Datasets:

Tasks:
Text Classification
Sub-tasks:
multi-label-classification
Languages:
English
Size:
100K<n<1M
ArXiv:
License:

Commit
·
dd486cd
0
Parent(s):
Update files from the datasets library (from 1.2.1)
Browse filesRelease notes: https://github.com/huggingface/datasets/releases/tag/1.2.1
- .gitattributes +27 -0
- README.md +298 -0
- dataset_infos.json +1 -0
- dummy/0.0.0/dummy_data.zip +3 -0
- swda.py +203 -0
.gitattributes
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bin.* filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,298 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
annotations_creators:
|
| 3 |
+
- found
|
| 4 |
+
language_creators:
|
| 5 |
+
- found
|
| 6 |
+
languages:
|
| 7 |
+
- en
|
| 8 |
+
licenses:
|
| 9 |
+
- cc-by-nc-sa-3-0
|
| 10 |
+
multilinguality:
|
| 11 |
+
- monolingual
|
| 12 |
+
size_categories:
|
| 13 |
+
- n<1K
|
| 14 |
+
source_datasets:
|
| 15 |
+
- extended|other-Switchboard-1 Telephone Speech Corpus, Release 2
|
| 16 |
+
task_categories:
|
| 17 |
+
- text-classification
|
| 18 |
+
task_ids:
|
| 19 |
+
- multi-label-classification
|
| 20 |
+
---
|
| 21 |
+
|
| 22 |
+
# Dataset Card for swda
|
| 23 |
+
|
| 24 |
+
## Table of Contents
|
| 25 |
+
- [Dataset Description](#dataset-description)
|
| 26 |
+
- [Dataset Summary](#dataset-summary)
|
| 27 |
+
- [Supported Tasks](#supported-tasks-and-leaderboards)
|
| 28 |
+
- [Languages](#languages)
|
| 29 |
+
- [Dataset Structure](#dataset-structure)
|
| 30 |
+
- [Data Instances](#data-instances)
|
| 31 |
+
- [Data Fields](#data-fields)
|
| 32 |
+
- [Data Splits](#data-splits)
|
| 33 |
+
- [Dataset Creation](#dataset-creation)
|
| 34 |
+
- [Curation Rationale](#curation-rationale)
|
| 35 |
+
- [Source Data](#source-data)
|
| 36 |
+
- [Annotations](#annotations)
|
| 37 |
+
- [Personal and Sensitive Information](#personal-and-sensitive-information)
|
| 38 |
+
- [Considerations for Using the Data](#considerations-for-using-the-data)
|
| 39 |
+
- [Social Impact of Dataset](#social-impact-of-dataset)
|
| 40 |
+
- [Discussion of Biases](#discussion-of-biases)
|
| 41 |
+
- [Other Known Limitations](#other-known-limitations)
|
| 42 |
+
- [Additional Information](#additional-information)
|
| 43 |
+
- [Dataset Curators](#dataset-curators)
|
| 44 |
+
- [Licensing Information](#licensing-information)
|
| 45 |
+
- [Citation Information](#citation-information)
|
| 46 |
+
|
| 47 |
+
## Dataset Description
|
| 48 |
+
|
| 49 |
+
- **Homepage: [The Switchboard Dialog Act Corpus](http://compprag.christopherpotts.net/swda.html)**
|
| 50 |
+
- **Repository: [NathanDuran/Switchboard-Corpus](https://github.com/NathanDuran/Switchboard-Corpus)**
|
| 51 |
+
- **Paper:[The Switchboard Dialog Act Corpus](http://compprag.christopherpotts.net/swda.html)**
|
| 52 |
+
= **Leaderboard: [Dialogue act classification](https://github.com/sebastianruder/NLP-progress/blob/master/english/dialogue.md#dialogue-act-classification)**
|
| 53 |
+
- **Point of Contact: [Christopher Potts](https://web.stanford.edu/~cgpotts/)**
|
| 54 |
+
|
| 55 |
+
### Dataset Summary
|
| 56 |
+
|
| 57 |
+
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2 with
|
| 58 |
+
turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information about the
|
| 59 |
+
associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
|
| 60 |
+
The SwDA is not inherently linked to the Penn Treebank 3 parses of Switchboard, and it is far from straightforward to
|
| 61 |
+
align the two resources. In addition, the SwDA is not distributed with the Switchboard's tables of metadata about the
|
| 62 |
+
conversations and their participants.
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
### Supported Tasks and Leaderboards
|
| 66 |
+
|
| 67 |
+
| Model | Accuracy | Paper / Source | Code |
|
| 68 |
+
| ------------- | :-----:| --- | --- |
|
| 69 |
+
| SGNN (Ravi et al., 2018) | 83.1 | [Self-Governing Neural Networks for On-Device Short Text Classification](https://www.aclweb.org/anthology/D18-1105.pdf)
|
| 70 |
+
| CASA (Raheja et al., 2019) | 82.9 | [Dialogue Act Classification with Context-Aware Self-Attention](https://www.aclweb.org/anthology/N19-1373.pdf)
|
| 71 |
+
| DAH-CRF (Li et al., 2019) | 82.3 | [A Dual-Attention Hierarchical Recurrent Neural Network for Dialogue Act Classification](https://www.aclweb.org/anthology/K19-1036.pdf)
|
| 72 |
+
| ALDMN (Wan et al., 2018) | 81.5 | [Improved Dynamic Memory Network for Dialogue Act Classification with Adversarial Training](https://arxiv.org/pdf/1811.05021.pdf)
|
| 73 |
+
| CRF-ASN (Chen et al., 2018) | 81.3 | [Dialogue Act Recognition via CRF-Attentive Structured Network](https://arxiv.org/abs/1711.05568) | |
|
| 74 |
+
| Bi-LSTM-CRF (Kumar et al., 2017) | 79.2 | [Dialogue Act Sequence Labeling using Hierarchical encoder with CRF](https://arxiv.org/abs/1709.04250) | [Link](https://github.com/YanWenqiang/HBLSTM-CRF) |
|
| 75 |
+
| RNN with 3 utterances in context (Bothe et al., 2018) | 77.34 | [A Context-based Approach for Dialogue Act Recognition using Simple Recurrent Neural Networks](https://arxiv.org/abs/1805.06280) | |
|
| 76 |
+
|
| 77 |
+
### Languages
|
| 78 |
+
|
| 79 |
+
The language supported is English.
|
| 80 |
+
|
| 81 |
+
## Dataset Structure
|
| 82 |
+
|
| 83 |
+
Utterance are tagged with the [SWBD-DAMSL](https://web.stanford.edu/~jurafsky/ws97/manual.august1.html) DA.
|
| 84 |
+
|
| 85 |
+
### Data Instances
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
An example from the dataset is:
|
| 89 |
+
|
| 90 |
+
`{'dialogue_act_tag': 17, 'speaker': 0, 'utterance_text': 'Okay.'}`
|
| 91 |
+
|
| 92 |
+
where 17 correspond to `fo_o_fw_"_by_bc` (Other)
|
| 93 |
+
|
| 94 |
+
### Data Fields
|
| 95 |
+
`speaker` - Refers to the current speaker talking. It is used to detect when a speaker change occurs.
|
| 96 |
+
There are two values for speaker: `A` and `B`. This does not mean we only have tow speakers in the whole datasets.
|
| 97 |
+
It's only used to signal if next utterance is from same speaker or from next speaker. Since we encoded all labels
|
| 98 |
+
`A=0` and `B=1`.
|
| 99 |
+
|
| 100 |
+
`utterance_text` - Text that a speaker says.
|
| 101 |
+
|
| 102 |
+
`dialogue_act_tag` - Dialogue act label associated with the `utterance_text`. There are 41 dialogue act labels for this
|
| 103 |
+
dataset. Each dialogue act label has a specific meaning:
|
| 104 |
+
|
| 105 |
+
| Int | Dialogue Act | Labels |
|
| 106 |
+
|-- |------------------------------ |----------------- |
|
| 107 |
+
| 0 | Statement-non-opinion | sd |
|
| 108 |
+
| 1 | Acknowledge (Backchannel) | b |
|
| 109 |
+
| 2 | Statement-opinion | sv |
|
| 110 |
+
| 3 | Uninterpretable | % |
|
| 111 |
+
| 4 | Agree/Accept | aa |
|
| 112 |
+
| 5 | Appreciation | ba |
|
| 113 |
+
| 6 | Yes-No-Question | qy |
|
| 114 |
+
| 7 | Yes Answers | ny |
|
| 115 |
+
| 8 | Conventional-closing | fc |
|
| 116 |
+
| 9 | Wh-Question | qw |
|
| 117 |
+
| 10 | No Answers | nn |
|
| 118 |
+
| 11 | Response Acknowledgement | bk |
|
| 119 |
+
| 12 | Hedge | h |
|
| 120 |
+
| 13 | Declarative Yes-No-Question | qy^d |
|
| 121 |
+
| 14 | Backchannel in Question Form | bh |
|
| 122 |
+
| 15 | Quotation | ^q |
|
| 123 |
+
| 16 | Summarize/Reformulate | bf |
|
| 124 |
+
| 17 | Other | fo_o_fw_"_by_bc |
|
| 125 |
+
| 18 | Affirmative Non-yes Answers | na |
|
| 126 |
+
| 19 | Action-directive | ad |
|
| 127 |
+
| 20 | Collaborative Completion | ^2 |
|
| 128 |
+
| 21 | Repeat-phrase | b^m |
|
| 129 |
+
| 22 | Open-Question | qo |
|
| 130 |
+
| 23 | Rhetorical-Question | qh |
|
| 131 |
+
| 24 | Hold Before Answer/Agreement | ^h |
|
| 132 |
+
| 25 | Reject | ar |
|
| 133 |
+
| 26 | Negative Non-no Answers | ng |
|
| 134 |
+
| 27 | Signal-non-understanding | br |
|
| 135 |
+
| 28 | Other Answers | no |
|
| 136 |
+
| 29 | Conventional-opening | fp |
|
| 137 |
+
| 30 | Or-Clause | qrr |
|
| 138 |
+
| 31 | Dispreferred Answers | arp_nd |
|
| 139 |
+
| 32 | 3rd-party-talk | t3 |
|
| 140 |
+
| 33 | Offers, Options Commits | oo_co_cc |
|
| 141 |
+
| 34 | Maybe/Accept-part | aap_am |
|
| 142 |
+
| 35 | Downplayer | t1 |
|
| 143 |
+
| 36 | Self-talk | bd |
|
| 144 |
+
| 37 | Tag-Question | ^g |
|
| 145 |
+
| 38 | Declarative Wh-Question | qw^d |
|
| 146 |
+
| 39 | Apology | fa |
|
| 147 |
+
| 40 | Thanking | ft |
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
## Data Stats
|
| 151 |
+
|
| 152 |
+
|Dialogue Act | Labels | Count | % | Train Count | Train % | Test Count | Test % | Val Count | Val %
|
| 153 |
+
--- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---:
|
| 154 |
+
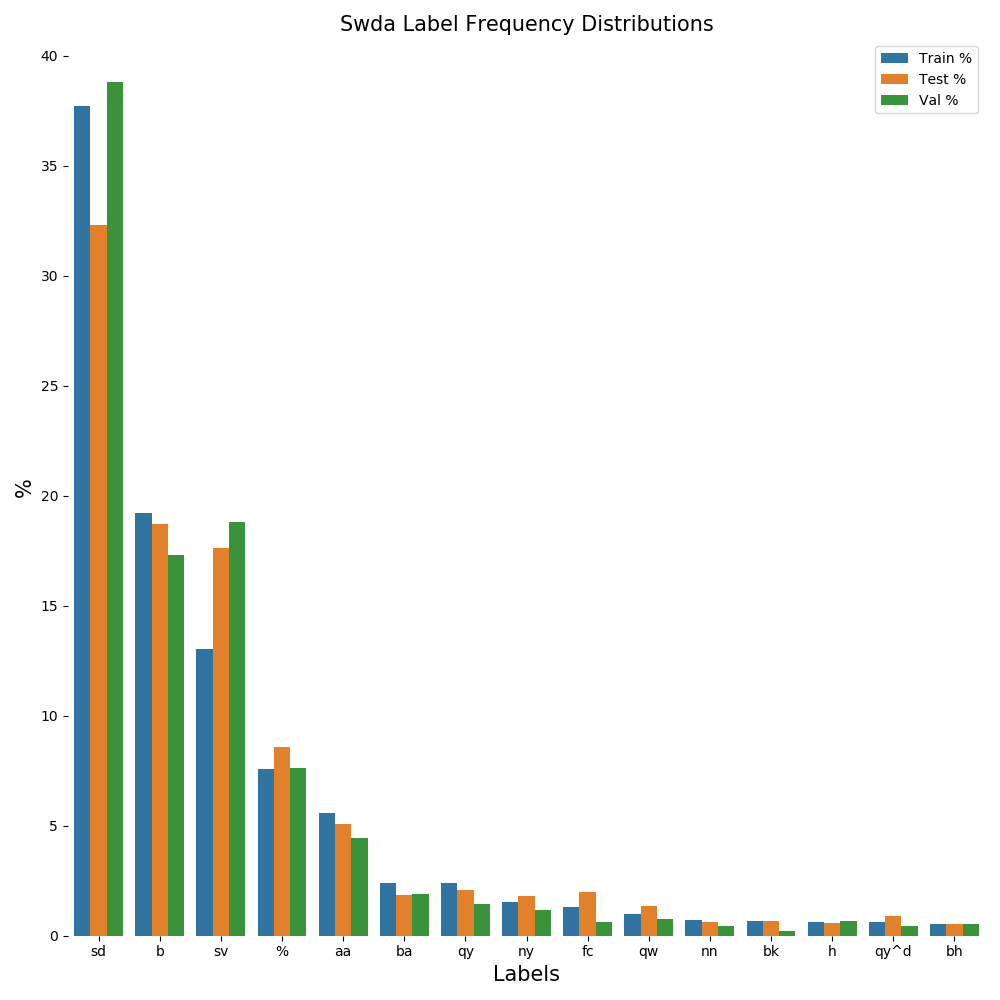
Statement-non-opinion | sd | 75136 | 37.62 | 72549 | 37.71 | 1317 | 32.30 | 1270 | 38.81
|
| 155 |
+
Acknowledge (Backchannel) | b | 38281 | 19.17 | 36950 | 19.21 | 764 | 18.73 | 567 | 17.33
|
| 156 |
+
Statement-opinion | sv | 26421 | 13.23 | 25087 | 13.04 | 718 | 17.61 | 616 | 18.83
|
| 157 |
+
Uninterpretable | % | 15195 | 7.61 | 14597 | 7.59 | 349 | 8.56 | 249 | 7.61
|
| 158 |
+
Agree/Accept | aa | 11123 | 5.57 | 10770 | 5.60 | 207 | 5.08 | 146 | 4.46
|
| 159 |
+
Appreciation | ba | 4757 | 2.38 | 4619 | 2.40 | 76 | 1.86 | 62 | 1.89
|
| 160 |
+
Yes-No-Question | qy | 4725 | 2.37 | 4594 | 2.39 | 84 | 2.06 | 47 | 1.44
|
| 161 |
+
Yes Answers | ny | 3030 | 1.52 | 2918 | 1.52 | 73 | 1.79 | 39 | 1.19
|
| 162 |
+
Conventional-closing | fc | 2581 | 1.29 | 2480 | 1.29 | 81 | 1.99 | 20 | 0.61
|
| 163 |
+
Wh-Question | qw | 1976 | 0.99 | 1896 | 0.99 | 55 | 1.35 | 25 | 0.76
|
| 164 |
+
No Answers | nn | 1374 | 0.69 | 1334 | 0.69 | 26 | 0.64 | 14 | 0.43
|
| 165 |
+
Response Acknowledgement | bk | 1306 | 0.65 | 1271 | 0.66 | 28 | 0.69 | 7 | 0.21
|
| 166 |
+
Hedge | h | 1226 | 0.61 | 1181 | 0.61 | 23 | 0.56 | 22 | 0.67
|
| 167 |
+
Declarative Yes-No-Question | qy^d | 1218 | 0.61 | 1167 | 0.61 | 36 | 0.88 | 15 | 0.46
|
| 168 |
+
Backchannel in Question Form | bh | 1053 | 0.53 | 1015 | 0.53 | 21 | 0.51 | 17 | 0.52
|
| 169 |
+
Quotation | ^q | 983 | 0.49 | 931 | 0.48 | 17 | 0.42 | 35 | 1.07
|
| 170 |
+
Summarize/Reformulate | bf | 952 | 0.48 | 905 | 0.47 | 23 | 0.56 | 24 | 0.73
|
| 171 |
+
Other | fo_o_fw_"_by_bc | 879 | 0.44 | 857 | 0.45 | 15 | 0.37 | 7 | 0.21
|
| 172 |
+
Affirmative Non-yes Answers | na | 847 | 0.42 | 831 | 0.43 | 10 | 0.25 | 6 | 0.18
|
| 173 |
+
Action-directive | ad | 745 | 0.37 | 712 | 0.37 | 27 | 0.66 | 6 | 0.18
|
| 174 |
+
Collaborative Completion | ^2 | 723 | 0.36 | 690 | 0.36 | 19 | 0.47 | 14 | 0.43
|
| 175 |
+
Repeat-phrase | b^m | 687 | 0.34 | 655 | 0.34 | 21 | 0.51 | 11 | 0.34
|
| 176 |
+
Open-Question | qo | 656 | 0.33 | 631 | 0.33 | 16 | 0.39 | 9 | 0.28
|
| 177 |
+
Rhetorical-Question | qh | 575 | 0.29 | 554 | 0.29 | 12 | 0.29 | 9 | 0.28
|
| 178 |
+
Hold Before Answer/Agreement | ^h | 556 | 0.28 | 539 | 0.28 | 7 | 0.17 | 10 | 0.31
|
| 179 |
+
Reject | ar | 344 | 0.17 | 337 | 0.18 | 3 | 0.07 | 4 | 0.12
|
| 180 |
+
Negative Non-no Answers | ng | 302 | 0.15 | 290 | 0.15 | 6 | 0.15 | 6 | 0.18
|
| 181 |
+
Signal-non-understanding | br | 298 | 0.15 | 286 | 0.15 | 9 | 0.22 | 3 | 0.09
|
| 182 |
+
Other Answers | no | 284 | 0.14 | 277 | 0.14 | 6 | 0.15 | 1 | 0.03
|
| 183 |
+
Conventional-opening | fp | 225 | 0.11 | 220 | 0.11 | 5 | 0.12 | 0 | 0.00
|
| 184 |
+
Or-Clause | qrr | 209 | 0.10 | 206 | 0.11 | 2 | 0.05 | 1 | 0.03
|
| 185 |
+
Dispreferred Answers | arp_nd | 207 | 0.10 | 204 | 0.11 | 3 | 0.07 | 0 | 0.00
|
| 186 |
+
3rd-party-talk | t3 | 117 | 0.06 | 115 | 0.06 | 0 | 0.00 | 2 | 0.06
|
| 187 |
+
Offers, Options Commits | oo_co_cc | 110 | 0.06 | 109 | 0.06 | 0 | 0.00 | 1 | 0.03
|
| 188 |
+
Maybe/Accept-part | aap_am | 104 | 0.05 | 97 | 0.05 | 7 | 0.17 | 0 | 0.00
|
| 189 |
+
Downplayer | t1 | 103 | 0.05 | 102 | 0.05 | 1 | 0.02 | 0 | 0.00
|
| 190 |
+
Self-talk | bd | 103 | 0.05 | 100 | 0.05 | 1 | 0.02 | 2 | 0.06
|
| 191 |
+
Tag-Question | ^g | 92 | 0.05 | 92 | 0.05 | 0 | 0.00 | 0 | 0.00
|
| 192 |
+
Declarative Wh-Question | qw^d | 80 | 0.04 | 79 | 0.04 | 1 | 0.02 | 0 | 0.00
|
| 193 |
+
Apology | fa | 79 | 0.04 | 76 | 0.04 | 2 | 0.05 | 1 | 0.03
|
| 194 |
+
Thanking | ft | 78 | 0.04 | 67 | 0.03 | 7 | 0.17 | 4 | 0.12
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
### Data Splits
|
| 200 |
+
|
| 201 |
+
he data is split into the original training and test sets suggested by the authors (1115 training and 19 test). The remaining 21 dialogues have been used as a validation set.
|
| 202 |
+
|
| 203 |
+
## Dataset Creation
|
| 204 |
+
|
| 205 |
+
### Curation Rationale
|
| 206 |
+
|
| 207 |
+
[More Information Needed]
|
| 208 |
+
|
| 209 |
+
### Source Data
|
| 210 |
+
|
| 211 |
+
#### Initial Data Collection and Normalization
|
| 212 |
+
|
| 213 |
+
- Total number of utterances: 199740
|
| 214 |
+
- Maximum utterance length: 133
|
| 215 |
+
- Mean utterance length: 9.6
|
| 216 |
+
- Total number of dialogues: 1155
|
| 217 |
+
- Maximum dialogue length: 457
|
| 218 |
+
- Mean dialogue length: 172.9
|
| 219 |
+
- Vocabulary size: 22301
|
| 220 |
+
- Number of labels: 41
|
| 221 |
+
- Number of dialogue in train set: 1115
|
| 222 |
+
- Maximum length of dialogue in train set: 457
|
| 223 |
+
- Number of dialogue in test set: 19
|
| 224 |
+
- Maximum length of dialogue in test set: 330
|
| 225 |
+
- Number of dialogue in val set: 21
|
| 226 |
+
- Maximum length of dialogue in val set: 299
|
| 227 |
+
|
| 228 |
+
#### Who are the source language producers?
|
| 229 |
+
|
| 230 |
+
[More Information Needed]
|
| 231 |
+
|
| 232 |
+
### Annotations
|
| 233 |
+
|
| 234 |
+
#### Annotation process
|
| 235 |
+
|
| 236 |
+
[More Information Needed]
|
| 237 |
+
|
| 238 |
+
#### Who are the annotators?
|
| 239 |
+
|
| 240 |
+
[More Information Needed]
|
| 241 |
+
|
| 242 |
+
### Personal and Sensitive Information
|
| 243 |
+
|
| 244 |
+
[More Information Needed]
|
| 245 |
+
|
| 246 |
+
## Considerations for Using the Data
|
| 247 |
+
|
| 248 |
+
### Social Impact of Dataset
|
| 249 |
+
|
| 250 |
+
[More Information Needed]
|
| 251 |
+
|
| 252 |
+
### Discussion of Biases
|
| 253 |
+
|
| 254 |
+
[More Information Needed]
|
| 255 |
+
|
| 256 |
+
### Other Known Limitations
|
| 257 |
+
|
| 258 |
+
[More Information Needed]
|
| 259 |
+
|
| 260 |
+
## Additional Information
|
| 261 |
+
|
| 262 |
+
### Dataset Curators
|
| 263 |
+
|
| 264 |
+
[Christopher Potts](https://web.stanford.edu/~cgpotts/), Stanford Linguistics.
|
| 265 |
+
|
| 266 |
+
### Licensing Information
|
| 267 |
+
|
| 268 |
+
This work is licensed under a [Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.](http://creativecommons.org/licenses/by-nc-sa/3.0/)
|
| 269 |
+
|
| 270 |
+
### Citation Information
|
| 271 |
+
|
| 272 |
+
```
|
| 273 |
+
@techreport{Jurafsky-etal:1997,
|
| 274 |
+
Address = {Boulder, CO},
|
| 275 |
+
Author = {Jurafsky, Daniel and Shriberg, Elizabeth and Biasca, Debra},
|
| 276 |
+
Institution = {University of Colorado, Boulder Institute of Cognitive Science},
|
| 277 |
+
Number = {97-02},
|
| 278 |
+
Title = {Switchboard {SWBD}-{DAMSL} Shallow-Discourse-Function Annotation Coders Manual, Draft 13},
|
| 279 |
+
Year = {1997}}
|
| 280 |
+
|
| 281 |
+
@article{Shriberg-etal:1998,
|
| 282 |
+
Author = {Shriberg, Elizabeth and Bates, Rebecca and Taylor, Paul and Stolcke, Andreas and Jurafsky, Daniel and Ries, Klaus and Coccaro, Noah and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},
|
| 283 |
+
Journal = {Language and Speech},
|
| 284 |
+
Number = {3--4},
|
| 285 |
+
Pages = {439--487},
|
| 286 |
+
Title = {Can Prosody Aid the Automatic Classification of Dialog Acts in Conversational Speech?},
|
| 287 |
+
Volume = {41},
|
| 288 |
+
Year = {1998}}
|
| 289 |
+
|
| 290 |
+
@article{Stolcke-etal:2000,
|
| 291 |
+
Author = {Stolcke, Andreas and Ries, Klaus and Coccaro, Noah and Shriberg, Elizabeth and Bates, Rebecca and Jurafsky, Daniel and Taylor, Paul and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},
|
| 292 |
+
Journal = {Computational Linguistics},
|
| 293 |
+
Number = {3},
|
| 294 |
+
Pages = {339--371},
|
| 295 |
+
Title = {Dialogue Act Modeling for Automatic Tagging and Recognition of Conversational Speech},
|
| 296 |
+
Volume = {26},
|
| 297 |
+
Year = {2000}}
|
| 298 |
+
```
|
dataset_infos.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"default": {"description": "The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2 with\nturn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information about the\nassociated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.\nThe SwDA is not inherently linked to the Penn Treebank 3 parses of Switchboard, and it is far from straightforward to\nalign the two resources. In addition, the SwDA is not distributed with the Switchboard's tables of metadata about the\nconversations and their participants.\n", "citation": "@techreport{Jurafsky-etal:1997,\n Address = {Boulder, CO},\n Author = {Jurafsky, Daniel and Shriberg, Elizabeth and Biasca, Debra},\n Institution = {University of Colorado, Boulder Institute of Cognitive Science},\n Number = {97-02},\n Title = {Switchboard {SWBD}-{DAMSL} Shallow-Discourse-Function Annotation Coders Manual, Draft 13},\n Year = {1997}}\n\n@article{Shriberg-etal:1998,\n Author = {Shriberg, Elizabeth and Bates, Rebecca and Taylor, Paul and Stolcke, Andreas and Jurafsky, Daniel and Ries, Klaus and Coccaro, Noah and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},\n Journal = {Language and Speech},\n Number = {3--4},\n Pages = {439--487},\n Title = {Can Prosody Aid the Automatic Classification of Dialog Acts in Conversational Speech?},\n Volume = {41},\n Year = {1998}}\n\n@article{Stolcke-etal:2000,\n Author = {Stolcke, Andreas and Ries, Klaus and Coccaro, Noah and Shriberg, Elizabeth and Bates, Rebecca and Jurafsky, Daniel and Taylor, Paul and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},\n Journal = {Computational Linguistics},\n Number = {3},\n Pages = {339--371},\n Title = {Dialogue Act Modeling for Automatic Tagging and Recognition of Conversational Speech},\n Volume = {26},\n Year = {2000}}\n", "homepage": "http://compprag.christopherpotts.net/swda.html", "license": "Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License", "features": {"speaker": {"num_classes": 2, "names": ["A", "B"], "names_file": null, "id": null, "_type": "ClassLabel"}, "utterance_text": {"dtype": "string", "id": null, "_type": "Value"}, "dialogue_act_tag": {"num_classes": 41, "names": ["sd", "b", "sv", "%", "aa", "ba", "qy", "ny", "fc", "qw", "nn", "bk", "h", "qy^d", "bh", "^q", "bf", "fo_o_fw_\"_by_bc", "na", "ad", "^2", "b^m", "qo", "qh", "^h", "ar", "ng", "br", "no", "fp", "qrr", "arp_nd", "t3", "oo_co_cc", "aap_am", "t1", "bd", "^g", "qw^d", "fa", "ft"], "names_file": null, "id": null, "_type": "ClassLabel"}}, "post_processed": null, "supervised_keys": null, "builder_name": "swda", "config_name": "default", "version": {"version_str": "0.0.0", "description": null, "major": 0, "minor": 0, "patch": 0}, "splits": {"train": {"name": "train", "num_bytes": 10912837, "num_examples": 192390, "dataset_name": "swda"}, "validation": {"name": "validation", "num_bytes": 189531, "num_examples": 3272, "dataset_name": "swda"}}, "download_checksums": {"https://github.com/NathanDuran/Switchboard-Corpus/raw/master/swda_data/train_set.txt": {"num_bytes": 8182921, "checksum": "0d4ca6fb17d985b8e0eb7ae7ca52bfdd9c6e7c4e9e07a8597d1c808937cb9e80"}, "https://github.com/NathanDuran/Switchboard-Corpus/raw/master/swda_data/val_set.txt": {"num_bytes": 143020, "checksum": "51be26976ad5aa76c01dcdcd85d9ecab216f88b019f5b7cca6afc07dd4879354"}, "https://github.com/NathanDuran/Switchboard-Corpus/raw/master/swda_data/test_set.txt": {"num_bytes": 168864, "checksum": "c54e677d887ab0efb5ef92250d61cca7a1e091b4eb556061dc6987d9e385cd72"}}, "download_size": 8494805, "post_processing_size": null, "dataset_size": 11102368, "size_in_bytes": 19597173}}
|
dummy/0.0.0/dummy_data.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7666f8bc05cc699408411a0b0837c51006a6fb4a7c3df74c4608bee83d99fdfd
|
| 3 |
+
size 1134
|
swda.py
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
"""
|
| 16 |
+
Switchboard Dialog Act Corpus
|
| 17 |
+
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2,
|
| 18 |
+
with turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information
|
| 19 |
+
about the associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
from __future__ import absolute_import, division, print_function
|
| 23 |
+
|
| 24 |
+
import datasets
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
# Citation as described here: https://github.com/cgpotts/swda#citation.
|
| 28 |
+
_CITATION = """\
|
| 29 |
+
@techreport{Jurafsky-etal:1997,
|
| 30 |
+
Address = {Boulder, CO},
|
| 31 |
+
Author = {Jurafsky, Daniel and Shriberg, Elizabeth and Biasca, Debra},
|
| 32 |
+
Institution = {University of Colorado, Boulder Institute of Cognitive Science},
|
| 33 |
+
Number = {97-02},
|
| 34 |
+
Title = {Switchboard {SWBD}-{DAMSL} Shallow-Discourse-Function Annotation Coders Manual, Draft 13},
|
| 35 |
+
Year = {1997}}
|
| 36 |
+
|
| 37 |
+
@article{Shriberg-etal:1998,
|
| 38 |
+
Author = {Shriberg, Elizabeth and Bates, Rebecca and Taylor, Paul and Stolcke, Andreas and Jurafsky, \
|
| 39 |
+
Daniel and Ries, Klaus and Coccaro, Noah and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},
|
| 40 |
+
Journal = {Language and Speech},
|
| 41 |
+
Number = {3--4},
|
| 42 |
+
Pages = {439--487},
|
| 43 |
+
Title = {Can Prosody Aid the Automatic Classification of Dialog Acts in Conversational Speech?},
|
| 44 |
+
Volume = {41},
|
| 45 |
+
Year = {1998}}
|
| 46 |
+
|
| 47 |
+
@article{Stolcke-etal:2000,
|
| 48 |
+
Author = {Stolcke, Andreas and Ries, Klaus and Coccaro, Noah and Shriberg, Elizabeth and Bates, Rebecca and \
|
| 49 |
+
Jurafsky, Daniel and Taylor, Paul and Martin, Rachel and Meteer, Marie and Van Ess-Dykema, Carol},
|
| 50 |
+
Journal = {Computational Linguistics},
|
| 51 |
+
Number = {3},
|
| 52 |
+
Pages = {339--371},
|
| 53 |
+
Title = {Dialogue Act Modeling for Automatic Tagging and Recognition of Conversational Speech},
|
| 54 |
+
Volume = {26},
|
| 55 |
+
Year = {2000}}
|
| 56 |
+
"""
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
# Description of dataset gathered from: https://github.com/cgpotts/swda#overview.
|
| 60 |
+
_DESCRIPTION = """\
|
| 61 |
+
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2 with
|
| 62 |
+
turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information about the
|
| 63 |
+
associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
|
| 64 |
+
The SwDA is not inherently linked to the Penn Treebank 3 parses of Switchboard, and it is far from straightforward to
|
| 65 |
+
align the two resources. In addition, the SwDA is not distributed with the Switchboard's tables of metadata about the
|
| 66 |
+
conversations and their participants.
|
| 67 |
+
"""
|
| 68 |
+
|
| 69 |
+
# Homepage gathered from: https://github.com/cgpotts/swda#overview.
|
| 70 |
+
_HOMEPAGE = "http://compprag.christopherpotts.net/swda.html"
|
| 71 |
+
|
| 72 |
+
# More details about the license: https://creativecommons.org/licenses/by-nc-sa/3.0/.
|
| 73 |
+
_LICENSE = "Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License"
|
| 74 |
+
|
| 75 |
+
# Dataset main url.
|
| 76 |
+
_URL = "https://github.com/NathanDuran/Switchboard-Corpus/raw/master/swda_data/"
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
class Swda(datasets.GeneratorBasedBuilder):
|
| 80 |
+
"""
|
| 81 |
+
Switchboard Dialog Act Corpus
|
| 82 |
+
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2,
|
| 83 |
+
with turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information
|
| 84 |
+
about the associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
|
| 85 |
+
"""
|
| 86 |
+
|
| 87 |
+
# Splits url extensions for train, validation and test.
|
| 88 |
+
_URLS = {"train": _URL + "train_set.txt", "dev": _URL + "val_set.txt", "test": _URL + "test_set.txt"}
|
| 89 |
+
|
| 90 |
+
def _info(self):
|
| 91 |
+
"""
|
| 92 |
+
Specify the datasets.DatasetInfo object which contains informations and typings for the dataset.
|
| 93 |
+
"""
|
| 94 |
+
|
| 95 |
+
return datasets.DatasetInfo(
|
| 96 |
+
# This is the description that will appear on the datasets page.
|
| 97 |
+
description=_DESCRIPTION,
|
| 98 |
+
# This defines the different columns of the dataset and their types.
|
| 99 |
+
features=datasets.Features(
|
| 100 |
+
{
|
| 101 |
+
"speaker": datasets.ClassLabel(
|
| 102 |
+
num_classes=2,
|
| 103 |
+
names=[
|
| 104 |
+
"A",
|
| 105 |
+
"B",
|
| 106 |
+
],
|
| 107 |
+
),
|
| 108 |
+
"utterance_text": datasets.Value("string"),
|
| 109 |
+
"dialogue_act_tag": datasets.ClassLabel(
|
| 110 |
+
num_classes=41,
|
| 111 |
+
names=[
|
| 112 |
+
"sd",
|
| 113 |
+
"b",
|
| 114 |
+
"sv",
|
| 115 |
+
"%",
|
| 116 |
+
"aa",
|
| 117 |
+
"ba",
|
| 118 |
+
"qy",
|
| 119 |
+
"ny",
|
| 120 |
+
"fc",
|
| 121 |
+
"qw",
|
| 122 |
+
"nn",
|
| 123 |
+
"bk",
|
| 124 |
+
"h",
|
| 125 |
+
"qy^d",
|
| 126 |
+
"bh",
|
| 127 |
+
"^q",
|
| 128 |
+
"bf",
|
| 129 |
+
'fo_o_fw_"_by_bc',
|
| 130 |
+
"na",
|
| 131 |
+
"ad",
|
| 132 |
+
"^2",
|
| 133 |
+
"b^m",
|
| 134 |
+
"qo",
|
| 135 |
+
"qh",
|
| 136 |
+
"^h",
|
| 137 |
+
"ar",
|
| 138 |
+
"ng",
|
| 139 |
+
"br",
|
| 140 |
+
"no",
|
| 141 |
+
"fp",
|
| 142 |
+
"qrr",
|
| 143 |
+
"arp_nd",
|
| 144 |
+
"t3",
|
| 145 |
+
"oo_co_cc",
|
| 146 |
+
"aap_am",
|
| 147 |
+
"t1",
|
| 148 |
+
"bd",
|
| 149 |
+
"^g",
|
| 150 |
+
"qw^d",
|
| 151 |
+
"fa",
|
| 152 |
+
"ft",
|
| 153 |
+
],
|
| 154 |
+
),
|
| 155 |
+
}
|
| 156 |
+
),
|
| 157 |
+
supervised_keys=None,
|
| 158 |
+
# Homepage of the dataset for documentation
|
| 159 |
+
homepage=_HOMEPAGE,
|
| 160 |
+
# License for the dataset if available
|
| 161 |
+
license=_LICENSE,
|
| 162 |
+
# Citation for the dataset
|
| 163 |
+
citation=_CITATION,
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
def _split_generators(self, dl_manager):
|
| 167 |
+
"""
|
| 168 |
+
Returns SplitGenerators.
|
| 169 |
+
This method is tasked with downloading/extracting the data and defining the splits.
|
| 170 |
+
"""
|
| 171 |
+
|
| 172 |
+
urls_to_download = self._URLS
|
| 173 |
+
downloaded_files = dl_manager.download_and_extract(urls_to_download)
|
| 174 |
+
|
| 175 |
+
return [
|
| 176 |
+
datasets.SplitGenerator(
|
| 177 |
+
name=datasets.Split.TRAIN, gen_kwargs={"filepath": downloaded_files["train"], "split": "train"}
|
| 178 |
+
),
|
| 179 |
+
datasets.SplitGenerator(
|
| 180 |
+
name=datasets.Split.VALIDATION, gen_kwargs={"filepath": downloaded_files["dev"], "split": "validation"}
|
| 181 |
+
),
|
| 182 |
+
]
|
| 183 |
+
|
| 184 |
+
def _generate_examples(self, filepath, split):
|
| 185 |
+
"""
|
| 186 |
+
Yields examples.
|
| 187 |
+
This method will receive as arguments the `gen_kwargs` defined in the previous `_split_generators` method.
|
| 188 |
+
It is in charge of opening the given file and yielding (key, example) tuples from the dataset
|
| 189 |
+
The key is not important, it's more here for legacy reason (legacy from tfds).
|
| 190 |
+
"""
|
| 191 |
+
|
| 192 |
+
with open(filepath, encoding="utf-8") as f:
|
| 193 |
+
for id_, row in enumerate(f):
|
| 194 |
+
|
| 195 |
+
# Parse row into speaker info | utterance text | dialogue act tag.
|
| 196 |
+
parsed_row = row.rstrip("\r\n").split("|")
|
| 197 |
+
|
| 198 |
+
# Also returning dialogue act integer label.
|
| 199 |
+
yield f"{split}-{id_}", {
|
| 200 |
+
"speaker": parsed_row[0],
|
| 201 |
+
"utterance_text": parsed_row[1],
|
| 202 |
+
"dialogue_act_tag": parsed_row[2],
|
| 203 |
+
}
|