

Commit
•
1352c88
1
Parent(s):
124701c
pr/kls-1 (#3)
Browse files- Added all `.csv` files os of 2022-10-08 (4ba708a833a2064337b3e487eb5e0dfc21a1d2e5)
- Initial 🌲📜`cannabis_licenses` data algorithms 🤖 (37c1d7cb64442f232c4aa2fd7c36425b09ace75b)
This view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- .gitignore +3 -0
- README.md +81 -78
- algorithms/get_licenses_ak.py +226 -3
- algorithms/get_licenses_az.py +274 -187
- algorithms/get_licenses_ca.py +8 -1
- algorithms/get_licenses_co.py +204 -4
- algorithms/get_licenses_ct.py +145 -3
- algorithms/get_licenses_il.py +177 -4
- algorithms/get_licenses_ma.py +126 -3
- algorithms/get_licenses_me.py +27 -25
- algorithms/get_licenses_mi.py +242 -4
- algorithms/get_licenses_mt.py +230 -104
- algorithms/get_licenses_nj.py +6 -1
- algorithms/get_licenses_nm.py +292 -4
- algorithms/get_licenses_nv.py +21 -6
- algorithms/get_licenses_or.py +27 -8
- algorithms/get_licenses_ri.py +160 -2
- algorithms/get_licenses_vt.py +234 -2
- algorithms/get_licenses_wa.py +136 -49
- algorithms/main.py +69 -28
- analysis/figures/cannabis-licenses-map.html +0 -0
- analysis/figures/cannabis-licenses-map.png +3 -0
- analysis/license_map.py +74 -59
- cannabis_licenses.py +16 -8
- data/ak/licenses-ak-2022-10-06T17-46-29.csv +3 -0
- data/{nv/retailers-nv-2022-09-30T07-41-59.xlsx → ak/retailers-ak-2022-10-06T17-46-29.csv} +2 -2
- data/{ca/licenses-ca-2022-09-21T19-02-29.xlsx → all/licenses-2022-10-06T18-46-11.csv} +2 -2
- data/all/licenses-2022-10-08T14-03-08.csv +3 -0
- data/all/retailers-2022-10-07T10-20-55.csv +3 -0
- data/{me/licenses-me-2022-09-30T16-44-03.xlsx → az/licenses-az-2022-10-07T10-12-07.csv} +2 -2
- data/{nv/licenses-nv-2022-09-30T07-37-45.xlsx → az/retailers-az-2022-10-07T10-12-07.csv} +2 -2
- data/ca/licenses-ca-2022-10-06T18-10-15.csv +3 -0
- data/co/licenses-co-2022-10-06T18-28-29.csv +3 -0
- data/co/retailers-co-2022-10-06T18-28-29.csv +3 -0
- data/{nj/licenses-nj-2022-09-29T16-17-38.xlsx → ct/retailers-ct-2022-10-06T18-28-33.csv} +2 -2
- data/il/retailers-il-2022-10-06T18-28-55.csv +3 -0
- data/ma/licenses-ma-2022-10-07T14-45-39.csv +3 -0
- data/ma/retailers-ma-2022-10-07T14-45-39.csv +3 -0
- data/me/licenses-me-2022-10-07T15-26-01.csv +3 -0
- data/mi/licenses-mi-2022-10-08T13-49-04.csv +3 -0
- data/mt/retailers-mt-2022-10-07T16-28-10.csv +3 -0
- data/nj/licenses-nj-2022-10-06T18-39-17.csv +3 -0
- data/nm/retailers-nm-2022-10-05T15-09-21.csv +3 -0
- data/nv/licenses-nv-2022-10-06T18-42-39.csv +3 -0
- data/nv/retailers-nv-2022-10-06T18-43-01.csv +3 -0
- data/or/licenses-or-2022-09-28T10-11-12.xlsx +0 -3
- data/or/licenses-or-2022-10-07T14-47-55.csv +3 -0
- data/ri/licenses-ri-2022-10-06T18-45-41.csv +3 -0
- data/vt/licenses-vt-2022-10-06T18-46-08.csv +3 -0
.gitattributes
CHANGED
|
@@ -50,3 +50,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 50 |
*.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 51 |
*.webp filter=lfs diff=lfs merge=lfs -text
|
| 52 |
*.xlsx filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 50 |
*.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 51 |
*.webp filter=lfs diff=lfs merge=lfs -text
|
| 52 |
*.xlsx filter=lfs diff=lfs merge=lfs -text
|
| 53 |
+
*.csv filter=lfs diff=lfs merge=lfs -text
|
.gitignore
CHANGED
|
@@ -12,3 +12,6 @@
|
|
| 12 |
|
| 13 |
# Ignore VS Code settings.
|
| 14 |
*.vscode
|
|
|
|
|
|
|
|
|
|
|
|
| 12 |
|
| 13 |
# Ignore VS Code settings.
|
| 14 |
*.vscode
|
| 15 |
+
|
| 16 |
+
# Ignore PyCache
|
| 17 |
+
*__pycache__
|
README.md
CHANGED
|
@@ -14,10 +14,15 @@ tags:
|
|
| 14 |
- cannabis
|
| 15 |
- licenses
|
| 16 |
- licensees
|
|
|
|
| 17 |
---
|
| 18 |
|
| 19 |
# Cannabis Licenses, Curated by Cannlytics
|
| 20 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 21 |
## Table of Contents
|
| 22 |
- [Table of Contents](#table-of-contents)
|
| 23 |
- [Dataset Description](#dataset-description)
|
|
@@ -49,58 +54,55 @@ tags:
|
|
| 49 |
|
| 50 |
### Dataset Summary
|
| 51 |
|
| 52 |
-
|
| 53 |
|
| 54 |
## Dataset Structure
|
| 55 |
|
| 56 |
-
The dataset is partitioned into subsets for each state.
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
| [Alaska](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/ak) | |
|
| 62 |
-
| [Arizona](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/az) |
|
| 63 |
-
| [California](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/ca) | ✅ |
|
| 64 |
-
| [Colorado](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/co) | |
|
| 65 |
-
| [Connecticut](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/ct) | |
|
| 66 |
-
| [Illinois](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/il) | |
|
| 67 |
-
| [Maine](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/me) | ✅ |
|
| 68 |
-
| [Massachusetts](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/ma) | |
|
| 69 |
-
| [Michigan](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/mi) | |
|
| 70 |
-
| [Montana](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/mt) | |
|
| 71 |
-
| [Nevada](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/nv) | ✅ |
|
| 72 |
-
| [New Jersey](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/nj) | ✅ |
|
| 73 |
-
|
|
| 74 |
-
| [
|
| 75 |
-
| [
|
| 76 |
-
| [
|
| 77 |
-
| [
|
| 78 |
-
|
| 79 |
-
|
|
|
|
|
|
|
| 80 |
|
| 81 |
-
-
|
| 82 |
-
- Virginia
|
| 83 |
-
|
| 84 |
-
Medical (18):
|
| 85 |
-
|
| 86 |
-
- District of Columbia (D.C.)
|
| 87 |
-
- Utah
|
| 88 |
-
- Oklahoma
|
| 89 |
-
- North Dakota
|
| 90 |
-
- South Dakota
|
| 91 |
-
- Minnesota
|
| 92 |
-
- Missouri
|
| 93 |
- Arkansas
|
|
|
|
|
|
|
|
|
|
| 94 |
- Louisiana
|
|
|
|
|
|
|
| 95 |
- Mississippi
|
| 96 |
-
-
|
| 97 |
-
-
|
|
|
|
| 98 |
- Ohio
|
| 99 |
-
-
|
| 100 |
- Pennsylvania
|
| 101 |
-
-
|
| 102 |
-
-
|
| 103 |
-
-
|
| 104 |
|
| 105 |
### Data Instances
|
| 106 |
|
|
@@ -122,33 +124,34 @@ Below is a non-exhaustive list of fields, used to standardize the various data t
|
|
| 122 |
|
| 123 |
| Field | Example | Description |
|
| 124 |
|-------|-----|-------------|
|
| 125 |
-
| `id` | `"1046"` |
|
| 126 |
-
| `license_number` | `"C10-0000423-LIC"` |
|
| 127 |
-
| `license_status` | `"Active"` |
|
| 128 |
-
| `license_status_date` | `""` |
|
| 129 |
-
| `license_term` | `"Provisional"` |
|
| 130 |
-
| `license_type` | `"Commercial -
|
| 131 |
-
| `license_designation` | `"Adult-Use and Medicinal"` |
|
| 132 |
-
| `issue_date` | `"2019-07-15T00:00:00"` |
|
| 133 |
-
| `expiration_date` | `"2023-07-14T00:00:00"` |
|
| 134 |
-
| `licensing_authority_id` | `"BCC"` |
|
| 135 |
-
| `licensing_authority` | `"Bureau of Cannabis Control (BCC)"` |
|
| 136 |
-
| `business_legal_name` | `"Movocan"` |
|
| 137 |
-
| `business_dba_name` | `"Movocan"` |
|
| 138 |
-
| `business_owner_name` | `"redacted"` |
|
| 139 |
-
| `business_structure` | `"Corporation"` |
|
| 140 |
-
| `activity` | `""` |
|
| 141 |
-
| `premise_street_address` | `"1632 Gateway Rd"` |
|
| 142 |
-
| `premise_city` | `"Calexico"` |
|
| 143 |
-
| `premise_state` | `"CA"` |
|
| 144 |
-
| `premise_county` | `"Imperial"` |
|
| 145 |
-
| `premise_zip_code` | `"92231"` |
|
| 146 |
-
| `business_email` | `"redacted@gmail.com"` |
|
| 147 |
-
| `business_phone` | `"(555) 555-5555"` |
|
| 148 |
-
| `
|
| 149 |
-
| `
|
| 150 |
-
| `
|
| 151 |
-
| `
|
|
|
|
| 152 |
|
| 153 |
### Data Splits
|
| 154 |
|
|
@@ -176,12 +179,12 @@ Data about organizations operating in the cannabis industry for each state is va
|
|
| 176 |
| Alaska | <https://www.commerce.alaska.gov/abc/marijuana/Home/licensesearch> |
|
| 177 |
| Arizona | <https://azcarecheck.azdhs.gov/s/?licenseType=null> |
|
| 178 |
| California | <https://search.cannabis.ca.gov/> |
|
| 179 |
-
| Colorado |
|
| 180 |
| Connecticut | <https://portal.ct.gov/DCP/Medical-Marijuana-Program/Connecticut-Medical-Marijuana-Dispensary-Facilities> |
|
| 181 |
-
| Illinois |
|
| 182 |
| Maine | <https://www.maine.gov/dafs/ocp/open-data/adult-use> |
|
| 183 |
-
| Massachusetts |
|
| 184 |
-
| Michigan |
|
| 185 |
| Montana | <https://mtrevenue.gov/cannabis/#CannabisLicenses> |
|
| 186 |
| Nevada | <https://ccb.nv.gov/list-of-licensees/> |
|
| 187 |
| New Jersey | <https://data.nj.gov/stories/s/ggm4-mprw> |
|
|
@@ -191,7 +194,7 @@ Data about organizations operating in the cannabis industry for each state is va
|
|
| 191 |
| Vermont | <https://ccb.vermont.gov/licenses> |
|
| 192 |
| Washington | <https://lcb.wa.gov/records/frequently-requested-lists> |
|
| 193 |
|
| 194 |
-
|
| 195 |
|
| 196 |
In the `algorithms` directory, you can find the algorithms used for data collection. You can use these algorithms to recreate the dataset. First, you will need to clone the repository:
|
| 197 |
|
|
@@ -241,7 +244,7 @@ The data is for adult-use cannabis licenses. It would be valuable to include med
|
|
| 241 |
### Dataset Curators
|
| 242 |
|
| 243 |
Curated by [🔥Cannlytics](https://cannlytics.com)<br>
|
| 244 |
-
<
|
| 245 |
|
| 246 |
### License
|
| 247 |
|
|
@@ -267,7 +270,7 @@ Please cite the following if you use the code examples in your research:
|
|
| 267 |
```bibtex
|
| 268 |
@misc{cannlytics2022,
|
| 269 |
title={Cannabis Data Science},
|
| 270 |
-
author={Skeate, Keegan},
|
| 271 |
journal={https://github.com/cannlytics/cannabis-data-science},
|
| 272 |
year={2022}
|
| 273 |
}
|
|
@@ -275,4 +278,4 @@ Please cite the following if you use the code examples in your research:
|
|
| 275 |
|
| 276 |
### Contributions
|
| 277 |
|
| 278 |
-
Thanks to [🔥Cannlytics](https://cannlytics.com), [@candy-o](https://github.com/candy-o), [@keeganskeate](https://github.com/keeganskeate), and the entire [Cannabis Data Science Team](https://meetup.com/cannabis-data-science/members) for their contributions.
|
|
|
|
| 14 |
- cannabis
|
| 15 |
- licenses
|
| 16 |
- licensees
|
| 17 |
+
- retail
|
| 18 |
---
|
| 19 |
|
| 20 |
# Cannabis Licenses, Curated by Cannlytics
|
| 21 |
|
| 22 |
+
<div align="center" style="text-align:center; margin-top:1rem; margin-bottom: 1rem;">
|
| 23 |
+
<img style="max-height:365px;width:100%;max-width:720px;" alt="" src="analysis/figures/cannabis-licenses-map.png">
|
| 24 |
+
</div>
|
| 25 |
+
|
| 26 |
## Table of Contents
|
| 27 |
- [Table of Contents](#table-of-contents)
|
| 28 |
- [Dataset Description](#dataset-description)
|
|
|
|
| 54 |
|
| 55 |
### Dataset Summary
|
| 56 |
|
| 57 |
+
**Cannabis Licenses** is a collection of cannabis license data for each state with permitted adult-use cannabis. The dataset also includes a sub-dataset, `all`, that includes all licenses.
|
| 58 |
|
| 59 |
## Dataset Structure
|
| 60 |
|
| 61 |
+
The dataset is partitioned into 18 subsets for each state and the aggregate.
|
| 62 |
+
|
| 63 |
+
| State | Code | Status |
|
| 64 |
+
|-------|------|--------|
|
| 65 |
+
| [All](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/all) | `all` | ✅ |
|
| 66 |
+
| [Alaska](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/ak) | `ak` | ✅ |
|
| 67 |
+
| [Arizona](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/az) | `az` | ✅ |
|
| 68 |
+
| [California](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/ca) | `ca` | ✅ |
|
| 69 |
+
| [Colorado](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/co) | `co` | ✅ |
|
| 70 |
+
| [Connecticut](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/ct) | `ct` | ✅ |
|
| 71 |
+
| [Illinois](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/il) | `il` | ✅ |
|
| 72 |
+
| [Maine](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/me) | `me` | ✅ |
|
| 73 |
+
| [Massachusetts](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/ma) | `ma` | ✅ |
|
| 74 |
+
| [Michigan](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/mi) | `mi` | ✅ |
|
| 75 |
+
| [Montana](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/mt) | `mt` | ✅ |
|
| 76 |
+
| [Nevada](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/nv) | `nv` | ✅ |
|
| 77 |
+
| [New Jersey](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/nj) | `nj` | ✅ |
|
| 78 |
+
| New York | `ny` | ⏳ Expected 2022 Q4 |
|
| 79 |
+
| [New Mexico](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/nm) | `nm` | ⚠️ Under development |
|
| 80 |
+
| [Oregon](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/or) | `or` | ✅ |
|
| 81 |
+
| [Rhode Island](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/ri) | `ri` | ✅ |
|
| 82 |
+
| [Vermont](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/vt) | `vt` | ✅ |
|
| 83 |
+
| Virginia | `va` | ⏳ Expected 2024 |
|
| 84 |
+
| [Washington](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/wa) | `wa` | ✅ |
|
| 85 |
+
|
| 86 |
+
The following (18) states have issued medical cannabis licenses, but are not (yet) included in the dataset:
|
| 87 |
|
| 88 |
+
- Alabama
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 89 |
- Arkansas
|
| 90 |
+
- Delaware
|
| 91 |
+
- District of Columbia (D.C.)
|
| 92 |
+
- Florida
|
| 93 |
- Louisiana
|
| 94 |
+
- Maryland
|
| 95 |
+
- Minnesota
|
| 96 |
- Mississippi
|
| 97 |
+
- Missouri
|
| 98 |
+
- New Hampshire
|
| 99 |
+
- North Dakota
|
| 100 |
- Ohio
|
| 101 |
+
- Oklahoma
|
| 102 |
- Pennsylvania
|
| 103 |
+
- South Dakota
|
| 104 |
+
- Utah
|
| 105 |
+
- West Virginia
|
| 106 |
|
| 107 |
### Data Instances
|
| 108 |
|
|
|
|
| 124 |
|
| 125 |
| Field | Example | Description |
|
| 126 |
|-------|-----|-------------|
|
| 127 |
+
| `id` | `"1046"` | A state-unique ID for the license. |
|
| 128 |
+
| `license_number` | `"C10-0000423-LIC"` | A unique license number. |
|
| 129 |
+
| `license_status` | `"Active"` | The status of the license. Only licenses that are active are included. |
|
| 130 |
+
| `license_status_date` | `"2022-04-20T00:00"` | The date the status was assigned, an ISO-formatted date if present. |
|
| 131 |
+
| `license_term` | `"Provisional"` | The term for the license. |
|
| 132 |
+
| `license_type` | `"Commercial - Retailer"` | The type of business license. |
|
| 133 |
+
| `license_designation` | `"Adult-Use and Medicinal"` | A state-specific classification for the license. |
|
| 134 |
+
| `issue_date` | `"2019-07-15T00:00:00"` | An issue date for the license, an ISO-formatted date if present. |
|
| 135 |
+
| `expiration_date` | `"2023-07-14T00:00:00"` | An expiration date for the license, an ISO-formatted date if present. |
|
| 136 |
+
| `licensing_authority_id` | `"BCC"` | A unique ID for the state licensing authority. |
|
| 137 |
+
| `licensing_authority` | `"Bureau of Cannabis Control (BCC)"` | The state licensing authority. |
|
| 138 |
+
| `business_legal_name` | `"Movocan"` | The legal name of the business that owns the license. |
|
| 139 |
+
| `business_dba_name` | `"Movocan"` | The name the license is doing business as. |
|
| 140 |
+
| `business_owner_name` | `"redacted"` | The name of the owner of the license. |
|
| 141 |
+
| `business_structure` | `"Corporation"` | The structure of the business that owns the license. |
|
| 142 |
+
| `activity` | `"Pending Inspection"` | Any relevant license activity. |
|
| 143 |
+
| `premise_street_address` | `"1632 Gateway Rd"` | The street address of the business. |
|
| 144 |
+
| `premise_city` | `"Calexico"` | The city of the business. |
|
| 145 |
+
| `premise_state` | `"CA"` | The state abbreviation of the business. |
|
| 146 |
+
| `premise_county` | `"Imperial"` | The county of the business. |
|
| 147 |
+
| `premise_zip_code` | `"92231"` | The zip code of the business. |
|
| 148 |
+
| `business_email` | `"redacted@gmail.com"` | The business email of the license. |
|
| 149 |
+
| `business_phone` | `"(555) 555-5555"` | The business phone of the license. |
|
| 150 |
+
| `business_website` | `"cannlytics.com"` | The business website of the license. |
|
| 151 |
+
| `parcel_number` | `"A42"` | An ID for the business location. |
|
| 152 |
+
| `premise_latitude` | `32.69035693` | The latitude of the business. |
|
| 153 |
+
| `premise_longitude` | `-115.38987552` | The longitude of the business. |
|
| 154 |
+
| `data_refreshed_date` | `"2022-09-21T12:16:33.3866667"` | An ISO-formatted time when the license data was updated. |
|
| 155 |
|
| 156 |
### Data Splits
|
| 157 |
|
|
|
|
| 179 |
| Alaska | <https://www.commerce.alaska.gov/abc/marijuana/Home/licensesearch> |
|
| 180 |
| Arizona | <https://azcarecheck.azdhs.gov/s/?licenseType=null> |
|
| 181 |
| California | <https://search.cannabis.ca.gov/> |
|
| 182 |
+
| Colorado | <https://sbg.colorado.gov/med/licensed-facilities> |
|
| 183 |
| Connecticut | <https://portal.ct.gov/DCP/Medical-Marijuana-Program/Connecticut-Medical-Marijuana-Dispensary-Facilities> |
|
| 184 |
+
| Illinois | <https://www.idfpr.com/LicenseLookup/AdultUseDispensaries.pdf> |
|
| 185 |
| Maine | <https://www.maine.gov/dafs/ocp/open-data/adult-use> |
|
| 186 |
+
| Massachusetts | <https://masscannabiscontrol.com/open-data/data-catalog/> |
|
| 187 |
+
| Michigan | <https://michigan.maps.arcgis.com/apps/webappviewer/index.html?id=cd5a1a76daaf470b823a382691c0ff60> |
|
| 188 |
| Montana | <https://mtrevenue.gov/cannabis/#CannabisLicenses> |
|
| 189 |
| Nevada | <https://ccb.nv.gov/list-of-licensees/> |
|
| 190 |
| New Jersey | <https://data.nj.gov/stories/s/ggm4-mprw> |
|
|
|
|
| 194 |
| Vermont | <https://ccb.vermont.gov/licenses> |
|
| 195 |
| Washington | <https://lcb.wa.gov/records/frequently-requested-lists> |
|
| 196 |
|
| 197 |
+
### Data Collection and Normalization
|
| 198 |
|
| 199 |
In the `algorithms` directory, you can find the algorithms used for data collection. You can use these algorithms to recreate the dataset. First, you will need to clone the repository:
|
| 200 |
|
|
|
|
| 244 |
### Dataset Curators
|
| 245 |
|
| 246 |
Curated by [🔥Cannlytics](https://cannlytics.com)<br>
|
| 247 |
+
<contact@cannlytics.com>
|
| 248 |
|
| 249 |
### License
|
| 250 |
|
|
|
|
| 270 |
```bibtex
|
| 271 |
@misc{cannlytics2022,
|
| 272 |
title={Cannabis Data Science},
|
| 273 |
+
author={Skeate, Keegan and O'Sullivan-Sutherland, Candace},
|
| 274 |
journal={https://github.com/cannlytics/cannabis-data-science},
|
| 275 |
year={2022}
|
| 276 |
}
|
|
|
|
| 278 |
|
| 279 |
### Contributions
|
| 280 |
|
| 281 |
+
Thanks to [🔥Cannlytics](https://cannlytics.com), [@candy-o](https://github.com/candy-o), [@hcadeaux](https://huggingface.co/hcadeaux), [@keeganskeate](https://github.com/keeganskeate), and the entire [Cannabis Data Science Team](https://meetup.com/cannabis-data-science/members) for their contributions.
|
algorithms/get_licenses_ak.py
CHANGED
|
@@ -6,7 +6,7 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
@@ -15,7 +15,230 @@ Description:
|
|
| 15 |
|
| 16 |
Data Source:
|
| 17 |
|
| 18 |
-
-
|
|
|
|
| 19 |
URL: <https://www.commerce.alaska.gov/abc/marijuana/Home/licensesearch>
|
| 20 |
|
| 21 |
-
"""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
+
Updated: 10/6/2022
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
|
|
| 15 |
|
| 16 |
Data Source:
|
| 17 |
|
| 18 |
+
- Department of Commerce, Community, and Economic Development
|
| 19 |
+
Alcohol and Marijuana Control Office
|
| 20 |
URL: <https://www.commerce.alaska.gov/abc/marijuana/Home/licensesearch>
|
| 21 |
|
| 22 |
+
"""
|
| 23 |
+
# Standard imports.
|
| 24 |
+
from datetime import datetime
|
| 25 |
+
import os
|
| 26 |
+
from time import sleep
|
| 27 |
+
from typing import Optional
|
| 28 |
+
|
| 29 |
+
# External imports.
|
| 30 |
+
from cannlytics.data.gis import search_for_address
|
| 31 |
+
from dotenv import dotenv_values
|
| 32 |
+
import pandas as pd
|
| 33 |
+
|
| 34 |
+
# Selenium imports.
|
| 35 |
+
from selenium import webdriver
|
| 36 |
+
from selenium.webdriver.chrome.options import Options
|
| 37 |
+
from selenium.webdriver.common.by import By
|
| 38 |
+
from selenium.webdriver.chrome.service import Service
|
| 39 |
+
try:
|
| 40 |
+
import chromedriver_binary # Adds chromedriver binary to path.
|
| 41 |
+
except ImportError:
|
| 42 |
+
pass # Otherwise, ChromeDriver should be in your path.
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
# Specify where your data lives.
|
| 46 |
+
DATA_DIR = '../data/ak'
|
| 47 |
+
ENV_FILE = '../.env'
|
| 48 |
+
|
| 49 |
+
# Specify state-specific constants.
|
| 50 |
+
STATE = 'AK'
|
| 51 |
+
ALASKA = {
|
| 52 |
+
'licensing_authority_id': 'AAMCO',
|
| 53 |
+
'licensing_authority': 'Alaska Alcohol and Marijuana Control Office',
|
| 54 |
+
'licenses_url': 'https://www.commerce.alaska.gov/abc/marijuana/Home/licensesearch',
|
| 55 |
+
'licenses': {
|
| 56 |
+
'columns': {
|
| 57 |
+
'License #': 'license_number',
|
| 58 |
+
'Business License #': 'id',
|
| 59 |
+
'Doing Business As': 'business_dba_name',
|
| 60 |
+
'License Type': 'license_type',
|
| 61 |
+
'License Status': 'license_status',
|
| 62 |
+
'Physical Address': 'address',
|
| 63 |
+
},
|
| 64 |
+
},
|
| 65 |
+
}
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def get_licenses_ak(
|
| 69 |
+
data_dir: Optional[str] = None,
|
| 70 |
+
env_file: Optional[str] = '.env',
|
| 71 |
+
):
|
| 72 |
+
"""Get Alaska cannabis license data."""
|
| 73 |
+
|
| 74 |
+
# Initialize Selenium and specify options.
|
| 75 |
+
service = Service()
|
| 76 |
+
options = Options()
|
| 77 |
+
options.add_argument('--window-size=1920,1200')
|
| 78 |
+
|
| 79 |
+
# DEV: Run with the browser open.
|
| 80 |
+
# options.headless = False
|
| 81 |
+
|
| 82 |
+
# PRODUCTION: Run with the browser closed.
|
| 83 |
+
options.add_argument('--headless')
|
| 84 |
+
options.add_argument('--disable-gpu')
|
| 85 |
+
options.add_argument('--no-sandbox')
|
| 86 |
+
|
| 87 |
+
# Initiate a Selenium driver.
|
| 88 |
+
driver = webdriver.Chrome(options=options, service=service)
|
| 89 |
+
|
| 90 |
+
# Load the license page.
|
| 91 |
+
driver.get(ALASKA['licenses_url'])
|
| 92 |
+
|
| 93 |
+
# Get the license type select.
|
| 94 |
+
license_types = []
|
| 95 |
+
options = driver.find_elements(by=By.TAG_NAME, value='option')
|
| 96 |
+
for option in options:
|
| 97 |
+
text = option.text
|
| 98 |
+
if text:
|
| 99 |
+
license_types.append(text)
|
| 100 |
+
|
| 101 |
+
# Iterate over all of the license types.
|
| 102 |
+
data = []
|
| 103 |
+
columns = list(ALASKA['licenses']['columns'].values())
|
| 104 |
+
for license_type in license_types:
|
| 105 |
+
|
| 106 |
+
# Set the text into the select.
|
| 107 |
+
select = driver.find_element(by=By.ID, value='SearchLicenseTypeID')
|
| 108 |
+
select.send_keys(license_type)
|
| 109 |
+
|
| 110 |
+
# Click search.
|
| 111 |
+
# TODO: There is probably an elegant way to wait for the table to load.
|
| 112 |
+
search_button = driver.find_element(by=By.ID, value='mariSearchBtn')
|
| 113 |
+
search_button.click()
|
| 114 |
+
sleep(2)
|
| 115 |
+
|
| 116 |
+
# Extract the table data.
|
| 117 |
+
table = driver.find_element(by=By.TAG_NAME, value='tbody')
|
| 118 |
+
rows = table.find_elements(by=By.TAG_NAME, value='tr')
|
| 119 |
+
for row in rows:
|
| 120 |
+
obs = {}
|
| 121 |
+
cells = row.find_elements(by=By.TAG_NAME, value='td')
|
| 122 |
+
for i, cell in enumerate(cells):
|
| 123 |
+
column = columns[i]
|
| 124 |
+
obs[column] = cell.text.replace('\n', ', ')
|
| 125 |
+
data.append(obs)
|
| 126 |
+
|
| 127 |
+
# End the browser session.
|
| 128 |
+
service.stop()
|
| 129 |
+
|
| 130 |
+
# Standardize the license data.
|
| 131 |
+
licenses = pd.DataFrame(data)
|
| 132 |
+
licenses = licenses.assign(
|
| 133 |
+
business_legal_name=licenses['business_dba_name'],
|
| 134 |
+
business_owner_name=None,
|
| 135 |
+
business_structure=None,
|
| 136 |
+
licensing_authority_id=ALASKA['licensing_authority_id'],
|
| 137 |
+
licensing_authority=ALASKA['licensing_authority'],
|
| 138 |
+
license_designation='Adult-Use',
|
| 139 |
+
license_status_date=None,
|
| 140 |
+
license_term=None,
|
| 141 |
+
premise_state=STATE,
|
| 142 |
+
parcel_number=None,
|
| 143 |
+
activity=None,
|
| 144 |
+
issue_date=None,
|
| 145 |
+
expiration_date=None,
|
| 146 |
+
)
|
| 147 |
+
|
| 148 |
+
# Restrict the license status to active.
|
| 149 |
+
active_license_types = [
|
| 150 |
+
'Active-Operating',
|
| 151 |
+
'Active-Pending Inspection',
|
| 152 |
+
'Delegated',
|
| 153 |
+
'Complete',
|
| 154 |
+
]
|
| 155 |
+
licenses = licenses.loc[licenses['license_status'].isin(active_license_types)]
|
| 156 |
+
|
| 157 |
+
# Assign the city and zip code.
|
| 158 |
+
licenses['premise_city'] = licenses['address'].apply(
|
| 159 |
+
lambda x: x.split(', ')[1]
|
| 160 |
+
)
|
| 161 |
+
licenses['premise_zip_code'] = licenses['address'].apply(
|
| 162 |
+
lambda x: x.split(', ')[2].replace(STATE, '').strip()
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
# Search for address for each retail license.
|
| 166 |
+
# Only search for a query once, then re-use the response.
|
| 167 |
+
# Note: There is probably a much, much more efficient way to do this!!!
|
| 168 |
+
config = dotenv_values(env_file)
|
| 169 |
+
api_key = config['GOOGLE_MAPS_API_KEY']
|
| 170 |
+
queries = {}
|
| 171 |
+
fields = [
|
| 172 |
+
'formatted_address',
|
| 173 |
+
'formatted_phone_number',
|
| 174 |
+
'geometry/location/lat',
|
| 175 |
+
'geometry/location/lng',
|
| 176 |
+
'website',
|
| 177 |
+
]
|
| 178 |
+
licenses = licenses.reset_index(drop=True)
|
| 179 |
+
licenses = licenses.assign(
|
| 180 |
+
premise_street_address=None,
|
| 181 |
+
premise_county=None,
|
| 182 |
+
premise_latitude=None,
|
| 183 |
+
premise_longitude=None,
|
| 184 |
+
business_phone=None,
|
| 185 |
+
business_website=None,
|
| 186 |
+
)
|
| 187 |
+
for index, row in licenses.iterrows():
|
| 188 |
+
|
| 189 |
+
# Query Google Place API, if necessary.
|
| 190 |
+
query = ', '.join([row['business_dba_name'], row['address']])
|
| 191 |
+
gis_data = queries.get(query)
|
| 192 |
+
if gis_data is None:
|
| 193 |
+
try:
|
| 194 |
+
gis_data = search_for_address(query, api_key=api_key, fields=fields)
|
| 195 |
+
except:
|
| 196 |
+
gis_data = {}
|
| 197 |
+
queries[query] = gis_data
|
| 198 |
+
|
| 199 |
+
# Record the query.
|
| 200 |
+
licenses.iat[index, licenses.columns.get_loc('premise_street_address')] = gis_data.get('street')
|
| 201 |
+
licenses.iat[index, licenses.columns.get_loc('premise_county')] = gis_data.get('county')
|
| 202 |
+
licenses.iat[index, licenses.columns.get_loc('premise_latitude')] = gis_data.get('latitude')
|
| 203 |
+
licenses.iat[index, licenses.columns.get_loc('premise_longitude')] = gis_data.get('longitude')
|
| 204 |
+
licenses.iat[index, licenses.columns.get_loc('business_phone')] = gis_data.get('formatted_phone_number')
|
| 205 |
+
licenses.iat[index, licenses.columns.get_loc('business_website')] = gis_data.get('website')
|
| 206 |
+
|
| 207 |
+
# Clean-up after GIS.
|
| 208 |
+
licenses.drop(columns=['address'], inplace=True)
|
| 209 |
+
|
| 210 |
+
# Optional: Search for business website for email and a photo.
|
| 211 |
+
licenses['business_email'] = None
|
| 212 |
+
licenses['business_image_url'] = None
|
| 213 |
+
|
| 214 |
+
# Get the refreshed date.
|
| 215 |
+
licenses['data_refreshed_date'] = datetime.now().isoformat()
|
| 216 |
+
|
| 217 |
+
# Save and return the data.
|
| 218 |
+
if data_dir is not None:
|
| 219 |
+
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 220 |
+
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 221 |
+
retailers = licenses.loc[licenses['license_type'] == 'Retail Marijuana Store']
|
| 222 |
+
licenses.to_csv(f'{data_dir}/licenses-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 223 |
+
retailers.to_csv(f'{data_dir}/retailers-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 224 |
+
return licenses
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
# === Test ===
|
| 228 |
+
if __name__ == '__main__':
|
| 229 |
+
|
| 230 |
+
# Support command line usage.
|
| 231 |
+
import argparse
|
| 232 |
+
try:
|
| 233 |
+
arg_parser = argparse.ArgumentParser()
|
| 234 |
+
arg_parser.add_argument('--d', dest='data_dir', type=str)
|
| 235 |
+
arg_parser.add_argument('--data_dir', dest='data_dir', type=str)
|
| 236 |
+
arg_parser.add_argument('--env', dest='env_file', type=str)
|
| 237 |
+
args = arg_parser.parse_args()
|
| 238 |
+
except SystemExit:
|
| 239 |
+
args = {'d': DATA_DIR, 'env_file': ENV_FILE}
|
| 240 |
+
|
| 241 |
+
# Get licenses, saving them to the specified directory.
|
| 242 |
+
data_dir = args.get('d', args.get('data_dir'))
|
| 243 |
+
env_file = args.get('env_file')
|
| 244 |
+
data = get_licenses_ak(data_dir, env_file=env_file)
|
algorithms/get_licenses_az.py
CHANGED
|
@@ -6,7 +6,7 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/27/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
@@ -27,23 +27,15 @@ from time import sleep
|
|
| 27 |
from typing import Optional
|
| 28 |
|
| 29 |
# External imports.
|
| 30 |
-
from bs4 import BeautifulSoup
|
| 31 |
from cannlytics.data.gis import geocode_addresses
|
| 32 |
-
from cannlytics.utils import camel_to_snake
|
| 33 |
-
from cannlytics.utils.constants import DEFAULT_HEADERS
|
| 34 |
-
import matplotlib.pyplot as plt
|
| 35 |
import pandas as pd
|
| 36 |
-
import
|
| 37 |
-
import seaborn as sns
|
| 38 |
|
| 39 |
# Selenium imports.
|
| 40 |
from selenium import webdriver
|
| 41 |
from selenium.webdriver.chrome.options import Options
|
| 42 |
from selenium.webdriver.common.by import By
|
| 43 |
from selenium.webdriver.chrome.service import Service
|
| 44 |
-
from selenium.common.exceptions import (
|
| 45 |
-
TimeoutException,
|
| 46 |
-
)
|
| 47 |
from selenium.webdriver.support import expected_conditions as EC
|
| 48 |
from selenium.webdriver.support.ui import WebDriverWait
|
| 49 |
try:
|
|
@@ -54,193 +46,288 @@ except ImportError:
|
|
| 54 |
|
| 55 |
# Specify where your data lives.
|
| 56 |
DATA_DIR = '../data/az'
|
|
|
|
| 57 |
|
| 58 |
# Specify state-specific constants.
|
| 59 |
STATE = 'AZ'
|
| 60 |
ARIZONA = {
|
| 61 |
'licensing_authority_id': 'ADHS',
|
| 62 |
'licensing_authority': 'Arizona Department of Health Services',
|
| 63 |
-
'
|
| 64 |
-
'url': 'https://azcarecheck.azdhs.gov/s/?licenseType=null',
|
| 65 |
-
},
|
| 66 |
}
|
| 67 |
|
| 68 |
-
# def get_licenses_az(
|
| 69 |
-
# data_dir: Optional[str] = None,
|
| 70 |
-
# env_file: Optional[str] = '.env',
|
| 71 |
-
# ):
|
| 72 |
-
# """Get Arizona cannabis license data."""
|
| 73 |
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
| 85 |
-
|
| 86 |
-
|
| 87 |
-
|
| 88 |
-
|
| 89 |
-
|
| 90 |
-
|
| 91 |
-
options.
|
| 92 |
-
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
driver.
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
more =
|
| 117 |
-
|
| 118 |
-
|
| 119 |
-
|
| 120 |
-
|
| 121 |
-
|
| 122 |
-
|
| 123 |
-
|
| 124 |
-
|
| 125 |
-
|
| 126 |
-
|
| 127 |
-
|
| 128 |
-
|
| 129 |
-
|
| 130 |
-
|
| 131 |
-
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
|
| 137 |
-
|
| 138 |
-
|
| 139 |
-
|
| 140 |
-
|
| 141 |
-
|
| 142 |
-
|
| 143 |
-
'
|
| 144 |
-
'
|
| 145 |
-
'
|
| 146 |
-
|
| 147 |
-
'
|
| 148 |
-
|
| 149 |
-
|
| 150 |
-
|
| 151 |
-
|
| 152 |
-
|
| 153 |
-
|
| 154 |
-
|
| 155 |
-
|
| 156 |
-
|
| 157 |
-
|
| 158 |
-
|
| 159 |
-
|
| 160 |
-
|
| 161 |
-
|
| 162 |
-
|
| 163 |
-
retailers
|
| 164 |
-
retailers
|
| 165 |
-
|
| 166 |
-
|
| 167 |
-
|
| 168 |
-
|
| 169 |
-
|
| 170 |
-
|
| 171 |
-
|
| 172 |
-
|
| 173 |
-
|
| 174 |
-
|
| 175 |
-
|
| 176 |
-
|
| 177 |
-
|
| 178 |
-
|
| 179 |
-
|
| 180 |
-
|
| 181 |
-
|
| 182 |
-
|
| 183 |
-
|
| 184 |
-
|
| 185 |
-
|
| 186 |
-
|
| 187 |
-
|
| 188 |
-
|
| 189 |
-
|
| 190 |
-
|
| 191 |
-
|
| 192 |
-
|
| 193 |
-
|
| 194 |
-
|
| 195 |
-
|
| 196 |
-
|
| 197 |
-
|
| 198 |
-
|
| 199 |
-
|
| 200 |
-
|
| 201 |
-
|
| 202 |
-
|
| 203 |
-
|
| 204 |
-
|
| 205 |
-
|
| 206 |
-
|
| 207 |
-
|
| 208 |
-
|
| 209 |
-
#
|
| 210 |
-
|
| 211 |
-
|
| 212 |
-
|
| 213 |
-
|
| 214 |
-
|
| 215 |
-
|
| 216 |
-
|
| 217 |
-
|
| 218 |
-
#
|
| 219 |
-
|
| 220 |
-
|
| 221 |
-
|
| 222 |
-
|
| 223 |
-
|
| 224 |
-
|
| 225 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 226 |
|
| 227 |
|
| 228 |
# === Test ===
|
| 229 |
-
|
| 230 |
-
|
| 231 |
-
#
|
| 232 |
-
|
| 233 |
-
|
| 234 |
-
|
| 235 |
-
|
| 236 |
-
|
| 237 |
-
|
| 238 |
-
|
| 239 |
-
|
| 240 |
-
|
| 241 |
-
|
| 242 |
-
#
|
| 243 |
-
|
| 244 |
-
|
| 245 |
-
|
| 246 |
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/27/2022
|
| 9 |
+
Updated: 10/7/2022
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
|
|
| 27 |
from typing import Optional
|
| 28 |
|
| 29 |
# External imports.
|
|
|
|
| 30 |
from cannlytics.data.gis import geocode_addresses
|
|
|
|
|
|
|
|
|
|
| 31 |
import pandas as pd
|
| 32 |
+
import zipcodes
|
|
|
|
| 33 |
|
| 34 |
# Selenium imports.
|
| 35 |
from selenium import webdriver
|
| 36 |
from selenium.webdriver.chrome.options import Options
|
| 37 |
from selenium.webdriver.common.by import By
|
| 38 |
from selenium.webdriver.chrome.service import Service
|
|
|
|
|
|
|
|
|
|
| 39 |
from selenium.webdriver.support import expected_conditions as EC
|
| 40 |
from selenium.webdriver.support.ui import WebDriverWait
|
| 41 |
try:
|
|
|
|
| 46 |
|
| 47 |
# Specify where your data lives.
|
| 48 |
DATA_DIR = '../data/az'
|
| 49 |
+
ENV_FILE = '../.env'
|
| 50 |
|
| 51 |
# Specify state-specific constants.
|
| 52 |
STATE = 'AZ'
|
| 53 |
ARIZONA = {
|
| 54 |
'licensing_authority_id': 'ADHS',
|
| 55 |
'licensing_authority': 'Arizona Department of Health Services',
|
| 56 |
+
'licenses_url': 'https://azcarecheck.azdhs.gov/s/?licenseType=null',
|
|
|
|
|
|
|
| 57 |
}
|
| 58 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 59 |
|
| 60 |
+
def county_from_zip(x):
|
| 61 |
+
"""Find a county given a zip code. Returns `None` if no match."""
|
| 62 |
+
try:
|
| 63 |
+
return zipcodes.matching(x)[0]['county']
|
| 64 |
+
except KeyError:
|
| 65 |
+
return None
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def get_licenses_az(
|
| 69 |
+
data_dir: Optional[str] = None,
|
| 70 |
+
env_file: Optional[str] = '.env',
|
| 71 |
+
):
|
| 72 |
+
"""Get Arizona cannabis license data."""
|
| 73 |
+
|
| 74 |
+
# Create directories if necessary.
|
| 75 |
+
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 76 |
+
|
| 77 |
+
# Initialize Selenium and specify options.
|
| 78 |
+
service = Service()
|
| 79 |
+
options = Options()
|
| 80 |
+
options.add_argument('--window-size=1920,1200')
|
| 81 |
+
|
| 82 |
+
# DEV: Run with the browser open.
|
| 83 |
+
# options.headless = False
|
| 84 |
+
|
| 85 |
+
# PRODUCTION: Run with the browser closed.
|
| 86 |
+
options.add_argument('--headless')
|
| 87 |
+
options.add_argument('--disable-gpu')
|
| 88 |
+
options.add_argument('--no-sandbox')
|
| 89 |
+
|
| 90 |
+
# Initiate a Selenium driver.
|
| 91 |
+
driver = webdriver.Chrome(options=options, service=service)
|
| 92 |
+
|
| 93 |
+
# Load the license page.
|
| 94 |
+
driver.get(ARIZONA['licenses_url'])
|
| 95 |
+
detect = (By.CLASS_NAME, 'slds-container_center')
|
| 96 |
+
WebDriverWait(driver, 30).until(EC.presence_of_element_located(detect))
|
| 97 |
+
|
| 98 |
+
# Get the map container.
|
| 99 |
+
container = driver.find_element(by=By.CLASS_NAME, value='slds-container_center')
|
| 100 |
+
|
| 101 |
+
# Click "Load more" until all of the licenses are visible.
|
| 102 |
+
more = True
|
| 103 |
+
while(more):
|
| 104 |
+
button = container.find_element(by=By.TAG_NAME, value='button')
|
| 105 |
+
driver.execute_script('arguments[0].scrollIntoView(true);', button)
|
| 106 |
+
button.click()
|
| 107 |
+
counter = container.find_element(by=By.CLASS_NAME, value='count-text')
|
| 108 |
+
more = int(counter.text.replace(' more', ''))
|
| 109 |
+
|
| 110 |
+
# Get license data for each retailer.
|
| 111 |
+
data = []
|
| 112 |
+
els = container.find_elements(by=By.CLASS_NAME, value='map-list__item')
|
| 113 |
+
for i, el in enumerate(els):
|
| 114 |
+
|
| 115 |
+
# Get a retailer's data.
|
| 116 |
+
count = i + 1
|
| 117 |
+
xpath = f'/html/body/div[3]/div[2]/div/div[2]/div[2]/div/div/c-azcc-portal-home/c-azcc-map/div/div[2]/div[2]/div[2]/div[{count}]/c-azcc-map-list-item/div'
|
| 118 |
+
list_item = el.find_element(by=By.XPATH, value=xpath)
|
| 119 |
+
body = list_item.find_element(by=By.CLASS_NAME, value='slds-media__body')
|
| 120 |
+
divs = body.find_elements(by=By.TAG_NAME, value='div')
|
| 121 |
+
name = divs[0].text
|
| 122 |
+
legal_name = divs[1].text
|
| 123 |
+
if not name:
|
| 124 |
+
name = legal_name
|
| 125 |
+
address = divs[3].text
|
| 126 |
+
address_parts = address.split(',')
|
| 127 |
+
parts = divs[2].text.split(' · ')
|
| 128 |
+
|
| 129 |
+
# Get the retailer's link to get more details.
|
| 130 |
+
link = divs[-1].find_element(by=By.TAG_NAME, value='a')
|
| 131 |
+
href = link.get_attribute('href')
|
| 132 |
+
|
| 133 |
+
# Record the retailer's data.
|
| 134 |
+
obs = {
|
| 135 |
+
'address': address,
|
| 136 |
+
'details_url': href,
|
| 137 |
+
'business_legal_name': legal_name,
|
| 138 |
+
'business_dba_name': name,
|
| 139 |
+
'business_phone': parts[-1],
|
| 140 |
+
'license_status': parts[0],
|
| 141 |
+
'license_type': parts[1],
|
| 142 |
+
'premise_street_address': address_parts[0].strip(),
|
| 143 |
+
'premise_city': address_parts[1].strip(),
|
| 144 |
+
'premise_zip_code': address_parts[-1].replace('AZ ', '').strip(),
|
| 145 |
+
}
|
| 146 |
+
data.append(obs)
|
| 147 |
+
|
| 148 |
+
# Standardize the retailer data.
|
| 149 |
+
retailers = pd.DataFrame(data)
|
| 150 |
+
retailers = retailers.assign(
|
| 151 |
+
business_email=None,
|
| 152 |
+
business_owner_name=None,
|
| 153 |
+
business_structure=None,
|
| 154 |
+
business_image_url=None,
|
| 155 |
+
business_website=None,
|
| 156 |
+
id=retailers.index,
|
| 157 |
+
licensing_authority_id=ARIZONA['licensing_authority_id'],
|
| 158 |
+
licensing_authority=ARIZONA['licensing_authority'],
|
| 159 |
+
license_designation='Adult-Use',
|
| 160 |
+
license_number=None,
|
| 161 |
+
license_status_date=None,
|
| 162 |
+
license_term=None,
|
| 163 |
+
premise_latitude=None,
|
| 164 |
+
premise_longitude=None,
|
| 165 |
+
premise_state=STATE,
|
| 166 |
+
issue_date=None,
|
| 167 |
+
expiration_date=None,
|
| 168 |
+
parcel_number=None,
|
| 169 |
+
activity=None,
|
| 170 |
+
)
|
| 171 |
+
|
| 172 |
+
# Get each retailer's details.
|
| 173 |
+
cultivators = pd.DataFrame(columns=retailers.columns)
|
| 174 |
+
manufacturers = pd.DataFrame(columns=retailers.columns)
|
| 175 |
+
for index, row in retailers.iterrows():
|
| 176 |
+
|
| 177 |
+
# Load the licenses's details webpage.
|
| 178 |
+
driver.get(row['details_url'])
|
| 179 |
+
detect = (By.CLASS_NAME, 'slds-container_center')
|
| 180 |
+
WebDriverWait(driver, 30).until(EC.presence_of_element_located(detect))
|
| 181 |
+
container = driver.find_element(by=By.CLASS_NAME, value='slds-container_center')
|
| 182 |
+
sleep(4)
|
| 183 |
+
|
| 184 |
+
# Get the `business_email`.
|
| 185 |
+
links = container.find_elements(by=By.TAG_NAME, value='a')
|
| 186 |
+
for link in links:
|
| 187 |
+
href = link.get_attribute('href')
|
| 188 |
+
if href is None: continue
|
| 189 |
+
if href.startswith('mailto'):
|
| 190 |
+
business_email = href.replace('mailto:', '')
|
| 191 |
+
col = retailers.columns.get_loc('business_email')
|
| 192 |
+
retailers.iat[index, col] = business_email
|
| 193 |
+
break
|
| 194 |
+
|
| 195 |
+
# Get the `license_number`
|
| 196 |
+
for link in links:
|
| 197 |
+
href = link.get_attribute('href')
|
| 198 |
+
if href is None: continue
|
| 199 |
+
if href.startswith('https://azdhs-licensing'):
|
| 200 |
+
col = retailers.columns.get_loc('license_number')
|
| 201 |
+
retailers.iat[index, col] = link.text
|
| 202 |
+
break
|
| 203 |
+
|
| 204 |
+
# Get the `premise_latitude` and `premise_longitude`.
|
| 205 |
+
for link in links:
|
| 206 |
+
href = link.get_attribute('href')
|
| 207 |
+
if href is None: continue
|
| 208 |
+
if href.startswith('https://maps.google.com/'):
|
| 209 |
+
coords = href.split('=')[1].split('&')[0].split(',')
|
| 210 |
+
lat_col = retailers.columns.get_loc('premise_latitude')
|
| 211 |
+
long_col = retailers.columns.get_loc('premise_longitude')
|
| 212 |
+
retailers.iat[index, lat_col] = float(coords[0])
|
| 213 |
+
retailers.iat[index, long_col] = float(coords[1])
|
| 214 |
+
break
|
| 215 |
+
|
| 216 |
+
# Get the `issue_date`.
|
| 217 |
+
key = 'License Effective'
|
| 218 |
+
el = container.find_element_by_xpath(f"//p[contains(text(),'{key}')]/following-sibling::lightning-formatted-text")
|
| 219 |
+
col = retailers.columns.get_loc('issue_date')
|
| 220 |
+
retailers.iat[index, col] = el.text
|
| 221 |
+
|
| 222 |
+
# Get the `expiration_date`.
|
| 223 |
+
key = 'License Expires'
|
| 224 |
+
el = container.find_element_by_xpath(f"//p[contains(text(),'{key}')]/following-sibling::lightning-formatted-text")
|
| 225 |
+
col = retailers.columns.get_loc('expiration_date')
|
| 226 |
+
retailers.iat[index, col] = el.text
|
| 227 |
+
|
| 228 |
+
# Get the `business_owner_name`.
|
| 229 |
+
key = 'Owner / License'
|
| 230 |
+
el = container.find_element_by_xpath(f"//p[contains(text(),'{key}')]/following-sibling::lightning-formatted-text")
|
| 231 |
+
col = retailers.columns.get_loc('expiration_date')
|
| 232 |
+
retailers.iat[index, col] = el.text
|
| 233 |
+
|
| 234 |
+
# Get the `license_designation` ("Services").
|
| 235 |
+
key = 'Services'
|
| 236 |
+
el = container.find_element_by_xpath(f"//p[contains(text(),'{key}')]/following-sibling::lightning-formatted-rich-text")
|
| 237 |
+
col = retailers.columns.get_loc('license_designation')
|
| 238 |
+
retailers.iat[index, col] = el.text
|
| 239 |
+
|
| 240 |
+
# Create entries for cultivations.
|
| 241 |
+
cultivator = retailers.iloc[index].copy()
|
| 242 |
+
key = 'Offsite Cultivation Address'
|
| 243 |
+
el = container.find_element_by_xpath(f"//p[contains(text(),'{key}')]/following-sibling::lightning-formatted-text")
|
| 244 |
+
address = el.text
|
| 245 |
+
if address:
|
| 246 |
+
parts = address.split(',')
|
| 247 |
+
cultivator['address'] = address
|
| 248 |
+
cultivator['premise_street_address'] = parts[0]
|
| 249 |
+
cultivator['premise_city'] = parts[1].strip()
|
| 250 |
+
cultivator['premise_zip_code'] = parts[-1].replace(STATE, '').strip()
|
| 251 |
+
cultivator['license_type'] = 'Offsite Cultivation'
|
| 252 |
+
cultivators.append(cultivator, ignore_index=True)
|
| 253 |
+
|
| 254 |
+
# Create entries for manufacturers.
|
| 255 |
+
manufacturer = retailers.iloc[index].copy()
|
| 256 |
+
key = 'Manufacture Address'
|
| 257 |
+
el = container.find_element_by_xpath(f"//p[contains(text(),'{key}')]/following-sibling::lightning-formatted-text")
|
| 258 |
+
address = el.text
|
| 259 |
+
if address:
|
| 260 |
+
parts = address.split(',')
|
| 261 |
+
manufacturer['address'] = address
|
| 262 |
+
manufacturer['premise_street_address'] = parts[0]
|
| 263 |
+
manufacturer['premise_city'] = parts[1].strip()
|
| 264 |
+
manufacturer['premise_zip_code'] = parts[-1].replace(STATE, '').strip()
|
| 265 |
+
manufacturer['license_type'] = 'Offsite Cultivation'
|
| 266 |
+
manufacturers.append(manufacturer, ignore_index=True)
|
| 267 |
+
|
| 268 |
+
# End the browser session.
|
| 269 |
+
service.stop()
|
| 270 |
+
retailers.drop(column=['address', 'details_url'], inplace=True)
|
| 271 |
+
|
| 272 |
+
# Lookup counties by zip code.
|
| 273 |
+
retailers['premise_county'] = retailers['premise_zip_code'].apply(county_from_zip)
|
| 274 |
+
cultivators['premise_county'] = cultivators['premise_zip_code'].apply(county_from_zip)
|
| 275 |
+
manufacturers['premise_county'] = manufacturers['premise_zip_code'].apply(county_from_zip)
|
| 276 |
+
|
| 277 |
+
# Setup geocoding
|
| 278 |
+
config = dotenv_values(env_file)
|
| 279 |
+
api_key = config['GOOGLE_MAPS_API_KEY']
|
| 280 |
+
drop_cols = ['state', 'state_name', 'county', 'address', 'formatted_address']
|
| 281 |
+
gis_cols = {'latitude': 'premise_latitude', 'longitude': 'premise_longitude'}
|
| 282 |
+
|
| 283 |
+
# # Geocode cultivators.
|
| 284 |
+
# cultivators = geocode_addresses(cultivators, api_key=api_key, address_field='address')
|
| 285 |
+
# cultivators.drop(columns=drop_cols, inplace=True)
|
| 286 |
+
# cultivators.rename(columns=gis_cols, inplace=True)
|
| 287 |
+
|
| 288 |
+
# # Geocode manufacturers.
|
| 289 |
+
# manufacturers = geocode_addresses(manufacturers, api_key=api_key, address_field='address')
|
| 290 |
+
# manufacturers.drop(columns=drop_cols, inplace=True)
|
| 291 |
+
# manufacturers.rename(columns=gis_cols, inplace=True)
|
| 292 |
+
|
| 293 |
+
# TODO: Lookup business website and image.
|
| 294 |
+
|
| 295 |
+
# Aggregate all licenses.
|
| 296 |
+
licenses = pd.concat([retailers, cultivators, manufacturers])
|
| 297 |
+
|
| 298 |
+
# Get the refreshed date.
|
| 299 |
+
timestamp = datetime.now().isoformat()
|
| 300 |
+
licenses['data_refreshed_date'] = timestamp
|
| 301 |
+
retailers['data_refreshed_date'] = timestamp
|
| 302 |
+
# cultivators['data_refreshed_date'] = timestamp
|
| 303 |
+
# manufacturers['data_refreshed_date'] = timestamp
|
| 304 |
+
|
| 305 |
+
# Save and return the data.
|
| 306 |
+
if data_dir is not None:
|
| 307 |
+
timestamp = timestamp[:19].replace(':', '-')
|
| 308 |
+
licenses.to_csv(f'{data_dir}/licenses-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 309 |
+
retailers.to_csv(f'{data_dir}/retailers-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 310 |
+
# cultivators.to_csv(f'{data_dir}/cultivators-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 311 |
+
# manufacturers.to_csv(f'{data_dir}/manufacturers-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 312 |
+
return licenses
|
| 313 |
|
| 314 |
|
| 315 |
# === Test ===
|
| 316 |
+
if __name__ == '__main__':
|
| 317 |
+
|
| 318 |
+
# Support command line usage.
|
| 319 |
+
import argparse
|
| 320 |
+
try:
|
| 321 |
+
arg_parser = argparse.ArgumentParser()
|
| 322 |
+
arg_parser.add_argument('--d', dest='data_dir', type=str)
|
| 323 |
+
arg_parser.add_argument('--data_dir', dest='data_dir', type=str)
|
| 324 |
+
arg_parser.add_argument('--env', dest='env_file', type=str)
|
| 325 |
+
args = arg_parser.parse_args()
|
| 326 |
+
except SystemExit:
|
| 327 |
+
args = {'d': DATA_DIR, 'env_file': ENV_FILE}
|
| 328 |
+
|
| 329 |
+
# Get licenses, saving them to the specified directory.
|
| 330 |
+
data_dir = args.get('d', args.get('data_dir'))
|
| 331 |
+
env_file = args.get('env_file')
|
| 332 |
+
data = get_licenses_az(data_dir, env_file=env_file)
|
| 333 |
|
algorithms/get_licenses_ca.py
CHANGED
|
@@ -80,11 +80,18 @@ def get_licenses_ca(
|
|
| 80 |
columns = [camel_to_snake(x) for x in columns]
|
| 81 |
license_data.columns = columns
|
| 82 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 83 |
# Save and return the data.
|
| 84 |
if data_dir is not None:
|
| 85 |
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 86 |
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 87 |
-
license_data.
|
| 88 |
return license_data
|
| 89 |
|
| 90 |
if __name__ == '__main__':
|
|
|
|
| 80 |
columns = [camel_to_snake(x) for x in columns]
|
| 81 |
license_data.columns = columns
|
| 82 |
|
| 83 |
+
# TODO: Lookup business website and image.
|
| 84 |
+
license_data['business_image_url'] = None
|
| 85 |
+
license_data['business_website'] = None
|
| 86 |
+
|
| 87 |
+
# Restrict to only active licenses.
|
| 88 |
+
license_data = license_data.loc[license_data['license_status'] == 'Active']
|
| 89 |
+
|
| 90 |
# Save and return the data.
|
| 91 |
if data_dir is not None:
|
| 92 |
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 93 |
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 94 |
+
license_data.to_csv(f'{data_dir}/licenses-ca-{timestamp}.csv', index=False)
|
| 95 |
return license_data
|
| 96 |
|
| 97 |
if __name__ == '__main__':
|
algorithms/get_licenses_co.py
CHANGED
|
@@ -6,7 +6,7 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
@@ -15,7 +15,207 @@ Description:
|
|
| 15 |
|
| 16 |
Data Source:
|
| 17 |
|
| 18 |
-
- Colorado
|
| 19 |
-
URL:
|
| 20 |
|
| 21 |
-
"""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
+
Updated: 10/4/2022
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
|
|
| 15 |
|
| 16 |
Data Source:
|
| 17 |
|
| 18 |
+
- Colorado Department of Revenue | Marijuana Enforcement Division
|
| 19 |
+
URL: <https://sbg.colorado.gov/med/licensed-facilities>
|
| 20 |
|
| 21 |
+
"""
|
| 22 |
+
# Standard imports.
|
| 23 |
+
from datetime import datetime
|
| 24 |
+
import os
|
| 25 |
+
from time import sleep
|
| 26 |
+
from typing import Optional
|
| 27 |
+
|
| 28 |
+
# External imports.
|
| 29 |
+
from bs4 import BeautifulSoup
|
| 30 |
+
from cannlytics.data.data import load_google_sheet
|
| 31 |
+
from cannlytics.data.gis import search_for_address
|
| 32 |
+
from dotenv import dotenv_values
|
| 33 |
+
import pandas as pd
|
| 34 |
+
import requests
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
# Specify where your data lives.
|
| 38 |
+
DATA_DIR = '../data/co'
|
| 39 |
+
ENV_FILE = '../.env'
|
| 40 |
+
|
| 41 |
+
# Specify state-specific constants.
|
| 42 |
+
STATE = 'CO'
|
| 43 |
+
COLORADO = {
|
| 44 |
+
'licensing_authority_id': 'MED',
|
| 45 |
+
'licensing_authority': 'Colorado Marijuana Enforcement Division',
|
| 46 |
+
'licenses_url': 'https://sbg.colorado.gov/med/licensed-facilities',
|
| 47 |
+
'licenses': {
|
| 48 |
+
'columns': {
|
| 49 |
+
'LicenseNumber': 'license_number',
|
| 50 |
+
'FacilityName': 'business_legal_name',
|
| 51 |
+
'DBA': 'business_dba_name',
|
| 52 |
+
'City': 'premise_city',
|
| 53 |
+
'ZipCode': 'premise_zip_code',
|
| 54 |
+
'DateUpdated': 'data_refreshed_date',
|
| 55 |
+
'Licensee Name ': 'business_legal_name',
|
| 56 |
+
'License # ': 'license_number',
|
| 57 |
+
'City ': 'premise_city',
|
| 58 |
+
'Zip': 'premise_zip_code',
|
| 59 |
+
},
|
| 60 |
+
'drop_columns': [
|
| 61 |
+
'FacilityType', # This causes an error with `license_type`.
|
| 62 |
+
'Potency',
|
| 63 |
+
'Solvents',
|
| 64 |
+
'Microbial',
|
| 65 |
+
'Pesticides',
|
| 66 |
+
'Mycotoxin',
|
| 67 |
+
'Elemental Impurities',
|
| 68 |
+
'Water Activity'
|
| 69 |
+
]
|
| 70 |
+
}
|
| 71 |
+
}
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def get_licenses_co(
|
| 75 |
+
data_dir: Optional[str] = None,
|
| 76 |
+
env_file: Optional[str] = '.env',
|
| 77 |
+
):
|
| 78 |
+
"""Get Colorado cannabis license data."""
|
| 79 |
+
|
| 80 |
+
# Get the licenses webpage.
|
| 81 |
+
url = COLORADO['licenses_url']
|
| 82 |
+
response = requests.get(url)
|
| 83 |
+
soup = BeautifulSoup(response.content, 'html.parser')
|
| 84 |
+
|
| 85 |
+
# Get the Google Sheets for each license type.
|
| 86 |
+
docs = {}
|
| 87 |
+
links = soup.find_all('a')
|
| 88 |
+
for link in links:
|
| 89 |
+
try:
|
| 90 |
+
href = link['href']
|
| 91 |
+
except KeyError:
|
| 92 |
+
pass
|
| 93 |
+
if 'docs.google' in href:
|
| 94 |
+
docs[link.text] = href
|
| 95 |
+
|
| 96 |
+
# Download each "Medical" and "Retail" Google Sheet.
|
| 97 |
+
licenses = pd.DataFrame()
|
| 98 |
+
license_designations = ['Medical', 'Retail']
|
| 99 |
+
columns=COLORADO['licenses']['columns']
|
| 100 |
+
drop_columns=COLORADO['licenses']['drop_columns']
|
| 101 |
+
for license_type, doc in docs.items():
|
| 102 |
+
for license_designation in license_designations:
|
| 103 |
+
license_data = load_google_sheet(doc, license_designation)
|
| 104 |
+
license_data['license_type'] = license_type
|
| 105 |
+
license_data['license_designation'] = license_designation
|
| 106 |
+
license_data.rename(columns=columns, inplace=True)
|
| 107 |
+
license_data.drop(columns=drop_columns, inplace=True, errors='ignore')
|
| 108 |
+
licenses = pd.concat([licenses, license_data])
|
| 109 |
+
sleep(0.22)
|
| 110 |
+
|
| 111 |
+
# Standardize the license data.
|
| 112 |
+
licenses = licenses.assign(
|
| 113 |
+
id=licenses['license_number'],
|
| 114 |
+
license_status=None,
|
| 115 |
+
licensing_authority_id=COLORADO['licensing_authority_id'],
|
| 116 |
+
licensing_authority=COLORADO['licensing_authority'],
|
| 117 |
+
license_designation='Adult-Use',
|
| 118 |
+
premise_state=STATE,
|
| 119 |
+
license_status_date=None,
|
| 120 |
+
license_term=None,
|
| 121 |
+
issue_date=None,
|
| 122 |
+
expiration_date=None,
|
| 123 |
+
business_owner_name=None,
|
| 124 |
+
business_structure=None,
|
| 125 |
+
activity=None,
|
| 126 |
+
parcel_number=None,
|
| 127 |
+
business_phone=None,
|
| 128 |
+
business_email=None,
|
| 129 |
+
business_image_url=None,
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
# Fill empty DBA names and strip trailing whitespace.
|
| 133 |
+
licenses.loc[licenses['business_dba_name'] == '', 'business_dba_name'] = licenses['business_legal_name']
|
| 134 |
+
licenses.business_dba_name.fillna(licenses.business_legal_name, inplace=True)
|
| 135 |
+
licenses.business_legal_name.fillna(licenses.business_dba_name, inplace=True)
|
| 136 |
+
licenses = licenses.loc[~licenses.business_dba_name.isna()]
|
| 137 |
+
licenses.business_dba_name = licenses.business_dba_name.apply(lambda x: x.strip())
|
| 138 |
+
licenses.business_legal_name = licenses.business_legal_name.apply(lambda x: x.strip())
|
| 139 |
+
|
| 140 |
+
# Optional: Turn all capital case to title case.
|
| 141 |
+
|
| 142 |
+
# Clean zip code column.
|
| 143 |
+
licenses['premise_zip_code'] = licenses['premise_zip_code'].apply(
|
| 144 |
+
lambda x: str(round(x)) if pd.notnull(x) else x
|
| 145 |
+
)
|
| 146 |
+
licenses.loc[licenses['premise_zip_code'].isnull(), 'premise_zip_code'] = ''
|
| 147 |
+
|
| 148 |
+
# Search for address for each retail license.
|
| 149 |
+
# Only search for a query once, then re-use the response.
|
| 150 |
+
# Note: There is probably a much, much more efficient way to do this!!!
|
| 151 |
+
config = dotenv_values(env_file)
|
| 152 |
+
api_key = config['GOOGLE_MAPS_API_KEY']
|
| 153 |
+
cols = ['business_dba_name', 'premise_city', 'premise_state', 'premise_zip_code']
|
| 154 |
+
retailers = licenses.loc[licenses['license_type'] == 'Stores']
|
| 155 |
+
retailers['query'] = retailers[cols].apply(
|
| 156 |
+
lambda row: ', '.join(row.values.astype(str)),
|
| 157 |
+
axis=1,
|
| 158 |
+
)
|
| 159 |
+
queries = {}
|
| 160 |
+
fields = [
|
| 161 |
+
'formatted_address',
|
| 162 |
+
'formatted_phone_number',
|
| 163 |
+
'geometry/location/lat',
|
| 164 |
+
'geometry/location/lng',
|
| 165 |
+
'website',
|
| 166 |
+
]
|
| 167 |
+
retailers = retailers.reset_index(drop=True)
|
| 168 |
+
retailers = retailers.assign(
|
| 169 |
+
premise_street_address=None,
|
| 170 |
+
premise_county=None,
|
| 171 |
+
premise_latitude=None,
|
| 172 |
+
premise_longitude=None,
|
| 173 |
+
business_website=None,
|
| 174 |
+
business_phone=None,
|
| 175 |
+
)
|
| 176 |
+
for index, row in retailers.iterrows():
|
| 177 |
+
query = row['query']
|
| 178 |
+
gis_data = queries.get(query)
|
| 179 |
+
if gis_data is None:
|
| 180 |
+
try:
|
| 181 |
+
gis_data = search_for_address(query, api_key=api_key, fields=fields)
|
| 182 |
+
except:
|
| 183 |
+
gis_data = {}
|
| 184 |
+
queries[query] = gis_data
|
| 185 |
+
retailers.iat[index, retailers.columns.get_loc('premise_street_address')] = gis_data.get('street')
|
| 186 |
+
retailers.iat[index, retailers.columns.get_loc('premise_county')] = gis_data.get('county')
|
| 187 |
+
retailers.iat[index, retailers.columns.get_loc('premise_latitude')] = gis_data.get('latitude')
|
| 188 |
+
retailers.iat[index, retailers.columns.get_loc('premise_longitude')] = gis_data.get('longitude')
|
| 189 |
+
retailers.iat[index, retailers.columns.get_loc('business_website')] = gis_data.get('website')
|
| 190 |
+
retailers.iat[index, retailers.columns.get_loc('business_phone')] = gis_data.get('formatted_phone_number')
|
| 191 |
+
|
| 192 |
+
# Clean-up after getting GIS data.
|
| 193 |
+
retailers.drop(columns=['query'], inplace=True)
|
| 194 |
+
|
| 195 |
+
# Save and return the data.
|
| 196 |
+
if data_dir is not None:
|
| 197 |
+
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 198 |
+
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 199 |
+
licenses.to_csv(f'{data_dir}/licenses-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 200 |
+
retailers.to_csv(f'{data_dir}/retailers-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 201 |
+
return licenses
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
# === Test ===
|
| 205 |
+
if __name__ == '__main__':
|
| 206 |
+
|
| 207 |
+
# Support command line usage.
|
| 208 |
+
import argparse
|
| 209 |
+
try:
|
| 210 |
+
arg_parser = argparse.ArgumentParser()
|
| 211 |
+
arg_parser.add_argument('--d', dest='data_dir', type=str)
|
| 212 |
+
arg_parser.add_argument('--data_dir', dest='data_dir', type=str)
|
| 213 |
+
arg_parser.add_argument('--env', dest='env_file', type=str)
|
| 214 |
+
args = arg_parser.parse_args()
|
| 215 |
+
except SystemExit:
|
| 216 |
+
args = {'d': DATA_DIR, 'env_file': ENV_FILE}
|
| 217 |
+
|
| 218 |
+
# Get licenses, saving them to the specified directory.
|
| 219 |
+
data_dir = args.get('d', args.get('data_dir'))
|
| 220 |
+
env_file = args.get('env_file')
|
| 221 |
+
data = get_licenses_co(data_dir, env_file=env_file)
|
algorithms/get_licenses_ct.py
CHANGED
|
@@ -6,7 +6,7 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
@@ -15,7 +15,149 @@ Description:
|
|
| 15 |
|
| 16 |
Data Source:
|
| 17 |
|
| 18 |
-
- Connecticut
|
| 19 |
URL: <https://portal.ct.gov/DCP/Medical-Marijuana-Program/Connecticut-Medical-Marijuana-Dispensary-Facilities>
|
| 20 |
|
| 21 |
-
"""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
+
Updated: 10/3/2022
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
|
|
| 15 |
|
| 16 |
Data Source:
|
| 17 |
|
| 18 |
+
- Connecticut State Department of Consumer Protection
|
| 19 |
URL: <https://portal.ct.gov/DCP/Medical-Marijuana-Program/Connecticut-Medical-Marijuana-Dispensary-Facilities>
|
| 20 |
|
| 21 |
+
"""
|
| 22 |
+
# Standard imports.
|
| 23 |
+
from datetime import datetime
|
| 24 |
+
import os
|
| 25 |
+
from typing import Optional
|
| 26 |
+
|
| 27 |
+
# External imports.
|
| 28 |
+
from bs4 import BeautifulSoup
|
| 29 |
+
from cannlytics.data.gis import geocode_addresses
|
| 30 |
+
from dotenv import dotenv_values
|
| 31 |
+
import pandas as pd
|
| 32 |
+
import requests
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
# Specify where your data lives.
|
| 36 |
+
DATA_DIR = '../data/ct'
|
| 37 |
+
ENV_FILE = '../.env'
|
| 38 |
+
|
| 39 |
+
# Specify state-specific constants.
|
| 40 |
+
STATE = 'CT'
|
| 41 |
+
CONNECTICUT = {
|
| 42 |
+
'licensing_authority_id': 'CSDCP',
|
| 43 |
+
'licensing_authority': 'Connecticut State Department of Consumer Protection',
|
| 44 |
+
'licenses_url': 'https://portal.ct.gov/DCP/Medical-Marijuana-Program/Connecticut-Medical-Marijuana-Dispensary-Facilities',
|
| 45 |
+
'retailers': {
|
| 46 |
+
'columns': [
|
| 47 |
+
'business_legal_name',
|
| 48 |
+
'address',
|
| 49 |
+
'business_website',
|
| 50 |
+
'business_email',
|
| 51 |
+
'business_phone',
|
| 52 |
+
]
|
| 53 |
+
}
|
| 54 |
+
}
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def get_licenses_ct(
|
| 58 |
+
data_dir: Optional[str] = None,
|
| 59 |
+
env_file: Optional[str] = '.env',
|
| 60 |
+
):
|
| 61 |
+
"""Get Connecticut cannabis license data."""
|
| 62 |
+
|
| 63 |
+
# Get the license webpage.
|
| 64 |
+
url = CONNECTICUT['licenses_url']
|
| 65 |
+
response = requests.get(url)
|
| 66 |
+
soup = BeautifulSoup(response.content, 'html.parser')
|
| 67 |
+
|
| 68 |
+
# Extract the license data.
|
| 69 |
+
data = []
|
| 70 |
+
columns = CONNECTICUT['retailers']['columns']
|
| 71 |
+
table = soup.find('table')
|
| 72 |
+
rows = table.find_all('tr')
|
| 73 |
+
for row in rows[1:]:
|
| 74 |
+
cells = row.find_all('td')
|
| 75 |
+
obs = {}
|
| 76 |
+
for i, cell in enumerate(cells):
|
| 77 |
+
column = columns[i]
|
| 78 |
+
obs[column] = cell.text
|
| 79 |
+
data.append(obs)
|
| 80 |
+
|
| 81 |
+
# Standardize the license data.
|
| 82 |
+
retailers = pd.DataFrame(data)
|
| 83 |
+
retailers = retailers.assign(
|
| 84 |
+
id=retailers.index,
|
| 85 |
+
license_status=None,
|
| 86 |
+
business_dba_name=retailers['business_legal_name'],
|
| 87 |
+
license_number=None,
|
| 88 |
+
licensing_authority_id=CONNECTICUT['licensing_authority_id'],
|
| 89 |
+
licensing_authority=CONNECTICUT['licensing_authority'],
|
| 90 |
+
license_designation='Adult-Use',
|
| 91 |
+
premise_state=STATE,
|
| 92 |
+
license_status_date=None,
|
| 93 |
+
license_term=None,
|
| 94 |
+
issue_date=None,
|
| 95 |
+
expiration_date=None,
|
| 96 |
+
business_owner_name=None,
|
| 97 |
+
business_structure=None,
|
| 98 |
+
activity=None,
|
| 99 |
+
parcel_number=None,
|
| 100 |
+
business_image_url=None,
|
| 101 |
+
license_type=None,
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
# Get address parts.
|
| 105 |
+
retailers['premise_street_address'] = retailers['address'].apply(
|
| 106 |
+
lambda x: x.split(',')[0]
|
| 107 |
+
)
|
| 108 |
+
retailers['premise_city'] = retailers['address'].apply(
|
| 109 |
+
lambda x: x.split('CT')[0].strip().split(',')[-2]
|
| 110 |
+
)
|
| 111 |
+
retailers['premise_zip_code'] = retailers['address'].apply(
|
| 112 |
+
lambda x: x.split('CT')[-1].replace('\xa0', '').replace(',', '').strip()
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
# Geocode the licenses.
|
| 116 |
+
config = dotenv_values(env_file)
|
| 117 |
+
google_maps_api_key = config['GOOGLE_MAPS_API_KEY']
|
| 118 |
+
retailers = geocode_addresses(
|
| 119 |
+
retailers,
|
| 120 |
+
api_key=google_maps_api_key,
|
| 121 |
+
address_field='address',
|
| 122 |
+
)
|
| 123 |
+
retailers['premise_city'] = retailers['formatted_address'].apply(
|
| 124 |
+
lambda x: x.split(', ')[1].split(',')[0] if STATE in str(x) else x
|
| 125 |
+
)
|
| 126 |
+
drop_cols = ['state', 'state_name', 'address', 'formatted_address']
|
| 127 |
+
retailers.drop(columns=drop_cols, inplace=True)
|
| 128 |
+
gis_cols = {
|
| 129 |
+
'county': 'premise_county',
|
| 130 |
+
'latitude': 'premise_latitude',
|
| 131 |
+
'longitude': 'premise_longitude'
|
| 132 |
+
}
|
| 133 |
+
retailers.rename(columns=gis_cols, inplace=True)
|
| 134 |
+
|
| 135 |
+
# Get the refreshed date.
|
| 136 |
+
retailers['data_refreshed_date'] = datetime.now().isoformat()
|
| 137 |
+
|
| 138 |
+
# Save and return the data.
|
| 139 |
+
if data_dir is not None:
|
| 140 |
+
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 141 |
+
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 142 |
+
retailers.to_csv(f'{data_dir}/retailers-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 143 |
+
return retailers
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
# === Test ===
|
| 147 |
+
if __name__ == '__main__':
|
| 148 |
+
|
| 149 |
+
# Support command line usage.
|
| 150 |
+
import argparse
|
| 151 |
+
try:
|
| 152 |
+
arg_parser = argparse.ArgumentParser()
|
| 153 |
+
arg_parser.add_argument('--d', dest='data_dir', type=str)
|
| 154 |
+
arg_parser.add_argument('--data_dir', dest='data_dir', type=str)
|
| 155 |
+
arg_parser.add_argument('--env', dest='env_file', type=str)
|
| 156 |
+
args = arg_parser.parse_args()
|
| 157 |
+
except SystemExit:
|
| 158 |
+
args = {'d': DATA_DIR, 'env_file': ENV_FILE}
|
| 159 |
+
|
| 160 |
+
# Get licenses, saving them to the specified directory.
|
| 161 |
+
data_dir = args.get('d', args.get('data_dir'))
|
| 162 |
+
env_file = args.get('env_file')
|
| 163 |
+
data = get_licenses_ct(data_dir, env_file=env_file)
|
algorithms/get_licenses_il.py
CHANGED
|
@@ -6,7 +6,7 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
@@ -15,7 +15,180 @@ Description:
|
|
| 15 |
|
| 16 |
Data Source:
|
| 17 |
|
| 18 |
-
- Illinois
|
| 19 |
-
|
|
|
|
| 20 |
|
| 21 |
-
"""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
+
Updated: 10/3/2022
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
|
|
| 15 |
|
| 16 |
Data Source:
|
| 17 |
|
| 18 |
+
- Illinois Department of Financial and Professional Regulation
|
| 19 |
+
Licensed Adult Use Cannabis Dispensaries
|
| 20 |
+
URL: <https://www.idfpr.com/LicenseLookup/AdultUseDispensaries.pdf>
|
| 21 |
|
| 22 |
+
"""
|
| 23 |
+
# Standard imports.
|
| 24 |
+
from datetime import datetime
|
| 25 |
+
import os
|
| 26 |
+
from typing import Optional
|
| 27 |
+
|
| 28 |
+
# External imports.
|
| 29 |
+
from dotenv import dotenv_values
|
| 30 |
+
from cannlytics.data.gis import geocode_addresses
|
| 31 |
+
import pandas as pd
|
| 32 |
+
import pdfplumber
|
| 33 |
+
import requests
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
# Specify where your data lives.
|
| 37 |
+
DATA_DIR = '../data/il'
|
| 38 |
+
ENV_FILE = '../.env'
|
| 39 |
+
|
| 40 |
+
# Specify state-specific constants.
|
| 41 |
+
STATE = 'IL'
|
| 42 |
+
ILLINOIS = {
|
| 43 |
+
'licensing_authority_id': 'IDFPR',
|
| 44 |
+
'licensing_authority': 'Illinois Department of Financial and Professional Regulation',
|
| 45 |
+
'retailers': {
|
| 46 |
+
'url': 'https://www.idfpr.com/LicenseLookup/AdultUseDispensaries.pdf',
|
| 47 |
+
'columns': [
|
| 48 |
+
'business_legal_name',
|
| 49 |
+
'business_dba_name',
|
| 50 |
+
'address',
|
| 51 |
+
'medical',
|
| 52 |
+
'issue_date',
|
| 53 |
+
'license_number',
|
| 54 |
+
],
|
| 55 |
+
},
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def get_licenses_il(
|
| 60 |
+
data_dir: Optional[str] = None,
|
| 61 |
+
env_file: Optional[str] = '.env',
|
| 62 |
+
**kwargs,
|
| 63 |
+
):
|
| 64 |
+
"""Get Illinois cannabis license data."""
|
| 65 |
+
|
| 66 |
+
# Create necessary directories.
|
| 67 |
+
pdf_dir = f'{data_dir}/pdfs'
|
| 68 |
+
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 69 |
+
if not os.path.exists(pdf_dir): os.makedirs(pdf_dir)
|
| 70 |
+
|
| 71 |
+
# Download the retailers PDF.
|
| 72 |
+
retailers_url = ILLINOIS['retailers']['url']
|
| 73 |
+
filename = f'{pdf_dir}/illinois_retailers.pdf'
|
| 74 |
+
response = requests.get(retailers_url)
|
| 75 |
+
with open(filename, 'wb') as f:
|
| 76 |
+
f.write(response.content)
|
| 77 |
+
|
| 78 |
+
# Read the retailers PDF.
|
| 79 |
+
pdf = pdfplumber.open(filename)
|
| 80 |
+
|
| 81 |
+
# Get the table data, excluding the headers and removing empty cells.
|
| 82 |
+
table_data = []
|
| 83 |
+
for i, page in enumerate(pdf.pages):
|
| 84 |
+
table = page.extract_table()
|
| 85 |
+
if i == 0:
|
| 86 |
+
table = table[4:]
|
| 87 |
+
table = [c for row in table
|
| 88 |
+
if (c := [elem for elem in row if elem is not None])]
|
| 89 |
+
table_data += table
|
| 90 |
+
|
| 91 |
+
# Standardize the data.
|
| 92 |
+
licensee_columns = ILLINOIS['retailers']['columns']
|
| 93 |
+
retailers = pd.DataFrame(table_data, columns=licensee_columns)
|
| 94 |
+
retailers = retailers.assign(
|
| 95 |
+
licensing_authority_id=ILLINOIS['licensing_authority_id'],
|
| 96 |
+
licensing_authority=ILLINOIS['licensing_authority'],
|
| 97 |
+
license_designation='Adult-Use',
|
| 98 |
+
premise_state=STATE,
|
| 99 |
+
license_status='Active',
|
| 100 |
+
license_status_date=None,
|
| 101 |
+
license_type='Commercial - Retailer',
|
| 102 |
+
license_term=None,
|
| 103 |
+
expiration_date=None,
|
| 104 |
+
business_legal_name=retailers['business_dba_name'],
|
| 105 |
+
business_owner_name=None,
|
| 106 |
+
business_structure=None,
|
| 107 |
+
business_email=None,
|
| 108 |
+
activity=None,
|
| 109 |
+
parcel_number=None,
|
| 110 |
+
id=retailers['license_number'],
|
| 111 |
+
business_image_url=None,
|
| 112 |
+
business_website=None,
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
# Apply `medical` to `license_designation`
|
| 116 |
+
retailers.loc[retailers['medical'] == 'Yes', 'license_designation'] = 'Adult-Use and Medicinal'
|
| 117 |
+
retailers.drop(columns=['medical'], inplace=True)
|
| 118 |
+
|
| 119 |
+
# Clean the organization names.
|
| 120 |
+
retailers['business_legal_name'] = retailers['business_legal_name'].str.replace('\n', '', regex=False)
|
| 121 |
+
retailers['business_dba_name'] = retailers['business_dba_name'].str.replace('*', '', regex=False)
|
| 122 |
+
|
| 123 |
+
# Separate address into 'street', 'city', 'state', 'zip_code', 'phone_number'.
|
| 124 |
+
streets, cities, states, zip_codes, phone_numbers = [], [], [], [], []
|
| 125 |
+
for index, row in retailers.iterrows():
|
| 126 |
+
parts = row.address.split(' \n')
|
| 127 |
+
streets.append(parts[0])
|
| 128 |
+
phone_numbers.append(parts[-1])
|
| 129 |
+
locales = parts[1]
|
| 130 |
+
city_locales = locales.split(', ')
|
| 131 |
+
state_locales = city_locales[-1].split(' ')
|
| 132 |
+
cities.append(city_locales[0])
|
| 133 |
+
states.append(state_locales[0])
|
| 134 |
+
zip_codes.append(state_locales[-1])
|
| 135 |
+
retailers['premise_street_address'] = pd.Series(streets)
|
| 136 |
+
retailers['premise_city'] = pd.Series(cities)
|
| 137 |
+
retailers['premise_state'] = pd.Series(states)
|
| 138 |
+
retailers['premise_zip_code'] = pd.Series(zip_codes)
|
| 139 |
+
retailers['business_phone'] = pd.Series(phone_numbers)
|
| 140 |
+
|
| 141 |
+
# Convert the issue date to ISO format.
|
| 142 |
+
retailers['issue_date'] = retailers['issue_date'].apply(
|
| 143 |
+
lambda x: pd.to_datetime(x).isoformat()
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
# Get the refreshed date.
|
| 147 |
+
date = pdf.metadata['ModDate'].replace('D:', '')
|
| 148 |
+
date = date[:4] + '-' + date[4:6] + '-' + date[6:8] + 'T' + date[8:10] + \
|
| 149 |
+
':' + date[10:12] + ':' + date[12:].replace("'", ':').rstrip(':')
|
| 150 |
+
retailers['data_refreshed_date'] = date
|
| 151 |
+
|
| 152 |
+
# Geocode licenses to get `premise_latitude` and `premise_longitude`.
|
| 153 |
+
config = dotenv_values(env_file)
|
| 154 |
+
google_maps_api_key = config['GOOGLE_MAPS_API_KEY']
|
| 155 |
+
retailers['address'] = retailers['address'].str.replace('*', '', regex=False)
|
| 156 |
+
retailers = geocode_addresses(
|
| 157 |
+
retailers,
|
| 158 |
+
api_key=google_maps_api_key,
|
| 159 |
+
address_field='address',
|
| 160 |
+
)
|
| 161 |
+
drop_cols = ['state', 'state_name', 'address', 'formatted_address']
|
| 162 |
+
retailers.drop(columns=drop_cols, inplace=True)
|
| 163 |
+
gis_cols = {
|
| 164 |
+
'county': 'premise_county',
|
| 165 |
+
'latitude': 'premise_latitude',
|
| 166 |
+
'longitude': 'premise_longitude'
|
| 167 |
+
}
|
| 168 |
+
retailers.rename(columns=gis_cols, inplace=True)
|
| 169 |
+
|
| 170 |
+
# Save and return the data.
|
| 171 |
+
if data_dir is not None:
|
| 172 |
+
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 173 |
+
retailers.to_csv(f'{data_dir}/retailers-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 174 |
+
return retailers
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
# === Test ===
|
| 178 |
+
if __name__ == '__main__':
|
| 179 |
+
|
| 180 |
+
# Support command line usage.
|
| 181 |
+
import argparse
|
| 182 |
+
try:
|
| 183 |
+
arg_parser = argparse.ArgumentParser()
|
| 184 |
+
arg_parser.add_argument('--d', dest='data_dir', type=str)
|
| 185 |
+
arg_parser.add_argument('--data_dir', dest='data_dir', type=str)
|
| 186 |
+
arg_parser.add_argument('--env', dest='env_file', type=str)
|
| 187 |
+
args = arg_parser.parse_args()
|
| 188 |
+
except SystemExit:
|
| 189 |
+
args = {'d': DATA_DIR, 'env_file': ENV_FILE}
|
| 190 |
+
|
| 191 |
+
# Get licenses, saving them to the specified directory.
|
| 192 |
+
data_dir = args.get('d', args.get('data_dir'))
|
| 193 |
+
env_file = args.get('env_file')
|
| 194 |
+
data = get_licenses_il(data_dir, env_file=env_file)
|
algorithms/get_licenses_ma.py
CHANGED
|
@@ -6,7 +6,7 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
@@ -15,9 +15,132 @@ Description:
|
|
| 15 |
|
| 16 |
Data Source:
|
| 17 |
|
| 18 |
-
- Massachusetts
|
| 19 |
-
URL:
|
| 20 |
|
| 21 |
"""
|
|
|
|
|
|
|
|
|
|
|
|
|
| 22 |
|
|
|
|
|
|
|
| 23 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
+
Updated: 10/7/2022
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
|
|
| 15 |
|
| 16 |
Data Source:
|
| 17 |
|
| 18 |
+
- Massachusetts Cannabis Control Commission Data Catalog
|
| 19 |
+
URL: <https://masscannabiscontrol.com/open-data/data-catalog/>
|
| 20 |
|
| 21 |
"""
|
| 22 |
+
# Standard imports.
|
| 23 |
+
from datetime import datetime
|
| 24 |
+
import os
|
| 25 |
+
from typing import Optional
|
| 26 |
|
| 27 |
+
# External imports.
|
| 28 |
+
from cannlytics.data.opendata import OpenData
|
| 29 |
|
| 30 |
+
|
| 31 |
+
# Specify where your data lives.
|
| 32 |
+
DATA_DIR = '../data/ma'
|
| 33 |
+
|
| 34 |
+
# Specify state-specific constants.
|
| 35 |
+
STATE = 'MA'
|
| 36 |
+
MASSACHUSETTS = {
|
| 37 |
+
'licensing_authority_id': 'MACCC',
|
| 38 |
+
'licensing_authority': 'Massachusetts Cannabis Control Commission',
|
| 39 |
+
'licenses': {
|
| 40 |
+
'columns': {
|
| 41 |
+
'license_number': 'license_number',
|
| 42 |
+
'business_name': 'business_legal_name',
|
| 43 |
+
'establishment_address_1': 'premise_street_address',
|
| 44 |
+
'establishment_address_2': 'premise_street_address_2',
|
| 45 |
+
'establishment_city': 'premise_city',
|
| 46 |
+
'establishment_zipcode': 'premise_zip_code',
|
| 47 |
+
'county': 'premise_county',
|
| 48 |
+
'license_type': 'license_type',
|
| 49 |
+
'application_status': 'license_status',
|
| 50 |
+
'lic_status': 'license_term',
|
| 51 |
+
'approved_license_type': 'license_designation',
|
| 52 |
+
'commence_operations_date': 'license_status_date',
|
| 53 |
+
'massachusetts_business': 'id',
|
| 54 |
+
'dba_name': 'business_dba_name',
|
| 55 |
+
'establishment_activities': 'activity',
|
| 56 |
+
'cccupdatedate': 'data_refreshed_date',
|
| 57 |
+
'establishment_state': 'premise_state',
|
| 58 |
+
'latitude': 'premise_latitude',
|
| 59 |
+
'longitude': 'premise_longitude',
|
| 60 |
+
},
|
| 61 |
+
'drop': [
|
| 62 |
+
'square_footage_establishment',
|
| 63 |
+
'cooperative_total_canopy',
|
| 64 |
+
'cooperative_cultivation_environment',
|
| 65 |
+
'establishment_cultivation_environment',
|
| 66 |
+
'abutters_count',
|
| 67 |
+
'is_abutters_notified',
|
| 68 |
+
'business_zipcode',
|
| 69 |
+
'dph_rmd_number',
|
| 70 |
+
'geocoded_county',
|
| 71 |
+
'geocoded_address',
|
| 72 |
+
'name_of_rmd',
|
| 73 |
+
'priority_applicant_type',
|
| 74 |
+
'rmd_priority_certification',
|
| 75 |
+
'dba_registration_city',
|
| 76 |
+
'county_lat',
|
| 77 |
+
'county_long',
|
| 78 |
+
]
|
| 79 |
+
},
|
| 80 |
+
}
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def get_licenses_ma(
|
| 84 |
+
data_dir: Optional[str] = None,
|
| 85 |
+
**kwargs,
|
| 86 |
+
):
|
| 87 |
+
"""Get Massachusetts cannabis license data."""
|
| 88 |
+
|
| 89 |
+
# Get the licenses data.
|
| 90 |
+
ccc = OpenData()
|
| 91 |
+
licenses = ccc.get_licensees('approved')
|
| 92 |
+
|
| 93 |
+
# Standardize the licenses data.
|
| 94 |
+
constants = MASSACHUSETTS['licenses']
|
| 95 |
+
licenses.drop(columns=constants['drop'], inplace=True)
|
| 96 |
+
licenses.rename(columns=constants['columns'], inplace=True)
|
| 97 |
+
licenses = licenses.assign(
|
| 98 |
+
licensing_authority_id=MASSACHUSETTS['licensing_authority_id'],
|
| 99 |
+
licensing_authority=MASSACHUSETTS['licensing_authority'],
|
| 100 |
+
business_structure=None,
|
| 101 |
+
business_email=None,
|
| 102 |
+
business_owner_name=None,
|
| 103 |
+
parcel_number=None,
|
| 104 |
+
issue_date=None,
|
| 105 |
+
expiration_date=None,
|
| 106 |
+
business_image_url=None,
|
| 107 |
+
business_website=None,
|
| 108 |
+
business_phone=None,
|
| 109 |
+
)
|
| 110 |
+
|
| 111 |
+
# Append `premise_street_address_2` to `premise_street_address`.
|
| 112 |
+
cols = ['premise_street_address', 'premise_street_address_2']
|
| 113 |
+
licenses['premise_street_address'] = licenses[cols].apply(
|
| 114 |
+
lambda x : '{} {}'.format(x[0].strip(), x[1]).replace('nan', '').strip().replace(' ', ' '),
|
| 115 |
+
axis=1,
|
| 116 |
+
)
|
| 117 |
+
licenses.drop(columns=['premise_street_address_2'], inplace=True)
|
| 118 |
+
|
| 119 |
+
# Optional: Look-up business websites for each license.
|
| 120 |
+
|
| 121 |
+
# Save and return the data.
|
| 122 |
+
if data_dir is not None:
|
| 123 |
+
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 124 |
+
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 125 |
+
retailers = licenses.loc[licenses['license_type'].str.contains('Retailer')]
|
| 126 |
+
retailers.to_csv(f'{data_dir}/retailers-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 127 |
+
licenses.to_csv(f'{data_dir}/licenses-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 128 |
+
return licenses
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
# === Test ===
|
| 132 |
+
if __name__ == '__main__':
|
| 133 |
+
|
| 134 |
+
# Support command line usage.
|
| 135 |
+
import argparse
|
| 136 |
+
try:
|
| 137 |
+
arg_parser = argparse.ArgumentParser()
|
| 138 |
+
arg_parser.add_argument('--d', dest='data_dir', type=str)
|
| 139 |
+
arg_parser.add_argument('--data_dir', dest='data_dir', type=str)
|
| 140 |
+
args = arg_parser.parse_args()
|
| 141 |
+
except SystemExit:
|
| 142 |
+
args = {'d': DATA_DIR}
|
| 143 |
+
|
| 144 |
+
# Get licenses, saving them to the specified directory.
|
| 145 |
+
data_dir = args.get('d', args.get('data_dir'))
|
| 146 |
+
data = get_licenses_ma(data_dir)
|
algorithms/get_licenses_me.py
CHANGED
|
@@ -6,7 +6,7 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
@@ -90,7 +90,7 @@ def get_licenses_me(
|
|
| 90 |
break
|
| 91 |
|
| 92 |
# Download the licenses workbook.
|
| 93 |
-
filename = licenses_url.split('/')[-1]
|
| 94 |
licenses_source_file = os.path.join(file_dir, filename)
|
| 95 |
response = requests.get(licenses_url)
|
| 96 |
with open(licenses_source_file, 'wb') as doc:
|
|
@@ -99,21 +99,24 @@ def get_licenses_me(
|
|
| 99 |
# Extract the data from the license workbook.
|
| 100 |
licenses = pd.read_excel(licenses_source_file)
|
| 101 |
licenses.rename(columns=MAINE['licenses']['columns'], inplace=True)
|
| 102 |
-
licenses
|
| 103 |
-
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
|
|
|
|
|
|
|
|
|
|
| 117 |
|
| 118 |
# Remove duplicates.
|
| 119 |
licenses.drop_duplicates(subset='license_number', inplace=True)
|
|
@@ -137,31 +140,30 @@ def get_licenses_me(
|
|
| 137 |
|
| 138 |
# Geocode licenses to get `premise_latitude` and `premise_longitude`.
|
| 139 |
config = dotenv_values(env_file)
|
| 140 |
-
|
| 141 |
cols = ['premise_city', 'premise_state']
|
| 142 |
licenses['address'] = licenses[cols].apply(
|
| 143 |
lambda row: ', '.join(row.values.astype(str)),
|
| 144 |
axis=1,
|
| 145 |
)
|
| 146 |
-
licenses = geocode_addresses(
|
| 147 |
-
licenses,
|
| 148 |
-
api_key=google_maps_api_key,
|
| 149 |
-
address_field='address',
|
| 150 |
-
)
|
| 151 |
drop_cols = ['state', 'state_name', 'address', 'formatted_address',
|
| 152 |
'contact_type', 'contact_city', 'contact_description']
|
| 153 |
-
licenses.drop(columns=drop_cols, inplace=True)
|
| 154 |
gis_cols = {
|
| 155 |
'county': 'premise_county',
|
| 156 |
'latitude': 'premise_latitude',
|
| 157 |
'longitude': 'premise_longitude',
|
| 158 |
}
|
|
|
|
|
|
|
|
|
|
|
|
|
| 159 |
licenses.rename(columns=gis_cols, inplace=True)
|
| 160 |
|
| 161 |
# Save and return the data.
|
| 162 |
if data_dir is not None:
|
| 163 |
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 164 |
-
licenses.
|
| 165 |
return licenses
|
| 166 |
|
| 167 |
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
+
Updated: 10/7/2022
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
|
|
| 90 |
break
|
| 91 |
|
| 92 |
# Download the licenses workbook.
|
| 93 |
+
filename = licenses_url.split('/')[-1].split('?')[0]
|
| 94 |
licenses_source_file = os.path.join(file_dir, filename)
|
| 95 |
response = requests.get(licenses_url)
|
| 96 |
with open(licenses_source_file, 'wb') as doc:
|
|
|
|
| 99 |
# Extract the data from the license workbook.
|
| 100 |
licenses = pd.read_excel(licenses_source_file)
|
| 101 |
licenses.rename(columns=MAINE['licenses']['columns'], inplace=True)
|
| 102 |
+
licenses = licenses.assign(
|
| 103 |
+
licensing_authority_id=MAINE['licensing_authority_id'],
|
| 104 |
+
licensing_authority=MAINE['licensing_authority'],
|
| 105 |
+
license_designation='Adult-Use',
|
| 106 |
+
premise_state=STATE,
|
| 107 |
+
license_status_date=None,
|
| 108 |
+
license_term=None,
|
| 109 |
+
issue_date=None,
|
| 110 |
+
expiration_date=None,
|
| 111 |
+
business_structure=None,
|
| 112 |
+
business_email=None,
|
| 113 |
+
business_phone=None,
|
| 114 |
+
activity=None,
|
| 115 |
+
parcel_number=None,
|
| 116 |
+
premise_street_address=None,
|
| 117 |
+
id=licenses['license_number'],
|
| 118 |
+
business_image_url=None,
|
| 119 |
+
)
|
| 120 |
|
| 121 |
# Remove duplicates.
|
| 122 |
licenses.drop_duplicates(subset='license_number', inplace=True)
|
|
|
|
| 140 |
|
| 141 |
# Geocode licenses to get `premise_latitude` and `premise_longitude`.
|
| 142 |
config = dotenv_values(env_file)
|
| 143 |
+
api_key = config['GOOGLE_MAPS_API_KEY']
|
| 144 |
cols = ['premise_city', 'premise_state']
|
| 145 |
licenses['address'] = licenses[cols].apply(
|
| 146 |
lambda row: ', '.join(row.values.astype(str)),
|
| 147 |
axis=1,
|
| 148 |
)
|
| 149 |
+
licenses = geocode_addresses(licenses, address_field='address', api_key=api_key)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 150 |
drop_cols = ['state', 'state_name', 'address', 'formatted_address',
|
| 151 |
'contact_type', 'contact_city', 'contact_description']
|
|
|
|
| 152 |
gis_cols = {
|
| 153 |
'county': 'premise_county',
|
| 154 |
'latitude': 'premise_latitude',
|
| 155 |
'longitude': 'premise_longitude',
|
| 156 |
}
|
| 157 |
+
licenses['premise_zip_code'] = licenses['formatted_address'].apply(
|
| 158 |
+
lambda x: x.split(', ')[2].split(',')[0].split(' ')[-1] if STATE in str(x) else x
|
| 159 |
+
)
|
| 160 |
+
licenses.drop(columns=drop_cols, inplace=True)
|
| 161 |
licenses.rename(columns=gis_cols, inplace=True)
|
| 162 |
|
| 163 |
# Save and return the data.
|
| 164 |
if data_dir is not None:
|
| 165 |
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 166 |
+
licenses.to_csv(f'{data_dir}/licenses-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 167 |
return licenses
|
| 168 |
|
| 169 |
|
algorithms/get_licenses_mi.py
CHANGED
|
@@ -6,7 +6,7 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
@@ -15,7 +15,245 @@ Description:
|
|
| 15 |
|
| 16 |
Data Source:
|
| 17 |
|
| 18 |
-
- Michigan
|
| 19 |
-
URL:
|
| 20 |
|
| 21 |
-
"""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
+
Updated: 10/8/2022
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
|
|
| 15 |
|
| 16 |
Data Source:
|
| 17 |
|
| 18 |
+
- Michigan Cannabis Regulatory Agency
|
| 19 |
+
URL: <https://michigan.maps.arcgis.com/apps/webappviewer/index.html?id=cd5a1a76daaf470b823a382691c0ff60>
|
| 20 |
|
| 21 |
+
"""
|
| 22 |
+
# Standard imports.
|
| 23 |
+
from datetime import datetime
|
| 24 |
+
import os
|
| 25 |
+
from time import sleep
|
| 26 |
+
from typing import Optional
|
| 27 |
+
|
| 28 |
+
# External imports.
|
| 29 |
+
from cannlytics.data.gis import geocode_addresses
|
| 30 |
+
from dotenv import dotenv_values
|
| 31 |
+
import pandas as pd
|
| 32 |
+
|
| 33 |
+
# Selenium imports.
|
| 34 |
+
from selenium import webdriver
|
| 35 |
+
from selenium.webdriver.chrome.options import Options
|
| 36 |
+
from selenium.webdriver.common.by import By
|
| 37 |
+
from selenium.webdriver.chrome.service import Service
|
| 38 |
+
from selenium.webdriver.support import expected_conditions as EC
|
| 39 |
+
from selenium.webdriver.support.ui import WebDriverWait
|
| 40 |
+
from selenium.webdriver.support.ui import Select
|
| 41 |
+
try:
|
| 42 |
+
import chromedriver_binary # Adds chromedriver binary to path.
|
| 43 |
+
except ImportError:
|
| 44 |
+
pass # Otherwise, ChromeDriver should be in your path.
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
# Specify where your data lives.
|
| 48 |
+
DATA_DIR = '../data/mi'
|
| 49 |
+
ENV_FILE = '../.env'
|
| 50 |
+
|
| 51 |
+
# Specify state-specific constants.
|
| 52 |
+
STATE = 'MI'
|
| 53 |
+
MICHIGAN = {
|
| 54 |
+
'licensing_authority_id': 'CRA',
|
| 55 |
+
'licensing_authority': 'Michigan Cannabis Regulatory Agency',
|
| 56 |
+
'licenses_url': 'https://aca-prod.accela.com/MIMM/Cap/CapHome.aspx?module=Adult_Use&TabName=Adult_Use',
|
| 57 |
+
'medicinal_url': 'https://aca-prod.accela.com/MIMM/Cap/CapHome.aspx?module=Licenses&TabName=Licenses&TabList=Home%7C0%7CLicenses%7C1%7CAdult_Use%7C2%7CEnforcement%7C3%7CRegistryCards%7C4%7CCurrentTabIndex%7C1',
|
| 58 |
+
'licenses': {
|
| 59 |
+
'columns': {
|
| 60 |
+
'Record Number': 'license_number',
|
| 61 |
+
'Record Type': 'license_type',
|
| 62 |
+
'License Name': 'business_legal_name',
|
| 63 |
+
'Address': 'address',
|
| 64 |
+
'Expiration Date': 'expiration_date',
|
| 65 |
+
'Status': 'license_status',
|
| 66 |
+
'Action': 'activity',
|
| 67 |
+
'Notes': 'license_designation',
|
| 68 |
+
'Disciplinary Action': 'license_term',
|
| 69 |
+
},
|
| 70 |
+
},
|
| 71 |
+
}
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def wait_for_id_invisible(driver, value, seconds=30):
|
| 75 |
+
"""Wait for a given value to be invisible."""
|
| 76 |
+
WebDriverWait(driver, seconds).until(
|
| 77 |
+
EC.invisibility_of_element((By.ID, value))
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def get_licenses_mi(
|
| 82 |
+
data_dir: Optional[str] = None,
|
| 83 |
+
env_file: Optional[str] = '.env',
|
| 84 |
+
):
|
| 85 |
+
"""Get Michigan cannabis license data."""
|
| 86 |
+
|
| 87 |
+
# Initialize Selenium and specify options.
|
| 88 |
+
service = Service()
|
| 89 |
+
options = Options()
|
| 90 |
+
options.add_argument('--window-size=1920,1200')
|
| 91 |
+
|
| 92 |
+
# DEV: Run with the browser open.
|
| 93 |
+
options.headless = False
|
| 94 |
+
|
| 95 |
+
# PRODUCTION: Run with the browser closed.
|
| 96 |
+
# options.add_argument('--headless')
|
| 97 |
+
# options.add_argument('--disable-gpu')
|
| 98 |
+
# options.add_argument('--no-sandbox')
|
| 99 |
+
|
| 100 |
+
# Initiate a Selenium driver.
|
| 101 |
+
driver = webdriver.Chrome(options=options, service=service)
|
| 102 |
+
|
| 103 |
+
# Load the license page.
|
| 104 |
+
url = MICHIGAN['licenses_url']
|
| 105 |
+
driver.get(url)
|
| 106 |
+
|
| 107 |
+
# Get the various license types, excluding certain types without addresses.
|
| 108 |
+
select = Select(driver.find_element(by=By.TAG_NAME, value='select'))
|
| 109 |
+
license_types = []
|
| 110 |
+
options = driver.find_elements(by=By.TAG_NAME, value='option')
|
| 111 |
+
for option in options:
|
| 112 |
+
text = option.text
|
| 113 |
+
if text and '--' not in text:
|
| 114 |
+
license_types.append(text)
|
| 115 |
+
|
| 116 |
+
# Restrict certain license types.
|
| 117 |
+
license_types = license_types[1:-2]
|
| 118 |
+
|
| 119 |
+
# FIXME: Iterate over license types.
|
| 120 |
+
data = []
|
| 121 |
+
columns = list(MICHIGAN['licenses']['columns'].values())
|
| 122 |
+
for license_type in license_types:
|
| 123 |
+
|
| 124 |
+
# Select the various license types.
|
| 125 |
+
try:
|
| 126 |
+
select.select_by_visible_text(license_type)
|
| 127 |
+
except:
|
| 128 |
+
pass
|
| 129 |
+
wait_for_id_invisible(driver, 'divGlobalLoading')
|
| 130 |
+
|
| 131 |
+
# Click the search button.
|
| 132 |
+
search_button = driver.find_element(by=By.ID, value='ctl00_PlaceHolderMain_btnNewSearch')
|
| 133 |
+
search_button.click()
|
| 134 |
+
wait_for_id_invisible(driver, 'divGlobalLoading')
|
| 135 |
+
|
| 136 |
+
# Iterate over all of the pages.
|
| 137 |
+
iterate = True
|
| 138 |
+
while iterate:
|
| 139 |
+
|
| 140 |
+
# Get all of the license data.
|
| 141 |
+
grid = driver.find_element(by=By.ID, value='ctl00_PlaceHolderMain_dvSearchList')
|
| 142 |
+
rows = grid.find_elements(by=By.TAG_NAME, value='tr')
|
| 143 |
+
rows = [x.text for x in rows]
|
| 144 |
+
rows = [x for x in rows if 'Download results' not in x and not x.startswith('< Prev')]
|
| 145 |
+
cells = []
|
| 146 |
+
for row in rows[1:]: # Skip the header.
|
| 147 |
+
obs = {}
|
| 148 |
+
cells = row.split('\n')
|
| 149 |
+
for i, cell in enumerate(cells):
|
| 150 |
+
column = columns[i]
|
| 151 |
+
obs[column] = cell
|
| 152 |
+
data.append(obs)
|
| 153 |
+
|
| 154 |
+
# Keep clicking the next button until the next button is disabled.
|
| 155 |
+
next_button = driver.find_elements(by=By.CLASS_NAME, value='aca_pagination_PrevNext')[-1]
|
| 156 |
+
current_page = driver.find_element(by=By.CLASS_NAME, value='SelectedPageButton').text
|
| 157 |
+
next_button.click()
|
| 158 |
+
wait_for_id_invisible(driver, 'divGlobalLoading')
|
| 159 |
+
next_page = driver.find_element(by=By.CLASS_NAME, value='SelectedPageButton').text
|
| 160 |
+
if current_page == next_page:
|
| 161 |
+
iterate = False
|
| 162 |
+
|
| 163 |
+
# TODO: Also get all of the medical licenses!
|
| 164 |
+
# https://aca-prod.accela.com/MIMM/Cap/CapHome.aspx?module=Licenses&TabName=Licenses&TabList=Home%7C0%7CLicenses%7C1%7CAdult_Use%7C2%7CEnforcement%7C3%7CRegistryCards%7C4%7CCurrentTabIndex%7C1
|
| 165 |
+
|
| 166 |
+
# End the browser session.
|
| 167 |
+
service.stop()
|
| 168 |
+
|
| 169 |
+
# Standardize the data.
|
| 170 |
+
licenses = pd.DataFrame(data)
|
| 171 |
+
licenses = licenses.assign(
|
| 172 |
+
id=licenses.index,
|
| 173 |
+
licensing_authority_id=MICHIGAN['licensing_authority_id'],
|
| 174 |
+
licensing_authority=MICHIGAN['licensing_authority'],
|
| 175 |
+
premise_state=STATE,
|
| 176 |
+
license_status_date=None,
|
| 177 |
+
issue_date=None,
|
| 178 |
+
business_owner_name=None,
|
| 179 |
+
business_structure=None,
|
| 180 |
+
parcel_number=None,
|
| 181 |
+
business_phone=None,
|
| 182 |
+
business_email=None,
|
| 183 |
+
business_image_url=None,
|
| 184 |
+
license_designation=None,
|
| 185 |
+
business_website=None,
|
| 186 |
+
business_dba_name=licenses['business_legal_name'],
|
| 187 |
+
)
|
| 188 |
+
|
| 189 |
+
# Assign `license_term` if necessary.
|
| 190 |
+
try:
|
| 191 |
+
licenses['license_term']
|
| 192 |
+
except KeyError:
|
| 193 |
+
licenses['license_term'] = None
|
| 194 |
+
|
| 195 |
+
# Clean `license_type`.
|
| 196 |
+
licenses['license_type'] = licenses['license_type'].apply(
|
| 197 |
+
lambda x: x.replace(' - License', '')
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
# Format expiration date as an ISO formatted date.
|
| 201 |
+
licenses['expiration_date'] = licenses['expiration_date'].apply(
|
| 202 |
+
lambda x: pd.to_datetime(x).isoformat()
|
| 203 |
+
)
|
| 204 |
+
|
| 205 |
+
# Geocode the licenses.
|
| 206 |
+
config = dotenv_values(env_file)
|
| 207 |
+
google_maps_api_key = config['GOOGLE_MAPS_API_KEY']
|
| 208 |
+
licenses = geocode_addresses(
|
| 209 |
+
licenses,
|
| 210 |
+
api_key=google_maps_api_key,
|
| 211 |
+
address_field='address',
|
| 212 |
+
)
|
| 213 |
+
licenses['premise_street_address'] = licenses['formatted_address'].apply(
|
| 214 |
+
lambda x: x.split(',')[0] if STATE in str(x) else x
|
| 215 |
+
)
|
| 216 |
+
licenses['premise_city'] = licenses['formatted_address'].apply(
|
| 217 |
+
lambda x: x.split(', ')[1].split(',')[0] if STATE in str(x) else x
|
| 218 |
+
)
|
| 219 |
+
licenses['premise_zip_code'] = licenses['formatted_address'].apply(
|
| 220 |
+
lambda x: x.split(', ')[2].split(',')[0].split(' ')[-1] if STATE in str(x) else x
|
| 221 |
+
)
|
| 222 |
+
drop_cols = ['state', 'state_name', 'address', 'formatted_address']
|
| 223 |
+
gis_cols = {
|
| 224 |
+
'county': 'premise_county',
|
| 225 |
+
'latitude': 'premise_latitude',
|
| 226 |
+
'longitude': 'premise_longitude'
|
| 227 |
+
}
|
| 228 |
+
licenses.drop(columns=drop_cols, inplace=True)
|
| 229 |
+
licenses.rename(columns=gis_cols, inplace=True)
|
| 230 |
+
|
| 231 |
+
# Get the refreshed date.
|
| 232 |
+
licenses['data_refreshed_date'] = datetime.now().isoformat()
|
| 233 |
+
|
| 234 |
+
# Save and return the data.
|
| 235 |
+
if data_dir is not None:
|
| 236 |
+
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 237 |
+
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 238 |
+
licenses.to_csv(f'{data_dir}/licenses-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 239 |
+
return licenses
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
# === Test ===
|
| 243 |
+
if __name__ == '__main__':
|
| 244 |
+
|
| 245 |
+
# Support command line usage.
|
| 246 |
+
import argparse
|
| 247 |
+
try:
|
| 248 |
+
arg_parser = argparse.ArgumentParser()
|
| 249 |
+
arg_parser.add_argument('--d', dest='data_dir', type=str)
|
| 250 |
+
arg_parser.add_argument('--data_dir', dest='data_dir', type=str)
|
| 251 |
+
arg_parser.add_argument('--env', dest='env_file', type=str)
|
| 252 |
+
args = arg_parser.parse_args()
|
| 253 |
+
except SystemExit:
|
| 254 |
+
args = {'d': DATA_DIR, 'env_file': ENV_FILE}
|
| 255 |
+
|
| 256 |
+
# Get licenses, saving them to the specified directory.
|
| 257 |
+
data_dir = args.get('d', args.get('data_dir'))
|
| 258 |
+
env_file = args.get('env_file')
|
| 259 |
+
data = get_licenses_mi(data_dir, env_file=env_file)
|
algorithms/get_licenses_mt.py
CHANGED
|
@@ -6,7 +6,7 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/27/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
@@ -22,12 +22,13 @@ Data Source:
|
|
| 22 |
# Standard imports.
|
| 23 |
from datetime import datetime
|
| 24 |
import os
|
| 25 |
-
from
|
| 26 |
|
| 27 |
# External imports.
|
| 28 |
-
from
|
| 29 |
-
from cannlytics.utils import camel_to_snake
|
| 30 |
from cannlytics.utils.constants import DEFAULT_HEADERS
|
|
|
|
|
|
|
| 31 |
import pdfplumber
|
| 32 |
import requests
|
| 33 |
|
|
@@ -39,6 +40,32 @@ ENV_FILE = '../.env'
|
|
| 39 |
# Specify state-specific constants.
|
| 40 |
STATE = 'MT'
|
| 41 |
MONTANA = {
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 42 |
'retailers': {
|
| 43 |
'url': 'https://mtrevenue.gov/?mdocs-file=60245',
|
| 44 |
'columns': ['city', 'dba', 'license_type', 'phone']
|
|
@@ -49,104 +76,203 @@ MONTANA = {
|
|
| 49 |
'transporters': {'url': 'https://mtrevenue.gov/?mdocs-file=72489'},
|
| 50 |
}
|
| 51 |
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
#
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
#
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
| 85 |
-
|
| 86 |
-
|
| 87 |
-
|
| 88 |
-
|
| 89 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 90 |
break
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
continue
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
|
| 117 |
-
#
|
| 118 |
-
|
| 119 |
-
|
| 120 |
-
|
| 121 |
-
|
| 122 |
-
|
| 123 |
-
|
| 124 |
-
#
|
| 125 |
-
|
| 126 |
-
|
| 127 |
-
|
| 128 |
-
|
| 129 |
-
|
| 130 |
-
|
| 131 |
-
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
|
| 137 |
-
|
| 138 |
-
|
| 139 |
-
|
| 140 |
-
|
| 141 |
-
|
| 142 |
-
|
| 143 |
-
|
| 144 |
-
|
| 145 |
-
|
| 146 |
-
|
| 147 |
-
|
| 148 |
-
|
| 149 |
-
|
| 150 |
-
|
| 151 |
-
|
| 152 |
-
#
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/27/2022
|
| 9 |
+
Updated: 10/5/2022
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
|
|
| 22 |
# Standard imports.
|
| 23 |
from datetime import datetime
|
| 24 |
import os
|
| 25 |
+
from typing import Optional
|
| 26 |
|
| 27 |
# External imports.
|
| 28 |
+
from cannlytics.data.gis import search_for_address
|
|
|
|
| 29 |
from cannlytics.utils.constants import DEFAULT_HEADERS
|
| 30 |
+
from dotenv import dotenv_values
|
| 31 |
+
import pandas as pd
|
| 32 |
import pdfplumber
|
| 33 |
import requests
|
| 34 |
|
|
|
|
| 40 |
# Specify state-specific constants.
|
| 41 |
STATE = 'MT'
|
| 42 |
MONTANA = {
|
| 43 |
+
'licensing_authority_id': 'MTCCD',
|
| 44 |
+
'licensing_authority': 'Montana Cannabis Control Division',
|
| 45 |
+
'licenses': {
|
| 46 |
+
'columns': [
|
| 47 |
+
{
|
| 48 |
+
'key': 'premise_city',
|
| 49 |
+
'name': 'City',
|
| 50 |
+
'area': [0, 0.25, 0.2, 0.95],
|
| 51 |
+
},
|
| 52 |
+
{
|
| 53 |
+
'key': 'business_legal_name',
|
| 54 |
+
'name': 'Location Name',
|
| 55 |
+
'area': [0.2, 0.25, 0.6, 0.95],
|
| 56 |
+
},
|
| 57 |
+
{
|
| 58 |
+
'key': 'license_designation',
|
| 59 |
+
'name': 'Sales Type',
|
| 60 |
+
'area': [0.6, 0.25, 0.75, 0.95],
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
'key': 'business_phone',
|
| 64 |
+
'name': 'Phone Number',
|
| 65 |
+
'area': [0.75, 0.25, 1, 0.95],
|
| 66 |
+
},
|
| 67 |
+
]
|
| 68 |
+
},
|
| 69 |
'retailers': {
|
| 70 |
'url': 'https://mtrevenue.gov/?mdocs-file=60245',
|
| 71 |
'columns': ['city', 'dba', 'license_type', 'phone']
|
|
|
|
| 76 |
'transporters': {'url': 'https://mtrevenue.gov/?mdocs-file=72489'},
|
| 77 |
}
|
| 78 |
|
| 79 |
+
|
| 80 |
+
def get_licenses_mt(
|
| 81 |
+
data_dir: Optional[str] = None,
|
| 82 |
+
env_file: Optional[str] = '.env',
|
| 83 |
+
):
|
| 84 |
+
"""Get Montana cannabis license data."""
|
| 85 |
+
|
| 86 |
+
# Create directories if necessary.
|
| 87 |
+
pdf_dir = f'{data_dir}/pdfs'
|
| 88 |
+
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 89 |
+
if not os.path.exists(pdf_dir): os.makedirs(pdf_dir)
|
| 90 |
+
|
| 91 |
+
# Download the retailers PDF.
|
| 92 |
+
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 93 |
+
outfile = f'{pdf_dir}/mt-retailers-{timestamp}.pdf'
|
| 94 |
+
response = requests.get(MONTANA['retailers']['url'], headers=DEFAULT_HEADERS)
|
| 95 |
+
with open(outfile, 'wb') as pdf:
|
| 96 |
+
pdf.write(response.content)
|
| 97 |
+
|
| 98 |
+
# Read the PDF.
|
| 99 |
+
doc = pdfplumber.open(outfile)
|
| 100 |
+
|
| 101 |
+
# Get the table rows.
|
| 102 |
+
rows = []
|
| 103 |
+
front_page = doc.pages[0]
|
| 104 |
+
width, height = front_page.width, front_page.height
|
| 105 |
+
x0, y0, x1, y1 = tuple([0, 0.25, 1, 0.95])
|
| 106 |
+
page_area = (x0 * width, y0 * height, x1 * width, y1 * height)
|
| 107 |
+
for page in doc.pages:
|
| 108 |
+
crop = page.within_bbox(page_area)
|
| 109 |
+
text = crop.extract_text()
|
| 110 |
+
lines = text.split('\n')
|
| 111 |
+
for line in lines:
|
| 112 |
+
rows.append(line)
|
| 113 |
+
|
| 114 |
+
# Get cities from the first column, used to identify the city for each line.
|
| 115 |
+
cities = []
|
| 116 |
+
city_area = MONTANA['licenses']['columns'][0]['area']
|
| 117 |
+
x0, y0, x1, y1 = tuple(city_area)
|
| 118 |
+
column_area = (x0 * width, y0 * height, x1 * width, y1 * height)
|
| 119 |
+
for page in doc.pages:
|
| 120 |
+
crop = page.within_bbox(column_area)
|
| 121 |
+
text = crop.extract_text()
|
| 122 |
+
lines = text.split('\n')
|
| 123 |
+
for line in lines:
|
| 124 |
+
cities.append(line)
|
| 125 |
+
|
| 126 |
+
# Find all of the unique cities.
|
| 127 |
+
cities = list(set(cities))
|
| 128 |
+
cities = [x for x in cities if x != 'City']
|
| 129 |
+
|
| 130 |
+
# Get all of the license data.
|
| 131 |
+
data = []
|
| 132 |
+
rows = [x for x in rows if not x.startswith('City')]
|
| 133 |
+
for row in rows:
|
| 134 |
+
|
| 135 |
+
# Get all of the license observation data.
|
| 136 |
+
obs = {}
|
| 137 |
+
text = str(row)
|
| 138 |
+
|
| 139 |
+
# Identify the city and remove the city from the name (only once b/c of DBAs!).
|
| 140 |
+
for city in cities:
|
| 141 |
+
if city in row:
|
| 142 |
+
obs['premise_city'] = city.title()
|
| 143 |
+
text = text.replace(city, '', 1).strip()
|
| 144 |
break
|
| 145 |
+
|
| 146 |
+
# Identify the license designation.
|
| 147 |
+
if 'Adult Use' in row:
|
| 148 |
+
parts = text.split('Adult Use')
|
| 149 |
+
obs['license_designation'] = 'Adult Use'
|
| 150 |
+
else:
|
| 151 |
+
parts = text.split('Medical Only')
|
| 152 |
+
obs['license_designation'] = 'Medical Only'
|
| 153 |
+
|
| 154 |
+
# Skip rows with double-row text.
|
| 155 |
+
if len(row) == 1: continue
|
| 156 |
+
|
| 157 |
+
# Record the name.
|
| 158 |
+
obs['business_legal_name'] = name = parts[0]
|
| 159 |
+
|
| 160 |
+
# Record the phone number.
|
| 161 |
+
if '(' in text:
|
| 162 |
+
obs['business_phone'] = parts[-1].strip()
|
| 163 |
+
|
| 164 |
+
# Record the observation.
|
| 165 |
+
data.append(obs)
|
| 166 |
+
|
| 167 |
+
# Aggregate the data.
|
| 168 |
+
retailers = pd.DataFrame(data)
|
| 169 |
+
retailers = retailers.loc[~retailers['premise_city'].isna()]
|
| 170 |
+
|
| 171 |
+
# Convert certain columns from upper case title case.
|
| 172 |
+
cols = ['business_legal_name', 'premise_city']
|
| 173 |
+
for col in cols:
|
| 174 |
+
retailers[col] = retailers[col].apply(
|
| 175 |
+
lambda x: x.title().replace('Llc', 'LLC').replace("'S", "'s").strip()
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
# Standardize the data.
|
| 179 |
+
retailers['id'] = retailers.index
|
| 180 |
+
retailers['license_number'] = None # FIXME: It would be awesome to find these!
|
| 181 |
+
retailers['licensing_authority_id'] = MONTANA['licensing_authority_id']
|
| 182 |
+
retailers['licensing_authority'] = MONTANA['licensing_authority']
|
| 183 |
+
retailers['premise_state'] = STATE
|
| 184 |
+
retailers['license_status'] = 'Active'
|
| 185 |
+
retailers['license_status_date'] = None
|
| 186 |
+
retailers['license_type'] = 'Commercial - Retailer'
|
| 187 |
+
retailers['license_term'] = None
|
| 188 |
+
retailers['issue_date'] = None
|
| 189 |
+
retailers['expiration_date'] = None
|
| 190 |
+
retailers['business_owner_name'] = None
|
| 191 |
+
retailers['business_structure'] = None
|
| 192 |
+
retailers['activity'] = None
|
| 193 |
+
retailers['parcel_number'] = None
|
| 194 |
+
retailers['business_email'] = None
|
| 195 |
+
retailers['business_image_url'] = None
|
| 196 |
+
|
| 197 |
+
# Separate any `business_dba_name` from `business_legal_name`.
|
| 198 |
+
retailers['business_dba_name'] = retailers['business_legal_name']
|
| 199 |
+
criterion = retailers['business_legal_name'].str.contains('Dba')
|
| 200 |
+
retailers.loc[criterion, 'business_dba_name'] = retailers.loc[criterion] \
|
| 201 |
+
['business_legal_name'].apply(lambda x: x.split('Dba')[-1].strip())
|
| 202 |
+
retailers.loc[criterion, 'business_legal_name'] = retailers.loc[criterion] \
|
| 203 |
+
['business_legal_name'].apply(lambda x: x.split('Dba')[0].strip())
|
| 204 |
+
|
| 205 |
+
# Search for address for each retail license.
|
| 206 |
+
# Only search for a query once, then re-use the response.
|
| 207 |
+
# Note: There is probably a much, much more efficient way to do this!!!
|
| 208 |
+
config = dotenv_values(env_file)
|
| 209 |
+
api_key = config['GOOGLE_MAPS_API_KEY']
|
| 210 |
+
cols = ['business_dba_name', 'premise_city', 'premise_state']
|
| 211 |
+
retailers['query'] = retailers[cols].apply(
|
| 212 |
+
lambda row: ', '.join(row.values.astype(str)),
|
| 213 |
+
axis=1,
|
| 214 |
+
)
|
| 215 |
+
queries = {}
|
| 216 |
+
fields = [
|
| 217 |
+
'formatted_address',
|
| 218 |
+
'geometry/location/lat',
|
| 219 |
+
'geometry/location/lng',
|
| 220 |
+
'website',
|
| 221 |
+
]
|
| 222 |
+
retailers = retailers.reset_index(drop=True)
|
| 223 |
+
retailers = retailers.assign(
|
| 224 |
+
premise_street_address=None,
|
| 225 |
+
premise_county=None,
|
| 226 |
+
premise_zip_code=None,
|
| 227 |
+
premise_latitude=None,
|
| 228 |
+
premise_longitude=None,
|
| 229 |
+
business_website=None,
|
| 230 |
+
)
|
| 231 |
+
for index, row in retailers.iterrows():
|
| 232 |
+
query = row['query']
|
| 233 |
+
gis_data = queries.get(query)
|
| 234 |
+
if gis_data is None:
|
| 235 |
+
try:
|
| 236 |
+
gis_data = search_for_address(query, api_key=api_key, fields=fields)
|
| 237 |
+
except:
|
| 238 |
+
gis_data = {}
|
| 239 |
+
queries[query] = gis_data
|
| 240 |
+
retailers.iat[index, retailers.columns.get_loc('premise_street_address')] = gis_data.get('street')
|
| 241 |
+
retailers.iat[index, retailers.columns.get_loc('premise_county')] = gis_data.get('county')
|
| 242 |
+
retailers.iat[index, retailers.columns.get_loc('premise_zip_code')] = gis_data.get('zipcode')
|
| 243 |
+
retailers.iat[index, retailers.columns.get_loc('premise_latitude')] = gis_data.get('latitude')
|
| 244 |
+
retailers.iat[index, retailers.columns.get_loc('premise_longitude')] = gis_data.get('longitude')
|
| 245 |
+
retailers.iat[index, retailers.columns.get_loc('business_website')] = gis_data.get('website')
|
| 246 |
+
|
| 247 |
+
# Clean-up after getting GIS data.
|
| 248 |
+
retailers.drop(columns=['query'], inplace=True)
|
| 249 |
+
|
| 250 |
+
# Get the refreshed date.
|
| 251 |
+
retailers['data_refreshed_date'] = datetime.now().isoformat()
|
| 252 |
+
|
| 253 |
+
# Save and return the data.
|
| 254 |
+
if data_dir is not None:
|
| 255 |
+
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 256 |
+
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 257 |
+
retailers.to_csv(f'{data_dir}/retailers-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 258 |
+
return retailers
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
# === Test ===
|
| 262 |
+
if __name__ == '__main__':
|
| 263 |
+
|
| 264 |
+
# Support command line usage.
|
| 265 |
+
import argparse
|
| 266 |
+
try:
|
| 267 |
+
arg_parser = argparse.ArgumentParser()
|
| 268 |
+
arg_parser.add_argument('--d', dest='data_dir', type=str)
|
| 269 |
+
arg_parser.add_argument('--data_dir', dest='data_dir', type=str)
|
| 270 |
+
arg_parser.add_argument('--env', dest='env_file', type=str)
|
| 271 |
+
args = arg_parser.parse_args()
|
| 272 |
+
except SystemExit:
|
| 273 |
+
args = {'d': DATA_DIR, 'env_file': ENV_FILE}
|
| 274 |
+
|
| 275 |
+
# Get licenses, saving them to the specified directory.
|
| 276 |
+
data_dir = args.get('d', args.get('data_dir'))
|
| 277 |
+
env_file = args.get('env_file')
|
| 278 |
+
data = get_licenses_mt(data_dir, env_file=env_file)
|
algorithms/get_licenses_nj.py
CHANGED
|
@@ -92,6 +92,11 @@ def get_licenses_nj(
|
|
| 92 |
data['business_email'] = None
|
| 93 |
data['activity'] = None
|
| 94 |
data['parcel_number'] = None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 95 |
|
| 96 |
# Convert certain columns from upper case title case.
|
| 97 |
cols = ['premise_city', 'premise_county', 'premise_street_address']
|
|
@@ -102,7 +107,7 @@ def get_licenses_nj(
|
|
| 102 |
if data_dir is not None:
|
| 103 |
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 104 |
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 105 |
-
data.
|
| 106 |
return data
|
| 107 |
|
| 108 |
|
|
|
|
| 92 |
data['business_email'] = None
|
| 93 |
data['activity'] = None
|
| 94 |
data['parcel_number'] = None
|
| 95 |
+
data['business_image_url'] = None
|
| 96 |
+
data['id'] = None
|
| 97 |
+
data['license_number'] = None
|
| 98 |
+
data['license_status'] = None
|
| 99 |
+
data['data_refreshed_date'] = datetime.now().isoformat()
|
| 100 |
|
| 101 |
# Convert certain columns from upper case title case.
|
| 102 |
cols = ['premise_city', 'premise_county', 'premise_street_address']
|
|
|
|
| 107 |
if data_dir is not None:
|
| 108 |
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 109 |
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 110 |
+
data.to_csv(f'{data_dir}/licenses-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 111 |
return data
|
| 112 |
|
| 113 |
|
algorithms/get_licenses_nm.py
CHANGED
|
@@ -6,7 +6,7 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
@@ -15,7 +15,295 @@ Description:
|
|
| 15 |
|
| 16 |
Data Source:
|
| 17 |
|
| 18 |
-
- New Mexico
|
| 19 |
-
URL:
|
| 20 |
|
| 21 |
-
"""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
+
Updated: 10/6/2022
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
|
|
| 15 |
|
| 16 |
Data Source:
|
| 17 |
|
| 18 |
+
- New Mexico Regulation and Licensing Department | Cannabis Control Division
|
| 19 |
+
URL: <https://nmrldlpi.force.com/bcd/s/public-search-license?division=CCD&language=en_US>
|
| 20 |
|
| 21 |
+
"""
|
| 22 |
+
# Standard imports.
|
| 23 |
+
from datetime import datetime
|
| 24 |
+
import os
|
| 25 |
+
from time import sleep
|
| 26 |
+
from typing import Optional
|
| 27 |
+
|
| 28 |
+
# External imports.
|
| 29 |
+
from cannlytics.data.gis import geocode_addresses, search_for_address
|
| 30 |
+
from dotenv import dotenv_values
|
| 31 |
+
import pandas as pd
|
| 32 |
+
|
| 33 |
+
# Selenium imports.
|
| 34 |
+
from selenium import webdriver
|
| 35 |
+
from selenium.webdriver.chrome.options import Options
|
| 36 |
+
from selenium.webdriver.common.by import By
|
| 37 |
+
from selenium.webdriver.chrome.service import Service
|
| 38 |
+
from selenium.webdriver.support import expected_conditions as EC
|
| 39 |
+
from selenium.webdriver.support.ui import WebDriverWait
|
| 40 |
+
try:
|
| 41 |
+
import chromedriver_binary # Adds chromedriver binary to path.
|
| 42 |
+
except ImportError:
|
| 43 |
+
pass # Otherwise, ChromeDriver should be in your path.
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
# Specify where your data lives.
|
| 47 |
+
DATA_DIR = '../data/nm'
|
| 48 |
+
ENV_FILE = '../.env'
|
| 49 |
+
|
| 50 |
+
# Specify state-specific constants.
|
| 51 |
+
STATE = 'NM'
|
| 52 |
+
NEW_MEXICO = {
|
| 53 |
+
'licensing_authority_id': 'NMCCD',
|
| 54 |
+
'licensing_authority': 'New Mexico Cannabis Control Division',
|
| 55 |
+
'licenses_url': 'https://nmrldlpi.force.com/bcd/s/public-search-license?division=CCD&language=en_US',
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def get_licenses_nm(
|
| 60 |
+
data_dir: Optional[str] = None,
|
| 61 |
+
env_file: Optional[str] = '.env',
|
| 62 |
+
):
|
| 63 |
+
"""Get New Mexico cannabis license data."""
|
| 64 |
+
|
| 65 |
+
# Create directories if necessary.
|
| 66 |
+
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 67 |
+
|
| 68 |
+
# Initialize Selenium and specify options.
|
| 69 |
+
service = Service()
|
| 70 |
+
options = Options()
|
| 71 |
+
options.add_argument('--window-size=1920,1200')
|
| 72 |
+
|
| 73 |
+
# DEV: Run with the browser open.
|
| 74 |
+
options.headless = False
|
| 75 |
+
|
| 76 |
+
# PRODUCTION: Run with the browser closed.
|
| 77 |
+
# options.add_argument('--headless')
|
| 78 |
+
# options.add_argument('--disable-gpu')
|
| 79 |
+
# options.add_argument('--no-sandbox')
|
| 80 |
+
|
| 81 |
+
# Initiate a Selenium driver.
|
| 82 |
+
driver = webdriver.Chrome(options=options, service=service)
|
| 83 |
+
|
| 84 |
+
# Load the license page.
|
| 85 |
+
driver.get(NEW_MEXICO['licenses_url'])
|
| 86 |
+
|
| 87 |
+
# FIXME: Wait for the page to load by waiting to detect the image.
|
| 88 |
+
# try:
|
| 89 |
+
# el = (By.CLASS_NAME, 'slds-radio--faux')
|
| 90 |
+
# WebDriverWait(driver, 15).until(EC.presence_of_element_located(el))
|
| 91 |
+
# except TimeoutException:
|
| 92 |
+
# print('Failed to load page within %i seconds.' % (30))
|
| 93 |
+
sleep(5)
|
| 94 |
+
|
| 95 |
+
# Get the main content and click "License Type" raido.
|
| 96 |
+
content = driver.find_element(by=By.CLASS_NAME, value='siteforceContentArea')
|
| 97 |
+
radio = content.find_element(by=By.CLASS_NAME, value='slds-radio--faux')
|
| 98 |
+
radio.click()
|
| 99 |
+
sleep(2)
|
| 100 |
+
|
| 101 |
+
# Select retailers.
|
| 102 |
+
# TODO: Also get "Cannabis Manufacturer", "Cannabis Producer", and
|
| 103 |
+
# "Cannabis Producer Microbusiness".
|
| 104 |
+
search = content.find_element(by=By.ID, value='comboboxId-40')
|
| 105 |
+
search.click()
|
| 106 |
+
choices = content.find_elements(by=By.CLASS_NAME, value='slds-listbox__item')
|
| 107 |
+
for choice in choices:
|
| 108 |
+
if choice.text == 'Cannabis Retailer':
|
| 109 |
+
choice.click()
|
| 110 |
+
sleep(2)
|
| 111 |
+
break
|
| 112 |
+
|
| 113 |
+
# Click the search button.
|
| 114 |
+
search = content.find_element(by=By.CLASS_NAME, value='vlocity-btn')
|
| 115 |
+
search.click()
|
| 116 |
+
sleep(2)
|
| 117 |
+
|
| 118 |
+
# Iterate over all of the pages.
|
| 119 |
+
# Wait for the table to load, then iterate over the pages.
|
| 120 |
+
sleep(5)
|
| 121 |
+
data = []
|
| 122 |
+
iterate = True
|
| 123 |
+
while(iterate):
|
| 124 |
+
|
| 125 |
+
# Get all of the licenses.
|
| 126 |
+
items = content.find_elements(by=By.CLASS_NAME, value='block-container')
|
| 127 |
+
for item in items[3:]:
|
| 128 |
+
text = item.text
|
| 129 |
+
if not text:
|
| 130 |
+
continue
|
| 131 |
+
values = text.split('\n')
|
| 132 |
+
data.append({
|
| 133 |
+
'license_type': values[0],
|
| 134 |
+
'license_status': values[1],
|
| 135 |
+
'business_legal_name': values[2],
|
| 136 |
+
'address': values[-1],
|
| 137 |
+
'details_url': '',
|
| 138 |
+
})
|
| 139 |
+
|
| 140 |
+
# Get the page number and stop at the last page.
|
| 141 |
+
# FIXME: This doesn't correctly break!
|
| 142 |
+
par = content.find_elements(by=By.TAG_NAME, value='p')[-1].text
|
| 143 |
+
page_number = int(par.split(' ')[2])
|
| 144 |
+
total_pages = int(par.split(' ')[-2])
|
| 145 |
+
if page_number == total_pages:
|
| 146 |
+
iterate = False
|
| 147 |
+
|
| 148 |
+
# Otherwise, click the next button.
|
| 149 |
+
buttons = content.find_elements(by=By.TAG_NAME, value='button')
|
| 150 |
+
for button in buttons:
|
| 151 |
+
if button.text == 'Next Page':
|
| 152 |
+
button.click()
|
| 153 |
+
sleep(5)
|
| 154 |
+
break
|
| 155 |
+
|
| 156 |
+
# Search for each license name, 1 by 1, to get details.
|
| 157 |
+
retailers = pd.DataFrame(columns=['business_legal_name'])
|
| 158 |
+
for i, licensee in enumerate(data):
|
| 159 |
+
|
| 160 |
+
# Skip recorded rows.
|
| 161 |
+
if len(retailers.loc[retailers['business_legal_name'] == licensee['business_legal_name']]):
|
| 162 |
+
continue
|
| 163 |
+
|
| 164 |
+
# Click the "Business Name" search field.
|
| 165 |
+
content = driver.find_element(by=By.CLASS_NAME, value='siteforceContentArea')
|
| 166 |
+
radio = content.find_elements(by=By.CLASS_NAME, value='slds-radio--faux')[1]
|
| 167 |
+
radio.click()
|
| 168 |
+
sleep(1)
|
| 169 |
+
|
| 170 |
+
# Enter the `business_legal_name` into the search.
|
| 171 |
+
search_field = content.find_element(by=By.CLASS_NAME, value='vlocity-input')
|
| 172 |
+
search_field.clear()
|
| 173 |
+
search_field.send_keys(licensee['business_legal_name'])
|
| 174 |
+
|
| 175 |
+
# Click the search button.
|
| 176 |
+
search = content.find_element(by=By.CLASS_NAME, value='vlocity-btn')
|
| 177 |
+
search.click()
|
| 178 |
+
|
| 179 |
+
# FIXME: Wait for the table to load.
|
| 180 |
+
# WebDriverWait(content, 5).until(EC.presence_of_element_located((By.CLASS_NAME, 'slds-button_icon')))
|
| 181 |
+
sleep(1.5)
|
| 182 |
+
|
| 183 |
+
# Click the "Action" button to get to the details page.
|
| 184 |
+
# FIXME: There can be multiple search candidates!
|
| 185 |
+
action = content.find_element(by=By.CLASS_NAME, value='slds-button_icon')
|
| 186 |
+
try:
|
| 187 |
+
action.click()
|
| 188 |
+
except:
|
| 189 |
+
continue # FIXME: Formally check if "No record found!".
|
| 190 |
+
|
| 191 |
+
# FIXME: Wait for the details page to load.
|
| 192 |
+
el = (By.CLASS_NAME, 'body')
|
| 193 |
+
WebDriverWait(driver, 5).until(EC.presence_of_element_located(el))
|
| 194 |
+
|
| 195 |
+
# Get the page
|
| 196 |
+
page = driver.find_element(by=By.CLASS_NAME, value='body')
|
| 197 |
+
|
| 198 |
+
# FIXME: Wait for the details to load!
|
| 199 |
+
# el = (By.TAG_NAME, 'vlocity_ins-omniscript-step')
|
| 200 |
+
# WebDriverWait(page, 5).until(EC.presence_of_element_located(el))
|
| 201 |
+
sleep(1.5)
|
| 202 |
+
|
| 203 |
+
# Get all of the details!
|
| 204 |
+
fields = [
|
| 205 |
+
'license_number',
|
| 206 |
+
'license_status',
|
| 207 |
+
'issue_date',
|
| 208 |
+
'expiration_date',
|
| 209 |
+
'business_owner_name',
|
| 210 |
+
]
|
| 211 |
+
values = page.find_elements(by=By.CLASS_NAME, value='field-value')
|
| 212 |
+
if len(values) > 5:
|
| 213 |
+
for j, value in enumerate(values[:5]):
|
| 214 |
+
data[i][fields[j]] = value.text
|
| 215 |
+
for value in values[5:]:
|
| 216 |
+
data[i]['business_owner_name'] += f', {value.text}'
|
| 217 |
+
else:
|
| 218 |
+
for j, value in enumerate(values):
|
| 219 |
+
data[i][fields[j]] = value.text
|
| 220 |
+
|
| 221 |
+
# Create multiple entries for each address!!!
|
| 222 |
+
premises = page.find_elements(by=By.CLASS_NAME, value='block-header')
|
| 223 |
+
for premise in premises:
|
| 224 |
+
values = premise.text.split('\n')
|
| 225 |
+
licensee['address'] = values[0].replace(',', ', ')
|
| 226 |
+
licensee['license_number'] = values[2]
|
| 227 |
+
retailers = pd.concat([retailers, pd.DataFrame([licensee])])
|
| 228 |
+
|
| 229 |
+
# Click the "Back to Search" button.
|
| 230 |
+
back_button = page.find_element(by=By.CLASS_NAME, value='vlocity-btn')
|
| 231 |
+
back_button.click()
|
| 232 |
+
sleep(1)
|
| 233 |
+
|
| 234 |
+
# End the browser session.
|
| 235 |
+
service.stop()
|
| 236 |
+
|
| 237 |
+
# Standardize the data, restricting to "Approved" retailers.
|
| 238 |
+
retailers = retailers.loc[retailers['license_status'] == 'Active']
|
| 239 |
+
retailers = retailers.assign(
|
| 240 |
+
business_email=None,
|
| 241 |
+
business_structure=None,
|
| 242 |
+
licensing_authority_id=NEW_MEXICO['licensing_authority_id'],
|
| 243 |
+
licensing_authority=NEW_MEXICO['licensing_authority'],
|
| 244 |
+
license_designation='Adult-Use',
|
| 245 |
+
license_status_date=None,
|
| 246 |
+
license_term=None,
|
| 247 |
+
premise_state=STATE,
|
| 248 |
+
parcel_number=None,
|
| 249 |
+
activity=None,
|
| 250 |
+
business_image_url=None,
|
| 251 |
+
business_website=None,
|
| 252 |
+
business_phone=None,
|
| 253 |
+
id=retailers['license_number'],
|
| 254 |
+
business_dba_name=retailers['business_legal_name'],
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
# Get the refreshed date.
|
| 258 |
+
retailers['data_refreshed_date'] = datetime.now().isoformat()
|
| 259 |
+
|
| 260 |
+
# Geocode licenses.
|
| 261 |
+
# FIXME: This is not working as intended. Perhaps try `search_for_address`?
|
| 262 |
+
config = dotenv_values(env_file)
|
| 263 |
+
api_key = config['GOOGLE_MAPS_API_KEY']
|
| 264 |
+
retailers = geocode_addresses(retailers, api_key=api_key, address_field='address')
|
| 265 |
+
retailers['premise_street_address'] = retailers['formatted_address'].apply(
|
| 266 |
+
lambda x: x.split(',')[0] if STATE in str(x) else x
|
| 267 |
+
)
|
| 268 |
+
retailers['premise_city'] = retailers['formatted_address'].apply(
|
| 269 |
+
lambda x: x.split(', ')[1].split(',')[0] if STATE in str(x) else x
|
| 270 |
+
)
|
| 271 |
+
retailers['premise_zip_code'] = retailers['formatted_address'].apply(
|
| 272 |
+
lambda x: x.split(', ')[2].split(',')[0].split(' ')[-1] if STATE in str(x) else x
|
| 273 |
+
)
|
| 274 |
+
drop_cols = ['state', 'state_name', 'address', 'formatted_address',
|
| 275 |
+
'details_url']
|
| 276 |
+
gis_cols = {
|
| 277 |
+
'county': 'premise_county',
|
| 278 |
+
'latitude': 'premise_latitude',
|
| 279 |
+
'longitude': 'premise_longitude'
|
| 280 |
+
}
|
| 281 |
+
retailers.drop(columns=drop_cols, inplace=True)
|
| 282 |
+
retailers.rename(columns=gis_cols, inplace=True)
|
| 283 |
+
|
| 284 |
+
# Save and return the data.
|
| 285 |
+
if data_dir is not None:
|
| 286 |
+
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 287 |
+
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 288 |
+
retailers.to_csv(f'{data_dir}/retailers-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 289 |
+
return retailers
|
| 290 |
+
|
| 291 |
+
|
| 292 |
+
# === Test ===
|
| 293 |
+
if __name__ == '__main__':
|
| 294 |
+
|
| 295 |
+
# Support command line usage.
|
| 296 |
+
import argparse
|
| 297 |
+
try:
|
| 298 |
+
arg_parser = argparse.ArgumentParser()
|
| 299 |
+
arg_parser.add_argument('--d', dest='data_dir', type=str)
|
| 300 |
+
arg_parser.add_argument('--data_dir', dest='data_dir', type=str)
|
| 301 |
+
arg_parser.add_argument('--env', dest='env_file', type=str)
|
| 302 |
+
args = arg_parser.parse_args()
|
| 303 |
+
except SystemExit:
|
| 304 |
+
args = {'d': DATA_DIR, 'env_file': ENV_FILE}
|
| 305 |
+
|
| 306 |
+
# Get licenses, saving them to the specified directory.
|
| 307 |
+
data_dir = args.get('d', args.get('data_dir'))
|
| 308 |
+
env_file = args.get('env_file')
|
| 309 |
+
data = get_licenses_nm(data_dir, env_file=env_file)
|
algorithms/get_licenses_nv.py
CHANGED
|
@@ -93,6 +93,7 @@ def get_licenses_nv(
|
|
| 93 |
# Extract and standardize the data from the workbook.
|
| 94 |
licenses = pd.read_excel(licenses_source_file, skiprows=1)
|
| 95 |
licenses.rename(columns=NEVADA['licenses']['columns'], inplace=True)
|
|
|
|
| 96 |
licenses['licensing_authority_id'] = NEVADA['licensing_authority_id']
|
| 97 |
licenses['licensing_authority'] = NEVADA['licensing_authority']
|
| 98 |
licenses['license_designation'] = 'Adult-Use'
|
|
@@ -107,6 +108,9 @@ def get_licenses_nv(
|
|
| 107 |
licenses['business_email'] = None
|
| 108 |
licenses['activity'] = None
|
| 109 |
licenses['parcel_number'] = None
|
|
|
|
|
|
|
|
|
|
| 110 |
|
| 111 |
# Convert certain columns from upper case title case.
|
| 112 |
cols = ['business_dba_name', 'premise_county']
|
|
@@ -123,7 +127,7 @@ def get_licenses_nv(
|
|
| 123 |
# Save the licenses
|
| 124 |
if data_dir is not None:
|
| 125 |
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 126 |
-
licenses.
|
| 127 |
|
| 128 |
#--------------------------------------------------------------------------
|
| 129 |
# Get retailer data
|
|
@@ -168,6 +172,15 @@ def get_licenses_nv(
|
|
| 168 |
retailers['business_email'] = None
|
| 169 |
retailers['activity'] = None
|
| 170 |
retailers['parcel_number'] = None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 171 |
|
| 172 |
# Geocode the retailers.
|
| 173 |
config = dotenv_values(env_file)
|
|
@@ -182,20 +195,22 @@ def get_licenses_nv(
|
|
| 182 |
api_key=google_maps_api_key,
|
| 183 |
address_field='address',
|
| 184 |
)
|
| 185 |
-
drop_cols = ['state', 'state_name', '
|
| 186 |
-
retailers.drop(columns=drop_cols, inplace=True)
|
| 187 |
gis_cols = {
|
|
|
|
| 188 |
'latitude': 'premise_latitude',
|
| 189 |
'longitude': 'premise_longitude'
|
| 190 |
}
|
|
|
|
|
|
|
|
|
|
|
|
|
| 191 |
retailers.rename(columns=gis_cols, inplace=True)
|
| 192 |
|
| 193 |
-
# Future work: Merge the retailers with the licenses data?
|
| 194 |
-
|
| 195 |
# Save the retailers
|
| 196 |
if data_dir is not None:
|
| 197 |
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 198 |
-
retailers.
|
| 199 |
|
| 200 |
# Return all of the data.
|
| 201 |
return pd.concat([licenses, retailers])
|
|
|
|
| 93 |
# Extract and standardize the data from the workbook.
|
| 94 |
licenses = pd.read_excel(licenses_source_file, skiprows=1)
|
| 95 |
licenses.rename(columns=NEVADA['licenses']['columns'], inplace=True)
|
| 96 |
+
licenses['id'] = licenses['license_number']
|
| 97 |
licenses['licensing_authority_id'] = NEVADA['licensing_authority_id']
|
| 98 |
licenses['licensing_authority'] = NEVADA['licensing_authority']
|
| 99 |
licenses['license_designation'] = 'Adult-Use'
|
|
|
|
| 108 |
licenses['business_email'] = None
|
| 109 |
licenses['activity'] = None
|
| 110 |
licenses['parcel_number'] = None
|
| 111 |
+
licenses['business_image_url'] = None
|
| 112 |
+
licenses['business_phone'] = None
|
| 113 |
+
licenses['business_website'] = None
|
| 114 |
|
| 115 |
# Convert certain columns from upper case title case.
|
| 116 |
cols = ['business_dba_name', 'premise_county']
|
|
|
|
| 127 |
# Save the licenses
|
| 128 |
if data_dir is not None:
|
| 129 |
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 130 |
+
licenses.to_csv(f'{data_dir}/licenses-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 131 |
|
| 132 |
#--------------------------------------------------------------------------
|
| 133 |
# Get retailer data
|
|
|
|
| 172 |
retailers['business_email'] = None
|
| 173 |
retailers['activity'] = None
|
| 174 |
retailers['parcel_number'] = None
|
| 175 |
+
retailers['business_website'] = None
|
| 176 |
+
retailers['business_image_url'] = None
|
| 177 |
+
retailers['business_phone'] = None
|
| 178 |
+
|
| 179 |
+
# FIXME: Merge `license_number`, `premise_county`, `data_refreshed_date`
|
| 180 |
+
# from licenses.
|
| 181 |
+
retailers['license_number'] = None
|
| 182 |
+
retailers['id'] = None
|
| 183 |
+
retailers['data_refreshed_date'] = datetime.now().isoformat()
|
| 184 |
|
| 185 |
# Geocode the retailers.
|
| 186 |
config = dotenv_values(env_file)
|
|
|
|
| 195 |
api_key=google_maps_api_key,
|
| 196 |
address_field='address',
|
| 197 |
)
|
| 198 |
+
drop_cols = ['state', 'state_name', 'address', 'formatted_address']
|
|
|
|
| 199 |
gis_cols = {
|
| 200 |
+
'county': 'premise_county',
|
| 201 |
'latitude': 'premise_latitude',
|
| 202 |
'longitude': 'premise_longitude'
|
| 203 |
}
|
| 204 |
+
licenses['premise_zip_code'] = licenses['formatted_address'].apply(
|
| 205 |
+
lambda x: x.split(', ')[2].split(',')[0].split(' ')[-1] if STATE in str(x) else x
|
| 206 |
+
)
|
| 207 |
+
retailers.drop(columns=drop_cols, inplace=True)
|
| 208 |
retailers.rename(columns=gis_cols, inplace=True)
|
| 209 |
|
|
|
|
|
|
|
| 210 |
# Save the retailers
|
| 211 |
if data_dir is not None:
|
| 212 |
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 213 |
+
retailers.to_csv(f'{data_dir}/retailers-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 214 |
|
| 215 |
# Return all of the data.
|
| 216 |
return pd.concat([licenses, retailers])
|
algorithms/get_licenses_or.py
CHANGED
|
@@ -6,7 +6,7 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/28/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
@@ -53,6 +53,10 @@ OREGON = {
|
|
| 53 |
'Med Grade': 'medicinal',
|
| 54 |
'Delivery': 'delivery',
|
| 55 |
},
|
|
|
|
|
|
|
|
|
|
|
|
|
| 56 |
},
|
| 57 |
}
|
| 58 |
|
|
@@ -90,12 +94,26 @@ def get_licenses_or(
|
|
| 90 |
data['license_designation'] = 'Adult-Use'
|
| 91 |
data['premise_state'] = 'OR'
|
| 92 |
data.loc[data['medicinal'] == 'Yes', 'license_designation'] = 'Adult-Use and Medicinal'
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
data['
|
| 96 |
-
data['
|
| 97 |
-
data['
|
| 98 |
-
data['
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 99 |
|
| 100 |
# Convert certain columns from upper case title case.
|
| 101 |
cols = ['business_dba_name', 'premise_city', 'premise_county',
|
|
@@ -138,6 +156,7 @@ def get_licenses_or(
|
|
| 138 |
}
|
| 139 |
data.rename(columns=columns, inplace=True)
|
| 140 |
data.drop(columns=['BUSINESS NAME', 'COUNTY'], inplace=True)
|
|
|
|
| 141 |
|
| 142 |
# Geocode licenses to get `premise_latitude` and `premise_longitude`.
|
| 143 |
config = dotenv_values(env_file)
|
|
@@ -171,7 +190,7 @@ def get_licenses_or(
|
|
| 171 |
# Save the license data.
|
| 172 |
if data_dir is not None:
|
| 173 |
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 174 |
-
data.
|
| 175 |
return data
|
| 176 |
|
| 177 |
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/28/2022
|
| 9 |
+
Updated: 10/7/2022
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
|
|
| 53 |
'Med Grade': 'medicinal',
|
| 54 |
'Delivery': 'delivery',
|
| 55 |
},
|
| 56 |
+
'drop_columns': [
|
| 57 |
+
'medicinal',
|
| 58 |
+
'delivery',
|
| 59 |
+
],
|
| 60 |
},
|
| 61 |
}
|
| 62 |
|
|
|
|
| 94 |
data['license_designation'] = 'Adult-Use'
|
| 95 |
data['premise_state'] = 'OR'
|
| 96 |
data.loc[data['medicinal'] == 'Yes', 'license_designation'] = 'Adult-Use and Medicinal'
|
| 97 |
+
data['business_image_url'] = None
|
| 98 |
+
data['license_status_date'] = None
|
| 99 |
+
data['license_term'] = None
|
| 100 |
+
data['issue_date'] = None
|
| 101 |
+
data['expiration_date'] = None
|
| 102 |
+
data['business_email'] = None
|
| 103 |
+
data['business_owner_name'] = None
|
| 104 |
+
data['business_structure'] = None
|
| 105 |
+
data['business_website'] = None
|
| 106 |
+
data['activity'] = None
|
| 107 |
+
data['business_phone'] = None
|
| 108 |
+
data['parcel_number'] = None
|
| 109 |
+
data['business_legal_name'] = data['business_dba_name']
|
| 110 |
+
|
| 111 |
+
# Optional: Convert `medicinal` and `delivery` columns to boolean.
|
| 112 |
+
# data['medicinal'] = data['medicinal'].map(dict(Yes=1))
|
| 113 |
+
# data['delivery'] = data['delivery'].map(dict(Yes=1))
|
| 114 |
+
# data['medicinal'].fillna(0, inplace=True)
|
| 115 |
+
# data['delivery'].fillna(0, inplace=True)
|
| 116 |
+
data.drop(columns=['medicinal', 'delivery'], inplace=True)
|
| 117 |
|
| 118 |
# Convert certain columns from upper case title case.
|
| 119 |
cols = ['business_dba_name', 'premise_city', 'premise_county',
|
|
|
|
| 156 |
}
|
| 157 |
data.rename(columns=columns, inplace=True)
|
| 158 |
data.drop(columns=['BUSINESS NAME', 'COUNTY'], inplace=True)
|
| 159 |
+
data['id'] = data['license_number']
|
| 160 |
|
| 161 |
# Geocode licenses to get `premise_latitude` and `premise_longitude`.
|
| 162 |
config = dotenv_values(env_file)
|
|
|
|
| 190 |
# Save the license data.
|
| 191 |
if data_dir is not None:
|
| 192 |
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 193 |
+
data.to_csv(f'{data_dir}/licenses-or-{timestamp}.csv', index=False)
|
| 194 |
return data
|
| 195 |
|
| 196 |
|
algorithms/get_licenses_ri.py
CHANGED
|
@@ -6,7 +6,7 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
@@ -18,4 +18,162 @@ Data Source:
|
|
| 18 |
- Rhode Island
|
| 19 |
URL: <https://dbr.ri.gov/office-cannabis-regulation/compassion-centers/licensed-compassion-centers>
|
| 20 |
|
| 21 |
-
"""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
+
Updated: 10/3/2022
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
|
|
| 18 |
- Rhode Island
|
| 19 |
URL: <https://dbr.ri.gov/office-cannabis-regulation/compassion-centers/licensed-compassion-centers>
|
| 20 |
|
| 21 |
+
"""
|
| 22 |
+
# Standard imports.
|
| 23 |
+
from datetime import datetime
|
| 24 |
+
import os
|
| 25 |
+
from typing import Optional
|
| 26 |
+
|
| 27 |
+
# External imports.
|
| 28 |
+
from bs4 import BeautifulSoup
|
| 29 |
+
from cannlytics.data.gis import geocode_addresses
|
| 30 |
+
from dotenv import dotenv_values
|
| 31 |
+
import pandas as pd
|
| 32 |
+
import requests
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
# Specify where your data lives.
|
| 36 |
+
DATA_DIR = '../data/ri'
|
| 37 |
+
ENV_FILE = '../.env'
|
| 38 |
+
|
| 39 |
+
# Specify state-specific constants.
|
| 40 |
+
STATE = 'RI'
|
| 41 |
+
RHODE_ISLAND = {
|
| 42 |
+
'licensing_authority_id': 'RIDBH',
|
| 43 |
+
'licensing_authority': 'Rhode Island Department of Business Regulation',
|
| 44 |
+
'retailers': {
|
| 45 |
+
'url': 'https://dbr.ri.gov/office-cannabis-regulation/compassion-centers/licensed-compassion-centers',
|
| 46 |
+
'columns': [
|
| 47 |
+
'license_number',
|
| 48 |
+
'business_legal_name',
|
| 49 |
+
'address',
|
| 50 |
+
'business_phone',
|
| 51 |
+
'license_designation',
|
| 52 |
+
],
|
| 53 |
+
}
|
| 54 |
+
}
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def get_licenses_ri(
|
| 58 |
+
data_dir: Optional[str] = None,
|
| 59 |
+
env_file: Optional[str] = '.env',
|
| 60 |
+
):
|
| 61 |
+
"""Get Rhode Island cannabis license data."""
|
| 62 |
+
|
| 63 |
+
# Get the licenses webpage.
|
| 64 |
+
url = RHODE_ISLAND['retailers']['url']
|
| 65 |
+
response = requests.get(url)
|
| 66 |
+
soup = BeautifulSoup(response.content, 'html.parser')
|
| 67 |
+
|
| 68 |
+
# Parse the table data.
|
| 69 |
+
data = []
|
| 70 |
+
columns = RHODE_ISLAND['retailers']['columns']
|
| 71 |
+
table = soup.find('table')
|
| 72 |
+
rows = table.find_all('tr')
|
| 73 |
+
for row in rows[1:]:
|
| 74 |
+
cells = row.find_all('td')
|
| 75 |
+
obs = {}
|
| 76 |
+
for i, cell in enumerate(cells):
|
| 77 |
+
column = columns[i]
|
| 78 |
+
obs[column] = cell.text
|
| 79 |
+
data.append(obs)
|
| 80 |
+
|
| 81 |
+
# Optional: It's possible to download the certificate to get it's `issue_date`.
|
| 82 |
+
|
| 83 |
+
# Standardize the license data.
|
| 84 |
+
retailers = pd.DataFrame(data)
|
| 85 |
+
retailers['id'] = retailers['license_number']
|
| 86 |
+
retailers['licensing_authority_id'] = RHODE_ISLAND['licensing_authority_id']
|
| 87 |
+
retailers['licensing_authority'] = RHODE_ISLAND['licensing_authority']
|
| 88 |
+
retailers['premise_state'] = STATE
|
| 89 |
+
retailers['license_type'] = 'Commercial - Retailer'
|
| 90 |
+
retailers['license_status'] = 'Active'
|
| 91 |
+
retailers['license_status_date'] = None
|
| 92 |
+
retailers['license_term'] = None
|
| 93 |
+
retailers['issue_date'] = None
|
| 94 |
+
retailers['expiration_date'] = None
|
| 95 |
+
retailers['business_owner_name'] = None
|
| 96 |
+
retailers['business_structure'] = None
|
| 97 |
+
retailers['business_email'] = None
|
| 98 |
+
retailers['activity'] = None
|
| 99 |
+
retailers['parcel_number'] = None
|
| 100 |
+
retailers['business_image_url'] = None
|
| 101 |
+
retailers['business_website'] = None
|
| 102 |
+
|
| 103 |
+
# Correct `license_designation`.
|
| 104 |
+
coding = dict(Yes='Adult Use and Cultivation', No='Adult Use')
|
| 105 |
+
retailers['license_designation'] = retailers['license_designation'].map(coding)
|
| 106 |
+
|
| 107 |
+
# Correct `business_dba_name`.
|
| 108 |
+
criterion = retailers['business_legal_name'].str.contains('D/B/A')
|
| 109 |
+
retailers['business_dba_name'] = retailers['business_legal_name']
|
| 110 |
+
retailers.loc[criterion, 'business_dba_name'] = retailers['business_legal_name'].apply(
|
| 111 |
+
lambda x: x.split('D/B/A')[1].strip() if 'D/B/A' in x else x
|
| 112 |
+
)
|
| 113 |
+
retailers.loc[criterion, 'business_legal_name'] = retailers['business_legal_name'].apply(
|
| 114 |
+
lambda x: x.split('D/B/A')[0].strip()
|
| 115 |
+
)
|
| 116 |
+
criterion = retailers['business_legal_name'].str.contains('F/K/A')
|
| 117 |
+
retailers.loc[criterion, 'business_dba_name'] = retailers['business_legal_name'].apply(
|
| 118 |
+
lambda x: x.split('F/K/A')[1].strip() if 'D/B/A' in x else x
|
| 119 |
+
)
|
| 120 |
+
retailers.loc[criterion, 'business_legal_name'] = retailers['business_legal_name'].apply(
|
| 121 |
+
lambda x: x.split('F/K/A')[0].strip()
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
# Get the refreshed date.
|
| 125 |
+
par = soup.find_all('p')[-1]
|
| 126 |
+
date = par.text.split('updated on ')[-1].split('.')[0]
|
| 127 |
+
retailers['data_refreshed_date'] = pd.to_datetime(date).isoformat()
|
| 128 |
+
|
| 129 |
+
# Geocode the licenses.
|
| 130 |
+
config = dotenv_values(env_file)
|
| 131 |
+
google_maps_api_key = config['GOOGLE_MAPS_API_KEY']
|
| 132 |
+
retailers = geocode_addresses(
|
| 133 |
+
retailers,
|
| 134 |
+
api_key=google_maps_api_key,
|
| 135 |
+
address_field='address',
|
| 136 |
+
)
|
| 137 |
+
retailers['premise_street_address'] = retailers['formatted_address'].apply(
|
| 138 |
+
lambda x: x.split(',')[0]
|
| 139 |
+
)
|
| 140 |
+
retailers['premise_city'] = retailers['formatted_address'].apply(
|
| 141 |
+
lambda x: x.split(', ')[1].split(',')[0]
|
| 142 |
+
)
|
| 143 |
+
retailers['premise_zip_code'] = retailers['formatted_address'].apply(
|
| 144 |
+
lambda x: x.split(', ')[2].split(',')[0].split(' ')[-1]
|
| 145 |
+
)
|
| 146 |
+
drop_cols = ['state', 'state_name', 'address', 'formatted_address']
|
| 147 |
+
retailers.drop(columns=drop_cols, inplace=True)
|
| 148 |
+
gis_cols = {
|
| 149 |
+
'county': 'premise_county',
|
| 150 |
+
'latitude': 'premise_latitude',
|
| 151 |
+
'longitude': 'premise_longitude'
|
| 152 |
+
}
|
| 153 |
+
retailers.rename(columns=gis_cols, inplace=True)
|
| 154 |
+
|
| 155 |
+
# Save and return the data.
|
| 156 |
+
if data_dir is not None:
|
| 157 |
+
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 158 |
+
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 159 |
+
retailers.to_csv(f'{data_dir}/licenses-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 160 |
+
return retailers
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
if __name__ == '__main__':
|
| 164 |
+
|
| 165 |
+
# Support command line usage.
|
| 166 |
+
import argparse
|
| 167 |
+
try:
|
| 168 |
+
arg_parser = argparse.ArgumentParser()
|
| 169 |
+
arg_parser.add_argument('--d', dest='data_dir', type=str)
|
| 170 |
+
arg_parser.add_argument('--data_dir', dest='data_dir', type=str)
|
| 171 |
+
arg_parser.add_argument('--env', dest='env_file', type=str)
|
| 172 |
+
args = arg_parser.parse_args()
|
| 173 |
+
except SystemExit:
|
| 174 |
+
args = {'d': DATA_DIR, 'env_file': ENV_FILE}
|
| 175 |
+
|
| 176 |
+
# Get licenses, saving them to the specified directory.
|
| 177 |
+
data_dir = args.get('d', args.get('data_dir'))
|
| 178 |
+
env_file = args.get('env_file')
|
| 179 |
+
data = get_licenses_ri(data_dir, env_file=env_file)
|
algorithms/get_licenses_vt.py
CHANGED
|
@@ -6,7 +6,7 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
@@ -18,4 +18,236 @@ Data Source:
|
|
| 18 |
- Vermont
|
| 19 |
URL: <https://ccb.vermont.gov/licenses>
|
| 20 |
|
| 21 |
-
"""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
+
Updated: 10/7/2022
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
|
|
| 18 |
- Vermont
|
| 19 |
URL: <https://ccb.vermont.gov/licenses>
|
| 20 |
|
| 21 |
+
"""
|
| 22 |
+
# Standard imports.
|
| 23 |
+
from datetime import datetime
|
| 24 |
+
import os
|
| 25 |
+
from typing import Optional
|
| 26 |
+
|
| 27 |
+
# External imports.
|
| 28 |
+
from bs4 import BeautifulSoup
|
| 29 |
+
from cannlytics.data.gis import geocode_addresses
|
| 30 |
+
from dotenv import dotenv_values
|
| 31 |
+
import pandas as pd
|
| 32 |
+
import requests
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
# Specify where your data lives.
|
| 36 |
+
DATA_DIR = '../data/vt'
|
| 37 |
+
ENV_FILE = '../.env'
|
| 38 |
+
|
| 39 |
+
# Specify state-specific constants.
|
| 40 |
+
STATE = 'VT'
|
| 41 |
+
VERMONT = {
|
| 42 |
+
'licensing_authority_id': 'VTCCB',
|
| 43 |
+
'licensing_authority': 'Vermont Cannabis Control Board',
|
| 44 |
+
'licenses_url': 'https://ccb.vermont.gov/licenses',
|
| 45 |
+
'licenses': {
|
| 46 |
+
'licensedcultivators': {
|
| 47 |
+
'columns': [
|
| 48 |
+
'business_legal_name',
|
| 49 |
+
'license_type',
|
| 50 |
+
'address',
|
| 51 |
+
'license_designation',
|
| 52 |
+
],
|
| 53 |
+
},
|
| 54 |
+
'outdoorcultivators': {
|
| 55 |
+
'columns': [
|
| 56 |
+
'business_legal_name',
|
| 57 |
+
'license_type',
|
| 58 |
+
'premise_city',
|
| 59 |
+
'license_designation',
|
| 60 |
+
],
|
| 61 |
+
},
|
| 62 |
+
'mixedcultivators': {
|
| 63 |
+
'columns': [
|
| 64 |
+
'business_legal_name',
|
| 65 |
+
'license_type',
|
| 66 |
+
'premise_city',
|
| 67 |
+
'license_designation',
|
| 68 |
+
],
|
| 69 |
+
},
|
| 70 |
+
'testinglaboratories': {
|
| 71 |
+
'columns': [
|
| 72 |
+
'business_legal_name',
|
| 73 |
+
'license_type',
|
| 74 |
+
'premise_city',
|
| 75 |
+
'license_designation',
|
| 76 |
+
'address'
|
| 77 |
+
],
|
| 78 |
+
},
|
| 79 |
+
'integrated': {
|
| 80 |
+
'columns': [
|
| 81 |
+
'business_legal_name',
|
| 82 |
+
'license_type',
|
| 83 |
+
'premise_city',
|
| 84 |
+
'license_designation',
|
| 85 |
+
],
|
| 86 |
+
},
|
| 87 |
+
'retailers': {
|
| 88 |
+
'columns': [
|
| 89 |
+
'business_legal_name',
|
| 90 |
+
'license_type',
|
| 91 |
+
'address',
|
| 92 |
+
'license_designation',
|
| 93 |
+
],
|
| 94 |
+
},
|
| 95 |
+
'manufacturers': {
|
| 96 |
+
'columns': [
|
| 97 |
+
'business_legal_name',
|
| 98 |
+
'license_type',
|
| 99 |
+
'premise_city',
|
| 100 |
+
'license_designation',
|
| 101 |
+
],
|
| 102 |
+
},
|
| 103 |
+
'wholesalers': {
|
| 104 |
+
'columns': [
|
| 105 |
+
'business_legal_name',
|
| 106 |
+
'license_type',
|
| 107 |
+
'premise_city',
|
| 108 |
+
'license_designation',
|
| 109 |
+
],
|
| 110 |
+
},
|
| 111 |
+
},
|
| 112 |
+
}
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def get_licenses_vt(
|
| 116 |
+
data_dir: Optional[str] = None,
|
| 117 |
+
env_file: Optional[str] = '.env',
|
| 118 |
+
):
|
| 119 |
+
"""Get Vermont cannabis license data."""
|
| 120 |
+
|
| 121 |
+
# Get the licenses from the webpage.
|
| 122 |
+
url = VERMONT['licenses_url']
|
| 123 |
+
response = requests.get(url)
|
| 124 |
+
soup = BeautifulSoup(response.content, 'html.parser')
|
| 125 |
+
|
| 126 |
+
# Parse the various table types.
|
| 127 |
+
data = []
|
| 128 |
+
for license_type, values in VERMONT['licenses'].items():
|
| 129 |
+
columns = values['columns']
|
| 130 |
+
table = block = soup.find(attrs={'id': f'block-{license_type}'})
|
| 131 |
+
rows = table.find_all('tr')
|
| 132 |
+
for row in rows[1:]:
|
| 133 |
+
cells = row.find_all('td')
|
| 134 |
+
obs = {}
|
| 135 |
+
for i, cell in enumerate(cells):
|
| 136 |
+
column = columns[i]
|
| 137 |
+
obs[column] = cell.text
|
| 138 |
+
data.append(obs)
|
| 139 |
+
|
| 140 |
+
# Standardize the licenses.
|
| 141 |
+
licenses = pd.DataFrame(data)
|
| 142 |
+
licenses['id'] = licenses.index
|
| 143 |
+
licenses['license_number'] = None # FIXME: It would be awesome to find these!
|
| 144 |
+
licenses['licensing_authority_id'] = VERMONT['licensing_authority_id']
|
| 145 |
+
licenses['licensing_authority'] = VERMONT['licensing_authority']
|
| 146 |
+
licenses['license_designation'] = 'Adult-Use'
|
| 147 |
+
licenses['premise_state'] = STATE
|
| 148 |
+
licenses['license_status'] = None
|
| 149 |
+
licenses['license_status_date'] = None
|
| 150 |
+
licenses['license_term'] = None
|
| 151 |
+
licenses['issue_date'] = None
|
| 152 |
+
licenses['expiration_date'] = None
|
| 153 |
+
licenses['business_owner_name'] = None
|
| 154 |
+
licenses['business_structure'] = None
|
| 155 |
+
licenses['activity'] = None
|
| 156 |
+
licenses['parcel_number'] = None
|
| 157 |
+
licenses['business_phone'] = None
|
| 158 |
+
licenses['business_email'] = None
|
| 159 |
+
licenses['business_image_url'] = None
|
| 160 |
+
licenses['business_website'] = None
|
| 161 |
+
|
| 162 |
+
# Separate the `license_designation` from `license_type` if (Tier x).
|
| 163 |
+
criterion = licenses['license_type'].str.contains('Tier ')
|
| 164 |
+
licenses.loc[criterion, 'license_designation'] = licenses.loc[criterion]['license_type'].apply(
|
| 165 |
+
lambda x: 'Tier ' + x.split('(Tier ')[1].rstrip(')')
|
| 166 |
+
)
|
| 167 |
+
licenses.loc[criterion, 'license_type'] = licenses.loc[criterion]['license_type'].apply(
|
| 168 |
+
lambda x: x.split('(Tier ')[0].strip()
|
| 169 |
+
)
|
| 170 |
+
|
| 171 |
+
# Separate labs' `business_email` and `business_phone` from the `address`.
|
| 172 |
+
criterion = licenses['license_type'] == 'Testing Lab'
|
| 173 |
+
licenses.loc[criterion, 'business_email'] = licenses.loc[criterion]['address'].apply(
|
| 174 |
+
lambda x: x.split('Email: ')[-1].rstrip('\n') if isinstance(x, str) else x
|
| 175 |
+
)
|
| 176 |
+
licenses.loc[criterion, 'business_phone'] = licenses.loc[criterion]['address'].apply(
|
| 177 |
+
lambda x: x.split('Phone: ')[-1].split('Email: ')[0].rstrip('\n') if isinstance(x, str) else x
|
| 178 |
+
)
|
| 179 |
+
licenses.loc[criterion, 'address'] = licenses.loc[criterion]['address'].apply(
|
| 180 |
+
lambda x: x.split('Phone: ')[0].replace('\n', ' ').strip() if isinstance(x, str) else x
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
# Split any DBA from the legal name.
|
| 184 |
+
splits = [';', 'DBA - ', '(DBA)', 'DBA ', 'dba ']
|
| 185 |
+
licenses['business_dba_name'] = licenses['business_legal_name']
|
| 186 |
+
for split in splits:
|
| 187 |
+
criterion = licenses['business_legal_name'].str.contains(split)
|
| 188 |
+
licenses.loc[criterion, 'business_dba_name'] = licenses.loc[criterion]['business_legal_name'].apply(
|
| 189 |
+
lambda x: x.split(split)[1].replace(')', '').strip() if split in x else x
|
| 190 |
+
)
|
| 191 |
+
licenses.loc[criterion, 'business_legal_name'] = licenses.loc[criterion]['business_legal_name'].apply(
|
| 192 |
+
lambda x: x.split(split)[0].replace('(', '').strip()
|
| 193 |
+
)
|
| 194 |
+
licenses.loc[licenses['business_legal_name'] == '', 'business_legal_name'] = licenses['business_dba_name']
|
| 195 |
+
|
| 196 |
+
# Get the refreshed date.
|
| 197 |
+
licenses['data_refreshed_date'] = datetime.now().isoformat()
|
| 198 |
+
|
| 199 |
+
# Geocode the licenses.
|
| 200 |
+
# FIXME: There are some wonky addresses that are output!
|
| 201 |
+
config = dotenv_values(env_file)
|
| 202 |
+
google_maps_api_key = config['GOOGLE_MAPS_API_KEY']
|
| 203 |
+
licenses = geocode_addresses(
|
| 204 |
+
licenses,
|
| 205 |
+
api_key=google_maps_api_key,
|
| 206 |
+
address_field='address',
|
| 207 |
+
)
|
| 208 |
+
licenses['premise_street_address'] = licenses['formatted_address'].apply(
|
| 209 |
+
lambda x: x.split(',')[0] if STATE in str(x) else x
|
| 210 |
+
)
|
| 211 |
+
licenses['premise_city'] = licenses['formatted_address'].apply(
|
| 212 |
+
lambda x: x.split(', ')[1].split(',')[0] if STATE in str(x) else x
|
| 213 |
+
)
|
| 214 |
+
licenses['premise_zip_code'] = licenses['formatted_address'].apply(
|
| 215 |
+
lambda x: x.split(', ')[2].split(',')[0].split(' ')[-1] if STATE in str(x) else x
|
| 216 |
+
)
|
| 217 |
+
drop_cols = ['state', 'state_name', 'address', 'formatted_address']
|
| 218 |
+
licenses.drop(columns=drop_cols, inplace=True)
|
| 219 |
+
gis_cols = {
|
| 220 |
+
'county': 'premise_county',
|
| 221 |
+
'latitude': 'premise_latitude',
|
| 222 |
+
'longitude': 'premise_longitude'
|
| 223 |
+
}
|
| 224 |
+
licenses.rename(columns=gis_cols, inplace=True)
|
| 225 |
+
|
| 226 |
+
# Save and return the data.
|
| 227 |
+
if data_dir is not None:
|
| 228 |
+
if not os.path.exists(data_dir): os.makedirs(data_dir)
|
| 229 |
+
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 230 |
+
retailers = licenses.loc[licenses['license_type'] == 'Retail']
|
| 231 |
+
licenses.to_csv(f'{data_dir}/licenses-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 232 |
+
retailers.to_csv(f'{data_dir}/retailers-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 233 |
+
return licenses
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
# === Test ===
|
| 237 |
+
if __name__ == '__main__':
|
| 238 |
+
|
| 239 |
+
# Support command line usage.
|
| 240 |
+
import argparse
|
| 241 |
+
try:
|
| 242 |
+
arg_parser = argparse.ArgumentParser()
|
| 243 |
+
arg_parser.add_argument('--d', dest='data_dir', type=str)
|
| 244 |
+
arg_parser.add_argument('--data_dir', dest='data_dir', type=str)
|
| 245 |
+
arg_parser.add_argument('--env', dest='env_file', type=str)
|
| 246 |
+
args = arg_parser.parse_args()
|
| 247 |
+
except SystemExit:
|
| 248 |
+
args = {'d': DATA_DIR, 'env_file': ENV_FILE}
|
| 249 |
+
|
| 250 |
+
# Get licenses, saving them to the specified directory.
|
| 251 |
+
data_dir = args.get('d', args.get('data_dir'))
|
| 252 |
+
env_file = args.get('env_file')
|
| 253 |
+
data = get_licenses_vt(data_dir, env_file=env_file)
|
algorithms/get_licenses_wa.py
CHANGED
|
@@ -6,7 +6,7 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
@@ -41,6 +41,49 @@ STATE = 'WA'
|
|
| 41 |
WASHINGTON = {
|
| 42 |
'licensing_authority_id': 'WSLCB',
|
| 43 |
'licensing_authority': 'Washington State Liquor and Cannabis Board',
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 44 |
'retailers': {
|
| 45 |
'key': 'CannabisApplicants',
|
| 46 |
'columns': {
|
|
@@ -57,10 +100,27 @@ WASHINGTON = {
|
|
| 57 |
'Privilege Status': 'license_status',
|
| 58 |
'Day Phone': 'business_phone',
|
| 59 |
},
|
| 60 |
-
}
|
| 61 |
}
|
| 62 |
|
| 63 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 64 |
def get_licenses_wa(
|
| 65 |
data_dir: Optional[str] = None,
|
| 66 |
env_file: Optional[str] = '.env',
|
|
@@ -74,52 +134,75 @@ def get_licenses_wa(
|
|
| 74 |
|
| 75 |
# Get the URLs for the license workbooks.
|
| 76 |
labs_url, medical_url, retailers_url = None, None, None
|
| 77 |
-
|
|
|
|
|
|
|
|
|
|
| 78 |
response = requests.get(url)
|
| 79 |
soup = BeautifulSoup(response.content, 'html.parser')
|
| 80 |
links = soup.find_all('a')
|
| 81 |
for link in links:
|
| 82 |
href = link['href']
|
| 83 |
-
if
|
| 84 |
labs_url = href
|
| 85 |
-
elif
|
| 86 |
retailers_url = href
|
| 87 |
-
elif
|
| 88 |
medical_url = href
|
| 89 |
break
|
| 90 |
|
| 91 |
-
#
|
| 92 |
-
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
retailers_source_file = os.path.join(file_dir, filename)
|
| 96 |
-
response = requests.get(retailers_url)
|
| 97 |
-
with open(retailers_source_file, 'wb') as doc:
|
| 98 |
-
doc.write(response.content)
|
| 99 |
|
| 100 |
# Extract and standardize the data from the workbook.
|
| 101 |
retailers = pd.read_excel(retailers_source_file)
|
| 102 |
retailers.rename(columns=WASHINGTON['retailers']['columns'], inplace=True)
|
| 103 |
-
retailers['licensing_authority_id'] = WASHINGTON['licensing_authority_id']
|
| 104 |
-
retailers['licensing_authority'] = WASHINGTON['licensing_authority']
|
| 105 |
retailers['license_designation'] = 'Adult-Use'
|
| 106 |
-
retailers['
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 117 |
|
| 118 |
# Keep only active licenses.
|
| 119 |
-
|
| 120 |
-
|
| 121 |
-
(retailers['license_status'] == 'ACTIVE TITLE CERTIFICATE')
|
| 122 |
-
]
|
| 123 |
|
| 124 |
# Convert certain columns from upper case title case.
|
| 125 |
cols = ['business_dba_name', 'premise_city', 'premise_county',
|
|
@@ -130,38 +213,42 @@ def get_licenses_wa(
|
|
| 130 |
# Get the refreshed date.
|
| 131 |
date = retailers_source_file.split('\\')[-1].split('.')[0]
|
| 132 |
date = date.replace('CannabisApplicants', '')
|
| 133 |
-
date = date[:2] + '-' + date[2:4] + '-' + date[4:]
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
# FIXME: Append `premise_street_address_2` to `premise_street_address`.
|
| 137 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 138 |
|
| 139 |
# Geocode licenses to get `premise_latitude` and `premise_longitude`.
|
| 140 |
config = dotenv_values(env_file)
|
| 141 |
-
|
| 142 |
cols = ['premise_street_address', 'premise_city', 'premise_state',
|
| 143 |
'premise_zip_code']
|
| 144 |
-
|
| 145 |
lambda row: ', '.join(row.values.astype(str)),
|
| 146 |
axis=1,
|
| 147 |
)
|
| 148 |
-
|
| 149 |
-
retailers,
|
| 150 |
-
api_key=google_maps_api_key,
|
| 151 |
-
address_field='address',
|
| 152 |
-
)
|
| 153 |
drop_cols = ['state', 'state_name', 'county', 'address', 'formatted_address']
|
| 154 |
-
|
| 155 |
-
|
| 156 |
-
|
| 157 |
-
|
| 158 |
-
|
| 159 |
-
retailers.rename(columns=gis_cols, inplace=True)
|
| 160 |
|
| 161 |
# Save and return the data.
|
| 162 |
if data_dir is not None:
|
| 163 |
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 164 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 165 |
return retailers
|
| 166 |
|
| 167 |
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
+
Updated: 10/7/2022
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
|
|
|
| 41 |
WASHINGTON = {
|
| 42 |
'licensing_authority_id': 'WSLCB',
|
| 43 |
'licensing_authority': 'Washington State Liquor and Cannabis Board',
|
| 44 |
+
'licenses_urls': 'https://lcb.wa.gov/records/frequently-requested-lists',
|
| 45 |
+
'labs': {
|
| 46 |
+
'key': 'Lab-List',
|
| 47 |
+
'columns': {
|
| 48 |
+
'Lab Name': 'business_legal_name',
|
| 49 |
+
'Lab #': 'license_number',
|
| 50 |
+
'Address 1': 'premise_street_address',
|
| 51 |
+
'Address 2': 'premise_street_address_2',
|
| 52 |
+
'City': 'premise_city',
|
| 53 |
+
'Zip': 'premise_zip_code',
|
| 54 |
+
'Phone': 'business_phone',
|
| 55 |
+
'Status': 'license_status',
|
| 56 |
+
'Certification Date': 'issue_date',
|
| 57 |
+
},
|
| 58 |
+
'drop_columns': [
|
| 59 |
+
'Pesticides',
|
| 60 |
+
'Heavy Metals',
|
| 61 |
+
'Mycotoxins',
|
| 62 |
+
'Water Activity',
|
| 63 |
+
'Terpenes',
|
| 64 |
+
],
|
| 65 |
+
},
|
| 66 |
+
'medical': {
|
| 67 |
+
'key': 'MedicalCannabisEndorsements',
|
| 68 |
+
'columns': {
|
| 69 |
+
'License': 'license_number',
|
| 70 |
+
'UBI': 'id',
|
| 71 |
+
'Tradename': 'business_dba_name',
|
| 72 |
+
'Privilege': 'license_type',
|
| 73 |
+
'Status': 'license_status',
|
| 74 |
+
'Med Privilege Code': 'license_designation',
|
| 75 |
+
'Termination Code': 'license_term',
|
| 76 |
+
'Street Adress': 'premise_street_address',
|
| 77 |
+
'Suite Rm': 'premise_street_address_2',
|
| 78 |
+
'City': 'premise_city',
|
| 79 |
+
'State': 'premise_state',
|
| 80 |
+
'County': 'premise_county',
|
| 81 |
+
'Zip Code': 'premise_zip_code',
|
| 82 |
+
'Date Created': 'issue_date',
|
| 83 |
+
'Day Phone': 'business_phone',
|
| 84 |
+
'Email': 'business_email',
|
| 85 |
+
},
|
| 86 |
+
},
|
| 87 |
'retailers': {
|
| 88 |
'key': 'CannabisApplicants',
|
| 89 |
'columns': {
|
|
|
|
| 100 |
'Privilege Status': 'license_status',
|
| 101 |
'Day Phone': 'business_phone',
|
| 102 |
},
|
| 103 |
+
},
|
| 104 |
}
|
| 105 |
|
| 106 |
|
| 107 |
+
def download_file(url, dest='./', headers=None):
|
| 108 |
+
"""Download a file from a given URL to a local destination.
|
| 109 |
+
Args:
|
| 110 |
+
url (str): The URL of the data file.
|
| 111 |
+
dest (str): The destination for the data file, `./` by default (optional).
|
| 112 |
+
headers (dict): HTTP headers, `None` by default (optional).
|
| 113 |
+
Returns:
|
| 114 |
+
(str): The location for the data file.
|
| 115 |
+
"""
|
| 116 |
+
filename = url.split('/')[-1]
|
| 117 |
+
data_file = os.path.join(dest, filename)
|
| 118 |
+
response = requests.get(url, headers=headers)
|
| 119 |
+
with open(data_file, 'wb') as doc:
|
| 120 |
+
doc.write(response.content)
|
| 121 |
+
return data_file
|
| 122 |
+
|
| 123 |
+
|
| 124 |
def get_licenses_wa(
|
| 125 |
data_dir: Optional[str] = None,
|
| 126 |
env_file: Optional[str] = '.env',
|
|
|
|
| 134 |
|
| 135 |
# Get the URLs for the license workbooks.
|
| 136 |
labs_url, medical_url, retailers_url = None, None, None
|
| 137 |
+
labs_key = WASHINGTON['labs']['key']
|
| 138 |
+
medical_key = WASHINGTON['medical']['key']
|
| 139 |
+
retailers_key = WASHINGTON['retailers']['key']
|
| 140 |
+
url = WASHINGTON['licenses_urls']
|
| 141 |
response = requests.get(url)
|
| 142 |
soup = BeautifulSoup(response.content, 'html.parser')
|
| 143 |
links = soup.find_all('a')
|
| 144 |
for link in links:
|
| 145 |
href = link['href']
|
| 146 |
+
if labs_key in href:
|
| 147 |
labs_url = href
|
| 148 |
+
elif retailers_key in href:
|
| 149 |
retailers_url = href
|
| 150 |
+
elif medical_key in href:
|
| 151 |
medical_url = href
|
| 152 |
break
|
| 153 |
|
| 154 |
+
# Download the workbooks.
|
| 155 |
+
lab_source_file = download_file(labs_url, dest=file_dir)
|
| 156 |
+
medical_source_file = download_file(medical_url, dest=file_dir)
|
| 157 |
+
retailers_source_file = download_file(retailers_url, dest=file_dir)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 158 |
|
| 159 |
# Extract and standardize the data from the workbook.
|
| 160 |
retailers = pd.read_excel(retailers_source_file)
|
| 161 |
retailers.rename(columns=WASHINGTON['retailers']['columns'], inplace=True)
|
|
|
|
|
|
|
| 162 |
retailers['license_designation'] = 'Adult-Use'
|
| 163 |
+
retailers['license_type'] = 'Adult-Use Retailer'
|
| 164 |
+
|
| 165 |
+
labs = pd.read_excel(lab_source_file)
|
| 166 |
+
labs.rename(columns=WASHINGTON['labs']['columns'], inplace=True)
|
| 167 |
+
labs.drop(columns=WASHINGTON['labs']['drop_columns'], inplace=True)
|
| 168 |
+
labs['license_type'] = 'Lab'
|
| 169 |
+
|
| 170 |
+
medical = pd.read_excel(medical_source_file, skiprows=2)
|
| 171 |
+
medical.rename(columns=WASHINGTON['medical']['columns'], inplace=True)
|
| 172 |
+
medical['license_designation'] = 'Medicinal'
|
| 173 |
+
medical['license_type'] = 'Medical Retailer'
|
| 174 |
+
|
| 175 |
+
# Aggregate the licenses.
|
| 176 |
+
licenses = pd.concat([retailers, medical, labs])
|
| 177 |
+
|
| 178 |
+
# Standardize all of the licenses at once!
|
| 179 |
+
licenses = licenses.assign(
|
| 180 |
+
licensing_authority_id=WASHINGTON['licensing_authority_id'],
|
| 181 |
+
licensing_authority=WASHINGTON['licensing_authority'],
|
| 182 |
+
premise_state=STATE,
|
| 183 |
+
license_status_date=None,
|
| 184 |
+
expiration_date=None,
|
| 185 |
+
activity=None,
|
| 186 |
+
parcel_number=None,
|
| 187 |
+
business_owner_name=None,
|
| 188 |
+
business_structure=None,
|
| 189 |
+
business_image_url=None,
|
| 190 |
+
business_website=None,
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
# Fill legal and DBA names.
|
| 194 |
+
licenses['id'].fillna(licenses['license_number'], inplace=True)
|
| 195 |
+
licenses['business_legal_name'].fillna(licenses['business_dba_name'], inplace=True)
|
| 196 |
+
licenses['business_dba_name'].fillna(licenses['business_legal_name'], inplace=True)
|
| 197 |
+
cols = ['business_legal_name', 'business_dba_name']
|
| 198 |
+
for col in cols:
|
| 199 |
+
licenses[col] = licenses[col].apply(
|
| 200 |
+
lambda x: x.title().replace('Llc', 'LLC').replace("'S", "'s").strip()
|
| 201 |
+
)
|
| 202 |
|
| 203 |
# Keep only active licenses.
|
| 204 |
+
license_statuses = ['Active', 'ACTIVE (ISSUED)', 'ACTIVE TITLE CERTIFICATE',]
|
| 205 |
+
licenses = licenses.loc[licenses['license_status'].isin(license_statuses)]
|
|
|
|
|
|
|
| 206 |
|
| 207 |
# Convert certain columns from upper case title case.
|
| 208 |
cols = ['business_dba_name', 'premise_city', 'premise_county',
|
|
|
|
| 213 |
# Get the refreshed date.
|
| 214 |
date = retailers_source_file.split('\\')[-1].split('.')[0]
|
| 215 |
date = date.replace('CannabisApplicants', '')
|
| 216 |
+
date = date[:2] + '-' + date[2:4] + '-' + date[4:8]
|
| 217 |
+
licenses['data_refreshed_date'] = pd.to_datetime(date).isoformat()
|
|
|
|
|
|
|
| 218 |
|
| 219 |
+
# Append `premise_street_address_2` to `premise_street_address`.
|
| 220 |
+
cols = ['premise_street_address', 'premise_street_address_2']
|
| 221 |
+
licenses['premise_street_address'] = licenses[cols].apply(
|
| 222 |
+
lambda x : '{} {}'.format(x[0].strip(), x[1]).replace('nan', '').strip().replace(' ', ' '),
|
| 223 |
+
axis=1,
|
| 224 |
+
)
|
| 225 |
+
licenses.drop(columns=['premise_street_address_2'], inplace=True)
|
| 226 |
|
| 227 |
# Geocode licenses to get `premise_latitude` and `premise_longitude`.
|
| 228 |
config = dotenv_values(env_file)
|
| 229 |
+
api_key = config['GOOGLE_MAPS_API_KEY']
|
| 230 |
cols = ['premise_street_address', 'premise_city', 'premise_state',
|
| 231 |
'premise_zip_code']
|
| 232 |
+
licenses['address'] = licenses[cols].apply(
|
| 233 |
lambda row: ', '.join(row.values.astype(str)),
|
| 234 |
axis=1,
|
| 235 |
)
|
| 236 |
+
licenses = geocode_addresses(licenses, address_field='address', api_key=api_key)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 237 |
drop_cols = ['state', 'state_name', 'county', 'address', 'formatted_address']
|
| 238 |
+
gis_cols = {'latitude': 'premise_latitude', 'longitude': 'premise_longitude'}
|
| 239 |
+
licenses.drop(columns=drop_cols, inplace=True)
|
| 240 |
+
licenses.rename(columns=gis_cols, inplace=True)
|
| 241 |
+
|
| 242 |
+
# TODO: Search for business website and image.
|
|
|
|
| 243 |
|
| 244 |
# Save and return the data.
|
| 245 |
if data_dir is not None:
|
| 246 |
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 247 |
+
licenses.to_csv(f'{data_dir}/licenses-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 248 |
+
retailers = licenses.loc[licenses['license_type'] == 'Adult-Use Retailer']
|
| 249 |
+
retailers.to_csv(f'{data_dir}/retailers-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 250 |
+
labs = licenses.loc[licenses['license_type'] == 'Lab']
|
| 251 |
+
labs.to_csv(f'{data_dir}/labs-{STATE.lower()}-{timestamp}.csv', index=False)
|
| 252 |
return retailers
|
| 253 |
|
| 254 |
|
algorithms/main.py
CHANGED
|
@@ -6,43 +6,89 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
| 13 |
|
| 14 |
-
Collect all cannabis license data from
|
| 15 |
|
| 16 |
-
|
| 17 |
-
|
| 18 |
✓ California
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
✓ Maine
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
|
| 26 |
✓ Nevada
|
| 27 |
✓ New Jersey
|
| 28 |
-
|
| 29 |
-
- New York
|
| 30 |
✓ Oregon
|
| 31 |
-
|
| 32 |
-
|
| 33 |
✓ Washington
|
| 34 |
-
|
| 35 |
"""
|
| 36 |
-
|
| 37 |
-
from
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 42 |
|
| 43 |
|
| 44 |
# === Test ===
|
| 45 |
-
if __name__ == '
|
| 46 |
|
| 47 |
# Support command line usage.
|
| 48 |
import argparse
|
|
@@ -60,9 +106,4 @@ if __name__ == '__main':
|
|
| 60 |
env_file = args.get('env_file')
|
| 61 |
|
| 62 |
# Get licenses for each state.
|
| 63 |
-
|
| 64 |
-
get_licenses_me(data_dir, env_file=env_file)
|
| 65 |
-
get_licenses_nj(data_dir, env_file=env_file)
|
| 66 |
-
get_licenses_nv(data_dir, env_file=env_file)
|
| 67 |
-
get_licenses_or(data_dir, env_file=env_file)
|
| 68 |
-
get_licenses_wa(data_dir, env_file=env_file)
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
+
Updated: 10/7/2022
|
| 10 |
License: <https://github.com/cannlytics/cannlytics/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
| 13 |
|
| 14 |
+
Collect all cannabis license data from states with permitted adult-use:
|
| 15 |
|
| 16 |
+
✓ Alaska (Selenium)
|
| 17 |
+
✓ Arizona (Selenium)
|
| 18 |
✓ California
|
| 19 |
+
✓ Colorado
|
| 20 |
+
✓ Connecticut
|
| 21 |
+
✓ Illinois
|
| 22 |
✓ Maine
|
| 23 |
+
✓ Massachusetts
|
| 24 |
+
✓ Michigan (Selenium)
|
| 25 |
+
✓ Montana
|
| 26 |
✓ Nevada
|
| 27 |
✓ New Jersey
|
| 28 |
+
x New Mexico (Selenium) (FIXME)
|
|
|
|
| 29 |
✓ Oregon
|
| 30 |
+
✓ Rhode Island
|
| 31 |
+
✓ Vermont
|
| 32 |
✓ Washington
|
|
|
|
| 33 |
"""
|
| 34 |
+
# Standard imports.
|
| 35 |
+
from datetime import datetime
|
| 36 |
+
import importlib
|
| 37 |
+
import os
|
| 38 |
+
|
| 39 |
+
# External imports.
|
| 40 |
+
import pandas as pd
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
# Specify state-specific algorithms.
|
| 44 |
+
ALGORITHMS = {
|
| 45 |
+
'ak': 'get_licenses_ak',
|
| 46 |
+
'az': 'get_licenses_az',
|
| 47 |
+
'ca': 'get_licenses_ca',
|
| 48 |
+
'co': 'get_licenses_co',
|
| 49 |
+
'ct': 'get_licenses_ct',
|
| 50 |
+
'il': 'get_licenses_il',
|
| 51 |
+
'ma': 'get_licenses_ma',
|
| 52 |
+
'me': 'get_licenses_me',
|
| 53 |
+
'mi': 'get_licenses_mi',
|
| 54 |
+
'mt': 'get_licenses_mt',
|
| 55 |
+
'nj': 'get_licenses_nj',
|
| 56 |
+
# 'nm': 'get_licenses_nm',
|
| 57 |
+
'nv': 'get_licenses_nv',
|
| 58 |
+
'or': 'get_licenses_or',
|
| 59 |
+
'ri': 'get_licenses_ri',
|
| 60 |
+
'vt': 'get_licenses_vt',
|
| 61 |
+
'wa': 'get_licenses_wa',
|
| 62 |
+
}
|
| 63 |
+
DATA_DIR = '../data'
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def main(data_dir, env_file):
|
| 67 |
+
"""Collect all cannabis license data from states with permitted adult-use,
|
| 68 |
+
dynamically importing modules and finding the entry point for each of the
|
| 69 |
+
`ALGORITHMS`."""
|
| 70 |
+
licenses = pd.DataFrame()
|
| 71 |
+
for state, algorithm in ALGORITHMS.items():
|
| 72 |
+
module = importlib.import_module(f'{algorithm}')
|
| 73 |
+
entry_point = getattr(module, algorithm)
|
| 74 |
+
try:
|
| 75 |
+
print(f'Getting license data for {state.upper()}.')
|
| 76 |
+
data = entry_point(data_dir, env_file=env_file)
|
| 77 |
+
if not os.path.exists(f'{DATA_DIR}/{state}'): os.makedirs(f'{DATA_DIR}/{state}')
|
| 78 |
+
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 79 |
+
data.to_csv(f'{DATA_DIR}/{state}/licenses-{state}-{timestamp}.csv', index=False)
|
| 80 |
+
licenses = pd.concat([licenses, data])
|
| 81 |
+
except:
|
| 82 |
+
print(f'Failed to collect {state.upper()} licenses.')
|
| 83 |
+
|
| 84 |
+
# Save all of the retailers.
|
| 85 |
+
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 86 |
+
licenses.to_csv(f'{DATA_DIR}/all/licenses-{timestamp}.csv', index=False)
|
| 87 |
+
return licenses
|
| 88 |
|
| 89 |
|
| 90 |
# === Test ===
|
| 91 |
+
if __name__ == '__main__':
|
| 92 |
|
| 93 |
# Support command line usage.
|
| 94 |
import argparse
|
|
|
|
| 106 |
env_file = args.get('env_file')
|
| 107 |
|
| 108 |
# Get licenses for each state.
|
| 109 |
+
all_licenses = main(data_dir, env_file)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
analysis/figures/cannabis-licenses-map.html
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
analysis/figures/cannabis-licenses-map.png
ADDED
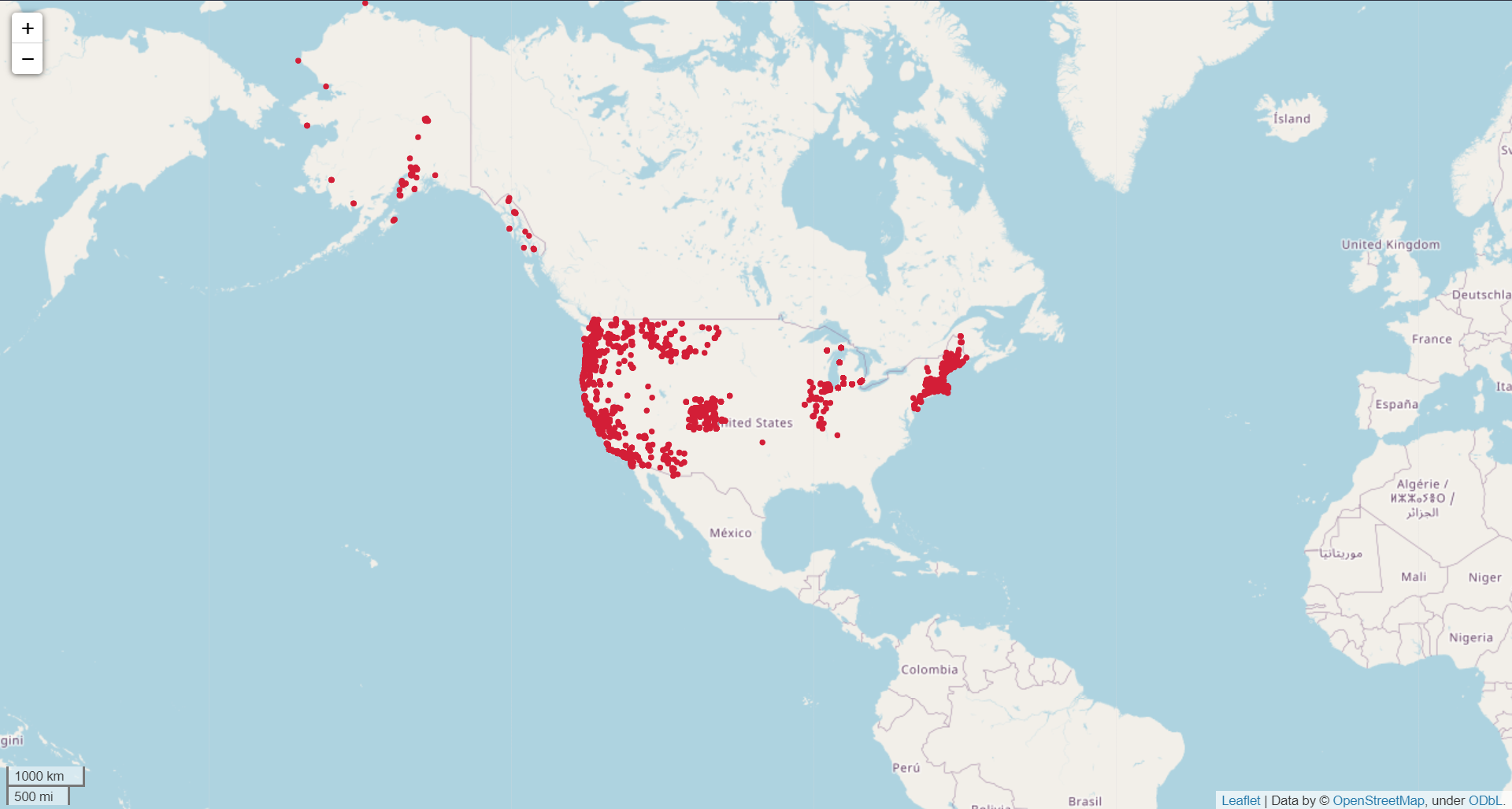
|
Git LFS Details
|
analysis/license_map.py
CHANGED
|
@@ -6,34 +6,35 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/22/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://github.com/cannlytics/cannabis-data-science/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
| 13 |
|
| 14 |
Map the adult-use cannabis retailers permitted in the United States:
|
| 15 |
|
| 16 |
-
|
| 17 |
-
|
| 18 |
✓ California
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
✓ Maine
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
|
| 26 |
✓ Nevada
|
| 27 |
✓ New Jersey
|
| 28 |
-
|
| 29 |
-
- New York
|
| 30 |
✓ Oregon
|
| 31 |
-
|
| 32 |
-
|
| 33 |
✓ Washington
|
| 34 |
|
| 35 |
"""
|
| 36 |
# Standard imports.
|
|
|
|
|
|
|
| 37 |
import os
|
| 38 |
|
| 39 |
# External imports.
|
|
@@ -42,50 +43,64 @@ import pandas as pd
|
|
| 42 |
|
| 43 |
|
| 44 |
# Specify where your data lives.
|
| 45 |
-
DATA_DIR = '../
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
data = []
|
| 61 |
-
for
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
data.
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
(~retailers['premise_longitude'].isnull()) &
|
| 70 |
-
(~retailers['premise_latitude'].isnull())
|
| 71 |
-
]
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
#-----------------------------------------------------------------------
|
| 75 |
-
# Look at the data!
|
| 76 |
-
#-----------------------------------------------------------------------
|
| 77 |
-
|
| 78 |
-
# Create an interactive map.
|
| 79 |
-
locations = retailers[['premise_latitude', 'premise_longitude']].to_numpy()
|
| 80 |
-
m = folium.Map(
|
| 81 |
-
location=[39.8283, -98.5795],
|
| 82 |
-
zoom_start=3,
|
| 83 |
-
control_scale=True,
|
| 84 |
-
)
|
| 85 |
-
for index, row in retailers.iterrows():
|
| 86 |
-
folium.Circle(
|
| 87 |
-
radius=5,
|
| 88 |
-
location=[row['premise_latitude'], row['premise_longitude']],
|
| 89 |
color='crimson',
|
| 90 |
-
|
| 91 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/22/2022
|
| 9 |
+
Updated: 10/8/2022
|
| 10 |
License: <https://github.com/cannlytics/cannabis-data-science/blob/main/LICENSE>
|
| 11 |
|
| 12 |
Description:
|
| 13 |
|
| 14 |
Map the adult-use cannabis retailers permitted in the United States:
|
| 15 |
|
| 16 |
+
✓ Alaska
|
| 17 |
+
✓ Arizona
|
| 18 |
✓ California
|
| 19 |
+
✓ Colorado
|
| 20 |
+
✓ Connecticut
|
| 21 |
+
✓ Illinois
|
| 22 |
✓ Maine
|
| 23 |
+
✓ Massachusetts
|
| 24 |
+
✓ Michigan
|
| 25 |
+
✓ Montana
|
| 26 |
✓ Nevada
|
| 27 |
✓ New Jersey
|
| 28 |
+
x New Mexico (FIXME)
|
|
|
|
| 29 |
✓ Oregon
|
| 30 |
+
✓ Rhode Island
|
| 31 |
+
✓ Vermont
|
| 32 |
✓ Washington
|
| 33 |
|
| 34 |
"""
|
| 35 |
# Standard imports.
|
| 36 |
+
from datetime import datetime
|
| 37 |
+
import json
|
| 38 |
import os
|
| 39 |
|
| 40 |
# External imports.
|
|
|
|
| 43 |
|
| 44 |
|
| 45 |
# Specify where your data lives.
|
| 46 |
+
DATA_DIR = '../'
|
| 47 |
+
|
| 48 |
+
# Read data subsets.
|
| 49 |
+
with open('../subsets.json', 'r') as f:
|
| 50 |
+
SUBSETS = json.loads(f.read())
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def aggregate_retailers(
|
| 54 |
+
datafiles,
|
| 55 |
+
index_col=0,
|
| 56 |
+
lat='premise_latitude',
|
| 57 |
+
long='premise_longitude',
|
| 58 |
+
):
|
| 59 |
+
"""Aggregate retailer license data files,
|
| 60 |
+
keeping only those with latitude and longitude."""
|
| 61 |
+
data = []
|
| 62 |
+
for filename in datafiles:
|
| 63 |
+
data.append(pd.read_csv(filename, index_col=index_col))
|
| 64 |
+
data = pd.concat(data)
|
| 65 |
+
return data.loc[(~data[lat].isnull()) & (~data[long].isnull())]
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def create_retailer_map(
|
| 69 |
+
df,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 70 |
color='crimson',
|
| 71 |
+
filename=None,
|
| 72 |
+
lat='premise_latitude',
|
| 73 |
+
long='premise_longitude',
|
| 74 |
+
):
|
| 75 |
+
"""Create a map of licensed retailers."""
|
| 76 |
+
m = folium.Map(
|
| 77 |
+
location=[39.8283, -98.5795],
|
| 78 |
+
zoom_start=3,
|
| 79 |
+
control_scale=True,
|
| 80 |
+
)
|
| 81 |
+
for _, row in df.iterrows():
|
| 82 |
+
folium.Circle(
|
| 83 |
+
radius=5,
|
| 84 |
+
location=[row[lat], row[long]],
|
| 85 |
+
color=color,
|
| 86 |
+
).add_to(m)
|
| 87 |
+
if filename:
|
| 88 |
+
m.save(filename)
|
| 89 |
+
return m
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
# === Test ===
|
| 93 |
+
if __name__ == '__main__':
|
| 94 |
+
|
| 95 |
+
# Aggregate retailers.
|
| 96 |
+
subsets = list(SUBSETS.values())
|
| 97 |
+
datafiles = [DATA_DIR + x['data_url'] for x in subsets]
|
| 98 |
+
retailers = aggregate_retailers(datafiles)
|
| 99 |
+
|
| 100 |
+
# Create the retailers map.
|
| 101 |
+
map_file = '../analysis/figures/cannabis-licenses-map.html'
|
| 102 |
+
m = create_retailer_map(retailers, filename=map_file)
|
| 103 |
+
|
| 104 |
+
# Save all of the retailers.
|
| 105 |
+
timestamp = datetime.now().isoformat()[:19].replace(':', '-')
|
| 106 |
+
retailers.to_csv(f'{DATA_DIR}/data/all/licenses-{timestamp}.csv', index=False)
|
cannabis_licenses.py
CHANGED
|
@@ -6,7 +6,7 @@ Authors:
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
-
Updated:
|
| 10 |
License: <https://huggingface.co/datasets/cannlytics/cannabis_licenses/blob/main/LICENSE>
|
| 11 |
"""
|
| 12 |
# Standard imports.
|
|
@@ -18,12 +18,13 @@ import pandas as pd
|
|
| 18 |
|
| 19 |
|
| 20 |
# Constants.
|
|
|
|
| 21 |
_VERSION = '1.0.0'
|
| 22 |
_HOMEPAGE = 'https://huggingface.co/datasets/cannlytics/cannabis_licenses'
|
| 23 |
_LICENSE = "https://opendatacommons.org/licenses/by/4-0/"
|
| 24 |
_DESCRIPTION = """\
|
| 25 |
Cannabis Licenses (https://cannlytics.com/data/licenses) is a
|
| 26 |
-
dataset of curated cannabis license data. The dataset consists of
|
| 27 |
sub-datasets for each state with permitted adult-use cannabis, as well
|
| 28 |
as a sub-dataset that includes all licenses.
|
| 29 |
"""
|
|
@@ -32,7 +33,7 @@ _CITATION = """\
|
|
| 32 |
author = {Skeate, Keegan and O'Sullivan-Sutherland, Candace},
|
| 33 |
title = {Cannabis Licenses},
|
| 34 |
booktitle = {Cannabis Data Science},
|
| 35 |
-
month = {
|
| 36 |
year = {2022},
|
| 37 |
address = {United States of America},
|
| 38 |
publisher = {Cannlytics}
|
|
@@ -47,14 +48,17 @@ FIELDS = datasets.Features({
|
|
| 47 |
'license_status_date': datasets.Value(dtype='string'),
|
| 48 |
'license_term': datasets.Value(dtype='string'),
|
| 49 |
'license_type': datasets.Value(dtype='string'),
|
|
|
|
| 50 |
'issue_date': datasets.Value(dtype='string'),
|
| 51 |
'expiration_date': datasets.Value(dtype='string'),
|
| 52 |
'licensing_authority_id': datasets.Value(dtype='string'),
|
| 53 |
'licensing_authority': datasets.Value(dtype='string'),
|
| 54 |
'business_legal_name': datasets.Value(dtype='string'),
|
| 55 |
'business_dba_name': datasets.Value(dtype='string'),
|
|
|
|
| 56 |
'business_owner_name': datasets.Value(dtype='string'),
|
| 57 |
'business_structure': datasets.Value(dtype='string'),
|
|
|
|
| 58 |
'activity': datasets.Value(dtype='string'),
|
| 59 |
'premise_street_address': datasets.Value(dtype='string'),
|
| 60 |
'premise_city': datasets.Value(dtype='string'),
|
|
@@ -132,8 +136,12 @@ if __name__ == '__main__':
|
|
| 132 |
|
| 133 |
from datasets import load_dataset
|
| 134 |
|
| 135 |
-
#
|
| 136 |
-
|
| 137 |
-
|
| 138 |
-
|
| 139 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
Keegan Skeate <https://github.com/keeganskeate>
|
| 7 |
Candace O'Sullivan-Sutherland <https://github.com/candy-o>
|
| 8 |
Created: 9/29/2022
|
| 9 |
+
Updated: 10/8/2022
|
| 10 |
License: <https://huggingface.co/datasets/cannlytics/cannabis_licenses/blob/main/LICENSE>
|
| 11 |
"""
|
| 12 |
# Standard imports.
|
|
|
|
| 18 |
|
| 19 |
|
| 20 |
# Constants.
|
| 21 |
+
_SCRIPT = 'cannabis_licenses.py'
|
| 22 |
_VERSION = '1.0.0'
|
| 23 |
_HOMEPAGE = 'https://huggingface.co/datasets/cannlytics/cannabis_licenses'
|
| 24 |
_LICENSE = "https://opendatacommons.org/licenses/by/4-0/"
|
| 25 |
_DESCRIPTION = """\
|
| 26 |
Cannabis Licenses (https://cannlytics.com/data/licenses) is a
|
| 27 |
+
dataset of curated cannabis license data. The dataset consists of 18
|
| 28 |
sub-datasets for each state with permitted adult-use cannabis, as well
|
| 29 |
as a sub-dataset that includes all licenses.
|
| 30 |
"""
|
|
|
|
| 33 |
author = {Skeate, Keegan and O'Sullivan-Sutherland, Candace},
|
| 34 |
title = {Cannabis Licenses},
|
| 35 |
booktitle = {Cannabis Data Science},
|
| 36 |
+
month = {October},
|
| 37 |
year = {2022},
|
| 38 |
address = {United States of America},
|
| 39 |
publisher = {Cannlytics}
|
|
|
|
| 48 |
'license_status_date': datasets.Value(dtype='string'),
|
| 49 |
'license_term': datasets.Value(dtype='string'),
|
| 50 |
'license_type': datasets.Value(dtype='string'),
|
| 51 |
+
'license_designation': datasets.Value(dtype='string'),
|
| 52 |
'issue_date': datasets.Value(dtype='string'),
|
| 53 |
'expiration_date': datasets.Value(dtype='string'),
|
| 54 |
'licensing_authority_id': datasets.Value(dtype='string'),
|
| 55 |
'licensing_authority': datasets.Value(dtype='string'),
|
| 56 |
'business_legal_name': datasets.Value(dtype='string'),
|
| 57 |
'business_dba_name': datasets.Value(dtype='string'),
|
| 58 |
+
'business_image_url': datasets.Value(dtype='string'),
|
| 59 |
'business_owner_name': datasets.Value(dtype='string'),
|
| 60 |
'business_structure': datasets.Value(dtype='string'),
|
| 61 |
+
'business_website': datasets.Value(dtype='string'),
|
| 62 |
'activity': datasets.Value(dtype='string'),
|
| 63 |
'premise_street_address': datasets.Value(dtype='string'),
|
| 64 |
'premise_city': datasets.Value(dtype='string'),
|
|
|
|
| 136 |
|
| 137 |
from datasets import load_dataset
|
| 138 |
|
| 139 |
+
# Define all of the dataset subsets.
|
| 140 |
+
subsets = list(SUBSETS.keys())
|
| 141 |
+
|
| 142 |
+
# Load each dataset subset.
|
| 143 |
+
for subset in subsets:
|
| 144 |
+
dataset = load_dataset(_SCRIPT, subset)
|
| 145 |
+
data = dataset['data']
|
| 146 |
+
assert len(data) > 0
|
| 147 |
+
print('Read %i %s data points.' % (len(data), subset))
|
data/ak/licenses-ak-2022-10-06T17-46-29.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eb8d27262257ea27210b83b9f52188a2e5df7cce69c972c9acf834a816a536f3
|
| 3 |
+
size 163578
|
data/{nv/retailers-nv-2022-09-30T07-41-59.xlsx → ak/retailers-ak-2022-10-06T17-46-29.csv}
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:180bbc362a8f184318959d766c7f2d715f60d5499666569d151dccaf5b96baa2
|
| 3 |
+
size 59583
|
data/{ca/licenses-ca-2022-09-21T19-02-29.xlsx → all/licenses-2022-10-06T18-46-11.csv}
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:091d343ceee078d47fa9a8c235060f8ee20a500bb3844f752cd243237aeaea0c
|
| 3 |
+
size 6961305
|
data/all/licenses-2022-10-08T14-03-08.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:75e7975601c8f9bc21918c9642dfc7ddcfbfd89427b1553ff754f0fd53d4d309
|
| 3 |
+
size 3192307
|
data/all/retailers-2022-10-07T10-20-55.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:63de8f476d9f52e9a0a1a3bf28f0fe3ad5e601bad87f5cd7b915ecda1e1c53df
|
| 3 |
+
size 1551940
|
data/{me/licenses-me-2022-09-30T16-44-03.xlsx → az/licenses-az-2022-10-07T10-12-07.csv}
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b9e87fee772c87b19d2caae58e4df9b00a5a6dead34178423a193b3b4fd237bb
|
| 3 |
+
size 86738
|
data/{nv/licenses-nv-2022-09-30T07-37-45.xlsx → az/retailers-az-2022-10-07T10-12-07.csv}
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ed851b83841db5526b3f21e954dfda1d6e15242ecd1f992cc0a285c3aee6c9f9
|
| 3 |
+
size 61925
|
data/ca/licenses-ca-2022-10-06T18-10-15.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9563c185dfe5f594203bee3dceeca3e5bd130d71077a1a359281a2b6e7834e20
|
| 3 |
+
size 5604246
|
data/co/licenses-co-2022-10-06T18-28-29.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:693636fbd2b290f8a121300ac86fa6831a4741aabf2db890393c83b596a9527b
|
| 3 |
+
size 448918
|
data/co/retailers-co-2022-10-06T18-28-29.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:427f3dcfe94b5feead000d0c0e8735a21c14928a1a702f3f90cfe2dd896759a4
|
| 3 |
+
size 261301
|
data/{nj/licenses-nj-2022-09-29T16-17-38.xlsx → ct/retailers-ct-2022-10-06T18-28-33.csv}
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8eae29b21d9124148d8dbe68f3cb158a88902b22c0532eda78627a6b81eafb04
|
| 3 |
+
size 5995
|
data/il/retailers-il-2022-10-06T18-28-55.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2f96d64d5efbf0103392d9c34483977c97d7c776b46cada18e7faf35807e4932
|
| 3 |
+
size 35040
|
data/ma/licenses-ma-2022-10-07T14-45-39.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:38036322058b3fc45112bca58728904a2cb9e48ade60371feb5edcdae934b8f0
|
| 3 |
+
size 260727
|
data/ma/retailers-ma-2022-10-07T14-45-39.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f076c79fc442d8f94142c724fa20bafa4e6c02e72431da594fc3d1cf892c61e2
|
| 3 |
+
size 101882
|
data/me/licenses-me-2022-10-07T15-26-01.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:92bbfa576b32396673cdc8c95ee5e4902ebf5ff33ed6084c988882ed41fe877e
|
| 3 |
+
size 128972
|
data/mi/licenses-mi-2022-10-08T13-49-04.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5295070f77b7a572c13de1c069428e5e71cc9dd422ad096745816c0d8fa64e1e
|
| 3 |
+
size 38635
|
data/mt/retailers-mt-2022-10-07T16-28-10.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2b1bd3b1dfdcb846bb3b3b002e9116596e8b9869b35a0462fcdf8d82176efcc9
|
| 3 |
+
size 117170
|
data/nj/licenses-nj-2022-10-06T18-39-17.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eeb27486bc5cfb4b8ab0568f85b2d48a5aadb77fd2f68850a4e325c8793aef64
|
| 3 |
+
size 5525
|
data/nm/retailers-nm-2022-10-05T15-09-21.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:978d2a7dab0c9e4dffdfb6e29d01974429de3cdd9887ac13893aec74790ef896
|
| 3 |
+
size 128187
|
data/nv/licenses-nv-2022-10-06T18-42-39.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2f0c00bfd35141ca85d1fb29cf1d972124e384bf5432d8ba060ffd236bed8d4b
|
| 3 |
+
size 129201
|
data/nv/retailers-nv-2022-10-06T18-43-01.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:df8707ab150055148ae3ab65313aa73f5d1f6ccb32bc4fc20785f4c3ba9e6ece
|
| 3 |
+
size 22015
|
data/or/licenses-or-2022-09-28T10-11-12.xlsx
DELETED
|
@@ -1,3 +0,0 @@
|
|
| 1 |
-
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:fb2221a123a531a5376cb4e8c27bc0d736e19a0dad75b868d33aa91f23e02c74
|
| 3 |
-
size 103522
|
|
|
|
|
|
|
|
|
|
|
|
data/or/licenses-or-2022-10-07T14-47-55.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:99cdb82c0ceb4741110f7e425ba0c2c380ca681f63683c77937c34c5cca0ce2b
|
| 3 |
+
size 209474
|
data/ri/licenses-ri-2022-10-06T18-45-41.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:303cf4840665188d577305de183ad2425b162abd7117e7ff08a9e423b2215e12
|
| 3 |
+
size 2029
|
data/vt/licenses-vt-2022-10-06T18-46-08.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d7c39454cba0f7aa44884128dd884a3b4b1f1aa23971e9b6e4e82a2077340223
|
| 3 |
+
size 44534
|