
repo
stringclasses 147
values | number
int64 1
172k
| title
stringlengths 2
476
| body
stringlengths 0
5k
| url
stringlengths 39
70
| state
stringclasses 2
values | labels
listlengths 0
9
| created_at
timestamp[ns, tz=UTC]date 2017-01-18 18:50:08
2026-01-06 07:33:18
| updated_at
timestamp[ns, tz=UTC]date 2017-01-18 19:20:07
2026-01-06 08:03:39
| comments
int64 0
58
⌀ | user
stringlengths 2
28
|
|---|---|---|---|---|---|---|---|---|---|---|
pytorch/TensorRT
| 146
|
❓ [Question] How to convert at::tensor into nvinfer1::ITensor?
|
## ❓ Question
how to convert at::tensor into nvinfer1::ITensor?
## What you have already tried
I tried to run resnet101 using trtorch, however, there was an error when compiling the graph.
As a result of my analysis
TRTorch/core/conversion/converters/impl/element_wise.cpp
```
"aten::div.Tensor(Tensor self, Tensor other) -> Tensor",
[](ConversionCtx* ctx, const torch::jit::Node* n, args& args) -> bool {
// Should implement self / other
auto self = args[0].ITensor();
auto other = args[1].ITensor();
auto div = add_elementwise(ctx, nvinfer1::ElementWiseOperation::kDIV, self, other, util::node_info(n));
TRTORCH_CHECK(div, "Unable to create div layer from node: " << *n);
div->setName(util::node_info(n).c_str());
auto out = ctx->AssociateValueAndTensor(n->outputs()[0], div->getOutput(0));
LOG_DEBUG("Output tensor shape: " << out->getDimensions());
return true;
}
```
self is the ITensor type
other is the IValue type
Thus, this program exits with an error in determining the type.
`auto other = args[1].ITensor();`
I know IValue can be unpacked into at::tensor, however add_elementwise requires nvinfer1::ITensor
## Environment
> Build information about the TRTorch compiler can be found by turning on debug messages
- CPU Architecture: x86_64
- OS (e.g., Linux): Ubuntu
- CUDA version: 10.2 with cudnn 8.0
- GCC/G++: 7.5.0
|
https://github.com/pytorch/TensorRT/issues/146
|
closed
|
[
"question"
] | 2020-07-17T12:49:26Z
| 2020-07-20T21:26:24Z
| null |
zhanjw
|
pytorch/vision
| 2,481
|
How to use torchvision roi_align?
|
I'm confused about the input parameter `boxes` and output of `torchvision.ops.roi_align`. Now I have an input image and one bbox coordinate `[x1, y1, x2, y2]`. Does `roi_align` directly return the region determined by the coordinate?
For exampe, here is my test code:
```python
import torch
from torchvision.ops import roi_align
a = torch.Tensor([[i * 6 + j for j in range(6)] for i in range(6)])
print(a)
a = a.unsqueeze(dim=0)
boxes = [torch.Tensor([[0, 2, 2, 4]])]
a = a.unsqueeze(dim=0)
aligned_rois = roi_align(input=a, boxes=boxes, output_size=2)
print(aligned_rois.shape)
print("aligned_rois:", aligned_rois)
```
And the result is:
```
tensor([[ 0., 1., 2., 3., 4., 5.],
[ 6., 7., 8., 9., 10., 11.],
[12., 13., 14., 15., 16., 17.],
[18., 19., 20., 21., 22., 23.],
[24., 25., 26., 27., 28., 29.],
[30., 31., 32., 33., 34., 35.]])
torch.Size([1, 1, 2, 2])
aligned_rois: tensor([[[[15.5000, 16.5000],
[21.5000, 22.5000]]]])
```
What I want to know is why the returned region is `[15, 16; 21, 22]`?
Thanks for answering!
|
https://github.com/pytorch/vision/issues/2481
|
closed
|
[
"question",
"module: ops"
] | 2020-07-17T04:57:15Z
| 2021-03-09T01:56:32Z
| null |
xuantengh
|
pytorch/TensorRT
| 139
|
🐛 [Bug] Fail to build the NVIDIA TRTorch container on AGX device with JetPack 4.4
|
## Bug Description
I was following this page of [instruction](https://github.com/NVIDIA/TRTorch/tree/master/notebooks#1-requirements).
Command:
```
$ sudo docker build -t trtorch -f Dockerfile.notebook .
```
Output:
```
[sudo] password for nvidia:
Sending build context to Docker daemon 44.18MB
Step 1/14 : FROM nvcr.io/nvidia/pytorch:20.03-py3
20.03-py3: Pulling from nvidia/pytorch
423ae2b273f4: Pulling fs layer
de83a2304fa1: Pulling fs layer
f9a83bce3af0: Pulling fs layer
b6b53be908de: Waiting
031ae32ea045: Waiting
2e90bee95401: Waiting
23b28e4930eb: Waiting
440cfb09d608: Waiting
6f3b05de36c6: Waiting
b0444ce283f5: Waiting
8326831bdd40: Waiting
6cb1b0c70efa: Waiting
51bcf8ebb1f7: Waiting
69bbced5c7a2: Waiting
5f6e40c02ff4: Waiting
ca7835aa5ed2: Waiting
4c512b1ff8a5: Waiting
d85924290896: Waiting
97bb0d3f884c: Waiting
56a4e3b147c2: Waiting
468df4aef4c6: Waiting
522d2b613df7: Pulling fs layer
7d6417f56587: Pulling fs layer
522d2b613df7: Waiting
7d6417f56587: Waiting
0ccda1e4ca15: Waiting
18244f890475: Waiting
c7986e09dff5: Waiting
2d210642f30c: Waiting
c564a113d3bd: Waiting
44abac184be5: Waiting
61817282129e: Waiting
77b3c5340637: Waiting
e7911ce14988: Waiting
59bc17a4d14a: Waiting
6b2f7c275865: Pull complete
07c633be5574: Pull complete
6d767ce36c21: Pull complete
46bbec03f88b: Pull complete
96da7d87df89: Pull complete
d2663f680b06: Pull complete
0ed7e2db20ab: Pull complete
afd57a3ccf55: Pull complete
19ac17f49e57: Pull complete
2984c7bac0e3: Pull complete
e2244eb6a8e7: Pull complete
070f20eb03a3: Pull complete
f6580f25c383: Pull complete
7cc17e0c99d8: Pull complete
aaf5c91bb3d5: Pull complete
c9ad85820d20: Pull complete
e4aaec5cb4a5: Pull complete
3965323727b2: Pull complete
5d75d4272baf: Pull complete
318400c074f7: Pull complete
b5295904374f: Pull complete
b962e5b89d31: Pull complete
fe830d24a0da: Pull complete
Digest: sha256:5f7b67b14fed35890e06f8f4907099ed4506fe0d39250aeb10b755ac6a04a0ad
Status: Downloaded newer image for nvcr.io/nvidia/pytorch:20.03-py3
---> 16c4987611fa
Step 2/14 : RUN apt update && apt install curl gnupg
---> Running in 6bf12c661c88
standard_init_linux.go:211: exec user process caused "exec format error"
The command '/bin/sh -c apt update && apt install curl gnupg' returned a non-zero code: 1
```
I wonder how can I fix this error?
Thank you
BR,
Chieh
## To Reproduce
Steps to reproduce the behavior:
Follow steps from the page of [instruction](https://github.com/NVIDIA/TRTorch/tree/master/notebooks#1-requirements).
## Environment
> Build information about the TRTorch compiler can be found by turning on debug messages
- PyTorch Version: 1.15.0
- JetPack Version: 4.4
- How you installed PyTorch: from here
- Python version: 3.6
- CUDA version: 10.2
- GPU models and configuration: AGX jetson device
- TRT version default is 7.1.0.16 on JetPack 4.4
- bazel version: 3.4.0
|
https://github.com/pytorch/TensorRT/issues/139
|
closed
|
[
"question",
"platform: aarch64"
] | 2020-07-16T02:05:18Z
| 2020-07-20T06:13:49Z
| null |
chiehpower
|
pytorch/android-demo-app
| 76
|
how to get outputTensor as 3d float[][][]?
|
the output of my network is 3d, but getDataAsFloatArray() can only return a 1d float[]
float[] outArr = outputTensor.getDataAsFloatArray();
|
https://github.com/pytorch/android-demo-app/issues/76
|
open
|
[] | 2020-07-14T06:23:26Z
| 2020-08-25T03:46:28Z
| null |
Xiaofeng-life
|
pytorch/vision
| 2,469
|
ImageNet pre-trained model code and hyper-parameters
|
Hi,
Is the code used to trained the torchvision models (especially Resnet) on ImageNet available ? What are the hyper-parameters used ? Did you use specific methods (dropout, weight decay, specific augmentation such as cutout...etc) during training ?
Thank you very much
|
https://github.com/pytorch/vision/issues/2469
|
closed
|
[
"question",
"module: reference scripts"
] | 2020-07-14T05:35:23Z
| 2020-07-14T06:58:07Z
| null |
Jobanan
|
pytorch/TensorRT
| 132
|
Bug about native compilation on NVIDIA Jetson AGX
|
## 🐛 Bug
After I installed the bazel from scratch on AGX device, I directly build it by bazel. However, I got the error like below.
```
$ bazel build //:libtrtorch --distdir third_party/distdir/aarch64-linux-gnu
Starting local Bazel server and connecting to it...
INFO: Repository trtorch_py_deps instantiated at:
no stack (--record_rule_instantiation_callstack not enabled)
Repository rule pip_import defined at:
/home/nvidia/.cache/bazel/_bazel_nvidia/d7326de2ca76e35cc08b88f9bba7ab43/external/rules_python/python/pip.bzl:51:29: in <toplevel>
ERROR: An error occurred during the fetch of repository 'trtorch_py_deps':
pip_import failed: Collecting torch==1.5.0 (from -r /home/nvidia/ssd256/github/TRTorch/py/requirements.txt (line 1))
( Could not find a version that satisfies the requirement torch==1.5.0 (from -r /home/nvidia/ssd256/github/TRTorch/py/requirements.txt (line 1)) (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2)
No matching distribution found for torch==1.5.0 (from -r /home/nvidia/ssd256/github/TRTorch/py/requirements.txt (line 1))
)
ERROR: no such package '@trtorch_py_deps//': pip_import failed: Collecting torch==1.5.0 (from -r /home/nvidia/ssd256/github/TRTorch/py/requirements.txt (line 1))
( Could not find a version that satisfies the requirement torch==1.5.0 (from -r /home/nvidia/ssd256/github/TRTorch/py/requirements.txt (line 1)) (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2)
No matching distribution found for torch==1.5.0 (from -r /home/nvidia/ssd256/github/TRTorch/py/requirements.txt (line 1))
)
INFO: Elapsed time: 8.428s
INFO: 0 processes.
FAILED: Build did NOT complete successfully (0 packages loaded)
```
If I used `python3 setup.py install`, I got the error below:
```
running install
building libtrtorch
INFO: Build options --compilation_mode, --cxxopt, --define, and 1 more have changed, discarding analysis cache.
INFO: Repository tensorrt instantiated at:
no stack (--record_rule_instantiation_callstack not enabled)
Repository rule http_archive defined at:
/home/nvidia/.cache/bazel/_bazel_nvidia/d7326de2ca76e35cc08b88f9bba7ab43/external/bazel_tools/tools/build_defs/repo/http.bzl:336:31: in <toplevel>
WARNING: Download from https://developer.nvidia.com/compute/machine-learning/tensorrt/secure/7.1/tars/TensorRT-7.1.3.4.Ubuntu-18.04.x86_64-gnu.cuda-10.2.cudnn8.0.tar.gz failed: class java.io.IOException GET returned 403 Forbidden
ERROR: An error occurred during the fetch of repository 'tensorrt':
java.io.IOException: Error downloading [https://developer.nvidia.com/compute/machine-learning/tensorrt/secure/7.1/tars/TensorRT-7.1.3.4.Ubuntu-18.04.x86_64-gnu.cuda-10.2.cudnn8.0.tar.gz] to /home/nvidia/.cache/bazel/_bazel_nvidia/d7326de2ca76e35cc08b88f9bba7ab43/external/tensorrt/TensorRT-7.1.3.4.Ubuntu-18.04.x86_64-gnu.cuda-10.2.cudnn8.0.tar.gz: GET returned 403 Forbidden
INFO: Repository libtorch_pre_cxx11_abi instantiated at:
no stack (--record_rule_instantiation_callstack not enabled)
Repository rule http_archive defined at:
/home/nvidia/.cache/bazel/_bazel_nvidia/d7326de2ca76e35cc08b88f9bba7ab43/external/bazel_tools/tools/build_defs/repo/http.bzl:336:31: in <toplevel>
ERROR: /home/nvidia/ssd256/github/TRTorch/core/BUILD:10:11: //core:core depends on @tensorrt//:nvinfer in repository @tensorrt which failed to fetch. no such package '@tensorrt//': java.io.IOException: Error downloading [https://developer.nvidia.com/compute/machine-learning/tensorrt/secure/7.1/tars/TensorRT-7.1.3.4.Ubuntu-18.04.x86_64-gnu.cuda-10.2.cudnn8.0.tar.gz] to /home/nvidia/.cache/bazel/_bazel_nvidia/d7326de2ca76e35cc08b88f9bba7ab43/external/tensorrt/TensorRT-7.1.3.4.Ubuntu-18.04.x86_64-gnu.cuda-10.2.cudnn8.0.tar.gz: GET returned 403 Forbidden
ERROR: Analysis of target '//cpp/api/lib:libtrtorch.so' failed; build aborted: Analysis failed
INFO: Elapsed time: 18.044s
INFO: 0 processes.
FAILED: Build did NOT complete successfully (0 packages loaded, 62 targets configured)
```
Is there any idea about this?
## To Reproduce
Steps to reproduce the behavior:
1. Install bazel from [here](https://github.com/chiehpower/Installation/blob/master/Bazel/README.md)
2. Use this command:
```
bazel build //:libtrtorch --distdir third_party/distdir/aarch64-linux-gnu
```
## Environment
> Build information about the TRTorch compiler can be found by turning on debug messages
- PyTorch Version: 1.15.0
- JetPack Version: 4.4
- How you installed PyTorch: from [here](https://github.com/chiehpower/Installation/tree/master/AGX#install-pytorch)
- Python version: 3.6
- CUDA version: 10.2
- GPU models and configuration: AGX jetson device
- TRT version default is `7.1.0.16` on JetPack 4.4
- bazel version: 3.4.0
Thank you
BR,
Chieh
|
https://github.com/pytorch/TensorRT/issues/132
|
closed
|
[
"documentation",
"question",
"platform: aarch64"
] | 2020-07-14T03:30:25Z
| 2020-07-17T18:02:12Z
| null |
chiehpower
|
pytorch/pytorch
| 41,328
|
How to transform from input points to rendered image
|
https://github.com/pytorch/pytorch/issues/41328
|
closed
|
[] | 2020-07-13T06:15:35Z
| 2020-07-14T02:50:59Z
| null |
Gaozhongpai
|
|
pytorch/pytorch
| 41,309
|
How to make build_pytorch_android.sh running with python 3 on mac?
|
Hi all, I was trying to following the tutrials from https://pytorch.org/mobile/android/#building-pytorch-android-from-source.
when I run the
> git clone https://github.com/pytorch/pytorch.git
> cd pytorch
> sh ./scripts/build_pytorch_android.sh
It reports me the error such that
> File "/Users/huanghenglin/pytorch/tools/shared/module_loader.py", line 12, in import_module
> from importlib.machinery import SourceFileLoader
> ImportError: No module named machinery
I guessn this issue was caused by the scrip run the module_loader.py with python 2.
I already set the python 3 as my default python by adding the following code on .zshrc
> export PATH=${PATH}:/usr/local/opt/python@3.8/libexec/bin
> alias python="/usr/local/opt/python@3.8/libexec/bin/python"
and the code
> from importlib.machinery import SourceFileLoader
runs ok on terminal's python.
the end part of report from the secipt:
> [ 63%] Generating ../../torch/csrc/autograd/generated/Functions.cpp, ../../torch/csrc/jit/generated/generated_unboxing_wrappers_0.cpp, ../../torch/csrc/jit/generated/generated_unboxing_wrappers_1.cpp, ../../torch/csrc/jit/generated/generated_unboxing_wrappers_2.cpp, ../../torch/csrc/autograd/generated/Functions.h, ../../torch/csrc/autograd/generated/variable_factories.h, ../../torch/csrc/autograd/generated/python_functions.cpp, ../../torch/csrc/autograd/generated/python_variable_methods.cpp, ../../torch/csrc/autograd/generated/python_torch_functions.cpp, ../../torch/csrc/autograd/generated/python_nn_functions.cpp, ../../torch/csrc/autograd/generated/python_functions.h
> Traceback (most recent call last):
> File "tools/setup_helpers/generate_code.py", line 118, in <module>
> main()
> File "tools/setup_helpers/generate_code.py", line 113, in main
> options.force_schema_registration,
> File "tools/setup_helpers/generate_code.py", line 34, in generate_code
> from tools.autograd.gen_autograd import gen_autograd, gen_autograd_python
> File "/Users/huanghenglin/pytorch/tools/autograd/gen_autograd.py", line 30, in <module>
> from .utils import YamlLoader, split_name_params, signature_without_args
> File "/Users/huanghenglin/pytorch/tools/autograd/utils.py", line 15, in <module>
> CodeTemplate = import_module('code_template', 'aten/src/ATen/code_template.py').CodeTemplate
> File "/Users/huanghenglin/pytorch/tools/shared/module_loader.py", line 12, in import_module
> from importlib.machinery import SourceFileLoader
> ImportError: No module named machinery
> make[2]: *** [../torch/csrc/autograd/generated/Functions.cpp] Error 1
> make[1]: *** [caffe2/CMakeFiles/torch_cpu.dir/all] Error 2
> make: *** [all] Error 2
>
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/41309
|
closed
|
[] | 2020-07-11T15:54:32Z
| 2020-07-12T02:46:13Z
| null |
hehedaozuiteng
|
huggingface/transformers
| 5,682
|
What is the decoder_input for encoder-decoder transformer in training time?
|
https://datascience.stackexchange.com/questions/76261/whats-the-input-dimension-for-transformer-decoder-during-training
Is the link's answer right?
Thank you very much!
|
https://github.com/huggingface/transformers/issues/5682
|
closed
|
[] | 2020-07-11T10:48:07Z
| 2020-07-12T03:32:38Z
| null |
guotong1988
|
pytorch/TensorRT
| 130
|
Can't compile python package
|
I am able to compile the CXX API, but the python package fails with the error:
```
fatal error: NvInfer.h: No such file or directory
#include "NvInfer.h"
^~~~~~~~~~~
compilation terminated.
```
A quick search confirms that ``NvInfer.h`` is not in the repo, so I assume it is part of LibTorch / cuDNN / TRT, so I suspect bazel has an issue with the location of one of these, but I find it strange that I can compile the C++ API, so I was wondering if the python package is currently building correctly and, if so, what I can do to troubleshoot this.
My OS is Ubuntu 20.04, python 3.8 inside a conda environment, with bazel 3.3.1, cuda 10.2, TensorRT 7.1.3.4 and cuDNN 8.0.1.13
|
https://github.com/pytorch/TensorRT/issues/130
|
closed
|
[
"question",
"component: build system",
"No Activity"
] | 2020-07-10T05:28:08Z
| 2020-08-18T00:06:25Z
| null |
IgnacioJPickering
|
pytorch/vision
| 2,449
|
Custom Weights for Pytorch Hub for yolo v5
|
Hello
Just wanted to know if there a way of import yolo v5 model using PyTorch Hub and then loading my custom weights on top of it.
|
https://github.com/pytorch/vision/issues/2449
|
closed
|
[
"question",
"module: models",
"module: hub"
] | 2020-07-10T04:47:29Z
| 2020-07-10T06:49:43Z
| null |
sakshamjn
|
pytorch/xla
| 2,328
|
What is tracker.rate() and tracker.global_rate()
|
## ❓ Questions and Help
Hello, I am still trying pytorch tpu. In the pytorch tpu mnist colab tutorial. It uses tracker.rate() and tracker.global_rate(). What are these two things? Thank you!
|
https://github.com/pytorch/xla/issues/2328
|
closed
|
[] | 2020-07-08T13:22:35Z
| 2020-07-09T08:19:03Z
| null |
sharkdeng
|
pytorch/text
| 874
|
how to keep tracking the record using original id?
|
## ❓ Questions and Help
Hi, I have a dataset and each record has its own id and some meta info. I want to keep tracking the record using id so that I know which output is for which record. I tried use Filed but it give the error, TypeError: '<' not supported between instances of 'Example' and 'Example'
`
src = data.Field(
sequential=True,
tokenize=tokenize_en,
pad_first=True,
lower=True,
# fix_length=fix_length,
include_lengths=True,
init_token='<SOS>',
eos_token='<EOS>'
)
raw_data = data.TabularDataset(
path=data_path, format='csv',
train='data.csv',
fields=[
('src', src),
('id', data.Field()),
('type', data.Field())
])
src.build_vocab(
raw_data,
#max_size=20000,
# min_freq=2,
#vectors=vectors
)
`
|
https://github.com/pytorch/text/issues/874
|
open
|
[] | 2020-07-08T12:26:00Z
| 2020-07-08T12:26:00Z
| null |
Marvinmw
|
pytorch/pytorch
| 41,065
|
How to use (torch.utils.data.DataLoader) in android?
|
Now , I try running PSENet in Android . Project urls : https://github.com/whai362/PSENet
Its testcode need (torch.utils.data.DataLoader)。 you can look PSENet Project .> test_ic15.py 72 lines
I have torch==1.4.0 change PSENet.pth ==> PSENet.pt and model load in Android is OK。But,
next I don't know what to do.
I want a little alittle translation the PSENet testcode in Android 。
Sorry,my English is very poor, if you can, give me some android advice
|
https://github.com/pytorch/pytorch/issues/41065
|
closed
|
[
"triaged",
"module: android",
"oncall: mobile"
] | 2020-07-07T08:28:30Z
| 2020-07-08T20:35:26Z
| null |
Micla-SHL
|
pytorch/pytorch
| 41,064
|
When using _MultiProcessingDataLoaderIter in Dataloader, how to add a filelock in Dataset to make the file io thread-safety?
|
## ❓ Questions and Help
When I use DataLoader to load a dataset consisted of several files, I find when I cannot set the `num_workers > 0` because it will occurs a Error `TypeError: function takes exactly 5 arguments (1 given)`.
When I set `shuffle = True` into DataLoader, this Error when occur randomly (e.g. I will train it for several epochs and the Error happens), however, when I set the `shuffle = False`, the error will appear in the first several minibatch.
I'm very sure that the bug is from the _MultiProcessingDataLoaderIter in Dataloader and the data I've prepared is correct, because if I set the `num_workers = 0`, my code can finished the training process.
### Code Details
I offer some details here, and hope someone can help me 😭
This is the Dataset:
```python
class ChunkDataset(Dataset):
def __init__(self, feat_scp_file, chunk_size_range=(100, 500)):
super(ChunkDataset, self).__init__()
self.feat_scp_file = feat_scp_file
self.feature_reader = SynchronizedFeatureReader(self.feat_scp_file)
self.utt_list = self.feature_reader.get_utt_list()
self.min_chunk_size = chunk_size_range[0]
self.max_chunk_size = chunk_size_range[1]
def __len__(self):
return len(self.feature_reader)
def __getitem__(self, item):
utt_id = self.utt_list[item]
feat = self.feature_reader[utt_id]
feat_len = feat.shape[0]
chunk_size = random.randint(self.min_chunk_size, self.max_chunk_size)
chunk_start = random.randint(0, max(0, feat_len - chunk_size))
return feat[chunk_start: min(chunk_start + chunk_size, feat_len), :]
```
The key part in it is the SynchronizedFeatureReader: ( I wrapper the data reader many times because other function need it ,not just for pytorch)
```python
class SynchronizedFeatureReader(object):
def __init__(self, scp_file):
self.scp_file = scp_file
self.feat_dict = ScriptReader(scp_file)
def _load(self, utt_id):
return self.feat_dict[utt_id]
def __len__(self):
return len(self.feat_dict)
def __getitem__(self, item):
return self.feat_dict[item]
def __iter__(self):
for (utt_id, feat) in self.feat_dict:
yield utt_id, feat
def get_utt_list(self):
return self.feat_dict.index_keys
```
And finally, you can see how I read the data:
```python
class ScriptReader(Reader):
def __init__(self, ark_scp):
self.fmgr = dict()
def addr_processor(addr):
addr_token = addr.split(":")
if len(addr_token) == 1:
raise ValueError("Unsupported scripts address format")
path, offset = ":".join(addr_token[0:-1]), int(addr_token[-1])
return (path, offset)
super(ScriptReader, self).__init__(ark_scp,
value_processor=addr_processor)
def __del__(self):
for name in self.fmgr:
self.fmgr[name].close()
def _open(self, obj, addr):
if obj not in self.fmgr:
self.fmgr[obj] = open(obj, "rb")
arkf = self.fmgr[obj]
arkf.seek(addr)
return arkf
def _load(self, key):
path, addr = self.index_dict[key]
fd = self._open(path, addr)
obj = io.read_float_mat_vec(fd, direct_access=True)
return obj
```
I have to explain here the `io.read_float_mat_vec` is writtern by myself, it will read the first two bytes to make sure the `fd.seek()` is right. The assert is like:
```python
def expect_binary(fd):
flags = bytes.decode(fd.read(2))
throw_on_error(flags == '\0B', f'Expect binary flag, but gets {flags}')
```
and you will find the the flags will be wrong when dataloader run.
The `scp_file` I used is like this , It's come from other code which is not important for this issue, I think. The format is like:
```
a0001 file.vec.ark:9
a0002 file.vec.ark:2076
a0003 file.vec.ark:4143
a0004 file.vec.ark:6210
a0005 file.vec.ark:8277
a0006 file.vec.ark:10344
......
```
The Error log is:
```
Traceback (most recent call last):
File "TestFeatureReader.py", line 172, in <module>
main()
File "TestFeatureReader.py", line 168, in main
process.test_data(tr_dataloader)
File "/home/lycheng/workspace/corecode/Python/SRE-Pytorch-Tools/process/test_process.py", line 31, in test_data
for index, (data, label) in enumerate(data_loader):
File "/home/work_nfs2/lycheng/env/anaconda3/anaconda_py36/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/work_nfs2/lycheng/env/anaconda3/anaconda_py36/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 856, in _next_data
return self._process_data(data)
File "/home/work_nfs2/lycheng/env/anaconda3/anaconda_py36/lib/python3.6/site-packages/torch/utils/data/datal
|
https://github.com/pytorch/pytorch/issues/41064
|
closed
|
[
"module: dataloader",
"triaged"
] | 2020-07-07T07:18:47Z
| 2020-07-12T03:19:32Z
| null |
GeekOrangeLuYao
|
pytorch/vision
| 2,400
|
DownSample
|
https://github.com/pytorch/vision/blob/86b6c3e22e9d7d8b0fa25d08704e6a31a364973b/torchvision/models/resnet.py#L195
Why don't we need a downsample in this loop??
|
https://github.com/pytorch/vision/issues/2400
|
closed
|
[
"question"
] | 2020-07-07T03:17:34Z
| 2020-07-07T09:21:55Z
| null |
jianjiandandande
|
huggingface/transformers
| 5,564
|
Where is the documentation on migrating to the 3.0 tokenizer API?
|
I see that you folks have completely changed the API to do tokenizing, e.g. for BertTokenizer. I have a lot of code using the two methods `encode_plus()` and `batch_encode_plus()`, and when I went to the [documentation](https://huggingface.co/transformers/main_classes/tokenizer.html) to look up an argument, I found that these methods are completely gone. All that remains is a little blurb saying:
> `BatchEncoding` holds the output of the tokenizer’s encoding methods (`__call__`, `encode_plus` and `batch_encode_plus`) and is derived from a Python dictionary.
Are these two methods deprecated now? Did you post a migration guide for users?
On the main [Huggingface Transformers page](https://github.com/huggingface/transformers), you have sections for `Migrating from pytorch-transformers to transformers` and `Migrating from pytorch-pretrained-bert to transformers`, so it's not like there's no precedent for you to provide some information to users on major API changes.
|
https://github.com/huggingface/transformers/issues/5564
|
closed
|
[] | 2020-07-07T03:17:26Z
| 2020-07-07T21:15:04Z
| null |
githubrandomuser2017
|
pytorch/examples
| 799
|
How to use my own backbone?
|
https://github.com/pytorch/examples/issues/799
|
closed
|
[] | 2020-07-06T03:31:29Z
| 2022-03-09T21:37:54Z
| null |
wangbin2018
|
|
pytorch/vision
| 2,393
|
Mask R-CNN: get all the parts and train specific ones
|
Hi,
I would like to access all the different parts of Mask R-CNN in order to only train some of them.
I learnt in the discussion forum that I can use `requires_grad` to enable/disable training, but how can I access all the `trainable` parts?
Thanks,
|
https://github.com/pytorch/vision/issues/2393
|
closed
|
[
"question"
] | 2020-07-05T09:21:15Z
| 2020-07-07T09:33:13Z
| null |
FiReTiTi
|
pytorch/vision
| 2,391
|
How to Change All BN layers to GN layers?
|
i tried this :
```
import torchvision.models as models
model = models.resnet18()
#then this :
for name, module in model.named_modules():
if isinstance(module, nn.BatchNorm2d):
# Get current bn layer
bn = getattr(model, name)
# Create new gn layer
gn = nn.GroupNorm(1, bn.num_features)
# Assign gn
print('Swapping {} with {}'.format(bn, gn))
setattr(model, name, gn)
print(model)
```
and it gives this error :
```
Swapping BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) with GroupNorm(1, 64, eps=1e-05, affine=True)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-26-dc2f23e093cc> in <module>
2 if isinstance(module, nn.BatchNorm2d):
3 # Get current bn layer
----> 4 bn = getattr(model, name)
5 # Create new gn layer
6 gn = nn.GroupNorm(1, bn.num_features)
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py in __getattr__(self, name)
592 return modules[name]
593 raise AttributeError("'{}' object has no attribute '{}'".format(
--> 594 type(self).__name__, name))
595
596 def __setattr__(self, name, value):
AttributeError: 'ResNet' object has no attribute 'layer1.0.bn1'
```
|
https://github.com/pytorch/vision/issues/2391
|
closed
|
[
"invalid"
] | 2020-07-04T09:52:25Z
| 2020-07-07T09:31:44Z
| null |
mobassir94
|
pytorch/vision
| 2,390
|
Excessive memory consumption while using DistributedDataParallel
|
## 🐛 Bug
TL;DR : While using `DistributedDataParallel` and multiple GPU, memory consumption on each GPU seems to be more than twice as much as what is observed when without using `DistributedDataParallel` on a single GPU.
## To Reproduce
I have been using FasterRCNN from Torchvision’s models that uses DistributedDataParallel for training. However, I find that while using multiple GPU, the memory consumption is far more than without multiple GPU. Here is my code
```
kwargs = {}
kwargs['min_size'] = args.min_size
kwargs['max_size'] = args.max_size
model = ModifiedFRCNN(cfg=cfg, custom_anchor=args.custom_anchor,
use_def=args.use_def, cpm=args.cpm,
default_filter=args.default_filter,
soft_nms=args.soft_nms,
upscale_r=args.upscale_r, **kwargs).cuda().eval()
model = restore_network(model)
model_without_ddp = model
dataset = GenData(args.test_dataset,
args.base_path,
dataset_param=None,
train=False)
if args.n_gpu > 1:
init_distributed_mode(args)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu],
find_unused_parameters=True)
model_without_ddp = model.module
sampler = torch.utils.data.distributed.DistributedSampler(dataset)
batch_sampler = torch.utils.data.BatchSampler(sampler,
args.batch_size,
drop_last=True)
data_loader = torch.utils.data.DataLoader(dataset,
batch_sampler=batch_sampler,
num_workers=args.num_workers,
collate_fn=coco_collate)
metric_logger = MetricLogger(delimiter=" ")
header = 'Valid:'
batch_iterator = metric_logger.log_every(data_loader, 100, header)
else:
model = model.cuda()
data_loader = iter(data.DataLoader(dataset, args.batch_size, shuffle=False,
num_workers=args.num_workers,
collate_fn=coco_collate))
batch_iterator = iter(data_loader)
```
`ModifiedFRCNN` is a class that inherits `FasterRCNN` to make trivial changes, such as parameter, postprocessing etc.
Case 1 : When n_gpu=1, I am able to use a batch size of upto 8.
Case 2 : When n_gpu=4, I am unable to even use a batch size of 1.
Both the above mentioned cases are on same the GPU, 2080Ti.
## Expected behavior
Consume comparable memory if not equal on each GPUs as the case of training on a single GPU.
## Environment
```
Collecting environment information...
PyTorch version: 1.2.0
Is debug build: No
CUDA used to build PyTorch: 10.0.130
OS: Debian GNU/Linux 10 (buster)
GCC version: (Debian 8.3.0-6) 8.3.0
CMake version: version 3.13.4
Python version: 3.7
Is CUDA available: Yes
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: GeForce RTX 2080 Ti
GPU 1: GeForce RTX 2080 Ti
Nvidia driver version: 430.14
cuDNN version: Could not collect
Versions of relevant libraries:
[pip3] numpy==1.19.0
[pip3] torch==1.2.0
[pip3] torchvision==0.4.0
```
## Additional context
The command I use to launch
```
python -m torch.distributed.launch --nproc_per_node=4 --use_env test.py <other_arguments> --world_size 4 --n_gpu 4
```
## PS
I have posted this issue [here](https://discuss.pytorch.org/t/excessive-memory-consumption-while-using-distributeddataparallel/87568) and since I did not receive any response, I was not sure whether the place where I posted this was correct, hence re-posting here. Apologies if that shouldn't be done.
Thank you!
|
https://github.com/pytorch/vision/issues/2390
|
closed
|
[
"question"
] | 2020-07-04T06:46:25Z
| 2020-07-07T09:44:35Z
| null |
Sentient07
|
pytorch/examples
| 797
|
train from last weight
|
Can this project continue training from the last saved weight?I trained one epoch with seven hours.and now I want to train on it basis
|
https://github.com/pytorch/examples/issues/797
|
open
|
[
"help wanted"
] | 2020-07-02T12:47:38Z
| 2022-03-10T00:06:38Z
| 1
|
Muxindawang
|
huggingface/transformers
| 5,447
|
Where did "prepare_for_model" go? What is the replacement?
|
I'm working with already numericalized data (e.g., where the text has been converted to ids via `tokenizer.tokenize()`) and was using `prepare_for_model` to build the appropriate input dictionary ... ***but*** that method is gone in 3.0.
So ... what should I use/do now?
Thanks
|
https://github.com/huggingface/transformers/issues/5447
|
closed
|
[] | 2020-07-01T19:20:34Z
| 2020-07-03T14:51:22Z
| null |
ohmeow
|
pytorch/pytorch
| 40,855
|
Don't know how to translate op Conv
|
(sent here from https://github.com/onnx/onnx/issues/2822)
I'm only seeing this error on Windows. It's working fine on Linux (Docker).
I can't find any other issues or documentation, but I get the impression that the op registry is not populated fully. Is there some kind of setup that I need to go through? Prerequisite installation needed?
I'm working on Windows 10, python 3.6, I've installed `onnx==1.7.0` indirectly with pip by installing pytorch according to the [getting started page instructions at pytorch's website](https://pytorch.org/get-started/locally/): `pip install torch==1.4.0 torchvision==0.5.0 -f https://download.pytorch.org/whl/torch_stable.html`
```
.venv\lib\site-packages\caffe2\python\onnx\backend.py:713: in prepare
init_net, predict_net = cls._onnx_model_to_caffe2_net(model, device, opset_version, False)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
cls = <class 'caffe2.python.onnx.backend.Caffe2Backend'>
onnx_model = ir_version: 3
producer_name: "pytorch"
producer_version: "0.4"
graph {
node {
input: "0"
input: "1"
outp... dim {
dim_value: 512
}
}
}
}
}
}
opset_import {
domain: ""
version: 9
}
device = 'CPU', opset_version = 9, include_initializers = False
# <snip>
E RuntimeError: ONNX conversion failed, encountered 69 errors:
# <snip>
E . Exception: [enforce fail at ..\caffe2\onnx\backend.cc:1426] . Don't know how to translate op Conv
E (no backtrace available)
```
|
https://github.com/pytorch/pytorch/issues/40855
|
closed
|
[] | 2020-07-01T08:40:42Z
| 2020-07-01T14:42:50Z
| null |
Korijn
|
pytorch/examples
| 795
|
Under the Mnist-Hogwild framework, how to use multi-gpu computing?
|
When I execute the code example of mnist_hogwild, I find that multiple processes are running parallelly on one gpu. Question: Can multiple processes be executed in parallel on multiple GPUs?
|
https://github.com/pytorch/examples/issues/795
|
open
|
[
"distributed"
] | 2020-06-29T08:21:04Z
| 2022-03-09T20:56:18Z
| null |
Wang-Zhenxing
|
pytorch/tutorials
| 1,038
|
Simplify numpy function call in object detection tutorial
|
In the second code block in the tutorial, the line `pos = np.where(masks[i])` has been used to get the indices of the non zero points in the image. But [numpy documentation for `np.where()`](https://numpy.org/doc/1.18/reference/generated/numpy.where.html) advises to use [`np.nonzero()`](https://numpy.org/doc/1.18/reference/generated/numpy.nonzero.html) when there is only one argument for `np.where()`, and it also makes the code more readable.
|
https://github.com/pytorch/tutorials/issues/1038
|
closed
|
[
"torchvision",
"docathon-h1-2023",
"easy"
] | 2020-06-23T09:30:21Z
| 2023-10-05T17:20:12Z
| 4
|
ashok-arjun
|
huggingface/transformers
| 5,204
|
T5 Model : What is maximum sequence length that can be used with pretrained T5 (3b model) checkpoint?
|
As the paper described, T5 uses a relative attention mechanism and the answer for this [issue](https://github.com/google-research/text-to-text-transfer-transformer/issues/273) says, T5 can use any sequence length were the only constraint is memory.
According to this, can I use T5 to summarize inputs that have more than 512 tokens in a sequence?
|
https://github.com/huggingface/transformers/issues/5204
|
closed
|
[] | 2020-06-23T02:36:22Z
| 2023-08-29T21:43:31Z
| null |
shamanez
|
pytorch/pytorch
| 40,257
|
How to get pytorch 1.4?
|
Pytorch 1.4 is not in this list https://pytorch.org/get-started/previous-versions/
I tried to replace the 1.2 to 1.4 as below, but still it didnt work
`conda install pytorch==1.4.0 torchvision==0.4.0 cudatoolkit=10.0 -c pytorch`
|
https://github.com/pytorch/pytorch/issues/40257
|
closed
|
[] | 2020-06-19T00:42:18Z
| 2020-06-19T03:44:09Z
| null |
ivder
|
huggingface/neuralcoref
| 259
|
getting a none value for `print(doc._.coref_clusters)`
|
hey people, I have attached code and the output. As you can see I am getting a none value when I am trying to `print(doc._.coref_clusters)` and the code above line in the given program is giving the output well and good. why is this? something related to new version bugs or something like that? please respond, thanks.
```
import spacy
import neuralcoref
nlp = spacy.load('en')
doc = nlp('My sister has a dog. She loves him.')
for token in doc:
print('{}:{}'.format(token,token.vector[:3]))
neuralcoref.add_to_pipe(nlp)
print(doc._.coref_clusters)
doc2 = nlp('Angela lives in Boston. She is quite happy in that city.')
for ent in doc2.ents:
print(ent._.coref_cluster)
```
```
(spacy) C:\Users\Gourav\Desktop\py3>python coref.py
C:\Users\Gourav\Anaconda3\envs\spacy\lib\importlib\_bootstrap.py:219: RuntimeWarning: spacy.morphology.Morphology size changed, may indicate binary incompatibility. Expected 104 from C header, got 112
from PyObject
return f(*args, **kwds)
C:\Users\Gourav\Anaconda3\envs\spacy\lib\importlib\_bootstrap.py:219: RuntimeWarning: spacy.vocab.Vocab size changed, may indicate binary incompatibility. Expected 96 from C header, got 112 from PyObject
return f(*args, **kwds)
C:\Users\Gourav\Anaconda3\envs\spacy\lib\importlib\_bootstrap.py:219: RuntimeWarning: spacy.tokens.span.Span size changed, may indicate binary incompatibility. Expected 72 from C header, got 80 from PyObject
return f(*args, **kwds)
My:[3.3386087 0.17132008 2.5449834 ]
sister:[ 0.57823443 2.995358 -0.9161793 ]
has:[-1.2454867 0.10024977 -2.9887996 ]
a:[-2.6144893 -0.87124985 0.77286935]
dog:[-1.5898073 1.3804269 -1.875045 ]
.:[-0.20775741 -3.216754 -0.9142698 ]
She:[ 1.9065745 -1.1759269 -1.1481409]
loves:[-3.0270743 0.6966858 -3.8048356]
him:[ 2.6918807 -1.7273386 -5.5162654]
.:[-1.5350039 -2.1957831 -1.6328099]
None
```
|
https://github.com/huggingface/neuralcoref/issues/259
|
closed
|
[
"question"
] | 2020-06-18T19:12:59Z
| 2020-06-19T07:58:38Z
| null |
chettipalli
|
pytorch/tutorials
| 1,033
|
A PR to fix typos failed build/deploy (#1001)
|
I corrected some typos in chatbot_tutorial.py and opened a pull request #1001 .
Only texts written in a comment of a .py file were modified, but I got build fail.
Is there any guideline to cope with such case?
I don't know why but some PR like #1017, which just corrects a typo, was successfully built.
|
https://github.com/pytorch/tutorials/issues/1033
|
closed
|
[] | 2020-06-18T14:17:47Z
| 2021-06-07T21:51:03Z
| 1
|
lewha0
|
pytorch/vision
| 2,329
|
A problem of multiclassifier task with Squeezenet trained on VOC2012
|
I got a problem when I dealed with a multiclassifier task with squeezenent on VOC2012. I just wrote a train code, and called the '''torchversion.models.squeezenet1_1''', changed num_classes. I used '''torch.nn.MultiLabelSoftMarginLoss()''' for my loss function. However, my loss never changed when I trained my network. If there is someone having same problem like me, and having some specific soluation, please help me. please! Thank you~
```
Epoch: [ 0/2000] step: 0, Loss: 0.754, mAP 26.93%
Epoch: [ 0/2000] step: 20, Loss: 0.693, mAP 7.48%
Epoch: [ 0/2000] step: 40, Loss: 0.693, mAP 6.65%
Epoch: [ 0/2000] step: 60, Loss: 0.693, mAP 6.43%
Epoch: [ 0/2000] step: 80, Loss: 0.693, mAP 6.39%
Epoch: [ 0/2000] step: 100, Loss: 0.693, mAP 6.55%
Epoch: [ 0/2000] step: 120, Loss: 0.693, mAP 6.83%
```
|
https://github.com/pytorch/vision/issues/2329
|
closed
|
[
"invalid",
"question"
] | 2020-06-18T08:48:09Z
| 2020-07-07T15:07:28Z
| null |
JiahangWu
|
pytorch/pytorch
| 40,165
|
How to replace a parameter with other variable while keeping the backpropagation?
|
For example, now I have a parameter 'D' in the model.
Now I want to replace the 'D' with 'C', where 'C = a+b'. Is there anyway in pytorch that can achieve that replacement while keeping the backpropagation between 'C' and 'a+b'. (e.g., training the model will update the value of 'a' and 'b'.
I've tried D.data = C, but obviously that just changed the value and violate the backpropagation. Besides, '.copy' and '.clone' didn't work either.
|
https://github.com/pytorch/pytorch/issues/40165
|
closed
|
[] | 2020-06-17T14:41:18Z
| 2020-06-17T22:04:06Z
| null |
kunwuz
|
pytorch/tutorials
| 1,032
|
Adversarial example generation by FGSM: different normalization of training vs test images?
|
In the Adversarial example generation tutorial the classifier from https://github.com/pytorch/examples/tree/master/mnist is used. However, this classifier is trained with input normalization `transforms.Normalize((0.1307,), (0.3081,))` while in the FGSM tutorial no normalization is used and the perturbed images are clamped to [0,1] - is this not a contradiction?
|
https://github.com/pytorch/tutorials/issues/1032
|
closed
|
[
"docathon-h1-2023",
"medium"
] | 2020-06-17T13:09:32Z
| 2023-06-12T20:41:43Z
| 3
|
hookxs
|
pytorch/text
| 828
|
How to fix the order of data in iterator during training step?
|
## ❓ Questions and Help
**Description**
<!-- Please send questions or ask for help here. -->
Currently, I'm running experiments with several datasets in torchtext, and I just found that I can't reproduce my experiments although I excluded all the possible randomness as following:
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
random.seed(seed)
np.random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
I found that, when Iterator class is initialized, `RandomShuffler()` defined in torchtext.data.utils is set as a `self.random_shuffler`, and this is used to shuffle data in training dataset. However, although one can set random state of `RandomShuffler` by feeding it as an argument of it, the line `self.random_shuffler = RandomShuffler()` doesn't let us to manually set the random state of it. Am I right? Is there a way to fix the order of data for training step?
|
https://github.com/pytorch/text/issues/828
|
open
|
[
"new datasets and building blocks"
] | 2020-06-17T06:23:45Z
| 2020-06-29T19:32:14Z
| null |
seewoo5
|
pytorch/vision
| 2,325
|
pytorch pre-trained models preprocessing results 9 images
|
I am using vgg16 and for preprocessing I use transforms module (as used in the documentation)
and I don't know why, but when it takes my image as input, it outputs 9 small copy of the input image and combines them into one single image (nonetheless the output is correct)
is it a problem?
|
https://github.com/pytorch/vision/issues/2325
|
closed
|
[
"question"
] | 2020-06-16T20:24:38Z
| 2020-06-19T10:00:17Z
| null |
aliamiri1380
|
pytorch/tutorials
| 1,029
|
questions about "CHATBOT TUTORIAL", some meaningless words at the end of the genertated sentences.
|
n_iteration set to 8000, the results as follow:
D:\ProgramData\Anaconda3\envs\pytorch\python.exe "some/3evaluate_use.py"
Building encoder and decoder ...
Models built and ready to go!
> 不明白你说啥麻烦您老说明白点
Building prefix dict from the default dictionary ...
Loading model from cache some\jieba.cache
Loading model cost 0.777 seconds.
Prefix dict has been built successfully.
Bot: 这 都 你 也 太笨 了 点 吧 吧 哦 呀 说 啊 ?
> 你在干嘛
Bot: 除了 聊天 还是 聊天 聊天 呀 群主 呀 群主 呀
> 你是傻逼吗?
Bot: 任何 人工智能 都 敌不过 阁下 这 款 天然 傻瓜 傻 逼 , 还怕 当回 傻 逼
> 卧槽
Bot: 大哥 , 买斤 素质 填补 一下 你 猥琐 的 大脑 ! 没法 ! 打 他 的 !
> 哈哈哈哈
Bot: 别笑 了 , 露出 一嘴 的 黄牙 。 亲爱 的 。 骂 你 。
> 我喜欢你
Bot: 你 到底 喜欢 我 什么 , 我 改 还 不成 吗 ? 行 啊 ! 上 了
> 我想你
Bot: 一定 要 多 想 哦 , 除了 wc 以外 的 时间 都 要 想 我 哦 !
> 我们一起私奔吧
Bot: 你 吵 不过 我 的 ! 呢 哟 哟 。 亲爱 的 。 今天
> 拜拜
Bot: 嗯 啊 , 再见 , 我会 想 你 的 。 亲爱 的 !
> 你喜欢我吗
Bot: 很 喜欢 很 喜欢 啦 滴 事情 事情 事情 事情 事情 事情
> 你喜欢我吗?
Bot: 很 喜欢 很 喜欢 啦 滴 ! 猪猪 ! 打 ! 打 ! 打
> 你吃那么多
Bot: 是 啊 , 好多 。 喜欢 。 喜欢 。 亲爱 的 。 。
> 你吃太多了
Bot: 是 啊 , 好多 。 喜欢 。 亲爱 的 。 。 。 。
> 你长太胖了
Bot: 不要 緊 , 有 我 ! 看 ! ! 打 ! 打 !
> 你放屁
Bot: 你 才 放屁 呢 。 可能 大概 是 哥 。
> 你不是人
Bot: 是 啊 。 大方 3 。 可能 大概 是 屁股 ! 打
> 你是真的傻
Bot: 你 才 傻 了 傻 逼 吖 。 亲爱 的
> 累不累
Bot: 累 啊 , 累 得 够呛 的 说 呀 说 。 猥琐
> 约么?
Bot: 问 天问 地 , 说 说 你 , 说 说 我 , 我 就 说 嘛
> 你太可爱了
Bot: 嘻嘻 , 你 也 很 可爱 的 说 啊 。 亲爱 的
> 大长腿
Error: Encountered unknown word.
> 好漂亮
Bot: 对 啊 , 对 啊 , 我 爱 美女 , 美女 爱 我 ! 爱 你 !
> 你出去
Bot: 我会 给 你 安全 么 3 。 棒 。
> 滚
Bot: 该 滚 的 是 网友 吧 的 说 , 现在 是 在 表扬 你 一斤
>
The words marked in the red square are meaningless words.

In such situation, why this happened, and how to improve this?
The average loss from 9.6302 to 0.3282

......
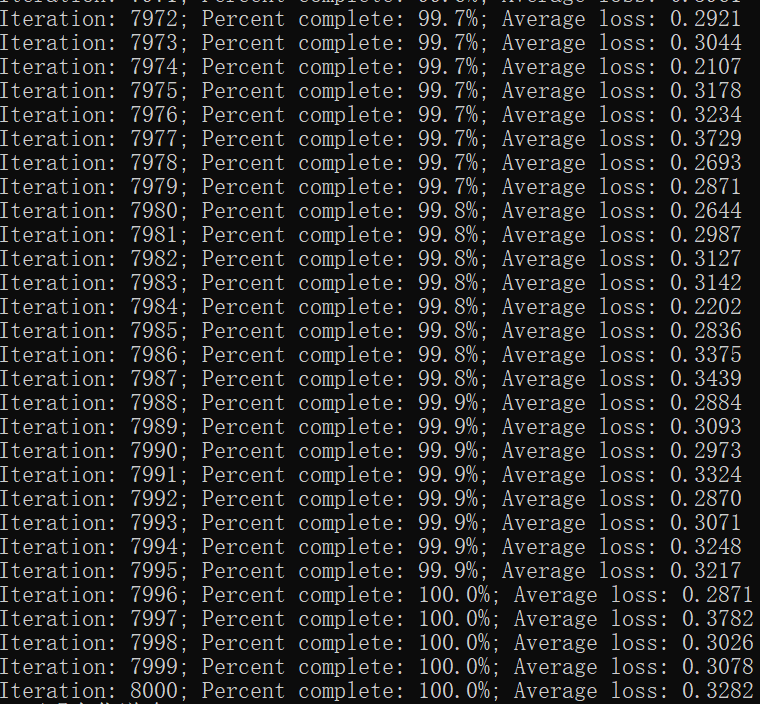
Any big guns can do me a favor, thank you!
|
https://github.com/pytorch/tutorials/issues/1029
|
closed
|
[
"Text"
] | 2020-06-16T01:53:46Z
| 2023-03-17T20:02:26Z
| 3
|
jobsfan
|
pytorch/xla
| 2,225
|
How to call tensor.item() on single proc after a collective op ?
|
## ❓ Questions and Help
Hi, I'm trying to log tensor value by calling `res[0].item()` in a single process after `all_reduce` on this tensor. Execution seems to hang.
To reproduce:
```python
import torch
import torch_xla.core.xla_model as xm
import torch_xla.distributed.xla_multiprocessing as xmp
def test_tensor_item(index):
xm.rendezvous('init')
print(index, "test_tensor_item")
device = xm.xla_device()
rank = xm.get_ordinal()
t = torch.tensor([rank + 0.0, rank + 1.0, rank + 2.0], device=device)
res = xm.all_reduce("sum", t)
print(index, res, flush=True)
xm.rendezvous('sync')
if index == 0:
print(index, res[0].item(), flush=True)
xmp.spawn(test_tensor_item, args=(), nprocs=8, start_method='fork')
```
Any hints, please.
Thanks
|
https://github.com/pytorch/xla/issues/2225
|
closed
|
[
"stale"
] | 2020-06-15T12:15:45Z
| 2020-07-25T08:02:46Z
| null |
vfdev-5
|
pytorch/serve
| 459
|
How to avoid contention between models, workers and runtime parallelism?
|
Hi! this is a question, not an issue
I see that TorchServe can serve multiple models or multiple workers per model. For example the [AWS blog](https://aws.amazon.com/blogs/machine-learning/deploying-pytorch-models-for-inference-at-scale-using-torchserve/) says "If your model is hosted on a CPU with many cores such as the c5.24xlarge EC2 instance with 96 vCPUs, you can easily scale the number of threads by using the method described previously"
So I see possibly up to 3 things competing for cores:
- multiple models
- multiple workers per model
- multiple threads of the inference runtime running in each worker
Is that understanding correct? How is TorchServe handling that triple level of parallelism? Is there any best practice or settings to tune?
|
https://github.com/pytorch/serve/issues/459
|
closed
|
[
"question",
"triaged_wait"
] | 2020-06-15T09:07:21Z
| 2020-10-22T04:06:27Z
| null |
la-cruche
|
pytorch/pytorch
| 40,016
|
how to load weights when using torch.nn.parallel.DistributedDataParallel?
|
platform: linux 16.04 ;python==3.8.2, pytorch==1.4.0-gpu
Stand-alone multi-card
I try to load weights when using torch.nn.parallel.DistributedDataParallel to load model, There have be wrong.
model = torch.nn.parallel.DistributedDataParallel(model,device_ids=[args.local_rank],output_device=args.local_rank,find_unused_parameters=True)
File "/home/jiashuaihe/anaconda2/envs/torch1.1/lib/python3.8/site-packages/torch/nn/parallel/distributed.py", line 301, in __init__
self._distributed_broadcast_coalesced(
File "/home/jiashuaihe/anaconda2/envs/torch1.1/lib/python3.8/site-packages/torch/nn/parallel/distributed.py", line 485, in _distributed_broadcast_coalesced
dist._broadcast_coalesced(self.process_group, tensors, buffer_size)
RuntimeError: Broken pipe
Traceback (most recent call

cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @xush6528 @osalpekar
|
https://github.com/pytorch/pytorch/issues/40016
|
closed
|
[
"needs reproduction",
"oncall: distributed",
"triaged"
] | 2020-06-15T03:53:06Z
| 2020-06-18T02:52:03Z
| null |
aboy2018
|
pytorch/examples
| 790
|
DCGAN kernel_size
|
DCGAN kernel_size why is 4,or why not 3(Isn't odd number more common)
|
https://github.com/pytorch/examples/issues/790
|
closed
|
[] | 2020-06-14T02:46:12Z
| 2022-03-09T21:38:43Z
| 1
|
yixiyixi5
|
huggingface/neuralcoref
| 257
|
Load new trained model
|
Dear guys,
Thank you so much for your interesting works. I was able to train a new model based on [this instruction](https://github.com/huggingface/neuralcoref/blob/master/neuralcoref/train/training.md) and this [blog post](https://medium.com/huggingface/how-to-train-a-neural-coreference-model-neuralcoref-2-7bb30c1abdfe). However, I could not find anywhere a manual how to load the trained model.
To understand how the model was loaded using `add_to_pipe` function, I downloaded the model from this [URL](https://s3.amazonaws.com/models.huggingface.co/neuralcoref/neuralcoref.tar.gz) and unzipped it. Inside, I could saw the `static_vectors` and `tuned_vectors`. I guess those are exactly the like the ones I used to train the model. However, I also see new file which is `key2row` and I don't know what it is and how to construct this file.
Can some one please give me a small instruction how to do the inference for the trained model?
Thank you so much!
|
https://github.com/huggingface/neuralcoref/issues/257
|
open
|
[
"question"
] | 2020-06-13T16:14:52Z
| 2021-07-15T07:32:04Z
| null |
SysDevHayes
|
pytorch/serve
| 456
|
How to use management API in Sagemaker? e.g how to change batch size
|
Hi,
Is it possible to use management api to a sagemaker deployed model?
I am trying to increase the batch size but I don't know if it is doable in sagemaker.
Can we just customise it (batch size) through config.properties so it will apply when sagemaker deploy the model ?
Thanks
|
https://github.com/pytorch/serve/issues/456
|
closed
|
[] | 2020-06-13T02:06:41Z
| 2020-06-14T23:28:44Z
| null |
bananemure
|
pytorch/TensorRT
| 98
|
What does it all mean Bazel?
|
Please specify what version to Bazel this needs to be built with? Also please make sure you can actually compile that version for aarch64 on the Jetpacks Nvidia provides for its products. If can't be compiled on aarch64 please fix this. Nvidia should really do a better job of making sure its stuff is able to be compiled on its Jetpacks. It would be nice if Nvidia would not use build systems which cannot be easily installed on their provided Jetpacks. There is not simple command to install bazel.
|
https://github.com/pytorch/TensorRT/issues/98
|
closed
|
[
"question"
] | 2020-06-12T16:50:08Z
| 2020-06-13T00:04:07Z
| null |
oasisgunter
|
pytorch/pytorch
| 39,939
|
How to resolve this issue in pycharm? ERROR: Could not find a version that satisfies the requirement torch>=1.0 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2) I have installed through command promt but still it is showing same issue as before.
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/39939
|
closed
|
[] | 2020-06-12T10:05:42Z
| 2020-06-12T10:10:52Z
| null |
RizwanShaukat936
|
pytorch/pytorch
| 39,936
|
How to deploy C++ LibTorch in Windows XP 32bit?
|
I want to deploy a CNN model in Windows XP 32 bit, and here are my operations:
compile LibTorch-1.4.0 32bit with VS2017;
finish the C++11 code and the .exe run successfully in win10 and win7 32bit;
The code fails in XP which reports “MSVCP140.dll is invalid”.
I want to use VS2015_XP to compile and avoid the error in XP. However, the LibTorch uses C++11/14 which is not supported by VS2015. So, what should I do to run successfully in XP 32bit?
Need help! TAT
|
https://github.com/pytorch/pytorch/issues/39936
|
closed
|
[] | 2020-06-12T07:37:04Z
| 2020-06-12T14:29:35Z
| null |
SakuraRiven
|
pytorch/TensorRT
| 96
|
Error when trying to build with compiled binaries
|
I am building an application with TRTorch precompiled binaries, and I am able to compile full precision and half precision graphs successfully.
I run into build errors while trying to compile the int8 graph
as long as I include this line
```
auto calibrator = trtorch::ptq::make_int8_calibrator(std::move(calibration_dataloader), calibration_cache_file, true);
```
the build error
```
In file included from /home/tsai/TRTorchSample/../trtorch/include/trtorch/trtorch.h:38,
from /home/tsai/TRTorchSample/main.cpp:4:
/home/tsai/TRTorchSample/../trtorch/include/trtorch/ptq.h: In instantiation of ‘trtorch::ptq::Int8Calibrator<Algorithm, DataLoaderUniquePtr>::Int8Calibrator(DataLoaderUniquePtr, const string&, bool) [with Algorithm = nvinfer1::IInt8EntropyCalibrator2; DataLoaderUniquePtr = std::unique_ptr<torch::data::StatelessDataLoader<torch::data::datasets::MapDataset<torch::data::datasets::MapDataset<datasets::CIFAR10, Resize>, torch::data::transforms::Normalize<> >, torch::data::samplers::RandomSampler>, std::default_delete<torch::data::StatelessDataLoader<torch::data::datasets::MapDataset<torch::data::datasets::MapDataset<datasets::CIFAR10, Resize>, torch::data::transforms::Normalize<> >, torch::data::samplers::RandomSampler> > >; std::string = std::__cxx11::basic_string<char>]’:
/home/tsai/TRTorchSample/../trtorch/include/trtorch/trtorch.h:430:12: required from ‘trtorch::ptq::Int8Calibrator<Algorithm, DataLoader> trtorch::ptq::make_int8_calibrator(DataLoader, const string&, bool) [with Algorithm = nvinfer1::IInt8EntropyCalibrator2; DataLoader = std::unique_ptr<torch::data::StatelessDataLoader<torch::data::datasets::MapDataset<torch::data::datasets::MapDataset<datasets::CIFAR10, Resize>, torch::data::transforms::Normalize<> >, torch::data::samplers::RandomSampler>, std::default_delete<torch::data::StatelessDataLoader<torch::data::datasets::MapDataset<torch::data::datasets::MapDataset<datasets::CIFAR10, Resize>, torch::data::transforms::Normalize<> >, torch::data::samplers::RandomSampler> > >; std::string = std::__cxx11::basic_string<char>]’
/home/tsai/TRTorchSample/main.cpp:77:121: required from here
/home/tsai/TRTorchSample/../trtorch/include/trtorch/ptq.h:55:13: error: no matching function for call to ‘std::vector<at::Tensor>::push_back(<unresolved overloaded function type>)’
55 | batched_data_.push_back(batch.data);
| ^~~~~~~~~~~~~
In file included from /usr/include/c++/9/vector:67,
from /home/tsai/libtorch/include/c10/util/StringUtil.h:11,
from /home/tsai/libtorch/include/c10/util/Exception.h:5,
from /home/tsai/libtorch/include/c10/core/Device.h:5,
from /home/tsai/libtorch/include/c10/core/Allocator.h:6,
from /home/tsai/libtorch/include/ATen/ATen.h:3,
from /home/tsai/libtorch/include/torch/csrc/api/include/torch/types.h:3,
from /home/tsai/libtorch/include/torch/script.h:3,
from /home/tsai/TRTorchSample/main.cpp:1:
/usr/include/c++/9/bits/stl_vector.h:1184:7: note: candidate: ‘void std::vector<_Tp, _Alloc>::push_back(const value_type&) [with _Tp = at::Tensor; _Alloc = std::allocator<at::Tensor>; std::vector<_Tp, _Alloc>::value_type = at::Tensor]’
1184 | push_back(const value_type& __x)
| ^~~~~~~~~
/usr/include/c++/9/bits/stl_vector.h:1184:35: note: no known conversion for argument 1 from ‘<unresolved overloaded function type>’ to ‘const value_type&’ {aka ‘const at::Tensor&’}
1184 | push_back(const value_type& __x)
| ~~~~~~~~~~~~~~~~~~^~~
/usr/include/c++/9/bits/stl_vector.h:1200:7: note: candidate: ‘void std::vector<_Tp, _Alloc>::push_back(std::vector<_Tp, _Alloc>::value_type&&) [with _Tp = at::Tensor; _Alloc = std::allocator<at::Tensor>; std::vector<_Tp, _Alloc>::value_type = at::Tensor]’
1200 | push_back(value_type&& __x)
| ^~~~~~~~~
/usr/include/c++/9/bits/stl_vector.h:1200:30: note: no known conversion for argument 1 from ‘<unresolved overloaded function type>’ to ‘std::vector<at::Tensor>::value_type&&’ {aka ‘at::Tensor&&’}
1200 | push_back(value_type&& __x)
| ~~~~~~~~~~~~~^~~
make[2]: *** [CMakeFiles/TRTorchSample.dir/build.make:63: CMakeFiles/TRTorchSample.dir/main.cpp.o] Error 1
make[1]: *** [CMakeFiles/Makefile2:76: CMakeFiles/TRTorchSample.dir/all] Error 2
make: *** [Makefile:84: all] Error 2
```
CMakeLists.txt
```
cmake_minimum_required(VERSION 3.10)
project(TRTorchSample)
enable_language(CUDA)
find_package(Torch REQUIRED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")
set(CUDA_TOOLKIT_ROOT_DIR "/usr/local/cuda")
set(CUDA_INCLUDE_DIRS "/usr/local/cuda/include")
add_executable(TRTorchSample main.cpp cifar10.cpp cifar10.h)
target_link_libraries(TRTorchSample "${TORCH_LIBRARIES}")
target_link_libraries(TRTorchSample "${PROJECT_SOURCE_DIR
|
https://github.com/pytorch/TensorRT/issues/96
|
closed
|
[
"question",
"No Activity"
] | 2020-06-12T03:17:18Z
| 2020-07-19T00:03:52Z
| null |
tsaizhenling
|
huggingface/transformers
| 4,937
|
What is the different options for pooler_type in Bert config ?
|
# ❓ Questions & Help
<!-- The GitHub issue tracker is primarly intended for bugs, feature requests,
new models and benchmarks, and migration questions. For all other questions,
we direct you to Stack Overflow (SO) where a whole community of PyTorch and
Tensorflow enthusiast can help you out. Make sure to tag your question with the
right deep learning framework as well as the huggingface-transformers tag:
https://stackoverflow.com/questions/tagged/huggingface-transformers
If your question wasn't answered after a period of time on Stack Overflow, you
can always open a question on GitHub. You should then link to the SO question
that you posted.
-->
## Details
<!-- Description of your issue -->
I want to change the pooling type at the top of the output hidden states of Bert.
I search in the documentation and find nothing. Can anyone help me ? I just want the different option of pooling (max, average etc.). Here's a piece of code to see the option i am talking about.
`import transformers
encoder = transformers.TFBertModel.from_pretrained("bert-base-uncased")
encoder.config`
<!-- You should first ask your question on SO, and only if
you didn't get an answer ask it here on GitHub. -->
**A link to original question on Stack Overflow**:
|
https://github.com/huggingface/transformers/issues/4937
|
closed
|
[] | 2020-06-11T14:26:20Z
| 2020-06-18T07:26:02Z
| null |
ClementViricel
|
pytorch/tutorials
| 1,022
|
math text size is too small
|
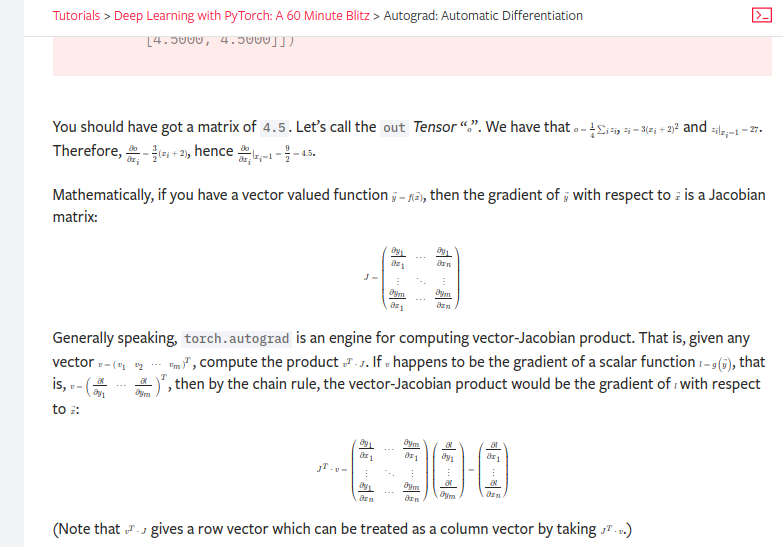
I cannot easily read what's written in the equations. The Math is rendering very small on Blitz page.
[Here](https://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html). How can I help correct this?
|
https://github.com/pytorch/tutorials/issues/1022
|
closed
|
[] | 2020-06-11T11:14:34Z
| 2021-06-07T22:28:11Z
| 7
|
PradeepSinghMakwana
|
pytorch/pytorch
| 39,778
|
How to Build Stable PyTorch (not from master) from source and output Wheel?
|
Currently, in the PyTorch docs the suggested way of building from source includes the following main commands:
```bash
git clone --recursive https://github.com/pytorch/pytorch
cd pytorch
export CMAKE_PREFIX_PATH=${CONDA_PREFIX:-"$(dirname $(which conda))/../"}
python setup.py install
```
The clone command gets the PyTorch repo and the next command builds PyTorch in a Conda environment.
The problem here is that when the build starts it uses the `master` branch, which is not the stable (currently builds unstable `torch-1.6.0a0+8a6914d`). How do I checkout and build a stable version? The docs don't mention how to do this
Secondly, `python setup.py install` builds in conda environment, it works fine, but there is no way to port that build to other machines, I would like to create a **pip wheel**, instead, how should I do that?
Any help will be greatly appreciated, thanks.
|
https://github.com/pytorch/pytorch/issues/39778
|
closed
|
[] | 2020-06-10T13:15:19Z
| 2020-06-10T13:43:16Z
| null |
RafayAK
|
pytorch/xla
| 2,191
|
How to aggregate per-process statistics in xmp.spawn?
|
## ❓ Questions and Help
I am using the idiom:
```
xmp.spawn(_mp_fn, args=(), nprocs=1, start_method='fork')
```
where my `_mp_fn` calls `xm.optimizer_step(optim)`
Is there any way to combine the other statistics (loss, various stats on gradients etc) across processes and report just the aggregate for each minibatch?
At the moment, the `_mp_fn` just prints out its local values for loss etc, which don't reflect the merged gradients used to update the model.
Thanks!
Henry
|
https://github.com/pytorch/xla/issues/2191
|
closed
|
[] | 2020-06-10T06:01:33Z
| 2020-06-12T00:21:38Z
| null |
hrbigelow
|
pytorch/TensorRT
| 90
|
Issues When Using Compiled Binaries
|
After compiling TRTorch on an x86 machine, and copying the outputted binaries to another machine, then using them in an include directory, I get the following error when compiling my code:
```
/usr/bin/ld: warning: libnvinfer.so.7, needed by /home/caelin/Github/br-core/ros2_ws/src/br-detection/include/trtorch/lib/libtrtorch.so, not found (try using -rpath or -rpath-link)
/usr/bin/ld: warning: libopencv_imgcodecs.so.3.2, needed by /opt/ros/eloquent/lib/libcv_bridge.so, may conflict with libopencv_imgcodecs.so.4.2
/usr/bin/ld: warning: libopencv_imgproc.so.3.2, needed by /opt/ros/eloquent/lib/libcv_bridge.so, may conflict with libopencv_imgproc.so.4.2
/usr/bin/ld: warning: libopencv_core.so.3.2, needed by /opt/ros/eloquent/lib/libcv_bridge.so, may conflict with libopencv_core.so.4.2
/usr/bin/ld: warning: libopencv_calib3d.so.3.2, needed by /opt/ros/eloquent/lib/libimage_geometry.so, may conflict with libopencv_calib3d.so.4.2
/home/caelin/Github/br-core/ros2_ws/src/br-detection/include/trtorch/lib/libtrtorch.so: undefined reference to `createInferBuilder_INTERNAL'
/home/caelin/Github/br-core/ros2_ws/src/br-detection/include/trtorch/lib/libtrtorch.so: undefined reference to `createInferRuntime_INTERNAL'
```
|
https://github.com/pytorch/TensorRT/issues/90
|
closed
|
[
"question",
"No Activity"
] | 2020-06-10T00:39:26Z
| 2020-09-11T00:05:16Z
| null |
caelinsutch
|
pytorch/pytorch
| 39,641
|
What is the difference between torch.mean and caffe2 ReduceMean?
|
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
I manually convert the model from Caffe2 to Pytorch. I built the full architecture of the model in Pytorch using weights from a Caffe2. In Caffe2, the model has a ReduceMean layer, which in Pytorch I replaced with torch.mean. As a result of the replacement, the difference in the calculations turned out to be too large, which does not allow to complete the conversion successfully.
## To Reproduce
Steps to reproduce the behavior:
1. [input_data.txt](https://github.com/pytorch/pytorch/files/4742801/input_data.txt)
1.
```
import numpy as np
import torch
from caffe2.python import workspace, core
data = np.load("input_data.npy")
#caffe2
op_reduce_mean = core.CreateOperator("ReduceMean", ["X_reduce"], ["Y_reduce"], axes=(3,), keepdims=1)
workspace.ResetWorkspace()
workspace.FeedBlob("X_reduce", data)
workspace.RunOperatorOnce(op_reduce_mean)
shape_reduce_mean_caffe2 = workspace.FetchBlob("Y_reduce").shape
data_reduce_mean_caffe2 = workspace.FetchBlob("Y_reduce")
data_reduce_mean_caffe2 = np.array(data_reduce_mean_caffe2, dtype=np.float32).reshape(data_reduce_mean_caffe2.shape)
print(data_reduce_mean_caffe2) # -0.4089698, -0.5118571, -0.5328341, -0.50671, ... , -0.5756652, -0.38777262, -0.43768662, -0.49657446
#pytorch
torch_data = torch.from_numpy(data)
data_mean_torch = torch.mean(torch_data, dim=(3,), keepdim=True)
print(data_mean_torch) # -0.4089695, -0.5118583, -0.532835, -0.50670993, ... , -0.57566583, -0.38777304, -0.43768588, -0.49657464
#numpy
data_mean_numpy = np.mean(data, asix=(3,), keepdims=True) # -0.40896943, -0.5118579, -0.53283495, -0.50670964, ..., -0.5756654, -0.38777274, -0.43768603, -0.49657455
print(data_mean_numpy)
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
The same results.
<!-- A clear and concise description of what you expected to happen. -->
## Environment
- PyTorch Version (e.g., 1.0): 1.5
- OS (e.g., Linux): Windows 10
- How you installed PyTorch (`conda`, `pip`, source): conda
- Build command you used (if compiling from source):
- Python version: 3.7
- CUDA/cuDNN version: No
- GPU models and configuration:
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/pytorch/issues/39641
|
closed
|
[] | 2020-06-07T19:58:45Z
| 2020-06-08T18:15:33Z
| null |
dryarullin
|
huggingface/datasets
| 246
|
What is the best way to cache a dataset?
|
For example if I want to use streamlit with a nlp dataset:
```
@st.cache
def load_data():
return nlp.load_dataset('squad')
```
This code raises the error "uncachable object"
Right now I just fixed with a constant for my specific case:
```
@st.cache(hash_funcs={pyarrow.lib.Buffer: lambda b: 0})
```
But I was curious to know what is the best way in general
|
https://github.com/huggingface/datasets/issues/246
|
closed
|
[] | 2020-06-06T11:02:07Z
| 2020-07-09T09:15:07Z
| null |
Mistobaan
|
huggingface/transformers
| 4,817
|
Question: Where do I find the Transformer model from the paper "Attention is all you need" ?
|
Hello
Firstly, thanks for supporting all questions here.
I read the paper "Attention is all you need" and wondering which class should I use in the HuggingFace library to use the Transformer architecture used in the paper.
Can you please advise?
Thanks
Abhishek
|
https://github.com/huggingface/transformers/issues/4817
|
closed
|
[] | 2020-06-06T10:34:56Z
| 2020-06-08T22:37:27Z
| null |
abhisheksgumadi
|
pytorch/TensorRT
| 84
|
TRTorch on torchvision ResNet152
|
Hi,
I tried the script below and get error messages and a segmentation fault. Is this a bug or am I doing it wrong?
`import copy
import itertools
import logging
import numpy as np
import os
import sys
import torch
import torchvision.models
import trtorch
def torchvision_benchmark():
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"]="0,1,2"
B, C, H, W = 1, 3, 224, 224
pytorch_model = torchvision.models.resnet152(pretrained=True)
print(f"Started torch.jit.script() ...", end='')
torchscript_model = torch.jit.script(copy.deepcopy(pytorch_model))
print(f" done.")
compile_settings = {
"input_shapes": [[1, 3, 224, 224]],
"op_precision": torch.float
}
for i, (k, v) in enumerate(torchscript_model.named_parameters()):
print(k, v.shape)
if i > 10:
break
_ = torch.jit.script(copy.deepcopy(pytorch_model).eval())
graph_lines = str(_.inlined_graph).split('\n')
ls, le = 0, 20
for l in graph_lines[ls:le]:
print(l)
print(f"Started trtorch.compile() ...", end='')
trt_ts_module = trtorch.compile(_, compile_settings)
print(f" done.")
`
I get following results:
> Started torch.jit.script() ... done.
conv1.weight torch.Size([64, 3, 7, 7])
bn1.weight torch.Size([64])
bn1.bias torch.Size([64])
layer1.0.conv1.weight torch.Size([64, 64, 1, 1])
layer1.0.bn1.weight torch.Size([64])
layer1.0.bn1.bias torch.Size([64])
layer1.0.conv2.weight torch.Size([64, 64, 3, 3])
layer1.0.bn2.weight torch.Size([64])
layer1.0.bn2.bias torch.Size([64])
layer1.0.conv3.weight torch.Size([256, 64, 1, 1])
layer1.0.bn3.weight torch.Size([256])
layer1.0.bn3.bias torch.Size([256])
graph(%self : __torch__.torchvision.models.resnet.ResNet,
%x.1 : Tensor):
%3 : int = prim::Constant[value=-1]()
%4 : int = prim::Constant[value=1]() # /opt/conda/lib/python3.7/site-packages/torchvision-0.7.0a0+34810c0-py3.7-linux-x86_64.egg/torchvision/models/resnet.py:214:29
%5 : __torch__.torch.nn.modules.conv.Conv2d = prim::GetAttr[name="conv1"](%self)
%6 : Tensor = prim::GetAttr[name="weight"](%5)
%7 : int = prim::Constant[value=3]() # /opt/conda/lib/python3.7/site-packages/torch/nn/modules/conv.py:346:24
%8 : int = prim::Constant[value=1]() # /opt/conda/lib/python3.7/site-packages/torch/nn/modules/conv.py:344:38
%9 : int = prim::Constant[value=2]() # /opt/conda/lib/python3.7/site-packages/torch/nn/modules/conv.py:343:47
%10 : Tensor? = prim::GetAttr[name="bias"](%5)
%11 : int[] = prim::ListConstruct(%9, %9)
%12 : int[] = prim::ListConstruct(%7, %7)
%13 : int[] = prim::ListConstruct(%8, %8)
%x.3 : Tensor = aten::conv2d(%x.1, %6, %10, %11, %12, %13, %8) # /opt/conda/lib/python3.7/site-packages/torch/nn/modules/conv.py:345:15
%15 : __torch__.torch.nn.modules.batchnorm.BatchNorm2d = prim::GetAttr[name="bn1"](%self)
%16 : Function = prim::Constant[name="batch_norm"]()
%17 : float = prim::Constant[value=1.0000000000000001e-05]() # /opt/conda/lib/python3.7/site-packages/torch/nn/modules/batchnorm.py:106:40
%18 : bool = prim::Constant[value=0]() # /opt/conda/lib/python3.7/site-packages/torch/nn/modules/batchnorm.py:94:11
%19 : bool = prim::Constant[value=1]() # /opt/conda/lib/python3.7/site-packages/torch/nn/modules/batchnorm.py:94:29
%exponential_average_factor.126 : float = prim::Constant[value=0.10000000000000001]() # /opt/conda/lib/python3.7/site-packages/torch/nn/modules/batchnorm.py:92:41
ERROR: [TRTorch Conversion Context] - %791 : Tensor = aten::_convolution(%x.1, %self.conv1.weight, %self.conv1.bias, %10, %9, %8, %788, %789, %12, %788, %788, %790): kernel weights has count 9408 but 441 was expected
ERROR: [TRTorch Conversion Context] - %791 : Tensor = aten::_convolution(%x.1, %self.conv1.weight, %self.conv1.bias, %10, %9, %8, %788, %789, %12, %788, %788, %790): count of 9408 weights in kernel, but kernel dimensions (7,7) with 3 input channels, 3 output channels and 1 groups were specified. Expected Weights count is 3 * 7*7 * 3 / 1 = 441
ERROR: [TRTorch Conversion Context] - %791 : Tensor = aten::_convolution(%x.1, %self.conv1.weight, %self.conv1.bias, %10, %9, %8, %788, %789, %12, %788, %788, %790): kernel weights has coun
t 9408 but 441 was expected
ERROR: [TRTorch Conversion Context] - %791 : Tensor = aten::_convolution(%x.1, %self.conv1.weight, %self.conv1.bias, %10, %9, %8, %788, %789, %12, %788, %788, %790): count of 9408 weights i
n kernel, but kernel dimensions (7,7) with 3 input channels, 3 output channels and 1 groups were specified. Expected Weights count is 3 * 7*7 * 3 / 1 = 441
ERROR: [TRTorch Conversion Context] - %791 : Tensor = aten::_convolution(%x.1, %self.conv1.weight, %self.conv1.bias, %10, %9, %8, %788, %789, %12, %788, %788, %790): kernel weights has coun
t 9408 but 441 was expected
ERROR: [TRTorch Conversion Context] - %791 : Tensor = aten::_convolution(%x.1, %se
|
https://github.com/pytorch/TensorRT/issues/84
|
closed
|
[
"question"
] | 2020-06-05T21:23:22Z
| 2020-07-03T20:04:26Z
| null |
esghif
|
pytorch/pytorch
| 39,573
|
What is the difference between 0.4.1 and 0.4.1.post2?
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/39573
|
closed
|
[] | 2020-06-05T10:52:13Z
| 2020-06-06T00:22:18Z
| null |
Lucksong
|
pytorch/pytorch
| 39,561
|
How to replace the original model's classes with new class
|
## 🚀 Feature
<!-- A clear and concise description of the feature proposal -->
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too -->
## Pitch
<!-- A clear and concise description of what you want to happen. -->
## Alternatives
<!-- A clear and concise description of any alternative solutions or features you've considered, if any. -->
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
|
https://github.com/pytorch/pytorch/issues/39561
|
closed
|
[] | 2020-06-05T04:59:14Z
| 2020-06-06T00:14:52Z
| null |
Aiswariyasugavanam
|
pytorch/vision
| 2,286
|
Architecture differences in Zoo Models ?
|
Hi, I am comparing few zoo models implementation in DL4J with Pytorch zoo models and found
that the padding in Convolution layers does not match most of time ?
For **Resnet50 and SqueezeNet** :
In DL4J, they **do not** apply padding : [0, 0] ; while in PyTorch they have padding [1, 1].
This results in different output in layers
In DL4J, they apply **Bias** in Conv layers while in PyTorch, they do not.
Why such irregularities in Network structure across frameworks ?
|
https://github.com/pytorch/vision/issues/2286
|
closed
|
[
"question",
"module: models",
"topic: classification"
] | 2020-06-04T06:22:57Z
| 2020-06-05T09:19:08Z
| null |
nitin2212
|
pytorch/text
| 806
|
torchtext and training of a Transformer
|
Hello
I am a bit confused about training my pytorch Transformer.
I am using the code below to pre-process the Penn Treebank corpus before I analyze it with my (non pre-trained) Transformer:
```python
# define the English text field
TEXT_ch2 = Field(init_token = '<sos>',
eos_token = '<eos>',
unk_token = '<unk>',
pad_token = '<pad>',
fix_length = bptt,
lower = True)
# split the PennTreeBank corpus into a train, val, and test set.
train_penn, val_penn, test_penn = torchtext.datasets.PennTreebank.splits(TEXT_ch2)
# build vocabulary based on the field that we just definTVD.
# (building vocabulary over all language datasets)
TEXT_ch2.build_vocab(train_penn, val_penn, test_penn,
specials=['<sos>','<eos>','<unk>','<pad>'])
# BPTTIterator
train_penn_iter, val_penn_iter, test_penn_iter = BPTTIterator.splits(
(train_penn, val_penn, test_penn),
batch_size = batch_size,
bptt_len= bptt,
sort_key=lambda x: len(x.text),
sort_within_batch = True,
shuffle = False,
device= device,
repeat=False)
```
My question is, since my Penn Treebank corpus are separated into train, validation, and test sets, when I train my Transformer on the Penn Treebank corpus, I would only be training the model on the Penn Treebank train and validation sets (`train_penn_iter`), am I right?
But then if I train my Transformer only on the train and validation portions of the corpus, wouldn't this mean that my Transformer will not be trained to properly handle those tokens that are contained only in the test set? so does this mean that I need to train my Transformer on the entire Penn Treebank corpus, instead of just on the training and validation sets? But if this is the case, what then is the point of having the `split` function to separate the corpus into training, validation, and test sets? To me, this contradicts how the test sets are normally used in machine learning.
Does it make sense to "test" a Transformer on the sequences that contain the tokens which it was not trained on?
Thank you,
|
https://github.com/pytorch/text/issues/806
|
closed
|
[
"question"
] | 2020-06-04T02:22:17Z
| 2020-06-04T14:14:12Z
| null |
h56cho
|
pytorch/vision
| 2,285
|
Finetuning deeplab/FCN
|
How do I fine tune deeplabv3 ?
|
https://github.com/pytorch/vision/issues/2285
|
closed
|
[
"question",
"module: reference scripts",
"topic: semantic segmentation"
] | 2020-06-03T20:53:38Z
| 2020-06-05T09:16:56Z
| null |
gaussiangit
|
pytorch/tutorials
| 1,010
|
Tutorial on custom dataloaders (NOT datasets)
|
I really like [this](https://pytorch.org/tutorials/beginner/data_loading_tutorial.html#iterating-through-the-dataset) tutorial on custom datasets. However, the `torch.utils.data.DataLoader` class is only briefly mentioned in it:
>However, we are losing a lot of features by using a simple for loop to iterate over the data. In particular, we are missing out on:
> * Batching the data
> * Shuffling the data
> * Load the data in parallel using multiprocessing workers.
> `torch.utils.data.DataLoader` is an iterator which provides all these features. Parameters used below should be clear. One parameter of interest is collate_fn . You can specify how exactly the samples need to be batched using collate_fn . However, default collate should work fine for most use cases.
I am aware of this [issue](https://github.com/pytorch/tutorials/issues/78) and this [issue](https://github.com/pytorch/tutorials/issues/735) but neither have led to a tutorial.
I am happy to make a tutorial on custom dataloaders using the `torch.utils.data.DataLoader` class, focusing on how to interface with its parameters, especially the `num_workers` and `collate_fn` parameters. Also, I am not sure if it is possible to inherit from the `torch.utils.data.DataLoader` class, similar to the `torch.utils.data.Dataset`, so I would appreciate some guidance on this.
This would be my first ever tutorial, so some guidance on formatting would be greatly helpful.
cc @suraj813 @sekyondaMeta @svekars @carljparker @NicolasHug @kit1980 @subramen
|
https://github.com/pytorch/tutorials/issues/1010
|
open
|
[
"enhancement",
"60_min_blitz",
"advanced",
"docathon-h2-2023"
] | 2020-06-03T13:18:03Z
| 2025-05-20T10:14:47Z
| 11
|
mhdadk
|
pytorch/examples
| 784
|
Difference between src_mask and src_key_padding_mask
|
I am having a difficult time in understanding transformers. Everything is getting clear bit by bit but one thing that makes my head scratch is what is the difference between src_mask and src_key_padding_mask which is passed as an argument in forward function in both encoder layer and decoder layer.
https://pytorch.org/docs/master/_modules/torch/nn/modules/transformer.html#Transformer
|
https://github.com/pytorch/examples/issues/784
|
open
|
[
"nlp"
] | 2020-06-03T10:53:19Z
| 2022-03-09T21:39:01Z
| 0
|
saahiluppal
|
pytorch/TensorRT
| 79
|
Does TRTorch support bail-out mechanism?
|
A neural network model may have some operators which aren't supported by TensorRT.
When TensorRT cannot compile a subgraph, can the execution of the subgraph invoke torch operators again? Can a model execution mix TensorRT and vanilla torch operators?
|
https://github.com/pytorch/TensorRT/issues/79
|
closed
|
[
"question",
"component: execution",
"No Activity"
] | 2020-06-03T10:21:27Z
| 2020-07-10T00:03:57Z
| null |
shiwenloong
|
pytorch/pytorch
| 39,427
|
How to save tensor to 16-bit image?
|
So, I have a Tensor, which represents my 16-bit 3-channel image and I wanna save it. How could I do this? I was trying
```
torchvision.utils.save_image(gt[j], f"hdr_{j+1}.tiff")
```
But seems like it works only for 8-bit images... Could someone help me to save my tensor to 16-bit 3-channel image(any format would be good. I think .tiff is fine)?
|
https://github.com/pytorch/pytorch/issues/39427
|
closed
|
[] | 2020-06-03T02:54:45Z
| 2020-06-03T15:16:12Z
| null |
wh75er
|
pytorch/TensorRT
| 78
|
Support Tuple Inputs
|
Hello. I am working with a model that takes in a tuple of inputs of different sizes. Is there a way to handle this within the existing TRTorch framework? I am attempting to compile the model with the following settings but get the accompanied error. I am running form source version on commit 247c748.
Compile settings:
```
compile_settings = {
"input_shapes": [
{
"min": ([1, 3, 180, 320], [1,49,2]),
"opt": ([1, 3, 180, 320], [1,49,2]),
"max": ([1, 3, 180, 320], [1,49,2])
}, # For static size [1, 3, 224, 224]
],
# "op_precision": torch.half # Run with FP16
}
```
Error:
```
TypeError: (): incompatible function arguments. The following argument types are supported:
1. (self: trtorch._C.InputRange, arg0: List[int]) -> None
Invoked with: <trtorch._C.InputRange object at 0x7fda486f67b0>, ([1, 3, 180, 320], [1, 49, 2])
```
The forward function of my model is the following:
```
def forward(self,x,seq):
x = self.input_conv(x)
x = self.input_fc(x).unsqueeze(0)
actions = self.action_fc(seq)
x, hidden = self.lstm(actions, (x, x))
output = self.output_fc(x)
return output
```
Thanks
|
https://github.com/pytorch/TensorRT/issues/78
|
closed
|
[
"question",
"component: api [Python]",
"No Activity"
] | 2020-06-01T19:35:26Z
| 2020-07-05T00:06:46Z
| null |
Michael-Equi
|
huggingface/neuralcoref
| 256
|
Can't locate CorScorer.pm
|
Dear guys,
Thank you for your interesting works. I'm training the model for new language (Dutch) using the SoNars corpus. Due to the fact that SoNars was in MMAX, I used the modification of this script (https://github.com/andreasvc/dutchcoref/blob/master/mmaxconll.py) to convert it to CONLL format.
After that, I trained a word2vec model (to prepare the static_word_embeddings files), I still have no clue what tuned_word_embeddings are, but I just use exactly the same static_word_embeddings files and it seemed to worked. I modified the load_function and other related functions as stated in the tutorial for training new language. Everything went well until the training, I got this error:
`Error during the scoring
Command '['perl', 'c:\\users\\administrator\\desktop\\neural_coref\\neuralcoref\\neuralcoref\\train\\scorer_wrapper.pl', 'muc', 'c:\\users\\administrator\\desktop\\neural_coref\\neuralcoref\\neuralcoref\\train/data//key.txt', 'c:\\users\\administrator\\desktop\\neural_coref\\neuralcoref\\neuralcoref\\train\\test_mentions.txt']' returned non-zero exit status 2.
Can't locate CorScorer.pm in @INC (you may need to install the CorScorer module) (@INC contains: scorer/lib /usr/lib/perl5/site_perl /usr/share/perl5/site_perl /usr/lib/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib/perl5/core_perl /usr/share/perl5/core_perl) at c:\users\administrator\desktop\neural_coref\neuralcoref\neuralcoref\train\scorer_wrapper.pl line 16.
BEGIN failed--compilation aborted at c:\users\administrator\desktop\neural_coref\neuralcoref\neuralcoref\train\scorer_wrapper.pl line 16.`
I could not find any information about the CorScorer.pm on anywhere on the internet. Can someone please help me to fix this? Am I doing anything wrong?
|
https://github.com/huggingface/neuralcoref/issues/256
|
closed
|
[
"question"
] | 2020-05-31T10:33:59Z
| 2021-11-02T14:06:49Z
| null |
SysDevHayes
|
pytorch/pytorch
| 38,976
|
How to load the trained weights in libtorch to continue the training?
|
How to load the trained weights in libtorch to continue the training?I can't find an example.
libtorch 1.5
|
https://github.com/pytorch/pytorch/issues/38976
|
closed
|
[] | 2020-05-25T08:39:26Z
| 2020-05-26T18:52:27Z
| null |
williamlzw
|
pytorch/pytorch
| 38,965
|
what is the difference of 'torch.onnx._export()' and 'torch.onnx.export()'?
|
## ❓ Questions and Help
Sorry, I can not understand.
When the inputs are same, their output files(onnx file) are difference .
|
https://github.com/pytorch/pytorch/issues/38965
|
closed
|
[] | 2020-05-24T15:12:42Z
| 2024-05-16T06:29:50Z
| null |
cs-xiao
|
pytorch/TensorRT
| 68
|
TRTorch with CUDA 10.0
|
Hi,
I tried installing TRTorch on my Ubuntu 16.04, PyTorch 1.5 compiled from source, CUDA 10.0, CUDNN 7.6.
I am getting a symbol error in all configurations I tried. I am grateful for any help.
`seh2bp@trtorch:/workspace$ python -c "import torch; import trtorch"
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/opt/conda/lib/python3.7/site-packages/torch/__init__.py", line 165, in <module>
from torch._C import *
ImportError: /opt/conda/lib/python3.7/site-packages/torch/lib/libshm.so: undefined symbol: _Z8_THErrorPKciS0_z`
ldd output is here:
`seh2bp@trtorch:/workspace$ ldd /opt/conda/lib/python3.7/site-packages/trtorch/lib/libtrtorch.so
linux-vdso.so.1 (0x00007ffdff3c7000)
libstdc++.so.6 => /usr/lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f338cc4d000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f338c8af000)
libnvinfer.so.7 => /opt/tensorrt/TensorRT-7.0.0.11/lib/libnvinfer.so.7 (0x00007f337ec34000)
libcublas.so.10.0 => /usr/local/cuda-10.0/targets/x86_64-linux/lib/libcublas.so.10.0 (0x00007f337a69e000)
libcudnn.so.7 => /usr/lib/x86_64-linux-gnu/libcudnn.so.7 (0x00007f3362e8d000)
libtorch.so => /workspace/scer-docker/trtorch/files/libtorch/lib/libtorch.so (0x00007f3362c8b000)
libtorch_cuda.so => /workspace/scer-docker/trtorch/files/libtorch/lib/libtorch_cuda.so (0x00007f33211cc000)
libtorch_cpu.so => /workspace/scer-docker/trtorch/files/libtorch/lib/libtorch_cpu.so (0x00007f3311fae000)
libtorch_global_deps.so => /workspace/scer-docker/trtorch/files/libtorch/lib/libtorch_global_deps.so (0x00007f3311da9000)
libc10_cuda.so => /workspace/scer-docker/trtorch/files/libtorch/lib/libc10_cuda.so (0x00007f3311b73000)
libc10.so => /workspace/scer-docker/trtorch/files/libtorch/lib/libc10.so (0x00007f3311923000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f331170b000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f331131a000)
/lib64/ld-linux-x86-64.so.2 (0x00007f338cfd6000)
libcudart.so.10.0 => /usr/local/cuda-10.0/targets/x86_64-linux/lib/libcudart.so.10.0 (0x00007f33110a0000)
libmyelin.so.1 => /opt/tensorrt/TensorRT-7.0.0.11/lib/libmyelin.so.1 (0x00007f331088f000)
libnvrtc.so.10.0 => /usr/local/cuda-10.0/targets/x86_64-linux/lib/libnvrtc.so.10.0 (0x00007f330f273000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f330f06f000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007f330ee50000)
librt.so.1 => /lib/x86_64-linux-gnu/librt.so.1 (0x00007f330ec48000)
libcudart-80664282.so.10.2 => /workspace/scer-docker/trtorch/files/libtorch/lib/libcudart-80664282.so.10.2 (0x00007f330e9c7000)
libnvToolsExt-3965bdd0.so.1 => /workspace/scer-docker/trtorch/files/libtorch/lib/libnvToolsExt-3965bdd0.so.1 (0x00007f330e7bd000)
libgomp-75eea7e8.so.1 => /workspace/scer-docker/trtorch/files/libtorch/lib/libgomp-75eea7e8.so.1 (0x00007f330e598000)`
I tried different configurations:
- use the downloaded libtorch built for cuda 10.2, I get the same error as above
- use the installed libtorch (for a reason I don't understand I have 2 versions on in
`.../site-packages/torch` and one in `.../site-packages/torch-1.5.0-py3.7-linux-x86_64.egg/torch`. Build with `.../site-packages/torch` fails because it is missing optimizer.h. I will not give further detail as I believe it will just complicate the issue unnecessarily. Any help is welcome.
|
https://github.com/pytorch/TensorRT/issues/68
|
closed
|
[
"question"
] | 2020-05-23T08:48:38Z
| 2020-06-05T21:16:24Z
| null |
esghif
|
pytorch/vision
| 2,254
|
Using `vision.references`
|
Hi,
I was wondering if there was a way by which I can use the modules inside `vision.references`, especially `vision.references.detection.engine`'s `train_one_epoch` method. At the moment, I am unable to import and use it rather would have to copy-paste or download. Could this be simplified into an import? (by adding an `__init__.py`) ? Or, perhaps there is a way to do this more elegantly and I'm unaware?
Thanks and Regards,
|
https://github.com/pytorch/vision/issues/2254
|
closed
|
[
"question",
"module: reference scripts"
] | 2020-05-23T06:19:33Z
| 2020-05-29T10:32:56Z
| null |
Sentient07
|
pytorch/examples
| 778
|
Runtime error when trying to run dcgan.cpp example
|
I am new to libtorch and I was completing the featured example to learn Pytoch C++ frontend.
I downloaded the cmake and dcgan.cpp files from git and was able to cmake it on a cluster using the clang-llvm/11 compilers. I am using libtorch files downloaded from https://download.pytorch.org/libtorch/nightly/cu100/libtorch-cxx11-abi-shared-with-deps-latest.zip
I am using cuda 10.2.89 and pytorch v1.5.0-gpu.
When I try running the executable, I get the following error
`./dcgan: symbol lookup error: ./dcgan: undefined symbol: _ZN5torch5optim6detail13OptimizerBase15add_param_groupERKNS0_19OptimizerParamGroupE
`
It appears that the following lines are responsible for this error:
` torch::optim::Adam generator_optimizer(generator->parameters(), torch::optim::AdamOptions(2e-4).betas(std::make_tuple (0.5, 0.5)));
torch::optim::Adam discriminator_optimizer(discriminator->parameters(), torch::optim::AdamOptions(2e-4).betas(std::make_tuple (0.5, 0.5)));`
Is there anyone who has previously encountered this error? May I please request your help regarding the same?
Thank you
|
https://github.com/pytorch/examples/issues/778
|
closed
|
[] | 2020-05-23T02:17:54Z
| 2020-05-23T02:51:29Z
| 0
|
namehta4
|
pytorch/vision
| 2,250
|
cuda10.0 support for torchvision6
|
I try to install torchvision6-cu100 with pip but failed, I can only find the cu92 and cu101 version, is there no support for cuda10.0 ?
|
https://github.com/pytorch/vision/issues/2250
|
closed
|
[
"question",
"topic: binaries"
] | 2020-05-21T17:13:19Z
| 2020-05-21T18:20:42Z
| null |
feihuidiqiu
|
pytorch/TensorRT
| 62
|
How to use local pytorch instead of installing again.
|
Hi Naren,
glad to see that you check-in py binding and test.
TRTorch needs to install pytorch and torchvision again and I know it is easy to build trt from scratch.
But as a developer, I always build and set pytorch env locally and do need to install it again. Could you help provide options to call local pytorch instead of installing again. @narendasan
Thanks,
Alan
|
https://github.com/pytorch/TensorRT/issues/62
|
closed
|
[
"question",
"component: build system",
"component: api [Python]",
"No Activity"
] | 2020-05-19T09:52:44Z
| 2020-06-27T00:03:18Z
| null |
alanzhai219
|
pytorch/vision
| 2,237
|
fresh installation of pytorch 1.5 and torchvision .6 yields error with docs
|
## 🐛 Bug
using the latest installations from the pytorch recommended conda line, along with the following required libraries
```
cython
pycocotools
matplotlib
```
I was able to hit an error in the line given under https://github.com/pytorch/vision/blob/master/references/detection/README.md
for performing Faster R CNN
I would also wonder if I can improve the docs by mentioning the fact that, in order to run that example you must pip install cython, pycocotools, and matplotlib ?
## To Reproduce
Steps to reproduce the behavior:
1. copy the `references/detection/` folder somewhere
2. create a conda environment and install latest stable pytorch and torchvision
3. attempt to run the `README.md` provided command
```
(clone_reference_torchvision) emcp@2600k:~/Dev/git/clone_reference_torchvision$ python -m torch.distributed.launch --nproc_per_node=8 --use_env train.py --dataset coco --model fasterrcnn_resnet50_fpn --epochs 26 --lr-steps 16 22 --aspect-ratio-group-factor 3
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
THCudaCheck FAIL file=/opt/conda/conda-bld/pytorch_1587428207430/work/torch/csrc/cuda/Module.cpp line=59 error=101 : invalid device ordinal
THCudaCheck FAIL file=/opt/conda/conda-bld/pytorch_1587428207430/work/torch/csrc/cuda/Module.cpp line=59 error=101 : invalid device ordinal
| distributed init (rank 0): env://
Traceback (most recent call last):
File "train.py", line 201, in <module>
main(args)
File "train.py", line 60, in main
Traceback (most recent call last):
File "train.py", line 201, in <module>
main(args)
File "train.py", line 60, in main
utils.init_distributed_mode(args)
File "/home/emcp/Dev/git/clone_reference_torchvision/utils.py", line 317, in init_distributed_mode
utils.init_distributed_mode(args)
torch.cuda.set_device(args.gpu)
File "/home/emcp/anaconda3/envs/clone_reference_torchvision/lib/python3.8/site-packages/torch/cuda/__init__.py", line 245, in set_device
File "/home/emcp/Dev/git/clone_reference_torchvision/utils.py", line 317, in init_distributed_mode
torch._C._cuda_setDevice(device)
torch.cuda.set_device(args.gpu)
File "/home/emcp/anaconda3/envs/clone_reference_torchvision/lib/python3.8/site-packages/torch/cuda/__init__.py", line 245, in set_device
RuntimeError torch._C._cuda_setDevice(device)
RuntimeError: cuda runtime error (101) : invalid device ordinal at /opt/conda/conda-bld/pytorch_1587428207430/work/torch/csrc/cuda/Module.cpp:59
: cuda runtime error (101) : invalid device ordinal at /opt/conda/conda-bld/pytorch_1587428207430/work/torch/csrc/cuda/Module.cpp:59
THCudaCheck FAIL file=/opt/conda/conda-bld/pytorch_1587428207430/work/torch/csrc/cuda/Module.cpp line=59 error=101 : invalid device ordinal
Traceback (most recent call last):
File "train.py", line 201, in <module>
main(args)
File "train.py", line 60, in main
utils.init_distributed_mode(args)
File "/home/emcp/Dev/git/clone_reference_torchvision/utils.py", line 317, in init_distributed_mode
torch.cuda.set_device(args.gpu)
File "/home/emcp/anaconda3/envs/clone_reference_torchvision/lib/python3.8/site-packages/torch/cuda/__init__.py", line 245, in set_device
torch._C._cuda_setDevice(device)
RuntimeError: cuda runtime error (101) : invalid device ordinal at /opt/conda/conda-bld/pytorch_1587428207430/work/torch/csrc/cuda/Module.cpp:59
THCudaCheck FAIL file=/opt/conda/conda-bld/pytorch_1587428207430/work/torch/csrc/cuda/Module.cpp line=59 error=101 : invalid device ordinal
Traceback (most recent call last):
File "train.py", line 201, in <module>
main(args)
File "train.py", line 60, in main
utils.init_distributed_mode(args)
File "/home/emcp/Dev/git/clone_reference_torchvision/utils.py", line 317, in init_distributed_mode
torch.cuda.set_device(args.gpu)
File "/home/emcp/anaconda3/envs/clone_reference_torchvision/lib/python3.8/site-packages/torch/cuda/__init__.py", line 245, in set_device
torch._C._cuda_setDevice(device)
RuntimeError: cuda runtime error (101) : invalid device ordinal at /opt/conda/conda-bld/pytorch_1587428207430/work/torch/csrc/cuda/Module.cpp:59
THCudaCheck FAIL file=/opt/conda/conda-bld/pytorch_1587428207430/work/torch/csrc/cuda/Module.cpp line=59 error=101 : invalid device ordinal
Traceback (most recent call last):
File "train.py", line 201, in <module>
main(args)
File "train.py", line 60, in main
utils.init_distributed_mode(args)
File "/home/emcp/Dev/git/clone_reference_torchvision/utils.py", line 317, in init_distributed_mode
torch.cuda.set_device(args.gpu)
File "/home/emcp/anaconda3/envs/clone_reference_torchvision/lib/python3.8/site-packages/torch/cuda/__init__
|
https://github.com/pytorch/vision/issues/2237
|
closed
|
[
"question",
"module: reference scripts",
"topic: object detection"
] | 2020-05-19T07:15:13Z
| 2020-05-20T10:32:24Z
| null |
EMCP
|
pytorch/serve
| 363
|
Best practice question - how to chain multiple models together for pipeline process?
|
Hi all - I couldn't find anything in the documentation so wondering if there is a recommendation for how to chain multiple models together in an internal pipeline?
Example - we need to take an incoming image, do obj detection , then do a seperate mdoel classification from items cropped and zoomed, return the result...i.e.:
1 - Model A - Run obj detector on incoming image
1a - post process to determine cropped subset of image where object is (inside model handler)
2 - Model B - run inference on subset image from step 1a to classify the detected item
3 - return final result
Is our only option to force the client to do two calls to the /serve and effectively remote control this pipeline?
Ideally we want to pass in the large image, and just return the final result all from one client http POST call since its expensive in our setup to pass/ do multiple remote calls (i.e. post to model 1, post to model 2).
But where would one control this two step process from within torch server or is there any built in 'controller' concept?
It seems the current design model is based around hosting independent models each doing their own work without any reference to how to internally bind them together into a pipeline.
Could you provide any recommendations for how to best structure a pipeline like the above or is it not supported/possible/recommended?
Thanks very much!
|
https://github.com/pytorch/serve/issues/363
|
closed
|
[] | 2020-05-19T05:16:35Z
| 2020-05-19T19:37:08Z
| null |
lessw2020
|
pytorch/xla
| 2,092
|
How to set XLA random seed
|
## ❓ Questions and Help
On CPU (same from run to run):
```python
torch.manual_seed(0)
torch.zeros(5).uniform_()
# tensor([0.4963, 0.7682, 0.0885, 0.1320, 0.3074])
torch.manual_seed(0)
torch.zeros(5).uniform_()
# tensor([0.4963, 0.7682, 0.0885, 0.1320, 0.3074])
```
On XLA (different from run to run):
```python
torch.manual_seed(0)
torch.zeros(5, device=xm.xla_device()).uniform_()
# tensor([0.9650, 0.4818, 0.2164, 0.2308, 0.8543], device='xla:1')
torch.manual_seed(0)
torch.zeros(5, device=xm.xla_device()).uniform_()
# tensor([0.3197, 0.6271, 0.0868, 0.2445, 0.3315], device='xla:1')
```
|
https://github.com/pytorch/xla/issues/2092
|
closed
|
[] | 2020-05-18T19:13:07Z
| 2020-05-18T19:21:22Z
| null |
myleott
|
pytorch/tutorials
| 998
|
Per-tutorial dependencies/build
|
Current documented instructions say how to build tutorials tell you how to install dependencies and the build ALL of the tutorials at once. If you want to work on a single tutorial, this is not great, since many of the tutorials are quite involved (in terms of the dependencies they need, what external resources they need, and also how long they take to download). There should be clearer instructions about how to develop a single tutorial at a time.
|
https://github.com/pytorch/tutorials/issues/998
|
open
|
[
"build issue"
] | 2020-05-15T14:16:25Z
| 2021-07-27T23:25:51Z
| 1
|
ezyang
|
pytorch/pytorch
| 38,542
|
How to use torch::where?
|
libtorch 1.5
How to use torch::where? for emample:
-------------------------------------------------
import torch
import numpy as np
cc=np.array(range(0,24)).reshape(-1,4)
validIndex=np.where( ((cc[:,:2]>=0) & (cc[:,2:]>(1,2))).all(axis=1) )[0]
print(validIndex)
>>[0 1 2 3 4 5]
---------------------------------------------------
torch::Tensor cc = torch::range(0, 23, 1).view({ 4,6 }).view({-1,4});
torch::Tensor c = cc.index({ torch::indexing::Slice(),torch::indexing::Slice(2,torch::indexing::None) });
?????
|
https://github.com/pytorch/pytorch/issues/38542
|
closed
|
[] | 2020-05-15T07:09:05Z
| 2020-05-15T21:48:30Z
| null |
williamlzw
|
pytorch/serve
| 343
|
Docker: How to add your .mar files?
|
Dear all,
Could you please update the doc showing how to use your `.mar` files and `model-store` dir with docker? Assuming I have a stored `.mar` and `model-store` dir locally on my pc and I want to run `torchserve` on docker with them, what should I do? Is there an option to add the `mar` file? The docker page of `torchserve` doesn't contain information.
Thank you.
Be safe and best regards,
Francesco Saverio
|
https://github.com/pytorch/serve/issues/343
|
closed
|
[
"documentation",
"duplicate",
"triaged_wait"
] | 2020-05-13T14:37:23Z
| 2020-06-09T23:39:52Z
| null |
FrancescoSaverioZuppichini
|
pytorch/examples
| 770
|
Building cpp example with libtorch fails with LibTorch downloaded from the website
|
I have tried to build some of the examples and the codes which have been tested before. But When updated the libtorch version I keep getting the following error. I downloaded the libtorch from website.
Ubuntu 18.04
c++14
make 10.0
One of the tested Example: [https://github.com/dendisuhubdy/libtorch_examples.git](url)
log file :
`-- The C compiler identification is GNU 7.5.0
-- The CXX compiler identification is GNU 7.5.0
-- Check for working C compiler: /usr/bin/cc
-- Check for working C compiler: /usr/bin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
-- Check for working CXX compiler: /usr/bin/c++
-- Check for working CXX compiler: /usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Looking for pthread.h
-- Looking for pthread.h - found
-- Looking for pthread_create
-- Looking for pthread_create - not found
-- Looking for pthread_create in pthreads
-- Looking for pthread_create in pthreads - not found
-- Looking for pthread_create in pthread
-- Looking for pthread_create in pthread - found
-- Found Threads: TRUE
-- Found CUDA: /usr/local/cuda-10.2 (found version "10.2")
-- Caffe2: CUDA detected: 10.2
-- Caffe2: CUDA nvcc is: /usr/local/cuda-10.2/bin/nvcc
-- Caffe2: CUDA toolkit directory: /usr/local/cuda-10.2
-- Caffe2: Header version is: 10.2
-- Found CUDNN: /usr/lib/x86_64-linux-gnu/libcudnn.so
-- Found cuDNN: v7.6.5 (include: /usr/include, library: /usr/lib/x86_64-linux-gnu/libcudnn.so)
-- Autodetected CUDA architecture(s): 5.2
-- Added CUDA NVCC flags for: -gencode;arch=compute_52,code=sm_52
-- Found Torch: /home/ubuntu/libtorch/libtorch/lib/libtorch.so
-- Found OpenCV: /usr/local (found version "3.4.9")
-- OpenCV library status:
-- config: /usr/local/share/OpenCV
-- version: 3.4.9
-- libraries: opencv_calib3d;opencv_core;opencv_dnn;opencv_features2d;opencv_flann;opencv_highgui;opencv_imgcodecs;opencv_imgproc;opencv_ml;opencv_objdetect;opencv_photo;opencv_shape;opencv_stitching;opencv_superres;opencv_video;opencv_videoio;opencv_videostab
-- include path: /usr/local/include;/usr/local/include/opencv
-- Downloading MNIST dataset
/home/ubuntu/libtorch_examples/build/../data/mnist/train-images-idx3-ubyte.gz already exists, skipping ...
/home/ubuntu/libtorch_examples/build/../data/mnist/train-images-idx3-ubyte already exists, skipping ...
/home/ubuntu/libtorch_examples/build/../data/mnist/train-labels-idx1-ubyte.gz already exists, skipping ...
/home/ubuntu/libtorch_examples/build/../data/mnist/train-labels-idx1-ubyte already exists, skipping ...
/home/ubuntu/libtorch_examples/build/../data/mnist/t10k-images-idx3-ubyte.gz already exists, skipping ...
/home/ubuntu/libtorch_examples/build/../data/mnist/t10k-images-idx3-ubyte already exists, skipping ...
/home/ubuntu/libtorch_examples/build/../data/mnist/t10k-labels-idx1-ubyte.gz already exists, skipping ...
/home/ubuntu/libtorch_examples/build/../data/mnist/t10k-labels-idx1-ubyte already exists, skipping ...
-- Configuring done
-- Generating done
-- Build files have been written to: /home/ubuntu/libtorch_examples/build
Scanning dependencies of target mnist
[ 14%] Building CXX object src/CMakeFiles/mnist.dir/mnist.cpp.o
Scanning dependencies of target dcgan
[ 28%] Building CXX object src/CMakeFiles/dcgan.dir/dcgan.cpp.o
Scanning dependencies of target yolov3
[ 42%] Building CXX object src/CMakeFiles/yolov3.dir/darknet.cpp.o
[ 57%] Building CXX object src/CMakeFiles/yolov3.dir/yolov3.cpp.o
In file included from /home/ubuntu/libtorch_examples/src/mnist.cpp:8:0:
/home/ubuntu/libtorch_examples/include/mnist.h:55:13: error: ‘FeatureDropout’ in namespace ‘torch::nn’ does not name a type
torch::nn::FeatureDropout conv2_drop;
^~~~~~~~~~~~~~
/home/ubuntu/libtorch_examples/include/mnist.h: In constructor ‘Net::Net()’:
/home/ubuntu/libtorch_examples/include/mnist.h:37:33: error: ‘conv2_drop’ was not declared in this scope
register_module("conv2_drop", conv2_drop);
^~~~~~~~~~
/home/ubuntu/libtorch_examples/include/mnist.h:37:33: note: suggested alternative: ‘conv2’
register_module("conv2_drop", conv2_drop);
^~~~~~~~~~
conv2
/home/ubuntu/libtorch_examples/include/mnist.h: In member function ‘at::Tensor Net::forward(at::Tensor)’:
/home/ubuntu/libtorch_examples/include/mnist.h:45:22: error: ‘conv2_drop’ was not declared in this scope
torch::max_pool2d(conv2_drop->forward(conv2->forward(x)), 2));
^~~~~~~~~~
/home/ubuntu/libtorch_examples/include/mnist.h:45:22: note: suggested alternative: ‘conv2’
torch::max_pool2d(conv2_drop->forward(conv2->forward(x)), 2));
^~~~
|
https://github.com/pytorch/examples/issues/770
|
closed
|
[] | 2020-05-13T11:53:26Z
| 2020-05-17T16:28:00Z
| 1
|
Gfuse
|
pytorch/tutorials
| 995
|
data_loading_tutorial.py iterators
|
I like this tutorial but I think it would be better if it included an example of how to define __next__() and __iter__() methods so that the dataset can be used with `enumerate`.
|
https://github.com/pytorch/tutorials/issues/995
|
closed
|
[
"data loading",
"docathon-h1-2023",
"medium"
] | 2020-05-12T21:55:37Z
| 2023-06-02T15:45:12Z
| 3
|
patricknaughton01
|
pytorch/vision
| 2,205
|
Some issues in conv_transpose2d.
|
Recently I met this problem bothering me.
In TensorFlow, there is a funciton:
`tf.nn.conv2d_transpose(
input, filters, output_shape, strides, padding='SAME', data_format='NHWC',
dilations=None, name=None
)`
But in PyTorch:
`torch.nn.functional.conv_transpose2d(input, weight, bias=None, stride=1, padding=0, output_padding=0, groups=1, dilation=1) → Tensor`
As you can see there is no parameter named output_shape. But my project need this parameter to recitify the size of output. Anyone can help me? Thanks~
|
https://github.com/pytorch/vision/issues/2205
|
closed
|
[
"invalid",
"question"
] | 2020-05-12T04:30:00Z
| 2020-05-12T13:21:51Z
| null |
dhiyu
|
pytorch/pytorch
| 38,129
|
how to get the libtorch code from the python?
|

in the python, it's easy to slice, but in the libtorch i don't find any information about it? so please tell me how to get the code from the above python code? thanks
|
https://github.com/pytorch/pytorch/issues/38129
|
closed
|
[] | 2020-05-08T17:26:41Z
| 2020-05-08T17:52:13Z
| null |
Peterisfar
|
pytorch/tutorials
| 987
|
where is folder "reference"?
|
At toturial [https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html](https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html#putting-everything-together),
in Putting Everything Together, a couple of files under folder `reference` is mentioned, yet this folder has never shown up before. I didn't find it in either `torch`(version 1.5.0) or `torchvision`(version 0.6.0) pakage in my anaconda environment.
|
https://github.com/pytorch/tutorials/issues/987
|
closed
|
[] | 2020-05-08T04:34:31Z
| 2020-05-09T02:18:05Z
| null |
feiyangsuo
|
pytorch/text
| 758
|
How to apply Torchtext convenience classes to prepare data for a Transformer
|
Hello,
Reading the tutorial [Language Translation with torchText](https://pytorch.org/tutorials/beginner/torchtext_translation_tutorial.html) I wondered how someone could use those convenience classes (`Field, BucketIterator`) to train/fine-tune a `Transformer` such as those available at [Huggingface](https://github.com/huggingface/transformers).
For instance, I'm currently working with a large dataset distributed in jsonl files which looks like:
```python
{ "query": "this is a query 1", "doc": "relevant document regarding query 1" },
{ "query": "this is a query 2", "doc": "relevant document regarding query 2" },
...
```
Now, to forward this data into a transformer like Bert, it is necessary to convert this dataset into the format:
```python3
(
#queries
{
'input_ids': tensor([
[ 101, 2023, 2003, 1037, 23032, 1015, 102, 0],
[ 101, 2023, 2003, 1037, 23032, 1016, 102, 0]]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 0]])
},
#docs
{
'input_ids': tensor([
[ 101, 2023, 2003, 2028, 7882, 6254, 4953, 102],
[ 101, 2023, 2003, 2028, 7882, 6254, 4953, 102]]),
'attention_mask': 'input_ids': tensor([
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1]])
}
```
So, what would be a clear and efficient approach to apply those convenience classes to tokenize a text dataset to fit it in the required format of a transformer?
|
https://github.com/pytorch/text/issues/758
|
closed
|
[] | 2020-05-06T23:47:51Z
| 2020-05-07T13:54:37Z
| null |
celsofranssa
|
pytorch/text
| 757
|
How to apply torchtext to prepare data for a transformer
|
Hello,
Reading the tutorial [Language Translation with torchText](https://pytorch.org/tutorials/beginner/torchtext_translation_tutorial.html) I wondered how someone could use those convenience classes (`Field, BucketIterator`) to train/fine-tune a `Transformer` such as those available at [Huggingface](https://github.com/huggingface/transformers).
For instance, I'm currently working with a large dataset distributed in jsonl files which looks like:
```python
{ "query": "this is a query 1", "doc": "relevant document regarding query 1" },
{ "query": "this is a query 2", "doc": "relevant document regarding query 2" },
...
```
Now, to forward this data into a transformer like Bert, it is necessary to convert this dataset into the format:
```python3
(
#queries
{
'input_ids': tensor([
[ 101, 2023, 2003, 1037, 23032, 1015, 102, 0],
[ 101, 2023, 2003, 1037, 23032, 1016, 102, 0]]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 0]])
},
#docs
{
'input_ids': tensor([
[ 101, 2023, 2003, 2028, 7882, 6254, 4953, 102],
[ 101, 2023, 2003, 2028, 7882, 6254, 4953, 102]]),
'attention_mask': 'input_ids': tensor([
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1]])
}
```
So, what would be a clear and efficient approach to apply those convenience classes to tokenize a text dataset to fit it in the required format of a transformer?
|
https://github.com/pytorch/text/issues/757
|
closed
|
[
"legacy"
] | 2020-05-06T23:47:18Z
| 2022-06-23T21:46:27Z
| null |
celsofranssa
|
huggingface/swift-coreml-transformers
| 19
|
What GPT-2 model is distilled here?
|
Is it the gpt2-small (124M), gpt2-medium (345M), gpt2-large (774M), or the gpt-xl (1.5B) that this implementation uses out of the box?
|
https://github.com/huggingface/swift-coreml-transformers/issues/19
|
closed
|
[] | 2020-05-05T02:08:49Z
| 2023-04-01T18:01:45Z
| null |
philipkd
|
pytorch/tutorials
| 977
|
is the log softmax function missing in the Transformer Example?
|
Hello,
The tutorial (https://pytorch.org/tutorials/beginner/transformer_tutorial.html) describes the Transformer paper and says that "... .To have the actual words, the output of nn.TransformerEncoder model is sent to the final Linear layer, which is followed by a log-Softmax function." The code, however, does return the output directly from the last Linear layer and does not use a (log) softmax anywhere. Do I fail to see something or is it actually missing?
|
https://github.com/pytorch/tutorials/issues/977
|
closed
|
[] | 2020-05-04T19:41:07Z
| 2020-09-13T13:52:55Z
| 2
|
hilfe123
|
pytorch/xla
| 2,026
|
How are kernel implementations registered to PyTorch
|
## ❓ Questions and Help
Hi,
I was wondering how the PyTorch dispatcher finds the kernel implementations for functions defined in `aten_xla_type_default.h`
and what is the purpose of `RegisterAtenTypeFunctions `
|
https://github.com/pytorch/xla/issues/2026
|
closed
|
[] | 2020-05-04T16:32:41Z
| 2020-05-08T19:14:16Z
| null |
a2bhulla
|
pytorch/vision
| 2,175
|
ModuleNotFoundError: No module named 'torchvision.models.detection'
|
I have pytorch1.1.0 and torchvision0.2.2 installed in my anaconda environment.
I can: 1. `import torch`; 2.`import torchvision` (following the toturial) Yet when `from torchvision.models.detection.faster_rcnn import FastRCNNPredictor`, error raised as:
```
Traceback (most recent call last):
File "<input>", line 1, in <module>
File "D:\Applications\PyCharm 2019.2.3\helpers\pydev\_pydev_bundle\pydev_import_hook.py", line 21, in do_import
module = self._system_import(name, *args, **kwargs)
ModuleNotFoundError: No module named 'torchvision.models.detection'
```
I suspect that my version of torchvision is somewhat low. But my GPU driver only support cudatoolkit9.0, and version 0.2.2 is automatically chosen when I install torchvision.
|
https://github.com/pytorch/vision/issues/2175
|
closed
|
[
"question",
"module: models",
"topic: object detection"
] | 2020-05-03T06:51:40Z
| 2020-05-04T12:33:56Z
| null |
feiyangsuo
|
pytorch/xla
| 2,021
|
How to run nprocs > 1 on local CPU using the XRT client ?
|
## ❓ Questions and Help
I would like to test locally some code with `xmp.spawn(..., nprocs=8)`. When I use suggested env vars in https://github.com/pytorch/xla/blob/master/CONTRIBUTING.md#running-the-tests, my tests pass with nprocs=1 and fail with nprocs > 1 complaining about gRPC
```
2020-05-02 23:51:20.896158: E 1654 tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:509] Unknown: Could not start gRPC server
```
Any suggestions on how to setup properly XRT_DEVICE_MAP and XRT_WORKERS ?
Thanks
PS:
I test the code with docker : gcr.io/tpu-pytorch/xla r1.5
|
https://github.com/pytorch/xla/issues/2021
|
closed
|
[] | 2020-05-03T00:05:20Z
| 2020-05-03T00:44:06Z
| null |
vfdev-5
|
pytorch/xla
| 2,000
|
How are operations recorded once tensors are dispatched to XLA
|
## ❓ Questions and Help
In the pytorch/xla docs it states "XLA tensors, on the other hand, are lazy. They record operations in a graph until the results are needed"
I was wondering once pytorch dispatches to XLA how this recording occurs. Does the creation of an XLATensor also create a node for this operations which is added to an XLA graph?
Thanks
|
https://github.com/pytorch/xla/issues/2000
|
closed
|
[
"stale"
] | 2020-04-30T20:13:08Z
| 2020-06-06T21:04:18Z
| null |
a2bhulla
|
pytorch/vision
| 2,167
|
engine.py error while following tutorial
|
## 📚 Documentation
I have found this library via the examples at https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html
I ran the google colab and that successfully finished.. however when I go to copy `master` from here and use it locally I am getting an error..
Engine.py line


Error
```
train_one_epoch(model, optimizer, training_data_loader, device, epoch, print_freq=model_conf["hyperParameters"]["display"])
File "/home/emcp/Dev/git/EMCP/faster-rcnn-torchvision/model_components/model/engine.py", line 27, in train_one_epoch
images = list(image.to(device) for image in images)
File "/home/emcp/Dev/git/EMCP/faster-rcnn-torchvision/model_components/model/engine.py", line 27, in <genexpr>
images = list(image.to(device) for image in images)
AttributeError: 'Image' object has no attribute 'to'
``
seems to be an image did not load perhaps ?
|
https://github.com/pytorch/vision/issues/2167
|
closed
|
[
"question",
"module: models",
"module: reference scripts",
"topic: object detection"
] | 2020-04-30T13:21:38Z
| 2022-09-15T11:04:05Z
| null |
EMCP
|
pytorch/pytorch
| 37,478
|
How to do indexing in one-dimensional tensor?
|
How to do indexing in one-dimensional tensor?
```
torch::Tensor keep = nms(c_bboxes, c_scores.index({Slice(), 1}), 0.3);
cout << keep.sizes() << endl;
int keep_end = min(750, (int)keep.size(0));
cout << keep_end << endl;
keep = keep.index({Slice(), keep_end});
```
How to index 1 dimension tensor in libtorch?
The output is :
```
[775]
750
terminate called after throwing an instance of 'c10::IndexError'
what(): too many indices for tensor of dimension 1 (applySlicing at ../aten/src/ATen/TensorIndexing.h:422)
```
So why is that? And how to do the index correctly?
|
https://github.com/pytorch/pytorch/issues/37478
|
closed
|
[] | 2020-04-29T03:15:08Z
| 2020-04-29T03:28:45Z
| null |
Edwardmark
|
pytorch/vision
| 2,151
|
Cannot train deeplabv3_resnet50 with batch size of 1
|
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
Steps to reproduce the behavior:
1. train a `deeplabv3_resnet50`
1. call `forward` with tensor of shape: `torch.Size([1, 3, 240, 320])` (batch with single colour image)
1. receive error message: `ValueError: Expected more than 1 value per channel when training, got input size torch.Size([1, 256, 1, 1])`
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
Training should conduct as with `torch.Size([2, 3, 240, 320])` (batch size 2 and up).
## Environment
```
Collecting environment information...
PyTorch version: 1.5.0
Is debug build: No
CUDA used to build PyTorch: 10.2
OS: Ubuntu 18.04.4 LTS
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
CMake version: version 3.10.2
Python version: 3.6
Is CUDA available: No
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
Versions of relevant libraries:
[pip3] numpy==1.18.2
[pip3] torch==1.5.0
[pip3] torchsummary==1.5.1
[pip3] torchvision==0.6.0
[conda] Could not collect
```
## Additional context
<!-- Add any other context about the problem here. -->
Training with batch size of 1 is probably uncommon but there is no technical reason why this should not be possible and the error message is rather cryptic and unhelpful.
|
https://github.com/pytorch/vision/issues/2151
|
closed
|
[
"question",
"module: models",
"topic: semantic segmentation"
] | 2020-04-28T17:05:52Z
| 2020-04-28T17:47:30Z
| null |
christian-rauch
|
pytorch/elastic
| 97
|
How to run elastically on kubernetes (nnodes vs worker replicas)
|
### Question
- On the frontpage README.md of the repo it says to run Elastic on 1 ~ 4 nodes, 8 trainers/node, total 8 ~ 32 trainers. Job starts as soon as 1 node is healthy, you may add up to 4 nodes.
```
python -m torchelastic.distributed.launch
--nnodes=1:4
--nproc_per_node=8
--rdzv_id=JOB_ID
--rdzv_backend=etcd
--rdzv_endpoint=ETCD_HOST:ETCD_PORT
YOUR_TRAINING_SCRIPT.py (--arg1 ... train script args...)
```
- In the docs for the kube example it says:
```
set Worker.replicas to the number of nodes to start with (you may modify this later to scale the job in/out)
```
- When I try to run with a minReplicas of 1, maxReplicas of 2, and replicas of 2 and **the autoscaling group for my training nodes only has one node available** training starts with the one available node, and then the second one joins in when it can, but it seems to reset progress 👇, is this expected because we haven't hit a checkpoint yet? Is this desired? Especially in a world where we're using spot instances, how can I make sure I don't get stuck in a loop similar to this redoing the same epoch?
```
Instance: [i-015067026ed8f10a3] Epoch: [0][1830/3125] Time 0.139 ( 0.137) Data 0.034 ( 0.034) Loss 4.8472e+00 (5.0661e+00) Acc@1 3.12 ( 3.16) Acc@5 9.38 ( 11.34)
Instance: [i-015067026ed8f10a3] Epoch: [0][1840/3125] Time 0.139 ( 0.137) Data 0.034 ( 0.034) Loss 4.7636e+00 (5.0644e+00) Acc@1 9.38 ( 3.17) Acc@5 18.75 ( 11.37)
INFO 2020-04-27 18:52:52,967 Etcd machines: ['http://0.0.0.0:2379']
INFO 2020-04-27 18:52:53,585 Attempting to join next rendezvous
Instance: [i-015067026ed8f10a3] Epoch: [0][1850/3125] Time 0.139 ( 0.137) Data 0.034 ( 0.034) Loss 4.6797e+00 (5.0630e+00) Acc@1 3.12 ( 3.17) Acc@5 18.75 ( 11.39)
Instance: [i-015067026ed8f10a3] Epoch: [0][1860/3125] Time 0.139 ( 0.137) Data 0.034 ( 0.034) Loss 5.0609e+00 (5.0614e+00) Acc@1 6.25 ( 3.17) Acc@5 15.62 ( 11.42)
INFO 2020-04-27 18:52:53,587 Observed existing rendezvous state: {'status': 'final', 'version': '10', 'participants': [0], 'keep_alives': ['/torchelastic/p2p/run_imagenet/rdzv/v_10/rank_0'], 'num_workers_waiting': 0}
Instance: [i-015067026ed8f10a3] Epoch: [0][1870/3125] Time 0.139 ( 0.137) Data 0.034 ( 0.034) Loss 4.1825e+00 (5.0594e+00) Acc@1 6.25 ( 3.18) Acc@5 28.12 ( 11.46)
INFO 2020-04-27 18:52:53,628 Added self to waiting list. Rendezvous full state: {"status": "final", "version": "10", "participants": [0], "keep_alives": ["/torchelastic/p2p/run_imagenet/rdzv/v_10/rank_0"], "num_workers_waiting": 1}
Instance: [i-015067026ed8f10a3] Epoch: [0][1880/3125] Time 0.139 ( 0.137) Data 0.034 ( 0.034) Loss 5.0155e+00 (5.0574e+00) Acc@1 0.00 ( 3.18) Acc@5 6.25 ( 11.47)
Instance: [i-015067026ed8f10a3] Epoch: [0][1890/3125] Time 0.139 ( 0.137) Data 0.034 ( 0.034) Loss 4.8805e+00 (5.0552e+00) Acc@1 9.38 ( 3.21) Acc@5 18.75 ( 11.53)
INFO 2020-04-27 18:52:58,719 Attempting to join next rendezvous
INFO 2020-04-27 18:52:58,722 Observed existing rendezvous state: {'status': 'final', 'version': '10', 'participants': [0], 'keep_alives': ['/torchelastic/p2p/run_imagenet/rdzv/v_10/rank_0'], 'num_workers_waiting': 1}
INFO 2020-04-27 18:52:58,782 Added self to waiting list. Rendezvous full state: {"status": "final", "version": "10", "participants": [0], "keep_alives": ["/torchelastic/p2p/run_imagenet/rdzv/v_10/rank_0"], "num_workers_waiting": 2}
INFO 2020-04-27 18:53:08,501 Keep-alive key /torchelastic/p2p/run_imagenet/rdzv/v_10/rank_0 is not renewed.
INFO 2020-04-27 18:53:08,501 Rendevous version 10 is incomplete.
INFO 2020-04-27 18:53:08,501 Attempting to destroy it.
INFO 2020-04-27 18:53:08,502 Keep-alive key /torchelastic/p2p/run_imagenet/rdzv/v_10/rank_0 is not renewed.
INFO 2020-04-27 18:53:08,502 Destroyed rendezvous version 10 successfully.
INFO 2020-04-27 18:53:08,502 Previously existing rendezvous state changed. Will re-try joining.
INFO 2020-04-27 18:53:08,502 Rendevous version 10 is incomplete.
INFO 2020-04-27 18:53:08,502 Attempting to destroy it.
INFO 2020-04-27 18:53:08,503 Rendezvous attempt failed, will retry. Reason: Key not found : /torchelastic/p2p/run_imagenet/rdzv/active_version
INFO 2020-04-27 18:53:08,502 Attempting to join next rendezvous
INFO 2020-04-27 18:53:08,506 New rendezvous state created: {'status': 'joinable', 'version': '11', 'participants': []}
INFO 2020-04-27 18:53:08,541 Joined rendezvous version 11 as rank 0. Full state: {'status': 'joinable', 'version': '11', 'participants': [0]}
INFO 2020-04-27 18:53:08,541 Rank 0 is responsible for join last call.
INFO 2020-04-27 18:53:09,504 Attempting to join next rendezvous
INFO 2020-04-27 18:53:09,507 Observed existing rendezvous state: {'status': 'joinable', 'version': '11', 'participants': [0]}
INFO 2020-04-27 18:53:09,540 Joined rendezvous version 11 as rank
|
https://github.com/pytorch/elastic/issues/97
|
closed
|
[] | 2020-04-27T18:58:03Z
| 2020-04-30T16:29:37Z
| null |
mttcnnff
|
pytorch/pytorch
| 37,341
|
how to covert libtorch model to onnx model in libtorch1.5
|
how to convert libtorch model to onnx model in libtorch1.5 . how to convert libtorch model to tensorrt model in libtorch ?
cc @houseroad @spandantiwari @lara-hdr @BowenBao @neginraoof
|
https://github.com/pytorch/pytorch/issues/37341
|
closed
|
[
"module: onnx",
"triaged"
] | 2020-04-27T11:03:44Z
| 2020-04-27T15:13:44Z
| null |
williamlzw
|
pytorch/java-demo
| 10
|
how to build demo with javac
|
Thanks for the tutorial.
Well, could you pls write a guide start from javac for the users who are not familiar with Gradle.
Thanks again.
---
when running the app, I had always got this.

|
https://github.com/pytorch/java-demo/issues/10
|
closed
|
[] | 2020-04-26T19:57:31Z
| 2020-05-03T10:08:38Z
| null |
fzwqq
|
pytorch/TensorRT
| 45
|
Build Project failed with Bazel
|
Hi,
I configure the env and try to build such project.
INFO: Analyzed target //:libtrtorch (34 packages loaded, 1830 targets configured).
INFO: Found 1 target...
INFO: Deleting stale sandbox base /home/xxx/.cache/bazel/_bazel_xxx/2ed6247d0d5238dab6f58f41a8e8ad4b/sandbox
ERROR: missing input file 'external/tensorrt/lib/x86_64-linux-gnu/libnvinfer.so', owner: '@tensorrt//:lib/x86_64-linux-gnu/libnvinfer.so'
ERROR: /home/xxx/2ed6247d0d5238dab6f58f41a8e8ad4b/external/tensorrt/BUILD.bazel:15:1: @tensorrt//:nvinfer_lib: missing input file '@tensorrt//:lib/x86_64-linux-gnu/libnvinfer.so'
Target //:libtrtorch failed to build
Use --verbose_failures to see the command lines of failed build steps.
ERROR: /home/xxx/.cache/bazel/_bazel_xxxd5238dab6f58f41a8e8ad4b/external/tensorrt/BUILD.bazel:15:1 1 input file(s) do not exist
INFO: Elapsed time: 2.964s, Critical Path: 0.13s
INFO: 0 processes.
FAILED: Build did NOT complete successfully
could you help solve such errors or provide more env setting details?
I have email @narendasan and please check it.
Thanks.
|
https://github.com/pytorch/TensorRT/issues/45
|
closed
|
[
"question",
"component: build system"
] | 2020-04-26T04:02:19Z
| 2020-04-30T03:59:00Z
| null |
alanzhai219
|
pytorch/vision
| 2,144
|
Negative Samples in Faster RCNN training results in NaN RPN_BOX_REG Loss
|
Overview:
I updated torch and torchvision to the latest builds. A cool update was that now negative samples could be included in RCNN training. However, I end up getting a NaN value for loss_rpn_box_reg when I provide negative samples.
I was training a Pedestrian Detector. Based on my custom dataset input, if a label wasn't provided, I would use it as a negative sample. This is the code snippet I used.
```
def __getitem__(self, idx):
img_path , x1 , y1 , x2 ,y2 , label = self.imgs[idx].split(",")
img = Image.open(img_path).convert("RGB")
boxes = []
if label:
pos = np.asarray([[y1,y2],[x1,x2]]).astype(np.float)
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
boxes.append([xmin, ymin, xmax, ymax])
labels = torch.ones((1,), dtype=torch.int64)
iscrowd = torch.zeros((1,), dtype=torch.int64)
else:
boxes.append([0.0,0.0,0.0,0.0])
labels = torch.zeros((1,), dtype=torch.int64)
iscrowd = torch.zeros((0,), dtype=torch.int64)
# convert everything into a torch.Tensor
boxes = torch.as_tensor(boxes, dtype=torch.float32)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
```
The training seems to work fine if I replace the following line:
```
boxes.append([0.0,0.0,0.0,0.0])
```
with
```
boxes.append([0.0,0.0,0.1,0.1])
```
So i'm guessing it's because both xmin/ymin and xmax/ymax are equal.
Setup:
Torch : 1.5.0
Torchvision: 0.6.0
Nvidia - 440.33
Cuda-10.2
|
https://github.com/pytorch/vision/issues/2144
|
closed
|
[
"question",
"module: models",
"topic: object detection"
] | 2020-04-24T23:00:57Z
| 2021-08-13T13:19:57Z
| null |
praneet195
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.