
repo
stringclasses 147
values | number
int64 1
172k
| title
stringlengths 2
476
| body
stringlengths 0
5k
| url
stringlengths 39
70
| state
stringclasses 2
values | labels
listlengths 0
9
| created_at
timestamp[ns, tz=UTC]date 2017-01-18 18:50:08
2026-01-06 07:33:18
| updated_at
timestamp[ns, tz=UTC]date 2017-01-18 19:20:07
2026-01-06 08:03:39
| comments
int64 0
58
⌀ | user
stringlengths 2
28
|
|---|---|---|---|---|---|---|---|---|---|---|
huggingface/sentence-transformers
| 497
|
What is the meaning of warmup_steps when I fine-tune the model, can I remove it?
|
```python
evaluator = evaluation.EmbeddingSimilarityEvaluator(sentences1, sentences2, scores)
# Define your train dataset, the dataloader and the train loss
train_dataset = SentencesDataset(train_data, model)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=32)
train_loss = losses.CosineSimilarityLoss(model)
# Tune the model
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=1, warmup_steps=100, evaluator=evaluator, evaluation_steps=100, output_path='./Ko2CnModel')
```
|
https://github.com/huggingface/sentence-transformers/issues/497
|
closed
|
[] | 2020-10-14T10:03:43Z
| 2020-10-14T10:31:27Z
| null |
wmathor
|
pytorch/vision
| 2,804
|
loss后面括号是什么Epoch: [0] [ 440/3560] eta: 0:22:22 lr: 0.00997769948251307 loss: 0.5050 (0.8583)
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
请问有谁知道loss后面括号里的是什么吗,也是loss吗,那是什么loss
|
https://github.com/pytorch/vision/issues/2804
|
closed
|
[
"question"
] | 2020-10-14T06:19:14Z
| 2020-10-14T08:19:45Z
| null |
ghost
|
huggingface/sentence-transformers
| 494
|
what is the license for this repository?
|
https://github.com/huggingface/sentence-transformers/issues/494
|
closed
|
[] | 2020-10-12T09:31:41Z
| 2020-10-12T09:32:15Z
| null |
pinkeshbadjatiya
|
|
huggingface/transformers
| 7,727
|
what is the perplexity of distilbert-base-uncased ?
|
# ❓ Questions & Help
## Details
In the [readme](https://github.com/huggingface/transformers/tree/master/examples/distillation) , it is said that distilbert-base-uncased is pretraind on the same data used to pretrain Bert, so I wonder what is the final perplexity or cross entropy of the pretrain?
|
https://github.com/huggingface/transformers/issues/7727
|
closed
|
[
"wontfix"
] | 2020-10-12T09:11:49Z
| 2020-12-20T13:34:47Z
| null |
OleNet
|
pytorch/vision
| 2,788
|
Error with torchvision.io.read_image with models
|
## 🐛 Bug

## To Reproduce
Steps to reproduce the behaviour:
Here is simple code to reproduce the error.
Notice that I'm not passing any transforms to image. Since `torchvision.io.read_image` will read normalized images only.
```
# from PIL import Image, ImageDraw
import torch
from torchvision.models.detection import fasterrcnn_resnet50_fpn
# from typing import Dict
from torchvision.io.image import read_image
img_path = "../test/assets/grace_hopper_517x606.jpg"
if __name__ == "__main__":
# img = torch.rand(3, 226, 226) # This Works
img = read_image(img_path) # This does not.
## img = Image.open(img_path) ## This works
## img = T.ToTensor()(img) ## With this
img = torch.unsqueeze(img, 0)
print(img.shape)
model = fasterrcnn_resnet50_fpn()
model = model.eval()
out = model(img)
print(out)
```
## Expected behavior
We should get output. This works if tensor is simply `torch.randn(1, 3, 226, 226)` and it should be same with `read_image`.
## Environment
- PyTorch / torchvision Version (e.g., 1.0 / 0.4.0): 1.6 torchvision: master
- OS (e.g., Linux): Windows
- How you installed PyTorch / torchvision (`conda`, `pip`, source): source
- Build command you used (if compiling from source): `pip install .`
- Python version: 3.6
- CUDA/cuDNN version: None
- GPU models and configuration: None
## Additional context
Maybe I have misinterpreted what `read_image` does.
cc @vfdev-5
|
https://github.com/pytorch/vision/issues/2788
|
closed
|
[
"question",
"module: transforms"
] | 2020-10-11T09:51:20Z
| 2023-12-16T16:40:18Z
| null |
oke-aditya
|
pytorch/pytorch
| 46,137
|
How to build on Arch Linux
|
# How to build on Arch Linux
Build from source doco:
https://github.com/pytorch/pytorch#from-source
## Cheat sheet:
Create new environment:
```
conda update -n base conda
conda create --name pytorch-build
activate pytorch-build
```
Install dependencies listed here:
https://github.com/pytorch/pytorch#install-dependencies
```
git submodule sync --recursive
git submodule update --init --recursive
make -j4
```
Build doco:
cd docs
pip install -r requirements.txt
# If necessary: pip install --ignore-installed certifi
make html
### Only if necessary
I was getting errors importing packages that I had explicitly installed:
conda update --all
The above submodule update will likely fix the below issues that needed to be "solved" otherwise:
If `glog` is required:
sudo pacman -S --asdeps google-glog
Have make find pthread:
CMAKE_THREAD_LIBS_INIT="-pthread" make
|
https://github.com/pytorch/pytorch/issues/46137
|
closed
|
[] | 2020-10-10T07:33:32Z
| 2020-10-12T04:37:49Z
| null |
HaleTom
|
pytorch/pytorch
| 46,081
|
where is the Source Code of torch.mode operator?
|
Hi, Developers,
I use PyTorch 1.5 (build from source code) and want to check the source code of the implementation of **torch.mode**.
However, I cannot find the **THFloatTensor_mode(values_, indices_, self_, dim, keepdim)**, where is it?
Really want to get your reply.
|
https://github.com/pytorch/pytorch/issues/46081
|
closed
|
[] | 2020-10-09T06:43:35Z
| 2020-10-10T08:42:08Z
| null |
ddummkopfer
|
pytorch/serve
| 712
|
how to register model present in local file system
|
I have `my-model`, present in `/path/to/models`; the path is local file system path.
**command to start `torchserve`**: `docker run -p 8080:8080 -p 8081:8081 --name my-serve pytorch/torchserve:0.2.0-cpu`
Then when I try to register `my-model` -> `curl -X POST "http://localhost:8081/models?url=/path/to/models/my-model.mar"`, I get:
{
"code": 404,
"type": "ModelNotFoundException",
"message": "Model not found in model store: /path/to/models/my-model.mar"
}
The _register api call_ link is broken on the [docs](https://pytorch.org/serve/server.html#arguments) and I couldn't find anywhere for local file system.
|
https://github.com/pytorch/serve/issues/712
|
closed
|
[
"triaged_wait"
] | 2020-10-06T10:29:33Z
| 2020-10-06T14:01:18Z
| null |
paniabhisek
|
pytorch/pytorch
| 45,856
|
What option(USE_NNAPI "Use NNAPI") is used for?
|
Hello all,
there is an `option(USE_NNAPI "Use NNAPI" OFF)` within [CMakeLists.txt#L179](https://github.com/pytorch/pytorch/blob/cf48872d28f945d47793f63e19c54dd15bf580f7/CMakeLists.txt#L179)
I'd like to know if this option is on, what is in this case enabled?
I do have a device with NN-API driver - is this help to use this device NN-API backend?
Thank you.
|
https://github.com/pytorch/pytorch/issues/45856
|
closed
|
[] | 2020-10-05T18:08:27Z
| 2020-10-05T21:19:31Z
| null |
peter197321
|
pytorch/elastic
| 130
|
How to programmatically determine if a training job has finished using `kubectl`?
|
## ❓ Questions and Help
How to programmatically determine if a training job has finished using `kubectl`?
The field `status.replicaStatuses.Worker.succeeded` seems to indicate the number of succeeded pods.
How does one determine if the whole job has succeeded?
This is useful when the training job is part of a workflow (e.g. orchestrated by argo or airflow).
### Please note that this issue tracker is not a help form and this issue will be closed.
Before submitting, please ensure you have gone through our documentation. Here
are some links that may be helpful:
* [What is torchelastic?](../../README.md)
* [Quickstart on AWS](../../aws/README.md)
* [Usage](../../USAGE.md)
* [Examples](../../examples/README.md)
* API documentation
* [Overview](../../USAGE.md)
* [Rendezvous documentation](../../torchelastic/rendezvous/README.md)
* [Checkpointing documentation](../../torchelastic/checkpoint/README.md)
* [Configuring](../../USAGE.md#configuring)
### Question
<!-- your question here -->
|
https://github.com/pytorch/elastic/issues/130
|
closed
|
[] | 2020-10-03T06:12:30Z
| 2020-10-28T08:18:54Z
| null |
darthsuogles
|
pytorch/pytorch
| 45,797
|
How to set a correct random seed?
|
Hi, I am using pytorch==1.3/1.1 with 4/2 GPUs to training network.
I use the following code to set random seed at the beginning of program:
`
def seed_torch(seed=1029):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
seed_torch()
`
The only random function I called during training/testing time is torch.randint.
However, I found that though I have set the random seed, the testing result is still different every time.
If I replace torch.randint with torch.zeros, I can get same accuracy even without setting the random seed.
I do not know why?
Can any one help me about this?
|
https://github.com/pytorch/pytorch/issues/45797
|
closed
|
[] | 2020-10-03T02:49:13Z
| 2020-10-05T20:47:56Z
| null |
densechen
|
pytorch/serve
| 711
|
[Question] How to debug custom handlers?
|
Hi! I am very excited about torch serve, so thanks to all contributors to this awesome tool!
I have already run my custom model with custom postprocessing and here is a question that I am struggling to find an answer on. Any help would be very appreciated!
Question:
How to debug my custom handlers? In other words, how can I see what is happening with the data on each step (i.e initialize, preprocess, inference, postprocess, and my custom one) in my IDE while sending requests to running torchserve server? I was able to fix simple issues using the `ts_log.log` file and it was helpful. BUT it becomes not very comfortable for me once I want to do something more complicated.
Thanks for any help!
|
https://github.com/pytorch/serve/issues/711
|
open
|
[
"triaged_wait"
] | 2020-10-02T18:38:28Z
| 2023-04-14T00:06:23Z
| null |
veronikayurchuk
|
pytorch/vision
| 2,740
|
ValueError: All bounding boxes should have positive height and width. Found invaid box [500.728515625, 533.3333129882812, 231.10546875, 255.2083282470703] for target at index 0.
|
i am training detecto for custom object detection. anyone who can help me as soon as possible. i will be very grateful to you.
here is the code.
from detecto import core, utils, visualize
dataset = core.Dataset('content/sample_data/newdataset/car/images/')
model = core.Model(['car'])
model.fit(dataset)
here is the output:
ValueError Traceback (most recent call last)
<ipython-input-8-02dc210525d1> in <module>()
4 model = core.Model(['car'])
5
----> 6 model.fit(dataset)
2 frames
/usr/local/lib/python3.6/dist-packages/torchvision/models/detection/generalized_rcnn.py in forward(self, images, targets)
91 raise ValueError("All bounding boxes should have positive height and width."
92 " Found invalid box {} for target at index {}."
---> 93 .format(degen_bb, target_idx))
94
95 features = self.backbone(images.tensors)
ValueError: All bounding boxes should have positive height and width. Found invaid box [500.728515625, 533.3333129882812, 231.10546875, 255.2083282470703] for target at index 0.
|
https://github.com/pytorch/vision/issues/2740
|
closed
|
[
"question",
"topic: object detection"
] | 2020-10-02T06:11:29Z
| 2024-05-13T09:19:30Z
| null |
kashf99
|
pytorch/serve
| 706
|
How to serve model trained over mmdetection framework?
|
I have trained my model using the MMdetection framework. After training the model, I have a checkpoint file in the .pth format and config file which helps in making inference/prediction. To draw an inference or making prediction steps take the following lines to generate predictions-
from mmdet.apis import init_detector, inference_detector, show_result,show_result_pyplot
import mmcv
config_file = 'path to configuration file path'
checkpoint_file = checkpoint path
img= 'image_path'
model = init_detector(config_file, checkpoint_file, device='cuda:0')
result = inference_detector(model, img)
Can you help me making it possible to serve mmdetection model through torch serve?
|
https://github.com/pytorch/serve/issues/706
|
closed
|
[
"bug",
"triaged_wait"
] | 2020-09-30T10:36:39Z
| 2022-07-30T13:40:08Z
| null |
Atul997
|
pytorch/tutorials
| 1,171
|
Efficiency of dcgan tutorial
|
When I run the [dcgan_faces_tutorial.py](https://github.com/pytorch/tutorials/blob/master/beginner_source/dcgan_faces_tutorial.py) script, I have noticed that two python processes are created on the CPU according to the top command.
```
27062 mahmood 20 0 9404132 1.5g 90116 D 31.9 1.6 5:55.09 python3
27004 mahmood 20 0 12.0g 3.3g 929032 S 7.3 3.5 1:56.48 python3
```
Also, the GPU utilization according to nvidia-smi is pretty low
```
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.67 Driver Version: 418.67 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce RTX 208... Off | 00000000:41:00.0 On | N/A |
| 45% 54C P2 94W / 260W | 1956MiB / 10984MiB | 9% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1196 G /usr/lib/xorg/Xorg 16MiB |
| 0 1226 G /usr/bin/gnome-shell 49MiB |
| 0 14727 G /usr/lib/xorg/Xorg 62MiB |
| 0 14898 G /usr/bin/gnome-shell 94MiB |
| 0 27004 C python3 1625MiB |
+-----------------------------------------------------------------------------+
```
Is that normal? I don't think so.
cc @datumbox @nairbv @fmassa @NicolasHug @YosuaMichael
|
https://github.com/pytorch/tutorials/issues/1171
|
closed
|
[
"question",
"module: vision",
"docathon-h1-2023",
"medium"
] | 2020-09-29T12:21:24Z
| 2023-06-01T07:18:28Z
| null |
mahmoodn
|
pytorch/examples
| 830
|
imagenet how to download the classicication dataset?
|
https://github.com/pytorch/examples/issues/830
|
closed
|
[] | 2020-09-29T07:05:24Z
| 2022-03-09T21:31:26Z
| null |
henbucuoshanghai
|
|
pytorch/text
| 1,013
|
How to pass new pre-trained embeddings while sharing the same vocabulary across torchtext.Field?
|
## ❓ Questions and Help
**Description**
I was trying to concatenate two embedding layers in my CNN from two different pre-trained embeddings, before applying my convolutions.
Here's the basic workflow:
# Load pre-trained embeddings (dim=100)
from torchtext.vocab import Vectors
vectors_amazon = Vectors(name='gensim_embeddings_amazon.txt', cache='{}/{}'.format(PROJECT_FOLDER, OUTPUT_FOLDER))
vectors_imdb = Vectors(name='gensim_embeddings_imdb.txt', cache='{}/{}'.format(PROJECT_FOLDER, OUTPUT_FOLDER))
Then I create my `text_field` and `label_field` as follow:
# Custom_tokenizer is my tokenizer, MAX_SIZE=20000
text_field = Field(sequential=True, use_vocab=True, tokenize=custom_tokenizer)
label_field = LabelField()
text_field.build_vocab(train_data,
max_size=MAX_SIZE,
vectors=vectors_amazon)
label_field.build_vocab(train_data)
and after creating my train/valid/test iterator with `BucketIterator`, I create my CNN `model` for sentiment analysis.
So far so good, the problem is that I'd like to create another embedding considering also the `vectors_imdb` and I'm stuck here, since for the embedding layer I'd do the following:
pretrained_embeddings = text_field.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
but I have no idea how I can pass to a `model.second_embedding.weight.data` the values in `vectors_imdb` while keeping the correct alignment between embeddings and sharing the same vocab (coming from my training data)
I tried something like
second_text_field = text_field
second_text_field.vocab.set_vectors(text_field.vocab.stoi, vectors_imdb, 100)
but of course it doesn't work since changing vectors in `second_text_field` also modify `text_field` ones.
How can I modify vectors while keeping the correct mapping word:vector representation?
I'm afraid the only way is to loop through `vectors_imdb` keeping only words that are in my vocab, sorting them so that the two embeddings match and pass the result to the second_embedding layer, right?
|
https://github.com/pytorch/text/issues/1013
|
open
|
[
"legacy"
] | 2020-09-28T17:27:14Z
| 2020-10-05T13:38:07Z
| null |
jacopo-repossi
|
pytorch/vision
| 2,717
|
What's the pretrained_settings for r2plus1d_18?
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
Hi,
I want to know the pretrained_settings for r2plus1d_18, which has not been implemented, including input_space,input_size,input_range,mean,std. In pytorch.pretrainedmodels, they implement resnet152, vgg19_bn, inceptionv4 with those pretrained_settings, which are necessary for TransformImage to transform the image. If include pretrained_settings, it will be more user-friendly for r3d_18,mc3_18,r2plus1d_18 models to extract vidoe frame features.Many thanks!

cc @bjuncek
|
https://github.com/pytorch/vision/issues/2717
|
closed
|
[
"question",
"module: models",
"module: video"
] | 2020-09-28T12:00:52Z
| 2020-09-29T12:20:12Z
| null |
XinyuLyu
|
pytorch/vision
| 2,711
|
Test the model with an image
|
Hello
I compressed Mask R-CNN and finished the training, but the checkpoint (.pth) is different from the regular one, what can I do if I want to load the checkpoint to Mask R-CNN to test its speed with a new image? Thank you!
|
https://github.com/pytorch/vision/issues/2711
|
closed
|
[
"question",
"module: models",
"topic: object detection"
] | 2020-09-27T16:26:52Z
| 2020-09-28T10:00:04Z
| null |
jiaerfei
|
pytorch/pytorch
| 45,387
|
How to build from a release tar package ?
|
Hi, I download newest release tar package and find it can not build pytorch, Can anyone help meo build this release version from source?
```
wget https://github.com/pytorch/pytorch/archive/v1.6.0.tar.gz
tar xf v1.6.0.tar.gz
cd pytorch-1.6.0
python3 setup.py install
```
output:
fatal: not a git repository (or any parent up to mount point /)
Stopping at filesystem boundary (GIT_DISCOVERY_ACROSS_FILESYSTEM not set).
Building wheel torch-1.6.0a0
-- Building version 1.6.0a0
Could not find /home/xzpeng/pytorch/pytorch-1.6.0/third_party/gloo/CMakeLists.txt
Did you run 'git submodule update --init --recursive'?
Does the release tar package support building from source?
cc @ezyang @seemethere @malfet @walterddr
|
https://github.com/pytorch/pytorch/issues/45387
|
closed
|
[
"module: binaries",
"triaged"
] | 2020-09-27T03:09:03Z
| 2020-09-29T19:11:21Z
| null |
haoren3696
|
pytorch/pytorch
| 45,386
|
How to convert pytorch model to Nvidia faster transformer?
|
Hi, i want to detect Bert model structure in pytorch model and convert the structure by Nvidia faster transformer op automatically.
Is there any existing project? If not, i want to develop one, so should i develop on origin pytorch or TorchScript? Should i develop a pass to detect Bert in TorchScript IR and replace it by faster transformer op?
Thankyou very much!
|
https://github.com/pytorch/pytorch/issues/45386
|
closed
|
[] | 2020-09-27T02:08:14Z
| 2020-09-28T15:56:34Z
| null |
wangxiang2713
|
pytorch/examples
| 826
|
language model bug?
|
https://github.com/pytorch/examples/blob/master/word_language_model/data.py#L46
on the last iteration of the loop ids holds onto the tensor before catting idss but no other iteration of ids is.
I get significantly better results after adding:
ids = []
Before catting idss into ids.
|
https://github.com/pytorch/examples/issues/826
|
closed
|
[] | 2020-09-25T18:14:49Z
| 2020-09-25T18:44:08Z
| 0
|
wesboyt
|
pytorch/tutorials
| 1,166
|
Char RNN classification with batch size
|
I'm replicating [this example](https://github.com/pytorch/tutorials/blob/master/intermediate_source/char_rnn_classification_tutorial.py) for a **classification** with a **char-rnn**.
```python
for iter in range(1, n_iters + 1):
category, line, category_tensor, line_tensor = randomTrainingExample()
output, loss = train(category_tensor, line_tensor)
current_loss += loss
```
I see that every epoch only 1 example is taken and random. I would like that each epoch **all the dataset** is taken with a specific **batch size** of examples. I can adjust the code to do this myself but I was wondering if some flags already exist.
Thank you
|
https://github.com/pytorch/tutorials/issues/1166
|
closed
|
[
"question",
"Text"
] | 2020-09-25T17:57:29Z
| 2024-12-11T17:57:11Z
| null |
paulthemagno
|
pytorch/pytorch
| 45,331
|
How to print C++ log like GRAPH_DEBUG?
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/45331
|
closed
|
[] | 2020-09-25T06:37:24Z
| 2020-09-25T14:36:45Z
| null |
liym27
|
pytorch/pytorch
| 45,328
|
How long would it takes for pytorch cuda version to support RTX30 series?
|
## 🚀 Feature
As the title. When would pytorch cuda version support RTX30 series?
|
https://github.com/pytorch/pytorch/issues/45328
|
closed
|
[] | 2020-09-25T05:55:51Z
| 2020-10-04T10:58:05Z
| null |
GregXu247
|
pytorch/pytorch
| 45,266
|
how to register hook on +, - ,*, / or how to get the input of them?
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
how to register hook on +, - ,*, / or how to get the input of them ?
|
https://github.com/pytorch/pytorch/issues/45266
|
closed
|
[] | 2020-09-24T09:20:57Z
| 2020-09-25T15:08:27Z
| null |
Stick-To
|
pytorch/tutorials
| 1,163
|
How do I go back to the old view of the site
|
Hi, I like the old version of the Pytorch website on the tutorial that I can view everything at once. But now they changed that I can only view like 7 to 5 of it on one page. How do I go back to the old one?
|
https://github.com/pytorch/tutorials/issues/1163
|
open
|
[] | 2020-09-21T09:32:53Z
| 2020-09-21T09:32:53Z
| null |
AliceSum
|
pytorch/pytorch
| 45,059
|
How to view C++ error report stack of pytorch?
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/45059
|
closed
|
[
"triaged"
] | 2020-09-21T09:09:54Z
| 2020-09-22T16:28:17Z
| null |
liym27
|
pytorch/xla
| 2,502
|
How to prevent cyclic computation graph in torch xla multiprocessing?
|
## ❓ Questions and Help
Hi,
I am trying to build a dynamics simulator software on the TPU. On the high level, it basically needs to do this (I have pre-trained the model separately elsewhere):
```
for i in range(num_of_step):
forces = model(positions)
new_positions = update_functions(forces, positions)
positions = new_positions
```
When I do this workflow on a single TPU, it is quite fast. While I am aware that there is generally an issue with slow `tensor.item()` call, the following sequence will work quite fast for me:
```
for i in range(num_of_step):
positions = torch.Tensor(structure.positions).to(xla_device, non_blocking=True)
forces = model(positions)
cpu_forces = forces.to(cpu_device).numpy()
structure.positions = update_function(cpu_forces, structure.positions)
```
However, when I do xla multiprocessing on the TPU, somehow the `.to(cpu_device)` call will be extremely slow. The code snippet looks like this:
```
def _map_fn(xla_index):
xla_device = xm.xla_device()
for i in range(num_of_step):
positions = torch.Tensor(structure.positions).to(xla_device, non_blocking=True)
model_indices = indexing_function(positions, xla_index)
forces = model(positions, model_indices).detach()
forces = xm.all_reduce(xm.REDUCE_SUM, forces).detach().clone()
cpu_forces = forces.to(cpu_device).numpy()
structure.positions = update_function(cpu_forces, structure.positions)
xm.rendezvous('sync_step')
xmp.spawn(_map_fn, nprocs=8, start_method='fork')
```
If I were to modify the software to eliminate `.to(cpu_device)` call, I can get this to run fast:
```
def _map_fn(xla_index):
xla_device = xm.xla_device()
structure.positions = torch.Tensor(structure.positions).to(xla_device, non_blocking=True)
for i in range(num_of_step):
positions = structure.positions.detach().clone()
model_indices = indexing_function(positions, xla_index)
forces = model(positions, model_indices).detach()
forces = xm.all_reduce(xm.REDUCE_SUM, forces).detach().clone()
structure.positions = update_function(forces, structure.positions).detach().clone()
xm.rendezvous('sync_step')
xmp.spawn(_map_fn, nprocs=8, start_method='fork')
```
However, the compiler seems to have decided to unfold this code snippet into one giant computation graph to execute at once. So I get a weird behavior... on a standard `structure` size, I can run 16 steps but the code won't run at all if I try to run 17 steps (no error thrown either). If I were to increase the input `structure` size by 2x, the compiler will only allow the code snippet to run & finish 8 steps (but won't start at all if I try to run 9 steps instead). So my suspicion is that this code snippet runs when the compiler can place the entire chain in a single graph in the TPU, despite my best effort to separate the computation graph from the `structure.positions` variable.
Do you have any suggestion on what I should look for? Is `.detach().clone()` the right method to separate the computation graph in pytorch XLA?
|
https://github.com/pytorch/xla/issues/2502
|
closed
|
[
"stale"
] | 2020-09-20T00:10:10Z
| 2020-11-02T01:19:35Z
| null |
jpmailoa
|
pytorch/tutorials
| 1,162
|
Problem of QAT Demo?
|
When i try PyTorch QAT Demo [GitHub File](https://github.com/pytorch/tutorials/blob/master/advanced_source/static_quantization_tutorial.py) [Webpage](https://pytorch.org/tutorials/advanced/static_quantization_tutorial.html#quantization-aware-training), i want to know how to find the scale and zero_point of the activations?
|
https://github.com/pytorch/tutorials/issues/1162
|
closed
|
[] | 2020-09-19T13:53:34Z
| 2020-09-20T13:05:45Z
| 0
|
wZuck
|
pytorch/pytorch
| 44,924
|
How to get the information like the output of Model.get_config() in keras?
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
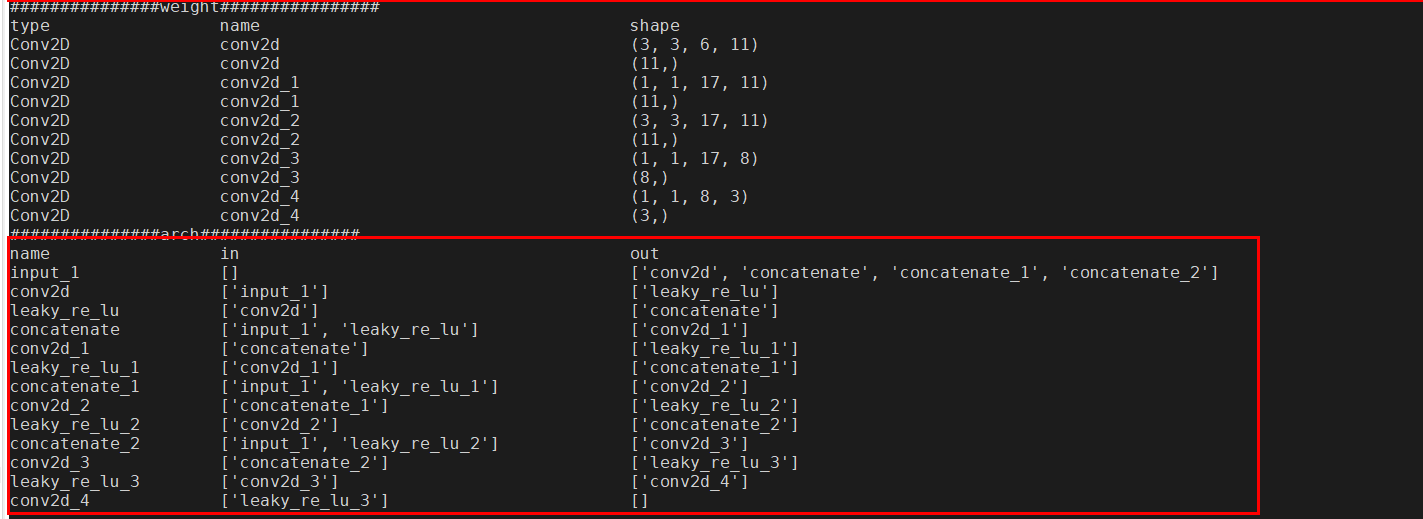
I want to get some information like this.
The input layer of one layer and the output layer of one layer.
|
https://github.com/pytorch/pytorch/issues/44924
|
closed
|
[] | 2020-09-18T00:54:18Z
| 2020-09-21T16:01:05Z
| null |
Stick-To
|
pytorch/java-demo
| 15
|
any instructions on how to use the downloaded libtorch in Maven project?
|
I am not familiar with Maven and I want to get some help on how to use the same libtorch in a Maven project, could anyone give me some hint?
|
https://github.com/pytorch/java-demo/issues/15
|
closed
|
[] | 2020-09-17T07:02:53Z
| 2021-07-19T19:11:47Z
| null |
xiaonanchong
|
pytorch/examples
| 822
|
Gradient vanishing of G in the DCGAN example
|
Hello,
I have trained the DCGAN with the default hyper-parameter settings on the downloaded "img_align_celeba" dataset (recommended in the tutorial). However, the results reveal strong gradient vanishing of G. While Loss_D keeps decreasing towards 0, Loss_G grows high (towards 100).
It seems that D is trained so well, preventing a good training on G. I didn't do any modifications on the code. Do you know what happened?
Thanks!
|
https://github.com/pytorch/examples/issues/822
|
open
|
[
"help wanted"
] | 2020-09-11T14:02:58Z
| 2022-03-09T21:32:12Z
| 0
|
zhan4817
|
pytorch/serve
| 681
|
how to deploy sentence transformer model which has bert-base-nli-mean-tokens weights using torchserve
|
i tried so many times to deploy my model using torchserve , it did not work
sometimes it is coming like this
2020-09-11 10:41:02,757 [INFO ] W-9004-encoder_model_1.0-stdout org.pytorch.serve.wlm.WorkerLifeCycle - File "/tmp/models/a7e46f396a6348deba9e844a002f7b36/handler.py", line 61, in handle
2020-09-11 10:41:02,757 [INFO ] W-9004-encoder_model_1.0-stdout org.pytorch.serve.wlm.WorkerLifeCycle - _service.initialize(context)
2020-09-11 10:41:02,757 [INFO ] W-9004-encoder_model_1.0-stdout org.pytorch.serve.wlm.WorkerLifeCycle - File "/tmp/models/a7e46f396a6348deba9e844a002f7b36/handler.py", line 23, in initialize
2020-09-11 10:41:02,757 [INFO ] W-9004-encoder_model_1.0-stdout org.pytorch.serve.wlm.WorkerLifeCycle - self.model = AutoModelForSequenceClassification.from_pretrained(model_dir)
2020-09-11 10:41:02,757 [WARN ] W-9004-encoder_model_1.0 org.pytorch.serve.wlm.BatchAggregator - Load model failed: encoder_model, error: Worker died.
2020-09-11 10:41:02,757 [INFO ] W-9004-encoder_model_1.0-stdout org.pytorch.serve.wlm.WorkerLifeCycle - File "/home/ubuntu/anaconda3/envs/torch/lib/python3.8/site-packages/transformers/modeling_auto.py", line 1359, in from_pretrained
2020-09-11 10:41:02,758 [INFO ] W-9004-encoder_model_1.0-stdout org.pytorch.serve.wlm.WorkerLifeCycle - config = AutoConfig.from_pretrained(pretrained_model_name_or_path, **kwargs)
2020-09-11 10:41:02,757 [DEBUG] W-9004-encoder_model_1.0 org.pytorch.serve.wlm.WorkerThread - W-9004-encoder_model_1.0 State change WORKER_STARTED -> WORKER_STOPPED
2020-09-11 10:41:02,758 [INFO ] W-9004-encoder_model_1.0-stdout org.pytorch.serve.wlm.WorkerLifeCycle - File "/home/ubuntu/anaconda3/envs/torch/lib/python3.8/site-packages/transformers/configuration_auto.py", line 214, in from_pretrained
2020-09-11 10:41:02,758 [INFO ] W-9004-encoder_model_1.0-stdout org.pytorch.serve.wlm.WorkerLifeCycle - raise ValueError(
2020-09-11 10:41:02,758 [INFO ] W-9004-encoder_model_1.0-stdout org.pytorch.serve.wlm.WorkerLifeCycle - ValueError: Unrecognized model in /tmp/models/a7e46f396a6348deba9e844a002f7b36. Should have a `model_type` key in its config.json, or contain one of the following strings in its name: retribert, t5, mobilebert, distilbert, albert, camembert, xlm-roberta, marian, mbart, bart, reformer, longformer, roberta, flaubert, bert, openai-gpt, gpt2, transfo-xl, xlnet, xlm, ctrl, electra, encoder-decoder
does torchserve needs a config.json , give me a suggestion on json file format
|
https://github.com/pytorch/serve/issues/681
|
closed
|
[
"triaged_wait"
] | 2020-09-11T05:16:34Z
| 2021-11-06T07:00:17Z
| null |
mgeethabhargava
|
pytorch/pytorch
| 44,460
|
How to package pytorch with the file build from source.
|
## ❓ Questions and Help
I've noticed in https://github.com/pytorch/pytorch/issues/31285 that pytorch only compile binaries for NV cards with CC 3.7 and up. Now i've build pytorch from source on my machine. Is there any way to package it into a new pip image please? Thanks a lot.
cc @malfet @seemethere @walterddr
|
https://github.com/pytorch/pytorch/issues/44460
|
closed
|
[
"module: build",
"triaged"
] | 2020-09-10T08:18:15Z
| 2022-10-20T22:55:01Z
| null |
Abbyyan
|
pytorch/pytorch
| 44,448
|
How to print optimized IR?
|
I read Pytorch 1.6 code: torch/csrc/jit/runtime/graph_executor.cpp, and see:
```
Inline(*opt_graph);
GRAPH_DEBUG("After Inline, before LowerGradOf\n", *opt_graph);
LowerGradOf(*opt_graph);
GRAPH_DEBUG(
"After LowerGradOf, before specializeAutogradZero\n", *opt_graph);
```
I want to print optimized IR, so i run: `export PYTORCH_JIT_LOG_LEVEL=">graph_executor"`, my pytorch code is:
```
import torch
def f(x, y):
a = x + y
b = x - y
c = a * b
d = c ** 3
e = d.sum()
return e
script_f = torch.jit.script(f)
x, h = torch.rand(3, 4), torch.rand(3, 4)
print(script_f(x, h))
```
However, i got nothing. If i use pytorch 1.4, i can get:
```
[DUMP graph_executor.cpp:550] Optimizing the following function:
[DUMP graph_executor.cpp:550] def source_dump(x: Tensor,
[DUMP graph_executor.cpp:550] y: Tensor) -> Tensor:
[DUMP graph_executor.cpp:550] a = torch.add(x, y, alpha=1)
[DUMP graph_executor.cpp:550] b = torch.sub(x, y, alpha=1)
[DUMP graph_executor.cpp:550] c = torch.mul(a, b)
[DUMP graph_executor.cpp:550] d = torch.pow(c, 3)
[DUMP graph_executor.cpp:550] return torch.sum(d, dtype=None)
```
but can't get GRAPH_DEBUG info.
I don't know the reason, i can get a lot of logs if i set `export PYTORCH_JIT_LOG_LEVEL=dead_code_elimination:guard_elimination` when i use pytorch 1.6, but got nothing with `export PYTORCH_JIT_LOG_LEVEL=">graph_executor"`
cc @gmagogsfm
|
https://github.com/pytorch/pytorch/issues/44448
|
closed
|
[
"oncall: jit"
] | 2020-09-10T03:02:33Z
| 2020-09-16T03:16:38Z
| null |
wangxiang2713
|
pytorch/pytorch
| 44,377
|
How to get optimized IR?
|
## How to get optimized IR?
Hi, i can get torch_script IR by print(script.grah), and i know the IR will be optimized several times while running.
So how can i get all of optimized IR while running torchscript code? Thankyou.
|
https://github.com/pytorch/pytorch/issues/44377
|
closed
|
[] | 2020-09-09T11:55:03Z
| 2020-09-09T14:41:25Z
| null |
wangxiang2713
|
pytorch/pytorch
| 44,353
|
DDP training with syncBatchNorm,how to catch and handle the exception in training processes?
|
When training with the DDP and syncBatchNorm, one process runing on one GPU, When I catch the gpu OOM exception, the training is blocked. What should we do?
My code is following, when OOM exception occurs in one process, I just ignore this batch, the training phase continue.
```
for i, (inputs, targets) in enumerate(train_loader):
try:
# do forward and backprop
except RuntimeError as e:
if 'out of memory' in str(e):
print('| WARNING: ran out of memory, skipping this batch.')
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
optimizer.zero_grad()
else:
raise e
```
when one process catch the exception, the others get blocked.
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @xush6528 @osalpekar @jiayisuse @agolynski
|
https://github.com/pytorch/pytorch/issues/44353
|
closed
|
[
"oncall: distributed",
"triaged"
] | 2020-09-09T01:53:41Z
| 2020-09-10T02:44:35Z
| null |
eeewhe
|
pytorch/vision
| 2,652
|
Image to Tensor data
|
Library: **pytorch_java_only-1.6.0**
I want to convert BufferedImage/File to Tensor data, is there some method or library for this?
Python solution:
```
image = Image.open(image_path)
image = image.convert('RGB')
transform = Compose([ToTensor()])
image = transform(image)
image = image.view(1, 3, 64, 64).cuda()
output = my_model(image)
output = output.view(-1, self.quantity)
output = nn.functional.softmax(output, dim=1)
output = torch.argmax(output, dim=1)
output = output.view(-1, self.size)[0]
```
I need something like that for pytorch_java. I'm sorry if my question is stupid i'm newbee
P.S: Thanks for reply
|
https://github.com/pytorch/vision/issues/2652
|
closed
|
[
"question"
] | 2020-09-07T21:19:22Z
| 2020-09-09T13:14:49Z
| null |
beeqwe
|
pytorch/pytorch
| 44,279
|
How to use CUDA Dynamic Parallelism in PyTorch CPP extension?
|
I found discussions at discuss.pytorch.org . But there is still no solution now.
Here is the error message:
```
error: kernel launch from __device__ or __global__ functions requires separate compilation mode
```
and
```
error: a __device__ function call cannot be configured
```
Thanks.
cc @ngimel
|
https://github.com/pytorch/pytorch/issues/44279
|
open
|
[
"module: cuda",
"triaged"
] | 2020-09-07T10:55:28Z
| 2021-09-18T11:30:15Z
| null |
qinjian623
|
pytorch/examples
| 821
|
Recommended RAM for training ResNeXt-101?
|
I am training a ResNeXt-101 model in an end-to-end manner on a version of ImageNet with 13k classes (using the method presented of the ImageNet Shuffle paper). This version contains around 12 M images. My machine has a single NVIDIA GeForce RTX 2080, intel i5 9400 and 16 GB of RAM. I am deploying 4 workers for this task. It seems that I don't get the best GPU utilization, since GPU-Util percentage ranges from 0% to 94%. Furthermore, each worker uses around 2GB of swap memory, which definitely degrades training speed/data fetch. This makes me wonder if my RAM is enough for this task. If I upgrade my RAM to 32 GB, am I expected to get a significant performance boost?
Thanks!!
|
https://github.com/pytorch/examples/issues/821
|
closed
|
[] | 2020-09-07T08:40:05Z
| 2022-03-09T21:36:05Z
| 1
|
AlexMetsai
|
pytorch/vision
| 2,647
|
rgb2hsv bug in functional_tensor.py.
|
https://github.com/pytorch/vision/blob/bb88c4520b835e79d5d3c4423eb7ff7c26fa2043/torchvision/transforms/functional_tensor.py#L429-L442
As stated in the comments, when `r=g=b`, the calculation of `h` is expected to be value `6`. However, in the current implementation, only `hr` will be counted in, because `hg` and `hr` are just ignored with the condition `(maxc != r)`. I think this is not expected and could lead to non-zero value of `h` when `r=g=b`.
cc @vfdev-5
|
https://github.com/pytorch/vision/issues/2647
|
closed
|
[
"question",
"module: transforms"
] | 2020-09-07T03:34:24Z
| 2020-09-09T10:08:37Z
| null |
yelantf
|
pytorch/pytorch
| 44,265
|
How to run a simple benchmark test on a custom RNN?
|
Say I have a custom LSTM cell... how can I use this repository to run a simple benchmark test on that?
|
https://github.com/pytorch/pytorch/issues/44265
|
closed
|
[
"triaged"
] | 2020-09-06T20:11:40Z
| 2020-09-09T16:37:19Z
| null |
slerman12
|
pytorch/benchmark
| 73
|
Add docs on how to profile benchmark models
|
https://github.com/pytorch/benchmark/issues/73
|
closed
|
[] | 2020-09-02T21:10:29Z
| 2023-07-26T18:51:23Z
| null |
wconstab
|
|
pytorch/TensorRT
| 181
|
❓ [Question] Is the module compiled by TRTorch thread safe?
|
Hi
If the native torchscript module is thread safe when its `forward` function is called from multithread, would the module compiled by TRTorch be thread safe?
|
https://github.com/pytorch/TensorRT/issues/181
|
closed
|
[
"feature request",
"question"
] | 2020-09-02T10:34:46Z
| 2021-11-11T01:23:36Z
| null |
uni19
|
pytorch/pytorch
| 43,946
|
How to use torch.nn.SyncBatchNorm and torch.uitls.checkpoint together
|
When I use net = torch.nn.SyncBatchNorm.convert_sync_batchnorm(net) to convert model,and use torch.uitls.checkpoint in model ,loss backward, It seems to be stuck in process communication
|
https://github.com/pytorch/pytorch/issues/43946
|
closed
|
[] | 2020-09-01T09:29:37Z
| 2020-09-01T09:47:25Z
| null |
devilztt
|
huggingface/transformers
| 6,790
|
What is the size of the context window in the 'openai-gpt' pre-trained model?
|
What is the size of the context window in the 'openai-gpt' pre-trained model?
# ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to the Hugging Face forum: https://discuss.huggingface.co/ .
You can also try Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. In this case, make sure to tag your
question with the right deep learning framework as well as the
huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
-->
## Details
<!-- Description of your issue -->
<!-- You should first ask your question on the forum or SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on the forum/Stack Overflow**:
|
https://github.com/huggingface/transformers/issues/6790
|
closed
|
[
"wontfix"
] | 2020-08-28T09:17:02Z
| 2020-11-07T05:42:47Z
| null |
lzl19971215
|
pytorch/serve
| 654
|
How to change Temp Directory?
|
## 📚 Documentation
<!-- A clear and concise description of what content in https://pytorch.org/serve/ is an issue. If this has to do with the general https://pytorch.org website, please file an issue at https://github.com/pytorch/pytorch.github.io/issues/new/choose instead. If this has to do with https://pytorch.org/tutorials, please file an issue at https://github.com/pytorch/tutorials/issues/new -->
My computer has little space to mount '/tmp'. And I can't find any helps.
Are there any way to change Temp Directory?
|
https://github.com/pytorch/serve/issues/654
|
closed
|
[
"triaged_wait"
] | 2020-08-27T09:06:21Z
| 2020-08-27T09:34:02Z
| null |
CSLujunyu
|
pytorch/vision
| 2,624
|
RuntimeError: each element in list of batch should be of equal size
|
## 🐛 Bug
```python
"python3.7/site-packages/torch/utils/data/_utils/collate.py", line 82, in default_collate
raise RuntimeError('each element in list of batch should be of equal size')
RuntimeError: each element in list of batch should be of equal size
```
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
Steps to reproduce the behavior:
```python
model = models.resnet50()
transform = transforms.Compose([
transforms.Resize((480, 640)),
transforms.ToTensor(),
])
train_dataset = datasets.CocoDetection(
root=args.train_dataset, annFile=args.train_annotation, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64)
for (img, anno) in train_loader:
out = model(img)
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
forward
<!-- A clear and concise description of what you expected to happen. -->
## Environment
Please copy and paste the output from our
[environment collection script](https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py)
(or fill out the checklist below manually).
You can get the script and run it with:
```
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
```
- PyTorch Version (e.g., 1.0): 1.6
- OS (e.g., Linux): Ubuntu
- How you installed PyTorch (`conda`, `pip`, source): conda -c pytorch
- Build command you used (if compiling from source):
- Python version: 3.7
- CUDA/cuDNN version: 10.2
- GPU models and configuration: V100
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
https://github.com/pytorch/pytorch/issues/42654
cc @pmeier
|
https://github.com/pytorch/vision/issues/2624
|
closed
|
[
"question",
"module: datasets"
] | 2020-08-27T05:53:50Z
| 2021-03-31T06:56:03Z
| null |
ZhiyuanChen
|
pytorch/pytorch
| 43,625
|
How to see the weight value of the quantified model?
|
How to see the weight value of the quantified model?
Error:
```
torch.nn.modules.module.ModuleAttributeError: 'LinearPackedParams' object has no attribute '_parameters'
```
Code:
```
import torch
import numpy as np
import matplotlib.pyplot as plt
MODLE_LOCATION = "./models/mfi_0.97400.pth"
MODLE_LOCATION_QUAN = "./models/quantized_1_model.pth"
TENSOR_NAME = "fc1.weight"
def plot_distribution(model_name, tensor_set, resolution):
model = torch.load(model_name)
print(model)
params = model.state_dict()
tensor_value = params[TENSOR_NAME]
tensor_value_np = tensor_value.numpy()
tensor_value_np = tensor_value_np.flatten()
bins = np.arange(-1, 1, resolution)
plt.hist(tensor_value_np,bins)
plt.title("histogram")
plt.show()
if __name__ == '__main__':
plot_distribution(MODLE_LOCATION, TENSOR_NAME, 0.01)
plot_distribution(MODLE_LOCATION_QUAN, TENSOR_NAME, 0.01)
```
Output:
```
(bnntorch) D:\FewShotMFI\Python\MFI_pytorch>python plt_distribution.py
LeNet5_Improved(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(bn1): BatchNorm2d(6, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(max_pool_1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(max_pool_2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=400, out_features=180, bias=True)
(dropout1): Dropout(p=0.2, inplace=False)
(fc2): Linear(in_features=180, out_features=100, bias=True)
(dropout2): Dropout(p=0.2, inplace=False)
(fc3): Linear(in_features=100, out_features=20, bias=True)
)
LeNet5_Improved(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(bn1): BatchNorm2d(6, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(max_pool_1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(max_pool_2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): DynamicQuantizedLinear(in_features=400, out_features=180, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(dropout1): Dropout(p=0.2, inplace=False)
(fc2): DynamicQuantizedLinear(in_features=180, out_features=100, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(dropout2): Dropout(p=0.2, inplace=False)
(fc3): DynamicQuantizedLinear(in_features=100, out_features=20, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
Traceback (most recent call last):
File "plt_distribution.py", line 26, in <module>
plot_distribution(MODLE_LOCATION_QUAN, TENSOR_NAME, 0.01)
File "plt_distribution.py", line 14, in plot_distribution
params = model.state_dict()
File "C:\Users\huangyongtao\AppData\Local\conda\conda\envs\bnntorch\lib\site-packages\torch\nn\modules\module.py", line 900, in state_dict
module.state_dict(destination, prefix + name + '.', keep_vars=keep_vars)
File "C:\Users\huangyongtao\AppData\Local\conda\conda\envs\bnntorch\lib\site-packages\torch\nn\modules\module.py", line 900, in state_dict
module.state_dict(destination, prefix + name + '.', keep_vars=keep_vars)
File "C:\Users\huangyongtao\AppData\Local\conda\conda\envs\bnntorch\lib\site-packages\torch\nn\modules\module.py", line 897, in state_dict
self._save_to_state_dict(destination, prefix, keep_vars)
File "C:\Users\huangyongtao\AppData\Local\conda\conda\envs\bnntorch\lib\site-packages\torch\nn\quantized\modules\linear.py", line 62, in _save_to_state_dict
super(LinearPackedParams, self)._save_to_state_dict(destination, prefix, keep_vars)
File "C:\Users\huangyongtao\AppData\Local\conda\conda\envs\bnntorch\lib\site-packages\torch\nn\modules\module.py", line 856, in _save_to_state_dict
for name, param in self._parameters.items():
File "C:\Users\huangyongtao\AppData\Local\conda\conda\envs\bnntorch\lib\site-packages\torch\nn\modules\module.py", line 772, in __getattr__
type(self).__name__, name))
torch.nn.modules.module.ModuleAttributeError: 'LinearPackedParams' object has no attribute '_parameters'
```
cc @jerryzh168 @jianyuh @dzhulgakov @raghuramank100 @jamesr66a @vkuzo
|
https://github.com/pytorch/pytorch/issues/43625
|
closed
|
[
"oncall: quantization",
"triaged"
] | 2020-08-26T15:31:53Z
| 2020-08-26T16:23:03Z
| null |
YongtaoHuang1994
|
pytorch/pytorch
| 43,536
|
How do I debug "RuntimeError: trying to initialize the default process group twice!"
|
## 🐛 Bug
When triggering distributed training in pytorch, the error `RuntimeError: trying to initialize the default process group twice!` occurs. How would one debug it?
## To Reproduce
Steps to reproduce the behavior:
1. on master node ip 10.163.60.19, run `local_rank=0; master_port=1303; python -m torch.distributed.launch --node_rank=$local_rank --master_addr="10.163.60.19" --master_port=$master_port regression_train.py --config_file weights/cnn3_pad_32_pad_ratio_5.ini --distributed 1 --local_rank $local_rank --master_addr 10.163.60.19 --master_port $master_port --world_size 2`
2. on slave node ip 10.163.60.18, run `local_rank=1; master_port=1303; python -m torch.distributed.launch --node_rank=$local_rank --master_addr="10.163.60.19" --master_port=$master_port regression_train.py --config_file weights/cnn3_pad_32_pad_ratio_5.ini --distributed 1 --local_rank $local_rank --master_addr 10.163.60.19 --master_port $master_port --world_size 2`
```
Traceback (most recent call last):
File "regression_train.py", line 180, in <module>
torch.distributed.init_process_group(backend=args.distributed_backend, world_size=args.world_size)
File "/home/kdang/anaconda3/envs/edge-detection/lib/python3.7/site-packages/torch/distributed/distributed_c10d.py", line 370, in init_process_group
raise RuntimeError("trying to initialize the default process group "
RuntimeError: trying to initialize the default process group twice!
Traceback (most recent call last):
File "/home/kdang/anaconda3/envs/edge-detection/lib/python3.7/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/kdang/anaconda3/envs/edge-detection/lib/python3.7/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/kdang/anaconda3/envs/edge-detection/lib/python3.7/site-packages/torch/distributed/launch.py", line 263, in <module>
main()
File "/home/kdang/anaconda3/envs/edge-detection/lib/python3.7/site-packages/torch/distributed/launch.py", line 259, in main
cmd=cmd)
subprocess.CalledProcessError: Command '['/home/kdang/anaconda3/envs/edge-detection/bin/python', '-u', 'regression_train.py', '--local_rank=0', '--config_file', 'weights/cnn3_pad_32_pad_ratio_5.ini', '--distributed', '1', '--local_rank', '0', '--master_addr', '10.163.60.19', '--master_port', '1303', '--world_size', '2']' returned non-zero exit status 1.
```
## Expected behavior
Distributed training should start
## Environment
```
(edge-detection) ➜ EDGE-DETECTION-TRAINER git:(master) python -m torch.utils.collect_env
Collecting environment information...
PyTorch version: 1.4.0
Is debug build: No
CUDA used to build PyTorch: 10.1
OS: Ubuntu 16.04.6 LTS
GCC version: (Ubuntu 5.4.0-6ubuntu1~16.04.12) 5.4.0 20160609
CMake version: version 3.5.1
Python version: 3.7
Is CUDA available: Yes
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: GeForce RTX 2080
Nvidia driver version: 418.152.00
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.4
/usr/local/cuda-10.1/targets/x86_64-linux/lib/libcudnn.so.7.6.4
Versions of relevant libraries:
[pip] numpy==1.18.1
[pip] torch==1.4.0
[pip] torchvision==0.5.0
[conda] mkl 2020.0 166 conda-forge
[conda] pytorch 1.4.0 py3.7_cuda10.1.243_cudnn7.6.3_0 pytorch
[conda] torchvision 0.5.0 py37_cu101 pytorch
(edge-detection) ➜ EDGE-DETECTION-TRAINER git:(master)
```
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @xush6528 @osalpekar @jiayisuse @agolynski
|
https://github.com/pytorch/pytorch/issues/43536
|
open
|
[
"oncall: distributed",
"triaged"
] | 2020-08-25T02:55:51Z
| 2023-12-04T14:46:49Z
| null |
wakandan
|
pytorch/pytorch
| 43,489
|
How to extract the hidden feature of a multi-submodule model
|
How to extract the feature in advantage (with dim=512), given a PyTorch model like below.
DuelingCnnDQN(
(cnn): Sequential(
(0): Conv2d(1, 32, kernel_size=(8, 8), stride=(4, 4))
(1): ReLU()
(2): Conv2d(32, 64, kernel_size=(4, 4), stride=(2, 2))
(3): ReLU()
(4): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
(5): ReLU()
(6): Flatten()
)
(advantage): Sequential(
(0): Linear(in_features=3136, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=6, bias=True)
)
(value): Sequential(
(0): Linear(in_features=3136, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=1, bias=True)
)
)
|
https://github.com/pytorch/pytorch/issues/43489
|
closed
|
[] | 2020-08-24T11:50:57Z
| 2020-08-24T20:51:30Z
| null |
xinghua-qu
|
pytorch/pytorch
| 43,463
|
from sources install pytorch on ubuntu18.04,the question is this.What should I do ?
|
-- Generating done
-- Build files have been written to: /home/wuji/pytorch/build
Traceback (most recent call last):
File "setup.py", line 737, in <module>
build_deps()
File "setup.py", line 321, in build_deps
cmake=cmake)
File "/home/wuji/pytorch/tools/build_pytorch_libs.py", line 59, in build_caffe2
rerun_cmake)
File "/home/wuji/pytorch/tools/setup_helpers/cmake.py", line 329, in generate
self.run(args, env=my_env)
File "/home/wuji/pytorch/tools/setup_helpers/cmake.py", line 141, in run
check_call(command, cwd=self.build_dir, env=env)
File "/home/wuji/anaconda3/lib/python3.7/subprocess.py", line 363, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['cmake', '-GNinja', '-DBUILD_PYTHON=True', '-DBUILD_TEST=True', '-DCMAKE_BUILD_TYPE=Release', '-DCMAKE_INSTALL_PREFIX=/home/wuji/pytorch/torch', '-DCMAKE_PREFIX_PATH=/home/wuji/anaconda3', '-DNUMPY_INCLUDE_DIR=/home/wuji/anaconda3/lib/python3.7/site-packages/numpy/core/include', '-DPYTHON_EXECUTABLE=/home/wuji/anaconda3/bin/python', '-DPYTHON_INCLUDE_DIR=/home/wuji/anaconda3/include/python3.7m', '-DPYTHON_LIBRARY=/home/wuji/anaconda3/lib/libpython3.7m.so.1.0', '-DTORCH_BUILD_VERSION=1.7.0a0+7c50c2f', '-DUSE_NUMPY=True', '/home/wuji/pytorch']' returned non-zero exit status 1.
cc @malfet
|
https://github.com/pytorch/pytorch/issues/43463
|
closed
|
[
"module: build",
"triaged"
] | 2020-08-23T02:05:48Z
| 2020-08-25T22:26:18Z
| null |
functail
|
pytorch/vision
| 2,599
|
Change default value of eps in FrozenBatchNorm to match BatchNorm
|
## ❓ Questions and Help
Hello
Loss is nan error occurs when I learn fast rcnn with resnext101 backbone
My code is as follows
```python
backbone = resnet_fpn_backbone('resnext101_32x8d', pretrained=True)
model = FasterRCNN(backbone, num_classes)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
```
error message
```
Epoch: [0] [ 0/7208] eta: 1:27:42 lr: 0.000040 loss: 40613806080.0000 (40613806080.0000) loss_box_reg: 7979147264.0000 (7979147264.0000) loss_classifier: 11993160704.0000 (11993160704.0000) loss_objectness: 9486380032.0000 (9486380032.0000) loss_rpn_box_reg: 11155118080.0000 (11155118080.0000) time: 0.7301 data: 0.4106 max mem: 1241
Loss is nan, stopping training
```
When i change the backbone to resnet50 and resnet152, no error occrus.
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/vision/issues/2599
|
closed
|
[
"question",
"topic: object detection"
] | 2020-08-21T04:56:22Z
| 2020-12-10T10:05:26Z
| null |
juyunsang
|
pytorch/pytorch_sphinx_theme
| 78
|
How to use it? Canonical way seems to not work
|
Dear All,
I have installed the theme using
```
pip install git+https://github.com/pytorch/pytorch_sphinx_theme.git
```
imported and included in my `conf.py` file as follows:
```python
extensions = [
"sphinx.ext.autodoc",
"sphinx.ext.githubpages",
'sphinx.ext.coverage',
"sphinx.ext.napoleon",
"pytorch_sphinx_theme", # <- HERE!
"recommonmark"
]
```
However, the theme is still `sphinx_rtd_theme`.
Thank you in advance.
Best Regards,
Francesco
|
https://github.com/pytorch/pytorch_sphinx_theme/issues/78
|
closed
|
[] | 2020-08-18T12:50:08Z
| 2020-08-18T12:50:50Z
| null |
FrancescoSaverioZuppichini
|
huggingface/tokenizers
| 374
|
where is the pre-build tokenizers for 'merge.txt and vacab.json'
|
or how to build my private version
|
https://github.com/huggingface/tokenizers/issues/374
|
closed
|
[] | 2020-08-17T08:45:13Z
| 2021-01-06T20:02:22Z
| null |
SeekPoint
|
pytorch/pytorch
| 43,135
|
How to use torch.utils.checkpoint and DistributedDataParallel together
|
when I use DistributedDataParallel in mutil-GPU , If I use checkpoint in the model forward ,it can not work
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @xush6528 @osalpekar @jiayisuse @agolynski
|
https://github.com/pytorch/pytorch/issues/43135
|
closed
|
[
"oncall: distributed",
"triaged"
] | 2020-08-17T06:54:13Z
| 2023-01-20T14:40:29Z
| null |
devilztt
|
pytorch/xla
| 2,433
|
How to speed up the compilation process for contributor for c++ lib
|
## ❓ Questions and Help
When I only modify 1 c++ file, I expect the compile process only need rebuild this c++ file and do related link process. In PyTorch, it uses ninja to speed up this process.
But when use "DEBUG=1 python setup.py develop", it will recompile whole TensorFlow and xla code by Bazel, it take a long time.
Any best practice your guy can share?
We should write down this part on the contributing.md.
Thanks
|
https://github.com/pytorch/xla/issues/2433
|
closed
|
[] | 2020-08-17T02:22:04Z
| 2020-08-19T00:20:11Z
| null |
maxwillzq
|
pytorch/text
| 938
|
How to use Torchtext model in flask app with vocabulary and vectors?
|
## ❓ Questions and Help
I have the the following code for my model:
```
TEXT = data.Field(tokenize="spacy", include_lengths=True)
LABEL = data.LabelField(dtype=torch.float)
from torchtext import datasets
train_data, valid_data = train_data.split(random_state=random.seed(SEED))
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
TEXT.build_vocab(train_data, vectors="glove.6B.100d", unk_init=torch.Tensor.normal_)
LABEL.build_vocab(train_data)
BATCH_SIZE = 64
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
sort_within_batch=True,
device=device,
)
class RNN(nn.Module):
def __init__(
self,
vocab_size,
embedding_dim,
hidden_dim,
output_dim,
n_layers,
bidirectional,
dropout,
pad_idx,
):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
self.rnn = nn.LSTM(
embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
dropout=dropout,
)
self.fc = nn.Linear(hidden_dim * 2, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text, text_lengths):
# text = [sent len, batch size]
embedded = self.dropout(self.embedding(text))
# embedded = [sent len, batch size, emb dim]
# pack sequence
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths)
packed_output, (hidden, cell) = self.rnn(packed_embedded)
# unpack sequence
output, output_lengths = nn.utils.rnn.pad_packed_sequence(packed_output)
# output = [sent len, batch size, hid dim * num directions]
# output over padding tokens are zero tensors
# hidden = [num layers * num directions, batch size, hid dim]
# cell = [num layers * num directions, batch size, hid dim]
# concat the final forward (hidden[-2,:,:]) and backward (hidden[-1,:,:]) hidden layers
# and apply dropout
hidden = self.dropout(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1))
# hidden = [batch size, hid dim * num directions]
return self.fc(hidden)
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 256
OUTPUT_DIM = 1
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.5
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = RNN(
INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX,
)
pretrained_embeddings = TEXT.vocab.vectors
print(pretrained_embeddings.shape)
model.embedding.weight.data.copy_(pretrained_embeddings)
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
optimizer = optim.Adam(model.parameters())
criterion = nn.BCEWithLogitsLoss()
model = model.to(device)
criterion = criterion.to(device)
*training and evaluation functions and such*
nlp = spacy.load("en")
def predict_sentiment(model, sentence):
model.eval()
tokenized = [tok.text for tok in nlp.tokenizer(sentence)]
indexed = [TEXT.vocab.stoi[t] for t in tokenized]
length = [len(indexed)]
tensor = torch.LongTensor(indexed).to(device)
tensor = tensor.unsqueeze(1)
length_tensor = torch.LongTensor(length)
prediction = torch.sigmoid(model(tensor, length_tensor))
return prediction.item()
```
saved and loaded in the same as this:
```
torch.save(model.state_dict(), "Finished Models/Pytorch/LSTM_w_vectors.pt")
model.load_state_dict(torch.load("Finished Models/Pytorch/LSTM_w_vectors.pt"))
```
How can I use import / deploy this model? Do I need to pickle the vocab and PAD_IDX?
|
https://github.com/pytorch/text/issues/938
|
closed
|
[] | 2020-08-16T19:54:22Z
| 2020-08-24T14:16:22Z
| null |
EmreTokyuez
|
pytorch/audio
| 879
|
How to index subsegments of audio tensor based on time
|
## How to select a subsegment from a tensor
Hello!
This may be a very noobie question but I can't get to solve it on my own.
Lets say I want to select the first 10 seconds of an audio sample that I have loaded into a torch tensor with torchaudio, how should I determine the indexes of the tensor that correspond to the 10sec sample?
I have done some playing with audio files with different sample rate and if I were to save a subset of the tensor to audio `.wav` the same index `[:, :600000]` (600000 elements of all channels) doesn't return.
So if I select the subset `[:, :600000]` of a waveform tensor with shape `torch.Size([1, 21091521])` and sample rate `16000` I will get the first ~38 seconds.
While If I select the subset `[:, :600000]` of a waveform tensor with shape `torch.Size([2, 5385600])
` and sample rate `44100` I will get the first ~14seconds.
I suspect this is basic audio theory and how is stored in different channels and how sample rate affects but I haven't been able to find information about it.
Based on the channels and sample rate of a tensor, can I select a subset of seconds of this one? If so, how can I?
Thanks
|
https://github.com/pytorch/audio/issues/879
|
closed
|
[] | 2020-08-14T11:40:28Z
| 2020-08-14T19:12:34Z
| null |
jiwidi
|
pytorch/pytorch
| 42,996
|
How to use and debug mixed-precision in 1.6.0 ?
|
## ❓ Questions and Help
Hi. I've been trying to take advantage of new mixed-precision set of tools, mainly following the instructions given in https://pytorch.org/docs/stable/amp.html#autocasting. My code is running, I see that the gradients are being scaled as expected, however, my memory footprint is de facto the same (inspected by nvidia-smi), and the overall execution time is even longer. I was wondering how I can debug this and what could possibly go wrong.
The changes to my code are minimal: (1) I added autocast context to the body of my forward method; and (2) gradient scaling updates as suggested in the tutorial. The operations in my code are standard, lots of CNN and torch.mm executions. My program is being executed on 8 GPUs, for data parallelism.
## Environment
- PyTorch Version: 1.6.0
- OS: Linux
- How you installed PyTorch: pip
- Python version: 3.7
- CUDA/cuDNN version: 10.1
- GPU models and configuration: 8 x Tesla V100
cc @mcarilli @jlin27
|
https://github.com/pytorch/pytorch/issues/42996
|
closed
|
[
"module: docs",
"triaged",
"module: amp (automated mixed precision)"
] | 2020-08-13T10:00:53Z
| 2020-08-31T13:02:07Z
| null |
djordjemila
|
pytorch/TensorRT
| 171
|
🐛 [Bug] Encountered bug when using TRTorch 0.3.0 and torch_1.6.0_update versions on Jetson Xavier AGX
|
## ❓ Question
Are there some missing instructions on how to build the TRTorch 'torch_1.6.0_update' for Jetson Xavier AGX?<!-- Your question -->
## What you have already tried
- Downloaded two TRTorch versions: 0.3.0. tag and torch_1.6.0_update
- Follow the Compilations TRTorch instructions of both versions
- Both versions compilation have errors:
- 0.3.0:
core/lowering/lowering.cpp:10:10: fatal error: torch/csrc/jit/passes/quantization.h: No such file or directory
#include "torch/csrc/jit/passes/quantization.h"
- torch_1.6.0_update:
ERROR:
/home/ubuntu/.cache/bazel/_bazel_root/7f0ba44765888be019f9da1ca19341ed/external/tensorrt/BUILD.bazel:63:10:
@tensorrt//:nvinfer_lib: invalid label '' in each branch in select expression of attribute 'static_library' in 'cc_import' rule
(including '//conditions:default'): empty package-relative label
ERROR: /home/ubuntu/Downloads/TRTorch-torch_1.6.0_update/core/util/BUILD:69:11: Target '@tensorrt//:nvinfer' contains
an error and its package is in error and referenced by '//core/util:trt_util'
ERROR: Analysis of target '//:libtrtorch' failed; build aborted: Analysis failed
## Environment
> Jetson Xavier AGX with JetPack 4.4
- PyTorch Version (e.g., 1.0): 1.6.0
- CPU Architecture: Jetson Xavier AGX
- OS (e.g., Linux): Jetson Xavier AGX JetPack 4.4
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): **pip**
- Build command you used (if compiling from source): NA
- Are you using local sources or building from archives: Build from JetPack 4.4
- Python version: 3.6.9
- CUDA version: 10.2
- GPU models and configuration: Jetson Xavier AGX
- Any other relevant information:
## Additional context
Attached are my edited WORKSPACE files.
[TRTorchBuildErrors.zip](https://github.com/NVIDIA/TRTorch/files/5068075/TRTorchBuildErrors.zip)
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/171
|
closed
|
[
"question",
"No Activity"
] | 2020-08-13T08:46:40Z
| 2020-09-23T00:05:53Z
| null |
OronG13
|
pytorch/audio
| 876
|
Where is version.py if I insist on building from source?
|
When I tried to install by `pip setup.py build`, I obtained the following **ERROR** message:
```console
-- Building version 0.7.0a0
Traceback (most recent call last):
File "setup.py", line 30, in <module>
with open(version_path, 'w') as f:
TypeError: expected str, bytes or os.PathLike object, not PosixPath
```
It looks **version.py** is missing.
Cheers
|
https://github.com/pytorch/audio/issues/876
|
closed
|
[] | 2020-08-12T09:01:40Z
| 2020-08-14T20:31:04Z
| null |
jiapei100
|
pytorch/text
| 919
|
Where is version.py if I insist on building from source?
|
When I tried to install by `pip setup.py build`, I obtained the following **ERROR** message:
```console
Traceback (most recent call last):
File "setup.py", line 48, in <module>
_export_version(VERSION, SHA)
File "setup.py", line 42, in _export_version
with open(version_path, 'w') as fileobj:
TypeError: expected str, bytes or os.PathLike object, not PosixPath
```
It looks **version.py** is missing.
Cheers
|
https://github.com/pytorch/text/issues/919
|
open
|
[] | 2020-08-12T09:00:36Z
| 2020-08-13T13:51:20Z
| null |
jiapei100
|
pytorch/vision
| 2,578
|
Calculate Training Accuracy on resnet152
|
I'm trying to calculate training accuracy on resnet152, however
`loss_dict = model(images, targets)`
only contains loss values.
Usually the model accepts only the images and the outputs are then passed to a loss function as well as used to calculate the accuracy. Calling it without the targets parameter results in:
`ValueError: In training mode, targets should be passed`
Sorry if this is the wrong place, I'm still quite a beginner.
|
https://github.com/pytorch/vision/issues/2578
|
closed
|
[
"invalid",
"question",
"module: models"
] | 2020-08-11T22:30:00Z
| 2020-08-21T14:11:44Z
| null |
FrostByteGER
|
pytorch/tutorials
| 1,117
|
But in Spatial Transformer Network?
|
Hi,
I am opening this issue because I noticed a weird behavior of the the spatial transformer networks implementation (https://github.com/pytorch/tutorials/blob/78e91c54dd0cd4fb0d02dfcc86fe94d16ab03df6/intermediate_source/spatial_transformer_tutorial.py#L57)
I summarized my findings [here](https://github.com/theRealSuperMario/pytorch_stn). In short, what is happening is that
when the input is normalised and then fed to the STN, the `F.grid_sample` call adds a zero-padding, however, the normalisation changes the background value from `0` to `-mean/std`.
(https://github.com/pytorch/tutorials/blob/78e91c54dd0cd4fb0d02dfcc86fe94d16ab03df6/intermediate_source/spatial_transformer_tutorial.py#L127)
This causes the STN to collapse very early and to actually never learn the correct transformation. You can actually see that in the example code already (https://pytorch.org/tutorials/intermediate/spatial_transformer_tutorial.html), because the learnt transformation is zooming OUT instead of zooming IN on the digits. For the original 28 x 28 images, this is not such a big problem, However, when you continue to cluttered MNIST as in the original publication, the difference is huge. Once again, please have a look [here](https://github.com/theRealSuperMario/pytorch_stn).
I think the tutorial for the STN should be updated and also include the cluttered MNIST example because that is what drives the point home. I would volunteer to do so, if I get the permission to go ahead.
Unfortunately, most other implementations I was able to find on the web also have this bug.
cc @sekyondaMeta @svekars @carljparker @NicolasHug @kit1980 @subramen
|
https://github.com/pytorch/tutorials/issues/1117
|
open
|
[
"Text",
"medium",
"docathon-h2-2023"
] | 2020-08-11T11:37:35Z
| 2023-11-01T16:41:21Z
| 5
|
theRealSuperMario
|
pytorch/vision
| 2,574
|
ValueError: bad value(s) in fds_to_keep
|
Traceback (most recent call last):
File "/home/sucom/hdd_1T/project/video_rec/my_video_rec/self_video_train.py", line 161, in <module>
trainer.train(task)
File "/home/sucom/.conda/envs/classy_vision/lib/python3.6/site-packages/classy_vision/trainer/local_trainer.py", line 27, in train
super().train(task)
File "/home/sucom/.conda/envs/classy_vision/lib/python3.6/site-packages/classy_vision/trainer/classy_trainer.py", line 45, in train
task.on_phase_start()
File "/home/sucom/.conda/envs/classy_vision/lib/python3.6/site-packages/classy_vision/tasks/classification_task.py", line 945, in on_phase_start
self.advance_phase()
File "/home/sucom/.conda/envs/classy_vision/lib/python3.6/site-packages/classy_vision/tasks/classification_task.py", line 847, in advance_phase
self.create_data_iterator()
File "/home/sucom/.conda/envs/classy_vision/lib/python3.6/site-packages/classy_vision/tasks/classification_task.py", line 900, in create_data_iterator
self.data_iterator = iter(self.dataloaders[self.phase_type])
File "/home/sucom/.conda/envs/classy_vision/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 279, in __iter__
return _MultiProcessingDataLoaderIter(self)
File "/home/sucom/.conda/envs/classy_vision/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 721, in __init__
w.start()
File "/home/sucom/.conda/envs/classy_vision/lib/python3.6/multiprocessing/process.py", line 105, in start
self._popen = self._Popen(self)
File "/home/sucom/.conda/envs/classy_vision/lib/python3.6/multiprocessing/context.py", line 284, in _Popen
return Popen(process_obj)
File "/home/sucom/.conda/envs/classy_vision/lib/python3.6/multiprocessing/popen_spawn_posix.py", line 32, in __init__
super().__init__(process_obj)
File "/home/sucom/.conda/envs/classy_vision/lib/python3.6/multiprocessing/popen_fork.py", line 19, in __init__
self._launch(process_obj)
File "/home/sucom/.conda/envs/classy_vision/lib/python3.6/multiprocessing/popen_spawn_posix.py", line 59, in _launch
cmd, self._fds)
File "/home/sucom/.conda/envs/classy_vision/lib/python3.6/multiprocessing/util.py", line 417, in spawnv_passfds
False, False, None)
ValueError: bad value(s) in fds_to_keep
|
https://github.com/pytorch/vision/issues/2574
|
closed
|
[
"invalid",
"question"
] | 2020-08-11T05:18:17Z
| 2020-08-11T17:21:26Z
| null |
siyangbing
|
pytorch/vision
| 2,572
|
How to fill in splits_dir and metadata_file in the video classification, my ufc101 data set only has pictures, how can I get them, if I can provide any help, I would be very grateful
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/vision/issues/2572
|
closed
|
[] | 2020-08-11T02:35:10Z
| 2020-08-11T06:16:55Z
| null |
siyangbing
|
pytorch/pytorch
| 42,777
|
custom function too slow, how to be as fast as native?
|
## function/Module too slow
### conext
ubuntu18.04.1 64 cuda11 pytorch1.6
```
class Relu0(Function):
@staticmethod
def forward(ctx, input,d=1):
ctx.save_for_backward(input) # save input for backward pass
x=torch.clone(input)
x[x<0]=0
return x
@staticmethod
def backward(ctx, grad_output,d=1):
input, = ctx.saved_tensors # restore input from context
grad_output[input<0]= 0
return grad_output
# more faster , not enough
def relu(x):
return (x>0)*x
# clamp fastest , any more?
```
### benchmark
Relu0.apply cost 10 times of torch.nn.functional.relu
above way seems not use accelerate library.
which operations can be as fast as native?
cc @VitalyFedyunin @ngimel
|
https://github.com/pytorch/pytorch/issues/42777
|
closed
|
[
"module: performance",
"triaged"
] | 2020-08-08T11:36:06Z
| 2020-08-15T07:48:42Z
| null |
laohur
|
pytorch/text
| 912
|
How to combine train and test set for IMDB Dataset in Torchtext / Pytorch
|
## ❓ Questions and Help
I want to use the examples in the test set of the IMDB Sentiment Analysis Dataset for training, as I have built my own benchmark with which I will compare the performance of various Models (my Matura Thesis)
So after trying, I got the appending working and also managed ot split it, so that I have a validation set as well. The code is the following:
```
from torchtext import datasets
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
import random
train_data, valid_data = train_data.split(random_state = random.seed(SEED))
from torch.utils.data import ConcatDataset
data_list = list()
data_list.append(train_data)
data_list.append(test_data)
train_data = ConcatDataset(data_list)
print(f'Number of validation examples: {len(valid_data)}')
print(f'Number of training examples: {len(train_data)}')
```
And I get the following split (which is my goal):
```
Number of validation examples: 7500
Number of training examples: 42500
```
Now when I want to built the vocab with the following code, I get this error:
```
MAX_VOCAB_SIZE = 25_000
LABEL.build_vocab(train_data)
TEXT.build_vocab(train_data, max_size = MAX_VOCAB_SIZE)
~\.conda\envs\matura-ml\lib\collections\__init__.py in update(*args, **kwds)
654 else:
--> 655 _count_elements(self, iterable)
656 if kwds:
TypeError: 'Example' object is not iterable
During handling of the above exception, another exception occurred:
TypeError Traceback (most recent call last)
in
1 MAX_VOCAB_SIZE = 25_000
2
----> 3 TEXT.build_vocab(train_data, max_size = MAX_VOCAB_SIZE)
4 LABEL.build_vocab(train_data)
~\.conda\envs\matura-ml\lib\site-packages\torchtext\data\field.py in build_vocab(self, *args, **kwargs)
299 counter.update(x)
300 except TypeError:
--> 301 counter.update(chain.from_iterable(x))
302 specials = list(OrderedDict.fromkeys(
303 tok for tok in [self.unk_token, self.pad_token, self.init_token,
TypeError: 'Example' object is not iterable
```
How can I combine the train and test split in the correct way?
|
https://github.com/pytorch/text/issues/912
|
closed
|
[
"legacy"
] | 2020-08-07T11:10:51Z
| 2020-08-08T22:34:43Z
| null |
EmreTokyuez
|
pytorch/pytorch
| 42,722
|
How to build libtorch static libraries on Windows?
|
I'm developing the Windows program using libtorch dynamic libraries released on pytorch website. However, I find the dynamic libraries are quite large (the torch_cpu.dll is larger than 100MB). Is there the static library version, or how could I build the libtorch static library by myself?
Look forward to your response. Thanks a lot!
cc @ezyang @seemethere @malfet @walterddr @peterjc123 @maxluk @nbcsm @guyang3532 @gunandrose4u @smartcat2010 @mszhanyi
|
https://github.com/pytorch/pytorch/issues/42722
|
closed
|
[
"module: binaries",
"module: build",
"module: windows",
"triaged",
"windows-triaged"
] | 2020-08-07T02:37:24Z
| 2024-08-12T13:36:33Z
| null |
lawlict
|
pytorch/tutorials
| 1,110
|
How to Inference non-val images in Transfer Learning Tutorial
|
The transfer learning tutorial is great, however it leaves off after evaluating the accuracy of the model. My goal is to then use the model that has been created to inference other images, but have run into trouble getting the new data adhere to the correct format and shape. Do you have any insight on how I could do this?
|
https://github.com/pytorch/tutorials/issues/1110
|
closed
|
[
"torchvision",
"docathon-h1-2023",
"medium"
] | 2020-08-06T00:53:45Z
| 2023-06-09T18:17:55Z
| null |
ScottMoffatLittle
|
pytorch/vision
| 2,555
|
Unable to load fasterrcnn state_dict with custom num_classes
|
## 🐛 Bug
torchvision.models.detection.fasterrcnn_resnet50_fpn() giving error when the parameter pretrained is set to True and num_classes parameter is also supplied(other than 91).
## To Reproduce
Steps to reproduce the behavior:
```
>> from torchvision import models
>> my_model = models.detection.fasterrcnn_resnet50_fpn(pretrained=True,num_classes=50)
```
The error that it gives
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/username/miniconda2/envs/form_ocr/lib/python3.7/site-packages/torchvision/models/detection/faster_rcnn.py", line 354, in fasterrcnn_resnet50_fpn
model.load_state_dict(state_dict)
File "/home/username/miniconda2/envs/form_ocr/lib/python3.7/site-packages/torch/nn/modules/module.py", line 847, in load_state_dict
self.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for FasterRCNN:
size mismatch for roi_heads.box_predictor.cls_score.weight: copying a param with shape torch.Size([91, 1024]) from checkpoint, the shape in current model is torch.Size([50, 1024]).
size mismatch for roi_heads.box_predictor.cls_score.bias: copying a param with shape torch.Size([91]) from checkpoint, the shape in current model is torch.Size([50]).
size mismatch for roi_heads.box_predictor.bbox_pred.weight: copying a param with shape torch.Size([364, 1024]) from checkpoint, the shape in current model is torch.Size([200, 1024]).
size mismatch for roi_heads.box_predictor.bbox_pred.bias: copying a param with shape torch.Size([364]) from checkpoint, the shape in current model is torch.Size([200]).
```
## Expected behavior
I was hoping it would load the state_dict on the base model and then change the `model.roi_heads.box_predictor.cls_score` layer.
Something like this perhaps,
```
from torchvision import models
import torch.nn as nn
class RCNN_Model(nn.Module):
def __init__(self,pretrained=True,out_classes=91):
super(RCNN_Model,self).__init__()
self.model = models.detection.fasterrcnn_resnet50_fpn(pretrained=pretrained)#,num_classes=out_classes)
if out_classes!=91:
self.model.roi_heads.box_predictor.cls_score = nn.Linear(in_features=1024,out_features=out_classes,bias=True)
def forward(self,x):
return self.model(x)
```
## Environment
```
PyTorch version: 1.5.1
Is debug build: No
CUDA used to build PyTorch: 10.2
OS: Ubuntu 18.04.3 LTS
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
CMake version: version 3.10.2
Python version: 3.7
Is CUDA available: No
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
Versions of relevant libraries:
[pip3] numpy==1.13.3
[pip3] torch==1.0.1.post2
[pip3] torchvision==0.4.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 9.0 h13b8566_0
[conda] mkl 2019.4 243
[conda] mkl-service 2.3.0 py37he904b0f_0
[conda] mkl_fft 1.0.14 py37ha843d7b_0
[conda] mkl_random 1.1.0 py37hd6b4f25_0
[conda] numpy 1.17.4 pypi_0 pypi
[conda] numpy-base 1.17.2 py37hde5b4d6_0
[conda] pytorch-nightly 1.0.0.dev20190328 py3.7_cuda9.0.176_cudnn7.4.2_0 pytorch
[conda] torch 1.5.1 pypi_0 pypi
[conda] torchvision 0.6.1 pypi_0 pypi
```
|
https://github.com/pytorch/vision/issues/2555
|
closed
|
[
"question",
"module: models"
] | 2020-08-05T13:09:57Z
| 2020-08-05T15:14:34Z
| null |
devarshi16
|
pytorch/tutorials
| 1,104
|
Error on https://pytorch.org/tutorials/intermediate/tensorboard_tutorial.html ?
|
In Section 6 of https://pytorch.org/tutorials/intermediate/tensorboard_tutorial.html, the following code is presented:
```
def add_pr_curve_tensorboard(class_index, test_probs, test_preds, global_step=0):
'''
Takes in a "class_index" from 0 to 9 and plots the corresponding
precision-recall curve
'''
tensorboard_preds = test_preds == class_index
tensorboard_probs = test_probs[:, class_index]
writer.add_pr_curve(classes[class_index],
tensorboard_preds,
tensorboard_probs,
global_step=global_step)
writer.close()
```
`writer.add_pr_curve` should take the _true_ labels, not a variable testing equality between the prediction and the class index (from `https://pytorch.org/docs/stable/tensorboard.html`), so I think the second argument, `tensorboard_preds`, is wrong: `tensorboard_preds = test_preds == class_index` tests whether the prediction is equal to the given class_index.
I think this should be something like `tensorboard_preds = labels == class_index`, which gives you 0/1 based on the true labels and not the predicted labels
|
https://github.com/pytorch/tutorials/issues/1104
|
closed
|
[
"docathon-h1-2023",
"medium"
] | 2020-08-04T20:43:47Z
| 2023-10-05T16:51:09Z
| 6
|
motiwari
|
pytorch/pytorch
| 42,505
|
how to use get_trace_graph to get the attribute of a node in trace graph in pytorch 1.6?
|
In pytorch 1.1 when using get_trace_graph to trace the model, we could get the node's attibution as follows:
%469 : bool = prim::Constant[value=0](), scope: Model/Backbone[backbone]/ConvBn[conv1]/BatchNorm2d[bn]
Then we could get the the attribution of the Node: backbone.conv1.bn and its class BatchNorm.
Then how to get the attribution name of the node in pytorch 1.6, as we can only get
%23 : float = prim::Constant[value=1]() # test.py:12:23
so how to get the attribution in pytorch 1.6
cc @suo @gmagogsfm
|
https://github.com/pytorch/pytorch/issues/42505
|
closed
|
[
"oncall: jit",
"triaged",
"days"
] | 2020-08-04T03:02:51Z
| 2020-08-13T11:20:07Z
| null |
ioou
|
pytorch/pytorch
| 42,445
|
how to run SVM/Random forest/xgboost on the pytorch?
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/42445
|
closed
|
[] | 2020-08-03T10:12:34Z
| 2020-08-03T17:17:24Z
| null |
cvJie
|
pytorch/pytorch
| 42,439
|
How to use libtorch on Jetson TX2
|
Refer to https://forums.developer.nvidia.com/t/pytorch-for-jetson-nano-version-1-5-0-now-available/72048,I successfully installed Pytorch 1.0.0 and torchvision0.2.2 on jetpack4.3.According to the authentication method, I also succeeded in authentication: python–>import torch…
However,I want to call a scriptModel by libtorch on a QT project.but meet the error:
error:undefined reference to ‘nvrtcGetProgramLogSize’
error:undefined reference to ‘culaunchKernel’
error:undefined reference to ‘nvrtcComplieProgram’
error:undefined reference to ‘nvrtcCreateProgram’
error:undefined reference to ‘nvrtcGetErrorString’
error:undefined reference to ‘cuModuleGetFunction’
and so on.
Also I can not find libnvrtc.so at ~/.local/lib/python3.6/site-packages/torch/lib.
what is the problem?
cc @ezyang @seemethere @malfet
|
https://github.com/pytorch/pytorch/issues/42439
|
open
|
[
"module: binaries",
"triaged",
"module: arm"
] | 2020-08-03T06:14:11Z
| 2020-08-05T21:03:37Z
| null |
xifanlover
|
pytorch/pytorch
| 42,404
|
How to deploy a "LSTMcell" style attention by torch.onnx?
|
I'm deploying a NMT network and I fail when I try to define attention module.
The first thing is that,when i put nn.LSTMcell in my init function,it would raise some errors which may caused by no inplementation in torch.onnx.
And when I want to replace it with nn.LSTM, i still get an error with torch.onnx:
```
class test(nn.Module):
def __init__(self):
super().__init__()
self.rnn = nn.LSTM(10, 20)
def forward(self, x ,hx,cx):
outputs = []
for i in range(x.shape[0]):
output ,next_step = self.rnn(x[[i]], (hx, cx))
hx,cx=next_step
outputs.append(output)
return torch.stack(outputs).squeeze(1)
input = torch.randn(6, 1, 10)
hx = torch.randn(1,1, 20)
cx = torch.randn(1,1, 20)
torch_model = torch.jit.script(test())
a=torch_model(input,hx,cx)
a.shape
#this turns out to be fine
torch.Size([6, 1, 20])
torch.onnx.export(torch_model,
(input,hx,cx),
"torch_model.onnx",
export_params=True,
opset_version=10,
input_names = ['input',"hx","cx"],
output_names = ['output'],
dynamic_axes={'input' : {0 : 'seq_length'},
'output' : {0 : 'seq_length'}},
example_outputs=a
)
# this will raise
RuntimeError: Unknown type bool encountered in graph lowering. This type is not supported in ONNX export.
```
Any help would be thankful!
cc @suo @gmagogsfm @houseroad @spandantiwari @lara-hdr @BowenBao @neginraoof
|
https://github.com/pytorch/pytorch/issues/42404
|
closed
|
[
"oncall: jit",
"module: onnx"
] | 2020-08-01T10:31:10Z
| 2021-10-18T05:09:31Z
| null |
andylida
|
huggingface/sentence-transformers
| 335
|
What is the key difference between mean pooling BERT vs. mean pooling sentence-transformers?
|
Hi!
If I run sentence-transformers without pre-training, is it equivalent to apply mean-pooling to the last layer of BERT?
For example, if I run the below code,
```python
# Use BERT for mapping tokens to embeddings
word_embedding_model = models.Transformer('bert-base-uncased')
# Apply mean pooling to get one fixed sized sentence vector
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
model.encode('This is an example')
```
will the embedding vector be different than averaging the last layer of BERT?
|
https://github.com/huggingface/sentence-transformers/issues/335
|
open
|
[] | 2020-08-01T02:35:56Z
| 2020-08-01T08:39:45Z
| null |
yuwon
|
pytorch/TensorRT
| 163
|
❓ [Question] Could your team provide a cmake version?
|
## ❓ Question
I think many people block in building stage?
|
https://github.com/pytorch/TensorRT/issues/163
|
closed
|
[
"question"
] | 2020-07-31T14:22:24Z
| 2020-08-01T02:29:39Z
| null |
alanzhai219
|
huggingface/pytorch-image-models
| 205
|
when I use the old version, the result is good,but I update the newest code, the result is error.what's wrong with me?
|
same dataset,and same train scripts,with this:
`
./distributed_train.sh 2 /data/data/product/product --model swsl_resnet50 --epochs 20 --warmup-epochs 1 --lr 0.001 --batch-size 16 --img-size 224 --num-classes 30 --pretrained --amp
`
the old code result:
Train: 10 [ 0/185 ( 0%)] Loss: 0.866020 (0.8660) Time: 0.599s, 53.41/s (0.599s, 53.41/s) LR: 1.000e-03 Data: 0.455 (0.455)
Train: 10 [ 50/185 ( 27%)] Loss: 0.857730 (0.8619) Time: 0.129s, 248.96/s (0.144s, 222.42/s) LR: 1.000e-03 Data: 0.003 (0.013)
Train: 10 [ 100/185 ( 54%)] Loss: 0.765654 (0.8298) Time: 0.129s, 247.52/s (0.139s, 230.35/s) LR: 1.000e-03 Data: 0.003 (0.008)
Train: 10 [ 150/185 ( 82%)] Loss: 0.984192 (0.8684) Time: 0.133s, 240.71/s (0.138s, 232.42/s) LR: 1.000e-03 Data: 0.003 (0.007)
Train: 10 [ 184/185 (100%)] Loss: 0.725536 (0.8398) Time: 0.191s, 167.12/s (0.137s, 232.97/s) LR: 1.000e-03 Data: 0.061 (0.006)
Test: [ 0/2] Time: 0.830 (0.830) Loss: 0.1307 (0.1307) Prec@1: 98.4375 (98.4375) Prec@5: 100.0000 (100.0000)
Test: [ 2/2] Time: 0.128 (0.348) Loss: 0.0857 (0.0974) Prec@1: 98.8889 (99.1329) Prec@5: 100.0000 (100.0000)
Current checkpoints:
('./output/train/20200731-174448-swsl_resnet50-224/checkpoint-3.pth.tar', 99.42196443590815)
('./output/train/20200731-174448-swsl_resnet50-224/checkpoint-8.pth.tar', 99.42196443590815)
('./output/train/20200731-174448-swsl_resnet50-224/checkpoint-5.pth.tar', 99.13294709486769)
('./output/train/20200731-174448-swsl_resnet50-224/checkpoint-10.pth.tar', 99.13294709486769)
#########################################################################
the new code reslut:
`
Train: 2 [ 0/185 ( 0%)] Loss: 1.102509 (1.1025) Time: 0.559s, 57.21/s (0.559s, 57.21/s) LR: 1.000e-03 Data: 0.413 (0.413)
Train: 2 [ 50/185 ( 27%)] Loss: 0.973374 (1.0379) Time: 0.131s, 244.76/s (0.142s, 225.78/s) LR: 1.000e-03 Data: 0.003 (0.012)
Train: 2 [ 100/185 ( 54%)] Loss: 1.284053 (1.1200) Time: 0.130s, 245.52/s (0.138s, 231.99/s) LR: 1.000e-03 Data: 0.003 (0.008)
Train: 2 [ 150/185 ( 82%)] Loss: 0.874424 (1.0586) Time: 0.157s, 204.25/s (0.137s, 233.52/s) LR: 1.000e-03 Data: 0.021 (0.007)
Train: 2 [ 184/185 (100%)] Loss: 0.963474 (1.0396) Time: 0.201s, 159.49/s (0.137s, 234.15/s) LR: 1.000e-03 Data: 0.066 (0.007)
Test: [ 0/10] Time: 0.455 (0.455) Loss: 6.2966 (6.2966) Acc@1: 0.0000 ( 0.0000) Acc@5: 0.0000 ( 0.0000)
Test: [ 10/10] Time: 0.087 (0.070) Loss: 6.2156 (6.4805) Acc@1: 0.0000 ( 0.0000) Acc@5: 7.6923 ( 1.1561)
Current checkpoints:
('./output/train/20200731-175136-swsl_resnet50-224/checkpoint-0.pth.tar', 0.28901735068745693)
('./output/train/20200731-175136-swsl_resnet50-224/checkpoint-1.pth.tar', 0.0)
('./output/train/20200731-175136-swsl_resnet50-224/checkpoint-2.pth.tar', 0.0)
|
https://github.com/huggingface/pytorch-image-models/issues/205
|
closed
|
[] | 2020-07-31T09:54:39Z
| 2020-08-03T09:45:04Z
| null |
runauto
|
pytorch/pytorch
| 42,349
|
I want to build the pytorch and link with openblas static library, so how to modify the CMakeList.txt ?
|
https://github.com/pytorch/pytorch/issues/42349
|
closed
|
[] | 2020-07-31T02:01:02Z
| 2020-08-01T08:25:07Z
| null |
lfcarol
|
|
pytorch/pytorch
| 42,268
|
how to enable CUDNN_TENSOR_OP_MATH for float32 torch.mm operator
|
I am wondering in pytorch, how to enable tensor cores for float32 torch.mm operations.
I posted the same question at https://discuss.pytorch.org/t/using-nvidia-tensor-core-for-float-mm-computation/90901,
but got no response. Thanks.
cc @ngimel
|
https://github.com/pytorch/pytorch/issues/42268
|
closed
|
[
"module: cuda",
"triaged"
] | 2020-07-30T00:58:17Z
| 2020-07-30T01:48:39Z
| null |
shz0116
|
pytorch/serve
| 566
|
How to use model archiver utility for complex projects?
|
I am trying to serve the model from the [NCRFpp](https://github.com/jiesutd/NCRFpp) project using torchserve. The files that are required by my custom _handler.py_ file are in multiple folders and have import statements which refer to this folder hierarchy. The model archiver zips all these files and extracts into a temporary folder at the same level without this folder hierarchy, leading to runtime errors because the import statements fail. How do I ensure that the import statements work, with same folder hierarchy as used during development, while using torchserve?
|
https://github.com/pytorch/serve/issues/566
|
closed
|
[
"triaged_wait"
] | 2020-07-29T13:44:24Z
| 2023-01-12T01:56:23Z
| null |
sagjounkani
|
pytorch/examples
| 806
|
How to use torch.multiprocessing in Windows
|
The following error occurred when I used the torch.multiprocessing [demo](https://github.com/pytorch/examples/tree/master/mnist_hogwild) provided by Pytorch.
C:\Users\user\anaconda3\python.exe D:/HPO-Pro/PBT3/main_demo.py
cuda
cuda
THCudaCheck FAIL file=..\torch/csrc/generic/StorageSharing.cpp line=247 error=801 : operation not supported
Traceback (most recent call last):
File "D:/HPO-Pro/PBT3/main_demo.py", line 88, in <module>
p.start()
File "C:\Users\user\anaconda3\lib\multiprocessing\process.py", line 112, in start
self._popen = self._Popen(self)
File "C:\Users\user\anaconda3\lib\multiprocessing\context.py", line 322, in _Popen
return Popen(process_obj)
File "C:\Users\user\anaconda3\lib\multiprocessing\popen_spawn_win32.py", line 89, in __init__
reduction.dump(process_obj, to_child)
File "C:\Users\user\anaconda3\lib\multiprocessing\reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
File "C:\Users\user\anaconda3\lib\site-packages\torch\multiprocessing\reductions.py", line 240, in reduce_tensor
event_sync_required) = storage._share_cuda_()
RuntimeError: cuda runtime error (801) : operation not supported at ..\torch/csrc/generic/StorageSharing.cpp:247
Can't I use CUDA while using torch.multiprocessing in Windows?
|
https://github.com/pytorch/examples/issues/806
|
open
|
[
"windows"
] | 2020-07-29T09:06:18Z
| 2022-03-09T20:46:19Z
| null |
zhong-xin
|
huggingface/transformers
| 6,092
|
i dont know what Tranier`s Dataset is.
|
# ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to the Hugging Face forum: https://discuss.huggingface.co/ .
You can also try Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. In this case, make sure to tag your
question with the right deep learning framework as well as the
huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
-->
## Details
<!-- Description of your issue -->


i thought its my customer dataset goes wrong, i dont konw what dataset it should return. the Trainer receive what dataset.
<!-- You should first ask your question on the forum or SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on the forum/Stack Overflow**:
|
https://github.com/huggingface/transformers/issues/6092
|
closed
|
[] | 2020-07-28T13:11:48Z
| 2020-07-28T13:48:43Z
| null |
Ted8000
|
pytorch/serve
| 558
|
Is there a way to test my handle file before serving my model?
|
Hi, i recently use TorchServer to serving my model. For each model i write a handle file, but i don't know how to test it. Is there a way to test my handle file before serving my model?
|
https://github.com/pytorch/serve/issues/558
|
closed
|
[
"question",
"triaged_wait"
] | 2020-07-28T09:35:33Z
| 2020-08-21T04:06:11Z
| null |
wangxiang2713
|
pytorch/TensorRT
| 157
|
“error while loading shared libraries: libnvinfer.so.7: cannot open shared object file: No such file or directory” when running sample
|
I'm trying to run the sample code. I've installed TRTorch according to the official [TRTorch](https://nvidia.github.io/TRTorch/tutorials/installation.html) instruction.
When the sample code is run (with the below command from this link) the given error arise: <br/>
>sudo bazel run //cpp/trtorchexec -- $(realpath /home/TRTorch/tests/modules/alexnet_scripted.jit.pt) "(1,3,228,228)"
>error while loading shared libraries: libnvinfer.so.7: cannot open shared object file: No such file or directory
Also, the LD_LIBRARY_PATH is set correctly.
>export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/TensorRT/TensorRT-7.0.0.11/lib
More info:
>TRTorch: latest version (python package and binary) <br/>
>TensorRT: 7.0.0.11 <br/>
>Pytorch: 1.5.1 <br/>
>CUDA: 10.2 <br/>
>Python: 3.6
|
https://github.com/pytorch/TensorRT/issues/157
|
closed
|
[
"question",
"No Activity"
] | 2020-07-28T08:02:31Z
| 2023-03-23T07:18:44Z
| null |
Soroorsh
|
huggingface/pytorch-image-models
| 201
|
where is CheckpointSaver?
|
hello, going over your repo
(thx for the great repo btw)
I can't find where the code for CheckpointSaver is...
nor do I find any checkpoint saved in my pc..
where can I find them??
|
https://github.com/huggingface/pytorch-image-models/issues/201
|
closed
|
[] | 2020-07-28T03:51:45Z
| 2020-07-28T04:32:20Z
| null |
ooodragon94
|
pytorch/vision
| 2,508
|
Number of anchors VS. number of aspect ratios.
|
https://github.com/pytorch/vision/blob/1aef87d01eec2c0989458387fa04baebcc86ea7b/torchvision/models/detection/faster_rcnn.py#L188
The line above seems to fetch, for each location, the number of aspect ratios of anchors (not multiplying by the number of different sized anchors).
|
https://github.com/pytorch/vision/issues/2508
|
closed
|
[
"question",
"module: models",
"topic: object detection"
] | 2020-07-25T16:15:42Z
| 2020-07-30T12:30:11Z
| null |
fulkast
|
pytorch/vision
| 2,505
|
Error when training Resnet with nn.DistributedDataParallel
|
When I try to train [Resnet](https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py) with `nn.DistributedDataParallel` using multi-gpus, the error occurs as below. But when I use only one gpu, it's just ok.
Some of the code:
```
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False) # decrease the channel, does't change size
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=False)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out = out + residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=9):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False) # the size become 1/2
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=False)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # the size become 1/2
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# self.fc = nn.Linear(512 * block.expansion, num_classes)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
# block: object, planes: output channel, blocks: the num of blocks
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion # the input channel num become 4 times
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = nn.init.normal_(x, mean=0, std=1024 ** -0.5)
# x = self.fc2(x)
return x
```
|
https://github.com/pytorch/vision/issues/2505
|
closed
|
[
"question",
"module: models",
"topic: classification"
] | 2020-07-24T08:38:04Z
| 2020-08-10T11:51:33Z
| null |
alwayshjia
|
pytorch/serve
| 553
|
Dump system metrics in a database
|
How should I access system metrics to dump it in a SQL database?
Also, what are the best practices for logging inference predictions in a database?
|
https://github.com/pytorch/serve/issues/553
|
closed
|
[
"question",
"triaged_wait"
] | 2020-07-24T07:23:39Z
| 2020-08-07T08:25:47Z
| null |
vishal-wiai
|
pytorch/pytorch
| 41,935
|
How to Upgrade PyTorch to 1.6 in Docker Image
|
## ❓ How to Upgrade PyTorch to 1.6 in Docker Image?
### Hi, I have a docker image that has pytorch 1.4, torchvision 0.5, cudnn 7.6.5 and cuda 10.1, and other tools and packages. I want to upgrade my pytorch to 1.6. Is there some way to do it without rebuild the whole image again?
Thanks!
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
cc @ezyang @seemethere @malfet
|
https://github.com/pytorch/pytorch/issues/41935
|
closed
|
[
"module: binaries",
"triaged",
"module: docker"
] | 2020-07-23T17:56:25Z
| 2021-01-26T20:11:26Z
| null |
zhenhuahu
|
pytorch/examples
| 802
|
How to use a pre-trained models weights?
|
How do we specify to use the pre-trained model? Typing in python main.py -a mobilenet_v2 is not giving me the model with pretrained weights.
|
https://github.com/pytorch/examples/issues/802
|
closed
|
[] | 2020-07-22T22:36:47Z
| 2022-03-09T21:37:31Z
| null |
stunbomb
|
pytorch/vision
| 2,502
|
Why do we need target put .to(device)?
|
Consider key points detection task.
The question refers to this line
https://github.com/pytorch/vision/blob/1aef87d01eec2c0989458387fa04baebcc86ea7b/references/detection/engine.py#L86
Seems to be redundant.
In my case, I comment out this line and remove .item() in line 95, and at least evaluation starts.
Moreover, COCO dataset output is a tuple({'image_id': int, 'annotations': list(...)}) and I do not get it how it could work in 86 line.
|
https://github.com/pytorch/vision/issues/2502
|
closed
|
[
"enhancement",
"question",
"module: reference scripts",
"topic: object detection"
] | 2020-07-22T13:38:19Z
| 2020-07-30T12:10:54Z
| null |
dmitrysarov
|
pytorch/pytorch
| 41,847
|
How to fix "Unknown IValue type for pickling: Device" in PyTorch 1.3?
|
## ❓ Questions and Help
I got a model trained with PyTorch 1.4. If I script and save this model with PyTorch 1.4, it will save successfully, but I need to script and save this model with PyTorch 1.3. When I save model with 1.3, I got error message:
```
RuntimeError: Unknown IValue type for pickling: Device (pushIValueImpl at /pytorch/torch/csrc/jit/pickler.cpp:125)
```
I want to know how to fix this `Device` issue. Thx.
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/41847
|
closed
|
[] | 2020-07-22T10:48:50Z
| 2020-07-23T01:53:53Z
| null |
kaituoxu
|
huggingface/transformers
| 5,940
|
What is the difference between the function of add_tokens() and add_special_tokens() in tokenizer
|
# ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to the Hugging Face forum: https://discuss.huggingface.co/ .
You can also try Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. In this case, make sure to tag your
question with the right deep learning framework as well as the
huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
-->
## Details
<!-- Description of your issue -->
When I read the code of tokenizer, I have a problem if I want to use a pretrained model in NMT task, I need to add some tag tokens, such as '2English' or '2French'. I think these tokens are special tokens, so which function should I use: add_tokens() or add_special_tokens(). What is the difference between them?
|
https://github.com/huggingface/transformers/issues/5940
|
closed
|
[] | 2020-07-21T15:29:14Z
| 2025-03-05T20:33:05Z
| null |
kugwzk
|
pytorch/vision
| 2,497
|
Grayscale image mask is transformed in a performance decreasing way with ToTensor()
|
## 🐛 Bug
Preface: This is only in the context of my usage, where I use a custom dataset for semantic segmentation. My goal was to train different models on a semantic segmentation dataset and obviously I wanted to use the torchvision transforms.
The dataset does not matter much, but the labels are interesting: The labels are grayscale in a 2d array with values from 0 to NUM_CLASSES). (I mean in form of a PIL image when I say array for the label)
I realized after training on a subset of the data, that the performance was incredibly bad and the models could not even overfit on a simple dataset.
I debugged for a while and finally realized, that the ToTensor() operation changes the arrays from (W, H) to (3, W, H) and the values become some float values because of the [0,255] to [0,1] rescaling. What I did not realize is how much of a performance impact this change has. When just using torch.tensor() to create a tensor from the array, the performance was WAY better (see chart below, the gray performance was using the torch.tensor approach). Note that in the chart, the ONLY change I made is replace the transforms (see in reproduction explanation).
Charts with MIoU and Loss, pink: HRNet with old transform, orange: DeepLabV3+ with old transform, grey: HRNet with new transform. (All pretrained on a different dataset btw)
## To Reproduce
Steps to reproduce the behavior:
1. Create labelset that does not use RGB labels but uses a grayscale array with each class having a corresponding number
1. Prepare a semantic segmentation model (I used HRNet and DeepLabV3+) for training
1. Load the dataset with these transforms for the labels:
```
label_transform = transforms.Compose([
transforms.Resize(downsampling_size, interpolation=Image.NEAREST),
transforms.ToTensor(),
])
```
1. Train the model, plot performance (mIoU is bad even though loss keeps decreasing)
1. Load the dataset with the following different transforms:
```
custom_to_tensor = lambda a : torch.tensor(np.array(a))
label_transform = transforms.Compose([
# Nearest interpolation to keep valid labels
transforms.Resize(downsampling_size, interpolation=Image.NEAREST),
custom_to_tensor,
])
```
1. Train again, realize the performance is way better??
## Expected behavior
ToTensor() should not lead to such a huge performance loss when using grayscale image masks :(
## Environment
Using pytorch/pytorch:1.5.1-cuda10.1-cudnn7-runtime with these pip dependencies installed:
* tensorboard==2.2.0
* matplotlib==3.2.2
* tensorboardx==2.0
* Pillow==7.2.0
* numpy==1.19.0
* python-box==5.0.1
* pytorch-ignite==0.4.0.post1
GPU is Nvidia Quadro P6000, only used one so far
## Additional context
I realize this might not be a bug per definition, but it still threw me for a loop. I absolutely did not expect the simple usage of ToTensor() to hinder the performance this much.
|
https://github.com/pytorch/vision/issues/2497
|
closed
|
[
"question",
"module: transforms"
] | 2020-07-21T12:07:06Z
| 2020-07-30T12:22:02Z
| null |
Areiser
|
pytorch/vision
| 2,486
|
Torchvision Object detection TPU Support
|
## ❓ Torchvision object detection models with TPU.
My doubt lies somewhere between feature request and question. hence posting here.
PyTorch supports TPU through torch_xla. It makes it possible to train models over TPU.
I guess most torchvision classification models can be used with transfer learning/training over TPU.
For torchvision object detection models, do they support TPU?
Some operations such as `NMS`, `rpn`, `roi_align` do not support TPU and hence I get an error as follows.
I was trying Faster R-CNN resnet50 fpn model for object detection.
```
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/torchvision/models/detection/generalized_rcnn.py", line 70, in forward
proposals, proposal_losses = self.rpn(images, features, targets)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/torchvision/models/detection/rpn.py", line 493, in forward
boxes, scores = self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level)
File "/usr/local/lib/python3.6/dist-packages/torchvision/models/detection/rpn.py", line 416, in filter_proposals
keep = box_ops.batched_nms(boxes, scores, lvl, self.nms_thresh)
RuntimeError: Cannot access data pointer of Tensor that doesn't have storage
```
My doubts/concerns/feature request.
1. Do torchvision object detection models support TPU training?
2. Any Plans for TPU support in future releases for these models?
3. Are these ops only CUDA native and GPU/CPU specific? Is there a work-around to train object detection / segmentation models with TPU?
|
https://github.com/pytorch/vision/issues/2486
|
open
|
[
"question",
"topic: object detection",
"new feature"
] | 2020-07-17T18:47:07Z
| 2021-05-02T18:03:08Z
| null |
oke-aditya
|
pytorch/pytorch
| 41,592
|
Add SpectralOps CPU implementation for ARM/PowerPC processors (where MKL is not available)
|
## 🐛 Bug
`fft: ATen not compiled with MKL support` RuntimeError thrown when trying to compute Spectrogram on Jetson Nano that uses ARM64 processor.
## To Reproduce
Code sample:
```
import torchaudio
waveform, sample_rate = torchaudio.load('test.wav')
spectrogram = torchaudio.transforms.Spectrogram(sample_rate)(waveform)
```
Stack trace:
```
Traceback (most recent call last):
File "spectrogram_test.py", line 4, in <module>
spectrogram = torchaudio.transforms.Spectrogram(sample_rate)(waveform)
File "/home/witty/ai-benchmark-2/lib/python3.6/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/witty/ai-benchmark-2/lib/python3.6/site-packages/torchaudio-0.7.0a0+102174e-py3.6-linux-aarch64.egg/torchaudio/transforms.py", line 84, in forward
self.win_length, self.power, self.normalized)
File "/home/witty/ai-benchmark-2/lib/python3.6/site-packages/torchaudio-0.7.0a0+102174e-py3.6-linux-aarch64.egg/torchaudio/functional.py", line 162, in spectrogram
waveform, n_fft, hop_length, win_length, window, True, "reflect", False, True
File "/home/witty/ai-benchmark-2/lib/python3.6/site-packages/torch/functional.py", line 465, in stft
return _VF.stft(input, n_fft, hop_length, win_length, window, normalized, onesided)
RuntimeError: fft: ATen not compiled with MKL support
```
## Expected behavior
Spectrogram from waveform created
## Environment
Commands used to install PyTorch:
```
wget https://nvidia.box.com/shared/static/yr6sjswn25z7oankw8zy1roow9cy5ur1.whl -O torch-1.6.0rc2-cp36-cp36m-linux_aarch64.whl
sudo apt-get install python-pip libopenblas-base libopenmpi-dev
pip install Cython
pip install numpy torch-1.6.0rc2-cp36-cp36m-linux_aarch64.whl
```
Commands used to install torchaudio:
sox:
```
sudo apt-get update -y
sudo apt-get install -y libsox-dev
pip install sox
```
torchaudio:
```
git clone https://github.com/pytorch/audio.git audio
cd audio && python setup.py install
```
`torchaudio.__version__` output:
`0.7.0a0+102174e`
`collect_env.py` output:
```
PyTorch version: 1.6.0
Is debug build: No
CUDA used to build PyTorch: 10.2
OS: Ubuntu 18.04.4 LTS
GCC version: (Ubuntu/Linaro 7.5.0-3ubuntu1~18.04) 7.5.0
CMake version: version 3.10.2
Python version: 3.6
Is CUDA available: Yes
CUDA runtime version: Could not collect
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Probably one of the following:
/usr/lib/aarch64-linux-gnu/libcudnn.so.8.0.0
/usr/lib/aarch64-linux-gnu/libcudnn_adv_infer.so.8.0.0
/usr/lib/aarch64-linux-gnu/libcudnn_adv_train.so.8.0.0
/usr/lib/aarch64-linux-gnu/libcudnn_cnn_infer.so.8.0.0
/usr/lib/aarch64-linux-gnu/libcudnn_cnn_train.so.8.0.0
/usr/lib/aarch64-linux-gnu/libcudnn_etc.so.8.0.0
/usr/lib/aarch64-linux-gnu/libcudnn_ops_infer.so.8.0.0
/usr/lib/aarch64-linux-gnu/libcudnn_ops_train.so.8.0.0
Versions of relevant libraries:
[pip3] numpy==1.16.1
[pip3] pytorch-ignite==0.3.0
[pip3] torch==1.6.0
[pip3] torchaudio==0.7.0a0+102174e
[conda] Could not collect
```
Other relevant information:
MKL is not installed, because it is not supported on ARM processors; oneDNN installed
## Additional context
I did not install MKL because it is not supported on ARM processors, so building PyTorch from source with MKL support is not possible. Is there any workaround to this problem?
cc @malfet @seemethere @walterddr @mruberry @peterbell10 @ezyang
|
https://github.com/pytorch/pytorch/issues/41592
|
closed
|
[
"module: build",
"triaged",
"module: POWER",
"module: arm",
"module: fft",
"function request"
] | 2020-07-17T13:02:43Z
| 2021-06-30T23:29:36Z
| null |
arnasRad
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.