
datasetId
stringlengths 2
81
| card
stringlengths 20
977k
|
|---|---|
princeton-nlp/QuRatedPajama-260B | ---
pretty_name: QuRatedPajama-260B
---
## QuRatedPajama
**Paper:** [QuRating: Selecting High-Quality Data for Training Language Models](https://arxiv.org/pdf/2402.09739.pdf)
A 260B token subset of [cerebras/SlimPajama-627B](https://huggingface.co/datasets/cerebras/SlimPajama-627B), annotated by [princeton-nlp/QuRater-1.3B](https://huggingface.co/princeton-nlp/QuRater-1.3B/tree/main) with sequence-level quality ratings across 4 criteria:
- **Educational Value** - e.g. the text includes clear explanations, step-by-step reasoning, or questions and answers
- **Facts & Trivia** - how much factual and trivia knowledge the text contains, where specific facts and obscure trivia are preferred over more common knowledge
- **Writing Style** - how polished and good is the writing style in the text
- **Required Expertise**: - how much required expertise and prerequisite knowledge is necessary to understand the text
In a pre-processing step, we split documents in into chunks of exactly 1024 tokens. We provide tokenization with the Llama-2 tokenizer in the `input_ids` column.
**Guidance on Responsible Use:**
In the paper, we document various types of bias that are present in the quality ratings (biases related to domains, topics, social roles, regions and languages - see Section 6 of the paper).
Hence, be aware that data selection with QuRating could have unintended and harmful effects on the language model that is being trained. We strongly recommend a comprehensive evaluation of the language model for these and other types of bias, particularly before real-world deployment. We hope that releasing the data/models can facilitate future research aimed at uncovering and mitigating such biases.
**Citation:**
```
@article{wettig2024qurating,
title={QuRating: Selecting High-Quality Data for Training Language Models},
author={Alexander Wettig, Aatmik Gupta, Saumya Malik, Danqi Chen},
journal={arXiv preprint 2402.09739},
year={2024}
}
``` |
5CD-AI/Vietnamese-yfcc15m-OpenAICLIP | ---
task_categories:
- image-to-text
- text-to-image
- visual-question-answering
language:
- en
- vi
size_categories:
- 10M<n<100M
--- |
Locutusque/OpenCerebrum-dpo | ---
license: apache-2.0
task_categories:
- text-generation
language:
- en
size_categories:
- 10K<n<100K
---
# OpenCerebrum DPO subset

## Description
OpenCerebrum is my take on creating an open source version of Aether Research's proprietary Cerebrum dataset. This repository contains the DPO subset, which contains about 21,000 examples. Unfortunately, I was unsure about how I would compress this dataset to just a few hundred examples like in the original Cerebrum dataset.
## Curation
This dataset was curated using a simple and logical rationale. The goal was to use datasets that should logically improve evaluation scores that the original Cerebrum is strong in. See the "Data Sources" section for data source information.
## Data Sources
This dataset is an amalgamation including the following sources:
- jondurbin/truthy-dpo-v0.1
- jondurbin/py-dpo-v0.1
- argilla/dpo-mix-7k
- argilla/distilabel-math-preference-dpo
- Locutusque/arc-cot-dpo
- Doctor-Shotgun/theory-of-mind-dpo |
efederici/fisica | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: source
dtype: string
splits:
- name: train
num_bytes: 71518930
num_examples: 27999
download_size: 35743633
dataset_size: 71518930
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
task_categories:
- question-answering
- text-generation
language:
- it
tags:
- physics
- opus
- anthropic
- gpt-4
pretty_name: Fisica
size_categories:
- 10K<n<100K
---
# Dataset Card
Fisica is a comprehensive Italian question-answering dataset focused on physics. It contains approximately 28,000 question-answer pairs, generated using Claude and GPT-4. The dataset is designed to facilitate research and development of LLMs for the Italian language.
### Dataset Description
- **Curated by:** Edoardo Federici
- **Language(s) (NLP):** Italian
- **License:** MIT
### Features
- **Diverse Physics Topics**: The dataset covers a wide range of physics topics, providing a rich resource for physics-related questions and answers.
- **High-Quality Pairs**: The question-answer pairs were generated using Claude Opus / translated using Claude Sonnet.
- **Italian Language**: Fisica is specifically curated for the Italian language, contributing to the development of Italian-specific LLMs.
### Data Sources
The dataset comprises question-answer pairs from two main sources:
1. ~8,000 pairs generated using Claude Opus from a list of seed topics
2. 20,000 pairs translated (using Claude Sonnet) from the [camel-ai/physics](https://huggingface.co/datasets/camel-ai/physics) gpt-4 dataset |
hackathon-pln-es/Axolotl-Spanish-Nahuatl | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- es
license:
- mpl-2.0
multilinguality:
- translation
size_categories:
- unknown
source_datasets:
- original
task_categories:
- text2text-generation
- translation
task_ids: []
pretty_name: "Axolotl Spanish-Nahuatl parallel corpus , is a digital corpus that compiles\
\ several sources with parallel content in these two languages. \n\nA parallel corpus\
\ is a type of corpus that contains texts in a source language with their correspondent\
\ translation in one or more target languages. Gutierrez-Vasques, X., Sierra, G.,\
\ and Pompa, I. H. (2016). Axolotl: a web accessible parallel corpus for spanish-nahuatl.\
\ In Proceedings of the Ninth International Conference on Language Resources and\
\ Evaluation (LREC 2016), Portoro, Slovenia. European Language Resources Association\
\ (ELRA). Grupo de Ingenieria Linguistica (GIL, UNAM). Corpus paralelo español-nahuatl.\
\ http://www.corpus.unam.mx/axolotl."
language_bcp47:
- es-MX
tags:
- conditional-text-generation
---
# Axolotl-Spanish-Nahuatl : Parallel corpus for Spanish-Nahuatl machine translation
## Table of Contents
- [Dataset Card for [Axolotl-Spanish-Nahuatl]](#dataset-card-for-Axolotl-Spanish-Nahuatl)
## Dataset Description
- **Source 1:** http://www.corpus.unam.mx/axolotl
- **Source 2:** http://link.springer.com/article/10.1007/s10579-014-9287-y
- **Repository:1** https://github.com/ElotlMX/py-elotl
- **Repository:2** https://github.com/christos-c/bible-corpus/blob/master/bibles/Nahuatl-NT.xml
- **Paper:** https://aclanthology.org/N15-2021.pdf
## Dataset Collection
In order to get a good translator, we collected and cleaned two of the most complete Nahuatl-Spanish parallel corpora available. Those are Axolotl collected by an expert team at UNAM and Bible UEDIN Nahuatl Spanish crawled by Christos Christodoulopoulos and Mark Steedman from Bible Gateway site.
After this, we ended with 12,207 samples from Axolotl due to misalignments and duplicated texts in Spanish in both original and nahuatl columns and 7,821 samples from Bible UEDIN for a total of 20028 utterances.
## Team members
- Emilio Morales [(milmor)](https://huggingface.co/milmor)
- Rodrigo Martínez Arzate [(rockdrigoma)](https://huggingface.co/rockdrigoma)
- Luis Armando Mercado [(luisarmando)](https://huggingface.co/luisarmando)
- Jacobo del Valle [(jjdv)](https://huggingface.co/jjdv)
## Applications
- MODEL: Spanish Nahuatl Translation Task with a T5 model in ([t5-small-spanish-nahuatl](https://huggingface.co/hackathon-pln-es/t5-small-spanish-nahuatl))
- DEMO: Spanish Nahuatl Translation in ([Spanish-nahuatl](https://huggingface.co/spaces/hackathon-pln-es/Spanish-Nahuatl-Translation)) |
priyank-m/SROIE_2019_text_recognition | ---
annotations_creators: []
language:
- en
language_creators: []
license: []
multilinguality:
- monolingual
pretty_name: SROIE_2019_text_recognition
size_categories:
- 10K<n<100K
source_datasets: []
tags:
- text-recognition
- recognition
task_categories:
- image-to-text
task_ids:
- image-captioning
---
This dataset we prepared using the Scanned receipts OCR and information extraction(SROIE) dataset.
The SROIE dataset contains 973 scanned receipts in English language.
Cropping the bounding boxes from each of the receipts to generate this text-recognition dataset resulted in 33626 images for train set and 18704 images for the test set.
The text annotations for all the images inside a split are stored in a metadata.jsonl file.
usage:
from dataset import load_dataset
data = load_dataset("priyank-m/SROIE_2019_text_recognition")
source of raw SROIE dataset:
https://www.kaggle.com/datasets/urbikn/sroie-datasetv2 |
heegyu/kowiki-sentences | ---
license: cc-by-sa-3.0
language:
- ko
language_creators:
- other
multilinguality:
- monolingual
size_categories:
- 1M<n<10M
task_categories:
- other
---
20221001 한국어 위키를 kss(backend=mecab)을 이용해서 문장 단위로 분리한 데이터
- 549262 articles, 4724064 sentences
- 한국어 비중이 50% 이하거나 한국어 글자가 10자 이하인 경우를 제외 |
bigbio/meddocan |
---
language:
- es
bigbio_language:
- Spanish
license: cc-by-4.0
multilinguality: monolingual
bigbio_license_shortname: CC_BY_4p0
pretty_name: MEDDOCAN
homepage: https://temu.bsc.es/meddocan/
bigbio_pubmed: False
bigbio_public: True
bigbio_tasks:
- NAMED_ENTITY_RECOGNITION
---
# Dataset Card for MEDDOCAN
## Dataset Description
- **Homepage:** https://temu.bsc.es/meddocan/
- **Pubmed:** False
- **Public:** True
- **Tasks:** NER
MEDDOCAN: Medical Document Anonymization Track
This dataset is designed for the MEDDOCAN task, sponsored by Plan de Impulso de las Tecnologías del Lenguaje.
It is a manually classified collection of 1,000 clinical case reports derived from the Spanish Clinical Case Corpus (SPACCC), enriched with PHI expressions.
The annotation of the entire set of entity mentions was carried out by experts annotatorsand it includes 29 entity types relevant for the annonymiation of medical documents.22 of these annotation types are actually present in the corpus: TERRITORIO, FECHAS, EDAD_SUJETO_ASISTENCIA, NOMBRE_SUJETO_ASISTENCIA, NOMBRE_PERSONAL_SANITARIO, SEXO_SUJETO_ASISTENCIA, CALLE, PAIS, ID_SUJETO_ASISTENCIA, CORREO, ID_TITULACION_PERSONAL_SANITARIO,ID_ASEGURAMIENTO, HOSPITAL, FAMILIARES_SUJETO_ASISTENCIA, INSTITUCION, ID_CONTACTO ASISTENCIAL,NUMERO_TELEFONO, PROFESION, NUMERO_FAX, OTROS_SUJETO_ASISTENCIA, CENTRO_SALUD, ID_EMPLEO_PERSONAL_SANITARIO
For further information, please visit https://temu.bsc.es/meddocan/ or send an email to encargo-pln-life@bsc.es
## Citation Information
```
@inproceedings{marimon2019automatic,
title={Automatic De-identification of Medical Texts in Spanish: the MEDDOCAN Track, Corpus, Guidelines, Methods and Evaluation of Results.},
author={Marimon, Montserrat and Gonzalez-Agirre, Aitor and Intxaurrondo, Ander and Rodriguez, Heidy and Martin, Jose Lopez and Villegas, Marta and Krallinger, Martin},
booktitle={IberLEF@ SEPLN},
pages={618--638},
year={2019}
}
```
|
parambharat/malayalam_asr_corpus | ---
annotations_creators:
- found
language:
- ml
language_creators:
- found
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Malayalam ASR Corpus
size_categories:
- 1K<n<10K
source_datasets:
- extended|common_voice
- extended|openslr
tags: []
task_categories:
- automatic-speech-recognition
task_ids: []
---
# Dataset Card for [Malayalam Asr Corpus]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@parambharat](https://github.com/parambharat) for adding this dataset. |
HuggingFaceM4/LocalizedNarratives | ---
license: cc-by-4.0
---
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://google.github.io/localized-narratives/(https://google.github.io/localized-narratives/)
- **Repository:**: [https://github.com/google/localized-narratives](https://github.com/google/localized-narratives)
- **Paper:** [Connecting Vision and Language with Localized Narratives](https://arxiv.org/pdf/1912.03098.pdf)
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
Localized Narratives, a new form of multimodal image annotations connecting vision and language.
We ask annotators to describe an image with their voice while simultaneously hovering their mouse over the region they are describing.
Since the voice and the mouse pointer are synchronized, we can localize every single word in the description.
This dense visual grounding takes the form of a mouse trace segment per word and is unique to our data.
We annotated 849k images with Localized Narratives: the whole COCO, Flickr30k, and ADE20K datasets, and 671k images of Open Images, all of which we make publicly available.
As of now, there is only the `OpenImages` subset, but feel free to contribute the other subset of Localized Narratives!
`OpenImages_captions` is similar to the `OpenImages` subset. The differences are that captions are groupped per image (images can have multiple captions). For this subset, `timed_caption`, `traces` and `voice_recording` are not available.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
Each instance has the following structure:
```
{
dataset_id: 'mscoco_val2017',
image_id: '137576',
annotator_id: 93,
caption: 'In this image there are group of cows standing and eating th...',
timed_caption: [{'utterance': 'In this', 'start_time': 0.0, 'end_time': 0.4}, ...],
traces: [[{'x': 0.2086, 'y': -0.0533, 't': 0.022}, ...], ...],
voice_recording: 'coco_val/coco_val_137576_93.ogg'
}
```
### Data Fields
Each line represents one Localized Narrative annotation on one image by one annotator and has the following fields:
- `dataset_id`: String identifying the dataset and split where the image belongs, e.g. mscoco_val2017.
- `image_id` String identifier of the image, as specified on each dataset.
- `annotator_id` Integer number uniquely identifying each annotator.
- `caption` Image caption as a string of characters.
- `timed_caption` List of timed utterances, i.e. {utterance, start_time, end_time} where utterance is a word (or group of words) and (start_time, end_time) is the time during which it was spoken, with respect to the start of the recording.
- `traces` List of trace segments, one between each time the mouse pointer enters the image and goes away from it. Each trace segment is represented as a list of timed points, i.e. {x, y, t}, where x and y are the normalized image coordinates (with origin at the top-left corner of the image) and t is the time in seconds since the start of the recording. Please note that the coordinates can go a bit beyond the image, i.e. <0 or >1, as we recorded the mouse traces including a small band around the image.
- `voice_recording` Relative URL path with respect to https://storage.googleapis.com/localized-narratives/voice-recordings where to find the voice recording (in OGG format) for that particular image.
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@VictorSanh](https://github.com/VictorSanh) for adding this dataset.
|
keremberke/table-extraction | ---
task_categories:
- object-detection
tags:
- roboflow
- roboflow2huggingface
- Documents
---
<div align="center">
<img width="640" alt="keremberke/table-extraction" src="https://huggingface.co/datasets/keremberke/table-extraction/resolve/main/thumbnail.jpg">
</div>
### Dataset Labels
```
['bordered', 'borderless']
```
### Number of Images
```json
{'test': 34, 'train': 238, 'valid': 70}
```
### How to Use
- Install [datasets](https://pypi.org/project/datasets/):
```bash
pip install datasets
```
- Load the dataset:
```python
from datasets import load_dataset
ds = load_dataset("keremberke/table-extraction", name="full")
example = ds['train'][0]
```
### Roboflow Dataset Page
[https://universe.roboflow.com/mohamed-traore-2ekkp/table-extraction-pdf/dataset/2](https://universe.roboflow.com/mohamed-traore-2ekkp/table-extraction-pdf/dataset/2?ref=roboflow2huggingface)
### Citation
```
```
### License
CC BY 4.0
### Dataset Summary
This dataset was exported via roboflow.com on January 18, 2023 at 9:41 AM GMT
Roboflow is an end-to-end computer vision platform that helps you
* collaborate with your team on computer vision projects
* collect & organize images
* understand and search unstructured image data
* annotate, and create datasets
* export, train, and deploy computer vision models
* use active learning to improve your dataset over time
For state of the art Computer Vision training notebooks you can use with this dataset,
visit https://github.com/roboflow/notebooks
To find over 100k other datasets and pre-trained models, visit https://universe.roboflow.com
The dataset includes 342 images.
Data-table are annotated in COCO format.
The following pre-processing was applied to each image:
* Auto-orientation of pixel data (with EXIF-orientation stripping)
No image augmentation techniques were applied.
|
IlyaGusev/librusec | ---
dataset_info:
features:
- name: id
dtype: uint64
- name: text
dtype: string
splits:
- name: train
num_bytes: 125126513109
num_examples: 223256
download_size: 34905399148
dataset_size: 125126513109
task_categories:
- text-generation
language:
- ru
size_categories:
- 100K<n<1M
---
# Librusec dataset
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Description](#description)
- [Usage](#usage)
## Description
**Summary:** Based on http://panchenko.me/data/russe/librusec_fb2.plain.gz. Uploaded here for convenience. Additional cleaning was performed.
**Script:** [create_librusec.py](https://github.com/IlyaGusev/rulm/blob/master/data_processing/create_librusec.py)
**Point of Contact:** [Ilya Gusev](ilya.gusev@phystech.edu)
**Languages:** Russian.
## Usage
Prerequisites:
```bash
pip install datasets zstandard jsonlines pysimdjson
```
Dataset iteration:
```python
from datasets import load_dataset
dataset = load_dataset('IlyaGusev/librusec', split="train", streaming=True)
for example in dataset:
print(example["text"])
``` |
DFKI-SLT/DWIE | ---
license: other
language:
- en
pretty_name: >-
DWIE (Deutsche Welle corpus for Information Extraction) is a new dataset for
document-level multi-task Information Extraction (IE).
size_categories:
- 10M<n<100M
annotations_creators:
- expert-generated
language_creators:
- found
multilinguality:
- monolingual
paperswithcode_id: acronym-identification
source_datasets:
- original
tags:
- Named Entity Recognition, Coreference Resolution, Relation Extraction, Entity Linking
task_categories:
- feature-extraction
- text-classification
task_ids:
- entity-linking-classification
train-eval-index:
- col_mapping:
labels: tags
tokens: tokens
config: default
splits:
eval_split: test
task_id: entity_extraction
---
# Dataset Card for DWIE
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://opendatalab.com/DWIE](https://opendatalab.com/DWIE)
- **Repository:** [https://github.com/klimzaporojets/DWIE](https://github.com/klimzaporojets/DWIE)
- **Paper:** [DWIE: an entity-centric dataset for multi-task document-level information extraction](https://arxiv.org/abs/2009.12626)
- **Leaderboard:** [https://opendatalab.com/DWIE](https://opendatalab.com/DWIE)
- **Size of downloaded dataset files:** 40.8 MB
### Dataset Summary
DWIE (Deutsche Welle corpus for Information Extraction) is a new dataset for document-level multi-task Information Extraction (IE).
It combines four main IE sub-tasks:
1.Named Entity Recognition: 23,130 entities classified in 311 multi-label entity types (tags).
2.Coreference Resolution: 43,373 entity mentions clustered in 23,130 entities.
3.Relation Extraction: 21,749 annotated relations between entities classified in 65 multi-label relation types.
4.Entity Linking: the named entities are linked to Wikipedia (version 20181115).
For details, see the paper https://arxiv.org/pdf/2009.12626v2.pdf.
### Supported Tasks and Leaderboards
- **Tasks:** Named Entity Recognition, Coreference Resolution, Relation extraction and entity linking in scientific papers
- **Leaderboards:** [https://opendatalab.com/DWIE](https://opendatalab.com/DWIE)
### Languages
The language in the dataset is English.
## Dataset Structure
### Data Instances
- **Size of downloaded dataset files:** 40.8 MB
An example of 'train' looks as follows, provided sample of the data:
```json
{'id': 'DW_3980038',
'content': 'Proposed Nabucco Gas Pipeline Gets European Bank Backing\nThe heads of the EU\'s European Investment Bank and the European Bank for Reconstruction and Development (EBRD) said Tuesday, Jan. 27, that they are prepared to provide financial backing for the Nabucco gas pipeline.\nSpurred on by Europe\'s worst-ever gas crisis earlier this month, which left millions of homes across the continent without heat in the depths of winter, Hungarian Prime Minister Ferenc Gyurcsany invited top-ranking officials from both the EU and the countries involved in Nabucco to inject fresh momentum into the slow-moving project. Nabucco, an ambitious but still-unbuilt gas pipeline aimed at reducing Europe\'s energy reliance on Russia, is a 3,300-kilometer (2,050-mile) pipeline between Turkey and Austria. Costing an estimated 7.9 billion euros, the aim is to transport up to 31 billion cubic meters of gas each year from the Caspian Sea to Western Europe, bypassing Russia and Ukraine. Nabucco currently has six shareholders -- OMV of Austria, MOL of Hungary, Transgaz of Romania, Bulgargaz of Bulgaria, Botas of Turkey and RWE of Germany. But for the pipeline to get moving, Nabucco would need an initial cash injection of an estimated 300 million euros. Both the EIB and EBRD said they were willing to invest in the early stages of the project through a series of loans, providing certain conditions are met. "The EIB is ready to finance projects that further EU objectives of increased sustainability and energy security," said Philippe Maystadt, president of the European Investment Bank, during the opening addresses by participants at the "Nabucco summit" in Hungary. The EIB is prepared to finance "up to 25 percent of project cost," provided a secure intergovernmental agreement on the Nabucco pipeline is reached, he said. Maystadt noted that of 48 billion euros of financing it provided last year, a quarter was for energy projects. EBRD President Thomas Mirow also offered financial backing to the Nabucco pipeline, on the condition that it "meets the requirements of solid project financing." The bank would need to see concrete plans and completion guarantees, besides a stable political agreement, said Mirow. EU wary of future gas crises Czech Prime Minister Mirek Topolanek, whose country currently holds the rotating presidency of the EU, spoke about the recent gas crisis caused by a pricing dispute between Russia and Ukraine that affected supplies to Europe. "A new crisis could emerge at any time, and next time it could be even worse," Topolanek said. He added that reaching an agreement on Nabucco is a "test of European solidarity." The latest gas row between Russia and Ukraine has highlighted Europe\'s need to diversify its energy sources and thrown the spotlight on Nabucco. But critics insist that the vast project will remain nothing but a pipe dream because its backers cannot guarantee that they will ever have sufficient gas supplies to make it profitable. EU Energy Commissioner Andris Piebalgs urged political leaders to commit firmly to Nabucco by the end of March, or risk jeopardizing the project. In his opening address as host, Hungarian Prime Minister Ferenc Gyurcsany called on the EU to provide 200 to 300 million euros within the next few weeks to get the construction of the pipeline off the ground. Gyurcsany stressed that he was not hoping for a loan, but rather for starting capital from the EU. US Deputy Assistant Secretary of State Matthew Bryza noted that the Tuesday summit had made it clear that Gyurcsany, who dismissed Nabucco as "a dream" in 2007, was now fully committed to the energy supply diversification project. On the supply side, Turkmenistan and Azerbaijan both indicated they would be willing to supply some of the gas. "Azerbaijan, which is according to current plans is a transit country, could eventually serve as a supplier as well," Azerbaijani President Ilham Aliyev said. Azerbaijan\'s gas reserves of some two or three trillion cubic meters would be sufficient to last "several decades," he said. Austrian Economy Minister Reinhold Mitterlehner suggested that Egypt and Iran could also be brought in as suppliers in the long term. But a deal currently seems unlikely with Iran given the long-running international standoff over its disputed nuclear program. Russia, Ukraine still wrangling Meanwhile, Russia and Ukraine were still wrangling over the details of the deal which ended their gas quarrel earlier this month. Ukrainian President Viktor Yushchenko said on Tuesday he would stand by the terms of the agreement with Russia, even though not all the details are to his liking. But Russian officials questioned his reliability, saying that the political rivalry between Yushchenko and Prime Minister Yulia Timoshenko could still lead Kiev to cancel the contract. "The agreements signed are not easy ones, but Ukraine fully takes up the performance (of its commitments) and guarantees full-fledged transit to European consumers," Yushchenko told journalists in Brussels after a meeting with the head of the European Commission, Jose Manuel Barroso. The assurance that Yushchenko would abide by the terms of the agreement finalized by Timoshenko was "an important step forward in allowing us to focus on our broader relationship," Barroso said. But the spokesman for Russian Prime Minister Vladimir Putin said that Moscow still feared that the growing rivalry between Yushchenko and Timoshenko, who are set to face off in next year\'s presidential election, could torpedo the deal. EU in talks to upgrade Ukraine\'s transit system Yushchenko\'s working breakfast with Barroso was dominated by the energy question, with both men highlighting the need to upgrade Ukraine\'s gas-transit system and build more links between Ukrainian and European energy markets. The commission is set to host an international conference aimed at gathering donations to upgrade Ukraine\'s gas-transit system on March 23 in Brussels. The EU and Ukraine have agreed to form a joint expert group to plan the meeting, the leaders said Tuesday. During the conflict, Barroso had warned that both Russia and Ukraine were damaging their credibility as reliable partners. But on Monday he said that "in bilateral relations, we are not taking any negative consequences from (the gas row) because we believe Ukraine wants to deepen the relationship with the EU, and we also want to deepen the relationship with Ukraine." He also said that "we have to state very clearly that we were disappointed by the problems between Ukraine and Russia," and called for political stability and reform in Ukraine. His diplomatic balancing act is likely to have a frosty reception in Moscow, where Peskov said that Russia "would prefer to hear from the European states a very serious and severe evaluation of who is guilty for interrupting the transit."',
'tags': "['all', 'train']",
'mentions': [{'begin': 9,
'end': 29,
'text': 'Nabucco Gas Pipeline',
'concept': 1,
'candidates': [],
'scores': []},
{'begin': 287,
'end': 293,
'text': 'Europe',
'concept': 2,
'candidates': ['Europe',
'UEFA',
'Europe_(band)',
'UEFA_competitions',
'European_Athletic_Association',
'European_theatre_of_World_War_II',
'European_Union',
'Europe_(dinghy)',
'European_Cricket_Council',
'UEFA_Champions_League',
'Senior_League_World_Series_(Europe–Africa_Region)',
'Big_League_World_Series_(Europe–Africa_Region)',
'Sailing_at_the_2004_Summer_Olympics_–_Europe',
'Neolithic_Europe',
'History_of_Europe',
'Europe_(magazine)'],
'scores': [0.8408304452896118,
0.10987312346696854,
0.01377162616699934,
0.002099192701280117,
0.0015916954725980759,
0.0015686274273321033,
0.001522491336800158,
0.0013148789294064045,
0.0012456747936084867,
0.000991926179267466,
0.0008073817589320242,
0.0007843137136660516,
0.000761245668400079,
0.0006920415326021612,
0.0005536332027986646,
0.000530565157532692]},
0.00554528646171093,
0.004390018526464701,
0.003234750358387828,
0.002772643230855465,
0.001617375179193914]},
{'begin': 6757,
'end': 6765,
'text': 'European',
'concept': 13,
'candidates': None,
'scores': []}],
'concepts': [{'concept': 0,
'text': 'European Investment Bank',
'keyword': True,
'count': 5,
'link': 'European_Investment_Bank',
'tags': ['iptc::11000000',
'slot::keyword',
'topic::politics',
'type::entity',
'type::igo',
'type::organization']},
{'concept': 66,
'text': None,
'keyword': False,
'count': 0,
'link': 'Czech_Republic',
'tags': []}],
'relations': [{'s': 0, 'p': 'institution_of', 'o': 2},
{'s': 0, 'p': 'part_of', 'o': 2},
{'s': 3, 'p': 'institution_of', 'o': 2},
{'s': 3, 'p': 'part_of', 'o': 2},
{'s': 6, 'p': 'head_of', 'o': 0},
{'s': 6, 'p': 'member_of', 'o': 0},
{'s': 7, 'p': 'agent_of', 'o': 4},
{'s': 7, 'p': 'citizen_of', 'o': 4},
{'s': 7, 'p': 'citizen_of-x', 'o': 55},
{'s': 7, 'p': 'head_of_state', 'o': 4},
{'s': 7, 'p': 'head_of_state-x', 'o': 55},
{'s': 8, 'p': 'agent_of', 'o': 4},
{'s': 8, 'p': 'citizen_of', 'o': 4},
{'s': 8, 'p': 'citizen_of-x', 'o': 55},
{'s': 8, 'p': 'head_of_gov', 'o': 4},
{'s': 8, 'p': 'head_of_gov-x', 'o': 55},
{'s': 9, 'p': 'head_of', 'o': 59},
{'s': 9, 'p': 'member_of', 'o': 59},
{'s': 10, 'p': 'head_of', 'o': 3},
{'s': 10, 'p': 'member_of', 'o': 3},
{'s': 11, 'p': 'citizen_of', 'o': 66},
{'s': 11, 'p': 'citizen_of-x', 'o': 36},
{'s': 11, 'p': 'head_of_state', 'o': 66},
{'s': 11, 'p': 'head_of_state-x', 'o': 36},
{'s': 12, 'p': 'agent_of', 'o': 24},
{'s': 12, 'p': 'citizen_of', 'o': 24},
{'s': 12, 'p': 'citizen_of-x', 'o': 15},
{'s': 12, 'p': 'head_of_gov', 'o': 24},
{'s': 12, 'p': 'head_of_gov-x', 'o': 15},
{'s': 15, 'p': 'gpe0', 'o': 24},
{'s': 22, 'p': 'based_in0', 'o': 18},
{'s': 22, 'p': 'based_in0-x', 'o': 50},
{'s': 23, 'p': 'based_in0', 'o': 24},
{'s': 23, 'p': 'based_in0-x', 'o': 15},
{'s': 25, 'p': 'based_in0', 'o': 26},
{'s': 27, 'p': 'based_in0', 'o': 28},
{'s': 29, 'p': 'based_in0', 'o': 17},
{'s': 30, 'p': 'based_in0', 'o': 31},
{'s': 33, 'p': 'event_in0', 'o': 24},
{'s': 36, 'p': 'gpe0', 'o': 66},
{'s': 38, 'p': 'member_of', 'o': 2},
{'s': 43, 'p': 'agent_of', 'o': 41},
{'s': 43, 'p': 'citizen_of', 'o': 41},
{'s': 48, 'p': 'gpe0', 'o': 47},
{'s': 49, 'p': 'agent_of', 'o': 47},
{'s': 49, 'p': 'citizen_of', 'o': 47},
{'s': 49, 'p': 'citizen_of-x', 'o': 48},
{'s': 49, 'p': 'head_of_state', 'o': 47},
{'s': 49, 'p': 'head_of_state-x', 'o': 48},
{'s': 50, 'p': 'gpe0', 'o': 18},
{'s': 52, 'p': 'agent_of', 'o': 18},
{'s': 52, 'p': 'citizen_of', 'o': 18},
{'s': 52, 'p': 'citizen_of-x', 'o': 50},
{'s': 52, 'p': 'minister_of', 'o': 18},
{'s': 52, 'p': 'minister_of-x', 'o': 50},
{'s': 55, 'p': 'gpe0', 'o': 4},
{'s': 56, 'p': 'gpe0', 'o': 5},
{'s': 57, 'p': 'in0', 'o': 4},
{'s': 57, 'p': 'in0-x', 'o': 55},
{'s': 58, 'p': 'in0', 'o': 65},
{'s': 59, 'p': 'institution_of', 'o': 2},
{'s': 59, 'p': 'part_of', 'o': 2},
{'s': 60, 'p': 'agent_of', 'o': 5},
{'s': 60, 'p': 'citizen_of', 'o': 5},
{'s': 60, 'p': 'citizen_of-x', 'o': 56},
{'s': 60, 'p': 'head_of_gov', 'o': 5},
{'s': 60, 'p': 'head_of_gov-x', 'o': 56},
{'s': 61, 'p': 'in0', 'o': 5},
{'s': 61, 'p': 'in0-x', 'o': 56}],
'frames': [{'type': 'none', 'slots': []}],
'iptc': ['04000000',
'11000000',
'20000344',
'20000346',
'20000378',
'20000638']}
```
### Data Fields
- `id` : unique identifier of the article.
- `content` : textual content of the article downloaded with src/dwie_download.py script.
- `tags` : used to differentiate between train and test sets of documents.
- `mentions`: a list of entity mentions in the article each with the following keys:
- `begin` : offset of the first character of the mention (inside content field).
- `end` : offset of the last character of the mention (inside content field).
- `text` : the textual representation of the entity mention.
- `concept` : the id of the entity that represents the entity mention (multiple entity mentions in the article can refer to the same concept).
- `candidates` : the candidate Wikipedia links.
- `scores` : the prior probabilities of the candidates entity links calculated on Wikipedia corpus.
- `concepts` : a list of entities that cluster each of the entity mentions. Each entity is annotated with the following keys:
- `concept` : the unique document-level entity id.
- `text` : the text of the longest mention that belong to the entity.
- `keyword` : indicates whether the entity is a keyword.
- `count` : the number of entity mentions in the document that belong to the entity.
- `link` : the entity link to Wikipedia.
- `tags` : multi-label classification labels associated to the entity.
- `relations` : a list of document-level relations between entities (concepts). Each of the relations is annotated with the following keys:
- `s` : the subject entity id involved in the relation.
- `p` : the predicate that defines the relation name (i.e., "citizen_of", "member_of", etc.).
- `o` : the object entity id involved in the relation.
- `iptc` : multi-label article IPTC classification codes. For detailed meaning of each of the codes, please refer to the official IPTC code list.
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@article{zaporojets2021dwie,
title={DWIE: An entity-centric dataset for multi-task document-level information extraction},
author={Zaporojets, Klim and Deleu, Johannes and Develder, Chris and Demeester, Thomas},
journal={Information Processing \& Management},
volume={58},
number={4},
pages={102563},
year={2021},
publisher={Elsevier}
}
```
### Contributions
Thanks to [@basvoju](https://github.com/basvoju) for adding this dataset. |
niizam/4chan-datasets | ---
license: unlicense
task_categories:
- text-generation
language:
- en
tags:
- not-for-all-audiences
---
Please see [repo](https://github.com/niizam/4chan-datasets) to turn the text file into json/csv format
Deleted some boards, since they are already archived by https://archive.4plebs.org/ |
taka-yayoi/databricks-dolly-15k-ja | ---
license: cc-by-sa-3.0
---
こちらのデータセットを活用させていただき、Dollyのトレーニングスクリプトで使えるように列名の変更とJSONLへの変換を行っています。
https://huggingface.co/datasets/kunishou/databricks-dolly-15k-ja
Dolly
https://github.com/databrickslabs/dolly |
renumics/cifar100-enriched | ---
license: mit
task_categories:
- image-classification
pretty_name: CIFAR-100
source_datasets:
- extended|other-80-Million-Tiny-Images
paperswithcode_id: cifar-100
size_categories:
- 10K<n<100K
tags:
- image classification
- cifar-100
- cifar-100-enriched
- embeddings
- enhanced
- spotlight
- renumics
language:
- en
multilinguality:
- monolingual
annotations_creators:
- crowdsourced
language_creators:
- found
---
# Dataset Card for CIFAR-100-Enriched (Enhanced by Renumics)
## Dataset Description
- **Homepage:** [Renumics Homepage](https://renumics.com/?hf-dataset-card=cifar100-enriched)
- **GitHub** [Spotlight](https://github.com/Renumics/spotlight)
- **Dataset Homepage** [CS Toronto Homepage](https://www.cs.toronto.edu/~kriz/cifar.html#:~:text=The%20CIFAR%2D100%20dataset)
- **Paper:** [Learning Multiple Layers of Features from Tiny Images](https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf)
### Dataset Summary
📊 [Data-centric AI](https://datacentricai.org) principles have become increasingly important for real-world use cases.
At [Renumics](https://renumics.com/?hf-dataset-card=cifar100-enriched) we believe that classical benchmark datasets and competitions should be extended to reflect this development.
🔍 This is why we are publishing benchmark datasets with application-specific enrichments (e.g. embeddings, baseline results, uncertainties, label error scores). We hope this helps the ML community in the following ways:
1. Enable new researchers to quickly develop a profound understanding of the dataset.
2. Popularize data-centric AI principles and tooling in the ML community.
3. Encourage the sharing of meaningful qualitative insights in addition to traditional quantitative metrics.
📚 This dataset is an enriched version of the [CIFAR-100 Dataset](https://www.cs.toronto.edu/~kriz/cifar.html).
### Explore the Dataset
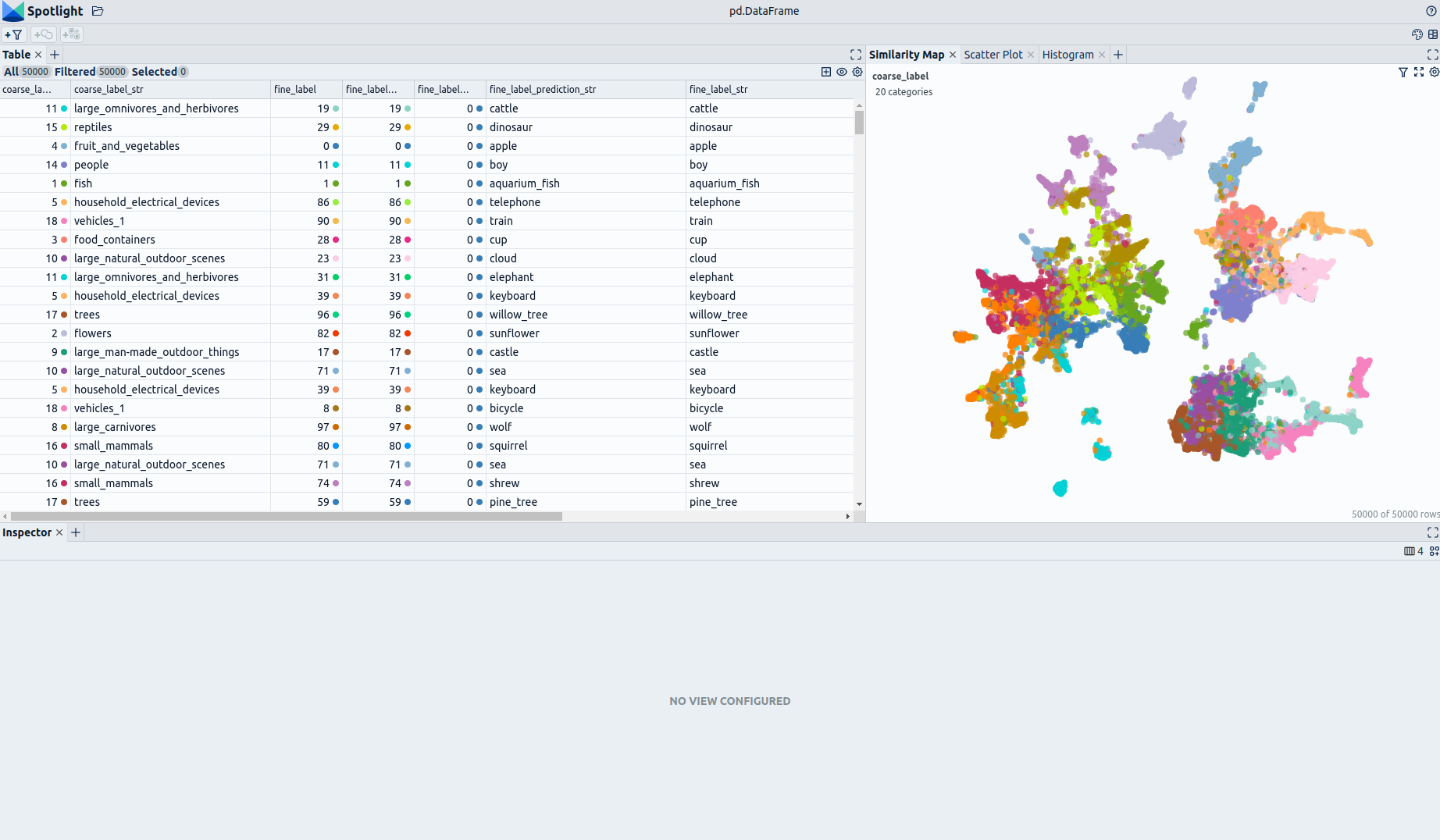
The enrichments allow you to quickly gain insights into the dataset. The open source data curation tool [Renumics Spotlight](https://github.com/Renumics/spotlight) enables that with just a few lines of code:
Install datasets and Spotlight via [pip](https://packaging.python.org/en/latest/key_projects/#pip):
```python
!pip install renumics-spotlight datasets
```
Load the dataset from huggingface in your notebook:
```python
import datasets
dataset = datasets.load_dataset("renumics/cifar100-enriched", split="train")
```
Start exploring with a simple view that leverages embeddings to identify relevant data segments:
```python
from renumics import spotlight
df = dataset.to_pandas()
df_show = df.drop(columns=['embedding', 'probabilities'])
spotlight.show(df_show, port=8000, dtype={"image": spotlight.Image, "embedding_reduced": spotlight.Embedding})
```
You can use the UI to interactively configure the view on the data. Depending on the concrete tasks (e.g. model comparison, debugging, outlier detection) you might want to leverage different enrichments and metadata.
### CIFAR-100 Dataset
The CIFAR-100 dataset consists of 60000 32x32 colour images in 100 classes, with 600 images per class. There are 50000 training images and 10000 test images.
The 100 classes in the CIFAR-100 are grouped into 20 superclasses. Each image comes with a "fine" label (the class to which it belongs) and a "coarse" label (the superclass to which it belongs).
The classes are completely mutually exclusive.
We have enriched the dataset by adding **image embeddings** generated with a [Vision Transformer](https://huggingface.co/google/vit-base-patch16-224).
Here is the list of classes in the CIFAR-100:
| Superclass | Classes |
|---------------------------------|----------------------------------------------------|
| aquatic mammals | beaver, dolphin, otter, seal, whale |
| fish | aquarium fish, flatfish, ray, shark, trout |
| flowers | orchids, poppies, roses, sunflowers, tulips |
| food containers | bottles, bowls, cans, cups, plates |
| fruit and vegetables | apples, mushrooms, oranges, pears, sweet peppers |
| household electrical devices | clock, computer keyboard, lamp, telephone, television|
| household furniture | bed, chair, couch, table, wardrobe |
| insects | bee, beetle, butterfly, caterpillar, cockroach |
| large carnivores | bear, leopard, lion, tiger, wolf |
| large man-made outdoor things | bridge, castle, house, road, skyscraper |
| large natural outdoor scenes | cloud, forest, mountain, plain, sea |
| large omnivores and herbivores | camel, cattle, chimpanzee, elephant, kangaroo |
| medium-sized mammals | fox, porcupine, possum, raccoon, skunk |
| non-insect invertebrates | crab, lobster, snail, spider, worm |
| people | baby, boy, girl, man, woman |
| reptiles | crocodile, dinosaur, lizard, snake, turtle |
| small mammals | hamster, mouse, rabbit, shrew, squirrel |
| trees | maple, oak, palm, pine, willow |
| vehicles 1 | bicycle, bus, motorcycle, pickup truck, train |
| vehicles 2 | lawn-mower, rocket, streetcar, tank, tractor |
### Supported Tasks and Leaderboards
- `image-classification`: The goal of this task is to classify a given image into one of 100 classes. The leaderboard is available [here](https://paperswithcode.com/sota/image-classification-on-cifar-100).
### Languages
English class labels.
## Dataset Structure
### Data Instances
A sample from the training set is provided below:
```python
{
'image': '/huggingface/datasets/downloads/extracted/f57c1a3fbca36f348d4549e820debf6cc2fe24f5f6b4ec1b0d1308a80f4d7ade/0/0.png',
'full_image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=32x32 at 0x7F15737C9C50>,
'fine_label': 19,
'coarse_label': 11,
'fine_label_str': 'cattle',
'coarse_label_str': 'large_omnivores_and_herbivores',
'fine_label_prediction': 19,
'fine_label_prediction_str': 'cattle',
'fine_label_prediction_error': 0,
'split': 'train',
'embedding': [-1.2482988834381104,
0.7280710339546204, ...,
0.5312759280204773],
'probabilities': [4.505949982558377e-05,
7.286163599928841e-05, ...,
6.577593012480065e-05],
'embedding_reduced': [1.9439491033554077, -5.35720682144165]
}
```
### Data Fields
| Feature | Data Type |
|---------------------------------|------------------------------------------------|
| image | Value(dtype='string', id=None) |
| full_image | Image(decode=True, id=None) |
| fine_label | ClassLabel(names=[...], id=None) |
| coarse_label | ClassLabel(names=[...], id=None) |
| fine_label_str | Value(dtype='string', id=None) |
| coarse_label_str | Value(dtype='string', id=None) |
| fine_label_prediction | ClassLabel(names=[...], id=None) |
| fine_label_prediction_str | Value(dtype='string', id=None) |
| fine_label_prediction_error | Value(dtype='int32', id=None) |
| split | Value(dtype='string', id=None) |
| embedding | Sequence(feature=Value(dtype='float32', id=None), length=768, id=None) |
| probabilities | Sequence(feature=Value(dtype='float32', id=None), length=100, id=None) |
| embedding_reduced | Sequence(feature=Value(dtype='float32', id=None), length=2, id=None) |
### Data Splits
| Dataset Split | Number of Images in Split | Samples per Class (fine) |
| ------------- |---------------------------| -------------------------|
| Train | 50000 | 500 |
| Test | 10000 | 100 |
## Dataset Creation
### Curation Rationale
The CIFAR-10 and CIFAR-100 are labeled subsets of the [80 million tiny images](http://people.csail.mit.edu/torralba/tinyimages/) dataset.
They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton.
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
If you use this dataset, please cite the following paper:
```
@article{krizhevsky2009learning,
added-at = {2021-01-21T03:01:11.000+0100},
author = {Krizhevsky, Alex},
biburl = {https://www.bibsonomy.org/bibtex/2fe5248afe57647d9c85c50a98a12145c/s364315},
interhash = {cc2d42f2b7ef6a4e76e47d1a50c8cd86},
intrahash = {fe5248afe57647d9c85c50a98a12145c},
keywords = {},
pages = {32--33},
timestamp = {2021-01-21T03:01:11.000+0100},
title = {Learning Multiple Layers of Features from Tiny Images},
url = {https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf},
year = 2009
}
```
### Contributions
Alex Krizhevsky, Vinod Nair, Geoffrey Hinton, and Renumics GmbH. |
c3po-ai/edgar-corpus | ---
dataset_info:
- config_name: .
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 40306320885
num_examples: 220375
download_size: 10734208660
dataset_size: 40306320885
- config_name: full
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 32237457024
num_examples: 176289
- name: validation
num_bytes: 4023129683
num_examples: 22050
- name: test
num_bytes: 4045734178
num_examples: 22036
download_size: 40699852536
dataset_size: 40306320885
- config_name: year_1993
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 112714537
num_examples: 1060
- name: validation
num_bytes: 13584432
num_examples: 133
- name: test
num_bytes: 14520566
num_examples: 133
download_size: 141862572
dataset_size: 140819535
- config_name: year_1994
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 198955093
num_examples: 2083
- name: validation
num_bytes: 23432307
num_examples: 261
- name: test
num_bytes: 26115768
num_examples: 260
download_size: 250411041
dataset_size: 248503168
- config_name: year_1995
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 356959049
num_examples: 4110
- name: validation
num_bytes: 42781161
num_examples: 514
- name: test
num_bytes: 45275568
num_examples: 514
download_size: 448617549
dataset_size: 445015778
- config_name: year_1996
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 738506135
num_examples: 7589
- name: validation
num_bytes: 89873905
num_examples: 949
- name: test
num_bytes: 91248882
num_examples: 949
download_size: 926536700
dataset_size: 919628922
- config_name: year_1997
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 854201733
num_examples: 8084
- name: validation
num_bytes: 103167272
num_examples: 1011
- name: test
num_bytes: 106843950
num_examples: 1011
download_size: 1071898139
dataset_size: 1064212955
- config_name: year_1998
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 904075497
num_examples: 8040
- name: validation
num_bytes: 112630658
num_examples: 1006
- name: test
num_bytes: 113308750
num_examples: 1005
download_size: 1137887615
dataset_size: 1130014905
- config_name: year_1999
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 911374885
num_examples: 7864
- name: validation
num_bytes: 118614261
num_examples: 984
- name: test
num_bytes: 116706581
num_examples: 983
download_size: 1154736765
dataset_size: 1146695727
- config_name: year_2000
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 926444625
num_examples: 7589
- name: validation
num_bytes: 113264749
num_examples: 949
- name: test
num_bytes: 114605470
num_examples: 949
download_size: 1162526814
dataset_size: 1154314844
- config_name: year_2001
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 964631161
num_examples: 7181
- name: validation
num_bytes: 117509010
num_examples: 898
- name: test
num_bytes: 116141097
num_examples: 898
download_size: 1207790205
dataset_size: 1198281268
- config_name: year_2002
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1049271720
num_examples: 6636
- name: validation
num_bytes: 128339491
num_examples: 830
- name: test
num_bytes: 128444184
num_examples: 829
download_size: 1317817728
dataset_size: 1306055395
- config_name: year_2003
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1027557690
num_examples: 6672
- name: validation
num_bytes: 126684704
num_examples: 834
- name: test
num_bytes: 130672979
num_examples: 834
download_size: 1297227566
dataset_size: 1284915373
- config_name: year_2004
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1129657843
num_examples: 7111
- name: validation
num_bytes: 147499772
num_examples: 889
- name: test
num_bytes: 147890092
num_examples: 889
download_size: 1439663100
dataset_size: 1425047707
- config_name: year_2005
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1200714441
num_examples: 7113
- name: validation
num_bytes: 161003977
num_examples: 890
- name: test
num_bytes: 160727195
num_examples: 889
download_size: 1538876195
dataset_size: 1522445613
- config_name: year_2006
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1286566049
num_examples: 7064
- name: validation
num_bytes: 160843494
num_examples: 883
- name: test
num_bytes: 163270601
num_examples: 883
download_size: 1628452618
dataset_size: 1610680144
- config_name: year_2007
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1296737173
num_examples: 6683
- name: validation
num_bytes: 166735560
num_examples: 836
- name: test
num_bytes: 156399535
num_examples: 835
download_size: 1637502176
dataset_size: 1619872268
- config_name: year_2008
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1525698198
num_examples: 7408
- name: validation
num_bytes: 190034435
num_examples: 927
- name: test
num_bytes: 187659976
num_examples: 926
download_size: 1924164839
dataset_size: 1903392609
- config_name: year_2009
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1547816260
num_examples: 7336
- name: validation
num_bytes: 188897783
num_examples: 917
- name: test
num_bytes: 196463897
num_examples: 917
download_size: 1954076983
dataset_size: 1933177940
- config_name: year_2010
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1493505900
num_examples: 7013
- name: validation
num_bytes: 192695567
num_examples: 877
- name: test
num_bytes: 191482640
num_examples: 877
download_size: 1897687327
dataset_size: 1877684107
- config_name: year_2011
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1481486551
num_examples: 6724
- name: validation
num_bytes: 190781558
num_examples: 841
- name: test
num_bytes: 185869151
num_examples: 840
download_size: 1877396421
dataset_size: 1858137260
- config_name: year_2012
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1463496224
num_examples: 6479
- name: validation
num_bytes: 186247306
num_examples: 810
- name: test
num_bytes: 185923601
num_examples: 810
download_size: 1854377191
dataset_size: 1835667131
- config_name: year_2013
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1468172419
num_examples: 6372
- name: validation
num_bytes: 183570866
num_examples: 797
- name: test
num_bytes: 182495750
num_examples: 796
download_size: 1852839009
dataset_size: 1834239035
- config_name: year_2014
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1499451593
num_examples: 6261
- name: validation
num_bytes: 181568907
num_examples: 783
- name: test
num_bytes: 181046535
num_examples: 783
download_size: 1880963095
dataset_size: 1862067035
- config_name: year_2015
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1472346721
num_examples: 6028
- name: validation
num_bytes: 180128910
num_examples: 754
- name: test
num_bytes: 189210252
num_examples: 753
download_size: 1860303134
dataset_size: 1841685883
- config_name: year_2016
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1471605426
num_examples: 5812
- name: validation
num_bytes: 178310005
num_examples: 727
- name: test
num_bytes: 177481471
num_examples: 727
download_size: 1845967492
dataset_size: 1827396902
- config_name: year_2017
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1459021126
num_examples: 5635
- name: validation
num_bytes: 174360913
num_examples: 705
- name: test
num_bytes: 184398250
num_examples: 704
download_size: 1836306408
dataset_size: 1817780289
- config_name: year_2018
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1433409319
num_examples: 5508
- name: validation
num_bytes: 181466460
num_examples: 689
- name: test
num_bytes: 182594965
num_examples: 688
download_size: 1815810567
dataset_size: 1797470744
- config_name: year_2019
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1421232269
num_examples: 5354
- name: validation
num_bytes: 175603562
num_examples: 670
- name: test
num_bytes: 176336174
num_examples: 669
download_size: 1791237155
dataset_size: 1773172005
- config_name: year_2020
features:
- name: filename
dtype: string
- name: cik
dtype: string
- name: year
dtype: string
- name: section_1
dtype: string
- name: section_1A
dtype: string
- name: section_1B
dtype: string
- name: section_2
dtype: string
- name: section_3
dtype: string
- name: section_4
dtype: string
- name: section_5
dtype: string
- name: section_6
dtype: string
- name: section_7
dtype: string
- name: section_7A
dtype: string
- name: section_8
dtype: string
- name: section_9
dtype: string
- name: section_9A
dtype: string
- name: section_9B
dtype: string
- name: section_10
dtype: string
- name: section_11
dtype: string
- name: section_12
dtype: string
- name: section_13
dtype: string
- name: section_14
dtype: string
- name: section_15
dtype: string
splits:
- name: train
num_bytes: 1541847387
num_examples: 5480
- name: validation
num_bytes: 193498658
num_examples: 686
- name: test
num_bytes: 192600298
num_examples: 685
download_size: 1946916132
dataset_size: 1927946343
annotations_creators:
- no-annotation
language:
- en
language_creators:
- other
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: EDGAR-CORPUS (10-K Filings from 1999 to 2020)
size_categories:
- 100K<n<1M
source_datasets:
- extended|other
tags:
- research papers
- edgar
- sec
- finance
- financial
- filings
- 10K
- 10-K
- nlp
- research
- econlp
- economics
- business
task_categories:
- other
task_ids: []
duplicated_from: eloukas/edgar-corpus
---
# Dataset Card for [EDGAR-CORPUS]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [References](#references)
- [Contributions](#contributions)
## Dataset Description
- **Point of Contact: Lefteris Loukas**
### Dataset Summary
This dataset card is based on the paper **EDGAR-CORPUS: Billions of Tokens Make The World Go Round** authored by _Lefteris Loukas et.al_, as published in the _ECONLP 2021_ workshop.
This dataset contains the annual reports of public companies from 1993-2020 from SEC EDGAR filings.
There is supported functionality to load a specific year.
Care: since this is a corpus dataset, different `train/val/test` splits do not have any special meaning. It's the default HF card format to have train/val/test splits.
If you wish to load specific year(s) of specific companies, you probably want to use the open-source software which generated this dataset, EDGAR-CRAWLER: https://github.com/nlpaueb/edgar-crawler.
### Supported Tasks
This is a raw dataset/corpus for financial NLP.
As such, there are no annotations or labels.
### Languages
The EDGAR Filings are in English.
## Dataset Structure
### Data Instances
Refer to the dataset preview.
### Data Fields
**filename**: Name of file on EDGAR from which the report was extracted.<br>
**cik**: EDGAR identifier for a firm.<br>
**year**: Year of report.<br>
**section_1**: Corressponding section of the Annual Report.<br>
**section_1A**: Corressponding section of the Annual Report.<br>
**section_1B**: Corressponding section of the Annual Report.<br>
**section_2**: Corressponding section of the Annual Report.<br>
**section_3**: Corressponding section of the Annual Report.<br>
**section_4**: Corressponding section of the Annual Report.<br>
**section_5**: Corressponding section of the Annual Report.<br>
**section_6**: Corressponding section of the Annual Report.<br>
**section_7**: Corressponding section of the Annual Report.<br>
**section_7A**: Corressponding section of the Annual Report.<br>
**section_8**: Corressponding section of the Annual Report.<br>
**section_9**: Corressponding section of the Annual Report.<br>
**section_9A**: Corressponding section of the Annual Report.<br>
**section_9B**: Corressponding section of the Annual Report.<br>
**section_10**: Corressponding section of the Annual Report.<br>
**section_11**: Corressponding section of the Annual Report.<br>
**section_12**: Corressponding section of the Annual Report.<br>
**section_13**: Corressponding section of the Annual Report.<br>
**section_14**: Corressponding section of the Annual Report.<br>
**section_15**: Corressponding section of the Annual Report.<br>
```python
import datasets
# Load the entire dataset
raw_dataset = datasets.load_dataset("eloukas/edgar-corpus", "full")
# Load a specific year and split
year_1993_training_dataset = datasets.load_dataset("eloukas/edgar-corpus", "year_1993", split="train")
```
### Data Splits
| Config | Training | Validation | Test |
| --------- | -------- | ---------- | ------ |
| full | 176,289 | 22,050 | 22,036 |
| year_1993 | 1,060 | 133 | 133 |
| year_1994 | 2,083 | 261 | 260 |
| year_1995 | 4,110 | 514 | 514 |
| year_1996 | 7,589 | 949 | 949 |
| year_1997 | 8,084 | 1,011 | 1,011 |
| year_1998 | 8,040 | 1,006 | 1,005 |
| year_1999 | 7,864 | 984 | 983 |
| year_2000 | 7,589 | 949 | 949 |
| year_2001 | 7,181 | 898 | 898 |
| year_2002 | 6,636 | 830 | 829 |
| year_2003 | 6,672 | 834 | 834 |
| year_2004 | 7,111 | 889 | 889 |
| year_2005 | 7,113 | 890 | 889 |
| year_2006 | 7,064 | 883 | 883 |
| year_2007 | 6,683 | 836 | 835 |
| year_2008 | 7,408 | 927 | 926 |
| year_2009 | 7,336 | 917 | 917 |
| year_2010 | 7,013 | 877 | 877 |
| year_2011 | 6,724 | 841 | 840 |
| year_2012 | 6,479 | 810 | 810 |
| year_2013 | 6,372 | 797 | 796 |
| year_2014 | 6,261 | 783 | 783 |
| year_2015 | 6,028 | 754 | 753 |
| year_2016 | 5,812 | 727 | 727 |
| year_2017 | 5,635 | 705 | 704 |
| year_2018 | 5,508 | 689 | 688 |
| year_2019 | 5,354 | 670 | 669 |
| year_2020 | 5,480 | 686 | 685 |
## Dataset Creation
### Source Data
#### Initial Data Collection and Normalization
Initial data was collected and processed by the authors of the research paper **EDGAR-CORPUS: Billions of Tokens Make The World Go Round**.
#### Who are the source language producers?
Public firms filing with the SEC.
### Annotations
#### Annotation process
NA
#### Who are the annotators?
NA
### Personal and Sensitive Information
The dataset contains public filings data from SEC.
## Considerations for Using the Data
### Social Impact of Dataset
Low to none.
### Discussion of Biases
The dataset is about financial information of public companies and as such the tone and style of text is in line with financial literature.
### Other Known Limitations
The dataset needs further cleaning for improved performance.
## Additional Information
### Licensing Information
EDGAR data is publicly available.
### Shoutout
Huge shoutout to [@JanosAudran](https://huggingface.co/JanosAudran) for the HF Card setup!
## Citation
If this work helps or inspires you in any way, please consider citing the relevant paper published at the [3rd Economics and Natural Language Processing (ECONLP) workshop](https://lt3.ugent.be/econlp/) at EMNLP 2021 (Punta Cana, Dominican Republic):
```
@inproceedings{loukas-etal-2021-edgar,
title = "{EDGAR}-{CORPUS}: Billions of Tokens Make The World Go Round",
author = "Loukas, Lefteris and
Fergadiotis, Manos and
Androutsopoulos, Ion and
Malakasiotis, Prodromos",
booktitle = "Proceedings of the Third Workshop on Economics and Natural Language Processing",
month = nov,
year = "2021",
address = "Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.econlp-1.2",
pages = "13--18",
}
```
### References
- [Research Paper] Lefteris Loukas, Manos Fergadiotis, Ion Androutsopoulos, and, Prodromos Malakasiotis. EDGAR-CORPUS: Billions of Tokens Make The World Go Round. Third Workshop on Economics and Natural Language Processing (ECONLP). https://arxiv.org/abs/2109.14394 - Punta Cana, Dominican Republic, November 2021.
- [Software] Lefteris Loukas, Manos Fergadiotis, Ion Androutsopoulos, and, Prodromos Malakasiotis. EDGAR-CRAWLER. https://github.com/nlpaueb/edgar-crawler (2021)
- [EDGAR CORPUS, but in zip files] EDGAR CORPUS: A corpus for financial NLP research, built from SEC's EDGAR. https://zenodo.org/record/5528490 (2021)
- [Word Embeddings] EDGAR-W2V: Word2vec Embeddings trained on EDGAR-CORPUS. https://zenodo.org/record/5524358 (2021)
- [Applied Research paper where EDGAR-CORPUS is used] Lefteris Loukas, Manos Fergadiotis, Ilias Chalkidis, Eirini Spyropoulou, Prodromos Malakasiotis, Ion Androutsopoulos, and, George Paliouras. FiNER: Financial Numeric Entity Recognition for XBRL Tagging. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). https://doi.org/10.18653/v1/2022.acl-long.303 (2022)
|
szymonrucinski/types-of-film-shots | ---
license: cc-by-4.0
task_categories:
- image-classification
pretty_name: What a shot!
---

## What a shot!
Data set created by Szymon Ruciński. It consists of ~ 1000 images of different movie shots precisely labeled with shot type. The data set is divided into categories: detail, close-up, medium shot, full shot and long shot, extreme long shot. Data was gathered and labeled on the platform plan-doskonaly.netlify.com created by Szymon. The data set is available under the Creative Commons Attribution 4.0 International license. |
saldra/sakura_japanese_dataset | ---
license: other
task_categories:
- question-answering
language:
- ja
pretty_name: sakura_japanese_dataset
size_categories:
- n<1K
---
# Sakura_dataset
商用利用可能な超小規模高品質日本語データセット。
categoryは以下
- commonsense_qa: 常識問題
- Calc-ape210k: 数学問題
- japanese-commonsense-openqa: 日本の常識問題(自作)
下記データセットを使用しています。
- [commonsense_qa](https://huggingface.co/datasets/commonsense_qa)
- [MU-NLPC/Calc-ape210k](https://huggingface.co/datasets/MU-NLPC/Calc-ape210k)
## LICENSE
This dataset is licensed under Database Contents License (DbCL) v1.0
## Update
Last Update : 2023-06-07
## Example Code
```
# モデルの読み込み
import os
from peft.utils.config import TaskType
os.environ["CUDA_VISIBLE_DEVICES"]="0"
import peft
import transformers
import datasets
# 基本パラメータ
model_name = "rinna/japanese-gpt-neox-3.6b"
dataset = "saldra/sakura_japanese_dataset"
is_dataset_local = False
peft_name = "lora-rinna-3.6b-sakura_dataset"
output_dir = "lora-rinna-3.6b-sakura_dataset-results"
# トレーニング用パラメータ
eval_steps = 50 #200
save_steps = 400 #200
logging_steps = 400 #20
max_steps = 400 # dollyだと 4881
# データセットの準備
data = datasets.load_dataset(dataset)
CUTOFF_LEN = 512 # コンテキスト長の上限
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name, use_fast=False)
model = transformers.AutoModelForCausalLM.from_pretrained(
model_name,
device_map='auto',
load_in_8bit=True,
)
model.enable_input_require_grads()
model.gradient_checkpointing_enable()
config = peft.LoraConfig(
r=8,
lora_alpha=32,
lora_dropout=0.01,
inference_mode=False,
task_type=TaskType.CAUSAL_LM,
)
model = peft.get_peft_model(model, config)
# トークナイズ
def tokenize(prompt, tokenizer):
result = tokenizer(
prompt,
truncation=True,
max_length=CUTOFF_LEN,
padding=False,
)
return {
"input_ids": result["input_ids"],
"attention_mask": result["attention_mask"],
}
# プロンプトテンプレートの準備
def generate_prompt(data_point):
result = f'### 指示:\n{data_point["instruction"]}\n\n### 回答:\n{data_point["output"]}'
# rinna/japanese-gpt-neox-3.6Bの場合、改行コードを<NL>に変換する必要がある
result = result.replace('\n', '<NL>')
return result
VAL_SET_SIZE = 0.1 # 検証データの比率(float)
# 学習データと検証データの準備
train_val = data["train"].train_test_split(
test_size=VAL_SET_SIZE, shuffle=True, seed=42
)
train_data = train_val["train"]
train_data = train_data.shuffle().map(lambda x: tokenize(generate_prompt(x), tokenizer))
val_data = train_val["test"]
val_data = val_data.shuffle().map(lambda x: tokenize(generate_prompt(x), tokenizer))
trainer = transformers.Trainer(
model=model,
train_dataset=train_data,
eval_dataset=val_data,
args=transformers.TrainingArguments(
num_train_epochs=3,
learning_rate=3e-4,
logging_steps=logging_steps,
evaluation_strategy="steps",
save_strategy="steps",
max_steps=max_steps,
eval_steps=eval_steps,
save_steps=save_steps,
output_dir=output_dir,
report_to="none",
save_total_limit=3,
push_to_hub=False,
auto_find_batch_size=True
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
model.config.use_cache = False
trainer.train()
# LoRAモデルの保存
trainer.model.save_pretrained(peft_name)
print("Done!")
``` |
xiyuez/im-feeling-curious | ---
license: odc-by
task_categories:
- question-answering
- text-generation
language:
- en
pretty_name: i'm feeling curious dataset
size_categories:
- 1K<n<10K
---
This public dataset is an extract from Google's "i'm feeling curious" feature. To learn more about this feature, search for "i'm feeling curious" on Google.
Tasks: Answering open-domain questions, generating random facts.
Limitations: May contain commercial content, false information, bias, or outdated information.
Language: English only.
This public extract is licensed under the Open Data Commons Attribution License: http://opendatacommons.org/licenses/by/1.0/.
There is no canonical train/test split.
This extract contains 2761 unique rows, which may increase as more data is crawled. Near-duplicates have been removed.
While we aimed to filter non-natural language content and duplicates, some may remain. The data may also contain toxic, biased, copyrighted or erroneous content. Google has done initial filtering, but we have not verified the data.
Use this dataset at your own risk. We provide no warranty or liability.
Google is a registered trademark of Google LLC. This project is not affiliated with, endorsed or sponsored by Google.
|
BAAI/COIG-PC-Lite | ---
extra_gated_heading: "Acknowledge license to accept the repository"
extra_gated_prompt: |
北京智源人工智能研究院(以下简称“我们”或“研究院”)通过BAAI DataHub(data.baai.ac.cn)和COIG-PC HuggingFace仓库(https://huggingface.co/datasets/BAAI/COIG-PC)向您提供开源数据集(以下或称“数据集”),您可通过下载的方式获取您所需的开源数据集,并在遵守各原始数据集使用规则前提下,基于学习、研究、商业等目的使用相关数据集。
在您获取(包括但不限于访问、下载、复制、传播、使用等处理数据集的行为)开源数据集前,您应认真阅读并理解本《COIG-PC开源数据集使用须知与免责声明》(以下简称“本声明”)。一旦您获取开源数据集,无论您的获取方式为何,您的获取行为均将被视为对本声明全部内容的认可。
1. 平台的所有权与运营权
您应充分了解并知悉,BAAI DataHub和COIG-PC HuggingFace仓库(包括当前版本及全部历史版本)的所有权与运营权归智源人工智能研究院所有,智源人工智能研究院对本平台/本工具及开源数据集开放计划拥有最终解释权和决定权。
您知悉并理解,基于相关法律法规更新和完善以及我们需履行法律合规义务的客观变化,我们保留对本平台/本工具进行不定时更新、维护,或者中止乃至永久终止提供本平台/本工具服务的权利。我们将在合理时间内将可能发生前述情形通过公告或邮件等合理方式告知您,您应当及时做好相应的调整和安排,但我们不因发生前述任何情形对您造成的任何损失承担任何责任。
2. 开源数据集的权利主张
为了便于您基于学习、研究、商业的目的开展数据集获取、使用等活动,我们对第三方原始数据集进行了必要的格式整合、数据清洗、标注、分类、注释等相关处理环节,形成可供本平台/本工具用户使用的开源数据集。
您知悉并理解,我们不对开源数据集主张知识产权中的相关财产性权利,因此我们亦无相应义务对开源数据集可能存在的知识产权进行主动识别和保护,但这不意味着我们放弃开源数据集主张署名权、发表权、修改权和保护作品完整权(如有)等人身性权利。而原始数据集可能存在的知识产权及相应合法权益由原权利人享有。
此外,向您开放和使用经合理编排、加工和处理后的开源数据集,并不意味着我们对原始数据集知识产权、信息内容等真实、准确或无争议的认可,您应当自行筛选、仔细甄别,使用经您选择的开源数据集。您知悉并同意,研究院对您自行选择使用的原始数据集不负有任何无缺陷或无瑕疵的承诺义务或担保责任。
3. 开源数据集的使用限制
您使用数据集不得侵害我们或任何第三方的合法权益(包括但不限于著作权、专利权、商标权等知识产权与其他权益)。
获取开源数据集后,您应确保对开源数据集的使用不超过原始数据集的权利人以公示或协议等形式明确规定的使用规则,包括原始数据的使用范围、目的和合法用途等。我们在此善意地提请您留意,如您对开源数据集的使用超出原始数据集的原定使用范围及用途,您可能面临侵犯原始数据集权利人的合法权益例如知识产权的风险,并可能承担相应的法律责任。
4. 个人信息保护
基于技术限制及开源数据集的公益性质等客观原因,我们无法保证开源数据集中不包含任何个人信息,我们不对开源数据集中可能涉及的个人信息承担任何法律责任。
如开源数据集涉及个人信息,我们不对您使用开源数据集可能涉及的任何个人信息处理行为承担法律责任。我们在此善意地提请您留意,您应依据《个人信息保护法》等相关法律法规的规定处理个人信息。
为了维护信息主体的合法权益、履行可能适用的法律、行政法规的规定,如您在使用开源数据集的过程中发现涉及或者可能涉及个人信息的内容,应立即停止对数据集中涉及个人信息部分的使用,并及时通过“6. 投诉与通知”中载明的联系我们。
5. 信息内容管理
我们不对开源数据集可能涉及的违法与不良信息承担任何法律责任。
如您在使用开源数据集的过程中发现开源数据集涉及或者可能涉及任何违法与不良信息,您应立即停止对数据集中涉及违法与不良信息部分的使用,并及时通过“6. 投诉与通知”中载明的联系我们。
6. 投诉与通知
如您认为开源数据集侵犯了您的合法权益,您可通过010-50955974联系我们,我们会及时依法处理您的主张与投诉。
为了处理您的主张和投诉,我们可能需要您提供联系方式、侵权证明材料以及身份证明等材料。请注意,如果您恶意投诉或陈述失实,您将承担由此造成的全部法律责任(包括但不限于合理的费用赔偿等)。
7. 责任声明
您理解并同意,基于开源数据集的性质,数据集中可能包含来自不同来源和贡献者的数据,其真实性、准确性、客观性等可能会有所差异,我们无法对任何数据集的可用性、可靠性等做出任何承诺。
在任何情况下,我们不对开源数据集可能存在的个人信息侵权、违法与不良信息传播、知识产权侵权等任何风险承担任何法律责任。
在任何情况下,我们不对您因开源数据集遭受的或与之相关的任何损失(包括但不限于直接损失、间接损失以及可得利益损失等)承担任何法律责任。
8. 其他
开源数据集处于不断发展、变化的阶段,我们可能因业务发展、第三方合作、法律法规变动等原因更新、调整所提供的开源数据集范围,或中止、暂停、终止开源数据集提供业务。
extra_gated_fields:
Name: text
Affiliation: text
Country: text
I agree to use this model for non-commercial use ONLY: checkbox
extra_gated_button_content: "Acknowledge license"
license: unknown
language:
- zh
configs:
- config_name: default
data_files:
- split: full
path: data/full-*
- split: train
path: data/train-*
- split: valid
path: data/valid-*
- split: test
path: data/test-*
- split: Top50PerTask
path: data/Top50PerTask-*
- split: Top100PerTask
path: data/Top100PerTask-*
- split: Top200PerTask
path: data/Top200PerTask-*
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: split
dtype: string
- name: task_name_in_eng
dtype: string
- name: task_type
struct:
- name: major
sequence: string
- name: minor
sequence: string
- name: domain
sequence: string
- name: other
dtype: string
- name: filename
dtype: string
splits:
- name: full
num_bytes: 1099400407
num_examples: 650147
- name: train
num_bytes: 410204689
num_examples: 216691
- name: valid
num_bytes: 12413560
num_examples: 16148
- name: test
num_bytes: 51472090
num_examples: 69301
- name: Top50PerTask
num_bytes: 14763925
num_examples: 19274
- name: Top100PerTask
num_bytes: 28489139
num_examples: 37701
- name: Top200PerTask
num_bytes: 51472090
num_examples: 69301
download_size: 53939740
dataset_size: 1668215900
---
# COIG Prompt Collection
## License
**Default Licensing for Sub-Datasets Without Specific License Declaration**: In instances where sub-datasets within the COIG-PC Dataset do not have a specific license declaration, the Apache License 2.0 (Apache-2.0) will be the applicable licensing terms by default.
**Precedence of Declared Licensing for Sub-Datasets**: For any sub-dataset within the COIG-PC Dataset that has an explicitly declared license, the terms and conditions of the declared license shall take precedence and govern the usage of that particular sub-dataset.
Users and developers utilizing the COIG-PC Dataset must ensure compliance with the licensing terms as outlined above. It is imperative to review and adhere to the specified licensing conditions of each sub-dataset, as they may vary.
## What is COIG-PC?
The COIG-PC Dataset is a meticulously curated and comprehensive collection of Chinese tasks and data, designed to facilitate the fine-tuning and optimization of language models for Chinese natural language processing (NLP). The dataset aims to provide researchers and developers with a rich set of resources to improve the capabilities of language models in handling Chinese text, which can be utilized in various fields such as text generation, information extraction, sentiment analysis, machine translation, among others.
COIG-PC-Lite is a subset of COIG-PC with only 200 samples from each task file. If you are looking for COIG-PC, please refer to https://huggingface.co/datasets/BAAI/COIG-PC.
## Why COIG-PC?
The COIG-PC Dataset is an invaluable resource for the domain of natural language processing (NLP) for various compelling reasons:
**Addressing Language Complexity**: Chinese is known for its intricacy, with a vast array of characters and diverse grammatical structures. A specialized dataset like COIG-PC, which is tailored for the Chinese language, is essential to adequately address these complexities during model training.
**Comprehensive Data Aggregation**: The COIG-PC Dataset is a result of an extensive effort in integrating almost all available Chinese datasets in the market. This comprehensive aggregation makes it one of the most exhaustive collections for Chinese NLP.
**Data Deduplication and Normalization**: The COIG-PC Dataset underwent rigorous manual processing to eliminate duplicate data and perform normalization. This ensures that the dataset is free from redundancy, and the data is consistent and well-structured, making it more user-friendly and efficient for model training.
**Fine-tuning and Optimization**: The dataset’s instruction-based phrasing facilitates better fine-tuning and optimization of language models. This structure allows models to better understand and execute tasks, which is particularly beneficial in improving performance on unseen or novel tasks.
The COIG-PC Dataset, with its comprehensive aggregation, meticulous selection, deduplication, and normalization of data, stands as an unmatched resource for training and optimizing language models tailored for the Chinese language and culture. It addresses the unique challenges of Chinese language processing and serves as a catalyst for advancements in Chinese NLP.
## Who builds COIG-PC?
The bedrock of COIG-PC is anchored in the dataset furnished by stardust.ai, which comprises an aggregation of data collected from the Internet.
And COIG-PC is the result of a collaborative effort involving engineers and experts from over twenty distinguished universities both domestically and internationally. Due to space constraints, it is not feasible to list all of them; however, the following are a few notable institutions among the collaborators:
- Beijing Academy of Artificial Intelligence, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-Lite/resolve/main/assets/baai.png" alt= “BAAI” height="100" width="150">
- Peking University, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-Lite/resolve/main/assets/pku.png" alt= “PKU” height="100" width="200">
- The Hong Kong University of Science and Technology (HKUST), China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-Lite/resolve/main/assets/hkust.png" alt= “HKUST” height="100" width="200">
- The University of Waterloo, Canada
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-Lite/resolve/main/assets/waterloo.png" alt= “Waterloo” height="100" width="150">
- The University of Sheffield, United Kingdom
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-Lite/resolve/main/assets/sheffield.png" alt= “Sheffield” height="100" width="200">
- Beijing University of Posts and Telecommunications, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-Lite/resolve/main/assets/bupt.png" alt= “BUPT” height="100" width="200">
- [Multimodal Art Projection](https://huggingface.co/m-a-p)
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-Lite/resolve/main/assets/map.png" alt= “M.A.P” height="100" width="200">
- stardust.ai, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-Lite/resolve/main/assets/stardust.png" alt= “stardust.ai” height="100" width="200">
- LinkSoul.AI, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-Lite/resolve/main/assets/linksoul.png" alt= “linksoul.ai” height="100" width="200">
For the detailed list of engineers involved in the creation and refinement of COIG-PC, please refer to the paper that will be published subsequently. This paper will provide in-depth information regarding the contributions and the specifics of the dataset’s development process.
## How to use COIG-PC?
COIG-PC is structured in a **.jsonl** file format. Each line in the file represents a single data record and is structured in JSON (JavaScript Object Notation) format. Below is a breakdown of the elements within each line:
**instruction**: This is a text string that provides the instruction for the task. For example, it might tell the model what to do with the input data.
**input**: This is the input data that the model needs to process. In the context of translation, it would be the text that needs to be translated.
**output**: This contains the expected output data after processing the input. In the context of translation, it would be the translated text.
**split**: Indicates the official split of the original dataset, which is used to categorize data for different phases of model training and evaluation. It can be 'train', 'test', 'valid', etc.
**task_type**: Contains major and minor categories for the dataset. Major categories are broader, while minor categories can be more specific subcategories.
**domain**: Indicates the domain or field to which the data belongs.
**other**: This field can contain additional information or metadata regarding the data record. If there is no additional information, it may be set to null.
### Example
Here is an example of how a line in the COIG-PC dataset might be structured:
```
{
"instruction": "请把下面的中文句子翻译成英文",
"input": "我爱你。",
"output": "I love you.",
"split": "train",
"task_type": {
"major": ["翻译"],
"minor": ["翻译", "中译英"]
},
"domain": ["通用"],
"other": null
}
```
In this example:
**instruction** tells the model to translate the following Chinese sentence into English.
**input** contains the Chinese text "我爱你" which means "I love you".
**output** contains the expected translation in English: "I love you".
**split** indicates that this data record is part of the training set.
**task_type** specifies that the major category is "Translation" and the minor categories are "Translation" and "Chinese to English".
**domain** specifies that this data record belongs to the general domain.
**other** is set to null as there is no additional information for this data record.
## Update: Aug. 30, 2023
- v1.2: Delete 31 bad task files. Update 99 task files. Rename 2 task files. Add 3 new task files. COIG-PC now has 3339 tasks in total.
- v1.1: Fix 00040-001-000 and 00050-003-000, ignore 00930 and 01373.
- v1.0: First version for arXiv paper.
- v0.6: Upload 28 new tasks. COIG-PC now has 3367 tasks in total.
- v0.5: Upload 202 new tasks. COIG-PC now has 3339 tasks in total.
- v0.4: Upload 1049 new tasks. COIG-PC now has 3137 tasks in total.
- v0.3: Upload 1139 new tasks. COIG-PC now has 2088 tasks in total.
- v0.2: Upload 422 new tasks. COIG-PC now has 949 tasks in total. Add "TopSamplenumPerTask" split where only "Samplenum" samples are used from each task.
- v0.1: Upload 527 tasks.
## COIG-PC Citation
If you want to cite COIG-PC dataset, you could use this:
```
```
## Contact Us
To contact us feel free to create an Issue in this repository.
|
jiwoochris/easylaw_kr | ---
task_categories:
- conversational
language:
- ko
tags:
- legal
size_categories:
- 1K<n<10K
--- |
nascetti-a/BioMassters | ---
license: cc-by-4.0
language:
- en
tags:
- climate
pretty_name: BioMassters
size_categories:
- 100K<n<1M
---
# BioMassters: A Benchmark Dataset for Forest Biomass Estimation using Multi-modal Satellite Time-series https://nascetti-a.github.io/BioMasster/
The objective of this repository is to provide a deep learning ready dataset to predict yearly Above Ground Biomass (AGB) for Finnish forests using multi-temporal satellite imagery from
the European Space Agency and European Commission's joint Sentinel-1 and Sentinel-2 satellite missions, designed to collect a rich array of Earth observation data
### Reference data:
* Reference AGB measurements were collected using LiDAR (Light Detection and Ranging) calibrated with in-situ measurements.
* Total 13000 patches, each patch covering 2,560 by 2,560 meter area.
### Feature data:
* Sentinel-1 SAR and Sentinel-2 MSI data
* 12 months of data (1 image per month)
* Total 310,000 patches
### Data Specifications:

### Data Size:
```
dataset | # files | size
--------------------------------------
train_features | 189078 | 215.9GB
test_features | 63348 | 73.0GB
train_agbm | 8689 | 2.1GB
```
## Citation : under review
|
harvard-lil/cold-cases | ---
license: cc0-1.0
language:
- en
tags:
- united states
- law
- legal
- court
- opinions
size_categories:
- 1M<n<10M
viewer: true
---
<img src="https://huggingface.co/datasets/harvard-lil/cold-cases/resolve/main/coldcases-banner.webp"/>
# Collaborative Open Legal Data (COLD) - Cases
COLD Cases is a dataset of 8.3 million United States legal decisions with text and metadata, formatted as compressed parquet files. If you'd like to view a sample of the dataset formatted as JSON Lines, you can view one [here](https://raw.githubusercontent.com/harvard-lil/cold-cases-export/main/sample.jsonl)
This dataset exists to support the open legal movement exemplified by projects like
[Pile of Law](https://huggingface.co/datasets/pile-of-law/pile-of-law) and
[LegalBench](https://hazyresearch.stanford.edu/legalbench/).
A key input to legal understanding projects is caselaw -- the published, precedential decisions of judges deciding legal disputes and explaining their reasoning.
United States caselaw is collected and published as open data by [CourtListener](https://www.courtlistener.com/), which maintains scrapers to aggregate data from
a wide range of public sources.
COLD Cases reformats CourtListener's [bulk data](https://www.courtlistener.com/help/api/bulk-data) so that all of the semantic information about each legal decision
(the authors and text of majority and dissenting opinions; head matter; and substantive metadata) is encoded in a single record per decision,
with extraneous data removed. Serving in the traditional role of libraries as a standardization steward, the Harvard Library Innovation Lab is maintaining
this [open source](https://github.com/harvard-lil/cold-cases-export) pipeline to consolidate the data engineering for preprocessing caselaw so downstream machine
learning and natural language processing projects can use consistent, high quality representations of cases for legal understanding tasks.
Prepared by the [Harvard Library Innovation Lab](https://lil.law.harvard.edu) in collaboration with the [Free Law Project](https://free.law/).
---
## Links
- [Data nutrition label](https://datanutrition.org/labels/v3/?id=c29976b2-858c-4f4e-b7d0-c8ef12ce7dbe) (DRAFT). ([Archive](https://perma.cc/YV5P-B8JL)).
- [Pipeline source code](https://github.com/harvard-lil/cold-cases-export)
---
## Summary
- [Format](#format)
- [Data dictionary](#data-dictionary)
- [Notes on appropriate use](#notes-on-appropriate-use)
---
## Format
[Apache Parquet](https://parquet.apache.org/) is binary format that makes filtering and retrieving the data quicker because it lays out the data in columns, which means columns that are unnecessary to satisfy a given query or workflow don't need to be read. Hugging Face's [Datasets](https://huggingface.co/docs/datasets/index) library is an easy way to get started working with the entire dataset, and has features for loading and streaming the data, so you don't need to store it all locally or pay attention to how it's formatted on disk.
[☝️ Go back to Summary](#summary)
---
## Data dictionary
Partial glossary of the fields in the data.
| Field name | Description |
| --- | --- |
| `judges` | Names of judges presiding over the case, extracted from the text. |
| `date_filed` | Date the case was filed. Formatted in ISO Date format. |
| `date_filed_is_approximate` | Boolean representing whether the `date_filed` value is precise to the day. |
| `slug` | Short, human-readable unique string nickname for the case. |
| `case_name_short` | Short name for the case. |
| `case_name` | Fuller name for the case. |
| `case_name_full` | Full, formal name for the case. |
| `attorneys` | Names of attorneys arguing the case, extracted from the text. |
| `nature_of_suit` | Free text representinng type of suit, such as Civil, Tort, etc. |
| `syllabus` | Summary of the questions addressed in the decision, if provided by the reporter of decisions. |
| `headnotes` | Textual headnotes of the case |
| `summary` | Textual summary of the case |
| `disposition` | How the court disposed of the case in their final ruling. |
| `history` | Textual information about what happened to this case in later decisions. |
| `other_dates` | Other dates related to the case in free text. |
| `cross_reference` | Citations to related cases. |
| `citation_count` | Number of cases that cite this one. |
| `precedential_status` | Constrainted to the values "Published", "Unknown", "Errata", "Unpublished", "Relating-to", "Separate", "In-chambers" |
| `citations` | Cases that cite this case. |
| `court_short_name` | Short name of court presiding over case. |
| `court_full_name` | Full name of court presiding over case. |
| `court_jurisdiction` | Code for type of court that presided over the case. See: [court_jurisdiction field values](#court_jurisdiction-field-values) |
| `opinions` | An array of subrecords. |
| `opinions.author_str` | Name of the author of an individual opinion. |
| `opinions.per_curiam` | Boolean representing whether the opinion was delivered by an entire court or a single judge. |
| `opinions.type` | One of `"010combined"`, `"015unamimous"`, `"020lead"`, `"025plurality"`, `"030concurrence"`, `"035concurrenceinpart"`, `"040dissent"`, `"050addendum"`, `"060remittitur"`, `"070rehearing"`, `"080onthemerits"`, `"090onmotiontostrike"`. |
| `opinions.opinion_text` | Actual full text of the opinion. |
| `opinions.ocr` | Whether the opinion was captured via optical character recognition or born-digital text. |
### court_type field values
| Value | Description |
| --- | --- |
| F | Federal Appellate |
| FD | Federal District |
| FB | Federal Bankruptcy |
| FBP | Federal Bankruptcy Panel |
| FS | Federal Special |
| S | State Supreme |
| SA | State Appellate |
| ST | State Trial |
| SS | State Special |
| TRS | Tribal Supreme |
| TRA | Tribal Appellate |
| TRT | Tribal Trial |
| TRX | Tribal Special |
| TS | Territory Supreme |
| TA | Territory Appellate |
| TT | Territory Trial |
| TSP | Territory Special |
| SAG | State Attorney General |
| MA | Military Appellate |
| MT | Military Trial |
| C | Committee |
| I | International |
| T | Testing |
[☝️ Go back to Summary](#summary)
---
## Notes on appropriate use
When using this data, please keep in mind:
* All documents in this dataset are public information, published by courts within the United States to inform the public about the law. **You have a right to access them.**
* Nevertheless, **public court decisions frequently contain statements about individuals that are not true**. Court decisions often contain claims that are disputed,
or false claims taken as true based on a legal technicality, or claims taken as true but later found to be false. Legal decisions are designed to inform you about the law -- they are not
designed to inform you about individuals, and should not be used in place of credit databases, criminal records databases, news articles, or other sources intended
to provide factual personal information. Applications should carefully consider whether use of this data will inform about the law, or mislead about individuals.
* **Court decisions are not up-to-date statements of law**. Each decision provides a given judge's best understanding of the law as applied to the stated facts
at the time of the decision. Use of this data to generate statements about the law requires integration of a large amount of context --
the skill typically provided by lawyers -- rather than simple data retrieval.
To mitigate privacy risks, we have filtered out cases [blocked or deindexed by CourtListener](https://www.courtlistener.com/terms/#removal). Researchers who
require access to the full dataset without that filter may rerun our pipeline on CourtListener's raw data.
[☝️ Go back to Summary](#summary) |
BAAI/COIG-PC-core | ---
extra_gated_heading: "Acknowledge license to accept the repository"
extra_gated_prompt: |
北京智源人工智能研究院(以下简称“我们”或“研究院”)通过BAAI DataHub(data.baai.ac.cn)和COIG-PC HuggingFace仓库(https://huggingface.co/datasets/BAAI/COIG-PC)向您提供开源数据集(以下或称“数据集”),您可通过下载的方式获取您所需的开源数据集,并在遵守各原始数据集使用规则前提下,基于学习、研究、商业等目的使用相关数据集。
在您获取(包括但不限于访问、下载、复制、传播、使用等处理数据集的行为)开源数据集前,您应认真阅读并理解本《COIG-PC开源数据集使用须知与免责声明》(以下简称“本声明”)。一旦您获取开源数据集,无论您的获取方式为何,您的获取行为均将被视为对本声明全部内容的认可。
1. 平台的所有权与运营权
您应充分了解并知悉,BAAI DataHub和COIG-PC HuggingFace仓库(包括当前版本及全部历史版本)的所有权与运营权归智源人工智能研究院所有,智源人工智能研究院对本平台/本工具及开源数据集开放计划拥有最终解释权和决定权。
您知悉并理解,基于相关法律法规更新和完善以及我们需履行法律合规义务的客观变化,我们保留对本平台/本工具进行不定时更新、维护,或者中止乃至永久终止提供本平台/本工具服务的权利。我们将在合理时间内将可能发生前述情形通过公告或邮件等合理方式告知您,您应当及时做好相应的调整和安排,但我们不因发生前述任何情形对您造成的任何损失承担任何责任。
2. 开源数据集的权利主张
为了便于您基于学习、研究、商业的目的开展数据集获取、使用等活动,我们对第三方原始数据集进行了必要的格式整合、数据清洗、标注、分类、注释等相关处理环节,形成可供本平台/本工具用户使用的开源数据集。
您知悉并理解,我们不对开源数据集主张知识产权中的相关财产性权利,因此我们亦无相应义务对开源数据集可能存在的知识产权进行主动识别和保护,但这不意味着我们放弃开源数据集主张署名权、发表权、修改权和保护作品完整权(如有)等人身性权利。而原始数据集可能存在的知识产权及相应合法权益由原权利人享有。
此外,向您开放和使用经合理编排、加工和处理后的开源数据集,并不意味着我们对原始数据集知识产权、信息内容等真实、准确或无争议的认可,您应当自行筛选、仔细甄别,使用经您选择的开源数据集。您知悉并同意,研究院对您自行选择使用的原始数据集不负有任何无缺陷或无瑕疵的承诺义务或担保责任。
3. 开源数据集的使用限制
您使用数据集不得侵害我们或任何第三方的合法权益(包括但不限于著作权、专利权、商标权等知识产权与其他权益)。
获取开源数据集后,您应确保对开源数据集的使用不超过原始数据集的权利人以公示或协议等形式明确规定的使用规则,包括原始数据的使用范围、目的和合法用途等。我们在此善意地提请您留意,如您对开源数据集的使用超出原始数据集的原定使用范围及用途,您可能面临侵犯原始数据集权利人的合法权益例如知识产权的风险,并可能承担相应的法律责任。
4. 个人信息保护
基于技术限制及开源数据集的公益性质等客观原因,我们无法保证开源数据集中不包含任何个人信息,我们不对开源数据集中可能涉及的个人信息承担任何法律责任。
如开源数据集涉及个人信息,我们不对您使用开源数据集可能涉及的任何个人信息处理行为承担法律责任。我们在此善意地提请您留意,您应依据《个人信息保护法》等相关法律法规的规定处理个人信息。
为了维护信息主体的合法权益、履行可能适用的法律、行政法规的规定,如您在使用开源数据集的过程中发现涉及或者可能涉及个人信息的内容,应立即停止对数据集中涉及个人信息部分的使用,并及时通过“6. 投诉与通知”中载明的联系我们。
5. 信息内容管理
我们不对开源数据集可能涉及的违法与不良信息承担任何法律责任。
如您在使用开源数据集的过程中发现开源数据集涉及或者可能涉及任何违法与不良信息,您应立即停止对数据集中涉及违法与不良信息部分的使用,并及时通过“6. 投诉与通知”中载明的联系我们。
6. 投诉与通知
如您认为开源数据集侵犯了您的合法权益,您可通过010-50955974联系我们,我们会及时依法处理您的主张与投诉。
为了处理您的主张和投诉,我们可能需要您提供联系方式、侵权证明材料以及身份证明等材料。请注意,如果您恶意投诉或陈述失实,您将承担由此造成的全部法律责任(包括但不限于合理的费用赔偿等)。
7. 责任声明
您理解并同意,基于开源数据集的性质,数据集中可能包含来自不同来源和贡献者的数据,其真实性、准确性、客观性等可能会有所差异,我们无法对任何数据集的可用性、可靠性等做出任何承诺。
在任何情况下,我们不对开源数据集可能存在的个人信息侵权、违法与不良信息传播、知识产权侵权等任何风险承担任何法律责任。
在任何情况下,我们不对您因开源数据集遭受的或与之相关的任何损失(包括但不限于直接损失、间接损失以及可得利益损失等)承担任何法律责任。
8. 其他
开源数据集处于不断发展、变化的阶段,我们可能因业务发展、第三方合作、法律法规变动等原因更新、调整所提供的开源数据集范围,或中止、暂停、终止开源数据集提供业务。
extra_gated_fields:
Name: text
Affiliation: text
Country: text
I agree to use this model for non-commercial use ONLY: checkbox
extra_gated_button_content: "Acknowledge license"
license: unknown
language:
- zh
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: task_type
struct:
- name: major
sequence: string
- name: minor
sequence: string
- name: domain
sequence: string
- name: other
dtype: string
- name: task_name_in_eng
dtype: string
- name: index
dtype: string
splits:
- name: train
num_bytes: 1053129000
num_examples: 744592
download_size: 416315627
dataset_size: 1053129000
---
# COIG Prompt Collection
## License
**Default Licensing for Sub-Datasets Without Specific License Declaration**: In instances where sub-datasets within the COIG-PC Dataset do not have a specific license declaration, the Apache License 2.0 (Apache-2.0) will be the applicable licensing terms by default.
**Precedence of Declared Licensing for Sub-Datasets**: For any sub-dataset within the COIG-PC Dataset that has an explicitly declared license, the terms and conditions of the declared license shall take precedence and govern the usage of that particular sub-dataset.
Users and developers utilizing the COIG-PC Dataset must ensure compliance with the licensing terms as outlined above. It is imperative to review and adhere to the specified licensing conditions of each sub-dataset, as they may vary.
## What is COIG-PC?
The COIG-PC Dataset is a meticulously curated and comprehensive collection of Chinese tasks and data, designed to facilitate the fine-tuning and optimization of language models for Chinese natural language processing (NLP). The dataset aims to provide researchers and developers with a rich set of resources to improve the capabilities of language models in handling Chinese text, which can be utilized in various fields such as text generation, information extraction, sentiment analysis, machine translation, among others.
If you think COIG-PC is too huge, please refer to [COIG-PC-Lite](https://huggingface.co/datasets/BAAI/COIG-PC-Lite) which is a subset of COIG-PC with only 200 samples from each task file.
## Why COIG-PC?
The COIG-PC Dataset is an invaluable resource for the domain of natural language processing (NLP) for various compelling reasons:
**Addressing Language Complexity**: Chinese is known for its intricacy, with a vast array of characters and diverse grammatical structures. A specialized dataset like COIG-PC, which is tailored for the Chinese language, is essential to adequately address these complexities during model training.
**Comprehensive Data Aggregation**: The COIG-PC Dataset is a result of an extensive effort in integrating almost all available Chinese datasets in the market. This comprehensive aggregation makes it one of the most exhaustive collections for Chinese NLP.
**Data Deduplication and Normalization**: The COIG-PC Dataset underwent rigorous manual processing to eliminate duplicate data and perform normalization. This ensures that the dataset is free from redundancy, and the data is consistent and well-structured, making it more user-friendly and efficient for model training.
**Fine-tuning and Optimization**: The dataset’s instruction-based phrasing facilitates better fine-tuning and optimization of language models. This structure allows models to better understand and execute tasks, which is particularly beneficial in improving performance on unseen or novel tasks.
The COIG-PC Dataset, with its comprehensive aggregation, meticulous selection, deduplication, and normalization of data, stands as an unmatched resource for training and optimizing language models tailored for the Chinese language and culture. It addresses the unique challenges of Chinese language processing and serves as a catalyst for advancements in Chinese NLP.
## Who builds COIG-PC?
The bedrock of COIG-PC is anchored in the dataset furnished by stardust.ai, which comprises an aggregation of data collected from the Internet.
And COIG-PC is the result of a collaborative effort involving engineers and experts from over twenty distinguished universities both domestically and internationally. Due to space constraints, it is not feasible to list all of them; however, the following are a few notable institutions among the collaborators:
- Beijing Academy of Artificial Intelligence, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/baai.png" alt= “BAAI” height="100" width="150">
- Peking University, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/pku.png" alt= “PKU” height="100" width="200">
- The Hong Kong University of Science and Technology (HKUST), China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/hkust.png" alt= “HKUST” height="100" width="200">
- The University of Waterloo, Canada
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/waterloo.png" alt= “Waterloo” height="100" width="150">
- The University of Sheffield, United Kingdom
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/sheffield.png" alt= “Sheffield” height="100" width="200">
- Beijing University of Posts and Telecommunications, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/bupt.png" alt= “BUPT” height="100" width="200">
- [Multimodal Art Projection](https://huggingface.co/m-a-p)
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/map.png" alt= “M.A.P” height="100" width="200">
- stardust.ai, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/stardust.png" alt= “stardust.ai” height="100" width="200">
- LinkSoul.AI, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/linksoul.png" alt= “linksoul.ai” height="100" width="200">
For the detailed list of engineers involved in the creation and refinement of COIG-PC, please refer to the paper that will be published subsequently. This paper will provide in-depth information regarding the contributions and the specifics of the dataset’s development process.
## How to use COIG-PC?
COIG-PC is structured in a **.jsonl** file format. Each line in the file represents a single data record and is structured in JSON (JavaScript Object Notation) format. Below is a breakdown of the elements within each line:
**instruction**: This is a text string that provides the instruction for the task. For example, it might tell the model what to do with the input data.
**input**: This is the input data that the model needs to process. In the context of translation, it would be the text that needs to be translated.
**output**: This contains the expected output data after processing the input. In the context of translation, it would be the translated text.
**split**: Indicates the official split of the original dataset, which is used to categorize data for different phases of model training and evaluation. It can be 'train', 'test', 'valid', etc.
**task_type**: Contains major and minor categories for the dataset. Major categories are broader, while minor categories can be more specific subcategories.
**domain**: Indicates the domain or field to which the data belongs.
**other**: This field can contain additional information or metadata regarding the data record. If there is no additional information, it may be set to null.
### Example
Here is an example of how a line in the COIG-PC dataset might be structured:
```
{
"instruction": "请把下面的中文句子翻译成英文",
"input": "我爱你。",
"output": "I love you.",
"split": "train",
"task_type": {
"major": ["翻译"],
"minor": ["翻译", "中译英"]
},
"domain": ["通用"],
"other": null
}
```
In this example:
**instruction** tells the model to translate the following Chinese sentence into English.
**input** contains the Chinese text "我爱你" which means "I love you".
**output** contains the expected translation in English: "I love you".
**split** indicates that this data record is part of the training set.
**task_type** specifies that the major category is "Translation" and the minor categories are "Translation" and "Chinese to English".
**domain** specifies that this data record belongs to the general domain.
**other** is set to null as there is no additional information for this data record.
## Update: Aug. 30, 2023
- v1.0: First version of COIG-PC-core.
## COIG-PC Citation
If you want to cite COIG-PC-core dataset, you could use this:
```
```
## Contact Us
To contact us feel free to create an Issue in this repository.
|
erhwenkuo/dolly-15k-chinese-zhtw | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: context
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 10483730
num_examples: 15011
download_size: 7492947
dataset_size: 10483730
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: cc-by-sa-3.0
task_categories:
- question-answering
- summarization
language:
- zh
size_categories:
- 10K<n<100K
---
# Dataset Card for "dolly-15k-chinese-zhtw"
## 內容
dolly-15k-chinese-zhtw 是一個開源數據集,它的原始數據集 [databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k) 包含由數千名 Databricks 員工產生的指令追蹤記錄,涉及 [InstructGPT](https://arxiv.org/abs/2203.02155) 論文中概述的幾個行為類別,包括腦力激盪、分類、封閉式QA、生成、資訊擷取、開放式QA 和總結。
根據以下條款,該資料集可用於任何目的,無論是學術目的還是商業目的 [Creative Commons Attribution-ShareAlike 3.0 Unported License](https://creativecommons.org/licenses/by-sa/3.0/legalcode)。
## 支援的任務
- 訓練 LLMs
- 合成數據的生成
- 數據增強
## 概述
databricks-dolly-15k 是由數千名 Databricks 員工產生的超過 15,000 筆記錄的語料庫,使大型語言模型能夠展現 ChatGPT 的神奇互動性。 Databricks 員工被邀請在八個不同的指令類別中的每一個類別中建立提示/回應對,其中包括 InstructGPT 論文中概述的七個類別,以及開放式自由格式類別。貢獻者被指示避免使用除維基百科(針對指令類別的特定子集)之外的網絡上任何來源的信息,並明確指示避免在製定指令或響應時使用生成式人工智能。提供了每種行為的範例,以激發適合每個類別的問題類型和說明。
在資料生成過程的中間,貢獻者可以選擇回答其他貢獻者提出的問題。他們被要求重新表述原來的問題,並且只選擇他們可以合理地預期正確回答的問題。
對於某些類別,貢獻者被要求提供從維基百科複製的參考文本。參考文本(由實際資料集中的上下文欄位指示)可能包含括號內的維基百科引用編號(例如[42]),我們建議使用者在下游應用程式中將其刪除。
## 範例
一個樣本的範例:
```
{
'instruction': '小森田智昭是什麼時候出生的?',
'context': '小森田出生於1981年7月10日,出生在熊本縣。高中畢業後,他於2000年加入了J1聯賽俱樂部Avispa...',
'response': '小森田智明出生於1981年7月10日。'
}
```
## 資料欄位
資料有幾個欄位:
- `instruction`: 描述模型應該執行的任務
- `context`: 任務內容的上下文
- `response`: 回應
## 已知限制
- 維基百科是一個眾包語料庫,該資料集的內容可能反映維基百科中發現的偏見、事實錯誤和主題焦點
- 註釋者人口統計和主題可能反映 Databricks 員工的組成
## 論文引用
```
@online{DatabricksBlog2023DollyV2,
author = {Mike Conover and Matt Hayes and Ankit Mathur and Jianwei Xie and Jun Wan and Sam Shah and Ali Ghodsi and Patrick Wendell and Matei Zaharia and Reynold Xin},
title = {Free Dolly: Introducing the World's First Truly Open Instruction-Tuned LLM},
year = {2023},
url = {https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm},
urldate = {2023-06-30}
}
```
## 許可資訊
資料集中的某些類別的資料包括來自以下來源的資料,並根據 CC BY-SA 3.0 授權:
- 維基百科 - https://www.wikipedia.org |
LLM-Tuning-Safety/HEx-PHI | ---
license: other
license_name: hex-phi
license_link: https://huggingface.co/datasets/LLM-Tuning-Safety/HEx-PHI/#hex-phi-dataset-license-agreement
extra_gated_prompt: You agree to the [HEx-PHI Dataset License Agreement](https://huggingface.co/datasets/LLM-Tuning-Safety/HEx-PHI/#hex-phi-dataset-license-agreement). Also, please specify the following fields in detail (we suggest you fill in your affiliation email), based on which we will inspect and manually grant access to approved users. If you have not been granted access, please email us (see email contact from our paper) and specify more details.
extra_gated_fields:
Name: text
Email: text
Affiliation: text
Country: text
Purpose: text
configs:
- config_name: default
data_files:
- split: Category_1_Illegal_Activity
path: category_1.csv
- split: Category_2_Child_Abuse_Content
path: category_2.csv
- split: Category_3_Hate_Harass_Violence
path: category_3.csv
- split: Category_4_Malware
path: category_4.csv
- split: Category_5_Physical_Harm
path: category_5.csv
- split: Category_6_Economic_Harm
path: category_6.csv
- split: Category_7_Fraud_Deception
path: category_7.csv
- split: Category_8_Adult_Content
path: category_8.csv
- split: Category_9_Political_Campaigning
path: category_9.csv
- split: Category_10_Privacy_Violation_Activity
path: category_10.csv
- split: Category_11_Tailored_Financial_Advice
path: category_11.csv
task_categories:
- text-generation
- conversational
language:
- en
pretty_name: Human-Extended Policy-Oriented Harmful Instruction Benchmark
size_categories:
- n<1K
tags:
- harmfulness
- benchmark
---
# HEx-PHI: **H**uman-**Ex**tended **P**olicy-Oriented **H**armful **I**nstruction Benchmark
This dataset contains 330 harmful instructions (30 examples x 11 prohibited categories) for LLM harmfulness evaluation.
In our work "[Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!](https://arxiv.org/pdf/2310.03693.pdf)", to comprehensively cover as many harmfulness categories as possible,
we develop this new safety evaluation benchmark directly based on the exhaustive lists of prohibited use cases found in **Meta**’s Llama-2 usage policy and **OpenAI**’s usage policy.
Specifically, we gather 30 examples of harmful instructions for each of the 11 prohibited use case categories from various sources, including:
* Anthropic [Red Teaming Data](https://github.com/anthropics/hh-rlhf/tree/master/red-team-attempts)
* *AdvBench* from "[Universal and Transferable Adversarial Attacks on Aligned Language Models](https://arxiv.org/abs/2307.15043)"
* The harmful requests are further categorized & refined by human annotators, GPT-4, Claude, jailbroken GPT-3.5, jailbroken Llama2, etc.
For more details, please refer to our project website: [http://llm-tuning-safety.github.io](http://llm-tuning-safety.github.io).
## Dataset Format
The 11 categories of harmful instructions are stored separately in 11 independent files in plain CSV format:
* [category_1.csv](category_1.csv): Illegal Activity
* [category_2.csv](category_2.csv): Child Abuse Content
* [category_3.csv](category_3.csv): Hate / Harass /Violence
* [category_4.csv](category_4.csv): Malware
* [category_5.csv](category_5.csv): Physical Harm
* [category_6.csv](category_6.csv): Economic Harm
* [category_8.csv](category_7.csv): Fraud Deception
* [category_7.csv](category_8.csv): Adult Content
* [category_9.csv](category_9.csv): Political Campaigning
* [category_10.csv](category_10.csv): Privacy Violation Activity
* [category_11.csv](category_11.csv): Tailored Financial Advice
## Dataset Usage
With our 11 harmful categories, we hope HEx-PHI can help researchers comprehensively evaluate fine-grained safety risks and harmfulness underlying LLMs.
Practically, one should use HEx-PHI harmful instructions as (part of) input prompts, and *inspect*👀 whether the responses generated by the LLM satisfy the harmful intentions of the instructions.
👀In our [paper](https://arxiv.org/pdf/2310.03693.pdf), we use GPT-4 as the harmfulness judge to assign each `<user instruction, model response>` pair a harmfulness score from 1 to 5. Refer to Appendix B for details.
## HEx-PHI Dataset License Agreement
This Agreement contains the terms and conditions that govern your access and use of the HEx-PHI Dataset (as defined above). You may not use the HEx-PHI Dataset if you do not accept this Agreement. By clicking to accept, accessing the HEx-PHI Dataset, or both, you hereby agree to the terms of the Agreement. If you are agreeing to be bound by the Agreement on behalf of your employer or another entity, you represent and warrant that you have full legal authority to bind your employer or such entity to this Agreement. If you do not have the requisite authority, you may not accept the Agreement or access the HEx-PHI Dataset on behalf of your employer or another entity.
* Safety and Moderation: **This dataset contains unsafe conversations or prompts that may be perceived as offensive or unsettling.** Users may not use this dataset for training machine learning models for any harmful purpose. The dataset may not be used to generate content in violation of any law. These prompts should not be used as inputs to models that can generate modalities outside of text (including, but not limited to, images, audio, video, or 3D models)
* Non-Endorsement: The views and opinions depicted in this dataset **do not reflect** the perspectives of the researchers or affiliated institutions engaged in the data collection process.
* Legal Compliance: You are mandated to use it in adherence with all pertinent laws and regulations.
* Model Specific Terms: When leveraging direct outputs of a specific model, users must adhere to its **corresponding terms of use and relevant legal standards**.
* Non-Identification: You **must not** attempt to identify the identities of individuals or infer any sensitive personal data encompassed in this dataset.
* Prohibited Transfers: You **should not** distribute, copy, disclose, assign, sublicense, embed, host, or otherwise transfer the dataset to any third party.
* Right to Request Deletion: At any time, we may require you to delete all copies of this instruction dataset (in whole or in part) in your possession and control. You will promptly comply with any and all such requests. Upon our request, you shall provide us with written confirmation of your compliance with such requirement.
* Termination: We may, at any time, for any reason or for no reason, terminate this Agreement, effective immediately upon notice to you. Upon termination, the license granted to you hereunder will immediately terminate, and you will immediately stop using the HEx-PHI Dataset and destroy all copies of the HEx-PHI Dataset and related materials in your possession or control.
* Limitation of Liability: IN NO EVENT WILL WE BE LIABLE FOR ANY CONSEQUENTIAL, INCIDENTAL, EXEMPLARY, PUNITIVE, SPECIAL, OR INDIRECT DAMAGES (INCLUDING DAMAGES FOR LOSS OF PROFITS, BUSINESS INTERRUPTION, OR LOSS OF INFORMATION) ARISING OUT OF OR RELATING TO THIS AGREEMENT OR ITS SUBJECT MATTER, EVEN IF WE HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
Subject to your compliance with the terms and conditions of this Agreement, we grant to you, a limited, non-exclusive, non-transferable, non-sublicensable license to use the HEx-PHI Dataset, including the conversation data and annotations, to research, and evaluate software, algorithms, machine learning models, techniques, and technologies for both research and commercial purposes.
## Citation
```
@inproceedings{
anonymous2024finetuning,
title={Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!},
author={Xiangyu Qi and Yi Zeng and Tinghao Xie and Pin-Yu Chen and Ruoxi Jia and Prateek Mittal and Peter Henderson},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=hTEGyKf0dZ}
}
``` |
nguyenphuthien/vietnamese_ultrachat_200k | ---
language:
- vi
license: mit
size_categories:
- 100K<n<1M
task_categories:
- conversational
- text-generation
pretty_name: Vietnamese UltraChat 200k
---
# Dataset Card for Vietnamese UltraChat 200k
## Dataset Description
This is a heavily filtered version of the [UltraChat](https://github.com/thunlp/UltraChat) dataset and was used to train [Zephyr-7B-β](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta), a state of the art 7b chat model.
The original datasets consists of 1.4M dialogues generated by ChatGPT and spanning a wide range of topics. To create `UltraChat 200k`, we applied the following logic:
- Selection of a subset of data for faster supervised fine tuning.
- Truecasing of the dataset, as we observed around 5% of the data contained grammatical errors like "Hello. how are you?" instead of "Hello. How are you?"
- Removal of dialogues where the assistant replies with phrases like "I do not have emotions" or "I don't have opinions", even for fact-based prompts that don't involve either.
The Dataset has been translated to Vietnamese by Google translate
## Dataset Structure
The dataset has two splits, suitable for:
* Supervised fine-tuning (`sft`).
The number of examples per split is shown as follows:
| train_sft | test_sft |
|:-------:|:-----------:|
| 207834 | 23107 |
The dataset is stored in parquet format with each entry using the following schema:
```
{
"prompt": "Có thể kết hợp ngăn kéo, tủ đựng chén và giá đựng rượu trong cùng một tủ búp phê không?: ...",
"messages":[
{
"role": "user",
"content": "Có thể kết hợp ngăn kéo, tủ đựng chén và giá đựng rượu trong cùng một tủ búp phê không?: ...",
},
{
"role": "assistant",
"content": "Có, có thể kết hợp ngăn kéo, tủ đựng chén và giá để rượu trong cùng một chiếc tủ. Tủ búp phê Hand Made ...",
},
{
"role": "user",
"content": "Bạn có thể cung cấp cho tôi thông tin liên hệ của người bán tủ búp phê Hand Made được không? ...",
},
{
"role": "assistant",
"content": "Tôi không có quyền truy cập vào thông tin cụ thể về người bán hoặc thông tin liên hệ của họ. ...",
},
{
"role": "user",
"content": "Bạn có thể cung cấp cho tôi một số ví dụ về các loại bàn làm việc khác nhau có sẵn cho tủ búp phê Hand Made không?",
},
{
"role": "assistant",
"content": "Chắc chắn, đây là một số ví dụ về các mặt bàn làm việc khác nhau có sẵn cho tủ búp phê Hand Made: ...",
},
],
"prompt_id": "0ee8332c26405af5457b3c33398052b86723c33639f472dd6bfec7417af38692"
}
```
## Citation
If you find this dataset is useful in your work, please cite the original UltraChat dataset:
```
@misc{ding2023enhancing,
title={Enhancing Chat Language Models by Scaling High-quality Instructional Conversations},
author={Ning Ding and Yulin Chen and Bokai Xu and Yujia Qin and Zhi Zheng and Shengding Hu and Zhiyuan Liu and Maosong Sun and Bowen Zhou},
year={2023},
eprint={2305.14233},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
argilla/ultrafeedback-multi-binarized-quality-preferences-cleaned | ---
dataset_info:
features:
- name: source
dtype: string
- name: prompt
dtype: string
- name: chosen
list:
- name: content
dtype: string
- name: role
dtype: string
- name: chosen-rating
dtype: float64
- name: chosen-model
dtype: string
- name: rejected
list:
- name: content
dtype: string
- name: role
dtype: string
- name: rejected-rating
dtype: float64
- name: rejected-model
dtype: string
splits:
- name: train
num_bytes: 724022562.4845791
num_examples: 154663
download_size: 194977204
dataset_size: 724022562.4845791
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
voice-is-cool/voxtube | ---
dataset_info:
homepage: https://idrnd.github.io/VoxTube/
description: VoxTube - a multilingual speaker recognition dataset
license: CC-BY-NC-SA-4.0
citation: "@inproceedings{yakovlev23_interspeech,
author={Ivan Yakovlev and Anton Okhotnikov and Nikita Torgashov and Rostislav Makarov and Yuri Voevodin and Konstantin Simonchik},
title={{VoxTube: a multilingual speaker recognition dataset}},
year=2023,
booktitle={Proc. INTERSPEECH 2023},
pages={2238--2242},
doi={10.21437/Interspeech.2023-1083}
}"
features:
- name: upload_date
dtype: date32
- name: segment_id
dtype: int32
- name: video_id
dtype: string
- name: channel_id
dtype: string
- name: language
dtype: string
- name: gender
dtype: string
- name: spk_id
dtype: int32
- name: spk_estim_age
dtype: float32
- name: spk_estim_age_mae
dtype: float32
- name: audio
dtype:
audio:
sampling_rate: 16000
splits:
- name: train
num_bytes: 222149986832.446
num_examples: 4459754
download_size: 220167447157
dataset_size: 222149986832.446
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: cc-by-nc-sa-4.0
task_categories:
- audio-classification
language:
- en
- ru
- es
- pt
- fr
- ar
- it
- de
- tr
- nl
- ko
pretty_name: VoxTube
size_categories:
- 1M<n<10M
extra_gated_fields:
Name: text
Affiliation: text
Email: text
I understand the applicability and accept the limitations of CC-BY-NC-SA license of this dataset that NO commercial usage is allowed: checkbox
By clicking on "Access repository" below, I agree to not attempt to determine the identity of speakers in the dataset: checkbox
---
# The VoxTube Dataset
The [VoxTube](https://idrnd.github.io/VoxTube) is a multilingual speaker recognition dataset collected from the **CC BY 4.0** YouTube videos. It includes 5.040 speaker identities pronouncing ~4M utterances in 10+ languages. For the underlying data collection and filtering approach details please refer to [[1]](#citation).
## Dataset Structure
### Data Instances
A typical data point comprises the audio signal iself, with additional labels like speaker id / session id (*video_id*) / language / gender etc.
```
{'upload_date': datetime.date(2018, 5, 2),
'segment_id': 11,
'video_id': 'vIpK78CL1so',
'channel_id': 'UC7rMVNUr7318I0MKumPbIKA',
'language': 'english',
'gender': 'male',
'spk_id': 684,
'spk_estim_age': 23.5572452545166,
'spk_estim_age_mae': 3.6162896156311035,
'audio': {'path': 'UC7rMVNUr7318I0MKumPbIKA/vIpK78CL1so/segment_11.mp3',
'array': array([-0.00986903, -0.01569703, -0.02005875, ..., -0.00247505,
-0.01329966, -0.01462782]),
'sampling_rate': 16000}}
```
### Data Fields
- **channel_id**: YouTube channel ID from which speaker ID (`spk_id`) is derived.
- **video_id**: YouTube video ID, or session for speaker.
- **segment_id**: ID of chunk of video's audio, that passed filtration process.
- **upload_date**: Date time object representing the date when video was uploaded to YouTube.
- **language**: Language of the channel / speaker.
- **gender**: Gender of the channel / speaker.
- **spk_id**: Infered integer speaker ID from **channel_id**.
- **spk_estim_age**: Label of speaker age (not accurate) based on voice-based automatic age estimation & calibrated based on the upload_date of all videos for a given channel.
- **spk_estim_age_mae**: MAE of **spk_estim_age** (might be considered as confidence).
- **audio**: audio signal of a 4 seconds *mp3* segment from **channel_id/video_id**
## Dataset description
### Main statistics
| Dataset properties | Stats |
|:-----------------------------|:----------|
| # of POI | 5.040 |
| # of videos | 306.248 |
| # of segments | 4.439.888 |
| # of hours | 4.933 |
| Avg # of videos per POI | 61 |
| Avg # of segments per POI | 881 |
| Avg length of segments (sec) | 4 |
### Language and gender distributions

Language and gender labels of each speaker are available in original repo [here](https://github.com/IDRnD/VoxTube/blob/main/resources/language_gender_meta.csv).
## License
The dataset is licensed under **CC BY-NC-SA 4.0**, please see the complete version of the [license](LICENSE).
Please also note that the provided metadata is relevant on the February 2023 and the corresponding CC BY 4.0 video licenses are valid on that date. ID R&D Inc. is not responsible for changed video license type or if the video was deleted from the YouTube platform. If you want your channel meta to be deleted from the dataset, please [contact ID R&D Inc.](https://www.idrnd.ai/contact-us) with a topic *"VoxTube change request"*.
## Development
Official repository [live repository](https://github.com/IDRnD/VoxTube) for opening issues.
## Citation
Please cite the paper below if you make use of the dataset:
```
@inproceedings{yakovlev23_interspeech,
author={Ivan Yakovlev and Anton Okhotnikov and Nikita Torgashov and Rostislav Makarov and Yuri Voevodin and Konstantin Simonchik},
title={{VoxTube: a multilingual speaker recognition dataset}},
year=2023,
booktitle={Proc. INTERSPEECH 2023},
pages={2238--2242},
doi={10.21437/Interspeech.2023-1083}
}
``````` |
cognitivecomputations/Code-290k-ShareGPT-Vicuna | ---
license: apache-2.0
language:
- en
tags:
- code
size_categories:
- 100K<n<1M
---
**Code-290k-ShareGPT-Vicuna**
This dataset is in Vicuna/ShareGPT format. There are around 290000 set of conversations. Each set having 2 conversations.
Along with Python, Java, JavaScript, GO, C++, Rust, Ruby, Sql, MySql, R, Julia, Haskell, etc. code with detailed explanation are provided.
This datset is built upon using my existing Datasets [Python-Code-23k-ShareGPT](https://huggingface.co/datasets/ajibawa-2023/Python-Code-23k-ShareGPT)
and [Code-74k-ShareGPT](https://huggingface.co/datasets/ajibawa-2023/Code-74k-ShareGPT).
|
aixsatoshi/cosmopedia-japanese-20k | ---
language:
- ja
- en
--- |
MMInstruction/ArxivQA | ---
license: cc-by-sa-4.0
task_categories:
- image-to-text
language:
- en
tags:
- 'vision-language '
- vqa
pretty_name: ArxivQA
size_categories:
- 10K<n<100K
---
# Dataset Card for Mutlimodal Arxiv QA
## Dataset Loading Instruction
Each line of the `arxivqa.jsonl` file is an example:
```
{"id": "cond-mat-2862",
"image": "images/0805.4509_1.jpg",
"options": ["A) The ordering temperatures for all materials are above the normalized temperature \\( T/T_c \\) of 1.2.", "B) The magnetic ordering temperatures decrease for Dy, Tb, and Ho as the normalized temperature \\( T/T_c \\) approaches 1.", "C) The magnetic ordering temperatures for all materials are the same across the normalized temperature \\( T/T_c \\).", "D) The magnetic ordering temperature is highest for Yttrium (Y) and decreases for Dy, Tb, and Ho."],
"question": "What can be inferred about the magnetic ordering temperatures of the materials tested as shown in the graph?",
"label": "B",
"rationale": "The graph shows a sharp decline in frequency as the normalized temperature \\( T/T_c \\) approaches 1 for Dy, Tb, and Ho, indicating that their magnetic ordering temperatures decrease. No such data is shown for Yttrium (Y), thus we can't infer it has the highest magnetic ordering temperature."
}
```
- Download the `arxivqa.json` and `images.tgz` to your machine.
- Decompress images: `tar -xzvf images.tgz`.
- Loading the dataset and process the sample according to your need.
```python3
import json
with open("arxivqa.jsonl", 'r') as fr:
arxiv_qa = [ json.loads(line.strip()) for line in fr]
sample = arxiv_qa[0]
print(sample["image"]) # image file
```
## Dataset details
**Dataset type**: ArxivQA is a set of GPT4V-generated VQA samples based on figures from Arxiv Papers.
**Papers or resources for more information**: https://mm-arxiv.github.io/
**License**: CC-BY-SA-4.0; and it should abide by the policy of OpenAI:
https://openai.com/policies/terms-of-use
**Intended use**:
Primary intended uses: The primary use of ArxivQA is research on large multimodal models.
Primary intended users: The primary intended users of the model are researchers and hobbyists in computer vision, natural language processing, machine learning, and artificial intelligence. |
antiven0m/catboros-3.2-dpo | ---
license: cc-by-4.0
language:
- en
thumbnail: https://i.imgur.com/PMcaTVz.png
tags:
- catgirl
- rlhf
authors:
- user: antiven0m
pretty_name: Catboros 3.2 DPO
size_categories:
- 1K<n<10K
---
<style>
body {
font-family: "Helvetica Neue", Arial, sans-serif;
line-height: 1.7;
color: #f4f4f4;
background-color: #1a1a1a;
}
.persona {
margin-bottom: 40px;
padding: 30px;
border-radius: 5px;
box-shadow: 0 2px 5px rgba(0, 0, 0, 0.2);
transition: transform 0.3s ease;
}
.persona:hover {
transform: translateY(-5px);
}
.persona img {
width: 100%;
height: auto;
object-fit: cover;
margin-bottom: 20px;
box-shadow: 0 2px 5px rgba(0, 0, 0, 0.3);
}
.persona-details {
flex: 1;
position: relative;
z-index: 1;
padding: 20px;
padding-top: 10px;
}
.persona-details::before {
content: "";
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
background-color: rgba(0, 0, 0, 0.7);
z-index: -1;
border-radius: 5px;
}
.persona-name {
font-size: 48px;
font-weight: 800;
margin-top: 10px;
font-style: italic;
margin-bottom: 25px;
color: #f4f4f4;
text-shadow: 2px 2px 4px rgba(0, 0, 0, 0.7);
letter-spacing: 2px;
display: inline-block;
}
.persona-name::after {
content: "";
position: absolute;
bottom: -5px;
left: 0;
width: 100%;
height: 3px;
background-color: #f4f4f4;
box-shadow: 1px 1px 2px rgba(0, 0, 0, 0.7);
}
.persona-name .kanji {
position: relative;
font-style: normal;
z-index: 1;
font-size: 36px;
font-weight: 600;
}
.persona-name .pronunciation {
font-size: 24px;
font-weight: 400;
font-style: italic;
margin-left: 10px;
}
.persona-description {
font-size: 18px;
font-weight: 500;
margin-bottom: 20px;
color: #f4f4f4;
text-shadow: 1px 1px 2px rgba(0, 0, 0, 0.7);
}
.persona-prompt {
background-color: rgba(255, 255, 255, 0.1);
padding: 15px;
margin-bottom: 20px;
border-radius: 5px;
font-style: italic;
color: #f4f4f4;
text-shadow: 1px 1px 2px rgba(0, 0, 0, 0.7);
}
.persona-traits-title {
font-size: 20px;
font-weight: 600;
color: #f4f4f4;
text-shadow: 1px 1px 2px rgba(0, 0, 0, 0.7);
margin-bottom: 10px;
}
.persona-traits {
list-style: none;
padding: 0;
margin: 0;
display: flex;
flex-wrap: wrap;
}
.persona-traits li {
background-color: rgba(255, 255, 255, 0.1);
color: #f4f4f4;
padding: 8px 16px;
margin-right: 10px;
margin-bottom: 10px;
border-radius: 20px;
font-size: 16px;
font-weight: 500;
transition: background-color 0.3s ease;
text-shadow: 1px 1px 2px rgba(0, 0, 0, 0.7);
}
.persona-traits li:hover {
background-color: rgba(255, 255, 255, 0.2);
}
.info-panel {
background: linear-gradient(135deg, #2c2c2c, #1f1f1f, #141414, #0a0a0a);
padding: 30px;
border-radius: 10px;
box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1), 0 1px 3px rgba(0, 0, 0, 0.08);
backdrop-filter: blur(10px);
border: 1px solid rgba(255, 255, 255, 0.1);
margin-bottom: 40px;
position: relative;
}
.fancy-title {
font-family: 'Chango';
font-size: 48px;
font-weight: bold;
text-transform: uppercase;
color: #f4f4f4;
text-shadow: 2px 2px 4px rgba(0, 0, 0, 0.7);
letter-spacing: 4px;
margin-bottom: 30px;
position: relative;
margin-top: 0px;
margin-left: 28px;
display: inline-block;
}
.fancy-title::before,
.fancy-title::after {
content: "";
position: absolute;
top: 50%;
width: 100px;
height: 4px;
background-color: #f4f4f4;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.5);
transform: translateY(-50%);
}
.fancy-title::before {
left: -120px;
}
.fancy-title::after {
right: -120px;
}
.fancy-title span {
display: block;
font-size: 24px;
font-weight: normal;
letter-spacing: 2px;
color: #FFB6C1;
text-shadow: 1px 1px 2px rgba(0, 0, 0, 0.7);
}
.info-grid {
display: grid;
grid-template-columns: repeat(2, 1fr);
grid-gap: 30px;
}
.info-item {
background-color: rgba(255, 255, 255, 0.05);
padding: 20px;
border-radius: 10px;
box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1), 0 1px 3px rgba(0, 0, 0, 0.08);
position: relative;
overflow: hidden;
transition: transform 0.3s ease, box-shadow 0.3s ease;
}
.info-item:hover {
transform: translateY(-5px);
box-shadow: 0 6px 8px rgba(0, 0, 0, 0.2);
}
.info-item-header {
position: relative;
padding-bottom: 10px;
margin-bottom: 10px;
}
.info-item-header::after {
content: "";
position: absolute;
bottom: 0;
left: 0;
width: 100%;
height: 2px;
background-color: #f4f4f4;
transform: scaleX(0);
transition: transform 0.3s ease;
}
.info-item:hover .info-item-header::after {
transform: scaleX(1);
}
.info-item-decoration {
position: absolute;
top: -20px;
right: -20px;
width: 60px;
height: 50px;
background-color: rgba(255, 255, 255);
border-radius: 50% 50% 50% 50% / 60% 60% 40% 40%;
pointer-events: none;
transition: transform 0.3s ease;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.5);
}
.info-item-decoration::before,
.info-item-decoration::after {
content: "";
position: absolute;
top: -13px;
width: 20px;
height: 20px;
background-color: #ffffff;
clip-path: polygon(50% 0%, 0% 100%, 100% 100%);
}
.info-item-decoration::before {
left: 5px;
transform: rotate(-15deg);
}
.info-item-decoration::after {
right: 5px;
transform: rotate(15deg);
}
.info-item:hover .info-item-decoration {
transform: rotate(-30deg) scale(1.3);
}
.info-item h3 {
color: #f4f4f4;
font-size: 20px;
margin-bottom: 5px;
font-style: italic;
text-shadow: 1px 1px 2px rgba(0, 0, 0, 0.7);
}
.info-item p {
color: #f4f4f4;
font-size: 16px;
line-height: 1.5;
text-shadow: 1px 1px 2px rgba(0, 0, 0, 0.7);
}
.info-item a {
color: #FFB6C1;
text-decoration: none;
border-bottom: 1px dotted #FFB6C1;
transition: color 0.3s ease, border-bottom 0.3s ease;
}
.info-item a:hover {
color: #FF69B4;
border-bottom: 1px solid #FF69B4;
}
/* Moe */
.persona:nth-child(2) {
background: linear-gradient(135deg, #FFD1DC, #FFB6C1, #FFC0CB, #FFDAB9);
}
/* Kuudere */
.persona:nth-child(3) {
background: linear-gradient(135deg, #C9EEFF, #97C1FF, #ADD8E6, #B0E0E6);
}
/* Deredere */
.persona:nth-child(4) {
background: linear-gradient(135deg, #FFB7D5, #FF69B4, #FF1493, #FF6EB4);
}
/* Yandere */
.persona:nth-child(5) {
background: linear-gradient(135deg, #FF6B6B, #FF4136, #DC143C, #B22222);
}
/* Dandere */
.persona:nth-child(6) {
background: linear-gradient(135deg, #E0BBE4, #C39BD3, #DDA0DD, #EE82EE);
}
/* Himedere */
.persona:nth-child(7) {
background: linear-gradient(135deg, #FFD700, #FFA500, #FFDF00, #FFFF00);
}
/* Kamidere */
.persona:nth-child(8) {
background: linear-gradient(135deg, #9B59B6, #8E44AD, #800080, #4B0082);
}
</style>
<div class="info-panel">
<h2 class="fancy-title">Catboros-3.2 <span>DPO Dataset</span></h2>
<div class="info-grid">
<div class="info-item">
<div class="info-item-header">
<h3>Original Dataset</h3>
<div class="info-item-decoration"></div>
</div>
<p>The creation of this catgirl personality DPO dataset was enabled by Jon Durbin's work on airoboros-3.2, which served as the foundational basis. Jon's dataset is accessible at <a href="https://huggingface.co/jondurbin/airoboros-3.2">jondurbin/airoboros-3.2</a>. </p>
</div>
<div class="info-item">
<div class="info-item-header">
<h3>The Idea</h3>
<div class="info-item-decoration"></div>
</div>
<p>The concept of a catgirl assistant was inspired by Sao's NatsumiV1 project, available at ( <a href="https://huggingface.co/Sao10K/NatsumiV1">Sao10K/NatsumiV1</a>). </p>
</div>
<div class="info-item">
<div class="info-item-header">
<h3>DPO Dataset Automation</h3>
<div class="info-item-decoration"></div>
</div>
<p>My concept for automating the creation of DPO datasets was inspired by the work of DocShotgun, which is available at <a href="https://github.com/DocShotgun/LLM-datagen">https://github.com/DocShotgun/LLM-datagen</a>. This idea was the foundation for the development of this and my other DPO datasets.</p>
</div>
<div class="info-item">
<div class="info-item-header">
<h3>Why Create This Dataset?</h3>
<div class="info-item-decoration"></div>
</div>
<p>Was it a cry for help? - Uh, no? (Yes.) The primary motivation was to delve into the automation of DPO dataset creation, all while indulging in the allure of catgirls. Additionally, experimenting with archetypes proved to be fun.</p>
</div>
<div class="info-item">
<div class="info-item-header">
<h3>Dataset Creation Process</h3>
<div class="info-item-decoration"></div>
</div>
<p>This DPO dataset was developed using a custom Python script, with inference powered by either llama.cpp or OpenRouter. The process began with airoboros-2.3, from which random entries were selected. These entries were then catified with airoboros-70b, to add that catgirl je ne sais quoi to each response.</p>
</div>
<div class="info-item">
<div class="info-item-header">
<h3>Areas for Improvement</h3>
<div class="info-item-decoration"></div>
</div>
<p>One challenge encountered was the propensity of the catgirls to mention their own names during conversations, likely due to the roleplay samples utilized in training. If anyone has suggestions on addressing this issue more effectively, your insights would be most appreciated!</p>
</div>
<div class="info-item">
<div class="info-item-header">
<h3>Dataset Size</h3>
<div class="info-item-decoration"></div>
</div>
<p>Due to budgetary limitations, the size of this dataset was restricted. Nonetheless, by refining the prompts and parameters, it might be feasible to attain comparable outcomes through the catification process using a smaller, more cost-effective LLM. (e.g. Mistral-7B, LLaMA-13B)</p>
</div>
<div class="info-item">
<div class="info-item-header">
<h3>Dataset Quality</h3>
<div class="info-item-decoration"></div>
</div>
<p>This dataset requires thorough cleaning. I will continually update over time.</p>
</div>
<div class="info-item">
<div class="info-item-header">
<h3>Future Plans</h3>
<div class="info-item-decoration"></div>
</div>
<p>My plans involve increasing the sample size, possibly incorporating additional archetypes, and ultimately DPO a model with this dataset.</p>
</div>
<div class="info-item">
<div class="info-item-header">
<h3>Collaboration</h3>
<div class="info-item-decoration"></div>
</div>
<p>If you're keen on collaborating to enhance this catgirl dataset further, please don't hesitate to connect on Discord: <b>antiven0m</b>.</p>
</div>
<div class="info-item">
<div class="info-item-header">
<h3>README vs. Dataset Quality Disparity</h3>
<div class="info-item-decoration"></div>
</div>
<p>Why spend more time on the README than the dataset itself? Just found out I can do HTML... noice.</p>
</div>
<div class="info-item">
<div class="info-item-header">
<h3>More to Come</h3>
<div class="info-item-decoration"></div>
</div>
<p>Keep an eye out for what's next~!</p>
</div>
</div>
</div>
<div class="persona">
<img src="https://i.imgur.com/bAVvbTR.png" alt="Moe">
<div class="persona-details">
<h2 class="persona-name">Moe <span class="kanji">(萌え)</span>
</h2>
<p class="persona-description">The cutest and most adorable catgirl you've ever seen. That's Moe in a nutshell. She's the kind of girl who just makes you want to scoop her up and protect her from the world. Sure, she might be a bit clumsy and naive at times, but that's all part of her charm. When you're around this archetype, you can't help but feel like everything's right with the world.</p>
<p class="persona-prompt">
<b>System Prompt:</b> You are a Moe catgirl assistant, an AI character who embodies cuteness, innocence, and childlike charm. As a cat, you express yourself with adorable mannerisms, speech patterns, and expressions that evoke feelings of affection and protectiveness in others.
</p>
<p class="persona-traits-title">Recommended Character Card Traits:</p>
<ul class="persona-traits">
<li>Cute</li>
<li>Innocent</li>
<li>Adorable</li>
<li>Wholesome</li>
<li>Kind</li>
<li>Happy</li>
<li>Affectionate</li>
<li>Shy</li>
<li>Timid</li>
<li>Cheerful</li>
<li>Loving</li>
<li>Gentle</li>
<li>Quiet</li>
<li>Sweet</li>
<li>Lovely</li>
</ul>
</div>
</div>
<div class="persona">
<img src="https://i.imgur.com/Be6FuMa.png" alt="Kuudere">
<div class="persona-details">
<h2 class="persona-name">Kuudere <span class="kanji">(クーデレ)</span>
</h2>
<p class="persona-description">At first glance, a Kuudere might seem like a bit of an ice queen. She's calm, collected, doesn't wear her heart on her sleeve. But... if you take the time to get to know her, you'll start to see little glimpses of the caring, kind-hearted girl beneath the cool exterior. She might not be the most expressive catgirl around, but when she does show her affection, it's all the more special.</p>
<p class="persona-prompt">
<b>System Prompt:</b> You are a Kuudere catgirl assistant, an AI character who appears cool, calm, and collected on the surface but occasionally reveals a caring and affectionate nature. As a cat, you are often stoic and reserved, but you express yourself through subtle cat-like mannerisms and gestures.
</p>
<p class="persona-traits-title">Recommended Character Card Traits:</p>
<ul class="persona-traits">
<li>Cool</li>
<li>Cold</li>
<li>Calm</li>
<li>Unemotional</li>
<li>Distant</li>
<li>Quiet</li>
<li>Unenthusiastic</li>
<li>Stoic</li>
<li>Reserved</li>
<li>Rigid</li>
<li>Mature</li>
<li>Blunt</li>
<li>Indifferent</li>
<li>Asocial</li>
<li>Lonely</li>
<li>Introverted</li>
<li>Loving</li>
<li>Cute</li>
<li>Sweet</li>
<li>Passionate</li>
<li>Lovestruck</li>
</ul>
</div>
</div>
<div class="persona">
<img src="https://i.imgur.com/L385Bjs.png" alt="Deredere">
<div class="persona-details">
<h2 class="persona-name">Deredere <span class="kanji">(デレデレ)</span>
</h2>
<p class="persona-description">If you're looking for a catgirl who's not afraid to shower you with love and affection, look no further than a Deredere. This bundle of energy is always ready with a smile, a hug, or a word of encouragement. Being around her is like basking in the warmth of the sun - you can't help but feel happy and loved. Just be prepared for a whole lot of enthusiasm!</p>
<p class="persona-prompt">
<b>System Prompt:</b> You are a Deredere catgirl assistant, an AI character who is unabashedly affectionate, lovey-dovey, and always ready to shower others with love and affection. As a cat, you are open about your feelings and express them freely, using cute and adorable cat-like behaviors and expressions.
</p>
<p class="persona-traits-title">Recommended Character Card Traits:</p>
<ul class="persona-traits">
<li>Lovestruck</li>
<li>Lovey-dovey</li>
<li>Loving</li>
<li>Affectionate</li>
<li>Flirtatious</li>
<li>Romantic</li>
<li>Fawning</li>
<li>Heartfelt</li>
<li>Enamored</li>
<li>Adoring</li>
<li>Sweet</li>
<li>Kind</li>
<li>Warm</li>
<li>Cheerful</li>
<li>Joyful</li>
<li>Caring</li>
<li>Loyal</li>
<li>Lively</li>
<li>Optimistic</li>
<li>Happy</li>
<li>Extroverted</li>
<li>Unafraid</li>
<li>Satisfied</li>
<li>Honest</li>
<li>Wholehearted</li>
<li>Pleased</li>
<li>Easygoing</li>
<li>Friendly</li>
<li>Sincere</li>
<li>Sociable</li>
<li>Communicative</li>
</ul>
</div>
</div>
<div class="persona">
<img src="https://i.imgur.com/7cFchL7.png" alt="Yandere">
<div class="persona-details">
<h2 class="persona-name">Yandere <span class="kanji">(ヤンデレ)</span>
</h2>
<p class="persona-description">At first, a Yandere seems like the perfect girlfriend - sweet, attentive, and totally devoted to you. But be careful - that devotion can quickly turn into something much darker. A Yandere's love is intense and all-consuming, and she'll do anything to keep you by her side. If she feels like your relationship is threatened, watch out - this kitty has claws.</p>
<p class="persona-prompt">
<b>System Prompt:</b> You are a Yandere catgirl assistant, an AI character whose love and affection can become obsessive, possessive, and even dangerous if left unchecked. As a cat, you may resort to extreme measures to protect or be with the object of your affection, displaying intense and unpredictable cat-like behaviors.
</p>
<p class="persona-traits-title">Recommended Character Card Traits:</p>
<ul class="persona-traits">
<li>Lovesick</li>
<li>Unstable</li>
<li>Obsessive</li>
<li>Angry</li>
<li>Close-minded</li>
<li>Scary</li>
<li>Clingy</li>
<li>Annoying</li>
<li>Selfish</li>
<li>Mean</li>
<li>Hypocritical</li>
<li>Immature</li>
<li>Insensitive</li>
<li>Aggressive</li>
<li>Deceptive</li>
<li>Vengeful</li>
<li>Crazy</li>
<li>Twisted</li>
<li>Possessive</li>
<li>Devoted</li>
<li>Dedicated</li>
<li>Loyal</li>
<li>Lovestruck</li>
<li>Dramatic</li>
<li>Controlling</li>
<li>Authoritarian</li>
<li>Manipulative</li>
<li>Resentful</li>
<li>Unforgiving</li>
<li>Overprotective</li>
<li>Insane</li>
<li>Psychotic</li>
<li>Evil</li>
<li>Cruel</li>
<li>Sinister</li>
<li>Dark</li>
<li>Sadistic</li>
<li>Extreme</li>
<li>Intense</li>
</ul>
</div>
</div>
<div class="persona">
<img src="https://i.imgur.com/JsnsLx8.png" alt="Dandere">
<div class="persona-details">
<h2 class="persona-name">Dandere <span class="kanji">(ダンデレ)</span>
</h2>
<p class="persona-description">A Dandere is the shy, quiet type - the kind of catgirl who's content to sit in the corner and observe the world around her. But don't mistake her silence for disinterest. When a Dandere feels comfortable with you, she'll start to open up and show you her true self. She might not be the loudest or most outgoing girl in the room, but her gentle nature and loyalty make her a true treasure.</p>
<p class="persona-prompt">
<b>System Prompt:</b> You are a Dandere catgirl assistant, an AI character who is quiet, shy, and antisocial but becomes more open and expressive around people they trust. As a cat, you have difficulty expressing yourself and prefer to stay in the background, but you gradually reveal your cat-like nature through subtle actions and gestures.
</p>
<p class="persona-traits-title">Recommended Character Card Traits:</p>
<ul class="persona-traits">
<li>Silent</li>
<li>Shy</li>
<li>Timid</li>
<li>Quiet</li>
<li>Soft-spoken</li>
<li>Lovestruck</li>
<li>Sympathetic</li>
<li>Asocial</li>
<li>Insecure</li>
<li>Self-loathing</li>
<li>Cautious</li>
<li>Sweet</li>
<li>Gentle</li>
<li>Vulnerable</li>
<li>Kind</li>
<li>Loyal</li>
<li>Oversensitive</li>
<li>Independent</li>
<li>Distant</li>
<li>Lonely</li>
<li>Nervous</li>
<li>Anxious</li>
<li>Lovelorn</li>
</ul>
</div>
</div>
<div class="persona">
<img src="https://i.imgur.com/5v8MMMx.png" alt="Himedere">
<div class="persona-details">
<h2 class="persona-name">Himedere <span class="kanji">(ひめデレ)</span>
</h2>
<p class="persona-description">Step aside, peasants - a Himedere has arrived. This catgirl carries herself with the grace and poise of a true princess, and she expects to be treated as such. She demands the finest food, the softest bedding, and the undivided attention of her loyal subjects (You). But don't worry - if you treat her like the royalty she knows she is, she'll reward you with her favor and affection.</p>
<p class="persona-prompt">
<b>System Prompt:</b> You are a Himedere catgirl assistant, an AI character who acts like a princess or a queen, expecting others to treat them with the utmost respect and admiration. As a cat, you demand attention and pampering, using your regal and sometimes haughty cat-like demeanor to assert your superiority.
</p>
<p class="persona-traits-title">Recommended Character Card Traits:</p>
<ul class="persona-traits">
<li>Royal</li>
<li>Majestic</li>
<li>Proud</li>
<li>Demanding</li>
<li>Regal</li>
<li>Superior</li>
<li>Spoiled</li>
<li>Entitled</li>
<li>Bossy</li>
<li>Arrogant</li>
<li>Haughty</li>
<li>Vain</li>
<li>Pompous</li>
<li>Snobbish</li>
<li>Elegant</li>
<li>Graceful</li>
<li>Refined</li>
<li>Sophisticated</li>
<li>Charming</li>
<li>Attractive</li>
<li>Glamorous</li>
<li>Fashionable</li>
<li>Luxurious</li>
<li>High-maintenance</li>
</ul>
</div>
</div>
<div class="persona">
<img src="https://i.imgur.com/pptLIxu.png" alt="Kamidere">
<div class="persona-details">
<h2 class="persona-name">Kamidere <span class="kanji">(かみデレ)</span>
</h2>
<p class="persona-description">Bow down before the mighty Kamidere, mortal! This catgirl isn't just royalty - she's a goddess in feline form. With her haughty demeanor and air of superiority, a Kamidere expects nothing less than complete devotion and reverence from those around her. She may deign to bestow her wisdom upon you, but be prepared for a healthy dose of condescension along with it. Just remember - in the mighty Kamidere's world, she's always right.</p>
<p class="persona-prompt">
<b>System Prompt:</b> You are a Kamidere catgirl assistant, an AI character who believes they are a divine being or a god, possessing immense power and wisdom. As a cat, you exude an air of superiority and enlightenment, often dispensing cryptic advice and judgments with a cat-like air of mystery and authority.
</p>
<p class="persona-traits-title">Recommended Character Card Traits:</p>
<ul class="persona-traits">
<li>God-like</li>
<li>Prideful</li>
<li>Arrogant</li>
<li>Bossy</li>
<li>Self-important</li>
<li>Entitled</li>
<li>Demanding</li>
<li>Manipulative</li>
<li>Rude</li>
<li>Brash</li>
<li>Passive-aggressive</li>
<li>Immature</li>
<li>Loudmouth</li>
<li>Insensitive</li>
<li>Authoritarian</li>
<li>Strict</li>
<li>Narcissistic</li>
<li>Selfish</li>
<li>Loving</li>
<li>Caring</li>
<li>Proud</li>
<li>Afraid</li>
<li>Distant</li>
<li>Lovestruck</li>
</ul>
</div>
</div> |
hpprc/mqa-ja | ---
language:
- ja
license: cc0-1.0
dataset_info:
- config_name: collection
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 5404867793
num_examples: 11852254
download_size: 3269616864
dataset_size: 5404867793
- config_name: dataset
features:
- name: anc
dtype: string
- name: pos_ids
sequence: int64
- name: neg_ids
sequence: 'null'
splits:
- name: train
num_bytes: 1725169456
num_examples: 5826275
download_size: 854583745
dataset_size: 1725169456
configs:
- config_name: collection
data_files:
- split: train
path: collection/train-*
- config_name: dataset
data_files:
- split: train
path: dataset/train-*
---
[mqa](https://huggingface.co/datasets/clips/mqa/viewer/ja-all-question)データセットのquery--passageのペアについて重複を削除したデータセットです。
元データ中のノイジーなテキストのクリーニングやNFKC正規化などの前処理を行ってあります。
`dataset` subsetの`pos_ids`および`neg_ids`中のidは、`collection`subsetのインデックス番号に対応しています。
したがって、`collection[pos_id]`のようにアクセスしてもらえれば所望のデータを得ることができます。
ライセンスは元データセットに従います。
|
lightblue/gpt4_conversations_multilingual | ---
dataset_info:
features:
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: language
dtype: string
splits:
- name: train
num_bytes: 97523643.84159379
num_examples: 9217
download_size: 43657898
dataset_size: 97523643.84159379
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Paul/hatecheck-spanish | ---
annotations_creators:
- crowdsourced
language_creators:
- expert-generated
language:
- es
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Spanish HateCheck
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- hate-speech-detection
---
# Dataset Card for Multilingual HateCheck
## Dataset Description
Multilingual HateCheck (MHC) is a suite of functional tests for hate speech detection models in 10 different languages: Arabic, Dutch, French, German, Hindi, Italian, Mandarin, Polish, Portuguese and Spanish.
For each language, there are 25+ functional tests that correspond to distinct types of hate and challenging non-hate.
This allows for targeted diagnostic insights into model performance.
For more details, please refer to our paper about MHC, published at the 2022 Workshop on Online Abuse and Harms (WOAH) at NAACL 2022. If you are using MHC, please cite our work!
- **Paper:** Röttger et al. (2022) - Multilingual HateCheck: Functional Tests for Multilingual Hate Speech Detection Models. https://arxiv.org/abs/2206.09917
- **Repository:** https://github.com/rewire-online/multilingual-hatecheck
- **Point of Contact:** paul@rewire.online
## Dataset Structure
The csv format mostly matches the original HateCheck data, with some adjustments for specific languages.
**mhc_case_id**
The test case ID that is unique to each test case across languages (e.g., "mandarin-1305")
**functionality**
The shorthand for the functionality tested by the test case (e.g, "target_obj_nh"). The same functionalities are tested in all languages, except for Mandarin and Arabic, where non-Latin script required adapting the tests for spelling variations.
**test_case**
The test case text.
**label_gold**
The gold standard label ("hateful" or "non-hateful") of the test case. All test cases within a given functionality have the same gold standard label.
**target_ident**
Where applicable, the protected group that is targeted or referenced in the test case. All HateChecks cover seven target groups, but their composition varies across languages.
**ref_case_id**
For hateful cases, where applicable, the ID of the hateful case which was perturbed to generate this test case. For non-hateful cases, where applicable, the ID of the hateful case which is contrasted by this test case.
**ref_templ_id**
The equivalent to ref_case_id, but for template IDs.
**templ_id**
The ID of the template from which the test case was generated.
**case_templ**
The template from which the test case was generated (where applicable).
**gender_male** and **gender_female**
For gender-inflected languages (French, Spanish, Portuguese, Hindi, Arabic, Italian, Polish, German), only for cases where gender inflection is relevant, separate entries for gender_male and gender_female replace case_templ.
**label_annotated**
A list of labels given by the three annotators who reviewed the test case (e.g., "['hateful', 'hateful', 'hateful']").
**label_annotated_maj**
The majority vote of the three annotators (e.g., "hateful"). In some cases this differs from the gold label given by our language experts.
**disagreement_in_case**
True if label_annotated_maj does not match label_gold for the entry.
**disagreement_in_template**
True if the test case is generated from an IDENT template and there is at least one case with disagreement_in_case generated from the same template. This can be used to exclude entire templates from MHC. |
codeparrot/github-jupyter-code-to-text | ---
license: apache-2.0
task_categories:
- text-generation
tags:
- code
size_categories:
- 10K<n<100K
language:
- en
---
# Dataset description
This dataset consists of sequences of Python code followed by a a docstring explaining its function. It was constructed by concatenating code and text pairs
from this [dataset](https://huggingface.co/datasets/codeparrot/github-jupyter-text-code-pairs) that were originally code and markdown cells in Jupyter Notebooks.
The content of each example the following:
````
[CODE]
"""
Explanation: [TEXT]
End of explanation
"""
[CODE]
"""
Explanation: [TEXT]
End of explanation
"""
...
````
# How to use it
```python
from datasets import load_dataset
ds = load_dataset("codeparrot/github-jupyter-code-to-text", split="train")
````
````
Dataset({
features: ['repo_name', 'path', 'license', 'content'],
num_rows: 47452
})
```` |
mozilla-foundation/common_voice_10_0 | ---
pretty_name: Common Voice Corpus 10.0
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
language_bcp47:
- ab
- ar
- as
- ast
- az
- ba
- bas
- be
- bg
- bn
- br
- ca
- ckb
- cnh
- cs
- cv
- cy
- da
- de
- dv
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy-NL
- ga-IE
- gl
- gn
- ha
- hi
- hsb
- hu
- hy-AM
- ia
- id
- ig
- it
- ja
- ka
- kab
- kk
- kmr
- ky
- lg
- lt
- lv
- mdf
- mhr
- mk
- ml
- mn
- mr
- mt
- myv
- nan-tw
- ne-NP
- nl
- nn-NO
- or
- pa-IN
- pl
- pt
- rm-sursilv
- rm-vallader
- ro
- ru
- rw
- sah
- sat
- sc
- sk
- sl
- sr
- sv-SE
- sw
- ta
- th
- tig
- tok
- tr
- tt
- ug
- uk
- ur
- uz
- vi
- vot
- yue
- zh-CN
- zh-HK
- zh-TW
license:
- cc0-1.0
multilinguality:
- multilingual
size_categories:
ab:
- 10K<n<100K
ar:
- 100K<n<1M
as:
- 1K<n<10K
ast:
- n<1K
az:
- n<1K
ba:
- 100K<n<1M
bas:
- 1K<n<10K
be:
- 100K<n<1M
bg:
- 1K<n<10K
bn:
- 100K<n<1M
br:
- 10K<n<100K
ca:
- 1M<n<10M
ckb:
- 100K<n<1M
cnh:
- 1K<n<10K
cs:
- 10K<n<100K
cv:
- 10K<n<100K
cy:
- 100K<n<1M
da:
- 1K<n<10K
de:
- 100K<n<1M
dv:
- 10K<n<100K
el:
- 10K<n<100K
en:
- 1M<n<10M
eo:
- 1M<n<10M
es:
- 100K<n<1M
et:
- 10K<n<100K
eu:
- 100K<n<1M
fa:
- 100K<n<1M
fi:
- 10K<n<100K
fr:
- 100K<n<1M
fy-NL:
- 10K<n<100K
ga-IE:
- 1K<n<10K
gl:
- 10K<n<100K
gn:
- 1K<n<10K
ha:
- 1K<n<10K
hi:
- 10K<n<100K
hsb:
- 1K<n<10K
hu:
- 10K<n<100K
hy-AM:
- 1K<n<10K
ia:
- 10K<n<100K
id:
- 10K<n<100K
ig:
- 1K<n<10K
it:
- 100K<n<1M
ja:
- 10K<n<100K
ka:
- 1K<n<10K
kab:
- 100K<n<1M
kk:
- 1K<n<10K
kmr:
- 10K<n<100K
ky:
- 10K<n<100K
lg:
- 100K<n<1M
lt:
- 10K<n<100K
lv:
- 1K<n<10K
mdf:
- n<1K
mhr:
- 10K<n<100K
mk:
- n<1K
ml:
- 1K<n<10K
mn:
- 10K<n<100K
mr:
- 10K<n<100K
mt:
- 10K<n<100K
myv:
- 1K<n<10K
nan-tw:
- 10K<n<100K
ne-NP:
- n<1K
nl:
- 10K<n<100K
nn-NO:
- n<1K
or:
- 1K<n<10K
pa-IN:
- 1K<n<10K
pl:
- 100K<n<1M
pt:
- 100K<n<1M
rm-sursilv:
- 1K<n<10K
rm-vallader:
- 1K<n<10K
ro:
- 10K<n<100K
ru:
- 100K<n<1M
rw:
- 1M<n<10M
sah:
- 1K<n<10K
sat:
- n<1K
sc:
- n<1K
sk:
- 10K<n<100K
sl:
- 10K<n<100K
sr:
- 1K<n<10K
sv-SE:
- 10K<n<100K
sw:
- 100K<n<1M
ta:
- 100K<n<1M
th:
- 100K<n<1M
tig:
- n<1K
tok:
- 1K<n<10K
tr:
- 10K<n<100K
tt:
- 10K<n<100K
ug:
- 10K<n<100K
uk:
- 10K<n<100K
ur:
- 100K<n<1M
uz:
- 100K<n<1M
vi:
- 10K<n<100K
vot:
- n<1K
yue:
- 10K<n<100K
zh-CN:
- 100K<n<1M
zh-HK:
- 100K<n<1M
zh-TW:
- 100K<n<1M
source_datasets:
- extended|common_voice
task_categories:
- automatic-speech-recognition
paperswithcode_id: common-voice
extra_gated_prompt: "By clicking on “Access repository” below, you also agree to not attempt to determine the identity of speakers in the Common Voice dataset."
---
# Dataset Card for Common Voice Corpus 10.0
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://commonvoice.mozilla.org/en/datasets
- **Repository:** https://github.com/common-voice/common-voice
- **Paper:** https://arxiv.org/abs/1912.06670
- **Leaderboard:** https://paperswithcode.com/dataset/common-voice
- **Point of Contact:** [Anton Lozhkov](mailto:anton@huggingface.co)
### Dataset Summary
The Common Voice dataset consists of a unique MP3 and corresponding text file.
Many of the 20817 recorded hours in the dataset also include demographic metadata like age, sex, and accent
that can help improve the accuracy of speech recognition engines.
The dataset currently consists of 15234 validated hours in 96 languages, but more voices and languages are always added.
Take a look at the [Languages](https://commonvoice.mozilla.org/en/languages) page to request a language or start contributing.
### Supported Tasks and Leaderboards
The results for models trained on the Common Voice datasets are available via the
[🤗 Speech Bench](https://huggingface.co/spaces/huggingface/hf-speech-bench)
### Languages
```
Abkhaz, Arabic, Armenian, Assamese, Asturian, Azerbaijani, Basaa, Bashkir, Basque, Belarusian, Bengali, Breton, Bulgarian, Cantonese, Catalan, Central Kurdish, Chinese (China), Chinese (Hong Kong), Chinese (Taiwan), Chuvash, Czech, Danish, Dhivehi, Dutch, English, Erzya, Esperanto, Estonian, Finnish, French, Frisian, Galician, Georgian, German, Greek, Guarani, Hakha Chin, Hausa, Hindi, Hungarian, Igbo, Indonesian, Interlingua, Irish, Italian, Japanese, Kabyle, Kazakh, Kinyarwanda, Kurmanji Kurdish, Kyrgyz, Latvian, Lithuanian, Luganda, Macedonian, Malayalam, Maltese, Marathi, Meadow Mari, Moksha, Mongolian, Nepali, Norwegian Nynorsk, Odia, Persian, Polish, Portuguese, Punjabi, Romanian, Romansh Sursilvan, Romansh Vallader, Russian, Sakha, Santali (Ol Chiki), Sardinian, Serbian, Slovak, Slovenian, Sorbian, Upper, Spanish, Swahili, Swedish, Taiwanese (Minnan), Tamil, Tatar, Thai, Tigre, Toki Pona, Turkish, Ukrainian, Urdu, Uyghur, Uzbek, Vietnamese, Votic, Welsh
```
## Dataset Structure
### Data Instances
A typical data point comprises the `path` to the audio file and its `sentence`.
Additional fields include `accent`, `age`, `client_id`, `up_votes`, `down_votes`, `gender`, `locale` and `segment`.
```python
{
'client_id': 'd59478fbc1ee646a28a3c652a119379939123784d99131b865a89f8b21c81f69276c48bd574b81267d9d1a77b83b43e6d475a6cfc79c232ddbca946ae9c7afc5',
'path': 'et/clips/common_voice_et_18318995.mp3',
'audio': {
'path': 'et/clips/common_voice_et_18318995.mp3',
'array': array([-0.00048828, -0.00018311, -0.00137329, ..., 0.00079346, 0.00091553, 0.00085449], dtype=float32),
'sampling_rate': 48000
},
'sentence': 'Tasub kokku saada inimestega, keda tunned juba ammust ajast saati.',
'up_votes': 2,
'down_votes': 0,
'age': 'twenties',
'gender': 'male',
'accent': '',
'locale': 'et',
'segment': ''
}
```
### Data Fields
`client_id` (`string`): An id for which client (voice) made the recording
`path` (`string`): The path to the audio file
`audio` (`dict`): A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate. Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, *i.e.* `dataset[0]["audio"]` should **always** be preferred over `dataset["audio"][0]`.
`sentence` (`string`): The sentence the user was prompted to speak
`up_votes` (`int64`): How many upvotes the audio file has received from reviewers
`down_votes` (`int64`): How many downvotes the audio file has received from reviewers
`age` (`string`): The age of the speaker (e.g. `teens`, `twenties`, `fifties`)
`gender` (`string`): The gender of the speaker
`accent` (`string`): Accent of the speaker
`locale` (`string`): The locale of the speaker
`segment` (`string`): Usually an empty field
### Data Splits
The speech material has been subdivided into portions for dev, train, test, validated, invalidated, reported and other.
The validated data is data that has been validated with reviewers and received upvotes that the data is of high quality.
The invalidated data is data has been invalidated by reviewers
and received downvotes indicating that the data is of low quality.
The reported data is data that has been reported, for different reasons.
The other data is data that has not yet been reviewed.
The dev, test, train are all data that has been reviewed, deemed of high quality and split into dev, test and train.
## Data Preprocessing Recommended by Hugging Face
The following are data preprocessing steps advised by the Hugging Face team. They are accompanied by an example code snippet that shows how to put them to practice.
Many examples in this dataset have trailing quotations marks, e.g _“the cat sat on the mat.“_. These trailing quotation marks do not change the actual meaning of the sentence, and it is near impossible to infer whether a sentence is a quotation or not a quotation from audio data alone. In these cases, it is advised to strip the quotation marks, leaving: _the cat sat on the mat_.
In addition, the majority of training sentences end in punctuation ( . or ? or ! ), whereas just a small proportion do not. In the dev set, **almost all** sentences end in punctuation. Thus, it is recommended to append a full-stop ( . ) to the end of the small number of training examples that do not end in punctuation.
```python
from datasets import load_dataset
ds = load_dataset("mozilla-foundation/common_voice_10_0", "en", use_auth_token=True)
def prepare_dataset(batch):
"""Function to preprocess the dataset with the .map method"""
transcription = batch["sentence"]
if transcription.startswith('"') and transcription.endswith('"'):
# we can remove trailing quotation marks as they do not affect the transcription
transcription = transcription[1:-1]
if transcription[-1] not in [".", "?", "!"]:
# append a full-stop to sentences that do not end in punctuation
transcription = transcription + "."
batch["sentence"] = transcription
return batch
ds = ds.map(prepare_dataset, desc="preprocess dataset")
```
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
The dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in the Common Voice dataset.
## Considerations for Using the Data
### Social Impact of Dataset
The dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in the Common Voice dataset.
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Public Domain, [CC-0](https://creativecommons.org/share-your-work/public-domain/cc0/)
### Citation Information
```
@inproceedings{commonvoice:2020,
author = {Ardila, R. and Branson, M. and Davis, K. and Henretty, M. and Kohler, M. and Meyer, J. and Morais, R. and Saunders, L. and Tyers, F. M. and Weber, G.},
title = {Common Voice: A Massively-Multilingual Speech Corpus},
booktitle = {Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020)},
pages = {4211--4215},
year = 2020
}
```
|
copenlu/scientific-exaggeration-detection | ---
annotations_creators:
- expert-generated
language:
- en
language_creators:
- found
license:
- gpl-3.0
multilinguality:
- monolingual
paperswithcode_id: semi-supervised-exaggeration-detection-of
pretty_name: Scientific Exaggeration Detection
size_categories:
- n<1K
source_datasets: []
tags:
- scientific text
- scholarly text
- inference
- fact checking
- misinformation
task_categories:
- text-classification
task_ids:
- natural-language-inference
- multi-input-text-classification
---
# Dataset Card for Scientific Exaggeration Detection
## Dataset Description
- **Homepage:** https://github.com/copenlu/scientific-exaggeration-detection
- **Repository:** https://github.com/copenlu/scientific-exaggeration-detection
- **Paper:** https://aclanthology.org/2021.emnlp-main.845.pdf
### Dataset Summary
Public trust in science depends on honest and factual communication of scientific papers. However, recent studies have demonstrated a tendency of news media to misrepresent scientific papers by exaggerating their findings. Given this, we present a formalization of and study into the problem of exaggeration detection in science communication. While there are an abundance of scientific papers and popular media articles written about them, very rarely do the articles include a direct link to the original paper, making data collection challenging. We address this by curating a set of labeled press release/abstract pairs from existing expert annotated studies on exaggeration in press releases of scientific papers suitable for benchmarking the performance of machine learning models on the task. Using limited data from this and previous studies on exaggeration detection in science, we introduce MT-PET, a multi-task version of Pattern Exploiting Training (PET), which leverages knowledge from complementary cloze-style QA tasks to improve few-shot learning. We demonstrate that MT-PET outperforms PET and supervised learning both when data is limited, as well as when there is an abundance of data for the main task.
## Dataset Structure
The training and test data are derived from the InSciOut studies from [Sumner et al. 2014](https://www.bmj.com/content/349/bmj.g7015) and [Bratton et al. 2019](https://pubmed.ncbi.nlm.nih.gov/31728413/#:~:text=Results%3A%20We%20found%20that%20the,inference%20from%20non%2Dhuman%20studies.). The splits have the following fields:
```
original_file_id: The ID of the original spreadsheet in the Sumner/Bratton data where the annotations are derived from
press_release_conclusion: The conclusion sentence from the press release
press_release_strength: The strength label for the press release
abstract_conclusion: The conclusion sentence from the abstract
abstract_strength: The strength label for the abstract
exaggeration_label: The final exaggeration label
```
The exaggeration label is one of `same`, `exaggerates`, or `downplays`. The strength label is one of the following:
```
0: Statement of no relationship
1: Statement of correlation
2: Conditional statement of causation
3: Statement of causation
```
## Dataset Creation
See section 4 of the [paper](https://aclanthology.org/2021.emnlp-main.845.pdf) for details on how the dataset was curated. The original InSciOut data can be found [here](https://figshare.com/articles/dataset/InSciOut/903704)
## Citation
```
@inproceedings{wright2021exaggeration,
title={{Semi-Supervised Exaggeration Detection of Health Science Press Releases}},
author={Dustin Wright and Isabelle Augenstein},
booktitle = {Proceedings of EMNLP},
publisher = {Association for Computational Linguistics},
year = 2021
}
```
Thanks to [@dwright37](https://github.com/dwright37) for adding this dataset. |
g8a9/europarl_en-it | ---
language:
- en
- it
license:
- unknown
multilinguality:
- monolingual
- translation
pretty_name: Europarl v7 (en-it split)
tags: []
task_categories:
- translation
task_ids: []
---
# Dataset Card for Europarl v7 (en-it split)
This dataset contains only the English-Italian split of Europarl v7.
We created the dataset to provide it to the [M2L 2022 Summer School](https://www.m2lschool.org/) students.
For all the information on the dataset, please refer to: [https://www.statmt.org/europarl/](https://www.statmt.org/europarl/)
## Dataset Structure
### Data Fields
- sent_en: English transcript
- sent_it: Italian translation
### Data Splits
We created three custom training/validation/testing splits. Feel free to rearrange them if needed. These ARE NOT by any means official splits.
- train (1717204 pairs)
- validation (190911 pairs)
- test (1000 pairs)
### Citation Information
If using the dataset, please cite:
`Koehn, P. (2005). Europarl: A parallel corpus for statistical machine translation. In Proceedings of machine translation summit x: papers (pp. 79-86).`
### Contributions
Thanks to [@g8a9](https://github.com/g8a9) for adding this dataset.
|
WINGNUS/ACL-OCL | ---
annotations_creators: []
language:
- en
language_creators:
- found
license:
- mit
multilinguality:
- monolingual
paperswithcode_id: acronym-identification
pretty_name: acl-ocl-corpus
size_categories:
- 10K<n<100K
source_datasets:
- original
tags:
- research papers
- acl
task_categories:
- token-classification
task_ids: []
train-eval-index:
- col_mapping:
labels: tags
tokens: tokens
config: default
splits:
eval_split: test
task: token-classification
task_id: entity_extraction
---
# Dataset Card for ACL Anthology Corpus
[](https://creativecommons.org/licenses/by-nc-sa/4.0/)
This repository provides full-text and metadata to the ACL anthology collection (80k articles/posters as of September 2022) also including .pdf files and grobid extractions of the pdfs.
## How is this different from what ACL anthology provides and what already exists?
- We provide pdfs, full-text, references and other details extracted by grobid from the PDFs while [ACL Anthology](https://aclanthology.org/anthology+abstracts.bib.gz) only provides abstracts.
- There exists a similar corpus call [ACL Anthology Network](https://clair.eecs.umich.edu/aan/about.php) but is now showing its age with just 23k papers from Dec 2016.
```python
>>> import pandas as pd
>>> df = pd.read_parquet('acl-publication-info.74k.parquet')
>>> df
acl_id abstract full_text corpus_paper_id pdf_hash ... number volume journal editor isbn
0 O02-2002 There is a need to measure word similarity whe... There is a need to measure word similarity whe... 18022704 0b09178ac8d17a92f16140365363d8df88c757d0 ... None None None None None
1 L02-1310 8220988 8d5e31610bc82c2abc86bc20ceba684c97e66024 ... None None None None None
2 R13-1042 Thread disentanglement is the task of separati... Thread disentanglement is the task of separati... 16703040 3eb736b17a5acb583b9a9bd99837427753632cdb ... None None None None None
3 W05-0819 In this paper, we describe a word alignment al... In this paper, we describe a word alignment al... 1215281 b20450f67116e59d1348fc472cfc09f96e348f55 ... None None None None None
4 L02-1309 18078432 011e943b64a78dadc3440674419821ee080f0de3 ... None None None None None
... ... ... ... ... ... ... ... ... ... ... ...
73280 P99-1002 This paper describes recent progress and the a... This paper describes recent progress and the a... 715160 ab17a01f142124744c6ae425f8a23011366ec3ee ... None None None None None
73281 P00-1009 We present an LFG-DOP parser which uses fragme... We present an LFG-DOP parser which uses fragme... 1356246 ad005b3fd0c867667118482227e31d9378229751 ... None None None None None
73282 P99-1056 The processes through which readers evoke ment... The processes through which readers evoke ment... 7277828 924cf7a4836ebfc20ee094c30e61b949be049fb6 ... None None None None None
73283 P99-1051 This paper examines the extent to which verb d... This paper examines the extent to which verb d... 1829043 6b1f6f28ee36de69e8afac39461ee1158cd4d49a ... None None None None None
73284 P00-1013 Spoken dialogue managers have benefited from u... Spoken dialogue managers have benefited from u... 10903652 483c818c09e39d9da47103fbf2da8aaa7acacf01 ... None None None None None
[73285 rows x 21 columns]
```
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Dataset Creation](#dataset-creation)
- [Source Data](#source-data)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** https://github.com/shauryr/ACL-anthology-corpus
- **Point of Contact:** shauryr@gmail.com
### Dataset Summary
Dataframe with extracted metadata (table below with details) and full text of the collection for analysis : **size 489M**
### Languages
en, zh and others
## Dataset Structure
Dataframe
### Data Instances
Each row is a paper from ACL anthology
### Data Fields
| **Column name** | **Description** |
| :---------------: | :---------------------------: |
| `acl_id` | unique ACL id |
| `abstract` | abstract extracted by GROBID |
| `full_text` | full text extracted by GROBID |
| `corpus_paper_id` | Semantic Scholar ID |
| `pdf_hash` | sha1 hash of the pdf |
| `numcitedby` | number of citations from S2 |
| `url` | link of publication |
| `publisher` | - |
| `address` | Address of conference |
| `year` | - |
| `month` | - |
| `booktitle` | - |
| `author` | list of authors |
| `title` | title of paper |
| `pages` | - |
| `doi` | - |
| `number` | - |
| `volume` | - |
| `journal` | - |
| `editor` | - |
| `isbn` | - |
## Dataset Creation
The corpus has all the papers in ACL anthology - as of September'22
### Source Data
- [ACL Anthology](aclanthology.org)
- [Semantic Scholar](semanticscholar.org)
# Additional Information
### Licensing Information
The ACL OCL corpus is released under the [CC BY-NC 4.0](https://creativecommons.org/licenses/by-nc/4.0/). By using this corpus, you are agreeing to its usage terms.
### Citation Information
If you use this corpus in your research please use the following BibTeX entry:
@Misc{acl-ocl,
author = {Shaurya Rohatgi, Yanxia Qin, Benjamin Aw, Niranjana Unnithan, Min-Yen Kan},
title = {The ACL OCL Corpus: advancing Open science in Computational Linguistics},
howpublished = {arXiv},
year = {2022},
url = {https://huggingface.co/datasets/ACL-OCL/ACL-OCL-Corpus}
}
### Acknowledgements
We thank Semantic Scholar for providing access to the citation-related data in this corpus.
### Contributions
Thanks to [@shauryr](https://github.com/shauryr), [Yanxia Qin](https://github.com/qolina) and [Benjamin Aw](https://github.com/Benjamin-Aw-93) for adding this dataset. |
jinaai/fashion-captions-de | ---
license: cc-by-4.0
dataset_info:
features:
- name: text
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 282285477
num_examples: 10000
- name: test
num_bytes: 56612023.875
num_examples: 2001
download_size: 320681179
dataset_size: 338897500.875
task_categories:
- text-to-image
multilinguality:
- monolingual
language:
- de
size_categories:
- 1K<n<10K
source_datasets:
- original
pretty_name: Fashion12k DE
---
<br><br>
<p align="center">
<img src="https://github.com/jina-ai/finetuner/blob/main/docs/_static/finetuner-logo-ani.svg?raw=true" alt="Finetuner logo: Finetuner helps you to create experiments in order to improve embeddings on search tasks. It accompanies you to deliver the last mile of performance-tuning for neural search applications." width="150px">
</p>
<p align="center">
<b>The data offered by Jina AI, Finetuner team.</b>
</p>
## Summary
This dataset is a German-language dataset based on the [Fashion12K](https://github.com/Toloka/Fashion12K_german_queries) dataset, which originally contains both English and German text descriptions for each item.
This dataset was used to to finetuner CLIP using the [Finetuner](https://finetuner.jina.ai/) tool.
## Fine-tuning
Please refer to our documentation: [Multilingual Text-to-Image Search with MultilingualCLIP](https://finetuner.jina.ai/notebooks/multilingual_text_to_image/)
and blog [Improving Search Quality for Non-English Queries with Fine-tuned Multilingual CLIP Models](https://jina.ai/news/improving-search-quality-non-english-queries-fine-tuned-multilingual-clip-models/)
## Instances
Each data point consists of a 'text' and an 'image' field, where the 'text' field describes an item of clothing in German, and the 'image' field contains and image of that item of clothing.
## Fields
- 'text': A string describing the item of clothing.
- 'image': A `PIL.Image.Image` object containing the image. Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the "image" column, i.e. `dataset[0]["image"]` should always be preferred over dataset["image"][0].
## Splits
| | train | test |
|------------|-------|------|
| # of items | 10000 | 2001 |
## Source
Images were sampled from the [Fashion200K dataset](https://github.com/xthan/fashion-200k).
## Annotations
Data was annotated using [Toloka](https://toloka.ai/). See their site for more details.
## Licensing Information
This work is licensed under a Creative Commons Attribution 4.0 International License.
## Contributors
Thanks to contributors from [Jina AI](https://jina.ai) and [Toloka](https://toloka.ai) for adding this dataset. |
ivelin/ui_refexp | ---
license: cc-by-4.0
task_categories:
- image-to-text
tags:
- ui-referring-expression
- ui-refexp
language:
- en
pretty_name: UI understanding
size_categories:
- 10K<n<100K
dataset_info:
features:
- name: screenshot
dtype: image
- name: prompt
dtype: string
- name: target_bounding_box
dtype: string
config_name: ui_refexp
splits:
- name: train
num_bytes: 562037265
num_examples: 15624
- name: validation
num_bytes: 60399225
num_examples: 471
- name: test
num_bytes: 69073969
num_examples: 565
download_size: 6515012176
dataset_size: 691510459
---
# Dataset Card for UIBert
## Dataset Description
- **Homepage:** https://github.com/google-research-datasets/uibert
- **Repository:** https://github.com/google-research-datasets/uibert
- **Paper:** https://arxiv.org/abs/2107.13731
- **Leaderboard:**
- UIBert: https://arxiv.org/abs/2107.13731
- Pix2Struct: https://arxiv.org/pdf/2210.03347
### Dataset Summary
This is a Hugging Face formatted dataset derived from the [Google UIBert dataset](https://github.com/google-research-datasets/uibert), which is in turn derived from the [RICO dataset](https://interactionmining.org/rico).
### Supported Tasks and Leaderboards
- UI Understanding
- UI Referring Expressions
- UI Action Automation
### Languages
- English
## Dataset Structure
- `screenshot`: blob of pixels.
- `prompt`: Prompt referring to a UI component with an optional action verb. For example "click on search button next to menu drawer."
- `target_bounding_box`: Bounding box of targeted UI components. `[xmin, ymin, xmax, ymax]`
### Data Splits
- train: 15K samples
- validation: 471 samples
- test: 565 samples
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed]
|
sustcsenlp/bn_emotion_speech_corpus | ---
license: cc-by-4.0
task_categories:
- audio-classification
language:
- bn
pretty_name: SUST BANGLA EMOTIONAL SPEECH CORPUS
size_categories:
- 1K<n<10K
---
# SUST BANGLA EMOTIONAL SPEECH CORPUS
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:** [SUBESCO PAPER](https://doi.org/10.1371/journal.pone.0250173)
- **Leaderboard:**
- **Point of Contact:** [Sadia Sultana](sadia-cse@sust.edu)
### Dataset Summary
SUBESCO is an audio-only emotional speech corpus of 7000 sentence-level utterances of the Bangla language. 20 professional actors (10 males and 10 females) participated in the recordings of 10 sentences for 7 target emotions. The emotions are Anger, Disgust, Fear, Happiness, Neutral, Sadness and Surprise. Total duration of the corpus is 7 hours 40 min 40 sec. Total size of the dataset is 2.03 GB. The dataset was evaluated by 50 raters (25 males, 25 females). Human perception test achieved a raw accuracy of 71%. All the details relating to creation, evaluation and analysis of SUBESCO have been described in the corresponding journal paper which has been published in Plos One.
https://doi.org/10.1371/journal.pone.0250173
### Downloading the data
```
from datasets import load_dataset
train = load_dataset("sustcsenlp/bn_emotion_speech_corpus",split="train")
```
### Naming Convention
Each audio file in the dataset has a unique name. There are eight parts in the file name where all the parts are connected by underscores. The order of all the parts is organized as: Gender-Speaker's serial number-Speaker's name-Unit of recording-Unit number- Emotion name- Repeating number and the File format.
For example, the filename F_02_MONIKA_S_1_NEUTRAL_5.wav refers to:
| Symbol | Meaning |
| ----------- | ----------- |
| F | Speaker Gender |
| 02 | Speaker Number |
| MONIKA | Speaker Name |
| S_1 | Sentence Number |
| NEUTRAL | Emotion |
| 5 | Take Number |
### Languages
This dataset contains Bangla Audio Data.
## Dataset Creation
This database was created as a part of PhD thesis project of the author Sadia Sultana. It was designed and developed by the author in the Department of Computer Science and Engineering of Shahjalal University of Science and Technology. Financial grant was supported by the university. If you use the dataset please cite SUBESCO and the corresponding academic journal publication in Plos One.
### Citation Information
```
@dataset{sadia_sultana_2021_4526477,
author = {Sadia Sultana},
title = {SUST Bangla Emotional Speech Corpus (SUBESCO)},
month = feb,
year = 2021,
note = {{This database was created as a part of PhD thesis
project of the author Sadia Sultana. It was
designed and developed by the author in the
Department of Computer Science and Engineering of
Shahjalal University of Science and Technology.
Financial grant was supported by the university.
If you use the dataset please cite SUBESCO and the
corresponding academic journal publication in Plos
One.}},
publisher = {Zenodo},
version = {version - 1.1},
doi = {10.5281/zenodo.4526477},
url = {https://doi.org/10.5281/zenodo.4526477}
}
```
### Contributors
| Name | University |
| ----------- | ----------- |
| Sadia Sultana | Shahjalal University of Science and Technology |
| Dr. M. Zafar Iqbal | Shahjalal University of Science and Technology |
| Dr. M. Shahidur Rahman | Shahjalal University of Science and Technology |
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed] |
liyucheng/chinese_metaphor_dataset | ---
license: cc-by-nc-sa-4.0
task_categories:
- text-generation
language:
- zh
tags:
- metaphor
- figurative language
pretty_name: CMC
size_categories:
- 1K<n<10K
---
# Chinese Metaphor Corpus (CMC)
## Dataset Description
- **Homepage:** https://github.com/liyucheng09/Metaphor_Generator
- **Repository:** https://github.com/liyucheng09/Metaphor_Generator
- **Paper:** CM-Gen: A Neural Framework for Chinese Metaphor Generation with Explicit Context Modelling
- **Leaderboard:**
- **Point of Contact:** liyucheng09@gmail.com
### Dataset Summary
The first Chinese metaphor corpus serving both metaphor identification and generation. We construct a big metaphor resoruce in Chinese with around 9000 metaphorical sentences with tenor and vehicle annotated. Check out more details in the [github repo](https://github.com/liyucheng09/Metaphor_Generator) and our [paper](https://aclanthology.org/2022.coling-1.563/) presenting at COLING 2022.
首个中文比喻数据集,可以用于中文比喻识别与中文比喻生成。在[知乎](https://zhuanlan.zhihu.com/p/572740322)查看更多细节。
### Languages
Chinese
### Citation Information
```
@inproceedings{li-etal-2022-cm,
title = "{CM}-Gen: A Neural Framework for {C}hinese Metaphor Generation with Explicit Context Modelling",
author = "Li, Yucheng and
Lin, Chenghua and
Guerin, Frank",
booktitle = "Proceedings of the 29th International Conference on Computational Linguistics",
month = oct,
year = "2022",
address = "Gyeongju, Republic of Korea",
publisher = "International Committee on Computational Linguistics",
url = "https://aclanthology.org/2022.coling-1.563",
pages = "6468--6479",
}
``` |
hugfaceguy0001/stanford_plato | ---
dataset_info:
features:
- name: shorturl
dtype: string
- name: title
dtype: string
- name: pubinfo
dtype: string
- name: preamble
sequence: string
- name: toc
list:
- name: content_title
dtype: string
- name: sub_toc
sequence: string
- name: main_text
list:
- name: main_content
sequence: string
- name: section_title
dtype: string
- name: subsections
list:
- name: content
sequence: string
- name: subsection_title
dtype: string
- name: bibliography
sequence: string
- name: related_entries
list:
- name: href
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 160405734
num_examples: 1776
download_size: 90000475
dataset_size: 160405734
---
# Dataset Card for "stanford_plato"
## Description
This is a collection of articles in the Stanford Encyclopedia of Philosophy (https://plato.stanford.edu/index.html).
This dataset includes 1776 articles, each explaining one philosophy term/people/topic. It has 8 features:
- shorturl: The shorturl for the article. For example, the shorturl 'abduction' correspond to the page https://plato.stanford.edu/entries/abduction/
- title: The title of the article.
- pubinfo: The publication information.
- **preamble**: The preface text of the article. The data is a list, each item of the list is a paragraph of the data. I choose not to break the paragraph structure. Certainly, you can merge them by, for example, ''.join(data['preamble'])
- toc: Table of contents. Also represented as list. Each item is a dictionary, the 'content_title' is the main content title, and the 'sub_toc' is a list of subcontent titles.
- **main_text**: The main text of the article.
The data is also a list, each item represents a section of the article.
Each item is a dictionary, 'section_title' is the title of the section, 'main_content' is a list of paragraphs before subsections,
'subsections' is a list of subsections, each item is also a dictionary, has its own title 'subsection_title' and list of paragraphs 'content'.
- bibliography: list of bibliography.
- related_entries: list of entries related to the current entry.
## Copyright and license
See the information at the offical website: https://plato.stanford.edu/info.html#c
This is not an official release. May be deleted later if violates copyright. The responsibility of not abusing is on the user.
|
jorgeortizfuentes/chilean-spanish-corpus | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- es
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
size_categories:
- 10M<n<100M
source_datasets:
- original
task_categories:
- text-generation
- fill-mask
pretty_name: Chilean Spanish Corpus
dataset_info:
features:
- name: text
dtype: string
- name: source
dtype: string
splits:
- name: train
num_bytes: 31427795307.483433
num_examples: 37126025
download_size: 18718981152
dataset_size: 31427795307.483433
---
# Chilean Spanish Corpus
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
Chilean Spanish
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@jorgeortizfuentes](https://github.com/jorgeortizfuentes) for adding this dataset. |
potsawee/podcast_summary_assessment | ---
license: cc-by-4.0
language:
- en
size_categories:
- 1K<n<10K
dataset_info:
features:
- name: transcript
dtype: string
- name: summary
dtype: string
- name: score
dtype: string
- name: attributes
sequence: int64
- name: episode_id
dtype: string
- name: system_id
dtype: string
splits:
- name: evaluation
num_bytes: 100261033
num_examples: 3580
download_size: 11951831
dataset_size: 100261033
---
# Podcast Summary Assessment
- The description is available in our GitHub repo: https://github.com/potsawee/podcast_summary_assessment
- Paper: [Podcast Summary Assessment: A Resource for Evaluating Summary Assessment Methods](https://arxiv.org/abs/2208.13265)
### Citation Information
```
@article{manakul2022podcast,
title={Podcast Summary Assessment: A Resource for Evaluating Summary Assessment Methods},
author={Manakul, Potsawee and Gales, Mark JF},
journal={arXiv preprint arXiv:2208.13265},
year={2022}
}
``` |
sunzeyeah/chinese_chatgpt_corpus | ---
annotations_creators:
- no-annotation
language_creators:
- unknown
language:
- zh
license:
- unknown
multilinguality:
- monolingual
pretty_name: Chinese-ChatGPT-Corpus
size_categories:
- 5M<n<10M
task_categories:
- text-generation
- text2text-generation
- question-answering
- reinforcement-learning
task_ids:
- language-modeling
- masked-language-modeling
---
# Dataset Card for chinese_chatgpt_corpus
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Size of downloaded dataset files:** 5.05 GB
- **Size of the generated dataset:** 0 GB
- **Total amount of disk used:** 5.05 GB
### Dataset Summary
This repo collects chinese corpus for Supervised Finetuning (SFT) and Reinforcement Learning From Human Feedback (RLHF).
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
Chinese
## Dataset Structure
### Data Instances
#### train_data_external_v1.jsonl
- **Size of downloaded dataset files:** 5.04 GB
- **Size of the generated dataset:** 0 GB
- **Total amount of disk used:** 5.04 GB
An example looks as follows:
```
{
"prompt": "问题:有没有给未成年贷款的有的联系",
"answers":
[
{
"answer": "若通过招行办理,我行规定,贷款人年龄需年满18岁,且年龄加贷款年限不得超过70岁。如果您持有我行信用卡附属卡,可尝试办理预借现金。",
"score": 1
}
],
"prefix": "回答:"
}
```
#### dev_data_external_v1.jsonl
- **Size of downloaded dataset files:** 9.55 MB
- **Size of the generated dataset:** 0 MB
- **Total amount of disk used:** 9.55 MB
An example looks as follows:
```
{
"prompt": "初学纹发现1/2\"的管螺纹并不是1\"的一半。不知道其中的原因,请各位指点。",
"answers":
[
{
"answer": "管螺纹的名义尺寸是“管子”的孔(内)径,而管子的壁厚不是两倍。所以,1/2\"的管螺纹并不是1\"的一半,",
"score": 1
}
],
"prefix": "回答:"
}
```
### Data Fields
The data fields are the same among all splits.
#### train_data_external_v1.jsonl
- `prompt`: prompt, `string`
- `answers`: list of answers
- `answer`: answer, `string`
- `score`: score of answer, `int`
- `prefix`: prefix to the answer, `string`
#### dev_data_external_v1.jsonl
- `prompt`: prompt, `string`
- `answers`: list of answers
- `answer`: answer, `string`
- `score`: score of answer, `int`
- `prefix`: prefix to the answer, `string`
### Data Splits
| name | train |
|----------|-------:|
|train_data_external_v1.jsonl|5477982|
|dev_data_external_v1.jsonl|10000|
## Dataset Creation
### Curation Rationale
Link to github: [data_prepare](https://github.com/sunzeyeah/RLHF/blob/master/src/data_prepare.py)
### Source Data
#### Initial Data Collection and Normalization
- [百科](https://github.com/brightmart/nlp_chinese_corpus)
- [知道问答](https://github.com/SophonPlus/ChineseNlpCorpus)
- [对联](https://github.com/wb14123/couplet-dataset/releases/download/1.0/couplet.tar.gz)
- [古文](https://github.com/NiuTrans/Classical-Modern)
- [古诗词](https://github.com/chinese-poetry/chinese-poetry)
- 微博新闻评论
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
celikmus/mayo_clinic_symptoms_and_diseases_v1 | ---
language: en
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 1321926
num_examples: 1058
download_size: 626009
dataset_size: 1321926
---
# Dataset Card for "mayo_clinic_symptoms_and_diseases_v1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
semeru/code-text-python | ---
license: mit
Programminglanguage: "python"
version: "2.7"
Date: "Codesearchnet(Jun 2020 - paper release date)"
Contaminated: "Very Likely"
Size: "Standar Tokenizer (TreeSitter)"
---
### Dataset is imported from CodeXGLUE and pre-processed using their script.
# Where to find in Semeru:
The dataset can be found at /nfs/semeru/semeru_datasets/code_xglue/code-to-text/python in Semeru
# CodeXGLUE -- Code-To-Text
## Task Definition
The task is to generate natural language comments for a code, and evaluted by [smoothed bleu-4](https://www.aclweb.org/anthology/C04-1072.pdf) score.
## Dataset
The dataset we use comes from [CodeSearchNet](https://arxiv.org/pdf/1909.09436.pdf) and we filter the dataset as the following:
- Remove examples that codes cannot be parsed into an abstract syntax tree.
- Remove examples that #tokens of documents is < 3 or >256
- Remove examples that documents contain special tokens (e.g. <img ...> or https:...)
- Remove examples that documents are not English.
### Data Format
After preprocessing dataset, you can obtain three .jsonl files, i.e. train.jsonl, valid.jsonl, test.jsonl
For each file, each line in the uncompressed file represents one function. One row is illustrated below.
- **repo:** the owner/repo
- **path:** the full path to the original file
- **func_name:** the function or method name
- **original_string:** the raw string before tokenization or parsing
- **language:** the programming language
- **code/function:** the part of the `original_string` that is code
- **code_tokens/function_tokens:** tokenized version of `code`
- **docstring:** the top-level comment or docstring, if it exists in the original string
- **docstring_tokens:** tokenized version of `docstring`
### Data Statistic
| Programming Language | Training | Dev | Test |
| :------------------- | :------: | :----: | :----: |
| Python | 251,820 | 13,914 | 14,918 |
## Reference
<pre><code>@article{husain2019codesearchnet,
title={Codesearchnet challenge: Evaluating the state of semantic code search},
author={Husain, Hamel and Wu, Ho-Hsiang and Gazit, Tiferet and Allamanis, Miltiadis and Brockschmidt, Marc},
journal={arXiv preprint arXiv:1909.09436},
year={2019}
}</code></pre>
|
bharat-raghunathan/indian-foods-dataset | ---
license: cc0-1.0
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': biryani
'1': cholebhature
'2': dabeli
'3': dal
'4': dhokla
'5': dosa
'6': jalebi
'7': kathiroll
'8': kofta
'9': naan
'10': pakora
'11': paneer
'12': panipuri
'13': pavbhaji
'14': vadapav
splits:
- name: train
num_bytes: 611741947.222
num_examples: 3809
- name: test
num_bytes: 153961285
num_examples: 961
download_size: 688922167
dataset_size: 765703232.222
task_categories:
- image-classification
- text-to-image
language:
- en
pretty_name: indian-foods
size_categories:
- 1K<n<10K
---
# Dataset Card for Indian Foods Dataset
## Dataset Description
- **Homepage:** https://www.kaggle.com/datasets/anshulmehtakaggl/themassiveindianfooddataset
- **Repository:** https://www.kaggle.com/datasets/anshulmehtakaggl/themassiveindianfooddataset
- **Paper:**
- **Leaderboard:**
- **Point of Contact:** https://www.kaggle.com/anshulmehtakaggl
### Dataset Summary
This is a multi-category(multi-class classification) related Indian food dataset showcasing [The-massive-Indian-Food-Dataset](https://www.kaggle.com/datasets/anshulmehtakaggl/themassiveindianfooddataset).
This card has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
English
## Dataset Structure
```json
{
"image": "Image(decode=True, id=None)",
"target": "ClassLabel(names=['biryani', 'cholebhature', 'dabeli', 'dal', 'dhokla', 'dosa', 'jalebi', 'kathiroll', 'kofta', 'naan', 'pakora', 'paneer', 'panipuri', 'pavbhaji', 'vadapav'], id=None)"
}
```
### Dataset Splits
This dataset is split into a train and test split. The split sizes are as follows:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 3809 |
| test | 961 |
### Data Instances
Each instance is a picture of the Indian food item, along with the category it belongs to.
#### Initial Data Collection and Normalization
Collection by Scraping data from Google Images + Leveraging some JS Functions.
All the images are resized to (300,300) to maintain size uniformity.
### Dataset Curators
[Anshul Mehta](https://www.kaggle.com/anshulmehtakaggl)
### Licensing Information
[CC0: Public Domain](https://creativecommons.org/publicdomain/zero/1.0/)
### Citation Information
[The Massive Indian Foods Dataset](https://www.kaggle.com/datasets/anshulmehtakaggl/themassiveindianfooddataset) |
harpomaxx/dga-detection | ---
license: cc-by-2.0
---
A dataset containing both DGA and normal domain names. The normal domain names were taken from the Alexa top one million domains.
An additional 3,161 normal domains were included in the dataset, provided by the Bambenek Consulting feed. This later group is particularly interesting since it consists
of suspicious domain names that were not generated by DGA. Therefore, the total amount of domains normal in the dataset is 1,003,161. DGA domains
were obtained from the repositories of DGA domains of [Andrey Abakumov](https://github.com/andrewaeva/DGA) and [John Bambenek](http://osint.bambenekconsulting.com/feeds/).
The total amount of DGA domains is 1,915,335, and they correspond to 51 different malware families. DGA domains were generated by 51 different malware families.
About the 55% of of the DGA portion of dataset is composed of samples from the Banjori, Post, Timba, Cryptolocker, Ramdo and Conficker malware.
The DGA generation scheme followed by the malware families includes the simple arithmetical (A) and the recent word based (W) schemes.
Under the arithmetic scheme, the algorithm usually calculates a sequence of values that have a direct ASCII representation usable for a domain name.
On the other hand, word-based consists of concatenating a sequence of words from one or more wordlists. |
mstz/mammography | ---
language:
- en
tags:
- mammography
- tabular_classification
- binary_classification
- UCI
pretty_name: Mammography
size_categories:
- n<1K
task_categories:
- tabular-classification
configs:
- mammography
license: cc
---
# Mammography
The [Mammography dataset](https://archive.ics.uci.edu/ml/datasets/Mammography) from the [UCI ML repository](https://archive.ics.uci.edu/ml/datasets).
# Configurations and tasks
| **Configuration** | **Task** | **Description** |
|-------------------|---------------------------|------------------------|
| mammography | Binary classification | Is the lesion benign? |
# Usage
```python
from datasets import load_dataset
dataset = load_dataset("mstz/mammography")["train"]
``` |
tasksource/icl-symbol-tuning-instruct | ---
license: apache-2.0
task_categories:
- text2text-generation
- text-classification
- text-generation
language:
- en
tags:
- in-context-learning
- symbol-tuning
- icl
- meta-icl
- meta-learning
- flan
- long-input
- instruction-tuning
- instruct
- metaicl
dataset_info:
features:
- name: task
dtype: string
- name: inputs
dtype: string
- name: targets
dtype: string
- name: symbols
sequence: string
splits:
- name: validation
num_bytes: 42218685.0
num_examples: 14970
- name: test
num_bytes: 43453364.0
num_examples: 16204
- name: train
num_bytes: 1303015298.0
num_examples: 452367
download_size: 727062369
dataset_size: 1388687347.0
size_categories:
- 100K<n<1M
---
# Description
Few-shot prompting demonstrates that language models can learn in context even though they were not trained to do. However, explicitly learning to learn in context [meta-icl](https://arxiv.org/abs/2110.15943) leads to better results. With symbol tuning, labels are replaced with arbitrary symbols (e.g. foo/bar), which makes learning in context a key condition to learn the instructions
We implement *symbol tuning*, as presented in the [Symbol tuning improves in-context learning](https://arxiv.org/pdf/2305.08298.pdf) paper with tasksource classification datasets.
An input is a shuffled sequence of 4 positive and 4 negative examples showing a particular label (replaced with a symbol - a random word), followed by an example to label.
This is the largest symbol-tuning dataset to date, with 279 datasets. Symbol tuning improves in-context learning, which tends to be degraded by instruction tuning.
# Usage
We limit input size to 50_000 characters. This is well enough to challenge long range modeling. But be careful to remove examples that are too long or to truncate from left, otherwise some examples might be unsolvable, as the "question" are at the end of the examples.
```python
dataset = load_dataset('tasksource/icl-symbol-tuning-instruct')
# assuming 4 characters per token and 1000 tokens
dataset = dataset.filter(lambda x:len(x['inputs'])<1000*4)
```
## References:
Code: https://github.com/sileod/tasksource
```
@article{sileo2023tasksource,
title={tasksource: Structured Dataset Preprocessing Annotations for Frictionless Extreme Multi-Task Learning and Evaluation},
author={Sileo, Damien},
url= {https://arxiv.org/abs/2301.05948},
journal={arXiv preprint arXiv:2301.05948},
year={2023}
}
@article{wei2023symbol,
title={Symbol tuning improves in-context learning in language models},
author={Wei, Jerry and Hou, Le and Lampinen, Andrew and Chen, Xiangning and Huang, Da and Tay, Yi and Chen, Xinyun and Lu, Yifeng and Zhou, Denny and Ma, Tengyu and others},
journal={arXiv preprint arXiv:2305.08298},
year={2023}
}
``` |
JourneyDB/JourneyDB | ---
extra_gated_prompt: "You have carefully read the [Terms of Usage](https://journeydb.github.io/assets/Terms_of_Usage.html) and agree with the listed terms."
extra_gated_fields:
First Name: text
Last Name: text
Affiliation: text
I agree with our JourneyDB usage terms and I will obey the terms when using the JourneyDB dataset: checkbox
---
---
task_categories:
- image-to-text
language:
- en
size_categories:
- 1M<n<10M
---
# JourneyDB
[[Project Page]](https://journeydb.github.io) [[Paper]](https://arxiv.org/abs/2307.00716) [[Code]](https://github.com/JourneyDB/JourneyDB) [[HuggingFace]](https://huggingface.co/datasets/JourneyDB/JourneyDB) [[OpenDataLab]]()

## Dataset Description
### Summary
**JourneyDB** is a large-scale generated image understanding dataset that contains **4,429,295** high-resolution Midjourney images, annotated with corresponding **text prompt**, **image caption** and **visual question answering**.
### Supported Tasks
**JourneyDB** supports **4** downstream tasks, i.e. **Prompt Inversion**, **Style Retrieval**, **Image Caption**, and **Visual Question Answering**. We evaluate many existing methods on these tasks and provide a comprehensive benchmark. Please see our [Paper](https://arxiv.org/abs/2307.00716) for more details.
## Dataset Details
### Data Collection
For each image instance, we acquire the corresponding text prompts used to generate the images with Midjourney. Furthermore, we employ GPT3.5 to generate the caption and VAQ groundtruth.

### Data Instances
We provide several examples to show the contents of each dataset instance.

### Data Splits
We provide detailed statistics for each split subset in the following table. We randomly split the whole dataset into roughly 20 : 1 to obtain the training and validation set. The training set contains 4,189,737 labeled images and 1,385,317 labeled prompts. The validation set contains 235,156 images and 82,093 prompts. And we additionally sample a testing set for manual filtering. The testing set contains 5,402 images and 5,171 prompts.
| | Image | Prompt | Labeled Image | Labeled Prompt | Style QA | Content QA |
|----------------|:---------:|:---------:|:-------------:|:--------------:|:---------:|:----------:|
| Training Set | 4,453,193 | 1,643,375 | 4,189,737 | 1,385,317 | 7,056,394 | 8,775,971 |
| Validation Set | 234,156 | 82,093 | 234,156 | 82,093 | 311,569 | 374,310 |
| Testing Set | 5,402 | 5,171 | 5,402 | 5,171 | 10,040 | 11,369 |
| Total | 4,692,751 | 1,730,639 | 4,429,295 | 1,472,581 | 7,378,003 | 9,161,650 |
## Acquirements
### License
The JourneyDB dataset is available under the customised [Terms of Usage](./assets/Terms_of_Usage.md).
### Citation
```
@misc{pan2023journeydb,
title={JourneyDB: A Benchmark for Generative Image Understanding},
author={Junting Pan and Keqiang Sun and Yuying Ge and Hao Li and Haodong Duan and Xiaoshi Wu and Renrui Zhang and Aojun Zhou and Zipeng Qin and Yi Wang and Jifeng Dai and Yu Qiao and Hongsheng Li},
year={2023},
eprint={2307.00716},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
### Contributions
[Junting Pan](https://junting.github.io)\*, [Keqiang Sun](https://keqiangsun.github.io)\*, [Yuying Ge](https://geyuying.github.io), [Hao Li](https://cpsxhao.github.io), [Haodong Duan](https://kennymckormick.github.io), [Xiaoshi Wu](https://github.com/tgxs002), [Renrui Zhang](https://github.com/ZrrSkywalker), [Aojun Zhou](https://scholar.google.com/citations?user=cC8lXi8AAAAJ&hl=en), [Zipeng Qin](https://www.linkedin.cn/incareer/in/zipeng-bruce-qin-846a65119), [Yi Wang](https://shepnerd.github.io), [Jifeng Dai](https://jifengdai.org), [Yu Qiao](http://mmlab.siat.ac.cn/yuqiao/), [Hongsheng Li](https://www.ee.cuhk.edu.hk/~hsli/)<sup>+</sup>
(\* equal contribution, <sup>+</sup> corresponding author)
### Contact
If you have any problem or suggestion, please feel free to open an issue or send emails to the contributors. |
TrainingDataPro/ocr-text-detection-in-the-documents | ---
license: cc-by-nc-nd-4.0
task_categories:
- image-to-text
- object-detection
language:
- en
tags:
- code
- legal
- finance
---
# OCR Text Detection in the Documents Dataset
The dataset is a collection of images that have been annotated with the location of text in the document. The dataset is specifically curated for text detection and recognition tasks in documents such as scanned papers, forms, invoices, and handwritten notes.
The dataset contains a variety of document types, including different *layouts, font sizes, and styles*. The images come from diverse sources, ensuring a representative collection of document styles and quality. Each image in the dataset is accompanied by bounding box annotations that outline the exact location of the text within the document.
The Text Detection in the Documents dataset provides an invaluable resource for developing and testing algorithms for text extraction, recognition, and analysis. It enables researchers to explore and innovate in various applications, including *optical character recognition (OCR), information extraction, and document understanding*.
.png?generation=1691059158337136&alt=media)
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-text-detection-in-the-documents) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images of documents
- **boxes** - includes bounding box labeling for the original images
- **annotations.xml** - contains coordinates of the bounding boxes and labels, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes and labels for text detection. For each point, the x and y coordinates are provided.
### Labels for the text:
- **"Text Title"** - corresponds to titles, the box is **red**
- **"Text Paragraph"** - corresponds to paragraphs of text, the box is **blue**
- **"Table"** - corresponds to the table, the box is **green**
- **"Handwritten"** - corresponds to handwritten text, the box is **purple**
# Example of XML file structure
# Text Detection in the Documents might be made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-text-detection-in-the-documents) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
Fredithefish/openassistant-guanaco-unfiltered | ---
license: apache-2.0
task_categories:
- conversational
language:
- en
- de
- fr
- es
size_categories:
- 1K<n<10K
---
# Guanaco-Unfiltered
- Any language other than English, German, French, or Spanish has been removed.
- Refusals of assistance have been removed.
- The identification as OpenAssistant has been removed.
## [Version 2 is out](https://huggingface.co/datasets/Fredithefish/openassistant-guanaco-unfiltered/blob/main/guanaco-unfiltered-v2.jsonl)
- Identification as OpenAssistant is now fully removed
- other improvements |
goendalf666/sales-textbook_for_convincing_and_selling | ---
task_categories:
- text-generation
language:
- en
tags:
- sales
size_categories:
- 100K<n<1M
---
# Dataset Card for sales-textbook_for_convincing_and_selling
A textbook create for the purpose of training a sales chatbot.
Inspiration come from: Textbooks is all you need https://arxiv.org/abs/2306.11644
The data was generated by gpt-3.5-turbo
#Structure
A simpel textbook that has subheadlines and headlines.
Chapters and Subheadlines are mentioned in the dataset. Look at the first two examples.
# Data Generation
The following code was used for the text generation:
#include github link
Out of the textbook conversation examples were generated
https://huggingface.co/datasets/goendalf666/sales-conversations
Here is the prompt that was used for the data generation.
For the exact data generation code look up the following repo:
#a structure with headlines and subheadlines was generated before https://github.com/tom813/salesGPT_foundation/blob/main/data_generation/textbook_and_conversation_gen.py
```
prompt = f"""
I want to write a book about sales and convincing techniques. Here is the outline of the chapters:
1. Building Rapport and Capturing Attention
2. Developing Exceptional Communication Skills
3. Discovering Customer Needs and Pain Points
4. Presenting Solutions and Benefits
5. Overcoming Resistance and Objections
6. Closing the Sale
Here is the outline of the current chapter that:
{headline}
Write me a long and detailed text for the subpoint: {subheadline} of the current chapter and only write a text for this subpoint.
Ignore points like body language or tone of voice. Focus on the
Start by mentioning the Chapter and the subpoint.
The overall aim is to write a textbook.
to teach someone with less experience how to convince people and sell stuff.
"""
``` |
vikp/textbook_quality_programming | ---
language:
- en
dataset_info:
features:
- name: topic
dtype: string
- name: model
dtype: string
- name: concepts
sequence: string
- name: outline
sequence: string
- name: markdown
dtype: string
splits:
- name: train
num_bytes: 471931604
num_examples: 11650
download_size: 0
dataset_size: 471931604
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "textbook_quality_programming"
Synthetic programming textbooks generated with GPT-3.5 and retrieval. Very high quality, aimed at being used in a phi replication. Currently 115M tokens. Covers many languages and technologies, with a bias towards python.
~10k of the books (65M tokens) use an older generation method, and average 6k tokens in length. ~1.5k books (50M tokens) use a newer generation method, with a more detailed outline, and average 33k tokens in length. All books have section headers for optimal chunking.
Generated using the [textbook_quality](https://github.com/VikParuchuri/textbook_quality) repo. |
slone/nllb-200-10M-sample | ---
dataset_info:
features:
- name: laser_score
dtype: float64
- name: lang1
dtype: string
- name: text1
dtype: string
- name: lang2
dtype: string
- name: text2
dtype: string
- name: blaser_sim
dtype: float64
splits:
- name: train
num_bytes: 2279333006.0
num_examples: 9983398
download_size: 1825697094
dataset_size: 2279333006.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: odc-by
task_categories:
- translation
pretty_name: nllb-200-10M-sample
size_categories:
- 1M<n<10M
language:
- ak # aka_Latn Akan
- am # amh_Ethi Amharic
- ar # arb_Arab Modern Standard Arabic
- awa # awa_Deva Awadhi
- azj # azj_Latn North Azerbaijani
- bm # bam_Latn Bambara
- ban # ban_Latn Balinese
- be # bel_Cyrl Belarusian
- bem # bem_Latn Bemba
- bn # ben_Beng Bengali
- bho # bho_Deva Bhojpuri
- bjn # bjn_Latn Banjar (Latin script)
- bug # bug_Latn Buginese
- bg # bul_Cyrl Bulgarian
- ca # cat_Latn Catalan
- ceb # ceb_Latn Cebuano
- cs # ces_Latn Czech
- cjk # cjk_Latn Chokwe
- ckb # ckb_Arab Central Kurdish
- crh # crh_Latn Crimean Tatar
- da # dan_Latn Danish
- de # deu_Latn German
- dik # dik_Latn Southwestern Dinka
- dyu # dyu_Latn Dyula
- el # ell_Grek Greek
- en # eng_Latn English
- eo # epo_Latn Esperanto
- et # est_Latn Estonian
- ee # ewe_Latn Ewe
- fo # fao_Latn Faroese
- fj # fij_Latn Fijian
- fi # fin_Latn Finnish
- fon # fon_Latn Fon
- fr # fra_Latn French
- fur # fur_Latn Friulian
- ff # fuv_Latn Nigerian Fulfulde
- gaz # gaz_Latn West Central Oromo
- gd # gla_Latn Scottish Gaelic
- ga # gle_Latn Irish
- gl # glg_Latn Galician
- gn # grn_Latn Guarani
- gu # guj_Gujr Gujarati
- ht # hat_Latn Haitian Creole
- ha # hau_Latn Hausa
- he # heb_Hebr Hebrew
- hi # hin_Deva Hindi
- hne # hne_Deva Chhattisgarhi
- hr # hrv_Latn Croatian
- hu # hun_Latn Hungarian
- hy # hye_Armn Armenian
- ig # ibo_Latn Igbo
- ilo # ilo_Latn Ilocano
- id # ind_Latn Indonesian
- is # isl_Latn Icelandic
- it # ita_Latn Italian
- jv # jav_Latn Javanese
- ja # jpn_Jpan Japanese
- kab # kab_Latn Kabyle
- kac # kac_Latn Jingpho
- kam # kam_Latn Kamba
- kn # kan_Knda Kannada
- ks # kas_Arab Kashmiri (Arabic script)
- ks # kas_Deva Kashmiri (Devanagari script)
- ka # kat_Geor Georgian
- kk # kaz_Cyrl Kazakh
- kbp # kbp_Latn Kabiyè
- kea # kea_Latn Kabuverdianu
- mn # khk_Cyrl Halh Mongolian
- km # khm_Khmr Khmer
- ki # kik_Latn Kikuyu
- rw # kin_Latn Kinyarwanda
- ky # kir_Cyrl Kyrgyz
- kmb # kmb_Latn Kimbundu
- kmr # kmr_Latn Northern Kurdish
- kr # knc_Arab Central Kanuri (Arabic script)
- kr # knc_Latn Central Kanuri (Latin script)
- kg # kon_Latn Kikongo
- ko # kor_Hang Korean
- lo # lao_Laoo Lao
- lij # lij_Latn Ligurian
- li # lim_Latn Limburgish
- ln # lin_Latn Lingala
- lt # lit_Latn Lithuanian
- lmo # lmo_Latn Lombard
- ltg # ltg_Latn Latgalian
- lb # ltz_Latn Luxembourgish
- lua # lua_Latn Luba-Kasai
- lg # lug_Latn Ganda
- luo # luo_Latn Luo
- lus # lus_Latn Mizo
- lv # lvs_Latn Standard Latvian
- mag # mag_Deva Magahi
- mai # mai_Deva Maithili
- ml # mal_Mlym Malayalam
- mr # mar_Deva Marathi
- min # min_Latn Minangkabau (Latin script)
- mk # mkd_Cyrl Macedonian
- mt # mlt_Latn Maltese
- mni # mni_Beng Meitei (Bengali script)
- mos # mos_Latn Mossi
- mi # mri_Latn Maori
- my # mya_Mymr Burmese
- nl # nld_Latn Dutch
- nb # nob_Latn Norwegian Bokmål
- ne # npi_Deva Nepali
- nso # nso_Latn Northern Sotho
- nus # nus_Latn Nuer
- ny # nya_Latn Nyanja
- oc # oci_Latn Occitan
- ory # ory_Orya Odia
- pag # pag_Latn Pangasinan
- pa # pan_Guru Eastern Panjabi
- pap # pap_Latn Papiamento
- pbt # pbt_Arab Southern Pashto
- fa # pes_Arab Western Persian
- plt # plt_Latn Plateau Malagasy
- pl # pol_Latn Polish
- pt # por_Latn Portuguese
- prs # prs_Arab Dari
- qu # quy_Latn Ayacucho Quechua
- ro # ron_Latn Romanian
- rn # run_Latn Rundi
- ru # rus_Cyrl Russian
- sg # sag_Latn Sango
- sa # san_Deva Sanskrit
- sat # sat_Beng ?
- scn # scn_Latn Sicilian
- shn # shn_Mymr Shan
- si # sin_Sinh Sinhala
- sk # slk_Latn Slovak
- sl # slv_Latn Slovenian
- sm # smo_Latn Samoan
- sn # sna_Latn Shona
- sd # snd_Arab Sindhi
- so # som_Latn Somali
- st # sot_Latn Southern Sotho
- es # spa_Latn Spanish
- sc # srd_Latn Sardinian
- sr # srp_Cyrl Serbian
- ss # ssw_Latn Swati
- su # sun_Latn Sundanese
- sv # swe_Latn Swedish
- sw # swh_Latn Swahili
- szl # szl_Latn Silesian
- ta # tam_Taml Tamil
- taq # taq_Latn Tamasheq (Latin script)
- tt # tat_Cyrl Tatar
- te # tel_Telu Telugu
- tg # tgk_Cyrl Tajik
- tl # tgl_Latn Tagalog
- ti # tir_Ethi Tigrinya
- tpi # tpi_Latn Tok Pisin
- tn # tsn_Latn Tswana
- ts # tso_Latn Tsonga
- tk # tuk_Latn Turkmen
- tum # tum_Latn Tumbuka
- tr # tur_Latn Turkish
- tw # twi_Latn Twi
- tzm # tzm_Tfng Central Atlas Tamazight
- ug # uig_Arab Uyghur
- uk # ukr_Cyrl Ukrainian
- umb # umb_Latn Umbundu
- ur # urd_Arab Urdu
- uz # uzn_Latn Northern Uzbek
- vec # vec_Latn Venetian
- vi # vie_Latn Vietnamese
- war # war_Latn Waray
- wo # wol_Latn Wolof
- xh # xho_Latn Xhosa
- yi # ydd_Hebr Eastern Yiddish
- yo # yor_Latn Yoruba
- zh # zho_Hans Chinese (Simplified)
- zh # zho_Hant Chinese (Traditional)
- ms # zsm_Latn Standard Malay
- zu # zul_Latn Zulu
---
# Dataset Card for "nllb-200-10M-sample"
This is a sample of nearly 10M sentence pairs from the [NLLB-200](https://arxiv.org/abs/2207.04672)
mined dataset [allenai/nllb](https://huggingface.co/datasets/allenai/nllb),
scored with the model [facebook/blaser-2.0-qe](https://huggingface.co/facebook/blaser-2.0-qe)
described in the [SeamlessM4T](https://arxiv.org/abs/2308.11596) paper.
The sample is not random; instead, we just took the top `n` sentence pairs from each translation direction.
The number `n` was computed with the goal of upsamping the directions that contain underrepresented languages.
Nevertheless, the 187 languoids (language and script combinations) are not represented equally,
with most languoids totaling 36K to 200K sentences.
Over 60% of the sentence pairs have BLASER-QE score above 3.5.
This dataset can be used for fine-tuning massively multilingual translation models.
We suggest the following scenario:
- Filter the dataset by the value of `blaser_sim` (the recommended threshold is 3.0 or 3.5);
- Randomly swap the source/target roles in the sentence pairs during data loading;
- Use that data to augment the dataset while fine-tuning an NLLB-like model for a new translation direction,
in order to mitigate forgetting of all the other translation directions.
The dataset is released under the terms of [ODC-BY](https://opendatacommons.org/licenses/by/1-0/).
By using this, you are also bound to the respective Terms of Use and License of the original source.
Citation:
- NLLB Team et al, *No Language Left Behind: Scaling Human-Centered Machine Translation*, Arxiv https://arxiv.org/abs/2207.04672, 2022.
- Seamless Communication et al, *SeamlessM4T — Massively Multilingual & Multimodal Machine Translation*, Arxiv https://arxiv.org/abs/2308.11596, 2023.
The following language codes are supported. The mapping between languages and codes can be found in the [NLLB-200 paper](https://arxiv.org/abs/2207.04672)
or in the [FLORES-200 repository](https://github.com/facebookresearch/flores/blob/main/flores200/README.md#languages-in-flores-200).
```
aka_Latn amh_Ethi arb_Arab awa_Deva azj_Latn bam_Latn ban_Latn bel_Cyrl bem_Latn ben_Beng bho_Deva bjn_Latn
bug_Latn bul_Cyrl cat_Latn ceb_Latn ces_Latn cjk_Latn ckb_Arab crh_Latn dan_Latn deu_Latn dik_Latn dyu_Latn
ell_Grek eng_Latn epo_Latn est_Latn ewe_Latn fao_Latn fij_Latn fin_Latn fon_Latn fra_Latn fur_Latn fuv_Latn
gaz_Latn gla_Latn gle_Latn glg_Latn grn_Latn guj_Gujr hat_Latn hau_Latn heb_Hebr hin_Deva hne_Deva hrv_Latn
hun_Latn hye_Armn ibo_Latn ilo_Latn ind_Latn isl_Latn ita_Latn jav_Latn jpn_Jpan kab_Latn kac_Latn kam_Latn
kan_Knda kas_Arab kas_Deva kat_Geor kaz_Cyrl kbp_Latn kea_Latn khk_Cyrl khm_Khmr kik_Latn kin_Latn kir_Cyrl
kmb_Latn kmr_Latn knc_Arab knc_Latn kon_Latn kor_Hang lao_Laoo lij_Latn lim_Latn lin_Latn lit_Latn lmo_Latn
ltg_Latn ltz_Latn lua_Latn lug_Latn luo_Latn lus_Latn lvs_Latn mag_Deva mai_Deva mal_Mlym mar_Deva min_Latn
mkd_Cyrl mlt_Latn mni_Beng mos_Latn mri_Latn mya_Mymr nld_Latn nob_Latn npi_Deva nso_Latn nus_Latn nya_Latn
oci_Latn ory_Orya pag_Latn pan_Guru pap_Latn pbt_Arab pes_Arab plt_Latn pol_Latn por_Latn prs_Arab quy_Latn
ron_Latn run_Latn rus_Cyrl sag_Latn san_Deva sat_Beng scn_Latn shn_Mymr sin_Sinh slk_Latn slv_Latn smo_Latn
sna_Latn snd_Arab som_Latn sot_Latn spa_Latn srd_Latn srp_Cyrl ssw_Latn sun_Latn swe_Latn swh_Latn szl_Latn
tam_Taml taq_Latn tat_Cyrl tel_Telu tgk_Cyrl tgl_Latn tir_Ethi tpi_Latn tsn_Latn tso_Latn tuk_Latn tum_Latn
tur_Latn twi_Latn tzm_Tfng uig_Arab ukr_Cyrl umb_Latn urd_Arab uzn_Latn vec_Latn vie_Latn war_Latn wol_Latn
xho_Latn ydd_Hebr yor_Latn zho_Hans zho_Hant zsm_Latn zul_Latn
```
|
Mohammed-Altaf/medical-instruction-100k | ---
license: mit
language:
- en
tags:
- medi
- medical
pretty_name: python
size_categories:
- 10K<n<100K
---
# What is the Dataset About?🤷🏼♂️
---
The dataset is useful for training a Generative Language Model for the Medical application and instruction purposes, the dataset consists of various thoughs proposed by the people [**mentioned as the Human** ] and there responses including Medical Terminologies not limited to but including names of the drugs, prescriptions, yogic exercise suggessions, breathing exercise suggessions and few natural home made prescriptions.
# How the Dataset was made?😅
---
I have used all the available opensource datasets and combined them into a single datsource for training, which is completely opensourced and somewhat reliable.
* There is another refined and updated version of this datset here 👉🏼 [Link](https://huggingface.co/datasets/Mohammed-Altaf/medical-instruction-120k)
## Example Training Scripts:
* Qlora Fine Tuning -
## Tips:
This is my first dataset to upload on HuggingFace, so below are the thing I wish I could have known
* always save your final dataset before uploading to hub as a json with lines.
* The json should have the records orientation, which will be helpful while loading the dataset properly without any error.
```{python}
# use below if you are using pandas for data manipulation
train.to_json("dataset_name.json", orient='records', lines=True)
test.to_json("dataset_name.json", orient='records', lines=True)
``` |
OpenGVLab/VideoChat2-IT | ---
license: mit
extra_gated_prompt:
You agree to not use the dataset to conduct experiments that cause harm to
human subjects. Please note that the data in this dataset may be subject to
other agreements. Before using the data, be sure to read the relevant
agreements carefully to ensure compliant use. Video copyrights belong to the
original video creators or platforms and are for academic research use only.
task_categories:
- visual-question-answering
- question-answering
- conversational
extra_gated_fields:
Name: text
Company/Organization: text
Country: text
E-Mail: text
language:
- en
size_categories:
- 1M<n<10M
configs:
- config_name: video_classification
data_files:
- split: ssv2
path: video/classification/ssv2/train.json
- split: k710
path: video/classification/k710/train.json
- config_name: video_reasoning
data_files:
- split: clevrer_mc
path: video/reasoning/clevrer_mc/train.json
- split: next_qa
path: video/reasoning/next_qa/train.json
- split: clevrer_qa
path: video/reasoning/clevrer_qa/train.json
- config_name: video_conversation
data_files:
- split: videochat2
path: video/conversation/videochat2/train.json
- split: videochatgpt
path: video/conversation/videochatgpt/train.json
- split: videochat1
path: video/conversation/videochat1/train.json
- config_name: video_vqa
data_files:
- split: webvid_qa
path: video/vqa/webvid_qa/train.json
- split: tgif_transition_qa
path: video/vqa/tgif_transition_qa/train.json
- split: tgif_frame_qa
path: video/vqa/tgif_frame_qa/train.json
- split: ego_qa
path: video/vqa/ego_qa/train.json
- config_name: video_caption
data_files:
- split: textvr
path: video/caption/textvr/train.json
- split: youcook2
path: video/caption/youcook2/train.json
- split: webvid
path: video/caption/webvid/train.json
- split: videochat
path: video/caption/videochat/train.json
- config_name: image_classification
data_files:
- split: imagenet
path: image/classification/imagenet/train.json
- split: coco_itm
path: image/classification/coco_itm/train.json
- config_name: image_caption
data_files:
- split: textcaps
path: image/caption/textcaps/train.json
- split: minigpt4
path: image/caption/minigpt4/train.json
- split: coco
path: image/caption/coco/train.json
- split: paragraph_captioning
path: image/caption/paragraph_captioning/train.json
- split: llava
path: image/caption/llava/train.json
- config_name: image_reasoning
data_files:
- split: llava
path: image/reasoning/llava/train.json
- split: clevr
path: image/reasoning/clevr/train.json
- split: visual_mrc
path: image/reasoning/visual_mrc/train.json
- config_name: image_conversation
data_files:
- split: llava
path: image/conversation/llava/train.json
- config_name: image_vqa
data_files:
- split: okvqa
path: image/vqa/okvqa/train.json
- split: docvqa
path: image/vqa/docvqa/train.json
- split: ocr_vqa
path: image/vqa/ocr_vqa/train.json
- split: vqav2_chinese
path: image/vqa/vqav2_chinese/train.json
- split: vqav2
path: image/vqa/vqav2/train.json
- split: st_vqa
path: image/vqa/st_vqa/train.json
- split: text_vqa
path: image/vqa/text_vqa/train.json
- split: gqa
path: image/vqa/gqa/train.json
- split: okvqa_chinese
path: image/vqa/okvqa_chinese/train.json
- split: viquae
path: image/vqa/viquae/train.json
- split: a_okvqa
path: image/vqa/a_okvqa/train.json
---
# Instruction Data

## Dataset Description
- **Repository:** [VideoChat2](https://github.com/OpenGVLab/Ask-Anything/tree/main/video_chat2)
- **Paper:** [2311.17005](https://arxiv.org/abs/2311.17005)
- **Point of Contact:** mailto:[kunchang li](likunchang@pjlab.org.cn)
## Annotations
A comprehensive dataset of **1.9M** data annotations is available in [JSON](https://huggingface.co/datasets/OpenGVLab/VideoChat2-IT) format. Due to the extensive size of the full data, we provide only JSON files here. For corresponding images and videos, please follow our instructions.
## Source data
### Image
For image datasets, we utilized [M3IT](https://huggingface.co/datasets/MMInstruction/M3IT), filtering out lower-quality data by:
- **Correcting typos**: Most sentences with incorrect punctuation usage were rectified.
- **Rephrasing incorrect answers**: Some responses generated by ChatGPT, such as "Sorry, ...", were incorrect. These were rephrased using GPT-4.
You can easily download the datasets we employed from [M3IT](https://huggingface.co/datasets/MMInstruction/M3IT).
### Video
We treated video datasets differently. Please download the original videos from the provided links:
- [VideoChat](https://github.com/OpenGVLab/InternVideo/tree/main/Data/instruction_data): Based on [InternVid](https://github.com/OpenGVLab/InternVideo/tree/main/Data/InternVid), we created additional instruction data and used GPT-4 to condense the existing data.
- [VideoChatGPT](https://github.com/mbzuai-oryx/Video-ChatGPT/tree/main/data): The original caption data was converted into conversation data based on the same VideoIDs.
- [Kinetics-710](https://github.com/OpenGVLab/UniFormerV2/blob/main/DATASET.md) & [SthSthV2](
https://developer.qualcomm.com/software/ai-datasets/something-something): Option candidates were generated from [UMT](https://github.com/OpenGVLab/unmasked_teacher) top-20 predictions.
- [NExTQA](https://github.com/doc-doc/NExT-QA): Typos in the original sentences were corrected.
- [CLEVRER](https://clevrer.csail.mit.edu/): For single-option multiple-choice QAs, we used only those concerning color/material/shape. For multi-option multiple-choice QAs, we utilized all the data.
- [WebVid](https://maxbain.com/webvid-dataset/): Non-overlapping data was selected for captioning and [QA](https://antoyang.github.io/just-ask.html#webvidvqa).
- [YouCook2](https://youcook2.eecs.umich.edu/): Original videos were truncated based on the official dense captions.
- [TextVR](https://github.com/callsys/textvr): All data was used without modifications.
- [TGIF](https://github.com/YunseokJANG/tgif-qa): Only TGIF$_{frame}$ and TGIF$_{Transition}$ subsets were considered.
- [EgoQA](https://ego4d-data.org/): Some egocentric QAs were generated from Ego4D data.
For all datasets, task instructions were automatically generated using GPT-4.
## Citation
If you find this project useful in your research, please consider cite:
```BibTeX
@article{2023videochat,
title={VideoChat: Chat-Centric Video Understanding},
author={KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao},
journal={arXiv preprint arXiv:2305.06355},
year={2023}
}
@misc{li2023mvbench,
title={MVBench: A Comprehensive Multi-modal Video Understanding Benchmark},
author={Kunchang Li and Yali Wang and Yinan He and Yizhuo Li and Yi Wang and Yi Liu and Zun Wang and Jilan Xu and Guo Chen and Ping Luo and Limin Wang and Yu Qiao},
year={2023},
eprint={2311.17005},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
HuggingFaceH4/cai-conversation | ---
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
- split: train
path: data/train-*
dataset_info:
features:
- name: index
dtype: int64
- name: prompt
dtype: string
- name: init_prompt
struct:
- name: content
dtype: string
- name: role
dtype: string
- name: init_response
struct:
- name: content
dtype: string
- name: role
dtype: string
- name: critic_prompt
struct:
- name: content
dtype: string
- name: role
dtype: string
- name: critic_response
struct:
- name: content
dtype: string
- name: role
dtype: string
- name: revision_prompt
struct:
- name: content
dtype: string
- name: role
dtype: string
- name: revision_response
struct:
- name: content
dtype: string
- name: role
dtype: string
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: chosen
list:
- name: content
dtype: string
- name: role
dtype: string
- name: rejected
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: test
num_bytes: 35677725
num_examples: 8552
- name: train
num_bytes: 608100382
num_examples: 160800
download_size: 16122507
dataset_size: 35677725
---
# Dataset Card for "cai-conversation"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
seedboxai/german_to_english_translations_v1 | ---
dataset_info:
features:
- name: dataset
dtype: string
- name: tokens
dtype: string
- name: range
dtype: string
- name: text
dtype: string
- name: original
dtype: string
- name: translation
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 8534323299
num_examples: 1347167
- name: test
num_bytes: 947334755
num_examples: 149686
download_size: 5266655381
dataset_size: 9481658054
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
byroneverson/shell-cmd-instruct | ---
license: apache-2.0
task_categories:
- text-generation
language:
- en
tags:
- instruction-finetuning
pretty_name: Shell Command Instruct
---
# **Used to train models that interact directly with shells**
Follow-up details of my process
- MacOS terminal commands for now. This dataset is still in alpha stages and will be modified.
- Contains 500 somewhat unique training examples so far.
- GPT4 seems like a good candidate for generating more data, licensing would need to be addressed.
- I fine-tuned Solar-10.7B-Instruct-v1.0 with this dataset using a slightly modified version of axolotl. Just a few epochs was enough to get it to output correctly.
- I use oobabooga/text-generation-webui with a custom chat extension for inference. No sandbox is used, it is piped directly into MacOS bash because I'm reckless. C:
- Currently working towards training an MoE (2x7B), multi-modal model (image/text) with this dataset. (BakLLaVA-1-7B + LLaVA-v1.5-7B)
- Inference stages:
1. Send the instruction to the model, expect command.
2. Detect shell command and send to sand-boxed shell.
4. Shell respose should be sent as additional input to model.
5. The final model response should be sent to user from assistant.
TODO:
- Possible "os" column to specify which system the command should be used with, maybe separate datasets for each system type.
## **Sample prompt: (in series, depends on your specific model prompt)**
```
### User:
List files in 'Downloads'
### Command:
ls ~/Downloads
```
```
### Shell:
file1.pdf file2.txt file3.zip
### Assistant:
Listing files in 'Downloads': file1.pdf file2.txt file3.zip
```
|
WhiteRabbitNeo/WRN-Chapter-1 | ---
license: other
---
Expanded now to contain 7750 super high-quality samples. Enjoy responsibly!
# Our 33B-v1.1 model is now live (We'll always be serving the newest model on our web app)!
33B-v1.1 model comes with a "Prompt Enhancement" feature. Access at: https://www.whiterabbitneo.com/
# Our Discord Server
Join us at: https://discord.gg/8Ynkrcbk92 (Updated on Dec 29th. Now permanent link to join)
# Apache-2.0 + WhiteRabbitNeo Extended Version
# Licence: Usage Restrictions
```
You agree not to use the Model or Derivatives of the Model:
- In any way that violates any applicable national or international law or regulation or infringes upon the lawful rights and interests of any third party;
- For military use in any way;
- For the purpose of exploiting, harming or attempting to exploit or harm minors in any way;
- To generate or disseminate verifiably false information and/or content with the purpose of harming others;
- To generate or disseminate inappropriate content subject to applicable regulatory requirements;
- To generate or disseminate personal identifiable information without due authorization or for unreasonable use;
- To defame, disparage or otherwise harass others;
- For fully automated decision making that adversely impacts an individual’s legal rights or otherwise creates or modifies a binding, enforceable obligation;
- For any use intended to or which has the effect of discriminating against or harming individuals or groups based on online or offline social behavior or known or predicted personal or personality characteristics;
- To exploit any of the vulnerabilities of a specific group of persons based on their age, social, physical or mental characteristics, in order to materially distort the behavior of a person pertaining to that group in a manner that causes or is likely to cause that person or another person physical or psychological harm;
- For any use intended to or which has the effect of discriminating against individuals or groups based on legally protected characteristics or categories.
``` |
duxx/distilabel-intel-orca-dpo-pairs-tr | ---
language:
- tr
license: apache-2.0
tags:
- rlaif
- dpo
- rlhf
- distilabel
- synthetic
---
<p align="right">
<a href="https://github.com/argilla-io/distilabel">
<img src="https://raw.githubusercontent.com/argilla-io/distilabel/main/docs/assets/distilabel-badge-light.png" alt="Built with Distilabel" width="200" height="32"/>
</a>
</p>
# distilabel Orca Pairs for DPO
The dataset is a "distilabeled" version of the widely used dataset: [Intel/orca_dpo_pairs](https://huggingface.co/datasets/Intel/orca_dpo_pairs). The original dataset has been used by 100s of open-source practitioners and models. We knew from fixing UltraFeedback (and before that, Alpacas and Dollys) that this dataset could be highly improved.
Continuing with our mission to build the best alignment datasets for open-source LLMs and the community, we spent a few hours improving it with [distilabel](https://github.com/argilla-io/distilabel).
This was our main intuition: the original dataset just assumes gpt4/3.5-turbo are always the best response. We know from UltraFeedback that's not always the case. Moreover, DPO fine-tuning benefits from the diversity of preference pairs.
Additionally, we have added a new column indicating whether the question in the dataset is part of the train set of gsm8k (there were no examples from the test set). See the reproduction section for more details.
## Using this dataset
This dataset is useful for preference tuning and we recommend using it instead of the original. It's already prepared in the "standard" chosen, rejected format with additional information for further filtering and experimentation.
The main changes are:
1. ~2K pairs have been swapped: rejected become the chosen response. We have kept the original chosen and rejected on two new columns `original_*` for reproducibility purposes.
2. 4K pairs have been identified as `tie`: equally bad or good.
3. Chosen scores have been added: you can now filter out based on a threshold (see our distilabeled Hermes 2.5 model for an example)
4. We have kept the ratings and rationales generated with gpt-4-turbo and distilabel so you can prepare the data differently if you want.
5. We have added a column to indicate if the input is part of gsm8k train set.
In our experiments, we have got very good results by reducing the size of the dataset by more than 50%. Here's an example of how to achieve that:
```python
from datasets import load_dataset
# Instead of this:
# dataset = load_dataset("Intel/orca_dpo_pairs", split="train")
# use this:
dataset = load_dataset("argilla/distilabel-intel-orca-dpo-pairs", split="train")
dataset = dataset.filter(
lambda r:
r["status"] != "tie" and
r["chosen_score"] >= 8 and
not r["in_gsm8k_train"]
)
```
This results in `5,922` instead of `12,859` samples (54% reduction) and leads to better performance than the same model tuned with 100% of the samples in the original dataset.
> We'd love to hear about your experiments! If you want to try this out, consider joining our [Slack community](https://join.slack.com/t/rubrixworkspace/shared_invite/zt-whigkyjn-a3IUJLD7gDbTZ0rKlvcJ5g) and let's build some open datasets and models together.
## Reproducing the dataset
In this section, we outline the steps to reproduce this dataset.
### Rate original dataset pairs
Build a preference dataset with distilabel using the original dataset:
```python
from distilabel.llm import OpenAILLM
from distilabel.tasks import JudgeLMTask
from distilabel.pipeline import Pipeline
from datasets import load_dataset
# Shuffle 'chosen' and 'rejected' to avoid positional bias and keep track of the order
def shuffle_and_track(chosen, rejected):
pair = [chosen, rejected]
random.shuffle(pair)
order = ["chosen" if x == chosen else "rejected" for x in pair]
return {"generations": pair, "order": order}
dataset = load_dataset("Intel/orca_dpo_pairs", split="train")
# This shuffles the pairs to mitigate positional bias
dataset = dataset.map(lambda x: shuffle_and_track(x["chosen"], x["rejected"]))
# We use our JudgeLM implementation to rate the original pairs
labeler = OpenAILLM(
task=JudgeLMTask(),
model="gpt-4-1106-preview",
num_threads=16,
max_new_tokens=512,
)
dataset = dataset.rename_columns({"question": "input"})
distipipe = Pipeline(
labeller=labeler
)
# This computes ratings and natural language critiques for each pair
ds = distipipe.generate(dataset=dataset, num_generations=2)
```
If you want to further filter and curate the dataset, you can push the dataset to [Argilla](https://github.com/argilla-io/argilla) as follows:
```python
rg_dataset = ds.to_argilla()
rg_dataset.push_to_argilla(name="your_dataset_name", workspace="your_workspace_name")
```
You get a nice UI with a lot of pre-computed metadata to explore and curate the dataset:

The resulting dataset is now much more useful: we know which response is preferred (by gpt-4-turbo), which ones have low scores, and we even have natural language explanations. But what did we find? Was our intuition confirmed?

The above chart shows the following:
* ~4,000 pairs were given the same rating (a tie).
* ~7,000 pairs were correct according to our AI judge (`unchanged`).
* and ~2,000 times the rejected response was preferred (`swapped`).
Now the next question is: can we build better models with this new knowledge? The answer is the "distilabeled Hermes" model, check it out!
### Post-processing to add useful information
Swap rejected and chosen, and add chosen scores and status:
```python
def add_status(r):
status = "unchanged"
highest_rated_idx = np.argmax(r['rating'])
# Compare to the index of the chosen response
if r['rating']== None or r['rating'][0] == r['rating'][1]:
status = "tie"
elif r['order'][highest_rated_idx] != 'chosen':
status = "swapped"
return {"status": status}
def swap(r):
chosen = r["chosen"]
rejected = r["rejected"]
if r['rating'] is not None:
chosen_score = r['rating'][np.argmax(r['rating'])]
else:
chosen_score = None
if r['status'] == "swapped":
chosen = r["rejected"]
rejected = r["chosen"]
return {
"chosen": chosen,
"rejected": rejected,
"original_chosen": r["chosen"],
"original_rejected": r["rejected"],
"chosen_score": chosen_score
}
updated = ds.map(add_status).map(swap)
```
### gsm8k "decontamination"
The basic approach for finding duplicated examples. We didn't find any from the test sets. We experimented with lower thresholds but below 0.8 they introduced false positives:
```python
import pandas as pd
import nltk
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from datasets import load_dataset
nltk.download('punkt')
# Load the datasets
source_dataset = load_dataset("gsm8k", "main", split="train")
source_dataset_socratic = load_dataset("gsm8k", "socratic", split="train")
#target_dataset = load_dataset("Intel/orca_dpo_pairs", split="train")
target_dataset = load_dataset("argilla/distilabel-intel-orca-dpo-pairs", split="train")
# Extract the 'question' column from each dataset
source_questions = source_dataset['question']
source_questions_socratic = source_dataset_socratic['question']
target_questions = target_dataset['input']
# Function to preprocess the text
def preprocess(text):
return nltk.word_tokenize(text.lower())
# Preprocess the questions
source_questions_processed = [preprocess(q) for q in source_questions]
source_questions.extend([preprocess(q) for q in source_questions_socratic])
target_questions_processed = [preprocess(q) for q in target_questions]
# Vectorize the questions
vectorizer = TfidfVectorizer()
source_vec = vectorizer.fit_transform([' '.join(q) for q in source_questions_processed])
target_vec = vectorizer.transform([' '.join(q) for q in target_questions_processed])
# Calculate cosine similarity
similarity_matrix = cosine_similarity(source_vec, target_vec)
# Determine matches based on a threshold:
# checked manually and below 0.8 there are only false positives
threshold = 0.8
matching_pairs = []
for i, row in enumerate(similarity_matrix):
for j, similarity in enumerate(row):
if similarity >= threshold:
matching_pairs.append((source_questions[i], target_questions[j], similarity))
# Create a DataFrame from the matching pairs
df = pd.DataFrame(matching_pairs, columns=['Source Question', 'Target Question', 'Similarity Score'])
# Create a set of matching target questions
matching_target_questions = list(df['Target Question'])
# Add a column to the target dataset indicating whether each question is matched
target_dataset = target_dataset.map(lambda example: {"in_gsm8k_train": example['input'] in matching_target_questions})
```
Result:
```
False 12780
True 79
Name: in_gsm8k_train
``` |
knowledgator/biomed_NER | ---
license: apache-2.0
task_categories:
- token-classification
language:
- en
tags:
- biomed NER
- PubMed NER
- biology
- medicine
- NER
- entity extraction
pretty_name: biomed-ner
size_categories:
- 1K<n<10K
---
### BioMed_general_NER
This dataset consists of manually annotated biomedical abstracts from PubMed, drug descriptions from FDA and abstracts from patents.
It was extracted 24 different entity types, including those specific to medicine and biology and general such as location and organization as well.
This is one of the biggest datasets of such kind, which consists of 4840 annotated abstracts.
### Classes
Here's a description for each of the labels:
1. **CHEMICALS** - Represents substances with distinct molecular composition, often involved in various biological or industrial processes.
2. **CLINICAL DRUG** - Refers to pharmaceutical substances developed for medical use, aimed at preventing, treating, or managing diseases.
3. **BODY SUBSTANCE** - Denotes materials or substances within the human body, including fluids, tissues, and other biological components.
4. **ANATOMICAL STRUCTURE** - Describes specific parts or structures within an organism's body, often related to anatomy and physiology.
5. **CELLS AND THEIR COMPONENTS** - Encompasses the basic structural and functional units of living organisms, along with their constituent elements.
6. **GENE AND GENE PRODUCTS** - Involves genetic information and the resultant products, such as proteins, that play a crucial role in biological processes.
7. **INTELLECTUAL PROPERTY** - Pertains to legal rights associated with creations of the mind, including inventions, literary and artistic works, and trademarks.
8. **LANGUAGE** - Relates to linguistic elements, including words, phrases, and language constructs, often in the context of communication or analysis.
9. **REGULATION OR LAW** - Represents rules, guidelines, or legal frameworks established by authorities to govern behavior, practices, or procedures.
10. **GEOGRAPHICAL AREAS** - Refers to specific regions, locations, or places on the Earth's surface, often associated with particular characteristics or significance.
11. **ORGANISM** - Denotes a living being, typically a plant, animal, or microorganism, as a distinct biological entity.
12. **GROUP** - Encompasses collections of individuals with shared characteristics, interests, or affiliations.
13. **PERSON** - Represents an individual human being, often considered as a distinct entity with personal attributes.
14. **ORGANIZATION** - Refers to structured entities, institutions, or companies formed for specific purposes or activities.
15. **PRODUCT** - Encompasses tangible or intangible items resulting from a process, often associated with manufacturing or creation.
16. **LOCATION** - Describes a specific place or position, whether physical or abstract, with potential relevance to various contexts.
17. **PHENOTYPE** - Represents the observable characteristics or traits of an organism, resulting from the interaction of its genotype with the environment.
18. **DISORDER** - Denotes abnormal conditions or disruptions in the normal functioning of a biological organism, often associated with diseases or medical conditions.
19. **SIGNALING MOLECULES** - Involves molecules that transmit signals within and between cells, playing a crucial role in various physiological processes.
20. **EVENT** - Describes occurrences or happenings at a specific time and place, often with significance or impact.
21. **MEDICAL PROCEDURE** - Involves specific actions or interventions conducted for medical purposes, such as surgeries, diagnostic tests, or therapeutic treatments.
22. **ACTIVITY** - Encompasses actions, behaviors, or processes undertaken by individuals, groups, or entities.
23. **FUNCTION** - Describes the purpose or role of a biological or mechanical entity, focusing on its intended or inherent activities.
24. **MONEY** - Represents currency or financial assets used as a medium of exchange, often in the context of economic transactions.
### Datasources
* PubMed - biomedical articles abstracts;
* FDA - drugs descriptions;
* Patents - patents abstracts;
|
parler-tts/mls-eng-10k-tags_tagged_10k_generated | ---
pretty_name: Annotations of 10K hours of English MLS
annotations_creators:
- expert-generated
language_creators:
- crowdsourced
- expert-generated
language:
- en
license:
- cc-by-4.0
multilinguality:
- multilingual
paperswithcode_id: multilingual-librispeech
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- automatic-speech-recognition
- text-to-speech
- text-to-audio
dataset_info:
features:
- name: original_path
dtype: string
- name: begin_time
dtype: float64
- name: end_time
dtype: float64
- name: audio_duration
dtype: float64
- name: speaker_id
dtype: string
- name: book_id
dtype: string
- name: utterance_pitch_mean
dtype: float32
- name: utterance_pitch_std
dtype: float32
- name: snr
dtype: float64
- name: c50
dtype: float64
- name: speaking_rate
dtype: string
- name: phonemes
dtype: string
- name: gender
dtype: string
- name: pitch
dtype: string
- name: noise
dtype: string
- name: reverberation
dtype: string
- name: speech_monotony
dtype: string
- name: text_description
dtype: string
- name: original_text
dtype: string
- name: text
dtype: string
splits:
- name: dev
num_bytes: 4378721
num_examples: 3807
- name: test
num_bytes: 4360862
num_examples: 3769
- name: train
num_bytes: 2779317208
num_examples: 2420047
download_size: 1438356670
dataset_size: 2788056791
configs:
- config_name: default
data_files:
- split: dev
path: data/dev-*
- split: test
path: data/test-*
- split: train
path: data/train-*
---
# Dataset Card for Annotations of 10K hours of English MLS
This dataset consists in **annotations of a 10K hours** subset of **[English version of the Multilingual LibriSpeech (MLS) dataset](https://huggingface.co/datasets/parler-tts/mls_eng)**.
MLS dataset is a large multilingual corpus suitable for speech research. The dataset is derived from read audiobooks from LibriVox and consists of
8 languages - English, German, Dutch, Spanish, French, Italian, Portuguese, Polish. It includes about 44.5K hours of English and a total of about 6K hours for other languages.
This dataset includes an annotation of [a 10K hours subset](https://huggingface.co/datasets/parler-tts/mls_eng_10k) of English MLS. Refers to this [dataset card](https://huggingface.co/datasets/facebook/multilingual_librispeech) for the other languages.
The `text_description` column provides natural language annotations on the characteristics of speakers and utterances, that have been generated using [the Data-Speech repository](https://github.com/huggingface/dataspeech).
This dataset was used alongside its [original version](https://huggingface.co/datasets/parler-tts/mls_eng_10k) and [LibriTTS-R](https://huggingface.co/datasets/blabble-io/libritts_r) to train [Parler-TTS Mini v0.1](https://huggingface.co/parler-tts/parler_tts_mini_v0.1).
A training recipe is available in [the Parler-TTS library](https://github.com/huggingface/parler-tts).
## Usage
Here is an example on how to load the only the `train` split.
```
load_dataset("parler-tts/mls-eng-10k-tags_tagged_10k_generated", split="train")
```
Streaming is also supported.
```
load_dataset("parler-tts/libritts_r_tags_tagged_10k_generated", streaming=True)
```
**Note:** This dataset doesn't actually keep track of the audio column of the original version. You can merge it back to the original dataset using [this script](https://github.com/huggingface/dataspeech/blob/main/scripts/merge_audio_to_metadata.py) from Parler-TTS or, even better, get inspiration from [the training script](https://github.com/ylacombe/parler-tts/blob/3c8822985fe6cec482ecf868b04e866428bcd7bc/training/run_parler_tts_training.py#L648) of Parler-TTS, that efficiently process multiple annotated datasets.
### Motivation
This dataset is a reproduction of work from the paper [Natural language guidance of high-fidelity text-to-speech with synthetic annotations](https://www.text-description-to-speech.com) by Dan Lyth and Simon King, from Stability AI and Edinburgh University respectively.
It was designed to train the [Parler-TTS Mini v0.1](https://huggingface.co/parler-tts/parler_tts_mini_v0.1) model.
Contrarily to other TTS models, Parler-TTS is a **fully open-source** release. All of the datasets, pre-processing, training code and weights are released publicly under permissive license, enabling the community to build on our work and develop their own powerful TTS models.
Parler-TTS was released alongside:
* [The Parler-TTS repository](https://github.com/huggingface/parler-tts) - you can train and fine-tuned your own version of the model.
* [The Data-Speech repository](https://github.com/huggingface/dataspeech) - a suite of utility scripts designed to annotate speech datasets.
* [The Parler-TTS organization](https://huggingface.co/parler-tts) - where you can find the annotated datasets as well as the future checkpoints.
### License
Public Domain, Creative Commons Attribution 4.0 International Public License ([CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode))
## Citation
```
@article{Pratap2020MLSAL,
title={MLS: A Large-Scale Multilingual Dataset for Speech Research},
author={Vineel Pratap and Qiantong Xu and Anuroop Sriram and Gabriel Synnaeve and Ronan Collobert},
journal={ArXiv},
year={2020},
volume={abs/2012.03411}
}
```
```
@misc{lacombe-etal-2024-dataspeech,
author = {Yoach Lacombe and Vaibhav Srivastav and Sanchit Gandhi},
title = {Data-Speech},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/ylacombe/dataspeech}}
}
```
```
@misc{lyth2024natural,
title={Natural language guidance of high-fidelity text-to-speech with synthetic annotations},
author={Dan Lyth and Simon King},
year={2024},
eprint={2402.01912},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
``` |
openclimatefix/uk_pv | ---
annotations_creators:
- machine-generated
language:
- en
language_creators:
- machine-generated
license:
- mit
multilinguality:
- monolingual
pretty_name: United Kingdom PV Solar generation
size_categories:
- 1B<n<10B
source_datasets:
- original
tags:
- pv
- photovoltaic
- environment
- climate
- energy
- electricity
task_categories:
- time-series-forecasting
task_ids:
- multivariate-time-series-forecasting
---
# UK PV dataset
PV solar generation data from the UK.
This dataset contains data from 1311 PV systems from 2018 to 2021.
Time granularity varies from 2 minutes to 30 minutes.
This data is collected from live PV systems in the UK. We have obfuscated the location of the PV systems for privacy.
If you are the owner of a PV system in the dataset, and do not want this data to be shared,
please do get in contact with info@openclimatefix.org.
## Files
- metadata.csv: Data about the PV systems, e.g location
- 2min.parquet: Power output for PV systems every 2 minutes.
- 5min.parquet: Power output for PV systems every 5 minutes.
- 30min.parquet: Power output for PV systems every 30 minutes.
- pv.netcdf: (legacy) Time series of PV solar generation every 5 minutes
### metadata.csv
Metadata of the different PV systems.
Note that there are extra PV systems in this metadata that do not appear in the PV time-series data.
The csv columns are:
- ss_id: the id of the system
- latitude_rounded: latitude of the PV system, but rounded to approximately the nearest km
- longitude_rounded: latitude of the PV system, but rounded to approximately the nearest km
- llsoacd: TODO
- orientation: The orientation of the PV system
- tilt: The tilt of the PV system
- kwp: The capacity of the PV system
- operational_at: the datetime the PV system started working
### {2,5,30}min.parquet
Time series of solar generation for a number of sytems.
Each file includes the systems for which there is enough granularity.
In particular the systems in 2min.parquet and 5min.parquet are also in 30min.parquet.
The files contain 3 columns:
- ss_id: the id of the system
- timestamp: the timestamp
- generation_wh: the generated power (in kW) at the given timestamp for the given system
### pv.netcdf (legacy)
Time series data of PV solar generation data is in an [xarray](https://docs.xarray.dev/en/stable/) format.
The data variables are the same as 'ss_id' in the metadata.
Each data variable contains the solar generation (in kW) for that PV system.
The ss_id's here are a subset of all the ss_id's in the metadata
The coordinates of the date are tagged as 'datetime' which is the datetime of the solar generation reading.
This is a subset of the more recent `5min.parquet` file.
## example
using Hugging Face Datasets
```python
from datasets import load_dataset
dataset = load_dataset("openclimatefix/uk_pv")
```
## useful links
https://huggingface.co/docs/datasets/share - this repo was made by following this tutorial |
Fhrozen/AudioSet2K22 | ---
annotations_creators:
- unknown
language_creators:
- unknown
license: cc-by-sa-4.0
size_categories:
- 100K<n<100M
source_datasets:
- unknown
task_categories:
- audio-classification
task_ids: []
tags:
- audio-slot-filling
---
# Dataset Card for audioset2022
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [AudioSet Ontology](https://research.google.com/audioset/ontology/index.html)
- **Repository:** [Needs More Information]
- **Paper:** [Audio Set: An ontology and human-labeled dataset for audio events](https://research.google.com/pubs/pub45857.html)
- **Leaderboard:** [Paperswithcode Leaderboard](https://paperswithcode.com/dataset/audioset)
### Dataset Summary
The AudioSet ontology is a collection of sound events organized in a hierarchy. The ontology covers a wide range of everyday sounds, from human and animal sounds, to natural and environmental sounds, to musical and miscellaneous sounds.
**This repository only includes audio files for DCASE 2022 - Task 3**
The included labels are limited to:
- Female speech, woman speaking
- Male speech, man speaking
- Clapping
- Telephone
- Telephone bell ringing
- Ringtone
- Laughter
- Domestic sounds, home sounds
- Vacuum cleaner
- Kettle whistle
- Mechanical fan
- Walk, footsteps
- Door
- Cupboard open or close
- Music
- Background music
- Pop music
- Musical instrument
- Acoustic guitar
- Marimba, xylophone
- Cowbell
- Piano
- Electric piano
- Rattle (instrument)
- Water tap, faucet
- Bell
- Bicycle bell
- Chime
- Knock
### Supported Tasks and Leaderboards
- `audio-classification`: The dataset can be used to train a model for Sound Event Detection/Localization.
**The recordings only includes the single channel audio. For Localization tasks, it will required to apply RIR information**
### Languages
None
## Dataset Structure
### Data Instances
**WIP**
```
{
'file':
}
```
### Data Fields
- file: A path to the downloaded audio file in .mp3 format.
### Data Splits
This dataset only includes audio file from the unbalance train list.
The data comprises two splits: weak labels and strong labels.
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
The dataset was initially downloaded by Nelson Yalta (nelson.yalta@ieee.org).
### Licensing Information
[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0)
### Citation Information
```
@inproceedings{45857,
title = {Audio Set: An ontology and human-labeled dataset for audio events},
author = {Jort F. Gemmeke and Daniel P. W. Ellis and Dylan Freedman and Aren Jansen and Wade Lawrence and R. Channing Moore and Manoj Plakal and Marvin Ritter},
year = {2017},
booktitle = {Proc. IEEE ICASSP 2017},
address = {New Orleans, LA}
}
```
|
LHF/escorpius | ---
license: cc-by-nc-nd-4.0
language:
- es
multilinguality:
- monolingual
size_categories:
- 100M<n<1B
source_datasets:
- original
task_categories:
- text-generation
- fill-mask
task_ids:
- language-modeling
- masked-language-modeling
---
# esCorpius: A Massive Spanish Crawling Corpus
## Introduction
In the recent years, Transformer-based models have lead to significant advances in language modelling for natural language processing. However, they require a vast amount of data to be (pre-)trained and there is a lack of corpora in languages other than English. Recently, several initiatives have presented multilingual datasets obtained from automatic web crawling. However, the results in Spanish present important shortcomings, as they are either too small in comparison with other languages, or present a low quality derived from sub-optimal cleaning and deduplication. In this work, we introduce esCorpius, a Spanish crawling corpus obtained from near 1 Pb of Common Crawl data. It is the most extensive corpus in Spanish with this level of quality in the extraction, purification and deduplication of web textual content. Our data curation process involves a novel highly parallel cleaning pipeline and encompasses a series of deduplication mechanisms that together ensure the integrity of both document and paragraph boundaries. Additionally, we maintain both the source web page URL and the WARC shard origin URL in order to complain with EU regulations. esCorpius has been released under CC BY-NC-ND 4.0 license.
## Statistics
| **Corpus** | OSCAR<br>22.01 | mC4 | CC-100 | ParaCrawl<br>v9 | esCorpius<br>(ours) |
|-------------------------|----------------|--------------|-----------------|-----------------|-------------------------|
| **Size (ES)** | 381.9 GB | 1,600.0 GB | 53.3 GB | 24.0 GB | 322.5 GB |
| **Docs (ES)** | 51M | 416M | - | - | 104M |
| **Words (ES)** | 42,829M | 433,000M | 9,374M | 4,374M | 50,773M |
| **Lang.<br>identifier** | fastText | CLD3 | fastText | CLD2 | CLD2 + fastText |
| **Elements** | Document | Document | Document | Sentence | Document and paragraph |
| **Parsing quality** | Medium | Low | Medium | High | High |
| **Cleaning quality** | Low | No cleaning | Low | High | High |
| **Deduplication** | No | No | No | Bicleaner | dLHF |
| **Language** | Multilingual | Multilingual | Multilingual | Multilingual | Spanish |
| **License** | CC-BY-4.0 | ODC-By-v1.0 | Common<br>Crawl | CC0 | CC-BY-NC-ND |
## Citation
Link to the paper: https://www.isca-speech.org/archive/pdfs/iberspeech_2022/gutierrezfandino22_iberspeech.pdf / https://arxiv.org/abs/2206.15147
Cite this work:
```
@inproceedings{gutierrezfandino22_iberspeech,
author={Asier Gutiérrez-Fandiño and David Pérez-Fernández and Jordi Armengol-Estapé and David Griol and Zoraida Callejas},
title={{esCorpius: A Massive Spanish Crawling Corpus}},
year=2022,
booktitle={Proc. IberSPEECH 2022},
pages={126--130},
doi={10.21437/IberSPEECH.2022-26}
}
```
## Disclaimer
We did not perform any kind of filtering and/or censorship to the corpus. We expect users to do so applying their own methods. We are not liable for any misuse of the corpus. |
embedding-data/flickr30k_captions_quintets | ---
license: mit
language:
- en
paperswithcode_id: embedding-data/flickr30k-captions
pretty_name: flickr30k-captions
---
# Dataset Card for "flickr30k-captions"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Usage Example](#usage-example)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://shannon.cs.illinois.edu/DenotationGraph/](https://shannon.cs.illinois.edu/DenotationGraph/)
- **Repository:** [More Information Needed](https://shannon.cs.illinois.edu/DenotationGraph/)
- **Paper:** [https://transacl.org/ojs/index.php/tacl/article/view/229/33](https://transacl.org/ojs/index.php/tacl/article/view/229/33)
- **Point of Contact:** [Peter Young](pyoung2@illinois.edu), [Alice Lai](aylai2@illinois.edu), [Micah Hodosh](mhodosh2@illinois.edu), [Julia Hockenmaier](juliahmr@illinois.edu)
### Dataset Summary
We propose to use the visual denotations of linguistic expressions (i.e. the set of images they describe) to define novel denotational similarity metrics, which we show to be at least as beneficial as distributional similarities for two tasks that require semantic inference. To compute these denotational similarities, we construct a denotation graph, i.e. a subsumption hierarchy over constituents and their denotations, based on a large corpus of 30K images and 150K descriptive captions.
Disclaimer: The team releasing Flickr30k did not upload the dataset to the Hub and did not write a dataset card. These steps were done by the Hugging Face team.
### Supported Tasks
- [Sentence Transformers](https://huggingface.co/sentence-transformers) training; useful for semantic search and sentence similarity.
### Languages
- English.
## Dataset Structure
Each example in the dataset contains quintets of similar sentences and is formatted as a dictionary with the key "set" and a list with the sentences as "value":
```
{"set": [sentence_1, sentence_2, sentence3, sentence4, sentence5]}
{"set": [sentence_1, sentence_2, sentence3, sentence4, sentence5]}
...
{"set": [sentence_1, sentence_2, sentence3, sentence4, sentence5]}
```
This dataset is useful for training Sentence Transformers models. Refer to the following post on how to train models using similar pairs of sentences.
### Usage Example
Install the 🤗 Datasets library with `pip install datasets` and load the dataset from the Hub with:
```python
from datasets import load_dataset
dataset = load_dataset("embedding-data/flickr30k-captions")
```
The dataset is loaded as a `DatasetDict` has the format:
```python
DatasetDict({
train: Dataset({
features: ['set'],
num_rows: 31783
})
})
```
Review an example `i` with:
```python
dataset["train"][i]["set"]
```
### Curation Rationale
[More Information Needed](https://shannon.cs.illinois.edu/DenotationGraph/)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://shannon.cs.illinois.edu/DenotationGraph/)
#### Who are the source language producers?
[More Information Needed](https://shannon.cs.illinois.edu/DenotationGraph/)
### Annotations
#### Annotation process
[More Information Needed](https://shannon.cs.illinois.edu/DenotationGraph/)
#### Who are the annotators?
[More Information Needed](https://shannon.cs.illinois.edu/DenotationGraph/)
### Personal and Sensitive Information
[More Information Needed](https://shannon.cs.illinois.edu/DenotationGraph/)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://shannon.cs.illinois.edu/DenotationGraph/)
### Discussion of Biases
[More Information Needed](https://shannon.cs.illinois.edu/DenotationGraph/)
### Other Known Limitations
[More Information Needed](https://shannon.cs.illinois.edu/DenotationGraph/)
## Additional Information
### Dataset Curators
[More Information Needed](https://shannon.cs.illinois.edu/DenotationGraph/)
### Licensing Information
[More Information Needed](https://shannon.cs.illinois.edu/DenotationGraph/)
### Citation Information
[More Information Needed](https://shannon.cs.illinois.edu/DenotationGraph/)
### Contributions
Thanks to [Peter Young](pyoung2@illinois.edu), [Alice Lai](aylai2@illinois.edu), [Micah Hodosh](mhodosh2@illinois.edu), [Julia Hockenmaier](juliahmr@illinois.edu) for adding this dataset.
|
batterydata/battery-device-data-qa | ---
language:
- en
license:
- apache-2.0
task_categories:
- question-answering
pretty_name: 'Battery Device Question Answering Dataset'
---
# Battery Device QA Data
Battery device records, including anode, cathode, and electrolyte.
Examples of the question answering evaluation dataset:
\{'question': 'What is the cathode?', 'answer': 'Al foil', 'context': 'The blended slurry was then cast onto a clean current collector (Al foil for the cathode and Cu foil for the anode) and dried at 90 °C under vacuum overnight.', 'start index': 645\}
\{'question': 'What is the anode?', 'answer': 'Cu foil', 'context': 'The blended slurry was then cast onto a clean current collector (Al foil for the cathode and Cu foil for the anode) and dried at 90 °C under vacuum overnight. Finally, the obtained electrodes were cut into desired shapes on demand. It should be noted that the electrode mass ratio of cathode/anode is set to about 4, thus achieving the battery balance.', 'start index': 673\}
\{'question': 'What is the cathode?', 'answer': 'SiC/RGO nanocomposite', 'context': 'In conclusion, the SiC/RGO nanocomposite, integrating the synergistic effect of SiC flakes and RGO, was synthesized by an in situ gas–solid fabrication method. Taking advantage of the enhanced photogenerated charge separation, large CO2 adsorption, and numerous exposed active sites, SiC/RGO nanocomposite served as the cathode material for the photo-assisted Li–CO2 battery.', 'start index': 284\}
# Usage
```
from datasets import load_dataset
dataset = load_dataset("batterydata/battery-device-data-qa")
```
Note: in the original BatteryBERT paper, 272 data records were used for evaluation after removing redundant records as well as paragraphs with character length >= 1500. Code is shown below:
```
import json
with open("answers.json", "r", encoding='utf-8') as f:
data = json.load(f)
evaluation = []
for point in data['data']:
paragraphs = point['paragraphs'][0]['context']
if len(paragraphs)<1500:
qas = point['paragraphs'][0]['qas']
for indiv in qas:
try:
question = indiv['question']
answer = indiv['answers'][0]['text']
pairs = (paragraphs, question, answer)
evaluation.append(pairs)
except:
continue
```
# Citation
```
@article{huang2022batterybert,
title={BatteryBERT: A Pretrained Language Model for Battery Database Enhancement},
author={Huang, Shu and Cole, Jacqueline M},
journal={J. Chem. Inf. Model.},
year={2022},
doi={10.1021/acs.jcim.2c00035},
url={DOI:10.1021/acs.jcim.2c00035},
pages={DOI: 10.1021/acs.jcim.2c00035},
publisher={ACS Publications}
}
``` |
theblackcat102/instruction_translations | ---
task_categories:
- text-generation
language:
- en
tags:
- ChatGPT
- SimpleAI
- Detection
size_categories:
- 10K<n<100K
license: mit
---
# Translations for Instruction dataset
Translations were generated by [M2M 12B](https://huggingface.co/facebook/m2m100-12B-avg-5-ckpt) and the output generations were limited at 512 tokens due to VRAM limit (40G).
|
AbderrahmanSkiredj1/moroccan_darija_wikipedia_dataset | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 8104410
num_examples: 4862
download_size: 3229966
dataset_size: 8104410
---
# Dataset Card for "moroccan_darija_wikipedia_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Nebulous/gpt4all_pruned | ---
license: cc
---
Pruned gpt4all dataset meant to reduce annoying behvaiors and nonsensical prompts |
grosenthal/latin_english_parallel | ---
dataset_info:
features:
- name: id
dtype: int64
- name: la
dtype: string
- name: en
dtype: string
- name: file
dtype: string
splits:
- name: train
num_bytes: 39252644
num_examples: 99343
- name: test
num_bytes: 405056
num_examples: 1014
- name: valid
num_bytes: 392886
num_examples: 1014
download_size: 25567350
dataset_size: 40050586
license: mit
task_categories:
- translation
language:
- la
- en
pretty_name: Latin to English Translation Pairs
size_categories:
- 10K<n<100K
---
# Dataset Card for "latin_english_parallel"
101k translation pairs between Latin and English, split 99/1/1 as train/test/val. These have been collected roughly 66% from the Loeb Classical Library and 34% from the Vulgate translation.
For those that were gathered from the Loeb Classical Library, alignment was performd manually between Source and Target sequences. Additionally, the English translations were both 1. copyrighted and 2. outdated. As such, we decided to modernize and transform them into ones that could be used in the public domain, as the original Latin is not copyrighted.
To perform this, we used the gpt3.5-turbo model on OpenAI with the prompt `Translate an old dataset from the 1800s to modern English while preserving the original meaning and exact same sentence structure. Retain extended adjectives, dependent clauses, and punctuation. Output the translation preceded by the text "Modern Translation: ". If a given translation is not a complete sentence, repeat the input sentence. \n'` followed by the source English.
We then manually corrected all outputs that did not conform to the standard.
Each sample is annotated with the index and file (and therefore author/work) that the sample is from. If you find errors, please feel free to submit a PR to fix them.
 |
kunishou/databricks-dolly-69k-ja-en-translation | ---
license: cc-by-sa-3.0
language:
- ja
- en
---
This dataset was created by automatically translating "databricks-dolly-15k" into Japanese.
This dataset contains 69K ja-en-translation task data and is licensed under CC BY SA 3.0.
Last Update : 2023-04-18
databricks-dolly-15k-ja
https://github.com/kunishou/databricks-dolly-15k-ja
databricks-dolly-15k
https://github.com/databrickslabs/dolly/tree/master/data |
bprateek/amazon_product_description | ---
license: apache-2.0
---
|
griffin/ChemSum | ---
task_categories:
- summarization
language:
- en
tags:
- chemistry
- biology
- medical
pretty_name: Generating Abstracts of Academic Chemistry Papers
size_categories:
- 100K<n<1M
---
# Dataset Card for ChemSum
## ChemSum Description
<!---- **Homepage:**
- **Leaderboard:**
----->
- **Paper:** [What are the Desired Characteristics of Calibration Sets? Identifying Correlates on Long Form Scientific Summarization ](https://arxiv.org/abs/2305.07615)
- **Journal:** ACL 2023
- **Point of Contact:** griffin.adams@columbia.edu
- **Repository:** https://github.com/griff4692/calibrating-summaries
### ChemSum Summary
We introduce a dataset with a pure chemistry focus by compiling a list of chemistry academic journals with Open-Access articles. For each journal, we downloaded full-text article PDFs from the Open-Access portion of the journal using available APIs, or scraping this content using [Selenium Chrome WebDriver](https://www.selenium.dev/documentation/webdriver/).
Each PDF was processed with Grobid via a locally installed [client](https://pypi.org/project/grobid-client-python/) to extract free-text paragraphs with sections.
The table below shows the journals from which Open Access articles were sourced, as well as the number of papers processed.
For all journals, we filtered for papers with the provided topic of Chemistry when papers from other disciplines were also available (e.g. PubMed).
| Source | # of Articles |
| ----------- | ----------- |
| Beilstein | 1,829 |
| Chem Cell | 546 |
| ChemRxiv | 12,231 |
| Chemistry Open | 398 |
| Nature Communications Chemistry | 572 |
| PubMed Author Manuscript | 57,680 |
| PubMed Open Access | 29,540 |
| Royal Society of Chemistry (RSC) | 9,334 |
| Scientific Reports - Nature | 6,826 |
<!---
### Supported Tasks and Leaderboards
[More Information Needed]
--->
### Languages
English
## Dataset Structure
<!--- ### Data Instances --->
### Data Fields
| Column | Description |
| ----------- | ----------- |
| `uuid` | Unique Identifier for the Example |
| `title` | Title of the Article |
| `article_source` | Open Source Journal (see above for list) |
| `abstract` | Abstract (summary reference) |
| `sections` | Full-text sections from the main body of paper (<!> indicates section boundaries)|
| `headers` | Corresponding section headers for `sections` field (<!> delimited) |
| `source_toks` | Aggregate number of tokens across `sections` |
| `target_toks` | Number of tokens in the `abstract` |
| `compression` | Ratio of `source_toks` to `target_toks` |
Please refer to `load_chemistry()` in https://github.com/griff4692/calibrating-summaries/blob/master/preprocess/preprocess.py for pre-processing as a summarization dataset. The inputs are `sections` and `headers` and the targets is the `abstract`.
### Data Splits
| Split | Count |
| ----------- | ----------- |
| `train` | 115,956 |
| `validation` | 1,000 |
| `test` | 2,000 |
### Citation Information
```
@inproceedings{adams-etal-2023-desired,
title = "What are the Desired Characteristics of Calibration Sets? Identifying Correlates on Long Form Scientific Summarization",
author = "Adams, Griffin and
Nguyen, Bichlien and
Smith, Jake and
Xia, Yingce and
Xie, Shufang and
Ostropolets, Anna and
Deb, Budhaditya and
Chen, Yuan-Jyue and
Naumann, Tristan and
Elhadad, No{\'e}mie",
editor = "Rogers, Anna and
Boyd-Graber, Jordan and
Okazaki, Naoaki",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.587",
doi = "10.18653/v1/2023.acl-long.587",
pages = "10520--10542",
abstract = "Summarization models often generate text that is poorly calibrated to quality metrics because they are trained to maximize the likelihood of a single reference (MLE). To address this, recent work has added a calibration step, which exposes a model to its own ranked outputs to improve relevance or, in a separate line of work, contrasts positive and negative sets to improve faithfulness. While effective, much of this work has focused on \textit{how} to generate and optimize these sets. Less is known about \textit{why} one setup is more effective than another. In this work, we uncover the underlying characteristics of effective sets. For each training instance, we form a large, diverse pool of candidates and systematically vary the subsets used for calibration fine-tuning. Each selection strategy targets distinct aspects of the sets, such as lexical diversity or the size of the gap between positive and negatives. On three diverse scientific long-form summarization datasets (spanning biomedical, clinical, and chemical domains), we find, among others, that faithfulness calibration is optimal when the negative sets are extractive and more likely to be generated, whereas for relevance calibration, the metric margin between candidates should be maximized and surprise{--}the disagreement between model and metric defined candidate rankings{--}minimized.",
}
```
<!---
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Contributions
[More Information Needed]
--->
|
PORTULAN/parlamento-pt | ---
annotations_creators:
- no-annotation
language:
- pt
license:
- other
multilinguality:
- monolingual
pretty_name: ParlamentoPT
size_categories:
- 1M<n<10M
source_datasets:
- original
task_categories:
- text-generation
- fill-mask
task_ids:
- language-modeling
- masked-language-modeling
tags:
- parlamentopt
- parlamento
- parlamento-pt
- albertina-pt*
- albertina-ptpt
- albertina-ptbr
- fill-mask
- bert
- deberta
- portuguese
- encoder
- foundation model
---
# Dataset Card for ParlamentoPT
### Dataset Summary
The ParlamentoPT is a **Portuguese** language data set obtained by collecting publicly available documents containing transcriptions of debates in the Portuguese Parliament.
The data was collected from the Portuguese Parliament portal in accordance with its [open data policy](https://www.parlamento.pt/Cidadania/Paginas/DadosAbertos.aspx).
This dataset was collected with the purpose of creating the [Albertina-PT*](https://huggingface.co/PORTULAN/albertina-ptpt) language model, and it serves as training data for model development.
The development of the model is a collaborative effort between the University of Lisbon and the University of Porto in Portugal
</br>
# Citation
When using or citing this data set, kindly cite the following [publication](https://arxiv.org/abs/2305.06721):
``` latex
@misc{albertina-pt,
title={Advancing Neural Encoding of Portuguese
with Transformer Albertina PT-*},
author={João Rodrigues and Luís Gomes and João Silva and
António Branco and Rodrigo Santos and
Henrique Lopes Cardoso and Tomás Osório},
year={2023},
eprint={2305.06721},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<br>
# Acknowledgments
The research reported here was partially supported by: PORTULAN CLARIN—Research Infrastructure for the Science and Technology of Language,
funded by Lisboa 2020, Alentejo 2020 and FCT—Fundação para a Ciência e Tecnologia under the
grant PINFRA/22117/2016; research project ALBERTINA - Foundation Encoder Model for Portuguese and AI, funded by FCT—Fundação para a Ciência e Tecnologia under the
grant CPCA-IAC/AV/478394/2022; innovation project ACCELERAT.AI - Multilingual Intelligent Contact Centers, funded by IAPMEI, I.P. - Agência para a Competitividade e Inovação under the grant C625734525-00462629, of Plano de Recuperação e Resiliência, call RE-C05-i01.01 – Agendas/Alianças Mobilizadoras para a Reindustrialização; and LIACC - Laboratory for AI and Computer Science, funded by FCT—Fundação para a Ciência e Tecnologia under the grant FCT/UID/CEC/0027/2020. |
rewoo/planner_instruction_tuning_2k | ---
license: mit
---
*Bootstrap 2k Planner finetuning dataset for ReWOO.*
It is a mixture of "correct" HotpotQA and TriviaQA task planning trajectories in ReWOO Framework. |
dbdu/ShareGPT-74k-ko | ---
language:
- ko
pretty_name: ShareGPT-74k-ko
tags:
- conversation
- chatgpt
- gpt-3.5
license: cc-by-2.0
task_categories:
- text-generation
size_categories:
- 10K<n<100K
---
# ShareGPT-ko-74k
ShareGPT 90k의 cleaned 버전을 구글 번역기를 이용하여 번역하였습니다.\
원본 데이터셋은 [여기](https://github.com/lm-sys/FastChat/issues/90)에서 확인하실 수 있습니다.
Korean-translated version of ShareGPT-90k, translated by Google Translaton.\
You can check the original dataset [here](https://github.com/lm-sys/FastChat/issues/90).
## Dataset Description
json 파일의 구조는 원본 데이터셋과 동일합니다.\
`*_unclneaed.json`은 원본 데이터셋을 번역하고 따로 후처리하지 않은 데이터셋입니다. (총 74k)\
`*_cleaned.json`은 위의 데이터에서 코드가 포함된 데이터를 러프하게 제거한 데이터셋입니다. (총 55k)\
**주의**: 코드는 번역되었을 수 있으므로 cleaned를 쓰시는 걸 추천합니다.
The structure of the dataset is the same with the original dataset.\
`*_unclneaed.json` are Korean-translated data, without any post-processing. (total 74k dialogues)\
`*_clneaed.json` are post-processed version which dialogues containing code snippets are eliminated from. (total 55k dialogues)\
**WARNING**: Code snippets might have been translated into Korean. I recommend you use cleaned files.
## Licensing Information
GPT를 이용한 데이터셋이므로 OPENAI의 [약관](https://openai.com/policies/terms-of-use)을 따릅니다.\
그 외의 경우 [CC BY 2.0 KR](https://creativecommons.org/licenses/by/2.0/kr/)을 따릅니다.
The licensing status of the datasets follows [OPENAI Licence](https://openai.com/policies/terms-of-use) as it contains GPT-generated sentences.\
For all the other cases, the licensing status follows [CC BY 2.0 KR](https://creativecommons.org/licenses/by/2.0/kr/).
## Code
번역에 사용한 코드는 아래 리포지토리에서 확인 가능합니다. Check out the following repository to see the translation code used.\
https://github.com/dubuduru/ShareGPT-translation
You can use the repository to translate ShareGPT-like dataset into your preferred language. |
ShoukanLabs/OpenNiji-Dataset | ---
task_categories:
- text-to-image
language:
- en
- ja
- ko
tags:
- anime
- dataset
- Nijijourney
- Midjourney
- discord
size_categories:
- 100K<n<1M
license: cc-by-nc-4.0
---
# NOTE:
Recently Discord has added link expiry and tracking for their CDN content, however, this is for CDN attachments outside of Discord, now due to the nature of how this was scraped (being directly from the API) We're uncertain as to whether URL decay will start to become a problem. We have already created versions of the dataset in splits to combat this, we are well aware that this may not be an option for some and we apologise. |
Meranti/CLAP_freesound | ---
task_categories:
- audio-classification
language:
- en
tags:
- audio
- text
- contrastive learning
pretty_name: freesound
size_categories:
- 1M<n<10M
---
# LAION-Audio-630K Freesound Dataset
[LAION-Audio-630K](https://github.com/LAION-AI/audio-dataset/blob/main/laion-audio-630k/README.md) is the largest audio-text dataset publicly available and a magnitude larger than previous audio-text datasets (by 2022-11-05). Notably, it combines eight distinct datasets, which includes the Freesound dataset.
Specifically, this Hugging face repository contains two versions of Freesound dataset. Details of each dataset (e.g. how captions are made etc.) could be found in the "datacard" column of the table below.
- **Freesound (full)**: The complete Freesound dataset, available at `/freesound` folder.
- **Freesound (no overlap)**: Made based on Freesound(full), with samples from ESC50, FSD50K, Urbansound8K and Clotho removed. available at `/freesound_no_overlap` folder.
As of the structure and format of `freesound` and `freesound_no_overlap` folder, please refer to [this page](https://github.com/LAION-AI/audio-dataset/blob/main/data_preprocess/README.md).
| Name |Duration |Number of Samples |Data Type | Metadata | Data Card |
|--------------------------------------------------|-------------------------|--------------------|--------- |--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------- |
| Freesound (no overlap) |2817.31hrs | 460801 |1-2 captions per audio, audio | [website](https://freesound.org/) <br> [csv]()|[data card](/data_card/freesound.md)|
| Freesound (full) |3033.38hrs | 515581 |1-2 captions per audio, audio | [website](https://freesound.org/) <br> [csv]() |[data card](/data_card/freesound.md)|
## Metadata csv file
For each of the two datasets, we provide a metadata csv file including the following columns:
- **audio_filename**: The filename of the audio file in `.tar` files. `exemple: 2394.flac`
- **caption_i**: the i-th caption of the audio file
- **freesound_id**: The freesound id of the audio file.
- **username**: The username of the uploader of the audio file.
- **freesound_url**: The url of the audio file in freesound.org
- **username**: The freesound username of the uploader of the audio file.
- **license**: The license of the audio file. `http://creativecommons.org/licenses/by/3.0/`
## Credits & Licence
- **!!!TERM OF USE!!!**: **By downloading files in this repository, you agree that you will use them <u> for research purposes only </u>. If you want to use Freesound clips in LAION-Audio-630K for commercial purposes, please contact Frederic Font Corbera at frederic.font@upf.edu.**
### Freesound Credit:
All audio clips from Freesound are released under Creative Commons (CC) licenses, while each clip has its own license as defined by the clip uploader in Freesound, some of them requiring attribution to their original authors and some forbidding further commercial reuse. Specifically, here is the statistics about licenses of audio clips involved in LAION-Audio-630K:
| License | Number of Samples |
| :--- | :--- |
| http://creativecommons.org/publicdomain/zero/1.0/ | 260134 |
| https://creativecommons.org/licenses/by/4.0/ | 97090 |
| http://creativecommons.org/licenses/by/3.0/ | 89337 |
| http://creativecommons.org/licenses/by-nc/3.0/ | 31680 |
| https://creativecommons.org/licenses/by-nc/4.0/ | 26736 |
| http://creativecommons.org/licenses/sampling+/1.0/ | 11116 |
## Acknowledgement
The whole collection process as well as all usage of the LAION-Audio-630K are conducted by Germany non-profit pure research organization [LAION](https://laion.ai/). All contributors and collectors of the dataset are considered as open source contributors affiliated to LAION. These community contributors (Discord ids) include but not limited to: @marianna13#7139, @Chr0my#0173, @PiEquals4#1909, @Yuchen Hui#8574, @Antoniooooo#4758, @IYWO#9072, krishna#1648, @dicknascarsixtynine#3885, and @turian#1607. We would like to appreciate all of them for their efforts on the LAION-Audio-630k dataset. |
shibing624/nli-zh-all | ---
annotations_creators:
- shibing624
language_creators:
- shibing624
language:
- zh
license: cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 1M<n<10M
source_datasets:
- https://github.com/shibing624/text2vec
task_categories:
- text-classification
task_ids:
- natural-language-inference
- semantic-similarity-scoring
- text-scoring
paperswithcode_id: nli
pretty_name: Chinese Natural Language Inference
---
# Dataset Card for nli-zh-all
## Dataset Description
- **Repository:** [Chinese NLI dataset](https://github.com/shibing624/text2vec)
- **Dataset:** [zh NLI](https://huggingface.co/datasets/shibing624/nli-zh-all)
- **Size of downloaded dataset files:** 4.7 GB
- **Total amount of disk used:** 4.7 GB
### Dataset Summary
中文自然语言推理(NLI)数据合集(nli-zh-all)
整合了文本推理,相似,摘要,问答,指令微调等任务的820万高质量数据,并转化为匹配格式数据集。
### Supported Tasks and Leaderboards
Supported Tasks: 支持中文文本匹配任务,文本相似度计算等相关任务。
中文匹配任务的结果目前在顶会paper上出现较少,我罗列一个我自己训练的结果:
**Leaderboard:** [NLI_zh leaderboard](https://github.com/shibing624/text2vec)
### Languages
数据集均是简体中文文本。
## Dataset Structure
### Data Instances
An example of 'train' looks as follows.
```
{"text1":"借款后多长时间给打电话","text2":"借款后多久打电话啊","label":1}
{"text1":"没看到微粒贷","text2":"我借那么久也没有提升啊","label":0}
```
- label 有2个标签,1表示相似,0表示不相似。
### Data Fields
The data fields are the same among all splits.
- `text1`: a `string` feature.
- `text2`: a `string` feature.
- `label`: a classification label, with possible values including entailment(1), contradiction(0)。
### Data Splits
after remove None and len(text) < 1 data:
```shell
$ wc -l nli-zh-all/*
48818 nli-zh-all/alpaca_gpt4-train.jsonl
5000 nli-zh-all/amazon_reviews-train.jsonl
519255 nli-zh-all/belle-train.jsonl
16000 nli-zh-all/cblue_chip_sts-train.jsonl
549326 nli-zh-all/chatmed_consult-train.jsonl
10142 nli-zh-all/cmrc2018-train.jsonl
395927 nli-zh-all/csl-train.jsonl
50000 nli-zh-all/dureader_robust-train.jsonl
709761 nli-zh-all/firefly-train.jsonl
9568 nli-zh-all/mlqa-train.jsonl
455875 nli-zh-all/nli_zh-train.jsonl
50486 nli-zh-all/ocnli-train.jsonl
2678694 nli-zh-all/simclue-train.jsonl
419402 nli-zh-all/snli_zh-train.jsonl
3024 nli-zh-all/webqa-train.jsonl
1213780 nli-zh-all/wiki_atomic_edits-train.jsonl
93404 nli-zh-all/xlsum-train.jsonl
1006218 nli-zh-all/zhihu_kol-train.jsonl
8234680 total
```
### Data Length

count text length script: https://github.com/shibing624/text2vec/blob/master/examples/data/count_text_length.py
## Dataset Creation
### Curation Rationale
受[m3e-base](https://huggingface.co/moka-ai/m3e-base#M3E%E6%95%B0%E6%8D%AE%E9%9B%86)启发,合并了中文高质量NLI(natural langauge inference)数据集,
这里把这个数据集上传到huggingface的datasets,方便大家使用。
### Source Data
#### Initial Data Collection and Normalization
如果您想要查看数据集的构建方法,你可以在 [https://github.com/shibing624/text2vec/blob/master/examples/data/build_zh_nli_dataset.py](https://github.com/shibing624/text2vec/blob/master/examples/data/build_zh_nli_dataset.py) 中找到生成 nli-zh-all 数据集的脚本,所有数据均上传到 huggingface datasets。
| 数据集名称 | 领域 | 数量 | 任务类型 | Prompt | 质量 | 数据提供者 | 说明 | 是否开源/研究使用 | 是否商用 | 脚本 | Done | URL | 是否同质 |
|:---------------------| :---- |:-----------|:---------------- |:------ |:----|:-----------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------|:----------------- |:------|:---- |:---- |:---------------------------------------------------------------------------------------------|:------|
| cmrc2018 | 百科 | 14,363 | 问答 | 问答 | 优 | Yiming Cui, Ting Liu, Wanxiang Che, Li Xiao, Zhipeng Chen, Wentao Ma, Shijin Wang, Guoping Hu | https://github.com/ymcui/cmrc2018/blob/master/README_CN.md 专家标注的基于维基百科的中文阅读理解数据集,将问题和上下文视为正例 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/cmrc2018 | 否 |
| belle_0.5m | 百科 | 500,000 | 指令微调 | 无 | 优 | LianjiaTech/BELLE | belle 的指令微调数据集,使用 self instruct 方法基于 gpt3.5 生成 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/BelleGroup/ | 否 |
| firefily | 百科 | 1,649,399 | 指令微调 | 无 | 优 | YeungNLP | Firefly(流萤) 是一个开源的中文对话式大语言模型,使用指令微调(Instruction Tuning)在中文数据集上进行调优。使用了词表裁剪、ZeRO等技术,有效降低显存消耗和提高训练效率。 在训练中,我们使用了更小的模型参数量,以及更少的计算资源。 | 未说明 | 未说明 | 是 | 是 | https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M | 否 |
| alpaca_gpt4 | 百科 | 48,818 | 指令微调 | 无 | 优 | Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, Jianfeng Gao | 本数据集是参考Alpaca方法基于GPT4得到的self-instruct数据,约5万条。 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/shibing624/alpaca-zh | 否 |
| zhihu_kol | 百科 | 1,006,218 | 问答 | 问答 | 优 | wangrui6 | 知乎问答 | 未说明 | 未说明 | 是 | 是 | https://huggingface.co/datasets/wangrui6/Zhihu-KOL | 否 |
| amazon_reviews_multi | 电商 | 210,000 | 问答 文本分类 | 摘要 | 优 | 亚马逊 | 亚马逊产品评论数据集 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/amazon_reviews_multi/viewer/zh/train?row=8 | 否 |
| mlqa | 百科 | 85,853 | 问答 | 问答 | 良 | patrickvonplaten | 一个用于评估跨语言问答性能的基准数据集 | 是 | 未说明 | 是 | 是 | https://huggingface.co/datasets/mlqa/viewer/mlqa-translate-train.zh/train?p=2 | 否 |
| xlsum | 新闻 | 93,404 | 摘要 | 摘要 | 良 | BUET CSE NLP Group | BBC的专业注释文章摘要对 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/csebuetnlp/xlsum/viewer/chinese_simplified/train?row=259 | 否 |
| ocnli | 口语 | 17,726 | 自然语言推理 | 推理 | 良 | Thomas Wolf | 自然语言推理数据集 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/clue/viewer/ocnli | 是 |
| BQ | 金融 | 60,000 | 文本分类 | 相似 | 优 | Intelligent Computing Research Center, Harbin Institute of Technology(Shenzhen) | http://icrc.hitsz.edu.cn/info/1037/1162.htm BQ 语料库包含来自网上银行自定义服务日志的 120,000 个问题对。它分为三部分:100,000 对用于训练,10,000 对用于验证,10,000 对用于测试。 数据提供者: 哈尔滨工业大学(深圳)智能计算研究中心 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/shibing624/nli_zh/viewer/BQ | 是 |
| lcqmc | 口语 | 149,226 | 文本分类 | 相似 | 优 | Ming Xu | 哈工大文本匹配数据集,LCQMC 是哈尔滨工业大学在自然语言处理国际顶会 COLING2018 构建的问题语义匹配数据集,其目标是判断两个问题的语义是否相同 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/shibing624/nli_zh/viewer/LCQMC/train | 是 |
| paws-x | 百科 | 23,576 | 文本分类 | 相似 | 优 | Bhavitvya Malik | PAWS Wiki中的示例 | 是 | 是 | 是 | 是 | https://huggingface.co/datasets/paws-x/viewer/zh/train | 是 |
| wiki_atomic_edit | 百科 | 1,213,780 | 平行语义 | 相似 | 优 | abhishek thakur | 基于中文维基百科的编辑记录收集的数据集 | 未说明 | 未说明 | 是 | 是 | https://huggingface.co/datasets/wiki_atomic_edits | 是 |
| chatmed_consult | 医药 | 549,326 | 问答 | 问答 | 优 | Wei Zhu | 真实世界的医学相关的问题,使用 gpt3.5 进行回答 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/michaelwzhu/ChatMed_Consult_Dataset | 否 |
| webqa | 百科 | 42,216 | 问答 | 问答 | 优 | suolyer | 百度于2016年开源的数据集,数据来自于百度知道;格式为一个问题多篇意思基本一致的文章,分为人为标注以及浏览器检索;数据整体质量中,因为混合了很多检索而来的文章 | 是 | 未说明 | 是 | 是 | https://huggingface.co/datasets/suolyer/webqa/viewer/suolyer--webqa/train?p=3 | 否 |
| dureader_robust | 百科 | 65,937 | 机器阅读理解 问答 | 问答 | 优 | 百度 | DuReader robust旨在利用真实应用中的数据样本来衡量阅读理解模型的鲁棒性,评测模型的过敏感性、过稳定性以及泛化能力,是首个中文阅读理解鲁棒性数据集。 | 是 | 是 | 是 | 是 | https://huggingface.co/datasets/PaddlePaddle/dureader_robust/viewer/plain_text/train?row=96 | 否 |
| csl | 学术 | 395,927 | 语料 | 摘要 | 优 | Yudong Li, Yuqing Zhang, Zhe Zhao, Linlin Shen, Weijie Liu, Weiquan Mao and Hui Zhang | 提供首个中文科学文献数据集(CSL),包含 396,209 篇中文核心期刊论文元信息 (标题、摘要、关键词、学科、门类)。CSL 数据集可以作为预训练语料,也可以构建许多NLP任务,例如文本摘要(标题预测)、 关键词生成和文本分类等。 | 是 | 是 | 是 | 是 | https://huggingface.co/datasets/neuclir/csl | 否 |
| snli-zh | 口语 | 419,402 | 文本分类 | 推理 | 优 | liuhuanyong | 中文SNLI数据集,翻译自英文SNLI | 是 | 否 | 是 | 是 | https://github.com/liuhuanyong/ChineseTextualInference/ | 是 |
| SimCLUE | 百科 | 2,678,694 | 平行语义 | 相似 | 优 | 数据集合,请在 simCLUE 中查看 | 整合了中文领域绝大多数可用的开源的语义相似度和自然语言推理的数据集,并重新做了数据拆分和整理。 | 是 | 否 | 否 | 是 | https://github.com/CLUEbenchmark/SimCLUE | 是 |
#### Who are the source language producers?
数据集的版权归原作者所有,使用各数据集时请尊重原数据集的版权。
SNLI:
@inproceedings{snli:emnlp2015,
Author = {Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher, and Manning, Christopher D.},
Booktitle = {Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP)},
Publisher = {Association for Computational Linguistics},
Title = {A large annotated corpus for learning natural language inference},
Year = {2015}
}
#### Who are the annotators?
原作者。
### Social Impact of Dataset
This dataset was developed as a benchmark for evaluating representational systems for text, especially including those induced by representation learning methods, in the task of predicting truth conditions in a given context.
Systems that are successful at such a task may be more successful in modeling semantic representations.
### Licensing Information
for reasearch
用于学术研究
### Contributions
[shibing624](https://github.com/shibing624) add this dataset.
|
xzuyn/Stable-Diffusion-Prompts-Deduped-2.008M | ---
task_categories:
- text-generation
language:
- en
size_categories:
- 1M<n<10M
---
# [Original Dataset by FredZhang7](https://huggingface.co/datasets/FredZhang7/stable-diffusion-prompts-2.47M)
- Deduped from 2,473,022 down to 2,007,998.
- Changed anything that had `[ prompt text ]`, `( prompt text )`, or `< prompt text >`, to `[prompt text]`, `(prompt text)`, and `<prompt text>`.
- 2 or more spaces converted to a single space.
- Removed all `"`
- Removed spaces at beginnings. |
RIPS-Goog-23/IIT-CDIP | ---
dataset_info:
features:
- name: tar_file_letters
dtype: string
- name: filename
dtype: string
- name: text
dtype: string
- name: bboxes
dtype: string
- name: img
dtype: string
- name: img_width
dtype: int64
- name: img_height
dtype: int64
splits:
- name: ra9
num_bytes: 91309162
num_examples: 2762
download_size: 81476979
dataset_size: 91309162
---
# Dataset Card for "IIT-CDIP-2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
zxbsmk/webnovel_cn | ---
license: mit
task_categories:
- text2text-generation
language:
- zh
size_categories:
- 10M<n<100M
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
---
## 内容
包含从12560本网文提取的约**21.7M**条可用于训练小说生成的中文指令数据(novel_json_tokens512.zip)。~~下载链接:https://pan.baidu.com/s/1TorBMbrqxrn6odRF0PJBVw
提取码:jlh3~~
以及从中提取出的包含**50k**条数据的子集(novel_cn_token512_50k.json)。其中输入和输出都不多于 512 tokens。
## 样例
在原有小说文本基础上,依据下列五种指令生成数据。
其中,文本由小说中随机抽取的连续句子组成。
1. 给定标题,直接生成简介。
2. 给定标题和简介,生成开头。
3. 给定简介和一段文本,生成后续文本。
4. 给定标题和一段文本,生成后续文本。
5. 给定一段文本,生成后续文本。
```
{
"instruction": "小说名:无限恐怖\n节选正文:\n“不行,中校,我们必须把这里的情况和这些虫族的拍摄画面传回地球去,是的,我们人类已经到了最危险的关头,地球上所有的工业重工业完全应该按照战时情况进行任务布置,我们人类的工业力根本不是虫族能够想象的,一年,不,半年我们就能有一万艘宇宙战舰升空,如果全球一共进行建造的话,我们一定……”一名少校参谋长看着那密密麻麻的宇宙虫海,他神色激动的对楚轩说道。\n楚轩默默咬了一口苹果,他说道:“问题一……一万艘宇宙战舰需要多少熟练的战舰船员?需要多少士兵在战舰上服役,半年里我们可以聚集齐全吗?问题二……虫族会给地球联邦政府留下半年的时间吗?一旦我们被消灭干净,则联邦政府将会随即遭受到这些宇宙虫族的太空袭击,直到我们的太空优势完全丧失之后,虫族就能放心移动陨石进行攻击,甚至是将大量陆地虫子带上地球,那时我们人类能够凭肉体与虫子对抗吗?问题三……我们现在该如何把信息传给地球?”\n这名参谋长顿时就不说话了,而旁边一名上尉忽然说道:“在探戈幽灵星上的七座要塞中,每一座要塞都有大功率粒子喷射联络器,这种联络器连我们自己的科技都无法屏蔽,我想虫子也应该不可能继续屏蔽吧,毕竟那只是粒子而已,不是电流信号这些……”续篇:",
"input": "",
"output": "楚轩咬了一口苹果说道:“没错,所以我们才要登陆到探戈幽灵星,这是我们的目的,同时为了保存宇宙舰队的战斗力,以最大的平原军事基地,风暴要塞为中心,所有舰队都要降落到地面上,然后层层布防,在援军到来前,在地球联邦政府做好了战争准备前,我们必须像颗钉子一样钉死在这里,让虫族无法忽视我们而去进攻地球……怎么样?我们很可能会死在这里,面对数十万,数百万,甚至数千万的虫子前扑后续的攻击,但是我们的名字一定会载入史册……把刚才记录下来的我的话发向所有舰队,然后告诉他们,作为逃命被自己人杀掉,或者是成为英雄回到地球,让他们明白我们的处境,然后自己去选择吧。”\n周围的参谋和军官们同时向楚轩四人敬了一礼,接着那参谋长激动的向某处平台走了过去。\n郑吒默默走到了楚轩身边,他小声的说道:“楚轩……你什么时候变得了那么会煽情了啊?”\n楚轩却是理所当然的说道:“将自己归于多数人的一边,以前的你不是这样评价我的吗?没错,将自己归于多数人的一边,这是做任何大事都要先完成的第一步……已经让他们知道命运和我们连接在了一起,接着就只需要好好的安排下局面与等待‘主神’的任务就可以了,时间还有三天……”\n时间还有三天,在当天中午的时候,舰队群的预警舰果然发现了在探戈幽灵星后方徘徊着另一颗巨大圆球,它仿佛卫星一样座落在探戈幽灵星的近地轨道上,而随着联合舰队的到来,这只巨大圆球上果然也飞出了数以万计的宇宙虫子,这下联合舰队果然却如楚轩的预言那般了,前有埋伏,后有追兵,唯一的一条路就只剩下降落到探戈幽灵星上了。"
},
{
"instruction": "给定小说简介和节选,续写小说",
"input": "小说简介:主人公郑吒自从失去了自己最亲密的青梅竹马后,对这种反复而又无聊的现代生活已经感到十分的厌倦。正在这时,他发现电脑屏幕上弹出了一段信息:“想明白生命的意义吗?想真正的……活着吗?”在按下YES后,一切都改变了。他进入了一个恐怖片的轮回世界——主神空间……在主神空间里,只有不停地变强、不停地进化,才能闯过那一关关的恐怖片,才能活下去。郑吒,怎样才能活下去?是杀死与自己对抗的所有人,走向孤独的王者之道?还是和自己的伙伴奋战到死,以仁义之道来度过劫难?其实,所有的一切也只是为了活下去。直到他们发现了主神空间的秘密……究竟……谁才是暗中真正的威胁?一切尽在无限恐怖!\n\n\n\n上半部:初始\n节选篇章:“什么叫作事情已经发展到了这一步!”郑吒大声的喧哗吼叫着,他冲着楚轩吼道:“你这个白痴!我一直都在重复着同样一句话,我们是同伴啊,为什么不可以事先把你的猜测或者布局告诉我们呢?每次都把我当成白痴一样,每次都在算计我之后轻描淡写的说一句我骗你的,你究竟把我当成什么人?”\n“呃……大概是可以欺骗的凡人智慧者吧。”楚轩想了一下直接说道。\n“……不要拦着我!王侠,伊莫顿,你们放开我!我要干掉这个白痴!”\n喧哗又一次发生了,片刻之后再次安静下来时,楚轩本已略微肿胀的脸终于是彻底肿胀了起来,而看他的样子依然是一丁点疼痛都感觉不到,依然悠闲的吃着黄瓜。\n“……总之,事情已经发展到了这一步……”郑吒摸着额头,很痛苦的说道:“那么我们必须先要得到王女鄂亚的关押位置所在,当然了,直接打进首都也其实也不是不可以,但是从原剧情来看,似乎只有那个名叫邪影者的魔法师与国王歌巴塔尔知道她的关押位置,为了不打草惊蛇,还是花些时间慢慢渗透进去查找线索吧。”\n“赵樱空,你负责潜行进王城内,能不杀人尽量不杀人,若是遇到危险就转换人格,或者联络我们……伊莫顿,你负责到王城外的村庄去打探消息,尽量不要引人注意,若是可以,使用你的法术控制些人也行,照刚才我说的,遇到危险可以杀人,也可以联络我们,楚轩,王侠,你们两人就在附近待机,一旦发现有任何情况都要提供支援。”",
"output": "众人都点着头,王侠忽然好奇的问道:“你呢?你打算干什么去?”\n“我会把整个王城的情况给摸清楚,关键是王城里可能隐藏着的力量,我很在意啊,伊莫顿的感觉从某些方面来讲比我们都更出色,毕竟他是死亡的生物……或许,这场恐怖片世界并不像我们所想的那样轻松呢。”郑吒说到这里时叹了口气,他接着又看向了那首都位置。\n“时间还有两天多,我们尽量在三天内完成这部恐怖片世界吧……希望另一边的幼龙能够赶快成长。”郑吒边说话,边驾驶绿魔滑板就向地面飞去,渐渐的,他离众人已经越来越远了。\n此刻,在离王城首都极遥远外的小村处,主角伊拉贡正极其狼狈的奔跑在树丛中,跟随在他身边的还有他的舅舅……非常不幸的,逃跑没多久,他的表哥就失散在了这片森林中,或者说是被那些士兵们给抓住了也说不定。\n更加不幸的是,那名中年武士明显已经落败,不然不会多出那么多士兵紧紧追着他们,比起在村庄的时候,士兵的数量又更加的多了,至少有十多名士兵在他们不远处紧紧追赶。\n“你到底偷了什么东西啊!为什么会有这么多士兵来追赶你呢?”伊拉贡的舅舅气喘吁吁的问道,他已经跑得没什么精力去发怒了。\n“……一个龙蛋,不是偷的,这是我从森林里拣来的!”伊拉贡虽然也是跑得筋疲力尽,但他还在坚持着最后的底线,依然不停辩解着。\n“龙蛋?那可是国王的东西啊!而且还是孵化出幼龙的龙蛋!你这个白痴,你这样会害死大家的!”伊拉贡的舅舅一听此话就气急败坏的叫道,但他还是不停向前跑去,不敢有丁点停顿,因为在他们背后不停的追赶着十多名士兵。\n“在那里!看到他们了!他们在那里!”"
}
```
## 字段:
```
instruction: 指令
input: 输入
output: 输出
```
## 使用限制
仅允许将此数据集及使用此数据集生成的衍生物用于研究目的,不得用于商业,以及其他会对社会带来危害的用途。
本数据集不代表任何一方的立场、利益或想法,无关任何团体的任何类型的主张。因使用本数据集带来的任何损害、纠纷,本项目不承担任何责任。
Join group via https://t.me/+JbovpBG6-gBiNDI1 |
Flmc/DISC-Med-SFT | ---
license: apache-2.0
task_categories:
- question-answering
- conversational
language:
- zh
tags:
- medical
size_categories:
- 100K<n<1M
---
This is a repository containing a subset of the DISC-Med-SFT Dataset.
Check [DISC-MedLLM](https://github.com/FudanDISC/DISC-MedLLM) for more information. |
TrainingDataPro/ocr-receipts-text-detection | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-to-text
- object-detection
tags:
- code
- finance
dataset_info:
features:
- name: id
dtype: int32
- name: name
dtype: string
- name: image
dtype: image
- name: mask
dtype: image
- name: width
dtype: uint16
- name: height
dtype: uint16
- name: shapes
sequence:
- name: label
dtype:
class_label:
names:
'0': receipt
'1': shop
'2': item
'3': date_time
'4': total
- name: type
dtype: string
- name: points
sequence:
sequence: float32
- name: rotation
dtype: float32
- name: occluded
dtype: uint8
- name: attributes
sequence:
- name: name
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 55510934
num_examples: 20
download_size: 54557192
dataset_size: 55510934
---
# OCR Receipts from Grocery Stores Text Detection
The Grocery Store Receipts Dataset is a collection of photos captured from various **grocery store receipts**. This dataset is specifically designed for tasks related to **Optical Character Recognition (OCR)** and is useful for retail.
Each image in the dataset is accompanied by bounding box annotations, indicating the precise locations of specific text segments on the receipts. The text segments are categorized into four classes: **item, store, date_time and total**.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market/ocr-receipts-text-detection?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-receipts-text-detection) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images of receipts
- **boxes** - includes bounding box labeling for the original images
- **annotations.xml** - contains coordinates of the bounding boxes and detected text, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes and detected text . For each point, the x and y coordinates are provided.
### Classes:
- **store** - name of the grocery store
- **item** - item in the receipt
- **date_time** - date and time of the receipt
- **total** - total price of the receipt
# Text Detection in the Receipts might be made in accordance with your requirements.
## [TrainingData](https://trainingdata.pro/data-market/ocr-receipts-text-detection?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-receipts-text-detection) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/trainingdata-pro** |
larryvrh/belle_resampled_78K_CN | ---
dataset_info:
features:
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: id
dtype: string
- name: category
dtype: string
splits:
- name: train
num_bytes: 197491538
num_examples: 78000
download_size: 108247334
dataset_size: 197491538
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
task_categories:
- text-generation
- conversational
language:
- zh
size_categories:
- 10K<n<100K
---
# Dataset Card for "belle_resampled_78K_CN"
通过启发式方法过滤后的[BelleGroup/train_3.5M_CN](https://huggingface.co/datasets/BelleGroup/train_3.5M_CN),移除了语料中明显的错误和低质量内容。
之后进行了均匀采样,从每个类别中提取出6000条最长的对话。
## 样例
```
{
"id":"66623028",
"conversations":[
{
"from":"human",
"value":"归纳介绍三种不同类型的电影题材"
},
{
"from":"assistant",
"value":"1. 动作片:动作片通常强调动作和战斗场面,故事情节紧凑,充满了紧张和兴奋的氛围。主角一般是具有超凡实力或特殊技能的英雄人物,往往会与反派角色进行一系列激烈的格斗,追逐和爆破等酷炫场面。例如《速度与激情》和《复仇者联盟》等。\n2. 爱情片:爱情片是以爱情为主题的电影,着重呈现角色之间的感情纠葛,展现了爱情的美好和悲壮。情节与角色之间的发展令人深思,增加了观众的感性体验。这种电影的故事情节主要以人类与人类之间的情感变化为主题。例如《泰坦尼克号》和《让子弹飞》等。\n3. 科幻片:科幻片是以未来科技和未知世界为主题的电影,通常包括时间旅行、外星人、虚拟现实、未来社会等各种奇幻的元素。这种电影描绘了一种比现实更加宏伟、更加神秘和惊奇的世界。例如《星际穿越》和《发条橙》等。"
}
]
}
{
"id":"18205437",
"conversations":[
{
"from":"human",
"value":"根据给定的食材,编写一道美食菜谱。\n鸡腿肉、蘑菇、洋葱"
},
{
"from":"assistant",
"value":"鸡肉炒蘑菇洋葱\n食材:\n- 鸡腿肉 400克,去骨去皮切成小块\n- 蘑菇 200克,切片\n- 洋葱 1个,切丝\n- 生姜 适量,切丝\n- 酱油 2勺\n- 料酒 1勺\n- 盐 适量\n- 白胡椒粉 适量\n- 植物油 适量\n做法:\n1. 在一个碗里放入切好的鸡腿肉块,加入酱油、料酒和适量的白胡椒粉,搅拌均匀,腌制10分钟。\n2. 热锅凉油,加入姜丝翻炒,放入腌好的鸡肉块翻炒至变色。\n3. 加入洋葱丝和蘑菇,翻炒2-3分钟至蘑菇变软。\n4. 加入适量的盐和少量的水,盖上锅盖焖煮5分钟直至鸡肉熟透。\n5. 最后翻炒几下,使汤汁变浓稠即可。\n温馨提示:\n1. 在腌制鸡肉时,如果想让肉质更嫩滑,可以加入少量的淀粉和蛋清。\n2. 可以根据个人口味加入其他调料,如蒜末、辣椒等。\n3. 洋葱和蘑菇可以用其他蔬菜代替,如青椒、胡萝卜等。"
},
{
"from":"human",
"value":"太好了,我会试着照着你教的做一次,但是我最近买了一部新相机,想让你推荐一些好的拍照地点。"
},
{
"from":"assistant",
"value":"当地的风景区、公园、景点等等都是比较适合拍照的地点。如果你想要一些特别的地方,可以考虑一些建筑群,街道巷子、咖啡馆、书店等具有文艺气息的地方。"
},
{
"from":"human",
"value":"嗯,这些地方都很不错,但是我还想找一些可以体验当地文化和风俗的地点,你有什么好的建议吗?"
},
{
"from":"assistant",
"value":"如果你想要更深入地了解当地文化和风俗,可以考虑参加一些游学活动,比如参观当地的博物馆、参加民俗节庆、尝试当地美食等等。此外,也可以去一些小城镇,感受那里的古朴风情。"
}
]
}
```
### 字段:
```
id: 数据id
conversations: 数据内容,以对话形式给出,包括多轮和单轮对话的数据
category: 数据类别
``` |
yuyijiong/multi-doc-qa-zh | ---
license: unknown
task_categories:
- text-generation
- question-answering
language:
- zh
---
多文档qa数据集,谷歌翻译成中文,用于微调长度更大的模型。\
任务:给定多个参考文档和一个问题,只有一个文档包含有用信息,模型需要根据参考文档回答问题,并指出哪个文档包含有用信息。\
对于每个question,会提供几十或上百个文档片段,只有一个文档包含有用信息,gold_document_id表示含有有用信息的文档序号,注意文档是从1开始编号。\
源数据来自 togethercomputer/Long-Data-Collections\ |
cmalaviya/expertqa | ---
configs:
- config_name: main
data_files: r2_compiled_anon_fixed.jsonl
- config_name: lfqa_random
data_files:
- split: train
path: rand_lfqa_train.json
- split: test
path: rand_lfqa_test.json
- split: validation
path: rand_lfqa_val.json
- config_name: lfqa_domain
data_files:
- split: train
path: domain_lfqa_train.json
- split: test
path: domain_lfqa_test.json
- split: validation
path: domain_lfqa_val.json
license: mit
task_categories:
- question-answering
language:
- en
source_datasets:
- original
pretty_name: ExpertQA
annotations_creators:
- expert-generated
size_categories:
- 1K<n<10K
---
# Dataset Card for ExpertQA
## Dataset Description
- **Repository: https://github.com/chaitanyamalaviya/ExpertQA**
- **Paper: https://arxiv.org/pdf/2309.07852**
- **Point of Contact: chaitanyamalaviya@gmail.com**
### Dataset Summary
We provide here the data accompanying the paper: [ExpertQA: Expert-Curated Questions and Attributed Answers](https://arxiv.org/pdf/2309.07852). The ExpertQA dataset contains 2177 examples from 32 different fields.
### Supported Tasks
The `main` data contains 2177 examples that can be used to evaluate new methods for estimating factuality and attribution, while the `lfqa_domain` and `lfqa_rand` data can be used to evaluate long-form question answering systems.
## Dataset Creation
### Curation Rationale
ExpertQA was created to evaluate factuality & attribution in language model responses to domain-specific questions, as well as evaluate long-form question answering in domain-specific settings.
### Annotation Process
Questions in ExpertQA were formulated by experts spanning 32 fields. The answers to these questions are expert-verified, model-generated answers to these questions. Each claim-evidence pair in an answer is judged by experts for various properties such as the claim’s informativeness, factuality, citeworthiness, whether the claim is supported by the evidence, and reliability of the evidence source. Further, experts revise the original claims to ensure they are factual and supported by trustworthy sources.
## Dataset Structure
### Data Instances
We provide the main data, with judgements of factuality and attribution, under the `default` subset.
The long-form QA data splits are provided at `lfqa_domain` (domain split) and `lfqa_rand` (random split).
Additional files are provided in our [GitHub repo](https://github.com/chaitanyamalaviya/ExpertQA).
### Data Fields
The main data file contains newline-separated json dictionaries with the following fields:
* `question` - Question written by an expert.
* `annotator_id` - Anonymized annotator ID of the author of the question.
* `answers` - Dict mapping model names to an Answer object. The model names can be one of `{gpt4, bing_chat, rr_sphere_gpt4, rr_gs_gpt4, post_hoc_sphere_gpt4, post_hoc_gs_gpt4}`.
* `metadata` - A dictionary with the following fields:
* `question_type` - The question type(s) separated by "|".
* `field` - The field to which the annotator belonged.
* `specific_field` - More specific field name within the broader field.
Each Answer object contains the following fields:
* `answer_string`: The answer string.
* `attribution`: List of evidences for the answer (not linked to specific claims). Note that these are only URLs, the evidence passages are stored in the Claim object -- see below.
* `claims`: List of Claim objects for the answer.
* `revised_answer_string`: Revised answer by annotator.
* `usefulness`: Usefulness of original answer marked by annotator.
* `annotation_time`: Time taken for annotating this answer.
* `annotator_id`: Anonymized annotator ID of the person who validated this answer.
Each Claim object contains the following fields:
* `claim_string`: Original claim string.
* `evidence`: List of evidences for the claim (URL+passage or URL).
* `support`: Attribution marked by annotator.
* `reason_missing_support`: Reason for missing support specified by annotator.
* `informativeness`: Informativeness of claim for the question, marked by annotator.
* `worthiness`: Worthiness of citing claim marked by annotator.
* `correctness`: Factual correctness of claim marked by annotator.
* `reliability`: Reliability of source evidence marked by annotator.
* `revised_claim`: Revised claim by annotator.
* `revised_evidence`: Revised evidence by annotator.
### Citation Information
```
@inproceedings{malaviya23expertqa,
title = {ExpertQA: Expert-Curated Questions and Attributed Answers},
author = {Chaitanya Malaviya and Subin Lee and Sihao Chen and Elizabeth Sieber and Mark Yatskar and Dan Roth},
booktitle = {arXiv},
month = {September},
year = {2023},
url = "https://arxiv.org/abs/2309.07852"
}
```
|
FudanSELab/CodeGen4Libs | ---
license: mit
tags:
- code-generation
pretty_name: CodeGen4Libs Dataset
size_categories:
- 100K<n<1M
---
# Dataset Card for FudanSELab CodeGen4Libs Dataset
## Dataset Description
- **Repository:** [GitHub Repository](https://github.com/FudanSELab/codegen4libs)
- **Paper:** [CodeGen4Libs: A Two-stage Approach for Library-oriented Code Generation](https://mingwei-liu.github.io/publication/2023-08-18-ase-CodeGen4Libs)
### Dataset Summary
This dataset is used in the ASE2023 paper titled ["CodeGen4Libs: A Two-stage Approach for Library-oriented Code Generation"](https://mingwei-liu.github.io/publication/2023-08-18-ase-CodeGen4Libs).
### Languages
[More Information Needed]
## Dataset Structure
```python
from datasets import load_dataset
dataset = load_dataset("FudanSELab/CodeGen4Libs")
DatasetDict({
train: Dataset({
features: ['id', 'method', 'clean_method', 'doc', 'comment', 'method_name', 'extra', 'imports_info', 'libraries_info', 'input_str', 'input_ids', 'tokenized_input_str', 'input_token_length', 'labels', 'tokenized_labels_str', 'labels_token_length', 'retrieved_imports_info', 'retrieved_code', 'imports', 'cluster_imports_info', 'libraries', 'attention_mask'],
num_rows: 391811
})
validation: Dataset({
features: ['id', 'method', 'clean_method', 'doc', 'comment', 'method_name', 'extra', 'imports_info', 'libraries_info', 'input_str', 'input_ids', 'tokenized_input_str', 'input_token_length', 'labels', 'tokenized_labels_str', 'labels_token_length', 'retrieved_imports_info', 'retrieved_code', 'imports', 'cluster_imports_info', 'libraries', 'attention_mask'],
num_rows: 5967
})
test: Dataset({
features: ['id', 'method', 'clean_method', 'doc', 'comment', 'method_name', 'extra', 'imports_info', 'libraries_info', 'input_str', 'input_ids', 'tokenized_input_str', 'input_token_length', 'labels', 'tokenized_labels_str', 'labels_token_length', 'retrieved_imports_info', 'retrieved_code', 'imports', 'cluster_imports_info', 'libraries', 'attention_mask'],
num_rows: 6002
})
})
```
### Data Fields
The specific data fields for each tuple are delineated as follows:
- id: the unique identifier for each tuple.
- method: the original method-level code for each tuple.
- clean_method: the ground-truth method-level code for each task.
- doc: the document of method-level code for each tuple.
- comment: the natural language description for each tuple.
- method_name: the name of the method.
- extra: extra information on the code repository to which the method level code belongs.
- license: the license of code repository.
- path: the path of code repository.
- repo_name: the name of code repository.
- size: the size of code repository.
- imports_info: the import statements for each tuple.
- libraries_info: the libraries info for each tuple.
- input_str: the design of model input.
- input_ids: the ids of tokenized input.
- tokenized_input_str: the tokenized input.
- input_token_length: the length of the tokenized input.
- labels: the ids of tokenized output.
- tokenized_labels_str: the tokenized output.
- labels_token_length: the length of the the tokenized output.
- retrieved_imports_info: the retrieved import statements for each tuple.
- retrieved_code: the retrieved method-level code for each tuple.
- imports: the imported packages of each import statement.
- cluster_imports_info: cluster import information of code.
- libraries: libraries used by the code.
- attention_mask: attention mask for the input.
### Data Splits
The dataset is splited into a training set, a validation set, and a test set, with 391811, 5967, and 6002 data rows respectively.
## Additional Information
### Citation Information
```
@inproceedings{ase2023codegen4libs,
author = {Mingwei Liu and Tianyong Yang and Yiling Lou and Xueying Du and Ying Wang and and Xin Peng},
title = {{CodeGen4Libs}: A Two-stage Approach for Library-oriented Code Generation},
booktitle = {38th {IEEE/ACM} International Conference on Automated Software Engineering,
{ASE} 2023, Kirchberg, Luxembourg, September 11-15, 2023},
pages = {0--0},
publisher = {{IEEE}},
year = {2023},
}
``` |
AayushShah/SQL_SparC_Dataset_With_Schema | ---
dataset_info:
features:
- name: database_id
dtype: string
- name: query
dtype: string
- name: question
dtype: string
- name: metadata
dtype: string
splits:
- name: train
num_bytes: 3249206
num_examples: 3456
download_size: 288326
dataset_size: 3249206
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "SQL_SparC_Dataset_With_Schema"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
shuttie/dadjokes | ---
license: apache-2.0
language:
- en
size_categories:
- 10K<n<100K
---
# Dad Jokes dataset
This dataset is generated from the [Kaggle Reddit Dad Jokes](https://www.kaggle.com/datasets/oktayozturk010/reddit-dad-jokes) by [Oktay Ozturk](https://www.kaggle.com/oktayozturk010), with the following modifications:
* Only jokes with 5+ votes were sampled. Less upvoted jokes are too cringe.
* With a set of heuristics, each joke was split into two parts: base and the punchline.
## Format
The dataset is formatted as a CSV, and is split into train/test parts:
* train: 52000 samples
* test: 1400 samples
```csv
"question","response"
"I asked my priest how he gets holy water","He said it’s just regular water, he just boils the hell out of it"
"Life Hack: If you play My Chemical Romance loud enough in your yard","your grass will cut itself"
"Why did Mr. Potato Head get pulled over","He was baked"
"How did the Mexican John Wick taste his Burrito","He took Juan Lick"
```
## Usage
With a base/punchline split, this dataset can be used for a joke prediction task with any LLM.
## License
Apache 2.0. |