
url
string | repository_url
string | labels_url
string | comments_url
string | events_url
string | html_url
string | id
int64 | node_id
string | number
int64 | title
string | user
dict | labels
list | state
string | locked
bool | assignee
dict | assignees
list | milestone
dict | comments
list | created_at
timestamp[ns, tz=UTC] | updated_at
timestamp[ns, tz=UTC] | closed_at
timestamp[ns, tz=UTC] | author_association
string | type
float64 | active_lock_reason
float64 | sub_issues_summary
dict | body
string | closed_by
dict | reactions
dict | timeline_url
string | performed_via_github_app
float64 | state_reason
string | draft
float64 | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/6283
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6283/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6283/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6283/events
|
https://github.com/huggingface/datasets/pull/6283
| 1,928,552,257
|
PR_kwDODunzps5cBlKq
| 6,283
|
Fix array cast/embed with null values
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006278 / 0.011353 (-0.005075) | 0.003692 / 0.011008 (-0.007316) | 0.080464 / 0.038508 (0.041956) | 0.064751 / 0.023109 (0.041642) | 0.318586 / 0.275898 (0.042688) | 0.351435 / 0.323480 (0.027955) | 0.005044 / 0.007986 (-0.002942) | 0.003034 / 0.004328 (-0.001295) | 0.063710 / 0.004250 (0.059460) | 0.050607 / 0.037052 (0.013555) | 0.318491 / 0.258489 (0.060001) | 0.365688 / 0.293841 (0.071847) | 0.027818 / 0.128546 (-0.100729) | 0.008119 / 0.075646 (-0.067527) | 0.262141 / 0.419271 (-0.157131) | 0.044710 / 0.043533 (0.001177) | 0.318875 / 0.255139 (0.063736) | 0.344559 / 0.283200 (0.061360) | 0.022861 / 0.141683 (-0.118822) | 1.452402 / 1.452155 (0.000247) | 1.502340 / 1.492716 (0.009624) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.219355 / 0.018006 (0.201349) | 0.433311 / 0.000490 (0.432822) | 0.006545 / 0.000200 (0.006345) | 0.000078 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024538 / 0.037411 (-0.012874) | 0.073346 / 0.014526 (0.058821) | 0.083824 / 0.176557 (-0.092733) | 0.145176 / 0.737135 (-0.591959) | 0.085941 / 0.296338 (-0.210397) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.395153 / 0.215209 (0.179944) | 3.944734 / 2.077655 (1.867080) | 1.883910 / 1.504120 (0.379790) | 1.690560 / 1.541195 (0.149365) | 1.775180 / 1.468490 (0.306690) | 0.506873 / 4.584777 (-4.077904) | 3.111095 / 3.745712 (-0.634617) | 2.915358 / 5.269862 (-2.354504) | 1.892886 / 4.565676 (-2.672791) | 0.058690 / 0.424275 (-0.365585) | 0.006550 / 0.007607 (-0.001057) | 0.463372 / 0.226044 (0.237328) | 4.640511 / 2.268929 (2.371583) | 2.321051 / 55.444624 (-53.123573) | 1.986330 / 6.876477 (-4.890147) | 2.160046 / 2.142072 (0.017973) | 0.597833 / 4.805227 (-4.207394) | 0.127946 / 6.500664 (-6.372718) | 0.059709 / 0.075469 (-0.015760) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.278966 / 1.841788 (-0.562822) | 17.863102 / 8.074308 (9.788794) | 13.896057 / 10.191392 (3.704665) | 0.147512 / 0.680424 (-0.532912) | 0.016771 / 0.534201 (-0.517430) | 0.335260 / 0.579283 (-0.244024) | 0.383019 / 0.434364 (-0.051345) | 0.384821 / 0.540337 (-0.155516) | 0.550143 / 1.386936 (-0.836793) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006234 / 0.011353 (-0.005118) | 0.003695 / 0.011008 (-0.007313) | 0.062654 / 0.038508 (0.024146) | 0.059397 / 0.023109 (0.036287) | 0.458375 / 0.275898 (0.182477) | 0.488951 / 0.323480 (0.165471) | 0.004971 / 0.007986 (-0.003014) | 0.002914 / 0.004328 (-0.001415) | 0.061184 / 0.004250 (0.056934) | 0.051246 / 0.037052 (0.014194) | 0.458035 / 0.258489 (0.199546) | 0.490838 / 0.293841 (0.196997) | 0.028746 / 0.128546 (-0.099800) | 0.008167 / 0.075646 (-0.067480) | 0.068006 / 0.419271 (-0.351265) | 0.041809 / 0.043533 (-0.001724) | 0.453896 / 0.255139 (0.198757) | 0.477583 / 0.283200 (0.194383) | 0.020906 / 0.141683 (-0.120777) | 1.443275 / 1.452155 (-0.008879) | 1.493431 / 1.492716 (0.000714) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.219903 / 0.018006 (0.201896) | 0.410275 / 0.000490 (0.409785) | 0.003919 / 0.000200 (0.003719) | 0.000078 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027850 / 0.037411 (-0.009561) | 0.080444 / 0.014526 (0.065918) | 0.089943 / 0.176557 (-0.086614) | 0.145810 / 0.737135 (-0.591326) | 0.090908 / 0.296338 (-0.205430) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.464386 / 0.215209 (0.249177) | 4.633787 / 2.077655 (2.556133) | 2.581658 / 1.504120 (1.077538) | 2.408486 / 1.541195 (0.867291) | 2.460491 / 1.468490 (0.992001) | 0.507512 / 4.584777 (-4.077265) | 3.190363 / 3.745712 (-0.555349) | 2.895581 / 5.269862 (-2.374280) | 1.871506 / 4.565676 (-2.694171) | 0.058469 / 0.424275 (-0.365806) | 0.006526 / 0.007607 (-0.001082) | 0.537641 / 0.226044 (0.311596) | 5.396660 / 2.268929 (3.127731) | 3.027028 / 55.444624 (-52.417596) | 2.703771 / 6.876477 (-4.172705) | 2.865576 / 2.142072 (0.723503) | 0.600103 / 4.805227 (-4.205124) | 0.127109 / 6.500664 (-6.373555) | 0.060985 / 0.075469 (-0.014484) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.365030 / 1.841788 (-0.476758) | 17.988218 / 8.074308 (9.913909) | 14.900796 / 10.191392 (4.709404) | 0.158211 / 0.680424 (-0.522213) | 0.018291 / 0.534201 (-0.515910) | 0.337437 / 0.579283 (-0.241846) | 0.383710 / 0.434364 (-0.050654) | 0.392341 / 0.540337 (-0.147997) | 0.561584 / 1.386936 (-0.825352) |\n\n</details>\n</details>\n\n\n",
"CI failures are unrelated",
"I also plan to address https://github.com/huggingface/datasets/issues/6280#issuecomment-1749310065 in this PR :).",
"Oh ok, ping me again whenever you want another review :)",
"Have you had a chance to continue this ? I can also take a look if you want",
"Yes, I'll finish it next week :).",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6283). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"@lhoestq Feel free to review this again. I've bumped PyArrow to 12.0.0 to simplify the implementation (no need for custom `array_concat` and less `pa.Array.from_buffers`). However, this makes `apache-beam` complain as it only supports `<12.0.0`. The next `apache-beam` release will set this boundary to `<15.0.0.`, so I think the only solution is to wait for it to be published.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005188 / 0.011353 (-0.006165) | 0.003997 / 0.011008 (-0.007011) | 0.062642 / 0.038508 (0.024134) | 0.028913 / 0.023109 (0.005804) | 0.248289 / 0.275898 (-0.027609) | 0.268084 / 0.323480 (-0.055396) | 0.004093 / 0.007986 (-0.003893) | 0.002822 / 0.004328 (-0.001506) | 0.048263 / 0.004250 (0.044012) | 0.041520 / 0.037052 (0.004468) | 0.263277 / 0.258489 (0.004788) | 0.289835 / 0.293841 (-0.004006) | 0.027621 / 0.128546 (-0.100925) | 0.010793 / 0.075646 (-0.064853) | 0.207624 / 0.419271 (-0.211648) | 0.035597 / 0.043533 (-0.007936) | 0.245706 / 0.255139 (-0.009433) | 0.268157 / 0.283200 (-0.015043) | 0.017310 / 0.141683 (-0.124373) | 1.130656 / 1.452155 (-0.321499) | 1.162134 / 1.492716 (-0.330583) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.094081 / 0.018006 (0.076075) | 0.302298 / 0.000490 (0.301809) | 0.000220 / 0.000200 (0.000020) | 0.000048 / 0.000054 (-0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019072 / 0.037411 (-0.018339) | 0.061162 / 0.014526 (0.046636) | 0.072820 / 0.176557 (-0.103737) | 0.122628 / 0.737135 (-0.614507) | 0.074962 / 0.296338 (-0.221377) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.277858 / 0.215209 (0.062649) | 2.688478 / 2.077655 (0.610823) | 1.397366 / 1.504120 (-0.106754) | 1.285078 / 1.541195 (-0.256117) | 1.291559 / 1.468490 (-0.176931) | 0.553646 / 4.584777 (-4.031131) | 2.355737 / 3.745712 (-1.389975) | 2.773025 / 5.269862 (-2.496836) | 1.731195 / 4.565676 (-2.834481) | 0.061372 / 0.424275 (-0.362903) | 0.004928 / 0.007607 (-0.002679) | 0.321703 / 0.226044 (0.095659) | 3.212927 / 2.268929 (0.943999) | 1.727104 / 55.444624 (-53.717521) | 1.479430 / 6.876477 (-5.397047) | 1.513436 / 2.142072 (-0.628637) | 0.629913 / 4.805227 (-4.175315) | 0.114607 / 6.500664 (-6.386057) | 0.041707 / 0.075469 (-0.033762) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.976060 / 1.841788 (-0.865727) | 11.575163 / 8.074308 (3.500855) | 9.521390 / 10.191392 (-0.670003) | 0.138725 / 0.680424 (-0.541699) | 0.013752 / 0.534201 (-0.520449) | 0.286252 / 0.579283 (-0.293031) | 0.263420 / 0.434364 (-0.170944) | 0.325531 / 0.540337 (-0.214806) | 0.419466 / 1.386936 (-0.967470) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005615 / 0.011353 (-0.005738) | 0.003884 / 0.011008 (-0.007124) | 0.049563 / 0.038508 (0.011055) | 0.032573 / 0.023109 (0.009464) | 0.276917 / 0.275898 (0.001019) | 0.298403 / 0.323480 (-0.025077) | 0.004367 / 0.007986 (-0.003618) | 0.002794 / 0.004328 (-0.001534) | 0.049105 / 0.004250 (0.044855) | 0.045597 / 0.037052 (0.008545) | 0.289762 / 0.258489 (0.031273) | 0.318440 / 0.293841 (0.024599) | 0.051883 / 0.128546 (-0.076664) | 0.010644 / 0.075646 (-0.065003) | 0.057455 / 0.419271 (-0.361816) | 0.033667 / 0.043533 (-0.009866) | 0.274424 / 0.255139 (0.019285) | 0.295890 / 0.283200 (0.012690) | 0.017029 / 0.141683 (-0.124654) | 1.130123 / 1.452155 (-0.322031) | 1.214827 / 1.492716 (-0.277889) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.094882 / 0.018006 (0.076876) | 0.302505 / 0.000490 (0.302015) | 0.000228 / 0.000200 (0.000028) | 0.000052 / 0.000054 (-0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021695 / 0.037411 (-0.015716) | 0.075196 / 0.014526 (0.060670) | 0.086641 / 0.176557 (-0.089915) | 0.124893 / 0.737135 (-0.612243) | 0.088765 / 0.296338 (-0.207574) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.303388 / 0.215209 (0.088179) | 2.934506 / 2.077655 (0.856852) | 1.608607 / 1.504120 (0.104487) | 1.494632 / 1.541195 (-0.046563) | 1.512801 / 1.468490 (0.044310) | 0.558563 / 4.584777 (-4.026214) | 2.383212 / 3.745712 (-1.362500) | 2.634629 / 5.269862 (-2.635233) | 1.729319 / 4.565676 (-2.836357) | 0.062345 / 0.424275 (-0.361930) | 0.004981 / 0.007607 (-0.002626) | 0.358333 / 0.226044 (0.132289) | 3.484229 / 2.268929 (1.215301) | 2.010043 / 55.444624 (-53.434581) | 1.693733 / 6.876477 (-5.182744) | 1.824150 / 2.142072 (-0.317922) | 0.650835 / 4.805227 (-4.154392) | 0.115933 / 6.500664 (-6.384732) | 0.041270 / 0.075469 (-0.034199) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.007949 / 1.841788 (-0.833838) | 12.000085 / 8.074308 (3.925776) | 10.453119 / 10.191392 (0.261727) | 0.143583 / 0.680424 (-0.536840) | 0.015937 / 0.534201 (-0.518264) | 0.286653 / 0.579283 (-0.292631) | 0.272359 / 0.434364 (-0.162005) | 0.330520 / 0.540337 (-0.209818) | 0.417015 / 1.386936 (-0.969921) |\n\n</details>\n</details>\n\n\n",
"Still the problem is occured.\r\nHuggingface is sucks 🤮🤮🤮🤮"
] | 2023-10-05T15:24:05Z
| 2024-07-04T07:24:20Z
| 2024-02-06T19:24:19Z
|
COLLABORATOR
| null | null | null |
Fixes issues with casting/embedding PyArrow list arrays with null values. It also bumps the required PyArrow version to 12.0.0 (over 9 months old) to simplify the implementation.
Fix #6280, fix #6311, fix #6360
(Also fixes https://github.com/huggingface/datasets/issues/5430 to make Beam compatible with PyArrow>=12.0.0)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6283/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6283/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6283.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6283",
"merged_at": "2024-02-06T19:24:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6283.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6283"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4715
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4715/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4715/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4715/events
|
https://github.com/huggingface/datasets/pull/4715
| 1,309,405,980
|
PR_kwDODunzps47pSui
| 4,715
|
Fix POS tags
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"CI failures are about missing content in the dataset cards or bad tags, and this is unrelated to this PR. Merging :)"
] | 2022-07-19T11:52:54Z
| 2022-07-19T12:54:34Z
| 2022-07-19T12:41:16Z
|
MEMBER
| null | null | null |
We're now using `part-of-speech` and not `part-of-speech-tagging`, see discussion here: https://github.com/huggingface/datasets/commit/114c09aff2fa1519597b46fbcd5a8e0c0d3ae020#r78794777
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4715/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4715/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4715.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4715",
"merged_at": "2022-07-19T12:41:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4715.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4715"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7107
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7107/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7107/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7107/events
|
https://github.com/huggingface/datasets/issues/7107
| 2,470,444,732
|
I_kwDODunzps6TP_68
| 7,107
|
load_dataset broken in 2.21.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1911631?v=4",
"events_url": "https://api.github.com/users/anjor/events{/privacy}",
"followers_url": "https://api.github.com/users/anjor/followers",
"following_url": "https://api.github.com/users/anjor/following{/other_user}",
"gists_url": "https://api.github.com/users/anjor/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/anjor",
"id": 1911631,
"login": "anjor",
"node_id": "MDQ6VXNlcjE5MTE2MzE=",
"organizations_url": "https://api.github.com/users/anjor/orgs",
"received_events_url": "https://api.github.com/users/anjor/received_events",
"repos_url": "https://api.github.com/users/anjor/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/anjor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anjor/subscriptions",
"type": "User",
"url": "https://api.github.com/users/anjor",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"There seems to be a PR related to the load_dataset path that went into 2.21.0 -- https://github.com/huggingface/datasets/pull/6862/files\r\n\r\nTaking a look at it now",
"+1\r\n\r\nDowngrading to 2.20.0 fixed my issue, hopefully helpful for others.",
"I tried adding a simple test to `test_load.py` with the alpaca eval dataset but the test didn't fail :(. \r\n\r\nSo looks like this might have something to do with the environment? ",
"There was an issue with the script of the \"tatsu-lab/alpaca_eval\" dataset.\r\n\r\nI was fixed with this PR: \r\n- [Fix FileNotFoundError](https://huggingface.co/datasets/tatsu-lab/alpaca_eval/discussions/2)\r\n\r\nIt should work now if you retry to load the dataset."
] | 2024-08-16T14:59:51Z
| 2024-08-18T09:28:43Z
| 2024-08-18T09:27:12Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
`eval_set = datasets.load_dataset("tatsu-lab/alpaca_eval", "alpaca_eval_gpt4_baseline", trust_remote_code=True)`
used to work till 2.20.0 but doesn't work in 2.21.0
In 2.20.0:

in 2.21.0:
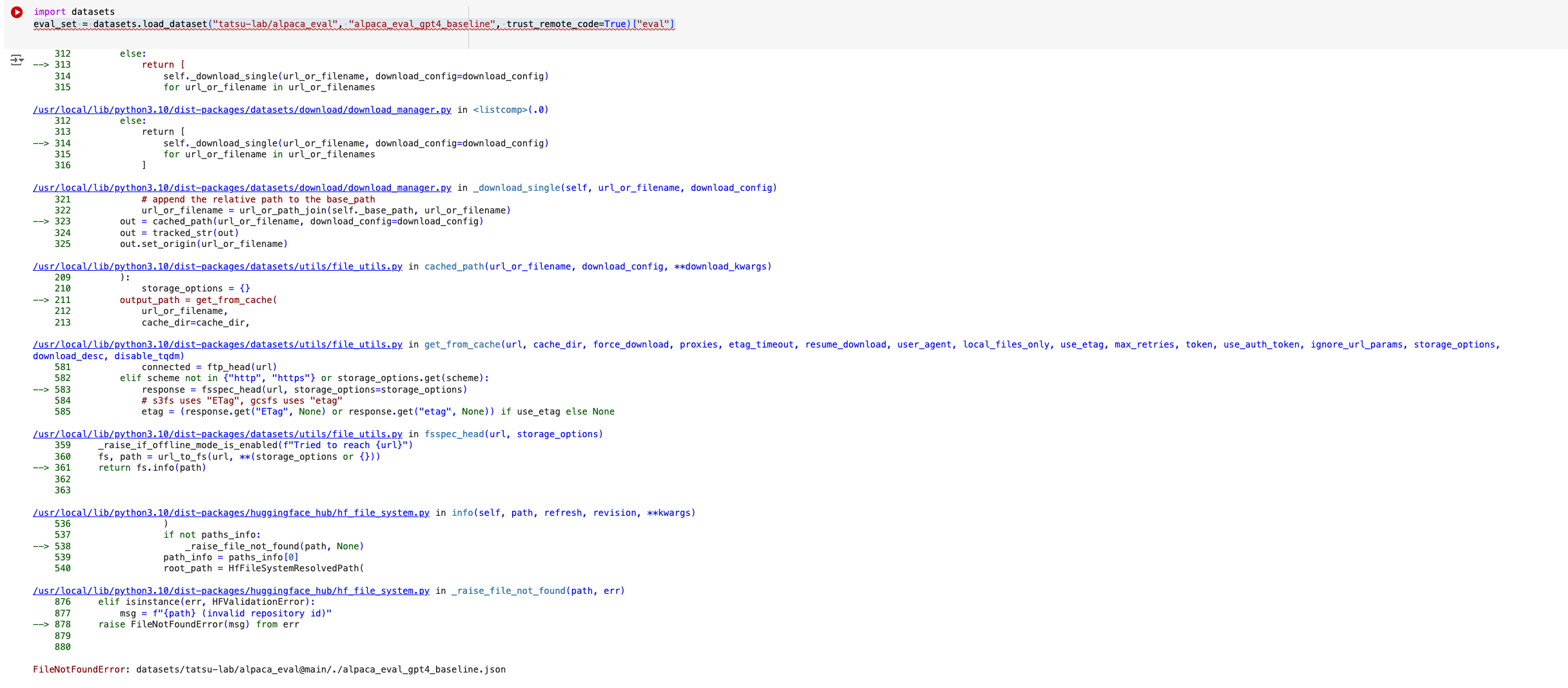
### Steps to reproduce the bug
1. Spin up a new google collab
2. `pip install datasets==2.21.0`
3. `import datasets`
4. `eval_set = datasets.load_dataset("tatsu-lab/alpaca_eval", "alpaca_eval_gpt4_baseline", trust_remote_code=True)`
5. Will throw an error.
### Expected behavior
Try steps 1-5 again but replace datasets version with 2.20.0, it will work
### Environment info
- `datasets` version: 2.21.0
- Platform: Linux-6.1.85+-x86_64-with-glibc2.35
- Python version: 3.10.12
- `huggingface_hub` version: 0.23.5
- PyArrow version: 17.0.0
- Pandas version: 2.1.4
- `fsspec` version: 2024.5.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7107/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7107/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5164
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5164/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5164/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5164/events
|
https://github.com/huggingface/datasets/pull/5164
| 1,422,813,247
|
PR_kwDODunzps5BhL4J
| 5,164
|
WIP: drop labels in Image and Audio folders by default
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna",
"user_view_type": "public"
}
] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"close in favor of https://github.com/huggingface/datasets/pull/5192"
] | 2022-10-25T17:21:49Z
| 2022-11-16T14:21:16Z
| 2022-11-02T14:03:02Z
|
CONTRIBUTOR
| null | null | null |
will fix https://github.com/huggingface/datasets/issues/5153 and redundant labels displaying for most of the images datasets on the Hub (which are used just to store files)
TODO: discuss adding `drop_labels` (and `drop_metadata`) params to yaml
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5164/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5164/timeline
| null | null | 1
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5164.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5164",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5164.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5164"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5039
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5039/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5039/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5039/events
|
https://github.com/huggingface/datasets/issues/5039
| 1,390,353,315
|
I_kwDODunzps5S3xuj
| 5,039
|
Hendrycks Checksum
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/9974388?v=4",
"events_url": "https://api.github.com/users/DanielHesslow/events{/privacy}",
"followers_url": "https://api.github.com/users/DanielHesslow/followers",
"following_url": "https://api.github.com/users/DanielHesslow/following{/other_user}",
"gists_url": "https://api.github.com/users/DanielHesslow/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/DanielHesslow",
"id": 9974388,
"login": "DanielHesslow",
"node_id": "MDQ6VXNlcjk5NzQzODg=",
"organizations_url": "https://api.github.com/users/DanielHesslow/orgs",
"received_events_url": "https://api.github.com/users/DanielHesslow/received_events",
"repos_url": "https://api.github.com/users/DanielHesslow/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/DanielHesslow/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DanielHesslow/subscriptions",
"type": "User",
"url": "https://api.github.com/users/DanielHesslow",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[
"Thanks for reporting, @DanielHesslow. We are fixing it. ",
"@albertvillanova thanks for taking care of this so quickly!",
"The dataset metadata is fixed. You can download it normally."
] | 2022-09-29T06:56:20Z
| 2022-09-29T10:23:30Z
| 2022-09-29T10:04:20Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
Hi,
The checksum for [hendrycks_test](https://huggingface.co/datasets/hendrycks_test) does not compare correctly, I guess it has been updated on the remote.
```
datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://people.eecs.berkeley.edu/~hendrycks/data.tar']
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5039/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5039/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/7441
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7441/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7441/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7441/events
|
https://github.com/huggingface/datasets/issues/7441
| 2,904,702,329
|
I_kwDODunzps6tIj15
| 7,441
|
`drop_last_batch` does not drop the last batch using IterableDataset + interleave_datasets + multi_worker
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4197249?v=4",
"events_url": "https://api.github.com/users/memray/events{/privacy}",
"followers_url": "https://api.github.com/users/memray/followers",
"following_url": "https://api.github.com/users/memray/following{/other_user}",
"gists_url": "https://api.github.com/users/memray/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/memray",
"id": 4197249,
"login": "memray",
"node_id": "MDQ6VXNlcjQxOTcyNDk=",
"organizations_url": "https://api.github.com/users/memray/orgs",
"received_events_url": "https://api.github.com/users/memray/received_events",
"repos_url": "https://api.github.com/users/memray/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/memray/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/memray/subscriptions",
"type": "User",
"url": "https://api.github.com/users/memray",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"Hi @memray, I’d like to help fix the issue with `drop_last_batch` not working when `num_workers > 1`. I’ll investigate and propose a solution. Thanks!\n",
"Thank you very much for offering to help! I also noticed a problem related to a previous issue and left a comment [here](https://github.com/huggingface/datasets/issues/6565#issuecomment-2708169303) (the code checks the validity before certain columns removed). Can you take a look as well?"
] | 2025-03-08T10:28:44Z
| 2025-03-09T21:27:33Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
See the script below
`drop_last_batch=True` is defined using map() for each dataset.
The last batch for each dataset is expected to be dropped, id 21-25.
The code behaves as expected when num_workers=0 or 1.
When using num_workers>1, 'a-11', 'b-11', 'a-12', 'b-12' are gone and instead 21 and 22 are sampled.
### Steps to reproduce the bug
```
from datasets import Dataset
from datasets import interleave_datasets
from torch.utils.data import DataLoader
def convert_to_str(batch, dataset_name):
batch['a'] = [f"{dataset_name}-{e}" for e in batch['a']]
return batch
def gen1():
for ii in range(1, 25):
yield {"a": ii}
def gen2():
for ii in range(1, 25):
yield {"a": ii}
# https://github.com/huggingface/datasets/issues/6565
if __name__ == '__main__':
dataset1 = Dataset.from_generator(gen1).to_iterable_dataset(num_shards=2)
dataset2 = Dataset.from_generator(gen2).to_iterable_dataset(num_shards=2)
dataset1 = dataset1.map(lambda x: convert_to_str(x, dataset_name="a"), batched=True, batch_size=10, drop_last_batch=True)
dataset2 = dataset2.map(lambda x: convert_to_str(x, dataset_name="b"), batched=True, batch_size=10, drop_last_batch=True)
interleaved = interleave_datasets([dataset1, dataset2], stopping_strategy="all_exhausted")
print(f"num_workers=0")
loader = DataLoader(interleaved, batch_size=5, num_workers=0)
i = 0
for b in loader:
print(i, b['a'])
i += 1
print('=-' * 20)
print(f"num_workers=1")
loader = DataLoader(interleaved, batch_size=5, num_workers=1)
i = 0
for b in loader:
print(i, b['a'])
i += 1
print('=-' * 20)
print(f"num_workers=2")
loader = DataLoader(interleaved, batch_size=5, num_workers=2)
i = 0
for b in loader:
print(i, b['a'])
i += 1
print('=-' * 20)
print(f"num_workers=3")
loader = DataLoader(interleaved, batch_size=5, num_workers=3)
i = 0
for b in loader:
print(i, b['a'])
i += 1
```
output is:
```
num_workers=0
0 ['a-1', 'b-1', 'a-2', 'b-2', 'a-3']
1 ['b-3', 'a-4', 'b-4', 'a-5', 'b-5']
2 ['a-6', 'b-6', 'a-7', 'b-7', 'a-8']
3 ['b-8', 'a-9', 'b-9', 'a-10', 'b-10']
4 ['a-11', 'b-11', 'a-12', 'b-12', 'a-13']
5 ['b-13', 'a-14', 'b-14', 'a-15', 'b-15']
6 ['a-16', 'b-16', 'a-17', 'b-17', 'a-18']
7 ['b-18', 'a-19', 'b-19', 'a-20', 'b-20']
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
num_workers=1
0 ['a-1', 'b-1', 'a-2', 'b-2', 'a-3']
1 ['b-3', 'a-4', 'b-4', 'a-5', 'b-5']
2 ['a-6', 'b-6', 'a-7', 'b-7', 'a-8']
3 ['b-8', 'a-9', 'b-9', 'a-10', 'b-10']
4 ['a-11', 'b-11', 'a-12', 'b-12', 'a-13']
5 ['b-13', 'a-14', 'b-14', 'a-15', 'b-15']
6 ['a-16', 'b-16', 'a-17', 'b-17', 'a-18']
7 ['b-18', 'a-19', 'b-19', 'a-20', 'b-20']
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
num_workers=2
0 ['a-1', 'b-1', 'a-2', 'b-2', 'a-3']
1 ['a-13', 'b-13', 'a-14', 'b-14', 'a-15']
2 ['b-3', 'a-4', 'b-4', 'a-5', 'b-5']
3 ['b-15', 'a-16', 'b-16', 'a-17', 'b-17']
4 ['a-6', 'b-6', 'a-7', 'b-7', 'a-8']
5 ['a-18', 'b-18', 'a-19', 'b-19', 'a-20']
6 ['b-8', 'a-9', 'b-9', 'a-10', 'b-10']
7 ['b-20', 'a-21', 'b-21', 'a-22', 'b-22']
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
num_workers=3
Too many dataloader workers: 3 (max is dataset.num_shards=2). Stopping 1 dataloader workers.
0 ['a-1', 'b-1', 'a-2', 'b-2', 'a-3']
1 ['a-13', 'b-13', 'a-14', 'b-14', 'a-15']
2 ['b-3', 'a-4', 'b-4', 'a-5', 'b-5']
3 ['b-15', 'a-16', 'b-16', 'a-17', 'b-17']
4 ['a-6', 'b-6', 'a-7', 'b-7', 'a-8']
5 ['a-18', 'b-18', 'a-19', 'b-19', 'a-20']
6 ['b-8', 'a-9', 'b-9', 'a-10', 'b-10']
7 ['b-20', 'a-21', 'b-21', 'a-22', 'b-22']
```
### Expected behavior
`'a-21', 'b-21', 'a-22', 'b-22'` should be dropped
### Environment info
- `datasets` version: 3.3.2
- Platform: Linux-5.15.0-1056-aws-x86_64-with-glibc2.31
- Python version: 3.10.16
- `huggingface_hub` version: 0.28.0
- PyArrow version: 19.0.0
- Pandas version: 2.2.3
- `fsspec` version: 2024.6.1
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7441/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7441/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5419
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5419/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5419/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5419/events
|
https://github.com/huggingface/datasets/issues/5419
| 1,531,999,850
|
I_kwDODunzps5bUHZq
| 5,419
|
label_column='labels' in datasets.TextClassification and 'label' or 'label_ids' in transformers.DataColator
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/172385?v=4",
"events_url": "https://api.github.com/users/CreatixEA/events{/privacy}",
"followers_url": "https://api.github.com/users/CreatixEA/followers",
"following_url": "https://api.github.com/users/CreatixEA/following{/other_user}",
"gists_url": "https://api.github.com/users/CreatixEA/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/CreatixEA",
"id": 172385,
"login": "CreatixEA",
"node_id": "MDQ6VXNlcjE3MjM4NQ==",
"organizations_url": "https://api.github.com/users/CreatixEA/orgs",
"received_events_url": "https://api.github.com/users/CreatixEA/received_events",
"repos_url": "https://api.github.com/users/CreatixEA/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/CreatixEA/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CreatixEA/subscriptions",
"type": "User",
"url": "https://api.github.com/users/CreatixEA",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi! Thanks for pointing out this inconsistency. Changing the default value at this point is probably not worth it, considering we've started discussing the state of the task API internally - we will most likely deprecate the current one and replace it with a more robust solution that relies on the `train_eval_index` field stored in the YAML section of the dataset cards.",
"The task templates API has been deprecated (will be removed in version 3.0), so I'm closing this issue."
] | 2023-01-13T09:40:07Z
| 2023-07-21T14:27:08Z
| 2023-07-21T14:27:08Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
When preparing a dataset for a task using `datasets.TextClassification`, the output feature is named `labels`. When preparing the trainer using the `transformers.DataCollator` the default column name is `label` if binary or `label_ids` if multi-class problem.
It is required to rename the column accordingly to the expected name : `label` or `label_ids`
### Steps to reproduce the bug
```python
from datasets import TextClassification, AutoTokenized, DataCollatorWithPadding
ds_prepared = my_dataset.prepare_for_task(TextClassification(text_column='TEXT', label_column='MY_LABEL_COLUMN_1_OR_0'))
print(ds_prepared)
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
ds_tokenized = ds_prepared.map(lambda x: tokenizer(x['text'], truncation=True), batched=True)
print(ds_tokenized)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
tf_data = model.prepare_tf_dataset(ds_tokenized, shuffle=True, batch_size=16, collate_fn=data_collator)
print(tf_data)
```
### Expected behavior
Without renaming the the column, the target column is not in the final tf_data since it is not in the column name expected by the data_collator.
To correct this, we have to rename the column:
```python
ds_prepared = my_dataset.prepare_for_task(TextClassification(text_column='TEXT', label_column='MY_LABEL_COLUMN_1_OR_0')).rename_column('labels', 'label')
```
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.15.79.1-microsoft-standard-WSL2-x86_64-with-glibc2.35
- Python version: 3.10.6
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
- `transformers` version: 4.26.0.dev0
- Platform: Linux-5.15.79.1-microsoft-standard-WSL2-x86_64-with-glibc2.35
- Python version: 3.10.6
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): not installed (NA)
- Tensorflow version (GPU?): 2.11.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5419/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5419/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6674
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6674/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6674/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6674/events
|
https://github.com/huggingface/datasets/issues/6674
| 2,139,595,576
|
I_kwDODunzps5_h6M4
| 6,674
|
Depprcated Overview.ipynb Link to new Quickstart Notebook invalid
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/55932554?v=4",
"events_url": "https://api.github.com/users/Codeblockz/events{/privacy}",
"followers_url": "https://api.github.com/users/Codeblockz/followers",
"following_url": "https://api.github.com/users/Codeblockz/following{/other_user}",
"gists_url": "https://api.github.com/users/Codeblockz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Codeblockz",
"id": 55932554,
"login": "Codeblockz",
"node_id": "MDQ6VXNlcjU1OTMyNTU0",
"organizations_url": "https://api.github.com/users/Codeblockz/orgs",
"received_events_url": "https://api.github.com/users/Codeblockz/received_events",
"repos_url": "https://api.github.com/users/Codeblockz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Codeblockz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Codeblockz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Codeblockz",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Good catch! Feel free to open a PR to fix the link."
] | 2024-02-16T22:51:35Z
| 2024-02-25T18:48:09Z
| 2024-02-25T18:48:09Z
|
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
For the dreprecated notebook found [here](https://github.com/huggingface/datasets/blob/main/notebooks/Overview.ipynb). The link to the new notebook is broken.
### Steps to reproduce the bug
Click the [Quickstart notebook](https://github.com/huggingface/notebooks/blob/main/datasets_doc/quickstart.ipynb) link in the notebook.
### Expected behavior
I believe is it suposed to link [here](https://github.com/huggingface/notebooks/blob/main/datasets_doc/en/quickstart.ipynb). That is mentioned in the readme.
### Environment info
Colab
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6674/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6674/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6173
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6173/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6173/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6173/events
|
https://github.com/huggingface/datasets/issues/6173
| 1,863,422,065
|
I_kwDODunzps5vEZBx
| 6,173
|
Fix CI for pyarrow 13.0.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[] | 2023-08-23T14:11:20Z
| 2023-08-25T13:06:53Z
| 2023-08-25T13:06:53Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
pyarrow 13.0.0 just came out
```
FAILED tests/test_formatting.py::ArrowExtractorTest::test_pandas_extractor - AssertionError: Attributes of Series are different
Attribute "dtype" are different
[left]: datetime64[us, UTC]
[right]: datetime64[ns, UTC]
```
```
FAILED tests/test_table.py::test_cast_sliced_fixed_size_array_to_features - TypeError: Couldn't cast array of type
fixed_size_list<item: int32>[3]
to
Sequence(feature=Value(dtype='int64', id=None), length=3, id=None)
```
e.g. in https://github.com/huggingface/datasets/actions/runs/5952253963/job/16143847230
first error may be related to https://github.com/apache/arrow/issues/33321
second one maybe because `feature.length * len(array) == len(array_values)` is not satisfied anymore somehow ?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6173/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6173/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6878
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6878/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6878/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6878/events
|
https://github.com/huggingface/datasets/pull/6878
| 2,282,879,491
|
PR_kwDODunzps5uviBh
| 6,878
|
Create function to convert to parquet
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6878). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005519 / 0.011353 (-0.005834) | 0.003877 / 0.011008 (-0.007131) | 0.063989 / 0.038508 (0.025480) | 0.032348 / 0.023109 (0.009239) | 0.238288 / 0.275898 (-0.037611) | 0.265337 / 0.323480 (-0.058143) | 0.004363 / 0.007986 (-0.003623) | 0.002755 / 0.004328 (-0.001574) | 0.049836 / 0.004250 (0.045585) | 0.048456 / 0.037052 (0.011403) | 0.246526 / 0.258489 (-0.011963) | 0.280753 / 0.293841 (-0.013088) | 0.027721 / 0.128546 (-0.100825) | 0.011031 / 0.075646 (-0.064615) | 0.204168 / 0.419271 (-0.215104) | 0.036203 / 0.043533 (-0.007330) | 0.238282 / 0.255139 (-0.016857) | 0.259608 / 0.283200 (-0.023591) | 0.017781 / 0.141683 (-0.123902) | 1.147821 / 1.452155 (-0.304334) | 1.194855 / 1.492716 (-0.297861) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.102837 / 0.018006 (0.084831) | 0.312300 / 0.000490 (0.311811) | 0.000224 / 0.000200 (0.000024) | 0.000047 / 0.000054 (-0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019410 / 0.037411 (-0.018001) | 0.065114 / 0.014526 (0.050588) | 0.076828 / 0.176557 (-0.099728) | 0.121741 / 0.737135 (-0.615394) | 0.079864 / 0.296338 (-0.216474) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.287773 / 0.215209 (0.072564) | 2.848936 / 2.077655 (0.771281) | 1.543819 / 1.504120 (0.039700) | 1.412708 / 1.541195 (-0.128487) | 1.454685 / 1.468490 (-0.013805) | 0.580155 / 4.584777 (-4.004622) | 2.372783 / 3.745712 (-1.372929) | 2.910514 / 5.269862 (-2.359347) | 1.813542 / 4.565676 (-2.752134) | 0.064569 / 0.424275 (-0.359706) | 0.005434 / 0.007607 (-0.002173) | 0.339309 / 0.226044 (0.113265) | 3.329972 / 2.268929 (1.061043) | 1.827597 / 55.444624 (-53.617028) | 1.592324 / 6.876477 (-5.284152) | 1.619743 / 2.142072 (-0.522329) | 0.659358 / 4.805227 (-4.145869) | 0.119887 / 6.500664 (-6.380777) | 0.043649 / 0.075469 (-0.031821) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.984563 / 1.841788 (-0.857225) | 12.395302 / 8.074308 (4.320994) | 9.904944 / 10.191392 (-0.286448) | 0.136141 / 0.680424 (-0.544282) | 0.014779 / 0.534201 (-0.519422) | 0.286146 / 0.579283 (-0.293137) | 0.265392 / 0.434364 (-0.168972) | 0.329484 / 0.540337 (-0.210854) | 0.425530 / 1.386936 (-0.961406) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005920 / 0.011353 (-0.005433) | 0.004068 / 0.011008 (-0.006940) | 0.052281 / 0.038508 (0.013773) | 0.034907 / 0.023109 (0.011798) | 0.269551 / 0.275898 (-0.006347) | 0.292390 / 0.323480 (-0.031090) | 0.004340 / 0.007986 (-0.003646) | 0.002864 / 0.004328 (-0.001464) | 0.051466 / 0.004250 (0.047216) | 0.046410 / 0.037052 (0.009358) | 0.280103 / 0.258489 (0.021614) | 0.310616 / 0.293841 (0.016775) | 0.031044 / 0.128546 (-0.097502) | 0.011004 / 0.075646 (-0.064643) | 0.059955 / 0.419271 (-0.359316) | 0.034156 / 0.043533 (-0.009377) | 0.268113 / 0.255139 (0.012974) | 0.283569 / 0.283200 (0.000369) | 0.019758 / 0.141683 (-0.121925) | 1.155583 / 1.452155 (-0.296572) | 1.225611 / 1.492716 (-0.267106) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.104302 / 0.018006 (0.086295) | 0.307324 / 0.000490 (0.306834) | 0.000219 / 0.000200 (0.000019) | 0.000045 / 0.000054 (-0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023672 / 0.037411 (-0.013739) | 0.081110 / 0.014526 (0.066584) | 0.091783 / 0.176557 (-0.084773) | 0.131738 / 0.737135 (-0.605397) | 0.092391 / 0.296338 (-0.203948) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.289341 / 0.215209 (0.074132) | 2.849894 / 2.077655 (0.772239) | 1.539679 / 1.504120 (0.035559) | 1.417975 / 1.541195 (-0.123220) | 1.473631 / 1.468490 (0.005141) | 0.583013 / 4.584777 (-4.001764) | 0.960106 / 3.745712 (-2.785606) | 2.962785 / 5.269862 (-2.307077) | 1.827539 / 4.565676 (-2.738138) | 0.063875 / 0.424275 (-0.360400) | 0.005251 / 0.007607 (-0.002356) | 0.347127 / 0.226044 (0.121082) | 3.417364 / 2.268929 (1.148435) | 1.965901 / 55.444624 (-53.478723) | 1.632337 / 6.876477 (-5.244140) | 1.683100 / 2.142072 (-0.458972) | 0.664951 / 4.805227 (-4.140277) | 0.119046 / 6.500664 (-6.381618) | 0.042828 / 0.075469 (-0.032641) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.999569 / 1.841788 (-0.842218) | 13.366482 / 8.074308 (5.292174) | 10.635396 / 10.191392 (0.444004) | 0.133840 / 0.680424 (-0.546584) | 0.016232 / 0.534201 (-0.517969) | 0.292764 / 0.579283 (-0.286519) | 0.128558 / 0.434364 (-0.305806) | 0.405596 / 0.540337 (-0.134741) | 0.429633 / 1.386936 (-0.957303) |\n\n</details>\n</details>\n\n\n"
] | 2024-05-07T10:27:07Z
| 2024-05-16T14:46:44Z
| 2024-05-16T14:38:23Z
|
MEMBER
| null | null | null |
Analogously with `delete_from_hub`, this PR:
- creates the Python function `convert_to_parquet`
- makes the corresponding CLI command use that function.
This way, the functionality can be used both from a terminal and from a Python console.
This PR also implements a test for convert_to_parquet function.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6878/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6878/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6878.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6878",
"merged_at": "2024-05-16T14:38:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6878.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6878"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7386
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7386/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7386/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7386/events
|
https://github.com/huggingface/datasets/issues/7386
| 2,840,032,524
|
I_kwDODunzps6pR3UM
| 7,386
|
Add bookfolder Dataset Builder for Digital Book Formats
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/22115108?v=4",
"events_url": "https://api.github.com/users/shikanime/events{/privacy}",
"followers_url": "https://api.github.com/users/shikanime/followers",
"following_url": "https://api.github.com/users/shikanime/following{/other_user}",
"gists_url": "https://api.github.com/users/shikanime/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shikanime",
"id": 22115108,
"login": "shikanime",
"node_id": "MDQ6VXNlcjIyMTE1MTA4",
"organizations_url": "https://api.github.com/users/shikanime/orgs",
"received_events_url": "https://api.github.com/users/shikanime/received_events",
"repos_url": "https://api.github.com/users/shikanime/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shikanime/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shikanime/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shikanime",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
| null |
[] | null |
[
"On second thought, probably not a good idea."
] | 2025-02-08T14:27:55Z
| 2025-02-08T14:30:10Z
| 2025-02-08T14:30:09Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
This feature proposes adding a new dataset builder called bookfolder to the datasets library. This builder would allow users to easily load datasets consisting of various digital book formats, including: AZW, AZW3, CB7, CBR, CBT, CBZ, EPUB, MOBI, and PDF.
### Motivation
Currently, loading datasets of these digital book files requires manual effort. This would also lower the barrier to entry for working with these formats, enabling more diverse and interesting datasets to be used within the Hugging Face ecosystem.
### Your contribution
This feature is rather simple as it will be based on the folder-based builder, similar to imagefolder. I'm willing to contribute to this feature by submitting a PR
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/22115108?v=4",
"events_url": "https://api.github.com/users/shikanime/events{/privacy}",
"followers_url": "https://api.github.com/users/shikanime/followers",
"following_url": "https://api.github.com/users/shikanime/following{/other_user}",
"gists_url": "https://api.github.com/users/shikanime/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shikanime",
"id": 22115108,
"login": "shikanime",
"node_id": "MDQ6VXNlcjIyMTE1MTA4",
"organizations_url": "https://api.github.com/users/shikanime/orgs",
"received_events_url": "https://api.github.com/users/shikanime/received_events",
"repos_url": "https://api.github.com/users/shikanime/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shikanime/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shikanime/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shikanime",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7386/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7386/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6984
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6984/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6984/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6984/events
|
https://github.com/huggingface/datasets/issues/6984
| 2,362,143,554
|
I_kwDODunzps6My3NC
| 6,984
|
Convert polars DataFrame back to datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38550511?v=4",
"events_url": "https://api.github.com/users/ljw20180420/events{/privacy}",
"followers_url": "https://api.github.com/users/ljw20180420/followers",
"following_url": "https://api.github.com/users/ljw20180420/following{/other_user}",
"gists_url": "https://api.github.com/users/ljw20180420/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ljw20180420",
"id": 38550511,
"login": "ljw20180420",
"node_id": "MDQ6VXNlcjM4NTUwNTEx",
"organizations_url": "https://api.github.com/users/ljw20180420/orgs",
"received_events_url": "https://api.github.com/users/ljw20180420/received_events",
"repos_url": "https://api.github.com/users/ljw20180420/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ljw20180420/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ljw20180420/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ljw20180420",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[
"Hi ! Thanks for reporting :)\r\n\r\nWe don't support `large_list` yet, though it should be added to `Sequence` IMO (maybe with a parameter `large=True` ?)"
] | 2024-06-19T11:38:48Z
| 2024-08-12T14:43:46Z
| 2024-08-12T14:43:46Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
This returns error.
```python
from datasets import Dataset
dsdf = Dataset.from_dict({"x": [[1, 2], [3, 4, 5]], "y": ["a", "b"]})
Dataset.from_polars(dsdf.to_polars())
```
ValueError: Arrow type large_list<item: int64> does not have a datasets dtype equivalent.
### Motivation
When datasets contain Sequence data type, it will be converted to Arrow type large_list. However, the reverse (from large_list to Sequence) does not work.
### Your contribution
No
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6984/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6984/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/4557
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4557/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4557/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4557/events
|
https://github.com/huggingface/datasets/pull/4557
| 1,283,473,889
|
PR_kwDODunzps46TGZK
| 4,557
|
Add evaluation metadata to wmt16
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun",
"user_view_type": "public"
}
|
[
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4557). All of your documentation changes will be reflected on that endpoint.",
"> Just to confirm: we should add this metadata via GitHub and not Hub PRs for canonical datasets right?\r\n\r\nyes :)",
"As discussed with @lewtun, we are closing this PR, because it requires first the task names to be aligned between AutoTrain and datasets."
] | 2022-06-24T09:04:23Z
| 2023-09-24T09:35:49Z
| 2022-09-23T09:36:32Z
|
MEMBER
| null | null | null |
Just to confirm: we should add this metadata via GitHub and not Hub PRs for canonical datasets right?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4557/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4557/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4557.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4557",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4557.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4557"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5661
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5661/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5661/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5661/events
|
https://github.com/huggingface/datasets/issues/5661
| 1,637,129,445
|
I_kwDODunzps5hlJzl
| 5,661
|
CI is broken: Unnecessary `dict` comprehension
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[] | 2023-03-23T09:13:01Z
| 2023-03-23T09:37:51Z
| 2023-03-23T09:37:51Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
CI check_code_quality is broken:
```
src/datasets/arrow_dataset.py:3267:35: C416 [*] Unnecessary `dict` comprehension (rewrite using `dict()`)
Found 1 error.
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5661/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5661/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/4848
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4848/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4848/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4848/events
|
https://github.com/huggingface/datasets/pull/4848
| 1,338,271,833
|
PR_kwDODunzps49JNj_
| 4,848
|
a
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/49282718?v=4",
"events_url": "https://api.github.com/users/Mr-Robot-001/events{/privacy}",
"followers_url": "https://api.github.com/users/Mr-Robot-001/followers",
"following_url": "https://api.github.com/users/Mr-Robot-001/following{/other_user}",
"gists_url": "https://api.github.com/users/Mr-Robot-001/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Mr-Robot-001",
"id": 49282718,
"login": "Mr-Robot-001",
"node_id": "MDQ6VXNlcjQ5MjgyNzE4",
"organizations_url": "https://api.github.com/users/Mr-Robot-001/orgs",
"received_events_url": "https://api.github.com/users/Mr-Robot-001/received_events",
"repos_url": "https://api.github.com/users/Mr-Robot-001/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Mr-Robot-001/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mr-Robot-001/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Mr-Robot-001",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[] | 2022-08-14T15:01:16Z
| 2022-08-14T15:09:59Z
| 2022-08-14T15:09:59Z
|
NONE
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/49282718?v=4",
"events_url": "https://api.github.com/users/Mr-Robot-001/events{/privacy}",
"followers_url": "https://api.github.com/users/Mr-Robot-001/followers",
"following_url": "https://api.github.com/users/Mr-Robot-001/following{/other_user}",
"gists_url": "https://api.github.com/users/Mr-Robot-001/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Mr-Robot-001",
"id": 49282718,
"login": "Mr-Robot-001",
"node_id": "MDQ6VXNlcjQ5MjgyNzE4",
"organizations_url": "https://api.github.com/users/Mr-Robot-001/orgs",
"received_events_url": "https://api.github.com/users/Mr-Robot-001/received_events",
"repos_url": "https://api.github.com/users/Mr-Robot-001/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Mr-Robot-001/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mr-Robot-001/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Mr-Robot-001",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4848/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4848/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4848.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4848",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4848.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4848"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5927
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5927/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5927/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5927/events
|
https://github.com/huggingface/datasets/issues/5927
| 1,744,009,032
|
I_kwDODunzps5n83dI
| 5,927
|
`IndexError` when indexing `Sequence` of `Array2D` with `None` values
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/45557362?v=4",
"events_url": "https://api.github.com/users/qgallouedec/events{/privacy}",
"followers_url": "https://api.github.com/users/qgallouedec/followers",
"following_url": "https://api.github.com/users/qgallouedec/following{/other_user}",
"gists_url": "https://api.github.com/users/qgallouedec/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/qgallouedec",
"id": 45557362,
"login": "qgallouedec",
"node_id": "MDQ6VXNlcjQ1NTU3MzYy",
"organizations_url": "https://api.github.com/users/qgallouedec/orgs",
"received_events_url": "https://api.github.com/users/qgallouedec/received_events",
"repos_url": "https://api.github.com/users/qgallouedec/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/qgallouedec/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/qgallouedec/subscriptions",
"type": "User",
"url": "https://api.github.com/users/qgallouedec",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Easy fix would be to add:\r\n\r\n```python\r\nnull_indices -= np.arange(len(null_indices))\r\n```\r\n\r\nbefore L279, but I'm not sure it's the most intuitive way to fix it.",
"Same issue here:\r\n\r\nhttps://github.com/huggingface/datasets/blob/7fcbe5b1575c8d162b65b9397b3dfda995a4e048/src/datasets/features/features.py#L1398\r\n\r\nFixed in #5948 "
] | 2023-06-06T14:36:22Z
| 2023-06-13T12:39:39Z
| 2023-06-09T13:23:50Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Having `None` values in a `Sequence` of `ArrayND` fails.
### Steps to reproduce the bug
```python
from datasets import Array2D, Dataset, Features, Sequence
data = [
[
[[0]],
None,
None,
]
]
feature = Sequence(Array2D((1, 1), dtype="int64"))
dataset = Dataset.from_dict({"a": data}, features=Features({"a": feature}))
dataset[0] # error raised only when indexing
```
```
Traceback (most recent call last):
File "/Users/quentingallouedec/gia/c.py", line 13, in <module>
dataset[0] # error raised only when indexing
File "/Users/quentingallouedec/gia/env/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 2658, in __getitem__
return self._getitem(key)
File "/Users/quentingallouedec/gia/env/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 2643, in _getitem
formatted_output = format_table(
File "/Users/quentingallouedec/gia/env/lib/python3.10/site-packages/datasets/formatting/formatting.py", line 634, in format_table
return formatter(pa_table, query_type=query_type)
File "/Users/quentingallouedec/gia/env/lib/python3.10/site-packages/datasets/formatting/formatting.py", line 406, in __call__
return self.format_row(pa_table)
File "/Users/quentingallouedec/gia/env/lib/python3.10/site-packages/datasets/formatting/formatting.py", line 441, in format_row
row = self.python_arrow_extractor().extract_row(pa_table)
File "/Users/quentingallouedec/gia/env/lib/python3.10/site-packages/datasets/formatting/formatting.py", line 144, in extract_row
return _unnest(pa_table.to_pydict())
File "pyarrow/table.pxi", line 4146, in pyarrow.lib.Table.to_pydict
File "pyarrow/table.pxi", line 1312, in pyarrow.lib.ChunkedArray.to_pylist
File "pyarrow/array.pxi", line 1521, in pyarrow.lib.Array.to_pylist
File "pyarrow/scalar.pxi", line 675, in pyarrow.lib.ListScalar.as_py
File "/Users/quentingallouedec/gia/env/lib/python3.10/site-packages/datasets/features/features.py", line 760, in to_pylist
return self.to_numpy(zero_copy_only=zero_copy_only).tolist()
File "/Users/quentingallouedec/gia/env/lib/python3.10/site-packages/datasets/features/features.py", line 725, in to_numpy
numpy_arr = np.insert(numpy_arr.astype(np.float64), null_indices, np.nan, axis=0)
File "<__array_function__ internals>", line 200, in insert
File "/Users/quentingallouedec/gia/env/lib/python3.10/site-packages/numpy/lib/function_base.py", line 5426, in insert
old_mask[indices] = False
IndexError: index 3 is out of bounds for axis 0 with size 3
```
AFAIK, the problem only occurs when you use a `Sequence` of `ArrayND`.
I strongly suspect that the problem comes from this line, or `np.insert` is misused:
https://github.com/huggingface/datasets/blob/02ee418831aba68d0be93227bce8b3f42ef8980f/src/datasets/features/features.py#L729
To put t simply, you want something that do that:
```python
import numpy as np
numpy_arr = np.zeros((1, 1, 1))
null_indices = np.array([1, 2])
np.insert(numpy_arr, null_indices, np.nan, axis=0)
# raise an error, instead of outputting
# array([[[ 0.]],
# [[nan]],
# [[nan]]])
```
### Expected behavior
The previous code should not raise an error.
### Environment info
- Python 3.10.11
- datasets 2.10.0
- pyarrow 12.0.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5927/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5927/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5997
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5997/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5997/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5997/events
|
https://github.com/huggingface/datasets/issues/5997
| 1,781,582,818
|
I_kwDODunzps5qMMvi
| 5,997
|
extend the map function so it can wrap around long text that does not fit in the context window
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/127623723?v=4",
"events_url": "https://api.github.com/users/siddhsql/events{/privacy}",
"followers_url": "https://api.github.com/users/siddhsql/followers",
"following_url": "https://api.github.com/users/siddhsql/following{/other_user}",
"gists_url": "https://api.github.com/users/siddhsql/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/siddhsql",
"id": 127623723,
"login": "siddhsql",
"node_id": "U_kgDOB5tiKw",
"organizations_url": "https://api.github.com/users/siddhsql/orgs",
"received_events_url": "https://api.github.com/users/siddhsql/received_events",
"repos_url": "https://api.github.com/users/siddhsql/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/siddhsql/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/siddhsql/subscriptions",
"type": "User",
"url": "https://api.github.com/users/siddhsql",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
| null |
[] | null |
[
"I just noticed the [docs](https://github.com/huggingface/datasets/blob/main/src/datasets/arrow_dataset.py#L2881C11-L2881C200) say:\r\n\r\n>If batched is `True` and `batch_size` is `n > 1`, then the function takes a batch of `n` examples as input and can return a batch with `n` examples, or with an arbitrary number of examples.\r\n\r\nso maybe this is a bug then.",
"All the values in a batch must be of the same length. So one solution is dropping all the input columns:\r\n```python\r\ndata = data.map(lambda samples: tokenizer(samples[\"text\"], max_length=tokenizer.model_max_length, truncation=True, stride=4, return_overflowing_tokens=True), batched=True, remove_columns=data.column_names)\r\n```\r\n\r\nAnother is padding/transforming the input columns to the tokenizer output's length (447). "
] | 2023-06-29T22:15:21Z
| 2023-07-03T17:58:52Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
I understand `dataset` provides a [`map`](https://github.com/huggingface/datasets/blob/main/src/datasets/arrow_dataset.py#L2849) function. This function in turn takes in a callable that is used to tokenize the text on which a model is trained. Frequently this text will not fit within a models's context window. In this case it would be useful to wrap around the text into multiple rows with each row fitting the model's context window. I tried to do it using this code as example which in turn I have borrowed from [here](https://stackoverflow.com/a/76343993/147530):
```
data = data.map(lambda samples: tokenizer(samples["text"], max_length=tokenizer.model_max_length, truncation=True, stride=4, return_overflowing_tokens=True), batched=True)
```
but running the code gives me this error:
```
File "/llm/fine-tune.py", line 117, in <module>
data = data.map(lambda samples: tokenizer(samples["text"], max_length=tokenizer.model_max_length, truncation=True, stride=4, return_overflowing_tokens=True), batched=True)
File "/llm/.env/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 580, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/llm/.env/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 545, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/llm/.env/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 3087, in map
for rank, done, content in Dataset._map_single(**dataset_kwargs):
File "/llm/.env/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 3480, in _map_single
writer.write_batch(batch)
File "/llm/.env/lib/python3.9/site-packages/datasets/arrow_writer.py", line 556, in write_batch
pa_table = pa.Table.from_arrays(arrays, schema=schema)
File "pyarrow/table.pxi", line 3798, in pyarrow.lib.Table.from_arrays
File "pyarrow/table.pxi", line 2962, in pyarrow.lib.Table.validate
File "pyarrow/error.pxi", line 100, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Column 1 named input_ids expected length 394 but got length 447
```
The lambda function I have provided is correctly chopping up long text so it wraps around (and because of this 394 samples become 447 after wrap around) but the dataset `map` function does not like it.
### Motivation
please see above
### Your contribution
I'm afraid I don't have much knowledge to help
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5997/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5997/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5507
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5507/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5507/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5507/events
|
https://github.com/huggingface/datasets/issues/5507
| 1,572,667,036
|
I_kwDODunzps5dvP6c
| 5,507
|
Optimise behaviour in respect to indices mapping
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
] | null |
[] | 2023-02-06T14:25:55Z
| 2023-02-28T18:19:18Z
| null |
COLLABORATOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
_Originally [posted](https://huggingface.slack.com/archives/C02V51Q3800/p1675443873878489?thread_ts=1675418893.373479&cid=C02V51Q3800) on Slack_
Considering all this, perhaps for Datasets 3.0, we can do the following:
* [ ] have `continuous=True` by default in `.shard` (requested in the survey and makes more sense for us since it doesn't create an indices mapping)
* [x] allow calling `save_to_disk` on "unflattened" datasets
* [ ] remove "hidden" expensive calls in `save_to_disk`, `unique`, `concatenate_datasets`, etc. For instance, instead of silently calling `flatten_indices` where it's needed, it's probably better to be explicit (considering how expensive these ops can be) and raise an error instead
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5507/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5507/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4598
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4598/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4598/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4598/events
|
https://github.com/huggingface/datasets/pull/4598
| 1,288,774,514
|
PR_kwDODunzps46kfOS
| 4,598
|
Host financial_phrasebank data on the Hub
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-06-29T13:59:31Z
| 2022-07-01T09:41:14Z
| 2022-07-01T09:29:36Z
|
MEMBER
| null | null | null |
Fix #4597.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4598/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4598/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4598.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4598",
"merged_at": "2022-07-01T09:29:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4598.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4598"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6091
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6091/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6091/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6091/events
|
https://github.com/huggingface/datasets/pull/6091
| 1,826,086,487
|
PR_kwDODunzps5Wov9Q
| 6,091
|
Bump fsspec from 2021.11.1 to 2022.3.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006640 / 0.011353 (-0.004713) | 0.004077 / 0.011008 (-0.006931) | 0.084905 / 0.038508 (0.046397) | 0.074004 / 0.023109 (0.050895) | 0.315968 / 0.275898 (0.040070) | 0.351594 / 0.323480 (0.028114) | 0.005623 / 0.007986 (-0.002362) | 0.003476 / 0.004328 (-0.000852) | 0.065089 / 0.004250 (0.060839) | 0.054683 / 0.037052 (0.017631) | 0.314983 / 0.258489 (0.056494) | 0.371776 / 0.293841 (0.077935) | 0.031727 / 0.128546 (-0.096819) | 0.008786 / 0.075646 (-0.066860) | 0.289905 / 0.419271 (-0.129367) | 0.053340 / 0.043533 (0.009807) | 0.311802 / 0.255139 (0.056663) | 0.351927 / 0.283200 (0.068727) | 0.024453 / 0.141683 (-0.117229) | 1.491727 / 1.452155 (0.039572) | 1.585027 / 1.492716 (0.092310) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.238757 / 0.018006 (0.220750) | 0.557691 / 0.000490 (0.557202) | 0.005158 / 0.000200 (0.004958) | 0.000204 / 0.000054 (0.000149) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028435 / 0.037411 (-0.008977) | 0.082219 / 0.014526 (0.067693) | 0.096932 / 0.176557 (-0.079625) | 0.153802 / 0.737135 (-0.583333) | 0.098338 / 0.296338 (-0.198001) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.383448 / 0.215209 (0.168238) | 3.816074 / 2.077655 (1.738420) | 1.835111 / 1.504120 (0.330991) | 1.662326 / 1.541195 (0.121131) | 1.720202 / 1.468490 (0.251712) | 0.483107 / 4.584777 (-4.101669) | 3.648528 / 3.745712 (-0.097184) | 4.020929 / 5.269862 (-1.248932) | 2.433141 / 4.565676 (-2.132536) | 0.057081 / 0.424275 (-0.367194) | 0.007303 / 0.007607 (-0.000304) | 0.461366 / 0.226044 (0.235322) | 4.609090 / 2.268929 (2.340162) | 2.355940 / 55.444624 (-53.088684) | 1.989833 / 6.876477 (-4.886644) | 2.201451 / 2.142072 (0.059378) | 0.586156 / 4.805227 (-4.219071) | 0.133486 / 6.500664 (-6.367178) | 0.060062 / 0.075469 (-0.015407) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.247845 / 1.841788 (-0.593942) | 19.624252 / 8.074308 (11.549944) | 14.305975 / 10.191392 (4.114583) | 0.168687 / 0.680424 (-0.511737) | 0.018075 / 0.534201 (-0.516126) | 0.393859 / 0.579283 (-0.185424) | 0.407272 / 0.434364 (-0.027092) | 0.463760 / 0.540337 (-0.076578) | 0.629930 / 1.386936 (-0.757006) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006760 / 0.011353 (-0.004593) | 0.004345 / 0.011008 (-0.006663) | 0.064379 / 0.038508 (0.025871) | 0.078295 / 0.023109 (0.055186) | 0.364532 / 0.275898 (0.088633) | 0.395852 / 0.323480 (0.072372) | 0.005659 / 0.007986 (-0.002327) | 0.003515 / 0.004328 (-0.000813) | 0.065030 / 0.004250 (0.060780) | 0.059950 / 0.037052 (0.022898) | 0.375420 / 0.258489 (0.116931) | 0.411579 / 0.293841 (0.117738) | 0.031575 / 0.128546 (-0.096972) | 0.008737 / 0.075646 (-0.066910) | 0.070350 / 0.419271 (-0.348922) | 0.050607 / 0.043533 (0.007075) | 0.359785 / 0.255139 (0.104646) | 0.382638 / 0.283200 (0.099438) | 0.025533 / 0.141683 (-0.116150) | 1.564379 / 1.452155 (0.112225) | 1.620642 / 1.492716 (0.127925) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.212779 / 0.018006 (0.194773) | 0.563827 / 0.000490 (0.563337) | 0.003767 / 0.000200 (0.003567) | 0.000103 / 0.000054 (0.000049) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030275 / 0.037411 (-0.007136) | 0.088108 / 0.014526 (0.073582) | 0.102454 / 0.176557 (-0.074103) | 0.156107 / 0.737135 (-0.581028) | 0.103961 / 0.296338 (-0.192378) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421395 / 0.215209 (0.206186) | 4.204935 / 2.077655 (2.127280) | 2.144929 / 1.504120 (0.640809) | 1.999341 / 1.541195 (0.458147) | 2.066966 / 1.468490 (0.598476) | 0.486135 / 4.584777 (-4.098642) | 3.628139 / 3.745712 (-0.117573) | 5.652683 / 5.269862 (0.382821) | 3.216721 / 4.565676 (-1.348956) | 0.057513 / 0.424275 (-0.366762) | 0.007553 / 0.007607 (-0.000055) | 0.494470 / 0.226044 (0.268426) | 4.949343 / 2.268929 (2.680414) | 2.654222 / 55.444624 (-52.790402) | 2.322257 / 6.876477 (-4.554220) | 2.555633 / 2.142072 (0.413561) | 0.588355 / 4.805227 (-4.216872) | 0.134481 / 6.500664 (-6.366183) | 0.062415 / 0.075469 (-0.013054) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.377578 / 1.841788 (-0.464209) | 19.805201 / 8.074308 (11.730893) | 14.128536 / 10.191392 (3.937144) | 0.164343 / 0.680424 (-0.516081) | 0.018553 / 0.534201 (-0.515648) | 0.398191 / 0.579283 (-0.181093) | 0.414268 / 0.434364 (-0.020096) | 0.462270 / 0.540337 (-0.078068) | 0.608497 / 1.386936 (-0.778439) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006966 / 0.011353 (-0.004387) | 0.004339 / 0.011008 (-0.006669) | 0.086682 / 0.038508 (0.048174) | 0.086143 / 0.023109 (0.063034) | 0.316106 / 0.275898 (0.040208) | 0.351422 / 0.323480 (0.027942) | 0.005916 / 0.007986 (-0.002069) | 0.003630 / 0.004328 (-0.000698) | 0.066980 / 0.004250 (0.062730) | 0.060031 / 0.037052 (0.022979) | 0.317487 / 0.258489 (0.058998) | 0.356280 / 0.293841 (0.062439) | 0.031816 / 0.128546 (-0.096730) | 0.008797 / 0.075646 (-0.066849) | 0.289848 / 0.419271 (-0.129424) | 0.055431 / 0.043533 (0.011898) | 0.318881 / 0.255139 (0.063742) | 0.332315 / 0.283200 (0.049116) | 0.025946 / 0.141683 (-0.115737) | 1.472904 / 1.452155 (0.020749) | 1.577973 / 1.492716 (0.085257) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.239056 / 0.018006 (0.221050) | 0.565406 / 0.000490 (0.564917) | 0.003606 / 0.000200 (0.003406) | 0.000080 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029771 / 0.037411 (-0.007640) | 0.085534 / 0.014526 (0.071008) | 0.107008 / 0.176557 (-0.069548) | 0.631583 / 0.737135 (-0.105552) | 0.104210 / 0.296338 (-0.192128) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.390675 / 0.215209 (0.175466) | 3.898746 / 2.077655 (1.821091) | 1.933048 / 1.504120 (0.428928) | 1.792162 / 1.541195 (0.250967) | 1.958045 / 1.468490 (0.489555) | 0.488632 / 4.584777 (-4.096144) | 3.696306 / 3.745712 (-0.049406) | 3.454600 / 5.269862 (-1.815262) | 2.176292 / 4.565676 (-2.389385) | 0.057617 / 0.424275 (-0.366658) | 0.007603 / 0.007607 (-0.000004) | 0.467843 / 0.226044 (0.241798) | 4.672928 / 2.268929 (2.404000) | 2.441096 / 55.444624 (-53.003529) | 2.133506 / 6.876477 (-4.742970) | 2.431167 / 2.142072 (0.289095) | 0.588567 / 4.805227 (-4.216661) | 0.136070 / 6.500664 (-6.364594) | 0.063395 / 0.075469 (-0.012074) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.255003 / 1.841788 (-0.586784) | 20.587656 / 8.074308 (12.513348) | 15.147817 / 10.191392 (4.956425) | 0.152039 / 0.680424 (-0.528384) | 0.018815 / 0.534201 (-0.515386) | 0.397458 / 0.579283 (-0.181825) | 0.431433 / 0.434364 (-0.002931) | 0.487890 / 0.540337 (-0.052448) | 0.675367 / 1.386936 (-0.711569) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007209 / 0.011353 (-0.004144) | 0.004372 / 0.011008 (-0.006636) | 0.066288 / 0.038508 (0.027780) | 0.091776 / 0.023109 (0.068667) | 0.390724 / 0.275898 (0.114826) | 0.434711 / 0.323480 (0.111231) | 0.005790 / 0.007986 (-0.002196) | 0.003562 / 0.004328 (-0.000767) | 0.066155 / 0.004250 (0.061904) | 0.062459 / 0.037052 (0.025406) | 0.406622 / 0.258489 (0.148133) | 0.433976 / 0.293841 (0.140135) | 0.032590 / 0.128546 (-0.095957) | 0.008856 / 0.075646 (-0.066790) | 0.072327 / 0.419271 (-0.346945) | 0.049958 / 0.043533 (0.006426) | 0.400164 / 0.255139 (0.145025) | 0.413339 / 0.283200 (0.130139) | 0.025283 / 0.141683 (-0.116399) | 1.487668 / 1.452155 (0.035514) | 1.537679 / 1.492716 (0.044962) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.257814 / 0.018006 (0.239808) | 0.571741 / 0.000490 (0.571251) | 0.000412 / 0.000200 (0.000212) | 0.000056 / 0.000054 (0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033893 / 0.037411 (-0.003518) | 0.094533 / 0.014526 (0.080008) | 0.105876 / 0.176557 (-0.070680) | 0.158675 / 0.737135 (-0.578460) | 0.107790 / 0.296338 (-0.188548) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.425796 / 0.215209 (0.210587) | 4.229159 / 2.077655 (2.151505) | 2.239613 / 1.504120 (0.735493) | 2.073830 / 1.541195 (0.532635) | 2.185508 / 1.468490 (0.717018) | 0.483984 / 4.584777 (-4.100793) | 3.645575 / 3.745712 (-0.100137) | 3.454767 / 5.269862 (-1.815095) | 2.141387 / 4.565676 (-2.424290) | 0.057570 / 0.424275 (-0.366705) | 0.007901 / 0.007607 (0.000294) | 0.501160 / 0.226044 (0.275116) | 5.012283 / 2.268929 (2.743355) | 2.701267 / 55.444624 (-52.743357) | 2.465409 / 6.876477 (-4.411068) | 2.696812 / 2.142072 (0.554739) | 0.587160 / 4.805227 (-4.218067) | 0.134175 / 6.500664 (-6.366489) | 0.062028 / 0.075469 (-0.013441) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.345632 / 1.841788 (-0.496155) | 21.077279 / 8.074308 (13.002971) | 14.700826 / 10.191392 (4.509434) | 0.156191 / 0.680424 (-0.524233) | 0.018991 / 0.534201 (-0.515210) | 0.400413 / 0.579283 (-0.178870) | 0.420597 / 0.434364 (-0.013767) | 0.486534 / 0.540337 (-0.053804) | 0.646606 / 1.386936 (-0.740330) |\n\n</details>\n</details>\n\n\n"
] | 2023-07-28T09:37:15Z
| 2023-07-28T10:16:11Z
| 2023-07-28T10:07:02Z
|
COLLABORATOR
| null | null | null |
Fix https://github.com/huggingface/datasets/issues/6087
(Colab installs 2023.6.0, so we should be good)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6091/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6091/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6091.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6091",
"merged_at": "2023-07-28T10:07:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6091.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6091"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7461
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7461/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7461/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7461/events
|
https://github.com/huggingface/datasets/issues/7461
| 2,925,608,123
|
I_kwDODunzps6uYTy7
| 7,461
|
List of images behave differently on IterableDataset and Dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1288009?v=4",
"events_url": "https://api.github.com/users/FredrikNoren/events{/privacy}",
"followers_url": "https://api.github.com/users/FredrikNoren/followers",
"following_url": "https://api.github.com/users/FredrikNoren/following{/other_user}",
"gists_url": "https://api.github.com/users/FredrikNoren/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/FredrikNoren",
"id": 1288009,
"login": "FredrikNoren",
"node_id": "MDQ6VXNlcjEyODgwMDk=",
"organizations_url": "https://api.github.com/users/FredrikNoren/orgs",
"received_events_url": "https://api.github.com/users/FredrikNoren/received_events",
"repos_url": "https://api.github.com/users/FredrikNoren/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/FredrikNoren/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FredrikNoren/subscriptions",
"type": "User",
"url": "https://api.github.com/users/FredrikNoren",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi ! Can you try with `datasets` ^3.4 released recently ? on my side it works with IterableDataset on the recent version :)\n\n```python\nIn [20]: def train_iterable_gen():\n ...: images = np.array(load_image(\"https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg\").resize((128, 128)))\n ...: yield {\n ...: \"images\": np.expand_dims(images, axis=0),\n ...: \"messages\": [\n ...: {\n ...: \"role\": \"user\",\n ...: \"content\": [{\"type\": \"image\", \"url\": \"https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg\" }]\n ...: },\n ...: {\n ...: \"role\": \"assistant\",\n ...: \"content\": [{\"type\": \"text\", \"text\": \"duck\" }]\n ...: }\n ...: ]\n ...: }\n ...: \n ...: train_ds = IterableDataset.from_generator(train_iterable_gen,\n ...: features=Features({\n ...: 'images': [datasets.Image(mode=None, decode=True, id=None)],\n ...: 'messages': [{'content': [{'text': datasets.Value(dtype='string', id=None), 'type': datasets.Value(dtype='string', id=None) }],\n ...: 'role': datasets.Value(dtype='string', id=None)}]\n ...: } )\n ...: )\n\n\nIn [21]: \n\nIn [21]: next(iter(train_ds))\n/Users/quentinlhoest/hf/datasets/src/datasets/features/image.py:338: UserWarning: Downcasting array dtype int64 to uint8 to be compatible with 'Pillow'\n warnings.warn(f\"Downcasting array dtype {dtype} to {dest_dtype} to be compatible with 'Pillow'\")\nOut[21]: \n{'images': [<PIL.PngImagePlugin.PngImageFile image mode=RGB size=128x128>],\n 'messages': [{'content': [{'text': None, 'type': 'image'}], 'role': 'user'},\n {'content': [{'type': 'text', 'text': 'duck'}], 'role': 'assistant'}]}\n```",
"Hm I tried it here and it works as expected, even on datasets 3.3.2. I guess maybe something in the SFTTrainer is doing additional processing on the dataset, I'll have a look there.\n\nThanks @lhoestq!"
] | 2025-03-17T15:59:23Z
| 2025-03-18T08:57:17Z
| 2025-03-18T08:57:16Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
This code:
```python
def train_iterable_gen():
images = np.array(load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg").resize((128, 128)))
yield {
"images": np.expand_dims(images, axis=0),
"messages": [
{
"role": "user",
"content": [{"type": "image", "url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg" }]
},
{
"role": "assistant",
"content": [{"type": "text", "text": "duck" }]
}
]
}
train_ds = Dataset.from_generator(train_iterable_gen,
features=Features({
'images': [datasets.Image(mode=None, decode=True, id=None)],
'messages': [{'content': [{'text': datasets.Value(dtype='string', id=None), 'type': datasets.Value(dtype='string', id=None) }], 'role': datasets.Value(dtype='string', id=None)}]
} )
)
```
works as I'd expect; if I iterate the dataset then the `images` column returns a `List[PIL.Image.Image]`, i.e. `'images': [<PIL.PngImagePlugin.PngImageFile image mode=RGB size=128x128 at 0x77EFB7EF4680>]`.
But if I change `Dataset` to `IterableDataset`, the `images` column changes into `'images': [{'path': None, 'bytes': ..]`
### Steps to reproduce the bug
The code above +
```python
def load_image(url):
response = requests.get(url)
image = Image.open(io.BytesIO(response.content))
return image
```
I'm feeding it to SFTTrainer
### Expected behavior
Dataset and IterableDataset would behave the same
### Environment info
```yaml
requires-python = ">=3.12"
dependencies = [
"av>=14.1.0",
"boto3>=1.36.7",
"datasets>=3.3.2",
"docker>=7.1.0",
"google-cloud-storage>=2.19.0",
"grpcio>=1.70.0",
"grpcio-tools>=1.70.0",
"moviepy>=2.1.2",
"open-clip-torch>=2.31.0",
"opencv-python>=4.11.0.86; sys_platform == 'darwin'",
"opencv-python-headless>=4.11.0.86; sys_platform == 'linux'",
"pandas>=2.2.3",
"pillow>=10.4.0",
"plotly>=6.0.0",
"py-spy>=0.4.0",
"pydantic>=2.10.6",
"pydantic-settings>=2.7.1",
"pymysql>=1.1.1",
"ray[data,default,serve,train,tune]>=2.43.0",
"torch>=2.6.0",
"torchmetrics>=1.6.1",
"torchvision>=0.21.0",
"transformers[torch]@git+https://github.com/huggingface/transformers",
"wandb>=0.19.4",
# https://github.com/Dao-AILab/flash-attention/issues/833
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu12torch2.6cxx11abiFALSE-cp312-cp312-linux_x86_64.whl; sys_platform == 'linux'",
"trl@https://github.com/huggingface/trl.git",
"peft>=0.14.0",
]
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1288009?v=4",
"events_url": "https://api.github.com/users/FredrikNoren/events{/privacy}",
"followers_url": "https://api.github.com/users/FredrikNoren/followers",
"following_url": "https://api.github.com/users/FredrikNoren/following{/other_user}",
"gists_url": "https://api.github.com/users/FredrikNoren/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/FredrikNoren",
"id": 1288009,
"login": "FredrikNoren",
"node_id": "MDQ6VXNlcjEyODgwMDk=",
"organizations_url": "https://api.github.com/users/FredrikNoren/orgs",
"received_events_url": "https://api.github.com/users/FredrikNoren/received_events",
"repos_url": "https://api.github.com/users/FredrikNoren/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/FredrikNoren/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FredrikNoren/subscriptions",
"type": "User",
"url": "https://api.github.com/users/FredrikNoren",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7461/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7461/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6297
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6297/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6297/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6297/events
|
https://github.com/huggingface/datasets/pull/6297
| 1,938,752,707
|
PR_kwDODunzps5ckXBa
| 6,297
|
Fix ArrayXD cast
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006920 / 0.011353 (-0.004433) | 0.004306 / 0.011008 (-0.006703) | 0.085961 / 0.038508 (0.047453) | 0.087008 / 0.023109 (0.063899) | 0.308953 / 0.275898 (0.033055) | 0.349919 / 0.323480 (0.026440) | 0.005705 / 0.007986 (-0.002281) | 0.003565 / 0.004328 (-0.000763) | 0.066272 / 0.004250 (0.062022) | 0.056438 / 0.037052 (0.019385) | 0.312927 / 0.258489 (0.054437) | 0.363081 / 0.293841 (0.069240) | 0.031947 / 0.128546 (-0.096600) | 0.008801 / 0.075646 (-0.066845) | 0.288657 / 0.419271 (-0.130615) | 0.053746 / 0.043533 (0.010213) | 0.305815 / 0.255139 (0.050676) | 0.327174 / 0.283200 (0.043975) | 0.024863 / 0.141683 (-0.116820) | 1.489718 / 1.452155 (0.037563) | 1.566726 / 1.492716 (0.074009) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.289273 / 0.018006 (0.271266) | 0.555519 / 0.000490 (0.555029) | 0.006522 / 0.000200 (0.006322) | 0.000105 / 0.000054 (0.000051) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031968 / 0.037411 (-0.005443) | 0.085113 / 0.014526 (0.070587) | 0.103931 / 0.176557 (-0.072625) | 0.158471 / 0.737135 (-0.578665) | 0.102633 / 0.296338 (-0.193705) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.399592 / 0.215209 (0.184383) | 4.004453 / 2.077655 (1.926798) | 2.047224 / 1.504120 (0.543104) | 1.896203 / 1.541195 (0.355008) | 1.974056 / 1.468490 (0.505566) | 0.485964 / 4.584777 (-4.098813) | 3.650648 / 3.745712 (-0.095064) | 3.475953 / 5.269862 (-1.793908) | 2.168105 / 4.565676 (-2.397571) | 0.058167 / 0.424275 (-0.366108) | 0.007517 / 0.007607 (-0.000090) | 0.475386 / 0.226044 (0.249342) | 4.758300 / 2.268929 (2.489372) | 2.527540 / 55.444624 (-52.917085) | 2.180544 / 6.876477 (-4.695933) | 2.460148 / 2.142072 (0.318076) | 0.589944 / 4.805227 (-4.215284) | 0.136474 / 6.500664 (-6.364190) | 0.061462 / 0.075469 (-0.014007) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.245816 / 1.841788 (-0.595972) | 20.376958 / 8.074308 (12.302650) | 14.764579 / 10.191392 (4.573187) | 0.152436 / 0.680424 (-0.527988) | 0.018580 / 0.534201 (-0.515621) | 0.394680 / 0.579283 (-0.184603) | 0.424162 / 0.434364 (-0.010202) | 0.465604 / 0.540337 (-0.074733) | 0.658531 / 1.386936 (-0.728405) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007105 / 0.011353 (-0.004248) | 0.004441 / 0.011008 (-0.006567) | 0.068792 / 0.038508 (0.030284) | 0.080371 / 0.023109 (0.057262) | 0.430263 / 0.275898 (0.154365) | 0.451743 / 0.323480 (0.128263) | 0.005987 / 0.007986 (-0.001999) | 0.003639 / 0.004328 (-0.000690) | 0.065462 / 0.004250 (0.061212) | 0.059852 / 0.037052 (0.022800) | 0.438390 / 0.258489 (0.179901) | 0.458679 / 0.293841 (0.164838) | 0.033044 / 0.128546 (-0.095502) | 0.008845 / 0.075646 (-0.066802) | 0.071772 / 0.419271 (-0.347500) | 0.048840 / 0.043533 (0.005307) | 0.415707 / 0.255139 (0.160568) | 0.431216 / 0.283200 (0.148017) | 0.024422 / 0.141683 (-0.117260) | 1.502249 / 1.452155 (0.050094) | 1.566767 / 1.492716 (0.074050) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.311352 / 0.018006 (0.293346) | 0.550395 / 0.000490 (0.549906) | 0.005190 / 0.000200 (0.004990) | 0.000116 / 0.000054 (0.000062) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034264 / 0.037411 (-0.003147) | 0.098712 / 0.014526 (0.084186) | 0.110906 / 0.176557 (-0.065651) | 0.161670 / 0.737135 (-0.575465) | 0.111023 / 0.296338 (-0.185316) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.435296 / 0.215209 (0.220087) | 4.331231 / 2.077655 (2.253576) | 2.305009 / 1.504120 (0.800889) | 2.154492 / 1.541195 (0.613297) | 2.344017 / 1.468490 (0.875527) | 0.496924 / 4.584777 (-4.087853) | 3.750782 / 3.745712 (0.005070) | 3.380193 / 5.269862 (-1.889669) | 2.161239 / 4.565676 (-2.404438) | 0.058456 / 0.424275 (-0.365819) | 0.007395 / 0.007607 (-0.000212) | 0.507824 / 0.226044 (0.281780) | 5.081564 / 2.268929 (2.812635) | 2.824080 / 55.444624 (-52.620544) | 2.458835 / 6.876477 (-4.417642) | 2.747897 / 2.142072 (0.605824) | 0.600727 / 4.805227 (-4.204500) | 0.135085 / 6.500664 (-6.365579) | 0.060506 / 0.075469 (-0.014963) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.376873 / 1.841788 (-0.464915) | 21.211922 / 8.074308 (13.137614) | 15.022845 / 10.191392 (4.831453) | 0.195388 / 0.680424 (-0.485036) | 0.020268 / 0.534201 (-0.513933) | 0.398971 / 0.579283 (-0.180312) | 0.427588 / 0.434364 (-0.006776) | 0.478044 / 0.540337 (-0.062293) | 0.687904 / 1.386936 (-0.699033) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006134 / 0.011353 (-0.005219) | 0.003655 / 0.011008 (-0.007354) | 0.081295 / 0.038508 (0.042787) | 0.060202 / 0.023109 (0.037093) | 0.330005 / 0.275898 (0.054107) | 0.361219 / 0.323480 (0.037739) | 0.004766 / 0.007986 (-0.003220) | 0.002942 / 0.004328 (-0.001386) | 0.063322 / 0.004250 (0.059072) | 0.047844 / 0.037052 (0.010791) | 0.340375 / 0.258489 (0.081886) | 0.406301 / 0.293841 (0.112460) | 0.027474 / 0.128546 (-0.101072) | 0.007991 / 0.075646 (-0.067655) | 0.262746 / 0.419271 (-0.156526) | 0.045575 / 0.043533 (0.002042) | 0.324123 / 0.255139 (0.068984) | 0.344399 / 0.283200 (0.061199) | 0.021806 / 0.141683 (-0.119877) | 1.425390 / 1.452155 (-0.026765) | 1.487920 / 1.492716 (-0.004796) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.217504 / 0.018006 (0.199498) | 0.420878 / 0.000490 (0.420388) | 0.007312 / 0.000200 (0.007112) | 0.000218 / 0.000054 (0.000163) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023507 / 0.037411 (-0.013905) | 0.073493 / 0.014526 (0.058967) | 0.084857 / 0.176557 (-0.091700) | 0.145130 / 0.737135 (-0.592005) | 0.085204 / 0.296338 (-0.211135) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.388767 / 0.215209 (0.173557) | 3.877998 / 2.077655 (1.800344) | 1.881447 / 1.504120 (0.377327) | 1.714555 / 1.541195 (0.173360) | 1.772551 / 1.468490 (0.304061) | 0.505146 / 4.584777 (-4.079631) | 3.045471 / 3.745712 (-0.700241) | 2.834436 / 5.269862 (-2.435426) | 1.859896 / 4.565676 (-2.705780) | 0.057806 / 0.424275 (-0.366469) | 0.006378 / 0.007607 (-0.001229) | 0.458339 / 0.226044 (0.232294) | 4.588125 / 2.268929 (2.319196) | 2.302215 / 55.444624 (-53.142409) | 1.981297 / 6.876477 (-4.895180) | 2.152967 / 2.142072 (0.010895) | 0.590166 / 4.805227 (-4.215061) | 0.125753 / 6.500664 (-6.374911) | 0.061583 / 0.075469 (-0.013887) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.232195 / 1.841788 (-0.609593) | 17.761159 / 8.074308 (9.686851) | 13.829498 / 10.191392 (3.638106) | 0.131936 / 0.680424 (-0.548488) | 0.016909 / 0.534201 (-0.517292) | 0.332615 / 0.579283 (-0.246668) | 0.358149 / 0.434364 (-0.076215) | 0.384251 / 0.540337 (-0.156087) | 0.536453 / 1.386936 (-0.850483) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006253 / 0.011353 (-0.005100) | 0.003639 / 0.011008 (-0.007370) | 0.062810 / 0.038508 (0.024302) | 0.063761 / 0.023109 (0.040652) | 0.450538 / 0.275898 (0.174640) | 0.483793 / 0.323480 (0.160313) | 0.004973 / 0.007986 (-0.003013) | 0.002918 / 0.004328 (-0.001411) | 0.062140 / 0.004250 (0.057889) | 0.050328 / 0.037052 (0.013275) | 0.455860 / 0.258489 (0.197371) | 0.492399 / 0.293841 (0.198558) | 0.028928 / 0.128546 (-0.099618) | 0.008166 / 0.075646 (-0.067481) | 0.067860 / 0.419271 (-0.351411) | 0.040990 / 0.043533 (-0.002542) | 0.451343 / 0.255139 (0.196204) | 0.473769 / 0.283200 (0.190569) | 0.021585 / 0.141683 (-0.120097) | 1.451040 / 1.452155 (-0.001115) | 1.516065 / 1.492716 (0.023349) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230994 / 0.018006 (0.212988) | 0.428404 / 0.000490 (0.427915) | 0.003777 / 0.000200 (0.003577) | 0.000074 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027394 / 0.037411 (-0.010018) | 0.081692 / 0.014526 (0.067166) | 0.091568 / 0.176557 (-0.084988) | 0.146149 / 0.737135 (-0.590987) | 0.092200 / 0.296338 (-0.204139) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.467086 / 0.215209 (0.251877) | 4.664862 / 2.077655 (2.587207) | 2.575703 / 1.504120 (1.071583) | 2.396587 / 1.541195 (0.855392) | 2.506064 / 1.468490 (1.037574) | 0.511942 / 4.584777 (-4.072834) | 3.196320 / 3.745712 (-0.549392) | 2.916627 / 5.269862 (-2.353235) | 1.919372 / 4.565676 (-2.646305) | 0.058769 / 0.424275 (-0.365506) | 0.006487 / 0.007607 (-0.001120) | 0.539095 / 0.226044 (0.313051) | 5.404675 / 2.268929 (3.135746) | 2.988962 / 55.444624 (-52.455662) | 2.670134 / 6.876477 (-4.206343) | 2.837414 / 2.142072 (0.695342) | 0.614776 / 4.805227 (-4.190451) | 0.125806 / 6.500664 (-6.374858) | 0.061593 / 0.075469 (-0.013876) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.346171 / 1.841788 (-0.495617) | 18.374626 / 8.074308 (10.300318) | 14.508723 / 10.191392 (4.317331) | 0.146771 / 0.680424 (-0.533652) | 0.018438 / 0.534201 (-0.515763) | 0.336944 / 0.579283 (-0.242339) | 0.385631 / 0.434364 (-0.048733) | 0.391922 / 0.540337 (-0.148416) | 0.568904 / 1.386936 (-0.818032) |\n\n</details>\n</details>\n\n\n"
] | 2023-10-11T21:14:59Z
| 2023-10-13T13:54:00Z
| 2023-10-13T13:45:30Z
|
COLLABORATOR
| null | null | null |
Fix #6291
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6297/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6297/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6297.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6297",
"merged_at": "2023-10-13T13:45:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6297.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6297"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6990
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6990/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6990/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6990/events
|
https://github.com/huggingface/datasets/issues/6990
| 2,366,660,785
|
I_kwDODunzps6NEGCx
| 6,990
|
Problematic rank after calling `split_dataset_by_node` twice
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/18402347?v=4",
"events_url": "https://api.github.com/users/yzhangcs/events{/privacy}",
"followers_url": "https://api.github.com/users/yzhangcs/followers",
"following_url": "https://api.github.com/users/yzhangcs/following{/other_user}",
"gists_url": "https://api.github.com/users/yzhangcs/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yzhangcs",
"id": 18402347,
"login": "yzhangcs",
"node_id": "MDQ6VXNlcjE4NDAyMzQ3",
"organizations_url": "https://api.github.com/users/yzhangcs/orgs",
"received_events_url": "https://api.github.com/users/yzhangcs/received_events",
"repos_url": "https://api.github.com/users/yzhangcs/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yzhangcs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yzhangcs/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yzhangcs",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"ah yes good catch ! feel free to open a PR with your suggested fix"
] | 2024-06-21T14:25:26Z
| 2024-06-25T16:19:19Z
| 2024-06-25T16:19:19Z
|
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
I'm trying to split `IterableDataset` by `split_dataset_by_node`.
But when doing split on a already split dataset, the resulting `rank` is greater than `world_size`.
### Steps to reproduce the bug
Here is the minimal code for reproduction:
```py
>>> from datasets import load_dataset
>>> from datasets.distributed import split_dataset_by_node
>>> dataset = load_dataset('fla-hub/slimpajama-test', split='train', streaming=True)
>>> dataset = split_dataset_by_node(dataset, 1, 32)
>>> dataset._distributed
DistributedConfig(rank=1, world_size=32)
>>> dataset = split_dataset_by_node(dataset, 1, 15)
>>> dataset._distributed
DistributedConfig(rank=481, world_size=480)
```
As you can see, the second rank 481 > 480, which is problematic.
### Expected behavior
I think this error comes from this line @lhoestq
https://github.com/huggingface/datasets/blob/a6ccf944e42c1a84de81bf326accab9999b86c90/src/datasets/iterable_dataset.py#L2943-L2944
We may need to obtain the rank first. Then the above code gives
```py
>>> dataset._distributed
DistributedConfig(rank=16, world_size=480)
```
### Environment info
datasets==2.20.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6990/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6990/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6850
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6850/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6850/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6850/events
|
https://github.com/huggingface/datasets/issues/6850
| 2,269,500,624
|
I_kwDODunzps6HRdTQ
| 6,850
|
Problem loading voxpopuli dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/40496687?v=4",
"events_url": "https://api.github.com/users/Namangarg110/events{/privacy}",
"followers_url": "https://api.github.com/users/Namangarg110/followers",
"following_url": "https://api.github.com/users/Namangarg110/following{/other_user}",
"gists_url": "https://api.github.com/users/Namangarg110/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Namangarg110",
"id": 40496687,
"login": "Namangarg110",
"node_id": "MDQ6VXNlcjQwNDk2Njg3",
"organizations_url": "https://api.github.com/users/Namangarg110/orgs",
"received_events_url": "https://api.github.com/users/Namangarg110/received_events",
"repos_url": "https://api.github.com/users/Namangarg110/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Namangarg110/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Namangarg110/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Namangarg110",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[
"Version 2.18 works without problem.",
"@Namangarg110 @mohsen-goodarzi The bug appears because the number of urls is less than 16 and the algorithm is meant to work on the previously created mode for a single url as stated on line 314: https://github.com/huggingface/datasets/blob/1bf8a46cc7b096d5c547ea3794f6a4b6c31ea762/src/datasets/download/download_manager.py#L314\r\n\r\nIn addition, previously `map_nested` function was supported without batching and it is meant to be the default performance. \r\n\r\nOne of the shortest walk-arounds would be changing the part of the manager with the current setting:\r\n```\r\n if len(url_or_urls) >= 16:\r\n download_func = partial(self._download_batched, download_config=download_config)\r\n else:\r\n download_func = partial(self._download_single, download_config=download_config)\r\n\r\n start_time = datetime.now()\r\n with stack_multiprocessing_download_progress_bars():\r\n downloaded_path_or_paths = map_nested(\r\n download_func,\r\n url_or_urls,\r\n map_tuple=True,\r\n num_proc=download_config.num_proc,\r\n desc=\"Downloading data files\",\r\n batched=True if len(url_or_urls) >= 16 else False,\r\n batch_size=-1,\r\n )\r\n```\r\n\r\nI would suggest to consider other datasets for similar issues and make a pull-request. ",
"Thanks for reporting @Namangarg110 and thanks for the investigation @MilanaShhanukova.\r\n\r\nApparently, there is an issue with the download functionality.\r\nI am proposing a fix."
] | 2024-04-29T16:46:51Z
| 2024-05-06T09:25:54Z
| 2024-05-06T09:25:54Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
```
Exception has occurred: FileNotFoundError
Couldn't find file at https://huggingface.co/datasets/facebook/voxpopuli/resolve/main/{'en': 'data/en/asr_train.tsv'}
```
Error in logic for link url creation. The link should be https://huggingface.co/datasets/facebook/voxpopuli/resolve/main/data/en/asr_train.tsv
Basically there should be links directly under ```metadata["train"]```, not under ```metadata["train"][self.config.languages[0]]```
same for audio urls
### Steps to reproduce the bug
```
from datasets import load_dataset
dataset = load_dataset("facebook/voxpopuli","en")
```
### Expected behavior
Dataset should be loaded successfully.
### Environment info
- `datasets` version: 2.19.0
- Platform: Linux-5.15.0-1041-aws-x86_64-with-glibc2.31
- Python version: 3.10.13
- `huggingface_hub` version: 0.22.2
- PyArrow version: 16.0.0
- Pandas version: 2.2.0
- `fsspec` version: 2023.12.2
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6850/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6850/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6412
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6412/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6412/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6412/events
|
https://github.com/huggingface/datasets/issues/6412
| 1,992,401,594
|
I_kwDODunzps52waK6
| 6,412
|
User token is printed out!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/25702692?v=4",
"events_url": "https://api.github.com/users/mohsen-goodarzi/events{/privacy}",
"followers_url": "https://api.github.com/users/mohsen-goodarzi/followers",
"following_url": "https://api.github.com/users/mohsen-goodarzi/following{/other_user}",
"gists_url": "https://api.github.com/users/mohsen-goodarzi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mohsen-goodarzi",
"id": 25702692,
"login": "mohsen-goodarzi",
"node_id": "MDQ6VXNlcjI1NzAyNjky",
"organizations_url": "https://api.github.com/users/mohsen-goodarzi/orgs",
"received_events_url": "https://api.github.com/users/mohsen-goodarzi/received_events",
"repos_url": "https://api.github.com/users/mohsen-goodarzi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mohsen-goodarzi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mohsen-goodarzi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mohsen-goodarzi",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Indeed, this is not a good practice. I've opened a PR that removes the token value from the (deprecation) warning."
] | 2023-11-14T10:01:34Z
| 2023-11-14T22:19:46Z
| 2023-11-14T22:19:46Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
This line prints user token on command line! Is it safe?
https://github.com/huggingface/datasets/blob/12ebe695b4748c5a26e08b44ed51955f74f5801d/src/datasets/load.py#L2091
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6412/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6412/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/7264
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7264/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7264/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7264/events
|
https://github.com/huggingface/datasets/pull/7264
| 2,624,047,640
|
PR_kwDODunzps6AYfwL
| 7,264
|
fix docs relative links
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7264). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update."
] | 2024-10-30T13:07:34Z
| 2024-10-30T13:10:13Z
| 2024-10-30T13:09:02Z
|
MEMBER
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7264/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7264/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7264.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7264",
"merged_at": "2024-10-30T13:09:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7264.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7264"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7023
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7023/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7023/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7023/events
|
https://github.com/huggingface/datasets/pull/7023
| 2,388,090,424
|
PR_kwDODunzps50TDot
| 7,023
|
Remove dead code for pyarrow < 15.0.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7023). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005669 / 0.011353 (-0.005684) | 0.004233 / 0.011008 (-0.006775) | 0.063550 / 0.038508 (0.025041) | 0.031269 / 0.023109 (0.008160) | 0.234280 / 0.275898 (-0.041618) | 0.264517 / 0.323480 (-0.058963) | 0.003310 / 0.007986 (-0.004676) | 0.003640 / 0.004328 (-0.000688) | 0.050139 / 0.004250 (0.045889) | 0.046909 / 0.037052 (0.009856) | 0.253101 / 0.258489 (-0.005388) | 0.280281 / 0.293841 (-0.013560) | 0.029558 / 0.128546 (-0.098989) | 0.012537 / 0.075646 (-0.063110) | 0.209624 / 0.419271 (-0.209648) | 0.036857 / 0.043533 (-0.006676) | 0.236957 / 0.255139 (-0.018182) | 0.260510 / 0.283200 (-0.022689) | 0.019802 / 0.141683 (-0.121881) | 1.141747 / 1.452155 (-0.310407) | 1.172617 / 1.492716 (-0.320099) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.107381 / 0.018006 (0.089375) | 0.308401 / 0.000490 (0.307911) | 0.000227 / 0.000200 (0.000027) | 0.000056 / 0.000054 (0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019504 / 0.037411 (-0.017907) | 0.063920 / 0.014526 (0.049394) | 0.075375 / 0.176557 (-0.101181) | 0.122707 / 0.737135 (-0.614428) | 0.080015 / 0.296338 (-0.216324) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.288716 / 0.215209 (0.073507) | 2.862022 / 2.077655 (0.784368) | 1.472510 / 1.504120 (-0.031610) | 1.332989 / 1.541195 (-0.208206) | 1.395140 / 1.468490 (-0.073350) | 0.728042 / 4.584777 (-3.856735) | 2.409914 / 3.745712 (-1.335799) | 2.912514 / 5.269862 (-2.357347) | 1.986980 / 4.565676 (-2.578697) | 0.078587 / 0.424275 (-0.345688) | 0.005601 / 0.007607 (-0.002006) | 0.342510 / 0.226044 (0.116466) | 3.354621 / 2.268929 (1.085692) | 1.852472 / 55.444624 (-53.592153) | 1.542567 / 6.876477 (-5.333910) | 1.726756 / 2.142072 (-0.415317) | 0.794567 / 4.805227 (-4.010660) | 0.135279 / 6.500664 (-6.365386) | 0.042591 / 0.075469 (-0.032878) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.968336 / 1.841788 (-0.873452) | 12.334614 / 8.074308 (4.260305) | 9.638775 / 10.191392 (-0.552617) | 0.143625 / 0.680424 (-0.536799) | 0.015475 / 0.534201 (-0.518726) | 0.313357 / 0.579283 (-0.265926) | 0.271257 / 0.434364 (-0.163107) | 0.362074 / 0.540337 (-0.178263) | 0.468595 / 1.386936 (-0.918341) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006243 / 0.011353 (-0.005110) | 0.004496 / 0.011008 (-0.006512) | 0.051271 / 0.038508 (0.012763) | 0.035718 / 0.023109 (0.012609) | 0.272623 / 0.275898 (-0.003275) | 0.297060 / 0.323480 (-0.026420) | 0.004801 / 0.007986 (-0.003185) | 0.003060 / 0.004328 (-0.001269) | 0.049990 / 0.004250 (0.045740) | 0.042413 / 0.037052 (0.005360) | 0.281268 / 0.258489 (0.022779) | 0.327224 / 0.293841 (0.033383) | 0.033745 / 0.128546 (-0.094801) | 0.012777 / 0.075646 (-0.062869) | 0.061808 / 0.419271 (-0.357464) | 0.034428 / 0.043533 (-0.009105) | 0.272211 / 0.255139 (0.017072) | 0.327260 / 0.283200 (0.044061) | 0.019756 / 0.141683 (-0.121927) | 1.137768 / 1.452155 (-0.314387) | 1.220347 / 1.492716 (-0.272369) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.099737 / 0.018006 (0.081731) | 0.304627 / 0.000490 (0.304137) | 0.000210 / 0.000200 (0.000011) | 0.000052 / 0.000054 (-0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023177 / 0.037411 (-0.014234) | 0.077505 / 0.014526 (0.062979) | 0.088957 / 0.176557 (-0.087599) | 0.129187 / 0.737135 (-0.607948) | 0.090386 / 0.296338 (-0.205953) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.291558 / 0.215209 (0.076349) | 2.874297 / 2.077655 (0.796642) | 1.562316 / 1.504120 (0.058196) | 1.439950 / 1.541195 (-0.101244) | 1.492316 / 1.468490 (0.023826) | 0.729885 / 4.584777 (-3.854892) | 0.985075 / 3.745712 (-2.760637) | 3.108313 / 5.269862 (-2.161549) | 1.998072 / 4.565676 (-2.567604) | 0.079367 / 0.424275 (-0.344908) | 0.005210 / 0.007607 (-0.002398) | 0.347335 / 0.226044 (0.121290) | 3.519375 / 2.268929 (1.250446) | 1.949395 / 55.444624 (-53.495229) | 1.650379 / 6.876477 (-5.226097) | 1.691606 / 2.142072 (-0.450466) | 0.816023 / 4.805227 (-3.989204) | 0.135318 / 6.500664 (-6.365346) | 0.041390 / 0.075469 (-0.034079) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.018964 / 1.841788 (-0.822823) | 13.120135 / 8.074308 (5.045827) | 10.618095 / 10.191392 (0.426703) | 0.134507 / 0.680424 (-0.545917) | 0.015895 / 0.534201 (-0.518306) | 0.302864 / 0.579283 (-0.276420) | 0.131117 / 0.434364 (-0.303247) | 0.342374 / 0.540337 (-0.197964) | 0.441640 / 1.386936 (-0.945296) |\n\n</details>\n</details>\n\n\n"
] | 2024-07-03T09:05:03Z
| 2024-07-03T09:24:46Z
| 2024-07-03T09:17:35Z
|
MEMBER
| null | null | null |
Remove dead code for pyarrow < 15.0.0.
Code is dead since the merge of:
- #6892
Fix #7022.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7023/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7023/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7023.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7023",
"merged_at": "2024-07-03T09:17:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7023.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7023"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7474
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7474/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7474/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7474/events
|
https://github.com/huggingface/datasets/pull/7474
| 2,945,066,258
|
PR_kwDODunzps6P91lM
| 7,474
|
Remove conditions for Python < 3.9
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17618148?v=4",
"events_url": "https://api.github.com/users/cyyever/events{/privacy}",
"followers_url": "https://api.github.com/users/cyyever/followers",
"following_url": "https://api.github.com/users/cyyever/following{/other_user}",
"gists_url": "https://api.github.com/users/cyyever/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cyyever",
"id": 17618148,
"login": "cyyever",
"node_id": "MDQ6VXNlcjE3NjE4MTQ4",
"organizations_url": "https://api.github.com/users/cyyever/orgs",
"received_events_url": "https://api.github.com/users/cyyever/received_events",
"repos_url": "https://api.github.com/users/cyyever/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cyyever/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cyyever/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cyyever",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7474). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"Thanks ! can you run `make style` to fix code formatting ? then we can merge",
"@lhoestq Done"
] | 2025-03-25T03:08:04Z
| 2025-04-16T00:11:06Z
| 2025-04-15T16:07:55Z
|
CONTRIBUTOR
| null | null | null |
This PR remove conditions for Python < 3.9.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7474/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7474/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7474.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7474",
"merged_at": "2025-04-15T16:07:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7474.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7474"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5522
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5522/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5522/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5522/events
|
https://github.com/huggingface/datasets/pull/5522
| 1,580,183,124
|
PR_kwDODunzps5JvTVp
| 5,522
|
Minor changes in JAX-formatting docstrings & type-hints
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_url": "https://api.github.com/users/alvarobartt/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/alvarobartt",
"id": 36760800,
"login": "alvarobartt",
"node_id": "MDQ6VXNlcjM2NzYwODAw",
"organizations_url": "https://api.github.com/users/alvarobartt/orgs",
"received_events_url": "https://api.github.com/users/alvarobartt/received_events",
"repos_url": "https://api.github.com/users/alvarobartt/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/alvarobartt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alvarobartt/subscriptions",
"type": "User",
"url": "https://api.github.com/users/alvarobartt",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"P.S. For more context, I'm currently exploring the integration of 🤗`datasets` with JAX, so in case you need any help or want me to try something specific just let me know! (`jnp.asarray`/`jnp.array(..., copy=False)` still no zero-copy 😭)",
"_The documentation is not available anymore as the PR was closed or merged._",
"> Hi ! Thanks for improving this :)\r\n\r\nGlad to help, @lhoestq! Also, regarding the questions in the `## What's missing?` can I have your input? Thanks 🤗 ",
"Whoops forgot to reply to these matters - sorry x)\r\n\r\nYea a JAX guide would be welcome in the documentation ! This can be done in a separate PR if you want :)\r\n\r\nPyarrow is always imported with `datasets`, so it doesn't really matter if it's under TYPE_CHECKING or not.\r\n\r\nRegarding the license : yes indeed it should be in every file, thanks for reporting.\r\n\r\nNo big preference between jnp.array and jnp.asarray, unless one offers better performance",
"> Whoops forgot to reply to these matters - sorry x)\r\n> \r\n> Yea a JAX guide would be welcome in the documentation ! This can be done in a separate PR if you want :)\r\n> \r\n> Pyarrow is always imported with `datasets`, so it doesn't really matter if it's under TYPE_CHECKING or not.\r\n> \r\n> Regarding the license : yes indeed it should be in every file, thanks for reporting.\r\n> \r\n> No big preference between jnp.array and jnp.asarray, unless one offers better performance\r\n\r\nCool @lhoestq thanks for the input there!\r\n\r\n1. I can create a separate PR for JAX-format usage\r\n2. Regarding that, makes sense, we can just not put it there, unless it's more clear that in that file `pyarrow` is just required for typing?\r\n3. Do you want me to add the License? In this PR? In a separate one?\r\n4. Ideally `jnp.asarray` is similar to `np.asarray` which in the case of `numpy` tends to be more efficient as it does zero-copy when possible, while `np.array` has `copy=True` by default, anyway as I mentioned before (and as you already know) the copy from `numpy` to `jax` is not zero-copy, while the other way around (`jax` to `numpy`) it is",
"Thanks, feel free to create separate PRs for the docs and the license.\r\n\r\nI guess you can move the `pyarrow` import back to where it was for consistency with the other files and we can merge this one ;)",
"> Thanks, feel free to create separate PRs for the docs and the license.\r\n> \r\n> I guess you can move the `pyarrow` import back to where it was for consistency with the other files and we can merge this one ;)\r\n\r\nCool thanks I'll do that! 👍🏻 ",
"Actually I just checked and there are still tens of thousands of users with jax 0.3.25 - so we need to support older versions as well. I guess it comes from `transformers` which doesn't support jax 0.4 (and doesn't want to until the jax team stops breaking the lib all the time).\r\n\r\nCould you make sure your changes work with older versions as well ? Sorry for not spotting this earlier.\r\nIf we have `\"jax>=0.2.8,!=0.3.2,<=0.4.3\"` that'b be nice, and we can update the latest supported release from time to time.\r\n\r\nIn the CI you can add `jax==0.2.8` for the `deps-minimum` job, and use `jax~=0.4.1` for the `deps-latest`.",
"> Actually I just checked and there are still tens of thousands of users with jax 0.3.25 - so we need to support older versions as well. I guess it comes from `transformers` which doesn't support jax 0.4 (and doesn't want to until the jax team stops breaking the lib all the time).\r\n> \r\n> Could you make sure your changes work with older versions as well ? Sorry for not spotting this earlier. If we have `\"jax>=0.2.8,!=0.3.2,<=0.4.3\"` that'b be nice, and we can update the latest supported release from time to time.\r\n> \r\n> In the CI you can add `jax==0.2.8` for the `deps-minimum` job, and use `jax~=0.4.1` for the `deps-latest`.\r\n\r\nOk, didn't know that @lhoestq thanks for the detailed context! Sure, I'll update it and make sure it's also compatible with older versions.",
"Oops forgot to add you as co-author of the last commit @lhoestq my bad 😞 ",
"So it should be fixed right now @lhoestq! The thing is that `jax` doesn't provide support for Python 3.7 due to its EOL next June (more information at https://endoflife.date/python)...\r\n\r\nAnyway, I can confirm that `jax.Array` type works with 0.3.25 and that the following code works fine:\r\n\r\n```python\r\nimport jax\r\nimport jax.numpy as jnp\r\n\r\nx = jnp.ones((1, 10), dtype=jnp.float32) # Is a `jnp.DeviceArray`\r\nassert isinstance(x, jax.Array) # Is `True`\r\n```\r\n\r\nSo we can still use 0.3.25 as the maximum supported version, as well as 0.3.6 for `jaxlib` so as to be consistent with 🤗`transformers`.\r\n\r\nThanks for your comments @lhoestq those were really useful!",
"Sorry for the spam, pinning versions leads to failure runs (not related to the type-hinting); I'll check that locally instead of here to avoid spam... Not pinning the dependencies work but I'll check the minimum required versions for both `jax` and `jaxlib` in Python 3.7",
"> Cool ! Thanks for trying to make the CI support it, but it's maybe not worth spending more time on this for now ^^\r\n> \r\n> merging :)\r\n\r\nDo you want me to work on the CI in a separate branch? Thanks for merging and for your help as always :)",
"> Do you want me to work on the CI in a separate branch? Thanks for merging and for your help as always :)\r\n\r\nIn the end I think we can keep it as is since we didn't modify the core code for jax. Maybe later if we do further changes and need to make sure we don't break anything ;) For example when we decide to add support for more recent versions",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010798 / 0.011353 (-0.000555) | 0.005690 / 0.011008 (-0.005318) | 0.116840 / 0.038508 (0.078332) | 0.041376 / 0.023109 (0.018266) | 0.345616 / 0.275898 (0.069718) | 0.413914 / 0.323480 (0.090434) | 0.009237 / 0.007986 (0.001252) | 0.004490 / 0.004328 (0.000162) | 0.085833 / 0.004250 (0.081582) | 0.050231 / 0.037052 (0.013179) | 0.367276 / 0.258489 (0.108787) | 0.393735 / 0.293841 (0.099894) | 0.043775 / 0.128546 (-0.084772) | 0.013215 / 0.075646 (-0.062432) | 0.391020 / 0.419271 (-0.028252) | 0.055102 / 0.043533 (0.011569) | 0.360333 / 0.255139 (0.105194) | 0.370531 / 0.283200 (0.087331) | 0.115484 / 0.141683 (-0.026199) | 1.694779 / 1.452155 (0.242625) | 1.756249 / 1.492716 (0.263532) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230508 / 0.018006 (0.212501) | 0.478681 / 0.000490 (0.478191) | 0.010305 / 0.000200 (0.010105) | 0.000147 / 0.000054 (0.000093) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030953 / 0.037411 (-0.006459) | 0.124320 / 0.014526 (0.109794) | 0.140417 / 0.176557 (-0.036140) | 0.189522 / 0.737135 (-0.547613) | 0.143635 / 0.296338 (-0.152704) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.485995 / 0.215209 (0.270786) | 4.799668 / 2.077655 (2.722014) | 2.195655 / 1.504120 (0.691535) | 1.940073 / 1.541195 (0.398879) | 2.053853 / 1.468490 (0.585363) | 0.825399 / 4.584777 (-3.759378) | 4.522180 / 3.745712 (0.776468) | 2.484626 / 5.269862 (-2.785236) | 1.727617 / 4.565676 (-2.838059) | 0.098808 / 0.424275 (-0.325467) | 0.014753 / 0.007607 (0.007146) | 0.606798 / 0.226044 (0.380754) | 5.918090 / 2.268929 (3.649162) | 2.668124 / 55.444624 (-52.776500) | 2.300447 / 6.876477 (-4.576030) | 2.411203 / 2.142072 (0.269130) | 0.999826 / 4.805227 (-3.805401) | 0.193683 / 6.500664 (-6.306981) | 0.069341 / 0.075469 (-0.006129) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.455816 / 1.841788 (-0.385972) | 17.176476 / 8.074308 (9.102168) | 16.359100 / 10.191392 (6.167708) | 0.199669 / 0.680424 (-0.480755) | 0.033456 / 0.534201 (-0.500745) | 0.512478 / 0.579283 (-0.066805) | 0.526350 / 0.434364 (0.091986) | 0.637669 / 0.540337 (0.097332) | 0.753821 / 1.386936 (-0.633115) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008176 / 0.011353 (-0.003177) | 0.005862 / 0.011008 (-0.005147) | 0.086123 / 0.038508 (0.047615) | 0.037144 / 0.023109 (0.014035) | 0.398328 / 0.275898 (0.122430) | 0.439126 / 0.323480 (0.115647) | 0.006455 / 0.007986 (-0.001531) | 0.004575 / 0.004328 (0.000246) | 0.083396 / 0.004250 (0.079146) | 0.052827 / 0.037052 (0.015775) | 0.401039 / 0.258489 (0.142550) | 0.441374 / 0.293841 (0.147533) | 0.041671 / 0.128546 (-0.086875) | 0.014098 / 0.075646 (-0.061548) | 0.100873 / 0.419271 (-0.318398) | 0.058690 / 0.043533 (0.015157) | 0.395817 / 0.255139 (0.140678) | 0.409226 / 0.283200 (0.126026) | 0.119804 / 0.141683 (-0.021879) | 1.704583 / 1.452155 (0.252428) | 1.782527 / 1.492716 (0.289811) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.255166 / 0.018006 (0.237160) | 0.485091 / 0.000490 (0.484601) | 0.007458 / 0.000200 (0.007258) | 0.000116 / 0.000054 (0.000061) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034531 / 0.037411 (-0.002880) | 0.134332 / 0.014526 (0.119806) | 0.144944 / 0.176557 (-0.031613) | 0.199352 / 0.737135 (-0.537783) | 0.152243 / 0.296338 (-0.144095) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.495361 / 0.215209 (0.280152) | 4.895144 / 2.077655 (2.817489) | 2.350419 / 1.504120 (0.846299) | 2.112131 / 1.541195 (0.570937) | 2.234469 / 1.468490 (0.765978) | 0.815862 / 4.584777 (-3.768915) | 4.531638 / 3.745712 (0.785926) | 2.405186 / 5.269862 (-2.864676) | 1.559020 / 4.565676 (-3.006656) | 0.100432 / 0.424275 (-0.323843) | 0.014217 / 0.007607 (0.006610) | 0.614622 / 0.226044 (0.388577) | 5.984541 / 2.268929 (3.715613) | 2.929897 / 55.444624 (-52.514727) | 2.484010 / 6.876477 (-4.392467) | 2.533538 / 2.142072 (0.391466) | 0.972119 / 4.805227 (-3.833108) | 0.193630 / 6.500664 (-6.307034) | 0.073694 / 0.075469 (-0.001775) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.503725 / 1.841788 (-0.338063) | 17.421529 / 8.074308 (9.347221) | 15.686433 / 10.191392 (5.495041) | 0.216688 / 0.680424 (-0.463736) | 0.020929 / 0.534201 (-0.513272) | 0.512523 / 0.579283 (-0.066760) | 0.499878 / 0.434364 (0.065514) | 0.639238 / 0.540337 (0.098900) | 0.769598 / 1.386936 (-0.617338) |\n\n</details>\n</details>\n\n\n",
"> > Do you want me to work on the CI in a separate branch? Thanks for merging and for your help as always :)\r\n> \r\n> In the end I think we can keep it as is since we didn't modify the core code for jax. Maybe later if we do further changes and need to make sure we don't break anything ;) For example when we decide to add support for more recent versions\r\n\r\nMakes sense, thank you @lhoestq!"
] | 2023-02-10T19:05:00Z
| 2023-02-15T14:48:27Z
| 2023-02-15T13:19:06Z
|
MEMBER
| null | null | null |
Hi to whoever is reading this! 🤗
## What's in this PR?
I was exploring the code regarding the `JaxFormatter` implemented in 🤗`datasets`, and found some things that IMO could be changed. Those are mainly regarding the docstrings and the type-hints based on `jax`'s 0.4.1 release where `jax.Array` was introduced as the default type for JAX-arrays (instead of `jnp.DeviceArray`, `jnp.SharedDeviceArray`, and `jnp.GlobalDeviceArray`). Even though `isinstance(..., jax.Array)` also works with lower versions such as e.g. `0.3.25`.
More information about the latter at [`jax` v0.4.1 - Release Notes](https://github.com/google/jax/releases/tag/jax-v0.4.1) and [jax.Array migration - JAX documentation](https://jax.readthedocs.io/en/latest/jax_array_migration.html).
## What's missing?
* Do you want me to write an entry in the documentation on how to use 🤗`datasets` with JAX as https://huggingface.co/docs/datasets/use_with_pytorch with PyTorch?
* Do we need to actually include `pyarrow` under the `TYPE_CHECKING` when needed? I just did it for JAX, but if we are OK with that, I can do that with the rest of the formatters, just LMK.
* Should the License header be included in `datasets.formatting.np_formatter`? If so, do I include the one from 2020 e.g. https://github.com/huggingface/datasets/blob/b065547654efa0ec633cf373ac1512884c68b2e1/src/datasets/formatting/tf_formatter.py#L1-L13
* Is there any reason why `jnp.array` is being used instead of `jnp.asarray`? There's no difference between both, just that `jnp.asarray` has `copy=False` as default, even though `numpy` to `jax.numpy` conversion is not zero-copy, but just asking :)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5522/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5522/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5522.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5522",
"merged_at": "2023-02-15T13:19:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5522.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5522"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6238
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6238/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6238/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6238/events
|
https://github.com/huggingface/datasets/issues/6238
| 1,895,207,828
|
I_kwDODunzps5w9pOU
| 6,238
|
`dataset.filter` ALWAYS removes the first item from the dataset when using batched=True
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1330693?v=4",
"events_url": "https://api.github.com/users/Taytay/events{/privacy}",
"followers_url": "https://api.github.com/users/Taytay/followers",
"following_url": "https://api.github.com/users/Taytay/following{/other_user}",
"gists_url": "https://api.github.com/users/Taytay/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Taytay",
"id": 1330693,
"login": "Taytay",
"node_id": "MDQ6VXNlcjEzMzA2OTM=",
"organizations_url": "https://api.github.com/users/Taytay/orgs",
"received_events_url": "https://api.github.com/users/Taytay/received_events",
"repos_url": "https://api.github.com/users/Taytay/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Taytay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Taytay/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Taytay",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"`filter` treats the function's output as a (selection) mask - `True` keeps the sample, and `False` drops it. In your case, `bool(0)` evaluates to `False`, so dropping the first sample is the correct behavior.",
"Oh gosh! 🤦 I totally misunderstood the API! My apologies!"
] | 2023-09-13T20:20:37Z
| 2023-09-17T07:05:07Z
| 2023-09-17T07:05:07Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
If you call batched=True when calling `filter`, the first item is _always_ filtered out, regardless of the filter condition.
### Steps to reproduce the bug
Here's a minimal example:
```python
def filter_batch_always_true(batch, indices):
print("First index being passed into this filter function: ", indices[0])
return indices # Keep all indices
data = {"value": list(range(10))}
dataset = Dataset.from_dict(data)
filtered_dataset = dataset.filter(filter_batch_always_true, with_indices=True, batched=True)
print("Length of original dataset: ", len(dataset))
print("Length of filtered_dataset: ", len(filtered_dataset))
print("Is equal to original? ", len(filtered_dataset) == len(dataset))
print("First item of filtered dataset: ", filtered_dataset[0])
print("Last item of filtered dataset: ", filtered_dataset[-1])
```
prints:
```
First index being passed into this filter function: 0
Length of original dataset: 10
Length of filtered_dataset: 9
Is equal to original? False
First item of filtered dataset: {'value': 1}
Last item of filtered dataset: {'value': 9}
```
### Expected behavior
Filter should respect the filter condition.
### Environment info
- `datasets` version: 2.14.4
- Platform: macOS-13.5-arm64-arm-64bit
- Python version: 3.9.18
- Huggingface_hub version: 0.17.1
- PyArrow version: 10.0.1
- Pandas version: 2.0.2
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1330693?v=4",
"events_url": "https://api.github.com/users/Taytay/events{/privacy}",
"followers_url": "https://api.github.com/users/Taytay/followers",
"following_url": "https://api.github.com/users/Taytay/following{/other_user}",
"gists_url": "https://api.github.com/users/Taytay/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Taytay",
"id": 1330693,
"login": "Taytay",
"node_id": "MDQ6VXNlcjEzMzA2OTM=",
"organizations_url": "https://api.github.com/users/Taytay/orgs",
"received_events_url": "https://api.github.com/users/Taytay/received_events",
"repos_url": "https://api.github.com/users/Taytay/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Taytay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Taytay/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Taytay",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6238/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6238/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6397
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6397/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6397/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6397/events
|
https://github.com/huggingface/datasets/issues/6397
| 1,987,622,152
|
I_kwDODunzps52eLUI
| 6,397
|
Raise a different exception for inexisting dataset vs files without known extension
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[] | 2023-11-10T13:22:14Z
| 2023-11-22T15:12:34Z
| 2023-11-22T15:12:34Z
|
COLLABORATOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
See https://github.com/huggingface/datasets-server/issues/2082#issuecomment-1805716557
We have the same error for:
- https://huggingface.co/datasets/severo/a_dataset_that_does_not_exist: a dataset that does not exist
- https://huggingface.co/datasets/severo/test_files_without_extension: a dataset with files without a known extension
```
>>> import datasets
>>> datasets.get_dataset_config_names('severo/a_dataset_that_does_not_exist')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py", line 351, in get_dataset_config_names
dataset_module = dataset_module_factory(
File "/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/load.py", line 1508, in dataset_module_factory
raise FileNotFoundError(
FileNotFoundError: Couldn't find a dataset script at /home/slesage/hf/datasets-server/services/worker/severo/a_dataset_that_does_not_exist/a_dataset_that_does_not_exist.py or any data file in the same directory. Couldn't find 'severo/a_dataset_that_does_not_exist' on the Hugging Face Hub either: FileNotFoundError: Dataset 'severo/a_dataset_that_does_not_exist' doesn't exist on the Hub. If the repo is private or gated, make sure to log in with `huggingface-cli login`.
>>> datasets.get_dataset_config_names('severo/test_files_without_extension')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py", line 351, in get_dataset_config_names
dataset_module = dataset_module_factory(
File "/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/load.py", line 1508, in dataset_module_factory
raise FileNotFoundError(
FileNotFoundError: Couldn't find a dataset script at /home/slesage/hf/datasets-server/services/worker/severo/test_files_without_extension/test_files_without_extension.py or any data file in the same directory. Couldn't find 'severo/test_files_without_extension' on the Hugging Face Hub either: FileNotFoundError: No (supported) data files or dataset script found in severo/test_files_without_extension.
```
To differentiate, we must parse the error message (only the end is different). We should have a different exception for these two errors.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6397/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6397/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6932
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6932/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6932/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6932/events
|
https://github.com/huggingface/datasets/pull/6932
| 2,324,729,267
|
PR_kwDODunzps5w9d7w
| 6,932
|
Update dataset_dict.py
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20263729?v=4",
"events_url": "https://api.github.com/users/Arunprakash-A/events{/privacy}",
"followers_url": "https://api.github.com/users/Arunprakash-A/followers",
"following_url": "https://api.github.com/users/Arunprakash-A/following{/other_user}",
"gists_url": "https://api.github.com/users/Arunprakash-A/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Arunprakash-A",
"id": 20263729,
"login": "Arunprakash-A",
"node_id": "MDQ6VXNlcjIwMjYzNzI5",
"organizations_url": "https://api.github.com/users/Arunprakash-A/orgs",
"received_events_url": "https://api.github.com/users/Arunprakash-A/received_events",
"repos_url": "https://api.github.com/users/Arunprakash-A/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Arunprakash-A/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Arunprakash-A/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Arunprakash-A",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"thanks !",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005050 / 0.011353 (-0.006303) | 0.003786 / 0.011008 (-0.007222) | 0.062406 / 0.038508 (0.023898) | 0.029459 / 0.023109 (0.006349) | 0.262388 / 0.275898 (-0.013510) | 0.274119 / 0.323480 (-0.049361) | 0.004085 / 0.007986 (-0.003901) | 0.002754 / 0.004328 (-0.001574) | 0.048779 / 0.004250 (0.044529) | 0.046187 / 0.037052 (0.009135) | 0.263513 / 0.258489 (0.005024) | 0.294260 / 0.293841 (0.000419) | 0.027391 / 0.128546 (-0.101155) | 0.010567 / 0.075646 (-0.065080) | 0.200225 / 0.419271 (-0.219046) | 0.036165 / 0.043533 (-0.007367) | 0.251757 / 0.255139 (-0.003382) | 0.268271 / 0.283200 (-0.014928) | 0.018446 / 0.141683 (-0.123237) | 1.125787 / 1.452155 (-0.326368) | 1.163172 / 1.492716 (-0.329544) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.004428 / 0.018006 (-0.013578) | 0.301730 / 0.000490 (0.301241) | 0.000215 / 0.000200 (0.000015) | 0.000045 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019424 / 0.037411 (-0.017987) | 0.062269 / 0.014526 (0.047743) | 0.074289 / 0.176557 (-0.102268) | 0.121069 / 0.737135 (-0.616067) | 0.076485 / 0.296338 (-0.219853) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.277315 / 0.215209 (0.062106) | 2.742027 / 2.077655 (0.664372) | 1.472970 / 1.504120 (-0.031150) | 1.350065 / 1.541195 (-0.191130) | 1.378806 / 1.468490 (-0.089684) | 0.567742 / 4.584777 (-4.017035) | 2.376752 / 3.745712 (-1.368960) | 2.662459 / 5.269862 (-2.607402) | 1.750396 / 4.565676 (-2.815280) | 0.063589 / 0.424275 (-0.360686) | 0.004987 / 0.007607 (-0.002620) | 0.326441 / 0.226044 (0.100397) | 3.224125 / 2.268929 (0.955197) | 1.801623 / 55.444624 (-53.643001) | 1.534712 / 6.876477 (-5.341765) | 1.652365 / 2.142072 (-0.489708) | 0.647624 / 4.805227 (-4.157603) | 0.117161 / 6.500664 (-6.383504) | 0.041908 / 0.075469 (-0.033561) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.954879 / 1.841788 (-0.886909) | 11.571875 / 8.074308 (3.497567) | 9.489146 / 10.191392 (-0.702246) | 0.141630 / 0.680424 (-0.538794) | 0.014764 / 0.534201 (-0.519437) | 0.285003 / 0.579283 (-0.294280) | 0.266138 / 0.434364 (-0.168226) | 0.323527 / 0.540337 (-0.216810) | 0.419658 / 1.386936 (-0.967278) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005359 / 0.011353 (-0.005994) | 0.003615 / 0.011008 (-0.007393) | 0.050692 / 0.038508 (0.012184) | 0.033632 / 0.023109 (0.010522) | 0.273614 / 0.275898 (-0.002284) | 0.303780 / 0.323480 (-0.019700) | 0.004171 / 0.007986 (-0.003814) | 0.002687 / 0.004328 (-0.001642) | 0.050002 / 0.004250 (0.045751) | 0.040824 / 0.037052 (0.003772) | 0.287759 / 0.258489 (0.029270) | 0.324144 / 0.293841 (0.030303) | 0.029101 / 0.128546 (-0.099445) | 0.010244 / 0.075646 (-0.065402) | 0.059599 / 0.419271 (-0.359672) | 0.033146 / 0.043533 (-0.010387) | 0.276592 / 0.255139 (0.021453) | 0.293670 / 0.283200 (0.010470) | 0.018270 / 0.141683 (-0.123413) | 1.126216 / 1.452155 (-0.325939) | 1.155658 / 1.492716 (-0.337058) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093537 / 0.018006 (0.075530) | 0.302706 / 0.000490 (0.302216) | 0.000216 / 0.000200 (0.000016) | 0.000052 / 0.000054 (-0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023118 / 0.037411 (-0.014293) | 0.076995 / 0.014526 (0.062469) | 0.089476 / 0.176557 (-0.087080) | 0.130705 / 0.737135 (-0.606430) | 0.090258 / 0.296338 (-0.206081) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.285920 / 0.215209 (0.070710) | 2.830581 / 2.077655 (0.752927) | 1.561695 / 1.504120 (0.057575) | 1.522791 / 1.541195 (-0.018403) | 1.429875 / 1.468490 (-0.038615) | 0.566683 / 4.584777 (-4.018094) | 0.957157 / 3.745712 (-2.788555) | 2.663718 / 5.269862 (-2.606143) | 1.748885 / 4.565676 (-2.816791) | 0.063697 / 0.424275 (-0.360578) | 0.004996 / 0.007607 (-0.002611) | 0.340042 / 0.226044 (0.113998) | 3.352792 / 2.268929 (1.083863) | 1.907189 / 55.444624 (-53.537435) | 1.608177 / 6.876477 (-5.268300) | 1.775438 / 2.142072 (-0.366634) | 0.645264 / 4.805227 (-4.159963) | 0.116441 / 6.500664 (-6.384223) | 0.040671 / 0.075469 (-0.034798) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.005050 / 1.841788 (-0.836738) | 12.040057 / 8.074308 (3.965749) | 10.213560 / 10.191392 (0.022168) | 0.138383 / 0.680424 (-0.542041) | 0.015409 / 0.534201 (-0.518792) | 0.283509 / 0.579283 (-0.295774) | 0.125501 / 0.434364 (-0.308863) | 0.318816 / 0.540337 (-0.221521) | 0.415454 / 1.386936 (-0.971482) |\n\n</details>\n</details>\n\n\n"
] | 2024-05-30T05:22:35Z
| 2024-06-04T12:56:20Z
| 2024-06-04T12:50:13Z
|
CONTRIBUTOR
| null | null | null |
shape returns (number of rows, number of columns)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6932/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6932/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6932.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6932",
"merged_at": "2024-06-04T12:50:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6932.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6932"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5341
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5341/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5341/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5341/events
|
https://github.com/huggingface/datasets/pull/5341
| 1,484,376,644
|
PR_kwDODunzps5Exohx
| 5,341
|
Remove tasks.json
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-08T11:04:35Z
| 2022-12-09T12:26:21Z
| 2022-12-09T12:23:20Z
|
MEMBER
| null | null | null |
After discussions in https://github.com/huggingface/datasets/pull/5335 we should remove this file that is not used anymore. We should update https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts instead.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5341/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5341/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5341.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5341",
"merged_at": "2022-12-09T12:23:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5341.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5341"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5266
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5266/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5266/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5266/events
|
https://github.com/huggingface/datasets/pull/5266
| 1,455,281,310
|
PR_kwDODunzps5DN9BT
| 5,266
|
Specify arguments as keywords in librosa.reshape to avoid future errors
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-11-18T14:58:47Z
| 2022-11-21T15:45:02Z
| 2022-11-21T15:41:57Z
|
CONTRIBUTOR
| null | null | null |
Fixes a warning and future deprecation from `librosa.reshape`:
```
FutureWarning: Pass orig_sr=16000, target_sr=48000 as keyword args. From version 0.10 passing these as positional arguments will result in an error
array = librosa.resample(array, sampling_rate, self.sampling_rate, res_type="kaiser_best")
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5266/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5266/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5266.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5266",
"merged_at": "2022-11-21T15:41:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5266.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5266"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6979
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6979/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6979/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6979/events
|
https://github.com/huggingface/datasets/issues/6979
| 2,360,175,363
|
I_kwDODunzps6MrWsD
| 6,979
|
How can I load partial parquet files only?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/21303438?v=4",
"events_url": "https://api.github.com/users/lucasjinreal/events{/privacy}",
"followers_url": "https://api.github.com/users/lucasjinreal/followers",
"following_url": "https://api.github.com/users/lucasjinreal/following{/other_user}",
"gists_url": "https://api.github.com/users/lucasjinreal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lucasjinreal",
"id": 21303438,
"login": "lucasjinreal",
"node_id": "MDQ6VXNlcjIxMzAzNDM4",
"organizations_url": "https://api.github.com/users/lucasjinreal/orgs",
"received_events_url": "https://api.github.com/users/lucasjinreal/received_events",
"repos_url": "https://api.github.com/users/lucasjinreal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lucasjinreal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lucasjinreal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lucasjinreal",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hello,\r\n\r\nHave you tried loading the dataset in streaming mode? [Documentation](https://huggingface.co/docs/datasets/v2.20.0/stream)\r\n\r\nThis way you wouldn't have to load it all. Also, let's be nice to Parquet, it's a really nice technology and we don't need to be mean :)",
"I have downloaded part of it, just want to know how to load part of it, stream mode is not work for me since my network (in china) not stable, I don't want do it all again and again.\r\n\r\nJust curious, doesn't there a way to load part of it?",
"Could you convert the IterableDataset to a Dataset after taking the first 100 rows with `.take`? This way, you would have a local copy of the first 100 rows on your system and thus won't need to download. Would that work?\r\n\r\nHere is a [SO question](https://stackoverflow.com/questions/76227219/can-i-convert-an-iterabledataset-to-dataset) detailing how to do the conversion.",
"I mean, the parquet is like:\r\n\r\n00000-0143554\r\n00001-0143554\r\n00002-0143554\r\n...\r\n00100-0143554\r\n...\r\n09100-0143554\r\n\r\nI just downloaded the first 9900 part of it. \r\n\r\nI can not load with load_dataset, it throw an error says my file is not same as parquet all amount.\r\n\r\nHow could I load the only I have? \r\n\r\n( I really don't want downlaod them all, cause, I don't need all, and pulus, its huge.... )\r\n\r\nAs I said, I have donwloaded about 9999... It's not about stream... I just wnat to konw how to load offline... part....",
"Hi, @lucasjinreal.\r\n\r\nI am not sure of understanding your issue. What is the error message and stack trace you get? What version of `datasets` are you using? Could you provide a reproducible example?\r\n\r\nWithout knowing all those details, I would naively say that you can load whatever number of Parquet files by using the \"parquet\" loader: https://huggingface.co/docs/datasets/loading#parquet\r\n```python\r\nds = load_dataset(\"parquet\", data_files=\"data/train-001*-of-00314.parquet\", split=\"train\")\r\n```",
"@albertvillanova Not sure you have tested with this or not, but I have tried,\r\n\r\nthe only error I got is it still laodding all parquet with a progress bar maxium to the whole number 014354, and it loads my 0 - 000999 part, then throws an error.\r\n\r\nSays Numinfo is not same.\r\n\r\nI am so confused,",
"Yes, my code snippet works.\n\nCould you copy-paste your code and the output? Otherwise we are not able to know what the issue is.",
"@albertvillanova Hi, thanks for the tracing of the issue.\r\n\r\nThis is the output:\r\n\r\n```\r\nython get_llava_recap_cc3m.py\r\nGenerating train split: 3%|███▋ | 101910/3199866 [00:16<08:30, 6065.67 examples/s]\r\nTraceback (most recent call last):\r\n File \"get_llava_recap_cc3m.py\", line 31, in <module>\r\n dataset = load_dataset(\"llava-recap-cc3m/\", data_files=\"data/train-0000*-of-00314.parquet\")\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/load.py\", line 2582, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/builder.py\", line 1005, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/builder.py\", line 1118, in _download_and_prepare\r\n verify_splits(self.info.splits, split_dict)\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/info_utils.py\", line 101, in verify_splits\r\n raise NonMatchingSplitsSizesError(str(bad_splits))\r\ndatasets.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=156885281898.75, num_examples=3199866, shard_lengths=None, dataset_name=None), 'recorded': SplitInfo(name='train', num_bytes=4994080770, num_examples=101910, shard_lengths=[10191, 10291, 10291, 10291, 10291, 10191, 10191, 10291, 10291, 9591], dataset_name='llava-recap-cc3m')}]\r\n```\r\n\r\nthis is my code:\r\n\r\n```\r\ndataset = load_dataset(\"llava-recap-cc3m/\", data_files=\"data/train-0000*-of-00314.parquet\")\r\n```\r\n\r\nMy situation and requirements:\r\n\r\n00314 is all, but I downlaode about 150, half of it, as you can see, i used `0000*-of-00314.` which should be at most 99 file being loaded.\r\n\r\nBut it just fail.\r\n\r\nCan u understand my issue now?\r\n\r\nIf so, then **do not** suggest me with stream, Just want to know, is there a way to load part if it...... **and please don't say you can not replicate my issue when you have downloaded them all**, my english is not good, but I think all situations and all prerequists I have addressed already.\r\n\r\n",
"I see you did not use the \"parquet\" loader as I suggested in my code snippet above: https://github.com/huggingface/datasets/issues/6979#issuecomment-2182031415\r\nPlease try passing \"parquet\" instead of \"llava-recap-cc3m/\" to `load_dataset`, and the complete path to data files in `data_files`:\r\n```python\r\nload_dataset(\"parquet\", data_files=\"llava-recap-cc3m/data/train-001*-of-00314.parquet\")\r\n```",
"Let me explain that you get the error because of this content within the `dataset_info` YAML tag in the `llava-recap-cc3m/README.md`:\r\n```\r\n - name: train\r\n num_bytes: 156885281898.75\r\n num_examples: 3199866\r\n```\r\n\r\nBy default, if there is that content in the README file, `load_dataset` performs a basic check to verify it the generated number of examples matches the expected one and raises a `NonMatchingSplitsSizesError` if that is not the case. \r\n\r\nYou can avoid this basic check by passing `verification_mode=\"no_checks\"`:\r\n```python\r\nload_dataset(\"llava-recap-cc3m/\", data_files=\"data/train-0000*-of-00314.parquet\", verification_mode=\"no_checks\")\r\n```",
"And please, next time you have an issue, please fill the Bug template issue with all the necessary information: https://github.com/huggingface/datasets/issues/new?assignees=&labels=&projects=&template=bug-report.yml\r\n\r\nOtherwise it is very difficult for us to understand the underlying problem and to propose a pertinent solution.",
"thank u albert!\r\n\r\nIt solved my issue!"
] | 2024-06-18T15:44:16Z
| 2024-06-21T17:09:32Z
| 2024-06-21T13:32:50Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
I have a HUGE dataset about 14TB, I unable to download all parquet all. I just take about 100 from it.
dataset = load_dataset("xx/", data_files="data/train-001*-of-00314.parquet")
How can I just using 000 - 100 from a 00314 from all partially?
I search whole net didn't found a solution, **this is stupid if they didn't support it, and I swear I wont using stupid parquet any more**
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6979/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6979/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6527
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6527/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6527/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6527/events
|
https://github.com/huggingface/datasets/pull/6527
| 2,053,966,748
|
PR_kwDODunzps5ip2vd
| 6,527
|
Release: 2.16.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6527). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004870 / 0.011353 (-0.006483) | 0.003606 / 0.011008 (-0.007402) | 0.062719 / 0.038508 (0.024211) | 0.031785 / 0.023109 (0.008676) | 0.238809 / 0.275898 (-0.037089) | 0.263000 / 0.323480 (-0.060480) | 0.002844 / 0.007986 (-0.005142) | 0.002698 / 0.004328 (-0.001631) | 0.048070 / 0.004250 (0.043819) | 0.042333 / 0.037052 (0.005280) | 0.243032 / 0.258489 (-0.015457) | 0.273197 / 0.293841 (-0.020644) | 0.027498 / 0.128546 (-0.101048) | 0.010592 / 0.075646 (-0.065055) | 0.204770 / 0.419271 (-0.214502) | 0.034837 / 0.043533 (-0.008696) | 0.242518 / 0.255139 (-0.012621) | 0.267461 / 0.283200 (-0.015739) | 0.018479 / 0.141683 (-0.123204) | 1.105444 / 1.452155 (-0.346710) | 1.163659 / 1.492716 (-0.329057) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.004717 / 0.018006 (-0.013289) | 0.303338 / 0.000490 (0.302849) | 0.000221 / 0.000200 (0.000021) | 0.000043 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018298 / 0.037411 (-0.019113) | 0.061225 / 0.014526 (0.046699) | 0.073514 / 0.176557 (-0.103043) | 0.120230 / 0.737135 (-0.616905) | 0.076195 / 0.296338 (-0.220144) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.284731 / 0.215209 (0.069522) | 2.773463 / 2.077655 (0.695809) | 1.498239 / 1.504120 (-0.005881) | 1.372143 / 1.541195 (-0.169052) | 1.448949 / 1.468490 (-0.019542) | 0.572516 / 4.584777 (-4.012261) | 2.404041 / 3.745712 (-1.341671) | 2.763047 / 5.269862 (-2.506814) | 1.722419 / 4.565676 (-2.843257) | 0.063104 / 0.424275 (-0.361172) | 0.004989 / 0.007607 (-0.002618) | 0.341864 / 0.226044 (0.115820) | 3.391635 / 2.268929 (1.122707) | 1.872694 / 55.444624 (-53.571931) | 1.594490 / 6.876477 (-5.281987) | 1.596940 / 2.142072 (-0.545132) | 0.645265 / 4.805227 (-4.159962) | 0.117408 / 6.500664 (-6.383256) | 0.042405 / 0.075469 (-0.033064) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.963207 / 1.841788 (-0.878580) | 11.676551 / 8.074308 (3.602243) | 10.194287 / 10.191392 (0.002895) | 0.130329 / 0.680424 (-0.550094) | 0.015381 / 0.534201 (-0.518820) | 0.288848 / 0.579283 (-0.290435) | 0.264781 / 0.434364 (-0.169583) | 0.321212 / 0.540337 (-0.219126) | 0.418308 / 1.386936 (-0.968628) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005533 / 0.011353 (-0.005819) | 0.003733 / 0.011008 (-0.007276) | 0.048877 / 0.038508 (0.010369) | 0.030263 / 0.023109 (0.007154) | 0.281161 / 0.275898 (0.005263) | 0.302971 / 0.323480 (-0.020509) | 0.003943 / 0.007986 (-0.004043) | 0.002717 / 0.004328 (-0.001612) | 0.047845 / 0.004250 (0.043594) | 0.045809 / 0.037052 (0.008757) | 0.283337 / 0.258489 (0.024848) | 0.312914 / 0.293841 (0.019073) | 0.029074 / 0.128546 (-0.099472) | 0.010775 / 0.075646 (-0.064871) | 0.057461 / 0.419271 (-0.361810) | 0.053756 / 0.043533 (0.010223) | 0.281809 / 0.255139 (0.026670) | 0.298339 / 0.283200 (0.015139) | 0.019270 / 0.141683 (-0.122413) | 1.117575 / 1.452155 (-0.334580) | 1.191703 / 1.492716 (-0.301013) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093513 / 0.018006 (0.075507) | 0.301267 / 0.000490 (0.300777) | 0.000211 / 0.000200 (0.000012) | 0.000045 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022278 / 0.037411 (-0.015133) | 0.076805 / 0.014526 (0.062279) | 0.088820 / 0.176557 (-0.087736) | 0.127903 / 0.737135 (-0.609233) | 0.092988 / 0.296338 (-0.203350) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.297787 / 0.215209 (0.082578) | 2.899652 / 2.077655 (0.821997) | 1.598830 / 1.504120 (0.094710) | 1.469398 / 1.541195 (-0.071797) | 1.511099 / 1.468490 (0.042609) | 0.559785 / 4.584777 (-4.024992) | 2.426448 / 3.745712 (-1.319264) | 2.798811 / 5.269862 (-2.471051) | 1.737790 / 4.565676 (-2.827887) | 0.062219 / 0.424275 (-0.362056) | 0.005120 / 0.007607 (-0.002487) | 0.351051 / 0.226044 (0.125007) | 3.492063 / 2.268929 (1.223134) | 1.965674 / 55.444624 (-53.478950) | 1.672874 / 6.876477 (-5.203603) | 1.709700 / 2.142072 (-0.432373) | 0.639347 / 4.805227 (-4.165880) | 0.126383 / 6.500664 (-6.374281) | 0.042731 / 0.075469 (-0.032738) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.968619 / 1.841788 (-0.873168) | 12.671030 / 8.074308 (4.596722) | 11.125347 / 10.191392 (0.933955) | 0.142983 / 0.680424 (-0.537441) | 0.015726 / 0.534201 (-0.518475) | 0.288610 / 0.579283 (-0.290673) | 0.276473 / 0.434364 (-0.157891) | 0.326590 / 0.540337 (-0.213748) | 0.423832 / 1.386936 (-0.963104) |\n\n</details>\n</details>\n\n\n"
] | 2023-12-22T13:59:56Z
| 2023-12-22T14:24:12Z
| 2023-12-22T14:17:55Z
|
MEMBER
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6527/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6527/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6527.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6527",
"merged_at": "2023-12-22T14:17:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6527.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6527"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7357
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7357/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7357/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7357/events
|
https://github.com/huggingface/datasets/issues/7357
| 2,770,456,127
|
I_kwDODunzps6lIc4_
| 7,357
|
Python process aborded with GIL issue when using image dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/25342812?v=4",
"events_url": "https://api.github.com/users/AlexKoff88/events{/privacy}",
"followers_url": "https://api.github.com/users/AlexKoff88/followers",
"following_url": "https://api.github.com/users/AlexKoff88/following{/other_user}",
"gists_url": "https://api.github.com/users/AlexKoff88/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AlexKoff88",
"id": 25342812,
"login": "AlexKoff88",
"node_id": "MDQ6VXNlcjI1MzQyODEy",
"organizations_url": "https://api.github.com/users/AlexKoff88/orgs",
"received_events_url": "https://api.github.com/users/AlexKoff88/received_events",
"repos_url": "https://api.github.com/users/AlexKoff88/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AlexKoff88/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AlexKoff88/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AlexKoff88",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"The issue seems to come from `pyarrow`, I opened an issue on their side at https://github.com/apache/arrow/issues/45214"
] | 2025-01-06T11:29:30Z
| 2025-03-08T15:59:36Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
The issue is visible only with the latest `datasets==3.2.0`.
When using image dataset the Python process gets aborted right before the exit with the following error:
```
Fatal Python error: PyGILState_Release: thread state 0x7fa1f409ade0 must be current when releasing
Python runtime state: finalizing (tstate=0x0000000000ad2958)
Thread 0x00007fa33d157740 (most recent call first):
<no Python frame>
Extension modules: numpy.core._multiarray_umath, numpy.core._multiarray_tests, numpy.linalg._umath_linalg, numpy.fft._pocketfft_internal, numpy.random._common, numpy.random.bit_generator, numpy.random._boun
ded_integers, numpy.random._mt19937, numpy.random.mtrand, numpy.random._philox, numpy.random._pcg64, numpy.random._sfc64, numpy.random._generator, pyarrow.lib, pandas._libs.tslibs.ccalendar, pandas._libs.ts
libs.np_datetime, pandas._libs.tslibs.dtypes, pandas._libs.tslibs.base, pandas._libs.tslibs.nattype, pandas._libs.tslibs.timezones, pandas._libs.tslibs.fields, pandas._libs.tslibs.timedeltas, pandas._libs.t
slibs.tzconversion, pandas._libs.tslibs.timestamps, pandas._libs.properties, pandas._libs.tslibs.offsets, pandas._libs.tslibs.strptime, pandas._libs.tslibs.parsing, pandas._libs.tslibs.conversion, pandas._l
ibs.tslibs.period, pandas._libs.tslibs.vectorized, pandas._libs.ops_dispatch, pandas._libs.missing, pandas._libs.hashtable, pandas._libs.algos, pandas._libs.interval, pandas._libs.lib, pyarrow._compute, pan
das._libs.ops, pandas._libs.hashing, pandas._libs.arrays, pandas._libs.tslib, pandas._libs.sparse, pandas._libs.internals, pandas._libs.indexing, pandas._libs.index, pandas._libs.writers, pandas._libs.join,
pandas._libs.window.aggregations, pandas._libs.window.indexers, pandas._libs.reshape, pandas._libs.groupby, pandas._libs.json, pandas._libs.parsers, pandas._libs.testing, charset_normalizer.md, requests.pa
ckages.charset_normalizer.md, requests.packages.chardet.md, yaml._yaml, markupsafe._speedups, PIL._imaging, torch._C, torch._C._dynamo.autograd_compiler, torch._C._dynamo.eval_frame, torch._C._dynamo.guards
, torch._C._dynamo.utils, torch._C._fft, torch._C._linalg, torch._C._nested, torch._C._nn, torch._C._sparse, torch._C._special, sentencepiece._sentencepiece, sklearn.__check_build._check_build, psutil._psut
il_linux, psutil._psutil_posix, scipy._lib._ccallback_c, scipy.sparse._sparsetools, _csparsetools, scipy.sparse._csparsetools, scipy.linalg._fblas, scipy.linalg._flapack, scipy.linalg.cython_lapack, scipy.l
inalg._cythonized_array_utils, scipy.linalg._solve_toeplitz, scipy.linalg._decomp_lu_cython, scipy.linalg._matfuncs_sqrtm_triu, scipy.linalg.cython_blas, scipy.linalg._matfuncs_expm, scipy.linalg._decomp_up
date, scipy.sparse.linalg._dsolve._superlu, scipy.sparse.linalg._eigen.arpack._arpack, scipy.sparse.linalg._propack._spropack, scipy.sparse.linalg._propack._dpropack, scipy.sparse.linalg._propack._cpropack,
scipy.sparse.linalg._propack._zpropack, scipy.sparse.csgraph._tools, scipy.sparse.csgraph._shortest_path, scipy.sparse.csgraph._traversal, scipy.sparse.csgraph._min_spanning_tree, scipy.sparse.csgraph._flo
w, scipy.sparse.csgraph._matching, scipy.sparse.csgraph._reordering, scipy.special._ufuncs_cxx, scipy.special._ufuncs, scipy.special._specfun, scipy.special._comb, scipy.special._ellip_harm_2, scipy.spatial
._ckdtree, scipy._lib.messagestream, scipy.spatial._qhull, scipy.spatial._voronoi, scipy.spatial._distance_wrap, scipy.spatial._hausdorff, scipy.spatial.transform._rotation, scipy.optimize._group_columns, s
cipy.optimize._trlib._trlib, scipy.optimize._lbfgsb, _moduleTNC, scipy.optimize._moduleTNC, scipy.optimize._cobyla, scipy.optimize._slsqp, scipy.optimize._minpack, scipy.optimize._lsq.givens_elimination, sc
ipy.optimize._zeros, scipy.optimize._highs.cython.src._highs_wrapper, scipy.optimize._highs._highs_wrapper, scipy.optimize._highs.cython.src._highs_constants, scipy.optimize._highs._highs_constants, scipy.l
inalg._interpolative, scipy.optimize._bglu_dense, scipy.optimize._lsap, scipy.optimize._direct, scipy.integrate._odepack, scipy.integrate._quadpack, scipy.integrate._vode, scipy.integrate._dop, scipy.integr
ate._lsoda, scipy.interpolate._fitpack, scipy.interpolate._dfitpack, scipy.interpolate._bspl, scipy.interpolate._ppoly, scipy.interpolate.interpnd, scipy.interpolate._rbfinterp_pythran, scipy.interpolate._r
gi_cython, scipy.special.cython_special, scipy.stats._stats, scipy.stats._biasedurn, scipy.stats._levy_stable.levyst, scipy.stats._stats_pythran, scipy._lib._uarray._uarray, scipy.stats._ansari_swilk_statis
tics, scipy.stats._sobol, scipy.stats._qmc_cy, scipy.stats._mvn, scipy.stats._rcont.rcont, scipy.stats._unuran.unuran_wrapper, scipy.ndimage._nd_image, _ni_label, scipy.ndimage._ni_label, sklearn.utils._isf
inite, sklearn.utils.sparsefuncs_fast, sklearn.utils.murmurhash, sklearn.utils._openmp_helpers, sklearn.metrics.cluster._expected_mutual_info_fast, sklearn.preprocessing._csr_polynomial_expansion, sklearn.p
reprocessing._target_encoder_fast, sklearn.metrics._dist_metrics, sklearn.metrics._pairwise_distances_reduction._datasets_pair, sklearn.utils._cython_blas, sklearn.metrics._pairwise_distances_reduction._bas
e, sklearn.metrics._pairwise_distances_reduction._middle_term_computer, sklearn.utils._heap, sklearn.utils._sorting, sklearn.metrics._pairwise_distances_reduction._argkmin, sklearn.metrics._pairwise_distanc
es_reduction._argkmin_classmode, sklearn.utils._vector_sentinel, sklearn.metrics._pairwise_distances_reduction._radius_neighbors, sklearn.metrics._pairwise_distances_reduction._radius_neighbors_classmode, s
klearn.metrics._pairwise_fast, PIL._imagingft, google._upb._message, h5py._errors, h5py.defs, h5py._objects, h5py.h5, h5py.utils, h5py.h5t, h5py.h5s, h5py.h5ac, h5py.h5p, h5py.h5r, h5py._proxy, h5py._conv,
h5py.h5z, h5py.h5a, h5py.h5d, h5py.h5ds, h5py.h5g, h5py.h5i, h5py.h5o, h5py.h5f, h5py.h5fd, h5py.h5pl, h5py.h5l, h5py._selector, _cffi_backend, pyarrow._parquet, pyarrow._fs, pyarrow._azurefs, pyarrow._hdfs
, pyarrow._gcsfs, pyarrow._s3fs, multidict._multidict, propcache._helpers_c, yarl._quoting_c, aiohttp._helpers, aiohttp._http_writer, aiohttp._http_parser, aiohttp._websocket, frozenlist._frozenlist, xxhash
._xxhash, pyarrow._json, pyarrow._acero, pyarrow._csv, pyarrow._dataset, pyarrow._dataset_orc, pyarrow._parquet_encryption, pyarrow._dataset_parquet_encryption, pyarrow._dataset_parquet, regex._regex, scipy
.io.matlab._mio_utils, scipy.io.matlab._streams, scipy.io.matlab._mio5_utils, PIL._imagingmath, PIL._webp (total: 236)
Aborted (core dumped)
```an
### Steps to reproduce the bug
Install `datasets==3.2.0`
Run the following script:
```python
import datasets
DATASET_NAME = "phiyodr/InpaintCOCO"
NUM_SAMPLES = 10
def preprocess_fn(example):
return {
"prompts": example["inpaint_caption"],
"images": example["coco_image"],
"masks": example["mask"],
}
default_dataset = datasets.load_dataset(
DATASET_NAME, split="test", streaming=True
).filter(lambda example: example["inpaint_caption"] != "").take(NUM_SAMPLES)
test_data = default_dataset.map(
lambda x: preprocess_fn(x), remove_columns=default_dataset.column_names
)
for data in test_data:
print(data["prompts"])
``
### Expected behavior
The script should not hang or crash.
### Environment info
- `datasets` version: 3.2.0
- Platform: Linux-5.15.0-50-generic-x86_64-with-glibc2.31
- Python version: 3.11.0
- `huggingface_hub` version: 0.25.1
- PyArrow version: 17.0.0
- Pandas version: 2.2.3
- `fsspec` version: 2024.2.0
| null |
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7357/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7357/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4977
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4977/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4977/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4977/events
|
https://github.com/huggingface/datasets/issues/4977
| 1,372,962,157
|
I_kwDODunzps5R1b1t
| 4,977
|
Providing dataset size
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/14205986?v=4",
"events_url": "https://api.github.com/users/sashavor/events{/privacy}",
"followers_url": "https://api.github.com/users/sashavor/followers",
"following_url": "https://api.github.com/users/sashavor/following{/other_user}",
"gists_url": "https://api.github.com/users/sashavor/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sashavor",
"id": 14205986,
"login": "sashavor",
"node_id": "MDQ6VXNlcjE0MjA1OTg2",
"organizations_url": "https://api.github.com/users/sashavor/orgs",
"received_events_url": "https://api.github.com/users/sashavor/received_events",
"repos_url": "https://api.github.com/users/sashavor/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sashavor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sashavor/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sashavor",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
| null |
[] | null |
[
"Hi @sashavor, thanks for your suggestion.\r\n\r\nUntil now we have the CLI command \r\n```\r\ndatasets-cli test datasets/<your-dataset-folder> --save_infos --all_configs\r\n```\r\nthat generates the `dataset_infos.json` with the size of the downloaded dataset, among other information.\r\n\r\nWe are currently in the middle of removing those JSON files and putting their information directly in the header of the `README.md` (as YAML tags). Normally, the CLI command should continue working but saving its output to the dataset card instead. See:\r\n- #4926",
"Additionally, the download size can be inferred by doing HEAD requests to the files to be downloaded. And for files hosted on the hub you can even get the file sizes using the Hub API",
"Amazing @albertvillanova ! I think just having that information visible in the dataset info (without having to do any requests/additional coding) would be really useful :hugs: "
] | 2022-09-14T13:09:27Z
| 2022-09-15T16:03:58Z
| null |
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
**Is your feature request related to a problem? Please describe.**
Especially for big datasets like [LAION](https://huggingface.co/datasets/laion/laion2B-en/), it's hard to know exactly the downloaded size (because there are many files and you don't have their exact size when downloaded).
**Describe the solution you'd like**
Auto-populating the downloaded dataset size on the dataset page would be really useful, including that of each split (when there are some).
**Describe alternatives you've considered**
People should be adding this to dataset cards, but I don't think that is systematically the case :slightly_smiling_face:
**Additional context**
Mentioned to @lhoestq
| null |
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4977/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4977/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6708
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6708/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6708/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6708/events
|
https://github.com/huggingface/datasets/pull/6708
| 2,164,158,579
|
PR_kwDODunzps5oczmi
| 6,708
|
Release: 2.18.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6708). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005442 / 0.011353 (-0.005910) | 0.003796 / 0.011008 (-0.007213) | 0.063663 / 0.038508 (0.025155) | 0.028901 / 0.023109 (0.005792) | 0.256742 / 0.275898 (-0.019156) | 0.279555 / 0.323480 (-0.043925) | 0.004128 / 0.007986 (-0.003858) | 0.002789 / 0.004328 (-0.001539) | 0.049463 / 0.004250 (0.045213) | 0.043461 / 0.037052 (0.006409) | 0.272975 / 0.258489 (0.014486) | 0.299057 / 0.293841 (0.005216) | 0.029030 / 0.128546 (-0.099516) | 0.010453 / 0.075646 (-0.065193) | 0.207611 / 0.419271 (-0.211660) | 0.037200 / 0.043533 (-0.006332) | 0.258327 / 0.255139 (0.003188) | 0.279746 / 0.283200 (-0.003454) | 0.018940 / 0.141683 (-0.122743) | 1.150379 / 1.452155 (-0.301776) | 1.217621 / 1.492716 (-0.275095) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095115 / 0.018006 (0.077109) | 0.299393 / 0.000490 (0.298903) | 0.000223 / 0.000200 (0.000023) | 0.000044 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018972 / 0.037411 (-0.018439) | 0.061669 / 0.014526 (0.047143) | 0.075605 / 0.176557 (-0.100951) | 0.125695 / 0.737135 (-0.611440) | 0.076654 / 0.296338 (-0.219684) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.286431 / 0.215209 (0.071222) | 2.763554 / 2.077655 (0.685899) | 1.489902 / 1.504120 (-0.014218) | 1.375082 / 1.541195 (-0.166113) | 1.418903 / 1.468490 (-0.049587) | 0.555646 / 4.584777 (-4.029131) | 2.410578 / 3.745712 (-1.335134) | 2.827453 / 5.269862 (-2.442408) | 1.764381 / 4.565676 (-2.801295) | 0.062937 / 0.424275 (-0.361339) | 0.004989 / 0.007607 (-0.002619) | 0.342115 / 0.226044 (0.116071) | 3.354660 / 2.268929 (1.085732) | 1.858418 / 55.444624 (-53.586206) | 1.586403 / 6.876477 (-5.290074) | 1.625762 / 2.142072 (-0.516311) | 0.643678 / 4.805227 (-4.161550) | 0.116764 / 6.500664 (-6.383900) | 0.042198 / 0.075469 (-0.033271) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.974953 / 1.841788 (-0.866835) | 11.748419 / 8.074308 (3.674111) | 9.753700 / 10.191392 (-0.437692) | 0.131330 / 0.680424 (-0.549094) | 0.018876 / 0.534201 (-0.515325) | 0.290078 / 0.579283 (-0.289205) | 0.264676 / 0.434364 (-0.169688) | 0.340285 / 0.540337 (-0.200052) | 0.445340 / 1.386936 (-0.941596) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005513 / 0.011353 (-0.005840) | 0.003665 / 0.011008 (-0.007344) | 0.049368 / 0.038508 (0.010860) | 0.032045 / 0.023109 (0.008936) | 0.280955 / 0.275898 (0.005057) | 0.299804 / 0.323480 (-0.023675) | 0.004391 / 0.007986 (-0.003594) | 0.002896 / 0.004328 (-0.001432) | 0.048914 / 0.004250 (0.044663) | 0.045448 / 0.037052 (0.008396) | 0.298779 / 0.258489 (0.040289) | 0.322012 / 0.293841 (0.028171) | 0.029449 / 0.128546 (-0.099097) | 0.010410 / 0.075646 (-0.065236) | 0.057867 / 0.419271 (-0.361405) | 0.053944 / 0.043533 (0.010411) | 0.278139 / 0.255139 (0.023000) | 0.297453 / 0.283200 (0.014254) | 0.018746 / 0.141683 (-0.122937) | 1.137890 / 1.452155 (-0.314264) | 1.206109 / 1.492716 (-0.286607) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091741 / 0.018006 (0.073735) | 0.300415 / 0.000490 (0.299925) | 0.000214 / 0.000200 (0.000014) | 0.000044 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022097 / 0.037411 (-0.015314) | 0.076853 / 0.014526 (0.062327) | 0.088440 / 0.176557 (-0.088116) | 0.127176 / 0.737135 (-0.609959) | 0.088976 / 0.296338 (-0.207363) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.300754 / 0.215209 (0.085545) | 2.917713 / 2.077655 (0.840058) | 1.619338 / 1.504120 (0.115218) | 1.501543 / 1.541195 (-0.039652) | 1.506032 / 1.468490 (0.037542) | 0.579481 / 4.584777 (-4.005296) | 2.458917 / 3.745712 (-1.286795) | 2.754621 / 5.269862 (-2.515241) | 1.796440 / 4.565676 (-2.769237) | 0.067547 / 0.424275 (-0.356728) | 0.005001 / 0.007607 (-0.002606) | 0.351030 / 0.226044 (0.124985) | 3.466282 / 2.268929 (1.197353) | 1.954661 / 55.444624 (-53.489964) | 1.688737 / 6.876477 (-5.187740) | 1.836762 / 2.142072 (-0.305311) | 0.656441 / 4.805227 (-4.148786) | 0.118258 / 6.500664 (-6.382406) | 0.041608 / 0.075469 (-0.033861) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.999696 / 1.841788 (-0.842092) | 12.383471 / 8.074308 (4.309162) | 10.338488 / 10.191392 (0.147096) | 0.150214 / 0.680424 (-0.530210) | 0.014997 / 0.534201 (-0.519204) | 0.288949 / 0.579283 (-0.290334) | 0.272012 / 0.434364 (-0.162352) | 0.327253 / 0.540337 (-0.213084) | 0.427594 / 1.386936 (-0.959342) |\n\n</details>\n</details>\n\n\n"
] | 2024-03-01T20:52:17Z
| 2024-03-01T21:03:01Z
| 2024-03-01T20:56:50Z
|
MEMBER
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6708/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6708/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6708.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6708",
"merged_at": "2024-03-01T20:56:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6708.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6708"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6722
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6722/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6722/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6722/events
|
https://github.com/huggingface/datasets/pull/6722
| 2,174,332,127
|
PR_kwDODunzps5o_ch0
| 6,722
|
Add details in docstring
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6722). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update."
] | 2024-03-07T17:02:07Z
| 2024-03-07T17:21:10Z
| 2024-03-07T17:21:08Z
|
COLLABORATOR
| null | null | null |
see https://github.com/huggingface/datasets-server/pull/2554#discussion_r1516516867
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6722/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6722/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6722.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6722",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6722.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6722"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6208
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6208/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6208/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6208/events
|
https://github.com/huggingface/datasets/pull/6208
| 1,879,572,646
|
PR_kwDODunzps5ZcnpJ
| 6,208
|
Do not filter out .zip extensions from no-script datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006797 / 0.011353 (-0.004556) | 0.003966 / 0.011008 (-0.007042) | 0.085296 / 0.038508 (0.046788) | 0.076873 / 0.023109 (0.053764) | 0.355795 / 0.275898 (0.079897) | 0.397132 / 0.323480 (0.073652) | 0.005325 / 0.007986 (-0.002660) | 0.003343 / 0.004328 (-0.000986) | 0.064966 / 0.004250 (0.060716) | 0.054519 / 0.037052 (0.017467) | 0.357864 / 0.258489 (0.099374) | 0.409238 / 0.293841 (0.115397) | 0.031620 / 0.128546 (-0.096926) | 0.008529 / 0.075646 (-0.067117) | 0.288502 / 0.419271 (-0.130769) | 0.053260 / 0.043533 (0.009728) | 0.355245 / 0.255139 (0.100106) | 0.384139 / 0.283200 (0.100939) | 0.024507 / 0.141683 (-0.117176) | 1.494696 / 1.452155 (0.042541) | 1.579847 / 1.492716 (0.087130) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.204011 / 0.018006 (0.186005) | 0.451729 / 0.000490 (0.451239) | 0.004628 / 0.000200 (0.004428) | 0.000081 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028342 / 0.037411 (-0.009069) | 0.084647 / 0.014526 (0.070121) | 0.096174 / 0.176557 (-0.080383) | 0.151753 / 0.737135 (-0.585382) | 0.096347 / 0.296338 (-0.199991) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.387179 / 0.215209 (0.171970) | 3.861552 / 2.077655 (1.783898) | 1.844033 / 1.504120 (0.339913) | 1.678811 / 1.541195 (0.137616) | 1.793207 / 1.468490 (0.324717) | 0.485836 / 4.584777 (-4.098941) | 3.566274 / 3.745712 (-0.179438) | 3.269888 / 5.269862 (-1.999974) | 2.042850 / 4.565676 (-2.522827) | 0.057088 / 0.424275 (-0.367187) | 0.007627 / 0.007607 (0.000019) | 0.460510 / 0.226044 (0.234465) | 4.602019 / 2.268929 (2.333090) | 2.390984 / 55.444624 (-53.053641) | 1.976150 / 6.876477 (-4.900327) | 2.193394 / 2.142072 (0.051322) | 0.582775 / 4.805227 (-4.222453) | 0.133408 / 6.500664 (-6.367256) | 0.060577 / 0.075469 (-0.014893) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.248505 / 1.841788 (-0.593283) | 19.771301 / 8.074308 (11.696993) | 14.327871 / 10.191392 (4.136479) | 0.155288 / 0.680424 (-0.525136) | 0.018310 / 0.534201 (-0.515891) | 0.393664 / 0.579283 (-0.185619) | 0.410578 / 0.434364 (-0.023786) | 0.459301 / 0.540337 (-0.081037) | 0.631921 / 1.386936 (-0.755015) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006827 / 0.011353 (-0.004526) | 0.004094 / 0.011008 (-0.006915) | 0.065299 / 0.038508 (0.026791) | 0.079496 / 0.023109 (0.056387) | 0.403661 / 0.275898 (0.127763) | 0.434449 / 0.323480 (0.110969) | 0.005398 / 0.007986 (-0.002588) | 0.003410 / 0.004328 (-0.000919) | 0.064832 / 0.004250 (0.060582) | 0.056303 / 0.037052 (0.019250) | 0.397848 / 0.258489 (0.139359) | 0.438244 / 0.293841 (0.144403) | 0.032637 / 0.128546 (-0.095909) | 0.008584 / 0.075646 (-0.067063) | 0.071406 / 0.419271 (-0.347866) | 0.048265 / 0.043533 (0.004732) | 0.397814 / 0.255139 (0.142675) | 0.421601 / 0.283200 (0.138402) | 0.023815 / 0.141683 (-0.117868) | 1.504814 / 1.452155 (0.052659) | 1.577185 / 1.492716 (0.084469) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.231775 / 0.018006 (0.213769) | 0.445437 / 0.000490 (0.444948) | 0.005252 / 0.000200 (0.005052) | 0.000093 / 0.000054 (0.000039) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032777 / 0.037411 (-0.004634) | 0.095054 / 0.014526 (0.080528) | 0.106429 / 0.176557 (-0.070127) | 0.160111 / 0.737135 (-0.577024) | 0.108075 / 0.296338 (-0.188263) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.426034 / 0.215209 (0.210825) | 4.244668 / 2.077655 (2.167013) | 2.257938 / 1.504120 (0.753818) | 2.087993 / 1.541195 (0.546798) | 2.170878 / 1.468490 (0.702387) | 0.485228 / 4.584777 (-4.099549) | 3.725912 / 3.745712 (-0.019800) | 3.286925 / 5.269862 (-1.982937) | 2.059929 / 4.565676 (-2.505748) | 0.057813 / 0.424275 (-0.366462) | 0.007518 / 0.007607 (-0.000089) | 0.506632 / 0.226044 (0.280588) | 5.048340 / 2.268929 (2.779411) | 2.744756 / 55.444624 (-52.699869) | 2.406636 / 6.876477 (-4.469841) | 2.617552 / 2.142072 (0.475480) | 0.588476 / 4.805227 (-4.216751) | 0.133518 / 6.500664 (-6.367146) | 0.060778 / 0.075469 (-0.014691) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.356416 / 1.841788 (-0.485372) | 20.467516 / 8.074308 (12.393208) | 15.265443 / 10.191392 (5.074051) | 0.169201 / 0.680424 (-0.511223) | 0.020087 / 0.534201 (-0.514114) | 0.402332 / 0.579283 (-0.176951) | 0.414848 / 0.434364 (-0.019516) | 0.470422 / 0.540337 (-0.069916) | 0.647266 / 1.386936 (-0.739670) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005804 / 0.011353 (-0.005549) | 0.003519 / 0.011008 (-0.007489) | 0.080003 / 0.038508 (0.041495) | 0.055419 / 0.023109 (0.032309) | 0.395254 / 0.275898 (0.119356) | 0.432714 / 0.323480 (0.109234) | 0.004438 / 0.007986 (-0.003548) | 0.002832 / 0.004328 (-0.001496) | 0.062026 / 0.004250 (0.057775) | 0.044334 / 0.037052 (0.007282) | 0.401278 / 0.258489 (0.142789) | 0.451516 / 0.293841 (0.157675) | 0.026791 / 0.128546 (-0.101755) | 0.007946 / 0.075646 (-0.067700) | 0.265166 / 0.419271 (-0.154106) | 0.044119 / 0.043533 (0.000586) | 0.399621 / 0.255139 (0.144482) | 0.422808 / 0.283200 (0.139609) | 0.019998 / 0.141683 (-0.121685) | 1.433559 / 1.452155 (-0.018596) | 1.596902 / 1.492716 (0.104186) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.195662 / 0.018006 (0.177656) | 0.423167 / 0.000490 (0.422677) | 0.003426 / 0.000200 (0.003227) | 0.000066 / 0.000054 (0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023318 / 0.037411 (-0.014094) | 0.072532 / 0.014526 (0.058006) | 0.082181 / 0.176557 (-0.094375) | 0.142214 / 0.737135 (-0.594921) | 0.083423 / 0.296338 (-0.212915) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.402270 / 0.215209 (0.187061) | 4.027607 / 2.077655 (1.949953) | 2.059803 / 1.504120 (0.555684) | 1.865115 / 1.541195 (0.323920) | 1.934976 / 1.468490 (0.466485) | 0.502145 / 4.584777 (-4.082632) | 2.970865 / 3.745712 (-0.774847) | 2.784155 / 5.269862 (-2.485707) | 1.822003 / 4.565676 (-2.743673) | 0.057699 / 0.424275 (-0.366576) | 0.006668 / 0.007607 (-0.000939) | 0.471164 / 0.226044 (0.245120) | 4.733079 / 2.268929 (2.464150) | 2.445119 / 55.444624 (-52.999505) | 2.132956 / 6.876477 (-4.743521) | 2.335998 / 2.142072 (0.193926) | 0.594881 / 4.805227 (-4.210347) | 0.125801 / 6.500664 (-6.374863) | 0.060780 / 0.075469 (-0.014689) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.233170 / 1.841788 (-0.608618) | 17.942205 / 8.074308 (9.867897) | 13.587020 / 10.191392 (3.395628) | 0.142110 / 0.680424 (-0.538314) | 0.016600 / 0.534201 (-0.517601) | 0.328659 / 0.579283 (-0.250624) | 0.347759 / 0.434364 (-0.086605) | 0.378651 / 0.540337 (-0.161687) | 0.523474 / 1.386936 (-0.863462) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006028 / 0.011353 (-0.005325) | 0.003552 / 0.011008 (-0.007456) | 0.062175 / 0.038508 (0.023667) | 0.057602 / 0.023109 (0.034493) | 0.444585 / 0.275898 (0.168687) | 0.471238 / 0.323480 (0.147758) | 0.004562 / 0.007986 (-0.003423) | 0.002871 / 0.004328 (-0.001457) | 0.063101 / 0.004250 (0.058851) | 0.046072 / 0.037052 (0.009020) | 0.448253 / 0.258489 (0.189764) | 0.478734 / 0.293841 (0.184893) | 0.028463 / 0.128546 (-0.100084) | 0.008090 / 0.075646 (-0.067557) | 0.068142 / 0.419271 (-0.351130) | 0.040517 / 0.043533 (-0.003016) | 0.447145 / 0.255139 (0.192006) | 0.469472 / 0.283200 (0.186273) | 0.019391 / 0.141683 (-0.122291) | 1.471195 / 1.452155 (0.019040) | 1.532966 / 1.492716 (0.040249) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.259894 / 0.018006 (0.241888) | 0.412987 / 0.000490 (0.412497) | 0.020780 / 0.000200 (0.020580) | 0.000084 / 0.000054 (0.000030) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026352 / 0.037411 (-0.011060) | 0.080024 / 0.014526 (0.065498) | 0.088041 / 0.176557 (-0.088516) | 0.142987 / 0.737135 (-0.594148) | 0.090108 / 0.296338 (-0.206231) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.458874 / 0.215209 (0.243665) | 4.573005 / 2.077655 (2.495351) | 2.507885 / 1.504120 (1.003765) | 2.335432 / 1.541195 (0.794238) | 2.379617 / 1.468490 (0.911126) | 0.503331 / 4.584777 (-4.081446) | 3.078284 / 3.745712 (-0.667428) | 2.750580 / 5.269862 (-2.519282) | 1.828100 / 4.565676 (-2.737577) | 0.057572 / 0.424275 (-0.366703) | 0.006553 / 0.007607 (-0.001054) | 0.532283 / 0.226044 (0.306239) | 5.310584 / 2.268929 (3.041656) | 2.943559 / 55.444624 (-52.501065) | 2.587544 / 6.876477 (-4.288932) | 2.718261 / 2.142072 (0.576188) | 0.590267 / 4.805227 (-4.214961) | 0.123229 / 6.500664 (-6.377435) | 0.060219 / 0.075469 (-0.015250) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.340773 / 1.841788 (-0.501014) | 18.420766 / 8.074308 (10.346458) | 14.630550 / 10.191392 (4.439158) | 0.146666 / 0.680424 (-0.533758) | 0.017905 / 0.534201 (-0.516296) | 0.332483 / 0.579283 (-0.246801) | 0.355490 / 0.434364 (-0.078874) | 0.382618 / 0.540337 (-0.157720) | 0.531336 / 1.386936 (-0.855600) |\n\n</details>\n</details>\n\n\n",
"There were CI errors unrelated to this PR.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008702 / 0.011353 (-0.002651) | 0.005060 / 0.011008 (-0.005948) | 0.097017 / 0.038508 (0.058509) | 0.073740 / 0.023109 (0.050631) | 0.435138 / 0.275898 (0.159240) | 0.512776 / 0.323480 (0.189296) | 0.006186 / 0.007986 (-0.001800) | 0.003970 / 0.004328 (-0.000358) | 0.089523 / 0.004250 (0.085273) | 0.054441 / 0.037052 (0.017389) | 0.447415 / 0.258489 (0.188926) | 0.464851 / 0.293841 (0.171010) | 0.050264 / 0.128546 (-0.078283) | 0.016643 / 0.075646 (-0.059004) | 0.350565 / 0.419271 (-0.068707) | 0.071220 / 0.043533 (0.027687) | 0.432531 / 0.255139 (0.177392) | 0.472994 / 0.283200 (0.189795) | 0.040229 / 0.141683 (-0.101454) | 1.743431 / 1.452155 (0.291276) | 1.778653 / 1.492716 (0.285936) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.261992 / 0.018006 (0.243986) | 0.571979 / 0.000490 (0.571489) | 0.006270 / 0.000200 (0.006071) | 0.000109 / 0.000054 (0.000054) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027821 / 0.037411 (-0.009590) | 0.081874 / 0.014526 (0.067348) | 0.103725 / 0.176557 (-0.072831) | 0.170593 / 0.737135 (-0.566542) | 0.108749 / 0.296338 (-0.187590) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.690774 / 0.215209 (0.475565) | 6.770902 / 2.077655 (4.693247) | 2.887218 / 1.504120 (1.383098) | 2.456226 / 1.541195 (0.915032) | 2.509422 / 1.468490 (1.040932) | 0.768451 / 4.584777 (-3.816326) | 4.988933 / 3.745712 (1.243221) | 4.151460 / 5.269862 (-1.118402) | 2.640472 / 4.565676 (-1.925205) | 0.093522 / 0.424275 (-0.330753) | 0.008614 / 0.007607 (0.001007) | 0.696281 / 0.226044 (0.470237) | 6.721077 / 2.268929 (4.452149) | 3.229760 / 55.444624 (-52.214864) | 2.668521 / 6.876477 (-4.207956) | 2.866420 / 2.142072 (0.724347) | 0.945328 / 4.805227 (-3.859899) | 0.197645 / 6.500664 (-6.303019) | 0.074442 / 0.075469 (-0.001027) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.630468 / 1.841788 (-0.211320) | 22.991661 / 8.074308 (14.917353) | 19.816919 / 10.191392 (9.625527) | 0.257410 / 0.680424 (-0.423014) | 0.027228 / 0.534201 (-0.506973) | 0.444515 / 0.579283 (-0.134768) | 0.597067 / 0.434364 (0.162703) | 0.528151 / 0.540337 (-0.012186) | 0.771276 / 1.386936 (-0.615660) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009154 / 0.011353 (-0.002199) | 0.004648 / 0.011008 (-0.006360) | 0.073054 / 0.038508 (0.034546) | 0.077146 / 0.023109 (0.054037) | 0.481659 / 0.275898 (0.205761) | 0.516985 / 0.323480 (0.193505) | 0.007447 / 0.007986 (-0.000538) | 0.003890 / 0.004328 (-0.000438) | 0.078701 / 0.004250 (0.074450) | 0.059183 / 0.037052 (0.022131) | 0.475350 / 0.258489 (0.216861) | 0.547834 / 0.293841 (0.253993) | 0.058440 / 0.128546 (-0.070106) | 0.013563 / 0.075646 (-0.062083) | 0.084320 / 0.419271 (-0.334951) | 0.065965 / 0.043533 (0.022433) | 0.483541 / 0.255139 (0.228402) | 0.513940 / 0.283200 (0.230740) | 0.042889 / 0.141683 (-0.098794) | 1.676050 / 1.452155 (0.223895) | 1.759206 / 1.492716 (0.266489) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.274848 / 0.018006 (0.256841) | 0.588965 / 0.000490 (0.588475) | 0.006312 / 0.000200 (0.006112) | 0.000120 / 0.000054 (0.000065) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033871 / 0.037411 (-0.003540) | 0.104013 / 0.014526 (0.089487) | 0.118457 / 0.176557 (-0.058099) | 0.178268 / 0.737135 (-0.558868) | 0.116972 / 0.296338 (-0.179366) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.609952 / 0.215209 (0.394743) | 5.788754 / 2.077655 (3.711100) | 2.812166 / 1.504120 (1.308046) | 2.362861 / 1.541195 (0.821666) | 2.641295 / 1.468490 (1.172804) | 0.767601 / 4.584777 (-3.817176) | 5.027439 / 3.745712 (1.281727) | 4.612511 / 5.269862 (-0.657351) | 2.654364 / 4.565676 (-1.911312) | 0.103100 / 0.424275 (-0.321175) | 0.012233 / 0.007607 (0.004626) | 0.749283 / 0.226044 (0.523238) | 7.511093 / 2.268929 (5.242165) | 3.585867 / 55.444624 (-51.858757) | 3.255110 / 6.876477 (-3.621366) | 3.260174 / 2.142072 (1.118102) | 0.958422 / 4.805227 (-3.846806) | 0.209096 / 6.500664 (-6.291568) | 0.075014 / 0.075469 (-0.000455) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.728283 / 1.841788 (-0.113504) | 25.411147 / 8.074308 (17.336839) | 21.335202 / 10.191392 (11.143810) | 0.199090 / 0.680424 (-0.481334) | 0.031288 / 0.534201 (-0.502913) | 0.449226 / 0.579283 (-0.130057) | 0.555570 / 0.434364 (0.121206) | 0.570297 / 0.540337 (0.029960) | 0.758673 / 1.386936 (-0.628263) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006862 / 0.011353 (-0.004491) | 0.003959 / 0.011008 (-0.007049) | 0.087219 / 0.038508 (0.048711) | 0.078335 / 0.023109 (0.055226) | 0.319019 / 0.275898 (0.043121) | 0.342871 / 0.323480 (0.019391) | 0.004065 / 0.007986 (-0.003921) | 0.004346 / 0.004328 (0.000017) | 0.065243 / 0.004250 (0.060993) | 0.056698 / 0.037052 (0.019646) | 0.326906 / 0.258489 (0.068417) | 0.354323 / 0.293841 (0.060482) | 0.031252 / 0.128546 (-0.097295) | 0.008587 / 0.075646 (-0.067060) | 0.300323 / 0.419271 (-0.118948) | 0.052810 / 0.043533 (0.009277) | 0.323866 / 0.255139 (0.068727) | 0.346011 / 0.283200 (0.062811) | 0.025584 / 0.141683 (-0.116099) | 1.464475 / 1.452155 (0.012320) | 1.530868 / 1.492716 (0.038152) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.208927 / 0.018006 (0.190921) | 0.454147 / 0.000490 (0.453657) | 0.003945 / 0.000200 (0.003746) | 0.000081 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029901 / 0.037411 (-0.007511) | 0.088889 / 0.014526 (0.074363) | 0.098181 / 0.176557 (-0.078375) | 0.156787 / 0.737135 (-0.580349) | 0.099015 / 0.296338 (-0.197324) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.384981 / 0.215209 (0.169772) | 3.831040 / 2.077655 (1.753386) | 1.858312 / 1.504120 (0.354192) | 1.686846 / 1.541195 (0.145651) | 1.771509 / 1.468490 (0.303019) | 0.485618 / 4.584777 (-4.099159) | 3.430961 / 3.745712 (-0.314751) | 3.264489 / 5.269862 (-2.005372) | 2.040125 / 4.565676 (-2.525551) | 0.057218 / 0.424275 (-0.367057) | 0.007640 / 0.007607 (0.000033) | 0.468072 / 0.226044 (0.242027) | 4.677214 / 2.268929 (2.408286) | 2.348425 / 55.444624 (-53.096199) | 1.994352 / 6.876477 (-4.882125) | 2.217020 / 2.142072 (0.074948) | 0.587467 / 4.805227 (-4.217760) | 0.133550 / 6.500664 (-6.367114) | 0.060571 / 0.075469 (-0.014898) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.271003 / 1.841788 (-0.570785) | 19.986365 / 8.074308 (11.912057) | 14.574046 / 10.191392 (4.382654) | 0.146212 / 0.680424 (-0.534212) | 0.018320 / 0.534201 (-0.515881) | 0.394524 / 0.579283 (-0.184759) | 0.399707 / 0.434364 (-0.034657) | 0.458965 / 0.540337 (-0.081372) | 0.619940 / 1.386936 (-0.766996) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006982 / 0.011353 (-0.004371) | 0.004061 / 0.011008 (-0.006947) | 0.064520 / 0.038508 (0.026012) | 0.076828 / 0.023109 (0.053719) | 0.402989 / 0.275898 (0.127090) | 0.439697 / 0.323480 (0.116217) | 0.005511 / 0.007986 (-0.002475) | 0.003378 / 0.004328 (-0.000950) | 0.064727 / 0.004250 (0.060477) | 0.058114 / 0.037052 (0.021062) | 0.402054 / 0.258489 (0.143565) | 0.442377 / 0.293841 (0.148536) | 0.032808 / 0.128546 (-0.095738) | 0.008604 / 0.075646 (-0.067043) | 0.070994 / 0.419271 (-0.348278) | 0.048738 / 0.043533 (0.005205) | 0.399786 / 0.255139 (0.144647) | 0.423537 / 0.283200 (0.140338) | 0.022397 / 0.141683 (-0.119286) | 1.504613 / 1.452155 (0.052458) | 1.571064 / 1.492716 (0.078348) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226876 / 0.018006 (0.208870) | 0.451477 / 0.000490 (0.450987) | 0.004511 / 0.000200 (0.004311) | 0.000095 / 0.000054 (0.000041) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032998 / 0.037411 (-0.004413) | 0.095843 / 0.014526 (0.081317) | 0.105684 / 0.176557 (-0.070873) | 0.158175 / 0.737135 (-0.578960) | 0.107297 / 0.296338 (-0.189041) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.434912 / 0.215209 (0.219703) | 4.326394 / 2.077655 (2.248740) | 2.287310 / 1.504120 (0.783190) | 2.127987 / 1.541195 (0.586793) | 2.202485 / 1.468490 (0.733995) | 0.494305 / 4.584777 (-4.090472) | 3.575176 / 3.745712 (-0.170536) | 3.354358 / 5.269862 (-1.915504) | 2.074293 / 4.565676 (-2.491383) | 0.058967 / 0.424275 (-0.365308) | 0.007712 / 0.007607 (0.000105) | 0.513734 / 0.226044 (0.287690) | 5.107538 / 2.268929 (2.838610) | 2.776190 / 55.444624 (-52.668434) | 2.425051 / 6.876477 (-4.451426) | 2.666715 / 2.142072 (0.524643) | 0.598844 / 4.805227 (-4.206383) | 0.134186 / 6.500664 (-6.366478) | 0.062403 / 0.075469 (-0.013066) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.346730 / 1.841788 (-0.495058) | 20.533190 / 8.074308 (12.458882) | 15.174443 / 10.191392 (4.983051) | 0.167204 / 0.680424 (-0.513219) | 0.020619 / 0.534201 (-0.513582) | 0.399033 / 0.579283 (-0.180250) | 0.394428 / 0.434364 (-0.039936) | 0.468792 / 0.540337 (-0.071545) | 0.640122 / 1.386936 (-0.746814) |\n\n</details>\n</details>\n\n\n"
] | 2023-09-04T06:07:12Z
| 2023-09-04T09:22:19Z
| 2023-09-04T09:13:32Z
|
MEMBER
| null | null | null |
This PR is a hotfix of:
- #6207
That PR introduced the filtering out of `.zip` extensions. This PR reverts that.
Hot fix #6207.
Maybe we should do patch releases: the bug was introduced in 2.13.1.
CC: @lhoestq
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6208/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6208/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6208.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6208",
"merged_at": "2023-09-04T09:13:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6208.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6208"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5846
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5846/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5846/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5846/events
|
https://github.com/huggingface/datasets/issues/5846
| 1,706,289,290
|
I_kwDODunzps5ls-iK
| 5,846
|
load_dataset('bigcode/the-stack-dedup', streaming=True) very slow!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4241811?v=4",
"events_url": "https://api.github.com/users/tbenthompson/events{/privacy}",
"followers_url": "https://api.github.com/users/tbenthompson/followers",
"following_url": "https://api.github.com/users/tbenthompson/following{/other_user}",
"gists_url": "https://api.github.com/users/tbenthompson/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tbenthompson",
"id": 4241811,
"login": "tbenthompson",
"node_id": "MDQ6VXNlcjQyNDE4MTE=",
"organizations_url": "https://api.github.com/users/tbenthompson/orgs",
"received_events_url": "https://api.github.com/users/tbenthompson/received_events",
"repos_url": "https://api.github.com/users/tbenthompson/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tbenthompson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tbenthompson/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tbenthompson",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
] | null |
[
"This is due to the slow resolution of the data files: https://github.com/huggingface/datasets/issues/5537.\r\n\r\nWe plan to switch to `huggingface_hub`'s `HfFileSystem` soon to make the resolution faster (will be up to 20x faster once we merge https://github.com/huggingface/huggingface_hub/pull/1443)\r\n\r\n",
"You're right, when I try to parse more than 50GB of text data, I also get very slow, usually taking hours or even tens of hours.",
"> You're right, when I try to parse more than 50GB of text data, I also get very slow, usually taking hours or even tens of hours.\r\n\r\nThat's unrelated to the problem discussed in this issue. ",
"> > You're right, when I try to parse more than 50GB of text data, I also get very slow, usually taking hours or even tens of hours.\r\n> \r\n> That's unrelated to the problem discussed in this issue.\r\n\r\nSorry, I misunderstood it.",
"Closing this issue as it has been addressed in `huggingface_hub`!\r\n\r\n(This now takes 25s to execute on my machine.)",
"Thanks for the improvements! 🎉🎉\n\n25 seconds is better but still about 2500x slower than this _should_ be! Loading a tiny 1-2KB metadata file is all that would be necessary with a better design.",
"Once we merge https://github.com/huggingface/huggingface_hub/pull/2103, this should only take a few seconds. \r\n\r\nFor the 2500x speed-up (without metadata files with pre-cached results), we wouldn't even be allowed to use `os.path` functions or `requests`/`aiohttp` for HTTP requests, so I don't think this is feasible for us as it would make the code unreadable.\r\n\r\nThe HF Datasets Hub is (almost) platform-agnostic, so you are free to implement your own library (in a faster language than Python) to achieve this kind of performance, and we would be happy to support it 🙂. "
] | 2023-05-11T17:58:57Z
| 2024-04-08T12:53:17Z
| 2024-04-05T12:28:58Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Running
```
import datasets
ds = datasets.load_dataset('bigcode/the-stack-dedup', streaming=True)
```
takes about 2.5 minutes!
I would expect this to be near instantaneous. With other datasets, the runtime is one or two seconds.
### Environment info
- `datasets` version: 2.11.0
- Platform: macOS-13.3.1-arm64-arm-64bit
- Python version: 3.10.10
- Huggingface_hub version: 0.13.4
- PyArrow version: 11.0.0
- Pandas version: 2.0.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5846/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5846/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6351
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6351/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6351/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6351/events
|
https://github.com/huggingface/datasets/pull/6351
| 1,961,982,988
|
PR_kwDODunzps5dyMvh
| 6,351
|
Fix use_dataset.mdx
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17672548?v=4",
"events_url": "https://api.github.com/users/angel-luis/events{/privacy}",
"followers_url": "https://api.github.com/users/angel-luis/followers",
"following_url": "https://api.github.com/users/angel-luis/following{/other_user}",
"gists_url": "https://api.github.com/users/angel-luis/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/angel-luis",
"id": 17672548,
"login": "angel-luis",
"node_id": "MDQ6VXNlcjE3NjcyNTQ4",
"organizations_url": "https://api.github.com/users/angel-luis/orgs",
"received_events_url": "https://api.github.com/users/angel-luis/received_events",
"repos_url": "https://api.github.com/users/angel-luis/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/angel-luis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/angel-luis/subscriptions",
"type": "User",
"url": "https://api.github.com/users/angel-luis",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007718 / 0.011353 (-0.003635) | 0.004730 / 0.011008 (-0.006278) | 0.097262 / 0.038508 (0.058754) | 0.077880 / 0.023109 (0.054771) | 0.363855 / 0.275898 (0.087957) | 0.394470 / 0.323480 (0.070990) | 0.006416 / 0.007986 (-0.001570) | 0.003596 / 0.004328 (-0.000732) | 0.076494 / 0.004250 (0.072243) | 0.062656 / 0.037052 (0.025603) | 0.366160 / 0.258489 (0.107671) | 0.421383 / 0.293841 (0.127542) | 0.035756 / 0.128546 (-0.092791) | 0.009430 / 0.075646 (-0.066217) | 0.327722 / 0.419271 (-0.091550) | 0.061252 / 0.043533 (0.017719) | 0.352167 / 0.255139 (0.097028) | 0.385166 / 0.283200 (0.101966) | 0.026656 / 0.141683 (-0.115027) | 1.718533 / 1.452155 (0.266378) | 1.886646 / 1.492716 (0.393930) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.254564 / 0.018006 (0.236558) | 0.490942 / 0.000490 (0.490452) | 0.011656 / 0.000200 (0.011456) | 0.000313 / 0.000054 (0.000259) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028753 / 0.037411 (-0.008659) | 0.093076 / 0.014526 (0.078550) | 0.096441 / 0.176557 (-0.080116) | 0.154848 / 0.737135 (-0.582287) | 0.092903 / 0.296338 (-0.203435) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.395611 / 0.215209 (0.180402) | 3.860736 / 2.077655 (1.783082) | 1.908808 / 1.504120 (0.404688) | 1.708975 / 1.541195 (0.167781) | 1.848173 / 1.468490 (0.379683) | 0.527022 / 4.584777 (-4.057755) | 3.815171 / 3.745712 (0.069459) | 3.621132 / 5.269862 (-1.648730) | 2.220238 / 4.565676 (-2.345439) | 0.063169 / 0.424275 (-0.361106) | 0.008906 / 0.007607 (0.001299) | 0.510478 / 0.226044 (0.284433) | 4.828116 / 2.268929 (2.559187) | 2.340801 / 55.444624 (-53.103824) | 2.040834 / 6.876477 (-4.835642) | 2.092316 / 2.142072 (-0.049757) | 0.579194 / 4.805227 (-4.226033) | 0.135525 / 6.500664 (-6.365139) | 0.062720 / 0.075469 (-0.012749) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.393091 / 1.841788 (-0.448697) | 19.751526 / 8.074308 (11.677218) | 14.161795 / 10.191392 (3.970403) | 0.163340 / 0.680424 (-0.517084) | 0.021504 / 0.534201 (-0.512697) | 0.393183 / 0.579283 (-0.186100) | 0.448407 / 0.434364 (0.014043) | 0.504169 / 0.540337 (-0.036169) | 0.663698 / 1.386936 (-0.723238) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007390 / 0.011353 (-0.003962) | 0.004381 / 0.011008 (-0.006628) | 0.074501 / 0.038508 (0.035993) | 0.078242 / 0.023109 (0.055133) | 0.481108 / 0.275898 (0.205210) | 0.512111 / 0.323480 (0.188631) | 0.006280 / 0.007986 (-0.001705) | 0.003820 / 0.004328 (-0.000509) | 0.071602 / 0.004250 (0.067351) | 0.068359 / 0.037052 (0.031307) | 0.478484 / 0.258489 (0.219995) | 0.519543 / 0.293841 (0.225702) | 0.036211 / 0.128546 (-0.092335) | 0.009433 / 0.075646 (-0.066213) | 0.086140 / 0.419271 (-0.333132) | 0.054177 / 0.043533 (0.010644) | 0.466726 / 0.255139 (0.211587) | 0.514085 / 0.283200 (0.230885) | 0.026729 / 0.141683 (-0.114954) | 1.743770 / 1.452155 (0.291615) | 1.833469 / 1.492716 (0.340753) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.251339 / 0.018006 (0.233333) | 0.472294 / 0.000490 (0.471804) | 0.013381 / 0.000200 (0.013181) | 0.000117 / 0.000054 (0.000062) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.037845 / 0.037411 (0.000433) | 0.105977 / 0.014526 (0.091451) | 0.124446 / 0.176557 (-0.052111) | 0.180432 / 0.737135 (-0.556703) | 0.120844 / 0.296338 (-0.175495) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.470928 / 0.215209 (0.255719) | 4.738154 / 2.077655 (2.660499) | 2.558618 / 1.504120 (1.054498) | 2.359745 / 1.541195 (0.818550) | 2.458438 / 1.468490 (0.989948) | 0.548580 / 4.584777 (-4.036197) | 3.912145 / 3.745712 (0.166433) | 3.764174 / 5.269862 (-1.505687) | 2.325265 / 4.565676 (-2.240411) | 0.078022 / 0.424275 (-0.346254) | 0.008279 / 0.007607 (0.000672) | 0.571635 / 0.226044 (0.345590) | 5.672445 / 2.268929 (3.403517) | 2.760577 / 55.444624 (-52.684047) | 2.544229 / 6.876477 (-4.332248) | 2.537509 / 2.142072 (0.395436) | 0.609858 / 4.805227 (-4.195369) | 0.131053 / 6.500664 (-6.369611) | 0.056433 / 0.075469 (-0.019036) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.567231 / 1.841788 (-0.274556) | 21.415586 / 8.074308 (13.341278) | 15.982328 / 10.191392 (5.790936) | 0.167648 / 0.680424 (-0.512776) | 0.023562 / 0.534201 (-0.510639) | 0.477307 / 0.579283 (-0.101976) | 0.471929 / 0.434364 (0.037566) | 0.549996 / 0.540337 (0.009659) | 0.753927 / 1.386936 (-0.633009) |\n\n</details>\n</details>\n\n\n"
] | 2023-10-25T18:21:08Z
| 2023-10-26T17:19:49Z
| 2023-10-26T17:10:27Z
|
CONTRIBUTOR
| null | null | null |
The current example isn't working because it can't find `labels` inside the Dataset object. So I've added an extra step to the process. Tested and working in Colab.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6351/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6351/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6351.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6351",
"merged_at": "2023-10-26T17:10:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6351.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6351"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5233
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5233/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5233/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5233/events
|
https://github.com/huggingface/datasets/pull/5233
| 1,447,906,868
|
PR_kwDODunzps5C1JVh
| 5,233
|
Fix shards in IterableDataset.from_generator
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-11-14T11:42:09Z
| 2022-11-14T14:16:03Z
| 2022-11-14T14:13:22Z
|
MEMBER
| null | null | null |
Allow to define a sharded iterable dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5233/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5233/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5233.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5233",
"merged_at": "2022-11-14T14:13:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5233.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5233"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5340
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5340/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5340/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5340/events
|
https://github.com/huggingface/datasets/pull/5340
| 1,483,182,158
|
PR_kwDODunzps5EtWo3
| 5,340
|
Clean up DatasetInfo and Dataset docstrings
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-08T00:17:53Z
| 2022-12-08T19:33:14Z
| 2022-12-08T19:30:10Z
|
MEMBER
| null | null | null |
This PR cleans up the docstrings for `DatasetInfo` and about half of the methods in `Dataset`.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5340/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5340/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5340.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5340",
"merged_at": "2022-12-08T19:30:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5340.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5340"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5956
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5956/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5956/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5956/events
|
https://github.com/huggingface/datasets/pull/5956
| 1,756,959,367
|
PR_kwDODunzps5S_1o2
| 5,956
|
Fix ArrowExamplesIterable.shard_data_sources
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005893 / 0.011353 (-0.005460) | 0.003682 / 0.011008 (-0.007327) | 0.098358 / 0.038508 (0.059850) | 0.028130 / 0.023109 (0.005020) | 0.305960 / 0.275898 (0.030062) | 0.334869 / 0.323480 (0.011390) | 0.003522 / 0.007986 (-0.004463) | 0.003683 / 0.004328 (-0.000645) | 0.079418 / 0.004250 (0.075168) | 0.037662 / 0.037052 (0.000609) | 0.310893 / 0.258489 (0.052404) | 0.341347 / 0.293841 (0.047506) | 0.027450 / 0.128546 (-0.101096) | 0.008381 / 0.075646 (-0.067265) | 0.316020 / 0.419271 (-0.103252) | 0.045079 / 0.043533 (0.001546) | 0.307806 / 0.255139 (0.052667) | 0.331804 / 0.283200 (0.048604) | 0.091806 / 0.141683 (-0.049877) | 1.492611 / 1.452155 (0.040457) | 1.551762 / 1.492716 (0.059046) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.201640 / 0.018006 (0.183634) | 0.422776 / 0.000490 (0.422286) | 0.003734 / 0.000200 (0.003535) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025429 / 0.037411 (-0.011982) | 0.104699 / 0.014526 (0.090173) | 0.110505 / 0.176557 (-0.066051) | 0.171252 / 0.737135 (-0.565883) | 0.113131 / 0.296338 (-0.183208) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.419914 / 0.215209 (0.204705) | 4.184414 / 2.077655 (2.106760) | 1.999263 / 1.504120 (0.495143) | 1.828669 / 1.541195 (0.287474) | 1.940366 / 1.468490 (0.471876) | 0.556939 / 4.584777 (-4.027838) | 3.389164 / 3.745712 (-0.356548) | 1.796323 / 5.269862 (-3.473538) | 1.048843 / 4.565676 (-3.516833) | 0.067315 / 0.424275 (-0.356960) | 0.011531 / 0.007607 (0.003923) | 0.517226 / 0.226044 (0.291182) | 5.167255 / 2.268929 (2.898326) | 2.431129 / 55.444624 (-53.013495) | 2.133913 / 6.876477 (-4.742564) | 2.359021 / 2.142072 (0.216948) | 0.666390 / 4.805227 (-4.138838) | 0.135147 / 6.500664 (-6.365517) | 0.064855 / 0.075469 (-0.010614) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.166530 / 1.841788 (-0.675258) | 14.060551 / 8.074308 (5.986242) | 14.171663 / 10.191392 (3.980271) | 0.285821 / 0.680424 (-0.394603) | 0.016867 / 0.534201 (-0.517334) | 0.369102 / 0.579283 (-0.210181) | 0.393580 / 0.434364 (-0.040784) | 0.423721 / 0.540337 (-0.116616) | 0.512559 / 1.386936 (-0.874377) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006674 / 0.011353 (-0.004679) | 0.004006 / 0.011008 (-0.007002) | 0.080160 / 0.038508 (0.041652) | 0.032508 / 0.023109 (0.009399) | 0.378168 / 0.275898 (0.102270) | 0.417796 / 0.323480 (0.094316) | 0.003706 / 0.007986 (-0.004280) | 0.002995 / 0.004328 (-0.001333) | 0.079275 / 0.004250 (0.075025) | 0.043690 / 0.037052 (0.006638) | 0.377717 / 0.258489 (0.119228) | 0.439801 / 0.293841 (0.145961) | 0.028438 / 0.128546 (-0.100108) | 0.008661 / 0.075646 (-0.066985) | 0.085280 / 0.419271 (-0.333991) | 0.043716 / 0.043533 (0.000183) | 0.370086 / 0.255139 (0.114947) | 0.403763 / 0.283200 (0.120563) | 0.095022 / 0.141683 (-0.046661) | 1.534376 / 1.452155 (0.082221) | 1.597658 / 1.492716 (0.104942) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.240229 / 0.018006 (0.222223) | 0.496281 / 0.000490 (0.495792) | 0.002165 / 0.000200 (0.001965) | 0.000075 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025330 / 0.037411 (-0.012081) | 0.102414 / 0.014526 (0.087888) | 0.112733 / 0.176557 (-0.063824) | 0.161181 / 0.737135 (-0.575955) | 0.114196 / 0.296338 (-0.182143) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.456808 / 0.215209 (0.241599) | 4.534937 / 2.077655 (2.457283) | 2.318834 / 1.504120 (0.814714) | 2.074085 / 1.541195 (0.532890) | 2.117409 / 1.468490 (0.648919) | 0.559110 / 4.584777 (-4.025667) | 3.371695 / 3.745712 (-0.374017) | 2.543154 / 5.269862 (-2.726708) | 1.360552 / 4.565676 (-3.205125) | 0.067602 / 0.424275 (-0.356674) | 0.011396 / 0.007607 (0.003789) | 0.561666 / 0.226044 (0.335622) | 5.607666 / 2.268929 (3.338737) | 2.802775 / 55.444624 (-52.641849) | 2.486162 / 6.876477 (-4.390315) | 2.390885 / 2.142072 (0.248813) | 0.667407 / 4.805227 (-4.137820) | 0.135948 / 6.500664 (-6.364717) | 0.067272 / 0.075469 (-0.008197) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.279664 / 1.841788 (-0.562124) | 15.188099 / 8.074308 (7.113791) | 14.380355 / 10.191392 (4.188963) | 0.140344 / 0.680424 (-0.540080) | 0.016832 / 0.534201 (-0.517369) | 0.364631 / 0.579283 (-0.214652) | 0.400306 / 0.434364 (-0.034058) | 0.430793 / 0.540337 (-0.109545) | 0.525923 / 1.386936 (-0.861013) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008502 / 0.011353 (-0.002851) | 0.005946 / 0.011008 (-0.005062) | 0.131279 / 0.038508 (0.092771) | 0.035400 / 0.023109 (0.012291) | 0.423240 / 0.275898 (0.147342) | 0.470248 / 0.323480 (0.146768) | 0.004949 / 0.007986 (-0.003037) | 0.004544 / 0.004328 (0.000215) | 0.106856 / 0.004250 (0.102605) | 0.046579 / 0.037052 (0.009527) | 0.441135 / 0.258489 (0.182646) | 0.470401 / 0.293841 (0.176561) | 0.047231 / 0.128546 (-0.081315) | 0.017278 / 0.075646 (-0.058368) | 0.401937 / 0.419271 (-0.017335) | 0.067151 / 0.043533 (0.023619) | 0.453908 / 0.255139 (0.198769) | 0.422171 / 0.283200 (0.138971) | 0.123583 / 0.141683 (-0.018100) | 1.852895 / 1.452155 (0.400740) | 1.827282 / 1.492716 (0.334566) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.246419 / 0.018006 (0.228413) | 0.576930 / 0.000490 (0.576440) | 0.007511 / 0.000200 (0.007312) | 0.000165 / 0.000054 (0.000111) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032732 / 0.037411 (-0.004680) | 0.130266 / 0.014526 (0.115740) | 0.150537 / 0.176557 (-0.026019) | 0.218554 / 0.737135 (-0.518582) | 0.148572 / 0.296338 (-0.147766) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.598611 / 0.215209 (0.383402) | 6.181219 / 2.077655 (4.103564) | 2.473468 / 1.504120 (0.969348) | 2.206374 / 1.541195 (0.665179) | 2.216707 / 1.468490 (0.748217) | 0.981295 / 4.584777 (-3.603482) | 5.716384 / 3.745712 (1.970672) | 5.882327 / 5.269862 (0.612466) | 2.761081 / 4.565676 (-1.804595) | 0.113544 / 0.424275 (-0.310731) | 0.015131 / 0.007607 (0.007524) | 0.850939 / 0.226044 (0.624894) | 8.046611 / 2.268929 (5.777682) | 3.340542 / 55.444624 (-52.104083) | 2.673692 / 6.876477 (-4.202785) | 2.926330 / 2.142072 (0.784257) | 1.176164 / 4.805227 (-3.629064) | 0.226745 / 6.500664 (-6.273919) | 0.085910 / 0.075469 (0.010441) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.483792 / 1.841788 (-0.357995) | 18.895009 / 8.074308 (10.820701) | 20.982461 / 10.191392 (10.791069) | 0.253085 / 0.680424 (-0.427339) | 0.031284 / 0.534201 (-0.502917) | 0.516569 / 0.579283 (-0.062714) | 0.635781 / 0.434364 (0.201417) | 0.604359 / 0.540337 (0.064022) | 0.725278 / 1.386936 (-0.661658) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009220 / 0.011353 (-0.002133) | 0.005792 / 0.011008 (-0.005216) | 0.099795 / 0.038508 (0.061287) | 0.033812 / 0.023109 (0.010703) | 0.459386 / 0.275898 (0.183488) | 0.518067 / 0.323480 (0.194587) | 0.005083 / 0.007986 (-0.002902) | 0.004145 / 0.004328 (-0.000183) | 0.103506 / 0.004250 (0.099255) | 0.050429 / 0.037052 (0.013377) | 0.478149 / 0.258489 (0.219660) | 0.531280 / 0.293841 (0.237440) | 0.047373 / 0.128546 (-0.081173) | 0.013647 / 0.075646 (-0.061999) | 0.115174 / 0.419271 (-0.304098) | 0.061099 / 0.043533 (0.017566) | 0.455002 / 0.255139 (0.199863) | 0.507765 / 0.283200 (0.224565) | 0.112219 / 0.141683 (-0.029464) | 1.873591 / 1.452155 (0.421436) | 1.952061 / 1.492716 (0.459345) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.283587 / 0.018006 (0.265581) | 0.587562 / 0.000490 (0.587073) | 0.001252 / 0.000200 (0.001052) | 0.000095 / 0.000054 (0.000040) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032706 / 0.037411 (-0.004705) | 0.137715 / 0.014526 (0.123189) | 0.131932 / 0.176557 (-0.044625) | 0.200042 / 0.737135 (-0.537094) | 0.159327 / 0.296338 (-0.137011) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.624061 / 0.215209 (0.408852) | 6.386235 / 2.077655 (4.308580) | 2.908786 / 1.504120 (1.404666) | 2.589855 / 1.541195 (1.048660) | 2.387988 / 1.468490 (0.919498) | 0.952625 / 4.584777 (-3.632152) | 5.571641 / 3.745712 (1.825929) | 2.711154 / 5.269862 (-2.558708) | 1.788015 / 4.565676 (-2.777662) | 0.104488 / 0.424275 (-0.319787) | 0.015213 / 0.007607 (0.007606) | 0.798446 / 0.226044 (0.572401) | 8.011614 / 2.268929 (5.742686) | 3.711951 / 55.444624 (-51.732673) | 2.896881 / 6.876477 (-3.979595) | 3.172116 / 2.142072 (1.030043) | 1.136816 / 4.805227 (-3.668411) | 0.239254 / 6.500664 (-6.261410) | 0.081136 / 0.075469 (0.005667) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.798246 / 1.841788 (-0.043542) | 19.497108 / 8.074308 (11.422800) | 23.450258 / 10.191392 (13.258866) | 0.250021 / 0.680424 (-0.430403) | 0.029138 / 0.534201 (-0.505063) | 0.532984 / 0.579283 (-0.046299) | 0.638161 / 0.434364 (0.203797) | 0.615720 / 0.540337 (0.075382) | 0.770621 / 1.386936 (-0.616315) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009120 / 0.011353 (-0.002233) | 0.005381 / 0.011008 (-0.005627) | 0.139719 / 0.038508 (0.101211) | 0.037229 / 0.023109 (0.014120) | 0.414633 / 0.275898 (0.138734) | 0.480313 / 0.323480 (0.156833) | 0.005027 / 0.007986 (-0.002959) | 0.005015 / 0.004328 (0.000687) | 0.108513 / 0.004250 (0.104263) | 0.056167 / 0.037052 (0.019115) | 0.407588 / 0.258489 (0.149099) | 0.518899 / 0.293841 (0.225058) | 0.048857 / 0.128546 (-0.079689) | 0.013694 / 0.075646 (-0.061952) | 0.418035 / 0.419271 (-0.001237) | 0.067755 / 0.043533 (0.024222) | 0.417740 / 0.255139 (0.162601) | 0.478622 / 0.283200 (0.195422) | 0.118290 / 0.141683 (-0.023393) | 1.901473 / 1.452155 (0.449319) | 1.978126 / 1.492716 (0.485409) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.271960 / 0.018006 (0.253954) | 0.602745 / 0.000490 (0.602255) | 0.005371 / 0.000200 (0.005171) | 0.000102 / 0.000054 (0.000048) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029620 / 0.037411 (-0.007791) | 0.122402 / 0.014526 (0.107877) | 0.132645 / 0.176557 (-0.043911) | 0.212635 / 0.737135 (-0.524500) | 0.136901 / 0.296338 (-0.159438) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.644017 / 0.215209 (0.428808) | 6.597151 / 2.077655 (4.519496) | 2.454471 / 1.504120 (0.950351) | 2.151357 / 1.541195 (0.610163) | 2.290748 / 1.468490 (0.822258) | 0.970194 / 4.584777 (-3.614583) | 5.475275 / 3.745712 (1.729563) | 2.772658 / 5.269862 (-2.497204) | 1.785311 / 4.565676 (-2.780366) | 0.114503 / 0.424275 (-0.309772) | 0.015374 / 0.007607 (0.007767) | 0.768413 / 0.226044 (0.542368) | 7.956219 / 2.268929 (5.687290) | 3.272138 / 55.444624 (-52.172486) | 2.539638 / 6.876477 (-4.336839) | 2.713526 / 2.142072 (0.571454) | 1.181221 / 4.805227 (-3.624006) | 0.236327 / 6.500664 (-6.264337) | 0.089815 / 0.075469 (0.014345) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.521805 / 1.841788 (-0.319983) | 18.196529 / 8.074308 (10.122221) | 20.287324 / 10.191392 (10.095932) | 0.256959 / 0.680424 (-0.423465) | 0.028846 / 0.534201 (-0.505355) | 0.522354 / 0.579283 (-0.056929) | 0.600216 / 0.434364 (0.165852) | 0.607668 / 0.540337 (0.067331) | 0.762101 / 1.386936 (-0.624835) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009227 / 0.011353 (-0.002126) | 0.005398 / 0.011008 (-0.005610) | 0.094998 / 0.038508 (0.056490) | 0.036633 / 0.023109 (0.013524) | 0.493317 / 0.275898 (0.217419) | 0.517216 / 0.323480 (0.193736) | 0.005510 / 0.007986 (-0.002476) | 0.004249 / 0.004328 (-0.000079) | 0.107936 / 0.004250 (0.103685) | 0.050223 / 0.037052 (0.013171) | 0.580275 / 0.258489 (0.321786) | 0.551477 / 0.293841 (0.257636) | 0.048758 / 0.128546 (-0.079788) | 0.013954 / 0.075646 (-0.061692) | 0.107021 / 0.419271 (-0.312250) | 0.064416 / 0.043533 (0.020884) | 0.485225 / 0.255139 (0.230086) | 0.513862 / 0.283200 (0.230663) | 0.118848 / 0.141683 (-0.022835) | 1.755396 / 1.452155 (0.303241) | 1.970349 / 1.492716 (0.477633) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.290743 / 0.018006 (0.272737) | 0.603293 / 0.000490 (0.602803) | 0.006814 / 0.000200 (0.006614) | 0.000156 / 0.000054 (0.000101) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029862 / 0.037411 (-0.007550) | 0.136530 / 0.014526 (0.122005) | 0.133728 / 0.176557 (-0.042829) | 0.194709 / 0.737135 (-0.542427) | 0.151080 / 0.296338 (-0.145258) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.649202 / 0.215209 (0.433993) | 6.637578 / 2.077655 (4.559923) | 3.040135 / 1.504120 (1.536015) | 2.671308 / 1.541195 (1.130113) | 2.722412 / 1.468490 (1.253922) | 0.953029 / 4.584777 (-3.631748) | 5.805002 / 3.745712 (2.059290) | 5.049939 / 5.269862 (-0.219922) | 2.284053 / 4.565676 (-2.281623) | 0.130399 / 0.424275 (-0.293876) | 0.014726 / 0.007607 (0.007119) | 0.932570 / 0.226044 (0.706526) | 8.576693 / 2.268929 (6.307765) | 4.032738 / 55.444624 (-51.411886) | 3.274715 / 6.876477 (-3.601762) | 3.513788 / 2.142072 (1.371716) | 1.130624 / 4.805227 (-3.674603) | 0.219597 / 6.500664 (-6.281067) | 0.081425 / 0.075469 (0.005956) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.735312 / 1.841788 (-0.106476) | 18.438587 / 8.074308 (10.364279) | 21.582310 / 10.191392 (11.390918) | 0.224040 / 0.680424 (-0.456384) | 0.027590 / 0.534201 (-0.506611) | 0.503598 / 0.579283 (-0.075685) | 0.624379 / 0.434364 (0.190015) | 0.571911 / 0.540337 (0.031574) | 0.723215 / 1.386936 (-0.663721) |\n\n</details>\n</details>\n\n\n"
] | 2023-06-14T13:50:38Z
| 2023-06-14T14:43:12Z
| 2023-06-14T14:33:45Z
|
MEMBER
| null | null | null |
ArrowExamplesIterable.shard_data_sources was outdated
I also fixed a warning message by not using format_type= in with_format()
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5956/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5956/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5956.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5956",
"merged_at": "2023-06-14T14:33:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5956.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5956"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5152
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5152/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5152/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5152/events
|
https://github.com/huggingface/datasets/issues/5152
| 1,420,808,919
|
I_kwDODunzps5Ur9LX
| 5,152
|
refactor FolderBasedBuilder and Image/AudioFolder tests
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna",
"user_view_type": "public"
}
|
[
{
"color": "B67A40",
"default": false,
"description": "Restructuring existing code without changing its external behavior",
"id": 2851292821,
"name": "refactoring",
"node_id": "MDU6TGFiZWwyODUxMjkyODIx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/refactoring"
}
] |
open
| false
| null |
[] | null |
[] | 2022-10-24T13:11:52Z
| 2022-10-24T13:11:52Z
| null |
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
Tests for FolderBasedBuilder, ImageFolder and AudioFolder are mostly duplicating each other. They need to be refactored and Audio/ImageFolder should have only tests specific to the loader.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5152/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5152/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6963
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6963/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6963/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6963/events
|
https://github.com/huggingface/datasets/pull/6963
| 2,344,269,477
|
PR_kwDODunzps5x_yu-
| 6,963
|
[Streaming] retry on requests errors
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6963). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"ci failures are r-unrelated to this PR, merging",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005532 / 0.011353 (-0.005821) | 0.004018 / 0.011008 (-0.006991) | 0.064685 / 0.038508 (0.026177) | 0.031303 / 0.023109 (0.008194) | 0.254670 / 0.275898 (-0.021228) | 0.271357 / 0.323480 (-0.052123) | 0.003372 / 0.007986 (-0.004614) | 0.004153 / 0.004328 (-0.000175) | 0.050381 / 0.004250 (0.046131) | 0.046837 / 0.037052 (0.009784) | 0.253166 / 0.258489 (-0.005323) | 0.294257 / 0.293841 (0.000416) | 0.029746 / 0.128546 (-0.098800) | 0.012519 / 0.075646 (-0.063127) | 0.208822 / 0.419271 (-0.210449) | 0.036925 / 0.043533 (-0.006608) | 0.247636 / 0.255139 (-0.007503) | 0.269102 / 0.283200 (-0.014097) | 0.019021 / 0.141683 (-0.122662) | 1.138825 / 1.452155 (-0.313330) | 1.203301 / 1.492716 (-0.289415) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095950 / 0.018006 (0.077944) | 0.303347 / 0.000490 (0.302857) | 0.000221 / 0.000200 (0.000022) | 0.000042 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019014 / 0.037411 (-0.018397) | 0.062220 / 0.014526 (0.047694) | 0.074811 / 0.176557 (-0.101745) | 0.122917 / 0.737135 (-0.614218) | 0.075765 / 0.296338 (-0.220574) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.288359 / 0.215209 (0.073150) | 2.849491 / 2.077655 (0.771837) | 1.479448 / 1.504120 (-0.024672) | 1.350560 / 1.541195 (-0.190635) | 1.366079 / 1.468490 (-0.102411) | 0.733609 / 4.584777 (-3.851168) | 2.416014 / 3.745712 (-1.329698) | 2.954834 / 5.269862 (-2.315028) | 1.985703 / 4.565676 (-2.579974) | 0.080589 / 0.424275 (-0.343686) | 0.005581 / 0.007607 (-0.002026) | 0.343706 / 0.226044 (0.117661) | 3.416257 / 2.268929 (1.147329) | 1.865937 / 55.444624 (-53.578687) | 1.545911 / 6.876477 (-5.330566) | 1.711004 / 2.142072 (-0.431069) | 0.821231 / 4.805227 (-3.983996) | 0.138865 / 6.500664 (-6.361799) | 0.046466 / 0.075469 (-0.029003) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.965632 / 1.841788 (-0.876155) | 11.812101 / 8.074308 (3.737792) | 9.399156 / 10.191392 (-0.792236) | 0.143325 / 0.680424 (-0.537099) | 0.014824 / 0.534201 (-0.519377) | 0.306143 / 0.579283 (-0.273140) | 0.264063 / 0.434364 (-0.170301) | 0.347820 / 0.540337 (-0.192517) | 0.476818 / 1.386936 (-0.910118) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005978 / 0.011353 (-0.005375) | 0.004482 / 0.011008 (-0.006526) | 0.053788 / 0.038508 (0.015280) | 0.033963 / 0.023109 (0.010853) | 0.267258 / 0.275898 (-0.008640) | 0.290916 / 0.323480 (-0.032563) | 0.004485 / 0.007986 (-0.003500) | 0.002876 / 0.004328 (-0.001453) | 0.048637 / 0.004250 (0.044386) | 0.042050 / 0.037052 (0.004997) | 0.278607 / 0.258489 (0.020118) | 0.315411 / 0.293841 (0.021570) | 0.032059 / 0.128546 (-0.096487) | 0.012851 / 0.075646 (-0.062795) | 0.061672 / 0.419271 (-0.357600) | 0.034545 / 0.043533 (-0.008988) | 0.262068 / 0.255139 (0.006929) | 0.291197 / 0.283200 (0.007997) | 0.019092 / 0.141683 (-0.122591) | 1.108690 / 1.452155 (-0.343464) | 1.161025 / 1.492716 (-0.331691) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.096775 / 0.018006 (0.078768) | 0.306825 / 0.000490 (0.306335) | 0.000210 / 0.000200 (0.000010) | 0.000054 / 0.000054 (-0.000000) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023160 / 0.037411 (-0.014251) | 0.078794 / 0.014526 (0.064268) | 0.088954 / 0.176557 (-0.087602) | 0.129488 / 0.737135 (-0.607648) | 0.091239 / 0.296338 (-0.205099) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.292911 / 0.215209 (0.077702) | 2.910802 / 2.077655 (0.833148) | 1.569310 / 1.504120 (0.065191) | 1.433807 / 1.541195 (-0.107388) | 1.478619 / 1.468490 (0.010129) | 0.720982 / 4.584777 (-3.863795) | 0.972104 / 3.745712 (-2.773608) | 3.026941 / 5.269862 (-2.242921) | 1.919170 / 4.565676 (-2.646506) | 0.079292 / 0.424275 (-0.344983) | 0.005227 / 0.007607 (-0.002380) | 0.345363 / 0.226044 (0.119319) | 3.416149 / 2.268929 (1.147221) | 1.938377 / 55.444624 (-53.506248) | 1.626037 / 6.876477 (-5.250440) | 1.644405 / 2.142072 (-0.497668) | 0.802485 / 4.805227 (-4.002742) | 0.135114 / 6.500664 (-6.365550) | 0.042015 / 0.075469 (-0.033454) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.014812 / 1.841788 (-0.826976) | 12.583844 / 8.074308 (4.509536) | 10.522495 / 10.191392 (0.331103) | 0.143336 / 0.680424 (-0.537088) | 0.015843 / 0.534201 (-0.518357) | 0.306556 / 0.579283 (-0.272727) | 0.129654 / 0.434364 (-0.304710) | 0.340442 / 0.540337 (-0.199896) | 0.445220 / 1.386936 (-0.941716) |\n\n</details>\n</details>\n\n\n"
] | 2024-06-10T15:51:56Z
| 2024-06-28T09:53:11Z
| 2024-06-28T09:46:52Z
|
MEMBER
| null | null | null |
reported in https://discuss.huggingface.co/t/speeding-up-streaming-of-large-datasets-fineweb/90714/6 when training using a streaming a dataloader
cc @Wauplin it looks like the retries from `hfh` are not always enough. In this PR I let `datasets` do additional retries (that users can configure in `datasets.config`) since I couldn't find an easy way to increase the max_retries for `hfh` users in general.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6963/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6963/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6963.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6963",
"merged_at": "2024-06-28T09:46:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6963.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6963"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4621
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4621/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4621/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4621/events
|
https://github.com/huggingface/datasets/issues/4621
| 1,293,030,128
|
I_kwDODunzps5NEhLw
| 4,621
|
ImageFolder raises an error with parameters drop_metadata=True and drop_labels=False when metadata.jsonl is present
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna",
"user_view_type": "public"
}
] | null |
[] | 2022-07-04T11:21:44Z
| 2022-07-15T14:24:24Z
| 2022-07-15T14:24:24Z
|
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
## Describe the bug
If you pass `drop_metadata=True` and `drop_labels=False` when a `data_dir` contains at least one `matadata.jsonl` file, you will get a KeyError. This is probably not a very useful case but we shouldn't get an error anyway. Asking users to move metadata files manually outside `data_dir` or pass features manually (when there is a tool that can infer them automatically) don't look like a good idea to me either.
## Steps to reproduce the bug
### Clone an example dataset from the Hub
```bash
git clone https://huggingface.co/datasets/nateraw/test-imagefolder-metadata
```
### Try to load it
```python
from datasets import load_dataset
ds = load_dataset("test-imagefolder-metadata", drop_metadata=True, drop_labels=False)
```
or even just
```python
ds = load_dataset("test-imagefolder-metadata", drop_metadata=True)
```
as `drop_labels=False` is a default value.
## Expected results
A DatasetDict object with two features: `"image"` and `"label"`.
## Actual results
```
Traceback (most recent call last):
File "/home/polina/workspace/datasets/debug.py", line 18, in <module>
ds = load_dataset(
File "/home/polina/workspace/datasets/src/datasets/load.py", line 1732, in load_dataset
builder_instance.download_and_prepare(
File "/home/polina/workspace/datasets/src/datasets/builder.py", line 704, in download_and_prepare
self._download_and_prepare(
File "/home/polina/workspace/datasets/src/datasets/builder.py", line 1227, in _download_and_prepare
super()._download_and_prepare(dl_manager, verify_infos, check_duplicate_keys=verify_infos)
File "/home/polina/workspace/datasets/src/datasets/builder.py", line 793, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/polina/workspace/datasets/src/datasets/builder.py", line 1218, in _prepare_split
example = self.info.features.encode_example(record)
File "/home/polina/workspace/datasets/src/datasets/features/features.py", line 1596, in encode_example
return encode_nested_example(self, example)
File "/home/polina/workspace/datasets/src/datasets/features/features.py", line 1165, in encode_nested_example
{
File "/home/polina/workspace/datasets/src/datasets/features/features.py", line 1165, in <dictcomp>
{
File "/home/polina/workspace/datasets/src/datasets/utils/py_utils.py", line 249, in zip_dict
yield key, tuple(d[key] for d in dicts)
File "/home/polina/workspace/datasets/src/datasets/utils/py_utils.py", line 249, in <genexpr>
yield key, tuple(d[key] for d in dicts)
KeyError: 'label'
```
## Environment info
`datasets` master branch
- `datasets` version: 2.3.3.dev0
- Platform: Linux-5.14.0-1042-oem-x86_64-with-glibc2.17
- Python version: 3.8.12
- PyArrow version: 6.0.1
- Pandas version: 1.4.1
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4621/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4621/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5949
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5949/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5949/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5949/events
|
https://github.com/huggingface/datasets/pull/5949
| 1,754,843,717
|
PR_kwDODunzps5S4oPC
| 5,949
|
Replace metadata utils with `huggingface_hub`'s RepoCard API
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006635 / 0.011353 (-0.004718) | 0.004439 / 0.011008 (-0.006570) | 0.107831 / 0.038508 (0.069323) | 0.035664 / 0.023109 (0.012555) | 0.393733 / 0.275898 (0.117835) | 0.418336 / 0.323480 (0.094856) | 0.005739 / 0.007986 (-0.002247) | 0.005737 / 0.004328 (0.001408) | 0.079820 / 0.004250 (0.075569) | 0.045402 / 0.037052 (0.008349) | 0.396108 / 0.258489 (0.137619) | 0.422951 / 0.293841 (0.129110) | 0.030506 / 0.128546 (-0.098040) | 0.009785 / 0.075646 (-0.065861) | 0.375302 / 0.419271 (-0.043969) | 0.054355 / 0.043533 (0.010823) | 0.399652 / 0.255139 (0.144513) | 0.410825 / 0.283200 (0.127625) | 0.109238 / 0.141683 (-0.032445) | 1.687532 / 1.452155 (0.235378) | 1.736829 / 1.492716 (0.244113) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226514 / 0.018006 (0.208508) | 0.487010 / 0.000490 (0.486520) | 0.006436 / 0.000200 (0.006236) | 0.000102 / 0.000054 (0.000048) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029097 / 0.037411 (-0.008315) | 0.122979 / 0.014526 (0.108453) | 0.129454 / 0.176557 (-0.047103) | 0.194006 / 0.737135 (-0.543129) | 0.137968 / 0.296338 (-0.158370) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.466425 / 0.215209 (0.251216) | 4.627307 / 2.077655 (2.549652) | 2.108840 / 1.504120 (0.604720) | 1.882547 / 1.541195 (0.341353) | 1.891077 / 1.468490 (0.422587) | 0.590646 / 4.584777 (-3.994131) | 4.176918 / 3.745712 (0.431205) | 2.071475 / 5.269862 (-3.198386) | 1.173815 / 4.565676 (-3.391862) | 0.075330 / 0.424275 (-0.348945) | 0.012944 / 0.007607 (0.005337) | 0.587080 / 0.226044 (0.361036) | 5.827053 / 2.268929 (3.558125) | 2.694258 / 55.444624 (-52.750366) | 2.276997 / 6.876477 (-4.599480) | 2.329678 / 2.142072 (0.187605) | 0.721860 / 4.805227 (-4.083367) | 0.159238 / 6.500664 (-6.341426) | 0.073013 / 0.075469 (-0.002456) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.345396 / 1.841788 (-0.496391) | 16.619283 / 8.074308 (8.544975) | 14.754754 / 10.191392 (4.563362) | 0.180784 / 0.680424 (-0.499639) | 0.020376 / 0.534201 (-0.513825) | 0.451010 / 0.579283 (-0.128273) | 0.481524 / 0.434364 (0.047160) | 0.564777 / 0.540337 (0.024440) | 0.683232 / 1.386936 (-0.703704) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007243 / 0.011353 (-0.004110) | 0.005262 / 0.011008 (-0.005746) | 0.084090 / 0.038508 (0.045581) | 0.037429 / 0.023109 (0.014320) | 0.404038 / 0.275898 (0.128140) | 0.445040 / 0.323480 (0.121560) | 0.006220 / 0.007986 (-0.001766) | 0.004256 / 0.004328 (-0.000072) | 0.083794 / 0.004250 (0.079544) | 0.052655 / 0.037052 (0.015603) | 0.414083 / 0.258489 (0.155594) | 0.458190 / 0.293841 (0.164349) | 0.032719 / 0.128546 (-0.095828) | 0.010063 / 0.075646 (-0.065583) | 0.092281 / 0.419271 (-0.326990) | 0.053888 / 0.043533 (0.010355) | 0.407813 / 0.255139 (0.152674) | 0.431692 / 0.283200 (0.148493) | 0.119799 / 0.141683 (-0.021884) | 1.709853 / 1.452155 (0.257698) | 1.771592 / 1.492716 (0.278876) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.246540 / 0.018006 (0.228534) | 0.483199 / 0.000490 (0.482709) | 0.002514 / 0.000200 (0.002315) | 0.000096 / 0.000054 (0.000042) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031576 / 0.037411 (-0.005835) | 0.130020 / 0.014526 (0.115495) | 0.140285 / 0.176557 (-0.036272) | 0.196164 / 0.737135 (-0.540972) | 0.143924 / 0.296338 (-0.152414) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.488549 / 0.215209 (0.273340) | 4.888055 / 2.077655 (2.810400) | 2.389163 / 1.504120 (0.885043) | 2.184626 / 1.541195 (0.643431) | 2.260227 / 1.468490 (0.791737) | 0.601331 / 4.584777 (-3.983446) | 4.386159 / 3.745712 (0.640447) | 3.345814 / 5.269862 (-1.924048) | 1.734360 / 4.565676 (-2.831317) | 0.073199 / 0.424275 (-0.351076) | 0.012397 / 0.007607 (0.004790) | 0.601411 / 0.226044 (0.375366) | 6.135000 / 2.268929 (3.866072) | 2.930169 / 55.444624 (-52.514456) | 2.532631 / 6.876477 (-4.343845) | 2.619351 / 2.142072 (0.477279) | 0.740954 / 4.805227 (-4.064274) | 0.162936 / 6.500664 (-6.337728) | 0.073885 / 0.075469 (-0.001585) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.502493 / 1.841788 (-0.339294) | 17.026756 / 8.074308 (8.952448) | 15.880958 / 10.191392 (5.689566) | 0.167261 / 0.680424 (-0.513163) | 0.020347 / 0.534201 (-0.513854) | 0.452902 / 0.579283 (-0.126381) | 0.481614 / 0.434364 (0.047250) | 0.539893 / 0.540337 (-0.000445) | 0.653401 / 1.386936 (-0.733535) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008268 / 0.011353 (-0.003084) | 0.005538 / 0.011008 (-0.005470) | 0.126136 / 0.038508 (0.087628) | 0.046100 / 0.023109 (0.022991) | 0.366882 / 0.275898 (0.090984) | 0.408912 / 0.323480 (0.085432) | 0.007090 / 0.007986 (-0.000895) | 0.004820 / 0.004328 (0.000491) | 0.091432 / 0.004250 (0.087181) | 0.058390 / 0.037052 (0.021338) | 0.368787 / 0.258489 (0.110298) | 0.419429 / 0.293841 (0.125588) | 0.034958 / 0.128546 (-0.093588) | 0.010526 / 0.075646 (-0.065120) | 0.463063 / 0.419271 (0.043791) | 0.070544 / 0.043533 (0.027011) | 0.366182 / 0.255139 (0.111043) | 0.390851 / 0.283200 (0.107652) | 0.128377 / 0.141683 (-0.013306) | 1.819385 / 1.452155 (0.367231) | 1.928834 / 1.492716 (0.436117) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.228413 / 0.018006 (0.210407) | 0.485511 / 0.000490 (0.485021) | 0.005395 / 0.000200 (0.005195) | 0.000119 / 0.000054 (0.000064) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035209 / 0.037411 (-0.002203) | 0.144492 / 0.014526 (0.129967) | 0.150467 / 0.176557 (-0.026089) | 0.223861 / 0.737135 (-0.513274) | 0.156363 / 0.296338 (-0.139975) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.517751 / 0.215209 (0.302542) | 5.150438 / 2.077655 (3.072783) | 2.483601 / 1.504120 (0.979481) | 2.279786 / 1.541195 (0.738592) | 2.374510 / 1.468490 (0.906020) | 0.637547 / 4.584777 (-3.947230) | 4.845393 / 3.745712 (1.099681) | 2.241554 / 5.269862 (-3.028307) | 1.290105 / 4.565676 (-3.275572) | 0.079791 / 0.424275 (-0.344484) | 0.014915 / 0.007607 (0.007308) | 0.640468 / 0.226044 (0.414423) | 6.394810 / 2.268929 (4.125881) | 3.012748 / 55.444624 (-52.431876) | 2.625565 / 6.876477 (-4.250912) | 2.792435 / 2.142072 (0.650363) | 0.782284 / 4.805227 (-4.022944) | 0.171628 / 6.500664 (-6.329036) | 0.081714 / 0.075469 (0.006245) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.592411 / 1.841788 (-0.249377) | 18.999604 / 8.074308 (10.925295) | 18.469946 / 10.191392 (8.278554) | 0.200878 / 0.680424 (-0.479546) | 0.021595 / 0.534201 (-0.512606) | 0.519247 / 0.579283 (-0.060036) | 0.534940 / 0.434364 (0.100576) | 0.656325 / 0.540337 (0.115987) | 0.789658 / 1.386936 (-0.597278) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008093 / 0.011353 (-0.003260) | 0.005524 / 0.011008 (-0.005484) | 0.092339 / 0.038508 (0.053831) | 0.045619 / 0.023109 (0.022510) | 0.449376 / 0.275898 (0.173478) | 0.478587 / 0.323480 (0.155107) | 0.006978 / 0.007986 (-0.001007) | 0.004622 / 0.004328 (0.000294) | 0.090618 / 0.004250 (0.086368) | 0.059321 / 0.037052 (0.022269) | 0.450989 / 0.258489 (0.192500) | 0.491652 / 0.293841 (0.197811) | 0.033308 / 0.128546 (-0.095238) | 0.010677 / 0.075646 (-0.064969) | 0.099836 / 0.419271 (-0.319435) | 0.055937 / 0.043533 (0.012404) | 0.440560 / 0.255139 (0.185421) | 0.475305 / 0.283200 (0.192105) | 0.130829 / 0.141683 (-0.010854) | 1.857943 / 1.452155 (0.405789) | 1.989534 / 1.492716 (0.496818) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.244715 / 0.018006 (0.226709) | 0.482866 / 0.000490 (0.482377) | 0.001100 / 0.000200 (0.000900) | 0.000095 / 0.000054 (0.000041) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.036288 / 0.037411 (-0.001124) | 0.147903 / 0.014526 (0.133377) | 0.154141 / 0.176557 (-0.022416) | 0.221863 / 0.737135 (-0.515272) | 0.162319 / 0.296338 (-0.134019) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.536972 / 0.215209 (0.321763) | 5.382866 / 2.077655 (3.305211) | 2.719575 / 1.504120 (1.215456) | 2.516596 / 1.541195 (0.975401) | 2.699602 / 1.468490 (1.231112) | 0.639886 / 4.584777 (-3.944891) | 5.109746 / 3.745712 (1.364034) | 2.260206 / 5.269862 (-3.009656) | 1.305506 / 4.565676 (-3.260170) | 0.080262 / 0.424275 (-0.344013) | 0.014801 / 0.007607 (0.007194) | 0.661228 / 0.226044 (0.435184) | 6.596485 / 2.268929 (4.327557) | 3.226114 / 55.444624 (-52.218510) | 2.859776 / 6.876477 (-4.016701) | 3.059355 / 2.142072 (0.917282) | 0.793413 / 4.805227 (-4.011814) | 0.176521 / 6.500664 (-6.324143) | 0.084062 / 0.075469 (0.008593) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.642085 / 1.841788 (-0.199703) | 20.355459 / 8.074308 (12.281151) | 17.979620 / 10.191392 (7.788228) | 0.229329 / 0.680424 (-0.451094) | 0.025681 / 0.534201 (-0.508520) | 0.534142 / 0.579283 (-0.045141) | 0.623439 / 0.434364 (0.189075) | 0.621938 / 0.540337 (0.081601) | 0.759038 / 1.386936 (-0.627898) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007703 / 0.011353 (-0.003649) | 0.005362 / 0.011008 (-0.005646) | 0.113111 / 0.038508 (0.074602) | 0.038891 / 0.023109 (0.015782) | 0.348938 / 0.275898 (0.073040) | 0.398079 / 0.323480 (0.074599) | 0.006707 / 0.007986 (-0.001278) | 0.004489 / 0.004328 (0.000160) | 0.087194 / 0.004250 (0.082943) | 0.054268 / 0.037052 (0.017216) | 0.359949 / 0.258489 (0.101460) | 0.402959 / 0.293841 (0.109118) | 0.032508 / 0.128546 (-0.096038) | 0.010224 / 0.075646 (-0.065422) | 0.387007 / 0.419271 (-0.032264) | 0.058971 / 0.043533 (0.015439) | 0.345085 / 0.255139 (0.089946) | 0.384306 / 0.283200 (0.101107) | 0.122253 / 0.141683 (-0.019430) | 1.706353 / 1.452155 (0.254199) | 1.840780 / 1.492716 (0.348063) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.254374 / 0.018006 (0.236368) | 0.497387 / 0.000490 (0.496897) | 0.012294 / 0.000200 (0.012094) | 0.000108 / 0.000054 (0.000054) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030902 / 0.037411 (-0.006509) | 0.132098 / 0.014526 (0.117573) | 0.140311 / 0.176557 (-0.036245) | 0.205887 / 0.737135 (-0.531249) | 0.143992 / 0.296338 (-0.152347) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.467367 / 0.215209 (0.252158) | 4.669936 / 2.077655 (2.592281) | 2.155358 / 1.504120 (0.651238) | 1.984132 / 1.541195 (0.442937) | 2.102352 / 1.468490 (0.633861) | 0.607014 / 4.584777 (-3.977763) | 4.396479 / 3.745712 (0.650767) | 4.666056 / 5.269862 (-0.603806) | 2.176649 / 4.565676 (-2.389028) | 0.072657 / 0.424275 (-0.351619) | 0.012367 / 0.007607 (0.004759) | 0.569706 / 0.226044 (0.343661) | 5.749083 / 2.268929 (3.480154) | 2.640824 / 55.444624 (-52.803801) | 2.310253 / 6.876477 (-4.566224) | 2.486748 / 2.142072 (0.344676) | 0.737891 / 4.805227 (-4.067336) | 0.163507 / 6.500664 (-6.337157) | 0.075776 / 0.075469 (0.000307) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.362710 / 1.841788 (-0.479078) | 17.010705 / 8.074308 (8.936396) | 15.084231 / 10.191392 (4.892839) | 0.218274 / 0.680424 (-0.462150) | 0.019555 / 0.534201 (-0.514646) | 0.456013 / 0.579283 (-0.123270) | 0.502772 / 0.434364 (0.068408) | 0.581480 / 0.540337 (0.041142) | 0.686952 / 1.386936 (-0.699984) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007976 / 0.011353 (-0.003377) | 0.005141 / 0.011008 (-0.005868) | 0.086629 / 0.038508 (0.048121) | 0.039553 / 0.023109 (0.016444) | 0.433028 / 0.275898 (0.157130) | 0.463444 / 0.323480 (0.139964) | 0.006967 / 0.007986 (-0.001018) | 0.005814 / 0.004328 (0.001485) | 0.086266 / 0.004250 (0.082015) | 0.055384 / 0.037052 (0.018332) | 0.428733 / 0.258489 (0.170243) | 0.475670 / 0.293841 (0.181829) | 0.032872 / 0.128546 (-0.095674) | 0.010664 / 0.075646 (-0.064983) | 0.094357 / 0.419271 (-0.324915) | 0.058386 / 0.043533 (0.014854) | 0.431114 / 0.255139 (0.175975) | 0.441728 / 0.283200 (0.158528) | 0.131942 / 0.141683 (-0.009740) | 1.782214 / 1.452155 (0.330060) | 1.843185 / 1.492716 (0.350469) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.247047 / 0.018006 (0.229041) | 0.488931 / 0.000490 (0.488441) | 0.002657 / 0.000200 (0.002457) | 0.000106 / 0.000054 (0.000052) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033893 / 0.037411 (-0.003518) | 0.131021 / 0.014526 (0.116495) | 0.142892 / 0.176557 (-0.033665) | 0.200955 / 0.737135 (-0.536180) | 0.151329 / 0.296338 (-0.145010) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.521138 / 0.215209 (0.305929) | 5.085207 / 2.077655 (3.007552) | 2.652901 / 1.504120 (1.148781) | 2.401545 / 1.541195 (0.860350) | 2.553461 / 1.468490 (1.084971) | 0.615347 / 4.584777 (-3.969430) | 4.448038 / 3.745712 (0.702326) | 2.049997 / 5.269862 (-3.219865) | 1.190602 / 4.565676 (-3.375075) | 0.073356 / 0.424275 (-0.350919) | 0.013685 / 0.007607 (0.006078) | 0.626705 / 0.226044 (0.400660) | 6.391941 / 2.268929 (4.123012) | 3.218864 / 55.444624 (-52.225760) | 2.858808 / 6.876477 (-4.017669) | 3.005808 / 2.142072 (0.863736) | 0.740725 / 4.805227 (-4.064502) | 0.161904 / 6.500664 (-6.338760) | 0.073727 / 0.075469 (-0.001742) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.488623 / 1.841788 (-0.353164) | 17.584367 / 8.074308 (9.510059) | 16.281818 / 10.191392 (6.090426) | 0.164482 / 0.680424 (-0.515942) | 0.020197 / 0.534201 (-0.514003) | 0.456750 / 0.579283 (-0.122533) | 0.501156 / 0.434364 (0.066792) | 0.549779 / 0.540337 (0.009442) | 0.650156 / 1.386936 (-0.736780) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008337 / 0.011353 (-0.003016) | 0.005911 / 0.011008 (-0.005097) | 0.129037 / 0.038508 (0.090529) | 0.046071 / 0.023109 (0.022962) | 0.418657 / 0.275898 (0.142759) | 0.490340 / 0.323480 (0.166860) | 0.006387 / 0.007986 (-0.001598) | 0.004724 / 0.004328 (0.000396) | 0.097953 / 0.004250 (0.093702) | 0.069025 / 0.037052 (0.031972) | 0.431178 / 0.258489 (0.172689) | 0.458363 / 0.293841 (0.164522) | 0.049341 / 0.128546 (-0.079205) | 0.014637 / 0.075646 (-0.061009) | 0.439800 / 0.419271 (0.020529) | 0.069905 / 0.043533 (0.026373) | 0.406775 / 0.255139 (0.151636) | 0.441989 / 0.283200 (0.158790) | 0.046009 / 0.141683 (-0.095674) | 1.847630 / 1.452155 (0.395475) | 1.904067 / 1.492716 (0.411351) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.288305 / 0.018006 (0.270299) | 0.594547 / 0.000490 (0.594058) | 0.005600 / 0.000200 (0.005400) | 0.000106 / 0.000054 (0.000052) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033847 / 0.037411 (-0.003564) | 0.125139 / 0.014526 (0.110613) | 0.147982 / 0.176557 (-0.028574) | 0.208396 / 0.737135 (-0.528739) | 0.144005 / 0.296338 (-0.152334) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.669175 / 0.215209 (0.453966) | 6.605289 / 2.077655 (4.527634) | 2.720468 / 1.504120 (1.216348) | 2.341355 / 1.541195 (0.800160) | 2.402069 / 1.468490 (0.933578) | 0.939303 / 4.584777 (-3.645474) | 5.718545 / 3.745712 (1.972833) | 2.856235 / 5.269862 (-2.413627) | 1.821555 / 4.565676 (-2.744121) | 0.105473 / 0.424275 (-0.318802) | 0.014490 / 0.007607 (0.006883) | 0.774349 / 0.226044 (0.548305) | 8.065048 / 2.268929 (5.796120) | 3.508482 / 55.444624 (-51.936143) | 2.822881 / 6.876477 (-4.053596) | 2.962947 / 2.142072 (0.820875) | 1.138944 / 4.805227 (-3.666284) | 0.248414 / 6.500664 (-6.252250) | 0.095665 / 0.075469 (0.020196) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.688231 / 1.841788 (-0.153557) | 18.673305 / 8.074308 (10.598997) | 22.768663 / 10.191392 (12.577271) | 0.211238 / 0.680424 (-0.469186) | 0.031380 / 0.534201 (-0.502821) | 0.517175 / 0.579283 (-0.062108) | 0.626437 / 0.434364 (0.192073) | 0.624225 / 0.540337 (0.083888) | 0.743746 / 1.386936 (-0.643191) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008888 / 0.011353 (-0.002464) | 0.005491 / 0.011008 (-0.005517) | 0.105013 / 0.038508 (0.066505) | 0.049456 / 0.023109 (0.026347) | 0.528989 / 0.275898 (0.253091) | 0.651871 / 0.323480 (0.328391) | 0.006683 / 0.007986 (-0.001302) | 0.004365 / 0.004328 (0.000037) | 0.098161 / 0.004250 (0.093911) | 0.075615 / 0.037052 (0.038563) | 0.543746 / 0.258489 (0.285257) | 0.650855 / 0.293841 (0.357014) | 0.050220 / 0.128546 (-0.078327) | 0.014471 / 0.075646 (-0.061175) | 0.115903 / 0.419271 (-0.303368) | 0.065925 / 0.043533 (0.022392) | 0.527797 / 0.255139 (0.272658) | 0.543834 / 0.283200 (0.260634) | 0.043005 / 0.141683 (-0.098678) | 1.842846 / 1.452155 (0.390691) | 1.970615 / 1.492716 (0.477899) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.287350 / 0.018006 (0.269343) | 0.591139 / 0.000490 (0.590649) | 0.006423 / 0.000200 (0.006223) | 0.000107 / 0.000054 (0.000052) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034594 / 0.037411 (-0.002818) | 0.137155 / 0.014526 (0.122629) | 0.154662 / 0.176557 (-0.021894) | 0.217834 / 0.737135 (-0.519301) | 0.159642 / 0.296338 (-0.136696) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.664288 / 0.215209 (0.449079) | 6.926912 / 2.077655 (4.849257) | 3.028957 / 1.504120 (1.524837) | 2.625178 / 1.541195 (1.083983) | 2.725316 / 1.468490 (1.256826) | 1.015715 / 4.584777 (-3.569062) | 5.834694 / 3.745712 (2.088982) | 5.105269 / 5.269862 (-0.164593) | 2.316194 / 4.565676 (-2.249483) | 0.113802 / 0.424275 (-0.310473) | 0.014079 / 0.007607 (0.006472) | 0.893727 / 0.226044 (0.667683) | 8.577701 / 2.268929 (6.308772) | 3.706907 / 55.444624 (-51.737717) | 3.087530 / 6.876477 (-3.788947) | 3.295004 / 2.142072 (1.152931) | 1.204172 / 4.805227 (-3.601055) | 0.248720 / 6.500664 (-6.251944) | 0.107208 / 0.075469 (0.031739) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.800058 / 1.841788 (-0.041730) | 19.253646 / 8.074308 (11.179338) | 22.590804 / 10.191392 (12.399412) | 0.270687 / 0.680424 (-0.409737) | 0.028678 / 0.534201 (-0.505522) | 0.534670 / 0.579283 (-0.044613) | 0.642881 / 0.434364 (0.208518) | 0.615521 / 0.540337 (0.075184) | 0.723733 / 1.386936 (-0.663203) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.017236 / 0.011353 (0.005883) | 0.005341 / 0.011008 (-0.005667) | 0.131471 / 0.038508 (0.092963) | 0.048868 / 0.023109 (0.025758) | 0.448942 / 0.275898 (0.173044) | 0.498721 / 0.323480 (0.175241) | 0.006825 / 0.007986 (-0.001161) | 0.004587 / 0.004328 (0.000259) | 0.104142 / 0.004250 (0.099891) | 0.075521 / 0.037052 (0.038469) | 0.439538 / 0.258489 (0.181049) | 0.498720 / 0.293841 (0.204879) | 0.051352 / 0.128546 (-0.077194) | 0.015070 / 0.075646 (-0.060576) | 0.441752 / 0.419271 (0.022480) | 0.089166 / 0.043533 (0.045633) | 0.428909 / 0.255139 (0.173770) | 0.446648 / 0.283200 (0.163448) | 0.042371 / 0.141683 (-0.099312) | 1.993948 / 1.452155 (0.541793) | 2.065756 / 1.492716 (0.573039) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.257279 / 0.018006 (0.239273) | 0.575453 / 0.000490 (0.574964) | 0.004120 / 0.000200 (0.003920) | 0.000114 / 0.000054 (0.000060) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034012 / 0.037411 (-0.003399) | 0.141737 / 0.014526 (0.127211) | 0.145241 / 0.176557 (-0.031316) | 0.226196 / 0.737135 (-0.510939) | 0.149526 / 0.296338 (-0.146813) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.665762 / 0.215209 (0.450553) | 6.683737 / 2.077655 (4.606083) | 2.869485 / 1.504120 (1.365365) | 2.462808 / 1.541195 (0.921613) | 2.526808 / 1.468490 (1.058318) | 0.957518 / 4.584777 (-3.627259) | 5.926261 / 3.745712 (2.180548) | 5.027822 / 5.269862 (-0.242040) | 2.643185 / 4.565676 (-1.922491) | 0.117014 / 0.424275 (-0.307261) | 0.015142 / 0.007607 (0.007535) | 0.835694 / 0.226044 (0.609650) | 8.427356 / 2.268929 (6.158427) | 3.649597 / 55.444624 (-51.795027) | 2.989607 / 6.876477 (-3.886870) | 3.043160 / 2.142072 (0.901088) | 1.158872 / 4.805227 (-3.646355) | 0.240456 / 6.500664 (-6.260208) | 0.089196 / 0.075469 (0.013726) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.689361 / 1.841788 (-0.152427) | 18.842158 / 8.074308 (10.767850) | 22.604249 / 10.191392 (12.412857) | 0.248487 / 0.680424 (-0.431936) | 0.029668 / 0.534201 (-0.504533) | 0.536283 / 0.579283 (-0.043001) | 0.663253 / 0.434364 (0.228890) | 0.622973 / 0.540337 (0.082635) | 0.735297 / 1.386936 (-0.651639) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009296 / 0.011353 (-0.002057) | 0.005955 / 0.011008 (-0.005053) | 0.105723 / 0.038508 (0.067215) | 0.051184 / 0.023109 (0.028074) | 0.527095 / 0.275898 (0.251197) | 0.631697 / 0.323480 (0.308217) | 0.006577 / 0.007986 (-0.001408) | 0.004452 / 0.004328 (0.000124) | 0.105921 / 0.004250 (0.101670) | 0.071951 / 0.037052 (0.034899) | 0.572518 / 0.258489 (0.314029) | 0.623957 / 0.293841 (0.330116) | 0.050861 / 0.128546 (-0.077686) | 0.014897 / 0.075646 (-0.060749) | 0.122013 / 0.419271 (-0.297258) | 0.067194 / 0.043533 (0.023661) | 0.530352 / 0.255139 (0.275213) | 0.563912 / 0.283200 (0.280712) | 0.034756 / 0.141683 (-0.106927) | 1.961580 / 1.452155 (0.509425) | 2.052412 / 1.492716 (0.559696) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.304996 / 0.018006 (0.286990) | 0.584899 / 0.000490 (0.584409) | 0.010444 / 0.000200 (0.010244) | 0.000134 / 0.000054 (0.000080) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032540 / 0.037411 (-0.004871) | 0.137349 / 0.014526 (0.122823) | 0.146233 / 0.176557 (-0.030323) | 0.206978 / 0.737135 (-0.530157) | 0.154380 / 0.296338 (-0.141959) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.705438 / 0.215209 (0.490229) | 7.042159 / 2.077655 (4.964504) | 3.285501 / 1.504120 (1.781381) | 2.904710 / 1.541195 (1.363515) | 2.952838 / 1.468490 (1.484348) | 0.987784 / 4.584777 (-3.596993) | 5.949550 / 3.745712 (2.203838) | 2.927148 / 5.269862 (-2.342714) | 1.870054 / 4.565676 (-2.695622) | 0.119548 / 0.424275 (-0.304727) | 0.014565 / 0.007607 (0.006958) | 0.858311 / 0.226044 (0.632266) | 8.721679 / 2.268929 (6.452750) | 4.100825 / 55.444624 (-51.343800) | 3.358093 / 6.876477 (-3.518383) | 3.499637 / 2.142072 (1.357564) | 1.208932 / 4.805227 (-3.596295) | 0.232961 / 6.500664 (-6.267703) | 0.089727 / 0.075469 (0.014258) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.780143 / 1.841788 (-0.061645) | 19.074991 / 8.074308 (11.000683) | 21.218487 / 10.191392 (11.027095) | 0.258690 / 0.680424 (-0.421734) | 0.029514 / 0.534201 (-0.504687) | 0.541764 / 0.579283 (-0.037519) | 0.640603 / 0.434364 (0.206239) | 0.635336 / 0.540337 (0.094999) | 0.756309 / 1.386936 (-0.630627) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009619 / 0.011353 (-0.001734) | 0.005683 / 0.011008 (-0.005325) | 0.136971 / 0.038508 (0.098463) | 0.051607 / 0.023109 (0.028497) | 0.439716 / 0.275898 (0.163818) | 0.486193 / 0.323480 (0.162713) | 0.006304 / 0.007986 (-0.001681) | 0.004489 / 0.004328 (0.000160) | 0.103837 / 0.004250 (0.099587) | 0.082954 / 0.037052 (0.045901) | 0.447286 / 0.258489 (0.188797) | 0.495434 / 0.293841 (0.201593) | 0.049244 / 0.128546 (-0.079302) | 0.015176 / 0.075646 (-0.060470) | 0.444406 / 0.419271 (0.025134) | 0.074766 / 0.043533 (0.031233) | 0.438585 / 0.255139 (0.183446) | 0.438232 / 0.283200 (0.155032) | 0.043372 / 0.141683 (-0.098311) | 2.057286 / 1.452155 (0.605131) | 2.049540 / 1.492716 (0.556824) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.298038 / 0.018006 (0.280031) | 0.630771 / 0.000490 (0.630281) | 0.008287 / 0.000200 (0.008087) | 0.000123 / 0.000054 (0.000068) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033637 / 0.037411 (-0.003775) | 0.128327 / 0.014526 (0.113801) | 0.150672 / 0.176557 (-0.025885) | 0.228521 / 0.737135 (-0.508614) | 0.142733 / 0.296338 (-0.153606) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.629072 / 0.215209 (0.413863) | 6.612047 / 2.077655 (4.534392) | 2.715594 / 1.504120 (1.211474) | 2.327823 / 1.541195 (0.786628) | 2.417508 / 1.468490 (0.949018) | 0.959134 / 4.584777 (-3.625643) | 5.669921 / 3.745712 (1.924209) | 2.977920 / 5.269862 (-2.291941) | 1.814564 / 4.565676 (-2.751112) | 0.120233 / 0.424275 (-0.304042) | 0.015859 / 0.007607 (0.008252) | 0.822618 / 0.226044 (0.596574) | 8.440306 / 2.268929 (6.171377) | 3.721611 / 55.444624 (-51.723013) | 2.954867 / 6.876477 (-3.921610) | 3.135364 / 2.142072 (0.993292) | 1.226475 / 4.805227 (-3.578752) | 0.246658 / 6.500664 (-6.254006) | 0.093920 / 0.075469 (0.018451) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.665631 / 1.841788 (-0.176157) | 19.136369 / 8.074308 (11.062061) | 23.659564 / 10.191392 (13.468172) | 0.273430 / 0.680424 (-0.406994) | 0.028180 / 0.534201 (-0.506021) | 0.559588 / 0.579283 (-0.019695) | 0.649203 / 0.434364 (0.214840) | 0.647113 / 0.540337 (0.106776) | 0.737978 / 1.386936 (-0.648958) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009104 / 0.011353 (-0.002249) | 0.006838 / 0.011008 (-0.004171) | 0.104516 / 0.038508 (0.066008) | 0.047986 / 0.023109 (0.024877) | 0.521849 / 0.275898 (0.245951) | 0.586281 / 0.323480 (0.262801) | 0.006225 / 0.007986 (-0.001760) | 0.005713 / 0.004328 (0.001384) | 0.111507 / 0.004250 (0.107257) | 0.072320 / 0.037052 (0.035267) | 0.551061 / 0.258489 (0.292572) | 0.628034 / 0.293841 (0.334193) | 0.055417 / 0.128546 (-0.073129) | 0.019613 / 0.075646 (-0.056034) | 0.123958 / 0.419271 (-0.295314) | 0.066132 / 0.043533 (0.022600) | 0.504461 / 0.255139 (0.249322) | 0.560428 / 0.283200 (0.277229) | 0.036098 / 0.141683 (-0.105585) | 1.927398 / 1.452155 (0.475243) | 2.015952 / 1.492716 (0.523235) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.313065 / 0.018006 (0.295059) | 0.609174 / 0.000490 (0.608684) | 0.008755 / 0.000200 (0.008555) | 0.000120 / 0.000054 (0.000066) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.040042 / 0.037411 (0.002630) | 0.136053 / 0.014526 (0.121527) | 0.143406 / 0.176557 (-0.033150) | 0.213080 / 0.737135 (-0.524055) | 0.154730 / 0.296338 (-0.141609) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.692706 / 0.215209 (0.477497) | 6.952968 / 2.077655 (4.875314) | 3.232023 / 1.504120 (1.727903) | 2.835450 / 1.541195 (1.294256) | 2.933821 / 1.468490 (1.465331) | 0.984712 / 4.584777 (-3.600065) | 6.127651 / 3.745712 (2.381939) | 2.956781 / 5.269862 (-2.313081) | 1.879928 / 4.565676 (-2.685748) | 0.111069 / 0.424275 (-0.313206) | 0.014598 / 0.007607 (0.006991) | 0.871486 / 0.226044 (0.645442) | 8.588500 / 2.268929 (6.319572) | 3.910740 / 55.444624 (-51.533885) | 3.115781 / 6.876477 (-3.760695) | 3.222367 / 2.142072 (1.080294) | 1.229680 / 4.805227 (-3.575547) | 0.232092 / 6.500664 (-6.268572) | 0.097717 / 0.075469 (0.022248) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.774193 / 1.841788 (-0.067595) | 19.863087 / 8.074308 (11.788779) | 24.058856 / 10.191392 (13.867464) | 0.214917 / 0.680424 (-0.465507) | 0.028771 / 0.534201 (-0.505430) | 0.544548 / 0.579283 (-0.034735) | 0.655882 / 0.434364 (0.221518) | 0.629110 / 0.540337 (0.088773) | 0.749246 / 1.386936 (-0.637690) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007075 / 0.011353 (-0.004278) | 0.005195 / 0.011008 (-0.005813) | 0.113043 / 0.038508 (0.074535) | 0.038442 / 0.023109 (0.015333) | 0.336310 / 0.275898 (0.060412) | 0.381888 / 0.323480 (0.058409) | 0.005990 / 0.007986 (-0.001996) | 0.003893 / 0.004328 (-0.000435) | 0.093123 / 0.004250 (0.088872) | 0.058449 / 0.037052 (0.021397) | 0.359463 / 0.258489 (0.100974) | 0.427485 / 0.293841 (0.133644) | 0.041454 / 0.128546 (-0.087092) | 0.013016 / 0.075646 (-0.062630) | 0.372849 / 0.419271 (-0.046422) | 0.059386 / 0.043533 (0.015853) | 0.381398 / 0.255139 (0.126259) | 0.367603 / 0.283200 (0.084403) | 0.033907 / 0.141683 (-0.107775) | 1.628903 / 1.452155 (0.176749) | 1.764131 / 1.492716 (0.271415) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.298329 / 0.018006 (0.280322) | 0.593030 / 0.000490 (0.592540) | 0.007653 / 0.000200 (0.007453) | 0.000091 / 0.000054 (0.000036) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025445 / 0.037411 (-0.011966) | 0.112062 / 0.014526 (0.097536) | 0.119863 / 0.176557 (-0.056693) | 0.178389 / 0.737135 (-0.558746) | 0.129934 / 0.296338 (-0.166404) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.532834 / 0.215209 (0.317625) | 5.250908 / 2.077655 (3.173253) | 2.086920 / 1.504120 (0.582800) | 1.799745 / 1.541195 (0.258550) | 1.909648 / 1.468490 (0.441158) | 0.825382 / 4.584777 (-3.759395) | 5.268304 / 3.745712 (1.522592) | 2.533347 / 5.269862 (-2.736515) | 1.730187 / 4.565676 (-2.835490) | 0.099824 / 0.424275 (-0.324451) | 0.012969 / 0.007607 (0.005362) | 0.732234 / 0.226044 (0.506189) | 6.989066 / 2.268929 (4.720138) | 2.873486 / 55.444624 (-52.571138) | 2.274351 / 6.876477 (-4.602125) | 2.311060 / 2.142072 (0.168987) | 1.125366 / 4.805227 (-3.679861) | 0.214522 / 6.500664 (-6.286142) | 0.077579 / 0.075469 (0.002110) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.670950 / 1.841788 (-0.170838) | 18.131528 / 8.074308 (10.057220) | 21.277823 / 10.191392 (11.086431) | 0.238807 / 0.680424 (-0.441617) | 0.032251 / 0.534201 (-0.501950) | 0.503859 / 0.579283 (-0.075424) | 0.604825 / 0.434364 (0.170461) | 0.555623 / 0.540337 (0.015286) | 0.647301 / 1.386936 (-0.739635) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010857 / 0.011353 (-0.000496) | 0.005581 / 0.011008 (-0.005427) | 0.094346 / 0.038508 (0.055838) | 0.053084 / 0.023109 (0.029975) | 0.457586 / 0.275898 (0.181688) | 0.545475 / 0.323480 (0.221995) | 0.006761 / 0.007986 (-0.001225) | 0.005094 / 0.004328 (0.000765) | 0.095509 / 0.004250 (0.091258) | 0.077182 / 0.037052 (0.040130) | 0.498717 / 0.258489 (0.240228) | 0.542433 / 0.293841 (0.248592) | 0.051547 / 0.128546 (-0.076999) | 0.014633 / 0.075646 (-0.061014) | 0.106843 / 0.419271 (-0.312428) | 0.068459 / 0.043533 (0.024926) | 0.435793 / 0.255139 (0.180654) | 0.475484 / 0.283200 (0.192285) | 0.039495 / 0.141683 (-0.102188) | 1.684906 / 1.452155 (0.232751) | 1.798693 / 1.492716 (0.305976) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.279853 / 0.018006 (0.261847) | 0.601016 / 0.000490 (0.600526) | 0.002055 / 0.000200 (0.001855) | 0.000219 / 0.000054 (0.000165) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030935 / 0.037411 (-0.006477) | 0.121197 / 0.014526 (0.106671) | 0.143360 / 0.176557 (-0.033197) | 0.200862 / 0.737135 (-0.536274) | 0.138656 / 0.296338 (-0.157683) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.613904 / 0.215209 (0.398695) | 6.155422 / 2.077655 (4.077767) | 2.777238 / 1.504120 (1.273118) | 2.473045 / 1.541195 (0.931851) | 2.604470 / 1.468490 (1.135980) | 0.898871 / 4.584777 (-3.685906) | 5.739666 / 3.745712 (1.993954) | 4.719822 / 5.269862 (-0.550040) | 2.727354 / 4.565676 (-1.838322) | 0.108232 / 0.424275 (-0.316043) | 0.013632 / 0.007607 (0.006025) | 0.771802 / 0.226044 (0.545757) | 7.987466 / 2.268929 (5.718537) | 3.609856 / 55.444624 (-51.834768) | 2.974421 / 6.876477 (-3.902056) | 2.956567 / 2.142072 (0.814495) | 1.093792 / 4.805227 (-3.711435) | 0.213369 / 6.500664 (-6.287295) | 0.084486 / 0.075469 (0.009017) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.693855 / 1.841788 (-0.147933) | 18.055027 / 8.074308 (9.980719) | 21.397964 / 10.191392 (11.206571) | 0.240549 / 0.680424 (-0.439875) | 0.031212 / 0.534201 (-0.502989) | 0.513657 / 0.579283 (-0.065626) | 0.651348 / 0.434364 (0.216985) | 0.603740 / 0.540337 (0.063402) | 0.752287 / 1.386936 (-0.634649) |\n\n</details>\n</details>\n\n\n"
] | 2023-06-13T13:03:19Z
| 2023-06-27T16:47:51Z
| 2023-06-27T16:38:32Z
|
COLLABORATOR
| null | null | null |
Use `huggingface_hub`'s RepoCard API instead of `DatasetMetadata` for modifying the card's YAML, and deprecate `datasets.utils.metadata` and `datasets.utils.readme`.
After removing these modules, we can also delete `datasets.utils.resources` since the moon landing repo now stores its own version of these resources for the metadata UI.
PS: this change requires bumping `huggingface_hub` to 0.13.0 (Transformers requires 0.14.0, so should be ok)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5949/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5949/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5949.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5949",
"merged_at": "2023-06-27T16:38:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5949.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5949"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6656
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6656/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6656/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6656/events
|
https://github.com/huggingface/datasets/issues/6656
| 2,127,338,377
|
I_kwDODunzps5-zJuJ
| 6,656
|
Error when loading a big local json file
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10062216?v=4",
"events_url": "https://api.github.com/users/Riccorl/events{/privacy}",
"followers_url": "https://api.github.com/users/Riccorl/followers",
"following_url": "https://api.github.com/users/Riccorl/following{/other_user}",
"gists_url": "https://api.github.com/users/Riccorl/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Riccorl",
"id": 10062216,
"login": "Riccorl",
"node_id": "MDQ6VXNlcjEwMDYyMjE2",
"organizations_url": "https://api.github.com/users/Riccorl/orgs",
"received_events_url": "https://api.github.com/users/Riccorl/received_events",
"repos_url": "https://api.github.com/users/Riccorl/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Riccorl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Riccorl/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Riccorl",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"I get similar when dealing with a large jsonl file (6k lines), \r\n\r\n> TypeError: Couldn't cast array of type timestamp[us] to null\r\n\r\nYet when I split it into 1k lines, files, load_dataset works fine!\r\n\r\nhttps://github.com/huggingface/course/issues/692\r\n\r\n",
"What's the proposed solution? :-)"
] | 2024-02-09T15:14:21Z
| 2024-11-29T10:06:57Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
When trying to load big json files from a local directory, `load_dataset` throws the following error
```
Traceback (most recent call last):
File "/miniconda3/envs/conda-env/lib/python3.10/site-packages/datasets/builder.py", line 1989, in _prepare_split_single
writer.write_table(table)
File "miniconda3/envs/conda-env/lib/python3.10/site-packages/datasets/arrow_writer.py", line 573, in write_table
pa_table = pa_table.combine_chunks()
File "pyarrow/table.pxi", line 3638, in pyarrow.lib.Table.combine_chunks
File "pyarrow/error.pxi", line 154, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 91, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: offset overflow while concatenating arrays
```
### Steps to reproduce the bug
1. Download a big file, e.g. `https://dl.fbaipublicfiles.com/dpr/data/retriever/biencoder-nq-train.json.gz`
2. Load it like `data = load_dataset("json", data_files=["nq-train.json"], split="train")`
```python
from datasets import load_dataset
data = load_dataset("json", data_files=["nq-train.json"], split="train")
```
A similarly formatted but smaller file, e.g. e.g. `https://dl.fbaipublicfiles.com/dpr/data/retriever/biencoder-nq-dev.json.gz` is loaded without issues
```python
from datasets import load_dataset
data = load_dataset("json", data_files=["nq-dev.json"], split="train")
```
### Expected behavior
It should load normally
### Environment info
- `datasets` version: 2.16.1
- Platform: Linux-5.18.10-76051810-generic-x86_64-with-glibc2.31
- Python version: 3.10.13
- `huggingface_hub` version: 0.20.3
- PyArrow version: 15.0.0
- Pandas version: 2.2.0
- `fsspec` version: 2023.10.0
| null |
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6656/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6656/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6692
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6692/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6692/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6692/events
|
https://github.com/huggingface/datasets/pull/6692
| 2,152,270,987
|
PR_kwDODunzps5n0XN1
| 6,692
|
Enhancement: Enable loading TSV files in load_dataset()
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/77767961?v=4",
"events_url": "https://api.github.com/users/harsh1504660/events{/privacy}",
"followers_url": "https://api.github.com/users/harsh1504660/followers",
"following_url": "https://api.github.com/users/harsh1504660/following{/other_user}",
"gists_url": "https://api.github.com/users/harsh1504660/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/harsh1504660",
"id": 77767961,
"login": "harsh1504660",
"node_id": "MDQ6VXNlcjc3NzY3OTYx",
"organizations_url": "https://api.github.com/users/harsh1504660/orgs",
"received_events_url": "https://api.github.com/users/harsh1504660/received_events",
"repos_url": "https://api.github.com/users/harsh1504660/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/harsh1504660/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/harsh1504660/subscriptions",
"type": "User",
"url": "https://api.github.com/users/harsh1504660",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi @harsh1504660,\r\n\r\nThanks for your work, but this functionality already exists. See my comment in the corresponding issue: https://github.com/huggingface/datasets/issues/6691#issuecomment-1963449923\r\n\r\nNext time you would like to contribute, I would suggest you take on an issue that is previously validated by one of the maintainers. Thanks anyway."
] | 2024-02-24T11:38:59Z
| 2024-02-26T15:33:50Z
| 2024-02-26T07:14:03Z
|
NONE
| null | null | null |
Fix #6691
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6692/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6692/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6692.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6692",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6692.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6692"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4779
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4779/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4779/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4779/events
|
https://github.com/huggingface/datasets/issues/4779
| 1,325,997,225
|
I_kwDODunzps5PCRyp
| 4,779
|
Loading natural_questions requires apache_beam even with existing preprocessed data
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
| null |
[] | null |
[] | 2022-08-02T15:06:57Z
| 2022-08-02T16:03:18Z
| 2022-08-02T16:03:18Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
## Describe the bug
When loading "natural_questions", the package "apache_beam" is required:
```
ImportError: To be able to use natural_questions, you need to install the following dependency: apache_beam.
Please install it using 'pip install apache_beam' for instance'
```
This requirement is unnecessary, once there exists preprocessed data and the script just needs to download it.
## Steps to reproduce the bug
```python
load_dataset("natural_questions", "dev", split="validation", revision="main")
```
## Expected results
No ImportError raised.
## Actual results
```
ImportError Traceback (most recent call last)
[<ipython-input-3-c938e7c05d02>](https://localhost:8080/#) in <module>()
----> 1 from datasets import load_dataset; ds = load_dataset("natural_questions", "dev", split="validation", revision="main")
[/usr/local/lib/python3.7/dist-packages/datasets/load.py](https://localhost:8080/#) in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, **config_kwargs)
1732 revision=revision,
1733 use_auth_token=use_auth_token,
-> 1734 **config_kwargs,
1735 )
1736
[/usr/local/lib/python3.7/dist-packages/datasets/load.py](https://localhost:8080/#) in load_dataset_builder(path, name, data_dir, data_files, cache_dir, features, download_config, download_mode, revision, use_auth_token, **config_kwargs)
1504 download_mode=download_mode,
1505 data_dir=data_dir,
-> 1506 data_files=data_files,
1507 )
1508
[/usr/local/lib/python3.7/dist-packages/datasets/load.py](https://localhost:8080/#) in dataset_module_factory(path, revision, download_config, download_mode, dynamic_modules_path, data_dir, data_files, **download_kwargs)
1245 f"Couldn't find '{path}' on the Hugging Face Hub either: {type(e1).__name__}: {e1}"
1246 ) from None
-> 1247 raise e1 from None
1248 else:
1249 raise FileNotFoundError(
[/usr/local/lib/python3.7/dist-packages/datasets/load.py](https://localhost:8080/#) in dataset_module_factory(path, revision, download_config, download_mode, dynamic_modules_path, data_dir, data_files, **download_kwargs)
1180 download_config=download_config,
1181 download_mode=download_mode,
-> 1182 dynamic_modules_path=dynamic_modules_path,
1183 ).get_module()
1184 elif path.count("/") == 1: # community dataset on the Hub
[/usr/local/lib/python3.7/dist-packages/datasets/load.py](https://localhost:8080/#) in get_module(self)
490 base_path=hf_github_url(path=self.name, name="", revision=revision),
491 imports=imports,
--> 492 download_config=self.download_config,
493 )
494 additional_files = [(config.DATASETDICT_INFOS_FILENAME, dataset_infos_path)] if dataset_infos_path else []
[/usr/local/lib/python3.7/dist-packages/datasets/load.py](https://localhost:8080/#) in _download_additional_modules(name, base_path, imports, download_config)
214 _them_str = "them" if len(needs_to_be_installed) > 1 else "it"
215 raise ImportError(
--> 216 f"To be able to use {name}, you need to install the following {_depencencies_str}: "
217 f"{', '.join(needs_to_be_installed)}.\nPlease install {_them_str} using 'pip install "
218 f"{' '.join(needs_to_be_installed.values())}' for instance'"
ImportError: To be able to use natural_questions, you need to install the following dependency: apache_beam.
Please install it using 'pip install apache_beam' for instance'
```
## Environment info
Colab notebook.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4779/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4779/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/7452
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7452/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7452/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7452/events
|
https://github.com/huggingface/datasets/pull/7452
| 2,920,354,783
|
PR_kwDODunzps6Orhw4
| 7,452
|
minor docs changes
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7452). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update."
] | 2025-03-14T14:14:04Z
| 2025-03-14T14:16:38Z
| 2025-03-14T14:14:20Z
|
MEMBER
| null | null | null |
before the release
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7452/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7452/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7452.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7452",
"merged_at": "2025-03-14T14:14:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7452.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7452"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6554
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6554/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6554/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6554/events
|
https://github.com/huggingface/datasets/issues/6554
| 2,063,839,916
|
I_kwDODunzps57A7Ks
| 6,554
|
Parquet exports are used even if revision is passed
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[
"I don't think this bug is a thing ? Do you have some code that leads to this issue ?"
] | 2024-01-03T11:32:26Z
| 2024-02-02T10:35:29Z
| 2024-02-02T10:35:29Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
We should not used Parquet exports if `revision` is passed.
I think this is a regression.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6554/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6554/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/4971
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4971/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4971/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4971/events
|
https://github.com/huggingface/datasets/pull/4971
| 1,370,319,516
|
PR_kwDODunzps4-zk3g
| 4,971
|
Preserve non-`input_colums` in `Dataset.map` if `input_columns` are specified
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-12T18:08:24Z
| 2022-09-13T13:51:08Z
| 2022-09-13T13:48:45Z
|
COLLABORATOR
| null | null | null |
Currently, if the `input_columns` list in `Dataset.map` is specified, the columns not in that list are dropped after the `map` transform.
This makes the behavior inconsistent with `IterableDataset.map`.
(It seems this issue was introduced by mistake in https://github.com/huggingface/datasets/pull/2246)
Fix https://github.com/huggingface/datasets/issues/4858
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4971/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4971/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4971.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4971",
"merged_at": "2022-09-13T13:48:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4971.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4971"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7535
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7535/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7535/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7535/events
|
https://github.com/huggingface/datasets/pull/7535
| 3,018,289,872
|
PR_kwDODunzps6T0lm3
| 7,535
|
Change dill version in requirements
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/98061329?v=4",
"events_url": "https://api.github.com/users/JGrel/events{/privacy}",
"followers_url": "https://api.github.com/users/JGrel/followers",
"following_url": "https://api.github.com/users/JGrel/following{/other_user}",
"gists_url": "https://api.github.com/users/JGrel/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JGrel",
"id": 98061329,
"login": "JGrel",
"node_id": "U_kgDOBdhMEQ",
"organizations_url": "https://api.github.com/users/JGrel/orgs",
"received_events_url": "https://api.github.com/users/JGrel/received_events",
"repos_url": "https://api.github.com/users/JGrel/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JGrel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JGrel/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JGrel",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7535). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update."
] | 2025-04-24T19:44:28Z
| 2025-04-25T09:31:44Z
| null |
NONE
| null | null | null |
Change dill version to >=0.3.9,<0.4.5 and check for errors
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7535/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7535/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7535.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7535",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7535.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7535"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6534
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6534/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6534/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6534/events
|
https://github.com/huggingface/datasets/issues/6534
| 2,056,002,548
|
I_kwDODunzps56jBv0
| 6,534
|
How to configure multiple folders in the same zip package
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12895488?v=4",
"events_url": "https://api.github.com/users/d710055071/events{/privacy}",
"followers_url": "https://api.github.com/users/d710055071/followers",
"following_url": "https://api.github.com/users/d710055071/following{/other_user}",
"gists_url": "https://api.github.com/users/d710055071/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/d710055071",
"id": 12895488,
"login": "d710055071",
"node_id": "MDQ6VXNlcjEyODk1NDg4",
"organizations_url": "https://api.github.com/users/d710055071/orgs",
"received_events_url": "https://api.github.com/users/d710055071/received_events",
"repos_url": "https://api.github.com/users/d710055071/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/d710055071/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/d710055071/subscriptions",
"type": "User",
"url": "https://api.github.com/users/d710055071",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"@albertvillanova"
] | 2023-12-26T03:56:20Z
| 2023-12-26T06:31:16Z
| null |
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
How should I write "config" in readme when all the data, such as train test, is in a zip file
train floder and test floder in data.zip
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6534/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6534/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5054
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5054/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5054/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5054/events
|
https://github.com/huggingface/datasets/pull/5054
| 1,394,152,728
|
PR_kwDODunzps5ABnd3
| 5,054
|
Fix license/citation information of squadshifts dataset card
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-03T05:19:13Z
| 2022-10-03T09:26:49Z
| 2022-10-03T09:24:30Z
|
MEMBER
| null | null | null |
This PR fixes the license/citation information of squadshifts dataset card, once the dataset owners have responded to our request for information:
- https://github.com/modestyachts/squadshifts-website/issues/1
Additionally, we have updated the mention in their website to our `datasets` library (they were referring old name `nlp`):
- https://github.com/modestyachts/squadshifts-website/pull/2#event-7500953009
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5054/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5054/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5054.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5054",
"merged_at": "2022-10-03T09:24:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5054.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5054"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6447
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6447/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6447/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6447/events
|
https://github.com/huggingface/datasets/issues/6447
| 2,008,195,298
|
I_kwDODunzps53sqDi
| 6,447
|
Support one dataset loader per config when using YAML
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
| null |
[] | null |
[] | 2023-11-23T13:03:07Z
| 2023-11-23T13:03:07Z
| null |
COLLABORATOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
See https://huggingface.co/datasets/datasets-examples/doc-unsupported-1
I would like to use CSV loader for the "csv" config, JSONL loader for the "jsonl" config, etc.
### Motivation
It would be more flexible for the users
### Your contribution
No specific contribution
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6447/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6447/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5895
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5895/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5895/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5895/events
|
https://github.com/huggingface/datasets/issues/5895
| 1,725,467,252
|
I_kwDODunzps5m2Ip0
| 5,895
|
The dir name and split strings are confused when loading ArmelR/stack-exchange-instruction dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/45357817?v=4",
"events_url": "https://api.github.com/users/DongHande/events{/privacy}",
"followers_url": "https://api.github.com/users/DongHande/followers",
"following_url": "https://api.github.com/users/DongHande/following{/other_user}",
"gists_url": "https://api.github.com/users/DongHande/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/DongHande",
"id": 45357817,
"login": "DongHande",
"node_id": "MDQ6VXNlcjQ1MzU3ODE3",
"organizations_url": "https://api.github.com/users/DongHande/orgs",
"received_events_url": "https://api.github.com/users/DongHande/received_events",
"repos_url": "https://api.github.com/users/DongHande/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/DongHande/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DongHande/subscriptions",
"type": "User",
"url": "https://api.github.com/users/DongHande",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Thanks for reporting, @DongHande.\r\n\r\nI think the issue is caused by the metadata in the dataset card: in the header of the `README.md`, they state that the dataset has 4 splits (\"finetune\", \"reward\", \"rl\", \"evaluation\"). \r\n```yaml\r\n splits:\r\n - name: finetune\r\n num_bytes: 6674567576\r\n num_examples: 3000000\r\n - name: reward\r\n num_bytes: 6674341521\r\n num_examples: 3000000\r\n - name: rl\r\n num_bytes: 6679279968\r\n num_examples: 3000000\r\n - name: evaluation\r\n num_bytes: 4022714493\r\n num_examples: 1807695\r\n```\r\n\r\n\r\nI guess the user wanted to define these as configs, instead of splits. This is not yet supported for no-script datasets, but will be soon supported. See:\r\n- #5331\r\n\r\nI think we should contact the dataset author to inform about the issue with the split names, as you already did: https://huggingface.co/datasets/ArmelR/stack-exchange-instruction/discussions/1\r\nLet's continue the discussion there!",
"Thank you! It has been fixed. "
] | 2023-05-25T09:39:06Z
| 2023-05-29T02:32:12Z
| 2023-05-29T02:32:12Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
When I load the ArmelR/stack-exchange-instruction dataset, I encounter a bug that may be raised by confusing the dir name string and the split string about the dataset.
When I use the script "datasets.load_dataset('ArmelR/stack-exchange-instruction', data_dir="data/finetune", split="train", use_auth_token=True)", it fails. But it succeeds when I add the "streaming = True" parameter.
The website of the dataset is https://huggingface.co/datasets/ArmelR/stack-exchange-instruction/ .
The traceback logs are as below:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/load.py", line 1797, in load_dataset
builder_instance.download_and_prepare(
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/builder.py", line 890, in download_and_prepare
self._download_and_prepare(
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/builder.py", line 985, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/builder.py", line 1706, in _prepare_split
split_info = self.info.splits[split_generator.name]
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/splits.py", line 530, in __getitem__
instructions = make_file_instructions(
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/arrow_reader.py", line 112, in make_file_instructions
name2filenames = {
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/arrow_reader.py", line 113, in <dictcomp>
info.name: filenames_for_dataset_split(
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/naming.py", line 70, in filenames_for_dataset_split
prefix = filename_prefix_for_split(dataset_name, split)
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/naming.py", line 54, in filename_prefix_for_split
if os.path.basename(name) != name:
File "/home/xxx/miniconda3/envs/code/lib/python3.9/posixpath.py", line 142, in basename
p = os.fspath(p)
TypeError: expected str, bytes or os.PathLike object, not NoneType
### Steps to reproduce the bug
1. import datasets library function: ```from datasets import load_dataset```
2. load dataset: ```ds=load_dataset('ArmelR/stack-exchange-instruction', data_dir="data/finetune", split="train", use_auth_token=True)```
### Expected behavior
The dataset can be loaded successfully without the streaming setting.
### Environment info
Linux,
python=3.9
datasets=2.12.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/45357817?v=4",
"events_url": "https://api.github.com/users/DongHande/events{/privacy}",
"followers_url": "https://api.github.com/users/DongHande/followers",
"following_url": "https://api.github.com/users/DongHande/following{/other_user}",
"gists_url": "https://api.github.com/users/DongHande/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/DongHande",
"id": 45357817,
"login": "DongHande",
"node_id": "MDQ6VXNlcjQ1MzU3ODE3",
"organizations_url": "https://api.github.com/users/DongHande/orgs",
"received_events_url": "https://api.github.com/users/DongHande/received_events",
"repos_url": "https://api.github.com/users/DongHande/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/DongHande/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DongHande/subscriptions",
"type": "User",
"url": "https://api.github.com/users/DongHande",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5895/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5895/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5079
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5079/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5079/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5079/events
|
https://github.com/huggingface/datasets/pull/5079
| 1,398,609,305
|
PR_kwDODunzps5AQemi
| 5,079
|
refactor: replace AssertionError with more meaningful exceptions (#5074)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20004072?v=4",
"events_url": "https://api.github.com/users/galbwe/events{/privacy}",
"followers_url": "https://api.github.com/users/galbwe/followers",
"following_url": "https://api.github.com/users/galbwe/following{/other_user}",
"gists_url": "https://api.github.com/users/galbwe/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/galbwe",
"id": 20004072,
"login": "galbwe",
"node_id": "MDQ6VXNlcjIwMDA0MDcy",
"organizations_url": "https://api.github.com/users/galbwe/orgs",
"received_events_url": "https://api.github.com/users/galbwe/received_events",
"repos_url": "https://api.github.com/users/galbwe/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/galbwe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/galbwe/subscriptions",
"type": "User",
"url": "https://api.github.com/users/galbwe",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-06T01:39:35Z
| 2022-10-07T14:35:43Z
| 2022-10-07T14:33:10Z
|
CONTRIBUTOR
| null | null | null |
Closes #5074
Replaces `AssertionError` in the following files with more descriptive exceptions:
- `src/datasets/arrow_reader.py`
- `src/datasets/builder.py`
- `src/datasets/utils/version.py`
The issue listed more files that needed to be fixed, but the rest of them were contained in the top-level `datasets` directory, which was removed when #4974 was merged
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5079/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5079/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5079.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5079",
"merged_at": "2022-10-07T14:33:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5079.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5079"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7478
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7478/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7478/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7478/events
|
https://github.com/huggingface/datasets/pull/7478
| 2,948,993,461
|
PR_kwDODunzps6QLPe3
| 7,478
|
update fsspec 2025.3.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/487783?v=4",
"events_url": "https://api.github.com/users/peteski22/events{/privacy}",
"followers_url": "https://api.github.com/users/peteski22/followers",
"following_url": "https://api.github.com/users/peteski22/following{/other_user}",
"gists_url": "https://api.github.com/users/peteski22/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/peteski22",
"id": 487783,
"login": "peteski22",
"node_id": "MDQ6VXNlcjQ4Nzc4Mw==",
"organizations_url": "https://api.github.com/users/peteski22/orgs",
"received_events_url": "https://api.github.com/users/peteski22/received_events",
"repos_url": "https://api.github.com/users/peteski22/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/peteski22/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/peteski22/subscriptions",
"type": "User",
"url": "https://api.github.com/users/peteski22",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Sorry for tagging you @lhoestq but since you merged the linked PR, I wondered if you might be able to help me get this triaged so it can be reviewed/rejected etc. 🙏🏼 ",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7478). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update."
] | 2025-03-26T09:53:05Z
| 2025-03-28T19:15:54Z
| 2025-03-28T15:51:55Z
|
CONTRIBUTOR
| null | null | null |
It appears there have been two releases of fsspec since this dependency was last updated, it would be great if Datasets could be updated so that it didn't hold back the usage of newer fsspec versions in consuming projects.
PR based on https://github.com/huggingface/datasets/pull/7352
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7478/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7478/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7478.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7478",
"merged_at": "2025-03-28T15:51:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7478.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7478"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5750
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5750/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5750/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5750/events
|
https://github.com/huggingface/datasets/issues/5750
| 1,668,289,067
|
I_kwDODunzps5jcBIr
| 5,750
|
Fail to create datasets from a generator when using Google Big Query
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/895720?v=4",
"events_url": "https://api.github.com/users/ivanprado/events{/privacy}",
"followers_url": "https://api.github.com/users/ivanprado/followers",
"following_url": "https://api.github.com/users/ivanprado/following{/other_user}",
"gists_url": "https://api.github.com/users/ivanprado/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ivanprado",
"id": 895720,
"login": "ivanprado",
"node_id": "MDQ6VXNlcjg5NTcyMA==",
"organizations_url": "https://api.github.com/users/ivanprado/orgs",
"received_events_url": "https://api.github.com/users/ivanprado/received_events",
"repos_url": "https://api.github.com/users/ivanprado/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ivanprado/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ivanprado/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ivanprado",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"`from_generator` expects a generator function, not a generator object, so this should work:\r\n```python\r\nfrom datasets import Dataset\r\nfrom google.cloud import bigquery\r\n\r\nclient = bigquery.Client()\r\n\r\ndef gen()\r\n # Perform a query.\r\n QUERY = (\r\n 'SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` '\r\n 'WHERE state = \"TX\" '\r\n 'LIMIT 100')\r\n query_job = client.query(QUERY) # API request\r\n yield from query_job.result() # Waits for query to finish\r\n\r\nds = Dataset.from_generator(rows)\r\n\r\nfor r in ds:\r\n print(r)\r\n```",
"@mariosasko your code was incomplete, so I tried to fix it:\r\n\r\n```py\r\nfrom datasets import Dataset\r\nfrom google.cloud import bigquery\r\n\r\nclient = bigquery.Client()\r\n\r\ndef gen():\r\n # Perform a query.\r\n QUERY = (\r\n 'SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` '\r\n 'WHERE state = \"TX\" '\r\n 'LIMIT 100')\r\n query_job = client.query(QUERY) # API request\r\n yield from query_job.result() # Waits for query to finish\r\n\r\nds = Dataset.from_generator(gen)\r\n\r\nfor r in ds:\r\n print(r)\r\n```\r\n\r\nThe error is also present in this case:\r\n\r\n```\r\n_pickle.PicklingError: Pickling client objects is explicitly not supported.\r\nClients have non-trivial state that is local and unpickleable.\r\n```\r\n\r\nI think it doesn't matter if the generator is an object or a function. The problem is that the generator is referencing an object that is not pickable (the client in this case). ",
"It does matter: this function expects a generator function, as stated in the docs.\r\n\r\nThis should work:\r\n```python\r\nfrom datasets import Dataset\r\nfrom google.cloud import bigquery\r\n\r\ndef gen():\r\n client = bigquery.Client()\r\n # Perform a query.\r\n QUERY = (\r\n 'SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` '\r\n 'WHERE state = \"TX\" '\r\n 'LIMIT 100')\r\n query_job = client.query(QUERY) # API request\r\n yield from query_job.result() # Waits for query to finish\r\n\r\nds = Dataset.from_generator(gen)\r\n\r\nfor r in ds:\r\n print(r)\r\n```\r\n\r\nWe could allow passing non-picklable objects and use a random hash for the generated arrow file. In that case, the caching mechanism would not work, meaning repeated calls with the same set of arguments would generate new datasets instead of reusing the cached version, but this behavior is still better than raising an error.",
"Thank you @mariosasko . Your last code is working indeed. Curiously, the important detail here was to wrap the client instantiation within the generator itself. If the line `client = bigquery.Client()` is moved outside, then the error is back.\r\n\r\nI see now also your point in regard to the generator being a generator function. We can close the issue if you want."
] | 2023-04-14T13:50:59Z
| 2023-04-17T12:20:43Z
| 2023-04-17T12:20:43Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Creating a dataset from a generator using `Dataset.from_generator()` fails if the generator is the [Google Big Query Python client](https://cloud.google.com/python/docs/reference/bigquery/latest). The problem is that the Big Query client is not pickable. And the function `create_config_id` tries to get a hash of the generator by pickling it. So the following error is generated:
```
_pickle.PicklingError: Pickling client objects is explicitly not supported.
Clients have non-trivial state that is local and unpickleable.
```
### Steps to reproduce the bug
1. Install the big query client and datasets `pip install google-cloud-bigquery datasets`
2. Run the following code:
```py
from datasets import Dataset
from google.cloud import bigquery
client = bigquery.Client()
# Perform a query.
QUERY = (
'SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` '
'WHERE state = "TX" '
'LIMIT 100')
query_job = client.query(QUERY) # API request
rows = query_job.result() # Waits for query to finish
ds = Dataset.from_generator(rows)
for r in ds:
print(r)
```
### Expected behavior
Two options:
1. Ignore the pickle errors when computing the hash
2. Provide a scape hutch so that we can avoid calculating the hash for the generator. For example, allowing to provide a hash from the user.
### Environment info
python 3.9
google-cloud-bigquery 3.9.0
datasets 2.11.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5750/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5750/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/4945
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4945/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4945/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4945/events
|
https://github.com/huggingface/datasets/issues/4945
| 1,364,691,096
|
I_kwDODunzps5RV4iY
| 4,945
|
Push to hub can push splits that do not respect the regex
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/LysandreJik",
"id": 30755778,
"login": "LysandreJik",
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"type": "User",
"url": "https://api.github.com/users/LysandreJik",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
| null |
[] | null |
[] | 2022-09-07T13:45:17Z
| 2022-09-13T10:16:35Z
| 2022-09-13T10:16:35Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
## Describe the bug
The `push_to_hub` method can push splits that do not respect the regex check that is used for downloads. Therefore, splits may be pushed but never re-used, which can be painful if the split was done after runtime preprocessing.
## Steps to reproduce the bug
```python
>>> from datasets import Dataset, DatasetDict, load_dataset
>>> d = Dataset.from_dict({'x': [1,2,3], 'y': [1,2,3]})
>>> di = DatasetDict()
>>> di['identifier-with-column'] = d
>>> di.push_to_hub('open-source-metrics/test')
Pushing split identifier-with-column to the Hub.
Pushing dataset shards to the dataset hub: 100%|██████████| 1/1 [00:04<00:00, 4.40s/it]
```
Loading it afterwards:
```python
>>> load_dataset('open-source-metrics/test')
Downloading: 100%|██████████| 610/610 [00:00<00:00, 432kB/s]
Using custom data configuration open-source-metrics--test-28b63ec7cde80488
Downloading and preparing dataset None/None (download: 950 bytes, generated: 48 bytes, post-processed: Unknown size, total: 998 bytes) to /home/lysandre/.cache/huggingface/datasets/open-source-metrics___parquet/open-source-metrics--test-28b63ec7cde80488/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec...
Downloading data files: 0%| | 0/1 [00:00<?, ?it/s]
Downloading data: 100%|██████████| 950/950 [00:00<00:00, 1.01MB/s]
Downloading data files: 100%|██████████| 1/1 [00:01<00:00, 1.48s/it]
Extracting data files: 100%|██████████| 1/1 [00:00<00:00, 2291.97it/s]
Traceback (most recent call last):
File "/home/lysandre/.pyenv/versions/3.10.6/lib/python3.10/code.py", line 90, in runcode
exec(code, self.locals)
File "<input>", line 1, in <module>
File "/home/lysandre/Workspaces/python/Metrics/GitHub-Metrics/.env/lib/python3.10/site-packages/datasets/load.py", line 1746, in load_dataset
builder_instance.download_and_prepare(
File "/home/lysandre/Workspaces/python/Metrics/GitHub-Metrics/.env/lib/python3.10/site-packages/datasets/builder.py", line 704, in download_and_prepare
self._download_and_prepare(
File "/home/lysandre/Workspaces/python/Metrics/GitHub-Metrics/.env/lib/python3.10/site-packages/datasets/builder.py", line 771, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/home/lysandre/Workspaces/python/Metrics/GitHub-Metrics/.env/lib/python3.10/site-packages/datasets/packaged_modules/parquet/parquet.py", line 48, in _split_generators
splits.append(datasets.SplitGenerator(name=split_name, gen_kwargs={"files": files}))
File "<string>", line 5, in __init__
File "/home/lysandre/Workspaces/python/Metrics/GitHub-Metrics/.env/lib/python3.10/site-packages/datasets/splits.py", line 599, in __post_init__
NamedSplit(self.name) # check that it's a valid split name
File "/home/lysandre/Workspaces/python/Metrics/GitHub-Metrics/.env/lib/python3.10/site-packages/datasets/splits.py", line 346, in __init__
raise ValueError(f"Split name should match '{_split_re}' but got '{split_name}'.")
ValueError: Split name should match '^\w+(\.\w+)*$' but got 'identifier-with-column'.
```
## Expected results
I would expect `push_to_hub` to stop me in my tracks if trying to upload a split that will not be working afterwards.
## Actual results
See above
## Environment info
- `datasets` version: 2.4.0
- Platform: Linux-5.15.64-1-lts-x86_64-with-glibc2.36
- Python version: 3.10.6
- PyArrow version: 9.0.0
- Pandas version: 1.4.4
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4945/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4945/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/7243
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7243/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7243/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7243/events
|
https://github.com/huggingface/datasets/issues/7243
| 2,602,853,172
|
I_kwDODunzps6bJGM0
| 7,243
|
ArrayXD with None as leading dim incompatible with DatasetCardData
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5719745?v=4",
"events_url": "https://api.github.com/users/alex-hh/events{/privacy}",
"followers_url": "https://api.github.com/users/alex-hh/followers",
"following_url": "https://api.github.com/users/alex-hh/following{/other_user}",
"gists_url": "https://api.github.com/users/alex-hh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/alex-hh",
"id": 5719745,
"login": "alex-hh",
"node_id": "MDQ6VXNlcjU3MTk3NDU=",
"organizations_url": "https://api.github.com/users/alex-hh/orgs",
"received_events_url": "https://api.github.com/users/alex-hh/received_events",
"repos_url": "https://api.github.com/users/alex-hh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/alex-hh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alex-hh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/alex-hh",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"It looks like `CardData` in `huggingface_hub` removes None values where it shouldn't. Indeed it calls `_remove_none` on the return of `to_dict()`:\r\n\r\n```python\r\n def to_dict(self) -> Dict[str, Any]:\r\n \"\"\"Converts CardData to a dict.\r\n\r\n Returns:\r\n `dict`: CardData represented as a dictionary ready to be dumped to a YAML\r\n block for inclusion in a README.md file.\r\n \"\"\"\r\n\r\n data_dict = copy.deepcopy(self.__dict__)\r\n self._to_dict(data_dict)\r\n return _remove_none(data_dict)\r\n```\r\n\r\nWould it be ok to remove `list()` from being scanned in `_remove_none` ? it could also be a specific behavior to DatasetCardData if necessary @Wauplin ",
"I have actually no idea why none values are removed in model and dataset card data... :see_no_evil:\r\nLooks like `_remove_none` has been introduced at the same time as the entire repocard module (see https://github.com/huggingface/huggingface_hub/pull/940). I would be tempted to remove `_remove_none` entirely actually and only remove \"top-level\" None values (i.e. if something like `pipeline_tag=None` due to a default value in kwargs => we remove it). Hard to tell what could be the side effects but I'm not against trying.\r\n\r\n\r\nHowever, I'm not really in favor in making an exception only for lists. It would mean that tuples, sets and dicts are filtered but not lists, which is pretty inconsistent.",
"let's do it for top level attributes yes",
"I opened https://github.com/huggingface/huggingface_hub/pull/2626 to address it :)",
"thanks !"
] | 2024-10-21T15:08:13Z
| 2024-10-22T14:18:10Z
| null |
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Creating a dataset with ArrayXD features leads to errors when downloading from hub due to DatasetCardData removing the Nones
@lhoestq
### Steps to reproduce the bug
```python
import numpy as np
from datasets import Array2D, Dataset, Features, load_dataset
def examples_generator():
for i in range(4):
yield {
"array_1d": np.zeros((10,1), dtype="uint16"),
"array_2d": np.zeros((10, 1), dtype="uint16"),
}
features = Features(array_1d=Array2D((None,1), "uint16"), array_2d=Array2D((None, 1), "uint16"))
dataset = Dataset.from_generator(examples_generator, features=features)
dataset.push_to_hub("alex-hh/test_array_1d2d")
ds = load_dataset("alex-hh/test_array_1d2d")
```
Source of error appears to be DatasetCardData.to_dict invoking DatasetCardData._remove_none
```python
from huggingface_hub import DatasetCardData
from datasets.info import DatasetInfosDict
dataset_card_data = DatasetCardData()
DatasetInfosDict({"default": dataset.info.copy()}).to_dataset_card_data(dataset_card_data)
print(dataset_card_data.to_dict()) # removes Nones in shape
```
### Expected behavior
Should be possible to load datasets saved with shape None in leading dimension
### Environment info
3.0.2 and latest huggingface_hub
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7243/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7243/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5744
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5744/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5744/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5744/events
|
https://github.com/huggingface/datasets/issues/5744
| 1,667,076,620
|
I_kwDODunzps5jXZIM
| 5,744
|
[BUG] With Pandas 2.0.0, `load_dataset` raises `TypeError: read_csv() got an unexpected keyword argument 'mangle_dupe_cols'`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/15572698?v=4",
"events_url": "https://api.github.com/users/keyboardAnt/events{/privacy}",
"followers_url": "https://api.github.com/users/keyboardAnt/followers",
"following_url": "https://api.github.com/users/keyboardAnt/following{/other_user}",
"gists_url": "https://api.github.com/users/keyboardAnt/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/keyboardAnt",
"id": 15572698,
"login": "keyboardAnt",
"node_id": "MDQ6VXNlcjE1NTcyNjk4",
"organizations_url": "https://api.github.com/users/keyboardAnt/orgs",
"received_events_url": "https://api.github.com/users/keyboardAnt/received_events",
"repos_url": "https://api.github.com/users/keyboardAnt/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/keyboardAnt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/keyboardAnt/subscriptions",
"type": "User",
"url": "https://api.github.com/users/keyboardAnt",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[
"Thanks for reporting, @keyboardAnt.\r\n\r\nWe haven't noticed any crash in our CI tests. Could you please indicate specifically the `load_dataset` command that crashes in your side, so that we can reproduce it?",
"This has been fixed in `datasets` 2.11",
"I am still getting this bug with the latest pandas and datasets lib installed. Anyone else?\r\n```\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"csv\", data_files={\"train\":\"/kaggle/working/train.csv\", \"test\":\"/kaggle/working/test.csv\"})\r\nprint(dataset)\r\n\r\n\r\n\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\nCell In[5], line 3\r\n 1 from datasets import load_dataset\r\n----> 3 dataset = load_dataset(\"csv\", data_files={\"train\":\"/kaggle/working/train.csv\", \"test\":\"/kaggle/working/test.csv\"})\r\n 4 print(dataset)\r\n\r\nFile /opt/conda/lib/python3.10/site-packages/datasets/load.py:1691, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, **config_kwargs)\r\n 1688 try_from_hf_gcs = path not in _PACKAGED_DATASETS_MODULES\r\n 1690 # Download and prepare data\r\n-> 1691 builder_instance.download_and_prepare(\r\n 1692 download_config=download_config,\r\n 1693 download_mode=download_mode,\r\n 1694 ignore_verifications=ignore_verifications,\r\n 1695 try_from_hf_gcs=try_from_hf_gcs,\r\n 1696 use_auth_token=use_auth_token,\r\n 1697 )\r\n 1699 # Build dataset for splits\r\n 1700 keep_in_memory = (\r\n 1701 keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)\r\n 1702 )\r\n\r\nFile /opt/conda/lib/python3.10/site-packages/datasets/builder.py:605, in DatasetBuilder.download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)\r\n 603 logger.warning(\"HF google storage unreachable. Downloading and preparing it from source\")\r\n 604 if not downloaded_from_gcs:\r\n--> 605 self._download_and_prepare(\r\n 606 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs\r\n 607 )\r\n 608 # Sync info\r\n 609 self.info.dataset_size = sum(split.num_bytes for split in self.info.splits.values())\r\n\r\nFile /opt/conda/lib/python3.10/site-packages/datasets/builder.py:694, in DatasetBuilder._download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)\r\n 690 split_dict.add(split_generator.split_info)\r\n 692 try:\r\n 693 # Prepare split will record examples associated to the split\r\n--> 694 self._prepare_split(split_generator, **prepare_split_kwargs)\r\n 695 except OSError as e:\r\n 696 raise OSError(\r\n 697 \"Cannot find data file. \"\r\n 698 + (self.manual_download_instructions or \"\")\r\n 699 + \"\\nOriginal error:\\n\"\r\n 700 + str(e)\r\n 701 ) from None\r\n\r\nFile /opt/conda/lib/python3.10/site-packages/datasets/builder.py:1151, in ArrowBasedBuilder._prepare_split(self, split_generator)\r\n 1149 generator = self._generate_tables(**split_generator.gen_kwargs)\r\n 1150 with ArrowWriter(features=self.info.features, path=fpath) as writer:\r\n-> 1151 for key, table in logging.tqdm(\r\n 1152 generator, unit=\" tables\", leave=False, disable=True # not logging.is_progress_bar_enabled()\r\n 1153 ):\r\n 1154 writer.write_table(table)\r\n 1155 num_examples, num_bytes = writer.finalize()\r\n\r\nFile /opt/conda/lib/python3.10/site-packages/tqdm/notebook.py:249, in tqdm_notebook.__iter__(self)\r\n 247 try:\r\n 248 it = super(tqdm_notebook, self).__iter__()\r\n--> 249 for obj in it:\r\n 250 # return super(tqdm...) will not catch exception\r\n 251 yield obj\r\n 252 # NB: except ... [ as ...] breaks IPython async KeyboardInterrupt\r\n\r\nFile /opt/conda/lib/python3.10/site-packages/tqdm/std.py:1170, in tqdm.__iter__(self)\r\n 1167 # If the bar is disabled, then just walk the iterable\r\n 1168 # (note: keep this check outside the loop for performance)\r\n 1169 if self.disable:\r\n-> 1170 for obj in iterable:\r\n 1171 yield obj\r\n 1172 return\r\n\r\nFile /opt/conda/lib/python3.10/site-packages/datasets/packaged_modules/csv/csv.py:154, in Csv._generate_tables(self, files)\r\n 152 dtype = {name: dtype.to_pandas_dtype() for name, dtype in zip(schema.names, schema.types)} if schema else None\r\n 153 for file_idx, file in enumerate(files):\r\n--> 154 csv_file_reader = pd.read_csv(file, iterator=True, dtype=dtype, **self.config.read_csv_kwargs)\r\n 155 try:\r\n 156 for batch_idx, df in enumerate(csv_file_reader):\r\n\r\nTypeError: read_csv() got an unexpected keyword argument 'mangle_dupe_cols'```",
"Feel free to update `datasets` to fix this issue\r\n\r\n```\r\npip install -U datasets\r\n```",
"I am still having the same issue with the version >= 2.14",
"Edit: Sorry, I found that our version is 2.2.1. Please ignore the following comment. This issue was already solved by this line:\r\nhttps://github.com/huggingface/datasets/blob/bf02cff8d70180a9e89328961ded9e3d8510fd22/src/datasets/packaged_modules/csv/csv.py#L18\r\n\r\n> This issue still exists as you can see in version 2.14:\r\n> https://github.com/huggingface/datasets/blob/bf02cff8d70180a9e89328961ded9e3d8510fd22/src/datasets/packaged_modules/csv/csv.py#L35\r\n> https://github.com/huggingface/datasets/blob/bf02cff8d70180a9e89328961ded9e3d8510fd22/src/datasets/packaged_modules/csv/csv.py#L84\r\n> that \"mangle_dupe_cols\" still exists in the arguments.\r\n> \r\n> And this error occurs at this line:\r\n> https://github.com/huggingface/datasets/blob/bf02cff8d70180a9e89328961ded9e3d8510fd22/src/datasets/packaged_modules/csv/csv.py#L185\r\n> where\r\n> ```python\r\n> file == '~/llama/llama-recipes/recipes/finetuning/gtrain_10k.csv'\r\n> dtype == None\r\n> self.config.pd_read_csv_kwargs == {\r\n> \"sep\": \",\",\r\n> \"header\": \"infer\",\r\n> \"index_col\": None,\r\n> \"usecols\": None,\r\n> \"mangle_dupe_cols\": True,\r\n> \"engine\": None,\r\n> \"true_values\": None,\r\n> \"false_values\": None,\r\n> \"skipinitialspace\": False,\r\n> \"skiprows\": None,\r\n> \"nrows\": None,\r\n> \"na_values\": None,\r\n> \"keep_default_na\": True,\r\n> \"na_filter\": True,\r\n> \"verbose\": False,\r\n> \"skip_blank_lines\": True,\r\n> \"thousands\": None,\r\n> \"decimal\": \".\",\r\n> \"lineterminator\": None,\r\n> \"quotechar\": '\"',\r\n> \"quoting\": 0,\r\n> \"escapechar\": None,\r\n> \"comment\": None,\r\n> \"encoding\": None,\r\n> \"dialect\": None,\r\n> \"skipfooter\": 0,\r\n> \"doublequote\": True,\r\n> \"memory_map\": False,\r\n> \"float_precision\": None,\r\n> \"chunksize\": 10000,\r\n> }\r\n> ```\r\n> for me.\r\n> \r\n> Here is where we got the error: https://github.com/meta-llama/llama-recipes/issues/426"
] | 2023-04-13T20:21:28Z
| 2024-04-09T16:13:59Z
| 2023-07-06T17:01:59Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
The `load_dataset` function with Pandas `1.5.3` has no issue (just a FutureWarning) but crashes with Pandas `2.0.0`.
For your convenience, I opened a draft Pull Request to fix it quickly: https://github.com/huggingface/datasets/pull/5745
---
* The FutureWarning mentioned above:
```
FutureWarning: the 'mangle_dupe_cols' keyword is deprecated and will be removed in a future version. Please take steps to stop the use of 'mangle_dupe_cols'
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 4,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5744/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5744/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6525
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6525/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6525/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6525/events
|
https://github.com/huggingface/datasets/pull/6525
| 2,053,119,357
|
PR_kwDODunzps5im-lL
| 6,525
|
BBox type
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6525). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"closing in favor of other ideas that would not involve any typing"
] | 2023-12-21T22:13:27Z
| 2024-01-11T06:34:51Z
| 2023-12-21T22:39:27Z
|
MEMBER
| null | null | null |
see [internal discussion](https://huggingface.slack.com/archives/C02EK7C3SHW/p1703097195609209)
Draft to get some feedback on a possible `BBox` feature type that can be used to get object detection bounding boxes data in one format or another.
```python
>>> from datasets import load_dataset, BBox
>>> ds = load_dataset("svhn", "full_numbers", split="train")
>>> ds[0]
{
'image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=107x46 at 0x126409BE0>,
'digits': {'bbox': [[38, 1, 21, 40], [57, 3, 16, 40]], 'label': [4, 6]}
}
>>> ds = ds.rename_column("digits", "annotations").cast_column("annotations", BBox(format="coco"))
>>> ds[0]
{
'image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=107x46 at 0x147730070>,
'annotations': [{'bbox': [38, 1, 21, 40], 'category_id': 4}, {'bbox': [57, 3, 16, 40], 'category_id': 6}]
}
```
note that it's a type for a list of bounding boxes, not just one - which would be needed to switch from a format to another using type casting.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6525/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6525/timeline
| null | null | 1
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6525.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6525",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6525.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6525"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4777
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4777/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4777/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4777/events
|
https://github.com/huggingface/datasets/pull/4777
| 1,324,548,784
|
PR_kwDODunzps48cByL
| 4,777
|
Require torchaudio<0.12.0 to avoid RuntimeError
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-08-01T14:50:50Z
| 2022-08-02T17:35:14Z
| 2022-08-02T17:21:39Z
|
MEMBER
| null | null | null |
Related to:
- https://github.com/huggingface/transformers/issues/18379
Fix partially #4776.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4777/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4777/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4777.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4777",
"merged_at": "2022-08-02T17:21:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4777.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4777"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6522
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6522/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6522/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6522/events
|
https://github.com/huggingface/datasets/issues/6522
| 2,052,332,528
|
I_kwDODunzps56VBvw
| 6,522
|
Loading HF Hub Dataset (private org repo) fails to load all features
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6579034?v=4",
"events_url": "https://api.github.com/users/versipellis/events{/privacy}",
"followers_url": "https://api.github.com/users/versipellis/followers",
"following_url": "https://api.github.com/users/versipellis/following{/other_user}",
"gists_url": "https://api.github.com/users/versipellis/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/versipellis",
"id": 6579034,
"login": "versipellis",
"node_id": "MDQ6VXNlcjY1NzkwMzQ=",
"organizations_url": "https://api.github.com/users/versipellis/orgs",
"received_events_url": "https://api.github.com/users/versipellis/received_events",
"repos_url": "https://api.github.com/users/versipellis/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/versipellis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/versipellis/subscriptions",
"type": "User",
"url": "https://api.github.com/users/versipellis",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[] | 2023-12-21T12:26:35Z
| 2023-12-21T13:24:31Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
When pushing a `Dataset` with multiple `Features` (`input`, `output`, `tags`) to Huggingface Hub (private org repo), and later downloading the `Dataset`, only `input` and `output` load - I believe the expected behavior is for all `Features` to be loaded by default?
### Steps to reproduce the bug
Pushing the data. `data_concat` is a `list` of `dict`s.
```python
for datum in data_concat:
datum_tags = {d["key"]: d["value"] for d in datum["tags"]}
split_fraction = # some logic that generates a train/test split number
if split_faction < test_fraction:
data_test.append(datum)
else:
data_train.append(datum)
dataset = DatasetDict(
{
"train": Dataset.from_list(data_train),
"test": Dataset.from_list(data_test),
"full": Dataset.from_list(data_concat),
},
)
dataset_shuffled = dataset.shuffle(seed=shuffle_seed)
dataset_shuffled.push_to_hub(
repo_id=hf_repo_id,
private=True,
config_name=m,
revision=revision,
token=hf_token,
)
```
Loading it later:
```python
dataset = datasets.load_dataset(
path=hf_repo_id,
name=name,
token=hf_token,
)
```
Produces:
```
DatasetDict({
train: Dataset({
features: ['input', 'output'],
num_rows: <obfuscated>
})
test: Dataset({
features: ['input', 'output'],
num_rows: <obfuscated>
})
full: Dataset({
features: ['input', 'output'],
num_rows: <obfuscated>
})
})
```
### Expected behavior
The expected result is below:
```
DatasetDict({
train: Dataset({
features: ['input', 'output', 'tags'],
num_rows: <obfuscated>
})
test: Dataset({
features: ['input', 'output', 'tags'],
num_rows: <obfuscated>
})
full: Dataset({
features: ['input', 'output', 'tags'],
num_rows: <obfuscated>
})
})
```
My workaround is as follows:
```python
dsinfo = datasets.get_dataset_config_info(
path=data_files,
config_name=data_config,
token=hf_token,
)
allfeatures = dsinfo.features.copy()
if "tags" not in allfeatures:
allfeatures["tags"] = [{"key": Value(dtype="string", id=None), "value": Value(dtype="string", id=None)}]
dataset = datasets.load_dataset(
path=data_files,
name=data_config,
features=allfeatures,
token=hf_token,
)
```
Interestingly enough (and perhaps a related bug?), if I don't add the `tags` to `allfeatures` above (i.e. only loading `input` and `output`), it throws an error when executing `load_dataset`:
```
ValueError: Couldn't cast
tags: list<element: struct<key: string, value: string>>
child 0, element: struct<key: string, value: string>
child 0, key: string
child 1, value: string
input: <obfuscated>
output: <obfuscated>
-- schema metadata --
huggingface: '{"info": {"features": {"tags": [{"key": {"dtype": "string",' + 532
to
{'input': <obfuscated>, 'output': <obfuscated>
because column names don't match
```
Traceback for this:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/bt/github/core/.venv/lib/python3.11/site-packages/datasets/load.py", line 2152, in load_dataset
builder_instance.download_and_prepare(
File "/Users/bt/github/core/.venv/lib/python3.11/site-packages/datasets/builder.py", line 948, in download_and_prepare
self._download_and_prepare(
File "/Users/bt/github/core/.venv/lib/python3.11/site-packages/datasets/builder.py", line 1043, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/Users/bt/github/core/.venv/lib/python3.11/site-packages/datasets/builder.py", line 1805, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/Users/bt/github/core/.venv/lib/python3.11/site-packages/datasets/builder.py", line 1950, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
```
### Environment info
- `datasets` version: 2.15.0
- Platform: macOS-14.0-arm64-arm-64bit
- Python version: 3.11.5
- `huggingface_hub` version: 0.19.4
- PyArrow version: 14.0.1
- Pandas version: 2.1.4
- `fsspec` version: 2023.10.0
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6522/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6522/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4763
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4763/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4763/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4763/events
|
https://github.com/huggingface/datasets/pull/4763
| 1,321,295,876
|
PR_kwDODunzps48RMKi
| 4,763
|
More rigorous shape inference in to_tf_dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Rocketknight1",
"id": 12866554,
"login": "Rocketknight1",
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Rocketknight1",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-07-28T18:04:15Z
| 2022-09-08T19:17:54Z
| 2022-09-08T19:15:41Z
|
MEMBER
| null | null | null |
`tf.data` needs to know the shape of tensors emitted from a `tf.data.Dataset`. Although `None` dimensions are possible, overusing them can cause problems - Keras uses the dataset tensor spec at compile-time, and so saying that a dimension is `None` when it's actually constant can hurt performance, or even cause training to fail for dimensions that are needed to determine the shape of weight tensors!
The compromise I used here was to sample several batches from the underlying dataset and apply the `collate_fn` to them, and then to see which dimensions were "empirically variable". There's an obvious problem here, though - if you sample 10 batches and they all have the same shape on a certain dimension, there's still a small chance that the 11th batch will be different, and Keras will throw an error if a dataset tries to emit a tensor whose shape doesn't match the spec.
I encountered this bug in practice once or twice for datasets that were mostly-but-not-totally constant on a given dimension, and I still don't have a perfect solution, but this PR should greatly reduce the risk. It samples many more batches, and also samples very small batches (size 2) - this increases the variability, making it more likely that a few outlier samples will be detected.
Ideally, of course, we'd determine the full output shape analytically, but that's surprisingly tricky when the `collate_fn` can be any arbitrary Python code!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Rocketknight1",
"id": 12866554,
"login": "Rocketknight1",
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Rocketknight1",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4763/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4763/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4763.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4763",
"merged_at": "2022-09-08T19:15:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4763.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4763"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7062
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7062/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7062/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7062/events
|
https://github.com/huggingface/datasets/pull/7062
| 2,424,467,484
|
PR_kwDODunzps52LUPR
| 7,062
|
Avoid calling http_head for non-HTTP URLs
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7062). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005591 / 0.011353 (-0.005761) | 0.003992 / 0.011008 (-0.007016) | 0.063932 / 0.038508 (0.025424) | 0.034572 / 0.023109 (0.011463) | 0.252532 / 0.275898 (-0.023366) | 0.271233 / 0.323480 (-0.052247) | 0.005146 / 0.007986 (-0.002840) | 0.002844 / 0.004328 (-0.001484) | 0.049555 / 0.004250 (0.045305) | 0.044111 / 0.037052 (0.007059) | 0.270131 / 0.258489 (0.011642) | 0.318109 / 0.293841 (0.024269) | 0.030247 / 0.128546 (-0.098300) | 0.012438 / 0.075646 (-0.063209) | 0.205160 / 0.419271 (-0.214112) | 0.036228 / 0.043533 (-0.007305) | 0.250664 / 0.255139 (-0.004475) | 0.263884 / 0.283200 (-0.019315) | 0.018141 / 0.141683 (-0.123541) | 1.128504 / 1.452155 (-0.323650) | 1.182543 / 1.492716 (-0.310173) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.094576 / 0.018006 (0.076570) | 0.301153 / 0.000490 (0.300664) | 0.000246 / 0.000200 (0.000046) | 0.000065 / 0.000054 (0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019143 / 0.037411 (-0.018268) | 0.062788 / 0.014526 (0.048262) | 0.074688 / 0.176557 (-0.101869) | 0.121799 / 0.737135 (-0.615336) | 0.076200 / 0.296338 (-0.220138) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.277002 / 0.215209 (0.061793) | 2.735738 / 2.077655 (0.658083) | 1.430408 / 1.504120 (-0.073712) | 1.309795 / 1.541195 (-0.231400) | 1.339083 / 1.468490 (-0.129407) | 0.702540 / 4.584777 (-3.882237) | 2.352468 / 3.745712 (-1.393244) | 2.913698 / 5.269862 (-2.356164) | 1.871739 / 4.565676 (-2.693938) | 0.077054 / 0.424275 (-0.347221) | 0.005055 / 0.007607 (-0.002552) | 0.330550 / 0.226044 (0.104505) | 3.272556 / 2.268929 (1.003627) | 1.805268 / 55.444624 (-53.639356) | 1.504791 / 6.876477 (-5.371686) | 1.511361 / 2.142072 (-0.630712) | 0.784451 / 4.805227 (-4.020776) | 0.132182 / 6.500664 (-6.368482) | 0.042516 / 0.075469 (-0.032954) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.946939 / 1.841788 (-0.894849) | 11.369607 / 8.074308 (3.295299) | 9.667350 / 10.191392 (-0.524042) | 0.138689 / 0.680424 (-0.541735) | 0.014416 / 0.534201 (-0.519785) | 0.300685 / 0.579283 (-0.278598) | 0.259709 / 0.434364 (-0.174655) | 0.341271 / 0.540337 (-0.199066) | 0.435609 / 1.386936 (-0.951327) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005726 / 0.011353 (-0.005627) | 0.004071 / 0.011008 (-0.006937) | 0.050837 / 0.038508 (0.012329) | 0.047000 / 0.023109 (0.023890) | 0.278543 / 0.275898 (0.002645) | 0.300526 / 0.323480 (-0.022954) | 0.004483 / 0.007986 (-0.003503) | 0.002835 / 0.004328 (-0.001494) | 0.050925 / 0.004250 (0.046675) | 0.041834 / 0.037052 (0.004782) | 0.285059 / 0.258489 (0.026570) | 0.324557 / 0.293841 (0.030716) | 0.038949 / 0.128546 (-0.089597) | 0.012145 / 0.075646 (-0.063501) | 0.061791 / 0.419271 (-0.357481) | 0.034493 / 0.043533 (-0.009040) | 0.274034 / 0.255139 (0.018895) | 0.295886 / 0.283200 (0.012686) | 0.018524 / 0.141683 (-0.123159) | 1.148766 / 1.452155 (-0.303388) | 1.207966 / 1.492716 (-0.284750) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.094078 / 0.018006 (0.076071) | 0.307850 / 0.000490 (0.307361) | 0.000224 / 0.000200 (0.000024) | 0.000079 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023502 / 0.037411 (-0.013910) | 0.077321 / 0.014526 (0.062795) | 0.091147 / 0.176557 (-0.085410) | 0.131111 / 0.737135 (-0.606025) | 0.090906 / 0.296338 (-0.205432) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.290700 / 0.215209 (0.075491) | 2.833655 / 2.077655 (0.756001) | 1.546371 / 1.504120 (0.042251) | 1.415337 / 1.541195 (-0.125858) | 1.445752 / 1.468490 (-0.022738) | 0.737880 / 4.584777 (-3.846897) | 0.961549 / 3.745712 (-2.784164) | 2.844021 / 5.269862 (-2.425841) | 2.023547 / 4.565676 (-2.542130) | 0.079791 / 0.424275 (-0.344484) | 0.005449 / 0.007607 (-0.002158) | 0.356381 / 0.226044 (0.130337) | 3.515555 / 2.268929 (1.246627) | 1.920407 / 55.444624 (-53.524217) | 1.628637 / 6.876477 (-5.247839) | 1.752995 / 2.142072 (-0.389077) | 0.807264 / 4.805227 (-3.997963) | 0.133627 / 6.500664 (-6.367037) | 0.041861 / 0.075469 (-0.033609) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.035643 / 1.841788 (-0.806144) | 12.114792 / 8.074308 (4.040484) | 10.185844 / 10.191392 (-0.005548) | 0.142354 / 0.680424 (-0.538070) | 0.015466 / 0.534201 (-0.518734) | 0.304681 / 0.579283 (-0.274603) | 0.124297 / 0.434364 (-0.310067) | 0.339907 / 0.540337 (-0.200430) | 0.436266 / 1.386936 (-0.950670) |\n\n</details>\n</details>\n\n\n"
] | 2024-07-23T07:25:09Z
| 2024-07-23T14:28:27Z
| 2024-07-23T14:21:08Z
|
MEMBER
| null | null | null |
Avoid calling `http_head` for non-HTTP URLs, by adding and `else` statement.
Currently, it makes an unnecessary HTTP call (which adds latency) for non-HTTP protocols, like FTP, S3,...
I discovered this while working in an unrelated issue.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7062/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7062/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7062.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7062",
"merged_at": "2024-07-23T14:21:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7062.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7062"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5865
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5865/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5865/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5865/events
|
https://github.com/huggingface/datasets/pull/5865
| 1,710,455,738
|
PR_kwDODunzps5QiHnw
| 5,865
|
Deprecate task api
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"If it's easy to keep supporting it we can keep it no ? There are many datasets on the hub that implement the tasks templates in dataset scripts and it's maybe easier to keep task templates than opening PRs to those datasets.",
"do we know if people use the tasks api?\r\n\r\nedit: i mean, i'm fine with removing it if it's not used much, especially considering that it's not documented well.",
"@lhoestq \r\n\r\nLess than 80 public datasets (all canonical) implement `task_templates`, so updating them should be easy.\r\n\r\nPS: I skipped gated datasets when checking for the presence of `task_templates`, but it's safe to assume their contribution to the total count is insignificant.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006480 / 0.011353 (-0.004872) | 0.003904 / 0.011008 (-0.007104) | 0.084287 / 0.038508 (0.045779) | 0.071438 / 0.023109 (0.048329) | 0.309823 / 0.275898 (0.033925) | 0.341038 / 0.323480 (0.017558) | 0.005163 / 0.007986 (-0.002822) | 0.003291 / 0.004328 (-0.001037) | 0.064473 / 0.004250 (0.060222) | 0.053385 / 0.037052 (0.016332) | 0.323561 / 0.258489 (0.065072) | 0.346332 / 0.293841 (0.052491) | 0.030588 / 0.128546 (-0.097958) | 0.008342 / 0.075646 (-0.067305) | 0.287205 / 0.419271 (-0.132067) | 0.051953 / 0.043533 (0.008420) | 0.310925 / 0.255139 (0.055786) | 0.344443 / 0.283200 (0.061244) | 0.022754 / 0.141683 (-0.118928) | 1.459648 / 1.452155 (0.007494) | 1.528413 / 1.492716 (0.035697) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.206404 / 0.018006 (0.188398) | 0.461864 / 0.000490 (0.461374) | 0.004501 / 0.000200 (0.004302) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026891 / 0.037411 (-0.010520) | 0.081206 / 0.014526 (0.066680) | 0.093648 / 0.176557 (-0.082908) | 0.148491 / 0.737135 (-0.588645) | 0.093874 / 0.296338 (-0.202464) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.401715 / 0.215209 (0.186506) | 4.018597 / 2.077655 (1.940943) | 2.029735 / 1.504120 (0.525615) | 1.860069 / 1.541195 (0.318875) | 1.935712 / 1.468490 (0.467222) | 0.485896 / 4.584777 (-4.098881) | 3.638177 / 3.745712 (-0.107535) | 5.124058 / 5.269862 (-0.145804) | 3.099666 / 4.565676 (-1.466011) | 0.057173 / 0.424275 (-0.367102) | 0.007240 / 0.007607 (-0.000367) | 0.478758 / 0.226044 (0.252713) | 4.798471 / 2.268929 (2.529543) | 2.502980 / 55.444624 (-52.941645) | 2.170650 / 6.876477 (-4.705827) | 2.381394 / 2.142072 (0.239321) | 0.578766 / 4.805227 (-4.226462) | 0.132342 / 6.500664 (-6.368322) | 0.059759 / 0.075469 (-0.015710) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.249238 / 1.841788 (-0.592549) | 19.224673 / 8.074308 (11.150365) | 13.786894 / 10.191392 (3.595502) | 0.164633 / 0.680424 (-0.515791) | 0.018065 / 0.534201 (-0.516136) | 0.390589 / 0.579283 (-0.188694) | 0.408993 / 0.434364 (-0.025370) | 0.457001 / 0.540337 (-0.083336) | 0.625327 / 1.386936 (-0.761609) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006827 / 0.011353 (-0.004526) | 0.004007 / 0.011008 (-0.007001) | 0.065239 / 0.038508 (0.026731) | 0.079829 / 0.023109 (0.056719) | 0.400323 / 0.275898 (0.124425) | 0.434158 / 0.323480 (0.110678) | 0.005314 / 0.007986 (-0.002671) | 0.003354 / 0.004328 (-0.000974) | 0.065044 / 0.004250 (0.060794) | 0.060315 / 0.037052 (0.023262) | 0.401513 / 0.258489 (0.143024) | 0.441119 / 0.293841 (0.147278) | 0.031783 / 0.128546 (-0.096763) | 0.008608 / 0.075646 (-0.067038) | 0.071755 / 0.419271 (-0.347517) | 0.048816 / 0.043533 (0.005283) | 0.393896 / 0.255139 (0.138757) | 0.412156 / 0.283200 (0.128956) | 0.024410 / 0.141683 (-0.117272) | 1.515159 / 1.452155 (0.063005) | 1.562217 / 1.492716 (0.069501) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.229993 / 0.018006 (0.211987) | 0.449898 / 0.000490 (0.449409) | 0.000376 / 0.000200 (0.000176) | 0.000056 / 0.000054 (0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030297 / 0.037411 (-0.007115) | 0.086737 / 0.014526 (0.072212) | 0.098312 / 0.176557 (-0.078244) | 0.152890 / 0.737135 (-0.584246) | 0.099335 / 0.296338 (-0.197003) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415786 / 0.215209 (0.200577) | 4.137606 / 2.077655 (2.059952) | 2.120082 / 1.504120 (0.615963) | 1.943984 / 1.541195 (0.402789) | 2.040821 / 1.468490 (0.572331) | 0.479273 / 4.584777 (-4.105504) | 3.563854 / 3.745712 (-0.181858) | 3.396071 / 5.269862 (-1.873790) | 2.011302 / 4.565676 (-2.554374) | 0.057202 / 0.424275 (-0.367073) | 0.007338 / 0.007607 (-0.000269) | 0.488378 / 0.226044 (0.262333) | 4.881615 / 2.268929 (2.612686) | 2.669685 / 55.444624 (-52.774939) | 2.258236 / 6.876477 (-4.618241) | 2.343303 / 2.142072 (0.201230) | 0.606762 / 4.805227 (-4.198466) | 0.133190 / 6.500664 (-6.367475) | 0.062971 / 0.075469 (-0.012498) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.345215 / 1.841788 (-0.496573) | 20.023713 / 8.074308 (11.949405) | 14.555777 / 10.191392 (4.364385) | 0.162388 / 0.680424 (-0.518036) | 0.018528 / 0.534201 (-0.515673) | 0.393055 / 0.579283 (-0.186229) | 0.411820 / 0.434364 (-0.022544) | 0.461705 / 0.540337 (-0.078633) | 0.629395 / 1.386936 (-0.757541) |\n\n</details>\n</details>\n\n\n",
"Ok ! I also know https://huggingface.co/datasets/hf-internal-testing/cats_vs_dogs_sample/blob/main/cats_vs_dogs_sample.py that needs to be updated as well",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009100 / 0.011353 (-0.002253) | 0.005158 / 0.011008 (-0.005850) | 0.109291 / 0.038508 (0.070782) | 0.086053 / 0.023109 (0.062943) | 0.469859 / 0.275898 (0.193961) | 0.476142 / 0.323480 (0.152662) | 0.006739 / 0.007986 (-0.001247) | 0.005077 / 0.004328 (0.000748) | 0.078193 / 0.004250 (0.073943) | 0.065956 / 0.037052 (0.028904) | 0.490323 / 0.258489 (0.231834) | 0.497418 / 0.293841 (0.203577) | 0.060562 / 0.128546 (-0.067984) | 0.016321 / 0.075646 (-0.059325) | 0.379703 / 0.419271 (-0.039568) | 0.087335 / 0.043533 (0.043802) | 0.488240 / 0.255139 (0.233101) | 0.497391 / 0.283200 (0.214191) | 0.040699 / 0.141683 (-0.100984) | 1.778925 / 1.452155 (0.326770) | 1.856436 / 1.492716 (0.363720) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.236428 / 0.018006 (0.218422) | 0.551950 / 0.000490 (0.551460) | 0.007400 / 0.000200 (0.007201) | 0.000120 / 0.000054 (0.000066) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028461 / 0.037411 (-0.008950) | 0.093441 / 0.014526 (0.078915) | 0.103868 / 0.176557 (-0.072688) | 0.176269 / 0.737135 (-0.560867) | 0.107760 / 0.296338 (-0.188578) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.593382 / 0.215209 (0.378173) | 5.863711 / 2.077655 (3.786057) | 2.493777 / 1.504120 (0.989657) | 2.088547 / 1.541195 (0.547352) | 2.173147 / 1.468490 (0.704656) | 0.875661 / 4.584777 (-3.709116) | 5.209023 / 3.745712 (1.463310) | 4.483261 / 5.269862 (-0.786600) | 2.843288 / 4.565676 (-1.722388) | 0.098488 / 0.424275 (-0.325787) | 0.008371 / 0.007607 (0.000764) | 0.668413 / 0.226044 (0.442368) | 6.709802 / 2.268929 (4.440873) | 3.132453 / 55.444624 (-52.312172) | 2.428736 / 6.876477 (-4.447741) | 2.560867 / 2.142072 (0.418794) | 0.983550 / 4.805227 (-3.821677) | 0.207072 / 6.500664 (-6.293592) | 0.073786 / 0.075469 (-0.001683) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.625871 / 1.841788 (-0.215917) | 23.481015 / 8.074308 (15.406707) | 20.556677 / 10.191392 (10.365285) | 0.238147 / 0.680424 (-0.442277) | 0.029453 / 0.534201 (-0.504748) | 0.464589 / 0.579283 (-0.114695) | 0.599129 / 0.434364 (0.164765) | 0.550146 / 0.540337 (0.009808) | 0.794646 / 1.386936 (-0.592290) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008613 / 0.011353 (-0.002739) | 0.004979 / 0.011008 (-0.006030) | 0.078095 / 0.038508 (0.039587) | 0.080285 / 0.023109 (0.057176) | 0.482881 / 0.275898 (0.206983) | 0.520442 / 0.323480 (0.196962) | 0.006241 / 0.007986 (-0.001744) | 0.003964 / 0.004328 (-0.000364) | 0.080027 / 0.004250 (0.075777) | 0.065209 / 0.037052 (0.028157) | 0.476113 / 0.258489 (0.217623) | 0.535383 / 0.293841 (0.241542) | 0.053084 / 0.128546 (-0.075462) | 0.014284 / 0.075646 (-0.061362) | 0.083859 / 0.419271 (-0.335413) | 0.061024 / 0.043533 (0.017492) | 0.477810 / 0.255139 (0.222671) | 0.508718 / 0.283200 (0.225518) | 0.036602 / 0.141683 (-0.105081) | 1.810422 / 1.452155 (0.358267) | 1.832833 / 1.492716 (0.340117) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.281443 / 0.018006 (0.263437) | 0.568249 / 0.000490 (0.567760) | 0.000493 / 0.000200 (0.000293) | 0.000077 / 0.000054 (0.000023) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033302 / 0.037411 (-0.004110) | 0.100433 / 0.014526 (0.085907) | 0.105465 / 0.176557 (-0.071091) | 0.161986 / 0.737135 (-0.575149) | 0.115736 / 0.296338 (-0.180603) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.622892 / 0.215209 (0.407683) | 6.144361 / 2.077655 (4.066706) | 2.849443 / 1.504120 (1.345323) | 2.544097 / 1.541195 (1.002902) | 2.579859 / 1.468490 (1.111369) | 0.826078 / 4.584777 (-3.758699) | 5.021808 / 3.745712 (1.276096) | 4.694784 / 5.269862 (-0.575077) | 2.796263 / 4.565676 (-1.769413) | 0.090983 / 0.424275 (-0.333292) | 0.008445 / 0.007607 (0.000838) | 0.744675 / 0.226044 (0.518631) | 7.662989 / 2.268929 (5.394060) | 3.665611 / 55.444624 (-51.779013) | 2.942836 / 6.876477 (-3.933641) | 2.874402 / 2.142072 (0.732329) | 1.010097 / 4.805227 (-3.795130) | 0.218008 / 6.500664 (-6.282656) | 0.087359 / 0.075469 (0.011890) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.655631 / 1.841788 (-0.186157) | 23.539596 / 8.074308 (15.465288) | 20.909512 / 10.191392 (10.718120) | 0.202092 / 0.680424 (-0.478332) | 0.029807 / 0.534201 (-0.504394) | 0.487591 / 0.579283 (-0.091692) | 0.573719 / 0.434364 (0.139355) | 0.531168 / 0.540337 (-0.009170) | 0.742375 / 1.386936 (-0.644561) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006247 / 0.011353 (-0.005106) | 0.003650 / 0.011008 (-0.007358) | 0.079655 / 0.038508 (0.041147) | 0.060279 / 0.023109 (0.037170) | 0.309033 / 0.275898 (0.033135) | 0.338479 / 0.323480 (0.014999) | 0.004651 / 0.007986 (-0.003335) | 0.002849 / 0.004328 (-0.001480) | 0.062852 / 0.004250 (0.058602) | 0.049230 / 0.037052 (0.012178) | 0.312502 / 0.258489 (0.054012) | 0.354558 / 0.293841 (0.060717) | 0.027497 / 0.128546 (-0.101049) | 0.007885 / 0.075646 (-0.067762) | 0.260232 / 0.419271 (-0.159040) | 0.045459 / 0.043533 (0.001926) | 0.311629 / 0.255139 (0.056490) | 0.367806 / 0.283200 (0.084606) | 0.020875 / 0.141683 (-0.120808) | 1.423802 / 1.452155 (-0.028352) | 1.497729 / 1.492716 (0.005013) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.185629 / 0.018006 (0.167623) | 0.441421 / 0.000490 (0.440931) | 0.004847 / 0.000200 (0.004647) | 0.000074 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022428 / 0.037411 (-0.014984) | 0.073375 / 0.014526 (0.058849) | 0.083194 / 0.176557 (-0.093363) | 0.143984 / 0.737135 (-0.593151) | 0.084128 / 0.296338 (-0.212211) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.397220 / 0.215209 (0.182010) | 3.954394 / 2.077655 (1.876740) | 1.920638 / 1.504120 (0.416518) | 1.744284 / 1.541195 (0.203089) | 1.802623 / 1.468490 (0.334133) | 0.501988 / 4.584777 (-4.082789) | 3.096071 / 3.745712 (-0.649642) | 4.648267 / 5.269862 (-0.621595) | 2.770995 / 4.565676 (-1.794682) | 0.057513 / 0.424275 (-0.366762) | 0.006315 / 0.007607 (-0.001292) | 0.467683 / 0.226044 (0.241639) | 4.683959 / 2.268929 (2.415031) | 2.384980 / 55.444624 (-53.059645) | 2.030894 / 6.876477 (-4.845583) | 2.148374 / 2.142072 (0.006302) | 0.585142 / 4.805227 (-4.220085) | 0.123173 / 6.500664 (-6.377491) | 0.059140 / 0.075469 (-0.016329) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.244707 / 1.841788 (-0.597080) | 18.176043 / 8.074308 (10.101735) | 13.742770 / 10.191392 (3.551378) | 0.149692 / 0.680424 (-0.530732) | 0.016591 / 0.534201 (-0.517610) | 0.342138 / 0.579283 (-0.237145) | 0.353931 / 0.434364 (-0.080433) | 0.392317 / 0.540337 (-0.148020) | 0.524011 / 1.386936 (-0.862925) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005937 / 0.011353 (-0.005416) | 0.003609 / 0.011008 (-0.007399) | 0.061729 / 0.038508 (0.023221) | 0.057844 / 0.023109 (0.034735) | 0.418051 / 0.275898 (0.142153) | 0.453014 / 0.323480 (0.129534) | 0.004530 / 0.007986 (-0.003456) | 0.002861 / 0.004328 (-0.001468) | 0.062236 / 0.004250 (0.057986) | 0.048612 / 0.037052 (0.011560) | 0.418487 / 0.258489 (0.159998) | 0.455114 / 0.293841 (0.161273) | 0.027419 / 0.128546 (-0.101127) | 0.007919 / 0.075646 (-0.067728) | 0.066940 / 0.419271 (-0.352331) | 0.041816 / 0.043533 (-0.001717) | 0.419788 / 0.255139 (0.164649) | 0.439682 / 0.283200 (0.156483) | 0.020902 / 0.141683 (-0.120781) | 1.473993 / 1.452155 (0.021838) | 1.532438 / 1.492716 (0.039722) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.228766 / 0.018006 (0.210760) | 0.412189 / 0.000490 (0.411699) | 0.000371 / 0.000200 (0.000171) | 0.000054 / 0.000054 (-0.000000) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026139 / 0.037411 (-0.011272) | 0.076626 / 0.014526 (0.062100) | 0.088262 / 0.176557 (-0.088295) | 0.143096 / 0.737135 (-0.594039) | 0.089642 / 0.296338 (-0.206696) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.423030 / 0.215209 (0.207821) | 4.218333 / 2.077655 (2.140679) | 2.280943 / 1.504120 (0.776823) | 2.051746 / 1.541195 (0.510551) | 2.101085 / 1.468490 (0.632595) | 0.495860 / 4.584777 (-4.088917) | 3.108065 / 3.745712 (-0.637647) | 2.944188 / 5.269862 (-2.325673) | 1.833693 / 4.565676 (-2.731984) | 0.057509 / 0.424275 (-0.366766) | 0.006406 / 0.007607 (-0.001201) | 0.497208 / 0.226044 (0.271164) | 4.974972 / 2.268929 (2.706044) | 2.786639 / 55.444624 (-52.657985) | 2.423815 / 6.876477 (-4.452662) | 2.446377 / 2.142072 (0.304305) | 0.584521 / 4.805227 (-4.220706) | 0.124129 / 6.500664 (-6.376535) | 0.061373 / 0.075469 (-0.014096) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.307076 / 1.841788 (-0.534711) | 18.443873 / 8.074308 (10.369565) | 13.835730 / 10.191392 (3.644338) | 0.159795 / 0.680424 (-0.520629) | 0.016643 / 0.534201 (-0.517558) | 0.334300 / 0.579283 (-0.244983) | 0.347136 / 0.434364 (-0.087228) | 0.394633 / 0.540337 (-0.145704) | 0.552445 / 1.386936 (-0.834491) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007273 / 0.011353 (-0.004080) | 0.004704 / 0.011008 (-0.006304) | 0.105857 / 0.038508 (0.067349) | 0.062493 / 0.023109 (0.039384) | 0.325704 / 0.275898 (0.049806) | 0.355795 / 0.323480 (0.032315) | 0.005552 / 0.007986 (-0.002433) | 0.003543 / 0.004328 (-0.000785) | 0.068098 / 0.004250 (0.063848) | 0.049563 / 0.037052 (0.012511) | 0.362956 / 0.258489 (0.104467) | 0.376047 / 0.293841 (0.082206) | 0.039272 / 0.128546 (-0.089275) | 0.011521 / 0.075646 (-0.064125) | 0.291899 / 0.419271 (-0.127373) | 0.056916 / 0.043533 (0.013383) | 0.365352 / 0.255139 (0.110213) | 0.357251 / 0.283200 (0.074051) | 0.031670 / 0.141683 (-0.110013) | 1.533294 / 1.452155 (0.081140) | 1.566580 / 1.492716 (0.073864) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.219812 / 0.018006 (0.201805) | 0.499808 / 0.000490 (0.499318) | 0.000343 / 0.000200 (0.000143) | 0.000066 / 0.000054 (0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024011 / 0.037411 (-0.013400) | 0.079686 / 0.014526 (0.065161) | 0.087925 / 0.176557 (-0.088631) | 0.149065 / 0.737135 (-0.588071) | 0.088514 / 0.296338 (-0.207824) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.495003 / 0.215209 (0.279794) | 5.106371 / 2.077655 (3.028717) | 2.285497 / 1.504120 (0.781377) | 2.056052 / 1.541195 (0.514858) | 2.024913 / 1.468490 (0.556423) | 0.726048 / 4.584777 (-3.858729) | 4.873945 / 3.745712 (1.128233) | 7.488671 / 5.269862 (2.218809) | 4.361208 / 4.565676 (-0.204469) | 0.089014 / 0.424275 (-0.335261) | 0.007178 / 0.007607 (-0.000429) | 0.633669 / 0.226044 (0.407625) | 6.328154 / 2.268929 (4.059226) | 3.071598 / 55.444624 (-52.373026) | 2.416077 / 6.876477 (-4.460399) | 2.431033 / 2.142072 (0.288961) | 0.918167 / 4.805227 (-3.887060) | 0.193829 / 6.500664 (-6.306836) | 0.073446 / 0.075469 (-0.002023) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.344994 / 1.841788 (-0.496793) | 19.911699 / 8.074308 (11.837391) | 17.182697 / 10.191392 (6.991305) | 0.216932 / 0.680424 (-0.463492) | 0.025415 / 0.534201 (-0.508786) | 0.416806 / 0.579283 (-0.162477) | 0.524934 / 0.434364 (0.090570) | 0.510783 / 0.540337 (-0.029554) | 0.687856 / 1.386936 (-0.699081) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008469 / 0.011353 (-0.002884) | 0.003797 / 0.011008 (-0.007211) | 0.067276 / 0.038508 (0.028768) | 0.066825 / 0.023109 (0.043716) | 0.394976 / 0.275898 (0.119078) | 0.432563 / 0.323480 (0.109083) | 0.006003 / 0.007986 (-0.001982) | 0.003399 / 0.004328 (-0.000930) | 0.070899 / 0.004250 (0.066649) | 0.050940 / 0.037052 (0.013887) | 0.378291 / 0.258489 (0.119802) | 0.429889 / 0.293841 (0.136048) | 0.043245 / 0.128546 (-0.085302) | 0.012182 / 0.075646 (-0.063465) | 0.074560 / 0.419271 (-0.344711) | 0.065290 / 0.043533 (0.021757) | 0.371209 / 0.255139 (0.116070) | 0.389731 / 0.283200 (0.106532) | 0.045729 / 0.141683 (-0.095954) | 1.451785 / 1.452155 (-0.000370) | 1.598539 / 1.492716 (0.105822) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.261357 / 0.018006 (0.243351) | 0.520142 / 0.000490 (0.519653) | 0.008305 / 0.000200 (0.008105) | 0.000089 / 0.000054 (0.000034) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026492 / 0.037411 (-0.010919) | 0.082430 / 0.014526 (0.067904) | 0.095979 / 0.176557 (-0.080578) | 0.151752 / 0.737135 (-0.585383) | 0.090086 / 0.296338 (-0.206252) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.535967 / 0.215209 (0.320758) | 5.228605 / 2.077655 (3.150950) | 2.395078 / 1.504120 (0.890959) | 2.185500 / 1.541195 (0.644306) | 2.219456 / 1.468490 (0.750966) | 0.764794 / 4.584777 (-3.819983) | 4.796617 / 3.745712 (1.050905) | 4.143450 / 5.269862 (-1.126411) | 2.527391 / 4.565676 (-2.038286) | 0.081418 / 0.424275 (-0.342857) | 0.007170 / 0.007607 (-0.000437) | 0.706071 / 0.226044 (0.480026) | 6.501060 / 2.268929 (4.232131) | 3.176315 / 55.444624 (-52.268309) | 2.443245 / 6.876477 (-4.433232) | 2.517832 / 2.142072 (0.375759) | 0.916254 / 4.805227 (-3.888973) | 0.184282 / 6.500664 (-6.316382) | 0.062613 / 0.075469 (-0.012857) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.444283 / 1.841788 (-0.397504) | 20.227311 / 8.074308 (12.153003) | 17.512856 / 10.191392 (7.321464) | 0.219556 / 0.680424 (-0.460868) | 0.024705 / 0.534201 (-0.509496) | 0.423215 / 0.579283 (-0.156068) | 0.513103 / 0.434364 (0.078739) | 0.473853 / 0.540337 (-0.066485) | 0.738165 / 1.386936 (-0.648771) |\n\n</details>\n</details>\n\n\n"
] | 2023-05-15T16:48:24Z
| 2023-07-10T12:33:59Z
| 2023-07-10T12:24:01Z
|
COLLABORATOR
| null | null | null |
The task API is not well adopted in the ecosystem, so this PR deprecates it. The `train_eval_index` is a newer, more flexible solution that should be used instead (I think?).
These are the projects that still use the task API :
* the image classification example in Transformers: [here](https://github.com/huggingface/transformers/blob/8f76dc8e5aaad58f2df7748b6d6970376f315a9a/examples/pytorch/image-classification/run_image_classification_no_trainer.py#L262) and [here](https://github.com/huggingface/transformers/blob/8f76dc8e5aaad58f2df7748b6d6970376f315a9a/examples/tensorflow/image-classification/run_image_classification.py#L277)
* autotrain: [here](https://github.com/huggingface/autotrain-backend/blob/455e274004b56f9377d64db4ab03671508fcc4cd/zeus/zeus/run/utils.py#L666)
* api-inference-community: [here](https://github.com/huggingface/api-inference-community/blob/fb8fb29d577a5bf01c82944db745489a6d6ed3d4/manage.py#L64) (but the rest of the code does not call the `resolve_dataset` function)
So we need to update these files after the merge.
cc @lewtun
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5865/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5865/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5865.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5865",
"merged_at": "2023-07-10T12:24:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5865.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5865"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6497
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6497/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6497/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6497/events
|
https://github.com/huggingface/datasets/issues/6497
| 2,041,994,274
|
I_kwDODunzps55tlwi
| 6,497
|
Support setting a default config name in push_to_hub
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[] | 2023-12-14T15:59:03Z
| 2023-12-18T11:50:04Z
| 2023-12-18T11:50:04Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
In order to convert script-datasets to no-script datasets, we need to support setting a default config name for those scripts that set one.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6497/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6497/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6718
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6718/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6718/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6718/events
|
https://github.com/huggingface/datasets/pull/6718
| 2,169,468,488
|
PR_kwDODunzps5ouwwE
| 6,718
|
Fix concurrent script loading with force_redownload
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6718). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005074 / 0.011353 (-0.006279) | 0.003505 / 0.011008 (-0.007503) | 0.063683 / 0.038508 (0.025175) | 0.029308 / 0.023109 (0.006199) | 0.246648 / 0.275898 (-0.029250) | 0.265546 / 0.323480 (-0.057933) | 0.004108 / 0.007986 (-0.003878) | 0.002683 / 0.004328 (-0.001646) | 0.048634 / 0.004250 (0.044383) | 0.043786 / 0.037052 (0.006733) | 0.262197 / 0.258489 (0.003708) | 0.291582 / 0.293841 (-0.002259) | 0.027472 / 0.128546 (-0.101074) | 0.010213 / 0.075646 (-0.065434) | 0.206744 / 0.419271 (-0.212527) | 0.036195 / 0.043533 (-0.007337) | 0.249090 / 0.255139 (-0.006049) | 0.280002 / 0.283200 (-0.003198) | 0.018568 / 0.141683 (-0.123115) | 1.124844 / 1.452155 (-0.327311) | 1.159358 / 1.492716 (-0.333359) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093186 / 0.018006 (0.075180) | 0.302331 / 0.000490 (0.301842) | 0.000217 / 0.000200 (0.000017) | 0.000046 / 0.000054 (-0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018727 / 0.037411 (-0.018684) | 0.061730 / 0.014526 (0.047204) | 0.074330 / 0.176557 (-0.102226) | 0.119769 / 0.737135 (-0.617366) | 0.075611 / 0.296338 (-0.220727) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.285063 / 0.215209 (0.069854) | 2.824809 / 2.077655 (0.747155) | 1.481858 / 1.504120 (-0.022262) | 1.350193 / 1.541195 (-0.191002) | 1.358012 / 1.468490 (-0.110478) | 0.557842 / 4.584777 (-4.026935) | 2.380729 / 3.745712 (-1.364983) | 2.798891 / 5.269862 (-2.470970) | 1.719288 / 4.565676 (-2.846388) | 0.061705 / 0.424275 (-0.362570) | 0.005431 / 0.007607 (-0.002176) | 0.343233 / 0.226044 (0.117189) | 3.375223 / 2.268929 (1.106295) | 1.838188 / 55.444624 (-53.606436) | 1.570015 / 6.876477 (-5.306461) | 1.573157 / 2.142072 (-0.568915) | 0.650678 / 4.805227 (-4.154549) | 0.116412 / 6.500664 (-6.384252) | 0.041754 / 0.075469 (-0.033715) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.970431 / 1.841788 (-0.871357) | 11.317128 / 8.074308 (3.242819) | 9.691240 / 10.191392 (-0.500152) | 0.142260 / 0.680424 (-0.538164) | 0.014131 / 0.534201 (-0.520070) | 0.289910 / 0.579283 (-0.289373) | 0.265648 / 0.434364 (-0.168715) | 0.323130 / 0.540337 (-0.217208) | 0.447005 / 1.386936 (-0.939931) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005322 / 0.011353 (-0.006031) | 0.003755 / 0.011008 (-0.007253) | 0.049646 / 0.038508 (0.011138) | 0.029669 / 0.023109 (0.006560) | 0.284151 / 0.275898 (0.008253) | 0.298351 / 0.323480 (-0.025128) | 0.004183 / 0.007986 (-0.003803) | 0.002683 / 0.004328 (-0.001645) | 0.048814 / 0.004250 (0.044563) | 0.045017 / 0.037052 (0.007965) | 0.287358 / 0.258489 (0.028869) | 0.317394 / 0.293841 (0.023553) | 0.030025 / 0.128546 (-0.098521) | 0.010854 / 0.075646 (-0.064793) | 0.058694 / 0.419271 (-0.360578) | 0.052287 / 0.043533 (0.008754) | 0.279038 / 0.255139 (0.023899) | 0.295442 / 0.283200 (0.012242) | 0.019413 / 0.141683 (-0.122270) | 1.146106 / 1.452155 (-0.306048) | 1.197777 / 1.492716 (-0.294939) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092191 / 0.018006 (0.074184) | 0.302672 / 0.000490 (0.302182) | 0.000623 / 0.000200 (0.000423) | 0.000048 / 0.000054 (-0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022067 / 0.037411 (-0.015345) | 0.081760 / 0.014526 (0.067235) | 0.087548 / 0.176557 (-0.089009) | 0.126405 / 0.737135 (-0.610730) | 0.089331 / 0.296338 (-0.207008) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.295821 / 0.215209 (0.080612) | 2.897930 / 2.077655 (0.820276) | 1.604500 / 1.504120 (0.100380) | 1.471502 / 1.541195 (-0.069692) | 1.497918 / 1.468490 (0.029428) | 0.576179 / 4.584777 (-4.008598) | 2.452103 / 3.745712 (-1.293609) | 2.668043 / 5.269862 (-2.601818) | 1.753544 / 4.565676 (-2.812133) | 0.064410 / 0.424275 (-0.359865) | 0.005027 / 0.007607 (-0.002580) | 0.351509 / 0.226044 (0.125465) | 3.479208 / 2.268929 (1.210280) | 1.990356 / 55.444624 (-53.454269) | 1.684920 / 6.876477 (-5.191556) | 1.794251 / 2.142072 (-0.347821) | 0.662692 / 4.805227 (-4.142535) | 0.118589 / 6.500664 (-6.382076) | 0.040813 / 0.075469 (-0.034656) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.002390 / 1.841788 (-0.839398) | 12.004617 / 8.074308 (3.930309) | 10.216005 / 10.191392 (0.024613) | 0.154354 / 0.680424 (-0.526070) | 0.015554 / 0.534201 (-0.518647) | 0.288741 / 0.579283 (-0.290542) | 0.276774 / 0.434364 (-0.157590) | 0.327055 / 0.540337 (-0.213282) | 0.435121 / 1.386936 (-0.951815) |\n\n</details>\n</details>\n\n\n"
] | 2024-03-05T15:04:20Z
| 2024-03-07T14:05:53Z
| 2024-03-07T13:58:04Z
|
MEMBER
| null | null | null |
I added `lock_importable_file` in `get_dataset_builder_class` and `extend_dataset_builder_for_streaming` to fix the issue, and I also added a test
cc @clefourrier
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6718/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6718/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6718.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6718",
"merged_at": "2024-03-07T13:58:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6718.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6718"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5114
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5114/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5114/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5114/events
|
https://github.com/huggingface/datasets/issues/5114
| 1,409,236,738
|
I_kwDODunzps5T_z8C
| 5,114
|
load_from_disk with remote filesystem fails due to a wrong temporary local folder path
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"events_url": "https://api.github.com/users/bruno-hays/events{/privacy}",
"followers_url": "https://api.github.com/users/bruno-hays/followers",
"following_url": "https://api.github.com/users/bruno-hays/following{/other_user}",
"gists_url": "https://api.github.com/users/bruno-hays/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bruno-hays",
"id": 48770768,
"login": "bruno-hays",
"node_id": "MDQ6VXNlcjQ4NzcwNzY4",
"organizations_url": "https://api.github.com/users/bruno-hays/orgs",
"received_events_url": "https://api.github.com/users/bruno-hays/received_events",
"repos_url": "https://api.github.com/users/bruno-hays/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bruno-hays/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bruno-hays/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bruno-hays",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
open
| false
| null |
[] | null |
[
"Hi Hubert! Could you please probably create a publicly available `gs://` dataset link? I think this would be easier for others to directly start to debug.",
"What seems to work is to change the line to:\r\n```\r\nfs.download(src_dataset_path, dataset_path.parent.as_posix(), recursive=True)\r\n```"
] | 2022-10-14T11:54:53Z
| 2022-11-19T07:13:10Z
| null |
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
## Describe the bug
The function load_from_disk fails when using a remote filesystem because of a wrong temporary path generation in the load_from_disk method of arrow_dataset.py:
```python
if is_remote_filesystem(fs):
src_dataset_path = extract_path_from_uri(dataset_path)
dataset_path = Dataset._build_local_temp_path(src_dataset_path)
fs.download(src_dataset_path, dataset_path.as_posix(), recursive=True)
```
If _dataset_path_ is `gs://speech/mydataset/train`, then _src_dataset_path_ will be `speech/mydataset/train` and _dataset_path_ will be something like `/var/folders/9s/gf0b/T/tmp6t/speech/mydataset/train`
Then, after downloading the **folder** _src_dataset_path_, you will get a path like `/var/folders/9s/gf0b/T/tmp6t/speech/mydataset/train/train/state.json` (notice we have train twice)
Instead of downloading the remote folder we should be downloading all the files in the folder for the path to be right:
```python
fs.download(os.path.join(src_dataset_path,*), dataset_path.as_posix(), recursive=True)
```
## Steps to reproduce the bug
```python
fs = gcsfs.GCSFileSystem(**storage_options)
dataset = load_from_disk("common_voice_processed") # loading local dataset previously saved locally, works fine
dataset.save_to_disk(output_dir, fs=fs) #works fine
dataset = load_from_disk(output_dir, fs=fs) # crashes
```
## Expected results
The dataset is loaded
## Actual results
FileNotFoundError: [Errno 2] No such file or directory: '/var/folders/9s/gf0b9jz15d517yrf7m3nvlxr0000gn/T/tmp6t5e221_/speech/datasets/tests/common_voice_processed/train/state.json'
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: datasets-2.6.1.dev0
- Platform: mac os monterey 12.5.1
- Python version: 3.8.13
- PyArrow version:pyarrow==9.0.0
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5114/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5114/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7402
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7402/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7402/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7402/events
|
https://github.com/huggingface/datasets/pull/7402
| 2,855,880,858
|
PR_kwDODunzps6LW8G3
| 7,402
|
Fix a typo in arrow_dataset.py
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7996256?v=4",
"events_url": "https://api.github.com/users/jingedawang/events{/privacy}",
"followers_url": "https://api.github.com/users/jingedawang/followers",
"following_url": "https://api.github.com/users/jingedawang/following{/other_user}",
"gists_url": "https://api.github.com/users/jingedawang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jingedawang",
"id": 7996256,
"login": "jingedawang",
"node_id": "MDQ6VXNlcjc5OTYyNTY=",
"organizations_url": "https://api.github.com/users/jingedawang/orgs",
"received_events_url": "https://api.github.com/users/jingedawang/received_events",
"repos_url": "https://api.github.com/users/jingedawang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jingedawang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jingedawang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jingedawang",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[] | 2025-02-16T04:52:02Z
| 2025-02-20T17:29:28Z
| 2025-02-20T17:29:28Z
|
CONTRIBUTOR
| null | null | null |
"in the feature" should be "in the future"
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7402/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7402/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7402.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7402",
"merged_at": "2025-02-20T17:29:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7402.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7402"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4812
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4812/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4812/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4812/events
|
https://github.com/huggingface/datasets/pull/4812
| 1,333,051,730
|
PR_kwDODunzps484Fzq
| 4,812
|
Fix bug in function validate_type for Python >= 3.9
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-08-09T10:32:42Z
| 2022-08-12T13:41:23Z
| 2022-08-12T13:27:04Z
|
MEMBER
| null | null | null |
Fix `validate_type` function, so that it uses `get_origin` instead. This makes the function forward compatible.
This fixes #4811 because:
```python
In [4]: typing.Optional[str]
Out[4]: typing.Optional[str]
In [5]: get_origin(typing.Optional[str])
Out[5]: typing.Union
```
Fix #4811.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4812/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4812/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4812.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4812",
"merged_at": "2022-08-12T13:27:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4812.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4812"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6011
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6011/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6011/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6011/events
|
https://github.com/huggingface/datasets/issues/6011
| 1,795,296,568
|
I_kwDODunzps5rAg04
| 6,011
|
Documentation: wiki_dpr Dataset has no metric_type for Faiss Index
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/29335344?v=4",
"events_url": "https://api.github.com/users/YichiRockyZhang/events{/privacy}",
"followers_url": "https://api.github.com/users/YichiRockyZhang/followers",
"following_url": "https://api.github.com/users/YichiRockyZhang/following{/other_user}",
"gists_url": "https://api.github.com/users/YichiRockyZhang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/YichiRockyZhang",
"id": 29335344,
"login": "YichiRockyZhang",
"node_id": "MDQ6VXNlcjI5MzM1MzQ0",
"organizations_url": "https://api.github.com/users/YichiRockyZhang/orgs",
"received_events_url": "https://api.github.com/users/YichiRockyZhang/received_events",
"repos_url": "https://api.github.com/users/YichiRockyZhang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/YichiRockyZhang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/YichiRockyZhang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/YichiRockyZhang",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi! You can do `ds.get_index(\"embeddings\").faiss_index.metric_type` to get the metric type and then match the result with the FAISS metric [enum](https://github.com/facebookresearch/faiss/blob/43d86e30736ede853c384b24667fc3ab897d6ba9/faiss/MetricType.h#L22-L36) (should be L2).",
"Ah! Thank you for pointing this out. FYI: the enum indicates it's using the inner product. Using `torch.inner` or `torch.dot` still produces a discrepancy compared to the built-in score. I think this is because of the compression/quantization that occurs with the FAISS index."
] | 2023-07-09T08:30:19Z
| 2023-07-11T03:02:36Z
| 2023-07-11T03:02:36Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
After loading `wiki_dpr` using:
```py
ds = load_dataset(path='wiki_dpr', name='psgs_w100.multiset.compressed', split='train')
print(ds.get_index("embeddings").metric_type) # prints nothing because the value is None
```
the index does not have a defined `metric_type`. This is an issue because I do not know how the `scores` are being computed for `get_nearest_examples()`.
### Steps to reproduce the bug
System: Python 3.9.16, Transformers 4.30.2, WSL
After loading `wiki_dpr` using:
```py
ds = load_dataset(path='wiki_dpr', name='psgs_w100.multiset.compressed', split='train')
print(ds.get_index("embeddings").metric_type) # prints nothing because the value is None
```
the index does not have a defined `metric_type`. This is an issue because I do not know how the `scores` are being computed for `get_nearest_examples()`.
```py
from transformers import DPRQuestionEncoder, DPRContextEncoder, DPRQuestionEncoderTokenizer, DPRContextEncoderTokenizer
tokenizer = DPRQuestionEncoderTokenizer.from_pretrained("facebook/dpr-question_encoder-multiset-base")
encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-multiset-base")
def encode_question(query, tokenizer=tokenizer, encoder=encoder):
inputs = tokenizer(query, return_tensors='pt')
question_embedding = encoder(**inputs)[0].detach().numpy()
return question_embedding
def get_knn(query, k=5, tokenizer=tokenizer, encoder=encoder, verbose=False):
enc_question = encode_question(query, tokenizer, encoder)
topk_results = ds.get_nearest_examples(index_name='embeddings',
query=enc_question,
k=k)
a = torch.tensor(enc_question[0]).reshape(768)
b = torch.tensor(topk_results.examples['embeddings'][0])
print(a.shape, b.shape)
print(torch.dot(a, b))
print((a-b).pow(2).sum())
return topk_results
```
The [FAISS documentation](https://github.com/facebookresearch/faiss/wiki/MetricType-and-distances) suggests the metric is usually L2 distance (without the square root) or the inner product. I compute both for the sample query:
```py
query = """ it catapulted into popular culture along with a line of action figures and other toys by Bandai.[2] By 2001, the media franchise had generated over $6 billion in toy sales.
Despite initial criticism that its action violence targeted child audiences, the franchise has been commercially successful."""
get_knn(query,k=5)
```
Here, I get dot product of 80.6020 and L2 distance of 77.6616 and
```py
NearestExamplesResults(scores=array([76.20431 , 75.312416, 74.945404, 74.866394, 74.68506 ],
dtype=float32), examples={'id': ['3081096', '2004811', '8908258', '9594124', '286575'], 'text': ['actors, resulting in the "Power Rangers" franchise which has continued since then into sequel TV series (with "Power Rangers Beast Morphers" set to premiere in 2019), comic books, video games, and three feature films, with a further cinematic universe planned. Following from the success of "Power Rangers", Saban acquired the rights to more of Toei\'s library, creating "VR Troopers" and "Big Bad Beetleborgs" from several Metal Hero Series shows and "Masked Rider" from Kamen Rider Series footage. DIC Entertainment joined this boom by acquiring the rights to "Gridman the Hyper Agent" and turning it into "Superhuman Samurai Syber-Squad". In 2002,',
```
Doing `k=1` indicates the higher the outputted number, the better the match, so the metric should not be L2 distance. However, my manually computed inner product (80.6) has a discrepancy with the reported (76.2). Perhaps, this has to do with me using the `compressed` embeddings?
### Expected behavior
```py
ds = load_dataset(path='wiki_dpr', name='psgs_w100.multiset.compressed', split='train')
print(ds.get_index("embeddings").metric_type) # METRIC_INNER_PRODUCT
```
### Environment info
- `datasets` version: 2.12.0
- Platform: Linux-4.18.0-477.13.1.el8_8.x86_64-x86_64-with-glibc2.28
- Python version: 3.9.16
- Huggingface_hub version: 0.14.1
- PyArrow version: 12.0.0
- Pandas version: 2.0.1
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/29335344?v=4",
"events_url": "https://api.github.com/users/YichiRockyZhang/events{/privacy}",
"followers_url": "https://api.github.com/users/YichiRockyZhang/followers",
"following_url": "https://api.github.com/users/YichiRockyZhang/following{/other_user}",
"gists_url": "https://api.github.com/users/YichiRockyZhang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/YichiRockyZhang",
"id": 29335344,
"login": "YichiRockyZhang",
"node_id": "MDQ6VXNlcjI5MzM1MzQ0",
"organizations_url": "https://api.github.com/users/YichiRockyZhang/orgs",
"received_events_url": "https://api.github.com/users/YichiRockyZhang/received_events",
"repos_url": "https://api.github.com/users/YichiRockyZhang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/YichiRockyZhang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/YichiRockyZhang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/YichiRockyZhang",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6011/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6011/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5583
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5583/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5583/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5583/events
|
https://github.com/huggingface/datasets/pull/5583
| 1,601,583,625
|
PR_kwDODunzps5K2mIz
| 5,583
|
Do no write index by default when exporting a dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009044 / 0.011353 (-0.002309) | 0.004244 / 0.011008 (-0.006765) | 0.106705 / 0.038508 (0.068197) | 0.029779 / 0.023109 (0.006670) | 0.289684 / 0.275898 (0.013786) | 0.347100 / 0.323480 (0.023620) | 0.007071 / 0.007986 (-0.000915) | 0.003734 / 0.004328 (-0.000595) | 0.077971 / 0.004250 (0.073720) | 0.035323 / 0.037052 (-0.001730) | 0.334520 / 0.258489 (0.076031) | 0.375804 / 0.293841 (0.081964) | 0.049211 / 0.128546 (-0.079335) | 0.016992 / 0.075646 (-0.058654) | 0.337208 / 0.419271 (-0.082064) | 0.053700 / 0.043533 (0.010167) | 0.295750 / 0.255139 (0.040611) | 0.330157 / 0.283200 (0.046958) | 0.097017 / 0.141683 (-0.044666) | 1.379353 / 1.452155 (-0.072802) | 1.402670 / 1.492716 (-0.090047) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.012685 / 0.018006 (-0.005321) | 0.474541 / 0.000490 (0.474051) | 0.006752 / 0.000200 (0.006552) | 0.000097 / 0.000054 (0.000042) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025735 / 0.037411 (-0.011676) | 0.092507 / 0.014526 (0.077982) | 0.100275 / 0.176557 (-0.076281) | 0.180359 / 0.737135 (-0.556777) | 0.104312 / 0.296338 (-0.192026) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.456558 / 0.215209 (0.241349) | 4.786667 / 2.077655 (2.709012) | 1.873169 / 1.504120 (0.369050) | 1.640935 / 1.541195 (0.099741) | 1.614543 / 1.468490 (0.146053) | 0.936144 / 4.584777 (-3.648633) | 4.699886 / 3.745712 (0.954174) | 2.398545 / 5.269862 (-2.871317) | 1.642808 / 4.565676 (-2.922868) | 0.124803 / 0.424275 (-0.299472) | 0.011848 / 0.007607 (0.004241) | 0.631684 / 0.226044 (0.405639) | 6.096052 / 2.268929 (3.827124) | 2.463052 / 55.444624 (-52.981572) | 1.928551 / 6.876477 (-4.947926) | 1.927790 / 2.142072 (-0.214283) | 1.098912 / 4.805227 (-3.706315) | 0.196343 / 6.500664 (-6.304321) | 0.063296 / 0.075469 (-0.012173) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.255032 / 1.841788 (-0.586755) | 13.853623 / 8.074308 (5.779315) | 16.303280 / 10.191392 (6.111888) | 0.227287 / 0.680424 (-0.453137) | 0.037527 / 0.534201 (-0.496674) | 0.449345 / 0.579283 (-0.129938) | 0.522054 / 0.434364 (0.087690) | 0.552848 / 0.540337 (0.012511) | 0.642994 / 1.386936 (-0.743942) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008470 / 0.011353 (-0.002883) | 0.005167 / 0.011008 (-0.005841) | 0.077794 / 0.038508 (0.039286) | 0.029228 / 0.023109 (0.006119) | 0.340828 / 0.275898 (0.064930) | 0.400170 / 0.323480 (0.076691) | 0.005485 / 0.007986 (-0.002500) | 0.003854 / 0.004328 (-0.000475) | 0.077597 / 0.004250 (0.073346) | 0.036519 / 0.037052 (-0.000533) | 0.335522 / 0.258489 (0.077033) | 0.412622 / 0.293841 (0.118781) | 0.044587 / 0.128546 (-0.083959) | 0.016024 / 0.075646 (-0.059623) | 0.092312 / 0.419271 (-0.326960) | 0.055660 / 0.043533 (0.012127) | 0.343140 / 0.255139 (0.088001) | 0.386403 / 0.283200 (0.103203) | 0.098634 / 0.141683 (-0.043049) | 1.326126 / 1.452155 (-0.126029) | 1.430316 / 1.492716 (-0.062400) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.222807 / 0.018006 (0.204801) | 0.473622 / 0.000490 (0.473132) | 0.000376 / 0.000200 (0.000176) | 0.000066 / 0.000054 (0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024599 / 0.037411 (-0.012813) | 0.100743 / 0.014526 (0.086217) | 0.112086 / 0.176557 (-0.064471) | 0.198294 / 0.737135 (-0.538842) | 0.111210 / 0.296338 (-0.185129) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.494120 / 0.215209 (0.278911) | 5.117958 / 2.077655 (3.040303) | 2.305131 / 1.504120 (0.801011) | 2.015591 / 1.541195 (0.474396) | 2.027284 / 1.468490 (0.558794) | 1.014241 / 4.584777 (-3.570536) | 4.738836 / 3.745712 (0.993124) | 2.519718 / 5.269862 (-2.750143) | 1.706379 / 4.565676 (-2.859298) | 0.122452 / 0.424275 (-0.301824) | 0.011500 / 0.007607 (0.003893) | 0.632864 / 0.226044 (0.406820) | 6.295457 / 2.268929 (4.026529) | 2.824897 / 55.444624 (-52.619727) | 2.324359 / 6.876477 (-4.552117) | 2.281046 / 2.142072 (0.138974) | 1.173570 / 4.805227 (-3.631657) | 0.197195 / 6.500664 (-6.303469) | 0.064845 / 0.075469 (-0.010624) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.273224 / 1.841788 (-0.568563) | 14.531155 / 8.074308 (6.456847) | 15.892176 / 10.191392 (5.700784) | 0.208051 / 0.680424 (-0.472373) | 0.023119 / 0.534201 (-0.511082) | 0.422317 / 0.579283 (-0.156966) | 0.519946 / 0.434364 (0.085582) | 0.544517 / 0.540337 (0.004179) | 0.605955 / 1.386936 (-0.780981) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010806 / 0.011353 (-0.000547) | 0.005631 / 0.011008 (-0.005378) | 0.113166 / 0.038508 (0.074657) | 0.042980 / 0.023109 (0.019871) | 0.344856 / 0.275898 (0.068958) | 0.404417 / 0.323480 (0.080938) | 0.012222 / 0.007986 (0.004236) | 0.004470 / 0.004328 (0.000141) | 0.088072 / 0.004250 (0.083822) | 0.049815 / 0.037052 (0.012763) | 0.366532 / 0.258489 (0.108043) | 0.392558 / 0.293841 (0.098717) | 0.045411 / 0.128546 (-0.083135) | 0.014118 / 0.075646 (-0.061529) | 0.392894 / 0.419271 (-0.026378) | 0.067713 / 0.043533 (0.024181) | 0.353013 / 0.255139 (0.097874) | 0.378375 / 0.283200 (0.095175) | 0.123686 / 0.141683 (-0.017996) | 1.665272 / 1.452155 (0.213118) | 1.748383 / 1.492716 (0.255667) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.011672 / 0.018006 (-0.006335) | 0.481667 / 0.000490 (0.481178) | 0.003644 / 0.000200 (0.003444) | 0.000092 / 0.000054 (0.000037) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030436 / 0.037411 (-0.006976) | 0.122577 / 0.014526 (0.108052) | 0.135409 / 0.176557 (-0.041148) | 0.220385 / 0.737135 (-0.516750) | 0.143140 / 0.296338 (-0.153199) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.471146 / 0.215209 (0.255937) | 4.645023 / 2.077655 (2.567368) | 2.126783 / 1.504120 (0.622663) | 1.907905 / 1.541195 (0.366710) | 1.969561 / 1.468490 (0.501071) | 0.798670 / 4.584777 (-3.786107) | 4.394787 / 3.745712 (0.649075) | 2.353535 / 5.269862 (-2.916327) | 1.501013 / 4.565676 (-3.064664) | 0.097472 / 0.424275 (-0.326803) | 0.014015 / 0.007607 (0.006408) | 0.589365 / 0.226044 (0.363320) | 5.897331 / 2.268929 (3.628402) | 2.656198 / 55.444624 (-52.788427) | 2.256082 / 6.876477 (-4.620395) | 2.271122 / 2.142072 (0.129050) | 0.961566 / 4.805227 (-3.843661) | 0.188303 / 6.500664 (-6.312361) | 0.073258 / 0.075469 (-0.002211) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.445266 / 1.841788 (-0.396522) | 16.876710 / 8.074308 (8.802402) | 16.004287 / 10.191392 (5.812895) | 0.212252 / 0.680424 (-0.468172) | 0.033186 / 0.534201 (-0.501015) | 0.520564 / 0.579283 (-0.058719) | 0.516865 / 0.434364 (0.082501) | 0.638482 / 0.540337 (0.098144) | 0.761959 / 1.386936 (-0.624977) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008101 / 0.011353 (-0.003252) | 0.005512 / 0.011008 (-0.005497) | 0.086138 / 0.038508 (0.047630) | 0.038605 / 0.023109 (0.015496) | 0.413082 / 0.275898 (0.137184) | 0.444016 / 0.323480 (0.120536) | 0.006196 / 0.007986 (-0.001790) | 0.005736 / 0.004328 (0.001408) | 0.086938 / 0.004250 (0.082688) | 0.052307 / 0.037052 (0.015255) | 0.415206 / 0.258489 (0.156717) | 0.481510 / 0.293841 (0.187669) | 0.041469 / 0.128546 (-0.087077) | 0.013481 / 0.075646 (-0.062165) | 0.101528 / 0.419271 (-0.317744) | 0.056507 / 0.043533 (0.012974) | 0.418166 / 0.255139 (0.163027) | 0.443834 / 0.283200 (0.160634) | 0.116434 / 0.141683 (-0.025249) | 1.651223 / 1.452155 (0.199068) | 1.746429 / 1.492716 (0.253713) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.242381 / 0.018006 (0.224375) | 0.478826 / 0.000490 (0.478337) | 0.000463 / 0.000200 (0.000264) | 0.000067 / 0.000054 (0.000013) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031743 / 0.037411 (-0.005668) | 0.126141 / 0.014526 (0.111616) | 0.134539 / 0.176557 (-0.042018) | 0.216546 / 0.737135 (-0.520590) | 0.143513 / 0.296338 (-0.152825) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.486915 / 0.215209 (0.271706) | 4.833812 / 2.077655 (2.756158) | 2.317785 / 1.504120 (0.813666) | 2.114181 / 1.541195 (0.572986) | 2.153896 / 1.468490 (0.685406) | 0.797490 / 4.584777 (-3.787287) | 4.369950 / 3.745712 (0.624238) | 2.305492 / 5.269862 (-2.964370) | 1.488860 / 4.565676 (-3.076816) | 0.098071 / 0.424275 (-0.326204) | 0.014129 / 0.007607 (0.006522) | 0.611311 / 0.226044 (0.385266) | 6.087482 / 2.268929 (3.818554) | 2.837676 / 55.444624 (-52.606948) | 2.451819 / 6.876477 (-4.424657) | 2.456763 / 2.142072 (0.314690) | 0.957637 / 4.805227 (-3.847590) | 0.190974 / 6.500664 (-6.309690) | 0.074497 / 0.075469 (-0.000972) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.466214 / 1.841788 (-0.375574) | 17.063925 / 8.074308 (8.989617) | 14.630326 / 10.191392 (4.438934) | 0.170570 / 0.680424 (-0.509854) | 0.023794 / 0.534201 (-0.510407) | 0.509175 / 0.579283 (-0.070108) | 0.506485 / 0.434364 (0.072121) | 0.616965 / 0.540337 (0.076628) | 0.718176 / 1.386936 (-0.668760) |\n\n</details>\n</details>\n\n\n"
] | 2023-02-27T17:04:46Z
| 2023-02-28T13:52:15Z
| 2023-02-28T13:44:04Z
|
COLLABORATOR
| null | null | null |
Ensures all the writers that use Pandas for conversion (JSON, CSV, SQL) do not export `index` by default (https://github.com/huggingface/datasets/pull/5490 only did this for CSV)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5583/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5583/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5583.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5583",
"merged_at": "2023-02-28T13:44:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5583.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5583"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6598
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6598/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6598/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6598/events
|
https://github.com/huggingface/datasets/issues/6598
| 2,084,236,605
|
I_kwDODunzps58Ou09
| 6,598
|
Unexpected keyword argument 'hf' when downloading CSV dataset from S3
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5592111?v=4",
"events_url": "https://api.github.com/users/dguenms/events{/privacy}",
"followers_url": "https://api.github.com/users/dguenms/followers",
"following_url": "https://api.github.com/users/dguenms/following{/other_user}",
"gists_url": "https://api.github.com/users/dguenms/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dguenms",
"id": 5592111,
"login": "dguenms",
"node_id": "MDQ6VXNlcjU1OTIxMTE=",
"organizations_url": "https://api.github.com/users/dguenms/orgs",
"received_events_url": "https://api.github.com/users/dguenms/received_events",
"repos_url": "https://api.github.com/users/dguenms/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dguenms/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dguenms/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dguenms",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"I am facing similar issue while reading a csv file from s3. Wondering if somebody has found a workaround. ",
"same thing happened to other formats like parquet",
"I am facing similar issue while reading a parquet file from s3.\r\ni try with every version between 2.14 to 2.16.1 but it dosen't work ",
"Re-define the DownloadConfig might work:\r\n\r\n```\r\nclass ReviseDownloadConfig(DownloadConfig):\r\n def __post_init__(self, use_auth_token):\r\n if use_auth_token != \"deprecated\":\r\n warnings.warn(\r\n \"'use_auth_token' was deprecated in favor of 'token' in version 2.14.0 and will be removed in 3.0.0.\\n\"\r\n f\"You can remove this warning by passing 'token={use_auth_token}' instead.\",\r\n FutureWarning,\r\n )\r\n self.token = use_auth_token\r\n\r\n def copy(self):\r\n return self.__class__(**{k: copy.deepcopy(v) for k, v in self.__dict__.items()})\r\n\r\ndownloadconfig = ReviseDownloadConfig()\r\n```\r\n",
"> Re-define the DownloadConfig might work:\r\n> \r\n> ```\r\n> class ReviseDownloadConfig(DownloadConfig):\r\n> def __post_init__(self, use_auth_token):\r\n> if use_auth_token != \"deprecated\":\r\n> warnings.warn(\r\n> \"'use_auth_token' was deprecated in favor of 'token' in version 2.14.0 and will be removed in 3.0.0.\\n\"\r\n> f\"You can remove this warning by passing 'token={use_auth_token}' instead.\",\r\n> FutureWarning,\r\n> )\r\n> self.token = use_auth_token\r\n> ```\r\nThis seemed to work for me.\r\n",
"use pandas and then convert to `Dataset`",
"I am currently facing the same issue while using a custom loading script with files located in a remote S3 instance. I was using the `download_custom` functionality but now it is deprecated mentioning that I should use the native S3 loading, which is not working. \r\n\r\nAs stated before, the library forces the existence of a `hf` key in the `storage_options` variable, which is **not** accepted by `s3fs` : \r\n\r\n```python\r\n.../site-packages/s3fs/core.py\", line 516, in set_session\r\n self.session = aiobotocore.session.AioSession(**self.kwargs)\r\nTypeError: __init__() got an unexpected keyword argument 'hf'.\r\n````\r\n\r\nMeanwhile, if my `storage_options` var stays like:\r\n```python\r\n{'key': '...',\r\n 'secret': '...',\r\n 'client_kwargs': {'endpoint_url': '...'}}\r\n```\r\nit works alright. ",
"Did anyone look into similar issues with model upload? setting s3 for checkpointing return `FileNotFoundError`"
] | 2024-01-16T15:16:01Z
| 2025-01-31T15:35:33Z
| 2024-07-23T14:30:10Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
I receive this error message when using `load_dataset` with "csv" path and `dataset_files=s3://...`:
```
TypeError: Session.__init__() got an unexpected keyword argument 'hf'
```
I found a similar issue here: https://stackoverflow.com/questions/77596258/aws-issue-load-dataset-from-s3-fails-with-unexpected-keyword-argument-error-in
Full stacktrace:
```
.../site-packages/datasets/load.py:2549: in load_dataset
builder_instance.download_and_prepare(
.../site-packages/datasets/builder.py:1005: in download_and_prepare
self._download_and_prepare(
.../site-packages/datasets/builder.py:1078: in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
.../site-packages/datasets/packaged_modules/csv/csv.py:147: in _split_generators
data_files = dl_manager.download_and_extract(self.config.data_files)
.../site-packages/datasets/download/download_manager.py:562: in download_and_extract
return self.extract(self.download(url_or_urls))
.../site-packages/datasets/download/download_manager.py:426: in download
downloaded_path_or_paths = map_nested(
.../site-packages/datasets/utils/py_utils.py:466: in map_nested
mapped = [
.../site-packages/datasets/utils/py_utils.py:467: in <listcomp>
_single_map_nested((function, obj, types, None, True, None))
.../site-packages/datasets/utils/py_utils.py:387: in _single_map_nested
mapped = [_single_map_nested((function, v, types, None, True, None)) for v in pbar]
.../site-packages/datasets/utils/py_utils.py:387: in <listcomp>
mapped = [_single_map_nested((function, v, types, None, True, None)) for v in pbar]
.../site-packages/datasets/utils/py_utils.py:370: in _single_map_nested
return function(data_struct)
.../site-packages/datasets/download/download_manager.py:451: in _download
out = cached_path(url_or_filename, download_config=download_config)
.../site-packages/datasets/utils/file_utils.py:188: in cached_path
output_path = get_from_cache(
...1/site-packages/datasets/utils/file_utils.py:511: in get_from_cache
response = fsspec_head(url, storage_options=storage_options)
.../site-packages/datasets/utils/file_utils.py:316: in fsspec_head
fs, _, paths = fsspec.get_fs_token_paths(url, storage_options=storage_options)
.../site-packages/fsspec/core.py:622: in get_fs_token_paths
fs = filesystem(protocol, **inkwargs)
.../site-packages/fsspec/registry.py:290: in filesystem
return cls(**storage_options)
.../site-packages/fsspec/spec.py:79: in __call__
obj = super().__call__(*args, **kwargs)
.../site-packages/s3fs/core.py:187: in __init__
self.s3 = self.connect()
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <s3fs.core.S3FileSystem object at 0x1500a1310>, refresh = True
def connect(self, refresh=True):
"""
Establish S3 connection object.
Parameters
----------
refresh : bool
Whether to create new session/client, even if a previous one with
the same parameters already exists. If False (default), an
existing one will be used if possible
"""
if refresh is False:
# back compat: we store whole FS instance now
return self.s3
anon, key, secret, kwargs, ckwargs, token, ssl = (
self.anon, self.key, self.secret, self.kwargs,
self.client_kwargs, self.token, self.use_ssl)
if not self.passed_in_session:
> self.session = botocore.session.Session(**self.kwargs)
E TypeError: Session.__init__() got an unexpected keyword argument 'hf'
```
### Steps to reproduce the bug
1. Assuming a valid CSV file located at `s3://bucket/data.csv`
2. Run the below code:
```
storage_options = {
"key": "...",
"secret": "...",
"client_kwargs": {
"endpoint_url": "...",
}
}
load_dataset("csv", data_files="s3://bucket/data.csv", storage_options=storage_options)
```
Encountered in version `2.16.1` but also reproduced in `2.16.0` and `2.15.0`.
Note: I encountered this in a unit test using a `moto` mock for S3, however since the error occurs before the session is instantiated, it should not be the issue.
### Expected behavior
No exception is raised, the boto3 session is created successfully, and the CSV file is downloaded successfully and returned as a dataset.
===
After some research I found that `DownloadConfig` has a `__post_init__` method that always forces this value to be set in its `storage_options`, even though in case of an S3 location the storage options get passed on to the S3 Session which does not expect this parameter. I assume this parameter is needed when reading from the huggingface hub and should not be set in this context.
Unfortunately there is nothing the user can do to work around it. Even if you manually do something like:
```
download_config = DownloadConfig()
del download_config.storage_options["hf"]
load_dataset("csv", data_files="s3://bucket/data.csv", download_config=download_config)
```
the library will still reinsert this parameter when `download_config = self.download_config.copy()` in line 418 of `download_manager.py` (`DownloadManager.download`).
Therefore `load_dataset` currently cannot be used to read a dataset in CSV format from an S3 location.
### Environment info
- `datasets` version: 2.16.1
- Platform: macOS-14.2.1-arm64-arm-64bit
- Python version: 3.11.7
- `huggingface_hub` version: 0.20.2
- PyArrow version: 14.0.2
- Pandas version: 2.1.4
- `fsspec` version: 2023.10.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 11,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 11,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6598/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6598/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6640
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6640/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6640/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6640/events
|
https://github.com/huggingface/datasets/issues/6640
| 2,115,864,531
|
I_kwDODunzps5-HYfT
| 6,640
|
Sign Language Support
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6684795?v=4",
"events_url": "https://api.github.com/users/Merterm/events{/privacy}",
"followers_url": "https://api.github.com/users/Merterm/followers",
"following_url": "https://api.github.com/users/Merterm/following{/other_user}",
"gists_url": "https://api.github.com/users/Merterm/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Merterm",
"id": 6684795,
"login": "Merterm",
"node_id": "MDQ6VXNlcjY2ODQ3OTU=",
"organizations_url": "https://api.github.com/users/Merterm/orgs",
"received_events_url": "https://api.github.com/users/Merterm/received_events",
"repos_url": "https://api.github.com/users/Merterm/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Merterm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Merterm/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Merterm",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
| null |
[] | null |
[] | 2024-02-02T21:54:51Z
| 2024-02-02T21:54:51Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
Currently, there are only several Sign Language labels, I would like to propose adding all the Signed Languages as new labels which are described in this ISO standard: https://www.evertype.com/standards/iso639/sign-language.html
### Motivation
Datasets currently only have labels for several signed languages. There are more signed languages in the world. Furthermore, some signed languages that have a lot of online data cannot be found because of this reason (for instance, German Sign Language, and there is no German Sign Language label on huggingface datasets even though there are a lot of readily available sign language datasets exist for German Sign Language, which are used very frequently in Sign Language Processing papers, and models.)
### Your contribution
I can submit a PR for this as well, adding the ISO codes and languages to the labels in datasets.
| null |
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6640/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6640/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7445
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7445/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7445/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7445/events
|
https://github.com/huggingface/datasets/pull/7445
| 2,911,507,923
|
PR_kwDODunzps6ONygU
| 7,445
|
Fix small bugs with async map
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7445). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update."
] | 2025-03-11T18:30:57Z
| 2025-03-13T10:38:03Z
| 2025-03-13T10:37:58Z
|
MEMBER
| null | null | null |
helpful for the next PR to enable parallel image/audio/video decoding and make multimodal datasets go brr (e.g. for lerobot)
- fix with_indices
- fix resuming with save_state_dict() / load_state_dict() - omg that wasn't easy
- remove unnecessary decoding in map() to enable parallelism in FormattedExampleIterable later
small bonus: keeping features in batch()
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7445/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7445/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7445.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7445",
"merged_at": "2025-03-13T10:37:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7445.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7445"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6531
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6531/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6531/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6531/events
|
https://github.com/huggingface/datasets/pull/6531
| 2,055,201,605
|
PR_kwDODunzps5it5Sm
| 6,531
|
Add polars compatibility
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11325244?v=4",
"events_url": "https://api.github.com/users/psmyth94/events{/privacy}",
"followers_url": "https://api.github.com/users/psmyth94/followers",
"following_url": "https://api.github.com/users/psmyth94/following{/other_user}",
"gists_url": "https://api.github.com/users/psmyth94/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/psmyth94",
"id": 11325244,
"login": "psmyth94",
"node_id": "MDQ6VXNlcjExMzI1MjQ0",
"organizations_url": "https://api.github.com/users/psmyth94/orgs",
"received_events_url": "https://api.github.com/users/psmyth94/received_events",
"repos_url": "https://api.github.com/users/psmyth94/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/psmyth94/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/psmyth94/subscriptions",
"type": "User",
"url": "https://api.github.com/users/psmyth94",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi ! thanks for adding polars support :)\r\n\r\nYou added from_polars in arrow_dataset.py but not to_polars, is this on purpose ?\r\n\r\nAlso no need to touch table.py imo, which is for arrow-only logic (tables are just wrappers of pyarrow.Table with the exact same methods + optimization to existing methods + separation between in-memory and memory-mapped)",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6531). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"Hi @lhoestq, thanks for pointing out the missing `to_polars` method.\r\n\r\nI see your point about `table.py` so I removed them.\r\n\r\nI also added tests in `test_arrow_dataset.py`, `test_dataset_dict.py`, and `test_formatting.py`. Let me know if I am missing any. ",
"duckdb index files were deleted yesterday in dataset_with_script@ref/convert/parquet so I changed the hash to reflect the new SHA.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004993 / 0.011353 (-0.006360) | 0.003658 / 0.011008 (-0.007350) | 0.063868 / 0.038508 (0.025360) | 0.030022 / 0.023109 (0.006912) | 0.246359 / 0.275898 (-0.029539) | 0.273409 / 0.323480 (-0.050070) | 0.003091 / 0.007986 (-0.004894) | 0.003383 / 0.004328 (-0.000945) | 0.050666 / 0.004250 (0.046415) | 0.040609 / 0.037052 (0.003557) | 0.267250 / 0.258489 (0.008761) | 0.289823 / 0.293841 (-0.004018) | 0.027635 / 0.128546 (-0.100911) | 0.010786 / 0.075646 (-0.064860) | 0.208442 / 0.419271 (-0.210830) | 0.036627 / 0.043533 (-0.006906) | 0.254116 / 0.255139 (-0.001023) | 0.274368 / 0.283200 (-0.008832) | 0.018222 / 0.141683 (-0.123460) | 1.184472 / 1.452155 (-0.267683) | 1.194309 / 1.492716 (-0.298407) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092861 / 0.018006 (0.074855) | 0.304736 / 0.000490 (0.304246) | 0.000219 / 0.000200 (0.000019) | 0.000175 / 0.000054 (0.000121) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019378 / 0.037411 (-0.018034) | 0.062342 / 0.014526 (0.047817) | 0.074107 / 0.176557 (-0.102450) | 0.121746 / 0.737135 (-0.615390) | 0.075657 / 0.296338 (-0.220681) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.286474 / 0.215209 (0.071265) | 2.832043 / 2.077655 (0.754389) | 1.453520 / 1.504120 (-0.050600) | 1.324714 / 1.541195 (-0.216480) | 1.335439 / 1.468490 (-0.133051) | 0.571753 / 4.584777 (-4.013024) | 2.427361 / 3.745712 (-1.318352) | 2.899838 / 5.269862 (-2.370024) | 1.775754 / 4.565676 (-2.789922) | 0.064177 / 0.424275 (-0.360098) | 0.004978 / 0.007607 (-0.002629) | 0.343585 / 0.226044 (0.117541) | 3.368494 / 2.268929 (1.099565) | 1.819825 / 55.444624 (-53.624800) | 1.502633 / 6.876477 (-5.373844) | 1.549182 / 2.142072 (-0.592891) | 0.658245 / 4.805227 (-4.146983) | 0.120052 / 6.500664 (-6.380612) | 0.043051 / 0.075469 (-0.032419) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.977055 / 1.841788 (-0.864733) | 11.595567 / 8.074308 (3.521259) | 9.450951 / 10.191392 (-0.740441) | 0.141060 / 0.680424 (-0.539364) | 0.014359 / 0.534201 (-0.519842) | 0.289938 / 0.579283 (-0.289345) | 0.266035 / 0.434364 (-0.168329) | 0.326802 / 0.540337 (-0.213536) | 0.431913 / 1.386936 (-0.955023) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005391 / 0.011353 (-0.005961) | 0.003724 / 0.011008 (-0.007284) | 0.050432 / 0.038508 (0.011924) | 0.029904 / 0.023109 (0.006794) | 0.270870 / 0.275898 (-0.005028) | 0.296773 / 0.323480 (-0.026706) | 0.004265 / 0.007986 (-0.003721) | 0.002751 / 0.004328 (-0.001577) | 0.050366 / 0.004250 (0.046116) | 0.046415 / 0.037052 (0.009363) | 0.283272 / 0.258489 (0.024783) | 0.320188 / 0.293841 (0.026347) | 0.029827 / 0.128546 (-0.098719) | 0.010736 / 0.075646 (-0.064910) | 0.059541 / 0.419271 (-0.359731) | 0.057080 / 0.043533 (0.013548) | 0.270653 / 0.255139 (0.015514) | 0.291235 / 0.283200 (0.008035) | 0.018590 / 0.141683 (-0.123093) | 1.129402 / 1.452155 (-0.322752) | 1.194499 / 1.492716 (-0.298217) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.102220 / 0.018006 (0.084214) | 0.302176 / 0.000490 (0.301686) | 0.000229 / 0.000200 (0.000029) | 0.000056 / 0.000054 (0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022809 / 0.037411 (-0.014602) | 0.076054 / 0.014526 (0.061528) | 0.087466 / 0.176557 (-0.089091) | 0.128495 / 0.737135 (-0.608640) | 0.089933 / 0.296338 (-0.206406) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.296546 / 0.215209 (0.081337) | 2.898693 / 2.077655 (0.821039) | 1.605002 / 1.504120 (0.100883) | 1.468370 / 1.541195 (-0.072825) | 1.503541 / 1.468490 (0.035051) | 0.577233 / 4.584777 (-4.007544) | 2.460154 / 3.745712 (-1.285558) | 2.755651 / 5.269862 (-2.514211) | 1.777711 / 4.565676 (-2.787966) | 0.063137 / 0.424275 (-0.361138) | 0.005056 / 0.007607 (-0.002551) | 0.350189 / 0.226044 (0.124145) | 3.485473 / 2.268929 (1.216545) | 1.952553 / 55.444624 (-53.492072) | 1.669108 / 6.876477 (-5.207369) | 1.788504 / 2.142072 (-0.353569) | 0.672869 / 4.805227 (-4.132359) | 0.117717 / 6.500664 (-6.382948) | 0.040499 / 0.075469 (-0.034970) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.048187 / 1.841788 (-0.793601) | 12.663229 / 8.074308 (4.588921) | 10.316487 / 10.191392 (0.125095) | 0.142537 / 0.680424 (-0.537887) | 0.016024 / 0.534201 (-0.518177) | 0.292735 / 0.579283 (-0.286548) | 0.273294 / 0.434364 (-0.161069) | 0.327636 / 0.540337 (-0.212701) | 0.443062 / 1.386936 (-0.943874) |\n\n</details>\n</details>\n\n\n",
"I'm so excited I tweeted about it: https://x.com/qlhoest/status/1766135995513082086?s=20 I hope it's fine !",
"Thanks @lhoestq for the support and totally fine with the share! Happy to see people excited for this 😃 "
] | 2023-12-24T20:03:23Z
| 2024-03-08T19:29:25Z
| 2024-03-08T15:22:58Z
|
CONTRIBUTOR
| null | null | null |
Hey there,
I've just finished adding support to convert and format to `polars.DataFrame`. This was in response to the open issue about integrating Polars [#3334](https://github.com/huggingface/datasets/issues/3334). Datasets can be switched to Polars format via `Dataset.set_format("polars")`. I've also included `to_polars` and `from_polars`. All polars functions are checked via config.POLARS_AVAILABLE.
A few notes:
This only supports `DataFrames` and not `LazyFrames`. This probably could be integrated fairly easily via `is_lazy` args in `set_format`, and `to_polars`.
Let me know your feedbacks.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 4,
"hooray": 2,
"laugh": 0,
"rocket": 0,
"total_count": 8,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6531/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6531/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6531.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6531",
"merged_at": "2024-03-08T15:22:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6531.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6531"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5111
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5111/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5111/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5111/events
|
https://github.com/huggingface/datasets/issues/5111
| 1,408,143,170
|
I_kwDODunzps5T7o9C
| 5,111
|
map and filter not working properly in multiprocessing with the new release 2.6.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "https://api.github.com/users/loubnabnl/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/loubnabnl",
"id": 44069155,
"login": "loubnabnl",
"node_id": "MDQ6VXNlcjQ0MDY5MTU1",
"organizations_url": "https://api.github.com/users/loubnabnl/orgs",
"received_events_url": "https://api.github.com/users/loubnabnl/received_events",
"repos_url": "https://api.github.com/users/loubnabnl/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/loubnabnl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/loubnabnl/subscriptions",
"type": "User",
"url": "https://api.github.com/users/loubnabnl",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null |
[
"Same bug exists with `num_proc=1` on colab. `3.7.14 (default, Sep 8 2022, 00:06:44) [GCC 7.5.0]` ",
"Thanks for reporting, @loubnabnl and for the additional information, @PartiallyTyped.\r\n\r\nHowever, I'm not able to reproduce this issue, neither locally nor on Colab:\r\n```\r\nDataset({\r\n features: ['repo_name', 'path', 'copies', 'size', 'content', 'license', 'hash', 'line_mean', 'line_max', 'alpha_frac', 'autogenerated'],\r\n num_rows: 10\r\n})\r\nDataset({\r\n features: ['repo_name', 'path', 'copies', 'size', 'content', 'license', 'hash', 'line_mean', 'line_max', 'alpha_frac', 'autogenerated'],\r\n num_rows: 10\r\n})\r\n```\r\nCC: @huggingface/datasets can anybody reproduce this?",
"This is the minimum reproducible example. I ran this on the premium instances of colab.\r\n\r\n```\r\n# !pip install datasets\r\nimport datasets\r\nfrom datasets import load_dataset\r\nds = load_dataset(\"copenlu/answerable_tydiqa\").filter(\"english\".__eq__, input_columns=\"language\")\r\nassert all(map(\"english\".__eq__, ds[\"train\"][\"language\"]))\r\n```\r\n\r\nIn my case, the number of samples is correct, however, the samples selected when indexing are wrong.\r\n\r\n```python\r\nDatasetDict({\r\n validation: Dataset({\r\n features: ['question_text', 'document_title', 'language', 'annotations', 'document_plaintext', 'document_url'],\r\n num_rows: 990\r\n })\r\n train: Dataset({\r\n features: ['question_text', 'document_title', 'language', 'annotations', 'document_plaintext', 'document_url'],\r\n num_rows: 7389\r\n })\r\n})\r\n```\r\n\r\nThe number of rows is indeed correct, and i have checked it with a version that works.",
"I can reproduce the issue on my mac too \r\n```\r\n- `datasets` version: 2.6.0\r\n- Platform: macOS-12.2.1-arm64-arm-64bit\r\n- Python version: 3.9.13\r\n- PyArrow version: 9.0.0\r\n- Pandas version: 1.4.3\r\n```\r\nBut not on Colab with python 3.7, maybe related to python version? (didn't manage to install python 3.9)\r\n```\r\n- `datasets` version: 2.6.0\r\n- Platform: Linux-5.10.133+-x86_64-with-Ubuntu-18.04-bionic\r\n- Python version: 3.7.14\r\n- PyArrow version: 9.0.0\r\n- Pandas version: 1.3.5\r\n```",
"I have the same issue, here's a simple notebook to reproduce: https://colab.research.google.com/drive/1Lvo9fg5DSpGUUgXW5JAutZ0bFsR-WV--?usp=sharing\r\n\r\n\r\n\r\n",
"I think there are 2 different issues here:\r\n- the one reported by @loubnabnl is related to multiprocessing in map and then filter; we should reproduce it first: I have tried with Python version 3.9.7 and I can't reproduce it either; maybe it is related to the version of PyArrow? To be checked.\r\n- the issue reported by @PartiallyTyped is related just to \"filter\" (without multiprocessing) and I can reproduce it.",
"Could you create another issue for the @PartiallyTyped one please ?\r\n\r\nRegarding the OP issue, I also tried on colab or locally on py3.7 or py3.10 but didn't reproduce",
"I have created another issue for the one reported by @PartiallyTyped: \r\n- #5112 ",
"I managed to reproduce your issue @loubnabnl on colab by upgrading pyarrow to 9.0.0 instead of 6.0.1",
"I managed to have a _super_ minimal reproducible example:\r\n```python\r\n\r\nfrom datasets import Dataset, concatenate_datasets\r\n\r\nds = concatenate_datasets([Dataset.from_dict({\"a\": [i]}) for i in range(10)])\r\nds2 = ds.map(lambda _: {}, batched=True)\r\nassert list(ds2) == list(ds)\r\n```\r\n(filter uses a batched `map` under the hood)",
"> the one reported by @loubnabnl is related to multiprocessing in map and then filter; we should reproduce it first: I have tried with Python version 3.9.7 and I can't reproduce it either; maybe it is related to the version of PyArrow? To be checked.\r\n\r\nSo finally it was related to PyArrow version! :+1: ",
"Doing a patch release asap :)",
"Did the patch release yesterday, lmk if you still have issues",
"It works now, thanks!\r\n"
] | 2022-10-13T17:00:55Z
| 2022-10-17T08:26:59Z
| 2022-10-14T14:59:59Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
## Describe the bug
When mapping is used on a dataset with more than one process, there is a weird behavior when trying to use `filter` , it's like only the samples from one worker are retrieved, one needs to specify the same `num_proc` in filter for it to work properly. This doesn't happen with `datasets` version 2.5.2
In the code below the data is filtered differently when we increase `num_proc` used in `map` although the datsets before and after mapping have identical elements.
## Steps to reproduce the bug
```python
import datasets
from datasets import load_dataset
def preprocess(example):
return example
ds = load_dataset("codeparrot/codeparrot-clean-valid", split="train").select([i for i in range(10)])
ds1 = ds.map(preprocess, num_proc=2)
ds2 = ds.map(preprocess)
# the datasets elements are the same
for i in range(len(ds1)):
assert ds1[i]==ds2[i]
print(f'Target column before filtering {ds1["autogenerated"]}')
print(f'Target column before filtering {ds2["autogenerated"]}')
print(f"datasets version {datasets.__version__}")
ds_filtered_1 = ds1.filter(lambda x: not x["autogenerated"])
ds_filtered_2 = ds2.filter(lambda x: not x["autogenerated"])
# all elements in Target column are false so they should all be kept, but for ds2 only the first 5=num_samples/num_proc are kept
print(ds_filtered_1)
print(ds_filtered_2)
```
```
Target column before filtering [False, False, False, False, False, False, False, False, False, False]
Target column before filtering [False, False, False, False, False, False, False, False, False, False]
Dataset({
features: ['repo_name', 'path', 'copies', 'size', 'content', 'license', 'hash', 'line_mean', 'line_max', 'alpha_frac', 'autogenerated'],
num_rows: 5
})
Dataset({
features: ['repo_name', 'path', 'copies', 'size', 'content', 'license', 'hash', 'line_mean', 'line_max', 'alpha_frac', 'autogenerated'],
num_rows: 10
})
```
## Expected results
Increasing `num_proc` in mapping shouldn't alter filtering. With the previous version 2.5.2 this doesn't happen
## Actual results
Filtering doesn't work properly when we increase `num_proc` in mapping but not when calling `filter`
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.6.0
- Platform: Linux-4.19.0-22-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.13
- PyArrow version: 8.0.0
- Pandas version: 1.4.2
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5111/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5111/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/4637
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4637/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4637/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4637/events
|
https://github.com/huggingface/datasets/issues/4637
| 1,294,818,236
|
I_kwDODunzps5NLVu8
| 4,637
|
The "all" split breaks streaming
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://api.github.com/users/cakiki/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cakiki",
"id": 3664563,
"login": "cakiki",
"node_id": "MDQ6VXNlcjM2NjQ1NjM=",
"organizations_url": "https://api.github.com/users/cakiki/orgs",
"received_events_url": "https://api.github.com/users/cakiki/received_events",
"repos_url": "https://api.github.com/users/cakiki/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cakiki/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cakiki/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cakiki",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
open
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[
"Thanks for reporting @cakiki.\r\n\r\nYes, this is a bug. We are investigating it.",
"@albertvillanova Nice! Let me know if it's something I can fix my self; would love to contribtue!",
"@cakiki I was working on this but if you would like to contribute, go ahead. I will close my PR. ;)\r\n\r\nFor the moment I just pushed the test (to see if it impacts other tests).",
"It impacted the test `test_generator_based_download_and_prepare` and I have fixed this.\r\n\r\nSo that you can copy the test I implemented in my PR and then implement a fix for this issue that passes the test `tests/test_builder.py::test_builder_as_streaming_dataset`.",
"Hi @cakiki are you still interested in working on this? Are you planning to open a PR?",
"Hi @albertvillanova ! Sorry it took so long; I wanted to spend this weekend working on it."
] | 2022-07-05T21:56:49Z
| 2022-07-15T13:59:30Z
| null |
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
## Describe the bug
Not sure if this is a bug or just the way streaming works, but setting `streaming=True` did not work when setting `split="all"`
## Steps to reproduce the bug
The following works:
```python
ds = load_dataset('super_glue', 'wsc.fixed', split='all')
```
The following throws `ValueError: Bad split: all. Available splits: ['train', 'validation', 'test']`:
```python
ds = load_dataset('super_glue', 'wsc.fixed', split='all', streaming=True)
```
## Expected results
An iterator over all splits.
## Actual results
I had to do the following to achieve the desired result:
```python
from itertools import chain
ds = load_dataset('super_glue', 'wsc.fixed', streaming=True)
it = chain.from_iterable(ds.values())
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.3.2
- Platform: Linux-4.15.0-176-generic-x86_64-with-glibc2.31
- Python version: 3.10.5
- PyArrow version: 8.0.0
- Pandas version: 1.4.3
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4637/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4637/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6716
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6716/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6716/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6716/events
|
https://github.com/huggingface/datasets/issues/6716
| 2,168,706,558
|
I_kwDODunzps6BQ9X-
| 6,716
|
Non-deterministic `Dataset.builder_name` value
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17039389?v=4",
"events_url": "https://api.github.com/users/harupy/events{/privacy}",
"followers_url": "https://api.github.com/users/harupy/followers",
"following_url": "https://api.github.com/users/harupy/following{/other_user}",
"gists_url": "https://api.github.com/users/harupy/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/harupy",
"id": 17039389,
"login": "harupy",
"node_id": "MDQ6VXNlcjE3MDM5Mzg5",
"organizations_url": "https://api.github.com/users/harupy/orgs",
"received_events_url": "https://api.github.com/users/harupy/received_events",
"repos_url": "https://api.github.com/users/harupy/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/harupy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/harupy/subscriptions",
"type": "User",
"url": "https://api.github.com/users/harupy",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"When `rotten_tomatoes` is printed out, the following warning message is also printed out:\r\n\r\n```\r\nYou can avoid this message in future by passing the argument `trust_remote_code=True`.\r\nPassing `trust_remote_code=True` will be mandatory to load this dataset from the next major release of `datasets`.\r\n```",
"Hi ! This behavior happens because the dataset was originakky created using a dataset script [rotten_tomatoes.py](https://huggingface.co/datasets/rotten_tomatoes/blob/26f40d324d7b281d8b3fb1c47f30f8b9957f206b/rotten_tomatoes.py) and because we added features recently allowing to download the dataset directly from Parquet files (parquet builder) without running the dataset script (rotten_tomatoes). The flakiness must come from the availability of the Parquet files (we automatically export them in the refs/convert/parquet branch and we recently had to move some files).\r\n\r\nAnyway the easy fix on our side is to remove the dataset script completely, let me open a PR at https://huggingface.co/datasets/rotten_tomatoes\r\n\r\nEDIT: opened https://huggingface.co/datasets/rotten_tomatoes/discussions/6, feel free to comment there if you're ok with that change",
"@lhoestq Thanks for the comment, explanation, and patch!",
"> we automatically export them in the refs/convert/parquet branch\r\n\r\nWhen this operation is in progress, the parquet files become temporarily unavailable?",
"> When this operation is in progress, the parquet files become temporarily unavailable?\r\n\r\nYes correct. I just merged the patch btw :)",
"@lhoestq Thanks for merging the PR! I think this issue can be closed."
] | 2024-03-05T09:23:21Z
| 2024-03-19T07:58:14Z
| 2024-03-19T07:58:14Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
I'm not sure if this is a bug, but `print(ds.builder_name)` in the following code sometimes prints out `rotten_tomatoes` instead of `parquet`:
```python
import datasets
for _ in range(100):
ds = datasets.load_dataset("rotten_tomatoes", split="train")
print(ds.builder_name) # prints out "rotten_tomatoes" sometimes instead of "parquet"
```
Output:
```
...
parquet
parquet
parquet
rotten_tomatoes
parquet
parquet
parquet
...
```
Here's a reproduction using GitHub Actions:
https://github.com/mlflow/mlflow/actions/runs/8153247984/job/22284263613?pr=11329#step:12:241
One of our tests is flaky because `builder_name` is not deterministic.
### Steps to reproduce the bug
1. Run the code above.
### Expected behavior
Always prints out `parquet`?
### Environment info
```
Copy-and-paste the text below in your GitHub issue.
- `datasets` version: 2.18.0
- Platform: Linux-6.5.0-1015-azure-x86_64-with-glibc2.34
- Python version: 3.8.18
- `huggingface_hub` version: 0.21.3
- PyArrow version: 15.0.0
- Pandas version: 2.0.3
- `fsspec` version: 2024.2.0
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17039389?v=4",
"events_url": "https://api.github.com/users/harupy/events{/privacy}",
"followers_url": "https://api.github.com/users/harupy/followers",
"following_url": "https://api.github.com/users/harupy/following{/other_user}",
"gists_url": "https://api.github.com/users/harupy/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/harupy",
"id": 17039389,
"login": "harupy",
"node_id": "MDQ6VXNlcjE3MDM5Mzg5",
"organizations_url": "https://api.github.com/users/harupy/orgs",
"received_events_url": "https://api.github.com/users/harupy/received_events",
"repos_url": "https://api.github.com/users/harupy/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/harupy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/harupy/subscriptions",
"type": "User",
"url": "https://api.github.com/users/harupy",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6716/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6716/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6172
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6172/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6172/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6172/events
|
https://github.com/huggingface/datasets/issues/6172
| 1,863,318,027
|
I_kwDODunzps5vD_oL
| 6,172
|
Make Dataset streaming queries retryable
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42299342?v=4",
"events_url": "https://api.github.com/users/rojagtap/events{/privacy}",
"followers_url": "https://api.github.com/users/rojagtap/followers",
"following_url": "https://api.github.com/users/rojagtap/following{/other_user}",
"gists_url": "https://api.github.com/users/rojagtap/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rojagtap",
"id": 42299342,
"login": "rojagtap",
"node_id": "MDQ6VXNlcjQyMjk5MzQy",
"organizations_url": "https://api.github.com/users/rojagtap/orgs",
"received_events_url": "https://api.github.com/users/rojagtap/received_events",
"repos_url": "https://api.github.com/users/rojagtap/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rojagtap/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rojagtap/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rojagtap",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
| null |
[] | null |
[
"Hi! The streaming mode also retries requests - `datasets.config.STREAMING_READ_MAX_RETRIES` (20 sec by default) controls the number of retries and `datasets.config.STREAMING_READ_RETRY_INTERVAL` (5 sec) the sleep time between retries.\r\n\r\n> At step 1800 I got a 504 HTTP status code error from Huggingface hub for my pytorch dataloader\r\n\r\nA minor Hub outage that we experienced yesterday could be the cause.",
"I wanted something similar. I have a huge dataset I want to process (laion-2b), but after processing several batches, it sometimes fails with this error: `HTTP 502 Bad Gateway for url`. I had the following code to handle it but this way I believe it restarts processing the data from the first batch? How can I set the attribute values you mention above?\r\n\r\n```\r\niterable_dataset = load_dataset(\"laion/laion2B-multi\", streaming=True, split='train')\r\ndataloader = DataLoader(iterable_dataset, batch_size=131072, collate_fn=custom_collate_fn, num_workers=8)\r\n\r\nMAX_RETRIES = 5\r\nRETRY_WAIT = 10 # wait 10 seconds before retry\r\n\r\n for retry in range(MAX_RETRIES):\r\n try:\r\n for j, batch in enumerate(dataloader):\r\n < process batch>\r\n\r\n except HfHubHTTPError as e:\r\n if \"502\" in str(e) and retry < MAX_RETRIES - 1:\r\n logging.warning(f\"Encountered a 502 error on batch {j}. Waiting for {RETRY_WAIT} seconds before retrying.\")\r\n time.sleep(RETRY_WAIT)\r\n continue\r\n else:\r\n raise",
"Hey all! Wondering if there's a way of making Datasets streaming mode somewhat robust to Hub outages? Over the weekend, I got two quite cryptic errors, which I reckon were probably from Hub issues:\r\n\r\n<details>\r\n<summary> Stack Trace 1 </summary>\r\n\r\n```\r\n File \"/home/sanchitgandhi/small-12-4-tpu-timestamped-prob-0.2/run_distillation.py\", line 2119, in <module>\r\n main()\r\n File \"/home/sanchitgandhi/small-12-4-tpu-timestamped-prob-0.2/run_distillation.py\", line 1954, in main\r\n for batch in train_loader:\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/utils/data/dataloader.py\", line 630, in __next__\r\n data = self._next_data()\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/utils/data/dataloader.py\", line 1325, in _next_data\r\n return self._process_data(data)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/utils/data/dataloader.py\", line 1371, in _process_data\r\n data.reraise()\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/_utils.py\", line 694, in reraise\r\n raise exception\r\nConnectionError: Caught ConnectionError in DataLoader worker process 8.\r\nOriginal Traceback (most recent call last):\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/aiohttp/connector.py\", line 1155, in _create_direct_connection\r\n hosts = await asyncio.shield(host_resolved)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/aiohttp/connector.py\", line 874, in _resolve_host\r\n addrs = await self._resolver.resolve(host, port, family=self._family)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/aiohttp/resolver.py\", line 33, in resolve\r\n infos = await self._loop.getaddrinfo(\r\n File \"/usr/lib/python3.10/asyncio/base_events.py\", line 863, in getaddrinfo\r\n return await self.run_in_executor(\r\n File \"/usr/lib/python3.10/concurrent/futures/thread.py\", line 58, in run\r\n result = self.fn(*self.args, **self.kwargs)\r\n File \"/usr/lib/python3.10/socket.py\", line 955, in getaddrinfo\r\n for res in _socket.getaddrinfo(host, port, family, type, proto, flags):\r\nsocket.gaierror: [Errno -3] Temporary failure in name resolution\r\nThe above exception was the direct cause of the following exception:\r\nTraceback (most recent call last):\r\n File \"/home/sanchitgandhi/datasets/src/datasets/download/streaming_download_manager.py\", line 333, in read_with_retries\r\n out = read(*args, **kwargs)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/fsspec/implementations/http.py\", line 612, in read\r\n return super().read(length)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/fsspec/spec.py\", line 1856, in read\r\n out = self.cache._fetch(self.loc, self.loc + length)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/fsspec/caching.py\", line 439, in _fetch\r\n new = self.fetcher(self.end, bend)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/fsspec/asyn.py\", line 118, in wrapper\r\n return sync(self.loop, func, *args, **kwargs)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/fsspec/asyn.py\", line 103, in sync\r\n raise return_result\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/fsspec/asyn.py\", line 56, in _runner\r\n result[0] = await coro\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/fsspec/implementations/http.py\", line 660, in async_fetch_range\r\n r = await self.session.get(\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/aiohttp/client.py\", line 562, in _request\r\n conn = await self._connector.connect(\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/aiohttp/connector.py\", line 540, in connect\r\n proto = await self._create_connection(req, traces, timeout)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/aiohttp/connector.py\", line 901, in _create_connection\r\n _, proto = await self._create_direct_connection(req, traces, timeout)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/aiohttp/connector.py\", line 1169, in _create_direct_connection\r\n raise ClientConnectorError(req.connection_key, exc) from exc\r\naiohttp.client_exceptions.ClientConnectorError: Cannot connect to host huggingface.co:443 ssl:default [Temporary failure in name resolution]\r\nThe above exception was the direct cause of the following exception:\r\nTraceback (most recent call last):\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/utils/data/_utils/worker.py\", line 308, in _worker_loop\r\n data = fetcher.fetch(index)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py\", line 32, in fetch\r\n data.append(next(self.dataset_iter))\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 1358, in __iter__\r\n yield from self._iter_pytorch()\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 1293, in _iter_pytorch\r\n for key, example in ex_iterable:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 982, in __iter__\r\n for x in self.ex_iterable:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 862, in __iter__\r\n yield from self._iter()\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 899, in _iter\r\n for key, example in iterator:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 862, in __iter__\r\n yield from self._iter()\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 899, in _iter\r\n for key, example in iterator:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 678, in __iter__\r\n yield from self._iter()\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 740, in _iter\r\n for key, example in iterator:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 862, in __iter__\r\n yield from self._iter()\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 899, in _iter\r\n for key, example in iterator:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 1114, in __iter__\r\n for key, example in self.ex_iterable:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 429, in __iter__\r\n if not iterators[i].hasnext():\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 106, in hasnext\r\n self._thenext = next(self.it)\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 678, in __iter__\r\n yield from self._iter()\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 740, in _iter\r\n for key, example in iterator:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 1114, in __iter__\r\n for key, example in self.ex_iterable:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 281, in __iter__\r\n for key, pa_table in self.generate_tables_fn(**self.kwargs):\r\n File \"/home/sanchitgandhi/.cache/huggingface/modules/datasets_modules/datasets/distil-whisper--switchboard-data/9472ee64cca0e1a7e11909c7033c2354511fa62805f81a2e07616980c765abfe/switchboard-data.py\", line 247, in _generate_tables\r\n for record_batch in pf.iter_batches():\r\n File \"pyarrow/_parquet.pyx\", line 1327, in iter_batches\r\n File \"/home/sanchitgandhi/datasets/src/datasets/download/streaming_download_manager.py\", line 342, in read_with_retries\r\n raise ConnectionError(\"Server Disconnected\") from disconnect_err\r\nConnectionError: Server Disconnected\r\n```\r\n\r\n</details>\r\n\r\n<details>\r\n<summary> Stack Trace 2 </summary>\r\n\r\n```\r\n File \"/home/sanchitgandhi/small-12-2-tpu-v3-timestamped-prob-0.2-bs-512/run_distillation.py\", line 2119, in <module>\r\n main()\r\n File \"/home/sanchitgandhi/small-12-2-tpu-v3-timestamped-prob-0.2-bs-512/run_distillation.py\", line 1954, in main\r\n for batch in train_loader:\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/utils/data/dataloader.py\", line 630, in __next__\r\n data = self._next_data()\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/utils/data/dataloader.py\", line 1325, in _next_data\r\n return self._process_data(data)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/utils/data/dataloader.py\", line 1371, in _process_data\r\n data.reraise()\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/_utils.py\", line 694, in reraise\r\n raise exception\r\nrequests.exceptions.ConnectionError: Caught ConnectionError in DataLoader worker process 13.\r\nOriginal Traceback (most recent call last):\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/urllib3/connectionpool.py\", line 791, in urlopen\r\n response = self._make_request(\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/urllib3/connectionpool.py\", line 537, in _make_request\r\n response = conn.getresponse()\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/urllib3/connection.py\", line 461, in getresponse\r\n httplib_response = super().getresponse()\r\n File \"/usr/lib/python3.10/http/client.py\", line 1375, in getresponse\r\n response.begin()\r\n File \"/usr/lib/python3.10/http/client.py\", line 318, in begin\r\n version, status, reason = self._read_status()\r\n File \"/usr/lib/python3.10/http/client.py\", line 287, in _read_status\r\n raise RemoteDisconnected(\"Remote end closed connection without\"\r\nhttp.client.RemoteDisconnected: Remote end closed connection without response\r\nDuring handling of the above exception, another exception occurred:\r\nTraceback (most recent call last):\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/requests/adapters.py\", line 486, in send\r\n resp = conn.urlopen(\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/urllib3/connectionpool.py\", line 845, in urlopen\r\n retries = retries.increment(\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/urllib3/util/retry.py\", line 470, in increment\r\n raise reraise(type(error), error, _stacktrace)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/urllib3/util/util.py\", line 38, in reraise\r\n raise value.with_traceback(tb)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/urllib3/connectionpool.py\", line 791, in urlopen\r\n response = self._make_request(\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/urllib3/connectionpool.py\", line 537, in _make_request\r\n response = conn.getresponse()\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/urllib3/connection.py\", line 461, in getresponse\r\n httplib_response = super().getresponse()\r\n File \"/usr/lib/python3.10/http/client.py\", line 1375, in getresponse\r\n response.begin()\r\n File \"/usr/lib/python3.10/http/client.py\", line 318, in begin\r\n version, status, reason = self._read_status()\r\n File \"/usr/lib/python3.10/http/client.py\", line 287, in _read_status\r\n raise RemoteDisconnected(\"Remote end closed connection without\"\r\nurllib3.exceptions.ProtocolError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))\r\nDuring handling of the above exception, another exception occurred:\r\nTraceback (most recent call last):\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/utils/data/_utils/worker.py\", line 308, in _worker_loop\r\n data = fetcher.fetch(index)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py\", line 32, in fetch\r\n data.append(next(self.dataset_iter))\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 1358, in __iter__\r\n yield from self._iter_pytorch()\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 1293, in _iter_pytorch\r\n for key, example in ex_iterable:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 982, in __iter__\r\n for x in self.ex_iterable:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 862, in __iter__\r\n yield from self._iter()\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 899, in _iter\r\n for key, example in iterator:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 862, in __iter__\r\n yield from self._iter()\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 899, in _iter\r\n for key, example in iterator:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 678, in __iter__\r\n yield from self._iter()\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 740, in _iter\r\n for key, example in iterator:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 862, in __iter__\r\n yield from self._iter()\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 899, in _iter\r\n for key, example in iterator:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 1114, in __iter__\r\n for key, example in self.ex_iterable:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 429, in __iter__\r\n if not iterators[i].hasnext():\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 106, in hasnext\r\n self._thenext = next(self.it)\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 678, in __iter__\r\n yield from self._iter()\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 740, in _iter\r\n for key, example in iterator:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 1114, in __iter__\r\n for key, example in self.ex_iterable:\r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 281, in __iter__\r\n for key, pa_table in self.generate_tables_fn(**self.kwargs):\r\n File \"/home/sanchitgandhi/datasets/src/datasets/packaged_modules/parquet/parquet.py\", line 87, in _generate_tables\r\n for batch_idx, record_batch in enumerate(\r\n File \"pyarrow/_parquet.pyx\", line 1327, in iter_batches\r\n File \"/home/sanchitgandhi/datasets/src/datasets/download/streaming_download_manager.py\", line 333, in read_with_retries\r\n out = read(*args, **kwargs)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/fsspec/spec.py\", line 1856, in read\r\n out = self.cache._fetch(self.loc, self.loc + length)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/fsspec/caching.py\", line 189, in _fetch\r\n self.cache = self.fetcher(start, end) # new block replaces old\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/huggingface_hub/hf_file_system.py\", line 410, in _fetch_range\r\n r = http_backoff(\"GET\", url, headers=headers)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/huggingface_hub/utils/_http.py\", line 258, in http_backoff\r\n response = session.request(method=method, url=url, **kwargs)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/requests/sessions.py\", line 589, in request\r\n resp = self.send(prep, **send_kwargs)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/requests/sessions.py\", line 703, in send\r\n r = adapter.send(request, **kwargs)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/huggingface_hub/utils/_http.py\", line 63, in send\r\n return super().send(request, *args, **kwargs)\r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/requests/adapters.py\", line 501, in send\r\n raise ConnectionError(err, request=request)\r\nrequests.exceptions.ConnectionError: (ProtocolError('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')), '(Request ID: 5fce9fc2-e22f-41c2-91af-529f13f1d611)')\r\n```\r\n\r\n</details>\r\n\r\nHaving streaming mode fail when the Hub goes down makes using it problematic for long training runs where large amounts of data is involved. However, this is the precise situation for which streaming mode is so appealing!\r\n\r\nWondering if there were a 'common' set of Hub errors that we could catch in `iterable_datasets` and prevent from crashing the script?\r\n\r\ncc @lhoestq @mariosasko ",
"Errors are already caught and requests are already retried.\r\n\r\nWhat you can do is increase the number of retries before an error is raised.\r\n\r\n```python\r\nimport datasets\r\n\r\ndatasets.config.STREAMING_READ_MAX_RETRIES = 20 # default\r\ndatasets.config.STREAMING_READ_RETRY_INTERVAL = 5 # default\r\n```"
] | 2023-08-23T13:15:38Z
| 2023-11-06T13:54:16Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
Streaming datasets, as intended, do not load the entire dataset in memory or disk. However, while querying the next data chunk from the remote, sometimes it is possible that the service is down or there might be other issues that may cause the query to fail. In such a scenario, it would be nice to make these queries retryable (perhaps with a backoff strategy).
### Motivation
I was working on a model and the model checkpoints after every 1000 steps. At step 1800 I got a 504 HTTP status code error from Huggingface hub for my pytorch `dataloader`. Given the size of my model and data, it took around 2 hours to reach 1800 steps and now it will take about an hour to recover the lost 800. It would be better to get a retryable querying strategy.
### Your contribution
It would be better if someone having experience in this area takes this up as this would require some testing.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6172/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6172/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7299
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7299/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7299/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7299/events
|
https://github.com/huggingface/datasets/issues/7299
| 2,695,378,251
|
I_kwDODunzps6gqDVL
| 7,299
|
Efficient Image Augmentation in Hugging Face Datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/46443190?v=4",
"events_url": "https://api.github.com/users/fabiozappo/events{/privacy}",
"followers_url": "https://api.github.com/users/fabiozappo/followers",
"following_url": "https://api.github.com/users/fabiozappo/following{/other_user}",
"gists_url": "https://api.github.com/users/fabiozappo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/fabiozappo",
"id": 46443190,
"login": "fabiozappo",
"node_id": "MDQ6VXNlcjQ2NDQzMTkw",
"organizations_url": "https://api.github.com/users/fabiozappo/orgs",
"received_events_url": "https://api.github.com/users/fabiozappo/received_events",
"repos_url": "https://api.github.com/users/fabiozappo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/fabiozappo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fabiozappo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/fabiozappo",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[] | 2024-11-26T16:50:32Z
| 2024-11-26T16:53:53Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
I'm using the Hugging Face datasets library to load images in batch and would like to apply a torchvision transform to solve the inconsistent image sizes in the dataset and apply some on the fly image augmentation. I can just think about using the collate_fn, but seems quite inefficient.
I'm new to the Hugging Face datasets library, I didn't find nothing in the documentation or the issues here on github.
Is there an existing way to add image transformations directly to the dataset loading pipeline?
### Steps to reproduce the bug
from datasets import load_dataset
from torch.utils.data import DataLoader
```python
def collate_fn(batch):
images = [item['image'] for item in batch]
texts = [item['text'] for item in batch]
return {
'images': images,
'texts': texts
}
dataset = load_dataset("Yuki20/pokemon_caption", split="train")
dataloader = DataLoader(dataset, batch_size=4, collate_fn=collate_fn)
# Output shows varying image sizes:
# [(1280, 1280), (431, 431), (789, 789), (769, 769)]
```
### Expected behavior
I'm looking for a way to resize images on-the-fly when loading the dataset, similar to PyTorch's Dataset.__getitem__ functionality. This would be more efficient than handling resizing in the collate_fn.
### Environment info
- `datasets` version: 3.1.0
- Platform: Linux-6.5.0-41-generic-x86_64-with-glibc2.35
- Python version: 3.11.10
- `huggingface_hub` version: 0.26.2
- PyArrow version: 18.0.0
- Pandas version: 2.2.3
- `fsspec` version: 2024.9.0
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7299/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7299/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4980
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4980/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4980/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4980/events
|
https://github.com/huggingface/datasets/issues/4980
| 1,374,868,083
|
I_kwDODunzps5R8tJz
| 4,980
|
Make `pyarrow` optional
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/240344?v=4",
"events_url": "https://api.github.com/users/KOLANICH/events{/privacy}",
"followers_url": "https://api.github.com/users/KOLANICH/followers",
"following_url": "https://api.github.com/users/KOLANICH/following{/other_user}",
"gists_url": "https://api.github.com/users/KOLANICH/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/KOLANICH",
"id": 240344,
"login": "KOLANICH",
"node_id": "MDQ6VXNlcjI0MDM0NA==",
"organizations_url": "https://api.github.com/users/KOLANICH/orgs",
"received_events_url": "https://api.github.com/users/KOLANICH/received_events",
"repos_url": "https://api.github.com/users/KOLANICH/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/KOLANICH/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KOLANICH/subscriptions",
"type": "User",
"url": "https://api.github.com/users/KOLANICH",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
| null |
[] | null |
[
"The whole datasets library is pretty much a wrapper to pyarrow (just take a look at some of the source for a Dataset) https://github.com/huggingface/datasets/blob/51aef08ad7053c0bfe8f9a961207b26df15850d3/src/datasets/arrow_dataset.py#L639 \r\n\r\nI think removing the pyarrow dependency would involve a complete rewrite / a different library with minimal functionality (datasets-lite ?)",
"Thanks for the proposal, @KOLANICH. And also thanks for your answer, @dconathan.\r\n\r\nIndeed, we are using `pyarrow` as the backend for our datasets, in order to cache them and also allow memory-mapping (using datasets larger than your RAM memory).\r\n\r\nOne way to avoid using `pyarrow` could be loading the datasets in streaming mode, by passing `streaming=True` to `load_dataset`. This way you basically get a generator for the dataset; nothing is downloaded, nor cached. ",
"Thanks for the info. Could `datasets` then be made optional for `transformers` instead? I used `transformers` only to deal with pretrained models to deploy them (convert to ONNX, and then I use TVM), so I don't really need `pyarrow` and `datasets` by now.\r\n"
] | 2022-09-15T17:38:03Z
| 2022-09-16T17:23:47Z
| 2022-09-16T17:23:47Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
**Is your feature request related to a problem? Please describe.**
Is `pyarrow` really needed for every dataset?
**Describe the solution you'd like**
It is made optional.
**Describe alternatives you've considered**
Likely, no.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/240344?v=4",
"events_url": "https://api.github.com/users/KOLANICH/events{/privacy}",
"followers_url": "https://api.github.com/users/KOLANICH/followers",
"following_url": "https://api.github.com/users/KOLANICH/following{/other_user}",
"gists_url": "https://api.github.com/users/KOLANICH/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/KOLANICH",
"id": 240344,
"login": "KOLANICH",
"node_id": "MDQ6VXNlcjI0MDM0NA==",
"organizations_url": "https://api.github.com/users/KOLANICH/orgs",
"received_events_url": "https://api.github.com/users/KOLANICH/received_events",
"repos_url": "https://api.github.com/users/KOLANICH/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/KOLANICH/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KOLANICH/subscriptions",
"type": "User",
"url": "https://api.github.com/users/KOLANICH",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4980/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4980/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5931
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5931/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5931/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5931/events
|
https://github.com/huggingface/datasets/issues/5931
| 1,745,408,784
|
I_kwDODunzps5oCNMQ
| 5,931
|
`datasets.map` not reusing cached copy by default
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/19718818?v=4",
"events_url": "https://api.github.com/users/bhavitvyamalik/events{/privacy}",
"followers_url": "https://api.github.com/users/bhavitvyamalik/followers",
"following_url": "https://api.github.com/users/bhavitvyamalik/following{/other_user}",
"gists_url": "https://api.github.com/users/bhavitvyamalik/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bhavitvyamalik",
"id": 19718818,
"login": "bhavitvyamalik",
"node_id": "MDQ6VXNlcjE5NzE4ODE4",
"organizations_url": "https://api.github.com/users/bhavitvyamalik/orgs",
"received_events_url": "https://api.github.com/users/bhavitvyamalik/received_events",
"repos_url": "https://api.github.com/users/bhavitvyamalik/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhavitvyamalik/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bhavitvyamalik",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"This can happen when a map transform cannot be hashed deterministically (e.g., an object referenced by the transform changes its state after the first call - an issue with fast tokenizers). The solution is to provide `cache_file_name` in the `map` call to check this file for the cached result instead of relying on the default caching mechanism."
] | 2023-06-07T09:03:33Z
| 2023-06-21T16:15:40Z
| 2023-06-21T16:15:40Z
|
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
When I load the dataset from local directory, it's cached copy is picked up after first time. However, for `map` operation, the operation is applied again and cached copy is not picked up. Is there any way to pick cached copy instead of processing it again? The only solution I could think of was to use `save_to_disk` after my last transform and then use that in my DataLoader pipeline. Are there any other solutions for the same?
One more thing, my dataset is occupying 6GB storage memory after I use `map`, is there any way I can reduce that memory usage?
### Steps to reproduce the bug
```
# make sure that dataset decodes audio with correct sampling rate
dataset_sampling_rate = next(iter(self.raw_datasets.values())).features["audio"].sampling_rate
if dataset_sampling_rate != self.feature_extractor.sampling_rate:
self.raw_datasets = self.raw_datasets.cast_column(
"audio", datasets.features.Audio(sampling_rate=self.feature_extractor.sampling_rate)
)
vectorized_datasets = self.raw_datasets.map(
self.prepare_dataset,
remove_columns=next(iter(self.raw_datasets.values())).column_names,
num_proc=self.num_workers,
desc="preprocess datasets",
)
# filter data that is longer than max_input_length
self.vectorized_datasets = vectorized_datasets.filter(
self.is_audio_in_length_range,
num_proc=self.num_workers,
input_columns=["input_length"],
)
def prepare_dataset(self, batch):
# load audio
sample = batch["audio"]
inputs = self.feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
batch["input_values"] = inputs.input_values[0]
batch["input_length"] = len(batch["input_values"])
batch["labels"] = self.tokenizer(batch["target_text"]).input_ids
return batch
```
### Expected behavior
`map` to use cached copy and if possible an alternative technique to reduce memory usage after using `map`
### Environment info
- `datasets` version: 2.12.0
- Platform: Linux-3.10.0-1160.71.1.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.8.16
- Huggingface_hub version: 0.15.1
- PyArrow version: 12.0.0
- Pandas version: 2.0.2
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5931/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5931/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6306
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6306/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6306/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6306/events
|
https://github.com/huggingface/datasets/issues/6306
| 1,946,363,452
|
I_kwDODunzps50AyY8
| 6,306
|
pyinstaller : OSError: could not get source code
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/57702070?v=4",
"events_url": "https://api.github.com/users/dusk877647949/events{/privacy}",
"followers_url": "https://api.github.com/users/dusk877647949/followers",
"following_url": "https://api.github.com/users/dusk877647949/following{/other_user}",
"gists_url": "https://api.github.com/users/dusk877647949/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dusk877647949",
"id": 57702070,
"login": "dusk877647949",
"node_id": "MDQ6VXNlcjU3NzAyMDcw",
"organizations_url": "https://api.github.com/users/dusk877647949/orgs",
"received_events_url": "https://api.github.com/users/dusk877647949/received_events",
"repos_url": "https://api.github.com/users/dusk877647949/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dusk877647949/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dusk877647949/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dusk877647949",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"more information:\r\n``` \r\nFile \"text2vec\\__init__.py\", line 8, in <module>\r\nFile \"<frozen importlib._bootstrap>\", line 1027, in _find_and_load\r\nFile \"<frozen importlib._bootstrap>\", line 1006, in _find_and_load_unlocked\r\nFile \"<frozen importlib._bootstrap>\", line 688, in _load_unlocked\r\nFile \"PyInstaller\\loader\\pyimod02_importers.py\", line 499, in exec_module\r\nFile \"text2vec\\bertmatching_model.py\", line 19, in <module>\r\nFile \"<frozen importlib._bootstrap>\", line 1027, in _find_and_load\r\nFile \"<frozen importlib._bootstrap>\", line 1006, in _find_and_load_unlocked\r\nFile \"<frozen importlib._bootstrap>\", line 688, in _load_unlocked\r\nFile \"PyInstaller\\loader\\pyimod02_importers.py\", line 499, in exec_module\r\nFile \"text2vec\\bertmatching_dataset.py\", line 7, in <module>\r\nFile \"<frozen importlib._bootstrap>\", line 1027, in _find_and_load\r\nFile \"<frozen importlib._bootstrap>\", line 1006, in _find_and_load_unlocked\r\nFile \"<frozen importlib._bootstrap>\", line 688, in _load_unlocked\r\nFile \"PyInstaller\\loader\\pyimod02_importers.py\", line 499, in exec_module\r\nFile \"datasets\\__init__.py\", line 52, in <module>\r\nFile \"<frozen importlib._bootstrap>\", line 1027, in _find_and_load\r\nFile \"<frozen importlib._bootstrap>\", line 1006, in _find_and_load_unlocked\r\nFile \"<frozen importlib._bootstrap>\", line 688, in _load_unlocked\r\nFile \"PyInstaller\\loader\\pyimod02_importers.py\", line 499, in exec_module\r\nFile \"datasets\\inspect.py\", line 30, in <module>\r\nFile \"<frozen importlib._bootstrap>\", line 1027, in _find_and_load\r\nFile \"<frozen importlib._bootstrap>\", line 1006, in _find_and_load_unlocked\r\nFile \"<frozen importlib._bootstrap>\", line 688, in _load_unlocked\r\nFile \"PyInstaller\\loader\\pyimod02_importers.py\", line 499, in exec_module\r\nFile \"datasets\\load.py\", line 58, in <module>\r\nFile \"<frozen importlib._bootstrap>\", line 1027, in _find_and_load\r\nFile \"<frozen importlib._bootstrap>\", line 1006, in _find_and_load_unlocked\r\nFile \"<frozen importlib._bootstrap>\", line 688, in _load_unlocked\r\nFile \"PyInstaller\\loader\\pyimod02_importers.py\", line 499, in exec_module\r\nFile \"datasets\\packaged_modules\\__init__.py\", line 31, in <module>\r\nFile \"inspect.py\", line 1147, in getsource\r\nFile \"inspect.py\", line 1129, in getsourcelines\r\nFile \"inspect.py\", line 958, in findsource\r\nOSError: could not get source code\r\n```\r\n",
"Can you share a reproducer? I haven't been able to reproduce the error myself.",
"> '\r\n\r\nthanks,I solve it.it's about pyinstaller.",
"1",
"> > '\r\n> \r\n> thanks,I solve it.it's about pyinstaller.\r\n\r\nI encountered the same error, how to solve it?"
] | 2023-10-17T01:41:51Z
| 2023-11-02T07:24:51Z
| 2023-10-18T14:03:42Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
I ran a package with pyinstaller and got the following error:
### Steps to reproduce the bug
```
...
File "datasets\__init__.py", line 52, in <module>
File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 688, in _load_unlocked
File "PyInstaller\loader\pyimod02_importers.py", line 499, in exec_module
File "datasets\inspect.py", line 30, in <module>
File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 688, in _load_unlocked
File "PyInstaller\loader\pyimod02_importers.py", line 499, in exec_module
File "datasets\load.py", line 58, in <module>
File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 688, in _load_unlocked
File "PyInstaller\loader\pyimod02_importers.py", line 499, in exec_module
File "datasets\packaged_modules\__init__.py", line 31, in <module>
File "inspect.py", line 1147, in getsource
File "inspect.py", line 1129, in getsourcelines
File "inspect.py", line 958, in findsource
OSError: could not get source code
```
### Expected behavior
I have looked up the relevant information, but I can't find a suitable reason
### Environment info
```python
python 3.10
datasets 2.14.4
pyinstaller 5.6.2
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/57702070?v=4",
"events_url": "https://api.github.com/users/dusk877647949/events{/privacy}",
"followers_url": "https://api.github.com/users/dusk877647949/followers",
"following_url": "https://api.github.com/users/dusk877647949/following{/other_user}",
"gists_url": "https://api.github.com/users/dusk877647949/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dusk877647949",
"id": 57702070,
"login": "dusk877647949",
"node_id": "MDQ6VXNlcjU3NzAyMDcw",
"organizations_url": "https://api.github.com/users/dusk877647949/orgs",
"received_events_url": "https://api.github.com/users/dusk877647949/received_events",
"repos_url": "https://api.github.com/users/dusk877647949/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dusk877647949/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dusk877647949/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dusk877647949",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6306/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6306/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/4603
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4603/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4603/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4603/events
|
https://github.com/huggingface/datasets/issues/4603
| 1,289,963,331
|
I_kwDODunzps5M40dD
| 4,603
|
CI fails recurrently and randomly on Windows
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
| null |
[] | null |
[] | 2022-06-30T10:59:58Z
| 2022-06-30T13:22:25Z
| 2022-06-30T13:22:25Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
As reported by @lhoestq,
The windows CI is currently flaky: some dependencies like `aiobotocore`, `multiprocess` and `seqeval` sometimes fail to install.
In particular it seems that building the wheels fail. Here is an example of logs:
```
Building wheel for seqeval (setup.py): started
Running command 'C:\tools\miniconda3\envs\py37\python.exe' -u -c 'import io, os, sys, setuptools, tokenize; sys.argv[0] = '"'"'C:\\Users\\circleci\\AppData\\Local\\Temp\\pip-install-h55pfgbv\\seqeval_d6cdb9d23ff6490b98b6c4bcaecb516e\\setup.py'"'"'; __file__='"'"'C:\\Users\\circleci\\AppData\\Local\\Temp\\pip-install-h55pfgbv\\seqeval_d6cdb9d23ff6490b98b6c4bcaecb516e\\setup.py'"'"';f = getattr(tokenize, '"'"'open'"'"', open)(__file__) if os.path.exists(__file__) else io.StringIO('"'"'from setuptools import setup; setup()'"'"');code = f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' bdist_wheel -d 'C:\Users\circleci\AppData\Local\Temp\pip-wheel-x3cc8ym6'
No parent package detected, impossible to derive `name`
running bdist_wheel
running build
running build_py
package init file 'seqeval\__init__.py' not found (or not a regular file)
package init file 'seqeval\metrics\__init__.py' not found (or not a regular file)
C:\tools\miniconda3\envs\py37\lib\site-packages\setuptools\command\install.py:37: SetuptoolsDeprecationWarning: setup.py install is deprecated. Use build and pip and other standards-based tools.
setuptools.SetuptoolsDeprecationWarning,
installing to build\bdist.win-amd64\wheel
running install
running install_lib
warning: install_lib: 'build\lib' does not exist -- no Python modules to install
running install_egg_info
running egg_info
creating UNKNOWN.egg-info
writing UNKNOWN.egg-info\PKG-INFO
writing dependency_links to UNKNOWN.egg-info\dependency_links.txt
writing top-level names to UNKNOWN.egg-info\top_level.txt
writing manifest file 'UNKNOWN.egg-info\SOURCES.txt'
reading manifest file 'UNKNOWN.egg-info\SOURCES.txt'
writing manifest file 'UNKNOWN.egg-info\SOURCES.txt'
Copying UNKNOWN.egg-info to build\bdist.win-amd64\wheel\.\UNKNOWN-0.0.0-py3.7.egg-info
running install_scripts
creating build\bdist.win-amd64\wheel\UNKNOWN-0.0.0.dist-info\WHEEL
creating 'C:\Users\circleci\AppData\Local\Temp\pip-wheel-x3cc8ym6\UNKNOWN-0.0.0-py3-none-any.whl' and adding 'build\bdist.win-amd64\wheel' to it
adding 'UNKNOWN-0.0.0.dist-info/METADATA'
adding 'UNKNOWN-0.0.0.dist-info/WHEEL'
adding 'UNKNOWN-0.0.0.dist-info/top_level.txt'
adding 'UNKNOWN-0.0.0.dist-info/RECORD'
removing build\bdist.win-amd64\wheel
Building wheel for seqeval (setup.py): finished with status 'done'
Created wheel for seqeval: filename=UNKNOWN-0.0.0-py3-none-any.whl size=963 sha256=67eb93a6e1ff4796c5882a13f9fa25bb0d3d103796e2525f9cecf3b2ef26d4b1
Stored in directory: c:\users\circleci\appdata\local\pip\cache\wheels\05\96\ee\7cac4e74f3b19e3158dce26a20a1c86b3533c43ec72a549fd7
WARNING: Built wheel for seqeval is invalid: Wheel has unexpected file name: expected 'seqeval', got 'UNKNOWN'
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4603/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4603/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6150
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6150/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6150/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6150/events
|
https://github.com/huggingface/datasets/issues/6150
| 1,850,740,456
|
I_kwDODunzps5uUA7o
| 6,150
|
Allow dataset implement .take
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1855278?v=4",
"events_url": "https://api.github.com/users/brando90/events{/privacy}",
"followers_url": "https://api.github.com/users/brando90/followers",
"following_url": "https://api.github.com/users/brando90/following{/other_user}",
"gists_url": "https://api.github.com/users/brando90/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/brando90",
"id": 1855278,
"login": "brando90",
"node_id": "MDQ6VXNlcjE4NTUyNzg=",
"organizations_url": "https://api.github.com/users/brando90/orgs",
"received_events_url": "https://api.github.com/users/brando90/received_events",
"repos_url": "https://api.github.com/users/brando90/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/brando90/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brando90/subscriptions",
"type": "User",
"url": "https://api.github.com/users/brando90",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
| null |
[] | null |
[
"```\r\n dataset = IterableDataset(dataset) if type(dataset) != IterableDataset else dataset # to force dataset.take(batch_size) to work in non-streaming mode\r\n ```\r\n",
"hf discuss: https://discuss.huggingface.co/t/how-does-one-make-dataset-take-512-work-with-streaming-false-with-hugging-face-data-set/50770",
"so: https://stackoverflow.com/questions/76902824/how-does-one-make-dataset-take512-work-with-streaming-false-with-hugging-fac",
"Feel free to work on this. In addition, `IterableDataset` supports `skip`, so we should also add this method to `Dataset`."
] | 2023-08-15T00:17:51Z
| 2023-08-17T13:49:37Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
I want to do:
```
dataset.take(512)
```
but it only works with streaming = True
### Motivation
uniform interface to data sets. Really surprising the above only works with streaming = True.
### Your contribution
Should be trivial to copy paste the IterableDataset .take to use the local path in the data (when streaming = False)
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6150/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6150/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5613
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5613/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5613/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5613/events
|
https://github.com/huggingface/datasets/issues/5613
| 1,611,875,473
|
I_kwDODunzps5gE0SR
| 5,613
|
Version mismatch with multiprocess and dill on Python 3.10
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1243668?v=4",
"events_url": "https://api.github.com/users/adampauls/events{/privacy}",
"followers_url": "https://api.github.com/users/adampauls/followers",
"following_url": "https://api.github.com/users/adampauls/following{/other_user}",
"gists_url": "https://api.github.com/users/adampauls/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/adampauls",
"id": 1243668,
"login": "adampauls",
"node_id": "MDQ6VXNlcjEyNDM2Njg=",
"organizations_url": "https://api.github.com/users/adampauls/orgs",
"received_events_url": "https://api.github.com/users/adampauls/received_events",
"repos_url": "https://api.github.com/users/adampauls/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/adampauls/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adampauls/subscriptions",
"type": "User",
"url": "https://api.github.com/users/adampauls",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"Sorry, I just found https://github.com/apache/beam/issues/24458. It seems this issue is being worked on. ",
"Reopening, since I think the docs should inform the user of this problem. For example, [this page](https://huggingface.co/docs/datasets/installation) says \r\n> Datasets is tested on Python 3.7+.\r\n\r\nbut it should probably say that Beam Datasets do not work with Python 3.10 (or link to a known issues page). ",
"Same problem on Colab using a vanilla setup running :\r\nPython 3.10.11 \r\napache-beam 2.47.0\r\ndatasets 2.12.0",
"Same problem, \r\npy 3.10.11\r\napache-beam==2.47.0\r\ndatasets==2.12.0",
"I have made a workaround by forcing an install of the version of `multiprocess` version `0.70.15` (after installing `datasets` and `apache-beam`). I can confirm that (on Python 3.10 in [this colab notebook](https://colab.research.google.com/drive/1PTeGlshamFcJZix_GiS3vMXX_YzAhGv0?usp=sharing)) `datasets` can download pre-processed Wikipedia dumps and can download non-pre-processed dumps using `beam_runner=\"DirectRunner\"`. I don't know if/how other `beam_runner`s can be made compatible.",
"Same problem.\r\n\r\n```\r\npython = \"^3.10\"\r\napache-beam = { extras = [\"gcp\"], version = \"2.54.0\" }\r\ndatasets = \"^2.18.0\"\r\n```"
] | 2023-03-06T17:14:41Z
| 2024-04-05T20:13:52Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Grabbing the latest version of `datasets` and `apache-beam` with `poetry` using Python 3.10 gives a crash at runtime. The crash is
```
File "/Users/adpauls/sc/git/DSI-transformers/data/NQ/create_NQ_train_vali.py", line 1, in <module>
import datasets
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/datasets/__init__.py", line 43, in <module>
from .arrow_dataset import Dataset
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 65, in <module>
from .arrow_reader import ArrowReader
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/datasets/arrow_reader.py", line 30, in <module>
from .download.download_config import DownloadConfig
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/datasets/download/__init__.py", line 9, in <module>
from .download_manager import DownloadManager, DownloadMode
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/datasets/download/download_manager.py", line 35, in <module>
from ..utils.py_utils import NestedDataStructure, map_nested, size_str
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/datasets/utils/py_utils.py", line 40, in <module>
import multiprocess.pool
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/multiprocess/pool.py", line 609, in <module>
class ThreadPool(Pool):
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/multiprocess/pool.py", line 611, in ThreadPool
from .dummy import Process
File "/Users/adpauls/Library/Caches/pypoetry/virtualenvs/yyy-oPbZ7mKM-py3.10/lib/python3.10/site-packages/multiprocess/dummy/__init__.py", line 87, in <module>
class Condition(threading._Condition):
AttributeError: module 'threading' has no attribute '_Condition'. Did you mean: 'Condition'?
```
I think this is a bad interaction of versions from `dill`, `multiprocess`, `apache-beam`, and `threading` from the Python (3.10) standard lib. Upgrading `multiprocess` to a version that does not crash like this is not possible because `apache-beam` pins `dill` to and old version:
```
Because multiprocess (0.70.10) depends on dill (>=0.3.2)
and apache-beam (2.45.0) depends on dill (>=0.3.1.1,<0.3.2), multiprocess (0.70.10) is incompatible with apache-beam (2.45.0).
And because no versions of apache-beam match >2.45.0,<3.0.0, multiprocess (0.70.10) is incompatible with apache-beam (>=2.45.0,<3.0.0).
So, because yyy depends on both apache-beam (^2.45.0) and multiprocess (0.70.10), version solving failed.
```
Perhaps it is not right to file a bug here, but I'm not totally sure whose fault it is. And in any case, this is an immediate blocker to using `datasets` out of the box.
Possibly related to https://github.com/huggingface/datasets/issues/5232.
### Steps to reproduce the bug
Steps to reproduce:
1. Make a poetry project with this configuration
```
[tool.poetry]
name = "yyy"
version = "0.1.0"
description = ""
authors = ["Adam Pauls <adpauls@gmail.com>"]
readme = "README.md"
packages = [{ include = "xxx" }]
[tool.poetry.dependencies]
python = ">=3.10,<3.11"
datasets = "^2.10.1"
apache-beam = "^2.45.0"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
```
2. `poetry install`.
3. `poetry run python -c "import datasets"`.
### Expected behavior
Script runs.
### Environment info
Python 3.10. Here are the versions installed by `poetry`:
```
•• Installing frozenlist (1.3.3)
• Installing idna (3.4)
• Installing multidict (6.0.4)
• Installing aiosignal (1.3.1)
• Installing async-timeout (4.0.2)
• Installing attrs (22.2.0)
• Installing certifi (2022.12.7)
• Installing charset-normalizer (3.1.0)
• Installing six (1.16.0)
• Installing urllib3 (1.26.14)
• Installing yarl (1.8.2)
• Installing aiohttp (3.8.4)
• Installing dill (0.3.1.1)
• Installing docopt (0.6.2)
• Installing filelock (3.9.0)
• Installing numpy (1.22.4)
• Installing pyparsing (3.0.9)
• Installing protobuf (3.19.4)
• Installing packaging (23.0)
• Installing python-dateutil (2.8.2)
• Installing pytz (2022.7.1)
• Installing pyyaml (6.0)
• Installing requests (2.28.2)
• Installing tqdm (4.65.0)
• Installing typing-extensions (4.5.0)
• Installing cloudpickle (2.2.1)
• Installing crcmod (1.7)
• Installing fastavro (1.7.2)
• Installing fasteners (0.18)
• Installing fsspec (2023.3.0)
• Installing grpcio (1.51.3)
• Installing hdfs (2.7.0)
• Installing httplib2 (0.20.4)
• Installing huggingface-hub (0.12.1)
• Installing multiprocess (0.70.9)
• Installing objsize (0.6.1)
• Installing orjson (3.8.7)
• Installing pandas (1.5.3)
• Installing proto-plus (1.22.2)
• Installing pyarrow (9.0.0)
• Installing pydot (1.4.2)
• Installing pymongo (3.13.0)
• Installing regex (2022.10.31)
• Installing responses (0.18.0)
• Installing xxhash (3.2.0)
• Installing zstandard (0.20.0)
• Installing apache-beam (2.45.0)
• Installing datasets (2.10.1)
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1243668?v=4",
"events_url": "https://api.github.com/users/adampauls/events{/privacy}",
"followers_url": "https://api.github.com/users/adampauls/followers",
"following_url": "https://api.github.com/users/adampauls/following{/other_user}",
"gists_url": "https://api.github.com/users/adampauls/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/adampauls",
"id": 1243668,
"login": "adampauls",
"node_id": "MDQ6VXNlcjEyNDM2Njg=",
"organizations_url": "https://api.github.com/users/adampauls/orgs",
"received_events_url": "https://api.github.com/users/adampauls/received_events",
"repos_url": "https://api.github.com/users/adampauls/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/adampauls/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adampauls/subscriptions",
"type": "User",
"url": "https://api.github.com/users/adampauls",
"user_view_type": "public"
}
|
{
"+1": 10,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 10,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5613/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5613/timeline
| null |
reopened
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5117
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5117/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5117/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5117/events
|
https://github.com/huggingface/datasets/issues/5117
| 1,409,571,346
|
I_kwDODunzps5UBFoS
| 5,117
|
Progress bars have color red and never completed to 100%
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/63857529?v=4",
"events_url": "https://api.github.com/users/echatzikyriakidis/events{/privacy}",
"followers_url": "https://api.github.com/users/echatzikyriakidis/followers",
"following_url": "https://api.github.com/users/echatzikyriakidis/following{/other_user}",
"gists_url": "https://api.github.com/users/echatzikyriakidis/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/echatzikyriakidis",
"id": 63857529,
"login": "echatzikyriakidis",
"node_id": "MDQ6VXNlcjYzODU3NTI5",
"organizations_url": "https://api.github.com/users/echatzikyriakidis/orgs",
"received_events_url": "https://api.github.com/users/echatzikyriakidis/received_events",
"repos_url": "https://api.github.com/users/echatzikyriakidis/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/echatzikyriakidis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/echatzikyriakidis/subscriptions",
"type": "User",
"url": "https://api.github.com/users/echatzikyriakidis",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/9879252?v=4",
"events_url": "https://api.github.com/users/david1542/events{/privacy}",
"followers_url": "https://api.github.com/users/david1542/followers",
"following_url": "https://api.github.com/users/david1542/following{/other_user}",
"gists_url": "https://api.github.com/users/david1542/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/david1542",
"id": 9879252,
"login": "david1542",
"node_id": "MDQ6VXNlcjk4NzkyNTI=",
"organizations_url": "https://api.github.com/users/david1542/orgs",
"received_events_url": "https://api.github.com/users/david1542/received_events",
"repos_url": "https://api.github.com/users/david1542/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/david1542/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/david1542/subscriptions",
"type": "User",
"url": "https://api.github.com/users/david1542",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/9879252?v=4",
"events_url": "https://api.github.com/users/david1542/events{/privacy}",
"followers_url": "https://api.github.com/users/david1542/followers",
"following_url": "https://api.github.com/users/david1542/following{/other_user}",
"gists_url": "https://api.github.com/users/david1542/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/david1542",
"id": 9879252,
"login": "david1542",
"node_id": "MDQ6VXNlcjk4NzkyNTI=",
"organizations_url": "https://api.github.com/users/david1542/orgs",
"received_events_url": "https://api.github.com/users/david1542/received_events",
"repos_url": "https://api.github.com/users/david1542/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/david1542/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/david1542/subscriptions",
"type": "User",
"url": "https://api.github.com/users/david1542",
"user_view_type": "public"
}
] | null |
[
"Hi @echatzikyriakidis, thanks for submitting the issue.\r\nWhich shell are you using exactly? I tried to run the command you sent, but I don't see colors at all 🧐\r\n\r\nI tried from bash and zsh as well.",
"Hi @david1542 ,\r\n\r\nI use Google Colab.\r\n",
"Got it. I [created a PR](https://github.com/huggingface/datasets/pull/5120) that fixes this issue. Turns out that the wrapping logic for the inner loop was slightly incorrect.",
"Thank you!",
"Hello @mariosasko \r\n\r\nI am still facing this issue. Was this problem fixed?\r\n\r\n\r\n\r\nI cleared the hugging face cache before running, and no error message was given. Let me know if you need a minimal repro of my code."
] | 2022-10-14T16:12:30Z
| 2024-06-19T19:03:42Z
| 2022-10-23T12:58:41Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
## Describe the bug
Progress bars after transformative operations turn in red and never be completed to 100%
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset('rotten_tomatoes', split='test').filter(lambda o: True)
```
## Expected results
Progress bar should be 100% and green
## Actual results
Progress bar turn in red and never completed to 100%
## Environment info
- `datasets` version: 2.6.1
- Platform: Linux-5.10.133+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.14
- PyArrow version: 6.0.1
- Pandas version: 1.3.5
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5117/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5117/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6045
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6045/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6045/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6045/events
|
https://github.com/huggingface/datasets/pull/6045
| 1,808,072,270
|
PR_kwDODunzps5Vr-r1
| 6,045
|
Check if column names match in Parquet loader only when config `features` are specified
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006557 / 0.011353 (-0.004796) | 0.004096 / 0.011008 (-0.006913) | 0.083577 / 0.038508 (0.045069) | 0.072092 / 0.023109 (0.048983) | 0.319192 / 0.275898 (0.043294) | 0.351845 / 0.323480 (0.028365) | 0.005475 / 0.007986 (-0.002511) | 0.003419 / 0.004328 (-0.000910) | 0.064562 / 0.004250 (0.060311) | 0.057930 / 0.037052 (0.020878) | 0.326085 / 0.258489 (0.067596) | 0.368316 / 0.293841 (0.074475) | 0.030502 / 0.128546 (-0.098044) | 0.008504 / 0.075646 (-0.067142) | 0.287217 / 0.419271 (-0.132054) | 0.052337 / 0.043533 (0.008804) | 0.319011 / 0.255139 (0.063872) | 0.352711 / 0.283200 (0.069511) | 0.023278 / 0.141683 (-0.118405) | 1.482578 / 1.452155 (0.030423) | 1.553391 / 1.492716 (0.060675) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.199628 / 0.018006 (0.181622) | 0.464571 / 0.000490 (0.464081) | 0.003512 / 0.000200 (0.003312) | 0.000072 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029109 / 0.037411 (-0.008302) | 0.082203 / 0.014526 (0.067677) | 0.096223 / 0.176557 (-0.080333) | 0.155598 / 0.737135 (-0.581537) | 0.097738 / 0.296338 (-0.198600) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.386135 / 0.215209 (0.170926) | 3.837157 / 2.077655 (1.759502) | 1.836869 / 1.504120 (0.332750) | 1.680592 / 1.541195 (0.139398) | 1.769456 / 1.468490 (0.300966) | 0.493150 / 4.584777 (-4.091627) | 3.589797 / 3.745712 (-0.155915) | 3.330000 / 5.269862 (-1.939861) | 2.059856 / 4.565676 (-2.505821) | 0.057951 / 0.424275 (-0.366324) | 0.007340 / 0.007607 (-0.000267) | 0.463203 / 0.226044 (0.237159) | 4.631514 / 2.268929 (2.362585) | 2.329887 / 55.444624 (-53.114738) | 2.008815 / 6.876477 (-4.867662) | 2.199067 / 2.142072 (0.056995) | 0.591417 / 4.805227 (-4.213810) | 0.137154 / 6.500664 (-6.363510) | 0.061326 / 0.075469 (-0.014143) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.269676 / 1.841788 (-0.572111) | 19.375167 / 8.074308 (11.300858) | 13.945419 / 10.191392 (3.754027) | 0.146482 / 0.680424 (-0.533942) | 0.018257 / 0.534201 (-0.515944) | 0.391684 / 0.579283 (-0.187599) | 0.411454 / 0.434364 (-0.022910) | 0.466260 / 0.540337 (-0.074077) | 0.655571 / 1.386936 (-0.731365) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006619 / 0.011353 (-0.004734) | 0.004102 / 0.011008 (-0.006907) | 0.064848 / 0.038508 (0.026340) | 0.074822 / 0.023109 (0.051713) | 0.366535 / 0.275898 (0.090637) | 0.395873 / 0.323480 (0.072394) | 0.005315 / 0.007986 (-0.002670) | 0.003270 / 0.004328 (-0.001059) | 0.064829 / 0.004250 (0.060578) | 0.056094 / 0.037052 (0.019042) | 0.370355 / 0.258489 (0.111866) | 0.406837 / 0.293841 (0.112996) | 0.031634 / 0.128546 (-0.096912) | 0.008569 / 0.075646 (-0.067077) | 0.071126 / 0.419271 (-0.348145) | 0.048629 / 0.043533 (0.005096) | 0.365175 / 0.255139 (0.110036) | 0.385234 / 0.283200 (0.102034) | 0.023295 / 0.141683 (-0.118388) | 1.466907 / 1.452155 (0.014752) | 1.523118 / 1.492716 (0.030401) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.227872 / 0.018006 (0.209866) | 0.451573 / 0.000490 (0.451083) | 0.000379 / 0.000200 (0.000179) | 0.000055 / 0.000054 (0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029496 / 0.037411 (-0.007915) | 0.086614 / 0.014526 (0.072088) | 0.098165 / 0.176557 (-0.078392) | 0.152218 / 0.737135 (-0.584917) | 0.101215 / 0.296338 (-0.195123) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.407519 / 0.215209 (0.192310) | 4.074704 / 2.077655 (1.997049) | 2.113185 / 1.504120 (0.609065) | 1.947461 / 1.541195 (0.406266) | 1.998521 / 1.468490 (0.530031) | 0.487463 / 4.584777 (-4.097313) | 3.465423 / 3.745712 (-0.280289) | 3.376498 / 5.269862 (-1.893363) | 2.001533 / 4.565676 (-2.564144) | 0.057052 / 0.424275 (-0.367223) | 0.007325 / 0.007607 (-0.000283) | 0.485648 / 0.226044 (0.259604) | 4.860191 / 2.268929 (2.591262) | 2.550340 / 55.444624 (-52.894284) | 2.231136 / 6.876477 (-4.645341) | 2.262539 / 2.142072 (0.120467) | 0.591422 / 4.805227 (-4.213805) | 0.132875 / 6.500664 (-6.367789) | 0.062154 / 0.075469 (-0.013315) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.321834 / 1.841788 (-0.519954) | 19.734750 / 8.074308 (11.660442) | 14.681049 / 10.191392 (4.489657) | 0.148894 / 0.680424 (-0.531530) | 0.018414 / 0.534201 (-0.515787) | 0.393377 / 0.579283 (-0.185906) | 0.402795 / 0.434364 (-0.031569) | 0.478624 / 0.540337 (-0.061714) | 0.656767 / 1.386936 (-0.730169) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007012 / 0.011353 (-0.004341) | 0.004120 / 0.011008 (-0.006888) | 0.083720 / 0.038508 (0.045212) | 0.083105 / 0.023109 (0.059996) | 0.323803 / 0.275898 (0.047905) | 0.340345 / 0.323480 (0.016865) | 0.005872 / 0.007986 (-0.002113) | 0.003528 / 0.004328 (-0.000801) | 0.065185 / 0.004250 (0.060935) | 0.063092 / 0.037052 (0.026040) | 0.314900 / 0.258489 (0.056411) | 0.349251 / 0.293841 (0.055410) | 0.031612 / 0.128546 (-0.096934) | 0.008541 / 0.075646 (-0.067105) | 0.289865 / 0.419271 (-0.129407) | 0.055264 / 0.043533 (0.011731) | 0.309152 / 0.255139 (0.054013) | 0.332625 / 0.283200 (0.049425) | 0.024306 / 0.141683 (-0.117377) | 1.489191 / 1.452155 (0.037037) | 1.562447 / 1.492716 (0.069731) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.236681 / 0.018006 (0.218675) | 0.567767 / 0.000490 (0.567277) | 0.003022 / 0.000200 (0.002822) | 0.000218 / 0.000054 (0.000164) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028698 / 0.037411 (-0.008714) | 0.081681 / 0.014526 (0.067155) | 0.099109 / 0.176557 (-0.077447) | 0.154381 / 0.737135 (-0.582754) | 0.098691 / 0.296338 (-0.197648) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.397985 / 0.215209 (0.182776) | 3.962499 / 2.077655 (1.884844) | 1.936158 / 1.504120 (0.432038) | 1.762339 / 1.541195 (0.221144) | 1.837451 / 1.468490 (0.368961) | 0.485655 / 4.584777 (-4.099122) | 3.538341 / 3.745712 (-0.207371) | 5.110095 / 5.269862 (-0.159767) | 3.066152 / 4.565676 (-1.499524) | 0.057505 / 0.424275 (-0.366770) | 0.007334 / 0.007607 (-0.000273) | 0.475622 / 0.226044 (0.249578) | 4.754091 / 2.268929 (2.485162) | 2.431379 / 55.444624 (-53.013246) | 2.106178 / 6.876477 (-4.770298) | 2.364305 / 2.142072 (0.222232) | 0.614038 / 4.805227 (-4.191190) | 0.148530 / 6.500664 (-6.352134) | 0.061033 / 0.075469 (-0.014436) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.242345 / 1.841788 (-0.599443) | 19.017266 / 8.074308 (10.942958) | 13.477782 / 10.191392 (3.286390) | 0.158513 / 0.680424 (-0.521911) | 0.018757 / 0.534201 (-0.515444) | 0.393773 / 0.579283 (-0.185510) | 0.416933 / 0.434364 (-0.017431) | 0.460012 / 0.540337 (-0.080326) | 0.637010 / 1.386936 (-0.749926) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006689 / 0.011353 (-0.004664) | 0.004168 / 0.011008 (-0.006840) | 0.065009 / 0.038508 (0.026501) | 0.073766 / 0.023109 (0.050657) | 0.369585 / 0.275898 (0.093687) | 0.407945 / 0.323480 (0.084465) | 0.005583 / 0.007986 (-0.002403) | 0.003494 / 0.004328 (-0.000835) | 0.065032 / 0.004250 (0.060782) | 0.057166 / 0.037052 (0.020114) | 0.370656 / 0.258489 (0.112166) | 0.428381 / 0.293841 (0.134540) | 0.031653 / 0.128546 (-0.096893) | 0.008731 / 0.075646 (-0.066915) | 0.071624 / 0.419271 (-0.347648) | 0.049364 / 0.043533 (0.005832) | 0.361824 / 0.255139 (0.106685) | 0.387615 / 0.283200 (0.104415) | 0.023228 / 0.141683 (-0.118455) | 1.476204 / 1.452155 (0.024049) | 1.553522 / 1.492716 (0.060806) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.266955 / 0.018006 (0.248948) | 0.556566 / 0.000490 (0.556076) | 0.000399 / 0.000200 (0.000199) | 0.000056 / 0.000054 (0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033104 / 0.037411 (-0.004307) | 0.088067 / 0.014526 (0.073541) | 0.103333 / 0.176557 (-0.073224) | 0.157061 / 0.737135 (-0.580074) | 0.105007 / 0.296338 (-0.191331) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.420826 / 0.215209 (0.205617) | 4.201656 / 2.077655 (2.124001) | 2.208336 / 1.504120 (0.704216) | 2.043780 / 1.541195 (0.502585) | 2.156215 / 1.468490 (0.687725) | 0.490485 / 4.584777 (-4.094292) | 3.611446 / 3.745712 (-0.134267) | 5.293140 / 5.269862 (0.023279) | 2.739778 / 4.565676 (-1.825899) | 0.058175 / 0.424275 (-0.366100) | 0.007633 / 0.007607 (0.000026) | 0.500773 / 0.226044 (0.274729) | 5.000900 / 2.268929 (2.731971) | 2.721200 / 55.444624 (-52.723424) | 2.349381 / 6.876477 (-4.527095) | 2.386261 / 2.142072 (0.244188) | 0.583174 / 4.805227 (-4.222053) | 0.134558 / 6.500664 (-6.366106) | 0.062157 / 0.075469 (-0.013312) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.351087 / 1.841788 (-0.490701) | 20.305703 / 8.074308 (12.231395) | 14.548518 / 10.191392 (4.357126) | 0.173720 / 0.680424 (-0.506704) | 0.018100 / 0.534201 (-0.516101) | 0.395187 / 0.579283 (-0.184097) | 0.414619 / 0.434364 (-0.019745) | 0.462515 / 0.540337 (-0.077823) | 0.617822 / 1.386936 (-0.769114) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006909 / 0.011353 (-0.004444) | 0.003954 / 0.011008 (-0.007054) | 0.084329 / 0.038508 (0.045821) | 0.074919 / 0.023109 (0.051809) | 0.319350 / 0.275898 (0.043451) | 0.347264 / 0.323480 (0.023785) | 0.005326 / 0.007986 (-0.002660) | 0.003323 / 0.004328 (-0.001006) | 0.064286 / 0.004250 (0.060036) | 0.054748 / 0.037052 (0.017696) | 0.324784 / 0.258489 (0.066295) | 0.361445 / 0.293841 (0.067605) | 0.031239 / 0.128546 (-0.097308) | 0.008361 / 0.075646 (-0.067286) | 0.287482 / 0.419271 (-0.131789) | 0.052093 / 0.043533 (0.008560) | 0.321454 / 0.255139 (0.066315) | 0.337999 / 0.283200 (0.054800) | 0.025807 / 0.141683 (-0.115876) | 1.501838 / 1.452155 (0.049683) | 1.574484 / 1.492716 (0.081767) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.193220 / 0.018006 (0.175214) | 0.448105 / 0.000490 (0.447615) | 0.002949 / 0.000200 (0.002749) | 0.000071 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028517 / 0.037411 (-0.008894) | 0.087281 / 0.014526 (0.072755) | 0.098295 / 0.176557 (-0.078262) | 0.156972 / 0.737135 (-0.580163) | 0.101250 / 0.296338 (-0.195088) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.383734 / 0.215209 (0.168525) | 3.821293 / 2.077655 (1.743638) | 1.866487 / 1.504120 (0.362367) | 1.722195 / 1.541195 (0.181000) | 1.843762 / 1.468490 (0.375272) | 0.484813 / 4.584777 (-4.099964) | 3.535381 / 3.745712 (-0.210331) | 5.502338 / 5.269862 (0.232477) | 3.256078 / 4.565676 (-1.309599) | 0.057312 / 0.424275 (-0.366963) | 0.007305 / 0.007607 (-0.000302) | 0.461523 / 0.226044 (0.235479) | 4.611828 / 2.268929 (2.342899) | 2.337180 / 55.444624 (-53.107445) | 2.040956 / 6.876477 (-4.835521) | 2.241233 / 2.142072 (0.099160) | 0.583727 / 4.805227 (-4.221500) | 0.132427 / 6.500664 (-6.368237) | 0.060306 / 0.075469 (-0.015163) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.282223 / 1.841788 (-0.559565) | 19.439745 / 8.074308 (11.365437) | 13.627657 / 10.191392 (3.436265) | 0.158975 / 0.680424 (-0.521449) | 0.018599 / 0.534201 (-0.515601) | 0.391136 / 0.579283 (-0.188147) | 0.410947 / 0.434364 (-0.023417) | 0.453889 / 0.540337 (-0.086448) | 0.620928 / 1.386936 (-0.766008) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006428 / 0.011353 (-0.004925) | 0.003980 / 0.011008 (-0.007028) | 0.065006 / 0.038508 (0.026498) | 0.076541 / 0.023109 (0.053432) | 0.358518 / 0.275898 (0.082620) | 0.394397 / 0.323480 (0.070917) | 0.005845 / 0.007986 (-0.002140) | 0.003258 / 0.004328 (-0.001071) | 0.064436 / 0.004250 (0.060186) | 0.056691 / 0.037052 (0.019639) | 0.367369 / 0.258489 (0.108880) | 0.420345 / 0.293841 (0.126504) | 0.031047 / 0.128546 (-0.097499) | 0.008430 / 0.075646 (-0.067216) | 0.071280 / 0.419271 (-0.347991) | 0.048872 / 0.043533 (0.005339) | 0.360073 / 0.255139 (0.104934) | 0.384150 / 0.283200 (0.100951) | 0.023189 / 0.141683 (-0.118494) | 1.500251 / 1.452155 (0.048096) | 1.545910 / 1.492716 (0.053194) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224861 / 0.018006 (0.206855) | 0.439901 / 0.000490 (0.439411) | 0.000372 / 0.000200 (0.000172) | 0.000054 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029914 / 0.037411 (-0.007497) | 0.086916 / 0.014526 (0.072390) | 0.099527 / 0.176557 (-0.077029) | 0.153031 / 0.737135 (-0.584104) | 0.100008 / 0.296338 (-0.196330) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.420305 / 0.215209 (0.205096) | 4.198224 / 2.077655 (2.120569) | 2.223807 / 1.504120 (0.719687) | 2.058475 / 1.541195 (0.517280) | 2.140405 / 1.468490 (0.671915) | 0.481224 / 4.584777 (-4.103553) | 3.593767 / 3.745712 (-0.151945) | 5.536710 / 5.269862 (0.266849) | 3.162048 / 4.565676 (-1.403629) | 0.056662 / 0.424275 (-0.367614) | 0.007301 / 0.007607 (-0.000306) | 0.507494 / 0.226044 (0.281450) | 5.047824 / 2.268929 (2.778896) | 2.715167 / 55.444624 (-52.729458) | 2.334916 / 6.876477 (-4.541560) | 2.406615 / 2.142072 (0.264543) | 0.572761 / 4.805227 (-4.232466) | 0.131248 / 6.500664 (-6.369416) | 0.062401 / 0.075469 (-0.013068) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.375896 / 1.841788 (-0.465892) | 19.836638 / 8.074308 (11.762329) | 14.246645 / 10.191392 (4.055253) | 0.164975 / 0.680424 (-0.515449) | 0.018293 / 0.534201 (-0.515908) | 0.394196 / 0.579283 (-0.185087) | 0.405895 / 0.434364 (-0.028469) | 0.459221 / 0.540337 (-0.081116) | 0.609898 / 1.386936 (-0.777038) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008463 / 0.011353 (-0.002890) | 0.004754 / 0.011008 (-0.006254) | 0.103574 / 0.038508 (0.065066) | 0.083541 / 0.023109 (0.060432) | 0.402498 / 0.275898 (0.126600) | 0.434944 / 0.323480 (0.111465) | 0.005766 / 0.007986 (-0.002219) | 0.003823 / 0.004328 (-0.000505) | 0.078433 / 0.004250 (0.074183) | 0.056948 / 0.037052 (0.019895) | 0.392539 / 0.258489 (0.134050) | 0.447226 / 0.293841 (0.153385) | 0.045845 / 0.128546 (-0.082701) | 0.014043 / 0.075646 (-0.061603) | 0.355768 / 0.419271 (-0.063503) | 0.065492 / 0.043533 (0.021960) | 0.408047 / 0.255139 (0.152908) | 0.468313 / 0.283200 (0.185113) | 0.033779 / 0.141683 (-0.107904) | 1.772198 / 1.452155 (0.320043) | 1.889127 / 1.492716 (0.396411) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.207107 / 0.018006 (0.189101) | 0.533261 / 0.000490 (0.532771) | 0.000864 / 0.000200 (0.000664) | 0.000105 / 0.000054 (0.000051) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032139 / 0.037411 (-0.005272) | 0.102002 / 0.014526 (0.087476) | 0.108780 / 0.176557 (-0.067777) | 0.202857 / 0.737135 (-0.534278) | 0.110378 / 0.296338 (-0.185960) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.582814 / 0.215209 (0.367605) | 5.870683 / 2.077655 (3.793028) | 2.510290 / 1.504120 (1.006171) | 2.146337 / 1.541195 (0.605142) | 2.239278 / 1.468490 (0.770788) | 0.861205 / 4.584777 (-3.723572) | 5.177394 / 3.745712 (1.431682) | 8.550713 / 5.269862 (3.280852) | 4.867715 / 4.565676 (0.302038) | 0.096665 / 0.424275 (-0.327610) | 0.008702 / 0.007607 (0.001095) | 0.748908 / 0.226044 (0.522863) | 7.302815 / 2.268929 (5.033887) | 3.205045 / 55.444624 (-52.239580) | 2.743914 / 6.876477 (-4.132562) | 2.831240 / 2.142072 (0.689167) | 1.103912 / 4.805227 (-3.701315) | 0.246075 / 6.500664 (-6.254589) | 0.092092 / 0.075469 (0.016623) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.591331 / 1.841788 (-0.250457) | 23.085848 / 8.074308 (15.011540) | 22.887963 / 10.191392 (12.696571) | 0.212735 / 0.680424 (-0.467689) | 0.027400 / 0.534201 (-0.506801) | 0.493822 / 0.579283 (-0.085461) | 0.574485 / 0.434364 (0.140121) | 0.574873 / 0.540337 (0.034536) | 0.826178 / 1.386936 (-0.560758) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009155 / 0.011353 (-0.002198) | 0.004976 / 0.011008 (-0.006032) | 0.079308 / 0.038508 (0.040799) | 0.093959 / 0.023109 (0.070850) | 0.449110 / 0.275898 (0.173212) | 0.493356 / 0.323480 (0.169876) | 0.006317 / 0.007986 (-0.001669) | 0.004179 / 0.004328 (-0.000150) | 0.076991 / 0.004250 (0.072740) | 0.061977 / 0.037052 (0.024924) | 0.493823 / 0.258489 (0.235333) | 0.491609 / 0.293841 (0.197768) | 0.049552 / 0.128546 (-0.078994) | 0.015174 / 0.075646 (-0.060472) | 0.090431 / 0.419271 (-0.328841) | 0.061597 / 0.043533 (0.018064) | 0.467672 / 0.255139 (0.212533) | 0.490542 / 0.283200 (0.207342) | 0.035048 / 0.141683 (-0.106635) | 1.807939 / 1.452155 (0.355784) | 1.854859 / 1.492716 (0.362142) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.236672 / 0.018006 (0.218666) | 0.542236 / 0.000490 (0.541746) | 0.016334 / 0.000200 (0.016134) | 0.000220 / 0.000054 (0.000165) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032051 / 0.037411 (-0.005360) | 0.115352 / 0.014526 (0.100826) | 0.125115 / 0.176557 (-0.051441) | 0.173670 / 0.737135 (-0.563466) | 0.117832 / 0.296338 (-0.178507) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.631513 / 0.215209 (0.416304) | 6.371688 / 2.077655 (4.294033) | 2.867240 / 1.504120 (1.363120) | 2.454907 / 1.541195 (0.913713) | 2.518860 / 1.468490 (1.050370) | 0.879973 / 4.584777 (-3.704804) | 5.170263 / 3.745712 (1.424551) | 7.986429 / 5.269862 (2.716567) | 4.828095 / 4.565676 (0.262418) | 0.097808 / 0.424275 (-0.326468) | 0.010541 / 0.007607 (0.002934) | 0.745601 / 0.226044 (0.519557) | 7.631683 / 2.268929 (5.362755) | 3.524255 / 55.444624 (-51.920369) | 2.866199 / 6.876477 (-4.010278) | 2.982483 / 2.142072 (0.840410) | 1.148957 / 4.805227 (-3.656270) | 0.217067 / 6.500664 (-6.283598) | 0.074357 / 0.075469 (-0.001112) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.714917 / 1.841788 (-0.126871) | 24.151348 / 8.074308 (16.077040) | 21.993604 / 10.191392 (11.802212) | 0.234883 / 0.680424 (-0.445541) | 0.028182 / 0.534201 (-0.506019) | 0.474050 / 0.579283 (-0.105233) | 0.557012 / 0.434364 (0.122648) | 0.537823 / 0.540337 (-0.002514) | 0.741488 / 1.386936 (-0.645448) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007640 / 0.011353 (-0.003713) | 0.004776 / 0.011008 (-0.006232) | 0.101582 / 0.038508 (0.063074) | 0.085113 / 0.023109 (0.062003) | 0.376000 / 0.275898 (0.100102) | 0.421117 / 0.323480 (0.097637) | 0.006095 / 0.007986 (-0.001891) | 0.003884 / 0.004328 (-0.000445) | 0.077263 / 0.004250 (0.073013) | 0.065262 / 0.037052 (0.028210) | 0.384041 / 0.258489 (0.125552) | 0.442229 / 0.293841 (0.148388) | 0.035706 / 0.128546 (-0.092840) | 0.009996 / 0.075646 (-0.065651) | 0.344925 / 0.419271 (-0.074346) | 0.062358 / 0.043533 (0.018825) | 0.371738 / 0.255139 (0.116599) | 0.407093 / 0.283200 (0.123894) | 0.026996 / 0.141683 (-0.114687) | 1.762705 / 1.452155 (0.310550) | 1.846777 / 1.492716 (0.354061) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.219660 / 0.018006 (0.201653) | 0.521795 / 0.000490 (0.521305) | 0.005344 / 0.000200 (0.005145) | 0.000098 / 0.000054 (0.000044) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.036027 / 0.037411 (-0.001385) | 0.100309 / 0.014526 (0.085784) | 0.113041 / 0.176557 (-0.063515) | 0.190037 / 0.737135 (-0.547099) | 0.114552 / 0.296338 (-0.181786) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.466364 / 0.215209 (0.251154) | 4.638745 / 2.077655 (2.561090) | 2.317875 / 1.504120 (0.813755) | 2.099241 / 1.541195 (0.558046) | 2.149827 / 1.468490 (0.681337) | 0.578913 / 4.584777 (-4.005864) | 4.281866 / 3.745712 (0.536154) | 3.778453 / 5.269862 (-1.491408) | 2.411704 / 4.565676 (-2.153972) | 0.068556 / 0.424275 (-0.355719) | 0.008779 / 0.007607 (0.001172) | 0.553165 / 0.226044 (0.327121) | 5.524520 / 2.268929 (3.255591) | 2.848444 / 55.444624 (-52.596181) | 2.468591 / 6.876477 (-4.407885) | 2.652117 / 2.142072 (0.510045) | 0.694124 / 4.805227 (-4.111103) | 0.157087 / 6.500664 (-6.343577) | 0.070706 / 0.075469 (-0.004763) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.492031 / 1.841788 (-0.349757) | 23.086596 / 8.074308 (15.012288) | 16.791351 / 10.191392 (6.599959) | 0.203932 / 0.680424 (-0.476492) | 0.021736 / 0.534201 (-0.512464) | 0.468344 / 0.579283 (-0.110939) | 0.493790 / 0.434364 (0.059426) | 0.563226 / 0.540337 (0.022889) | 0.780384 / 1.386936 (-0.606553) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007980 / 0.011353 (-0.003373) | 0.004696 / 0.011008 (-0.006312) | 0.076712 / 0.038508 (0.038204) | 0.095915 / 0.023109 (0.072805) | 0.433615 / 0.275898 (0.157717) | 0.482477 / 0.323480 (0.158997) | 0.007029 / 0.007986 (-0.000957) | 0.003842 / 0.004328 (-0.000487) | 0.076331 / 0.004250 (0.072081) | 0.069755 / 0.037052 (0.032703) | 0.458914 / 0.258489 (0.200425) | 0.486155 / 0.293841 (0.192314) | 0.036966 / 0.128546 (-0.091580) | 0.010082 / 0.075646 (-0.065564) | 0.083886 / 0.419271 (-0.335385) | 0.059329 / 0.043533 (0.015796) | 0.453782 / 0.255139 (0.198643) | 0.459508 / 0.283200 (0.176308) | 0.028400 / 0.141683 (-0.113283) | 1.796406 / 1.452155 (0.344251) | 1.881161 / 1.492716 (0.388445) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.235053 / 0.018006 (0.217047) | 0.501907 / 0.000490 (0.501417) | 0.005211 / 0.000200 (0.005011) | 0.000101 / 0.000054 (0.000046) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.037752 / 0.037411 (0.000341) | 0.107299 / 0.014526 (0.092773) | 0.120307 / 0.176557 (-0.056250) | 0.187542 / 0.737135 (-0.549593) | 0.121805 / 0.296338 (-0.174533) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.490039 / 0.215209 (0.274830) | 4.919169 / 2.077655 (2.841515) | 2.520610 / 1.504120 (1.016490) | 2.324473 / 1.541195 (0.783279) | 2.421195 / 1.468490 (0.952705) | 0.576314 / 4.584777 (-4.008463) | 4.304752 / 3.745712 (0.559040) | 3.881151 / 5.269862 (-1.388710) | 2.409777 / 4.565676 (-2.155900) | 0.067400 / 0.424275 (-0.356875) | 0.009235 / 0.007607 (0.001627) | 0.586601 / 0.226044 (0.360556) | 5.850080 / 2.268929 (3.581152) | 3.064859 / 55.444624 (-52.379766) | 2.701734 / 6.876477 (-4.174743) | 2.926190 / 2.142072 (0.784117) | 0.698511 / 4.805227 (-4.106716) | 0.158273 / 6.500664 (-6.342392) | 0.074530 / 0.075469 (-0.000939) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.607113 / 1.841788 (-0.234674) | 23.499279 / 8.074308 (15.424971) | 17.049509 / 10.191392 (6.858117) | 0.175689 / 0.680424 (-0.504735) | 0.021762 / 0.534201 (-0.512439) | 0.491450 / 0.579283 (-0.087833) | 0.487557 / 0.434364 (0.053193) | 0.570104 / 0.540337 (0.029766) | 0.761527 / 1.386936 (-0.625409) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008725 / 0.011353 (-0.002628) | 0.005156 / 0.011008 (-0.005852) | 0.095147 / 0.038508 (0.056639) | 0.084916 / 0.023109 (0.061807) | 0.390769 / 0.275898 (0.114871) | 0.434716 / 0.323480 (0.111237) | 0.005982 / 0.007986 (-0.002004) | 0.004323 / 0.004328 (-0.000006) | 0.074712 / 0.004250 (0.070461) | 0.058889 / 0.037052 (0.021837) | 0.403997 / 0.258489 (0.145508) | 0.443361 / 0.293841 (0.149520) | 0.045908 / 0.128546 (-0.082639) | 0.013562 / 0.075646 (-0.062085) | 0.330683 / 0.419271 (-0.088588) | 0.064821 / 0.043533 (0.021288) | 0.407202 / 0.255139 (0.152063) | 0.409930 / 0.283200 (0.126730) | 0.032693 / 0.141683 (-0.108990) | 1.630181 / 1.452155 (0.178026) | 1.729680 / 1.492716 (0.236963) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.261240 / 0.018006 (0.243234) | 0.581850 / 0.000490 (0.581360) | 0.002997 / 0.000200 (0.002797) | 0.000107 / 0.000054 (0.000053) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029279 / 0.037411 (-0.008133) | 0.085004 / 0.014526 (0.070478) | 0.127782 / 0.176557 (-0.048774) | 0.168852 / 0.737135 (-0.568283) | 0.098697 / 0.296338 (-0.197641) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.546417 / 0.215209 (0.331208) | 5.602186 / 2.077655 (3.524531) | 2.597049 / 1.504120 (1.092930) | 2.384880 / 1.541195 (0.843685) | 2.444516 / 1.468490 (0.976026) | 0.796562 / 4.584777 (-3.788214) | 5.239440 / 3.745712 (1.493727) | 7.087768 / 5.269862 (1.817906) | 4.308476 / 4.565676 (-0.257200) | 0.091215 / 0.424275 (-0.333060) | 0.007942 / 0.007607 (0.000335) | 0.690059 / 0.226044 (0.464015) | 6.727809 / 2.268929 (4.458880) | 3.294522 / 55.444624 (-52.150103) | 2.604088 / 6.876477 (-4.272389) | 2.786970 / 2.142072 (0.644898) | 0.918817 / 4.805227 (-3.886410) | 0.191451 / 6.500664 (-6.309213) | 0.069557 / 0.075469 (-0.005912) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.486377 / 1.841788 (-0.355411) | 22.363470 / 8.074308 (14.289162) | 19.963684 / 10.191392 (9.772292) | 0.204161 / 0.680424 (-0.476263) | 0.034570 / 0.534201 (-0.499631) | 0.467937 / 0.579283 (-0.111346) | 0.564870 / 0.434364 (0.130506) | 0.511133 / 0.540337 (-0.029204) | 0.777084 / 1.386936 (-0.609852) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008612 / 0.011353 (-0.002741) | 0.004993 / 0.011008 (-0.006015) | 0.080769 / 0.038508 (0.042261) | 0.075923 / 0.023109 (0.052814) | 0.442271 / 0.275898 (0.166373) | 0.495625 / 0.323480 (0.172146) | 0.006467 / 0.007986 (-0.001518) | 0.004001 / 0.004328 (-0.000328) | 0.077309 / 0.004250 (0.073059) | 0.063466 / 0.037052 (0.026414) | 0.452460 / 0.258489 (0.193971) | 0.494063 / 0.293841 (0.200223) | 0.045751 / 0.128546 (-0.082796) | 0.013402 / 0.075646 (-0.062245) | 0.085760 / 0.419271 (-0.333511) | 0.056532 / 0.043533 (0.012999) | 0.440596 / 0.255139 (0.185457) | 0.459540 / 0.283200 (0.176340) | 0.035897 / 0.141683 (-0.105786) | 1.728264 / 1.452155 (0.276109) | 1.808142 / 1.492716 (0.315426) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.285094 / 0.018006 (0.267088) | 0.598440 / 0.000490 (0.597950) | 0.003476 / 0.000200 (0.003276) | 0.000103 / 0.000054 (0.000048) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035106 / 0.037411 (-0.002305) | 0.091724 / 0.014526 (0.077198) | 0.122803 / 0.176557 (-0.053754) | 0.182114 / 0.737135 (-0.555022) | 0.116196 / 0.296338 (-0.180143) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.585420 / 0.215209 (0.370211) | 5.790370 / 2.077655 (3.712715) | 2.833247 / 1.504120 (1.329127) | 2.627949 / 1.541195 (1.086755) | 2.643050 / 1.468490 (1.174560) | 0.792036 / 4.584777 (-3.792741) | 5.145084 / 3.745712 (1.399372) | 4.423679 / 5.269862 (-0.846182) | 2.802778 / 4.565676 (-1.762898) | 0.093983 / 0.424275 (-0.330292) | 0.009260 / 0.007607 (0.001652) | 0.720302 / 0.226044 (0.494258) | 7.116959 / 2.268929 (4.848031) | 3.574782 / 55.444624 (-51.869843) | 3.009330 / 6.876477 (-3.867147) | 3.126488 / 2.142072 (0.984415) | 0.949144 / 4.805227 (-3.856083) | 0.195143 / 6.500664 (-6.305521) | 0.072490 / 0.075469 (-0.002979) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.626368 / 1.841788 (-0.215419) | 23.683021 / 8.074308 (15.608713) | 20.085297 / 10.191392 (9.893905) | 0.267057 / 0.680424 (-0.413367) | 0.028306 / 0.534201 (-0.505894) | 0.478448 / 0.579283 (-0.100835) | 0.597619 / 0.434364 (0.163256) | 0.544737 / 0.540337 (0.004399) | 0.761805 / 1.386936 (-0.625131) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009359 / 0.011353 (-0.001994) | 0.004848 / 0.011008 (-0.006160) | 0.099471 / 0.038508 (0.060963) | 0.079483 / 0.023109 (0.056373) | 0.375281 / 0.275898 (0.099383) | 0.415566 / 0.323480 (0.092086) | 0.006317 / 0.007986 (-0.001669) | 0.005145 / 0.004328 (0.000817) | 0.080345 / 0.004250 (0.076094) | 0.064540 / 0.037052 (0.027487) | 0.385897 / 0.258489 (0.127408) | 0.432576 / 0.293841 (0.138735) | 0.055109 / 0.128546 (-0.073437) | 0.014166 / 0.075646 (-0.061480) | 0.350870 / 0.419271 (-0.068402) | 0.087483 / 0.043533 (0.043950) | 0.402288 / 0.255139 (0.147149) | 0.391997 / 0.283200 (0.108798) | 0.045233 / 0.141683 (-0.096450) | 1.795002 / 1.452155 (0.342847) | 1.839063 / 1.492716 (0.346347) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220851 / 0.018006 (0.202845) | 0.513391 / 0.000490 (0.512901) | 0.003740 / 0.000200 (0.003540) | 0.000107 / 0.000054 (0.000053) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035287 / 0.037411 (-0.002124) | 0.090670 / 0.014526 (0.076144) | 0.115651 / 0.176557 (-0.060905) | 0.180469 / 0.737135 (-0.556667) | 0.106955 / 0.296338 (-0.189384) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.632381 / 0.215209 (0.417172) | 6.185151 / 2.077655 (4.107497) | 2.548263 / 1.504120 (1.044143) | 2.194931 / 1.541195 (0.653737) | 2.368685 / 1.468490 (0.900194) | 0.956467 / 4.584777 (-3.628310) | 5.280904 / 3.745712 (1.535192) | 4.783057 / 5.269862 (-0.486805) | 3.218493 / 4.565676 (-1.347184) | 0.103545 / 0.424275 (-0.320730) | 0.008424 / 0.007607 (0.000817) | 0.736303 / 0.226044 (0.510259) | 7.354305 / 2.268929 (5.085376) | 3.280670 / 55.444624 (-52.163954) | 2.478628 / 6.876477 (-4.397848) | 2.623290 / 2.142072 (0.481217) | 1.033064 / 4.805227 (-3.772163) | 0.206496 / 6.500664 (-6.294168) | 0.066449 / 0.075469 (-0.009020) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.508756 / 1.841788 (-0.333031) | 21.866012 / 8.074308 (13.791704) | 21.887761 / 10.191392 (11.696369) | 0.231415 / 0.680424 (-0.449008) | 0.028917 / 0.534201 (-0.505284) | 0.468761 / 0.579283 (-0.110522) | 0.568236 / 0.434364 (0.133872) | 0.550156 / 0.540337 (0.009818) | 0.783197 / 1.386936 (-0.603739) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009413 / 0.011353 (-0.001939) | 0.004951 / 0.011008 (-0.006058) | 0.071402 / 0.038508 (0.032893) | 0.068455 / 0.023109 (0.045346) | 0.425216 / 0.275898 (0.149318) | 0.431928 / 0.323480 (0.108448) | 0.006477 / 0.007986 (-0.001509) | 0.003891 / 0.004328 (-0.000437) | 0.076898 / 0.004250 (0.072647) | 0.057522 / 0.037052 (0.020470) | 0.449585 / 0.258489 (0.191096) | 0.431356 / 0.293841 (0.137515) | 0.049728 / 0.128546 (-0.078818) | 0.014456 / 0.075646 (-0.061190) | 0.084618 / 0.419271 (-0.334653) | 0.064482 / 0.043533 (0.020949) | 0.456377 / 0.255139 (0.201238) | 0.433949 / 0.283200 (0.150749) | 0.036577 / 0.141683 (-0.105106) | 1.819742 / 1.452155 (0.367588) | 1.694691 / 1.492716 (0.201975) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224610 / 0.018006 (0.206604) | 0.494586 / 0.000490 (0.494096) | 0.004506 / 0.000200 (0.004307) | 0.000119 / 0.000054 (0.000065) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033172 / 0.037411 (-0.004239) | 0.100562 / 0.014526 (0.086036) | 0.116499 / 0.176557 (-0.060058) | 0.153717 / 0.737135 (-0.583418) | 0.140047 / 0.296338 (-0.156291) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.635922 / 0.215209 (0.420713) | 6.359792 / 2.077655 (4.282137) | 2.689083 / 1.504120 (1.184963) | 2.330574 / 1.541195 (0.789380) | 2.583535 / 1.468490 (1.115044) | 0.902737 / 4.584777 (-3.682040) | 5.136586 / 3.745712 (1.390874) | 4.570824 / 5.269862 (-0.699037) | 3.029953 / 4.565676 (-1.535724) | 0.103961 / 0.424275 (-0.320314) | 0.007908 / 0.007607 (0.000301) | 0.723290 / 0.226044 (0.497246) | 7.678599 / 2.268929 (5.409671) | 3.342522 / 55.444624 (-52.102102) | 2.774659 / 6.876477 (-4.101817) | 2.966496 / 2.142072 (0.824423) | 1.025395 / 4.805227 (-3.779832) | 0.222246 / 6.500664 (-6.278418) | 0.072455 / 0.075469 (-0.003014) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.603637 / 1.841788 (-0.238151) | 21.387722 / 8.074308 (13.313414) | 22.855221 / 10.191392 (12.663829) | 0.222147 / 0.680424 (-0.458277) | 0.030763 / 0.534201 (-0.503438) | 0.472586 / 0.579283 (-0.106697) | 0.560161 / 0.434364 (0.125797) | 0.551941 / 0.540337 (0.011604) | 0.711254 / 1.386936 (-0.675682) |\n\n</details>\n</details>\n\n\n"
] | 2023-07-17T15:50:15Z
| 2023-07-24T14:45:56Z
| 2023-07-24T14:35:03Z
|
COLLABORATOR
| null | null | null |
Fix #6039
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6045/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6045/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6045.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6045",
"merged_at": "2023-07-24T14:35:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6045.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6045"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7224
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7224/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7224/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7224/events
|
https://github.com/huggingface/datasets/pull/7224
| 2,583,233,980
|
PR_kwDODunzps5-bLNR
| 7,224
|
fallback to default feature casting in case custom features not available during dataset loading
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5719745?v=4",
"events_url": "https://api.github.com/users/alex-hh/events{/privacy}",
"followers_url": "https://api.github.com/users/alex-hh/followers",
"following_url": "https://api.github.com/users/alex-hh/following{/other_user}",
"gists_url": "https://api.github.com/users/alex-hh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/alex-hh",
"id": 5719745,
"login": "alex-hh",
"node_id": "MDQ6VXNlcjU3MTk3NDU=",
"organizations_url": "https://api.github.com/users/alex-hh/orgs",
"received_events_url": "https://api.github.com/users/alex-hh/received_events",
"repos_url": "https://api.github.com/users/alex-hh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/alex-hh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alex-hh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/alex-hh",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[] | 2024-10-12T16:13:56Z
| 2024-10-12T16:13:56Z
| null |
CONTRIBUTOR
| null | null | null |
a fix for #7223 in case datasets is happy to support this kind of extensibility! seems cool / powerful for allowing sharing of datasets with potentially different feature types
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7224/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7224/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7224.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7224",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7224.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7224"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7337
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7337/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7337/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7337/events
|
https://github.com/huggingface/datasets/issues/7337
| 2,744,877,569
|
I_kwDODunzps6jm4IB
| 7,337
|
One or several metadata.jsonl were found, but not in the same directory or in a parent directory of
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/67250532?v=4",
"events_url": "https://api.github.com/users/mst272/events{/privacy}",
"followers_url": "https://api.github.com/users/mst272/followers",
"following_url": "https://api.github.com/users/mst272/following{/other_user}",
"gists_url": "https://api.github.com/users/mst272/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mst272",
"id": 67250532,
"login": "mst272",
"node_id": "MDQ6VXNlcjY3MjUwNTMy",
"organizations_url": "https://api.github.com/users/mst272/orgs",
"received_events_url": "https://api.github.com/users/mst272/received_events",
"repos_url": "https://api.github.com/users/mst272/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mst272/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mst272/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mst272",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"Hmmm I double checked in the source code and I found a contradiction: in the current implementation the metadata file is ignored if it's not in the same archive as the zip image somehow:\r\n\r\nhttps://github.com/huggingface/datasets/blob/caa705e8bf4bedf1a956f48b545283b2ca14170a/src/datasets/packaged_modules/folder_based_builder/folder_based_builder.py#L352-L353\r\n\r\nin the tests suite the metadata file is placed inside the archive:\r\n\r\nhttps://github.com/huggingface/datasets/blob/caa705e8bf4bedf1a956f48b545283b2ca14170a/tests/packaged_modules/test_imagefolder.py#L223-L223\r\n\r\nThanks for reporting this issue, it seems the documentation is wrong and we never implemented the support for zip + metadata outside zip. We might rewrite part of this code soon though to make it more flexible, it can be a good occasion to fix this. In the meantime feel free to open a PR to fix the documentation if you'd like"
] | 2024-12-17T12:58:43Z
| 2025-01-03T15:28:13Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
ImageFolder with metadata.jsonl error. I downloaded liuhaotian/LLaVA-CC3M-Pretrain-595K locally from Hugging Face. According to the tutorial in https://huggingface.co/docs/datasets/image_dataset#image-captioning, only put images.zip and metadata.jsonl containing information in the same folder. However, after loading, an error was reported: One or several metadata.jsonl were found, but not in the same directory or in a parent directory of.
The data in my jsonl file is as follows:
> {"id": "GCC_train_002448550", "file_name": "GCC_train_002448550.jpg", "conversations": [{"from": "human", "value": "<image>\nProvide a brief description of the given image."}, {"from": "gpt", "value": "a view of a city , where the flyover was proposed to reduce the increasing traffic on thursday ."}]}
### Steps to reproduce the bug
from datasets import load_dataset
image = load_dataset("imagefolder",data_dir='data/opensource_data')
### Expected behavior
success
### Environment info
datasets==3.2.0
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7337/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7337/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5223
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5223/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5223/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5223/events
|
https://github.com/huggingface/datasets/pull/5223
| 1,442,610,658
|
PR_kwDODunzps5CjT9Z
| 5,223
|
Add SQL guide
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5223). All of your documentation changes will be reflected on that endpoint.",
"I think we may want more content on this page that's not SQL related. Some of that content probably already lives in the main `load` docs page, but might be bad to remove major things like csv/pandas from there...WDYT we should do @lhoestq ?",
"Maybe the main load page can only show one example and redirect to this page for more details ?\r\n\r\nWe can do the same for pandas stuff: have one example in load, and redirect to this page for more details",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5223). All of your documentation changes will be reflected on that endpoint."
] | 2022-11-09T19:10:27Z
| 2022-11-15T17:40:25Z
| 2022-11-15T17:40:21Z
|
MEMBER
| null | null | null |
This PR adapts @nateraw's awesome SQL notebook as a guide for the docs!
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5223/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5223/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5223.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5223",
"merged_at": "2022-11-15T17:40:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5223.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5223"
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.