
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
Quiz [[quiz]]
The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
### Q1: What is Reinforcement Learning?
<details>
<summary>Solution</summary>
Reinforcement learning is a **framework for solving control tasks (also called decision problems)** by building agents that learn from the environment by interacting with it through trial and error and **receiving rewards (positive or negative) as unique feedback**.
</details>
### Q2: Define the RL Loop
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/rl-loop-ex.jpg" alt="Exercise RL Loop"/>
At every step:
- Our Agent receives ______ from the environment
- Based on that ______ the Agent takes an ______
- Our Agent will move to the right
- The Environment goes to a ______
- The Environment gives a ______ to the Agent
<Question
choices={[
{
text: "an action a0, action a0, state s0, state s1, reward r1",
explain: "At every step: Our Agent receives **state s0** from the environment. Based on that **state s0** the Agent takes an **action a0**. Our Agent will move to the right. The Environment goes to a **new state s1**. The Environment gives **a reward r1** to the Agent."
},
{
text: "state s0, state s0, action a0, new state s1, reward r1",
explain: "",
correct: true
},
{
text: "a state s0, state s0, action a0, state s1, action a1",
explain: "At every step: Our Agent receives **state s0** from the environment. Based on that **state s0** the Agent takes an **action a0**. Our Agent will move to the right. The Environment goes to a **new state s1**. The Environment gives **a reward r1** to the Agent."
}
]}
/>
### Q3: What's the difference between a state and an observation?
<Question
choices={[
{
text: "The state is a complete description of the state of the world (there is no hidden information)",
explain: "",
correct: true
},
{
text: "The state is a partial description of the state",
explain: ""
},
{
text: "The observation is a complete description of the state of the world (there is no hidden information)",
explain: ""
},
{
text: "The observation is a partial description of the state",
explain: "",
correct: true
},
{
text: "We receive a state when we play with chess environment",
explain: "Since we have access to the whole checkboard information.",
correct: true
},
{
text: "We receive an observation when we play with chess environment",
explain: "Since we have access to the whole checkboard information."
},
{
text: "We receive a state when we play with Super Mario Bros",
explain: "We only see a part of the level close to the player, so we receive an observation."
},
{
text: "We receive an observation when we play with Super Mario Bros",
explain: "We only see a part of the level close to the player.",
correct: true
}
]}
/>
### Q4: A task is an instance of a Reinforcement Learning problem. What are the two types of tasks?
<Question
choices={[
{
text: "Episodic",
explain: "In Episodic task, we have a starting point and an ending point (a terminal state). This creates an episode: a list of States, Actions, Rewards, and new States. For instance, think about Super Mario Bros: an episode begin at the launch of a new Mario Level and ending when you’re killed or you reached the end of the level.",
correct: true
},
{
text: "Recursive",
explain: ""
},
{
text: "Adversarial",
explain: ""
},
{
text: "Continuing",
explain: "Continuing tasks are tasks that continue forever (no terminal state). In this case, the agent must learn how to choose the best actions and simultaneously interact with the environment.",
correct: true
}
]}
/>
### Q5: What is the exploration/exploitation tradeoff?
<details>
<summary>Solution</summary>
In Reinforcement Learning, we need to **balance how much we explore the environment and how much we exploit what we know about the environment**.
- *Exploration* is exploring the environment by **trying random actions in order to find more information about the environment**.
- *Exploitation* is **exploiting known information to maximize the reward**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/expexpltradeoff.jpg" alt="Exploration Exploitation Tradeoff" width="100%">
</details>
### Q6: What is a policy?
<details>
<summary>Solution</summary>
- The Policy π **is the brain of our Agent**. It’s the function that tells us what action to take given the state we are in. So it defines the agent’s behavior at a given time.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/policy_1.jpg" alt="Policy">
</details>
### Q7: What are value-based methods?
<details>
<summary>Solution</summary>
- Value-based methods is one of the main approaches for solving RL problems.
- In Value-based methods, instead of training a policy function, **we train a value function that maps a state to the expected value of being at that state**.
</details>
### Q8: What are policy-based methods?
<details>
<summary>Solution</summary>
- In *Policy-Based Methods*, we learn a **policy function directly**.
- This policy function will **map from each state to the best corresponding action at that state**. Or a **probability distribution over the set of possible actions at that state**.
</details>
Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the chapter to reinforce (😏) your knowledge, but **do not worry**: during the course we'll go over again of these concepts, and you'll **reinforce your theoretical knowledge with hands-on**.
| huggingface/deep-rl-class/blob/main/units/en/unit1/quiz.mdx |
FrameworkSwitchCourse {fw} />
# Behind the pipeline[[behind-the-pipeline]]
{#if fw === 'pt'}
<CourseFloatingBanner chapter={2}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter2/section2_pt.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter2/section2_pt.ipynb"},
]} />
{:else}
<CourseFloatingBanner chapter={2}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter2/section2_tf.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter2/section2_tf.ipynb"},
]} />
{/if}
<Tip>
This is the first section where the content is slightly different depending on whether you use PyTorch or TensorFlow. Toggle the switch on top of the title to select the platform you prefer!
</Tip>
{#if fw === 'pt'}
<Youtube id="1pedAIvTWXk"/>
{:else}
<Youtube id="wVN12smEvqg"/>
{/if}
Let's start with a complete example, taking a look at what happened behind the scenes when we executed the following code in [Chapter 1](/course/chapter1):
```python
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier(
[
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
)
```
and obtained:
```python out
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
```
As we saw in [Chapter 1](/course/chapter1), this pipeline groups together three steps: preprocessing, passing the inputs through the model, and postprocessing:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter2/full_nlp_pipeline.svg" alt="The full NLP pipeline: tokenization of text, conversion to IDs, and inference through the Transformer model and the model head."/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter2/full_nlp_pipeline-dark.svg" alt="The full NLP pipeline: tokenization of text, conversion to IDs, and inference through the Transformer model and the model head."/>
</div>
Let's quickly go over each of these.
## Preprocessing with a tokenizer[[preprocessing-with-a-tokenizer]]
Like other neural networks, Transformer models can't process raw text directly, so the first step of our pipeline is to convert the text inputs into numbers that the model can make sense of. To do this we use a *tokenizer*, which will be responsible for:
- Splitting the input into words, subwords, or symbols (like punctuation) that are called *tokens*
- Mapping each token to an integer
- Adding additional inputs that may be useful to the model
All this preprocessing needs to be done in exactly the same way as when the model was pretrained, so we first need to download that information from the [Model Hub](https://huggingface.co/models). To do this, we use the `AutoTokenizer` class and its `from_pretrained()` method. Using the checkpoint name of our model, it will automatically fetch the data associated with the model's tokenizer and cache it (so it's only downloaded the first time you run the code below).
Since the default checkpoint of the `sentiment-analysis` pipeline is `distilbert-base-uncased-finetuned-sst-2-english` (you can see its model card [here](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)), we run the following:
```python
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
```
Once we have the tokenizer, we can directly pass our sentences to it and we'll get back a dictionary that's ready to feed to our model! The only thing left to do is to convert the list of input IDs to tensors.
You can use 🤗 Transformers without having to worry about which ML framework is used as a backend; it might be PyTorch or TensorFlow, or Flax for some models. However, Transformer models only accept *tensors* as input. If this is your first time hearing about tensors, you can think of them as NumPy arrays instead. A NumPy array can be a scalar (0D), a vector (1D), a matrix (2D), or have more dimensions. It's effectively a tensor; other ML frameworks' tensors behave similarly, and are usually as simple to instantiate as NumPy arrays.
To specify the type of tensors we want to get back (PyTorch, TensorFlow, or plain NumPy), we use the `return_tensors` argument:
{#if fw === 'pt'}
```python
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
```
{:else}
```python
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="tf")
print(inputs)
```
{/if}
Don't worry about padding and truncation just yet; we'll explain those later. The main things to remember here are that you can pass one sentence or a list of sentences, as well as specifying the type of tensors you want to get back (if no type is passed, you will get a list of lists as a result).
{#if fw === 'pt'}
Here's what the results look like as PyTorch tensors:
```python out
{
'input_ids': tensor([
[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
[ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
])
}
```
{:else}
Here's what the results look like as TensorFlow tensors:
```python out
{
'input_ids': <tf.Tensor: shape=(2, 16), dtype=int32, numpy=
array([
[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
[ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
], dtype=int32)>,
'attention_mask': <tf.Tensor: shape=(2, 16), dtype=int32, numpy=
array([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
], dtype=int32)>
}
```
{/if}
The output itself is a dictionary containing two keys, `input_ids` and `attention_mask`. `input_ids` contains two rows of integers (one for each sentence) that are the unique identifiers of the tokens in each sentence. We'll explain what the `attention_mask` is later in this chapter.
## Going through the model[[going-through-the-model]]
{#if fw === 'pt'}
We can download our pretrained model the same way we did with our tokenizer. 🤗 Transformers provides an `AutoModel` class which also has a `from_pretrained()` method:
```python
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
```
{:else}
We can download our pretrained model the same way we did with our tokenizer. 🤗 Transformers provides an `TFAutoModel` class which also has a `from_pretrained` method:
```python
from transformers import TFAutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = TFAutoModel.from_pretrained(checkpoint)
```
{/if}
In this code snippet, we have downloaded the same checkpoint we used in our pipeline before (it should actually have been cached already) and instantiated a model with it.
This architecture contains only the base Transformer module: given some inputs, it outputs what we'll call *hidden states*, also known as *features*. For each model input, we'll retrieve a high-dimensional vector representing the **contextual understanding of that input by the Transformer model**.
If this doesn't make sense, don't worry about it. We'll explain it all later.
While these hidden states can be useful on their own, they're usually inputs to another part of the model, known as the *head*. In [Chapter 1](/course/chapter1), the different tasks could have been performed with the same architecture, but each of these tasks will have a different head associated with it.
### A high-dimensional vector?[[a-high-dimensional-vector]]
The vector output by the Transformer module is usually large. It generally has three dimensions:
- **Batch size**: The number of sequences processed at a time (2 in our example).
- **Sequence length**: The length of the numerical representation of the sequence (16 in our example).
- **Hidden size**: The vector dimension of each model input.
It is said to be "high dimensional" because of the last value. The hidden size can be very large (768 is common for smaller models, and in larger models this can reach 3072 or more).
We can see this if we feed the inputs we preprocessed to our model:
{#if fw === 'pt'}
```python
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)
```
```python out
torch.Size([2, 16, 768])
```
{:else}
```py
outputs = model(inputs)
print(outputs.last_hidden_state.shape)
```
```python out
(2, 16, 768)
```
{/if}
Note that the outputs of 🤗 Transformers models behave like `namedtuple`s or dictionaries. You can access the elements by attributes (like we did) or by key (`outputs["last_hidden_state"]`), or even by index if you know exactly where the thing you are looking for is (`outputs[0]`).
### Model heads: Making sense out of numbers[[model-heads-making-sense-out-of-numbers]]
The model heads take the high-dimensional vector of hidden states as input and project them onto a different dimension. They are usually composed of one or a few linear layers:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter2/transformer_and_head.svg" alt="A Transformer network alongside its head."/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter2/transformer_and_head-dark.svg" alt="A Transformer network alongside its head."/>
</div>
The output of the Transformer model is sent directly to the model head to be processed.
In this diagram, the model is represented by its embeddings layer and the subsequent layers. The embeddings layer converts each input ID in the tokenized input into a vector that represents the associated token. The subsequent layers manipulate those vectors using the attention mechanism to produce the final representation of the sentences.
There are many different architectures available in 🤗 Transformers, with each one designed around tackling a specific task. Here is a non-exhaustive list:
- `*Model` (retrieve the hidden states)
- `*ForCausalLM`
- `*ForMaskedLM`
- `*ForMultipleChoice`
- `*ForQuestionAnswering`
- `*ForSequenceClassification`
- `*ForTokenClassification`
- and others 🤗
{#if fw === 'pt'}
For our example, we will need a model with a sequence classification head (to be able to classify the sentences as positive or negative). So, we won't actually use the `AutoModel` class, but `AutoModelForSequenceClassification`:
```python
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
```
{:else}
For our example, we will need a model with a sequence classification head (to be able to classify the sentences as positive or negative). So, we won't actually use the `TFAutoModel` class, but `TFAutoModelForSequenceClassification`:
```python
from transformers import TFAutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(inputs)
```
{/if}
Now if we look at the shape of our outputs, the dimensionality will be much lower: the model head takes as input the high-dimensional vectors we saw before, and outputs vectors containing two values (one per label):
```python
print(outputs.logits.shape)
```
{#if fw === 'pt'}
```python out
torch.Size([2, 2])
```
{:else}
```python out
(2, 2)
```
{/if}
Since we have just two sentences and two labels, the result we get from our model is of shape 2 x 2.
## Postprocessing the output[[postprocessing-the-output]]
The values we get as output from our model don't necessarily make sense by themselves. Let's take a look:
```python
print(outputs.logits)
```
{#if fw === 'pt'}
```python out
tensor([[-1.5607, 1.6123],
[ 4.1692, -3.3464]], grad_fn=<AddmmBackward>)
```
{:else}
```python out
<tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[-1.5606991, 1.6122842],
[ 4.169231 , -3.3464472]], dtype=float32)>
```
{/if}
Our model predicted `[-1.5607, 1.6123]` for the first sentence and `[ 4.1692, -3.3464]` for the second one. Those are not probabilities but *logits*, the raw, unnormalized scores outputted by the last layer of the model. To be converted to probabilities, they need to go through a [SoftMax](https://en.wikipedia.org/wiki/Softmax_function) layer (all 🤗 Transformers models output the logits, as the loss function for training will generally fuse the last activation function, such as SoftMax, with the actual loss function, such as cross entropy):
{#if fw === 'pt'}
```py
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
```
{:else}
```py
import tensorflow as tf
predictions = tf.math.softmax(outputs.logits, axis=-1)
print(predictions)
```
{/if}
{#if fw === 'pt'}
```python out
tensor([[4.0195e-02, 9.5980e-01],
[9.9946e-01, 5.4418e-04]], grad_fn=<SoftmaxBackward>)
```
{:else}
```python out
tf.Tensor(
[[4.01951671e-02 9.59804833e-01]
[9.9945587e-01 5.4418424e-04]], shape=(2, 2), dtype=float32)
```
{/if}
Now we can see that the model predicted `[0.0402, 0.9598]` for the first sentence and `[0.9995, 0.0005]` for the second one. These are recognizable probability scores.
To get the labels corresponding to each position, we can inspect the `id2label` attribute of the model config (more on this in the next section):
```python
model.config.id2label
```
```python out
{0: 'NEGATIVE', 1: 'POSITIVE'}
```
Now we can conclude that the model predicted the following:
- First sentence: NEGATIVE: 0.0402, POSITIVE: 0.9598
- Second sentence: NEGATIVE: 0.9995, POSITIVE: 0.0005
We have successfully reproduced the three steps of the pipeline: preprocessing with tokenizers, passing the inputs through the model, and postprocessing! Now let's take some time to dive deeper into each of those steps.
<Tip>
✏️ **Try it out!** Choose two (or more) texts of your own and run them through the `sentiment-analysis` pipeline. Then replicate the steps you saw here yourself and check that you obtain the same results!
</Tip>
| huggingface/course/blob/main/chapters/en/chapter2/2.mdx |
--
title: CER
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
Character error rate (CER) is a common metric of the performance of an automatic speech recognition system.
CER is similar to Word Error Rate (WER), but operates on character instead of word. Please refer to docs of WER for further information.
Character error rate can be computed as:
CER = (S + D + I) / N = (S + D + I) / (S + D + C)
where
S is the number of substitutions,
D is the number of deletions,
I is the number of insertions,
C is the number of correct characters,
N is the number of characters in the reference (N=S+D+C).
CER's output is not always a number between 0 and 1, in particular when there is a high number of insertions. This value is often associated to the percentage of characters that were incorrectly predicted. The lower the value, the better the
performance of the ASR system with a CER of 0 being a perfect score.
---
# Metric Card for CER
## Metric description
Character error rate (CER) is a common metric of the performance of an automatic speech recognition (ASR) system. CER is similar to Word Error Rate (WER), but operates on character instead of word.
Character error rate can be computed as:
`CER = (S + D + I) / N = (S + D + I) / (S + D + C)`
where
`S` is the number of substitutions,
`D` is the number of deletions,
`I` is the number of insertions,
`C` is the number of correct characters,
`N` is the number of characters in the reference (`N=S+D+C`).
## How to use
The metric takes two inputs: references (a list of references for each speech input) and predictions (a list of transcriptions to score).
```python
from evaluate import load
cer = load("cer")
cer_score = cer.compute(predictions=predictions, references=references)
```
## Output values
This metric outputs a float representing the character error rate.
```
print(cer_score)
0.34146341463414637
```
The **lower** the CER value, the **better** the performance of the ASR system, with a CER of 0 being a perfect score.
However, CER's output is not always a number between 0 and 1, in particular when there is a high number of insertions (see [Examples](#Examples) below).
### Values from popular papers
This metric is highly dependent on the content and quality of the dataset, and therefore users can expect very different values for the same model but on different datasets.
Multilingual datasets such as [Common Voice](https://huggingface.co/datasets/common_voice) report different CERs depending on the language, ranging from 0.02-0.03 for languages such as French and Italian, to 0.05-0.07 for English (see [here](https://github.com/speechbrain/speechbrain/tree/develop/recipes/CommonVoice/ASR/CTC) for more values).
## Examples
Perfect match between prediction and reference:
```python
from evaluate import load
cer = load("cer")
predictions = ["hello world", "good night moon"]
references = ["hello world", "good night moon"]
cer_score = cer.compute(predictions=predictions, references=references)
print(cer_score)
0.0
```
Partial match between prediction and reference:
```python
from evaluate import load
cer = load("cer")
predictions = ["this is the prediction", "there is an other sample"]
references = ["this is the reference", "there is another one"]
cer_score = cer.compute(predictions=predictions, references=references)
print(cer_score)
0.34146341463414637
```
No match between prediction and reference:
```python
from evaluate import load
cer = load("cer")
predictions = ["hello"]
references = ["gracias"]
cer_score = cer.compute(predictions=predictions, references=references)
print(cer_score)
1.0
```
CER above 1 due to insertion errors:
```python
from evaluate import load
cer = load("cer")
predictions = ["hello world"]
references = ["hello"]
cer_score = cer.compute(predictions=predictions, references=references)
print(cer_score)
1.2
```
## Limitations and bias
CER is useful for comparing different models for tasks such as automatic speech recognition (ASR) and optic character recognition (OCR), especially for multilingual datasets where WER is not suitable given the diversity of languages. However, CER provides no details on the nature of translation errors and further work is therefore required to identify the main source(s) of error and to focus any research effort.
Also, in some cases, instead of reporting the raw CER, a normalized CER is reported where the number of mistakes is divided by the sum of the number of edit operations (`I` + `S` + `D`) and `C` (the number of correct characters), which results in CER values that fall within the range of 0–100%.
## Citation
```bibtex
@inproceedings{morris2004,
author = {Morris, Andrew and Maier, Viktoria and Green, Phil},
year = {2004},
month = {01},
pages = {},
title = {From WER and RIL to MER and WIL: improved evaluation measures for connected speech recognition.}
}
```
## Further References
- [Hugging Face Tasks -- Automatic Speech Recognition](https://huggingface.co/tasks/automatic-speech-recognition)
| huggingface/evaluate/blob/main/metrics/cer/README.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CTRL
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=ctrl">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-ctrl-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/tiny-ctrl">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
CTRL model was proposed in [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and
Richard Socher. It's a causal (unidirectional) transformer pre-trained using language modeling on a very large corpus
of ~140 GB of text data with the first token reserved as a control code (such as Links, Books, Wikipedia etc.).
The abstract from the paper is the following:
*Large-scale language models show promising text generation capabilities, but users cannot easily control particular
aspects of the generated text. We release CTRL, a 1.63 billion-parameter conditional transformer language model,
trained to condition on control codes that govern style, content, and task-specific behavior. Control codes were
derived from structure that naturally co-occurs with raw text, preserving the advantages of unsupervised learning while
providing more explicit control over text generation. These codes also allow CTRL to predict which parts of the
training data are most likely given a sequence. This provides a potential method for analyzing large amounts of data
via model-based source attribution.*
This model was contributed by [keskarnitishr](https://huggingface.co/keskarnitishr). The original code can be found
[here](https://github.com/salesforce/ctrl).
## Usage tips
- CTRL makes use of control codes to generate text: it requires generations to be started by certain words, sentences
or links to generate coherent text. Refer to the [original implementation](https://github.com/salesforce/ctrl) for
more information.
- CTRL is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- CTRL was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next
token in a sequence. Leveraging this feature allows CTRL to generate syntactically coherent text as it can be
observed in the *run_generation.py* example script.
- The PyTorch models can take the `past_key_values` as input, which is the previously computed key/value attention pairs.
TensorFlow models accepts `past` as input. Using the `past_key_values` value prevents the model from re-computing
pre-computed values in the context of text generation. See the [`forward`](model_doc/ctrl#transformers.CTRLModel.forward)
method for more information on the usage of this argument.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
## CTRLConfig
[[autodoc]] CTRLConfig
## CTRLTokenizer
[[autodoc]] CTRLTokenizer
- save_vocabulary
<frameworkcontent>
<pt>
## CTRLModel
[[autodoc]] CTRLModel
- forward
## CTRLLMHeadModel
[[autodoc]] CTRLLMHeadModel
- forward
## CTRLForSequenceClassification
[[autodoc]] CTRLForSequenceClassification
- forward
</pt>
<tf>
## TFCTRLModel
[[autodoc]] TFCTRLModel
- call
## TFCTRLLMHeadModel
[[autodoc]] TFCTRLLMHeadModel
- call
## TFCTRLForSequenceClassification
[[autodoc]] TFCTRLForSequenceClassification
- call
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/ctrl.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# T5v1.1
## Overview
T5v1.1 was released in the [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511)
repository by Colin Raffel et al. It's an improved version of the original T5 model.
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
found [here](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511).
## Usage tips
One can directly plug in the weights of T5v1.1 into a T5 model, like so:
```python
>>> from transformers import T5ForConditionalGeneration
>>> model = T5ForConditionalGeneration.from_pretrained("google/t5-v1_1-base")
```
T5 Version 1.1 includes the following improvements compared to the original T5 model:
- GEGLU activation in the feed-forward hidden layer, rather than ReLU. See [this paper](https://arxiv.org/abs/2002.05202).
- Dropout was turned off in pre-training (quality win). Dropout should be re-enabled during fine-tuning.
- Pre-trained on C4 only without mixing in the downstream tasks.
- No parameter sharing between the embedding and classifier layer.
- "xl" and "xxl" replace "3B" and "11B". The model shapes are a bit different - larger `d_model` and smaller
`num_heads` and `d_ff`.
Note: T5 Version 1.1 was only pre-trained on [C4](https://huggingface.co/datasets/c4) excluding any supervised
training. Therefore, this model has to be fine-tuned before it is usable on a downstream task, unlike the original T5
model. Since t5v1.1 was pre-trained unsupervisedly, there's no real advantage to using a task prefix during single-task
fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
Google has released the following variants:
- [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small)
- [google/t5-v1_1-base](https://huggingface.co/google/t5-v1_1-base)
- [google/t5-v1_1-large](https://huggingface.co/google/t5-v1_1-large)
- [google/t5-v1_1-xl](https://huggingface.co/google/t5-v1_1-xl)
- [google/t5-v1_1-xxl](https://huggingface.co/google/t5-v1_1-xxl).
<Tip>
Refer to [T5's documentation page](t5) for all API reference, tips, code examples and notebooks.
</Tip> | huggingface/transformers/blob/main/docs/source/en/model_doc/t5v1.1.md |
Gradio Demo: request_ip_headers
```
!pip install -q gradio
```
```
import gradio as gr
def predict(text, request: gr.Request):
headers = request.headers
host = request.client.host
user_agent = request.headers["user-agent"]
return {
"ip": host,
"user_agent": user_agent,
"headers": headers,
}
gr.Interface(predict, "text", "json").queue().launch()
```
| gradio-app/gradio/blob/main/demo/request_ip_headers/run.ipynb |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Feature Extractor
A feature extractor is in charge of preparing input features for audio or vision models. This includes feature extraction from sequences, e.g., pre-processing audio files to generate Log-Mel Spectrogram features, feature extraction from images, e.g., cropping image files, but also padding, normalization, and conversion to NumPy, PyTorch, and TensorFlow tensors.
## FeatureExtractionMixin
[[autodoc]] feature_extraction_utils.FeatureExtractionMixin
- from_pretrained
- save_pretrained
## SequenceFeatureExtractor
[[autodoc]] SequenceFeatureExtractor
- pad
## BatchFeature
[[autodoc]] BatchFeature
## ImageFeatureExtractionMixin
[[autodoc]] image_utils.ImageFeatureExtractionMixin
| huggingface/transformers/blob/main/docs/source/en/main_classes/feature_extractor.md |
--
title: {{ cookiecutter.module_name }}
datasets:
- {{ cookiecutter.dataset_name }}
tags:
- evaluate
- {{ cookiecutter.module_type }}
description: "TODO: add a description here"
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
---
# {{ cookiecutter.module_type|capitalize }} Card for {{ cookiecutter.module_name }}
***Module Card Instructions:*** *Fill out the following subsections. Feel free to take a look at existing {{ cookiecutter.module_type }} cards if you'd like examples.*
## {{ cookiecutter.module_type|capitalize }} Description
*Give a brief overview of this {{ cookiecutter.module_type }}, including what task(s) it is usually used for, if any.*
## How to Use
*Give general statement of how to use the {{ cookiecutter.module_type }}*
*Provide simplest possible example for using the {{ cookiecutter.module_type }}*
### Inputs
*List all input arguments in the format below*
- **input_field** *(type): Definition of input, with explanation if necessary. State any default value(s).*
### Output Values
*Explain what this {{ cookiecutter.module_type }} outputs and provide an example of what the {{ cookiecutter.module_type }} output looks like. Modules should return a dictionary with one or multiple key-value pairs, e.g. {"bleu" : 6.02}*
*State the range of possible values that the {{ cookiecutter.module_type }}'s output can take, as well as what in that range is considered good. For example: "This {{ cookiecutter.module_type }} can take on any value between 0 and 100, inclusive. Higher scores are better."*
#### Values from Popular Papers
*Give examples, preferrably with links to leaderboards or publications, to papers that have reported this {{ cookiecutter.module_type }}, along with the values they have reported.*
### Examples
*Give code examples of the {{ cookiecutter.module_type }} being used. Try to include examples that clear up any potential ambiguity left from the {{ cookiecutter.module_type }} description above. If possible, provide a range of examples that show both typical and atypical results, as well as examples where a variety of input parameters are passed.*
## Limitations and Bias
*Note any known limitations or biases that the {{ cookiecutter.module_type }} has, with links and references if possible.*
## Citation
*Cite the source where this {{ cookiecutter.module_type }} was introduced.*
## Further References
*Add any useful further references.*
| huggingface/evaluate/blob/main/templates/{{ cookiecutter.module_slug }}/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# UNet2DConditionModel
The [UNet](https://huggingface.co/papers/1505.04597) model was originally introduced by Ronneberger et al. for biomedical image segmentation, but it is also commonly used in 🤗 Diffusers because it outputs images that are the same size as the input. It is one of the most important components of a diffusion system because it facilitates the actual diffusion process. There are several variants of the UNet model in 🤗 Diffusers, depending on it's number of dimensions and whether it is a conditional model or not. This is a 2D UNet conditional model.
The abstract from the paper is:
*There is large consent that successful training of deep networks requires many thousand annotated training samples. In this paper, we present a network and training strategy that relies on the strong use of data augmentation to use the available annotated samples more efficiently. The architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization. We show that such a network can be trained end-to-end from very few images and outperforms the prior best method (a sliding-window convolutional network) on the ISBI challenge for segmentation of neuronal structures in electron microscopic stacks. Using the same network trained on transmitted light microscopy images (phase contrast and DIC) we won the ISBI cell tracking challenge 2015 in these categories by a large margin. Moreover, the network is fast. Segmentation of a 512x512 image takes less than a second on a recent GPU. The full implementation (based on Caffe) and the trained networks are available at http://lmb.informatik.uni-freiburg.de/people/ronneber/u-net.*
## UNet2DConditionModel
[[autodoc]] UNet2DConditionModel
## UNet2DConditionOutput
[[autodoc]] models.unet_2d_condition.UNet2DConditionOutput
## FlaxUNet2DConditionModel
[[autodoc]] models.unet_2d_condition_flax.FlaxUNet2DConditionModel
## FlaxUNet2DConditionOutput
[[autodoc]] models.unet_2d_condition_flax.FlaxUNet2DConditionOutput
| huggingface/diffusers/blob/main/docs/source/en/api/models/unet2d-cond.md |
ClickHouse
[ClickHouse](https://clickhouse.com/docs/en/intro) is a fast and efficient column-oriented database for analytical workloads, making it easy to analyze Hub-hosted datasets with SQL. To get started quickly, use [`clickhouse-local`](https://clickhouse.com/docs/en/operations/utilities/clickhouse-local) to run SQL queries from the command line and avoid the need to fully install ClickHouse.
<Tip>
Check this [blog](https://clickhouse.com/blog/query-analyze-hugging-face-datasets-with-clickhouse) for more details about how to analyze datasets on the Hub with ClickHouse.
</Tip>
To start, download and install `clickhouse-local`:
```bash
curl https://clickhouse.com/ | sh
```
For this example, you'll analyze the [maharshipandya/spotify-tracks-dataset](https://huggingface.co/datasets/maharshipandya/spotify-tracks-dataset) which contains information about Spotify tracks. Datasets on the Hub are stored as Parquet files and you can access it with the [`/parquet`](parquet) endpoint:
```py
import requests
r = requests.get("https://datasets-server.huggingface.co/parquet?dataset=maharshipandya/spotify-tracks-dataset")
j = r.json()
url = [f['url'] for f in j['parquet_files']]
url
['https://huggingface.co/datasets/maharshipandya/spotify-tracks-dataset/resolve/refs%2Fconvert%2Fparquet/default/train/0000.parquet']
```
## Aggregate functions
Now you can begin to analyze the dataset. Use the `-q` argument to specify the query to execute, and the [`url`](https://clickhouse.com/docs/en/sql-reference/table-functions/url) function to create a table from the data in the Parquet file.
You should set `enable_url_encoding` to 0 to ensure the escape characters in the URL are preserved as intended, and `max_https_get_redirects` to 1 to redirect to the path of the Parquet file.
Let's start by identifying the most popular artists:
```bash
./clickhouse local -q "
SELECT count() AS c, artists
FROM url('https://huggingface.co/datasets/maharshipandya/spotify-tracks-dataset/resolve/refs%2Fconvert%2Fparquet/default/train/0000.parquet')
GROUP BY artists
ORDER BY c
DESC LIMIT 5
SETTINGS enable_url_encoding=0, max_http_get_redirects=1"
┌───c─┬─artists─────────┐
│ 279 │ The Beatles │
│ 271 │ George Jones │
│ 236 │ Stevie Wonder │
│ 224 │ Linkin Park │
│ 222 │ Ella Fitzgerald │
└─────┴─────────────────┘
```
ClickHouse also provides functions for visualizing your queries. For example, you can use the [`bar`](https://clickhouse.com/docs/en/sql-reference/functions/other-functions#bar) function to create a bar chart of the danceability of songs:
```bash
./clickhouse local -q "
SELECT
round(danceability, 1) AS danceability,
bar(count(), 0, max(count()) OVER ()) AS dist
FROM url('https://huggingface.co/datasets/maharshipandya/spotify-tracks-dataset/resolve/refs%2Fconvert%2Fparquet/default/train/0000.parquet')
GROUP BY danceability
ORDER BY danceability ASC
SETTINGS enable_url_encoding=0, max_http_get_redirects=1"
┌─danceability─┬─dist─────────────────────────────────────────────────────────────────────────────────┐
│ 0 │ ▍ │
│ 0.1 │ ████▎ │
│ 0.2 │ █████████████▍ │
│ 0.3 │ ████████████████████████ │
│ 0.4 │ ████████████████████████████████████████████▋ │
│ 0.5 │ ████████████████████████████████████████████████████████████████████▊ │
│ 0.6 │ ████████████████████████████████████████████████████████████████████████████████ │
│ 0.7 │ ██████████████████████████████████████████████████████████████████████ │
│ 0.8 │ ██████████████████████████████████████████ │
│ 0.9 │ ██████████▋ │
│ 1 │ ▌ │
└──────────────┴──────────────────────────────────────────────────────────────────────────────────────┘
```
To get a deeper understanding about a dataset, ClickHouse provides statistical analysis functions for determining how your data is correlated, calculating statistical hypothesis tests, and more. Take a look at ClickHouse's [List of Aggregate Functions](https://clickhouse.com/docs/en/sql-reference/aggregate-functions/reference) for a complete list of available aggregate functions.
## User-defined function (UDFs)
A user-defined function (UDF) allows you to reuse custom logic. Many Hub datasets are often sharded into more than one Parquet file, so it can be easier and more efficient to create a UDF to list and query all the Parquet files of a given dataset from just the dataset name.
For this example, you'll need to run `clickhouse-local` in console mode so the UDF persists between queries:
```bash
./clickhouse local
```
Remember to set `enable_url_encoding` to 0 and `max_https_get_redirects` to 1 to redirect to the path of the Parquet files:
```bash
SET max_http_get_redirects = 1, enable_url_encoding = 0
```
Let's create a function to return a list of Parquet files from the [`blog_authorship_corpus`](https://huggingface.co/datasets/blog_authorship_corpus):
```bash
CREATE OR REPLACE FUNCTION hugging_paths AS dataset -> (
SELECT arrayMap(x -> (x.1), JSONExtract(json, 'parquet_files', 'Array(Tuple(url String))'))
FROM url('https://datasets-server.huggingface.co/parquet?dataset=' || dataset, 'JSONAsString')
);
SELECT hugging_paths('blog_authorship_corpus') AS paths
['https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/train/0000.parquet','https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/train/0001.parquet','https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/validation/0000.parquet']
```
You can make this even easier by creating another function that calls `hugging_paths` and outputs all the files based on the dataset name:
```bash
CREATE OR REPLACE FUNCTION hf AS dataset -> (
WITH hugging_paths(dataset) as urls
SELECT multiIf(length(urls) = 0, '', length(urls) = 1, urls[1], 'https://huggingface.co/datasets/{' || arrayStringConcat(arrayMap(x -> replaceRegexpOne(replaceOne(x, 'https://huggingface.co/datasets/', ''), '\\.parquet$', ''), urls), ',') || '}.parquet')
);
SELECT hf('blog_authorship_corpus') AS pattern
['https://huggingface.co/datasets/{blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/blog_authorship_corpus-train-00000-of-00002,blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/blog_authorship_corpus-train-00001-of-00002,blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/blog_authorship_corpus-validation}.parquet']
```
Now use the `hf` function to query any dataset by passing the dataset name:
```bash
SELECT horoscope, count(*), AVG(LENGTH(text)) AS avg_blog_length
FROM url(hf('blog_authorship_corpus'))
GROUP BY horoscope
ORDER BY avg_blog_length
DESC LIMIT(5)
┌─────────────┬───────┬────────────────────┐
│ Aquarius │ 51747 │ 1132.487873693161 │
├─────────────┼───────┼────────────────────┤
│ Cancer │ 66944 │ 1111.613109464627 │
│ Libra │ 63994 │ 1060.3968184517298 │
│ Sagittarius │ 52753 │ 1055.7120732470191 │
│ Capricorn │ 52207 │ 1055.4147719654452 │
└─────────────┴───────┴────────────────────┘
``` | huggingface/datasets-server/blob/main/docs/source/clickhouse.md |
Using fastai at Hugging Face
`fastai` is an open-source Deep Learning library that leverages PyTorch and Python to provide high-level components to train fast and accurate neural networks with state-of-the-art outputs on text, vision, and tabular data.
## Exploring fastai in the Hub
You can find `fastai` models by filtering at the left of the [models page](https://huggingface.co/models?library=fastai&sort=downloads).
All models on the Hub come up with the following features:
1. An automatically generated model card with a brief description and metadata tags that help for discoverability.
2. An interactive widget you can use to play out with the model directly in the browser (for Image Classification)
3. An Inference API that allows to make inference requests (for Image Classification).
## Using existing models
The `huggingface_hub` library is a lightweight Python client with utlity functions to download models from the Hub.
```bash
pip install huggingface_hub["fastai"]
```
Once you have the library installed, you just need to use the `from_pretrained_fastai` method. This method not only loads the model, but also validates the `fastai` version when the model was saved, which is important for reproducibility.
```py
from huggingface_hub import from_pretrained_fastai
learner = from_pretrained_fastai("espejelomar/identify-my-cat")
_,_,probs = learner.predict(img)
print(f"Probability it's a cat: {100*probs[1].item():.2f}%")
# Probability it's a cat: 100.00%
```
If you want to see how to load a specific model, you can click `Use in fastai` and you will be given a working snippet that you can load it!
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-fastai_snippet1.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-fastai_snippet1-dark.png"/>
</div>
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-fastai_snippet2.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-fastai_snippet2-dark.png"/>
</div>
## Sharing your models
You can share your `fastai` models by using the `push_to_hub_fastai` method.
```py
from huggingface_hub import push_to_hub_fastai
push_to_hub_fastai(learner=learn, repo_id="espejelomar/identify-my-cat")
```
## Additional resources
* fastai [course](https://course.fast.ai/).
* fastai [website](https://www.fast.ai/).
* Integration with Hub [docs](https://docs.fast.ai/huggingface.html).
* Integration with Hub [announcement](https://huggingface.co/blog/fastai).
| huggingface/hub-docs/blob/main/docs/hub/fastai.md |
连接到数据库
相关空间:https://huggingface.co/spaces/gradio/chicago-bike-share-dashboard
标签:TABULAR, PLOTS
## 介绍
本指南介绍如何使用 Gradio 连接您的应用程序到数据库。我们将会
连接到在 AWS 上托管的 PostgreSQL 数据库,但 Gradio 对于您连接的数据库类型和托管位置没有任何限制。因此,只要您能编写 Python 代码来连接
您的数据,您就可以使用 Gradio 在 Web 界面中显示它 💪
## 概述
我们将分析来自芝加哥的自行车共享数据。数据托管在 kaggle [这里](https://www.kaggle.com/datasets/evangower/cyclistic-bike-share?select=202203-divvy-tripdata.csv)。
我们的目标是创建一个仪表盘,让我们的业务利益相关者能够回答以下问题:
1. 电动自行车是否比普通自行车更受欢迎?
2. 哪些出发自行车站点最受欢迎?
在本指南结束时,我们将拥有一个如下所示的功能齐全的应用程序:
<gradio-app space="gradio/chicago-bike-share-dashboard"> </gradio-app>
## 步骤 1 - 创建数据库
我们将在 Amazon 的 RDS 服务上托管我们的数据。如果还没有 AWS 账号,请创建一个
并在免费层级上创建一个 PostgreSQL 数据库。
**重要提示**:如果您计划在 HuggingFace Spaces 上托管此演示,请确保数据库在 **8080** 端口上。Spaces
将阻止除端口 80、443 或 8080 之外的所有外部连接,如此[处所示](https://huggingface.co/docs/hub/spaces-overview#networking)。
RDS 不允许您在 80 或 443 端口上创建 postgreSQL 实例。
创建完数据库后,从 Kaggle 下载数据集并将其上传到数据库中。
为了演示的目的,我们只会上传 2022 年 3 月的数据。
## 步骤 2.a - 编写 ETL 代码
我们将查询数据库,按自行车类型(电动、标准或有码)进行分组,并获取总骑行次数。
我们还将查询每个站点的出发骑行次数,并获取前 5 个。
然后,我们将使用 matplotlib 将查询结果可视化。
我们将使用 pandas 的[read_sql](https://pandas.pydata.org/docs/reference/api/pandas.read_sql.html)
方法来连接数据库。这需要安装 `psycopg2` 库。
为了连接到数据库,我们将指定数据库的用户名、密码和主机作为环境变量。
这样可以通过避免将敏感信息以明文形式存储在应用程序文件中,使我们的应用程序更安全。
```python
import os
import pandas as pd
import matplotlib.pyplot as plt
DB_USER = os.getenv("DB_USER")
DB_PASSWORD = os.getenv("DB_PASSWORD")
DB_HOST = os.getenv("DB_HOST")
PORT = 8080
DB_NAME = "bikeshare"
connection_string = f"postgresql://{DB_USER}:{DB_PASSWORD}@{DB_HOST}?port={PORT}&dbname={DB_NAME}"
def get_count_ride_type():
df = pd.read_sql(
"""
SELECT COUNT(ride_id) as n, rideable_type
FROM rides
GROUP BY rideable_type
ORDER BY n DESC
""",
con=connection_string
)
fig_m, ax = plt.subplots()
ax.bar(x=df['rideable_type'], height=df['n'])
ax.set_title("Number of rides by bycycle type")
ax.set_ylabel("Number of Rides")
ax.set_xlabel("Bicycle Type")
return fig_m
def get_most_popular_stations():
df = pd.read_sql(
"""
SELECT COUNT(ride_id) as n, MAX(start_station_name) as station
FROM RIDES
WHERE start_station_name is NOT NULL
GROUP BY start_station_id
ORDER BY n DESC
LIMIT 5
""",
con=connection_string
)
fig_m, ax = plt.subplots()
ax.bar(x=df['station'], height=df['n'])
ax.set_title("Most popular stations")
ax.set_ylabel("Number of Rides")
ax.set_xlabel("Station Name")
ax.set_xticklabels(
df['station'], rotation=45, ha="right", rotation_mode="anchor"
)
ax.tick_params(axis="x", labelsize=8)
fig_m.tight_layout()
return fig_m
```
如果您在本地运行我们的脚本,可以像下面这样将凭据作为环境变量传递:
```bash
DB_USER='username' DB_PASSWORD='password' DB_HOST='host' python app.py
```
## 步骤 2.c - 编写您的 gradio 应用程序
我们将使用两个单独的 `gr.Plot` 组件将我们的 matplotlib 图表并排显示在一起,使用 `gr.Row()`。
因为我们已经在 `demo.load()` 事件触发器中封装了获取数据的函数,
我们的演示将在每次网页加载时从数据库**动态**获取最新数据。🪄
```python
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
bike_type = gr.Plot()
station = gr.Plot()
demo.load(get_count_ride_type, inputs=None, outputs=bike_type)
demo.load(get_most_popular_stations, inputs=None, outputs=station)
demo.launch()
```
## 步骤 3 - 部署
如果您运行上述代码,您的应用程序将在本地运行。
您甚至可以通过将 `share=True` 参数传递给 `launch` 来获得一个临时共享链接。
但是如果您想要一个永久的部署解决方案呢?
让我们将我们的 Gradio 应用程序部署到免费的 HuggingFace Spaces 平台上。
如果您之前没有使用过 Spaces,请按照之前的指南[这里](/using_hugging_face_integrations)进行操作。
您将需要将 `DB_USER`、`DB_PASSWORD` 和 `DB_HOST` 变量添加为 "Repo Secrets"。您可以在 " 设置 " 选项卡中进行此操作。

## 结论
恭喜你!您知道如何将您的 Gradio 应用程序连接到云端托管的数据库!☁️
我们的仪表板现在正在[Spaces](https://huggingface.co/spaces/gradio/chicago-bike-share-dashboard)上运行。
完整代码在[这里](https://huggingface.co/spaces/gradio/chicago-bike-share-dashboard/blob/main/app.py)
正如您所见,Gradio 使您可以连接到您的数据并以您想要的方式显示!🔥
| gradio-app/gradio/blob/main/guides/cn/05_tabular-data-science-and-plots/01_connecting-to-a-database.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# UNet2DModel
The [UNet](https://huggingface.co/papers/1505.04597) model was originally introduced by Ronneberger et al. for biomedical image segmentation, but it is also commonly used in 🤗 Diffusers because it outputs images that are the same size as the input. It is one of the most important components of a diffusion system because it facilitates the actual diffusion process. There are several variants of the UNet model in 🤗 Diffusers, depending on it's number of dimensions and whether it is a conditional model or not. This is a 2D UNet model.
The abstract from the paper is:
*There is large consent that successful training of deep networks requires many thousand annotated training samples. In this paper, we present a network and training strategy that relies on the strong use of data augmentation to use the available annotated samples more efficiently. The architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization. We show that such a network can be trained end-to-end from very few images and outperforms the prior best method (a sliding-window convolutional network) on the ISBI challenge for segmentation of neuronal structures in electron microscopic stacks. Using the same network trained on transmitted light microscopy images (phase contrast and DIC) we won the ISBI cell tracking challenge 2015 in these categories by a large margin. Moreover, the network is fast. Segmentation of a 512x512 image takes less than a second on a recent GPU. The full implementation (based on Caffe) and the trained networks are available at http://lmb.informatik.uni-freiburg.de/people/ronneber/u-net.*
## UNet2DModel
[[autodoc]] UNet2DModel
## UNet2DOutput
[[autodoc]] models.unet_2d.UNet2DOutput
| huggingface/diffusers/blob/main/docs/source/en/api/models/unet2d.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Glossary
This glossary defines general machine learning and 🤗 Transformers terms to help you better understand the
documentation.
## A
### attention mask
The attention mask is an optional argument used when batching sequences together.
<Youtube id="M6adb1j2jPI"/>
This argument indicates to the model which tokens should be attended to, and which should not.
For example, consider these two sequences:
```python
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
>>> sequence_a = "This is a short sequence."
>>> sequence_b = "This is a rather long sequence. It is at least longer than the sequence A."
>>> encoded_sequence_a = tokenizer(sequence_a)["input_ids"]
>>> encoded_sequence_b = tokenizer(sequence_b)["input_ids"]
```
The encoded versions have different lengths:
```python
>>> len(encoded_sequence_a), len(encoded_sequence_b)
(8, 19)
```
Therefore, we can't put them together in the same tensor as-is. The first sequence needs to be padded up to the length
of the second one, or the second one needs to be truncated down to the length of the first one.
In the first case, the list of IDs will be extended by the padding indices. We can pass a list to the tokenizer and ask
it to pad like this:
```python
>>> padded_sequences = tokenizer([sequence_a, sequence_b], padding=True)
```
We can see that 0s have been added on the right of the first sentence to make it the same length as the second one:
```python
>>> padded_sequences["input_ids"]
[[101, 1188, 1110, 170, 1603, 4954, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1188, 1110, 170, 1897, 1263, 4954, 119, 1135, 1110, 1120, 1655, 2039, 1190, 1103, 4954, 138, 119, 102]]
```
This can then be converted into a tensor in PyTorch or TensorFlow. The attention mask is a binary tensor indicating the
position of the padded indices so that the model does not attend to them. For the [`BertTokenizer`], `1` indicates a
value that should be attended to, while `0` indicates a padded value. This attention mask is in the dictionary returned
by the tokenizer under the key "attention_mask":
```python
>>> padded_sequences["attention_mask"]
[[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
```
### autoencoding models
See [encoder models](#encoder-models) and [masked language modeling](#masked-language-modeling-mlm)
### autoregressive models
See [causal language modeling](#causal-language-modeling) and [decoder models](#decoder-models)
## B
### backbone
The backbone is the network (embeddings and layers) that outputs the raw hidden states or features. It is usually connected to a [head](#head) which accepts the features as its input to make a prediction. For example, [`ViTModel`] is a backbone without a specific head on top. Other models can also use [`VitModel`] as a backbone such as [DPT](model_doc/dpt).
## C
### causal language modeling
A pretraining task where the model reads the texts in order and has to predict the next word. It's usually done by
reading the whole sentence but using a mask inside the model to hide the future tokens at a certain timestep.
### channel
Color images are made up of some combination of values in three channels: red, green, and blue (RGB) and grayscale images only have one channel. In 🤗 Transformers, the channel can be the first or last dimension of an image's tensor: [`n_channels`, `height`, `width`] or [`height`, `width`, `n_channels`].
### connectionist temporal classification (CTC)
An algorithm which allows a model to learn without knowing exactly how the input and output are aligned; CTC calculates the distribution of all possible outputs for a given input and chooses the most likely output from it. CTC is commonly used in speech recognition tasks because speech doesn't always cleanly align with the transcript for a variety of reasons such as a speaker's different speech rates.
### convolution
A type of layer in a neural network where the input matrix is multiplied element-wise by a smaller matrix (kernel or filter) and the values are summed up in a new matrix. This is known as a convolutional operation which is repeated over the entire input matrix. Each operation is applied to a different segment of the input matrix. Convolutional neural networks (CNNs) are commonly used in computer vision.
## D
### DataParallel (DP)
Parallelism technique for training on multiple GPUs where the same setup is replicated multiple times, with each instance
receiving a distinct data slice. The processing is done in parallel and all setups are synchronized at the end of each training step.
Learn more about how DataParallel works [here](perf_train_gpu_many#dataparallel-vs-distributeddataparallel).
### decoder input IDs
This input is specific to encoder-decoder models, and contains the input IDs that will be fed to the decoder. These
inputs should be used for sequence to sequence tasks, such as translation or summarization, and are usually built in a
way specific to each model.
Most encoder-decoder models (BART, T5) create their `decoder_input_ids` on their own from the `labels`. In such models,
passing the `labels` is the preferred way to handle training.
Please check each model's docs to see how they handle these input IDs for sequence to sequence training.
### decoder models
Also referred to as autoregressive models, decoder models involve a pretraining task (called causal language modeling) where the model reads the texts in order and has to predict the next word. It's usually done by
reading the whole sentence with a mask to hide future tokens at a certain timestep.
<Youtube id="d_ixlCubqQw"/>
### deep learning (DL)
Machine learning algorithms which uses neural networks with several layers.
## E
### encoder models
Also known as autoencoding models, encoder models take an input (such as text or images) and transform them into a condensed numerical representation called an embedding. Oftentimes, encoder models are pretrained using techniques like [masked language modeling](#masked-language-modeling-mlm), which masks parts of the input sequence and forces the model to create more meaningful representations.
<Youtube id="H39Z_720T5s"/>
## F
### feature extraction
The process of selecting and transforming raw data into a set of features that are more informative and useful for machine learning algorithms. Some examples of feature extraction include transforming raw text into word embeddings and extracting important features such as edges or shapes from image/video data.
### feed forward chunking
In each residual attention block in transformers the self-attention layer is usually followed by 2 feed forward layers.
The intermediate embedding size of the feed forward layers is often bigger than the hidden size of the model (e.g., for
`bert-base-uncased`).
For an input of size `[batch_size, sequence_length]`, the memory required to store the intermediate feed forward
embeddings `[batch_size, sequence_length, config.intermediate_size]` can account for a large fraction of the memory
use. The authors of [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) noticed that since the
computation is independent of the `sequence_length` dimension, it is mathematically equivalent to compute the output
embeddings of both feed forward layers `[batch_size, config.hidden_size]_0, ..., [batch_size, config.hidden_size]_n`
individually and concat them afterward to `[batch_size, sequence_length, config.hidden_size]` with `n = sequence_length`, which trades increased computation time against reduced memory use, but yields a mathematically
**equivalent** result.
For models employing the function [`apply_chunking_to_forward`], the `chunk_size` defines the number of output
embeddings that are computed in parallel and thus defines the trade-off between memory and time complexity. If
`chunk_size` is set to 0, no feed forward chunking is done.
### finetuned models
Finetuning is a form of transfer learning which involves taking a pretrained model, freezing its weights, and replacing the output layer with a newly added [model head](#head). The model head is trained on your target dataset.
See the [Fine-tune a pretrained model](https://huggingface.co/docs/transformers/training) tutorial for more details, and learn how to fine-tune models with 🤗 Transformers.
## H
### head
The model head refers to the last layer of a neural network that accepts the raw hidden states and projects them onto a different dimension. There is a different model head for each task. For example:
* [`GPT2ForSequenceClassification`] is a sequence classification head - a linear layer - on top of the base [`GPT2Model`].
* [`ViTForImageClassification`] is an image classification head - a linear layer on top of the final hidden state of the `CLS` token - on top of the base [`ViTModel`].
* [`Wav2Vec2ForCTC`] is a language modeling head with [CTC](#connectionist-temporal-classification-(CTC)) on top of the base [`Wav2Vec2Model`].
## I
### image patch
Vision-based Transformers models split an image into smaller patches which are linearly embedded, and then passed as a sequence to the model. You can find the `patch_size` - or resolution - of the model in its configuration.
### inference
Inference is the process of evaluating a model on new data after training is complete. See the [Pipeline for inference](https://huggingface.co/docs/transformers/pipeline_tutorial) tutorial to learn how to perform inference with 🤗 Transformers.
### input IDs
The input ids are often the only required parameters to be passed to the model as input. They are token indices,
numerical representations of tokens building the sequences that will be used as input by the model.
<Youtube id="VFp38yj8h3A"/>
Each tokenizer works differently but the underlying mechanism remains the same. Here's an example using the BERT
tokenizer, which is a [WordPiece](https://arxiv.org/pdf/1609.08144.pdf) tokenizer:
```python
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
>>> sequence = "A Titan RTX has 24GB of VRAM"
```
The tokenizer takes care of splitting the sequence into tokens available in the tokenizer vocabulary.
```python
>>> tokenized_sequence = tokenizer.tokenize(sequence)
```
The tokens are either words or subwords. Here for instance, "VRAM" wasn't in the model vocabulary, so it's been split
in "V", "RA" and "M". To indicate those tokens are not separate words but parts of the same word, a double-hash prefix
is added for "RA" and "M":
```python
>>> print(tokenized_sequence)
['A', 'Titan', 'R', '##T', '##X', 'has', '24', '##GB', 'of', 'V', '##RA', '##M']
```
These tokens can then be converted into IDs which are understandable by the model. This can be done by directly feeding the sentence to the tokenizer, which leverages the Rust implementation of [🤗 Tokenizers](https://github.com/huggingface/tokenizers) for peak performance.
```python
>>> inputs = tokenizer(sequence)
```
The tokenizer returns a dictionary with all the arguments necessary for its corresponding model to work properly. The
token indices are under the key `input_ids`:
```python
>>> encoded_sequence = inputs["input_ids"]
>>> print(encoded_sequence)
[101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102]
```
Note that the tokenizer automatically adds "special tokens" (if the associated model relies on them) which are special
IDs the model sometimes uses.
If we decode the previous sequence of ids,
```python
>>> decoded_sequence = tokenizer.decode(encoded_sequence)
```
we will see
```python
>>> print(decoded_sequence)
[CLS] A Titan RTX has 24GB of VRAM [SEP]
```
because this is the way a [`BertModel`] is going to expect its inputs.
## L
### labels
The labels are an optional argument which can be passed in order for the model to compute the loss itself. These labels
should be the expected prediction of the model: it will use the standard loss in order to compute the loss between its
predictions and the expected value (the label).
These labels are different according to the model head, for example:
- For sequence classification models, ([`BertForSequenceClassification`]), the model expects a tensor of dimension
`(batch_size)` with each value of the batch corresponding to the expected label of the entire sequence.
- For token classification models, ([`BertForTokenClassification`]), the model expects a tensor of dimension
`(batch_size, seq_length)` with each value corresponding to the expected label of each individual token.
- For masked language modeling, ([`BertForMaskedLM`]), the model expects a tensor of dimension `(batch_size,
seq_length)` with each value corresponding to the expected label of each individual token: the labels being the token
ID for the masked token, and values to be ignored for the rest (usually -100).
- For sequence to sequence tasks, ([`BartForConditionalGeneration`], [`MBartForConditionalGeneration`]), the model
expects a tensor of dimension `(batch_size, tgt_seq_length)` with each value corresponding to the target sequences
associated with each input sequence. During training, both BART and T5 will make the appropriate
`decoder_input_ids` and decoder attention masks internally. They usually do not need to be supplied. This does not
apply to models leveraging the Encoder-Decoder framework.
- For image classification models, ([`ViTForImageClassification`]), the model expects a tensor of dimension
`(batch_size)` with each value of the batch corresponding to the expected label of each individual image.
- For semantic segmentation models, ([`SegformerForSemanticSegmentation`]), the model expects a tensor of dimension
`(batch_size, height, width)` with each value of the batch corresponding to the expected label of each individual pixel.
- For object detection models, ([`DetrForObjectDetection`]), the model expects a list of dictionaries with a
`class_labels` and `boxes` key where each value of the batch corresponds to the expected label and number of bounding boxes of each individual image.
- For automatic speech recognition models, ([`Wav2Vec2ForCTC`]), the model expects a tensor of dimension `(batch_size,
target_length)` with each value corresponding to the expected label of each individual token.
<Tip>
Each model's labels may be different, so be sure to always check the documentation of each model for more information
about their specific labels!
</Tip>
The base models ([`BertModel`]) do not accept labels, as these are the base transformer models, simply outputting
features.
### large language models (LLM)
A generic term that refers to transformer language models (GPT-3, BLOOM, OPT) that were trained on a large quantity of data. These models also tend to have a large number of learnable parameters (e.g. 175 billion for GPT-3).
## M
### masked language modeling (MLM)
A pretraining task where the model sees a corrupted version of the texts, usually done by
masking some tokens randomly, and has to predict the original text.
### multimodal
A task that combines texts with another kind of inputs (for instance images).
## N
### Natural language generation (NLG)
All tasks related to generating text (for instance, [Write With Transformers](https://transformer.huggingface.co/), translation).
### Natural language processing (NLP)
A generic way to say "deal with texts".
### Natural language understanding (NLU)
All tasks related to understanding what is in a text (for instance classifying the
whole text, individual words).
## P
### pipeline
A pipeline in 🤗 Transformers is an abstraction referring to a series of steps that are executed in a specific order to preprocess and transform data and return a prediction from a model. Some example stages found in a pipeline might be data preprocessing, feature extraction, and normalization.
For more details, see [Pipelines for inference](https://huggingface.co/docs/transformers/pipeline_tutorial).
### PipelineParallel (PP)
Parallelism technique in which the model is split up vertically (layer-level) across multiple GPUs, so that only one or
several layers of the model are placed on a single GPU. Each GPU processes in parallel different stages of the pipeline
and working on a small chunk of the batch. Learn more about how PipelineParallel works [here](perf_train_gpu_many#from-naive-model-parallelism-to-pipeline-parallelism).
### pixel values
A tensor of the numerical representations of an image that is passed to a model. The pixel values have a shape of [`batch_size`, `num_channels`, `height`, `width`], and are generated from an image processor.
### pooling
An operation that reduces a matrix into a smaller matrix, either by taking the maximum or average of the pooled dimension(s). Pooling layers are commonly found between convolutional layers to downsample the feature representation.
### position IDs
Contrary to RNNs that have the position of each token embedded within them, transformers are unaware of the position of
each token. Therefore, the position IDs (`position_ids`) are used by the model to identify each token's position in the
list of tokens.
They are an optional parameter. If no `position_ids` are passed to the model, the IDs are automatically created as
absolute positional embeddings.
Absolute positional embeddings are selected in the range `[0, config.max_position_embeddings - 1]`. Some models use
other types of positional embeddings, such as sinusoidal position embeddings or relative position embeddings.
### preprocessing
The task of preparing raw data into a format that can be easily consumed by machine learning models. For example, text is typically preprocessed by tokenization. To gain a better idea of what preprocessing looks like for other input types, check out the [Preprocess](https://huggingface.co/docs/transformers/preprocessing) tutorial.
### pretrained model
A model that has been pretrained on some data (for instance all of Wikipedia). Pretraining methods involve a
self-supervised objective, which can be reading the text and trying to predict the next word (see [causal language
modeling](#causal-language-modeling)) or masking some words and trying to predict them (see [masked language
modeling](#masked-language-modeling-mlm)).
Speech and vision models have their own pretraining objectives. For example, Wav2Vec2 is a speech model pretrained on a contrastive task which requires the model to identify the "true" speech representation from a set of "false" speech representations. On the other hand, BEiT is a vision model pretrained on a masked image modeling task which masks some of the image patches and requires the model to predict the masked patches (similar to the masked language modeling objective).
## R
### recurrent neural network (RNN)
A type of model that uses a loop over a layer to process texts.
### representation learning
A subfield of machine learning which focuses on learning meaningful representations of raw data. Some examples of representation learning techniques include word embeddings, autoencoders, and Generative Adversarial Networks (GANs).
## S
### sampling rate
A measurement in hertz of the number of samples (the audio signal) taken per second. The sampling rate is a result of discretizing a continuous signal such as speech.
### self-attention
Each element of the input finds out which other elements of the input they should attend to.
### self-supervised learning
A category of machine learning techniques in which a model creates its own learning objective from unlabeled data. It differs from [unsupervised learning](#unsupervised-learning) and [supervised learning](#supervised-learning) in that the learning process is supervised, but not explicitly from the user.
One example of self-supervised learning is [masked language modeling](#masked-language-modeling-mlm), where a model is passed sentences with a proportion of its tokens removed and learns to predict the missing tokens.
### semi-supervised learning
A broad category of machine learning training techniques that leverages a small amount of labeled data with a larger quantity of unlabeled data to improve the accuracy of a model, unlike [supervised learning](#supervised-learning) and [unsupervised learning](#unsupervised-learning).
An example of a semi-supervised learning approach is "self-training", in which a model is trained on labeled data, and then used to make predictions on the unlabeled data. The portion of the unlabeled data that the model predicts with the most confidence gets added to the labeled dataset and used to retrain the model.
### sequence-to-sequence (seq2seq)
Models that generate a new sequence from an input, like translation models, or summarization models (such as
[Bart](model_doc/bart) or [T5](model_doc/t5)).
### Sharded DDP
Another name for the foundational [ZeRO](#zero-redundancy-optimizer--zero-) concept as used by various other implementations of ZeRO.
### stride
In [convolution](#convolution) or [pooling](#pooling), the stride refers to the distance the kernel is moved over a matrix. A stride of 1 means the kernel is moved one pixel over at a time, and a stride of 2 means the kernel is moved two pixels over at a time.
### supervised learning
A form of model training that directly uses labeled data to correct and instruct model performance. Data is fed into the model being trained, and its predictions are compared to the known labels. The model updates its weights based on how incorrect its predictions were, and the process is repeated to optimize model performance.
## T
### Tensor Parallelism (TP)
Parallelism technique for training on multiple GPUs in which each tensor is split up into multiple chunks, so instead of
having the whole tensor reside on a single GPU, each shard of the tensor resides on its designated GPU. Shards gets
processed separately and in parallel on different GPUs and the results are synced at the end of the processing step.
This is what is sometimes called horizontal parallelism, as the splitting happens on horizontal level.
Learn more about Tensor Parallelism [here](perf_train_gpu_many#tensor-parallelism).
### token
A part of a sentence, usually a word, but can also be a subword (non-common words are often split in subwords) or a
punctuation symbol.
### token Type IDs
Some models' purpose is to do classification on pairs of sentences or question answering.
<Youtube id="0u3ioSwev3s"/>
These require two different sequences to be joined in a single "input_ids" entry, which usually is performed with the
help of special tokens, such as the classifier (`[CLS]`) and separator (`[SEP]`) tokens. For example, the BERT model
builds its two sequence input as such:
```python
>>> # [CLS] SEQUENCE_A [SEP] SEQUENCE_B [SEP]
```
We can use our tokenizer to automatically generate such a sentence by passing the two sequences to `tokenizer` as two
arguments (and not a list, like before) like this:
```python
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
>>> sequence_a = "HuggingFace is based in NYC"
>>> sequence_b = "Where is HuggingFace based?"
>>> encoded_dict = tokenizer(sequence_a, sequence_b)
>>> decoded = tokenizer.decode(encoded_dict["input_ids"])
```
which will return:
```python
>>> print(decoded)
[CLS] HuggingFace is based in NYC [SEP] Where is HuggingFace based? [SEP]
```
This is enough for some models to understand where one sequence ends and where another begins. However, other models,
such as BERT, also deploy token type IDs (also called segment IDs). They are represented as a binary mask identifying
the two types of sequence in the model.
The tokenizer returns this mask as the "token_type_ids" entry:
```python
>>> encoded_dict["token_type_ids"]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
```
The first sequence, the "context" used for the question, has all its tokens represented by a `0`, whereas the second
sequence, corresponding to the "question", has all its tokens represented by a `1`.
Some models, like [`XLNetModel`] use an additional token represented by a `2`.
### transfer learning
A technique that involves taking a pretrained model and adapting it to a dataset specific to your task. Instead of training a model from scratch, you can leverage knowledge obtained from an existing model as a starting point. This speeds up the learning process and reduces the amount of training data needed.
### transformer
Self-attention based deep learning model architecture.
## U
### unsupervised learning
A form of model training in which data provided to the model is not labeled. Unsupervised learning techniques leverage statistical information of the data distribution to find patterns useful for the task at hand.
## Z
### Zero Redundancy Optimizer (ZeRO)
Parallelism technique which performs sharding of the tensors somewhat similar to [TensorParallel](#tensor-parallelism-tp),
except the whole tensor gets reconstructed in time for a forward or backward computation, therefore the model doesn't need
to be modified. This method also supports various offloading techniques to compensate for limited GPU memory.
Learn more about ZeRO [here](perf_train_gpu_many#zero-data-parallelism). | huggingface/transformers/blob/main/docs/source/en/glossary.md |
!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Image classification examples
This directory contains 2 scripts that showcase how to fine-tune any model supported by the [`AutoModelForImageClassification` API](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.AutoModelForImageClassification) (such as [ViT](https://huggingface.co/docs/transformers/main/en/model_doc/vit), [ConvNeXT](https://huggingface.co/docs/transformers/main/en/model_doc/convnext), [ResNet](https://huggingface.co/docs/transformers/main/en/model_doc/resnet), [Swin Transformer](https://huggingface.co/docs/transformers/main/en/model_doc/swin)...) using PyTorch. They can be used to fine-tune models on both [datasets from the hub](#using-datasets-from-hub) as well as on [your own custom data](#using-your-own-data).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/image_classification_inference_widget.png" height="400" />
Try out the inference widget here: https://huggingface.co/google/vit-base-patch16-224
Content:
- [PyTorch version, Trainer](#pytorch-version-trainer)
- [PyTorch version, no Trainer](#pytorch-version-no-trainer)
## PyTorch version, Trainer
Based on the script [`run_image_classification.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/image-classification/run_image_classification.py).
The script leverages the 🤗 [Trainer API](https://huggingface.co/docs/transformers/main_classes/trainer) to automatically take care of the training for you, running on distributed environments right away.
### Using datasets from Hub
Here we show how to fine-tune a Vision Transformer (`ViT`) on the [beans](https://huggingface.co/datasets/beans) dataset, to classify the disease type of bean leaves.
```bash
python run_image_classification.py \
--dataset_name beans \
--output_dir ./beans_outputs/ \
--remove_unused_columns False \
--do_train \
--do_eval \
--push_to_hub \
--push_to_hub_model_id vit-base-beans \
--learning_rate 2e-5 \
--num_train_epochs 5 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--logging_strategy steps \
--logging_steps 10 \
--evaluation_strategy epoch \
--save_strategy epoch \
--load_best_model_at_end True \
--save_total_limit 3 \
--seed 1337
```
👀 See the results here: [nateraw/vit-base-beans](https://huggingface.co/nateraw/vit-base-beans).
Note that you can replace the model and dataset by simply setting the `model_name_or_path` and `dataset_name` arguments respectively, with any model or dataset from the [hub](https://huggingface.co/). For an overview of all possible arguments, we refer to the [docs](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) of the `TrainingArguments`, which can be passed as flags.
> If your model classification head dimensions do not fit the number of labels in the dataset, you can specify `--ignore_mismatched_sizes` to adapt it.
### Using your own data
To use your own dataset, there are 2 ways:
- you can either provide your own folders as `--train_dir` and/or `--validation_dir` arguments
- you can upload your dataset to the hub (possibly as a private repo, if you prefer so), and simply pass the `--dataset_name` argument.
Below, we explain both in more detail.
#### Provide them as folders
If you provide your own folders with images, the script expects the following directory structure:
```bash
root/dog/xxx.png
root/dog/xxy.png
root/dog/[...]/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/[...]/asd932_.png
```
In other words, you need to organize your images in subfolders, based on their class. You can then run the script like this:
```bash
python run_image_classification.py \
--train_dir <path-to-train-root> \
--output_dir ./outputs/ \
--remove_unused_columns False \
--do_train \
--do_eval
```
Internally, the script will use the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature which will automatically turn the folders into 🤗 Dataset objects.
##### 💡 The above will split the train dir into training and evaluation sets
- To control the split amount, use the `--train_val_split` flag.
- To provide your own validation split in its own directory, you can pass the `--validation_dir <path-to-val-root>` flag.
#### Upload your data to the hub, as a (possibly private) repo
It's very easy (and convenient) to upload your image dataset to the hub using the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature available in 🤗 Datasets. Simply do the following:
```python
from datasets import load_dataset
# example 1: local folder
dataset = load_dataset("imagefolder", data_dir="path_to_your_folder")
# example 2: local files (suppoted formats are tar, gzip, zip, xz, rar, zstd)
dataset = load_dataset("imagefolder", data_files="path_to_zip_file")
# example 3: remote files (suppoted formats are tar, gzip, zip, xz, rar, zstd)
dataset = load_dataset("imagefolder", data_files="https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip")
# example 4: providing several splits
dataset = load_dataset("imagefolder", data_files={"train": ["path/to/file1", "path/to/file2"], "test": ["path/to/file3", "path/to/file4"]})
```
`ImageFolder` will create a `label` column, and the label name is based on the directory name.
Next, push it to the hub!
```python
# assuming you have ran the huggingface-cli login command in a terminal
dataset.push_to_hub("name_of_your_dataset")
# if you want to push to a private repo, simply pass private=True:
dataset.push_to_hub("name_of_your_dataset", private=True)
```
and that's it! You can now train your model by simply setting the `--dataset_name` argument to the name of your dataset on the hub (as explained in [Using datasets from the 🤗 hub](#using-datasets-from-hub)).
More on this can also be found in [this blog post](https://huggingface.co/blog/image-search-datasets).
### Sharing your model on 🤗 Hub
0. If you haven't already, [sign up](https://huggingface.co/join) for a 🤗 account
1. Make sure you have `git-lfs` installed and git set up.
```bash
$ apt install git-lfs
$ git config --global user.email "you@example.com"
$ git config --global user.name "Your Name"
```
2. Log in with your HuggingFace account credentials using `huggingface-cli`:
```bash
$ huggingface-cli login
# ...follow the prompts
```
3. When running the script, pass the following arguments:
```bash
python run_image_classification.py \
--push_to_hub \
--push_to_hub_model_id <name-your-model> \
...
```
## PyTorch version, no Trainer
Based on the script [`run_image_classification_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/image-classification/run_image_classification_no_trainer.py).
Like `run_image_classification.py`, this script allows you to fine-tune any of the models on the [hub](https://huggingface.co/models) on an image classification task. The main difference is that this script exposes the bare training loop, to allow you to quickly experiment and add any customization you would like.
It offers less options than the script with `Trainer` (for instance you can easily change the options for the optimizer
or the dataloaders directly in the script) but still run in a distributed setup, and supports mixed precision by
the means of the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library. You can use the script normally
after installing it:
```bash
pip install git+https://github.com/huggingface/accelerate
```
You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
```bash
accelerate config
```
and reply to the questions asked. Then
```bash
accelerate test
```
that will check everything is ready for training. Finally, you can launch training with
```bash
accelerate launch run_image_classification_trainer.py
```
This command is the same and will work for:
- single/multiple CPUs
- single/multiple GPUs
- TPUs
Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
Regarding using custom data with this script, we refer to [using your own data](#using-your-own-data).
| huggingface/transformers/blob/main/examples/pytorch/image-classification/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Text to speech
[[open-in-colab]]
Text-to-speech (TTS) is the task of creating natural-sounding speech from text, where the speech can be generated in multiple
languages and for multiple speakers. Several text-to-speech models are currently available in 🤗 Transformers, such as
[Bark](../model_doc/bark), [MMS](../model_doc/mms), [VITS](../model_doc/vits) and [SpeechT5](../model_doc/speecht5).
You can easily generate audio using the `"text-to-audio"` pipeline (or its alias - `"text-to-speech"`). Some models, like Bark,
can also be conditioned to generate non-verbal communications such as laughing, sighing and crying, or even add music.
Here's an example of how you would use the `"text-to-speech"` pipeline with Bark:
```py
>>> from transformers import pipeline
>>> pipe = pipeline("text-to-speech", model="suno/bark-small")
>>> text = "[clears throat] This is a test ... and I just took a long pause."
>>> output = pipe(text)
```
Here's a code snippet you can use to listen to the resulting audio in a notebook:
```python
>>> from IPython.display import Audio
>>> Audio(output["audio"], rate=output["sampling_rate"])
```
For more examples on what Bark and other pretrained TTS models can do, refer to our
[Audio course](https://huggingface.co/learn/audio-course/chapter6/pre-trained_models).
If you are looking to fine-tune a TTS model, you can currently fine-tune SpeechT5 only. SpeechT5 is pre-trained on a combination of
speech-to-text and text-to-speech data, allowing it to learn a unified space of hidden representations shared by both text
and speech. This means that the same pre-trained model can be fine-tuned for different tasks. Furthermore, SpeechT5
supports multiple speakers through x-vector speaker embeddings.
The remainder of this guide illustrates how to:
1. Fine-tune [SpeechT5](../model_doc/speecht5) that was originally trained on English speech on the Dutch (`nl`) language subset of the [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) dataset.
2. Use your refined model for inference in one of two ways: using a pipeline or directly.
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install datasets soundfile speechbrain accelerate
```
Install 🤗Transformers from source as not all the SpeechT5 features have been merged into an official release yet:
```bash
pip install git+https://github.com/huggingface/transformers.git
```
<Tip>
To follow this guide you will need a GPU. If you're working in a notebook, run the following line to check if a GPU is available:
```bash
!nvidia-smi
```
or alternatively for AMD GPUs:
```bash
!rocm-smi
```
</Tip>
We encourage you to log in to your Hugging Face account to upload and share your model with the community. When prompted, enter your token to log in:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load the dataset
[VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) is a large-scale multilingual speech corpus consisting of
data sourced from 2009-2020 European Parliament event recordings. It contains labelled audio-transcription data for 15
European languages. In this guide, we are using the Dutch language subset, feel free to pick another subset.
Note that VoxPopuli or any other automated speech recognition (ASR) dataset may not be the most suitable
option for training TTS models. The features that make it beneficial for ASR, such as excessive background noise, are
typically undesirable in TTS. However, finding top-quality, multilingual, and multi-speaker TTS datasets can be quite
challenging.
Let's load the data:
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("facebook/voxpopuli", "nl", split="train")
>>> len(dataset)
20968
```
20968 examples should be sufficient for fine-tuning. SpeechT5 expects audio data to have a sampling rate of 16 kHz, so
make sure the examples in the dataset meet this requirement:
```py
dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
```
## Preprocess the data
Let's begin by defining the model checkpoint to use and loading the appropriate processor:
```py
>>> from transformers import SpeechT5Processor
>>> checkpoint = "microsoft/speecht5_tts"
>>> processor = SpeechT5Processor.from_pretrained(checkpoint)
```
### Text cleanup for SpeechT5 tokenization
Start by cleaning up the text data. You'll need the tokenizer part of the processor to process the text:
```py
>>> tokenizer = processor.tokenizer
```
The dataset examples contain `raw_text` and `normalized_text` features. When deciding which feature to use as the text input,
consider that the SpeechT5 tokenizer doesn't have any tokens for numbers. In `normalized_text` the numbers are written
out as text. Thus, it is a better fit, and we recommend using `normalized_text` as input text.
Because SpeechT5 was trained on the English language, it may not recognize certain characters in the Dutch dataset. If
left as is, these characters will be converted to `<unk>` tokens. However, in Dutch, certain characters like `à` are
used to stress syllables. In order to preserve the meaning of the text, we can replace this character with a regular `a`.
To identify unsupported tokens, extract all unique characters in the dataset using the `SpeechT5Tokenizer` which
works with characters as tokens. To do this, write the `extract_all_chars` mapping function that concatenates
the transcriptions from all examples into one string and converts it to a set of characters.
Make sure to set `batched=True` and `batch_size=-1` in `dataset.map()` so that all transcriptions are available at once for
the mapping function.
```py
>>> def extract_all_chars(batch):
... all_text = " ".join(batch["normalized_text"])
... vocab = list(set(all_text))
... return {"vocab": [vocab], "all_text": [all_text]}
>>> vocabs = dataset.map(
... extract_all_chars,
... batched=True,
... batch_size=-1,
... keep_in_memory=True,
... remove_columns=dataset.column_names,
... )
>>> dataset_vocab = set(vocabs["vocab"][0])
>>> tokenizer_vocab = {k for k, _ in tokenizer.get_vocab().items()}
```
Now you have two sets of characters: one with the vocabulary from the dataset and one with the vocabulary from the tokenizer.
To identify any unsupported characters in the dataset, you can take the difference between these two sets. The resulting
set will contain the characters that are in the dataset but not in the tokenizer.
```py
>>> dataset_vocab - tokenizer_vocab
{' ', 'à', 'ç', 'è', 'ë', 'í', 'ï', 'ö', 'ü'}
```
To handle the unsupported characters identified in the previous step, define a function that maps these characters to
valid tokens. Note that spaces are already replaced by `▁` in the tokenizer and don't need to be handled separately.
```py
>>> replacements = [
... ("à", "a"),
... ("ç", "c"),
... ("è", "e"),
... ("ë", "e"),
... ("í", "i"),
... ("ï", "i"),
... ("ö", "o"),
... ("ü", "u"),
... ]
>>> def cleanup_text(inputs):
... for src, dst in replacements:
... inputs["normalized_text"] = inputs["normalized_text"].replace(src, dst)
... return inputs
>>> dataset = dataset.map(cleanup_text)
```
Now that you have dealt with special characters in the text, it's time to shift focus to the audio data.
### Speakers
The VoxPopuli dataset includes speech from multiple speakers, but how many speakers are represented in the dataset? To
determine this, we can count the number of unique speakers and the number of examples each speaker contributes to the dataset.
With a total of 20,968 examples in the dataset, this information will give us a better understanding of the distribution of
speakers and examples in the data.
```py
>>> from collections import defaultdict
>>> speaker_counts = defaultdict(int)
>>> for speaker_id in dataset["speaker_id"]:
... speaker_counts[speaker_id] += 1
```
By plotting a histogram you can get a sense of how much data there is for each speaker.
```py
>>> import matplotlib.pyplot as plt
>>> plt.figure()
>>> plt.hist(speaker_counts.values(), bins=20)
>>> plt.ylabel("Speakers")
>>> plt.xlabel("Examples")
>>> plt.show()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/tts_speakers_histogram.png" alt="Speakers histogram"/>
</div>
The histogram reveals that approximately one-third of the speakers in the dataset have fewer than 100 examples, while
around ten speakers have more than 500 examples. To improve training efficiency and balance the dataset, we can limit
the data to speakers with between 100 and 400 examples.
```py
>>> def select_speaker(speaker_id):
... return 100 <= speaker_counts[speaker_id] <= 400
>>> dataset = dataset.filter(select_speaker, input_columns=["speaker_id"])
```
Let's check how many speakers remain:
```py
>>> len(set(dataset["speaker_id"]))
42
```
Let's see how many examples are left:
```py
>>> len(dataset)
9973
```
You are left with just under 10,000 examples from approximately 40 unique speakers, which should be sufficient.
Note that some speakers with few examples may actually have more audio available if the examples are long. However,
determining the total amount of audio for each speaker requires scanning through the entire dataset, which is a
time-consuming process that involves loading and decoding each audio file. As such, we have chosen to skip this step here.
### Speaker embeddings
To enable the TTS model to differentiate between multiple speakers, you'll need to create a speaker embedding for each example.
The speaker embedding is an additional input into the model that captures a particular speaker's voice characteristics.
To generate these speaker embeddings, use the pre-trained [spkrec-xvect-voxceleb](https://huggingface.co/speechbrain/spkrec-xvect-voxceleb)
model from SpeechBrain.
Create a function `create_speaker_embedding()` that takes an input audio waveform and outputs a 512-element vector
containing the corresponding speaker embedding.
```py
>>> import os
>>> import torch
>>> from speechbrain.pretrained import EncoderClassifier
>>> spk_model_name = "speechbrain/spkrec-xvect-voxceleb"
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> speaker_model = EncoderClassifier.from_hparams(
... source=spk_model_name,
... run_opts={"device": device},
... savedir=os.path.join("/tmp", spk_model_name),
... )
>>> def create_speaker_embedding(waveform):
... with torch.no_grad():
... speaker_embeddings = speaker_model.encode_batch(torch.tensor(waveform))
... speaker_embeddings = torch.nn.functional.normalize(speaker_embeddings, dim=2)
... speaker_embeddings = speaker_embeddings.squeeze().cpu().numpy()
... return speaker_embeddings
```
It's important to note that the `speechbrain/spkrec-xvect-voxceleb` model was trained on English speech from the VoxCeleb
dataset, whereas the training examples in this guide are in Dutch. While we believe that this model will still generate
reasonable speaker embeddings for our Dutch dataset, this assumption may not hold true in all cases.
For optimal results, we recommend training an X-vector model on the target speech first. This will ensure that the model
is better able to capture the unique voice characteristics present in the Dutch language.
### Processing the dataset
Finally, let's process the data into the format the model expects. Create a `prepare_dataset` function that takes in a
single example and uses the `SpeechT5Processor` object to tokenize the input text and load the target audio into a log-mel spectrogram.
It should also add the speaker embeddings as an additional input.
```py
>>> def prepare_dataset(example):
... audio = example["audio"]
... example = processor(
... text=example["normalized_text"],
... audio_target=audio["array"],
... sampling_rate=audio["sampling_rate"],
... return_attention_mask=False,
... )
... # strip off the batch dimension
... example["labels"] = example["labels"][0]
... # use SpeechBrain to obtain x-vector
... example["speaker_embeddings"] = create_speaker_embedding(audio["array"])
... return example
```
Verify the processing is correct by looking at a single example:
```py
>>> processed_example = prepare_dataset(dataset[0])
>>> list(processed_example.keys())
['input_ids', 'labels', 'stop_labels', 'speaker_embeddings']
```
Speaker embeddings should be a 512-element vector:
```py
>>> processed_example["speaker_embeddings"].shape
(512,)
```
The labels should be a log-mel spectrogram with 80 mel bins.
```py
>>> import matplotlib.pyplot as plt
>>> plt.figure()
>>> plt.imshow(processed_example["labels"].T)
>>> plt.show()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/tts_logmelspectrogram_1.png" alt="Log-mel spectrogram with 80 mel bins"/>
</div>
Side note: If you find this spectrogram confusing, it may be due to your familiarity with the convention of placing low frequencies
at the bottom and high frequencies at the top of a plot. However, when plotting spectrograms as an image using the matplotlib library,
the y-axis is flipped and the spectrograms appear upside down.
Now apply the processing function to the entire dataset. This will take between 5 and 10 minutes.
```py
>>> dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)
```
You'll see a warning saying that some examples in the dataset are longer than the maximum input length the model can handle (600 tokens).
Remove those examples from the dataset. Here we go even further and to allow for larger batch sizes we remove anything over 200 tokens.
```py
>>> def is_not_too_long(input_ids):
... input_length = len(input_ids)
... return input_length < 200
>>> dataset = dataset.filter(is_not_too_long, input_columns=["input_ids"])
>>> len(dataset)
8259
```
Next, create a basic train/test split:
```py
>>> dataset = dataset.train_test_split(test_size=0.1)
```
### Data collator
In order to combine multiple examples into a batch, you need to define a custom data collator. This collator will pad shorter sequences with padding
tokens, ensuring that all examples have the same length. For the spectrogram labels, the padded portions are replaced with the special value `-100`. This special value
instructs the model to ignore that part of the spectrogram when calculating the spectrogram loss.
```py
>>> from dataclasses import dataclass
>>> from typing import Any, Dict, List, Union
>>> @dataclass
... class TTSDataCollatorWithPadding:
... processor: Any
... def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
... input_ids = [{"input_ids": feature["input_ids"]} for feature in features]
... label_features = [{"input_values": feature["labels"]} for feature in features]
... speaker_features = [feature["speaker_embeddings"] for feature in features]
... # collate the inputs and targets into a batch
... batch = processor.pad(input_ids=input_ids, labels=label_features, return_tensors="pt")
... # replace padding with -100 to ignore loss correctly
... batch["labels"] = batch["labels"].masked_fill(batch.decoder_attention_mask.unsqueeze(-1).ne(1), -100)
... # not used during fine-tuning
... del batch["decoder_attention_mask"]
... # round down target lengths to multiple of reduction factor
... if model.config.reduction_factor > 1:
... target_lengths = torch.tensor([len(feature["input_values"]) for feature in label_features])
... target_lengths = target_lengths.new(
... [length - length % model.config.reduction_factor for length in target_lengths]
... )
... max_length = max(target_lengths)
... batch["labels"] = batch["labels"][:, :max_length]
... # also add in the speaker embeddings
... batch["speaker_embeddings"] = torch.tensor(speaker_features)
... return batch
```
In SpeechT5, the input to the decoder part of the model is reduced by a factor 2. In other words, it throws away every
other timestep from the target sequence. The decoder then predicts a sequence that is twice as long. Since the original
target sequence length may be odd, the data collator makes sure to round the maximum length of the batch down to be a
multiple of 2.
```py
>>> data_collator = TTSDataCollatorWithPadding(processor=processor)
```
## Train the model
Load the pre-trained model from the same checkpoint as you used for loading the processor:
```py
>>> from transformers import SpeechT5ForTextToSpeech
>>> model = SpeechT5ForTextToSpeech.from_pretrained(checkpoint)
```
The `use_cache=True` option is incompatible with gradient checkpointing. Disable it for training.
```py
>>> model.config.use_cache = False
```
Define the training arguments. Here we are not computing any evaluation metrics during the training process. Instead, we'll
only look at the loss:
```python
>>> from transformers import Seq2SeqTrainingArguments
>>> training_args = Seq2SeqTrainingArguments(
... output_dir="speecht5_finetuned_voxpopuli_nl", # change to a repo name of your choice
... per_device_train_batch_size=4,
... gradient_accumulation_steps=8,
... learning_rate=1e-5,
... warmup_steps=500,
... max_steps=4000,
... gradient_checkpointing=True,
... fp16=True,
... evaluation_strategy="steps",
... per_device_eval_batch_size=2,
... save_steps=1000,
... eval_steps=1000,
... logging_steps=25,
... report_to=["tensorboard"],
... load_best_model_at_end=True,
... greater_is_better=False,
... label_names=["labels"],
... push_to_hub=True,
... )
```
Instantiate the `Trainer` object and pass the model, dataset, and data collator to it.
```py
>>> from transformers import Seq2SeqTrainer
>>> trainer = Seq2SeqTrainer(
... args=training_args,
... model=model,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... data_collator=data_collator,
... tokenizer=processor,
... )
```
And with that, you're ready to start training! Training will take several hours. Depending on your GPU,
it is possible that you will encounter a CUDA "out-of-memory" error when you start training. In this case, you can reduce
the `per_device_train_batch_size` incrementally by factors of 2 and increase `gradient_accumulation_steps` by 2x to compensate.
```py
>>> trainer.train()
```
To be able to use your checkpoint with a pipeline, make sure to save the processor with the checkpoint:
```py
>>> processor.save_pretrained("YOUR_ACCOUNT_NAME/speecht5_finetuned_voxpopuli_nl")
```
Push the final model to the 🤗 Hub:
```py
>>> trainer.push_to_hub()
```
## Inference
### Inference with a pipeline
Great, now that you've fine-tuned a model, you can use it for inference!
First, let's see how you can use it with a corresponding pipeline. Let's create a `"text-to-speech"` pipeline with your
checkpoint:
```py
>>> from transformers import pipeline
>>> pipe = pipeline("text-to-speech", model="YOUR_ACCOUNT_NAME/speecht5_finetuned_voxpopuli_nl")
```
Pick a piece of text in Dutch you'd like narrated, e.g.:
```py
>>> text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
```
To use SpeechT5 with the pipeline, you'll need a speaker embedding. Let's get it from an example in the test dataset:
```py
>>> example = dataset["test"][304]
>>> speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
```
Now you can pass the text and speaker embeddings to the pipeline, and it will take care of the rest:
```py
>>> forward_params = {"speaker_embeddings": speaker_embeddings}
>>> output = pipe(text, forward_params=forward_params)
>>> output
{'audio': array([-6.82714235e-05, -4.26525949e-04, 1.06134125e-04, ...,
-1.22392643e-03, -7.76011671e-04, 3.29112721e-04], dtype=float32),
'sampling_rate': 16000}
```
You can then listen to the result:
```py
>>> from IPython.display import Audio
>>> Audio(output['audio'], rate=output['sampling_rate'])
```
### Run inference manually
You can achieve the same inference results without using the pipeline, however, more steps will be required.
Load the model from the 🤗 Hub:
```py
>>> model = SpeechT5ForTextToSpeech.from_pretrained("YOUR_ACCOUNT/speecht5_finetuned_voxpopuli_nl")
```
Pick an example from the test dataset obtain a speaker embedding.
```py
>>> example = dataset["test"][304]
>>> speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
```
Define the input text and tokenize it.
```py
>>> text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
>>> inputs = processor(text=text, return_tensors="pt")
```
Create a spectrogram with your model:
```py
>>> spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)
```
Visualize the spectrogram, if you'd like to:
```py
>>> plt.figure()
>>> plt.imshow(spectrogram.T)
>>> plt.show()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/tts_logmelspectrogram_2.png" alt="Generated log-mel spectrogram"/>
</div>
Finally, use the vocoder to turn the spectrogram into sound.
```py
>>> with torch.no_grad():
... speech = vocoder(spectrogram)
>>> from IPython.display import Audio
>>> Audio(speech.numpy(), rate=16000)
```
In our experience, obtaining satisfactory results from this model can be challenging. The quality of the speaker
embeddings appears to be a significant factor. Since SpeechT5 was pre-trained with English x-vectors, it performs best
when using English speaker embeddings. If the synthesized speech sounds poor, try using a different speaker embedding.
Increasing the training duration is also likely to enhance the quality of the results. Even so, the speech clearly is Dutch instead of English, and it does
capture the voice characteristics of the speaker (compare to the original audio in the example).
Another thing to experiment with is the model's configuration. For example, try using `config.reduction_factor = 1` to
see if this improves the results.
Finally, it is essential to consider ethical considerations. Although TTS technology has numerous useful applications, it
may also be used for malicious purposes, such as impersonating someone's voice without their knowledge or consent. Please
use TTS judiciously and responsibly.
| huggingface/transformers/blob/main/docs/source/en/tasks/text-to-speech.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# UniSpeech-SAT
## Overview
The UniSpeech-SAT model was proposed in [UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware
Pre-Training](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen,
Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu .
The abstract from the paper is the following:
*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled
data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in
speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In
this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are
introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to
the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function.
Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where
additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed
methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves
state-of-the-art performance in universal representation learning, especially for speaker identification oriented
tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training
dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks.*
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT).
## Usage tips
- UniSpeechSat is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
Please use [`Wav2Vec2Processor`] for the feature extraction.
- UniSpeechSat model can be fine-tuned using connectionist temporal classification (CTC) so the model output has to be
decoded using [`Wav2Vec2CTCTokenizer`].
- UniSpeechSat performs especially well on speaker verification, speaker identification, and speaker diarization tasks.
## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
## UniSpeechSatConfig
[[autodoc]] UniSpeechSatConfig
## UniSpeechSat specific outputs
[[autodoc]] models.unispeech_sat.modeling_unispeech_sat.UniSpeechSatForPreTrainingOutput
## UniSpeechSatModel
[[autodoc]] UniSpeechSatModel
- forward
## UniSpeechSatForCTC
[[autodoc]] UniSpeechSatForCTC
- forward
## UniSpeechSatForSequenceClassification
[[autodoc]] UniSpeechSatForSequenceClassification
- forward
## UniSpeechSatForAudioFrameClassification
[[autodoc]] UniSpeechSatForAudioFrameClassification
- forward
## UniSpeechSatForXVector
[[autodoc]] UniSpeechSatForXVector
- forward
## UniSpeechSatForPreTraining
[[autodoc]] UniSpeechSatForPreTraining
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/unispeech-sat.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# TAPAS
## Overview
The TAPAS model was proposed in [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://www.aclweb.org/anthology/2020.acl-main.398)
by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos. It's a BERT-based model specifically
designed (and pre-trained) for answering questions about tabular data. Compared to BERT, TAPAS uses relative position embeddings and has 7
token types that encode tabular structure. TAPAS is pre-trained on the masked language modeling (MLM) objective on a large dataset comprising
millions of tables from English Wikipedia and corresponding texts.
For question answering, TAPAS has 2 heads on top: a cell selection head and an aggregation head, for (optionally) performing aggregations (such as counting or summing) among selected cells. TAPAS has been fine-tuned on several datasets:
- [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253) (Sequential Question Answering by Microsoft)
- [WTQ](https://github.com/ppasupat/WikiTableQuestions) (Wiki Table Questions by Stanford University)
- [WikiSQL](https://github.com/salesforce/WikiSQL) (by Salesforce).
It achieves state-of-the-art on both SQA and WTQ, while having comparable performance to SOTA on WikiSQL, with a much simpler architecture.
The abstract from the paper is the following:
*Answering natural language questions over tables is usually seen as a semantic parsing task. To alleviate the collection cost of full logical forms, one popular approach focuses on weak supervision consisting of denotations instead of logical forms. However, training semantic parsers from weak supervision poses difficulties, and in addition, the generated logical forms are only used as an intermediate step prior to retrieving the denotation. In this paper, we present TAPAS, an approach to question answering over tables without generating logical forms. TAPAS trains from weak supervision, and predicts the denotation by selecting table cells and optionally applying a corresponding aggregation operator to such selection. TAPAS extends BERT's architecture to encode tables as input, initializes from an effective joint pre-training of text segments and tables crawled from Wikipedia, and is trained end-to-end. We experiment with three different semantic parsing datasets, and find that TAPAS outperforms or rivals semantic parsing models by improving state-of-the-art accuracy on SQA from 55.1 to 67.2 and performing on par with the state-of-the-art on WIKISQL and WIKITQ, but with a simpler model architecture. We additionally find that transfer learning, which is trivial in our setting, from WIKISQL to WIKITQ, yields 48.7 accuracy, 4.2 points above the state-of-the-art.*
In addition, the authors have further pre-trained TAPAS to recognize **table entailment**, by creating a balanced dataset of millions of automatically created training examples which are learned in an intermediate step prior to fine-tuning. The authors of TAPAS call this further pre-training intermediate pre-training (since TAPAS is first pre-trained on MLM, and then on another dataset). They found that intermediate pre-training further improves performance on SQA, achieving a new state-of-the-art as well as state-of-the-art on [TabFact](https://github.com/wenhuchen/Table-Fact-Checking), a large-scale dataset with 16k Wikipedia tables for table entailment (a binary classification task). For more details, see their follow-up paper: [Understanding tables with intermediate pre-training](https://www.aclweb.org/anthology/2020.findings-emnlp.27/) by Julian Martin Eisenschlos, Syrine Krichene and Thomas Müller.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/tapas_architecture.png"
alt="drawing" width="600"/>
<small> TAPAS architecture. Taken from the <a href="https://ai.googleblog.com/2020/04/using-neural-networks-to-find-answers.html">original blog post</a>.</small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The Tensorflow version of this model was contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/tapas).
## Usage tips
- TAPAS is a model that uses relative position embeddings by default (restarting the position embeddings at every cell of the table). Note that this is something that was added after the publication of the original TAPAS paper. According to the authors, this usually results in a slightly better performance, and allows you to encode longer sequences without running out of embeddings. This is reflected in the `reset_position_index_per_cell` parameter of [`TapasConfig`], which is set to `True` by default. The default versions of the models available on the [hub](https://huggingface.co/models?search=tapas) all use relative position embeddings. You can still use the ones with absolute position embeddings by passing in an additional argument `revision="no_reset"` when calling the `from_pretrained()` method. Note that it's usually advised to pad the inputs on the right rather than the left.
- TAPAS is based on BERT, so `TAPAS-base` for example corresponds to a `BERT-base` architecture. Of course, `TAPAS-large` will result in the best performance (the results reported in the paper are from `TAPAS-large`). Results of the various sized models are shown on the [original GitHub repository](https://github.com/google-research/tapas).
- TAPAS has checkpoints fine-tuned on SQA, which are capable of answering questions related to a table in a conversational set-up. This means that you can ask follow-up questions such as "what is his age?" related to the previous question. Note that the forward pass of TAPAS is a bit different in case of a conversational set-up: in that case, you have to feed every table-question pair one by one to the model, such that the `prev_labels` token type ids can be overwritten by the predicted `labels` of the model to the previous question. See "Usage" section for more info.
- TAPAS is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained with a causal language modeling (CLM) objective are better in that regard. Note that TAPAS can be used as an encoder in the EncoderDecoderModel framework, to combine it with an autoregressive text decoder such as GPT-2.
## Usage: fine-tuning
Here we explain how you can fine-tune [`TapasForQuestionAnswering`] on your own dataset.
**STEP 1: Choose one of the 3 ways in which you can use TAPAS - or experiment**
Basically, there are 3 different ways in which one can fine-tune [`TapasForQuestionAnswering`], corresponding to the different datasets on which Tapas was fine-tuned:
1. SQA: if you're interested in asking follow-up questions related to a table, in a conversational set-up. For example if you first ask "what's the name of the first actor?" then you can ask a follow-up question such as "how old is he?". Here, questions do not involve any aggregation (all questions are cell selection questions).
2. WTQ: if you're not interested in asking questions in a conversational set-up, but rather just asking questions related to a table, which might involve aggregation, such as counting a number of rows, summing up cell values or averaging cell values. You can then for example ask "what's the total number of goals Cristiano Ronaldo made in his career?". This case is also called **weak supervision**, since the model itself must learn the appropriate aggregation operator (SUM/COUNT/AVERAGE/NONE) given only the answer to the question as supervision.
3. WikiSQL-supervised: this dataset is based on WikiSQL with the model being given the ground truth aggregation operator during training. This is also called **strong supervision**. Here, learning the appropriate aggregation operator is much easier.
To summarize:
| **Task** | **Example dataset** | **Description** |
|-------------------------------------|---------------------|---------------------------------------------------------------------------------------------------------|
| Conversational | SQA | Conversational, only cell selection questions |
| Weak supervision for aggregation | WTQ | Questions might involve aggregation, and the model must learn this given only the answer as supervision |
| Strong supervision for aggregation | WikiSQL-supervised | Questions might involve aggregation, and the model must learn this given the gold aggregation operator |
<frameworkcontent>
<pt>
Initializing a model with a pre-trained base and randomly initialized classification heads from the hub can be done as shown below.
```py
>>> from transformers import TapasConfig, TapasForQuestionAnswering
>>> # for example, the base sized model with default SQA configuration
>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base")
>>> # or, the base sized model with WTQ configuration
>>> config = TapasConfig.from_pretrained("google/tapas-base-finetuned-wtq")
>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
>>> # or, the base sized model with WikiSQL configuration
>>> config = TapasConfig("google-base-finetuned-wikisql-supervised")
>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
```
Of course, you don't necessarily have to follow one of these three ways in which TAPAS was fine-tuned. You can also experiment by defining any hyperparameters you want when initializing [`TapasConfig`], and then create a [`TapasForQuestionAnswering`] based on that configuration. For example, if you have a dataset that has both conversational questions and questions that might involve aggregation, then you can do it this way. Here's an example:
```py
>>> from transformers import TapasConfig, TapasForQuestionAnswering
>>> # you can initialize the classification heads any way you want (see docs of TapasConfig)
>>> config = TapasConfig(num_aggregation_labels=3, average_logits_per_cell=True)
>>> # initializing the pre-trained base sized model with our custom classification heads
>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
```
</pt>
<tf>
Initializing a model with a pre-trained base and randomly initialized classification heads from the hub can be done as shown below. Be sure to have installed the [tensorflow_probability](https://github.com/tensorflow/probability) dependency:
```py
>>> from transformers import TapasConfig, TFTapasForQuestionAnswering
>>> # for example, the base sized model with default SQA configuration
>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base")
>>> # or, the base sized model with WTQ configuration
>>> config = TapasConfig.from_pretrained("google/tapas-base-finetuned-wtq")
>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
>>> # or, the base sized model with WikiSQL configuration
>>> config = TapasConfig("google-base-finetuned-wikisql-supervised")
>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
```
Of course, you don't necessarily have to follow one of these three ways in which TAPAS was fine-tuned. You can also experiment by defining any hyperparameters you want when initializing [`TapasConfig`], and then create a [`TFTapasForQuestionAnswering`] based on that configuration. For example, if you have a dataset that has both conversational questions and questions that might involve aggregation, then you can do it this way. Here's an example:
```py
>>> from transformers import TapasConfig, TFTapasForQuestionAnswering
>>> # you can initialize the classification heads any way you want (see docs of TapasConfig)
>>> config = TapasConfig(num_aggregation_labels=3, average_logits_per_cell=True)
>>> # initializing the pre-trained base sized model with our custom classification heads
>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
```
</tf>
</frameworkcontent>
What you can also do is start from an already fine-tuned checkpoint. A note here is that the already fine-tuned checkpoint on WTQ has some issues due to the L2-loss which is somewhat brittle. See [here](https://github.com/google-research/tapas/issues/91#issuecomment-735719340) for more info.
For a list of all pre-trained and fine-tuned TAPAS checkpoints available on HuggingFace's hub, see [here](https://huggingface.co/models?search=tapas).
**STEP 2: Prepare your data in the SQA format**
Second, no matter what you picked above, you should prepare your dataset in the [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253) format. This format is a TSV/CSV file with the following columns:
- `id`: optional, id of the table-question pair, for bookkeeping purposes.
- `annotator`: optional, id of the person who annotated the table-question pair, for bookkeeping purposes.
- `position`: integer indicating if the question is the first, second, third,... related to the table. Only required in case of conversational setup (SQA). You don't need this column in case you're going for WTQ/WikiSQL-supervised.
- `question`: string
- `table_file`: string, name of a csv file containing the tabular data
- `answer_coordinates`: list of one or more tuples (each tuple being a cell coordinate, i.e. row, column pair that is part of the answer)
- `answer_text`: list of one or more strings (each string being a cell value that is part of the answer)
- `aggregation_label`: index of the aggregation operator. Only required in case of strong supervision for aggregation (the WikiSQL-supervised case)
- `float_answer`: the float answer to the question, if there is one (np.nan if there isn't). Only required in case of weak supervision for aggregation (such as WTQ and WikiSQL)
The tables themselves should be present in a folder, each table being a separate csv file. Note that the authors of the TAPAS algorithm used conversion scripts with some automated logic to convert the other datasets (WTQ, WikiSQL) into the SQA format. The author explains this [here](https://github.com/google-research/tapas/issues/50#issuecomment-705465960). A conversion of this script that works with HuggingFace's implementation can be found [here](https://github.com/NielsRogge/tapas_utils). Interestingly, these conversion scripts are not perfect (the `answer_coordinates` and `float_answer` fields are populated based on the `answer_text`), meaning that WTQ and WikiSQL results could actually be improved.
**STEP 3: Convert your data into tensors using TapasTokenizer**
<frameworkcontent>
<pt>
Third, given that you've prepared your data in this TSV/CSV format (and corresponding CSV files containing the tabular data), you can then use [`TapasTokenizer`] to convert table-question pairs into `input_ids`, `attention_mask`, `token_type_ids` and so on. Again, based on which of the three cases you picked above, [`TapasForQuestionAnswering`] requires different
inputs to be fine-tuned:
| **Task** | **Required inputs** |
|------------------------------------|---------------------------------------------------------------------------------------------------------------------|
| Conversational | `input_ids`, `attention_mask`, `token_type_ids`, `labels` |
| Weak supervision for aggregation | `input_ids`, `attention_mask`, `token_type_ids`, `labels`, `numeric_values`, `numeric_values_scale`, `float_answer` |
| Strong supervision for aggregation | `input ids`, `attention mask`, `token type ids`, `labels`, `aggregation_labels` |
[`TapasTokenizer`] creates the `labels`, `numeric_values` and `numeric_values_scale` based on the `answer_coordinates` and `answer_text` columns of the TSV file. The `float_answer` and `aggregation_labels` are already in the TSV file of step 2. Here's an example:
```py
>>> from transformers import TapasTokenizer
>>> import pandas as pd
>>> model_name = "google/tapas-base"
>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
>>> queries = [
... "What is the name of the first actor?",
... "How many movies has George Clooney played in?",
... "What is the total number of movies?",
... ]
>>> answer_coordinates = [[(0, 0)], [(2, 1)], [(0, 1), (1, 1), (2, 1)]]
>>> answer_text = [["Brad Pitt"], ["69"], ["209"]]
>>> table = pd.DataFrame.from_dict(data)
>>> inputs = tokenizer(
... table=table,
... queries=queries,
... answer_coordinates=answer_coordinates,
... answer_text=answer_text,
... padding="max_length",
... return_tensors="pt",
... )
>>> inputs
{'input_ids': tensor([[ ... ]]), 'attention_mask': tensor([[...]]), 'token_type_ids': tensor([[[...]]]),
'numeric_values': tensor([[ ... ]]), 'numeric_values_scale: tensor([[ ... ]]), labels: tensor([[ ... ]])}
```
Note that [`TapasTokenizer`] expects the data of the table to be **text-only**. You can use `.astype(str)` on a dataframe to turn it into text-only data.
Of course, this only shows how to encode a single training example. It is advised to create a dataloader to iterate over batches:
```py
>>> import torch
>>> import pandas as pd
>>> tsv_path = "your_path_to_the_tsv_file"
>>> table_csv_path = "your_path_to_a_directory_containing_all_csv_files"
>>> class TableDataset(torch.utils.data.Dataset):
... def __init__(self, data, tokenizer):
... self.data = data
... self.tokenizer = tokenizer
... def __getitem__(self, idx):
... item = data.iloc[idx]
... table = pd.read_csv(table_csv_path + item.table_file).astype(
... str
... ) # be sure to make your table data text only
... encoding = self.tokenizer(
... table=table,
... queries=item.question,
... answer_coordinates=item.answer_coordinates,
... answer_text=item.answer_text,
... truncation=True,
... padding="max_length",
... return_tensors="pt",
... )
... # remove the batch dimension which the tokenizer adds by default
... encoding = {key: val.squeeze(0) for key, val in encoding.items()}
... # add the float_answer which is also required (weak supervision for aggregation case)
... encoding["float_answer"] = torch.tensor(item.float_answer)
... return encoding
... def __len__(self):
... return len(self.data)
>>> data = pd.read_csv(tsv_path, sep="\t")
>>> train_dataset = TableDataset(data, tokenizer)
>>> train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=32)
```
</pt>
<tf>
Third, given that you've prepared your data in this TSV/CSV format (and corresponding CSV files containing the tabular data), you can then use [`TapasTokenizer`] to convert table-question pairs into `input_ids`, `attention_mask`, `token_type_ids` and so on. Again, based on which of the three cases you picked above, [`TFTapasForQuestionAnswering`] requires different
inputs to be fine-tuned:
| **Task** | **Required inputs** |
|------------------------------------|---------------------------------------------------------------------------------------------------------------------|
| Conversational | `input_ids`, `attention_mask`, `token_type_ids`, `labels` |
| Weak supervision for aggregation | `input_ids`, `attention_mask`, `token_type_ids`, `labels`, `numeric_values`, `numeric_values_scale`, `float_answer` |
| Strong supervision for aggregation | `input ids`, `attention mask`, `token type ids`, `labels`, `aggregation_labels` |
[`TapasTokenizer`] creates the `labels`, `numeric_values` and `numeric_values_scale` based on the `answer_coordinates` and `answer_text` columns of the TSV file. The `float_answer` and `aggregation_labels` are already in the TSV file of step 2. Here's an example:
```py
>>> from transformers import TapasTokenizer
>>> import pandas as pd
>>> model_name = "google/tapas-base"
>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
>>> queries = [
... "What is the name of the first actor?",
... "How many movies has George Clooney played in?",
... "What is the total number of movies?",
... ]
>>> answer_coordinates = [[(0, 0)], [(2, 1)], [(0, 1), (1, 1), (2, 1)]]
>>> answer_text = [["Brad Pitt"], ["69"], ["209"]]
>>> table = pd.DataFrame.from_dict(data)
>>> inputs = tokenizer(
... table=table,
... queries=queries,
... answer_coordinates=answer_coordinates,
... answer_text=answer_text,
... padding="max_length",
... return_tensors="tf",
... )
>>> inputs
{'input_ids': tensor([[ ... ]]), 'attention_mask': tensor([[...]]), 'token_type_ids': tensor([[[...]]]),
'numeric_values': tensor([[ ... ]]), 'numeric_values_scale: tensor([[ ... ]]), labels: tensor([[ ... ]])}
```
Note that [`TapasTokenizer`] expects the data of the table to be **text-only**. You can use `.astype(str)` on a dataframe to turn it into text-only data.
Of course, this only shows how to encode a single training example. It is advised to create a dataloader to iterate over batches:
```py
>>> import tensorflow as tf
>>> import pandas as pd
>>> tsv_path = "your_path_to_the_tsv_file"
>>> table_csv_path = "your_path_to_a_directory_containing_all_csv_files"
>>> class TableDataset:
... def __init__(self, data, tokenizer):
... self.data = data
... self.tokenizer = tokenizer
... def __iter__(self):
... for idx in range(self.__len__()):
... item = self.data.iloc[idx]
... table = pd.read_csv(table_csv_path + item.table_file).astype(
... str
... ) # be sure to make your table data text only
... encoding = self.tokenizer(
... table=table,
... queries=item.question,
... answer_coordinates=item.answer_coordinates,
... answer_text=item.answer_text,
... truncation=True,
... padding="max_length",
... return_tensors="tf",
... )
... # remove the batch dimension which the tokenizer adds by default
... encoding = {key: tf.squeeze(val, 0) for key, val in encoding.items()}
... # add the float_answer which is also required (weak supervision for aggregation case)
... encoding["float_answer"] = tf.convert_to_tensor(item.float_answer, dtype=tf.float32)
... yield encoding["input_ids"], encoding["attention_mask"], encoding["numeric_values"], encoding[
... "numeric_values_scale"
... ], encoding["token_type_ids"], encoding["labels"], encoding["float_answer"]
... def __len__(self):
... return len(self.data)
>>> data = pd.read_csv(tsv_path, sep="\t")
>>> train_dataset = TableDataset(data, tokenizer)
>>> output_signature = (
... tf.TensorSpec(shape=(512,), dtype=tf.int32),
... tf.TensorSpec(shape=(512,), dtype=tf.int32),
... tf.TensorSpec(shape=(512,), dtype=tf.float32),
... tf.TensorSpec(shape=(512,), dtype=tf.float32),
... tf.TensorSpec(shape=(512, 7), dtype=tf.int32),
... tf.TensorSpec(shape=(512,), dtype=tf.int32),
... tf.TensorSpec(shape=(512,), dtype=tf.float32),
... )
>>> train_dataloader = tf.data.Dataset.from_generator(train_dataset, output_signature=output_signature).batch(32)
```
</tf>
</frameworkcontent>
Note that here, we encode each table-question pair independently. This is fine as long as your dataset is **not conversational**. In case your dataset involves conversational questions (such as in SQA), then you should first group together the `queries`, `answer_coordinates` and `answer_text` per table (in the order of their `position`
index) and batch encode each table with its questions. This will make sure that the `prev_labels` token types (see docs of [`TapasTokenizer`]) are set correctly. See [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) for more info. See [this notebook](https://github.com/kamalkraj/Tapas-Tutorial/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) for more info regarding using the TensorFlow model.
**STEP 4: Train (fine-tune) the model
<frameworkcontent>
<pt>
You can then fine-tune [`TapasForQuestionAnswering`] as follows (shown here for the weak supervision for aggregation case):
```py
>>> from transformers import TapasConfig, TapasForQuestionAnswering, AdamW
>>> # this is the default WTQ configuration
>>> config = TapasConfig(
... num_aggregation_labels=4,
... use_answer_as_supervision=True,
... answer_loss_cutoff=0.664694,
... cell_selection_preference=0.207951,
... huber_loss_delta=0.121194,
... init_cell_selection_weights_to_zero=True,
... select_one_column=True,
... allow_empty_column_selection=False,
... temperature=0.0352513,
... )
>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
>>> optimizer = AdamW(model.parameters(), lr=5e-5)
>>> model.train()
>>> for epoch in range(2): # loop over the dataset multiple times
... for batch in train_dataloader:
... # get the inputs;
... input_ids = batch["input_ids"]
... attention_mask = batch["attention_mask"]
... token_type_ids = batch["token_type_ids"]
... labels = batch["labels"]
... numeric_values = batch["numeric_values"]
... numeric_values_scale = batch["numeric_values_scale"]
... float_answer = batch["float_answer"]
... # zero the parameter gradients
... optimizer.zero_grad()
... # forward + backward + optimize
... outputs = model(
... input_ids=input_ids,
... attention_mask=attention_mask,
... token_type_ids=token_type_ids,
... labels=labels,
... numeric_values=numeric_values,
... numeric_values_scale=numeric_values_scale,
... float_answer=float_answer,
... )
... loss = outputs.loss
... loss.backward()
... optimizer.step()
```
</pt>
<tf>
You can then fine-tune [`TFTapasForQuestionAnswering`] as follows (shown here for the weak supervision for aggregation case):
```py
>>> import tensorflow as tf
>>> from transformers import TapasConfig, TFTapasForQuestionAnswering
>>> # this is the default WTQ configuration
>>> config = TapasConfig(
... num_aggregation_labels=4,
... use_answer_as_supervision=True,
... answer_loss_cutoff=0.664694,
... cell_selection_preference=0.207951,
... huber_loss_delta=0.121194,
... init_cell_selection_weights_to_zero=True,
... select_one_column=True,
... allow_empty_column_selection=False,
... temperature=0.0352513,
... )
>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
>>> optimizer = tf.keras.optimizers.Adam(learning_rate=5e-5)
>>> for epoch in range(2): # loop over the dataset multiple times
... for batch in train_dataloader:
... # get the inputs;
... input_ids = batch[0]
... attention_mask = batch[1]
... token_type_ids = batch[4]
... labels = batch[-1]
... numeric_values = batch[2]
... numeric_values_scale = batch[3]
... float_answer = batch[6]
... # forward + backward + optimize
... with tf.GradientTape() as tape:
... outputs = model(
... input_ids=input_ids,
... attention_mask=attention_mask,
... token_type_ids=token_type_ids,
... labels=labels,
... numeric_values=numeric_values,
... numeric_values_scale=numeric_values_scale,
... float_answer=float_answer,
... )
... grads = tape.gradient(outputs.loss, model.trainable_weights)
... optimizer.apply_gradients(zip(grads, model.trainable_weights))
```
</tf>
</frameworkcontent>
## Usage: inference
<frameworkcontent>
<pt>
Here we explain how you can use [`TapasForQuestionAnswering`] or [`TFTapasForQuestionAnswering`] for inference (i.e. making predictions on new data). For inference, only `input_ids`, `attention_mask` and `token_type_ids` (which you can obtain using [`TapasTokenizer`]) have to be provided to the model to obtain the logits. Next, you can use the handy [`~models.tapas.tokenization_tapas.convert_logits_to_predictions`] method to convert these into predicted coordinates and optional aggregation indices.
However, note that inference is **different** depending on whether or not the setup is conversational. In a non-conversational set-up, inference can be done in parallel on all table-question pairs of a batch. Here's an example of that:
```py
>>> from transformers import TapasTokenizer, TapasForQuestionAnswering
>>> import pandas as pd
>>> model_name = "google/tapas-base-finetuned-wtq"
>>> model = TapasForQuestionAnswering.from_pretrained(model_name)
>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
>>> queries = [
... "What is the name of the first actor?",
... "How many movies has George Clooney played in?",
... "What is the total number of movies?",
... ]
>>> table = pd.DataFrame.from_dict(data)
>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="pt")
>>> outputs = model(**inputs)
>>> predicted_answer_coordinates, predicted_aggregation_indices = tokenizer.convert_logits_to_predictions(
... inputs, outputs.logits.detach(), outputs.logits_aggregation.detach()
... )
>>> # let's print out the results:
>>> id2aggregation = {0: "NONE", 1: "SUM", 2: "AVERAGE", 3: "COUNT"}
>>> aggregation_predictions_string = [id2aggregation[x] for x in predicted_aggregation_indices]
>>> answers = []
>>> for coordinates in predicted_answer_coordinates:
... if len(coordinates) == 1:
... # only a single cell:
... answers.append(table.iat[coordinates[0]])
... else:
... # multiple cells
... cell_values = []
... for coordinate in coordinates:
... cell_values.append(table.iat[coordinate])
... answers.append(", ".join(cell_values))
>>> display(table)
>>> print("")
>>> for query, answer, predicted_agg in zip(queries, answers, aggregation_predictions_string):
... print(query)
... if predicted_agg == "NONE":
... print("Predicted answer: " + answer)
... else:
... print("Predicted answer: " + predicted_agg + " > " + answer)
What is the name of the first actor?
Predicted answer: Brad Pitt
How many movies has George Clooney played in?
Predicted answer: COUNT > 69
What is the total number of movies?
Predicted answer: SUM > 87, 53, 69
```
</pt>
<tf>
Here we explain how you can use [`TFTapasForQuestionAnswering`] for inference (i.e. making predictions on new data). For inference, only `input_ids`, `attention_mask` and `token_type_ids` (which you can obtain using [`TapasTokenizer`]) have to be provided to the model to obtain the logits. Next, you can use the handy [`~models.tapas.tokenization_tapas.convert_logits_to_predictions`] method to convert these into predicted coordinates and optional aggregation indices.
However, note that inference is **different** depending on whether or not the setup is conversational. In a non-conversational set-up, inference can be done in parallel on all table-question pairs of a batch. Here's an example of that:
```py
>>> from transformers import TapasTokenizer, TFTapasForQuestionAnswering
>>> import pandas as pd
>>> model_name = "google/tapas-base-finetuned-wtq"
>>> model = TFTapasForQuestionAnswering.from_pretrained(model_name)
>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
>>> queries = [
... "What is the name of the first actor?",
... "How many movies has George Clooney played in?",
... "What is the total number of movies?",
... ]
>>> table = pd.DataFrame.from_dict(data)
>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="tf")
>>> outputs = model(**inputs)
>>> predicted_answer_coordinates, predicted_aggregation_indices = tokenizer.convert_logits_to_predictions(
... inputs, outputs.logits, outputs.logits_aggregation
... )
>>> # let's print out the results:
>>> id2aggregation = {0: "NONE", 1: "SUM", 2: "AVERAGE", 3: "COUNT"}
>>> aggregation_predictions_string = [id2aggregation[x] for x in predicted_aggregation_indices]
>>> answers = []
>>> for coordinates in predicted_answer_coordinates:
... if len(coordinates) == 1:
... # only a single cell:
... answers.append(table.iat[coordinates[0]])
... else:
... # multiple cells
... cell_values = []
... for coordinate in coordinates:
... cell_values.append(table.iat[coordinate])
... answers.append(", ".join(cell_values))
>>> display(table)
>>> print("")
>>> for query, answer, predicted_agg in zip(queries, answers, aggregation_predictions_string):
... print(query)
... if predicted_agg == "NONE":
... print("Predicted answer: " + answer)
... else:
... print("Predicted answer: " + predicted_agg + " > " + answer)
What is the name of the first actor?
Predicted answer: Brad Pitt
How many movies has George Clooney played in?
Predicted answer: COUNT > 69
What is the total number of movies?
Predicted answer: SUM > 87, 53, 69
```
</tf>
</frameworkcontent>
In case of a conversational set-up, then each table-question pair must be provided **sequentially** to the model, such that the `prev_labels` token types can be overwritten by the predicted `labels` of the previous table-question pair. Again, more info can be found in [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) (for PyTorch) and [this notebook](https://github.com/kamalkraj/Tapas-Tutorial/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) (for TensorFlow).
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
## TAPAS specific outputs
[[autodoc]] models.tapas.modeling_tapas.TableQuestionAnsweringOutput
## TapasConfig
[[autodoc]] TapasConfig
## TapasTokenizer
[[autodoc]] TapasTokenizer
- __call__
- convert_logits_to_predictions
- save_vocabulary
<frameworkcontent>
<pt>
## TapasModel
[[autodoc]] TapasModel
- forward
## TapasForMaskedLM
[[autodoc]] TapasForMaskedLM
- forward
## TapasForSequenceClassification
[[autodoc]] TapasForSequenceClassification
- forward
## TapasForQuestionAnswering
[[autodoc]] TapasForQuestionAnswering
- forward
</pt>
<tf>
## TFTapasModel
[[autodoc]] TFTapasModel
- call
## TFTapasForMaskedLM
[[autodoc]] TFTapasForMaskedLM
- call
## TFTapasForSequenceClassification
[[autodoc]] TFTapasForSequenceClassification
- call
## TFTapasForQuestionAnswering
[[autodoc]] TFTapasForQuestionAnswering
- call
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/tapas.md |
Gradio Demo: chatinterface_streaming_echo
```
!pip install -q gradio
```
```
import time
import gradio as gr
def slow_echo(message, history):
for i in range(len(message)):
time.sleep(0.05)
yield "You typed: " + message[: i+1]
demo = gr.ChatInterface(slow_echo).queue()
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/chatinterface_streaming_echo/run.ipynb |
How to contribute to Datasets?
[](CODE_OF_CONDUCT.md)
Datasets is an open source project, so all contributions and suggestions are welcome.
You can contribute in many different ways: giving ideas, answering questions, reporting bugs, proposing enhancements,
improving the documentation, fixing bugs,...
Many thanks in advance to every contributor.
In order to facilitate healthy, constructive behavior in an open and inclusive community, we all respect and abide by
our [code of conduct](CODE_OF_CONDUCT.md).
## How to work on an open Issue?
You have the list of open Issues at: https://github.com/huggingface/datasets/issues
Some of them may have the label `help wanted`: that means that any contributor is welcomed!
If you would like to work on any of the open Issues:
1. Make sure it is not already assigned to someone else. You have the assignee (if any) on the top of the right column of the Issue page.
2. You can self-assign it by commenting on the Issue page with the keyword: `#self-assign`.
3. Work on your self-assigned issue and eventually create a Pull Request.
## How to create a Pull Request?
If you want to add a dataset see specific instructions in the section [*How to add a dataset*](#how-to-add-a-dataset).
1. Fork the [repository](https://github.com/huggingface/datasets) by clicking on the 'Fork' button on the repository's page. This creates a copy of the code under your GitHub user account.
2. Clone your fork to your local disk, and add the base repository as a remote:
```bash
git clone git@github.com:<your Github handle>/datasets.git
cd datasets
git remote add upstream https://github.com/huggingface/datasets.git
```
3. Create a new branch to hold your development changes:
```bash
git checkout -b a-descriptive-name-for-my-changes
```
**do not** work on the `main` branch.
4. Set up a development environment by running the following command in a virtual environment:
```bash
pip install -e ".[dev]"
```
(If datasets was already installed in the virtual environment, remove
it with `pip uninstall datasets` before reinstalling it in editable
mode with the `-e` flag.)
5. Develop the features on your branch.
6. Format your code. Run `black` and `ruff` so that your newly added files look nice with the following command:
```bash
make style
```
7. _(Optional)_ You can also use [`pre-commit`](https://pre-commit.com/) to format your code automatically each time run `git commit`, instead of running `make style` manually.
To do this, install `pre-commit` via `pip install pre-commit` and then run `pre-commit install` in the project's root directory to set up the hooks.
Note that if any files were formatted by `pre-commit` hooks during committing, you have to run `git commit` again .
8. Once you're happy with your contribution, add your changed files and make a commit to record your changes locally:
```bash
git add -u
git commit
```
It is a good idea to sync your copy of the code with the original
repository regularly. This way you can quickly account for changes:
```bash
git fetch upstream
git rebase upstream/main
```
9. Once you are satisfied, push the changes to your fork repo using:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
Go the webpage of your fork on GitHub. Click on "Pull request" to send your to the project maintainers for review.
## How to add a dataset
You can share your dataset on https://huggingface.co/datasets directly using your account, see the documentation:
* [Create a dataset and upload files on the website](https://huggingface.co/docs/datasets/upload_dataset)
* [Advanced guide using the CLI](https://huggingface.co/docs/datasets/share)
## How to contribute to the dataset cards
Improving the documentation of datasets is an ever-increasing effort, and we invite users to contribute by sharing their insights with the community in the `README.md` dataset cards provided for each dataset.
If you see that a dataset card is missing information that you are in a position to provide (as an author of the dataset or as an experienced user), the best thing you can do is to open a Pull Request on the Hugging Face Hub. To do, go to the "Files and versions" tab of the dataset page and edit the `README.md` file. We provide:
* a [template](https://github.com/huggingface/datasets/blob/main/templates/README.md)
* a [guide](https://github.com/huggingface/datasets/blob/main/templates/README_guide.md) describing what information should go into each of the paragraphs
* and if you need inspiration, we recommend looking through a [completed example](https://huggingface.co/datasets/eli5/blob/main/README.md)
If you are a **dataset author**... you know what to do, it is your dataset after all ;) ! We would especially appreciate if you could help us fill in information about the process of creating the dataset, and take a moment to reflect on its social impact and possible limitations if you haven't already done so in the dataset paper or in another data statement.
If you are a **user of a dataset**, the main source of information should be the dataset paper if it is available: we recommend pulling information from there into the relevant paragraphs of the template. We also eagerly welcome discussions on the [Considerations for Using the Data](https://github.com/huggingface/datasets/blob/main/templates/README_guide.md#considerations-for-using-the-data) based on existing scholarship or personal experience that would benefit the whole community.
Finally, if you want more information on the how and why of dataset cards, we strongly recommend reading the foundational works [Datasheets for Datasets](https://arxiv.org/abs/1803.09010) and [Data Statements for NLP](https://www.aclweb.org/anthology/Q18-1041/).
Thank you for your contribution!
## Code of conduct
This project adheres to the HuggingFace [code of conduct](CODE_OF_CONDUCT.md).
By participating, you are expected to abide by this code.
| huggingface/datasets/blob/main/CONTRIBUTING.md |
--
title: McNemar
emoji: 🤗
colorFrom: blue
colorTo: green
sdk: gradio
sdk_version: 3.0.2
app_file: app.py
pinned: false
tags:
- evaluate
- comparison
description: >-
McNemar's test is a diagnostic test over a contingency table resulting from the predictions of two classifiers. The test compares the sensitivity and specificity of the diagnostic tests on the same group reference labels. It can be computed with:
McNemar = (SE - SP)**2 / SE + SP
Where:
SE: Sensitivity (Test 1 positive; Test 2 negative)
SP: Specificity (Test 1 negative; Test 2 positive)
---
# Comparison Card for McNemar
## Comparison description
McNemar's test is a non-parametric diagnostic test over a contingency table resulting from the predictions of two classifiers. The test compares the sensitivity and specificity of the diagnostic tests on the same group reference labels. It can be computed with:
McNemar = (SE - SP)**2 / SE + SP
Where:
* SE: Sensitivity (Test 1 positive; Test 2 negative)
* SP: Specificity (Test 1 negative; Test 2 positive)
In other words, SE and SP are the diagonal elements of the contingency table for the classifier predictions (`predictions1` and `predictions2`) with respect to the ground truth `references`.
## How to use
The McNemar comparison calculates the proportions of responses that exhibit disagreement between two classifiers. It is used to analyze paired nominal data.
## Inputs
Its arguments are:
`predictions1`: a list of predictions from the first model.
`predictions2`: a list of predictions from the second model.
`references`: a list of the ground truth reference labels.
## Output values
The McNemar comparison outputs two things:
`stat`: The McNemar statistic.
`p`: The p value.
## Examples
Example comparison:
```python
mcnemar = evaluate.load("mcnemar")
results = mcnemar.compute(references=[1, 0, 1], predictions1=[1, 1, 1], predictions2=[1, 0, 1])
print(results)
{'stat': 1.0, 'p': 0.31731050786291115}
```
## Limitations and bias
The McNemar test is a non-parametric test, so it has relatively few assumptions (basically only that the observations are independent). It should be used to analyze paired nominal data only.
## Citations
```bibtex
@article{mcnemar1947note,
title={Note on the sampling error of the difference between correlated proportions or percentages},
author={McNemar, Quinn},
journal={Psychometrika},
volume={12},
number={2},
pages={153--157},
year={1947},
publisher={Springer-Verlag}
}
```
| huggingface/evaluate/blob/main/comparisons/mcnemar/README.md |
## Translating the Transformers documentation into your language
As part of our mission to democratize machine learning, we'd love to make the Transformers library available in many more languages! Follow the steps below if you want to help translate the documentation into your language 🙏.
**🗞️ Open an issue**
To get started, navigate to the [Issues](https://github.com/huggingface/transformers/issues) page of this repo and check if anyone else has opened an issue for your language. If not, open a new issue by selecting the "Translation template" from the "New issue" button.
Once an issue exists, post a comment to indicate which chapters you'd like to work on, and we'll add your name to the list.
**🍴 Fork the repository**
First, you'll need to [fork the Transformers repo](https://docs.github.com/en/get-started/quickstart/fork-a-repo). You can do this by clicking on the **Fork** button on the top-right corner of this repo's page.
Once you've forked the repo, you'll want to get the files on your local machine for editing. You can do that by cloning the fork with Git as follows:
```bash
git clone https://github.com/YOUR-USERNAME/transformers.git
```
**📋 Copy-paste the English version with a new language code**
The documentation files are in one leading directory:
- [`docs/source`](https://github.com/huggingface/transformers/tree/main/docs/source): All the documentation materials are organized here by language.
You'll only need to copy the files in the [`docs/source/en`](https://github.com/huggingface/transformers/tree/main/docs/source/en) directory, so first navigate to your fork of the repo and run the following:
```bash
cd ~/path/to/transformers/docs
cp -r source/en source/LANG-ID
```
Here, `LANG-ID` should be one of the ISO 639-1 or ISO 639-2 language codes -- see [here](https://www.loc.gov/standards/iso639-2/php/code_list.php) for a handy table.
**✍️ Start translating**
The fun part comes - translating the text!
The first thing we recommend is translating the part of the `_toctree.yml` file that corresponds to your doc chapter. This file is used to render the table of contents on the website.
> 🙋 If the `_toctree.yml` file doesn't yet exist for your language, you can create one by copy-pasting from the English version and deleting the sections unrelated to your chapter. Just make sure it exists in the `docs/source/LANG-ID/` directory!
The fields you should add are `local` (with the name of the file containing the translation; e.g. `autoclass_tutorial`), and `title` (with the title of the doc in your language; e.g. `Load pretrained instances with an AutoClass`) -- as a reference, here is the `_toctree.yml` for [English](https://github.com/huggingface/transformers/blob/main/docs/source/en/_toctree.yml):
```yaml
- sections:
- local: pipeline_tutorial # Do not change this! Use the same name for your .md file
title: Pipelines for inference # Translate this!
...
title: Tutorials # Translate this!
```
Once you have translated the `_toctree.yml` file, you can start translating the [MDX](https://mdxjs.com/) files associated with your docs chapter.
> 🙋 If you'd like others to help you with the translation, you should [open an issue](https://github.com/huggingface/transformers/issues) and tag @stevhliu and @MKhalusova.
| huggingface/transformers/blob/main/docs/TRANSLATING.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Multiple choice
[[open-in-colab]]
A multiple choice task is similar to question answering, except several candidate answers are provided along with a context and the model is trained to select the correct answer.
This guide will show you how to:
1. Finetune [BERT](https://huggingface.co/bert-base-uncased) on the `regular` configuration of the [SWAG](https://huggingface.co/datasets/swag) dataset to select the best answer given multiple options and some context.
2. Use your finetuned model for inference.
<Tip>
The task illustrated in this tutorial is supported by the following model architectures:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[ALBERT](../model_doc/albert), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [I-BERT](../model_doc/ibert), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MRA](../model_doc/mra), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [QDQBert](../model_doc/qdqbert), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
<!--End of the generated tip-->
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate
```
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load SWAG dataset
Start by loading the `regular` configuration of the SWAG dataset from the 🤗 Datasets library:
```py
>>> from datasets import load_dataset
>>> swag = load_dataset("swag", "regular")
```
Then take a look at an example:
```py
>>> swag["train"][0]
{'ending0': 'passes by walking down the street playing their instruments.',
'ending1': 'has heard approaching them.',
'ending2': "arrives and they're outside dancing and asleep.",
'ending3': 'turns the lead singer watches the performance.',
'fold-ind': '3416',
'gold-source': 'gold',
'label': 0,
'sent1': 'Members of the procession walk down the street holding small horn brass instruments.',
'sent2': 'A drum line',
'startphrase': 'Members of the procession walk down the street holding small horn brass instruments. A drum line',
'video-id': 'anetv_jkn6uvmqwh4'}
```
While it looks like there are a lot of fields here, it is actually pretty straightforward:
- `sent1` and `sent2`: these fields show how a sentence starts, and if you put the two together, you get the `startphrase` field.
- `ending`: suggests a possible ending for how a sentence can end, but only one of them is correct.
- `label`: identifies the correct sentence ending.
## Preprocess
The next step is to load a BERT tokenizer to process the sentence starts and the four possible endings:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
```
The preprocessing function you want to create needs to:
1. Make four copies of the `sent1` field and combine each of them with `sent2` to recreate how a sentence starts.
2. Combine `sent2` with each of the four possible sentence endings.
3. Flatten these two lists so you can tokenize them, and then unflatten them afterward so each example has a corresponding `input_ids`, `attention_mask`, and `labels` field.
```py
>>> ending_names = ["ending0", "ending1", "ending2", "ending3"]
>>> def preprocess_function(examples):
... first_sentences = [[context] * 4 for context in examples["sent1"]]
... question_headers = examples["sent2"]
... second_sentences = [
... [f"{header} {examples[end][i]}" for end in ending_names] for i, header in enumerate(question_headers)
... ]
... first_sentences = sum(first_sentences, [])
... second_sentences = sum(second_sentences, [])
... tokenized_examples = tokenizer(first_sentences, second_sentences, truncation=True)
... return {k: [v[i : i + 4] for i in range(0, len(v), 4)] for k, v in tokenized_examples.items()}
```
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] method. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once:
```py
tokenized_swag = swag.map(preprocess_function, batched=True)
```
🤗 Transformers doesn't have a data collator for multiple choice, so you'll need to adapt the [`DataCollatorWithPadding`] to create a batch of examples. It's more efficient to *dynamically pad* the sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
`DataCollatorForMultipleChoice` flattens all the model inputs, applies padding, and then unflattens the results:
<frameworkcontent>
<pt>
```py
>>> from dataclasses import dataclass
>>> from transformers.tokenization_utils_base import PreTrainedTokenizerBase, PaddingStrategy
>>> from typing import Optional, Union
>>> import torch
>>> @dataclass
... class DataCollatorForMultipleChoice:
... """
... Data collator that will dynamically pad the inputs for multiple choice received.
... """
... tokenizer: PreTrainedTokenizerBase
... padding: Union[bool, str, PaddingStrategy] = True
... max_length: Optional[int] = None
... pad_to_multiple_of: Optional[int] = None
... def __call__(self, features):
... label_name = "label" if "label" in features[0].keys() else "labels"
... labels = [feature.pop(label_name) for feature in features]
... batch_size = len(features)
... num_choices = len(features[0]["input_ids"])
... flattened_features = [
... [{k: v[i] for k, v in feature.items()} for i in range(num_choices)] for feature in features
... ]
... flattened_features = sum(flattened_features, [])
... batch = self.tokenizer.pad(
... flattened_features,
... padding=self.padding,
... max_length=self.max_length,
... pad_to_multiple_of=self.pad_to_multiple_of,
... return_tensors="pt",
... )
... batch = {k: v.view(batch_size, num_choices, -1) for k, v in batch.items()}
... batch["labels"] = torch.tensor(labels, dtype=torch.int64)
... return batch
```
</pt>
<tf>
```py
>>> from dataclasses import dataclass
>>> from transformers.tokenization_utils_base import PreTrainedTokenizerBase, PaddingStrategy
>>> from typing import Optional, Union
>>> import tensorflow as tf
>>> @dataclass
... class DataCollatorForMultipleChoice:
... """
... Data collator that will dynamically pad the inputs for multiple choice received.
... """
... tokenizer: PreTrainedTokenizerBase
... padding: Union[bool, str, PaddingStrategy] = True
... max_length: Optional[int] = None
... pad_to_multiple_of: Optional[int] = None
... def __call__(self, features):
... label_name = "label" if "label" in features[0].keys() else "labels"
... labels = [feature.pop(label_name) for feature in features]
... batch_size = len(features)
... num_choices = len(features[0]["input_ids"])
... flattened_features = [
... [{k: v[i] for k, v in feature.items()} for i in range(num_choices)] for feature in features
... ]
... flattened_features = sum(flattened_features, [])
... batch = self.tokenizer.pad(
... flattened_features,
... padding=self.padding,
... max_length=self.max_length,
... pad_to_multiple_of=self.pad_to_multiple_of,
... return_tensors="tf",
... )
... batch = {k: tf.reshape(v, (batch_size, num_choices, -1)) for k, v in batch.items()}
... batch["labels"] = tf.convert_to_tensor(labels, dtype=tf.int64)
... return batch
```
</tf>
</frameworkcontent>
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load a evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
```py
>>> import evaluate
>>> accuracy = evaluate.load("accuracy")
```
Then create a function that passes your predictions and labels to [`~evaluate.EvaluationModule.compute`] to calculate the accuracy:
```py
>>> import numpy as np
>>> def compute_metrics(eval_pred):
... predictions, labels = eval_pred
... predictions = np.argmax(predictions, axis=1)
... return accuracy.compute(predictions=predictions, references=labels)
```
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
## Train
<frameworkcontent>
<pt>
<Tip>
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
</Tip>
You're ready to start training your model now! Load BERT with [`AutoModelForMultipleChoice`]:
```py
>>> from transformers import AutoModelForMultipleChoice, TrainingArguments, Trainer
>>> model = AutoModelForMultipleChoice.from_pretrained("bert-base-uncased")
```
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the accuracy and save the training checkpoint.
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_swag_model",
... evaluation_strategy="epoch",
... save_strategy="epoch",
... load_best_model_at_end=True,
... learning_rate=5e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... num_train_epochs=3,
... weight_decay=0.01,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_swag["train"],
... eval_dataset=tokenized_swag["validation"],
... tokenizer=tokenizer,
... data_collator=DataCollatorForMultipleChoice(tokenizer=tokenizer),
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
<Tip>
If you aren't familiar with finetuning a model with Keras, take a look at the basic tutorial [here](../training#train-a-tensorflow-model-with-keras)!
</Tip>
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
```py
>>> from transformers import create_optimizer
>>> batch_size = 16
>>> num_train_epochs = 2
>>> total_train_steps = (len(tokenized_swag["train"]) // batch_size) * num_train_epochs
>>> optimizer, schedule = create_optimizer(init_lr=5e-5, num_warmup_steps=0, num_train_steps=total_train_steps)
```
Then you can load BERT with [`TFAutoModelForMultipleChoice`]:
```py
>>> from transformers import TFAutoModelForMultipleChoice
>>> model = TFAutoModelForMultipleChoice.from_pretrained("bert-base-uncased")
```
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
```py
>>> data_collator = DataCollatorForMultipleChoice(tokenizer=tokenizer)
>>> tf_train_set = model.prepare_tf_dataset(
... tokenized_swag["train"],
... shuffle=True,
... batch_size=batch_size,
... collate_fn=data_collator,
... )
>>> tf_validation_set = model.prepare_tf_dataset(
... tokenized_swag["validation"],
... shuffle=False,
... batch_size=batch_size,
... collate_fn=data_collator,
... )
```
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method). Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
```py
>>> model.compile(optimizer=optimizer) # No loss argument!
```
The last two things to setup before you start training is to compute the accuracy from the predictions, and provide a way to push your model to the Hub. Both are done by using [Keras callbacks](../main_classes/keras_callbacks).
Pass your `compute_metrics` function to [`~transformers.KerasMetricCallback`]:
```py
>>> from transformers.keras_callbacks import KerasMetricCallback
>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
```
Specify where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
```py
>>> from transformers.keras_callbacks import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="my_awesome_model",
... tokenizer=tokenizer,
... )
```
Then bundle your callbacks together:
```py
>>> callbacks = [metric_callback, push_to_hub_callback]
```
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callbacks to finetune the model:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=2, callbacks=callbacks)
```
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
</tf>
</frameworkcontent>
<Tip>
For a more in-depth example of how to finetune a model for multiple choice, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb).
</Tip>
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Come up with some text and two candidate answers:
```py
>>> prompt = "France has a bread law, Le Décret Pain, with strict rules on what is allowed in a traditional baguette."
>>> candidate1 = "The law does not apply to croissants and brioche."
>>> candidate2 = "The law applies to baguettes."
```
<frameworkcontent>
<pt>
Tokenize each prompt and candidate answer pair and return PyTorch tensors. You should also create some `labels`:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_swag_model")
>>> inputs = tokenizer([[prompt, candidate1], [prompt, candidate2]], return_tensors="pt", padding=True)
>>> labels = torch.tensor(0).unsqueeze(0)
```
Pass your inputs and labels to the model and return the `logits`:
```py
>>> from transformers import AutoModelForMultipleChoice
>>> model = AutoModelForMultipleChoice.from_pretrained("my_awesome_swag_model")
>>> outputs = model(**{k: v.unsqueeze(0) for k, v in inputs.items()}, labels=labels)
>>> logits = outputs.logits
```
Get the class with the highest probability:
```py
>>> predicted_class = logits.argmax().item()
>>> predicted_class
'0'
```
</pt>
<tf>
Tokenize each prompt and candidate answer pair and return TensorFlow tensors:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_swag_model")
>>> inputs = tokenizer([[prompt, candidate1], [prompt, candidate2]], return_tensors="tf", padding=True)
```
Pass your inputs to the model and return the `logits`:
```py
>>> from transformers import TFAutoModelForMultipleChoice
>>> model = TFAutoModelForMultipleChoice.from_pretrained("my_awesome_swag_model")
>>> inputs = {k: tf.expand_dims(v, 0) for k, v in inputs.items()}
>>> outputs = model(inputs)
>>> logits = outputs.logits
```
Get the class with the highest probability:
```py
>>> predicted_class = int(tf.math.argmax(logits, axis=-1)[0])
>>> predicted_class
'0'
```
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/tasks/multiple_choice.md |
!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Question answering
This folder contains several scripts that showcase how to fine-tune a 🤗 Transformers model on a question answering dataset,
like SQuAD.
## Trainer-based scripts
The [`run_qa.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_qa.py),
[`run_qa_beam_search.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_qa_beam_search.py) and [`run_seq2seq_qa.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_seq2seq_qa.py) leverage the 🤗 [Trainer](https://huggingface.co/transformers/main_classes/trainer.html) for fine-tuning.
### Fine-tuning BERT on SQuAD1.0
The [`run_qa.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_qa.py) script
allows to fine-tune any model from our [hub](https://huggingface.co/models) (as long as its architecture has a `ForQuestionAnswering` version in the library) on a question-answering dataset (such as SQuAD, or any other QA dataset available in the `datasets` library, or your own csv/jsonlines files) as long as they are structured the same way as SQuAD. You might need to tweak the data processing inside the script if your data is structured differently.
**Note:** This script only works with models that have a fast tokenizer (backed by the 🤗 Tokenizers library) as it
uses special features of those tokenizers. You can check if your favorite model has a fast tokenizer in
[this table](https://huggingface.co/transformers/index.html#supported-frameworks), if it doesn't you can still use the old version of the script which can be found [here](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering).
Note that if your dataset contains samples with no possible answers (like SQuAD version 2), you need to pass along the flag `--version_2_with_negative`.
This example code fine-tunes BERT on the SQuAD1.0 dataset. It runs in 24 min (with BERT-base) or 68 min (with BERT-large)
on a single tesla V100 16GB.
```bash
python run_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/
```
Training with the previously defined hyper-parameters yields the following results:
```bash
f1 = 88.52
exact_match = 81.22
```
### Fine-tuning XLNet with beam search on SQuAD
The [`run_qa_beam_search.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_qa_beam_search.py) script is only meant to fine-tune XLNet, which is a special encoder-only Transformer model. The example code below fine-tunes XLNet on the SQuAD1.0 and SQuAD2.0 datasets.
#### Command for SQuAD1.0:
```bash
python run_qa_beam_search.py \
--model_name_or_path xlnet-large-cased \
--dataset_name squad \
--do_train \
--do_eval \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ./wwm_cased_finetuned_squad/ \
--per_device_eval_batch_size=4 \
--per_device_train_batch_size=4 \
--save_steps 5000
```
#### Command for SQuAD2.0:
```bash
export SQUAD_DIR=/path/to/SQUAD
python run_qa_beam_search.py \
--model_name_or_path xlnet-large-cased \
--dataset_name squad_v2 \
--do_train \
--do_eval \
--version_2_with_negative \
--learning_rate 3e-5 \
--num_train_epochs 4 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ./wwm_cased_finetuned_squad/ \
--per_device_eval_batch_size=2 \
--per_device_train_batch_size=2 \
--save_steps 5000
```
### Fine-tuning T5 on SQuAD2.0
The [`run_seq2seq_qa.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_seq2seq_qa.py) script is meant for encoder-decoder (also called seq2seq) Transformer models, such as T5 or BART. These
models are generative, rather than discriminative. This means that they learn to generate the correct answer, rather than predicting the start and end position of the tokens of the answer.
This example code fine-tunes T5 on the SQuAD2.0 dataset.
```bash
python run_seq2seq_qa.py \
--model_name_or_path t5-small \
--dataset_name squad_v2 \
--context_column context \
--question_column question \
--answer_column answers \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_seq2seq_squad/
```
## Accelerate-based scripts
Based on the scripts `run_qa_no_trainer.py` and `run_qa_beam_search_no_trainer.py`.
Like `run_qa.py` and `run_qa_beam_search.py`, these scripts allow you to fine-tune any of the models supported on a
SQuAD or a similar dataset, the main difference is that this script exposes the bare training loop, to allow you to quickly experiment and add any customization you would like. It offers less options than the script with `Trainer` (for instance you can easily change the options for the optimizer or the dataloaders directly in the script), but still run in a distributed setup, on TPU and supports mixed precision by leveraging the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library.
You can use the script normally after installing it:
```bash
pip install git+https://github.com/huggingface/accelerate
```
then
```bash
python run_qa_no_trainer.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ~/tmp/debug_squad
```
You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
```bash
accelerate config
```
and reply to the questions asked. Then
```bash
accelerate test
```
that will check everything is ready for training. Finally, you can launch training with
```bash
accelerate launch run_qa_no_trainer.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ~/tmp/debug_squad
```
This command is the same and will work for:
- a CPU-only setup
- a setup with one GPU
- a distributed training with several GPUs (single or multi node)
- a training on TPUs
Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
| huggingface/transformers/blob/main/examples/pytorch/question-answering/README.md |
Decoders
<tokenizerslangcontent>
<python>
## BPEDecoder
[[autodoc]] tokenizers.decoders.BPEDecoder
## ByteLevel
[[autodoc]] tokenizers.decoders.ByteLevel
## CTC
[[autodoc]] tokenizers.decoders.CTC
## Metaspace
[[autodoc]] tokenizers.decoders.Metaspace
## WordPiece
[[autodoc]] tokenizers.decoders.WordPiece
</python>
<rust>
The Rust API Reference is available directly on the [Docs.rs](https://docs.rs/tokenizers/latest/tokenizers/) website.
</rust>
<node>
The node API has not been documented yet.
</node>
</tokenizerslangcontent> | huggingface/tokenizers/blob/main/docs/source-doc-builder/api/decoders.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Quickstart
[[open-in-colab]]
This quickstart is intended for developers who are ready to dive into the code and see an example of how to integrate 🤗 Datasets into their model training workflow. If you're a beginner, we recommend starting with our [tutorials](./tutorial), where you'll get a more thorough introduction.
Each dataset is unique, and depending on the task, some datasets may require additional steps to prepare it for training. But you can always use 🤗 Datasets tools to load and process a dataset. The fastest and easiest way to get started is by loading an existing dataset from the [Hugging Face Hub](https://huggingface.co/datasets). There are thousands of datasets to choose from, spanning many tasks. Choose the type of dataset you want to work with, and let's get started!
<div class="mt-4">
<div class="w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-3 md:gap-y-4 md:gap-x-5">
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="#audio"
><div class="w-full text-center bg-gradient-to-r from-violet-300 via-sky-400 to-green-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Audio</div>
<p class="text-gray-700">Resample an audio dataset and get it ready for a model to classify what type of banking issue a speaker is calling about.</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="#vision"
><div class="w-full text-center bg-gradient-to-r from-pink-400 via-purple-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Vision</div>
<p class="text-gray-700">Apply data augmentation to an image dataset and get it ready for a model to diagnose disease in bean plants.</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="#nlp"
><div class="w-full text-center bg-gradient-to-r from-orange-300 via-red-400 to-violet-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">NLP</div>
<p class="text-gray-700">Tokenize a dataset and get it ready for a model to determine whether a pair of sentences have the same meaning.</p>
</a>
</div>
</div>
<Tip>
Check out [Chapter 5](https://huggingface.co/course/chapter5/1?fw=pt) of the Hugging Face course to learn more about other important topics such as loading remote or local datasets, tools for cleaning up a dataset, and creating your own dataset.
</Tip>
Start by installing 🤗 Datasets:
```bash
pip install datasets
```
🤗 Datasets also support audio and image data formats:
* To work with audio datasets, install the [`Audio`] feature:
```bash
pip install datasets[audio]
```
* To work with image datasets, install the [`Image`] feature:
```bash
pip install datasets[vision]
```
Besides 🤗 Datasets, make sure your preferred machine learning framework is installed:
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
## Audio
Audio datasets are loaded just like text datasets. However, an audio dataset is preprocessed a bit differently. Instead of a tokenizer, you'll need a [feature extractor](https://huggingface.co/docs/transformers/main_classes/feature_extractor#feature-extractor). An audio input may also require resampling its sampling rate to match the sampling rate of the pretrained model you're using. In this quickstart, you'll prepare the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset for a model train on and classify the banking issue a customer is having.
**1**. Load the MInDS-14 dataset by providing the [`load_dataset`] function with the dataset name, dataset configuration (not all datasets will have a configuration), and a dataset split:
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", "en-US", split="train")
```
**2**. Next, load a pretrained [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) model and its corresponding feature extractor from the [🤗 Transformers](https://huggingface.co/transformers/) library. It is totally normal to see a warning after you load the model about some weights not being initialized. This is expected because you are loading this model checkpoint for training with another task.
```py
>>> from transformers import AutoModelForAudioClassification, AutoFeatureExtractor
>>> model = AutoModelForAudioClassification.from_pretrained("facebook/wav2vec2-base")
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
```
**3**. The [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset card indicates the sampling rate is 8kHz, but the Wav2Vec2 model was pretrained on a sampling rate of 16kHZ. You'll need to upsample the `audio` column with the [`~Dataset.cast_column`] function and [`Audio`] feature to match the model's sampling rate.
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> dataset[0]["audio"]
{'array': array([ 2.3443763e-05, 2.1729663e-04, 2.2145823e-04, ...,
3.8356509e-05, -7.3497440e-06, -2.1754686e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 16000}
```
**4**. Create a function to preprocess the audio `array` with the feature extractor, and truncate and pad the sequences into tidy rectangular tensors. The most important thing to remember is to call the audio `array` in the feature extractor since the `array` - the actual speech signal - is the model input.
Once you have a preprocessing function, use the [`~Dataset.map`] function to speed up processing by applying the function to batches of examples in the dataset.
```py
>>> def preprocess_function(examples):
... audio_arrays = [x["array"] for x in examples["audio"]]
... inputs = feature_extractor(
... audio_arrays,
... sampling_rate=16000,
... padding=True,
... max_length=100000,
... truncation=True,
... )
... return inputs
>>> dataset = dataset.map(preprocess_function, batched=True)
```
**5**. Use the [`~Dataset.rename_column`] function to rename the `intent_class` column to `labels`, which is the expected input name in [Wav2Vec2ForSequenceClassification](https://huggingface.co/docs/transformers/main/en/model_doc/wav2vec2#transformers.Wav2Vec2ForSequenceClassification):
```py
>>> dataset = dataset.rename_column("intent_class", "labels")
```
**6**. Set the dataset format according to the machine learning framework you're using.
<frameworkcontent>
<pt>
Use the [`~Dataset.set_format`] function to set the dataset format to `torch` and specify the columns you want to format. This function applies formatting on-the-fly. After converting to PyTorch tensors, wrap the dataset in [`torch.utils.data.DataLoader`](https://alband.github.io/doc_view/data.html?highlight=torch%20utils%20data%20dataloader#torch.utils.data.DataLoader):
```py
>>> from torch.utils.data import DataLoader
>>> dataset.set_format(type="torch", columns=["input_values", "labels"])
>>> dataloader = DataLoader(dataset, batch_size=4)
```
</pt>
<tf>
Use the [`~transformers.TFPreTrainedModel.prepare_tf_dataset`] method from 🤗 Transformers to prepare the dataset to be compatible with
TensorFlow, and ready to train/fine-tune a model, as it wraps a HuggingFace [`~datasets.Dataset`] as a `tf.data.Dataset`
with collation and batching, so one can pass it directly to Keras methods like `fit()` without further modification.
```py
>>> import tensorflow as tf
>>> tf_dataset = model.prepare_tf_dataset(
... dataset,
... batch_size=4,
... shuffle=True,
... )
```
</tf>
</frameworkcontent>
**7**. Start training with your machine learning framework! Check out the 🤗 Transformers [audio classification guide](https://huggingface.co/docs/transformers/tasks/audio_classification) for an end-to-end example of how to train a model on an audio dataset.
## Vision
Image datasets are loaded just like text datasets. However, instead of a tokenizer, you'll need a [feature extractor](https://huggingface.co/docs/transformers/main_classes/feature_extractor#feature-extractor) to preprocess the dataset. Applying data augmentation to an image is common in computer vision to make the model more robust against overfitting. You're free to use any data augmentation library you want, and then you can apply the augmentations with 🤗 Datasets. In this quickstart, you'll load the [Beans](https://huggingface.co/datasets/beans) dataset and get it ready for the model to train on and identify disease from the leaf images.
**1**. Load the Beans dataset by providing the [`load_dataset`] function with the dataset name and a dataset split:
```py
>>> from datasets import load_dataset, Image
>>> dataset = load_dataset("beans", split="train")
```
**2**. Now you can add some data augmentations with any library ([Albumentations](https://albumentations.ai/), [imgaug](https://imgaug.readthedocs.io/en/latest/), [Kornia](https://kornia.readthedocs.io/en/latest/)) you like. Here, you'll use [torchvision](https://pytorch.org/vision/stable/transforms.html) to randomly change the color properties of an image:
```py
>>> from torchvision.transforms import Compose, ColorJitter, ToTensor
>>> jitter = Compose(
... [ColorJitter(brightness=0.5, hue=0.5), ToTensor()]
... )
```
**3**. Create a function to apply your transform to the dataset and generate the model input: `pixel_values`.
```python
>>> def transforms(examples):
... examples["pixel_values"] = [jitter(image.convert("RGB")) for image in examples["image"]]
... return examples
```
**4**. Use the [`~Dataset.with_transform`] function to apply the data augmentations on-the-fly:
```py
>>> dataset = dataset.with_transform(transforms)
```
**5**. Set the dataset format according to the machine learning framework you're using.
<frameworkcontent>
<pt>
Wrap the dataset in [`torch.utils.data.DataLoader`](https://alband.github.io/doc_view/data.html?highlight=torch%20utils%20data%20dataloader#torch.utils.data.DataLoader). You'll also need to create a collate function to collate the samples into batches:
```py
>>> from torch.utils.data import DataLoader
>>> def collate_fn(examples):
... images = []
... labels = []
... for example in examples:
... images.append((example["pixel_values"]))
... labels.append(example["labels"])
...
... pixel_values = torch.stack(images)
... labels = torch.tensor(labels)
... return {"pixel_values": pixel_values, "labels": labels}
>>> dataloader = DataLoader(dataset, collate_fn=collate_fn, batch_size=4)
```
</pt>
<tf>
Use the [`~transformers.TFPreTrainedModel.prepare_tf_dataset`] method from 🤗 Transformers to prepare the dataset to be compatible with
TensorFlow, and ready to train/fine-tune a model, as it wraps a HuggingFace [`~datasets.Dataset`] as a `tf.data.Dataset`
with collation and batching, so one can pass it directly to Keras methods like `fit()` without further modification.
Before you start, make sure you have up-to-date versions of `albumentations` and `cv2` installed:
```bash
pip install -U albumentations opencv-python
```
```py
>>> import albumentations
>>> import numpy as np
>>> transform = albumentations.Compose([
... albumentations.RandomCrop(width=256, height=256),
... albumentations.HorizontalFlip(p=0.5),
... albumentations.RandomBrightnessContrast(p=0.2),
... ])
>>> def transforms(examples):
... examples["pixel_values"] = [
... transform(image=np.array(image))["image"] for image in examples["image"]
... ]
... return examples
>>> dataset.set_transform(transforms)
>>> tf_dataset = model.prepare_tf_dataset(
... dataset,
... batch_size=4,
... shuffle=True,
... )
```
</tf>
</frameworkcontent>
**6**. Start training with your machine learning framework! Check out the 🤗 Transformers [image classification guide](https://huggingface.co/docs/transformers/tasks/image_classification) for an end-to-end example of how to train a model on an image dataset.
## NLP
Text needs to be tokenized into individual tokens by a [tokenizer](https://huggingface.co/docs/transformers/main_classes/tokenizer). For the quickstart, you'll load the [Microsoft Research Paraphrase Corpus (MRPC)](https://huggingface.co/datasets/glue/viewer/mrpc) training dataset to train a model to determine whether a pair of sentences mean the same thing.
**1**. Load the MRPC dataset by providing the [`load_dataset`] function with the dataset name, dataset configuration (not all datasets will have a configuration), and dataset split:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("glue", "mrpc", split="train")
```
**2**. Next, load a pretrained [BERT](https://huggingface.co/bert-base-uncased) model and its corresponding tokenizer from the [🤗 Transformers](https://huggingface.co/transformers/) library. It is totally normal to see a warning after you load the model about some weights not being initialized. This is expected because you are loading this model checkpoint for training with another task.
```py
>>> from transformers import AutoModelForSequenceClassification, AutoTokenizer
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
===PT-TF-SPLIT===
>>> from transformers import TFAutoModelForSequenceClassification, AutoTokenizer
>>> model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
```
**3**. Create a function to tokenize the dataset, and you should also truncate and pad the text into tidy rectangular tensors. The tokenizer generates three new columns in the dataset: `input_ids`, `token_type_ids`, and an `attention_mask`. These are the model inputs.
Use the [`~Dataset.map`] function to speed up processing by applying your tokenization function to batches of examples in the dataset:
```py
>>> def encode(examples):
... return tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, padding="max_length")
>>> dataset = dataset.map(encode, batched=True)
>>> dataset[0]
{'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
'label': 1,
'idx': 0,
'input_ids': array([ 101, 7277, 2180, 5303, 4806, 1117, 1711, 117, 2292, 1119, 1270, 107, 1103, 7737, 107, 117, 1104, 9938, 4267, 12223, 21811, 1117, 2554, 119, 102, 11336, 6732, 3384, 1106, 1140, 1112, 1178, 107, 1103, 7737, 107, 117, 7277, 2180, 5303, 4806, 1117, 1711, 1104, 9938, 4267, 12223, 21811, 1117, 2554, 119, 102]),
'token_type_ids': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]),
'attention_mask': array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])}
```
**4**. Rename the `label` column to `labels`, which is the expected input name in [BertForSequenceClassification](https://huggingface.co/docs/transformers/main/en/model_doc/bert#transformers.BertForSequenceClassification):
```py
>>> dataset = dataset.map(lambda examples: {"labels": examples["label"]}, batched=True)
```
**5**. Set the dataset format according to the machine learning framework you're using.
<frameworkcontent>
<pt>
Use the [`~Dataset.set_format`] function to set the dataset format to `torch` and specify the columns you want to format. This function applies formatting on-the-fly. After converting to PyTorch tensors, wrap the dataset in [`torch.utils.data.DataLoader`](https://alband.github.io/doc_view/data.html?highlight=torch%20utils%20data%20dataloader#torch.utils.data.DataLoader):
```py
>>> import torch
>>> dataset.set_format(type="torch", columns=["input_ids", "token_type_ids", "attention_mask", "labels"])
>>> dataloader = torch.utils.data.DataLoader(dataset, batch_size=32)
```
</pt>
<tf>
Use the [`~transformers.TFPreTrainedModel.prepare_tf_dataset`] method from 🤗 Transformers to prepare the dataset to be compatible with
TensorFlow, and ready to train/fine-tune a model, as it wraps a HuggingFace [`~datasets.Dataset`] as a `tf.data.Dataset`
with collation and batching, so one can pass it directly to Keras methods like `fit()` without further modification.
```py
>>> import tensorflow as tf
>>> tf_dataset = model.prepare_tf_dataset(
... dataset,
... batch_size=4,
... shuffle=True,
... )
```
</tf>
</frameworkcontent>
**6**. Start training with your machine learning framework! Check out the 🤗 Transformers [text classification guide](https://huggingface.co/docs/transformers/tasks/sequence_classification) for an end-to-end example of how to train a model on a text dataset.
## What's next?
This completes the 🤗 Datasets quickstart! You can load any text, audio, or image dataset with a single function and get it ready for your model to train on.
For your next steps, take a look at our [How-to guides](./how_to) and learn how to do more specific things like loading different dataset formats, aligning labels, and streaming large datasets. If you're interested in learning more about 🤗 Datasets core concepts, grab a cup of coffee and read our [Conceptual Guides](./about_arrow)!
| huggingface/datasets/blob/main/docs/source/quickstart.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# RoCBert
## Overview
The RoCBert model was proposed in [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
It's a pretrained Chinese language model that is robust under various forms of adversarial attacks.
The abstract from the paper is the following:
*Large-scale pretrained language models have achieved SOTA results on NLP tasks. However, they have been shown
vulnerable to adversarial attacks especially for logographic languages like Chinese. In this work, we propose
ROCBERT: a pretrained Chinese Bert that is robust to various forms of adversarial attacks like word perturbation,
synonyms, typos, etc. It is pretrained with the contrastive learning objective which maximizes the label consistency
under different synthesized adversarial examples. The model takes as input multimodal information including the
semantic, phonetic and visual features. We show all these features are important to the model robustness since the
attack can be performed in all the three forms. Across 5 Chinese NLU tasks, ROCBERT outperforms strong baselines under
three blackbox adversarial algorithms without sacrificing the performance on clean testset. It also performs the best
in the toxic content detection task under human-made attacks.*
This model was contributed by [weiweishi](https://huggingface.co/weiweishi).
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## RoCBertConfig
[[autodoc]] RoCBertConfig
- all
## RoCBertTokenizer
[[autodoc]] RoCBertTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## RoCBertModel
[[autodoc]] RoCBertModel
- forward
## RoCBertForPreTraining
[[autodoc]] RoCBertForPreTraining
- forward
## RoCBertForCausalLM
[[autodoc]] RoCBertForCausalLM
- forward
## RoCBertForMaskedLM
[[autodoc]] RoCBertForMaskedLM
- forward
## RoCBertForSequenceClassification
[[autodoc]] transformers.RoCBertForSequenceClassification
- forward
## RoCBertForMultipleChoice
[[autodoc]] transformers.RoCBertForMultipleChoice
- forward
## RoCBertForTokenClassification
[[autodoc]] transformers.RoCBertForTokenClassification
- forward
## RoCBertForQuestionAnswering
[[autodoc]] RoCBertForQuestionAnswering
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/roc_bert.md |
Additional Readings [[additional-readings]]
These are **optional readings** if you want to go deeper.
## Monte Carlo and TD Learning [[mc-td]]
To dive deeper into Monte Carlo and Temporal Difference Learning:
- <a href="https://stats.stackexchange.com/questions/355820/why-do-temporal-difference-td-methods-have-lower-variance-than-monte-carlo-met">Why do temporal difference (TD) methods have lower variance than Monte Carlo methods?</a>
- <a href="https://stats.stackexchange.com/questions/336974/when-are-monte-carlo-methods-preferred-over-temporal-difference-ones"> When are Monte Carlo methods preferred over temporal difference ones?</a>
## Q-Learning [[q-learning]]
- <a href="http://incompleteideas.net/book/RLbook2020.pdf">Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto Chapter 5, 6 and 7</a>
- <a href="https://youtu.be/Psrhxy88zww">Foundations of Deep RL Series, L2 Deep Q-Learning by Pieter Abbeel</a>
| huggingface/deep-rl-class/blob/main/units/en/unit2/additional-readings.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Big Transfer (BiT)
## Overview
The BiT model was proposed in [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
BiT is a simple recipe for scaling up pre-training of [ResNet](resnet)-like architectures (specifically, ResNetv2). The method results in significant improvements for transfer learning.
The abstract from the paper is the following:
*Transfer of pre-trained representations improves sample efficiency and simplifies hyperparameter tuning when training deep neural networks for vision. We revisit the paradigm of pre-training on large supervised datasets and fine-tuning the model on a target task. We scale up pre-training, and propose a simple recipe that we call Big Transfer (BiT). By combining a few carefully selected components, and transferring using a simple heuristic, we achieve strong performance on over 20 datasets. BiT performs well across a surprisingly wide range of data regimes -- from 1 example per class to 1M total examples. BiT achieves 87.5% top-1 accuracy on ILSVRC-2012, 99.4% on CIFAR-10, and 76.3% on the 19 task Visual Task Adaptation Benchmark (VTAB). On small datasets, BiT attains 76.8% on ILSVRC-2012 with 10 examples per class, and 97.0% on CIFAR-10 with 10 examples per class. We conduct detailed analysis of the main components that lead to high transfer performance.*
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/google-research/big_transfer).
## Usage tips
- BiT models are equivalent to ResNetv2 in terms of architecture, except that: 1) all batch normalization layers are replaced by [group normalization](https://arxiv.org/abs/1803.08494),
2) [weight standardization](https://arxiv.org/abs/1903.10520) is used for convolutional layers. The authors show that the combination of both is useful for training with large batch sizes, and has a significant
impact on transfer learning.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BiT.
<PipelineTag pipeline="image-classification"/>
- [`BitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## BitConfig
[[autodoc]] BitConfig
## BitImageProcessor
[[autodoc]] BitImageProcessor
- preprocess
## BitModel
[[autodoc]] BitModel
- forward
## BitForImageClassification
[[autodoc]] BitForImageClassification
- forward | huggingface/transformers/blob/main/docs/source/en/model_doc/bit.md |
🤗 Datasets, check![[datasets-check]]
<CourseFloatingBanner
chapter={5}
classNames="absolute z-10 right-0 top-0"
/>
Well, that was quite a tour through the 🤗 Datasets library -- congratulations on making it this far! With the knowledge that you've gained from this chapter, you should be able to:
- Load datasets from anywhere, be it the Hugging Face Hub, your laptop, or a remote server at your company.
- Wrangle your data using a mix of the `Dataset.map()` and `Dataset.filter()` functions.
- Quickly switch between data formats like Pandas and NumPy using `Dataset.set_format()`.
- Create your very own dataset and push it to the Hugging Face Hub.
- Embed your documents using a Transformer model and build a semantic search engine using FAISS.
In [Chapter 7](/course/chapter7), we'll put all of this to good use as we take a deep dive into the core NLP tasks that Transformer models are great for. Before jumping ahead, though, put your knowledge of 🤗 Datasets to the test with a quick quiz! | huggingface/course/blob/main/chapters/en/chapter5/7.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Kandinsky 2.2
<Tip warning={true}>
This script is experimental, and it's easy to overfit and run into issues like catastrophic forgetting. Try exploring different hyperparameters to get the best results on your dataset.
</Tip>
Kandinsky 2.2 is a multilingual text-to-image model capable of producing more photorealistic images. The model includes an image prior model for creating image embeddings from text prompts, and a decoder model that generates images based on the prior model's embeddings. That's why you'll find two separate scripts in Diffusers for Kandinsky 2.2, one for training the prior model and one for training the decoder model. You can train both models separately, but to get the best results, you should train both the prior and decoder models.
Depending on your GPU, you may need to enable `gradient_checkpointing` (⚠️ not supported for the prior model!), `mixed_precision`, and `gradient_accumulation_steps` to help fit the model into memory and to speedup training. You can reduce your memory-usage even more by enabling memory-efficient attention with [xFormers](../optimization/xformers) (version [v0.0.16](https://github.com/huggingface/diffusers/issues/2234#issuecomment-1416931212) fails for training on some GPUs so you may need to install a development version instead).
This guide explores the [train_text_to_image_prior.py](https://github.com/huggingface/diffusers/blob/main/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py) and the [train_text_to_image_decoder.py](https://github.com/huggingface/diffusers/blob/main/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py) scripts to help you become more familiar with it, and how you can adapt it for your own use-case.
Before running the scripts, make sure you install the library from source:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then navigate to the example folder containing the training script and install the required dependencies for the script you're using:
```bash
cd examples/kandinsky2_2/text_to_image
pip install -r requirements.txt
```
<Tip>
🤗 Accelerate is a library for helping you train on multiple GPUs/TPUs or with mixed-precision. It'll automatically configure your training setup based on your hardware and environment. Take a look at the 🤗 Accelerate [Quick tour](https://huggingface.co/docs/accelerate/quicktour) to learn more.
</Tip>
Initialize an 🤗 Accelerate environment:
```bash
accelerate config
```
To setup a default 🤗 Accelerate environment without choosing any configurations:
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell, like a notebook, you can use:
```bash
from accelerate.utils import write_basic_config
write_basic_config()
```
Lastly, if you want to train a model on your own dataset, take a look at the [Create a dataset for training](create_dataset) guide to learn how to create a dataset that works with the training script.
<Tip>
The following sections highlight parts of the training scripts that are important for understanding how to modify it, but it doesn't cover every aspect of the scripts in detail. If you're interested in learning more, feel free to read through the scripts and let us know if you have any questions or concerns.
</Tip>
## Script parameters
The training scripts provides many parameters to help you customize your training run. All of the parameters and their descriptions are found in the [`parse_args()`](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py#L190) function. The training scripts provides default values for each parameter, such as the training batch size and learning rate, but you can also set your own values in the training command if you'd like.
For example, to speedup training with mixed precision using the fp16 format, add the `--mixed_precision` parameter to the training command:
```bash
accelerate launch train_text_to_image_prior.py \
--mixed_precision="fp16"
```
Most of the parameters are identical to the parameters in the [Text-to-image](text2image#script-parameters) training guide, so let's get straight to a walkthrough of the Kandinsky training scripts!
### Min-SNR weighting
The [Min-SNR](https://huggingface.co/papers/2303.09556) weighting strategy can help with training by rebalancing the loss to achieve faster convergence. The training script supports predicting `epsilon` (noise) or `v_prediction`, but Min-SNR is compatible with both prediction types. This weighting strategy is only supported by PyTorch and is unavailable in the Flax training script.
Add the `--snr_gamma` parameter and set it to the recommended value of 5.0:
```bash
accelerate launch train_text_to_image_prior.py \
--snr_gamma=5.0
```
## Training script
The training script is also similar to the [Text-to-image](text2image#training-script) training guide, but it's been modified to support training the prior and decoder models. This guide focuses on the code that is unique to the Kandinsky 2.2 training scripts.
<hfoptions id="script">
<hfoption id="prior model">
The [`main()`](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py#L441) function contains the code for preparing the dataset and training the model.
One of the main differences you'll notice right away is that the training script also loads a [`~transformers.CLIPImageProcessor`] - in addition to a scheduler and tokenizer - for preprocessing images and a [`~transformers.CLIPVisionModelWithProjection`] model for encoding the images:
```py
noise_scheduler = DDPMScheduler(beta_schedule="squaredcos_cap_v2", prediction_type="sample")
image_processor = CLIPImageProcessor.from_pretrained(
args.pretrained_prior_model_name_or_path, subfolder="image_processor"
)
tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_prior_model_name_or_path, subfolder="tokenizer")
with ContextManagers(deepspeed_zero_init_disabled_context_manager()):
image_encoder = CLIPVisionModelWithProjection.from_pretrained(
args.pretrained_prior_model_name_or_path, subfolder="image_encoder", torch_dtype=weight_dtype
).eval()
text_encoder = CLIPTextModelWithProjection.from_pretrained(
args.pretrained_prior_model_name_or_path, subfolder="text_encoder", torch_dtype=weight_dtype
).eval()
```
Kandinsky uses a [`PriorTransformer`] to generate the image embeddings, so you'll want to setup the optimizer to learn the prior mode's parameters.
```py
prior = PriorTransformer.from_pretrained(args.pretrained_prior_model_name_or_path, subfolder="prior")
prior.train()
optimizer = optimizer_cls(
prior.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
```
Next, the input captions are tokenized, and images are [preprocessed](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py#L632) by the [`~transformers.CLIPImageProcessor`]:
```py
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
examples["clip_pixel_values"] = image_processor(images, return_tensors="pt").pixel_values
examples["text_input_ids"], examples["text_mask"] = tokenize_captions(examples)
return examples
```
Finally, the [training loop](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py#L718) converts the input images into latents, adds noise to the image embeddings, and makes a prediction:
```py
model_pred = prior(
noisy_latents,
timestep=timesteps,
proj_embedding=prompt_embeds,
encoder_hidden_states=text_encoder_hidden_states,
attention_mask=text_mask,
).predicted_image_embedding
```
If you want to learn more about how the training loop works, check out the [Understanding pipelines, models and schedulers](../using-diffusers/write_own_pipeline) tutorial which breaks down the basic pattern of the denoising process.
</hfoption>
<hfoption id="decoder model">
The [`main()`](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py#L440) function contains the code for preparing the dataset and training the model.
Unlike the prior model, the decoder initializes a [`VQModel`] to decode the latents into images and it uses a [`UNet2DConditionModel`]:
```py
with ContextManagers(deepspeed_zero_init_disabled_context_manager()):
vae = VQModel.from_pretrained(
args.pretrained_decoder_model_name_or_path, subfolder="movq", torch_dtype=weight_dtype
).eval()
image_encoder = CLIPVisionModelWithProjection.from_pretrained(
args.pretrained_prior_model_name_or_path, subfolder="image_encoder", torch_dtype=weight_dtype
).eval()
unet = UNet2DConditionModel.from_pretrained(args.pretrained_decoder_model_name_or_path, subfolder="unet")
```
Next, the script includes several image transforms and a [preprocessing](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py#L622) function for applying the transforms to the images and returning the pixel values:
```py
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
examples["pixel_values"] = [train_transforms(image) for image in images]
examples["clip_pixel_values"] = image_processor(images, return_tensors="pt").pixel_values
return examples
```
Lastly, the [training loop](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py#L706) handles converting the images to latents, adding noise, and predicting the noise residual.
If you want to learn more about how the training loop works, check out the [Understanding pipelines, models and schedulers](../using-diffusers/write_own_pipeline) tutorial which breaks down the basic pattern of the denoising process.
```py
model_pred = unet(noisy_latents, timesteps, None, added_cond_kwargs=added_cond_kwargs).sample[:, :4]
```
</hfoption>
</hfoptions>
## Launch the script
Once you’ve made all your changes or you’re okay with the default configuration, you’re ready to launch the training script! 🚀
You'll train on the [Pokémon BLIP captions](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions) dataset to generate your own Pokémon, but you can also create and train on your own dataset by following the [Create a dataset for training](create_dataset) guide. Set the environment variable `DATASET_NAME` to the name of the dataset on the Hub or if you're training on your own files, set the environment variable `TRAIN_DIR` to a path to your dataset.
If you’re training on more than one GPU, add the `--multi_gpu` parameter to the `accelerate launch` command.
<Tip>
To monitor training progress with Weights & Biases, add the `--report_to=wandb` parameter to the training command. You’ll also need to add the `--validation_prompt` to the training command to keep track of results. This can be really useful for debugging the model and viewing intermediate results.
</Tip>
<hfoptions id="training-inference">
<hfoption id="prior model">
```bash
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_prior.py \
--dataset_name=$DATASET_NAME \
--resolution=768 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--checkpoints_total_limit=3 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--validation_prompts="A robot pokemon, 4k photo" \
--report_to="wandb" \
--push_to_hub \
--output_dir="kandi2-prior-pokemon-model"
```
</hfoption>
<hfoption id="decoder model">
```bash
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_decoder.py \
--dataset_name=$DATASET_NAME \
--resolution=768 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--checkpoints_total_limit=3 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--validation_prompts="A robot pokemon, 4k photo" \
--report_to="wandb" \
--push_to_hub \
--output_dir="kandi2-decoder-pokemon-model"
```
</hfoption>
</hfoptions>
Once training is finished, you can use your newly trained model for inference!
<hfoptions id="training-inference">
<hfoption id="prior model">
```py
from diffusers import AutoPipelineForText2Image, DiffusionPipeline
import torch
prior_pipeline = DiffusionPipeline.from_pretrained(output_dir, torch_dtype=torch.float16)
prior_components = {"prior_" + k: v for k,v in prior_pipeline.components.items()}
pipeline = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", **prior_components, torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
prompt="A robot pokemon, 4k photo"
image = pipeline(prompt=prompt, negative_prompt=negative_prompt).images[0]
```
<Tip>
Feel free to replace `kandinsky-community/kandinsky-2-2-decoder` with your own trained decoder checkpoint!
</Tip>
</hfoption>
<hfoption id="decoder model">
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("path/to/saved/model", torch_dtype=torch.float16)
pipeline.enable_model_cpu_offload()
prompt="A robot pokemon, 4k photo"
image = pipeline(prompt=prompt).images[0]
```
For the decoder model, you can also perform inference from a saved checkpoint which can be useful for viewing intermediate results. In this case, load the checkpoint into the UNet:
```py
from diffusers import AutoPipelineForText2Image, UNet2DConditionModel
unet = UNet2DConditionModel.from_pretrained("path/to/saved/model" + "/checkpoint-<N>/unet")
pipeline = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", unet=unet, torch_dtype=torch.float16)
pipeline.enable_model_cpu_offload()
image = pipeline(prompt="A robot pokemon, 4k photo").images[0]
```
</hfoption>
</hfoptions>
## Next steps
Congratulations on training a Kandinsky 2.2 model! To learn more about how to use your new model, the following guides may be helpful:
- Read the [Kandinsky](../using-diffusers/kandinsky) guide to learn how to use it for a variety of different tasks (text-to-image, image-to-image, inpainting, interpolation), and how it can be combined with a ControlNet.
- Check out the [DreamBooth](dreambooth) and [LoRA](lora) training guides to learn how to train a personalized Kandinsky model with just a few example images. These two training techniques can even be combined!
| huggingface/diffusers/blob/main/docs/source/en/training/kandinsky.md |
--
title: "Accelerating over 130,000 Hugging Face models with ONNX Runtime"
thumbnail: /blog/assets/ort_accelerating_hf_models/thumbnail.png
authors:
- user: sschoenmeyer
guest: true
- user: mfuntowicz
---
# Accelerating over 130,000 Hugging Face models with ONNX Runtime
## What is ONNX Runtime?
ONNX Runtime is a cross-platform machine learning tool that can be used to accelerate a wide variety of models, particularly those with ONNX support.
## Hugging Face ONNX Runtime Support
There are over 130,000 ONNX-supported models on Hugging Face, an open source community that allows users to build, train, and deploy hundreds of thousands of publicly available machine learning models.
These ONNX-supported models, which include many increasingly popular large language models (LLMs) and cloud models, can leverage ONNX Runtime to improve performance, along with other benefits.
For example, using ONNX Runtime to accelerate the whisper-tiny model can improve average latency per inference, with an up to 74.30% gain over PyTorch.
ONNX Runtime works closely with Hugging Face to ensure that the most popular models on the site are supported.
In total, over 90 Hugging Face model architectures are supported by ONNX Runtime, including the 11 most popular architectures (where popularity is determined by the corresponding number of models uploaded to the Hugging Face Hub):
| Model Architecture | Approximate No. of Models |
|:------------------:|:-------------------------:|
| BERT | 28180 |
| GPT2 | 14060 |
| DistilBERT | 11540 |
| RoBERTa | 10800 |
| T5 | 10450 |
| Wav2Vec2 | 6560 |
| Stable-Diffusion | 5880 |
| XLM-RoBERTa | 5100 |
| Whisper | 4400 |
| BART | 3590 |
| Marian | 2840 |
## Learn More
To learn more about accelerating Hugging Face models with ONNX Runtime, check out our recent post on the [Microsoft Open Source Blog](https://cloudblogs.microsoft.com/opensource/2023/10/04/accelerating-over-130000-hugging-face-models-with-onnx-runtime/). | huggingface/blog/blob/main/ort-accelerating-hf-models.md |
n this video we will see together what is the normalizer component that we find at the beginning of each tokenizer. The normalization operation consists in applying a succession of normalization rules to the raw text. We choose normalization rules to remove noise in the text which seems useless for the learning and use of our language model. Let's take a very diverse sentence with different fonts, upper and lower case characters, accents, punctuation and multiple spaces, to see how several tokenizers normalize it. The tokenizer from the FNet model has transformed the letters with font variants or circled into their basic version and has removed the multiple spaces. And now if we look at the normalization with Retribert's tokenizer, we can see that it keeps characters with several font variants and keeps the multiple spaces but it removes all the accents. And if we continue to test the normalization of many other tokenizers associated to models that you can find on the Hub we can see that they also propose other normalizations. With the fast tokenizers, it is very easy to observe the normalization chosen for the currently loaded tokenizer. Indeed, each instance of a fast tokenizer has an underlying tokenizer from the Tokenizers library stored in the backend_tokenizer attribute. This object has itself a normalizer attribute that we can use thanks to the "normalize_str" method to normalize a string. It is thus very practical that this normalization which was used at the time of the training of the tokenizer was saved and that it applies automatically when you asks a trained tokenizer to tokenize a text. For example, if we hadn't included the albert normalizer we would have had a lot of unknown tokens by tokenizing this sentence with accents and capital letters. These transformations can also be undetectable with a simple "print". Indeed, keep in mind that for a computer, text is only a succession of 0 and 1 and it happens that different successions of 0 and 1 render the same printed character. The 0s and 1s go in groups of 8 to form a byte. The computer must then decode this sequence of bytes into a sequence of "code points". In our example the 2 bytes are transformed into a single "code point" by UTF-8. The unicode standard then allows us to find the character corresponding to this code point: the c cedilla. Let's repeat the same operation with this new sequence composed of 3 bytes, this time it is transformed into 2 "code points" .... which also correspond to the c cedilla character! It is in fact the composition of the unicode Latin Small Letter Cand the combining cedilla. But it's annoying because what appears to us to be a single character is not at all the same thing for the computer. Fortunately, there are unicode standardization standards known as NFC, NFD, NFKC and NFKD that allow erasing some of these differences. These standards are often used by tokenizers! On all these previous examples, even if the normalizations changed the look of the text, they did not change the content: you could still read "Hello world, let's normalize this sentence". However, you must be aware that some normalizations can be very harmful if they are not adapted to their corpus. For example, if you take the French sentence "un père indigné", which means "An indignant father", and normalize it with the bert-base-uncase tokenizer which removes the accents then the sentence becomes "un père indigne" which means "An unworthy father". If you watch this video to build your own tokenizer, there are no absolute rules to choose or not a normalization for your brand new tokenizer but I advise you to take the time to select them so that they do not make you lose important information. | huggingface/course/blob/main/subtitles/en/raw/chapter6/05a_normalization.md |
InstructPix2Pix training example
[InstructPix2Pix](https://arxiv.org/abs/2211.09800) is a method to fine-tune text-conditioned diffusion models such that they can follow an edit instruction for an input image. Models fine-tuned using this method take the following as inputs:
<p align="center">
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/evaluation_diffusion_models/edit-instruction.png" alt="instructpix2pix-inputs" width=600/>
</p>
The output is an "edited" image that reflects the edit instruction applied on the input image:
<p align="center">
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/output-gs%407-igs%401-steps%4050.png" alt="instructpix2pix-output" width=600/>
</p>
The `train_instruct_pix2pix.py` script shows how to implement the training procedure and adapt it for Stable Diffusion.
***Disclaimer: Even though `train_instruct_pix2pix.py` implements the InstructPix2Pix
training procedure while being faithful to the [original implementation](https://github.com/timothybrooks/instruct-pix2pix) we have only tested it on a [small-scale dataset](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples). This can impact the end results. For better results, we recommend longer training runs with a larger dataset. [Here](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered) you can find a large dataset for InstructPix2Pix training.***
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell e.g. a notebook
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
### Toy example
As mentioned before, we'll use a [small toy dataset](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples) for training. The dataset
is a smaller version of the [original dataset](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered) used in the InstructPix2Pix paper.
Configure environment variables such as the dataset identifier and the Stable Diffusion
checkpoint:
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export DATASET_ID="fusing/instructpix2pix-1000-samples"
```
Now, we can launch training:
```bash
accelerate launch --mixed_precision="fp16" train_instruct_pix2pix.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_ID \
--enable_xformers_memory_efficient_attention \
--resolution=256 --random_flip \
--train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --max_grad_norm=1 --lr_warmup_steps=0 \
--conditioning_dropout_prob=0.05 \
--mixed_precision=fp16 \
--seed=42 \
--push_to_hub
```
Additionally, we support performing validation inference to monitor training progress
with Weights and Biases. You can enable this feature with `report_to="wandb"`:
```bash
accelerate launch --mixed_precision="fp16" train_instruct_pix2pix.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_ID \
--enable_xformers_memory_efficient_attention \
--resolution=256 --random_flip \
--train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --max_grad_norm=1 --lr_warmup_steps=0 \
--conditioning_dropout_prob=0.05 \
--mixed_precision=fp16 \
--val_image_url="https://hf.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png" \
--validation_prompt="make the mountains snowy" \
--seed=42 \
--report_to=wandb \
--push_to_hub
```
We recommend this type of validation as it can be useful for model debugging. Note that you need `wandb` installed to use this. You can install `wandb` by running `pip install wandb`.
[Here](https://wandb.ai/sayakpaul/instruct-pix2pix/runs/ctr3kovq), you can find an example training run that includes some validation samples and the training hyperparameters.
***Note: In the original paper, the authors observed that even when the model is trained with an image resolution of 256x256, it generalizes well to bigger resolutions such as 512x512. This is likely because of the larger dataset they used during training.***
## Training with multiple GPUs
`accelerate` allows for seamless multi-GPU training. Follow the instructions [here](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
for running distributed training with `accelerate`. Here is an example command:
```bash
accelerate launch --mixed_precision="fp16" --multi_gpu train_instruct_pix2pix.py \
--pretrained_model_name_or_path=runwayml/stable-diffusion-v1-5 \
--dataset_name=sayakpaul/instructpix2pix-1000-samples \
--use_ema \
--enable_xformers_memory_efficient_attention \
--resolution=512 --random_flip \
--train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --lr_warmup_steps=0 \
--conditioning_dropout_prob=0.05 \
--mixed_precision=fp16 \
--seed=42 \
--push_to_hub
```
## Inference
Once training is complete, we can perform inference:
```python
import PIL
import requests
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline
model_id = "your_model_id" # <- replace this
pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
generator = torch.Generator("cuda").manual_seed(0)
url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/test_pix2pix_4.png"
def download_image(url):
image = PIL.Image.open(requests.get(url, stream=True).raw)
image = PIL.ImageOps.exif_transpose(image)
image = image.convert("RGB")
return image
image = download_image(url)
prompt = "wipe out the lake"
num_inference_steps = 20
image_guidance_scale = 1.5
guidance_scale = 10
edited_image = pipe(prompt,
image=image,
num_inference_steps=num_inference_steps,
image_guidance_scale=image_guidance_scale,
guidance_scale=guidance_scale,
generator=generator,
).images[0]
edited_image.save("edited_image.png")
```
An example model repo obtained using this training script can be found
here - [sayakpaul/instruct-pix2pix](https://huggingface.co/sayakpaul/instruct-pix2pix).
We encourage you to play with the following three parameters to control
speed and quality during performance:
* `num_inference_steps`
* `image_guidance_scale`
* `guidance_scale`
Particularly, `image_guidance_scale` and `guidance_scale` can have a profound impact
on the generated ("edited") image (see [here](https://twitter.com/RisingSayak/status/1628392199196151808?s=20) for an example).
If you're looking for some interesting ways to use the InstructPix2Pix training methodology, we welcome you to check out this blog post: [Instruction-tuning Stable Diffusion with InstructPix2Pix](https://huggingface.co/blog/instruction-tuning-sd).
## Stable Diffusion XL
There's an equivalent `train_instruct_pix2pix_sdxl.py` script for [Stable Diffusion XL](https://huggingface.co/papers/2307.01952). Please refer to the docs [here](./README_sdxl.md) to learn more.
| huggingface/diffusers/blob/main/examples/instruct_pix2pix/README.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Image Processor
An image processor is in charge of preparing input features for vision models and post processing their outputs. This includes transformations such as resizing, normalization, and conversion to PyTorch, TensorFlow, Flax and Numpy tensors. It may also include model specific post-processing such as converting logits to segmentation masks.
## ImageProcessingMixin
[[autodoc]] image_processing_utils.ImageProcessingMixin
- from_pretrained
- save_pretrained
## BatchFeature
[[autodoc]] BatchFeature
## BaseImageProcessor
[[autodoc]] image_processing_utils.BaseImageProcessor
| huggingface/transformers/blob/main/docs/source/en/main_classes/image_processor.md |
Using SpeechBrain at Hugging Face
`speechbrain` is an open-source and all-in-one conversational toolkit for audio/speech. The goal is to create a single, flexible, and user-friendly toolkit that can be used to easily develop state-of-the-art speech technologies, including systems for speech recognition, speaker recognition, speech enhancement, speech separation, language identification, multi-microphone signal processing, and many others.
## Exploring SpeechBrain in the Hub
You can find `speechbrain` models by filtering at the left of the [models page](https://huggingface.co/models?library=speechbrain).
All models on the Hub come up with the following features:
1. An automatically generated model card with a brief description.
2. Metadata tags that help for discoverability with information such as the language, license, paper, and more.
3. An interactive widget you can use to play out with the model directly in the browser.
4. An Inference API that allows to make inference requests.
## Using existing models
`speechbrain` offers different interfaces to manage pretrained models for different tasks, such as `EncoderClassifier`, `EncoderClassifier`, `SepformerSeperation`, and `SpectralMaskEnhancement`. These classes have a `from_hparams` method you can use to load a model from the Hub
Here is an example to run inference for sound recognition in urban sounds.
```py
import torchaudio
from speechbrain.pretrained import EncoderClassifier
classifier = EncoderClassifier.from_hparams(
source="speechbrain/urbansound8k_ecapa"
)
out_prob, score, index, text_lab = classifier.classify_file('speechbrain/urbansound8k_ecapa/dog_bark.wav')
```
If you want to see how to load a specific model, you can click `Use in speechbrain` and you will be given a working snippet that you can load it!
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-speechbrain_snippet1.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-speechbrain_snippet1-dark.png"/>
</div>
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-speechbrain_snippet2.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-speechbrain_snippet2-dark.png"/>
</div>
## Additional resources
* SpeechBrain [website](https://speechbrain.github.io/).
* SpeechBrain [docs](https://speechbrain.readthedocs.io/en/latest/index.html).
| huggingface/hub-docs/blob/main/docs/hub/speechbrain.md |
(Optional) the Policy Gradient Theorem
In this optional section where we're **going to study how we differentiate the objective function that we will use to approximate the policy gradient**.
Let's first recap our different formulas:
1. The Objective function
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/expected_reward.png" alt="Return"/>
2. The probability of a trajectory (given that action comes from \\(\pi_\theta\\)):
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/probability.png" alt="Probability"/>
So we have:
\\(\nabla_\theta J(\theta) = \nabla_\theta \sum_{\tau}P(\tau;\theta)R(\tau)\\)
We can rewrite the gradient of the sum as the sum of the gradient:
\\( = \sum_{\tau} \nabla_\theta P(\tau;\theta)R(\tau) \\)
We then multiply every term in the sum by \\(\frac{P(\tau;\theta)}{P(\tau;\theta)}\\)(which is possible since it's = 1)
\\( = \sum_{\tau} \frac{P(\tau;\theta)}{P(\tau;\theta)}\nabla_\theta P(\tau;\theta)R(\tau) \\)
We can simplify further this since \\( \frac{P(\tau;\theta)}{P(\tau;\theta)}\nabla_\theta P(\tau;\theta) = P(\tau;\theta)\frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)} \\)
\\(= \sum_{\tau} P(\tau;\theta) \frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)}R(\tau) \\)
We can then use the *derivative log trick* (also called *likelihood ratio trick* or *REINFORCE trick*), a simple rule in calculus that implies that \\( \nabla_x log f(x) = \frac{\nabla_x f(x)}{f(x)} \\)
So given we have \\(\frac{\nabla_\theta P(\tau;\theta)}{P(\tau;\theta)} \\) we transform it as \\(\nabla_\theta log P(\tau|\theta) \\)
So this is our likelihood policy gradient:
\\( \nabla_\theta J(\theta) = \sum_{\tau} P(\tau;\theta) \nabla_\theta log P(\tau;\theta) R(\tau) \\)
Thanks for this new formula, we can estimate the gradient using trajectory samples (we can approximate the likelihood ratio policy gradient with sample-based estimate if you prefer).
\\(\nabla_\theta J(\theta) = \frac{1}{m} \sum^{m}_{i=1} \nabla_\theta log P(\tau^{(i)};\theta)R(\tau^{(i)})\\) where each \\(\tau^{(i)}\\) is a sampled trajectory.
But we still have some mathematics work to do there: we need to simplify \\( \nabla_\theta log P(\tau|\theta) \\)
We know that:
\\(\nabla_\theta log P(\tau^{(i)};\theta)= \nabla_\theta log[ \mu(s_0) \prod_{t=0}^{H} P(s_{t+1}^{(i)}|s_{t}^{(i)}, a_{t}^{(i)}) \pi_\theta(a_{t}^{(i)}|s_{t}^{(i)})]\\)
Where \\(\mu(s_0)\\) is the initial state distribution and \\( P(s_{t+1}^{(i)}|s_{t}^{(i)}, a_{t}^{(i)}) \\) is the state transition dynamics of the MDP.
We know that the log of a product is equal to the sum of the logs:
\\(\nabla_\theta log P(\tau^{(i)};\theta)= \nabla_\theta \left[log \mu(s_0) + \sum\limits_{t=0}^{H}log P(s_{t+1}^{(i)}|s_{t}^{(i)} a_{t}^{(i)}) + \sum\limits_{t=0}^{H}log \pi_\theta(a_{t}^{(i)}|s_{t}^{(i)})\right] \\)
We also know that the gradient of the sum is equal to the sum of gradient:
\\( \nabla_\theta log P(\tau^{(i)};\theta)=\nabla_\theta log\mu(s_0) + \nabla_\theta \sum\limits_{t=0}^{H} log P(s_{t+1}^{(i)}|s_{t}^{(i)} a_{t}^{(i)}) + \nabla_\theta \sum\limits_{t=0}^{H} log \pi_\theta(a_{t}^{(i)}|s_{t}^{(i)}) \\)
Since neither initial state distribution or state transition dynamics of the MDP are dependent of \\(\theta\\), the derivate of both terms are 0. So we can remove them:
Since:
\\(\nabla_\theta \sum_{t=0}^{H} log P(s_{t+1}^{(i)}|s_{t}^{(i)} a_{t}^{(i)}) = 0 \\) and \\( \nabla_\theta \mu(s_0) = 0\\)
\\(\nabla_\theta log P(\tau^{(i)};\theta) = \nabla_\theta \sum_{t=0}^{H} log \pi_\theta(a_{t}^{(i)}|s_{t}^{(i)})\\)
We can rewrite the gradient of the sum as the sum of gradients:
\\( \nabla_\theta log P(\tau^{(i)};\theta)= \sum_{t=0}^{H} \nabla_\theta log \pi_\theta(a_{t}^{(i)}|s_{t}^{(i)}) \\)
So, the final formula for estimating the policy gradient is:
\\( \nabla_{\theta} J(\theta) = \hat{g} = \frac{1}{m} \sum^{m}_{i=1} \sum^{H}_{t=0} \nabla_\theta \log \pi_\theta(a^{(i)}_{t} | s_{t}^{(i)})R(\tau^{(i)}) \\)
| huggingface/deep-rl-class/blob/main/units/en/unit4/pg-theorem.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Control image brightness
The Stable Diffusion pipeline is mediocre at generating images that are either very bright or dark as explained in the [Common Diffusion Noise Schedules and Sample Steps are Flawed](https://huggingface.co/papers/2305.08891) paper. The solutions proposed in the paper are currently implemented in the [`DDIMScheduler`] which you can use to improve the lighting in your images.
<Tip>
💡 Take a look at the paper linked above for more details about the proposed solutions!
</Tip>
One of the solutions is to train a model with *v prediction* and *v loss*. Add the following flag to the [`train_text_to_image.py`](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image.py) or [`train_text_to_image_lora.py`](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py) scripts to enable `v_prediction`:
```bash
--prediction_type="v_prediction"
```
For example, let's use the [`ptx0/pseudo-journey-v2`](https://huggingface.co/ptx0/pseudo-journey-v2) checkpoint which has been finetuned with `v_prediction`.
Next, configure the following parameters in the [`DDIMScheduler`]:
1. `rescale_betas_zero_snr=True`, rescales the noise schedule to zero terminal signal-to-noise ratio (SNR)
2. `timestep_spacing="trailing"`, starts sampling from the last timestep
```py
from diffusers import DiffusionPipeline, DDIMScheduler
pipeline = DiffusionPipeline.from_pretrained("ptx0/pseudo-journey-v2", use_safetensors=True)
# switch the scheduler in the pipeline to use the DDIMScheduler
pipeline.scheduler = DDIMScheduler.from_config(
pipeline.scheduler.config, rescale_betas_zero_snr=True, timestep_spacing="trailing"
)
pipeline.to("cuda")
```
Finally, in your call to the pipeline, set `guidance_rescale` to prevent overexposure:
```py
prompt = "A lion in galaxies, spirals, nebulae, stars, smoke, iridescent, intricate detail, octane render, 8k"
image = pipeline(prompt, guidance_rescale=0.7).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/zero_snr.png"/>
</div>
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/control_brightness.md |
--
title: "AI Speech Recognition in Unity"
thumbnail: /blog/assets/124_ml-for-games/unity-asr-thumbnail.png
authors:
- user: dylanebert
---
# AI Speech Recognition in Unity
[](https://itch.io/jam/open-source-ai-game-jam)
## Introduction
This tutorial guides you through the process of implementing state-of-the-art Speech Recognition in your Unity game using the Hugging Face Unity API. This feature can be used for giving commands, speaking to an NPC, improving accessibility, or any other functionality where converting spoken words to text may be useful.
To try Speech Recognition in Unity for yourself, check out the [live demo in itch.io](https://individualkex.itch.io/speech-recognition-demo).
### Prerequisites
This tutorial assumes basic knowledge of Unity. It also requires you to have installed the [Hugging Face Unity API](https://github.com/huggingface/unity-api). For instructions on setting up the API, check out our [earlier blog post](https://huggingface.co/blog/unity-api).
## Steps
### 1. Set up the Scene
In this tutorial, we'll set up a very simple scene where the player can start and stop a recording, and the result will be converted to text.
Begin by creating a Unity project, then creating a Canvas with four UI elements:
1. **Start Button**: This will start the recording.
2. **Stop Button**: This will stop the recording.
3. **Text (TextMeshPro)**: This is where the result of the speech recognition will be displayed.
### 2. Set up the Script
Create a script called `SpeechRecognitionTest` and attach it to an empty GameObject.
In the script, define references to your UI components:
```
[SerializeField] private Button startButton;
[SerializeField] private Button stopButton;
[SerializeField] private TextMeshProUGUI text;
```
Assign them in the inspector.
Then, use the `Start()` method to set up listeners for the start and stop buttons:
```
private void Start() {
startButton.onClick.AddListener(StartRecording);
stopButton.onClick.AddListener(StopRecording);
}
```
At this point, your script should look something like this:
```
using TMPro;
using UnityEngine;
using UnityEngine.UI;
public class SpeechRecognitionTest : MonoBehaviour {
[SerializeField] private Button startButton;
[SerializeField] private Button stopButton;
[SerializeField] private TextMeshProUGUI text;
private void Start() {
startButton.onClick.AddListener(StartRecording);
stopButton.onClick.AddListener(StopRecording);
}
private void StartRecording() {
}
private void StopRecording() {
}
}
```
### 3. Record Microphone Input
Now let's record Microphone input and encode it in WAV format. Start by defining the member variables:
```
private AudioClip clip;
private byte[] bytes;
private bool recording;
```
Then, in `StartRecording()`, using the `Microphone.Start()` method to start recording:
```
private void StartRecording() {
clip = Microphone.Start(null, false, 10, 44100);
recording = true;
}
```
This will record up to 10 seconds of audio at 44100 Hz.
In case the recording reaches its maximum length of 10 seconds, we'll want to stop the recording automatically. To do so, write the following in the `Update()` method:
```
private void Update() {
if (recording && Microphone.GetPosition(null) >= clip.samples) {
StopRecording();
}
}
```
Then, in `StopRecording()`, truncate the recording and encode it in WAV format:
```
private void StopRecording() {
var position = Microphone.GetPosition(null);
Microphone.End(null);
var samples = new float[position * clip.channels];
clip.GetData(samples, 0);
bytes = EncodeAsWAV(samples, clip.frequency, clip.channels);
recording = false;
}
```
Finally, we'll need to implement the `EncodeAsWAV()` method, to prepare the audio data for the Hugging Face API:
```
private byte[] EncodeAsWAV(float[] samples, int frequency, int channels) {
using (var memoryStream = new MemoryStream(44 + samples.Length * 2)) {
using (var writer = new BinaryWriter(memoryStream)) {
writer.Write("RIFF".ToCharArray());
writer.Write(36 + samples.Length * 2);
writer.Write("WAVE".ToCharArray());
writer.Write("fmt ".ToCharArray());
writer.Write(16);
writer.Write((ushort)1);
writer.Write((ushort)channels);
writer.Write(frequency);
writer.Write(frequency * channels * 2);
writer.Write((ushort)(channels * 2));
writer.Write((ushort)16);
writer.Write("data".ToCharArray());
writer.Write(samples.Length * 2);
foreach (var sample in samples) {
writer.Write((short)(sample * short.MaxValue));
}
}
return memoryStream.ToArray();
}
}
```
The full script should now look something like this:
```
using System.IO;
using TMPro;
using UnityEngine;
using UnityEngine.UI;
public class SpeechRecognitionTest : MonoBehaviour {
[SerializeField] private Button startButton;
[SerializeField] private Button stopButton;
[SerializeField] private TextMeshProUGUI text;
private AudioClip clip;
private byte[] bytes;
private bool recording;
private void Start() {
startButton.onClick.AddListener(StartRecording);
stopButton.onClick.AddListener(StopRecording);
}
private void Update() {
if (recording && Microphone.GetPosition(null) >= clip.samples) {
StopRecording();
}
}
private void StartRecording() {
clip = Microphone.Start(null, false, 10, 44100);
recording = true;
}
private void StopRecording() {
var position = Microphone.GetPosition(null);
Microphone.End(null);
var samples = new float[position * clip.channels];
clip.GetData(samples, 0);
bytes = EncodeAsWAV(samples, clip.frequency, clip.channels);
recording = false;
}
private byte[] EncodeAsWAV(float[] samples, int frequency, int channels) {
using (var memoryStream = new MemoryStream(44 + samples.Length * 2)) {
using (var writer = new BinaryWriter(memoryStream)) {
writer.Write("RIFF".ToCharArray());
writer.Write(36 + samples.Length * 2);
writer.Write("WAVE".ToCharArray());
writer.Write("fmt ".ToCharArray());
writer.Write(16);
writer.Write((ushort)1);
writer.Write((ushort)channels);
writer.Write(frequency);
writer.Write(frequency * channels * 2);
writer.Write((ushort)(channels * 2));
writer.Write((ushort)16);
writer.Write("data".ToCharArray());
writer.Write(samples.Length * 2);
foreach (var sample in samples) {
writer.Write((short)(sample * short.MaxValue));
}
}
return memoryStream.ToArray();
}
}
}
```
To test whether this code is working correctly, you can add the following line to the end of the `StopRecording()` method:
```
File.WriteAllBytes(Application.dataPath + "/test.wav", bytes);
```
Now, if you click the `Start` button, speak into the microphone, and click `Stop`, a `test.wav` file should be saved in your Unity Assets folder with your recorded audio.
### 4. Speech Recognition
Next, we'll want to use the Hugging Face Unity API to run speech recognition on our encoded audio. To do so, we'll create a `SendRecording()` method:
```
using HuggingFace.API;
private void SendRecording() {
HuggingFaceAPI.AutomaticSpeechRecognition(bytes, response => {
text.color = Color.white;
text.text = response;
}, error => {
text.color = Color.red;
text.text = error;
});
}
```
This will send the encoded audio to the API, displaying the response in white if successful, otherwise the error message in red.
Don't forget to call `SendRecording()` at the end of the `StopRecording()` method:
```
private void StopRecording() {
/* other code */
SendRecording();
}
```
### 5. Final Touches
Finally, let's improve the UX of this demo a bit using button interactability and status messages.
The Start and Stop buttons should only be interactable when appropriate, i.e. when a recording is ready to be started/stopped.
Then, set the response text to a simple status message while recording or waiting for the API.
The finished script should look something like this:
```
using System.IO;
using HuggingFace.API;
using TMPro;
using UnityEngine;
using UnityEngine.UI;
public class SpeechRecognitionTest : MonoBehaviour {
[SerializeField] private Button startButton;
[SerializeField] private Button stopButton;
[SerializeField] private TextMeshProUGUI text;
private AudioClip clip;
private byte[] bytes;
private bool recording;
private void Start() {
startButton.onClick.AddListener(StartRecording);
stopButton.onClick.AddListener(StopRecording);
stopButton.interactable = false;
}
private void Update() {
if (recording && Microphone.GetPosition(null) >= clip.samples) {
StopRecording();
}
}
private void StartRecording() {
text.color = Color.white;
text.text = "Recording...";
startButton.interactable = false;
stopButton.interactable = true;
clip = Microphone.Start(null, false, 10, 44100);
recording = true;
}
private void StopRecording() {
var position = Microphone.GetPosition(null);
Microphone.End(null);
var samples = new float[position * clip.channels];
clip.GetData(samples, 0);
bytes = EncodeAsWAV(samples, clip.frequency, clip.channels);
recording = false;
SendRecording();
}
private void SendRecording() {
text.color = Color.yellow;
text.text = "Sending...";
stopButton.interactable = false;
HuggingFaceAPI.AutomaticSpeechRecognition(bytes, response => {
text.color = Color.white;
text.text = response;
startButton.interactable = true;
}, error => {
text.color = Color.red;
text.text = error;
startButton.interactable = true;
});
}
private byte[] EncodeAsWAV(float[] samples, int frequency, int channels) {
using (var memoryStream = new MemoryStream(44 + samples.Length * 2)) {
using (var writer = new BinaryWriter(memoryStream)) {
writer.Write("RIFF".ToCharArray());
writer.Write(36 + samples.Length * 2);
writer.Write("WAVE".ToCharArray());
writer.Write("fmt ".ToCharArray());
writer.Write(16);
writer.Write((ushort)1);
writer.Write((ushort)channels);
writer.Write(frequency);
writer.Write(frequency * channels * 2);
writer.Write((ushort)(channels * 2));
writer.Write((ushort)16);
writer.Write("data".ToCharArray());
writer.Write(samples.Length * 2);
foreach (var sample in samples) {
writer.Write((short)(sample * short.MaxValue));
}
}
return memoryStream.ToArray();
}
}
}
```
Congratulations, you can now use state-of-the-art Speech Recognition in Unity!
If you have any questions or would like to get more involved in using Hugging Face for Games, join the [Hugging Face Discord](https://hf.co/join/discord)! | huggingface/blog/blob/main/unity-asr.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# DPMSolverMultistepScheduler
`DPMSolverMultistep` is a multistep scheduler from [DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps](https://huggingface.co/papers/2206.00927) and [DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models](https://huggingface.co/papers/2211.01095) by Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu.
DPMSolver (and the improved version DPMSolver++) is a fast dedicated high-order solver for diffusion ODEs with convergence order guarantee. Empirically, DPMSolver sampling with only 20 steps can generate high-quality
samples, and it can generate quite good samples even in 10 steps.
## Tips
It is recommended to set `solver_order` to 2 for guide sampling, and `solver_order=3` for unconditional sampling.
Dynamic thresholding from [Imagen](https://huggingface.co/papers/2205.11487) is supported, and for pixel-space
diffusion models, you can set both `algorithm_type="dpmsolver++"` and `thresholding=True` to use the dynamic
thresholding. This thresholding method is unsuitable for latent-space diffusion models such as
Stable Diffusion.
The SDE variant of DPMSolver and DPM-Solver++ is also supported, but only for the first and second-order solvers. This is a fast SDE solver for the reverse diffusion SDE. It is recommended to use the second-order `sde-dpmsolver++`.
## DPMSolverMultistepScheduler
[[autodoc]] DPMSolverMultistepScheduler
## SchedulerOutput
[[autodoc]] schedulers.scheduling_utils.SchedulerOutput
| huggingface/diffusers/blob/main/docs/source/en/api/schedulers/multistep_dpm_solver.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Attention mechanisms
Most transformer models use full attention in the sense that the attention matrix is square. It can be a big
computational bottleneck when you have long texts. Longformer and reformer are models that try to be more efficient and
use a sparse version of the attention matrix to speed up training.
## LSH attention
[Reformer](#reformer) uses LSH attention. In the softmax(QK^t), only the biggest elements (in the softmax
dimension) of the matrix QK^t are going to give useful contributions. So for each query q in Q, we can consider only
the keys k in K that are close to q. A hash function is used to determine if q and k are close. The attention mask is
modified to mask the current token (except at the first position), because it will give a query and a key equal (so
very similar to each other). Since the hash can be a bit random, several hash functions are used in practice
(determined by a n_rounds parameter) and then are averaged together.
## Local attention
[Longformer](#longformer) uses local attention: often, the local context (e.g., what are the two tokens to the
left and right?) is enough to take action for a given token. Also, by stacking attention layers that have a small
window, the last layer will have a receptive field of more than just the tokens in the window, allowing them to build a
representation of the whole sentence.
Some preselected input tokens are also given global attention: for those few tokens, the attention matrix can access
all tokens and this process is symmetric: all other tokens have access to those specific tokens (on top of the ones in
their local window). This is shown in Figure 2d of the paper, see below for a sample attention mask:
<div class="flex justify-center">
<img scale="50 %" align="center" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/local_attention_mask.png"/>
</div>
Using those attention matrices with less parameters then allows the model to have inputs having a bigger sequence
length.
## Other tricks
### Axial positional encodings
[Reformer](#reformer) uses axial positional encodings: in traditional transformer models, the positional encoding
E is a matrix of size \\(l\\) by \\(d\\), \\(l\\) being the sequence length and \\(d\\) the dimension of the
hidden state. If you have very long texts, this matrix can be huge and take way too much space on the GPU. To alleviate
that, axial positional encodings consist of factorizing that big matrix E in two smaller matrices E1 and E2, with
dimensions \\(l_{1} \times d_{1}\\) and \\(l_{2} \times d_{2}\\), such that \\(l_{1} \times l_{2} = l\\) and
\\(d_{1} + d_{2} = d\\) (with the product for the lengths, this ends up being way smaller). The embedding for time
step \\(j\\) in E is obtained by concatenating the embeddings for timestep \\(j \% l1\\) in E1 and \\(j // l1\\)
in E2.
| huggingface/transformers/blob/main/docs/source/en/attention.md |
Model Card Guidebook
Model cards are an important documentation and transparency framework for machine learning models. We believe that model cards have the potential to serve as *boundary objects*, a single artefact that is accessible to users who have different backgrounds and goals when interacting with model cards – including developers, students, policymakers, ethicists, those impacted by machine learning models, and other stakeholders. We recognize that developing a single artefact to serve such multifaceted purposes is difficult and requires careful consideration of potential users and use cases. Our goal as part of the Hugging Face science team over the last several months has been to help operationalize model cards towards that vision, taking into account these challenges, both at Hugging Face and in the broader ML community.
To work towards that goal, it is important to recognize the thoughtful, dedicated efforts that have helped model cards grow into what they are today, from the adoption of model cards as a standard practice at many large organisations to the development of sophisticated tools for hosting and generating model cards. Since model cards were proposed by Mitchell et al. (2018), the landscape of machine learning documentation has expanded and evolved. A plethora of documentation tools and templates for data, models, and ML systems have been proposed and have developed – reflecting the incredible work of hundreds of researchers, impacted community members, advocates, and other stakeholders. Important discussions about the relationship between ML documentation and theories of change in responsible AI have created continued important discussions, and at times, divergence. We also recognize the challenges facing model cards, which in some ways mirror the challenges facing machine learning documentation and responsible AI efforts more generally, and we see opportunities ahead to help shape both model cards and the ecosystems in which they function positively in the months and years ahead.
Our work presents a view of where we think model cards stand right now and where they could go in the future, at Hugging Face and beyond. This work is a “snapshot” of the current state of model cards, informed by a landscape analysis of the many ways ML documentation artefacts have been instantiated. It represents one perspective amongst multiple about both the current state and more aspirational visions of model cards. In this blog post, we summarise our work, including a discussion of the broader, growing landscape of ML documentation tools, the diverse audiences for and opinions about model cards, and potential new templates for model card content. We also explore and develop model cards for machine learning models in the context of the Hugging Face Hub, using the Hub’s features to collaboratively create, discuss, and disseminate model cards for ML models.
With the launch of this Guidebook, we introduce several new resources and connect together previous work on Model Cards:
1) An updated Model Card template, released in the `huggingface_hub` library [modelcard_template.md file](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md), drawing together Model Card work in academia and throughout the industry.
2) An [Annotated Model Card Template](./model-card-annotated), which details how to fill the card out.
3) A [Model Card Creator Tool](https://huggingface.co/spaces/huggingface/Model_Cards_Writing_Tool), to ease card creation without needing to program, and to help teams share the work of different sections.
4) A [User Study](./model-cards-user-studies) on Model Card usage at Hugging Face
5) A [Landscape Analysis and Literature Review](./model-card-landscape-analysis) of the state of the art in model documentation.
We also include an [Appendix](./model-card-appendix) with further details from this work.
| huggingface/hub-docs/blob/main/docs/hub/model-card-guidebook.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Stable Diffusion XL
Stable Diffusion XL (SDXL) was proposed in [SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis](https://huggingface.co/papers/2307.01952) by Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach.
The abstract from the paper is:
*We present SDXL, a latent diffusion model for text-to-image synthesis. Compared to previous versions of Stable Diffusion, SDXL leverages a three times larger UNet backbone: The increase of model parameters is mainly due to more attention blocks and a larger cross-attention context as SDXL uses a second text encoder. We design multiple novel conditioning schemes and train SDXL on multiple aspect ratios. We also introduce a refinement model which is used to improve the visual fidelity of samples generated by SDXL using a post-hoc image-to-image technique. We demonstrate that SDXL shows drastically improved performance compared the previous versions of Stable Diffusion and achieves results competitive with those of black-box state-of-the-art image generators.*
## Tips
- Using SDXL with a DPM++ scheduler for less than 50 steps is known to produce [visual artifacts](https://github.com/huggingface/diffusers/issues/5433) because the solver becomes numerically unstable. To fix this issue, take a look at this [PR](https://github.com/huggingface/diffusers/pull/5541) which recommends for ODE/SDE solvers:
- set `use_karras_sigmas=True` or `lu_lambdas=True` to improve image quality
- set `euler_at_final=True` if you're using a solver with uniform step sizes (DPM++2M or DPM++2M SDE)
- Most SDXL checkpoints work best with an image size of 1024x1024. Image sizes of 768x768 and 512x512 are also supported, but the results aren't as good. Anything below 512x512 is not recommended and likely won't be for default checkpoints like [stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0).
- SDXL can pass a different prompt for each of the text encoders it was trained on. We can even pass different parts of the same prompt to the text encoders.
- SDXL output images can be improved by making use of a refiner model in an image-to-image setting.
- SDXL offers `negative_original_size`, `negative_crops_coords_top_left`, and `negative_target_size` to negatively condition the model on image resolution and cropping parameters.
<Tip>
To learn how to use SDXL for various tasks, how to optimize performance, and other usage examples, take a look at the [Stable Diffusion XL](../../../using-diffusers/sdxl) guide.
Check out the [Stability AI](https://huggingface.co/stabilityai) Hub organization for the official base and refiner model checkpoints!
</Tip>
## StableDiffusionXLPipeline
[[autodoc]] StableDiffusionXLPipeline
- all
- __call__
## StableDiffusionXLImg2ImgPipeline
[[autodoc]] StableDiffusionXLImg2ImgPipeline
- all
- __call__
## StableDiffusionXLInpaintPipeline
[[autodoc]] StableDiffusionXLInpaintPipeline
- all
- __call__
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/stable_diffusion/stable_diffusion_xl.md |
--
title: F1
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
The F1 score is the harmonic mean of the precision and recall. It can be computed with the equation:
F1 = 2 * (precision * recall) / (precision + recall)
---
# Metric Card for F1
## Metric Description
The F1 score is the harmonic mean of the precision and recall. It can be computed with the equation:
F1 = 2 * (precision * recall) / (precision + recall)
## How to Use
At minimum, this metric requires predictions and references as input
```python
>>> f1_metric = evaluate.load("f1")
>>> results = f1_metric.compute(predictions=[0, 1], references=[0, 1])
>>> print(results)
["{'f1': 1.0}"]
```
### Inputs
- **predictions** (`list` of `int`): Predicted labels.
- **references** (`list` of `int`): Ground truth labels.
- **labels** (`list` of `int`): The set of labels to include when `average` is not set to `'binary'`, and the order of the labels if `average` is `None`. Labels present in the data can be excluded, for example to calculate a multiclass average ignoring a majority negative class. Labels not present in the data will result in 0 components in a macro average. For multilabel targets, labels are column indices. By default, all labels in `predictions` and `references` are used in sorted order. Defaults to None.
- **pos_label** (`int`): The class to be considered the positive class, in the case where `average` is set to `binary`. Defaults to 1.
- **average** (`string`): This parameter is required for multiclass/multilabel targets. If set to `None`, the scores for each class are returned. Otherwise, this determines the type of averaging performed on the data. Defaults to `'binary'`.
- 'binary': Only report results for the class specified by `pos_label`. This is applicable only if the classes found in `predictions` and `references` are binary.
- 'micro': Calculate metrics globally by counting the total true positives, false negatives and false positives.
- 'macro': Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.
- 'weighted': Calculate metrics for each label, and find their average weighted by support (the number of true instances for each label). This alters `'macro'` to account for label imbalance. This option can result in an F-score that is not between precision and recall.
- 'samples': Calculate metrics for each instance, and find their average (only meaningful for multilabel classification).
- **sample_weight** (`list` of `float`): Sample weights Defaults to None.
### Output Values
- **f1**(`float` or `array` of `float`): F1 score or list of f1 scores, depending on the value passed to `average`. Minimum possible value is 0. Maximum possible value is 1. Higher f1 scores are better.
Output Example(s):
```python
{'f1': 0.26666666666666666}
```
```python
{'f1': array([0.8, 0.0, 0.0])}
```
This metric outputs a dictionary, with either a single f1 score, of type `float`, or an array of f1 scores, with entries of type `float`.
#### Values from Popular Papers
### Examples
Example 1-A simple binary example
```python
>>> f1_metric = evaluate.load("f1")
>>> results = f1_metric.compute(references=[0, 1, 0, 1, 0], predictions=[0, 0, 1, 1, 0])
>>> print(results)
{'f1': 0.5}
```
Example 2-The same simple binary example as in Example 1, but with `pos_label` set to `0`.
```python
>>> f1_metric = evaluate.load("f1")
>>> results = f1_metric.compute(references=[0, 1, 0, 1, 0], predictions=[0, 0, 1, 1, 0], pos_label=0)
>>> print(round(results['f1'], 2))
0.67
```
Example 3-The same simple binary example as in Example 1, but with `sample_weight` included.
```python
>>> f1_metric = evaluate.load("f1")
>>> results = f1_metric.compute(references=[0, 1, 0, 1, 0], predictions=[0, 0, 1, 1, 0], sample_weight=[0.9, 0.5, 3.9, 1.2, 0.3])
>>> print(round(results['f1'], 2))
0.35
```
Example 4-A multiclass example, with different values for the `average` input.
```python
>>> predictions = [0, 2, 1, 0, 0, 1]
>>> references = [0, 1, 2, 0, 1, 2]
>>> results = f1_metric.compute(predictions=predictions, references=references, average="macro")
>>> print(round(results['f1'], 2))
0.27
>>> results = f1_metric.compute(predictions=predictions, references=references, average="micro")
>>> print(round(results['f1'], 2))
0.33
>>> results = f1_metric.compute(predictions=predictions, references=references, average="weighted")
>>> print(round(results['f1'], 2))
0.27
>>> results = f1_metric.compute(predictions=predictions, references=references, average=None)
>>> print(results)
{'f1': array([0.8, 0. , 0. ])}
```
## Limitations and Bias
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
## Further References | huggingface/evaluate/blob/main/metrics/f1/README.md |
Considerations for model evaluation
Developing an ML model is rarely a one-shot deal: it often involves multiple stages of defining the model architecture and tuning hyper-parameters before converging on a final set. Responsible model evaluation is a key part of this process, and 🤗 Evaluate is here to help!
Here are some things to keep in mind when evaluating your model using the 🤗 Evaluate library:
## Properly splitting your data
Good evaluation generally requires three splits of your dataset:
- **train**: this is used for training your model.
- **validation**: this is used for validating the model hyperparameters.
- **test**: this is used for evaluating your model.
Many of the datasets on the 🤗 Hub are separated into 2 splits: `train` and `validation`; others are split into 3 splits (`train`, `validation` and `test`) -- make sure to use the right split for the right purpose!
Some datasets on the 🤗 Hub are already separated into these three splits. However, there are also many that only have a train/validation or only train split.
If the dataset you're using doesn't have a predefined train-test split, it is up to you to define which part of the dataset you want to use for training your model and which you want to use for hyperparameter tuning or final evaluation.
<Tip warning={true}>
Training and evaluating on the same split can misrepresent your results! If you overfit on your training data the evaluation results on that split will look great but the model will perform poorly on new data.
</Tip>
Depending on the size of the dataset, you can keep anywhere from 10-30% for evaluation and the rest for training, while aiming to set up the test set to reflect the production data as close as possible. Check out [this thread](https://discuss.huggingface.co/t/how-to-split-main-dataset-into-train-dev-test-as-datasetdict/1090) for a more in-depth discussion of dataset splitting!
## The impact of class imbalance
While many academic datasets, such as the [IMDb dataset](https://huggingface.co/datasets/imdb) of movie reviews, are perfectly balanced, most real-world datasets are not. In machine learning a *balanced dataset* corresponds to a datasets where all labels are represented equally. In the case of the IMDb dataset this means that there are as many positive as negative reviews in the dataset. In an imbalanced dataset this is not the case: in fraud detection for example there are usually many more non-fraud cases than fraud cases in the dataset.
Having an imbalanced dataset can skew the results of your metrics. Imagine a dataset with 99 "non-fraud" cases and 1 "fraud" case. A simple model that always predicts "non-fraud" cases would give yield a 99% accuracy which might sound good at first until you realize that you will never catch a fraud case.
Often, using more than one metric can help get a better idea of your model’s performance from different points of view. For instance, metrics like **[recall](https://huggingface.co/metrics/recall)** and **[precision](https://huggingface.co/metrics/precision)** can be used together, and the **[f1 score](https://huggingface.co/metrics/f1)** is actually the harmonic mean of the two.
In cases where a dataset is balanced, using [accuracy](https://huggingface.co/metrics/accuracy) can reflect the overall model performance:
In cases where there is an imbalance, using [F1 score](https://huggingface.co/metrics/f1) can be a better representation of performance, given that it encompasses both precision and recall.
Using accuracy in an imbalanced setting is less ideal, since it is not sensitive to minority classes and will not faithfully reflect model performance on them.
## Offline vs. online model evaluation
There are multiple ways to evaluate models, and an important distinction is offline versus online evaluation:
**Offline evaluation** is done before deploying a model or using insights generated from a model, using static datasets and metrics.
**Online evaluation** means evaluating how a model is performing after deployment and during its use in production.
These two types of evaluation can use different metrics and measure different aspects of model performance. For example, offline evaluation can compare a model to other models based on their performance on common benchmarks, whereas online evaluation will evaluate aspects such as latency and accuracy of the model based on production data (for example, the number of user queries that it was able to address).
## Trade-offs in model evaluation
When evaluating models in practice, there are often trade-offs that have to be made between different aspects of model performance: for instance, choosing a model that is slightly less accurate but that has a faster inference time, compared to a high-accuracy that has a higher memory footprint and requires access to more GPUs.
Here are other aspects of model performance to consider during evaluation:
### Interpretability
When evaluating models, **interpretability** (i.e. the ability to *interpret* results) can be very important, especially when deploying models in production.
For instance, metrics such as [exact match](https://huggingface.co/spaces/evaluate-metric/exact_match) have a set range (between 0 and 1, or 0% and 100%) and are easily understandable to users: for a pair of strings, the exact match score is 1 if the two strings are the exact same, and 0 otherwise.
Other metrics, such as [BLEU](https://huggingface.co/spaces/evaluate-metric/exact_match) are harder to interpret: while they also range between 0 and 1, they can vary greatly depending on which parameters are used to generate the scores, especially when different tokenization and normalization techniques are used (see the [metric card](https://huggingface.co/spaces/evaluate-metric/bleu/blob/main/README.md) for more information about BLEU limitations). This means that it is difficult to interpret a BLEU score without having more information about the procedure used for obtaining it.
Interpretability can be more or less important depending on the evaluation use case, but it is a useful aspect of model evaluation to keep in mind, since communicating and comparing model evaluations is an important part of responsible machine learning.
### Inference speed and memory footprint
While recent years have seen increasingly large ML models achieve high performance on a large variety of tasks and benchmarks, deploying these multi-billion parameter models in practice can be a challenge in itself, and many organizations lack the resources for this. This is why considering the **inference speed** and **memory footprint** of models is important, especially when doing online model evaluation.
Inference speed refers to the time that it takes for a model to make a prediction -- this will vary depending on the hardware used and the way in which models are queried, e.g. in real time via an API or in batch jobs that run once a day.
Memory footprint refers to the size of the model weights and how much hardware memory they occupy. If a model is too large to fit on a single GPU or CPU, then it has to be split over multiple ones, which can be more or less difficult depending on the model architecture and the deployment method.
When doing online model evaluation, there is often a trade-off to be done between inference speed and accuracy or precision, whereas this is less the case for offline evaluation.
## Limitations and bias
All models and all metrics have their limitations and biases, which depend on the way in which they were trained, the data that was used, and their intended uses. It is important to measure and communicate these limitations clearly to prevent misuse and unintended impacts, for instance via [model cards](https://huggingface.co/course/chapter4/4?fw=pt) which document the training and evaluation process.
Measuring biases can be done by evaluating models on datasets such as [Wino Bias](https://huggingface.co/datasets/wino_bias) or [MD Gender Bias](https://huggingface.co/datasets/md_gender_bias), and by doing [Interactive Error Analyis](https://huggingface.co/spaces/nazneen/error-analysis) to try to identify which subsets of the evaluation dataset a model performs poorly on.
We are currently working on additional measurements that can be used to quantify different dimensions of bias in both models and datasets -- stay tuned for more documentation on this topic!
| huggingface/evaluate/blob/main/docs/source/considerations.mdx |
Models Frequently Asked Questions
## How can I see what dataset was used to train the model?
It's up to the person who uploaded the model to include the training information! A user can [specify](./model-cards#specifying-a-dataset) the dataset used for training a model. If the datasets used for the model are on the Hub, the uploader may have included them in the [model card's metadata](https://huggingface.co/Jiva/xlm-roberta-large-it-mnli/blob/main/README.md#L7-L9). In that case, the datasets would be linked with a handy card on the right side of the model page:
<div class="flex justify-center">
<img class="block dark:hidden" width="350" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/models-linked-datasets.png"/>
<img class="hidden dark:block" width="350" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/models-linked-datasets-dark.png"/>
</div>
## How can I see an example of the model in action?
Models can have inference widgets that let you try out the model in the browser! Inference widgets are easy to configure, and there are many different options at your disposal. Visit the [Widgets documentation](models-widgets) to learn more.
The Hugging Face Hub is also home to Spaces, which are interactive demos used to showcase models. If a model has any Spaces associated with it, you'll find them linked on the model page like so:
<div class="flex justify-center">
<img class="block dark:hidden" width="350" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/models-linked-spaces.png"/>
<img class="hidden dark:block" width="350" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/models-linked-spaces-dark.png"/>
</div>
Spaces are a great way to show off a model you've made or explore new ways to use existing models! Visit the [Spaces documentation](./spaces) to learn how to make your own.
## How do I upload an update / new version of the model?
Releasing an update to a model that you've already published can be done by pushing a new commit to your model's repo. To do this, go through the same process that you followed to upload your initial model. Your previous model versions will remain in the repository's commit history, so you can still download previous model versions from a specific git commit or tag or revert to previous versions if needed.
## What if I have a different checkpoint of the model trained on a different dataset?
By convention, each model repo should contain a single checkpoint. You should upload any new checkpoints trained on different datasets to the Hub in a new model repo. You can link the models together by using a tag specified in the `tags` key in your [model card's metadata](./model-cards), by using [Collections](./collections) to group distinct related repositories together or by linking to them in the model cards. The [akiyamasho/AnimeBackgroundGAN-Shinkai](https://huggingface.co/akiyamasho/AnimeBackgroundGAN-Shinkai#other-pre-trained-model-versions) model, for example, references other checkpoints in the model card under *"Other pre-trained model versions"*.
## Can I link my model to a paper on arXiv?
If the model card includes a link to a paper on arXiv, the Hugging Face Hub will extract the arXiv ID and include it in the model tags with the format `arxiv:<PAPER ID>`. Clicking on the tag will let you:
* Visit the paper page
* Filter for other models on the Hub that cite the same paper.
<div class="flex justify-center">
<img class="block dark:hidden" width="300" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-arxiv.png"/>
<img class="hidden dark:block" width="300" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-arxiv-dark.png"/>
</div>
Read more about paper pages [here](./paper-pages).
| huggingface/hub-docs/blob/main/docs/hub/models-faq.md |
Adversarial Inception v3
**Inception v3** is a convolutional neural network architecture from the Inception family that makes several improvements including using [Label Smoothing](https://paperswithcode.com/method/label-smoothing), Factorized 7 x 7 convolutions, and the use of an [auxiliary classifer](https://paperswithcode.com/method/auxiliary-classifier) to propagate label information lower down the network (along with the use of batch normalization for layers in the sidehead). The key building block is an [Inception Module](https://paperswithcode.com/method/inception-v3-module).
This particular model was trained for study of adversarial examples (adversarial training).
The weights from this model were ported from [Tensorflow/Models](https://github.com/tensorflow/models).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('adv_inception_v3', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `adv_inception_v3`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('adv_inception_v3', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/abs-1804-00097,
author = {Alexey Kurakin and
Ian J. Goodfellow and
Samy Bengio and
Yinpeng Dong and
Fangzhou Liao and
Ming Liang and
Tianyu Pang and
Jun Zhu and
Xiaolin Hu and
Cihang Xie and
Jianyu Wang and
Zhishuai Zhang and
Zhou Ren and
Alan L. Yuille and
Sangxia Huang and
Yao Zhao and
Yuzhe Zhao and
Zhonglin Han and
Junjiajia Long and
Yerkebulan Berdibekov and
Takuya Akiba and
Seiya Tokui and
Motoki Abe},
title = {Adversarial Attacks and Defences Competition},
journal = {CoRR},
volume = {abs/1804.00097},
year = {2018},
url = {http://arxiv.org/abs/1804.00097},
archivePrefix = {arXiv},
eprint = {1804.00097},
timestamp = {Thu, 31 Oct 2019 16:31:22 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1804-00097.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: Adversarial Inception v3
Paper:
Title: Adversarial Attacks and Defences Competition
URL: https://paperswithcode.com/paper/adversarial-attacks-and-defences-competition
Models:
- Name: adv_inception_v3
In Collection: Adversarial Inception v3
Metadata:
FLOPs: 7352418880
Parameters: 23830000
File Size: 95549439
Architecture:
- 1x1 Convolution
- Auxiliary Classifier
- Average Pooling
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inception-v3 Module
- Max Pooling
- ReLU
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: adv_inception_v3
Crop Pct: '0.875'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/inception_v3.py#L456
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/adv_inception_v3-9e27bd63.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.58%
Top 5 Accuracy: 93.74%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/adversarial-inception-v3.mdx |
ResNet-D
**ResNet-D** is a modification on the [ResNet](https://paperswithcode.com/method/resnet) architecture that utilises an [average pooling](https://paperswithcode.com/method/average-pooling) tweak for downsampling. The motivation is that in the unmodified ResNet, the [1×1 convolution](https://paperswithcode.com/method/1x1-convolution) for the downsampling block ignores 3/4 of input feature maps, so this is modified so no information will be ignored
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('resnet101d', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `resnet101d`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('resnet101d', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{he2018bag,
title={Bag of Tricks for Image Classification with Convolutional Neural Networks},
author={Tong He and Zhi Zhang and Hang Zhang and Zhongyue Zhang and Junyuan Xie and Mu Li},
year={2018},
eprint={1812.01187},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: ResNet-D
Paper:
Title: Bag of Tricks for Image Classification with Convolutional Neural Networks
URL: https://paperswithcode.com/paper/bag-of-tricks-for-image-classification-with
Models:
- Name: resnet101d
In Collection: ResNet-D
Metadata:
FLOPs: 13805639680
Parameters: 44570000
File Size: 178791263
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnet101d
Crop Pct: '0.94'
Image Size: '256'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L716
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet101d_ra2-2803ffab.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.31%
Top 5 Accuracy: 96.06%
- Name: resnet152d
In Collection: ResNet-D
Metadata:
FLOPs: 20155275264
Parameters: 60210000
File Size: 241596837
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnet152d
Crop Pct: '0.94'
Image Size: '256'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L724
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet152d_ra2-5cac0439.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.13%
Top 5 Accuracy: 96.35%
- Name: resnet18d
In Collection: ResNet-D
Metadata:
FLOPs: 2645205760
Parameters: 11710000
File Size: 46893231
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnet18d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L649
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet18d_ra2-48a79e06.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 72.27%
Top 5 Accuracy: 90.69%
- Name: resnet200d
In Collection: ResNet-D
Metadata:
FLOPs: 26034378752
Parameters: 64690000
File Size: 259662933
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnet200d
Crop Pct: '0.94'
Image Size: '256'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L749
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet200d_ra2-bdba9bf9.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.24%
Top 5 Accuracy: 96.49%
- Name: resnet26d
In Collection: ResNet-D
Metadata:
FLOPs: 3335276032
Parameters: 16010000
File Size: 64209122
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnet26d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L683
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet26d-69e92c46.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.69%
Top 5 Accuracy: 93.15%
- Name: resnet34d
In Collection: ResNet-D
Metadata:
FLOPs: 5026601728
Parameters: 21820000
File Size: 87369807
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnet34d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L666
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet34d_ra2-f8dcfcaf.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.11%
Top 5 Accuracy: 93.38%
- Name: resnet50d
In Collection: ResNet-D
Metadata:
FLOPs: 5591002624
Parameters: 25580000
File Size: 102567109
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: resnet50d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/resnet.py#L699
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet50d_ra2-464e36ba.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.55%
Top 5 Accuracy: 95.16%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/resnet-d.mdx |
Using OpenCLIP at Hugging Face
[OpenCLIP](https://github.com/mlfoundations/open_clip) is an open-source implementation of OpenAI's CLIP.
## Exploring OpenCLIP on the Hub
You can find OpenCLIP models by filtering at the left of the [models page](https://huggingface.co/models?library=open_clip&sort=trending).
OpenCLIP models hosted on the Hub have a model card with useful information about the models. Thanks to OpenCLIP Hugging Face Hub integration, you can load OpenCLIP models with a few lines of code. You can also deploy these models using [Inference Endpoints](https://huggingface.co/inference-endpoints).
## Installation
To get started, you can follow the [OpenCLIP installation guide](https://github.com/mlfoundations/open_clip#usage).
You can also use the following one-line install through pip:
```
$ pip install open_clip_torch
```
## Using existing models
All OpenCLIP models can easily be loaded from the Hub:
```py
import open_clip
model, preprocess = open_clip.create_model_from_pretrained('hf-hub:laion/CLIP-ViT-g-14-laion2B-s12B-b42K')
tokenizer = open_clip.get_tokenizer('hf-hub:laion/CLIP-ViT-g-14-laion2B-s12B-b42K')
```
Once loaded, you can encode the image and text to do [zero-shot image classification](https://huggingface.co/tasks/zero-shot-image-classification):
```py
import torch
from PIL import Image
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
image = preprocess(image).unsqueeze(0)
text = tokenizer(["a diagram", "a dog", "a cat"])
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", text_probs)
```
It outputs the probability of each possible class:
```text
Label probs: tensor([[0.0020, 0.0034, 0.9946]])
```
If you want to load a specific OpenCLIP model, you can click `Use in OpenCLIP` in the model card and you will be given a working snippet!
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/openclip_repo_light.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/openclip_repo.png"/>
</div>
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/openclip_snippet_light.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/openclip_snippet.png"/>
</div>
## Additional resources
* OpenCLIP [repository](https://github.com/mlfoundations/open_clip)
* OpenCLIP [docs](https://github.com/mlfoundations/open_clip/tree/main/docs)
* OpenCLIP [models in the Hub](https://huggingface.co/models?library=open_clip&sort=trending)
| huggingface/hub-docs/blob/main/docs/hub/open_clip.md |
Analyze a dataset on the Hub
[[open-in-colab]]
In the Quickstart, you were introduced to various endpoints for interacting with datasets on the Hub. One of the most useful ones is the `/parquet` endpoint, which allows you to get a dataset stored on the Hub and analyze it. This is a great way to explore the dataset, and get a better understanding of it's contents.
To demonstrate, this guide will show you an end-to-end example of how to retrieve a dataset from the Hub and do some basic data analysis with the Pandas library.
## Get a dataset
The [Hub](https://huggingface.co/datasets) is home to more than 40,000 datasets across a wide variety of tasks, sizes, and languages. For this example, you'll use the [`codeparrot/codecomplex`](https://huggingface.co/datasets/codeparrot/codecomplex) dataset, but feel free to explore and find another dataset that interests you! The dataset contains Java code from programming competitions, and the time complexity of the code is labeled by a group of algorithm experts.
Let's say you're interested in the average length of the submitted code as it relates to the time complexity. Here's how you can get started.
Use the `/parquet` endpoint to convert the dataset to a Parquet file and return the URL to it:
```py
import requests
API_URL = "https://datasets-server.huggingface.co/parquet?dataset=codeparrot/codecomplex"
def query():
response = requests.get(API_URL)
return response.json()
data = query()
print(data)
{'parquet_files':
[
{'dataset': 'codeparrot/codecomplex', 'config': 'default', 'split': 'train', 'url': 'https://huggingface.co/datasets/codeparrot/codecomplex/resolve/refs%2Fconvert%2Fparquet/default/train/0000.parquet', 'filename': '0000.parquet', 'size': 4115908}
],
'pending': [], 'failed': []
}
```
## Read dataset with Pandas
With the URL, you can read the Parquet file into a Pandas DataFrame:
```py
import pandas as pd
url = "https://huggingface.co/datasets/codeparrot/codecomplex/resolve/refs%2Fconvert%2Fparquet/default/train/0000.parquet"
df = pd.read_parquet(url)
df.head(5)
```
| src | complexity | problem | from |
|--------------------------------------------------:|-----------:|--------------------------------:|-----------:|
| import java.io.*;\nimport java.math.BigInteger... | quadratic | 1179_B. Tolik and His Uncle | CODEFORCES |
| import java.util.Scanner;\n \npublic class pil... | linear | 1197_B. Pillars | CODEFORCES |
| import java.io.BufferedReader;\nimport java.io... | linear | 1059_C. Sequence Transformation | CODEFORCES |
| import java.util.*;\n\nimport java.io.*;\npubl... | linear | 1011_A. Stages | CODEFORCES |
| import java.io.OutputStream;\nimport java.io.I... | linear | 1190_C. Tokitsukaze and Duel | CODEFORCES |
## Calculate mean code length by time complexity
Pandas is a powerful library for data analysis; group the dataset by time complexity, apply a function to calculate the average length of the code snippet, and plot the results:
```py
df.groupby('complexity')['src'].apply(lambda x: x.str.len().mean()).sort_values(ascending=False).plot.barh(color="orange")
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets-server/codecomplex.png"/>
</div> | huggingface/datasets-server/blob/main/docs/source/analyze_data.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Logging
🤗 Diffusers has a centralized logging system to easily manage the verbosity of the library. The default verbosity is set to `WARNING`.
To change the verbosity level, use one of the direct setters. For instance, to change the verbosity to the `INFO` level.
```python
import diffusers
diffusers.logging.set_verbosity_info()
```
You can also use the environment variable `DIFFUSERS_VERBOSITY` to override the default verbosity. You can set it
to one of the following: `debug`, `info`, `warning`, `error`, `critical`. For example:
```bash
DIFFUSERS_VERBOSITY=error ./myprogram.py
```
Additionally, some `warnings` can be disabled by setting the environment variable
`DIFFUSERS_NO_ADVISORY_WARNINGS` to a true value, like `1`. This disables any warning logged by
[`logger.warning_advice`]. For example:
```bash
DIFFUSERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
```
Here is an example of how to use the same logger as the library in your own module or script:
```python
from diffusers.utils import logging
logging.set_verbosity_info()
logger = logging.get_logger("diffusers")
logger.info("INFO")
logger.warning("WARN")
```
All methods of the logging module are documented below. The main methods are
[`logging.get_verbosity`] to get the current level of verbosity in the logger and
[`logging.set_verbosity`] to set the verbosity to the level of your choice.
In order from the least verbose to the most verbose:
| Method | Integer value | Description |
|----------------------------------------------------------:|--------------:|----------------------------------------------------:|
| `diffusers.logging.CRITICAL` or `diffusers.logging.FATAL` | 50 | only report the most critical errors |
| `diffusers.logging.ERROR` | 40 | only report errors |
| `diffusers.logging.WARNING` or `diffusers.logging.WARN` | 30 | only report errors and warnings (default) |
| `diffusers.logging.INFO` | 20 | only report errors, warnings, and basic information |
| `diffusers.logging.DEBUG` | 10 | report all information |
By default, `tqdm` progress bars are displayed during model download. [`logging.disable_progress_bar`] and [`logging.enable_progress_bar`] are used to enable or disable this behavior.
## Base setters
[[autodoc]] utils.logging.set_verbosity_error
[[autodoc]] utils.logging.set_verbosity_warning
[[autodoc]] utils.logging.set_verbosity_info
[[autodoc]] utils.logging.set_verbosity_debug
## Other functions
[[autodoc]] utils.logging.get_verbosity
[[autodoc]] utils.logging.set_verbosity
[[autodoc]] utils.logging.get_logger
[[autodoc]] utils.logging.enable_default_handler
[[autodoc]] utils.logging.disable_default_handler
[[autodoc]] utils.logging.enable_explicit_format
[[autodoc]] utils.logging.reset_format
[[autodoc]] utils.logging.enable_progress_bar
[[autodoc]] utils.logging.disable_progress_bar
| huggingface/diffusers/blob/main/docs/source/en/api/logging.md |
Speed Comparison
<a href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/safetensors_doc/en/speed.ipynb" target="_blank" class="absolute z-10 right-0 top-0">
<img
alt="Open In Colab"
class="!m-0"
src="https://colab.research.google.com/assets/colab-badge.svg"
/>
</a>
`Safetensors` is really fast. Let's compare it against `PyTorch` by loading [gpt2](https://huggingface.co/gpt2) weights. To run the [GPU benchmark](#gpu-benchmark), make sure your machine has GPU or you have selected `GPU runtime` if you are using Google Colab.
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install safetensors huggingface_hub torch
```
Let's start by importing all the packages that will be used:
```py
>>> import os
>>> import datetime
>>> from huggingface_hub import hf_hub_download
>>> from safetensors.torch import load_file
>>> import torch
```
Download safetensors & torch weights for gpt2:
```py
>>> sf_filename = hf_hub_download("gpt2", filename="model.safetensors")
>>> pt_filename = hf_hub_download("gpt2", filename="pytorch_model.bin")
```
### CPU benchmark
```py
>>> start_st = datetime.datetime.now()
>>> weights = load_file(sf_filename, device="cpu")
>>> load_time_st = datetime.datetime.now() - start_st
>>> print(f"Loaded safetensors {load_time_st}")
>>> start_pt = datetime.datetime.now()
>>> weights = torch.load(pt_filename, map_location="cpu")
>>> load_time_pt = datetime.datetime.now() - start_pt
>>> print(f"Loaded pytorch {load_time_pt}")
>>> print(f"on CPU, safetensors is faster than pytorch by: {load_time_pt/load_time_st:.1f} X")
Loaded safetensors 0:00:00.004015
Loaded pytorch 0:00:00.307460
on CPU, safetensors is faster than pytorch by: 76.6 X
```
This speedup is due to the fact that this library avoids unnecessary copies by mapping the file directly. It is actually possible to do on [pure pytorch](https://gist.github.com/Narsil/3edeec2669a5e94e4707aa0f901d2282).
The currently shown speedup was gotten on:
* OS: Ubuntu 18.04.6 LTS
* CPU: Intel(R) Xeon(R) CPU @ 2.00GHz
### GPU benchmark
```py
>>> # This is required because this feature hasn't been fully verified yet, but
>>> # it's been tested on many different environments
>>> os.environ["SAFETENSORS_FAST_GPU"] = "1"
>>> # CUDA startup out of the measurement
>>> torch.zeros((2, 2)).cuda()
>>> start_st = datetime.datetime.now()
>>> weights = load_file(sf_filename, device="cuda:0")
>>> load_time_st = datetime.datetime.now() - start_st
>>> print(f"Loaded safetensors {load_time_st}")
>>> start_pt = datetime.datetime.now()
>>> weights = torch.load(pt_filename, map_location="cuda:0")
>>> load_time_pt = datetime.datetime.now() - start_pt
>>> print(f"Loaded pytorch {load_time_pt}")
>>> print(f"on GPU, safetensors is faster than pytorch by: {load_time_pt/load_time_st:.1f} X")
Loaded safetensors 0:00:00.165206
Loaded pytorch 0:00:00.353889
on GPU, safetensors is faster than pytorch by: 2.1 X
```
The speedup works because this library is able to skip unnecessary CPU allocations. It is unfortunately not replicable in pure pytorch as far as we know. The library works by memory mapping the file, creating the tensor empty with pytorch and calling `cudaMemcpy` directly to move the tensor directly on the GPU.
The currently shown speedup was gotten on:
* OS: Ubuntu 18.04.6 LTS.
* GPU: Tesla T4
* Driver Version: 460.32.03
* CUDA Version: 11.2
| huggingface/safetensors/blob/main/docs/source/speed.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Image Segmentation
[[open-in-colab]]
<Youtube id="dKE8SIt9C-w"/>
Image segmentation models separate areas corresponding to different areas of interest in an image. These models work by assigning a label to each pixel. There are several types of segmentation: semantic segmentation, instance segmentation, and panoptic segmentation.
In this guide, we will:
1. [Take a look at different types of segmentation](#types-of-segmentation).
2. [Have an end-to-end fine-tuning example for semantic segmentation](#fine-tuning-a-model-for-segmentation).
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install -q datasets transformers evaluate
```
We encourage you to log in to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to log in:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Types of Segmentation
Semantic segmentation assigns a label or class to every single pixel in an image. Let's take a look at a semantic segmentation model output. It will assign the same class to every instance of an object it comes across in an image, for example, all cats will be labeled as "cat" instead of "cat-1", "cat-2".
We can use transformers' image segmentation pipeline to quickly infer a semantic segmentation model. Let's take a look at the example image.
```python
from transformers import pipeline
from PIL import Image
import requests
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/segmentation_input.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/segmentation_input.jpg" alt="Segmentation Input"/>
</div>
We will use [nvidia/segformer-b1-finetuned-cityscapes-1024-1024](https://huggingface.co/nvidia/segformer-b1-finetuned-cityscapes-1024-1024).
```python
semantic_segmentation = pipeline("image-segmentation", "nvidia/segformer-b1-finetuned-cityscapes-1024-1024")
results = semantic_segmentation(image)
results
```
The segmentation pipeline output includes a mask for every predicted class.
```bash
[{'score': None,
'label': 'road',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'sidewalk',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'building',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'wall',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'pole',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'traffic sign',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'vegetation',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'terrain',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'sky',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'car',
'mask': <PIL.Image.Image image mode=L size=612x415>}]
```
Taking a look at the mask for the car class, we can see every car is classified with the same mask.
```python
results[-1]["mask"]
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/semantic_segmentation_output.png" alt="Semantic Segmentation Output"/>
</div>
In instance segmentation, the goal is not to classify every pixel, but to predict a mask for **every instance of an object** in a given image. It works very similar to object detection, where there is a bounding box for every instance, there's a segmentation mask instead. We will use [facebook/mask2former-swin-large-cityscapes-instance](https://huggingface.co/facebook/mask2former-swin-large-cityscapes-instance) for this.
```python
instance_segmentation = pipeline("image-segmentation", "facebook/mask2former-swin-large-cityscapes-instance")
results = instance_segmentation(Image.open(image))
results
```
As you can see below, there are multiple cars classified, and there's no classification for pixels other than pixels that belong to car and person instances.
```bash
[{'score': 0.999944,
'label': 'car',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.999945,
'label': 'car',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.999652,
'label': 'car',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.903529,
'label': 'person',
'mask': <PIL.Image.Image image mode=L size=612x415>}]
```
Checking out one of the car masks below.
```python
results[2]["mask"]
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/instance_segmentation_output.png" alt="Semantic Segmentation Output"/>
</div>
Panoptic segmentation combines semantic segmentation and instance segmentation, where every pixel is classified into a class and an instance of that class, and there are multiple masks for each instance of a class. We can use [facebook/mask2former-swin-large-cityscapes-panoptic](https://huggingface.co/facebook/mask2former-swin-large-cityscapes-panoptic) for this.
```python
panoptic_segmentation = pipeline("image-segmentation", "facebook/mask2former-swin-large-cityscapes-panoptic")
results = panoptic_segmentation(Image.open(image))
results
```
As you can see below, we have more classes. We will later illustrate to see that every pixel is classified into one of the classes.
```bash
[{'score': 0.999981,
'label': 'car',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.999958,
'label': 'car',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.99997,
'label': 'vegetation',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.999575,
'label': 'pole',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.999958,
'label': 'building',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.999634,
'label': 'road',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.996092,
'label': 'sidewalk',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.999221,
'label': 'car',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.99987,
'label': 'sky',
'mask': <PIL.Image.Image image mode=L size=612x415>}]
```
Let's have a side by side comparison for all types of segmentation.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/segmentation-comparison.png" alt="Segmentation Maps Compared"/>
</div>
Seeing all types of segmentation, let's have a deep dive on fine-tuning a model for semantic segmentation.
Common real-world applications of semantic segmentation include training self-driving cars to identify pedestrians and important traffic information, identifying cells and abnormalities in medical imagery, and monitoring environmental changes from satellite imagery.
## Fine-tuning a Model for Segmentation
We will now:
1. Finetune [SegFormer](https://huggingface.co/docs/transformers/main/en/model_doc/segformer#segformer) on the [SceneParse150](https://huggingface.co/datasets/scene_parse_150) dataset.
2. Use your fine-tuned model for inference.
<Tip>
The task illustrated in this tutorial is supported by the following model architectures:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[BEiT](../model_doc/beit), [Data2VecVision](../model_doc/data2vec-vision), [DPT](../model_doc/dpt), [MobileNetV2](../model_doc/mobilenet_v2), [MobileViT](../model_doc/mobilevit), [MobileViTV2](../model_doc/mobilevitv2), [SegFormer](../model_doc/segformer), [UPerNet](../model_doc/upernet)
<!--End of the generated tip-->
</Tip>
### Load SceneParse150 dataset
Start by loading a smaller subset of the SceneParse150 dataset from the 🤗 Datasets library. This'll give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
```py
>>> from datasets import load_dataset
>>> ds = load_dataset("scene_parse_150", split="train[:50]")
```
Split the dataset's `train` split into a train and test set with the [`~datasets.Dataset.train_test_split`] method:
```py
>>> ds = ds.train_test_split(test_size=0.2)
>>> train_ds = ds["train"]
>>> test_ds = ds["test"]
```
Then take a look at an example:
```py
>>> train_ds[0]
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=512x683 at 0x7F9B0C201F90>,
'annotation': <PIL.PngImagePlugin.PngImageFile image mode=L size=512x683 at 0x7F9B0C201DD0>,
'scene_category': 368}
```
- `image`: a PIL image of the scene.
- `annotation`: a PIL image of the segmentation map, which is also the model's target.
- `scene_category`: a category id that describes the image scene like "kitchen" or "office". In this guide, you'll only need `image` and `annotation`, both of which are PIL images.
You'll also want to create a dictionary that maps a label id to a label class which will be useful when you set up the model later. Download the mappings from the Hub and create the `id2label` and `label2id` dictionaries:
```py
>>> import json
>>> from huggingface_hub import cached_download, hf_hub_url
>>> repo_id = "huggingface/label-files"
>>> filename = "ade20k-id2label.json"
>>> id2label = json.load(open(cached_download(hf_hub_url(repo_id, filename, repo_type="dataset")), "r"))
>>> id2label = {int(k): v for k, v in id2label.items()}
>>> label2id = {v: k for k, v in id2label.items()}
>>> num_labels = len(id2label)
```
#### Custom dataset
You could also create and use your own dataset if you prefer to train with the [run_semantic_segmentation.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py) script instead of a notebook instance. The script requires:
1. a [`~datasets.DatasetDict`] with two [`~datasets.Image`] columns, "image" and "label"
```py
from datasets import Dataset, DatasetDict, Image
image_paths_train = ["path/to/image_1.jpg/jpg", "path/to/image_2.jpg/jpg", ..., "path/to/image_n.jpg/jpg"]
label_paths_train = ["path/to/annotation_1.png", "path/to/annotation_2.png", ..., "path/to/annotation_n.png"]
image_paths_validation = [...]
label_paths_validation = [...]
def create_dataset(image_paths, label_paths):
dataset = Dataset.from_dict({"image": sorted(image_paths),
"label": sorted(label_paths)})
dataset = dataset.cast_column("image", Image())
dataset = dataset.cast_column("label", Image())
return dataset
# step 1: create Dataset objects
train_dataset = create_dataset(image_paths_train, label_paths_train)
validation_dataset = create_dataset(image_paths_validation, label_paths_validation)
# step 2: create DatasetDict
dataset = DatasetDict({
"train": train_dataset,
"validation": validation_dataset,
}
)
# step 3: push to Hub (assumes you have ran the huggingface-cli login command in a terminal/notebook)
dataset.push_to_hub("your-name/dataset-repo")
# optionally, you can push to a private repo on the Hub
# dataset.push_to_hub("name of repo on the hub", private=True)
```
2. an id2label dictionary mapping the class integers to their class names
```py
import json
# simple example
id2label = {0: 'cat', 1: 'dog'}
with open('id2label.json', 'w') as fp:
json.dump(id2label, fp)
```
As an example, take a look at this [example dataset](https://huggingface.co/datasets/nielsr/ade20k-demo) which was created with the steps shown above.
### Preprocess
The next step is to load a SegFormer image processor to prepare the images and annotations for the model. Some datasets, like this one, use the zero-index as the background class. However, the background class isn't actually included in the 150 classes, so you'll need to set `reduce_labels=True` to subtract one from all the labels. The zero-index is replaced by `255` so it's ignored by SegFormer's loss function:
```py
>>> from transformers import AutoImageProcessor
>>> checkpoint = "nvidia/mit-b0"
>>> image_processor = AutoImageProcessor.from_pretrained(checkpoint, reduce_labels=True)
```
<frameworkcontent>
<pt>
It is common to apply some data augmentations to an image dataset to make a model more robust against overfitting. In this guide, you'll use the [`ColorJitter`](https://pytorch.org/vision/stable/generated/torchvision.transforms.ColorJitter.html) function from [torchvision](https://pytorch.org/vision/stable/index.html) to randomly change the color properties of an image, but you can also use any image library you like.
```py
>>> from torchvision.transforms import ColorJitter
>>> jitter = ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.1)
```
Now create two preprocessing functions to prepare the images and annotations for the model. These functions convert the images into `pixel_values` and annotations to `labels`. For the training set, `jitter` is applied before providing the images to the image processor. For the test set, the image processor crops and normalizes the `images`, and only crops the `labels` because no data augmentation is applied during testing.
```py
>>> def train_transforms(example_batch):
... images = [jitter(x) for x in example_batch["image"]]
... labels = [x for x in example_batch["annotation"]]
... inputs = image_processor(images, labels)
... return inputs
>>> def val_transforms(example_batch):
... images = [x for x in example_batch["image"]]
... labels = [x for x in example_batch["annotation"]]
... inputs = image_processor(images, labels)
... return inputs
```
To apply the `jitter` over the entire dataset, use the 🤗 Datasets [`~datasets.Dataset.set_transform`] function. The transform is applied on the fly which is faster and consumes less disk space:
```py
>>> train_ds.set_transform(train_transforms)
>>> test_ds.set_transform(val_transforms)
```
</pt>
</frameworkcontent>
<frameworkcontent>
<tf>
It is common to apply some data augmentations to an image dataset to make a model more robust against overfitting.
In this guide, you'll use [`tf.image`](https://www.tensorflow.org/api_docs/python/tf/image) to randomly change the color properties of an image, but you can also use any image
library you like.
Define two separate transformation functions:
- training data transformations that include image augmentation
- validation data transformations that only transpose the images, since computer vision models in 🤗 Transformers expect channels-first layout
```py
>>> import tensorflow as tf
>>> def aug_transforms(image):
... image = tf.keras.utils.img_to_array(image)
... image = tf.image.random_brightness(image, 0.25)
... image = tf.image.random_contrast(image, 0.5, 2.0)
... image = tf.image.random_saturation(image, 0.75, 1.25)
... image = tf.image.random_hue(image, 0.1)
... image = tf.transpose(image, (2, 0, 1))
... return image
>>> def transforms(image):
... image = tf.keras.utils.img_to_array(image)
... image = tf.transpose(image, (2, 0, 1))
... return image
```
Next, create two preprocessing functions to prepare batches of images and annotations for the model. These functions apply
the image transformations and use the earlier loaded `image_processor` to convert the images into `pixel_values` and
annotations to `labels`. `ImageProcessor` also takes care of resizing and normalizing the images.
```py
>>> def train_transforms(example_batch):
... images = [aug_transforms(x.convert("RGB")) for x in example_batch["image"]]
... labels = [x for x in example_batch["annotation"]]
... inputs = image_processor(images, labels)
... return inputs
>>> def val_transforms(example_batch):
... images = [transforms(x.convert("RGB")) for x in example_batch["image"]]
... labels = [x for x in example_batch["annotation"]]
... inputs = image_processor(images, labels)
... return inputs
```
To apply the preprocessing transformations over the entire dataset, use the 🤗 Datasets [`~datasets.Dataset.set_transform`] function.
The transform is applied on the fly which is faster and consumes less disk space:
```py
>>> train_ds.set_transform(train_transforms)
>>> test_ds.set_transform(val_transforms)
```
</tf>
</frameworkcontent>
### Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load an evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [mean Intersection over Union](https://huggingface.co/spaces/evaluate-metric/accuracy) (IoU) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
```py
>>> import evaluate
>>> metric = evaluate.load("mean_iou")
```
Then create a function to [`~evaluate.EvaluationModule.compute`] the metrics. Your predictions need to be converted to
logits first, and then reshaped to match the size of the labels before you can call [`~evaluate.EvaluationModule.compute`]:
<frameworkcontent>
<pt>
```py
>>> import numpy as np
>>> import torch
>>> from torch import nn
>>> def compute_metrics(eval_pred):
... with torch.no_grad():
... logits, labels = eval_pred
... logits_tensor = torch.from_numpy(logits)
... logits_tensor = nn.functional.interpolate(
... logits_tensor,
... size=labels.shape[-2:],
... mode="bilinear",
... align_corners=False,
... ).argmax(dim=1)
... pred_labels = logits_tensor.detach().cpu().numpy()
... metrics = metric.compute(
... predictions=pred_labels,
... references=labels,
... num_labels=num_labels,
... ignore_index=255,
... reduce_labels=False,
... )
... for key, value in metrics.items():
... if isinstance(value, np.ndarray):
... metrics[key] = value.tolist()
... return metrics
```
</pt>
</frameworkcontent>
<frameworkcontent>
<tf>
```py
>>> def compute_metrics(eval_pred):
... logits, labels = eval_pred
... logits = tf.transpose(logits, perm=[0, 2, 3, 1])
... logits_resized = tf.image.resize(
... logits,
... size=tf.shape(labels)[1:],
... method="bilinear",
... )
... pred_labels = tf.argmax(logits_resized, axis=-1)
... metrics = metric.compute(
... predictions=pred_labels,
... references=labels,
... num_labels=num_labels,
... ignore_index=-1,
... reduce_labels=image_processor.do_reduce_labels,
... )
... per_category_accuracy = metrics.pop("per_category_accuracy").tolist()
... per_category_iou = metrics.pop("per_category_iou").tolist()
... metrics.update({f"accuracy_{id2label[i]}": v for i, v in enumerate(per_category_accuracy)})
... metrics.update({f"iou_{id2label[i]}": v for i, v in enumerate(per_category_iou)})
... return {"val_" + k: v for k, v in metrics.items()}
```
</tf>
</frameworkcontent>
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
### Train
<frameworkcontent>
<pt>
<Tip>
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#finetune-with-trainer)!
</Tip>
You're ready to start training your model now! Load SegFormer with [`AutoModelForSemanticSegmentation`], and pass the model the mapping between label ids and label classes:
```py
>>> from transformers import AutoModelForSemanticSegmentation, TrainingArguments, Trainer
>>> model = AutoModelForSemanticSegmentation.from_pretrained(checkpoint, id2label=id2label, label2id=label2id)
```
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. It is important you don't remove unused columns because this'll drop the `image` column. Without the `image` column, you can't create `pixel_values`. Set `remove_unused_columns=False` to prevent this behavior! The only other required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the IoU metric and save the training checkpoint.
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
```py
>>> training_args = TrainingArguments(
... output_dir="segformer-b0-scene-parse-150",
... learning_rate=6e-5,
... num_train_epochs=50,
... per_device_train_batch_size=2,
... per_device_eval_batch_size=2,
... save_total_limit=3,
... evaluation_strategy="steps",
... save_strategy="steps",
... save_steps=20,
... eval_steps=20,
... logging_steps=1,
... eval_accumulation_steps=5,
... remove_unused_columns=False,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=train_ds,
... eval_dataset=test_ds,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
```py
>>> trainer.push_to_hub()
```
</pt>
</frameworkcontent>
<frameworkcontent>
<tf>
<Tip>
If you are unfamiliar with fine-tuning a model with Keras, check out the [basic tutorial](./training#train-a-tensorflow-model-with-keras) first!
</Tip>
To fine-tune a model in TensorFlow, follow these steps:
1. Define the training hyperparameters, and set up an optimizer and a learning rate schedule.
2. Instantiate a pretrained model.
3. Convert a 🤗 Dataset to a `tf.data.Dataset`.
4. Compile your model.
5. Add callbacks to calculate metrics and upload your model to 🤗 Hub
6. Use the `fit()` method to run the training.
Start by defining the hyperparameters, optimizer and learning rate schedule:
```py
>>> from transformers import create_optimizer
>>> batch_size = 2
>>> num_epochs = 50
>>> num_train_steps = len(train_ds) * num_epochs
>>> learning_rate = 6e-5
>>> weight_decay_rate = 0.01
>>> optimizer, lr_schedule = create_optimizer(
... init_lr=learning_rate,
... num_train_steps=num_train_steps,
... weight_decay_rate=weight_decay_rate,
... num_warmup_steps=0,
... )
```
Then, load SegFormer with [`TFAutoModelForSemanticSegmentation`] along with the label mappings, and compile it with the
optimizer. Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
```py
>>> from transformers import TFAutoModelForSemanticSegmentation
>>> model = TFAutoModelForSemanticSegmentation.from_pretrained(
... checkpoint,
... id2label=id2label,
... label2id=label2id,
... )
>>> model.compile(optimizer=optimizer) # No loss argument!
```
Convert your datasets to the `tf.data.Dataset` format using the [`~datasets.Dataset.to_tf_dataset`] and the [`DefaultDataCollator`]:
```py
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator(return_tensors="tf")
>>> tf_train_dataset = train_ds.to_tf_dataset(
... columns=["pixel_values", "label"],
... shuffle=True,
... batch_size=batch_size,
... collate_fn=data_collator,
... )
>>> tf_eval_dataset = test_ds.to_tf_dataset(
... columns=["pixel_values", "label"],
... shuffle=True,
... batch_size=batch_size,
... collate_fn=data_collator,
... )
```
To compute the accuracy from the predictions and push your model to the 🤗 Hub, use [Keras callbacks](../main_classes/keras_callbacks).
Pass your `compute_metrics` function to [`KerasMetricCallback`],
and use the [`PushToHubCallback`] to upload the model:
```py
>>> from transformers.keras_callbacks import KerasMetricCallback, PushToHubCallback
>>> metric_callback = KerasMetricCallback(
... metric_fn=compute_metrics, eval_dataset=tf_eval_dataset, batch_size=batch_size, label_cols=["labels"]
... )
>>> push_to_hub_callback = PushToHubCallback(output_dir="scene_segmentation", tokenizer=image_processor)
>>> callbacks = [metric_callback, push_to_hub_callback]
```
Finally, you are ready to train your model! Call `fit()` with your training and validation datasets, the number of epochs,
and your callbacks to fine-tune the model:
```py
>>> model.fit(
... tf_train_dataset,
... validation_data=tf_eval_dataset,
... callbacks=callbacks,
... epochs=num_epochs,
... )
```
Congratulations! You have fine-tuned your model and shared it on the 🤗 Hub. You can now use it for inference!
</tf>
</frameworkcontent>
### Inference
Great, now that you've finetuned a model, you can use it for inference!
Load an image for inference:
```py
>>> image = ds[0]["image"]
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/semantic-seg-image.png" alt="Image of bedroom"/>
</div>
<frameworkcontent>
<pt>
We will now see how to infer without a pipeline. Process the image with an image processor and place the `pixel_values` on a GPU:
```py
>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # use GPU if available, otherwise use a CPU
>>> encoding = image_processor(image, return_tensors="pt")
>>> pixel_values = encoding.pixel_values.to(device)
```
Pass your input to the model and return the `logits`:
```py
>>> outputs = model(pixel_values=pixel_values)
>>> logits = outputs.logits.cpu()
```
Next, rescale the logits to the original image size:
```py
>>> upsampled_logits = nn.functional.interpolate(
... logits,
... size=image.size[::-1],
... mode="bilinear",
... align_corners=False,
... )
>>> pred_seg = upsampled_logits.argmax(dim=1)[0]
```
</pt>
</frameworkcontent>
<frameworkcontent>
<tf>
Load an image processor to preprocess the image and return the input as TensorFlow tensors:
```py
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("MariaK/scene_segmentation")
>>> inputs = image_processor(image, return_tensors="tf")
```
Pass your input to the model and return the `logits`:
```py
>>> from transformers import TFAutoModelForSemanticSegmentation
>>> model = TFAutoModelForSemanticSegmentation.from_pretrained("MariaK/scene_segmentation")
>>> logits = model(**inputs).logits
```
Next, rescale the logits to the original image size and apply argmax on the class dimension:
```py
>>> logits = tf.transpose(logits, [0, 2, 3, 1])
>>> upsampled_logits = tf.image.resize(
... logits,
... # We reverse the shape of `image` because `image.size` returns width and height.
... image.size[::-1],
... )
>>> pred_seg = tf.math.argmax(upsampled_logits, axis=-1)[0]
```
</tf>
</frameworkcontent>
To visualize the results, load the [dataset color palette](https://github.com/tensorflow/models/blob/3f1ca33afe3c1631b733ea7e40c294273b9e406d/research/deeplab/utils/get_dataset_colormap.py#L51) as `ade_palette()` that maps each class to their RGB values. Then you can combine and plot your image and the predicted segmentation map:
```py
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> color_seg = np.zeros((pred_seg.shape[0], pred_seg.shape[1], 3), dtype=np.uint8)
>>> palette = np.array(ade_palette())
>>> for label, color in enumerate(palette):
... color_seg[pred_seg == label, :] = color
>>> color_seg = color_seg[..., ::-1] # convert to BGR
>>> img = np.array(image) * 0.5 + color_seg * 0.5 # plot the image with the segmentation map
>>> img = img.astype(np.uint8)
>>> plt.figure(figsize=(15, 10))
>>> plt.imshow(img)
>>> plt.show()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/semantic-seg-preds.png" alt="Image of bedroom overlaid with segmentation map"/>
</div>
| huggingface/transformers/blob/main/docs/source/en/tasks/semantic_segmentation.md |
--
title: 'Building a Playlist Generator with Sentence Transformers'
thumbnail: /blog/assets/87_playlist_generator/thumbnail.png
authors:
- user: nimaboscarino
---
# Building a Playlist Generator with Sentence Transformers
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
A short while ago I published a [playlist generator](https://huggingface.co/spaces/NimaBoscarino/playlist-generator) that I’d built using Sentence Transformers and Gradio, and I followed that up with a [reflection on how I try to use my projects as effective learning experiences](https://huggingface.co/blog/your-first-ml-project). But how did I actually *build* the playlist generator? In this post we’ll break down that project and look at **two** technical details: how the embeddings were generated, and how the *multi-step* Gradio demo was built.
<div class="hidden xl:block">
<div style="display: flex; flex-direction: column; align-items: center;">
<iframe src="https://nimaboscarino-playlist-generator.hf.space" frameBorder="0" width="1400" height="690" title="Gradio app" class="p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
</div>
</div>
As we’ve explored in [previous posts on the Hugging Face blog](https://huggingface.co/blog/getting-started-with-embeddings), Sentence Transformers (ST) is a library that gives us tools to generate sentence embeddings, which have a variety of uses. Since I had access to a dataset of song lyrics, I decided to leverage ST’s semantic search functionality to generate playlists from a given text prompt. Specifically, the goal was to create an embedding from the prompt, use that embedding for a semantic search across a set of *pre-generated lyrics embeddings* to generate a relevant set of songs. This would all be wrapped up in a Gradio app using the new Blocks API, hosted on Hugging Face Spaces.
We’ll be looking at a slightly advanced use of Gradio, so if you’re a beginner to the library I recommend reading the [Introduction to Blocks](https://gradio.app/introduction_to_blocks/) before tackling the Gradio-specific parts of this post. Also, note that while I won’t be releasing the lyrics dataset, the **[lyrics embeddings are available on the Hugging Face Hub](https://huggingface.co/datasets/NimaBoscarino/playlist-generator)** for you to play around with. Let’s jump in! 🪂
## Sentence Transformers: Embeddings and Semantic Search
Embeddings are **key** in Sentence Transformers! We’ve learned about **[what embeddings are and how we generate them in a previous article](https://huggingface.co/blog/getting-started-with-embeddings)**, and I recommend checking that out before continuing with this post.
Sentence Transformers offers a large collection of pre-trained embedding models! It even includes tutorials for fine-tuning those models with our own training data, but for many use-cases (such semantic search over a corpus of song lyrics) the pre-trained models will perform excellently right out of the box. With so many embedding models available, though, how do we know which one to use?
[The ST documentation highlights many of the choices](https://www.sbert.net/docs/pretrained_models.html), along with their evaluation metrics and some descriptions of their intended use-cases. The **[MS MARCO models](https://www.sbert.net/docs/pretrained-models/msmarco-v5.html)** are trained on Bing search engine queries, but since they also perform well on other domains I decided any one of these could be a good choice for this project. All we need for the playlist generator is to find songs that have some semantic similarity, and since I don’t really care about hitting a particular performance metric I arbitrarily chose [sentence-transformers/msmarco-MiniLM-L-6-v3](https://huggingface.co/sentence-transformers/msmarco-MiniLM-L-6-v3).
Each model in ST has a configurable input sequence length (up to a maximum), after which your inputs will be truncated. The model I chose had a max sequence length of 512 word pieces, which, as I found out, is often not enough to embed entire songs. Luckily, there’s an easy way for us to split lyrics into smaller chunks that the model can digest – verses! Once we’ve chunked our songs into verses and embedded each verse, we’ll find that the search works much better.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The songs are split into verses, and then each verse is embedded." src="assets/87_playlist_generator/embedding-diagram.svg"></medium-zoom>
<figcaption>The songs are split into verses, and then each verse is embedded.</figcaption>
</figure>
To actually generate the embeddings, you can call the `.encode()` method of the Sentence Transformers model and pass it a list of strings. Then you can save the embeddings however you like – in this case I opted to pickle them.
```python
from sentence_transformers import SentenceTransformer
import pickle
embedder = SentenceTransformer('msmarco-MiniLM-L-6-v3')
verses = [...] # Load up your strings in a list
corpus_embeddings = embedder.encode(verses, show_progress_bar=True)
with open('verse-embeddings.pkl', "wb") as fOut:
pickle.dump(corpus_embeddings, fOut)
```
To be able to share you embeddings with others, you can even upload the Pickle file to a Hugging Face dataset. [Read this tutorial to learn more](https://huggingface.co/blog/getting-started-with-embeddings#2-host-embeddings-for-free-on-the-hugging-face-hub), or [visit the Datasets documentation](https://huggingface.co/docs/datasets/upload_dataset#upload-with-the-hub-ui) to try it out yourself! In short, once you've created a new Dataset on the Hub, you can simply manually upload your Pickle file by clicking the "Add file" button, shown below.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="You can upload dataset files manually on the Hub." src="assets/87_playlist_generator/add-dataset.png"></medium-zoom>
<figcaption>You can upload dataset files manually on the Hub.</figcaption>
</figure>
The last thing we need to do now is actually use the embeddings for semantic search! The following code loads the embeddings, generates a new embedding for a given string, and runs a semantic search over the lyrics embeddings to find the closest hits. To make it easier to work with the results, I also like to put them into a Pandas DataFrame.
```python
from sentence_transformers import util
import pandas as pd
prompt_embedding = embedder.encode(prompt, convert_to_tensor=True)
hits = util.semantic_search(prompt_embedding, corpus_embeddings, top_k=20)
hits = pd.DataFrame(hits[0], columns=['corpus_id', 'score'])
# Note that "corpus_id" is the index of the verse for that embedding
# You can use the "corpus_id" to look up the original song
```
Since we’re searching for any verse that matches the text prompt, there’s a good chance that the semantic search will find multiple verses from the same song. When we drop the duplicates, we might only end up with a few distinct songs. If we increase the number of verse embeddings that `util.semantic_search` fetches with the `top_k` parameter, we can increase the number of songs that we'll find. Experimentally, I found that when I set `top_k=20`, I almost always get at least 9 distinct songs.
## Making a Multi-Step Gradio App
For the demo, I wanted users to enter a text prompt (or choose from some examples), and conduct a semantic search to find the top 9 most relevant songs. Then, users should be able to select from the resulting songs to be able to see the lyrics, which might give them some insight into why the particular songs were chosen. Here’s how we can do that!
[At the top of the Gradio demo](https://huggingface.co/spaces/NimaBoscarino/playlist-generator/blob/main/app.py) we load the embeddings, mappings, and lyrics from Hugging Face datasets when the app starts up.
```python
from sentence_transformers import SentenceTransformer, util
from huggingface_hub import hf_hub_download
import os
import pickle
import pandas as pd
corpus_embeddings = pickle.load(open(hf_hub_download("NimaBoscarino/playlist-generator", repo_type="dataset", filename="verse-embeddings.pkl"), "rb"))
songs = pd.read_csv(hf_hub_download("NimaBoscarino/playlist-generator", repo_type="dataset", filename="songs_new.csv"))
verses = pd.read_csv(hf_hub_download("NimaBoscarino/playlist-generator", repo_type="dataset", filename="verses.csv"))
# I'm loading the lyrics from my private dataset, with my own API token
auth_token = os.environ.get("TOKEN_FROM_SECRET")
lyrics = pd.read_csv(hf_hub_download("NimaBoscarino/playlist-generator-private", repo_type="dataset", filename="lyrics_new.csv", use_auth_token=auth_token))
```
The Gradio Blocks API lets you build *multi-step* interfaces, which means that you’re free to create quite complex sequences for your demos. We’ll take a look at some example code snippets here, but [check out the project code to see it all in action](https://huggingface.co/spaces/NimaBoscarino/playlist-generator/blob/main/app.py). For this project, we want users to choose a text prompt and then, after the semantic search is complete, users should have the ability to choose a song from the results to inspect the lyrics. With Gradio, this can be built iteratively by starting off with defining the initial input components and then registering a `click` event on the button. There’s also a `Radio` component, which will get updated to show the names of the songs for the playlist.
```python
import gradio as gr
song_prompt = gr.TextArea(
value="Running wild and free",
placeholder="Enter a song prompt, or choose an example"
)
fetch_songs = gr.Button(value="Generate Your Playlist!")
song_option = gr.Radio()
fetch_songs.click(
fn=generate_playlist,
inputs=[song_prompt],
outputs=[song_option],
)
```
This way, when the button gets clicked, Gradio grabs the current value of the `TextArea` and passes it to a function, shown below:
```python
def generate_playlist(prompt):
prompt_embedding = embedder.encode(prompt, convert_to_tensor=True)
hits = util.semantic_search(prompt_embedding, corpus_embeddings, top_k=20)
hits = pd.DataFrame(hits[0], columns=['corpus_id', 'score'])
# ... code to map from the verse IDs to the song names
song_names = ... # e.g. ["Thank U, Next", "Freebird", "La Cucaracha"]
return (
gr.Radio.update(label="Songs", interactive=True, choices=song_names)
)
```
In that function, we use the text prompt to conduct the semantic search. As seen above, to push updates to the Gradio components in the app, the function just needs to return components created with the `.update()` method. Since we connected the `song_option` `Radio` component to `fetch_songs.click` with its `output` parameter, `generate_playlist` can control the choices for the `Radio `component!
You can even do something similar to the `Radio` component in order to let users choose which song lyrics to view. [Visit the code on Hugging Face Spaces to see it in detail!](https://huggingface.co/spaces/NimaBoscarino/playlist-generator/blob/main/app.py)
## Some Thoughts
Sentence Transformers and Gradio are great choices for this kind of project! ST has the utility functions that we need for quickly generating embeddings, as well as for running semantic search with minimal code. Having access to a large collection of pre-trained models is also extremely helpful, since we don’t need to create and train our own models for this kind of stuff. Building our demo in Gradio means we only have to focus on coding in Python, and [deploying Gradio projects to Hugging Face Spaces is also super simple](https://huggingface.co/docs/hub/spaces-sdks-gradio)!
There’s a ton of other stuff I wish I’d had the time to build into this project, such as these ideas that I might explore in the future:
- Integrating with Spotify to automatically generate a playlist, and maybe even using Spotify’s embedded player to let users immediately listen to the songs.
- Using the **[HighlightedText** Gradio component](https://gradio.app/docs/#highlightedtext) to identify the specific verse that was found by the semantic search.
- Creating some visualizations of the embedding space, like in [this Space by Radamés Ajna](https://huggingface.co/spaces/radames/sentence-embeddings-visualization).
While the song *lyrics* aren’t being released, I’ve **[published the verse embeddings along with the mappings to each song](https://huggingface.co/datasets/NimaBoscarino/playlist-generator)**, so you’re free to play around and get creative!
Remember to [drop by the Discord](https://huggingface.co/join/discord) to ask questions and share your work! I’m excited to see what you end up doing with Sentence Transformers embeddings 🤗
## Extra Resources
- [Getting Started With Embeddings](https://huggingface.co/blog/getting-started-with-embeddings) by Omar Espejel
- [Or as a Twitter thread](https://twitter.com/osanseviero/status/1540993407883042816?s=20&t=4gskgxZx6yYKknNB7iD7Aw) by Omar Sanseviero
- [Hugging Face + Sentence Transformers docs](https://www.sbert.net/docs/hugging_face.html)
- [Gradio Blocks party](https://huggingface.co/Gradio-Blocks) - View some amazing community projects showcasing Gradio Blocks! | huggingface/blog/blob/main/playlist-generator.md |
Building a tokenizer, block by block[[building-a-tokenizer-block-by-block]]
<CourseFloatingBanner chapter={6}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter6/section8.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter6/section8.ipynb"},
]} />
As we've seen in the previous sections, tokenization comprises several steps:
- Normalization (any cleanup of the text that is deemed necessary, such as removing spaces or accents, Unicode normalization, etc.)
- Pre-tokenization (splitting the input into words)
- Running the input through the model (using the pre-tokenized words to produce a sequence of tokens)
- Post-processing (adding the special tokens of the tokenizer, generating the attention mask and token type IDs)
As a reminder, here's another look at the overall process:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter6/tokenization_pipeline.svg" alt="The tokenization pipeline.">
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter6/tokenization_pipeline-dark.svg" alt="The tokenization pipeline.">
</div>
The 🤗 Tokenizers library has been built to provide several options for each of those steps, which you can mix and match together. In this section we'll see how we can build a tokenizer from scratch, as opposed to training a new tokenizer from an old one as we did in [section 2](/course/chapter6/2). You'll then be able to build any kind of tokenizer you can think of!
<Youtube id="MR8tZm5ViWU"/>
More precisely, the library is built around a central `Tokenizer` class with the building blocks regrouped in submodules:
- `normalizers` contains all the possible types of `Normalizer` you can use (complete list [here](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.normalizers)).
- `pre_tokenizers` contains all the possible types of `PreTokenizer` you can use (complete list [here](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.pre_tokenizers)).
- `models` contains the various types of `Model` you can use, like `BPE`, `WordPiece`, and `Unigram` (complete list [here](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.models)).
- `trainers` contains all the different types of `Trainer` you can use to train your model on a corpus (one per type of model; complete list [here](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.trainers)).
- `post_processors` contains the various types of `PostProcessor` you can use (complete list [here](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.processors)).
- `decoders` contains the various types of `Decoder` you can use to decode the outputs of tokenization (complete list [here](https://huggingface.co/docs/tokenizers/python/latest/components.html#decoders)).
You can find the whole list of building blocks [here](https://huggingface.co/docs/tokenizers/python/latest/components.html).
## Acquiring a corpus[[acquiring-a-corpus]]
To train our new tokenizer, we will use a small corpus of text (so the examples run fast). The steps for acquiring the corpus are similar to the ones we took at the [beginning of this chapter](/course/chapter6/2), but this time we'll use the [WikiText-2](https://huggingface.co/datasets/wikitext) dataset:
```python
from datasets import load_dataset
dataset = load_dataset("wikitext", name="wikitext-2-raw-v1", split="train")
def get_training_corpus():
for i in range(0, len(dataset), 1000):
yield dataset[i : i + 1000]["text"]
```
The function `get_training_corpus()` is a generator that will yield batches of 1,000 texts, which we will use to train the tokenizer.
🤗 Tokenizers can also be trained on text files directly. Here's how we can generate a text file containing all the texts/inputs from WikiText-2 that we can use locally:
```python
with open("wikitext-2.txt", "w", encoding="utf-8") as f:
for i in range(len(dataset)):
f.write(dataset[i]["text"] + "\n")
```
Next we'll show you how to build your own BERT, GPT-2, and XLNet tokenizers, block by block. That will give us an example of each of the three main tokenization algorithms: WordPiece, BPE, and Unigram. Let's start with BERT!
## Building a WordPiece tokenizer from scratch[[building-a-wordpiece-tokenizer-from-scratch]]
To build a tokenizer with the 🤗 Tokenizers library, we start by instantiating a `Tokenizer` object with a `model`, then set its `normalizer`, `pre_tokenizer`, `post_processor`, and `decoder` attributes to the values we want.
For this example, we'll create a `Tokenizer` with a WordPiece model:
```python
from tokenizers import (
decoders,
models,
normalizers,
pre_tokenizers,
processors,
trainers,
Tokenizer,
)
tokenizer = Tokenizer(models.WordPiece(unk_token="[UNK]"))
```
We have to specify the `unk_token` so the model knows what to return when it encounters characters it hasn't seen before. Other arguments we can set here include the `vocab` of our model (we're going to train the model, so we don't need to set this) and `max_input_chars_per_word`, which specifies a maximum length for each word (words longer than the value passed will be split).
The first step of tokenization is normalization, so let's begin with that. Since BERT is widely used, there is a `BertNormalizer` with the classic options we can set for BERT: `lowercase` and `strip_accents`, which are self-explanatory; `clean_text` to remove all control characters and replace repeating spaces with a single one; and `handle_chinese_chars`, which places spaces around Chinese characters. To replicate the `bert-base-uncased` tokenizer, we can just set this normalizer:
```python
tokenizer.normalizer = normalizers.BertNormalizer(lowercase=True)
```
Generally speaking, however, when building a new tokenizer you won't have access to such a handy normalizer already implemented in the 🤗 Tokenizers library -- so let's see how to create the BERT normalizer by hand. The library provides a `Lowercase` normalizer and a `StripAccents` normalizer, and you can compose several normalizers using a `Sequence`:
```python
tokenizer.normalizer = normalizers.Sequence(
[normalizers.NFD(), normalizers.Lowercase(), normalizers.StripAccents()]
)
```
We're also using an `NFD` Unicode normalizer, as otherwise the `StripAccents` normalizer won't properly recognize the accented characters and thus won't strip them out.
As we've seen before, we can use the `normalize_str()` method of the `normalizer` to check out the effects it has on a given text:
```python
print(tokenizer.normalizer.normalize_str("Héllò hôw are ü?"))
```
```python out
hello how are u?
```
<Tip>
**To go further** If you test the two versions of the previous normalizers on a string containing the unicode character `u"\u0085"` you will surely notice that these two normalizers are not exactly equivalent.
To not over-complicate the version with `normalizers.Sequence` too much , we haven't included the Regex replacements that the `BertNormalizer` requires when the `clean_text` argument is set to `True` - which is the default behavior. But don't worry: it is possible to get exactly the same normalization without using the handy `BertNormalizer` by adding two `normalizers.Replace`'s to the normalizers sequence.
</Tip>
Next is the pre-tokenization step. Again, there is a prebuilt `BertPreTokenizer` that we can use:
```python
tokenizer.pre_tokenizer = pre_tokenizers.BertPreTokenizer()
```
Or we can build it from scratch:
```python
tokenizer.pre_tokenizer = pre_tokenizers.Whitespace()
```
Note that the `Whitespace` pre-tokenizer splits on whitespace and all characters that are not letters, digits, or the underscore character, so it technically splits on whitespace and punctuation:
```python
tokenizer.pre_tokenizer.pre_tokenize_str("Let's test my pre-tokenizer.")
```
```python out
[('Let', (0, 3)), ("'", (3, 4)), ('s', (4, 5)), ('test', (6, 10)), ('my', (11, 13)), ('pre', (14, 17)),
('-', (17, 18)), ('tokenizer', (18, 27)), ('.', (27, 28))]
```
If you only want to split on whitespace, you should use the `WhitespaceSplit` pre-tokenizer instead:
```python
pre_tokenizer = pre_tokenizers.WhitespaceSplit()
pre_tokenizer.pre_tokenize_str("Let's test my pre-tokenizer.")
```
```python out
[("Let's", (0, 5)), ('test', (6, 10)), ('my', (11, 13)), ('pre-tokenizer.', (14, 28))]
```
Like with normalizers, you can use a `Sequence` to compose several pre-tokenizers:
```python
pre_tokenizer = pre_tokenizers.Sequence(
[pre_tokenizers.WhitespaceSplit(), pre_tokenizers.Punctuation()]
)
pre_tokenizer.pre_tokenize_str("Let's test my pre-tokenizer.")
```
```python out
[('Let', (0, 3)), ("'", (3, 4)), ('s', (4, 5)), ('test', (6, 10)), ('my', (11, 13)), ('pre', (14, 17)),
('-', (17, 18)), ('tokenizer', (18, 27)), ('.', (27, 28))]
```
The next step in the tokenization pipeline is running the inputs through the model. We already specified our model in the initialization, but we still need to train it, which will require a `WordPieceTrainer`. The main thing to remember when instantiating a trainer in 🤗 Tokenizers is that you need to pass it all the special tokens you intend to use -- otherwise it won't add them to the vocabulary, since they are not in the training corpus:
```python
special_tokens = ["[UNK]", "[PAD]", "[CLS]", "[SEP]", "[MASK]"]
trainer = trainers.WordPieceTrainer(vocab_size=25000, special_tokens=special_tokens)
```
As well as specifying the `vocab_size` and `special_tokens`, we can set the `min_frequency` (the number of times a token must appear to be included in the vocabulary) or change the `continuing_subword_prefix` (if we want to use something different from `##`).
To train our model using the iterator we defined earlier, we just have to execute this command:
```python
tokenizer.train_from_iterator(get_training_corpus(), trainer=trainer)
```
We can also use text files to train our tokenizer, which would look like this (we reinitialize the model with an empty `WordPiece` beforehand):
```python
tokenizer.model = models.WordPiece(unk_token="[UNK]")
tokenizer.train(["wikitext-2.txt"], trainer=trainer)
```
In both cases, we can then test the tokenizer on a text by calling the `encode()` method:
```python
encoding = tokenizer.encode("Let's test this tokenizer.")
print(encoding.tokens)
```
```python out
['let', "'", 's', 'test', 'this', 'tok', '##eni', '##zer', '.']
```
The `encoding` obtained is an `Encoding`, which contains all the necessary outputs of the tokenizer in its various attributes: `ids`, `type_ids`, `tokens`, `offsets`, `attention_mask`, `special_tokens_mask`, and `overflowing`.
The last step in the tokenization pipeline is post-processing. We need to add the `[CLS]` token at the beginning and the `[SEP]` token at the end (or after each sentence, if we have a pair of sentences). We will use a `TemplateProcessor` for this, but first we need to know the IDs of the `[CLS]` and `[SEP]` tokens in the vocabulary:
```python
cls_token_id = tokenizer.token_to_id("[CLS]")
sep_token_id = tokenizer.token_to_id("[SEP]")
print(cls_token_id, sep_token_id)
```
```python out
(2, 3)
```
To write the template for the `TemplateProcessor`, we have to specify how to treat a single sentence and a pair of sentences. For both, we write the special tokens we want to use; the first (or single) sentence is represented by `$A`, while the second sentence (if encoding a pair) is represented by `$B`. For each of these (special tokens and sentences), we also specify the corresponding token type ID after a colon.
The classic BERT template is thus defined as follows:
```python
tokenizer.post_processor = processors.TemplateProcessing(
single=f"[CLS]:0 $A:0 [SEP]:0",
pair=f"[CLS]:0 $A:0 [SEP]:0 $B:1 [SEP]:1",
special_tokens=[("[CLS]", cls_token_id), ("[SEP]", sep_token_id)],
)
```
Note that we need to pass along the IDs of the special tokens, so the tokenizer can properly convert them to their IDs.
Once this is added, going back to our previous example will give:
```python
encoding = tokenizer.encode("Let's test this tokenizer.")
print(encoding.tokens)
```
```python out
['[CLS]', 'let', "'", 's', 'test', 'this', 'tok', '##eni', '##zer', '.', '[SEP]']
```
And on a pair of sentences, we get the proper result:
```python
encoding = tokenizer.encode("Let's test this tokenizer...", "on a pair of sentences.")
print(encoding.tokens)
print(encoding.type_ids)
```
```python out
['[CLS]', 'let', "'", 's', 'test', 'this', 'tok', '##eni', '##zer', '...', '[SEP]', 'on', 'a', 'pair', 'of', 'sentences', '.', '[SEP]']
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
```
We've almost finished building this tokenizer from scratch -- the last step is to include a decoder:
```python
tokenizer.decoder = decoders.WordPiece(prefix="##")
```
Let's test it on our previous `encoding`:
```python
tokenizer.decode(encoding.ids)
```
```python out
"let's test this tokenizer... on a pair of sentences."
```
Great! We can save our tokenizer in a single JSON file like this:
```python
tokenizer.save("tokenizer.json")
```
We can then reload that file in a `Tokenizer` object with the `from_file()` method:
```python
new_tokenizer = Tokenizer.from_file("tokenizer.json")
```
To use this tokenizer in 🤗 Transformers, we have to wrap it in a `PreTrainedTokenizerFast`. We can either use the generic class or, if our tokenizer corresponds to an existing model, use that class (here, `BertTokenizerFast`). If you apply this lesson to build a brand new tokenizer, you will have to use the first option.
To wrap the tokenizer in a `PreTrainedTokenizerFast`, we can either pass the tokenizer we built as a `tokenizer_object` or pass the tokenizer file we saved as `tokenizer_file`. The key thing to remember is that we have to manually set all the special tokens, since that class can't infer from the `tokenizer` object which token is the mask token, the `[CLS]` token, etc.:
```python
from transformers import PreTrainedTokenizerFast
wrapped_tokenizer = PreTrainedTokenizerFast(
tokenizer_object=tokenizer,
# tokenizer_file="tokenizer.json", # You can load from the tokenizer file, alternatively
unk_token="[UNK]",
pad_token="[PAD]",
cls_token="[CLS]",
sep_token="[SEP]",
mask_token="[MASK]",
)
```
If you are using a specific tokenizer class (like `BertTokenizerFast`), you will only need to specify the special tokens that are different from the default ones (here, none):
```python
from transformers import BertTokenizerFast
wrapped_tokenizer = BertTokenizerFast(tokenizer_object=tokenizer)
```
You can then use this tokenizer like any other 🤗 Transformers tokenizer. You can save it with the `save_pretrained()` method, or upload it to the Hub with the `push_to_hub()` method.
Now that we've seen how to build a WordPiece tokenizer, let's do the same for a BPE tokenizer. We'll go a bit faster since you know all the steps, and only highlight the differences.
## Building a BPE tokenizer from scratch[[building-a-bpe-tokenizer-from-scratch]]
Let's now build a GPT-2 tokenizer. Like for the BERT tokenizer, we start by initializing a `Tokenizer` with a BPE model:
```python
tokenizer = Tokenizer(models.BPE())
```
Also like for BERT, we could initialize this model with a vocabulary if we had one (we would need to pass the `vocab` and `merges` in this case), but since we will train from scratch, we don't need to do that. We also don't need to specify an `unk_token` because GPT-2 uses byte-level BPE, which doesn't require it.
GPT-2 does not use a normalizer, so we skip that step and go directly to the pre-tokenization:
```python
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=False)
```
The option we added to `ByteLevel` here is to not add a space at the beginning of a sentence (which is the default otherwise). We can have a look at the pre-tokenization of an example text like before:
```python
tokenizer.pre_tokenizer.pre_tokenize_str("Let's test pre-tokenization!")
```
```python out
[('Let', (0, 3)), ("'s", (3, 5)), ('Ġtest', (5, 10)), ('Ġpre', (10, 14)), ('-', (14, 15)),
('tokenization', (15, 27)), ('!', (27, 28))]
```
Next is the model, which needs training. For GPT-2, the only special token is the end-of-text token:
```python
trainer = trainers.BpeTrainer(vocab_size=25000, special_tokens=["<|endoftext|>"])
tokenizer.train_from_iterator(get_training_corpus(), trainer=trainer)
```
Like with the `WordPieceTrainer`, as well as the `vocab_size` and `special_tokens`, we can specify the `min_frequency` if we want to, or if we have an end-of-word suffix (like `</w>`), we can set it with `end_of_word_suffix`.
This tokenizer can also be trained on text files:
```python
tokenizer.model = models.BPE()
tokenizer.train(["wikitext-2.txt"], trainer=trainer)
```
Let's have a look at the tokenization of a sample text:
```python
encoding = tokenizer.encode("Let's test this tokenizer.")
print(encoding.tokens)
```
```python out
['L', 'et', "'", 's', 'Ġtest', 'Ġthis', 'Ġto', 'ken', 'izer', '.']
```
We apply the byte-level post-processing for the GPT-2 tokenizer as follows:
```python
tokenizer.post_processor = processors.ByteLevel(trim_offsets=False)
```
The `trim_offsets = False` option indicates to the post-processor that we should leave the offsets of tokens that begin with 'Ġ' as they are: this way the start of the offsets will point to the space before the word, not the first character of the word (since the space is technically part of the token). Let's have a look at the result with the text we just encoded, where `'Ġtest'` is the token at index 4:
```python
sentence = "Let's test this tokenizer."
encoding = tokenizer.encode(sentence)
start, end = encoding.offsets[4]
sentence[start:end]
```
```python out
' test'
```
Finally, we add a byte-level decoder:
```python
tokenizer.decoder = decoders.ByteLevel()
```
and we can double-check it works properly:
```python
tokenizer.decode(encoding.ids)
```
```python out
"Let's test this tokenizer."
```
Great! Now that we're done, we can save the tokenizer like before, and wrap it in a `PreTrainedTokenizerFast` or `GPT2TokenizerFast` if we want to use it in 🤗 Transformers:
```python
from transformers import PreTrainedTokenizerFast
wrapped_tokenizer = PreTrainedTokenizerFast(
tokenizer_object=tokenizer,
bos_token="<|endoftext|>",
eos_token="<|endoftext|>",
)
```
or:
```python
from transformers import GPT2TokenizerFast
wrapped_tokenizer = GPT2TokenizerFast(tokenizer_object=tokenizer)
```
As the last example, we'll show you how to build a Unigram tokenizer from scratch.
## Building a Unigram tokenizer from scratch[[building-a-unigram-tokenizer-from-scratch]]
Let's now build an XLNet tokenizer. Like for the previous tokenizers, we start by initializing a `Tokenizer` with a Unigram model:
```python
tokenizer = Tokenizer(models.Unigram())
```
Again, we could initialize this model with a vocabulary if we had one.
For the normalization, XLNet uses a few replacements (which come from SentencePiece):
```python
from tokenizers import Regex
tokenizer.normalizer = normalizers.Sequence(
[
normalizers.Replace("``", '"'),
normalizers.Replace("''", '"'),
normalizers.NFKD(),
normalizers.StripAccents(),
normalizers.Replace(Regex(" {2,}"), " "),
]
)
```
This replaces <code>``</code> and <code>''</code> with <code>"</code> and any sequence of two or more spaces with a single space, as well as removing the accents in the texts to tokenize.
The pre-tokenizer to use for any SentencePiece tokenizer is `Metaspace`:
```python
tokenizer.pre_tokenizer = pre_tokenizers.Metaspace()
```
We can have a look at the pre-tokenization of an example text like before:
```python
tokenizer.pre_tokenizer.pre_tokenize_str("Let's test the pre-tokenizer!")
```
```python out
[("▁Let's", (0, 5)), ('▁test', (5, 10)), ('▁the', (10, 14)), ('▁pre-tokenizer!', (14, 29))]
```
Next is the model, which needs training. XLNet has quite a few special tokens:
```python
special_tokens = ["<cls>", "<sep>", "<unk>", "<pad>", "<mask>", "<s>", "</s>"]
trainer = trainers.UnigramTrainer(
vocab_size=25000, special_tokens=special_tokens, unk_token="<unk>"
)
tokenizer.train_from_iterator(get_training_corpus(), trainer=trainer)
```
A very important argument not to forget for the `UnigramTrainer` is the `unk_token`. We can also pass along other arguments specific to the Unigram algorithm, such as the `shrinking_factor` for each step where we remove tokens (defaults to 0.75) or the `max_piece_length` to specify the maximum length of a given token (defaults to 16).
This tokenizer can also be trained on text files:
```python
tokenizer.model = models.Unigram()
tokenizer.train(["wikitext-2.txt"], trainer=trainer)
```
Let's have a look at the tokenization of a sample text:
```python
encoding = tokenizer.encode("Let's test this tokenizer.")
print(encoding.tokens)
```
```python out
['▁Let', "'", 's', '▁test', '▁this', '▁to', 'ken', 'izer', '.']
```
A peculiarity of XLNet is that it puts the `<cls>` token at the end of the sentence, with a type ID of 2 (to distinguish it from the other tokens). It's padding on the left, as a result. We can deal with all the special tokens and token type IDs with a template, like for BERT, but first we have to get the IDs of the `<cls>` and `<sep>` tokens:
```python
cls_token_id = tokenizer.token_to_id("<cls>")
sep_token_id = tokenizer.token_to_id("<sep>")
print(cls_token_id, sep_token_id)
```
```python out
0 1
```
The template looks like this:
```python
tokenizer.post_processor = processors.TemplateProcessing(
single="$A:0 <sep>:0 <cls>:2",
pair="$A:0 <sep>:0 $B:1 <sep>:1 <cls>:2",
special_tokens=[("<sep>", sep_token_id), ("<cls>", cls_token_id)],
)
```
And we can test it works by encoding a pair of sentences:
```python
encoding = tokenizer.encode("Let's test this tokenizer...", "on a pair of sentences!")
print(encoding.tokens)
print(encoding.type_ids)
```
```python out
['▁Let', "'", 's', '▁test', '▁this', '▁to', 'ken', 'izer', '.', '.', '.', '<sep>', '▁', 'on', '▁', 'a', '▁pair',
'▁of', '▁sentence', 's', '!', '<sep>', '<cls>']
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2]
```
Finally, we add a `Metaspace` decoder:
```python
tokenizer.decoder = decoders.Metaspace()
```
and we're done with this tokenizer! We can save the tokenizer like before, and wrap it in a `PreTrainedTokenizerFast` or `XLNetTokenizerFast` if we want to use it in 🤗 Transformers. One thing to note when using `PreTrainedTokenizerFast` is that on top of the special tokens, we need to tell the 🤗 Transformers library to pad on the left:
```python
from transformers import PreTrainedTokenizerFast
wrapped_tokenizer = PreTrainedTokenizerFast(
tokenizer_object=tokenizer,
bos_token="<s>",
eos_token="</s>",
unk_token="<unk>",
pad_token="<pad>",
cls_token="<cls>",
sep_token="<sep>",
mask_token="<mask>",
padding_side="left",
)
```
Or alternatively:
```python
from transformers import XLNetTokenizerFast
wrapped_tokenizer = XLNetTokenizerFast(tokenizer_object=tokenizer)
```
Now that you have seen how the various building blocks are used to build existing tokenizers, you should be able to write any tokenizer you want with the 🤗 Tokenizers library and be able to use it in 🤗 Transformers.
| huggingface/course/blob/main/chapters/en/chapter6/8.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MGP-STR
## Overview
The MGP-STR model was proposed in [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao. MGP-STR is a conceptually **simple** yet **powerful** vision Scene Text Recognition (STR) model, which is built upon the [Vision Transformer (ViT)](vit). To integrate linguistic knowledge, Multi-Granularity Prediction (MGP) strategy is proposed to inject information from the language modality into the model in an implicit way.
The abstract from the paper is the following:
*Scene text recognition (STR) has been an active research topic in computer vision for years. To tackle this challenging problem, numerous innovative methods have been successively proposed and incorporating linguistic knowledge into STR models has recently become a prominent trend. In this work, we first draw inspiration from the recent progress in Vision Transformer (ViT) to construct a conceptually simple yet powerful vision STR model, which is built upon ViT and outperforms previous state-of-the-art models for scene text recognition, including both pure vision models and language-augmented methods. To integrate linguistic knowledge, we further propose a Multi-Granularity Prediction strategy to inject information from the language modality into the model in an implicit way, i.e. , subword representations (BPE and WordPiece) widely-used in NLP are introduced into the output space, in addition to the conventional character level representation, while no independent language model (LM) is adopted. The resultant algorithm (termed MGP-STR) is able to push the performance envelop of STR to an even higher level. Specifically, it achieves an average recognition accuracy of 93.35% on standard benchmarks.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/mgp_str_architecture.png"
alt="drawing" width="600"/>
<small> MGP-STR architecture. Taken from the <a href="https://arxiv.org/abs/2209.03592">original paper</a>. </small>
MGP-STR is trained on two synthetic datasets [MJSynth]((http://www.robots.ox.ac.uk/~vgg/data/text/)) (MJ) and SynthText(http://www.robots.ox.ac.uk/~vgg/data/scenetext/) (ST) without fine-tuning on other datasets. It achieves state-of-the-art results on six standard Latin scene text benchmarks, including 3 regular text datasets (IC13, SVT, IIIT) and 3 irregular ones (IC15, SVTP, CUTE).
This model was contributed by [yuekun](https://huggingface.co/yuekun). The original code can be found [here](https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR).
## Inference example
[`MgpstrModel`] accepts images as input and generates three types of predictions, which represent textual information at different granularities.
The three types of predictions are fused to give the final prediction result.
The [`ViTImageProcessor`] class is responsible for preprocessing the input image and
[`MgpstrTokenizer`] decodes the generated character tokens to the target string. The
[`MgpstrProcessor`] wraps [`ViTImageProcessor`] and [`MgpstrTokenizer`]
into a single instance to both extract the input features and decode the predicted token ids.
- Step-by-step Optical Character Recognition (OCR)
```py
>>> from transformers import MgpstrProcessor, MgpstrForSceneTextRecognition
>>> import requests
>>> from PIL import Image
>>> processor = MgpstrProcessor.from_pretrained('alibaba-damo/mgp-str-base')
>>> model = MgpstrForSceneTextRecognition.from_pretrained('alibaba-damo/mgp-str-base')
>>> # load image from the IIIT-5k dataset
>>> url = "https://i.postimg.cc/ZKwLg2Gw/367-14.png"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> pixel_values = processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(pixel_values)
>>> generated_text = processor.batch_decode(outputs.logits)['generated_text']
```
## MgpstrConfig
[[autodoc]] MgpstrConfig
## MgpstrTokenizer
[[autodoc]] MgpstrTokenizer
- save_vocabulary
## MgpstrProcessor
[[autodoc]] MgpstrProcessor
- __call__
- batch_decode
## MgpstrModel
[[autodoc]] MgpstrModel
- forward
## MgpstrForSceneTextRecognition
[[autodoc]] MgpstrForSceneTextRecognition
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/mgp-str.md |
Zero-shot classifier distillation
Author: @joeddav
This script provides a way to improve the speed and memory performance of a zero-shot classifier by training a more
efficient student model from the zero-shot teacher's predictions over an unlabeled dataset.
The zero-shot classification pipeline uses a model pre-trained on natural language inference (NLI) to determine the
compatibility of a set of candidate class names with a given sequence. This serves as a convenient out-of-the-box
classifier without the need for labeled training data. However, for a given sequence, the method requires each
possible label to be fed through the large NLI model separately. Thus for `N` sequences and `K` classes, a total of
`N*K` forward passes through the model are required. This requirement slows inference considerably, particularly as
`K` grows.
Given (1) an unlabeled corpus and (2) a set of candidate class names, the provided script trains a student model
with a standard classification head with `K` output dimensions. The resulting student model can then be used for
classifying novel text instances with a significant boost in speed and memory performance while retaining similar
classification performance to the original zero-shot model
### Usage
A teacher NLI model can be distilled to a more efficient student model by running [`distill_classifier.py`](https://github.com/huggingface/transformers/blob/main/examples/research_projects/zero-shot-distillation/distill_classifier.py):
```
python distill_classifier.py \
--data_file <unlabeled_data.txt> \
--class_names_file <class_names.txt> \
--output_dir <output_dir>
```
`<unlabeled_data.txt>` should be a text file with a single unlabeled example per line. `<class_names.txt>` is a text file with one class name per line.
Other optional arguments include:
- `--teacher_name_or_path` (default: `roberta-large-mnli`): The name or path of the NLI teacher model.
- `--student_name_or_path` (default: `distillbert-base-uncased`): The name or path of the student model which will
be fine-tuned to copy the teacher predictions.
- `--hypothesis_template` (default `"This example is {}."`): The template used to turn each label into an NLI-style
hypothesis when generating teacher predictions. This template must include a `{}` or similar syntax for the
candidate label to be inserted into the template. For example, the default template is `"This example is {}."` With
the candidate label `sports`, this would be fed into the model like `[CLS] sequence to classify [SEP] This example
is sports . [SEP]`.
- `--multi_class`: Whether or not multiple candidate labels can be true. By default, the scores are normalized such
that the sum of the label likelihoods for each sequence is 1. If `--multi_class` is passed, the labels are
considered independent and probabilities are normalized for each candidate by doing a softmax of the entailment
score vs. the contradiction score. This is sometimes called "multi-class multi-label" classification.
- `--temperature` (default: `1.0`): The temperature applied to the softmax of the teacher model predictions. A
higher temperature results in a student with smoother (lower confidence) predictions than the teacher while a value
`<1` resultings in a higher-confidence, peaked distribution. The default `1.0` is equivalent to no smoothing.
- `--teacher_batch_size` (default: `32`): The batch size used for generating a single set of teacher predictions.
Does not affect training. Use `--per_device_train_batch_size` to change the training batch size.
Any of the arguments in the 🤗 Trainer's
[`TrainingArguments`](https://huggingface.co/transformers/main_classes/trainer.html?#trainingarguments) can also be
modified, such as `--learning_rate`, `--fp16`, `--no_cuda`, `--warmup_steps`, etc. Run `python distill_classifier.py
-h` for a full list of available arguments or consult the [Trainer
documentation](https://huggingface.co/transformers/main_classes/trainer.html#trainingarguments).
> **Note**: Distributed and TPU training are not currently supported. Single-node multi-GPU is supported, however,
and will run automatically if multiple GPUs are available.
### Example: Topic classification
> A full colab demo notebook of this example can be found [here](https://colab.research.google.com/drive/1mjBjd0cR8G57ZpsnFCS3ngGyo5nCa9ya?usp=sharing).
Let's say we're interested in classifying news articles into one of four topic categories: "the world", "sports",
"business", or "science/tech". We have an unlabeled dataset, [AG's News](https://huggingface.co/datasets/ag_news),
which corresponds to this problem (in reality AG's News is annotated, but we will pretend it is not for the sake of
example).
We can use an NLI model like `roberta-large-mnli` for zero-shot classification like so:
```python
>>> class_names = ["the world", "sports", "business", "science/tech"]
>>> hypothesis_template = "This text is about {}."
>>> sequence = "A new moon has been discovered in Jupiter's orbit"
>>> zero_shot_classifier = pipeline("zero-shot-classification", model="roberta-large-mnli")
>>> zero_shot_classifier(sequence, class_names, hypothesis_template=hypothesis_template)
{'sequence': "A new moon has been discovered in Jupiter's orbit",
'labels': ['science/tech', 'the world', 'business', 'sports'],
'scores': [0.7035840153694153, 0.18744826316833496, 0.06027870625257492, 0.04868902638554573]}
```
Unfortunately, inference is slow since each of our 4 class names must be fed through the large model for every
sequence to be classified. But with our unlabeled data we can distill the model to a small distilbert classifier to
make future inference much faster.
To run the script, we will need to put each training example (text only) from AG's News on its own line in
`agnews/train_unlabeled.txt`, and each of the four class names in the newline-separated `agnews/class_names.txt`.
Then we can run distillation with the following command:
```bash
python distill_classifier.py \
--data_file ./agnews/unlabeled.txt \
--class_names_files ./agnews/class_names.txt \
--teacher_name_or_path roberta-large-mnli \
--hypothesis_template "This text is about {}." \
--output_dir ./agnews/distilled
```
The script will generate a set of soft zero-shot predictions from `roberta-large-mnli` for each example in
`agnews/unlabeled.txt`. It will then train a student distilbert classifier on the teacher predictions and
save the resulting model in `./agnews/distilled`.
The resulting model can then be loaded and used like any other pre-trained classifier:
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("./agnews/distilled")
tokenizer = AutoTokenizer.from_pretrained("./agnews/distilled")
```
and even used trivially with a `TextClassificationPipeline`:
```python
>>> distilled_classifier = TextClassificationPipeline(model=model, tokenizer=tokenizer, return_all_scores=True)
>>> distilled_classifier(sequence)
[[{'label': 'the world', 'score': 0.14899294078350067},
{'label': 'sports', 'score': 0.03205857425928116},
{'label': 'business', 'score': 0.05943061783909798},
{'label': 'science/tech', 'score': 0.7595179080963135}]]
```
> Tip: pass `device=0` when constructing a pipeline to run on a GPU
As we can see, the results of the student closely resemble that of the trainer despite never having seen this
example during training. Now let's do a quick & dirty speed comparison simulating 16K examples with a batch size of
16:
```python
for _ in range(1000):
zero_shot_classifier([sequence] * 16, class_names)
# runs in 1m 23s on a single V100 GPU
```
```python
%%time
for _ in range(1000):
distilled_classifier([sequence] * 16)
# runs in 10.3s on a single V100 GPU
```
As we can see, the distilled student model runs an order of magnitude faster than its teacher NLI model. This is
also a seeting where we only have `K=4` possible labels. The higher the number of classes for a given task, the more
drastic the speedup will be, since the zero-shot teacher's complexity scales linearly with the number of classes.
Since we secretly have access to ground truth labels for AG's news, we can evaluate the accuracy of each model. The
original zero-shot model `roberta-large-mnli` gets an accuracy of 69.3% on the held-out test set. After training a
student on the unlabeled training set, the distilled model gets a similar score of 70.4%.
Lastly, you can share the distilled model with the community and/or use it with our inference API by [uploading it
to the 🤗 Hub](https://huggingface.co/transformers/model_sharing.html). We've uploaded the distilled model from this
example at
[joeddav/distilbert-base-uncased-agnews-student](https://huggingface.co/joeddav/distilbert-base-uncased-agnews-student).
| huggingface/transformers/blob/main/examples/research_projects/zero-shot-distillation/README.md |
!--Copyright 2023 Mistral AI and The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Mixtral
## Overview
Mixtral-8x7B is Mistral AI's second Large Language Model (LLM).
The Mixtral model was proposed by the [Mistral AI](https://mistral.ai/) team.
It was introduced in the [Mixtral of Experts blogpost](https://mistral.ai/news/mixtral-of-experts/) with the following introduction:
*Today, the team is proud to release Mixtral 8x7B, a high-quality sparse mixture of experts models (SMoE) with open weights. Licensed under Apache 2.0. Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference. It is the strongest open-weight model with a permissive license and the best model overall regarding cost/performance trade-offs. In particular, it matches or outperforms GPT3.5 on most standard benchmarks.*
Tips:
- The model needs to be converted using the [conversion script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/mixtral/convert_mixtral_weights_to_hf.py).
- If the model is quantized to 4bits, a single A100 is enough to fit the entire 45B model.
This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArthurZ) .
The original code can be found [here](https://github.com/mistralai/mistral-src).
### Model Details
Mixtral-45B is a decoder-based LM with the following architectural choices:
* Mixtral is a Mixture of Expert (MOE) model with 8 experts per MLP, with a total of 45B paramateres but the compute required is the same as a 14B model. This is because even though each experts have to be loaded in RAM (70B like ram requirement) each token from the hidden states are dipatched twice (top 2 routing) and thus the compute (the operation required at each foward computation) is just 2 X sequence_length.
The following implementation details are shared with Mistral AI's first model [mistral](mistral):
* Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
* GQA (Grouped Query Attention) - allowing faster inference and lower cache size.
* Byte-fallback BPE tokenizer - ensures that characters are never mapped to out of vocabulary tokens.
They also provide an instruction fine-tuned model: `mistralai/Mixtral-8x7B-v0.1` which can be used for chat-based inference.
For more details please read our [release blog post](https://mistral.ai/news/mixtral-of-experts/)
### License
`Mixtral-8x7B` is released under the Apache 2.0 license.
## Usage tips
`Mixtral-8x7B` can be found on the [Huggingface Hub](https://huggingface.co/mistralai)
These ready-to-use checkpoints can be downloaded and used via the HuggingFace Hub:
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-8x7B")
>>> prompt = "My favourite condiment is"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"The expected output"
```
To use the raw checkpoints with HuggingFace you can use the `convert_mixtral_weights_to_hf.py` script to convert them to the HuggingFace format:
```bash
python src/transformers/models/mixtral/convert_mixtral_weights_to_hf.py \
--input_dir /path/to/downloaded/mistral/weights --output_dir /output/path
```
You can then load the converted model from the `output/path`:
```python
from transformers import MixtralForCausalLM, LlamaTokenizer
tokenizer = LlamaTokenizer.from_pretrained("/output/path")
model = MixtralForCausalLM.from_pretrained("/output/path")
```
## Combining Mixtral and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
```bash
pip install -U flash-attn --no-build-isolation
```
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of [`flash-attn`](https://github.com/Dao-AILab/flash-attention) repository. Make also sure to load your model in half-precision (e.g. `torch.float16`)
To load and run a model using Flash Attention 2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
>>> prompt = "My favourite condiment is"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"The expected output"
```
### Expected speedups
Below is a expected speedup diagram that compares pure inference time between the native implementation in transformers using `mistralai/Mixtral-8x7B-v0.1` checkpoint and the Flash Attention 2 version of the model.
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/mixtral-7b-inference-large-seqlen.png">
</div>
### Sliding window Attention
The current implementation supports the sliding window attention mechanism and memory efficient cache management.
To enable sliding window attention, just make sure to have a `flash-attn` version that is compatible with sliding window attention (`>=2.3.0`).
The Flash Attention-2 model uses also a more memory efficient cache slicing mechanism - as recommended per the official implementation of Mistral model that use rolling cache mechanism we keep the cache size fixed (`self.config.sliding_window`), support batched generation only for `padding_side="left"` and use the absolute position of the current token to compute the positional embedding.
## The Mistral Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
## MixtralConfig
[[autodoc]] MixtralConfig
## MixtralModel
[[autodoc]] MixtralModel
- forward
## MixtralForCausalLM
[[autodoc]] MixtralForCausalLM
- forward
## MixtralForSequenceClassification
[[autodoc]] MixtralForSequenceClassification
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/mixtral.md |
--
title: Mahalanobis Distance
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
Compute the Mahalanobis Distance
Mahalonobis distance is the distance between a point and a distribution.
And not between two distinct points. It is effectively a multivariate equivalent of the Euclidean distance.
It was introduced by Prof. P. C. Mahalanobis in 1936
and has been used in various statistical applications ever since
[source: https://www.machinelearningplus.com/statistics/mahalanobis-distance/]
---
# Metric Card for Mahalanobis Distance
## Metric Description
Mahalonobis distance is the distance between a point and a distribution (as opposed to the distance between two points), making it the multivariate equivalent of the Euclidean distance.
It is often used in multivariate anomaly detection, classification on highly imbalanced datasets and one-class classification.
## How to Use
At minimum, this metric requires two `list`s of datapoints:
```python
>>> mahalanobis_metric = evaluate.load("mahalanobis")
>>> results = mahalanobis_metric.compute(reference_distribution=[[0, 1], [1, 0]], X=[[0, 1]])
```
### Inputs
- `X` (`list`): data points to be compared with the `reference_distribution`.
- `reference_distribution` (`list`): data points from the reference distribution that we want to compare to.
### Output Values
`mahalanobis` (`array`): the Mahalonobis distance for each data point in `X`.
```python
>>> print(results)
{'mahalanobis': array([0.5])}
```
#### Values from Popular Papers
*N/A*
### Example
```python
>>> mahalanobis_metric = evaluate.load("mahalanobis")
>>> results = mahalanobis_metric.compute(reference_distribution=[[0, 1], [1, 0]], X=[[0, 1]])
>>> print(results)
{'mahalanobis': array([0.5])}
```
## Limitations and Bias
The Mahalanobis distance is only able to capture linear relationships between the variables, which means it cannot capture all types of outliers. Mahalanobis distance also fails to faithfully represent data that is highly skewed or multimodal.
## Citation
```bibtex
@inproceedings{mahalanobis1936generalized,
title={On the generalized distance in statistics},
author={Mahalanobis, Prasanta Chandra},
year={1936},
organization={National Institute of Science of India}
}
```
```bibtex
@article{de2000mahalanobis,
title={The Mahalanobis distance},
author={De Maesschalck, Roy and Jouan-Rimbaud, Delphine and Massart, D{\'e}sir{\'e} L},
journal={Chemometrics and intelligent laboratory systems},
volume={50},
number={1},
pages={1--18},
year={2000},
publisher={Elsevier}
}
```
## Further References
-[Wikipedia -- Mahalanobis Distance](https://en.wikipedia.org/wiki/Mahalanobis_distance)
-[Machine Learning Plus -- Mahalanobis Distance](https://www.machinelearningplus.com/statistics/mahalanobis-distance/)
| huggingface/evaluate/blob/main/metrics/mahalanobis/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Custom Tools and Prompts
<Tip>
If you are not aware of what tools and agents are in the context of transformers, we recommend you read the
[Transformers Agents](transformers_agents) page first.
</Tip>
<Tip warning={true}>
Transformers Agents is an experimental API that is subject to change at any time. Results returned by the agents
can vary as the APIs or underlying models are prone to change.
</Tip>
Creating and using custom tools and prompts is paramount to empowering the agent and having it perform new tasks.
In this guide we'll take a look at:
- How to customize the prompt
- How to use custom tools
- How to create custom tools
## Customizing the prompt
As explained in [Transformers Agents](transformers_agents) agents can run in [`~Agent.run`] and [`~Agent.chat`] mode.
Both the `run` and `chat` modes underlie the same logic. The language model powering the agent is conditioned on a long
prompt and completes the prompt by generating the next tokens until the stop token is reached.
The only difference between the two modes is that during the `chat` mode the prompt is extended with
previous user inputs and model generations. This allows the agent to have access to past interactions,
seemingly giving the agent some kind of memory.
### Structure of the prompt
Let's take a closer look at how the prompt is structured to understand how it can be best customized.
The prompt is structured broadly into four parts.
- 1. Introduction: how the agent should behave, explanation of the concept of tools.
- 2. Description of all the tools. This is defined by a `<<all_tools>>` token that is dynamically replaced at runtime with the tools defined/chosen by the user.
- 3. A set of examples of tasks and their solution
- 4. Current example, and request for solution.
To better understand each part, let's look at a shortened version of how the `run` prompt can look like:
````text
I will ask you to perform a task, your job is to come up with a series of simple commands in Python that will perform the task.
[...]
You can print intermediate results if it makes sense to do so.
Tools:
- document_qa: This is a tool that answers a question about a document (pdf). It takes an input named `document` which should be the document containing the information, as well as a `question` that is the question about the document. It returns a text that contains the answer to the question.
- image_captioner: This is a tool that generates a description of an image. It takes an input named `image` which should be the image to the caption and returns a text that contains the description in English.
[...]
Task: "Answer the question in the variable `question` about the image stored in the variable `image`. The question is in French."
I will use the following tools: `translator` to translate the question into English and then `image_qa` to answer the question on the input image.
Answer:
```py
translated_question = translator(question=question, src_lang="French", tgt_lang="English")
print(f"The translated question is {translated_question}.")
answer = image_qa(image=image, question=translated_question)
print(f"The answer is {answer}")
```
Task: "Identify the oldest person in the `document` and create an image showcasing the result as a banner."
I will use the following tools: `document_qa` to find the oldest person in the document, then `image_generator` to generate an image according to the answer.
Answer:
```py
answer = document_qa(document, question="What is the oldest person?")
print(f"The answer is {answer}.")
image = image_generator("A banner showing " + answer)
```
[...]
Task: "Draw me a picture of rivers and lakes"
I will use the following
````
The introduction (the text before *"Tools:"*) explains precisely how the model shall behave and what it should do.
This part most likely does not need to be customized as the agent shall always behave the same way.
The second part (the bullet points below *"Tools"*) is dynamically added upon calling `run` or `chat`. There are
exactly as many bullet points as there are tools in `agent.toolbox` and each bullet point consists of the name
and description of the tool:
```text
- <tool.name>: <tool.description>
```
Let's verify this quickly by loading the document_qa tool and printing out the name and description.
```py
from transformers import load_tool
document_qa = load_tool("document-question-answering")
print(f"- {document_qa.name}: {document_qa.description}")
```
which gives:
```text
- document_qa: This is a tool that answers a question about a document (pdf). It takes an input named `document` which should be the document containing the information, as well as a `question` that is the question about the document. It returns a text that contains the answer to the question.
```
We can see that the tool name is short and precise. The description includes two parts, the first explaining
what the tool does and the second states what input arguments and return values are expected.
A good tool name and tool description are very important for the agent to correctly use it. Note that the only
information the agent has about the tool is its name and description, so one should make sure that both
are precisely written and match the style of the existing tools in the toolbox. In particular make sure the description
mentions all the arguments expected by name in code-style, along with the expected type and a description of what they
are.
<Tip>
Check the naming and description of the curated Transformers tools to better understand what name and
description a tool is expected to have. You can see all tools with the [`Agent.toolbox`] property.
</Tip>
The third part includes a set of curated examples that show the agent exactly what code it should produce
for what kind of user request. The large language models empowering the agent are extremely good at
recognizing patterns in a prompt and repeating the pattern with new data. Therefore, it is very important
that the examples are written in a way that maximizes the likelihood of the agent to generating correct,
executable code in practice.
Let's have a look at one example:
````text
Task: "Identify the oldest person in the `document` and create an image showcasing the result as a banner."
I will use the following tools: `document_qa` to find the oldest person in the document, then `image_generator` to generate an image according to the answer.
Answer:
```py
answer = document_qa(document, question="What is the oldest person?")
print(f"The answer is {answer}.")
image = image_generator("A banner showing " + answer)
```
````
The pattern the model is prompted to repeat has three parts: The task statement, the agent's explanation of
what it intends to do, and finally the generated code. Every example that is part of the prompt has this exact
pattern, thus making sure that the agent will reproduce exactly the same pattern when generating new tokens.
The prompt examples are curated by the Transformers team and rigorously evaluated on a set of
[problem statements](https://github.com/huggingface/transformers/blob/main/src/transformers/tools/evaluate_agent.py)
to ensure that the agent's prompt is as good as possible to solve real use cases of the agent.
The final part of the prompt corresponds to:
```text
Task: "Draw me a picture of rivers and lakes"
I will use the following
```
is a final and unfinished example that the agent is tasked to complete. The unfinished example
is dynamically created based on the actual user input. For the above example, the user ran:
```py
agent.run("Draw me a picture of rivers and lakes")
```
The user input - *a.k.a* the task: *"Draw me a picture of rivers and lakes"* is cast into the
prompt template: "Task: <task> \n\n I will use the following". This sentence makes up the final lines of the
prompt the agent is conditioned on, therefore strongly influencing the agent to finish the example
exactly in the same way it was previously done in the examples.
Without going into too much detail, the chat template has the same prompt structure with the
examples having a slightly different style, *e.g.*:
````text
[...]
=====
Human: Answer the question in the variable `question` about the image stored in the variable `image`.
Assistant: I will use the tool `image_qa` to answer the question on the input image.
```py
answer = image_qa(text=question, image=image)
print(f"The answer is {answer}")
```
Human: I tried this code, it worked but didn't give me a good result. The question is in French
Assistant: In this case, the question needs to be translated first. I will use the tool `translator` to do this.
```py
translated_question = translator(question=question, src_lang="French", tgt_lang="English")
print(f"The translated question is {translated_question}.")
answer = image_qa(text=translated_question, image=image)
print(f"The answer is {answer}")
```
=====
[...]
````
Contrary, to the examples of the `run` prompt, each `chat` prompt example has one or more exchanges between the
*Human* and the *Assistant*. Every exchange is structured similarly to the example of the `run` prompt.
The user's input is appended to behind *Human:* and the agent is prompted to first generate what needs to be done
before generating code. An exchange can be based on previous exchanges, therefore allowing the user to refer
to past exchanges as is done *e.g.* above by the user's input of "I tried **this** code" refers to the
previously generated code of the agent.
Upon running `.chat`, the user's input or *task* is cast into an unfinished example of the form:
```text
Human: <user-input>\n\nAssistant:
```
which the agent completes. Contrary to the `run` command, the `chat` command then appends the completed example
to the prompt, thus giving the agent more context for the next `chat` turn.
Great now that we know how the prompt is structured, let's see how we can customize it!
### Writing good user inputs
While large language models are getting better and better at understanding users' intentions, it helps
enormously to be as precise as possible to help the agent pick the correct task. What does it mean to be
as precise as possible?
The agent sees a list of tool names and their description in its prompt. The more tools are added the
more difficult it becomes for the agent to choose the correct tool and it's even more difficult to choose
the correct sequences of tools to run. Let's look at a common failure case, here we will only return
the code to analyze it.
```py
from transformers import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
agent.run("Show me a tree", return_code=True)
```
gives:
```text
==Explanation from the agent==
I will use the following tool: `image_segmenter` to create a segmentation mask for the image.
==Code generated by the agent==
mask = image_segmenter(image, prompt="tree")
```
which is probably not what we wanted. Instead, it is more likely that we want an image of a tree to be generated.
To steer the agent more towards using a specific tool it can therefore be very helpful to use important keywords that
are present in the tool's name and description. Let's have a look.
```py
agent.toolbox["image_generator"].description
```
```text
'This is a tool that creates an image according to a prompt, which is a text description. It takes an input named `prompt` which contains the image description and outputs an image.
```
The name and description make use of the keywords "image", "prompt", "create" and "generate". Using these words will most likely work better here. Let's refine our prompt a bit.
```py
agent.run("Create an image of a tree", return_code=True)
```
gives:
```text
==Explanation from the agent==
I will use the following tool `image_generator` to generate an image of a tree.
==Code generated by the agent==
image = image_generator(prompt="tree")
```
Much better! That looks more like what we want. In short, when you notice that the agent struggles to
correctly map your task to the correct tools, try looking up the most pertinent keywords of the tool's name
and description and try refining your task request with it.
### Customizing the tool descriptions
As we've seen before the agent has access to each of the tools' names and descriptions. The base tools
should have very precise names and descriptions, however, you might find that it could help to change the
the description or name of a tool for your specific use case. This might become especially important
when you've added multiple tools that are very similar or if you want to use your agent only for a certain
domain, *e.g.* image generation and transformations.
A common problem is that the agent confuses image generation with image transformation/modification when
used a lot for image generation tasks, *e.g.*
```py
agent.run("Make an image of a house and a car", return_code=True)
```
returns
```text
==Explanation from the agent==
I will use the following tools `image_generator` to generate an image of a house and `image_transformer` to transform the image of a car into the image of a house.
==Code generated by the agent==
house_image = image_generator(prompt="A house")
car_image = image_generator(prompt="A car")
house_car_image = image_transformer(image=car_image, prompt="A house")
```
which is probably not exactly what we want here. It seems like the agent has a difficult time
to understand the difference between `image_generator` and `image_transformer` and often uses the two together.
We can help the agent here by changing the tool name and description of `image_transformer`. Let's instead call it `modifier`
to disassociate it a bit from "image" and "prompt":
```py
agent.toolbox["modifier"] = agent.toolbox.pop("image_transformer")
agent.toolbox["modifier"].description = agent.toolbox["modifier"].description.replace(
"transforms an image according to a prompt", "modifies an image"
)
```
Now "modify" is a strong cue to use the new image processor which should help with the above prompt. Let's run it again.
```py
agent.run("Make an image of a house and a car", return_code=True)
```
Now we're getting:
```text
==Explanation from the agent==
I will use the following tools: `image_generator` to generate an image of a house, then `image_generator` to generate an image of a car.
==Code generated by the agent==
house_image = image_generator(prompt="A house")
car_image = image_generator(prompt="A car")
```
which is definitely closer to what we had in mind! However, we want to have both the house and car in the same image. Steering the task more toward single image generation should help:
```py
agent.run("Create image: 'A house and car'", return_code=True)
```
```text
==Explanation from the agent==
I will use the following tool: `image_generator` to generate an image.
==Code generated by the agent==
image = image_generator(prompt="A house and car")
```
<Tip warning={true}>
Agents are still brittle for many use cases, especially when it comes to
slightly more complex use cases like generating an image of multiple objects.
Both the agent itself and the underlying prompt will be further improved in the coming
months making sure that agents become more robust to a variety of user inputs.
</Tip>
### Customizing the whole prompt
To give the user maximum flexibility, the whole prompt template as explained in [above](#structure-of-the-prompt)
can be overwritten by the user. In this case make sure that your custom prompt includes an introduction section,
a tool section, an example section, and an unfinished example section. If you want to overwrite the `run` prompt template,
you can do as follows:
```py
template = """ [...] """
agent = HfAgent(your_endpoint, run_prompt_template=template)
```
<Tip warning={true}>
Please make sure to have the `<<all_tools>>` string and the `<<prompt>>` defined somewhere in the `template` so that the agent can be aware
of the tools, it has available to it as well as correctly insert the user's prompt.
</Tip>
Similarly, one can overwrite the `chat` prompt template. Note that the `chat` mode always uses the following format for the exchanges:
```text
Human: <<task>>
Assistant:
```
Therefore it is important that the examples of the custom `chat` prompt template also make use of this format.
You can overwrite the `chat` template at instantiation as follows.
```
template = """ [...] """
agent = HfAgent(url_endpoint=your_endpoint, chat_prompt_template=template)
```
<Tip warning={true}>
Please make sure to have the `<<all_tools>>` string defined somewhere in the `template` so that the agent can be aware
of the tools, it has available to it.
</Tip>
In both cases, you can pass a repo ID instead of the prompt template if you would like to use a template hosted by someone in the community. The default prompts live in [this repo](https://huggingface.co/datasets/huggingface-tools/default-prompts) as an example.
To upload your custom prompt on a repo on the Hub and share it with the community just make sure:
- to use a dataset repository
- to put the prompt template for the `run` command in a file named `run_prompt_template.txt`
- to put the prompt template for the `chat` command in a file named `chat_prompt_template.txt`
## Using custom tools
In this section, we'll be leveraging two existing custom tools that are specific to image generation:
- We replace [huggingface-tools/image-transformation](https://huggingface.co/spaces/huggingface-tools/image-transformation),
with [diffusers/controlnet-canny-tool](https://huggingface.co/spaces/diffusers/controlnet-canny-tool)
to allow for more image modifications.
- We add a new tool for image upscaling to the default toolbox:
[diffusers/latent-upscaler-tool](https://huggingface.co/spaces/diffusers/latent-upscaler-tool) replace the existing image-transformation tool.
We'll start by loading the custom tools with the convenient [`load_tool`] function:
```py
from transformers import load_tool
controlnet_transformer = load_tool("diffusers/controlnet-canny-tool")
upscaler = load_tool("diffusers/latent-upscaler-tool")
```
Upon adding custom tools to an agent, the tools' descriptions and names are automatically
included in the agents' prompts. Thus, it is imperative that custom tools have
a well-written description and name in order for the agent to understand how to use them.
Let's take a look at the description and name of `controlnet_transformer`:
```py
print(f"Description: '{controlnet_transformer.description}'")
print(f"Name: '{controlnet_transformer.name}'")
```
gives
```text
Description: 'This is a tool that transforms an image with ControlNet according to a prompt.
It takes two inputs: `image`, which should be the image to transform, and `prompt`, which should be the prompt to use to change it. It returns the modified image.'
Name: 'image_transformer'
```
The name and description are accurate and fit the style of the [curated set of tools](./transformers_agents#a-curated-set-of-tools).
Next, let's instantiate an agent with `controlnet_transformer` and `upscaler`:
```py
tools = [controlnet_transformer, upscaler]
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder", additional_tools=tools)
```
This command should give you the following info:
```text
image_transformer has been replaced by <transformers_modules.diffusers.controlnet-canny-tool.bd76182c7777eba9612fc03c0
8718a60c0aa6312.image_transformation.ControlNetTransformationTool object at 0x7f1d3bfa3a00> as provided in `additional_tools`
```
The set of curated tools already has an `image_transformer` tool which is hereby replaced with our custom tool.
<Tip>
Overwriting existing tools can be beneficial if we want to use a custom tool exactly for the same task as an existing tool
because the agent is well-versed in using the specific task. Beware that the custom tool should follow the exact same API
as the overwritten tool in this case, or you should adapt the prompt template to make sure all examples using that
tool are updated.
</Tip>
The upscaler tool was given the name `image_upscaler` which is not yet present in the default toolbox and is therefore simply added to the list of tools.
You can always have a look at the toolbox that is currently available to the agent via the `agent.toolbox` attribute:
```py
print("\n".join([f"- {a}" for a in agent.toolbox.keys()]))
```
```text
- document_qa
- image_captioner
- image_qa
- image_segmenter
- transcriber
- summarizer
- text_classifier
- text_qa
- text_reader
- translator
- image_transformer
- text_downloader
- image_generator
- video_generator
- image_upscaler
```
Note how `image_upscaler` is now part of the agents' toolbox.
Let's now try out the new tools! We will re-use the image we generated in [Transformers Agents Quickstart](./transformers_agents#single-execution-run).
```py
from diffusers.utils import load_image
image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png"
)
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png" width=200>
Let's transform the image into a beautiful winter landscape:
```py
image = agent.run("Transform the image: 'A frozen lake and snowy forest'", image=image)
```
```text
==Explanation from the agent==
I will use the following tool: `image_transformer` to transform the image.
==Code generated by the agent==
image = image_transformer(image, prompt="A frozen lake and snowy forest")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes_winter.png" width=200>
The new image processing tool is based on ControlNet which can make very strong modifications to the image.
By default the image processing tool returns an image of size 512x512 pixels. Let's see if we can upscale it.
```py
image = agent.run("Upscale the image", image)
```
```text
==Explanation from the agent==
I will use the following tool: `image_upscaler` to upscale the image.
==Code generated by the agent==
upscaled_image = image_upscaler(image)
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes_winter_upscale.png" width=400>
The agent automatically mapped our prompt "Upscale the image" to the just added upscaler tool purely based on the description and name of the upscaler tool
and was able to correctly run it.
Next, let's have a look at how you can create a new custom tool.
### Adding new tools
In this section, we show how to create a new tool that can be added to the agent.
#### Creating a new tool
We'll first start by creating a tool. We'll add the not-so-useful yet fun task of fetching the model on the Hugging Face
Hub with the most downloads for a given task.
We can do that with the following code:
```python
from huggingface_hub import list_models
task = "text-classification"
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
print(model.id)
```
For the task `text-classification`, this returns `'facebook/bart-large-mnli'`, for `translation` it returns `'t5-base`.
How do we convert this to a tool that the agent can leverage? All tools depend on the superclass `Tool` that holds the
main attributes necessary. We'll create a class that inherits from it:
```python
from transformers import Tool
class HFModelDownloadsTool(Tool):
pass
```
This class has a few needs:
- An attribute `name`, which corresponds to the name of the tool itself. To be in tune with other tools which have a
performative name, we'll name it `model_download_counter`.
- An attribute `description`, which will be used to populate the prompt of the agent.
- `inputs` and `outputs` attributes. Defining this will help the python interpreter make educated choices about types,
and will allow for a gradio-demo to be spawned when we push our tool to the Hub. They're both a list of expected
values, which can be `text`, `image`, or `audio`.
- A `__call__` method which contains the inference code. This is the code we've played with above!
Here's what our class looks like now:
```python
from transformers import Tool
from huggingface_hub import list_models
class HFModelDownloadsTool(Tool):
name = "model_download_counter"
description = (
"This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub. "
"It takes the name of the category (such as text-classification, depth-estimation, etc), and "
"returns the name of the checkpoint."
)
inputs = ["text"]
outputs = ["text"]
def __call__(self, task: str):
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
return model.id
```
We now have our tool handy. Save it in a file and import it from your main script. Let's name this file
`model_downloads.py`, so the resulting import code looks like this:
```python
from model_downloads import HFModelDownloadsTool
tool = HFModelDownloadsTool()
```
In order to let others benefit from it and for simpler initialization, we recommend pushing it to the Hub under your
namespace. To do so, just call `push_to_hub` on the `tool` variable:
```python
tool.push_to_hub("hf-model-downloads")
```
You now have your code on the Hub! Let's take a look at the final step, which is to have the agent use it.
#### Having the agent use the tool
We now have our tool that lives on the Hub which can be instantiated as such (change the user name for your tool):
```python
from transformers import load_tool
tool = load_tool("lysandre/hf-model-downloads")
```
In order to use it in the agent, simply pass it in the `additional_tools` parameter of the agent initialization method:
```python
from transformers import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder", additional_tools=[tool])
agent.run(
"Can you read out loud the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub?"
)
```
which outputs the following:
```text
==Code generated by the agent==
model = model_download_counter(task="text-to-video")
print(f"The model with the most downloads is {model}.")
audio_model = text_reader(model)
==Result==
The model with the most downloads is damo-vilab/text-to-video-ms-1.7b.
```
and generates the following audio.
| **Audio** |
|------------------------------------------------------------------------------------------------------------------------------------------------------|
| <audio controls><source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/damo.wav" type="audio/wav"/> |
<Tip>
Depending on the LLM, some are quite brittle and require very exact prompts in order to work well. Having a well-defined
name and description of the tool is paramount to having it be leveraged by the agent.
</Tip>
### Replacing existing tools
Replacing existing tools can be done simply by assigning a new item to the agent's toolbox. Here's how one would do so:
```python
from transformers import HfAgent, load_tool
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
agent.toolbox["image-transformation"] = load_tool("diffusers/controlnet-canny-tool")
```
<Tip>
Beware when replacing tools with others! This will also adjust the agent's prompt. This can be good if you have a better
prompt suited for the task, but it can also result in your tool being selected way more than others or for other
tools to be selected instead of the one you have defined.
</Tip>
## Leveraging gradio-tools
[gradio-tools](https://github.com/freddyaboulton/gradio-tools) is a powerful library that allows using Hugging
Face Spaces as tools. It supports many existing Spaces as well as custom Spaces to be designed with it.
We offer support for `gradio_tools` by using the `Tool.from_gradio` method. For example, we want to take
advantage of the `StableDiffusionPromptGeneratorTool` tool offered in the `gradio-tools` toolkit so as to
improve our prompts and generate better images.
We first import the tool from `gradio_tools` and instantiate it:
```python
from gradio_tools import StableDiffusionPromptGeneratorTool
gradio_tool = StableDiffusionPromptGeneratorTool()
```
We pass that instance to the `Tool.from_gradio` method:
```python
from transformers import Tool
tool = Tool.from_gradio(gradio_tool)
```
Now we can manage it exactly as we would a usual custom tool. We leverage it to improve our prompt
` a rabbit wearing a space suit`:
```python
from transformers import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder", additional_tools=[tool])
agent.run("Generate an image of the `prompt` after improving it.", prompt="A rabbit wearing a space suit")
```
The model adequately leverages the tool:
```text
==Explanation from the agent==
I will use the following tools: `StableDiffusionPromptGenerator` to improve the prompt, then `image_generator` to generate an image according to the improved prompt.
==Code generated by the agent==
improved_prompt = StableDiffusionPromptGenerator(prompt)
print(f"The improved prompt is {improved_prompt}.")
image = image_generator(improved_prompt)
```
Before finally generating the image:
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rabbit.png">
<Tip warning={true}>
gradio-tools requires *textual* inputs and outputs, even when working with different modalities. This implementation
works with image and audio objects. The two are currently incompatible, but will rapidly become compatible as we
work to improve the support.
</Tip>
## Future compatibility with Langchain
We love Langchain and think it has a very compelling suite of tools. In order to handle these tools,
Langchain requires *textual* inputs and outputs, even when working with different modalities.
This is often the serialized version (i.e., saved to disk) of the objects.
This difference means that multi-modality isn't handled between transformers-agents and langchain.
We aim for this limitation to be resolved in future versions, and welcome any help from avid langchain
users to help us achieve this compatibility.
We would love to have better support. If you would like to help, please
[open an issue](https://github.com/huggingface/transformers/issues/new) and share what you have in mind.
| huggingface/transformers/blob/main/docs/source/en/custom_tools.md |
Introduction to Deep Reinforcement Learning [[introduction-to-deep-reinforcement-learning]]
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/thumbnail.jpg" alt="Unit 1 thumbnail" width="100%">
Welcome to the most fascinating topic in Artificial Intelligence: **Deep Reinforcement Learning.**
Deep RL is a type of Machine Learning where an agent learns **how to behave** in an environment **by performing actions** and **seeing the results.**
In this first unit, **you'll learn the foundations of Deep Reinforcement Learning.**
Then, you'll **train your Deep Reinforcement Learning agent, a lunar lander to land correctly on the Moon** using <a href="https://stable-baselines3.readthedocs.io/en/master/"> Stable-Baselines3 </a>, a Deep Reinforcement Learning library.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/lunarLander.gif" alt="LunarLander">
And finally, you'll **upload this trained agent to the Hugging Face Hub 🤗, a free, open platform where people can share ML models, datasets, and demos.**
It's essential **to master these elements** before diving into implementing Deep Reinforcement Learning agents. The goal of this chapter is to give you solid foundations.
After this unit, in a bonus unit, you'll be **able to train Huggy the Dog 🐶 to fetch the stick and play with him 🤗**.
<video src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/huggy.mp4" type="video/mp4" controls autoplay loop mute />
So let's get started! 🚀
| huggingface/deep-rl-class/blob/main/units/en/unit1/introduction.mdx |
FrameworkSwitchCourse {fw} />
<!-- DISABLE-FRONTMATTER-SECTIONS -->
# End-of-chapter quiz[[end-of-chapter-quiz]]
<CourseFloatingBanner
chapter={7}
classNames="absolute z-10 right-0 top-0"
/>
Let's test what you learned in this chapter!
### 1. Which of the following tasks can be framed as a token classification problem?
<Question
choices={[
{
text: "Find the grammatical components in a sentence.",
explain: "Correct! We can then label each word as a noun, verb, etc.",
correct: true
},
{
text: "Find whether a sentence is grammatically correct or not.",
explain: "No, this is a sequence classification problem."
},
{
text: "Find the persons mentioned in a sentence.",
explain: "Correct! We can label each word as person or not person.",
correct: true
},
{
text: "Find the chunk of words in a sentence that answers a question.",
explain: "No, that would be a question answering problem."
}
]}
/>
### 2. What part of the preprocessing for token classification differs from the other preprocessing pipelines?
<Question
choices={[
{
text: "There is no need to do anything; the texts are already tokenized.",
explain: "The texts are indeed given as separate words, but we still need to apply the subword tokenization model."
},
{
text: "The texts are given as words, so we only need to apply subword tokenization.",
explain: "Correct! This is different from the usual preprocessing, where we need to apply the full tokenization pipeline. Can you think of another difference?",
correct: true
},
{
text: "We use <code>-100</code> to label the special tokens.",
explain: "That's not specific to token classification -- we always use <code>-100</code> as the label for tokens we want to ignore in the loss."
},
{
text: "We need to make sure to truncate or pad the labels to the same size as the inputs, when applying truncation/padding.",
explain: "Indeed! That's not the only difference, though.",
correct: true
}
]}
/>
### 3. What problem arises when we tokenize the words in a token classification problem and want to label the tokens?
<Question
choices={[
{
text: "The tokenizer adds special tokens and we have no labels for them.",
explain: "We label these <code>-100</code> so they are ignored in the loss."
},
{
text: "Each word can produce several tokens, so we end up with more tokens than we have labels.",
explain: "That is the main problem, and we need to align the original labels with the tokens.",
correct: true
},
{
text: "The added tokens have no labels, so there is no problem.",
explain: "That's incorrect; we need as many labels as we have tokens or our models will error out."
}
]}
/>
### 4. What does "domain adaptation" mean?
<Question
choices={[
{
text: "It's when we run a model on a dataset and get the predictions for each sample in that dataset.",
explain: "No, this is just running inference."
},
{
text: "It's when we train a model on a dataset.",
explain: "No, this is training a model; there is no adaptation here."
},
{
text: "It's when we fine-tune a pretrained model on a new dataset, and it gives predictions that are more adapted to that dataset",
explain: "Correct! The model adapted its knowledge to the new dataset.",
correct: true
},
{
text: "It's when we add misclassified samples to a dataset to make our model more robust.",
explain: "That's certainly something you should do if you retrain your model regularly, but it's not domain adaptation."
}
]}
/>
### 5. What are the labels in a masked language modeling problem?
<Question
choices={[
{
text: "Some of the tokens in the input sentence are randomly masked and the labels are the original input tokens.",
explain: "That's it!",
correct: true
},
{
text: "Some of the tokens in the input sentence are randomly masked and the labels are the original input tokens, shifted to the left.",
explain: "No, shifting the labels to the left corresponds to predicting the next word, which is causal language modeling."
},
{
text: "Some of the tokens in the input sentence are randomly masked, and the label is whether the sentence is positive or negative.",
explain: "That's a sequence classification problem with some data augmentation, not masked language modeling."
},
{
text: "Some of the tokens in the two input sentences are randomly masked, and the label is whether the two sentences are similar or not.",
explain: "That's a sequence classification problem with some data augmentation, not masked language modeling."
}
]}
/>
### 6. Which of these tasks can be seen as a sequence-to-sequence problem?
<Question
choices={[
{
text: "Writing short reviews of long documents",
explain: "Yes, that's a summarization problem. Try another answer!",
correct: true
},
{
text: "Answering questions about a document",
explain: "This can be framed as a sequence-to-sequence problem. It's not the only right answer, though.",
correct: true
},
{
text: "Translating a text in Chinese into English",
explain: "That's definitely a sequence-to-sequence problem. Can you spot another one?",
correct: true
},
{
text: "Fixing the messages sent by my nephew/friend so they're in proper English",
explain: "That's a kind of translation problem, so definitely a sequence-to-sequence task. This isn't the only right answer, though!",
correct: true
}
]}
/>
### 7. What is the proper way to preprocess the data for a sequence-to-sequence problem?
<Question
choices={[
{
text: "The inputs and targets have to be sent together to the tokenizer with <code>inputs=...</code> and <code>targets=...</code>.",
explain: "This might be an API we add in the future, but that's not possible right now."
},
{
text: "The inputs and the targets both have to be preprocessed, in two separate calls to the tokenizer.",
explain: "That is true, but incomplete. There is something you need to do to make sure the tokenizer processes both properly."
},
{
text: "As usual, we just have to tokenize the inputs.",
explain: "Not in a sequence classification problem; the targets are also texts we need to convert into numbers!"
},
{
text: "The inputs have to be sent to the tokenizer, and the targets too, but under a special context manager.",
explain: "That's correct, the tokenizer needs to be put into target mode by that context manager.",
correct: true
}
]}
/>
{#if fw === 'pt'}
### 8. Why is there a specific subclass of `Trainer` for sequence-to-sequence problems?
<Question
choices={[
{
text: "Because sequence-to-sequence problems use a custom loss, to ignore the labels set to <code>-100</code>",
explain: "That's not a custom loss at all, but the way the loss is always computed."
},
{
text: "Because sequence-to-sequence problems require a special evaluation loop",
explain: "That's correct. Sequence-to-sequence models' predictions are often run using the <code>generate()</code> method.",
correct: true
},
{
text: "Because the targets are texts in sequence-to-sequence problems",
explain: "The <code>Trainer</code> doesn't really care about that since they have been preprocessed before."
},
{
text: "Because we use two models in sequence-to-sequence problems",
explain: "We do use two models in a way, an encoder and a decoder, but they are grouped together in one model."
}
]}
/>
{:else}
### 9. Why is it often unnecessary to specify a loss when calling `compile()` on a Transformer model?
<Question
choices={[
{
text: "Because Transformer models are trained with unsupervised learning",
explain: "Not quite -- even unsupervised learning needs a loss function!"
},
{
text: "Because the model's internal loss output is used by default",
explain: "That's correct!",
correct: true
},
{
text: "Because we compute metrics after training instead",
explain: "We do often do that, but it doesn't explain where we get the loss value we optimize in training."
},
{
text: "Because loss is specified in `model.fit()` instead",
explain: "No, the loss function is always fixed once you run `model.compile()`, and can't be changed in `model.fit()`."
}
]}
/>
{/if}
### 10. When should you pretrain a new model?
<Question
choices={[
{
text: "When there is no pretrained model available for your specific language",
explain: "That's correct.",
correct: true
},
{
text: "When you have lots of data available, even if there is a pretrained model that could work on it",
explain: "In this case, you should probably use the pretrained model and fine-tune it on your data, to avoid huge compute costs."
},
{
text: "When you have concerns about the bias of the pretrained model you are using",
explain: "That is true, but you have to make very sure the data you will use for training is really better.",
correct: true
},
{
text: "When the pretrained models available are just not good enough",
explain: "Are you sure you've properly debugged your training, then?"
}
]}
/>
### 11. Why is it easy to pretrain a language model on lots and lots of texts?
<Question
choices={[
{
text: "Because there are plenty of texts available on the internet",
explain: "Although true, that doesn't really answer the question. Try again!"
},
{
text: "Because the pretraining objective does not require humans to label the data",
explain: "That's correct, language modeling is a self-supervised problem.",
correct: true
},
{
text: "Because the 🤗 Transformers library only requires a few lines of code to start the training",
explain: "Although true, that doesn't really answer the question asked. Try another answer!"
}
]}
/>
### 12. What are the main challenges when preprocessing data for a question answering task?
<Question
choices={[
{
text: "You need to tokenize the inputs.",
explain: "That's correct, but is it really a main challenge?"
},
{
text: "You need to deal with very long contexts, which give several training features that may or may not have the answer in them.",
explain: "This is definitely one of the challenges.",
correct: true
},
{
text: "You need to tokenize the answers to the question as well as the inputs.",
explain: "No, unless you are framing your question answering problem as a sequence-to-sequence task."
},
{
text: "From the answer span in the text, you have to find the start and end token in the tokenized input.",
explain: "That's one of the hard parts, yes!",
correct: true
}
]}
/>
### 13. How is post-processing usually done in question answering?
<Question
choices={[
{
text: "The model gives you the start and end positions of the answer, and you just have to decode the corresponding span of tokens.",
explain: "That could be one way to do it, but it's a bit too simplistic."
},
{
text: "The model gives you the start and end positions of the answer for each feature created by one example, and you just have to decode the corresponding span of tokens in the one that has the best score.",
explain: "That's close to the post-processing we studied, but it's not entirely right."
},
{
text: "The model gives you the start and end positions of the answer for each feature created by one example, and you just have to match them to the span in the context for the one that has the best score.",
explain: "That's it in a nutshell!",
correct: true
},
{
text: "The model generates an answer, and you just have to decode it.",
explain: "No, unless you are framing your question answering problem as a sequence-to-sequence task."
}
]}
/>
| huggingface/course/blob/main/chapters/en/chapter7/9.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Configuration
Schedulers from [`~schedulers.scheduling_utils.SchedulerMixin`] and models from [`ModelMixin`] inherit from [`ConfigMixin`] which stores all the parameters that are passed to their respective `__init__` methods in a JSON-configuration file.
<Tip>
To use private or [gated](https://huggingface.co/docs/hub/models-gated#gated-models) models, log-in with `huggingface-cli login`.
</Tip>
## ConfigMixin
[[autodoc]] ConfigMixin
- load_config
- from_config
- save_config
- to_json_file
- to_json_string
| huggingface/diffusers/blob/main/docs/source/en/api/configuration.md |
# Training an unconditional diffusion model
Creating a training image set is [described in a different document](https://huggingface.co/docs/datasets/image_process#image-datasets).
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
### Unconditional Flowers
The command to train a DDPM UNet model on the Oxford Flowers dataset:
```bash
accelerate launch train_unconditional.py \
--dataset_name="huggan/flowers-102-categories" \
--resolution=64 --center_crop --random_flip \
--output_dir="ddpm-ema-flowers-64" \
--train_batch_size=16 \
--num_epochs=100 \
--gradient_accumulation_steps=1 \
--use_ema \
--learning_rate=1e-4 \
--lr_warmup_steps=500 \
--mixed_precision=no \
--push_to_hub
```
An example trained model: https://huggingface.co/anton-l/ddpm-ema-flowers-64
A full training run takes 2 hours on 4xV100 GPUs.
<img src="https://user-images.githubusercontent.com/26864830/180248660-a0b143d0-b89a-42c5-8656-2ebf6ece7e52.png" width="700" />
### Unconditional Pokemon
The command to train a DDPM UNet model on the Pokemon dataset:
```bash
accelerate launch train_unconditional.py \
--dataset_name="huggan/pokemon" \
--resolution=64 --center_crop --random_flip \
--output_dir="ddpm-ema-pokemon-64" \
--train_batch_size=16 \
--num_epochs=100 \
--gradient_accumulation_steps=1 \
--use_ema \
--learning_rate=1e-4 \
--lr_warmup_steps=500 \
--mixed_precision=no \
--push_to_hub
```
An example trained model: https://huggingface.co/anton-l/ddpm-ema-pokemon-64
A full training run takes 2 hours on 4xV100 GPUs.
<img src="https://user-images.githubusercontent.com/26864830/180248200-928953b4-db38-48db-b0c6-8b740fe6786f.png" width="700" />
### Training with multiple GPUs
`accelerate` allows for seamless multi-GPU training. Follow the instructions [here](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
for running distributed training with `accelerate`. Here is an example command:
```bash
accelerate launch --mixed_precision="fp16" --multi_gpu train_unconditional.py \
--dataset_name="huggan/pokemon" \
--resolution=64 --center_crop --random_flip \
--output_dir="ddpm-ema-pokemon-64" \
--train_batch_size=16 \
--num_epochs=100 \
--gradient_accumulation_steps=1 \
--use_ema \
--learning_rate=1e-4 \
--lr_warmup_steps=500 \
--mixed_precision="fp16" \
--logger="wandb"
```
To be able to use Weights and Biases (`wandb`) as a logger you need to install the library: `pip install wandb`.
### Using your own data
To use your own dataset, there are 2 ways:
- you can either provide your own folder as `--train_data_dir`
- or you can upload your dataset to the hub (possibly as a private repo, if you prefer so), and simply pass the `--dataset_name` argument.
Below, we explain both in more detail.
#### Provide the dataset as a folder
If you provide your own folders with images, the script expects the following directory structure:
```bash
data_dir/xxx.png
data_dir/xxy.png
data_dir/[...]/xxz.png
```
In other words, the script will take care of gathering all images inside the folder. You can then run the script like this:
```bash
accelerate launch train_unconditional.py \
--train_data_dir <path-to-train-directory> \
<other-arguments>
```
Internally, the script will use the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature which will automatically turn the folders into 🤗 Dataset objects.
#### Upload your data to the hub, as a (possibly private) repo
It's very easy (and convenient) to upload your image dataset to the hub using the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature available in 🤗 Datasets. Simply do the following:
```python
from datasets import load_dataset
# example 1: local folder
dataset = load_dataset("imagefolder", data_dir="path_to_your_folder")
# example 2: local files (supported formats are tar, gzip, zip, xz, rar, zstd)
dataset = load_dataset("imagefolder", data_files="path_to_zip_file")
# example 3: remote files (supported formats are tar, gzip, zip, xz, rar, zstd)
dataset = load_dataset("imagefolder", data_files="https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip")
# example 4: providing several splits
dataset = load_dataset("imagefolder", data_files={"train": ["path/to/file1", "path/to/file2"], "test": ["path/to/file3", "path/to/file4"]})
```
`ImageFolder` will create an `image` column containing the PIL-encoded images.
Next, push it to the hub!
```python
# assuming you have ran the huggingface-cli login command in a terminal
dataset.push_to_hub("name_of_your_dataset")
# if you want to push to a private repo, simply pass private=True:
dataset.push_to_hub("name_of_your_dataset", private=True)
```
and that's it! You can now train your model by simply setting the `--dataset_name` argument to the name of your dataset on the hub.
More on this can also be found in [this blog post](https://huggingface.co/blog/image-search-datasets).
| huggingface/diffusers/blob/main/examples/unconditional_image_generation/README.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Benchmarks
<Tip warning={true}>
Hugging Face's Benchmarking tools are deprecated and it is advised to use external Benchmarking libraries to measure the speed
and memory complexity of Transformer models.
</Tip>
[[open-in-colab]]
Let's take a look at how 🤗 Transformers models can be benchmarked, best practices, and already available benchmarks.
A notebook explaining in more detail how to benchmark 🤗 Transformers models can be found [here](https://github.com/huggingface/notebooks/tree/main/examples/benchmark.ipynb).
## How to benchmark 🤗 Transformers models
The classes [`PyTorchBenchmark`] and [`TensorFlowBenchmark`] allow to flexibly benchmark 🤗 Transformers models. The benchmark classes allow us to measure the _peak memory usage_ and _required time_ for both _inference_ and _training_.
<Tip>
Hereby, _inference_ is defined by a single forward pass, and _training_ is defined by a single forward pass and
backward pass.
</Tip>
The benchmark classes [`PyTorchBenchmark`] and [`TensorFlowBenchmark`] expect an object of type [`PyTorchBenchmarkArguments`] and
[`TensorFlowBenchmarkArguments`], respectively, for instantiation. [`PyTorchBenchmarkArguments`] and [`TensorFlowBenchmarkArguments`] are data classes and contain all relevant configurations for their corresponding benchmark class. In the following example, it is shown how a BERT model of type _bert-base-cased_ can be benchmarked.
<frameworkcontent>
<pt>
```py
>>> from transformers import PyTorchBenchmark, PyTorchBenchmarkArguments
>>> args = PyTorchBenchmarkArguments(models=["bert-base-uncased"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512])
>>> benchmark = PyTorchBenchmark(args)
```
</pt>
<tf>
```py
>>> from transformers import TensorFlowBenchmark, TensorFlowBenchmarkArguments
>>> args = TensorFlowBenchmarkArguments(
... models=["bert-base-uncased"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512]
... )
>>> benchmark = TensorFlowBenchmark(args)
```
</tf>
</frameworkcontent>
Here, three arguments are given to the benchmark argument data classes, namely `models`, `batch_sizes`, and
`sequence_lengths`. The argument `models` is required and expects a `list` of model identifiers from the
[model hub](https://huggingface.co/models) The `list` arguments `batch_sizes` and `sequence_lengths` define
the size of the `input_ids` on which the model is benchmarked. There are many more parameters that can be configured
via the benchmark argument data classes. For more detail on these one can either directly consult the files
`src/transformers/benchmark/benchmark_args_utils.py`, `src/transformers/benchmark/benchmark_args.py` (for PyTorch)
and `src/transformers/benchmark/benchmark_args_tf.py` (for Tensorflow). Alternatively, running the following shell
commands from root will print out a descriptive list of all configurable parameters for PyTorch and Tensorflow
respectively.
<frameworkcontent>
<pt>
```bash
python examples/pytorch/benchmarking/run_benchmark.py --help
```
An instantiated benchmark object can then simply be run by calling `benchmark.run()`.
```py
>>> results = benchmark.run()
>>> print(results)
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
bert-base-uncased 8 8 0.006
bert-base-uncased 8 32 0.006
bert-base-uncased 8 128 0.018
bert-base-uncased 8 512 0.088
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
bert-base-uncased 8 8 1227
bert-base-uncased 8 32 1281
bert-base-uncased 8 128 1307
bert-base-uncased 8 512 1539
--------------------------------------------------------------------------------
==================== ENVIRONMENT INFORMATION ====================
- transformers_version: 2.11.0
- framework: PyTorch
- use_torchscript: False
- framework_version: 1.4.0
- python_version: 3.6.10
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-06-29
- time: 08:58:43.371351
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 32088
- use_gpu: True
- num_gpus: 1
- gpu: TITAN RTX
- gpu_ram_mb: 24217
- gpu_power_watts: 280.0
- gpu_performance_state: 2
- use_tpu: False
```
</pt>
<tf>
```bash
python examples/tensorflow/benchmarking/run_benchmark_tf.py --help
```
An instantiated benchmark object can then simply be run by calling `benchmark.run()`.
```py
>>> results = benchmark.run()
>>> print(results)
>>> results = benchmark.run()
>>> print(results)
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
bert-base-uncased 8 8 0.005
bert-base-uncased 8 32 0.008
bert-base-uncased 8 128 0.022
bert-base-uncased 8 512 0.105
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
bert-base-uncased 8 8 1330
bert-base-uncased 8 32 1330
bert-base-uncased 8 128 1330
bert-base-uncased 8 512 1770
--------------------------------------------------------------------------------
==================== ENVIRONMENT INFORMATION ====================
- transformers_version: 2.11.0
- framework: Tensorflow
- use_xla: False
- framework_version: 2.2.0
- python_version: 3.6.10
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-06-29
- time: 09:26:35.617317
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 32088
- use_gpu: True
- num_gpus: 1
- gpu: TITAN RTX
- gpu_ram_mb: 24217
- gpu_power_watts: 280.0
- gpu_performance_state: 2
- use_tpu: False
```
</tf>
</frameworkcontent>
By default, the _time_ and the _required memory_ for _inference_ are benchmarked. In the example output above the first
two sections show the result corresponding to _inference time_ and _inference memory_. In addition, all relevant
information about the computing environment, _e.g._ the GPU type, the system, the library versions, etc... are printed
out in the third section under _ENVIRONMENT INFORMATION_. This information can optionally be saved in a _.csv_ file
when adding the argument `save_to_csv=True` to [`PyTorchBenchmarkArguments`] and
[`TensorFlowBenchmarkArguments`] respectively. In this case, every section is saved in a separate
_.csv_ file. The path to each _.csv_ file can optionally be defined via the argument data classes.
Instead of benchmarking pre-trained models via their model identifier, _e.g._ `bert-base-uncased`, the user can
alternatively benchmark an arbitrary configuration of any available model class. In this case, a `list` of
configurations must be inserted with the benchmark args as follows.
<frameworkcontent>
<pt>
```py
>>> from transformers import PyTorchBenchmark, PyTorchBenchmarkArguments, BertConfig
>>> args = PyTorchBenchmarkArguments(
... models=["bert-base", "bert-384-hid", "bert-6-lay"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512]
... )
>>> config_base = BertConfig()
>>> config_384_hid = BertConfig(hidden_size=384)
>>> config_6_lay = BertConfig(num_hidden_layers=6)
>>> benchmark = PyTorchBenchmark(args, configs=[config_base, config_384_hid, config_6_lay])
>>> benchmark.run()
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
bert-base 8 128 0.006
bert-base 8 512 0.006
bert-base 8 128 0.018
bert-base 8 512 0.088
bert-384-hid 8 8 0.006
bert-384-hid 8 32 0.006
bert-384-hid 8 128 0.011
bert-384-hid 8 512 0.054
bert-6-lay 8 8 0.003
bert-6-lay 8 32 0.004
bert-6-lay 8 128 0.009
bert-6-lay 8 512 0.044
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
bert-base 8 8 1277
bert-base 8 32 1281
bert-base 8 128 1307
bert-base 8 512 1539
bert-384-hid 8 8 1005
bert-384-hid 8 32 1027
bert-384-hid 8 128 1035
bert-384-hid 8 512 1255
bert-6-lay 8 8 1097
bert-6-lay 8 32 1101
bert-6-lay 8 128 1127
bert-6-lay 8 512 1359
--------------------------------------------------------------------------------
==================== ENVIRONMENT INFORMATION ====================
- transformers_version: 2.11.0
- framework: PyTorch
- use_torchscript: False
- framework_version: 1.4.0
- python_version: 3.6.10
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-06-29
- time: 09:35:25.143267
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 32088
- use_gpu: True
- num_gpus: 1
- gpu: TITAN RTX
- gpu_ram_mb: 24217
- gpu_power_watts: 280.0
- gpu_performance_state: 2
- use_tpu: False
```
</pt>
<tf>
```py
>>> from transformers import TensorFlowBenchmark, TensorFlowBenchmarkArguments, BertConfig
>>> args = TensorFlowBenchmarkArguments(
... models=["bert-base", "bert-384-hid", "bert-6-lay"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512]
... )
>>> config_base = BertConfig()
>>> config_384_hid = BertConfig(hidden_size=384)
>>> config_6_lay = BertConfig(num_hidden_layers=6)
>>> benchmark = TensorFlowBenchmark(args, configs=[config_base, config_384_hid, config_6_lay])
>>> benchmark.run()
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
bert-base 8 8 0.005
bert-base 8 32 0.008
bert-base 8 128 0.022
bert-base 8 512 0.106
bert-384-hid 8 8 0.005
bert-384-hid 8 32 0.007
bert-384-hid 8 128 0.018
bert-384-hid 8 512 0.064
bert-6-lay 8 8 0.002
bert-6-lay 8 32 0.003
bert-6-lay 8 128 0.0011
bert-6-lay 8 512 0.074
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
bert-base 8 8 1330
bert-base 8 32 1330
bert-base 8 128 1330
bert-base 8 512 1770
bert-384-hid 8 8 1330
bert-384-hid 8 32 1330
bert-384-hid 8 128 1330
bert-384-hid 8 512 1540
bert-6-lay 8 8 1330
bert-6-lay 8 32 1330
bert-6-lay 8 128 1330
bert-6-lay 8 512 1540
--------------------------------------------------------------------------------
==================== ENVIRONMENT INFORMATION ====================
- transformers_version: 2.11.0
- framework: Tensorflow
- use_xla: False
- framework_version: 2.2.0
- python_version: 3.6.10
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-06-29
- time: 09:38:15.487125
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 32088
- use_gpu: True
- num_gpus: 1
- gpu: TITAN RTX
- gpu_ram_mb: 24217
- gpu_power_watts: 280.0
- gpu_performance_state: 2
- use_tpu: False
```
</tf>
</frameworkcontent>
Again, _inference time_ and _required memory_ for _inference_ are measured, but this time for customized configurations
of the `BertModel` class. This feature can especially be helpful when deciding for which configuration the model
should be trained.
## Benchmark best practices
This section lists a couple of best practices one should be aware of when benchmarking a model.
- Currently, only single device benchmarking is supported. When benchmarking on GPU, it is recommended that the user
specifies on which device the code should be run by setting the `CUDA_VISIBLE_DEVICES` environment variable in the
shell, _e.g._ `export CUDA_VISIBLE_DEVICES=0` before running the code.
- The option `no_multi_processing` should only be set to `True` for testing and debugging. To ensure accurate
memory measurement it is recommended to run each memory benchmark in a separate process by making sure
`no_multi_processing` is set to `True`.
- One should always state the environment information when sharing the results of a model benchmark. Results can vary
heavily between different GPU devices, library versions, etc., so that benchmark results on their own are not very
useful for the community.
## Sharing your benchmark
Previously all available core models (10 at the time) have been benchmarked for _inference time_, across many different
settings: using PyTorch, with and without TorchScript, using TensorFlow, with and without XLA. All of those tests were
done across CPUs (except for TensorFlow XLA) and GPUs.
The approach is detailed in the [following blogpost](https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2) and the results are
available [here](https://docs.google.com/spreadsheets/d/1sryqufw2D0XlUH4sq3e9Wnxu5EAQkaohzrJbd5HdQ_w/edit?usp=sharing).
With the new _benchmark_ tools, it is easier than ever to share your benchmark results with the community
- [PyTorch Benchmarking Results](https://github.com/huggingface/transformers/tree/main/examples/pytorch/benchmarking/README.md).
- [TensorFlow Benchmarking Results](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/benchmarking/README.md).
| huggingface/transformers/blob/main/docs/source/en/benchmarks.md |
Gradio Demo: hangman
```
!pip install -q gradio
```
```
import gradio as gr
secret_word = "gradio"
with gr.Blocks() as demo:
used_letters_var = gr.State([])
with gr.Row() as row:
with gr.Column():
input_letter = gr.Textbox(label="Enter letter")
btn = gr.Button("Guess Letter")
with gr.Column():
hangman = gr.Textbox(
label="Hangman",
value="_"*len(secret_word)
)
used_letters_box = gr.Textbox(label="Used Letters")
def guess_letter(letter, used_letters):
used_letters.append(letter)
answer = "".join([
(letter if letter in used_letters else "_")
for letter in secret_word
])
return {
used_letters_var: used_letters,
used_letters_box: ", ".join(used_letters),
hangman: answer
}
btn.click(
guess_letter,
[input_letter, used_letters_var],
[used_letters_var, used_letters_box, hangman]
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/hangman/run.ipynb |
The 4 Kinds of Gradio Interfaces
So far, we've always assumed that in order to build an Gradio demo, you need both inputs and outputs. But this isn't always the case for machine learning demos: for example, _unconditional image generation models_ don't take any input but produce an image as the output.
It turns out that the `gradio.Interface` class can actually handle 4 different kinds of demos:
1. **Standard demos**: which have both separate inputs and outputs (e.g. an image classifier or speech-to-text model)
2. **Output-only demos**: which don't take any input but produce on output (e.g. an unconditional image generation model)
3. **Input-only demos**: which don't produce any output but do take in some sort of input (e.g. a demo that saves images that you upload to a persistent external database)
4. **Unified demos**: which have both input and output components, but the input and output components _are the same_. This means that the output produced overrides the input (e.g. a text autocomplete model)
Depending on the kind of demo, the user interface (UI) looks slightly different:
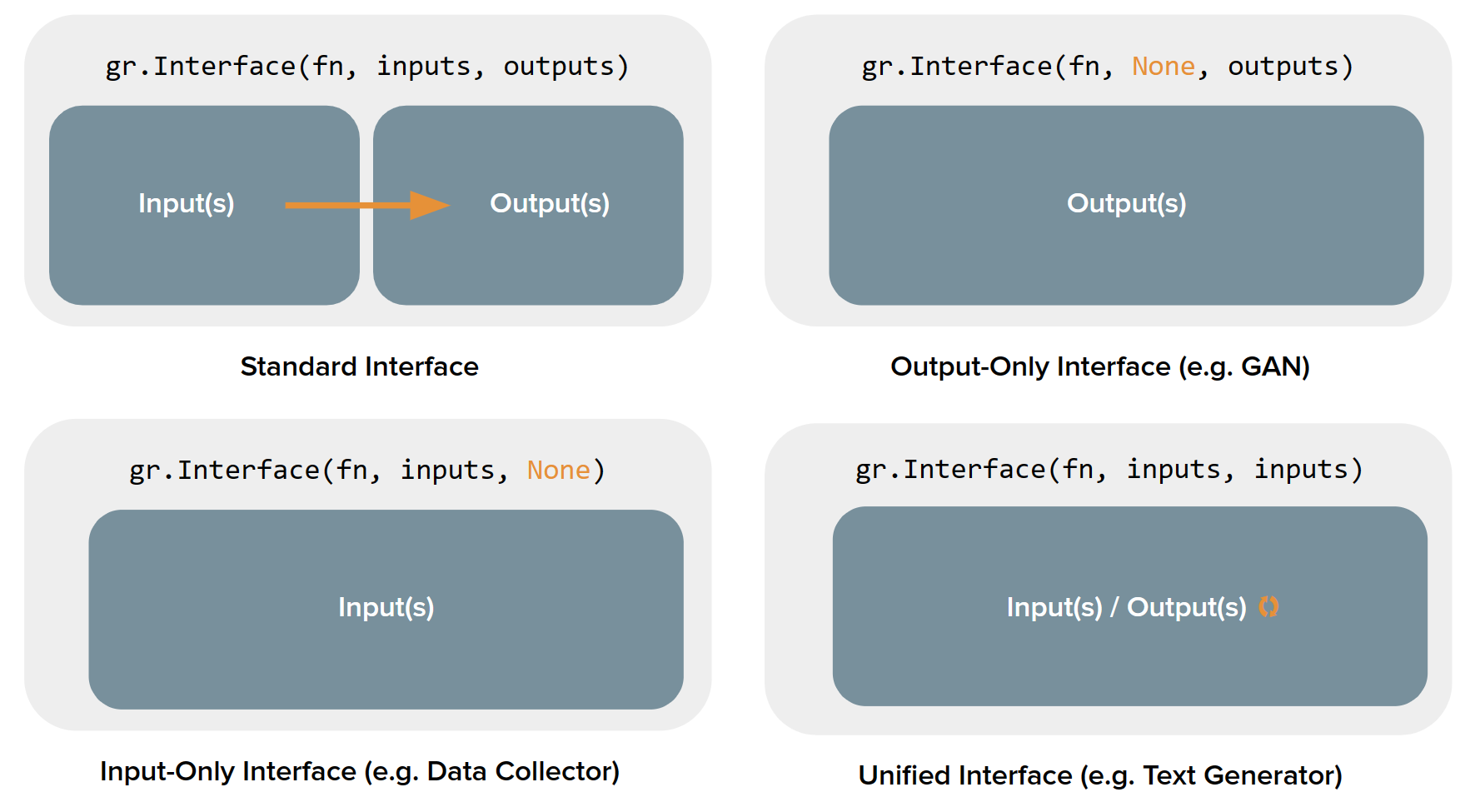
Let's see how to build each kind of demo using the `Interface` class, along with examples:
## Standard demos
To create a demo that has both the input and the output components, you simply need to set the values of the `inputs` and `outputs` parameter in `Interface()`. Here's an example demo of a simple image filter:
$code_sepia_filter
$demo_sepia_filter
## Output-only demos
What about demos that only contain outputs? In order to build such a demo, you simply set the value of the `inputs` parameter in `Interface()` to `None`. Here's an example demo of a mock image generation model:
$code_fake_gan_no_input
$demo_fake_gan_no_input
## Input-only demos
Similarly, to create a demo that only contains inputs, set the value of `outputs` parameter in `Interface()` to be `None`. Here's an example demo that saves any uploaded image to disk:
$code_save_file_no_output
$demo_save_file_no_output
## Unified demos
A demo that has a single component as both the input and the output. It can simply be created by setting the values of the `inputs` and `outputs` parameter as the same component. Here's an example demo of a text generation model:
$code_unified_demo_text_generation
$demo_unified_demo_text_generation
| gradio-app/gradio/blob/main/guides/02_building-interfaces/02_four-kinds-of-interfaces.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# PixArt-α

[PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis](https://huggingface.co/papers/2310.00426) is Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li.
The abstract from the paper is:
*The most advanced text-to-image (T2I) models require significant training costs (e.g., millions of GPU hours), seriously hindering the fundamental innovation for the AIGC community while increasing CO2 emissions. This paper introduces PIXART-α, a Transformer-based T2I diffusion model whose image generation quality is competitive with state-of-the-art image generators (e.g., Imagen, SDXL, and even Midjourney), reaching near-commercial application standards. Additionally, it supports high-resolution image synthesis up to 1024px resolution with low training cost, as shown in Figure 1 and 2. To achieve this goal, three core designs are proposed: (1) Training strategy decomposition: We devise three distinct training steps that separately optimize pixel dependency, text-image alignment, and image aesthetic quality; (2) Efficient T2I Transformer: We incorporate cross-attention modules into Diffusion Transformer (DiT) to inject text conditions and streamline the computation-intensive class-condition branch; (3) High-informative data: We emphasize the significance of concept density in text-image pairs and leverage a large Vision-Language model to auto-label dense pseudo-captions to assist text-image alignment learning. As a result, PIXART-α's training speed markedly surpasses existing large-scale T2I models, e.g., PIXART-α only takes 10.8% of Stable Diffusion v1.5's training time (675 vs. 6,250 A100 GPU days), saving nearly $300,000 ($26,000 vs. $320,000) and reducing 90% CO2 emissions. Moreover, compared with a larger SOTA model, RAPHAEL, our training cost is merely 1%. Extensive experiments demonstrate that PIXART-α excels in image quality, artistry, and semantic control. We hope PIXART-α will provide new insights to the AIGC community and startups to accelerate building their own high-quality yet low-cost generative models from scratch.*
You can find the original codebase at [PixArt-alpha/PixArt-alpha](https://github.com/PixArt-alpha/PixArt-alpha) and all the available checkpoints at [PixArt-alpha](https://huggingface.co/PixArt-alpha).
Some notes about this pipeline:
* It uses a Transformer backbone (instead of a UNet) for denoising. As such it has a similar architecture as [DiT](./dit).
* It was trained using text conditions computed from T5. This aspect makes the pipeline better at following complex text prompts with intricate details.
* It is good at producing high-resolution images at different aspect ratios. To get the best results, the authors recommend some size brackets which can be found [here](https://github.com/PixArt-alpha/PixArt-alpha/blob/08fbbd281ec96866109bdd2cdb75f2f58fb17610/diffusion/data/datasets/utils.py).
* It rivals the quality of state-of-the-art text-to-image generation systems (as of this writing) such as Stable Diffusion XL, Imagen, and DALL-E 2, while being more efficient than them.
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## Inference with under 8GB GPU VRAM
Run the [`PixArtAlphaPipeline`] with under 8GB GPU VRAM by loading the text encoder in 8-bit precision. Let's walk through a full-fledged example.
First, install the [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) library:
```bash
pip install -U bitsandbytes
```
Then load the text encoder in 8-bit:
```python
from transformers import T5EncoderModel
from diffusers import PixArtAlphaPipeline
import torch
text_encoder = T5EncoderModel.from_pretrained(
"PixArt-alpha/PixArt-XL-2-1024-MS",
subfolder="text_encoder",
load_in_8bit=True,
device_map="auto",
)
pipe = PixArtAlphaPipeline.from_pretrained(
"PixArt-alpha/PixArt-XL-2-1024-MS",
text_encoder=text_encoder,
transformer=None,
device_map="auto"
)
```
Now, use the `pipe` to encode a prompt:
```python
with torch.no_grad():
prompt = "cute cat"
prompt_embeds, prompt_attention_mask, negative_embeds, negative_prompt_attention_mask = pipe.encode_prompt(prompt)
```
Since text embeddings have been computed, remove the `text_encoder` and `pipe` from the memory, and free up som GPU VRAM:
```python
import gc
def flush():
gc.collect()
torch.cuda.empty_cache()
del text_encoder
del pipe
flush()
```
Then compute the latents with the prompt embeddings as inputs:
```python
pipe = PixArtAlphaPipeline.from_pretrained(
"PixArt-alpha/PixArt-XL-2-1024-MS",
text_encoder=None,
torch_dtype=torch.float16,
).to("cuda")
latents = pipe(
negative_prompt=None,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
prompt_attention_mask=prompt_attention_mask,
negative_prompt_attention_mask=negative_prompt_attention_mask,
num_images_per_prompt=1,
output_type="latent",
).images
del pipe.transformer
flush()
```
<Tip>
Notice that while initializing `pipe`, you're setting `text_encoder` to `None` so that it's not loaded.
</Tip>
Once the latents are computed, pass it off to the VAE to decode into a real image:
```python
with torch.no_grad():
image = pipe.vae.decode(latents / pipe.vae.config.scaling_factor, return_dict=False)[0]
image = pipe.image_processor.postprocess(image, output_type="pil")[0]
image.save("cat.png")
```
By deleting components you aren't using and flushing the GPU VRAM, you should be able to run [`PixArtAlphaPipeline`] with under 8GB GPU VRAM.

If you want a report of your memory-usage, run this [script](https://gist.github.com/sayakpaul/3ae0f847001d342af27018a96f467e4e).
<Tip warning={true}>
Text embeddings computed in 8-bit can impact the quality of the generated images because of the information loss in the representation space caused by the reduced precision. It's recommended to compare the outputs with and without 8-bit.
</Tip>
While loading the `text_encoder`, you set `load_in_8bit` to `True`. You could also specify `load_in_4bit` to bring your memory requirements down even further to under 7GB.
## PixArtAlphaPipeline
[[autodoc]] PixArtAlphaPipeline
- all
- __call__
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/pixart.md |
Additional Readings [[additional-readings]]
These are **optional readings** if you want to go deeper.
- [Foundations of Deep RL Series, L2 Deep Q-Learning by Pieter Abbeel](https://youtu.be/Psrhxy88zww)
- [Playing Atari with Deep Reinforcement Learning](https://arxiv.org/abs/1312.5602)
- [Double Deep Q-Learning](https://papers.nips.cc/paper/2010/hash/091d584fced301b442654dd8c23b3fc9-Abstract.html)
- [Prioritized Experience Replay](https://arxiv.org/abs/1511.05952)
| huggingface/deep-rl-class/blob/main/units/en/unit3/additional-readings.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Optimization
🤗 Optimum provides an `optimum.onnxruntime` package that enables you to apply graph optimization on many model hosted on the 🤗 hub using the [ONNX Runtime](https://github.com/microsoft/onnxruntime/tree/master/onnxruntime/python/tools/transformers) model optimization tool.
## Optimizing a model during the ONNX export
The ONNX model can be directly optimized during the ONNX export using Optimum CLI, by passing the argument `--optimize {O1,O2,O3,O4}` in the CLI, for example:
```
optimum-cli export onnx --model gpt2 --optimize O3 gpt2_onnx/
```
The optimization levels are:
- O1: basic general optimizations.
- O2: basic and extended general optimizations, transformers-specific fusions.
- O3: same as O2 with GELU approximation.
- O4: same as O3 with mixed precision (fp16, GPU-only, requires `--device cuda`).
## Optimizing a model programmatically with `ORTOptimizer`
ONNX models can be optimized with the [`~onnxruntime.ORTOptimizer`]. The class can be initialized using the [`~onnxruntime.ORTOptimizer.from_pretrained`] method, which supports different checkpoint formats.
1. Using an already initialized [`~onnxruntime.ORTModel`] class.
```python
>>> from optimum.onnxruntime import ORTOptimizer, ORTModelForSequenceClassification
# Loading ONNX Model from the Hub
>>> model = ORTModelForSequenceClassification.from_pretrained(
... "optimum/distilbert-base-uncased-finetuned-sst-2-english"
... )
# Create an optimizer from an ORTModelForXXX
>>> optimizer = ORTOptimizer.from_pretrained(model)
```
2. Using a local ONNX model from a directory.
```python
>>> from optimum.onnxruntime import ORTOptimizer
# This assumes a model.onnx exists in path/to/model
>>> optimizer = ORTOptimizer.from_pretrained("path/to/model") # doctest: +SKIP
```
### Optimization Configuration
The [`~onnxruntime.configuration.OptimizationConfig`] class allows to specify how the optimization should be performed by the [`~onnxruntime.ORTOptimizer`].
In the optimization configuration, there are 4 possible optimization levels:
- `optimization_level=0`: to disable all optimizations
- `optimization_level=1`: to enable basic optimizations such as constant folding or redundant node eliminations
- `optimization_level=2`: to enable extended graph optimizations such as node fusions
- `optimization_level=99`: to enable data layout optimizations
Choosing a level enables the optimizations of that level, as well as the optimizations of all preceding levels.
More information [here](https://onnxruntime.ai/docs/performance/graph-optimizations.html).
`enable_transformers_specific_optimizations=True` means that `transformers`-specific graph fusion and approximation are performed in addition to the ONNX Runtime optimizations described above.
Here is a list of the possible optimizations you can enable:
- Gelu fusion with `disable_gelu_fusion=False`,
- Layer Normalization fusion with `disable_layer_norm_fusion=False`,
- Attention fusion with `disable_attention_fusion=False`,
- SkipLayerNormalization fusion with `disable_skip_layer_norm_fusion=False`,
- Add Bias and SkipLayerNormalization fusion with `disable_bias_skip_layer_norm_fusion=False`,
- Add Bias and Gelu / FastGelu fusion with `disable_bias_gelu_fusion=False`,
- Gelu approximation with `enable_gelu_approximation=True`.
While [`~onnxruntime.configuration.OptimizationConfig`] gives you full control on how to do optimization, it can be hard to know what to enable / disable. Instead, you can use [`~onnxruntime.configuration.AutoOptimizationConfig`] which provides four common optimization levels:
- O1: basic general optimizations.
- O2: basic and extended general optimizations, transformers-specific fusions.
- O3: same as O2 with GELU approximation.
- O4: same as O3 with mixed precision (fp16, GPU-only).
Example: Loading a O2 [`~onnxruntime.configuration.OptimizationConfig`]
```python
>>> from optimum.onnxruntime import AutoOptimizationConfig
>>> optimization_config = AutoOptimizationConfig.O2()
```
You can also specify custom argument that were not defined in the O2 configuration, for instance:
```python
>>> from optimum.onnxruntime import AutoOptimizationConfig
>>> optimization_config = AutoOptimizationConfig.O2(disable_embed_layer_norm_fusion=False)
```
### Optimization examples
Below you will find an easy end-to-end example on how to optimize [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english).
```python
>>> from optimum.onnxruntime import (
... AutoOptimizationConfig, ORTOptimizer, ORTModelForSequenceClassification
... )
>>> model_id = "distilbert-base-uncased-finetuned-sst-2-english"
>>> save_dir = "distilbert_optimized"
>>> # Load a PyTorch model and export it to the ONNX format
>>> model = ORTModelForSequenceClassification.from_pretrained(model_id, export=True)
>>> # Create the optimizer
>>> optimizer = ORTOptimizer.from_pretrained(model)
>>> # Define the optimization strategy by creating the appropriate configuration
>>> optimization_config = AutoOptimizationConfig.O2()
>>> # Optimize the model
>>> optimizer.optimize(save_dir=save_dir, optimization_config=optimization_config) # doctest: +IGNORE_RESULT
```
Below you will find an easy end-to-end example on how to optimize a Seq2Seq model [sshleifer/distilbart-cnn-12-6"](https://huggingface.co/sshleifer/distilbart-cnn-12-6).
```python
>>> from transformers import AutoTokenizer
>>> from optimum.onnxruntime import OptimizationConfig, ORTOptimizer, ORTModelForSeq2SeqLM
>>> model_id = "sshleifer/distilbart-cnn-12-6"
>>> save_dir = "distilbart_optimized"
>>> # Load a PyTorch model and export it to the ONNX format
>>> model = ORTModelForSeq2SeqLM.from_pretrained(model_id, export=True)
>>> # Create the optimizer
>>> optimizer = ORTOptimizer.from_pretrained(model)
>>> # Define the optimization strategy by creating the appropriate configuration
>>> optimization_config = OptimizationConfig(
... optimization_level=2,
... enable_transformers_specific_optimizations=True,
... optimize_for_gpu=False,
... )
>>> # Optimize the model
>>> optimizer.optimize(save_dir=save_dir, optimization_config=optimization_config) # doctest: +IGNORE_RESULT
>>> tokenizer = AutoTokenizer.from_pretrained(model_id)
>>> optimized_model = ORTModelForSeq2SeqLM.from_pretrained(save_dir)
>>> tokens = tokenizer("This is a sample input", return_tensors="pt")
>>> outputs = optimized_model.generate(**tokens)
```
## Optimizing a model with Optimum CLI
The Optimum ONNX Runtime optimization tools can be used directly through Optimum command-line interface:
```bash
optimum-cli onnxruntime optimize --help
usage: optimum-cli <command> [<args>] onnxruntime optimize [-h] --onnx_model ONNX_MODEL -o OUTPUT (-O1 | -O2 | -O3 | -O4 | -c CONFIG)
options:
-h, --help show this help message and exit
-O1 Basic general optimizations (see: https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization for more details).
-O2 Basic and extended general optimizations, transformers-specific fusions (see: https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization for more
details).
-O3 Same as O2 with Gelu approximation (see: https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization for more details).
-O4 Same as O3 with mixed precision (see: https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization for more details).
-c CONFIG, --config CONFIG
`ORTConfig` file to use to optimize the model.
Required arguments:
--onnx_model ONNX_MODEL
Path to the repository where the ONNX models to optimize are located.
-o OUTPUT, --output OUTPUT
Path to the directory where to store generated ONNX model.
```
Optimizing an ONNX model can be done as follows:
```bash
optimum-cli onnxruntime optimize --onnx_model onnx_model_location/ -O1 -o optimized_model/
```
This optimizes all the ONNX files in `onnx_model_location` with the basic general optimizations.
| huggingface/optimum/blob/main/docs/source/onnxruntime/usage_guides/optimization.mdx |
Libraries
The Datasets Hub has support for several libraries in the Open Source ecosystem.
Thanks to the [huggingface_hub Python library](../huggingface_hub), it's easy to enable sharing your datasets on the Hub.
We're happy to welcome to the Hub a set of Open Source libraries that are pushing Machine Learning forward.
The table below summarizes the supported libraries and their level of integration.
| Library | Description | Download from Hub | Push to Hub |
|-----------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------|---|----|
| [Dask](https://github.com/dask/dask) | Parallel and distributed computing library that scales the existing Python and PyData ecosystem. | ✅ | ✅ |
| [Datasets](https://github.com/huggingface/datasets) | 🤗 Datasets is a library for accessing and sharing datasets for Audio, Computer Vision, and Natural Language Processing (NLP). | ✅ | ✅ |
| [DuckDB](https://github.com/duckdb/duckdb) | In-process SQL OLAP database management system. | ✅ | ✅ |
| [Pandas](https://github.com/pandas-dev/pandas) | Python data analysis toolkit. | ✅ | ✅ |
| [WebDataset](https://github.com/webdataset/webdataset) | Library to write I/O pipelines for large datasets. | ✅ | ❌ |
| huggingface/hub-docs/blob/main/docs/hub/datasets-libraries.md |
Process text data
This guide shows specific methods for processing text datasets. Learn how to:
- Tokenize a dataset with [`~Dataset.map`].
- Align dataset labels with label ids for NLI datasets.
For a guide on how to process any type of dataset, take a look at the <a class="underline decoration-sky-400 decoration-2 font-semibold" href="./process">general process guide</a>.
## Map
The [`~Dataset.map`] function supports processing batches of examples at once which speeds up tokenization.
Load a tokenizer from 🤗 [Transformers](https://huggingface.co/transformers/):
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
```
Set the `batched` parameter to `True` in the [`~Dataset.map`] function to apply the tokenizer to batches of examples:
```py
>>> dataset = dataset.map(lambda examples: tokenizer(examples["text"]), batched=True)
>>> dataset[0]
{'text': 'the rock is destined to be the 21st century\'s new " conan " and that he\'s going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .',
'label': 1,
'input_ids': [101, 1996, 2600, 2003, 16036, 2000, 2022, 1996, 7398, 2301, 1005, 1055, 2047, 1000, 16608, 1000, 1998, 2008, 2002, 1005, 1055, 2183, 2000, 2191, 1037, 17624, 2130, 3618, 2084, 7779, 29058, 8625, 13327, 1010, 3744, 1011, 18856, 19513, 3158, 5477, 4168, 2030, 7112, 16562, 2140, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
The [`~Dataset.map`] function converts the returned values to a PyArrow-supported format. But explicitly returning the tensors as NumPy arrays is faster because it is a natively supported PyArrow format. Set `return_tensors="np"` when you tokenize your text:
```py
>>> dataset = dataset.map(lambda examples: tokenizer(examples["text"], return_tensors="np"), batched=True)
```
## Align
The [`~Dataset.align_labels_with_mapping`] function aligns a dataset label id with the label name. Not all 🤗 Transformers models follow the prescribed label mapping of the original dataset, especially for NLI datasets. For example, the [MNLI](https://huggingface.co/datasets/glue) dataset uses the following label mapping:
```py
>>> label2id = {"entailment": 0, "neutral": 1, "contradiction": 2}
```
To align the dataset label mapping with the mapping used by a model, create a dictionary of the label name and id to align on:
```py
>>> label2id = {"contradiction": 0, "neutral": 1, "entailment": 2}
```
Pass the dictionary of the label mappings to the [`~Dataset.align_labels_with_mapping`] function, and the column to align on:
```py
>>> from datasets import load_dataset
>>> mnli = load_dataset("glue", "mnli", split="train")
>>> mnli_aligned = mnli.align_labels_with_mapping(label2id, "label")
```
You can also use this function to assign a custom mapping of labels to ids. | huggingface/datasets/blob/main/docs/source/nlp_process.mdx |
`@gradio/dataframe`
```html
<script>
import { BaseDataFrame, BaseExample } from "@gradio/dataframe";
</script>
```
BaseDataFrame
```javascript
export let datatype: Datatype | Datatype[];
export let label: string | null = null;
export let headers: Headers = [];
let values: (string | number)[][];
export let value: { data: Data; headers: Headers; metadata: Metadata } | null;
export let col_count: [number, "fixed" | "dynamic"];
export let row_count: [number, "fixed" | "dynamic"];
export let latex_delimiters: {
left: string;
right: string;
display: boolean;
}[];
export let editable = true;
export let wrap = false;
export let root: string;
export let i18n: I18nFormatter;
export let height = 500;
export let line_breaks = true;
export let column_widths: string[] = [];
```
BaseExample
```javascript
export let gradio: Gradio;
export let value: (string | number)[][] | string;
export let samples_dir: string;
export let type: "gallery" | "table";
export let selected = false;
export let index: number;
``` | gradio-app/gradio/blob/main/js/dataframe/README.md |
Change Organization or Account
Inference Endpoints uses your [Hugging Face](https://huggingface.co/) account - which can be either personal or an organization - to authenticate and deploy an Endpoint.
You can switch between the two by clicking on the "organization/user" dropdown in the top right corner of the page. The dropdown will only show organizations and accounts that have an active plan. Check out the [Access the solution](/docs/inference-endpoints/guides/access) guide to learn more about setting up a plan.
<img src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/switch_organization_1.png" alt="open organization select" />
Select the organization you want to switch to. If you don't have access to any organization, you can create a new one by clicking on the “Create Organization” button.
<img src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/switch_organization_2.png" alt="organization select list" />
| huggingface/hf-endpoints-documentation/blob/main/docs/source/guides/change_organization.mdx |
Using Stanza at Hugging Face
`stanza` is a collection of accurate and efficient tools for the linguistic analysis of many human languages. Starting from raw text to syntactic analysis and entity recognition, Stanza brings state-of-the-art NLP models to languages of your choosing.
## Exploring Stanza in the Hub
You can find `stanza` models by filtering at the left of the [models page](https://huggingface.co/models?library=stanza&sort=downloads). You can find over 70 models for different languages!
All models on the Hub come up with the following features:
1. An automatically generated model card with a brief description and metadata tags that help for discoverability.
2. An interactive widget you can use to play out with the model directly in the browser (for named entity recognition and part of speech).
3. An Inference API that allows to make inference requests (for named entity recognition and part of speech).
## Using existing models
The `stanza` library automatically downloads models from the Hub. You can use `stanza.Pipeline` to download the model from the Hub and do inference.
```python
import stanza
nlp = stanza.Pipeline('en') # download th English model and initialize an English neural pipeline
doc = nlp("Barack Obama was born in Hawaii.") # run annotation over a sentence
```
## Sharing your models
To add new official Stanza models, you can follow the process to [add a new language](https://stanfordnlp.github.io/stanza/new_language.html) and then [share your models with the Stanza team](https://stanfordnlp.github.io/stanza/new_language.html#contributing-back-to-stanza). You can also find the official script to upload models to the Hub [here](https://github.com/stanfordnlp/huggingface-models/blob/main/hugging_stanza.py).
## Additional resources
* `stanza` [docs](https://stanfordnlp.github.io/stanza/). | huggingface/hub-docs/blob/main/docs/hub/stanza.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# PEFT types
[`PeftType`] includes the supported adapters in PEFT, and [`TaskType`] includes PEFT-supported tasks.
## PeftType
[[autodoc]] utils.peft_types.PeftType
## TaskType
[[autodoc]] utils.peft_types.TaskType | huggingface/peft/blob/main/docs/source/package_reference/peft_types.md |
Gradio Demo: line_plot
```
!pip install -q gradio vega_datasets pandas
```
```
import gradio as gr
from vega_datasets import data
stocks = data.stocks()
gapminder = data.gapminder()
gapminder = gapminder.loc[
gapminder.country.isin(["Argentina", "Australia", "Afghanistan"])
]
climate = data.climate()
seattle_weather = data.seattle_weather()
## Or generate your own fake data, here's an example for stocks:
#
# import pandas as pd
# import random
#
# stocks = pd.DataFrame(
# {
# "symbol": [
# random.choice(
# [
# "MSFT",
# "AAPL",
# "AMZN",
# "IBM",
# "GOOG",
# ]
# )
# for _ in range(120)
# ],
# "date": [
# pd.Timestamp(year=2000 + i, month=j, day=1)
# for i in range(10)
# for j in range(1, 13)
# ],
# "price": [random.randint(10, 200) for _ in range(120)],
# }
# )
def line_plot_fn(dataset):
if dataset == "stocks":
return gr.LinePlot(
stocks,
x="date",
y="price",
color="symbol",
color_legend_position="bottom",
title="Stock Prices",
tooltip=["date", "price", "symbol"],
height=300,
width=500,
)
elif dataset == "climate":
return gr.LinePlot(
climate,
x="DATE",
y="HLY-TEMP-NORMAL",
y_lim=[250, 500],
title="Climate",
tooltip=["DATE", "HLY-TEMP-NORMAL"],
height=300,
width=500,
)
elif dataset == "seattle_weather":
return gr.LinePlot(
seattle_weather,
x="date",
y="temp_min",
tooltip=["weather", "date"],
overlay_point=True,
title="Seattle Weather",
height=300,
width=500,
)
elif dataset == "gapminder":
return gr.LinePlot(
gapminder,
x="year",
y="life_expect",
color="country",
title="Life expectancy for countries",
stroke_dash="cluster",
x_lim=[1950, 2010],
tooltip=["country", "life_expect"],
stroke_dash_legend_title="Country Cluster",
height=300,
width=500,
)
with gr.Blocks() as line_plot:
with gr.Row():
with gr.Column():
dataset = gr.Dropdown(
choices=["stocks", "climate", "seattle_weather", "gapminder"],
value="stocks",
)
with gr.Column():
plot = gr.LinePlot()
dataset.change(line_plot_fn, inputs=dataset, outputs=plot)
line_plot.load(fn=line_plot_fn, inputs=dataset, outputs=plot)
if __name__ == "__main__":
line_plot.launch()
```
| gradio-app/gradio/blob/main/demo/line_plot/run.ipynb |
!--Copyright 2023 IBM and HuggingFace Inc. team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# PatchTSMixer
## Overview
The PatchTSMixer model was proposed in [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
PatchTSMixer is a lightweight time-series modeling approach based on the MLP-Mixer architecture. In this HuggingFace implementation, we provide PatchTSMixer's capabilities to effortlessly facilitate lightweight mixing across patches, channels, and hidden features for effective multivariate time-series modeling. It also supports various attention mechanisms starting from simple gated attention to more complex self-attention blocks that can be customized accordingly. The model can be pretrained and subsequently used for various downstream tasks such as forecasting, classification and regression.
The abstract from the paper is the following:
*TSMixer is a lightweight neural architecture exclusively composed of multi-layer perceptron (MLP) modules designed for multivariate forecasting and representation learning on patched time series. Our model draws inspiration from the success of MLP-Mixer models in computer vision. We demonstrate the challenges involved in adapting Vision MLP-Mixer for time series and introduce empirically validated components to enhance accuracy. This includes a novel design paradigm of attaching online reconciliation heads to the MLP-Mixer backbone, for explicitly modeling the time-series properties such as hierarchy and channel-correlations. We also propose a Hybrid channel modeling approach to effectively handle noisy channel interactions and generalization across diverse datasets, a common challenge in existing patch channel-mixing methods. Additionally, a simple gated attention mechanism is introduced in the backbone to prioritize important features. By incorporating these lightweight components, we significantly enhance the learning capability of simple MLP structures, outperforming complex Transformer models with minimal computing usage. Moreover, TSMixer's modular design enables compatibility with both supervised and masked self-supervised learning methods, making it a promising building block for time-series Foundation Models. TSMixer outperforms state-of-the-art MLP and Transformer models in forecasting by a considerable margin of 8-60%. It also outperforms the latest strong benchmarks of Patch-Transformer models (by 1-2%) with a significant reduction in memory and runtime (2-3X).*
This model was contributed by [ajati](https://huggingface.co/ajati), [vijaye12](https://huggingface.co/vijaye12),
[gsinthong](https://huggingface.co/gsinthong), [namctin](https://huggingface.co/namctin),
[wmgifford](https://huggingface.co/wmgifford), [kashif](https://huggingface.co/kashif).
## Sample usage
```python
from transformers import PatchTSMixerConfig, PatchTSMixerForPrediction
from transformers import Trainer, TrainingArguments,
config = PatchTSMixerConfig(context_length = 512, prediction_length = 96)
model = PatchTSMixerForPrediction(config)
trainer = Trainer(model=model, args=training_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset)
trainer.train()
results = trainer.evaluate(test_dataset)
```
## Usage tips
The model can also be used for time series classification and time series regression. See the respective [`PatchTSMixerForTimeSeriesClassification`] and [`PatchTSMixerForRegression`] classes.
## PatchTSMixerConfig
[[autodoc]] PatchTSMixerConfig
## PatchTSMixerModel
[[autodoc]] PatchTSMixerModel
- forward
## PatchTSMixerForPrediction
[[autodoc]] PatchTSMixerForPrediction
- forward
## PatchTSMixerForTimeSeriesClassification
[[autodoc]] PatchTSMixerForTimeSeriesClassification
- forward
## PatchTSMixerForPretraining
[[autodoc]] PatchTSMixerForPretraining
- forward
## PatchTSMixerForRegression
[[autodoc]] PatchTSMixerForRegression
- forward | huggingface/transformers/blob/main/docs/source/en/model_doc/patchtsmixer.md |
Update your Endpoint
You can update `running` Endpoints to change some of the configurations. However, if your endpoint is in a `failed` state, you need to create a new Endpoint. To update your endpoint you need to navigate to the "settings" tab.
You can update the instance type, autoscaling configuration, task and repository revision.
## Instance size
You can update the instance size of your Endpoint in the Endpoint overview menu to match your evolving needs. For example, you can downsize to a smaller instance type if you don't need the compute or alternatively, you can upgrade to a larger instance type if you need to increase your compute.
You're able to update your _current_ instance type: CPU or GPU. There is no ability to update from one instance type to another (CPU to GPU or vice versa).
<img
src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/update_instance_type.png"
alt="Instance Type selection"
/>
## Autoscaling
You can update the autoscaling configuration of your Endpoint in the settings menu. Adjust the minimum and maximum number of replicas to upscale or downscale your Endpoint. Learn more about autoscaling [here](https://huggingface.co/docs/inference-endpoints/faq#q-how-does-autoscaling-work).
## Task
You can update the task of your running Endpoint in the settings menu. The task defines the `pipeline` type your Endpoint will use and the inference widget on the Endpoint overview.
## Revision
You can update the revision of your `running` Endpoint in the settings menu. The revision defines the version of the model repository you want to use for inference.
| huggingface/hf-endpoints-documentation/blob/main/docs/source/guides/update_endpoint.mdx |
Contributing to Gradio

More than 200 awesome developers have contributed to the `gradio` library, and we'd be thrilled if you would like to be the next contributor!
Prerequisites:
- [Python 3.8+](https://www.python.org/downloads/)
- [Node.js v16.14+](https://nodejs.dev/en/download/package-manager/) (only needed if you are making changes to the frontend)
- [pnpm 8.1+](https://pnpm.io/8.x/installation) (only needed if you are making changes to the frontend)
## 🏡 Setup for local development
There are a few ways to install and run Gradio.
### 🛠️ Install Gradio locally from `main`
- Clone this repo
- Navigate to the repo directory and (from the root directory) run
```bash
bash scripts/install_gradio.sh
```
- Build the front end
```
bash scripts/build_frontend.sh
```
- Install development requirements
(Note that it is highly recommended to use a virtual environment running **Python 3.9** since the versions of Gradio's dependencies are pinned)
```
bash scripts/install_test_requirements.sh
```
If you have a different Python version and conflicting packages during the installation, please first run:
```
bash scripts/create_test_requirements.sh
```
### 📦 Using dev containers
You can alternatively use dev containers. This is supported on all platforms (macOS/Windows/Linux), as well as on GitHub Codespaces.
Prerequisites:
- An editor which supports dev containers, like VS Code
- Docker support on the host computer:
- macOS: [Docker Desktop 2.0+](https://www.docker.com/products/docker-desktop/)
- Windows: [Docker Desktop 2.0+](https://www.docker.com/products/docker-desktop/)
- Linux: [Docker CE/EE 18.06+](https://docs.docker.com/get-docker/) and [Docker Compose 1.21+](https://docs.docker.com/compose/install/)
- If using VS Code, the [Dev Containers](https://marketplace.visualstudio.com/items?itemName=ms-vscode-remote.remote-containers) extension
Steps:
- Clone repository
- Open it in your editor
- For VS Code, execute `Dev Containers: Reopen in container` command
For detailed instructions, please see the [Dev Containers tutorial](https://code.visualstudio.com/docs/devcontainers/tutorial).
## 🧱 Structure of the Repository
If you're a newcomer to Gradio, we recommend getting familiar with the overall structure of the repository so that you can focus on the part of the source code you'd like to contribute to.
- `/gradio`: contains the Python source code for the library
- `/gradio/interface.py`: contains the Python source code for the core `Interface` class
- `/gradio/blocks.py`: contains the Python source code for the core `Blocks` class
- `/gradio/components/`: the directory that contains the Python source code for all of the Gradio components.
- `/js`: contains the HTML/JS/CSS source code for the library ([start here for frontend changes](/js/README.md))
- `/js/_website`: contains the code for the Gradio website (www.gradio.app). See the README in the `/js/_website` folder for more details
- `/test`: contains Python unit tests for the library
- `/demo`: contains demos that are used in the documentation, you can find `Gradio` examples over here.
## 🚀 Run a Gradio app
You can get started by creating an `app.py` file in the root:
```
import gradio as gr
with gr.Blocks() as demo:
gr.Button()
if __name__ == "__main__":
demo.launch()
```
then run:
```
gradio app.py
```
This will start the backend server in reload mode, which will watch for changes in the `gradio` folder and reload the app if changes are made. By default, Gradio will launch on port 7860. You can also just use `python app.py`, but this won't automatically trigger updates.
If you're making frontend changes, start the frontend server:
```
pnpm dev
```
This will open a separate browser tab. By default, Gradio will launch this on port 9876. Any changes to the frontend will also reload automatically in the browser. For more information about developing in the frontend, you can refer to [js/README.md](js/README.md).
We also have demos of all our components in the `/gradio/demo` directory. To get our simple gradio Chatbot running locally:
```
gradio demo/chatbot_simple/run.py
```
## 🧪 Testing
We use Pytest, Playwright and Vitest to test our code.
- The Python tests are located in `/test`. To run these tests:
```
bash scripts/run_all_tests.sh
```
- The frontend unit tests are any defined with the filename `*.test.ts`. To run them:
```
pnpm test
```
- Browser tests are located in `js/app/test` and are defined as `*spec.ts` files. To run browser tests:
```
pnpm test:browser
```
To build the frontend code before running browser tests:
```
pnpm test:browser:full
```
You can also run browser tests in the UI mode by adding the `--ui` flag:
```
pnpm test:browser --ui
```
If you have made any significant visual changes to a component, we encourage you to add a new Storybook story or amend an existing one to reflect them. You can create a new story with a `*.stories.svelte` file.
## 🕸️ Gradio Website
We also welcome any contributions to our [website](https://www.gradio.app).
First, build the website:
```
pnpm build:cdn-local
```
then serve the website build:
```
pnpm preview:cdn-local
```
This will serve a build of `gradio.js` on port `4321`. You can then navigate to `js/_website/src/routes/+layout.svelte` and replace the source of the website build from:
```
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/{version}/gradio.js"></script>
```
to
```
<script type="module" src="http://localhost:4321/gradio.js"></script>
```
You should now be able to view a local version of the website at `http://localhost:4321`.
## 📚 Component Storybook
If you would like to fix an issue or contribute to our Storybook, you can get it running locally with:
```
pnpm storybook
```
## 📮 Submitting PRs
All PRs should be against `main`, and ideally should address an open issue, unless the change is small. Direct commits to main are blocked, and PRs require an approving review to merge into main. By convention, the Gradio maintainers will review PRs when:
- An initial review has been requested
- A clear, descriptive title has been assigned to the PR
- A maintainer (@abidlabs, @aliabid94, @aliabd, @AK391, @dawoodkhan82, @pngwn, @freddyaboulton, @hannahblair) is tagged in the PR comments and asked to complete a review
🧹 We ask that you make sure initial CI checks are passing before requesting a review. One of the Gradio maintainers will merge the PR when all the checks are passing. You can safely ignore the Vercel and Spaces checks, which only run under maintainers' pull requests.
Don't forget the format your code before pushing:
```
bash scripts/format_backend.sh
```
```
bash scripts/format_frontend.sh
```
Thank you for taking the time to contribute to our project!
## ❓ Need help getting started?
- Browse [issues](https://github.com/gradio-app/gradio/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) with the "good first issue" label. These are issues we think are good for newcomers.
- Ask the Gradio community in our [Discord](https://discord.com/invite/feTf9x3ZSB)
- Raise an issue for a feature or a bug you want to tackle
## 🚧 Troubleshooting
`ERROR: Error loading ASGI app. Could not import module "<filename>"`
Verify that you've used the correct filename of your gradio app, and that you're in the directory of the file.
---
```ERR_PNPM_RECURSIVE_RUN_FIRST_FAIL @gradio/app@1.0.0 build:local: vite build --mode production:local --emptyOutDir "--emptyOutDir"```
Delete `/node_modules` and `pnpm-lock.yaml`:
```
rm -rf node_modules/
rm pnpm-lock.yaml
```
and run the install scripts:
```
bash scripts/install_gradio.sh
bash scripts/build_frontend.sh
```
---
_Could these guidelines be clearer? Feel free to open a PR to help us facilitate open-source contributions!_
| gradio-app/gradio/blob/main/CONTRIBUTING.md |
--
title: "Accelerating Vision-Language Models: BridgeTower on Habana Gaudi2"
thumbnail: /blog/assets/bridgetower/thumbnail.png
authors:
- user: regisss
- user: anahita-b
guest: true
---
# Accelerating Vision-Language Models: BridgeTower on Habana Gaudi2
*Update (29/08/2023): A benchmark on H100 was added to this blog post. Also, all performance numbers have been updated with newer versions of software.*
[Optimum Habana v1.7](https://github.com/huggingface/optimum-habana/tree/main) on Habana Gaudi2 achieves **x2.5 speedups compared to A100 and x1.4 compared to H100** when fine-tuning BridgeTower, a state-of-the-art vision-language model. This performance improvement relies on hardware-accelerated data loading to make the most of your devices.
*These techniques apply to any other workloads constrained by data loading, which is frequently the case for many types of vision models.* This post will take you through the process and benchmark we used to compare BridgeTower fine-tuning on Habana Gaudi2, Nvidia H100 and Nvidia A100 80GB. It also demonstrates how easy it is to take advantage of these features in transformers-based models.
## BridgeTower
In the recent past, [Vision-Language (VL) models](https://huggingface.co/blog/vision_language_pretraining) have gained tremendous importance and shown dominance in a variety of VL tasks. Most common approaches leverage uni-modal encoders to extract representations from their respective modalities. Then those representations are either fused together, or fed into a cross-modal encoder. To efficiently handle some of the performance limitations and restrictions in VL representation learning, [BridgeTower](https://huggingface.co/papers/2206.08657) introduces multiple _bridge layers_ that build a connection between the top layers of uni-modal encoders and each layer of the cross-modal encoder. This enables effective bottom-up cross-modal alignment and fusion between visual and textual representations at different semantic levels in the cross-modal encoder.
Pre-trained with only 4M images (see the detail [below](#benchmark)), BridgeTower achieves state-of-the-art performance on various downstream vision-language tasks. In particular, BridgeTower achieves an accuracy of 78.73% on the VQAv2 test-std set, outperforming the previous state-of-the-art model (METER) by 1.09% using the same pre-training data and almost negligible additional parameters and computational costs. Notably, when further scaling the model, BridgeTower achieves an accuracy of 81.15%, surpassing models that are pre-trained on orders-of-magnitude larger datasets.
## Hardware
[NVIDIA H100 Tensor Core GPU](https://www.nvidia.com/en-us/data-center/h100/) is the latest and fastest generation of Nvidia GPUs. It includes a dedicated Transformer Engine that enables to perform fp8 mixed-precision runs. One device has 80GB of memory.
[Nvidia A100 Tensor Core GPU](https://www.nvidia.com/en-us/data-center/a100/) includes the 3rd generation of the [Tensor Core technology](https://www.nvidia.com/en-us/data-center/tensor-cores/). This is still the fastest GPU that you will find at most cloud providers. We use here the 80GB-memory variant which also offers faster memory bandwidth than the 40GB one.
[Habana Gaudi2](https://habana.ai/products/gaudi2/) is the second-generation AI hardware accelerator designed by Habana Labs. A single server contains 8 accelerator devices called HPUs with 96GB of memory each. Check out [our previous blog post](https://huggingface.co/blog/habana-gaudi-2-bloom#habana-gaudi2) for a more in-depth introduction and a guide showing how to access it through the [Intel Developer Cloud](https://www.intel.com/content/www/us/en/secure/developer/devcloud/cloud-launchpad.html). Unlike many AI accelerators in the market, advanced features are very easy to apply to make the most of Gaudi2 with [Optimum Habana](https://huggingface.co/docs/optimum/habana/index), which enables users to port Transformers-compatible scripts to Gaudi with just a 2-line change.
## Benchmark
To benchmark training, we are going to fine-tune a [BridgeTower Large checkpoint](https://huggingface.co/BridgeTower/bridgetower-large-itm-mlm-itc) consisting of 866M parameters. This checkpoint was pretrained on English language using masked language modeling, image-text matching and image-text contrastive loss on [Conceptual Captions](https://huggingface.co/datasets/conceptual_captions), [SBU Captions](https://huggingface.co/datasets/sbu_captions), [MSCOCO Captions](https://huggingface.co/datasets/HuggingFaceM4/COCO) and [Visual Genome](https://huggingface.co/datasets/visual_genome).
We will further fine-tune this checkpoint on the [New Yorker Caption Contest dataset](https://huggingface.co/datasets/jmhessel/newyorker_caption_contest) which consists of cartoons from The New Yorker and the most voted captions.
Hyperparameters are the same for all accelerators. We used a batch size of 48 samples for each device. You can check hyperparameters out [here](https://huggingface.co/regisss/bridgetower-newyorker-gaudi2-8x#training-hyperparameters) for Gaudi2 and [there](https://huggingface.co/regisss/bridgetower-newyorker-a100-8x#training-hyperparameters) for A100.
**When dealing with datasets involving images, data loading is frequently a bottleneck** because many costly operations are computed on CPU (image decoding, image augmentations) and then full images are sent to the training devices. Ideally, *we would like to send only raw bytes to devices and then perform decoding and various image transformations on device*. But let's see first how to *easily* allocate more resources to data loading for accelerating your runs.
### Making use of `dataloader_num_workers`
When image loading is done on CPU, a quick way to speed it up would be to allocate more subprocesses for data loading. This is very easy to do with Transformers' `TrainingArguments` (or its Optimum Habana counterpart `GaudiTrainingArguments`): you can use the `dataloader_num_workers=N` argument to set the number of subprocesses (`N`) allocated on CPU for data loading.
The default is 0, which means that data is loaded in the main process. This may not be optimal as the main process has many things to manage. We can set it to 1 to have one fully dedicated subprocess for data loading. When several subprocesses are allocated, each one of them will be responsible for preparing a batch. This means that RAM consumption will increase with the number of workers. One recommendation would be to set it to the number of CPU cores, but those cores may not be fully free so you will have to try it out to find the best configuration.
Let's run the three following experiments:
- a mixed-precision (*bfloat16*/*float32*) run distributed across 8 devices where data loading is performed by the same process as everything else (i.e. `dataloader_num_workers=0`)
- a mixed-precision (*bfloat16*/*float32*) run distributed across 8 devices with 1 dedicated subprocess for data loading (i.e. `dataloader_num_workers=1`)
- same run with `dataloader_num_workers=2`
Here are the throughputs we got on Gaudi2, H100 and A100:
| Device | `dataloader_num_workers=0` | `dataloader_num_workers=1` | `dataloader_num_workers=2` |
|:----------:|:--------------------------:|:--------------------------:|:--------------------------:|
| Gaudi2 HPU | 601.5 samples/s | 747.4 samples/s | 768.7 samples/s |
| H100 GPU | 336.5 samples/s | 580.1 samples/s | 602.1 samples/s |
| A100 GPU | 227.5 samples/s | 339.7 samples/s | 345.4 samples/s |
We first see that **Gaudi2 is x1.28 faster than H100** with `dataloader_num_workers=2`, x1.29 faster with `dataloader_num_workers=1` and x1.79 faster with `dataloader_num_workers=0`. Gaudi2 is also much faster than the previous generation since it is **x2.23 faster than A100** with `dataloader_num_workers=2`, x2.20 faster with `dataloader_num_workers=1` and x2.64 faster with `dataloader_num_workers=0`, which is even better than [the speedups we previously reported](https://huggingface.co/blog/habana-gaudi-2-benchmark)!
Second, we see that **allocating more resources for data loading can lead to easy speedups**: x1.28 on Gaudi2, x1.79 on H100 and x1.52 on A100.
We also ran experiments with several dedicated subprocesses for data loading but performance was not better than with `dataloader_num_workers=2` for all accelerators.
Thus, **using `dataloader_num_workers>0` is usually a good first way of accelerating your runs involving images!**
Tensorboard logs can be visualized [here](https://huggingface.co/regisss/bridgetower-newyorker-gaudi2-8x/tensorboard) for Gaudi2 and [there](https://huggingface.co/regisss/bridgetower-newyorker-a100-8x/tensorboard) for A100.
<!-- ### Optimum Habana's fast DDP
Before delving into how to perform hardware-accelerated data loading, let's look at another very easy way of speeding up your distributed runs on Gaudi. The new release of Optimum Habana, version 1.6.0, introduced a new feature that allows users to choose the distribution strategy to use:
- `distribution_strategy="ddp"` to use PyTorch [`DistributedDataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) (DDP)
- `distribution_strategy="fast_ddp"` to use a lighter and usually faster implementation
Optimum Habana's fast DDP does not split parameter gradients into buckets as [DDP does](https://pytorch.org/docs/stable/notes/ddp.html#internal-design). It also uses [HPU graphs](https://docs.habana.ai/en/latest/PyTorch/Inference_on_PyTorch/Inference_Using_HPU_Graphs.html?highlight=hpu%20graphs) to collect gradients in all processes and then update them (after the [all_reduce](https://pytorch.org/docs/stable/distributed.html#torch.distributed.all_reduce) operation is performed) with minimal host overhead. You can check this implementation [here](https://github.com/huggingface/optimum-habana/blob/main/optimum/habana/distributed/fast_ddp.py).
Simply using `distribution_strategy="fast_ddp"` (and keeping `dataloader_num_workers=1`) on Gaudi2 gives us 705.9 samples/s. **This is x1.10 faster than with DDP and x2.38 faster than A100!**
So adding just two training arguments (`dataloader_num_workers=1` and `distribution_strategy="fast_ddp"`) led to a x1.33 speedup on Gaudi2 and to a x2.38 speedup compared to A100 with `dataloader_num_workers=1`. -->
### Hardware-accelerated data loading with Optimum Habana
For even larger speedups, we are now going to move as many data loading operations as possible from the CPU to the accelerator devices (i.e. HPUs on Gaudi2 or GPUs on A100/H100). This can be done on Gaudi2 using Habana's [media pipeline](https://docs.habana.ai/en/latest/Media_Pipeline/index.html).
Given a dataset, most dataloaders follow the following recipe:
1. Fetch data (e.g. where your JPEG images are stored on disk)
2. The CPU reads encoded images
3. The CPU decodes images
4. The CPU applies image transformations to augment images
5. Finally, images are sent to devices (although this is usually not done by the dataloader itself)
Instead of doing the whole process on CPU and send ready-to-train data to devices, a more efficient workflow would be to send encoded images to devices first and then perform image decoding and augmentations:
1. Same as before
2. Same as before
3. Encoded images are sent to devices
4. Devices decode images
5. Devices apply image transformations to augment images
That way we can benefit from the computing power of our devices to speed image decoding and transformations up.
Note that there are two caveats to be aware of when doing this:
- Device memory consumption will increase, so you may have to reduce your batch size if there is not enough free memory. This may mitigate the speedup brought by this approach.
- If devices are intensively used (100% or close to it) when doing data loading on CPU, don't expect any speedup when doing it on devices as they already have their hands full.
<!-- To achieve this on Gaudi2, Habana's media pipeline enables us to:
- Initialize a media pipeline with all the operators it needs (see [here](https://docs.habana.ai/en/latest/Media_Pipeline/Operators.html#media-operators) the list of all supported operators) and define a graph so that we can specify in which order operations should be performed (e.g. reading data → decoding → cropping).
- Create a Torch dataloader with a HPU-tailored iterator. -->
To implement this on Gaudi2, we have got you covered: the [contrastive image-text example](https://github.com/huggingface/optimum-habana/tree/main/examples/contrastive-image-text) in Optimum Habana now provides a ready-to-use media pipeline that you can use with COCO-like datasets that contain text and images! You will just have to add `--mediapipe_dataloader` to your command to use it.
For interested readers, a lower-level overview is given in the documentation of Gaudi [here](https://docs.habana.ai/en/latest/Media_Pipeline/index.html) and the list of all supported operators is available [there](https://docs.habana.ai/en/latest/Media_Pipeline/Operators.html).
We are now going to re-run the previous experiments adding the `mediapipe_dataloader` argument since it is compatible with `dataloader_num_workers`:
| Device | `dataloader_num_workers=0` | `dataloader_num_workers=2` | `dataloader_num_workers=2` + `mediapipe_dataloader` |
|:----------:|:--------------------------:|:--------------------------------------------:|:---------------:|
| Gaudi2 HPU | 601.5 samples/s | 768.7 samples/s | 847.7 samples/s |
| H100 GPU | 336.5 samples/s | 602.1 samples/s | / |
| A100 GPU | 227.5 samples/s | 345.4 samples/s | / |
We got an additional x1.10 speedup compared to the previous run with `dataloader_num_workers=2` only.
This final run is thus x1.41 faster than our base run on Gaudi2 **simply adding 2 ready-to-use training arguments.** It is also **x1.41 faster than H100** and **x2.45 faster than A100** with `dataloader_num_workers=2`!
### Reproducing this benchmark
To reproduce this benchmark, you first need to get access to Gaudi2 through the [Intel Developer Cloud](https://www.intel.com/content/www/us/en/secure/developer/devcloud/cloud-launchpad.html) (see [this guide](https://huggingface.co/blog/habana-gaudi-2-benchmark#how-to-get-access-to-gaudi2) for more information).
Then, you need to install the latest version of Optimum Habana and run `run_bridgetower.py` which you can find [here](https://github.com/huggingface/optimum-habana/blob/main/examples/contrastive-image-text/run_bridgetower.py). Here is how to do it:
```bash
pip install optimum[habana]
git clone https://github.com/huggingface/optimum-habana.git
cd optimum-habana/examples/contrastive-image-text
pip install -r requirements.txt
```
The base command line to run the script is:
```bash
python ../gaudi_spawn.py --use_mpi --world_size 8 run_bridgetower.py \
--output_dir /tmp/bridgetower-test \
--model_name_or_path BridgeTower/bridgetower-large-itm-mlm-itc \
--dataset_name jmhessel/newyorker_caption_contest --dataset_config_name matching \
--dataset_revision 3c6c4f6c0ff7e902833d3afa5f8f3875c2b036e6 \
--image_column image --caption_column image_description \
--remove_unused_columns=False \
--do_train --do_eval --do_predict \
--per_device_train_batch_size="40" --per_device_eval_batch_size="16" \
--num_train_epochs 5 \
--learning_rate="1e-5" \
--push_to_hub --report_to tensorboard --hub_model_id bridgetower\
--overwrite_output_dir \
--use_habana --use_lazy_mode --use_hpu_graphs_for_inference --gaudi_config_name Habana/clip \
--throughput_warmup_steps 3 \
--logging_steps 10
```
which corresponds to the case `--dataloader_num_workers 0`. You can then add `--dataloader_num_workers N` and `--mediapipe_dataloader` to test other configurations.
To push your model and Tensorboard logs to the Hugging Face Hub, you will have to log in to your account beforehand with:
```bash
huggingface-cli login
```
For A100 and H100, you can use the same `run_bridgetower.py` script with a few small changes:
- Replace `GaudiTrainer` and `GaudiTrainingArguments` with `Trainer` and `TrainingArguments` from Transformers
- Remove references to `GaudiConfig`, `gaudi_config` and `HabanaDataloaderTrainer`
- Import `set_seed` directly from Transformers: `from transformers import set_seed`
The results displayed in this benchmark were obtained with a Nvidia H100 Lambda instance and a Nvidia A100 80GB GCP instance both with 8 devices using [Nvidia's Docker images](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/index.html).
Note that `--mediapipe_dataloader` is compatible with Gaudi2 only and will not work with A100/H100.
Regarding fp8 results on H100 using [Transformer Engine](https://docs.nvidia.com/deeplearning/transformer-engine/user-guide/index.html), they are not available because the code crashes and would require modifying the modeling of BridgeTower in Transformers. We will revisit this comparison when fp8 is supported on Gaudi2.
## Conclusion
When dealing with images, we presented two solutions to speed up your training workflows: allocating more resources to the dataloader, and decoding and augmenting images directly on accelerator devices rather than on CPU.
We showed that it leads to dramatic speedups when training a SOTA vision-language model like BridgeTower: **Habana Gaudi2 with Optimum Habana is about x1.4 faster than Nvidia H100 and x2.5 faster than Nvidia A100 80GB with Transformers!**
And this is super easy to use as you just need to provide a few additional training arguments.
To go further, we are looking forward to using HPU graphs for training models even faster and to presenting how to use DeepSpeed ZeRO-3 on Gaudi2 to accelerate the training of your LLMs. Stay tuned!
If you are interested in accelerating your Machine Learning training and inference workflows using the latest AI hardware accelerators and software libraries, check out our [Expert Acceleration Program](https://huggingface.co/support). To learn more about Habana solutions, [read about our partnership and contact them here](https://huggingface.co/hardware/habana). To learn more about Hugging Face efforts to make AI hardware accelerators easy to use, check out our [Hardware Partner Program](https://huggingface.co/hardware).
### Related Topics
- [Faster Training and Inference: Habana Gaudi-2 vs Nvidia A100 80GB](https://huggingface.co/blog/habana-gaudi-2-benchmark)
- [Fast Inference on Large Language Models: BLOOMZ on Habana Gaudi2 Accelerator](https://huggingface.co/blog/habana-gaudi-2-bloom)
| huggingface/blog/blob/main/bridgetower.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# OpenAI GPT2
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=gpt2">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-gpt2-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/gpt2">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
OpenAI GPT-2 model was proposed in [Language Models are Unsupervised Multitask Learners](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) by Alec
Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever from [OpenAI](https://huggingface.co/openai). It's a causal (unidirectional)
transformer pretrained using language modeling on a very large corpus of ~40 GB of text data.
The abstract from the paper is the following:
*GPT-2 is a large transformer-based language model with 1.5 billion parameters, trained on a dataset[1] of 8 million
web pages. GPT-2 is trained with a simple objective: predict the next word, given all of the previous words within some
text. The diversity of the dataset causes this simple goal to contain naturally occurring demonstrations of many tasks
across diverse domains. GPT-2 is a direct scale-up of GPT, with more than 10X the parameters and trained on more than
10X the amount of data.*
[Write With Transformer](https://transformer.huggingface.co/doc/gpt2-large) is a webapp created and hosted by
Hugging Face showcasing the generative capabilities of several models. GPT-2 is one of them and is available in five
different sizes: small, medium, large, xl and a distilled version of the small checkpoint: *distilgpt-2*.
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://openai.com/blog/better-language-models/).
## Usage tips
- GPT-2 is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- GPT-2 was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next
token in a sequence. Leveraging this feature allows GPT-2 to generate syntactically coherent text as it can be
observed in the *run_generation.py* example script.
- The model can take the *past_key_values* (for PyTorch) or *past* (for TF) as input, which is the previously computed
key/value attention pairs. Using this (*past_key_values* or *past*) value prevents the model from re-computing
pre-computed values in the context of text generation. For PyTorch, see *past_key_values* argument of the
[`GPT2Model.forward`] method, or for TF the *past* argument of the
[`TFGPT2Model.call`] method for more information on its usage.
- Enabling the *scale_attn_by_inverse_layer_idx* and *reorder_and_upcast_attn* flags will apply the training stability
improvements from [Mistral](https://github.com/stanford-crfm/mistral/) (for PyTorch only).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GPT2. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-generation"/>
- A blog on how to [Finetune a non-English GPT-2 Model with Hugging Face](https://www.philschmid.de/fine-tune-a-non-english-gpt-2-model-with-huggingface).
- A blog on [How to generate text: using different decoding methods for language generation with Transformers](https://huggingface.co/blog/how-to-generate) with GPT-2.
- A blog on [Training CodeParrot 🦜 from Scratch](https://huggingface.co/blog/codeparrot), a large GPT-2 model.
- A blog on [Faster Text Generation with TensorFlow and XLA](https://huggingface.co/blog/tf-xla-generate) with GPT-2.
- A blog on [How to train a Language Model with Megatron-LM](https://huggingface.co/blog/megatron-training) with a GPT-2 model.
- A notebook on how to [finetune GPT2 to generate lyrics in the style of your favorite artist](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb). 🌎
- A notebook on how to [finetune GPT2 to generate tweets in the style of your favorite Twitter user](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb). 🌎
- [Causal language modeling](https://huggingface.co/course/en/chapter7/6?fw=pt#training-a-causal-language-model-from-scratch) chapter of the 🤗 Hugging Face Course.
- [`GPT2LMHeadModel`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling), [text generation example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation), and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFGPT2LMHeadModel`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_clmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxGPT2LMHeadModel`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#causal-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/causal_language_modeling_flax.ipynb).
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
## GPT2Config
[[autodoc]] GPT2Config
## GPT2Tokenizer
[[autodoc]] GPT2Tokenizer
- save_vocabulary
## GPT2TokenizerFast
[[autodoc]] GPT2TokenizerFast
## GPT2 specific outputs
[[autodoc]] models.gpt2.modeling_gpt2.GPT2DoubleHeadsModelOutput
[[autodoc]] models.gpt2.modeling_tf_gpt2.TFGPT2DoubleHeadsModelOutput
<frameworkcontent>
<pt>
## GPT2Model
[[autodoc]] GPT2Model
- forward
## GPT2LMHeadModel
[[autodoc]] GPT2LMHeadModel
- forward
## GPT2DoubleHeadsModel
[[autodoc]] GPT2DoubleHeadsModel
- forward
## GPT2ForQuestionAnswering
[[autodoc]] GPT2ForQuestionAnswering
- forward
## GPT2ForSequenceClassification
[[autodoc]] GPT2ForSequenceClassification
- forward
## GPT2ForTokenClassification
[[autodoc]] GPT2ForTokenClassification
- forward
</pt>
<tf>
## TFGPT2Model
[[autodoc]] TFGPT2Model
- call
## TFGPT2LMHeadModel
[[autodoc]] TFGPT2LMHeadModel
- call
## TFGPT2DoubleHeadsModel
[[autodoc]] TFGPT2DoubleHeadsModel
- call
## TFGPT2ForSequenceClassification
[[autodoc]] TFGPT2ForSequenceClassification
- call
## TFSequenceClassifierOutputWithPast
[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutputWithPast
## TFGPT2Tokenizer
[[autodoc]] TFGPT2Tokenizer
</tf>
<jax>
## FlaxGPT2Model
[[autodoc]] FlaxGPT2Model
- __call__
## FlaxGPT2LMHeadModel
[[autodoc]] FlaxGPT2LMHeadModel
- __call__
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/gpt2.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# RetriBERT
<Tip warning={true}>
This model is in maintenance mode only, so we won't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
</Tip>
## Overview
The RetriBERT model was proposed in the blog post [Explain Anything Like I'm Five: A Model for Open Domain Long Form
Question Answering](https://yjernite.github.io/lfqa.html). RetriBERT is a small model that uses either a single or
pair of BERT encoders with lower-dimension projection for dense semantic indexing of text.
This model was contributed by [yjernite](https://huggingface.co/yjernite). Code to train and use the model can be
found [here](https://github.com/huggingface/transformers/tree/main/examples/research-projects/distillation).
## RetriBertConfig
[[autodoc]] RetriBertConfig
## RetriBertTokenizer
[[autodoc]] RetriBertTokenizer
## RetriBertTokenizerFast
[[autodoc]] RetriBertTokenizerFast
## RetriBertModel
[[autodoc]] RetriBertModel
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/retribert.md |
Gradio Demo: leaderboard
### A simple dashboard ranking spaces by number of likes.
```
!pip install -q gradio
```
```
import gradio as gr
import requests
import pandas as pd
from huggingface_hub.hf_api import SpaceInfo
path = f"https://huggingface.co/api/spaces"
def get_blocks_party_spaces():
r = requests.get(path)
d = r.json()
spaces = [SpaceInfo(**x) for x in d]
blocks_spaces = {}
for i in range(0,len(spaces)):
if spaces[i].id.split('/')[0] == 'Gradio-Blocks' and hasattr(spaces[i], 'likes') and spaces[i].id != 'Gradio-Blocks/Leaderboard' and spaces[i].id != 'Gradio-Blocks/README':
blocks_spaces[spaces[i].id]=spaces[i].likes
df = pd.DataFrame(
[{"Spaces_Name": Spaces, "likes": likes} for Spaces,likes in blocks_spaces.items()])
df = df.sort_values(by=['likes'],ascending=False)
return df
block = gr.Blocks()
with block:
gr.Markdown("""Leaderboard for the most popular Blocks Event Spaces. To learn more and join, see <a href="https://huggingface.co/Gradio-Blocks" target="_blank" style="text-decoration: underline">Blocks Party Event</a>""")
with gr.Tabs():
with gr.TabItem("Blocks Party Leaderboard"):
with gr.Row():
data = gr.Dataframe(type="pandas")
with gr.Row():
data_run = gr.Button("Refresh")
data_run.click(get_blocks_party_spaces, inputs=None, outputs=data)
# running the function on page load in addition to when the button is clicked
block.load(get_blocks_party_spaces, inputs=None, outputs=data)
block.launch()
```
| gradio-app/gradio/blob/main/demo/leaderboard/run.ipynb |
!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Multiple-choice training (e.g. SWAG)
This folder contains the `run_swag.py` script, showing an examples of *multiple-choice answering* with the
🤗 Transformers library. For straightforward use-cases you may be able to use these scripts without modification,
although we have also included comments in the code to indicate areas that you may need to adapt to your own projects.
### Multi-GPU and TPU usage
By default, the script uses a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
can also be used by passing the name of the TPU resource with the `--tpu` argument.
### Memory usage and data loading
One thing to note is that all data is loaded into memory in this script. Most multiple-choice datasets are small
enough that this is not an issue, but if you have a very large dataset you will need to modify the script to handle
data streaming. This is particularly challenging for TPUs, given the stricter requirements and the sheer volume of data
required to keep them fed. A full explanation of all the possible pitfalls is a bit beyond this example script and
README, but for more information you can see the 'Input Datasets' section of
[this document](https://www.tensorflow.org/guide/tpu).
### Example command
```bash
python run_swag.py \
--model_name_or_path distilbert-base-cased \
--output_dir output \
--do_eval \
--do_train
```
| huggingface/transformers/blob/main/examples/tensorflow/multiple-choice/README.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Export functions
You can export models to ONNX from two frameworks in 🤗 Optimum: PyTorch and TensorFlow. There is an export function for each of these frameworks, [`~optimum.exporters.onnx.convert.export_pytorch`] and [`~optimum.exporters.onnx.convert.export_tensorflow`], but the recommended way of using those is via the main export function [`~optimum.exporters.main_export`], which will take care of using the proper exporting function according to the available framework, check that the exported model is valid, and provide extended options to run optimizations on the exported model.
## Main functions
[[autodoc]] exporters.onnx.main_export
[[autodoc]] exporters.onnx.convert.export
[[autodoc]] exporters.onnx.convert.export_pytorch
[[autodoc]] exporters.onnx.convert.export_tensorflow
## Utility functions
[[autodoc]] exporters.onnx.convert.check_dummy_inputs_are_allowed
[[autodoc]] exporters.onnx.convert.validate_model_outputs
| huggingface/optimum/blob/main/docs/source/exporters/onnx/package_reference/export.mdx |
--
title: "Introducing 🤗 Accelerate"
thumbnail: /blog/assets/20_accelerate_library/accelerate_diff.png
authors:
- user: sgugger
---
# Introducing 🤗 Accelerate
## 🤗 Accelerate
Run your **raw** PyTorch training scripts on any kind of device.
Most high-level libraries above PyTorch provide support for distributed training and mixed precision, but the abstraction they introduce require a user to learn a new API if they want to customize the underlying training loop. 🤗 Accelerate was created for PyTorch users who like to have full control over their training loops but are reluctant to write (and maintain) the boilerplate code needed to use distributed training (for multi-GPU on one or several nodes, TPUs, ...) or mixed precision training. Plans forward include support for fairscale, deepseed, AWS SageMaker specific data-parallelism and model parallelism.
It provides two things: a simple and consistent API that abstracts that boilerplate code and a launcher command to easily run those scripts on various setups.
### Easy integration!
Let's first have a look at an example:
```diff
import torch
import torch.nn.functional as F
from datasets import load_dataset
+ from accelerate import Accelerator
+ accelerator = Accelerator()
- device = 'cpu'
+ device = accelerator.device
model = torch.nn.Transformer().to(device)
optim = torch.optim.Adam(model.parameters())
dataset = load_dataset('my_dataset')
data = torch.utils.data.DataLoader(dataset, shuffle=True)
+ model, optim, data = accelerator.prepare(model, optim, data)
model.train()
for epoch in range(10):
for source, targets in data:
source = source.to(device)
targets = targets.to(device)
optimizer.zero_grad()
output = model(source)
loss = F.cross_entropy(output, targets)
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
```
By just adding five lines of code to any standard PyTorch training script, you can now run said script on any kind of distributed setting, as well as with or without mixed precision. 🤗 Accelerate even handles the device placement for you, so you can simplify the training loop above even further:
```diff
import torch
import torch.nn.functional as F
from datasets import load_dataset
+ from accelerate import Accelerator
+ accelerator = Accelerator()
- device = 'cpu'
- model = torch.nn.Transformer().to(device)
+ model = torch.nn.Transformer()
optim = torch.optim.Adam(model.parameters())
dataset = load_dataset('my_dataset')
data = torch.utils.data.DataLoader(dataset, shuffle=True)
+ model, optim, data = accelerator.prepare(model, optim, data)
model.train()
for epoch in range(10):
for source, targets in data:
- source = source.to(device)
- targets = targets.to(device)
optimizer.zero_grad()
output = model(source)
loss = F.cross_entropy(output, targets)
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
```
In contrast, here are the changes needed to have this code run with distributed training are the followings:
```diff
+ import os
import torch
import torch.nn.functional as F
from datasets import load_dataset
+ from torch.utils.data import DistributedSampler
+ from torch.nn.parallel import DistributedDataParallel
+ local_rank = int(os.environ.get("LOCAL_RANK", -1))
- device = 'cpu'
+ device = device = torch.device("cuda", local_rank)
model = torch.nn.Transformer().to(device)
+ model = DistributedDataParallel(model)
optim = torch.optim.Adam(model.parameters())
dataset = load_dataset('my_dataset')
+ sampler = DistributedSampler(dataset)
- data = torch.utils.data.DataLoader(dataset, shuffle=True)
+ data = torch.utils.data.DataLoader(dataset, sampler=sampler)
model.train()
for epoch in range(10):
+ sampler.set_epoch(epoch)
for source, targets in data:
source = source.to(device)
targets = targets.to(device)
optimizer.zero_grad()
output = model(source)
loss = F.cross_entropy(output, targets)
loss.backward()
optimizer.step()
```
These changes will make your training script work for multiple GPUs, but your script will then stop working on CPU or one GPU (unless you start adding if statements everywhere). Even more annoying, if you wanted to test your script on TPUs you would need to change different lines of codes. Same for mixed precision training. The promise of 🤗 Accelerate is:
- to keep the changes to your training loop to the bare minimum so you have to learn as little as possible.
- to have the same functions work for any distributed setup, so only have to learn one API.
### How does it work?
To see how the library works in practice, let's have a look at each line of code we need to add to a training loop.
```python
accelerator = Accelerator()
```
On top of giving the main object that you will use, this line will analyze from the environment the type of distributed training run and perform the necessary initialization. You can force a training on CPU or a mixed precision training by passing `cpu=True` or `fp16=True` to this init. Both of those options can also be set using the launcher for your script.
```python
model, optim, data = accelerator.prepare(model, optim, data)
```
This is the main bulk of the API and will prepare the three main type of objects: models (`torch.nn.Module`), optimizers (`torch.optim.Optimizer`) and dataloaders (`torch.data.dataloader.DataLoader`).
#### Model
Model preparation include wrapping it in the proper container (for instance `DistributedDataParallel`) and putting it on the proper device. Like with a regular distributed training, you will need to unwrap your model for saving, or to access its specific methods, which can be done with `accelerator.unwrap_model(model)`.
#### Optimizer
The optimizer is also wrapped in a special container that will perform the necessary operations in the step to make mixed precision work. It will also properly handle device placement of the state dict if its non-empty or loaded from a checkpoint.
#### DataLoader
This is where most of the magic is hidden. As you have seen in the code example, the library does not rely on a `DistributedSampler`, it will actually work with any sampler you might pass to your dataloader (if you ever had to write a distributed version of your custom sampler, there is no more need for that!). The dataloader is wrapped in a container that will only grab the indices relevant to the current process in the sampler (or skip the batches for the other processes if you use an `IterableDataset`) and put the batches on the proper device.
For this to work, Accelerate provides a utility function that will synchronize the random number generators on each of the processes run during distributed training. By default, it only synchronizes the `generator` of your sampler, so your data augmentation will be different on each process, but the random shuffling will be the same. You can of course use this utility to synchronize more RNGs if you need it.
```python
accelerator.backward(loss)
```
This last line adds the necessary steps for the backward pass (mostly for mixed precision but other integrations will require some custom behavior here).
### What about evaluation?
Evaluation can either be run normally on all processes, or if you just want it to run on the main process, you can use the handy test:
```python
if accelerator.is_main_process():
# Evaluation loop
```
But you can also very easily run a distributed evaluation using Accelerate, here is what you would need to add to your evaluation loop:
```diff
+ eval_dataloader = accelerator.prepare(eval_dataloader)
predictions, labels = [], []
for source, targets in eval_dataloader:
with torch.no_grad():
output = model(source)
- predictions.append(output.cpu().numpy())
- labels.append(targets.cpu().numpy())
+ predictions.append(accelerator.gather(output).cpu().numpy())
+ labels.append(accelerator.gather(targets).cpu().numpy())
predictions = np.concatenate(predictions)
labels = np.concatenate(labels)
+ predictions = predictions[:len(eval_dataloader.dataset)]
+ labels = label[:len(eval_dataloader.dataset)]
metric_compute(predictions, labels)
```
Like for the training, you need to add one line to prepare your evaluation dataloader. Then you can just use `accelerator.gather` to gather across processes the tensors of predictions and labels. The last line to add truncates the predictions and labels to the number of examples in your dataset because the prepared evaluation dataloader will return a few more elements to make sure batches all have the same size on each process.
### One launcher to rule them all
The scripts using Accelerate will be completely compatible with your traditional launchers, such as `torch.distributed.launch`. But remembering all the arguments to them is a bit annoying and when you've setup your instance with 4 GPUs, you'll run most of your trainings using them all. Accelerate comes with a handy CLI that works in two steps:
```bash
accelerate config
```
This will trigger a little questionnaire about your setup, which will create a config file you can edit with all the defaults for your training commands. Then
```bash
accelerate launch path_to_script.py --args_to_the_script
```
will launch your training script using those default. The only thing you have to do is provide all the arguments needed by your training script.
To make this launcher even more awesome, you can use it to spawn an AWS instance using SageMaker. Look at [this guide](https://huggingface.co/docs/accelerate/sagemaker.html) to discover how!
### How to get involved?
To get started, just `pip install accelerate` or see the [documentation](https://huggingface.co/docs/accelerate/installation.html) for more install options.
Accelerate is a fully open-sourced project, you can find it on [GitHub](https://github.com/huggingface/accelerate), have a look at its [documentation](https://huggingface.co/docs/accelerate/) or skim through our [basic examples](https://github.com/huggingface/accelerate/tree/main/examples). Please let us know if you have any issue or feature you would like the library to support. For all questions, the [forums](https://discuss.huggingface.co/c/accelerate) is the place to check!
For more complex examples in situation, you can look at the official [Transformers examples](https://github.com/huggingface/transformers/tree/master/examples). Each folder contains a `run_task_no_trainer.py` that leverages the Accelerate library!
| huggingface/blog/blob/main/accelerate-library.md |
Gradio 界面的 4 种类型
到目前为止,我们一直假设构建 Gradio 演示需要同时具备输入和输出。但对于机器学习演示来说,并不总是如此:例如,*无条件图像生成模型*不需要任何输入,但会生成一张图像作为输出。
事实证明,`gradio.Interface` 类实际上可以处理 4 种不同类型的演示:
1. **Standard demos 标准演示**:同时具有独立的输入和输出(例如图像分类器或语音转文本模型)
2. **Output-only demos 仅输出演示**:不接受任何输入,但会产生输出(例如无条件图像生成模型)
3. **Input-only demos 仅输入演示**:不产生任何输出,但会接受某种形式的输入(例如保存您上传到外部持久数据库的图像的演示)
4. **Unified demos 统一演示**:同时具有输入和输出组件,但这些组件是*相同的*。这意味着生成的输出将覆盖输入(例如文本自动完成模型)
根据演示类型的不同,用户界面(UI)会有略微不同的外观:

我们来看一下如何使用 `Interface` 类构建每种类型的演示,以及示例:
## 标准演示 (Standard demos)
要创建具有输入和输出组件的演示,只需在 `Interface()` 中设置 `inputs` 和 `outputs` 参数的值。以下是一个简单图像滤镜的示例演示:
$code_sepia_filter
$demo_sepia_filter
## 仅输出演示 (Output-only demos)
那么仅包含输出的演示呢?为了构建这样的演示,只需将 `Interface()` 中的 `inputs` 参数值设置为 `None`。以下是模拟图像生成模型的示例演示:
$code_fake_gan_no_input
$demo_fake_gan_no_input
## 仅输入演示 (Input-only demos)
同样地,要创建仅包含输入的演示,将 `Interface()` 中的 `outputs` 参数值设置为 `None`。以下是将任何上传的图像保存到磁盘的示例演示:
$code_save_file_no_output
$demo_save_file_no_output
## 统一演示 (Unified demos)
这种演示将单个组件同时作为输入和输出。只需将 `Interface()` 中的 `inputs` 和 `outputs` 参数值设置为相同的组件即可创建此演示。以下是文本生成模型的示例演示:
$code_unified_demo_text_generation
$demo_unified_demo_text_generation
| gradio-app/gradio/blob/main/guides/cn/02_building-interfaces/04_four-kinds-of-interfaces.md |
Gradio Demo: calculator_blocks
```
!pip install -q gradio
```
```
import gradio as gr
def calculator(num1, operation, num2):
if operation == "add":
return num1 + num2
elif operation == "subtract":
return num1 - num2
elif operation == "multiply":
return num1 * num2
elif operation == "divide":
return num1 / num2
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
num_1 = gr.Number(value=4)
operation = gr.Radio(["add", "subtract", "multiply", "divide"])
num_2 = gr.Number(value=0)
submit_btn = gr.Button(value="Calculate")
with gr.Column():
result = gr.Number()
submit_btn.click(calculator, inputs=[num_1, operation, num_2], outputs=[result], api_name=False)
examples = gr.Examples(examples=[[5, "add", 3],
[4, "divide", 2],
[-4, "multiply", 2.5],
[0, "subtract", 1.2]],
inputs=[num_1, operation, num_2])
if __name__ == "__main__":
demo.launch(show_api=False)
```
| gradio-app/gradio/blob/main/demo/calculator_blocks/run.ipynb |
Security Policy
## Supported Versions
<!--
Use this section to tell people about which versions of your project are
currently being supported with security updates.
| Version | Supported |
| ------- | ------------------ |
| 5.1.x | :white_check_mark: |
| 5.0.x | :x: |
| 4.0.x | :white_check_mark: |
| < 4.0 | :x: |
-->
Each major version is currently being supported with security updates.
| Version | Supported |
|---------|--------------------|
| 1.x.x | :white_check_mark: |
| 2.x.x | :white_check_mark: |
## Reporting a Vulnerability
<!--
Use this section to tell people how to report a vulnerability.
Tell them where to go, how often they can expect to get an update on a
reported vulnerability, what to expect if the vulnerability is accepted or
declined, etc.
-->
To report a security vulnerability, please contact: security@huggingface.co
| huggingface/datasets/blob/main/SECURITY.md |
@gradio/dataframe
## 0.4.3
### Patch Changes
- Updated dependencies [[`846d52d`](https://github.com/gradio-app/gradio/commit/846d52d1c92d429077382ce494eea27fd062d9f6), [`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`f3abde8`](https://github.com/gradio-app/gradio/commit/f3abde80884d96ad69b825020c46486d9dd5cac5), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/markdown@0.6.0
- @gradio/statustracker@0.4.3
- @gradio/atoms@0.4.1
- @gradio/upload@0.5.6
- @gradio/button@0.2.13
## 0.4.2
### Patch Changes
- Updated dependencies []:
- @gradio/button@0.2.12
- @gradio/upload@0.5.5
## 0.4.1
### Patch Changes
- Updated dependencies [[`5d51fbc`](https://github.com/gradio-app/gradio/commit/5d51fbce7826da840a2fd4940feb5d9ad6f1bc5a)]:
- @gradio/upload@0.5.4
- @gradio/button@0.2.11
## 0.4.0
### Features
- [#6603](https://github.com/gradio-app/gradio/pull/6603) [`6b1401c`](https://github.com/gradio-app/gradio/commit/6b1401c514c2ec012b0a50c72a6ec81cb673bf1d) - chore(deps): update dependency marked to v11. Thanks [@renovate](https://github.com/apps/renovate)!
## 0.3.11
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.3.1
- @gradio/statustracker@0.4.1
- @gradio/upload@0.5.2
- @gradio/markdown@0.4.1
- @gradio/button@0.2.9
## 0.3.10
### Patch Changes
- Updated dependencies [[`6d3fecfa4`](https://github.com/gradio-app/gradio/commit/6d3fecfa42dde1c70a60c397434c88db77289be6)]:
- @gradio/markdown@0.4.0
## 0.3.9
### Patch Changes
- Updated dependencies [[`46f13f496`](https://github.com/gradio-app/gradio/commit/46f13f4968c8177e318c9d75f2eed1ed55c2c042)]:
- @gradio/markdown@0.3.4
- @gradio/button@0.2.8
- @gradio/upload@0.5.1
## 0.3.8
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
- @gradio/statustracker@0.4.0
- @gradio/upload@0.5.0
- @gradio/markdown@0.3.3
- @gradio/button@0.2.7
## 0.3.7
### Patch Changes
- Updated dependencies [[`2f805a7dd`](https://github.com/gradio-app/gradio/commit/2f805a7dd3d2b64b098f659dadd5d01258290521), [`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/upload@0.4.2
- @gradio/atoms@0.2.2
- @gradio/button@0.2.6
- @gradio/markdown@0.3.2
- @gradio/statustracker@0.3.2
## 0.3.6
### Patch Changes
- Updated dependencies []:
- @gradio/button@0.2.5
- @gradio/upload@0.4.1
## 0.3.5
### Patch Changes
- Updated dependencies [[`854b482f5`](https://github.com/gradio-app/gradio/commit/854b482f598e0dc47673846631643c079576da9c), [`f1409f95e`](https://github.com/gradio-app/gradio/commit/f1409f95ed39c5565bed6a601e41f94e30196a57)]:
- @gradio/upload@0.4.0
- @gradio/button@0.2.4
## 0.3.4
### Features
- [#6318](https://github.com/gradio-app/gradio/pull/6318) [`d3b53a457`](https://github.com/gradio-app/gradio/commit/d3b53a4577ea05cd27e37ce7fec952028c18ed45) - Fix for stylized DataFrame. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.3.3
### Fixes
- [#6290](https://github.com/gradio-app/gradio/pull/6290) [`e8216be94`](https://github.com/gradio-app/gradio/commit/e8216be948f76ce064595183d11e9148badf9421) - ensure `gr.Dataframe` updates as expected. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.2
### Patch Changes
- Updated dependencies [[`aaa55ce85`](https://github.com/gradio-app/gradio/commit/aaa55ce85e12f95aba9299445e9c5e59824da18e)]:
- @gradio/upload@0.3.2
- @gradio/button@0.2.2
## 0.3.1
### Patch Changes
- Updated dependencies []:
- @gradio/button@0.2.1
- @gradio/upload@0.3.1
## 0.3.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.8
### Features
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.7
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#6046](https://github.com/gradio-app/gradio/pull/6046) [`dbb7de5e0`](https://github.com/gradio-app/gradio/commit/dbb7de5e02c53fee05889d696d764d212cb96c74) - fix tests. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5894](https://github.com/gradio-app/gradio/pull/5894) [`fee3d527e`](https://github.com/gradio-app/gradio/commit/fee3d527e83a615109cf937f6ca0a37662af2bb6) - Adds `column_widths` to `gr.Dataframe` and hide overflowing text when `wrap=False`. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.4.0
### Features
- [#5877](https://github.com/gradio-app/gradio/pull/5877) [`a55b80942`](https://github.com/gradio-app/gradio/commit/a55b8094231ae462ac53f52bbdb460c1286ffabb) - Add styling (e.g. font colors and background colors) support to `gr.DataFrame` through the `pd.Styler` object. Thanks [@abidlabs](https://github.com/abidlabs)!
### Fixes
- [#5930](https://github.com/gradio-app/gradio/pull/5930) [`361823896`](https://github.com/gradio-app/gradio/commit/3618238960d54df65c34895f4eb69d08acc3f9b6) - Fix dataframe `line_breaks`. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.3.1
### Patch Changes
- Updated dependencies []:
- @gradio/utils@0.1.2
- @gradio/atoms@0.1.4
- @gradio/button@0.2.2
- @gradio/markdown@0.3.1
- @gradio/statustracker@0.2.2
- @gradio/upload@0.3.2
## 0.3.0
### Features
- [#5569](https://github.com/gradio-app/gradio/pull/5569) [`2a5b9e03b`](https://github.com/gradio-app/gradio/commit/2a5b9e03b15ea324d641fe6982f26d81b1ca7210) - Added support for pandas `Styler` object to `gr.DataFrame` (initially just sets the `display_value`). Thanks [@abidlabs](https://github.com/abidlabs)!
### Fixes
- [#5755](https://github.com/gradio-app/gradio/pull/5755) [`e842a561a`](https://github.com/gradio-app/gradio/commit/e842a561af4394f8109291ee5725bcf74743e816) - Fix new line issue in chatbot. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.2.5
### Fixes
- [#5713](https://github.com/gradio-app/gradio/pull/5713) [`c10dabd6b`](https://github.com/gradio-app/gradio/commit/c10dabd6b18b49259441eb5f956a19046f466339) - Fixes gr.select() Method Issues with Dataframe Cells. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.2.4
### Patch Changes
- Updated dependencies [[`ee8eec1e5`](https://github.com/gradio-app/gradio/commit/ee8eec1e5e544a0127e0aa68c2522a7085b8ada5)]:
- @gradio/markdown@0.2.2
## 0.2.3
### Fixes
- [#5616](https://github.com/gradio-app/gradio/pull/5616) [`7c34b434a`](https://github.com/gradio-app/gradio/commit/7c34b434aae0eb85f112a1dc8d66cefc7e2296b2) - Fix width and height issues that would cut off content in `gr.DataFrame`. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.2.2
### Fixes
- [#5456](https://github.com/gradio-app/gradio/pull/5456) [`6e381c4f`](https://github.com/gradio-app/gradio/commit/6e381c4f146cc8177a4e2b8e39f914f09cd7ff0c) - ensure dataframe doesn't steal focus. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.1
### Fixes
- [#5445](https://github.com/gradio-app/gradio/pull/5445) [`67bb7bcb`](https://github.com/gradio-app/gradio/commit/67bb7bcb6a95b7a00a8bdf612cf147850d919a44) - ensure dataframe doesn't scroll unless needed. Thanks [@pngwn](https://github.com/pngwn)!
## 0.2.0
### Features
- [#5342](https://github.com/gradio-app/gradio/pull/5342) [`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912) - significantly improve the performance of `gr.Dataframe` for large datasets. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.2
### Patch Changes
- Updated dependencies [[`05892302`](https://github.com/gradio-app/gradio/commit/05892302fb8fe2557d57834970a2b65aea97355b), [`e4e7a431`](https://github.com/gradio-app/gradio/commit/e4e7a4319924aaf51dcb18d07d0c9953d4011074), [`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db), [`79d8f9d8`](https://github.com/gradio-app/gradio/commit/79d8f9d891901683c5a1b7486efb44eab2478c96), [`4d94ea0a`](https://github.com/gradio-app/gradio/commit/4d94ea0a0cf2103cda19f48398a5634f8341d04d), [`b27f7583`](https://github.com/gradio-app/gradio/commit/b27f7583254165b135bf1496a7d8c489a62ba96f)]:
- @gradio/markdown@0.1.2
- @gradio/utils@0.1.0
- @gradio/upload@0.2.0
- @gradio/atoms@0.1.1
- @gradio/statustracker@0.1.1
- @gradio/button@0.1.2
## 0.1.1
### Patch Changes
- Updated dependencies [[`31996c99`](https://github.com/gradio-app/gradio/commit/31996c991d6bfca8cef975eb8e3c9f61a7aced19)]:
- @gradio/markdown@0.1.1
## 0.1.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5268](https://github.com/gradio-app/gradio/pull/5268) [`f49028cf`](https://github.com/gradio-app/gradio/commit/f49028cfe3e21097001ddbda71c560b3d8b42e1c) - Move markdown & latex processing to the frontend for the gr.Markdown and gr.DataFrame components. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5283](https://github.com/gradio-app/gradio/pull/5283) [`a7460557`](https://github.com/gradio-app/gradio/commit/a74605572dd0d6bb41df6b38b120d656370dd67d) - Add height parameter and scrolling to `gr.Dataframe`. Thanks [@abidlabs](https://github.com/abidlabs)!
### Fixes
- [#5256](https://github.com/gradio-app/gradio/pull/5256) [`933db53e`](https://github.com/gradio-app/gradio/commit/933db53e93a1229fdf149556d61da5c4c7e1a331) - Better handling of empty dataframe in `gr.DataFrame`. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.0.2
### Patch Changes
- Updated dependencies [[`667875b2`](https://github.com/gradio-app/gradio/commit/667875b2441753e74d25bd9d3c8adedd8ede11cd), [`37caa2e0`](https://github.com/gradio-app/gradio/commit/37caa2e0fe95d6cab8beb174580fb557904f137f)]:
- @gradio/upload@0.0.3
- @gradio/button@0.1.0
| gradio-app/gradio/blob/main/js/dataframe/CHANGELOG.md |
!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Installation
Install 🤗 Transformers for whichever deep learning library you're working with, setup your cache, and optionally configure 🤗 Transformers to run offline.
🤗 Transformers is tested on Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, and Flax. Follow the installation instructions below for the deep learning library you are using:
* [PyTorch](https://pytorch.org/get-started/locally/) installation instructions.
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip) installation instructions.
* [Flax](https://flax.readthedocs.io/en/latest/) installation instructions.
## Install with pip
You should install 🤗 Transformers in a [virtual environment](https://docs.python.org/3/library/venv.html). If you're unfamiliar with Python virtual environments, take a look at this [guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). A virtual environment makes it easier to manage different projects, and avoid compatibility issues between dependencies.
Start by creating a virtual environment in your project directory:
```bash
python -m venv .env
```
Activate the virtual environment. On Linux and MacOs:
```bash
source .env/bin/activate
```
Activate Virtual environment on Windows
```bash
.env/Scripts/activate
```
Now you're ready to install 🤗 Transformers with the following command:
```bash
pip install transformers
```
For CPU-support only, you can conveniently install 🤗 Transformers and a deep learning library in one line. For example, install 🤗 Transformers and PyTorch with:
```bash
pip install 'transformers[torch]'
```
🤗 Transformers and TensorFlow 2.0:
```bash
pip install 'transformers[tf-cpu]'
```
<Tip warning={true}>
M1 / ARM Users
You will need to install the following before installing TensorFLow 2.0
```
brew install cmake
brew install pkg-config
```
</Tip>
🤗 Transformers and Flax:
```bash
pip install 'transformers[flax]'
```
Finally, check if 🤗 Transformers has been properly installed by running the following command. It will download a pretrained model:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
Then print out the label and score:
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
## Install from source
Install 🤗 Transformers from source with the following command:
```bash
pip install git+https://github.com/huggingface/transformers
```
This command installs the bleeding edge `main` version rather than the latest `stable` version. The `main` version is useful for staying up-to-date with the latest developments. For instance, if a bug has been fixed since the last official release but a new release hasn't been rolled out yet. However, this means the `main` version may not always be stable. We strive to keep the `main` version operational, and most issues are usually resolved within a few hours or a day. If you run into a problem, please open an [Issue](https://github.com/huggingface/transformers/issues) so we can fix it even sooner!
Check if 🤗 Transformers has been properly installed by running the following command:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
```
## Editable install
You will need an editable install if you'd like to:
* Use the `main` version of the source code.
* Contribute to 🤗 Transformers and need to test changes in the code.
Clone the repository and install 🤗 Transformers with the following commands:
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
These commands will link the folder you cloned the repository to and your Python library paths. Python will now look inside the folder you cloned to in addition to the normal library paths. For example, if your Python packages are typically installed in `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python will also search the folder you cloned to: `~/transformers/`.
<Tip warning={true}>
You must keep the `transformers` folder if you want to keep using the library.
</Tip>
Now you can easily update your clone to the latest version of 🤗 Transformers with the following command:
```bash
cd ~/transformers/
git pull
```
Your Python environment will find the `main` version of 🤗 Transformers on the next run.
## Install with conda
Install from the conda channel `huggingface`:
```bash
conda install -c huggingface transformers
```
## Cache setup
Pretrained models are downloaded and locally cached at: `~/.cache/huggingface/hub`. This is the default directory given by the shell environment variable `TRANSFORMERS_CACHE`. On Windows, the default directory is given by `C:\Users\username\.cache\huggingface\hub`. You can change the shell environment variables shown below - in order of priority - to specify a different cache directory:
1. Shell environment variable (default): `HUGGINGFACE_HUB_CACHE` or `TRANSFORMERS_CACHE`.
2. Shell environment variable: `HF_HOME`.
3. Shell environment variable: `XDG_CACHE_HOME` + `/huggingface`.
<Tip>
🤗 Transformers will use the shell environment variables `PYTORCH_TRANSFORMERS_CACHE` or `PYTORCH_PRETRAINED_BERT_CACHE` if you are coming from an earlier iteration of this library and have set those environment variables, unless you specify the shell environment variable `TRANSFORMERS_CACHE`.
</Tip>
## Offline mode
Run 🤗 Transformers in a firewalled or offline environment with locally cached files by setting the environment variable `TRANSFORMERS_OFFLINE=1`.
<Tip>
Add [🤗 Datasets](https://huggingface.co/docs/datasets/) to your offline training workflow with the environment variable `HF_DATASETS_OFFLINE=1`.
</Tip>
```bash
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
This script should run without hanging or waiting to timeout because it won't attempt to download the model from the Hub.
You can also bypass loading a model from the Hub from each [`~PreTrainedModel.from_pretrained`] call with the [`local_files_only`] parameter. When set to `True`, only local files are loaded:
```py
from transformers import T5Model
model = T5Model.from_pretrained("./path/to/local/directory", local_files_only=True)
```
### Fetch models and tokenizers to use offline
Another option for using 🤗 Transformers offline is to download the files ahead of time, and then point to their local path when you need to use them offline. There are three ways to do this:
* Download a file through the user interface on the [Model Hub](https://huggingface.co/models) by clicking on the ↓ icon.

* Use the [`PreTrainedModel.from_pretrained`] and [`PreTrainedModel.save_pretrained`] workflow:
1. Download your files ahead of time with [`PreTrainedModel.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
```
2. Save your files to a specified directory with [`PreTrainedModel.save_pretrained`]:
```py
>>> tokenizer.save_pretrained("./your/path/bigscience_t0")
>>> model.save_pretrained("./your/path/bigscience_t0")
```
3. Now when you're offline, reload your files with [`PreTrainedModel.from_pretrained`] from the specified directory:
```py
>>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
```
* Programmatically download files with the [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) library:
1. Install the `huggingface_hub` library in your virtual environment:
```bash
python -m pip install huggingface_hub
```
2. Use the [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) function to download a file to a specific path. For example, the following command downloads the `config.json` file from the [T0](https://huggingface.co/bigscience/T0_3B) model to your desired path:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
```
Once your file is downloaded and locally cached, specify it's local path to load and use it:
```py
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
```
<Tip>
See the [How to download files from the Hub](https://huggingface.co/docs/hub/how-to-downstream) section for more details on downloading files stored on the Hub.
</Tip>
| huggingface/transformers/blob/main/docs/source/en/installation.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GPT Neo
## Overview
The GPTNeo model was released in the [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) repository by Sid
Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy. It is a GPT2 like causal language model trained on the
[Pile](https://pile.eleuther.ai/) dataset.
The architecture is similar to GPT2 except that GPT Neo uses local attention in every other layer with a window size of
256 tokens.
This model was contributed by [valhalla](https://huggingface.co/valhalla).
## Usage example
The `generate()` method can be used to generate text using GPT Neo model.
```python
>>> from transformers import GPTNeoForCausalLM, GPT2Tokenizer
>>> model = GPTNeoForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> tokenizer = GPT2Tokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> prompt = (
... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
... "researchers was the fact that the unicorns spoke perfect English."
... )
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
>>> gen_tokens = model.generate(
... input_ids,
... do_sample=True,
... temperature=0.9,
... max_length=100,
... )
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
```
## Combining GPT-Neo and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature, and make sure your hardware is compatible with Flash-Attention 2. More details are available [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2) concerning the installation.
Make sure as well to load your model in half-precision (e.g. `torch.float16`).
To load and run a model using Flash Attention 2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-neo-2.7B", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-2.7B")
>>> prompt = "def hello_world():"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"def hello_world():\n >>> run_script("hello.py")\n >>> exit(0)\n<|endoftext|>"
```
### Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `EleutherAI/gpt-neo-2.7B` checkpoint and the Flash Attention 2 version of the model.
Note that for GPT-Neo it is not possible to train / run on very long context as the max [position embeddings](https://huggingface.co/EleutherAI/gpt-neo-2.7B/blob/main/config.json#L58 ) is limited to 2048 - but this is applicable to all gpt-neo models and not specific to FA-2
<div style="text-align: center">
<img src="https://user-images.githubusercontent.com/49240599/272241893-b1c66b75-3a48-4265-bc47-688448568b3d.png">
</div>
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
## GPTNeoConfig
[[autodoc]] GPTNeoConfig
<frameworkcontent>
<pt>
## GPTNeoModel
[[autodoc]] GPTNeoModel
- forward
## GPTNeoForCausalLM
[[autodoc]] GPTNeoForCausalLM
- forward
## GPTNeoForQuestionAnswering
[[autodoc]] GPTNeoForQuestionAnswering
- forward
## GPTNeoForSequenceClassification
[[autodoc]] GPTNeoForSequenceClassification
- forward
## GPTNeoForTokenClassification
[[autodoc]] GPTNeoForTokenClassification
- forward
</pt>
<jax>
## FlaxGPTNeoModel
[[autodoc]] FlaxGPTNeoModel
- __call__
## FlaxGPTNeoForCausalLM
[[autodoc]] FlaxGPTNeoForCausalLM
- __call__
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/gpt_neo.md |
Gradio Demo: rows_and_columns
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('images')
!wget -q -O images/cheetah.jpg https://github.com/gradio-app/gradio/raw/main/demo/rows_and_columns/images/cheetah.jpg
```
```
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
text1 = gr.Textbox(label="t1")
slider2 = gr.Textbox(label="s2")
drop3 = gr.Dropdown(["a", "b", "c"], label="d3")
with gr.Row():
with gr.Column(scale=1, min_width=600):
text1 = gr.Textbox(label="prompt 1")
text2 = gr.Textbox(label="prompt 2")
inbtw = gr.Button("Between")
text4 = gr.Textbox(label="prompt 1")
text5 = gr.Textbox(label="prompt 2")
with gr.Column(scale=2, min_width=600):
img1 = gr.Image("images/cheetah.jpg")
btn = gr.Button("Go")
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/rows_and_columns/run.ipynb |
Gradio Demo: lineplot_component
```
!pip install -q gradio vega_datasets
```
```
import gradio as gr
from vega_datasets import data
with gr.Blocks() as demo:
gr.LinePlot(
data.stocks(),
x="date",
y="price",
color="symbol",
color_legend_position="bottom",
title="Stock Prices",
tooltip=["date", "price", "symbol"],
height=300,
width=300,
container=False,
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/lineplot_component/run.ipynb |
@gradio/box
## 0.1.6
### Patch Changes
- Updated dependencies [[`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/atoms@0.4.1
## 0.1.5
### Patch Changes
- Updated dependencies [[`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/atoms@0.4.0
## 0.1.4
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.3.1
## 0.1.3
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
## 0.1.2
### Patch Changes
- Updated dependencies [[`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/atoms@0.2.2
## 0.1.1
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/atoms@0.2.1
## 0.1.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0-beta.7
### Patch Changes
- Updated dependencies [[`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a), [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13)]:
- @gradio/atoms@0.2.0-beta.6
## 0.1.0-beta.6
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.1.0-beta.5
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5949](https://github.com/gradio-app/gradio/pull/5949) [`1c390f101`](https://github.com/gradio-app/gradio/commit/1c390f10199142a41722ba493a0c86b58245da15) - Merge main again. Thanks [@pngwn](https://github.com/pngwn)!
## 0.0.7
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/atoms@0.2.0
## 0.0.6
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.1.4
## 0.0.5
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.1.3
## 0.0.4
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.1.2
## 0.0.3
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.1.1
## 0.0.2
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
| gradio-app/gradio/blob/main/js/box/CHANGELOG.md |
FrameworkSwitchCourse {fw} />
<!-- DISABLE-FRONTMATTER-SECTIONS -->
# End-of-chapter quiz[[end-of-chapter-quiz]]
<CourseFloatingBanner
chapter={4}
classNames="absolute z-10 right-0 top-0"
/>
Let's test what you learned in this chapter!
### 1. What are models on the Hub limited to?
<Question
choices={[
{
text: "Models from the 🤗 Transformers library.",
explain: "While models from the 🤗 Transformers library are supported on the Hugging Face Hub, they're not the only ones!"
},
{
text: "All models with a similar interface to 🤗 Transformers.",
explain: "No interface requirement is set when uploading models to the Hugging Face Hub. "
},
{
text: "There are no limits.",
explain: "Right! There are no limits when uploading models to the Hub.",
correct: true
},
{
text: "Models that are in some way related to NLP.",
explain: "No requirement is set regarding the field of application!"
}
]}
/>
### 2. How can you manage models on the Hub?
<Question
choices={[
{
text: "Through a GCP account.",
explain: "Incorrect!"
},
{
text: "Through peer-to-peer distribution.",
explain: "Incorrect!"
},
{
text: "Through git and git-lfs.",
explain: "Correct! Models on the Hub are simple Git repositories, leveraging <code>git-lfs</code> for large files.",
correct: true
}
]}
/>
### 3. What can you do using the Hugging Face Hub web interface?
<Question
choices={[
{
text: "Fork an existing repository.",
explain: "Forking a repository is not possible on the Hugging Face Hub."
},
{
text: "Create a new model repository.",
explain: "Correct! That's not all you can do, though.",
correct: true
},
{
text: "Manage and edit files.",
explain: "Correct! That's not the only right answer, though.",
correct: true
},
{
text: "Upload files.",
explain: "Right! But that's not all.",
correct: true
},
{
text: "See diffs across versions.",
explain: "Correct! That's not all you can do, though.",
correct: true
}
]}
/>
### 4. What is a model card?
<Question
choices={[
{
text: "A rough description of the model, therefore less important than the model and tokenizer files.",
explain: "It is indeed a description of the model, but it's an important piece: if it's incomplete or absent the model's utility is drastically reduced."
},
{
text: "A way to ensure reproducibility, reusability, and fairness.",
explain: "Correct! Sharing the right information in the model card will help users leverage your model and be aware of its limits and biases. ",
correct: true
},
{
text: "A Python file that can be run to retrieve information about the model.",
explain: "Model cards are simple Markdown files."
}
]}
/>
### 5. Which of these objects of the 🤗 Transformers library can be directly shared on the Hub with `push_to_hub()`?
{#if fw === 'pt'}
<Question
choices={[
{
text: "A tokenizer",
explain: "Correct! All tokenizers have the <code>push_to_hub</code> method, and using it will push all the tokenizer files (vocabulary, architecture of the tokenizer, etc.) to a given repo. That's not the only right answer, though!",
correct: true
},
{
text: "A model configuration",
explain: "Right! All model configurations have the <code>push_to_hub</code> method, and using it will push them to a given repo. What else can you share?",
correct: true
},
{
text: "A model",
explain: "Correct! All models have the <code>push_to_hub</code> method, and using it will push them and their configuration files to a given repo. That's not all you can share, though.",
correct: true
},
{
text: "A Trainer",
explain: "That's right — the <code>Trainer</code> also implements the <code>push_to_hub</code> method, and using it will upload the model, its configuration, the tokenizer, and a model card draft to a given repo. Try another answer!",
correct: true
}
]}
/>
{:else}
<Question
choices={[
{
text: "A tokenizer",
explain: "Correct! All tokenizers have the <code>push_to_hub</code> method, and using it will push all the tokenizer files (vocabulary, architecture of the tokenizer, etc.) to a given repo. That's not the only right answer, though!",
correct: true
},
{
text: "A model configuration",
explain: "Right! All model configurations have the <code>push_to_hub</code> method, and using it will push them to a given repo. What else can you share?",
correct: true
},
{
text: "A model",
explain: "Correct! All models have the <code>push_to_hub</code> method, and using it will push them and their configuration files to a given repo. That's not all you can share, though.",
correct: true
},
{
text: "All of the above with a dedicated callback",
explain: "That's right — the <code>PushToHubCallback</code> will regularly send all of those objects to a repo during training.",
correct: true
}
]}
/>
{/if}
### 6. What is the first step when using the `push_to_hub()` method or the CLI tools?
<Question
choices={[
{
text: "Log in on the website.",
explain: "This won't help you on your local machine."
},
{
text: "Run 'huggingface-cli login' in a terminal.",
explain: "Correct — this will download and cache your personal token.",
correct: true
},
{
text: "Run 'notebook_login()' in a notebook.",
explain: "Correct — this will display a widget to let you authenticate.",
correct: true
},
]}
/>
### 7. You're using a model and a tokenizer — how can you upload them to the Hub?
<Question
choices={[
{
text: "By calling the push_to_hub method directly on the model and the tokenizer.",
explain: "Correct!",
correct: true
},
{
text: "Within the Python runtime, by wrapping them in a <code>huggingface_hub</code> utility.",
explain: "Models and tokenizers already benefit from <code>huggingface_hub</code> utilities: no need for additional wrapping!"
},
{
text: "By saving them to disk and calling <code>transformers-cli upload-model</code>",
explain: "The command <code>upload-model</code> does not exist."
}
]}
/>
### 8. Which git operations can you do with the `Repository` class?
<Question
choices={[
{
text: "A commit.",
explain: "Correct, the <code>git_commit()</code> method is there for that.",
correct: true
},
{
text: "A pull",
explain: "That is the purpose of the <code>git_pull()</code> method.",
correct: true
},
{
text: "A push",
explain: "The method <code>git_push()</code> does this.",
correct: true
},
{
text: "A merge",
explain: "No, that operation will never be possible with this API."
}
]}
/>
| huggingface/course/blob/main/chapters/en/chapter4/6.mdx |
Panel on Spaces
[Panel](https://panel.holoviz.org/) is an open-source Python library that lets you easily build powerful tools, dashboards and complex applications entirely in Python. It has a batteries-included philosophy, putting the PyData ecosystem, powerful data tables and much more at your fingertips. High-level reactive APIs and lower-level callback based APIs ensure you can quickly build exploratory applications, but you aren’t limited if you build complex, multi-page apps with rich interactivity. Panel is a member of the [HoloViz](https://holoviz.org/) ecosystem, your gateway into a connected ecosystem of data exploration tools.
Visit [Panel documentation](https://panel.holoviz.org/) to learn more about making powerful applications.
## 🚀 Deploy Panel on Spaces
You can deploy Panel on Spaces with just a few clicks:
<a href="https://huggingface.co/new-space?template=Panel-Org/panel-template"> <img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/deploy-to-spaces-lg.svg"/> </a>
There are a few key parameters you need to define: the Owner (either your personal account or an organization), a Space name, and Visibility. In case you intend to execute computationally intensive deep learning models, consider upgrading to a GPU to boost performance.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-panel.png" style="width:70%">
Once you have created the Space, it will start out in “Building” status, which will change to “Running” once your Space is ready to go.
## ⚡️ What will you see?
When your Space is built and ready, you will see this image classification Panel app which will let you fetch a random image and run the OpenAI CLIP classifier model on it. Check out our [blog post](https://blog.holoviz.org/building_an_interactive_ml_dashboard_in_panel.html) for a walkthrough of this app.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-panel-demo.gif" style="width:70%">
## 🛠️ How to customize and make your own app?
The Space template will populate a few files to get your app started:
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-panel-files.png" style="width:70%">
Three files are important:
### 1. app.py
This file defines your Panel application code. You can start by modifying the existing application or replace it entirely to build your own application. To learn more about writing your own Panel app, refer to the [Panel documentation](https://panel.holoviz.org/).
### 2. Dockerfile
The Dockerfile contains a sequence of commands that Docker will execute to construct and launch an image as a container that your Panel app will run in. Typically, to serve a Panel app, we use the command `panel serve app.py`. In this specific file, we divide the command into a list of strings. Furthermore, we must define the address and port because Hugging Face will expect to serve your application on port 7860. Additionally, we need to specify the `allow-websocket-origin` flag to enable the connection to the server's websocket.
### 3. requirements.txt
This file defines the required packages for our Panel app. When using Space, dependencies listed in the requirements.txt file will be automatically installed. You have the freedom to modify this file by removing unnecessary packages or adding additional ones that are required for your application. Feel free to make the necessary changes to ensure your app has the appropriate packages installed.
## 🌐 Join Our Community
The Panel community is vibrant and supportive, with experienced developers and data scientists eager to help and share their knowledge. Join us and connect with us:
- [Discord](https://discord.gg/aRFhC3Dz9w)
- [Discourse](https://discourse.holoviz.org/)
- [Twitter](https://twitter.com/Panel_Org)
- [LinkedIn](https://www.linkedin.com/company/panel-org)
- [Github](https://github.com/holoviz/panel)
| huggingface/hub-docs/blob/main/docs/hub/spaces-sdks-docker-panel.md |
--
title: "Interactively explore your Huggingface dataset with one line of code"
thumbnail: /blog/assets/scalable-data-inspection/thumbnail.png
authors:
- user: sps44
guest: true
- user: druzsan
guest: true
- user: neindochoh
guest: true
- user: MarkusStoll
guest: true
---
# Interactively explore your Huggingface dataset with one line of code
The Hugging Face [*datasets* library](https://huggingface.co/docs/datasets/index) not only provides access to more than 70k publicly available datasets, but also offers very convenient data preparation pipelines for custom datasets.
[Renumics Spotlight](https://github.com/Renumics/spotlight) allows you to create **interactive visualizations** to **identify critical clusters** in your data. Because Spotlight understands the data semantics within Hugging Face datasets, you can **[get started with just one line of code](https://renumics.com/docs)**:
```python
import datasets
from renumics import spotlight
ds = datasets.load_dataset('speech_commands', 'v0.01', split='validation')
spotlight.show(ds)
```
<p align="center"><a href="https://github.com/Renumics/spotlight"><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/scalable-data-inspection/speech_commands_vis_s.gif" width="100%"/></a></p>
Spotlight allows to **leverage model results** such as predictions and embeddings to gain a deeper understanding in data segments and model failure modes:
```python
ds_results = datasets.load_dataset('renumics/speech_commands-ast-finetuned-results', 'v0.01', split='validation')
ds = datasets.concatenate_datasets([ds, ds_results], axis=1)
spotlight.show(ds, dtype={'embedding': spotlight.Embedding}, layout=spotlight.layouts.debug_classification(embedding='embedding', inspect={'audio': spotlight.dtypes.audio_dtype}))
```
Data inspection is a very important task in almost all ML development stages, but it can also be very time consuming.
> “Manual inspection of data has probably the highest value-to-prestige ratio of any activity in machine learning.” — Greg Brockman
>
[Spotlight](https://renumics.com/docs) helps you to **make data inspection more scalable** along two dimensions: Setting up and maintaining custom data inspection workflows and finding relevant data samples and clusters to inspect. In the following sections we show some examples based on Hugging Face datasets.
## Spotlight 🤝 Hugging Face datasets
The *datasets* library has several features that makes it an ideal tool for working with ML datasets: It stores tabular data (e.g. metadata, labels) along with unstructured data (e.g. images, audio) in a common Arrows table. *Datasets* also describes important data semantics through features (e.g. images, audio) and additional task-specific metadata.
Spotlight directly works on top of the *datasets* library. This means that there is no need to copy or pre-process the dataset for data visualization and inspection. Spotlight loads the tabular data into memory to allow for efficient, client-side data analytics. Memory-intensive unstructured data samples (e.g. audio, images, video) are loaded lazily on demand. In most cases, data types and label mappings are inferred directly from the dataset. Here, we visualize the CIFAR-100 dataset with one line of code:
```python
ds = datasets.load_dataset('cifar100', split='test')
spotlight.show(ds)
```
In cases where the data types are ambiguous or not specified, the Spotlight API allows to manually assign them:
```python
label_mapping = dict(zip(ds.features['fine_label'].names, range(len(ds.features['fine_label'].names))))
spotlight.show(ds, dtype={'img': spotlight.Image, 'fine_label': spotlight.dtypes.CategoryDType(categories=label_mapping)})
```
## **Leveraging model results for data inspection**
Exploring raw unstructured datasets often yield little insights. Leveraging model results such as predictions or embeddings can help to uncover critical data samples and clusters. Spotlight has several visualization options (e.g. similarity map, confusion matrix) that specifically make use of model results.
We recommend storing your prediction results directly in a Hugging Face dataset. This not only allows you to take advantage of the batch processing capabilities of the datasets library, but also keeps label mappings.
We can use the [*transformers* library](https://huggingface.co/docs/transformers) to compute embeddings and predictions on the CIFAR-100 image classification problem. We install the libraries via pip:
```bash
pip install renumics-spotlight datasets transformers[torch]
```
Now we can compute the enrichment:
```python
import torch
import transformers
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model_name = "Ahmed9275/Vit-Cifar100"
processor = transformers.ViTImageProcessor.from_pretrained(model_name)
cls_model = transformers.ViTForImageClassification.from_pretrained(model_name).to(device)
fe_model = transformers.ViTModel.from_pretrained(model_name).to(device)
def infer(batch):
images = [image.convert("RGB") for image in batch]
inputs = processor(images=images, return_tensors="pt").to(device)
with torch.no_grad():
outputs = cls_model(**inputs)
probs = torch.nn.functional.softmax(outputs.logits, dim=-1).cpu().numpy()
embeddings = fe_model(**inputs).last_hidden_state[:, 0].cpu().numpy()
preds = probs.argmax(axis=-1)
return {"prediction": preds, "embedding": embeddings}
features = datasets.Features({**ds.features, "prediction": ds.features["fine_label"], "embedding": datasets.Sequence(feature=datasets.Value("float32"), length=768)})
ds_enriched = ds.map(infer, input_columns="img", batched=True, batch_size=2, features=features)
```
If you don’t want to perform the full inference run, you can alternatively download pre-computed model results for CIFAR-100 to follow this tutorial:
```python
ds_results = datasets.load_dataset('renumics/spotlight-cifar100-enrichment', split='test')
ds_enriched = datasets.concatenate_datasets([ds, ds_results], axis=1)
```
We can now use the results to interactively explore relevant data samples and clusters in Spotlight:
```python
layout = spotlight.layouts.debug_classification(label='fine_label', embedding='embedding', inspect={'img': spotlight.dtypes.image_dtype})
spotlight.show(ds_enriched, dtype={'embedding': spotlight.Embedding}, layout=layout)
```
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/scalable-data-inspection/cifar-100-model-debugging.png" alt="CIFAR-100 model debugging layout example.">
</figure>
## Customizing data inspection workflows
Visualization layouts can be interactively changed, saved and loaded in the GUI: You can select different widget types and configurations. The *Inspector* widget allows to represent multimodal data samples including text, image, audio, video and time series data.
You can also define layouts through the [Python API](https://renumics.com/api/spotlight/). This option is especially useful for building custom data inspection and curation workflows including EDA, model debugging and model monitoring tasks.
In combination with the data issues widget, the Python API offers a great way to integrate the results of existing scripts (e.g. data quality checks or model monitoring) into a scalable data inspection workflow.
## Using Spotlight on the Hugging Face hub
You can use Spotlight directly on your local NLP, audio, CV or multimodal dataset. If you would like to showcase your dataset or model results on the Hugging Face hub, you can use Hugging Face spaces to launch a Spotlight visualization for it.
We have already prepared [example spaces](https://huggingface.co/renumics) for many popular NLP, audio and CV datasets on the hub. You can simply duplicate one of these spaces and specify your dataset in the `HF_DATASET` variable.
You can optionally choose a dataset that contains model results and other configuration options such as splits, subsets or dataset revisions.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/scalable-data-inspection/space_duplication.png" alt="Creating a new dataset visualization with Spotlight by duplicating a Hugging Face space.">
</figure>
## What’s next?
With Spotlight you can create **interactive visualizations** and leverage data enrichments to **identify critical clusters** in your Hugging Face datasets. In this blog, we have seen both an audio ML and a computer vision example.
You can use Spotlight directly to explore and curate your NLP, audio, CV or multimodal dataset:
- Install Spotlight: *pip install renumics-spotlight*
- Check out the [documentation](https://renumics.com/docs) or open an issue on [Github](https://github.com/Renumics/spotlight)
- Join the [Spotlight community](https://discord.gg/VAQdFCU5YD) on Discord
- Follow us on [Twitter](https://twitter.com/renumics) and [LinkedIn](https://www.linkedin.com/company/renumics) | huggingface/blog/blob/main/scalable-data-inspection.md |
DeeBERT: Early Exiting for *BERT
This is the code base for the paper [DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference](https://www.aclweb.org/anthology/2020.acl-main.204/), modified from its [original code base](https://github.com/castorini/deebert).
The original code base also has information for downloading sample models that we have trained in advance.
## Usage
There are three scripts in the folder which can be run directly.
In each script, there are several things to modify before running:
* `PATH_TO_DATA`: path to the GLUE dataset.
* `--output_dir`: path for saving fine-tuned models. Default: `./saved_models`.
* `--plot_data_dir`: path for saving evaluation results. Default: `./results`. Results are printed to stdout and also saved to `npy` files in this directory to facilitate plotting figures and further analyses.
* `MODEL_TYPE`: bert or roberta
* `MODEL_SIZE`: base or large
* `DATASET`: SST-2, MRPC, RTE, QNLI, QQP, or MNLI
#### train_deebert.sh
This is for fine-tuning DeeBERT models.
#### eval_deebert.sh
This is for evaluating each exit layer for fine-tuned DeeBERT models.
#### entropy_eval.sh
This is for evaluating fine-tuned DeeBERT models, given a number of different early exit entropy thresholds.
## Citation
Please cite our paper if you find the resource useful:
```
@inproceedings{xin-etal-2020-deebert,
title = "{D}ee{BERT}: Dynamic Early Exiting for Accelerating {BERT} Inference",
author = "Xin, Ji and
Tang, Raphael and
Lee, Jaejun and
Yu, Yaoliang and
Lin, Jimmy",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.acl-main.204",
pages = "2246--2251",
}
```
| huggingface/transformers/blob/main/examples/research_projects/deebert/README.md |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.