
repo
stringclasses 147
values | number
int64 1
172k
| title
stringlengths 2
476
| body
stringlengths 0
5k
| url
stringlengths 39
70
| state
stringclasses 2
values | labels
listlengths 0
9
| created_at
timestamp[ns, tz=UTC]date 2017-01-18 18:50:08
2026-01-06 07:33:18
| updated_at
timestamp[ns, tz=UTC]date 2017-01-18 19:20:07
2026-01-06 08:03:39
| comments
int64 0
58
⌀ | user
stringlengths 2
28
|
|---|---|---|---|---|---|---|---|---|---|---|
pytorch/examples
| 759
|
torch::Tensor can't be use with std::tuple or std::vector?
|
#include <torch/torch.h>
#include <Windows.h>
#include <iostream>
#include <string>
#include <vector>
auto ReadRsv(const std::string path) {
HANDLE filea= CreateFileA((LPCSTR)path.c_str(), GENERIC_READ, FILE_SHARE_READ | FILE_SHARE_WRITE, NULL, OPEN_EXISTING, FILE_FLAG_SEQUENTIAL_SCAN,NULL);
int cout;
int length;
ReadFile(filea, &cout,4,NULL,NULL);
std::vector<std::tuple<torch::Tensor, torch::Tensor>> rsv;
byte* dataa = new byte[784];
byte* datab = new byte[1];
DWORD hasread;
for (int i = 0; i<cout; ++i) {
ReadFile(filea, &length, 4, &hasread, NULL);
ReadFile(filea, &dataa, 784, &hasread, NULL);
torch::Tensor line = torch::from_blob(&dataa, { 784 },torch::kByte);
ReadFile(filea, &datab, 1, &hasread, NULL);
torch::Tensor label = torch::from_blob(&datab, { 1 }, torch::kByte);
rsv.push_back(std::make_tuple(line,label)); //wrong?
}
delete []dataa;
delete []datab;
CloseHandle(filea);
return rsv;
}
--------------------------------------------------
win10 x64;libtorch 1.5 release x64;
------------------------
download rsv file: https://share.weiyun.com/5DYsiDe
-------------
when i=0,it run success,but when i=1,it run wrong.
0x00007FFD618EF7E4 (torch_cpu.dll) (in consoleapplication1.exe) throws an exception: 0xC0000005: an access conflict occurs while writing to location 0x0000000000000000.
Remove this sentence and it will run successfully ->rsv.push_back(std::make_tuple(line,label));
|
https://github.com/pytorch/examples/issues/759
|
open
|
[
"c++"
] | 2020-04-24T04:46:38Z
| 2022-03-09T20:49:36Z
| 1
|
williamlzw
|
pytorch/pytorch
| 37,201
|
Libtorch:how to create tensor from tensorRT fp16 cuda half type pointer?
|
how to create tensor from tensorRT fp16 half type pointer in libtorch?
I am working on a detection model. I change the backbone of it to tensorRT to do FP16 inference, and the detection code such as decode boxes and nms is done in libtorch and torchvisoin, so how to create fp16 tensor from tensorRT half type pointers?
The important code is to illustrate the issue:
```
// tensorRT code to get half type outpus
half_float::half* outputs[18];
doInference(*engine, data, outputs, 1);
// to get the final outputs with libtorch
vector<torch::Tensor> output;
//???? how to feed the date in outpus to output????
// get the result with libtorch method detect_trt->forward
auto res = detect_trt->forward(output);
```
Thanks in advance.
cc @yf225 @glaringlee
|
https://github.com/pytorch/pytorch/issues/37201
|
closed
|
[
"module: cpp",
"triaged"
] | 2020-04-24T02:19:45Z
| 2020-04-29T03:28:20Z
| null |
Edwardmark
|
pytorch/pytorch
| 37,134
|
C++ model output is a List, how to get each item?
|
## ❓ Questions and Help
I'm using PyTorch1.3 and libtorch1.3.
In python, my scripted model's returned type is `List[List[Dict[str, Tensor]]]`
In C++, I get model output from `auto output = model.forward(inputs);`, I find that output is a `GenericList`. I don't know how to access each item of GenericList, and I want to know how to get each Tensor from Dict[str, Tensor].
Thx.
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/37134
|
closed
|
[] | 2020-04-23T07:53:56Z
| 2020-04-23T12:07:01Z
| null |
kaituoxu
|
pytorch/pytorch
| 37,132
|
How to rebuild the libtorch to get the lib.so after download the libtorch from https://download.pytorch.org/libtorch/nightly/cu92/libtorch-win-shared-with-deps-latest.zip?
|
how to build and make libtorch after I change the code in https://download.pytorch.org/libtorch/nightly/cu92/libtorch-win-shared-with-deps-latest.zip?
Any guide please?
Thanks in advance.
|
https://github.com/pytorch/pytorch/issues/37132
|
closed
|
[] | 2020-04-23T06:08:40Z
| 2020-04-23T07:22:20Z
| null |
Edwardmark
|
pytorch/examples
| 757
|
the learning rate of word_language_model
|
Hi, I have a question about the learning rate in the example "word_language_model",
the init lr = 20, which seems very large, can you tell me why lr is set to equal 20?
Thanks a lot!
If you have some advices about improving the performance, please let me know and thanks
|
https://github.com/pytorch/examples/issues/757
|
open
|
[
"help wanted",
"nlp"
] | 2020-04-22T09:07:29Z
| 2024-04-02T21:27:56Z
| 3
|
zhangyingbit
|
pytorch/pytorch
| 36,991
|
how to convert quantization_ware_training model to onnx
|
## ❓ Questions and Help
python 3.6
pytorch version: 1.4.0
onnx 1.6.0
In most issues, some of them mentioned about this question. but I still don't know how to convert a int8 model to onnx. I followed the tutorial (https://pytorch.org/tutorials/advanced/static_quantization_tutorial.html#quantization-aware-training) to try to train a quantization model, the pretrained model is got from model zoo. I already got the int8 model, but how to convert it to onnx??
|
https://github.com/pytorch/pytorch/issues/36991
|
closed
|
[] | 2020-04-21T08:31:29Z
| 2020-04-21T20:19:36Z
| null |
onesnow123q
|
pytorch/examples
| 755
|
Process doesn't exit properly for single-node distributed setting.
|
Hello, I trained an ImageNet using the following arguments,
```
CUDA_VISIBLE_DEVICES=0,2,3,4 python main.py /media/ramdisk/images --arch resnet18 -j 16 --multiprocessing-distributed --dist-url 'tcp://127.0.0.1:52038' --dist-backend 'nccl' --world-size 1 --rank 0 --print-freq 2500
```
The visible devices were set to 0,2,3,4 since I had to leave it empty for another use at the time, and print-freq was set at 2500 to avoid generating too much std outputs. The training runs well, but its termination is not so smooth.
Here is the last few lines of [log](https://github.com/pytorch/examples/files/4498140/log.txt), and a capture of the nvidia-smi at the time.
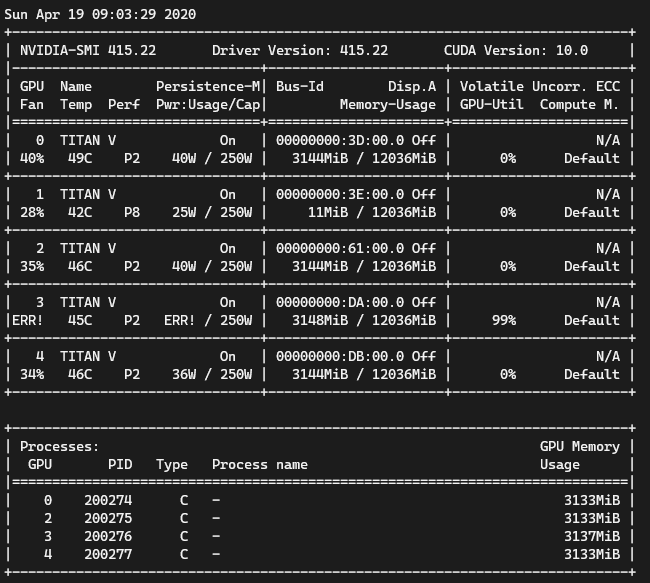
One of the gpu shows an ERR! on GPU Fan and Power usage. And even after killing the processes manually, the error remains. (I had to restart the server in order to get out of the ERR state)
1. Why does the processes remain?
2. What is the proper way to terminate them?
|
https://github.com/pytorch/examples/issues/755
|
open
|
[
"distributed"
] | 2020-04-19T01:28:55Z
| 2022-03-09T20:52:47Z
| 0
|
inventor71
|
pytorch/examples
| 754
|
Why the kernel size of discriminator & generator is 4 in dcgan
|
I don't understand, is there any special role? or cited other model?
thanks!
|
https://github.com/pytorch/examples/issues/754
|
closed
|
[] | 2020-04-18T00:33:19Z
| 2022-03-09T21:44:47Z
| 2
|
mltloveyy
|
pytorch/examples
| 753
|
Imagenet data?
|
I'd like to use the imagenet example to train a resnet on the whole imagenet dataset... The problem is I can't seem to actually find the entire dataset anywhere (14 million images). The URLs link on the imagenet website is dead. Does anyone know the standard way to get the classification dataset? i.e. how were the pretrained models in pytorch trained?
|
https://github.com/pytorch/examples/issues/753
|
closed
|
[] | 2020-04-18T00:01:24Z
| 2021-08-11T23:05:25Z
| 3
|
justinblaber
|
huggingface/neuralcoref
| 250
|
How to improve processing speed?
|
Hi.
Could you give me some information about how to tune the parameters to make processing faster, even at the expense of accuracy?
How much impact does the `greedyness` parameter have on speed?
Thanks!
|
https://github.com/huggingface/neuralcoref/issues/250
|
closed
|
[
"question",
"wontfix",
"perf / speed"
] | 2020-04-17T16:32:08Z
| 2022-01-09T04:06:48Z
| null |
murphd40
|
pytorch/examples
| 751
|
Example of MNIST using RNN
|
Hi @osalpekar ,
I would like to implement an example of MNIST using RNN.
**Motivation:** Create pytorch example similar to Official Tensorflow Keras RNN example using MNIST [here](https://www.tensorflow.org/guide/keras/rnn)
I have written and tested the code by modifying following example on MNIST [here](https://github.com/pytorch/examples/tree/master/mnist) . Please let me know if I can raise a PR for this.
Thanks and regards,
Rakesh
|
https://github.com/pytorch/examples/issues/751
|
closed
|
[] | 2020-04-16T11:52:49Z
| 2022-03-10T00:30:41Z
| 6
|
rakesh-malviya
|
pytorch/vision
| 2,109
|
development plan of "functional_tensor"
|
## ❓ Questions and Help
Hi torchvision team,
This is Nic from NVIDIA, thanks for sharing your great work on data processing solutions!
1. I saw you developed "functional_tensor.py" to support Tensor type data but didn't find where it is used in transforms, may I know the reason?
2. And what's your future plan of transforms for Numpy and Tensor data type?
Actually, I found 2 Tensor only transforms, others are for PIL or numpy.
3. If you want to support both Tensor and Numpy for all transforms, explicitly ask users to select transform for Numpy or for Tensor?
Or implicitly detect data type in transforms and use "function.py" or "function_tensor.py"?
Thanks in advance.
|
https://github.com/pytorch/vision/issues/2109
|
closed
|
[
"question",
"module: transforms"
] | 2020-04-16T02:10:03Z
| 2020-10-21T08:23:16Z
| null |
Nic-Ma
|
pytorch/vision
| 2,108
|
Not getting proper mask as instance.
|
Hi guys
Use pretrained weights=yes
no. of epoch=400
no. of class=1
At the time of prediction i am not getting individual masks for individual object. i am getting some extra mask but those are empty or partial . what can be the reason?
|
https://github.com/pytorch/vision/issues/2108
|
closed
|
[
"question",
"module: models",
"topic: object detection"
] | 2020-04-15T11:41:30Z
| 2020-04-15T15:11:43Z
| null |
vivekdeepquanty
|
pytorch/vision
| 2,106
|
I can't load mobilenet under version 0.5.0
|
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
Steps to reproduce the behavior:
1.a =models.mobilenet()
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'module' object is not callable
## Expected behavior
load the mobilenet model, but I can find mobilenet module in dir(torchvision.models)
<!-- A clear and concise description of what you expected to happen. -->
## Environment
ubuntu16.04
torchvision version 0.5.0
Please copy and paste the output from our
[environment collection script](https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py)
(or fill out the checklist below manually).
You can get the script and run it with:
```
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
```
- PyTorch / torchvision Version (e.g., 1.0 / 0.4.0):
- OS (e.g., Linux):
- How you installed PyTorch / torchvision (`conda`, `pip`, source):pip
- Build command you used (if compiling from source):
- Python version:
- CUDA/cuDNN version:
- GPU models and configuration:
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/vision/issues/2106
|
closed
|
[
"question",
"module: models",
"topic: classification"
] | 2020-04-15T06:08:59Z
| 2020-04-15T10:04:09Z
| null |
lunasdejavu
|
pytorch/pytorch
| 36,644
|
I had build pytourch from source. But how to install after making a build?
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
Can anybody let me know how to install after build from source?
|
https://github.com/pytorch/pytorch/issues/36644
|
closed
|
[] | 2020-04-15T06:04:05Z
| 2020-04-18T05:34:15Z
| null |
tnavadiya
|
pytorch/vision
| 2,103
|
size -> size() ?
|
traceback
```
Traceback (most recent call last):
File "/Users/maksim/Library/Application Support/JetBrains/Toolbox/apps/PyCharm-P/ch-0/193.6911.25/PyCharm.app/Contents/plugins/python/helpers/pydev/_pydevd_bundle/pydevd_exec2.py", line 3, in Exec
exec(exp, global_vars, local_vars)
File "<string>", line 3, in <module>
File "/Users/maksim/dev_projects/denoising-fluorescence/denoising/venv/lib/python3.7/site-packages/torchvision/transforms/transforms.py", line 247, in __call__
return F.center_crop(img, self.size)
File "/Users/maksim/dev_projects/denoising-fluorescence/denoising/venv/lib/python3.7/site-packages/torchvision/transforms/functional.py", line 382, in center_crop
image_width, image_height = img.size
TypeError: cannot unpack non-iterable builtin_function_or_method object
>>> img.size()
torch.Size([1, 1, 2160, 2560])
```
line with bug
https://github.com/pytorch/vision/blob/master/torchvision/transforms/functional.py#L374
my version numbers
```
torch==1.4.0
torchvision==0.5.0
```
|
https://github.com/pytorch/vision/issues/2103
|
closed
|
[
"question",
"module: transforms"
] | 2020-04-14T14:15:57Z
| 2020-04-14T15:09:30Z
| null |
makslevental
|
pytorch/pytorch
| 36,574
|
how to remove ios dependency
|
I have written pytorch c++ app.
I clone pytorch code and build it as per guidelines in pytorch mobile
when i compile the app for x86_64 i am getting ios dependencies as below.
please help me avoid these ios errors. I want to run app in x86 linux pc.
-- The C compiler identification is GNU 6.5.0
-- The CXX compiler identification is GNU 6.5.0
-- Check for working C compiler: /usr/bin/cc
-- Check for working C compiler: /usr/bin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
-- Check for working CXX compiler: /usr/bin/c++
-- Check for working CXX compiler: /usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Found torch: /home/anilkumar.av/pytorch-mobile/pytorch/build_android/install/lib/libtorch.a
-- Configuring done
-- Generating done
-- Build files have been written to: /home/anilkumar.av/pytorch-mobile/helloworld/build
Scanning dependencies of target pythExec
[ 50%] Building CXX object CMakeFiles/pythExec.dir/pythExec.cpp.o
[100%] Linking CXX executable pythExec
/home/anilkumar.av/pytorch-mobile/pytorch/build_android/install/lib/libc10.a(TensorImpl.cpp.o): In function `std::__ndk1::basic_ios<char, std::__ndk1::char_traits<char> >::init(std::__ndk1::basic_streambuf<char, std::__ndk1::char_traits<char> >*)':
/home/anilkumar.av/Android/Sdk/ndk/21.0.6113669/toolchains/llvm/prebuilt/linux-x86_64/sysroot/usr/include/c++/v1/ios:711: undefined reference to `std::__ndk1::ios_base::init(void*)'
/home/anilkumar.av/pytorch-mobile/pytorch/build_android/install/lib/libc10.a(TensorImpl.cpp.o): In function `basic_streambuf':
/home/anilkumar.av/Android/Sdk/ndk/21.0.6113669/toolchains/llvm/prebuilt/linux-x86_64/sysroot/usr/include/c++/v1/streambuf:232: undefined reference to `std::__ndk1::locale::locale()'
|
https://github.com/pytorch/pytorch/issues/36574
|
closed
|
[] | 2020-04-14T09:54:47Z
| 2020-04-14T15:19:48Z
| null |
avanilkumar
|
pytorch/vision
| 2,101
|
Where to download torchvision0.5.1 .whl files
|
Hi,
I would like to download the torchvision 0.5.1 version but I cannot find a source to download the .whl file.
It is not in pypi.org nor in pytorch.org, nor anaconda.org.
I have proxy issues on my computer so I can not use pip command, I need to download the .whl file first.
Can you help me by giving an address of the 0.5.1 version? or some other hint to solve this? Thank you.
|
https://github.com/pytorch/vision/issues/2101
|
closed
|
[
"question",
"topic: binaries"
] | 2020-04-14T09:12:26Z
| 2020-04-14T13:32:57Z
| null |
300LiterPropofol
|
pytorch/pytorch
| 36,554
|
How to save sth in python-api pytorch, but load it in libtorch?
|
How can I save some tensor in python, but load it in libtorch:
I save tensor named piror using python, using the code:
```
torch.save(prior, 'prior.pth')
```
And I load the tensor in libtorch using C++, by the following code:
```
std::vector<torch::Tensor> tensorVec;
torch::load(tensorVec, "/app/model/prior.pth");
torch::Tensor priors = tensorVec[0];
```
But I got the error:
terminate called after throwing an instance of 'c10::Error'
what(): `torch::jit::load()` received a file from `torch.save()`, but `torch::jit::load()` can only load files produced by `torch.jit.save()` (load at ../torch/csrc/jit/serialization/import.cpp:285)
Why is that? And what should I do to solve the issue? Thanks in advance.
cc @suo @yf225
|
https://github.com/pytorch/pytorch/issues/36554
|
closed
|
[
"oncall: jit",
"module: cpp",
"module: serialization"
] | 2020-04-14T02:14:09Z
| 2020-04-14T14:31:07Z
| null |
Edwardmark
|
pytorch/serve
| 192
|
Steps for how to preserve model store state across docker container restarts
|
When running torchserve in docker containers, provide steps for how to preserve state across container restarts
|
https://github.com/pytorch/serve/issues/192
|
closed
|
[
"enhancement"
] | 2020-04-12T21:37:27Z
| 2022-02-09T23:49:05Z
| null |
chauhang
|
pytorch/serve
| 191
|
Add steps for how to run gpu docker container
|
Please add the steps for running GPU docker container in the docker readme. Steps should describe how to specify the gpus to be used on a multi-gpu machine
eg
`docker run --rm -it --gpus device=0 -p 8080:8080 -p 8081:8081 torchserve:v0.1-gpu-latest`
where device=0,1,2,3 selects GPUs indexed by ordinals 0,1,2 and 3, respectively. torchserve will see only these GPUs. If you specify device=all, then the torchserve will see all the available GPUs.
|
https://github.com/pytorch/serve/issues/191
|
closed
|
[
"documentation"
] | 2020-04-12T20:05:15Z
| 2020-06-09T23:47:47Z
| null |
chauhang
|
pytorch/vision
| 2,095
|
Unable to reproduce Faster RCNN evaluation metrics on pascal voc 2010 for Object Detection
|
Hi Everyone,
I am training the **pretrained Faster RCNN model** on PASCAL VOC 2010 dataset for Object Detection by following this pyTorch finetuning tutorial: [pytorch.org/tutorials/intermediate/torchvision_tutorial.html](https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html)
```
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes=21)
```
I also tried changing backbone to mobilenet_v2 as described in the above tutorial but results were much worse.
I am using this dataset loading code with a batch size of 2: [https://github.com/pytorch/vision/issues/1097#issuecomment-508917489](https://github.com/pytorch/vision/issues/1097#issuecomment-508917489). I am also using RandomHorizontalFlip transformation while training. I train the models using the code in the tutorial ([github.com/pytorch/vision/blob/master/references/detection/engine.py](https://github.com/pytorch/vision/blob/master/references/detection/engine.py)).
The model performance on val dataset degrades after 5th epoch and the best **mAP** I could get is about **47%** which is much less than the expected performance (69.9%). Please note that I train on train split and evaluate on val split whereas in the paper, the model is trained on trainval and tested on test split but I don't think this can lead to such a reduction of performance.
```
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.0001, momentum=0.9, weight_decay=0.005)
# optimizer = torch.optim.Adam(params, lr=0.0001, weight_decay=0.005)
# Adam gives much worse results (< 10% mAP!) for some reason!
for epoch in range(30):
train_one_epoch(model, optimizer, train_loader, device, epoch, print_freq=1000)
evaluate(model, val_loader, device=device)
```
```
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.472
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.768
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.522
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.188
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.402
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.518
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.412
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.599
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.607
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.318
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.535
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.650
```
Can anyone please help me resolve the issue? Do I have to make any changes to the default parameters in torchvision's faster_rcnn implementation?
**Specifications:**
Python - v3.7.3
pyTorch - v1.3.0
torchvision - v0.4.1
CUDA - v10.1
GPU - NVIDIA GeForce RTX 2080 8GB
Thanks for your time!
|
https://github.com/pytorch/vision/issues/2095
|
closed
|
[
"question",
"module: reference scripts",
"topic: object detection"
] | 2020-04-12T03:26:34Z
| 2020-04-25T00:31:08Z
| null |
kevalmorabia97
|
pytorch/pytorch
| 36,384
|
[quantization] how to quantize model which include not support to quantize layer
|
Hi, I have a model which include `prelu` layer, not support to quantize in current pytorch version, how to quantize this model for x86 CPU now? I try to define this model with the following format:
```python
self.convbn1 = QuantizableConvBNBlock(xxx) (has defined)
self.prelu = nn.PReLU()
self.convbn2 = QuantizableConvBNBlock(xxx)
self.quant = torch.quantization.QuantStub()
self.dequant = torch.quantization.DeQuantStub()
def forward(self, x):
x = self.quant(x)
x = self.convbn1(x)
x = self.dequant(x)
x = self.prelu(x)
x = self.quant(x)
x = self.convbn2(x)
...
```
but I found after perform the quantization-aware training following tutorial, eval result is very terrible, what is the reason and how to solve it ?
Thanks
|
https://github.com/pytorch/pytorch/issues/36384
|
closed
|
[] | 2020-04-10T13:24:18Z
| 2020-04-13T04:19:47Z
| null |
zhangyongwei93
|
pytorch/vision
| 2,089
|
How to use torchvision.ops.nms in cpp?
|
How to use torchvision.ops.nms in cpp?
What should I include and how to call the funciton? Any doc?
|
https://github.com/pytorch/vision/issues/2089
|
closed
|
[
"help wanted",
"module: documentation",
"module: c++ frontend"
] | 2020-04-10T09:57:56Z
| 2021-02-08T13:19:28Z
| null |
Edwardmark
|
pytorch/ELF
| 165
|
How to parse SGF files analyzed by ELF GO
|
Hi, I want to ask for more detailed information about SGF files provided in the Facebook elf-go tools.
https://ai.facebook.com/tools/elf-opengo
In the above link, SGF files analyzed by elf-go are provided and I want to analyze those files.
More specifically SGF files in the link below.
https://dl.fbaipublicfiles.com/elfopengo/analysis/data/gogod_commentary_sgfs.gzip
The format is slightly different from typical SGF files. Each line in the recorded move includes additional tree structured information generated by elf-go.
But I cannot find detailed information about the format of the file nor how to parse them.
Can I get a parser for these files? Or any detailed instructions on how to parse them correctly?
Thank you.
|
https://github.com/pytorch/ELF/issues/165
|
open
|
[] | 2020-04-10T08:32:52Z
| 2020-04-10T08:32:52Z
| null |
mibastro
|
pytorch/pytorch
| 36,367
|
how to ensure the quality of pytorch framework?
|
Hi, I am a postgrad student, and I am developing my own deep-learning framework inside my lab, I just curious about how you guys maintained your framwork?Besides unit tests, is there any methods that can guarantee qulity?
|
https://github.com/pytorch/pytorch/issues/36367
|
closed
|
[] | 2020-04-10T05:02:35Z
| 2020-04-13T04:14:45Z
| null |
MountainHil
|
pytorch/ios-demo-app
| 14
|
how to quantize the mobilenet
|
would you please provide the steps to quantize the mobilenet?
https://github.com/pytorch/ios-demo-app/blob/master/PyTorchDemo/PyTorchDemo/ImageClassification/model/mobilenet_quantized.pt
|
https://github.com/pytorch/ios-demo-app/issues/14
|
closed
|
[] | 2020-04-09T10:32:56Z
| 2020-12-16T07:38:59Z
| null |
ronjian
|
pytorch/vision
| 2,083
|
COCO AP of FPN with ResNet-50 backbone for object detection
|
Hi @fmassa, thanks for the great codes.
I am confused about COCO AP of `Faster R-CNN ResNet-50 FPN`,
from [Document](https://pytorch.org/docs/stable/torchvision/models.html) and #925 and [Source Code](https://github.com/pytorch/vision/blob/master/references/detection/train.py#L156,L173),
I guess that the model `Faster R-CNN ResNet-50 FPN` was trained with following hyperparameters and got AP 37.0, am I right?
| Repo | Network | box AP | scheduler | epochs | lr-steps | batch size | lr |
|:-----------------------------:|:-------------:|:----------:|:-------------:|:---------:|:----------------:|:--------------:|:--------:|
| vision | R-50 FPN | 37.0 | **2x** | 26 | 16, 22 | 16 | 0.02 |
> batch_size = 2 * 8 (NUM_GPU) = 16
However, I noticed that the box AP in [maskrcnn-benchmark](https://github.com/facebookresearch/maskrcnn-benchmark/blob/master/MODEL_ZOO.md#end-to-end-faster-and-mask-r-cnn-baselines) and [Detectron](https://github.com/facebookresearch/Detectron/blob/master/MODEL_ZOO.md#end-to-end-faster--mask-r-cnn-baselines) seems to have better performance as below:
| Repo | Network | box AP | scheduler | epochs | lr-steps | batch size | lr |
|:-----------------------------:|:-------------:|:----------:|:-------------:|:---------:|:-----------------:|:--------------:|:--------:|
| maskrcnn-benchmark | R-50 FPN | 36.8 | **1x** | 12.28 | 8.19, 10.92 | 16 | 0.02 |
| Detectron | R-50 FPN | 36.7 | **1x** | 12.28 | 8.19, 10.92 | 16 | 0.02 |
| Detectron | R-50 FPN | 37.9 | **2x** | 24.56 | 16.37, 21.83 | 16 | 0.02 |
> from [maskrcnn-benchmark 1x config](https://github.com/facebookresearch/maskrcnn-benchmark/blob/master/configs/e2e_faster_rcnn_R_50_FPN_1x.yaml)
> epochs = 90000 (steps) * 16 (batch size) / 117266 (training images per epoch) = 12.28
> btw, COCO2017 has 118287 training images but only 117266 training images contain at least one object
I would like to know what causes this gap?
- 37.0 (torchvision 2x) vs 36.8 (maskrcnn-benchmark 1x)
- 37.0 (torchvision 2x) vs 37.9 (Detectron 2x)
Besides, could I have the result which trained with scheduler 1x?
| Repo | Network | box AP | scheduler | epochs | lr-steps | batch size | lr |
|:-----------------------------:|:-------------:|:----------:|:-------------:|:---------:|:----------------:|:--------------:|:--------:|
| vision | R-50 FPN | ?? | **1x** | 13 | 8, 11 | 16 | 0.02 |
Thank you!
|
https://github.com/pytorch/vision/issues/2083
|
closed
|
[
"question",
"module: models",
"topic: object detection"
] | 2020-04-09T03:44:06Z
| 2020-04-27T00:59:56Z
| null |
potterhsu
|
pytorch/vision
| 2,082
|
Does vision cpp api support half cuda precision ?
|
Does vision cpp api support half cuda precision ?
I see that in the CMakelist.txt, it used flags as -D__CUDA_NO_HALF_OPERATORS_.
https://github.com/pytorch/vision/blob/master/CMakeLists.txt#L10
|
https://github.com/pytorch/vision/issues/2082
|
closed
|
[
"question",
"module: c++ frontend"
] | 2020-04-09T03:29:21Z
| 2020-04-16T06:49:46Z
| null |
Edwardmark
|
pytorch/vision
| 2,079
|
batch normalization affects model.eval's prediction
|
## 🐛 Bug
I'm not entirely sure if I maybe do not miss something VERY obvious here, feel free to tell me if that is the case, however I think it might be a bug: Batch normalization should only affect the input during training. However, I find with an easy experiment, that this is not the case. Note that dropout is not applied.
## To Reproduce
Steps to reproduce the behavior:
0. generate Input "input_"
1. initialize model densenet121
2. set model to eval mode and predict using prediction1 = model(input_)
3. set model to training mode
4. predict something (without model update!)
5. set model to eval mode again
6. predict class from the same input prediction2 = model(input_)
7. note that there was no weight update and the prediction1 != prediction2
```python
from torchvision import models
import torch
def set_parameter_requires_grad(model):
for param in model.parameters():
param.requires_grad = False
if __name__ == "__main__":
model = models.densenet121(pretrained=True)
set_parameter_requires_grad(model)
input_ = torch.zeros((1,3, 224, 224))
model.eval()
eval_value = model(input_)
model.train()
another_variable = model(input_)
model.eval()
eval_value_2 = model(input_)
print(eval_value[0,0:3])
print(eval_value_2[0,0:3])
###### RETURNS######
tensor([-0.3295, 0.2166, -0.6806])
tensor([-0.5839, 0.4981, -0.4104])
```
## Expected behavior
I expected the model to be independent from batch normalization during model.eval(), i.e. prediction1 == prediction2
## Environment
tested on ubuntu 1804 and windows 10 using python 3.7, torchvision 0.5.0 and torch 1.4.0
__
Edit: I'm stupid. The batch normalization layers apply the statistics seen in the training during the evaluation. I closed this issue.
|
https://github.com/pytorch/vision/issues/2079
|
closed
|
[
"question"
] | 2020-04-08T19:27:33Z
| 2020-04-09T10:09:54Z
| null |
dnns92
|
pytorch/TensorRT
| 37
|
Should the compiler check to see if modules are in eval mode?
|
https://github.com/pytorch/TensorRT/issues/37
|
closed
|
[
"question",
"component: core"
] | 2020-04-07T22:03:59Z
| 2020-05-28T20:33:41Z
| null |
narendasan
|
|
pytorch/pytorch
| 36,132
|
how to get cuda stream in torch 1.5?
|
I previous using this get cuda stream:
```
modulated_deformable_col2im_coord_cuda(THCState_getCurrentStream(state),
```
I found this API gone `THCState_getCurrentStream` without even a deprecation warning, what's the altinate of this API?
in torch 1.5?
cc @yf225
|
https://github.com/pytorch/pytorch/issues/36132
|
closed
|
[
"module: cpp",
"triaged"
] | 2020-04-07T06:59:27Z
| 2020-04-09T03:21:48Z
| null |
lucasjinreal
|
pytorch/text
| 723
|
How to use custom parsers in Torchtext
|
I would like to use custom parser like nltk in torchtext, how to do that?
|
https://github.com/pytorch/text/issues/723
|
closed
|
[] | 2020-04-05T07:56:22Z
| 2022-06-24T00:15:05Z
| null |
nawshad
|
pytorch/vision
| 2,063
|
Wrong lr schedule in semantic segmentation sample?
|
Hi! I am using the semantic segmentation reference training scripts and I think I found an issue with the lr scheduler.
In the documentation of [torch.optim.lr_scheduler.LambdaLR](https://pytorch.org/docs/stable/optim.html#torch.optim.lr_scheduler.LambdaLR) it says that the lambda function receives an integer parameter epoch, but in the training reference script it looks that the parameter `x` is used as if it was the global step: https://github.com/pytorch/vision/blob/e61538cba036c42bab23ce8f9d205da9889977ae/references/segmentation/train.py#L158
If I understand it correctly, this is the poly learning rate policy used in [DeepLab](https://arxiv.org/pdf/1606.00915.pdf), so I think that instead it should be:
```python
lambda x: (1 - x / args.epochs) ** 0.9)
```
Also, it'd be interesting to have a way of changing the learning rate at the finer resolution of iterations, instead of epochs.
@fmassa what do you think?
|
https://github.com/pytorch/vision/issues/2063
|
closed
|
[
"question",
"module: reference scripts"
] | 2020-04-04T17:56:02Z
| 2020-04-06T13:26:57Z
| null |
oscmansan
|
pytorch/text
| 722
|
How to load a word embedding dictionary using torchtext
|
Hi,
I have tried to write that to a gensim word2vec format then load, but it throws error about string to float conversion. Is there a standard way to use custom pre-trained embedding (not created through gensim) which is a python dictionary to load using torchtext?
Thanks,
|
https://github.com/pytorch/text/issues/722
|
open
|
[] | 2020-04-04T01:05:08Z
| 2020-04-06T15:57:47Z
| null |
nawshad
|
pytorch/pytorch
| 35,877
|
How to use a network B to obtain a tensor and use it to replace the weight of a layer of network A, and this back propagation process will train A and B
|
## ❓ Questions and Help
### How to use a network B to obtain a tensor and use it to replace the weight of a layer of network A and this backpropagation process will train A and B。
I make a code, which uses the weight of a layer of network A as input into network B. then B output a tensor and I use it to replace the weight of a layer of the network A. But I find the weight only needs the type of nn.Parameter() and I convert the tensor to Parameter type, but I find the weight of network B does not get an update. Can you help me please!
It's noted that I want to train the weight of network B by the loss of the network A.
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/35877
|
closed
|
[] | 2020-04-02T13:28:13Z
| 2020-04-06T17:09:36Z
| null |
syiswell
|
pytorch/tutorials
| 924
|
5x5 kernel size instead of 3x3?
|
Hi, I just read this tutorial on your official website [NEURAL NETWORKS](https://pytorch.org/tutorials/beginner/blitz/neural_networks_tutorial.html#sphx-glr-beginner-blitz-neural-networks-tutorial-py)
and think according to the image and the following code, maybe the kernel size of the first convolution layer should be 5x5 instead of 3x3.
If we follow [this formula](https://stackoverflow.com/questions/44193270/how-to-calculate-the-output-size-after-convolving-and-pooling-to-the-input-image) and by default the argument of **conv2d** is **padding = 0** and **stride = 1**, we have
* **1st conv2d with 5x5 kernel**: 32x32 -> 28x28
* **1st max pooling**: 28x28 -> 14x14
* **2nd conv2d with 3x3 kernel**: 14x14 -> 12x12
* **2nd max pooling**: 12x12 -> 6x6
Which will explain both the image and the following linear layer (6x6 image dimension) in your code.
|
https://github.com/pytorch/tutorials/issues/924
|
closed
|
[] | 2020-04-02T08:36:52Z
| 2021-04-26T20:13:45Z
| 1
|
sudo-bcli
|
pytorch/TensorRT
| 34
|
What the advantages of TRTorch?
|
I used to use torch2trt to convert pytorch module, could you explain the advatage over torch2trt?
If the model contain op that tensorrt don't support, can trtorch convert it to engine?
Otherwise run the op supported by tensorrt with tensorrt, and other use libtorch?
I really appreciate for your great works, if you can answer my doubts, I will be very grateful.
|
https://github.com/pytorch/TensorRT/issues/34
|
closed
|
[
"question"
] | 2020-04-01T10:07:45Z
| 2020-05-28T20:33:19Z
| null |
dancingpipi
|
pytorch/pytorch
| 35,759
|
how to do 3d data augmentation in parallel on the gpu?
|
I have a lot of 3d data and need to do various data augmentation. I want to do data augmentation in parallel on the gpu, but it seems that pytorch does not allow gpu operation in the dataloader. Is there any good way?
cc @ngimel @SsnL
|
https://github.com/pytorch/pytorch/issues/35759
|
open
|
[
"module: dataloader",
"module: cuda",
"triaged"
] | 2020-03-31T15:25:22Z
| 2020-04-01T13:23:34Z
| null |
chuxiang93
|
pytorch/tutorials
| 918
|
Saving the weights
|
After training for certain iterations. How to save the weights, Which can be used for further analysis
|
https://github.com/pytorch/tutorials/issues/918
|
closed
|
[] | 2020-03-31T08:39:49Z
| 2021-06-08T21:29:42Z
| 1
|
SRIKARHI
|
pytorch/TensorRT
| 28
|
How can I build TRTorch without network?
|
as the title.
|
https://github.com/pytorch/TensorRT/issues/28
|
closed
|
[
"question",
"component: build system"
] | 2020-03-30T08:15:49Z
| 2020-04-24T17:29:30Z
| null |
dancingpipi
|
pytorch/ELF
| 163
|
How to use ELF in Sabaki or gogui?
|
Could anybody help tell me how to use ELF OpenGo with Sabaki or gogui?
don't use weight of leelazero-elf.
|
https://github.com/pytorch/ELF/issues/163
|
closed
|
[] | 2020-03-28T11:37:49Z
| 2020-05-21T06:43:16Z
| null |
herogan2017
|
pytorch/vision
| 2,021
|
IndexError: list index out of range
|
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
Steps to reproduce the behavior:
1. Run the [TorchVision Object Detection Finetuning Tutorial](https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html).
2. For the model, I used the instructions for
> 2. Modifying the model to add a different backbone
But I keep getting the following error:
`---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-16-159df024665a> in <module>
4 for epoch in range(num_epochs):
5 # train for one epoch, printing every 10 iterations
----> 6 train_one_epoch(model, optimizer, train_loader, device, epoch, print_freq=10)
7 # update the learning rate
8 lr_scheduler.step()
/Volumes/Samsung_T5/OneDrive - Coventry University/detector/faster_rcnn_v23/engine.py in train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq)
28 targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
29
---> 30 loss_dict = model(imgs1, targets)
31
32 losses = sum(loss for loss in loss_dict.values())
~/opt/miniconda3/envs/torch/lib/python3.8/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
530 result = self._slow_forward(*input, **kwargs)
531 else:
--> 532 result = self.forward(*input, **kwargs)
533 for hook in self._forward_hooks.values():
534 hook_result = hook(self, input, result)
~/opt/miniconda3/envs/torch/lib/python3.8/site-packages/torchvision/models/detection/generalized_rcnn.py in forward(self, images, targets)
69 features = OrderedDict([('0', features)])
70 proposals, proposal_losses = self.rpn(images, features, targets)
---> 71 detections, detector_losses = self.roi_heads(features, proposals, images.image_sizes, targets)
72 detections = self.transform.postprocess(detections, images.image_sizes, original_image_sizes)
73
~/opt/miniconda3/envs/torch/lib/python3.8/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
530 result = self._slow_forward(*input, **kwargs)
531 else:
--> 532 result = self.forward(*input, **kwargs)
533 for hook in self._forward_hooks.values():
534 hook_result = hook(self, input, result)
~/opt/miniconda3/envs/torch/lib/python3.8/site-packages/torchvision/models/detection/roi_heads.py in forward(self, features, proposals, image_shapes, targets)
754 matched_idxs = None
755
--> 756 box_features = self.box_roi_pool(features, proposals, image_shapes)
757 box_features = self.box_head(box_features)
758 class_logits, box_regression = self.box_predictor(box_features)
~/opt/miniconda3/envs/torch/lib/python3.8/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
530 result = self._slow_forward(*input, **kwargs)
531 else:
--> 532 result = self.forward(*input, **kwargs)
533 for hook in self._forward_hooks.values():
534 hook_result = hook(self, input, result)
~/opt/miniconda3/envs/torch/lib/python3.8/site-packages/torchvision/ops/poolers.py in forward(self, x, boxes, image_shapes)
186 rois = self.convert_to_roi_format(boxes)
187 if self.scales is None:
--> 188 self.setup_scales(x_filtered, image_shapes)
189
190 scales = self.scales
~/opt/miniconda3/envs/torch/lib/python3.8/site-packages/torchvision/ops/poolers.py in setup_scales(self, features, image_shapes)
159 # get the levels in the feature map by leveraging the fact that the network always
160 # downsamples by a factor of 2 at each level.
--> 161 lvl_min = -torch.log2(torch.tensor(scales[0], dtype=torch.float32)).item()
162 lvl_max = -torch.log2(torch.tensor(scales[-1], dtype=torch.float32)).item()
163 self.scales = scales
IndexError: list index out of range`
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
I tried different models and adjusted the actors and scales, but keep getting this error.
## Environment
```
PyTorch version: 1.4.0
Is debug build: No
CUDA used to build PyTorch: None
OS: Mac OSX 10.15.3
GCC version: Could not collect
CMake version: Could not collect
Python version: 3.8
Is CUDA available: No
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
Versions of relevant libraries:
[pip] numpy==1.18.1
[pip] torch==1.4.0
[pip] torchvision==0.5.0
[conda] blas
|
https://github.com/pytorch/vision/issues/2021
|
closed
|
[
"question",
"module: models",
"topic: object detection"
] | 2020-03-26T16:27:03Z
| 2024-03-26T17:41:15Z
| null |
17sarf
|
pytorch/vision
| 2,019
|
How to plot masks of maskrcnn?
|
Hello,
Does someone know how to plot masks of maskrcnn? In the output of maskrcnn_inference in roi_heads.py mask_logits pass through sigmoid to become mask_probs and its output_size is generally very small to correctly see anything (28*28 by default, which is defined in the roi_align parameters). I tried to binarize this mask_probs using cv2.threshold (with threshold value equals to np.median of mask_probs) then convert to polygon with cv2.findcontours and finally resize it in the image shape but the results are not good.
Thanks
|
https://github.com/pytorch/vision/issues/2019
|
closed
|
[
"question",
"topic: object detection",
"module: utils"
] | 2020-03-26T15:19:47Z
| 2021-05-06T13:27:06Z
| null |
leglandudu69
|
pytorch/pytorch
| 35,372
|
How to support single-process-multiple-devices in DistributedDataParallel other than CUDA device
|
Hi,
I am investigating to extend the DistributedDataParallel to other accelerator devices than CUDA devices.
Not only to support single-process-single-device but also to support the single-process-multiple-devices and multple-processes-multiple-devices.
There are a lot of CUDA dependency in the DistributedDataParallel.
My question is:
1. How to override CUDA logical dependency and dispatch the gather and scatter (and other APIs used) to the c10d backend without modifying the distributed.py ? [https://github.com/pytorch/pytorch/blob/master/torch/nn/parallel/distributed.py](url)
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @agolynski @SciPioneer @H-Huang @mrzzd @cbalioglu @gcramer23
|
https://github.com/pytorch/pytorch/issues/35372
|
open
|
[
"oncall: distributed"
] | 2020-03-25T08:52:08Z
| 2021-06-04T13:57:34Z
| null |
JohnLLLL
|
pytorch/tutorials
| 905
|
prune: model sparity increase,but inference time doesn't cut down
|
`prune.l1_unstructured(conv_module, name='weight', amount=0.8)<br>prune.remove(conv_module, 'weight')`
with these two function, I process all module with convolution,and their sparsity become 80%.
but the model inference time incease. Is it expected ?
and another question is that after prune,I save model with:
`torch.save(model.state_dict(), 'new_model.pth')`
and then ,load the save model,it's module sparsity go back to 0 , How to save pruned model correctly ?
Thank you !
|
https://github.com/pytorch/tutorials/issues/905
|
closed
|
[] | 2020-03-25T02:26:48Z
| 2021-06-08T22:05:51Z
| 1
|
gyc-code
|
huggingface/transformers
| 3,424
|
Where is the code of Bart fine-tuning?Thanks
|
https://github.com/huggingface/transformers/issues/3424
|
closed
|
[] | 2020-03-25T01:54:34Z
| 2020-04-16T15:03:10Z
| null |
qiunlp
|
|
pytorch/examples
| 742
|
No saved *.png in checkpoint in dcgan.cpp
|
In the README file of "DCGAN Example with the PyTorch C++ Frontend" it says that:
_The training script periodically generates image samples. Use the display_samples.py script situated in this folder to generate a plot image. For example:_
But the dcgan.cpp file just saves the model in *.pt format, doesnt save any picture. Then, the command stated in the README:
```
$ python display_samples.py -i dcgan-sample-10.png
Saved out.png
```
Gives an error as ```dcgan-sample-10.png``` doesnt exist
|
https://github.com/pytorch/examples/issues/742
|
open
|
[
"bug",
"help wanted"
] | 2020-03-24T15:15:32Z
| 2023-04-20T20:59:19Z
| 3
|
hect1995
|
pytorch/vision
| 2,007
|
Learning rate become 0
|
my lr was 0.0001
But after some epoch it become zero.
Epoch: [15] [ 0/209] eta: 0:03:06 lr: 0.000000 loss: 0.5737 (0.5737) loss_classifier: 0.0601 (0.0601) loss_box_reg: 0.0831 (0.0831) loss_mask: 0.4023 (0.4023) loss_objectness: 0.0062 (0.0062) loss_rpn_box_reg: 0.0221 (0.0221) time: 0.8938 data: 0.2370 max mem: 6450
Epoch: [15] [ 10/209] eta: 0:02:13 lr: 0.000000 loss: 0.5818 (0.6080) loss_classifier: 0.0609 (0.0621) loss_box_reg: 0.0782 (0.0759) loss_mask: 0.4273 (0.4496) loss_objectness: 0.0061 (0.0073) loss_rpn_box_reg: 0.0119 (0.0132) time: 0.6731 data: 0.0303 max mem: 6450
Epoch: [15] [ 20/209] eta: 0:02:05 lr: 0.000000 loss: 0.5848 (0.5937) loss_classifier: 0.0595 (0.0620) loss_box_reg: 0.0693 (0.0756) loss_mask: 0.4273 (0.4355) loss_objectness: 0.0060 (0.0068) loss_rpn_box_reg: 0.0118 (0.0138) time: 0.6527 data: 0.0096 max mem: 6450
Epoch: [15] [ 30/209] eta: 0:01:59 lr: 0.000000 loss: 0.5848 (0.5950) loss_classifier: 0.0616 (0.0626) loss_box_reg: 0.0710 (0.0762) loss_mask: 0.4182 (0.4338) loss_objectness: 0.0065 (0.0087) loss_rpn_box_reg: 0.0106 (0.0137) time: 0.6611 data: 0.0098 max mem: 6450
Epoch: [15] [ 40/209] eta: 0:01:50 lr: 0.000000 loss: 0.5718 (0.5921) loss_classifier: 0.0639 (0.0642) loss_box_reg: 0.0767 (0.0768) loss_mask: 0.4173 (0.4295) loss_objectness: 0.0072 (0.0086) loss_rpn_box_reg: 0.0101 (0.0130) time: 0.6396 data: 0.0092 max mem: 6450
Epoch: [15] [ 50/209] eta: 0:01:43 lr: 0.000000 loss: 0.5703 (0.5907) loss_classifier: 0.0640 (0.0655) loss_box_reg: 0.0798 (0.0764) loss_mask: 0.4035 (0.4259) loss_objectness: 0.0062 (0.0098) loss_rpn_box_reg: 0.0109 (0.0131) time: 0.6363 data: 0.0088 max mem: 6450
i am training on custom data with 2(1class+background) class.
|
https://github.com/pytorch/vision/issues/2007
|
closed
|
[
"question",
"module: reference scripts",
"topic: object detection"
] | 2020-03-24T13:01:26Z
| 2020-03-25T14:28:20Z
| null |
vivekdeepquanty
|
pytorch/vision
| 2,004
|
Suspicious results
|
## Questions about suspicious results ❓
I've trained MaskRCNN with a pre-trained ResNet50 to segment nuclei in immunofluorescence images. The results are really good, so thanks again for this terrific implementation.
However, I've noticed in some cases that an object (here a nucleus) might be cut in multiple small parts (see bottom right part of the attached image).
<img width="531" alt="Capture d’écran 2020-03-23 à 15 27 27" src="https://user-images.githubusercontent.com/6014800/77369519-0fcfa600-6d1c-11ea-820d-3186fc1bc037.png">
We can observe that the nucleus labeled 247 is cut in multiple parts.
I get that in most detection/segmentation applications, an object can partially obfuscate another one that is further in a scene. But, is it a normal behavior for this implementation?
|
https://github.com/pytorch/vision/issues/2004
|
closed
|
[
"question",
"module: models",
"topic: object detection"
] | 2020-03-23T22:38:10Z
| 2020-03-24T18:18:58Z
| null |
FiReTiTi
|
pytorch/FBGEMM
| 328
|
quantized matrix multiplication question
|
Could you please point me to a quantized matrix-matrix multiplication example in the test or benchmark directory ? That is to say,
C = A * B // A, B, C are single-precision floating-point matrices
C' = dequant (quant(A) * quant (B) ) // quant(A) and quant(B) are int8 matrices
Thanks
|
https://github.com/pytorch/FBGEMM/issues/328
|
closed
|
[
"question"
] | 2020-03-23T04:03:40Z
| 2022-03-18T06:43:26Z
| null |
jinz2014
|
pytorch/examples
| 740
|
Question: How to cite your work
|
Hi,
I am writing a paper that modifies the codes for the example of MNIST dataset in your repository. May I ask how you would prefer that I cite your work?
Thank you.
|
https://github.com/pytorch/examples/issues/740
|
closed
|
[] | 2020-03-22T21:30:47Z
| 2020-04-11T18:13:40Z
| null |
hql5143
|
pytorch/pytorch
| 35,159
|
How to implement bmm between two sparse tensor
|
## 🚀 Feature
<!-- A clear and concise description of the feature proposal -->
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too -->
## Pitch
<!-- A clear and concise description of what you want to happen. -->
## Alternatives
<!-- A clear and concise description of any alternative solutions or features you've considered, if any. -->
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
|
https://github.com/pytorch/pytorch/issues/35159
|
closed
|
[] | 2020-03-21T16:57:58Z
| 2020-03-23T18:46:54Z
| null |
xhcgit
|
pytorch/pytorch
| 35,153
|
How to impove conv2d performance in cpu mode
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
1. when i use PIP to install pytorch, con2d perforamance is better
2. when i down pytorch 1.0.0 source code in gitlab, bad performance
3.USE_MKL or OPENMP or some other optimizition results in the performance difference?
Here is con2d op shape:
Conv2d(64, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
way 1:
pytorch install:
conda install pytorch-cpu==1.0.0 torchvision-cpu==0.2.1 cpuonly -c pytorch
log: the conv2D infer time :3.85 s
way 2:
down pytorch 1.0.0 source code and compile with "python setup.py install"
log: the conv2D infer time :13.63 s
|
https://github.com/pytorch/pytorch/issues/35153
|
closed
|
[] | 2020-03-21T07:33:23Z
| 2020-03-23T09:04:07Z
| null |
daydayfun
|
pytorch/examples
| 738
|
Neural Style fails if style image has an alpha channel
|
In `fast_neural_style/neural_style/neural_style.py` line 55, if the style image has an alpha channel, then the generated tensor has 4 dimensions and this causes `utils.normalize_batch` to throw due to a tensor dimension mismatch a few lines down.
I've _fixed_ this by appending `.convert('RGB')` so line 55 now reads
```
style = utils.load_image(args.style_image, size=args.style_size).convert('RGB')
```
The `ImageFolder` data loader does the same transformation, however, maybe a warning should be issued since it is the key file.
|
https://github.com/pytorch/examples/issues/738
|
open
|
[
"help wanted"
] | 2020-03-20T17:00:20Z
| 2022-03-09T21:48:53Z
| 0
|
hackf5
|
pytorch/tutorials
| 899
|
How to apply torch.quantization.quantize_dynamic for conv2d layer?
|
I am working on quantizing resnet50 model. I tried to use the following command.
```
quantized_model = torch.quantization.quantize_dynamic(
resnet18, {torch.nn.Conv2d,torch.nn.Linear}, dtype=torch.qint8
)
```
But only the linear layer has quaantized but not the convolutional layer. Can anyone help me how to dynamically quantize the convolutional layer?
|
https://github.com/pytorch/tutorials/issues/899
|
open
|
[
"quantization"
] | 2020-03-20T09:02:12Z
| 2021-07-30T20:28:16Z
| null |
Midhilesh29
|
pytorch/vision
| 1,999
|
Request Mobilenet fpn
|
## 🚀 Feature
Hi I want to write mobilenet fpn.
## Motivation
Improve MaskRCNN speed and accuracy.
## Pitch
<!-- A clear and concise description of what you want to happen. -->
## Alternatives
<!-- A clear and concise description of any alternative solutions or features you've considered, if any. -->
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
## Code:
**/torchvision/models/detection/backbone_utils.py**
```
from collections import OrderedDict
from torch import nn
from torchvision.ops.feature_pyramid_network import FeaturePyramidNetwork, LastLevelMaxPool
from torchvision.ops import misc as misc_nn_ops
from .._utils import IntermediateLayerGetter
from .. import resnet
from .. import mobilenet_v2
from torchvision.models import mobilenet_v2 as MobileNetV2
class BackboneWithFPN(nn.Sequential):
def __init__(self, backbone, return_layers, in_channels_list, out_channels):
body = IntermediateLayerGetter(backbone, return_layers=return_layers)
fpn = FeaturePyramidNetwork(
in_channels_list=in_channels_list,
out_channels=out_channels,
extra_blocks=LastLevelMaxPool(),
)
super(BackboneWithFPN, self).__init__(OrderedDict(
[("body", body), ("fpn", fpn)]))
self.out_channels = out_channels
def resnet_fpn_backbone(backbone_name, pretrained):
backbone = resnet.__dict__[backbone_name](
pretrained=pretrained,
norm_layer=misc_nn_ops.FrozenBatchNorm2d)
# freeze layers
for name, parameter in backbone.named_parameters():
if 'layer2' not in name and 'layer3' not in name and 'layer4' not in name:
parameter.requires_grad_(False)
return_layers = {'layer1': 0, 'layer2': 1, 'layer3': 2, 'layer4': 3}
in_channels_stage2 = backbone.inplanes // 8
in_channels_list = [
in_channels_stage2,
in_channels_stage2 * 2,
in_channels_stage2 * 4,
in_channels_stage2 * 8,
]
out_channels = 256
return BackboneWithFPN(backbone, return_layers, in_channels_list, out_channels)
class FPNMobileNet(nn.Module):
def __init__(self, pretrained=True):
super().__init__()
net = MobileNetV2(pretrained)
self.features = net.features
self.layer1= nn.Sequential(*self.features[0:4])
self.layer2 = nn.Sequential(*self.features[4:7])
self.layer3 = nn.Sequential(*self.features[7:11])
self.layer4 = nn.Sequential(*self.features[11:19])
for param in self.features.parameters():
param.requires_grad = False
def forward(self, x):
# Bottom-up pathway, from ResNet
enc0 = self.layer1(x)
enc1 = self.layer2(enc0) # 256
enc2 = self.layer3(enc1) # 512
enc3 = self.layer4(enc2) # 1024
return enc3
def mobilenet_fpn_backbone(pretrained):
backbone = FPNMobileNet(pretrained)
print(backbone)
# freeze layers
for name, parameter in backbone.named_parameters():
if 'layer2' not in name and 'layer3' not in name and 'layer4' not in name:
parameter.requires_grad_(False)
return_layers = {'layer1': 0, 'layer2': 1, 'layer3': 2, 'layer4': 3}
in_channels_stage2 =1280 // 8
in_channels_list = [
in_channels_stage2,
in_channels_stage2 * 2,
in_channels_stage2 * 4,
in_channels_stage2 * 8,
]
out_channels = 256
return BackboneWithFPN(backbone, return_layers, in_channels_list, out_channels)
```
**/torchvision/models/detection/mobilenet_fpn.py**
```
from .backbone_utils import mobilenet_fpn_backbone
def fpn(pretrained = True):
backbone = mobilenet_fpn_backbone( pretrained)
return backbone
```
**demo.py**
```from torchvision.models.detection import mobilenet_fpn
backbone = mobilenet_fpn.fpn(True)
backbone.eval()
x = torch.rand(1,3, 100, 100)
out = backbone(x)
print(out)
```
## Bug:
"RuntimeError: Given groups=1, weight of size 32 3 3 3, expected input[1, 1280, 4, 4] to have 3 channels, but got 1280 channels instead"
|
https://github.com/pytorch/vision/issues/1999
|
closed
|
[
"question",
"module: models",
"topic: object detection",
"topic: feature extraction"
] | 2020-03-20T08:34:56Z
| 2020-11-30T07:22:50Z
| null |
finnickniu
|
pytorch/android-demo-app
| 68
|
How to create a new nlp model?
|
Thanks for the project.
The example successful run on Android.
However, I want to create my our model for other nlp tasks.
So, can you show me the way to create the nlp model? Or the source of creating model-reddit16-f140225004_2.pt1?
|
https://github.com/pytorch/android-demo-app/issues/68
|
open
|
[] | 2020-03-20T07:45:01Z
| 2020-05-20T01:29:55Z
| null |
anbo724
|
pytorch/vision
| 1,986
|
Training scheme of the pretrained imagenet models?
|
Hi,
Are the pretrained models reported by torchvision using the same hyper-parameters as https://github.com/pytorch/examples/blob/master/imagenet/main.py? I used the default hyper-parameters to train mobilenet_v2, but the results were much worse than reported.
Thanks
|
https://github.com/pytorch/vision/issues/1986
|
closed
|
[
"question",
"module: models",
"module: reference scripts"
] | 2020-03-15T09:16:29Z
| 2020-03-19T18:43:05Z
| null |
tzm1003306213
|
huggingface/transformers
| 3,283
|
What is the most effective way to use BERT , ROBERTA , GPT-2 architectures as frozen feature extractors ?
|
We use pretrained self-supervised learning (SSL) models for NLP as feature extractors for downstream tasks like sentiment analysis. In most of such cases, we add a simple new classification layer and **fine-tune the whole model**. With the SSL models getting bigger and the amount of unsupervised training data is huge it would be nice if we can use the problem agnostic behavior of SSL embeddings. In other words if we use them as **Frozen Feature extractors**, we can save lot of time and computational cost.
**Have anyone seen a good review on using SSL networks as frozen feature extractors?**
|
https://github.com/huggingface/transformers/issues/3283
|
closed
|
[
"Discussion",
"wontfix"
] | 2020-03-15T09:06:20Z
| 2020-06-02T09:15:03Z
| null |
shamanez
|
pytorch/pytorch
| 34,775
|
How to do a split operation for dataset, not random split. I mean just like dataset[0:100] and dataset[100:200]]
|
How to do a split operation for dataset, not random split. I mean just like dataset[0:100] and dataset[100:200]]
|
https://github.com/pytorch/pytorch/issues/34775
|
closed
|
[] | 2020-03-15T02:28:33Z
| 2020-03-15T02:37:14Z
| null |
HymEric
|
pytorch/pytorch
| 34,773
|
How to write codes to support second order derivative (double backward) for custom CUDA extension
|
Hi,
I am lost in figuring out how to compute second order derivatives for custom CUDA extensions after reading the [Extend Torch With Cpp and CUDA](https://pytorch.org/tutorials/advanced/cpp_extension.html).
Could somebody tell me how to do this? Many thanks!
|
https://github.com/pytorch/pytorch/issues/34773
|
closed
|
[] | 2020-03-15T01:17:24Z
| 2020-03-18T15:03:39Z
| null |
xieshuqin
|
pytorch/pytorch
| 34,720
|
Where is dd.h ?
|
```console
....../pytorch/third_party/sleef/src/quad/sleefsimdqp.c:111:10: fatal error: dd.h: No such file or directory
#include "dd.h"
^~~~~~
compilation terminated.
sleef/src/quad/CMakeFiles/sleefquadavx512f_obj.dir/build.make:70: recipe for target 'sleef/src/quad/CMakeFiles/sleefquadavx512f_obj.dir/sleefsimdqp.c.o' failed
make[2]: *** [sleef/src/quad/CMakeFiles/sleefquadavx512f_obj.dir/sleefsimdqp.c.o] Error 1
make[2]: Leaving directory '....../pytorch/build_18.04'
CMakeFiles/Makefile2:4939: recipe for target 'sleef/src/quad/CMakeFiles/sleefquadavx512f_obj.dir/all' failed
make[1]: *** [sleef/src/quad/CMakeFiles/sleefquadavx512f_obj.dir/all] Error 2
make[1]: *** Waiting for unfinished jobs....
....../pytorch/third_party/sleef/src/quad/sleefsimdqp.c:111:10: fatal error: dd.h: No such file or directory
#include "dd.h"
^~~~~~
compilation terminated.
sleef/src/quad/CMakeFiles/sleefquadavx2_obj.dir/build.make:70: recipe for target 'sleef/src/quad/CMakeFiles/sleefquadavx2_obj.dir/sleefsimdqp.c.o' failed
make[2]: *** [sleef/src/quad/CMakeFiles/sleefquadavx2_obj.dir/sleefsimdqp.c.o] Error 1
make[2]: Leaving directory '....../pytorch/build_18.04'
CMakeFiles/Makefile2:5329: recipe for target 'sleef/src/quad/CMakeFiles/sleefquadavx2_obj.dir/all' failed
make[1]: *** [sleef/src/quad/CMakeFiles/sleefquadavx2_obj.dir/all] Error 2
make[2]: Leaving directory '....../pytorch/build_18.04'
[ 63%] Built target ATEN_CPU_FILES_GEN_TARGET
make[2]: Leaving directory '....../pytorch/build_18.04'
[ 63%] Built target generate-torch-sources
make[1]: Leaving directory '....../pytorch/build_18.04'
Makefile:165: recipe for target 'all' failed
make: *** [all] Error 2
```
|
https://github.com/pytorch/pytorch/issues/34720
|
closed
|
[] | 2020-03-13T17:31:27Z
| 2020-03-14T00:15:45Z
| null |
jiapei100
|
pytorch/TensorRT
| 13
|
RFC: Converter API
|
Right now the Converter API expects lambdas of the type: `(ConversionCtx* ctx, torch::jit::Node* n, kwargs* args) -> bool`
Questions:
1. The bool return is a quick way to signal success or failure in converting the op. This could be something more descriptive
2. Right now it is the responsibility of converters to log associations between `torch::jit::Value`s and `nvinfer1::ITensors`s so that later is significantly easier to assemble the arguments to a node. It may be nice if you could return a vector of unions of IValues and ITensors and have the converter executor do the insertions. This would probably need to rely on some guarantee that order of return is easy to determine and constant
|
https://github.com/pytorch/TensorRT/issues/13
|
closed
|
[
"question",
"priority: low",
"component: converters",
"No Activity"
] | 2020-03-13T01:07:55Z
| 2020-06-10T00:02:51Z
| null |
narendasan
|
pytorch/TensorRT
| 7
|
RFC: How should engines be integrated into the JIT Interpreter?
|
Right now as a side effect of registering an engine in the execution manager, a new op specifically for the engine is registered in the op registry. For instance running a ResNet backbone will be implemented with a new op with schema `trt::execute_engine_55d1de7b7b50(Tensor in_input_38) -> (Tensor)`. We could also have a generic op like `trt::execute_engine(int id, Tensor in_input_38, ...) -> (Tensor, ...)` and rely on information in the engine manager to run the correct engine, as long as variadic arguments (and returns) work.
|
https://github.com/pytorch/TensorRT/issues/7
|
closed
|
[
"question",
"component: execution"
] | 2020-03-11T20:08:12Z
| 2020-05-28T20:34:13Z
| null |
narendasan
|
pytorch/TensorRT
| 6
|
Verify that engine runs in the correct stream
|
This is the stream that is used right now
`c10::cuda::CUDAStream stream = c10::cuda::getCurrentCUDAStream(inputs[0].device().index());`
Will this always be correct? What are the cases where this will give an incorrect stream?
|
https://github.com/pytorch/TensorRT/issues/6
|
closed
|
[
"question",
"component: execution",
"No Activity"
] | 2020-03-11T19:59:20Z
| 2020-07-09T00:17:53Z
| null |
narendasan
|
pytorch/vision
| 1,964
|
The simplest way to use checkpoint to maximize the GPU memory usage
|
## ❓ The simplest way to use checkpoint to maximize the GPU memory usage
Hi, guys,
I am learning about how to use the checkpoint to optimize the GPU memory usage, and I see there is a example in [densenet.py](https://github.com/pytorch/vision/blob/216035315185edec747dca8879d7197e7fb22c7d/torchvision/models/densenet.py#L53) as
```python
@torch.jit.unused # noqa: T484
def call_checkpoint_bottleneck(self, input):
# type: (List[Tensor]) -> Tensor
def closure(*inputs):
return self.bn_function(*inputs)
return cp.checkpoint(closure, input)
```
Firstly, I think using checkpoint to maximize the GPU memory usage **only apply to activation modules, such as ReLU**. So, why not just create an new Module like:
```python
class cp_ReLU(nn.Module):
def __init__(self, inplace) -> None:
super(cp_ReLU, self).__init__()
relu = nn.ReLU(inplace = inplace)
def forward(self, x):
y=cp.checkpoint(relu, x)
return y
```
And use cp_ReLU instead of original ReLU in all the places where a ReLU is need as:
```python
if self.memory_efficient:
self.add_module('relu2', nn.ReLU(inplace=True)),
else
self.add_module('relu2', cp_ReLU(inplace=True)),
```
I think this kind of implementation will make best use of the checkpoint.
Am I right?
Or would checkpoint also have effect to other kinds of modules like, Conv2d or BatchNorm2d?
Your suggestion and answer will be appreciated!
|
https://github.com/pytorch/vision/issues/1964
|
closed
|
[
"question",
"module: models"
] | 2020-03-11T10:37:12Z
| 2020-03-12T18:03:53Z
| null |
songyuc
|
huggingface/neuralcoref
| 248
|
German Training not working
|
Hi we tried to train your model for german. We used Glove in german but it doesnt work.
How does the binary static_word_embeddings.npy needs to be structured?
|
https://github.com/huggingface/neuralcoref/issues/248
|
closed
|
[
"question",
"wontfix",
"training",
"feat / coref"
] | 2020-03-11T10:25:36Z
| 2022-01-09T04:06:40Z
| null |
SimonF89
|
huggingface/transformers
| 3,205
|
where is the position emdeddings in bert for training a new model from scratch ?
|
# ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. Make sure to tag your question with the
right deep learning framework as well as the huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
If your question wasn't answered after a period of time on Stack Overflow, you
can always open a question on GitHub. You should then link to the SO question
that you posted.
-->
## Details
<!-- Description of your issue -->
<!-- You should first ask your question on SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on Stack Overflow**:
|
https://github.com/huggingface/transformers/issues/3205
|
closed
|
[
"wontfix"
] | 2020-03-10T13:35:16Z
| 2020-05-16T17:44:04Z
| null |
2hip3ng
|
huggingface/transformers
| 3,193
|
Where is the default download address for pre-trained weight
|
# ❓ Questions & Help
```
from transformers import DistilBertTokenizer, DistilBertModel
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from_pretrained('distilbert-base-uncased')
```
I can't find the downloaded file.
Thanks for your help
|
https://github.com/huggingface/transformers/issues/3193
|
closed
|
[] | 2020-03-09T17:35:47Z
| 2020-03-09T17:52:49Z
| null |
649459021
|
pytorch/vision
| 1,952
|
FastRCNNPredictor doesn't return prediction in evaluation
|
## 🐛 Bug
Dear all,
I am doing object detection in an image with one class. After training, `FastRCNNPredictor` does not return anything in validation mode. I have followed this official tutorial https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html.
Thanks.
## To Reproduce
Steps to reproduce the behavior:
I have created a custom dataset, this is one of the output:
```
tensor([[[0.0549, 0.0549, 0.0549, ..., 0.1647, 0.1569, 0.1569],
[0.0549, 0.0549, 0.0549, ..., 0.1686, 0.1569, 0.1569],
[0.0549, 0.0549, 0.0549, ..., 0.1647, 0.1569, 0.1529],
...,
[0.0471, 0.0471, 0.0471, ..., 0.1490, 0.1490, 0.1490],
[0.0471, 0.0471, 0.0471, ..., 0.1490, 0.1490, 0.1490],
[0.0471, 0.0471, 0.0471, ..., 0.1490, 0.1490, 0.1490]],
[[0.0471, 0.0471, 0.0471, ..., 0.1255, 0.1176, 0.1176],
[0.0471, 0.0471, 0.0471, ..., 0.1294, 0.1176, 0.1176],
[0.0471, 0.0471, 0.0471, ..., 0.1255, 0.1176, 0.1137],
...,
[0.0235, 0.0235, 0.0235, ..., 0.1098, 0.1098, 0.1098],
[0.0235, 0.0235, 0.0235, ..., 0.1098, 0.1098, 0.1098],
[0.0235, 0.0235, 0.0235, ..., 0.1098, 0.1098, 0.1098]],
[[0.0510, 0.0510, 0.0510, ..., 0.1176, 0.1098, 0.1098],
[0.0510, 0.0510, 0.0510, ..., 0.1216, 0.1098, 0.1098],
[0.0510, 0.0510, 0.0510, ..., 0.1176, 0.1098, 0.1059],
...,
[0.0314, 0.0314, 0.0314, ..., 0.1059, 0.1059, 0.1059],
[0.0314, 0.0314, 0.0314, ..., 0.1059, 0.1059, 0.1059],
[0.0314, 0.0314, 0.0314, ..., 0.1059, 0.1059, 0.1059]]]),
{'boxes': tensor([[315.0003, 213.5002, 626.0004, 329.5002]]),
'labels': tensor([0]),
'image_id': tensor([1]),
'area': tensor([36503.9961]),
'iscrowd': tensor([0])})
```
To prove its correctness I have also visualized the bbox on the image:

Then I create a `Dataloader`:
```python
dl = DataLoader(ds, batch_size=8, num_workers=4, collate_fn=lambda x: tuple(zip(*x)))
model = fasterrcnn_resnet50_fpn(num_classes=1).to(device)
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)
```
Training works:
```python
model.train()
for i in range(5):
for images, targets in dl:
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k,v in t.items()} for t in targets]
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
optimizer.zero_grad()
losses.backward()
optimizer.step()
print(losses)
```
Output:
```
tensor(0.6391, device='cuda:0', grad_fn=<AddBackward0>)
tensor(0.6329, device='cuda:0', grad_fn=<AddBackward0>)
tensor(0.6139, device='cuda:0', grad_fn=<AddBackward0>)
tensor(0.5965, device='cuda:0', grad_fn=<AddBackward0>)
tensor(0.5814, device='cuda:0', grad_fn=<AddBackward0>)
tensor(0.5468, device='cuda:0', grad_fn=<AddBackward0>)
tensor(0.5049, device='cuda:0', grad_fn=<AddBackward0>)
tensor(0.4502, device='cuda:0', grad_fn=<AddBackward0>)
tensor(0.3787, device='cuda:0', grad_fn=<AddBackward0>)
tensor(0.2502, device='cuda:0', grad_fn=<AddBackward0>)
tensor(0.1605, device='cuda:0', grad_fn=<AddBackward0>)
tensor(0.0940, device='cuda:0', grad_fn=<AddBackward0>)
tensor(0.0558, device='cuda:0', grad_fn=<AddBackward0>)
tensor(0.0507, device='cuda:0', grad_fn=<AddBackward0>)
tensor(0.0413, device='cuda:0', grad_fn=<AddBackward0>)
```
But, when I try to get a prediction I have no output:
```python
model = model.eval()
with torch.no_grad():
model = model.cuda()
pred = model([ds[2][0].cuda()])
```
`pred` is
```
[{'boxes': tensor([], size=(0, 4)),
'labels': tensor([], dtype=torch.int64),
'scores': tensor([])}]
```
Thank you in advance
## Expected behavior
The model should return a valid prediction.
## Environment
```
PyTorch version: 1.4.0
Is debug build: No
CUDA used to build PyTorch: 10.1
OS: Ubuntu 18.04.4 LTS
GCC version: (Ubuntu 7.4.0-1ubuntu1~18.04.1) 7.4.0
CMake version: Could not collect
Python version: 3.7
Is CUDA available: Yes
CUDA runtime version: 10.1.243
GPU models and configuration: GPU 0: GeForce GTX 1080 Ti
Nvidia driver version: 430.50
cuDNN version: Could not collect
Versions of relevant libraries:
[pip] efficientnet-pytorch==0.5.1
[pip] msgpack-numpy==0.4.3.2
[pip] numpy==1.17.4
[pip] PytorchStorage==0.0.0
[pip] torch==1.4.0
[pip] torchbearer==0.5.3
[pip] torchlego==0.0.0
[pip] torchsummary==1.5.1
[pip] torchvision==0.5.0
[conda] _pytorch_select 0.2 gpu_0
[conda] blas 1.0 mkl
[conda] efficie
|
https://github.com/pytorch/vision/issues/1952
|
closed
|
[
"question",
"module: models",
"topic: object detection"
] | 2020-03-09T09:27:19Z
| 2024-12-25T07:03:50Z
| null |
FrancescoSaverioZuppichini
|
pytorch/pytorch
| 34,437
|
How to quantize CNN in pytorch 1.3?
|
I tried to quantize CNN refer to https://pytorch.org/tutorials/advanced/dynamic_quantization_tutorial.html
but I got this error:
RuntimeError: Didn't find engine for operation quantized::linear_prepack NoQEngine
How can I solve it?
my environment:
pytorch1.3.0+cpu
windows 10
python3.7
|
https://github.com/pytorch/pytorch/issues/34437
|
closed
|
[] | 2020-03-08T03:12:25Z
| 2020-03-08T06:41:59Z
| null |
zhanyike
|
pytorch/vision
| 1,944
|
Use the pretrained model of ResNet50 on ImageNet, the val acc is 4% less than reported.
|
As the title mentioned, anyone have met the same issue?Thx!
|
https://github.com/pytorch/vision/issues/1944
|
closed
|
[
"question",
"awaiting response",
"needs discussion",
"module: models",
"topic: classification"
] | 2020-03-05T14:17:18Z
| 2020-10-21T08:25:11Z
| null |
liu-zhenhua
|
pytorch/examples
| 726
|
How can I sue freeze_support() in the train.py?
|
https://github.com/pytorch/examples/issues/726
|
closed
|
[] | 2020-03-05T03:00:07Z
| 2020-03-05T03:01:18Z
| 0
|
K-M-Ibrahim-Khalilullah
|
|
pytorch/tutorials
| 873
|
Regarding torch.utils.data.DataLoader and batch_size
|
Hi all the high-level engineers!
I am very new to pytorch and even to pythone.
Nonetheless, I am trying to understand pytorch by the documentation of the tutorial of pytorch.
Now I am going through TRAINING A CLASSIFIER using dataset, CIFAR10.
Code Link: https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html
In the code, there is the lines as follows;
for i, data in enumerate(trainloader, 0):
inputs, labels=data
I have checked the size of data[0] and input[0], and they are different and it was [4, 3, 32, 32] and [3, 32, 32] respectively.
I understand that data[0] has the size of [4, 3, 32, 32] as it is the first batch that contains 4 images.
Question
1. But why is the size of input[0] [3, 32, 32]? As I checked, input[0] is the first image of the data[0].
Why is input[0] only taking the first image of data[0]? According to the code, input[0]=data[0], shouldn't it ?
2. According to the tutorial, "data is a list of [inputs, labels]". But I don't see labels[0] value in data[0].
Why is so?
Sorry if it is too basic, but please help.
|
https://github.com/pytorch/tutorials/issues/873
|
closed
|
[] | 2020-03-03T18:48:08Z
| 2021-07-30T21:15:54Z
| 2
|
jjong2ya
|
pytorch/vision
| 1,934
|
torchvision.models.detection.fasterrcnn_resnet50_fpn has loss_rpn_box_reg exploding to nan after evaluation
|
## 🐛 Bug / Misuse?
I'm attempting to use `torchvision.models.detection.fasterrcnn_resnet50_fpn` on a custom dataset, following along with the [Detection Finetuning Tutorial](https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html) where applicable.
However, I consistently have an issue where the loss of `loss_rpn_box_reg` appears to rapidly explode, but _only_ after the first epoch has completed **(edit: the culprit now appears to be the call to the evaluation function).**
I've ruled out every annotation / dataloading issue I can think of (no boxes w/ non-positive dims or out-of-bounds coords, etc).
I've also (hopefully) ruled out issues with the RPN by following the steps to replace the `AnchorGenerator` and `RPNHead` outlined in #978
```
rpn_anchor_generator = AnchorGenerator(sizes=config.RPN_ANCHOR_SIZES,
aspect_ratios=config.RPN_ANCHOR_ASPECT_RATIOS)
rpn_head = RPNHead(in_channels=model.backbone.out_channels,
num_anchors=rpn_anchor_generator.num_anchors_per_location()[0])
model.rpn.anchor_generator = rpn_anchor_generator
model.rpn.head = rpn_head
```
And, if it's relevant, replaced the `RoIHeads` box predictor:
```
box_predictor = FastRCNNPredictor(in_channels=model.roi_heads.box_predictor.cls_score.in_features,
num_classes=len(dataset_util.ClassLabelEnum) + 1)
model.roi_heads.box_predictor = box_predictor
```
I've also been tinkering with my choice of optimizer & scheduler as well as trying to drastically lower LR or change batch size, just to see if anything seems to impact it (to no avail).
Below is a stack trace of this behavior on a small dummy subset. The behavior is similar on the full dataset, with `loss_rpn_box_reg` apparently exploding to `nan` shortly after the first epoch.
```
Epoch: [0] [0/5] eta: 0:00:03 lr: 0.001254 loss: 4.8643 (4.8643) loss_classifier: 3.7656 (3.7656) loss_box_reg: 0.0778 (0.0778) loss_objectness: 0.6919 (0.6919) loss_rpn_box_reg: 0.3290 (0.3290) time: 0.7243 data: 0.1862 max mem: 2508
Epoch: [0] [4/5] eta: 0:00:00 lr: 0.005000 loss: 2.9177 (3.2553) loss_classifier: 1.8250 (2.1365) loss_box_reg: 0.1284 (0.1319) loss_objectness: 0.6914 (0.6905) loss_rpn_box_reg: 0.3255 (0.2964) time: 0.4570 data: 0.0405 max mem: 2776
Epoch: [0] Total time: 0:00:02 (0.4618 s / it)
creating index...
index created!
Test: [0/5] eta: 0:00:01 model_time: 0.0841 (0.0841) evaluator_time: 0.0014 (0.0014) time: 0.2295 data: 0.1396 max mem: 2776
Test: [4/5] eta: 0:00:00 model_time: 0.0819 (0.0821) evaluator_time: 0.0007 (0.0008) time: 0.1168 data: 0.0296 max mem: 2776
Test: Total time: 0:00:00 (0.1209 s / it)
Averaged stats: model_time: 0.0819 (0.0821) evaluator_time: 0.0007 (0.0008)
Accumulating evaluation results...
DONE (t=0.01s).
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
Epoch: [1] [0/5] eta: 0:00:03 lr: 0.005000 loss: 17.6448 (17.6448) loss_classifier: 0.4119 (0.4119) loss_box_reg: 0.0663 (0.0663) loss_objectness: 0.6992 (0.6992) loss_rpn_box_reg: 16.4674 (16.4674) time: 0.6068 data: 0.1749 max mem: 2776
Loss is nan, stopping training
{'loss_classifier': tensor(0.4476, device='cuda:0', grad_fn=<NllLossBackward>), 'loss_box_reg': tensor(0.0805, device='cuda:0', grad_fn=<DivBackward0>), 'loss_objectness': tensor(0.6914, device='cuda:0', grad_fn=<BinaryCrossEntropyWithLogitsBackward>), 'loss_rpn_box_reg': tensor(nan, device='cuda:0', grad_fn=<DivBackward0>)}
```
Could I be horribly misusing the model API or incorrectly setting any hparams? This is my first time really working with `torch` & `torchvision` in-depth, so any and all suggestions are hugely appreciated.
## Environment
Bare-metal + conda environment, single GPU set-up.
- PyTorch / torchvision Version (e.g., 1.0 / 0.4.0): **1.4.0 / 0.5.0**
- OS (e.g., Linux): **Ubuntu 18.04**
- How you installed PyTorch / torchvision (`conda`, `pip`, source): **pip (from pypi) i
|
https://github.com/pytorch/vision/issues/1934
|
closed
|
[
"question",
"module: models",
"module: reference scripts",
"topic: object detection"
] | 2020-03-03T16:40:50Z
| 2020-03-24T15:43:09Z
| null |
dsandii
|
pytorch/vision
| 1,953
|
roi_pool is seem to be different from which in FasterRCNN
|
```python
import torchvision
import torch
a = torch.linspace(1,8*8,8*8).reshape(1, 1, 8, 8)
boxes = torch.tensor([[0,0,3,3]],dtype=a.dtype)
out = torchvision.ops.roi_pool(a, boxes, output_size=(2,2))
```
i expect that out would be [[10 12],[26 28]]
but it's [[26 26],[26 28]]
and, i try more
```python
import torchvision
import torch
a = torch.linspace(1,8*8,8*8).reshape(1, 1, 8, 8)
boxes = torch.tensor([[1,1,3,3]],dtype=a.dtype)
out = torchvision.ops.roi_pool(a, boxes, output_size=(2,2))
```
out is
[[4.373779945881600000e+15 4.373779945881600000e+15],
[4.373779945881600000e+15 4.373779945881600000e+15]]
that is so werid, i think roi_pool should be like [this](https://deepsense.ai/region-of-interest-pooling-explained/)
cc @fmassa
|
https://github.com/pytorch/vision/issues/1953
|
closed
|
[
"question",
"module: ops"
] | 2020-03-03T11:16:38Z
| 2020-03-10T12:34:38Z
| null |
SeniorCtrlPlayer
|
pytorch/vision
| 1,933
|
error
|
Sorry to bother you here,I saw your comment at maskrcnn-benchmark, and I encountered the following error, even using boxlist[[0]] is the same error, can you help me please? Thank you!

|
https://github.com/pytorch/vision/issues/1933
|
closed
|
[
"invalid",
"question"
] | 2020-03-03T09:19:16Z
| 2020-03-10T14:47:23Z
| null |
buxpeng
|
pytorch/vision
| 1,930
|
Summary of TorchScript and ONNX support
|
Hi,
Is there a summary somewhere of the current state of support for TorchScript and ONNX by the models in this repo? A complete summary would include the version of support for both CPU and GPU.
I'm mostly interested in FasterRCNN but I got confused looking around the related issues. I suppose a general summary could save time to other end users.
|
https://github.com/pytorch/vision/issues/1930
|
closed
|
[
"question",
"module: models",
"module: onnx",
"torchscript"
] | 2020-03-02T22:30:31Z
| 2020-03-10T16:12:12Z
| null |
MLaurenceFournier
|
pytorch/vision
| 1,926
|
Support for different pooling options with Faster R-CNN
|
I've been trying to setup a Faster R-CNN network to detect lesions on CT images.
Therefor I wanted to use the FasterRCNN class which is provided by torchvision. However, I've noticed that the framework is very great except for the supported pooling (roi_box_pooling). The pooling only allows a [MultiScaleRoIAlign](https://github.com/pytorch/vision/blob/master/torchvision/models/detection/faster_rcnn.py#L168). Is it possible to use the MultiScaleRoIAlign for any use-case?
I wanted to setup my network like it is described in this [project](https://github.com/chenyuntc/simple-faster-rcnn-pytorch):
That's my idea so far:
```python
class BoxHead(torch.nn.Module):
def __init__(self, vgg):
super(BoxHead, self).__init__()
self.classifier = torch.nn.Sequential(*list(vgg.classifier._modules.values())[:-1])
def forward(self, x):
x = x.flatten(start_dim=1)
x = self.classifier(x)
return x
# VGG16 backbone
vgg = vgg16(pretrained=True)
backbone = vgg.features[:-1]
for layer in backbone[:10]:
for p in layer.parameters():
p.requires_grad = False
backbone.out_channels = 512
box_head = BoxHead(vgg)
# RPN - Anchor Generator
anchor_generator = AnchorGenerator(sizes=((8, 16, 32),), aspect_ratios=((0.5, 1.0, 1.5),))
# Head - Box RoI pooling
roi_pooler = MultiScaleRoIAlign(featmap_names=['0'], output_size=7, sampling_ratio=2)
# Faster RCNN - Model
model = FasterRCNN(
backbone=backbone,
min_size=224, max_size=224,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler,
box_head=box_head,
box_predictor=FastRCNNPredictor(4096, num_classes=2)
)
```
|
https://github.com/pytorch/vision/issues/1926
|
closed
|
[
"question",
"module: models",
"topic: object detection"
] | 2020-03-01T16:31:14Z
| 2020-03-10T14:57:42Z
| null |
FHellmann
|
pytorch/vision
| 1,929
|
cannot use group norm in torchvision API
|
## 🐛 Bug
Cannot use nn.GroupNorm for "norm_layer" in torchvision.models.resnet50. However, nn.GroupNorm is supposed to be OK since there are codes to initialize the weights of nn.GroupNorm in the resnet50 file.
## To Reproduce
```
import torch.nn as nn
import torchvision
net = torchvision.models.resnet50(norm_layer=nn.BatchNorm2d)
net = torchvision.models.resnet50(norm_layer=nn.GroupNorm)
```
## Expected behavior
Both nets should be OK, however the second raised an error in torchvision/models/resnet.py line 143. nn.GroupNorm should have two arguments.
## Environment
PyTorch version: 1.4.0
Is debug build: No
CUDA used to build PyTorch: None
OS: Mac OSX 10.13.6
GCC version: Could not collect
CMake version: version 3.14.5
Python version: 3.7
Is CUDA available: No
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
Versions of relevant libraries:
[pip3] numpy==1.18.1
[pip3] torch==1.4.0
[pip3] torchvision==0.5.0
[conda] torch 1.4.0 pypi_0 pypi
[conda] torchvision 0.5.0 pypi_0 pypi
|
https://github.com/pytorch/vision/issues/1929
|
closed
|
[
"question",
"module: models",
"topic: classification"
] | 2020-03-01T11:32:15Z
| 2020-03-04T12:57:31Z
| null |
hukkai
|
pytorch/vision
| 1,925
|
module 'torchvision' has no attribute '__version__' [0.4.2]
|
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
Steps to reproduce the behavior:
1. `print("Torchvision Version: ",torchvision.__version__)`
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
AttributeError: module 'torchvision' has no attribute '__version__'
## Environment
- PyTorch / torchvision Version (e.g., 1.0 / 0.4.0): pytorch: 1.3.1, torchvision: 0.4.2
- OS (e.g., Linux): Ubuntu 19.10
- How you installed PyTorch / torchvision (`conda`, `pip`, source): conda
- Python version: 3.7
- CUDA/cuDNN version: 1.01
|
https://github.com/pytorch/vision/issues/1925
|
closed
|
[
"question",
"topic: binaries"
] | 2020-03-01T09:37:32Z
| 2020-03-04T11:59:03Z
| null |
duskybomb
|
pytorch/xla
| 1,708
|
How to properly clip gradients with data parallel training?
|
The XLA API recommends that we call `xm.optimizer_step(optimizer)`, which [allreduces the gradients and performs the optimization step](https://github.com/pytorch/xla/blob/ffde50813f01b57d6e782a63aac6453bfa12ffdf/torch_xla/core/xla_model.py#L429-L455).
Gradient clipping is typically performed on the reduced gradients, however it seems the current API doesn't give us access to the reduced gradients before taking the optimization step.
The code for `optimizer_step` is pretty simple, so I'm also wondering why we have `xm.optimizer_step` interface in the first place, compared to the more standard DistributedDataParallel interface that PyTorch uses. For example, in fairseq we have a [very simple DistributedDataParallel wrapper](https://github.com/pytorch/fairseq/blob/master/fairseq/legacy_distributed_data_parallel.py) that just calls allreduce, so it seems something like that could be a drop-in replacement here.
Is there something else special happening with `xm.optimizer_step` that I'm missing?
|
https://github.com/pytorch/xla/issues/1708
|
closed
|
[] | 2020-02-29T14:13:03Z
| 2023-08-31T12:27:07Z
| null |
myleott
|
pytorch/android-demo-app
| 62
|
How to apply quantization to models?
|
The iOS demo has to set a quantization backend before loading the model, is this operation necessary on Android? and how?
|
https://github.com/pytorch/android-demo-app/issues/62
|
open
|
[] | 2020-02-27T21:54:17Z
| 2020-05-15T08:47:13Z
| null |
himajin2045
|
pytorch/pytorch
| 33,809
|
How to release the gpu memory after use interpolate?
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
After used the interpolate ,the gpu memory can not be released during inference。I try to use torch.cuda.empty_cache() after, but it can work only in feding the images one by one。when theimages is concurrently fedding ,the GPU still increase。Can you tell me how to do?
|
https://github.com/pytorch/pytorch/issues/33809
|
closed
|
[] | 2020-02-26T10:04:47Z
| 2020-02-26T18:21:30Z
| null |
lyc6749
|
pytorch/vision
| 1,912
|
A weird problem: "No module named 'torchvision.models'; 'torchvision' is not a package"
|
https://github.com/pytorch/vision/issues/1912
|
closed
|
[
"question"
] | 2020-02-24T03:09:41Z
| 2020-02-26T02:48:55Z
| null |
TengFeiHan0
|
|
pytorch/pytorch
| 33,673
|
python int type how to convert to at::IntArrayRef
|
## ❓ Questions and Help
When I write C++/CUDA extension, I use at::IntArrayRef in my C++ source code. But I build custom layer using python, I find that I do not use my C++ extension. Because int of python does not convert to at::IntArrayRef of C++. How to solve this problem?
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/33673
|
closed
|
[] | 2020-02-23T16:56:54Z
| 2020-02-23T19:34:10Z
| null |
ghost
|
pytorch/vision
| 1,904
|
DenseNet generated image embeddings have very small variance and are sparse
|
I'm working with pretrained DenseNet161 model to learn and generate image embeddings.
I consider output of adaptive_avg_pool2d layer image embedding. I noticed that it's very sparse and has small variance. If we consider a batch of 64 images, variance of the same feature over all images in a batch is ~2e-6. Also the feature values are just very small (~1e-3). This is for pretrained model, if I start fine-tuning the model, some features quickly become 0 across all images in the batch.
Surprisingly, this is not the case for resnet. Running the same training for resnet50 results in expected features of size ~[0, 2] and variance around 1.
This is stunning difference for me. Not sure if there's some problem with implementation or this is just DenseNet works. Please let me know if you have similar experiences.
|
https://github.com/pytorch/vision/issues/1904
|
closed
|
[
"question",
"awaiting response",
"module: models",
"topic: classification"
] | 2020-02-21T22:44:45Z
| 2021-01-06T17:42:28Z
| null |
zlenyk
|
pytorch/xla
| 1,675
|
What is "Lowering" referring to?
|
## ❓ Questions and Help
Sorry for the stupid question, but what is meant by "Lowering", as it applies to LowerContext class, which appears to convert IR->XLA?
such as:
```cpp
XlaOpVector LoweringContext::LowerNode(const Node* node) {
...
}
```
|
https://github.com/pytorch/xla/issues/1675
|
closed
|
[] | 2020-02-21T22:29:36Z
| 2020-02-21T23:48:31Z
| null |
cjolivier01
|
pytorch/xla
| 1,672
|
How to join a model from distributed replicas?
|
## ❓ Questions and Help
From what I understand, a deepcopy model replica is deployed on each XLA device and then individually trained on non-overlapping data (via ParallelLoader). Each model can then be also evaluated via the same approach.
I would like to save a model for production use. But now I assume I have 8 different models (from each XLA core) trained on different data batches. Are they all synced after training and have the same weights (so I just choose random XLA model) or do I need to somehow manually merge them?
|
https://github.com/pytorch/xla/issues/1672
|
closed
|
[] | 2020-02-21T04:45:16Z
| 2020-02-21T05:56:23Z
| null |
AVancans
|
pytorch/vision
| 1,901
|
DeeplapV3 accuracy result for person
|
Can I know the accuracy of the Deeplap v3-Resnet-101 pre-trained model evaluated on COCO val2017 dataset
for **person** class only?
I searched about it but I did not find the accuracy for each class?
|
https://github.com/pytorch/vision/issues/1901
|
closed
|
[
"question",
"module: models",
"topic: semantic segmentation"
] | 2020-02-20T12:56:41Z
| 2020-02-25T15:50:39Z
| null |
muna-cs
|
pytorch/vision
| 1,900
|
Why the inplace in the ReLU in deeplabv3.py is not set True?
|
Hi guys,
I am reproducing DeepLabV3+ these days, and I learning about the code of [deeplabv3.py](https://github.com/pytorch/vision/blob/2f64dd90e14fe5463b4e5bd152d56e4a6f0419de/torchvision/models/segmentation/deeplabv3.py).
And I found that some ReLUs in this code don't use "inplace = True", like,
```python
def __init__(self, in_channels, atrous_rates):
super(ASPP, self).__init__()
out_channels = 256
modules = []
modules.append(nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU()))
rate1, rate2, rate3 = tuple(atrous_rates)
modules.append(ASPPConv(in_channels, out_channels, rate1))
modules.append(ASPPConv(in_channels, out_channels, rate2))
modules.append(ASPPConv(in_channels, out_channels, rate3))
modules.append(ASPPPooling(in_channels, out_channels))
self.convs = nn.ModuleList(modules)
self.project = nn.Sequential(
nn.Conv2d(5 * out_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Dropout(0.5))
```
So what is the consideration of not using "inplace = True" here?
Any answer or idea will be appreciated!
|
https://github.com/pytorch/vision/issues/1900
|
closed
|
[
"question",
"module: models",
"topic: semantic segmentation"
] | 2020-02-20T06:20:33Z
| 2020-02-25T15:52:10Z
| null |
songyuc
|
huggingface/blog
| 5
|
Where is the CoNLL-2003 formatted Esperanto dataset ref. in the tutorial?
|
> Using a dataset of annotated Esperanto POS tags formatted in the CoNLL-2003 format
Where is this dataset?
Thanks!
|
https://github.com/huggingface/blog/issues/5
|
open
|
[] | 2020-02-20T04:26:54Z
| 2020-03-04T16:30:32Z
| null |
ohmeow
|
pytorch/vision
| 1,896
|
How can I get the intermediate layers if I used the nn.Sequential to make a Module
|
Hi guys,
I am reproducing the DeepLabV3+ these days,
and I write a Module like this,
```python
self.entry_flow = nn.Sequential()
# entry_flow的第一个卷积层
self.entry_flow.add_module("conv1", nn.Conv2d(3, 32, 3, 2, 0, bias=False))
self.entry_flow.add_module("bn_relu1", BNReLU(32))
self.entry_flow.add_module("conv2", nn.Conv2d(32, 64, 3, bias=False))
self.entry_flow.add_module("bn_relu2", BNReLU(64))
# 添加三个Block模块
self.entry_flow.add_module("block1", XceptionBlock(64, 64, [1, 1, 2]))
self.entry_flow.add_module("block2", XceptionBlock(128, 128, [1, 1, 2]))
self.entry_flow.add_module("block2", XceptionBlock(256, 256, [1, 1, 2]))
```
and I am wondering if I can get the the intermediate output of inner module "block1" and "block2"?
Any answer or suggestion will be appreciated!
|
https://github.com/pytorch/vision/issues/1896
|
closed
|
[
"question",
"module: models",
"topic: feature extraction"
] | 2020-02-18T04:14:26Z
| 2020-02-25T15:55:06Z
| null |
songyuc
|
pytorch/tutorials
| 853
|
happy to contribute my intuitive visual guide to how convolutions and transposed convenient work
|
Unlike fully connected linear layers, convolutions layers need a bit of work to calculate the size of the data as it passes through them.
There aren't many easy to understand guides on how convolution works. Many report that transposed convolution is particularly difficult to understand.
As part of my upcoming book on GANs with PyTorch I include an appendix with worked examples of convolutions and transposed convolutions, which I've also published a version of online for free access.
[https://makeyourownneuralnetwork.blogspot.com/2020/02/calculating-output-size-of-convolutions.html](https://makeyourownneuralnetwork.blogspot.com/2020/02/calculating-output-size-of-convolutions.html)
I'd be happy if you thought these should be included in the Pytorch tutorials, or linked to from there.
Also happy to receive feedback on improving them.
The main point of the guide is to develop an intuitive understanding, avoiding too much mathematical jargon.
An example of the friendly style of diagrams used ...
|
https://github.com/pytorch/tutorials/issues/853
|
open
|
[] | 2020-02-17T17:46:06Z
| 2020-02-20T13:56:34Z
| null |
makeyourownneuralnetwork
|
pytorch/vision
| 1,895
|
It seems the IntermediateLayerGetter will not use the forward function in the original model
|
Hi guys,
I am working on reproducing DeepLabV3+ model these days,
and I need to get some intermediate layers from the backbone.
And I found a class of `IntermediateLayerGetter` with similar effect.
When I read the code, I found that in the `forward` function of `IntermediateLayerGetter`, that the `IntermediateLayerGetter` would do the inference like,
```python
for name, module in self.named_children():
x = module(x)
# rest of the code
```
But this may mean that, the `IntermediateLayerGetter` class would not use the `forward` function in the original wrapped model, which seems unsuual.
I don't think this would let the original model behave in a right way.
Any explanation or idea would be appreciated!
|
https://github.com/pytorch/vision/issues/1895
|
closed
|
[
"question",
"module: models",
"topic: feature extraction"
] | 2020-02-17T12:02:27Z
| 2020-02-25T15:22:30Z
| null |
songyuc
|
pytorch/vision
| 1,894
|
Can I use the IntermediateLayerGetter function for my customized backbone network?
|
Hi, guys,
I am reimplementing DeepLabV3+ model these days,
and I need to return some of the intermediate layers from my customized backbone network,
and I found the `IntermediateLayerGetter` function with the similar effect.
So I am wondering if I can use the `IntermediateLayerGetter` function to get the intermediate layers from my customized backbone?
Any idea or answer will be appreciated!
|
https://github.com/pytorch/vision/issues/1894
|
closed
|
[
"question",
"module: models",
"topic: feature extraction"
] | 2020-02-17T11:33:10Z
| 2020-02-27T19:40:34Z
| null |
songyuc
|
pytorch/vision
| 1,892
|
How to look at bbox predictions after training?
|
Hi, I finetuned a pretrained Faster RCNN model.
I used the instance segmentation Mask RCNN pytorch tutorial as a guide.
I finished training and can't figure out how to look at bbox predictions.
For segmentation prediction, the guide used the following to display the mask
Image.fromarray(prediction[0]['masks'][0, 0].mul(255).byte().cpu().numpy())
I tried
Image.fromarray(prediction[0]['boxes'].mul(255).byte().cpu().numpy())
But this doesn't work.
link to tutorial I followed : https://colab.research.google.com/github/pytorch/vision/blob/temp-tutorial/tutorials/torchvision_finetuning_instance_segmentation.ipynb#scrollTo=5v5S3bm07SO1
I used the following to train on a custom dataset.
- def get_faster_rcnn_model(num_classes):
- model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
- num_classes = 2 # 1 class (person) + background
- in_features = model.roi_heads.box_predictor.cls_score.in_features
- model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
-
- return model
|
https://github.com/pytorch/vision/issues/1892
|
closed
|
[
"question",
"module: models",
"topic: object detection"
] | 2020-02-17T04:36:23Z
| 2020-02-25T15:45:56Z
| null |
alareza619
|
pytorch/vision
| 1,891
|
Pre-trained segmentation models can't load state dicts
|
<img width="1024" alt="Screen Shot 2020-02-16 at 7 51 57 PM" src="https://user-images.githubusercontent.com/37163544/74622526-07b99080-50f6-11ea-8483-bc891aeb5f3a.png">
|
https://github.com/pytorch/vision/issues/1891
|
closed
|
[
"question",
"module: models",
"topic: semantic segmentation"
] | 2020-02-17T03:53:49Z
| 2020-02-27T19:34:26Z
| null |
devanshuDesai
|
pytorch/vision
| 1,888
|
convert_to_coco_api so slow
|
i found that it costs about 20min for the convert_to_coco_api to process 670 images when i evaluate my model per epoch. But WHY so slow?
|
https://github.com/pytorch/vision/issues/1888
|
closed
|
[
"question",
"module: reference scripts",
"topic: object detection"
] | 2020-02-15T05:14:15Z
| 2020-02-27T19:43:04Z
| null |
cl2227619761
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.