


Update README.md (#4)
Browse files- Update README.md (7ef108f2212d83fc16e5718c63ee0f3a650aa3c2)
Co-authored-by: Albert Sawczyn <asawczyn@users.noreply.huggingface.co>
README.md
CHANGED
|
@@ -32,6 +32,20 @@ The purpose of this task is to restore punctuation in the ASR recognition of tex
|
|
| 32 |
|
| 33 |
|
| 34 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 35 |
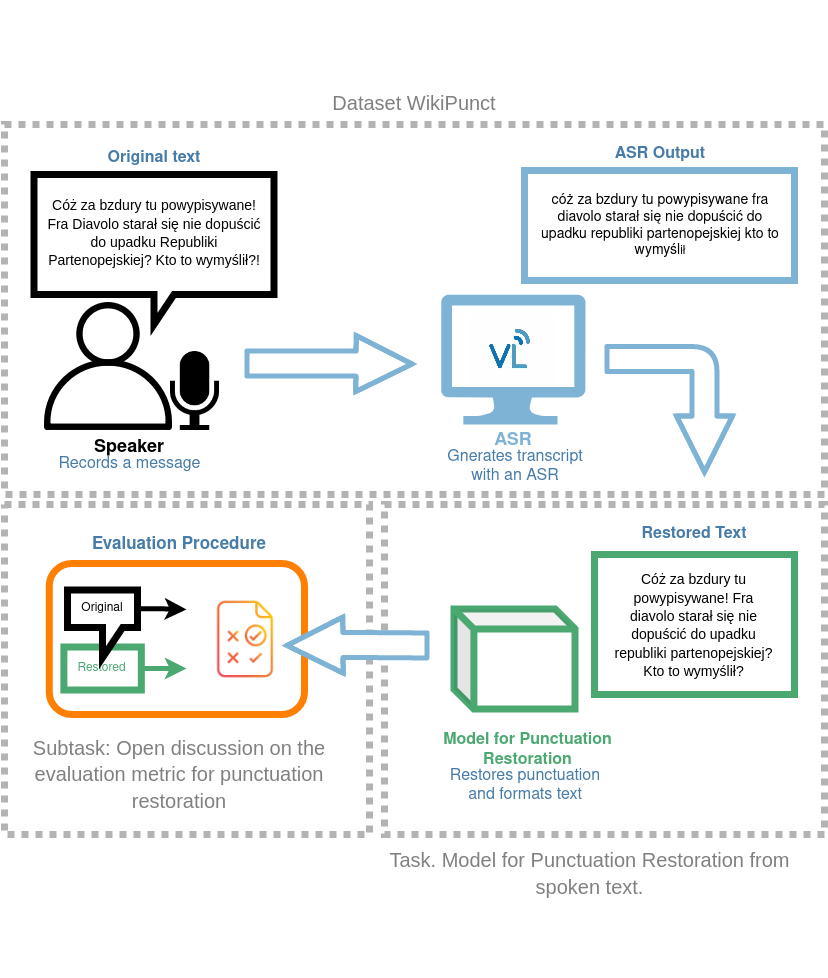
## Dataset – WikiPunct
|
| 36 |
|
| 37 |
WikiPunct is a crowdsourced text and audio data set of Polish Wikipedia pages read out loud by Polish lectors. The dataset is divided into two parts:conversational(WikiTalks)and information (WikiNews). Over a hundred people were involved in the production of the audio component. The total length of audio data reaches almost thirty-six hours, including the test set. Steps were taken to balance the male-to-female ratio.
|
|
|
|
| 32 |
|
| 33 |

|
| 34 |
|
| 35 |
+
**Input** ('tokens*'* column): sequence of tokens
|
| 36 |
+
|
| 37 |
+
**Output** ('tags*'* column): sequence of tags
|
| 38 |
+
|
| 39 |
+
**Measurements**: F1-score (seqeval)
|
| 40 |
+
|
| 41 |
+
**Example**:
|
| 42 |
+
|
| 43 |
+
Input: `['selekcjoner', 'szosowej', 'kadry', 'elity', 'mężczyzn', 'piotr', 'wadecki', 'ogłosił', '27', 'marca', '2008', 'r', 'szeroki', 'skład', 'zawodników', 'którzy', 'będą', 'rywalizować', 'o', 'miejsce', 'w', 'reprezentacji', 'na', 'tour', 'de', 'pologne', 'lista', 'liczy', '22', 'nazwiska', 'zawodników', 'zarówno', 'z', 'zagranicznych', 'jaki', 'i', 'polskich', 'ekip', 'spośród', '22', 'wybrańców', 'selekcjonera', 'do', 'składu', 'dostanie', 'się', 'tylko', 'ośmiu', 'kolarzy', 'którzy', 'we', 'wrześniu', 'będą', 'rywalizować', 'z', 'najlepszymi', 'grupami', 'kolarskimi', 'na', 'świecie', 'w', 'kręgu', 'zainteresowania', 'wadeckiego', 'znajduje', 'się', 'także', 'pięciu', 'innych', 'zawodników', 'ale', 'oni', 'prawdopodobnie', 'wystartują', 'w', 'polskim', 'tourze', 'w', 'szeregach', 'swoich', 'ekip', 'szeroka', 'kadra', 'na', 'tour', 'de', 'pologne', 'dariusz', 'baranowski', 'łukasz', 'bodnar', 'bartosz', 'huzarski', 'błażej', 'janiaczyk', 'tomasz', 'kiendyś', 'mateusz', 'komar', 'tomasz', 'lisowicz', 'piotr', 'mazur', 'jacek', 'morajko', 'przemysław', 'niemiec', 'marek', 'rutkiewicz', 'krzysztof', 'szczawiński', 'mateusz', 'taciak', 'adam', 'wadecki', 'mariusz', 'witecki', 'piotr', 'zaradny', 'piotr', 'zieliński', 'mateusz', 'mróz', 'marek', 'wesoły', 'jarosław', 'rębiewski', 'robert', 'radosz', 'jarosław', 'dąbrowski']`
|
| 44 |
+
|
| 45 |
+
Input (translated by DeepL): `the selector of the men's elite road cycling team piotr wadecki announced on march 27, 2008 a wide line-up of riders who will compete for a place in the national team for the tour de pologne the list includes 22 names of riders both from foreign and Polish teams out of the 22 selected by the selector only eight riders will get into the line-up who in September will compete with the best cycling groups in the world wadecki's circle of interest also includes five other cyclists, but they will probably compete in the Polish tour in the ranks of their teams wide cadre for the tour de pologne dariusz baranowski łukasz bodnar bartosz huzarski błażej janiaczyk tomasz kiendyś mateusz komar tomasz lisowicz piotr mazur jacek morajko przemysław german marek rutkiewicz krzysztof szczawiński mateusz taciak adam wadecki mariusz witecki piotr zaradny piotr zieliński mateusz mróz marek wesoły jarosław rębiewski robert radosz jarosław dąbrowski`
|
| 46 |
+
|
| 47 |
+
Output: `['O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-.', 'O', 'O', 'B-,', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-.', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-,', 'O', 'O', 'O', 'B-.', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-,', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-.', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-,', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-.', 'O', 'O', 'O', 'O', 'O', 'B-:', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']`
|
| 48 |
+
|
| 49 |
## Dataset – WikiPunct
|
| 50 |
|
| 51 |
WikiPunct is a crowdsourced text and audio data set of Polish Wikipedia pages read out loud by Polish lectors. The dataset is divided into two parts:conversational(WikiTalks)and information (WikiNews). Over a hundred people were involved in the production of the audio component. The total length of audio data reaches almost thirty-six hours, including the test set. Steps were taken to balance the male-to-female ratio.
|