
url
string | repository_url
string | labels_url
string | comments_url
string | events_url
string | html_url
string | id
int64 | node_id
string | number
int64 | title
string | user
dict | labels
list | state
string | locked
bool | assignee
dict | assignees
list | milestone
dict | comments
list | created_at
timestamp[ns, tz=UTC] | updated_at
timestamp[ns, tz=UTC] | closed_at
timestamp[ns, tz=UTC] | author_association
string | type
float64 | active_lock_reason
float64 | sub_issues_summary
dict | body
string | closed_by
dict | reactions
dict | timeline_url
string | performed_via_github_app
float64 | state_reason
string | draft
float64 | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5061
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5061/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5061/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5061/events
|
https://github.com/huggingface/datasets/issues/5061
| 1,395,476,770
|
I_kwDODunzps5TLUki
| 5,061
|
`_pickle.PicklingError: logger cannot be pickled` in multiprocessing `map`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url": "https://api.github.com/users/ZhaofengWu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ZhaofengWu",
"id": 11954789,
"login": "ZhaofengWu",
"node_id": "MDQ6VXNlcjExOTU0Nzg5",
"organizations_url": "https://api.github.com/users/ZhaofengWu/orgs",
"received_events_url": "https://api.github.com/users/ZhaofengWu/received_events",
"repos_url": "https://api.github.com/users/ZhaofengWu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ZhaofengWu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZhaofengWu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ZhaofengWu",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
| null |
[] | null |
[
"This is maybe related to python 3.10, do you think you could try on 3.8 ?\r\n\r\nIn the meantime we'll keep improving the support for 3.10. Let me add a dedicated CI",
"I did some binary search and seems like the root cause is either `multiprocess` or `dill`. python 3.10 is fine. Specifically:\r\n- `multiprocess==0.70.12.2, dill==0.3.4`: works\r\n- `multiprocess==0.70.12.2, dill==0.3.5.1`: doesn't work\r\n- `multiprocess==0.70.13, dill==0.3.5.1`: doesn't work\r\n- `multiprocess==0.70.13, dill==0.3.4`: can't test, `multiprocess==0.70.13` requires `dill>=0.3.5.1`\r\n\r\nI will pin their versions on my end. I don't have enough knowledge of how python multiprocessing works to debug this, but ideally there could be a fix. It's also possible that I'm doing something wrong in my code, but again the `.name` of the logger that failed to pickle is `datasets.fingerprint`, which I'm not using directly.",
"Do you know which logger fails at being pickled ?",
"I'm not 100% sure how to figure it out -- the stack trace above doesn't clearly give me a place where I can print out who owns the logger, etc. I only found out its `.name` is `datasets.fingerprint` by printing right before\r\n```\r\n File \".../logging/__init__.py\", line 1774, in __reduce__\r\n raise pickle.PicklingError('logger cannot be pickled')\r\n```\r\nIf you have any idea on how to find it out, please let me know.",
"Ok I see, not sure why it triggers this error though, in `logging.py` the code is\r\n\r\nhttps://github.com/python/cpython/blob/c9da063e32725a66495e4047b8a5ed13e72d9e8e/Lib/logging/__init__.py#L1769-L1775\r\n\r\nand on my side it works on 3.10 with dill 0.3.5.1 and multiprocess 0.70.13\r\n```python\r\n>>> datasets.fingerprint.logger.__reduce__() \r\n(<function logging.getLogger(name=None)>, ('datasets.fingerprint',))\r\n```\r\nCould you try to run this code ?\r\n\r\nAre you in an environment where the loggers are instantiated differently ? Can you check the source code of `logging.Logger.__reduce__` in `\".../logging/__init__.py\", line 1774` ?",
"Closing due to inactivity."
] | 2022-10-03T23:51:38Z
| 2023-07-21T14:43:35Z
| 2023-07-21T14:43:34Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
## Describe the bug
When I `map` with multiple processes, this error occurs. The `.name` of the `logger` that fails to pickle in the final line is `datasets.fingerprint`.
```
File "~/project/dataset.py", line 204, in <dictcomp>
split: dataset.map(
File ".../site-packages/datasets/arrow_dataset.py", line 2489, in map
transformed_shards[index] = async_result.get()
File ".../site-packages/multiprocess/pool.py", line 771, in get
raise self._value
File ".../site-packages/multiprocess/pool.py", line 537, in _handle_tasks
put(task)
File ".../site-packages/multiprocess/connection.py", line 214, in send
self._send_bytes(_ForkingPickler.dumps(obj))
File ".../site-packages/multiprocess/reduction.py", line 54, in dumps
cls(buf, protocol, *args, **kwds).dump(obj)
File ".../site-packages/dill/_dill.py", line 620, in dump
StockPickler.dump(self, obj)
File ".../pickle.py", line 487, in dump
self.save(obj)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../pickle.py", line 902, in save_tuple
save(element)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../site-packages/dill/_dill.py", line 1963, in save_function
_save_with_postproc(pickler, (_create_function, (
File ".../site-packages/dill/_dill.py", line 1140, in _save_with_postproc
pickler.save_reduce(*reduction, obj=obj)
File ".../pickle.py", line 717, in save_reduce
save(state)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../pickle.py", line 887, in save_tuple
save(element)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../site-packages/dill/_dill.py", line 1251, in save_module_dict
StockPickler.save_dict(pickler, obj)
File ".../pickle.py", line 972, in save_dict
self._batch_setitems(obj.items())
File ".../pickle.py", line 998, in _batch_setitems
save(v)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../site-packages/dill/_dill.py", line 1963, in save_function
_save_with_postproc(pickler, (_create_function, (
File ".../site-packages/dill/_dill.py", line 1140, in _save_with_postproc
pickler.save_reduce(*reduction, obj=obj)
File ".../pickle.py", line 717, in save_reduce
save(state)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../pickle.py", line 887, in save_tuple
save(element)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../site-packages/dill/_dill.py", line 1251, in save_module_dict
StockPickler.save_dict(pickler, obj)
File ".../pickle.py", line 972, in save_dict
self._batch_setitems(obj.items())
File ".../pickle.py", line 998, in _batch_setitems
save(v)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../site-packages/dill/_dill.py", line 1963, in save_function
_save_with_postproc(pickler, (_create_function, (
File ".../site-packages/dill/_dill.py", line 1154, in _save_with_postproc
pickler._batch_setitems(iter(source.items()))
File ".../pickle.py", line 998, in _batch_setitems
save(v)
File ".../pickle.py", line 578, in save
rv = reduce(self.proto)
File ".../logging/__init__.py", line 1774, in __reduce__
raise pickle.PicklingError('logger cannot be pickled')
_pickle.PicklingError: logger cannot be pickled
```
## Steps to reproduce the bug
Sorry I failed to have a minimal reproducible example, but the offending line on my end is
```python
dataset.map(
lambda examples: self.tokenize(examples), # this doesn't matter, lambda e: [1] * len(...) also breaks. In fact I'm pretty sure it breaks before executing this lambda
batched=True,
num_proc=4,
)
```
This does work when `num_proc=1`, so it's likely a multiprocessing thing.
## Expected results
`map` succeeds
## Actual results
The error trace above.
## Environment info
- `datasets` version: 1.16.1 and 2.5.1 both failed
- Platform: Ubuntu 20.04.4 LTS
- Python version: 3.10.4
- PyArrow version: 9.0.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5061/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5061/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6327
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6327/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6327/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6327/events
|
https://github.com/huggingface/datasets/issues/6327
| 1,955,470,755
|
I_kwDODunzps50jh2j
| 6,327
|
FileNotFoundError when trying to load the downloaded dataset with `load_dataset(..., streaming=True)`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/18402347?v=4",
"events_url": "https://api.github.com/users/yzhangcs/events{/privacy}",
"followers_url": "https://api.github.com/users/yzhangcs/followers",
"following_url": "https://api.github.com/users/yzhangcs/following{/other_user}",
"gists_url": "https://api.github.com/users/yzhangcs/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yzhangcs",
"id": 18402347,
"login": "yzhangcs",
"node_id": "MDQ6VXNlcjE4NDAyMzQ3",
"organizations_url": "https://api.github.com/users/yzhangcs/orgs",
"received_events_url": "https://api.github.com/users/yzhangcs/received_events",
"repos_url": "https://api.github.com/users/yzhangcs/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yzhangcs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yzhangcs/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yzhangcs",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"You can clone the `togethercomputer/RedPajama-Data-1T-Sample` repo and load the dataset with `load_dataset(\"path/to/cloned_repo\")` to use it offline.",
"@mariosasko Thank you for your kind reply! I'll try it as a workaround.\r\nDoes that mean that currently it's not supported to simply load with a short name?",
"It is, but manually downloading repo files to the cache can easily lead to failure (the HF cache is not meant to be modified by a user besides deleting the files 🙂), as in your case. Hence, the clone + `load_dataset(\"path/to/cloned_repo\")` workflow should be used instead."
] | 2023-10-21T12:27:03Z
| 2023-10-23T18:50:07Z
| 2023-10-23T18:50:07Z
|
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Hi, I'm trying to load the dataset `togethercomputer/RedPajama-Data-1T-Sample` with `load_dataset` in streaming mode, i.e., `streaming=True`, but `FileNotFoundError` occurs.
### Steps to reproduce the bug
I've downloaded the dataset and save it to the cache dir in advance. My hope is loading the files in offline environment and without taking too much hours to prepross the entire data before running into the training process.
So I try the following code to load the files streamingly
```py
dataset = load_dataset('togethercomputer/RedPajama-Data-1T-Sample', streaming=True)
print(next(iter(dataset['train'])))
```
Sadly, it raises the following:
```
FileNotFoundError: [Errno 2] No such file or directory: 'CURRENT_CODE_PATH/arxiv_sample.jsonl'
```
I've noticed that the dataset can be properly found in the begining
```
Using the latest cached version of the module from /root/.cache/huggingface/modules/datasets_modules/datasets/togethercomputer--RedPajama-Data-1T-Sample/6ea3bc8ec2e84ec6d2df1930942e9028ace8c5b9d9143823cf911c50bbd92039 (last modified on Sat Oct 21 20:12:57 2023) since it couldn't be found locally at togethercomputer/RedPajama-Data-1T-Sample., or remotely on the Hugging Face Hub.
```
But it seems that the paths couldn't be properly parsed when loading iteratively.
How should I fix this error. I've tried specifying `data_files` or `data_dir` as `.../arxiv_sample.jsonl` but none of them works.
Thanks.
### Expected behavior
Properly load the dataset.
### Environment info
`datasets==2.14.5`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/18402347?v=4",
"events_url": "https://api.github.com/users/yzhangcs/events{/privacy}",
"followers_url": "https://api.github.com/users/yzhangcs/followers",
"following_url": "https://api.github.com/users/yzhangcs/following{/other_user}",
"gists_url": "https://api.github.com/users/yzhangcs/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yzhangcs",
"id": 18402347,
"login": "yzhangcs",
"node_id": "MDQ6VXNlcjE4NDAyMzQ3",
"organizations_url": "https://api.github.com/users/yzhangcs/orgs",
"received_events_url": "https://api.github.com/users/yzhangcs/received_events",
"repos_url": "https://api.github.com/users/yzhangcs/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yzhangcs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yzhangcs/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yzhangcs",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6327/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6327/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5277
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5277/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5277/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5277/events
|
https://github.com/huggingface/datasets/pull/5277
| 1,459,388,551
|
PR_kwDODunzps5Dbybu
| 5,277
|
Remove YAML integer keys from class_label metadata
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Also note that this approach is valid when metadata keys are str, but also if they are int.\r\n- This will be helpful for any community dataset using old integer keys in their metadata",
"perfect !"
] | 2022-11-22T08:34:07Z
| 2022-11-22T13:58:26Z
| 2022-11-22T13:55:49Z
|
MEMBER
| null | null | null |
Fix partially #5275.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5277/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5277/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5277.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5277",
"merged_at": "2022-11-22T13:55:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5277.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5277"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5488
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5488/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5488/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5488/events
|
https://github.com/huggingface/datasets/issues/5488
| 1,565,025,262
|
I_kwDODunzps5dSGPu
| 5,488
|
Error loading MP3 files from CommonVoice
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/110259722?v=4",
"events_url": "https://api.github.com/users/kradonneoh/events{/privacy}",
"followers_url": "https://api.github.com/users/kradonneoh/followers",
"following_url": "https://api.github.com/users/kradonneoh/following{/other_user}",
"gists_url": "https://api.github.com/users/kradonneoh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kradonneoh",
"id": 110259722,
"login": "kradonneoh",
"node_id": "U_kgDOBpJuCg",
"organizations_url": "https://api.github.com/users/kradonneoh/orgs",
"received_events_url": "https://api.github.com/users/kradonneoh/received_events",
"repos_url": "https://api.github.com/users/kradonneoh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kradonneoh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kradonneoh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kradonneoh",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi @kradonneoh, thanks for reporting.\r\n\r\nPlease note that to work with audio datasets (and specifically with MP3 files) we have detailed installation instructions in our docs: https://huggingface.co/docs/datasets/installation#audio\r\n- one of the requirements is torchaudio<0.12.0\r\n\r\nLet us know if the problem persists after having followed them.",
"I saw that and have followed it (hence the Expected Behavior section of the bug report). \r\n\r\nIs there no intention of updating to the latest version? It does limit the version of `torch` I can use, which isn’t ideal.",
"@kradonneoh hey! actually with `ffmpeg4` loading of mp3 files should work, so this is a not expected behavior and we need to investigate it. It works on my side with `torchaudio==0.13` and `ffmpeg==4.2.7`. Which `torchaudio` version do you use?\r\n\r\n`datasets` should support decoding of mp3 files with `torchaudio` when its version is `>0.12` but as you noted it requires `ffmpeg>4`, we need to fix this in the documentation, thank you for pointing to this! \r\n\r\nBut according to your traceback it seems that it tries to use [`libsndfile`](https://github.com/libsndfile/libsndfile) backend for mp3 decoding. And `libsndfile` library supports mp3 decoding starting from version 1.1.0 which on Linux has to be compiled from source for now afaik. \r\n\r\nfyi - we are aiming at getting rid of `torchaudio` dependency at all by the next major library release in favor of `libsndfile` too.",
"We now decode MP3 with `soundfile`, so I'm closing this issue"
] | 2023-01-31T21:25:33Z
| 2023-03-02T16:25:14Z
| 2023-03-02T16:25:13Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
When loading a CommonVoice dataset with `datasets==2.9.0` and `torchaudio>=0.12.0`, I get an error reading the audio arrays:
```python
---------------------------------------------------------------------------
LibsndfileError Traceback (most recent call last)
~/.local/lib/python3.8/site-packages/datasets/features/audio.py in _decode_mp3(self, path_or_file)
310 try: # try torchaudio anyway because sometimes it works (depending on the os and os packages installed)
--> 311 array, sampling_rate = self._decode_mp3_torchaudio(path_or_file)
312 except RuntimeError:
~/.local/lib/python3.8/site-packages/datasets/features/audio.py in _decode_mp3_torchaudio(self, path_or_file)
351
--> 352 array, sampling_rate = torchaudio.load(path_or_file, format="mp3")
353 if self.sampling_rate and self.sampling_rate != sampling_rate:
~/.local/lib/python3.8/site-packages/torchaudio/backend/soundfile_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
204 """
--> 205 with soundfile.SoundFile(filepath, "r") as file_:
206 if file_.format != "WAV" or normalize:
~/.local/lib/python3.8/site-packages/soundfile.py in __init__(self, file, mode, samplerate, channels, subtype, endian, format, closefd)
654 format, subtype, endian)
--> 655 self._file = self._open(file, mode_int, closefd)
656 if set(mode).issuperset('r+') and self.seekable():
~/.local/lib/python3.8/site-packages/soundfile.py in _open(self, file, mode_int, closefd)
1212 err = _snd.sf_error(file_ptr)
-> 1213 raise LibsndfileError(err, prefix="Error opening {0!r}: ".format(self.name))
1214 if mode_int == _snd.SFM_WRITE:
LibsndfileError: Error opening <_io.BytesIO object at 0x7fa539462090>: File contains data in an unknown format.
```
I assume this is because there's some issue with the mp3 decoding process. I've verified that I have `ffmpeg>=4` (on a Linux distro), which appears to be the fallback backend for `torchaudio,` (at least according to #4889).
### Steps to reproduce the bug
```python
dataset = load_dataset("mozilla-foundation/common_voice_11_0", "be", split="train")
dataset[0]
```
### Expected behavior
Similar behavior to `torchaudio<0.12.0`, which doesn't result in a `LibsndfileError`
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 10.0.1
- Pandas version: 1.5.1
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5488/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5488/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6935
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6935/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6935/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6935/events
|
https://github.com/huggingface/datasets/issues/6935
| 2,325,612,022
|
I_kwDODunzps6KngX2
| 6,935
|
Support for pathlib.Path in datasets 2.19.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12202811?v=4",
"events_url": "https://api.github.com/users/lamyiowce/events{/privacy}",
"followers_url": "https://api.github.com/users/lamyiowce/followers",
"following_url": "https://api.github.com/users/lamyiowce/following{/other_user}",
"gists_url": "https://api.github.com/users/lamyiowce/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lamyiowce",
"id": 12202811,
"login": "lamyiowce",
"node_id": "MDQ6VXNlcjEyMjAyODEx",
"organizations_url": "https://api.github.com/users/lamyiowce/orgs",
"received_events_url": "https://api.github.com/users/lamyiowce/received_events",
"repos_url": "https://api.github.com/users/lamyiowce/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lamyiowce/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lamyiowce/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lamyiowce",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"+1 I just noticed this when I tried to update `datasets` today.",
"The same issue, I also get error."
] | 2024-05-30T12:53:36Z
| 2025-01-14T11:50:22Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
After the recent update of `datasets`, Dataset.save_to_disk does not accept a pathlib.Path anymore. It was supported in 2.18.0 and previous versions. Is this intentional? Was it supported before only because of a Python dusk-typing miracle?
### Steps to reproduce the bug
```
from datasets import Dataset
import pathlib
path = pathlib.Path("./my_out_path")
Dataset.from_dict(
{"text": ["hello world"], "label": [777], "split": ["train"]}
.save_to_disk(path)
```
This results in an error when using datasets 2.19:
```
Traceback (most recent call last):
File "<stdin>", line 3, in <module>
File "/Users/jb/scratch/venv/lib/python3.11/site-packages/datasets/arrow_dataset.py", line 1515, in save_to_disk
fs, _ = url_to_fs(dataset_path, **(storage_options or {}))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/jb/scratch/venv/lib/python3.11/site-packages/fsspec/core.py", line 383, in url_to_fs
chain = _un_chain(url, kwargs)
^^^^^^^^^^^^^^^^^^^^^^
File "/Users/jb/scratch/venv/lib/python3.11/site-packages/fsspec/core.py", line 323, in _un_chain
if "::" in path
^^^^^^^^^^^^
TypeError: argument of type 'PosixPath' is not iterable
```
Converting to str works, however.
```
Dataset.from_dict(
{"text": ["hello world"], "label": [777], "split": ["train"]}
).save_to_disk(str(path))
```
### Expected behavior
My dataset gets saved to disk without an error.
### Environment info
aiohttp==3.9.5
aiosignal==1.3.1
attrs==23.2.0
certifi==2024.2.2
charset-normalizer==3.3.2
datasets==2.19.0
dill==0.3.8
filelock==3.14.0
frozenlist==1.4.1
fsspec==2024.3.1
huggingface-hub==0.23.2
idna==3.7
multidict==6.0.5
multiprocess==0.70.16
numpy==1.26.4
packaging==24.0
pandas==2.2.2
pyarrow==16.1.0
pyarrow-hotfix==0.6
python-dateutil==2.9.0.post0
pytz==2024.1
PyYAML==6.0.1
requests==2.32.3
six==1.16.0
tqdm==4.66.4
typing_extensions==4.12.0
tzdata==2024.1
urllib3==2.2.1
xxhash==3.4.1
yarl==1.9.4
| null |
{
"+1": 6,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 6,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6935/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6935/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5501
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5501/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5501/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5501/events
|
https://github.com/huggingface/datasets/pull/5501
| 1,569,644,159
|
PR_kwDODunzps5JMTn8
| 5,501
|
Increase chunk size for speeding up file downloads
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/204321?v=4",
"events_url": "https://api.github.com/users/Narsil/events{/privacy}",
"followers_url": "https://api.github.com/users/Narsil/followers",
"following_url": "https://api.github.com/users/Narsil/following{/other_user}",
"gists_url": "https://api.github.com/users/Narsil/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Narsil",
"id": 204321,
"login": "Narsil",
"node_id": "MDQ6VXNlcjIwNDMyMQ==",
"organizations_url": "https://api.github.com/users/Narsil/orgs",
"received_events_url": "https://api.github.com/users/Narsil/received_events",
"repos_url": "https://api.github.com/users/Narsil/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Narsil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Narsil/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Narsil",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5501). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008407 / 0.011353 (-0.002946) | 0.004651 / 0.011008 (-0.006357) | 0.100367 / 0.038508 (0.061859) | 0.029107 / 0.023109 (0.005998) | 0.302798 / 0.275898 (0.026900) | 0.354379 / 0.323480 (0.030899) | 0.006985 / 0.007986 (-0.001001) | 0.003365 / 0.004328 (-0.000963) | 0.078312 / 0.004250 (0.074062) | 0.034205 / 0.037052 (-0.002847) | 0.310431 / 0.258489 (0.051941) | 0.346239 / 0.293841 (0.052398) | 0.033800 / 0.128546 (-0.094747) | 0.011515 / 0.075646 (-0.064131) | 0.323588 / 0.419271 (-0.095684) | 0.040766 / 0.043533 (-0.002767) | 0.300914 / 0.255139 (0.045775) | 0.332983 / 0.283200 (0.049784) | 0.087500 / 0.141683 (-0.054182) | 1.469505 / 1.452155 (0.017350) | 1.505119 / 1.492716 (0.012403) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.187319 / 0.018006 (0.169313) | 0.405498 / 0.000490 (0.405008) | 0.001000 / 0.000200 (0.000800) | 0.000069 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022583 / 0.037411 (-0.014828) | 0.098096 / 0.014526 (0.083570) | 0.104272 / 0.176557 (-0.072284) | 0.142801 / 0.737135 (-0.594335) | 0.109749 / 0.296338 (-0.186590) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.423343 / 0.215209 (0.208134) | 4.215116 / 2.077655 (2.137461) | 1.899714 / 1.504120 (0.395594) | 1.689579 / 1.541195 (0.148384) | 1.710292 / 1.468490 (0.241801) | 0.690976 / 4.584777 (-3.893801) | 3.432501 / 3.745712 (-0.313212) | 1.899600 / 5.269862 (-3.370261) | 1.279801 / 4.565676 (-3.285876) | 0.082763 / 0.424275 (-0.341512) | 0.012545 / 0.007607 (0.004938) | 0.531381 / 0.226044 (0.305336) | 5.320077 / 2.268929 (3.051148) | 2.370705 / 55.444624 (-53.073919) | 2.007089 / 6.876477 (-4.869388) | 2.062412 / 2.142072 (-0.079661) | 0.814998 / 4.805227 (-3.990229) | 0.149822 / 6.500664 (-6.350842) | 0.064399 / 0.075469 (-0.011070) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.226196 / 1.841788 (-0.615591) | 13.823443 / 8.074308 (5.749134) | 13.813667 / 10.191392 (3.622275) | 0.161289 / 0.680424 (-0.519135) | 0.028569 / 0.534201 (-0.505632) | 0.390360 / 0.579283 (-0.188923) | 0.396217 / 0.434364 (-0.038147) | 0.483120 / 0.540337 (-0.057217) | 0.570041 / 1.386936 (-0.816895) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006422 / 0.011353 (-0.004931) | 0.004528 / 0.011008 (-0.006481) | 0.076043 / 0.038508 (0.037535) | 0.027631 / 0.023109 (0.004522) | 0.340622 / 0.275898 (0.064724) | 0.376694 / 0.323480 (0.053214) | 0.004993 / 0.007986 (-0.002992) | 0.003403 / 0.004328 (-0.000926) | 0.074521 / 0.004250 (0.070270) | 0.037568 / 0.037052 (0.000516) | 0.343423 / 0.258489 (0.084934) | 0.387729 / 0.293841 (0.093888) | 0.031790 / 0.128546 (-0.096757) | 0.011767 / 0.075646 (-0.063879) | 0.085182 / 0.419271 (-0.334090) | 0.042867 / 0.043533 (-0.000666) | 0.341269 / 0.255139 (0.086130) | 0.368460 / 0.283200 (0.085261) | 0.090153 / 0.141683 (-0.051530) | 1.536490 / 1.452155 (0.084335) | 1.596403 / 1.492716 (0.103686) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.222373 / 0.018006 (0.204367) | 0.396145 / 0.000490 (0.395655) | 0.000384 / 0.000200 (0.000184) | 0.000062 / 0.000054 (0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024801 / 0.037411 (-0.012610) | 0.099711 / 0.014526 (0.085185) | 0.106094 / 0.176557 (-0.070463) | 0.147819 / 0.737135 (-0.589316) | 0.110065 / 0.296338 (-0.186274) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.442863 / 0.215209 (0.227654) | 4.420043 / 2.077655 (2.342388) | 2.070136 / 1.504120 (0.566016) | 1.862363 / 1.541195 (0.321168) | 1.910890 / 1.468490 (0.442400) | 0.702570 / 4.584777 (-3.882207) | 3.435855 / 3.745712 (-0.309857) | 1.871290 / 5.269862 (-3.398572) | 1.169321 / 4.565676 (-3.396355) | 0.083674 / 0.424275 (-0.340601) | 0.012823 / 0.007607 (0.005216) | 0.539330 / 0.226044 (0.313285) | 5.403317 / 2.268929 (3.134389) | 2.536508 / 55.444624 (-52.908117) | 2.179629 / 6.876477 (-4.696847) | 2.207586 / 2.142072 (0.065514) | 0.812256 / 4.805227 (-3.992972) | 0.152915 / 6.500664 (-6.347749) | 0.068431 / 0.075469 (-0.007038) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.294982 / 1.841788 (-0.546806) | 13.912811 / 8.074308 (5.838503) | 13.415658 / 10.191392 (3.224266) | 0.149531 / 0.680424 (-0.530893) | 0.016785 / 0.534201 (-0.517416) | 0.381055 / 0.579283 (-0.198228) | 0.392084 / 0.434364 (-0.042280) | 0.472614 / 0.540337 (-0.067724) | 0.559799 / 1.386936 (-0.827137) |\n\n</details>\n</details>\n\n\n",
"We simply do GET requests to hf.co to download files from the Hub right now. We may switch to hfh when we update how we do caching \r\n\r\nYou can try on any dataset hosted on the hub like `imagenet-1k`",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010931 / 0.011353 (-0.000422) | 0.005730 / 0.011008 (-0.005278) | 0.116653 / 0.038508 (0.078145) | 0.041439 / 0.023109 (0.018330) | 0.359559 / 0.275898 (0.083661) | 0.408398 / 0.323480 (0.084918) | 0.009193 / 0.007986 (0.001208) | 0.006024 / 0.004328 (0.001695) | 0.087743 / 0.004250 (0.083492) | 0.048636 / 0.037052 (0.011584) | 0.363133 / 0.258489 (0.104643) | 0.407144 / 0.293841 (0.113303) | 0.044610 / 0.128546 (-0.083936) | 0.014075 / 0.075646 (-0.061571) | 0.396506 / 0.419271 (-0.022766) | 0.057014 / 0.043533 (0.013482) | 0.358254 / 0.255139 (0.103115) | 0.399887 / 0.283200 (0.116687) | 0.115337 / 0.141683 (-0.026346) | 1.731655 / 1.452155 (0.279500) | 1.813276 / 1.492716 (0.320560) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.210197 / 0.018006 (0.192191) | 0.475887 / 0.000490 (0.475397) | 0.003323 / 0.000200 (0.003123) | 0.000100 / 0.000054 (0.000045) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031686 / 0.037411 (-0.005725) | 0.131167 / 0.014526 (0.116641) | 0.137919 / 0.176557 (-0.038637) | 0.184843 / 0.737135 (-0.552293) | 0.144998 / 0.296338 (-0.151340) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.471371 / 0.215209 (0.256162) | 4.693739 / 2.077655 (2.616084) | 2.251567 / 1.504120 (0.747447) | 1.993653 / 1.541195 (0.452458) | 2.053236 / 1.468490 (0.584746) | 0.809226 / 4.584777 (-3.775551) | 4.494120 / 3.745712 (0.748408) | 2.436921 / 5.269862 (-2.832940) | 1.541973 / 4.565676 (-3.023704) | 0.098401 / 0.424275 (-0.325874) | 0.014329 / 0.007607 (0.006722) | 0.597813 / 0.226044 (0.371769) | 5.964035 / 2.268929 (3.695107) | 2.709283 / 55.444624 (-52.735341) | 2.323537 / 6.876477 (-4.552940) | 2.401707 / 2.142072 (0.259635) | 0.976379 / 4.805227 (-3.828848) | 0.194638 / 6.500664 (-6.306026) | 0.076904 / 0.075469 (0.001435) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.516877 / 1.841788 (-0.324911) | 18.228010 / 8.074308 (10.153702) | 16.631750 / 10.191392 (6.440358) | 0.176030 / 0.680424 (-0.504394) | 0.033769 / 0.534201 (-0.500432) | 0.520511 / 0.579283 (-0.058773) | 0.531764 / 0.434364 (0.097400) | 0.648658 / 0.540337 (0.108321) | 0.779124 / 1.386936 (-0.607812) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008635 / 0.011353 (-0.002718) | 0.005785 / 0.011008 (-0.005223) | 0.087042 / 0.038508 (0.048534) | 0.039632 / 0.023109 (0.016523) | 0.419719 / 0.275898 (0.143821) | 0.463860 / 0.323480 (0.140380) | 0.006621 / 0.007986 (-0.001364) | 0.004655 / 0.004328 (0.000327) | 0.087003 / 0.004250 (0.082753) | 0.057122 / 0.037052 (0.020069) | 0.417820 / 0.258489 (0.159331) | 0.485981 / 0.293841 (0.192140) | 0.042606 / 0.128546 (-0.085940) | 0.014369 / 0.075646 (-0.061278) | 0.101939 / 0.419271 (-0.317333) | 0.058303 / 0.043533 (0.014770) | 0.415053 / 0.255139 (0.159914) | 0.439914 / 0.283200 (0.156714) | 0.134628 / 0.141683 (-0.007055) | 1.765464 / 1.452155 (0.313309) | 1.843963 / 1.492716 (0.351247) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.307156 / 0.018006 (0.289150) | 0.476657 / 0.000490 (0.476167) | 0.019718 / 0.000200 (0.019518) | 0.000160 / 0.000054 (0.000105) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035286 / 0.037411 (-0.002125) | 0.138094 / 0.014526 (0.123568) | 0.144768 / 0.176557 (-0.031789) | 0.191386 / 0.737135 (-0.545750) | 0.151988 / 0.296338 (-0.144350) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.504733 / 0.215209 (0.289523) | 5.027048 / 2.077655 (2.949394) | 2.441571 / 1.504120 (0.937451) | 2.198242 / 1.541195 (0.657047) | 2.298473 / 1.468490 (0.829983) | 0.848048 / 4.584777 (-3.736729) | 4.613102 / 3.745712 (0.867390) | 2.522824 / 5.269862 (-2.747037) | 1.610159 / 4.565676 (-2.955517) | 0.105197 / 0.424275 (-0.319078) | 0.015195 / 0.007607 (0.007588) | 0.626976 / 0.226044 (0.400932) | 6.268459 / 2.268929 (3.999530) | 3.014387 / 55.444624 (-52.430237) | 2.554102 / 6.876477 (-4.322375) | 2.656051 / 2.142072 (0.513979) | 1.027978 / 4.805227 (-3.777249) | 0.200686 / 6.500664 (-6.299978) | 0.077104 / 0.075469 (0.001635) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.485228 / 1.841788 (-0.356560) | 18.319949 / 8.074308 (10.245641) | 15.855739 / 10.191392 (5.664347) | 0.204365 / 0.680424 (-0.476059) | 0.023824 / 0.534201 (-0.510377) | 0.505000 / 0.579283 (-0.074283) | 0.502866 / 0.434364 (0.068502) | 0.629574 / 0.540337 (0.089237) | 0.746602 / 1.386936 (-0.640334) |\n\n</details>\n</details>\n\n\n"
] | 2023-02-03T10:50:10Z
| 2023-02-09T11:04:11Z
| null |
CONTRIBUTOR
| null | null | null |
Original fix: https://github.com/huggingface/huggingface_hub/pull/1267
Not sure this function is actually still called though.
I haven't done benches on this. Is there a dataset where files are hosted on the hub through cloudfront so we can have the same setup as in `hf_hub` ?
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5501/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5501/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5501.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5501",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5501.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5501"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7199
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7199/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7199/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7199/events
|
https://github.com/huggingface/datasets/pull/7199
| 2,566,788,225
|
PR_kwDODunzps59pN_M
| 7,199
|
Add with_rank to Dataset.from_generator
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17828087?v=4",
"events_url": "https://api.github.com/users/muthissar/events{/privacy}",
"followers_url": "https://api.github.com/users/muthissar/followers",
"following_url": "https://api.github.com/users/muthissar/following{/other_user}",
"gists_url": "https://api.github.com/users/muthissar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/muthissar",
"id": 17828087,
"login": "muthissar",
"node_id": "MDQ6VXNlcjE3ODI4MDg3",
"organizations_url": "https://api.github.com/users/muthissar/orgs",
"received_events_url": "https://api.github.com/users/muthissar/received_events",
"repos_url": "https://api.github.com/users/muthissar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/muthissar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muthissar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/muthissar",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[] | 2024-10-04T16:51:53Z
| 2024-10-04T16:51:53Z
| null |
NONE
| null | null | null |
Adds `with_rank` to `Dataset.from_generator`. As for `Dataset.map` and `Dataset.filter`, this is useful when creating cache files using multi-GPU.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7199/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7199/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7199.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7199",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7199.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7199"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5643
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5643/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5643/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5643/events
|
https://github.com/huggingface/datasets/pull/5643
| 1,626,160,220
|
PR_kwDODunzps5MI9zO
| 5,643
|
Support PyArrow arrays as column values in `from_dict`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006665 / 0.011353 (-0.004688) | 0.004842 / 0.011008 (-0.006166) | 0.097802 / 0.038508 (0.059294) | 0.032292 / 0.023109 (0.009182) | 0.327522 / 0.275898 (0.051624) | 0.351851 / 0.323480 (0.028371) | 0.005197 / 0.007986 (-0.002789) | 0.003781 / 0.004328 (-0.000547) | 0.073213 / 0.004250 (0.068963) | 0.045819 / 0.037052 (0.008767) | 0.331323 / 0.258489 (0.072834) | 0.376978 / 0.293841 (0.083137) | 0.035014 / 0.128546 (-0.093532) | 0.011853 / 0.075646 (-0.063793) | 0.344031 / 0.419271 (-0.075240) | 0.049094 / 0.043533 (0.005561) | 0.327054 / 0.255139 (0.071915) | 0.349053 / 0.283200 (0.065853) | 0.095413 / 0.141683 (-0.046269) | 1.451593 / 1.452155 (-0.000562) | 1.505568 / 1.492716 (0.012851) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.211624 / 0.018006 (0.193618) | 0.437569 / 0.000490 (0.437079) | 0.003775 / 0.000200 (0.003575) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025915 / 0.037411 (-0.011496) | 0.104085 / 0.014526 (0.089559) | 0.111064 / 0.176557 (-0.065493) | 0.167316 / 0.737135 (-0.569819) | 0.117255 / 0.296338 (-0.179084) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424241 / 0.215209 (0.209032) | 4.251365 / 2.077655 (2.173710) | 2.074036 / 1.504120 (0.569916) | 1.858022 / 1.541195 (0.316828) | 1.819929 / 1.468490 (0.351439) | 0.704153 / 4.584777 (-3.880624) | 3.750506 / 3.745712 (0.004794) | 3.149836 / 5.269862 (-2.120026) | 1.729540 / 4.565676 (-2.836137) | 0.087287 / 0.424275 (-0.336988) | 0.012304 / 0.007607 (0.004697) | 0.513811 / 0.226044 (0.287767) | 5.129427 / 2.268929 (2.860498) | 2.489253 / 55.444624 (-52.955371) | 2.122746 / 6.876477 (-4.753730) | 2.208528 / 2.142072 (0.066456) | 0.843386 / 4.805227 (-3.961841) | 0.169320 / 6.500664 (-6.331344) | 0.064085 / 0.075469 (-0.011384) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.184361 / 1.841788 (-0.657427) | 14.013478 / 8.074308 (5.939170) | 13.936774 / 10.191392 (3.745382) | 0.138009 / 0.680424 (-0.542415) | 0.017192 / 0.534201 (-0.517009) | 0.420938 / 0.579283 (-0.158345) | 0.413390 / 0.434364 (-0.020974) | 0.500244 / 0.540337 (-0.040094) | 0.582499 / 1.386936 (-0.804437) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006709 / 0.011353 (-0.004643) | 0.004847 / 0.011008 (-0.006161) | 0.074740 / 0.038508 (0.036232) | 0.032126 / 0.023109 (0.009017) | 0.343248 / 0.275898 (0.067350) | 0.376822 / 0.323480 (0.053342) | 0.005547 / 0.007986 (-0.002439) | 0.005080 / 0.004328 (0.000752) | 0.074634 / 0.004250 (0.070384) | 0.044735 / 0.037052 (0.007682) | 0.357895 / 0.258489 (0.099406) | 0.401150 / 0.293841 (0.107310) | 0.035485 / 0.128546 (-0.093061) | 0.011978 / 0.075646 (-0.063668) | 0.087567 / 0.419271 (-0.331704) | 0.050233 / 0.043533 (0.006701) | 0.337476 / 0.255139 (0.082337) | 0.385064 / 0.283200 (0.101865) | 0.102733 / 0.141683 (-0.038950) | 1.456238 / 1.452155 (0.004083) | 1.539468 / 1.492716 (0.046752) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.203156 / 0.018006 (0.185149) | 0.448898 / 0.000490 (0.448408) | 0.002843 / 0.000200 (0.002644) | 0.000222 / 0.000054 (0.000168) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027836 / 0.037411 (-0.009576) | 0.109889 / 0.014526 (0.095364) | 0.119378 / 0.176557 (-0.057179) | 0.171208 / 0.737135 (-0.565927) | 0.124240 / 0.296338 (-0.172098) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.425374 / 0.215209 (0.210165) | 4.252994 / 2.077655 (2.175339) | 2.006410 / 1.504120 (0.502290) | 1.812821 / 1.541195 (0.271626) | 1.857618 / 1.468490 (0.389128) | 0.714564 / 4.584777 (-3.870213) | 3.803040 / 3.745712 (0.057328) | 2.075452 / 5.269862 (-3.194410) | 1.344868 / 4.565676 (-3.220809) | 0.088705 / 0.424275 (-0.335570) | 0.012481 / 0.007607 (0.004874) | 0.528022 / 0.226044 (0.301977) | 5.268878 / 2.268929 (2.999949) | 2.467858 / 55.444624 (-52.976767) | 2.138681 / 6.876477 (-4.737796) | 2.134928 / 2.142072 (-0.007145) | 0.851518 / 4.805227 (-3.953709) | 0.175085 / 6.500664 (-6.325579) | 0.063555 / 0.075469 (-0.011914) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.265788 / 1.841788 (-0.576000) | 14.683444 / 8.074308 (6.609136) | 14.055848 / 10.191392 (3.864456) | 0.145260 / 0.680424 (-0.535164) | 0.017064 / 0.534201 (-0.517137) | 0.424836 / 0.579283 (-0.154447) | 0.418345 / 0.434364 (-0.016019) | 0.491408 / 0.540337 (-0.048930) | 0.594387 / 1.386936 (-0.792549) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006870 / 0.011353 (-0.004483) | 0.004602 / 0.011008 (-0.006406) | 0.100075 / 0.038508 (0.061567) | 0.028720 / 0.023109 (0.005611) | 0.304212 / 0.275898 (0.028314) | 0.348423 / 0.323480 (0.024943) | 0.005266 / 0.007986 (-0.002720) | 0.003473 / 0.004328 (-0.000855) | 0.077563 / 0.004250 (0.073313) | 0.040066 / 0.037052 (0.003013) | 0.304039 / 0.258489 (0.045550) | 0.348721 / 0.293841 (0.054881) | 0.032127 / 0.128546 (-0.096419) | 0.011583 / 0.075646 (-0.064063) | 0.326853 / 0.419271 (-0.092418) | 0.043158 / 0.043533 (-0.000375) | 0.310111 / 0.255139 (0.054973) | 0.332869 / 0.283200 (0.049670) | 0.088384 / 0.141683 (-0.053299) | 1.509245 / 1.452155 (0.057091) | 1.575393 / 1.492716 (0.082677) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.212839 / 0.018006 (0.194833) | 0.431407 / 0.000490 (0.430918) | 0.002639 / 0.000200 (0.002439) | 0.000076 / 0.000054 (0.000021) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024945 / 0.037411 (-0.012466) | 0.101312 / 0.014526 (0.086787) | 0.107873 / 0.176557 (-0.068683) | 0.169579 / 0.737135 (-0.567556) | 0.109922 / 0.296338 (-0.186417) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422091 / 0.215209 (0.206882) | 4.227174 / 2.077655 (2.149519) | 1.957964 / 1.504120 (0.453844) | 1.812076 / 1.541195 (0.270882) | 1.966666 / 1.468490 (0.498176) | 0.698710 / 4.584777 (-3.886067) | 3.431824 / 3.745712 (-0.313888) | 1.898646 / 5.269862 (-3.371215) | 1.172096 / 4.565676 (-3.393581) | 0.083383 / 0.424275 (-0.340892) | 0.012793 / 0.007607 (0.005186) | 0.522501 / 0.226044 (0.296457) | 5.240049 / 2.268929 (2.971121) | 2.349286 / 55.444624 (-53.095338) | 2.051117 / 6.876477 (-4.825360) | 2.255652 / 2.142072 (0.113580) | 0.813668 / 4.805227 (-3.991560) | 0.153770 / 6.500664 (-6.346894) | 0.068323 / 0.075469 (-0.007146) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.197204 / 1.841788 (-0.644584) | 14.146212 / 8.074308 (6.071904) | 14.469765 / 10.191392 (4.278373) | 0.130024 / 0.680424 (-0.550400) | 0.016858 / 0.534201 (-0.517343) | 0.382949 / 0.579283 (-0.196334) | 0.393414 / 0.434364 (-0.040950) | 0.447910 / 0.540337 (-0.092427) | 0.529842 / 1.386936 (-0.857094) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006903 / 0.011353 (-0.004450) | 0.004695 / 0.011008 (-0.006313) | 0.077457 / 0.038508 (0.038949) | 0.028624 / 0.023109 (0.005514) | 0.340767 / 0.275898 (0.064869) | 0.378811 / 0.323480 (0.055331) | 0.005996 / 0.007986 (-0.001990) | 0.003481 / 0.004328 (-0.000848) | 0.076284 / 0.004250 (0.072034) | 0.042564 / 0.037052 (0.005511) | 0.340908 / 0.258489 (0.082419) | 0.384952 / 0.293841 (0.091111) | 0.032057 / 0.128546 (-0.096489) | 0.011697 / 0.075646 (-0.063949) | 0.085941 / 0.419271 (-0.333331) | 0.042464 / 0.043533 (-0.001069) | 0.339309 / 0.255139 (0.084170) | 0.368105 / 0.283200 (0.084905) | 0.093382 / 0.141683 (-0.048301) | 1.467220 / 1.452155 (0.015065) | 1.563105 / 1.492716 (0.070389) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.260631 / 0.018006 (0.242625) | 0.418155 / 0.000490 (0.417665) | 0.009539 / 0.000200 (0.009339) | 0.000103 / 0.000054 (0.000048) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025494 / 0.037411 (-0.011917) | 0.106034 / 0.014526 (0.091508) | 0.109878 / 0.176557 (-0.066678) | 0.160754 / 0.737135 (-0.576382) | 0.113226 / 0.296338 (-0.183112) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.442989 / 0.215209 (0.227780) | 4.447040 / 2.077655 (2.369385) | 2.082529 / 1.504120 (0.578409) | 1.876952 / 1.541195 (0.335757) | 1.968341 / 1.468490 (0.499851) | 0.704317 / 4.584777 (-3.880460) | 3.466190 / 3.745712 (-0.279523) | 1.924954 / 5.269862 (-3.344908) | 1.199763 / 4.565676 (-3.365913) | 0.084320 / 0.424275 (-0.339955) | 0.012956 / 0.007607 (0.005349) | 0.538905 / 0.226044 (0.312861) | 5.426593 / 2.268929 (3.157665) | 2.509287 / 55.444624 (-52.935338) | 2.174829 / 6.876477 (-4.701648) | 2.239214 / 2.142072 (0.097141) | 0.810031 / 4.805227 (-3.995196) | 0.153534 / 6.500664 (-6.347130) | 0.069578 / 0.075469 (-0.005891) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.294068 / 1.841788 (-0.547720) | 14.601899 / 8.074308 (6.527591) | 14.469282 / 10.191392 (4.277890) | 0.130024 / 0.680424 (-0.550400) | 0.016895 / 0.534201 (-0.517306) | 0.382583 / 0.579283 (-0.196700) | 0.388938 / 0.434364 (-0.045426) | 0.448416 / 0.540337 (-0.091922) | 0.533261 / 1.386936 (-0.853675) |\n\n</details>\n</details>\n\n\n"
] | 2023-03-15T19:32:40Z
| 2023-03-16T17:23:06Z
| 2023-03-16T17:15:40Z
|
COLLABORATOR
| null | null | null |
For consistency with `pa.Table.from_pydict`, which supports both Python lists and PyArrow arrays as column values.
"Fixes" https://discuss.huggingface.co/t/pyarrow-lib-floatarray-did-not-recognize-python-value-type-when-inferring-an-arrow-data-type/33417
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5643/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5643/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5643.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5643",
"merged_at": "2023-03-16T17:15:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5643.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5643"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7280
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7280/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7280/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7280/events
|
https://github.com/huggingface/datasets/issues/7280
| 2,639,977,077
|
I_kwDODunzps6dWtp1
| 7,280
|
Add filename in error message when ReadError or similar occur
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/37046039?v=4",
"events_url": "https://api.github.com/users/elisa-aleman/events{/privacy}",
"followers_url": "https://api.github.com/users/elisa-aleman/followers",
"following_url": "https://api.github.com/users/elisa-aleman/following{/other_user}",
"gists_url": "https://api.github.com/users/elisa-aleman/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/elisa-aleman",
"id": 37046039,
"login": "elisa-aleman",
"node_id": "MDQ6VXNlcjM3MDQ2MDM5",
"organizations_url": "https://api.github.com/users/elisa-aleman/orgs",
"received_events_url": "https://api.github.com/users/elisa-aleman/received_events",
"repos_url": "https://api.github.com/users/elisa-aleman/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/elisa-aleman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/elisa-aleman/subscriptions",
"type": "User",
"url": "https://api.github.com/users/elisa-aleman",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"Hi Elisa, please share the error traceback here, and if you manage to find the location in the `datasets` code where the error occurs, feel free to open a PR to add the necessary logging / improve the error message.",
"> please share the error traceback\n\nI don't have access to it but it should be during [this exception](https://github.com/huggingface/datasets/blob/2049c00921c59cdeb835137a1c49639cf175af07/src/datasets/builder.py#L1643) which happens during the loading of a dataset. If one of the downloaded files is corrupted, the for loop will not yield correctly, and the error will come from, say, in the case of tar files, [this iterable](https://github.com/huggingface/datasets/blob/2049c00921c59cdeb835137a1c49639cf175af07/src/datasets/utils/file_utils.py#L1293) which has no explicit error handling that leaves clues as to which file has failed.\n\nI only know the case for tar files, but I consider this issue could be happening across different file types too.",
"I think having a better error handling for this tar iterable would be useful already, maybe a simple try/except in `_iter_from_urlpath` that checks for `tarfile.ReadError` and raises an error with the `urlpath` mentioned in the error ?",
"I think not just from higher calls like the `_iter_from_urlpath` but directly wherever a file is attempted to be opened would be the best case, as the traceback would simply lead to that.",
"so maybe there should be better error messages in each dataset builder definition ? e.g. in https://github.com/huggingface/datasets/blob/main/src/datasets/packaged_modules/webdataset/webdataset.py for webdataset TAR archives"
] | 2024-11-07T06:00:53Z
| 2024-11-20T13:23:12Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
Please update error messages to include relevant information for debugging when loading datasets with `load_dataset()` that may have a few corrupted files.
Whenever downloading a full dataset, some files might be corrupted (either at the source or from downloading corruption).
However the errors often only let me know it was a tar file if `tarfile.ReadError` appears on the traceback, and I imagine similarly for other file types.
This makes it really hard to debug which file is corrupted, and when dealing with very large datasets, it shouldn't be necessary to force download everything again.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7280/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7280/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4649
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4649/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4649/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4649/events
|
https://github.com/huggingface/datasets/issues/4649
| 1,296,673,712
|
I_kwDODunzps5NSauw
| 4,649
|
Add PAQ dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_url": "https://api.github.com/users/omarespejel/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/omarespejel",
"id": 4755430,
"login": "omarespejel",
"node_id": "MDQ6VXNlcjQ3NTU0MzA=",
"organizations_url": "https://api.github.com/users/omarespejel/orgs",
"received_events_url": "https://api.github.com/users/omarespejel/received_events",
"repos_url": "https://api.github.com/users/omarespejel/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/omarespejel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/omarespejel/subscriptions",
"type": "User",
"url": "https://api.github.com/users/omarespejel",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
closed
| false
| null |
[] | null |
[
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/PAQ_pairs)"
] | 2022-07-07T01:29:42Z
| 2022-07-14T02:06:27Z
| 2022-07-14T02:06:27Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
## Adding a Dataset
- **Name:** *PAQ*
- **Description:** *This repository contains code and models to support the research paper PAQ: 65 Million Probably-Asked Questions and What You Can Do With Them*
- **Paper:** *https://arxiv.org/abs/2102.07033*
- **Data:** *https://huggingface.co/datasets/sentence-transformers/embedding-training-data/resolve/main/PAQ_pairs.jsonl.gz*
- **Motivation:** *Dataset for training and evaluating models of conversational response*
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_url": "https://api.github.com/users/omarespejel/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/omarespejel",
"id": 4755430,
"login": "omarespejel",
"node_id": "MDQ6VXNlcjQ3NTU0MzA=",
"organizations_url": "https://api.github.com/users/omarespejel/orgs",
"received_events_url": "https://api.github.com/users/omarespejel/received_events",
"repos_url": "https://api.github.com/users/omarespejel/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/omarespejel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/omarespejel/subscriptions",
"type": "User",
"url": "https://api.github.com/users/omarespejel",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4649/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4649/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6402
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6402/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6402/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6402/events
|
https://github.com/huggingface/datasets/pull/6402
| 1,989,094,542
|
PR_kwDODunzps5fOBdK
| 6,402
|
Update torch_formatter.py
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/32204417?v=4",
"events_url": "https://api.github.com/users/varunneal/events{/privacy}",
"followers_url": "https://api.github.com/users/varunneal/followers",
"following_url": "https://api.github.com/users/varunneal/following{/other_user}",
"gists_url": "https://api.github.com/users/varunneal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/varunneal",
"id": 32204417,
"login": "varunneal",
"node_id": "MDQ6VXNlcjMyMjA0NDE3",
"organizations_url": "https://api.github.com/users/varunneal/orgs",
"received_events_url": "https://api.github.com/users/varunneal/received_events",
"repos_url": "https://api.github.com/users/varunneal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/varunneal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/varunneal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/varunneal",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6402). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005391 / 0.011353 (-0.005962) | 0.003908 / 0.011008 (-0.007100) | 0.064342 / 0.038508 (0.025834) | 0.031385 / 0.023109 (0.008275) | 0.251869 / 0.275898 (-0.024030) | 0.294875 / 0.323480 (-0.028605) | 0.003053 / 0.007986 (-0.004933) | 0.002881 / 0.004328 (-0.001448) | 0.050072 / 0.004250 (0.045822) | 0.044463 / 0.037052 (0.007411) | 0.264646 / 0.258489 (0.006157) | 0.296024 / 0.293841 (0.002183) | 0.027832 / 0.128546 (-0.100714) | 0.010937 / 0.075646 (-0.064710) | 0.207799 / 0.419271 (-0.211472) | 0.036423 / 0.043533 (-0.007110) | 0.251022 / 0.255139 (-0.004117) | 0.271366 / 0.283200 (-0.011833) | 0.019780 / 0.141683 (-0.121903) | 1.149634 / 1.452155 (-0.302521) | 1.196476 / 1.492716 (-0.296240) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.094857 / 0.018006 (0.076850) | 0.312159 / 0.000490 (0.311669) | 0.000215 / 0.000200 (0.000015) | 0.000042 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018858 / 0.037411 (-0.018553) | 0.062022 / 0.014526 (0.047496) | 0.078302 / 0.176557 (-0.098255) | 0.122199 / 0.737135 (-0.614936) | 0.076044 / 0.296338 (-0.220294) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.286414 / 0.215209 (0.071205) | 2.785446 / 2.077655 (0.707791) | 1.438248 / 1.504120 (-0.065872) | 1.307558 / 1.541195 (-0.233636) | 1.337172 / 1.468490 (-0.131318) | 0.582228 / 4.584777 (-4.002549) | 2.457207 / 3.745712 (-1.288505) | 2.906692 / 5.269862 (-2.363169) | 1.833020 / 4.565676 (-2.732656) | 0.063549 / 0.424275 (-0.360726) | 0.005080 / 0.007607 (-0.002527) | 0.333178 / 0.226044 (0.107133) | 3.332463 / 2.268929 (1.063534) | 1.797209 / 55.444624 (-53.647415) | 1.514446 / 6.876477 (-5.362031) | 1.601252 / 2.142072 (-0.540820) | 0.664933 / 4.805227 (-4.140294) | 0.120140 / 6.500664 (-6.380524) | 0.042769 / 0.075469 (-0.032700) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.983738 / 1.841788 (-0.858050) | 11.996685 / 8.074308 (3.922376) | 9.594757 / 10.191392 (-0.596635) | 0.146680 / 0.680424 (-0.533744) | 0.014455 / 0.534201 (-0.519746) | 0.292546 / 0.579283 (-0.286737) | 0.270381 / 0.434364 (-0.163983) | 0.326759 / 0.540337 (-0.213579) | 0.423387 / 1.386936 (-0.963549) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005659 / 0.011353 (-0.005694) | 0.004841 / 0.011008 (-0.006167) | 0.049598 / 0.038508 (0.011090) | 0.031796 / 0.023109 (0.008687) | 0.265967 / 0.275898 (-0.009931) | 0.287648 / 0.323480 (-0.035832) | 0.004264 / 0.007986 (-0.003721) | 0.002759 / 0.004328 (-0.001569) | 0.049249 / 0.004250 (0.044999) | 0.049526 / 0.037052 (0.012474) | 0.357765 / 0.258489 (0.099276) | 0.307563 / 0.293841 (0.013722) | 0.030329 / 0.128546 (-0.098217) | 0.010536 / 0.075646 (-0.065111) | 0.057547 / 0.419271 (-0.361724) | 0.059874 / 0.043533 (0.016341) | 0.264946 / 0.255139 (0.009807) | 0.283666 / 0.283200 (0.000466) | 0.021005 / 0.141683 (-0.120677) | 1.170959 / 1.452155 (-0.281195) | 1.206232 / 1.492716 (-0.286484) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.097567 / 0.018006 (0.079561) | 0.308585 / 0.000490 (0.308095) | 0.000220 / 0.000200 (0.000020) | 0.000052 / 0.000054 (-0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023267 / 0.037411 (-0.014144) | 0.075896 / 0.014526 (0.061370) | 0.087341 / 0.176557 (-0.089216) | 0.130270 / 0.737135 (-0.606866) | 0.091086 / 0.296338 (-0.205252) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.298728 / 0.215209 (0.083519) | 2.876498 / 2.077655 (0.798843) | 1.591584 / 1.504120 (0.087464) | 1.461251 / 1.541195 (-0.079944) | 1.483276 / 1.468490 (0.014786) | 0.572344 / 4.584777 (-4.012433) | 2.474050 / 3.745712 (-1.271662) | 2.707051 / 5.269862 (-2.562811) | 1.759210 / 4.565676 (-2.806466) | 0.063420 / 0.424275 (-0.360855) | 0.005014 / 0.007607 (-0.002593) | 0.344490 / 0.226044 (0.118446) | 3.411065 / 2.268929 (1.142137) | 1.937232 / 55.444624 (-53.507392) | 1.665826 / 6.876477 (-5.210650) | 1.824377 / 2.142072 (-0.317696) | 0.631630 / 4.805227 (-4.173597) | 0.115791 / 6.500664 (-6.384873) | 0.040846 / 0.075469 (-0.034623) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.015248 / 1.841788 (-0.826540) | 12.738696 / 8.074308 (4.664388) | 10.324303 / 10.191392 (0.132911) | 0.153597 / 0.680424 (-0.526827) | 0.015396 / 0.534201 (-0.518805) | 0.287160 / 0.579283 (-0.292123) | 0.279886 / 0.434364 (-0.154478) | 0.324128 / 0.540337 (-0.216210) | 0.456089 / 1.386936 (-0.930847) |\n\n</details>\n</details>\n\n\n"
] | 2023-11-11T19:40:41Z
| 2024-03-15T11:31:53Z
| 2024-03-15T11:25:37Z
|
CONTRIBUTOR
| null | null | null |
Ensure PyTorch images are converted to (C, H, W) instead of (H, W, C). See #6394 for motivation.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6402/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6402/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6402.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6402",
"merged_at": "2024-03-15T11:25:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6402.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6402"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7534
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7534/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7534/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7534/events
|
https://github.com/huggingface/datasets/issues/7534
| 3,017,259,407
|
I_kwDODunzps6z17mP
| 7,534
|
TensorFlow RaggedTensor Support (batch-level)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7490199?v=4",
"events_url": "https://api.github.com/users/Lundez/events{/privacy}",
"followers_url": "https://api.github.com/users/Lundez/followers",
"following_url": "https://api.github.com/users/Lundez/following{/other_user}",
"gists_url": "https://api.github.com/users/Lundez/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Lundez",
"id": 7490199,
"login": "Lundez",
"node_id": "MDQ6VXNlcjc0OTAxOTk=",
"organizations_url": "https://api.github.com/users/Lundez/orgs",
"received_events_url": "https://api.github.com/users/Lundez/received_events",
"repos_url": "https://api.github.com/users/Lundez/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Lundez/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Lundez/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Lundez",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
| null |
[] | null |
[] | 2025-04-24T13:14:52Z
| 2025-04-24T13:17:20Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
Hi,
Currently datasets does not support RaggedTensor output on batch-level.
When building a Object Detection Dataset (with TensorFlow) I need to enable RaggedTensors as that's how BBoxes & classes are expected from the Keras Model POV.
Currently there's a error thrown saying that "Nested Data is not supported".
It'd be very helpful if this was fixed! :)
### Motivation
Enabling Object Detection pipelines for TensorFlow.
### Your contribution
With guidance I'd happily help making the PR.
The current implementation with DataCollator and later enforcing `np.array` is the problematic part (at the end of `np_get_batch` in `tf_utils.py`). As `numpy` don't support "Raggednes"
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7534/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7534/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5012
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5012/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5012/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5012/events
|
https://github.com/huggingface/datasets/issues/5012
| 1,382,851,096
|
I_kwDODunzps5SbKIY
| 5,012
|
Force JSON format regardless of file naming on S3
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/112650299?v=4",
"events_url": "https://api.github.com/users/junwang-wish/events{/privacy}",
"followers_url": "https://api.github.com/users/junwang-wish/followers",
"following_url": "https://api.github.com/users/junwang-wish/following{/other_user}",
"gists_url": "https://api.github.com/users/junwang-wish/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/junwang-wish",
"id": 112650299,
"login": "junwang-wish",
"node_id": "U_kgDOBrboOw",
"organizations_url": "https://api.github.com/users/junwang-wish/orgs",
"received_events_url": "https://api.github.com/users/junwang-wish/received_events",
"repos_url": "https://api.github.com/users/junwang-wish/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/junwang-wish/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/junwang-wish/subscriptions",
"type": "User",
"url": "https://api.github.com/users/junwang-wish",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
| null |
[] | null |
[
"Hi ! Support for URIs like `s3://...` is not implemented yet in `data_files=`. You can use the HTTP URL instead if your data is public in the meantime",
"Hi,\r\nI want to make sure I understand this response. I have a set of files on S3 that are private for security reasons. Because they are not public files I cannot read those files (many are parquet) into my hf notebooks in Kaggle? That can't be correct, can it? ",
"Hi ! There is a discussion at https://github.com/huggingface/datasets/issues/5281\r\n\r\nUsing the latest `datasets` 2.11 you can try passing fsspec URLs to private buckets to `data_files` in `load_dataset()`. Though this is still experimental and undocumented, so feedback is welcome. You may not have the best experience though, since anything related to performance and caching hasn't been tested properly yet.",
"closing this one since data_files supports fsspec (still experimental/untested/undocumented for s3 though)"
] | 2022-09-22T18:28:15Z
| 2023-08-16T09:58:36Z
| 2023-08-16T09:58:36Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
I have a file on S3 created by Data Version Control, it looks like `s3://dvc/ac/badff5b134382a0f25248f1b45d7b2` but contains a json file. If I run
```python
dataset = load_dataset(
"json",
data_files='s3://dvc/ac/badff5b134382a0f25248f1b45d7b2'
)
```
It gives me
```
InvalidSchema: No connection adapters were found for 's3://dvc/ac/badff5b134382a0f25248f1b45d7b2'
```
However, I cannot go ahead and change the names of the s3 file. Is there a way to "force" load a S3 url with certain decoder (JSON, CSV, etc.) regardless of s3 URL naming?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5012/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5012/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/4887
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4887/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4887/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4887/events
|
https://github.com/huggingface/datasets/pull/4887
| 1,349,426,693
|
PR_kwDODunzps49t_PM
| 4,887
|
Add "cc-by-nc-sa-2.0" to list of licenses
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_url": "https://api.github.com/users/osanseviero/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/osanseviero",
"id": 7246357,
"login": "osanseviero",
"node_id": "MDQ6VXNlcjcyNDYzNTc=",
"organizations_url": "https://api.github.com/users/osanseviero/orgs",
"received_events_url": "https://api.github.com/users/osanseviero/received_events",
"repos_url": "https://api.github.com/users/osanseviero/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/osanseviero/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/osanseviero/subscriptions",
"type": "User",
"url": "https://api.github.com/users/osanseviero",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Sorry for the issue @albertvillanova! I think it's now fixed! :heart: "
] | 2022-08-24T13:11:49Z
| 2022-08-26T10:31:32Z
| 2022-08-26T10:29:20Z
|
CONTRIBUTOR
| null | null | null |
Datasets side of https://github.com/huggingface/hub-docs/pull/285
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4887/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4887/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4887.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4887",
"merged_at": "2022-08-26T10:29:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4887.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4887"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6902
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6902/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6902/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6902/events
|
https://github.com/huggingface/datasets/pull/6902
| 2,300,256,241
|
PR_kwDODunzps5vqLIv
| 6,902
|
Make CLI convert_to_parquet not raise error if no rights to create script branch
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6902). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005026 / 0.011353 (-0.006327) | 0.003672 / 0.011008 (-0.007336) | 0.062776 / 0.038508 (0.024268) | 0.032056 / 0.023109 (0.008947) | 0.245359 / 0.275898 (-0.030540) | 0.269371 / 0.323480 (-0.054109) | 0.004205 / 0.007986 (-0.003780) | 0.002774 / 0.004328 (-0.001555) | 0.048958 / 0.004250 (0.044708) | 0.046442 / 0.037052 (0.009390) | 0.263924 / 0.258489 (0.005434) | 0.291854 / 0.293841 (-0.001987) | 0.027299 / 0.128546 (-0.101248) | 0.010332 / 0.075646 (-0.065315) | 0.202677 / 0.419271 (-0.216595) | 0.037732 / 0.043533 (-0.005801) | 0.246028 / 0.255139 (-0.009111) | 0.272100 / 0.283200 (-0.011099) | 0.018497 / 0.141683 (-0.123186) | 1.101192 / 1.452155 (-0.350962) | 1.149683 / 1.492716 (-0.343033) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.097838 / 0.018006 (0.079832) | 0.305598 / 0.000490 (0.305108) | 0.000230 / 0.000200 (0.000030) | 0.000045 / 0.000054 (-0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019489 / 0.037411 (-0.017922) | 0.061902 / 0.014526 (0.047376) | 0.074825 / 0.176557 (-0.101732) | 0.121664 / 0.737135 (-0.615472) | 0.076440 / 0.296338 (-0.219898) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.279194 / 0.215209 (0.063985) | 2.756777 / 2.077655 (0.679123) | 1.429298 / 1.504120 (-0.074822) | 1.313423 / 1.541195 (-0.227771) | 1.340466 / 1.468490 (-0.128024) | 0.556349 / 4.584777 (-4.028428) | 2.355910 / 3.745712 (-1.389802) | 2.806733 / 5.269862 (-2.463128) | 1.741903 / 4.565676 (-2.823773) | 0.061556 / 0.424275 (-0.362719) | 0.005477 / 0.007607 (-0.002130) | 0.327856 / 0.226044 (0.101812) | 3.283092 / 2.268929 (1.014164) | 1.797776 / 55.444624 (-53.646848) | 1.498683 / 6.876477 (-5.377794) | 1.518501 / 2.142072 (-0.623572) | 0.632267 / 4.805227 (-4.172960) | 0.116505 / 6.500664 (-6.384159) | 0.042446 / 0.075469 (-0.033023) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.982841 / 1.841788 (-0.858947) | 11.709436 / 8.074308 (3.635128) | 9.570519 / 10.191392 (-0.620873) | 0.141968 / 0.680424 (-0.538456) | 0.014299 / 0.534201 (-0.519902) | 0.285101 / 0.579283 (-0.294182) | 0.267118 / 0.434364 (-0.167246) | 0.324720 / 0.540337 (-0.215617) | 0.423626 / 1.386936 (-0.963310) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005567 / 0.011353 (-0.005786) | 0.003703 / 0.011008 (-0.007306) | 0.050516 / 0.038508 (0.012008) | 0.032617 / 0.023109 (0.009508) | 0.276546 / 0.275898 (0.000648) | 0.299798 / 0.323480 (-0.023682) | 0.004282 / 0.007986 (-0.003704) | 0.002719 / 0.004328 (-0.001609) | 0.049424 / 0.004250 (0.045173) | 0.042924 / 0.037052 (0.005871) | 0.287785 / 0.258489 (0.029296) | 0.315490 / 0.293841 (0.021649) | 0.029533 / 0.128546 (-0.099013) | 0.010575 / 0.075646 (-0.065071) | 0.058210 / 0.419271 (-0.361061) | 0.033269 / 0.043533 (-0.010263) | 0.273325 / 0.255139 (0.018186) | 0.291762 / 0.283200 (0.008563) | 0.018922 / 0.141683 (-0.122761) | 1.118913 / 1.452155 (-0.333242) | 1.175554 / 1.492716 (-0.317162) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.099920 / 0.018006 (0.081914) | 0.317188 / 0.000490 (0.316698) | 0.000211 / 0.000200 (0.000011) | 0.000045 / 0.000054 (-0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022297 / 0.037411 (-0.015114) | 0.077775 / 0.014526 (0.063249) | 0.090239 / 0.176557 (-0.086317) | 0.130498 / 0.737135 (-0.606638) | 0.092010 / 0.296338 (-0.204328) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.293534 / 0.215209 (0.078325) | 2.866070 / 2.077655 (0.788415) | 1.547147 / 1.504120 (0.043027) | 1.419684 / 1.541195 (-0.121510) | 1.432128 / 1.468490 (-0.036362) | 0.571365 / 4.584777 (-4.013412) | 0.968879 / 3.745712 (-2.776833) | 2.797415 / 5.269862 (-2.472446) | 1.767821 / 4.565676 (-2.797856) | 0.063281 / 0.424275 (-0.360994) | 0.005072 / 0.007607 (-0.002535) | 0.344547 / 0.226044 (0.118502) | 3.383888 / 2.268929 (1.114959) | 1.879537 / 55.444624 (-53.565087) | 1.598392 / 6.876477 (-5.278085) | 1.627788 / 2.142072 (-0.514284) | 0.641199 / 4.805227 (-4.164028) | 0.116349 / 6.500664 (-6.384315) | 0.041940 / 0.075469 (-0.033529) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.002494 / 1.841788 (-0.839294) | 12.310056 / 8.074308 (4.235748) | 9.819718 / 10.191392 (-0.371674) | 0.134745 / 0.680424 (-0.545679) | 0.016223 / 0.534201 (-0.517978) | 0.284791 / 0.579283 (-0.294492) | 0.124665 / 0.434364 (-0.309699) | 0.381601 / 0.540337 (-0.158737) | 0.413007 / 1.386936 (-0.973929) |\n\n</details>\n</details>\n\n\n"
] | 2024-05-16T12:21:27Z
| 2024-06-03T04:43:17Z
| 2024-05-16T12:51:05Z
|
MEMBER
| null | null | null |
Make CLI convert_to_parquet not raise error if no rights to create "script" branch.
Not that before this PR, the error was not critical because it was raised at the end of the script, once all the rest of the steps were already performed.
Fix #6901.
Bug introduced in datasets-2.19.0 by:
- #6809
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6902/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6902/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6902.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6902",
"merged_at": "2024-05-16T12:51:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6902.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6902"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7143
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7143/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7143/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7143/events
|
https://github.com/huggingface/datasets/pull/7143
| 2,512,327,211
|
PR_kwDODunzps56xCm6
| 7,143
|
Modify add_column() to optionally accept a FeatureType as param
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20443618?v=4",
"events_url": "https://api.github.com/users/varadhbhatnagar/events{/privacy}",
"followers_url": "https://api.github.com/users/varadhbhatnagar/followers",
"following_url": "https://api.github.com/users/varadhbhatnagar/following{/other_user}",
"gists_url": "https://api.github.com/users/varadhbhatnagar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/varadhbhatnagar",
"id": 20443618,
"login": "varadhbhatnagar",
"node_id": "MDQ6VXNlcjIwNDQzNjE4",
"organizations_url": "https://api.github.com/users/varadhbhatnagar/orgs",
"received_events_url": "https://api.github.com/users/varadhbhatnagar/received_events",
"repos_url": "https://api.github.com/users/varadhbhatnagar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/varadhbhatnagar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/varadhbhatnagar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/varadhbhatnagar",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Requesting review @lhoestq \r\nI will also update the docs if this looks good.",
"Cool ! maybe you can rename the argument `feature` and with type `FeatureType` ? This way it would work the same way as `.cast_column()` ?",
"@lhoestq Since there is no way to get a `pyarrow.Schema` from a `FeatureType`, I had to go via `Features`. How does this look?",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7143). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"@lhoestq done!",
"@lhoestq anything pending on this?"
] | 2024-09-08T10:56:57Z
| 2024-09-17T06:01:23Z
| 2024-09-16T15:11:01Z
|
CONTRIBUTOR
| null | null | null |
Fix #7142.
**Before (Add + Cast)**:
```
from datasets import load_dataset, Value
ds = load_dataset("rotten_tomatoes", split="test")
lst = [i for i in range(len(ds))]
ds = ds.add_column("new_col", lst)
# Assigns int64 to new_col by default
print(ds.features)
ds = ds.cast_column("new_col", Value(dtype="uint16", id=None))
print(ds.features)
```
**Before (Numpy Workaround)**:
```
from datasets import load_dataset
import numpy as np
ds = load_dataset("rotten_tomatoes", split="test")
lst = [i for i in range(len(ds))]
ds = ds.add_column("new_col", np.array(lst, dtype=np.uint16))
print(ds.features)
```
**After**:
```
from datasets import load_dataset, Value
ds = load_dataset("rotten_tomatoes", split="test")
lst = [i for i in range(len(ds))]
val = Value(dtype="uint16", id=None))
ds = ds.add_column("new_col", lst, feature=val)
print(ds.features)
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7143/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7143/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7143.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7143",
"merged_at": "2024-09-16T15:11:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7143.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7143"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5169
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5169/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5169/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5169/events
|
https://github.com/huggingface/datasets/pull/5169
| 1,425,075,254
|
PR_kwDODunzps5Bow1Q
| 5,169
|
Add "ipykernel" to list of `co_filename`s to remove
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/32967787?v=4",
"events_url": "https://api.github.com/users/gpucce/events{/privacy}",
"followers_url": "https://api.github.com/users/gpucce/followers",
"following_url": "https://api.github.com/users/gpucce/following{/other_user}",
"gists_url": "https://api.github.com/users/gpucce/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gpucce",
"id": 32967787,
"login": "gpucce",
"node_id": "MDQ6VXNlcjMyOTY3Nzg3",
"organizations_url": "https://api.github.com/users/gpucce/orgs",
"received_events_url": "https://api.github.com/users/gpucce/received_events",
"repos_url": "https://api.github.com/users/gpucce/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gpucce/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gpucce/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gpucce",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"I don't know how I could add some tests for this, although jupyter is not among the dependencies so at least that would need to be added. If someone can tell a recommended way I will try to do it!",
"So testing by myself and looking around the jupyter codebase it looks like the `co_filename` of objects created within jupyter is of the form `f\"{tempfile.tempdir}/ipykernel_{id1}/{id2}.py\"` however I can't find the exact command setting it so I [asked in discourse](https://discourse.jupyter.org/t/co-filename-within-notebooks/16538). For now adapted the `co_filename` filter and added tests according to this I hope to get an answer and possibly fix based on that.",
"Ok ! I think it's fine to just check if the parent folder is named like `ipykernel_*` then\r\n\r\nsee the source code of how it's created:\r\n\r\nhttps://github.com/ipython/ipykernel/blob/7f73ff705510b35d1e2faad7f5a676c620ce08d4/ipykernel/compiler.py#L72-L75",
"Should look better now didn't notice the duplicated tests",
"_The documentation is not available anymore as the PR was closed or merged._",
"Should work now on windows too",
"I did the changes you suggested and tried to rebase, the first part went fine, the second less so :( \r\n\r\nIf you have time to spare, can you tell me what should I do now to fix this? thanks",
"Instead of rebasing you can just merge `main` into your branch, otherwise the GitHub preview of your PR shows changes of from `main`.\r\n\r\nFeel free to close this PR and create a new one. Or alternatively your can force push to this PR with a new clean git history.",
"I have force-pushed and merged main, only shows the right changes, if you can run CI one more time it should be ok now",
"Hi, sorry I have been busy, the thing is I can't really understand why the test fail, besides the ugly thing I had done in the last commit to check if within CI smth stange happened with `os`, locally tests pass",
"The CI wasn't passing when using the latest version `dill==0.3.6`. We have a separate function to dump CodeType objects for 0.3.6\r\n\r\nI applied the same changes you did to this other function as well - it should be all good now",
"> The CI wasn't passing when using the latest version `dill==0.3.6`. We have a separate function to dump CodeType objects for 0.3.6\r\n> \r\n> I applied the same changes you did to this other function as well - it should be all good now\r\n\r\nThanks, it would have taken a long time to figure out :)"
] | 2022-10-27T05:56:17Z
| 2022-11-02T15:46:00Z
| 2022-11-02T15:43:20Z
|
CONTRIBUTOR
| null | null | null |
Should resolve #5157
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5169/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5169/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5169.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5169",
"merged_at": "2022-11-02T15:43:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5169.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5169"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7170
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7170/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7170/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7170/events
|
https://github.com/huggingface/datasets/pull/7170
| 2,546,944,016
|
PR_kwDODunzps58mfF5
| 7,170
|
Support JSON lines with missing columns
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7170). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update."
] | 2024-09-25T05:08:15Z
| 2024-09-26T06:42:09Z
| 2024-09-26T06:42:07Z
|
MEMBER
| null | null | null |
Support JSON lines with missing columns.
Fix #7169.
The implemented test raised:
```
datasets.table.CastError: Couldn't cast
age: int64
to
{'age': Value(dtype='int32', id=None), 'name': Value(dtype='string', id=None)}
because column names don't match
```
Related to:
- #7160
- #7162
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7170/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7170/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7170.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7170",
"merged_at": "2024-09-26T06:42:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7170.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7170"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6928
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6928/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6928/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6928/events
|
https://github.com/huggingface/datasets/pull/6928
| 2,322,267,727
|
PR_kwDODunzps5w1ECb
| 6,928
|
Update process.mdx: Code Listings Fixes
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16918280?v=4",
"events_url": "https://api.github.com/users/FadyMorris/events{/privacy}",
"followers_url": "https://api.github.com/users/FadyMorris/followers",
"following_url": "https://api.github.com/users/FadyMorris/following{/other_user}",
"gists_url": "https://api.github.com/users/FadyMorris/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/FadyMorris",
"id": 16918280,
"login": "FadyMorris",
"node_id": "MDQ6VXNlcjE2OTE4Mjgw",
"organizations_url": "https://api.github.com/users/FadyMorris/orgs",
"received_events_url": "https://api.github.com/users/FadyMorris/received_events",
"repos_url": "https://api.github.com/users/FadyMorris/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/FadyMorris/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FadyMorris/subscriptions",
"type": "User",
"url": "https://api.github.com/users/FadyMorris",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005062 / 0.011353 (-0.006291) | 0.003410 / 0.011008 (-0.007598) | 0.062241 / 0.038508 (0.023733) | 0.030294 / 0.023109 (0.007185) | 0.249249 / 0.275898 (-0.026649) | 0.267718 / 0.323480 (-0.055761) | 0.003047 / 0.007986 (-0.004938) | 0.002661 / 0.004328 (-0.001668) | 0.049142 / 0.004250 (0.044892) | 0.047929 / 0.037052 (0.010877) | 0.255262 / 0.258489 (-0.003227) | 0.286241 / 0.293841 (-0.007600) | 0.027064 / 0.128546 (-0.101482) | 0.010374 / 0.075646 (-0.065273) | 0.201454 / 0.419271 (-0.217818) | 0.036586 / 0.043533 (-0.006947) | 0.255200 / 0.255139 (0.000061) | 0.267660 / 0.283200 (-0.015539) | 0.018621 / 0.141683 (-0.123062) | 1.159821 / 1.452155 (-0.292334) | 1.171597 / 1.492716 (-0.321120) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.004752 / 0.018006 (-0.013254) | 0.295427 / 0.000490 (0.294937) | 0.000225 / 0.000200 (0.000025) | 0.000052 / 0.000054 (-0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018914 / 0.037411 (-0.018497) | 0.061180 / 0.014526 (0.046654) | 0.073649 / 0.176557 (-0.102907) | 0.120142 / 0.737135 (-0.616993) | 0.074754 / 0.296338 (-0.221585) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.286637 / 0.215209 (0.071428) | 2.807941 / 2.077655 (0.730287) | 1.473577 / 1.504120 (-0.030542) | 1.353112 / 1.541195 (-0.188083) | 1.363020 / 1.468490 (-0.105470) | 0.567745 / 4.584777 (-4.017032) | 2.384887 / 3.745712 (-1.360826) | 2.685132 / 5.269862 (-2.584730) | 1.755922 / 4.565676 (-2.809755) | 0.062296 / 0.424275 (-0.361979) | 0.004941 / 0.007607 (-0.002666) | 0.346752 / 0.226044 (0.120707) | 3.378623 / 2.268929 (1.109694) | 1.809070 / 55.444624 (-53.635555) | 1.531490 / 6.876477 (-5.344986) | 1.687954 / 2.142072 (-0.454119) | 0.639917 / 4.805227 (-4.165310) | 0.118455 / 6.500664 (-6.382209) | 0.043072 / 0.075469 (-0.032397) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.977154 / 1.841788 (-0.864634) | 11.380127 / 8.074308 (3.305819) | 9.621632 / 10.191392 (-0.569760) | 0.141768 / 0.680424 (-0.538655) | 0.014120 / 0.534201 (-0.520081) | 0.285073 / 0.579283 (-0.294210) | 0.264801 / 0.434364 (-0.169563) | 0.322357 / 0.540337 (-0.217981) | 0.431192 / 1.386936 (-0.955744) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005162 / 0.011353 (-0.006191) | 0.003499 / 0.011008 (-0.007509) | 0.049667 / 0.038508 (0.011159) | 0.032473 / 0.023109 (0.009363) | 0.259988 / 0.275898 (-0.015910) | 0.285723 / 0.323480 (-0.037757) | 0.004197 / 0.007986 (-0.003789) | 0.002710 / 0.004328 (-0.001618) | 0.049235 / 0.004250 (0.044984) | 0.040440 / 0.037052 (0.003387) | 0.276791 / 0.258489 (0.018302) | 0.311990 / 0.293841 (0.018149) | 0.029217 / 0.128546 (-0.099329) | 0.010217 / 0.075646 (-0.065429) | 0.057844 / 0.419271 (-0.361427) | 0.032799 / 0.043533 (-0.010734) | 0.260705 / 0.255139 (0.005566) | 0.280439 / 0.283200 (-0.002761) | 0.018682 / 0.141683 (-0.123001) | 1.135946 / 1.452155 (-0.316208) | 1.163144 / 1.492716 (-0.329572) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.097968 / 0.018006 (0.079961) | 0.309276 / 0.000490 (0.308786) | 0.000214 / 0.000200 (0.000014) | 0.000051 / 0.000054 (-0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022623 / 0.037411 (-0.014788) | 0.075471 / 0.014526 (0.060945) | 0.087928 / 0.176557 (-0.088629) | 0.129537 / 0.737135 (-0.607599) | 0.089376 / 0.296338 (-0.206963) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.298223 / 0.215209 (0.083014) | 2.940462 / 2.077655 (0.862807) | 1.586024 / 1.504120 (0.081904) | 1.451161 / 1.541195 (-0.090034) | 1.457707 / 1.468490 (-0.010783) | 0.571172 / 4.584777 (-4.013604) | 0.961591 / 3.745712 (-2.784121) | 2.661258 / 5.269862 (-2.608604) | 1.755172 / 4.565676 (-2.810504) | 0.063430 / 0.424275 (-0.360845) | 0.005034 / 0.007607 (-0.002573) | 0.352356 / 0.226044 (0.126312) | 3.454986 / 2.268929 (1.186057) | 1.967375 / 55.444624 (-53.477249) | 1.638465 / 6.876477 (-5.238012) | 1.774098 / 2.142072 (-0.367975) | 0.650094 / 4.805227 (-4.155134) | 0.117377 / 6.500664 (-6.383287) | 0.041229 / 0.075469 (-0.034240) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.014356 / 1.841788 (-0.827432) | 12.175823 / 8.074308 (4.101515) | 10.657486 / 10.191392 (0.466094) | 0.145080 / 0.680424 (-0.535344) | 0.015563 / 0.534201 (-0.518638) | 0.287093 / 0.579283 (-0.292190) | 0.127164 / 0.434364 (-0.307200) | 0.318518 / 0.540337 (-0.221820) | 0.415333 / 1.386936 (-0.971603) |\n\n</details>\n</details>\n\n\n"
] | 2024-05-29T03:17:07Z
| 2024-06-04T13:08:19Z
| 2024-06-04T12:55:00Z
|
CONTRIBUTOR
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6928/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6928/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6928.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6928",
"merged_at": "2024-06-04T12:55:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6928.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6928"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7397
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7397/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7397/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7397/events
|
https://github.com/huggingface/datasets/pull/7397
| 2,852,829,763
|
PR_kwDODunzps6LMuQD
| 7,397
|
Kannada dataset(Conversations, Wikipedia etc)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/146451281?v=4",
"events_url": "https://api.github.com/users/Likhith2612/events{/privacy}",
"followers_url": "https://api.github.com/users/Likhith2612/followers",
"following_url": "https://api.github.com/users/Likhith2612/following{/other_user}",
"gists_url": "https://api.github.com/users/Likhith2612/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Likhith2612",
"id": 146451281,
"login": "Likhith2612",
"node_id": "U_kgDOCLqrUQ",
"organizations_url": "https://api.github.com/users/Likhith2612/orgs",
"received_events_url": "https://api.github.com/users/Likhith2612/received_events",
"repos_url": "https://api.github.com/users/Likhith2612/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Likhith2612/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Likhith2612/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Likhith2612",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi ! feel free to uplad the CSV on https://huggingface.co/datasets :)\r\n\r\nwe don't store the datasets' data in this github repository"
] | 2025-02-14T06:53:03Z
| 2025-02-20T17:28:54Z
| 2025-02-20T17:28:53Z
|
NONE
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7397/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7397/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7397.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7397",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7397.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7397"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4836
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4836/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4836/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4836/events
|
https://github.com/huggingface/datasets/issues/4836
| 1,337,067,632
|
I_kwDODunzps5Psghw
| 4,836
|
Is it possible to pass multiple links to a split in load script?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/43045767?v=4",
"events_url": "https://api.github.com/users/sadrasabouri/events{/privacy}",
"followers_url": "https://api.github.com/users/sadrasabouri/followers",
"following_url": "https://api.github.com/users/sadrasabouri/following{/other_user}",
"gists_url": "https://api.github.com/users/sadrasabouri/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sadrasabouri",
"id": 43045767,
"login": "sadrasabouri",
"node_id": "MDQ6VXNlcjQzMDQ1NzY3",
"organizations_url": "https://api.github.com/users/sadrasabouri/orgs",
"received_events_url": "https://api.github.com/users/sadrasabouri/received_events",
"repos_url": "https://api.github.com/users/sadrasabouri/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sadrasabouri/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sadrasabouri/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sadrasabouri",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
| null |
[] | null |
[] | 2022-08-12T11:06:11Z
| 2022-08-12T11:06:11Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
**Is your feature request related to a problem? Please describe.**
I wanted to use a python loading script in hugging face datasets that use different sources of text (it's somehow a compilation of multiple datasets + my own dataset) based on how `load_dataset` [works](https://huggingface.co/docs/datasets/loading) I assumed I could do something like bellow in my loading script:
```python
...
_URL = "MY_DATASET_URL/resolve/main/data/"
_URLS = {
"train": [
"FIRST_URL_TO.txt",
_URL + "train-00000-of-00001-676bfebbc8742592.parquet"
]
}
...
```
but when loading the dataset it raises the following error:
```python
File ~/.local/lib/python3.8/site-packages/datasets/builder.py:704, in DatasetBuilder.download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
702 logger.warning("HF google storage unreachable. Downloading and preparing it from source")
703 if not downloaded_from_gcs:
--> 704 self._download_and_prepare(
705 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
...
668 if isinstance(a, str):
669 # Force-cast str subclasses to str (issue #21127)
670 parts.append(str(a))
TypeError: expected str, bytes or os.PathLike object, not list
```
**Describe the solution you'd like**
I believe since it's possible for `load_dataset` to get list of URLs instead of just a URL for `train` split it can be possible here too.
**Describe alternatives you've considered**
An alternative solution would be to download all needed datasets locally and `push_to_hub` them all, but since the datasets I'm talking about are huge it's not among my options.
**Additional context**
I think loading `text` beside the `parquet` is completely a different issue but I believe I can figure it out by proposing a config for my dataset to load each entry of `_URLS['train']` separately either by `load_dataset("text", ...` or `load_dataset("parquet", ...`.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4836/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4836/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5231
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5231/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5231/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5231/events
|
https://github.com/huggingface/datasets/issues/5231
| 1,445,883,267
|
I_kwDODunzps5WLm2D
| 5,231
|
Using `set_format(type='torch', columns=columns)` makes Array2D/3D columns stop formatting correctly
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/99206017?v=4",
"events_url": "https://api.github.com/users/plamb-viso/events{/privacy}",
"followers_url": "https://api.github.com/users/plamb-viso/followers",
"following_url": "https://api.github.com/users/plamb-viso/following{/other_user}",
"gists_url": "https://api.github.com/users/plamb-viso/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/plamb-viso",
"id": 99206017,
"login": "plamb-viso",
"node_id": "U_kgDOBenDgQ",
"organizations_url": "https://api.github.com/users/plamb-viso/orgs",
"received_events_url": "https://api.github.com/users/plamb-viso/received_events",
"repos_url": "https://api.github.com/users/plamb-viso/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/plamb-viso/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/plamb-viso/subscriptions",
"type": "User",
"url": "https://api.github.com/users/plamb-viso",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"In case others find this, the problem was not with set_format, but my usages of `to_pandas()` and `from_pandas()` which I was using during dataset splitting; somewhere in the chain of converting to and from pandas the `Array2D/Array3D` types get converted to series of `Sequence()` types"
] | 2022-11-11T18:54:36Z
| 2022-11-11T20:42:29Z
| 2022-11-11T18:59:50Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
I have a Dataset with two Features defined as follows:
```
'image': Array3D(dtype="int64", shape=(3, 224, 224)),
'bbox': Array2D(dtype="int64", shape=(512, 4)),
```
On said dataset, if I `dataset.set_format(type='torch')` and then use the dataset in a dataloader, these columns are correctly cast to Tensors of (batch_size, 3, 224, 244) for example.
However, if I `dataset.set_format(type='torch', columns=['image', 'bbox'])` these columns are cast to Lists of tensors and miss the batch size completely (the 3 dimension is the list length).
I'm currently digging through datasets formatting code to try and find out why, but was curious if someone knew an immediate solution for this.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/99206017?v=4",
"events_url": "https://api.github.com/users/plamb-viso/events{/privacy}",
"followers_url": "https://api.github.com/users/plamb-viso/followers",
"following_url": "https://api.github.com/users/plamb-viso/following{/other_user}",
"gists_url": "https://api.github.com/users/plamb-viso/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/plamb-viso",
"id": 99206017,
"login": "plamb-viso",
"node_id": "U_kgDOBenDgQ",
"organizations_url": "https://api.github.com/users/plamb-viso/orgs",
"received_events_url": "https://api.github.com/users/plamb-viso/received_events",
"repos_url": "https://api.github.com/users/plamb-viso/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/plamb-viso/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/plamb-viso/subscriptions",
"type": "User",
"url": "https://api.github.com/users/plamb-viso",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5231/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5231/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5137
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5137/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5137/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5137/events
|
https://github.com/huggingface/datasets/issues/5137
| 1,414,642,723
|
I_kwDODunzps5UUbwj
| 5,137
|
Align task tags in dataset metadata
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[
"I removed all the invalid task_ids in datasts without namespace, based on the <s>(internal)</s> types.ts",
"(Types.ts is not internal it's public)",
"I have opened PRs to fix the task_ids in all datasets within a namespace as well.\r\n\r\nWorking on task_categories...",
"For future reference: this fix had some complications\r\n\r\nWhen trying to open a PR to fix the task tags, an exception was thrown if:\r\n- the metadata contained \"languages\" or \"licenses\" (instead of \"language\" or \"license\")\r\n- the metadata contained a non-valid language: `en-US` (instead of `en`), `no` (instead of `'no'`),...\r\n- the metadata contained a non-valid license\r\n- either `task_categories` or `task_ids` was not an array (a dict for each config)\r\n- the metadata contained non-valid tag names\r\n\r\nErrors:\r\n```\r\nValueError: - Error: \"languages\" is deprecated. Use \"language\" instead.\r\n```\r\n```\r\nValueError: - Error: \"licenses\" is deprecated. Use \"license\" instead.\r\n```\r\n```\r\nValueError: - Error: \"language[17]\" must only contain lowercase characters\r\n```\r\n```\r\nValueError: - Error: \"language[0]\" with value \"cz, de, it\" is not valid. It must be an ISO 639-1, 639-2 or 639-3 code (two/three letters), or a special value like \"code\", \"multilingual\". If you want to use BCP-47 identifiers, you can specify them in language_bcp47.\r\n```\r\n```\r\nValueError: - Error: \"task_ids\" must be an array\r\n```",
"All Hub datasets are done.",
"great job! did you have feedback from Hub users/i.E. repo authors?",
"Yes, @julien-c. These are some of the feedbacks:\r\n- Most people just thank for the fix: [cahya/librivox-indonesia](https://huggingface.co/datasets/cahya/librivox-indonesia/discussions/1#6357cd8a292a050ebd705f84), [TurkuNLP/xlsum-fi](https://huggingface.co/datasets/TurkuNLP/xlsum-fi/discussions/1#6357828aa1f8ad1c31bcbe46), [coastalcph/fairlex](https://huggingface.co/datasets/coastalcph/fairlex/discussions/4#6351a527a8e595171ab1aef2)\r\n- Why are we changing their task names? [joelito/lextreme](https://huggingface.co/datasets/joelito/lextreme/discussions/1#6351b576fe367c0d9b12041b)\r\n - I take note of this for the next bulk operation; besides the PR title, we should also add a description to explain the reason for the change and also maybe putting a link to some pertinent GH Issue page\r\n- Some of them ask where to find the list of the supported task values is: [dennlinger/klexikon](https://huggingface.co/datasets/dennlinger/klexikon/discussions/3#6356b3ea80f8cb3ab777ac5c), [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad/discussions/1#635262467e4cc3135fd09f58)\r\n - Currently, the list is here: https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts#L85\r\n - Maybe we could made them more easily accessible\r\n- Some people do not agree about current \"hierarchy\":\r\n - text-scoring: [emrecan/nli_tr_for_simcse](https://huggingface.co/datasets/emrecan/nli_tr_for_simcse/discussions/1#6357c1b128792d8cdd51e9f9) (but referring to [emrecan/nli_tr_for_simcse](https://huggingface.co/datasets/emrecan/nli_tr_for_simcse/discussions/2/files))\r\n - Before \"text-scoring\" was a task_category, with task_ids [\"semantic-similarity-scoring\", \"sentiment-scoring\"]\r\n - Now all three are task_ids [\"text-scoring\", \"semantic-similarity-scoring\", \"sentiment-scoring\"] under the task_category \"text-classification\"\r\n - People complain that their scoring tasks are not classification task\r\n - binary-classification: why don't we have binary-classification? We have multi-class-classification, multi-label-classification and sentiment-classification, but not binary-classification\r\n - symbolic-regression: [yoshitomo-matsubara/srsd-feynman_hard](https://huggingface.co/datasets/yoshitomo-matsubara/srsd-feynman_hard/discussions/2#63614194c12a09b8a31457cc), [yoshitomo-matsubara/srsd-feynman_medium](https://huggingface.co/datasets/yoshitomo-matsubara/srsd-feynman_medium/discussions/2#6361418aeee0d27f04379e43), [yoshitomo-matsubara/srsd-feynman_easy](https://huggingface.co/datasets/yoshitomo-matsubara/srsd-feynman_easy/discussions/2#6361416e00905b1ffb8d0112)\r\n - Why don't we have symbolic-regression task?\r\n\r\nNOTE: I'm editing this comment to add more feedback",
"As someone with feedback on the updates (which I highly appreciate seeing included here :D), a few comments from a \"user perspective\": \r\n\r\n* I think the general confusion for me was also surrounding the hierarchy; it doesn't really become super clear (even when using the tagger space) that one is a subset of the other, especially since it seems to be still possible to include fine-grained tasks without the \"parent category\"?\r\n* The datasets explorer still shows tags that are no longer valid (e.g., super specific ones such as `summarization-other-paper-abstract-generation`, but also ones that should be `task_categories`, such as `summarization`). I'm assuming this will be fixed soon, but until then it can confuse people who don't understand why they suddenly can't use seemingly still valid tags anymore.\r\n* As I mentioned to @albertvillanova, having a dedicated page in the docs with explanations (especially wrt the difference between `task_categories` and `task_ids`) would be super helpful. However, I think it would have been sufficient to just include some description in the dataset PRs where you can link to the Github/other discussion on the topic :) That way, I can check myself what changes are expected to happen.\r\n\r\nThanks again for the streamlining process, I personally learned a fair bit about the tagging structure in the meantime!\r\nBest,\r\nDennis",
"Thanks to you both for your feedback! super useful! cc'ing @osanseviero too 🙂\r\n\r\n> The datasets explorer still shows tags that are no longer valid\r\n\r\nwait which explorer is that? is it https://huggingface.co/datasets/viewer/ ?\r\n",
"Sorry, this one: https://huggingface.co/datasets \r\nAnd then selecting the \"Fine-Grained Tasks\".",
"good feedback! we'll improve this",
"Super useful feedback, thanks a lot!",
"- Some people do not agree about current \"hierarchy\":\r\n - symbolic-regression: [yoshitomo-matsubara/srsd-feynman_hard](https://huggingface.co/datasets/yoshitomo-matsubara/srsd-feynman_hard/discussions/2#63614194c12a09b8a31457cc), [yoshitomo-matsubara/srsd-feynman_medium](https://huggingface.co/datasets/yoshitomo-matsubara/srsd-feynman_medium/discussions/2#6361418aeee0d27f04379e43), [yoshitomo-matsubara/srsd-feynman_easy](https://huggingface.co/datasets/yoshitomo-matsubara/srsd-feynman_easy/discussions/2#6361416e00905b1ffb8d0112)\r\n - Why don't we have symbolic-regression task?",
"@albertvillanova \r\nThank you for sharing our voice here!\r\n\r\nYes, we want `symbolic-regression` to be listed as a task. This task has been attracting attention from the machine learning/deep learning community, and unfortunately existing symbolic regression datasets are de-centralized in the community (hosted at individual platforms like author website, github, etc).\r\nIt would be great for the community if Hugging Face can support the task."
] | 2022-10-19T09:41:42Z
| 2022-11-10T05:25:58Z
| 2022-10-25T06:17:00Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
## Describe
Once we have agreed on a common naming for task tags for all open source projects, we should align on them.
## Steps
- [x] Align task tags in canonical datasets
- [x] task_categories: 4 datasets
- [x] task_ids (by @lhoestq)
- [x] Open PRs in community datasets
- [x] task_categories: 451 datasets
- [x] task_ids: 556 datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5137/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5137/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6456
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6456/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6456/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6456/events
|
https://github.com/huggingface/datasets/pull/6456
| 2,015,186,090
|
PR_kwDODunzps5gmDJY
| 6,456
|
Don't require trust_remote_code in inspect_dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005705 / 0.011353 (-0.005648) | 0.003536 / 0.011008 (-0.007473) | 0.062852 / 0.038508 (0.024343) | 0.053902 / 0.023109 (0.030793) | 0.239465 / 0.275898 (-0.036433) | 0.270829 / 0.323480 (-0.052651) | 0.004052 / 0.007986 (-0.003934) | 0.002775 / 0.004328 (-0.001554) | 0.048475 / 0.004250 (0.044225) | 0.039430 / 0.037052 (0.002377) | 0.244318 / 0.258489 (-0.014171) | 0.277539 / 0.293841 (-0.016302) | 0.027637 / 0.128546 (-0.100909) | 0.010875 / 0.075646 (-0.064771) | 0.208839 / 0.419271 (-0.210432) | 0.036984 / 0.043533 (-0.006549) | 0.246355 / 0.255139 (-0.008784) | 0.271200 / 0.283200 (-0.011999) | 0.020636 / 0.141683 (-0.121047) | 1.078472 / 1.452155 (-0.373683) | 1.155701 / 1.492716 (-0.337015) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.100971 / 0.018006 (0.082965) | 0.310996 / 0.000490 (0.310507) | 0.000218 / 0.000200 (0.000018) | 0.000055 / 0.000054 (0.000000) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019300 / 0.037411 (-0.018111) | 0.060625 / 0.014526 (0.046099) | 0.073778 / 0.176557 (-0.102778) | 0.120280 / 0.737135 (-0.616855) | 0.075288 / 0.296338 (-0.221051) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.289838 / 0.215209 (0.074629) | 2.859492 / 2.077655 (0.781837) | 1.528478 / 1.504120 (0.024358) | 1.417911 / 1.541195 (-0.123283) | 1.444227 / 1.468490 (-0.024263) | 0.566799 / 4.584777 (-4.017978) | 2.402526 / 3.745712 (-1.343186) | 2.805241 / 5.269862 (-2.464620) | 1.798572 / 4.565676 (-2.767104) | 0.062920 / 0.424275 (-0.361355) | 0.004995 / 0.007607 (-0.002612) | 0.340688 / 0.226044 (0.114644) | 3.347967 / 2.268929 (1.079039) | 1.898464 / 55.444624 (-53.546160) | 1.604784 / 6.876477 (-5.271693) | 1.648864 / 2.142072 (-0.493209) | 0.642242 / 4.805227 (-4.162985) | 0.117567 / 6.500664 (-6.383097) | 0.041911 / 0.075469 (-0.033558) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.949099 / 1.841788 (-0.892689) | 12.367323 / 8.074308 (4.293015) | 10.694238 / 10.191392 (0.502846) | 0.143424 / 0.680424 (-0.537000) | 0.014569 / 0.534201 (-0.519632) | 0.289127 / 0.579283 (-0.290156) | 0.270490 / 0.434364 (-0.163874) | 0.326470 / 0.540337 (-0.213867) | 0.432223 / 1.386936 (-0.954713) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005380 / 0.011353 (-0.005973) | 0.003582 / 0.011008 (-0.007426) | 0.049341 / 0.038508 (0.010833) | 0.053274 / 0.023109 (0.030165) | 0.284319 / 0.275898 (0.008421) | 0.334248 / 0.323480 (0.010768) | 0.004032 / 0.007986 (-0.003953) | 0.002682 / 0.004328 (-0.001646) | 0.048317 / 0.004250 (0.044067) | 0.040157 / 0.037052 (0.003105) | 0.284594 / 0.258489 (0.026105) | 0.341567 / 0.293841 (0.047726) | 0.029639 / 0.128546 (-0.098908) | 0.010780 / 0.075646 (-0.064867) | 0.057990 / 0.419271 (-0.361282) | 0.032730 / 0.043533 (-0.010803) | 0.290328 / 0.255139 (0.035189) | 0.298563 / 0.283200 (0.015363) | 0.018546 / 0.141683 (-0.123137) | 1.143157 / 1.452155 (-0.308998) | 1.191391 / 1.492716 (-0.301326) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093802 / 0.018006 (0.075796) | 0.312771 / 0.000490 (0.312282) | 0.000221 / 0.000200 (0.000021) | 0.000045 / 0.000054 (-0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021867 / 0.037411 (-0.015544) | 0.069064 / 0.014526 (0.054538) | 0.082270 / 0.176557 (-0.094287) | 0.120222 / 0.737135 (-0.616913) | 0.084628 / 0.296338 (-0.211710) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.295505 / 0.215209 (0.080296) | 2.891105 / 2.077655 (0.813450) | 1.619480 / 1.504120 (0.115360) | 1.498290 / 1.541195 (-0.042905) | 1.547896 / 1.468490 (0.079406) | 0.575188 / 4.584777 (-4.009589) | 2.434426 / 3.745712 (-1.311286) | 2.899286 / 5.269862 (-2.370576) | 1.806085 / 4.565676 (-2.759591) | 0.063660 / 0.424275 (-0.360616) | 0.004933 / 0.007607 (-0.002674) | 0.348274 / 0.226044 (0.122229) | 3.447900 / 2.268929 (1.178971) | 1.956237 / 55.444624 (-53.488387) | 1.680416 / 6.876477 (-5.196061) | 1.732307 / 2.142072 (-0.409766) | 0.668428 / 4.805227 (-4.136799) | 0.119161 / 6.500664 (-6.381503) | 0.041694 / 0.075469 (-0.033775) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.973730 / 1.841788 (-0.868058) | 12.082452 / 8.074308 (4.008144) | 10.624836 / 10.191392 (0.433444) | 0.144027 / 0.680424 (-0.536397) | 0.014830 / 0.534201 (-0.519370) | 0.289946 / 0.579283 (-0.289337) | 0.281939 / 0.434364 (-0.152424) | 0.325639 / 0.540337 (-0.214699) | 0.551690 / 1.386936 (-0.835246) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005279 / 0.011353 (-0.006074) | 0.003506 / 0.011008 (-0.007502) | 0.062579 / 0.038508 (0.024071) | 0.052809 / 0.023109 (0.029700) | 0.274693 / 0.275898 (-0.001205) | 0.283917 / 0.323480 (-0.039563) | 0.003950 / 0.007986 (-0.004036) | 0.002772 / 0.004328 (-0.001557) | 0.048127 / 0.004250 (0.043877) | 0.037771 / 0.037052 (0.000719) | 0.280595 / 0.258489 (0.022106) | 0.292310 / 0.293841 (-0.001531) | 0.027890 / 0.128546 (-0.100656) | 0.010771 / 0.075646 (-0.064875) | 0.207285 / 0.419271 (-0.211987) | 0.036179 / 0.043533 (-0.007354) | 0.253617 / 0.255139 (-0.001522) | 0.276107 / 0.283200 (-0.007093) | 0.018253 / 0.141683 (-0.123430) | 1.112219 / 1.452155 (-0.339936) | 1.166756 / 1.492716 (-0.325960) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095159 / 0.018006 (0.077152) | 0.306097 / 0.000490 (0.305608) | 0.000219 / 0.000200 (0.000019) | 0.000042 / 0.000054 (-0.000013) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019056 / 0.037411 (-0.018355) | 0.060445 / 0.014526 (0.045919) | 0.073553 / 0.176557 (-0.103004) | 0.120306 / 0.737135 (-0.616829) | 0.075613 / 0.296338 (-0.220725) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.277839 / 0.215209 (0.062630) | 2.761037 / 2.077655 (0.683382) | 1.508524 / 1.504120 (0.004404) | 1.368994 / 1.541195 (-0.172201) | 1.415961 / 1.468490 (-0.052529) | 0.570490 / 4.584777 (-4.014287) | 2.356355 / 3.745712 (-1.389357) | 2.806626 / 5.269862 (-2.463235) | 1.757849 / 4.565676 (-2.807827) | 0.063504 / 0.424275 (-0.360771) | 0.005021 / 0.007607 (-0.002586) | 0.338880 / 0.226044 (0.112836) | 3.290947 / 2.268929 (1.022018) | 1.818238 / 55.444624 (-53.626386) | 1.529970 / 6.876477 (-5.346507) | 1.557085 / 2.142072 (-0.584987) | 0.645352 / 4.805227 (-4.159876) | 0.123066 / 6.500664 (-6.377598) | 0.043387 / 0.075469 (-0.032082) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.974512 / 1.841788 (-0.867276) | 11.976411 / 8.074308 (3.902103) | 10.361084 / 10.191392 (0.169692) | 0.127171 / 0.680424 (-0.553253) | 0.014091 / 0.534201 (-0.520110) | 0.288608 / 0.579283 (-0.290675) | 0.261886 / 0.434364 (-0.172478) | 0.331632 / 0.540337 (-0.208705) | 0.437002 / 1.386936 (-0.949934) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005129 / 0.011353 (-0.006224) | 0.003490 / 0.011008 (-0.007518) | 0.049005 / 0.038508 (0.010497) | 0.054077 / 0.023109 (0.030968) | 0.276653 / 0.275898 (0.000755) | 0.298752 / 0.323480 (-0.024728) | 0.003979 / 0.007986 (-0.004007) | 0.002625 / 0.004328 (-0.001703) | 0.047951 / 0.004250 (0.043701) | 0.040969 / 0.037052 (0.003916) | 0.279879 / 0.258489 (0.021390) | 0.306244 / 0.293841 (0.012403) | 0.029025 / 0.128546 (-0.099522) | 0.010450 / 0.075646 (-0.065197) | 0.056846 / 0.419271 (-0.362426) | 0.033476 / 0.043533 (-0.010057) | 0.273340 / 0.255139 (0.018201) | 0.294783 / 0.283200 (0.011584) | 0.019105 / 0.141683 (-0.122578) | 1.126389 / 1.452155 (-0.325766) | 1.183369 / 1.492716 (-0.309348) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.094995 / 0.018006 (0.076989) | 0.306984 / 0.000490 (0.306495) | 0.000224 / 0.000200 (0.000024) | 0.000043 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021880 / 0.037411 (-0.015532) | 0.069674 / 0.014526 (0.055148) | 0.082191 / 0.176557 (-0.094366) | 0.120956 / 0.737135 (-0.616179) | 0.083843 / 0.296338 (-0.212495) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.295139 / 0.215209 (0.079929) | 2.860520 / 2.077655 (0.782865) | 1.578892 / 1.504120 (0.074772) | 1.451003 / 1.541195 (-0.090192) | 1.483099 / 1.468490 (0.014609) | 0.550491 / 4.584777 (-4.034286) | 2.430352 / 3.745712 (-1.315360) | 2.874468 / 5.269862 (-2.395393) | 1.741474 / 4.565676 (-2.824202) | 0.062563 / 0.424275 (-0.361712) | 0.004962 / 0.007607 (-0.002645) | 0.343747 / 0.226044 (0.117703) | 3.419046 / 2.268929 (1.150118) | 1.943774 / 55.444624 (-53.500851) | 1.650989 / 6.876477 (-5.225488) | 1.704083 / 2.142072 (-0.437990) | 0.645447 / 4.805227 (-4.159780) | 0.125105 / 6.500664 (-6.375559) | 0.041319 / 0.075469 (-0.034150) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.959708 / 1.841788 (-0.882079) | 12.235906 / 8.074308 (4.161598) | 10.575402 / 10.191392 (0.384010) | 0.143619 / 0.680424 (-0.536805) | 0.015517 / 0.534201 (-0.518684) | 0.285231 / 0.579283 (-0.294052) | 0.281549 / 0.434364 (-0.152815) | 0.326649 / 0.540337 (-0.213689) | 0.565706 / 1.386936 (-0.821230) |\n\n</details>\n</details>\n\n\n"
] | 2023-11-28T19:47:07Z
| 2023-11-30T10:40:23Z
| 2023-11-30T10:34:12Z
|
MEMBER
| null | null | null |
don't require `trust_remote_code` in (deprecated) `inspect_dataset` (it defeats its purpose)
(not super important but we might as well keep it until the next major release)
this is needed to fix the tests in https://github.com/huggingface/datasets/pull/6448
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6456/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6456/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6456.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6456",
"merged_at": "2023-11-30T10:34:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6456.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6456"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5415
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5415/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5415/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5415/events
|
https://github.com/huggingface/datasets/issues/5415
| 1,526,904,861
|
I_kwDODunzps5bArgd
| 5,415
|
RuntimeError: Sharding is ambiguous for this dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[] | 2023-01-10T07:36:11Z
| 2023-01-18T14:09:04Z
| 2023-01-18T14:09:03Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
When loading some datasets, a RuntimeError is raised.
For example, for "ami" dataset: https://huggingface.co/datasets/ami/discussions/3
```
.../huggingface/datasets/src/datasets/builder.py in _prepare_split(self, split_generator, check_duplicate_keys, file_format, num_proc, max_shard_size)
1415 fpath = path_join(self._output_dir, fname)
1416
-> 1417 num_input_shards = _number_of_shards_in_gen_kwargs(split_generator.gen_kwargs)
1418 if num_input_shards <= 1 and num_proc is not None:
1419 logger.warning(
.../huggingface/datasets/src/datasets/utils/sharding.py in _number_of_shards_in_gen_kwargs(gen_kwargs)
10 lists_lengths = {key: len(value) for key, value in gen_kwargs.items() if isinstance(value, list)}
11 if len(set(lists_lengths.values())) > 1:
---> 12 raise RuntimeError(
13 (
14 "Sharding is ambiguous for this dataset: "
RuntimeError: Sharding is ambiguous for this dataset: we found several data sources lists of different lengths, and we don't know over which list we should parallelize:
- key samples_paths has length 6
- key ids has length 7
- key verification_ids has length 6
To fix this, check the 'gen_kwargs' and make sure to use lists only for data sources, and use tuples otherwise. In the end there should only be one single list, or several lists with the same length.
```
This behavior was introduced when implementing multiprocessing by PR:
- #5107
### Steps to reproduce the bug
```python
ds = load_dataset("ami", "microphone-single", split="train", revision="2d7620bb7c3f1aab9f329615c3bdb598069d907a")
```
### Expected behavior
No error raised.
### Environment info
Since datasets 2.7.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5415/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5415/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6958
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6958/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6958/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6958/events
|
https://github.com/huggingface/datasets/issues/6958
| 2,337,476,383
|
I_kwDODunzps6LUw8f
| 6,958
|
My Private Dataset doesn't exist on the Hub or cannot be accessed
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/39621324?v=4",
"events_url": "https://api.github.com/users/wangguan1995/events{/privacy}",
"followers_url": "https://api.github.com/users/wangguan1995/followers",
"following_url": "https://api.github.com/users/wangguan1995/following{/other_user}",
"gists_url": "https://api.github.com/users/wangguan1995/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/wangguan1995",
"id": 39621324,
"login": "wangguan1995",
"node_id": "MDQ6VXNlcjM5NjIxMzI0",
"organizations_url": "https://api.github.com/users/wangguan1995/orgs",
"received_events_url": "https://api.github.com/users/wangguan1995/received_events",
"repos_url": "https://api.github.com/users/wangguan1995/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/wangguan1995/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wangguan1995/subscriptions",
"type": "User",
"url": "https://api.github.com/users/wangguan1995",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"I can load public dataset, but for my private dataset it fails",
"https://huggingface.co/docs/datasets/upload_dataset",
"I have checked the API HTTP link. Repository Not Found for url: https://huggingface.co/api/datasets/xxx/xxx.\r\n\r\n\r\n\r\nIt just works fine.",
"It seems that everything is in a mass huh....\r\n\r\n\r\n",
"https://huggingface.co/datasets/rajpurkar/squad/blob/main/squad.py fails again",
"https://github.com/huggingface/datasets/blob/main/templates/new_dataset_script.py#L81 can not use this, too complex. I just need a def to load my file to a dict",
"I am facing the same issue. Did you find a fix?",
"You should authenticate to be able to access private or gated repos: https://huggingface.co/docs/hub/datasets-gated#access-gated-datasets-as-a-user"
] | 2024-06-06T06:52:19Z
| 2024-07-01T11:27:46Z
| 2024-07-01T11:27:46Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
```
File "/root/miniconda3/envs/gino_conda/lib/python3.9/site-packages/datasets/load.py", line 1852, in dataset_module_factory
raise DatasetNotFoundError(msg + f" at revision '{revision}'" if revision else msg)
datasets.exceptions.DatasetNotFoundError: Dataset 'xxx' doesn't exist on the Hub or cannot be accessed
>>> dataset = load_dataset("xxxx", token=True)
404 error 404 Client Error. (Request ID: Root=xxxx)
Repository Not Found for url: https://huggingface.co/api/datasets/xxx/xxx.
Please make sure you specified the correct `repo_id` and `repo_type`.
If you are trying to access a private or gated repo, make sure you are authenticated.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/root/miniconda3/envs/gino_conda/lib/python3.9/site-packages/datasets/load.py", line 2593, in load_dataset
builder_instance = load_dataset_builder(
File "/root/miniconda3/envs/gino_conda/lib/python3.9/site-packages/datasets/load.py", line 2265, in load_dataset_builder
dataset_module = dataset_module_factory(
File "/root/miniconda3/envs/gino_conda/lib/python3.9/site-packages/datasets/load.py", line 1910, in dataset_module_factory
raise e1 from None
File "/root/miniconda3/envs/gino_conda/lib/python3.9/site-packages/datasets/load.py", line 1852, in dataset_module_factory
raise DatasetNotFoundError(msg + f" at revision '{revision}'" if revision else msg)
datasets.exceptions.DatasetNotFoundError: Dataset 'xxx' doesn't exist on the Hub or cannot be accessed
```
### Steps to reproduce the bug
123
### Expected behavior
123
### Environment info
123
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6958/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6958/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5318
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5318/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5318/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5318/events
|
https://github.com/huggingface/datasets/pull/5318
| 1,470,749,750
|
PR_kwDODunzps5EB6RM
| 5,318
|
Origin/fix missing features error
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12104720?v=4",
"events_url": "https://api.github.com/users/eunseojo/events{/privacy}",
"followers_url": "https://api.github.com/users/eunseojo/followers",
"following_url": "https://api.github.com/users/eunseojo/following{/other_user}",
"gists_url": "https://api.github.com/users/eunseojo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/eunseojo",
"id": 12104720,
"login": "eunseojo",
"node_id": "MDQ6VXNlcjEyMTA0NzIw",
"organizations_url": "https://api.github.com/users/eunseojo/orgs",
"received_events_url": "https://api.github.com/users/eunseojo/received_events",
"repos_url": "https://api.github.com/users/eunseojo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/eunseojo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eunseojo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/eunseojo",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"please review :) @lhoestq @ola13 thankoo",
"Thanks :) I just updated the test to make sure it works even when there's a column missing, and did a minor change to json.py to add the missing columns for the other kinds of JSON files as well (I moved the code to`self._cast_table`)",
"Thanks Unso! If @lhoestq is happy then I'm also happy :D",
"When I noticed the ping, this PR had already been merged...\r\n\r\nLuckily, PyArrow's `read_json` behaves the same when `explicit_schema` is given via `ParseOptions`, so I'm okay with this change (our JSON loader doesn't use `read_json` for decoding JSON in some scenarios, so this manual approach is the right one).\r\n"
] | 2022-12-01T06:18:39Z
| 2022-12-12T19:06:42Z
| 2022-12-04T05:49:39Z
|
CONTRIBUTOR
| null | null | null |
This fixes the problem of when the dataset_load function reads a function with "features" provided but some read batches don't have columns that later show up. For instance, the provided "features" requires columns A,B,C but only columns B,C show. This fixes this by adding the column A with nulls.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12104720?v=4",
"events_url": "https://api.github.com/users/eunseojo/events{/privacy}",
"followers_url": "https://api.github.com/users/eunseojo/followers",
"following_url": "https://api.github.com/users/eunseojo/following{/other_user}",
"gists_url": "https://api.github.com/users/eunseojo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/eunseojo",
"id": 12104720,
"login": "eunseojo",
"node_id": "MDQ6VXNlcjEyMTA0NzIw",
"organizations_url": "https://api.github.com/users/eunseojo/orgs",
"received_events_url": "https://api.github.com/users/eunseojo/received_events",
"repos_url": "https://api.github.com/users/eunseojo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/eunseojo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eunseojo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/eunseojo",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5318/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5318/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5318.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5318",
"merged_at": "2022-12-04T05:49:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5318.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5318"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6580
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6580/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6580/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6580/events
|
https://github.com/huggingface/datasets/issues/6580
| 2,075,645,042
|
I_kwDODunzps57t9Ry
| 6,580
|
dataset cache only stores one config of the dataset in parquet dir, and uses that for all other configs resulting in showing same data in all configs.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/78641018?v=4",
"events_url": "https://api.github.com/users/kartikgupta321/events{/privacy}",
"followers_url": "https://api.github.com/users/kartikgupta321/followers",
"following_url": "https://api.github.com/users/kartikgupta321/following{/other_user}",
"gists_url": "https://api.github.com/users/kartikgupta321/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kartikgupta321",
"id": 78641018,
"login": "kartikgupta321",
"node_id": "MDQ6VXNlcjc4NjQxMDE4",
"organizations_url": "https://api.github.com/users/kartikgupta321/orgs",
"received_events_url": "https://api.github.com/users/kartikgupta321/received_events",
"repos_url": "https://api.github.com/users/kartikgupta321/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kartikgupta321/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kartikgupta321/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kartikgupta321",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[] | 2024-01-11T03:14:18Z
| 2024-01-20T12:46:16Z
| 2024-01-20T12:46:16Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
ds = load_dataset("ai2_arc", "ARC-Easy"), i have tried to force redownload, delete cache and changing the cache dir.
### Steps to reproduce the bug
dataset = []
dataset_name = "ai2_arc"
possible_configs = [
'ARC-Challenge',
'ARC-Easy'
]
for config in possible_configs:
dataset_slice = load_dataset(dataset_name, config,ignore_verifications=True,cache_dir='ai2_arc_files')
dataset.append(dataset_slice)
### Expected behavior
all configs should get saved in cache with their respective names.
### Environment info
ai2_arc
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/78641018?v=4",
"events_url": "https://api.github.com/users/kartikgupta321/events{/privacy}",
"followers_url": "https://api.github.com/users/kartikgupta321/followers",
"following_url": "https://api.github.com/users/kartikgupta321/following{/other_user}",
"gists_url": "https://api.github.com/users/kartikgupta321/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kartikgupta321",
"id": 78641018,
"login": "kartikgupta321",
"node_id": "MDQ6VXNlcjc4NjQxMDE4",
"organizations_url": "https://api.github.com/users/kartikgupta321/orgs",
"received_events_url": "https://api.github.com/users/kartikgupta321/received_events",
"repos_url": "https://api.github.com/users/kartikgupta321/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kartikgupta321/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kartikgupta321/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kartikgupta321",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6580/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6580/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6905
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6905/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6905/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6905/events
|
https://github.com/huggingface/datasets/issues/6905
| 2,303,098,587
|
I_kwDODunzps6JRn7b
| 6,905
|
Extraction protocol for arrow files is not defined
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26553095?v=4",
"events_url": "https://api.github.com/users/radulescupetru/events{/privacy}",
"followers_url": "https://api.github.com/users/radulescupetru/followers",
"following_url": "https://api.github.com/users/radulescupetru/following{/other_user}",
"gists_url": "https://api.github.com/users/radulescupetru/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/radulescupetru",
"id": 26553095,
"login": "radulescupetru",
"node_id": "MDQ6VXNlcjI2NTUzMDk1",
"organizations_url": "https://api.github.com/users/radulescupetru/orgs",
"received_events_url": "https://api.github.com/users/radulescupetru/received_events",
"repos_url": "https://api.github.com/users/radulescupetru/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/radulescupetru/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/radulescupetru/subscriptions",
"type": "User",
"url": "https://api.github.com/users/radulescupetru",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Fixed in https://github.com/huggingface/datasets/pull/7083"
] | 2024-05-17T16:01:41Z
| 2025-02-06T19:50:22Z
| 2025-02-06T19:50:20Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Passing files with `.arrow` extension into data_files argument, at least when `streaming=True` is very slow.
### Steps to reproduce the bug
Basically it goes through the `_get_extraction_protocol` method located [here](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/file_utils.py#L820)
The method then looks at some base known extensions where `arrow` is not defined so it proceeds to determine the compression with the magic number method which is slow when dealing with a lot of files which are stored in s3 and by looking at this predefined list, I don't see `arrow` in there either so in the end it return None:
```
MAGIC_NUMBER_TO_COMPRESSION_PROTOCOL = {
bytes.fromhex("504B0304"): "zip",
bytes.fromhex("504B0506"): "zip", # empty archive
bytes.fromhex("504B0708"): "zip", # spanned archive
bytes.fromhex("425A68"): "bz2",
bytes.fromhex("1F8B"): "gzip",
bytes.fromhex("FD377A585A00"): "xz",
bytes.fromhex("04224D18"): "lz4",
bytes.fromhex("28B52FFD"): "zstd",
}
```
### Expected behavior
My expectation is that `arrow` would be in the known lists so it would return None without going through the magic number method.
### Environment info
datasets 2.19.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26553095?v=4",
"events_url": "https://api.github.com/users/radulescupetru/events{/privacy}",
"followers_url": "https://api.github.com/users/radulescupetru/followers",
"following_url": "https://api.github.com/users/radulescupetru/following{/other_user}",
"gists_url": "https://api.github.com/users/radulescupetru/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/radulescupetru",
"id": 26553095,
"login": "radulescupetru",
"node_id": "MDQ6VXNlcjI2NTUzMDk1",
"organizations_url": "https://api.github.com/users/radulescupetru/orgs",
"received_events_url": "https://api.github.com/users/radulescupetru/received_events",
"repos_url": "https://api.github.com/users/radulescupetru/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/radulescupetru/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/radulescupetru/subscriptions",
"type": "User",
"url": "https://api.github.com/users/radulescupetru",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6905/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6905/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/7505
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7505/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7505/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7505/events
|
https://github.com/huggingface/datasets/issues/7505
| 2,979,926,156
|
I_kwDODunzps6xnhCM
| 7,505
|
HfHubHTTPError: 403 Forbidden: None. Cannot access content at: https://hf.co/api/s3proxy
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1412262?v=4",
"events_url": "https://api.github.com/users/hissain/events{/privacy}",
"followers_url": "https://api.github.com/users/hissain/followers",
"following_url": "https://api.github.com/users/hissain/following{/other_user}",
"gists_url": "https://api.github.com/users/hissain/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hissain",
"id": 1412262,
"login": "hissain",
"node_id": "MDQ6VXNlcjE0MTIyNjI=",
"organizations_url": "https://api.github.com/users/hissain/orgs",
"received_events_url": "https://api.github.com/users/hissain/received_events",
"repos_url": "https://api.github.com/users/hissain/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hissain/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hissain/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hissain",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[] | 2025-04-08T14:08:40Z
| 2025-04-08T14:08:40Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
I have already logged in Huggingface using CLI with my valid token. Now trying to download the datasets using following code:
from transformers import WhisperProcessor, WhisperForConditionalGeneration, WhisperTokenizer, Trainer, TrainingArguments, DataCollatorForSeq2Seq
from datasets import load_dataset, DatasetDict, Audio
def load_and_preprocess_dataset():
dataset = load_dataset("mozilla-foundation/common_voice_17_0", "bn")
dataset = dataset.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
dataset = dataset["train"].train_test_split(test_size=0.1)
dataset = DatasetDict({
"train": dataset["train"],
"test": dataset["test"]
})
return dataset
load_and_preprocess_dataset()
I am getting following error:
Downloading data: 100%
25/25 [00:01<00:00, 25.31files/s]
---------------------------------------------------------------------------
HTTPError Traceback (most recent call last)
File ~/github/bangla-asr/.venv/lib/python3.11/site-packages/huggingface_hub/utils/_http.py:409, in hf_raise_for_status(response, endpoint_name)
408 try:
--> 409 response.raise_for_status()
410 except HTTPError as e:
File ~/github/bangla-asr/.venv/lib/python3.11/site-packages/requests/models.py:1024, in Response.raise_for_status(self)
1023 if http_error_msg:
-> 1024 raise HTTPError(http_error_msg, response=self)
HTTPError: 403 Client Error: BlockSIEL for url: https://hf.co/api/s3proxy?GET=https%3A%2F%2Fhf-hub-lfs-us-east-1.s3.us-east-1.amazonaws.com%2Frepos%2Fa3%2F86%2Fa386bf65687d8a6928c1ea57c383aa3faade32f5171150e25af3fc1cfc273db8%2F67f1ac9cabd539bfbff3acbc549b60647833a250dc638866f22bf1b64e68806d%3FX-Amz-Algorithm%3DAWS4-HMAC-SHA256%26X-Amz-Content-Sha256%3DUNSIGNED-PAYLOAD%26X-Amz-Credential%3DAKIA2JU7TKAQLC2QXPN7%252F20250408%252Fus-east-1%252Fs3%252Faws4_request%26X-Amz-Date%3D20250408T134345Z%26X-Amz-Expires%3D3600%26X-Amz-Signature%3D621e731d4fd6d08afbf568379797746ab8e2b853b6728ff5e1122fef6e56880b%26X-Amz-SignedHeaders%3Dhost%26response-content-disposition%3Dinline%253B%2520filename%252A%253DUTF-8%2527%2527bn_validated_1.tar%253B%2520filename%253D%2522bn_validated_1.tar%2522%253B%26response-content-type%3Dapplication%252Fx-tar%26x-id%3DGetObject&HEAD=https%3A%2F%2Fhf-hub-lfs-us-east-1.s3.us-east-1.amazonaws.com%2Frepos%2Fa3%2F86%2Fa386bf65687d8a6928c1ea57c383aa3faade32f5171150e25af3fc1cfc273db8%2F67f1ac9cabd539bfbff3acbc549b60647833a250dc638866f22bf1b64e68806d%3FX-Amz-Algorithm%3DAWS4-HMAC-SHA256%26X-Amz-Content-Sha256%3DUNSIGNED-PAYLOAD%26X-Amz-Credential%3DAKIA2JU7TKAQLC2QXPN7%252F20250408%252Fus-east-1%252Fs3%252Faws4_request%26X-Amz-Date%3D20250408T134345Z%26X-Amz-Expires%3D3600%26X-Amz-Signature%3D15254fb79d30b0dc36b94a28138e675e0e00bb475b8a3ae774418500b095a661%26X-Amz-SignedHeaders%3Dhost&sign=eyJhbGciOiJIUzI1NiJ9.eyJyZWRpcmVjdF9kb21haW4iOiJoZi1odWItbGZzLXVzLWVhc3QtMS5zMy51cy1lYXN0LTEuYW1hem9uYXdzLmNvbSIsImlhdCI6MTc0NDExOTgyNSwiZXhwIjoxNzQ0MjA2MjI1LCJpc3MiOiJodHRwczovL2h1Z2dpbmdmYWNlLmNvIn0.5sJzudFDU3SmOdOLlwmQCOfQFf2r7y9590HoX8WBkRk
The above exception was the direct cause of the following exception:
HfHubHTTPError Traceback (most recent call last)
Cell In[16], line 15
9 dataset = DatasetDict({
10 "train": dataset["train"],
11 "test": dataset["test"]
12 })
13 return dataset
---> 15 load_and_preprocess_dataset()
17 # def setup_model():
18 # processor = WhisperProcessor.from_pretrained("openai/whisper-base")
...
475 range_header = response.request.headers.get("Range")
HfHubHTTPError: 403 Forbidden: None.
Cannot access content at: https://hf.co/api/s3proxy?GET=https%3A%2F%2Fhf-hub-lfs-us-east-1.s3.us-east-1.amazonaws.com%2Frepos%2Fa3%2F86%2Fa386bf6568724a6928c1ea57c383aa3faade32f5171150e25af3fc1cfc273db8%2F67f1ac9cabd539bfbff3acbc549b60647833a250dc638786f22bf1b64e68806d%3FX-Amz-Algorithm%3DAWS4-HMAC-SHA256%26X-Amz-Content-Sha256%3DUNSIGNED-PAYLOAD%26X-Amz-Credential%3DAKIA2JU7TKAQLC2QXPN7%252F20250408%252Fus-east-1%252Fs3%252Faws4_request%26X-Amz-Date%3D20250408T134345Z%26X-Amz-Expires%3D3600%26X-Amz-Signature%3D621e731d4fd6d08afbf568379797746ab394b853b6728ff5e1122fef6e56880b%26X-Amz-SignedHeaders%3Dhost%26response-content-disposition%3Dinline%253B%2520filename%252A%253DUTF-8%2527%2527bn_validated_1.tar%253B%2520filename%253D%2522bn_validated_1.tar%2522%253B%26response-content-type%3Dapplication%252Fx-tar%26x-id%3DGetObject&HEAD=https%3A%2F%2Fhf-hub-lfs-us-east-1.s3.us-east-1.amazonaws.com%2Frepos%2Fa3%2F86%2Fa386bf65687ab76928c1ea57c383aa3faade32f5171150e25af3fc1cfc273db8%2F67f1ac9cabd539bfbff3acbc549b60647833a250d2338866f222f1b64e68806d%3FX-Amz-Algorithm%3DAWS4-HMAC-SHA256%26X-Amz-Content-Sha256%3DUNSIGNED-PAYLOAD%26X-Amz-Credential%3DAKIA2JU7TKAQLC2QXPN7%252F20250408%252Fus-east-1%252Fs3%252Faws4_request%26X-Amz-Date%3D20250408T134345Z%26X-Amz-Expires%3D3600%26X-Amz-Signature%3D15254fb79d30b0dc36b94a28138e675e0e00bb475b8a3ae774418500b095a661%26X-Amz-SignedHeaders%3Dhost&sign=eyJhbGciOiJIUzI1NiJ9.eyJyZWRpcmVjds9kb21haW4iOiJoZi1odWItbGZzLXVzLWVhc3QtMS5zMy51cy1lYXN0LTEuYW1hem9uYXdzLmNvbSIsImlhdCI6MTc0NDExOT2yNSwiZXhwIjoxNzQ0MjA2MjI1LCJpc3MiOiJodHRwczovL2h1Z2dpbmdmYWNlLmNvIn0.5sJzudFDU3SmOdOLlwmQdOfQFf2r7y9590HoX8WBkRk.
Make sure your token has the correct permissions.
**What's wrong with the code?** Please note that the error is happening only when I am running from my office network due to probably proxy. Which URL, I need to take a proxy exception?
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7505/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7505/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5647
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5647/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5647/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5647/events
|
https://github.com/huggingface/datasets/issues/5647
| 1,628,225,544
|
I_kwDODunzps5hDMAI
| 5,647
|
Make all print statements optional
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/49101362?v=4",
"events_url": "https://api.github.com/users/gagan3012/events{/privacy}",
"followers_url": "https://api.github.com/users/gagan3012/followers",
"following_url": "https://api.github.com/users/gagan3012/following{/other_user}",
"gists_url": "https://api.github.com/users/gagan3012/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gagan3012",
"id": 49101362,
"login": "gagan3012",
"node_id": "MDQ6VXNlcjQ5MTAxMzYy",
"organizations_url": "https://api.github.com/users/gagan3012/orgs",
"received_events_url": "https://api.github.com/users/gagan3012/received_events",
"repos_url": "https://api.github.com/users/gagan3012/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gagan3012/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gagan3012/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gagan3012",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
| null |
[] | null |
[
"related to #5444 ",
"We now log these messages instead of printing them (addressed in #6019), so I'm closing this issue."
] | 2023-03-16T20:30:07Z
| 2023-07-21T14:20:25Z
| 2023-07-21T14:20:24Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
Make all print statements optional to speed up the development
### Motivation
Im loading multiple tiny datasets and all the print statements make the loading slower
### Your contribution
I can help contribute
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5647/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5647/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/7475
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7475/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7475/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7475/events
|
https://github.com/huggingface/datasets/issues/7475
| 2,946,640,570
|
I_kwDODunzps6voiq6
| 7,475
|
IterableDataset's state_dict shard_example_idx is always equal to the number of samples in a shard
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"events_url": "https://api.github.com/users/bruno-hays/events{/privacy}",
"followers_url": "https://api.github.com/users/bruno-hays/followers",
"following_url": "https://api.github.com/users/bruno-hays/following{/other_user}",
"gists_url": "https://api.github.com/users/bruno-hays/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bruno-hays",
"id": 48770768,
"login": "bruno-hays",
"node_id": "MDQ6VXNlcjQ4NzcwNzY4",
"organizations_url": "https://api.github.com/users/bruno-hays/orgs",
"received_events_url": "https://api.github.com/users/bruno-hays/received_events",
"repos_url": "https://api.github.com/users/bruno-hays/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bruno-hays/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bruno-hays/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bruno-hays",
"user_view_type": "public"
}
|
[] |
open
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/other_user}",
"gists_url": "https://api.github.com/users/Harry-Yang0518/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Harry-Yang0518",
"id": 129883215,
"login": "Harry-Yang0518",
"node_id": "U_kgDOB73cTw",
"organizations_url": "https://api.github.com/users/Harry-Yang0518/orgs",
"received_events_url": "https://api.github.com/users/Harry-Yang0518/received_events",
"repos_url": "https://api.github.com/users/Harry-Yang0518/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Harry-Yang0518/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Harry-Yang0518/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Harry-Yang0518",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/other_user}",
"gists_url": "https://api.github.com/users/Harry-Yang0518/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Harry-Yang0518",
"id": 129883215,
"login": "Harry-Yang0518",
"node_id": "U_kgDOB73cTw",
"organizations_url": "https://api.github.com/users/Harry-Yang0518/orgs",
"received_events_url": "https://api.github.com/users/Harry-Yang0518/received_events",
"repos_url": "https://api.github.com/users/Harry-Yang0518/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Harry-Yang0518/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Harry-Yang0518/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Harry-Yang0518",
"user_view_type": "public"
}
] | null |
[
"Hey, I’d love to work on this issue but I am a beginner, can I work it with you?",
"Hello. I'm sorry but I don't have much time to get in the details for now.\nHave you managed to reproduce the issue with the code provided ?\nIf you want to work on it, you can self-assign and ask @lhoestq for directions",
"Hi Bruno, I am trying to reproduce it this later in this week and let you know what I found.",
"#self-assign",
"Good catch, I tried and if the dataset is bigger (e.g. `range(9999)`) it returns `\"shard_example_idx\": 1000` with is the `config.DEFAULT_MAX_BATCH_SIZE`\n\nhttps://github.com/huggingface/datasets/blob/94ccd1b4fada8a92cea96dc8df4e915041d695b6/src/datasets/arrow_dataset.py#L5313-L5317\n\nIt looks like the state_dict is incorrect in that case, it should account for this and use the `RebatchedArrowExamplesIterable` which buffers the batch of 1000 rows and counts the iteration within the batch in the state_dict",
"\nHello @lhoestq,\n\nI’ve been debugging the `IterableDataset.state_dict()` behavior and applied a patch to `ArrowExamplesIterable._iter_arrow()` in an attempt to fix the issue described in #7475—specifically, that `shard_example_idx` always equals the number of samples in the shard, even if only a few examples have been consumed.\n\n### What I Tried\n\nI updated `_iter_arrow` to slice off already-consumed rows and increment the state only by the number of actual examples yielded, like this:\n\n```python\nclass ArrowExamplesIterable(_BaseExamplesIterable):\n # ... __init__ and _init_state_dict as before ...\n\n def _iter_arrow(self):\n shard_idx_start = self._state_dict[\"shard_idx\"] if self._state_dict else 0\n\n for gen_kwargs in islice(\n _split_gen_kwargs(self.kwargs, max_num_jobs=self.num_shards),\n shard_idx_start, None\n ):\n shard_example_idx_start = self._state_dict[\"shard_example_idx\"] if self._state_dict else 0\n shard_example_idx = 0\n\n for key, pa_table in self.generate_tables_fn(**gen_kwargs):\n num_rows = len(pa_table)\n next_idx = shard_example_idx + num_rows\n\n if next_idx <= shard_example_idx_start:\n shard_example_idx = next_idx\n continue\n\n offset = max(0, shard_example_idx_start - shard_example_idx)\n sliced_table = pa_table.slice(offset)\n\n if self._state_dict:\n self._state_dict[\"shard_example_idx\"] += len(sliced_table)\n\n yield key, sliced_table\n shard_example_idx = next_idx\n\n if self._state_dict:\n self._state_dict[\"shard_idx\"] += 1\n self._state_dict[\"shard_example_idx\"] = 0\n```\n\nI verified that the updated code was being used, and I added debug prints to confirm the table slicing and counter updates.\n\n### The Issue Still Exists\n\nDespite the changes, the behavior remains the same. Running this minimal repro:\n\n```python\nds = Dataset.from_dict({\"a\": range(6)}).to_iterable_dataset(num_shards=1)\nfor idx, example in enumerate(ds):\n print(example)\n if idx == 2:\n print(\"checkpoint\")\n print(ds.state_dict())\n break\n```\n\nStill outputs:\n\n```bash\n{'a': 0}\n{'a': 1}\n{'a': 2}\ncheckpoint\n{'examples_iterable': {'shard_idx': 0, 'shard_example_idx': 6, 'type': 'ArrowExamplesIterable'}, 'epoch': 0}\n```\n\nEven though only 3 examples were consumed, `shard_example_idx` jumps to 6.\n\n### Questions\n\n- Could there be another place (e.g., in `__iter__`, `RebatchedArrowExamplesIterable`, or the `IterableDataset` wrapper) that's still using the old logic and overriding the state?\n- Is there a better location to intercept and count yielded examples?\n- Would you recommend tracking a new `true_example_idx` to avoid modifying existing behavior?\n\nLet me know your thoughts—happy to iterate further and submit a PR once we align on the right approach. Thanks again for your help and feedback!"
] | 2025-03-25T13:58:07Z
| 2025-04-18T00:49:37Z
| null |
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
I've noticed a strange behaviour with Iterable state_dict: the value of shard_example_idx is always equal to the amount of samples in a shard.
### Steps to reproduce the bug
I am reusing the example from the doc
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(6)}).to_iterable_dataset(num_shards=1)
state_dict = None
# Iterate through the dataset and print examples
for idx, example in enumerate(ds):
print(example)
if idx == 2:
state_dict = ds.state_dict()
print("checkpoint")
break
print(state_dict)
```
Returns:
```
{'a': 0}
{'a': 1}
checkpoint
{'examples_iterable': {'shard_idx': 0, 'shard_example_idx': 6, 'type': 'ArrowExamplesIterable'}, 'epoch': 0}
```
### Expected behavior
shard_example_idx should be 2 instead of 6
If we run with num_shards=2, then shard_example_idx is 3 instead of 2 and so on.
### Environment info
- `datasets` version: 3.4.1
- Platform: macOS-14.6.1-arm64-arm-64bit
- Python version: 3.12.9
- `huggingface_hub` version: 0.29.3
- PyArrow version: 19.0.1
- Pandas version: 2.2.3
- `fsspec` version: 2024.12.0
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7475/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7475/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6629
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6629/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6629/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6629/events
|
https://github.com/huggingface/datasets/pull/6629
| 2,105,774,482
|
PR_kwDODunzps5lV0aF
| 6,629
|
Support push_to_hub without org/user to default to logged-in user
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6629). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"@huggingface/datasets, feel free to review this PR so that it can be included in the next release.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005222 / 0.011353 (-0.006131) | 0.003621 / 0.011008 (-0.007387) | 0.063091 / 0.038508 (0.024583) | 0.029395 / 0.023109 (0.006285) | 0.231445 / 0.275898 (-0.044453) | 0.256716 / 0.323480 (-0.066764) | 0.004905 / 0.007986 (-0.003081) | 0.002703 / 0.004328 (-0.001625) | 0.048526 / 0.004250 (0.044276) | 0.041382 / 0.037052 (0.004330) | 0.247468 / 0.258489 (-0.011021) | 0.270670 / 0.293841 (-0.023171) | 0.028088 / 0.128546 (-0.100458) | 0.010661 / 0.075646 (-0.064985) | 0.205812 / 0.419271 (-0.213459) | 0.035880 / 0.043533 (-0.007653) | 0.237310 / 0.255139 (-0.017829) | 0.255440 / 0.283200 (-0.027760) | 0.018334 / 0.141683 (-0.123349) | 1.128815 / 1.452155 (-0.323340) | 1.204771 / 1.492716 (-0.287945) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.089175 / 0.018006 (0.071169) | 0.298584 / 0.000490 (0.298095) | 0.000206 / 0.000200 (0.000006) | 0.000043 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018532 / 0.037411 (-0.018880) | 0.061158 / 0.014526 (0.046632) | 0.074177 / 0.176557 (-0.102380) | 0.119408 / 0.737135 (-0.617728) | 0.073821 / 0.296338 (-0.222518) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.277630 / 0.215209 (0.062420) | 2.735038 / 2.077655 (0.657383) | 1.437251 / 1.504120 (-0.066868) | 1.304596 / 1.541195 (-0.236598) | 1.316830 / 1.468490 (-0.151661) | 0.551057 / 4.584777 (-4.033720) | 2.337247 / 3.745712 (-1.408465) | 2.761501 / 5.269862 (-2.508361) | 1.729000 / 4.565676 (-2.836677) | 0.069398 / 0.424275 (-0.354877) | 0.005059 / 0.007607 (-0.002548) | 0.359594 / 0.226044 (0.133550) | 3.283325 / 2.268929 (1.014397) | 1.777410 / 55.444624 (-53.667214) | 1.518522 / 6.876477 (-5.357954) | 1.546712 / 2.142072 (-0.595361) | 0.627047 / 4.805227 (-4.178180) | 0.117058 / 6.500664 (-6.383606) | 0.043437 / 0.075469 (-0.032032) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.056303 / 1.841788 (-0.785484) | 11.552295 / 8.074308 (3.477987) | 10.184582 / 10.191392 (-0.006810) | 0.129061 / 0.680424 (-0.551363) | 0.014093 / 0.534201 (-0.520108) | 0.292268 / 0.579283 (-0.287015) | 0.264750 / 0.434364 (-0.169614) | 0.334770 / 0.540337 (-0.205567) | 0.436749 / 1.386936 (-0.950187) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005408 / 0.011353 (-0.005945) | 0.003650 / 0.011008 (-0.007358) | 0.054263 / 0.038508 (0.015755) | 0.031112 / 0.023109 (0.008003) | 0.270582 / 0.275898 (-0.005316) | 0.303506 / 0.323480 (-0.019974) | 0.004351 / 0.007986 (-0.003635) | 0.002654 / 0.004328 (-0.001674) | 0.049631 / 0.004250 (0.045381) | 0.045209 / 0.037052 (0.008156) | 0.284992 / 0.258489 (0.026503) | 0.316653 / 0.293841 (0.022812) | 0.049526 / 0.128546 (-0.079020) | 0.010696 / 0.075646 (-0.064951) | 0.057859 / 0.419271 (-0.361413) | 0.034227 / 0.043533 (-0.009306) | 0.269656 / 0.255139 (0.014517) | 0.288766 / 0.283200 (0.005567) | 0.017892 / 0.141683 (-0.123791) | 1.167492 / 1.452155 (-0.284662) | 1.217263 / 1.492716 (-0.275454) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.089306 / 0.018006 (0.071299) | 0.300774 / 0.000490 (0.300284) | 0.000198 / 0.000200 (-0.000002) | 0.000042 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022050 / 0.037411 (-0.015361) | 0.076781 / 0.014526 (0.062255) | 0.086597 / 0.176557 (-0.089959) | 0.125094 / 0.737135 (-0.612042) | 0.089412 / 0.296338 (-0.206927) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.287444 / 0.215209 (0.072235) | 2.830047 / 2.077655 (0.752392) | 1.567492 / 1.504120 (0.063372) | 1.439875 / 1.541195 (-0.101320) | 1.461699 / 1.468490 (-0.006791) | 0.569595 / 4.584777 (-4.015182) | 2.454391 / 3.745712 (-1.291322) | 2.655829 / 5.269862 (-2.614032) | 1.756122 / 4.565676 (-2.809554) | 0.063333 / 0.424275 (-0.360942) | 0.005086 / 0.007607 (-0.002521) | 0.351210 / 0.226044 (0.125166) | 3.375545 / 2.268929 (1.106617) | 1.945367 / 55.444624 (-53.499258) | 1.662635 / 6.876477 (-5.213841) | 1.762859 / 2.142072 (-0.379213) | 0.651889 / 4.805227 (-4.153339) | 0.118341 / 6.500664 (-6.382323) | 0.040897 / 0.075469 (-0.034572) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.005270 / 1.841788 (-0.836518) | 12.247847 / 8.074308 (4.173539) | 10.828131 / 10.191392 (0.636739) | 0.129741 / 0.680424 (-0.550683) | 0.015184 / 0.534201 (-0.519017) | 0.295440 / 0.579283 (-0.283843) | 0.276759 / 0.434364 (-0.157605) | 0.329046 / 0.540337 (-0.211291) | 0.421750 / 1.386936 (-0.965186) |\n\n</details>\n</details>\n\n\n"
] | 2024-01-29T15:36:52Z
| 2024-02-05T12:35:43Z
| 2024-02-05T12:29:36Z
|
MEMBER
| null | null | null |
This behavior is aligned with:
- the behavior of `datasets` before merging #6519
- the behavior described in the corresponding docstring
- the behavior of `huggingface_hub.create_repo`
Revert "Support push_to_hub canonical datasets (#6519)"
- This reverts commit a887ee78835573f5d80f9e414e8443b4caff3541.
Fix #6597.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6629/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6629/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6629.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6629",
"merged_at": "2024-02-05T12:29:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6629.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6629"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7168
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7168/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7168/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7168/events
|
https://github.com/huggingface/datasets/issues/7168
| 2,546,710,631
|
I_kwDODunzps6Xy7hn
| 7,168
|
sd1.5 diffusers controlnet training script gives new error
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/90132896?v=4",
"events_url": "https://api.github.com/users/Night1099/events{/privacy}",
"followers_url": "https://api.github.com/users/Night1099/followers",
"following_url": "https://api.github.com/users/Night1099/following{/other_user}",
"gists_url": "https://api.github.com/users/Night1099/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Night1099",
"id": 90132896,
"login": "Night1099",
"node_id": "MDQ6VXNlcjkwMTMyODk2",
"organizations_url": "https://api.github.com/users/Night1099/orgs",
"received_events_url": "https://api.github.com/users/Night1099/received_events",
"repos_url": "https://api.github.com/users/Night1099/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Night1099/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Night1099/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Night1099",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"not sure why the issue is formatting oddly",
"I guess this is a dupe of\r\n\r\nhttps://github.com/huggingface/datasets/issues/7071",
"this turned out to be because of a bad image in dataset"
] | 2024-09-25T01:42:49Z
| 2024-09-30T05:24:03Z
| 2024-09-30T05:24:02Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
This will randomly pop up during training now
```
Traceback (most recent call last):
File "/workspace/diffusers/examples/controlnet/train_controlnet.py", line 1192, in <module>
main(args)
File "/workspace/diffusers/examples/controlnet/train_controlnet.py", line 1041, in main
for step, batch in enumerate(train_dataloader):
File "/usr/local/lib/python3.11/dist-packages/accelerate/data_loader.py", line 561, in __iter__
next_batch = next(dataloader_iter)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/torch/utils/data/dataloader.py", line 630, in __next__
data = self._next_data()
^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/torch/utils/data/dataloader.py", line 673, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/torch/utils/data/_utils/fetch.py", line 50, in fetch
data = self.dataset.__getitems__(possibly_batched_index)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/arrow_dataset.py", line 2746, in __getitems__
batch = self.__getitem__(keys)
^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/arrow_dataset.py", line 2742, in __getitem__
return self._getitem(key)
^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/arrow_dataset.py", line 2727, in _getitem
formatted_output = format_table(
^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/formatting/formatting.py", line 639, in format_table
return formatter(pa_table, query_type=query_type)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/formatting/formatting.py", line 407, in __call__
return self.format_batch(pa_table)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/formatting/formatting.py", line 521, in format_batch
batch = self.python_features_decoder.decode_batch(batch)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/formatting/formatting.py", line 228, in decode_batch
return self.features.decode_batch(batch) if self.features else batch
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/features/features.py", line 2084, in decode_batch
[
File "/usr/local/lib/python3.11/dist-packages/datasets/features/features.py", line 2085, in <listcomp>
decode_nested_example(self[column_name], value, token_per_repo_id=token_per_repo_id)
File "/usr/local/lib/python3.11/dist-packages/datasets/features/features.py", line 1403, in decode_nested_example
return schema.decode_example(obj, token_per_repo_id=token_per_repo_id)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/datasets/features/image.py", line 188, in decode_example
image.load() # to avoid "Too many open files" errors
```
### Steps to reproduce the bug
Train on diffusers sd1.5 controlnet example script
This will pop up randomly, you can see in wandb below when i manually resume run everytime this error appears

### Expected behavior
Training to continue without above error
### Environment info
- datasets version: 3.0.0
- Platform: Linux-6.5.0-44-generic-x86_64-with-glibc2.35
- Python version: 3.11.9
- huggingface_hub version: 0.25.1
- PyArrow version: 17.0.0
- Pandas version: 2.2.3
- fsspec version: 2024.6.1
Training on 4090
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/90132896?v=4",
"events_url": "https://api.github.com/users/Night1099/events{/privacy}",
"followers_url": "https://api.github.com/users/Night1099/followers",
"following_url": "https://api.github.com/users/Night1099/following{/other_user}",
"gists_url": "https://api.github.com/users/Night1099/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Night1099",
"id": 90132896,
"login": "Night1099",
"node_id": "MDQ6VXNlcjkwMTMyODk2",
"organizations_url": "https://api.github.com/users/Night1099/orgs",
"received_events_url": "https://api.github.com/users/Night1099/received_events",
"repos_url": "https://api.github.com/users/Night1099/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Night1099/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Night1099/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Night1099",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7168/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7168/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5699
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5699/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5699/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5699/events
|
https://github.com/huggingface/datasets/issues/5699
| 1,652,437,419
|
I_kwDODunzps5ifjGr
| 5,699
|
Issue when wanting to split in memory a cached dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47528215?v=4",
"events_url": "https://api.github.com/users/FrancoisNoyez/events{/privacy}",
"followers_url": "https://api.github.com/users/FrancoisNoyez/followers",
"following_url": "https://api.github.com/users/FrancoisNoyez/following{/other_user}",
"gists_url": "https://api.github.com/users/FrancoisNoyez/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/FrancoisNoyez",
"id": 47528215,
"login": "FrancoisNoyez",
"node_id": "MDQ6VXNlcjQ3NTI4MjE1",
"organizations_url": "https://api.github.com/users/FrancoisNoyez/orgs",
"received_events_url": "https://api.github.com/users/FrancoisNoyez/received_events",
"repos_url": "https://api.github.com/users/FrancoisNoyez/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/FrancoisNoyez/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FrancoisNoyez/subscriptions",
"type": "User",
"url": "https://api.github.com/users/FrancoisNoyez",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"Hi ! Good catch, this is wrong indeed and thanks for opening a PR :)",
"Facing the same issue. Kindly fix this bug."
] | 2023-04-03T17:00:07Z
| 2024-05-15T13:12:18Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
**In the 'train_test_split' method of the Dataset class** (defined datasets/arrow_dataset.py), **if 'self.cache_files' is not empty**, then, **regarding the input parameters 'train_indices_cache_file_name' and 'test_indices_cache_file_name', if they are None**, we modify them to make them not None, to see if we can just provide back / work from cached data. But if we can't provide cached data, we move on with the call to the method, except those two values are not None anymore, which will conflict with the use of the 'keep_in_memory' parameter down the line.
Indeed, at some point we end up calling the 'select' method, **and if 'keep_in_memory' is True**, since the value of this method's parameter 'indices_cache_file_name' is now not None anymore, **an exception is raised, whose message is "Please use either 'keep_in_memory' or 'indices_cache_file_name' but not both.".**
Because of that, it's impossible to perform a train / test split of a cached dataset while requesting that the result not be cached. Which is inconvenient when one is just performing experiments, with no intention of caching the result.
Aside from this being inconvenient, **the code which lead up to that situation seems simply wrong** to me: the input variable should not be modified so as to change the user's intention just to perform a test, if that test can fail and respecting the user's intention is necessary to proceed in that case.
To fix this, I suggest to use other variables / other variable names, in order to host the value(s) needed to perform the test, so as not to change the originally input values needed by the rest of the method's code.
Also, **I don't see why an exception should be raised when the 'select' method is called with both 'keep_in_memory'=True and 'indices_cache_file_name'!=None**: should the use of 'keep_in_memory' not prevail anyway, specifying that the user does not want to perform caching, and so making irrelevant the value of 'indices_cache_file_name'? This is indeed what happens when we look further in the code, in the '\_select_with_indices_mapping' method: when 'keep_in_memory' is True, then the value of indices_cache_file_name does not matter, the data will be written to a stream buffer anyway.
Hence I suggest to remove the raising of exception in those circumstances. Notably, to remove the raising of it in the 'select', '\_select_with_indices_mapping', 'shuffle' and 'map' methods.
### Steps to reproduce the bug
```python
import datasets
def generate_examples():
for i in range(10):
yield {"id": i}
dataset_ = datasets.Dataset.from_generator(
generate_examples,
keep_in_memory=False,
)
dataset_.train_test_split(
test_size=3,
shuffle=False,
keep_in_memory=True,
train_indices_cache_file_name=None,
test_indices_cache_file_name=None,
)
```
### Expected behavior
The result of the above code should be a DatasetDict instance.
Instead, we get the following exception stack:
```python
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[3], line 1
----> 1 dataset_.train_test_split(
2 test_size=3,
3 shuffle=False,
4 keep_in_memory=True,
5 train_indices_cache_file_name=None,
6 test_indices_cache_file_name=None,
7 )
File ~/Work/Developments/datasets/src/datasets/arrow_dataset.py:528, in transmit_format.<locals>.wrapper(*args, **kwargs)
521 self_format = {
522 "type": self._format_type,
523 "format_kwargs": self._format_kwargs,
524 "columns": self._format_columns,
525 "output_all_columns": self._output_all_columns,
526 }
527 # apply actual function
--> 528 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
529 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
530 # re-apply format to the output
File ~/Work/Developments/datasets/src/datasets/fingerprint.py:511, in fingerprint_transform.<locals>._fingerprint.<locals>.wrapper(*args, **kwargs)
507 validate_fingerprint(kwargs[fingerprint_name])
509 # Call actual function
--> 511 out = func(dataset, *args, **kwargs)
513 # Update fingerprint of in-place transforms + update in-place history of transforms
515 if inplace: # update after calling func so that the fingerprint doesn't change if the function fails
File ~/Work/Developments/datasets/src/datasets/arrow_dataset.py:4428, in Dataset.train_test_split(self, test_size, train_size, shuffle, stratify_by_column, seed, generator, keep_in_memory, load_from_cache_file, train_indices_cache_file_name, test_indices_cache_file_name, writer_batch_size, train_new_fingerprint, test_new_fingerprint)
4425 test_indices = permutation[:n_test]
4426 train_indices = permutation[n_test : (n_test + n_train)]
-> 4428 train_split = self.select(
4429 indices=train_indices,
4430 keep_in_memory=keep_in_memory,
4431 indices_cache_file_name=train_indices_cache_file_name,
4432 writer_batch_size=writer_batch_size,
4433 new_fingerprint=train_new_fingerprint,
4434 )
4435 test_split = self.select(
4436 indices=test_indices,
4437 keep_in_memory=keep_in_memory,
(...)
4440 new_fingerprint=test_new_fingerprint,
4441 )
4443 return DatasetDict({"train": train_split, "test": test_split})
File ~/Work/Developments/datasets/src/datasets/arrow_dataset.py:528, in transmit_format.<locals>.wrapper(*args, **kwargs)
521 self_format = {
522 "type": self._format_type,
523 "format_kwargs": self._format_kwargs,
524 "columns": self._format_columns,
525 "output_all_columns": self._output_all_columns,
526 }
527 # apply actual function
--> 528 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
529 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
530 # re-apply format to the output
File ~/Work/Developments/datasets/src/datasets/fingerprint.py:511, in fingerprint_transform.<locals>._fingerprint.<locals>.wrapper(*args, **kwargs)
507 validate_fingerprint(kwargs[fingerprint_name])
509 # Call actual function
--> 511 out = func(dataset, *args, **kwargs)
513 # Update fingerprint of in-place transforms + update in-place history of transforms
515 if inplace: # update after calling func so that the fingerprint doesn't change if the function fails
File ~/Work/Developments/datasets/src/datasets/arrow_dataset.py:3679, in Dataset.select(self, indices, keep_in_memory, indices_cache_file_name, writer_batch_size, new_fingerprint)
3645 """Create a new dataset with rows selected following the list/array of indices.
3646
3647 Args:
(...)
3676 ```
3677 """
3678 if keep_in_memory and indices_cache_file_name is not None:
-> 3679 raise ValueError("Please use either `keep_in_memory` or `indices_cache_file_name` but not both.")
3681 if len(self.list_indexes()) > 0:
3682 raise DatasetTransformationNotAllowedError(
3683 "Using `.select` on a dataset with attached indexes is not allowed. You can first run `.drop_index() to remove your index and then re-add it."
3684 )
ValueError: Please use either `keep_in_memory` or `indices_cache_file_name` but not both.
```
### Environment info
- `datasets` version: 2.11.1.dev0
- Platform: Linux-5.4.236-1-MANJARO-x86_64-with-glibc2.2.5
- Python version: 3.8.12
- Huggingface_hub version: 0.13.3
- PyArrow version: 11.0.0
- Pandas version: 2.0.0
***
***
EDIT:
Now with a pull request to fix this [here](https://github.com/huggingface/datasets/pull/5700)
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5699/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5699/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5131
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5131/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5131/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5131/events
|
https://github.com/huggingface/datasets/issues/5131
| 1,413,534,863
|
I_kwDODunzps5UQNSP
| 5,131
|
WikiText 103 tokenizer hangs
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12433427?v=4",
"events_url": "https://api.github.com/users/TrentBrick/events{/privacy}",
"followers_url": "https://api.github.com/users/TrentBrick/followers",
"following_url": "https://api.github.com/users/TrentBrick/following{/other_user}",
"gists_url": "https://api.github.com/users/TrentBrick/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/TrentBrick",
"id": 12433427,
"login": "TrentBrick",
"node_id": "MDQ6VXNlcjEyNDMzNDI3",
"organizations_url": "https://api.github.com/users/TrentBrick/orgs",
"received_events_url": "https://api.github.com/users/TrentBrick/received_events",
"repos_url": "https://api.github.com/users/TrentBrick/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/TrentBrick/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TrentBrick/subscriptions",
"type": "User",
"url": "https://api.github.com/users/TrentBrick",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
| null |
[] | null |
[
"any updates on this? It happens to me on [OpenWikiText-20%](https://huggingface.co/datasets/Bingsu/openwebtext_20p) dataset, but not on [OpenWebText-10k](https://huggingface.co/datasets/stas/openwebtext-10k). This is really strange because I don't change anything else in my running script.\r\n\r\ntransformers version 4.18.0.dev0\r\ndatasets version 1.18.0"
] | 2022-10-18T16:44:00Z
| 2023-08-08T08:42:40Z
| 2023-07-21T14:41:51Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
See issue here: https://github.com/huggingface/transformers/issues/19702
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5131/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5131/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/4869
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4869/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4869/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4869/events
|
https://github.com/huggingface/datasets/pull/4869
| 1,345,513,758
|
PR_kwDODunzps49hBGY
| 4,869
|
Fix typos in documentation
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/85993954?v=4",
"events_url": "https://api.github.com/users/fl-lo/events{/privacy}",
"followers_url": "https://api.github.com/users/fl-lo/followers",
"following_url": "https://api.github.com/users/fl-lo/following{/other_user}",
"gists_url": "https://api.github.com/users/fl-lo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/fl-lo",
"id": 85993954,
"login": "fl-lo",
"node_id": "MDQ6VXNlcjg1OTkzOTU0",
"organizations_url": "https://api.github.com/users/fl-lo/orgs",
"received_events_url": "https://api.github.com/users/fl-lo/received_events",
"repos_url": "https://api.github.com/users/fl-lo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/fl-lo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fl-lo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/fl-lo",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-08-21T15:10:03Z
| 2022-08-22T09:25:39Z
| 2022-08-22T09:09:58Z
|
CONTRIBUTOR
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4869/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4869/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4869.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4869",
"merged_at": "2022-08-22T09:09:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4869.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4869"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4697
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4697/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4697/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4697/events
|
https://github.com/huggingface/datasets/issues/4697
| 1,307,332,253
|
I_kwDODunzps5N7E6d
| 4,697
|
Trouble with streaming frgfm/imagenette vision dataset with TAR archive
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26927750?v=4",
"events_url": "https://api.github.com/users/frgfm/events{/privacy}",
"followers_url": "https://api.github.com/users/frgfm/followers",
"following_url": "https://api.github.com/users/frgfm/following{/other_user}",
"gists_url": "https://api.github.com/users/frgfm/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/frgfm",
"id": 26927750,
"login": "frgfm",
"node_id": "MDQ6VXNlcjI2OTI3NzUw",
"organizations_url": "https://api.github.com/users/frgfm/orgs",
"received_events_url": "https://api.github.com/users/frgfm/received_events",
"repos_url": "https://api.github.com/users/frgfm/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/frgfm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/frgfm/subscriptions",
"type": "User",
"url": "https://api.github.com/users/frgfm",
"user_view_type": "public"
}
|
[
{
"color": "fef2c0",
"default": false,
"description": "",
"id": 3287858981,
"name": "streaming",
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[
"Hi @frgfm, thanks for reporting.\r\n\r\nAs the error message says, streaming mode is not supported out of the box when the dataset contains TAR archive files.\r\n\r\nTo make the dataset streamable, you have to use `dl_manager.iter_archive`.\r\n\r\nThere are several examples in other datasets, e.g. food101: https://huggingface.co/datasets/food101/blob/main/food101.py\r\n\r\nAnd yes, as the link you pointed out, for the streaming to be possible, the metadata file must be loaded before all of the images:\r\n- either this is the case when iterating the archive (and you get the metadata file before the images)\r\n- or you have to extract the metadata file by hand and upload it separately to the Hub",
"Hi @albertvillanova :wave:\r\n\r\nThanks! Yeah I saw that but since I didn't have any metadata, I wasn't sure whether I should create them myself.\r\n\r\nSo one last question:\r\nWhat is the metadata supposed to be for archives? The relative path of all files in it?\r\n_(Sorry I'm a bit confused since it's quite hard to debug using the single error message from the data preview :sweat_smile: )_",
"Hi @frgfm, streaming a dataset that contains a TAR file requires some tweaks because (contrary to ZIP files), tha TAR archive does not allow random access to any of the contained member files. Instead they have to be accessed sequentially (in the order in which they were put into the TAR file when created) and yielded.\r\n\r\nSo when iterating over the TAR file content, when an image file is found, we need to yield it (and not keeping it in memory, which will require huge RAM memory for large datasets). But when yielding an image file, we also need to yield with it what we call \"metadata\": the class label, and other textual information (for example, for audio files, sometimes we also add info such as the speaker ID, their sex, their age,...).\r\n\r\nAll this information usually is stored in what we call the metadata file: either a JSON or a CSV/TSV file.\r\n\r\nBut if this is also inside the TAR archive, we need to find this file in the first place when iterating the TAR archive, so that we already have this information when we find an image file and we can yield the image file and its metadata info.\r\n\r\nTherefore:\r\n- either the TAR archive contains the metadata file as the first member when iterating it (something we cannot change as it is done at the creation of the TAR file)\r\n- or if not, then we need to have the metadata file elsewhere\r\n - in these cases, what we do (if the dataset license allows it) is:\r\n - we download the TAR file locally, we extract the metadata file and we host the metadata on the Hub\r\n - we modify the dataset loading script so that it first downloads the metadata file (and reads it) and only then starts iterating the content of the TAR archive file\r\n\r\nSee an example of this process we recently did for \"google/fleurs\" (their metadata files for \"train\" were at the end of the TAR archives, after all audio files): https://huggingface.co/datasets/google/fleurs/discussions/4\r\n- we uploaded the metadata file to the Hub\r\n- we adapted the loading script to use it",
"Hi @albertvillanova :wave: \r\n\r\nThanks, since my last message, I went through the repo of https://huggingface.co/datasets/food101/blob/main/food101.py and managed to get it to work in the end :pray: \r\n\r\nHere it is: https://huggingface.co/datasets/frgfm/imagenette\r\n\r\nI appreciate you opening an issue to document the process, it might help a few!",
"Great to see that you manage to make your dataset streamable. :rocket: \r\n\r\nI'm closing this issue, as for the docs update there is another issue opened:\r\n- #4711"
] | 2022-07-18T02:51:09Z
| 2022-08-01T15:10:57Z
| 2022-08-01T15:10:57Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Link
https://huggingface.co/datasets/frgfm/imagenette
### Description
Hello there :wave:
Thanks for the amazing work you've done with HF Datasets! I've just started playing with it, and managed to upload my first dataset. But for the second one, I'm having trouble with the preview since there is some archive extraction involved :sweat_smile:
Basically, I get a:
```
Status code: 400
Exception: NotImplementedError
Message: Extraction protocol for TAR archives like 'https://s3.amazonaws.com/fast-ai-imageclas/imagenette2.tgz' is not implemented in streaming mode. Please use `dl_manager.iter_archive` instead.
```
I've tried several things and checked this issue https://github.com/huggingface/datasets/issues/4181 as well, but no luck so far!
Could you point me in the right direction please? :pray:
### Owner
Yes
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4697/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4697/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5574
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5574/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5574/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5574/events
|
https://github.com/huggingface/datasets/issues/5574
| 1,598,104,691
|
I_kwDODunzps5fQSRz
| 5,574
|
c4 dataset streaming fails with `FileNotFoundError`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/202907?v=4",
"events_url": "https://api.github.com/users/krasserm/events{/privacy}",
"followers_url": "https://api.github.com/users/krasserm/followers",
"following_url": "https://api.github.com/users/krasserm/following{/other_user}",
"gists_url": "https://api.github.com/users/krasserm/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/krasserm",
"id": 202907,
"login": "krasserm",
"node_id": "MDQ6VXNlcjIwMjkwNw==",
"organizations_url": "https://api.github.com/users/krasserm/orgs",
"received_events_url": "https://api.github.com/users/krasserm/received_events",
"repos_url": "https://api.github.com/users/krasserm/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/krasserm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/krasserm/subscriptions",
"type": "User",
"url": "https://api.github.com/users/krasserm",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Also encountering this issue for every dataset I try to stream! Installed datasets from main:\r\n```\r\n- `datasets` version: 2.10.1.dev0\r\n- Platform: macOS-13.1-arm64-arm-64bit\r\n- Python version: 3.9.13\r\n- PyArrow version: 10.0.1\r\n- Pandas version: 1.5.2\r\n```\r\n\r\nRepro:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nspigi = load_dataset(\"kensho/spgispeech\", \"dev\", split=\"validation\", streaming=True, use_auth_token=True)\r\nsample = next(iter(spigi))\r\n```\r\n\r\n<details>\r\n<summary> Traceback </summary>\r\n\r\n```python\r\n---------------------------------------------------------------------------\r\nClientResponseError Traceback (most recent call last)\r\nFile ~/venv/lib/python3.9/site-packages/fsspec/implementations/http.py:407, in HTTPFileSystem._info(self, url, **kwargs)\r\n 405 try:\r\n 406 info.update(\r\n--> 407 await _file_info(\r\n 408 self.encode_url(url),\r\n 409 size_policy=policy,\r\n 410 session=session,\r\n 411 **self.kwargs,\r\n 412 **kwargs,\r\n 413 )\r\n 414 )\r\n 415 if info.get(\"size\") is not None:\r\n\r\nFile ~/venv/lib/python3.9/site-packages/fsspec/implementations/http.py:792, in _file_info(url, session, size_policy, **kwargs)\r\n 791 async with r:\r\n--> 792 r.raise_for_status()\r\n 794 # TODO:\r\n 795 # recognise lack of 'Accept-Ranges',\r\n 796 # or 'Accept-Ranges': 'none' (not 'bytes')\r\n 797 # to mean streaming only, no random access => return None\r\n\r\nFile ~/venv/lib/python3.9/site-packages/aiohttp/client_reqrep.py:1005, in ClientResponse.raise_for_status(self)\r\n 1004 self.release()\r\n-> 1005 raise ClientResponseError(\r\n 1006 self.request_info,\r\n 1007 self.history,\r\n 1008 status=self.status,\r\n 1009 message=self.reason,\r\n 1010 headers=self.headers,\r\n 1011 )\r\n\r\nClientResponseError: 403, message='Forbidden', url=URL('[https://cdn-lfs.huggingface.co/repos/e2/89/e28905247d6f48bb4edad5baf9b1bb4158e897a13fdf18bf3b8ee89ff8387ab8/46eca7431a7b6bad344bf451800e5b10cea1dd168f26d1027a6d9eb374b7fac3?response-content-disposition=attachment%3B+filename*%3DUTF-8''dev.csv%3B+filename%3D%22dev.csv%22%3B&response-content-type=text/csv&Expires=1677494732&Policy=eyJTdGF0ZW1lbnQiOlt7IlJlc291cmNlIjoiaHR0cHM6Ly9jZG4tbGZzLmh1Z2dpbmdmYWNlLmNvL3JlcG9zL2UyLzg5L2UyODkwNTI0N2Q2ZjQ4YmI0ZWRhZDViYWY5YjFiYjQxNThlODk3YTEzZmRmMThiZjNiOGVlODlmZjgzODdhYjgvNDZlY2E3NDMxYTdiNmJhZDM0NGJmNDUxODAwZTViMTBjZWExZGQxNjhmMjZkMTAyN2E2ZDllYjM3NGI3ZmFjMz9yZXNwb25zZS1jb250ZW50LWRpc3Bvc2l0aW9uPSomcmVzcG9uc2UtY29udGVudC10eXBlPXRleHQlMkZjc3YiLCJDb25kaXRpb24iOnsiRGF0ZUxlc3NUaGFuIjp7IkFXUzpFcG9jaFRpbWUiOjE2Nzc0OTQ3MzJ9fX1dfQ__&Signature=EzQB9f7xPckvqfFB6LzcyR-wzTnQCqtPDdWtQUzZ3QJ-gY-IHG5mxQITJgMr1nVTbJZrPmGAaDngMcPFUfSQa8RmCqYH~dZl-UGE8CO4neKNUT1DvA2WEvLDS4WaAJ3SN-9rX0uFb03~c1QS78cIgIRboYvf6ugKiJz86Bd7Vs~tcp201JFR0A6jIMseqApOnkb9d8dHMP3Ny~F6gO3Qf2QpEWM-QsDIyw2Kz2QV55nq8TsDpRYZCZo50~WwD~73Hej0PoDhEA1K37d19pa0CQhkaN-gjCrbT9xLabbvhJWa~ZkWcMdD0teCgjYqv1wKyvFXDAxukxLGEc7OBXVbYw__&Key-Pair-Id=KVTP0A1DKRTAX](https://cdn-lfs.huggingface.co/repos/e2/89/e28905247d6f48bb4edad5baf9b1bb4158e897a13fdf18bf3b8ee89ff8387ab8/46eca7431a7b6bad344bf451800e5b10cea1dd168f26d1027a6d9eb374b7fac3?response-content-disposition=attachment%3B+filename*%3DUTF-8%27%27dev.csv%3B+filename%3D%22dev.csv%22%3B&response-content-type=text/csv&Expires=1677494732&Policy=eyJTdGF0ZW1lbnQiOlt7IlJlc291cmNlIjoiaHR0cHM6Ly9jZG4tbGZzLmh1Z2dpbmdmYWNlLmNvL3JlcG9zL2UyLzg5L2UyODkwNTI0N2Q2ZjQ4YmI0ZWRhZDViYWY5YjFiYjQxNThlODk3YTEzZmRmMThiZjNiOGVlODlmZjgzODdhYjgvNDZlY2E3NDMxYTdiNmJhZDM0NGJmNDUxODAwZTViMTBjZWExZGQxNjhmMjZkMTAyN2E2ZDllYjM3NGI3ZmFjMz9yZXNwb25zZS1jb250ZW50LWRpc3Bvc2l0aW9uPSomcmVzcG9uc2UtY29udGVudC10eXBlPXRleHQlMkZjc3YiLCJDb25kaXRpb24iOnsiRGF0ZUxlc3NUaGFuIjp7IkFXUzpFcG9jaFRpbWUiOjE2Nzc0OTQ3MzJ9fX1dfQ__&Signature=EzQB9f7xPckvqfFB6LzcyR-wzTnQCqtPDdWtQUzZ3QJ-gY-IHG5mxQITJgMr1nVTbJZrPmGAaDngMcPFUfSQa8RmCqYH~dZl-UGE8CO4neKNUT1DvA2WEvLDS4WaAJ3SN-9rX0uFb03~c1QS78cIgIRboYvf6ugKiJz86Bd7Vs~tcp201JFR0A6jIMseqApOnkb9d8dHMP3Ny~F6gO3Qf2QpEWM-QsDIyw2Kz2QV55nq8TsDpRYZCZo50~WwD~73Hej0PoDhEA1K37d19pa0CQhkaN-gjCrbT9xLabbvhJWa~ZkWcMdD0teCgjYqv1wKyvFXDAxukxLGEc7OBXVbYw__&Key-Pair-Id=KVTP0A1DKRTAX)')\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nFileNotFoundError Traceback (most recent call last)\r\nCell In[5], line 4\r\n 1 from datasets import load_dataset\r\n 3 spigi = load_dataset(\"kensho/spgispeech\", \"dev\", split=\"validation\", streaming=True)\r\n----> 4 sample = next(iter(spigi))\r\n\r\nFile ~/datasets/src/datasets/iterable_dataset.py:937, in IterableDataset.__iter__(self)\r\n 934 yield from self._iter_pytorch(ex_iterable)\r\n 935 return\r\n--> 937 for key, example in ex_iterable:\r\n 938 if self.features:\r\n 939 # `IterableDataset` automatically fills missing columns with None.\r\n 940 # This is done with `_apply_feature_types_on_example`.\r\n 941 yield _apply_feature_types_on_example(\r\n 942 example, self.features, token_per_repo_id=self._token_per_repo_id\r\n 943 )\r\n\r\nFile ~/datasets/src/datasets/iterable_dataset.py:113, in ExamplesIterable.__iter__(self)\r\n 112 def __iter__(self):\r\n--> 113 yield from self.generate_examples_fn(**self.kwargs)\r\n\r\nFile ~/.cache/huggingface/modules/datasets_modules/datasets/kensho--spgispeech/5fbf75dd9ef795a9b5a673457d2cbaf0b8fa0de8fb62acbd1da338d83a41e2f0/spgispeech.py:186, in Spgispeech._generate_examples(self, local_extracted_archive_paths, archives, meta_path)\r\n 183 dict_keys = [\"wav_filename\", \"wav_filesize\", \"transcript\"]\r\n 185 logging.info(\"Reading metadata...\")\r\n--> 186 with open(meta_path, encoding=\"utf-8\") as f:\r\n 187 csvreader = csv.DictReader(f, delimiter=\"|\")\r\n 188 metadata = {x[\"wav_filename\"]: dict((k, x[k]) for k in dict_keys) for x in csvreader}\r\n\r\nFile ~/datasets/src/datasets/streaming.py:70, in extend_module_for_streaming.<locals>.wrap_auth.<locals>.wrapper(*args, **kwargs)\r\n 68 @wraps(function)\r\n 69 def wrapper(*args, **kwargs):\r\n---> 70 return function(*args, use_auth_token=use_auth_token, **kwargs)\r\n\r\nFile ~/datasets/src/datasets/download/streaming_download_manager.py:495, in xopen(file, mode, use_auth_token, *args, **kwargs)\r\n 493 kwargs = {**kwargs, **new_kwargs}\r\n 494 try:\r\n--> 495 file_obj = fsspec.open(file, mode=mode, *args, **kwargs).open()\r\n 496 except ValueError as e:\r\n 497 if str(e) == \"Cannot seek streaming HTTP file\":\r\n\r\nFile ~/venv/lib/python3.9/site-packages/fsspec/core.py:135, in OpenFile.open(self)\r\n 128 def open(self):\r\n 129 \"\"\"Materialise this as a real open file without context\r\n 130 \r\n 131 The OpenFile object should be explicitly closed to avoid enclosed file\r\n 132 instances persisting. You must, therefore, keep a reference to the OpenFile\r\n 133 during the life of the file-like it generates.\r\n 134 \"\"\"\r\n--> 135 return self.__enter__()\r\n\r\nFile ~/venv/lib/python3.9/site-packages/fsspec/core.py:103, in OpenFile.__enter__(self)\r\n 100 def __enter__(self):\r\n 101 mode = self.mode.replace(\"t\", \"\").replace(\"b\", \"\") + \"b\"\r\n--> 103 f = self.fs.open(self.path, mode=mode)\r\n 105 self.fobjects = [f]\r\n 107 if self.compression is not None:\r\n\r\nFile ~/venv/lib/python3.9/site-packages/fsspec/spec.py:1106, in AbstractFileSystem.open(self, path, mode, block_size, cache_options, compression, **kwargs)\r\n 1104 else:\r\n 1105 ac = kwargs.pop(\"autocommit\", not self._intrans)\r\n-> 1106 f = self._open(\r\n 1107 path,\r\n 1108 mode=mode,\r\n 1109 block_size=block_size,\r\n 1110 autocommit=ac,\r\n 1111 cache_options=cache_options,\r\n 1112 **kwargs,\r\n 1113 )\r\n 1114 if compression is not None:\r\n 1115 from fsspec.compression import compr\r\n\r\nFile ~/venv/lib/python3.9/site-packages/fsspec/implementations/http.py:346, in HTTPFileSystem._open(self, path, mode, block_size, autocommit, cache_type, cache_options, size, **kwargs)\r\n 344 kw[\"asynchronous\"] = self.asynchronous\r\n 345 kw.update(kwargs)\r\n--> 346 size = size or self.info(path, **kwargs)[\"size\"]\r\n 347 session = sync(self.loop, self.set_session)\r\n 348 if block_size and size:\r\n\r\nFile ~/venv/lib/python3.9/site-packages/fsspec/asyn.py:113, in sync_wrapper.<locals>.wrapper(*args, **kwargs)\r\n 110 @functools.wraps(func)\r\n 111 def wrapper(*args, **kwargs):\r\n 112 self = obj or args[0]\r\n--> 113 return sync(self.loop, func, *args, **kwargs)\r\n\r\nFile ~/venv/lib/python3.9/site-packages/fsspec/asyn.py:98, in sync(loop, func, timeout, *args, **kwargs)\r\n 96 raise FSTimeoutError from return_result\r\n 97 elif isinstance(return_result, BaseException):\r\n---> 98 raise return_result\r\n 99 else:\r\n 100 return return_result\r\n\r\nFile ~/venv/lib/python3.9/site-packages/fsspec/asyn.py:53, in _runner(event, coro, result, timeout)\r\n 51 coro = asyncio.wait_for(coro, timeout=timeout)\r\n 52 try:\r\n---> 53 result[0] = await coro\r\n 54 except Exception as ex:\r\n 55 result[0] = ex\r\n\r\nFile ~/venv/lib/python3.9/site-packages/fsspec/implementations/http.py:420, in HTTPFileSystem._info(self, url, **kwargs)\r\n 417 except Exception as exc:\r\n 418 if policy == \"get\":\r\n 419 # If get failed, then raise a FileNotFoundError\r\n--> 420 raise FileNotFoundError(url) from exc\r\n 421 logger.debug(str(exc))\r\n 423 return {\"name\": url, \"size\": None, **info, \"type\": \"file\"}\r\n\r\nFileNotFoundError: https://huggingface.co/datasets/kensho/spgispeech/resolve/main/data/meta/dev.csv\r\n```\r\n</details>",
"Hi ! We're investigating this issue, sorry for the inconvenience",
"This has been resolved ! Thanks for reporting",
"Wow, thanks for the very quick fix!",
"This problem now appears again, this time with an underlying HTTP 502 status code:\r\n\r\n```\r\naiohttp.client_exceptions.ClientResponseError: 502, message='Bad Gateway', url=URL('https://huggingface.co/datasets/allenai/c4/resolve/1ddc917116b730e1859edef32896ec5c16be51d0/en/c4-validation.00002-of-00008.json.gz')\r\n```",
"Re-executing a minute later, the underlying cause is an HTTP 403 status code, as reported yesterday:\r\n\r\n```\r\naiohttp.client_exceptions.ClientResponseError: 403, message='Forbidden', url=URL('https://cdn-lfs.huggingface.co/datasets/allenai/c4/4bf6b248b0f910dcde2cdf2118d6369d8208c8f9515ec29ab73e531f380b18e2?response-content-disposition=attachment%3B+filename*%3DUTF-8''c4-validation.00002-of-00008.json.gz%3B+filename%3D%22c4-validation.00002-of-00008.json.gz%22%3B&response-content-type=application/gzip&Expires=1677571273&Policy=eyJTdGF0ZW1lbnQiOlt7IlJlc291cmNlIjoiaHR0cHM6Ly9jZG4tbGZzLmh1Z2dpbmdmYWNlLmNvL2RhdGFzZXRzL2FsbGVuYWkvYzQvNGJmNmIyNDhiMGY5MTBkY2RlMmNkZjIxMThkNjM2OWQ4MjA4YzhmOTUxNWVjMjlhYjczZTUzMWYzODBiMThlMj9yZXNwb25zZS1jb250ZW50LWRpc3Bvc2l0aW9uPSomcmVzcG9uc2UtY29udGVudC10eXBlPWFwcGxpY2F0aW9uJTJGZ3ppcCIsIkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTY3NzU3MTI3M319fV19&Signature=WW42NOKkLuX~xVB1QfbkqzdvGo2AOXpgbF3PjTXy6iKd~ffilr1N9ScPXfvTXqy5yvdhJg1G0xJy1zYtUjGAL8GEx3Av-0vIhpWMGYTM8XKEU5gYA9qt30oVtNph6TkTYSABrsYTaj-hzQL9WCgyapmjvG69ETMh4wj44r2rcbk4T3j0l6l4u76Gh~lyRSll3aK4qycdUwcyL7FECDu~0W1mJIJwKkCrWHhSpHJSshb-0ElwG71pq4eyQ5g2uxHdK6JbRF7loxUpRQQJ1vlk0EHXdw0wTMaQ9tqHy6xcrQd8Ep0Yvx3tUD8MR0vWOcbQKnL6LwPQByc8tkChlpjnig__&Key-Pair-Id=KVTP0A1DKRTAX')\r\n```",
"I'm facing the same problem. Interestingly using `wget` I can download the file. ",
"It's been resolved again ;)",
"> It's been resolved again ;)\r\n\r\nI'm experiencing the same issue when trying to load this dataset, `FileNotFoundError: https://huggingface.co/datasets/allenai/c4/resolve/1ddc917116b730e1859edef32896ec5c16be51d0/realnewslike/c4-train.00000-of-00512.json.gz`",
"Experiencing the same issues as above : `FileNotFoundError: https://huggingface.co/datasets/allenai/c4/resolve/1ddc917116b730e1859edef32896ec5c16be51d0/en/c4-train.00000-of-01024.json.gz\r\nIf the repo is private or gated, make sure to log in with `huggingface-cli login`.`\r\n\r\nHave made sure to login as well, issue persists.",
"> Experiencing the same issues as above : `FileNotFoundError: https://huggingface.co/datasets/allenai/c4/resolve/1ddc917116b730e1859edef32896ec5c16be51d0/en/c4-train.00000-of-01024.json.gz If the repo is private or gated, make sure to log in with `huggingface-cli login`.`\r\n> \r\n> Have made sure to login as well, issue persists.\r\n\r\nI meet the same issue",
"I meet the same issue"
] | 2023-02-24T07:57:32Z
| 2023-12-18T07:32:32Z
| 2023-02-27T04:03:38Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Loading the `c4` dataset in streaming mode with `load_dataset("c4", "en", split="validation", streaming=True)` and then using it fails with a `FileNotFoundException`.
### Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("c4", "en", split="train", streaming=True)
next(iter(dataset))
```
causes a
```
FileNotFoundError: https://huggingface.co/datasets/allenai/c4/resolve/1ddc917116b730e1859edef32896ec5c16be51d0/en/c4-train.00000-of-01024.json.gz
```
I can download this file manually though e.g. by entering this URL in a browser.
There is an underlying HTTP 403 status code:
```
aiohttp.client_exceptions.ClientResponseError: 403, message='Forbidden', url=URL('https://cdn-lfs.huggingface.co/datasets/allenai/c4/8ef8d75b0e045dec4aa5123a671b4564466b0707086a7ed1ba8721626dfffbc9?response-content-disposition=attachment%3B+filename*%3DUTF-8''c4-train.00000-of-01024.json.gz%3B+filename%3D%22c4-train.00000-of-01024.json.gz%22%3B&response-content-type=application/gzip&Expires=1677483770&Policy=eyJTdGF0ZW1lbnQiOlt7IlJlc291cmNlIjoiaHR0cHM6Ly9jZG4tbGZzLmh1Z2dpbmdmYWNlLmNvL2RhdGFzZXRzL2FsbGVuYWkvYzQvOGVmOGQ3NWIwZTA0NWRlYzRhYTUxMjNhNjcxYjQ1NjQ0NjZiMDcwNzA4NmE3ZWQxYmE4NzIxNjI2ZGZmZmJjOT9yZXNwb25zZS1jb250ZW50LWRpc3Bvc2l0aW9uPSomcmVzcG9uc2UtY29udGVudC10eXBlPWFwcGxpY2F0aW9uJTJGZ3ppcCIsIkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTY3NzQ4Mzc3MH19fV19&Signature=yjL3UeY72cf2xpnvPvD68eAYOEe2qtaUJV55sB-jnPskBJEMwpMJcBZvg2~GqXZdM3O-GWV-Z3CI~d4u5VCb4YZ-HlmOjr3VBYkvox2EKiXnBIhjMecf2UVUPtxhTa9kBVlWjqu4qKzB9gKXZF2Cwpp5ctLzapEaT2nnqF84RAL-rsqMA3I~M8vWWfivQsbBK63hMfgZqqKMgdWM0iKMaItveDl0ufQ29azMFmsR7qd8V7sU2Z-F1fAeohS8HpN9OOnClW34yi~YJ2AbgZJJBXA~qsylfVA0Qp7Q~yX~q4P8JF1vmJ2BjkiSbGrj3bAXOGugpOVU5msI52DT88yMdA__&Key-Pair-Id=KVTP0A1DKRTAX')
```
### Expected behavior
This should retrieve the first example from the C4 validation set. This worked a few days ago but stopped working now.
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-5.15.0-60-generic-x86_64-with-glibc2.31
- Python version: 3.9.16
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/202907?v=4",
"events_url": "https://api.github.com/users/krasserm/events{/privacy}",
"followers_url": "https://api.github.com/users/krasserm/followers",
"following_url": "https://api.github.com/users/krasserm/following{/other_user}",
"gists_url": "https://api.github.com/users/krasserm/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/krasserm",
"id": 202907,
"login": "krasserm",
"node_id": "MDQ6VXNlcjIwMjkwNw==",
"organizations_url": "https://api.github.com/users/krasserm/orgs",
"received_events_url": "https://api.github.com/users/krasserm/received_events",
"repos_url": "https://api.github.com/users/krasserm/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/krasserm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/krasserm/subscriptions",
"type": "User",
"url": "https://api.github.com/users/krasserm",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5574/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5574/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/7440
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7440/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7440/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7440/events
|
https://github.com/huggingface/datasets/issues/7440
| 2,903,740,662
|
I_kwDODunzps6tE5D2
| 7,440
|
IterableDataset raises FileNotFoundError instead of retrying
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/145220868?v=4",
"events_url": "https://api.github.com/users/bauwenst/events{/privacy}",
"followers_url": "https://api.github.com/users/bauwenst/followers",
"following_url": "https://api.github.com/users/bauwenst/following{/other_user}",
"gists_url": "https://api.github.com/users/bauwenst/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bauwenst",
"id": 145220868,
"login": "bauwenst",
"node_id": "U_kgDOCKflBA",
"organizations_url": "https://api.github.com/users/bauwenst/orgs",
"received_events_url": "https://api.github.com/users/bauwenst/received_events",
"repos_url": "https://api.github.com/users/bauwenst/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bauwenst/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bauwenst/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bauwenst",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"I have since been training more models with identical architectures over the same dataset, and it is completely unstable. One has now failed at chunk9/1215, whilst others have gotten past that.\n```python\nFileNotFoundError: zstd://example_train_1215.jsonl::hf://datasets/cerebras/SlimPajama-627B@2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/train/chunk9/example_train_1215.jsonl.zst\n```\nBelow is the full training log, where you can clearly see the intermittent dataset issues. Note again that this model only got to epoch 0.11, whereas I have other models training on the exact same dataset right now that have gotten way beyond that. This is quickly turning into a highly expensive bug which I didn't have issues with in the past half year of using the same setup.\n<details>\n<summary>Training log of failed run</summary>\n\n```python\n 1%| | 64/8192 [56:27<87:25:33, 38.72s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 5ef28452-e903-4bd8-946d-f0c77f558a2a)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk5/example_holdout_4799.jsonl.zst\n 1%| | 64/8192 [56:51<87:25:33, 38.72s/it]Retrying in 1s [Retry 1/5].\n 2%|▏ | 192/8192 [2:40:14<85:29:44, 38.47s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: ba6e4c51-f4a4-407e-9934-3772550b7ce9)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk1/example_holdout_2770.jsonl.zst\n 2%|▏ | 192/8192 [2:40:53<85:29:44, 38.47s/it]Retrying in 1s [Retry 1/5].\n 2%|▏ | 192/8192 [2:40:53<85:29:44, 38.47s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: bdf2cfaa-7e0b-46a0-bec1-b1e573fa7998)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk4/example_holdout_4386.jsonl.zst\n 2%|▏ | 192/8192 [2:42:16<85:29:44, 38.47s/it]Retrying in 1s [Retry 1/5].\n 2%|▏ | 192/8192 [2:42:16<85:29:44, 38.47s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 1dc5e455-8042-4c7b-9b97-5ded33dfea34)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk1/example_holdout_1763.jsonl.zst\n 2%|▏ | 192/8192 [2:42:30<85:29:44, 38.47s/it]Retrying in 1s [Retry 1/5].\n 2%|▏ | 192/8192 [2:42:30<85:29:44, 38.47s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 9cf29917-8111-41fe-80aa-953df65c5803)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk4/example_holdout_5509.jsonl.zst\n 2%|▏ | 192/8192 [2:44:31<85:29:44, 38.47s/it]Retrying in 1s [Retry 1/5].\n 2%|▏ | 192/8192 [2:44:31<85:29:44, 38.47s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 2515a0b0-3d81-409f-940c-e78ed5e2dbf8)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk4/example_holdout_3093.jsonl.zst\n 2%|▏ | 192/8192 [2:45:13<85:29:44, 38.47s/it]Retrying in 1s [Retry 1/5].\n 2%|▏ | 192/8192 [2:45:13<85:29:44, 38.47s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: a4c1e0c7-1c7a-4377-bc7e-6f076473072b)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk4/example_holdout_3422.jsonl.zst\n 2%|▏ | 192/8192 [2:46:26<85:29:44, 38.47s/it]Retrying in 1s [Retry 1/5].\n 2%|▏ | 192/8192 [2:46:26<85:29:44, 38.47s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: c7b0d366-db86-4d0c-a4e0-be251d26519e)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk3/example_holdout_2250.jsonl.zst\n 2%|▏ | 192/8192 [2:47:24<85:29:44, 38.47s/it]Retrying in 1s [Retry 1/5].\n 2%|▏ | 192/8192 [2:47:24<85:29:44, 38.47s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: b0df5a1a-4836-46cf-8e45-58a7c1553309)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk3/example_holdout_6161.jsonl.zst\n 2%|▏ | 192/8192 [2:49:10<85:29:44, 38.47s/it]Retrying in 1s [Retry 1/5].\n 2%|▏ | 192/8192 [2:49:10<85:29:44, 38.47s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: c1d97368-c0ae-45bb-ae10-5559b3ebc4e4)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk3/example_holdout_5782.jsonl.zst\n 2%|▏ | 192/8192 [2:49:30<85:29:44, 38.47s/it]Retrying in 1s [Retry 1/5].\n{'eval_loss': 10.482319831848145, 'eval_runtime': 902.7516, 'eval_samples_per_second': 18.149, 'eval_steps_per_second': 0.142, 'epoch': 0, 'num_input_tokens_seen': 0}\n{'loss': 10.4895, 'grad_norm': 2.9147818088531494, 'learning_rate': 3.90625e-06, 'epoch': 0.0, 'num_input_tokens_seen': 1048576}\n{'loss': 10.4832, 'grad_norm': 2.8206892013549805, 'learning_rate': 7.8125e-06, 'epoch': 0.0, 'num_input_tokens_seen': 2097152}\n{'loss': 10.4851, 'grad_norm': 2.910552978515625, 'learning_rate': 1.171875e-05, 'epoch': 0.0, 'num_input_tokens_seen': 3145728}\n{'loss': 10.486, 'grad_norm': 2.8042073249816895, 'learning_rate': 1.5625e-05, 'epoch': 0.0, 'num_input_tokens_seen': 4194304}\n{'loss': 10.4719, 'grad_norm': 2.83260440826416, 'learning_rate': 1.953125e-05, 'epoch': 0.0, 'num_input_tokens_seen': 5242880}\n{'loss': 10.4482, 'grad_norm': 2.916527032852173, 'learning_rate': 2.34375e-05, 'epoch': 0.0, 'num_input_tokens_seen': 6291456}\n{'loss': 10.4113, 'grad_norm': 2.911870241165161, 'learning_rate': 2.734375e-05, 'epoch': 0.0, 'num_input_tokens_seen': 7340032}\n{'loss': 10.3863, 'grad_norm': 2.8873367309570312, 'learning_rate': 3.125e-05, 'epoch': 0.0, 'num_input_tokens_seen': 8388608}\n{'loss': 10.3557, 'grad_norm': 2.7183432579040527, 'learning_rate': 3.5156250000000004e-05, 'epoch': 0.0, 'num_input_tokens_seen': 9437184}\n{'loss': 10.2795, 'grad_norm': 2.6743927001953125, 'learning_rate': 3.90625e-05, 'epoch': 0.0, 'num_input_tokens_seen': 10485760}\n{'loss': 10.2148, 'grad_norm': 2.3173940181732178, 'learning_rate': 4.296875e-05, 'epoch': 0.0, 'num_input_tokens_seen': 11534336}\n{'loss': 10.1482, 'grad_norm': 2.09787917137146, 'learning_rate': 4.6875e-05, 'epoch': 0.0, 'num_input_tokens_seen': 12582912}\n{'loss': 10.1024, 'grad_norm': 1.889390468597412, 'learning_rate': 5.0781250000000004e-05, 'epoch': 0.0, 'num_input_tokens_seen': 13631488}\n{'loss': 10.0418, 'grad_norm': 1.8319090604782104, 'learning_rate': 5.46875e-05, 'epoch': 0.0, 'num_input_tokens_seen': 14680064}\n{'loss': 10.0081, 'grad_norm': 1.7302652597427368, 'learning_rate': 5.859375e-05, 'epoch': 0.0, 'num_input_tokens_seen': 15728640}\n{'loss': 9.9525, 'grad_norm': 1.767600417137146, 'learning_rate': 6.25e-05, 'epoch': 0.0, 'num_input_tokens_seen': 16777216}\n{'loss': 9.9326, 'grad_norm': 2.1608240604400635, 'learning_rate': 6.640625e-05, 'epoch': 0.0, 'num_input_tokens_seen': 17825792}\n{'loss': 9.8478, 'grad_norm': 1.7399269342422485, 'learning_rate': 7.031250000000001e-05, 'epoch': 0.0, 'num_input_tokens_seen': 18874368}\n{'loss': 9.8215, 'grad_norm': 1.6564425230026245, 'learning_rate': 7.421875e-05, 'epoch': 0.0, 'num_input_tokens_seen': 19922944}\n{'loss': 9.7732, 'grad_norm': 1.6452653408050537, 'learning_rate': 7.8125e-05, 'epoch': 0.0, 'num_input_tokens_seen': 20971520}\n{'loss': 9.6896, 'grad_norm': 1.7053238153457642, 'learning_rate': 8.203125e-05, 'epoch': 0.0, 'num_input_tokens_seen': 22020096}\n{'loss': 9.6356, 'grad_norm': 1.7050201892852783, 'learning_rate': 8.59375e-05, 'epoch': 0.0, 'num_input_tokens_seen': 23068672}\n{'loss': 9.5781, 'grad_norm': 1.7155998945236206, 'learning_rate': 8.984375e-05, 'epoch': 0.0, 'num_input_tokens_seen': 24117248}\n{'loss': 9.5355, 'grad_norm': 1.697864294052124, 'learning_rate': 9.375e-05, 'epoch': 0.0, 'num_input_tokens_seen': 25165824}\n{'loss': 9.4718, 'grad_norm': 1.7598071098327637, 'learning_rate': 9.765625e-05, 'epoch': 0.0, 'num_input_tokens_seen': 26214400}\n{'loss': 9.3972, 'grad_norm': 1.7407673597335815, 'learning_rate': 0.00010156250000000001, 'epoch': 0.0, 'num_input_tokens_seen': 27262976}\n{'loss': 9.3303, 'grad_norm': 1.7710134983062744, 'learning_rate': 0.00010546875, 'epoch': 0.0, 'num_input_tokens_seen': 28311552}\n{'loss': 9.2973, 'grad_norm': 1.716180682182312, 'learning_rate': 0.000109375, 'epoch': 0.0, 'num_input_tokens_seen': 29360128}\n{'loss': 9.2049, 'grad_norm': 1.7579947710037231, 'learning_rate': 0.00011328125, 'epoch': 0.0, 'num_input_tokens_seen': 30408704}\n{'loss': 9.1656, 'grad_norm': 1.6988558769226074, 'learning_rate': 0.0001171875, 'epoch': 0.0, 'num_input_tokens_seen': 31457280}\n{'loss': 9.0966, 'grad_norm': 1.7036350965499878, 'learning_rate': 0.00012109375, 'epoch': 0.0, 'num_input_tokens_seen': 32505856}\n{'loss': 9.0107, 'grad_norm': 1.752451777458191, 'learning_rate': 0.000125, 'epoch': 0.0, 'num_input_tokens_seen': 33554432}\n{'loss': 8.9788, 'grad_norm': 1.6769776344299316, 'learning_rate': 0.00012890625, 'epoch': 0.0, 'num_input_tokens_seen': 34603008}\n{'loss': 8.9155, 'grad_norm': 1.6497987508773804, 'learning_rate': 0.0001328125, 'epoch': 0.0, 'num_input_tokens_seen': 35651584}\n{'loss': 8.8008, 'grad_norm': 1.722798466682434, 'learning_rate': 0.00013671875, 'epoch': 0.0, 'num_input_tokens_seen': 36700160}\n{'loss': 8.7727, 'grad_norm': 1.6046854257583618, 'learning_rate': 0.00014062500000000002, 'epoch': 0.0, 'num_input_tokens_seen': 37748736}\n{'loss': 8.682, 'grad_norm': 1.6132164001464844, 'learning_rate': 0.00014453125, 'epoch': 0.0, 'num_input_tokens_seen': 38797312}\n{'loss': 8.6516, 'grad_norm': 1.558968424797058, 'learning_rate': 0.0001484375, 'epoch': 0.0, 'num_input_tokens_seen': 39845888}\n{'loss': 8.5935, 'grad_norm': 1.6083673238754272, 'learning_rate': 0.00015234375, 'epoch': 0.0, 'num_input_tokens_seen': 40894464}\n{'loss': 8.4852, 'grad_norm': 1.5469273328781128, 'learning_rate': 0.00015625, 'epoch': 0.0, 'num_input_tokens_seen': 41943040}\n{'loss': 8.4342, 'grad_norm': 1.46219801902771, 'learning_rate': 0.00016015625, 'epoch': 0.01, 'num_input_tokens_seen': 42991616}\n{'loss': 8.3213, 'grad_norm': 1.473191261291504, 'learning_rate': 0.0001640625, 'epoch': 0.01, 'num_input_tokens_seen': 44040192}\n{'loss': 8.3193, 'grad_norm': 1.4024137258529663, 'learning_rate': 0.00016796875000000001, 'epoch': 0.01, 'num_input_tokens_seen': 45088768}\n{'loss': 8.1853, 'grad_norm': 1.3591463565826416, 'learning_rate': 0.000171875, 'epoch': 0.01, 'num_input_tokens_seen': 46137344}\n{'loss': 8.1109, 'grad_norm': 1.3547109365463257, 'learning_rate': 0.00017578125, 'epoch': 0.01, 'num_input_tokens_seen': 47185920}\n{'loss': 8.0741, 'grad_norm': 1.268977403640747, 'learning_rate': 0.0001796875, 'epoch': 0.01, 'num_input_tokens_seen': 48234496}\n{'loss': 8.0032, 'grad_norm': 1.222671389579773, 'learning_rate': 0.00018359375, 'epoch': 0.01, 'num_input_tokens_seen': 49283072}\n{'loss': 7.9346, 'grad_norm': 1.154278039932251, 'learning_rate': 0.0001875, 'epoch': 0.01, 'num_input_tokens_seen': 50331648}\n{'loss': 7.8823, 'grad_norm': 1.1396397352218628, 'learning_rate': 0.00019140625, 'epoch': 0.01, 'num_input_tokens_seen': 51380224}\n{'loss': 7.8444, 'grad_norm': 1.0608373880386353, 'learning_rate': 0.0001953125, 'epoch': 0.01, 'num_input_tokens_seen': 52428800}\n{'loss': 7.7794, 'grad_norm': 1.0165436267852783, 'learning_rate': 0.00019921875000000001, 'epoch': 0.01, 'num_input_tokens_seen': 53477376}\n{'loss': 7.7567, 'grad_norm': 0.8742461204528809, 'learning_rate': 0.00020312500000000002, 'epoch': 0.01, 'num_input_tokens_seen': 54525952}\n{'loss': 7.6489, 'grad_norm': 0.8699902296066284, 'learning_rate': 0.00020703125, 'epoch': 0.01, 'num_input_tokens_seen': 55574528}\n{'loss': 7.6062, 'grad_norm': 0.809831440448761, 'learning_rate': 0.0002109375, 'epoch': 0.01, 'num_input_tokens_seen': 56623104}\n{'loss': 7.5511, 'grad_norm': 0.7423847317695618, 'learning_rate': 0.00021484375, 'epoch': 0.01, 'num_input_tokens_seen': 57671680}\n{'loss': 7.4435, 'grad_norm': 0.7614696025848389, 'learning_rate': 0.00021875, 'epoch': 0.01, 'num_input_tokens_seen': 58720256}\n{'loss': 7.564, 'grad_norm': 0.5147746801376343, 'learning_rate': 0.00022265625, 'epoch': 0.01, 'num_input_tokens_seen': 59768832}\n{'loss': 7.5278, 'grad_norm': 0.4705545902252197, 'learning_rate': 0.0002265625, 'epoch': 0.01, 'num_input_tokens_seen': 60817408}\n{'loss': 7.5479, 'grad_norm': 0.3745419979095459, 'learning_rate': 0.00023046875000000001, 'epoch': 0.01, 'num_input_tokens_seen': 61865984}\n{'loss': 7.4759, 'grad_norm': 0.3893500566482544, 'learning_rate': 0.000234375, 'epoch': 0.01, 'num_input_tokens_seen': 62914560}\n{'loss': 7.5032, 'grad_norm': 0.31959569454193115, 'learning_rate': 0.00023828125, 'epoch': 0.01, 'num_input_tokens_seen': 63963136}\n{'loss': 7.421, 'grad_norm': 0.3203206956386566, 'learning_rate': 0.0002421875, 'epoch': 0.01, 'num_input_tokens_seen': 65011712}\n{'loss': 7.4998, 'grad_norm': 0.2730390429496765, 'learning_rate': 0.00024609375, 'epoch': 0.01, 'num_input_tokens_seen': 66060288}\n{'loss': 7.4157, 'grad_norm': 0.34872403740882874, 'learning_rate': 0.00025, 'epoch': 0.01, 'num_input_tokens_seen': 67108864}\n[2025-03-10 16:17:04 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 5ef28452-e903-4bd8-946d-f0c77f558a2a)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk5/example_holdout_4799.jsonl.zst\n[2025-03-10 16:17:04 WARNING] Retrying in 1s [Retry 1/5].\n{'eval_loss': 7.471163749694824, 'eval_runtime': 651.4801, 'eval_samples_per_second': 25.149, 'eval_steps_per_second': 0.196, 'epoch': 0.01, 'num_input_tokens_seen': 67108864}\n{'loss': 7.5083, 'grad_norm': 0.339502215385437, 'learning_rate': 0.00025390625, 'epoch': 0.01, 'num_input_tokens_seen': 68157440}\n{'loss': 7.7083, 'grad_norm': 0.6426190137863159, 'learning_rate': 0.0002578125, 'epoch': 0.01, 'num_input_tokens_seen': 69206016}\n{'loss': 7.446, 'grad_norm': 0.9138129353523254, 'learning_rate': 0.00026171875, 'epoch': 0.01, 'num_input_tokens_seen': 70254592}\n{'loss': 7.3747, 'grad_norm': 1.2179911136627197, 'learning_rate': 0.000265625, 'epoch': 0.01, 'num_input_tokens_seen': 71303168}\n{'loss': 7.367, 'grad_norm': 0.7108445167541504, 'learning_rate': 0.00026953125, 'epoch': 0.01, 'num_input_tokens_seen': 72351744}\n{'loss': 7.4751, 'grad_norm': 0.7580183744430542, 'learning_rate': 0.0002734375, 'epoch': 0.01, 'num_input_tokens_seen': 73400320}\n{'loss': 7.3405, 'grad_norm': 0.7545790076255798, 'learning_rate': 0.00027734375000000003, 'epoch': 0.01, 'num_input_tokens_seen': 74448896}\n{'loss': 7.4194, 'grad_norm': 0.4764443039894104, 'learning_rate': 0.00028125000000000003, 'epoch': 0.01, 'num_input_tokens_seen': 75497472}\n{'loss': 7.2826, 'grad_norm': 0.5942808985710144, 'learning_rate': 0.00028515625, 'epoch': 0.01, 'num_input_tokens_seen': 76546048}\n{'loss': 7.3945, 'grad_norm': 0.5272891521453857, 'learning_rate': 0.0002890625, 'epoch': 0.01, 'num_input_tokens_seen': 77594624}\n{'loss': 7.3492, 'grad_norm': 0.465085506439209, 'learning_rate': 0.00029296875, 'epoch': 0.01, 'num_input_tokens_seen': 78643200}\n{'loss': 7.3658, 'grad_norm': 0.6932719349861145, 'learning_rate': 0.000296875, 'epoch': 0.01, 'num_input_tokens_seen': 79691776}\n{'loss': 7.3554, 'grad_norm': 0.49396172165870667, 'learning_rate': 0.00030078125, 'epoch': 0.01, 'num_input_tokens_seen': 80740352}\n{'loss': 7.2916, 'grad_norm': 0.3178255558013916, 'learning_rate': 0.0003046875, 'epoch': 0.01, 'num_input_tokens_seen': 81788928}\n{'loss': 7.2871, 'grad_norm': 0.5465154647827148, 'learning_rate': 0.00030859375, 'epoch': 0.01, 'num_input_tokens_seen': 82837504}\n{'loss': 7.262, 'grad_norm': 0.4718130826950073, 'learning_rate': 0.0003125, 'epoch': 0.01, 'num_input_tokens_seen': 83886080}\n{'loss': 7.2845, 'grad_norm': 0.5033366680145264, 'learning_rate': 0.00031640625, 'epoch': 0.01, 'num_input_tokens_seen': 84934656}\n{'loss': 7.2525, 'grad_norm': 0.5601146817207336, 'learning_rate': 0.0003203125, 'epoch': 0.01, 'num_input_tokens_seen': 85983232}\n{'loss': 7.1971, 'grad_norm': 0.5764456987380981, 'learning_rate': 0.00032421875, 'epoch': 0.01, 'num_input_tokens_seen': 87031808}\n{'loss': 7.1988, 'grad_norm': 0.6154745817184448, 'learning_rate': 0.000328125, 'epoch': 0.01, 'num_input_tokens_seen': 88080384}\n{'loss': 7.1987, 'grad_norm': 0.6701765656471252, 'learning_rate': 0.00033203125, 'epoch': 0.01, 'num_input_tokens_seen': 89128960}\n{'loss': 7.3324, 'grad_norm': 0.5648972988128662, 'learning_rate': 0.00033593750000000003, 'epoch': 0.01, 'num_input_tokens_seen': 90177536}\n{'loss': 7.2233, 'grad_norm': 0.5782461166381836, 'learning_rate': 0.00033984375000000003, 'epoch': 0.01, 'num_input_tokens_seen': 91226112}\n{'loss': 7.1995, 'grad_norm': 0.540762722492218, 'learning_rate': 0.00034375, 'epoch': 0.01, 'num_input_tokens_seen': 92274688}\n{'loss': 7.1214, 'grad_norm': 0.9524508118629456, 'learning_rate': 0.00034765625, 'epoch': 0.01, 'num_input_tokens_seen': 93323264}\n{'loss': 7.1603, 'grad_norm': 1.4820659160614014, 'learning_rate': 0.0003515625, 'epoch': 0.01, 'num_input_tokens_seen': 94371840}\n{'loss': 7.2364, 'grad_norm': 0.6124428510665894, 'learning_rate': 0.00035546875, 'epoch': 0.01, 'num_input_tokens_seen': 95420416}\n{'loss': 7.0258, 'grad_norm': 0.8897235989570618, 'learning_rate': 0.000359375, 'epoch': 0.01, 'num_input_tokens_seen': 96468992}\n{'loss': 7.1182, 'grad_norm': 0.9263321757316589, 'learning_rate': 0.00036328125, 'epoch': 0.01, 'num_input_tokens_seen': 97517568}\n{'loss': 7.109, 'grad_norm': 0.5800505876541138, 'learning_rate': 0.0003671875, 'epoch': 0.01, 'num_input_tokens_seen': 98566144}\n{'loss': 7.0449, 'grad_norm': 0.6776424050331116, 'learning_rate': 0.00037109375, 'epoch': 0.01, 'num_input_tokens_seen': 99614720}\n{'loss': 7.1272, 'grad_norm': 0.7616431713104248, 'learning_rate': 0.000375, 'epoch': 0.01, 'num_input_tokens_seen': 100663296}\n{'loss': 7.046, 'grad_norm': 0.5346249938011169, 'learning_rate': 0.00037890625, 'epoch': 0.01, 'num_input_tokens_seen': 101711872}\n{'loss': 7.0713, 'grad_norm': 0.6108944416046143, 'learning_rate': 0.0003828125, 'epoch': 0.01, 'num_input_tokens_seen': 102760448}\n{'loss': 7.1459, 'grad_norm': 0.4430749714374542, 'learning_rate': 0.00038671875, 'epoch': 0.01, 'num_input_tokens_seen': 103809024}\n{'loss': 7.0709, 'grad_norm': 0.6020255088806152, 'learning_rate': 0.000390625, 'epoch': 0.01, 'num_input_tokens_seen': 104857600}\n{'loss': 7.0144, 'grad_norm': 0.5525627732276917, 'learning_rate': 0.00039453125, 'epoch': 0.01, 'num_input_tokens_seen': 105906176}\n{'loss': 7.0926, 'grad_norm': 0.6909684538841248, 'learning_rate': 0.00039843750000000003, 'epoch': 0.01, 'num_input_tokens_seen': 106954752}\n{'loss': 7.0289, 'grad_norm': 0.5576740503311157, 'learning_rate': 0.00040234375000000003, 'epoch': 0.01, 'num_input_tokens_seen': 108003328}\n{'loss': 6.9173, 'grad_norm': 0.48874178528785706, 'learning_rate': 0.00040625000000000004, 'epoch': 0.01, 'num_input_tokens_seen': 109051904}\n{'loss': 6.9777, 'grad_norm': 0.3904782831668854, 'learning_rate': 0.00041015625, 'epoch': 0.01, 'num_input_tokens_seen': 110100480}\n{'loss': 6.9473, 'grad_norm': 0.3953755795955658, 'learning_rate': 0.0004140625, 'epoch': 0.01, 'num_input_tokens_seen': 111149056}\n{'loss': 6.9071, 'grad_norm': 0.43107134103775024, 'learning_rate': 0.00041796875, 'epoch': 0.01, 'num_input_tokens_seen': 112197632}\n{'loss': 6.9277, 'grad_norm': 0.33989447355270386, 'learning_rate': 0.000421875, 'epoch': 0.01, 'num_input_tokens_seen': 113246208}\n{'loss': 6.914, 'grad_norm': 0.3267095983028412, 'learning_rate': 0.00042578125, 'epoch': 0.01, 'num_input_tokens_seen': 114294784}\n{'loss': 6.6865, 'grad_norm': 0.4201946556568146, 'learning_rate': 0.0004296875, 'epoch': 0.01, 'num_input_tokens_seen': 115343360}\n{'loss': 6.8229, 'grad_norm': 0.345426082611084, 'learning_rate': 0.00043359375, 'epoch': 0.01, 'num_input_tokens_seen': 116391936}\n{'loss': 6.8599, 'grad_norm': 0.4104400873184204, 'learning_rate': 0.0004375, 'epoch': 0.01, 'num_input_tokens_seen': 117440512}\n{'loss': 6.7656, 'grad_norm': 0.6487549543380737, 'learning_rate': 0.00044140625, 'epoch': 0.01, 'num_input_tokens_seen': 118489088}\n{'loss': 6.8654, 'grad_norm': 1.5497283935546875, 'learning_rate': 0.0004453125, 'epoch': 0.01, 'num_input_tokens_seen': 119537664}\n{'loss': 6.8207, 'grad_norm': 1.9772824048995972, 'learning_rate': 0.00044921875, 'epoch': 0.01, 'num_input_tokens_seen': 120586240}\n{'loss': 6.7802, 'grad_norm': 0.9341455101966858, 'learning_rate': 0.000453125, 'epoch': 0.01, 'num_input_tokens_seen': 121634816}\n{'loss': 6.8017, 'grad_norm': 1.3528856039047241, 'learning_rate': 0.00045703125, 'epoch': 0.01, 'num_input_tokens_seen': 122683392}\n{'loss': 6.8344, 'grad_norm': 0.5852281451225281, 'learning_rate': 0.00046093750000000003, 'epoch': 0.01, 'num_input_tokens_seen': 123731968}\n{'loss': 6.8259, 'grad_norm': 0.9776580929756165, 'learning_rate': 0.00046484375000000003, 'epoch': 0.01, 'num_input_tokens_seen': 124780544}\n{'loss': 6.7581, 'grad_norm': 1.0398296117782593, 'learning_rate': 0.00046875, 'epoch': 0.01, 'num_input_tokens_seen': 125829120}\n{'loss': 6.7795, 'grad_norm': 1.1206268072128296, 'learning_rate': 0.00047265625, 'epoch': 0.01, 'num_input_tokens_seen': 126877696}\n{'loss': 6.5667, 'grad_norm': 0.6790318489074707, 'learning_rate': 0.0004765625, 'epoch': 0.01, 'num_input_tokens_seen': 127926272}\n{'loss': 6.7297, 'grad_norm': 1.2275055646896362, 'learning_rate': 0.00048046875, 'epoch': 0.02, 'num_input_tokens_seen': 128974848}\n{'loss': 6.7104, 'grad_norm': 1.1354466676712036, 'learning_rate': 0.000484375, 'epoch': 0.02, 'num_input_tokens_seen': 130023424}\n{'loss': 6.7025, 'grad_norm': 0.9035728573799133, 'learning_rate': 0.00048828125, 'epoch': 0.02, 'num_input_tokens_seen': 131072000}\n{'loss': 6.6391, 'grad_norm': 1.3942680358886719, 'learning_rate': 0.0004921875, 'epoch': 0.02, 'num_input_tokens_seen': 132120576}\n{'loss': 6.6011, 'grad_norm': 0.7435236573219299, 'learning_rate': 0.00049609375, 'epoch': 0.02, 'num_input_tokens_seen': 133169152}\n{'loss': 6.5135, 'grad_norm': 0.5970368385314941, 'learning_rate': 0.0005, 'epoch': 0.02, 'num_input_tokens_seen': 134217728}\n{'eval_loss': 6.573822021484375, 'eval_runtime': 629.9441, 'eval_samples_per_second': 26.009, 'eval_steps_per_second': 0.203, 'epoch': 0.02, 'num_input_tokens_seen': 134217728}\n{'loss': 6.5509, 'grad_norm': 0.7936264276504517, 'learning_rate': 0.00050390625, 'epoch': 0.02, 'num_input_tokens_seen': 135266304}\n{'loss': 6.6008, 'grad_norm': 0.6225885152816772, 'learning_rate': 0.0005078125, 'epoch': 0.02, 'num_input_tokens_seen': 136314880}\n{'loss': 6.4821, 'grad_norm': 0.5519376993179321, 'learning_rate': 0.00051171875, 'epoch': 0.02, 'num_input_tokens_seen': 137363456}\n{'loss': 6.3411, 'grad_norm': 0.5908603668212891, 'learning_rate': 0.000515625, 'epoch': 0.02, 'num_input_tokens_seen': 138412032}\n{'loss': 6.3464, 'grad_norm': 0.5101401209831238, 'learning_rate': 0.00051953125, 'epoch': 0.02, 'num_input_tokens_seen': 139460608}\n{'loss': 6.3638, 'grad_norm': 0.7352246046066284, 'learning_rate': 0.0005234375, 'epoch': 0.02, 'num_input_tokens_seen': 140509184}\n{'loss': 6.3429, 'grad_norm': 0.49651673436164856, 'learning_rate': 0.00052734375, 'epoch': 0.02, 'num_input_tokens_seen': 141557760}\n{'loss': 6.2987, 'grad_norm': 0.4835755527019501, 'learning_rate': 0.00053125, 'epoch': 0.02, 'num_input_tokens_seen': 142606336}\n{'loss': 6.2982, 'grad_norm': 0.5940163731575012, 'learning_rate': 0.00053515625, 'epoch': 0.02, 'num_input_tokens_seen': 143654912}\n{'loss': 6.267, 'grad_norm': 0.7658674120903015, 'learning_rate': 0.0005390625, 'epoch': 0.02, 'num_input_tokens_seen': 144703488}\n{'loss': 6.2102, 'grad_norm': 0.6704416275024414, 'learning_rate': 0.00054296875, 'epoch': 0.02, 'num_input_tokens_seen': 145752064}\n{'loss': 6.1956, 'grad_norm': 0.6615312099456787, 'learning_rate': 0.000546875, 'epoch': 0.02, 'num_input_tokens_seen': 146800640}\n{'loss': 6.286, 'grad_norm': 0.7957404255867004, 'learning_rate': 0.0005507812500000001, 'epoch': 0.02, 'num_input_tokens_seen': 147849216}\n{'loss': 6.2483, 'grad_norm': 0.6477276682853699, 'learning_rate': 0.0005546875000000001, 'epoch': 0.02, 'num_input_tokens_seen': 148897792}\n{'loss': 6.0944, 'grad_norm': 0.5753227472305298, 'learning_rate': 0.0005585937500000001, 'epoch': 0.02, 'num_input_tokens_seen': 149946368}\n{'loss': 6.0995, 'grad_norm': 0.5871054530143738, 'learning_rate': 0.0005625000000000001, 'epoch': 0.02, 'num_input_tokens_seen': 150994944}\n{'loss': 6.112, 'grad_norm': 0.7046136856079102, 'learning_rate': 0.00056640625, 'epoch': 0.02, 'num_input_tokens_seen': 152043520}\n{'loss': 6.102, 'grad_norm': 0.9357424378395081, 'learning_rate': 0.0005703125, 'epoch': 0.02, 'num_input_tokens_seen': 153092096}\n{'loss': 6.1407, 'grad_norm': 1.0577837228775024, 'learning_rate': 0.00057421875, 'epoch': 0.02, 'num_input_tokens_seen': 154140672}\n{'loss': 5.9836, 'grad_norm': 0.7795257568359375, 'learning_rate': 0.000578125, 'epoch': 0.02, 'num_input_tokens_seen': 155189248}\n{'loss': 6.1041, 'grad_norm': 0.8117634057998657, 'learning_rate': 0.00058203125, 'epoch': 0.02, 'num_input_tokens_seen': 156237824}\n{'loss': 5.9474, 'grad_norm': 0.8311094045639038, 'learning_rate': 0.0005859375, 'epoch': 0.02, 'num_input_tokens_seen': 157286400}\n{'loss': 5.9365, 'grad_norm': 0.8269851803779602, 'learning_rate': 0.00058984375, 'epoch': 0.02, 'num_input_tokens_seen': 158334976}\n{'loss': 5.9668, 'grad_norm': 0.701510488986969, 'learning_rate': 0.00059375, 'epoch': 0.02, 'num_input_tokens_seen': 159383552}\n{'loss': 5.9874, 'grad_norm': 0.49938252568244934, 'learning_rate': 0.00059765625, 'epoch': 0.02, 'num_input_tokens_seen': 160432128}\n{'loss': 5.8505, 'grad_norm': 0.6981683969497681, 'learning_rate': 0.0006015625, 'epoch': 0.02, 'num_input_tokens_seen': 161480704}\n{'loss': 6.0156, 'grad_norm': 0.5023297071456909, 'learning_rate': 0.00060546875, 'epoch': 0.02, 'num_input_tokens_seen': 162529280}\n{'loss': 5.8299, 'grad_norm': 0.6075630187988281, 'learning_rate': 0.000609375, 'epoch': 0.02, 'num_input_tokens_seen': 163577856}\n{'loss': 5.8203, 'grad_norm': 0.6051607728004456, 'learning_rate': 0.00061328125, 'epoch': 0.02, 'num_input_tokens_seen': 164626432}\n{'loss': 5.7705, 'grad_norm': 0.6384783983230591, 'learning_rate': 0.0006171875, 'epoch': 0.02, 'num_input_tokens_seen': 165675008}\n{'loss': 5.791, 'grad_norm': 0.5084705948829651, 'learning_rate': 0.00062109375, 'epoch': 0.02, 'num_input_tokens_seen': 166723584}\n{'loss': 5.6743, 'grad_norm': 0.4278322160243988, 'learning_rate': 0.000625, 'epoch': 0.02, 'num_input_tokens_seen': 167772160}\n{'loss': 5.7112, 'grad_norm': 0.5151192545890808, 'learning_rate': 0.00062890625, 'epoch': 0.02, 'num_input_tokens_seen': 168820736}\n{'loss': 5.5128, 'grad_norm': 0.6542677283287048, 'learning_rate': 0.0006328125, 'epoch': 0.02, 'num_input_tokens_seen': 169869312}\n{'loss': 5.6735, 'grad_norm': 0.6016008257865906, 'learning_rate': 0.00063671875, 'epoch': 0.02, 'num_input_tokens_seen': 170917888}\n{'loss': 5.6525, 'grad_norm': 0.48695647716522217, 'learning_rate': 0.000640625, 'epoch': 0.02, 'num_input_tokens_seen': 171966464}\n{'loss': 5.6051, 'grad_norm': 0.5894989371299744, 'learning_rate': 0.00064453125, 'epoch': 0.02, 'num_input_tokens_seen': 173015040}\n{'loss': 5.6377, 'grad_norm': 0.7626883387565613, 'learning_rate': 0.0006484375, 'epoch': 0.02, 'num_input_tokens_seen': 174063616}\n{'loss': 5.6038, 'grad_norm': 0.745198130607605, 'learning_rate': 0.00065234375, 'epoch': 0.02, 'num_input_tokens_seen': 175112192}\n{'loss': 5.5465, 'grad_norm': 0.7876908779144287, 'learning_rate': 0.00065625, 'epoch': 0.02, 'num_input_tokens_seen': 176160768}\n{'loss': 5.5903, 'grad_norm': 0.7416785359382629, 'learning_rate': 0.00066015625, 'epoch': 0.02, 'num_input_tokens_seen': 177209344}\n{'loss': 5.4993, 'grad_norm': 0.4493878185749054, 'learning_rate': 0.0006640625, 'epoch': 0.02, 'num_input_tokens_seen': 178257920}\n{'loss': 5.5612, 'grad_norm': 0.5095419883728027, 'learning_rate': 0.00066796875, 'epoch': 0.02, 'num_input_tokens_seen': 179306496}\n{'loss': 5.378, 'grad_norm': 0.6330733895301819, 'learning_rate': 0.0006718750000000001, 'epoch': 0.02, 'num_input_tokens_seen': 180355072}\n{'loss': 5.4875, 'grad_norm': 0.4710595905780792, 'learning_rate': 0.0006757812500000001, 'epoch': 0.02, 'num_input_tokens_seen': 181403648}\n{'loss': 5.4221, 'grad_norm': 0.5276287198066711, 'learning_rate': 0.0006796875000000001, 'epoch': 0.02, 'num_input_tokens_seen': 182452224}\n{'loss': 5.308, 'grad_norm': 0.6985499858856201, 'learning_rate': 0.0006835937500000001, 'epoch': 0.02, 'num_input_tokens_seen': 183500800}\n{'loss': 5.4455, 'grad_norm': 0.4874110519886017, 'learning_rate': 0.0006875, 'epoch': 0.02, 'num_input_tokens_seen': 184549376}\n{'loss': 5.476, 'grad_norm': 0.5807638764381409, 'learning_rate': 0.00069140625, 'epoch': 0.02, 'num_input_tokens_seen': 185597952}\n{'loss': 5.2876, 'grad_norm': 0.5431288480758667, 'learning_rate': 0.0006953125, 'epoch': 0.02, 'num_input_tokens_seen': 186646528}\n{'loss': 5.3881, 'grad_norm': 0.7681945562362671, 'learning_rate': 0.00069921875, 'epoch': 0.02, 'num_input_tokens_seen': 187695104}\n{'loss': 5.4006, 'grad_norm': 0.7372023463249207, 'learning_rate': 0.000703125, 'epoch': 0.02, 'num_input_tokens_seen': 188743680}\n{'loss': 5.3813, 'grad_norm': 0.7354347109794617, 'learning_rate': 0.00070703125, 'epoch': 0.02, 'num_input_tokens_seen': 189792256}\n{'loss': 5.3393, 'grad_norm': 0.5908933281898499, 'learning_rate': 0.0007109375, 'epoch': 0.02, 'num_input_tokens_seen': 190840832}\n{'loss': 5.3024, 'grad_norm': 0.5665153861045837, 'learning_rate': 0.00071484375, 'epoch': 0.02, 'num_input_tokens_seen': 191889408}\n{'loss': 5.2782, 'grad_norm': 0.5930947661399841, 'learning_rate': 0.00071875, 'epoch': 0.02, 'num_input_tokens_seen': 192937984}\n{'loss': 5.3199, 'grad_norm': 0.5926457643508911, 'learning_rate': 0.00072265625, 'epoch': 0.02, 'num_input_tokens_seen': 193986560}\n{'loss': 5.2949, 'grad_norm': 0.548610270023346, 'learning_rate': 0.0007265625, 'epoch': 0.02, 'num_input_tokens_seen': 195035136}\n{'loss': 5.3143, 'grad_norm': 0.6023995280265808, 'learning_rate': 0.00073046875, 'epoch': 0.02, 'num_input_tokens_seen': 196083712}\n{'loss': 5.2982, 'grad_norm': 1.0335254669189453, 'learning_rate': 0.000734375, 'epoch': 0.02, 'num_input_tokens_seen': 197132288}\n{'loss': 5.2933, 'grad_norm': 1.2596269845962524, 'learning_rate': 0.00073828125, 'epoch': 0.02, 'num_input_tokens_seen': 198180864}\n{'loss': 5.2524, 'grad_norm': 0.6956535577774048, 'learning_rate': 0.0007421875, 'epoch': 0.02, 'num_input_tokens_seen': 199229440}\n{'loss': 5.3543, 'grad_norm': 0.946761429309845, 'learning_rate': 0.00074609375, 'epoch': 0.02, 'num_input_tokens_seen': 200278016}\n{'loss': 5.1616, 'grad_norm': 0.9568974375724792, 'learning_rate': 0.00075, 'epoch': 0.02, 'num_input_tokens_seen': 201326592}\n[2025-03-10 18:01:06 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: ba6e4c51-f4a4-407e-9934-3772550b7ce9)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk1/example_holdout_2770.jsonl.zst\n[2025-03-10 18:01:06 WARNING] Retrying in 1s [Retry 1/5].\n[2025-03-10 18:02:30 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: bdf2cfaa-7e0b-46a0-bec1-b1e573fa7998)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk4/example_holdout_4386.jsonl.zst\n[2025-03-10 18:02:30 WARNING] Retrying in 1s [Retry 1/5].\n[2025-03-10 18:02:44 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 1dc5e455-8042-4c7b-9b97-5ded33dfea34)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk1/example_holdout_1763.jsonl.zst\n[2025-03-10 18:02:44 WARNING] Retrying in 1s [Retry 1/5].\n[2025-03-10 18:04:45 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 9cf29917-8111-41fe-80aa-953df65c5803)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk4/example_holdout_5509.jsonl.zst\n[2025-03-10 18:04:45 WARNING] Retrying in 1s [Retry 1/5].\n[2025-03-10 18:05:26 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 2515a0b0-3d81-409f-940c-e78ed5e2dbf8)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk4/example_holdout_3093.jsonl.zst\n[2025-03-10 18:05:26 WARNING] Retrying in 1s [Retry 1/5].\n[2025-03-10 18:06:39 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: a4c1e0c7-1c7a-4377-bc7e-6f076473072b)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk4/example_holdout_3422.jsonl.zst\n[2025-03-10 18:06:39 WARNING] Retrying in 1s [Retry 1/5].\n[2025-03-10 18:07:37 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: c7b0d366-db86-4d0c-a4e0-be251d26519e)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk3/example_holdout_2250.jsonl.zst\n[2025-03-10 18:07:37 WARNING] Retrying in 1s [Retry 1/5].\n[2025-03-10 18:09:23 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: b0df5a1a-4836-46cf-8e45-58a7c1553309)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk3/example_holdout_6161.jsonl.zst\n[2025-03-10 18:09:23 WARNING] Retrying in 1s [Retry 1/5].\n[2025-03-10 18:09:44 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: c1d97368-c0ae-45bb-ae10-5559b3ebc4e4)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk3/example_holdout_5782.jsonl.zst\n[2025-03-10 18:09:44 WARNING] Retrying in 1s [Retry 1/5].\n{'eval_loss': 5.276012420654297, 'eval_runtime': 754.8295, 'eval_samples_per_second': 21.706, 'eval_steps_per_second': 0.17, 'epoch': 0.02, 'num_input_tokens_seen': 201326592}\n{'loss': 5.2363, 'grad_norm': 0.8435476422309875, 'learning_rate': 0.00075390625, 'epoch': 0.02, 'num_input_tokens_seen': 202375168}\n{'loss': 5.1035, 'grad_norm': 1.1267820596694946, 'learning_rate': 0.0007578125, 'epoch': 0.02, 'num_input_tokens_seen': 203423744}\n{'loss': 5.3017, 'grad_norm': 0.8555666208267212, 'learning_rate': 0.00076171875, 'epoch': 0.02, 'num_input_tokens_seen': 204472320}\n{'loss': 5.1679, 'grad_norm': 0.7608171105384827, 'learning_rate': 0.000765625, 'epoch': 0.02, 'num_input_tokens_seen': 205520896}\n{'loss': 5.2326, 'grad_norm': 0.6787221431732178, 'learning_rate': 0.00076953125, 'epoch': 0.02, 'num_input_tokens_seen': 206569472}\n{'loss': 5.144, 'grad_norm': 0.6404955983161926, 'learning_rate': 0.0007734375, 'epoch': 0.02, 'num_input_tokens_seen': 207618048}\n{'loss': 5.1933, 'grad_norm': 0.6099393367767334, 'learning_rate': 0.00077734375, 'epoch': 0.02, 'num_input_tokens_seen': 208666624}\n{'loss': 5.0498, 'grad_norm': 0.5971768498420715, 'learning_rate': 0.00078125, 'epoch': 0.02, 'num_input_tokens_seen': 209715200}\n{'loss': 5.1443, 'grad_norm': 0.642633318901062, 'learning_rate': 0.00078515625, 'epoch': 0.02, 'num_input_tokens_seen': 210763776}\n{'loss': 5.2125, 'grad_norm': 0.706398606300354, 'learning_rate': 0.0007890625, 'epoch': 0.02, 'num_input_tokens_seen': 211812352}\n{'loss': 5.1882, 'grad_norm': 0.817449688911438, 'learning_rate': 0.00079296875, 'epoch': 0.02, 'num_input_tokens_seen': 212860928}\n{'loss': 5.0905, 'grad_norm': 0.9392185807228088, 'learning_rate': 0.0007968750000000001, 'epoch': 0.02, 'num_input_tokens_seen': 213909504}\n{'loss': 5.059, 'grad_norm': 0.5305852890014648, 'learning_rate': 0.0008007812500000001, 'epoch': 0.03, 'num_input_tokens_seen': 214958080}\n{'loss': 5.0838, 'grad_norm': 0.7662672996520996, 'learning_rate': 0.0008046875000000001, 'epoch': 0.03, 'num_input_tokens_seen': 216006656}\n{'loss': 5.0112, 'grad_norm': 0.5768160223960876, 'learning_rate': 0.0008085937500000001, 'epoch': 0.03, 'num_input_tokens_seen': 217055232}\n{'loss': 4.9684, 'grad_norm': 0.5972586870193481, 'learning_rate': 0.0008125000000000001, 'epoch': 0.03, 'num_input_tokens_seen': 218103808}\n{'loss': 5.0764, 'grad_norm': 0.559498131275177, 'learning_rate': 0.00081640625, 'epoch': 0.03, 'num_input_tokens_seen': 219152384}\n{'loss': 5.0117, 'grad_norm': 0.555585503578186, 'learning_rate': 0.0008203125, 'epoch': 0.03, 'num_input_tokens_seen': 220200960}\n{'loss': 5.1955, 'grad_norm': 0.6180793046951294, 'learning_rate': 0.00082421875, 'epoch': 0.03, 'num_input_tokens_seen': 221249536}\n{'loss': 5.1265, 'grad_norm': 0.5784006118774414, 'learning_rate': 0.000828125, 'epoch': 0.03, 'num_input_tokens_seen': 222298112}\n{'loss': 5.03, 'grad_norm': 0.5200456380844116, 'learning_rate': 0.00083203125, 'epoch': 0.03, 'num_input_tokens_seen': 223346688}\n{'loss': 5.051, 'grad_norm': 0.5112505555152893, 'learning_rate': 0.0008359375, 'epoch': 0.03, 'num_input_tokens_seen': 224395264}\n{'loss': 5.0994, 'grad_norm': 0.44979697465896606, 'learning_rate': 0.00083984375, 'epoch': 0.03, 'num_input_tokens_seen': 225443840}\n{'loss': 4.94, 'grad_norm': 0.46642380952835083, 'learning_rate': 0.00084375, 'epoch': 0.03, 'num_input_tokens_seen': 226492416}\n{'loss': 5.0562, 'grad_norm': 0.49667519330978394, 'learning_rate': 0.00084765625, 'epoch': 0.03, 'num_input_tokens_seen': 227540992}\n{'loss': 4.9217, 'grad_norm': 0.4302496314048767, 'learning_rate': 0.0008515625, 'epoch': 0.03, 'num_input_tokens_seen': 228589568}\n{'loss': 4.8588, 'grad_norm': 0.5326887369155884, 'learning_rate': 0.00085546875, 'epoch': 0.03, 'num_input_tokens_seen': 229638144}\n{'loss': 4.8501, 'grad_norm': 0.45604026317596436, 'learning_rate': 0.000859375, 'epoch': 0.03, 'num_input_tokens_seen': 230686720}\n{'loss': 4.8774, 'grad_norm': 0.4497997462749481, 'learning_rate': 0.00086328125, 'epoch': 0.03, 'num_input_tokens_seen': 231735296}\n{'loss': 5.0143, 'grad_norm': 0.526670515537262, 'learning_rate': 0.0008671875, 'epoch': 0.03, 'num_input_tokens_seen': 232783872}\n{'loss': 4.9512, 'grad_norm': 0.5823948979377747, 'learning_rate': 0.00087109375, 'epoch': 0.03, 'num_input_tokens_seen': 233832448}\n{'loss': 4.915, 'grad_norm': 0.6516634821891785, 'learning_rate': 0.000875, 'epoch': 0.03, 'num_input_tokens_seen': 234881024}\n{'loss': 4.9318, 'grad_norm': 0.7564677596092224, 'learning_rate': 0.00087890625, 'epoch': 0.03, 'num_input_tokens_seen': 235929600}\n{'loss': 4.9041, 'grad_norm': 0.7170491814613342, 'learning_rate': 0.0008828125, 'epoch': 0.03, 'num_input_tokens_seen': 236978176}\n{'loss': 4.9727, 'grad_norm': 0.7671059966087341, 'learning_rate': 0.00088671875, 'epoch': 0.03, 'num_input_tokens_seen': 238026752}\n{'loss': 4.7895, 'grad_norm': 0.8752806782722473, 'learning_rate': 0.000890625, 'epoch': 0.03, 'num_input_tokens_seen': 239075328}\n{'loss': 4.8845, 'grad_norm': 0.8313667178153992, 'learning_rate': 0.00089453125, 'epoch': 0.03, 'num_input_tokens_seen': 240123904}\n{'loss': 4.8325, 'grad_norm': 0.9223323464393616, 'learning_rate': 0.0008984375, 'epoch': 0.03, 'num_input_tokens_seen': 241172480}\n{'loss': 4.8991, 'grad_norm': 0.7362072467803955, 'learning_rate': 0.00090234375, 'epoch': 0.03, 'num_input_tokens_seen': 242221056}\n{'loss': 4.7443, 'grad_norm': 0.6667400598526001, 'learning_rate': 0.00090625, 'epoch': 0.03, 'num_input_tokens_seen': 243269632}\n{'loss': 4.8913, 'grad_norm': 0.5431771874427795, 'learning_rate': 0.00091015625, 'epoch': 0.03, 'num_input_tokens_seen': 244318208}\n{'loss': 4.8997, 'grad_norm': 0.5542160272598267, 'learning_rate': 0.0009140625, 'epoch': 0.03, 'num_input_tokens_seen': 245366784}\n{'loss': 4.8448, 'grad_norm': 0.6110911965370178, 'learning_rate': 0.0009179687500000001, 'epoch': 0.03, 'num_input_tokens_seen': 246415360}\n{'loss': 4.7975, 'grad_norm': 0.5550041794776917, 'learning_rate': 0.0009218750000000001, 'epoch': 0.03, 'num_input_tokens_seen': 247463936}\n{'loss': 4.87, 'grad_norm': 0.4778221547603607, 'learning_rate': 0.0009257812500000001, 'epoch': 0.03, 'num_input_tokens_seen': 248512512}\n{'loss': 4.7594, 'grad_norm': 0.35899603366851807, 'learning_rate': 0.0009296875000000001, 'epoch': 0.03, 'num_input_tokens_seen': 249561088}\n{'loss': 4.8338, 'grad_norm': 0.494094580411911, 'learning_rate': 0.0009335937500000001, 'epoch': 0.03, 'num_input_tokens_seen': 250609664}\n{'loss': 4.7424, 'grad_norm': 0.4671477675437927, 'learning_rate': 0.0009375, 'epoch': 0.03, 'num_input_tokens_seen': 251658240}\n{'loss': 4.7593, 'grad_norm': 0.4691649079322815, 'learning_rate': 0.00094140625, 'epoch': 0.03, 'num_input_tokens_seen': 252706816}\n{'loss': 4.7869, 'grad_norm': 0.6212939023971558, 'learning_rate': 0.0009453125, 'epoch': 0.03, 'num_input_tokens_seen': 253755392}\n{'loss': 4.7925, 'grad_norm': 0.621306300163269, 'learning_rate': 0.00094921875, 'epoch': 0.03, 'num_input_tokens_seen': 254803968}\n{'loss': 4.7714, 'grad_norm': 0.6991429328918457, 'learning_rate': 0.000953125, 'epoch': 0.03, 'num_input_tokens_seen': 255852544}\n{'loss': 5.2726, 'grad_norm': 1.016664743423462, 'learning_rate': 0.00095703125, 'epoch': 0.03, 'num_input_tokens_seen': 256901120}\n{'loss': 4.9125, 'grad_norm': 1.3091747760772705, 'learning_rate': 0.0009609375, 'epoch': 0.03, 'num_input_tokens_seen': 257949696}\n{'loss': 4.839, 'grad_norm': 1.2617076635360718, 'learning_rate': 0.00096484375, 'epoch': 0.03, 'num_input_tokens_seen': 258998272}\n{'loss': 4.8412, 'grad_norm': 0.9403041005134583, 'learning_rate': 0.00096875, 'epoch': 0.03, 'num_input_tokens_seen': 260046848}\n{'loss': 5.0193, 'grad_norm': 0.9802642464637756, 'learning_rate': 0.00097265625, 'epoch': 0.03, 'num_input_tokens_seen': 261095424}\n{'loss': 4.7372, 'grad_norm': 0.9636861085891724, 'learning_rate': 0.0009765625, 'epoch': 0.03, 'num_input_tokens_seen': 262144000}\n{'loss': 4.7878, 'grad_norm': 0.7803710699081421, 'learning_rate': 0.00098046875, 'epoch': 0.03, 'num_input_tokens_seen': 263192576}\n{'loss': 4.8126, 'grad_norm': 0.7087182402610779, 'learning_rate': 0.000984375, 'epoch': 0.03, 'num_input_tokens_seen': 264241152}\n{'loss': 4.7252, 'grad_norm': 0.7220279574394226, 'learning_rate': 0.00098828125, 'epoch': 0.03, 'num_input_tokens_seen': 265289728}\n{'loss': 4.7419, 'grad_norm': 0.6956494450569153, 'learning_rate': 0.0009921875, 'epoch': 0.03, 'num_input_tokens_seen': 266338304}\n{'loss': 4.8041, 'grad_norm': 0.8009976148605347, 'learning_rate': 0.00099609375, 'epoch': 0.03, 'num_input_tokens_seen': 267386880}\n{'loss': 4.7016, 'grad_norm': 0.6665300130844116, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 268435456}\n{'eval_loss': 4.753816604614258, 'eval_runtime': 661.8529, 'eval_samples_per_second': 24.755, 'eval_steps_per_second': 0.193, 'epoch': 0.03, 'num_input_tokens_seen': 268435456}\n{'loss': 4.6762, 'grad_norm': 0.5311985611915588, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 269484032}\n{'loss': 4.6296, 'grad_norm': 0.5160760879516602, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 270532608}\n{'loss': 4.7422, 'grad_norm': 0.5964047312736511, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 271581184}\n{'loss': 4.7396, 'grad_norm': 0.4793979227542877, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 272629760}\n{'loss': 4.733, 'grad_norm': 0.5280688405036926, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 273678336}\n{'loss': 4.9591, 'grad_norm': 0.8669152855873108, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 274726912}\n{'loss': 4.7953, 'grad_norm': 0.8417720198631287, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 275775488}\n{'loss': 4.7972, 'grad_norm': 0.9349585175514221, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 276824064}\n{'loss': 4.7233, 'grad_norm': 0.8441230654716492, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 277872640}\n{'loss': 4.8032, 'grad_norm': 0.7163352370262146, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 278921216}\n{'loss': 4.4369, 'grad_norm': 1.0364480018615723, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 279969792}\n{'loss': 4.557, 'grad_norm': 1.012042760848999, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 281018368}\n{'loss': 4.7696, 'grad_norm': 1.1818541288375854, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 282066944}\n{'loss': 4.7835, 'grad_norm': 0.8296499848365784, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 283115520}\n{'loss': 4.761, 'grad_norm': 0.6920194625854492, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 284164096}\n{'loss': 4.6239, 'grad_norm': 0.8495435118675232, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 285212672}\n{'loss': 4.6914, 'grad_norm': 0.6536931991577148, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 286261248}\n{'loss': 4.776, 'grad_norm': 0.7161967754364014, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 287309824}\n{'loss': 4.7096, 'grad_norm': 0.5441194176673889, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 288358400}\n{'loss': 4.7278, 'grad_norm': 0.5437328219413757, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 289406976}\n{'loss': 4.6126, 'grad_norm': 0.49404028058052063, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 290455552}\n{'loss': 4.6594, 'grad_norm': 0.4274217188358307, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 291504128}\n{'loss': 4.6365, 'grad_norm': 0.48871853947639465, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 292552704}\n{'loss': 4.5999, 'grad_norm': 0.5101707577705383, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 293601280}\n{'loss': 4.5869, 'grad_norm': 0.4579870104789734, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 294649856}\n{'loss': 4.5993, 'grad_norm': 0.44694098830223083, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 295698432}\n{'loss': 4.6369, 'grad_norm': 0.42955130338668823, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 296747008}\n{'loss': 4.5973, 'grad_norm': 0.532283365726471, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 297795584}\n{'loss': 4.3953, 'grad_norm': 0.5553389191627502, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 298844160}\n{'loss': 4.5501, 'grad_norm': 0.4733176529407501, 'learning_rate': 0.001, 'epoch': 0.03, 'num_input_tokens_seen': 299892736}\n{'loss': 4.4896, 'grad_norm': 0.5510519742965698, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 300941312}\n{'loss': 4.348, 'grad_norm': 0.5312983393669128, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 301989888}\n{'loss': 4.4, 'grad_norm': 0.4173823297023773, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 303038464}\n{'loss': 4.4971, 'grad_norm': 0.4799824357032776, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 304087040}\n{'loss': 4.5507, 'grad_norm': 0.4494017958641052, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 305135616}\n{'loss': 4.5655, 'grad_norm': 0.36501485109329224, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 306184192}\n{'loss': 4.5189, 'grad_norm': 0.4833853840827942, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 307232768}\n{'loss': 4.5387, 'grad_norm': 0.5214531421661377, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 308281344}\n{'loss': 4.5509, 'grad_norm': 0.5383253693580627, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 309329920}\n{'loss': 4.4112, 'grad_norm': 0.5364778637886047, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 310378496}\n{'loss': 4.568, 'grad_norm': 0.3624066114425659, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 311427072}\n{'loss': 4.5289, 'grad_norm': 0.5469081401824951, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 312475648}\n{'loss': 4.4953, 'grad_norm': 0.5212593674659729, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 313524224}\n{'loss': 4.4614, 'grad_norm': 0.36742305755615234, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 314572800}\n{'loss': 4.4757, 'grad_norm': 0.43591663241386414, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 315621376}\n{'loss': 4.5321, 'grad_norm': 0.483548104763031, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 316669952}\n{'loss': 4.449, 'grad_norm': 0.3971082866191864, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 317718528}\n{'loss': 4.4539, 'grad_norm': 0.3416251540184021, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 318767104}\n{'loss': 4.3456, 'grad_norm': 0.45731472969055176, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 319815680}\n{'loss': 4.4179, 'grad_norm': 0.4462226331233978, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 320864256}\n{'loss': 4.3691, 'grad_norm': 0.3393065631389618, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 321912832}\n{'loss': 4.4361, 'grad_norm': 0.39659640192985535, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 322961408}\n{'loss': 4.4166, 'grad_norm': 0.42212849855422974, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 324009984}\n{'loss': 4.3931, 'grad_norm': 0.3403238356113434, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 325058560}\n{'loss': 4.3003, 'grad_norm': 0.3405858278274536, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 326107136}\n{'loss': 4.4339, 'grad_norm': 0.42516669631004333, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 327155712}\n{'loss': 4.4258, 'grad_norm': 0.4387160539627075, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 328204288}\n{'loss': 4.3774, 'grad_norm': 0.3546140193939209, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 329252864}\n{'loss': 4.3261, 'grad_norm': 0.3842155933380127, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 330301440}\n{'loss': 4.2843, 'grad_norm': 0.32807183265686035, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 331350016}\n{'loss': 4.3627, 'grad_norm': 0.3635430932044983, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 332398592}\n{'loss': 4.3304, 'grad_norm': 0.32113364338874817, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 333447168}\n{'loss': 4.258, 'grad_norm': 0.3261938989162445, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 334495744}\n{'loss': 4.392, 'grad_norm': 0.35287028551101685, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 335544320}\n{'eval_loss': 4.340233325958252, 'eval_runtime': 641.4064, 'eval_samples_per_second': 25.544, 'eval_steps_per_second': 0.2, 'epoch': 0.04, 'num_input_tokens_seen': 335544320}\n{'loss': 4.4095, 'grad_norm': 0.30875736474990845, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 336592896}\n{'loss': 3.8896, 'grad_norm': 0.6334038972854614, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 337641472}\n{'loss': 4.449, 'grad_norm': 0.5519331693649292, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 338690048}\n{'loss': 4.4388, 'grad_norm': 0.4262654185295105, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 339738624}\n{'loss': 4.3918, 'grad_norm': 0.4348645508289337, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 340787200}\n{'loss': 4.3677, 'grad_norm': 0.3858915865421295, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 341835776}\n{'loss': 4.3343, 'grad_norm': 0.4542510509490967, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 342884352}\n{'loss': 4.3196, 'grad_norm': 0.4413583278656006, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 343932928}\n{'loss': 4.322, 'grad_norm': 0.5200892686843872, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 344981504}\n{'loss': 4.2409, 'grad_norm': 0.4969848692417145, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 346030080}\n{'loss': 4.2263, 'grad_norm': 0.43436068296432495, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 347078656}\n{'loss': 4.2271, 'grad_norm': 0.4760046899318695, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 348127232}\n{'loss': 4.3567, 'grad_norm': 0.43881112337112427, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 349175808}\n{'loss': 4.2606, 'grad_norm': 0.5361112952232361, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 350224384}\n{'loss': 4.3831, 'grad_norm': 0.5959597229957581, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 351272960}\n{'loss': 4.2899, 'grad_norm': 0.6709368824958801, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 352321536}\n{'loss': 4.2263, 'grad_norm': 0.6585149168968201, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 353370112}\n{'loss': 4.3428, 'grad_norm': 0.5447191596031189, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 354418688}\n{'loss': 4.3642, 'grad_norm': 0.576545238494873, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 355467264}\n{'loss': 4.025, 'grad_norm': 0.7567218542098999, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 356515840}\n{'loss': 4.2593, 'grad_norm': 0.6053742170333862, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 357564416}\n{'loss': 4.2864, 'grad_norm': 0.54949551820755, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 358612992}\n{'loss': 4.3183, 'grad_norm': 0.4792100489139557, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 359661568}\n{'loss': 4.2957, 'grad_norm': 0.4366244077682495, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 360710144}\n{'loss': 4.3502, 'grad_norm': 0.5610309839248657, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 361758720}\n{'loss': 4.2673, 'grad_norm': 0.42132946848869324, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 362807296}\n{'loss': 4.2565, 'grad_norm': 0.45927727222442627, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 363855872}\n{'loss': 4.3009, 'grad_norm': 0.40793168544769287, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 364904448}\n{'loss': 4.2584, 'grad_norm': 0.3818293511867523, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 365953024}\n{'loss': 4.3187, 'grad_norm': 0.4942944645881653, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 367001600}\n{'loss': 4.2056, 'grad_norm': 0.5316190719604492, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 368050176}\n{'loss': 4.2403, 'grad_norm': 0.4738222658634186, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 369098752}\n{'loss': 4.244, 'grad_norm': 0.41153445839881897, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 370147328}\n{'loss': 4.2876, 'grad_norm': 0.35864201188087463, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 371195904}\n{'loss': 4.2457, 'grad_norm': 0.4317127466201782, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 372244480}\n{'loss': 4.2138, 'grad_norm': 0.4922076165676117, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 373293056}\n{'loss': 4.1875, 'grad_norm': 0.5150508880615234, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 374341632}\n{'loss': 4.1485, 'grad_norm': 0.40701162815093994, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 375390208}\n{'loss': 4.1062, 'grad_norm': 0.40378910303115845, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 376438784}\n{'loss': 4.226, 'grad_norm': 0.4435281753540039, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 377487360}\n{'loss': 4.2034, 'grad_norm': 0.37908127903938293, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 378535936}\n{'loss': 4.1502, 'grad_norm': 0.408202588558197, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 379584512}\n{'loss': 4.1623, 'grad_norm': 0.4542413651943207, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 380633088}\n{'loss': 4.206, 'grad_norm': 0.5084658861160278, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 381681664}\n{'loss': 4.1867, 'grad_norm': 0.432908833026886, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 382730240}\n{'loss': 4.2377, 'grad_norm': 0.38273656368255615, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 383778816}\n{'loss': 4.1443, 'grad_norm': 0.39886555075645447, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 384827392}\n{'loss': 4.16, 'grad_norm': 0.4073260724544525, 'learning_rate': 0.001, 'epoch': 0.04, 'num_input_tokens_seen': 385875968}\n{'loss': 4.0871, 'grad_norm': 0.46062660217285156, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 386924544}\n{'loss': 4.1655, 'grad_norm': 0.3555128574371338, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 387973120}\n{'loss': 4.1993, 'grad_norm': 0.35318323969841003, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 389021696}\n{'loss': 4.0745, 'grad_norm': 0.3469637632369995, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 390070272}\n{'loss': 4.1844, 'grad_norm': 0.3650517761707306, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 391118848}\n{'loss': 4.1744, 'grad_norm': 0.4310692846775055, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 392167424}\n{'loss': 4.1896, 'grad_norm': 0.465585857629776, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 393216000}\n{'loss': 4.0568, 'grad_norm': 0.5539769530296326, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 394264576}\n{'loss': 4.2642, 'grad_norm': 0.5437971949577332, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 395313152}\n{'loss': 4.1705, 'grad_norm': 0.6534202694892883, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 396361728}\n{'loss': 3.9844, 'grad_norm': 0.7271204590797424, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 397410304}\n{'loss': 4.105, 'grad_norm': 0.7395262122154236, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 398458880}\n{'loss': 4.2332, 'grad_norm': 0.9734097719192505, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 399507456}\n{'loss': 4.1501, 'grad_norm': 1.1519765853881836, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 400556032}\n{'loss': 4.0756, 'grad_norm': 0.7837873697280884, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 401604608}\n{'loss': 4.013, 'grad_norm': 0.8097010850906372, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 402653184}\n{'eval_loss': 4.120734214782715, 'eval_runtime': 626.8806, 'eval_samples_per_second': 26.136, 'eval_steps_per_second': 0.204, 'epoch': 0.05, 'num_input_tokens_seen': 402653184}\n{'loss': 4.0955, 'grad_norm': 0.6811020970344543, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 403701760}\n{'loss': 4.0917, 'grad_norm': 0.5382081270217896, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 404750336}\n{'loss': 4.0414, 'grad_norm': 0.4250117242336273, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 405798912}\n{'loss': 4.1051, 'grad_norm': 0.4233124256134033, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 406847488}\n{'loss': 4.1475, 'grad_norm': 0.41960859298706055, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 407896064}\n{'loss': 4.0322, 'grad_norm': 0.4991297423839569, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 408944640}\n{'loss': 4.0664, 'grad_norm': 0.43890711665153503, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 409993216}\n{'loss': 4.1126, 'grad_norm': 0.38538315892219543, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 411041792}\n{'loss': 4.0591, 'grad_norm': 0.41170960664749146, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 412090368}\n{'loss': 4.1145, 'grad_norm': 0.42465972900390625, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 413138944}\n{'loss': 4.0393, 'grad_norm': 0.4215935468673706, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 414187520}\n{'loss': 3.9509, 'grad_norm': 0.5031537413597107, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 415236096}\n{'loss': 3.9314, 'grad_norm': 0.5212794542312622, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 416284672}\n{'loss': 4.062, 'grad_norm': 0.5779813528060913, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 417333248}\n{'loss': 4.0264, 'grad_norm': 0.5523960590362549, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 418381824}\n{'loss': 4.0366, 'grad_norm': 0.501869797706604, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 419430400}\n{'loss': 4.016, 'grad_norm': 0.390077143907547, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 420478976}\n{'loss': 3.9438, 'grad_norm': 0.39393457770347595, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 421527552}\n{'loss': 3.9882, 'grad_norm': 0.3395244777202606, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 422576128}\n{'loss': 3.95, 'grad_norm': 0.3985426425933838, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 423624704}\n{'loss': 3.9708, 'grad_norm': 0.4353885352611542, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 424673280}\n{'loss': 3.9959, 'grad_norm': 0.39546582102775574, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 425721856}\n{'loss': 3.9475, 'grad_norm': 0.3725046217441559, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 426770432}\n{'loss': 3.8599, 'grad_norm': 0.5391167998313904, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 427819008}\n{'loss': 3.9765, 'grad_norm': 0.5383077263832092, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 428867584}\n{'loss': 3.8999, 'grad_norm': 0.4455236494541168, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 429916160}\n{'loss': 4.0357, 'grad_norm': 0.4489726722240448, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 430964736}\n{'loss': 3.992, 'grad_norm': 0.45914894342422485, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 432013312}\n{'loss': 3.9556, 'grad_norm': 0.5718650817871094, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 433061888}\n{'loss': 3.9797, 'grad_norm': 0.5529163479804993, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 434110464}\n{'loss': 3.9479, 'grad_norm': 0.4689369201660156, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 435159040}\n{'loss': 3.9358, 'grad_norm': 0.448303759098053, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 436207616}\n{'loss': 3.9699, 'grad_norm': 0.4203392565250397, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 437256192}\n{'loss': 3.8173, 'grad_norm': 0.4046834707260132, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 438304768}\n{'loss': 3.8183, 'grad_norm': 0.3998134136199951, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 439353344}\n{'loss': 3.8477, 'grad_norm': 0.4120945632457733, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 440401920}\n{'loss': 3.8486, 'grad_norm': 0.39726078510284424, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 441450496}\n{'loss': 3.942, 'grad_norm': 0.399142861366272, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 442499072}\n{'loss': 3.9038, 'grad_norm': 0.41262856125831604, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 443547648}\n{'loss': 3.8447, 'grad_norm': 0.4645870327949524, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 444596224}\n{'loss': 3.9215, 'grad_norm': 0.49330976605415344, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 445644800}\n{'loss': 4.5329, 'grad_norm': 4.813076972961426, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 446693376}\n{'loss': 3.763, 'grad_norm': 1.0100675821304321, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 447741952}\n{'loss': 3.9888, 'grad_norm': 1.2422761917114258, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 448790528}\n{'loss': 3.9209, 'grad_norm': 1.1251254081726074, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 449839104}\n{'loss': 4.1438, 'grad_norm': 1.926529049873352, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 450887680}\n{'loss': 4.0952, 'grad_norm': 1.2948275804519653, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 451936256}\n{'loss': 3.9411, 'grad_norm': 1.1000643968582153, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 452984832}\n{'loss': 3.988, 'grad_norm': 1.3160468339920044, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 454033408}\n{'loss': 4.0241, 'grad_norm': 1.0201517343521118, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 455081984}\n{'loss': 3.9875, 'grad_norm': 0.9689710140228271, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 456130560}\n{'loss': 3.8684, 'grad_norm': 1.045577049255371, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 457179136}\n{'loss': 3.865, 'grad_norm': 0.931566059589386, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 458227712}\n{'loss': 3.728, 'grad_norm': 0.945274293422699, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 459276288}\n{'loss': 3.955, 'grad_norm': 0.7679930925369263, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 460324864}\n{'loss': 4.4113, 'grad_norm': 0.889451801776886, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 461373440}\n{'loss': 3.8928, 'grad_norm': 0.9069199562072754, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 462422016}\n{'loss': 3.9624, 'grad_norm': 0.8945743441581726, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 463470592}\n{'loss': 3.9698, 'grad_norm': 0.7373656630516052, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 464519168}\n{'loss': 3.921, 'grad_norm': 0.6688440442085266, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 465567744}\n{'loss': 3.8908, 'grad_norm': 0.5442579984664917, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 466616320}\n{'loss': 3.9138, 'grad_norm': 0.5583804845809937, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 467664896}\n{'loss': 3.8731, 'grad_norm': 0.504666268825531, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 468713472}\n{'loss': 3.7961, 'grad_norm': 0.4965992867946625, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 469762048}\n{'eval_loss': 3.7728981971740723, 'eval_runtime': 616.374, 'eval_samples_per_second': 26.581, 'eval_steps_per_second': 0.208, 'epoch': 0.05, 'num_input_tokens_seen': 469762048}\n{'loss': 3.8829, 'grad_norm': 0.44414225220680237, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 470810624}\n{'loss': 3.6939, 'grad_norm': 0.5276159644126892, 'learning_rate': 0.001, 'epoch': 0.05, 'num_input_tokens_seen': 471859200}\n{'loss': 3.8173, 'grad_norm': 0.4666613042354584, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 472907776}\n{'loss': 3.6884, 'grad_norm': 0.4581243097782135, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 473956352}\n{'loss': 3.789, 'grad_norm': 0.4697781205177307, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 475004928}\n{'loss': 3.8791, 'grad_norm': 0.5336131453514099, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 476053504}\n{'loss': 3.8077, 'grad_norm': 0.5709654092788696, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 477102080}\n{'loss': 3.8421, 'grad_norm': 0.5592761039733887, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 478150656}\n{'loss': 3.8135, 'grad_norm': 0.4490680694580078, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 479199232}\n{'loss': 3.7535, 'grad_norm': 0.3931736648082733, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 480247808}\n{'loss': 3.7885, 'grad_norm': 0.41578060388565063, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 481296384}\n{'loss': 3.6255, 'grad_norm': 0.429817795753479, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 482344960}\n{'loss': 3.7202, 'grad_norm': 0.49616578221321106, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 483393536}\n 9%|▊ | 704/8192 [9:33:48<79:08:04, 38.05s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 0faae356-e828-4cff-9a49-42b397431927)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk4/example_holdout_185.jsonl.zst\n 9%|▊ | 704/8192 [9:38:28<79:08:04, 38.05s/it]Retrying in 1s [Retry 1/5].\n 9%|▊ | 704/8192 [9:38:28<79:08:04, 38.05s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 9557423f-6937-4f70-b50f-05b0c01f5bf3)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk4/example_holdout_4035.jsonl.zst\n 9%|▊ | 704/8192 [9:44:58<79:08:04, 38.05s/it]Retrying in 1s [Retry 1/5].\n 10%|█ | 832/8192 [11:28:20<80:32:25, 39.39s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 939d1d36-c607-4d3c-a0a0-8e447579340b)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk3/example_holdout_165.jsonl.zst\n 10%|█ | 832/8192 [11:30:25<80:32:25, 39.39s/it]Retrying in 1s [Retry 1/5].\n 10%|█ | 832/8192 [11:30:25<80:32:25, 39.39s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 0b99bfd1-07ae-46db-81fa-fc6ef0eabdbc)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk3/example_holdout_1529.jsonl.zst\n 10%|█ | 832/8192 [11:38:24<80:32:25, 39.39s/it]Retrying in 1s [Retry 1/5].\n 10%|█ | 832/8192 [11:38:24<80:32:25, 39.39s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: c208d1bb-5d13-45d2-9a01-1d5a2defa598)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk5/example_holdout_4562.jsonl.zst\n 10%|█ | 832/8192 [11:39:58<80:32:25, 39.39s/it]Retrying in 1s [Retry 1/5].\n 10%|█ | 832/8192 [11:39:58<80:32:25, 39.39s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 2bf98b5c-473b-4e00-aca2-b152efddb992)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk3/example_holdout_4414.jsonl.zst\n 10%|█ | 832/8192 [11:41:00<80:32:25, 39.39s/it]Retrying in 1s [Retry 1/5].\n 11%|█ | 896/8192 [12:24:54<77:09:28, 38.07s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 3b8321b9-2d88-4bfa-9eca-b201c444cba3)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk5/example_holdout_405.jsonl.zst\n 11%|█ | 896/8192 [12:25:55<77:09:28, 38.07s/it]Retrying in 1s [Retry 1/5].\n 11%|█ | 896/8192 [12:25:55<77:09:28, 38.07s/it]'(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: a98a238a-c0a4-4295-8502-316a89a7ae29)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk1/example_holdout_2524.jsonl.zst\n 11%|█ | 896/8192 [12:33:14<77:09:28, 38.07s/it]Retrying in 1s [Retry 1/5].\n 11%|█▏ | 922/8192 [12:52:49<76:09:46, 37.71s/it]'(ProtocolError('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')), '(Request ID: 36a7cc72-4605-416a-8742-59488d719150)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/train/chunk1/example_train_5267.jsonl.zst\n 11%|█▏ | 922/8192 [12:52:59<76:09:46, 37.71s/it]Retrying in 1s [Retry 1/5].\n 12%|█▏ | 943/8192 [13:06:07<76:15:57, 37.88s/it]\n{'loss': 3.7796, 'grad_norm': 0.4774172008037567, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 484442112}\n{'loss': 3.7779, 'grad_norm': 0.45830512046813965, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 485490688}\n{'loss': 3.6516, 'grad_norm': 0.4130597710609436, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 486539264}\n{'loss': 3.7018, 'grad_norm': 0.3804127275943756, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 487587840}\n{'loss': 3.6893, 'grad_norm': 0.36560356616973877, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 488636416}\n{'loss': 3.6362, 'grad_norm': 0.3827981948852539, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 489684992}\n{'loss': 3.5987, 'grad_norm': 0.37492236495018005, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 490733568}\n{'loss': 3.7165, 'grad_norm': 0.46995237469673157, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 491782144}\n{'loss': 3.6097, 'grad_norm': 0.4908960461616516, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 492830720}\n{'loss': 3.6035, 'grad_norm': 0.5318525433540344, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 493879296}\n{'loss': 3.6643, 'grad_norm': 0.4848596453666687, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 494927872}\n{'loss': 3.6586, 'grad_norm': 0.4421922266483307, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 495976448}\n{'loss': 3.5902, 'grad_norm': 0.4107126295566559, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 497025024}\n{'loss': 3.6937, 'grad_norm': 0.3975088894367218, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 498073600}\n{'loss': 3.6496, 'grad_norm': 0.4559416174888611, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 499122176}\n{'loss': 3.66, 'grad_norm': 0.41401296854019165, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 500170752}\n{'loss': 3.5551, 'grad_norm': 0.45235902070999146, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 501219328}\n{'loss': 3.4794, 'grad_norm': 0.427593857049942, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 502267904}\n{'loss': 3.5345, 'grad_norm': 0.4024144411087036, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 503316480}\n{'loss': 3.5784, 'grad_norm': 0.410284161567688, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 504365056}\n{'loss': 3.6177, 'grad_norm': 0.37683290243148804, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 505413632}\n{'loss': 3.5883, 'grad_norm': 0.417323499917984, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 506462208}\n{'loss': 3.5888, 'grad_norm': 0.4327872693538666, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 507510784}\n{'loss': 3.5891, 'grad_norm': 0.5366392731666565, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 508559360}\n{'loss': 3.3725, 'grad_norm': 0.45735156536102295, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 509607936}\n{'loss': 3.5674, 'grad_norm': 0.4255360960960388, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 510656512}\n{'loss': 3.3523, 'grad_norm': 0.6517689824104309, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 511705088}\n{'loss': 3.5901, 'grad_norm': 0.5713740587234497, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 512753664}\n{'loss': 3.542, 'grad_norm': 0.5570502281188965, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 513802240}\n{'loss': 3.4246, 'grad_norm': 0.6477808356285095, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 514850816}\n{'loss': 3.4954, 'grad_norm': 0.5195346474647522, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 515899392}\n{'loss': 3.6516, 'grad_norm': 0.5446246862411499, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 516947968}\n{'loss': 3.5955, 'grad_norm': 0.5475099086761475, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 517996544}\n{'loss': 3.5516, 'grad_norm': 0.4719395041465759, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 519045120}\n{'loss': 3.5439, 'grad_norm': 0.43647533655166626, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 520093696}\n{'loss': 3.579, 'grad_norm': 0.5048384070396423, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 521142272}\n{'loss': 3.4742, 'grad_norm': 0.4902295172214508, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 522190848}\n{'loss': 3.4363, 'grad_norm': 0.525496244430542, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 523239424}\n{'loss': 3.3658, 'grad_norm': 0.5224571824073792, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 524288000}\n{'loss': 3.4816, 'grad_norm': 0.45781856775283813, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 525336576}\n{'loss': 3.4612, 'grad_norm': 0.3764704763889313, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 526385152}\n{'loss': 3.5172, 'grad_norm': 0.3994409143924713, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 527433728}\n{'loss': 3.5462, 'grad_norm': 0.45144984126091003, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 528482304}\n{'loss': 3.5079, 'grad_norm': 0.4901409149169922, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 529530880}\n{'loss': 3.5187, 'grad_norm': 0.45689818263053894, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 530579456}\n{'loss': 3.4408, 'grad_norm': 0.4650699198246002, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 531628032}\n{'loss': 3.4019, 'grad_norm': 0.40419647097587585, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 532676608}\n{'loss': 3.5255, 'grad_norm': 0.3895981013774872, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 533725184}\n{'loss': 3.312, 'grad_norm': 0.46533191204071045, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 534773760}\n{'loss': 3.4233, 'grad_norm': 0.5021492838859558, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 535822336}\n{'loss': 3.4211, 'grad_norm': 0.6763796806335449, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 536870912}\n{'eval_loss': 3.38647198677063, 'eval_runtime': 681.5531, 'eval_samples_per_second': 24.039, 'eval_steps_per_second': 0.188, 'epoch': 0.06, 'num_input_tokens_seen': 536870912}\n{'loss': 3.2825, 'grad_norm': 0.75739586353302, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 537919488}\n{'loss': 3.4758, 'grad_norm': 0.49962809681892395, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 538968064}\n{'loss': 3.4105, 'grad_norm': 0.47640085220336914, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 540016640}\n{'loss': 3.4393, 'grad_norm': 0.4722411632537842, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 541065216}\n{'loss': 3.4254, 'grad_norm': 0.4715781807899475, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 542113792}\n{'loss': 3.3992, 'grad_norm': 0.474001407623291, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 543162368}\n{'loss': 3.4274, 'grad_norm': 0.48976385593414307, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 544210944}\n{'loss': 3.3255, 'grad_norm': 0.4819697141647339, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 545259520}\n{'loss': 3.3679, 'grad_norm': 0.37490880489349365, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 546308096}\n{'loss': 3.377, 'grad_norm': 0.4356544315814972, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 547356672}\n{'loss': 3.4294, 'grad_norm': 0.3786229193210602, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 548405248}\n{'loss': 3.2323, 'grad_norm': 0.4364008605480194, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 549453824}\n{'loss': 3.4615, 'grad_norm': 0.39242950081825256, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 550502400}\n{'loss': 3.3589, 'grad_norm': 0.4270903766155243, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 551550976}\n{'loss': 3.4366, 'grad_norm': 0.4204763174057007, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 552599552}\n{'loss': 3.3859, 'grad_norm': 0.554025411605835, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 553648128}\n{'loss': 3.2353, 'grad_norm': 0.5719075798988342, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 554696704}\n{'loss': 3.3798, 'grad_norm': 0.4803822338581085, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 555745280}\n{'loss': 3.1191, 'grad_norm': 0.5494056344032288, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 556793856}\n{'loss': 3.424, 'grad_norm': 0.4569101333618164, 'learning_rate': 0.001, 'epoch': 0.06, 'num_input_tokens_seen': 557842432}\n{'loss': 3.4299, 'grad_norm': 0.48103874921798706, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 558891008}\n{'loss': 3.3483, 'grad_norm': 0.44187718629837036, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 559939584}\n{'loss': 3.3196, 'grad_norm': 0.4359618127346039, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 560988160}\n{'loss': 3.4479, 'grad_norm': 0.37653473019599915, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 562036736}\n{'loss': 3.2509, 'grad_norm': 0.4397211968898773, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 563085312}\n{'loss': 3.4193, 'grad_norm': 0.5013746619224548, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 564133888}\n{'loss': 3.3391, 'grad_norm': 0.5044407844543457, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 565182464}\n{'loss': 3.3223, 'grad_norm': 0.45118412375450134, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 566231040}\n{'loss': 3.3041, 'grad_norm': 0.5617747902870178, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 567279616}\n{'loss': 3.3436, 'grad_norm': 0.5154598355293274, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 568328192}\n{'loss': 3.3739, 'grad_norm': 0.4647876024246216, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 569376768}\n{'loss': 3.3366, 'grad_norm': 0.3766598701477051, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 570425344}\n{'loss': 3.3098, 'grad_norm': 0.40857356786727905, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 571473920}\n{'loss': 3.0331, 'grad_norm': 0.4163903594017029, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 572522496}\n{'loss': 3.3184, 'grad_norm': 0.38519713282585144, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 573571072}\n{'loss': 3.3886, 'grad_norm': 0.38155344128608704, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 574619648}\n{'loss': 3.2855, 'grad_norm': 0.3684964179992676, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 575668224}\n{'loss': 3.0484, 'grad_norm': 0.3504279553890228, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 576716800}\n{'loss': 3.2702, 'grad_norm': 0.42653048038482666, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 577765376}\n{'loss': 3.312, 'grad_norm': 0.4263192415237427, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 578813952}\n{'loss': 3.3355, 'grad_norm': 0.4272316098213196, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 579862528}\n{'loss': 3.2806, 'grad_norm': 0.40996676683425903, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 580911104}\n{'loss': 3.2504, 'grad_norm': 0.403242826461792, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 581959680}\n{'loss': 3.2924, 'grad_norm': 0.46690869331359863, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 583008256}\n{'loss': 3.1466, 'grad_norm': 0.515250027179718, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 584056832}\n{'loss': 3.2898, 'grad_norm': 0.4872475266456604, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 585105408}\n{'loss': 3.3699, 'grad_norm': 0.43510228395462036, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 586153984}\n{'loss': 3.1568, 'grad_norm': 0.4732394814491272, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 587202560}\n{'loss': 3.2145, 'grad_norm': 0.49767330288887024, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 588251136}\n{'loss': 3.2966, 'grad_norm': 0.4968816936016083, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 589299712}\n{'loss': 3.2249, 'grad_norm': 0.4123048782348633, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 590348288}\n{'loss': 3.3819, 'grad_norm': 0.4349605143070221, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 591396864}\n{'loss': 3.3477, 'grad_norm': 0.47485488653182983, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 592445440}\n{'loss': 3.3202, 'grad_norm': 0.46784669160842896, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 593494016}\n{'loss': 3.2231, 'grad_norm': 0.42318931221961975, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 594542592}\n{'loss': 3.2901, 'grad_norm': 0.40393564105033875, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 595591168}\n{'loss': 3.2065, 'grad_norm': 0.4144214391708374, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 596639744}\n{'loss': 2.8698, 'grad_norm': 0.40921372175216675, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 597688320}\n{'loss': 3.2242, 'grad_norm': 0.35226207971572876, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 598736896}\n{'loss': 3.2125, 'grad_norm': 0.43364742398262024, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 599785472}\n{'loss': 3.2296, 'grad_norm': 0.4272080361843109, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 600834048}\n{'loss': 2.9346, 'grad_norm': 0.4155097007751465, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 601882624}\n{'loss': 3.2706, 'grad_norm': 0.4263918697834015, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 602931200}\n{'loss': 3.3124, 'grad_norm': 0.43336594104766846, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 603979776}\n{'eval_loss': 3.1686322689056396, 'eval_runtime': 664.0006, 'eval_samples_per_second': 24.675, 'eval_steps_per_second': 0.193, 'epoch': 0.07, 'num_input_tokens_seen': 603979776}\n{'loss': 3.349, 'grad_norm': 0.4504219889640808, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 605028352}\n{'loss': 3.3015, 'grad_norm': 0.5899333953857422, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 606076928}\n{'loss': 3.2036, 'grad_norm': 0.5814825892448425, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 607125504}\n{'loss': 3.2786, 'grad_norm': 0.3971703350543976, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 608174080}\n{'loss': 3.0979, 'grad_norm': 0.5669280290603638, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 609222656}\n{'loss': 3.0683, 'grad_norm': 0.4786263406276703, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 610271232}\n{'loss': 3.1731, 'grad_norm': 0.46415817737579346, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 611319808}\n{'loss': 3.2282, 'grad_norm': 0.4295870363712311, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 612368384}\n{'loss': 3.2196, 'grad_norm': 0.4184265732765198, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 613416960}\n{'loss': 3.2445, 'grad_norm': 0.4624122381210327, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 614465536}\n{'loss': 3.1135, 'grad_norm': 0.3681364059448242, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 615514112}\n{'loss': 3.1877, 'grad_norm': 0.3612712621688843, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 616562688}\n{'loss': 3.308, 'grad_norm': 0.34696292877197266, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 617611264}\n{'loss': 3.4995, 'grad_norm': 0.5025363564491272, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 618659840}\n{'loss': 3.1853, 'grad_norm': 0.6652331352233887, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 619708416}\n{'loss': 3.1844, 'grad_norm': 0.7156277894973755, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 620756992}\n{'loss': 3.2325, 'grad_norm': 0.5241081118583679, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 621805568}\n{'loss': 2.972, 'grad_norm': 0.5001779198646545, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 622854144}\n{'loss': 3.1742, 'grad_norm': 0.4062795341014862, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 623902720}\n{'loss': 3.2539, 'grad_norm': 0.4671201705932617, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 624951296}\n{'loss': 3.1948, 'grad_norm': 0.3894169330596924, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 625999872}\n{'loss': 3.2469, 'grad_norm': 0.4665684998035431, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 627048448}\n{'loss': 3.2742, 'grad_norm': 0.43211206793785095, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 628097024}\n{'loss': 3.1195, 'grad_norm': 0.4476025700569153, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 629145600}\n{'loss': 3.2127, 'grad_norm': 0.3596750795841217, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 630194176}\n{'loss': 3.1741, 'grad_norm': 0.40869519114494324, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 631242752}\n{'loss': 3.1708, 'grad_norm': 0.36658936738967896, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 632291328}\n{'loss': 3.0925, 'grad_norm': 0.35227081179618835, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 633339904}\n{'loss': 3.171, 'grad_norm': 0.3942136764526367, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 634388480}\n{'loss': 3.1729, 'grad_norm': 0.3163004219532013, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 635437056}\n{'loss': 3.1683, 'grad_norm': 0.35835322737693787, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 636485632}\n{'loss': 3.1118, 'grad_norm': 0.3395129144191742, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 637534208}\n{'loss': 3.2123, 'grad_norm': 0.38003110885620117, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 638582784}\n{'loss': 3.167, 'grad_norm': 0.4000258445739746, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 639631360}\n{'loss': 3.0668, 'grad_norm': 0.38393035531044006, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 640679936}\n{'loss': 2.9125, 'grad_norm': 0.38961607217788696, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 641728512}\n{'loss': 3.1024, 'grad_norm': 0.3406165540218353, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 642777088}\n{'loss': 3.1262, 'grad_norm': 0.4859096109867096, 'learning_rate': 0.001, 'epoch': 0.07, 'num_input_tokens_seen': 643825664}\n{'loss': 3.1155, 'grad_norm': 0.5454179048538208, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 644874240}\n{'loss': 3.1594, 'grad_norm': 0.46631914377212524, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 645922816}\n{'loss': 3.1164, 'grad_norm': 0.4049534797668457, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 646971392}\n{'loss': 2.9272, 'grad_norm': 0.32954707741737366, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 648019968}\n{'loss': 3.0888, 'grad_norm': 0.409853458404541, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 649068544}\n{'loss': 3.2185, 'grad_norm': 0.43080267310142517, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 650117120}\n{'loss': 3.1871, 'grad_norm': 0.4323279857635498, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 651165696}\n{'loss': 2.9759, 'grad_norm': 0.3696155846118927, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 652214272}\n{'loss': 3.1058, 'grad_norm': 0.3963398337364197, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 653262848}\n{'loss': 3.1214, 'grad_norm': 0.4020082652568817, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 654311424}\n{'loss': 3.0678, 'grad_norm': 0.4210987091064453, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 655360000}\n{'loss': 2.9177, 'grad_norm': 0.44535601139068604, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 656408576}\n{'loss': 3.1005, 'grad_norm': 0.363700807094574, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 657457152}\n{'loss': 3.0285, 'grad_norm': 0.393673837184906, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 658505728}\n{'loss': 3.031, 'grad_norm': 0.3472498059272766, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 659554304}\n{'loss': 3.1837, 'grad_norm': 0.45663976669311523, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 660602880}\n{'loss': 3.1636, 'grad_norm': 0.44765880703926086, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 661651456}\n{'loss': 3.0421, 'grad_norm': 0.5289708375930786, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 662700032}\n{'loss': 2.9394, 'grad_norm': 0.5272406339645386, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 663748608}\n{'loss': 3.2419, 'grad_norm': 0.5471237301826477, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 664797184}\n{'loss': 3.1506, 'grad_norm': 0.5762659311294556, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 665845760}\n{'loss': 3.1258, 'grad_norm': 0.5486758351325989, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 666894336}\n{'loss': 3.1686, 'grad_norm': 0.4877275228500366, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 667942912}\n{'loss': 3.1062, 'grad_norm': 0.35992035269737244, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 668991488}\n{'loss': 3.1655, 'grad_norm': 0.39184319972991943, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 670040064}\n{'loss': 3.1455, 'grad_norm': 0.46003854274749756, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 671088640}\n{'eval_loss': 3.036459445953369, 'eval_runtime': 676.6057, 'eval_samples_per_second': 24.215, 'eval_steps_per_second': 0.189, 'epoch': 0.08, 'num_input_tokens_seen': 671088640}\n{'loss': 3.1058, 'grad_norm': 0.45958808064460754, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 672137216}\n{'loss': 3.0861, 'grad_norm': 0.41562288999557495, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 673185792}\n{'loss': 3.1135, 'grad_norm': 0.38576263189315796, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 674234368}\n{'loss': 2.9998, 'grad_norm': 0.3936232924461365, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 675282944}\n{'loss': 3.1349, 'grad_norm': 0.3888678252696991, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 676331520}\n{'loss': 2.9192, 'grad_norm': 0.31759846210479736, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 677380096}\n{'loss': 3.1324, 'grad_norm': 0.3801535964012146, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 678428672}\n{'loss': 3.1064, 'grad_norm': 0.36299699544906616, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 679477248}\n{'loss': 3.2258, 'grad_norm': 0.36732324957847595, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 680525824}\n{'loss': 3.2162, 'grad_norm': 0.42108356952667236, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 681574400}\n{'loss': 3.2189, 'grad_norm': 0.4113474190235138, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 682622976}\n{'loss': 3.0585, 'grad_norm': 0.39936116337776184, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 683671552}\n{'loss': 3.0693, 'grad_norm': 0.35424771904945374, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 684720128}\n{'loss': 3.1134, 'grad_norm': 0.3333597183227539, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 685768704}\n{'loss': 3.0536, 'grad_norm': 0.37569180130958557, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 686817280}\n{'loss': 3.1396, 'grad_norm': 0.33836638927459717, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 687865856}\n{'loss': 3.1353, 'grad_norm': 0.31407052278518677, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 688914432}\n{'loss': 2.9977, 'grad_norm': 0.34316036105155945, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 689963008}\n{'loss': 3.1683, 'grad_norm': 0.3779186010360718, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 691011584}\n{'loss': 2.9567, 'grad_norm': 0.3414095342159271, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 692060160}\n{'loss': 3.0806, 'grad_norm': 0.31614938378334045, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 693108736}\n{'loss': 3.0975, 'grad_norm': 0.35552725195884705, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 694157312}\n{'loss': 3.0241, 'grad_norm': 0.38724133372306824, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 695205888}\n{'loss': 3.0701, 'grad_norm': 0.3581823408603668, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 696254464}\n{'loss': 3.0222, 'grad_norm': 0.3632317781448364, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 697303040}\n{'loss': 3.0188, 'grad_norm': 0.40560677647590637, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 698351616}\n{'loss': 3.106, 'grad_norm': 0.3953804075717926, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 699400192}\n{'loss': 3.1552, 'grad_norm': 0.40652376413345337, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 700448768}\n{'loss': 2.8893, 'grad_norm': 0.3625616133213043, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 701497344}\n{'loss': 2.9183, 'grad_norm': 0.3450768291950226, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 702545920}\n{'loss': 2.9828, 'grad_norm': 0.36742398142814636, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 703594496}\n{'loss': 3.0327, 'grad_norm': 0.3611394762992859, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 704643072}\n{'loss': 3.1466, 'grad_norm': 0.3593210279941559, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 705691648}\n{'loss': 3.0163, 'grad_norm': 0.3994838297367096, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 706740224}\n{'loss': 3.0563, 'grad_norm': 0.41202738881111145, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 707788800}\n{'loss': 3.0912, 'grad_norm': 0.3404449224472046, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 708837376}\n{'loss': 3.0108, 'grad_norm': 0.3745224177837372, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 709885952}\n{'loss': 3.0864, 'grad_norm': 0.4320204555988312, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 710934528}\n{'loss': 3.0387, 'grad_norm': 0.34649956226348877, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 711983104}\n{'loss': 3.013, 'grad_norm': 0.34744057059288025, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 713031680}\n{'loss': 3.0985, 'grad_norm': 0.3638330101966858, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 714080256}\n{'loss': 3.1498, 'grad_norm': 0.43823716044425964, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 715128832}\n{'loss': 3.0366, 'grad_norm': 0.6364668011665344, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 716177408}\n{'loss': 2.9614, 'grad_norm': 0.6294976472854614, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 717225984}\n{'loss': 3.0619, 'grad_norm': 0.5871465802192688, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 718274560}\n{'loss': 3.1489, 'grad_norm': 0.7779986262321472, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 719323136}\n{'loss': 3.1331, 'grad_norm': 1.102079153060913, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 720371712}\n{'loss': 3.1423, 'grad_norm': 0.6352481245994568, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 721420288}\n{'loss': 3.1509, 'grad_norm': 0.5698557496070862, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 722468864}\n{'loss': 2.6683, 'grad_norm': 0.501290500164032, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 723517440}\n{'loss': 3.0334, 'grad_norm': 0.4512772560119629, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 724566016}\n{'loss': 3.0485, 'grad_norm': 0.4409146308898926, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 725614592}\n{'loss': 3.0154, 'grad_norm': 0.3902524411678314, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 726663168}\n{'loss': 3.0742, 'grad_norm': 0.3692473769187927, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 727711744}\n{'loss': 2.8306, 'grad_norm': 0.385005384683609, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 728760320}\n{'loss': 2.9258, 'grad_norm': 0.37514418363571167, 'learning_rate': 0.001, 'epoch': 0.08, 'num_input_tokens_seen': 729808896}\n{'loss': 3.0061, 'grad_norm': 0.42038342356681824, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 730857472}\n{'loss': 3.0588, 'grad_norm': 0.40415653586387634, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 731906048}\n{'loss': 2.9542, 'grad_norm': 0.38514354825019836, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 732954624}\n{'loss': 2.9252, 'grad_norm': 0.3861909806728363, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 734003200}\n{'loss': 2.8432, 'grad_norm': 0.40519189834594727, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 735051776}\n{'loss': 2.9779, 'grad_norm': 0.37011685967445374, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 736100352}\n{'loss': 2.9908, 'grad_norm': 0.34850460290908813, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 737148928}\n{'loss': 2.9589, 'grad_norm': 0.371500700712204, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 738197504}\n[2025-03-11 00:58:41 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 0faae356-e828-4cff-9a49-42b397431927)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk4/example_holdout_185.jsonl.zst\n[2025-03-11 00:58:41 WARNING] Retrying in 1s [Retry 1/5].\n[2025-03-11 01:05:12 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 9557423f-6937-4f70-b50f-05b0c01f5bf3)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk4/example_holdout_4035.jsonl.zst\n[2025-03-11 01:05:12 WARNING] Retrying in 1s [Retry 1/5].\n{'eval_loss': 2.9496541023254395, 'eval_runtime': 714.5105, 'eval_samples_per_second': 22.93, 'eval_steps_per_second': 0.179, 'epoch': 0.09, 'num_input_tokens_seen': 738197504}\n{'loss': 2.9029, 'grad_norm': 0.3044391870498657, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 739246080}\n{'loss': 2.8536, 'grad_norm': 0.34875407814979553, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 740294656}\n{'loss': 2.8478, 'grad_norm': 0.4568244516849518, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 741343232}\n{'loss': 3.1164, 'grad_norm': 0.44005003571510315, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 742391808}\n{'loss': 2.8584, 'grad_norm': 0.39490336179733276, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 743440384}\n{'loss': 3.0681, 'grad_norm': 0.4427798092365265, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 744488960}\n{'loss': 3.0315, 'grad_norm': 0.4771106243133545, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 745537536}\n{'loss': 2.8794, 'grad_norm': 0.4624035656452179, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 746586112}\n{'loss': 2.9624, 'grad_norm': 0.4244724214076996, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 747634688}\n{'loss': 2.9925, 'grad_norm': 0.39176708459854126, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 748683264}\n{'loss': 2.9753, 'grad_norm': 0.43686383962631226, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 749731840}\n{'loss': 3.0718, 'grad_norm': 0.4536241590976715, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 750780416}\n{'loss': 3.0065, 'grad_norm': 0.3421417772769928, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 751828992}\n{'loss': 2.8965, 'grad_norm': 0.30937010049819946, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 752877568}\n{'loss': 3.0347, 'grad_norm': 0.33371758460998535, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 753926144}\n{'loss': 3.0133, 'grad_norm': 0.3285418450832367, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 754974720}\n{'loss': 3.1219, 'grad_norm': 0.33177846670150757, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 756023296}\n{'loss': 2.9354, 'grad_norm': 0.36487525701522827, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 757071872}\n{'loss': 3.133, 'grad_norm': 0.35576146841049194, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 758120448}\n{'loss': 2.9771, 'grad_norm': 0.4217855930328369, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 759169024}\n{'loss': 2.9906, 'grad_norm': 0.4007001519203186, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 760217600}\n{'loss': 3.0219, 'grad_norm': 0.36323100328445435, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 761266176}\n{'loss': 2.89, 'grad_norm': 0.323297381401062, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 762314752}\n{'loss': 2.8566, 'grad_norm': 0.3450233042240143, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 763363328}\n{'loss': 3.0536, 'grad_norm': 0.36228489875793457, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 764411904}\n{'loss': 2.9259, 'grad_norm': 0.3553276062011719, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 765460480}\n{'loss': 2.8431, 'grad_norm': 0.37074941396713257, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 766509056}\n{'loss': 3.0549, 'grad_norm': 0.4105451703071594, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 767557632}\n{'loss': 2.8431, 'grad_norm': 0.4433744549751282, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 768606208}\n{'loss': 2.9545, 'grad_norm': 0.4024113416671753, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 769654784}\n{'loss': 2.9237, 'grad_norm': 0.3534025549888611, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 770703360}\n{'loss': 2.9306, 'grad_norm': 0.3788505792617798, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 771751936}\n{'loss': 2.9218, 'grad_norm': 0.3302527666091919, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 772800512}\n{'loss': 3.0647, 'grad_norm': 0.36651748418807983, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 773849088}\n{'loss': 3.0289, 'grad_norm': 0.35838624835014343, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 774897664}\n{'loss': 2.9157, 'grad_norm': 0.34652525186538696, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 775946240}\n{'loss': 2.9358, 'grad_norm': 0.37369009852409363, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 776994816}\n{'loss': 3.0725, 'grad_norm': 0.37748783826828003, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 778043392}\n{'loss': 2.8444, 'grad_norm': 0.339287132024765, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 779091968}\n{'loss': 2.859, 'grad_norm': 0.3415367305278778, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 780140544}\n{'loss': 2.9334, 'grad_norm': 0.3661401569843292, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 781189120}\n{'loss': 3.0287, 'grad_norm': 0.3512025773525238, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 782237696}\n{'loss': 2.8093, 'grad_norm': 0.3412944972515106, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 783286272}\n{'loss': 2.9112, 'grad_norm': 0.35280412435531616, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 784334848}\n{'loss': 2.8939, 'grad_norm': 0.3652521073818207, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 785383424}\n{'loss': 2.961, 'grad_norm': 0.3336659371852875, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 786432000}\n{'loss': 2.9547, 'grad_norm': 0.3242711126804352, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 787480576}\n{'loss': 2.8035, 'grad_norm': 0.3276830017566681, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 788529152}\n{'loss': 2.9639, 'grad_norm': 0.32558611035346985, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 789577728}\n{'loss': 2.9981, 'grad_norm': 0.32141759991645813, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 790626304}\n{'loss': 2.8053, 'grad_norm': 0.33697575330734253, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 791674880}\n{'loss': 2.9265, 'grad_norm': 0.3305177092552185, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 792723456}\n{'loss': 2.9357, 'grad_norm': 0.3303467035293579, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 793772032}\n{'loss': 2.9209, 'grad_norm': 0.33826348185539246, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 794820608}\n{'loss': 3.0134, 'grad_norm': 0.3682444393634796, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 795869184}\n{'loss': 2.8786, 'grad_norm': 0.364545613527298, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 796917760}\n{'loss': 3.0202, 'grad_norm': 0.4031524360179901, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 797966336}\n{'loss': 2.4912, 'grad_norm': 0.40752920508384705, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 799014912}\n{'loss': 2.9311, 'grad_norm': 0.36912065744400024, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 800063488}\n{'loss': 2.8768, 'grad_norm': 0.3906254172325134, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 801112064}\n{'loss': 2.8677, 'grad_norm': 0.3680756092071533, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 802160640}\n{'loss': 2.967, 'grad_norm': 0.42479801177978516, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 803209216}\n{'loss': 3.0138, 'grad_norm': 0.4966808259487152, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 804257792}\n{'loss': 2.9186, 'grad_norm': 0.413562536239624, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 805306368}\n{'eval_loss': 2.8718671798706055, 'eval_runtime': 1149.5487, 'eval_samples_per_second': 14.253, 'eval_steps_per_second': 0.111, 'epoch': 0.09, 'num_input_tokens_seen': 805306368}\n{'loss': 2.8717, 'grad_norm': 0.3343268632888794, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 806354944}\n{'loss': 3.0123, 'grad_norm': 0.42326104640960693, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 807403520}\n{'loss': 2.9691, 'grad_norm': 0.35408785939216614, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 808452096}\n{'loss': 2.8862, 'grad_norm': 0.35168665647506714, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 809500672}\n{'loss': 2.9754, 'grad_norm': 0.3385300934314728, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 810549248}\n{'loss': 2.751, 'grad_norm': 0.36974239349365234, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 811597824}\n{'loss': 2.8481, 'grad_norm': 0.3535187244415283, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 812646400}\n{'loss': 2.9605, 'grad_norm': 0.39851564168930054, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 813694976}\n{'loss': 2.9251, 'grad_norm': 0.35983574390411377, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 814743552}\n{'loss': 2.8766, 'grad_norm': 0.34153202176094055, 'learning_rate': 0.001, 'epoch': 0.09, 'num_input_tokens_seen': 815792128}\n{'loss': 2.9205, 'grad_norm': 0.3700859546661377, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 816840704}\n{'loss': 2.7621, 'grad_norm': 0.3954067528247833, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 817889280}\n{'loss': 2.886, 'grad_norm': 0.4191531538963318, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 818937856}\n{'loss': 2.9203, 'grad_norm': 0.3315434157848358, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 819986432}\n{'loss': 2.9563, 'grad_norm': 0.3308311700820923, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 821035008}\n{'loss': 2.9391, 'grad_norm': 0.3073643445968628, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 822083584}\n{'loss': 2.7197, 'grad_norm': 0.3343094289302826, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 823132160}\n{'loss': 2.909, 'grad_norm': 0.31464704871177673, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 824180736}\n{'loss': 2.8581, 'grad_norm': 0.40213140845298767, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 825229312}\n{'loss': 2.9224, 'grad_norm': 0.36158621311187744, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 826277888}\n{'loss': 2.985, 'grad_norm': 0.3831183910369873, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 827326464}\n{'loss': 2.8964, 'grad_norm': 0.3219353258609772, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 828375040}\n{'loss': 3.0832, 'grad_norm': 0.31743234395980835, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 829423616}\n{'loss': 2.9602, 'grad_norm': 0.3629371225833893, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 830472192}\n{'loss': 2.8327, 'grad_norm': 0.3800980746746063, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 831520768}\n{'loss': 2.8298, 'grad_norm': 0.3349006772041321, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 832569344}\n{'loss': 2.9633, 'grad_norm': 0.3282972276210785, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 833617920}\n{'loss': 2.9234, 'grad_norm': 0.3283899128437042, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 834666496}\n{'loss': 2.9754, 'grad_norm': 0.33885031938552856, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 835715072}\n{'loss': 2.8825, 'grad_norm': 0.3113347589969635, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 836763648}\n{'loss': 2.9483, 'grad_norm': 0.3759271204471588, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 837812224}\n{'loss': 2.8577, 'grad_norm': 0.38608986139297485, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 838860800}\n{'loss': 2.6639, 'grad_norm': 0.3253604471683502, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 839909376}\n{'loss': 2.8295, 'grad_norm': 0.31234994530677795, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 840957952}\n{'loss': 2.9323, 'grad_norm': 0.37187162041664124, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 842006528}\n{'loss': 3.2357, 'grad_norm': 0.5417175889015198, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 843055104}\n{'loss': 2.8982, 'grad_norm': 0.6133915781974792, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 844103680}\n{'loss': 2.928, 'grad_norm': 0.7637872099876404, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 845152256}\n{'loss': 2.9283, 'grad_norm': 0.7322977781295776, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 846200832}\n{'loss': 2.8209, 'grad_norm': 0.5112255215644836, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 847249408}\n{'loss': 2.8696, 'grad_norm': 0.49990609288215637, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 848297984}\n{'loss': 2.9193, 'grad_norm': 0.4511178135871887, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 849346560}\n{'loss': 2.9658, 'grad_norm': 0.4653412997722626, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 850395136}\n{'loss': 2.889, 'grad_norm': 0.3913695812225342, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 851443712}\n{'loss': 2.9534, 'grad_norm': 0.39285045862197876, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 852492288}\n{'loss': 2.8341, 'grad_norm': 0.5052099227905273, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 853540864}\n{'loss': 3.0436, 'grad_norm': 0.5978823900222778, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 854589440}\n{'loss': 2.9484, 'grad_norm': 0.4584784507751465, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 855638016}\n{'loss': 2.8786, 'grad_norm': 0.40823692083358765, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 856686592}\n{'loss': 2.942, 'grad_norm': 0.4448293447494507, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 857735168}\n{'loss': 2.9347, 'grad_norm': 0.4112764596939087, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 858783744}\n{'loss': 2.8359, 'grad_norm': 0.3826068341732025, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 859832320}\n{'loss': 2.9277, 'grad_norm': 0.37165558338165283, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 860880896}\n{'loss': 2.6527, 'grad_norm': 0.4285834729671478, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 861929472}\n{'loss': 2.8451, 'grad_norm': 0.36497727036476135, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 862978048}\n{'loss': 2.9039, 'grad_norm': 0.35966625809669495, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 864026624}\n{'loss': 2.9268, 'grad_norm': 0.3529391586780548, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 865075200}\n{'loss': 2.9953, 'grad_norm': 0.3455546498298645, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 866123776}\n{'loss': 2.9307, 'grad_norm': 0.3788530230522156, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 867172352}\n{'loss': 2.9448, 'grad_norm': 0.35837656259536743, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 868220928}\n{'loss': 2.9937, 'grad_norm': 0.3842633366584778, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 869269504}\n{'loss': 2.8324, 'grad_norm': 0.32774215936660767, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 870318080}\n{'loss': 2.8613, 'grad_norm': 0.327158659696579, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 871366656}\n{'loss': 2.7653, 'grad_norm': 0.3515920639038086, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 872415232}\n[2025-03-11 02:50:38 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 939d1d36-c607-4d3c-a0a0-8e447579340b)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk3/example_holdout_165.jsonl.zst\n[2025-03-11 02:50:39 WARNING] Retrying in 1s [Retry 1/5].\n[2025-03-11 02:58:37 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 0b99bfd1-07ae-46db-81fa-fc6ef0eabdbc)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk3/example_holdout_1529.jsonl.zst\n[2025-03-11 02:58:37 WARNING] Retrying in 1s [Retry 1/5].\n[2025-03-11 03:00:11 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: c208d1bb-5d13-45d2-9a01-1d5a2defa598)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk5/example_holdout_4562.jsonl.zst\n[2025-03-11 03:00:11 WARNING] Retrying in 1s [Retry 1/5].\n[2025-03-11 03:01:14 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 2bf98b5c-473b-4e00-aca2-b152efddb992)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk3/example_holdout_4414.jsonl.zst\n[2025-03-11 03:01:14 WARNING] Retrying in 1s [Retry 1/5].\n{'eval_loss': 2.816462278366089, 'eval_runtime': 954.8041, 'eval_samples_per_second': 17.16, 'eval_steps_per_second': 0.134, 'epoch': 0.1, 'num_input_tokens_seen': 872415232}\n{'loss': 2.867, 'grad_norm': 0.3173666000366211, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 873463808}\n{'loss': 2.8701, 'grad_norm': 0.3399354815483093, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 874512384}\n{'loss': 2.8575, 'grad_norm': 0.36704689264297485, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 875560960}\n{'loss': 2.9582, 'grad_norm': 0.33231136202812195, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 876609536}\n{'loss': 2.7719, 'grad_norm': 0.34316956996917725, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 877658112}\n{'loss': 2.8915, 'grad_norm': 0.3483976423740387, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 878706688}\n{'loss': 2.7566, 'grad_norm': 0.3104913532733917, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 879755264}\n{'loss': 3.0013, 'grad_norm': 0.38844239711761475, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 880803840}\n{'loss': 2.5568, 'grad_norm': 0.40875244140625, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 881852416}\n{'loss': 2.8336, 'grad_norm': 0.3538399934768677, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 882900992}\n{'loss': 2.9391, 'grad_norm': 0.3494492471218109, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 883949568}\n{'loss': 2.8535, 'grad_norm': 0.3472343981266022, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 884998144}\n{'loss': 2.9836, 'grad_norm': 0.34867390990257263, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 886046720}\n{'loss': 2.8416, 'grad_norm': 0.3527415096759796, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 887095296}\n{'loss': 2.8756, 'grad_norm': 0.3338777422904968, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 888143872}\n{'loss': 2.8428, 'grad_norm': 0.3345812261104584, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 889192448}\n{'loss': 2.8977, 'grad_norm': 0.31487980484962463, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 890241024}\n{'loss': 2.9543, 'grad_norm': 0.3655254542827606, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 891289600}\n{'loss': 2.9423, 'grad_norm': 0.33075806498527527, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 892338176}\n{'loss': 2.9001, 'grad_norm': 0.34644609689712524, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 893386752}\n{'loss': 2.9029, 'grad_norm': 0.39070528745651245, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 894435328}\n{'loss': 2.9101, 'grad_norm': 0.39556533098220825, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 895483904}\n{'loss': 2.8119, 'grad_norm': 0.39002978801727295, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 896532480}\n{'loss': 3.0102, 'grad_norm': 0.37797507643699646, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 897581056}\n{'loss': 2.666, 'grad_norm': 0.4306756258010864, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 898629632}\n{'loss': 2.9257, 'grad_norm': 0.4526049494743347, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 899678208}\n{'loss': 2.8196, 'grad_norm': 0.3978416621685028, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 900726784}\n{'loss': 2.9057, 'grad_norm': 0.3925896883010864, 'learning_rate': 0.001, 'epoch': 0.1, 'num_input_tokens_seen': 901775360}\n{'loss': 3.0017, 'grad_norm': 0.45828214287757874, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 902823936}\n{'loss': 2.89, 'grad_norm': 0.4745008647441864, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 903872512}\n{'loss': 2.7335, 'grad_norm': 0.4270082116127014, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 904921088}\n{'loss': 2.8234, 'grad_norm': 0.38832950592041016, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 905969664}\n{'loss': 2.8618, 'grad_norm': 0.3907729387283325, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 907018240}\n{'loss': 2.8703, 'grad_norm': 0.368655264377594, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 908066816}\n{'loss': 2.8321, 'grad_norm': 0.41538506746292114, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 909115392}\n{'loss': 2.886, 'grad_norm': 0.41877180337905884, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 910163968}\n{'loss': 2.6224, 'grad_norm': 0.33238673210144043, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 911212544}\n{'loss': 2.8617, 'grad_norm': 0.4095931351184845, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 912261120}\n{'loss': 2.8172, 'grad_norm': 0.41708603501319885, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 913309696}\n{'loss': 2.7658, 'grad_norm': 0.37449270486831665, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 914358272}\n{'loss': 2.9042, 'grad_norm': 0.3935737609863281, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 915406848}\n{'loss': 2.7612, 'grad_norm': 0.3586251735687256, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 916455424}\n{'loss': 2.8785, 'grad_norm': 0.3712047338485718, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 917504000}\n{'loss': 2.739, 'grad_norm': 0.37707045674324036, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 918552576}\n{'loss': 2.8372, 'grad_norm': 0.3432702422142029, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 919601152}\n{'loss': 2.5638, 'grad_norm': 0.3493041396141052, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 920649728}\n{'loss': 2.8759, 'grad_norm': 0.3401539623737335, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 921698304}\n{'loss': 3.0048, 'grad_norm': 0.4632040858268738, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 922746880}\n{'loss': 2.9394, 'grad_norm': 0.4968065023422241, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 923795456}\n{'loss': 2.8441, 'grad_norm': 0.5426673889160156, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 924844032}\n{'loss': 2.9975, 'grad_norm': 0.4630672037601471, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 925892608}\n{'loss': 2.9584, 'grad_norm': 0.38806748390197754, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 926941184}\n{'loss': 2.8904, 'grad_norm': 0.39797642827033997, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 927989760}\n{'loss': 2.5774, 'grad_norm': 0.4063512980937958, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 929038336}\n{'loss': 2.812, 'grad_norm': 0.3161136209964752, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 930086912}\n{'loss': 2.7483, 'grad_norm': 0.3628361225128174, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 931135488}\n{'loss': 2.7916, 'grad_norm': 0.37376269698143005, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 932184064}\n{'loss': 2.7985, 'grad_norm': 0.3399117887020111, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 933232640}\n{'loss': 2.7107, 'grad_norm': 0.3453179597854614, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 934281216}\n{'loss': 2.9254, 'grad_norm': 0.39461833238601685, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 935329792}\n{'loss': 2.8487, 'grad_norm': 0.3668413460254669, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 936378368}\n{'loss': 2.7928, 'grad_norm': 0.28304487466812134, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 937426944}\n{'loss': 2.8503, 'grad_norm': 0.35816267132759094, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 938475520}\n{'loss': 3.0328, 'grad_norm': 0.3540339469909668, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 939524096}\n[2025-03-11 03:46:08 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: 3b8321b9-2d88-4bfa-9eca-b201c444cba3)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk5/example_holdout_405.jsonl.zst\n[2025-03-11 03:46:08 WARNING] Retrying in 1s [Retry 1/5].\n[2025-03-11 03:53:27 WARNING] '(ReadTimeoutError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Read timed out. (read timeout=10)\"), '(Request ID: a98a238a-c0a4-4295-8502-316a89a7ae29)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk1/example_holdout_2524.jsonl.zst\n[2025-03-11 03:53:27 WARNING] Retrying in 1s [Retry 1/5].\n{'eval_loss': 2.7651162147521973, 'eval_runtime': 687.962, 'eval_samples_per_second': 23.815, 'eval_steps_per_second': 0.186, 'epoch': 0.11, 'num_input_tokens_seen': 939524096}\n{'loss': 2.9368, 'grad_norm': 0.34962671995162964, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 940572672}\n{'loss': 2.3627, 'grad_norm': 0.37516310811042786, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 941621248}\n{'loss': 2.8854, 'grad_norm': 0.3487492501735687, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 942669824}\n{'loss': 2.7892, 'grad_norm': 0.37180987000465393, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 943718400}\n{'loss': 2.8067, 'grad_norm': 0.3387952744960785, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 944766976}\n{'loss': 2.841, 'grad_norm': 0.32076528668403625, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 945815552}\n{'loss': 2.7965, 'grad_norm': 0.3348572552204132, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 946864128}\n{'loss': 2.6788, 'grad_norm': 0.3531329929828644, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 947912704}\n{'loss': 2.7276, 'grad_norm': 0.300353467464447, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 948961280}\n{'loss': 2.8189, 'grad_norm': 0.3258875012397766, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 950009856}\n{'loss': 2.8388, 'grad_norm': 0.3434987962245941, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 951058432}\n{'loss': 2.856, 'grad_norm': 0.33045029640197754, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 952107008}\n{'loss': 2.658, 'grad_norm': 0.34896957874298096, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 953155584}\n{'loss': 2.8484, 'grad_norm': 0.3819083273410797, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 954204160}\n{'loss': 2.8402, 'grad_norm': 0.39541998505592346, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 955252736}\n{'loss': 2.8281, 'grad_norm': 0.3843367397785187, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 956301312}\n{'loss': 2.8339, 'grad_norm': 0.4067714214324951, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 957349888}\n{'loss': 2.8693, 'grad_norm': 0.3071018159389496, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 958398464}\n{'loss': 2.6747, 'grad_norm': 0.3676702380180359, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 959447040}\n{'loss': 2.6961, 'grad_norm': 0.357799232006073, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 960495616}\n{'loss': 2.7944, 'grad_norm': 0.318391352891922, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 961544192}\n{'loss': 2.8084, 'grad_norm': 0.32000190019607544, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 962592768}\n{'loss': 2.8024, 'grad_norm': 0.3250137269496918, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 963641344}\n{'loss': 2.7951, 'grad_norm': 0.33021438121795654, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 964689920}\n{'loss': 2.8069, 'grad_norm': 0.3257495164871216, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 965738496}\n{'loss': 2.8148, 'grad_norm': 0.3608018159866333, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 966787072}\n[2025-03-11 04:13:12 WARNING] '(ProtocolError('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')), '(Request ID: 36a7cc72-4605-416a-8742-59488d719150)')' thrown while requesting GET https://huggingface.co/datasets/cerebras/SlimPajama-627B/resolve/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/train/chunk1/example_train_5267.jsonl.zst\n[2025-03-11 04:13:12 WARNING] Retrying in 1s [Retry 1/5].\n{'loss': 2.8089, 'grad_norm': 0.3657573163509369, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 967835648}\n{'loss': 2.8243, 'grad_norm': 0.3791966736316681, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 968884224}\n{'loss': 2.6837, 'grad_norm': 0.4036826193332672, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 969932800}\n{'loss': 2.6694, 'grad_norm': 0.34643635153770447, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 970981376}\n{'loss': 2.8455, 'grad_norm': 0.35321497917175293, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 972029952}\n{'loss': 2.5156, 'grad_norm': 0.3488744795322418, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 973078528}\n{'loss': 2.7185, 'grad_norm': 0.33396172523498535, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 974127104}\n{'loss': 2.856, 'grad_norm': 0.36425134539604187, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 975175680}\n{'loss': 2.7639, 'grad_norm': 0.34361588954925537, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 976224256}\n{'loss': 2.7777, 'grad_norm': 0.45501893758773804, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 977272832}\n{'loss': 2.8692, 'grad_norm': 0.4391760230064392, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 978321408}\n{'loss': 2.7885, 'grad_norm': 0.385729044675827, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 979369984}\n{'loss': 2.8622, 'grad_norm': 0.4122815728187561, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 980418560}\n{'loss': 2.674, 'grad_norm': 0.3223947584629059, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 981467136}\n{'loss': 2.7148, 'grad_norm': 0.39820024371147156, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 982515712}\n{'loss': 2.6975, 'grad_norm': 0.38311144709587097, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 983564288}\n{'loss': 2.8515, 'grad_norm': 0.4324709177017212, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 984612864}\n{'loss': 2.5684, 'grad_norm': 0.3579341471195221, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 985661440}\n{'loss': 2.9478, 'grad_norm': 0.4081536531448364, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 986710016}\n{'loss': 2.7375, 'grad_norm': 0.4332145154476166, 'learning_rate': 0.001, 'epoch': 0.11, 'num_input_tokens_seen': 987758592}\n{'loss': 2.7773, 'grad_norm': 0.43510711193084717, 'learning_rate': 0.001, 'epoch': 0.12, 'num_input_tokens_seen': 988807168}\n...\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/utils/file_utils.py\", line 1378, in _iter_from_urlpaths\n raise FileNotFoundError(urlpath)\nFileNotFoundError: zstd://example_train_1215.jsonl::hf://datasets/cerebras/SlimPajama-627B@2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/train/chunk9/example_train_1215.jsonl.zst\n```\n\n</details>",
"Two more today:\n```python\nFileNotFoundError: zstd://example_holdout_5012.jsonl::hf://datasets/cerebras/SlimPajama-627B@2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk4/example_holdout_5012.jsonl.zst\n```\nand\n```python\nFileNotFoundError: zstd://example_holdout_3073.jsonl::hf://datasets/cerebras/SlimPajama-627B@2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/validation/chunk2/example_holdout_3073.jsonl.zst\n```\nboth of which exist on the hub ([here](https://huggingface.co/datasets/cerebras/SlimPajama-627B/blob/main/validation/chunk4/example_holdout_5012.jsonl.zst) and [here](https://huggingface.co/datasets/cerebras/SlimPajama-627B/blob/main/validation/chunk2/example_holdout_3073.jsonl.zst)).",
"I also observe the same thing when using streaming with DCLM dataset with 64 GPUs. I have tried ```export HF_DATASETS_STREAMING_PARALLELISM=1``` but doesn't help.",
"Another error today, this time a 504 gateway timeout `HfHubHTTPError`. I have no idea if this is related, but I suspect that it is considering the setup is identical. Notably though, the two errors I posted yesterday were for evaluation (hence the `holdout` in the URLs) whereas today there was no problem doing that first evaluation, but now the `train` split failed.\n```python\n...\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/iterable_dataset.py\", line 2226, in __iter__\n for key, example in ex_iterable:\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/iterable_dataset.py\", line 1499, in __iter__\n for x in self.ex_iterable:\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/iterable_dataset.py\", line 1067, in __iter__\n yield from self._iter()\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/iterable_dataset.py\", line 1231, in _iter\n for key, transformed_example in iter_outputs():\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/iterable_dataset.py\", line 1207, in iter_outputs\n for i, key_example in inputs_iterator:\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/iterable_dataset.py\", line 1111, in iter_inputs\n for key, example in iterator:\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/iterable_dataset.py\", line 371, in __iter__\n for key, pa_table in self.generate_tables_fn(**gen_kwags):\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/packaged_modules/json/json.py\", line 114, in _generate_tables\n with open(file, \"rb\") as f:\n ^^^^^^^^^^^^^^^^\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/streaming.py\", line 75, in wrapper\n return function(*args, download_config=download_config, **kwargs)\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/utils/file_utils.py\", line 948, in xopen\n file_obj = fsspec.open(file, mode=mode, *args, **kwargs).open()\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/fsspec/core.py\", line 147, in open\n return self.__enter__()\n ^^^^^^^^^^^^^^^^\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/fsspec/core.py\", line 105, in __enter__\n f = self.fs.open(self.path, mode=mode)\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/fsspec/spec.py\", line 1301, in open\n f = self._open(\n ^^^^^^^^^^^\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/filesystems/compression.py\", line 85, in _open\n return self._open_with_fsspec().open()\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/fsspec/core.py\", line 147, in open\n return self.__enter__()\n ^^^^^^^^^^^^^^^^\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/fsspec/core.py\", line 105, in __enter__\n f = self.fs.open(self.path, mode=mode)\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/fsspec/spec.py\", line 1301, in open\n f = self._open(\n ^^^^^^^^^^^\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/huggingface_hub/hf_file_system.py\", line 234, in _open\n return HfFileSystemFile(self, path, mode=mode, revision=revision, block_size=block_size, **kwargs)\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/huggingface_hub/hf_file_system.py\", line 691, in __init__\n self.details = fs.info(self.resolved_path.unresolve(), expand_info=False)\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/huggingface_hub/hf_file_system.py\", line 524, in info\n self.ls(parent_path, expand_info=False)\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/huggingface_hub/hf_file_system.py\", line 284, in ls\n out = self._ls_tree(path, refresh=refresh, revision=revision, **kwargs)\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/huggingface_hub/hf_file_system.py\", line 375, in _ls_tree\n for path_info in tree:\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/huggingface_hub/hf_api.py\", line 3080, in list_repo_tree\n for path_info in paginate(path=tree_url, headers=headers, params={\"recursive\": recursive, \"expand\": expand}):\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/huggingface_hub/utils/_pagination.py\", line 46, in paginate\n hf_raise_for_status(r)\n File \"/miniconda3/envs/draft/lib/python3.11/site-packages/huggingface_hub/utils/_http.py\", line 477, in hf_raise_for_status\n raise _format(HfHubHTTPError, str(e), response) from e\nhuggingface_hub.errors.HfHubHTTPError: 504 Server Error: Gateway Time-out for url: https://huggingface.co/api/datasets/cerebras/SlimPajama-627B/tree/2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/train%2Fchunk8?recursive=False&expand=False&cursor=ZXlKbWFXeGxYMjVoYldVaU9pSjBjbUZwYmk5amFIVnVhemd2WlhoaGJYQnNaVjkwY21GcGJsOHpOams0TG1wemIyNXNMbnB6ZENKOTozMDAw\n```",
"Another one today:\n```python\nFileNotFoundError: zstd://example_train_4985.jsonl::hf://datasets/cerebras/SlimPajama-627B@2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/train/chunk5/example_train_4985.jsonl.zst\n```",
"This is a constant issue, and has been for six months, at least. Currently, half of my streaming datasets are failing with errors like this.\n\nMuennighoff/natural-instructions:\n```\n File \"/home/crow/repos/praxis/.venv/lib/python3.13/site-packages/datasets/utils/file_utils.py\", line 1379, in _iter_from_urlpaths\n raise FileNotFoundError(urlpath)\nFileNotFoundError: hf://datasets/Muennighoff/natural-instructions@a29a9757125f4bb1c26445ad0d2ef7d9b2cc9c4c/train/task343_winomt_classification_profession_anti_train.jsonl\n```\nopen-phi/textbooks:\n```\n File \"/home/crow/repos/praxis/.venv/lib/python3.13/site-packages/datasets/utils/file_utils.py\", line 1379, in _iter_from_urlpaths\n raise FileNotFoundError(urlpath)\nFileNotFoundError: hf://datasets/open-phi/textbooks@292aaae99cbecacad50f692d7327887f05dacaf2/data/train-00000-of-00001-b513d9e388d56453.parquet\n```\nHuggingFaceTB/smoltalk:\n```\n File \"/home/crow/repos/praxis/.venv/lib/python3.13/site-packages/datasets/utils/file_utils.py\", line 1379, in _iter_from_urlpaths\n raise FileNotFoundError(urlpath)\nFileNotFoundError: hf://datasets/HuggingFaceTB/smoltalk@5feaf2fd3ffca7c237fc38d1861bc30365d48ffa/data/all/train-00003-of-00009.parquet\n```"
] | 2025-03-07T19:14:18Z
| 2025-04-17T23:40:35Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
In https://github.com/huggingface/datasets/issues/6843 it was noted that the streaming feature of `datasets` is highly susceptible to outages and doesn't back off for long (or even *at all*).
I was training a model while streaming SlimPajama and training crashed with a `FileNotFoundError`. I can only assume that this was due to a momentary outage considering the file in question, `train/chunk9/example_train_3889.jsonl.zst`, [exists like all other files in SlimPajama](https://huggingface.co/datasets/cerebras/SlimPajama-627B/blob/main/train/chunk9/example_train_3889.jsonl.zst).
```python
...
File "/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/iterable_dataset.py", line 2226, in __iter__
for key, example in ex_iterable:
File "/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/iterable_dataset.py", line 1499, in __iter__
for x in self.ex_iterable:
File "/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/iterable_dataset.py", line 1067, in __iter__
yield from self._iter()
File "/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/iterable_dataset.py", line 1231, in _iter
for key, transformed_example in iter_outputs():
File "/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/iterable_dataset.py", line 1207, in iter_outputs
for i, key_example in inputs_iterator:
File "/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/iterable_dataset.py", line 1111, in iter_inputs
for key, example in iterator:
File "/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/iterable_dataset.py", line 371, in __iter__
for key, pa_table in self.generate_tables_fn(**gen_kwags):
File "/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/packaged_modules/json/json.py", line 99, in _generate_tables
for file_idx, file in enumerate(itertools.chain.from_iterable(files)):
File "/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/utils/track.py", line 50, in __iter__
for x in self.generator(*self.args):
File "/miniconda3/envs/draft/lib/python3.11/site-packages/datasets/utils/file_utils.py", line 1378, in _iter_from_urlpaths
raise FileNotFoundError(urlpath)
FileNotFoundError: zstd://example_train_3889.jsonl::hf://datasets/cerebras/SlimPajama-627B@2d0accdd58c5d5511943ca1f5ff0e3eb5e293543/train/chunk9/example_train_3889.jsonl.zst
```
That final `raise` is at the bottom of the following snippet:
https://github.com/huggingface/datasets/blob/f693f4e93aabafa878470c80fd42ddb10ec550d6/src/datasets/utils/file_utils.py#L1354-L1379
So clearly, something choked up in `xisfile`.
### Steps to reproduce the bug
This happens when streaming a dataset and iterating over it. In my case, that iteration is done in Trainer's `inner_training_loop`, but this is not relevant to the iterator.
```python
File "/miniconda3/envs/draft/lib/python3.11/site-packages/accelerate/data_loader.py", line 835, in __iter__
next_batch, next_batch_info = self._fetch_batches(main_iterator)
```
### Expected behavior
This bug and the linked issue have one thing in common: *when streaming fails to retrieve an example, the entire program gives up and crashes*. As users, we cannot even protect ourselves from this: when we are iterating over a dataset, we can't make `datasets` skip over a bad example or wait a little longer to retry the iteration, because when a Python generator/iterator raises an error, it loses all its context.
In other words: if you have something that looks like `for b in a: for c in b: for d in c:`, errors in the innermost loop can only be caught by a `try ... except` in `c.__iter__()`. There should be such exception handling in `datasets` and it should have a **configurable exponential back-off**: first wait and retry after 1 minute, then 2 minutes, then 4 minutes, then 8 minutes, ... and after a given amount of retries, **skip the bad example**, and **only after** skipping a given amount of examples, give up and crash. This was requested in https://github.com/huggingface/datasets/issues/6843 too, since currently there is only linear backoff *and* it is clearly not applied to `xisfile`.
### Environment info
- `datasets` version: 3.3.2 *(the latest version)*
- Platform: Linux-4.18.0-513.24.1.el8_9.x86_64-x86_64-with-glibc2.28
- Python version: 3.11.7
- `huggingface_hub` version: 0.26.5
- PyArrow version: 15.0.0
- Pandas version: 2.2.0
- `fsspec` version: 2024.10.0
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7440/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7440/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5031
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5031/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5031/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5031/events
|
https://github.com/huggingface/datasets/pull/5031
| 1,388,201,146
|
PR_kwDODunzps4_t82_
| 5,031
|
Support hfh 0.10 implicit auth
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq it is now released so you can move forward with it :) ",
"I took your comments into account @Wauplin :)\r\nI also bumped the requirement to 0.2.0 because we're using `set_access_token`\r\n\r\ncc @albertvillanova WDYT ? I edited the CI job to also check for our minimum supported version of hfh at the same time as the minimum pyarrow version",
"@lhoestq great, thanks ! :)"
] | 2022-09-27T18:37:49Z
| 2022-09-30T09:18:24Z
| 2022-09-30T09:15:59Z
|
MEMBER
| null | null | null |
In huggingface-hub 0.10 the `token` parameter is deprecated for dataset_info and list_repo_files in favor of use_auth_token.
Moreover if use_auth_token=None then the user's token is used implicitly.
I took those two changes into account
Close https://github.com/huggingface/datasets/issues/4990
TODO:
- [x] fix tests
We should wait hfh 0.10 to be relased first to make sure it works correctly before merging
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5031/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5031/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5031.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5031",
"merged_at": "2022-09-30T09:15:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5031.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5031"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4826
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4826/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4826/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4826/events
|
https://github.com/huggingface/datasets/pull/4826
| 1,335,987,583
|
PR_kwDODunzps49B0V3
| 4,826
|
Fix language tags in dataset cards
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"The non-passing tests are caused by other missing information in the dataset cards."
] | 2022-08-11T13:47:14Z
| 2022-08-11T14:17:48Z
| 2022-08-11T14:03:12Z
|
MEMBER
| null | null | null |
Fix language tags in all dataset cards, so that they are validated (aligned with our `languages.json` resource).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4826/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4826/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4826.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4826",
"merged_at": "2022-08-11T14:03:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4826.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4826"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5824
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5824/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5824/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5824/events
|
https://github.com/huggingface/datasets/pull/5824
| 1,697,152,148
|
PR_kwDODunzps5P1rIZ
| 5,824
|
Fix incomplete docstring for `BuilderConfig`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/21087104?v=4",
"events_url": "https://api.github.com/users/Laurent2916/events{/privacy}",
"followers_url": "https://api.github.com/users/Laurent2916/followers",
"following_url": "https://api.github.com/users/Laurent2916/following{/other_user}",
"gists_url": "https://api.github.com/users/Laurent2916/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Laurent2916",
"id": 21087104,
"login": "Laurent2916",
"node_id": "MDQ6VXNlcjIxMDg3MTA0",
"organizations_url": "https://api.github.com/users/Laurent2916/orgs",
"received_events_url": "https://api.github.com/users/Laurent2916/received_events",
"repos_url": "https://api.github.com/users/Laurent2916/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Laurent2916/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Laurent2916/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Laurent2916",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007658 / 0.011353 (-0.003695) | 0.005497 / 0.011008 (-0.005511) | 0.097142 / 0.038508 (0.058633) | 0.034602 / 0.023109 (0.011493) | 0.304191 / 0.275898 (0.028293) | 0.329103 / 0.323480 (0.005624) | 0.005936 / 0.007986 (-0.002049) | 0.004324 / 0.004328 (-0.000004) | 0.073387 / 0.004250 (0.069137) | 0.049657 / 0.037052 (0.012604) | 0.301352 / 0.258489 (0.042863) | 0.343095 / 0.293841 (0.049254) | 0.036767 / 0.128546 (-0.091779) | 0.012438 / 0.075646 (-0.063208) | 0.333804 / 0.419271 (-0.085468) | 0.064557 / 0.043533 (0.021024) | 0.302397 / 0.255139 (0.047258) | 0.319739 / 0.283200 (0.036540) | 0.119264 / 0.141683 (-0.022418) | 1.465309 / 1.452155 (0.013155) | 1.578194 / 1.492716 (0.085478) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.256552 / 0.018006 (0.238545) | 0.555344 / 0.000490 (0.554854) | 0.004845 / 0.000200 (0.004645) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027215 / 0.037411 (-0.010197) | 0.107071 / 0.014526 (0.092545) | 0.116343 / 0.176557 (-0.060213) | 0.172646 / 0.737135 (-0.564490) | 0.123366 / 0.296338 (-0.172973) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.411421 / 0.215209 (0.196212) | 4.126028 / 2.077655 (2.048373) | 1.975826 / 1.504120 (0.471706) | 1.784404 / 1.541195 (0.243210) | 1.848697 / 1.468490 (0.380207) | 0.686400 / 4.584777 (-3.898377) | 3.677649 / 3.745712 (-0.068063) | 2.077787 / 5.269862 (-3.192075) | 1.310912 / 4.565676 (-3.254764) | 0.083980 / 0.424275 (-0.340295) | 0.012183 / 0.007607 (0.004575) | 0.506969 / 0.226044 (0.280924) | 5.094730 / 2.268929 (2.825802) | 2.419790 / 55.444624 (-53.024834) | 2.106592 / 6.876477 (-4.769884) | 2.244309 / 2.142072 (0.102237) | 0.814312 / 4.805227 (-3.990915) | 0.167872 / 6.500664 (-6.332792) | 0.065339 / 0.075469 (-0.010130) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.193314 / 1.841788 (-0.648474) | 14.980621 / 8.074308 (6.906313) | 14.352452 / 10.191392 (4.161060) | 0.164531 / 0.680424 (-0.515893) | 0.017432 / 0.534201 (-0.516769) | 0.422193 / 0.579283 (-0.157090) | 0.410047 / 0.434364 (-0.024317) | 0.497011 / 0.540337 (-0.043326) | 0.581395 / 1.386936 (-0.805541) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007214 / 0.011353 (-0.004139) | 0.005449 / 0.011008 (-0.005559) | 0.074320 / 0.038508 (0.035812) | 0.034261 / 0.023109 (0.011152) | 0.378265 / 0.275898 (0.102367) | 0.414419 / 0.323480 (0.090939) | 0.005804 / 0.007986 (-0.002182) | 0.004205 / 0.004328 (-0.000124) | 0.073266 / 0.004250 (0.069015) | 0.050444 / 0.037052 (0.013392) | 0.372999 / 0.258489 (0.114510) | 0.436032 / 0.293841 (0.142191) | 0.035432 / 0.128546 (-0.093114) | 0.012581 / 0.075646 (-0.063065) | 0.085777 / 0.419271 (-0.333495) | 0.046902 / 0.043533 (0.003369) | 0.378732 / 0.255139 (0.123593) | 0.401746 / 0.283200 (0.118547) | 0.113398 / 0.141683 (-0.028285) | 1.463851 / 1.452155 (0.011696) | 1.566387 / 1.492716 (0.073670) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.261246 / 0.018006 (0.243240) | 0.546730 / 0.000490 (0.546241) | 0.005245 / 0.000200 (0.005045) | 0.000103 / 0.000054 (0.000048) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029441 / 0.037411 (-0.007970) | 0.111834 / 0.014526 (0.097308) | 0.122411 / 0.176557 (-0.054145) | 0.171288 / 0.737135 (-0.565847) | 0.130338 / 0.296338 (-0.166001) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.433405 / 0.215209 (0.218196) | 4.315790 / 2.077655 (2.238135) | 2.121934 / 1.504120 (0.617814) | 1.924123 / 1.541195 (0.382928) | 2.029077 / 1.468490 (0.560587) | 0.710245 / 4.584777 (-3.874532) | 3.844393 / 3.745712 (0.098681) | 3.576580 / 5.269862 (-1.693281) | 1.930985 / 4.565676 (-2.634691) | 0.092186 / 0.424275 (-0.332090) | 0.012307 / 0.007607 (0.004700) | 0.533722 / 0.226044 (0.307677) | 5.324447 / 2.268929 (3.055519) | 2.615451 / 55.444624 (-52.829174) | 2.282310 / 6.876477 (-4.594167) | 2.319847 / 2.142072 (0.177774) | 0.849364 / 4.805227 (-3.955864) | 0.172722 / 6.500664 (-6.327942) | 0.064721 / 0.075469 (-0.010748) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.289942 / 1.841788 (-0.551846) | 15.875062 / 8.074308 (7.800754) | 14.784682 / 10.191392 (4.593290) | 0.144432 / 0.680424 (-0.535991) | 0.017703 / 0.534201 (-0.516498) | 0.424357 / 0.579283 (-0.154926) | 0.419078 / 0.434364 (-0.015286) | 0.489331 / 0.540337 (-0.051006) | 0.585284 / 1.386936 (-0.801652) |\n\n</details>\n</details>\n\n\n"
] | 2023-05-05T07:34:28Z
| 2023-05-05T12:39:14Z
| 2023-05-05T12:31:54Z
|
CONTRIBUTOR
| null | null | null |
Fixes #5820
Also fixed a couple of typos I spotted
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5824/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5824/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5824.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5824",
"merged_at": "2023-05-05T12:31:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5824.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5824"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7439
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7439/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7439/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7439/events
|
https://github.com/huggingface/datasets/pull/7439
| 2,900,143,289
|
PR_kwDODunzps6NoCdD
| 7,439
|
Fix multi gpu process example
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/46050679?v=4",
"events_url": "https://api.github.com/users/SwayStar123/events{/privacy}",
"followers_url": "https://api.github.com/users/SwayStar123/followers",
"following_url": "https://api.github.com/users/SwayStar123/following{/other_user}",
"gists_url": "https://api.github.com/users/SwayStar123/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/SwayStar123",
"id": 46050679,
"login": "SwayStar123",
"node_id": "MDQ6VXNlcjQ2MDUwNjc5",
"organizations_url": "https://api.github.com/users/SwayStar123/orgs",
"received_events_url": "https://api.github.com/users/SwayStar123/received_events",
"repos_url": "https://api.github.com/users/SwayStar123/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/SwayStar123/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SwayStar123/subscriptions",
"type": "User",
"url": "https://api.github.com/users/SwayStar123",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Okay nevermind looks like to works both ways for models. but my doubt still remains, isnt this changing the device of the model every batch?"
] | 2025-03-06T11:29:19Z
| 2025-03-06T17:07:28Z
| 2025-03-06T17:06:38Z
|
NONE
| null | null | null |
to is not an inplace function.
But i am not sure about this code anyway, i think this is modifying the global variable `model` everytime the function is called? Which is on every batch? So it is juggling the same model on every gpu right? Isnt that very inefficient?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/46050679?v=4",
"events_url": "https://api.github.com/users/SwayStar123/events{/privacy}",
"followers_url": "https://api.github.com/users/SwayStar123/followers",
"following_url": "https://api.github.com/users/SwayStar123/following{/other_user}",
"gists_url": "https://api.github.com/users/SwayStar123/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/SwayStar123",
"id": 46050679,
"login": "SwayStar123",
"node_id": "MDQ6VXNlcjQ2MDUwNjc5",
"organizations_url": "https://api.github.com/users/SwayStar123/orgs",
"received_events_url": "https://api.github.com/users/SwayStar123/received_events",
"repos_url": "https://api.github.com/users/SwayStar123/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/SwayStar123/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SwayStar123/subscriptions",
"type": "User",
"url": "https://api.github.com/users/SwayStar123",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7439/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7439/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7439.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7439",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7439.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7439"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5234
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5234/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5234/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5234/events
|
https://github.com/huggingface/datasets/pull/5234
| 1,447,999,062
|
PR_kwDODunzps5C1diq
| 5,234
|
fix: dataset path should be absolute
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/30353?v=4",
"events_url": "https://api.github.com/users/vigsterkr/events{/privacy}",
"followers_url": "https://api.github.com/users/vigsterkr/followers",
"following_url": "https://api.github.com/users/vigsterkr/following{/other_user}",
"gists_url": "https://api.github.com/users/vigsterkr/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vigsterkr",
"id": 30353,
"login": "vigsterkr",
"node_id": "MDQ6VXNlcjMwMzUz",
"organizations_url": "https://api.github.com/users/vigsterkr/orgs",
"received_events_url": "https://api.github.com/users/vigsterkr/received_events",
"repos_url": "https://api.github.com/users/vigsterkr/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vigsterkr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vigsterkr/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vigsterkr",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Good catch thanks ! Have you tried to use the absolue path in `MemoryMappedTable.__init__` in `table.py`?\r\n\r\nI think it can fix issues with relative paths at more levels than just fixing it `load_from_disk`. If it works I think it would be a more robust fix to this issue",
"@lhoestq right, that actually fixed it indeed. I've pushed the changes (one-liner). lemme know if there's anything else you need for this fix",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-11-14T12:47:40Z
| 2022-12-07T23:49:22Z
| 2022-12-07T23:46:34Z
|
CONTRIBUTOR
| null | null | null |
cache_file_name depends on dataset's path.
A simple way where this could cause a problem:
```
import os
import datasets
def add_prefix(example):
example["text"] = "Review: " + example["text"]
return example
ds = datasets.load_from_disk("a/relative/path")
os.chdir("/tmp")
ds_1 = ds.map(add_prefix)
```
while it may feel that the `chdir` is quite constructed, there are many scenarios when the current working dir can/will change...
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5234/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5234/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5234.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5234",
"merged_at": "2022-12-07T23:46:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5234.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5234"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4876
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4876/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4876/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4876/events
|
https://github.com/huggingface/datasets/issues/4876
| 1,348,202,678
|
I_kwDODunzps5QW_C2
| 4,876
|
Move DatasetInfo from `datasets_infos.json` to the YAML tags in `README.md`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null |
[
"also @osanseviero @Pierrci @SBrandeis potentially",
"Love this in principle 🚀 \r\n\r\nLet's keep in mind users might rely on `dataset_infos.json` already.\r\n\r\nI'm not convinced by the two-syntax solution, wouldn't it be simpler to have only one syntax with a `default` config for datasets with only one config? ie, always having the `configs` field. This makes parsing the metadata easier IMO.\r\n\r\nMight also be good to wrap the tags under a `datasets_info` tag as follows:\r\n\r\n```yaml\r\ndescription: ...\r\ncitation: ...\r\ndataset_infos:\r\n download_size: 35142551\r\n dataset_size: 89789763\r\n version: 1.0.0\r\n configs:\r\n - ...\r\n[...]\r\n```\r\n\r\nLet's also keep in mind that extracting YAML metadata from a markdown readme is a bit more fastidious for users than just parsing a JSON file.",
"> Let's keep in mind users might rely on dataset_infos.json already.\r\n\r\nYea we'll full full backward compatibility\r\n\r\n> Let's also keep in mind that extracting YAML metadata from a markdown readme is a bit more fastidious for users than just parsing a JSON file.\r\n\r\nThe main things that may use or ingest these data IMO are:\r\n- users in the UI or IDE\r\n- `datasets` to populate `DatasetInfo` python object\r\n- moon landing which is already parsing YAML\r\n\r\nAm I missing something ? If not I think it's ok to use YAML\r\n\r\n> Might also be good to wrap the tags under a datasets_info tag as follows:\r\n\r\nMaybe one single syntax like this then ?\r\n```yaml\r\ndataset_infos:\r\n- config: unlabeled\r\n download_size: 35142551\r\n dataset_size: 89789763\r\n version: 1.0.0\r\n splits:\r\n - name: train\r\n num_examples: 10000\r\n features:\r\n - name: text\r\n dtype: string\r\n- config: labeled\r\n download_size: 35142551\r\n dataset_size: 89789763\r\n version: 1.0.0\r\n splits:\r\n - name: train\r\n num_examples: 100\r\n features:\r\n - name: text\r\n dtype: string\r\n - name: label\r\n dtype: ClassLabel\r\n names:\r\n - negative\r\n - positive\r\n```\r\nand when you have only one config\r\n```yaml\r\ndataset_infos:\r\n- config: default\r\n splits:\r\n - name: train\r\n num_examples: 10000\r\n features:\r\n - name: text\r\n dtype: string\r\n```",
"love the idea, and the trend in general to move more things (like tasks) to a single place (YAML).\r\n\r\nalso, if you browse files on a dataset's page (in \"Files and versions\"), raw `README.md` files looks nice and readable, while `.json` files are just one long line that users need to scroll. \r\n\r\n> Let's also keep in mind that extracting YAML metadata from a markdown readme is a bit more fastidious for users than just parsing a JSON file.\r\n\r\ndo users often parse `datasets_infos.json` file themselves? ",
"> do users often parse datasets_infos.json file themselves?\r\n\r\nNot AFAIK, but I'm sure there should be a few users.\r\nUsers that access these info via the `DatasetInfo` from `datasets` won't see the change though e.g.\r\n```python\r\n>> from datasets import get_datasets_infos\r\n>>> get_datasets_infos(\"squad\")\r\n{'plain_text': DatasetInfo(description='Stanford Question Answering Dataset...\r\n```",
"> Maybe one single syntax like this then ?\r\n\r\nLGTM!\r\n\r\n> The main things that may use or ingest these data IMO are:\r\n> - users in the UI or IDE\r\n> - datasets to populate DatasetInfo python object\r\n> - moon landing which is already parsing YAML\r\n\r\nFair point!\r\n\r\nHaving dataset info in the README's YAML is great for API / `huggingface_hub` consumers as well as it will be inserted in the `cardData` field out of the box 🔥 \r\n",
"Very supportive of this!\r\n\r\nNesting an array of configs inside `dataset_infos: ` sounds good to me. One small tweak is that `config: default` can be optional for the default config (which can be the first one by convention)\r\n\r\nWe'll be able to implement metadata validation on the Hub side so we ensure that those metadata are always in the right format (maybe for @coyotte508 ? cc @Pierrci). From a quick glance the `features` might be the harder part to validate here, any doc will be welcome.\r\n\r\n### Other high-level points:\r\n- as we move from mostly academic datasets to *all* datasets (which include the data inside the repos), my intuition is that more and more datasets (Hub-stored) are going to be **single-config**\r\n- similarly, less and less datasets will have a loading script, **just the data + some metadata**\r\n- to lower the barrier to entry to contribution, in the long term users shouldn't need to compute/update this data via a command line. It could be filled automatically on the Hub through a \"bot\" inside Discussions & Pull requests for instance.",
"re: `config: default`\r\n\r\nNote also that the default config is not named `default`, afaiu, but create from the repo name, eg: https://huggingface.co/datasets/nbtpj/bionlp2021SAS default config is `nbtpj--bionlp2021SAS` (which is awful)",
"> Note also that the default config is not named default, afaiu, but create from the repo name, eg: https://huggingface.co/datasets/nbtpj/bionlp2021SAS default config is nbtpj--bionlp2021SAS (which is awful)\r\n\r\nWe can change this to `default` I think or something else",
"> From a quick glance the features might be the harder part to validate here, any doc will be welcome.\r\n\r\nI dug into features validation, see:\r\n\r\n- the OpenAPI spec: https://github.com/huggingface/datasets-server/blob/main/chart/static-files/openapi.json#L460-L697\r\n- the node.js code: https://github.com/huggingface/moon-landing/blob/upgrade-datasets-server-client/server/lib/datasets/FeatureType.ts",
"> We can change this to default I think or something else\r\n\r\nI created https://github.com/huggingface/datasets/issues/4902 to discuss that",
"> Note also that the default config is not named `default`, afaiu, but create from the repo name\r\n\r\nin case of single-config you can even hide the config name from the UI IMO\r\n\r\n> I dug into features validation, see: the OpenAPI spec\r\n\r\nin moon-landing we use [Joi](https://joi.dev/api/) to validate metadata so we would need to generate from Joi code from the OpenAPI spec (or from somewhere else) but I guess that's doable – or just rewrite it manually, as it won't change often",
"I remember there was an ongoing discussion on this topic:\r\n- #3507\r\n\r\nI recall some of the concerns raised on that discussion:\r\n- @lhoestq: Tensorflow Datasets catalog includes a community catalog where you can find and use HF datasets. They are using the exported dataset_infos.json files from github to get the metadata: [#3507 (comment)](https://github.com/huggingface/datasets/issues/3507#issuecomment-1056997627)\r\n- @severo: [#3507 (comment)](https://github.com/huggingface/datasets/issues/3507#issuecomment-1042779776)\r\n - the metadata header might be very long, before reaching the start of the README/dataset card. \r\n - It also somewhat prevents including large strings like the checksums\r\n - two concepts are mixed in the same file (metadata and documentation). This means that if you're interested only in one of them, you still have to know how to parse the whole file. \r\n- @severo: the future \"datasets server\" could be in charge of generating the dataset-info.json file: [#3507 (comment)](https://github.com/huggingface/datasets/issues/3507#issuecomment-1033752157)",
"Thanks for bringing these points up !\r\n\r\n> @lhoestq: Tensorflow Datasets catalog includes a community catalog where you can find and use HF datasets. They are using the exported dataset_infos.json files from github to get the metadata: https://github.com/huggingface/datasets/issues/3507#issuecomment-1056997627\r\n\r\nThe TFDS implementation is not super advanced, so it's ok IMO as long as we don't break all the dataset scripts. Note that users can still use `to_tf_dataset`.\r\n\r\nWe had a chance to discuss the two nexts points with @julien-c as well:\r\n\r\n> @severo: https://github.com/huggingface/datasets/issues/3507#issuecomment-1042779776\r\nthe metadata header might be very long, before reaching the start of the README/dataset card.\r\n\r\nIf we don't add the checksums we should be fine. We can also set a maximum number of supported configs in the README to keep it readable.\r\n\r\n> @severo: the future \"datasets server\" could be in charge of generating the dataset-info.json file: https://github.com/huggingface/datasets/issues/3507#issuecomment-1033752157\r\n\r\nI guess the \"HF Hub actions\" could open PRs to do the same in the YAML directly\r\n",
"Thanks for linking that similar discussion for context, @albertvillanova!"
] | 2022-08-23T16:16:41Z
| 2022-10-03T09:11:13Z
| 2022-10-03T09:11:13Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
Currently there are two places to find metadata for datasets:
- datasets_infos.json, which contains **per dataset config**
- description
- citation
- license
- splits and sizes
- checksums of the data files
- feature types
- and more
- YAML tags, which contain
- license
- language
- train-eval-index
- and more
It would be nice to have a single place instead. We can rely on the YAML tags more than the JSON file for consistency with models. And it would all be indexed by our back-end directly, which is nice to have.
One way would be to move everything to the YAML tags except the checksums (there can be tens of thousands of them). The description/citation is already in the dataset card so we probably don't need to have them in the YAML card, it would be redundant.
Here is an example for SQuAD
```yaml
download_size: 35142551
dataset_size: 89789763
version: 1.0.0
splits:
- name: train
num_examples: 87599
num_bytes: 79317110
- name: validation
num_examples: 10570
num_bytes: 10472653
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
struct:
- name: text
list:
dtype: string
- name: answer_start
list:
dtype: int32
```
Since there is only one configuration for SQuAD, this structure is ok. For datasets with several configs we can see in a second step, but IMO it would be ok to have these fields per config using another syntax
```yaml
configs:
- config: unlabeled
splits:
- name: train
num_examples: 10000
features:
- name: text
dtype: string
- config: labeled
splits:
- name: train
num_examples: 100
features:
- name: text
dtype: string
- name: label
dtype: ClassLabel
names:
- negative
- positive
```
So in the end you could specify a YAML tag either at the top level (for all configs) or per config in the `configs` field
Alternatively we could keep config specific stuff in the `dataset_infos.json` as it it today
Not sure yet what's the best approach here but cc @julien-c @mariosasko @albertvillanova @polinaeterna for feedback :)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 4,
"heart": 3,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 7,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4876/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4876/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6590
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6590/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6590/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6590/events
|
https://github.com/huggingface/datasets/issues/6590
| 2,082,000,084
|
I_kwDODunzps58GMzU
| 6,590
|
Feature request: Multi-GPU dataset mapping for SDXL training
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/17604849?v=4",
"events_url": "https://api.github.com/users/kopyl/events{/privacy}",
"followers_url": "https://api.github.com/users/kopyl/followers",
"following_url": "https://api.github.com/users/kopyl/following{/other_user}",
"gists_url": "https://api.github.com/users/kopyl/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kopyl",
"id": 17604849,
"login": "kopyl",
"node_id": "MDQ6VXNlcjE3NjA0ODQ5",
"organizations_url": "https://api.github.com/users/kopyl/orgs",
"received_events_url": "https://api.github.com/users/kopyl/received_events",
"repos_url": "https://api.github.com/users/kopyl/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kopyl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kopyl/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kopyl",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
| null |
[] | null |
[] | 2024-01-15T13:06:06Z
| 2024-01-15T13:07:07Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
We need to speed up SDXL dataset pre-process. Please make it possible to use multiple GPUs for the [official SDXL trainer](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_sdxl.py) :)
### Motivation
Pre-computing 3 million of images takes around 2 days.
Would be nice to be able to be able to do multi-GPU (or even better – multi-GPU + multi-node) vae and embedding precompute...
### Your contribution
I'm not sure i can wrap my head around the multi-GPU mapping...
Plus it's too expensive for me to take x2 A100 and spend a day just figuring out the staff since I don't have a job right now.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6590/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6590/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6457
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6457/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6457/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6457/events
|
https://github.com/huggingface/datasets/issues/6457
| 2,015,650,563
|
I_kwDODunzps54JGMD
| 6,457
|
`TypeError`: huggingface_hub.hf_file_system.HfFileSystem.find() got multiple values for keyword argument 'maxdepth'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/79070834?v=4",
"events_url": "https://api.github.com/users/wasertech/events{/privacy}",
"followers_url": "https://api.github.com/users/wasertech/followers",
"following_url": "https://api.github.com/users/wasertech/following{/other_user}",
"gists_url": "https://api.github.com/users/wasertech/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/wasertech",
"id": 79070834,
"login": "wasertech",
"node_id": "MDQ6VXNlcjc5MDcwODM0",
"organizations_url": "https://api.github.com/users/wasertech/orgs",
"received_events_url": "https://api.github.com/users/wasertech/received_events",
"repos_url": "https://api.github.com/users/wasertech/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/wasertech/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wasertech/subscriptions",
"type": "User",
"url": "https://api.github.com/users/wasertech",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Updating `fsspec>=2023.10.0` did solve the issue.",
"May be it should be pinned somewhere?",
"> Maybe this should go in datasets directly... anyways you can easily fix this error by updating datasets>=2.15.1.dev0.\r\n\r\n@lhoestq @mariosasko for what I understand this is a bug fixed in `datasets` already, right? No need to do anything in `huggingface_hub`?",
"I've opened a PR with a fix in `huggingface_hub`: https://github.com/huggingface/huggingface_hub/pull/1875",
"Thanks! PR is merged and will be shipped in next release of `huggingface_hub`."
] | 2023-11-29T01:57:36Z
| 2023-11-29T15:39:03Z
| 2023-11-29T02:02:38Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Please see https://github.com/huggingface/huggingface_hub/issues/1872
### Steps to reproduce the bug
Please see https://github.com/huggingface/huggingface_hub/issues/1872
### Expected behavior
Please see https://github.com/huggingface/huggingface_hub/issues/1872
### Environment info
Please see https://github.com/huggingface/huggingface_hub/issues/1872
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/79070834?v=4",
"events_url": "https://api.github.com/users/wasertech/events{/privacy}",
"followers_url": "https://api.github.com/users/wasertech/followers",
"following_url": "https://api.github.com/users/wasertech/following{/other_user}",
"gists_url": "https://api.github.com/users/wasertech/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/wasertech",
"id": 79070834,
"login": "wasertech",
"node_id": "MDQ6VXNlcjc5MDcwODM0",
"organizations_url": "https://api.github.com/users/wasertech/orgs",
"received_events_url": "https://api.github.com/users/wasertech/received_events",
"repos_url": "https://api.github.com/users/wasertech/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/wasertech/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wasertech/subscriptions",
"type": "User",
"url": "https://api.github.com/users/wasertech",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6457/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6457/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5090
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5090/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5090/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5090/events
|
https://github.com/huggingface/datasets/issues/5090
| 1,401,102,407
|
I_kwDODunzps5TgyBH
| 5,090
|
Review sync issues from GitHub to Hub
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[
"Nice!!"
] | 2022-10-07T12:31:56Z
| 2022-10-08T07:07:36Z
| 2022-10-08T07:07:36Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
## Describe the bug
We have discovered that sometimes there were sync issues between GitHub and Hub datasets, after a merge commit to main branch.
For example:
- this merge commit: https://github.com/huggingface/datasets/commit/d74a9e8e4bfff1fed03a4cab99180a841d7caf4b
- was not properly synced with the Hub: https://github.com/huggingface/datasets/actions/runs/3002495269/jobs/4819769684
```
[main 9e641de] Add Papers with Code ID to scifact dataset (#4941)
Author: Albert Villanova del Moral <albertvillanova@users.noreply.huggingface.co>
1 file changed, 42 insertions(+), 14 deletions(-)
push failed !
GitCommandError(['git', 'push'], 1, b'remote: ---------------------------------------------------------- \nremote: Sorry, your push was rejected during YAML metadata verification: \nremote: - Error: "license" does not match any of the allowed types \nremote: ---------------------------------------------------------- \nremote: Please find the documentation at: \nremote: https://huggingface.co/docs/hub/models-cards#model-card-metadata \nremote: ---------------------------------------------------------- \nTo [https://huggingface.co/datasets/scifact.git\n](https://huggingface.co/datasets/scifact.git/n) ! [remote rejected] main -> main (pre-receive hook declined)\nerror: failed to push some refs to \'[https://huggingface.co/datasets/scifact.git\](https://huggingface.co/datasets/scifact.git/)'', b'')
```
We are reviewing sync issues in previous commits to recover them and repushing to the Hub.
TODO: Review
- [x] #4941
- scifact
- [x] #4931
- scifact
- [x] #4753
- wikipedia
- [x] #4554
- wmt17, wmt19, wmt_t2t
- Fixed with "Release 2.4.0" commit: https://github.com/huggingface/datasets/commit/401d4c4f9b9594cb6527c599c0e7a72ce1a0ea49
- https://huggingface.co/datasets/wmt17/commit/5c0afa83fbbd3508ff7627c07f1b27756d1379ea
- https://huggingface.co/datasets/wmt19/commit/b8ad5bf1960208a376a0ab20bc8eac9638f7b400
- https://huggingface.co/datasets/wmt_t2t/commit/b6d67191804dd0933476fede36754a436b48d1fc
- [x] #4607
- [x] #4416
- lccc
- Fixed with "Release 2.3.0" commit: https://huggingface.co/datasets/lccc/commit/8b1f8cf425b5653a0a4357a53205aac82ce038d1
- [x] #4367
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5090/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5090/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/4727
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4727/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4727/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4727/events
|
https://github.com/huggingface/datasets/issues/4727
| 1,312,645,391
|
I_kwDODunzps5OPWEP
| 4,727
|
Dataset Viewer issue for TheNoob3131/mosquito-data
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"events_url": "https://api.github.com/users/thenerd31/events{/privacy}",
"followers_url": "https://api.github.com/users/thenerd31/followers",
"following_url": "https://api.github.com/users/thenerd31/following{/other_user}",
"gists_url": "https://api.github.com/users/thenerd31/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thenerd31",
"id": 53668030,
"login": "thenerd31",
"node_id": "MDQ6VXNlcjUzNjY4MDMw",
"organizations_url": "https://api.github.com/users/thenerd31/orgs",
"received_events_url": "https://api.github.com/users/thenerd31/received_events",
"repos_url": "https://api.github.com/users/thenerd31/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thenerd31/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thenerd31/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thenerd31",
"user_view_type": "public"
}
|
[
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] |
closed
| false
| null |
[] | null |
[
"The preview is working OK:\r\n\r\n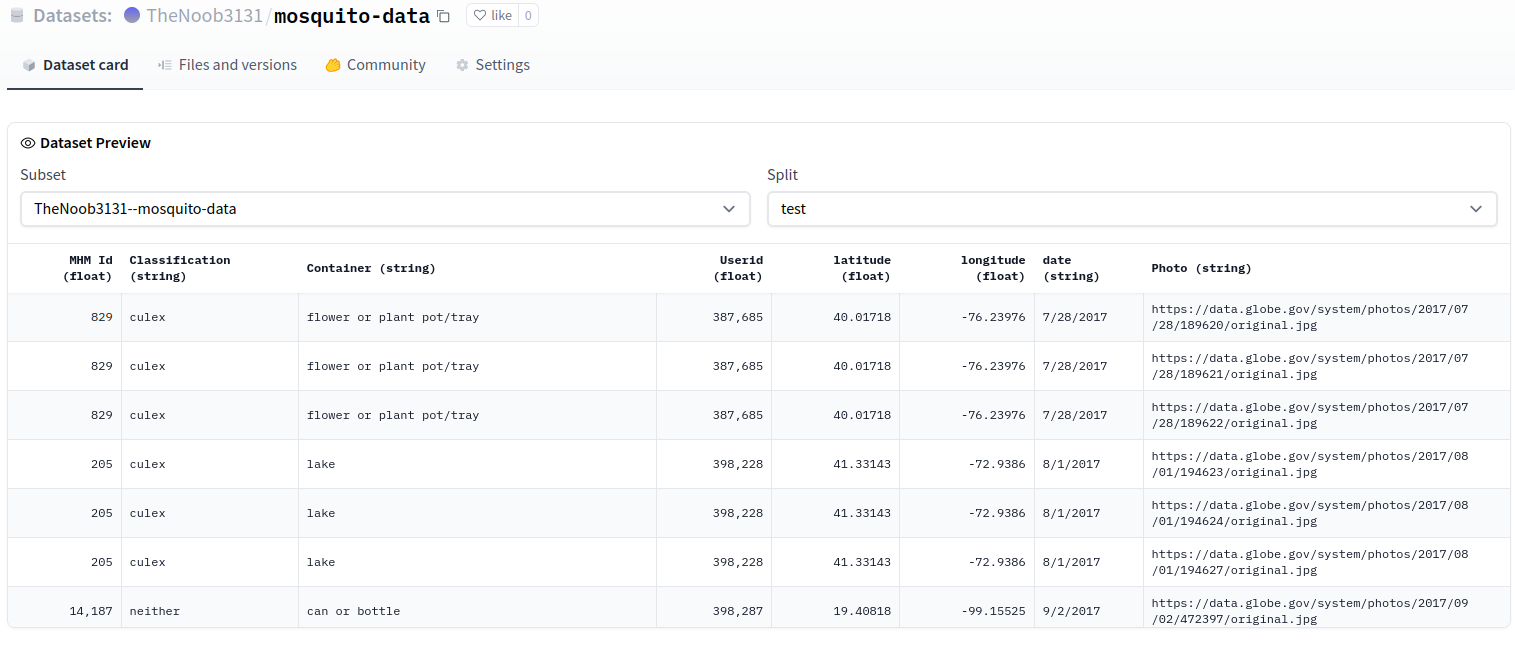\r\n\r\n"
] | 2022-07-21T05:24:48Z
| 2022-07-21T07:51:56Z
| 2022-07-21T07:45:01Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Link
https://huggingface.co/datasets/TheNoob3131/mosquito-data/viewer/TheNoob3131--mosquito-data/test
### Description
Dataset preview not showing with large files. Says 'split cache is empty' even though there are train and test splits.
### Owner
_No response_
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4727/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4727/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/7457
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7457/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7457/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7457/events
|
https://github.com/huggingface/datasets/issues/7457
| 2,924,886,467
|
I_kwDODunzps6uVjnD
| 7,457
|
Document the HF_DATASETS_CACHE env variable
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/92166725?v=4",
"events_url": "https://api.github.com/users/LSerranoPEReN/events{/privacy}",
"followers_url": "https://api.github.com/users/LSerranoPEReN/followers",
"following_url": "https://api.github.com/users/LSerranoPEReN/following{/other_user}",
"gists_url": "https://api.github.com/users/LSerranoPEReN/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/LSerranoPEReN",
"id": 92166725,
"login": "LSerranoPEReN",
"node_id": "U_kgDOBX5aRQ",
"organizations_url": "https://api.github.com/users/LSerranoPEReN/orgs",
"received_events_url": "https://api.github.com/users/LSerranoPEReN/received_events",
"repos_url": "https://api.github.com/users/LSerranoPEReN/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/LSerranoPEReN/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LSerranoPEReN/subscriptions",
"type": "User",
"url": "https://api.github.com/users/LSerranoPEReN",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/other_user}",
"gists_url": "https://api.github.com/users/Harry-Yang0518/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Harry-Yang0518",
"id": 129883215,
"login": "Harry-Yang0518",
"node_id": "U_kgDOB73cTw",
"organizations_url": "https://api.github.com/users/Harry-Yang0518/orgs",
"received_events_url": "https://api.github.com/users/Harry-Yang0518/received_events",
"repos_url": "https://api.github.com/users/Harry-Yang0518/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Harry-Yang0518/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Harry-Yang0518/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Harry-Yang0518",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/other_user}",
"gists_url": "https://api.github.com/users/Harry-Yang0518/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Harry-Yang0518",
"id": 129883215,
"login": "Harry-Yang0518",
"node_id": "U_kgDOB73cTw",
"organizations_url": "https://api.github.com/users/Harry-Yang0518/orgs",
"received_events_url": "https://api.github.com/users/Harry-Yang0518/received_events",
"repos_url": "https://api.github.com/users/Harry-Yang0518/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Harry-Yang0518/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Harry-Yang0518/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Harry-Yang0518",
"user_view_type": "public"
}
] | null |
[
"Strongly agree to this, in addition, I am also suffering to change the cache location similar to other issues (since I changed the environmental variables).\nhttps://github.com/huggingface/datasets/issues/6886",
"`HF_DATASETS_CACHE` should be documented there indeed, feel free to open a PR :) ",
"Hey, I’d love to work on this issue! Could you assign it to me?",
"sure ! you can also comment #self-assign in an issue and a bot assigns you automatically :)"
] | 2025-03-17T12:24:50Z
| 2025-03-20T10:36:46Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
Hello,
I have a use case where my team is sharing models and dataset in shared directory to avoid duplication.
I noticed that the [cache documentation for datasets](https://huggingface.co/docs/datasets/main/en/cache) only mention the `HF_HOME` environment variable but never the `HF_DATASETS_CACHE`.
It should be nice to add `HF_DATASETS_CACHE` to datasets documentation if it's an intended feature.
If it's not, I think a depreciation warning would be appreciated.
### Motivation
This variable is fully working and similar to what `HF_HUB_CACHE` does for models, so it's nice to know that this exists. This seems to be a quick change to implement.
### Your contribution
I could contribute since this is only affecting a small portion of the documentation
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7457/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7457/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5047
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5047/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5047/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5047/events
|
https://github.com/huggingface/datasets/pull/5047
| 1,392,088,398
|
PR_kwDODunzps4_64bS
| 5,047
|
Fix cats_vs_dogs
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-30T08:47:29Z
| 2022-09-30T10:23:22Z
| 2022-09-30T09:34:28Z
|
MEMBER
| null | null | null |
Reported in https://github.com/huggingface/datasets/pull/3878
I updated the number of examples
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5047/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5047/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5047.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5047",
"merged_at": "2022-09-30T09:34:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5047.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5047"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4753
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4753/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4753/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4753/events
|
https://github.com/huggingface/datasets/pull/4753
| 1,319,571,745
|
PR_kwDODunzps48Ll8G
| 4,753
|
Add `language_bcp47` tag
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-07-27T13:31:16Z
| 2022-07-27T14:50:03Z
| 2022-07-27T14:37:56Z
|
MEMBER
| null | null | null |
Following (internal) https://github.com/huggingface/moon-landing/pull/3509, we need to move the bcp47 tags to `language_bcp47` and keep the `language` tag for iso 639 1-2-3 codes. In particular I made sure that all the tags in `languages` are not longer than 3 characters. I moved the rest to `language_bcp47` and fixed some of them.
After this PR is merged I think we can simplify the language validation from the DatasetMetadata class (and keep it bare-bone just for the tagging app)
PS: the CI is failing because of missing content in dataset cards that are unrelated to this PR
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4753/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4753/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4753.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4753",
"merged_at": "2022-07-27T14:37:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4753.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4753"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5443
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5443/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5443/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5443/events
|
https://github.com/huggingface/datasets/pull/5443
| 1,550,178,914
|
PR_kwDODunzps5ILbk8
| 5,443
|
Update share tutorial
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009885 / 0.011353 (-0.001468) | 0.005338 / 0.011008 (-0.005670) | 0.099967 / 0.038508 (0.061459) | 0.036860 / 0.023109 (0.013751) | 0.295283 / 0.275898 (0.019385) | 0.369504 / 0.323480 (0.046024) | 0.008267 / 0.007986 (0.000281) | 0.004375 / 0.004328 (0.000046) | 0.076294 / 0.004250 (0.072043) | 0.047058 / 0.037052 (0.010006) | 0.314463 / 0.258489 (0.055974) | 0.348125 / 0.293841 (0.054284) | 0.038334 / 0.128546 (-0.090213) | 0.012102 / 0.075646 (-0.063544) | 0.333049 / 0.419271 (-0.086223) | 0.050727 / 0.043533 (0.007195) | 0.299244 / 0.255139 (0.044105) | 0.318210 / 0.283200 (0.035010) | 0.112609 / 0.141683 (-0.029074) | 1.450377 / 1.452155 (-0.001778) | 1.485177 / 1.492716 (-0.007539) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.287083 / 0.018006 (0.269077) | 0.564268 / 0.000490 (0.563778) | 0.003578 / 0.000200 (0.003378) | 0.000093 / 0.000054 (0.000039) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026755 / 0.037411 (-0.010657) | 0.105857 / 0.014526 (0.091331) | 0.118291 / 0.176557 (-0.058266) | 0.155735 / 0.737135 (-0.581401) | 0.122527 / 0.296338 (-0.173812) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.396992 / 0.215209 (0.181783) | 3.958562 / 2.077655 (1.880908) | 1.781570 / 1.504120 (0.277451) | 1.617743 / 1.541195 (0.076549) | 1.753504 / 1.468490 (0.285013) | 0.681509 / 4.584777 (-3.903268) | 3.816910 / 3.745712 (0.071198) | 2.087359 / 5.269862 (-3.182503) | 1.328380 / 4.565676 (-3.237297) | 0.083542 / 0.424275 (-0.340733) | 0.012081 / 0.007607 (0.004473) | 0.505127 / 0.226044 (0.279082) | 5.075136 / 2.268929 (2.806208) | 2.259871 / 55.444624 (-53.184753) | 1.944302 / 6.876477 (-4.932175) | 2.102624 / 2.142072 (-0.039449) | 0.819779 / 4.805227 (-3.985448) | 0.165584 / 6.500664 (-6.335080) | 0.061774 / 0.075469 (-0.013695) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.208258 / 1.841788 (-0.633530) | 14.841635 / 8.074308 (6.767327) | 14.484515 / 10.191392 (4.293123) | 0.156464 / 0.680424 (-0.523959) | 0.028839 / 0.534201 (-0.505362) | 0.440860 / 0.579283 (-0.138423) | 0.433892 / 0.434364 (-0.000472) | 0.515339 / 0.540337 (-0.024998) | 0.608838 / 1.386936 (-0.778098) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007548 / 0.011353 (-0.003804) | 0.005464 / 0.011008 (-0.005544) | 0.096987 / 0.038508 (0.058479) | 0.034472 / 0.023109 (0.011363) | 0.391249 / 0.275898 (0.115351) | 0.432779 / 0.323480 (0.109299) | 0.006170 / 0.007986 (-0.001816) | 0.004316 / 0.004328 (-0.000013) | 0.074184 / 0.004250 (0.069934) | 0.054254 / 0.037052 (0.017202) | 0.397947 / 0.258489 (0.139458) | 0.451253 / 0.293841 (0.157412) | 0.037098 / 0.128546 (-0.091449) | 0.012649 / 0.075646 (-0.062997) | 0.333533 / 0.419271 (-0.085739) | 0.050247 / 0.043533 (0.006714) | 0.390446 / 0.255139 (0.135307) | 0.410547 / 0.283200 (0.127347) | 0.110888 / 0.141683 (-0.030795) | 1.452160 / 1.452155 (0.000006) | 1.596331 / 1.492716 (0.103615) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.256061 / 0.018006 (0.238055) | 0.552674 / 0.000490 (0.552184) | 0.003362 / 0.000200 (0.003162) | 0.000095 / 0.000054 (0.000040) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030199 / 0.037411 (-0.007213) | 0.110288 / 0.014526 (0.095762) | 0.127412 / 0.176557 (-0.049145) | 0.165428 / 0.737135 (-0.571707) | 0.131658 / 0.296338 (-0.164680) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441946 / 0.215209 (0.226737) | 4.414209 / 2.077655 (2.336555) | 2.284530 / 1.504120 (0.780410) | 2.110752 / 1.541195 (0.569557) | 2.210751 / 1.468490 (0.742260) | 0.698829 / 4.584777 (-3.885948) | 3.819044 / 3.745712 (0.073332) | 3.274021 / 5.269862 (-1.995840) | 1.781284 / 4.565676 (-2.784393) | 0.085264 / 0.424275 (-0.339011) | 0.012360 / 0.007607 (0.004753) | 0.553519 / 0.226044 (0.327475) | 5.466395 / 2.268929 (3.197467) | 2.825839 / 55.444624 (-52.618786) | 2.439451 / 6.876477 (-4.437026) | 2.582534 / 2.142072 (0.440462) | 0.841644 / 4.805227 (-3.963583) | 0.172288 / 6.500664 (-6.328376) | 0.067215 / 0.075469 (-0.008254) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.283623 / 1.841788 (-0.558165) | 15.753163 / 8.074308 (7.678855) | 14.983263 / 10.191392 (4.791871) | 0.187584 / 0.680424 (-0.492840) | 0.017999 / 0.534201 (-0.516202) | 0.427157 / 0.579283 (-0.152126) | 0.435456 / 0.434364 (0.001092) | 0.496800 / 0.540337 (-0.043537) | 0.592557 / 1.386936 (-0.794379) |\n\n</details>\n</details>\n\n\n"
] | 2023-01-20T01:09:14Z
| 2023-01-20T15:44:45Z
| 2023-01-20T15:37:30Z
|
MEMBER
| null | null | null |
Based on feedback from discussion #5423, this PR updates the sharing tutorial with a mention of writing your own dataset loading script to support more advanced dataset creation options like multiple configs.
I'll open a separate PR to update the *Create a Dataset card* with the new Hub metadata UI update 😄
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5443/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5443/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5443.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5443",
"merged_at": "2023-01-20T15:37:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5443.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5443"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6121
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6121/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6121/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6121/events
|
https://github.com/huggingface/datasets/pull/6121
| 1,836,761,712
|
PR_kwDODunzps5XMsWd
| 6,121
|
Small typo in the code example of create imagefolder dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/19688994?v=4",
"events_url": "https://api.github.com/users/WangXin93/events{/privacy}",
"followers_url": "https://api.github.com/users/WangXin93/followers",
"following_url": "https://api.github.com/users/WangXin93/following{/other_user}",
"gists_url": "https://api.github.com/users/WangXin93/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/WangXin93",
"id": 19688994,
"login": "WangXin93",
"node_id": "MDQ6VXNlcjE5Njg4OTk0",
"organizations_url": "https://api.github.com/users/WangXin93/orgs",
"received_events_url": "https://api.github.com/users/WangXin93/received_events",
"repos_url": "https://api.github.com/users/WangXin93/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/WangXin93/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/WangXin93/subscriptions",
"type": "User",
"url": "https://api.github.com/users/WangXin93",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi,\r\n\r\nI found a small typo in the code example of create imagefolder dataset. It confused me a little when I first saw it.\r\n\r\nBest Regards.\r\n\r\nXin"
] | 2023-08-04T13:36:59Z
| 2023-08-04T13:45:32Z
| 2023-08-04T13:41:43Z
|
NONE
| null | null | null |
Fix type of code example of load imagefolder dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/19688994?v=4",
"events_url": "https://api.github.com/users/WangXin93/events{/privacy}",
"followers_url": "https://api.github.com/users/WangXin93/followers",
"following_url": "https://api.github.com/users/WangXin93/following{/other_user}",
"gists_url": "https://api.github.com/users/WangXin93/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/WangXin93",
"id": 19688994,
"login": "WangXin93",
"node_id": "MDQ6VXNlcjE5Njg4OTk0",
"organizations_url": "https://api.github.com/users/WangXin93/orgs",
"received_events_url": "https://api.github.com/users/WangXin93/received_events",
"repos_url": "https://api.github.com/users/WangXin93/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/WangXin93/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/WangXin93/subscriptions",
"type": "User",
"url": "https://api.github.com/users/WangXin93",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6121/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6121/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6121.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6121",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6121.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6121"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4949
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4949/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4949/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4949/events
|
https://github.com/huggingface/datasets/pull/4949
| 1,365,251,916
|
PR_kwDODunzps4-iqzI
| 4,949
|
Update enwik8 fixing the broken link
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/54819091?v=4",
"events_url": "https://api.github.com/users/mtanghu/events{/privacy}",
"followers_url": "https://api.github.com/users/mtanghu/followers",
"following_url": "https://api.github.com/users/mtanghu/following{/other_user}",
"gists_url": "https://api.github.com/users/mtanghu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mtanghu",
"id": 54819091,
"login": "mtanghu",
"node_id": "MDQ6VXNlcjU0ODE5MDkx",
"organizations_url": "https://api.github.com/users/mtanghu/orgs",
"received_events_url": "https://api.github.com/users/mtanghu/received_events",
"repos_url": "https://api.github.com/users/mtanghu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mtanghu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mtanghu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mtanghu",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Closing pull request to following contributing guidelines of making a new branch and will make a new pull request"
] | 2022-09-07T22:17:14Z
| 2022-09-08T03:14:04Z
| 2022-09-08T03:14:04Z
|
CONTRIBUTOR
| null | null | null |
The current enwik8 dataset link give a 502 bad gateway error which can be view on https://huggingface.co/datasets/enwik8 (click the dropdown to see the dataset preview, it will show the error). This corrects the links, and json metadata as well as adds a little bit more information about enwik8.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/54819091?v=4",
"events_url": "https://api.github.com/users/mtanghu/events{/privacy}",
"followers_url": "https://api.github.com/users/mtanghu/followers",
"following_url": "https://api.github.com/users/mtanghu/following{/other_user}",
"gists_url": "https://api.github.com/users/mtanghu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mtanghu",
"id": 54819091,
"login": "mtanghu",
"node_id": "MDQ6VXNlcjU0ODE5MDkx",
"organizations_url": "https://api.github.com/users/mtanghu/orgs",
"received_events_url": "https://api.github.com/users/mtanghu/received_events",
"repos_url": "https://api.github.com/users/mtanghu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mtanghu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mtanghu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mtanghu",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4949/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4949/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4949.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4949",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4949.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4949"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4759
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4759/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4759/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4759/events
|
https://github.com/huggingface/datasets/issues/4759
| 1,320,783,300
|
I_kwDODunzps5OuY3E
| 4,759
|
Dataset Viewer issue for Toygar/turkish-offensive-language-detection
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/44132720?v=4",
"events_url": "https://api.github.com/users/tanyelai/events{/privacy}",
"followers_url": "https://api.github.com/users/tanyelai/followers",
"following_url": "https://api.github.com/users/tanyelai/following{/other_user}",
"gists_url": "https://api.github.com/users/tanyelai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tanyelai",
"id": 44132720,
"login": "tanyelai",
"node_id": "MDQ6VXNlcjQ0MTMyNzIw",
"organizations_url": "https://api.github.com/users/tanyelai/orgs",
"received_events_url": "https://api.github.com/users/tanyelai/received_events",
"repos_url": "https://api.github.com/users/tanyelai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tanyelai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tanyelai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tanyelai",
"user_view_type": "public"
}
|
[
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
}
] | null |
[
"I refreshed the dataset viewer manually, it's fixed now. Sorry for the inconvenience.\r\n<img width=\"1557\" alt=\"Capture d’écran 2022-07-28 à 09 17 39\" src=\"https://user-images.githubusercontent.com/1676121/181514666-92d7f8e1-ddc1-4769-84f3-f1edfdb902e8.png\">\r\n\r\n"
] | 2022-07-28T11:21:43Z
| 2022-07-28T13:17:56Z
| 2022-07-28T13:17:48Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Link
https://huggingface.co/datasets/Toygar/turkish-offensive-language-detection
### Description
Status code: 400
Exception: Status400Error
Message: The dataset does not exist.
Hi, I provided train.csv, test.csv and valid.csv files. However, viewer says dataset does not exist.
Should I need to do anything else?
### Owner
Yes
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4759/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4759/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/7286
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7286/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7286/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7286/events
|
https://github.com/huggingface/datasets/issues/7286
| 2,645,350,151
|
I_kwDODunzps6drNcH
| 7,286
|
Concurrent loading in `load_from_disk` - `num_proc` as a param
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5240449?v=4",
"events_url": "https://api.github.com/users/unography/events{/privacy}",
"followers_url": "https://api.github.com/users/unography/followers",
"following_url": "https://api.github.com/users/unography/following{/other_user}",
"gists_url": "https://api.github.com/users/unography/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/unography",
"id": 5240449,
"login": "unography",
"node_id": "MDQ6VXNlcjUyNDA0NDk=",
"organizations_url": "https://api.github.com/users/unography/orgs",
"received_events_url": "https://api.github.com/users/unography/received_events",
"repos_url": "https://api.github.com/users/unography/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/unography/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/unography/subscriptions",
"type": "User",
"url": "https://api.github.com/users/unography",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
| null |
[] | null |
[] | 2024-11-08T23:21:40Z
| 2024-11-09T16:14:37Z
| 2024-11-09T16:14:37Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
https://github.com/huggingface/datasets/pull/6464 mentions a `num_proc` param while loading dataset from disk, but can't find that in the documentation and code anywhere
### Motivation
Make loading large datasets from disk faster
### Your contribution
Happy to contribute if given pointers
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5240449?v=4",
"events_url": "https://api.github.com/users/unography/events{/privacy}",
"followers_url": "https://api.github.com/users/unography/followers",
"following_url": "https://api.github.com/users/unography/following{/other_user}",
"gists_url": "https://api.github.com/users/unography/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/unography",
"id": 5240449,
"login": "unography",
"node_id": "MDQ6VXNlcjUyNDA0NDk=",
"organizations_url": "https://api.github.com/users/unography/orgs",
"received_events_url": "https://api.github.com/users/unography/received_events",
"repos_url": "https://api.github.com/users/unography/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/unography/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/unography/subscriptions",
"type": "User",
"url": "https://api.github.com/users/unography",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7286/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7286/timeline
| null |
not_planned
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6948
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6948/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6948/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6948/events
|
https://github.com/huggingface/datasets/issues/6948
| 2,331,758,300
|
I_kwDODunzps6K-87c
| 6,948
|
to_tf_dataset: Visible devices cannot be modified after being initialized
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7151661?v=4",
"events_url": "https://api.github.com/users/logasja/events{/privacy}",
"followers_url": "https://api.github.com/users/logasja/followers",
"following_url": "https://api.github.com/users/logasja/following{/other_user}",
"gists_url": "https://api.github.com/users/logasja/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/logasja",
"id": 7151661,
"login": "logasja",
"node_id": "MDQ6VXNlcjcxNTE2NjE=",
"organizations_url": "https://api.github.com/users/logasja/orgs",
"received_events_url": "https://api.github.com/users/logasja/received_events",
"repos_url": "https://api.github.com/users/logasja/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/logasja/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/logasja/subscriptions",
"type": "User",
"url": "https://api.github.com/users/logasja",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[] | 2024-06-03T18:10:57Z
| 2024-06-03T18:10:57Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
When trying to use to_tf_dataset with a custom data_loader collate_fn when I use parallelism I am met with the following error as many times as number of workers there were in ``num_workers``.
File "/opt/miniconda/envs/env/lib/python3.11/site-packages/multiprocess/process.py", line 314, in _bootstrap
self.run()
File "/opt/miniconda/envs/env/lib/python3.11/site-packages/multiprocess/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/opt/miniconda/envs/env/lib/python3.11/site-packages/datasets/utils/tf_utils.py", line 438, in worker_loop
tf.config.set_visible_devices([], "GPU") # Make sure workers don't try to allocate GPU memory
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/miniconda/envs/env/lib/python3.11/site-packages/tensorflow/python/framework/config.py", line 566, in set_visible_devices
context.context().set_visible_devices(devices, device_type)
File "/opt/miniconda/envs/env/lib/python3.11/site-packages/tensorflow/python/eager/context.py", line 1737, in set_visible_devices
raise RuntimeError(
RuntimeError: Visible devices cannot be modified after being initialized
### Steps to reproduce the bug
1. Download a dataset using HuggingFace load_dataset
2. Define a function that transforms the data in some way to be used in the collate_fn argument
3. Provide a ``batch_size`` and ``num_workers`` value in the ``to_tf_dataset`` function
4. Either retrieve directly or use tfds benchmark to test the dataset
``` python
from datasets import load_datasets
import tensorflow_datasets as tfds
from keras_cv.layers import Resizing
def data_loader(examples):
x = Resizing(examples[0]['image'], 256, 256, crop_to_aspect_ratio=True)
return {X[0]: x}
ds = load_datasets("logasja/FDF", split="test")
ds = ds.to_tf_dataset(collate_fn=data_loader, batch_size=16, num_workers=2)
tfds.benchmark(ds)
```
### Expected behavior
Use multiple processes to apply transformations from the collate_fn to the tf dataset on the CPU.
### Environment info
- `datasets` version: 2.19.1
- Platform: Linux-6.5.0-1023-oracle-x86_64-with-glibc2.35
- Python version: 3.11.8
- `huggingface_hub` version: 0.22.2
- PyArrow version: 15.0.2
- Pandas version: 2.2.1
- `fsspec` version: 2024.2.0
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6948/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6948/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4673
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4673/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4673/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4673/events
|
https://github.com/huggingface/datasets/issues/4673
| 1,301,010,331
|
I_kwDODunzps5Ni9eb
| 4,673
|
load_datasets on csv returns everything as a string
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/25102613?v=4",
"events_url": "https://api.github.com/users/courtneysprouse/events{/privacy}",
"followers_url": "https://api.github.com/users/courtneysprouse/followers",
"following_url": "https://api.github.com/users/courtneysprouse/following{/other_user}",
"gists_url": "https://api.github.com/users/courtneysprouse/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/courtneysprouse",
"id": 25102613,
"login": "courtneysprouse",
"node_id": "MDQ6VXNlcjI1MTAyNjEz",
"organizations_url": "https://api.github.com/users/courtneysprouse/orgs",
"received_events_url": "https://api.github.com/users/courtneysprouse/received_events",
"repos_url": "https://api.github.com/users/courtneysprouse/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/courtneysprouse/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/courtneysprouse/subscriptions",
"type": "User",
"url": "https://api.github.com/users/courtneysprouse",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
| null |
[] | null |
[
"Hi @courtneysprouse, thanks for reporting.\r\n\r\nYes, you are right: by default the \"csv\" loader loads all columns as strings. \r\n\r\nYou could tweak this behavior by passing the `feature` argument to `load_dataset`, but it is also true that currently it is not possible to perform some kind of casts, due to lacking of implementation in PyArrow. For example:\r\n```python\r\nimport datasets\r\n\r\nfeatures = datasets.Features(\r\n {\r\n \"tokens\": datasets.Sequence(datasets.Value(\"string\")),\r\n \"ner_tags\": datasets.Sequence(datasets.Value(\"int32\")),\r\n }\r\n)\r\n\r\nnew_conll = datasets.load_dataset(\"csv\", data_files=\"ner_conll.csv\", features=features)\r\n```\r\ngives `ArrowNotImplementedError` error:\r\n```\r\n/usr/local/lib/python3.7/dist-packages/pyarrow/error.pxi in pyarrow.lib.check_status()\r\n\r\nArrowNotImplementedError: Unsupported cast from string to list using function cast_list\r\n```\r\n\r\nOn the other hand, if you just would like to save and afterwards load your dataset, you could use `save_to_disk` and `load_from_disk` instead. These functions preserve all data types.\r\n```python\r\n>>> orig_conll.save_to_disk(\"ner_conll\")\r\n\r\n>>> from datasets import load_from_disk\r\n\r\n>>> new_conll = load_from_disk(\"ner_conll\")\r\n>>> new_conll\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['id', 'tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],\r\n num_rows: 14042\r\n })\r\n validation: Dataset({\r\n features: ['id', 'tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],\r\n num_rows: 3251\r\n })\r\n test: Dataset({\r\n features: ['id', 'tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],\r\n num_rows: 3454\r\n })\r\n})\r\n>>> new_conll[\"train\"][0]\r\n{'chunk_tags': [11, 21, 11, 12, 21, 22, 11, 12, 0],\r\n 'id': '0',\r\n 'ner_tags': [3, 0, 7, 0, 0, 0, 7, 0, 0],\r\n 'pos_tags': [22, 42, 16, 21, 35, 37, 16, 21, 7],\r\n 'tokens': ['EU',\r\n 'rejects',\r\n 'German',\r\n 'call',\r\n 'to',\r\n 'boycott',\r\n 'British',\r\n 'lamb',\r\n '.']}\r\n>>> new_conll[\"train\"].features\r\n{'chunk_tags': Sequence(feature=ClassLabel(num_classes=23, names=['O', 'B-ADJP', 'I-ADJP', 'B-ADVP', 'I-ADVP', 'B-CONJP', 'I-CONJP', 'B-INTJ', 'I-INTJ', 'B-LST', 'I-LST', 'B-NP', 'I-NP', 'B-PP', 'I-PP', 'B-PRT', 'I-PRT', 'B-SBAR', 'I-SBAR', 'B-UCP', 'I-UCP', 'B-VP', 'I-VP'], id=None), length=-1, id=None),\r\n 'id': Value(dtype='string', id=None),\r\n 'ner_tags': Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], id=None), length=-1, id=None),\r\n 'pos_tags': Sequence(feature=ClassLabel(num_classes=47, names=['\"', \"''\", '#', '$', '(', ')', ',', '.', ':', '``', 'CC', 'CD', 'DT', 'EX', 'FW', 'IN', 'JJ', 'JJR', 'JJS', 'LS', 'MD', 'NN', 'NNP', 'NNPS', 'NNS', 'NN|SYM', 'PDT', 'POS', 'PRP', 'PRP$', 'RB', 'RBR', 'RBS', 'RP', 'SYM', 'TO', 'UH', 'VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ', 'WDT', 'WP', 'WP$', 'WRB'], id=None), length=-1, id=None),\r\n 'tokens': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)}\r\n```",
"Hi @albertvillanova!\r\n\r\nThanks so much for your suggestions! That worked! ",
"> Hi @courtneysprouse, thanks for reporting.\r\n> \r\n> Yes, you are right: by default the \"csv\" loader loads all columns as strings.\r\n> \r\n> You could tweak this behavior by passing the `feature` argument to `load_dataset`, but it is also true that currently it is not possible to perform some kind of casts, due to lacking of implementation in PyArrow. For example:\r\n> \r\n> ```python\r\n> import datasets\r\n> \r\n> features = datasets.Features(\r\n> {\r\n> \"tokens\": datasets.Sequence(datasets.Value(\"string\")),\r\n> \"ner_tags\": datasets.Sequence(datasets.Value(\"int32\")),\r\n> }\r\n> )\r\n> \r\n> new_conll = datasets.load_dataset(\"csv\", data_files=\"ner_conll.csv\", features=features)\r\n> ```\r\n> \r\n> gives `ArrowNotImplementedError` error:\r\n> \r\n> ```\r\n> /usr/local/lib/python3.7/dist-packages/pyarrow/error.pxi in pyarrow.lib.check_status()\r\n> \r\n> ArrowNotImplementedError: Unsupported cast from string to list using function cast_list\r\n> ```\r\n> \r\n> On the other hand, if you just would like to save and afterwards load your dataset, you could use `save_to_disk` and `load_from_disk` instead. These functions preserve all data types.\r\n> \r\n> ```python\r\n> >>> orig_conll.save_to_disk(\"ner_conll\")\r\n> \r\n> >>> from datasets import load_from_disk\r\n> \r\n> >>> new_conll = load_from_disk(\"ner_conll\")\r\n> >>> new_conll\r\n> DatasetDict({\r\n> train: Dataset({\r\n> features: ['id', 'tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],\r\n> num_rows: 14042\r\n> })\r\n> validation: Dataset({\r\n> features: ['id', 'tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],\r\n> num_rows: 3251\r\n> })\r\n> test: Dataset({\r\n> features: ['id', 'tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],\r\n> num_rows: 3454\r\n> })\r\n> })\r\n> >>> new_conll[\"train\"][0]\r\n> {'chunk_tags': [11, 21, 11, 12, 21, 22, 11, 12, 0],\r\n> 'id': '0',\r\n> 'ner_tags': [3, 0, 7, 0, 0, 0, 7, 0, 0],\r\n> 'pos_tags': [22, 42, 16, 21, 35, 37, 16, 21, 7],\r\n> 'tokens': ['EU',\r\n> 'rejects',\r\n> 'German',\r\n> 'call',\r\n> 'to',\r\n> 'boycott',\r\n> 'British',\r\n> 'lamb',\r\n> '.']}\r\n> >>> new_conll[\"train\"].features\r\n> {'chunk_tags': Sequence(feature=ClassLabel(num_classes=23, names=['O', 'B-ADJP', 'I-ADJP', 'B-ADVP', 'I-ADVP', 'B-CONJP', 'I-CONJP', 'B-INTJ', 'I-INTJ', 'B-LST', 'I-LST', 'B-NP', 'I-NP', 'B-PP', 'I-PP', 'B-PRT', 'I-PRT', 'B-SBAR', 'I-SBAR', 'B-UCP', 'I-UCP', 'B-VP', 'I-VP'], id=None), length=-1, id=None),\r\n> 'id': Value(dtype='string', id=None),\r\n> 'ner_tags': Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], id=None), length=-1, id=None),\r\n> 'pos_tags': Sequence(feature=ClassLabel(num_classes=47, names=['\"', \"''\", '#', '$', '(', ')', ',', '.', ':', '``', 'CC', 'CD', 'DT', 'EX', 'FW', 'IN', 'JJ', 'JJR', 'JJS', 'LS', 'MD', 'NN', 'NNP', 'NNPS', 'NNS', 'NN|SYM', 'PDT', 'POS', 'PRP', 'PRP$', 'RB', 'RBR', 'RBS', 'RP', 'SYM', 'TO', 'UH', 'VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ', 'WDT', 'WP', 'WP$', 'WRB'], id=None), length=-1, id=None),\r\n> 'tokens': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)}\r\n> ```\r\n\r\nIt seems that by default, the 'csv' loader doesn’t load all columns as strings. When I load a column with numbers that start with 0, datasets removes the leading 0 and converts this column to an integer type. How can I set it to load all columns as strings?"
] | 2022-07-11T17:30:24Z
| 2024-11-05T03:55:10Z
| 2022-07-12T13:33:08Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
## Describe the bug
If you use:
`conll_dataset.to_csv("ner_conll.csv")`
It will create a csv file with all of your data as expected, however when you load it with:
`conll_dataset = load_dataset("csv", data_files="ner_conll.csv")`
everything is read in as a string. For example if I look at everything in 'ner_tags' I get back `['[3 0 7 0 0 0 7 0 0]', '[1 2]', '[5 0]']` instead of what I originally saved which was `[[3, 0, 7, 0, 0, 0, 7, 0, 0], [1, 2], [5, 0]]`
I think maybe there is something funky going on with the csv delimiter
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
#load original conll dataset
orig_conll = load_dataset("conll2003")
#save original conll as a csv
orig_conll.to_csv("ner_conll.csv")
#reload conll data as a csv
new_conll = load_dataset("csv", data_files="ner_conll.csv")`
```
## Expected results
A clear and concise description of the expected results.
I would expect the data be returned as the data type I saved it as. I.e. if I save a list of ints
[[3, 0, 7, 0, 0, 0, 7, 0, 0]], I shouldnt get back a string ['[3 0 7 0 0 0 7 0 0]']
I also get back a string when I pass a list of strings ['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
## Actual results
A list of strings `['[3 0 7 0 0 0 7 0 0]', '[1 2]', '[5 0]']`
A string "['EU' 'rejects' 'German' 'call' 'to' 'boycott' 'British' 'lamb' '.']"
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-5.4.0-121-generic-x86_64-with-glibc2.17
- Python version: 3.8.13
- PyArrow version: 8.0.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/25102613?v=4",
"events_url": "https://api.github.com/users/courtneysprouse/events{/privacy}",
"followers_url": "https://api.github.com/users/courtneysprouse/followers",
"following_url": "https://api.github.com/users/courtneysprouse/following{/other_user}",
"gists_url": "https://api.github.com/users/courtneysprouse/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/courtneysprouse",
"id": 25102613,
"login": "courtneysprouse",
"node_id": "MDQ6VXNlcjI1MTAyNjEz",
"organizations_url": "https://api.github.com/users/courtneysprouse/orgs",
"received_events_url": "https://api.github.com/users/courtneysprouse/received_events",
"repos_url": "https://api.github.com/users/courtneysprouse/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/courtneysprouse/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/courtneysprouse/subscriptions",
"type": "User",
"url": "https://api.github.com/users/courtneysprouse",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4673/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4673/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5401
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5401/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5401/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5401/events
|
https://github.com/huggingface/datasets/pull/5401
| 1,517,160,935
|
PR_kwDODunzps5Gh1XQ
| 5,401
|
Support Dataset conversion from/to Spark
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5401). All of your documentation changes will be reflected on that endpoint.",
"Cool thanks !\r\n\r\nSpark DataFrame are usually quite big, and I believe here `from_spark` would load everything in the driver node's RAM, which is quite limiting. Same for `to_spark` which would load everything in the driver node's RAM before sending the data to the executor. Maybe we can mention this in the docstring ?\r\n\r\nTo transfer big datasets from/into the HF ecosystem using Spark maybe we can just make sure that `pyspark` can read/write to the HF Hub, and that `datasets` can read from HDFS/S3/etc.",
"Yes @lhoestq , consider this as a first integration of the Datasets library with Spark.\r\n- This PR implements the basic conversion between both.\r\n - And yes, we are using the Spark's `pandas` API (that uses `pyarrow` under the hood): everything is transferred to the driver.\r\n - Note that we are converting from/to a Datasets dataset: this is not distributed\r\n\r\nThe next step is to support the integration of the HF Hub with Spark, that I think should be done using `hffs`.",
"Thinking more about it I don't really see how those two methods help in practice, since one can already do `datasets` <-> pandas <-> spark and those two methods don't add value over this.\r\n\r\nHowever I think it can be good documentation to explain that it's possible to do it and it's super simple"
] | 2023-01-03T09:57:40Z
| 2023-01-05T14:21:33Z
| null |
MEMBER
| null | null | null |
This PR implements Spark integration by supporting `Dataset` conversion from/to Spark `DataFrame`.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5401/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5401/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5401.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5401",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5401.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5401"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5667
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5667/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5667/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5667/events
|
https://github.com/huggingface/datasets/pull/5667
| 1,637,789,361
|
PR_kwDODunzps5Mv8Im
| 5,667
|
Jax requires jaxlib
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008592 / 0.011353 (-0.002761) | 0.005182 / 0.011008 (-0.005826) | 0.097916 / 0.038508 (0.059408) | 0.034612 / 0.023109 (0.011503) | 0.313760 / 0.275898 (0.037862) | 0.353422 / 0.323480 (0.029942) | 0.005880 / 0.007986 (-0.002106) | 0.004123 / 0.004328 (-0.000205) | 0.073634 / 0.004250 (0.069384) | 0.049349 / 0.037052 (0.012297) | 0.317381 / 0.258489 (0.058892) | 0.365821 / 0.293841 (0.071980) | 0.036482 / 0.128546 (-0.092065) | 0.012126 / 0.075646 (-0.063521) | 0.334640 / 0.419271 (-0.084631) | 0.050551 / 0.043533 (0.007018) | 0.310472 / 0.255139 (0.055333) | 0.349049 / 0.283200 (0.065850) | 0.101343 / 0.141683 (-0.040340) | 1.447903 / 1.452155 (-0.004252) | 1.518793 / 1.492716 (0.026077) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.210971 / 0.018006 (0.192965) | 0.449471 / 0.000490 (0.448982) | 0.003596 / 0.000200 (0.003396) | 0.000084 / 0.000054 (0.000029) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027386 / 0.037411 (-0.010025) | 0.112683 / 0.014526 (0.098157) | 0.117603 / 0.176557 (-0.058954) | 0.174186 / 0.737135 (-0.562949) | 0.123510 / 0.296338 (-0.172829) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422595 / 0.215209 (0.207386) | 4.224713 / 2.077655 (2.147058) | 2.006359 / 1.504120 (0.502240) | 1.823767 / 1.541195 (0.282572) | 1.898340 / 1.468490 (0.429849) | 0.721656 / 4.584777 (-3.863121) | 3.823498 / 3.745712 (0.077785) | 2.172380 / 5.269862 (-3.097481) | 1.469773 / 4.565676 (-3.095904) | 0.086978 / 0.424275 (-0.337297) | 0.012642 / 0.007607 (0.005035) | 0.517830 / 0.226044 (0.291785) | 5.171150 / 2.268929 (2.902221) | 2.495238 / 55.444624 (-52.949386) | 2.114380 / 6.876477 (-4.762097) | 2.274329 / 2.142072 (0.132257) | 0.863855 / 4.805227 (-3.941372) | 0.174127 / 6.500664 (-6.326537) | 0.065939 / 0.075469 (-0.009530) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.208831 / 1.841788 (-0.632957) | 15.016704 / 8.074308 (6.942396) | 14.721231 / 10.191392 (4.529839) | 0.144140 / 0.680424 (-0.536284) | 0.017781 / 0.534201 (-0.516420) | 0.425679 / 0.579283 (-0.153604) | 0.416747 / 0.434364 (-0.017617) | 0.490160 / 0.540337 (-0.050177) | 0.583639 / 1.386936 (-0.803297) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007670 / 0.011353 (-0.003683) | 0.005383 / 0.011008 (-0.005626) | 0.075756 / 0.038508 (0.037248) | 0.033373 / 0.023109 (0.010263) | 0.341017 / 0.275898 (0.065119) | 0.378890 / 0.323480 (0.055410) | 0.005945 / 0.007986 (-0.002040) | 0.004179 / 0.004328 (-0.000150) | 0.074588 / 0.004250 (0.070337) | 0.048564 / 0.037052 (0.011511) | 0.338774 / 0.258489 (0.080285) | 0.391081 / 0.293841 (0.097240) | 0.036659 / 0.128546 (-0.091887) | 0.012241 / 0.075646 (-0.063406) | 0.086910 / 0.419271 (-0.332361) | 0.049745 / 0.043533 (0.006212) | 0.332810 / 0.255139 (0.077671) | 0.360317 / 0.283200 (0.077117) | 0.103399 / 0.141683 (-0.038283) | 1.456754 / 1.452155 (0.004599) | 1.542644 / 1.492716 (0.049928) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.207182 / 0.018006 (0.189176) | 0.455659 / 0.000490 (0.455169) | 0.003609 / 0.000200 (0.003409) | 0.000092 / 0.000054 (0.000038) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029556 / 0.037411 (-0.007856) | 0.114215 / 0.014526 (0.099690) | 0.127721 / 0.176557 (-0.048836) | 0.177070 / 0.737135 (-0.560065) | 0.128840 / 0.296338 (-0.167499) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.428176 / 0.215209 (0.212967) | 4.274324 / 2.077655 (2.196669) | 2.020058 / 1.504120 (0.515938) | 1.823343 / 1.541195 (0.282148) | 1.924688 / 1.468490 (0.456198) | 0.719195 / 4.584777 (-3.865582) | 3.760445 / 3.745712 (0.014733) | 2.133813 / 5.269862 (-3.136049) | 1.364876 / 4.565676 (-3.200801) | 0.087523 / 0.424275 (-0.336752) | 0.013712 / 0.007607 (0.006105) | 0.528403 / 0.226044 (0.302359) | 5.307780 / 2.268929 (3.038851) | 2.496747 / 55.444624 (-52.947877) | 2.169136 / 6.876477 (-4.707341) | 2.235719 / 2.142072 (0.093646) | 0.875281 / 4.805227 (-3.929946) | 0.172369 / 6.500664 (-6.328295) | 0.064667 / 0.075469 (-0.010802) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.262594 / 1.841788 (-0.579193) | 15.182681 / 8.074308 (7.108373) | 14.725663 / 10.191392 (4.534271) | 0.180961 / 0.680424 (-0.499462) | 0.017632 / 0.534201 (-0.516569) | 0.427531 / 0.579283 (-0.151752) | 0.431741 / 0.434364 (-0.002622) | 0.503251 / 0.540337 (-0.037087) | 0.597423 / 1.386936 (-0.789513) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009761 / 0.011353 (-0.001592) | 0.006779 / 0.011008 (-0.004229) | 0.132786 / 0.038508 (0.094277) | 0.037721 / 0.023109 (0.014611) | 0.435685 / 0.275898 (0.159787) | 0.447488 / 0.323480 (0.124009) | 0.006848 / 0.007986 (-0.001137) | 0.005099 / 0.004328 (0.000771) | 0.097384 / 0.004250 (0.093133) | 0.056663 / 0.037052 (0.019610) | 0.463407 / 0.258489 (0.204918) | 0.502544 / 0.293841 (0.208703) | 0.053817 / 0.128546 (-0.074729) | 0.020253 / 0.075646 (-0.055393) | 0.446653 / 0.419271 (0.027382) | 0.064465 / 0.043533 (0.020932) | 0.455375 / 0.255139 (0.200236) | 0.458378 / 0.283200 (0.175178) | 0.109124 / 0.141683 (-0.032559) | 1.957338 / 1.452155 (0.505184) | 1.960391 / 1.492716 (0.467674) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.219566 / 0.018006 (0.201560) | 0.558181 / 0.000490 (0.557691) | 0.004678 / 0.000200 (0.004478) | 0.000125 / 0.000054 (0.000071) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032643 / 0.037411 (-0.004768) | 0.147375 / 0.014526 (0.132849) | 0.130821 / 0.176557 (-0.045736) | 0.203202 / 0.737135 (-0.533933) | 0.145186 / 0.296338 (-0.151153) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.665773 / 0.215209 (0.450564) | 6.674021 / 2.077655 (4.596366) | 2.662372 / 1.504120 (1.158253) | 2.333327 / 1.541195 (0.792132) | 2.221413 / 1.468490 (0.752923) | 1.287001 / 4.584777 (-3.297776) | 5.534326 / 3.745712 (1.788614) | 3.188809 / 5.269862 (-2.081052) | 2.261717 / 4.565676 (-2.303960) | 0.151910 / 0.424275 (-0.272366) | 0.020509 / 0.007607 (0.012902) | 0.863608 / 0.226044 (0.637564) | 8.442155 / 2.268929 (6.173227) | 3.438260 / 55.444624 (-52.006364) | 2.692503 / 6.876477 (-4.183974) | 2.810997 / 2.142072 (0.668925) | 1.477345 / 4.805227 (-3.327882) | 0.261942 / 6.500664 (-6.238722) | 0.086347 / 0.075469 (0.010878) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.529072 / 1.841788 (-0.312716) | 17.213019 / 8.074308 (9.138711) | 21.887309 / 10.191392 (11.695917) | 0.259660 / 0.680424 (-0.420763) | 0.027916 / 0.534201 (-0.506285) | 0.554103 / 0.579283 (-0.025180) | 0.614566 / 0.434364 (0.180202) | 0.700456 / 0.540337 (0.160119) | 0.756860 / 1.386936 (-0.630077) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009267 / 0.011353 (-0.002086) | 0.006414 / 0.011008 (-0.004594) | 0.102404 / 0.038508 (0.063896) | 0.034885 / 0.023109 (0.011776) | 0.413191 / 0.275898 (0.137293) | 0.483901 / 0.323480 (0.160422) | 0.006614 / 0.007986 (-0.001372) | 0.004608 / 0.004328 (0.000280) | 0.096717 / 0.004250 (0.092467) | 0.055123 / 0.037052 (0.018071) | 0.417786 / 0.258489 (0.159297) | 0.490886 / 0.293841 (0.197045) | 0.056951 / 0.128546 (-0.071595) | 0.021073 / 0.075646 (-0.054574) | 0.116576 / 0.419271 (-0.302695) | 0.063968 / 0.043533 (0.020435) | 0.420495 / 0.255139 (0.165356) | 0.449667 / 0.283200 (0.166467) | 0.115318 / 0.141683 (-0.026365) | 1.899398 / 1.452155 (0.447243) | 1.992175 / 1.492716 (0.499459) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.233076 / 0.018006 (0.215070) | 0.518377 / 0.000490 (0.517887) | 0.000809 / 0.000200 (0.000609) | 0.000101 / 0.000054 (0.000047) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030951 / 0.037411 (-0.006460) | 0.134940 / 0.014526 (0.120414) | 0.147789 / 0.176557 (-0.028767) | 0.205854 / 0.737135 (-0.531281) | 0.146726 / 0.296338 (-0.149613) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.648006 / 0.215209 (0.432797) | 6.416688 / 2.077655 (4.339033) | 2.696462 / 1.504120 (1.192342) | 2.293071 / 1.541195 (0.751877) | 2.319426 / 1.468490 (0.850935) | 1.332398 / 4.584777 (-3.252379) | 5.706956 / 3.745712 (1.961244) | 4.464473 / 5.269862 (-0.805388) | 2.817364 / 4.565676 (-1.748312) | 0.157595 / 0.424275 (-0.266680) | 0.015721 / 0.007607 (0.008114) | 0.806055 / 0.226044 (0.580010) | 7.927795 / 2.268929 (5.658866) | 3.461251 / 55.444624 (-51.983373) | 2.664466 / 6.876477 (-4.212010) | 2.660041 / 2.142072 (0.517968) | 1.531135 / 4.805227 (-3.274092) | 0.260293 / 6.500664 (-6.240371) | 0.077440 / 0.075469 (0.001971) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.687325 / 1.841788 (-0.154463) | 17.905080 / 8.074308 (9.830772) | 21.046794 / 10.191392 (10.855402) | 0.245335 / 0.680424 (-0.435089) | 0.026830 / 0.534201 (-0.507371) | 0.510798 / 0.579283 (-0.068485) | 0.590041 / 0.434364 (0.155677) | 0.607440 / 0.540337 (0.067102) | 0.725030 / 1.386936 (-0.661906) |\n\n</details>\n</details>\n\n\n",
"I self-assigned #5666 and I was working on it... without success: https://github.com/huggingface/datasets/tree/fix-5666\r\n\r\nI think your approach is the right one because installation of jax is not trivial...\r\n\r\nNext time it would be better that you self-assign an issue before working on it, so that we avoid duplicate work... :sweat_smile: ",
"Oh sorry I forgot to self assign this time",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008436 / 0.011353 (-0.002917) | 0.005702 / 0.011008 (-0.005306) | 0.113518 / 0.038508 (0.075010) | 0.039639 / 0.023109 (0.016530) | 0.353200 / 0.275898 (0.077302) | 0.382428 / 0.323480 (0.058948) | 0.007419 / 0.007986 (-0.000566) | 0.005640 / 0.004328 (0.001311) | 0.083905 / 0.004250 (0.079655) | 0.053258 / 0.037052 (0.016205) | 0.371069 / 0.258489 (0.112580) | 0.390439 / 0.293841 (0.096598) | 0.042679 / 0.128546 (-0.085867) | 0.013438 / 0.075646 (-0.062208) | 0.390116 / 0.419271 (-0.029155) | 0.068782 / 0.043533 (0.025249) | 0.352620 / 0.255139 (0.097481) | 0.371939 / 0.283200 (0.088739) | 0.126157 / 0.141683 (-0.015525) | 1.694638 / 1.452155 (0.242484) | 1.799211 / 1.492716 (0.306495) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.260099 / 0.018006 (0.242092) | 0.489852 / 0.000490 (0.489362) | 0.012549 / 0.000200 (0.012349) | 0.000275 / 0.000054 (0.000221) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032235 / 0.037411 (-0.005177) | 0.125325 / 0.014526 (0.110799) | 0.137242 / 0.176557 (-0.039315) | 0.206566 / 0.737135 (-0.530570) | 0.143260 / 0.296338 (-0.153078) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.478510 / 0.215209 (0.263301) | 4.746439 / 2.077655 (2.668784) | 2.195072 / 1.504120 (0.690952) | 1.958163 / 1.541195 (0.416969) | 2.028566 / 1.468490 (0.560075) | 0.821289 / 4.584777 (-3.763488) | 4.765529 / 3.745712 (1.019817) | 2.378753 / 5.269862 (-2.891108) | 1.514776 / 4.565676 (-3.050900) | 0.100673 / 0.424275 (-0.323602) | 0.014720 / 0.007607 (0.007113) | 0.606388 / 0.226044 (0.380343) | 5.975285 / 2.268929 (3.706357) | 2.866762 / 55.444624 (-52.577862) | 2.392132 / 6.876477 (-4.484345) | 2.546487 / 2.142072 (0.404415) | 0.982394 / 4.805227 (-3.822833) | 0.201195 / 6.500664 (-6.299469) | 0.077781 / 0.075469 (0.002312) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.420613 / 1.841788 (-0.421174) | 17.743030 / 8.074308 (9.668722) | 16.752344 / 10.191392 (6.560951) | 0.167464 / 0.680424 (-0.512960) | 0.020908 / 0.534201 (-0.513293) | 0.502919 / 0.579283 (-0.076364) | 0.506375 / 0.434364 (0.072011) | 0.602695 / 0.540337 (0.062358) | 0.689398 / 1.386936 (-0.697538) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008713 / 0.011353 (-0.002640) | 0.006152 / 0.011008 (-0.004856) | 0.091264 / 0.038508 (0.052756) | 0.040284 / 0.023109 (0.017174) | 0.417598 / 0.275898 (0.141700) | 0.460141 / 0.323480 (0.136661) | 0.006589 / 0.007986 (-0.001397) | 0.004671 / 0.004328 (0.000343) | 0.089360 / 0.004250 (0.085110) | 0.055113 / 0.037052 (0.018061) | 0.415241 / 0.258489 (0.156752) | 0.470566 / 0.293841 (0.176725) | 0.042963 / 0.128546 (-0.085584) | 0.014421 / 0.075646 (-0.061225) | 0.106333 / 0.419271 (-0.312939) | 0.057810 / 0.043533 (0.014277) | 0.417889 / 0.255139 (0.162750) | 0.444236 / 0.283200 (0.161036) | 0.119508 / 0.141683 (-0.022175) | 1.736209 / 1.452155 (0.284055) | 1.790319 / 1.492716 (0.297602) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.219184 / 0.018006 (0.201178) | 0.493931 / 0.000490 (0.493441) | 0.006727 / 0.000200 (0.006527) | 0.000103 / 0.000054 (0.000049) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034415 / 0.037411 (-0.002996) | 0.132165 / 0.014526 (0.117639) | 0.143138 / 0.176557 (-0.033418) | 0.200052 / 0.737135 (-0.537083) | 0.148906 / 0.296338 (-0.147433) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.483686 / 0.215209 (0.268476) | 4.849874 / 2.077655 (2.772220) | 2.374276 / 1.504120 (0.870156) | 2.168334 / 1.541195 (0.627139) | 2.285983 / 1.468490 (0.817493) | 0.833041 / 4.584777 (-3.751735) | 4.665915 / 3.745712 (0.920203) | 4.543559 / 5.269862 (-0.726302) | 2.246926 / 4.565676 (-2.318750) | 0.098490 / 0.424275 (-0.325785) | 0.014934 / 0.007607 (0.007327) | 0.591878 / 0.226044 (0.365834) | 6.039852 / 2.268929 (3.770923) | 2.881244 / 55.444624 (-52.563381) | 2.486297 / 6.876477 (-4.390179) | 2.564642 / 2.142072 (0.422569) | 0.985684 / 4.805227 (-3.819543) | 0.199101 / 6.500664 (-6.301563) | 0.078138 / 0.075469 (0.002669) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.647744 / 1.841788 (-0.194043) | 18.986464 / 8.074308 (10.912156) | 17.246575 / 10.191392 (7.055183) | 0.219151 / 0.680424 (-0.461273) | 0.022219 / 0.534201 (-0.511982) | 0.547207 / 0.579283 (-0.032076) | 0.525943 / 0.434364 (0.091579) | 0.616909 / 0.540337 (0.076572) | 0.757423 / 1.386936 (-0.629513) |\n\n</details>\n</details>\n\n\n"
] | 2023-03-23T15:41:09Z
| 2023-03-23T16:23:11Z
| 2023-03-23T16:14:52Z
|
MEMBER
| null | null | null |
close https://github.com/huggingface/datasets/issues/5666
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5667/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5667/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5667.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5667",
"merged_at": "2023-03-23T16:14:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5667.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5667"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7208
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7208/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7208/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7208/events
|
https://github.com/huggingface/datasets/issues/7208
| 2,575,484,256
|
I_kwDODunzps6ZgsVg
| 7,208
|
Iterable dataset.filter should not override features
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5719745?v=4",
"events_url": "https://api.github.com/users/alex-hh/events{/privacy}",
"followers_url": "https://api.github.com/users/alex-hh/followers",
"following_url": "https://api.github.com/users/alex-hh/following{/other_user}",
"gists_url": "https://api.github.com/users/alex-hh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/alex-hh",
"id": 5719745,
"login": "alex-hh",
"node_id": "MDQ6VXNlcjU3MTk3NDU=",
"organizations_url": "https://api.github.com/users/alex-hh/orgs",
"received_events_url": "https://api.github.com/users/alex-hh/received_events",
"repos_url": "https://api.github.com/users/alex-hh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/alex-hh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alex-hh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/alex-hh",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"closed by https://github.com/huggingface/datasets/pull/7209, thanks @alex-hh !"
] | 2024-10-09T10:23:45Z
| 2024-10-09T16:08:46Z
| 2024-10-09T16:08:45Z
|
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
When calling filter on an iterable dataset, the features get set to None
### Steps to reproduce the bug
import numpy as np
import time
from datasets import Dataset, Features, Array3D
```python
features=Features(**{"array0": Array3D((None, 10, 10), dtype="float32"), "array1": Array3D((None,10,10), dtype="float32")})
dataset = Dataset.from_dict({f"array{i}": [np.zeros((x,10,10), dtype=np.float32) for x in [2000,1000]*25] for i in range(2)}, features=features)
ds = dataset.to_iterable_dataset()
orig_column_names = ds.column_names
ds = ds.filter(lambda x: True)
assert ds.column_names == orig_column_names
```
### Expected behavior
Filter should preserve features information
### Environment info
3.0.2
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7208/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7208/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/7503
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7503/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7503/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7503/events
|
https://github.com/huggingface/datasets/issues/7503
| 2,978,512,625
|
I_kwDODunzps6xiH7x
| 7,503
|
Inconsistency between load_dataset and load_from_disk functionality
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/60975422?v=4",
"events_url": "https://api.github.com/users/zzzzzec/events{/privacy}",
"followers_url": "https://api.github.com/users/zzzzzec/followers",
"following_url": "https://api.github.com/users/zzzzzec/following{/other_user}",
"gists_url": "https://api.github.com/users/zzzzzec/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zzzzzec",
"id": 60975422,
"login": "zzzzzec",
"node_id": "MDQ6VXNlcjYwOTc1NDIy",
"organizations_url": "https://api.github.com/users/zzzzzec/orgs",
"received_events_url": "https://api.github.com/users/zzzzzec/received_events",
"repos_url": "https://api.github.com/users/zzzzzec/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zzzzzec/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zzzzzec/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zzzzzec",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"Hi ! you can find more info here: https://github.com/huggingface/datasets/issues/5044#issuecomment-1263714347\n\n> What's the recommended approach for this use case? Should I manually process my gsm8k-new dataset to make it compatible with load_dataset? Is there a standard way to convert between these formats?\n\nYou can use push_to_hub() or to_parquet() for example"
] | 2025-04-08T03:46:22Z
| 2025-04-15T12:39:53Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
## Issue Description
I've encountered confusion when using `load_dataset` and `load_from_disk` in the datasets library. Specifically, when working offline with the gsm8k dataset, I can load it using a local path:
```python
import datasets
ds = datasets.load_dataset('/root/xxx/datasets/gsm8k', 'main')
```
output:
```text
DatasetDict({
train: Dataset({
features: ['question', 'answer'],
num_rows: 7473
})
test: Dataset({
features: ['question', 'answer'],
num_rows: 1319
})
})
```
This works as expected. However, after processing the dataset (converting answer format from #### to \boxed{})
```python
import datasets
ds = datasets.load_dataset('/root/xxx/datasets/gsm8k', 'main')
ds_train = ds['train']
ds_test = ds['test']
import re
def convert(sample):
solution = sample['answer']
solution = re.sub(r'####\s*(\S+)', r'\\boxed{\1}', solution)
sample = {
'problem': sample['question'],
'solution': solution
}
return sample
ds_train = ds_train.map(convert, remove_columns=['question', 'answer'])
ds_test = ds_test.map(convert,remove_columns=['question', 'answer'])
```
I saved it using save_to_disk:
```python
from datasets.dataset_dict import DatasetDict
data_dict = DatasetDict({
'train': ds_train,
'test': ds_test
})
data_dict.save_to_disk('/root/xxx/datasets/gsm8k-new')
```
But now I can only load it using load_from_disk:
```python
new_ds = load_from_disk('/root/xxx/datasets/gsm8k-new')
```
output:
```text
DatasetDict({
train: Dataset({
features: ['problem', 'solution'],
num_rows: 7473
})
test: Dataset({
features: ['problem', 'solution'],
num_rows: 1319
})
})
```
Attempting to use load_dataset produces unexpected results:
```python
new_ds = load_dataset('/root/xxx/datasets/gsm8k-new')
```
output:
```text
DatasetDict({
train: Dataset({
features: ['_data_files', '_fingerprint', '_format_columns', '_format_kwargs', '_format_type', '_output_all_columns', '_split'],
num_rows: 1
})
test: Dataset({
features: ['_data_files', '_fingerprint', '_format_columns', '_format_kwargs', '_format_type', '_output_all_columns', '_split'],
num_rows: 1
})
})
```
Questions
1. Why is it designed such that after using `save_to_disk`, the dataset cannot be loaded with `load_dataset`? For small projects with limited code, it might be relatively easy to change all instances of `load_dataset` to `load_from_disk`. However, for complex frameworks like TRL or lighteval, diving into the framework code to change `load_dataset` to `load_from_disk` is extremely tedious and error-prone.
Additionally, `load_from_disk` cannot load datasets directly downloaded from the hub, which means that if you need to modify a dataset, you have to choose between using `load_from_disk` or `load_dataset`. This creates an unnecessary dichotomy in the API and complicates workflow when working with modified datasets.
2. What's the recommended approach for this use case? Should I manually process my gsm8k-new dataset to make it compatible with load_dataset? Is there a standard way to convert between these formats?
thanks~
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7503/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7503/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6858
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6858/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6858/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6858/events
|
https://github.com/huggingface/datasets/issues/6858
| 2,274,917,185
|
I_kwDODunzps6HmHtB
| 6,858
|
Segmentation fault
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/554155?v=4",
"events_url": "https://api.github.com/users/scampion/events{/privacy}",
"followers_url": "https://api.github.com/users/scampion/followers",
"following_url": "https://api.github.com/users/scampion/following{/other_user}",
"gists_url": "https://api.github.com/users/scampion/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/scampion",
"id": 554155,
"login": "scampion",
"node_id": "MDQ6VXNlcjU1NDE1NQ==",
"organizations_url": "https://api.github.com/users/scampion/orgs",
"received_events_url": "https://api.github.com/users/scampion/received_events",
"repos_url": "https://api.github.com/users/scampion/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/scampion/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/scampion/subscriptions",
"type": "User",
"url": "https://api.github.com/users/scampion",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"I downloaded the jsonl file and extract it manually. \r\nThe issue seems to be related to pyarrow.json \r\n\r\n\r\n\r\npython3 -q -X faulthandler -c \"from datasets import load_dataset; load_dataset('json', data_files='/Users/scampion/Downloads/1998-09.jsonl')\"\r\nGenerating train split: 0 examples [00:00, ? examples/s]Fatal Python error: Segmentation fault\r\n\r\nThread 0x00007000000c1000 (most recent call first):\r\n <no Python frame>\r\n\r\nThread 0x00007000024df000 (most recent call first):\r\n File \"/usr/local/Cellar/python@3.11/3.11.7/Frameworks/Python.framework/Versions/3.11/lib/python3.11/threading.py\", line 331 in wait\r\n File \"/usr/local/Cellar/python@3.11/3.11.7/Frameworks/Python.framework/Versions/3.11/lib/python3.11/threading.py\", line 629 in wait\r\n File \"/Users/scampion/src/test/venv_test/lib/python3.11/site-packages/tqdm/_monitor.py\", line 60 in run\r\n File \"/usr/local/Cellar/python@3.11/3.11.7/Frameworks/Python.framework/Versions/3.11/lib/python3.11/threading.py\", line 1045 in _bootstrap_inner\r\n File \"/usr/local/Cellar/python@3.11/3.11.7/Frameworks/Python.framework/Versions/3.11/lib/python3.11/threading.py\", line 1002 in _bootstrap\r\n\r\nThread 0x00007ff845c66640 (most recent call first):\r\n File \"/Users/scampion/src/test/venv_test/lib/python3.11/site-packages/datasets/packaged_modules/json/json.py\", line 122 in _generate_tables\r\n File \"/Users/scampion/src/test/venv_test/lib/python3.11/site-packages/datasets/builder.py\", line 1995 in _prepare_split_single\r\n File \"/Users/scampion/src/test/venv_test/lib/python3.11/site-packages/datasets/builder.py\", line 1882 in _prepare_split\r\n File \"/Users/scampion/src/test/venv_test/lib/python3.11/site-packages/datasets/builder.py\", line 1122 in _download_and_prepare\r\n File \"/Users/scampion/src/test/venv_test/lib/python3.11/site-packages/datasets/builder.py\", line 1027 in download_and_prepare\r\n File \"/Users/scampion/src/test/venv_test/lib/python3.11/site-packages/datasets/load.py\", line 2609 in load_dataset\r\n File \"<string>\", line 1 in <module>\r\n\r\nExtension modules: numpy.core._multiarray_umath, numpy.core._multiarray_tests, numpy.linalg._umath_linalg, numpy.fft._pocketfft_internal, numpy.random._common, numpy.random.bit_generator, numpy.random._bounded_integers, numpy.random._mt19937, numpy.random.mtrand, numpy.random._philox, numpy.random._pcg64, numpy.random._sfc64, numpy.random._generator, pyarrow.lib, pyarrow._hdfsio, pandas._libs.tslibs.ccalendar, pandas._libs.tslibs.np_datetime, pandas._libs.tslibs.dtypes, pandas._libs.tslibs.base, pandas._libs.tslibs.nattype, pandas._libs.tslibs.timezones, pandas._libs.tslibs.fields, pandas._libs.tslibs.timedeltas, pandas._libs.tslibs.tzconversion, pandas._libs.tslibs.timestamps, pandas._libs.properties, pandas._libs.tslibs.offsets, pandas._libs.tslibs.strptime, pandas._libs.tslibs.parsing, pandas._libs.tslibs.conversion, pandas._libs.tslibs.period, pandas._libs.tslibs.vectorized, pandas._libs.ops_dispatch, pandas._libs.missing, pandas._libs.hashtable, pandas._libs.algos, pandas._libs.interval, pandas._libs.lib, pyarrow._compute, pandas._libs.ops, pandas._libs.hashing, pandas._libs.arrays, pandas._libs.tslib, pandas._libs.sparse, pandas._libs.internals, pandas._libs.indexing, pandas._libs.index, pandas._libs.writers, pandas._libs.join, pandas._libs.window.aggregations, pandas._libs.window.indexers, pandas._libs.reshape, pandas._libs.groupby, pandas._libs.json, pandas._libs.parsers, pandas._libs.testing, charset_normalizer.md, yaml._yaml, pyarrow._parquet, pyarrow._fs, pyarrow._hdfs, pyarrow._gcsfs, pyarrow._s3fs, multidict._multidict, yarl._quoting_c, aiohttp._helpers, aiohttp._http_writer, aiohttp._http_parser, aiohttp._websocket, frozenlist._frozenlist, xxhash._xxhash, pyarrow._json (total: 72)\r\n[1] 56678 segmentation fault python3 -q -X faulthandler -c\r\n/usr/local/Cellar/python@3.11/3.11.7/Frameworks/Python.framework/Versions/3.11/lib/python3.11/multiprocessing/resource_tracker.py:254: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown\r\n warnings.warn('resource_tracker: There appear to be %d '\r\n(venv_test)",
"The error comes from data where one line contains \"null\""
] | 2024-05-02T08:28:49Z
| 2024-05-03T08:43:21Z
| 2024-05-03T08:42:36Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Using various version for datasets, I'm no more longer able to load that dataset without a segmentation fault.
Several others files are also concerned.
### Steps to reproduce the bug
# Create a new venv
python3 -m venv venv_test
source venv_test/bin/activate
# Install the latest version
pip install datasets
# Load that dataset
python3 -q -X faulthandler -c "from datasets import load_dataset; load_dataset('EuropeanParliament/Eurovoc', '1998-09')"
### Expected behavior
Data must be loaded
### Environment info
datasets==2.19.0
Python 3.11.7
Darwin 22.5.0 Darwin Kernel Version 22.5.0: Mon Apr 24 20:51:50 PDT 2023; root:xnu-8796.121.2~5/RELEASE_X86_64 x86_64
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/554155?v=4",
"events_url": "https://api.github.com/users/scampion/events{/privacy}",
"followers_url": "https://api.github.com/users/scampion/followers",
"following_url": "https://api.github.com/users/scampion/following{/other_user}",
"gists_url": "https://api.github.com/users/scampion/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/scampion",
"id": 554155,
"login": "scampion",
"node_id": "MDQ6VXNlcjU1NDE1NQ==",
"organizations_url": "https://api.github.com/users/scampion/orgs",
"received_events_url": "https://api.github.com/users/scampion/received_events",
"repos_url": "https://api.github.com/users/scampion/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/scampion/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/scampion/subscriptions",
"type": "User",
"url": "https://api.github.com/users/scampion",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6858/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6858/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5592
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5592/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5592/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5592/events
|
https://github.com/huggingface/datasets/pull/5592
| 1,603,619,124
|
PR_kwDODunzps5K9dWr
| 5,592
|
Fix docstring example
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009526 / 0.011353 (-0.001827) | 0.005132 / 0.011008 (-0.005876) | 0.101312 / 0.038508 (0.062804) | 0.035703 / 0.023109 (0.012594) | 0.301788 / 0.275898 (0.025890) | 0.368411 / 0.323480 (0.044932) | 0.008163 / 0.007986 (0.000177) | 0.005462 / 0.004328 (0.001134) | 0.077282 / 0.004250 (0.073031) | 0.044139 / 0.037052 (0.007086) | 0.312280 / 0.258489 (0.053791) | 0.351870 / 0.293841 (0.058029) | 0.038266 / 0.128546 (-0.090281) | 0.012051 / 0.075646 (-0.063595) | 0.335109 / 0.419271 (-0.084163) | 0.047596 / 0.043533 (0.004064) | 0.300931 / 0.255139 (0.045792) | 0.325705 / 0.283200 (0.042505) | 0.100472 / 0.141683 (-0.041211) | 1.475037 / 1.452155 (0.022882) | 1.520059 / 1.492716 (0.027343) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.211096 / 0.018006 (0.193089) | 0.442988 / 0.000490 (0.442498) | 0.003644 / 0.000200 (0.003444) | 0.000090 / 0.000054 (0.000036) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027492 / 0.037411 (-0.009919) | 0.108981 / 0.014526 (0.094455) | 0.117836 / 0.176557 (-0.058720) | 0.161220 / 0.737135 (-0.575915) | 0.124765 / 0.296338 (-0.171574) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.413480 / 0.215209 (0.198271) | 4.111355 / 2.077655 (2.033700) | 1.933024 / 1.504120 (0.428904) | 1.727467 / 1.541195 (0.186272) | 1.827106 / 1.468490 (0.358616) | 0.688209 / 4.584777 (-3.896568) | 3.759672 / 3.745712 (0.013960) | 2.163806 / 5.269862 (-3.106056) | 1.473521 / 4.565676 (-3.092155) | 0.082859 / 0.424275 (-0.341416) | 0.012320 / 0.007607 (0.004713) | 0.515321 / 0.226044 (0.289277) | 5.158651 / 2.268929 (2.889722) | 2.489123 / 55.444624 (-52.955501) | 2.218910 / 6.876477 (-4.657566) | 2.257306 / 2.142072 (0.115233) | 0.861477 / 4.805227 (-3.943750) | 0.165857 / 6.500664 (-6.334807) | 0.063723 / 0.075469 (-0.011746) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.195163 / 1.841788 (-0.646625) | 14.954518 / 8.074308 (6.880210) | 14.272289 / 10.191392 (4.080897) | 0.167420 / 0.680424 (-0.513004) | 0.028907 / 0.534201 (-0.505294) | 0.450117 / 0.579283 (-0.129166) | 0.448532 / 0.434364 (0.014168) | 0.534406 / 0.540337 (-0.005931) | 0.633468 / 1.386936 (-0.753468) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007658 / 0.011353 (-0.003694) | 0.005266 / 0.011008 (-0.005742) | 0.075293 / 0.038508 (0.036785) | 0.034442 / 0.023109 (0.011333) | 0.346558 / 0.275898 (0.070660) | 0.391496 / 0.323480 (0.068017) | 0.005852 / 0.007986 (-0.002133) | 0.004121 / 0.004328 (-0.000207) | 0.074254 / 0.004250 (0.070004) | 0.048361 / 0.037052 (0.011309) | 0.344613 / 0.258489 (0.086124) | 0.401497 / 0.293841 (0.107656) | 0.037243 / 0.128546 (-0.091303) | 0.012505 / 0.075646 (-0.063142) | 0.087188 / 0.419271 (-0.332084) | 0.050114 / 0.043533 (0.006581) | 0.340454 / 0.255139 (0.085315) | 0.361087 / 0.283200 (0.077887) | 0.104692 / 0.141683 (-0.036991) | 1.419432 / 1.452155 (-0.032722) | 1.524709 / 1.492716 (0.031993) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.231820 / 0.018006 (0.213814) | 0.445791 / 0.000490 (0.445301) | 0.000442 / 0.000200 (0.000242) | 0.000061 / 0.000054 (0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030445 / 0.037411 (-0.006967) | 0.111183 / 0.014526 (0.096657) | 0.123494 / 0.176557 (-0.053063) | 0.173121 / 0.737135 (-0.564014) | 0.124968 / 0.296338 (-0.171371) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.428854 / 0.215209 (0.213645) | 4.270262 / 2.077655 (2.192608) | 2.012075 / 1.504120 (0.507955) | 1.826564 / 1.541195 (0.285370) | 1.931699 / 1.468490 (0.463209) | 0.728762 / 4.584777 (-3.856015) | 3.879640 / 3.745712 (0.133928) | 3.325715 / 5.269862 (-1.944147) | 1.818573 / 4.565676 (-2.747104) | 0.087879 / 0.424275 (-0.336396) | 0.012530 / 0.007607 (0.004923) | 0.530249 / 0.226044 (0.304204) | 5.286110 / 2.268929 (3.017181) | 2.566649 / 55.444624 (-52.877975) | 2.210162 / 6.876477 (-4.666315) | 2.297562 / 2.142072 (0.155490) | 0.906161 / 4.805227 (-3.899066) | 0.171914 / 6.500664 (-6.328750) | 0.064182 / 0.075469 (-0.011287) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.285781 / 1.841788 (-0.556006) | 16.159072 / 8.074308 (8.084763) | 14.087492 / 10.191392 (3.896100) | 0.148789 / 0.680424 (-0.531635) | 0.018078 / 0.534201 (-0.516123) | 0.427748 / 0.579283 (-0.151535) | 0.447079 / 0.434364 (0.012715) | 0.535917 / 0.540337 (-0.004421) | 0.627491 / 1.386936 (-0.759445) |\n\n</details>\n</details>\n\n\n"
] | 2023-02-28T18:42:37Z
| 2023-02-28T19:26:33Z
| 2023-02-28T19:19:15Z
|
MEMBER
| null | null | null |
Fixes #5581 to use the correct output for the `set_format` method.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5592/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5592/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5592.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5592",
"merged_at": "2023-02-28T19:19:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5592.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5592"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7473
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7473/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7473/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7473/events
|
https://github.com/huggingface/datasets/issues/7473
| 2,939,034,643
|
I_kwDODunzps6vLhwT
| 7,473
|
Webdataset data format problem
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1017189?v=4",
"events_url": "https://api.github.com/users/edmcman/events{/privacy}",
"followers_url": "https://api.github.com/users/edmcman/followers",
"following_url": "https://api.github.com/users/edmcman/following{/other_user}",
"gists_url": "https://api.github.com/users/edmcman/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/edmcman",
"id": 1017189,
"login": "edmcman",
"node_id": "MDQ6VXNlcjEwMTcxODk=",
"organizations_url": "https://api.github.com/users/edmcman/orgs",
"received_events_url": "https://api.github.com/users/edmcman/received_events",
"repos_url": "https://api.github.com/users/edmcman/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/edmcman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/edmcman/subscriptions",
"type": "User",
"url": "https://api.github.com/users/edmcman",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"I was able to work around it"
] | 2025-03-21T17:23:52Z
| 2025-03-21T19:19:58Z
| 2025-03-21T19:19:58Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Please see https://huggingface.co/datasets/ejschwartz/idioms/discussions/1
Error code: FileFormatMismatchBetweenSplitsError
All three splits, train, test, and validation, use webdataset. But only the train split has more than one file. How can I force the other two splits to also be interpreted as being the webdataset format? (I don't think there is currently a way, but happy to be told that I am wrong.)
### Steps to reproduce the bug
```
import datasets
datasets.load_dataset("ejschwartz/idioms")
### Expected behavior
The dataset loads. Alternatively, there is a YAML syntax for manually specifying the format.
### Environment info
- `datasets` version: 3.2.0
- Platform: Linux-6.8.0-52-generic-x86_64-with-glibc2.35
- Python version: 3.10.12
- `huggingface_hub` version: 0.28.1
- PyArrow version: 19.0.0
- Pandas version: 2.2.3
- `fsspec` version: 2024.9.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1017189?v=4",
"events_url": "https://api.github.com/users/edmcman/events{/privacy}",
"followers_url": "https://api.github.com/users/edmcman/followers",
"following_url": "https://api.github.com/users/edmcman/following{/other_user}",
"gists_url": "https://api.github.com/users/edmcman/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/edmcman",
"id": 1017189,
"login": "edmcman",
"node_id": "MDQ6VXNlcjEwMTcxODk=",
"organizations_url": "https://api.github.com/users/edmcman/orgs",
"received_events_url": "https://api.github.com/users/edmcman/received_events",
"repos_url": "https://api.github.com/users/edmcman/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/edmcman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/edmcman/subscriptions",
"type": "User",
"url": "https://api.github.com/users/edmcman",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7473/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7473/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6671
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6671/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6671/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6671/events
|
https://github.com/huggingface/datasets/issues/6671
| 2,138,727,870
|
I_kwDODunzps5_emW-
| 6,671
|
CSV builder raises deprecation warning on verbose parameter
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[] | 2024-02-16T14:23:46Z
| 2024-02-19T09:20:23Z
| 2024-02-19T09:20:23Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
CSV builder raises a deprecation warning on `verbose` parameter:
```
FutureWarning: The 'verbose' keyword in pd.read_csv is deprecated and will be removed in a future version.
```
See:
- https://github.com/pandas-dev/pandas/pull/56556
- https://github.com/pandas-dev/pandas/pull/57450
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6671/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6671/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/7127
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7127/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7127/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7127/events
|
https://github.com/huggingface/datasets/issues/7127
| 2,486,524,966
|
I_kwDODunzps6UNVwm
| 7,127
|
Caching shuffles by np.random.Generator results in unintiutive behavior
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11832922?v=4",
"events_url": "https://api.github.com/users/el-hult/events{/privacy}",
"followers_url": "https://api.github.com/users/el-hult/followers",
"following_url": "https://api.github.com/users/el-hult/following{/other_user}",
"gists_url": "https://api.github.com/users/el-hult/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/el-hult",
"id": 11832922,
"login": "el-hult",
"node_id": "MDQ6VXNlcjExODMyOTIy",
"organizations_url": "https://api.github.com/users/el-hult/orgs",
"received_events_url": "https://api.github.com/users/el-hult/received_events",
"repos_url": "https://api.github.com/users/el-hult/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/el-hult/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/el-hult/subscriptions",
"type": "User",
"url": "https://api.github.com/users/el-hult",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"I first thought this was a mistake of mine, and also posted on stack overflow. https://stackoverflow.com/questions/78913797/iterating-a-huggingface-dataset-from-disk-using-generator-seems-broken-how-to-d \r\n\r\nIt seems to me the issue is the caching step in \r\n\r\nhttps://github.com/huggingface/datasets/blob/be5cff059a2a5b89d7a97bc04739c4919ab8089f/src/datasets/arrow_dataset.py#L4306-L4316\r\n\r\nbecause the shuffle happens after checking the cache, the rng state won't advance if the cache is used. This is VERY confusing. Also not documented.\r\n\r\nMy proposal is that you remove the API for using a Generator, and only keep the seed-based API since that is functional and cache-compatible."
] | 2024-08-26T10:29:48Z
| 2025-03-10T17:12:57Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Create a dataset. Save it to disk. Load from disk. Shuffle, usning a `np.random.Generator`. Iterate. Shuffle again. Iterate. The iterates are different since the supplied np.random.Generator has progressed between the shuffles.
Load dataset from disk again. Shuffle and Iterate. See same result as before. Shuffle and iterate, and this time it does not have the same shuffling as ion previous run.
The motivation is I have a deep learning loop with
```
for epoch in range(10):
for batch in dataset.shuffle(generator=generator).iter(batch_size=32):
.... # do stuff
```
where I want a new shuffling at every epoch. Instead I get the same shuffling.
### Steps to reproduce the bug
Run the code below two times.
```python
import datasets
import numpy as np
generator = np.random.default_rng(0)
ds = datasets.Dataset.from_dict(mapping={"X":range(1000)})
ds.save_to_disk("tmp")
print("First loop: ", end="")
for _ in range(10):
print(next(ds.shuffle(generator=generator).iter(batch_size=1))['X'], end=", ")
print("")
print("Second loop: ", end="")
ds = datasets.Dataset.load_from_disk("tmp")
for _ in range(10):
print(next(ds.shuffle(generator=generator).iter(batch_size=1))['X'], end=", ")
print("")
```
The output is:
```
$ python main.py
Saving the dataset (1/1 shards): 100%|███████████████████████████████████████████████████████████████████████| 1000/1000 [00:00<00:00, 495019.95 examples/s]
First loop: 459, 739, 72, 943, 241, 181, 845, 830, 896, 334,
Second loop: 741, 847, 944, 795, 483, 842, 717, 865, 231, 840,
$ python main.py
Saving the dataset (1/1 shards): 100%|████████████████████████████████████████████████████████████████████████| 1000/1000 [00:00<00:00, 22243.40 examples/s]
First loop: 459, 739, 72, 943, 241, 181, 845, 830, 896, 334,
Second loop: 741, 741, 741, 741, 741, 741, 741, 741, 741, 741,
```
The second loop, on the second run, only spits out "741, 741, 741...." which is *not* the desired output
### Expected behavior
I want the dataset to shuffle at every epoch since I provide it with a generator for shuffling.
### Environment info
Datasets version 2.21.0
Ubuntu linux.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7127/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7127/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7373
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7373/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7373/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7373/events
|
https://github.com/huggingface/datasets/issues/7373
| 2,793,237,139
|
I_kwDODunzps6mfWqT
| 7,373
|
Excessive RAM Usage After Dataset Concatenation concatenate_datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/40773225?v=4",
"events_url": "https://api.github.com/users/sam-hey/events{/privacy}",
"followers_url": "https://api.github.com/users/sam-hey/followers",
"following_url": "https://api.github.com/users/sam-hey/following{/other_user}",
"gists_url": "https://api.github.com/users/sam-hey/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sam-hey",
"id": 40773225,
"login": "sam-hey",
"node_id": "MDQ6VXNlcjQwNzczMjI1",
"organizations_url": "https://api.github.com/users/sam-hey/orgs",
"received_events_url": "https://api.github.com/users/sam-hey/received_events",
"repos_url": "https://api.github.com/users/sam-hey/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sam-hey/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sam-hey/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sam-hey",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"\n\n\n\nAdding a img from memray\nhttps://gist.github.com/sam-hey/00c958f13fb0f7b54d17197fe353002f",
"I'm having the same issue where concatenation seems to use a huge amount of RAM.\n\n```python\n# Load all chunks and concatenate them into a final dataset.\n chunk_datasets = [\n Dataset.load_from_disk(file, keep_in_memory=False)\n for file in tqdm(chunk_files, desc=\"Loading chunk datasets\")\n ]\n logging.info(\"Concatenating chunk datasets...\")\n final_dataset = concatenate_datasets(chunk_datasets)\n```\n\nThis is a real issue for me as the final dataset is a few terabytes in size. I'm using datasets version `3.1.0`. Also tested with version `3.4.1`",
"I did have a short look, the error seems to be from `memory_map` and the stream not being closed. \n\nhttps://github.com/huggingface/datasets/blob/5f8d2ad9a1b0bccfd962d998987228addfd5be9f/src/datasets/table.py#L48-L50\n\n\nDid not have the time to test jet: https://github.com/sam-hey/datasets/tree/fix/concatenate_datasets\n\nI will probably have a better look in a couple of days. \n\n"
] | 2025-01-16T16:33:10Z
| 2025-03-27T17:40:59Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
When loading a dataset from disk, concatenating it, and starting the training process, the RAM usage progressively increases until the kernel terminates the process due to excessive memory consumption.
https://github.com/huggingface/datasets/issues/2276
### Steps to reproduce the bug
```python
from datasets import DatasetDict, concatenate_datasets
dataset = DatasetDict.load_from_disk("data")
...
...
combined_dataset = concatenate_datasets(
[dataset[split] for split in dataset]
)
#start SentenceTransformer training
```
### Expected behavior
I would not expect RAM utilization to increase after concatenation. Removing the concatenation step resolves the issue
### Environment info
sentence-transformers==3.1.1
datasets==3.2.0
python3.10
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7373/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7373/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6056
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6056/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6056/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6056/events
|
https://github.com/huggingface/datasets/pull/6056
| 1,815,086,963
|
PR_kwDODunzps5WD4RY
| 6,056
|
Implement proper checkpointing for dataset uploading with resume function that does not require remapping shards that have already been uploaded
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10792502?v=4",
"events_url": "https://api.github.com/users/AntreasAntoniou/events{/privacy}",
"followers_url": "https://api.github.com/users/AntreasAntoniou/followers",
"following_url": "https://api.github.com/users/AntreasAntoniou/following{/other_user}",
"gists_url": "https://api.github.com/users/AntreasAntoniou/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AntreasAntoniou",
"id": 10792502,
"login": "AntreasAntoniou",
"node_id": "MDQ6VXNlcjEwNzkyNTAy",
"organizations_url": "https://api.github.com/users/AntreasAntoniou/orgs",
"received_events_url": "https://api.github.com/users/AntreasAntoniou/received_events",
"repos_url": "https://api.github.com/users/AntreasAntoniou/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AntreasAntoniou/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AntreasAntoniou/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AntreasAntoniou",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6056). All of your documentation changes will be reflected on that endpoint.",
"@lhoestq Reading the filenames is something I tried earlier, but I decided to use the yaml direction because:\r\n\r\n1. The yaml file name is constructed to retain information about the shard_size, and total number of shards, hence ensuring that the files uploaded are not just files that have the same name but actually represent a different configuration of shard_size, and total number of shards. \r\n2. Remembering the total file size is done easily in the yaml, whereas alternatively I am not sure how one could access the file size of the uploaded files without downloading them.\r\n3. I also had an issue earlier with the hashes not being consistent with which the yaml helped -- but this is no longer an issue as I found a way around it. \r\n\r\nIf 1 and 2 can be achieved without an additional yaml, then I would be willing to make those changes. Let me know of any ideas. 1. could be done by changing the data file names, but I'd rather not do that as to prevent breaking existing datasets that try to upload updates to their data. ",
"If the file name depends on the shard's fingerprint **before** mapping then we can know if a shard has been uploaded before mapping and without requiring an extra YAML file. It should do the job imo\r\n\r\n> I also had an issue earlier with the hashes not being consistent with which the yaml helped -- but this is no longer an issue as I found a way around it.\r\n\r\nwhat was the issue ?",
"> If the file name depends on the shard's fingerprint **before** mapping then we can know if a shard has been uploaded before mapping and without requiring an extra YAML file. It should do the job imo\r\n> \r\n> > I also had an issue earlier with the hashes not being consistent with which the yaml helped -- but this is no longer an issue as I found a way around it.\r\n> \r\n> what was the issue ?\r\n\r\nYou are right. I was having some other issue earlier that I need more input from you guys to overcome, and when I overcame it the yaml was just legacy from before. I'll update the PR. ",
"> If the file name depends on the shard's fingerprint **before** mapping then we can know if a shard has been uploaded before mapping and without requiring an extra YAML file. It should do the job imo\r\n> \r\n> > I also had an issue earlier with the hashes not being consistent with which the yaml helped -- but this is no longer an issue as I found a way around it.\r\n> \r\n> what was the issue ?\r\n\r\nI remembered what it was, and why I needed the yaml. I needed it so it could remember the progress for a particular num_shards setup, as different num_shards would lead to different number of splits, and a user might switch between them while uploading, and I did not want the index to be conflated with one of another num_shards setup. \r\n\r\nAny idea how we deal with that without a yaml?",
"If the user changes the num_shards parameters then we should re-upload everything.\r\n\r\nIt happens that the num_shards is part of the parquet file names, so it restarts the upload from scratch without having to write additional logic :)"
] | 2023-07-21T03:13:21Z
| 2023-08-17T08:26:53Z
| null |
NONE
| null | null | null |
Context: issue #5990
In order to implement the checkpointing, I introduce a metadata folder that keeps one yaml file for each set that one is uploading. This yaml keeps track of what shards have already been uploaded, and which one the idx of the latest one was. Using this information I am then able to easily get the push_to_hub function to retrieve on demand past history of uploads and continue mapping and uploading from where it was left off.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6056/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6056/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6056.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6056",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6056.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6056"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6153
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6153/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6153/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6153/events
|
https://github.com/huggingface/datasets/issues/6153
| 1,852,630,074
|
I_kwDODunzps5ubOQ6
| 6,153
|
custom load dataset to hub
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20493493?v=4",
"events_url": "https://api.github.com/users/andysingal/events{/privacy}",
"followers_url": "https://api.github.com/users/andysingal/followers",
"following_url": "https://api.github.com/users/andysingal/following{/other_user}",
"gists_url": "https://api.github.com/users/andysingal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/andysingal",
"id": 20493493,
"login": "andysingal",
"node_id": "MDQ6VXNlcjIwNDkzNDkz",
"organizations_url": "https://api.github.com/users/andysingal/orgs",
"received_events_url": "https://api.github.com/users/andysingal/received_events",
"repos_url": "https://api.github.com/users/andysingal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/andysingal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/andysingal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/andysingal",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"This is an issue for the [Datasets repo](https://github.com/huggingface/datasets).",
"> This is an issue for the [Datasets repo](https://github.com/huggingface/datasets).\r\n\r\nThanks @sgugger , I guess I will wait for them to address the issue . Looking forward to hearing from them ",
"You can use `.push_to_hub(\"<username>/<repo>\")` to push a `Dataset` to the Hub.",
"> You can use `.push_to_hub(\"<username>/<repo>\")` to push a `Dataset` to the Hub.\r\n\r\nhow about subset? like `.load_dataset(\"<username>/<repo>\", \"<subset>\")`, how can I upload multi-dataset in one repo? thanks a lot ! ",
"> > You can use `.push_to_hub(\"<username>/<repo>\")` to push a `Dataset` to the Hub.\r\n> \r\n> how about subset? like `.load_dataset(\"<username>/<repo>\", \"<subset>\")`, how can I upload multi-dataset in one repo? thanks a lot !\r\n\r\nI solved it by upgrading `Datasets` version to 2.15.0"
] | 2023-08-13T04:42:22Z
| 2023-11-21T11:50:28Z
| 2023-10-08T17:04:16Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### System Info
kaggle notebook
i transformed dataset:
```
dataset = load_dataset("Dahoas/first-instruct-human-assistant-prompt")
```
to
formatted_dataset:
```
Dataset({
features: ['message_tree_id', 'message_tree_text'],
num_rows: 33143
})
```
but would like to know how to upload to hub
### Who can help?
@ArthurZucker @younesbelkada
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
shared above
### Expected behavior
load dataset to hub
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6153/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6153/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6705
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6705/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6705/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6705/events
|
https://github.com/huggingface/datasets/pull/6705
| 2,163,768,640
|
PR_kwDODunzps5obdbY
| 6,705
|
Fix data_files when passing data_dir
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6705). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005014 / 0.011353 (-0.006339) | 0.003371 / 0.011008 (-0.007637) | 0.063622 / 0.038508 (0.025114) | 0.026551 / 0.023109 (0.003442) | 0.244602 / 0.275898 (-0.031296) | 0.269981 / 0.323480 (-0.053499) | 0.003959 / 0.007986 (-0.004027) | 0.002678 / 0.004328 (-0.001650) | 0.049421 / 0.004250 (0.045170) | 0.039926 / 0.037052 (0.002873) | 0.256609 / 0.258489 (-0.001881) | 0.281934 / 0.293841 (-0.011907) | 0.027794 / 0.128546 (-0.100752) | 0.010130 / 0.075646 (-0.065516) | 0.207471 / 0.419271 (-0.211800) | 0.035423 / 0.043533 (-0.008110) | 0.246987 / 0.255139 (-0.008152) | 0.265413 / 0.283200 (-0.017787) | 0.018287 / 0.141683 (-0.123396) | 1.117550 / 1.452155 (-0.334604) | 1.151713 / 1.492716 (-0.341003) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095632 / 0.018006 (0.077626) | 0.304315 / 0.000490 (0.303825) | 0.000214 / 0.000200 (0.000014) | 0.000049 / 0.000054 (-0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018591 / 0.037411 (-0.018820) | 0.062081 / 0.014526 (0.047555) | 0.075137 / 0.176557 (-0.101420) | 0.119116 / 0.737135 (-0.618020) | 0.075254 / 0.296338 (-0.221085) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.286161 / 0.215209 (0.070952) | 2.793824 / 2.077655 (0.716169) | 1.492523 / 1.504120 (-0.011597) | 1.372158 / 1.541195 (-0.169037) | 1.385921 / 1.468490 (-0.082569) | 0.568700 / 4.584777 (-4.016077) | 2.340451 / 3.745712 (-1.405262) | 2.712022 / 5.269862 (-2.557840) | 1.712479 / 4.565676 (-2.853197) | 0.060906 / 0.424275 (-0.363369) | 0.004909 / 0.007607 (-0.002698) | 0.338227 / 0.226044 (0.112182) | 3.331329 / 2.268929 (1.062400) | 1.845646 / 55.444624 (-53.598978) | 1.559384 / 6.876477 (-5.317093) | 1.577683 / 2.142072 (-0.564390) | 0.629367 / 4.805227 (-4.175860) | 0.118645 / 6.500664 (-6.382019) | 0.041517 / 0.075469 (-0.033952) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.962237 / 1.841788 (-0.879551) | 11.232566 / 8.074308 (3.158258) | 9.627141 / 10.191392 (-0.564251) | 0.129732 / 0.680424 (-0.550692) | 0.013701 / 0.534201 (-0.520500) | 0.291869 / 0.579283 (-0.287414) | 0.269298 / 0.434364 (-0.165066) | 0.342502 / 0.540337 (-0.197835) | 0.455891 / 1.386936 (-0.931045) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005256 / 0.011353 (-0.006097) | 0.003419 / 0.011008 (-0.007589) | 0.049681 / 0.038508 (0.011173) | 0.029566 / 0.023109 (0.006457) | 0.268010 / 0.275898 (-0.007888) | 0.293721 / 0.323480 (-0.029759) | 0.004249 / 0.007986 (-0.003737) | 0.002643 / 0.004328 (-0.001685) | 0.048758 / 0.004250 (0.044508) | 0.044294 / 0.037052 (0.007241) | 0.279584 / 0.258489 (0.021095) | 0.311150 / 0.293841 (0.017309) | 0.029443 / 0.128546 (-0.099103) | 0.010314 / 0.075646 (-0.065333) | 0.057770 / 0.419271 (-0.361501) | 0.050953 / 0.043533 (0.007420) | 0.268283 / 0.255139 (0.013144) | 0.289155 / 0.283200 (0.005956) | 0.017742 / 0.141683 (-0.123941) | 1.163963 / 1.452155 (-0.288192) | 1.200580 / 1.492716 (-0.292136) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.096365 / 0.018006 (0.078359) | 0.307257 / 0.000490 (0.306767) | 0.000265 / 0.000200 (0.000065) | 0.000049 / 0.000054 (-0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021862 / 0.037411 (-0.015550) | 0.075502 / 0.014526 (0.060976) | 0.087800 / 0.176557 (-0.088756) | 0.125468 / 0.737135 (-0.611667) | 0.088207 / 0.296338 (-0.208132) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.324184 / 0.215209 (0.108975) | 3.198442 / 2.077655 (1.120787) | 1.862801 / 1.504120 (0.358682) | 1.728637 / 1.541195 (0.187443) | 1.727997 / 1.468490 (0.259507) | 0.571590 / 4.584777 (-4.013187) | 2.448661 / 3.745712 (-1.297051) | 2.665943 / 5.269862 (-2.603919) | 1.731718 / 4.565676 (-2.833958) | 0.063644 / 0.424275 (-0.360631) | 0.004989 / 0.007607 (-0.002619) | 0.364543 / 0.226044 (0.138498) | 3.615859 / 2.268929 (1.346930) | 2.131637 / 55.444624 (-53.312987) | 1.857317 / 6.876477 (-5.019159) | 1.992813 / 2.142072 (-0.149260) | 0.654662 / 4.805227 (-4.150565) | 0.117631 / 6.500664 (-6.383034) | 0.040934 / 0.075469 (-0.034535) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.013802 / 1.841788 (-0.827985) | 11.899873 / 8.074308 (3.825565) | 10.291297 / 10.191392 (0.099905) | 0.155245 / 0.680424 (-0.525179) | 0.014449 / 0.534201 (-0.519752) | 0.286331 / 0.579283 (-0.292952) | 0.273111 / 0.434364 (-0.161253) | 0.321182 / 0.540337 (-0.219155) | 0.433406 / 1.386936 (-0.953530) |\n\n</details>\n</details>\n\n\n"
] | 2024-03-01T16:38:53Z
| 2024-03-01T18:59:06Z
| 2024-03-01T18:52:49Z
|
MEMBER
| null | null | null |
This code should not return empty data files
```python
from datasets import load_dataset_builder
revision = "3d406e70bc21c3ca92a9a229b4c6fc3ed88279fd"
b = load_dataset_builder("bigcode/the-stack-v2-dedup", data_dir="data/Dockerfile", revision=revision)
print(b.config.data_files)
```
Previously it would return no data files because it would apply the YAML `data_files: data/**/train-*` pattern to this directory
cc @anton-l
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6705/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6705/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6705.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6705",
"merged_at": "2024-03-01T18:52:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6705.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6705"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4939
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4939/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4939/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4939/events
|
https://github.com/huggingface/datasets/pull/4939
| 1,363,468,679
|
PR_kwDODunzps4-cw4A
| 4,939
|
Fix NonMatchingChecksumError in adv_glue dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-06T15:31:16Z
| 2022-09-06T17:42:10Z
| 2022-09-06T17:39:16Z
|
MEMBER
| null | null | null |
Fix issue reported on the Hub: https://huggingface.co/datasets/adv_glue/discussions/1
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4939/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4939/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4939.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4939",
"merged_at": "2022-09-06T17:39:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4939.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4939"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6802
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6802/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6802/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6802/events
|
https://github.com/huggingface/datasets/pull/6802
| 2,237,365,489
|
PR_kwDODunzps5sV0m8
| 6,802
|
Fix typo in docs (upload CLI)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11801849?v=4",
"events_url": "https://api.github.com/users/Wauplin/events{/privacy}",
"followers_url": "https://api.github.com/users/Wauplin/followers",
"following_url": "https://api.github.com/users/Wauplin/following{/other_user}",
"gists_url": "https://api.github.com/users/Wauplin/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Wauplin",
"id": 11801849,
"login": "Wauplin",
"node_id": "MDQ6VXNlcjExODAxODQ5",
"organizations_url": "https://api.github.com/users/Wauplin/orgs",
"received_events_url": "https://api.github.com/users/Wauplin/received_events",
"repos_url": "https://api.github.com/users/Wauplin/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Wauplin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Wauplin/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Wauplin",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6802). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004991 / 0.011353 (-0.006362) | 0.003574 / 0.011008 (-0.007434) | 0.062369 / 0.038508 (0.023861) | 0.029966 / 0.023109 (0.006857) | 0.256140 / 0.275898 (-0.019758) | 0.283705 / 0.323480 (-0.039775) | 0.003170 / 0.007986 (-0.004816) | 0.002732 / 0.004328 (-0.001597) | 0.048048 / 0.004250 (0.043798) | 0.044497 / 0.037052 (0.007445) | 0.273206 / 0.258489 (0.014717) | 0.294593 / 0.293841 (0.000752) | 0.027251 / 0.128546 (-0.101295) | 0.010205 / 0.075646 (-0.065441) | 0.205979 / 0.419271 (-0.213293) | 0.035416 / 0.043533 (-0.008117) | 0.256260 / 0.255139 (0.001121) | 0.270580 / 0.283200 (-0.012620) | 0.019659 / 0.141683 (-0.122024) | 1.138722 / 1.452155 (-0.313432) | 1.170535 / 1.492716 (-0.322182) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091588 / 0.018006 (0.073582) | 0.301280 / 0.000490 (0.300791) | 0.000209 / 0.000200 (0.000009) | 0.000048 / 0.000054 (-0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019684 / 0.037411 (-0.017727) | 0.061166 / 0.014526 (0.046640) | 0.072999 / 0.176557 (-0.103558) | 0.119264 / 0.737135 (-0.617871) | 0.074555 / 0.296338 (-0.221784) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.283210 / 0.215209 (0.068001) | 2.762284 / 2.077655 (0.684629) | 1.472700 / 1.504120 (-0.031420) | 1.352734 / 1.541195 (-0.188461) | 1.363287 / 1.468490 (-0.105203) | 0.558175 / 4.584777 (-4.026602) | 2.391648 / 3.745712 (-1.354064) | 2.787109 / 5.269862 (-2.482752) | 1.725635 / 4.565676 (-2.840042) | 0.061827 / 0.424275 (-0.362448) | 0.005351 / 0.007607 (-0.002256) | 0.337540 / 0.226044 (0.111496) | 3.353181 / 2.268929 (1.084252) | 1.829599 / 55.444624 (-53.615026) | 1.567691 / 6.876477 (-5.308786) | 1.605680 / 2.142072 (-0.536393) | 0.642182 / 4.805227 (-4.163045) | 0.117321 / 6.500664 (-6.383343) | 0.042555 / 0.075469 (-0.032915) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.991099 / 1.841788 (-0.850689) | 11.545219 / 8.074308 (3.470911) | 9.777574 / 10.191392 (-0.413818) | 0.130237 / 0.680424 (-0.550186) | 0.015068 / 0.534201 (-0.519133) | 0.286029 / 0.579283 (-0.293254) | 0.266778 / 0.434364 (-0.167586) | 0.321468 / 0.540337 (-0.218869) | 0.425371 / 1.386936 (-0.961565) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005144 / 0.011353 (-0.006208) | 0.004046 / 0.011008 (-0.006962) | 0.050552 / 0.038508 (0.012043) | 0.030716 / 0.023109 (0.007607) | 0.273462 / 0.275898 (-0.002436) | 0.290649 / 0.323480 (-0.032831) | 0.004093 / 0.007986 (-0.003893) | 0.002700 / 0.004328 (-0.001628) | 0.048833 / 0.004250 (0.044582) | 0.040059 / 0.037052 (0.003007) | 0.282496 / 0.258489 (0.024007) | 0.309176 / 0.293841 (0.015335) | 0.029207 / 0.128546 (-0.099339) | 0.010740 / 0.075646 (-0.064907) | 0.057692 / 0.419271 (-0.361580) | 0.032570 / 0.043533 (-0.010963) | 0.269048 / 0.255139 (0.013909) | 0.287351 / 0.283200 (0.004151) | 0.017565 / 0.141683 (-0.124118) | 1.161628 / 1.452155 (-0.290526) | 1.187236 / 1.492716 (-0.305480) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095552 / 0.018006 (0.077546) | 0.312449 / 0.000490 (0.311959) | 0.000219 / 0.000200 (0.000019) | 0.000052 / 0.000054 (-0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022425 / 0.037411 (-0.014986) | 0.074941 / 0.014526 (0.060416) | 0.086784 / 0.176557 (-0.089772) | 0.125630 / 0.737135 (-0.611506) | 0.088632 / 0.296338 (-0.207706) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.293003 / 0.215209 (0.077794) | 2.881826 / 2.077655 (0.804172) | 1.612840 / 1.504120 (0.108720) | 1.492727 / 1.541195 (-0.048468) | 1.520023 / 1.468490 (0.051532) | 0.558715 / 4.584777 (-4.026062) | 2.431093 / 3.745712 (-1.314619) | 2.782672 / 5.269862 (-2.487189) | 1.721611 / 4.565676 (-2.844065) | 0.063466 / 0.424275 (-0.360809) | 0.005221 / 0.007607 (-0.002386) | 0.352917 / 0.226044 (0.126873) | 3.443742 / 2.268929 (1.174814) | 1.981190 / 55.444624 (-53.463435) | 1.695396 / 6.876477 (-5.181081) | 1.709959 / 2.142072 (-0.432113) | 0.649267 / 4.805227 (-4.155960) | 0.116604 / 6.500664 (-6.384060) | 0.040688 / 0.075469 (-0.034781) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.023182 / 1.841788 (-0.818605) | 12.046760 / 8.074308 (3.972452) | 10.294706 / 10.191392 (0.103314) | 0.132323 / 0.680424 (-0.548101) | 0.016141 / 0.534201 (-0.518060) | 0.286620 / 0.579283 (-0.292663) | 0.272299 / 0.434364 (-0.162065) | 0.320995 / 0.540337 (-0.219343) | 0.424138 / 1.386936 (-0.962798) |\n\n</details>\n</details>\n\n\n",
"> Should it also be applied to this example a few lines later ?\r\n\r\nYes!",
"done in https://github.com/huggingface/datasets/pull/6804"
] | 2024-04-11T10:05:05Z
| 2024-04-11T16:19:00Z
| 2024-04-11T13:19:43Z
|
CONTRIBUTOR
| null | null | null |
Related to https://huggingface.slack.com/archives/C04RG8YRVB8/p1712643948574129 (interal)
Positional args must be placed before optional args.
Feel free to merge whenever it's ready.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6802/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6802/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6802.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6802",
"merged_at": "2024-04-11T13:19:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6802.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6802"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5794
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5794/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5794/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5794/events
|
https://github.com/huggingface/datasets/issues/5794
| 1,685,196,061
|
I_kwDODunzps5kcg0d
| 5,794
|
CI ZeroDivisionError
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
| null |
[] | null |
[
"Hello!\r\nThis issue seems to have been fixed in https://github.com/huggingface/transformers/pull/24049 \r\nI was looking for my first issue to work on when I noticed this; not sure if there is a specific protocol for suggesting to close an issue.",
"Thanks for informing, @zeppdev. I am closing this issue.\r\n\r\nFixed by:\r\n- huggingface/transformers#24049"
] | 2023-04-26T14:55:23Z
| 2024-05-17T09:12:11Z
| 2024-05-17T09:12:11Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
Sometimes when running our CI on Windows, we get a ZeroDivisionError:
```
FAILED tests/test_metric_common.py::LocalMetricTest::test_load_metric_frugalscore - ZeroDivisionError: float division by zero
```
See for example:
- https://github.com/huggingface/datasets/actions/runs/4809358266/jobs/8560513110
- https://github.com/huggingface/datasets/actions/runs/4798359836/jobs/8536573688
```
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
split = 'test', start_time = 1682516718.8236516, num_samples = 2, num_steps = 1
def speed_metrics(split, start_time, num_samples=None, num_steps=None):
"""
Measure and return speed performance metrics.
This function requires a time snapshot `start_time` before the operation to be measured starts and this function
should be run immediately after the operation to be measured has completed.
Args:
- split: name to prefix metric (like train, eval, test...)
- start_time: operation start time
- num_samples: number of samples processed
"""
runtime = time.time() - start_time
result = {f"{split}_runtime": round(runtime, 4)}
if num_samples is not None:
> samples_per_second = num_samples / runtime
E ZeroDivisionError: float division by zero
C:\hostedtoolcache\windows\Python\3.7.9\x64\lib\site-packages\transformers\trainer_utils.py:354: ZeroDivisionError
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5794/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5794/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5839
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5839/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5839/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5839/events
|
https://github.com/huggingface/datasets/issues/5839
| 1,704,554,718
|
I_kwDODunzps5lmXDe
| 5,839
|
Make models/functions optimized with `torch.compile` hashable
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
] | null |
[] | 2023-05-10T20:02:08Z
| 2023-11-28T16:29:33Z
| 2023-11-28T16:29:33Z
|
COLLABORATOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
As reported in https://github.com/huggingface/datasets/issues/5819, hashing functions/transforms that reference a model, or a function, optimized with `torch.compile` currently fails due to them not being picklable (the concrete error can be found in the linked issue).
The solutions to consider:
1. hashing/pickling the original, uncompiled version of a compiled model/function (attributes `_orig_mod`/`_torchdynamo_orig_callable`) (less precise than the 2nd option as it ignores the other params of `torch.compute`)
2. wait for https://github.com/pytorch/pytorch/issues/101107 to be resolved
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5839/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5839/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/4625
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4625/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4625/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4625/events
|
https://github.com/huggingface/datasets/pull/4625
| 1,293,163,744
|
PR_kwDODunzps46zELz
| 4,625
|
Unpack `dl_manager.iter_files` to allow parallization
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Cool thanks ! Yup it sounds like the right solution.\r\n\r\nIt looks like `_generate_tables` needs to be updated as well to fix the CI"
] | 2022-07-04T13:16:58Z
| 2022-07-05T11:11:54Z
| 2022-07-05T11:00:48Z
|
COLLABORATOR
| null | null | null |
Iterate over data files outside `dl_manager.iter_files` to allow parallelization in streaming mode.
(The issue reported [here](https://discuss.huggingface.co/t/dataset-only-have-n-shard-1-when-has-multiple-shards-in-repo/19887))
PS: Another option would be to override `FilesIterable.__getitem__` to make it indexable and check for that type in `_shard_kwargs` and `n_shards,` but IMO this solution adds too much unnecessary complexity.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4625/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4625/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4625.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4625",
"merged_at": "2022-07-05T11:00:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4625.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4625"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5182
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5182/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5182/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5182/events
|
https://github.com/huggingface/datasets/issues/5182
| 1,431,029,547
|
I_kwDODunzps5VS8cr
| 5,182
|
Add notebook / other resource links to the task-specific data loading guides
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul",
"user_view_type": "public"
}
] | null |
[
"Yea this would be great! We would need an object detection tutorial notebook too if it doesn't already exist there. ",
"There is one: https://huggingface.co/docs/datasets/object_detection.\r\n\r\nI will start the work. "
] | 2022-11-01T07:57:26Z
| 2022-11-03T01:49:57Z
| 2022-11-03T01:49:57Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
Does it make sense to include links to notebooks / scripts that show how to use a dataset for training / fine-tuning a model?
For example, here in [https://huggingface.co/docs/datasets/image_classification] we could include a mention of https://github.com/huggingface/notebooks/blob/main/examples/image_classification.ipynb.
Applies to https://huggingface.co/docs/datasets/object_detection as well.
Cc: @osanseviero @nateraw
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5182/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5182/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6676
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6676/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6676/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6676/events
|
https://github.com/huggingface/datasets/issues/6676
| 2,140,648,619
|
I_kwDODunzps5_l7Sr
| 6,676
|
Can't Read List of JSON Files Properly
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20232088?v=4",
"events_url": "https://api.github.com/users/lordsoffallen/events{/privacy}",
"followers_url": "https://api.github.com/users/lordsoffallen/followers",
"following_url": "https://api.github.com/users/lordsoffallen/following{/other_user}",
"gists_url": "https://api.github.com/users/lordsoffallen/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lordsoffallen",
"id": 20232088,
"login": "lordsoffallen",
"node_id": "MDQ6VXNlcjIwMjMyMDg4",
"organizations_url": "https://api.github.com/users/lordsoffallen/orgs",
"received_events_url": "https://api.github.com/users/lordsoffallen/received_events",
"repos_url": "https://api.github.com/users/lordsoffallen/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lordsoffallen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lordsoffallen/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lordsoffallen",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"Found the issue, if there are other files in the directory, it gets caught into this `*` so essentially it should be `*.json`. Could we possibly to check for list of files to make sure the pattern matches json files and raise error if not?",
"I don't think we should filter for `*.json` as this might silently remove desired files for many users. And this could be a major breaking change for many organizations.\r\n\r\nYou could do the globbing yourself which would keep the code clean.\r\n\r\n```python\r\nfrom glob import glob\r\n\r\nDataset.from_json(glob('folder/*.json'))\r\n```",
"I think it should still be fine to log a warning message in case the folder contains different files? I also don't get why would this be breaking as in the end using `from_FILE_TYPE` should be able to read a specific file type only. Maybe some other use case I am not aware of but since globbing or this case not mentioned anywhere in the doc, I spent quite a bit of time trying to figure out where the issue was. Just making sure it's clear for users."
] | 2024-02-17T22:58:15Z
| 2024-03-02T20:47:22Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Trying to read a bunch of JSON files into Dataset class but default approach doesn't work. I don't get why it works when I read it one by one but not when I pass as a list :man_shrugging:
The code fails with
```
ArrowInvalid: JSON parse error: Invalid value. in row 0
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 0: invalid start byte
DatasetGenerationError: An error occurred while generating the dataset
```
### Steps to reproduce the bug
This doesn't work
```
from datasets import Dataset
# dir contains 100 json files.
Dataset.from_json("/PUT SOME PATH HERE/*")
```
This works:
```
from datasets import concatenate_datasets
ls_ds = []
for file in list_of_json_files:
ls_ds.append(Dataset.from_json(file))
ds = concatenate_datasets(ls_ds)
```
### Expected behavior
I expect this to read json files properly as error is not clear
### Environment info
- `datasets` version: 2.17.0
- Platform: Linux-6.5.0-15-generic-x86_64-with-glibc2.35
- Python version: 3.10.13
- `huggingface_hub` version: 0.20.2
- PyArrow version: 15.0.0
- Pandas version: 2.2.0
- `fsspec` version: 2023.10.0
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6676/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6676/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6421
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6421/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6421/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6421/events
|
https://github.com/huggingface/datasets/pull/6421
| 1,994,451,553
|
PR_kwDODunzps5fgG1h
| 6,421
|
Add pyarrow-hotfix to release docs
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] |
closed
| false
| null |
[] | null |
[
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004755 / 0.011353 (-0.006598) | 0.002683 / 0.011008 (-0.008325) | 0.061701 / 0.038508 (0.023193) | 0.030123 / 0.023109 (0.007013) | 0.238186 / 0.275898 (-0.037712) | 0.266570 / 0.323480 (-0.056910) | 0.002898 / 0.007986 (-0.005088) | 0.002381 / 0.004328 (-0.001948) | 0.048033 / 0.004250 (0.043782) | 0.044529 / 0.037052 (0.007477) | 0.246728 / 0.258489 (-0.011761) | 0.302066 / 0.293841 (0.008225) | 0.024008 / 0.128546 (-0.104539) | 0.006626 / 0.075646 (-0.069020) | 0.202000 / 0.419271 (-0.217272) | 0.056492 / 0.043533 (0.012959) | 0.243417 / 0.255139 (-0.011722) | 0.263947 / 0.283200 (-0.019253) | 0.020481 / 0.141683 (-0.121202) | 1.130635 / 1.452155 (-0.321520) | 1.180570 / 1.492716 (-0.312146) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095541 / 0.018006 (0.077535) | 0.306152 / 0.000490 (0.305662) | 0.000217 / 0.000200 (0.000017) | 0.000044 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018593 / 0.037411 (-0.018818) | 0.063029 / 0.014526 (0.048503) | 0.074312 / 0.176557 (-0.102245) | 0.119882 / 0.737135 (-0.617254) | 0.074066 / 0.296338 (-0.222273) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.275409 / 0.215209 (0.060200) | 2.727061 / 2.077655 (0.649407) | 1.415632 / 1.504120 (-0.088488) | 1.294922 / 1.541195 (-0.246273) | 1.341636 / 1.468490 (-0.126854) | 0.403250 / 4.584777 (-4.181527) | 2.384657 / 3.745712 (-1.361055) | 2.604131 / 5.269862 (-2.665731) | 1.558888 / 4.565676 (-3.006789) | 0.046008 / 0.424275 (-0.378267) | 0.004819 / 0.007607 (-0.002789) | 0.331046 / 0.226044 (0.105002) | 3.340950 / 2.268929 (1.072021) | 1.801077 / 55.444624 (-53.643548) | 1.479162 / 6.876477 (-5.397315) | 1.503713 / 2.142072 (-0.638359) | 0.474931 / 4.805227 (-4.330296) | 0.101869 / 6.500664 (-6.398795) | 0.041946 / 0.075469 (-0.033523) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.955641 / 1.841788 (-0.886147) | 11.441032 / 8.074308 (3.366724) | 10.267731 / 10.191392 (0.076339) | 0.128735 / 0.680424 (-0.551689) | 0.013942 / 0.534201 (-0.520259) | 0.266620 / 0.579283 (-0.312663) | 0.262334 / 0.434364 (-0.172029) | 0.302713 / 0.540337 (-0.237624) | 0.430323 / 1.386936 (-0.956613) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004670 / 0.011353 (-0.006683) | 0.002671 / 0.011008 (-0.008338) | 0.048949 / 0.038508 (0.010441) | 0.052520 / 0.023109 (0.029411) | 0.272614 / 0.275898 (-0.003284) | 0.292618 / 0.323480 (-0.030862) | 0.004016 / 0.007986 (-0.003969) | 0.002430 / 0.004328 (-0.001899) | 0.048313 / 0.004250 (0.044063) | 0.038647 / 0.037052 (0.001595) | 0.279893 / 0.258489 (0.021404) | 0.305371 / 0.293841 (0.011530) | 0.023710 / 0.128546 (-0.104836) | 0.006999 / 0.075646 (-0.068648) | 0.053315 / 0.419271 (-0.365956) | 0.032417 / 0.043533 (-0.011115) | 0.272066 / 0.255139 (0.016927) | 0.291717 / 0.283200 (0.008518) | 0.018127 / 0.141683 (-0.123556) | 1.173611 / 1.452155 (-0.278544) | 1.183659 / 1.492716 (-0.309057) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.094831 / 0.018006 (0.076824) | 0.304911 / 0.000490 (0.304421) | 0.000225 / 0.000200 (0.000025) | 0.000049 / 0.000054 (-0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.020948 / 0.037411 (-0.016463) | 0.070255 / 0.014526 (0.055729) | 0.081371 / 0.176557 (-0.095186) | 0.118932 / 0.737135 (-0.618203) | 0.082207 / 0.296338 (-0.214132) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.294067 / 0.215209 (0.078858) | 2.856981 / 2.077655 (0.779326) | 1.598392 / 1.504120 (0.094273) | 1.479093 / 1.541195 (-0.062102) | 1.509495 / 1.468490 (0.041005) | 0.396303 / 4.584777 (-4.188473) | 2.429077 / 3.745712 (-1.316635) | 2.525037 / 5.269862 (-2.744824) | 1.503332 / 4.565676 (-3.062345) | 0.046191 / 0.424275 (-0.378084) | 0.004858 / 0.007607 (-0.002750) | 0.349528 / 0.226044 (0.123484) | 3.401451 / 2.268929 (1.132522) | 1.989613 / 55.444624 (-53.455012) | 1.664528 / 6.876477 (-5.211949) | 1.669076 / 2.142072 (-0.472997) | 0.467090 / 4.805227 (-4.338137) | 0.098137 / 6.500664 (-6.402527) | 0.040448 / 0.075469 (-0.035021) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.969578 / 1.841788 (-0.872210) | 12.064705 / 8.074308 (3.990396) | 10.991438 / 10.191392 (0.800046) | 0.130149 / 0.680424 (-0.550275) | 0.015357 / 0.534201 (-0.518844) | 0.266567 / 0.579283 (-0.312717) | 0.270619 / 0.434364 (-0.163744) | 0.305978 / 0.540337 (-0.234359) | 0.411164 / 1.386936 (-0.975772) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009810 / 0.011353 (-0.001543) | 0.005411 / 0.011008 (-0.005598) | 0.111670 / 0.038508 (0.073162) | 0.050288 / 0.023109 (0.027179) | 0.415625 / 0.275898 (0.139727) | 0.479382 / 0.323480 (0.155902) | 0.005104 / 0.007986 (-0.002882) | 0.007122 / 0.004328 (0.002793) | 0.079626 / 0.004250 (0.075375) | 0.079421 / 0.037052 (0.042369) | 0.406722 / 0.258489 (0.148233) | 0.461511 / 0.293841 (0.167670) | 0.053812 / 0.128546 (-0.074734) | 0.014315 / 0.075646 (-0.061331) | 0.389636 / 0.419271 (-0.029636) | 0.111859 / 0.043533 (0.068326) | 0.411703 / 0.255139 (0.156564) | 0.457072 / 0.283200 (0.173872) | 0.039807 / 0.141683 (-0.101876) | 1.744064 / 1.452155 (0.291909) | 1.968321 / 1.492716 (0.475604) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.341839 / 0.018006 (0.323833) | 0.628083 / 0.000490 (0.627593) | 0.023787 / 0.000200 (0.023587) | 0.000601 / 0.000054 (0.000547) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034170 / 0.037411 (-0.003241) | 0.091159 / 0.014526 (0.076633) | 0.108993 / 0.176557 (-0.067563) | 0.186906 / 0.737135 (-0.550229) | 0.109753 / 0.296338 (-0.186586) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.684138 / 0.215209 (0.468929) | 6.634852 / 2.077655 (4.557198) | 3.102870 / 1.504120 (1.598750) | 2.831023 / 1.541195 (1.289828) | 2.831597 / 1.468490 (1.363107) | 0.903584 / 4.584777 (-3.681193) | 5.503341 / 3.745712 (1.757629) | 4.970283 / 5.269862 (-0.299579) | 3.139413 / 4.565676 (-1.426264) | 0.109848 / 0.424275 (-0.314427) | 0.008501 / 0.007607 (0.000894) | 0.823815 / 0.226044 (0.597770) | 7.963355 / 2.268929 (5.694426) | 4.002010 / 55.444624 (-51.442614) | 3.229390 / 6.876477 (-3.647087) | 3.166413 / 2.142072 (1.024341) | 1.030313 / 4.805227 (-3.774914) | 0.219394 / 6.500664 (-6.281270) | 0.077760 / 0.075469 (0.002291) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.580309 / 1.841788 (-0.261479) | 24.279185 / 8.074308 (16.204877) | 22.305293 / 10.191392 (12.113901) | 0.235711 / 0.680424 (-0.444713) | 0.030342 / 0.534201 (-0.503859) | 0.498137 / 0.579283 (-0.081146) | 0.619173 / 0.434364 (0.184809) | 0.529904 / 0.540337 (-0.010434) | 0.822547 / 1.386936 (-0.564389) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009375 / 0.011353 (-0.001978) | 0.006009 / 0.011008 (-0.004999) | 0.074080 / 0.038508 (0.035572) | 0.089454 / 0.023109 (0.066345) | 0.473458 / 0.275898 (0.197560) | 0.462558 / 0.323480 (0.139078) | 0.006415 / 0.007986 (-0.001571) | 0.004777 / 0.004328 (0.000448) | 0.076563 / 0.004250 (0.072313) | 0.062793 / 0.037052 (0.025741) | 0.455860 / 0.258489 (0.197371) | 0.485281 / 0.293841 (0.191440) | 0.052966 / 0.128546 (-0.075580) | 0.021600 / 0.075646 (-0.054046) | 0.090407 / 0.419271 (-0.328864) | 0.063951 / 0.043533 (0.020418) | 0.487561 / 0.255139 (0.232422) | 0.479958 / 0.283200 (0.196758) | 0.039263 / 0.141683 (-0.102420) | 1.727215 / 1.452155 (0.275061) | 1.962039 / 1.492716 (0.469323) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.296267 / 0.018006 (0.278261) | 0.604982 / 0.000490 (0.604493) | 0.007842 / 0.000200 (0.007642) | 0.000096 / 0.000054 (0.000041) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034317 / 0.037411 (-0.003094) | 0.097796 / 0.014526 (0.083270) | 0.126034 / 0.176557 (-0.050522) | 0.180873 / 0.737135 (-0.556262) | 0.125410 / 0.296338 (-0.170928) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.608278 / 0.215209 (0.393069) | 6.154006 / 2.077655 (4.076351) | 2.822342 / 1.504120 (1.318222) | 2.568263 / 1.541195 (1.027068) | 2.518545 / 1.468490 (1.050055) | 0.863186 / 4.584777 (-3.721591) | 5.367969 / 3.745712 (1.622257) | 4.737691 / 5.269862 (-0.532170) | 2.917620 / 4.565676 (-1.648056) | 0.100731 / 0.424275 (-0.323544) | 0.008611 / 0.007607 (0.001004) | 0.735523 / 0.226044 (0.509479) | 7.552790 / 2.268929 (5.283862) | 3.821835 / 55.444624 (-51.622789) | 2.878259 / 6.876477 (-3.998217) | 2.957686 / 2.142072 (0.815613) | 0.964630 / 4.805227 (-3.840598) | 0.207098 / 6.500664 (-6.293566) | 0.084215 / 0.075469 (0.008746) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.711020 / 1.841788 (-0.130768) | 24.034122 / 8.074308 (15.959814) | 21.378504 / 10.191392 (11.187112) | 0.233433 / 0.680424 (-0.446990) | 0.037214 / 0.534201 (-0.496987) | 0.511952 / 0.579283 (-0.067332) | 0.591486 / 0.434364 (0.157123) | 0.606549 / 0.540337 (0.066211) | 0.833773 / 1.386936 (-0.553163) |\n\n</details>\n</details>\n\n\n"
] | 2023-11-15T10:06:44Z
| 2023-11-15T13:49:55Z
| 2023-11-15T13:38:22Z
|
MEMBER
| null | null | null |
Add `pyarrow-hotfix` to release docs.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6421/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6421/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6421.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6421",
"merged_at": "2023-11-15T13:38:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6421.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6421"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6224
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6224/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6224/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6224/events
|
https://github.com/huggingface/datasets/pull/6224
| 1,886,043,692
|
PR_kwDODunzps5Zym3j
| 6,224
|
Ignore `dataset_info.json` in data files resolution
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009450 / 0.011353 (-0.001903) | 0.007339 / 0.011008 (-0.003669) | 0.110150 / 0.038508 (0.071641) | 0.087794 / 0.023109 (0.064685) | 0.472099 / 0.275898 (0.196201) | 0.476622 / 0.323480 (0.153142) | 0.005057 / 0.007986 (-0.002929) | 0.005262 / 0.004328 (0.000933) | 0.103059 / 0.004250 (0.098808) | 0.069815 / 0.037052 (0.032763) | 0.489377 / 0.258489 (0.230888) | 0.547087 / 0.293841 (0.253247) | 0.048883 / 0.128546 (-0.079663) | 0.019192 / 0.075646 (-0.056454) | 0.410865 / 0.419271 (-0.008407) | 0.076215 / 0.043533 (0.032682) | 0.484825 / 0.255139 (0.229686) | 0.519035 / 0.283200 (0.235835) | 0.042030 / 0.141683 (-0.099653) | 1.909630 / 1.452155 (0.457475) | 2.120869 / 1.492716 (0.628153) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.267600 / 0.018006 (0.249594) | 0.619135 / 0.000490 (0.618645) | 0.005897 / 0.000200 (0.005697) | 0.000142 / 0.000054 (0.000087) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033265 / 0.037411 (-0.004146) | 0.104476 / 0.014526 (0.089950) | 0.129199 / 0.176557 (-0.047358) | 0.196898 / 0.737135 (-0.540238) | 0.118852 / 0.296338 (-0.177487) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.598908 / 0.215209 (0.383699) | 6.263096 / 2.077655 (4.185441) | 2.672134 / 1.504120 (1.168014) | 2.428706 / 1.541195 (0.887511) | 2.431651 / 1.468490 (0.963161) | 0.918465 / 4.584777 (-3.666312) | 5.667857 / 3.745712 (1.922145) | 5.113696 / 5.269862 (-0.156166) | 3.276805 / 4.565676 (-1.288872) | 0.101829 / 0.424275 (-0.322446) | 0.010224 / 0.007607 (0.002617) | 0.741547 / 0.226044 (0.515502) | 7.517002 / 2.268929 (5.248073) | 3.546353 / 55.444624 (-51.898272) | 2.845956 / 6.876477 (-4.030521) | 3.172777 / 2.142072 (1.030705) | 1.153485 / 4.805227 (-3.651742) | 0.225758 / 6.500664 (-6.274906) | 0.084333 / 0.075469 (0.008864) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.704645 / 1.841788 (-0.137143) | 27.044110 / 8.074308 (18.969801) | 24.653837 / 10.191392 (14.462445) | 0.235452 / 0.680424 (-0.444971) | 0.029285 / 0.534201 (-0.504916) | 0.576122 / 0.579283 (-0.003161) | 0.626263 / 0.434364 (0.191899) | 0.600201 / 0.540337 (0.059864) | 0.838406 / 1.386936 (-0.548530) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.013754 / 0.011353 (0.002401) | 0.005954 / 0.011008 (-0.005054) | 0.089766 / 0.038508 (0.051258) | 0.096126 / 0.023109 (0.073017) | 0.556455 / 0.275898 (0.280557) | 0.579302 / 0.323480 (0.255822) | 0.009222 / 0.007986 (0.001236) | 0.006128 / 0.004328 (0.001800) | 0.099725 / 0.004250 (0.095475) | 0.075642 / 0.037052 (0.038589) | 0.556645 / 0.258489 (0.298156) | 0.615898 / 0.293841 (0.322057) | 0.057728 / 0.128546 (-0.070818) | 0.016746 / 0.075646 (-0.058900) | 0.098053 / 0.419271 (-0.321219) | 0.066676 / 0.043533 (0.023143) | 0.534156 / 0.255139 (0.279017) | 0.590020 / 0.283200 (0.306820) | 0.038782 / 0.141683 (-0.102901) | 1.952301 / 1.452155 (0.500146) | 2.104255 / 1.492716 (0.611539) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.305945 / 0.018006 (0.287939) | 0.643915 / 0.000490 (0.643426) | 0.006268 / 0.000200 (0.006068) | 0.000156 / 0.000054 (0.000102) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.039891 / 0.037411 (0.002479) | 0.117888 / 0.014526 (0.103363) | 0.134230 / 0.176557 (-0.042326) | 0.212544 / 0.737135 (-0.524591) | 0.128858 / 0.296338 (-0.167480) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.718165 / 0.215209 (0.502955) | 7.023867 / 2.077655 (4.946212) | 3.391344 / 1.504120 (1.887224) | 3.021248 / 1.541195 (1.480053) | 3.010217 / 1.468490 (1.541727) | 0.932608 / 4.584777 (-3.652169) | 5.787536 / 3.745712 (2.041824) | 5.221305 / 5.269862 (-0.048557) | 3.282552 / 4.565676 (-1.283125) | 0.105486 / 0.424275 (-0.318789) | 0.009800 / 0.007607 (0.002193) | 0.839358 / 0.226044 (0.613314) | 8.279712 / 2.268929 (6.010784) | 4.118466 / 55.444624 (-51.326158) | 3.407738 / 6.876477 (-3.468739) | 3.632538 / 2.142072 (1.490466) | 1.109673 / 4.805227 (-3.695555) | 0.216541 / 6.500664 (-6.284123) | 0.094031 / 0.075469 (0.018562) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.983979 / 1.841788 (0.142191) | 27.125882 / 8.074308 (19.051573) | 24.714002 / 10.191392 (14.522610) | 0.264417 / 0.680424 (-0.416007) | 0.034783 / 0.534201 (-0.499418) | 0.533304 / 0.579283 (-0.045979) | 0.647798 / 0.434364 (0.213434) | 0.588680 / 0.540337 (0.048343) | 0.854250 / 1.386936 (-0.532686) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006664 / 0.011353 (-0.004689) | 0.004164 / 0.011008 (-0.006844) | 0.085192 / 0.038508 (0.046684) | 0.073578 / 0.023109 (0.050469) | 0.356379 / 0.275898 (0.080481) | 0.389381 / 0.323480 (0.065902) | 0.005527 / 0.007986 (-0.002459) | 0.003488 / 0.004328 (-0.000840) | 0.065640 / 0.004250 (0.061390) | 0.055013 / 0.037052 (0.017960) | 0.358002 / 0.258489 (0.099513) | 0.400663 / 0.293841 (0.106822) | 0.030937 / 0.128546 (-0.097609) | 0.008838 / 0.075646 (-0.066808) | 0.287488 / 0.419271 (-0.131784) | 0.051503 / 0.043533 (0.007971) | 0.353945 / 0.255139 (0.098806) | 0.388778 / 0.283200 (0.105579) | 0.023346 / 0.141683 (-0.118337) | 1.479621 / 1.452155 (0.027466) | 1.559164 / 1.492716 (0.066448) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.245160 / 0.018006 (0.227154) | 0.561890 / 0.000490 (0.561400) | 0.004339 / 0.000200 (0.004139) | 0.000083 / 0.000054 (0.000028) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028460 / 0.037411 (-0.008952) | 0.082046 / 0.014526 (0.067520) | 0.098005 / 0.176557 (-0.078552) | 0.154171 / 0.737135 (-0.582965) | 0.097632 / 0.296338 (-0.198707) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.389993 / 0.215209 (0.174784) | 3.893287 / 2.077655 (1.815632) | 1.885668 / 1.504120 (0.381549) | 1.715055 / 1.541195 (0.173860) | 1.778008 / 1.468490 (0.309518) | 0.482818 / 4.584777 (-4.101959) | 3.572153 / 3.745712 (-0.173559) | 3.267666 / 5.269862 (-2.002196) | 2.088394 / 4.565676 (-2.477282) | 0.056961 / 0.424275 (-0.367314) | 0.007784 / 0.007607 (0.000177) | 0.466586 / 0.226044 (0.240542) | 4.652505 / 2.268929 (2.383576) | 2.491392 / 55.444624 (-52.953233) | 2.127600 / 6.876477 (-4.748877) | 2.296778 / 2.142072 (0.154705) | 0.582332 / 4.805227 (-4.222895) | 0.134372 / 6.500664 (-6.366292) | 0.061737 / 0.075469 (-0.013732) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.253647 / 1.841788 (-0.588140) | 19.802353 / 8.074308 (11.728045) | 14.262815 / 10.191392 (4.071423) | 0.169489 / 0.680424 (-0.510935) | 0.018108 / 0.534201 (-0.516093) | 0.391711 / 0.579283 (-0.187572) | 0.406169 / 0.434364 (-0.028195) | 0.456728 / 0.540337 (-0.083609) | 0.633538 / 1.386936 (-0.753398) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006661 / 0.011353 (-0.004692) | 0.004181 / 0.011008 (-0.006827) | 0.064945 / 0.038508 (0.026437) | 0.073965 / 0.023109 (0.050856) | 0.406549 / 0.275898 (0.130651) | 0.441568 / 0.323480 (0.118089) | 0.005579 / 0.007986 (-0.002407) | 0.003523 / 0.004328 (-0.000805) | 0.065270 / 0.004250 (0.061019) | 0.055596 / 0.037052 (0.018544) | 0.407701 / 0.258489 (0.149212) | 0.444609 / 0.293841 (0.150768) | 0.031749 / 0.128546 (-0.096797) | 0.008680 / 0.075646 (-0.066966) | 0.071154 / 0.419271 (-0.348117) | 0.047376 / 0.043533 (0.003843) | 0.406409 / 0.255139 (0.151270) | 0.420477 / 0.283200 (0.137278) | 0.023707 / 0.141683 (-0.117976) | 1.484516 / 1.452155 (0.032361) | 1.568493 / 1.492716 (0.075777) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.266534 / 0.018006 (0.248528) | 0.573806 / 0.000490 (0.573316) | 0.006247 / 0.000200 (0.006048) | 0.000165 / 0.000054 (0.000110) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033436 / 0.037411 (-0.003976) | 0.091947 / 0.014526 (0.077421) | 0.105556 / 0.176557 (-0.071000) | 0.162094 / 0.737135 (-0.575041) | 0.107879 / 0.296338 (-0.188459) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.429126 / 0.215209 (0.213917) | 4.281329 / 2.077655 (2.203675) | 2.295406 / 1.504120 (0.791286) | 2.123336 / 1.541195 (0.582141) | 2.190804 / 1.468490 (0.722314) | 0.492972 / 4.584777 (-4.091805) | 3.638485 / 3.745712 (-0.107227) | 3.304576 / 5.269862 (-1.965285) | 2.063694 / 4.565676 (-2.501983) | 0.058549 / 0.424275 (-0.365726) | 0.007591 / 0.007607 (-0.000016) | 0.504268 / 0.226044 (0.278223) | 5.031990 / 2.268929 (2.763061) | 2.773173 / 55.444624 (-52.671451) | 2.430789 / 6.876477 (-4.445688) | 2.699900 / 2.142072 (0.557828) | 0.593220 / 4.805227 (-4.212007) | 0.133710 / 6.500664 (-6.366954) | 0.059840 / 0.075469 (-0.015629) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.351158 / 1.841788 (-0.490629) | 20.176310 / 8.074308 (12.102002) | 14.933202 / 10.191392 (4.741810) | 0.169920 / 0.680424 (-0.510503) | 0.020156 / 0.534201 (-0.514045) | 0.397440 / 0.579283 (-0.181843) | 0.409395 / 0.434364 (-0.024969) | 0.471066 / 0.540337 (-0.069271) | 0.642670 / 1.386936 (-0.744266) |\n\n</details>\n</details>\n\n\n"
] | 2023-09-07T14:43:51Z
| 2023-09-07T15:46:10Z
| 2023-09-07T15:37:20Z
|
COLLABORATOR
| null | null | null |
`save_to_disk` creates this file, but also [`HugginFaceDatasetSever`](https://github.com/gradio-app/gradio/blob/26fef8c7f85a006c7e25cdbed1792df19c512d02/gradio/flagging.py#L214), so this is needed to avoid issues such as [this one](https://discord.com/channels/879548962464493619/1149295819938349107/1149295819938349107).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6224/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6224/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6224.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6224",
"merged_at": "2023-09-07T15:37:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6224.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6224"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7457
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7457/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7457/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7457/events
|
https://github.com/huggingface/datasets/issues/7457
| 2,924,886,467
|
I_kwDODunzps6uVjnD
| 7,457
|
Document the HF_DATASETS_CACHE env variable
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/92166725?v=4",
"events_url": "https://api.github.com/users/LSerranoPEReN/events{/privacy}",
"followers_url": "https://api.github.com/users/LSerranoPEReN/followers",
"following_url": "https://api.github.com/users/LSerranoPEReN/following{/other_user}",
"gists_url": "https://api.github.com/users/LSerranoPEReN/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/LSerranoPEReN",
"id": 92166725,
"login": "LSerranoPEReN",
"node_id": "U_kgDOBX5aRQ",
"organizations_url": "https://api.github.com/users/LSerranoPEReN/orgs",
"received_events_url": "https://api.github.com/users/LSerranoPEReN/received_events",
"repos_url": "https://api.github.com/users/LSerranoPEReN/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/LSerranoPEReN/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LSerranoPEReN/subscriptions",
"type": "User",
"url": "https://api.github.com/users/LSerranoPEReN",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/other_user}",
"gists_url": "https://api.github.com/users/Harry-Yang0518/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Harry-Yang0518",
"id": 129883215,
"login": "Harry-Yang0518",
"node_id": "U_kgDOB73cTw",
"organizations_url": "https://api.github.com/users/Harry-Yang0518/orgs",
"received_events_url": "https://api.github.com/users/Harry-Yang0518/received_events",
"repos_url": "https://api.github.com/users/Harry-Yang0518/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Harry-Yang0518/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Harry-Yang0518/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Harry-Yang0518",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/other_user}",
"gists_url": "https://api.github.com/users/Harry-Yang0518/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Harry-Yang0518",
"id": 129883215,
"login": "Harry-Yang0518",
"node_id": "U_kgDOB73cTw",
"organizations_url": "https://api.github.com/users/Harry-Yang0518/orgs",
"received_events_url": "https://api.github.com/users/Harry-Yang0518/received_events",
"repos_url": "https://api.github.com/users/Harry-Yang0518/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Harry-Yang0518/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Harry-Yang0518/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Harry-Yang0518",
"user_view_type": "public"
}
] | null |
[
"Strongly agree to this, in addition, I am also suffering to change the cache location similar to other issues (since I changed the environmental variables).\nhttps://github.com/huggingface/datasets/issues/6886",
"`HF_DATASETS_CACHE` should be documented there indeed, feel free to open a PR :) ",
"Hey, I’d love to work on this issue! Could you assign it to me?",
"sure ! you can also comment #self-assign in an issue and a bot assigns you automatically :)"
] | 2025-03-17T12:24:50Z
| 2025-03-20T10:36:46Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
Hello,
I have a use case where my team is sharing models and dataset in shared directory to avoid duplication.
I noticed that the [cache documentation for datasets](https://huggingface.co/docs/datasets/main/en/cache) only mention the `HF_HOME` environment variable but never the `HF_DATASETS_CACHE`.
It should be nice to add `HF_DATASETS_CACHE` to datasets documentation if it's an intended feature.
If it's not, I think a depreciation warning would be appreciated.
### Motivation
This variable is fully working and similar to what `HF_HUB_CACHE` does for models, so it's nice to know that this exists. This seems to be a quick change to implement.
### Your contribution
I could contribute since this is only affecting a small portion of the documentation
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7457/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7457/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6698
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6698/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6698/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6698/events
|
https://github.com/huggingface/datasets/pull/6698
| 2,157,752,392
|
PR_kwDODunzps5oG6Xt
| 6,698
|
Faster `xlistdir`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6698). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"CI failure is unrelated to the changes.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005499 / 0.011353 (-0.005854) | 0.003824 / 0.011008 (-0.007184) | 0.064230 / 0.038508 (0.025722) | 0.028962 / 0.023109 (0.005853) | 0.283540 / 0.275898 (0.007642) | 0.300774 / 0.323480 (-0.022706) | 0.003405 / 0.007986 (-0.004581) | 0.002796 / 0.004328 (-0.001532) | 0.049834 / 0.004250 (0.045584) | 0.045924 / 0.037052 (0.008872) | 0.274818 / 0.258489 (0.016328) | 0.306189 / 0.293841 (0.012348) | 0.028304 / 0.128546 (-0.100242) | 0.011496 / 0.075646 (-0.064150) | 0.208236 / 0.419271 (-0.211036) | 0.035720 / 0.043533 (-0.007813) | 0.261190 / 0.255139 (0.006051) | 0.281545 / 0.283200 (-0.001655) | 0.019388 / 0.141683 (-0.122295) | 1.134999 / 1.452155 (-0.317156) | 1.203053 / 1.492716 (-0.289663) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.096007 / 0.018006 (0.078000) | 0.316958 / 0.000490 (0.316469) | 0.000210 / 0.000200 (0.000010) | 0.000053 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018330 / 0.037411 (-0.019081) | 0.063299 / 0.014526 (0.048773) | 0.073833 / 0.176557 (-0.102723) | 0.122285 / 0.737135 (-0.614850) | 0.077352 / 0.296338 (-0.218987) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.304487 / 0.215209 (0.089278) | 3.017666 / 2.077655 (0.940012) | 1.664292 / 1.504120 (0.160172) | 1.448446 / 1.541195 (-0.092748) | 1.435612 / 1.468490 (-0.032878) | 0.569704 / 4.584777 (-4.015073) | 2.362015 / 3.745712 (-1.383698) | 2.910380 / 5.269862 (-2.359481) | 1.814560 / 4.565676 (-2.751116) | 0.063986 / 0.424275 (-0.360289) | 0.005022 / 0.007607 (-0.002585) | 0.363528 / 0.226044 (0.137483) | 3.641940 / 2.268929 (1.373011) | 1.961589 / 55.444624 (-53.483035) | 1.603683 / 6.876477 (-5.272793) | 1.663144 / 2.142072 (-0.478928) | 0.645628 / 4.805227 (-4.159599) | 0.118759 / 6.500664 (-6.381905) | 0.042631 / 0.075469 (-0.032838) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.985648 / 1.841788 (-0.856140) | 13.082558 / 8.074308 (5.008250) | 9.909811 / 10.191392 (-0.281581) | 0.131340 / 0.680424 (-0.549083) | 0.013983 / 0.534201 (-0.520218) | 0.289869 / 0.579283 (-0.289414) | 0.271775 / 0.434364 (-0.162589) | 0.334853 / 0.540337 (-0.205485) | 0.457017 / 1.386936 (-0.929919) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005580 / 0.011353 (-0.005773) | 0.003788 / 0.011008 (-0.007221) | 0.049401 / 0.038508 (0.010893) | 0.030372 / 0.023109 (0.007263) | 0.278554 / 0.275898 (0.002655) | 0.302462 / 0.323480 (-0.021018) | 0.004412 / 0.007986 (-0.003573) | 0.002825 / 0.004328 (-0.001504) | 0.047826 / 0.004250 (0.043576) | 0.047903 / 0.037052 (0.010851) | 0.293098 / 0.258489 (0.034609) | 0.322777 / 0.293841 (0.028936) | 0.030010 / 0.128546 (-0.098536) | 0.011187 / 0.075646 (-0.064459) | 0.057639 / 0.419271 (-0.361632) | 0.059693 / 0.043533 (0.016160) | 0.280288 / 0.255139 (0.025149) | 0.294022 / 0.283200 (0.010823) | 0.019635 / 0.141683 (-0.122048) | 1.154733 / 1.452155 (-0.297422) | 1.200808 / 1.492716 (-0.291908) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.099682 / 0.018006 (0.081676) | 0.319521 / 0.000490 (0.319031) | 0.000224 / 0.000200 (0.000024) | 0.000053 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022042 / 0.037411 (-0.015370) | 0.078842 / 0.014526 (0.064317) | 0.088715 / 0.176557 (-0.087841) | 0.126832 / 0.737135 (-0.610303) | 0.089217 / 0.296338 (-0.207122) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.300099 / 0.215209 (0.084890) | 2.907746 / 2.077655 (0.830092) | 1.619418 / 1.504120 (0.115298) | 1.495693 / 1.541195 (-0.045501) | 1.544956 / 1.468490 (0.076466) | 0.556652 / 4.584777 (-4.028124) | 2.414408 / 3.745712 (-1.331304) | 2.737227 / 5.269862 (-2.532635) | 1.763187 / 4.565676 (-2.802490) | 0.062207 / 0.424275 (-0.362069) | 0.005076 / 0.007607 (-0.002531) | 0.349880 / 0.226044 (0.123836) | 3.425355 / 2.268929 (1.156427) | 1.972094 / 55.444624 (-53.472531) | 1.710650 / 6.876477 (-5.165827) | 1.902218 / 2.142072 (-0.239855) | 0.640699 / 4.805227 (-4.164529) | 0.117879 / 6.500664 (-6.382785) | 0.042412 / 0.075469 (-0.033057) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.030131 / 1.841788 (-0.811656) | 12.750637 / 8.074308 (4.676329) | 10.352636 / 10.191392 (0.161244) | 0.141139 / 0.680424 (-0.539285) | 0.015343 / 0.534201 (-0.518858) | 0.294931 / 0.579283 (-0.284352) | 0.275237 / 0.434364 (-0.159127) | 0.336669 / 0.540337 (-0.203668) | 0.429945 / 1.386936 (-0.956991) |\n\n</details>\n</details>\n\n\n"
] | 2024-02-27T22:55:08Z
| 2024-02-27T23:44:49Z
| 2024-02-27T23:38:14Z
|
COLLABORATOR
| null | null | null |
Pass `detail=False` to the `fsspec` `listdir` to avoid unnecessarily fetching expensive metadata about the paths.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6698/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6698/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6698.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6698",
"merged_at": "2024-02-27T23:38:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6698.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6698"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7118
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7118/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7118/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7118/events
|
https://github.com/huggingface/datasets/pull/7118
| 2,477,676,893
|
PR_kwDODunzps549yu4
| 7,118
|
Allow numpy-2.1 and test it without audio extra
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7118). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005674 / 0.011353 (-0.005679) | 0.003919 / 0.011008 (-0.007089) | 0.062665 / 0.038508 (0.024157) | 0.031750 / 0.023109 (0.008641) | 0.234809 / 0.275898 (-0.041089) | 0.264454 / 0.323480 (-0.059026) | 0.004265 / 0.007986 (-0.003720) | 0.002757 / 0.004328 (-0.001572) | 0.048921 / 0.004250 (0.044671) | 0.050765 / 0.037052 (0.013713) | 0.246185 / 0.258489 (-0.012305) | 0.287011 / 0.293841 (-0.006829) | 0.030754 / 0.128546 (-0.097792) | 0.012368 / 0.075646 (-0.063278) | 0.203841 / 0.419271 (-0.215431) | 0.037579 / 0.043533 (-0.005953) | 0.238165 / 0.255139 (-0.016974) | 0.264375 / 0.283200 (-0.018824) | 0.018663 / 0.141683 (-0.123020) | 1.143897 / 1.452155 (-0.308258) | 1.218130 / 1.492716 (-0.274586) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.102112 / 0.018006 (0.084106) | 0.303214 / 0.000490 (0.302724) | 0.000232 / 0.000200 (0.000032) | 0.000043 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019401 / 0.037411 (-0.018010) | 0.062444 / 0.014526 (0.047919) | 0.076497 / 0.176557 (-0.100060) | 0.122309 / 0.737135 (-0.614826) | 0.077178 / 0.296338 (-0.219160) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282931 / 0.215209 (0.067722) | 2.783587 / 2.077655 (0.705932) | 1.464076 / 1.504120 (-0.040044) | 1.333912 / 1.541195 (-0.207282) | 1.367391 / 1.468490 (-0.101099) | 0.736702 / 4.584777 (-3.848075) | 2.413625 / 3.745712 (-1.332087) | 2.949549 / 5.269862 (-2.320313) | 1.910308 / 4.565676 (-2.655369) | 0.077419 / 0.424275 (-0.346856) | 0.005159 / 0.007607 (-0.002448) | 0.345595 / 0.226044 (0.119551) | 3.433205 / 2.268929 (1.164277) | 1.844443 / 55.444624 (-53.600181) | 1.527475 / 6.876477 (-5.349002) | 1.544315 / 2.142072 (-0.597758) | 0.803942 / 4.805227 (-4.001285) | 0.134131 / 6.500664 (-6.366533) | 0.042638 / 0.075469 (-0.032831) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.975158 / 1.841788 (-0.866629) | 11.726187 / 8.074308 (3.651879) | 9.403347 / 10.191392 (-0.788045) | 0.131583 / 0.680424 (-0.548840) | 0.014358 / 0.534201 (-0.519843) | 0.301360 / 0.579283 (-0.277923) | 0.266529 / 0.434364 (-0.167835) | 0.341669 / 0.540337 (-0.198668) | 0.425751 / 1.386936 (-0.961186) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005911 / 0.011353 (-0.005442) | 0.004093 / 0.011008 (-0.006915) | 0.049936 / 0.038508 (0.011428) | 0.031828 / 0.023109 (0.008719) | 0.273874 / 0.275898 (-0.002025) | 0.296871 / 0.323480 (-0.026609) | 0.004470 / 0.007986 (-0.003516) | 0.002902 / 0.004328 (-0.001426) | 0.048848 / 0.004250 (0.044597) | 0.042320 / 0.037052 (0.005268) | 0.287957 / 0.258489 (0.029468) | 0.321033 / 0.293841 (0.027192) | 0.032996 / 0.128546 (-0.095550) | 0.012244 / 0.075646 (-0.063403) | 0.060493 / 0.419271 (-0.358779) | 0.034630 / 0.043533 (-0.008902) | 0.277254 / 0.255139 (0.022115) | 0.292822 / 0.283200 (0.009623) | 0.017966 / 0.141683 (-0.123717) | 1.167432 / 1.452155 (-0.284723) | 1.231837 / 1.492716 (-0.260880) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.099970 / 0.018006 (0.081964) | 0.313240 / 0.000490 (0.312750) | 0.000217 / 0.000200 (0.000017) | 0.000043 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022928 / 0.037411 (-0.014483) | 0.077058 / 0.014526 (0.062532) | 0.090147 / 0.176557 (-0.086409) | 0.129416 / 0.737135 (-0.607720) | 0.091021 / 0.296338 (-0.205318) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.300697 / 0.215209 (0.085488) | 2.944649 / 2.077655 (0.866995) | 1.609106 / 1.504120 (0.104986) | 1.483762 / 1.541195 (-0.057433) | 1.519433 / 1.468490 (0.050943) | 0.714129 / 4.584777 (-3.870648) | 0.991848 / 3.745712 (-2.753864) | 2.966340 / 5.269862 (-2.303521) | 1.905427 / 4.565676 (-2.660249) | 0.079041 / 0.424275 (-0.345234) | 0.005671 / 0.007607 (-0.001936) | 0.356037 / 0.226044 (0.129993) | 3.504599 / 2.268929 (1.235670) | 1.979207 / 55.444624 (-53.465417) | 1.695030 / 6.876477 (-5.181447) | 1.703978 / 2.142072 (-0.438095) | 0.800871 / 4.805227 (-4.004357) | 0.134414 / 6.500664 (-6.366250) | 0.041743 / 0.075469 (-0.033726) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.029879 / 1.841788 (-0.811909) | 12.132252 / 8.074308 (4.057944) | 10.596576 / 10.191392 (0.405184) | 0.132237 / 0.680424 (-0.548187) | 0.016239 / 0.534201 (-0.517962) | 0.301831 / 0.579283 (-0.277452) | 0.127966 / 0.434364 (-0.306398) | 0.341081 / 0.540337 (-0.199256) | 0.448996 / 1.386936 (-0.937940) |\n\n</details>\n</details>\n\n\n"
] | 2024-08-21T10:29:35Z
| 2024-08-21T11:05:03Z
| 2024-08-21T10:58:15Z
|
MEMBER
| null | null | null |
Allow numpy-2.1 and test it without audio extra.
This PR reverts:
- #7114
Note that audio extra tests can be included again with numpy-2.1 once next numba-0.61.0 version is released.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7118/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7118/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7118.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7118",
"merged_at": "2024-08-21T10:58:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7118.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7118"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7529
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7529/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7529/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7529/events
|
https://github.com/huggingface/datasets/issues/7529
| 3,007,118,969
|
I_kwDODunzps6zPP55
| 7,529
|
audio folder builder cannot detect custom split name
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/37548991?v=4",
"events_url": "https://api.github.com/users/phineas-pta/events{/privacy}",
"followers_url": "https://api.github.com/users/phineas-pta/followers",
"following_url": "https://api.github.com/users/phineas-pta/following{/other_user}",
"gists_url": "https://api.github.com/users/phineas-pta/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/phineas-pta",
"id": 37548991,
"login": "phineas-pta",
"node_id": "MDQ6VXNlcjM3NTQ4OTkx",
"organizations_url": "https://api.github.com/users/phineas-pta/orgs",
"received_events_url": "https://api.github.com/users/phineas-pta/received_events",
"repos_url": "https://api.github.com/users/phineas-pta/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/phineas-pta/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/phineas-pta/subscriptions",
"type": "User",
"url": "https://api.github.com/users/phineas-pta",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[] | 2025-04-20T16:53:21Z
| 2025-04-20T16:53:21Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
when using audio folder builder (`load_dataset("audiofolder", data_dir="/path/to/folder")`), it cannot detect custom split name other than train/validation/test
### Steps to reproduce the bug
i have the following folder structure
```
my_dataset/
├── train/
│ ├── lorem.wav
│ ├── …
│ └── metadata.csv
├── test/
│ ├── ipsum.wav
│ ├── …
│ └── metadata.csv
├── validation/
│ ├── dolor.wav
│ ├── …
│ └── metadata.csv
└── custom/
├── sit.wav
├── …
└── metadata.csv
```
using `ds = load_dataset("audiofolder", data_dir="/path/to/my_dataset")`
### Expected behavior
i got `ds` with only 3 splits train/validation/test, whenever i rename train/validation/test folder it also disappear if i re-create `ds`
### Environment info
- `datasets` version: 3.5.0
- Platform: Windows-11-10.0.26100-SP0
- Python version: 3.12.8
- `huggingface_hub` version: 0.30.2
- PyArrow version: 18.1.0
- Pandas version: 2.2.3
- `fsspec` version: 2024.9.0
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7529/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7529/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4806
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4806/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4806/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4806/events
|
https://github.com/huggingface/datasets/pull/4806
| 1,332,664,038
|
PR_kwDODunzps482yiS
| 4,806
|
Fix opus_gnome dataset card
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/38291975?v=4",
"events_url": "https://api.github.com/users/gojiteji/events{/privacy}",
"followers_url": "https://api.github.com/users/gojiteji/followers",
"following_url": "https://api.github.com/users/gojiteji/following{/other_user}",
"gists_url": "https://api.github.com/users/gojiteji/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gojiteji",
"id": 38291975,
"login": "gojiteji",
"node_id": "MDQ6VXNlcjM4MjkxOTc1",
"organizations_url": "https://api.github.com/users/gojiteji/orgs",
"received_events_url": "https://api.github.com/users/gojiteji/received_events",
"repos_url": "https://api.github.com/users/gojiteji/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gojiteji/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gojiteji/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gojiteji",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"@gojiteji why have you closed this PR and created an identical one?\r\n- #4807 ",
"@albertvillanova \r\nI forgot to follow \"How to create a Pull\" in CONTRIBUTING.md in this branch.",
"Both are identical. And you can push additional commits to this branch.",
"I see. Thank you for your comment.",
"Anyway, @gojiteji thanks for your contribution and this fix.",
"Once you have modified the `opus_gnome` dataset card, our Continuous Integration test suite performs some tests on it that make some additional requirements: the errors that appear have nothing to do with your contribution, but with these additional quality requirements.",
"> the errors that appear have nothing to do with your contribution, but with these additional quality requirements.\r\n\r\nIs there anything I should do?",
"If you would like to address them as well in this PR, it would be awesome: https://github.com/huggingface/datasets/runs/7741104780?check_suite_focus=true\r\n",
"These are the 2 error messages:\r\n```\r\nE ValueError: The following issues have been found in the dataset cards:\r\nE README Validation:\r\nE The following issues were found for the README at `/home/runner/work/datasets/datasets/datasets/opus_gnome/README.md`:\r\nE -\tNo first-level heading starting with `Dataset Card for` found in README. Skipping further validation for this README.\r\n\r\nE The following issues have been found in the dataset cards:\r\nE YAML tags:\r\nE Could not validate the metadata, found the following errors:\r\nE * field 'language':\r\nE \t['ara', 'cat', 'foo', 'gr', 'nqo', 'tmp'] are not registered tags for 'language', reference at https://github.com/huggingface/datasets/tree/main/src/datasets/utils/resources/languages.json\r\n```",
"In principle there are 2 errors:\r\n\r\nThe first one says, the title of the README does not start with `Dataset Card for`:\r\n- The README title is: `# Dataset Card Creation Guide`\r\n- According to the [template here](https://github.com/huggingface/datasets/blob/main/templates/README.md), it should be: `# Dataset Card for [Dataset Name]`",
"In relation with the languages:\r\n- you should check whether the language codes are properly spelled\r\n- and if so, adding them to our `languages.json` file, so that they are properly validated",
"Thank you for the detailed information. I'm checking it now.",
"```\r\nE ValueError: The following issues have been found in the dataset cards:\r\nE README Validation:\r\nE The following issues were found for the README at `/home/runner/work/datasets/datasets/datasets/opus_gnome/README.md`:\r\nE -\tExpected some content in section `Data Instances` but it is empty.\r\nE -\tExpected some content in section `Data Fields` but it is empty.\r\nE -\tExpected some content in section `Data Splits` but it is empty.\r\n```",
"I added `ara`, `cat`, `gr`, and `nqo` to `languages.json` and removed `foo` and `tmp` from `README.md`.\r\nI also write Data Instances, Data Fields, and Data Splits in `README.md`.",
"Thanks for your investigation and fixes to the dataset card structure! I'm just making some suggestions before merging this PR: see below.",
"Should I create PR for `config.json` to add ` ara cat gr nqo` first?\r\nI think I can pass this failing after that.\r\n\r\nOr removing `ara, cat, gr, nqo, foo, tmp` from `README.md`. ",
"Once you address these issues, all the CI tests will pass.",
"Once the remaining changes are addressed (see unresolved above), we will be able to merge this:\r\n- [ ] Remove \"ara\" from README\r\n- [ ] Remove \"cat\" from README\r\n- [ ] Remove \"gr\" from README\r\n- [ ] Replace \"tmp\" with \"tyj\" in README\r\n- [ ] Add \"tyj\" to `languages.json`:\r\n ```\r\n \"tyj\": \"Tai Do; Tai Yo\",",
"I did the five changes."
] | 2022-08-09T03:40:15Z
| 2022-08-09T12:06:46Z
| 2022-08-09T11:52:04Z
|
CONTRIBUTOR
| null | null | null |
I fixed a issue #4805.
I changed `"gnome"` to `"opus_gnome"` in[ README.md](https://github.com/huggingface/datasets/tree/main/datasets/opus_gnome#dataset-summary).
Fix #4805
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 2,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4806/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4806/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4806.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4806",
"merged_at": "2022-08-09T11:52:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4806.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4806"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5098
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5098/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5098/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5098/events
|
https://github.com/huggingface/datasets/issues/5098
| 1,404,058,518
|
I_kwDODunzps5TsDuW
| 5,098
|
Classes label error when loading symbolic links using imagefolder
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/49552732?v=4",
"events_url": "https://api.github.com/users/horizon86/events{/privacy}",
"followers_url": "https://api.github.com/users/horizon86/followers",
"following_url": "https://api.github.com/users/horizon86/following{/other_user}",
"gists_url": "https://api.github.com/users/horizon86/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/horizon86",
"id": 49552732,
"login": "horizon86",
"node_id": "MDQ6VXNlcjQ5NTUyNzMy",
"organizations_url": "https://api.github.com/users/horizon86/orgs",
"received_events_url": "https://api.github.com/users/horizon86/received_events",
"repos_url": "https://api.github.com/users/horizon86/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/horizon86/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/horizon86/subscriptions",
"type": "User",
"url": "https://api.github.com/users/horizon86",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
},
{
"color": "DF8D62",
"default": false,
"description": "",
"id": 4614514401,
"name": "hacktoberfest",
"node_id": "LA_kwDODunzps8AAAABEwvm4Q",
"url": "https://api.github.com/repos/huggingface/datasets/labels/hacktoberfest"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/riccardobucco",
"id": 9295277,
"login": "riccardobucco",
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"type": "User",
"url": "https://api.github.com/users/riccardobucco",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/riccardobucco",
"id": 9295277,
"login": "riccardobucco",
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"type": "User",
"url": "https://api.github.com/users/riccardobucco",
"user_view_type": "public"
}
] | null |
[
"It can be solved temporarily by remove `resolve` in \r\nhttps://github.com/huggingface/datasets/blob/bef23be3d9543b1ca2da87ab2f05070201044ddc/src/datasets/data_files.py#L278",
"Hi, thanks for reporting and suggesting a fix! We still need to account for `.`/`..` in the file path, so a more robust fix would be `Path(os.path.abspath(filepath))`.",
"> Hi, thanks for reporting and suggesting a fix! We still need to account for `.`/`..` in the file path, so a more robust fix would be `Path(os.path.abspath(filepath))`.\r\n\r\nThanks for your reply!"
] | 2022-10-11T06:10:58Z
| 2022-11-14T14:40:20Z
| 2022-11-14T14:40:20Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
**Is your feature request related to a problem? Please describe.**
Like this: #4015
When there are **symbolic links** to pictures in the data folder, the parent folder name of the **real file** will be used as the class name instead of the parent folder of the symbolic link itself. Can you give an option to decide whether to enable symbolic link tracking?
This is inconsistent with the `torchvision.datasets.ImageFolder` behavior.
For example:
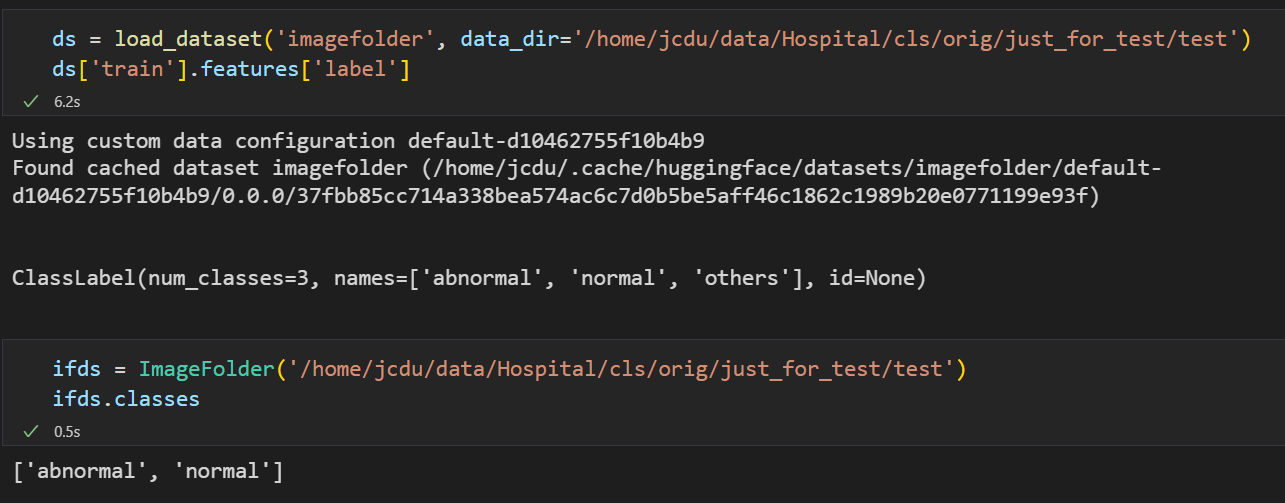

It use `others` in green circle as class label but not `abnormal`, I wish `load_dataset` not use the real file parent as label.
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context about the feature request here.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5098/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5098/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6046
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6046/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6046/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6046/events
|
https://github.com/huggingface/datasets/issues/6046
| 1,808,154,414
|
I_kwDODunzps5rxj8u
| 6,046
|
Support proxy and user-agent in fsspec calls
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "BDE59C",
"default": false,
"description": "Issues a bit more difficult than \"Good First\" issues",
"id": 3761482852,
"name": "good second issue",
"node_id": "LA_kwDODunzps7gM6xk",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20second%20issue"
}
] |
open
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/95092167?v=4",
"events_url": "https://api.github.com/users/zutarich/events{/privacy}",
"followers_url": "https://api.github.com/users/zutarich/followers",
"following_url": "https://api.github.com/users/zutarich/following{/other_user}",
"gists_url": "https://api.github.com/users/zutarich/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zutarich",
"id": 95092167,
"login": "zutarich",
"node_id": "U_kgDOBar9xw",
"organizations_url": "https://api.github.com/users/zutarich/orgs",
"received_events_url": "https://api.github.com/users/zutarich/received_events",
"repos_url": "https://api.github.com/users/zutarich/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zutarich/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zutarich/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zutarich",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/95092167?v=4",
"events_url": "https://api.github.com/users/zutarich/events{/privacy}",
"followers_url": "https://api.github.com/users/zutarich/followers",
"following_url": "https://api.github.com/users/zutarich/following{/other_user}",
"gists_url": "https://api.github.com/users/zutarich/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zutarich",
"id": 95092167,
"login": "zutarich",
"node_id": "U_kgDOBar9xw",
"organizations_url": "https://api.github.com/users/zutarich/orgs",
"received_events_url": "https://api.github.com/users/zutarich/received_events",
"repos_url": "https://api.github.com/users/zutarich/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zutarich/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zutarich/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zutarich",
"user_view_type": "public"
}
] | null |
[
"hii @lhoestq can you assign this issue to me?\r\n",
"You can reply \"#self-assign\" to this issue to automatically get assigned to it :)\r\nLet me know if you have any questions or if I can help",
"#2289 ",
"Actually i am quite new to figure it out how everything goes and done \r\n\r\n> You can reply \"#self-assign\" to this issue to automatically get assigned to it :)\r\n> Let me know if you have any questions or if I can help\r\n\r\nwhen i wrote #self-assign it automatically got converted to some number is it correct or i have done it some wrong way, I am quite new to open source thus wanna try to learn and explore it",
"#2289 #self-assign ",
"Ah yea github tries to replace the #self-assign with an issue link. I guess you can try to copy-paste instead to see if it works\r\n\r\nAnyway let me assign you manually",
"thanks a lot @lhoestq ! though i have a very lil idea of the issue, i am new. as i said before, but gonna try my best shot to do it.\r\ncan you please suggest some tips or anything from your side, how basically we approach it will be really helpfull.\r\nWill try my best!",
"The HfFileSystem from the `huggingface_hub` package can already read the HTTP_PROXY and HTTPS_PROXY environment variables. So the remaining thing missing is the `user_agent` that the user may include in a `DownloadConfig` object. The user agent can be used for regular http calls but also calls to the HfFileSystem.\r\n\r\n- for http, the `user_agent` isn't passed from `DownloadConfig` to `get_datasets_user_agent` in `_prepare_single_hop_path_and_storage_options` in `streaming_download_manager.py` so we need to include it\r\n- for HfFileSystem I think it requires a PR in https://github.com/huggingface/huggingface_hub to include it in the `HfFileSystem.__init__`"
] | 2023-07-17T16:39:26Z
| 2023-10-09T13:49:14Z
| null |
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
Since we switched to the new HfFileSystem we no longer apply user's proxy and user-agent.
Using the HTTP_PROXY and HTTPS_PROXY environment variables works though since we use aiohttp to call the HF Hub.
This can be implemented in `_prepare_single_hop_path_and_storage_options`.
Though ideally the `HfFileSystem` could support passing at least the proxies
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6046/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6046/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4926
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4926/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4926/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4926/events
|
https://github.com/huggingface/datasets/pull/4926
| 1,360,384,484
|
PR_kwDODunzps4-Srm1
| 4,926
|
Dataset infos in yaml
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Alright this is ready for review :)\r\nI mostly would like your opinion on the YAML structure and what we can do in the docs (IMO we can add the docs about those fields in the Hub docs). Other than that let me know if the changes in info.py and features.py look good to you",
"LGTM and looking forward to having this merged!! ❤️ ",
"We plan to do a release today, we'll merge this after the release :)\r\n\r\nEDIT: actually tomorrow",
"Created https://github.com/huggingface/datasets/pull/5018 where I added the YAML `dataset_info` of every single dataset in this repo\r\n\r\nsee other dataset cards: [imagenet-1k](https://github.com/huggingface/datasets/blob/040102f100964a33fd334e2695f1c493fa6b92db/datasets/imagenet-1k/README.md), [glue](https://github.com/huggingface/datasets/blob/040102f100964a33fd334e2695f1c493fa6b92db/datasets/glue/README.md), [flores](https://github.com/huggingface/datasets/blob/040102f100964a33fd334e2695f1c493fa6b92db/datasets/flores/README.md), [gem](https://github.com/huggingface/datasets/blob/040102f100964a33fd334e2695f1c493fa6b92db/datasets/gem/README.md)",
"Took your comments into account and updated `push_to_hub` to push the dataset_info to the README.md instead of json :) Let me know if it sounds good to you now !"
] | 2022-09-02T16:10:05Z
| 2024-05-04T14:52:50Z
| 2022-10-03T09:11:12Z
|
MEMBER
| null | null | null |
To simplify the addition of new datasets, we'd like to have the dataset infos in the YAML and deprecate the dataset_infos.json file. YAML is readable and easy to edit, and the YAML metadata of the readme already contain dataset metadata so we would have everything in one place.
To be more specific, I moved these fields from DatasetInfo to the YAML:
- config_name (if there are several configs)
- download_size
- dataset_size
- features
- splits
Here is what I ended up with for `squad`:
```yaml
dataset_info:
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: text
dtype: string
- name: answer_start
dtype: int32
splits:
- name: train
num_bytes: 79346360
num_examples: 87599
- name: validation
num_bytes: 10473040
num_examples: 10570
config_name: plain_text
download_size: 35142551
dataset_size: 89819400
```
and it can be a list if there are several configs
I already did the change for `conll2000` and `crime_and_punish` as an example.
## Implementation details
### Load/Read
This is done via `DatasetInfosDict.write_to_directory/from_directory`
I had to implement a custom the YAML export logic for `SplitDict`, `Version` and `Features`.
The first two are trivial, but the logic for `Features` is more complicated, because I added a simplification step (or the YAML would be too long and less readable): it's just a formatting step to remove unnecessary nesting of YAML data.
### Other changes
I had to update the DatasetModule factories to also download the README.md alongside the dataset scripts/data files, and not just the dataset_infos.json
## YAML validation
I removed the old validation code that was in metadata.py, now we can just use the Hub YAML validation
## Datasets-cli
The `datasets-cli test --save_infos` command now creates a README.md file with the dataset_infos in it, instead of a datasets_infos.json file
## Backward compatibility
`dataset_infos.json` files are still supported and loaded if they exist to have full backward compatibility.
Though I removed the unnecessary keys when the value is the default (like all the `id: null` from the Value feature types) to make them easier to read.
## TODO
- [x] add comments
- [x] tests
- [x] document the new YAML fields
- [x] try to reload the new dataset_infos.json file content with an old version of `datasets`
## EDITS
- removed "config_name" when there's only one config
- removed "version" for now (?), because it's not useful in general
- renamed the yaml field "dataset_info" instead of "dataset_infos", since it only has one by default (and because "infos" is not english)
Fix https://github.com/huggingface/datasets/issues/4876 and fix #2773
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4926/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4926/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4926.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4926",
"merged_at": "2022-10-03T09:11:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4926.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4926"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6479
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6479/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6479/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6479/events
|
https://github.com/huggingface/datasets/pull/6479
| 2,029,040,121
|
PR_kwDODunzps5hVLom
| 6,479
|
More robust preupload retry mechanism
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6479). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005669 / 0.011353 (-0.005683) | 0.003684 / 0.011008 (-0.007324) | 0.063477 / 0.038508 (0.024969) | 0.068760 / 0.023109 (0.045651) | 0.252741 / 0.275898 (-0.023157) | 0.286499 / 0.323480 (-0.036981) | 0.003311 / 0.007986 (-0.004674) | 0.003487 / 0.004328 (-0.000842) | 0.049636 / 0.004250 (0.045385) | 0.040983 / 0.037052 (0.003931) | 0.262230 / 0.258489 (0.003740) | 0.292131 / 0.293841 (-0.001710) | 0.028231 / 0.128546 (-0.100315) | 0.010912 / 0.075646 (-0.064734) | 0.211248 / 0.419271 (-0.208023) | 0.036679 / 0.043533 (-0.006854) | 0.258139 / 0.255139 (0.003000) | 0.277568 / 0.283200 (-0.005631) | 0.019576 / 0.141683 (-0.122107) | 1.102588 / 1.452155 (-0.349567) | 1.178587 / 1.492716 (-0.314130) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.098968 / 0.018006 (0.080962) | 0.298777 / 0.000490 (0.298287) | 0.000220 / 0.000200 (0.000020) | 0.000043 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.020408 / 0.037411 (-0.017003) | 0.062832 / 0.014526 (0.048306) | 0.076047 / 0.176557 (-0.100509) | 0.125209 / 0.737135 (-0.611926) | 0.079098 / 0.296338 (-0.217240) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.285603 / 0.215209 (0.070394) | 2.811530 / 2.077655 (0.733875) | 1.481012 / 1.504120 (-0.023108) | 1.362740 / 1.541195 (-0.178455) | 1.448999 / 1.468490 (-0.019491) | 0.557740 / 4.584777 (-4.027037) | 2.391377 / 3.745712 (-1.354335) | 2.973181 / 5.269862 (-2.296681) | 1.837147 / 4.565676 (-2.728530) | 0.064445 / 0.424275 (-0.359831) | 0.004992 / 0.007607 (-0.002615) | 0.339207 / 0.226044 (0.113162) | 3.378508 / 2.268929 (1.109580) | 1.843969 / 55.444624 (-53.600655) | 1.597794 / 6.876477 (-5.278682) | 1.657665 / 2.142072 (-0.484407) | 0.654267 / 4.805227 (-4.150961) | 0.120408 / 6.500664 (-6.380256) | 0.045298 / 0.075469 (-0.030171) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.949030 / 1.841788 (-0.892758) | 12.922161 / 8.074308 (4.847852) | 11.115660 / 10.191392 (0.924268) | 0.130556 / 0.680424 (-0.549868) | 0.016278 / 0.534201 (-0.517923) | 0.288137 / 0.579283 (-0.291146) | 0.265978 / 0.434364 (-0.168386) | 0.331491 / 0.540337 (-0.208847) | 0.437782 / 1.386936 (-0.949154) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005342 / 0.011353 (-0.006010) | 0.003636 / 0.011008 (-0.007373) | 0.049527 / 0.038508 (0.011019) | 0.054856 / 0.023109 (0.031746) | 0.271922 / 0.275898 (-0.003976) | 0.295654 / 0.323480 (-0.027826) | 0.004023 / 0.007986 (-0.003963) | 0.002814 / 0.004328 (-0.001515) | 0.048963 / 0.004250 (0.044712) | 0.039936 / 0.037052 (0.002884) | 0.274336 / 0.258489 (0.015847) | 0.310100 / 0.293841 (0.016259) | 0.030006 / 0.128546 (-0.098540) | 0.010750 / 0.075646 (-0.064896) | 0.057989 / 0.419271 (-0.361283) | 0.033692 / 0.043533 (-0.009841) | 0.274084 / 0.255139 (0.018945) | 0.289428 / 0.283200 (0.006229) | 0.018739 / 0.141683 (-0.122944) | 1.126224 / 1.452155 (-0.325931) | 1.171595 / 1.492716 (-0.321121) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093983 / 0.018006 (0.075977) | 0.298516 / 0.000490 (0.298026) | 0.000221 / 0.000200 (0.000022) | 0.000053 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022498 / 0.037411 (-0.014914) | 0.071909 / 0.014526 (0.057383) | 0.083940 / 0.176557 (-0.092617) | 0.121059 / 0.737135 (-0.616076) | 0.084141 / 0.296338 (-0.212198) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.301792 / 0.215209 (0.086583) | 2.971971 / 2.077655 (0.894317) | 1.618718 / 1.504120 (0.114598) | 1.495816 / 1.541195 (-0.045379) | 1.546709 / 1.468490 (0.078219) | 0.571448 / 4.584777 (-4.013329) | 2.459182 / 3.745712 (-1.286531) | 2.937584 / 5.269862 (-2.332278) | 1.804670 / 4.565676 (-2.761007) | 0.062264 / 0.424275 (-0.362011) | 0.004915 / 0.007607 (-0.002692) | 0.355054 / 0.226044 (0.129009) | 3.490468 / 2.268929 (1.221539) | 1.978948 / 55.444624 (-53.465677) | 1.701020 / 6.876477 (-5.175457) | 1.744684 / 2.142072 (-0.397388) | 0.635880 / 4.805227 (-4.169347) | 0.115933 / 6.500664 (-6.384732) | 0.042646 / 0.075469 (-0.032823) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.999486 / 1.841788 (-0.842302) | 13.373854 / 8.074308 (5.299546) | 10.959784 / 10.191392 (0.768392) | 0.131032 / 0.680424 (-0.549392) | 0.015059 / 0.534201 (-0.519142) | 0.289892 / 0.579283 (-0.289391) | 0.279383 / 0.434364 (-0.154981) | 0.337670 / 0.540337 (-0.202668) | 0.597102 / 1.386936 (-0.789834) |\n\n</details>\n</details>\n\n\n"
] | 2023-12-06T17:19:38Z
| 2023-12-06T19:47:29Z
| 2023-12-06T19:41:06Z
|
COLLABORATOR
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6479/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6479/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6479.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6479",
"merged_at": "2023-12-06T19:41:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6479.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6479"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6225
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6225/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6225/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6225/events
|
https://github.com/huggingface/datasets/issues/6225
| 1,887,054,320
|
I_kwDODunzps5weinw
| 6,225
|
Conversion from RGB to BGR in Object Detection tutorial
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/33297401?v=4",
"events_url": "https://api.github.com/users/samokhinv/events{/privacy}",
"followers_url": "https://api.github.com/users/samokhinv/followers",
"following_url": "https://api.github.com/users/samokhinv/following{/other_user}",
"gists_url": "https://api.github.com/users/samokhinv/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/samokhinv",
"id": 33297401,
"login": "samokhinv",
"node_id": "MDQ6VXNlcjMzMjk3NDAx",
"organizations_url": "https://api.github.com/users/samokhinv/orgs",
"received_events_url": "https://api.github.com/users/samokhinv/received_events",
"repos_url": "https://api.github.com/users/samokhinv/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/samokhinv/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/samokhinv/subscriptions",
"type": "User",
"url": "https://api.github.com/users/samokhinv",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Good catch!"
] | 2023-09-08T06:49:19Z
| 2023-09-08T17:52:18Z
| 2023-09-08T17:52:17Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
The [tutorial](https://huggingface.co/docs/datasets/main/en/object_detection) mentions the necessity of conversion the input image from BGR to RGB
> albumentations expects the image to be in BGR format, not RGB, so you’ll have to convert the image before applying the transform.
[Link to tutorial](https://github.com/huggingface/datasets/blob/0a068dbf3b446417ffd89d32857608394ec699e6/docs/source/object_detection.mdx#L77)
However, relevant albumentations' tutorials [on channels conversion](https://albumentations.ai/docs/examples/example/#read-the-image-from-the-disk-and-convert-it-from-the-bgr-color-space-to-the-rgb-color-space) and [on boxes](https://albumentations.ai/docs/examples/example_bboxes/) imply that it's not really true no more.
I suggest removing this outdated conversion from the tutorial.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6225/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6225/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6792
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6792/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6792/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6792/events
|
https://github.com/huggingface/datasets/pull/6792
| 2,231,318,682
|
PR_kwDODunzps5sBEyn
| 6,792
|
Fix cache conflict in `_check_legacy_cache2`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6792). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005212 / 0.011353 (-0.006141) | 0.003536 / 0.011008 (-0.007472) | 0.063042 / 0.038508 (0.024534) | 0.032654 / 0.023109 (0.009545) | 0.242040 / 0.275898 (-0.033858) | 0.267735 / 0.323480 (-0.055745) | 0.003188 / 0.007986 (-0.004797) | 0.002697 / 0.004328 (-0.001631) | 0.050127 / 0.004250 (0.045877) | 0.045960 / 0.037052 (0.008908) | 0.260926 / 0.258489 (0.002437) | 0.293953 / 0.293841 (0.000112) | 0.028352 / 0.128546 (-0.100194) | 0.010558 / 0.075646 (-0.065088) | 0.208104 / 0.419271 (-0.211167) | 0.035889 / 0.043533 (-0.007644) | 0.246265 / 0.255139 (-0.008874) | 0.271819 / 0.283200 (-0.011381) | 0.018491 / 0.141683 (-0.123192) | 1.299274 / 1.452155 (-0.152881) | 1.205932 / 1.492716 (-0.286784) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095574 / 0.018006 (0.077568) | 0.306493 / 0.000490 (0.306003) | 0.000216 / 0.000200 (0.000016) | 0.000042 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018304 / 0.037411 (-0.019107) | 0.061312 / 0.014526 (0.046786) | 0.074483 / 0.176557 (-0.102073) | 0.122231 / 0.737135 (-0.614905) | 0.075315 / 0.296338 (-0.221024) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.275632 / 0.215209 (0.060423) | 2.696402 / 2.077655 (0.618747) | 1.418657 / 1.504120 (-0.085463) | 1.300014 / 1.541195 (-0.241181) | 1.299148 / 1.468490 (-0.169342) | 0.561893 / 4.584777 (-4.022884) | 2.410710 / 3.745712 (-1.335002) | 2.749058 / 5.269862 (-2.520803) | 1.712835 / 4.565676 (-2.852841) | 0.062278 / 0.424275 (-0.361997) | 0.005040 / 0.007607 (-0.002567) | 0.330352 / 0.226044 (0.104308) | 3.291274 / 2.268929 (1.022345) | 1.780987 / 55.444624 (-53.663638) | 1.514764 / 6.876477 (-5.361713) | 1.533892 / 2.142072 (-0.608181) | 0.632307 / 4.805227 (-4.172921) | 0.116011 / 6.500664 (-6.384653) | 0.041964 / 0.075469 (-0.033505) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.982713 / 1.841788 (-0.859075) | 11.521597 / 8.074308 (3.447289) | 9.713063 / 10.191392 (-0.478329) | 0.132115 / 0.680424 (-0.548309) | 0.014564 / 0.534201 (-0.519637) | 0.294087 / 0.579283 (-0.285196) | 0.267399 / 0.434364 (-0.166965) | 0.327967 / 0.540337 (-0.212370) | 0.419279 / 1.386936 (-0.967657) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005098 / 0.011353 (-0.006255) | 0.003513 / 0.011008 (-0.007495) | 0.050121 / 0.038508 (0.011613) | 0.030842 / 0.023109 (0.007732) | 0.271323 / 0.275898 (-0.004575) | 0.293592 / 0.323480 (-0.029887) | 0.004225 / 0.007986 (-0.003761) | 0.002802 / 0.004328 (-0.001527) | 0.049035 / 0.004250 (0.044785) | 0.040748 / 0.037052 (0.003696) | 0.282542 / 0.258489 (0.024053) | 0.303779 / 0.293841 (0.009938) | 0.029213 / 0.128546 (-0.099333) | 0.010578 / 0.075646 (-0.065068) | 0.058053 / 0.419271 (-0.361219) | 0.032830 / 0.043533 (-0.010703) | 0.272226 / 0.255139 (0.017087) | 0.290485 / 0.283200 (0.007285) | 0.017968 / 0.141683 (-0.123714) | 1.166998 / 1.452155 (-0.285156) | 1.256354 / 1.492716 (-0.236362) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.096126 / 0.018006 (0.078120) | 0.306303 / 0.000490 (0.305813) | 0.000246 / 0.000200 (0.000047) | 0.000049 / 0.000054 (-0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022413 / 0.037411 (-0.014998) | 0.075008 / 0.014526 (0.060482) | 0.087703 / 0.176557 (-0.088854) | 0.127358 / 0.737135 (-0.609777) | 0.088817 / 0.296338 (-0.207521) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.301103 / 0.215209 (0.085894) | 2.965441 / 2.077655 (0.887787) | 1.608075 / 1.504120 (0.103955) | 1.479214 / 1.541195 (-0.061981) | 1.492039 / 1.468490 (0.023549) | 0.574455 / 4.584777 (-4.010322) | 2.483234 / 3.745712 (-1.262478) | 2.795901 / 5.269862 (-2.473961) | 1.742034 / 4.565676 (-2.823642) | 0.064170 / 0.424275 (-0.360105) | 0.005572 / 0.007607 (-0.002035) | 0.349500 / 0.226044 (0.123456) | 3.482161 / 2.268929 (1.213232) | 1.950065 / 55.444624 (-53.494559) | 1.675270 / 6.876477 (-5.201207) | 1.674534 / 2.142072 (-0.467538) | 0.657478 / 4.805227 (-4.147749) | 0.117534 / 6.500664 (-6.383130) | 0.040880 / 0.075469 (-0.034589) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.035276 / 1.841788 (-0.806511) | 12.035581 / 8.074308 (3.961273) | 10.127778 / 10.191392 (-0.063614) | 0.142289 / 0.680424 (-0.538134) | 0.014702 / 0.534201 (-0.519499) | 0.288206 / 0.579283 (-0.291077) | 0.282251 / 0.434364 (-0.152113) | 0.323479 / 0.540337 (-0.216858) | 0.419019 / 1.386936 (-0.967917) |\n\n</details>\n</details>\n\n\n"
] | 2024-04-08T14:05:42Z
| 2024-04-09T11:34:08Z
| 2024-04-09T11:27:58Z
|
MEMBER
| null | null | null |
It was reloading from the wrong cache dir because of a bug in `_check_legacy_cache2`. This function should not trigger if there are config_kwars like `sample_by=`
fix https://github.com/huggingface/datasets/issues/6758
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6792/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6792/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6792.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6792",
"merged_at": "2024-04-09T11:27:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6792.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6792"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7470
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7470/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7470/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7470/events
|
https://github.com/huggingface/datasets/issues/7470
| 2,937,236,323
|
I_kwDODunzps6vEqtj
| 7,470
|
Is it possible to shard a single-sharded IterableDataset?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/511073?v=4",
"events_url": "https://api.github.com/users/jonathanasdf/events{/privacy}",
"followers_url": "https://api.github.com/users/jonathanasdf/followers",
"following_url": "https://api.github.com/users/jonathanasdf/following{/other_user}",
"gists_url": "https://api.github.com/users/jonathanasdf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jonathanasdf",
"id": 511073,
"login": "jonathanasdf",
"node_id": "MDQ6VXNlcjUxMTA3Mw==",
"organizations_url": "https://api.github.com/users/jonathanasdf/orgs",
"received_events_url": "https://api.github.com/users/jonathanasdf/received_events",
"repos_url": "https://api.github.com/users/jonathanasdf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jonathanasdf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonathanasdf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jonathanasdf",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi ! Maybe you can look for an option in your dataset to partition your data based on a deterministic filter ? For example each worker could stream the data based on `row.id % num_shards` or something like that ?",
"So the recommendation is to start out with multiple shards initially and re-sharding after is not expected to work? :(\n\nWould something like the following work? Some DiskCachingIterableDataset, where worker 0 streams from the datasource, but also writes to disk, and all of the other workers read from what worker 0 wrote? Then that would produce a stream with a deterministic order and we can subsample.",
"To be honest it would be cool to support native multiprocessing in `IterableDataset.map` so you can parallelize any specific processing step without having to rely on a torch Dataloader. What do you think ?\n\nrelated: https://github.com/huggingface/datasets/issues/7193 https://github.com/huggingface/datasets/issues/3444 \noriginal issue: https://github.com/huggingface/datasets/issues/2642\n\nAlternatively the DiskCachingIterableDataset idea works, just note that to make it work with a torch Dataloader with num_workers>0 you'll need:\n1. to make your own `torch.utils.data.IterableDataset` and have rank=0 stream the data and share them with the other workers (either via disk as suggested or IPC)\n2. take into account that`datasets.IterableDataset` will yield 0 examples for ranks with id>0 if there is only one shard, but in your case it's ok since you'd only stream from rank=0",
"Ohh that would be pretty cool!\n\nThanks for the suggestions, as there's no actionable items for this repo I'm going to close this issue now."
] | 2025-03-21T04:33:37Z
| 2025-03-26T09:34:46Z
| 2025-03-26T06:49:28Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
I thought https://github.com/huggingface/datasets/pull/7252 might be applicable but looking at it maybe not.
Say we have a process, eg. a database query, that can return data in slightly different order each time. So, the initial query needs to be run by a single thread (not to mention running multiple times incurs more cost too). But the results are also big enough that we don't want to materialize it entirely and instead stream it with an IterableDataset.
But after we have the results we want to split it up across workers to parallelize processing.
Is something like this possible to do?
Here's a failed attempt. The end result should be that each of the shards has unique data, but unfortunately with this attempt the generator gets run once in each shard and the results end up with duplicates...
```
import random
import datasets
def gen():
print('RUNNING GENERATOR!')
items = list(range(10))
random.shuffle(items)
yield from items
ds = datasets.IterableDataset.from_generator(gen)
print('dataset contents:')
for item in ds:
print(item)
print()
print('dataset contents (2):')
for item in ds:
print(item)
print()
num_shards = 3
def sharded(shard_id):
for i, example in enumerate(ds):
if i % num_shards in shard_id:
yield example
ds1 = datasets.IterableDataset.from_generator(
sharded, gen_kwargs={'shard_id': list(range(num_shards))}
)
for shard in range(num_shards):
print('shard', shard)
for item in ds1.shard(num_shards, shard):
print(item)
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/511073?v=4",
"events_url": "https://api.github.com/users/jonathanasdf/events{/privacy}",
"followers_url": "https://api.github.com/users/jonathanasdf/followers",
"following_url": "https://api.github.com/users/jonathanasdf/following{/other_user}",
"gists_url": "https://api.github.com/users/jonathanasdf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jonathanasdf",
"id": 511073,
"login": "jonathanasdf",
"node_id": "MDQ6VXNlcjUxMTA3Mw==",
"organizations_url": "https://api.github.com/users/jonathanasdf/orgs",
"received_events_url": "https://api.github.com/users/jonathanasdf/received_events",
"repos_url": "https://api.github.com/users/jonathanasdf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jonathanasdf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonathanasdf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jonathanasdf",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7470/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7470/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6533
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6533/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6533/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6533/events
|
https://github.com/huggingface/datasets/issues/6533
| 2,055,929,101
|
I_kwDODunzps56iv0N
| 6,533
|
ted_talks_iwslt | Error: Config name is missing
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/35850903?v=4",
"events_url": "https://api.github.com/users/rayliuca/events{/privacy}",
"followers_url": "https://api.github.com/users/rayliuca/followers",
"following_url": "https://api.github.com/users/rayliuca/following{/other_user}",
"gists_url": "https://api.github.com/users/rayliuca/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rayliuca",
"id": 35850903,
"login": "rayliuca",
"node_id": "MDQ6VXNlcjM1ODUwOTAz",
"organizations_url": "https://api.github.com/users/rayliuca/orgs",
"received_events_url": "https://api.github.com/users/rayliuca/received_events",
"repos_url": "https://api.github.com/users/rayliuca/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rayliuca/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rayliuca/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rayliuca",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
] | null |
[
"Hi ! Thanks for reporting. I opened https://github.com/huggingface/datasets/pull/6544 to fix this",
"We just released 2.16.1 with a fix:\r\n\r\n```\r\npip install -U datasets\r\n```"
] | 2023-12-26T00:38:18Z
| 2023-12-30T18:58:21Z
| 2023-12-30T16:09:50Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Running load_dataset using the newest `datasets` library like below on the ted_talks_iwslt using year pair data will throw an error "Config name is missing"
see also:
https://huggingface.co/datasets/ted_talks_iwslt/discussions/3
likely caused by #6493, where the `and not config_kwargs` part in the if logic was removed
https://github.com/huggingface/datasets/blob/ef3b5dd3633995c95d77f35fb17f89ff44990bc4/src/datasets/builder.py#L512
### Steps to reproduce the bug
run:
```python
load_dataset("ted_talks_iwslt", language_pair=("ja", "en"), year="2015")
```
### Expected behavior
Load the data without error
### Environment info
datasets 2.16.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6533/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6533/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/4941
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4941/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4941/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4941/events
|
https://github.com/huggingface/datasets/pull/4941
| 1,363,622,861
|
PR_kwDODunzps4-dQ9F
| 4,941
|
Add Papers with Code ID to scifact dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-06T17:46:37Z
| 2022-09-06T18:28:17Z
| 2022-09-06T18:26:01Z
|
MEMBER
| null | null | null |
This PR:
- adds Papers with Code ID
- forces sync between GitHub and Hub, which previously failed due to Hub validation error of the license tag: https://github.com/huggingface/datasets/runs/8200223631?check_suite_focus=true
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4941/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4941/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4941.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4941",
"merged_at": "2022-09-06T18:26:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4941.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4941"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7502
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7502/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7502/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7502/events
|
https://github.com/huggingface/datasets/issues/7502
| 2,977,453,814
|
I_kwDODunzps6xeFb2
| 7,502
|
`load_dataset` of size 40GB creates a cache of >720GB
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_url": "https://api.github.com/users/pietrolesci/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/pietrolesci",
"id": 61748653,
"login": "pietrolesci",
"node_id": "MDQ6VXNlcjYxNzQ4NjUz",
"organizations_url": "https://api.github.com/users/pietrolesci/orgs",
"received_events_url": "https://api.github.com/users/pietrolesci/received_events",
"repos_url": "https://api.github.com/users/pietrolesci/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/pietrolesci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pietrolesci/subscriptions",
"type": "User",
"url": "https://api.github.com/users/pietrolesci",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi ! Parquet is a compressed format. When you load a dataset, it uncompresses the Parquet data into Arrow data on your disk. That's why you can indeed end up with 720GB of uncompressed data on disk. The uncompression is needed to enable performant dataset objects (especially for random access).\n\nTo save some storage you can instead load the dataset with `streaming=True`. This way you get an `IterableDataset` that reads the Parquet data iteratively without ever writing to disk.\n\nPS: `ReadInstruction` might not be implemented for `streaming=True`, if it's the case you can use `ds.take()` and `ds.skip()` instead",
"Hi @lhoestq, thanks a lot for your answer. This makes perfect sense. I will try using the streaming mode. Closing the issue."
] | 2025-04-07T16:52:34Z
| 2025-04-15T15:22:12Z
| 2025-04-15T15:22:11Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
Hi there,
I am trying to load a dataset from the Hugging Face Hub and split it into train and validation splits. Somehow, when I try to do it with `load_dataset`, it exhausts my disk quota. So, I tried manually downloading the parquet files from the hub and loading them as follows:
```python
ds = DatasetDict(
{
"train": load_dataset(
"parquet",
data_dir=f"{local_dir}/{tok}",
cache_dir=cache_dir,
num_proc=min(12, os.cpu_count()), # type: ignore
split=ReadInstruction("train", from_=0, to=NUM_TRAIN, unit="abs"), # type: ignore
),
"validation": load_dataset(
"parquet",
data_dir=f"{local_dir}/{tok}",
cache_dir=cache_dir,
num_proc=min(12, os.cpu_count()), # type: ignore
split=ReadInstruction("train", from_=NUM_TRAIN, unit="abs"), # type: ignore
)
}
)
```
which still strangely creates 720GB of cache. In addition, if I remove the raw parquet file folder (`f"{local_dir}/{tok}"` in this example), I am not able to load anything. So, I am left wondering what this cache is doing. Am I missing something? Is there a solution to this problem?
Thanks a lot in advance for your help!
A related issue: https://github.com/huggingface/transformers/issues/10204#issue-809007443.
---
Python: 3.11.11
datasets: 3.5.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_url": "https://api.github.com/users/pietrolesci/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/pietrolesci",
"id": 61748653,
"login": "pietrolesci",
"node_id": "MDQ6VXNlcjYxNzQ4NjUz",
"organizations_url": "https://api.github.com/users/pietrolesci/orgs",
"received_events_url": "https://api.github.com/users/pietrolesci/received_events",
"repos_url": "https://api.github.com/users/pietrolesci/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/pietrolesci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pietrolesci/subscriptions",
"type": "User",
"url": "https://api.github.com/users/pietrolesci",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7502/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7502/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6233
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6233/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6233/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6233/events
|
https://github.com/huggingface/datasets/pull/6233
| 1,891,804,286
|
PR_kwDODunzps5aF3kd
| 6,233
|
Update README.md
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/95188570?v=4",
"events_url": "https://api.github.com/users/NinoRisteski/events{/privacy}",
"followers_url": "https://api.github.com/users/NinoRisteski/followers",
"following_url": "https://api.github.com/users/NinoRisteski/following{/other_user}",
"gists_url": "https://api.github.com/users/NinoRisteski/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/NinoRisteski",
"id": 95188570,
"login": "NinoRisteski",
"node_id": "U_kgDOBax2Wg",
"organizations_url": "https://api.github.com/users/NinoRisteski/orgs",
"received_events_url": "https://api.github.com/users/NinoRisteski/received_events",
"repos_url": "https://api.github.com/users/NinoRisteski/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/NinoRisteski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NinoRisteski/subscriptions",
"type": "User",
"url": "https://api.github.com/users/NinoRisteski",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008370 / 0.011353 (-0.002983) | 0.004674 / 0.011008 (-0.006334) | 0.103912 / 0.038508 (0.065404) | 0.101668 / 0.023109 (0.078559) | 0.417945 / 0.275898 (0.142047) | 0.454805 / 0.323480 (0.131325) | 0.004763 / 0.007986 (-0.003223) | 0.003934 / 0.004328 (-0.000394) | 0.078446 / 0.004250 (0.074196) | 0.068383 / 0.037052 (0.031331) | 0.415100 / 0.258489 (0.156611) | 0.475272 / 0.293841 (0.181431) | 0.036884 / 0.128546 (-0.091662) | 0.010097 / 0.075646 (-0.065549) | 0.354962 / 0.419271 (-0.064309) | 0.062688 / 0.043533 (0.019155) | 0.420643 / 0.255139 (0.165504) | 0.446504 / 0.283200 (0.163304) | 0.029075 / 0.141683 (-0.112608) | 1.791517 / 1.452155 (0.339363) | 1.859820 / 1.492716 (0.367104) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.246929 / 0.018006 (0.228923) | 0.519593 / 0.000490 (0.519103) | 0.006848 / 0.000200 (0.006648) | 0.000168 / 0.000054 (0.000114) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035179 / 0.037411 (-0.002232) | 0.115582 / 0.014526 (0.101057) | 0.128235 / 0.176557 (-0.048321) | 0.187123 / 0.737135 (-0.550012) | 0.120862 / 0.296338 (-0.175477) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.463406 / 0.215209 (0.248197) | 4.615517 / 2.077655 (2.537863) | 2.250513 / 1.504120 (0.746393) | 2.061226 / 1.541195 (0.520032) | 2.189938 / 1.468490 (0.721448) | 0.582984 / 4.584777 (-4.001793) | 4.299464 / 3.745712 (0.553751) | 4.037274 / 5.269862 (-1.232588) | 2.608967 / 4.565676 (-1.956710) | 0.068944 / 0.424275 (-0.355331) | 0.009501 / 0.007607 (0.001894) | 0.567436 / 0.226044 (0.341392) | 5.662738 / 2.268929 (3.393809) | 2.849094 / 55.444624 (-52.595530) | 2.461013 / 6.876477 (-4.415464) | 2.663245 / 2.142072 (0.521172) | 0.704528 / 4.805227 (-4.100699) | 0.163583 / 6.500664 (-6.337081) | 0.075719 / 0.075469 (0.000250) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.604743 / 1.841788 (-0.237044) | 24.512054 / 8.074308 (16.437746) | 17.870939 / 10.191392 (7.679547) | 0.199188 / 0.680424 (-0.481236) | 0.023820 / 0.534201 (-0.510381) | 0.487520 / 0.579283 (-0.091763) | 0.512543 / 0.434364 (0.078179) | 0.575138 / 0.540337 (0.034801) | 0.759863 / 1.386936 (-0.627073) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010516 / 0.011353 (-0.000837) | 0.004779 / 0.011008 (-0.006229) | 0.078482 / 0.038508 (0.039974) | 0.108533 / 0.023109 (0.085424) | 0.498692 / 0.275898 (0.222794) | 0.534698 / 0.323480 (0.211218) | 0.007624 / 0.007986 (-0.000362) | 0.003938 / 0.004328 (-0.000391) | 0.077317 / 0.004250 (0.073067) | 0.078056 / 0.037052 (0.041004) | 0.493648 / 0.258489 (0.235159) | 0.540891 / 0.293841 (0.247050) | 0.040377 / 0.128546 (-0.088169) | 0.010155 / 0.075646 (-0.065491) | 0.084384 / 0.419271 (-0.334888) | 0.061419 / 0.043533 (0.017886) | 0.494474 / 0.255139 (0.239335) | 0.524656 / 0.283200 (0.241456) | 0.029052 / 0.141683 (-0.112631) | 1.794584 / 1.452155 (0.342429) | 1.939987 / 1.492716 (0.447270) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.377404 / 0.018006 (0.359398) | 0.516562 / 0.000490 (0.516072) | 0.109555 / 0.000200 (0.109356) | 0.001126 / 0.000054 (0.001071) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.039793 / 0.037411 (0.002382) | 0.123001 / 0.014526 (0.108475) | 0.127536 / 0.176557 (-0.049021) | 0.191681 / 0.737135 (-0.545455) | 0.128590 / 0.296338 (-0.167748) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.513689 / 0.215209 (0.298480) | 5.135114 / 2.077655 (3.057459) | 2.797885 / 1.504120 (1.293765) | 2.715332 / 1.541195 (1.174137) | 2.746437 / 1.468490 (1.277947) | 0.596480 / 4.584777 (-3.988297) | 4.382013 / 3.745712 (0.636301) | 3.965956 / 5.269862 (-1.303906) | 2.545206 / 4.565676 (-2.020471) | 0.069620 / 0.424275 (-0.354655) | 0.009321 / 0.007607 (0.001714) | 0.612424 / 0.226044 (0.386379) | 6.107037 / 2.268929 (3.838109) | 3.447246 / 55.444624 (-51.997379) | 3.073262 / 6.876477 (-3.803215) | 3.280185 / 2.142072 (1.138113) | 0.704776 / 4.805227 (-4.100451) | 0.160488 / 6.500664 (-6.340176) | 0.075730 / 0.075469 (0.000261) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.697035 / 1.841788 (-0.144753) | 24.766118 / 8.074308 (16.691809) | 18.476699 / 10.191392 (8.285307) | 0.176594 / 0.680424 (-0.503830) | 0.024249 / 0.534201 (-0.509952) | 0.478743 / 0.579283 (-0.100541) | 0.518774 / 0.434364 (0.084410) | 0.581498 / 0.540337 (0.041161) | 0.797784 / 1.386936 (-0.589152) |\n\n</details>\n</details>\n\n\n"
] | 2023-09-12T06:53:06Z
| 2023-09-13T18:20:50Z
| 2023-09-13T18:10:04Z
|
CONTRIBUTOR
| null | null | null |
fixed a typo
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6233/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6233/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6233.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6233",
"merged_at": "2023-09-13T18:10:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6233.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6233"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6164
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6164/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6164/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6164/events
|
https://github.com/huggingface/datasets/pull/6164
| 1,859,560,007
|
PR_kwDODunzps5YZZAJ
| 6,164
|
Fix: Missing a MetadataConfigs init when the repo has a `datasets_info.json` but no README
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/22726840?v=4",
"events_url": "https://api.github.com/users/clefourrier/events{/privacy}",
"followers_url": "https://api.github.com/users/clefourrier/followers",
"following_url": "https://api.github.com/users/clefourrier/following{/other_user}",
"gists_url": "https://api.github.com/users/clefourrier/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/clefourrier",
"id": 22726840,
"login": "clefourrier",
"node_id": "MDQ6VXNlcjIyNzI2ODQw",
"organizations_url": "https://api.github.com/users/clefourrier/orgs",
"received_events_url": "https://api.github.com/users/clefourrier/received_events",
"repos_url": "https://api.github.com/users/clefourrier/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/clefourrier/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/clefourrier/subscriptions",
"type": "User",
"url": "https://api.github.com/users/clefourrier",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006874 / 0.011353 (-0.004479) | 0.004276 / 0.011008 (-0.006732) | 0.085198 / 0.038508 (0.046690) | 0.084281 / 0.023109 (0.061171) | 0.344767 / 0.275898 (0.068869) | 0.377798 / 0.323480 (0.054318) | 0.005656 / 0.007986 (-0.002330) | 0.003601 / 0.004328 (-0.000727) | 0.065486 / 0.004250 (0.061235) | 0.056191 / 0.037052 (0.019139) | 0.351412 / 0.258489 (0.092923) | 0.398591 / 0.293841 (0.104750) | 0.031662 / 0.128546 (-0.096884) | 0.008901 / 0.075646 (-0.066745) | 0.290423 / 0.419271 (-0.128849) | 0.053793 / 0.043533 (0.010260) | 0.347968 / 0.255139 (0.092829) | 0.376978 / 0.283200 (0.093778) | 0.026745 / 0.141683 (-0.114938) | 1.514119 / 1.452155 (0.061964) | 1.580920 / 1.492716 (0.088203) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.273648 / 0.018006 (0.255642) | 0.575176 / 0.000490 (0.574686) | 0.003557 / 0.000200 (0.003357) | 0.000093 / 0.000054 (0.000038) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031714 / 0.037411 (-0.005697) | 0.089166 / 0.014526 (0.074640) | 0.101525 / 0.176557 (-0.075032) | 0.161855 / 0.737135 (-0.575281) | 0.101391 / 0.296338 (-0.194947) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.380947 / 0.215209 (0.165738) | 3.800527 / 2.077655 (1.722873) | 1.820789 / 1.504120 (0.316669) | 1.657327 / 1.541195 (0.116132) | 1.776242 / 1.468490 (0.307752) | 0.486954 / 4.584777 (-4.097823) | 3.688340 / 3.745712 (-0.057372) | 3.354453 / 5.269862 (-1.915409) | 2.119995 / 4.565676 (-2.445682) | 0.057446 / 0.424275 (-0.366829) | 0.007752 / 0.007607 (0.000145) | 0.461907 / 0.226044 (0.235862) | 4.617870 / 2.268929 (2.348942) | 2.337025 / 55.444624 (-53.107599) | 1.964770 / 6.876477 (-4.911707) | 2.252066 / 2.142072 (0.109993) | 0.591585 / 4.805227 (-4.213642) | 0.134655 / 6.500664 (-6.366009) | 0.060646 / 0.075469 (-0.014823) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.263271 / 1.841788 (-0.578517) | 20.822286 / 8.074308 (12.747978) | 14.710256 / 10.191392 (4.518864) | 0.167285 / 0.680424 (-0.513139) | 0.018302 / 0.534201 (-0.515899) | 0.401023 / 0.579283 (-0.178260) | 0.428956 / 0.434364 (-0.005407) | 0.466120 / 0.540337 (-0.074218) | 0.637868 / 1.386936 (-0.749069) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007174 / 0.011353 (-0.004179) | 0.004418 / 0.011008 (-0.006590) | 0.065731 / 0.038508 (0.027223) | 0.090457 / 0.023109 (0.067348) | 0.387306 / 0.275898 (0.111408) | 0.427178 / 0.323480 (0.103698) | 0.005699 / 0.007986 (-0.002286) | 0.003662 / 0.004328 (-0.000666) | 0.066190 / 0.004250 (0.061940) | 0.062860 / 0.037052 (0.025808) | 0.388855 / 0.258489 (0.130366) | 0.427853 / 0.293841 (0.134012) | 0.032770 / 0.128546 (-0.095776) | 0.008780 / 0.075646 (-0.066866) | 0.071156 / 0.419271 (-0.348116) | 0.050174 / 0.043533 (0.006641) | 0.385254 / 0.255139 (0.130115) | 0.405069 / 0.283200 (0.121869) | 0.025561 / 0.141683 (-0.116122) | 1.506907 / 1.452155 (0.054752) | 1.543270 / 1.492716 (0.050554) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.304651 / 0.018006 (0.286645) | 0.577269 / 0.000490 (0.576780) | 0.004479 / 0.000200 (0.004279) | 0.000127 / 0.000054 (0.000073) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034070 / 0.037411 (-0.003341) | 0.097664 / 0.014526 (0.083138) | 0.106969 / 0.176557 (-0.069588) | 0.163093 / 0.737135 (-0.574043) | 0.109384 / 0.296338 (-0.186955) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.414823 / 0.215209 (0.199614) | 4.148390 / 2.077655 (2.070735) | 2.114038 / 1.504120 (0.609918) | 1.959316 / 1.541195 (0.418121) | 2.098138 / 1.468490 (0.629648) | 0.486338 / 4.584777 (-4.098439) | 3.642850 / 3.745712 (-0.102863) | 3.458311 / 5.269862 (-1.811551) | 2.185662 / 4.565676 (-2.380014) | 0.057555 / 0.424275 (-0.366720) | 0.007522 / 0.007607 (-0.000085) | 0.497975 / 0.226044 (0.271931) | 4.971528 / 2.268929 (2.702600) | 2.614087 / 55.444624 (-52.830537) | 2.288406 / 6.876477 (-4.588070) | 2.564067 / 2.142072 (0.421995) | 0.582248 / 4.805227 (-4.222979) | 0.134931 / 6.500664 (-6.365733) | 0.062689 / 0.075469 (-0.012780) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.343331 / 1.841788 (-0.498457) | 21.398950 / 8.074308 (13.324642) | 14.620971 / 10.191392 (4.429579) | 0.169779 / 0.680424 (-0.510644) | 0.018683 / 0.534201 (-0.515518) | 0.396152 / 0.579283 (-0.183131) | 0.409596 / 0.434364 (-0.024768) | 0.482875 / 0.540337 (-0.057463) | 0.659977 / 1.386936 (-0.726959) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006662 / 0.011353 (-0.004691) | 0.003959 / 0.011008 (-0.007049) | 0.084447 / 0.038508 (0.045939) | 0.070267 / 0.023109 (0.047158) | 0.310301 / 0.275898 (0.034403) | 0.339866 / 0.323480 (0.016386) | 0.004008 / 0.007986 (-0.003977) | 0.003270 / 0.004328 (-0.001058) | 0.064997 / 0.004250 (0.060746) | 0.053151 / 0.037052 (0.016099) | 0.327867 / 0.258489 (0.069378) | 0.368560 / 0.293841 (0.074719) | 0.031436 / 0.128546 (-0.097111) | 0.008547 / 0.075646 (-0.067099) | 0.288513 / 0.419271 (-0.130758) | 0.051833 / 0.043533 (0.008300) | 0.312660 / 0.255139 (0.057521) | 0.347180 / 0.283200 (0.063980) | 0.024982 / 0.141683 (-0.116701) | 1.472487 / 1.452155 (0.020333) | 1.550138 / 1.492716 (0.057422) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.208443 / 0.018006 (0.190437) | 0.451927 / 0.000490 (0.451437) | 0.004452 / 0.000200 (0.004252) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029164 / 0.037411 (-0.008247) | 0.085801 / 0.014526 (0.071275) | 0.096229 / 0.176557 (-0.080327) | 0.153063 / 0.737135 (-0.584072) | 0.097712 / 0.296338 (-0.198626) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.383969 / 0.215209 (0.168760) | 3.829216 / 2.077655 (1.751561) | 1.854466 / 1.504120 (0.350346) | 1.684149 / 1.541195 (0.142954) | 1.759422 / 1.468490 (0.290932) | 0.480229 / 4.584777 (-4.104548) | 3.653363 / 3.745712 (-0.092349) | 3.264456 / 5.269862 (-2.005406) | 2.020579 / 4.565676 (-2.545097) | 0.056920 / 0.424275 (-0.367355) | 0.007625 / 0.007607 (0.000018) | 0.458559 / 0.226044 (0.232515) | 4.580288 / 2.268929 (2.311359) | 2.353783 / 55.444624 (-53.090841) | 1.967223 / 6.876477 (-4.909253) | 2.182707 / 2.142072 (0.040634) | 0.631341 / 4.805227 (-4.173886) | 0.141656 / 6.500664 (-6.359008) | 0.059918 / 0.075469 (-0.015551) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.279635 / 1.841788 (-0.562153) | 19.725763 / 8.074308 (11.651455) | 14.477946 / 10.191392 (4.286554) | 0.164360 / 0.680424 (-0.516064) | 0.018286 / 0.534201 (-0.515915) | 0.394935 / 0.579283 (-0.184348) | 0.419638 / 0.434364 (-0.014726) | 0.460366 / 0.540337 (-0.079972) | 0.636876 / 1.386936 (-0.750060) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006568 / 0.011353 (-0.004785) | 0.004270 / 0.011008 (-0.006738) | 0.065522 / 0.038508 (0.027014) | 0.071597 / 0.023109 (0.048487) | 0.394929 / 0.275898 (0.119031) | 0.427548 / 0.323480 (0.104068) | 0.005320 / 0.007986 (-0.002665) | 0.003366 / 0.004328 (-0.000962) | 0.065780 / 0.004250 (0.061530) | 0.055390 / 0.037052 (0.018338) | 0.397950 / 0.258489 (0.139461) | 0.435800 / 0.293841 (0.141959) | 0.031816 / 0.128546 (-0.096730) | 0.008555 / 0.075646 (-0.067091) | 0.072110 / 0.419271 (-0.347161) | 0.049077 / 0.043533 (0.005544) | 0.390065 / 0.255139 (0.134926) | 0.410294 / 0.283200 (0.127094) | 0.023389 / 0.141683 (-0.118294) | 1.491491 / 1.452155 (0.039336) | 1.551057 / 1.492716 (0.058341) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.243869 / 0.018006 (0.225862) | 0.451961 / 0.000490 (0.451471) | 0.019834 / 0.000200 (0.019634) | 0.000114 / 0.000054 (0.000059) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031031 / 0.037411 (-0.006380) | 0.088189 / 0.014526 (0.073663) | 0.101743 / 0.176557 (-0.074814) | 0.155236 / 0.737135 (-0.581899) | 0.101245 / 0.296338 (-0.195094) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422178 / 0.215209 (0.206969) | 4.199989 / 2.077655 (2.122334) | 2.228816 / 1.504120 (0.724696) | 2.057172 / 1.541195 (0.515978) | 2.162651 / 1.468490 (0.694161) | 0.491186 / 4.584777 (-4.093591) | 3.666221 / 3.745712 (-0.079491) | 3.289531 / 5.269862 (-1.980331) | 2.050027 / 4.565676 (-2.515650) | 0.057464 / 0.424275 (-0.366811) | 0.007379 / 0.007607 (-0.000228) | 0.506532 / 0.226044 (0.280487) | 5.066385 / 2.268929 (2.797456) | 2.694405 / 55.444624 (-52.750219) | 2.372200 / 6.876477 (-4.504277) | 2.562724 / 2.142072 (0.420652) | 0.615474 / 4.805227 (-4.189753) | 0.148284 / 6.500664 (-6.352380) | 0.061380 / 0.075469 (-0.014089) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.332649 / 1.841788 (-0.509139) | 20.591063 / 8.074308 (12.516755) | 14.105253 / 10.191392 (3.913861) | 0.151886 / 0.680424 (-0.528537) | 0.018200 / 0.534201 (-0.516001) | 0.395278 / 0.579283 (-0.184005) | 0.407113 / 0.434364 (-0.027251) | 0.473168 / 0.540337 (-0.067170) | 0.660766 / 1.386936 (-0.726170) |\n\n</details>\n</details>\n\n\n"
] | 2023-08-21T14:57:54Z
| 2023-08-21T16:27:05Z
| 2023-08-21T16:18:26Z
|
MEMBER
| null | null | null |
When I try to push to an arrow repo (can provide the link on Slack), it uploads the files but fails to update the metadata, with
```
File "app.py", line 123, in add_new_eval
eval_results[level].push_to_hub(my_repo, token=TOKEN, split=SPLIT)
File "blabla_my_env_path/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 5501, in push_to_hub
if not metadata_configs:
UnboundLocalError: local variable 'metadata_configs' referenced before assignment
```
This fixes it.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6164/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6164/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6164.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6164",
"merged_at": "2023-08-21T16:18:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6164.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6164"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6526
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6526/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6526/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6526/events
|
https://github.com/huggingface/datasets/pull/6526
| 2,053,726,451
|
PR_kwDODunzps5ipB5v
| 6,526
|
Preserve order of configs and splits when using Parquet exports
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6526). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005101 / 0.011353 (-0.006252) | 0.003471 / 0.011008 (-0.007537) | 0.062293 / 0.038508 (0.023785) | 0.032650 / 0.023109 (0.009541) | 0.249241 / 0.275898 (-0.026657) | 0.277079 / 0.323480 (-0.046400) | 0.002971 / 0.007986 (-0.005015) | 0.002637 / 0.004328 (-0.001691) | 0.048415 / 0.004250 (0.044165) | 0.042832 / 0.037052 (0.005779) | 0.247840 / 0.258489 (-0.010649) | 0.283994 / 0.293841 (-0.009847) | 0.027764 / 0.128546 (-0.100782) | 0.010544 / 0.075646 (-0.065102) | 0.208810 / 0.419271 (-0.210462) | 0.035744 / 0.043533 (-0.007789) | 0.252811 / 0.255139 (-0.002328) | 0.276163 / 0.283200 (-0.007036) | 0.018581 / 0.141683 (-0.123102) | 1.130043 / 1.452155 (-0.322112) | 1.194298 / 1.492716 (-0.298418) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.004488 / 0.018006 (-0.013518) | 0.302072 / 0.000490 (0.301582) | 0.000211 / 0.000200 (0.000012) | 0.000044 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.017799 / 0.037411 (-0.019613) | 0.061146 / 0.014526 (0.046620) | 0.081796 / 0.176557 (-0.094761) | 0.120407 / 0.737135 (-0.616729) | 0.075211 / 0.296338 (-0.221127) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.295349 / 0.215209 (0.080140) | 2.953511 / 2.077655 (0.875857) | 1.495332 / 1.504120 (-0.008788) | 1.364144 / 1.541195 (-0.177051) | 1.429562 / 1.468490 (-0.038928) | 0.574325 / 4.584777 (-4.010452) | 2.384352 / 3.745712 (-1.361360) | 2.843625 / 5.269862 (-2.426236) | 1.806802 / 4.565676 (-2.758875) | 0.065076 / 0.424275 (-0.359199) | 0.004970 / 0.007607 (-0.002638) | 0.339935 / 0.226044 (0.113891) | 3.375103 / 2.268929 (1.106175) | 1.822921 / 55.444624 (-53.621703) | 1.546126 / 6.876477 (-5.330350) | 1.573630 / 2.142072 (-0.568442) | 0.655081 / 4.805227 (-4.150146) | 0.122446 / 6.500664 (-6.378218) | 0.042220 / 0.075469 (-0.033249) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.942127 / 1.841788 (-0.899661) | 11.470401 / 8.074308 (3.396093) | 10.025961 / 10.191392 (-0.165431) | 0.129087 / 0.680424 (-0.551337) | 0.014141 / 0.534201 (-0.520060) | 0.285470 / 0.579283 (-0.293813) | 0.266755 / 0.434364 (-0.167608) | 0.323391 / 0.540337 (-0.216947) | 0.427645 / 1.386936 (-0.959291) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005578 / 0.011353 (-0.005775) | 0.003734 / 0.011008 (-0.007274) | 0.049200 / 0.038508 (0.010692) | 0.030981 / 0.023109 (0.007872) | 0.281195 / 0.275898 (0.005297) | 0.309950 / 0.323480 (-0.013530) | 0.004046 / 0.007986 (-0.003939) | 0.002709 / 0.004328 (-0.001620) | 0.048505 / 0.004250 (0.044254) | 0.046245 / 0.037052 (0.009193) | 0.280130 / 0.258489 (0.021641) | 0.313739 / 0.293841 (0.019898) | 0.029828 / 0.128546 (-0.098718) | 0.011152 / 0.075646 (-0.064495) | 0.057753 / 0.419271 (-0.361518) | 0.055112 / 0.043533 (0.011580) | 0.281861 / 0.255139 (0.026722) | 0.304402 / 0.283200 (0.021203) | 0.019931 / 0.141683 (-0.121752) | 1.150585 / 1.452155 (-0.301570) | 1.217850 / 1.492716 (-0.274866) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091552 / 0.018006 (0.073546) | 0.301772 / 0.000490 (0.301282) | 0.000225 / 0.000200 (0.000025) | 0.000046 / 0.000054 (-0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023189 / 0.037411 (-0.014223) | 0.078741 / 0.014526 (0.064216) | 0.092320 / 0.176557 (-0.084236) | 0.129636 / 0.737135 (-0.607500) | 0.091673 / 0.296338 (-0.204665) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.298542 / 0.215209 (0.083333) | 2.899358 / 2.077655 (0.821703) | 1.673896 / 1.504120 (0.169776) | 1.489518 / 1.541195 (-0.051677) | 1.542853 / 1.468490 (0.074363) | 0.559843 / 4.584777 (-4.024934) | 2.422101 / 3.745712 (-1.323611) | 2.844592 / 5.269862 (-2.425270) | 1.794527 / 4.565676 (-2.771150) | 0.064615 / 0.424275 (-0.359660) | 0.005078 / 0.007607 (-0.002530) | 0.355112 / 0.226044 (0.129068) | 3.462129 / 2.268929 (1.193200) | 1.975393 / 55.444624 (-53.469231) | 1.706513 / 6.876477 (-5.169963) | 1.716954 / 2.142072 (-0.425118) | 0.642094 / 4.805227 (-4.163133) | 0.119215 / 6.500664 (-6.381449) | 0.041941 / 0.075469 (-0.033528) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.986774 / 1.841788 (-0.855014) | 12.702049 / 8.074308 (4.627741) | 11.727663 / 10.191392 (1.536271) | 0.135008 / 0.680424 (-0.545416) | 0.016055 / 0.534201 (-0.518146) | 0.293564 / 0.579283 (-0.285719) | 0.284884 / 0.434364 (-0.149480) | 0.332524 / 0.540337 (-0.207814) | 0.425392 / 1.386936 (-0.961544) |\n\n</details>\n</details>\n\n\n"
] | 2023-12-22T10:35:56Z
| 2023-12-22T11:42:22Z
| 2023-12-22T11:36:14Z
|
MEMBER
| null | null | null |
Preserve order of configs and splits, as defined in dataset infos.
Fix #6521.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6526/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6526/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6526.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6526",
"merged_at": "2023-12-22T11:36:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6526.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6526"
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.