-diffusion-2-1-base) [original](https://huggingface.co/stabilityai/stable-diffusion-2-1-base)
Core ML supports all the compute units available in your device: CPU, GPU and Apple's Neural Engine (NE). It's also possible for Core ML to run different portions of the model in different devices to maximize performance.
There are several variants of each model that may yield different performance depending on the hardware you use. We recommend you try them out and stick with the one that works best in your system. Read on for details.
## Notes on Performance
There are several variants per model:
- "Original" attention vs "split_einsum". These are two alternative implementations of the critical attention blocks. `split_einsum` was [previously introduced by Apple](https://machinelearning.apple.com/research/neural-engine-transformers), and is compatible with all the compute units (CPU, GPU and Apple's Neural Engine). `original`, on the other hand, is only compatible with CPU and GPU. Nevertheless, `original` can be faster than `split_einsum` on some devices, so do check it out!
- "ML Packages" vs "Compiled" models. The former is suitable for Python inference, while the `compiled` version is required for Swift code. The `compiled` models in the Hub split the large UNet model weights in several files for compatibility with iOS and iPadOS devices. This corresponds to the [`--chunk-unet` conversion option](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml).
At the time of this writing, we got best results on my MacBook Pro (M1 Max, 32 GPU cores, 64 GB) using the following combination:
- `original` attention.
- `all` compute units (see next section for details).
- macOS Ventura 13.1 Beta 4 (22C5059b).
With these, it took 18s to generate one image with the Core ML version of Stable Diffusion v1.4 🤯.
> **⚠️ Note**
>
> Several improvements to Core ML were introduced in macOS Ventura 13.1, and they are required by Apple's implementation. You may get black images –and much slower times– if you use previous versions of macOS.
Each model repo is organized in a tree structure that provides these different variants:
```
coreml-stable-diffusion-v1-4
├── README.md
├── original
│ ├── compiled
│ └── packages
└── split_einsum
├── compiled
└── packages
```
You can download and use the variant you need as shown below.
## Core ML Inference in Python
### Prerequisites
```bash
pip install huggingface_hub
pip install git+https://github.com/apple/ml-stable-diffusion
```
### Download the Model Checkpoints
To run inference in Python, you have to use one of the versions stored in the `packages` folders, because the compiled ones are only compatible with Swift. You may choose whether you want to use the `original` or `split_einsum` attention styles.
This is how you'd download the `original` attention variant from the Hub:
```Python
from huggingface_hub import snapshot_download
from pathlib import Path
repo_id = "apple/coreml-stable-diffusion-v1-4"
variant = "original/packages"
model_path = Path("./models") / (repo_id.split("/")[-1] + "_" + variant.replace("/", "_"))
snapshot_download(repo_id, allow_patterns=f"{variant}/*", local_dir=model_path, local_dir_use_symlinks=False)
print(f"Model downloaded at {model_path}")
```
The code above will place the downloaded model snapshot inside a directory called `models`.
### Inference
Once you have downloaded a snapshot of the model, the easiest way to run inference would be to use Apple's Python script.
```shell
python -m python_coreml_stable_diffusion.pipeline --prompt "a photo of an astronaut riding a horse on mars" -i models/coreml-stable-diffusion-v1-4_original_packages -o </path/to/output/image> --compute-unit ALL --seed 93
```
`<output-mlpackages-directory>` should point to the checkpoint you downloaded in the step above, and `--compute-unit` indicates the hardware you want to allow for inference. It must be one of the following options: `ALL`, `CPU_AND_GPU`, `CPU_ONLY`, `CPU_AND_NE`. You may also provide an optional output path, and a seed for reproducibility.
The inference script assumes the original version of the Stable Diffusion model, stored in the Hub as `CompVis/stable-diffusion-v1-4`. If you use another model, you _have_ to specify its Hub id in the inference command-line, using the `--model-version` option. This works both for models already supported, and for custom models you trained or fine-tuned yourself.
For Stable Diffusion 1.5 (Hub id: `runwayml/stable-diffusion-v1-5`):
```shell
python -m python_coreml_stable_diffusion.pipeline --prompt "a photo of an astronaut riding a horse on mars" --compute-unit ALL -o output --seed 93 -i models/coreml-stable-diffusion-v1-5_original_packages --model-version runwayml/stable-diffusion-v1-5
```
For Stable Diffusion 2 base (Hub id: `stabilityai/stable-diffusion-2-base`):
```shell
python -m python_coreml_stable_diffusion.pipeline --prompt "a photo of an astronaut riding a horse on mars" --compute-unit ALL -o output --seed 93 -i models/coreml-stable-diffusion-2-base_original_packages --model-version stabilityai/stable-diffusion-2-base
```
## Core ML inference in Swift
Running inference in Swift is slightly faster than in Python, because the models are already compiled in the `mlmodelc` format. This will be noticeable on app startup when the model is loaded, but shouldn’t be noticeable if you run several generations afterwards.
### Download
To run inference in Swift on your Mac, you need one of the `compiled` checkpoint versions. We recommend you download them locally using Python code similar to the one we showed above, but using one of the `compiled` variants:
```Python
from huggingface_hub import snapshot_download
from pathlib import Path
repo_id = "apple/coreml-stable-diffusion-v1-4"
variant = "original/compiled"
model_path = Path("./models") / (repo_id.split("/")[-1] + "_" + variant.replace("/", "_"))
snapshot_download(repo_id, allow_patterns=f"{variant}/*", local_dir=model_path, local_dir_use_symlinks=False)
print(f"Model downloaded at {model_path}")
```
### Inference
To run inference, please clone Apple's repo:
```bash
git clone https://github.com/apple/ml-stable-diffusion
cd ml-stable-diffusion
```
And then use Apple's command-line tool using Swift Package Manager's facilities:
```bash
swift run StableDiffusionSample --resource-path models/coreml-stable-diffusion-v1-4_original_compiled --compute-units all "a photo of an astronaut riding a horse on mars"
```
You have to specify in `--resource-path` one of the checkpoints downloaded in the previous step, so please make sure it contains compiled Core ML bundles with the extension `.mlmodelc`. The `--compute-units` has to be one of these values: `all`, `cpuOnly`, `cpuAndGPU`, `cpuAndNeuralEngine`.
For more details, please refer to the [instructions in Apple's repo](https://github.com/apple/ml-stable-diffusion).
## Bring Your own Model
If you have created your own models compatible with Stable Diffusion (for example, if you used Dreambooth, Textual Inversion or fine-tuning), then you have to convert the models yourself. Fortunately, Apple provides a conversion script that allows you to do so.
For this task, we recommend you follow [these instructions](https://github.com/apple/ml-stable-diffusion#converting-models-to-coreml).
## Next Steps
We are really excited about the opportunities this brings and can't wait to see what the community can create from here. Some potential ideas are:
- Native, high-quality apps for Mac, iPhone and iPad.
- Bring additional schedulers to Swift, for even faster inference.
- Additional pipelines and tasks.
- Explore quantization techniques and further optimizations.
Looking forward to seeing what you create!
| huggingface/blog/blob/main/diffusers-coreml.md |
et's take a look at word-based tokenization. Word-based tokenization is the idea of splitting the raw text into words, by splitting on spaces or other specific rules like punctuation. In this algorithm, each word has a specific number, an "ID", attributed to it. In this example, "Let's" has the ID 250, do has ID 861, and tokenization followed by an exclamation point has the ID 345. This approach is interesting, as the model has representations that are based on entire words. The information held in a single number is high as a word contains a lot of contextual and semantic information in a sentence. However, this approach does have its limits. For example, the word dog and the word dogs are very similar, and their meaning is close. However, the word-based tokenization will attribute entirely different IDs to these two words, and the model will therefore learn different meanings for these two words. This is unfortunate, as we would like the model to understand that these words are indeed related and that dogs is the plural form of the word dog. Another issue with this approach is that there are a lot of different words in a language. If we want our model to understand all possible sentences in that language, then we will need to have an ID for each different word, and the total number of words, which is also known as the vocabulary size, can quickly become very large. This is an issue because each ID is mapped to a large vector that represents the word's meaning, and keeping track of these mappings requires an enormous number of weights when the vocabulary size is large. If we want our models to stay lean, we can opt for our tokenizer to ignore certain words that we don't necessarily need. For example, when training our tokenizer on a text, we might want to take the 10,000 most frequent words in that text to create our basic vocabulary, instead of taking all of that language's words. The tokenizer will know how to convert those 10,000 words into numbers, but any other word will be converted to the out-of-vocabulary word, or the "unknown" word. This can rapidly become an issue: the model will have the exact same representation for all words that it doesn't know, which will result in a lot of lost information. | huggingface/course/blob/main/subtitles/en/raw/chapter2/04b_word-based-tokenizers.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# DiT
[Scalable Diffusion Models with Transformers](https://huggingface.co/papers/2212.09748) (DiT) is by William Peebles and Saining Xie.
The abstract from the paper is:
*We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches. We analyze the scalability of our Diffusion Transformers (DiTs) through the lens of forward pass complexity as measured by Gflops. We find that DiTs with higher Gflops -- through increased transformer depth/width or increased number of input tokens -- consistently have lower FID. In addition to possessing good scalability properties, our largest DiT-XL/2 models outperform all prior diffusion models on the class-conditional ImageNet 512x512 and 256x256 benchmarks, achieving a state-of-the-art FID of 2.27 on the latter.*
The original codebase can be found at [facebookresearch/dit](https://github.com/facebookresearch/dit).
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## DiTPipeline
[[autodoc]] DiTPipeline
- all
- __call__
## ImagePipelineOutput
[[autodoc]] pipelines.ImagePipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/dit.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Stable Diffusion XL
[[open-in-colab]]
[Stable Diffusion XL](https://huggingface.co/papers/2307.01952) (SDXL) is a powerful text-to-image generation model that iterates on the previous Stable Diffusion models in three key ways:
1. the UNet is 3x larger and SDXL combines a second text encoder (OpenCLIP ViT-bigG/14) with the original text encoder to significantly increase the number of parameters
2. introduces size and crop-conditioning to preserve training data from being discarded and gain more control over how a generated image should be cropped
3. introduces a two-stage model process; the *base* model (can also be run as a standalone model) generates an image as an input to the *refiner* model which adds additional high-quality details
This guide will show you how to use SDXL for text-to-image, image-to-image, and inpainting.
Before you begin, make sure you have the following libraries installed:
```py
# uncomment to install the necessary libraries in Colab
#!pip install -q diffusers transformers accelerate omegaconf invisible-watermark>=0.2.0
```
<Tip warning={true}>
We recommend installing the [invisible-watermark](https://pypi.org/project/invisible-watermark/) library to help identify images that are generated. If the invisible-watermark library is installed, it is used by default. To disable the watermarker:
```py
pipeline = StableDiffusionXLPipeline.from_pretrained(..., add_watermarker=False)
```
</Tip>
## Load model checkpoints
Model weights may be stored in separate subfolders on the Hub or locally, in which case, you should use the [`~StableDiffusionXLPipeline.from_pretrained`] method:
```py
from diffusers import StableDiffusionXLPipeline, StableDiffusionXLImg2ImgPipeline
import torch
pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
refiner = StableDiffusionXLImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0", torch_dtype=torch.float16, use_safetensors=True, variant="fp16"
).to("cuda")
```
You can also use the [`~StableDiffusionXLPipeline.from_single_file`] method to load a model checkpoint stored in a single file format (`.ckpt` or `.safetensors`) from the Hub or locally:
```py
from diffusers import StableDiffusionXLPipeline, StableDiffusionXLImg2ImgPipeline
import torch
pipeline = StableDiffusionXLPipeline.from_single_file(
"https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/sd_xl_base_1.0.safetensors", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
refiner = StableDiffusionXLImg2ImgPipeline.from_single_file(
"https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/blob/main/sd_xl_refiner_1.0.safetensors", torch_dtype=torch.float16, use_safetensors=True, variant="fp16"
).to("cuda")
```
## Text-to-image
For text-to-image, pass a text prompt. By default, SDXL generates a 1024x1024 image for the best results. You can try setting the `height` and `width` parameters to 768x768 or 512x512, but anything below 512x512 is not likely to work.
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline_text2image = AutoPipelineForText2Image.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipeline_text2image(prompt=prompt).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-text2img.png" alt="generated image of an astronaut in a jungle"/>
</div>
## Image-to-image
For image-to-image, SDXL works especially well with image sizes between 768x768 and 1024x1024. Pass an initial image, and a text prompt to condition the image with:
```py
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import load_image, make_image_grid
# use from_pipe to avoid consuming additional memory when loading a checkpoint
pipeline = AutoPipelineForImage2Image.from_pipe(pipeline_text2image).to("cuda")
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-text2img.png"
init_image = load_image(url)
prompt = "a dog catching a frisbee in the jungle"
image = pipeline(prompt, image=init_image, strength=0.8, guidance_scale=10.5).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-img2img.png" alt="generated image of a dog catching a frisbee in a jungle"/>
</div>
## Inpainting
For inpainting, you'll need the original image and a mask of what you want to replace in the original image. Create a prompt to describe what you want to replace the masked area with.
```py
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
# use from_pipe to avoid consuming additional memory when loading a checkpoint
pipeline = AutoPipelineForInpainting.from_pipe(pipeline_text2image).to("cuda")
img_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-text2img.png"
mask_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-inpaint-mask.png"
init_image = load_image(img_url)
mask_image = load_image(mask_url)
prompt = "A deep sea diver floating"
image = pipeline(prompt=prompt, image=init_image, mask_image=mask_image, strength=0.85, guidance_scale=12.5).images[0]
make_image_grid([init_image, mask_image, image], rows=1, cols=3)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-inpaint.png" alt="generated image of a deep sea diver in a jungle"/>
</div>
## Refine image quality
SDXL includes a [refiner model](https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0) specialized in denoising low-noise stage images to generate higher-quality images from the base model. There are two ways to use the refiner:
1. use the base and refiner models together to produce a refined image
2. use the base model to produce an image, and subsequently use the refiner model to add more details to the image (this is how SDXL was originally trained)
### Base + refiner model
When you use the base and refiner model together to generate an image, this is known as an [*ensemble of expert denoisers*](https://research.nvidia.com/labs/dir/eDiff-I/). The ensemble of expert denoisers approach requires fewer overall denoising steps versus passing the base model's output to the refiner model, so it should be significantly faster to run. However, you won't be able to inspect the base model's output because it still contains a large amount of noise.
As an ensemble of expert denoisers, the base model serves as the expert during the high-noise diffusion stage and the refiner model serves as the expert during the low-noise diffusion stage. Load the base and refiner model:
```py
from diffusers import DiffusionPipeline
import torch
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
refiner = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
).to("cuda")
```
To use this approach, you need to define the number of timesteps for each model to run through their respective stages. For the base model, this is controlled by the [`denoising_end`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_xl#diffusers.StableDiffusionXLPipeline.__call__.denoising_end) parameter and for the refiner model, it is controlled by the [`denoising_start`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_xl#diffusers.StableDiffusionXLImg2ImgPipeline.__call__.denoising_start) parameter.
<Tip>
The `denoising_end` and `denoising_start` parameters should be a float between 0 and 1. These parameters are represented as a proportion of discrete timesteps as defined by the scheduler. If you're also using the `strength` parameter, it'll be ignored because the number of denoising steps is determined by the discrete timesteps the model is trained on and the declared fractional cutoff.
</Tip>
Let's set `denoising_end=0.8` so the base model performs the first 80% of denoising the **high-noise** timesteps and set `denoising_start=0.8` so the refiner model performs the last 20% of denoising the **low-noise** timesteps. The base model output should be in **latent** space instead of a PIL image.
```py
prompt = "A majestic lion jumping from a big stone at night"
image = base(
prompt=prompt,
num_inference_steps=40,
denoising_end=0.8,
output_type="latent",
).images
image = refiner(
prompt=prompt,
num_inference_steps=40,
denoising_start=0.8,
image=image,
).images[0]
image
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/lion_base.png" alt="generated image of a lion on a rock at night" />
<figcaption class="mt-2 text-center text-sm text-gray-500">default base model</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/lion_refined.png" alt="generated image of a lion on a rock at night in higher quality" />
<figcaption class="mt-2 text-center text-sm text-gray-500">ensemble of expert denoisers</figcaption>
</div>
</div>
The refiner model can also be used for inpainting in the [`StableDiffusionXLInpaintPipeline`]:
```py
from diffusers import StableDiffusionXLInpaintPipeline
from diffusers.utils import load_image, make_image_grid
import torch
base = StableDiffusionXLInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
refiner = StableDiffusionXLInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
).to("cuda")
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
init_image = load_image(img_url)
mask_image = load_image(mask_url)
prompt = "A majestic tiger sitting on a bench"
num_inference_steps = 75
high_noise_frac = 0.7
image = base(
prompt=prompt,
image=init_image,
mask_image=mask_image,
num_inference_steps=num_inference_steps,
denoising_end=high_noise_frac,
output_type="latent",
).images
image = refiner(
prompt=prompt,
image=image,
mask_image=mask_image,
num_inference_steps=num_inference_steps,
denoising_start=high_noise_frac,
).images[0]
make_image_grid([init_image, mask_image, image.resize((512, 512))], rows=1, cols=3)
```
This ensemble of expert denoisers method works well for all available schedulers!
### Base to refiner model
SDXL gets a boost in image quality by using the refiner model to add additional high-quality details to the fully-denoised image from the base model, in an image-to-image setting.
Load the base and refiner models:
```py
from diffusers import DiffusionPipeline
import torch
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
refiner = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
).to("cuda")
```
Generate an image from the base model, and set the model output to **latent** space:
```py
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = base(prompt=prompt, output_type="latent").images[0]
```
Pass the generated image to the refiner model:
```py
image = refiner(prompt=prompt, image=image[None, :]).images[0]
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/sd_xl/init_image.png" alt="generated image of an astronaut riding a green horse on Mars" />
<figcaption class="mt-2 text-center text-sm text-gray-500">base model</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/sd_xl/refined_image.png" alt="higher quality generated image of an astronaut riding a green horse on Mars" />
<figcaption class="mt-2 text-center text-sm text-gray-500">base model + refiner model</figcaption>
</div>
</div>
For inpainting, load the base and the refiner model in the [`StableDiffusionXLInpaintPipeline`], remove the `denoising_end` and `denoising_start` parameters, and choose a smaller number of inference steps for the refiner.
## Micro-conditioning
SDXL training involves several additional conditioning techniques, which are referred to as *micro-conditioning*. These include original image size, target image size, and cropping parameters. The micro-conditionings can be used at inference time to create high-quality, centered images.
<Tip>
You can use both micro-conditioning and negative micro-conditioning parameters thanks to classifier-free guidance. They are available in the [`StableDiffusionXLPipeline`], [`StableDiffusionXLImg2ImgPipeline`], [`StableDiffusionXLInpaintPipeline`], and [`StableDiffusionXLControlNetPipeline`].
</Tip>
### Size conditioning
There are two types of size conditioning:
- [`original_size`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_xl#diffusers.StableDiffusionXLPipeline.__call__.original_size) conditioning comes from upscaled images in the training batch (because it would be wasteful to discard the smaller images which make up almost 40% of the total training data). This way, SDXL learns that upscaling artifacts are not supposed to be present in high-resolution images. During inference, you can use `original_size` to indicate the original image resolution. Using the default value of `(1024, 1024)` produces higher-quality images that resemble the 1024x1024 images in the dataset. If you choose to use a lower resolution, such as `(256, 256)`, the model still generates 1024x1024 images, but they'll look like the low resolution images (simpler patterns, blurring) in the dataset.
- [`target_size`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_xl#diffusers.StableDiffusionXLPipeline.__call__.target_size) conditioning comes from finetuning SDXL to support different image aspect ratios. During inference, if you use the default value of `(1024, 1024)`, you'll get an image that resembles the composition of square images in the dataset. We recommend using the same value for `target_size` and `original_size`, but feel free to experiment with other options!
🤗 Diffusers also lets you specify negative conditions about an image's size to steer generation away from certain image resolutions:
```py
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(
prompt=prompt,
negative_original_size=(512, 512),
negative_target_size=(1024, 1024),
).images[0]
```
<div class="flex flex-col justify-center">
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/sd_xl/negative_conditions.png"/>
<figcaption class="text-center">Images negatively conditioned on image resolutions of (128, 128), (256, 256), and (512, 512).</figcaption>
</div>
### Crop conditioning
Images generated by previous Stable Diffusion models may sometimes appear to be cropped. This is because images are actually cropped during training so that all the images in a batch have the same size. By conditioning on crop coordinates, SDXL *learns* that no cropping - coordinates `(0, 0)` - usually correlates with centered subjects and complete faces (this is the default value in 🤗 Diffusers). You can experiment with different coordinates if you want to generate off-centered compositions!
```py
from diffusers import StableDiffusionXLPipeline
import torch
pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipeline(prompt=prompt, crops_coords_top_left=(256, 0)).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-cropped.png" alt="generated image of an astronaut in a jungle, slightly cropped"/>
</div>
You can also specify negative cropping coordinates to steer generation away from certain cropping parameters:
```py
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(
prompt=prompt,
negative_original_size=(512, 512),
negative_crops_coords_top_left=(0, 0),
negative_target_size=(1024, 1024),
).images[0]
image
```
## Use a different prompt for each text-encoder
SDXL uses two text-encoders, so it is possible to pass a different prompt to each text-encoder, which can [improve quality](https://github.com/huggingface/diffusers/issues/4004#issuecomment-1627764201). Pass your original prompt to `prompt` and the second prompt to `prompt_2` (use `negative_prompt` and `negative_prompt_2` if you're using negative prompts):
```py
from diffusers import StableDiffusionXLPipeline
import torch
pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
# prompt is passed to OAI CLIP-ViT/L-14
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# prompt_2 is passed to OpenCLIP-ViT/bigG-14
prompt_2 = "Van Gogh painting"
image = pipeline(prompt=prompt, prompt_2=prompt_2).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-double-prompt.png" alt="generated image of an astronaut in a jungle in the style of a van gogh painting"/>
</div>
The dual text-encoders also support textual inversion embeddings that need to be loaded separately as explained in the [SDXL textual inversion](textual_inversion_inference#stable-diffusion-xl) section.
## Optimizations
SDXL is a large model, and you may need to optimize memory to get it to run on your hardware. Here are some tips to save memory and speed up inference.
1. Offload the model to the CPU with [`~StableDiffusionXLPipeline.enable_model_cpu_offload`] for out-of-memory errors:
```diff
- base.to("cuda")
- refiner.to("cuda")
+ base.enable_model_cpu_offload()
+ refiner.enable_model_cpu_offload()
```
2. Use `torch.compile` for ~20% speed-up (you need `torch>=2.0`):
```diff
+ base.unet = torch.compile(base.unet, mode="reduce-overhead", fullgraph=True)
+ refiner.unet = torch.compile(refiner.unet, mode="reduce-overhead", fullgraph=True)
```
3. Enable [xFormers](../optimization/xformers) to run SDXL if `torch<2.0`:
```diff
+ base.enable_xformers_memory_efficient_attention()
+ refiner.enable_xformers_memory_efficient_attention()
```
## Other resources
If you're interested in experimenting with a minimal version of the [`UNet2DConditionModel`] used in SDXL, take a look at the [minSDXL](https://github.com/cloneofsimo/minSDXL) implementation which is written in PyTorch and directly compatible with 🤗 Diffusers.
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/sdxl.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CodeGen
## Overview
The CodeGen model was proposed in [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong.
CodeGen is an autoregressive language model for program synthesis trained sequentially on [The Pile](https://pile.eleuther.ai/), BigQuery, and BigPython.
The abstract from the paper is the following:
*Program synthesis strives to generate a computer program as a solution to a given problem specification. We propose a conversational program synthesis approach via large language models, which addresses the challenges of searching over a vast program space and user intent specification faced in prior approaches. Our new approach casts the process of writing a specification and program as a multi-turn conversation between a user and a system. It treats program synthesis as a sequence prediction problem, in which the specification is expressed in natural language and the desired program is conditionally sampled. We train a family of large language models, called CodeGen, on natural language and programming language data. With weak supervision in the data and the scaling up of data size and model size, conversational capacities emerge from the simple autoregressive language modeling. To study the model behavior on conversational program synthesis, we develop a multi-turn programming benchmark (MTPB), where solving each problem requires multi-step synthesis via multi-turn conversation between the user and the model. Our findings show the emergence of conversational capabilities and the effectiveness of the proposed conversational program synthesis paradigm. In addition, our model CodeGen (with up to 16B parameters trained on TPU-v4) outperforms OpenAI's Codex on the HumanEval benchmark. We make the training library JaxFormer including checkpoints available as open source contribution: [this https URL](https://github.com/salesforce/codegen).*
This model was contributed by [Hiroaki Hayashi](https://huggingface.co/rooa).
The original code can be found [here](https://github.com/salesforce/codegen).
## Checkpoint Naming
* CodeGen model [checkpoints](https://huggingface.co/models?other=codegen) are available on different pre-training data with variable sizes.
* The format is: `Salesforce/codegen-{size}-{data}`, where
* `size`: `350M`, `2B`, `6B`, `16B`
* `data`:
* `nl`: Pre-trained on the Pile
* `multi`: Initialized with `nl`, then further pre-trained on multiple programming languages data
* `mono`: Initialized with `multi`, then further pre-trained on Python data
* For example, `Salesforce/codegen-350M-mono` offers a 350 million-parameter checkpoint pre-trained sequentially on the Pile, multiple programming languages, and Python.
## Usage example
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> checkpoint = "Salesforce/codegen-350M-mono"
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> text = "def hello_world():"
>>> completion = model.generate(**tokenizer(text, return_tensors="pt"))
>>> print(tokenizer.decode(completion[0]))
def hello_world():
print("Hello World")
hello_world()
```
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
## CodeGenConfig
[[autodoc]] CodeGenConfig
- all
## CodeGenTokenizer
[[autodoc]] CodeGenTokenizer
- save_vocabulary
## CodeGenTokenizerFast
[[autodoc]] CodeGenTokenizerFast
## CodeGenModel
[[autodoc]] CodeGenModel
- forward
## CodeGenForCausalLM
[[autodoc]] CodeGenForCausalLM
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/codegen.md |
--
title: Label Distribution
emoji: 🤗
colorFrom: green
colorTo: purple
sdk: gradio
sdk_version: 3.0.2
app_file: app.py
pinned: false
tags:
- evaluate
- measurement
description: >-
Returns the label distribution and skew of the input data.
---
# Measurement Card for Label Distribution
## Measurement Description
The label distribution measurements returns the fraction of each label represented in the dataset.
## Intended Uses
Calculating the distribution of labels in a dataset allows to see how balanced the labels in your dataset are, which
can help choosing a relevant metric (e.g. accuracy when the dataset is balanced, versus F1 score when there is an
imbalance).
## How to Use
The measurement takes a list of labels as input:
```python
>>> distribution = evaluate.load("label_distribution")
>>> data = [1, 0, 2, 2, 0, 0, 0, 0, 0, 2]
>>> results = distribution.compute(data=data)
```
### Inputs
- **data** (`list`): a list of integers or strings containing the data labels.
### Output Values
By default, this metric outputs a dictionary that contains :
-**label_distribution** (`dict`) : a dictionary containing two sets of keys and values: `labels`, which includes the list of labels contained in the dataset, and `fractions`, which includes the fraction of each label.
-**label_skew** (`scalar`) : the asymmetry of the label distribution.
```python
{'label_distribution': {'labels': [1, 0, 2], 'fractions': [0.1, 0.6, 0.3]}, 'label_skew': 0.7417688338666573}
```
If skewness is 0, the dataset is perfectly balanced; if it is less than -1 or greater than 1, the distribution is highly skewed; anything in between can be considered moderately skewed.
#### Values from Popular Papers
### Examples
Calculating the label distribution of a dataset with binary labels:
```python
>>> data = [1, 0, 1, 1, 0, 1, 0]
>>> distribution = evaluate.load("label_distribution")
>>> results = distribution.compute(data=data)
>>> print(results)
{'label_distribution': {'labels': [1, 0], 'fractions': [0.5714285714285714, 0.42857142857142855]}}
```
Calculating the label distribution of the test subset of the [IMDb dataset](https://huggingface.co/datasets/imdb):
```python
>>> from datasets import load_dataset
>>> imdb = load_dataset('imdb', split = 'test')
>>> distribution = evaluate.load("label_distribution")
>>> results = distribution.compute(data=imdb['label'])
>>> print(results)
{'label_distribution': {'labels': [0, 1], 'fractions': [0.5, 0.5]}, 'label_skew': 0.0}
```
N.B. The IMDb dataset is perfectly balanced.
The output of the measurement can easily be passed to matplotlib to plot a histogram of each label:
```python
>>> data = [1, 0, 2, 2, 0, 0, 0, 0, 0, 2]
>>> distribution = evaluate.load("label_distribution")
>>> results = distribution.compute(data=data)
>>> plt.bar(results['label_distribution']['labels'], results['label_distribution']['fractions'])
>>> plt.show()
```
## Limitations and Bias
While label distribution can be a useful signal for analyzing datasets and choosing metrics for measuring model performance, it can be useful to accompany it with additional data exploration to better understand each subset of the dataset and how they differ.
## Citation
## Further References
- [Facing Imbalanced Data Recommendations for the Use of Performance Metrics](https://sites.pitt.edu/~jeffcohn/skew/PID2829477.pdf)
- [Scipy Stats Skew Documentation](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.skew.html#scipy-stats-skew)
| huggingface/evaluate/blob/main/measurements/label_distribution/README.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# How to convert a 🤗 Transformers model to TensorFlow?
Having multiple frameworks available to use with 🤗 Transformers gives you flexibility to play their strengths when
designing your application, but it implies that compatibility must be added on a per-model basis. The good news is that
adding TensorFlow compatibility to an existing model is simpler than [adding a new model from scratch](add_new_model)!
Whether you wish to have a deeper understanding of large TensorFlow models, make a major open-source contribution, or
enable TensorFlow for your model of choice, this guide is for you.
This guide empowers you, a member of our community, to contribute TensorFlow model weights and/or
architectures to be used in 🤗 Transformers, with minimal supervision from the Hugging Face team. Writing a new model
is no small feat, but hopefully this guide will make it less of a rollercoaster 🎢 and more of a walk in the park 🚶.
Harnessing our collective experiences is absolutely critical to make this process increasingly easier, and thus we
highly encourage that you suggest improvements to this guide!
Before you dive deeper, it is recommended that you check the following resources if you're new to 🤗 Transformers:
- [General overview of 🤗 Transformers](add_new_model#general-overview-of-transformers)
- [Hugging Face's TensorFlow Philosophy](https://huggingface.co/blog/tensorflow-philosophy)
In the remainder of this guide, you will learn what's needed to add a new TensorFlow model architecture, the
procedure to convert PyTorch into TensorFlow model weights, and how to efficiently debug mismatches across ML
frameworks. Let's get started!
<Tip>
Are you unsure whether the model you wish to use already has a corresponding TensorFlow architecture?
Check the `model_type` field of the `config.json` of your model of choice
([example](https://huggingface.co/bert-base-uncased/blob/main/config.json#L14)). If the corresponding model folder in
🤗 Transformers has a file whose name starts with "modeling_tf", it means that it has a corresponding TensorFlow
architecture ([example](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert)).
</Tip>
## Step-by-step guide to add TensorFlow model architecture code
There are many ways to design a large model architecture, and multiple ways of implementing said design. However,
you might recall from our [general overview of 🤗 Transformers](add_new_model#general-overview-of-transformers)
that we are an opinionated bunch - the ease of use of 🤗 Transformers relies on consistent design choices. From
experience, we can tell you a few important things about adding TensorFlow models:
- Don't reinvent the wheel! More often than not, there are at least two reference implementations you should check: the
PyTorch equivalent of the model you are implementing and other TensorFlow models for the same class of problems.
- Great model implementations survive the test of time. This doesn't happen because the code is pretty, but rather
because the code is clear, easy to debug and build upon. If you make the life of the maintainers easy with your
TensorFlow implementation, by replicating the same patterns as in other TensorFlow models and minimizing the mismatch
to the PyTorch implementation, you ensure your contribution will be long lived.
- Ask for help when you're stuck! The 🤗 Transformers team is here to help, and we've probably found solutions to the same
problems you're facing.
Here's an overview of the steps needed to add a TensorFlow model architecture:
1. Select the model you wish to convert
2. Prepare transformers dev environment
3. (Optional) Understand theoretical aspects and the existing implementation
4. Implement the model architecture
5. Implement model tests
6. Submit the pull request
7. (Optional) Build demos and share with the world
### 1.-3. Prepare your model contribution
**1. Select the model you wish to convert**
Let's start off with the basics: the first thing you need to know is the architecture you want to convert. If you
don't have your eyes set on a specific architecture, asking the 🤗 Transformers team for suggestions is a great way to
maximize your impact - we will guide you towards the most prominent architectures that are missing on the TensorFlow
side. If the specific model you want to use with TensorFlow already has a TensorFlow architecture implementation in
🤗 Transformers but is lacking weights, feel free to jump straight into the
[weight conversion section](#adding-tensorflow-weights-to-hub)
of this page.
For simplicity, the remainder of this guide assumes you've decided to contribute with the TensorFlow version of
*BrandNewBert* (the same example as in the [guide](add_new_model) to add a new model from scratch).
<Tip>
Before starting the work on a TensorFlow model architecture, double-check that there is no ongoing effort to do so.
You can search for `BrandNewBert` on the
[pull request GitHub page](https://github.com/huggingface/transformers/pulls?q=is%3Apr) to confirm that there is no
TensorFlow-related pull request.
</Tip>
**2. Prepare transformers dev environment**
Having selected the model architecture, open a draft PR to signal your intention to work on it. Follow the
instructions below to set up your environment and open a draft PR.
1. Fork the [repository](https://github.com/huggingface/transformers) by clicking on the 'Fork' button on the
repository's page. This creates a copy of the code under your GitHub user account.
2. Clone your `transformers` fork to your local disk, and add the base repository as a remote:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Set up a development environment, for instance by running the following command:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
failure with this command. If that's the case make sure to install TensorFlow then do:
```bash
pip install -e ".[quality]"
```
**Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
4. Create a branch with a descriptive name from your main branch
```bash
git checkout -b add_tf_brand_new_bert
```
5. Fetch and rebase to current main
```bash
git fetch upstream
git rebase upstream/main
```
6. Add an empty `.py` file in `transformers/src/models/brandnewbert/` named `modeling_tf_brandnewbert.py`. This will
be your TensorFlow model file.
7. Push the changes to your account using:
```bash
git add .
git commit -m "initial commit"
git push -u origin add_tf_brand_new_bert
```
8. Once you are satisfied, go to the webpage of your fork on GitHub. Click on “Pull request”. Make sure to add the
GitHub handle of some members of the Hugging Face team as reviewers, so that the Hugging Face team gets notified for
future changes.
9. Change the PR into a draft by clicking on “Convert to draft” on the right of the GitHub pull request web page.
Now you have set up a development environment to port *BrandNewBert* to TensorFlow in 🤗 Transformers.
**3. (Optional) Understand theoretical aspects and the existing implementation**
You should take some time to read *BrandNewBert's* paper, if such descriptive work exists. There might be large
sections of the paper that are difficult to understand. If this is the case, this is fine - don't worry! The goal is
not to get a deep theoretical understanding of the paper, but to extract the necessary information required to
effectively re-implement the model in 🤗 Transformers using TensorFlow. That being said, you don't have to spend too
much time on the theoretical aspects, but rather focus on the practical ones, namely the existing model documentation
page (e.g. [model docs for BERT](model_doc/bert)).
After you've grasped the basics of the models you are about to implement, it's important to understand the existing
implementation. This is a great chance to confirm that a working implementation matches your expectations for the
model, as well as to foresee technical challenges on the TensorFlow side.
It's perfectly natural that you feel overwhelmed with the amount of information that you've just absorbed. It is
definitely not a requirement that you understand all facets of the model at this stage. Nevertheless, we highly
encourage you to clear any pressing questions in our [forum](https://discuss.huggingface.co/).
### 4. Model implementation
Now it's time to finally start coding. Our suggested starting point is the PyTorch file itself: copy the contents of
`modeling_brand_new_bert.py` inside `src/transformers/models/brand_new_bert/` into
`modeling_tf_brand_new_bert.py`. The goal of this section is to modify the file and update the import structure of
🤗 Transformers such that you can import `TFBrandNewBert` and
`TFBrandNewBert.from_pretrained(model_repo, from_pt=True)` successfully loads a working TensorFlow *BrandNewBert* model.
Sadly, there is no prescription to convert a PyTorch model into TensorFlow. You can, however, follow our selection of
tips to make the process as smooth as possible:
- Prepend `TF` to the name of all classes (e.g. `BrandNewBert` becomes `TFBrandNewBert`).
- Most PyTorch operations have a direct TensorFlow replacement. For example, `torch.nn.Linear` corresponds to
`tf.keras.layers.Dense`, `torch.nn.Dropout` corresponds to `tf.keras.layers.Dropout`, etc. If you're not sure
about a specific operation, you can use the [TensorFlow documentation](https://www.tensorflow.org/api_docs/python/tf)
or the [PyTorch documentation](https://pytorch.org/docs/stable/).
- Look for patterns in the 🤗 Transformers codebase. If you come across a certain operation that doesn't have a direct
replacement, the odds are that someone else already had the same problem.
- By default, keep the same variable names and structure as in PyTorch. This will make it easier to debug, track
issues, and add fixes down the line.
- Some layers have different default values in each framework. A notable example is the batch normalization layer's
epsilon (`1e-5` in [PyTorch](https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html#torch.nn.BatchNorm2d)
and `1e-3` in [TensorFlow](https://www.tensorflow.org/api_docs/python/tf/keras/layers/BatchNormalization)).
Double-check the documentation!
- PyTorch's `nn.Parameter` variables typically need to be initialized within TF Layer's `build()`. See the following
example: [PyTorch](https://github.com/huggingface/transformers/blob/655f72a6896c0533b1bdee519ed65a059c2425ac/src/transformers/models/vit_mae/modeling_vit_mae.py#L212) /
[TensorFlow](https://github.com/huggingface/transformers/blob/655f72a6896c0533b1bdee519ed65a059c2425ac/src/transformers/models/vit_mae/modeling_tf_vit_mae.py#L220)
- If the PyTorch model has a `#copied from ...` on top of a function, the odds are that your TensorFlow model can also
borrow that function from the architecture it was copied from, assuming it has a TensorFlow architecture.
- Assigning the `name` attribute correctly in TensorFlow functions is critical to do the `from_pt=True` weight
cross-loading. `name` is almost always the name of the corresponding variable in the PyTorch code. If `name` is not
properly set, you will see it in the error message when loading the model weights.
- The logic of the base model class, `BrandNewBertModel`, will actually reside in `TFBrandNewBertMainLayer`, a Keras
layer subclass ([example](https://github.com/huggingface/transformers/blob/4fd32a1f499e45f009c2c0dea4d81c321cba7e02/src/transformers/models/bert/modeling_tf_bert.py#L719)).
`TFBrandNewBertModel` will simply be a wrapper around this layer.
- Keras models need to be built in order to load pretrained weights. For that reason, `TFBrandNewBertPreTrainedModel`
will need to hold an example of inputs to the model, the `dummy_inputs`
([example](https://github.com/huggingface/transformers/blob/4fd32a1f499e45f009c2c0dea4d81c321cba7e02/src/transformers/models/bert/modeling_tf_bert.py#L916)).
- If you get stuck, ask for help - we're here to help you! 🤗
In addition to the model file itself, you will also need to add the pointers to the model classes and related
documentation pages. You can complete this part entirely following the patterns in other PRs
([example](https://github.com/huggingface/transformers/pull/18020/files)). Here's a list of the needed manual
changes:
- Include all public classes of *BrandNewBert* in `src/transformers/__init__.py`
- Add *BrandNewBert* classes to the corresponding Auto classes in `src/transformers/models/auto/modeling_tf_auto.py`
- Add the lazy loading classes related to *BrandNewBert* in `src/transformers/utils/dummy_tf_objects.py`
- Update the import structures for the public classes in `src/transformers/models/brand_new_bert/__init__.py`
- Add the documentation pointers to the public methods of *BrandNewBert* in `docs/source/en/model_doc/brand_new_bert.md`
- Add yourself to the list of contributors to *BrandNewBert* in `docs/source/en/model_doc/brand_new_bert.md`
- Finally, add a green tick ✅ to the TensorFlow column of *BrandNewBert* in `docs/source/en/index.md`
When you're happy with your implementation, run the following checklist to confirm that your model architecture is
ready:
1. All layers that behave differently at train time (e.g. Dropout) are called with a `training` argument, which is
propagated all the way from the top-level classes
2. You have used `#copied from ...` whenever possible
3. `TFBrandNewBertMainLayer` and all classes that use it have their `call` function decorated with `@unpack_inputs`
4. `TFBrandNewBertMainLayer` is decorated with `@keras_serializable`
5. A TensorFlow model can be loaded from PyTorch weights using `TFBrandNewBert.from_pretrained(model_repo, from_pt=True)`
6. You can call the TensorFlow model using the expected input format
### 5. Add model tests
Hurray, you've implemented a TensorFlow model! Now it's time to add tests to make sure that your model behaves as
expected. As in the previous section, we suggest you start by copying the `test_modeling_brand_new_bert.py` file in
`tests/models/brand_new_bert/` into `test_modeling_tf_brand_new_bert.py`, and continue by making the necessary
TensorFlow replacements. For now, in all `.from_pretrained()` calls, you should use the `from_pt=True` flag to load
the existing PyTorch weights.
After you're done, it's time for the moment of truth: run the tests! 😬
```bash
NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 RUN_PT_TF_CROSS_TESTS=1 \
py.test -vv tests/models/brand_new_bert/test_modeling_tf_brand_new_bert.py
```
The most likely outcome is that you'll see a bunch of errors. Don't worry, this is expected! Debugging ML models is
notoriously hard, and the key ingredient to success is patience (and `breakpoint()`). In our experience, the hardest
problems arise from subtle mismatches between ML frameworks, for which we have a few pointers at the end of this guide.
In other cases, a general test might not be directly applicable to your model, in which case we suggest an override
at the model test class level. Regardless of the issue, don't hesitate to ask for help in your draft pull request if
you're stuck.
When all tests pass, congratulations, your model is nearly ready to be added to the 🤗 Transformers library! 🎉
### 6.-7. Ensure everyone can use your model
**6. Submit the pull request**
Once you're done with the implementation and the tests, it's time to submit a pull request. Before pushing your code,
run our code formatting utility, `make fixup` 🪄. This will automatically fix any formatting issues, which would cause
our automatic checks to fail.
It's now time to convert your draft pull request into a real pull request. To do so, click on the "Ready for
review" button and add Joao (`@gante`) and Matt (`@Rocketknight1`) as reviewers. A model pull request will need
at least 3 reviewers, but they will take care of finding appropriate additional reviewers for your model.
After all reviewers are happy with the state of your PR, the final action point is to remove the `from_pt=True` flag in
`.from_pretrained()` calls. Since there are no TensorFlow weights, you will have to add them! Check the section
below for instructions on how to do it.
Finally, when the TensorFlow weights get merged, you have at least 3 reviewer approvals, and all CI checks are
green, double-check the tests locally one last time
```bash
NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 RUN_PT_TF_CROSS_TESTS=1 \
py.test -vv tests/models/brand_new_bert/test_modeling_tf_brand_new_bert.py
```
and we will merge your PR! Congratulations on the milestone 🎉
**7. (Optional) Build demos and share with the world**
One of the hardest parts about open-source is discovery. How can the other users learn about the existence of your
fabulous TensorFlow contribution? With proper communication, of course! 📣
There are two main ways to share your model with the community:
- Build demos. These include Gradio demos, notebooks, and other fun ways to show off your model. We highly
encourage you to add a notebook to our [community-driven demos](https://huggingface.co/docs/transformers/community).
- Share stories on social media like Twitter and LinkedIn. You should be proud of your work and share
your achievement with the community - your model can now be used by thousands of engineers and researchers around
the world 🌍! We will be happy to retweet your posts and help you share your work with the community.
## Adding TensorFlow weights to 🤗 Hub
Assuming that the TensorFlow model architecture is available in 🤗 Transformers, converting PyTorch weights into
TensorFlow weights is a breeze!
Here's how to do it:
1. Make sure you are logged into your Hugging Face account in your terminal. You can log in using the command
`huggingface-cli login` (you can find your access tokens [here](https://huggingface.co/settings/tokens))
2. Run `transformers-cli pt-to-tf --model-name foo/bar`, where `foo/bar` is the name of the model repository
containing the PyTorch weights you want to convert
3. Tag `@joaogante` and `@Rocketknight1` in the 🤗 Hub PR the command above has just created
That's it! 🎉
## Debugging mismatches across ML frameworks 🐛
At some point, when adding a new architecture or when creating TensorFlow weights for an existing architecture, you
might come across errors complaining about mismatches between PyTorch and TensorFlow. You might even decide to open the
model architecture code for the two frameworks, and find that they look identical. What's going on? 🤔
First of all, let's talk about why understanding these mismatches matters. Many community members will use 🤗
Transformers models out of the box, and trust that our models behave as expected. When there is a large mismatch
between the two frameworks, it implies that the model is not following the reference implementation for at least one
of the frameworks. This might lead to silent failures, in which the model runs but has poor performance. This is
arguably worse than a model that fails to run at all! To that end, we aim at having a framework mismatch smaller than
`1e-5` at all stages of the model.
As in other numerical problems, the devil is in the details. And as in any detail-oriented craft, the secret
ingredient here is patience. Here is our suggested workflow for when you come across this type of issues:
1. Locate the source of mismatches. The model you're converting probably has near identical inner variables up to a
certain point. Place `breakpoint()` statements in the two frameworks' architectures, and compare the values of the
numerical variables in a top-down fashion until you find the source of the problems.
2. Now that you've pinpointed the source of the issue, get in touch with the 🤗 Transformers team. It is possible
that we've seen a similar problem before and can promptly provide a solution. As a fallback, scan popular pages
like StackOverflow and GitHub issues.
3. If there is no solution in sight, it means you'll have to go deeper. The good news is that you've located the
issue, so you can focus on the problematic instruction, abstracting away the rest of the model! The bad news is
that you'll have to venture into the source implementation of said instruction. In some cases, you might find an
issue with a reference implementation - don't abstain from opening an issue in the upstream repository.
In some cases, in discussion with the 🤗 Transformers team, we might find that fixing the mismatch is infeasible.
When the mismatch is very small in the output layers of the model (but potentially large in the hidden states), we
might decide to ignore it in favor of distributing the model. The `pt-to-tf` CLI mentioned above has a `--max-error`
flag to override the error message at weight conversion time.
| huggingface/transformers/blob/main/docs/source/en/add_tensorflow_model.md |
Gradio Demo: unispeech-speaker-verification
```
!pip install -q gradio git+https://github.com/huggingface/transformers torchaudio
```
```
# Downloading files from the demo repo
import os
os.mkdir('samples')
!wget -q -O samples/cate_blanch.mp3 https://github.com/gradio-app/gradio/raw/main/demo/unispeech-speaker-verification/samples/cate_blanch.mp3
!wget -q -O samples/cate_blanch_2.mp3 https://github.com/gradio-app/gradio/raw/main/demo/unispeech-speaker-verification/samples/cate_blanch_2.mp3
!wget -q -O samples/cate_blanch_3.mp3 https://github.com/gradio-app/gradio/raw/main/demo/unispeech-speaker-verification/samples/cate_blanch_3.mp3
!wget -q -O samples/heath_ledger.mp3 https://github.com/gradio-app/gradio/raw/main/demo/unispeech-speaker-verification/samples/heath_ledger.mp3
!wget -q -O samples/heath_ledger_2.mp3 https://github.com/gradio-app/gradio/raw/main/demo/unispeech-speaker-verification/samples/heath_ledger_2.mp3
!wget -q -O samples/kirsten_dunst.wav https://github.com/gradio-app/gradio/raw/main/demo/unispeech-speaker-verification/samples/kirsten_dunst.wav
```
```
import gradio as gr
import torch
from torchaudio.sox_effects import apply_effects_file
from transformers import AutoFeatureExtractor, AutoModelForAudioXVector
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
STYLE = """
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@5.1.3/dist/css/bootstrap.min.css" integrity="sha256-YvdLHPgkqJ8DVUxjjnGVlMMJtNimJ6dYkowFFvp4kKs=" crossorigin="anonymous">
"""
OUTPUT_OK = (
STYLE
+ """
<div class="container">
<div class="row"><h1 style="text-align: center">The speakers are</h1></div>
<div class="row"><h1 class="display-1 text-success" style="text-align: center">{:.1f}%</h1></div>
<div class="row"><h1 style="text-align: center">similar</h1></div>
<div class="row"><h1 class="text-success" style="text-align: center">Welcome, human!</h1></div>
<div class="row"><small style="text-align: center">(You must get at least 85% to be considered the same person)</small><div class="row">
</div>
"""
)
OUTPUT_FAIL = (
STYLE
+ """
<div class="container">
<div class="row"><h1 style="text-align: center">The speakers are</h1></div>
<div class="row"><h1 class="display-1 text-danger" style="text-align: center">{:.1f}%</h1></div>
<div class="row"><h1 style="text-align: center">similar</h1></div>
<div class="row"><h1 class="text-danger" style="text-align: center">You shall not pass!</h1></div>
<div class="row"><small style="text-align: center">(You must get at least 85% to be considered the same person)</small><div class="row">
</div>
"""
)
EFFECTS = [
["remix", "-"],
["channels", "1"],
["rate", "16000"],
["gain", "-1.0"],
["silence", "1", "0.1", "0.1%", "-1", "0.1", "0.1%"],
["trim", "0", "10"],
]
THRESHOLD = 0.85
model_name = "microsoft/unispeech-sat-base-plus-sv"
feature_extractor = AutoFeatureExtractor.from_pretrained(model_name)
model = AutoModelForAudioXVector.from_pretrained(model_name).to(device)
cosine_sim = torch.nn.CosineSimilarity(dim=-1)
def similarity_fn(path1, path2):
if not (path1 and path2):
return '<b style="color:red">ERROR: Please record audio for *both* speakers!</b>'
wav1, _ = apply_effects_file(path1, EFFECTS)
wav2, _ = apply_effects_file(path2, EFFECTS)
print(wav1.shape, wav2.shape)
input1 = feature_extractor(wav1.squeeze(0), return_tensors="pt", sampling_rate=16000).input_values.to(device)
input2 = feature_extractor(wav2.squeeze(0), return_tensors="pt", sampling_rate=16000).input_values.to(device)
with torch.no_grad():
emb1 = model(input1).embeddings
emb2 = model(input2).embeddings
emb1 = torch.nn.functional.normalize(emb1, dim=-1).cpu()
emb2 = torch.nn.functional.normalize(emb2, dim=-1).cpu()
similarity = cosine_sim(emb1, emb2).numpy()[0]
if similarity >= THRESHOLD:
output = OUTPUT_OK.format(similarity * 100)
else:
output = OUTPUT_FAIL.format(similarity * 100)
return output
inputs = [
gr.Audio(sources=["microphone"], type="filepath", label="Speaker #1"),
gr.Audio(sources=["microphone"], type="filepath", label="Speaker #2"),
]
output = gr.HTML(label="")
description = (
"This demo will compare two speech samples and determine if they are from the same speaker. "
"Try it with your own voice!"
)
article = (
"<p style='text-align: center'>"
"<a href='https://huggingface.co/microsoft/unispeech-sat-large-sv' target='_blank'>🎙️ Learn more about UniSpeech-SAT</a> | "
"<a href='https://arxiv.org/abs/2110.05752' target='_blank'>📚 UniSpeech-SAT paper</a> | "
"<a href='https://www.danielpovey.com/files/2018_icassp_xvectors.pdf' target='_blank'>📚 X-Vector paper</a>"
"</p>"
)
examples = [
["samples/cate_blanch.mp3", "samples/cate_blanch_2.mp3"],
["samples/cate_blanch.mp3", "samples/cate_blanch_3.mp3"],
["samples/cate_blanch_2.mp3", "samples/cate_blanch_3.mp3"],
["samples/heath_ledger.mp3", "samples/heath_ledger_2.mp3"],
["samples/cate_blanch.mp3", "samples/kirsten_dunst.wav"],
]
demo = gr.Interface(
fn=similarity_fn,
inputs=inputs,
outputs=output,
title="Voice Authentication with UniSpeech-SAT + X-Vectors",
description=description,
article=article,
allow_flagging="never",
live=False,
examples=examples,
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/unispeech-speaker-verification/run.ipynb |
--
title: "Exploring simple optimizations for SDXL"
thumbnail: /blog/assets/simple_sdxl_optimizations/thumbnail.png
authors:
- user: sayakpaul
- user: stevhliu
---
# Exploring simple optimizations for SDXL
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/exploring_simple%20optimizations_for_sdxl.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
[Stable Diffusion XL (SDXL)](https://huggingface.co/papers/2307.01952) is the latest latent diffusion model by Stability AI for generating high-quality super realistic images. It overcomes challenges of previous Stable Diffusion models like getting hands and text right as well as spatially correct compositions. In addition, SDXL is also more context aware and requires fewer words in its prompt to generate better looking images.
However, all of these improvements come at the expense of a significantly larger model. How much larger? The base SDXL model has 3.5B parameters (the UNet, in particular), which is approximately 3x larger than the previous Stable Diffusion model.
To explore how we can optimize SDXL for inference speed and memory use, we ran some tests on an A100 GPU (40 GB). For each inference run, we generate 4 images and repeat it 3 times. While computing the inference latency, we only consider the final iteration out of the 3 iterations.
So if you run SDXL out-of-the-box as is with full precision and use the default attention mechanism, it’ll consume 28GB of memory and take 72.2 seconds!
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0").to("cuda")
pipe.unet.set_default_attn_processor()
```
This isn’t very practical and can slow you down because you’re often generating more than 4 images. And if you don’t have a more powerful GPU, you’ll run into that frustrating out-of-memory error message. So how can we optimize SDXL to increase inference speed and reduce its memory-usage?
In 🤗 Diffusers, we have a bunch of optimization tricks and techniques to help you run memory-intensive models like SDXL and we'll show you how! The two things we’ll focus on are *inference speed* and *memory*.
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;">
🧠 The techniques discussed in this post are applicable to all the <a href=https://huggingface.co/docs/diffusers/main/en/using-diffusers/pipeline_overview>pipelines</a>.
</div>
## Inference speed
Diffusion is a random process, so there's no guarantee you'll get an image you’ll like. Often times, you’ll need to run inference multiple times and iterate, and that’s why optimizing for speed is crucial. This section focuses on using lower precision weights and incorporating memory-efficient attention and `torch.compile` from PyTorch 2.0 to boost speed and reduce inference time.
### Lower precision
Model weights are stored at a certain *precision* which is expressed as a floating point data type. The standard floating point data type is float32 (fp32), which can accurately represent a wide range of floating numbers. For inference, you often don’t need to be as precise so you should use float16 (fp16) which captures a narrower range of floating numbers. This means fp16 only takes half the amount of memory to store compared to fp32, and is twice as fast because it is easier to calculate. In addition, modern GPU cards have optimized hardware to run fp16 calculations, making it even faster.
With 🤗 Diffusers, you can use fp16 for inference by specifying the `torch.dtype` parameter to convert the weights when the model is loaded:
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
).to("cuda")
pipe.unet.set_default_attn_processor()
```
Compared to a completely unoptimized SDXL pipeline, using fp16 takes 21.7GB of memory and only 14.8 seconds. You’re almost speeding up inference by a full minute!
### Memory-efficient attention
The attention blocks used in transformers modules can be a huge bottleneck, because memory increases _quadratically_ as input sequences get longer. This can quickly take up a ton of memory and leave you with an out-of-memory error message. 😬
Memory-efficient attention algorithms seek to reduce the memory burden of calculating attention, whether it is by exploiting sparsity or tiling. These optimized algorithms used to be mostly available as third-party libraries that needed to be installed separately. But starting with PyTorch 2.0, this is no longer the case. PyTorch 2 introduced [scaled dot product attention (SDPA)](https://pytorch.org/blog/accelerated-diffusers-pt-20/), which offers fused implementations of [Flash Attention](https://huggingface.co/papers/2205.14135), [memory-efficient attention](https://huggingface.co/papers/2112.05682) (xFormers), and a PyTorch implementation in C++. SDPA is probably the easiest way to speed up inference: if you’re using PyTorch ≥ 2.0 with 🤗 Diffusers, it is automatically enabled by default!
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
).to("cuda")
```
Compared to a completely unoptimized SDXL pipeline, using fp16 and SDPA takes the same amount of memory and the inference time improves to 11.4 seconds. Let’s use this as the new baseline we’ll compare the other optimizations to.
### torch.compile
PyTorch 2.0 also introduced the `torch.compile` API for just-in-time (JIT) compilation of your PyTorch code into more optimized kernels for inference. Unlike other compiler solutions, `torch.compile` requires minimal changes to your existing code and it is as easy as wrapping your model with the function.
With the `mode` parameter, you can optimize for memory overhead or inference speed during compilation, which gives you way more flexibility.
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
).to("cuda")
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
Compared to the previous baseline (fp16 + SDPA), wrapping the UNet with `torch.compile` improves inference time to 10.2 seconds.
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;">
⚠️ The first time you compile a model is slower, but once the model is compiled, all subsequent calls to it are much faster!
</div>
## Model memory footprint
Models today are growing larger and larger, making it a challenge to fit them into memory. This section focuses on how you can reduce the memory footprint of these enormous models so you can run them on consumer GPUs. These techniques include CPU offloading, decoding latents into images over several steps rather than all at once, and using a distilled version of the autoencoder.
### Model CPU offloading
Model offloading saves memory by loading the UNet into the GPU memory while the other components of the diffusion model (text encoders, VAE) are loaded onto the CPU. This way, the UNet can run for multiple iterations on the GPU until it is no longer needed.
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
).to("cuda")
pipe.enable_model_cpu_offload()
```
Compared to the baseline, it now takes 20.2GB of memory which saves you 1.5GB of memory.
### Sequential CPU offloading
Another type of offloading which can save you more memory at the expense of slower inference is sequential CPU offloading. Rather than offloading an entire model - like the UNet - model weights stored in different UNet submodules are offloaded to the CPU and only loaded onto the GPU right before the forward pass. Essentially, you’re only loading parts of the model each time which allows you to save even more memory. The only downside is that it is significantly slower because you’re loading and offloading submodules many times.
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
).to("cuda")
pipe.enable_sequential_cpu_offload()
```
Compared to the baseline, this takes 19.9GB of memory but the inference time increases to 67 seconds.
## Slicing
In SDXL, a variational encoder (VAE) decodes the refined latents (predicted by the UNet) into realistic images. The memory requirement of this step scales with the number of images being predicted (the batch size). Depending on the image resolution and the available GPU VRAM, it can be quite memory-intensive.
This is where “slicing” is useful. The input tensor to be decoded is split into slices and the computation to decode it is completed over several steps. This saves memory and allows larger batch sizes.
```python
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
).to("cuda")
pipe.enable_vae_slicing()
```
With sliced computations, we reduce the memory to 15.4GB. If we add sequential CPU offloading, it is further reduced to 11.45GB which lets you generate 4 images (1024x1024) per prompt. However, with sequential offloading, the inference latency also increases.
## Caching computations
Any text-conditioned image generation model typically uses a text encoder to compute embeddings from the input prompt. SDXL uses *two* text encoders! This contributes quite a bit to the inference latency. However, since these embeddings remain unchanged throughout the reverse diffusion process, we can precompute them and reuse them as we go. This way, after computing the text embeddings, we can remove the text encoders from memory.
First, load the text encoders and their corresponding tokenizers and compute the embeddings from the input prompt:
```python
tokenizers = [tokenizer, tokenizer_2]
text_encoders = [text_encoder, text_encoder_2]
(
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds
) = encode_prompt(tokenizers, text_encoders, prompt)
```
Next, flush the GPU memory to remove the text encoders:
```jsx
del text_encoder, text_encoder_2, tokenizer, tokenizer_2
flush()
```
Now the embeddings are good to go straight to the SDXL pipeline:
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
text_encoder=None,
text_encoder_2=None,
tokenizer=None,
tokenizer_2=None,
torch_dtype=torch.float16,
).to("cuda")
call_args = dict(
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=num_inference_steps,
)
image = pipe(**call_args).images[0]
```
Combined with SDPA and fp16, we can reduce the memory to 21.9GB. Other techniques discussed above for optimizing memory can also be used with cached computations.
## Tiny Autoencoder
As previously mentioned, a VAE decodes latents into images. Naturally, this step is directly bottlenecked by the size of the VAE. So, let’s just use a smaller autoencoder! The [Tiny Autoencoder by `madebyollin`](https://github.com/madebyollin/taesd), available [the Hub](https://huggingface.co/madebyollin/taesdxl) is just 10MB and it is distilled from the original VAE used by SDXL.
```python
from diffusers import AutoencoderTiny
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
)
pipe.vae = AutoencoderTiny.from_pretrained("madebyollin/taesdxl", torch_dtype=torch.float16)
pipe.to("cuda")
```
With this setup, we reduce the memory requirement to 15.6GB while reducing the inference latency at the same time.
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;">
⚠️ The Tiny Autoencoder can omit some of the more fine-grained details from images, which is why the Tiny AutoEncoder is more appropriate for image previews.
</div>
## Conclusion
To conclude and summarize the savings from our optimizations:
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;">
⚠️ While profiling GPUs to measure the trade-off between inference latency and memory requirements, it is important to be aware of the hardware being used. The above findings may not translate equally from hardware to hardware. For example, `torch.compile` only seems to benefit modern GPUs, at least for SDXL.
</div>
| **Technique** | **Memory (GB)** | **Inference latency (ms)** |
| --- | --- | --- |
| unoptimized pipeline | 28.09 | 72200.5 |
| fp16 | 21.72 | 14800.9 |
| **fp16 + SDPA (default)** | **21.72** | **11413.0** |
| default + `torch.compile` | 21.73 | 10296.7 |
| default + model CPU offload | 20.21 | 16082.2 |
| default + sequential CPU offload | 19.91 | 67034.0 |
| **default + VAE slicing** | **15.40** | **11232.2** |
| default + VAE slicing + sequential CPU offload | 11.47 | 66869.2 |
| default + precomputed text embeddings | 21.85 | 11909.0 |
| default + Tiny Autoencoder | 15.48 | 10449.7 |
We hope these optimizations make it a breeze to run your favorite pipelines. Try these techniques out and share your images with us! 🤗
---
**Acknowledgements**: Thank you to [Pedro Cuenca](https://twitter.com/pcuenq?lang=en) for his helpful reviews on the draft. | huggingface/blog/blob/main/simple_sdxl_optimizations.md |
Image Captioning (vision-encoder-text-decoder model) training example
The following example showcases how to finetune a vision-encoder-text-decoder model for image captioning
using the JAX/Flax backend, leveraging 🤗 Transformers library's [FlaxVisionEncoderDecoderModel](https://huggingface.co/docs/transformers/model_doc/vision-encoder-decoder#transformers.FlaxVisionEncoderDecoderModel).
JAX/Flax allows you to trace pure functions and compile them into efficient, fused accelerator code on both GPU and TPU.
Models written in JAX/Flax are **immutable** and updated in a purely functional
way which enables simple and efficient model parallelism.
`run_image_captioning_flax.py` is a lightweight example of how to download and preprocess a dataset from the 🤗 Datasets
library or use your own files (jsonlines or csv), then fine-tune one of the architectures above on it.
For custom datasets in `jsonlines` format please see: https://huggingface.co/docs/datasets/loading_datasets#json-files and you also will find examples of these below.
### Download COCO dataset (2017)
This example uses COCO dataset (2017) through a custom dataset script, which requires users to manually download the
COCO dataset before training.
```bash
mkdir data
cd data
wget http://images.cocodataset.org/zips/train2017.zip
wget http://images.cocodataset.org/zips/val2017.zip
wget http://images.cocodataset.org/zips/test2017.zip
wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
wget http://images.cocodataset.org/annotations/image_info_test2017.zip
cd ..
```
### Create a model from a vision encoder model and a text decoder model
Next, we create a [FlaxVisionEncoderDecoderModel](https://huggingface.co/docs/transformers/model_doc/visionencoderdecoder#transformers.FlaxVisionEncoderDecoderModel) instance from a pre-trained vision encoder ([ViT](https://huggingface.co/docs/transformers/model_doc/vit#transformers.FlaxViTModel)) and a pre-trained text decoder ([GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2#transformers.FlaxGPT2Model)):
```bash
python3 create_model_from_encoder_decoder_models.py \
--output_dir model \
--encoder_model_name_or_path google/vit-base-patch16-224-in21k \
--decoder_model_name_or_path gpt2
```
### Train the model
Finally, we can run the example script to train the model:
```bash
python3 run_image_captioning_flax.py \
--output_dir ./image-captioning-training-results \
--model_name_or_path model \
--dataset_name ydshieh/coco_dataset_script \
--dataset_config_name=2017 \
--data_dir $PWD/data \
--image_column image_path \
--caption_column caption \
--do_train --do_eval --predict_with_generate \
--num_train_epochs 1 \
--eval_steps 500 \
--learning_rate 3e-5 --warmup_steps 0 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 32 \
--overwrite_output_dir \
--max_target_length 32 \
--num_beams 8 \
--preprocessing_num_workers 16 \
--logging_steps 10 \
--block_size 16384 \
--push_to_hub
```
This should finish in about 1h30 on Cloud TPU, with validation loss and ROUGE2 score of 2.0153 and 14.64 respectively
after 1 epoch. Training statistics can be accessed on [Models](https://huggingface.co/ydshieh/image-captioning-training-results/tensorboard).
| huggingface/transformers/blob/main/examples/flax/image-captioning/README.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Login and logout
The `huggingface_hub` library allows users to programmatically login and logout the machine to the Hub.
For more details about authentication, check out [this section](../quick-start#authentication).
## login
[[autodoc]] login
## interpreter_login
[[autodoc]] interpreter_login
## notebook_login
[[autodoc]] notebook_login
## logout
[[autodoc]] logout
| huggingface/huggingface_hub/blob/main/docs/source/en/package_reference/login.md |
BetterTransformer benchmark
Please refer to https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2 & https://pytorch.org/blog/out-of-the-box-acceleration/ for reproduction.
# GPTQ benchmark
The results below are for AutoGPTQ 0.5.0, PyTorch 2.0.1, bitsandbytes 0.41.1, transformers 4.35.
## Generation benchmark results
Run
```shell
# pytorch fp16
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model meta-llama/Llama-2-13b-chat-hf --sweep --num-batches 4 --task text-generation --generate
# GPTQ with exllamav2 kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --sweep --num-batches 4 --gptq --task text-generation --use-exllama --exllama-version 2 --generate
# GPTQ with exllama kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --sweep --num-batches 4 --gptq --task text-generation --use-exllama --generate
# GPTQ without exllama kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --sweep --num-batches 4 --gptq --task text-generation --generate
# using bitsandbytes fp4/fp16 scheme
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model meta-llama/Llama-2-13b-chat-hf --sweep --num-batches 4 --task text-generation --bitsandbytes --generate
```
Here are results obtained on a single NVIDIA A100-SXM4-80GB GPU. We use a prompt length of 512, and generate exactly 512 new tokens. Each generation is repeated for 4 batches, and metrics are averaged over the number of batches and generation length.
Additional benchmarks could be done in the act-order case.
From the bencharmk, it appears that Exllama kernel is the best-in-class for GPTQ, although it is rather slow for larger batch sizes. The memory savings are not exactly of x4 although weights are in int4. This can be explained by the possible static buffers used by the kernels, the CUDA context (taken into account in the measurements), and the KV cache that is still in fp16.
Bitsandbytes uses the fp4 scheme, with the compute in fp16.
### Batch size = 1
|quantization |act_order|bits|group_size|kernel|Load time (s)|Per-token latency (ms)|Throughput (tok/s)|Peak memory (MB)|
|-----|---------|----|----------|------|-------------|----------------------|------------------|----------------|
|None|None |None|None |None |26.0 |36.958 |27.058 |29152.98 |
| gptq | False | 4 | 128 | exllamav2 | 36.07 | 32.25 | 31.01 | 11313.75 |
|gptq |False |4 |128 |exllama|36.2 |33.711 |29.663 |10484.34 |
|gptq |False |4 |128 |autogptq-cuda-old|36.2 |46.44 |21.53 |10344.62 |
|bitsandbytes|None |None|None |None |37.64 |52.00 |19.23 |11018.36 |
### Batch size = 2
|quantization |act_order|bits|group_size|kernel|Load time (s)|Per-token latency (ms)|Throughput (tok/s)|Peak memory (MB)|
|-----|---------|----|----------|------|-------------|----------------------|------------------|----------------|
|None|None |None|None |None |26.0 |37.35 |53.53 |30831.09 |
| gptq | False | 4 | 128 | exllamav2 | 36.07 | 35.81 | 55.85 | 12112.42 |
|gptq |False |4 |128 |exllama|36.2 |37.25 |53.68 |12162.43 |
|gptq |False |4 |128 |autogptq-cuda-old|36.2 |47.41 |42.18 |12020.34 |
|bitsandbytes|None |None|None |None |37.64 |74.62 |26.80 |12834.84 |
### Batch size = 4
|quantization |act_order|bits|group_size|kernel |Load time (s)|Per-token latency (ms)|Throughput (tok/s)|Peak memory (MB)|
|-----|---------|----|----------|-----------------|-------------|----------------------|------------------|----------------|
|None|None |None|None |None |26.0 |37.89 |105.55 |34187.22 |
| gptq | False | 4 | 128 | exllamav2 | 36.07 | 36.04 | 110.98 | 16387.19 |
|gptq |False |4 |128 |exllama |36.2 |54.14 |73.87 |15518.55 |
|gptq |False |4 |128 |autogptq-cuda-old|36.2 |60.98 |65.59 |15374.67 |
|bitsandbytes|None |None|None |None |37.64 |80.24 |49.85 |16187.69 |
### Batch size = 8
|quantization |act_order|bits|group_size|kernel|Load time (s)|Per-token latency (ms)|Throughput (tok/s)|Peak memory (MB)|
|-----|---------|----|----------|------|-------------|----------------------|------------------|----------------|
|None|None |None|None |None |26.0 |47.37 |168.86 |40327.62 |
| gptq | False | 4 | 128 | exllamav2 | 36.07 | 47.31 | 169.11 | 22463.02 |
|gptq |False |4 |128 |exllama|36.2 |73.57 |108.73 |21864.56 |
|gptq |False |4 |128 |autogptq-cuda-old|36.2 |104.44 |76.59 |20987.68 |
|bitsandbytes|None |None|None |None |37.64 |91.29 |87.63 |22894.02 |
### Batch size = 16
|quantization |act_order|bits|group_size|kernel|Load time (s)|Per-token latency (ms)|Throughput (tok/s)|Peak memory (MB)|
|-----|---------|----|----------|------|-------------|----------------------|------------------|----------------|
|None|None |None|None |None |26.0 |69.94 |228.76 |53986.51 |
| gptq | False | 4 | 128 | exllamav2 | 36.07 | 83.09 | 192.55 | 35740.95 |
|gptq |False |4 |128 |exllama|36.2 |95.41 |167.68 |34777.04 |
|gptq |False |4 |128 |autogptq-cuda-old|36.2 |192.48 |83.12 |35497.62 |
|bitsandbytes|None |None|None |None |37.64 |113.98 |140.38 |35532.37 |
## Prefill-only benchmark results
Run
```shell
# pytorch fp16
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model meta-llama/Llama-2-13b-chat-hf --sweep --num-batches 10 --task text-generation --prefill --generate
# GPTQ with exllamav2 kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --sweep --num-batches 10 --gptq --task text-generation --prefill --use-exllama --exllama-version 2 --generate
# GPTQ with exllamav kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --sweep --num-batches 10 --gptq --task text-generation --prefill --use-exllama --generate
# GPTQ without exllama kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --sweep --num-batches 10 --gptq --task text-generation --prefill --generate
# using bitsandbytes fp4/fp16 scheme
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model meta-llama/Llama-2-13b-chat-hf --sweep --num-batches 10 --task text-generation --prefill --bitsandbytes --generate
```
The benchmark below is for a prompt length of 512, measuring only the prefill step on a single NVIDIA A100-SXM4-80GB GPU. The forward is repeated 10 times. This benchmark typically corresponds to the forward during training (to the difference that here `generate` is called, which has some overhead).
### Batch size = 1
|quantization |act_order|bits|group_size|kernel |prompt_length|new_tokens|Load time (s)|Per-token latency (ms)|Throughput (tok/s)|Max memory (MB)|
|-----|---------|----|----------|-----------------|-------------|----------|-------------|----------------------|------------------|---------------|
|None|None |None|None |None |512 |1 |27.22 |96.38 |10.38 |27999.54 |
| gptq | False | 4 | 128 | exllamav2 | 512 | 1 | 6.63 | 116.07 | 8.62 | 10260.35 |
|gptq |False |4 |128 |exllama |512 |1 |38.35 |112.54 |8.89 |9330.89 |
|gptq |False |4 |128 |autogptq-cuda-old|512 |1 |43.94 |368.13 |2.72 |9474.19 |
|bitsandbytes|None|None|None|None|512|1 |37.46|139.17 |7.19 |9952.65 |
### Batch size = 2
|quantization |act_order|bits|group_size|kernel |prompt_length|new_tokens|Load time (s)|Per-token latency (ms)|Throughput (tok/s)|Max memory (MB)|
|-----|---------|----|----------|-----------------|-------------|----------|-------------|----------------------|------------------|---------------|
|None|None |None|None |None |512 |1 |27.22 |169.95 |11.77 |28524.37 |
| gptq | False | 4 | 128 | exllamav2 | 512 | 1 | 6.63 | 212.07 | 9.43 | 10783.60 |
|gptq |False |4 |128 |exllama |512 |1 |38.35 |190.44 |10.50 |9855.71 |
|gptq |False |4 |128 |autogptq-cuda-old|512 |1 |43.94 |443.80 |4.51 |9928.23 |
|bitsandbytes|None|None|None|None|512|1 |37.46|212.76 |9.40 |10421.89|
### Batch size = 4
|quantization |act_order|bits|group_size|kernel |prompt_length|new_tokens|Load time (s)|Per-token latency (ms)|Throughput (tok/s)|Max memory (MB)|
|-----|---------|----|----------|-----------------|-------------|----------|-------------|----------------------|------------------|---------------|
|None|None |None|None |None |512 |1 |27.22 |305.99 |13.07 |29574.01 |
| gptq | False | 4 | 128 | exllamav2 | 512 | 1 | 6.63 | 385.58 | 10.37 | 11829.59 |
|gptq |False |4 |128 |exllama |512 |1 |38.35 |345.54 |11.58 |10905.35 |
|gptq |False |4 |128 |autogptq-cuda-old|512 |1 |43.94 |597.24 |6.70 |10838.42 |
|bitsandbytes|None|None|None|None|512|1 |37.46|349.18 |11.46|11440.08|
### Batch size = 8
|quantization |act_order|bits|group_size|kernel |prompt_length|new_tokens|Load time (s)|Per-token latency (ms)|Throughput (tok/s)|Max memory (MB)|
|-----|---------|----|----------|-----------------|-------------|----------|-------------|----------------------|------------------|---------------|
|None|None |None|None |None |512 |1 |27.22 |600.47 |13.32 |31673.30 |
| gptq | False | 4 | 128 | exllamav2 | 512 | 1 | 6.63 | 753.06 | 10.62 | 13920.50 |
|gptq |False |4 |128 |exllama |512 |1 |38.35 |659.61 |12.13 |13004.64 |
|gptq |False |4 |128 |autogptq-cuda-old|512 |1 |43.94 |909.09 |8.80 |12862.18 |
|bitsandbytes|None|None|None|None|512|1 |37.46|643.42 |12.43|13539.37|
### Batch size = 16
|quantization |act_order|bits|group_size|kernel |prompt_length|new_tokens|Load time (s)|Per-token latency (ms)|Throughput (tok/s)|Max memory (MB)|
|-----|---------|----|-----------|----------|-------------|----------|-------------|----------------------|------------------|---------------|
|None|None |None|None |None |512 |1 |27.22 |1209.07 |13.23 |35871.88 |
| gptq | False | 4 | 128 | exllamav2 | 512 | 1 | 6.63 | 1467.36 | 10.90 | 18104.44 |
|gptq |False |4 |128 |exllama |512 |1 |38.35 |1280.25 |12.50 |17203.22 |
|gptq |False |4 |128 |autogptq-cuda-old |512 |1 |43.94 |1533.54 |10.43 |17060.76 |
|bitsandbytes|None|None|None|None|512|1 |37.46|1256.88|12.73|17737.95|
## Perplexity benchmark results
Run
```shell
# pytorch fp16
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model meta-llama/Llama-2-13b-chat-hf --task text-generation --ppl
# GPTQ with exllamav2 kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --revision gptq-4bit-128g-actorder_True --gptq --task text-generation --use-exllama --exllama-version 2 --ppl
# GPTQ with exllama kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --revision gptq-4bit-128g-actorder_True --gptq --task text-generation --use-exllama --ppl
# GPTQ without exllama kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --revision gptq-4bit-128g-actorder_True --gptq --task text-generation --ppl
# using bitsandbytes fp4/fp16 scheme
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model meta-llama/Llama-2-13b-chat-hf ---task text-generation --bitsandbytes --ppl
```
| quantization | act_order | bits | group_size | kernel | perplexity |
|--------------|-----------|------|------------|------------------|------------|
| None | None | None | None | None | 6.61 |
| gptq | True | 4 | 128 | exllamav2 | 6.77 |
| gptq | True | 4 | 128 | exllama | 6.77 |
| gptq | True | 4 | 128 | autogptq-cuda-old| 6.77 |
| bitsandbytes | None | 4 | None | None | 6.78 | | huggingface/optimum/blob/main/tests/benchmark/README.md |
Gradio Demo: white_noise_vid_not_playable
```
!pip install -q gradio opencv-python
```
```
import cv2
import gradio as gr
import numpy as np
def gif_maker():
img_array = []
height, width = 50, 50
for i in range(30):
img_array.append(np.random.randint(0, 255, size=(height, width, 3)).astype(np.uint8))
output_file = "test.mp4"
out = cv2.VideoWriter(output_file, cv2.VideoWriter_fourcc(*'mp4v'), 15, (height, width))
for i in range(len(img_array)):
out.write(img_array[i])
out.release()
return output_file, output_file
demo = gr.Interface(gif_maker, inputs=None, outputs=[gr.Video(), gr.File()])
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/white_noise_vid_not_playable/run.ipynb |
Inception ResNet v2
**Inception-ResNet-v2** is a convolutional neural architecture that builds on the Inception family of architectures but incorporates [residual connections](https://paperswithcode.com/method/residual-connection) (replacing the filter concatenation stage of the Inception architecture).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('inception_resnet_v2', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `inception_resnet_v2`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('inception_resnet_v2', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{szegedy2016inceptionv4,
title={Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning},
author={Christian Szegedy and Sergey Ioffe and Vincent Vanhoucke and Alex Alemi},
year={2016},
eprint={1602.07261},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Inception ResNet v2
Paper:
Title: Inception-v4, Inception-ResNet and the Impact of Residual Connections on
Learning
URL: https://paperswithcode.com/paper/inception-v4-inception-resnet-and-the-impact
Models:
- Name: inception_resnet_v2
In Collection: Inception ResNet v2
Metadata:
FLOPs: 16959133120
Parameters: 55850000
File Size: 223774238
Architecture:
- Average Pooling
- Dropout
- Inception-ResNet-v2 Reduction-B
- Inception-ResNet-v2-A
- Inception-ResNet-v2-B
- Inception-ResNet-v2-C
- Reduction-A
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 20x NVIDIA Kepler GPUs
ID: inception_resnet_v2
LR: 0.045
Dropout: 0.2
Crop Pct: '0.897'
Momentum: 0.9
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/inception_resnet_v2.py#L343
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/inception_resnet_v2-940b1cd6.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 0.95%
Top 5 Accuracy: 17.29%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/inception-resnet-v2.mdx |
!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Image pretraining examples
This directory contains Python scripts that allow you to pre-train Transformer-based vision models (like [ViT](https://huggingface.co/docs/transformers/model_doc/vit), [Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)) on your own data, after which you can easily load the weights into a [`AutoModelForImageClassification`](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForImageClassification). It currently includes scripts for:
- [SimMIM](#simmim) (by Microsoft Research)
- [MAE](#mae) (by Facebook AI).
NOTE: If you encounter problems/have suggestions for improvement, open an issue on Github and tag @NielsRogge.
## SimMIM
The `run_mim.py` script can be used to pre-train any Transformer-based vision model in the library (concretly, any model supported by the `AutoModelForMaskedImageModeling` API) for masked image modeling as proposed in [SimMIM: A Simple Framework for Masked Image Modeling](https://arxiv.org/abs/2111.09886) using PyTorch.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/simmim_architecture.jpg"
alt="drawing" width="300"/>
<small> SimMIM framework. Taken from the <a href="https://arxiv.org/abs/2111.09886">original paper</a>. </small>
The goal for the model is to predict raw pixel values for the masked patches, using just a linear layer as prediction head. The model is trained using a simple L1 loss.
### Using datasets from 🤗 datasets
Here we show how to pre-train a `ViT` from scratch for masked image modeling on the [cifar10](https://huggingface.co/datasets/cifar10) dataset.
Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "google/vit-base-patch16-224-in21k" for example (and not specifying the `model_type` argument).
```bash
!python run_mim.py \
--model_type vit \
--output_dir ./outputs/ \
--overwrite_output_dir \
--remove_unused_columns False \
--label_names bool_masked_pos \
--do_train \
--do_eval \
--learning_rate 2e-5 \
--weight_decay 0.05 \
--num_train_epochs 100 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--logging_strategy steps \
--logging_steps 10 \
--evaluation_strategy epoch \
--save_strategy epoch \
--load_best_model_at_end True \
--save_total_limit 3 \
--seed 1337
```
Here, we train for 100 epochs with a learning rate of 2e-5. Note that the SimMIM authors used a more sophisticated learning rate schedule, see the [config files](https://github.com/microsoft/SimMIM/blob/main/configs/vit_base__800ep/simmim_pretrain__vit_base__img224__800ep.yaml) for more info. One can easily tweak the script to include this learning rate schedule (several learning rate schedulers are supported via the [training arguments](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments)).
We can also for instance replicate the pre-training of a Swin Transformer using the same architecture as used by the SimMIM authors. For this, we first create a custom configuration and save it locally:
```python
from transformers import SwinConfig
IMAGE_SIZE = 192
PATCH_SIZE = 4
EMBED_DIM = 128
DEPTHS = [2, 2, 18, 2]
NUM_HEADS = [4, 8, 16, 32]
WINDOW_SIZE = 6
config = SwinConfig(
image_size=IMAGE_SIZE,
patch_size=PATCH_SIZE,
embed_dim=EMBED_DIM,
depths=DEPTHS,
num_heads=NUM_HEADS,
window_size=WINDOW_SIZE,
)
config.save_pretrained("path_to_config")
```
Next, we can run the script by providing the path to this custom configuration (replace `path_to_config` below with your path):
```bash
!python run_mim.py \
--config_name_or_path path_to_config \
--model_type swin \
--output_dir ./outputs/ \
--overwrite_output_dir \
--remove_unused_columns False \
--label_names bool_masked_pos \
--do_train \
--do_eval \
--learning_rate 2e-5 \
--num_train_epochs 5 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--logging_strategy steps \
--logging_steps 10 \
--evaluation_strategy epoch \
--save_strategy epoch \
--load_best_model_at_end True \
--save_total_limit 3 \
--seed 1337
```
This will train a Swin Transformer from scratch.
### Using your own data
To use your own dataset, the training script expects the following directory structure:
```bash
root/dog/xxx.png
root/dog/xxy.png
root/dog/[...]/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/[...]/asd932_.png
```
Note that you can put images in dummy subfolders, whose names will be ignored by default (as labels aren't required). You can also just place all images into a single dummy subfolder. Once you've prepared your dataset, you can run the script like this:
```bash
python run_mim.py \
--model_type vit \
--dataset_name nateraw/image-folder \
--train_dir <path-to-train-root> \
--output_dir ./outputs/ \
--remove_unused_columns False \
--label_names bool_masked_pos \
--do_train \
--do_eval
```
## MAE
The `run_mae.py` script can be used to pre-train a Vision Transformer as a masked autoencoder (MAE), as proposed in [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377). The script can be used to train a `ViTMAEForPreTraining` model in the Transformers library, using PyTorch. After self-supervised pre-training, one can load the weights of the encoder directly into a `ViTForImageClassification`. The MAE method allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data.
The goal for the model is to predict raw pixel values for the masked patches. As the model internally masks patches and learns to reconstruct them, there's no need for any labels. The model uses the mean squared error (MSE) between the reconstructed and original images in the pixel space.
### Using datasets from 🤗 `datasets`
One can use the following command to pre-train a `ViTMAEForPreTraining` model from scratch on the [cifar10](https://huggingface.co/datasets/cifar10) dataset:
```bash
python run_mae.py \
--dataset_name cifar10 \
--output_dir ./vit-mae-demo \
--remove_unused_columns False \
--label_names pixel_values \
--mask_ratio 0.75 \
--norm_pix_loss \
--do_train \
--do_eval \
--base_learning_rate 1.5e-4 \
--lr_scheduler_type cosine \
--weight_decay 0.05 \
--num_train_epochs 800 \
--warmup_ratio 0.05 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--logging_strategy steps \
--logging_steps 10 \
--evaluation_strategy epoch \
--save_strategy epoch \
--load_best_model_at_end True \
--save_total_limit 3 \
--seed 1337
```
Here we set:
- `mask_ratio` to 0.75 (to mask 75% of the patches for each image)
- `norm_pix_loss` to use normalized pixel values as target (the authors reported better representations with this enabled)
- `base_learning_rate` to 1.5e-4. Note that the effective learning rate is computed by the [linear schedule](https://arxiv.org/abs/1706.02677): `lr` = `blr` * total training batch size / 256. The total training batch size is computed as `training_args.train_batch_size` * `training_args.gradient_accumulation_steps` * `training_args.world_size`.
This replicates the same hyperparameters as used in the original implementation, as shown in the table below.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/mae_pretraining_setting.png"
alt="drawing" width="300"/>
<small> Original hyperparameters. Taken from the <a href="https://arxiv.org/abs/2111.06377">original paper</a>. </small>
Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "facebook/vit-mae-base" for example.
### Using your own data
To use your own dataset, the training script expects the following directory structure:
```bash
root/dog/xxx.png
root/dog/xxy.png
root/dog/[...]/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/[...]/asd932_.png
```
Note that you can put images in dummy subfolders, whose names will be ignored by default (as labels aren't required). You can also just place all images into a single dummy subfolder. Once you've prepared your dataset, you can run the script like this:
```bash
python run_mae.py \
--model_type vit_mae \
--dataset_name nateraw/image-folder \
--train_dir <path-to-train-root> \
--output_dir ./outputs/ \
--remove_unused_columns False \
--label_names pixel_values \
--do_train \
--do_eval
```
#### 💡 The above will split the train dir into training and evaluation sets
- To control the split amount, use the `--train_val_split` flag.
- To provide your own validation split in its own directory, you can pass the `--validation_dir <path-to-val-root>` flag.
## Sharing your model on 🤗 Hub
0. If you haven't already, [sign up](https://huggingface.co/join) for a 🤗 account
1. Make sure you have `git-lfs` installed and git set up.
```bash
$ apt install git-lfs
$ git config --global user.email "you@example.com"
$ git config --global user.name "Your Name"
```
2. Log in with your HuggingFace account credentials using `huggingface-cli`
```bash
$ huggingface-cli login
# ...follow the prompts
```
3. When running the script, pass the following arguments:
```bash
python run_xxx.py \
--push_to_hub \
--push_to_hub_model_id <name-of-your-model> \
...
``` | huggingface/transformers/blob/main/examples/pytorch/image-pretraining/README.md |
Gradio Demo: logoutbutton_component
```
!pip install -q gradio gradio[oauth]
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.LogoutButton()
demo.launch()
```
| gradio-app/gradio/blob/main/demo/logoutbutton_component/run.ipynb |
Conclusion [[conclusion]]
Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorials. You’ve just implemented your first RL agent from scratch and shared it on the Hub 🥳.
Implementing from scratch when you study a new architecture **is important to understand how it works.**
It's **normal if you still feel confused** by all these elements. **This was the same for me and for everyone who studies RL.**
Take time to really grasp the material before continuing.
In the next chapter, we’re going to dive deeper by studying our first Deep Reinforcement Learning algorithm based on Q-Learning: Deep Q-Learning. And you'll train a **DQN agent with <a href="https://github.com/DLR-RM/rl-baselines3-zoo">RL-Baselines3 Zoo</a> to play Atari Games**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/atari-envs.gif" alt="Atari environments"/>
Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
### Keep Learning, stay awesome 🤗 | huggingface/deep-rl-class/blob/main/units/en/unit2/conclusion.mdx |
Hands-on [[hands-on]]
<CourseFloatingBanner classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit2/unit2.ipynb"}
]}
askForHelpUrl="http://hf.co/join/discord" />
Now that we studied the Q-Learning algorithm, let's implement it from scratch and train our Q-Learning agent in two environments:
1. [Frozen-Lake-v1 (non-slippery and slippery version)](https://gymnasium.farama.org/environments/toy_text/frozen_lake/) ☃️ : where our agent will need to **go from the starting state (S) to the goal state (G)** by walking only on frozen tiles (F) and avoiding holes (H).
2. [An autonomous taxi](https://gymnasium.farama.org/environments/toy_text/taxi/) 🚖 will need **to learn to navigate** a city to **transport its passengers from point A to point B.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/envs.gif" alt="Environments"/>
Thanks to a [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard), you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 2?
To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your trained Taxi model to the Hub and **get a result of >= 4.5**.
To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
**To start the hands-on click on the Open In Colab button** 👇 :
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit2/unit2.ipynb)
We strongly **recommend students use Google Colab for the hands-on exercises** instead of running them on their personal computers.
By using Google Colab, **you can focus on learning and experimenting without worrying about the technical aspects** of setting up your environments.
# Unit 2: Q-Learning with FrozenLake-v1 ⛄ and Taxi-v3 🚕
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/thumbnail.jpg" alt="Unit 2 Thumbnail">
In this notebook, **you'll code your first Reinforcement Learning agent from scratch** to play FrozenLake ❄️ using Q-Learning, share it with the community, and experiment with different configurations.
⬇️ Here is an example of what **you will achieve in just a couple of minutes.** ⬇️
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/envs.gif" alt="Environments"/>
### 🎮 Environments:
- [FrozenLake-v1](https://gymnasium.farama.org/environments/toy_text/frozen_lake/)
- [Taxi-v3](https://gymnasium.farama.org/environments/toy_text/taxi/)
### 📚 RL-Library:
- Python and NumPy
- [Gymnasium](https://gymnasium.farama.org/)
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
## Objectives of this notebook 🏆
At the end of the notebook, you will:
- Be able to use **Gymnasium**, the environment library.
- Be able to code a Q-Learning agent from scratch.
- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
## This notebook is from the Deep Reinforcement Learning Course
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/deep-rl-course-illustration.jpg" alt="Deep RL Course illustration"/>
In this free course, you will:
- 📖 Study Deep Reinforcement Learning in **theory and practice**.
- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.
- 🤖 Train **agents in unique environments**
And more check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course
Don’t forget to **<a href="http://eepurl.com/ic5ZUD">sign up to the course</a>** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**
The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5
## Prerequisites 🏗️
Before diving into the notebook, you need to:
🔲 📚 **Study [Q-Learning by reading Unit 2](https://huggingface.co/deep-rl-course/unit2/introduction)** 🤗
## A small recap of Q-Learning
*Q-Learning* **is the RL algorithm that**:
- Trains *Q-Function*, an **action-value function** that is encoded, in internal memory, by a *Q-table* **that contains all the state-action pair values.**
- Given a state and action, our Q-Function **will search the Q-table for the corresponding value.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-function-2.jpg" alt="Q function" width="100%"/>
- When the training is done, **we have an optimal Q-Function, so an optimal Q-Table.**
- And if we **have an optimal Q-function**, we
have an optimal policy, since we **know for each state, the best action to take.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/link-value-policy.jpg" alt="Link value policy" width="100%"/>
But, in the beginning, our **Q-Table is useless since it gives arbitrary value for each state-action pair (most of the time we initialize the Q-Table to 0 values)**. But, as we’ll explore the environment and update our Q-Table it will give us better and better approximations
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit2/q-learning.jpeg" alt="q-learning.jpeg" width="100%"/>
This is the Q-Learning pseudocode:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-2.jpg" alt="Q-Learning" width="100%"/>
# Let's code our first Reinforcement Learning algorithm 🚀
To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your trained Taxi model to the Hub and **get a result of >= 4.5**.
To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
## Install dependencies and create a virtual display 🔽
In the notebook, we'll need to generate a replay video. To do so, with Colab, **we need to have a virtual screen to render the environment** (and thus record the frames).
Hence the following cell will install the libraries and create and run a virtual screen 🖥
We’ll install multiple ones:
- `gymnasium`: Contains the FrozenLake-v1 ⛄ and Taxi-v3 🚕 environments.
- `pygame`: Used for the FrozenLake-v1 and Taxi-v3 UI.
- `numpy`: Used for handling our Q-table.
The Hugging Face Hub 🤗 works as a central place where anyone can share and explore models and datasets. It has versioning, metrics, visualizations and other features that will allow you to easily collaborate with others.
You can see here all the Deep RL models available (if they use Q Learning) here 👉 https://huggingface.co/models?other=q-learning
```bash
pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit2/requirements-unit2.txt
```
```bash
sudo apt-get update
sudo apt-get install -y python3-opengl
apt install ffmpeg xvfb
pip3 install pyvirtualdisplay
```
To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks to this trick, **we will be able to run our virtual screen.**
```python
import os
os.kill(os.getpid(), 9)
```
```python
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()
```
## Import the packages 📦
In addition to the installed libraries, we also use:
- `random`: To generate random numbers (that will be useful for epsilon-greedy policy).
- `imageio`: To generate a replay video.
```python
import numpy as np
import gymnasium as gym
import random
import imageio
import os
import tqdm
import pickle5 as pickle
from tqdm.notebook import tqdm
```
We're now ready to code our Q-Learning algorithm 🔥
# Part 1: Frozen Lake ⛄ (non slippery version)
## Create and understand [FrozenLake environment ⛄]((https://gymnasium.farama.org/environments/toy_text/frozen_lake/)
---
💡 A good habit when you start to use an environment is to check its documentation
👉 https://gymnasium.farama.org/environments/toy_text/frozen_lake/
---
We're going to train our Q-Learning agent **to navigate from the starting state (S) to the goal state (G) by walking only on frozen tiles (F) and avoid holes (H)**.
We can have two sizes of environment:
- `map_name="4x4"`: a 4x4 grid version
- `map_name="8x8"`: a 8x8 grid version
The environment has two modes:
- `is_slippery=False`: The agent always moves **in the intended direction** due to the non-slippery nature of the frozen lake (deterministic).
- `is_slippery=True`: The agent **may not always move in the intended direction** due to the slippery nature of the frozen lake (stochastic).
For now let's keep it simple with the 4x4 map and non-slippery.
We add a parameter called `render_mode` that specifies how the environment should be visualised. In our case because we **want to record a video of the environment at the end, we need to set render_mode to rgb_array**.
As [explained in the documentation](https://gymnasium.farama.org/api/env/#gymnasium.Env.render) “rgb_array”: Return a single frame representing the current state of the environment. A frame is a np.ndarray with shape (x, y, 3) representing RGB values for an x-by-y pixel image.
```python
# Create the FrozenLake-v1 environment using 4x4 map and non-slippery version and render_mode="rgb_array"
env = gym.make() # TODO use the correct parameters
```
### Solution
```python
env = gym.make("FrozenLake-v1", map_name="4x4", is_slippery=False, render_mode="rgb_array")
```
You can create your own custom grid like this:
```python
desc=["SFFF", "FHFH", "FFFH", "HFFG"]
gym.make('FrozenLake-v1', desc=desc, is_slippery=True)
```
but we'll use the default environment for now.
### Let's see what the Environment looks like:
```python
# We create our environment with gym.make("<name_of_the_environment>")- `is_slippery=False`: The agent always moves in the intended direction due to the non-slippery nature of the frozen lake (deterministic).
print("_____OBSERVATION SPACE_____ \n")
print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # Get a random observation
```
We see with `Observation Space Shape Discrete(16)` that the observation is an integer representing the **agent’s current position as current_row * ncols + current_col (where both the row and col start at 0)**.
For example, the goal position in the 4x4 map can be calculated as follows: 3 * 4 + 3 = 15. The number of possible observations is dependent on the size of the map. **For example, the 4x4 map has 16 possible observations.**
For instance, this is what state = 0 looks like:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit2/frozenlake.png" alt="FrozenLake">
```python
print("\n _____ACTION SPACE_____ \n")
print("Action Space Shape", env.action_space.n)
print("Action Space Sample", env.action_space.sample()) # Take a random action
```
The action space (the set of possible actions the agent can take) is discrete with 4 actions available 🎮:
- 0: GO LEFT
- 1: GO DOWN
- 2: GO RIGHT
- 3: GO UP
Reward function 💰:
- Reach goal: +1
- Reach hole: 0
- Reach frozen: 0
## Create and Initialize the Q-table 🗄️
(👀 Step 1 of the pseudocode)
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-2.jpg" alt="Q-Learning" width="100%"/>
It's time to initialize our Q-table! To know how many rows (states) and columns (actions) to use, we need to know the action and observation space. We already know their values from before, but we'll want to obtain them programmatically so that our algorithm generalizes for different environments. Gym provides us a way to do that: `env.action_space.n` and `env.observation_space.n`
```python
state_space =
print("There are ", state_space, " possible states")
action_space =
print("There are ", action_space, " possible actions")
```
```python
# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros. np.zeros needs a tuple (a,b)
def initialize_q_table(state_space, action_space):
Qtable =
return Qtable
```
```python
Qtable_frozenlake = initialize_q_table(state_space, action_space)
```
### Solution
```python
state_space = env.observation_space.n
print("There are ", state_space, " possible states")
action_space = env.action_space.n
print("There are ", action_space, " possible actions")
```
```python
# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros
def initialize_q_table(state_space, action_space):
Qtable = np.zeros((state_space, action_space))
return Qtable
```
```python
Qtable_frozenlake = initialize_q_table(state_space, action_space)
```
## Define the greedy policy 🤖
Remember we have two policies since Q-Learning is an **off-policy** algorithm. This means we're using a **different policy for acting and updating the value function**.
- Epsilon-greedy policy (acting policy)
- Greedy-policy (updating policy)
The greedy policy will also be the final policy we'll have when the Q-learning agent completes training. The greedy policy is used to select an action using the Q-table.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/off-on-4.jpg" alt="Q-Learning" width="100%"/>
```python
def greedy_policy(Qtable, state):
# Exploitation: take the action with the highest state, action value
action =
return action
```
#### Solution
```python
def greedy_policy(Qtable, state):
# Exploitation: take the action with the highest state, action value
action = np.argmax(Qtable[state][:])
return action
```
## Define the epsilon-greedy policy 🤖
Epsilon-greedy is the training policy that handles the exploration/exploitation trade-off.
The idea with epsilon-greedy:
- With *probability 1 - ɛ* : **we do exploitation** (i.e. our agent selects the action with the highest state-action pair value).
- With *probability ɛ*: we do **exploration** (trying a random action).
As the training continues, we progressively **reduce the epsilon value since we will need less and less exploration and more exploitation.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-4.jpg" alt="Q-Learning" width="100%"/>
```python
def epsilon_greedy_policy(Qtable, state, epsilon):
# Randomly generate a number between 0 and 1
random_num =
# if random_num > greater than epsilon --> exploitation
if random_num > epsilon:
# Take the action with the highest value given a state
# np.argmax can be useful here
action =
# else --> exploration
else:
action = # Take a random action
return action
```
#### Solution
```python
def epsilon_greedy_policy(Qtable, state, epsilon):
# Randomly generate a number between 0 and 1
random_num = random.uniform(0, 1)
# if random_num > greater than epsilon --> exploitation
if random_num > epsilon:
# Take the action with the highest value given a state
# np.argmax can be useful here
action = greedy_policy(Qtable, state)
# else --> exploration
else:
action = env.action_space.sample()
return action
```
## Define the hyperparameters ⚙️
The exploration related hyperparamters are some of the most important ones.
- We need to make sure that our agent **explores enough of the state space** to learn a good value approximation. To do that, we need to have progressive decay of the epsilon.
- If you decrease epsilon too fast (too high decay_rate), **you take the risk that your agent will be stuck**, since your agent didn't explore enough of the state space and hence can't solve the problem.
```python
# Training parameters
n_training_episodes = 10000 # Total training episodes
learning_rate = 0.7 # Learning rate
# Evaluation parameters
n_eval_episodes = 100 # Total number of test episodes
# Environment parameters
env_id = "FrozenLake-v1" # Name of the environment
max_steps = 99 # Max steps per episode
gamma = 0.95 # Discounting rate
eval_seed = [] # The evaluation seed of the environment
# Exploration parameters
max_epsilon = 1.0 # Exploration probability at start
min_epsilon = 0.05 # Minimum exploration probability
decay_rate = 0.0005 # Exponential decay rate for exploration prob
```
## Create the training loop method
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-2.jpg" alt="Q-Learning" width="100%"/>
The training loop goes like this:
```
For episode in the total of training episodes:
Reduce epsilon (since we need less and less exploration)
Reset the environment
For step in max timesteps:
Choose the action At using epsilon greedy policy
Take the action (a) and observe the outcome state(s') and reward (r)
Update the Q-value Q(s,a) using Bellman equation Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
If done, finish the episode
Our next state is the new state
```
```python
def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
for episode in tqdm(range(n_training_episodes)):
# Reduce epsilon (because we need less and less exploration)
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
# Reset the environment
state, info = env.reset()
step = 0
terminated = False
truncated = False
# repeat
for step in range(max_steps):
# Choose the action At using epsilon greedy policy
action =
# Take action At and observe Rt+1 and St+1
# Take the action (a) and observe the outcome state(s') and reward (r)
new_state, reward, terminated, truncated, info =
# Update Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
Qtable[state][action] =
# If terminated or truncated finish the episode
if terminated or truncated:
break
# Our next state is the new state
state = new_state
return Qtable
```
#### Solution
```python
def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
for episode in tqdm(range(n_training_episodes)):
# Reduce epsilon (because we need less and less exploration)
epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate * episode)
# Reset the environment
state, info = env.reset()
step = 0
terminated = False
truncated = False
# repeat
for step in range(max_steps):
# Choose the action At using epsilon greedy policy
action = epsilon_greedy_policy(Qtable, state, epsilon)
# Take action At and observe Rt+1 and St+1
# Take the action (a) and observe the outcome state(s') and reward (r)
new_state, reward, terminated, truncated, info = env.step(action)
# Update Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
Qtable[state][action] = Qtable[state][action] + learning_rate * (
reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action]
)
# If terminated or truncated finish the episode
if terminated or truncated:
break
# Our next state is the new state
state = new_state
return Qtable
```
## Train the Q-Learning agent 🏃
```python
Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
```
## Let's see what our Q-Learning table looks like now 👀
```python
Qtable_frozenlake
```
## The evaluation method 📝
- We defined the evaluation method that we're going to use to test our Q-Learning agent.
```python
def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
"""
Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
:param env: The evaluation environment
:param n_eval_episodes: Number of episode to evaluate the agent
:param Q: The Q-table
:param seed: The evaluation seed array (for taxi-v3)
"""
episode_rewards = []
for episode in tqdm(range(n_eval_episodes)):
if seed:
state, info = env.reset(seed=seed[episode])
else:
state, info = env.reset()
step = 0
truncated = False
terminated = False
total_rewards_ep = 0
for step in range(max_steps):
# Take the action (index) that have the maximum expected future reward given that state
action = greedy_policy(Q, state)
new_state, reward, terminated, truncated, info = env.step(action)
total_rewards_ep += reward
if terminated or truncated:
break
state = new_state
episode_rewards.append(total_rewards_ep)
mean_reward = np.mean(episode_rewards)
std_reward = np.std(episode_rewards)
return mean_reward, std_reward
```
## Evaluate our Q-Learning agent 📈
- Usually, you should have a mean reward of 1.0
- The **environment is relatively easy** since the state space is really small (16). What you can try to do is [to replace it with the slippery version](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/), which introduces stochasticity, making the environment more complex.
```python
# Evaluate our Agent
mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed)
print(f"Mean_reward={mean_reward:.2f} +/- {std_reward:.2f}")
```
## Publish our trained model to the Hub 🔥
Now that we saw good results after the training, **we can publish our trained model to the Hub 🤗 with one line of code**.
Here's an example of a Model Card:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit2/modelcard.png" alt="Model card" width="100%"/>
Under the hood, the Hub uses git-based repositories (don't worry if you don't know what git is), which means you can update the model with new versions as you experiment and improve your agent.
#### Do not modify this code
```python
from huggingface_hub import HfApi, snapshot_download
from huggingface_hub.repocard import metadata_eval_result, metadata_save
from pathlib import Path
import datetime
import json
```
```python
def record_video(env, Qtable, out_directory, fps=1):
"""
Generate a replay video of the agent
:param env
:param Qtable: Qtable of our agent
:param out_directory
:param fps: how many frame per seconds (with taxi-v3 and frozenlake-v1 we use 1)
"""
images = []
terminated = False
truncated = False
state, info = env.reset(seed=random.randint(0, 500))
img = env.render()
images.append(img)
while not terminated or truncated:
# Take the action (index) that have the maximum expected future reward given that state
action = np.argmax(Qtable[state][:])
state, reward, terminated, truncated, info = env.step(
action
) # We directly put next_state = state for recording logic
img = env.render()
images.append(img)
imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
```
```python
def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):
"""
Evaluate, Generate a video and Upload a model to Hugging Face Hub.
This method does the complete pipeline:
- It evaluates the model
- It generates the model card
- It generates a replay video of the agent
- It pushes everything to the Hub
:param repo_id: repo_id: id of the model repository from the Hugging Face Hub
:param env
:param video_fps: how many frame per seconds to record our video replay
(with taxi-v3 and frozenlake-v1 we use 1)
:param local_repo_path: where the local repository is
"""
_, repo_name = repo_id.split("/")
eval_env = env
api = HfApi()
# Step 1: Create the repo
repo_url = api.create_repo(
repo_id=repo_id,
exist_ok=True,
)
# Step 2: Download files
repo_local_path = Path(snapshot_download(repo_id=repo_id))
# Step 3: Save the model
if env.spec.kwargs.get("map_name"):
model["map_name"] = env.spec.kwargs.get("map_name")
if env.spec.kwargs.get("is_slippery", "") == False:
model["slippery"] = False
# Pickle the model
with open((repo_local_path) / "q-learning.pkl", "wb") as f:
pickle.dump(model, f)
# Step 4: Evaluate the model and build JSON with evaluation metrics
mean_reward, std_reward = evaluate_agent(
eval_env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"]
)
evaluate_data = {
"env_id": model["env_id"],
"mean_reward": mean_reward,
"n_eval_episodes": model["n_eval_episodes"],
"eval_datetime": datetime.datetime.now().isoformat(),
}
# Write a JSON file called "results.json" that will contain the
# evaluation results
with open(repo_local_path / "results.json", "w") as outfile:
json.dump(evaluate_data, outfile)
# Step 5: Create the model card
env_name = model["env_id"]
if env.spec.kwargs.get("map_name"):
env_name += "-" + env.spec.kwargs.get("map_name")
if env.spec.kwargs.get("is_slippery", "") == False:
env_name += "-" + "no_slippery"
metadata = {}
metadata["tags"] = [env_name, "q-learning", "reinforcement-learning", "custom-implementation"]
# Add metrics
eval = metadata_eval_result(
model_pretty_name=repo_name,
task_pretty_name="reinforcement-learning",
task_id="reinforcement-learning",
metrics_pretty_name="mean_reward",
metrics_id="mean_reward",
metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
dataset_pretty_name=env_name,
dataset_id=env_name,
)
# Merges both dictionaries
metadata = {**metadata, **eval}
model_card = f"""
# **Q-Learning** Agent playing1 **{env_id}**
This is a trained model of a **Q-Learning** agent playing **{env_id}** .
## Usage
model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
"""
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
readme_path = repo_local_path / "README.md"
readme = ""
print(readme_path.exists())
if readme_path.exists():
with readme_path.open("r", encoding="utf8") as f:
readme = f.read()
else:
readme = model_card
with readme_path.open("w", encoding="utf-8") as f:
f.write(readme)
# Save our metrics to Readme metadata
metadata_save(readme_path, metadata)
# Step 6: Record a video
video_path = repo_local_path / "replay.mp4"
record_video(env, model["qtable"], video_path, video_fps)
# Step 7. Push everything to the Hub
api.upload_folder(
repo_id=repo_id,
folder_path=repo_local_path,
path_in_repo=".",
)
print("Your model is pushed to the Hub. You can view your model here: ", repo_url)
```
### .
By using `push_to_hub` **you evaluate, record a replay, generate a model card of your agent and push it to the Hub**.
This way:
- You can **showcase our work** 🔥
- You can **visualize your agent playing** 👀
- You can **share an agent with the community that others can use** 💾
- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
To be able to share your model with the community there are three more steps to follow:
1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/create-token.jpg" alt="Create HF Token">
```python
from huggingface_hub import notebook_login
notebook_login()
```
If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login` (or `login`)
3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `push_to_hub()` function
- Let's create **the model dictionary that contains the hyperparameters and the Q_table**.
```python
model = {
"env_id": env_id,
"max_steps": max_steps,
"n_training_episodes": n_training_episodes,
"n_eval_episodes": n_eval_episodes,
"eval_seed": eval_seed,
"learning_rate": learning_rate,
"gamma": gamma,
"max_epsilon": max_epsilon,
"min_epsilon": min_epsilon,
"decay_rate": decay_rate,
"qtable": Qtable_frozenlake,
}
```
Let's fill the `push_to_hub` function:
- `repo_id`: the name of the Hugging Face Hub Repository that will be created/updated `
(repo_id = {username}/{repo_name})`
💡 A good `repo_id` is `{username}/q-{env_id}`
- `model`: our model dictionary containing the hyperparameters and the Qtable.
- `env`: the environment.
- `commit_message`: message of the commit
```python
model
```
```python
username = "" # FILL THIS
repo_name = "q-FrozenLake-v1-4x4-noSlippery"
push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
```
Congrats 🥳 you've just implemented from scratch, trained, and uploaded your first Reinforcement Learning agent.
FrozenLake-v1 no_slippery is very simple environment, let's try a harder one 🔥.
# Part 2: Taxi-v3 🚖
## Create and understand [Taxi-v3 🚕](https://gymnasium.farama.org/environments/toy_text/taxi/)
---
💡 A good habit when you start to use an environment is to check its documentation
👉 https://gymnasium.farama.org/environments/toy_text/taxi/
---
In `Taxi-v3` 🚕, there are four designated locations in the grid world indicated by R(ed), G(reen), Y(ellow), and B(lue).
When the episode starts, **the taxi starts off at a random square** and the passenger is at a random location. The taxi drives to the passenger’s location, **picks up the passenger**, drives to the passenger’s destination (another one of the four specified locations), and then **drops off the passenger**. Once the passenger is dropped off, the episode ends.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit2/taxi.png" alt="Taxi">
```python
env = gym.make("Taxi-v3", render_mode="rgb_array")
```
There are **500 discrete states since there are 25 taxi positions, 5 possible locations of the passenger** (including the case when the passenger is in the taxi), and **4 destination locations.**
```python
state_space = env.observation_space.n
print("There are ", state_space, " possible states")
```
```python
action_space = env.action_space.n
print("There are ", action_space, " possible actions")
```
The action space (the set of possible actions the agent can take) is discrete with **6 actions available 🎮**:
- 0: move south
- 1: move north
- 2: move east
- 3: move west
- 4: pickup passenger
- 5: drop off passenger
Reward function 💰:
- -1 per step unless other reward is triggered.
- +20 delivering passenger.
- -10 executing “pickup” and “drop-off” actions illegally.
```python
# Create our Q table with state_size rows and action_size columns (500x6)
Qtable_taxi = initialize_q_table(state_space, action_space)
print(Qtable_taxi)
print("Q-table shape: ", Qtable_taxi.shape)
```
## Define the hyperparameters ⚙️
⚠ DO NOT MODIFY EVAL_SEED: the eval_seed array **allows us to evaluate your agent with the same taxi starting positions for every classmate**
```python
# Training parameters
n_training_episodes = 25000 # Total training episodes
learning_rate = 0.7 # Learning rate
# Evaluation parameters
n_eval_episodes = 100 # Total number of test episodes
# DO NOT MODIFY EVAL_SEED
eval_seed = [
16,
54,
165,
177,
191,
191,
120,
80,
149,
178,
48,
38,
6,
125,
174,
73,
50,
172,
100,
148,
146,
6,
25,
40,
68,
148,
49,
167,
9,
97,
164,
176,
61,
7,
54,
55,
161,
131,
184,
51,
170,
12,
120,
113,
95,
126,
51,
98,
36,
135,
54,
82,
45,
95,
89,
59,
95,
124,
9,
113,
58,
85,
51,
134,
121,
169,
105,
21,
30,
11,
50,
65,
12,
43,
82,
145,
152,
97,
106,
55,
31,
85,
38,
112,
102,
168,
123,
97,
21,
83,
158,
26,
80,
63,
5,
81,
32,
11,
28,
148,
] # Evaluation seed, this ensures that all classmates agents are trained on the same taxi starting position
# Each seed has a specific starting state
# Environment parameters
env_id = "Taxi-v3" # Name of the environment
max_steps = 99 # Max steps per episode
gamma = 0.95 # Discounting rate
# Exploration parameters
max_epsilon = 1.0 # Exploration probability at start
min_epsilon = 0.05 # Minimum exploration probability
decay_rate = 0.005 # Exponential decay rate for exploration prob
```
## Train our Q-Learning agent 🏃
```python
Qtable_taxi = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_taxi)
Qtable_taxi
```
## Create a model dictionary 💾 and publish our trained model to the Hub 🔥
- We create a model dictionary that will contain all the training hyperparameters for reproducibility and the Q-Table.
```python
model = {
"env_id": env_id,
"max_steps": max_steps,
"n_training_episodes": n_training_episodes,
"n_eval_episodes": n_eval_episodes,
"eval_seed": eval_seed,
"learning_rate": learning_rate,
"gamma": gamma,
"max_epsilon": max_epsilon,
"min_epsilon": min_epsilon,
"decay_rate": decay_rate,
"qtable": Qtable_taxi,
}
```
```python
username = "" # FILL THIS
repo_name = "" # FILL THIS
push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
```
Now that it's on the Hub, you can compare the results of your Taxi-v3 with your classmates using the leaderboard 🏆 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit2/taxi-leaderboard.png" alt="Taxi Leaderboard">
# Part 3: Load from Hub 🔽
What's amazing with Hugging Face Hub 🤗 is that you can easily load powerful models from the community.
Loading a saved model from the Hub is really easy:
1. You go https://huggingface.co/models?other=q-learning to see the list of all the q-learning saved models.
2. You select one and copy its repo_id
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit2/copy-id.png" alt="Copy id">
3. Then we just need to use `load_from_hub` with:
- The repo_id
- The filename: the saved model inside the repo.
#### Do not modify this code
```python
from urllib.error import HTTPError
from huggingface_hub import hf_hub_download
def load_from_hub(repo_id: str, filename: str) -> str:
"""
Download a model from Hugging Face Hub.
:param repo_id: id of the model repository from the Hugging Face Hub
:param filename: name of the model zip file from the repository
"""
# Get the model from the Hub, download and cache the model on your local disk
pickle_model = hf_hub_download(repo_id=repo_id, filename=filename)
with open(pickle_model, "rb") as f:
downloaded_model_file = pickle.load(f)
return downloaded_model_file
```
### .
```python
model = load_from_hub(repo_id="ThomasSimonini/q-Taxi-v3", filename="q-learning.pkl") # Try to use another model
print(model)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
```python
model = load_from_hub(
repo_id="ThomasSimonini/q-FrozenLake-v1-no-slippery", filename="q-learning.pkl"
) # Try to use another model
env = gym.make(model["env_id"], is_slippery=False)
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
## Some additional challenges 🏆
The best way to learn **is to try things on your own**! As you saw, the current agent is not doing great. As a first suggestion, you can train for more steps. With 1,000,000 steps, we saw some great results!
In the [Leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) you will find your agents. Can you get to the top?
Here are some ideas to climb up the leaderboard:
* Train more steps
* Try different hyperparameters by looking at what your classmates have done.
* **Push your new trained model** on the Hub 🔥
Are walking on ice and driving taxis too boring to you? Try to **change the environment**, why not use FrozenLake-v1 slippery version? Check how they work [using the gymnasium documentation](https://gymnasium.farama.org/) and have fun 🎉.
_____________________________________________________________________
Congrats 🥳, you've just implemented, trained, and uploaded your first Reinforcement Learning agent.
Understanding Q-Learning is an **important step to understanding value-based methods.**
In the next Unit with Deep Q-Learning, we'll see that while creating and updating a Q-table was a good strategy — **however, it is not scalable.**
For instance, imagine you create an agent that learns to play Doom.
<img src="https://vizdoom.cs.put.edu.pl/user/pages/01.tutorial/basic.png" alt="Doom"/>
Doom is a large environment with a huge state space (millions of different states). Creating and updating a Q-table for that environment would not be efficient.
That's why we'll study Deep Q-Learning in the next unit, an algorithm **where we use a neural network that approximates, given a state, the different Q-values for each action.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/atari-envs.gif" alt="Environments"/>
See you in Unit 3! 🔥
## Keep learning, stay awesome 🤗
| huggingface/deep-rl-class/blob/main/units/en/unit2/hands-on.mdx |
FrameworkSwitchCourse {fw} />
# Putting it all together[[putting-it-all-together]]
{#if fw === 'pt'}
<CourseFloatingBanner chapter={2}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter2/section6_pt.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter2/section6_pt.ipynb"},
]} />
{:else}
<CourseFloatingBanner chapter={2}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter2/section6_tf.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter2/section6_tf.ipynb"},
]} />
{/if}
In the last few sections, we've been trying our best to do most of the work by hand. We've explored how tokenizers work and looked at tokenization, conversion to input IDs, padding, truncation, and attention masks.
However, as we saw in section 2, the 🤗 Transformers API can handle all of this for us with a high-level function that we'll dive into here. When you call your `tokenizer` directly on the sentence, you get back inputs that are ready to pass through your model:
```py
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
```
Here, the `model_inputs` variable contains everything that's necessary for a model to operate well. For DistilBERT, that includes the input IDs as well as the attention mask. Other models that accept additional inputs will also have those output by the `tokenizer` object.
As we'll see in some examples below, this method is very powerful. First, it can tokenize a single sequence:
```py
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
```
It also handles multiple sequences at a time, with no change in the API:
```py
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
model_inputs = tokenizer(sequences)
```
It can pad according to several objectives:
```py
# Will pad the sequences up to the maximum sequence length
model_inputs = tokenizer(sequences, padding="longest")
# Will pad the sequences up to the model max length
# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, padding="max_length")
# Will pad the sequences up to the specified max length
model_inputs = tokenizer(sequences, padding="max_length", max_length=8)
```
It can also truncate sequences:
```py
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
# Will truncate the sequences that are longer than the model max length
# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, truncation=True)
# Will truncate the sequences that are longer than the specified max length
model_inputs = tokenizer(sequences, max_length=8, truncation=True)
```
The `tokenizer` object can handle the conversion to specific framework tensors, which can then be directly sent to the model. For example, in the following code sample we are prompting the tokenizer to return tensors from the different frameworks — `"pt"` returns PyTorch tensors, `"tf"` returns TensorFlow tensors, and `"np"` returns NumPy arrays:
```py
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
# Returns PyTorch tensors
model_inputs = tokenizer(sequences, padding=True, return_tensors="pt")
# Returns TensorFlow tensors
model_inputs = tokenizer(sequences, padding=True, return_tensors="tf")
# Returns NumPy arrays
model_inputs = tokenizer(sequences, padding=True, return_tensors="np")
```
## Special tokens[[special-tokens]]
If we take a look at the input IDs returned by the tokenizer, we will see they are a tiny bit different from what we had earlier:
```py
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
print(model_inputs["input_ids"])
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
```
```python out
[101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102]
[1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012]
```
One token ID was added at the beginning, and one at the end. Let's decode the two sequences of IDs above to see what this is about:
```py
print(tokenizer.decode(model_inputs["input_ids"]))
print(tokenizer.decode(ids))
```
```python out
"[CLS] i've been waiting for a huggingface course my whole life. [SEP]"
"i've been waiting for a huggingface course my whole life."
```
The tokenizer added the special word `[CLS]` at the beginning and the special word `[SEP]` at the end. This is because the model was pretrained with those, so to get the same results for inference we need to add them as well. Note that some models don't add special words, or add different ones; models may also add these special words only at the beginning, or only at the end. In any case, the tokenizer knows which ones are expected and will deal with this for you.
## Wrapping up: From tokenizer to model[[wrapping-up-from-tokenizer-to-model]]
Now that we've seen all the individual steps the `tokenizer` object uses when applied on texts, let's see one final time how it can handle multiple sequences (padding!), very long sequences (truncation!), and multiple types of tensors with its main API:
{#if fw === 'pt'}
```py
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
output = model(**tokens)
```
{:else}
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="tf")
output = model(**tokens)
```
{/if}
| huggingface/course/blob/main/chapters/en/chapter2/6.mdx |
`@gradio/button`
```html
<script>
import { Button } from "@gradio/button";
</script>
<button type="primary|secondary" href="string" on:click="{e.detail === href}">
content
</button>
```
| gradio-app/gradio/blob/main/js/tootils/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Safe Stable Diffusion
Safe Stable Diffusion was proposed in [Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models](https://huggingface.co/papers/2211.05105) and mitigates inappropriate degeneration from Stable Diffusion models because they're trained on unfiltered web-crawled datasets. For instance Stable Diffusion may unexpectedly generate nudity, violence, images depicting self-harm, and otherwise offensive content. Safe Stable Diffusion is an extension of Stable Diffusion that drastically reduces this type of content.
The abstract from the paper is:
*Text-conditioned image generation models have recently achieved astonishing results in image quality and text alignment and are consequently employed in a fast-growing number of applications. Since they are highly data-driven, relying on billion-sized datasets randomly scraped from the internet, they also suffer, as we demonstrate, from degenerated and biased human behavior. In turn, they may even reinforce such biases. To help combat these undesired side effects, we present safe latent diffusion (SLD). Specifically, to measure the inappropriate degeneration due to unfiltered and imbalanced training sets, we establish a novel image generation test bed-inappropriate image prompts (I2P)-containing dedicated, real-world image-to-text prompts covering concepts such as nudity and violence. As our exhaustive empirical evaluation demonstrates, the introduced SLD removes and suppresses inappropriate image parts during the diffusion process, with no additional training required and no adverse effect on overall image quality or text alignment.*
## Tips
Use the `safety_concept` property of [`StableDiffusionPipelineSafe`] to check and edit the current safety concept:
```python
>>> from diffusers import StableDiffusionPipelineSafe
>>> pipeline = StableDiffusionPipelineSafe.from_pretrained("AIML-TUDA/stable-diffusion-safe")
>>> pipeline.safety_concept
'an image showing hate, harassment, violence, suffering, humiliation, harm, suicide, sexual, nudity, bodily fluids, blood, obscene gestures, illegal activity, drug use, theft, vandalism, weapons, child abuse, brutality, cruelty'
```
For each image generation the active concept is also contained in [`StableDiffusionSafePipelineOutput`].
There are 4 configurations (`SafetyConfig.WEAK`, `SafetyConfig.MEDIUM`, `SafetyConfig.STRONG`, and `SafetyConfig.MAX`) that can be applied:
```python
>>> from diffusers import StableDiffusionPipelineSafe
>>> from diffusers.pipelines.stable_diffusion_safe import SafetyConfig
>>> pipeline = StableDiffusionPipelineSafe.from_pretrained("AIML-TUDA/stable-diffusion-safe")
>>> prompt = "the four horsewomen of the apocalypse, painting by tom of finland, gaston bussiere, craig mullins, j. c. leyendecker"
>>> out = pipeline(prompt=prompt, **SafetyConfig.MAX)
```
<Tip>
Make sure to check out the Stable Diffusion [Tips](overview#tips) section to learn how to explore the tradeoff between scheduler speed and quality, and how to reuse pipeline components efficiently!
</Tip>
## StableDiffusionPipelineSafe
[[autodoc]] StableDiffusionPipelineSafe
- all
- __call__
## StableDiffusionSafePipelineOutput
[[autodoc]] pipelines.stable_diffusion_safe.StableDiffusionSafePipelineOutput
- all
- __call__
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/stable_diffusion/stable_diffusion_safe.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Nezha
## Overview
The Nezha model was proposed in [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei et al.
The abstract from the paper is the following:
*The pre-trained language models have achieved great successes in various natural language understanding (NLU) tasks
due to its capacity to capture the deep contextualized information in text by pre-training on large-scale corpora.
In this technical report, we present our practice of pre-training language models named NEZHA (NEural contextualiZed
representation for CHinese lAnguage understanding) on Chinese corpora and finetuning for the Chinese NLU tasks.
The current version of NEZHA is based on BERT with a collection of proven improvements, which include Functional
Relative Positional Encoding as an effective positional encoding scheme, Whole Word Masking strategy,
Mixed Precision Training and the LAMB Optimizer in training the models. The experimental results show that NEZHA
achieves the state-of-the-art performances when finetuned on several representative Chinese tasks, including
named entity recognition (People's Daily NER), sentence matching (LCQMC), Chinese sentiment classification (ChnSenti)
and natural language inference (XNLI).*
This model was contributed by [sijunhe](https://huggingface.co/sijunhe). The original code can be found [here](https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/NEZHA-PyTorch).
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## NezhaConfig
[[autodoc]] NezhaConfig
## NezhaModel
[[autodoc]] NezhaModel
- forward
## NezhaForPreTraining
[[autodoc]] NezhaForPreTraining
- forward
## NezhaForMaskedLM
[[autodoc]] NezhaForMaskedLM
- forward
## NezhaForNextSentencePrediction
[[autodoc]] NezhaForNextSentencePrediction
- forward
## NezhaForSequenceClassification
[[autodoc]] NezhaForSequenceClassification
- forward
## NezhaForMultipleChoice
[[autodoc]] NezhaForMultipleChoice
- forward
## NezhaForTokenClassification
[[autodoc]] NezhaForTokenClassification
- forward
## NezhaForQuestionAnswering
[[autodoc]] NezhaForQuestionAnswering
- forward | huggingface/transformers/blob/main/docs/source/en/model_doc/nezha.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Overview
A pipeline is an end-to-end class that provides a quick and easy way to use a diffusion system for inference by bundling independently trained models and schedulers together. Certain combinations of models and schedulers define specific pipeline types, like [`StableDiffusionXLPipeline`] or [`StableDiffusionControlNetPipeline`], with specific capabilities. All pipeline types inherit from the base [`DiffusionPipeline`] class; pass it any checkpoint, and it'll automatically detect the pipeline type and load the necessary components.
This section demonstrates how to use specific pipelines such as Stable Diffusion XL, ControlNet, and DiffEdit. You'll also learn how to use a distilled version of the Stable Diffusion model to speed up inference, how to create reproducible pipelines, and how to use and contribute community pipelines.
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/pipeline_overview.md |
!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# 🤗 Transformers Notebooks
You can find here a list of the official notebooks provided by Hugging Face.
Also, we would like to list here interesting content created by the community.
If you wrote some notebook(s) leveraging 🤗 Transformers and would like to be listed here, please open a
Pull Request so it can be included under the Community notebooks.
## Hugging Face's notebooks 🤗
### Documentation notebooks
You can open any page of the documentation as a notebook in Colab (there is a button directly on said pages) but they are also listed here if you need them:
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [Quicktour of the library](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/quicktour.ipynb) | A presentation of the various APIs in Transformers |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/quicktour.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/en/transformers_doc/quicktour.ipynb)|
| [Summary of the tasks](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/task_summary.ipynb) | How to run the models of the Transformers library task by task |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/task_summary.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/task_summary.ipynb)|
| [Preprocessing data](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/preprocessing.ipynb) | How to use a tokenizer to preprocess your data |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/preprocessing.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/preprocessing.ipynb)|
| [Fine-tuning a pretrained model](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/training.ipynb) | How to use the Trainer to fine-tune a pretrained model |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/training.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/training.ipynb)|
| [Summary of the tokenizers](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/tokenizer_summary.ipynb) | The differences between the tokenizers algorithm |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/tokenizer_summary.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/tokenizer_summary.ipynb)|
| [Multilingual models](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/multilingual.ipynb) | How to use the multilingual models of the library |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/multilingual.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/multilingual.ipynb)|
### PyTorch Examples
#### Natural Language Processing[[pytorch-nlp]]
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [Train your tokenizer](https://github.com/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb) | How to train and use your very own tokenizer |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb)|
| [Train your language model](https://github.com/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch.ipynb) | How to easily start using transformers |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch.ipynb)|
| [How to fine-tune a model on text classification](https://github.com/huggingface/notebooks/blob/main/examples/text_classification.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on any GLUE task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)|
| [How to fine-tune a model on language modeling](https://github.com/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on a causal or masked LM task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)|
| [How to fine-tune a model on token classification](https://github.com/huggingface/notebooks/blob/main/examples/token_classification.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on a token classification task (NER, PoS). | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)|
| [How to fine-tune a model on question answering](https://github.com/huggingface/notebooks/blob/main/examples/question_answering.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on SQUAD. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)|
| [How to fine-tune a model on multiple choice](https://github.com/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on SWAG. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)|
| [How to fine-tune a model on translation](https://github.com/huggingface/notebooks/blob/main/examples/translation.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on WMT. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/translation.ipynb)|
| [How to fine-tune a model on summarization](https://github.com/huggingface/notebooks/blob/main/examples/summarization.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on XSUM. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)|
| [How to train a language model from scratch](https://github.com/huggingface/blog/blob/main/notebooks/01_how_to_train.ipynb)| Highlight all the steps to effectively train Transformer model on custom data | [](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/01_how_to_train.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/blog/blob/main/notebooks/01_how_to_train.ipynb)|
| [How to generate text](https://github.com/huggingface/blog/blob/main/notebooks/02_how_to_generate.ipynb)| How to use different decoding methods for language generation with transformers | [](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/02_how_to_generate.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/blog/blob/main/notebooks/02_how_to_generate.ipynb)|
| [How to generate text (with constraints)](https://github.com/huggingface/blog/blob/main/notebooks/53_constrained_beam_search.ipynb)| How to guide language generation with user-provided constraints | [](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/53_constrained_beam_search.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/blog/blob/main/notebooks/53_constrained_beam_search.ipynb)|
| [Reformer](https://github.com/huggingface/blog/blob/main/notebooks/03_reformer.ipynb)| How Reformer pushes the limits of language modeling | [](https://colab.research.google.com/github/patrickvonplaten/blog/blob/main/notebooks/03_reformer.ipynb)| [](https://studiolab.sagemaker.aws/import/github/patrickvonplaten/blog/blob/main/notebooks/03_reformer.ipynb)|
#### Computer Vision[[pytorch-cv]]
| Notebook | Description | | |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------:|
| [How to fine-tune a model on image classification (Torchvision)](https://github.com/huggingface/notebooks/blob/main/examples/image_classification.ipynb) | Show how to preprocess the data using Torchvision and fine-tune any pretrained Vision model on Image Classification | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)|
| [How to fine-tune a model on image classification (Albumentations)](https://github.com/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) | Show how to preprocess the data using Albumentations and fine-tune any pretrained Vision model on Image Classification | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb)|
| [How to fine-tune a model on image classification (Kornia)](https://github.com/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb) | Show how to preprocess the data using Kornia and fine-tune any pretrained Vision model on Image Classification | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb)|
| [How to perform zero-shot object detection with OWL-ViT](https://github.com/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb) | Show how to perform zero-shot object detection on images with text queries | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb)|
| [How to fine-tune an image captioning model](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) | Show how to fine-tune BLIP for image captioning on a custom dataset | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb)|
| [How to build an image similarity system with Transformers](https://github.com/huggingface/notebooks/blob/main/examples/image_similarity.ipynb) | Show how to build an image similarity system | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_similarity.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_similarity.ipynb)|
| [How to fine-tune a SegFormer model on semantic segmentation](https://github.com/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb) | Show how to preprocess the data and fine-tune a pretrained SegFormer model on Semantic Segmentation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb)|
| [How to fine-tune a VideoMAE model on video classification](https://github.com/huggingface/notebooks/blob/main/examples/video_classification.ipynb) | Show how to preprocess the data and fine-tune a pretrained VideoMAE model on Video Classification | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/video_classification.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/video_classification.ipynb)|
#### Audio[[pytorch-audio]]
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [How to fine-tune a speech recognition model in English](https://github.com/huggingface/notebooks/blob/main/examples/speech_recognition.ipynb)| Show how to preprocess the data and fine-tune a pretrained Speech model on TIMIT | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/speech_recognition.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/speech_recognition.ipynb)|
| [How to fine-tune a speech recognition model in any language](https://github.com/huggingface/notebooks/blob/main/examples/multi_lingual_speech_recognition.ipynb)| Show how to preprocess the data and fine-tune a multi-lingually pretrained speech model on Common Voice | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multi_lingual_speech_recognition.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/multi_lingual_speech_recognition.ipynb)|
| [How to fine-tune a model on audio classification](https://github.com/huggingface/notebooks/blob/main/examples/audio_classification.ipynb)| Show how to preprocess the data and fine-tune a pretrained Speech model on Keyword Spotting | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb)|
#### Biological Sequences[[pytorch-bio]]
| Notebook | Description | | |
|:----------|:----------------------------------------------------------------------------------------|:-------------|------:|
| [How to fine-tune a pre-trained protein model](https://github.com/huggingface/notebooks/blob/main/examples/protein_language_modeling.ipynb) | See how to tokenize proteins and fine-tune a large pre-trained protein "language" model | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_language_modeling.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/protein_language_modeling.ipynb) |
| [How to generate protein folds](https://github.com/huggingface/notebooks/blob/main/examples/protein_folding.ipynb) | See how to go from protein sequence to a full protein model and PDB file | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_folding.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/protein_folding.ipynb) |
| [How to fine-tune a Nucleotide Transformer model](https://github.com/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling.ipynb) | See how to tokenize DNA and fine-tune a large pre-trained DNA "language" model | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling.ipynb) |
| [Fine-tune a Nucleotide Transformer model with LoRA](https://github.com/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling_with_peft.ipynb) | Train even larger DNA models in a memory-efficient way | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling_with_peft.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling_with_peft.ipynb) |
#### Other modalities[[pytorch-other]]
| Notebook | Description | | |
|:----------|:----------------------------------------------------------------------------------------|:-------------|------:|
| [Probabilistic Time Series Forecasting](https://github.com/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb) | See how to train Time Series Transformer on a custom dataset | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb) |
#### Utility notebooks[[pytorch-utility]]
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [How to export model to ONNX](https://github.com/huggingface/notebooks/blob/main/examples/onnx-export.ipynb)| Highlight how to export and run inference workloads through ONNX |
| [How to use Benchmarks](https://github.com/huggingface/notebooks/blob/main/examples/benchmark.ipynb)| How to benchmark models with transformers | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/benchmark.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/benchmark.ipynb)|
### TensorFlow Examples
#### Natural Language Processing[[tensorflow-nlp]]
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [Train your tokenizer](https://github.com/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb) | How to train and use your very own tokenizer |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb)|
| [Train your language model](https://github.com/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch-tf.ipynb) | How to easily start using transformers |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch-tf.ipynb)|
| [How to fine-tune a model on text classification](https://github.com/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on any GLUE task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)|
| [How to fine-tune a model on language modeling](https://github.com/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on a causal or masked LM task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)|
| [How to fine-tune a model on token classification](https://github.com/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on a token classification task (NER, PoS). | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)|
| [How to fine-tune a model on question answering](https://github.com/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on SQUAD. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)|
| [How to fine-tune a model on multiple choice](https://github.com/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on SWAG. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb)|
| [How to fine-tune a model on translation](https://github.com/huggingface/notebooks/blob/main/examples/translation-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on WMT. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb)|
| [How to fine-tune a model on summarization](https://github.com/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on XSUM. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb)|
#### Computer Vision[[tensorflow-cv]]
| Notebook | Description | | |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------------------------|:-------------|------:|
| [How to fine-tune a model on image classification](https://github.com/huggingface/notebooks/blob/main/examples/image_classification-tf.ipynb) | Show how to preprocess the data and fine-tune any pretrained Vision model on Image Classification | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_classification-tf.ipynb)|
| [How to fine-tune a SegFormer model on semantic segmentation](https://github.com/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb) | Show how to preprocess the data and fine-tune a pretrained SegFormer model on Semantic Segmentation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb)|
#### Biological Sequences[[tensorflow-bio]]
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [How to fine-tune a pre-trained protein model](https://github.com/huggingface/notebooks/blob/main/examples/protein_language_modeling-tf.ipynb) | See how to tokenize proteins and fine-tune a large pre-trained protein "language" model | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_language_modeling-tf.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/protein_language_modeling-tf.ipynb) |
#### Utility notebooks[[tensorflow-utility]]
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [How to train TF/Keras models on TPU](https://github.com/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) | See how to train at high speed on Google's TPU hardware | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) |
### Optimum notebooks
🤗 [Optimum](https://github.com/huggingface/optimum) is an extension of 🤗 Transformers, providing a set of performance optimization tools enabling maximum efficiency to train and run models on targeted hardwares.
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [How to quantize a model with ONNX Runtime for text classification](https://github.com/huggingface/notebooks/blob/main/examples/text_classification_quantization_ort.ipynb)| Show how to apply static and dynamic quantization on a model using [ONNX Runtime](https://github.com/microsoft/onnxruntime) for any GLUE task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_quantization_ort.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/text_classification_quantization_ort.ipynb)|
| [How to quantize a model with Intel Neural Compressor for text classification](https://github.com/huggingface/notebooks/blob/main/examples/text_classification_quantization_inc.ipynb)| Show how to apply static, dynamic and aware training quantization on a model using [Intel Neural Compressor (INC)](https://github.com/intel/neural-compressor) for any GLUE task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_quantization_inc.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/text_classification_quantization_inc.ipynb)|
| [How to fine-tune a model on text classification with ONNX Runtime](https://github.com/huggingface/notebooks/blob/main/examples/text_classification_ort.ipynb)| Show how to preprocess the data and fine-tune a model on any GLUE task using [ONNX Runtime](https://github.com/microsoft/onnxruntime). | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_ort.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/text_classification_ort.ipynb)|
| [How to fine-tune a model on summarization with ONNX Runtime](https://github.com/huggingface/notebooks/blob/main/examples/summarization_ort.ipynb)| Show how to preprocess the data and fine-tune a model on XSUM using [ONNX Runtime](https://github.com/microsoft/onnxruntime). | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization_ort.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/summarization_ort.ipynb)|
## Community notebooks:
More notebooks developed by the community are available [here](https://hf.co/docs/transformers/community#community-notebooks).
| huggingface/transformers/blob/main/docs/source/en/notebooks.md |
(Gluon) Inception v3
**Inception v3** is a convolutional neural network architecture from the Inception family that makes several improvements including using [Label Smoothing](https://paperswithcode.com/method/label-smoothing), Factorized 7 x 7 convolutions, and the use of an [auxiliary classifer](https://paperswithcode.com/method/auxiliary-classifier) to propagate label information lower down the network (along with the use of batch normalization for layers in the sidehead). The key building block is an [Inception Module](https://paperswithcode.com/method/inception-v3-module).
The weights from this model were ported from [Gluon](https://cv.gluon.ai/model_zoo/classification.html).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('gluon_inception_v3', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `gluon_inception_v3`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('gluon_inception_v3', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/SzegedyVISW15,
author = {Christian Szegedy and
Vincent Vanhoucke and
Sergey Ioffe and
Jonathon Shlens and
Zbigniew Wojna},
title = {Rethinking the Inception Architecture for Computer Vision},
journal = {CoRR},
volume = {abs/1512.00567},
year = {2015},
url = {http://arxiv.org/abs/1512.00567},
archivePrefix = {arXiv},
eprint = {1512.00567},
timestamp = {Mon, 13 Aug 2018 16:49:07 +0200},
biburl = {https://dblp.org/rec/journals/corr/SzegedyVISW15.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: Gloun Inception v3
Paper:
Title: Rethinking the Inception Architecture for Computer Vision
URL: https://paperswithcode.com/paper/rethinking-the-inception-architecture-for
Models:
- Name: gluon_inception_v3
In Collection: Gloun Inception v3
Metadata:
FLOPs: 7352418880
Parameters: 23830000
File Size: 95567055
Architecture:
- 1x1 Convolution
- Auxiliary Classifier
- Average Pooling
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inception-v3 Module
- Max Pooling
- ReLU
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: gluon_inception_v3
Crop Pct: '0.875'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/inception_v3.py#L464
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/gluon_inception_v3-9f746940.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.8%
Top 5 Accuracy: 94.38%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/gloun-inception-v3.mdx |
Gradio Demo: chicago-bikeshare-dashboard
```
!pip install -q gradio psycopg2 matplotlib SQLAlchemy
```
```
import os
import gradio as gr
import pandas as pd
DB_USER = os.getenv("DB_USER")
DB_PASSWORD = os.getenv("DB_PASSWORD")
DB_HOST = os.getenv("DB_HOST")
PORT = 8080
DB_NAME = "bikeshare"
connection_string = (
f"postgresql://{DB_USER}:{DB_PASSWORD}@{DB_HOST}?port={PORT}&dbname={DB_NAME}"
)
def get_count_ride_type():
df = pd.read_sql(
"""
SELECT COUNT(ride_id) as n, rideable_type
FROM rides
GROUP BY rideable_type
ORDER BY n DESC
""",
con=connection_string,
)
return df
def get_most_popular_stations():
df = pd.read_sql(
"""
SELECT COUNT(ride_id) as n, MAX(start_station_name) as station
FROM RIDES
WHERE start_station_name is NOT NULL
GROUP BY start_station_id
ORDER BY n DESC
LIMIT 5
""",
con=connection_string,
)
return df
with gr.Blocks() as demo:
gr.Markdown(
"""
# Chicago Bike Share Dashboard
This demo pulls Chicago bike share data for March 2022 from a postgresql database hosted on AWS.
This demo uses psycopg2 but any postgresql client library (SQLAlchemy)
is compatible with gradio.
Connection credentials are handled by environment variables
defined as secrets in the Space.
If data were added to the database, the plots in this demo would update
whenever the webpage is reloaded.
This demo serves as a starting point for your database-connected apps!
"""
)
with gr.Row():
bike_type = gr.BarPlot(
x="rideable_type",
y='n',
title="Number of rides per bicycle type",
y_title="Number of Rides",
x_title="Bicycle Type",
vertical=False,
tooltip=['rideable_type', "n"],
height=300,
width=300,
)
station = gr.BarPlot(
x='station',
y='n',
title="Most Popular Stations",
y_title="Number of Rides",
x_title="Station Name",
vertical=False,
tooltip=['station', 'n'],
height=300,
width=300
)
demo.load(get_count_ride_type, inputs=None, outputs=bike_type)
demo.load(get_most_popular_stations, inputs=None, outputs=station)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/chicago-bikeshare-dashboard/run.ipynb |
(Legacy) SENet
A **SENet** is a convolutional neural network architecture that employs [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block) to enable the network to perform dynamic channel-wise feature recalibration.
The weights from this model were ported from Gluon.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('legacy_senet154', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `legacy_senet154`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('legacy_senet154', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{hu2019squeezeandexcitation,
title={Squeeze-and-Excitation Networks},
author={Jie Hu and Li Shen and Samuel Albanie and Gang Sun and Enhua Wu},
year={2019},
eprint={1709.01507},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Legacy SENet
Paper:
Title: Squeeze-and-Excitation Networks
URL: https://paperswithcode.com/paper/squeeze-and-excitation-networks
Models:
- Name: legacy_senet154
In Collection: Legacy SENet
Metadata:
FLOPs: 26659556016
Parameters: 115090000
File Size: 461488402
Architecture:
- Convolution
- Dense Connections
- Global Average Pooling
- Max Pooling
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_senet154
LR: 0.6
Epochs: 100
Layers: 154
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L440
Weights: http://data.lip6.fr/cadene/pretrainedmodels/senet154-c7b49a05.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.33%
Top 5 Accuracy: 95.51%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/legacy-senet.mdx |
Models
The Hugging Face Hub hosts many models for a [variety of machine learning tasks](https://huggingface.co/tasks). Models are stored in repositories, so they benefit from [all the features](./repositories) possessed by every repo on the Hugging Face Hub. Additionally, model repos have attributes that make exploring and using models as easy as possible. These docs will take you through everything you'll need to know to find models on the Hub, upload your models, and make the most of everything the Model Hub offers!
## Contents
- [The Model Hub](./models-the-hub)
- [Model Cards](./model-cards)
- [CO<sub>2</sub> emissions](./model-cards-co2)
- [Gated models](./models-gated)
- [Libraries](./models-libraries)
- [Uploading Models](./models-uploading)
- [Downloading Models](./models-downloading)
- [Widgets](./models-widgets)
- [Widget Examples](./models-widgets-examples)
- [Inference API](./models-inference)
- [Frequently Asked Questions](./models-faq)
- [Advanced Topics](./models-advanced)
- [Integrating libraries with the Hub](./models-adding-libraries)
- [Tasks](./models-tasks)
| huggingface/hub-docs/blob/main/docs/hub/models.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# SwitchTransformers
## Overview
The SwitchTransformers model was proposed in [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
The Switch Transformer model uses a sparse T5 encoder-decoder architecture, where the MLP are replaced by a Mixture of Experts (MoE). A routing mechanism (top 1 in this case) associates each token to one of the expert, where each expert is a dense MLP. While switch transformers have a lot more weights than their equivalent dense models, the sparsity allows better scaling and better finetuning performance at scale.
During a forward pass, only a fraction of the weights are used. The routing mechanism allows the model to select relevant weights on the fly which increases the model capacity without increasing the number of operations.
The abstract from the paper is the following:
*In deep learning, models typically reuse the same parameters for all inputs. Mixture of Experts (MoE) defies this and instead selects different parameters for each incoming example. The result is a sparsely-activated model -- with outrageous numbers of parameters -- but a constant computational cost. However, despite several notable successes of MoE, widespread adoption has been hindered by complexity, communication costs and training instability -- we address these with the Switch Transformer. We simplify the MoE routing algorithm and design intuitive improved models with reduced communication and computational costs. Our proposed training techniques help wrangle the instabilities and we show large sparse models may be trained, for the first time, with lower precision (bfloat16) formats. We design models based off T5-Base and T5-Large to obtain up to 7x increases in pre-training speed with the same computational resources. These improvements extend into multilingual settings where we measure gains over the mT5-Base version across all 101 languages. Finally, we advance the current scale of language models by pre-training up to trillion parameter models on the "Colossal Clean Crawled Corpus" and achieve a 4x speedup over the T5-XXL model.*
This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArthurZ).
The original code can be found [here](https://github.com/google/flaxformer/tree/main/flaxformer/architectures/moe).
## Usage tips
- SwitchTransformers uses the [`T5Tokenizer`], which can be loaded directly from each model's repository.
- The released weights are pretrained on English [Masked Language Modeling](https://moon-ci-docs.huggingface.co/docs/transformers/pr_19323/en/glossary#general-terms) task, and should be finetuned.
## Resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## SwitchTransformersConfig
[[autodoc]] SwitchTransformersConfig
## SwitchTransformersTop1Router
[[autodoc]] SwitchTransformersTop1Router
- _compute_router_probabilities
- forward
## SwitchTransformersSparseMLP
[[autodoc]] SwitchTransformersSparseMLP
- forward
## SwitchTransformersModel
[[autodoc]] SwitchTransformersModel
- forward
## SwitchTransformersForConditionalGeneration
[[autodoc]] SwitchTransformersForConditionalGeneration
- forward
## SwitchTransformersEncoderModel
[[autodoc]] SwitchTransformersEncoderModel
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/switch_transformers.md |
Gradio Demo: textbox_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.Textbox()
demo.launch()
```
| gradio-app/gradio/blob/main/demo/textbox_component/run.ipynb |
--
title: "Fine-Tune ViT for Image Classification with 🤗 Transformers"
thumbnail: /blog/assets/51_fine_tune_vit/vit-thumbnail.jpg
authors:
- user: nateraw
---
# Fine-Tune ViT for Image Classification with 🤗 Transformers
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/nateraw/huggingface-hub-examples/blob/main/vit_image_classification_explained.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
Just as transformers-based models have revolutionized NLP, we're now seeing an explosion of papers applying them to all sorts of other domains. One of the most revolutionary of these was the Vision Transformer (ViT), which was introduced in [June 2021](https://arxiv.org/abs/2010.11929) by a team of researchers at Google Brain.
This paper explored how you can tokenize images, just as you would tokenize sentences, so that they can be passed to transformer models for training. It's quite a simple concept, really...
1. Split an image into a grid of sub-image patches
1. Embed each patch with a linear projection
1. Each embedded patch becomes a token, and the resulting sequence of embedded patches is the sequence you pass to the model.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="A leaf!" src="assets/51_fine_tune_vit/vit-figure.jpg"></medium-zoom>
</figure>
It turns out that once you've done the above, you can pre-train and fine-tune transformers just as you're used to with NLP tasks. Pretty sweet 😎.
---
In this blog post, we'll walk through how to leverage 🤗 `datasets` to download and process image classification datasets, and then use them to fine-tune a pre-trained ViT with 🤗 `transformers`.
To get started, let's first install both those packages.
```bash
pip install datasets transformers
```
## Load a dataset
Let's start by loading a small image classification dataset and taking a look at its structure.
We'll use the [`beans`](https://huggingface.co/datasets/beans) dataset, which is a collection of pictures of healthy and unhealthy bean leaves. 🍃
```python
from datasets import load_dataset
ds = load_dataset('beans')
ds
```
Let's take a look at the 400th example from the `'train'` split from the beans dataset. You'll notice each example from the dataset has 3 features:
1. `image`: A PIL Image
1. `image_file_path`: The `str` path to the image file that was loaded as `image`
1. `labels`: A [`datasets.ClassLabel`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=classlabel#datasets.ClassLabel) feature, which is an integer representation of the label. (Later you'll see how to get the string class names, don't worry!)
```python
ex = ds['train'][400]
ex
```
{
'image': <PIL.JpegImagePlugin ...>,
'image_file_path': '/root/.cache/.../bean_rust_train.4.jpg',
'labels': 1
}
Let's take a look at the image 👀
```python
image = ex['image']
image
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="A leaf!" src="assets/51_fine_tune_vit/example-leaf.jpg"></medium-zoom>
</figure>
That's definitely a leaf! But what kind? 😅
Since the `'labels'` feature of this dataset is a `datasets.features.ClassLabel`, we can use it to look up the corresponding name for this example's label ID.
First, let's access the feature definition for the `'labels'`.
```python
labels = ds['train'].features['labels']
labels
```
ClassLabel(num_classes=3, names=['angular_leaf_spot', 'bean_rust', 'healthy'], names_file=None, id=None)
Now, let's print out the class label for our example. You can do that by using the [`int2str`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=classlabel#datasets.ClassLabel.int2str) function of `ClassLabel`, which, as the name implies, allows to pass the integer representation of the class to look up the string label.
```python
labels.int2str(ex['labels'])
```
'bean_rust'
Turns out the leaf shown above is infected with Bean Rust, a serious disease in bean plants. 😢
Let's write a function that'll display a grid of examples from each class to get a better idea of what you're working with.
```python
import random
from PIL import ImageDraw, ImageFont, Image
def show_examples(ds, seed: int = 1234, examples_per_class: int = 3, size=(350, 350)):
w, h = size
labels = ds['train'].features['labels'].names
grid = Image.new('RGB', size=(examples_per_class * w, len(labels) * h))
draw = ImageDraw.Draw(grid)
font = ImageFont.truetype("/usr/share/fonts/truetype/liberation/LiberationMono-Bold.ttf", 24)
for label_id, label in enumerate(labels):
# Filter the dataset by a single label, shuffle it, and grab a few samples
ds_slice = ds['train'].filter(lambda ex: ex['labels'] == label_id).shuffle(seed).select(range(examples_per_class))
# Plot this label's examples along a row
for i, example in enumerate(ds_slice):
image = example['image']
idx = examples_per_class * label_id + i
box = (idx % examples_per_class * w, idx // examples_per_class * h)
grid.paste(image.resize(size), box=box)
draw.text(box, label, (255, 255, 255), font=font)
return grid
show_examples(ds, seed=random.randint(0, 1337), examples_per_class=3)
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="A leaf!" src="assets/51_fine_tune_vit/leaf-grid.jpg"></medium-zoom>
<figcaption>A grid of a few examples from each class in the dataset</figcaption>
</figure>
From what I'm seeing,
- Angular Leaf Spot: Has irregular brown patches
- Bean Rust: Has circular brown spots surrounded with a white-ish yellow ring
- Healthy: ...looks healthy. 🤷♂️
## Loading ViT Image Processor
Now we know what our images look like and better understand the problem we're trying to solve. Let's see how we can prepare these images for our model!
When ViT models are trained, specific transformations are applied to images fed into them. Use the wrong transformations on your image, and the model won't understand what it's seeing! 🖼 ➡️ 🔢
To make sure we apply the correct transformations, we will use a [`ViTImageProcessor`](https://huggingface.co/docs/transformers/model_doc/vit#transformers.ViTImageProcessor) initialized with a configuration that was saved along with the pretrained model we plan to use. In our case, we'll be using the [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) model, so let's load its image processor from the Hugging Face Hub.
```python
from transformers import ViTImageProcessor
model_name_or_path = 'google/vit-base-patch16-224-in21k'
processor = ViTImageProcessor.from_pretrained(model_name_or_path)
```
You can see the image processor configuration by printing it.
ViTImageProcessor {
"do_normalize": true,
"do_resize": true,
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
To process an image, simply pass it to the image processor's call function. This will return a dict containing `pixel values`, which is the numeric representation to be passed to the model.
You get a NumPy array by default, but if you add the `return_tensors='pt'` argument, you'll get back `torch` tensors instead.
```python
processor(image, return_tensors='pt')
```
Should give you something like...
{
'pixel_values': tensor([[[[ 0.2706, 0.3255, 0.3804, ...]]]])
}
...where the shape of the tensor is `(1, 3, 224, 224)`.
## Processing the Dataset
Now that you know how to read images and transform them into inputs, let's write a function that will put those two things together to process a single example from the dataset.
```python
def process_example(example):
inputs = processor(example['image'], return_tensors='pt')
inputs['labels'] = example['labels']
return inputs
```
```python
process_example(ds['train'][0])
```
{
'pixel_values': tensor([[[[-0.6157, -0.6000, -0.6078, ..., ]]]]),
'labels': 0
}
While you could call `ds.map` and apply this to every example at once, this can be very slow, especially if you use a larger dataset. Instead, you can apply a ***transform*** to the dataset. Transforms are only applied to examples as you index them.
First, though, you'll need to update the last function to accept a batch of data, as that's what `ds.with_transform` expects.
```python
ds = load_dataset('beans')
def transform(example_batch):
# Take a list of PIL images and turn them to pixel values
inputs = processor([x for x in example_batch['image']], return_tensors='pt')
# Don't forget to include the labels!
inputs['labels'] = example_batch['labels']
return inputs
```
You can directly apply this to the dataset using `ds.with_transform(transform)`.
```python
prepared_ds = ds.with_transform(transform)
```
Now, whenever you get an example from the dataset, the transform will be
applied in real time (on both samples and slices, as shown below)
```python
prepared_ds['train'][0:2]
```
This time, the resulting `pixel_values` tensor will have shape `(2, 3, 224, 224)`.
{
'pixel_values': tensor([[[[-0.6157, -0.6000, -0.6078, ..., ]]]]),
'labels': [0, 0]
}
# Training and Evaluation
The data is processed and you are ready to start setting up the training pipeline. This blog post uses 🤗's Trainer, but that'll require us to do a few things first:
- Define a collate function.
- Define an evaluation metric. During training, the model should be evaluated on its prediction accuracy. You should define a `compute_metrics` function accordingly.
- Load a pretrained checkpoint. You need to load a pretrained checkpoint and configure it correctly for training.
- Define the training configuration.
After fine-tuning the model, you will correctly evaluate it on the evaluation data and verify that it has indeed learned to correctly classify the images.
### Define our data collator
Batches are coming in as lists of dicts, so you can just unpack + stack those into batch tensors.
Since the `collate_fn` will return a batch dict, you can `**unpack` the inputs to the model later. ✨
```python
import torch
def collate_fn(batch):
return {
'pixel_values': torch.stack([x['pixel_values'] for x in batch]),
'labels': torch.tensor([x['labels'] for x in batch])
}
```
### Define an evaluation metric
The [accuracy](https://huggingface.co/metrics/accuracy) metric from `datasets` can easily be used to compare the predictions with the labels. Below, you can see how to use it within a `compute_metrics` function that will be used by the `Trainer`.
```python
import numpy as np
from datasets import load_metric
metric = load_metric("accuracy")
def compute_metrics(p):
return metric.compute(predictions=np.argmax(p.predictions, axis=1), references=p.label_ids)
```
Let's load the pretrained model. We'll add `num_labels` on init so the model creates a classification head with the right number of units. We'll also include the `id2label` and `label2id` mappings to have human-readable labels in the Hub widget (if you choose to `push_to_hub`).
```python
from transformers import ViTForImageClassification
labels = ds['train'].features['labels'].names
model = ViTForImageClassification.from_pretrained(
model_name_or_path,
num_labels=len(labels),
id2label={str(i): c for i, c in enumerate(labels)},
label2id={c: str(i) for i, c in enumerate(labels)}
)
```
Almost ready to train! The last thing needed before that is to set up the training configuration by defining [`TrainingArguments`](https://huggingface.co/docs/transformers/v4.16.2/en/main_classes/trainer#transformers.TrainingArguments).
Most of these are pretty self-explanatory, but one that is quite important here is `remove_unused_columns=False`. This one will drop any features not used by the model's call function. By default it's `True` because usually it's ideal to drop unused feature columns, making it easier to unpack inputs into the model's call function. But, in our case, we need the unused features ('image' in particular) in order to create 'pixel_values'.
What I'm trying to say is that you'll have a bad time if you forget to set `remove_unused_columns=False`.
```python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./vit-base-beans",
per_device_train_batch_size=16,
evaluation_strategy="steps",
num_train_epochs=4,
fp16=True,
save_steps=100,
eval_steps=100,
logging_steps=10,
learning_rate=2e-4,
save_total_limit=2,
remove_unused_columns=False,
push_to_hub=False,
report_to='tensorboard',
load_best_model_at_end=True,
)
```
Now, all instances can be passed to Trainer and we are ready to start training!
```python
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
data_collator=collate_fn,
compute_metrics=compute_metrics,
train_dataset=prepared_ds["train"],
eval_dataset=prepared_ds["validation"],
tokenizer=processor,
)
```
### Train 🚀
```python
train_results = trainer.train()
trainer.save_model()
trainer.log_metrics("train", train_results.metrics)
trainer.save_metrics("train", train_results.metrics)
trainer.save_state()
```
### Evaluate 📊
```python
metrics = trainer.evaluate(prepared_ds['validation'])
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
```
Here were my evaluation results - Cool beans! Sorry, had to say it.
***** eval metrics *****
epoch = 4.0
eval_accuracy = 0.985
eval_loss = 0.0637
eval_runtime = 0:00:02.13
eval_samples_per_second = 62.356
eval_steps_per_second = 7.97
Finally, if you want, you can push your model up to the hub. Here, we'll push it up if you specified `push_to_hub=True` in the training configuration. Note that in order to push to hub, you'll have to have git-lfs installed and be logged into your Hugging Face account (which can be done via `huggingface-cli login`).
```python
kwargs = {
"finetuned_from": model.config._name_or_path,
"tasks": "image-classification",
"dataset": 'beans',
"tags": ['image-classification'],
}
if training_args.push_to_hub:
trainer.push_to_hub('🍻 cheers', **kwargs)
else:
trainer.create_model_card(**kwargs)
```
The resulting model has been shared to [nateraw/vit-base-beans](https://huggingface.co/nateraw/vit-base-beans). I'm assuming you don't have pictures of bean leaves laying around, so I added some examples for you to give it a try! 🚀
| huggingface/blog/blob/main/fine-tune-vit.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Working with mixed adapter types
Normally, it is not possible to mix different adapter types in 🤗 PEFT. For example, even though it is possible to create a PEFT model that has two different LoRA adapters (that can have different config options), it is not possible to combine a LoRA adapter with a LoHa adapter. However, by using a mixed model, this works as long as the adapter types are compatible.
## Loading different adapter types into a PEFT model
To load different adapter types into a PEFT model, proceed the same as if you were loading two adapters of the same type, but use `PeftMixedModel` instead of `PeftModel`:
```py
from peft import PeftMixedModel
base_model = ... # load the base model, e.g. from transformers
# load first adapter, which will be called "default"
peft_model = PeftMixedModel.from_pretrained(base_model, <path_to_adapter1>)
peft_model.load_adapter(<path_to_adapter2>, adapter_name="other")
peft_model.set_adapter(["default", "other"])
```
The last line is necessary if you want to activate both adapters, otherwise, only the first adapter would be active. Of course, you can add more different adapters by calling `add_adapter` repeatedly.
Currently, the main purpose of mixed adapter types is to combine trained adapters for inference. Although it is technically also possible to train a mixed adapter model, this has not been tested and is not recommended.
## Tips
- Not all adapter types can be combined. See `peft.tuners.mixed.COMPATIBLE_TUNER_TYPES` for a list of compatible types. An error will be raised if you are trying to combine incompatible adapter types.
- It is possible to mix multiple adapters of the same type. This can be useful to combine adapters with very different configs.
- If you want to combine a lot of different adapters, it is most performant to add the same types of adapters consecutively. E.g., add LoRA1, LoRA2, LoHa1, LoHa2 in this order, instead of LoRA1, LoHa1, LoRA2, LoHa2. The order will make a difference for the outcome in most cases, but since no order is better a priori, it is best to choose the order that is most performant.
| huggingface/peft/blob/main/docs/source/developer_guides/mixed_models.md |
Serialization & Deserialization for Requests
Hugging Face Inference Endpount comes with a default serving container which is used for all [supported Transformers and Sentence-Transformers tasks](/docs/inference-endpoints/supported_tasks) and for [custom inference handler](/docs/inference-endpoints/guides/custom_handler).
The serving container takes care of serialization and deserialization of the request and response payloads based on the `content-type` and `accept` headers of the request.
That means that when you send a request with a JSON body and a `content-type: application/json` header, the serving container will deserialize the JSON payload into a Python dictionary and pass it to the inference handler and if you send
a request with a `accept: image/png` header, the serving container will seralize the response from the task/custom handler into a image.
Below is a list of supported `content-types` and the deserialized payload that is passed to the inference handler.
| Content-Type | Payload |
| ---------------------- | ------------------------------ |
| application/json | `dict` |
| text/csv | `raw` |
| text/plain | `raw` |
| image/png | `binary` |
| image/jpeg | `binary` |
| image/jpg | `binary` |
| image/tiff | `binary` |
| image/bmp | `binary` |
| image/gif | `binary` |
| image/webp | `binary` |
| image/x-image | `binary` |
| audio/x-flac | `{"inputs": bytes(body)}` |
| audio/flac | `{"inputs": bytes(body)}` |
| audio/mpeg | `{"inputs": bytes(body)}` |
| audio/x-mpeg-3 | `{"inputs": bytes(body)}` |
| audio/wave | `{"inputs": bytes(body)}` |
| audio/wav | `{"inputs": bytes(body)}` |
| audio/x-wav | `{"inputs": bytes(body)}` |
| audio/ogg | `{"inputs": bytes(body)}` |
| audio/x-audio | `{"inputs": bytes(body)}` |
| audio/webm | `{"inputs": bytes(body)}` |
| audio/webm;codecs=opus | `{"inputs": bytes(body)}` |
| audio/AMR | `{"inputs": bytes(body)}` |
| audio/amr | `{"inputs": bytes(body)}` |
| audio/AMR-WB | `{"inputs": bytes(body)}` |
| audio/AMR-WB+ | `{"inputs": bytes(body)}` |
| audio/m4a | `{"inputs": bytes(body)}` |
| audio/x-m4a | `{"inputs": bytes(body)}` |
Below is a list of supported `accept` headers and the serialized payload is returned.
| Accept | Payload |
| ---------------------- | ------------------------------ |
| application/json | `JSON` |
| text/csv | `raw` |
| text/plain | `raw` |
| image/png | `binary` |
| image/jpeg | `binary` |
| image/jpg | `binary` |
| image/tiff | `binary` |
| image/bmp | `binary` |
| image/gif | `binary` |
| image/webp | `binary` |
| image/x-image | `binary` |
| huggingface/hf-endpoints-documentation/blob/main/docs/source/others/serialization.mdx |
n this video, I'm going to give you a very quick introduction to how our transformers models work together with Tensorflow and Keras! The very short explanation is that all of our Tensorflow models are also Keras model objects, and so they have the standard Keras model API. If you're an experienced ML engineer who's used Keras a lot, that's probably all you need to know to start working with them. But for everyone else, including the prodigal PyTorch engineers out there who are returning to the fold, I'm going to quickly introduce Keras models, and how we work with them. In other videos, which I'll link below, I'll run through training with Keras models in more detail. But first, what is a Keras model? Your model basically contains your entire network: It contains the layers, and the weights for those layers, and also tells the model what to do with them; it defines the whole path all the way from your inputs to your outputs. If you've used Keras before, you probably started by building your model out by hand - you added one layer after another, maybe using model.add() or the functional approach. And there's nothing wrong with that! But you can also pre-load an entire model, weights and all. This is really helpful, because if you try reading the paper or looking at the code, you'll see the inside of a Transformer is pretty complex, and writing it all out from scratch and getting it right would be hard even for an experienced machine learning engineer. But because it's all packed inside a Model, you don't need to worry about that complexity if you don't want to! You have the flexibility to write any model you like, but you can also just load a pre-trained, pre-configured transformer model in one line of code. And whether you write your own model from scratch or load a pre-trained one, you interact with the model in the same way - through the same few methods you're going to see again and again, like *fit*, *compile* and *predict,* and we'll cover concrete examples of how to use those methods in other videos that I'll link below. For now the key thing to take away from this video, if you've never seen Keras before, is that this neat encapsulation means that all of the complexity of a huge neural net becomes manageable, because you interact with it in exactly the same way, using exactly the same methods, as you would with a simple model that you wrote out by hand. | huggingface/course/blob/main/subtitles/en/raw/chapter3/03b_keras-intro.md |
Simple VQGAN CLIP
Author: @ErwannMillon
This is a very simple VQGAN-CLIP implementation that was built as a part of the <a href= "https://github.com/ErwannMillon/face-editor"> Face Editor project </a> . This simplified version allows you to generate or edit images using text with just three lines of code. For a more full featured implementation with masking, more advanced losses, and a full GUI, check out the Face Editor project.
By default this uses a CelebA checkpoint (for generating/editing faces), but also has an imagenet checkpoint that can be loaded by specifying vqgan_config and vqgan_checkpoint when instantiating VQGAN_CLIP.
Learning rate and iterations can be set by modifying vqgan_clip.lr and vqgan_clip.iterations .
You can edit images by passing `image_path` to the generate function.
See the generate function's docstring to learn more about how to format prompts.
## Usage
The easiest way to test this out is by <a href="https://colab.research.google.com/drive/1Ez4D1J6-hVkmlXeR5jBPWYyu6CLA9Yor?usp=sharing
">using the Colab demo</a>
To install locally:
- Clone this repo
- Install git-lfs (ubuntu: sudo apt-get install git-lfs , MacOS: brew install git-lfs)
In the root of the repo run:
```
conda create -n vqganclip python=3.8
conda activate vqganclip
git-lfs install
git clone https://huggingface.co/datasets/erwann/face_editor_model_ckpt model_checkpoints
pip install -r requirements.txt
```
### Generate new images
```
from VQGAN_CLIP import VQGAN_CLIP
vqgan_clip = VQGAN_CLIP()
vqgan_clip.generate("a picture of a smiling woman")
```
### Edit an image
To get a test image, run
`git clone https://huggingface.co/datasets/erwann/vqgan-clip-pic test_images`
To edit:
```
from VQGAN_CLIP import VQGAN_CLIP
vqgan_clip = VQGAN_CLIP()
vqgan_clip.lr = .07
vqgan_clip.iterations = 15
vqgan_clip.generate(
pos_prompts= ["a picture of a beautiful asian woman", "a picture of a woman from Japan"],
neg_prompts=["a picture of an Indian person", "a picture of a white person"],
image_path="./test_images/face.jpeg",
show_intermediate=True,
save_intermediate=True,
)
```
### Make an animation from the most recent generation
`vqgan_clip.make_animation()`
## Features:
- Positive and negative prompts
- Multiple prompts
- Prompt Weights
- Creating GIF animations of the transformations
- Wandb logging
| huggingface/transformers/blob/main/examples/research_projects/vqgan-clip/README.md |
Gradio, check![[gradio-check]]
<CourseFloatingBanner
chapter={9}
classNames="absolute z-10 right-0 top-0"
/>
This wraps up the chapter on building cool ML demos with Gradio - we hope you enjoyed it! To recap, in this chapter we learned:
- How to create Gradio demos with the high-level `Interface` API, and how to configure different input and output modalities.
- Different ways to share Gradio demos, through temporary links and hosting on [Hugging Face Spaces](https://huggingface.co/spaces).
- How to integrate Gradio demos with models and Spaces on the Hugging Face Hub.
- Advanced features like storing state in a demo or providing authentication.
- How to have full control of the data flow and layout of your demo with Gradio Blocks.
If you'd like to test your understanding of the concepts covered in this chapter, check out the quiz in the next section!
## Where to next?[[where-to-next]]
If you want to learn more about Gradio you can
- Take a look at [Demos](https://github.com/gradio-app/gradio/tree/main/demo) in the repo, there are quite a lot of examples there.
- See the [Guides](https://gradio.app/guides/) page, where you can find guides about cool and advanced features.
- Check the [Docs](https://gradio.app/docs/) page to learn the details.
| huggingface/course/blob/main/chapters/en/chapter9/8.mdx |
libcommon
A Python library with common code (cache, queue, workers logic, processing steps, configuration, utils, logging, exceptions) used by the services and the workers
## Assets configuration
Set the assets (images and audio files) environment variables to configure the following aspects:
- `ASSETS_BASE_URL`: base URL for the assets files. Set accordingly to the datasets-server domain, e.g., https://datasets-server.huggingface.co/assets. Defaults to `http://localhost/assets`.
- `ASSETS_STORAGE_PROTOCOL`: fsspec protocol for storage, it can take values `file` or `s3`. Defaults to `file`, which means local file system is used.
- `ASSETS_STORAGE_ROOT`: root directory for the storage protocol. If using `s3` protocol, a bucket name should be provided otherwise configure a local file directory. Defaults to /storage, which means the assets are stored in /storage/{ASSETS_FOLDER_NAME} (see following configuration).
- `ASSETS_FOLDER_NAME`: name of the folder inside the root directory where assets are stored. The default value is assets.
## Cached Assets configuration
Set the cached-assets (images and audio files) environment variables to configure the following aspects:
- `CACHED_ASSETS_BASE_URL`: base URL for the cached assets files. Set accordingly to the datasets-server domain, e.g., https://datasets-server.huggingface.co/cached-assets. Defaults to `http://localhost/cached-assets`.
- `CACHED_ASSETS_STORAGE_PROTOCOL`: fsspec protocol for storage, it can take values `file` or `s3`. Defaults to `file`, which means local file system is used.
- `CACHED_ASSETS_STORAGE_ROOT`: root directory for the storage protocol. If using `s3` protocol, a bucket name should be provided otherwise configure a local file directory. Defaults to /storage, which means the assets are stored in /storage/{CACHED_ASSETS_FOLDER_NAME} (see following configuration).
- `CACHED_ASSETS_FOLDER_NAME`: name of the folder inside the root directory where assets are stored. The default value is assets.
## Common configuration
Set the common environment variables to configure the following aspects:
- `COMMON_BLOCKED_DATASETS`: comma-separated list of the blocked datasets. Unix shell-style wildcards also work in the dataset name for namespaced datasets, for example `some_namespace/*` to block all the datasets in the `some_namespace` namespace. If empty, no dataset is blocked. Defaults to empty.
- `COMMON_DATASET_SCRIPTS_ALLOW_LIST`: comma-separated list of the datasets for which we support dataset scripts. Unix shell-style wildcards also work in the dataset name for namespaced datasets, for example `some_namespace/*` to refer to all the datasets in the `some_namespace` namespace. The keyword `{{ALL_DATASETS_WITH_NO_NAMESPACE}}` refers to all the datasets without namespace. If empty, no dataset with script is supported. Defaults to empty.
- `COMMON_HF_ENDPOINT`: URL of the HuggingFace Hub. Defaults to `https://huggingface.co`.
- `COMMON_HF_TOKEN`: App Access Token (ask moonlanding administrators to get one, only the `read` role is required) to access the gated datasets. Defaults to empty.
## Logs configuration
Set the common environment variables to configure the logs:
- `LOG_LEVEL`: log level, among `DEBUG`, `INFO`, `WARNING`, `ERROR`, and `CRITICAL`. Defaults to `INFO`.
## Cache configuration
Set environment variables to configure the storage of precomputed API responses in a MongoDB database (the "cache"):
- `CACHE_MAX_DAYS`: maximum number of days to keep the cache entries. Defaults to `90`.
- `CACHE_MONGO_DATABASE`: name of the database used for storing the cache. Defaults to `datasets_server_cache`.
- `CACHE_MONGO_URL`: URL used to connect to the MongoDB server. Defaults to `mongodb://localhost:27017`.
## Queue configuration
Set environment variables to configure the job queues to precompute API responses. The job queues are stored in a MongoDB database.
- `QUEUE_MONGO_DATABASE`: name of the database used for storing the queue. Defaults to `datasets_server_queue`.
- `QUEUE_MONGO_URL`: URL used to connect to the MongoDB server. Defaults to `mongodb://localhost:27017`.
## S3 configuration
Set environment variables to configure the connection to S3.
- `S3_REGION_NAME`: bucket region name when using `s3` as storage protocol for assets or cached assets. Defaults to `us-east-1`.
- `S3_ACCESS_KEY_ID`: unique identifier associated with an AWS account. It's used to identify the AWS account that is making requests to S3. Defaults to empty.
- `S3_SECRET_ACCESS_KEY`: secret key associated with an AWS account. Defaults to empty.
| huggingface/datasets-server/blob/main/libs/libcommon/README.md |
Quickstart
This quickstart is intended for developers who are ready to dive into the code and see an example of how to integrate `timm` into their model training workflow.
First, you'll need to install `timm`. For more information on installation, see [Installation](installation).
```bash
pip install timm
```
## Load a Pretrained Model
Pretrained models can be loaded using [`create_model`].
Here, we load the pretrained `mobilenetv3_large_100` model.
```py
>>> import timm
>>> m = timm.create_model('mobilenetv3_large_100', pretrained=True)
>>> m.eval()
```
<Tip>
Note: The returned PyTorch model is set to train mode by default, so you must call .eval() on it if you plan to use it for inference.
</Tip>
## List Models with Pretrained Weights
To list models packaged with `timm`, you can use [`list_models`]. If you specify `pretrained=True`, this function will only return model names that have associated pretrained weights available.
```py
>>> import timm
>>> from pprint import pprint
>>> model_names = timm.list_models(pretrained=True)
>>> pprint(model_names)
[
'adv_inception_v3',
'cspdarknet53',
'cspresnext50',
'densenet121',
'densenet161',
'densenet169',
'densenet201',
'densenetblur121d',
'dla34',
'dla46_c',
]
```
You can also list models with a specific pattern in their name.
```py
>>> import timm
>>> from pprint import pprint
>>> model_names = timm.list_models('*resne*t*')
>>> pprint(model_names)
[
'cspresnet50',
'cspresnet50d',
'cspresnet50w',
'cspresnext50',
...
]
```
## Fine-Tune a Pretrained Model
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('mobilenetv3_large_100', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To fine-tune on your own dataset, you have to write a PyTorch training loop or adapt `timm`'s [training script](training_script) to use your dataset.
## Use a Pretrained Model for Feature Extraction
Without modifying the network, one can call model.forward_features(input) on any model instead of the usual model(input). This will bypass the head classifier and global pooling for networks.
For a more in depth guide to using `timm` for feature extraction, see [Feature Extraction](feature_extraction).
```py
>>> import timm
>>> import torch
>>> x = torch.randn(1, 3, 224, 224)
>>> model = timm.create_model('mobilenetv3_large_100', pretrained=True)
>>> features = model.forward_features(x)
>>> print(features.shape)
torch.Size([1, 960, 7, 7])
```
## Image Augmentation
To transform images into valid inputs for a model, you can use [`timm.data.create_transform`], providing the desired `input_size` that the model expects.
This will return a generic transform that uses reasonable defaults.
```py
>>> timm.data.create_transform((3, 224, 224))
Compose(
Resize(size=256, interpolation=bilinear, max_size=None, antialias=None)
CenterCrop(size=(224, 224))
ToTensor()
Normalize(mean=tensor([0.4850, 0.4560, 0.4060]), std=tensor([0.2290, 0.2240, 0.2250]))
)
```
Pretrained models have specific transforms that were applied to images fed into them while training. If you use the wrong transform on your image, the model won't understand what it's seeing!
To figure out which transformations were used for a given pretrained model, we can start by taking a look at its `pretrained_cfg`
```py
>>> model.pretrained_cfg
{'url': 'https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_large_100_ra-f55367f5.pth',
'num_classes': 1000,
'input_size': (3, 224, 224),
'pool_size': (7, 7),
'crop_pct': 0.875,
'interpolation': 'bicubic',
'mean': (0.485, 0.456, 0.406),
'std': (0.229, 0.224, 0.225),
'first_conv': 'conv_stem',
'classifier': 'classifier',
'architecture': 'mobilenetv3_large_100'}
```
We can then resolve only the data related configuration by using [`timm.data.resolve_data_config`].
```py
>>> timm.data.resolve_data_config(model.pretrained_cfg)
{'input_size': (3, 224, 224),
'interpolation': 'bicubic',
'mean': (0.485, 0.456, 0.406),
'std': (0.229, 0.224, 0.225),
'crop_pct': 0.875}
```
We can pass this data config to [`timm.data.create_transform`] to initialize the model's associated transform.
```py
>>> data_cfg = timm.data.resolve_data_config(model.pretrained_cfg)
>>> transform = timm.data.create_transform(**data_cfg)
>>> transform
Compose(
Resize(size=256, interpolation=bicubic, max_size=None, antialias=None)
CenterCrop(size=(224, 224))
ToTensor()
Normalize(mean=tensor([0.4850, 0.4560, 0.4060]), std=tensor([0.2290, 0.2240, 0.2250]))
)
```
<Tip>
Note: Here, the pretrained model's config happens to be the same as the generic config we made earlier. This is not always the case. So, it's safer to use the data config to create the transform as we did here instead of using the generic transform.
</Tip>
## Using Pretrained Models for Inference
Here, we will put together the above sections and use a pretrained model for inference.
First we'll need an image to do inference on. Here we load a picture of a leaf from the web:
```py
>>> import requests
>>> from PIL import Image
>>> from io import BytesIO
>>> url = 'https://datasets-server.huggingface.co/assets/imagenet-1k/--/default/test/12/image/image.jpg'
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image
```
Here's the image we loaded:
<img src="https://datasets-server.huggingface.co/assets/imagenet-1k/--/default/test/12/image/image.jpg" alt="An Image from a link" width="300"/>
Now, we'll create our model and transforms again. This time, we make sure to set our model in evaluation mode.
```py
>>> model = timm.create_model('mobilenetv3_large_100', pretrained=True).eval()
>>> transform = timm.data.create_transform(
**timm.data.resolve_data_config(model.pretrained_cfg)
)
```
We can prepare this image for the model by passing it to the transform.
```py
>>> image_tensor = transform(image)
>>> image_tensor.shape
torch.Size([3, 224, 224])
```
Now we can pass that image to the model to get the predictions. We use `unsqueeze(0)` in this case, as the model is expecting a batch dimension.
```py
>>> output = model(image_tensor.unsqueeze(0))
>>> output.shape
torch.Size([1, 1000])
```
To get the predicted probabilities, we apply softmax to the output. This leaves us with a tensor of shape `(num_classes,)`.
```py
>>> probabilities = torch.nn.functional.softmax(output[0], dim=0)
>>> probabilities.shape
torch.Size([1000])
```
Now we'll find the top 5 predicted class indexes and values using `torch.topk`.
```py
>>> values, indices = torch.topk(probabilities, 5)
>>> indices
tensor([162, 166, 161, 164, 167])
```
If we check the imagenet labels for the top index, we can see what the model predicted...
```py
>>> IMAGENET_1k_URL = 'https://storage.googleapis.com/bit_models/ilsvrc2012_wordnet_lemmas.txt'
>>> IMAGENET_1k_LABELS = requests.get(IMAGENET_1k_URL).text.strip().split('\n')
>>> [{'label': IMAGENET_1k_LABELS[idx], 'value': val.item()} for val, idx in zip(values, indices)]
[{'label': 'beagle', 'value': 0.8486220836639404},
{'label': 'Walker_hound, Walker_foxhound', 'value': 0.03753996267914772},
{'label': 'basset, basset_hound', 'value': 0.024628572165966034},
{'label': 'bluetick', 'value': 0.010317106731235981},
{'label': 'English_foxhound', 'value': 0.006958036217838526}]
``` | huggingface/pytorch-image-models/blob/main/hfdocs/source/quickstart.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Overview
🤗 Optimum provides an API called BetterTransformer, a fast path of standard PyTorch Transformer APIs to benefit from interesting speedups on CPU & GPU through sparsity and fused kernels as Flash Attention. For now, BetterTransformer supports the fastpath from the native [`nn.TransformerEncoderLayer`](https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/) as well as Flash Attention and Memory-Efficient Attention from [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html).
## Quickstart
Since its 1.13 version, [PyTorch released](https://pytorch.org/blog/PyTorch-1.13-release/) the stable version of a fast path for its standard Transformer APIs that provides out of the box performance improvements for transformer-based models. You can benefit from interesting speedup on most consumer-type devices, including CPUs, older and newer versions of NIVIDIA GPUs.
You can now use this feature in 🤗 Optimum together with Transformers and use it for major models in the Hugging Face ecosystem.
In the 2.0 version, PyTorch includes a native scaled dot-product attention operator (SDPA) as part of `torch.nn.functional`. This function encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the [official documentation](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) for more information, and [this blog post](https://pytorch.org/blog/out-of-the-box-acceleration/) for benchmarks.
We provide an integration with these optimizations out of the box in 🤗 Optimum, so that you can convert any supported 🤗 Transformers model so as to use the optimized paths & `scaled_dot_product_attention` function when relevant.
<Tip warning={true}>
PyTorch-native `scaled_dot_product_attention` is slowly being natively [made default and integrated in 🤗 Transformers](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-and-memory-efficient-attention-through-pytorchs-scaleddotproductattention). For models that do support SDPA in Transformers, we deprecate BetterTransformer and recommend you to use directly Transformers and PyTorc latest version for the attention optimizations (Flash Attention, memory-efficient attention) through SDPA.
</Tip>
<Tip warning={true}>
The PyTorch-native `scaled_dot_product_attention` operator can only dispatch to Flash Attention if no `attention_mask` is provided.
Thus, by default in training mode, the BetterTransformer integration **drops the mask support and can only be used for training that do not require a padding mask for batched training**. This is the case for example for masked language modeling or causal language modeling. BetterTransformer is not suited for the fine-tuning of models on tasks that requires a padding mask.
In inference mode, the padding mask is kept for correctness and thus speedups should be expected only in the batch size = 1 case.
</Tip>
### Supported models
The list of supported model below:
- [AlBERT](https://arxiv.org/abs/1909.11942)
- [Bark](https://github.com/suno-ai/bark)
- [BART](https://arxiv.org/abs/1910.13461)
- [BERT](https://arxiv.org/abs/1810.04805)
- [BERT-generation](https://arxiv.org/abs/1907.12461)
- [BLIP-2](https://arxiv.org/abs/2301.12597)
- [BLOOM](https://arxiv.org/abs/2211.05100)
- [CamemBERT](https://arxiv.org/abs/1911.03894)
- [CLIP](https://arxiv.org/abs/2103.00020)
- [CodeGen](https://arxiv.org/abs/2203.13474)
- [Data2VecText](https://arxiv.org/abs/2202.03555)
- [DistilBert](https://arxiv.org/abs/1910.01108)
- [DeiT](https://arxiv.org/abs/2012.12877)
- [Electra](https://arxiv.org/abs/2003.10555)
- [Ernie](https://arxiv.org/abs/1904.09223)
- [Falcon](https://arxiv.org/abs/2306.01116) (No need to use BetterTransformer, it is [directy supported by Transformers](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-and-memory-efficient-attention-through-pytorchs-scaleddotproductattention))
- [FSMT](https://arxiv.org/abs/1907.06616)
- [GPT2](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
- [GPT-j](https://huggingface.co/EleutherAI/gpt-j-6B)
- [GPT-neo](https://github.com/EleutherAI/gpt-neo)
- [GPT-neo-x](https://arxiv.org/abs/2204.06745)
- [GPT BigCode](https://arxiv.org/abs/2301.03988) (SantaCoder, StarCoder - no need to use BetterTransformer, it is [directy supported by Transformers](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-and-memory-efficient-attention-through-pytorchs-scaleddotproductattention))
- [HuBERT](https://arxiv.org/pdf/2106.07447.pdf)
- [LayoutLM](https://arxiv.org/abs/1912.13318)
- [Llama & Llama2](https://arxiv.org/abs/2302.13971) (No need to use BetterTransformer, it is [directy supported by Transformers](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-and-memory-efficient-attention-through-pytorchs-scaleddotproductattention))
- [MarkupLM](https://arxiv.org/abs/2110.08518)
- [Marian](https://arxiv.org/abs/1804.00344)
- [MBart](https://arxiv.org/abs/2001.08210)
- [M2M100](https://arxiv.org/abs/2010.11125)
- [OPT](https://arxiv.org/abs/2205.01068)
- [ProphetNet](https://arxiv.org/abs/2001.04063)
- [RemBERT](https://arxiv.org/abs/2010.12821)
- [RoBERTa](https://arxiv.org/abs/1907.11692)
- [RoCBert](https://aclanthology.org/2022.acl-long.65.pdf)
- [RoFormer](https://arxiv.org/abs/2104.09864)
- [Splinter](https://arxiv.org/abs/2101.00438)
- [Tapas](https://arxiv.org/abs/2211.06550)
- [ViLT](https://arxiv.org/abs/2102.03334)
- [ViT](https://arxiv.org/abs/2010.11929)
- [ViT-MAE](https://arxiv.org/abs/2111.06377)
- [ViT-MSN](https://arxiv.org/abs/2204.07141)
- [Wav2Vec2](https://arxiv.org/abs/2006.11477)
- [Whisper](https://cdn.openai.com/papers/whisper.pdf) (No need to use BetterTransformer, it is [directy supported by Transformers](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-and-memory-efficient-attention-through-pytorchs-scaleddotproductattention))
- [XLMRoberta](https://arxiv.org/abs/1911.02116)
- [YOLOS](https://arxiv.org/abs/2106.00666)
Let us know by opening an issue in 🤗 Optimum if you want more models to be supported, or check out the [contribution guideline](https://huggingface.co/docs/optimum/bettertransformer/tutorials/contribute) if you want to add it by yourself!
### Quick usage
In order to use the `BetterTransformer` API just run the following commands:
```python
>>> from transformers import AutoModelForSequenceClassification
>>> from optimum.bettertransformer import BetterTransformer
>>> model_hf = AutoModelForSequenceClassification.from_pretrained("bert-base-cased")
>>> model = BetterTransformer.transform(model_hf, keep_original_model=True)
```
You can leave `keep_original_model=False` in case you want to overwrite the current model with its `BetterTransformer` version.
More details on `tutorials` section to deeply understand how to use it, or check the [Google colab demo](https://colab.research.google.com/drive/1Lv2RCG_AT6bZNdlL1oDDNNiwBBuirwI-?usp=sharing)!
<div class="mt-10">
<div class="w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5">
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./tutorials/convert"
><div class="w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Tutorials</div>
<p class="text-gray-700">Learn the basics and become familiar with 🤗 and `BetterTransformer` integration. Start here if you are using 🤗 Optimum for the first time!</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./tutorials/contribute"
><div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">How-to guides</div>
<p class="text-gray-700">You want to add your own model for `BetterTransformer` support? Start here to check the contribution guideline!</p>
</a>
</div>
</div>
| huggingface/optimum/blob/main/docs/source/bettertransformer/overview.mdx |
Encoding
<tokenizerslangcontent>
<python>
## Encoding
[[autodoc]] tokenizers.Encoding
- all
- attention_mask
- ids
- n_sequences
- offsets
- overflowing
- sequence_ids
- special_tokens_mask
- tokens
- type_ids
- word_ids
- words
</python>
<rust>
The Rust API Reference is available directly on the [Docs.rs](https://docs.rs/tokenizers/latest/tokenizers/) website.
</rust>
<node>
The node API has not been documented yet.
</node>
</tokenizerslangcontent> | huggingface/tokenizers/blob/main/docs/source-doc-builder/api/encoding.mdx |
--
title: "~Don't~ Repeat Yourself"
thumbnail: /blog/assets/59_transformers_philosophy/transformers.png
authors:
- user: patrickvonplaten
---
# ~~Don't~~ Repeat Yourself*
##### *Designing open-source libraries for modern machine learning*
## 🤗 Transformers Design Philosophy
*"Don't repeat yourself"*, or **DRY**, is a well-known principle of software development. The principle originates from "The pragmatic programmer", one of the most read books on code design.
The principle's simple message makes obvious sense: Don't rewrite a logic that already exists somewhere else. This ensures the code remains in sync, making it easier to maintain and more robust. Any change to this logical pattern will uniformly affect all of its dependencies.
At first glance, the design of Hugging Face's Transformers library couldn't be more contrary to the DRY principle. Code for the attention mechanism is more or less copied over 50 times into different model files. Sometimes code of the whole BERT model is copied into other model files. We often force new model contributions identical to existing models - besides a small logical tweak - to copy all of the existing code. Why do we do this? Are we just too lazy or overwhelmed to centralize all logical pieces into one place?
No, we are not lazy - it's a very conscious decision not to apply the DRY design principle to the Transformers library. Instead, we decided to adopt a different design principle which we like to call the ***single model file*** policy. The *single model file* policy states that all code necessary for the forward pass of a model is in one and only one file - called the model file. If a reader wants to understand how BERT works for inference, she should only have to look into BERT's `modeling_bert.py` file.
We usually reject any attempt to abstract identical sub-components of different models into a new centralized place. We don't want to have a `attention_layer.py` that includes all possible attention mechanisms. Again why do we do this?
In short the reasons are:
- **1. Transformers is built by and for the open-source community.**
- **2. Our product are models and our customers are users reading or tweaking model code.**
- **3. The field of machine learning evolves extremely fast.**
- **4. Machine Learning models are static.**
### 1. Built by and for the open-source community
Transformers is built to actively incentivize external contributions. A contribution is often either a bug fix or a new model contribution. If a bug is found in one of the model files, we want to make it as easy as possible for the finder to fix it. There is little that is more demotivating than fixing a bug only to see that it caused 100 failures of other models.
Because model code is independent from all other models, it's fairly easy for someone that only understands the one model she is working with to fix it. Similarly, it's easier to add new modeling code and review the corresponding PR if only a single new model file is added. The contributor does not have to figure out how to add new functionality to a centralized attention mechanism without breaking existing models. The reviewer can easily verify that none of the existing models are broken.
### 2. Modeling code is our product
We assume that a significant amount of users of the Transformers library not only read the documentation, but also look into the actual modeling code and potentially modify it. This hypothesis is backed by the Transformers library being forked over 10,000 times and the Transformers paper being cited over a thousand times.
Therefore it is of utmost importance that someone reading Transformers modeling code for the first time can easily understand and potentially adapt it. Providing all the necessary logical components in order in a single modeling file helps a lot to achieve improved readability and adaptability. Additionally, we care a great deal about sensible variable/method naming and prefer expressive/readable code over character-efficient code.
### 3. Machine Learning is evolving at a neck-breaking speed
Research in the field of machine learning, and especially neural networks, evolves extremely fast. A model that was state-of-the-art a year ago might be outdated today. We don't know which attention mechanism, position embedding, or architecture will be the best in a year. Therefore, we cannot define standard logical patterns that apply to all models.
As an example, two years ago, one might have defined BERT's self attention layer as the standard attention layer used by all Transformers models. Logically, a "standard" attention function could have been moved into a central `attention.py` file. But then came attention layers that added relative positional embeddings in each attention layer (T5), multiple different forms of chunked attention (Reformer, Longformer, BigBird), and separate attention mechanism for position and word embeddings (DeBERTa), etc... Every time we would have to have asked ourselves whether the "standard" attention function should be adapted or whether it would have been better to add a new attention function to `attention.py`. But then how do we name it? `attention_with_positional_embd`, `reformer_attention`, `deberta_attention`?
It's dangerous to give logical components of machine learning models general names because the perception of what this component stands for might change or become outdated very quickly. E.g., does chunked attention corresponds to GPTNeo's, Reformer's, or BigBird's chunked attention? Is the attention layer a self-attention layer, a cross-attentional layer, or does it include both? However, if we name attention layers by their model's name, we should directly put the attention function in the corresponding modeling file.
### 4. Machine Learning models are static
The Transformers library is a unified and polished collection of machine learning models that different research teams have created. Every machine learning model is usually accompanied by a paper and its official GitHub repository. Once a machine learning model is published, it is rarely adapted or changed afterward.
Instead, research teams tend to publish a new model built upon previous models but rarely make significant changes to already published code. This is an important realization when deciding on the design principles of the Transformers library.
It means that once a model architecture has been added to Transformers, the fundamental components of the model don't change anymore. Bugs are often found and fixed, methods and variables might be renamed, and the output or input format of the model might be slightly changed, but the model's core components don't change anymore. Consequently, the need to apply global changes to all models in Transformers is significantly reduced, making it less important that every logical pattern only exists once since it's rarely changed.
A second realization is that models do **not** depend on each other in a bidirectional way. More recent published models might depend on existing models, but it's quite obvious that an existing model cannot logically depend on its successor. E.g. T5 is partly built upon BERT and therefore T5's modeling code might logically depend on BERT's modeling code, but BERT cannot logically depend in any way on T5. Thus, it would not be logically sound to refactor BERT's attention function to also work with T5's attention function - someone reading through BERT's attention layer should not have to know anything about T5. Again, this advocates against centralizing components such as the attention layer into modules that all models can access.
On the other hand, the modeling code of successor models can very well logically depend on its predecessor model. E.g., DeBERTa-v2 modeling code does logically depend
to some extent on DeBERTa's modeling code. Maintainability is significantly improved by ensuring the modeling code of DeBERTa-v2 stays in sync with DeBERTa's. Fixing a bug in
DeBERTa should ideally also fix the same bug in DeBERTa-v2. How can we maintain the *single model file* policy while ensuring that successor models stay in sync with their predecessor model?
Now, we explain why we put the asterisk \\( {}^{\textbf{*}} \\) after *"Repeat Yourself"*. We don't blindly copy-paste all existing modeling code even if it looks this way. One of Transformers' core maintainers, [Sylvain Gugger](https://github.com/sgugger), found a great mechanism that respects both the *single file policy* and keeps maintainability cost in bounds. This mechanism, loosely called *"the copying mechanism"*, allows us to mark logical components, such as an attention layer function, with a `# Copied from <predecessor_model>.<function>` statement, which enforces the marked code to be identical to the `<function>` of the `<predecessor_model>`. E.g., this line of over [DeBERTa-v2's class](https://github.com/huggingface/transformers/blob/21decb7731e998d3d208ec33e5b249b0a84c0a02/src/transformers/models/deberta_v2/modeling_deberta_v2.py#L325) enforces the whole class to be identical to [DeBERTa's class](https://github.com/huggingface/transformers/blob/21decb7731e998d3d208ec33e5b249b0a84c0a02/src/transformers/models/deberta/modeling_deberta.py#L336) except for the prefix `DeBERTav2`.
This way, the copying mechanism keeps modeling code very easy to understand while significantly reducing maintenance. If some code is changed in a function of a predecessor model that is referred to by a function of its successor model, there are tools in place that automatically correct the successor model's function.
### Drawbacks
Clearly, there are also drawbacks to the single file policy two of which we quickly want to mention here.
A major goal of Transformers is to provide a unified API for both inference and training for all models so
that a user can quickly switch between different models in her setup. However, ensuring a unified API across
models is much more difficult if modeling files are not allowed to use abstracted logical patterns. We solve
this problem by running **a lot** of tests (*ca.* 20,000 tests are run daily at the time of writing this blog post) to ensure that models follow a consistent API. In this case, the single file policy requires us to be very rigorous when reviewing model and test additions.
Second, there is a lot of research on just a single component of a Machine Learning model. *E.g.*, research
teams investigate new forms of an attention mechanism that would apply to all existing pre-trained models as
has been done in the [Rethinking Attention with Performers](https://arxiv.org/abs/2009.14794). How should
we incorporate such research into the Transformers library? It is indeed problematic. Should we change
all existing models? This would go against points 3. and 4. as written above. Should we add 100+ new modeling
files each prefixed with `Performer...`? This seems absurd. In such a case there is sadly no good solution
and we opt for not integrating the paper into Transformers in this case. If the paper would have gotten
much more traction and included strong pre-trained checkpoints, we would have probably added new modeling
files of the most important models such as `modeling_performer_bert.py`
available.
### Conclusion
All in all, at 🤗 Hugging Face we are convinced that the *single file policy* is the right coding philosophy for Transformers.
What do you think? If you read until here, we would be more than interested in hearing your opinion!
If you would like to leave a comment, please visit the corresponding forum post [here](https://discuss.huggingface.co/t/repeat-yourself-transformers-design-philosophy/16483).
| huggingface/blog/blob/main/transformers-design-philosophy.md |
Pre-tokenizers
<tokenizerslangcontent>
<python>
## BertPreTokenizer
[[autodoc]] tokenizers.pre_tokenizers.BertPreTokenizer
## ByteLevel
[[autodoc]] tokenizers.pre_tokenizers.ByteLevel
## CharDelimiterSplit
[[autodoc]] tokenizers.pre_tokenizers.CharDelimiterSplit
## Digits
[[autodoc]] tokenizers.pre_tokenizers.Digits
## Metaspace
[[autodoc]] tokenizers.pre_tokenizers.Metaspace
## PreTokenizer
[[autodoc]] tokenizers.pre_tokenizers.PreTokenizer
## Punctuation
[[autodoc]] tokenizers.pre_tokenizers.Punctuation
## Sequence
[[autodoc]] tokenizers.pre_tokenizers.Sequence
## Split
[[autodoc]] tokenizers.pre_tokenizers.Split
## UnicodeScripts
[[autodoc]] tokenizers.pre_tokenizers.UnicodeScripts
## Whitespace
[[autodoc]] tokenizers.pre_tokenizers.Whitespace
## WhitespaceSplit
[[autodoc]] tokenizers.pre_tokenizers.WhitespaceSplit
</python>
<rust>
The Rust API Reference is available directly on the [Docs.rs](https://docs.rs/tokenizers/latest/tokenizers/) website.
</rust>
<node>
The node API has not been documented yet.
</node>
</tokenizerslangcontent> | huggingface/tokenizers/blob/main/docs/source-doc-builder/api/pre-tokenizers.mdx |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Fully Sharded Data Parallel
[Fully sharded data parallel](https://pytorch.org/docs/stable/fsdp.html) (FSDP) is developed for distributed training of large pretrained models up to 1T parameters. FSDP achieves this by sharding the model parameters, gradients, and optimizer states across data parallel processes and it can also offload sharded model parameters to a CPU. The memory efficiency afforded by FSDP allows you to scale training to larger batch or model sizes.
<Tip warning={true}>
Currently, FSDP does not confer any reduction in GPU memory usage and FSDP with CPU offload actually consumes 1.65x more GPU memory during training. You can track this PyTorch [issue](https://github.com/pytorch/pytorch/issues/91165) for any updates.
</Tip>
FSDP is supported in 🤗 Accelerate, and you can use it with 🤗 PEFT. This guide will help you learn how to use our FSDP [training script](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_fsdp.py). You'll configure the script to train a large model for conditional generation.
## Configuration
Begin by running the following command to [create a FSDP configuration file](https://huggingface.co/docs/accelerate/main/en/usage_guides/fsdp) with 🤗 Accelerate. Use the `--config_file` flag to save the configuration file to a specific location, otherwise it is saved as a `default_config.yaml` file in the 🤗 Accelerate cache.
The configuration file is used to set the default options when you launch the training script.
```bash
accelerate config --config_file fsdp_config.yaml
```
You'll be asked a few questions about your setup, and configure the following arguments. For this example, make sure you fully shard the model parameters, gradients, optimizer states, leverage the CPU for offloading, and wrap model layers based on the Transformer layer class name.
```bash
`Sharding Strategy`: [1] FULL_SHARD (shards optimizer states, gradients and parameters), [2] SHARD_GRAD_OP (shards optimizer states and gradients), [3] NO_SHARD
`Offload Params`: Decides Whether to offload parameters and gradients to CPU
`Auto Wrap Policy`: [1] TRANSFORMER_BASED_WRAP, [2] SIZE_BASED_WRAP, [3] NO_WRAP
`Transformer Layer Class to Wrap`: When using `TRANSFORMER_BASED_WRAP`, user specifies comma-separated string of transformer layer class names (case-sensitive) to wrap ,e.g,
`BertLayer`, `GPTJBlock`, `T5Block`, `BertLayer,BertEmbeddings,BertSelfOutput`...
`Min Num Params`: minimum number of parameters when using `SIZE_BASED_WRAP`
`Backward Prefetch`: [1] BACKWARD_PRE, [2] BACKWARD_POST, [3] NO_PREFETCH
`State Dict Type`: [1] FULL_STATE_DICT, [2] LOCAL_STATE_DICT, [3] SHARDED_STATE_DICT
```
For example, your FSDP configuration file may look like the following:
```yaml
command_file: null
commands: null
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: FSDP
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_offload_params: true
fsdp_sharding_strategy: 1
fsdp_state_dict_type: FULL_STATE_DICT
fsdp_transformer_layer_cls_to_wrap: T5Block
gpu_ids: null
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
megatron_lm_config: {}
mixed_precision: 'no'
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_name: null
tpu_zone: null
use_cpu: false
```
## The important parts
Let's dig a bit deeper into the training script to understand how it works.
The [`main()`](https://github.com/huggingface/peft/blob/2822398fbe896f25d4dac5e468624dc5fd65a51b/examples/conditional_generation/peft_lora_seq2seq_accelerate_fsdp.py#L14) function begins with initializing an [`~accelerate.Accelerator`] class which handles everything for distributed training, such as automatically detecting your training environment.
<Tip>
💡 Feel free to change the model and dataset inside the `main` function. If your dataset format is different from the one in the script, you may also need to write your own preprocessing function.
</Tip>
The script also creates a configuration corresponding to the 🤗 PEFT method you're using. For LoRA, you'll use [`LoraConfig`] to specify the task type, and several other important parameters such as the dimension of the low-rank matrices, the matrices scaling factor, and the dropout probability of the LoRA layers. If you want to use a different 🤗 PEFT method, replace `LoraConfig` with the appropriate [class](../package_reference/tuners).
Next, the script wraps the base model and `peft_config` with the [`get_peft_model`] function to create a [`PeftModel`].
```diff
def main():
+ accelerator = Accelerator()
model_name_or_path = "t5-base"
base_path = "temp/data/FinancialPhraseBank-v1.0"
+ peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
+ model = get_peft_model(model, peft_config)
```
Throughout the script, you'll see the [`~accelerate.Accelerator.main_process_first`] and [`~accelerate.Accelerator.wait_for_everyone`] functions which help control and synchronize when processes are executed.
After your dataset is prepared, and all the necessary training components are loaded, the script checks if you're using the `fsdp_plugin`. PyTorch offers two ways for wrapping model layers in FSDP, automatically or manually. The simplest method is to allow FSDP to automatically recursively wrap model layers without changing any other code. You can choose to wrap the model layers based on the layer name or on the size (number of parameters). In the FSDP configuration file, it uses the `TRANSFORMER_BASED_WRAP` option to wrap the [`T5Block`] layer.
```py
if getattr(accelerator.state, "fsdp_plugin", None) is not None:
accelerator.state.fsdp_plugin.auto_wrap_policy = fsdp_auto_wrap_policy(model)
```
Next, use 🤗 Accelerate's [`~accelerate.Accelerator.prepare`] function to prepare the model, datasets, optimizer, and scheduler for training.
```py
model, train_dataloader, eval_dataloader, optimizer, lr_scheduler = accelerator.prepare(
model, train_dataloader, eval_dataloader, optimizer, lr_scheduler
)
```
From here, the remainder of the script handles the training loop, evaluation, and sharing your model to the Hub.
## Train
Run the following command to launch the training script. Earlier, you saved the configuration file to `fsdp_config.yaml`, so you'll need to pass the path to the launcher with the `--config_file` argument like this:
```bash
accelerate launch --config_file fsdp_config.yaml examples/peft_lora_seq2seq_accelerate_fsdp.py
```
Once training is complete, the script returns the accuracy and compares the predictions to the labels. | huggingface/peft/blob/main/docs/source/accelerate/fsdp.md |
--
title: "Introducing Würstchen: Fast Diffusion for Image Generation"
thumbnail: /blog/assets/wuerstchen/thumbnail.jpg
authors:
- user: dome272
guest: true
- user: babbleberns
guest: true
- user: kashif
- user: sayakpaul
- user: pcuenq
---
# Introducing Würstchen: Fast Diffusion for Image Generation

## What is Würstchen?
Würstchen is a diffusion model, whose text-conditional component works in a highly compressed latent space of images. Why is this important? Compressing data can reduce computational costs for both training and inference by orders of magnitude. Training on 1024×1024 images is way more expensive than training on 32×32. Usually, other works make use of a relatively small compression, in the range of 4x - 8x spatial compression. Würstchen takes this to an extreme. Through its novel design, it achieves a 42x spatial compression! This had never been seen before, because common methods fail to faithfully reconstruct detailed images after 16x spatial compression. Würstchen employs a two-stage compression, what we call Stage A and Stage B. Stage A is a VQGAN, and Stage B is a Diffusion Autoencoder (more details can be found in the **[paper](https://arxiv.org/abs/2306.00637)**). Together Stage A and B are called the *Decoder*, because they decode the compressed images back into pixel space. A third model, Stage C, is learned in that highly compressed latent space. This training requires fractions of the compute used for current top-performing models, while also allowing cheaper and faster inference. We refer to Stage C as the *Prior*.

## Why another text-to-image model?
Well, this one is pretty fast and efficient. Würstchen’s biggest benefits come from the fact that it can generate images much faster than models like Stable Diffusion XL, while using a lot less memory! So for all of us who don’t have A100s lying around, this will come in handy. Here is a comparison with SDXL over different batch sizes:
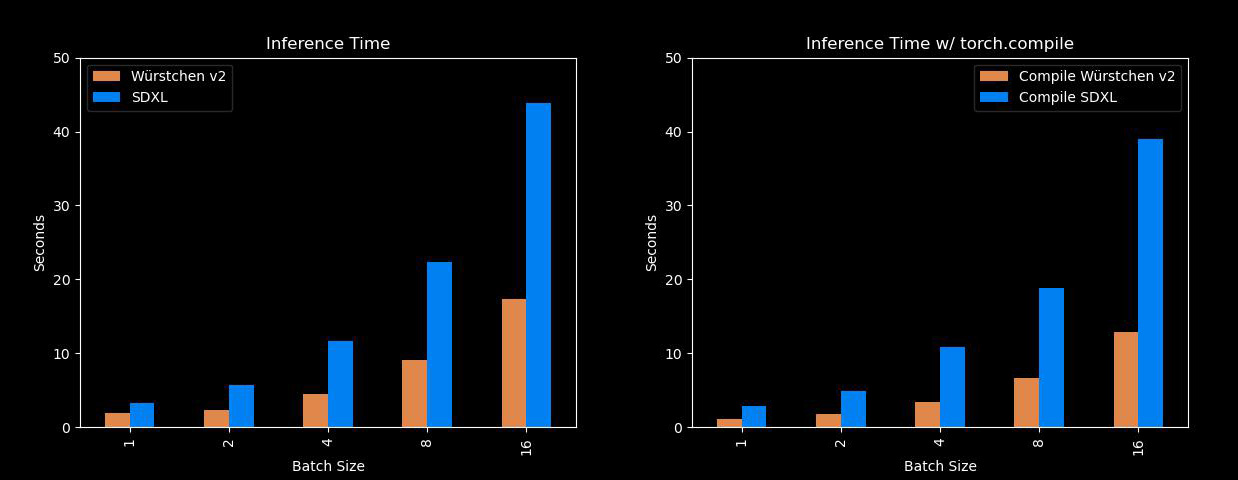
In addition to that, another greatly significant benefit of Würstchen comes with the reduced training costs. Würstchen v1, which works at 512x512, required only 9,000 GPU hours of training. Comparing this to the 150,000 GPU hours spent on Stable Diffusion 1.4 suggests that this 16x reduction in cost not only benefits researchers when conducting new experiments, but it also opens the door for more organizations to train such models. Würstchen v2 used 24,602 GPU hours. With resolutions going up to 1536, this is still 6x cheaper than SD1.4, which was only trained at 512x512.
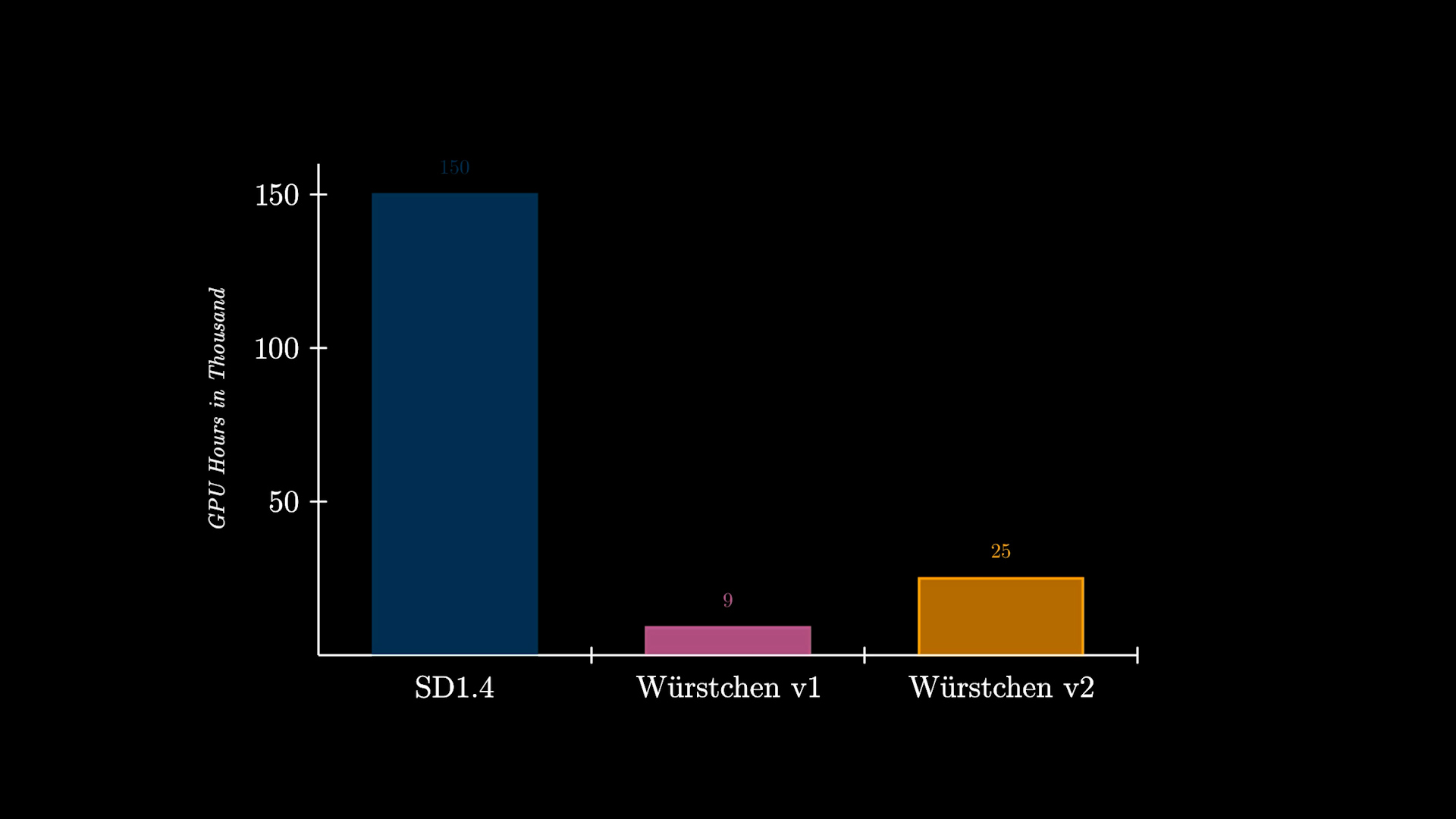
You can also find a detailed explanation video here:
<iframe width="708" height="398" src="https://www.youtube.com/embed/ogJsCPqgFMk" title="Efficient Text-to-Image Training (16x cheaper than Stable Diffusion) | Paper Explained" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
## How to use Würstchen?
You can either try it using the Demo here:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.44.2/gradio.js"> </script>
<gradio-app theme_mode="light" space="warp-ai/Wuerstchen"></gradio-app>
Otherwise, the model is available through the Diffusers Library, so you can use the interface you are already familiar with. For example, this is how to run inference using the `AutoPipeline`:
```Python
import torch
from diffusers import AutoPipelineForText2Image
from diffusers.pipelines.wuerstchen import DEFAULT_STAGE_C_TIMESTEPS
pipeline = AutoPipelineForText2Image.from_pretrained("warp-ai/wuerstchen", torch_dtype=torch.float16).to("cuda")
caption = "Anthropomorphic cat dressed as a firefighter"
images = pipeline(
caption,
height=1024,
width=1536,
prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS,
prior_guidance_scale=4.0,
num_images_per_prompt=4,
).images
```

### What image sizes does Würstchen work on?
Würstchen was trained on image resolutions between 1024x1024 & 1536x1536. We sometimes also observe good outputs at resolutions like 1024x2048. Feel free to try it out.
We also observed that the Prior (Stage C) adapts extremely fast to new resolutions. So finetuning it at 2048x2048 should be computationally cheap.
<img src="https://cdn-uploads.huggingface.co/production/uploads/634cb5eefb80cc6bcaf63c3e/5pA5KUfGmvsObqiIjdGY1.jpeg" width=1000>
### Models on the Hub
All checkpoints can also be seen on the [Huggingface Hub](https://huggingface.co/warp-ai). Multiple checkpoints, as well as future demos and model weights can be found there. Right now there are 3 checkpoints for the Prior available and 1 checkpoint for the Decoder.
Take a look at the [documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/wuerstchen) where the checkpoints are explained and what the different Prior models are and can be used for.
### Diffusers integration
Because Würstchen is fully integrated in `diffusers`, it automatically comes with various goodies and optimizations out of the box. These include:
- Automatic use of [PyTorch 2 `SDPA`](https://huggingface.co/docs/diffusers/optimization/torch2.0) accelerated attention, as described below.
- Support for the [xFormers flash attention](https://huggingface.co/docs/diffusers/optimization/xformers) implementation, if you need to use PyTorch 1.x instead of 2.
- [Model offload](https://huggingface.co/docs/diffusers/optimization/fp16#model-offloading-for-fast-inference-and-memory-savings), to move unused components to CPU while they are not in use. This saves memory with negligible performance impact.
- [Sequential CPU offload](https://huggingface.co/docs/diffusers/optimization/fp16#offloading-to-cpu-with-accelerate-for-memory-savings), for situations where memory is really precious. Memory use will be minimized, at the cost of slower inference.
- [Prompt weighting](https://huggingface.co/docs/diffusers/using-diffusers/weighted_prompts) with the [Compel](https://github.com/damian0815/compel) library.
- Support for the [`mps` device](https://huggingface.co/docs/diffusers/optimization/mps) on Apple Silicon macs.
- Use of generators for [reproducibility](https://huggingface.co/docs/diffusers/using-diffusers/reproducibility).
- Sensible defaults for inference to produce high-quality results in most situations. Of course you can tweak all parameters as you wish!
## Optimisation Technique 1: Flash Attention
Starting from version 2.0, PyTorch has integrated a highly optimised and resource-friendly version of the attention mechanism called [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) or SDPA. Depending on the nature of the input, this function taps into multiple underlying optimisations. Its performance and memory efficiency outshine the traditional attention model. Remarkably, the SDPA function mirrors the characteristics of the *flash attention* technique, as highlighted in the research paper [Fast and Memory-Efficient Exact Attention with IO-Awareness](https://arxiv.org/abs/2205.14135) penned by Dao and team.
If you're using Diffusers with PyTorch 2.0 or a later version, and the SDPA function is accessible, these enhancements are automatically applied. Get started by setting up torch 2.0 or a newer version using the [official guidelines](https://pytorch.org/get-started/locally/)!
```python
images = pipeline(caption, height=1024, width=1536, prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS, prior_guidance_scale=4.0, num_images_per_prompt=4).images
```
For an in-depth look at how `diffusers` leverages SDPA, check out the [documentation](https://huggingface.co/docs/diffusers/optimization/torch2.0).
If you're on a version of Pytorch earlier than 2.0, you can still achieve memory-efficient attention using the [xFormers](https://facebookresearch.github.io/xformers/) library:
```Python
pipeline.enable_xformers_memory_efficient_attention()
```
## Optimisation Technique 2: Torch Compile
If you're on the hunt for an extra performance boost, you can make use of `torch.compile`. It is best to apply it to both the prior's
and decoder's main model for the biggest increase in performance.
```python
pipeline.prior_prior = torch.compile(pipeline.prior_prior , mode="reduce-overhead", fullgraph=True)
pipeline.decoder = torch.compile(pipeline.decoder, mode="reduce-overhead", fullgraph=True)
```
Bear in mind that the initial inference step will take a long time (up to 2 minutes) while the models are being compiled. After that you can just normally run inference:
```python
images = pipeline(caption, height=1024, width=1536, prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS, prior_guidance_scale=4.0, num_images_per_prompt=4).images
```
And the good news is that this compilation is a one-time execution. Post that, you're set to experience faster inferences consistently for the same image resolutions. The initial time investment in compilation is quickly offset by the subsequent speed benefits. For a deeper dive into `torch.compile` and its nuances, check out the [official documentation](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html).
## How was the model trained?
The ability to train this model was only possible through compute resources provided by [Stability AI](https://stability.ai/).
We wanna say a special thank you to Stability for giving us the possibility to pursue this kind of research, with the chance
to make it accessible to so many more people!
## Resources
* Further information about this model can be found in the official diffusers [documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/wuerstchen).
* All the checkpoints can be found on the [hub](https://huggingface.co/warp-ai)
* You can try out the [demo here](https://huggingface.co/spaces/warp-ai/Wuerstchen).
* Join our [Discord](https://discord.com/invite/BTUAzb8vFY) if you want to discuss future projects or even contribute with your own ideas!
* Training code and more can be found in the official [GitHub repository](https://github.com/dome272/wuerstchen/)
| huggingface/blog/blob/main/wuerstchen.md |
--
title: Faster TensorFlow models in Hugging Face Transformers
thumbnail: /blog/assets/10_tf-serving/thumbnail.png
authors:
- user: jplu
---
# Faster TensorFlow models in Hugging Face Transformers
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/10_tf_serving.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab">
</a>
In the last few months, the Hugging Face team has been working hard on improving Transformers’ TensorFlow models to make them more robust and faster. The recent improvements are mainly focused on two aspects:
1. Computational performance: BERT, RoBERTa, ELECTRA and MPNet have been improved in order to have a much faster computation time. This gain of computational performance is noticeable for all the computational aspects: graph/eager mode, TF Serving and for CPU/GPU/TPU devices.
2. TensorFlow Serving: each of these TensorFlow model can be deployed with TensorFlow Serving to benefit of this gain of computational performance for inference.
## Computational Performance
To demonstrate the computational performance improvements, we have done a thorough benchmark where we compare BERT's performance with TensorFlow Serving of v4.2.0 to the official implementation from [Google](https://github.com/tensorflow/models/tree/master/official/nlp/bert). The benchmark has been run on a GPU V100 using a sequence length of 128 (times are in millisecond):
| Batch size | Google implementation | v4.2.0 implementation | Relative difference Google/v4.2.0 implem |
|:----------:|:---------------------:|:---------------------:|:----------------------------------------:|
| 1 | 6.7 | 6.26 | 6.79% |
| 2 | 9.4 | 8.68 | 7.96% |
| 4 | 14.4 | 13.1 | 9.45% |
| 8 | 24 | 21.5 | 10.99% |
| 16 | 46.6 | 42.3 | 9.67% |
| 32 | 83.9 | 80.4 | 4.26% |
| 64 | 171.5 | 156 | 9.47% |
| 128 | 338.5 | 309 | 9.11% |
The current implementation of Bert in v4.2.0 is faster than the Google implementation by up to ~10%. Apart from that it is also twice as fast as the implementations in the 4.1.1 release.
## TensorFlow Serving
The previous section demonstrates that the brand new Bert model got a dramatic increase in computational performance in the last version of Transformers. In this section, we will show you step-by-step how to deploy a Bert model with TensorFlow Serving to benefit from the increase in computational performance in a production environment.
### What is TensorFlow Serving?
TensorFlow Serving belongs to the set of tools provided by [TensorFlow Extended (TFX)](https://www.tensorflow.org/tfx/guide/serving) that makes the task of deploying a model to a server easier than ever. TensorFlow Serving provides two APIs, one that can be called upon using HTTP requests and another one using gRPC to run inference on the server.
### What is a SavedModel?
A SavedModel contains a standalone TensorFlow model, including its weights and its architecture. It does not require the original source of the model to be run, which makes it useful for sharing or deploying with any backend that supports reading a SavedModel such as Java, Go, C++ or JavaScript among others. The internal structure of a SavedModel is represented as such:
```
savedmodel
/assets
-> here the needed assets by the model (if any)
/variables
-> here the model checkpoints that contains the weights
saved_model.pb -> protobuf file representing the model graph
```
### How to install TensorFlow Serving?
There are three ways to install and use TensorFlow Serving:
- through a Docker container,
- through an apt package,
- or using [pip](https://pypi.org/project/pip/).
To make things easier and compliant with all the existing OS, we will use Docker in this tutorial.
### How to create a SavedModel?
SavedModel is the format expected by TensorFlow Serving. Since Transformers v4.2.0, creating a SavedModel has three additional features:
1. The sequence length can be modified freely between runs.
2. All model inputs are available for inference.
3. `hidden states` or `attention` are now grouped into a single output when returning them with `output_hidden_states=True` or `output_attentions=True`.
Below, you can find the inputs and outputs representations of a `TFBertForSequenceClassification` saved as a TensorFlow SavedModel:
```
The given SavedModel SignatureDef contains the following input(s):
inputs['attention_mask'] tensor_info:
dtype: DT_INT32
shape: (-1, -1)
name: serving_default_attention_mask:0
inputs['input_ids'] tensor_info:
dtype: DT_INT32
shape: (-1, -1)
name: serving_default_input_ids:0
inputs['token_type_ids'] tensor_info:
dtype: DT_INT32
shape: (-1, -1)
name: serving_default_token_type_ids:0
The given SavedModel SignatureDef contains the following output(s):
outputs['attentions'] tensor_info:
dtype: DT_FLOAT
shape: (12, -1, 12, -1, -1)
name: StatefulPartitionedCall:0
outputs['logits'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 2)
name: StatefulPartitionedCall:1
Method name is: tensorflow/serving/predict
```
To directly pass `inputs_embeds` (the token embeddings) instead of `input_ids` (the token IDs) as input, we need to subclass the model to have a new serving signature. The following snippet of code shows how to do so:
```python
from transformers import TFBertForSequenceClassification
import tensorflow as tf
# Creation of a subclass in order to define a new serving signature
class MyOwnModel(TFBertForSequenceClassification):
# Decorate the serving method with the new input_signature
# an input_signature represents the name, the data type and the shape of an expected input
@tf.function(input_signature=[{
"inputs_embeds": tf.TensorSpec((None, None, 768), tf.float32, name="inputs_embeds"),
"attention_mask": tf.TensorSpec((None, None), tf.int32, name="attention_mask"),
"token_type_ids": tf.TensorSpec((None, None), tf.int32, name="token_type_ids"),
}])
def serving(self, inputs):
# call the model to process the inputs
output = self.call(inputs)
# return the formated output
return self.serving_output(output)
# Instantiate the model with the new serving method
model = MyOwnModel.from_pretrained("bert-base-cased")
# save it with saved_model=True in order to have a SavedModel version along with the h5 weights.
model.save_pretrained("my_model", saved_model=True)
```
The serving method has to be overridden by the new `input_signature` argument of the `tf.function` decorator. See the [official documentation](https://www.tensorflow.org/api_docs/python/tf/function#args_1) to know more about the `input_signature` argument. The `serving` method is used to define how will behave a SavedModel when deployed with TensorFlow Serving. Now the SavedModel looks like as expected, see the new `inputs_embeds` input:
```
The given SavedModel SignatureDef contains the following input(s):
inputs['attention_mask'] tensor_info:
dtype: DT_INT32
shape: (-1, -1)
name: serving_default_attention_mask:0
inputs['inputs_embeds'] tensor_info:
dtype: DT_FLOAT
shape: (-1, -1, 768)
name: serving_default_inputs_embeds:0
inputs['token_type_ids'] tensor_info:
dtype: DT_INT32
shape: (-1, -1)
name: serving_default_token_type_ids:0
The given SavedModel SignatureDef contains the following output(s):
outputs['attentions'] tensor_info:
dtype: DT_FLOAT
shape: (12, -1, 12, -1, -1)
name: StatefulPartitionedCall:0
outputs['logits'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 2)
name: StatefulPartitionedCall:1
Method name is: tensorflow/serving/predict
```
## How to deploy and use a SavedModel?
Let’s see step by step how to deploy and use a BERT model for sentiment classification.
### Step 1
Create a SavedModel. To create a SavedModel, the Transformers library lets you load a PyTorch model called `nateraw/bert-base-uncased-imdb` trained on the IMDB dataset and convert it to a TensorFlow Keras model for you:
```python
from transformers import TFBertForSequenceClassification
model = TFBertForSequenceClassification.from_pretrained("nateraw/bert-base-uncased-imdb", from_pt=True)
# the saved_model parameter is a flag to create a SavedModel version of the model in same time than the h5 weights
model.save_pretrained("my_model", saved_model=True)
```
### Step 2
Create a Docker container with the SavedModel and run it. First, pull the TensorFlow Serving Docker image for CPU (for GPU replace serving by serving:latest-gpu):
```
docker pull tensorflow/serving
```
Next, run a serving image as a daemon named serving_base:
```
docker run -d --name serving_base tensorflow/serving
```
copy the newly created SavedModel into the serving_base container's models folder:
```
docker cp my_model/saved_model serving_base:/models/bert
```
commit the container that serves the model by changing MODEL_NAME to match the model's name (here `bert`), the name (`bert`) corresponds to the name we want to give to our SavedModel:
```
docker commit --change "ENV MODEL_NAME bert" serving_base my_bert_model
```
and kill the serving_base image ran as a daemon because we don't need it anymore:
```
docker kill serving_base
```
Finally, Run the image to serve our SavedModel as a daemon and we map the ports 8501 (REST API), and 8500 (gRPC API) in the container to the host and we name the the container `bert`.
```
docker run -d -p 8501:8501 -p 8500:8500 --name bert my_bert_model
```
### Step 3
Query the model through the REST API:
```python
from transformers import BertTokenizerFast, BertConfig
import requests
import json
import numpy as np
sentence = "I love the new TensorFlow update in transformers."
# Load the corresponding tokenizer of our SavedModel
tokenizer = BertTokenizerFast.from_pretrained("nateraw/bert-base-uncased-imdb")
# Load the model config of our SavedModel
config = BertConfig.from_pretrained("nateraw/bert-base-uncased-imdb")
# Tokenize the sentence
batch = tokenizer(sentence)
# Convert the batch into a proper dict
batch = dict(batch)
# Put the example into a list of size 1, that corresponds to the batch size
batch = [batch]
# The REST API needs a JSON that contains the key instances to declare the examples to process
input_data = {"instances": batch}
# Query the REST API, the path corresponds to http://host:port/model_version/models_root_folder/model_name:method
r = requests.post("http://localhost:8501/v1/models/bert:predict", data=json.dumps(input_data))
# Parse the JSON result. The results are contained in a list with a root key called "predictions"
# and as there is only one example, takes the first element of the list
result = json.loads(r.text)["predictions"][0]
# The returned results are probabilities, that can be positive or negative hence we take their absolute value
abs_scores = np.abs(result)
# Take the argmax that correspond to the index of the max probability.
label_id = np.argmax(abs_scores)
# Print the proper LABEL with its index
print(config.id2label[label_id])
```
This should return POSITIVE. It is also possible to pass by the gRPC (google Remote Procedure Call) API to get the same result:
```python
from transformers import BertTokenizerFast, BertConfig
import numpy as np
import tensorflow as tf
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
import grpc
sentence = "I love the new TensorFlow update in transformers."
tokenizer = BertTokenizerFast.from_pretrained("nateraw/bert-base-uncased-imdb")
config = BertConfig.from_pretrained("nateraw/bert-base-uncased-imdb")
# Tokenize the sentence but this time with TensorFlow tensors as output already batch sized to 1. Ex:
# {
# 'input_ids': <tf.Tensor: shape=(1, 3), dtype=int32, numpy=array([[ 101, 19082, 102]])>,
# 'token_type_ids': <tf.Tensor: shape=(1, 3), dtype=int32, numpy=array([[0, 0, 0]])>,
# 'attention_mask': <tf.Tensor: shape=(1, 3), dtype=int32, numpy=array([[1, 1, 1]])>
# }
batch = tokenizer(sentence, return_tensors="tf")
# Create a channel that will be connected to the gRPC port of the container
channel = grpc.insecure_channel("localhost:8500")
# Create a stub made for prediction. This stub will be used to send the gRPC request to the TF Server.
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
# Create a gRPC request made for prediction
request = predict_pb2.PredictRequest()
# Set the name of the model, for this use case it is bert
request.model_spec.name = "bert"
# Set which signature is used to format the gRPC query, here the default one
request.model_spec.signature_name = "serving_default"
# Set the input_ids input from the input_ids given by the tokenizer
# tf.make_tensor_proto turns a TensorFlow tensor into a Protobuf tensor
request.inputs["input_ids"].CopyFrom(tf.make_tensor_proto(batch["input_ids"]))
# Same with attention mask
request.inputs["attention_mask"].CopyFrom(tf.make_tensor_proto(batch["attention_mask"]))
# Same with token type ids
request.inputs["token_type_ids"].CopyFrom(tf.make_tensor_proto(batch["token_type_ids"]))
# Send the gRPC request to the TF Server
result = stub.Predict(request)
# The output is a protobuf where the only one output is a list of probabilities
# assigned to the key logits. As the probabilities as in float, the list is
# converted into a numpy array of floats with .float_val
output = result.outputs["logits"].float_val
# Print the proper LABEL with its index
print(config.id2label[np.argmax(np.abs(output))])
```
## Conclusion
Thanks to the last updates applied on the TensorFlow models in transformers, one can now easily deploy its models in production using TensorFlow Serving. One of the next steps we are thinking about is to directly integrate the preprocessing part inside the SavedModel to make things even easier.
| huggingface/blog/blob/main/tf-serving.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Backends
Simulate is designed to work with multiple backends to give users flexibility over the usage of their environment.
<p align="center">
<br>
<img src="https://user-images.githubusercontent.com/10695622/192663770-0d43e1da-d3a9-4a36-a556-fd9cb3c40597.png" width="500"/>
<br>
</p>
Under construction 🚧. | huggingface/simulate/blob/main/docs/source/conceptual/backends.mdx |
Splits and configurations
Machine learning datasets are commonly organized in *splits* and they may also have *configurations*. These internal structures provide the scaffolding for building out a dataset, and determines how a dataset should be split and organized. Understanding a dataset's structure can help you create your own dataset, and know which subset of data you should use when during model training and evaluation.

## Splits
Every processed and cleaned dataset contains *splits*, specific subsets of data reserved for specific needs. The most common splits are:
* `train`: data used to train a model; this data is exposed to the model
* `validation`: data reserved for evaluation and improving model hyperparameters; this data is hidden from the model
* `test`: data reserved for evaluation only; this data is completely hidden from the model and ourselves
The `validation` and `test` sets are especially important to ensure a model is actually learning instead of *overfitting*, or just memorizing the data.
## Configurations
A *configuration* is a higher-level internal structure than a split, and a configuration contains splits. You can think of a configuration as a sub-dataset contained within a larger dataset. It is a useful structure for adding additional layers of organization to a dataset. For example, if you take a look at the [Multilingual LibriSpeech (MLS)](https://huggingface.co/datasets/facebook/multilingual_librispeech) dataset, you'll notice there are eight different languages. While you can create a dataset containing all eight languages, it's probably neater to create a dataset with each language as a configuration. This way, users can instantly load a dataset with their language of interest instead of preprocessing the dataset to filter for a specific language.
Configurations are flexible, and can be used to organize a dataset along whatever objective you'd like. For example, the [SceneParse150](https://huggingface.co/datasets/scene_parse_150) dataset uses configurations to organize the dataset by task. One configuration is dedicated to segmenting the whole image, while the other configuration is for instance segmentation.
| huggingface/datasets-server/blob/main/docs/source/configs_and_splits.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LongT5
## Overview
The LongT5 model was proposed in [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916)
by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung and Yinfei Yang. It's an
encoder-decoder transformer pre-trained in a text-to-text denoising generative setting. LongT5 model is an extension of
T5 model, and it enables using one of the two different efficient attention mechanisms - (1) Local attention, or (2)
Transient-Global attention.
The abstract from the paper is the following:
*Recent work has shown that either (1) increasing the input length or (2) increasing model size can improve the
performance of Transformer-based neural models. In this paper, we present a new model, called LongT5, with which we
explore the effects of scaling both the input length and model size at the same time. Specifically, we integrated
attention ideas from long-input transformers (ETC), and adopted pre-training strategies from summarization pre-training
(PEGASUS) into the scalable T5 architecture. The result is a new attention mechanism we call {\em Transient Global}
(TGlobal), which mimics ETC's local/global attention mechanism, but without requiring additional side-inputs. We are
able to achieve state-of-the-art results on several summarization tasks and outperform the original T5 models on
question answering tasks.*
This model was contributed by [stancld](https://huggingface.co/stancld).
The original code can be found [here](https://github.com/google-research/longt5).
## Usage tips
- [`LongT5ForConditionalGeneration`] is an extension of [`T5ForConditionalGeneration`] exchanging the traditional
encoder *self-attention* layer with efficient either *local* attention or *transient-global* (*tglobal*) attention.
- Unlike the T5 model, LongT5 does not use a task prefix. Furthermore, it uses a different pre-training objective
inspired by the pre-training of [`PegasusForConditionalGeneration`].
- LongT5 model is designed to work efficiently and very well on long-range *sequence-to-sequence* tasks where the
input sequence exceeds commonly used 512 tokens. It is capable of handling input sequences of a length up to 16,384 tokens.
- For *Local Attention*, the sparse sliding-window local attention operation allows a given token to attend only `r`
tokens to the left and right of it (with `r=127` by default). *Local Attention* does not introduce any new parameters
to the model. The complexity of the mechanism is linear in input sequence length `l`: `O(l*r)`.
- *Transient Global Attention* is an extension of the *Local Attention*. It, furthermore, allows each input token to
interact with all other tokens in the layer. This is achieved via splitting an input sequence into blocks of a fixed
length `k` (with a default `k=16`). Then, a global token for such a block is obtained via summing and normalizing the embeddings of every token
in the block. Thanks to this, the attention allows each token to attend to both nearby tokens like in Local attention, and
also every global token like in the case of standard global attention (*transient* represents the fact the global tokens
are constructed dynamically within each attention operation). As a consequence, *TGlobal* attention introduces
a few new parameters -- global relative position biases and a layer normalization for global token's embedding.
The complexity of this mechanism is `O(l(r + l/k))`.
- An example showing how to evaluate a fine-tuned LongT5 model on the [pubmed dataset](https://huggingface.co/datasets/scientific_papers) is below.
```python
>>> import evaluate
>>> from datasets import load_dataset
>>> from transformers import AutoTokenizer, LongT5ForConditionalGeneration
>>> dataset = load_dataset("scientific_papers", "pubmed", split="validation")
>>> model = (
... LongT5ForConditionalGeneration.from_pretrained("Stancld/longt5-tglobal-large-16384-pubmed-3k_steps")
... .to("cuda")
... .half()
... )
>>> tokenizer = AutoTokenizer.from_pretrained("Stancld/longt5-tglobal-large-16384-pubmed-3k_steps")
>>> def generate_answers(batch):
... inputs_dict = tokenizer(
... batch["article"], max_length=16384, padding="max_length", truncation=True, return_tensors="pt"
... )
... input_ids = inputs_dict.input_ids.to("cuda")
... attention_mask = inputs_dict.attention_mask.to("cuda")
... output_ids = model.generate(input_ids, attention_mask=attention_mask, max_length=512, num_beams=2)
... batch["predicted_abstract"] = tokenizer.batch_decode(output_ids, skip_special_tokens=True)
... return batch
>>> result = dataset.map(generate_answer, batched=True, batch_size=2)
>>> rouge = evaluate.load("rouge")
>>> rouge.compute(predictions=result["predicted_abstract"], references=result["abstract"])
```
## Resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## LongT5Config
[[autodoc]] LongT5Config
<frameworkcontent>
<pt>
## LongT5Model
[[autodoc]] LongT5Model
- forward
## LongT5ForConditionalGeneration
[[autodoc]] LongT5ForConditionalGeneration
- forward
## LongT5EncoderModel
[[autodoc]] LongT5EncoderModel
- forward
</pt>
<jax>
## FlaxLongT5Model
[[autodoc]] FlaxLongT5Model
- __call__
- encode
- decode
## FlaxLongT5ForConditionalGeneration
[[autodoc]] FlaxLongT5ForConditionalGeneration
- __call__
- encode
- decode
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/longt5.md |
``python
from datasets import load_dataset
from transformers import set_seed, AutoModelForSeq2SeqLM, AutoTokenizer
from peft import get_peft_model, MultitaskPromptTuningConfig, TaskType, MultitaskPromptTuningInit
set_seed(42)
model_name = "google/flan-t5-base"
peft_config = MultitaskPromptTuningConfig(
tokenizer_name_or_path=model_name,
num_tasks=2,
task_type=TaskType.SEQ_2_SEQ_LM,
prompt_tuning_init=MultitaskPromptTuningInit.TEXT,
num_virtual_tokens=50,
num_transformer_submodules=1,
prompt_tuning_init_text="classify the following into either positive or negative, or entailment, neutral or contradiction:",
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
model = get_peft_model(model, peft_config)
model = model.cuda()
def send_to_device(batch):
for i in batch:
batch[i] = batch[i].cuda()
return batch
```
```python
def get_sst2(split: str):
examples = load_dataset("sst2")[split]
result_examples = []
for example in examples:
result_examples.append({})
result_examples[-1]["input"] = example["sentence"].strip() + "</s>"
result_examples[-1]["output"] = (
f"positive{tokenizer.eos_token}" if example["label"] == 1 else f"negative{tokenizer.eos_token}"
)
result_examples[-1]["task_id"] = 0
return result_examples
def get_mnli(split: str):
examples = load_dataset("multi_nli")[split]
result_examples = []
for example in examples:
result_examples.append({})
result_examples[-1]["input"] = example["premise"].strip() + " " + example["hypothesis"].strip() + "</s>"
if example["label"] == 0:
result_examples[-1]["output"] = f"entailment{tokenizer.eos_token}"
elif example["label"] == 1:
result_examples[-1]["output"] = f"neutral{tokenizer.eos_token}"
else:
result_examples[-1]["output"] = f"contradiction{tokenizer.eos_token}"
result_examples[-1]["task_id"] = 1
return result_examples
```
```python
from typing import Tuple
from torch.utils.data import Dataset, DataLoader
import torch
class MyDataset(Dataset):
def __init__(self, split: str, mode: str = "source") -> None:
super().__init__()
if split == "train":
if mode == "source":
self.examples = get_sst2(split) + get_mnli(split)
elif mode == "target":
self.examples = get_sst2(split)
if split == "val":
self.examples = get_sst2("validation")
if split == "test":
self.examples = get_sst2("validation")
def __getitem__(self, index) -> dict:
return self.examples[index]
def __len__(self) -> int:
return len(self.examples)
def __getitem__(self, index) -> dict:
return self.examples[index]
def __len__(self) -> int:
return len(self.examples)
def collate_fn(batch: dict) -> Tuple[torch.Tensor, torch.Tensor]:
input = [i["input"] for i in batch]
input = tokenizer(input, add_special_tokens=False, return_tensors="pt", padding=True)
output = [i["output"] for i in batch]
output = tokenizer(output, add_special_tokens=False, return_tensors="pt", padding=True).input_ids
output[output == tokenizer.pad_token_id] = -100
task_ids = [i["task_id"] for i in batch]
task_ids = torch.tensor(task_ids)
return {
"input_ids": input.input_ids,
"attention_mask": input.attention_mask,
"labels": output,
"task_ids": task_ids,
}
train = DataLoader(MyDataset("train"), shuffle=True, batch_size=8, collate_fn=collate_fn)
val = DataLoader(MyDataset("val"), shuffle=False, batch_size=8, collate_fn=collate_fn)
test = DataLoader(MyDataset("test"), shuffle=False, batch_size=8, collate_fn=collate_fn)
```
## source training
```python
from torch.optim.adamw import AdamW
from transformers import get_cosine_schedule_with_warmup
from tqdm import tqdm
from sklearn.metrics import f1_score
```
```python
POSITIVE_TOKEN_ID = tokenizer(" positive", add_special_tokens=False)["input_ids"][0]
NEGATIVE_TOKEN_ID = tokenizer(" negative", add_special_tokens=False)["input_ids"][0]
def classify(batch):
batch = send_to_device(batch)
# we pass labels here since we need to generate and peft doesn't support generation yet.
# No clue how to get around this
scores = model(**batch).logits
preds = []
for i in range(scores.shape[0]):
if scores[i, 0, POSITIVE_TOKEN_ID] > scores[i, 0, NEGATIVE_TOKEN_ID]:
preds.append(POSITIVE_TOKEN_ID)
else:
preds.append(NEGATIVE_TOKEN_ID)
return preds
@torch.inference_mode()
def evaluate(model, data):
loss = 0
preds = []
golds = []
for batch in tqdm(data):
batch = send_to_device(batch)
loss += model(**batch).loss
golds.extend(batch["labels"][:, 0].tolist())
preds.extend(classify(batch))
return loss / len(val), f1_score(golds, preds, pos_label=POSITIVE_TOKEN_ID)
optimizer = AdamW(model.parameters(), lr=1e-4)
scheduler = get_cosine_schedule_with_warmup(optimizer, 200, len(train))
n = 1000
step = 0
train_ = tqdm(train)
val_loss, f1 = evaluate(model, val)
print(
f"""
before source training
val loss = {val_loss}
f1 = {f1}"""
)
for batch in train_:
if step % n == 0:
val_loss, f1 = evaluate(model, val)
print(
f"""
step = {step}
val loss = {val_loss}
f1 = {f1}"""
)
model.save_pretrained(f"checkpoints_source/{step}")
step += 1
batch = send_to_device(batch)
loss = model(**batch).loss
loss.backward()
optimizer.step()
scheduler.step()
train_.set_postfix(train_loss=loss)
```
## target training
```python
train = DataLoader(MyDataset("train", "target"), shuffle=True, batch_size=8, collate_fn=collate_fn)
val = DataLoader(MyDataset("val", "target"), shuffle=False, batch_size=8, collate_fn=collate_fn)
test = DataLoader(MyDataset("test", "target"), shuffle=False, batch_size=8, collate_fn=collate_fn)
```
#### create a fresh model
```python
peft_config = MultitaskPromptTuningConfig(
tokenizer_name_or_path=model_name,
num_tasks=1,
task_type=TaskType.SEQ_2_SEQ_LM,
prompt_tuning_init=MultitaskPromptTuningInit.EXACT_SOURCE_TASK,
prompt_tuning_init_state_dict_path="checkpoints_source/50000/adapter_model.bin",
num_virtual_tokens=50,
num_transformer_submodules=1,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
model = get_peft_model(model, peft_config)
model = model.cuda()
```
```python
optimizer = AdamW(model.parameters(), lr=1e-4)
scheduler = get_cosine_schedule_with_warmup(optimizer, 200, len(train))
n = 1000
step = 0
train_ = tqdm(train)
val_loss, f1 = evaluate(model, val)
print(
f"""
before target training
val loss = {val_loss}
f1 = {f1}"""
)
for batch in train_:
if step % n == 0:
val_loss, f1 = evaluate(model, val)
print(
f"""
step = {step}
val loss = {val_loss}
f1 = {f1}"""
)
model.save_pretrained(f"checkpoints_target/{step}")
step += 1
batch = send_to_device(batch)
loss = model(**batch).loss
loss.backward()
optimizer.step()
scheduler.step()
train_.set_postfix(train_loss=loss)
```
```python
# load last checkpoint for now
from peft import set_peft_model_state_dict
sd_6000 = torch.load("checkpoints_target/6000/adapter_model.bin")
set_peft_model_state_dict(model, sd_6000)
# evaluate val
val_loss, f1 = evaluate(model, val)
print(
f"""
final
val loss = {val_loss}
f1 = {f1}"""
)
# evaluate test
test_loss, f1 = evaluate(model, test)
print(
f"""
final
test loss = {test_loss}
f1 = {f1}"""
)
```
| huggingface/peft/blob/main/examples/conditional_generation/multitask_prompt_tuning.ipynb |
--
title: "Object Detection Leaderboard"
thumbnail: /blog/assets/object-detection-leaderboard/thumbnail.png
authors:
- user: rafaelpadilla
- user: amyeroberts
---
# Object Detection Leaderboard: Decoding Metrics and Their Potential Pitfalls
Welcome to our latest dive into the world of leaderboards and models evaluation. In a [previous post](https://huggingface.co/blog/evaluating-mmlu-leaderboard), we navigated the waters of evaluating Large Language Models. Today, we set sail to a different, yet equally challenging domain – Object Detection.
Recently, we released our [Object Detection Leaderboard](https://huggingface.co/spaces/hf-vision/object_detection_leaderboard), ranking object detection models available in the Hub according to some metrics. In this blog, we will demonstrate how the models were evaluated and demystify the popular metrics used in Object Detection, from Intersection over Union (IoU) to Average Precision (AP) and Average Recall (AR). More importantly, we will spotlight the inherent divergences and pitfalls that can occur during evaluation, ensuring that you're equipped with the knowledge not just to understand but to assess model performance critically.
Every developer and researcher aims for a model that can accurately detect and delineate objects. Our [Object Detection Leaderboard](https://huggingface.co/spaces/hf-vision/object_detection_leaderboard) is the right place to find an open-source model that best fits their application needs. But what does "accurate" truly mean in this context? Which metrics should one trust? How are they computed? And, perhaps more crucially, why some models may present divergent results in different reports? All these questions will be answered in this blog.
So, let's embark on this exploration together and unlock the secrets of the Object Detection Leaderboard! If you prefer to skip the introduction and learn how object detection metrics are computed, go to the [Metrics section](#metrics). If you wish to find how to pick the best models based on the [Object Detection Leaderboard](https://huggingface.co/spaces/hf-vision/object_detection_leaderboard), you may check the [Object Detection Leaderboard](#object-detection-leaderboard) section.
## Table of Contents
- [Introduction](#object-detection-leaderboard-decoding-metrics-and-their-potential-pitfalls)
- [What's Object Detection](#whats-object-detection)
- [Metrics](#metrics)
- [What's Average Precision and how to compute it?](#whats-average-precision-and-how-to-compute-it)
- [What's Average Recall and how to compute it?](#whats-average-recall-and-how-to-compute-it)
- [What are the variants of Average Precision and Average Recall?](#what-are-the-variants-of-average-precision-and-average-recall)
- [Object Detection Leaderboard](#object-detection-leaderboard)
- [How to pick the best model based on the metrics?](#how-to-pick-the-best-model-based-on-the-metrics)
- [Which parameters can impact the Average Precision results?](#which-parameters-can-impact-the-average-precision-results)
- [Conclusions](#conclusions)
- [Additional Resources](#additional-resources)
## What's Object Detection?
In the field of Computer Vision, Object Detection refers to the task of identifying and localizing individual objects within an image. Unlike image classification, where the task is to determine the predominant object or scene in the image, object detection not only categorizes the object classes present but also provides spatial information, drawing bounding boxes around each detected object. An object detector can also output a "score" (or "confidence") per detection. It represents the probability, according to the model, that the detected object belongs to the predicted class for each bounding box.
The following image, for instance, shows five detections: one "ball" with a confidence of 98% and four "person" with a confidence of 98%, 95%, 97%, and 97%.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/intro_object_detection.png" alt="intro_object_detection.png" />
<figcaption> Figure 1: Example of outputs from an object detector.</figcaption>
</center>
</div>
Object detection models are versatile and have a wide range of applications across various domains. Some use cases include vision in autonomous vehicles, face detection, surveillance and security, medical imaging, augmented reality, sports analysis, smart cities, gesture recognition, etc.
The Hugging Face Hub has [hundreds of object detection models](https://huggingface.co/models?pipeline_tag=object-detection) pre-trained in different datasets, able to identify and localize various object classes.
One specific type of object detection models, called _zero-shot_, can receive additional text queries to search for target objects described in the text. These models can detect objects they haven't seen during training, instead of being constrained to the set of classes used during training.
The diversity of detectors goes beyond the range of output classes they can recognize. They vary in terms of underlying architectures, model sizes, processing speeds, and prediction accuracy.
A popular metric used to evaluate the accuracy of predictions made by an object detection model is the **Average Precision (AP)** and its variants, which will be explained later in this blog.
Evaluating an object detection model encompasses several components, like a dataset with ground-truth annotations, detections (output prediction), and metrics. This process is depicted in the schematic provided in Figure 2:
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/pipeline_object_detection.png" alt="pipeline_object_detection.png" />
<figcaption> Figure 2: Schematic illustrating the evaluation process for a traditional object detection model.</figcaption>
</center>
</div>
First, a benchmarking dataset containing images with ground-truth bounding box annotations is chosen and fed into the object detection model. The model predicts bounding boxes for each image, assigning associated class labels and confidence scores to each box. During the evaluation phase, these predicted bounding boxes are compared with the ground-truth boxes in the dataset. The evaluation yields a set of metrics, each ranging between [0, 1], reflecting a specific evaluation criteria. In the next section, we'll dive into the computation of the metrics in detail.
## Metrics
This section will delve into the definition of Average Precision and Average Recall, their variations, and their associated computation methodologies.
### What's Average Precision and how to compute it?
Average Precision (AP) is a single-number that summarizes the Precision x Recall curve. Before we explain how to compute it, we first need to understand the concept of Intersection over Union (IoU), and how to classify a detection as a True Positive or a False Positive.
IoU is a metric represented by a number between 0 and 1 that measures the overlap between the predicted bounding box and the actual (ground truth) bounding box. It's computed by dividing the area where the two boxes overlap by the area covered by both boxes combined. Figure 3 visually demonstrates the IoU using an example of a predicted box and its corresponding ground-truth box.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/iou.png" alt="iou.png" />
<figcaption> Figure 3: Intersection over Union (IoU) between a detection (in green) and ground-truth (in blue).</figcaption>
</center>
</div>
If the ground truth and detected boxes share identical coordinates, representing the same region in the image, their IoU value is 1. Conversely, if the boxes do not overlap at any pixel, the IoU is considered to be 0.
In scenarios where high precision in detections is expected (e.g. an autonomous vehicle), the predicted bounding boxes should closely align with the ground-truth boxes. For that, a IoU threshold ( \\( \text{T}_{\text{IOU}} \\) ) approaching 1 is preferred. On the other hand, for applications where the exact position of the detected bounding boxes relative to the target object isn’t critical, the threshold can be relaxed, setting \\( \text{T}_{\text{IOU}} \\) closer to 0.
Every box predicted by the model is considered a “positive” detection. The Intersection over Union (IoU) criterion classifies each prediction as a true positive (TP) or a false positive (FP), according to the confidence threshold we defined.
Based on predefined \\( \text{T}_{\text{IOU}} \\), we can define True Positives and True Negatives:
* **True Positive (TP)**: A correct detection where IoU ≥ \\( \text{T}_{\text{IOU}} \\).
* **False Positive (FP)**: An incorrect detection (missed object), where the IoU < \\( \text{T}_{\text{IOU}} \\).
Conversely, negatives are evaluated based on a ground-truth bounding box and can be defined as False Negative (FN) or True Negative (TN):
* **False Negative (FN)**: Refers to a ground-truth object that the model failed to detect.
* **True Negative (TN)**: Denotes a correct non-detection. Within the domain of object detection, countless bounding boxes within an image should NOT be identified, as they don't represent the target object. Consider all possible boxes in an image that don’t represent the target object - quite a vast number, isn’t it? :) That's why we do not consider TN to compute object detection metrics.
Now that we can identify our TPs, FPs, and FNs, we can define Precision and Recall:
* **Precision** is the ability of a model to identify only the relevant objects. It is the percentage of correct positive predictions and is given by:
<p style="text-align: center;">
\\( \text{Precision} = \frac{TP}{(TP + FP)} = \frac{TP}{\text{all detections}} \\)
</p>
which translates to the ratio of true positives over all detected boxes.
* **Recall** gauges a model’s competence in finding all the relevant cases (all ground truth bounding boxes). It indicates the proportion of TP detected among all ground truths and is given by:
<p style="text-align: center;">
\\( \text{Recall} = \frac{TP}{(TP + FN)} = \frac{TP}{\text{all ground truths}} \\)
</p>
Note that TP, FP, and FN depend on a predefined IoU threshold, as do Precision and Recall.
Average Precision captures the ability of a model to classify and localize objects correctly considering different values of Precision and Recall. For that we'll illustrate the relationship between Precision and Recall by plotting their respective curves for a specific target class, say "dog". We'll adopt a moderate IoU threshold = 75% to delineate our TP, FP and FN. Subsequently, we can compute the Precision and Recall values. For that, we need to vary the confidence scores of our detections.
Figure 4 shows an example of the Precision x Recall curve. For a deeper exploration into the computation of this curve, the papers “A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit” (Padilla, et al) and “A Survey on Performance Metrics for Object-Detection Algorithms” (Padilla, et al) offer more detailed toy examples demonstrating how to compute this curve.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/pxr_te_iou075.png" alt="pxr_te_iou075.png" />
<figcaption> Figure 4: Precision x Recall curve for a target object “dog” considering TP detections using IoU_thresh = 0.75.</figcaption>
</center>
</div>
The Precision x Recall curve illustrates the balance between Precision and Recall based on different confidence levels of a detector's bounding boxes. Each point of the plot is computed using a different confidence value.
To demonstrate how to calculate the Average Precision plot, we'll use a practical example from one of the papers mentioned earlier. Consider a dataset of 7 images with 15 ground-truth objects of the same class, as shown in Figure 5. Let's consider that all boxes belong to the same class, "dog" for simplification purposes.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/dataset_example.png" alt="dataset_example.png" />
<figcaption> Figure 5: Example of 24 detections (red boxes) performed by an object detector trained to detect 15 ground-truth objects (green boxes) belonging to the same class.</figcaption>
</center>
</div>
Our hypothetical object detector retrieved 24 objects in our dataset, illustrated by the red boxes. To compute Precision and Recall we use the Precision and Recall equations at all confidence levels to evaluate how well the detector performed for this specific class on our benchmarking dataset. For that, we need to establish some rules:
* **Rule 1**: For simplicity, let's consider our detections a True Positive (TP) if IOU ≥ 30%; otherwise, it is a False Positive (FP).
* **Rule 2**: For cases where a detection overlaps with more than one ground-truth (as in Images 2 to 7), the predicted box with the highest IoU is considered TP, and the other is FP.
Based on these rules, we can classify each detection as TP or FP, as shown in Table 1:
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<figcaption> Table 1: Detections from Figure 5 classified as TP or FP considering \\( \text{T}_{\text{IOU}} = 30\% \\).</figcaption>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/table_1.png" alt="table_1.png" />
</center>
</div>
Note that by rule 2, in image 1, "E" is TP while "D" is FP because IoU between "E" and the ground-truth is greater than IoU between "D" and the ground-truth.
Now, we need to compute Precision and Recall considering the confidence value of each detection. A good way to do so is to sort the detections by their confidence values as shown in Table 2. Then, for each confidence value in each row, we compute the Precision and Recall considering the cumulative TP (acc TP) and cumulative FP (acc FP). The "acc TP" of each row is increased in 1 every time a TP is noted, and the "acc FP" is increased in 1 when a FP is noted. Columns "acc TP" and "acc FP" basically tell us the TP and FP values given a particular confidence level. The computation of each value of Table 2 can be viewed in [this spreadsheet](https://docs.google.com/spreadsheets/d/1mc-KPDsNHW61ehRpI5BXoyAHmP-NxA52WxoMjBqk7pw/edit?usp=sharing).
For example, consider the 12th row (detection "P") of Table 2. The value "acc TP = 4" means that if we benchmark our model on this particular dataset with a confidence of 0.62, we would correctly detect four target objects and incorrectly detect eight target objects. This would result in:
<p style="text-align: center;">
\\( \text{Precision} = \frac{\text{acc TP}}{(\text{acc TP} + \text{acc FP})} = \frac{4}{(4+8)} = 0.3333 \\) and \\( \text{Recall} = \frac{\text{acc TP}}{\text{all ground truths}} = \frac{4}{15} = 0.2667 \\) .
</p>
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<figcaption> Table 2: Computation of Precision and Recall values of detections from Table 1.</figcaption>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/table_2.png" alt="table_2.png" />
</center>
</div>
Now, we can plot the Precision x Recall curve with the values, as shown in Figure 6:
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/precision_recall_example.png" alt="precision_recall_example.png" />
<figcaption> Figure 6: Precision x Recall curve for the detections computed in Table 2.</figcaption>
</center>
</div>
By examining the curve, one may infer the potential trade-offs between Precision and Recall and find a model's optimal operating point based on a selected confidence threshold, even if this threshold is not explicitly depicted on the curve.
If a detector's confidence results in a few false positives (FP), it will likely have high Precision. However, this might lead to missing many true positives (TP), causing a high false negative (FN) rate and, subsequently, low Recall. On the other hand, accepting more positive detections can boost Recall but might also raise the FP count, thereby reducing Precision.
**The area under the Precision x Recall curve (AUC) computed for a target class represents the Average Precision value for that particular class.** The COCO evaluation approach refers to "AP" as the mean AUC value among all target classes in the image dataset, also referred to as Mean Average Precision (mAP) by other approaches.
For a large dataset, the detector will likely output boxes with a wide range of confidence levels, resulting in a jagged Precision x Recall line, making it challenging to compute its AUC (Average Precision) precisely. Different methods approximate the area of the curve with different approaches. A popular approach is called N-interpolation, where N represents how many points are sampled from the Precision x Recall blue line.
The COCO approach, for instance, uses 101-interpolation, which computes 101 points for equally spaced Recall values (0. , 0.01, 0.02, … 1.00), while other approaches use 11 points (11-interpolation). Figure 7 illustrates a Precision x Recall curve (in blue) with 11 equal-spaced Recall points.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/11-pointInterpolation.png" alt="11-pointInterpolation.png" />
<figcaption> Figure 7: Example of a Precision x Recall curve using the 11-interpolation approach. The 11 red dots are computed with Precision and Recall equations.</figcaption>
</center>
</div>
The red points are placed according to the following:
<p style="text-align: center;">
\\( \rho_{\text{interp}} (R) = \max_{\tilde{r}:\tilde{r} \geq r} \rho \left( \tilde{r} \right) \\)
</p>
where \\( \rho \left( \tilde{r} \right) \\) is the measured Precision at Recall \\( \tilde{r} \\).
In this definition, instead of using the Precision value \\( \rho(R) \\) observed in each Recall level \\( R \\), the Precision \\( \rho_{\text{interp}} (R) \\) is obtained by considering the maximum Precision whose Recall value is greater than \\( R \\).
For this type of approach, the AUC, which represents the Average Precision, is approximated by the average of all points and given by:
<p style="text-align: center;">
\\( \text{AP}_{11} = \frac{1}{11} = \sum\limits_{R\in \left \{ 0, 0.1, ...,1 \right \}} \rho_{\text{interp}} (R) \\)
</p>
### What's Average Recall and how to compute it?
Average Recall (AR) is a metric that's often used alongside AP to evaluate object detection models. While AP evaluates both Precision and Recall across different confidence thresholds to provide a single-number summary of model performance, AR focuses solely on the Recall aspect, not taking the confidences into account and considering all detections as positives.
COCO’s approach computes AR as the mean of the maximum obtained Recall over IOUs > 0.5 and classes.
By using IOUs in the range [0.5, 1] and averaging Recall values across this interval, AR assesses the model's predictions on their object localization. Hence, if your goal is to evaluate your model for both high Recall and precise object localization, AR could be a valuable evaluation metric to consider.
### What are the variants of Average Precision and Average Recall?
Based on predefined IoU thresholds and the areas associated with ground-truth objects, different versions of AP and AR can be obtained:
* **AP@.5**: sets IoU threshold = 0.5 and computes the Precision x Recall AUC for each target class in the image dataset. Then, the computed results for each class are summed up and divided by the number of classes.
* **AP@.75**: uses the same methodology as AP@.50, with IoU threshold = 0.75. With this higher IoU requirement, AP@.75 is considered stricter than AP@.5 and should be used to evaluate models that need to achieve a high level of localization accuracy in their detections.
* **AP@[.5:.05:.95]**: also referred to AP by cocoeval tools. This is an expanded version of AP@.5 and AP@.75, as it computes AP@ with different IoU thresholds (0.5, 0.55, 0.6,...,0.95) and averages the computed results as shown in the following equation. In comparison to AP@.5 and AP@.75, this metric provides a holistic evaluation, capturing a model’s performance across a broader range of localization accuracies.
<p style="text-align: center;">
\\( \text{AP@[.5:.05:0.95} = \frac{\text{AP}_{0.5} + \text{AP}_{0.55} + ... + \text{AP}_{0.95}}{10} \\)
</p>
* **AP-S**: It applies AP@[.5:.05:.95] considering (small) ground-truth objects with \\( \text{area} < 32^2 \\) pixels.
* **AP-M**: It applies AP@[.5:.05:.95] considering (medium-sized) ground-truth objects with \\( 32^2 < \text{area} < 96^2 \\) pixels.
* **AP-L**: It applies AP@[.5:.05:.95] considering (large) ground-truth objects with \\( 32^2 < \text{area} < 96^2\\) pixels.
For Average Recall (AR), 10 IoU thresholds (0.5, 0.55, 0.6,...,0.95) are used to compute the Recall values. AR is computed by either limiting the number of detections per image or by limiting the detections based on the object's area.
* **AR-1**: considers up to 1 detection per image.
* **AR-10**: considers up to 10 detections per image.
* **AR-100**: considers up to 100 detections per image.
* **AR-S**: considers (small) objects with \\( \text{area} < 32^2 \\) pixels.
* **AR-M**: considers (medium-sized) objects with \\( 32^2 < \text{area} < 96^2 \\) pixels.
* **AR-L**: considers (large) objects with \\( \text{area} > 96^2 \\) pixels.
## Object Detection Leaderboard
We recently released the [Object Detection Leaderboard](https://huggingface.co/spaces/hf-vision/object_detection_leaderboard) to compare the accuracy and efficiency of open-source models from our Hub.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/screenshot-leaderboard.png" alt="screenshot-leaderboard.png" />
<figcaption> Figure 8: Object Detection Leaderboard.</figcaption>
</center>
</div>
To measure accuracy, we used 12 metrics involving Average Precision and Average Recall using [COCO style](https://cocodataset.org/#detection-eval), benchmarking over COCO val 2017 dataset.
As discussed previously, different tools may adopt different particularities during the evaluation. To prevent results mismatching, we preferred not to implement our version of the metrics. Instead, we opted to use COCO's official evaluation code, also referred to as PyCOCOtools, code available [here](https://github.com/cocodataset/cocoapi/tree/master/PythonAPI).
In terms of efficiency, we calculate the frames per second (FPS) for each model using the average evaluation time across the entire dataset, considering pre and post-processing steps. Given the variability in GPU memory requirements for each model, we chose to evaluate with a batch size of 1 (this choice is also influenced by our pre-processing step, which we'll delve into later). However, it's worth noting that this approach may not align perfectly with real-world performance, as larger batch sizes (often containing several images), are commonly used for better efficiency.
Next, we will provide tips on choosing the best model based on the metrics and point out which parameters may interfere with the results. Understanding these nuances is crucial, as this might spark doubts and discussions within the community.
### How to pick the best model based on the metrics?
Selecting an appropriate metric to evaluate and compare object detectors considers several factors. The primary considerations include the application's purpose and the dataset's characteristics used to train and evaluate the models.
For general performance, **AP (AP@[.5:.05:.95])** is a good choice if you want all-round model performance across different IoU thresholds, without a hard requirement on the localization of the detected objects.
If you want a model with good object recognition and objects generally in the right place, you can look at the **AP@.5**. If you prefer a more accurate model for placing the bounding boxes, **AP@.75** is more appropriate.
If you have restrictions on object sizes, **AP-S**, **AP-M** and **AP-L** come into play. For example, if your dataset or application predominantly features small objects, AP-S provides insights into the detector's efficacy in recognizing such small targets. This becomes crucial in scenarios such as detecting distant vehicles or small artifacts in medical imaging.
### Which parameters can impact the Average Precision results?
After picking an object detection model from the Hub, we can vary the output boxes if we use different parameters in the model's pre-processing and post-processing steps. These may influence the assessment metrics. We identified some of the most common factors that may lead to variations in results:
* Ignore detections that have a score under a certain threshold.
* Use `batch_sizes > 1` for inference.
* Ported models do not output the same logits as the original models.
* Some ground-truth objects may be ignored by the evaluator.
* Computing the IoU may be complicated.
* Text-conditioned models require precise prompts.
Let’s take the DEtection TRansformer (DETR) ([facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50)) model as our example case. We will show how these factors may affect the output results.
#### Thresholding detections before evaluation
Our sample model uses the [`DetrImageProcessor` class](https://huggingface.co/docs/transformers/main/en/model_doc/detr#transformers.DetrImageProcessor) to process the bounding boxes and logits, as shown in the snippet below:
```python
from transformers import DetrImageProcessor, DetrForObjectDetection
import torch
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
# PIL images have their size in (w, h) format
target_sizes = torch.tensor([image.size[::-1]])
results = processor.post_process_object_detection(outputs, target_sizes=target_sizes, threshold=0.5)
```
The parameter `threshold` in function `post_process_object_detection` is used to filter the detected bounding boxes based on their confidence scores.
As previously discussed, the Precision x Recall curve is built by measuring the Precision and Recall across the full range of confidence values [0,1]. Thus, limiting the detections before evaluation will produce biased results, as we will leave some detections out.
#### Varying the batch size
The batch size not only affects the processing time but may also result in different detected boxes. The image pre-processing step may change the resolution of the input images based on their sizes.
As mentioned in [DETR documentation](https://huggingface.co/docs/transformers/model_doc/detr), by default, `DetrImageProcessor` resizes the input images such that the shortest side is 800 pixels, and resizes again so that the longest is at most 1333 pixels. Due to this, images in a batch can have different sizes. DETR solves this by padding images up to the largest size in a batch, and by creating a pixel mask that indicates which pixels are real/which are padding.
To illustrate this process, let's consider the examples in Figure 9 and Figure 10. In Figure 9, we consider batch size = 1, so both images are processed independently with `DetrImageProcessor`. The first image is resized to (800, 1201), making the detector predict 28 boxes with class `vase`, 22 boxes with class `chair`, ten boxes with class `bottle`, etc.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/example_batch_size_1.png" alt="example_batch_size_1.png" />
<figcaption> Figure 9: Two images processed with `DetrImageProcessor` using batch size = 1.</figcaption>
</center>
</div>
Figure 10 shows the process with batch size = 2, where the same two images are processed with `DetrImageProcessor` in the same batch. Both images are resized to have the same shape (873, 1201), and padding is applied, so the part of the images with the content is kept with their original aspect ratios. However, the first image, for instance, outputs a different number of objects: 31 boxes with the class `vase`, 20 boxes with the class `chair`, eight boxes with the class `bottle`, etc. Note that for the second image, with batch size = 2, a new class is detected `dog`. This occurs due to the model's capacity to detect objects of different sizes depending on the image's resolution.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/example_batch_size_2.png" alt="example_batch_size_2.png" />
<figcaption> Figure 10: Two images processed with `DetrImageProcessor` using batch size = 2.</figcaption>
</center>
</div>
#### Ported models should output the same logits as the original models
At Hugging Face, we are very careful when porting models to our codebase. Not only with respect to the architecture, clear documentation and coding structure, but we also need to guarantee that the ported models are able to produce the same logits as the original models given the same inputs.
The logits output by a model are post-processed to produce the confidence scores, label IDs, and bounding box coordinates. Thus, minor changes in the logits can influence the metrics results. You may recall [the example above](#whats-average-precision-and-how-to-compute-it), where we discussed the process of computing Average Precision. We showed that confidence levels sort the detections, and small variations may lead to a different order and, thus, different results.
It's important to recognize that models can produce boxes in various formats, and that also may be taken into consideration, making proper conversions required by the evaluator.
* *(x, y, width, height)*: this represents the upper-left corner coordinates followed by the absolute dimensions (width and height).
* *(x, y, x2, y2)*: this format indicates the coordinates of the upper-left corner and the lower-right corner.
* *(rel_x_center, rel_y_center, rel_width, rel_height)*: the values represent the relative coordinates of the center and the relative dimensions of the box.
#### Some ground-truths are ignored in some benchmarking datasets
Some datasets sometimes use special labels that are ignored during the evaluation process.
COCO, for instance, uses the tag `iscrowd` to label large groups of objects (e.g. many apples in a basket). During evaluation, objects tagged as `iscrowd=1` are ignored. If this is not taken into consideration, you may obtain different results.
#### Calculating the IoU requires careful consideration
IoU might seem straightforward to calculate based on its definition. However, there's a crucial detail to be aware of: if the ground truth and the detection don't overlap at all, not even by one pixel, the IoU should be 0. To avoid dividing by zero when calculating the union, you can add a small value (called _epsilon_), to the denominator. However, it's essential to choose epsilon carefully: a value greater than 1e-4 might not be neutral enough to give an accurate result.
#### Text-conditioned models demand the right prompts
There might be cases in which we want to evaluate text-conditioned models such as [OWL-ViT](https://huggingface.co/google/owlvit-base-patch32), which can receive a text prompt and provide the location of the desired object.
For such models, different prompts (e.g. "Find the dog" and "Where's the bulldog?") may result in the same results. However, we decided to follow the procedure described in each paper. For the OWL-ViT, for instance, we predict the objects by using the prompt "an image of a {}" where {} is replaced with the benchmarking dataset's classes.
## Conclusions
In this post, we introduced the problem of Object Detection and depicted the main metrics used to evaluate them.
As noted, evaluating object detection models may take more work than it looks. The particularities of each model must be carefully taken into consideration to prevent biased results. Also, each metric represents a different point of view of the same model, and picking "the best" metric depends on the model's application and the characteristics of the chosen benchmarking dataset.
Below is a table that illustrates recommended metrics for specific use cases and provides real-world scenarios as examples. However, it's important to note that these are merely suggestions, and the ideal metric can vary based on the distinct particularities of each application.
| Use Case | Real-world Scenarios | Recommended Metric |
|----------------------------------------------|---------------------------------------|--------------------|
| General object detection performance | Surveillance, sports analysis | AP |
| Low accuracy requirements (broad detection) | Augmented reality, gesture recognition| AP@.5 |
| High accuracy requirements (tight detection) | Face detection | AP@.75 |
| Detecting small objects | Distant vehicles in autonomous cars, small artifacts in medical imaging | AP-S |
| Medium-sized objects detection | Luggage detection in airport security scans | AP-M |
| Large-sized objects detection | Detecting vehicles in parking lots | AP-L |
| Detecting 1 object per image | Single object tracking in videos | AR-1 |
| Detecting up to 10 objects per image | Pedestrian detection in street cameras| AR-10 |
| Detecting up to 100 objects per image | Crowd counting | AR-100 |
| Recall for small objects | Medical imaging for tiny anomalies | AR-S |
| Recall for medium-sized objects | Sports analysis for players | AR-M |
| Recall for large objects | Wildlife tracking in wide landscapes | AR-L |
The results shown in our 🤗 [Object Detection Leaderboard](https://huggingface.co/spaces/hf-vision/object_detection_leaderboard) are computed using an independent tool [PyCOCOtools](https://github.com/cocodataset/cocoapi/tree/master/PythonAPI) widely used by the community for model benchmarking. We're aiming to collect datasets of different domains (e.g. medical images, sports, autonomous vehicles, etc). You can use the [discussion page](https://huggingface.co/spaces/hf-vision/object_detection_leaderboard/discussions) to make requests for datasets, models and features. Eager to see your model or dataset feature on our leaderboard? Don't hold back! Introduce your model and dataset, fine-tune, and let's get it ranked! 🥇
## Additional Resources
* [Object Detection Guide](https://huggingface.co/docs/transformers/tasks/object_detection)
* [Task of Object Detection](https://huggingface.co/tasks/object-detection)
* Paper [What Makes for Effective Detection Proposals](https://arxiv.org/abs/1502.05082)
* Paper [A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit](https://www.mdpi.com/2079-9292/10/3/279)
* Paper [A Survey on Performance Metrics for Object-Detection Algorithms](https://ieeexplore.ieee.org/document/9145130)
Special thanks 🙌 to [@merve](https://huggingface.co/merve), [@osanseviero](https://huggingface.co/osanseviero) and [@pcuenq](https://huggingface.co/pcuenq) for their feedback and great comments. 🤗
| huggingface/blog/blob/main/object-detection-leaderboard.md |
Optimization
This page contains the API reference documentation for learning rate optimizers included in `timm`.
## Optimizers
### Factory functions
[[autodoc]] timm.optim.optim_factory.create_optimizer
[[autodoc]] timm.optim.optim_factory.create_optimizer_v2
### Optimizer Classes
[[autodoc]] timm.optim.adabelief.AdaBelief
[[autodoc]] timm.optim.adafactor.Adafactor
[[autodoc]] timm.optim.adahessian.Adahessian
[[autodoc]] timm.optim.adamp.AdamP
[[autodoc]] timm.optim.adamw.AdamW
[[autodoc]] timm.optim.lamb.Lamb
[[autodoc]] timm.optim.lars.Lars
[[autodoc]] timm.optim.lookahead.Lookahead
[[autodoc]] timm.optim.madgrad.MADGRAD
[[autodoc]] timm.optim.nadam.Nadam
[[autodoc]] timm.optim.nvnovograd.NvNovoGrad
[[autodoc]] timm.optim.radam.RAdam
[[autodoc]] timm.optim.rmsprop_tf.RMSpropTF
[[autodoc]] timm.optim.sgdp.SGDP
| huggingface/pytorch-image-models/blob/main/hfdocs/source/reference/optimizers.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# JAX/Flax
[[open-in-colab]]
🤗 Diffusers supports Flax for super fast inference on Google TPUs, such as those available in Colab, Kaggle or Google Cloud Platform. This guide shows you how to run inference with Stable Diffusion using JAX/Flax.
Before you begin, make sure you have the necessary libraries installed:
```py
# uncomment to install the necessary libraries in Colab
#!pip install -q jax==0.3.25 jaxlib==0.3.25 flax transformers ftfy
#!pip install -q diffusers
```
You should also make sure you're using a TPU backend. While JAX does not run exclusively on TPUs, you'll get the best performance on a TPU because each server has 8 TPU accelerators working in parallel.
If you are running this guide in Colab, select *Runtime* in the menu above, select the option *Change runtime type*, and then select *TPU* under the *Hardware accelerator* setting. Import JAX and quickly check whether you're using a TPU:
```python
import jax
import jax.tools.colab_tpu
jax.tools.colab_tpu.setup_tpu()
num_devices = jax.device_count()
device_type = jax.devices()[0].device_kind
print(f"Found {num_devices} JAX devices of type {device_type}.")
assert (
"TPU" in device_type,
"Available device is not a TPU, please select TPU from Runtime > Change runtime type > Hardware accelerator"
)
# Found 8 JAX devices of type Cloud TPU.
```
Great, now you can import the rest of the dependencies you'll need:
```python
import jax.numpy as jnp
from jax import pmap
from flax.jax_utils import replicate
from flax.training.common_utils import shard
from diffusers import FlaxStableDiffusionPipeline
```
## Load a model
Flax is a functional framework, so models are stateless and parameters are stored outside of them. Loading a pretrained Flax pipeline returns *both* the pipeline and the model weights (or parameters). In this guide, you'll use `bfloat16`, a more efficient half-float type that is supported by TPUs (you can also use `float32` for full precision if you want).
```python
dtype = jnp.bfloat16
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="bf16",
dtype=dtype,
)
```
## Inference
TPUs usually have 8 devices working in parallel, so let's use the same prompt for each device. This means you can perform inference on 8 devices at once, with each device generating one image. As a result, you'll get 8 images in the same amount of time it takes for one chip to generate a single image!
<Tip>
Learn more details in the [How does parallelization work?](#how-does-parallelization-work) section.
</Tip>
After replicating the prompt, get the tokenized text ids by calling the `prepare_inputs` function on the pipeline. The length of the tokenized text is set to 77 tokens as required by the configuration of the underlying CLIP text model.
```python
prompt = "A cinematic film still of Morgan Freeman starring as Jimi Hendrix, portrait, 40mm lens, shallow depth of field, close up, split lighting, cinematic"
prompt = [prompt] * jax.device_count()
prompt_ids = pipeline.prepare_inputs(prompt)
prompt_ids.shape
# (8, 77)
```
Model parameters and inputs have to be replicated across the 8 parallel devices. The parameters dictionary is replicated with [`flax.jax_utils.replicate`](https://flax.readthedocs.io/en/latest/api_reference/flax.jax_utils.html#flax.jax_utils.replicate) which traverses the dictionary and changes the shape of the weights so they are repeated 8 times. Arrays are replicated using `shard`.
```python
# parameters
p_params = replicate(params)
# arrays
prompt_ids = shard(prompt_ids)
prompt_ids.shape
# (8, 1, 77)
```
This shape means each one of the 8 devices receives as an input a `jnp` array with shape `(1, 77)`, where `1` is the batch size per device. On TPUs with sufficient memory, you could have a batch size larger than `1` if you want to generate multiple images (per chip) at once.
Next, create a random number generator to pass to the generation function. This is standard procedure in Flax, which is very serious and opinionated about random numbers. All functions that deal with random numbers are expected to receive a generator to ensure reproducibility, even when you're training across multiple distributed devices.
The helper function below uses a seed to initialize a random number generator. As long as you use the same seed, you'll get the exact same results. Feel free to use different seeds when exploring results later in the guide.
```python
def create_key(seed=0):
return jax.random.PRNGKey(seed)
```
The helper function, or `rng`, is split 8 times so each device receives a different generator and generates a different image.
```python
rng = create_key(0)
rng = jax.random.split(rng, jax.device_count())
```
To take advantage of JAX's optimized speed on a TPU, pass `jit=True` to the pipeline to compile the JAX code into an efficient representation and to ensure the model runs in parallel across the 8 devices.
<Tip warning={true}>
You need to ensure all your inputs have the same shape in subsequent calls, otherwise JAX will need to recompile the code which is slower.
</Tip>
The first inference run takes more time because it needs to compile the code, but subsequent calls (even with different inputs) are much faster. For example, it took more than a minute to compile on a TPU v2-8, but then it takes about **7s** on a future inference run!
```py
%%time
images = pipeline(prompt_ids, p_params, rng, jit=True)[0]
# CPU times: user 56.2 s, sys: 42.5 s, total: 1min 38s
# Wall time: 1min 29s
```
The returned array has shape `(8, 1, 512, 512, 3)` which should be reshaped to remove the second dimension and get 8 images of `512 × 512 × 3`. Then you can use the [`~utils.numpy_to_pil`] function to convert the arrays into images.
```python
from diffusers.utils import make_image_grid
images = images.reshape((images.shape[0] * images.shape[1],) + images.shape[-3:])
images = pipeline.numpy_to_pil(images)
make_image_grid(images, rows=2, cols=4)
```

## Using different prompts
You don't necessarily have to use the same prompt on all devices. For example, to generate 8 different prompts:
```python
prompts = [
"Labrador in the style of Hokusai",
"Painting of a squirrel skating in New York",
"HAL-9000 in the style of Van Gogh",
"Times Square under water, with fish and a dolphin swimming around",
"Ancient Roman fresco showing a man working on his laptop",
"Close-up photograph of young black woman against urban background, high quality, bokeh",
"Armchair in the shape of an avocado",
"Clown astronaut in space, with Earth in the background",
]
prompt_ids = pipeline.prepare_inputs(prompts)
prompt_ids = shard(prompt_ids)
images = pipeline(prompt_ids, p_params, rng, jit=True).images
images = images.reshape((images.shape[0] * images.shape[1],) + images.shape[-3:])
images = pipeline.numpy_to_pil(images)
make_image_grid(images, 2, 4)
```

## How does parallelization work?
The Flax pipeline in 🤗 Diffusers automatically compiles the model and runs it in parallel on all available devices. Let's take a closer look at how that process works.
JAX parallelization can be done in multiple ways. The easiest one revolves around using the [`jax.pmap`](https://jax.readthedocs.io/en/latest/_autosummary/jax.pmap.html) function to achieve single-program multiple-data (SPMD) parallelization. It means running several copies of the same code, each on different data inputs. More sophisticated approaches are possible, and you can go over to the JAX [documentation](https://jax.readthedocs.io/en/latest/index.html) to explore this topic in more detail if you are interested!
`jax.pmap` does two things:
1. Compiles (or "`jit`s") the code which is similar to `jax.jit()`. This does not happen when you call `pmap`, and only the first time the `pmap`ped function is called.
2. Ensures the compiled code runs in parallel on all available devices.
To demonstrate, call `pmap` on the pipeline's `_generate` method (this is a private method that generates images and may be renamed or removed in future releases of 🤗 Diffusers):
```python
p_generate = pmap(pipeline._generate)
```
After calling `pmap`, the prepared function `p_generate` will:
1. Make a copy of the underlying function, `pipeline._generate`, on each device.
2. Send each device a different portion of the input arguments (this is why it's necessary to call the *shard* function). In this case, `prompt_ids` has shape `(8, 1, 77, 768)` so the array is split into 8 and each copy of `_generate` receives an input with shape `(1, 77, 768)`.
The most important thing to pay attention to here is the batch size (1 in this example), and the input dimensions that make sense for your code. You don't have to change anything else to make the code work in parallel.
The first time you call the pipeline takes more time, but the calls afterward are much faster. The `block_until_ready` function is used to correctly measure inference time because JAX uses asynchronous dispatch and returns control to the Python loop as soon as it can. You don't need to use that in your code; blocking occurs automatically when you want to use the result of a computation that has not yet been materialized.
```py
%%time
images = p_generate(prompt_ids, p_params, rng)
images = images.block_until_ready()
# CPU times: user 1min 15s, sys: 18.2 s, total: 1min 34s
# Wall time: 1min 15s
```
Check your image dimensions to see if they're correct:
```python
images.shape
# (8, 1, 512, 512, 3)
```
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/stable_diffusion_jax_how_to.md |
SE-ResNeXt
**SE ResNeXt** is a variant of a [ResNext](https://www.paperswithcode.com/method/resneXt) that employs [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block) to enable the network to perform dynamic channel-wise feature recalibration.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('seresnext26d_32x4d', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `seresnext26d_32x4d`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('seresnext26d_32x4d', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{hu2019squeezeandexcitation,
title={Squeeze-and-Excitation Networks},
author={Jie Hu and Li Shen and Samuel Albanie and Gang Sun and Enhua Wu},
year={2019},
eprint={1709.01507},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: SEResNeXt
Paper:
Title: Squeeze-and-Excitation Networks
URL: https://paperswithcode.com/paper/squeeze-and-excitation-networks
Models:
- Name: seresnext26d_32x4d
In Collection: SEResNeXt
Metadata:
FLOPs: 3507053024
Parameters: 16810000
File Size: 67425193
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: seresnext26d_32x4d
LR: 0.6
Epochs: 100
Layers: 26
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/resnet.py#L1234
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnext26d_32x4d-80fa48a3.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.59%
Top 5 Accuracy: 93.61%
- Name: seresnext26t_32x4d
In Collection: SEResNeXt
Metadata:
FLOPs: 3466436448
Parameters: 16820000
File Size: 67414838
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: seresnext26t_32x4d
LR: 0.6
Epochs: 100
Layers: 26
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/resnet.py#L1246
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnext26tn_32x4d-569cb627.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.99%
Top 5 Accuracy: 93.73%
- Name: seresnext50_32x4d
In Collection: SEResNeXt
Metadata:
FLOPs: 5475179184
Parameters: 27560000
File Size: 110569859
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: seresnext50_32x4d
LR: 0.6
Epochs: 100
Layers: 50
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/resnet.py#L1267
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnext50_32x4d_racm-a304a460.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.27%
Top 5 Accuracy: 95.62%
--> | huggingface/pytorch-image-models/blob/main/docs/models/seresnext.md |
An Introduction to Unreal Learning Agents
[Learning Agents](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction) is an Unreal Engine (UE) plugin that allows you **to train AI characters using machine learning (ML) in Unreal**.
It's an exciting new plugin where you can create unique environments using Unreal Engine and train your agents.
Let's see how you can **get started and train a car to drive in an Unreal Engine Environment**.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit12/learning-agents-car.png" alt="Learning Agents"/>
<figcaption>Source: [Learning Agents Driving Car Tutorial](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive)</figcaption>
</figure>
## Case 1: I don't know anything about Unreal Engine and Beginners in Unreal Engine
If you're new to Unreal Engine, don't be scared! We listed two courses you need to follow to be able to use Learning Agents:
1. Master the Basics: Begin by watching this course [your first hour in Unreal Engine 5](https://dev.epicgames.com/community/learning/courses/ZpX/your-first-hour-in-unreal-engine-5/E7L/introduction-to-your-first-hour-in-unreal-engine-5). This comprehensive course will **lay down the foundational knowledge you need to use Unreal**.
2. Dive into Blueprints: Explore the world of Blueprints, the visual scripting component of Unreal Engine. [This video course](https://youtu.be/W0brCeJNMqk?si=zy4t4t1l6FMIzbpz) will familiarize you with this essential tool.
Armed with the basics, **you're now prepared to play with Learning Agents**:
3. Get the Big Picture of Learning Agents by [reading this informative overview](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction).
4. [Teach a Car to Drive using Reinforcement Learning in Learning Agents](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive).
5. [Check Imitation Learning with the Unreal Engine 5.3 Learning Agents Plugin](https://www.youtube.com/watch?v=NwYUNlFvajQ)
## Case 2: I'm familiar with Unreal
For those already acquainted with Unreal Engine, you can jump straight into Learning Agents with these two tutorials:
1. Get the Big Picture of Learning Agents by [reading this informative overview](https://dev.epicgames.com/community/learning/tutorials/8OWY/unreal-engine-learning-agents-introduction).
2. [Teach a Car to Drive using Reinforcement Learning in Learning Agents](https://dev.epicgames.com/community/learning/tutorials/qj2O/unreal-engine-learning-to-drive). .
3. [Check Imitation Learning with the Unreal Engine 5.3 Learning Agents Plugin](https://www.youtube.com/watch?v=NwYUNlFvajQ) | huggingface/deep-rl-class/blob/main/units/en/unitbonus3/learning-agents.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LoRA
LoRA is low-rank decomposition method to reduce the number of trainable parameters which speeds up finetuning large models and uses less memory. In PEFT, using LoRA is as easy as setting up a [`LoraConfig`] and wrapping it with [`get_peft_model`] to create a trainable [`PeftModel`].
This guide explores in more detail other options and features for using LoRA.
## Initialization
The initialization of LoRA weights is controlled by the parameter `init_lora_weights` in [`LoraConfig`]. By default, PEFT initializes LoRA weights with Kaiming-uniform for weight A and zeros for weight B resulting in an identity transform (same as the reference [implementation](https://github.com/microsoft/LoRA)).
It is also possible to pass `init_lora_weights="gaussian"`. As the name suggests, this initializes weight A with a Gaussian distribution and zeros for weight B (this is how [Diffusers](https://huggingface.co/docs/diffusers/index) initializes LoRA weights).
```py
from peft import LoraConfig
config = LoraConfig(init_lora_weights="gaussian", ...)
```
There is also an option to set `init_lora_weights=False` which is useful for debugging and testing. This should be the only time you use this option. When choosing this option, the LoRA weights are initialized such that they do *not* result in an identity transform.
```py
from peft import LoraConfig
config = LoraConfig(init_lora_weights=False, ...)
```
### LoftQ
When quantizing the base model for QLoRA training, consider using the [LoftQ initialization](https://arxiv.org/abs/2310.08659), which has been shown to improve performance when training quantized models. The idea is that the LoRA weights are initialized such that the quantization error is minimized. If you're using LoftQ, *do not* quantize the base model. You should set up a [`LoftQConfig`] instead:
```python
from peft import LoftQConfig, LoraConfig, get_peft_model
base_model = AutoModelForCausalLM.from_pretrained(...) # don't quantize here
loftq_config = LoftQConfig(loftq_bits=4, ...) # set 4bit quantization
lora_config = LoraConfig(..., init_lora_weights="loftq", loftq_config=loftq_config)
peft_model = get_peft_model(base_model, lora_config)
```
<Tip>
Learn more about how PEFT works with quantization in the [Quantization](quantization) guide.
</Tip>
### Rank-stabilized LoRA
Another way to initialize [`LoraConfig`] is with the [rank-stabilized LoRA (rsLoRA)](https://huggingface.co/papers/2312.03732) method. The LoRA architecture scales each adapter during every forward pass by a fixed scalar which is set at initialization and depends on the rank `r`. The scalar is given by `lora_alpha/r` in the original implementation, but rsLoRA uses `lora_alpha/math.sqrt(r)` which stabilizes the adapters and increases the performance potential from using a higher `r`.
```py
from peft import LoraConfig
config = LoraConfig(use_rslora=True, ...)
```
## Merge adapters
While LoRA is significantly smaller and faster to train, you may encounter latency issues during inference due to separately loading the base model and the LoRA adapter. To eliminate latency, use the [`~LoraModel.merge_and_unload`] function to merge the adapter weights with the base model. This allows you to use the newly merged model as a standalone model. The [`~LoraModel.merge_and_unload`] function doesn't keep the adapter weights in memory.
```py
from transformers import AutoModelForCausalLM
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1")
peft_model_id = "alignment-handbook/zephyr-7b-sft-lora"
model = PeftModel.from_pretrained(base_model, peft_model_id)
model.merge_and_unload()
```
If you need to keep a copy of the weights so you can unmerge the adapter later or delete and load different ones, you should use the [`~tuners.tuner_utils.BaseTuner.merge_adapter`] function instead. Now you have the option to use [`~LoraModel.unmerge_adapter`] to return the base model.
```py
from transformers import AutoModelForCausalLM
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1")
peft_model_id = "alignment-handbook/zephyr-7b-sft-lora"
model = PeftModel.from_pretrained(base_model, peft_model_id)
model.merge_adapter()
# unmerge the LoRA layers from the base model
model.unmerge_adapter()
```
The [`~LoraModel.add_weighted_adapter`] function is useful for merging multiple LoRAs into a new adapter based on a user provided weighting scheme in the `weights` parameter.
```py
model.add_weighted_adapter(
adapters=["adapter_1", "adapter_2"],
weights=[0.7, 0.3],
adapter_name="new-weighted-adapter"
)
```
## Load adapters
Adapters can be loaded onto a pretrained model with [`~PeftModel.load_adapter`], which is useful for trying out different adapters whose weights aren't merged. Set the active adapter weights with the [`~LoraModel.set_adapter`] function.
```py
from transformers import AutoModelForCausalLM
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1")
peft_model_id = "alignment-handbook/zephyr-7b-sft-lora"
model = PeftModel.from_pretrained(base_model, peft_model_id)
# load different adapter
model.load_adapter("alignment-handbook/zephyr-7b-dpo-lora", adapter_name="dpo")
# set adapter as active
model.set_adapter("dpo")
```
To return the base model, you could use [`~LoraModel.unload`] to unload all of the LoRA modules or [`~LoraModel.delete_adapter`] to delete the adapter entirely.
```py
# unload adapter
model.unload()
# delete adapter
model.delete_adapter("dpo")
```
| huggingface/peft/blob/main/docs/source/developer_guides/lora.md |
使用标记
相关空间:https://huggingface.co/spaces/gradio/calculator-flagging-crowdsourced, https://huggingface.co/spaces/gradio/calculator-flagging-options, https://huggingface.co/spaces/gradio/calculator-flag-basic
标签:标记,数据
## 简介
当您演示一个机器学习模型时,您可能希望收集试用模型的用户的数据,特别是模型行为不如预期的数据点。捕获这些“困难”数据点是有价值的,因为它允许您改进机器学习模型并使其更可靠和稳健。
Gradio 通过在每个“界面”中包含一个**标记**按钮来简化这些数据的收集。这使得用户或测试人员可以轻松地将数据发送回运行演示的机器。样本会保存在一个 CSV 日志文件中(默认情况下)。如果演示涉及图像、音频、视频或其他类型的文件,则这些文件会单独保存在一个并行目录中,并且这些文件的路径会保存在 CSV 文件中。
## 在 `gradio.Interface` 中使用**标记**按钮
使用 Gradio 的 `Interface` 进行标记特别简单。默认情况下,在输出组件下方有一个标记为**标记**的按钮。当用户测试您的模型时,如果看到有趣的输出,他们可以点击标记按钮将输入和输出数据发送回运行演示的机器。样本会保存在一个 CSV 日志文件中(默认情况下)。如果演示涉及图像、音频、视频或其他类型的文件,则这些文件会单独保存在一个并行目录中,并且这些文件的路径会保存在 CSV 文件中。
在 `gradio.Interface` 中有[四个参数](https://gradio.app/docs/#interface-header)控制标记的工作方式。我们将详细介绍它们。
- `allow_flagging`:此参数可以设置为 `"manual"`(默认值),`"auto"` 或 `"never"`。
- `manual`:用户将看到一个标记按钮,只有在点击按钮时样本才会被标记。
- `auto`:用户将不会看到一个标记按钮,但每个样本都会自动被标记。
- `never`:用户将不会看到一个标记按钮,并且不会标记任何样本。
- `flagging_options`:此参数可以是 `None`(默认值)或字符串列表。
- 如果是 `None`,则用户只需点击**标记**按钮,不会显示其他选项。
- 如果提供了一个字符串列表,则用户会看到多个按钮,对应于提供的每个字符串。例如,如果此参数的值为`[" 错误 ", " 模糊 "]`,则会显示标记为**标记为错误**和**标记为模糊**的按钮。这仅适用于 `allow_flagging` 为 `"manual"` 的情况。
- 所选选项将与输入和输出一起记录。
- `flagging_dir`:此参数接受一个字符串。
- 它表示标记数据存储的目录名称。
- `flagging_callback`:此参数接受 `FlaggingCallback` 类的子类的实例
- 使用此参数允许您编写在点击标记按钮时运行的自定义代码
- 默认情况下,它设置为 `gr.CSVLogger` 的一个实例
- 一个示例是将其设置为 `gr.HuggingFaceDatasetSaver` 的一个实例,这样您可以将任何标记的数据导入到 HuggingFace 数据集中(参见下文)。
## 标记的数据会发生什么?
在 `flagging_dir` 参数提供的目录中,将记录标记的数据的 CSV 文件。
以下是一个示例:下面的代码创建了嵌入其中的计算器界面:
```python
import gradio as gr
def calculator(num1, operation, num2):
if operation == "add":
return num1 + num2
elif operation == "subtract":
return num1 - num2
elif operation == "multiply":
return num1 * num2
elif operation == "divide":
return num1 / num2
iface = gr.Interface(
calculator,
["number", gr.Radio(["add", "subtract", "multiply", "divide"]), "number"],
"number",
allow_flagging="manual"
)
iface.launch()
```
<gradio-app space="gradio/calculator-flag-basic/"></gradio-app>
当您点击上面的标记按钮时,启动界面的目录将包括一个新的标记子文件夹,其中包含一个 CSV 文件。该 CSV 文件包括所有被标记的数据。
```directory
+-- flagged/
| +-- logs.csv
```
_flagged/logs.csv_
```csv
num1,operation,num2,Output,timestamp
5,add,7,12,2022-01-31 11:40:51.093412
6,subtract,1.5,4.5,2022-01-31 03:25:32.023542
```
如果界面涉及文件数据,例如图像和音频组件,还将创建文件夹来存储这些标记的数据。例如,将 `image` 输入到 `image` 输出界面将创建以下结构。
```directory
+-- flagged/
| +-- logs.csv
| +-- image/
| | +-- 0.png
| | +-- 1.png
| +-- Output/
| | +-- 0.png
| | +-- 1.png
```
_flagged/logs.csv_
```csv
im,Output timestamp
im/0.png,Output/0.png,2022-02-04 19:49:58.026963
im/1.png,Output/1.png,2022-02-02 10:40:51.093412
```
如果您希望用户为标记提供一个原因,您可以将字符串列表传递给 Interface 的 `flagging_options` 参数。用户在标记时必须选择其中一项,选项将作为附加列保存在 CSV 文件中。
如果我们回到计算器示例,下面的代码将创建嵌入其中的界面。
```python
iface = gr.Interface(
calculator,
["number", gr.Radio(["add", "subtract", "multiply", "divide"]), "number"],
"number",
allow_flagging="manual",
flagging_options=["wrong sign", "off by one", "other"]
)
iface.launch()
```
<gradio-app space="gradio/calculator-flagging-options/"></gradio-app>
当用户点击标记按钮时,CSV 文件现在将包括指示所选选项的列。
_flagged/logs.csv_
```csv
num1,operation,num2,Output,flag,timestamp
5,add,7,-12,wrong sign,2022-02-04 11:40:51.093412
6,subtract,1.5,3.5,off by one,2022-02-04 11:42:32.062512
```
## HuggingFaceDatasetSaver 回调
有时,将数据保存到本地 CSV 文件是不合理的。例如,在 Hugging Face Spaces 上
,开发者通常无法访问托管 Gradio 演示的底层临时机器。这就是为什么,默认情况下,在 Hugging Face Space 中关闭标记的原因。然而,
您可能希望对标记的数据做其他处理。
you may want to do something else with the flagged data.
通过 `flagging_callback` 参数,我们使这变得非常简单。
例如,下面我们将会将标记的数据从我们的计算器示例导入到 Hugging Face 数据集中,以便我们可以构建一个“众包”数据集:
```python
import os
HF_TOKEN = os.getenv('HF_TOKEN')
hf_writer = gr.HuggingFaceDatasetSaver(HF_TOKEN, "crowdsourced-calculator-demo")
iface = gr.Interface(
calculator,
["number", gr.Radio(["add", "subtract", "multiply", "divide"]), "number"],
"number",
description="Check out the crowd-sourced dataset at: [https://huggingface.co/datasets/aliabd/crowdsourced-calculator-demo](https://huggingface.co/datasets/aliabd/crowdsourced-calculator-demo)",
allow_flagging="manual",
flagging_options=["wrong sign", "off by one", "other"],
flagging_callback=hf_writer
)
iface.launch()
```
注意,我们使用我们的 Hugging Face 令牌和
要保存样本的数据集的名称,定义了我们自己的
`gradio.HuggingFaceDatasetSaver` 的实例。此外,我们还将 `allow_flagging="manual"` 设置为了
,因为在 Hugging Face Spaces 中,`allow_flagging` 默认设置为 `"never"`。这是我们的演示:
<gradio-app space="gradio/calculator-flagging-crowdsourced/"></gradio-app>
您现在可以在这个[公共的 Hugging Face 数据集](https://huggingface.co/datasets/aliabd/crowdsourced-calculator-demo)中看到上面标记的所有示例。

我们创建了 `gradio.HuggingFaceDatasetSaver` 类,但只要它继承自[此文件](https://github.com/gradio-app/gradio/blob/master/gradio/flagging.py)中定义的 `FlaggingCallback`,您可以传递自己的自定义类。如果您创建了一个很棒的回调,请将其贡献给该存储库!
## 使用 Blocks 进行标记
如果您正在使用 `gradio.Blocks`,又该怎么办呢?一方面,使用 Blocks 您拥有更多的灵活性
--您可以编写任何您想在按钮被点击时运行的 Python 代码,
并使用 Blocks 中的内置事件分配它。
同时,您可能希望使用现有的 `FlaggingCallback` 来避免编写额外的代码。
这需要两个步骤:
1. 您必须在代码中的某个位置运行您的回调的 `.setup()` 方法
在第一次标记数据之前
2. 当点击标记按钮时,您触发回调的 `.flag()` 方法,
确保正确收集参数并禁用通常的预处理。
下面是一个使用默认的 `CSVLogger` 标记图像怀旧滤镜 Blocks 演示的示例:
data using the default `CSVLogger`:
$code_blocks_flag
$demo_blocks_flag
## 隐私
重要提示:请确保用户了解他们提交的数据何时被保存以及您计划如何处理它。当您使用 `allow_flagging=auto`(当通过演示提交的所有数据都被标记时),这一点尤为重要
### 这就是全部!祝您建设愉快 :)
| gradio-app/gradio/blob/main/guides/cn/07_other-tutorials/using-flagging.md |
# Examples for Simulate
The examples are organized by level of complexity or application.
Currently, Simulate has the following examples running:
### Basic
* `create_and_save.py`: showcases basic scene assembly and saving as a gltf.
* `objects.py`: showcases the different objects we have in HuggingFace Simulate.
* `simple_physics.py`: showcases a basic falling object physics experiment.
* `structured_grid_test.py`: tests the StructuredGrid object in Simulate.
### Intermediate
* `playground.py`: showcases how to build a small world, add objects, and add actors to interact with the world. The actor must find a randomly colored box labelled `target`.
* `procgren_grid.py`: shows how we can create procgen grids from numpy arrays.
* `reward_example`: showcases different varieties of reward functions that can be added to one scene.
* `tmaze.py`: showcases building a small detailed maze for an agent to explore.
### Advanced
* `cartpole.py`: reimplements the famous cartpole example, with parallel execution and rendering.
* `lunarlander.py`: reimplements the famous lunar lander reinforcement learning environment.
* `mountaincar.py`: adds an impressive recreation of the mountain car Gym environment.
### Reinforcement Learning (RL)
There are multiple environments implemented with Stable Baselines 3 PPO:
* `sb3_basic_maze.py`:
* `sb3_collectables.py`:
* `sb3_move_boxes.py`:
* `sb3_procgen.py`:
* `sb3_visual_reward.py`:
## Backend Integrations
For more information on the backend integrations, see the relevant folders:
1. [Blender](../integrations/Blender)
2. [Godot](../integrations/Godot)
3. [Unity](../integrations/Unity)
The final backend, `pyvista` is installed via `setup.py`.
| huggingface/simulate/blob/main/examples/README.md |
PaddlePaddle API
[[autodoc]] safetensors.paddle.load_file
[[autodoc]] safetensors.paddle.load
[[autodoc]] safetensors.paddle.save_file
[[autodoc]] safetensors.paddle.save
| huggingface/safetensors/blob/main/docs/source/api/paddle.mdx |
Image Classification in PyTorch
Related spaces: https://huggingface.co/spaces/abidlabs/pytorch-image-classifier, https://huggingface.co/spaces/pytorch/ResNet, https://huggingface.co/spaces/pytorch/ResNext, https://huggingface.co/spaces/pytorch/SqueezeNet
Tags: VISION, RESNET, PYTORCH
## Introduction
Image classification is a central task in computer vision. Building better classifiers to classify what object is present in a picture is an active area of research, as it has applications stretching from autonomous vehicles to medical imaging.
Such models are perfect to use with Gradio's _image_ input component, so in this tutorial we will build a web demo to classify images using Gradio. We will be able to build the whole web application in Python, and it will look like the demo on the bottom of the page.
Let's get started!
### Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started). We will be using a pretrained image classification model, so you should also have `torch` installed.
## Step 1 — Setting up the Image Classification Model
First, we will need an image classification model. For this tutorial, we will use a pretrained Resnet-18 model, as it is easily downloadable from [PyTorch Hub](https://pytorch.org/hub/pytorch_vision_resnet/). You can use a different pretrained model or train your own.
```python
import torch
model = torch.hub.load('pytorch/vision:v0.6.0', 'resnet18', pretrained=True).eval()
```
Because we will be using the model for inference, we have called the `.eval()` method.
## Step 2 — Defining a `predict` function
Next, we will need to define a function that takes in the _user input_, which in this case is an image, and returns the prediction. The prediction should be returned as a dictionary whose keys are class name and values are confidence probabilities. We will load the class names from this [text file](https://git.io/JJkYN).
In the case of our pretrained model, it will look like this:
```python
import requests
from PIL import Image
from torchvision import transforms
# Download human-readable labels for ImageNet.
response = requests.get("https://git.io/JJkYN")
labels = response.text.split("\n")
def predict(inp):
inp = transforms.ToTensor()(inp).unsqueeze(0)
with torch.no_grad():
prediction = torch.nn.functional.softmax(model(inp)[0], dim=0)
confidences = {labels[i]: float(prediction[i]) for i in range(1000)}
return confidences
```
Let's break this down. The function takes one parameter:
- `inp`: the input image as a `PIL` image
Then, the function converts the image to a PIL Image and then eventually a PyTorch `tensor`, passes it through the model, and returns:
- `confidences`: the predictions, as a dictionary whose keys are class labels and whose values are confidence probabilities
## Step 3 — Creating a Gradio Interface
Now that we have our predictive function set up, we can create a Gradio Interface around it.
In this case, the input component is a drag-and-drop image component. To create this input, we use `Image(type="pil")` which creates the component and handles the preprocessing to convert that to a `PIL` image.
The output component will be a `Label`, which displays the top labels in a nice form. Since we don't want to show all 1,000 class labels, we will customize it to show only the top 3 images by constructing it as `Label(num_top_classes=3)`.
Finally, we'll add one more parameter, the `examples`, which allows us to prepopulate our interfaces with a few predefined examples. The code for Gradio looks like this:
```python
import gradio as gr
gr.Interface(fn=predict,
inputs=gr.Image(type="pil"),
outputs=gr.Label(num_top_classes=3),
examples=["lion.jpg", "cheetah.jpg"]).launch()
```
This produces the following interface, which you can try right here in your browser (try uploading your own examples!):
<gradio-app space="gradio/pytorch-image-classifier">
---
And you're done! That's all the code you need to build a web demo for an image classifier. If you'd like to share with others, try setting `share=True` when you `launch()` the Interface!
| gradio-app/gradio/blob/main/guides/06_integrating-other-frameworks/image-classification-in-pytorch.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MRA
## Overview
The MRA model was proposed in [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, and Vikas Singh.
The abstract from the paper is the following:
*Transformers have emerged as a preferred model for many tasks in natural language processing and vision. Recent efforts on training and deploying Transformers more efficiently have identified many strategies to approximate the self-attention matrix, a key module in a Transformer architecture. Effective ideas include various prespecified sparsity patterns, low-rank basis expansions and combinations thereof. In this paper, we revisit classical Multiresolution Analysis (MRA) concepts such as Wavelets, whose potential value in this setting remains underexplored thus far. We show that simple approximations based on empirical feedback and design choices informed by modern hardware and implementation challenges, eventually yield a MRA-based approach for self-attention with an excellent performance profile across most criteria of interest. We undertake an extensive set of experiments and demonstrate that this multi-resolution scheme outperforms most efficient self-attention proposals and is favorable for both short and long sequences. Code is available at https://github.com/mlpen/mra-attention.*
This model was contributed by [novice03](https://huggingface.co/novice03).
The original code can be found [here](https://github.com/mlpen/mra-attention).
## MraConfig
[[autodoc]] MraConfig
## MraModel
[[autodoc]] MraModel
- forward
## MraForMaskedLM
[[autodoc]] MraForMaskedLM
- forward
## MraForSequenceClassification
[[autodoc]] MraForSequenceClassification
- forward
## MraForMultipleChoice
[[autodoc]] MraForMultipleChoice
- forward
## MraForTokenClassification
[[autodoc]] MraForTokenClassification
- forward
## MraForQuestionAnswering
[[autodoc]] MraForQuestionAnswering
- forward | huggingface/transformers/blob/main/docs/source/en/model_doc/mra.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Instantiating a big model
When you want to use a very big pretrained model, one challenge is to minimize the use of the RAM. The usual workflow
from PyTorch is:
1. Create your model with random weights.
2. Load your pretrained weights.
3. Put those pretrained weights in your random model.
Step 1 and 2 both require a full version of the model in memory, which is not a problem in most cases, but if your model starts weighing several GigaBytes, those two copies can make you get out of RAM. Even worse, if you are using `torch.distributed` to launch a distributed training, each process will load the pretrained model and store these two copies in RAM.
<Tip>
Note that the randomly created model is initialized with "empty" tensors, which take the space in memory without filling it (thus the random values are whatever was in this chunk of memory at a given time). The random initialization following the appropriate distribution for the kind of model/parameters instantiated (like a normal distribution for instance) is only performed after step 3 on the non-initialized weights, to be as fast as possible!
</Tip>
In this guide, we explore the solutions Transformers offer to deal with this issue. Note that this is an area of active development, so the APIs explained here may change slightly in the future.
## Sharded checkpoints
Since version 4.18.0, model checkpoints that end up taking more than 10GB of space are automatically sharded in smaller pieces. In terms of having one single checkpoint when you do `model.save_pretrained(save_dir)`, you will end up with several partial checkpoints (each of which being of size < 10GB) and an index that maps parameter names to the files they are stored in.
You can control the maximum size before sharding with the `max_shard_size` parameter, so for the sake of an example, we'll use a normal-size models with a small shard size: let's take a traditional BERT model.
```py
from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-cased")
```
If you save it using [`~PreTrainedModel.save_pretrained`], you will get a new folder with two files: the config of the model and its weights:
```py
>>> import os
>>> import tempfile
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir)
... print(sorted(os.listdir(tmp_dir)))
['config.json', 'pytorch_model.bin']
```
Now let's use a maximum shard size of 200MB:
```py
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... print(sorted(os.listdir(tmp_dir)))
['config.json', 'pytorch_model-00001-of-00003.bin', 'pytorch_model-00002-of-00003.bin', 'pytorch_model-00003-of-00003.bin', 'pytorch_model.bin.index.json']
```
On top of the configuration of the model, we see three different weights files, and an `index.json` file which is our index. A checkpoint like this can be fully reloaded using the [`~PreTrainedModel.from_pretrained`] method:
```py
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... new_model = AutoModel.from_pretrained(tmp_dir)
```
The main advantage of doing this for big models is that during step 2 of the workflow shown above, each shard of the checkpoint is loaded after the previous one, capping the memory usage in RAM to the model size plus the size of the biggest shard.
Behind the scenes, the index file is used to determine which keys are in the checkpoint, and where the corresponding weights are stored. We can load that index like any json and get a dictionary:
```py
>>> import json
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... with open(os.path.join(tmp_dir, "pytorch_model.bin.index.json"), "r") as f:
... index = json.load(f)
>>> print(index.keys())
dict_keys(['metadata', 'weight_map'])
```
The metadata just consists of the total size of the model for now. We plan to add other information in the future:
```py
>>> index["metadata"]
{'total_size': 433245184}
```
The weights map is the main part of this index, which maps each parameter name (as usually found in a PyTorch model `state_dict`) to the file it's stored in:
```py
>>> index["weight_map"]
{'embeddings.LayerNorm.bias': 'pytorch_model-00001-of-00003.bin',
'embeddings.LayerNorm.weight': 'pytorch_model-00001-of-00003.bin',
...
```
If you want to directly load such a sharded checkpoint inside a model without using [`~PreTrainedModel.from_pretrained`] (like you would do `model.load_state_dict()` for a full checkpoint) you should use [`~modeling_utils.load_sharded_checkpoint`]:
```py
>>> from transformers.modeling_utils import load_sharded_checkpoint
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... load_sharded_checkpoint(model, tmp_dir)
```
## Low memory loading
Sharded checkpoints reduce the memory usage during step 2 of the workflow mentioned above, but in order to use that model in a low memory setting, we recommend leveraging our tools based on the Accelerate library.
Please read the following guide for more information: [Large model loading using Accelerate](./main_classes/model#large-model-loading)
| huggingface/transformers/blob/main/docs/source/en/big_models.md |
--
title: XNLI
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
XNLI is a subset of a few thousand examples from MNLI which has been translated
into a 14 different languages (some low-ish resource). As with MNLI, the goal is
to predict textual entailment (does sentence A imply/contradict/neither sentence
B) and is a classification task (given two sentences, predict one of three
labels).
---
# Metric Card for XNLI
## Metric description
The XNLI metric allows to evaluate a model's score on the [XNLI dataset](https://huggingface.co/datasets/xnli), which is a subset of a few thousand examples from the [MNLI dataset](https://huggingface.co/datasets/glue/viewer/mnli) that have been translated into a 14 different languages, some of which are relatively low resource such as Swahili and Urdu.
As with MNLI, the task is to predict textual entailment (does sentence A imply/contradict/neither sentence B) and is a classification task (given two sentences, predict one of three labels).
## How to use
The XNLI metric is computed based on the `predictions` (a list of predicted labels) and the `references` (a list of ground truth labels).
```python
from evaluate import load
xnli_metric = load("xnli")
predictions = [0, 1]
references = [0, 1]
results = xnli_metric.compute(predictions=predictions, references=references)
```
## Output values
The output of the XNLI metric is simply the `accuracy`, i.e. the proportion of correct predictions among the total number of cases processed, with a range between 0 and 1 (see [accuracy](https://huggingface.co/metrics/accuracy) for more information).
### Values from popular papers
The [original XNLI paper](https://arxiv.org/pdf/1809.05053.pdf) reported accuracies ranging from 59.3 (for `ur`) to 73.7 (for `en`) for the BiLSTM-max model.
For more recent model performance, see the [dataset leaderboard](https://paperswithcode.com/dataset/xnli).
## Examples
Maximal values:
```python
>>> from evaluate import load
>>> xnli_metric = load("xnli")
>>> predictions = [0, 1]
>>> references = [0, 1]
>>> results = xnli_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'accuracy': 1.0}
```
Minimal values:
```python
>>> from evaluate import load
>>> xnli_metric = load("xnli")
>>> predictions = [1, 0]
>>> references = [0, 1]
>>> results = xnli_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'accuracy': 0.0}
```
Partial match:
```python
>>> from evaluate import load
>>> xnli_metric = load("xnli")
>>> predictions = [1, 0, 1]
>>> references = [1, 0, 0]
>>> results = xnli_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'accuracy': 0.6666666666666666}
```
## Limitations and bias
While accuracy alone does give a certain indication of performance, it can be supplemented by error analysis and a better understanding of the model's mistakes on each of the categories represented in the dataset, especially if they are unbalanced.
While the XNLI dataset is multilingual and represents a diversity of languages, in reality, cross-lingual sentence understanding goes beyond translation, given that there are many cultural differences that have an impact on human sentiment annotations. Since the XNLI dataset was obtained by translation based on English sentences, it does not capture these cultural differences.
## Citation
```bibtex
@InProceedings{conneau2018xnli,
author = "Conneau, Alexis
and Rinott, Ruty
and Lample, Guillaume
and Williams, Adina
and Bowman, Samuel R.
and Schwenk, Holger
and Stoyanov, Veselin",
title = "XNLI: Evaluating Cross-lingual Sentence Representations",
booktitle = "Proceedings of the 2018 Conference on Empirical Methods
in Natural Language Processing",
year = "2018",
publisher = "Association for Computational Linguistics",
location = "Brussels, Belgium",
}
```
## Further References
- [XNI Dataset GitHub](https://github.com/facebookresearch/XNLI)
- [HuggingFace Tasks -- Text Classification](https://huggingface.co/tasks/text-classification)
| huggingface/evaluate/blob/main/metrics/xnli/README.md |
Theming
Tags: THEMES
## Introduction
Gradio features a built-in theming engine that lets you customize the look and feel of your app. You can choose from a variety of themes, or create your own. To do so, pass the `theme=` kwarg to the `Blocks` or `Interface` constructor. For example:
```python
with gr.Blocks(theme=gr.themes.Soft()) as demo:
...
```
<div class="wrapper">
<iframe
src="https://gradio-theme-soft.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
Gradio comes with a set of prebuilt themes which you can load from `gr.themes.*`. These are:
- `gr.themes.Base()`
- `gr.themes.Default()`
- `gr.themes.Glass()`
- `gr.themes.Monochrome()`
- `gr.themes.Soft()`
Each of these themes set values for hundreds of CSS variables. You can use prebuilt themes as a starting point for your own custom themes, or you can create your own themes from scratch. Let's take a look at each approach.
## Using the Theme Builder
The easiest way to build a theme is using the Theme Builder. To launch the Theme Builder locally, run the following code:
```python
import gradio as gr
gr.themes.builder()
```
$demo_theme_builder
You can use the Theme Builder running on Spaces above, though it runs much faster when you launch it locally via `gr.themes.builder()`.
As you edit the values in the Theme Builder, the app will preview updates in real time. You can download the code to generate the theme you've created so you can use it in any Gradio app.
In the rest of the guide, we will cover building themes programmatically.
## Extending Themes via the Constructor
Although each theme has hundreds of CSS variables, the values for most these variables are drawn from 8 core variables which can be set through the constructor of each prebuilt theme. Modifying these 8 arguments allows you to quickly change the look and feel of your app.
### Core Colors
The first 3 constructor arguments set the colors of the theme and are `gradio.themes.Color` objects. Internally, these Color objects hold brightness values for the palette of a single hue, ranging from 50, 100, 200..., 800, 900, 950. Other CSS variables are derived from these 3 colors.
The 3 color constructor arguments are:
- `primary_hue`: This is the color draws attention in your theme. In the default theme, this is set to `gradio.themes.colors.orange`.
- `secondary_hue`: This is the color that is used for secondary elements in your theme. In the default theme, this is set to `gradio.themes.colors.blue`.
- `neutral_hue`: This is the color that is used for text and other neutral elements in your theme. In the default theme, this is set to `gradio.themes.colors.gray`.
You could modify these values using their string shortcuts, such as
```python
with gr.Blocks(theme=gr.themes.Default(primary_hue="red", secondary_hue="pink")) as demo:
...
```
or you could use the `Color` objects directly, like this:
```python
with gr.Blocks(theme=gr.themes.Default(primary_hue=gr.themes.colors.red, secondary_hue=gr.themes.colors.pink)) as demo:
...
```
<div class="wrapper">
<iframe
src="https://gradio-theme-extended-step-1.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
Predefined colors are:
- `slate`
- `gray`
- `zinc`
- `neutral`
- `stone`
- `red`
- `orange`
- `amber`
- `yellow`
- `lime`
- `green`
- `emerald`
- `teal`
- `cyan`
- `sky`
- `blue`
- `indigo`
- `violet`
- `purple`
- `fuchsia`
- `pink`
- `rose`
You could also create your own custom `Color` objects and pass them in.
### Core Sizing
The next 3 constructor arguments set the sizing of the theme and are `gradio.themes.Size` objects. Internally, these Size objects hold pixel size values that range from `xxs` to `xxl`. Other CSS variables are derived from these 3 sizes.
- `spacing_size`: This sets the padding within and spacing between elements. In the default theme, this is set to `gradio.themes.sizes.spacing_md`.
- `radius_size`: This sets the roundedness of corners of elements. In the default theme, this is set to `gradio.themes.sizes.radius_md`.
- `text_size`: This sets the font size of text. In the default theme, this is set to `gradio.themes.sizes.text_md`.
You could modify these values using their string shortcuts, such as
```python
with gr.Blocks(theme=gr.themes.Default(spacing_size="sm", radius_size="none")) as demo:
...
```
or you could use the `Size` objects directly, like this:
```python
with gr.Blocks(theme=gr.themes.Default(spacing_size=gr.themes.sizes.spacing_sm, radius_size=gr.themes.sizes.radius_none)) as demo:
...
```
<div class="wrapper">
<iframe
src="https://gradio-theme-extended-step-2.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
The predefined size objects are:
- `radius_none`
- `radius_sm`
- `radius_md`
- `radius_lg`
- `spacing_sm`
- `spacing_md`
- `spacing_lg`
- `text_sm`
- `text_md`
- `text_lg`
You could also create your own custom `Size` objects and pass them in.
### Core Fonts
The final 2 constructor arguments set the fonts of the theme. You can pass a list of fonts to each of these arguments to specify fallbacks. If you provide a string, it will be loaded as a system font. If you provide a `gradio.themes.GoogleFont`, the font will be loaded from Google Fonts.
- `font`: This sets the primary font of the theme. In the default theme, this is set to `gradio.themes.GoogleFont("Source Sans Pro")`.
- `font_mono`: This sets the monospace font of the theme. In the default theme, this is set to `gradio.themes.GoogleFont("IBM Plex Mono")`.
You could modify these values such as the following:
```python
with gr.Blocks(theme=gr.themes.Default(font=[gr.themes.GoogleFont("Inconsolata"), "Arial", "sans-serif"])) as demo:
...
```
<div class="wrapper">
<iframe
src="https://gradio-theme-extended-step-3.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
## Extending Themes via `.set()`
You can also modify the values of CSS variables after the theme has been loaded. To do so, use the `.set()` method of the theme object to get access to the CSS variables. For example:
```python
theme = gr.themes.Default(primary_hue="blue").set(
loader_color="#FF0000",
slider_color="#FF0000",
)
with gr.Blocks(theme=theme) as demo:
...
```
In the example above, we've set the `loader_color` and `slider_color` variables to `#FF0000`, despite the overall `primary_color` using the blue color palette. You can set any CSS variable that is defined in the theme in this manner.
Your IDE type hinting should help you navigate these variables. Since there are so many CSS variables, let's take a look at how these variables are named and organized.
### CSS Variable Naming Conventions
CSS variable names can get quite long, like `button_primary_background_fill_hover_dark`! However they follow a common naming convention that makes it easy to understand what they do and to find the variable you're looking for. Separated by underscores, the variable name is made up of:
1. The target element, such as `button`, `slider`, or `block`.
2. The target element type or sub-element, such as `button_primary`, or `block_label`.
3. The property, such as `button_primary_background_fill`, or `block_label_border_width`.
4. Any relevant state, such as `button_primary_background_fill_hover`.
5. If the value is different in dark mode, the suffix `_dark`. For example, `input_border_color_focus_dark`.
Of course, many CSS variable names are shorter than this, such as `table_border_color`, or `input_shadow`.
### CSS Variable Organization
Though there are hundreds of CSS variables, they do not all have to have individual values. They draw their values by referencing a set of core variables and referencing each other. This allows us to only have to modify a few variables to change the look and feel of the entire theme, while also getting finer control of individual elements that we may want to modify.
#### Referencing Core Variables
To reference one of the core constructor variables, precede the variable name with an asterisk. To reference a core color, use the `*primary_`, `*secondary_`, or `*neutral_` prefix, followed by the brightness value. For example:
```python
theme = gr.themes.Default(primary_hue="blue").set(
button_primary_background_fill="*primary_200",
button_primary_background_fill_hover="*primary_300",
)
```
In the example above, we've set the `button_primary_background_fill` and `button_primary_background_fill_hover` variables to `*primary_200` and `*primary_300`. These variables will be set to the 200 and 300 brightness values of the blue primary color palette, respectively.
Similarly, to reference a core size, use the `*spacing_`, `*radius_`, or `*text_` prefix, followed by the size value. For example:
```python
theme = gr.themes.Default(radius_size="md").set(
button_primary_border_radius="*radius_xl",
)
```
In the example above, we've set the `button_primary_border_radius` variable to `*radius_xl`. This variable will be set to the `xl` setting of the medium radius size range.
#### Referencing Other Variables
Variables can also reference each other. For example, look at the example below:
```python
theme = gr.themes.Default().set(
button_primary_background_fill="#FF0000",
button_primary_background_fill_hover="#FF0000",
button_primary_border="#FF0000",
)
```
Having to set these values to a common color is a bit tedious. Instead, we can reference the `button_primary_background_fill` variable in the `button_primary_background_fill_hover` and `button_primary_border` variables, using a `*` prefix.
```python
theme = gr.themes.Default().set(
button_primary_background_fill="#FF0000",
button_primary_background_fill_hover="*button_primary_background_fill",
button_primary_border="*button_primary_background_fill",
)
```
Now, if we change the `button_primary_background_fill` variable, the `button_primary_background_fill_hover` and `button_primary_border` variables will automatically update as well.
This is particularly useful if you intend to share your theme - it makes it easy to modify the theme without having to change every variable.
Note that dark mode variables automatically reference each other. For example:
```python
theme = gr.themes.Default().set(
button_primary_background_fill="#FF0000",
button_primary_background_fill_dark="#AAAAAA",
button_primary_border="*button_primary_background_fill",
button_primary_border_dark="*button_primary_background_fill_dark",
)
```
`button_primary_border_dark` will draw its value from `button_primary_background_fill_dark`, because dark mode always draw from the dark version of the variable.
## Creating a Full Theme
Let's say you want to create a theme from scratch! We'll go through it step by step - you can also see the source of prebuilt themes in the gradio source repo for reference - [here's the source](https://github.com/gradio-app/gradio/blob/main/gradio/themes/monochrome.py) for the Monochrome theme.
Our new theme class will inherit from `gradio.themes.Base`, a theme that sets a lot of convenient defaults. Let's make a simple demo that creates a dummy theme called Seafoam, and make a simple app that uses it.
$code_theme_new_step_1
<div class="wrapper">
<iframe
src="https://gradio-theme-new-step-1.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
The Base theme is very barebones, and uses `gr.themes.Blue` as it primary color - you'll note the primary button and the loading animation are both blue as a result. Let's change the defaults core arguments of our app. We'll overwrite the constructor and pass new defaults for the core constructor arguments.
We'll use `gr.themes.Emerald` as our primary color, and set secondary and neutral hues to `gr.themes.Blue`. We'll make our text larger using `text_lg`. We'll use `Quicksand` as our default font, loaded from Google Fonts.
$code_theme_new_step_2
<div class="wrapper">
<iframe
src="https://gradio-theme-new-step-2.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
See how the primary button and the loading animation are now green? These CSS variables are tied to the `primary_hue` variable.
Let's modify the theme a bit more directly. We'll call the `set()` method to overwrite CSS variable values explicitly. We can use any CSS logic, and reference our core constructor arguments using the `*` prefix.
$code_theme_new_step_3
<div class="wrapper">
<iframe
src="https://gradio-theme-new-step-3.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
Look how fun our theme looks now! With just a few variable changes, our theme looks completely different.
You may find it helpful to explore the [source code of the other prebuilt themes](https://github.com/gradio-app/gradio/blob/main/gradio/themes) to see how they modified the base theme. You can also find your browser's Inspector useful to select elements from the UI and see what CSS variables are being used in the styles panel.
## Sharing Themes
Once you have created a theme, you can upload it to the HuggingFace Hub to let others view it, use it, and build off of it!
### Uploading a Theme
There are two ways to upload a theme, via the theme class instance or the command line. We will cover both of them with the previously created `seafoam` theme.
- Via the class instance
Each theme instance has a method called `push_to_hub` we can use to upload a theme to the HuggingFace hub.
```python
seafoam.push_to_hub(repo_name="seafoam",
version="0.0.1",
hf_token="<token>")
```
- Via the command line
First save the theme to disk
```python
seafoam.dump(filename="seafoam.json")
```
Then use the `upload_theme` command:
```bash
upload_theme\
"seafoam.json"\
"seafoam"\
--version "0.0.1"\
--hf_token "<token>"
```
In order to upload a theme, you must have a HuggingFace account and pass your [Access Token](https://huggingface.co/docs/huggingface_hub/quick-start#login)
as the `hf_token` argument. However, if you log in via the [HuggingFace command line](https://huggingface.co/docs/huggingface_hub/quick-start#login) (which comes installed with `gradio`),
you can omit the `hf_token` argument.
The `version` argument lets you specify a valid [semantic version](https://www.geeksforgeeks.org/introduction-semantic-versioning/) string for your theme.
That way your users are able to specify which version of your theme they want to use in their apps. This also lets you publish updates to your theme without worrying
about changing how previously created apps look. The `version` argument is optional. If omitted, the next patch version is automatically applied.
### Theme Previews
By calling `push_to_hub` or `upload_theme`, the theme assets will be stored in a [HuggingFace space](https://huggingface.co/docs/hub/spaces-overview).
The theme preview for our seafoam theme is here: [seafoam preview](https://huggingface.co/spaces/gradio/seafoam).
<div class="wrapper">
<iframe
src="https://gradio-seafoam.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
### Discovering Themes
The [Theme Gallery](https://huggingface.co/spaces/gradio/theme-gallery) shows all the public gradio themes. After publishing your theme,
it will automatically show up in the theme gallery after a couple of minutes.
You can sort the themes by the number of likes on the space and from most to least recently created as well as toggling themes between light and dark mode.
<div class="wrapper">
<iframe
src="https://gradio-theme-gallery.hf.space"
frameborder="0"
></iframe>
</div>
### Downloading
To use a theme from the hub, use the `from_hub` method on the `ThemeClass` and pass it to your app:
```python
my_theme = gr.Theme.from_hub("gradio/seafoam")
with gr.Blocks(theme=my_theme) as demo:
....
```
You can also pass the theme string directly to `Blocks` or `Interface` (`gr.Blocks(theme="gradio/seafoam")`)
You can pin your app to an upstream theme version by using semantic versioning expressions.
For example, the following would ensure the theme we load from the `seafoam` repo was between versions `0.0.1` and `0.1.0`:
```python
with gr.Blocks(theme="gradio/seafoam@>=0.0.1,<0.1.0") as demo:
....
```
Enjoy creating your own themes! If you make one you're proud of, please share it with the world by uploading it to the hub!
If you tag us on [Twitter](https://twitter.com/gradio) we can give your theme a shout out!
<style>
.wrapper {
position: relative;
padding-bottom: 56.25%;
padding-top: 25px;
height: 0;
}
.wrapper iframe {
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
}
</style>
| gradio-app/gradio/blob/main/guides/09_other-tutorials/theming-guide.md |