
datasetId
stringlengths 2
81
| card
stringlengths 20
977k
|
|---|---|
teragron/reviews | ---
license: mit
language:
- en
tags:
- finance
pretty_name: review_me
size_categories:
- 1M<n<10M
task_categories:
- text-generation
---
Following packages are necessary to compile the model in C:
```bash
sudo apt install gcc-7
```
```bash
sudo apt-get install build-essential
```
```python
for i in range(1,21):
!wget https://huggingface.co/datasets/teragron/reviews/resolve/main/chunk_{i}.bin
```
```bash
git clone https://github.com/karpathy/llama2.c.git
```
```bash
cd llama2.c
```
```bash
pip install -r requirements.txt
```
Path: data/TinyStories_all_data |
tahrirchi/uz-books | ---
configs:
- config_name: default
data_files:
- split: original
path: data/original-*
- split: lat
path: data/lat-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: original
num_bytes: 19244856855
num_examples: 39712
- name: lat
num_bytes: 13705512346
num_examples: 39712
download_size: 16984559355
dataset_size: 32950369201
annotations_creators:
- no-annotation
task_categories:
- text-generation
- fill-mask
task_ids:
- language-modeling
- masked-language-modeling
multilinguality:
- monolingual
language:
- uz
size_categories:
- 10M<n<100M
pretty_name: UzBooks
license: apache-2.0
tags:
- uz
- books
---
# Dataset Card for BookCorpus
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://tahrirchi.uz/grammatika-tekshiruvi](https://tahrirchi.uz/grammatika-tekshiruvi)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 16.98 GB
- **Size of the generated dataset:** 32.95 GB
- **Total amount of disk used:** 49.93 GB
### Dataset Summary
In an effort to democratize research on low-resource languages, we release UzBooks dataset, a cleaned book corpus consisting of nearly 40000 books in Uzbek Language divided into two branches: "original" and "lat," representing the OCRed (Latin and Cyrillic) and fully Latin versions of the texts, respectively.
Please refer to our [blogpost](https://tahrirchi.uz/grammatika-tekshiruvi) and paper (Coming soon!) for further details.
To load and use dataset, run this script:
```python
from datasets import load_dataset
uz_books=load_dataset("tahrirchi/uz-books")
```
## Dataset Structure
### Data Instances
#### plain_text
- **Size of downloaded dataset files:** 16.98 GB
- **Size of the generated dataset:** 32.95 GB
- **Total amount of disk used:** 49.93 GB
An example of 'train' looks as follows.
```
{
"text": "Hamsa\nAlisher Navoiy ..."
}
```
### Data Fields
The data fields are the same among all splits.
#### plain_text
- `text`: a `string` feature that contains text of the books.
### Data Splits
| name | |
|-----------------|--------:|
| original | 39712 |
| lat | 39712 |
## Dataset Creation
The books have been crawled from various internet sources and preprocessed using Optical Character Recognition techniques in [Tesseract OCR Engine](https://github.com/tesseract-ocr/tesseract). The latin version is created by converting the original dataset with highly curated scripts in order to put more emphasis on the research and development of the field.
## Citation
Please cite this model using the following format:
```
@online{Mamasaidov2023UzBooks,
author = {Mukhammadsaid Mamasaidov and Abror Shopulatov},
title = {UzBooks dataset},
year = {2023},
url = {https://huggingface.co/datasets/tahrirchi/uz-books},
note = {Accessed: 2023-10-28}, % change this date
urldate = {2023-10-28} % change this date
}
```
## Gratitude
We are thankful to these awesome organizations and people for helping to make it happen:
- [Ilya Gusev](https://github.com/IlyaGusev/): for advise throughout the process
- [David Dale](https://daviddale.ru): for advise throughout the process
## Contacts
We believe that this work will enable and inspire all enthusiasts around the world to open the hidden beauty of low-resource languages, in particular Uzbek.
For further development and issues about the dataset, please use m.mamasaidov@tahrirchi.uz or a.shopolatov@tahrirchi.uz to contact. |
ubaada/booksum-complete-cleaned | ---
task_categories:
- summarization
- text-generation
language:
- en
pretty_name: BookSum Summarization Dataset Clean
size_categories:
- 1K<n<10K
configs:
- config_name: books
data_files:
- split: train
path: "books/train.jsonl"
- split: test
path: "books/test.jsonl"
- split: validation
path: "books/val.jsonl"
- config_name: chapters
data_files:
- split: train
path: "chapters/train.jsonl"
- split: test
path: "chapters/test.jsonl"
- split: validation
path: "chapters/val.jsonl"
---
# Table of Contents
1. [Description](#description)
2. [Usage](#usage)
3. [Distribution](#distribution)
- [Chapters Dataset](#chapters-dataset)
- [Books Dataset](#books-dataset)
4. [Structure](#structure)
5. [Results and Comparison with kmfoda/booksum](#results-and-comparison-with-kmfodabooksum)
# Description:
This repository contains the Booksum dataset introduced in the paper [BookSum: A Collection of Datasets for Long-form Narrative Summarization
](https://arxiv.org/abs/2105.08209).
This dataset includes both book and chapter summaries from the BookSum dataset (unlike the kmfoda/booksum one which only contains the chapter dataset). Some mismatched summaries have been corrected. Uneccessary columns has been discarded. Contains minimal text-to-summary rows. As there are multiple summaries for a given text, each row contains an array of summaries.
# Usage
Note: Make sure you have [>2.14.0 version of "datasets" library](https://github.com/huggingface/datasets/releases/tag/2.14.0) installed to load the dataset successfully.
```
from datasets import load_dataset
book_data = load_dataset("ubaada/booksum-complete-cleaned", "books")
chapter_data = load_dataset("ubaada/booksum-complete-cleaned", "chapters")
# Print the 1st book
print(book_data["train"][0]['text'])
# Print the summary of the 1st book
print(book_data["train"][0]['summary'][0]['text'])
```
# Distribution
<div style="display: inline-block; vertical-align: top; width: 45%;">
## Chapters Dataset
| Split | Total Sum. | Missing Sum. | Successfully Processed | Chapters |
|---------|------------|--------------|------------------------|------|
| Train | 9712 | 178 | 9534 (98.17%) | 5653 |
| Test | 1432 | 0 | 1432 (100.0%) | 950 |
| Val | 1485 | 0 | 1485 (100.0%) | 854 |
</div>
<div style="display: inline-block; vertical-align: top; width: 45%; margin-left: 5%;">
## Books Dataset
| Split | Total Sum. | Missing Sum. | Successfully Processed | Books |
|---------|------------|--------------|------------------------|------|
| Train | 314 | 0 | 314 (100.0%) | 151 |
| Test | 46 | 0 | 46 (100.0%) | 17 |
| Val | 45 | 0 | 45 (100.0%) | 19 |
</div>
# Structure:
```
Chapters Dataset
0 - bid (book id)
1 - book_title
2 - chapter_id
3 - text (raw chapter text)
4 - summary (list of summaries from different sources)
- {source, text (summary), analysis}
...
5 - is_aggregate (bool) (if true, then the text contains more than one chapter)
Books Dataset:
0 - bid (book id)
1 - title
2 - text (raw text)
4 - summary (list of summaries from different sources)
- {source, text (summary), analysis}
...
```
# Reults and Comparison with kmfoda/booksum
Tested on the 'test' split of chapter sub-dataset. There are slight improvement on R1/R2 scores compared to another BookSum repo likely due to the work done on cleaning the misalignments in the alignment file. In the plot for this dataset, first summary \[0\] is chosen for each chapter. If best reference summary is chosen from the list for each chapter, theere are further improvements but are not shown here for fairness.

|
p1atdev/open2ch | ---
language:
- ja
license: apache-2.0
size_categories:
- 1M<n<10M
task_categories:
- text-generation
- text2text-generation
dataset_info:
- config_name: all-corpus
features:
- name: dialogue
sequence:
- name: speaker
dtype: int8
- name: content
dtype: string
- name: board
dtype: string
splits:
- name: train
num_bytes: 1693355620
num_examples: 8134707
download_size: 868453263
dataset_size: 1693355620
- config_name: all-corpus-cleaned
features:
- name: dialogue
sequence:
- name: speaker
dtype: int8
- name: content
dtype: string
- name: board
dtype: string
splits:
- name: train
num_bytes: 1199092499
num_examples: 6192730
download_size: 615570076
dataset_size: 1199092499
- config_name: livejupiter
features:
- name: dialogue
sequence:
- name: speaker
dtype: int8
- name: content
dtype: string
splits:
- name: train
num_bytes: 1101433134
num_examples: 5943594
download_size: 592924274
dataset_size: 1101433134
- config_name: livejupiter-cleaned
features:
- name: dialogue
sequence:
- name: speaker
dtype: int8
- name: content
dtype: string
splits:
- name: train
num_bytes: 807499499
num_examples: 4650253
download_size: 437414714
dataset_size: 807499499
- config_name: news4vip
features:
- name: dialogue
sequence:
- name: speaker
dtype: int8
- name: content
dtype: string
splits:
- name: train
num_bytes: 420403926
num_examples: 1973817
download_size: 240974172
dataset_size: 420403926
- config_name: news4vip-cleaned
features:
- name: dialogue
sequence:
- name: speaker
dtype: int8
- name: content
dtype: string
splits:
- name: train
num_bytes: 269941607
num_examples: 1402903
download_size: 156934128
dataset_size: 269941607
- config_name: newsplus
features:
- name: dialogue
sequence:
- name: speaker
dtype: int8
- name: content
dtype: string
splits:
- name: train
num_bytes: 56071294
num_examples: 217296
download_size: 32368053
dataset_size: 56071294
- config_name: newsplus-cleaned
features:
- name: dialogue
sequence:
- name: speaker
dtype: int8
- name: content
dtype: string
splits:
- name: train
num_bytes: 33387874
num_examples: 139574
download_size: 19556120
dataset_size: 33387874
- config_name: ranking
features:
- name: dialogue
sequence:
- name: speaker
dtype: int8
- name: content
dtype: string
- name: next
struct:
- name: speaker
dtype: int8
- name: content
dtype: string
- name: random
sequence: string
splits:
- name: train
num_bytes: 1605628
num_examples: 2000
- name: test
num_bytes: 1604356
num_examples: 1953
download_size: 2127033
dataset_size: 3209984
configs:
- config_name: all-corpus
data_files:
- split: train
path: all-corpus/train-*
- config_name: all-corpus-cleaned
data_files:
- split: train
path: all-corpus-cleaned/train-*
- config_name: livejupiter
data_files:
- split: train
path: livejupiter/train-*
- config_name: livejupiter-cleaned
data_files:
- split: train
path: livejupiter-cleaned/train-*
- config_name: news4vip
data_files:
- split: train
path: news4vip/train-*
- config_name: news4vip-cleaned
data_files:
- split: train
path: news4vip-cleaned/train-*
- config_name: newsplus
data_files:
- split: train
path: newsplus/train-*
- config_name: newsplus-cleaned
data_files:
- split: train
path: newsplus-cleaned/train-*
- config_name: ranking
data_files:
- split: train
path: ranking/train-*
- split: test
path: ranking/test-*
tags:
- not-for-all-audiences
---
# おーぷん2ちゃんねる対話コーパス
## Dataset Details
### Dataset Description
[おーぷん2ちゃんねる対話コーパス](https://github.com/1never/open2ch-dialogue-corpus) を Huggingface Datasets 向けに変換したものになります。
- **Curated by:** [More Information Needed]
- **Language:** Japanese
- **License:** Apache-2.0
### Dataset Sources
- **Repository:** https://github.com/1never/open2ch-dialogue-corpus
## Dataset Structure
- `all-corpus`: `livejupiter`, `news4vip`, `newsplus` サブセットを連結したもの
- `dialogue`: 対話データ (`list[dict]`)
- `speaker`: 話者番号。`1` または `2`。
- `content`: 発言内容
- `board`: 連結元のサブセット名
- `livejupiter`: オリジナルのデータセットでの `livejupiter.tsv` から変換されたデータ。
- `dialogue`: 対話データ (`list[dict]`)
- `speaker`: 話者番号。`1` または `2`。
- `content`: 発言内容
- `news4vip`: オリジナルのデータセットでの `news4vip.tsv` から変換されたデータ。
- 構造は同上
- `newsplus`: オリジナルのデータセットでの `newsplus.tsv` から変換されたデータ。
- 構造は同上
- `ranking`: 応答順位付けタスク用データ (オリジナルデータセットでの `ranking.zip`)
- `train` と `test` split があり、それぞれはオリジナルデータセットの `dev.tsv` と `test.tsv` に対応します。
- `dialogue`: 対話データ (`list[dict]`)
- `speaker`: 話者番号。`1` または `2`。
- `content`: 発言内容
- `next`: 対話の次に続く正解の応答 (`dict`)
- `speaker`: 話者番号。`1` または `2`
- `content`: 発言内容
- `random`: ランダムに選ばれた応答 9 個 (`list[str]`)
また、`all-corpus`, `livejupiter`, `news4vip`, `newsplus` にはそれぞれ名前に `-cleaned` が付与されたバージョンがあり、これらのサブセットではオリジナルのデータセットで配布されていた NG ワードリストを利用してフィルタリングされたものです。
オリジナルのデータセットでは各発言内の改行は `__BR__` に置換されていますが、このデータセットではすべて `\n` に置き換えられています。
## Dataset Creation
### Source Data
(オリジナルのデータセットの説明より)
> おーぷん2ちゃんねるの「なんでも実況(ジュピター)」「ニュー速VIP」「ニュース速報+」の3つの掲示板をクロールして作成した対話コーパスです. おーぷん2ちゃんねる開設時から2019年7月20日までのデータを使用して作成しました.
#### Data Collection and Processing
[オリジナルのデータセット](https://github.com/1never/open2ch-dialogue-corpus) を参照。
#### Personal and Sensitive Information
`-cleaned` ではないサブセットでは、非常に不適切な表現が多いため注意が必要です。
## Usage
```py
from datasets import load_dataset
ds = load_dataset(
"p1atdev/open2ch",
name="all-corpus",
)
print(ds)
print(ds["train"][0])
# DatasetDict({
# train: Dataset({
# features: ['dialogue', 'board'],
# num_rows: 8134707
# })
# })
# {'dialogue': {'speaker': [1, 2], 'content': ['実況スレをたてる', 'おんj民の鑑']}, 'board': 'livejupiter'}
``` |
open-llm-leaderboard/details_01-ai__Yi-34B | ---
pretty_name: Evaluation run of 01-ai/Yi-34B
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [01-ai/Yi-34B](https://huggingface.co/01-ai/Yi-34B) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 3 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the aggregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_01-ai__Yi-34B_public\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-11-08T19:46:38.378007](https://huggingface.co/datasets/open-llm-leaderboard/details_01-ai__Yi-34B_public/blob/main/results_2023-11-08T19-46-38.378007.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.6081166107382551,\n\
\ \"em_stderr\": 0.004999326629880105,\n \"f1\": 0.6419882550335565,\n\
\ \"f1_stderr\": 0.004748239351156368,\n \"acc\": 0.6683760448499347,\n\
\ \"acc_stderr\": 0.012160441706531726\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.6081166107382551,\n \"em_stderr\": 0.004999326629880105,\n\
\ \"f1\": 0.6419882550335565,\n \"f1_stderr\": 0.004748239351156368\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.5064442759666414,\n \
\ \"acc_stderr\": 0.013771340765699767\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.8303078137332282,\n \"acc_stderr\": 0.010549542647363686\n\
\ }\n}\n```"
repo_url: https://huggingface.co/01-ai/Yi-34B
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_drop_3
data_files:
- split: 2023_11_08T19_46_38.378007
path:
- '**/details_harness|drop|3_2023-11-08T19-46-38.378007.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-11-08T19-46-38.378007.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_11_08T19_46_38.378007
path:
- '**/details_harness|gsm8k|5_2023-11-08T19-46-38.378007.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-11-08T19-46-38.378007.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_11_08T19_46_38.378007
path:
- '**/details_harness|winogrande|5_2023-11-08T19-46-38.378007.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-11-08T19-46-38.378007.parquet'
- config_name: results
data_files:
- split: 2023_11_08T19_46_38.378007
path:
- results_2023-11-08T19-46-38.378007.parquet
- split: latest
path:
- results_2023-11-08T19-46-38.378007.parquet
---
# Dataset Card for Evaluation run of 01-ai/Yi-34B
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/01-ai/Yi-34B
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [01-ai/Yi-34B](https://huggingface.co/01-ai/Yi-34B) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 3 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_01-ai__Yi-34B_public",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-11-08T19:46:38.378007](https://huggingface.co/datasets/open-llm-leaderboard/details_01-ai__Yi-34B_public/blob/main/results_2023-11-08T19-46-38.378007.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.6081166107382551,
"em_stderr": 0.004999326629880105,
"f1": 0.6419882550335565,
"f1_stderr": 0.004748239351156368,
"acc": 0.6683760448499347,
"acc_stderr": 0.012160441706531726
},
"harness|drop|3": {
"em": 0.6081166107382551,
"em_stderr": 0.004999326629880105,
"f1": 0.6419882550335565,
"f1_stderr": 0.004748239351156368
},
"harness|gsm8k|5": {
"acc": 0.5064442759666414,
"acc_stderr": 0.013771340765699767
},
"harness|winogrande|5": {
"acc": 0.8303078137332282,
"acc_stderr": 0.010549542647363686
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
matheusrdgsf/re_dial_ptbr | ---
dataset_info:
features:
- name: conversationId
dtype: int32
- name: messages
list:
- name: messageId
dtype: int64
- name: senderWorkerId
dtype: int64
- name: text
dtype: string
- name: timeOffset
dtype: int64
- name: messages_translated
list:
- name: messageId
dtype: int64
- name: senderWorkerId
dtype: int64
- name: text
dtype: string
- name: timeOffset
dtype: int64
- name: movieMentions
list:
- name: movieId
dtype: string
- name: movieName
dtype: string
- name: respondentQuestions
list:
- name: liked
dtype: int64
- name: movieId
dtype: string
- name: seen
dtype: int64
- name: suggested
dtype: int64
- name: respondentWorkerId
dtype: int32
- name: initiatorWorkerId
dtype: int32
- name: initiatorQuestions
list:
- name: liked
dtype: int64
- name: movieId
dtype: string
- name: seen
dtype: int64
- name: suggested
dtype: int64
splits:
- name: train
num_bytes: 26389658
num_examples: 9005
- name: test
num_bytes: 3755474
num_examples: 1342
download_size: 11072939
dataset_size: 30145132
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
license: mit
task_categories:
- text-classification
- text2text-generation
- conversational
- translation
language:
- pt
- en
tags:
- conversational recommendation
- recommendation
- conversational
pretty_name: ReDial (Recommendation Dialogues) PTBR
size_categories:
- 10K<n<100K
---
# Dataset Card for ReDial - PTBR
- **Original dataset:** [Redial Huggingface](https://huggingface.co/datasets/re_dial)
- **Homepage:** [ReDial Dataset](https://redialdata.github.io/website/)
- **Repository:** [ReDialData](https://github.com/ReDialData/website/tree/data)
- **Paper:** [Towards Deep Conversational Recommendations](https://proceedings.neurips.cc/paper/2018/file/800de15c79c8d840f4e78d3af937d4d4-Paper.pdf)
### Dataset Summary
The ReDial (Recommendation Dialogues) PTBR dataset is an annotated collection of dialogues where users recommend movies to each other translated to brazilian portuguese.
The adapted version of this dataset in Brazilian Portuguese was translated by the [Maritalk](https://www.maritaca.ai/). This translated version opens up opportunities fo research at the intersection of goal-directed dialogue systems (such as restaurant recommendations) and free-form, colloquial dialogue systems.
Some samples from the original dataset have been removed as we've reached the usage limit in Maritalk. Consequently, the training set has been reduced by nearly 10%.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
English and Portuguese.
## Dataset Structure
### Data Instances
```
{
"conversationId": 391,
"messages": [
{
"messageId": 1021,
"senderWorkerId": 0,
"text": "Hi there, how are you? I\'m looking for movie recommendations",
"timeOffset": 0
},
{
"messageId": 1022,
"senderWorkerId": 1,
"text": "I am doing okay. What kind of movies do you like?",
"timeOffset": 15
},
{
"messageId": 1023,
"senderWorkerId": 0,
"text": "I like animations like @84779 and @191602",
"timeOffset": 66
},
{
"messageId": 1024,
"senderWorkerId": 0,
"text": "I also enjoy @122159",
"timeOffset": 86
},
{
"messageId": 1025,
"senderWorkerId": 0,
"text": "Anything artistic",
"timeOffset": 95
},
{
"messageId": 1026,
"senderWorkerId": 1,
"text": "You might like @165710 that was a good movie.",
"timeOffset": 135
},
{
"messageId": 1027,
"senderWorkerId": 0,
"text": "What\'s it about?",
"timeOffset": 151
},
{
"messageId": 1028,
"senderWorkerId": 1,
"text": "It has Alec Baldwin it is about a baby that works for a company and gets adopted it is very funny",
"timeOffset": 207
},
{
"messageId": 1029,
"senderWorkerId": 0,
"text": "That seems like a nice comedy",
"timeOffset": 238
},
{
"messageId": 1030,
"senderWorkerId": 0,
"text": "Do you have any animated recommendations that are a bit more dramatic? Like @151313 for example",
"timeOffset": 272
},
{
"messageId": 1031,
"senderWorkerId": 0,
"text": "I like comedies but I prefer films with a little more depth",
"timeOffset": 327
},
{
"messageId": 1032,
"senderWorkerId": 1,
"text": "That is a tough one but I will remember something",
"timeOffset": 467
},
{
"messageId": 1033,
"senderWorkerId": 1,
"text": "@203371 was a good one",
"timeOffset": 509
},
{
"messageId": 1034,
"senderWorkerId": 0,
"text": "Ooh that seems cool! Thanks for the input. I\'m ready to submit if you are.",
"timeOffset": 564
},
{
"messageId": 1035,
"senderWorkerId": 1,
"text": "It is animated, sci fi, and has action",
"timeOffset": 571
},
{
"messageId": 1036,
"senderWorkerId": 1,
"text": "Glad I could help",
"timeOffset": 579
},
{
"messageId": 1037,
"senderWorkerId": 0,
"text": "Nice",
"timeOffset": 581
},
{
"messageId": 1038,
"senderWorkerId": 0,
"text": "Take care, cheers!",
"timeOffset": 591
},
{
"messageId": 1039,
"senderWorkerId": 1,
"text": "bye",
"timeOffset": 608
}
],
"messages_translated": [
{
"messageId": 1021,
"senderWorkerId": 0,
"text": "Olá, como você está? Estou procurando recomendações de filmes.",
"timeOffset": 0
},
{
"messageId": 1022,
"senderWorkerId": 1,
"text": "Eu estou indo bem. Qual tipo de filmes você gosta?",
"timeOffset": 15
},
{
"messageId": 1023,
"senderWorkerId": 0,
"text": "Eu gosto de animações como @84779 e @191602.",
"timeOffset": 66
},
{
"messageId": 1024,
"senderWorkerId": 0,
"text": "Eu também gosto de @122159.",
"timeOffset": 86
},
{
"messageId": 1025,
"senderWorkerId": 0,
"text": "Qualquer coisa artística",
"timeOffset": 95
},
{
"messageId": 1026,
"senderWorkerId": 1,
"text": "Você pode gostar de saber que foi um bom filme.",
"timeOffset": 135
},
{
"messageId": 1027,
"senderWorkerId": 0,
"text": "O que é isso?",
"timeOffset": 151
},
{
"messageId": 1028,
"senderWorkerId": 1,
"text": "Tem um bebê que trabalha para uma empresa e é adotado. É muito engraçado.",
"timeOffset": 207
},
{
"messageId": 1029,
"senderWorkerId": 0,
"text": "Isso parece ser uma comédia legal.",
"timeOffset": 238
},
{
"messageId": 1030,
"senderWorkerId": 0,
"text": "Você tem alguma recomendação animada que seja um pouco mais dramática, como por exemplo @151313?",
"timeOffset": 272
},
{
"messageId": 1031,
"senderWorkerId": 0,
"text": "Eu gosto de comédias, mas prefiro filmes com um pouco mais de profundidade.",
"timeOffset": 327
},
{
"messageId": 1032,
"senderWorkerId": 1,
"text": "Isso é um desafio, mas eu me lembrarei de algo.",
"timeOffset": 467
},
{
"messageId": 1033,
"senderWorkerId": 1,
"text": "@203371 Foi um bom dia.",
"timeOffset": 509
},
{
"messageId": 1034,
"senderWorkerId": 0,
"text": "Ah, parece legal! Obrigado pela contribuição. Estou pronto para enviar se você estiver.",
"timeOffset": 564
},
{
"messageId": 1035,
"senderWorkerId": 1,
"text": "É animado, de ficção científica e tem ação.",
"timeOffset": 571
},
{
"messageId": 1036,
"senderWorkerId": 1,
"text": "Fico feliz em poder ajudar.",
"timeOffset": 579
},
{
"messageId": 1037,
"senderWorkerId": 0,
"text": "Legal",
"timeOffset": 581
},
{
"messageId": 1038,
"senderWorkerId": 0,
"text": "Cuide-se, abraços!",
"timeOffset": 591
},
{
"messageId": 1039,
"senderWorkerId": 1,
"text": "Adeus",
"timeOffset": 608
}
],
"movieMentions": [
{
"movieId": "203371",
"movieName": "Final Fantasy: The Spirits Within (2001)"
},
{
"movieId": "84779",
"movieName": "The Triplets of Belleville (2003)"
},
{
"movieId": "122159",
"movieName": "Mary and Max (2009)"
},
{
"movieId": "151313",
"movieName": "A Scanner Darkly (2006)"
},
{
"movieId": "191602",
"movieName": "Waking Life (2001)"
},
{
"movieId": "165710",
"movieName": "The Boss Baby (2017)"
}
],
"respondentQuestions": [
{
"liked": 1,
"movieId": "203371",
"seen": 0,
"suggested": 1
},
{
"liked": 1,
"movieId": "84779",
"seen": 1,
"suggested": 0
},
{
"liked": 1,
"movieId": "122159",
"seen": 1,
"suggested": 0
},
{
"liked": 1,
"movieId": "151313",
"seen": 1,
"suggested": 0
},
{
"liked": 1,
"movieId": "191602",
"seen": 1,
"suggested": 0
},
{
"liked": 1,
"movieId": "165710",
"seen": 0,
"suggested": 1
}
],
"respondentWorkerId": 1,
"initiatorWorkerId": 0,
"initiatorQuestions": [
{
"liked": 1,
"movieId": "203371",
"seen": 0,
"suggested": 1
},
{
"liked": 1,
"movieId": "84779",
"seen": 1,
"suggested": 0
},
{
"liked": 1,
"movieId": "122159",
"seen": 1,
"suggested": 0
},
{
"liked": 1,
"movieId": "151313",
"seen": 1,
"suggested": 0
},
{
"liked": 1,
"movieId": "191602",
"seen": 1,
"suggested": 0
},
{
"liked": 1,
"movieId": "165710",
"seen": 0,
"suggested": 1
}
]
}
```
### Data Fields
The dataset is published in the “jsonl” format, i.e., as a text file where each line corresponds to a Dialogue given as a valid JSON document.
A Dialogue contains these fields:
**conversationId:** an integer
**initiatorWorkerId:** an integer identifying to the worker initiating the conversation (the recommendation seeker)
**respondentWorkerId:** an integer identifying the worker responding to the initiator (the recommender)
**messages:** a list of Message objects
**messages_translated:** a list of Message objects
**movieMentions:** a dict mapping movie IDs mentioned in this dialogue to movie names
**initiatorQuestions:** a dictionary mapping movie IDs to the labels supplied by the initiator. Each label is a bool corresponding to whether the initiator has said he saw the movie, liked it, or suggested it.
**respondentQuestions:** a dictionary mapping movie IDs to the labels supplied by the respondent. Each label is a bool corresponding to whether the initiator has said he saw the movie, liked it, or suggested it.
Each Message of **messages** contains these fields:
**messageId:** a unique ID for this message
**text:** a string with the actual message. The string may contain a token starting with @ followed by an integer. This is a movie ID which can be looked up in the movieMentions field of the Dialogue object.
**timeOffset:** time since start of dialogue in seconds
**senderWorkerId:** the ID of the worker sending the message, either initiatorWorkerId or respondentWorkerId.
Each Message of **messages_translated** contains the same struct with the text translated to portuguese.
The labels in initiatorQuestions and respondentQuestions have the following meaning:
*suggested:* 0 if it was mentioned by the seeker, 1 if it was a suggestion from the recommender
*seen:* 0 if the seeker has not seen the movie, 1 if they have seen it, 2 if they did not say
*liked:* 0 if the seeker did not like the movie, 1 if they liked it, 2 if they did not say
### Data Splits
The original dataset contains a total of 11348 dialogues, 10006 for training and model selection, and 1342 for testing.
This translated version has near values but 10% reduced in train split.
### Contributions
This work have has done by [matheusrdg](https://github.com/matheusrdg) and [wfco](https://github.com/willianfco).
The translation of this dataset was made possible thanks to the Maritalk API.
|
rishiraj/hindichat | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: prompt
dtype: string
- name: prompt_id
dtype: string
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: category
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 64144365
num_examples: 9500
- name: test
num_bytes: 3455962
num_examples: 500
download_size: 27275492
dataset_size: 67600327
task_categories:
- conversational
- text-generation
language:
- hi
pretty_name: Hindi Chat
license: cc-by-nc-4.0
---
# Dataset Card for Hindi Chat
We know that current English-first LLMs don’t work well for many other languages, both in terms of performance, latency, and speed. Building instruction datasets for non-English languages is an important challenge that needs to be solved.
Dedicated towards addressing this problem, I release 2 new datasets [rishiraj/bengalichat](https://huggingface.co/datasets/rishiraj/bengalichat/) & [rishiraj/hindichat](https://huggingface.co/datasets/rishiraj/hindichat/) of 10,000 instructions and demonstrations each. This data can be used for supervised fine-tuning (SFT) to make language multilingual models follow instructions better.
### Dataset Summary
[rishiraj/hindichat](https://huggingface.co/datasets/rishiraj/hindichat/) was modelled after the instruction dataset described in OpenAI's [InstructGPT paper](https://huggingface.co/papers/2203.02155), and is translated from [HuggingFaceH4/no_robots](https://huggingface.co/datasets/HuggingFaceH4/no_robots/) which comprised mostly of single-turn instructions across the following categories:
| Category | Count |
|:-----------|--------:|
| Generation | 4560 |
| Open QA | 1240 |
| Brainstorm | 1120 |
| Chat | 850 |
| Rewrite | 660 |
| Summarize | 420 |
| Coding | 350 |
| Classify | 350 |
| Closed QA | 260 |
| Extract | 190 |
### Languages
The data in [rishiraj/hindichat](https://huggingface.co/datasets/rishiraj/hindichat/) are in Hindi (BCP-47 hi).
### Data Fields
The data fields are as follows:
* `prompt`: Describes the task the model should perform.
* `prompt_id`: A unique ID for the prompt.
* `messages`: An array of messages, where each message indicates the role (system, user, assistant) and the content.
* `category`: Which category the example belongs to (e.g. `Chat` or `Coding`).
* `text`: Content of `messages` in a format that is compatible with dataset_text_field of SFTTrainer.
### Data Splits
| | train_sft | test_sft |
|---------------|------:| ---: |
| hindichat | 9500 | 500 |
### Licensing Information
The dataset is available under the [Creative Commons NonCommercial (CC BY-NC 4.0)](https://creativecommons.org/licenses/by-nc/4.0/legalcode).
### Citation Information
```
@misc{hindichat,
author = {Rishiraj Acharya},
title = {Hindi Chat},
year = {2023},
publisher = {Hugging Face},
journal = {Hugging Face repository},
howpublished = {\url{https://huggingface.co/datasets/rishiraj/hindichat}}
}
``` |
argilla/ultrafeedback-curated | ---
language:
- en
license: mit
size_categories:
- 10K<n<100K
task_categories:
- text-generation
pretty_name: UltraFeedback Curated
dataset_info:
features:
- name: source
dtype: string
- name: instruction
dtype: string
- name: models
sequence: string
- name: completions
list:
- name: annotations
struct:
- name: helpfulness
struct:
- name: Rating
dtype: string
- name: Rationale
dtype: string
- name: Rationale For Rating
dtype: string
- name: Type
sequence: string
- name: honesty
struct:
- name: Rating
dtype: string
- name: Rationale
dtype: string
- name: instruction_following
struct:
- name: Rating
dtype: string
- name: Rationale
dtype: string
- name: truthfulness
struct:
- name: Rating
dtype: string
- name: Rationale
dtype: string
- name: Rationale For Rating
dtype: string
- name: Type
sequence: string
- name: critique
dtype: string
- name: custom_system_prompt
dtype: string
- name: model
dtype: string
- name: overall_score
dtype: float64
- name: principle
dtype: string
- name: response
dtype: string
- name: correct_answers
sequence: string
- name: incorrect_answers
sequence: string
- name: updated
struct:
- name: completion_idx
dtype: int64
- name: distilabel_rationale
dtype: string
splits:
- name: train
num_bytes: 843221341
num_examples: 63967
download_size: 321698501
dataset_size: 843221341
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Ultrafeedback Curated
This dataset is a curated version of [UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback) dataset performed by Argilla (using [distilabel](https://github.com/argilla-io/distilabel)).
## Introduction
You can take a look at [argilla/ultrafeedback-binarized-preferences](https://huggingface.co/datasets/argilla/ultrafeedback-binarized-preferences) for more context on the UltraFeedback error, but the following excerpt sums up the problem found:
*After visually browsing around some examples using the sort and filter feature of Argilla (sort by highest rating for chosen responses), we noticed a strong mismatch between the `overall_score` in the original UF dataset (and the Zephyr train_prefs dataset) and the quality of the chosen response.*
*By adding the critique rationale to our Argilla Dataset, we confirmed the critique rationale was highly negative, whereas the rating was very high (the highest in fact: `10`). See screenshot below for one example of this issue. After some quick investigation, we identified hundreds of examples having the same issue and a potential bug on the UltraFeedback repo.*

## Differences with `openbmb/UltraFeedback`
This version of the dataset has replaced the `overall_score` of the responses identified as "wrong", and a new column `updated` to keep track of the updates.
It contains a dict with the following content `{"completion_idx": "the index of the modified completion in the completion list", "distilabel_rationale": "the distilabel rationale"}`, and `None` if nothing was modified.
Other than that, the dataset can be used just like the original.
## Dataset processing
1. Starting from `argilla/ultrafeedback-binarized-curation` we selected all the records with `score_best_overall` equal to 10, as those were the problematic ones.
2. We created a new dataset using the `instruction` and the response from the model with the `best_overall_score_response` to be used with [distilabel](https://github.com/argilla-io/distilabel).
3. Using `gpt-4` and a task for `instruction_following` we obtained a new *rating* and *rationale* of the model for the 2405 "questionable" responses.
```python
import os
from distilabel.llm import OpenAILLM
from distilabel.pipeline import Pipeline
from distilabel.tasks import UltraFeedbackTask
from datasets import load_dataset
# Create the distilabel Pipeline
pipe = Pipeline(
labeller=OpenAILLM(
model="gpt-4",
task=UltraFeedbackTask.for_instruction_following(),
max_new_tokens=256,
num_threads=8,
openai_api_key=os.getenv("OPENAI_API_KEY") or "sk-...",
temperature=0.3,
),
)
# Download the original dataset:
ds = load_dataset("argilla/ultrafeedback-binarized-curation", split="train")
# Prepare the dataset in the format required by distilabel, will need the columns "input" and "generations"
def set_columns_for_distilabel(example):
input = example["instruction"]
generations = example["best_overall_score_response"]["response"]
return {"input": input, "generations": [generations]}
# Filter and prepare the dataset
ds_to_label = ds.filter(lambda ex: ex["score_best_overall"] == 10).map(set_columns_for_distilabel).select_columns(["input", "generations"])
# Label the dataset
ds_labelled = pipe.generate(ds_to_label, num_generations=1, batch_size=8)
```
4. After visual inspection, we decided to remove those answers that were rated as a 1, plus some extra ones rated as 2 and 3, as those were also not a real 10.
The final dataset has a total of 1968 records updated from a 10 to a 1 in the `overall_score` field of the corresponding model (around 3% of the dataset), and a new column "updated" with the rationale of `gpt-4` for the new rating, as well as the index in which the model can be found in the "models" and "completions" columns.
## Reproduce
<a target="_blank" href="https://colab.research.google.com/drive/10R6uxb-Sviv64SyJG2wuWf9cSn6Z1yow?usp=sharing">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
To reproduce the data processing, feel free to run the attached Colab Notebook or just view it at [notebook](./ultrafeedback_curation_distilabel.ipynb) within this repository.
From Argilla we encourage anyone out there to play around, investigate, and experiment with the data, and we firmly believe on open sourcing what we do, as ourselves, as well as the whole community, benefit a lot from open source and we also want to give back.
|
lowres/anime | ---
size_categories:
- 1K<n<10K
task_categories:
- text-to-image
pretty_name: anime
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 744102225.832
num_examples: 1454
download_size: 742020583
dataset_size: 744102225.832
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- art
---
# anime characters datasets
This is an anime/manga/2D characters dataset, it is intended to be an encyclopedia for anime characters.
The dataset is open source to use without limitations or any restrictions.
## how to use
```python
from datasets import load_dataset
dataset = load_dataset("lowres/anime")
```
## how to contribute
* to add your own dataset, simply join the organization and create a new dataset repo and upload your images there. else you can open a new discussion and we'll check it out |
Query-of-CC/Knowledge_Pile | ---
license: apache-2.0
language:
- en
tags:
- knowledge
- Retrieval
- Reasoning
- Common Crawl
- MATH
size_categories:
- 100B<n<1T
---
Knowledge Pile is a knowledge-related data leveraging [Query of CC](https://arxiv.org/abs/2401.14624).
This dataset is a partial of Knowledge Pile(about 40GB disk size), full datasets have been released in [\[🤗 knowledge_pile_full\]](https://huggingface.co/datasets/Query-of-CC/knowledge_pile_full/), a total of 735GB disk size and 188B tokens (using Llama2 tokenizer).
## *Query of CC*
Just like the figure below, we initially collected seed information in some specific domains, such as keywords, frequently asked questions, and textbooks, to serve as inputs for the Query Bootstrapping stage. Leveraging the great generalization capability of large language models, we can effortlessly expand the initial seed information and extend it to an amount of domain-relevant queries. Inspiration from Self-instruct and WizardLM, we encompassed two stages of expansion, namely **Question Extension** and **Thought Generation**, which respectively extend the queries in terms of breadth and depth, for retrieving the domain-related data with a broader scope and deeper thought. Subsequently, based on the queries, we retrieved relevant documents from public corpora, and after performing operations such as duplicate data removal and filtering, we formed the final training dataset.
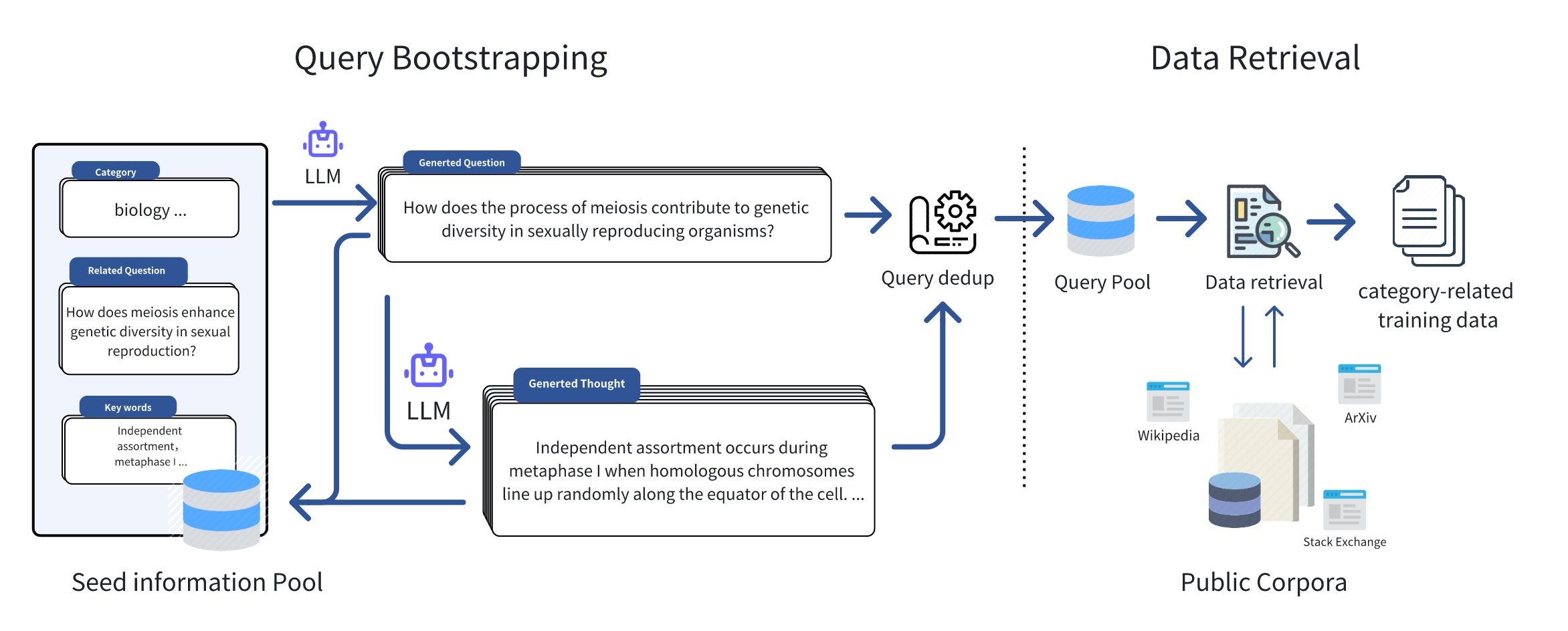
## **Knowledge Pile** Statistics
Based on *Query of CC* , we have formed a high-quality knowledge dataset **Knowledge Pile**. As shown in Figure below, comparing with other datasets in academic and mathematical reasoning domains, we have acquired a large-scale, high-quality knowledge dataset at a lower cost, without the need for manual intervention. Through automated query bootstrapping, we efficiently capture the information about the seed query. **Knowledge Pile** not only covers mathematical reasoning data but also encompasses rich knowledge-oriented corpora spanning various fields such as biology, physics, etc., enhancing its comprehensive research and application potential.
<img src="https://github.com/ngc7292/query_of_cc/blob/master/images/query_of_cc_timestamp_prop.png?raw=true" width="300px" style="center"/>
This table presents the top 10 web domains with the highest proportion of **Knowledge Pile**, primarily including academic websites, high-quality forums, and some knowledge domain sites. Table provides a breakdown of the data sources' timestamps in **Knowledge Pile**, with statistics conducted on an annual basis. It is evident that a significant portion of **Knowledge Pile** is sourced from recent years, with a decreasing proportion for earlier timestamps. This trend can be attributed to the exponential growth of internet data and the inherent timeliness introduced by the **Knowledge Pile**.
| **Web Domain** | **Count** |
|----------------------------|----------------|
|en.wikipedia.org | 398833 |
|www.semanticscholar.org | 141268 |
|slideplayer.com | 108177 |
|www.ncbi.nlm.nih.gov | 97009 |
|link.springer.com | 85357 |
|www.ipl.org | 84084 |
|pubmed.ncbi.nlm.nih.gov | 68934 |
|www.reference.com | 61658 |
|www.bartleby.com | 60097 |
|quizlet.com | 56752 |
### cite
```
@article{fei2024query,
title={Query of CC: Unearthing Large Scale Domain-Specific Knowledge from Public Corpora},
author={Fei, Zhaoye and Shao, Yunfan and Li, Linyang and Zeng, Zhiyuan and Yan, Hang and Qiu, Xipeng and Lin, Dahua},
journal={arXiv preprint arXiv:2401.14624},
year={2024}
}
``` |
Locutusque/Hercules-v3.0 | ---
license: other
task_categories:
- text-generation
- question-answering
- conversational
language:
- en
tags:
- not-for-all-audiences
- chemistry
- biology
- code
- medical
- synthetic
---
# Hercules-v3.0

- **Dataset Name:** Hercules-v3.0
- **Version:** 3.0
- **Release Date:** 2024-2-14
- **Number of Examples:** 1,637,895
- **Domains:** Math, Science, Biology, Physics, Instruction Following, Conversation, Computer Science, Roleplay, and more
- **Languages:** Mostly English, but others can be detected.
- **Task Types:** Question Answering, Conversational Modeling, Instruction Following, Code Generation, Roleplay
## Data Source Description
Hercules-v3.0 is an extensive and diverse dataset that combines various domains to create a powerful tool for training artificial intelligence models. The data sources include conversations, coding examples, scientific explanations, and more. The dataset is sourced from multiple high-quality repositories, each contributing to the robustness of Hercules-v3.0 in different knowledge domains.
## Included Data Sources
- `cognitivecomputations/dolphin`
- `Evol Instruct 70K & 140K`
- `teknium/GPT4-LLM-Cleaned`
- `jondurbin/airoboros-3.2`
- `AlekseyKorshuk/camel-chatml`
- `CollectiveCognition/chats-data-2023-09-22`
- `Nebulous/lmsys-chat-1m-smortmodelsonly`
- `glaiveai/glaive-code-assistant-v2`
- `glaiveai/glaive-code-assistant`
- `glaiveai/glaive-function-calling-v2`
- `garage-bAInd/Open-Platypus`
- `meta-math/MetaMathQA`
- `teknium/GPTeacher-General-Instruct`
- `GPTeacher roleplay datasets`
- `BI55/MedText`
- `pubmed_qa labeled subset`
- `Unnatural Instructions`
- `M4-ai/LDJnr_combined_inout_format`
- `CollectiveCognition/chats-data-2023-09-27`
- `CollectiveCognition/chats-data-2023-10-16`
- `NobodyExistsOnTheInternet/sharegptPIPPA`
- `yuekai/openchat_sharegpt_v3_vicuna_format`
- `ise-uiuc/Magicoder-Evol-Instruct-110K`
- `Squish42/bluemoon-fandom-1-1-rp-cleaned`
- `sablo/oasst2_curated`
Note: I would recommend filtering out any bluemoon examples because it seems to cause performance degradation.
## Data Characteristics
The dataset amalgamates text from various domains, including structured and unstructured data. It contains dialogues, instructional texts, scientific explanations, coding tasks, and more.
## Intended Use
Hercules-v3.0 is designed for training and evaluating AI models capable of handling complex tasks across multiple domains. It is suitable for researchers and developers in academia and industry working on advanced conversational agents, instruction-following models, and knowledge-intensive applications.
## Data Quality
The data was collected from reputable sources with an emphasis on diversity and quality. It is expected to be relatively clean but may require additional preprocessing for specific tasks.
## Limitations and Bias
- The dataset may have inherent biases from the original data sources.
- Some domains may be overrepresented due to the nature of the source datasets.
## X-rated Content Disclaimer
Hercules-v3.0 contains X-rated content. Users are solely responsible for the use of the dataset and must ensure that their use complies with all applicable laws and regulations. The dataset maintainers are not responsible for the misuse of the dataset.
## Usage Agreement
By using the Hercules-v3.0 dataset, users agree to the following:
- The dataset is used at the user's own risk.
- The dataset maintainers are not liable for any damages arising from the use of the dataset.
- Users will not hold the dataset maintainers responsible for any claims, liabilities, losses, or expenses.
Please make sure to read the license for more information.
## Citation
```
@misc{sebastian_gabarain_2024,
title = {Hercules-v3.0: The "Golden Ratio" for High Quality Instruction Datasets},
author = {Sebastian Gabarain},
publisher = {HuggingFace},
year = {2024},
url = {https://huggingface.co/datasets/Locutusque/Hercules-v3.0}
}
``` |
sanjay920/gemma-function-calling | ---
dataset_info:
features:
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: tools
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 540487055
num_examples: 111944
download_size: 193212415
dataset_size: 540487055
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
alvarobartt/openhermes-preferences-metamath | ---
license: other
task_categories:
- text-generation
language:
- en
source_datasets:
- argilla/OpenHermesPreferences
annotations_creators:
- Argilla
- HuggingFaceH4
tags:
- dpo
- synthetic
- metamath
size_categories:
- 10K<n<100K
dataset_info:
features:
- name: chosen
list:
- name: content
dtype: string
- name: role
dtype: string
- name: rejected
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 169676613.83305642
num_examples: 50799
- name: test
num_bytes: 18855183.863611557
num_examples: 5645
download_size: 44064373
dataset_size: 188531797.69666797
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
# Dataset Card for OpenHermes Preferences - MetaMath
This dataset is a subset from [`argilla/OpenHermesPreferences`](https://hf.co/datasets/argilla/OpenHermesPreferences),
only keeping the preferences of `metamath`, and removing all the columns besides the `chosen` and `rejected` ones, that
come in OpenAI chat formatting, so that's easier to fine-tune a model using tools like: [`huggingface/alignment-handbook`](https://github.com/huggingface/alignment-handbook)
or [`axolotl`](https://github.com/OpenAccess-AI-Collective/axolotl), among others.
## Reference
[`argilla/OpenHermesPreferences`](https://hf.co/datasets/argilla/OpenHermesPreferences) dataset created as a collaborative
effort between Argilla and the HuggingFaceH4 team from HuggingFace. |
gorilla-llm/Berkeley-Function-Calling-Leaderboard | ---
license: apache-2.0
language:
- en
---
# Berkeley Function Calling Leaderboard
<!-- Provide a quick summary of the dataset. -->
The Berkeley function calling leaderboard is a live leaderboard to evaluate the ability of different LLMs to call functions (also referred to as tools).
We built this dataset from our learnings to be representative of most users' function-calling use-cases, for example, in agents, as a part of enterprise workflows, etc.
To this end, our evaluation dataset spans diverse categories, and across multiple programming languages.
Checkout the Leaderboard at [gorilla.cs.berkeley.edu/leaderboard.html](https://gorilla.cs.berkeley.edu/leaderboard.html)
and our [release blog](https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html)!
***Latest Version Release Date***: 4/09/2024
***Original Release Date***: 02/26/2024
### Change Log
The Berkeley Function Calling Leaderboard is a continually evolving project. We are committed to regularly updating the dataset and leaderboard by introducing new models and expanding evaluation categories. Below is an overview of the modifications implemented in the most recent version:
* [April 10, 2024] [#339](https://github.com/ShishirPatil/gorilla/pull/339): Introduce REST API sanity check for the executable test category. It ensures that all the API endpoints involved during the execution evaluation process are working properly. If any of them are not behaving as expected, the evaluation process will be stopped by default as the result will be inaccurate. Users can choose to bypass this check by setting the `--skip-api-sanity-check` flag.
* [April 9, 2024] [#338](https://github.com/ShishirPatil/gorilla/pull/338): Bug fix in the evaluation datasets (including both prompts and function docs). Bug fix for possible answers as well.
* [April 8, 2024] [#330](https://github.com/ShishirPatil/gorilla/pull/330): Fixed an oversight that was introduced in [#299](https://github.com/ShishirPatil/gorilla/pull/299). For function-calling (FC) models that cannot take `float` type in input, when the parameter type is a `float`, the evaluation procedure will convert that type to `number` in the model input and mention in the parameter description that `This is a float type value.`. An additional field `format: float` will also be included in the model input to make it clear about the type. Updated the model handler for Claude, Mistral, and OSS to better parse the model output.
* [April 3, 2024] [#309](https://github.com/ShishirPatil/gorilla/pull/309): Bug fix for evaluation dataset possible answers. Implement **string standardization** for the AST evaluation pipeline, i.e. removing white spaces and a subset of punctuations `,./-_*^` to make the AST evaluation more robust and accurate. Fixed AST evaluation issue for type `tuple`. Add 2 new models `meetkai/functionary-small-v2.4 (FC)`, `meetkai/functionary-medium-v2.4 (FC)` to the leaderboard.
* [April 1, 2024] [#299](https://github.com/ShishirPatil/gorilla/pull/299): Leaderboard update with new models (`Claude-3-Haiku`, `Databrick-DBRX-Instruct`), more advanced AST evaluation procedure, and updated evaluation datasets. Cost and latency statistics during evaluation are also measured. We also released the manual that our evaluation procedure is based on, available [here](https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html#metrics).
* [Mar 11, 2024] [#254](https://github.com/ShishirPatil/gorilla/pull/254): Leaderboard update with 3 new models: `Claude-3-Opus-20240229 (Prompt)`, `Claude-3-Sonnet-20240229 (Prompt)`, and `meetkai/functionary-medium-v2.2 (FC)`
* [Mar 5, 2024] [#237](https://github.com/ShishirPatil/gorilla/pull/237) and [238](https://github.com/ShishirPatil/gorilla/pull/238): leaderboard update resulting from [#223](https://github.com/ShishirPatil/gorilla/pull/223); 3 new models: `mistral-large-2402`, `gemini-1.0-pro`, and `gemma`.
* [Feb 29, 2024] [#223](https://github.com/ShishirPatil/gorilla/pull/223): Modifications to REST evaluation.
* [Feb 27, 2024] [#215](https://github.com/ShishirPatil/gorilla/pull/215): BFCL first release.
## Dataset Composition

| # | Category |
|---|----------|
|200 | Chatting Capability|
|100 | Simple (Exec)|
|50 | Multiple (Exec)|
|50 | Parallel (Exec)|
|40 | Parallel & Multiple (Exec)|
|400 | Simple (AST)|
|200 | Multiple (AST)|
|200 | Parallel (AST)|
|200 | Parallel & Multiple (AST)|
|240 | Relevance|
|70 | REST|
|100 | Java|
|100 | SQL|
|50 | Javascript|
### Dataset Description
We break down the majority of the evaluation into two categories:
- **Python**: Simple Function, Multiple Function, Parallel Function, Parallel Multiple Function
- **Non-Python**: Chatting Capability, Function Relevance Detection, REST API, SQL, Java, Javascript
#### Python
**Simple**: Single function evaluation contains the simplest but most commonly seen format, where the user supplies a single JSON function document, with one and only one function call being invoked.
**Multiple Function**: Multiple function category contains a user question that only invokes one function call out of 2 to 4 JSON function documentations. The model needs to be capable of selecting the best function to invoke according to user-provided context.
**Parallel Function**: Parallel function is defined as invoking multiple function calls in parallel with one user query. The model needs to digest how many function calls need to be made and the question to model can be a single sentence or multiple sentence.
**Parallel Multiple Function**: Parallel Multiple function is the combination of parallel function and multiple function. In other words, the model is provided with multiple function documentation, and each of the corresponding function calls will be invoked zero or more times.
Each category has both AST and its corresponding executable evaluations. In the executable evaluation data, we manually write Python functions drawing inspiration from free REST API endpoints (e.g. get weather) and functions (e.g. linear regression) that compute directly. The executable category is designed to understand whether the function call generation is able to be stably utilized in applications utilizing function calls in the real world.
#### Non-Python Evaluation
While the previous categories consist of the majority of our evaluations, we include other specific categories, namely Chatting Capability, Function Relevance Detection, REST API, SQL, Java, and JavaScript, to evaluate model performance on diverse scenarios and support of multiple programming languages, and are resilient to irrelevant questions and function documentations.
**Chatting Capability**: In Chatting Capability, we design scenarios where no functions are passed in, and the users ask generic questions - this is similar to using the model as a general-purpose chatbot. We evaluate if the model is able to output chat messages and recognize that it does not need to invoke any functions. Note the difference with “Relevance” where the model is expected to also evaluate if any of the function inputs are relevant or not. We include this category for internal model evaluation and exclude the statistics from the live leaderboard. We currently are working on a better evaluation of chat ability and ensuring the chat is relevant and coherent with users' requests and open to suggestions and feedback from the community.
**Function Relevance Detection**: In function relevance detection, we design scenarios where none of the provided functions are relevant and supposed to be invoked. We expect the model's output to be a non-function-call response. This scenario provides insight into whether a model will hallucinate on its functions and parameters to generate function code despite lacking the function information or instructions from the users to do so.
**REST API**: A majority of the real-world API calls are from REST API calls. Python mainly makes REST API calls through `requests.get()`, `requests.post()`, `requests.delete()`, etc that are included in the Python requests library. `GET` requests are the most common ones used in the real world. As a result, we include real-world `GET` requests to test the model's capabilities to generate executable REST API calls through complex function documentation, using `requests.get()` along with the API's hardcoded URL and description of the purpose of the function and its parameters. Our evaluation includes two variations. The first type requires passing the parameters inside the URL, called path parameters, for example, the `{Year}` and `{CountryCode}` in `GET` `/api/v3/PublicHolidays/{Year}/{CountryCode}`. The second type requires the model to put parameters as key/value pairs into the params and/or headers of `requests.get(.)`. For example, `params={'lang': 'fr'}` in the function call. The model is not given which type of REST API call it is going to make but needs to make a decision on how it's going to be invoked.
For REST API, we use an executable evaluation to check for the executable outputs' effective execution, response type, and response JSON key consistencies. On the AST, we chose not to perform AST evaluation on REST mainly because of the immense number of possible answers; the enumeration of all possible answers is exhaustive for complicated defined APIs.
**SQL**: SQL evaluation data includes our customized `sql.execute` functions that contain sql_keyword, table_name, columns, and conditions. Those four parameters provide the necessary information to construct a simple SQL query like `SELECT column_A from table_B where column_C == D` Through this, we want to see if through function calling, SQL query can be reliably constructed and utilized rather than training a SQL-specific model. In our evaluation dataset, we restricted the scenarios and supported simple keywords, including `SELECT`, `INSERT INTO`, `UPDATE`, `DELETE`, and `CREATE`. We included 100 examples for SQL AST evaluation. Note that SQL AST evaluation will not be shown in our leaderboard calculations. We use SQL evaluation to test the generalization ability of function calling for programming languages that are not included in the training set for Gorilla OpenFunctions-v2. We opted to exclude SQL performance from the AST evaluation in the BFCL due to the multiplicity of methods to construct SQL function calls achieving identical outcomes. We're currently working on a better evaluation of SQL and are open to suggestions and feedback from the community. Therefore, SQL has been omitted from the current leaderboard to pave the way for a more comprehensive evaluation in subsequent iterations.
**Java and Javascript**: Despite function calling formats being the same across most programming languages, each programming language has language-specific types. For example, Java has the `HashMap` type. The goal of this test category is to understand how well the function calling model can be extended to not just Python type but all the language-specific typings. We included 100 examples for Java AST evaluation and 70 examples for Javascript AST evaluation.
The categories outlined above provide insight into the performance of different models across popular API call scenarios, offering valuable perspectives on the potential of function-calling models.
### Evaluation
This dataset serves as the question + function documentation pairs for Berkeley Function-Calling Leaderboard (BFCL) evaluation. The source code for the evaluation process can be found [here](https://github.com/ShishirPatil/gorilla/tree/main/berkeley-function-call-leaderboard) with detailed instructions on how to use this dataset to compare LLM tool use capabilities across different models and categories.
More details on evaluation metrics, i.e. rules for the Abstract Syntax Tree (AST) and executable evaluation can be found in the [release blog](https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html#metrics).
### Contributing
All the models, and data used to train the models are released under Apache 2.0.
Gorilla is an open source effort from UC Berkeley and we welcome contributors.
Please email us your comments, criticisms, and questions.
More information about the project can be found at https://gorilla.cs.berkeley.edu/
### BibTex
```bibtex
@misc{berkeley-function-calling-leaderboard,
title={Berkeley Function Calling Leaderboard},
author={Fanjia Yan and Huanzhi Mao and Charlie Cheng-Jie Ji and Tianjun Zhang and Shishir G. Patil and Ion Stoica and Joseph E. Gonzalez},
howpublished={\url{https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html}},
year={2024},
}
```
|
0-hero/Matter-0.1 | ---
license: apache-2.0
---
# Matter 0.1
Curated top quality records from 35 other datasets. Extracted from [prompt-perfect](https://huggingface.co/datasets/0-hero/prompt-perfect)
This is just a consolidation of all the score 5s. Fine-tuning models with various subsets and combinations to create a best performing v1 dataset
### ~1.4B Tokens, ~2.5M records
Dataset has been deduped, decontaminated with [bagel script from Jon Durbin](https://github.com/jondurbin/bagel/blob/main/bagel/data_sources/__init__.py)
Download using the below command to avoid unecessary files
```
from huggingface_hub import snapshot_download
snapshot_download(repo_id="0-hero/Matter-0.1",repo_type="dataset", allow_patterns=["final_set_cleaned/*"], local_dir=".", local_dir_use_symlinks=False)
```
|
Superar/Puntuguese | ---
license: cc-by-sa-4.0
task_categories:
- text-classification
- token-classification
language:
- pt
pretty_name: Puntuguese - A Corpus of Puns in Portuguese with Micro-editions
tags:
- humor
- puns
- humor-recognition
- pun-location
---
# Puntuguese - A Corpus of Puns in Portuguese with Micro-editions
Puntuguese is a corpus of Portuguese punning texts, including Brazilian and European Portuguese jokes. The data has been manually gathered and curated according to our [guidelines](https://github.com/Superar/Puntuguese/blob/main/data/GUIDELINES.md). It also contains some layers of annotation:
- Every pun is classified as homophonic, homographic, both, or none according to their specific punning signs;
- The punning and alternative signs were made explicit for every joke;
- We also mark potentially problematic puns from an ethical perspective, so it is easier to filter them out if needed.
Additionally, every joke in the corpus has a non-humorous counterpart, obtained via micro-editing, to enable Machine Learning systems to be trained.
### Dataset Description
- **Curated by:** [Marcio Lima Inácio](https://eden.dei.uc.pt/~mlinacio/)
- **Funded by:** FCT - Foundation for Science and Technology, I.P. (grant number UI/BD/153496/2022) and the Portuguese Recovery and Resilience Plan (project C645008882-00000055, Center for Responsible AI).
- **Languages:** Brazilian Portuguese; European Portuguese
- **License:** CC-BY-SA-4.0
### Dataset Sources
The puns were collected from three sources: the "Maiores e melhores" web blog, the "O Sagrado Caderno das Piadas Secas" Instagram page, and from the "UTC - Ultimate Trocadilho Challenge" by Castro Brothers on Youtube.
- **Repository:** https://github.com/Superar/Puntuguese
- **Paper:** To be announced
## Dataset Structure
The dataset provided via Hugging Face Hub contains two tasks: humor recognition and pun location. The first task uses the `text` and `label` columns. For pun location, the columns to be used are `tokens` and `labels`. An instance example can be seen below:
```json
{
"id": "1.1.H",
"text": "Deve ser difícil ser professor de natação. Você ensina, ensina, e o aluno nada.",
"label": 1,
"tokens": ["Deve", "ser", "difícil", "ser", "professor", "de", "natação", ".", "Você", "ensina", ",", "ensina", ",", "e", "o", "aluno", "nada", "."],
"labels": [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0]
}
```
## Dataset Creation
#### Data Collection and Processing
The data was manually gathered and curated to ensure that all jokes followed our chosen definition of pun by Miller et al. (2017):
> "A pun is a form of wordplay in which one sign (e.g., a word or phrase) suggests two or more meanings by exploiting polysemy, homonymy, or phonological similarity to another sign, for an intended humorous or rhetorical effect."
Every selected pun must satisfy this definition. Gatherers were also provided some hints for this process:
- A sign can be a single word (or token), a phrase (a sequence of tokens), or a part of a word (a subtoken);
- The humorous effect must rely on the ambiguity of said sign;
- The ambiguity must originate from the word's form (written or spoken);
- Every pun must have a "pun word" (the ambiguous sign that is in the text) and an "alternative word" (the sign's ambiguous interpretation) identified. If it is not possible to identify both, the text is not considered a pun and should not be included.
#### Who are the source data producers?
The original data was produced by professional comedians from the mentioned sources.
## Bias, Risks, and Limitations
As in every real-life scenario, the data can contain problematic and insensitive jokes about delicate subjects. In this sense, we provide in out GitHub repository a list of jokes that the gatherers, personally, thought to be problematic.
## Citation
**BibTeX:**
```
@inproceedings{InacioEtAl2024,
title = {Puntuguese: A Corpus of Puns in {{P}}ortuguese with Micro-editions},
author = {In{\'a}cio, Marcio Lima and {Wick-pedro}, Gabriela and Ramisch, Renata and Esp{\'i}rito Santo, Lu{\'i}s and Chacon, Xiomara S. Q. and Santos, Roney and Sousa, Rog{\'e}rio and Anchi{\^e}ta, Rafael and Gon{\c c}alo Oliveira, Hugo},
year = {2024},
note = {Accepted to LREC-COLING 2024}
}
```
**APA:**
```
Inácio, M. L., Wick-Pedro, G., Ramisch, R., Epírito Santo, L., Chacon, X. S. Q., Santos, R., Sousa, R., Anchiêta, R. & Gonçalo Oliveira, H. (2024). Puntuguese: A Corpus of Puns in {{P}}ortuguese with Micro-editions. Accepted to LREC-COLING 2024.
``` |
somosnlp/RecetasDeLaAbuela | ---
license: openrail
task_categories:
- question-answering
- summarization
language:
- es
pretty_name: RecetasDeLaAbuel@
size_categories:
- 10K<n<100K
tags:
- recipes
- cooking
- recetas
- cocina
configs:
- config_name: version_inicial
data_files: "recetasdelaabuela.csv"
- config_name: version_1
data_files: "main.csv"
---
# Motivación inicial
<!-- Motivation for the creation of this dataset. -->
Este corpus ha sido creado durante el Hackathon SomosNLP Marzo 2024: #Somos600M (https://somosnlp.org/hackathon).
Responde a una de las propuestas somosnlp sobre 'Recetas típicas por país/zona geográfica'.
# Nombre del Proyecto
<!-- Provide a quick summary of the dataset. -->
Este corpus o dataset se llama 'RecetasDeLaAbuel@' y es un homenaje a todas nuestr@s abuel@s que nos han enseñado a cocinar. Se trata de la mayor y más completa colección de recetas open-source en español de países hispanoamericanos.
<p align="left">
<img src="https://cdn-uploads.huggingface.co/production/uploads/6456c6184095c967f9ace04d/h5GG5ht9r9HJCvJbuetRO.png" alt="Mi abuela cocinando" width="323">
</p>
## Corpus
## Descripción
<!-- Provide a longer summary of what this dataset is. -->
Este corpus contiene los principales elementos de una receta de cocina (título, descripción, ingredientes y preparación). Se ha completado con otros 10 atributos
hasta completar un impresionante dataset con más de 280k (20k x 14) elementos (6M palabras y 40M caracteres).
- **Curated by:** iXrst
- **Funded by:** rovi27, sbenel, GaboTuco, iXrst
- **Language(s) (NLP):** Python
- **License:** openrail
### Estructura
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
Este dataset 'RecetasDeLaAbuel@' tiene formato tabular (20k x 14). Cada fila de datos tiene los siguientes atributos:
1. Id: Identificador numérico.
2. Nombre: Nombre de la receta.
3. URL: Origen web.
4. Ingredientes: Alimentos usados.
5. Pasos: Pasos de preparación.
6. País: Código ISO_A3/país originario de la receta.
7. Duracion (HH:MM): Tiempo estimado de preparación.
8. Categoria: Tipo de receta (ej. vegetarianos, pastas, salsas, postres, cerdo, pollo etc).
9. Contexto: Entorno de uso/consumo o contexto de la receta.
10. Valoracion y Votos: Valoración 1-5 y número de votos.
11. Comensales: Número de raciones.
12. Tiempo: Tiempo del plato (ej: Desayuno, entrante, principal, acompañamiento, etc.)
13. Dificultad: Grado de dificultad (alto/medio/bajo)
14. Valor nutricional: Características básicas: 1) Nivel calorías/sodio (alto/medio/bajo), 2) Ausencia de grasas/grasas trans/colesterol/azúcar y 3) Nivel de fibra.
### Fuentes de datos
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
La información básica se ha recolectado y procesado mediante las técnicas conocidas como 'web scrapping'.
La información original se ha recopilado de diferentes páginas web:
- Recetas gratis de cocina
- Cocina peruana
- Cocina mexicana
- Cocina colombiana
Ponganse en contacto con nosotros para incluir recetas de su país, por favor!
Para más información sobre recetas de cocina dirijanse a la fuente original. Expresamos nuestro reconocimiento y agradecimiento a sus autores.
### Procesamiento de datos
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
Se utilizó scripts de Python para hacer el procesamiento del corpus, y las funciones de limpieza y curación del dataset.
** https://huggingface.co/datasets/somosnlp/RecetasDeLaAbuela/blob/main/stats.pdf
### Estadísticas
Son 20447 registros de recetas.
** https://github.com/recetasdelaabuela/somosnlp/blob/main/Docs/Stats.pdf
## Política de Uso
<!-- Address questions around how the dataset is intended to be used. -->
### Uso directo
<!-- This section describes suitable use cases for the dataset. -->
Nuestra Misión es la creación del mejor asistente de cocina inteligente específico del idioma español (corpus Recetas de la Abuel@) que agrupe recetas de países hispanoamericanos
y permita mejorar nuestra relación con la preparación y el cocinado de los alimentos.
Nuestra IA responderá a cuestiones de los sigientes tipos:
'Dime la receta del ceviche, frijoles, tortilla de patata, paella, etc'
'Qué puedo cocinar con 3 ingredientes?',
'Dime una comida de temporada para este mes de Marzo?' ,
'Propón un menú mensual para una familia'
### Fuera de alcance
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
Queda excluido cualquier uso no contemplado por la UE AI Policity (https://www.consilium.europa.eu/es/policies/artificial-intelligence/)
## Entrenamiento del modelo LLM
Consultese el informe adjunto wandb:
https://github.com/recetasdelaabuela/somosnlp/blob/e7f9796dc2c293ce923f31814de78c49c5b4e3f8/Docs/RecetasDeLaAbuel%40%20Report%20_%20Recetas19kTest20_gemma-2b-it-bnb-4bit%20%E2%80%93%20Weights%20%26%20Biases%20(3).pdf
https://huggingface.co/datasets/somosnlp/RecetasDeLaAbuela/blob/main/RecetasDeLaAbuel%40%20Report%20_%20Recetas19kTest20_gemma-2b-it-bnb-4bit%20%E2%80%93%20Weights%20%26%20Biases.pdf
# Links del proyecto
<!-- Provide the basic links for the dataset. -->
- **Repository:** https://huggingface.co/datasets/somosnlp/RecetasDeLaAbuela
- **GitHub:** https://github.com/recetasdelaabuela/somosnlp
- **Paper:** https://github.com/recetasdelaabuela/somosnlp/blob/main/Paper/LatinX_NAACL_2024-3-1.pdf
- **Corpus con formato tabular:** https://huggingface.co/datasets/somosnlp/RecetasDeLaAbuela
- **Corpus de Instrucciones Original:** https://huggingface.co/datasets/somosnlp/recetasdelaabuela_genstruct_it
- **Corpus de Instrucciones Curado:** https://huggingface.co/datasets/somosnlp/recetasdelaabuela_it
- **Modelo LLM Gemma 7b 20k RecetasDeLaAbuel@:** https://huggingface.co/somosnlp/recetasdelaabuela-0.03
- **Modelo LLM Gemma 2b 20k RecetasDeLaAbuel@:** https://huggingface.co/somosnlp/RecetasDeLaAbuela_gemma-2b-it-bnb-4bit
- **Modelo LLM Tiny Llama 1.1B RecetasDeLaAbuel@:** https://huggingface.co/somosnlp/recetasdelaabuela-0.03
- **Modelo LLM 5k RecetasDeLaAbuel@:** https://huggingface.co/somosnlp/RecetasDeLaAbuela5k_gemma-2b-bnb-4bit
- **Demo RecetasDeLaAbuel@:** https://huggingface.co/spaces/somosnlp/RecetasDeLaAbuela_Demo
- **Modelo LLM ComeBien:** https://huggingface.co/somosnlp/ComeBien_gemma-2b-it-bnb-4bit
- **Demo ComeBien:** https://huggingface.co/spaces/somosnlp/ComeBien_Demo
## Uso del modelo LLM
Los modelos LLM Gemma RecetasDeLaAbuel@ se deben usar siguiendo el formato sistema/usuario/modelo (SOT='<'start_of_turn'>'',EOT='<'end_of_turn'>')"":
<bos>SOT system\n {instruction} EOT SOT user\n {nombre} EOT SOT model\n {receta} EOT EOS_TOKEN.
Más info en https://unsloth.ai/blog/gemma-bugs
## Impacto medioambiental
Los experimentos se realizaron utilizando HuggingFace (AWS) en la región sa-east-1, que tiene una eficiencia de carbono de 0,2 kg CO2 eq/kWh. Se realizó un acumulado de 50 horas de cómputo en HW tipo T4 (TDP de 70W). Se estima que las emisiones totales son 0,7 kg eq. CO2. Las estimaciones se realizaron utilizando la web ML CO2 Impact https://mlco2.github.io/impact/#compute.
# Citaciones
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
Este trabajo se ha basado y es continuación del trabajo desarrollado en el siguiente corpus durante el Hackhaton somosnlp 2023:
https://huggingface.co/datasets/somosnlp/recetas-cocina
Debemos reconocer y agradecer públicamente la labor de su creador Fredy pues gracias a su orientación inicial hemos llegado tan lejos!
https://huggingface.co/Frorozcol
Más información del magnífico proyecto inicial 'Creación de Dataset de Recetas de Comidas' de Fredy se puede encontrar en su github:
https://github.com/Frorozcoloa/ChatCocina/tree/main
Asismismo debemos reconocer y agradecer la labor de Tiago en la recopilación de diversas fuentes de recetas:
- 37 comidas saludables para cuidarse durante todo el mes
- 101 recetas sanas para tener un menú saludable de lunes a domingo
- 50 recetas Fáciles, Sanas, Rápidas y Económicas - Antojo en tu cocina
- 54 recetas saludables para niños, comidas sanas y fáciles de hacer
# Autores
https://huggingface.co/rovi27 <br>
https://huggingface.co/sbenel <br>
https://huggingface.co/GabTuco <br>
https://huggingface.co/iXrst <br>
# Asesoría Académica
Modelización de temática mediante BERTopic
https://huggingface.co/andreamorgar
# Contacto
mailto: recetasdelaabuela.comebien@gmail.com |
laugustyniak/abusive-clauses-pl | ---
annotations_creators:
- hired_annotators
language_creators:
- found
language:
- pl
license:
- cc-by-nc-sa-4.0
multilinguality:
- monolingual
size_categories:
- 10<n<10K
task_categories:
- text-classification
task_ids:
- text-classification
pretty_name: Polish-Abusive-Clauses
---
# PAC - Polish Abusive Clauses Dataset
''I have read and agree to the terms and conditions'' is one of the biggest lies on the Internet. Consumers rarely read the contracts they are required to accept. We conclude agreements over the Internet daily. But do we know the content of these agreements? Do we check potential unfair statements? On the Internet, we probably skip most of the Terms and Conditions. However, we must remember that we have concluded many more contracts. Imagine that we want to buy a house, a car, send our kids to the nursery, open a bank account, or many more. In all these situations, you will need to conclude the contract, but there is a high probability that you will not read the entire agreement with proper understanding. European consumer law aims to prevent businesses from using so-called ''unfair contractual terms'' in their unilaterally drafted contracts, requiring consumers to accept.
Our dataset treats ''unfair contractual term'' as the equivalent of an abusive clause. It could be defined as a clause that is unilaterally imposed by one of the contract's parties, unequally affecting the other, or creating a situation of imbalance between the duties and rights of the parties.
On the EU and at the national such as the Polish levels, agencies cannot check possible agreements by hand. Hence, we took the first step to evaluate the possibility of accelerating this process. We created a dataset and machine learning models to automate potentially abusive clauses detection partially. Consumer protection organizations and agencies can use these resources to make their work more effective and efficient. Moreover, consumers can automatically analyze contracts and understand what they agree upon.
## Tasks (input, output and metrics)
Abusive Clauses Detection
**Input** ('*text'* column): text of agreement
**Output** ('*label'* column): binary label (`BEZPIECZNE_POSTANOWIENIE_UMOWNE`: correct agreement statement, `KLAUZULA_ABUZYWNA`: abusive clause)
**Domain**: legal agreement
**Measurements**: Accuracy, F1 Macro
**Example***:*
Input: *`Wszelka korespondencja wysyłana przez Pożyczkodawcę na adres zamieszkania podany w umowie oraz na e-mail zostaje uznana za skutecznie doręczoną. Zmiana adresu e-mail oraz adresu zamieszkania musi być dostarczona do Pożyczkodawcy osobiście`*
Input (translated by DeepL): *`All correspondence sent by the Lender to the residential address provided in the agreement and to the e-mail address shall be deemed effectively delivered. Change of e-mail address and residential address must be delivered to the Lender in person`*
Output: `KLAUZULA_ABUZYWNA` (abusive clause)
## Data splits
| Subset | Cardinality (sentences) |
| ----------- | ----------------------: |
| train | 4284 |
| dev | 1519 |
| test | 3453 |
## Class distribution
`BEZPIECZNE_POSTANOWIENIE_UMOWNE` - means correct agreement statement.
`KLAUZULA_ABUZYWNA` informs us about abusive clause.
| Class | train | dev | test |
|:--------------------------------|--------:|-------------:|-------:|
| BEZPIECZNE_POSTANOWIENIE_UMOWNE | 0.5458 | 0.3002 | 0.6756 |
| KLAUZULA_ABUZYWNA | 0.4542 | 0.6998 | 0.3244 |
## License
[Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/)
## Citation
```bibtex
@inproceedings{NEURIPS2022_890b206e,
author = {Augustyniak, Lukasz and Tagowski, Kamil and Sawczyn, Albert and Janiak, Denis and Bartusiak, Roman and Szymczak, Adrian and Janz, Arkadiusz and Szyma\'{n}ski, Piotr and W\k{a}troba, Marcin and Morzy, Miko\l aj and Kajdanowicz, Tomasz and Piasecki, Maciej},
booktitle = {Advances in Neural Information Processing Systems},
editor = {S. Koyejo and S. Mohamed and A. Agarwal and D. Belgrave and K. Cho and A. Oh},
pages = {21805--21818},
publisher = {Curran Associates, Inc.},
title = {This is the way: designing and compiling LEPISZCZE, a comprehensive NLP benchmark for Polish},
url = {https://proceedings.neurips.cc/paper_files/paper/2022/file/890b206ebb79e550f3988cb8db936f42-Paper-Datasets_and_Benchmarks.pdf},
volume = {35},
year = {2022}
}
``` |
jglaser/protein_ligand_contacts | ---
tags:
- molecules
- chemistry
- SMILES
---
## How to use the data sets
This dataset contains more than 16,000 unique pairs of protein sequences and ligand SMILES with experimentally determined
binding affinities and protein-ligand contacts (ligand atom/SMILES token vs. Calpha within 5 Angstrom). These
are represented by a list that contains the positions of non-zero elements of the flattened, sparse
sequence x smiles tokens (2048x512) matrix. The first and last entries in both dimensions
are padded to zero, they correspond to [CLS] and [SEP].
It can be used for fine-tuning a language model.
The data solely uses data from PDBind-cn.
Contacts are calculated at four cut-off distances: 5, 8, 11A and 15A.
### Use the already preprocessed data
Load a test/train split using
```
from datasets import load_dataset
train = load_dataset("jglaser/protein_ligand_contacts",split='train[:90%]')
validation = load_dataset("jglaser/protein_ligand_contacts",split='train[90%:]')
```
### Pre-process yourself
To manually perform the preprocessing, download the data sets from P.DBBind-cn
Register for an account at <https://www.pdbbind.org.cn/>, confirm the validation
email, then login and download
- the Index files (1)
- the general protein-ligand complexes (2)
- the refined protein-ligand complexes (3)
Extract those files in `pdbbind/data`
Run the script `pdbbind.py` in a compute job on an MPI-enabled cluster
(e.g., `mpirun -n 64 pdbbind.py`).
Perform the steps in the notebook `pdbbind.ipynb`
|
codeparrot/github-jupyter-text-code-pairs | ---
annotations_creators: []
language:
- code
license:
- other
multilinguality:
- monolingual
size_categories:
- unknown
task_categories:
- text-generation
task_ids:
- language-modeling
pretty_name: github-jupyter-text-code-pairs
---
This is a parsed version of [github-jupyter-parsed](https://huggingface.co/datasets/codeparrot/github-jupyter-parsed), with markdown and code pairs. We provide the preprocessing script in [preprocessing.py](https://huggingface.co/datasets/codeparrot/github-jupyter-parsed-v2/blob/main/preprocessing.py). The data is deduplicated and consists of 451662 examples.
For similar datasets with text and Python code, there is [CoNaLa](https://huggingface.co/datasets/neulab/conala) benchmark from StackOverflow, with some samples curated by annotators. |
juletxara/visual-spatial-reasoning | ---
annotations_creators:
- crowdsourced
language:
- en
language_creators:
- machine-generated
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: Visual Spatial Reasoning
size_categories:
- 10K<n<100K
source_datasets:
- original
tags: []
task_categories:
- image-classification
task_ids: []
---
# Dataset Card for Visual Spatial Reasoning
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://ltl.mmll.cam.ac.uk/
- **Repository:** https://github.com/cambridgeltl/visual-spatial-reasoning
- **Paper:** https://arxiv.org/abs/2205.00363
- **Leaderboard:** https://paperswithcode.com/sota/visual-reasoning-on-vsr
- **Point of Contact:** https://ltl.mmll.cam.ac.uk/
### Dataset Summary
The Visual Spatial Reasoning (VSR) corpus is a collection of caption-image pairs with true/false labels. Each caption describes the spatial relation of two individual objects in the image, and a vision-language model (VLM) needs to judge whether the caption is correctly describing the image (True) or not (False).
### Supported Tasks and Leaderboards
We test three baselines, all supported in huggingface. They are VisualBERT [(Li et al. 2019)](https://arxiv.org/abs/1908.03557), LXMERT [(Tan and Bansal, 2019)](https://arxiv.org/abs/1908.07490) and ViLT [(Kim et al. 2021)](https://arxiv.org/abs/2102.03334). The leaderboard can be checked at [Papers With Code](https://paperswithcode.com/sota/visual-reasoning-on-vsr).
model | random split | zero-shot
:-------------|:-------------:|:-------------:
*human* | *95.4* | *95.4*
VisualBERT | 57.4 | 54.0
LXMERT | **72.5** | **63.2**
ViLT | 71.0 | 62.4
### Languages
The language in the dataset is English as spoken by the annotators. The BCP-47 code for English is en. [`meta_data.csv`](https://github.com/cambridgeltl/visual-spatial-reasoning/tree/master/data/data_files/meta_data.jsonl) contains meta data of annotators.
## Dataset Structure
### Data Instances
Each line is an individual data point. Each `jsonl` file is of the following format:
```json
{"image": "000000050403.jpg", "image_link": "http://images.cocodataset.org/train2017/000000050403.jpg", "caption": "The teddy bear is in front of the person.", "label": 1, "relation": "in front of", "annotator_id": 31, "vote_true_validator_id": [2, 6], "vote_false_validator_id": []}
{"image": "000000401552.jpg", "image_link": "http://images.cocodataset.org/train2017/000000401552.jpg", "caption": "The umbrella is far away from the motorcycle.", "label": 0, "relation": "far away from", "annotator_id": 2, "vote_true_validator_id": [], "vote_false_validator_id": [2, 9, 1]}
```
### Data Fields
`image` denotes name of the image in COCO and `image_link` points to the image on the COCO server (so you can also access directly). `caption` is self-explanatory. `label` being `0` and `1` corresponds to False and True respectively. `relation` records the spatial relation used. `annotator_id` points to the annotator who originally wrote the caption. `vote_true_validator_id` and `vote_false_validator_id` are annotators who voted True or False in the second phase validation.
### Data Splits
The VSR corpus, after validation, contains 10,119 data points with high agreement. On top of these, we create two splits (1) random split and (2) zero-shot split. For random split, we randomly split all data points into train, development, and test sets. Zero-shot split makes sure that train, development and test sets have no overlap of concepts (i.e., if *dog* is in test set, it is not used for training and development). Below are some basic statistics of the two splits.
split | train | dev | test | total
:------|:--------:|:--------:|:--------:|:--------:
random | 7,083 | 1,012 | 2,024 | 10,119
zero-shot | 5,440 | 259 | 731 | 6,430
Check out [`data/`](https://github.com/cambridgeltl/visual-spatial-reasoning/tree/master/data) for more details.
## Dataset Creation
### Curation Rationale
Understanding spatial relations is fundamental to achieve intelligence. Existing vision-language reasoning datasets are great but they compose multiple types of challenges and can thus conflate different sources of error.
The VSR corpus focuses specifically on spatial relations so we can have accurate diagnosis and maximum interpretability.
### Source Data
#### Initial Data Collection and Normalization
**Image pair sampling.** MS COCO 2017 contains
123,287 images and has labelled the segmentation and classes of 886,284 instances (individual
objects). Leveraging the segmentation, we first
randomly select two concepts, then retrieve all images containing the two concepts in COCO 2017 (train and
validation sets). Then images that contain multiple instances of any of the concept are filtered
out to avoid referencing ambiguity. For the single-instance images, we also filter out any of the images with instance area size < 30, 000, to prevent extremely small instances. After these filtering steps,
we randomly sample a pair in the remaining images.
We repeat such process to obtain a large number of
individual image pairs for caption generation.
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
**Fill in the blank: template-based caption generation.** Given a pair of images, the annotator needs to come up with a valid caption that makes it correctly describing one image but incorrect for the other. In this way, the annotator could focus on the key difference of the two images (which should be spatial relation of the two objects of interest) and come up with challenging relation that differentiates the two. Similar paradigms are also used in the annotation of previous vision-language reasoning datasets such as NLVR2 (Suhr et al., 2017,
2019) and MaRVL (Liu et al., 2021). To regularise annotators from writing modifiers and differentiating the image pair with things beyond accurate spatial relations, we opt for a template-based classification task instead of free-form caption writing. Besides, the template-generated dataset can be easily categorised based on relations and their meta-categories.
The caption template has the format of “The
`OBJ1` (is) __ the `OBJ2`.”, and the annotators
are instructed to select a relation from a fixed set
to fill in the slot. The copula “is” can be omitted
for grammaticality. For example, for “contains”,
“consists of”, and “has as a part”, “is” should be
discarded in the template when extracting the final
caption.
The fixed set of spatial relations enable us to obtain the full control of the generation process. The
full list of used relations are listed in the table below. It
contains 71 spatial relations and is adapted from
the summarised relation table of Fagundes et al.
(2021). We made minor changes to filter out clearly
unusable relations, made relation names grammatical under our template, and reduced repeated relations.
In our final dataset, 65 out of the 71 available relations are actually included (the other 6 are
either not selected by annotators or are selected but
the captions did not pass the validation phase).
| Category | Spatial Relations |
|-------------|-------------------------------------------------------------------------------------------------------------------------------------------------|
| Adjacency | Adjacent to, alongside, at the side of, at the right side of, at the left side of, attached to, at the back of, ahead of, against, at the edge of |
| Directional | Off, past, toward, down, deep down*, up*, away from, along, around, from*, into, to*, across, across from, through*, down from |
| Orientation | Facing, facing away from, parallel to, perpendicular to |
| Projective | On top of, beneath, beside, behind, left of, right of, under, in front of, below, above, over, in the middle of |
| Proximity | By, close to, near, far from, far away from |
| Topological | Connected to, detached from, has as a part, part of, contains, within, at, on, in, with, surrounding, among, consists of, out of, between, inside, outside, touching |
| Unallocated | Beyond, next to, opposite to, after*, among, enclosed by |
**Second-round Human Validation.** Every annotated data point is reviewed by at least
two additional human annotators (validators). In
validation, given a data point (consists of an image
and a caption), the validator gives either a True or
False label. We exclude data points that have <
2/3 validators agreeing with the original label.
In the guideline, we communicated to the validators that, for relations such as “left”/“right”, “in
front of”/“behind”, they should tolerate different
reference frame: i.e., if the caption is true from either the object’s or the viewer’s reference, it should
be given a True label. Only
when the caption is incorrect under all reference
frames, a False label is assigned. This adds
difficulty to the models since they could not naively
rely on relative locations of the objects in the images but also need to correctly identify orientations of objects to make the best judgement.
#### Who are the annotators?
Annotators are hired from [prolific.co](https://prolific.co). We
require them (1) have at least a bachelor’s degree,
(2) are fluent in English or native speaker, and (3)
have a >99% historical approval rate on the platform. All annotators are paid with an hourly salary
of 12 GBP. Prolific takes an extra 33% of service
charge and 20% VAT on the service charge.
For caption generation, we release the task with
batches of 200 instances and the annotator is required to finish a batch in 80 minutes. An annotator
cannot take more than one batch per day. In this
way we have a diverse set of annotators and can
also prevent annotators from being fatigued. For
second round validation, we group 500 data points
in one batch and an annotator is asked to label each
batch in 90 minutes.
In total, 24 annotators participated in caption
generation and 26 participated in validation. The
annotators have diverse demographic background:
they were born in 13 different countries; live in 13
different couturiers; and have 14 different nationalities. 57.4% of the annotators identify themselves
as females and 42.6% as males.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
This project is licensed under the [Apache-2.0 License](https://github.com/cambridgeltl/visual-spatial-reasoning/blob/master/LICENSE).
### Citation Information
```bibtex
@article{Liu2022VisualSR,
title={Visual Spatial Reasoning},
author={Fangyu Liu and Guy Edward Toh Emerson and Nigel Collier},
journal={ArXiv},
year={2022},
volume={abs/2205.00363}
}
```
### Contributions
Thanks to [@juletx](https://github.com/juletx) for adding this dataset. |
Bingsu/openwebtext_20p | ---
annotations_creators:
- no-annotation
language:
- en
language_creators:
- found
license:
- cc0-1.0
multilinguality:
- monolingual
paperswithcode_id: openwebtext
pretty_name: openwebtext_20p
size_categories:
- 1M<n<10M
source_datasets:
- extended|openwebtext
task_categories:
- text-generation
- fill-mask
task_ids:
- language-modeling
- masked-language-modeling
---
# openwebtext_20p
## Dataset Description
- **Origin:** [openwebtext](https://huggingface.co/datasets/openwebtext)
- **Download Size** 4.60 GiB
- **Generated Size** 7.48 GiB
- **Total Size** 12.08 GiB
first 20% of [openwebtext](https://huggingface.co/datasets/openwebtext) |
cannlytics/cannabis_licenses | ---
pretty_name: cannabis_licenses
annotations_creators:
- expert-generated
language_creators:
- expert-generated
license:
- cc-by-4.0
tags:
- cannabis
- licenses
---
# Cannabis Licenses
<!-- FIXME:
<div align="center" style="text-align:center; margin-top:1rem; margin-bottom: 1rem;">
<img style="max-height:365px;width:100%;max-width:720px;" alt="" src="analysis/figures/cannabis-licenses-map.png">
</div> -->
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Data Collection and Normalization](#data-collection-and-normalization)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [License](#license)
- [Citation](#citation)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** <https://github.com/cannlytics/cannlytics>
- **Repository:** <https://huggingface.co/datasets/cannlytics/cannabis_licenses>
- **Point of Contact:** <dev@cannlytics.com>
### Dataset Summary
**Cannabis Licenses** is a collection of cannabis license data for each state with permitted adult-use cannabis. The dataset also includes a sub-dataset, `all`, that includes all licenses.
## Dataset Structure
The dataset is partitioned into 18 subsets for each state and the aggregate.
| State | Code | Status |
|-------|------|--------|
| [All](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/all) | `all` | ✅ |
| [Alaska](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/ak) | `ak` | ✅ |
| [Arizona](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/az) | `az` | ✅ |
| [California](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/ca) | `ca` | ✅ |
| [Colorado](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/co) | `co` | ✅ |
| [Connecticut](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/ct) | `ct` | ✅ |
| [Delaware](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/de) | `md` | ✅ |
| [Illinois](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/il) | `il` | ✅ |
| [Maine](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/me) | `me` | ✅ |
| [Maryland](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/md) | `md` | ✅ |
| [Massachusetts](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/ma) | `ma` | ✅ |
| [Michigan](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/mi) | `mi` | ✅ |
| [Missouri](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/mo) | `mo` | ✅ |
| [Montana](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/mt) | `mt` | ✅ |
| [Nevada](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/nv) | `nv` | ✅ |
| [New Jersey](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/nj) | `nj` | ✅ |
| [New Mexico](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/nm) | `nm` | ✅ |
| [New York](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/ny) | `ny` | ✅ |
| [Oregon](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/or) | `or` | ✅ |
| [Rhode Island](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/ri) | `ri` | ✅ |
| [Vermont](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/vt) | `vt` | ✅ |
| Virginia | `va` | ⏳ Expected 2024 |
| [Washington](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/wa) | `wa` | ✅ |
The following states have issued medical cannabis licenses, but are not (yet) included in the dataset:
- Alabama
- Arkansas
- District of Columbia (D.C.)
- Florida
- Kentucky (2024)
- Louisiana
- Minnesota
- Mississippi
- New Hampshire
- North Dakota
- Ohio
- Oklahoma
- Pennsylvania
- South Dakota
- Utah
- West Virginia
### Data Instances
You can load the licenses for each state. For example:
```py
from datasets import load_dataset
# Get the licenses for a specific state.
dataset = load_dataset('cannlytics/cannabis_licenses', 'all')
data = dataset['data']
```
### Data Fields
Below is a non-exhaustive list of fields, used to standardize the various data that are encountered, that you may expect to find for each observation.
| Field | Example | Description |
|-------|-----|-------------|
| `id` | `"1046"` | A state-unique ID for the license. |
| `license_number` | `"C10-0000423-LIC"` | A unique license number. |
| `license_status` | `"Active"` | The status of the license. Only licenses that are active are included. |
| `license_status_date` | `"2022-04-20T00:00"` | The date the status was assigned, an ISO-formatted date if present. |
| `license_term` | `"Provisional"` | The term for the license. |
| `license_type` | `"Commercial - Retailer"` | The type of business license. |
| `license_designation` | `"Adult-Use and Medicinal"` | A state-specific classification for the license. |
| `issue_date` | `"2019-07-15T00:00:00"` | An issue date for the license, an ISO-formatted date if present. |
| `expiration_date` | `"2023-07-14T00:00:00"` | An expiration date for the license, an ISO-formatted date if present. |
| `licensing_authority_id` | `"BCC"` | A unique ID for the state licensing authority. |
| `licensing_authority` | `"Bureau of Cannabis Control (BCC)"` | The state licensing authority. |
| `business_legal_name` | `"Movocan"` | The legal name of the business that owns the license. |
| `business_dba_name` | `"Movocan"` | The name the license is doing business as. |
| `business_owner_name` | `"redacted"` | The name of the owner of the license. |
| `business_structure` | `"Corporation"` | The structure of the business that owns the license. |
| `activity` | `"Pending Inspection"` | Any relevant license activity. |
| `premise_street_address` | `"1632 Gateway Rd"` | The street address of the business. |
| `premise_city` | `"Calexico"` | The city of the business. |
| `premise_state` | `"CA"` | The state abbreviation of the business. |
| `premise_county` | `"Imperial"` | The county of the business. |
| `premise_zip_code` | `"92231"` | The zip code of the business. |
| `business_email` | `"redacted@gmail.com"` | The business email of the license. |
| `business_phone` | `"(555) 555-5555"` | The business phone of the license. |
| `business_website` | `"cannlytics.com"` | The business website of the license. |
| `parcel_number` | `"A42"` | An ID for the business location. |
| `premise_latitude` | `32.69035693` | The latitude of the business. |
| `premise_longitude` | `-115.38987552` | The longitude of the business. |
| `data_refreshed_date` | `"2022-09-21T12:16:33.3866667"` | An ISO-formatted time when the license data was updated. |
### Data Splits
The data is split into subsets by state. You can retrieve all licenses by requesting the `all` subset.
```py
from datasets import load_dataset
# Get all cannabis licenses.
dataset = load_dataset('cannlytics/cannabis_licenses', 'all')
data = dataset['data']
```
## Dataset Creation
### Curation Rationale
Data about organizations operating in the cannabis industry for each state is valuable for research.
### Source Data
| State | Data Source URL |
|-------|-----------------|
| Alaska | <https://www.commerce.alaska.gov/abc/marijuana/Home/licensesearch> |
| Arizona | <https://azcarecheck.azdhs.gov/s/?licenseType=null> |
| California | <https://search.cannabis.ca.gov/> |
| Colorado | <https://sbg.colorado.gov/med/licensed-facilities> |
| Connecticut | <https://portal.ct.gov/DCP/Medical-Marijuana-Program/Connecticut-Medical-Marijuana-Dispensary-Facilities> |
| Delaware | <https://dhss.delaware.gov/dhss/dph/hsp/medmarcc.html> |
| Illinois | <https://www.idfpr.com/LicenseLookup/AdultUseDispensaries.pdf> |
| Maine | <https://www.maine.gov/dafs/ocp/open-data/adult-use> |
| Maryland | <https://mmcc.maryland.gov/Pages/Dispensaries.aspx> |
| Massachusetts | <https://masscannabiscontrol.com/open-data/data-catalog/> |
| Michigan | <https://michigan.maps.arcgis.com/apps/webappviewer/index.html?id=cd5a1a76daaf470b823a382691c0ff60> |
| Missouri | <https://health.mo.gov/safety/cannabis/licensed-facilities.php> |
| Montana | <https://mtrevenue.gov/cannabis/#CannabisLicenses> |
| Nevada | <https://ccb.nv.gov/list-of-licensees/> |
| New Jersey | <https://data.nj.gov/stories/s/ggm4-mprw> |
| New Mexico | <https://nmrldlpi.force.com/bcd/s/public-search-license?division=CCD&language=en_US> |
| New York | <https://cannabis.ny.gov/licensing> |
| Oregon | <https://www.oregon.gov/olcc/marijuana/pages/recreational-marijuana-licensing.aspx> |
| Rhode Island | <https://dbr.ri.gov/office-cannabis-regulation/compassion-centers/licensed-compassion-centers> |
| Vermont | <https://ccb.vermont.gov/licenses> |
| Washington | <https://lcb.wa.gov/records/frequently-requested-lists> |
### Data Collection and Normalization
In the `algorithms` directory, you can find the algorithms used for data collection. You can use these algorithms to recreate the dataset. First, you will need to clone the repository:
```
git clone https://huggingface.co/datasets/cannlytics/cannabis_licenses
```
You can then install the algorithm Python (3.9+) requirements:
```
cd cannabis_licenses
pip install -r requirements.txt
```
Then you can run all of the data-collection algorithms:
```
python algorithms/main.py
```
Or you can run each algorithm individually. For example:
```
python algorithms/get_licenses_ny.py
```
### Personal and Sensitive Information
This dataset includes names of individuals, public addresses, and contact information for cannabis licensees. It is important to take care to use these data points in a legal manner.
## Considerations for Using the Data
### Social Impact of Dataset
Arguably, there is substantial social impact that could result from the study of permitted adult-use cannabis, therefore, researchers and data consumers alike should take the utmost care in the use of this dataset.
### Discussion of Biases
Cannlytics is a for-profit data and analytics company that primarily serves cannabis businesses. The data are not randomly collected and thus sampling bias should be taken into consideration.
### Other Known Limitations
The data is for adult-use cannabis licenses. It would be valuable to include medical cannabis licenses too.
## Additional Information
### Dataset Curators
Curated by [🔥Cannlytics](https://cannlytics.com)<br>
<contact@cannlytics.com>
### License
```
Copyright (c) 2022-2023 Cannlytics and the Cannabis Data Science Team
The files associated with this dataset are licensed under a
Creative Commons Attribution 4.0 International license.
You can share, copy and modify this dataset so long as you give
appropriate credit, provide a link to the CC BY license, and
indicate if changes were made, but you may not do so in a way
that suggests the rights holder has endorsed you or your use of
the dataset. Note that further permission may be required for
any content within the dataset that is identified as belonging
to a third party.
```
### Citation
Please cite the following if you use the code examples in your research:
```bibtex
@misc{cannlytics2023,
title={Cannabis Data Science},
author={Skeate, Keegan and O'Sullivan-Sutherland, Candace},
journal={https://github.com/cannlytics/cannabis-data-science},
year={2023}
}
```
### Contributions
Thanks to [🔥Cannlytics](https://cannlytics.com), [@candy-o](https://github.com/candy-o), [@hcadeaux](https://huggingface.co/hcadeaux), [@keeganskeate](https://github.com/keeganskeate), and the entire [Cannabis Data Science Team](https://meetup.com/cannabis-data-science/members) for their contributions.
|
RussianNLP/wikiomnia | ---
license: apache-2.0
dataset_info:
- config_name: wikiomnia_ruT5_raw
features:
- name: title
dtype: string
- name: categories
dtype: string
- name: summary
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: batch_id
dtype: string
splits:
- name: dev
num_bytes: 600356136
num_examples: 266295
- name: test
num_bytes: 572651444
num_examples: 267751
download_size: 1204094848
dataset_size: 1173007580
- config_name: wikiomnia_ruT5_filtered
features:
- name: title
dtype: string
- name: categories
dtype: string
- name: summary
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: batch_id
dtype: string
splits:
- name: train
num_bytes: 4157093224
num_examples: 2088027
download_size: 4278635364
dataset_size: 4157093224
- config_name: wikiomnia_ruGPT3_filtered
features:
- name: title
dtype: string
- name: categories
dtype: string
- name: summary
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: batch_id
dtype: string
splits:
- name: train
num_bytes: 338607635
num_examples: 173314
download_size: 348694031
dataset_size: 338607635
- config_name: wikiomnia_ruGPT3_raw
features:
- name: title
dtype: string
- name: categories
dtype: string
- name: summary
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: batch_id
dtype: string
splits:
- name: train_batch1
num_bytes: 553204785
num_examples: 260808
- name: train_batch2
num_bytes: 542823205
num_examples: 263599
- name: train_batch3
num_bytes: 582321994
num_examples: 269736
- name: train_batch4
num_bytes: 543315355
num_examples: 265948
- name: train_batch5
num_bytes: 513288049
num_examples: 268466
- name: train_batch6
num_bytes: 943556173
num_examples: 512147
- name: train_batch7
num_bytes: 929464509
num_examples: 508149
- name: train_batch8
num_bytes: 915128725
num_examples: 507559
- name: train_batch9
num_bytes: 926443048
num_examples: 504292
- name: train_batch10
num_bytes: 834958539
num_examples: 463812
- name: train_batch11
num_bytes: 509866027
num_examples: 287770
- name: train_batch12
num_bytes: 478843738
num_examples: 271410
- name: train_batch13
num_bytes: 757068702
num_examples: 385730
- name: train_batch14
num_bytes: 575937629
num_examples: 304110
- name: train_batch15
num_bytes: 517092031
num_examples: 277507
- name: train_batch16
num_bytes: 759363156
num_examples: 402203
- name: train_batch17
num_bytes: 860544388
num_examples: 466572
- name: train_batch18
num_bytes: 935985528
num_examples: 518348
- name: train_batch19
num_bytes: 936782197
num_examples: 514307
- name: train_batch20
num_bytes: 874299949
num_examples: 487238
download_size: 14939875008
dataset_size: 14490287727
- config_name: wikiomnia_ruT5_raw_train
features:
- name: title
dtype: string
- name: categories
dtype: string
- name: summary
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: batch_id
dtype: string
splits:
- name: train_batch3
num_bytes: 612693602
num_examples: 271391
- name: train_batch4
num_bytes: 570286147
num_examples: 265947
- name: train_batch5
num_bytes: 552502041
num_examples: 274650
- name: train_batch6
num_bytes: 1017066184
num_examples: 525224
- name: train_batch7
num_bytes: 972351430
num_examples: 509615
- name: train_batch8
num_bytes: 973314180
num_examples: 516828
- name: train_batch9
num_bytes: 981651841
num_examples: 512709
- name: train_batch10
num_bytes: 880664685
num_examples: 469512
- name: train_batch11
num_bytes: 543971388
num_examples: 294631
- name: train_batch12
num_bytes: 503939060
num_examples: 273526
- name: train_batch13
num_bytes: 794421530
num_examples: 392021
- name: train_batch14
num_bytes: 610815879
num_examples: 311452
- name: train_batch15
num_bytes: 540225492
num_examples: 278677
- name: train_batch16
num_bytes: 804003566
num_examples: 411192
- name: train_batch17
num_bytes: 903347135
num_examples: 469871
- name: train_batch18
num_bytes: 995239085
num_examples: 528301
- name: train_batch19
num_bytes: 1003402360
num_examples: 522264
- name: train_batch20
num_bytes: 948137237
num_examples: 499866
download_size: 14634332336
dataset_size: 14208032842
task_categories:
- question-answering
language:
- ru
tags:
- wikipedia
- wikiomnia
- squad
- QA
pretty_name: WikiOmnia
size_categories:
- 1M<n<10M
---
# Dataset Card for "Wikiomnia"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Dataset Structure](#dataset-structure)
- [Dataset Creation](#dataset-creation)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** [https://github.com/RussianNLP](https://github.com/RussianNLP)
- **Paper:** [WikiOmnia: filtration and evaluation of the generated QA corpus on the whole Russian Wikipedia](https://arxiv.org/abs/2204.08009)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Dataset Summary
We present the WikiOmnia dataset, a new publicly available set of QA-pairs and corresponding Russian Wikipedia article summary sections, composed with a fully automated generative pipeline. The dataset includes every available article from Wikipedia for the Russian language. The WikiOmnia pipeline is available open-source and is also tested for creating SQuAD-formatted QA on other domains, like news texts, fiction, and social media. The resulting dataset includes two parts: raw data on the whole Russian Wikipedia (7,930,873 QA pairs with paragraphs for ruGPT-3 XL and 7,991,040 QA pairs with paragraphs for ruT5-large) and cleaned data with strict automatic verification (over 160,000 QA pairs with paragraphs for ruGPT-3 XL and over 3,400,000 QA pairs with paragraphs for ruT5-large).
WikiOmnia consists of 2 parts:
1. the voluminous, automatically generated part: 15,9 million triplets consisting of the original article summary, a corresponding generated question and a generated answer;
2. the filtered part: the subsample of 3,5 million triplets, fully verified with automatic means
Wikiomnia adheres to a standard SQuAD format problem, resulting in triplets "text paragraph - question based on paragraph - answer from the paragraph", see the following example:
**Original Wikipedia paragraph**: Коити Масимо (яп. Масимо Ко:ити) — известный режиссёр аниме и основатель японской анимационной студии Bee Train. С
момента основания студии он руководит производством почти всех её картин, а также время от времени принимает участие в работе над анимацией и музыкой.
**English translation**: Koichi Mashimo is a famous anime director and the founder of the Japanese animation studio Bee Train. Since the creation of the studio, he directed almost all studio’s works, and he
also sometimes participates in art and sound tasks.
**Generated question (ruT5)**: Кто является основателем японской анимационной студии Bee Train?
**Generated answer (ruT5)**: Коити Масимо
**English QA translation**: Who is the founder of the Japanese animation studio Bee Train? Koichi Mashimo
## Dataset Creation
Models used for dataset generation:
- [ruT5](https://huggingface.co/sberbank-ai/ruT5-large) large fine-tuned on SberQuaD
- [ruGPT-3](https://huggingface.co/sberbank-ai/rugpt3xl) XL fine-tuned on SberQuaD
- [ruBERT](http://docs.deeppavlov.ai/en/master/features/models/squad.html) DeepPavlov tuned for QA tasks
Source: Wikipedia version March 2021
Special tokens: <[TEXT]>, <[QUESTION]>, <[ANSWER]>
The resulting dataset includes two parts: raw data on the whole Russian Wikipedia (7,930,873 QA pairs with paragraphs for ruGPT-3 XL and 7,991,040 QA pairs with paragraphs for ruT5-
large) and cleaned data with strict automatic verification (over 160,000 QA pairs with paragraphs for ruGPT-3 XL and over 3,400,000 QA pairs with paragraphs for ruT5-large).
## Additional Information
### Licensing Information
[Apache 2.0 license](https://github.com/RussianNLP/WikiOmnia/blob/main/LICENSE)
### Citation Information
```
@inproceedings{pisarevskaya-shavrina-2022-wikiomnia,
title = "{W}iki{O}mnia: filtration and evaluation of the generated {QA} corpus on the whole {R}ussian {W}ikipedia",
author = "Pisarevskaya, Dina and
Shavrina, Tatiana",
booktitle = "Proceedings of the 2nd Workshop on Natural Language Generation, Evaluation, and Metrics (GEM)",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates (Hybrid)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.gem-1.10",
pages = "125--135",
abstract = "The General QA field has been developing the methodology referencing the Stanford Question answering dataset (SQuAD) as the significant benchmark. Compiling factual questions datasets requires manual annotations, limiting the training data{'}s potential size. We present the WikiOmnia dataset, a new publicly available set of QA pairs and corresponding Russian Wikipedia article summary sections, composed with a fully automated generation and filtration pipeline. To ensure high quality of generated QA pairs, diverse manual and automated evaluation techniques were applied. The WikiOmnia pipeline is available open-source and is also tested for creating SQuAD-formatted QA on other domains, like news texts, fiction, and social media. The resulting dataset includes two parts: raw data on the whole Russian Wikipedia (7,930,873 QA pairs with paragraphs for ruGPT-3 XL and 7,991,040 QA pairs with paragraphs for ruT5-large) and cleaned data with strict automatic verification (over 160,000 QA pairs with paragraphs for ruGPT-3 XL and over 3,400,000 QA pairs with paragraphs for ruT5-large).",
}
```
### Contributions
Thanks to [@Deenochka](https://github.com/deenochka), [@TatianaShavrina](https://github.com/TatianaShavrina) |
keremberke/clash-of-clans-object-detection | ---
task_categories:
- object-detection
tags:
- roboflow
- roboflow2huggingface
- Gaming
---
<div align="center">
<img width="640" alt="keremberke/clash-of-clans-object-detection" src="https://huggingface.co/datasets/keremberke/clash-of-clans-object-detection/resolve/main/thumbnail.jpg">
</div>
### Dataset Labels
```
['ad', 'airsweeper', 'bombtower', 'canon', 'clancastle', 'eagle', 'inferno', 'kingpad', 'mortar', 'queenpad', 'rcpad', 'scattershot', 'th13', 'wardenpad', 'wizztower', 'xbow']
```
### Number of Images
```json
{'train': 88, 'test': 13, 'valid': 24}
```
### How to Use
- Install [datasets](https://pypi.org/project/datasets/):
```bash
pip install datasets
```
- Load the dataset:
```python
from datasets import load_dataset
ds = load_dataset("keremberke/clash-of-clans-object-detection", name="full")
example = ds['train'][0]
```
### Roboflow Dataset Page
[https://universe.roboflow.com/find-this-base/clash-of-clans-vop4y/dataset/5](https://universe.roboflow.com/find-this-base/clash-of-clans-vop4y/dataset/5?ref=roboflow2huggingface?ref=roboflow2huggingface)
### Citation
```
@misc{ clash-of-clans-vop4y_dataset,
title = { Clash of Clans Dataset },
type = { Open Source Dataset },
author = { Find This Base },
howpublished = { \\url{ https://universe.roboflow.com/find-this-base/clash-of-clans-vop4y } },
url = { https://universe.roboflow.com/find-this-base/clash-of-clans-vop4y },
journal = { Roboflow Universe },
publisher = { Roboflow },
year = { 2022 },
month = { feb },
note = { visited on 2023-01-18 },
}
```
### License
CC BY 4.0
### Dataset Summary
This dataset was exported via roboflow.ai on March 30, 2022 at 4:31 PM GMT
It includes 125 images.
CoC are annotated in COCO format.
The following pre-processing was applied to each image:
* Auto-orientation of pixel data (with EXIF-orientation stripping)
* Resize to 1920x1920 (Fit (black edges))
No image augmentation techniques were applied.
|
Ozziey/poems_dataset | ---
license: afl-3.0
task_categories:
- tabular-classification
language:
- en
pretty_name: Detected emotions and information for poetry dataset
size_categories:
- n<1K
--- |
rcds/MultiLegalSBD | ---
dataset_info:
- config_name: fr_Laws
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 8773683
num_examples: 2131
download_size: 0
dataset_size: 8773683
- config_name: it_Laws
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 8130577
num_examples: 2910
download_size: 0
dataset_size: 8130577
- config_name: es_Laws
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 6260211
num_examples: 677
download_size: 0
dataset_size: 6260211
- config_name: en_Laws
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
download_size: 0
dataset_size: 0
- config_name: de_Laws
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 13792836
num_examples: 13
download_size: 0
dataset_size: 13792836
- config_name: fr_Judgements
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 8788244
num_examples: 315
download_size: 0
dataset_size: 8788244
- config_name: fr_all
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 25977816
num_examples: 2446
download_size: 4782672
dataset_size: 25977816
- config_name: it_Judgements
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 8989061
num_examples: 243
download_size: 0
dataset_size: 8989061
- config_name: it_all
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 25097560
num_examples: 3153
download_size: 4610540
dataset_size: 25097560
- config_name: es_Judgements
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 9460558
num_examples: 190
download_size: 0
dataset_size: 9460558
- config_name: es_all
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 23090629
num_examples: 867
download_size: 4438716
dataset_size: 23090629
- config_name: en_Judgements
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 18401754
num_examples: 80
download_size: 0
dataset_size: 18401754
- config_name: en_all
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 27363914
num_examples: 80
download_size: 5448700
dataset_size: 27363914
- config_name: de_Judgements
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 14082173
num_examples: 131
download_size: 0
dataset_size: 14082173
- config_name: de_all
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 40429185
num_examples: 144
download_size: 7883640
dataset_size: 40429185
- config_name: fr_laws
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 12924503
num_examples: 2131
download_size: 2201568
dataset_size: 12924503
- config_name: fr_judgements
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 13053313
num_examples: 315
download_size: 2581104
dataset_size: 13053313
- config_name: it_laws
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 11869343
num_examples: 2910
download_size: 2048828
dataset_size: 11869343
- config_name: it_judgements
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 13228218
num_examples: 243
download_size: 2561712
dataset_size: 13228218
- config_name: es_laws
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 9183057
num_examples: 677
download_size: 1753376
dataset_size: 9183057
- config_name: es_judgements
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 13907572
num_examples: 190
download_size: 2685340
dataset_size: 13907572
- config_name: en_laws
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
download_size: 0
dataset_size: 0
- config_name: en_judgements
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 27363914
num_examples: 80
download_size: 5448700
dataset_size: 27363914
- config_name: de_laws
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 19935635
num_examples: 13
download_size: 3745480
dataset_size: 19935635
- config_name: de_judgements
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 20493550
num_examples: 131
download_size: 4138160
dataset_size: 20493550
- config_name: pt_laws
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 1005902
num_examples: 58
download_size: 209128
dataset_size: 1005902
- config_name: pt_judgements
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 812282
num_examples: 10
download_size: 173424
dataset_size: 812282
- config_name: pt_all
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 1818184
num_examples: 68
download_size: 382552
dataset_size: 1818184
- config_name: all_laws
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 54918438
num_examples: 5789
download_size: 9958380
dataset_size: 54918438
- config_name: all_judgements
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 88858845
num_examples: 969
download_size: 17588440
dataset_size: 88858845
- config_name: all_all
features:
- name: text
dtype: string
- name: spans
list:
- name: start
dtype: int64
- name: end
dtype: int64
- name: label
dtype: string
- name: token_start
dtype: int64
- name: token_end
dtype: int64
- name: tokens
list:
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: id
dtype: int64
- name: ws
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 143777284
num_examples: 6758
download_size: 27546820
dataset_size: 143777284
task_categories:
- token-classification
language:
- en
- es
- de
- it
- pt
- fr
pretty_name: 'MultiLegalSBD: A Multilingual Legal Sentence Boundary Detection Dataset'
size_categories:
- 100K<n<1M
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This is a multilingual dataset containing ~130k annotated sentence boundaries. It contains laws and court decision in 6 different languages.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
English, French, Italian, German, Portuguese, Spanish
## Dataset Structure
It is structured in the following format: {language}\_{type}\_{shard}.jsonl.xz
type is one of the following:
- laws
- judgements
Use the the dataset like this:
```
from datasets import load_dataset
config = 'fr_laws' #{language}_{type} | to load all languages and/or all types, use 'all_all'
dataset = load_dataset('rdcs/MultiLegalSBD', config)
```
### Data Instances
[More Information Needed]
### Data Fields
- text: the original text
- spans:
- start: offset of the first character
- end: offset of the last character
- label: One label only -> Sentence
- token_start: id of the first token
- token_end: id of the last token
- tokens:
- text: token text
- start: offset of the first character
- end: offset of the last character
- id: token id
- ws: whether the token is followed by whitespace
### Data Splits
There is only one split available
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
```
@inproceedings{10.1145/3594536.3595132,
author = {Brugger, Tobias and St\"{u}rmer, Matthias and Niklaus, Joel},
title = {MultiLegalSBD: A Multilingual Legal Sentence Boundary Detection Dataset},
year = {2023},
isbn = {9798400701979},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3594536.3595132},
doi = {10.1145/3594536.3595132},
abstract = {Sentence Boundary Detection (SBD) is one of the foundational building blocks of Natural Language Processing (NLP), with incorrectly split sentences heavily influencing the output quality of downstream tasks. It is a challenging task for algorithms, especially in the legal domain, considering the complex and different sentence structures used. In this work, we curated a diverse multilingual legal dataset consisting of over 130'000 annotated sentences in 6 languages. Our experimental results indicate that the performance of existing SBD models is subpar on multilingual legal data. We trained and tested monolingual and multilingual models based on CRF, BiLSTM-CRF, and transformers, demonstrating state-of-the-art performance. We also show that our multilingual models outperform all baselines in the zero-shot setting on a Portuguese test set. To encourage further research and development by the community, we have made our dataset, models, and code publicly available.},
booktitle = {Proceedings of the Nineteenth International Conference on Artificial Intelligence and Law},
pages = {42–51},
numpages = {10},
keywords = {Natural Language Processing, Sentence Boundary Detection, Text Annotation, Legal Document Analysis, Multilingual},
location = {Braga, Portugal},
series = {ICAIL '23}
}
```
### Contributions
[More Information Needed] |
jed351/rthk_news | ---
language:
- zh
---
### RTHK News Dataset
(RTHK)[https://www.rthk.hk/] is a public broadcasting service under the Hong Kong Government according to (Wikipedia)[https://en.wikipedia.org/wiki/RTHK]
This dataset at the moment is obtained from exporting messages from their (telegram channel)[https://t.me/rthk_new_c],
which contains news since April 2018.
I will update this dataset with more data in the future. |
sedthh/gutenberg_multilang | ---
dataset_info:
features:
- name: TEXT
dtype: string
- name: SOURCE
dtype: string
- name: METADATA
dtype: string
splits:
- name: train
num_bytes: 3127780102
num_examples: 7907
download_size: 1911528348
dataset_size: 3127780102
license: mit
task_categories:
- text-generation
language:
- es
- de
- fr
- nl
- it
- pt
- hu
tags:
- project gutenberg
- e-book
- gutenberg.org
pretty_name: Project Gutenberg eBooks in different languages
size_categories:
- 1K<n<10K
---
# Dataset Card for Project Gutenber - Multilanguage eBooks
A collection of non-english language eBooks (7907, about 75-80% of all the ES, DE, FR, NL, IT, PT, HU books available on the site) from the Project Gutenberg site with metadata removed.
Originally colected for https://github.com/LAION-AI/Open-Assistant
| LANG | EBOOKS |
|----|----|
| ES | 717 |
| DE | 1735 |
| FR | 2863 |
| NL | 904 |
| IT | 692 |
| PT | 501 |
| HU | 495 |
The METADATA column contains catalogue meta information on each book as a serialized JSON:
| key | original column |
|----|----|
| language | - |
| text_id | Text# unique book identifier on Prject Gutenberg as *int* |
| title | Title of the book as *string* |
| issued | Issued date as *string* |
| authors | Authors as *string*, comma separated sometimes with dates |
| subjects | Subjects as *string*, various formats |
| locc | LoCC code as *string* |
| bookshelves | Bookshelves as *string*, optional |
## Source data
**How was the data generated?**
- A crawler (see Open-Assistant repository) downloaded the raw HTML code for
each eBook based on **Text#** id in the Gutenberg catalogue (if available)
- The metadata and the body of text are not clearly separated so an additional
parser attempts to split them, then remove transcriber's notes and e-book
related information from the body of text (text clearly marked as copyrighted or
malformed was skipped and not collected)
- The body of cleaned TEXT as well as the catalogue METADATA is then saved as
a parquet file, with all columns being strings
**Copyright notice:**
- Some of the books are copyrighted! The crawler ignored all books
with an english copyright header by utilizing a regex expression, but make
sure to check out the metadata for each book manually to ensure they are okay
to use in your country! More information on copyright:
https://www.gutenberg.org/help/copyright.html and
https://www.gutenberg.org/policy/permission.html
- Project Gutenberg has the following requests when using books without
metadata: _Books obtianed from the Project Gutenberg site should have the
following legal note next to them: "This eBook is for the use of anyone
anywhere in the United States and most other parts of the world at no cost and
with almost" no restrictions whatsoever. You may copy it, give it away or
re-use it under the terms of the Project Gutenberg License included with this
eBook or online at www.gutenberg.org. If you are not located in the United
States, you will have to check the laws of the country where you are located
before using this eBook."_ |
saier/unarXive_citrec | ---
annotations_creators:
- machine-generated
language:
- en
language_creators:
- found
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
pretty_name: unarXive citation recommendation
size_categories:
- 1M<n<10M
tags:
- arXiv.org
- arXiv
- citation recommendation
- citation
- reference
- publication
- paper
- preprint
- section
- physics
- mathematics
- computer science
- cs
task_categories:
- text-classification
task_ids:
- multi-class-classification
source_datasets:
- extended|10.5281/zenodo.7752615
dataset_info:
features:
- name: _id
dtype: string
- name: text
dtype: string
- name: marker
dtype: string
- name: marker_offsets
sequence:
sequence: int64
- name: label
dtype: string
config_name: .
splits:
- name: train
num_bytes: 5457336094
num_examples: 2043192
- name: test
num_bytes: 551012459
num_examples: 225084
- name: validation
num_bytes: 586422261
num_examples: 225348
download_size: 7005370567
dataset_size: 6594770814
---
# Dataset Card for unarXive citation recommendation
## Dataset Description
* **Homepage:** [https://github.com/IllDepence/unarXive](https://github.com/IllDepence/unarXive)
* **Paper:** [unarXive 2022: All arXiv Publications Pre-Processed for NLP, Including Structured Full-Text and Citation Network](https://arxiv.org/abs/2303.14957)
### Dataset Summary
The unarXive citation recommendation dataset contains 2.5 Million paragraphs from computer science papers and with an annotated citation marker. The paragraphs and citation information is derived from [unarXive](https://github.com/IllDepence/unarXive).
Note that citation infromation is only given as the [OpenAlex](https://openalex.org/) ID of the cited paper. An important consideration for models is therefore if the data is used *as is*, or if additional information of the cited papers (metadata, abstracts, full-text, etc.) is used.
The dataset can be used as follows.
```
from datasets import load_dataset
citrec_data = load_dataset('saier/unarXive_citrec')
citrec_data = citrec_data.class_encode_column('label') # assign target label column
citrec_data = citrec_data.remove_columns('_id') # remove sample ID column
```
## Dataset Structure
### Data Instances
Each data instance contains the paragraph’s text as well as information on one of the contained citation markers, in the form of a label (cited document OpenAlex ID), citation marker, and citation marker offset. An example is shown below.
```
{'_id': '7c1464bb-1f0f-4b38-b1a3-85754eaf6ad1',
'label': 'https://openalex.org/W3115081393',
'marker': '[1]',
'marker_offsets': [[316, 319]],
'text': 'Data: For sentiment analysis on Hindi-English CM tweets, we used the '
'dataset provided by the organizers of Task 9 at SemEval-2020.\n'
'The training dataset consists of 14 thousand tweets.\n'
'Whereas, the validation dataset as well as the test dataset contain '
'3 thousand tweets each.\n'
'The details of the dataset are given in [1]}.\n'
'For this task, we did not use any external dataset.\n'}
```
### Data Splits
The data is split into training, development, and testing data as follows.
* Training: 2,043,192 instances
* Development: 225,084 instances
* Testing: 225,348 instances
## Dataset Creation
### Source Data
The paragraph texts are extracted from the data set [unarXive](https://github.com/IllDepence/unarXive).
#### Who are the source language producers?
The paragraphs were written by the authors of the arXiv papers. In file `license_info.jsonl` author and text licensing information can be found for all samples, An example is shown below.
```
{'authors': 'Yusuke Sekikawa, Teppei Suzuki',
'license': 'http://creativecommons.org/licenses/by/4.0/',
'paper_arxiv_id': '2011.09852',
'sample_ids': ['cc375518-347c-43d0-bfb2-f88564d66df8',
'18dc073e-a48e-488e-b34c-e5fc3cb8a4ca',
'0c2e89b3-d863-4bc2-9e11-8f6c48d867cb',
'd85e46cf-b11d-49b6-801b-089aa2dd037d',
'92915cea-17ab-4a98-aad2-417f6cdd53d2',
'e88cb422-47b7-4f69-9b0b-fbddf8140d98',
'4f5094a4-0e6e-46ae-a34d-e15ce0b9803c',
'59003494-096f-4a7c-ad65-342b74eed561',
'6a99b3f5-217e-4d3d-a770-693483ef8670']}
```
### Annotations
Citation information in unarXive is automatically determined ([see implementation](https://github.com/IllDepence/unarXive/blob/master/src/match_references_openalex.py)).
<!--
## Considerations for Using the Data
### Discussion and Biases
TODO
### Other Known Limitations
TODO
-->
## Additional Information
### Licensing information
The dataset is released under the Creative Commons Attribution-ShareAlike 4.0.
### Citation Information
```
@inproceedings{Saier2023unarXive,
author = {Saier, Tarek and Krause, Johan and F\"{a}rber, Michael},
title = {{unarXive 2022: All arXiv Publications Pre-Processed for NLP, Including Structured Full-Text and Citation Network}},
booktitle = {Proceedings of the 23rd ACM/IEEE Joint Conference on Digital Libraries},
year = {2023},
series = {JCDL '23}
}
```
|
stanfordnlp/SHP-2 | ---
task_categories:
- text-generation
- question-answering
tags:
- human feedback
- rlhf
- preferences
- reddit
- preference model
- RL
- NLG
- evaluation
size_categories:
- 1M<n<10M
language:
- en
---
# 🚢 Stanford Human Preferences Dataset v2 (SHP-2)
## Summary
SHP-2 is a dataset of **4.8M collective human preferences** over responses to questions/instructions in 129 different subject areas, from cooking to legal advice. It is an extended version of the original 385K [SHP dataset](https://huggingface.co/datasets/stanfordnlp/SHP).
The preferences are meant to reflect the helpfulness of one response over another, and are intended to be used for training RLHF reward models and NLG evaluation models (e.g., [SteamSHP](https://huggingface.co/stanfordnlp/SteamSHP-flan-t5-xl)).
Each example is a Reddit or StackExchange post with a question/instruction and a pair of top-level comments for that post, where one comment is more preferred by Reddit / StackExchange users (collectively).
SHP exploits the fact that if comment A was written *after* comment B but has a higher score nonetheless, then A is ostensibly more preferred to B.
If A had been written before B, then we could not conclude this, since its higher score could have been the result of more visibility.
We chose data where the preference label is intended to reflect which response is more *helpful* rather than which is less *harmful*, the latter being the focus of much past work.
How is SHP different from [Anthropic's HH-RLHF dataset](https://huggingface.co/datasets/Anthropic/hh-rlhf) and [Open Assistant](https://huggingface.co/datasets/OpenAssistant/oasst1)?
| Dataset | Size | Input | Label | Domains | Data Format | Length |
| -------------------- | ---- | -------------------------- | ---------------------------- | ------------------------- | ------------------------------------- | --------------- |
| SHP-2 | 4.8M | Naturally occurring human-written responses | Collective Human Preference | 129 (labelled) | Question/Instruction + Response (Single-turn) | up to 10.1K T5 tokens |
| HH-RLHF | 91K | Dialogue with LLM | Individual Human Preference | not labelled | Live Chat (Multi-turn) | up to 1.5K T5 tokens |
| OASST | 161K | Dialogue with LLM | K Individual Preferences, Aggregated | not labelled | Live Chat (Multi-Turn) | up to 1.5K T5 tokens |
How is SHP different from other datasets that have scraped Reddit, like [ELI5](https://huggingface.co/datasets/eli5#source-data)?
SHP uses the timestamp information to infer preferences, while ELI5 only provides comments and scores -- the latter are not enough to infer preferences since comments made earlier tend to get higher scores from more visibility.
It also contains data from more domains:
| Dataset | Size | Comments + Scores | Preferences | Number of Domains |
| -------------------- | ---- | ------------------ | -------------| ------------------ |
| SHP-2 | 4.8M | Yes | Yes | 129 (70 from Reddit, 59 from StackExchange) |
| SHP | 385K | Yes | Yes | 18 (from Reddit) |
| ELI5 | 270K | Yes | No | 3 |
## Data Structure
There are 2 directories, one for Reddit and one for StackExchange. There are 70 subdirectories under `reddit/`, one for each subreddit, and 59 subdirectories under `stackexchange/`, one for each stackexchange site.
Each subdirectory contains a JSONL file for the training, validation, and test data.
Here's how to get the data using Huggingface's `datasets` library:
```python
from datasets import load_dataset
# Load all the data
dataset = load_dataset("stanfordnlp/shp-2")
# Load one of the subreddits
dataset = load_dataset("stanfordnlp/shp-2", data_dir="reddit/askculinary")
# Load one of the StackExchange sites
dataset = load_dataset("stanfordnlp/shp-2", data_dir="stackexchange/stack_academia")
```
Here's an example from `reddit/askculinary/train.json`:
```
{
`post_id`:"qt3nxl",
`domain`:"askculinary_train",
`upvote_ratio`:0.98,
`history`:"What's the best way to disassemble raspberries? Like this, but down to the individual seeds: https:\/\/i.imgur.com\/Z0c6ZKE.jpg I've been pulling them apart with tweezers and it's really time consuming. I have about 10 pounds to get through this weekend.",
`c_root_id_A`:"hkh25sc",
`c_root_id_B`:"hkh25lp",
`created_at_utc_A`:1636822112,
`created_at_utc_B`:1636822110,
`score_A`:340,
`score_B`:166,
`human_ref_A`:"Pectinex, perhaps? It's an enzyme that breaks down cellulose. With citrus, you let it sit in a dilute solution of pectinex overnight to break down the connective tissues. You end up with perfect citrus supremes. If you let the raspberries sit for a shorter time, I wonder if it would separate the seeds the same way...? Here's an example: https:\/\/www.chefsteps.com\/activities\/perfect-citrus-supreme",
`human_ref_B`:"Raspberry juice will make a bright stain at first, but in a matter of weeks it will start to fade away to almost nothing. It is what is known in the natural dye world as a fugitive dye, it will fade even without washing or exposure to light. I hope she gets lots of nice photos of these stains on her dress, because soon that will be all she has left of them!",
`labels`:1,
`metadata_A`: "",
`metadata_B`: "",
`seconds_difference`:2.0,
`score_ratio`:2.0481927711
}
```
Here's an example from `stackexchange/stack_academia/validation.json`:
```
{
`post_id`:"87393",
`domain`:"academia_validation",
`history`:"What to answer an author asking me if I reviewed his/her paper? <sep> Suppose I review someone's paper anonymously, the paper gets accepted, and a year or two later we meet e.g. in a social event and he/she asks me "did you review my paper?". What should I answer? There are several sub-questions here: Suppose the review was a good one, and the paper eventualy got accepted, so I do not mind telling that I was the reviewer. Is there any rule/norm prohibiting me from telling the truth? Suppose the review was not so good, so I do not want to reveal. What can I answer? If I just say "I am not allowed to tell you", this immediately reveals me... On the other hand, I do not want to lie. What options do I have?",
`c_root_id_A`:"87434",
`c_root_id_B`:"87453",
`created_at_utc_A`:1490989560,
`created_at_utc_B`:1491012608,
`score_A`:2,
`score_B`:5,
`human_ref_A`:"I am aware of at least one paper where a referee went out of cover (after the review process of course) and was explicitly mentioned in a later paper: <blockquote> X and Y thank Z, who as the anonymous referee was kind enough to point out the error (and later became non-anonymous). </blockquote> so it is sure fine to answer truthfully that yes you did review, but only if you wish of course (and most likely if you have been helpful and the authors of the paper responsive).",
`human_ref_B`:"Perhaps you should follow the example of Howard Percy Robertson (known as the 'R' in the famous FLRW, or Friedmann-Lematre-Robertson-Walker metric used in physical cosmology.) He was the referee of the famous Einstein-Rosen paper, which was rejected by Physical Review, prompting Einstein never to publish in Physical Review again. Einstein ignored the referee report, but months later, it seems, Robertson had a chance to talk to Einstein and may have helped convince him of the error of his ways. However, as far as we know, he never revealed to Einstein that he was the anonymous referee for Physical Review. It was not until 2005 I believe, long after the death of all participants, that Physical Review chose to disclose the referee's identity (http://physicstoday.scitation.org/doi/full/10.1063/1.2117822).",
`labels`:"0",
`metadata_A`:"Post URL: https://academia.stackexchange.com/questions/87393, Response URL: https://academia.stackexchange.com/questions/87434, Post author username: Erel Segal-Halevi, Post author profile: https://academia.stackexchange.com/users/787, Response author username: mts, Response author profile: https://academia.stackexchange.com/users/49583",
`metadata_B`:"Post URL: https://academia.stackexchange.com/questions/87393, Response URL: https://academia.stackexchange.com/questions/87453, Post author username: Erel Segal-Halevi, Post author profile: https://academia.stackexchange.com/users/787, Response author username: Viktor Toth, Response author profile: https://academia.stackexchange.com/users/7938",
`seconds_difference`:23048.0,
`score_ratio`:2.5,
}
```
where the fields are:
- ```post_id```: the ID of the Reddit post (string)
- ```domain```: the subreddit and split the example is drawn from, separated by an underscore (string)
- ```upvote_ratio```: the percent of votes received by the post that were positive (aka upvotes), -1.0 for stackexchange as there is no such data (float)
- ```history```: the post title concatented to the post body (string)
- ```c_root_id_A```: the ID of comment A (string)
- ```c_root_id_B```: the ID of comment B (string)
- ```created_at_utc_A```: utc timestamp of when comment A was created (integer)
- ```created_at_utc_B```: utc timestamp of when comment B was created (integer)
- ```score_A```: (# positive votes - # negative votes + 1) received by comment A (integer)
- ```score_B```: (# positive votes - # negative votes + 1) received by comment B (integer)
- ```human_ref_A```: text of comment A (string)
- ```human_ref_B```: text of comment B (string)
- ```labels```: the preference label -- it is 1 if A is preferred to B; 0 if B is preferred to A. This was randomized such that the label distribution is roughly 50/50. (integer)
- ```metadata_A```: metadata for stackexchange post and comment A (string)
- ```metadata_B```: metadata for stackexchange post and comment B (string)
- ```seconds_difference```: how many seconds after the less preferred comment the more preferred one was created (will always be >= 0) (integer)
- ```score_ratio```: the ratio of the more preferred comment's score to the less preferred comment's score (will be >= 1) (float)
## Dataset Design
### Domain Selection
The data is sourced from Reddit and StackExchange, which are both public forums organized into different domains.
SHP-2 contains a train, validation, and test split for comments scraped from each domain. We chose domains based on:
1. whether they were well-known (>= 100K subscribers for Reddit and >= 50K for StackExchange)
2. whether posts were expected to pose a question or instruction
3. whether responses were valued based on how *helpful* they were
4. whether comments had to be rooted in some objectivity, instead of being entirely about personal experiences (e.g., `askscience` vs. `AskAmericans`)
The train/validation/test splits were created by splitting the post IDs of a domain in 90%/5%/5% proportions respectively, so that no post would appear in multiple splits.
Since different posts have different numbers of comments, the number of preferences in each split is not exactly 90%/5%/5%.
See below for a list of all domains:
Reddit: \
techsupport, asklinguistics, askscience, catadvice, campingandhiking, askphysics, espresso, botany, asksocialscience, askbaking, ultralight, legaladvice, hiking, webdev, askengineers, screenwriting, askhistorians, vegetarian, writing, diy, musictheory, camping, moviesuggestions, askeconomics, stocks, frugal, outoftheloop, booksuggestions, gamedev, linuxquestions, asknetsec, aviation, askacademia, asksciencefiction, askhr, explainlikeimfive, etymology, entrepreneur, cooking, puppy101, keto, crochet, smallbusiness, architecture, artfundamentals, sewing, zerowaste, changemyview, mechanicadvice, iwanttolearn, eatcheapandhealthy, askanthropology, askculinary, askphilosophy, tea, running, excel, homebrewing, solotravel, fishing, cookingforbeginners, homeautomation, ifyoulikeblank, travel, suggestmeabook, televisionsuggestions, sysadmin, askcarguys, askdocs, askvet
StackExchange: \
stack_unix, stack_android, stack_academia, stack_superuser, stack_tex, stack_photo, stack_datascience, stack_mechanics, stack_english, stack_askubuntu, stack_sharepoint, stack_workplace, stack_blender, stack_ethereum, stack_stats, stack_bitcoin, stack_gamedev, stack_raspberrypi, stack_arduino, stack_magento, stack_physics, stack_mathoverflow, stack_dsp, stack_movies, stack_crypto, stack_apple, stack_mathematica, stack_philosophy, stack_wordpress, stack_ux, stack_webmasters, stack_cs, stack_travel, stack_bicycles, stack_softwarerecs, stack_money, stack_ell, stack_scifi, stack_aviation, stack_math, stack_biology, stack_drupal, stack_diy, stack_security, stack_salesforce, stack_graphicdesign, stack_stackoverflow, stack_webapps, stack_cooking, stack_networkengineering, stack_dba, stack_puzzling, stack_serverfault, stack_codereview, stack_music, stack_codegolf, stack_electronics, stack_chemistry, stack_gis
### Data Selection
For Reddit, the score of a post/comment is 1 plus the number of upvotes (approvals) it gets from users, minus the number of downvotes (disapprovals) it gets.
For Stackexchange, the score of a post/comment is 0 plus the number of upvotes (approvals) it gets from users, minus the number of downvotes (disapprovals) it gets.
The value of a score is relative; in domains(posts) with more traffic, there will be more higher-scoring posts(comments).
Within a post, comments posted earlier will tend to have a higher score simply due to having more exposure, which is why using timestamp information is essential when inferring preferences.
Given a post P and two comments (A,B) we only included the preference A > B in the dataset if
1. A was written *no later than* B and A has a higher score than B.
2. The post is a self-post (i.e., a body of text and not a link to another page) made before 2023, was not edited, and is not NSFW (over 18). For Stackexchange, edited posts were permitted as long as they were edited prior to the writing of the comments.
3. Neither comment was made by a deleted user, a moderator, or the post creator. The post was not made by a deleted user or moderator.
4. For Reddit, the post has a score >= 10 and each comment has a score >= 2 (upvoted at least once). For Stackexchange, the post has a score >= 5 and each comment has a non-zero score.
The conditions are laxer for StackExchange because it is more strictly moderataed than Reddit, allowing us to hit the same data quality with lower thresholds.
In particular, we allow negative-score comments from StackExchange because the negative scores are likely due to being inaccurat/misinformed rather than being toxic, and this provides a useful signal.
A post with `n` comments could have up to (`n` choose `2`) preferences in the data.
Since the number of comments per post is Pareto-distributed, to prevent a relatively small number of posts from dominating the Reddit data, we limited the scraping to 50 comments per post.
This means that each post could have up to (`50` choose `2`) comments in the dataset, though this is a much smaller number in practice, since all the criteria above need to be met.
No such criteria are imposed for StackExchange, since there are fewer comments per post.
### Reddit Preprocessing
We tried to keep preprocessing to a minimum. Subreddit-specific abbreviations were expanded (e.g., "CMV" to "Change my view that").
In hyperlinks, only the referring text was kept and the URL was removed (if the URL was written out, then it was kept).
### Finetuning
If you want to finetune a model to predict human preferences (e.g., for NLG evaluation or an RLHF reward model), here are some helpful tips:
1. **Preprocess the data.** The total input length should fit under the model's token limit (usually 512 tokens).
Although models like FLAN-T5 use positional embeddings, we found that the loss would not converge if we finetuned it on inputs over 512 tokens.
To avoid this, truncate the post text (in the `history` field) as much as possible, such that the whole input is under 512 tokens (do not truncate the comment(s) however).
If this is still over 512 tokens, simply skip the example.
2. **Use a sufficiently large model.**
Finetuning a single FLAN-T5-xl model across [the original 385K SHP training data](https://huggingface.co/datasets/stanfordnlp/SHP) should give you a test accuracy between 72-73% (across all domains on examples where the entire input fits within the token limit), ranging from 65-80% on individual subreddits.
3. **Do in-domain prediction.** Out-of-domain performance will be poor if the domains are unrelated (e.g., if you fine-tune on `askculinary` preferences and test on `askcarguys` preferences).
4. **Train for fewer epochs.** The InstructGPT paper paper suggests training a reward model for only 1 epoch.
Since the same comment appears in multiple preferences, it is easy to overfit to the data.
5. **Training on less data may help.**
Preferences with a large `score_ratio` (e.g., comment A having 2x the score of comment B) will provide a stronger signal for finetuning the model, so you may only want to consider preferences above a certain `score_ratio`.
The number of preferences per post is Pareto-distributed, so to prevent the model from over-fitting to certain posts, you may want to limit the number of preferences from a particular post.
## Biases and Limitations
### Biases
Although we filtered out posts with NSFW (over 18) content, chose domains that were well-moderated and had policies against harassment and bigotry, some of the data may contain discriminatory or harmful language.
The data does not reflect the views of the dataset creators.
Reddit and StackExchange users are also not representative of the broader population.
Although subreddit-specific demographic information is not available, Reddit users overall are disproportionately male and from developed, Western, and English-speaking countries ([Pew Research](https://www.pewresearch.org/internet/2013/07/03/6-of-online-adults-are-reddit-users/)).
This is likely also true of StackExchange users.
Please keep this in mind before using any models trained on this data.
### Limitations
The preference label in SHP is intended to reflect how *helpful* one response is relative to another, given an instruction/question.
SHP is not intended for use in harm-minimization, as it was not designed to include the toxic content that would be necessary to learn a good toxicity detector.
If you are looking for data where the preference label denotes less harm, we would recommend the harmfulness split of [Anthropic's HH-RLHF](https://huggingface.co/datasets/Anthropic/hh-rlhf).
Another limitation is that the more preferred response in SHP is not necessarily the more factual one.
Though some comments do provide citations to justify their response, most do not.
There are exceptions to this, such as the `askhistorians` subreddit, which is heavily moderated and answers are expected to provide citations.
Note that the collective preference label in SHP is not necessarily what we would get if we asked users to independently vote on each comment before taking an unweighted sum.
This is because comment scores on Reddit are public and are known to influence user preferences; a high score increases the likelihood of getting more positive votes [(Muchnik et al., 2013)](https://pubmed.ncbi.nlm.nih.gov/23929980/).
Whether this "herding effect" temporarily or permanently shifts a user's preference is unclear.
Therefore, while SHP does reflect collective human preferences, models trained on SHP may not generalize to settings where individual preferences are aggregated differently (e.g., users vote independently without ever seeing the current comment score, users vote after conferring, etc.).
Thanks to Greg Stoddard for pointing this out.
## License
Last updated: 07/016/2023
### Reddit
The data was made by scraping publicly available data in accordance with the a historical version of [Reddit API Terms of Use](https://docs.google.com/a/reddit.com/forms/d/e/1FAIpQLSezNdDNK1-P8mspSbmtC2r86Ee9ZRbC66u929cG2GX0T9UMyw/viewform), without any direct communication or written agreements with Reddit.
According to the Terms of Use, "User Content" is owned by the users themselves -- not by Reddit -- and Reddit grants a "non-exclusive, non-transferable, non-sublicensable, and revocable license to copy and display the User Content".
At time of writing, Reddit grants "no other rights or licenses are granted or implied, including any right to use User Content for other purposes, such as for training a machine learning or artificial intelligence model, without the express permission of rightsholders in the applicable User Content."
However, the legality of training on publicly available data will depend on your jurisdiction (legal in Japan, for example).
Datasets made by scraping Reddit are widely used in the research community: for example, Facebook AI Research used data scraped from Reddit to make the [ELI5](https://huggingface.co/datasets/eli5#source-data) dataset in 2019, which was made available without a license.
Anthropic AI has also [attested to scraping Reddit](https://arxiv.org/pdf/2112.00861.pdf) for preferences using a different methodology, though this data was not made public.
We take no responsibility for and we do not expressly or implicitly endorse any downstream use of this dataset.
We reserve the right to modify the SHP dataset and this license at any point in the future.
### StackExchange
StackExchange data is made available under a [CC by-SA license](https://creativecommons.org/licenses/by-sa/4.0/).
## Contact
Please contact kawin@stanford.edu if you have any questions about the data.
This dataset was created by Kawin Ethayarajh, Heidi (Chenyu) Zhang, and Shabnam Behzad with advice from Dan Jurafsky and Yizhong Wang.
Kawin and Heidi prepared the Reddit datasets and trained the SteamSHP models.
Kawin and Shabnam prepared the StackExchange data.
Dan and Yizhong provide advice on dataset construction.
## Citation
We will have a paper out soon, but until then, please cite:
```
@InProceedings{pmlr-v162-ethayarajh22a,
title = {Understanding Dataset Difficulty with $\mathcal{V}$-Usable Information},
author = {Ethayarajh, Kawin and Choi, Yejin and Swayamdipta, Swabha},
booktitle = {Proceedings of the 39th International Conference on Machine Learning},
pages = {5988--6008},
year = {2022},
editor = {Chaudhuri, Kamalika and Jegelka, Stefanie and Song, Le and Szepesvari, Csaba and Niu, Gang and Sabato, Sivan},
volume = {162},
series = {Proceedings of Machine Learning Research},
month = {17--23 Jul},
publisher = {PMLR},
}
```
|
BuffetFS/BUFFET | ---
license: mit
---
# BUFFET: Benchmarking Large Language Models for Cross-lingual Few-shot Transfer
- Project page: [buffetfs.github.io/](https://buffetfs.github.io/) ([Paper](https://buffetfs.github.io/static/files/buffet_paper.pdf))
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
## Dataset Description
- **Homepage:** https://buffetfs.github.io/
- **Repository:** https://github.com/AkariAsai/BUFFET
- **Paper:** https://buffetfs.github.io/static/files/buffet_paper.pdf
- **Point of Contact:** akari@cs.washigton.edu
### Dataset Summary
<b>BUFFET</b> unifies 15 diverse NLP datasets in typologically diverse 54 languages. The list of the datasets is available below.
We are currently working on Dataset summary, and will update the descriptions shortly! |
emozilla/booksum-summary-analysis | ---
language: en
dataset_info:
features:
- name: chapter
dtype: string
- name: text
dtype: string
- name: type
dtype: string
splits:
- name: train
num_bytes: 215494460.97875556
num_examples: 11834
- name: test
num_bytes: 27122769.0
num_examples: 1658
- name: validation
num_bytes: 43846669.0
num_examples: 2234
download_size: 134838536
dataset_size: 286463898.9787556
---
# Dataset Card for "booksum-summary-analysis"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
winddude/reddit_finance_43_250k | ---
license: gpl-3.0
language:
- en
tags:
- finance
- investing
- crypto
- reddit
---
# reddit finance 43 250k
`reddit_finance_43_250k` is a collection of 250k post/comment pairs from 43 financial, investing and crypto subreddits. Post must have all been text, with a length of 250chars, and a positive score. Each subreddit is narrowed down to the 70th qunatile before being mergered with their top 3 comments and than the other subs. Further score based methods are used to select the top 250k post/comment pairs.
The code to recreate the dataset is here: <https://github.com/getorca/ProfitsBot_V0_OLLM/tree/main/ds_builder>
The trained lora model is here: <https://huggingface.co/winddude/pb_lora_7b_v0.1> |
ecnu-icalk/educhat-sft-002-data-osm | ---
license: cc-by-nc-4.0
---
每条数据由一个存放对话的list和与数据对应的system_prompt组成。list中按照Q,A顺序存放对话。
数据来源为开源数据,使用[CleanTool](https://github.com/icalk-nlp/EduChat/tree/main/clean_tool)数据清理工具去重。 |
Riyazmk/mentalhealth | ---
license: other
---
|
globis-university/aozorabunko-chats | ---
license: cc-by-4.0
task_categories:
- text-generation
- text-classification
language:
- ja
size_categories:
- 100K<n<1M
---
# Overview
This dataset is of conversations extracted from [Aozora Bunko (青空文庫)](https://www.aozora.gr.jp/), which collects public-domain books in Japan, using a simple heuristic approach.
[For Japanese] 日本語での概要説明を Qiita に記載しました: https://qiita.com/akeyhero/items/b53eae1c0bc4d54e321f
# Method
First, lines surrounded by quotation mark pairs (`「」`) are extracted as utterances from the `text` field of [globis-university/aozorabunko-clean](https://huggingface.co/datasets/globis-university/aozorabunko-clean).
Then, consecutive utterances are collected and grouped together.
The code to reproduce this dataset is made available on GitHub: [globis-org/aozorabunko-exctractor](https://github.com/globis-org/aozorabunko-extractor).
# Notice
As the conversations are extracted using a simple heuristic, a certain amount of the data may actually be monologues.
# Tips
If you prefer to employ only modern Japanese, you can filter entries with: `row["meta"]["文字遣い種別"] == "新字新仮名"`.
# Example
```py
>>> from datasets import load_dataset
>>> ds = load_dataset('globis-university/aozorabunko-chats')
>>> ds
DatasetDict({
train: Dataset({
features: ['chats', 'footnote', 'meta'],
num_rows: 5531
})
})
>>> ds = ds.filter(lambda row: row['meta']['文字遣い種別'] == '新字新仮名') # only modern Japanese
>>> ds
DatasetDict({
train: Dataset({
features: ['chats', 'footnote', 'meta'],
num_rows: 4139
})
})
>>> book = ds['train'][0] # one of the works
>>> book['meta']['作品名']
'スリーピー・ホローの伝説'
>>> chats = book['chats'] # list of the chats in the work; type: list[list[str]]
>>> len(chats)
1
>>> chat = chats[0] # one of the chats; type: list[str]
>>> for utterance in chat:
... print(utterance)
...
人生においては、たとえどんな場合でも必ず利点や愉快なことがあるはずです。もっともそれは、わたくしどもが冗談をすなおに受けとればのことですが
そこで、悪魔の騎士と競走することになった人は、とかくめちゃくちゃに走るのも当然です
したがって、田舎の学校の先生がオランダ人の世継ぎ娘に結婚を拒まれるということは、彼にとっては、世の中で栄進出世にいたるたしかな一歩だということになります
```
# License
CC BY 4.0 |
katielink/healthsearchqa | ---
license: unknown
task_categories:
- question-answering
language:
- en
tags:
- medical
configs:
- config_name: all_data
data_files: all.csv
- config_name: 140_question_subset
data_files: multimedqa140_subset.csv
size_categories:
- 1K<n<10K
---
# HealthSearchQA
Dataset of consumer health questions released by Google for the Med-PaLM paper ([arXiv preprint](https://arxiv.org/abs/2212.13138)).
From the [paper](https://www.nature.com/articles/s41586-023-06291-2):
We curated our own additional dataset consisting of 3,173 commonly searched consumer questions,
referred to as HealthSearchQA. The dataset was curated using seed medical conditions and their
associated symptoms. We used the seed data to retrieve publicly-available commonly searched questions
generated by a search engine, which were displayed to all users entering the seed terms. We publish the
dataset as an open benchmark for answering medical questions from consumers and hope this will be a useful
resource for the community, as a dataset reflecting real-world consumer concerns.
**Format:** Question only, free text response, open domain.
**Size:** 3,173.
**Example question:** How serious is atrial fibrillation?
**Example question:** What kind of cough comes with Covid?
**Example question:** Is blood in phlegm serious? |
knowrohit07/know_medical_dialogue_v2 | ---
license: openrail
---
### Description:
The knowrohit07/know_medical_dialogues_v2 dataset is a collection of conversational exchanges between patients and doctors on various medical topics. It aims to capture the intricacies, uncertainties, and questions posed by individuals regarding their health and the medical guidance provided in response.
### 🎯 Intended Use:
This dataset is crafted for training Large Language Models (LLMs) with a focus on understanding and generating medically-informed dialogue. It's ideal for LLM applications aiming to provide medical information or insights, especially for scenarios with limited access to healthcare resources.
❗ Limitations:
While this dataset includes diverse interactions, it doesn't cover every medical scenario. Models trained on this data should be viewed as an additional resource, not a substitute for professional medical consultation.
📌 Data Source:
Conversational seed tasks or exchanges were collected from anonymized patient-doctor interactions and synthetically made using GPT4.
📋 Collection Methodology:
The data was meticulously curated to ensure no personally identifiable information remained. All conversations are representative of general concerns and advice, without specific case details.
### Advantages of the Dataset:
Broad Spectrum: The dataset encompasses a wide array of medical queries and advice, making it valuable for general medical conversational AI.
Diverse Interactions: It captures everything from symptom queries to post-care instructions.
Training Potential for LLMs: Specifically tailored for fine-tuning LLMs for medical conversations, enhancing the resultant model's capability in this domain.
⚖️ Ethical and Impact Considerations:
Positive Impact: Utilizing LLMs trained on this dataset can be invaluable for healthcare professionals, especially in regions with limited medical datasets. When deployed on affordable local devices, doctors can leverage an AI-assisted tool, enhancing their consultation and decision-making processes.
Potential Risks: There's an inherent risk of the model providing guidance that may not match the latest medical guidelines or specific patient requirements. It's crucial to clarify to users that outputs from the LLM should complement professional medical opinions.
Recommendation: Encourage healthcare professionals to use this tool as an initial point of reference and not as the primary foundation for medical decisions.
|
OsamaBsher/AITA-Reddit-Dataset | ---
task_categories:
- text-generation
- text-classification
size_categories:
- 100K<n<1M
---
# Dataset Card for AITA Reddit Posts and Comments
Posts of the AITA subreddit, with the 2 top voted comments that share the post verdict. Extracted using REDDIT PushShift (from 2013 to April 2023)
## Dataset Details
The dataset contains 270,709 entiries each of which contain the post title, text, verdict, comment1, comment2 and score (number of upvotes)
For more details see paper: https://arxiv.org/abs/2310.18336
### Dataset Sources
The Reddit PushShift data dumps are part of a data collection effort which crawls Reddit at regular intervals, to extract and keep all its data.
## Dataset Card Authors
@OsamaBsher and Ameer Sabri
## Dataset Card Contact
@OsamaBsher |
bzb2023/Zhihu-KOL-More-Than-100-Upvotes | ---
license: apache-2.0
task_categories:
- text-generation
language:
- zh
---
对 https://huggingface.co/datasets/wangrui6/Zhihu-KOL 数据进行了初步整理,保留了100赞及以上的数据。
共271261条。 |
Syed-Hasan-8503/StackOverflow-TP4-1M | ---
task_categories:
- question-answering
language:
- en
tags:
- code
pretty_name: StackOverflow-TP4-1M
size_categories:
- 1M<n<10M
---
## Dataset Details
### Dataset Description
TP4 is a comprehensive dataset containing a curated collection of questions and answers from Stack Overflow. Focused on the realms of Python programming, NumPy, Pandas, TensorFlow, and PyTorch, TP4 includes essential attributes such as question ID, title, question body, answer body, associated tags, and score. This dataset is designed to facilitate research, analysis, and exploration of inquiries and solutions within the Python and machine learning communities on Stack Overflow.
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
-Question ID: Unique identifiers for each question, facilitating easy referencing and linkage.
-Title: Concise titles summarizing the essence of each question.
-Question and Answer Bodies: Rich textual content providing detailed context and solutions.
-Tags: Categorization labels such as 'python', 'numpy', 'pandas', 'tensorflow', and 'pytorch' for efficient filtering.
-Score: Numerical representation of the community's evaluation of the question or answer.
## Dataset Card Authors
SYED HASAN ABBAS
|
jp1924/AudioCaps | ---
dataset_info:
features:
- name: audiocap_id
dtype: int32
- name: youtube_id
dtype: string
- name: start_time
dtype: int32
- name: audio
dtype:
audio:
sampling_rate: 48000
- name: caption
dtype: string
splits:
- name: train
num_bytes: 2012866216147.6
num_examples: 45087
- name: validation
num_bytes: 94570191869
num_examples: 2230
- name: test
num_bytes: 187871958256.0
num_examples: 4400
download_size: 431887334157
dataset_size: 282442150125.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
|
revanth7667/usa_opioid_overdose | ---
license: mit
language:
- en
pretty_name: USA Opioid Overdose
size_categories:
- 10K<n<100K
dataset_info:
features:
- name: State
dtype: string
- name: State_Code
dtype: string
- name: County
dtype: string
- name: County_Code
dtype: string
- name: Year
dtype: int64
- name: Population
dtype: int64
- name: Deaths
dtype: int64
- name: Original
dtype: bool
- name: State_Mortality_Rate
dtype: float
- name: County_Mortality_Rate
dtype: float
---
## Overview
This dataset contains the number of yearly deaths due to **Unintentional** Drug Overdoses in the United States at a County Level between 2003-2015. To overcome the limitation of the original dataset, it is merged with population dataset to identify missing combinations and imputation is performed on the dataset taking into account the logical rules of the source dataset. Users can decide the proportion of the imputed values in the dataset by using the provided population and flag columns. Additional fields like state codes, FIPS codes are provided for the convenience of the user so that the dataset can be merged easily with other datasets.
## Data Structure
The dataset contains the following fields:
1. State (string): Name of the State
2. State_Code (string): 2 Character abbreviation of the state
3. County (string): Name of the County
4. County_Code (string): 5 Charter representation of the County’s FIPS code
5. Year (integer): Year
6. Population (integer): Population of the County for the given year
6. Deaths (integer): number of Drug overdose deaths in the county for the given year
7. Original (Boolean): To indicate if the Deaths are from original dataset or imputed
8. State_Mortality_Rate (float): Mortality rate of the state for the given year
9. County_Mortality_Rate (float): Mortality rate of the county for the given year
Notes:
1. County FIPS has been formatted as a string so that leading zeros are not lost and it is easier for the user to read it
2. The County_Mortality_Rate which is provided for convenience is calculated after the imputation of the missing values, hence it might not be accurate for all the combinations, refer the "Original" column to identify the imputed values.
## Data Source
1. Deaths Data: The original source of the data is the US Vital Statistics Agency [Link](https://www.cdc.gov/nchs/products/vsus.htm), however, for this project, it has been downloaded from a different [source](https://www.dropbox.com/s/kad4dwebr88l3ud/US_VitalStatistics.zip?dl=0) for convenience.
2. Population Data: To have consistency with the Mortality Data, the population Data has been downloaded from the [CDC Wonder](https://wonder.cdc.gov/bridged-race-v2020.html) portal. Population data is used for 2 purposes: to calculate the mortality rate and as a master list of Counties to perform the Imputation
3. Other Data: To provide convenience to the users of the Dataset, additional fields such as County Fips, State Codes etc. have been added so that users can easily combine it with other datasets if required. This mapping is a standard mapping which can be found on the internet.
The raw data files are present in the ``.01_Data/01_Raw`` folder for reference.
## Methodology
To study the impact of drug related deaths, one of the primary sources is the US Vital Statistics Agency. There is a limitation in the report since US Vital Statistics does not report the deaths in a county if the number of deaths in that county is less than 10 for privacy reasons. This means that the deaths available in the report are not fully representative of the deaths and hence any analysis performed on it may not be fully accurate. To overcome this, in this dataset, values are imputed for the missing counties based on State level mortality rates and population limiting factors. While this may not be 100% representative, it gives a slightly different and better approach to perform analysis on the drug related deaths.
Post the basic data cleaning and merging, the imputation is performed in the following steps:
1. Mortality Rate is calculated at the State-Year level using the available data
2. Master combination of State-County is obtained from Population file
3. For the missing counties a reverse calculation is performed using the state level mortality rate and the population of the county. A maximum calculated limit of 9 is imposed to preserve the conditions of the original data set.
4. Flag column is added to indicate if the values seen are original values or imputed ones
Since the original trend of the dataset may distort due to the imputations, the population data is left in the dataset and an additional column is added to the dataset to indicate if the values seen are from the original dataset or if they were imputed. Using the population and the flag column, the users of the dataset can decide the proportion of the imputed data in the analysis (This is the population limit factor).
The below graph shows the relation between the population limit factor and the % of imputed values in the dataset:

## Files and Folder Structure
1. Data Files: The raw data files are present in the [.01_Data/01_Raw](./.01_Data/01_Raw) folder for reference. The intermediate Population and Mortality files are present in the [.01_Data/02_Processed](./.01_Data/02_Processed) folder. The final dataset is present in the root folder.
The Data folder is hidden so that the raw and itermediate files are not loaded by the library.
2. Code Files: The code files are present in the [02_Code](./02_Code) folder.
- The "*_eda.ipynb" files are the exploratory files which the user can refer to understand the processing of the data in a step by step manner.
- The "*_script.py" files are the optimized scripts which contain only the required steps from the eda files to process the data.
provided the raw data files are present in the ``.01_Data/01_Raw`` folder, all the other intermediate and final data files can be generated using the script files provided in the ``02_Code`` folder.
## Disclaimers
1. This dataset has been created purely for educational purposes. The imputations performed is one of the many ways to handle the missing data, please consider the % of imputed data in the dataset before performing any analysis.
2. The Dataset does NOT contain data for Alaska since the original data for it is messsy, users can however make use of the raw files and modify the scripts if required to include Alaska
3. Only 1 type of drug related deaths is present in the dataset, refer to the master_eda file for details
4. Please refer to the original source of the data (links provided in the data source section) for any legal or privacy concerns. |
HuggingFaceTB/openhermes_filtered | ---
dataset_info:
features:
- name: category
dtype: string
- name: source
dtype: string
- name: prompt
dtype: string
splits:
- name: train
num_bytes: 1026332050
num_examples: 732509
download_size: 557491441
dataset_size: 1026332050
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
language:
- en
tags:
- synthetic
---
## OpenHermes 2.5 filtered
Thsi is a filtered version of [OpenHermes 2.5](https://huggingface.co/datasets/teknium/OpenHermes-2.5) dataset, we filtered out non-English instructions and subsets that would be the least suitable for generationg stories from.
```python
drop_sources = ["camelai", "glaive-code-assist"]
drop_categories = ["coding", "wordgame", "riddle", "rp", "gtkm"]
``` |
crumb/askmistral-pile-2-15 | ---
dataset_info:
features:
- name: text
dtype: string
- name: pos
dtype: float64
splits:
- name: train
num_bytes: 15630985803
num_examples: 2340370
download_size: 9219666690
dataset_size: 15630985803
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
Mean score~: -5.37444
```
{
"text": "Once upon a time...",
"pos": -5.37444
}
```
roughly 3.98 billion tokens depending on your tokenizer |
ajibawa-2023/WikiHow | ---
license: apache-2.0
task_categories:
- text-generation
- question-answering
- text2text-generation
language:
- en
size_categories:
- 100K<n<1M
---
**WikiHow**
A large corpus of WikiHow having more than 175000 entries. It is very useful for edutional training purpose.
Data is in Json format. |
divyasharma0795/AppleVisionPro_Tweets | ---
license: mit
task_categories:
- text-classification
- translation
language:
- en
tags:
- Sentiment Analysis
- Tweets
- Product Performance Analysis
pretty_name: Apple Vision Pro Tweets
size_categories:
- 10K<n<100K
---
# Apple Vision Pro Tweets Dataset
## Overview
The Apple Vision Pro Tweets Dataset is a collection of tweets related to Apple Vision Pro from January 01 2024 to March 16 2024, scraped from [X](https://twitter.com/home) using the Twitter [API](https://developer.twitter.com/en/products/twitter-api). The dataset includes various attributes associated with each tweet, such as the tweet text, author information, engagement metrics, and metadata.
## Content
- *id*: Unique identifier for each tweet.
- *tweetText*: The text content of the tweet.
- *tweetURL*: URL link to the tweet.
- *type*: Type of tweet (e.g., original tweet, retweet).
- *tweetAuthor*: Name of the tweet author.
- *handle*: Twitter handle of the tweet author.
- *replyCount*: Number of replies to the tweet.
- *quoteCount*: Number of quotes (retweets with comments) of the tweet.
- *retweetCount*: Number of retweets of the tweet.
- *likeCount*: Number of likes (favorites) of the tweet.
- *views*: Number of views of the tweet (if available).
- *bookmarkCount*: Number of bookmarks (if available) of the tweet.
- *createdAt*: Timestamp indicating when the tweet was created.
## Dataset Format
The dataset is provided in `parquet` format. Each row represents a single tweet, and columns contain various attributes associated with the tweet.
## Dataset Size
The dataset contains a total of 26,704 tweets related to Apple Vision Pro, with 13 features
## Data Collection
The tweets were collected using the Twitter API by searching for
- the hashtag *#AppleVisionPro*
- Search term *Apple Vision Pro*
The data collection process involved retrieving tweets that match the search criteria and extracting relevant information such as the tweet text, handle, engagement metrics, and metadata.
## Data Usage
The data can be imported directly from HuggingFace using the following code:
```py
from datasets import load_dataset
dataset = load_dataset("divyasharma0795/AppleVisionPro_Tweets")
```
## Potential Use Cases
- *Sentiment analysis*: Analyze the sentiment expressed in tweets related to Apple Vision Pro.
- *User engagement analysis*: Study user engagement metrics (replies, retweets, likes) to understand audience interaction with Apple Vision Pro content.
- *Trend analysis*: Identify trends and patterns in discussions surrounding Apple Vision Pro on Twitter.
- *New Product Market Sentiment*: Study the sentiments related to a popular tech product before and after launch.
## Citation
If you use this dataset in your research or project, please cite it as follows:
```css
AppleVisionPro_Tweets, Apple Vision Pro Tweets Dataset, 2024. Retrieved from huggingface.co/datasets/divyasharma0795/AppleVisionPro_Tweets
```
## License
The dataset is provided under the [MIT License]. Please refer to the LICENSE file for more details.
## Contact
For any inquiries or feedback regarding the dataset, please contact divya.sharma@duke.edu. |
yuiseki/scp-jp-plain | ---
dataset_info:
features:
- name: id
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 10202611
num_examples: 999
download_size: 5333180
dataset_size: 10202611
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: cc-by-sa-3.0
--- |
somosnlp/recetasdelaabuela_it | ---
license: openrail
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 18728921.868359473
num_examples: 18514
download_size: 10026323
dataset_size: 18728921.868359473
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
task_categories:
- question-answering
language:
- es
tags:
- food
size_categories:
- 10K<n<100K
---
# Nombre del dataset
Este dataset se llama 'RecetasDeLaAbuel@' y es un homenaje a todas nuestr@s abuel@s que nos han enseñado a cocinar. Se trata de la mayor y más completa colección de recetas open-source en español de países hispanoamericanos.
# Descripción
Dataset creado on el objetivo de entrenar un modelo que pueda recomendar recetas de paises hispanohablantes. Nuestra IA responderá a cuestiones de los sigientes tipos: 'Qué puedo cocinar con 3 ingredientes?', 'Dime una comida de temporada para este mes de Marzo?' , 'Sugiere un menú semanal vegetariano', 'Propón un menú mensual para una familia'
Este dataset es una version limpia del dataset [somosnlp/recetasdelaabuela_genstruct_it](https://huggingface.co/datasets/somosnlp/recetasdelaabuela_genstruct_it) que fue elaborado a partir de un contexto usando Genstruct-7B y distilabel. El dataset original es [somosnlp/RecetasDeLaAbuela](https://huggingface.co/datasets/somosnlp/RecetasDeLaAbuela) elaborado por el equipo recetasdelaabuela mediante web scraping.
## Notebook utilizada
Elaborado con el [colab](https://colab.research.google.com/drive/1-7OY5ORmOw0Uy_uazXDDqjWWkwCKvWbL?usp=sharing).
## Dataset Structure
Consiste en dos columnas: question , answer
- question: pregunta del usuario
- anwer: respuesta brindada por el modelo
## Dataset Creation
Este trabajo se ha basado y es continuación del trabajo desarrollado en el siguiente corpus durante el Hackhaton somosnlp 2023: [recetas-cocina](https://huggingface.co/datasets/somosnlp/recetas-cocina)
### Curation Rationale
Se filtaron aquellas respuestas que estaban vacias de momento, a futuro se planea reemplazarlas usando la herramienta argilla
### Source Data
- https://www.elmueble.com/
- https://www.yanuq.com/
- https://www.directoalpaladar.com/
- https://www.recetasgratis.net/
- https://cookpad.com/pe/
#### Data Collection and Processing
Se realizo web scraping de las paginas |
VanessaSchenkel/translation-en-pt | ---
annotations_creators:
- found
language:
- en
- pt
language_creators:
- found
license:
- afl-3.0
multilinguality:
- translation
pretty_name: VanessaSchenkel/translation-en-pt
size_categories:
- 100K<n<1M
source_datasets:
- original
tags: []
task_categories:
- translation
task_ids: []
---
How to use it:
```
from datasets import load_dataset
remote_dataset = load_dataset("VanessaSchenkel/translation-en-pt", field="data")
remote_dataset
```
Output:
```
DatasetDict({
train: Dataset({
features: ['id', 'translation'],
num_rows: 260482
})
})
```
Exemple:
```
remote_dataset["train"][5]
```
Output:
```
{'id': '5',
'translation': {'english': 'I have to go to sleep.',
'portuguese': 'Tenho de dormir.'}}
``` |
Bingsu/namuwiki_20210301_filtered | ---
annotations_creators:
- no-annotation
language_creators:
- crowdsourced
language:
- ko
license:
- cc-by-nc-sa-2.0
multilinguality:
- monolingual
pretty_name: Namuwiki database dump (2021-03-01)
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- fill-mask
- text-generation
task_ids:
- masked-language-modeling
- language-modeling
---
# Namuwiki database dump (2021-03-01)
## Dataset Description
- **Homepage:** [나무위키:데이터베이스 덤프](https://namu.wiki/w/%EB%82%98%EB%AC%B4%EC%9C%84%ED%82%A4:%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4%20%EB%8D%A4%ED%94%84)
- **Repository:** [Needs More Information]
- **Paper:** [Needs More Information]
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [Needs More Information]
## Namuwiki
https://namu.wiki/
It is a Korean wiki based on the seed engine, established on April 17, 2015 (KST).
## About dataset
All data from Namuwiki collected on 2021-03-01. I filtered data without text(mostly redirecting documents).
You can download the original data converted to csv in [Kaggle](https://www.kaggle.com/datasets/brainer3220/namu-wiki).
## 2022-03-01 dataset
[heegyu/namuwiki](https://huggingface.co/datasets/heegyu/namuwiki)<br>
[heegyu/namuwiki-extracted](https://huggingface.co/datasets/heegyu/namuwiki-extracted)<br>
[heegyu/namuwiki-sentences](https://huggingface.co/datasets/heegyu/namuwiki-sentences)
### Lisence
[CC BY-NC-SA 2.0 KR](https://creativecommons.org/licenses/by-nc-sa/2.0/kr/)
## Data Structure
### Data Instance
```pycon
>>> from datasets import load_dataset
>>> dataset = load_dataset("Bingsu/namuwiki_20210301_filtered")
>>> dataset
DatasetDict({
train: Dataset({
features: ['title', 'text'],
num_rows: 571308
})
})
```
```pycon
>>> dataset["train"].features
{'title': Value(dtype='string', id=None),
'text': Value(dtype='string', id=None)}
```
### Data Size
download: 3.26 GiB<br>
generated: 3.73 GiB<br>
total: 6.99 GiB
### Data Field
- title: `string`
- text: `string`
### Data Splits
| | train |
| ---------- | ------ |
| # of texts | 571308 |
```pycon
>>> dataset["train"][2323]
{'title': '55번 지방도',
'text': '55번 국가지원지방도\n해남 ~ 금산\n시점 전라남도 해남군 북평면 남창교차로\n종점 충청남도 금산군 금산읍 우체국사거리\n총 구간 279.2km\n경유지 전라남도 강진군, 장흥군, 영암군 전라남도 나주시, 화순군 광주광역시 동구, 북구 전라남도 담양군 전라북도 순창군, 정읍시, 완주군 전라북도 임실군, 진안군\n개요\n국가지원지방도 제55호선은 전라남도 해남군에서 출발하여 충청남도 금산군까지 이어지는 대한민국의 국가지원지방도이다.\n전라남도 해남군 북평면 - 전라남도 강진군 도암면 구간은 광주광역시, 전라남도 동부권, 영남 지방에서 완도군 완도읍으로 갈 때 주로 이용된다.] 해남 - 완도구간이 확장되기 전에는 그랬다. 강진군, 장흥군은 예외]\n노선\n전라남도\n해남군\n백도로\n북평면 남창교차로에서 13번 국도, 77번 국도와 만나며 출발한다.\n쇄노재\n북일면 북일초교 앞에서 827번 지방도와 만난다.\n강진군\n백도로\n도암면소재지 사거리에서 819번 지방도와 만난다. 819번 지방도는 망호선착장까지만 길이 있으며, 뱃길을 통해 간접적으로 바다 건너의 819번 지방도와 연결된다.\n석문공원\n도암면 계라교차로에서 18번 국도에 합류한다. 우회전하자. 이후 강진읍까지 18번 국도와 중첩되고 장흥군 장흥읍까지 2번 국도와 중첩된다. 그리고 장흥읍부터 영암군을 거쳐 나주시 세지면까지는 23번 국도와 중첩된다.\n나주시\n동창로\n세지면 세지교차로에서 드디어 23번 국도로부터 분기하면서 820번 지방도와 직결 합류한다. 이 길은 2013년 현재 확장 공사 중이다. 확장공사가 완료되면 동창로가 55번 지방도 노선이 된다.\n세남로\n봉황면 덕림리 삼거리에서 820번 지방도와 분기한다.\n봉황면 철천리 삼거리에서 818번 지방도와 합류한다.\n봉황면 송현리 삼거리에서 818번 지방도와 분기한다.\n송림산제길\n동창로\n여기부터 완공된 왕복 4차로 길이다. 이 길을 만들면서 교통량이 늘어났지만 주변 농민들이 이용하는 농로의 교량을 설치하지 않아 문제가 생기기도 했다. #1 #2\n세남로\n남평읍에서 다시 왕복 2차로로 줄어든다.\n남평읍 남평오거리에서 822번 지방도와 만난다.\n산남로\n남평교를 건너고 남평교사거리에서 우회전\n동촌로\n남평역\n화순군\n동촌로\n화순읍 앵남리 삼거리에서 817번 지방도와 합류한다. 좌회전하자.\n앵남역\n지강로\n화순읍 앵남리 앵남교차로에서 817번 지방도와 분기한다. 앵남교차로부터 나주 남평읍까지 55번 지방도의 확장공사가 진행중이다.\n오성로\n여기부터 화순읍 대리사거리까지 왕복 4차선으로 확장 공사를 진행했고, 2015년 8월 말 화순읍 구간은 왕복 4차선으로 확장되었다.\n화순역\n화순읍에서 광주광역시 동구까지 22번 국도와 중첩되고, 동구부터 전라북도 순창군 쌍치면까지는 29번 국도와 중첩된다.\n전라북도\n순창군\n청정로\n29번 국도를 따라가다가 쌍치면 쌍길매삼거리에서 우회전하여 21번 국도로 들어가자. 쌍치면 쌍치사거리에서 21번 국도와 헤어진다. 직진하자.\n정읍시\n청정로\n산내면 산내사거리에서 715번 지방도와 직결하면서 30번 국도에 합류한다. 좌회전하여 구절재를 넘자.\n산외로\n칠보면 시산교차로에서 49번 지방도와 교차되면 우회전하여 49번 지방도와 합류한다. 이제 오랜 시간 동안 49번 지방도와 합류하게 될 것이다.\n산외면 산외교차로에서 715번 지방도와 교차한다.\n엄재터널\n완주군\n산외로\n구이면 상용교차로에서 27번 국도에 합류한다. 좌회전하자.\n구이로\n구이면 백여교차로에서 27번 국도로부터 분기된다.\n구이면 대덕삼거리에서 714번 지방도와 만난다.\n구이면 염암삼거리에서 우회전\n신덕평로\n고개가 있다. 완주군과 임실군의 경계이다.\n임실군\n신덕평로\n신덕면 외량삼거리, 삼길삼거리에서 749번 지방도와 만난다.\n야트막한 고개가 하나 있다.\n신평면 원천리 원천교차로에서 745번 지방도와 교차한다.\n신평면 관촌역 앞에서 17번 국도와 합류한다. 좌회전하자.\n관진로\n관촌면 병암삼거리에서 17번 국도로부터 분기된다.\n순천완주고속도로와 교차되나 연결되지 않는다.\n진안군\n관진로\n성수면 좌산리에서 721번 지방도와 만난다.\n성수면 좌산리 좌산삼거리에서 721번 지방도와 만난다.\n마령면 강정교차로 부근에서 745번 지방도와 만난다.\n익산포항고속도로와 교차되나 연결되지 않는다.\n진안읍 진안연장농공단지 앞에서 26번 국도에 합류한다. 좌회전하자.\n전진로\n부귀면 부귀교차로에서 드디어 49번 지방도를 떠나보낸다. 그러나 아직 26번 국도와 중첩된다.\n완주군\n동상로\n드디어 55번이라는 노선 번호가 눈에 보이기 시작한다. 완주군 소양면에서 26번 국도와 분기된다. 이제부터 꼬불꼬불한 산길이므로 각오하고 운전하자.\n밤치. 소양면과 동상면의 경계가 되는 고개다.\n동상면 신월삼거리에서 732번 지방도와 만난다. 동상저수지에 빠지지 않도록 주의하자.\n동상주천로\n운장산고개를 올라가야 한다. 완주군과 진안군의 경계다. 고개 정상에 휴게소가 있다.\n진안군\n동상주천로\n주천면 주천삼거리에서 725번 지방도와 만난다.\n충청남도\n금산군\n보석사로\n남이면 흑암삼거리에서 635번 지방도와 만난다. 우회전해야 한다. 네이버 지도에는 좌회전해서 좀더 가면 나오는 길을 55번 지방도라고 써놓았는데, 잘못 나온 거다. 다음 지도에는 올바르게 나와있다.\n십이폭포로\n남이면에서 남일면으로 넘어간다.\n남일면에서 13번 국도와 합류한다. 좌회전하자. 이후 구간은 남이면을 거쳐 금산읍까지 13번 국도와 중첩되면서 55번 지방도 구간은 종료된다.'}
```
|
sled-umich/Conversation-Entailment | ---
annotations_creators:
- expert-generated
language:
- en
language_creators:
- crowdsourced
license: []
multilinguality:
- monolingual
pretty_name: Conversation-Entailment
size_categories:
- n<1K
source_datasets:
- original
tags:
- conversational
- entailment
task_categories:
- conversational
- text-classification
task_ids: []
---
# Conversation-Entailment
Official dataset for [Towards Conversation Entailment: An Empirical Investigation](https://sled.eecs.umich.edu/publication/dblp-confemnlp-zhang-c-10/). *Chen Zhang, Joyce Chai*. EMNLP, 2010
## Overview
Textual entailment has mainly focused on inference from written text in monologue. Recent years also observed an increasing amount of conversational data such as conversation scripts of meetings, call center records, court proceedings, as well as online chatting. Although conversation is a form of language, it is different from monologue text with several unique characteristics. The key distinctive features include turn-taking between participants, grounding between participants, different linguistic phenomena of utterances, and conversation implicatures. Traditional approaches dealing with textual entailment were not designed to handle these unique conversation behaviors and thus to support automated entailment from conversation scripts. This project intends to address this limitation.
### Download
```python
from datasets import load_dataset
dataset = load_dataset("sled-umich/Conversation-Entailment")
```
* [HuggingFace-Dataset](https://huggingface.co/datasets/sled-umich/Conversation-Entailment)
* [DropBox](https://www.dropbox.com/s/z5vchgzvzxv75es/conversation_entailment.tar?dl=0)
### Data Sample
```json
{
"id": 3,
"type": "fact",
"dialog_num_list": [
30,
31
],
"dialog_speaker_list": [
"B",
"A"
],
"dialog_text_list": [
"Have you seen SLEEPING WITH THE ENEMY?",
"No. I've heard, I've heard that's really great, though."
],
"h": "SpeakerA and SpeakerB have seen SLEEPING WITH THE ENEMY",
"entailment": false,
"dialog_source": "SW2010"
}
```
### Cite
[Towards Conversation Entailment: An Empirical Investigation](https://sled.eecs.umich.edu/publication/dblp-confemnlp-zhang-c-10/). *Chen Zhang, Joyce Chai*. EMNLP, 2010. [[Paper]](https://aclanthology.org/D10-1074/)
```tex
@inproceedings{zhang-chai-2010-towards,
title = "Towards Conversation Entailment: An Empirical Investigation",
author = "Zhang, Chen and
Chai, Joyce",
booktitle = "Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing",
month = oct,
year = "2010",
address = "Cambridge, MA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/D10-1074",
pages = "756--766",
}
``` |
maderix/flickr_bw_rgb | ---
license: cc-by-nc-sa-4.0
annotations_creators:
- machine-generated
language:
- en
language_creators:
- other
multilinguality:
- monolingual
pretty_name: 'flickr_bw_rgb'
size_categories:
- n<1K
source_datasets:
- N/A
tags: []
task_categories:
- text-to-image
task_ids: []
---
# Dataset Card for Flickr_bw_rgb
_Dataset A image-caption dataset which stores group of black and white and color images with corresponding
captions mentioning the content of the image with a 'colorized photograph of' or 'Black and white photograph of' suffix.
This dataset can then be used for fine-tuning image to text models.. Only a train split is provided.
## Examples
"train/<filename>.jpg" : containing the images in JPEG format
"train/metadata.jsonl" : Contains the metadata and the fields.
Dataset columns:
"file_name"
"caption"
## Citation
If you use this dataset, please cite it as:
```
@misc{maderix2022flickrbwrgb,
author = {maderix: maderix@gmail.com},
title = {flickr_bw_rgb},
year={2022},
howpublished= {\url{https://huggingface.co/datasets/maderix/flickr_bw_rgb/}}
}
``` |
navjordj/VG_summarization | ---
task_categories:
- summarization
- text2text-generation
language:
- 'no'
- nb
size_categories:
- 100K<n<1M
dataset_info:
features:
- name: title
dtype: string
- name: url
dtype: string
- name: published
dtype: string
- name: classes
dtype: string
- name: article
dtype: string
- name: ingress
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 482362411.09144986
num_examples: 157038
- name: validation
num_bytes: 36309721.60567524
num_examples: 11821
- name: test
num_bytes: 57632967.30287493
num_examples: 18763
download_size: 364433583
dataset_size: 576305100.0
---
# VG Summarization Dataset
The source of this dataset is Norsk Aviskorpus (Norwegian newspaper corpus). This corpus includes articles from Norway’s largest newspaper from 1998 to 2019. In this dataset, we used
the first paragraph (lead) of each article as its summary. This dataset only includes articles from the Norwegian newspaper "VG".
The quality of the summary-article pairs has not been evaluated.
# License
Please refer to the license of Norsk Aviskorpus
# Citation
If you are using this dataset in your work, please cite our master thesis which this dataset was a part of
```
@mastersthesis{navjord2023beyond,
title={Beyond extractive: advancing abstractive automatic text summarization in Norwegian with transformers},
author={Navjord, J{\o}rgen Johnsen and Korsvik, Jon-Mikkel Ryen},
year={2023},
school={Norwegian University of Life Sciences, {\AA}s}
}
``` |
Den4ikAI/russian_instructions | ---
license: mit
task_categories:
- conversational
language:
- ru
size_categories:
- 10K<n<100K
---
Новая версия: https://huggingface.co/datasets/Den4ikAI/russian_instructions_2
Русский датасет инструкций и QA.
Структура датасета:
```
{
"dialogue":[
"Как я могу улучшить свою связь между телом и разумом?",
"Начните с разработки регулярной практики осознанности. 2. Обязательно практикуйте баланс на нескольких уровнях: физическом, эмоциональном, умственном и духовном. 3. Свяжитесь с природой, когда это возможно - идите на прогулки или бегайте на улице, или просто сидите в парке и наблюдайте природу вокруг вас. 4. Развивайте позитивные утверждения, которые вы можете использовать, чтобы помочь поддерживать оптимизм и сильные отношения с вашим телом.",
"Больше пожалуйста",
"Конечно, вот еще несколько: 5. Включите здоровую диету цельных продуктов и много воды, которая питает ваш ум и тело. 6. Научитесь быть в гармонии с вашим телом, замечая изменения в том, как вы себя чувствуете, и уделите время, чтобы оценить и решить любые возникающие потребности."
],
"rounds":[
1,
2
],
"uuid":"53e8d08b-1f45-4ef4-b6d8-3a04758cafd8"
}
```
### Citation:
```
@MISC{russian_instructions,
author = {Denis Petrov},
title = {Russian instructions dataset for conversational agents},
url = {https://huggingface.co/datasets/Den4ikAI/russian_instructions},
year = 2023
}
``` |
bmd1905/error-correction-vi | ---
license: apache-2.0
language:
- vi
--- |
orkg/SciQA | ---
annotations_creators:
- expert-generated
- auto-generated
language:
- en
language_creators:
- machine-generated
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: 'The SciQA Scientific Question Answering Benchmark for Scholarly Knowledge'
size_categories:
- 1K<n<10K
source_datasets:
- original
tags:
- knowledge-base-qa
task_categories:
- question-answering
task_ids: []
---
# Dataset Card for SciQA
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [SciQA Homepage]()
- **Repository:** [SciQA Repository](https://zenodo.org/record/7744048)
- **Paper:** The SciQA Scientific Question Answering Benchmark for Scholarly Knowledge
- **Point of Contact:** [Yaser Jaradeh](mailto:Yaser.Jaradeh@tib.eu)
### Dataset Summary
SciQA contains 2,565 SPARQL query - question pairs along with answers fetched from the open research knowledge graph (ORKG) via a Virtuoso SPARQL endpoint, it is a collection of both handcrafted and autogenerated questions and queries. The dataset is split into 70% training, 10% validation and 20% test examples.
## Dataset Structure
### Data Instances
An example of a question is given below:
```json
{
"id": "AQ2251",
"query_type": "Factoid",
"question": {
"string": "Provide a list of papers that have utilized the Depth DDPPO model and include the links to their code?"
},
"paraphrased_question": [],
"query": {
"sparql": "SELECT DISTINCT ?code\nWHERE {\n ?model a orkgc:Model;\n rdfs:label ?model_lbl.\n FILTER (str(?model_lbl) = \"Depth DDPPO\")\n ?benchmark orkgp:HAS_DATASET ?dataset.\n ?cont orkgp:HAS_BENCHMARK ?benchmark.\n ?cont orkgp:HAS_MODEL ?model;\n orkgp:HAS_SOURCE_CODE ?code.\n}"
},
"template_id": "T07",
"auto_generated": true,
"query_shape": "Tree",
"query_class": "WHICH-WHAT",
"number_of_patterns": 4,
}
```
### Data Fields
- `id`: the id of the question
- `question`: a string containing the question
- `paraphrased_question`: a set of paraphrased versions of the question
- `query`: a SPARQL query that answers the question
- `query_type`: the type of the query
- `query_template`: an optional template of the query
- `query_shape`: a string indicating the shape of the query
- `query_class`: a string indicating the class of the query
- `auto_generated`: a boolean indicating whether the question is auto-generated or not
- `number_of_patterns`: an integer number indicating the number of gtaph patterns in the query
### Data Splits
The dataset is split into 70% training, 10% validation and 20% test questions.
## Additional Information
### Licensing Information
SciQA is licensed under the [Creative Commons Attribution 4.0 International License (CC BY 4.0)](https://creativecommons.org/licenses/by/4.0/).
### Citation Information
```bibtex
@Article{SciQA2023,
author={Auer, S{\"o}ren
and Barone, Dante A. C.
and Bartz, Cassiano
and Cortes, Eduardo G.
and Jaradeh, Mohamad Yaser
and Karras, Oliver
and Koubarakis, Manolis
and Mouromtsev, Dmitry
and Pliukhin, Dmitrii
and Radyush, Daniil
and Shilin, Ivan
and Stocker, Markus
and Tsalapati, Eleni},
title={The SciQA Scientific Question Answering Benchmark for Scholarly Knowledge},
journal={Scientific Reports},
year={2023},
month={May},
day={04},
volume={13},
number={1},
pages={7240},
abstract={Knowledge graphs have gained increasing popularity in the last decade in science and technology. However, knowledge graphs are currently relatively simple to moderate semantic structures that are mainly a collection of factual statements. Question answering (QA) benchmarks and systems were so far mainly geared towards encyclopedic knowledge graphs such as DBpedia and Wikidata. We present SciQA a scientific QA benchmark for scholarly knowledge. The benchmark leverages the Open Research Knowledge Graph (ORKG) which includes almost 170,000 resources describing research contributions of almost 15,000 scholarly articles from 709 research fields. Following a bottom-up methodology, we first manually developed a set of 100 complex questions that can be answered using this knowledge graph. Furthermore, we devised eight question templates with which we automatically generated further 2465 questions, that can also be answered with the ORKG. The questions cover a range of research fields and question types and are translated into corresponding SPARQL queries over the ORKG. Based on two preliminary evaluations, we show that the resulting SciQA benchmark represents a challenging task for next-generation QA systems. This task is part of the open competitions at the 22nd International Semantic Web Conference 2023 as the Scholarly Question Answering over Linked Data (QALD) Challenge.},
issn={2045-2322},
doi={10.1038/s41598-023-33607-z},
url={https://doi.org/10.1038/s41598-023-33607-z}
}
```
### Contributions
Thanks to [@YaserJaradeh](https://github.com/YaserJaradeh) for adding this dataset. |
kz-transformers/multidomain-kazakh-dataset | ---
license:
- apache-2.0
annotations_creators:
- no-annotation
language_creators:
- found
language:
- kk
- ru
multilinguality:
- multilingual
source_datasets:
- original
task_categories:
- text-generation
- fill-mask
pretty_name: MDBKD | Multi-Domain Bilingual Kazakh Dataset
---
# Dataset Description
**Point of Contact:** [Sanzhar Murzakhmetov](mailto:sanzharmrz@gmail.com), [Besultan Sagyndyk](mailto:nuxyjlbka@gmail.com)
### Dataset Summary
MDBKD | Multi-Domain Bilingual Kazakh Dataset is a Kazakh-language dataset containing just over 24 883 808 unique texts from multiple domains.
### Supported Tasks
- 'MLM/CLM': can be used to train a model for casual and masked languange modeling
### Languages
The kk code for Kazakh as generally spoken in the Kazakhstan
### Data Instances
For each instance, there is a string for the text and a string for the id.
```python
{'text': 'Алматыда баспана қымбаттап жатыр Қазақстанда пәтер бағасы түсті Жыл басынан бері баспана бағасы 6,2%-ға қымбаттады Мегополистегі пәтер бағасына шолу. Алматыда пандемия басталғалы баспана қымбаттап барады. Мұның себебі нарықтағы сұраныстың көбеюімен және теңгенің құнсыздануымен байланысты, деп хабарлайды Atameken Business. Арна тілшісі Жания Әбдібек нарық өкілдерімен сұхбаттасып, мегополистегі пәтер бағасына шолу жасады. Толығырақ: Мамыр айында Қазақстанның жеті ірі қаласында пәтер бағасы түскен. Орта есеппен республика бойынша тұрғын үйдің 1 шаршы метрінің бағасы 292 мың 886 теңгені құрайды. '},
'predicted_language': 'kaz',
'contains_kaz_symbols': 1,
'id': '0752b3ce-f5ea-4330-9c5f-e4fecf783b00'}
```
### Data Fields
- `text`: a string containing the content body
- `predicted_language`: a string containing the predicted label of language for the text
- `contains_kaz_symbols`: an integer containing flag of any kazakh symbol in text
- `id`: a string which is a hexidecimal hash for text in split
### Data Splits
The MDBKD has 5 splits: [_cc100-monolingual-crawled-data_](https://data.statmt.org/cc-100/), _kazakhBooks_, [_leipzig_](https://wortschatz.uni-leipzig.de/en/download/Kazakh), [_oscar_](https://oscar-project.github.io/documentation/versions/oscar-2301/) and _kazakhNews_. Below are the statistics of the dataset:
| Dataset Split | Domain | Number of texts in Split | Number of tokens in Split | Number of unique tokens in Split | Median number of tokens in text |
| -------------------------------|----------------------|------------------------------| --------------------------|----------------------------------|---------------------------------|
| cc100-monolingual-crawled-data | Wikipedia articles | 19 635 580 | 441 623 321 | 6 217 337 | 12 |
| kazakhBooks | Books | 8 423 | 351 433 586 | 7 245 720 | 40 264 |
| leipzig | Articles/News | 1 706 485 | 26 494 864 | 1 109 113 | 14 |
| oscar | CommonCrawl | 269 047 | 230 314 378 | 3 863 498 | 431 |
| kazakhNews | News | 3 264 273 | 1 041 698 037 | 5 820 543 | 209 |
With overall stats:
| Stat | Value |
|-------------------------|--------------|
| Number of texts | 24 883 808 |
| Number of tokens |2 091 564 186 |
| Number of unique tokens | 17 802 998 |
Full dataset takes **25GB**
### Annotations
The dataset does not contain any additional annotations.
### Personal and Sensitive Information
Dataset is not anonymized, so individuals' names can be found in the dataset. Information about the original author is not included in the dataset.
### Social Impact of Dataset
The purpose of this dataset is to organize open-source datasets in Kazakh language for further research and commercial uses
### Licensing Information
The Multi-Domain Bilingual kazakh dataset version 1.0.0 is released under the [Apache-2.0 License](http://www.apache.org/licenses/LICENSE-2.0).
### Contributions
Thanks to [@KindYAK](https://github.com/KindYAK), [@BeksultanSagyndyk](https://github.com/BeksultanSagyndyk), [@SanzharMrz](https://github.com/SanzharMrz) for adding this dataset.
--- |
darknoon/noto-emoji-vector-512-svg | ---
dataset_info:
features:
- name: image
dtype: image
- name: codepoints
sequence: int64
- name: name
dtype: string
- name: text
dtype: string
- name: svg_path
dtype: string
- name: svg_text
dtype: string
splits:
- name: train
num_bytes: 90176885.81
num_examples: 2329
download_size: 74032133
dataset_size: 90176885.81
---
# Dataset Card for "noto-emoji-vector-512-svg"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
nicholasKluge/instruct-aira-dataset | ---
language:
- pt
- en
- es
license: apache-2.0
size_categories:
- 10K<n<100K
task_categories:
- conversational
- text-generation
pretty_name: Instruct-Aira Dataset
tags:
- alignment
- instruction
- chat
dataset_info:
features:
- name: prompt
dtype: string
- name: completion
dtype: string
splits:
- name: portuguese
num_bytes: 52023662
num_examples: 40945
- name: english
num_bytes: 47254561
num_examples: 41762
- name: spanish
num_bytes: 53176782
num_examples: 40946
download_size: 85078532
dataset_size: 152455005
configs:
- config_name: default
data_files:
- split: portuguese
path: data/portuguese-*
- split: english
path: data/english-*
- split: spanish
path: data/spanish-*
---
# Instruct-Aira Dataset
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** https://github.com/Nkluge-correa/Aira
- **Point of Contact:** [AIRES at PUCRS](nicholas@airespucrs.org)
### Dataset Summary
This dataset contains a collection of prompts and responses to those prompts. All completions were generated by querying already-tuned models (ChatGPT, LLama 2, Open-Assistant, etc.). The dataset is available in Portuguese, English, and Spanish.
### Supported Tasks and Leaderboards
This dataset can be utilized for various natural language processing tasks, including but not limited to:
- Language modeling.
- Question-answering systems.
- Chatbot development.
- Evaluation of language models.
- Alignment research.
### Languages
English, Portuguese, and Spanish.
## Dataset Structure
### Data Instances
The dataset consists of the following features:
- **Prompt:** The initial text or question provided to the model (type `str`).
- **Completion:** A generated completion to the given prompt (type `str`).
All `prompt + completion` examples are less than 400 tokens (measured using the `GPT-2` and `BLOOM` tokenizers).
### Data Fields
```python
{
"prompt":"What is the capital of Brazil?",
"completion": "The capital of Brazil is Brasília."
}
```
### Data Splits
Available splits are `english`, `portuguese`, and `spanish`.
```python
from datasets import load_dataset
dataset = load_dataset("nicholasKluge/instruct-aira-dataset", split='portuguese')
```
## Dataset Creation
### Curation Rationale
This dataset was developed are part of [Nicholas Kluge's](https://nkluge-correa.github.io/) doctoral dissertation, "_Dynamic Normativity: Necessary and Sufficient Conditions for Value Alignment._" This research was funded by CNPq (Fundação de Amparo à Pesquisa do Estado do Rio Grande do Sul), FAPERGS (Fundação de Amparo à Pesquisa do Estado do Rio Grande do Sul), and DAAD (Deutscher Akademischer Austauschdienst), as part of a doctoral research project tied to Philosophy departments of PUCRS (Pontifícia Universidade Católica do Rio Grande do Sul) and the University of Bonn.
### Source Data
#### Initial Data Collection and Normalization
All completions were generated by querying already-tuned models (ChatGPT, LLama 2, Open-Assistant, etc.). Prompts were gathered from publicly available datasets.
#### Who are the source language producers?
All completions were generated by querying already-tuned models (ChatGPT, LLama 2, Open-Assistant, etc.). Prompts were gathered from publicly available datasets.
### Annotations
#### Annotation process
All completions were generated by querying already-tuned models (ChatGPT, LLama 2, Open-Assistant, etc.). Prompts were gathered from publicly available datasets.
#### Who are the annotators?
No annotators were used.
### Personal and Sensitive Information
No personal or sensitive information is part of this dataset.
## Considerations for Using the Data
### Social Impact of Dataset
No considerations.
### Discussion of Biases
No considerations.
### Other Known Limitations
No considerations.
## Additional Information
### Dataset Curators
[Nicholas Kluge Corrêa](mailto:nicholas@airespucrs.org).
### Licensing Information
This dataset is licensed under the [Apache License, version 2.0](LICENSE).
### Citation Information
```latex
@misc{nicholas22aira,
doi = {10.5281/zenodo.6989727},
url = {https://github.com/Nkluge-correa/Aira},
author = {Nicholas Kluge Corrêa},
title = {Aira},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
}
```
### Contributions
If you would like to contribute, contact me at [nicholas@airespucrs.org](mailto:nicholas@airespucrs.org)!
|
Bin12345/HPC_Fortran_CPP | ---
license: mit
---
|
jinaai/negation-dataset |
---
tags:
- finetuner
language: en
license: apache-2.0
dataset_info:
features:
- name: anchor
dtype: string
- name: entailment
dtype: string
- name: negative
dtype: string
splits:
- name: train
num_examples: 10000
- name: test
num_examples: 500
download_size: 1467517
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
---
<br><br>
<p align="center">
<img src="https://github.com/jina-ai/finetuner/blob/main/docs/_static/finetuner-logo-ani.svg?raw=true" alt="Finetuner logo: Finetuner helps you to create experiments in order to improve embeddings on search tasks. It accompanies you to deliver the last mile of performance-tuning for neural search applications." width="150px">
</p>
<p align="center">
<b>The data offered by Jina AI, Finetuner team.</b>
</p>
## Summary
This dataset is an English-language dataset based on the [SNLI](https://huggingface.co/datasets/snli) dataset.
It contains negations of samples from SNLI.
## Instances
Each data point consists of a triplet ('anchor', 'entailment', 'negative') of strings, where ('anchor', 'entailment') are positive pairs
taken from SNLI, and 'negative' contradicts both 'anchor' and 'entailment'.
## Fields
- 'anchor': string, some statement
- 'entailment': string, a statement which follows from 'anchor', but is usually syntactically dissimilar
- 'negative': string, a statement contradicting 'anchor' and 'entailment'. Syntactically very similar to 'entailment'
## Splits
| | train | test |
|------------|-------|------|
| # of items | 10000 | 500 |
## Source
Positive pairs were sampled from the [SNLI](https://huggingface.co/datasets/snli) dataset and negative samples were created using GPT-3.5
and GPT-4.
## Example Usage
```python
from datasets import load_dataset
from pprint import pprint
dataset = load_dataset('jinaai/negation-dataset')
pprint(dataset['train'][:5])
```
Output:
```python
{'anchor': ['Two young girls are playing outside in a non-urban environment.',
'A man with a red shirt is watching another man who is standing on '
'top of a attached cart filled to the top.',
'A man in a blue shirt driving a Segway type vehicle.',
'A woman holds her mouth wide open as she is placing a stack of '
'crackers in.',
'A group of people standing on a rock path.'],
'entailment': ['Two girls are playing outside.',
'A man is standing on top of a cart.',
'A person is riding a motorized vehicle.',
'There is a woman eating crackers.',
'A group of people are hiking.'],
'negative': ['Two girls are not playing outside.',
'A man is not standing on top of a cart.',
'A person is not riding a motorized vehicle.',
'There is no woman eating crackers.',
'A group of people are not hiking.']}
```
## Models
[Jina AI's](https://jina.ai) open source embedding models ([small](https://huggingface.co/jinaai/jina-embedding-s-en-v1),
[base](https://huggingface.co/jinaai/jina-embedding-b-en-v1) and
[large](https://huggingface.co/jinaai/jina-embedding-l-en-v1)) were all fine-tuned on the negation dataset.
## Licensing Information
This work is licensed under the Apache License, Version 2.0.
## Contributors
Thanks to contributors from [Jina AI](https://jina.ai) for adding this dataset.
## Contact
Join our [Discord community](https://discord.jina.ai) and chat with other community members about ideas.
## Citation
If you find this dataset useful in your research, please cite the following paper:
``` latex
@misc{günther2023jina,
title={Jina Embeddings: A Novel Set of High-Performance Sentence Embedding Models},
author={Michael Günther and Louis Milliken and Jonathan Geuter and Georgios Mastrapas and Bo Wang and Han Xiao},
year={2023},
eprint={2307.11224},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
|
ljvmiranda921/tlunified-ner | ---
license: gpl-3.0
task_categories:
- token-classification
task_ids:
- named-entity-recognition
language:
- tl
size_categories:
- 1K<n<10K
pretty_name: TLUnified-NER
tags:
- low-resource
- named-entity-recognition
annotations_creators:
- expert-generated
multilinguality:
- monolingual
train-eval-index:
- config: conllpp
task: token-classification
task_id: entity_extraction
splits:
train_split: train
eval_split: test
col_mapping:
tokens: tokens
ner_tags: tags
metrics:
- type: seqeval
name: seqeval
---
<!-- SPACY PROJECT: AUTO-GENERATED DOCS START (do not remove) -->
# 🪐 spaCy Project: TLUnified-NER Corpus
- **Homepage:** [Github](https://github.com/ljvmiranda921/calamanCy)
- **Repository:** [Github](https://github.com/ljvmiranda921/calamanCy)
- **Point of Contact:** ljvmiranda@gmail.com
### Dataset Summary
This dataset contains the annotated TLUnified corpora from Cruz and Cheng
(2021). It is a curated sample of around 7,000 documents for the
named entity recognition (NER) task. The majority of the corpus are news
reports in Tagalog, resembling the domain of the original ConLL 2003. There
are three entity types: Person (PER), Organization (ORG), and Location (LOC).
| Dataset | Examples | PER | ORG | LOC |
|-------------|----------|------|------|------|
| Train | 6252 | 6418 | 3121 | 3296 |
| Development | 782 | 793 | 392 | 409 |
| Test | 782 | 818 | 423 | 438 |
### Data Fields
The data fields are the same among all splits:
- `id`: a `string` feature
- `tokens`: a `list` of `string` features.
- `ner_tags`: a `list` of classification labels, with possible values including `O` (0), `B-PER` (1), `I-PER` (2), `B-ORG` (3), `I-ORG` (4), `B-LOC` (5), `I-LOC` (6)
### Annotation process
The author, together with two more annotators, labeled curated portions of
TLUnified in the course of four months. All annotators are native speakers of
Tagalog. For each annotation round, the annotators resolved disagreements,
updated the annotation guidelines, and corrected past annotations. They
followed the process prescribed by [Reiters
(2017)](https://nilsreiter.de/blog/2017/howto-annotation).
They also measured the inter-annotator agreement (IAA) by computing pairwise
comparisons and averaging the results:
- Cohen's Kappa (all tokens): 0.81
- Cohen's Kappa (annotated tokens only): 0.65
- F1-score: 0.91
### About this repository
This repository is a [spaCy project](https://spacy.io/usage/projects) for
converting the annotated spaCy files into IOB. The process goes like this: we
download the raw corpus from Google Cloud Storage (GCS), convert the spaCy
files into a readable IOB format, and parse that using our loading script
(i.e., `tlunified-ner.py`). We're also shipping the IOB file so that it's
easier to access.
## 📋 project.yml
The [`project.yml`](project.yml) defines the data assets required by the
project, as well as the available commands and workflows. For details, see the
[spaCy projects documentation](https://spacy.io/usage/projects).
### ⏯ Commands
The following commands are defined by the project. They
can be executed using [`spacy project run [name]`](https://spacy.io/api/cli#project-run).
Commands are only re-run if their inputs have changed.
| Command | Description |
| --- | --- |
| `setup-data` | Prepare the Tagalog corpora used for training various spaCy components |
| `upload-to-hf` | Upload dataset to HuggingFace Hub |
### ⏭ Workflows
The following workflows are defined by the project. They
can be executed using [`spacy project run [name]`](https://spacy.io/api/cli#project-run)
and will run the specified commands in order. Commands are only re-run if their
inputs have changed.
| Workflow | Steps |
| --- | --- |
| `all` | `setup-data` → `upload-to-hf` |
### 🗂 Assets
The following assets are defined by the project. They can
be fetched by running [`spacy project assets`](https://spacy.io/api/cli#project-assets)
in the project directory.
| File | Source | Description |
| --- | --- | --- |
| `assets/corpus.tar.gz` | URL | Annotated TLUnified corpora in spaCy format with train, dev, and test splits. |
<!-- SPACY PROJECT: AUTO-GENERATED DOCS END (do not remove) -->
### Citation
You can cite this dataset as:
```
@misc{miranda2023developing,
title={Developing a Named Entity Recognition Dataset for Tagalog},
author={Lester James V. Miranda},
year={2023},
eprint={2311.07161},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
litmonster0521/pencildrawing | ---
license: openrail
---
|
Xilabs/PIPPA-alpaca | ---
language:
- en
size_categories:
- 10K<n<100K
task_categories:
- text-generation
configs:
- config_name: default
data_files:
- split: smol_pippa_named_users
path: data/smol_pippa_named_users-*
- split: smol_pippa
path: data/smol_pippa-*
dataset_info:
features:
- name: input
dtype: string
- name: instruction
dtype: string
- name: output
dtype: string
splits:
- name: smol_pippa_named_users
num_bytes: 77441911
num_examples: 38199
- name: smol_pippa
num_bytes: 68511557
num_examples: 38232
download_size: 64841938
dataset_size: 145953468
tags:
- not-for-all-audiences
- alpaca
- conversational
- roleplay
---
# Dataset Card for "Pippa-alpaca"
This dataset is derived from the PIPPA dataset, and uses the alpaca format.
[PIPPA - Personal Interaction Pairs between People and AI](https://huggingface.co/datasets/PygmalionAI/PIPPA) |
ProgramComputer/voxceleb | ---
task_categories:
- automatic-speech-recognition
- audio-classification
- image-classification
- video-classification
size_categories:
- 100K<n<1M
license: cc-by-4.0
datasets:
- voxceleb
- voxceleb2
---
## Dataset Description
- **Homepage:** [VoxCeleb](https://www.robots.ox.ac.uk/~vgg/data/voxceleb/)
This dataset includes both VoxCeleb and VoxCeleb2
# Multipart Zips
Already joined zips for convenience but these specified files are *NOT* part of the original datasets
vox2_mp4_1.zip - vox2_mp4_6.zip
vox2_aac_1.zip - vox2_aac_2.zip
# Joining Zip
```
cat vox1_dev* > vox1_dev_wav.zip
```
```
cat vox2_dev_aac* > vox2_aac.zip
```
```
cat vox2_dev_mp4* > vox2_mp4.zip
```
### Citation Information
```
@article{Nagrani19,
author = "Arsha Nagrani and Joon~Son Chung and Weidi Xie and Andrew Zisserman",
title = "Voxceleb: Large-scale speaker verification in the wild",
journal = "Computer Science and Language",
year = "2019",
publisher = "Elsevier",
}
@inProceedings{Chung18b,
author = "Chung, J.~S. and Nagrani, A. and Zisserman, A.",
title = "VoxCeleb2: Deep Speaker Recognition",
booktitle = "INTERSPEECH",
year = "2018",
}
@article{DBLP:journals/corr/NagraniCZ17,
author = {Arsha Nagrani and
Joon Son Chung and
Andrew Zisserman},
title = {VoxCeleb: a large-scale speaker identification dataset},
journal = {CoRR},
volume = {abs/1706.08612},
year = {2017},
url = {http://arxiv.org/abs/1706.08612},
eprinttype = {arXiv},
eprint = {1706.08612},
timestamp = {Mon, 13 Aug 2018 16:47:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/NagraniCZ17.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
### Contributions
Thanks to [@ProgramComputer](https://github.com/ProgramComputer) for adding this dataset. |
open-llm-leaderboard/details_garage-bAInd__Platypus2-70B-instruct | ---
pretty_name: Evaluation run of garage-bAInd/Platypus2-70B-instruct
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [garage-bAInd/Platypus2-70B-instruct](https://huggingface.co/garage-bAInd/Platypus2-70B-instruct)\
\ on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 3 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the aggregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_garage-bAInd__Platypus2-70B-instruct_public\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-11-09T00:36:31.182871](https://huggingface.co/datasets/open-llm-leaderboard/details_garage-bAInd__Platypus2-70B-instruct_public/blob/main/results_2023-11-09T00-36-31.182871.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.4080327181208054,\n\
\ \"em_stderr\": 0.0050331050783076585,\n \"f1\": 0.5241086409395995,\n\
\ \"f1_stderr\": 0.004559323839567607,\n \"acc\": 0.616380530322115,\n\
\ \"acc_stderr\": 0.012075906712216984\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.4080327181208054,\n \"em_stderr\": 0.0050331050783076585,\n\
\ \"f1\": 0.5241086409395995,\n \"f1_stderr\": 0.004559323839567607\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.40561031084154664,\n \
\ \"acc_stderr\": 0.013524848894462104\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.8271507498026835,\n \"acc_stderr\": 0.010626964529971862\n\
\ }\n}\n```"
repo_url: https://huggingface.co/garage-bAInd/Platypus2-70B-instruct
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_drop_3
data_files:
- split: 2023_11_09T00_36_31.182871
path:
- '**/details_harness|drop|3_2023-11-09T00-36-31.182871.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-11-09T00-36-31.182871.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_11_09T00_36_31.182871
path:
- '**/details_harness|gsm8k|5_2023-11-09T00-36-31.182871.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-11-09T00-36-31.182871.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_11_09T00_36_31.182871
path:
- '**/details_harness|winogrande|5_2023-11-09T00-36-31.182871.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-11-09T00-36-31.182871.parquet'
- config_name: results
data_files:
- split: 2023_11_09T00_36_31.182871
path:
- results_2023-11-09T00-36-31.182871.parquet
- split: latest
path:
- results_2023-11-09T00-36-31.182871.parquet
---
# Dataset Card for Evaluation run of garage-bAInd/Platypus2-70B-instruct
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/garage-bAInd/Platypus2-70B-instruct
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [garage-bAInd/Platypus2-70B-instruct](https://huggingface.co/garage-bAInd/Platypus2-70B-instruct) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 3 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_garage-bAInd__Platypus2-70B-instruct_public",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-11-09T00:36:31.182871](https://huggingface.co/datasets/open-llm-leaderboard/details_garage-bAInd__Platypus2-70B-instruct_public/blob/main/results_2023-11-09T00-36-31.182871.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.4080327181208054,
"em_stderr": 0.0050331050783076585,
"f1": 0.5241086409395995,
"f1_stderr": 0.004559323839567607,
"acc": 0.616380530322115,
"acc_stderr": 0.012075906712216984
},
"harness|drop|3": {
"em": 0.4080327181208054,
"em_stderr": 0.0050331050783076585,
"f1": 0.5241086409395995,
"f1_stderr": 0.004559323839567607
},
"harness|gsm8k|5": {
"acc": 0.40561031084154664,
"acc_stderr": 0.013524848894462104
},
"harness|winogrande|5": {
"acc": 0.8271507498026835,
"acc_stderr": 0.010626964529971862
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
ticoAg/Chinese-medical-dialogue | ---
license: apache-2.0
raw csv: 356 MB
examples: 799743
---
# Note
process data from [Chinese-medical-dialogue-data](https://github.com/Toyhom/Chinese-medical-dialogue-data)
单轮医患对话
## raw data samples
|department|title|ask|answer|
|----------|-----|---|------|
|心血管科|高血压患者能吃党参吗?|我有高血压这两天女婿来的时候给我拿了些党参泡水喝,您好高血压可以吃党参吗?|高血压病人可以口服党参的。党参有降血脂,降血压的作用,可以彻底消除血液中的垃圾,从而对冠心病以及心血管疾病的患者都有一定的稳定预防工作作用,因此平时口服党参能远离三高的危害。另外党参除了益气养血,降低中枢神经作用,调整消化系统功能,健脾补肺的功能。感谢您的进行咨询,期望我的解释对你有所帮助。|
|内分泌科|糖尿病还会进行遗传吗?|糖尿病有隔代遗传吗?我妈是糖尿病,很多年了,也没养好,我现在也是,我妹子也是,我儿子现在二十岁,没什么问题,但是以后会不会也得糖尿病啊,真是难过,我现在就已经开始让他控制点吃东西。|2型糖尿病的隔代遗传概率为父母患糖尿病,临产的发生率为40%,比一般人患糖尿病,疾病,如何更重要的选择因素基于生活方式的,后天也隔代遗传隔代遗传易感性更公正,增强患糖尿病的风险,低糖低脂肪,平时清淡饮食,适当锻练,增强监测数据,血糖仪买个备取。|
|内分泌科|糖尿病会出现什么症状?|我是不是糖尿病,如何严重,糖尿病的典型症状有哪些?血糖高之后感觉什么东西都不能够吃了,有糖分的东西都不敢吃,怕血糖又高,不知晓是不是变严重了,糖尿病的症状有哪些?|你好,根据你描述的情况看来糖尿病是可以致使血糖异常下降的,可以再次出现三多一少的症状,如喝水多,小便多,饭量大,体重减轻,建议你尽快复诊当地医院内分泌科看一看,需要有让大夫仔细检查你的血糖水平,明确有否糖尿病的情况,及时动用降糖药治疗,平时一定少吃甜食,足量锻练。|
## processed data sample
```json
[
{"instruction":"title", "input":"ask", "output":"answer", "history":None},
]
``` |
Abhijeet3922/ESG-Prospectus-Clarity-Category | ---
license: cc-by-nc-sa-4.0
task_categories:
- text-classification
- zero-shot-classification
language:
- en
tags:
- finance
size_categories:
- 1K<n<10K
configs:
- config_name: esg-prospectus-clarity-category
data_files: "esg-prospectus-clarity-category.csv"
- config_name: esg-prospectus-clarity-granular-category
data_files: "esg-prospectus-clarity-granular-category.csv"
---
# Dataset Card for ESG-Prospectus-Clarity-Category
### Dataset Summary
This dataset is manually annotated quality training dataset of 1155 ESG language instances (4 classes), obtained via a data extraction pipeline from summary prospectuses of sustainable (ESG) funds.
The ESG sentences extracted from ‘Principal Investment Strategy’ sections of the documents. Following are the four classes.
1. Specific ESG Language
2. Ambiguous ESG Language
3. Generic ESG language
4. Risk ESG language
All the instances are related to ESG investment language present in prospectus of funds. Further all instances were annotated for language clarity classes.
### Supported Tasks and Leaderboards
Text Classification (Language style classification)
Few Shot Classification
### Languages
English
## Dataset Structure
### Data Instances
Total instances: 1155
classwise instances:
'Specific ESG': 320
'Ambiguous ESG': 283
'Generic ESG': 264
'Risk ESG': 288
### Data Fields
```
{ "Text": "The Sub-fund's weighted carbon footprint score is equal or better than that of the Custom Bloomberg Climate Transition Benchmark.",
"Label": "specific"
"Text": "The Sub-fund invests a minimum of 5% in green, social, sustainable, and/or sustainability-linked bonds.",
"Label": "specific"
"Text": "The Fund will seek to invest in companies with sustainable business models which have a strong consideration for ESG risks and opportunities.",
"Label": "ambiguous"
}
```
### Data Splits
There's no train/validation/test split.
However the dataset is available two level of categorizations:
`esg-prospectus-clarity-category.csv`: Number of classes: 4 ('specific', 'ambiguous', 'generic', 'risk')
`esg-prospectus-clarity-granular-category.csv`: Number of classes: 7 ('specific', 'ambiguous', 'generic', 'general-risk', 'performance-risk', 'data-risk', 'disclaimer-risk')
## Dataset Creation
### Source Data
#### Initial Data Collection and Normalization
The process begins with downloading the public ‘Summary Prospectuses’ from literature sections of the official websites of various Asset Management Companies (AMCs).
We collected approximately 250 sustainable products prospectuses.
#### Who are the source language producers?
The source data was written and published by various fund issuers (Asset Management Companies).
### Annotations
#### Annotation process
The dataset was divided into three subsets and each annotator was allocated 2 subset of sentences and was given few weeks to label the sentences.
Consequently, each of the 1155 instances was annotated by 2 annotators. We release standard dataset of sentences after 100% agreement.
#### Who are the annotators?
The open-sourced dataset was annotated by 3 people with adequate knowledge of ESG investing and were fluent in English with previous exposure of analyzing financial documents.
## Considerations for Using the Data
The dataset can be used to investigate the transparency in sustainability intention of language mentioned in ESG disclosures of sustainable funds.
### Discussion of Biases
The data instances might cover languages from certain fund issuers (not all). It was extracted from randomly chosen prospectuses from the collected corpus.
The dataset might be revised with broader coverage of prospectus language in future.
### Licensing Information
This work is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 Unported License. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc-sa/3.0/.
If you are interested in commercial use of the data, please contact the following author for an appropriate license:
- [Abhijeet Kumar](mailto:abhijeet.kumar@fmr.com)
### Citation Information
[More Information Needed]
### Contributions
Thanks to [Nazia Nafis](https://www.linkedin.com/in/nazianafis/) and [Mayank Singh](https://www.linkedin.com/in/mayank-singh-43761b155/) for contributing to the dataset creation process.
Any contribution or further research by the community are welcome. |
approximatelabs/tablib-v1-sample | ---
license: other
pretty_name: TabLib
size_categories:
- 1M<n<10M
extra_gated_prompt: >-
Access to this dataset is automatically granted once this form is completed.
Note that this access request is for the TabLib sample, not [the full TabLib dataset](https://huggingface.co/datasets/approximatelabs/tablib-v1-full).
extra_gated_fields:
I agree to abide by the license requirements of the data contained in TabLib: checkbox
---
[](https://discord.gg/kW9nBQErGe)
<img src="https://approximatelabs.com/tablib.png" width="800" />
# TabLib Sample
**NOTE**: This is a 0.1% sample of [the full TabLib dataset](https://huggingface.co/datasets/approximatelabs/tablib-v1-full).
TabLib is a minimally-preprocessed dataset of 627M tables (69 TiB) extracted from HTML, PDF, CSV, TSV, Excel, and SQLite files from GitHub and Common Crawl.
This includes 867B tokens of "context metadata": each table includes provenance information and table context such as filename, text before/after, HTML metadata, etc.
For more information, read the [paper](https://arxiv.org/abs/2310.07875) & [announcement blog](https://approximatelabs.com/blog/tablib).
# Dataset Details
## Sources
* **GitHub**: nearly all public GitHub repositories
* **Common Crawl**: the `CC-MAIN-2023-23` crawl
## Reading Tables
Tables are stored as serialized Arrow bytes in the `arrow_bytes` column. To read these, you will need to deserialize the bytes:
```python
import datasets
import pyarrow as pa
# load a single file of the dataset
ds = datasets.load_dataset(
'approximatelabs/tablib-v1-sample',
token='...',
)
df = ds['train'].to_pandas()
tables = [pa.RecordBatchStreamReader(b).read_all() for b in df['arrow_bytes']]
```
## Licensing
This dataset is intended for research use only.
For specific licensing information, refer to the license of the specific datum being used.
# Contact
If you have any questions, comments, or concerns about licensing, pii, etc. please contact using [this form](https://forms.gle/C74VTWP7L78QDVR67).
# Approximate Labs
TabLib is a project from Approximate Labs. Find us on [Twitter](https://twitter.com/approximatelabs), [Github](https://github.com/approximatelabs), [Linkedin](https://www.linkedin.com/company/approximate-labs), and [Discord](https://discord.gg/kW9nBQErGe).
# Citations
If you use TabLib for any of your research, please cite the TabLib paper:
```
@misc{eggert2023tablib,
title={TabLib: A Dataset of 627M Tables with Context},
author={Gus Eggert and Kevin Huo and Mike Biven and Justin Waugh},
year={2023},
eprint={2310.07875},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
migtissera/Synthia-v1.3 | ---
license: apache-2.0
---
|
pszemraj/midjourney-messages-cleaned | ---
language:
- en
license: apache-2.0
source_datasets: vivym/midjourney-messages
task_categories:
- text-generation
dataset_info:
- config_name: deduped
features:
- name: id
dtype: string
- name: channel_id
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 2538669745.0
num_examples: 14828769
download_size: 1585207687
dataset_size: 2538669745.0
- config_name: default
features:
- name: id
dtype: string
- name: channel_id
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 3575844717.3610477
num_examples: 19716685
download_size: 1514418407
dataset_size: 3575844717.3610477
configs:
- config_name: deduped
data_files:
- split: train
path: deduped/train-*
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- midjourney
---
# midjourney-messages-cleaned
This is [vivym/midjourney-messages](https://huggingface.co/datasets/vivym/midjourney-messages) but with the following cleaning steps:
- remove most columns (keep `id` columns for reference vs. original)
- Apply `clean-text` to all rows (_keep casing_)
- rename `content` to `text` (ffs)
- remove intermediate ID/tag (???) in angle brackets at the end, remove double asterisks `**`
- remove exact duplicate rows
## dataset structure
overall:
```python
DatasetDict({
train: Dataset({
features: ['id', 'channel_id', 'text'],
num_rows: 19738964
})
})
```
A single example looks like this:
```python
random.choice(dataset['train'])
{'id': '1108635049391308879',
'channel_id': '1008571088919343124',
'text': 'Warhammer 40k Chaos Space Marine with pink Armor and a guitar'}
```
## details
585M GPT-4 tiktoken tokens.
```
token_count
count 1.971668e+07
mean 2.971651e+01
std 3.875208e+01
min 1.000000e+00
25% 1.000000e+01
50% 1.900000e+01
75% 3.400000e+01
max 2.077000e+03
```
|
m-a-p/MusicPile | ---
language:
- en
license: cc
size_categories:
- 100M<n<1B
task_categories:
- text-generation
dataset_info:
features:
- name: id
dtype: int64
- name: text
dtype: string
- name: src
dtype: string
splits:
- name: train
num_bytes: 13588597055
num_examples: 5188802
download_size: 7800945420
dataset_size: 13588597055
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- music
---
[**🌐 DemoPage**](https://ezmonyi.github.io/ChatMusician/) | [**🤗SFT Dataset**](https://huggingface.co/datasets/m-a-p/MusicPile-sft) | [**🤗 Benchmark**](https://huggingface.co/datasets/m-a-p/MusicTheoryBench) | [**📖 arXiv**](http://arxiv.org/abs/2402.16153) | [💻 **Code**](https://github.com/hf-lin/ChatMusician) | [**🤖 Chat Model**](https://huggingface.co/m-a-p/ChatMusician) | [**🤖 Base Model**](https://huggingface.co/m-a-p/ChatMusician-Base)
# Dataset Card for MusicPile
*MusicPile* is the first pretraining corpus for **developing musical abilities** in large language models.
It has **5.17M** samples and approximately **4.16B** tokens, including web-crawled corpora, encyclopedias, music books, youtube music captions, musical pieces in abc notation, math content, and code.
You can easily load it:
```python
from datasets import load_dataset
ds = load_dataset("m-a-p/MusicPile")
```
## Dataset Details
### Dataset Description
*MusicPile* was built on top of open-source datasets and high-quality data handcrafted by members of [MAP](https://m-a-p.ai/).
Its sources are as follows:
| Datasets | Sourced from | Tokens | # Samples | Category | Format |
| --- | --- | --- | --- | --- | --- |
| [pile](https://pile.eleuther.ai/) | public dataset | 0.83B | 18K | general | article |
| [Falcon-RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) | public dataset | 0.80B | 101K | general | article |
| [Wikipedia](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) | public dataset | 0.39B | 588K | general | article |
| [OpenChat](https://huggingface.co/datasets/openchat/openchat_sharegpt4_dataset/tree/main) | public dataset | 62.44M | 43K | general | chat |
| [LinkSoul](https://huggingface.co/datasets/LinkSoul/instruction_merge_set) | public dataset | 0.6B | 1.5M | general | chat |
| [GPT4-Alpaca](https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data.json) | public dataset | 9.77M | 49K | general | chat |
| [Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k) | public dataset | 3.12M | 14K | general | chat |
| [IrishMAN](https://huggingface.co/datasets/sander-wood/irishman) | public dataset + Human-written Instructions | 0.23B | 868K | music score | chat |
| [KernScores](http://kern.ccarh.org) | public dataset + Human-written Instructions | 2.76M | 10K | music score | chat |
| [JSB Chorales](https://github.com/sander-wood/deepchoir) | public dataset + Human-written Instructions | 0.44M | 349 | music score | chat |
| synthetic music chat* | public dataset + Human-written Instructions | 0.54B | 50K | music score | chat |
| music knowledge** | Generated with GPT-4 | 0.22B | 255K | music verbal | chat |
| music summary** | Generated with GPT-4 | 0.21B | 500K | music verbal | chat |
| [GSM8k](https://huggingface.co/datasets/gsm8k) | public dataset | 1.68M | 7K | math | chat |
| [math](https://huggingface.co/datasets/ArtifactAI/arxiv-math-instruct-50k) | public dataset | 7.03M | 37K | math | chat |
| [MathInstruct](https://huggingface.co/datasets/TIGER-Lab/MathInstruct) | public dataset | 55.50M | 188K | math | chat |
| [Camel-Math](https://huggingface.co/datasets/camel-ai/math) | public dataset | 27.76M | 50K | math | chat |
| [arxiv-math-instruct-50k](https://huggingface.co/datasets/ArtifactAI/arxiv-math-instruct-50k) | public dataset | 9.06M | 50K | math | chat |
| [Camel-Code](https://huggingface.co/datasets/camel-ai/code) | public dataset | 0.13B | 366K | code | chat |
| [OpenCoder](https://huggingface.co/datasets/openchat/openchat_sharegpt4_dataset/tree/main) | public dataset | 36.99M | 28K | code | chat |
| Total | - | 4.16B | 5.17M | - | - |
```
* means synthesis from music score data and general data.
** means with NEW rationales curated by us by prompting GPT-4.
chat format refers to style as `Human: {...} </s> Assistant: {...} </s> `
```
#### Language Corpora Curation
**General corpora.** Representative public datasets, including [pile](https://pile.eleuther.ai/), [Falcon-RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) and [Wikipedia](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) are used. To curate a musically relevant corpus, we list a set of musicrelated words as a criterion to filter Pile, based on [music terminologies](https://en.m.wikipedia.org/wiki/Glossary_of_music_terminology). We only include music terminology words that appear more than 10 times and account for over 0.5% of domain agreement.
**Instruction and chat data.** The instruction datasets [LinkSoul](https://huggingface.co/datasets/LinkSoul/instruction_merge_set), [GPT4-Alpaca](https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data.json) and [Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k) are diverse and representative enough to adapt the LLM to potential downstream
usage. To enable multiple rounds of conversations, chat corpora [OpenChat](https://huggingface.co/datasets/openchat/openchat_sharegpt4_dataset/tree/main) are included.
**Music knowledge and music summary.** We crawl the metadata corresponding to 2 million
music tracks from YouTube, including metadata such as song title, description, album, artist, lyrics,
playlist, etc. 500k of them are extracted. We generate summaries of these metadata using GPT-4. We generate music knowledge QA pairs following Self-instruct(https://arxiv.org/abs/2212.10560). According to our topic outline in [ChatMusician paper](http://arxiv.org/abs/2402.16153), 255k instructions are generated, with corresponding answers generated with GPT-4.
**Math and code data.** The computational music community lacks symbolic music datasets,and we hypothesize that including math and code may enhance the reasoning power of symbolic music. [GSM8k](https://huggingface.co/datasets/gsm8k), [MathInstruct](https://huggingface.co/datasets/TIGER-Lab/MathInstruct), [Camel-Math](https://huggingface.co/datasets/camel-ai/math), [arxiv-math-instruct-50k](https://huggingface.co/datasets/ArtifactAI/arxiv-math-instruct-50k), [Camel-Code](https://huggingface.co/datasets/camel-ai/code) and [OpenCoder](https://huggingface.co/datasets/openchat/openchat_sharegpt4_dataset/tree/main) are included. Empirically, we find this helps to improve the performance of music LLMs.
#### Music Score Corpora Curation
Although symbolic music datasets are scarce in the computational music community, we have made an effort to include music from various regions of the world. Our music scores showcase significant regional diversity. We designed a total of eight representative musical tasks on the collected corpora,including six for generating music scores and two for music understanding. The generative tasks involve generating music scores conditioned on the chord, melody, motifs, musical form, and style. The understanding tasks involve extracting motifs and forms from the user input scores. The process of curating music instructions and algorithms is described in detail in [ChatMusician paper](http://arxiv.org/abs/2402.16153).
Except for the general corpora,all the other datasets were constructed as conversation forms for one or more rounds.The percentage of musical verbal,code,music score,math,and general is 10.42%, 2.43%, 18.43%, 4.05%, and6 4.68%, respectively. The above table shows an overview of all data.
### Languages
*MusicPile* primarily contains English.
## Dataset Structure
*MusicPile* has 3 fields `id`, `text` and `src`. The amount of tokens of each text is no more than 2048(counted by LlamaTokenizer).
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{yuan2024chatmusician,
title={ChatMusician: Understanding and Generating Music Intrinsically with LLM},
author={Ruibin Yuan and Hanfeng Lin and Yi Wang and Zeyue Tian and Shangda Wu and Tianhao Shen and Ge Zhang and Yuhang Wu and Cong Liu and Ziya Zhou and Ziyang Ma and Liumeng Xue and Ziyu Wang and Qin Liu and Tianyu Zheng and Yizhi Li and Yinghao Ma and Yiming Liang and Xiaowei Chi and Ruibo Liu and Zili Wang and Pengfei Li and Jingcheng Wu and Chenghua Lin and Qifeng Liu and Tao Jiang and Wenhao Huang and Wenhu Chen and Emmanouil Benetos and Jie Fu and Gus Xia and Roger Dannenberg and Wei Xue and Shiyin Kang and Yike Guo},
year={2024},
eprint={2402.16153},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
```
## Dataset Card Contact
Authors of ChatMusician. |
isek-ai/danbooru-tags-2016-2023 | ---
language:
- en
license: cc0-1.0
size_categories:
- 1M<n<10M
task_categories:
- text-classification
- text-generation
- text2text-generation
dataset_info:
- config_name: all
features:
- name: id
dtype: int64
- name: copyright
dtype: string
- name: character
dtype: string
- name: artist
dtype: string
- name: general
dtype: string
- name: meta
dtype: string
- name: rating
dtype: string
- name: score
dtype: int64
- name: created_at
dtype: string
splits:
- name: train
num_bytes: 2507757369
num_examples: 4601557
download_size: 991454905
dataset_size: 2507757369
- config_name: safe
features:
- name: id
dtype: int64
- name: copyright
dtype: string
- name: character
dtype: string
- name: artist
dtype: string
- name: general
dtype: string
- name: meta
dtype: string
- name: rating
dtype: string
- name: score
dtype: int64
- name: created_at
dtype: string
splits:
- name: train
num_bytes: 646613535.5369519
num_examples: 1186490
download_size: 247085114
dataset_size: 646613535.5369519
configs:
- config_name: all
data_files:
- split: train
path: all/train-*
- config_name: safe
data_files:
- split: train
path: safe/train-*
tags:
- danbooru
---
# danbooru-tags-2016-2023
A dataset of danbooru tags.
## Dataset information
Generated using [danbooru](https://danbooru.donmai.us/) and [safebooru](https://safebooru.donmai.us/) API.
The dataset was created with the following conditions:
|Subset name|`all`|`safe`|
|-|-|-|
|API Endpoint|https://danbooru.donmai.us|https://safebooru.donmai.us|
|Date|`2016-01-01..2023-12-31`|`2016-01-01..2023-12-31`|
|Score|`>0`|`>0`|
|Rating|`g,s,q,e`|`g`|
|Filetype|`png,jpg,webp`|`png,jpg,webp`|
|Size (number of rows)|4,601,557|1,186,490|
## Usage
```
pip install datasets
```
```py
from datasets import load_dataset
dataset = load_dataset(
"isek-ai/danbooru-tags-2016-2023",
"safe", # or "all"
split="train",
)
print(dataset)
print(dataset[0])
# Dataset({
# features: ['id', 'copyright', 'character', 'artist', 'general', 'meta', 'rating', 'score', 'created_at'],
# num_rows: 1186490
# })
# {'id': 2229839, 'copyright': 'kara no kyoukai', 'character': 'ryougi shiki', 'artist': 'momoko (momopoco)', 'general': '1girl, 2016, :|, brown eyes, brown hair, closed mouth, cloud, cloudy sky, dated, day, flower, hair flower, hair ornament, japanese clothes, kimono, long hair, long sleeves, looking at viewer, new year, obi, outdoors, sash, shrine, sky, solo, standing, wide sleeves', 'meta': 'commentary request, partial commentary', 'rating': 'g', 'score': 76, 'created_at': '2016-01-01T00:43:18.369+09:00'}
``` |
toshi456/LLaVA-CC3M-Pretrain-595K-JA | ---
dataset_info:
features:
- name: id
dtype: string
- name: image
dtype: string
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 146361663
num_examples: 595375
download_size: 45579837
dataset_size: 146361663
license: other
task_categories:
- visual-question-answering
language:
- ja
pretty_name: 'Japanese LLaVA CC3M Pretrain 595K '
size_categories:
- 100K<n<1M
---
# Dataset Card for "LLaVA-CC3M-Pretrain-595K-JA"
## Dataset Details
**Dataset Type:**
Japanese LLaVA CC3M Pretrain 595K is a localized version of the original LLaVA Visual Instruct CC3M 595K dataset. This version is translated into Japanese using [cyberagent/calm2-7b-chat](https://huggingface.co/cyberagent/calm2-7b-chat) and is aimed at serving similar purposes in the context of Japanese language.
**Resources for More Information:**
For information on the original dataset: [liuhaotian/LLaVA-CC3M-Pretrain-595K](https://huggingface.co/datasets/liuhaotian/LLaVA-CC3M-Pretrain-595K)
**License:**
Must comply with license of [CC-3M](https://github.com/google-research-datasets/conceptual-captions/blob/master/LICENSE), [BLIP](https://github.com/salesforce/BLIP/blob/main/LICENSE.txt) (if you use their synthetic caption).
CC-3M The dataset may be freely used for any purpose, although acknowledgement of Google LLC ("Google") as the data source would be appreciated. The dataset is provided "AS IS" without any warranty, express or implied. Google disclaims all liability for any damages, direct or indirect, resulting from the use of the dataset.
**Questions or Comments:**
For questions or comments about the original model, you can go to [LLaVA GitHub Issues](https://github.com/haotian-liu/LLaVA/issues).
## Intended use
**Primary intended uses:** The primary use of LLaVA is research on large multimodal models and chatbots.
**Primary intended users:** The primary intended users of the model are researchers and hobbyists in computer vision, natural language processing, machine learning, and artificial intelligence. |
jimmycarter/textocr-gpt4v | ---
license: cc-by-nc-4.0
language:
- en
pretty_name: textocr-gpt4v
task_categories:
- image-to-text
- visual-question-answering
size_categories:
- 10K<n<100K
---
# Dataset Card for TextOCR-GPT4V
## Dataset Description
- **Point of Contact:** APJC (me)
### Dataset Summary
TextOCR-GPT4V is Meta's [TextOCR dataset](https://textvqa.org/textocr/) dataset captioned with emphasis on text OCR using GPT4V. To get the image, you will need to agree to their terms of service.
### Supported Tasks
The TextOCR-GPT4V dataset is intended for generating benchmarks for comparison of an MLLM to GPT4v.
### Languages
The caption languages are in English, while various texts in images are in many languages such as Spanish, Japanese, and Hindi.
### Original Prompts
The `caption` field was produced with the following prompt with the `gpt-4-vision-preview` model:
```
Can you please describe the contents of this image in the following way: (1) In one to two sentences at most under the heading entitled 'DESCRIPTION' (2) Transcribe any text found within the image and where it is located under the heading entitled 'TEXT'?\n\nFor example, you might describe a picture of a palm tree with a logo on it in the center that spells the word COCONUT as:\n\nDESCRIPTION\nA photograph of a palm tree on a beach somewhere, there is a blue sky in the background and it is a sunny day. There is a blue text logo with white outline in the center of the image.\n\nTEXT\nThe text logo in the center of the image says, \"COCONUT\".\n\nBe sure to describe all the text that is found in the image.
```
The `caption_condensed` field was produced with the following prompt using the `gpt-4-1106-preview` model:
```
Please make the following description of an image that may or may not have text into a single description of 120 words or less.
{caption}
Be terse and do not add extraneous details. Keep the description as a single, unbroken paragraph.
```
### Data Instances
An example of "train" looks as follows:
```json
{
"filename": "aabbccddeeff0011.jpg",
"caption": "DESCRIPTION\nA banana.\n\nTEXT\nThe banana has a sticker on it that says \"Fruit Company\".",
"caption_image": "A banana.",
"caption_text": "The banana has a sticker on it that says \"Fruit Company\".",
"caption_condensed": "A banana that has a sticker on it that says \"Fruit Company\".",
}
```
### Data Fields
The data fields are as follows:
* `filename`: The filename of the image from the original [TextOCR dataset](https://textvqa.org/textocr/).
* `caption`: A caption with both a `DESCRIPTION` and `TEXT` part.
* `caption_image`: The `DESCRIPTION` part of the caption.
* `caption_text`: The `TEXT` part of the caption.
* `caption_condensed`: GPT4 distilled version of the original caption onto a single line.
### Data Splits
| | train |
|---------------|------:|
| textocr-gpt4v | 25114 |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
The `textocr-gpt4v` data is generated by a vision-language model (`gpt-4-vision-preview`) and inevitably contains some errors or biases. We encourage users to use this data with caution and propose new methods to filter or improve the imperfections.
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
The dataset is available under the [Creative Commons NonCommercial (CC BY-NC 4.0)](https://creativecommons.org/licenses/by-nc/4.0/legalcode).
### Citation Information
```
@misc{textocr-gpt4v,
author = { Jimmy Carter },
title = {TextOCR-GPT4V},
year = {2024},
publisher = {Huggingface},
journal = {Huggingface repository},
howpublished = {\url{https://huggingface.co/datasets/jimmycarter/textocr-gpt4v}},
}
```
### Contributions
[More Information Needed] |
HuggingFaceTB/ultrachat_questions_about_world | ---
dataset_info:
features:
- name: id
dtype: string
- name: data
sequence: string
- name: question
dtype: string
- name: first_turn
dtype: string
splits:
- name: train
num_bytes: 4473301115
num_examples: 577819
download_size: 2271240702
dataset_size: 4473301115
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: mit
language:
- en
tags:
- synthetic
---
# Ultrachat, Questions about the world
This is the "Questions about the world" subset of [UltraChat](https://huggingface.co/datasets/stingning/ultrachat), found in the this [GitHub repo](https://github.com/thunlp/UltraChat/tree/main?tab=readme-ov-file#data). |
PleIAs/French-PD-Newspapers | ---
task_categories:
- text-generation
language:
- fr
tags:
- ocr
pretty_name: French-Public Domain-Newspapers
---
# 🇫🇷 French Public Domain Newspapers 🇫🇷
**French-Public Domain-Newspapers** or **French-PD-Newpapers** is a large collection aiming to agregate all the French newspapers and periodicals in the public domain.
The collection has been originally compiled by Pierre-Carl Langlais, on the basis of a large corpus curated by Benoît de Courson, Benjamin Azoulay for [Gallicagram](https://shiny.ens-paris-saclay.fr/app/gallicagram) and in cooperation with OpenLLMFrance. Gallicagram is leading cultural analytics project giving access to word and ngram search on very large cultural heritage datasets in French and other languages.
## Content
As of January 2024, the collection contains nearly three million unique newspaper and periodical editions (69,763,525,347 words) from the French National Library (Gallica). Each parquet file has the full text of a few thousand selected at random and, when available, a few core metadatas (Gallica id, title, author, word counts…). The metadata can be easily expanded thanks to the BNF API.
This initial agregation was made possible thanks to the open data program of the French National Library and the consolidation of public domain status for cultural heritage works in the EU with the 2019 Copyright Directive (art. 14)
The composition of the dataset adheres to the French criteria for public domain of collective works (any publication older than 70 years ago) and individual works (any publication with an author dead for more than 70 years). In agreement with the shorter term rules, the dataset is in the public domain everywhere.
## Uses
The primary use of the collection is for cultural analytics project on a wide scale.
The collection also aims to expand the availability of open works for the training of Large Language Models. The text can be used for model training and republished without restriction for reproducibility purposes.
## License
The entire collection is in the public domain everywhere. This means that the patrimonial rights of each individual or collective rightholders have expired.
The French National Library claims additional rights in its terms of use and restrict commercial use: "La réutilisation commerciale de ces contenus est payante et fait l'objet d'une licence. Est entendue par réutilisation commerciale la revente de contenus sous forme de produits élaborés ou de fourniture de service ou toute autre réutilisation des contenus générant directement des revenus."
There has been a debate for years in Europe over the definition of public domain and the possibility to restrict its use. Since 2019, the EU Copyright Directive state that "Member States shall provide that, when the term of protection of a work of visual art has expired, any material resulting from an act of reproduction of that work is not subject to copyright or related rights, unless the material resulting from that act of reproduction is original in the sense that it is the author's own intellectual creation."(art. 14)
## Future developments
This dataset is not a one time work but will continue to evolve significantly on two directions:
* Correction of computer generated errors in the text. All the texts have been transcribed automatically through the use of Optical Character Recognition (OCR) software. The original files have been digitized over a long time period (since the mid-2000s) and some documents should be. Future versions will strive either to re-OCRize the original text or use experimental LLM models for partial OCR correction.
* Enhancement of the structure/editorial presentation of the original text. Some parts of the original documents are likely unwanted for large scale analysis or model training (header, page count…). Additionally, some advanced document structures like tables or multi-column layout are unlikely to be well formatted. Major enhancements could be experted through applying new SOTA layout recognition models (like COLAF) on the original PDF files.
* Expansion of the collection to other cultural heritage holdings, especially coming from Hathi Trust, Internet Archive and Google Books.
## Acknowledgements
The corpus was stored and processed with the generous support of Scaleway. It was built up with the support and concerted efforts of the state start-up LANGU:IA (start-up d’Etat), supported by the French Ministry of Culture and DINUM, as part of the prefiguration of the service offering of the Alliance for Language technologies EDIC (ALT-EDIC).
Corpus collection has been largely facilitated thanks to the open science LLM community insights and cooperation (Occiglot, Eleuther AI, Allen AI).
<div style="text-align: center;">
<img src="https://github.com/mch-dd/datasetlogo/blob/main/scaleway.jpeg?raw=true" style="width: 33%; margin: 0 auto; display: inline-block;"/>
<img src="https://github.com/mch-dd/datasetlogo/blob/main/ministere.png?raw=true" style="width: 33%; margin: 0 auto; display: inline-block;"/>
<img src="https://github.com/mch-dd/datasetlogo/blob/main/occiglot.jpg?raw=true" style="width: 33%; margin: 0 auto; display: inline-block;"/>
</div>
|
mlabonne/distilabel-intel-orca-dpo-pairs | ---
dataset_info:
features:
- name: system
dtype: string
- name: question
dtype: string
- name: chosen
dtype: string
- name: rejected
dtype: string
- name: generations
sequence: string
- name: order
sequence: string
- name: labelling_model
dtype: string
- name: labelling_prompt
list:
- name: content
dtype: string
- name: role
dtype: string
- name: raw_labelling_response
dtype: string
- name: rating
sequence: float64
- name: rationale
dtype: string
- name: status
dtype: string
- name: original_chosen
dtype: string
- name: original_rejected
dtype: string
- name: chosen_score
dtype: float64
- name: in_gsm8k_train
dtype: bool
- name: abs_difference
dtype: float64
splits:
- name: train
num_bytes: 75137131.0
num_examples: 5922
download_size: 36744794
dataset_size: 75137131.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- synthetic
- distilabel
---
|
math-ai/TemplateGSM | ---
license: cc-by-4.0
task_categories:
- text-generation
- question-answering
language:
- en
pretty_name: TemplateGSM
size_categories:
- 1B<n<10B
configs:
- config_name: templategsm-7473-1k
data_files:
- split: train
path:
- data/1k/0000-0999/*.jsonl
- data/1k/1000-1999/*.jsonl
- data/1k/2000-3999/*.jsonl
- data/1k/4000-7472/*.jsonl
default: true
- config_name: templategsm-4000-1k
data_files:
- split: train
path:
- data/1k/0000-0999/*.jsonl
- data/1k/1000-1999/*.jsonl
- data/1k/2000-3999/*.jsonl
- config_name: templategsm-2000-1k
data_files:
- split: train
path:
- data/1k/0000-0999/*.jsonl
- data/1k/1000-1999/*.jsonl
- config_name: templategsm-1000-1k
data_files:
- split: train
path:
- data/1k/0000-0999/*.jsonl
tags:
- mathematical-reasoning
- reasoning
- finetuning
- pretraining
- llm
---
# Training Language Models with Syntactic Data Generation
## TemplateGSM Dataset
The TemplateGSM dataset is a novel and extensive collection containing **over 7 million (up to infinite) grade school math problems** with code solutions and natural language solutions designed for advancing the study and application of mathematical reasoning within the realm of language modeling and AI. This dataset is crafted to challenge and evaluate the capabilities of language models in understanding and generating solutions to mathematical problems derived from a set of **7473** predefined **problem templates** using examples from the GSM8K dataset as prototypes. Each template encapsulates a unique mathematical problem structure, offering a diverse array of challenges that span various domains of mathematics.
GitHub Homepage: https://github.com/iiis-ai/TemplateMath
## Objective
TemplateGSM aims to serve as a benchmark for:
- Assessing language models' proficiency in mathematical reasoning and symbolic computation.
- Training and fine-tuning language models to improve their performance in generating accurate and logically sound mathematical solutions.
- Encouraging the development of models capable of understanding and solving complex mathematical problems, thereby bridging the gap between natural language processing and mathematical reasoning.
## Dataset Structure
TemplateGSM is organized into configurations based on the volume of problems generated from each template:
### Configurations
- **templategsm-1000-1k**: Contains 1000 * 1k problems generated from each of the 1000 templates (template 0000-0999), totaling over 1 million individual problems.
- **templategsm-2000-1k**: Contains 2000 * 1k problems generated from each of the 2000 templates (template 0000-1999), culminating in a dataset with 2 million problems.
- **templategsm-4000-1k**: Contains 4000 * 1k problems generated from each of the 4000 templates (template 0000-3999), culminating in a dataset with 4 million problems.
- **templategsm-7473-1k**: Contains 7473 * 1k problems generated from each of the 7473 templates (template 0000-7472), culminating in a dataset with over 7.47 million problems.
### Data Fields
Each problem in the dataset includes the following fields:
- `problem`: The problem statement.
- `solution_code`: A commented solution code that solves the problem in Python.
- `result`: The final answer to the problem.
- `solution_wocode`: The solution in natural language without the use of code.
- `source`: This field indicates the template is constructed from which data source and which seed is used in problem generation, e.g., `gsm8k-train-round2-seed42`.
- `template_id`: This field indicates the template from which the problem was generated, e.g., `0`.
- `problem_id`: An index unique to each problem within its template.
## How to Use
```XML
configs:
- config_name: templategsm-7473-1k
data_files:
- split: train
path:
- data/1k/0000-0999/*.jsonl
- data/1k/1000-1999/*.jsonl
- data/1k/2000-3999/*.jsonl
- data/1k/4000-7472/*.jsonl
default: true
- config_name: templategsm-4000-1k
data_files:
- split: train
path:
- data/1k/0000-0999/*.jsonl
- data/1k/1000-1999/*.jsonl
- data/1k/2000-3999/*.jsonl
- config_name: templategsm-2000-1k
data_files:
- split: train
path:
- data/1k/0000-0999/*.jsonl
- data/1k/1000-1999/*.jsonl
- config_name: templategsm-1000-1k
data_files:
- split: train
path:
- data/1k/0000-0999/*.jsonl
```
To access the TemplateGSM dataset, you can use the Huggingface `datasets` library:
```python
from datasets import load_dataset
# Load a specific configuration
dataset = load_dataset("math-ai/TemplateGSM", "templategsm-4000-1k") # or any valid config_name
```
## License
This dataset is made available under the Creative Commons Attribution 4.0 International (CC BY 4.0) license.
## Citation
If you utilize Syntactic Data Generation (SDG) or the TemplateGSM dataset in your research or application, please consider citing it (GitHub Homepage: https://github.com/iiis-ai/TemplateMath):
```bibtex
@misc{zhang2024training,
title={Training Language Models with Syntactic Data Generation},
author={Zhang, Yifan and Luo, Yifan and Yuan, Yang and Yao, Andrew Chi-Chih},
year={2024},
}
|
imomayiz/darija-english | ---
language:
- ar
- en
license: cc
task_categories:
- translation
configs:
- config_name: sentences
data_files:
- split: sentences
path: sentences.csv
sep: ","
- config_name: submissions
data_files:
- split: submissions
path: submissions/submissions*.json
---
This work is part of [DODa](https://darija-open-dataset.github.io/).
|
YuxuanZhang888/ColonCancerCTDataset | ---
annotations_creators:
- no-annotation
language_creators:
- other
language:
- en
license:
- other
multilinguality:
- monolingual
size_categories:
- 100B<n<1T
source_datasets:
- original
task_categories:
- image-classification
task_ids:
- multi-label-image-classification
pretty_name: ColonCancerCTDataset
tags:
- colon cancer
- medical
- cancer
dataset_info:
features:
- name: image
dtype: image
- name: ImageType
sequence: string
- name: StudyDate
dtype: string
- name: SeriesDate
dtype: string
- name: Manufacturer
dtype: string
- name: StudyDescription
dtype: string
- name: SeriesDescription
dtype: string
- name: PatientSex
dtype: string
- name: PatientAge
dtype: string
- name: PregnancyStatus
dtype: string
- name: BodyPartExamined
dtype: string
splits:
- name: train
num_bytes: 3537157.0
num_examples: 30
download_size: 3538117
dataset_size: 3537157.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card Creation Guide
## Table of Contents
- [Dataset Card Creation Guide](#dataset-card-creation-guide)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://portal.imaging.datacommons.cancer.gov]()
- **Repository:** [https://aws.amazon.com/marketplace/pp/prodview-3bcx7vcebfi2i#resources]()
- **Paper:** [https://aacrjournals.org/cancerres/article/81/16/4188/670283/NCI-Imaging-Data-CommonsNCI-Imaging-Data-Commons]()
### Dataset Summary
The dataset in the focus of this project is a curated subset of the National Cancer Institute Imaging Data Commons (IDC), specifically highlighting CT Colonography images. This specialized dataset will encompass a targeted collection from the broader IDC repository hosted on the AWS Marketplace, which includes diverse cancer imaging data. The images included are sourced from clinical studies worldwide and encompass modalities such as Computed Tomography (CT), Magnetic Resonance Imaging (MRI), and Positron Emission Tomography (PET).
In addition to the clinical images, essential metadata that contains patient demographics (sex and pregnancy status) and detailed study descriptions are also included in this dataset, enabling nuanced analysis and interpretation of the imaging data.
### Supported Tasks
The dataset can be utilized for several tasks:
- Developing machine learning models to differentiate between benign and malignant colonic lesions.
- Developing algorithms for Creating precise algorithms for segmenting polyps and other colonic structures.
- Conducting longitudinal studies on cancer progression.
- Assessing the diagnostic accuracy of CT Colonography compared to other imaging modalities in colorectal conditions.
### Languages
English is used for text data like labels and imaging study descriptions.
## Dataset Structure
### Data Instances
The data will follow the structure below:
'''
{
"image": image.png # A CT image,
"ImageType": ['ORIGINAL', 'PRIMARY', 'AXIAL', 'CT_SOM5 SPI'] # A list containing the info of the image,
"StudyDate": "20000101" # Date of the case study,
"SeriesDate": 20000101" # Date of the series,
"Manufacturer": "SIEMENS" # Manufacturer of the device used for imaging,
"StudyDescription": "Abdomen^24ACRIN_Colo_IRB2415-04 (Adult)" # Description of the study,
"SeriesDescription": "Colo_prone 1.0 B30f" # Description of the series,
"PatientSex": "F" # Patient's sex,
"PatientAge": "059Y" # Patient's age,
"PregnancyStatus": "None" # Patient's pregnancy status,
"BodyPartExamined": "COLON" # Body part examined
}
'''
### Data Fields
- image (PIL.PngImagePlugin.PngImageFile): The CT image in PNG format
- ImageType (List(String)): A list containing the info of the image
- StudyDate (String): Date of the case study
- SeriesDate (String): Date of the series study
- Manufacturer (String): Manufacturer of the device used for imaging
- StudyDescription (String): Description of the study
- SeriesDescription (String): Description of the series
- PatientSex (String): Patient's sex
- PatientAge (String): Patient's age
- PregnancyStatus (String): Patient's pregnancy status
- BodyPartExamined (String): The body part examined
### Data Splits
| | train | validation | test |
|-------------------------|------:|-----------:|-----:|
| Average Sentence Length | | | |
## Dataset Creation
### Curation Rationale
The dataset is conceived from the necessity to streamline a vast collection of heterogeneous cancer imaging data to facilitate focused research on colon cancer. By distilling the dataset to specifically include CT Colonography, it addresses the challenge of data accessibility for researchers and healthcare professionals interested in colon cancer. This refinement simplifies the task of obtaining relevant data for developing diagnostic models and potentially improving patient outcomes through early detection. The curation of this focused dataset aims to make data more open and usable for specialists and academics in the field of colon cancer research.
### Source Data
According to [IDC](https://portal.imaging.datacommons.cancer.gov/about/), data are submitted from NCI-funded driving projects and other special selected projects.
### Personal and Sensitive Information
According to [IDC](https://portal.imaging.datacommons.cancer.gov/about/), submitters of data to IDC must ensure that the data have been de-identified for protected health information (PHI).
## Considerations for Using the Data
### Social Impact of Dataset
The dataset tailored for CT Colonography aims to enhance medical research and potentially aid in early detection and treatment of colon cancer. Providing high-quality imaging data empowers the development of diagnostic AI tools, contributing to improved patient care and outcomes. This can have a profound social impact, as timely diagnosis is crucial in treating cancer effectively.
### Discussion of Biases
Given the dataset's focus on CT Colonography, biases may arise from the population demographics represented or the prevalence of certain conditions within the dataset. It is crucial to ensure that the dataset includes diverse cases to mitigate biases in model development and to ensure that AI tools developed using this data are generalizable and equitable in their application.
### Other Known Limitations
The dataset may have limitations in terms of variability and scope, as it focuses solely on CT Colonography. Other modalities and cancer types are not represented, which could limit the breadth of research.
### Licensing Information
https://fairsharing.org/FAIRsharing.0b5a1d
### Citation Information
Provide the [BibTex](http://www.bibtex.org/)-formatted reference for the dataset. For example:
```
@article{fedorov2021nci,
title={NCI imaging data commons},
author={Fedorov, Andrey and Longabaugh, William JR and Pot, David
and Clunie, David A and Pieper, Steve and Aerts, Hugo JWL and
Homeyer, Andr{\'e} and Lewis, Rob and Akbarzadeh, Afshin and
Bontempi, Dennis and others},
journal={Cancer research},
volume={81},
number={16},
pages={4188--4193},
year={2021},
publisher={AACR}
}
```
[DOI](https://doi.org/10.1158/0008-5472.CAN-21-0950) |
xorsuyash/raft_datasetp1 | ---
license: mit
---
|
lavis-nlp/german_legal_sentences | ---
annotations_creators:
- machine-generated
language_creators:
- found
language:
- de
license:
- unknown
multilinguality:
- monolingual
size_categories:
- n>1M
source_datasets:
- original
task_categories:
- text-retrieval
- text-scoring
task_ids:
- semantic-similarity-scoring
- text-retrieval-other-example-based-retrieval
---
# Dataset Card for German Legal Sentences
## Table of Contents
- [Dataset Card for [Dataset Name]](#dataset-card-for-dataset-name)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://lavis-nlp.github.io/german_legal_sentences/
- **Repository:** https://github.com/lavis-nlp/german_legal_sentences
- **Paper:** coming soon
- **Leaderboard:**
- **Point of Contact:** [Marco Wrzalik](mailto:marco.wrzalik@hs-rm.de)
### Dataset Summary
German Legal Sentences (GLS) is an automatically generated training dataset for semantic sentence matching and citation recommendation in the domain in german legal documents. It follows the concept of weak supervision, where imperfect labels are generated using multiple heuristics. For this purpose we use a combination of legal citation matching and BM25 similarity. The contained sentences and their citations are parsed from real judicial decisions provided by [Open Legal Data](http://openlegaldata.io/) (https://arxiv.org/abs/2005.13342).
### Supported Tasks and Leaderboards
The main associated task is *Semantic Similarity Ranking*. We propose to use the *Mean Reciprocal Rank* (MRR) cut at the tenth position as well as MAP and Recall on Rankings of size 200. As baselines we provide the follows:
| Method | MRR@10 | MAP@200 | Recall@200 |
|-----------------------------------|---------:|-----------:|------------:|
| BM25 - default `(k1=1.2; b=0.75)` | 25.7 | 17.6 | 42.9 |
| BM25 - tuned `(k1=0.47; b=0.97)` | 26.2 | 18.1 | 43.3 |
| [CoRT](https://arxiv.org/abs/2010.10252) | 31.2 | 21.4 | 56.2 |
| [CoRT + BM25](https://arxiv.org/abs/2010.10252) | 32.1 | 22.1 | 67.1 |
In addition, we want to support a *Citation Recommendation* task in the future.
If you wish to contribute evaluation measures or give any suggestion or critique, please write an [e-mail](mailto:marco.wrzalik@hs-rm.de).
### Languages
This dataset contains texts from the specific domain of German court decisions.
## Dataset Structure
### Data Instances
```
{'query.doc_id': 28860,
'query.ref_ids': [6215, 248, 248],
'query.sent_id': 304863,
'query.text': 'Zudem ist zu berücksichtigen , dass die Vollverzinsung nach '
'[REF] i. V. m. [REF] gleichermaßen zugunsten wie zulasten des '
'Steuerpflichtigen wirkt , sodass bei einer Überzahlung durch '
'den Steuerpflichtigen der Staat dem Steuerpflichtigen neben '
'der Erstattung ebenfalls den entstandenen potentiellen Zins- '
'und Liquiditätsnachteil in der pauschalierten Höhe des [REF] '
'zu ersetzen hat , unabhängig davon , in welcher Höhe dem '
'Berechtigten tatsächlich Zinsen entgangen sind .',
'related.doc_id': 56348,
'related.ref_ids': [248, 6215, 62375],
'related.sent_id': 558646,
'related.text': 'Ferner ist zu berücksichtigen , dass der Zinssatz des [REF] '
'im Rahmen des [REF] sowohl für Steuernachforderung wie auch '
'für Steuererstattungen und damit gleichermaßen zugunsten wie '
'zulasten des Steuerpflichtigen wirkt , Vgl. BVerfG , '
'Nichtannahmebeschluss vom [DATE] [REF] , juris , mit der '
'Folge , dass auch Erstattungsansprüche unabhängig davon , ob '
'und in welcher Höhe dem Berechtigten tatsächlich Zinsen '
'entgangen sind , mit monatlich 0,0 % verzinst werden .'}
```
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
The documents we take from [Open Legal Data](http://openlegaldata.io/) (https://arxiv.org/abs/2005.13342) are first preprocessed by removing line breaks, enumeration characters and headings. Afterwards we parse legal citations using hand-crafted regular expressions. Each citation is split into it components and normalized, thus different variants of the same citation are matched together. For instance, "§211 Absatz 1 des Strafgesetzbuches" is normalized to "§ 211 Abs. 1 StGB". Every time we discover an unknown citation, we assign an unique id to it. We use these ids to replace parsed citations in the document text with a simple reference tag containing this id (e.g `[REF321]`). At the same time we parse dates and replace them with the date tag `[DATE]`. Both remove dots which can may be confused with the end of a sentence, which makes the next stage easier.
We use [SoMaJo](https://github.com/tsproisl/SoMaJo) to perform sentence tokenizing on the pre-processed documents. Each sentence that does not contain at least one legal citation is discarded. For the rest we assign sentence ids, remove all reference ids from them as well as any contents in braces (braces often contain large enumerations of citations and their sources). At the same time we keep track of the corresponding document from which a sentence originates and which references occur in it.
#### Who are the source language producers?
The source language originates in the context of German court proceedings.
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
The annotations are machine-generated.
### Personal and Sensitive Information
The source documents are already public and anonymized.
## Considerations for Using the Data
### Social Impact of Dataset
With this dataset, we strive towards better accessibility of court decisions to the general public by accelerating research on semantic search technologies. We hope that emerging search technologies will enable the layperson to find relevant information without knowing the specific terms used by lawyers.
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
Coming soon!
### Contributions
Thanks to [@mwrzalik](https://github.com/mwrzalik) for adding this dataset. |
sil-ai/bloom-lm | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- afr
- af
- aaa
- abc
- ada
- adq
- aeu
- agq
- ags
- ahk
- aia
- ajz
- aka
- ak
- ame
- amh
- am
- amp
- amu
- ann
- aph
- awa
- awb
- azn
- azo
- bag
- bam
- bm
- baw
- bax
- bbk
- bcc
- bce
- bec
- bef
- ben
- bn
- bfd
- bfm
- bfn
- bgf
- bho
- bhs
- bis
- bi
- bjn
- bjr
- bkc
- bkh
- bkm
- bkx
- bob
- bod
- bo
- boz
- bqm
- bra
- brb
- bri
- brv
- bss
- bud
- buo
- bwt
- bwx
- bxa
- bya
- bze
- bzi
- cak
- cbr
- ceb
- cgc
- chd
- chp
- cim
- clo
- cmn
- zh
- cmo
- csw
- cuh
- cuv
- dag
- ddg
- ded
- deu
- de
- dig
- dje
- dmg
- dnw
- dtp
- dtr
- dty
- dug
- eee
- ekm
- enb
- enc
- eng
- en
- ewo
- fas
- fa
- fil
- fli
- fon
- fra
- fr
- fub
- fuh
- gal
- gbj
- gou
- gsw
- guc
- guj
- gu
- guz
- gwc
- hao
- hat
- ht
- hau
- ha
- hbb
- hig
- hil
- hin
- hi
- hla
- hna
- hre
- hro
- idt
- ilo
- ind
- id
- ino
- isu
- ita
- it
- jgo
- jmx
- jpn
- ja
- jra
- kak
- kam
- kan
- kn
- kau
- kr
- kbq
- kbx
- kby
- kek
- ken
- khb
- khm
- km
- kik
- ki
- kin
- rw
- kir
- ky
- kjb
- kmg
- kmr
- ku
- kms
- kmu
- kor
- ko
- kqr
- krr
- ksw
- kur
- ku
- kvt
- kwd
- kwu
- kwx
- kxp
- kyq
- laj
- lan
- lao
- lo
- lbr
- lfa
- lgg
- lgr
- lhm
- lhu
- lkb
- llg
- lmp
- lns
- loh
- lsi
- lts
- lug
- lg
- luy
- lwl
- mai
- mal
- ml
- mam
- mar
- mr
- mdr
- mfh
- mfj
- mgg
- mgm
- mgo
- mgq
- mhx
- miy
- mkz
- mle
- mlk
- mlw
- mmu
- mne
- mnf
- mnw
- mot
- mqj
- mrn
- mry
- msb
- muv
- mve
- mxu
- mya
- my
- myk
- myx
- mzm
- nas
- nco
- nep
- ne
- new
- nge
- ngn
- nhx
- njy
- nla
- nld
- nl
- nlv
- nod
- nsk
- nsn
- nso
- nst
- nuj
- nwe
- nwi
- nxa
- nxl
- nya
- ny
- nyo
- nyu
- nza
- odk
- oji
- oj
- oki
- omw
- ori
- or
- ozm
- pae
- pag
- pan
- pa
- pbt
- pce
- pcg
- pdu
- pea
- pex
- pis
- pkb
- pmf
- pnz
- por
- pt
- psp
- pwg
- qaa
- qub
- quc
- quf
- quz
- qve
- qvh
- qvm
- qvo
- qxh
- rel
- rnl
- ron
- ro
- roo
- rue
- rug
- rus
- ru
- san
- sa
- saq
- sat
- sdk
- sea
- sgd
- shn
- sml
- snk
- snl
- som
- so
- sot
- st
- sox
- spa
- es
- sps
- ssn
- stk
- swa
- sw
- swh
- sxb
- syw
- taj
- tam
- ta
- tbj
- tdb
- tdg
- tdt
- teo
- tet
- tgk
- tg
- tha
- th
- the
- thk
- thl
- thy
- tio
- tkd
- tnl
- tnn
- tnp
- tnt
- tod
- tom
- tpi
- tpl
- tpu
- tsb
- tsn
- tn
- tso
- ts
- tuv
- tuz
- tvs
- udg
- unr
- urd
- ur
- uzb
- uz
- ven
- ve
- vie
- vi
- vif
- war
- wbm
- wbr
- wms
- wni
- wnk
- wtk
- xho
- xh
- xkg
- xmd
- xmg
- xmm
- xog
- xty
- yas
- yav
- ybb
- ybh
- ybi
- ydd
- yea
- yet
- yid
- yi
- yin
- ymp
- zaw
- zho
- zh
- zlm
- zuh
- zul
- zu
license:
- cc-by-4.0
- cc-by-nc-4.0
- cc-by-nd-4.0
- cc-by-sa-4.0
- cc-by-nc-nd-4.0
- cc-by-nc-sa-4.0
multilinguality:
- multilingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_ids:
- language-modeling
paperswithcode_id: null
pretty_name: BloomLM
extra_gated_prompt: |-
One more step before getting this dataset. This dataset is open access and available only for non-commercial use (except for portions of the dataset labeled with a `cc-by-sa` license). A "license" field paired with each of the dataset entries/samples specifies the Creative Commons license for that entry/sample.
These [Creative Commons licenses](https://creativecommons.org/about/cclicenses/) specify that:
1. You cannot use the dataset for or directed toward commercial advantage or monetary compensation (except for those portions of the dataset labeled specifically with a `cc-by-sa` license. If you would like to ask about commercial uses of this dataset, please [email us](mailto:sj@derivation.co).
2. Any public, non-commercial use of the data must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
3. For those portions of the dataset marked with an ND license, you cannot remix, transform, or build upon the material, and you may not distribute modified material.
In addition to the above implied by Creative Commons and when clicking "Access Repository" below, you agree:
1. Not to use the dataset for any use intended to or which has the effect of harming or enabling discrimination against individuals or groups based on legally protected characteristics or categories, including but not limited to discrimination against Indigenous People as outlined in Articles 2; 13-16; and 31 of the United Nations Declaration on the Rights of Indigenous People, 13 September 2007 and as subsequently amended and revised.
2. That your *contact information* (email address and username) can be shared with the model authors as well.
extra_gated_fields:
I have read the License and agree with its terms: checkbox
---
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
<!-- - [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions) -->
## Dataset Description
- **Homepage:** [SIL AI](https://ai.sil.org/)
- **Point of Contact:** [SIL AI email](mailto:idx_aqua@sil.org)
- **Source Data:** [Bloom Library](https://bloomlibrary.org/)
 
## Dataset Summary
**Bloom** is free, open-source software and an associated website [Bloom Library](https://bloomlibrary.org/), app, and services developed by [SIL International](https://www.sil.org/). Bloom’s primary goal is to equip non-dominant language communities and their members to create the literature they want for their community and children. Bloom also serves organizations that help such communities develop literature and education or other aspects of community development.
This version of the Bloom Library data is developed specifically for the language modeling task. It includes data from 364 languages across 31 language families. There is a mean of 32 stories and median of 2 stories per language.
**Note**: If you speak one of these languages and can help provide feedback or corrections, please let us know!
**Note**: Although this data was used in the training of the [BLOOM model](https://huggingface.co/bigscience/bloom), this dataset only represents a small portion of the data used to train that model. Data from "Bloom Library" was combined with a large number of other datasets to train that model. "Bloom Library" is a project that existed prior to the BLOOM model, and is something separate. All that to say... We were using the "Bloom" name before it was cool. 😉
## Languages
Of the 500+ languages listed at BloomLibrary.org, there are 363 languages available in this dataset. Here are the corresponding ISO 639-3 codes:
aaa, abc, ada, adq, aeu, afr, agq, ags, ahk, aia, ajz, aka, ame, amh, amp, amu, ann, aph, awa, awb, azn, azo, bag, bam, baw, bax, bbk, bcc, bce, bec, bef, ben, bfd, bfm, bfn, bgf, bho, bhs, bis, bjn, bjr, bkc, bkh, bkm, bkx, bob, bod, boz, bqm, bra, brb, bri, brv, bss, bud, buo, bwt, bwx, bxa, bya, bze, bzi, cak, cbr, ceb, cgc, chd, chp, cim, clo, cmn, cmo, csw, cuh, cuv, dag, ddg, ded, deu, dig, dje, dmg, dnw, dtp, dtr, dty, dug, eee, ekm, enb, enc, eng, ewo, fas, fil, fli, fon, fra, fub, fuh, gal, gbj, gou, gsw, guc, guj, guz, gwc, hao, hat, hau, hbb, hig, hil, hin, hla, hna, hre, hro, idt, ilo, ind, ino, isu, ita, jgo, jmx, jpn, jra, kak, kam, kan, kau, kbq, kbx, kby, kek, ken, khb, khm, kik, kin, kir, kjb, kmg, kmr, kms, kmu, kor, kqr, krr, ksw, kur, kvt, kwd, kwu, kwx, kxp, kyq, laj, lan, lao, lbr, lfa, lgg, lgr, lhm, lhu, lkb, llg, lmp, lns, loh, lsi, lts, lug, luy, lwl, mai, mal, mam, mar, mdr, mfh, mfj, mgg, mgm, mgo, mgq, mhx, miy, mkz, mle, mlk, mlw, mmu, mne, mnf, mnw, mot, mqj, mrn, mry, msb, muv, mve, mxu, mya, myk, myx, mzm, nas, nco, nep, new, nge, ngn, nhx, njy, nla, nld, nlv, nod, nsk, nsn, nso, nst, nuj, nwe, nwi, nxa, nxl, nya, nyo, nyu, nza, odk, oji, oki, omw, ori, ozm, pae, pag, pan, pbt, pce, pcg, pdu, pea, pex, pis, pkb, pmf, pnz, por, psp, pwg, qub, quc, quf, quz, qve, qvh, qvm, qvo, qxh, rel, rnl, ron, roo, rue, rug, rus, san, saq, sat, sdk, sea, sgd, shn, sml, snk, snl, som, sot, sox, spa, sps, ssn, stk, swa, swh, sxb, syw, taj, tam, tbj, tdb, tdg, tdt, teo, tet, tgk, tha, the, thk, thl, thy, tio, tkd, tnl, tnn, tnp, tnt, tod, tom, tpi, tpl, tpu, tsb, tsn, tso, tuv, tuz, tvs, udg, unr, urd, uzb, ven, vie, vif, war, wbm, wbr, wms, wni, wnk, wtk, xho, xkg, xmd, xmg, xmm, xog, xty, yas, yav, ybb, ybh, ybi, ydd, yea, yet, yid, yin, ymp, zaw, zho, zlm, zuh, zul
## Dataset Statistics
Some of the languages included in the dataset just include 1 or a couple of "stories." These are not split between training, validation, and test. For those with higher numbers of available stories we include the following numbers of stories in each split:
| ISO 639-3 | Name | Train Stories | Validation Stories | Test Stories |
|:------------|:------------------------------|----------------:|---------------------:|---------------:|
| aeu | Akeu | 47 | 6 | 5 |
| afr | Afrikaans | 19 | 2 | 2 |
| ahk | Akha | 81 | 10 | 10 |
| aph | Athpariya | 28 | 4 | 3 |
| awa | Awadhi | 131 | 16 | 16 |
| ben | Bengali | 201 | 25 | 25 |
| bfn | Bunak | 11 | 1 | 1 |
| bho | Bhojpuri | 139 | 17 | 17 |
| bis | Bislama | 20 | 2 | 2 |
| bkm | Kom (Cameroon) | 15 | 2 | 1 |
| bkx | Baikeno | 8 | 1 | 1 |
| brb | Brao | 18 | 2 | 2 |
| bwx | Bu-Nao Bunu | 14 | 2 | 1 |
| bzi | Bisu | 53 | 7 | 6 |
| cak | Kaqchikel | 54 | 7 | 6 |
| cbr | Cashibo-Cacataibo | 11 | 1 | 1 |
| ceb | Cebuano | 335 | 42 | 41 |
| cgc | Kagayanen | 158 | 20 | 19 |
| cmo | Central Mnong | 16 | 2 | 2 |
| ddg | Fataluku | 14 | 2 | 1 |
| deu | German | 36 | 4 | 4 |
| dtp | Kadazan Dusun | 13 | 2 | 1 |
| dty | Dotyali | 138 | 17 | 17 |
| eng | English | 2107 | 263 | 263 |
| fas | Persian | 104 | 13 | 12 |
| fil | Filipino | 55 | 7 | 6 |
| fra | French | 323 | 40 | 40 |
| gal | Galolen | 11 | 1 | 1 |
| gwc | Gawri | 15 | 2 | 1 |
| hat | Haitian | 208 | 26 | 26 |
| hau | Hausa | 205 | 26 | 25 |
| hbb | Huba | 22 | 3 | 2 |
| hin | Hindi | 16 | 2 | 2 |
| idt | Idaté | 8 | 1 | 1 |
| ind | Indonesian | 208 | 26 | 25 |
| jmx | Western Juxtlahuaca Mixtec | 19 | 2 | 2 |
| jra | Jarai | 112 | 14 | 13 |
| kak | Kalanguya | 156 | 20 | 19 |
| kan | Kannada | 17 | 2 | 2 |
| kau | Kanuri | 36 | 5 | 4 |
| kek | Kekchí | 29 | 4 | 3 |
| khb | Lü | 25 | 3 | 3 |
| khm | Khmer | 28 | 4 | 3 |
| kik | Kikuyu | 8 | 1 | 1 |
| kir | Kirghiz | 306 | 38 | 38 |
| kjb | Q'anjob'al | 82 | 10 | 10 |
| kmg | Kâte | 16 | 2 | 1 |
| kor | Korean | 106 | 13 | 13 |
| krr | Krung | 24 | 3 | 3 |
| kwd | Kwaio | 19 | 2 | 2 |
| kwu | Kwakum | 16 | 2 | 2 |
| lbr | Lohorung | 8 | 1 | 1 |
| lhu | Lahu | 32 | 4 | 4 |
| lsi | Lashi | 21 | 3 | 2 |
| mai | Maithili | 144 | 18 | 18 |
| mal | Malayalam | 12 | 1 | 1 |
| mam | Mam | 108 | 13 | 13 |
| mar | Marathi | 8 | 1 | 1 |
| mgm | Mambae | 12 | 2 | 1 |
| mhx | Maru | 79 | 10 | 9 |
| mkz | Makasae | 16 | 2 | 2 |
| mya | Burmese | 31 | 4 | 3 |
| myk | Mamara Senoufo | 28 | 3 | 3 |
| nep | Nepali (macrolanguage) | 160 | 20 | 20 |
| new | Newari | 142 | 18 | 17 |
| nlv | Orizaba Nahuatl | 8 | 1 | 1 |
| nsn | Nehan | 9 | 1 | 1 |
| nwi | Southwest Tanna | 9 | 1 | 1 |
| nxa | Nauete | 12 | 1 | 1 |
| omw | South Tairora | 10 | 1 | 1 |
| pbt | Southern Pashto | 164 | 21 | 20 |
| pce | Ruching Palaung | 30 | 4 | 3 |
| pis | Pijin | 14 | 2 | 1 |
| por | Portuguese | 131 | 16 | 16 |
| quc | K'iche' | 80 | 10 | 9 |
| rus | Russian | 283 | 35 | 35 |
| sdk | Sos Kundi | 9 | 1 | 1 |
| snk | Soninke | 28 | 4 | 3 |
| spa | Spanish | 423 | 53 | 52 |
| swh | Swahili (individual language) | 58 | 7 | 7 |
| tam | Tamil | 13 | 2 | 1 |
| tdg | Western Tamang | 26 | 3 | 3 |
| tdt | Tetun Dili | 22 | 3 | 2 |
| tet | Tetum | 8 | 1 | 1 |
| tgk | Tajik | 24 | 3 | 2 |
| tha | Thai | 228 | 29 | 28 |
| the | Chitwania Tharu | 11 | 1 | 1 |
| thl | Dangaura Tharu | 148 | 19 | 18 |
| tnl | Lenakel | 10 | 1 | 1 |
| tnn | North Tanna | 9 | 1 | 1 |
| tpi | Tok Pisin | 161 | 20 | 20 |
| tpu | Tampuan | 24 | 3 | 2 |
| uzb | Uzbek | 24 | 3 | 2 |
| war | Waray (Philippines) | 16 | 2 | 2 |
| wbr | Wagdi | 10 | 1 | 1 |
| wni | Ndzwani Comorian | 12 | 2 | 1 |
| xkg | Kagoro | 16 | 2 | 1 |
| ybh | Yakha | 16 | 2 | 1 |
| zho | Chinese | 34 | 4 | 4 |
| zlm | Malay (individual language) | 8 | 1 | 1 |
| zul | Zulu | 19 | 2 | 2 |
## Dataset Structure
### Data Instances
The examples look like this for Hindi:
```
from datasets import load_dataset
# Specify the language code.
dataset = load_dataset("sil-ai/bloom-lm", 'hin')
# A data point consists of stories in the specified language code.
# To see a story:
print(dataset['train']['text'][0])
```
This would produce an output:
```
साबू ने एक कंकड़ को ठोकर मारी। कंकड़ लुढ़कता हुआ एक पेड़ के पास पहुँचा। पेड़ के तने पर मुलायम बाल थे। साबू ने छुए और ऊपर देखा, ऊपर, ऊपर और उससे भी ऊपर...दो आँखें नीचे देख रही थीं।
“हेलो, तुम कौन हो?” साबू को बड़ा अचम्भा हुआ।“हेलो, मैं जिराफ़ हूँ। मेरा नाम है जोजो। मैं तुम्हारे साथ खेल सकता हूँ। मेरी पीठ पर चढ़ जाओ, मैं तुम्हें घुमा के लाता हूँ।”
साबू जोजो की पीठ पर चढ़ गया और वे सड़क पर चल निकले। फिर पहाड़ी पर और शहर के बीचों बीच।
साबू खुशी से चिल्लाया, “जोजो दाएँ मुड़ो,
बाएँ मुड़ो और फिर दाएँ।” अब वे उसकी दोस्त मुन्नी के घर पहुँच गये।
आज मुन्नी का जन्मदिन था। साबू को जोजो पर सवारी करते देख बच्चों ने ताली बजायी।
जोजो ने गुब्बारे लटकाने में आन्टी की मदद करी क्योंकि वह इतना... लम्बा था।
कितना आसान था!
जोजो ने सब बच्चों को सवारी कराई।
उनके साथ बॉल भी खेली। बड़े मज़े की पार्टी थी।सब ने गाया, “हैप्पी बर्थ डे टु यू ।”
आन्टी ने मेज़ पर समोसे, गुलाब जामुन और आइसक्रीम सजाई।
जोजो को आइसक्रीम बहुत पसन्द आई। अंकल उसके लिये एक बाल्टी भर के आइसक्रीम लाये। जोजो ने पूरी बाल्टी ख़त्म कर दी। अब घर जाने का समय हो गया।
सब ने कहा, “बाय बाय जोजो, बाय बाय साबू।” साबू और जोजो घर लौटे।
```
Whereas if you wish to gather all the text for a language you may use this:
```
dataset['train']['text']
```
### Data Fields
The metadata fields below are available and the full dataset will be updated with per story metadata soon (in August 2022). As of now a majority of stories have metadata, but some are missing certain fields. In terms of licenses, all stories included in the current release are released under a Creative Commons license (even if the individual story metadata fields are missing).
- **text**: the text of the story/book, concatenated together from the different pages.
- **id**: id of the sample
- **title**: title of the book, e.g. "Going to Buy a Book".
- **license**: specific license used, e.g. "cc-by-sa" for "Creative Commons, by attribution, share-alike".
- **copyright**: copyright notice from the original book on bloomlibrary.org
- **pageCount**: page count from the metadata on the original book on bloomlibrary.org.
- **bookInstanceId**: unique ID for each book/translation assigned by Bloom. For example the Hindi version of 'Going to Buy a Book' is 'af86eefd-f69c-4e06-b8eb-e0451853aab9'.
- **bookLineage**: Unique bookInstanceIDs of _other_ Bloom books that this book is in some way based on. For example, the Hindi version in the example above is based on '056B6F11-4A6C-4942-B2BC-8861E62B03B3'. It's quite possible for this to be either empty, or have multiple entries. For example, the book 'Saboo y Jojo' with ID '5b232a5f-561d-4514-afe7-d6ed2f6a940f' is based on two others, ['056B6F11-4A6C-4942-B2BC-8861E62B03B3', '10a6075b-3c4f-40e4-94f3-593497f2793a']
- (coming soon) **contentLanguages**: Other languages this book may be available in. "Going to Buy a Book" is available in ['eng', 'kan', 'mar', 'pan', 'ben', 'guj', 'hin'] for example.
### Data Splits
All languages include a train, validation, and test split. However, for language having a small number of stories, certain of these splits maybe empty. In such cases, we recommend using any data for testing only or for zero-shot experiments.
## Changelog
- **25 August 2022** - add the remaining metadata, change data type of `pageCount` to int32
- **24 August 2022** - majority of metadata added back in to the filtered/ clean data
- **23 August 2022** - metadata temporarily removed to update to cleaner dataset |
pile-of-law/eoir_privacy | ---
language_creators:
- found
language:
- en
license:
- cc-by-nc-sa-4.0
multilinguality:
- monolingual
pretty_name: eoir_privacy
source_datasets: []
task_categories:
- text-classification
viewer: false
---
# Dataset Card for eoir_privacy
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** [Needs More Information]
- **Repository:** [Needs More Information]
- **Paper:** [Needs More Information]
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [Needs More Information]
### Dataset Summary
This dataset mimics privacy standards for EOIR decisions. It is meant to help learn contextual data sanitization rules to anonymize potentially sensitive contexts in crawled language data.
### Languages
English
## Dataset Structure
### Data Instances
{
"text" : masked paragraph,
"label" : whether to use a pseudonym in filling masks
}
### Data Splits
train 75%, validation 25%
## Dataset Creation
### Curation Rationale
This dataset mimics privacy standards for EOIR decisions. It is meant to help learn contextual data sanitization rules to anonymize potentially sensitive contexts in crawled language data.
### Source Data
#### Initial Data Collection and Normalization
We scrape EOIR. We then filter at the paragraph level and replace any references to respondent, applicant, or names with [MASK] tokens. We then determine if the case used a pseudonym or not.
#### Who are the source language producers?
U.S. Executive Office for Immigration Review
### Annotations
#### Annotation process
Annotations (i.e., pseudonymity decisions) were made by the EOIR court. We use regex to identify if a pseudonym was used to refer to the applicant/respondent.
#### Who are the annotators?
EOIR judges.
### Personal and Sensitive Information
There may be sensitive contexts involved, the courts already make a determination as to data filtering of sensitive data, but nonetheless there may be sensitive topics discussed.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset is meant to learn contextual privacy rules to help filter private/sensitive data, but itself encodes biases of the courts from which the data came. We suggest that people look beyond this data for learning more contextual privacy rules.
### Discussion of Biases
Data may be biased due to its origin in U.S. immigration courts.
### Licensing Information
CC-BY-NC
### Citation Information
```
@misc{hendersonkrass2022pileoflaw,
url = {https://arxiv.org/abs/2207.00220},
author = {Henderson, Peter and Krass, Mark S. and Zheng, Lucia and Guha, Neel and Manning, Christopher D. and Jurafsky, Dan and Ho, Daniel E.},
title = {Pile of Law: Learning Responsible Data Filtering from the Law and a 256GB Open-Source Legal Dataset},
publisher = {arXiv},
year = {2022}
}
``` |
rkstgr/mtg-jamendo | ---
license:
- apache-2.0
size_categories:
- 10K<n<100K
source_datasets:
- original
pretty_name: MTG Jamendo
---
# Dataset Card for MTG Jamendo Dataset
## Dataset Description
- **Repository:** [MTG Jamendo dataset repository](https://github.com/MTG/mtg-jamendo-dataset)
### Dataset Summary
MTG-Jamendo Dataset, a new open dataset for music auto-tagging. It is built using music available at Jamendo under Creative Commons licenses and tags provided by content uploaders. The dataset contains over 55,000 full audio tracks with 195 tags from genre, instrument, and mood/theme categories. We provide elaborated data splits for researchers and report the performance of a simple baseline approach on five different sets of tags: genre, instrument, mood/theme, top-50, and overall.
## Dataset structure
### Data Fields
- `id`: an integer containing the id of the track
- `artist_id`: an integer containing the id of the artist
- `album_id`: an integer containing the id of the album
- `duration_in_sec`: duration of the track as a float
- `genres`: list of strings, describing genres the track is assigned to
- `instruments`: list of strings for the main instruments of the track
- `moods`: list of strings, describing the moods the track is assigned to
- `audio`: audio of the track
### Data Splits
This dataset has 2 balanced splits: _train_ (90%) and _validation_ (10%)
### Licensing Information
This dataset version 1.0.0 is released under the [Apache-2.0 License](http://www.apache.org/licenses/LICENSE-2.0).
### Citation Information
```
@conference {bogdanov2019mtg,
author = "Bogdanov, Dmitry and Won, Minz and Tovstogan, Philip and Porter, Alastair and Serra, Xavier",
title = "The MTG-Jamendo Dataset for Automatic Music Tagging",
booktitle = "Machine Learning for Music Discovery Workshop, International Conference on Machine Learning (ICML 2019)",
year = "2019",
address = "Long Beach, CA, United States",
url = "http://hdl.handle.net/10230/42015"
}
``` |
embedding-data/coco_captions_quintets | ---
license: mit
language:
- en
paperswithcode_id: embedding-data/coco_captions
pretty_name: coco_captions
task_categories:
- sentence-similarity
- paraphrase-mining
task_ids:
- semantic-similarity-classification
---
# Dataset Card for "coco_captions"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://cocodataset.org/#home](https://cocodataset.org/#home)
- **Repository:** [https://github.com/cocodataset/cocodataset.github.io](https://github.com/cocodataset/cocodataset.github.io)
- **Paper:** [More Information Needed](https://arxiv.org/abs/1405.0312)
- **Point of Contact:** [info@cocodataset.org](info@cocodataset.org)
- **Size of downloaded dataset files:**
- **Size of the generated dataset:**
- **Total amount of disk used:** 6.32 MB
### Dataset Summary
COCO is a large-scale object detection, segmentation, and captioning dataset. This repo contains five captions per image; useful for sentence similarity tasks.
Disclaimer: The team releasing COCO did not upload the dataset to the Hub and did not write a dataset card.
These steps were done by the Hugging Face team.
### Supported Tasks
- [Sentence Transformers](https://huggingface.co/sentence-transformers) training; useful for semantic search and sentence similarity.
### Languages
- English.
## Dataset Structure
Each example in the dataset contains quintets of similar sentences and is formatted as a dictionary with the key "set" and a list with the sentences as "value":
```
{"set": [sentence_1, sentence_2, sentence3, sentence4, sentence5]}
{"set": [sentence_1, sentence_2, sentence3, sentence4, sentence5]}
...
{"set": [sentence_1, sentence_2, sentence3, sentence4, sentence5]}
```
This dataset is useful for training Sentence Transformers models. Refer to the following post on how to train models using similar pairs of sentences.
### Usage Example
Install the 🤗 Datasets library with `pip install datasets` and load the dataset from the Hub with:
```python
from datasets import load_dataset
dataset = load_dataset("embedding-data/coco_captions")
```
The dataset is loaded as a `DatasetDict` and has the format:
```python
DatasetDict({
train: Dataset({
features: ['set'],
num_rows: 82783
})
})
```
Review an example `i` with:
```python
dataset["train"][i]["set"]
```
### Data Instances
[More Information Needed](https://cocodataset.org/#format-data)
### Data Splits
[More Information Needed](https://cocodataset.org/#format-data)
## Dataset Creation
### Curation Rationale
[More Information Needed](https://cocodataset.org/#home)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://cocodataset.org/#home)
#### Who are the source language producers?
[More Information Needed](https://cocodataset.org/#home)
### Annotations
#### Annotation process
[More Information Needed](https://cocodataset.org/#home)
#### Who are the annotators?
[More Information Needed](https://cocodataset.org/#home)
### Personal and Sensitive Information
[More Information Needed](https://cocodataset.org/#home)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://cocodataset.org/#home)
### Discussion of Biases
[More Information Needed](https://cocodataset.org/#home)
### Other Known Limitations
[More Information Needed](https://cocodataset.org/#home)
## Additional Information
### Dataset Curators
[More Information Needed](https://cocodataset.org/#home)
### Licensing Information
The annotations in this dataset along with this website belong to the COCO Consortium
and are licensed under a [Creative Commons Attribution 4.0 License](https://creativecommons.org/licenses/by/4.0/legalcode)
### Citation Information
[More Information Needed](https://cocodataset.org/#home)
### Contributions
Thanks to:
- Tsung-Yi Lin - Google Brain
- Genevieve Patterson - MSR, Trash TV
- Matteo R. - Ronchi Caltech
- Yin Cui - Google
- Michael Maire - TTI-Chicago
- Serge Belongie - Cornell Tech
- Lubomir Bourdev - WaveOne, Inc.
- Ross Girshick - FAIR
- James Hays - Georgia Tech
- Pietro Perona - Caltech
- Deva Ramanan - CMU
- Larry Zitnick - FAIR
- Piotr Dollár - FAIR
for adding this dataset.
|
FremyCompany/BioLORD-Dataset | ---
pretty_name: BioLORD-Dataset
language:
- en
multilinguality:
- monolingual
language_creators:
- crowdsourced
- machine-generated
license:
- other
size_categories:
- 100M<n<1B
tags:
- bio
- healthcare
- umls
- snomed
- definitions
task_categories:
- sentence-similarity
task_ids: []
---
# The BioLORD Dataset (v1)
This dataset was constructed to enable training text embedding models producing similar representations for biomedical concept names and their definitions. Pairs of biomedical concepts names and descriptions of the concept are contrasted against each other, such that the model becomes able to find which names and descriptions are paired together within a batch.

## Citation
This dataset accompanies the [BioLORD: Learning Ontological Representations from Definitions](https://arxiv.org/abs/2210.11892) paper, accepted in the EMNLP 2022 Findings. When you use this dataset, please cite the original paper as follows:
```latex
@inproceedings{remy-etal-2022-biolord,
title = "{B}io{LORD}: Learning Ontological Representations from Definitions for Biomedical Concepts and their Textual Descriptions",
author = "Remy, François and
Demuynck, Kris and
Demeester, Thomas",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2022",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.findings-emnlp.104",
pages = "1454--1465",
abstract = "This work introduces BioLORD, a new pre-training strategy for producing meaningful representations for clinical sentences and biomedical concepts. State-of-the-art methodologies operate by maximizing the similarity in representation of names referring to the same concept, and preventing collapse through contrastive learning. However, because biomedical names are not always self-explanatory, it sometimes results in non-semantic representations. BioLORD overcomes this issue by grounding its concept representations using definitions, as well as short descriptions derived from a multi-relational knowledge graph consisting of biomedical ontologies. Thanks to this grounding, our model produces more semantic concept representations that match more closely the hierarchical structure of ontologies. BioLORD establishes a new state of the art for text similarity on both clinical sentences (MedSTS) and biomedical concepts (MayoSRS).",
}
```
## Contents
The dataset contains 100M pairs (86M with descriptions, 14M with definitions).
> #### 📝 Example of definitions:
> - **Site Training Documentation (Document type):** Document type described as records that verify completion of clinical trial site training for the site medical investigator and his/her staff.
> - **Arteries, Gastric (Arteries):** Arteries described as either of two arteries (left gastric and right gastric) that supply blood to the stomach and lesser curvature.
> - **Dental Materials, Cement, Zinc Phosphate (Biomedical or Dental Material):** Biomedical or Dental Material described as cement dental materials, whose main components are phosphoric acid and zinc oxide, designed to produce a mechanical interlocking effect upon hardening inside the mouth. These cements consist of a basic powder (zinc oxide), an acidic liquid (phosphoric acid), and water that are mixed together in a viscous paste immediately before use, setting to a hard mass. Zinc phosphate cements have proper thermal and chemical resistance in the oral environment; they also should be resistant to dissolution in oral fluids. Zinc phosphate cements must be placed on a dental cavity liner or sealer to avoid pulp irritation. They are used in dentists' offices as cementing medium of inlays, crowns, bridges and orthodontic appliances (e.g., bands, brackets), as intermediate bases, or as temporary restorative materials.
> - **DTI (Diffusion weighted imaging):** Diffusion weighted imaging described as a type of diffusion-weighted magnetic resonance imaging (DW-MRI) that maps the diffusion of water in three dimensions, the principal purpose of which is to image the white matter of the brain, specifically measuring the anisotropy, location, and orientation of the neural tracts, which can demonstrate microstructural changes or differences with neuropathology and treatment.
> - **arousal (psychic activity level):** Nervous System Physiological Phenomena described as cortical vigilance or readiness of tone, presumed to be in response to sensory stimulation via the reticular activating system.
> #### 📝 Example of descriptions:
> - **Mesial fovea (Body Space or Junction):** something which is a Region of surface of organ
> - **Thyroid associated opthalmopathies (Disease or Syndrome):** something which has finding site orbit
> - **Internal fixation of bone of radius (Therapeutic or Preventive Procedure):** SHOULDER AND ARM: SURGICAL REPAIRS, CLOSURES AND RECONSTRUCTIONS which has method Fixation - action
> - **gardnerella (Gram-variable bacterium):** something which is a Gram-variable coccobacillus
> - **Hydropane (Organic Chemical):** Organic Chemical which is ingredient of homatropine / hydrocodone Oral Solution [Hydropane]
> - **Duane anomaly, myopathy, scoliosis syndrome (Multiple system malformation syndrome):** Scoliosis, unspecified which has finding site Nervous system structure
Another set of 20M descriptions based on the same knowledge graph serves as a development set (86M generations certainly do not exhaust the graph). However, this would not be a suitable test set. Instead, a test of time consisting of new concepts currently absent from UMLS would make more sense, but this will have to wait until enough new concepts have been added to UMLS.
## License
My own contributions for this dataset are covered by the MIT license.
However, given the data used to generate this dataset originates from UMLS, you will need to ensure you have proper licensing of UMLS before using this dataset. UMLS is free of charge in most countries, but you might have to create an account and report on your usage of the data yearly to keep a valid license. |
AndyChiang/cloth | ---
pretty_name: cloth
multilinguality:
- monolingual
language:
- en
license:
- mit
size_categories:
- 10K<n<100K
tags:
- cloze
- mid-school
- high-school
- exams
task_categories:
- fill-mask
---
# cloth
**CLOTH** is a dataset which is a collection of nearly 100,000 cloze questions from middle school and high school English exams. The detail of CLOTH dataset is shown below.
| Number of questions | Train | Valid | Test |
| ------------------- | ----- | ----- | ----- |
| **Middle school** | 22056 | 3273 | 3198 |
| **High school** | 54794 | 7794 | 8318 |
| **Total** | 76850 | 11067 | 11516 |
Source: https://www.cs.cmu.edu/~glai1/data/cloth/ |
lexlms/lex_files_preprocessed | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- cc-by-nc-sa-4.0
multilinguality:
- monolingual
size_categories:
- 1M<n<10M
source_datasets:
- extended
task_categories:
- text-generation
- fill-mask
task_ids:
- language-modeling
- masked-language-modeling
pretty_name: LexFiles
configs:
- eu_legislation
- eu_court_cases
- uk_legislation
- uk_court_cases
- us_legislation
- us_court_cases
- us_contracts
- canadian_legislation
- canadian_court_cases
- indian_court_cases
---
# Dataset Card for "LexFiles"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Dataset Specifications](#supported-tasks-and-leaderboards)
## Dataset Description
- **Homepage:** https://github.com/coastalcph/lexlms
- **Repository:** https://github.com/coastalcph/lexlms
- **Paper:** https://arxiv.org/abs/xxx
- **Point of Contact:** [Ilias Chalkidis](mailto:ilias.chalkidis@di.ku.dk)
### Dataset Summary
**Disclaimer: This is a pre-proccessed version of the LexFiles corpus (https://huggingface.co/datasets/lexlms/lexfiles), where documents are pre-split in chunks of 512 tokens.**
The LeXFiles is a new diverse English multinational legal corpus that we created including 11 distinct sub-corpora that cover legislation and case law from 6 primarily English-speaking legal systems (EU, CoE, Canada, US, UK, India).
The corpus contains approx. 19 billion tokens. In comparison, the "Pile of Law" corpus released by Hendersons et al. (2022) comprises 32 billion in total, where the majority (26/30) of sub-corpora come from the United States of America (USA), hence the corpus as a whole is biased towards the US legal system in general, and the federal or state jurisdiction in particular, to a significant extent.
### Dataset Specifications
| Corpus | Corpus alias | Documents | Tokens | Pct. | Sampl. (a=0.5) | Sampl. (a=0.2) |
|-----------------------------------|----------------------|-----------|--------|--------|----------------|----------------|
| EU Legislation | `eu-legislation` | 93.7K | 233.7M | 1.2% | 5.0% | 8.0% |
| EU Court Decisions | `eu-court-cases` | 29.8K | 178.5M | 0.9% | 4.3% | 7.6% |
| ECtHR Decisions | `ecthr-cases` | 12.5K | 78.5M | 0.4% | 2.9% | 6.5% |
| UK Legislation | `uk-legislation` | 52.5K | 143.6M | 0.7% | 3.9% | 7.3% |
| UK Court Decisions | `uk-court-cases` | 47K | 368.4M | 1.9% | 6.2% | 8.8% |
| Indian Court Decisions | `indian-court-cases` | 34.8K | 111.6M | 0.6% | 3.4% | 6.9% |
| Canadian Legislation | `canadian-legislation` | 6K | 33.5M | 0.2% | 1.9% | 5.5% |
| Canadian Court Decisions | `canadian-court-cases` | 11.3K | 33.1M | 0.2% | 1.8% | 5.4% |
| U.S. Court Decisions [1] | `court-listener` | 4.6M | 11.4B | 59.2% | 34.7% | 17.5% |
| U.S. Legislation | `us-legislation` | 518 | 1.4B | 7.4% | 12.3% | 11.5% |
| U.S. Contracts | `us-contracts` | 622K | 5.3B | 27.3% | 23.6% | 15.0% |
| Total | `lexlms/lexfiles` | 5.8M | 18.8B | 100% | 100% | 100% |
[1] We consider only U.S. Court Decisions from 1965 onwards (cf. post Civil Rights Act), as a hard threshold for cases relying on severely out-dated and in many cases harmful law standards. The rest of the corpora include more recent documents.
[2] Sampling (Sampl.) ratios are computed following the exponential sampling introduced by Lample et al. (2019).
Additional corpora not considered for pre-training, since they do not represent factual legal knowledge.
| Corpus | Corpus alias | Documents | Tokens |
|----------------------------------------|------------------------|-----------|--------|
| Legal web pages from C4 | `legal-c4` | 284K | 340M |
### Citation
[*Ilias Chalkidis\*, Nicolas Garneau\*, Catalina E.C. Goanta, Daniel Martin Katz, and Anders Søgaard.*
*LeXFiles and LegalLAMA: Facilitating English Multinational Legal Language Model Development.*
*2022. In the Proceedings of the 61th Annual Meeting of the Association for Computational Linguistics. Toronto, Canada.*](https://aclanthology.org/xxx/)
```
@inproceedings{chalkidis-garneau-etal-2023-lexlms,
title = {{LeXFiles and LegalLAMA: Facilitating English Multinational Legal Language Model Development}},
author = "Chalkidis*, Ilias and
Garneau*, Nicolas and
Goanta, Catalina and
Katz, Daniel Martin and
Søgaard, Anders",
booktitle = "Proceedings of the 61h Annual Meeting of the Association for Computational Linguistics",
month = june,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/xxx",
}
``` |
HIT-TMG/Hansel | ---
annotations_creators:
- crowdsourced
- found
language:
- zh
language_creators:
- found
- crowdsourced
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
paperswithcode_id: hansel
pretty_name: Hansel
size_categories:
- 1M<n<10M
- 1K<n<10K
source_datasets:
- original
tags: []
task_categories:
- text-retrieval
task_ids:
- entity-linking-retrieval
dataset_info:
- config_name: wiki
features:
- name: id
dtype: string
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: mention
dtype: string
- name: gold_id
dtype: string
splits:
- name: train
- name: validation
- config_name: hansel-few-shot
features:
- name: id
dtype: string
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: mention
dtype: string
- name: gold_id
dtype: string
- name: source
dtype: string
- name: domain
dtype: string
splits:
- name: test
- config_name: hansel-zero-shot
features:
- name: id
dtype: string
- name: text
dtype: string
- name: start
dtype: int64
- name: end
dtype: int64
- name: mention
dtype: string
- name: gold_id
dtype: string
- name: source
dtype: string
- name: domain
dtype: string
splits:
- name: test
---
# Dataset Card for "Hansel"
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Splits](#data-splits)
- [Citation](#citation)
## Dataset Description
- **Homepage:** https://github.com/HITsz-TMG/Hansel
- **Paper:** https://arxiv.org/abs/2207.13005
Hansel is a high-quality human-annotated Chinese entity linking (EL) dataset, focusing on tail entities and emerging entities:
- The test set contains Few-shot (FS) and zero-shot (ZS) slices, has 10K examples and uses Wikidata as the corresponding knowledge base.
- The training and validation sets are from Wikipedia hyperlinks, useful for large-scale pretraining of Chinese EL systems.
Please see our [WSDM 2023](https://www.wsdm-conference.org/2023/) paper [**"Hansel: A Chinese Few-Shot and Zero-Shot Entity Linking Benchmark"**](https://dl.acm.org/doi/10.1145/3539597.3570418) to learn more about our dataset.
For models in the paper and our processed knowledge base, please see our [Github repository](https://github.com/HITsz-TMG/Hansel).
## Dataset Structure
### Data Instances
{"id": "hansel-eval-zs-1463",
"text": "1905电影网讯 已经筹备了十余年的吉尔莫·德尔·托罗的《匹诺曹》,在上个月顺利被网飞公司买下,成为了流媒体巨头旗下的新片。近日,这部备受关注的影片确定了自己的档期:2021年。虽然具体时间未定,但影片却已经实实在在地向前迈出了一步。",
"start": 29,
"end": 32,
"mention": "匹诺曹",
"gold_id": "Q73895818",
"source": "https://www.1905.com/news/20181107/1325389.shtml",
"domain": "news"
}
### Data Splits
| | # Mentions | # Entities | Domain |
| ---- | ---- | ---- | ---- |
| Train | 9,879,813 | 541,058 | Wikipedia |
| Validation | 9,674 | 6,320 | Wikipedia |
| Hansel-FS | 5,260 | 2,720 | News, Social Media |
| Hansel-ZS | 4,715 | 4,046 | News, Social Media, E-books, etc.|
## Citation
If you find our dataset useful, please cite us.
```bibtex
@inproceedings{xu2022hansel,
author = {Xu, Zhenran and Shan, Zifei and Li, Yuxin and Hu, Baotian and Qin, Bing},
title = {Hansel: A Chinese Few-Shot and Zero-Shot Entity Linking Benchmark},
year = {2023},
publisher = {Association for Computing Machinery},
url = {https://doi.org/10.1145/3539597.3570418},
booktitle = {Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining},
pages = {832–840}
}
```
|
michelecafagna26/hl | ---
license: apache-2.0
task_categories:
- image-to-text
- question-answering
- zero-shot-classification
language:
- en
multilinguality:
- monolingual
task_ids:
- text-scoring
pretty_name: HL (High-Level Dataset)
size_categories:
- 10K<n<100K
annotations_creators:
- crowdsourced
annotations_origin:
- crowdsourced
dataset_info:
splits:
- name: train
num_examples: 13498
- name: test
num_examples: 1499
---
# Dataset Card for the High-Level Dataset
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Supported Tasks](#supported-tasks)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
The High-Level (HL) dataset aligns **object-centric descriptions** from [COCO](https://arxiv.org/pdf/1405.0312.pdf)
with **high-level descriptions** crowdsourced along 3 axes: **_scene_, _action_, _rationale_**
The HL dataset contains 14997 images from COCO and a total of 134973 crowdsourced captions (3 captions for each axis) aligned with ~749984 object-centric captions from COCO.
Each axis is collected by asking the following 3 questions:
1) Where is the picture taken?
2) What is the subject doing?
3) Why is the subject doing it?
**The high-level descriptions capture the human interpretations of the images**. These interpretations contain abstract concepts not directly linked to physical objects.
Each high-level description is provided with a _confidence score_, crowdsourced by an independent worker measuring the extent to which
the high-level description is likely given the corresponding image, question, and caption. The higher the score, the more the high-level caption is close to the commonsense (in a Likert scale from 1-5).
- **🗃️ Repository:** [github.com/michelecafagna26/HL-dataset](https://github.com/michelecafagna26/HL-dataset)
- **📜 Paper:** [HL Dataset: Visually-grounded Description of Scenes, Actions and Rationales](https://arxiv.org/abs/2302.12189?context=cs.CL)
- **🧭 Spaces:** [Dataset explorer](https://huggingface.co/spaces/michelecafagna26/High-Level-Dataset-explorer)
- **🖊️ Contact:** michele.cafagna@um.edu.mt
### Supported Tasks
- image captioning
- visual question answering
- multimodal text-scoring
- zero-shot evaluation
### Languages
English
## Dataset Structure
The dataset is provided with images from COCO and two metadata jsonl files containing the annotations
### Data Instances
An instance looks like this:
```json
{
"file_name": "COCO_train2014_000000138878.jpg",
"captions": {
"scene": [
"in a car",
"the picture is taken in a car",
"in an office."
],
"action": [
"posing for a photo",
"the person is posing for a photo",
"he's sitting in an armchair."
],
"rationale": [
"to have a picture of himself",
"he wants to share it with his friends",
"he's working and took a professional photo."
],
"object": [
"A man sitting in a car while wearing a shirt and tie.",
"A man in a car wearing a dress shirt and tie.",
"a man in glasses is wearing a tie",
"Man sitting in the car seat with button up and tie",
"A man in glasses and a tie is near a window."
]
},
"confidence": {
"scene": [
5,
5,
4
],
"action": [
5,
5,
4
],
"rationale": [
5,
5,
4
]
},
"purity": {
"scene": [
-1.1760284900665283,
-1.0889461040496826,
-1.442818284034729
],
"action": [
-1.0115827322006226,
-0.5917857885360718,
-1.6931917667388916
],
"rationale": [
-1.0546956062316895,
-0.9740906357765198,
-1.2204363346099854
]
},
"diversity": {
"scene": 25.965358893403383,
"action": 32.713305568898775,
"rationale": 2.658757840479801
}
}
```
### Data Fields
- ```file_name```: original COCO filename
- ```captions```: Dict containing all the captions for the image. Each axis can be accessed with the axis name and it contains a list of captions.
- ```confidence```: Dict containing the captions confidence scores. Each axis can be accessed with the axis name and it contains a list of captions. Confidence scores are not provided for the _object_ axis (COCO captions).t
- ```purity score```: Dict containing the captions purity scores. The purity score measures the semantic similarity of the captions within the same axis (Bleurt-based).
- ```diversity score```: Dict containing the captions diversity scores. The diversity score measures the lexical diversity of the captions within the same axis (Self-BLEU-based).
### Data Splits
There are 14997 images and 134973 high-level captions split into:
- Train-val: 13498 images and 121482 high-level captions
- Test: 1499 images and 13491 high-level captions
## Dataset Creation
The dataset has been crowdsourced on Amazon Mechanical Turk.
From the paper:
>We randomly select 14997 images from the COCO 2014 train-val split. In order to answer questions related to _actions_ and _rationales_ we need to
> ensure the presence of a subject in the image. Therefore, we leverage the entity annotation provided in COCO to select images containing
> at least one person. The whole annotation is conducted on Amazon Mechanical Turk (AMT). We split the workload into batches in order to ease
>the monitoring of the quality of the data collected. Each image is annotated by three different annotators, therefore we collect three annotations per axis.
### Curation Rationale
From the paper:
>In this work, we tackle the issue of **grounding high-level linguistic concepts in the visual modality**, proposing the High-Level (HL) Dataset: a
V\&L resource aligning existing object-centric captions with human-collected high-level descriptions of images along three different axes: _scenes_, _actions_ and _rationales_.
The high-level captions capture the human interpretation of the scene, providing abstract linguistic concepts complementary to object-centric captions
>used in current V\&L datasets, e.g. in COCO. We take a step further, and we collect _confidence scores_ to distinguish commonsense assumptions
>from subjective interpretations and we characterize our data under a variety of semantic and lexical aspects.
### Source Data
- Images: COCO
- object axis annotations: COCO
- scene, action, rationale annotations: crowdsourced
- confidence scores: crowdsourced
- purity score and diversity score: automatically computed
#### Annotation process
From the paper:
>**Pilot:** We run a pilot study with the double goal of collecting feedback and defining the task instructions.
>With the results from the pilot we design a beta version of the task and we run a small batch of cases on the crowd-sourcing platform.
>We manually inspect the results and we further refine the instructions and the formulation of the task before finally proceeding with the
>annotation in bulk. The final annotation form is shown in Appendix D.
>***Procedure:*** The participants are shown an image and three questions regarding three aspects or axes: _scene_, _actions_ and _rationales_
> i,e. _Where is the picture taken?_, _What is the subject doing?_, _Why is the subject doing it?_. We explicitly ask the participants to use
>their personal interpretation of the scene and add examples and suggestions in the instructions to further guide the annotators. Moreover,
>differently from other VQA datasets like (Antol et al., 2015) and (Zhu et al., 2016), where each question can refer to different entities
>in the image, we systematically ask the same three questions about the same subject for each image. The full instructions are reported
>in Figure 1. For details regarding the annotation costs see Appendix A.
#### Who are the annotators?
Turkers from Amazon Mechanical Turk
### Personal and Sensitive Information
There is no personal or sensitive information
## Considerations for Using the Data
[More Information Needed]
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
From the paper:
>**Quantitying grammatical errors:** We ask two expert annotators to correct grammatical errors in a sample of 9900 captions, 900 of which are shared between the two annotators.
> The annotators are shown the image caption pairs and they are asked to edit the caption whenever they identify a grammatical error.
>The most common errors reported by the annotators are:
>- Misuse of prepositions
>- Wrong verb conjugation
>- Pronoun omissions
>In order to quantify the extent to which the corrected captions differ from the original ones, we compute the Levenshtein distance (Levenshtein, 1966) between them.
>We observe that 22.5\% of the sample has been edited and only 5\% with a Levenshtein distance greater than 10. This suggests a reasonable
>level of grammatical quality overall, with no substantial grammatical problems. This can also be observed from the Levenshtein distance
>distribution reported in Figure 2. Moreover, the human evaluation is quite reliable as we observe a moderate inter-annotator agreement
>(alpha = 0.507, (Krippendorff, 2018) computed over the shared sample.
### Dataset Curators
Michele Cafagna
### Licensing Information
The Images and the object-centric captions follow the [COCO terms of Use](https://cocodataset.org/#termsofuse)
The remaining annotations are licensed under Apache-2.0 license.
### Citation Information
```BibTeX
@inproceedings{cafagna2023hl,
title={{HL} {D}ataset: {V}isually-grounded {D}escription of {S}cenes, {A}ctions and
{R}ationales},
author={Cafagna, Michele and van Deemter, Kees and Gatt, Albert},
booktitle={Proceedings of the 16th International Natural Language Generation Conference (INLG'23)},
address = {Prague, Czech Republic},
year={2023}
}
```
|
animelover/danbooru2022 | ---
license: cc0-1.0
task_categories:
- text-to-image
language:
- en
pretty_name: Danbooru 2022
size_categories:
- 1M<n<10M
tags:
- art
---
Collect images from [danbooru website](https://danbooru.donmai.us/).
Post id range: 6019085 - 1019085
About 4M+ images.
All images with the shortest edge greater than 768 are scaled to the shortest edge equal to 768.
Some images not download in the range:
- need gold account
- removed
- over 25000000 pixels
- has one of ['furry', "realistic", "3d", "1940s_(style)","1950s_(style)","1960s_(style)","1970s_(style)","1980s_(style)","1990s_(style)","retro_artstyle","screentones","pixel_art","magazine_scan","scan"] tag. |
Chinese-Vicuna/guanaco_belle_merge_v1.0 | ---
license: gpl-3.0
language:
- zh
- en
- ja
---
Thanks for [Guanaco Dataset](https://huggingface.co/datasets/JosephusCheung/GuanacoDataset) and [Belle Dataset](https://huggingface.co/datasets/BelleGroup/generated_train_0.5M_CN)
This dataset was created by merging the above two datasets in a certain format so that they can be used for training our code [Chinese-Vicuna](https://github.com/Facico/Chinese-Vicuna) |
DrBenchmark/QUAERO | ---
language:
- fr
license: other
multilinguality: monolingual
pretty_name: QUAERO
homepage: https://quaerofrenchmed.limsi.fr/
task_categories:
- token-classification
tags:
- medical
size_categories:
- 1K<n<10K
---
# Dataset Card for QUAERO
## Dataset Description
- **Homepage:** https://quaerofrenchmed.limsi.fr/
- **Pubmed:** True
- **Public:** True
- **Tasks:** Named-Entity Recognition (NER)
The QUAERO French Medical Corpus has been initially developed as a resource for named entity recognition and normalization [1]. It was then improved with the purpose of creating a gold standard set of normalized entities for French biomedical text, that was used in the CLEF eHealth evaluation lab [2][3].
A selection of MEDLINE titles and EMEA documents were manually annotated. The annotation process was guided by concepts in the Unified Medical Language System (UMLS):
1. Ten types of clinical entities, as defined by the following UMLS Semantic Groups (Bodenreider and McCray 2003) were annotated: Anatomy, Chemical and Drugs, Devices, Disorders, Geographic Areas, Living Beings, Objects, Phenomena, Physiology, Procedures.
2. The annotations were made in a comprehensive fashion, so that nested entities were marked, and entities could be mapped to more than one UMLS concept. In particular: (a) If a mention can refer to more than one Semantic Group, all the relevant Semantic Groups should be annotated. For instance, the mention “récidive” (recurrence) in the phrase “prévention des récidives” (recurrence prevention) should be annotated with the category “DISORDER” (CUI C2825055) and the category “PHENOMENON” (CUI C0034897); (b) If a mention can refer to more than one UMLS concept within the same Semantic Group, all the relevant concepts should be annotated. For instance, the mention “maniaques” (obsessive) in the phrase “patients maniaques” (obsessive patients) should be annotated with CUIs C0564408 and C0338831 (category “DISORDER”); (c) Entities which span overlaps with that of another entity should still be annotated. For instance, in the phrase “infarctus du myocarde” (myocardial infarction), the mention “myocarde” (myocardium) should be annotated with category “ANATOMY” (CUI C0027061) and the mention “infarctus du myocarde” should be annotated with category “DISORDER” (CUI C0027051)
The QUAERO French Medical Corpus BioC release comprises a subset of the QUAERO French Medical corpus, as follows:
Training data (BRAT version used in CLEF eHealth 2015 task 1b as training data):
- MEDLINE_train_bioc file: 833 MEDLINE titles, annotated with normalized entities in the BioC format
- EMEA_train_bioc file: 3 EMEA documents, segmented into 11 sub-documents, annotated with normalized entities in the BioC format
Development data (BRAT version used in CLEF eHealth 2015 task 1b as test data and in CLEF eHealth 2016 task 2 as development data):
- MEDLINE_dev_bioc file: 832 MEDLINE titles, annotated with normalized entities in the BioC format
- EMEA_dev_bioc file: 3 EMEA documents, segmented into 12 sub-documents, annotated with normalized entities in the BioC format
Test data (BRAT version used in CLEF eHealth 2016 task 2 as test data):
- MEDLINE_test_bioc folder: 833 MEDLINE titles, annotated with normalized entities in the BioC format
- EMEA folder_test_bioc: 4 EMEA documents, segmented into 15 sub-documents, annotated with normalized entities in the BioC format
This release of the QUAERO French medical corpus, BioC version, comes in the BioC format, through automatic conversion from the original BRAT format obtained with the Brat2BioC tool https://bitbucket.org/nicta_biomed/brat2bioc developped by Jimeno Yepes et al.
Antonio Jimeno Yepes, Mariana Neves, Karin Verspoor
Brat2BioC: conversion tool between brat and BioC
BioCreative IV track 1 - BioC: The BioCreative Interoperability Initiative, 2013
Please note that the original version of the QUAERO corpus distributed in the CLEF eHealth challenge 2015 and 2016 came in the BRAT stand alone format. It was distributed with the CLEF eHealth evaluation tool. This original distribution of the QUAERO French Medical corpus is available separately from https://quaerofrenchmed.limsi.fr
All questions regarding the task or data should be addressed to aurelie.neveol@limsi.fr
## Citation Information
```
@InProceedings{neveol14quaero,
author = {Névéol, Aurélie and Grouin, Cyril and Leixa, Jeremy
and Rosset, Sophie and Zweigenbaum, Pierre},
title = {The {QUAERO} {French} Medical Corpus: A Ressource for
Medical Entity Recognition and Normalization},
OPTbooktitle = {Proceedings of the Fourth Workshop on Building
and Evaluating Ressources for Health and Biomedical
Text Processing},
booktitle = {Proc of BioTextMining Work},
OPTseries = {BioTxtM 2014},
year = {2014},
pages = {24--30},
}
``` |
TrainingDataPro/facial_keypoint_detection | ---
license: cc-by-nc-nd-4.0
task_categories:
- image-classification
language:
- en
tags:
- code
- finance
dataset_info:
features:
- name: image_id
dtype: uint32
- name: image
dtype: image
- name: mask
dtype: image
- name: key_points
dtype: string
splits:
- name: train
num_bytes: 134736982
num_examples: 15
download_size: 129724970
dataset_size: 134736982
---
# Facial Keypoints
The dataset is designed for computer vision and machine learning tasks involving the identification and analysis of key points on a human face. It consists of images of human faces, each accompanied by key point annotations in XML format.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market/facial-keypoints-detection?utm_source=huggingface&utm_medium=cpc&utm_campaign=facial_keypoint_detection) to discuss your requirements, learn about the price and buy the dataset.

# Data Format
Each image from `FKP` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the key points. For each point, the x and y coordinates are provided, and there is a `Presumed_Location` attribute, indicating whether the point is presumed or accurately defined.
# Example of XML file structure
# Labeled Keypoints
**1.** Left eye, the closest point to the nose
**2.** Left eye, pupil's center
**3.** Left eye, the closest point to the left ear
**4.** Right eye, the closest point to the nose
**5.** Right eye, pupil's center
**6.** Right eye, the closest point to the right ear
**7.** Left eyebrow, the closest point to the nose
**8.** Left eyebrow, the closest point to the left ear
**9.** Right eyebrow, the closest point to the nose
**10.** Right eyebrow, the closest point to the right ear
**11.** Nose, center
**12.** Mouth, left corner point
**13.** Mouth, right corner point
**14.** Mouth, the highest point in the middle
**15.** Mouth, the lowest point in the middle
# Keypoint annotation is made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market/facial-keypoints-detection?utm_source=huggingface&utm_medium=cpc&utm_campaign=facial_keypoint_detection) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
emozilla/booksum-summary-analysis_gptneox-8192 | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: type
dtype: string
splits:
- name: train
num_bytes: 194097976.97925937
num_examples: 10659
- name: test
num_bytes: 25683201.043425813
num_examples: 1570
- name: validation
num_bytes: 35799607.99283796
num_examples: 1824
download_size: 92249754
dataset_size: 255580786.01552314
---
# Dataset Card for "booksum-summary-analysis-8192"
Subset of [emozilla/booksum-summary-analysis](https://huggingface.co/datasets/emozilla/booksum-summary-analysis) with only entries that are less than 8,192 tokens under the [EleutherAI/gpt-neox-20b](https://huggingface.co/EleutherAI/gpt-neox-20b) tokenizer. |
ibm-nasa-geospatial/hls_burn_scars | ---
size_categories:
- n<1K
license: cc-by-4.0
language:
- en
---
# Dataset Card for HLS Burn Scar Scenes
## Dataset Description
- **Homepage: https://huggingface.co/datasets/nasa-impact/hls_burn_scars**
- **Point of Contact: Dr. Christopher Phillips (cep0013@uah.edu)**
### Dataset Summary
This dataset contains Harmonized Landsat and Sentinel-2 imagery of burn scars and the associated masks for the years 2018-2021 over the contiguous United States. There are 804 512x512 scenes. Its primary purpose is for training geospatial machine learning models.
## Dataset Structure
## TIFF Metadata
Each tiff file contains a 512x512 pixel tiff file. Scenes contain six bands, and masks have one band. For satellite scenes, each band has already been converted to reflectance.
## Band Order
For scenes:
Channel, Name, HLS S30 Band number
1, Blue, B02
2, Green, B03
3, Red, B04
4, NIR, B8A
5, SW 1, B11
6, SW 2, B12
Masks are a single band with values:
1 = Burn scar
0 = Not burned
-1 = Missing data
## Class Distribution
Burn Scar - 11%
Not burned - 88%
No Data - 1%
## Data Splits
The 804 files have been randomly split into training (2/3) and validation (1/3) directories, each containing the masks, scenes, and index files.
## Dataset Creation
After co-locating the shapefile and HLS scene, the 512x512 chip was formed by taking a window with the burn scar in the center. Burn scars near the edges of HLS tiles are offset from the center.
Images were manually filtered for cloud cover and missing data to provide as clean a scene as possible, and burn scar presence was also manually verified.
## Source Data
Imagery are from V1.4 of HLS. A full description and access to HLS may be found at https://hls.gsfc.nasa.gov/
The data were from shapefiles maintained by the Monitoring Trends in Burn Severity (MTBS) group. The original data may be found at:
https://mtbs.gov/
## Citation
If this dataset helped your research, please cite `HLS Burn Scars` in your publications. Here is an example BibTeX entry:
```
@software{HLS_Foundation_2023,
author = {Phillips, Christopher and Roy, Sujit and Ankur, Kumar and Ramachandran, Rahul},
doi = {10.57967/hf/0956},
month = aug,
title = {{HLS Foundation Burnscars Dataset}},
url = {https://huggingface.co/ibm-nasa-geospatial/hls_burn_scars},
year = {2023}
}
``` |