
url
string | repository_url
string | labels_url
string | comments_url
string | events_url
string | html_url
string | id
int64 | node_id
string | number
int64 | title
string | user
dict | labels
list | state
string | locked
bool | assignee
dict | assignees
list | milestone
dict | comments
list | created_at
timestamp[ns, tz=UTC] | updated_at
timestamp[ns, tz=UTC] | closed_at
timestamp[ns, tz=UTC] | author_association
string | type
float64 | active_lock_reason
float64 | sub_issues_summary
dict | body
string | closed_by
dict | reactions
dict | timeline_url
string | performed_via_github_app
float64 | state_reason
string | draft
float64 | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5429
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5429/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5429/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5429/events
|
https://github.com/huggingface/datasets/pull/5429
| 1,535,192,687
|
PR_kwDODunzps5HeuyT
| 5,429
|
Fix CI by temporarily pinning apache-beam < 2.44.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2023-01-16T16:20:09Z
| 2023-01-16T16:51:42Z
| 2023-01-16T16:49:03Z
|
MEMBER
| null | null | null |
Temporarily pin apache-beam < 2.44.0
Fix #5426.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5429/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5429/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5429.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5429",
"merged_at": "2023-01-16T16:49:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5429.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5429"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6288
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6288/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6288/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6288/events
|
https://github.com/huggingface/datasets/issues/6288
| 1,935,005,457
|
I_kwDODunzps5zVdcR
| 6,288
|
Dataset.from_pandas with a DataFrame of PIL.Images
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
| null |
[] | null |
[
"A duplicate of https://github.com/huggingface/datasets/issues/4796.\r\n\r\nWe could get this for free by implementing the `Image` feature as an extension type, as shown in [this](https://colab.research.google.com/drive/1Uzm_tXVpGTwbzleDConWcNjacwO1yxE4?usp=sharing) Colab (example with UUIDs).\r\n",
"+1 to this\r\nCalling this line with a df that contains a PIL image (as they are returned from load_dataset)\r\n`ds = Dataset.from_pandas(df)`\r\nResults in this error:\r\n`ArrowInvalid: ('Could not convert <PIL.PngImagePlugin.PngImageFile image mode=RGB size=1024x1024 at 0x2B41F2D70> with type PngImageFile: did not recognize Python value type when inferring an Arrow data type', 'Conversion failed for column image with type object')`",
"I found something that can be used as solution.\r\n\r\nI have the same problem when I've try to load the images from a pamdas dataset\r\n\r\nIf you have all on a pandas dataset try \r\nDataset.from_dict( your_df.reset_index(drop=True).to_dict(orient='list'), split=set_your_split)\r\n\r\nAnd this avoid the error"
] | 2023-10-10T10:29:16Z
| 2024-11-29T16:35:30Z
| null |
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
Currently type inference doesn't know what to do with a Pandas Series of PIL.Image objects, though it would be nice to get a Dataset with the Image type this way
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6288/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6288/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6200
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6200/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6200/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6200/events
|
https://github.com/huggingface/datasets/pull/6200
| 1,875,169,551
|
PR_kwDODunzps5ZOCee
| 6,200
|
Temporarily pin pandas < 2.1.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008978 / 0.011353 (-0.002375) | 0.005143 / 0.011008 (-0.005865) | 0.104787 / 0.038508 (0.066279) | 0.077069 / 0.023109 (0.053960) | 0.427703 / 0.275898 (0.151805) | 0.469865 / 0.323480 (0.146386) | 0.004618 / 0.007986 (-0.003368) | 0.004074 / 0.004328 (-0.000255) | 0.088656 / 0.004250 (0.084405) | 0.059798 / 0.037052 (0.022746) | 0.465906 / 0.258489 (0.207417) | 0.510281 / 0.293841 (0.216440) | 0.051192 / 0.128546 (-0.077354) | 0.013623 / 0.075646 (-0.062024) | 0.379339 / 0.419271 (-0.039932) | 0.077393 / 0.043533 (0.033860) | 0.445165 / 0.255139 (0.190026) | 0.473577 / 0.283200 (0.190378) | 0.038125 / 0.141683 (-0.103558) | 1.858635 / 1.452155 (0.406480) | 1.869033 / 1.492716 (0.376316) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.209011 / 0.018006 (0.191004) | 0.550978 / 0.000490 (0.550488) | 0.004904 / 0.000200 (0.004704) | 0.000106 / 0.000054 (0.000051) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031418 / 0.037411 (-0.005993) | 0.089623 / 0.014526 (0.075098) | 0.103491 / 0.176557 (-0.073066) | 0.178158 / 0.737135 (-0.558978) | 0.108515 / 0.296338 (-0.187824) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.648293 / 0.215209 (0.433084) | 6.332361 / 2.077655 (4.254707) | 2.469076 / 1.504120 (0.964956) | 2.286228 / 1.541195 (0.745033) | 2.257408 / 1.468490 (0.788918) | 0.918027 / 4.584777 (-3.666750) | 5.229539 / 3.745712 (1.483827) | 4.676150 / 5.269862 (-0.593712) | 3.220411 / 4.565676 (-1.345266) | 0.095863 / 0.424275 (-0.328413) | 0.008696 / 0.007607 (0.001089) | 0.722356 / 0.226044 (0.496312) | 7.796690 / 2.268929 (5.527762) | 3.715044 / 55.444624 (-51.729581) | 2.852696 / 6.876477 (-4.023780) | 2.891838 / 2.142072 (0.749766) | 1.195536 / 4.805227 (-3.609691) | 0.246908 / 6.500664 (-6.253756) | 0.079454 / 0.075469 (0.003984) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.652740 / 1.841788 (-0.189047) | 23.791791 / 8.074308 (15.717482) | 22.778999 / 10.191392 (12.587607) | 0.253878 / 0.680424 (-0.426546) | 0.031367 / 0.534201 (-0.502834) | 0.509460 / 0.579283 (-0.069823) | 0.603085 / 0.434364 (0.168721) | 0.603890 / 0.540337 (0.063553) | 0.826606 / 1.386936 (-0.560330) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010407 / 0.011353 (-0.000946) | 0.004751 / 0.011008 (-0.006257) | 0.086761 / 0.038508 (0.048253) | 0.087281 / 0.023109 (0.064172) | 0.498409 / 0.275898 (0.222511) | 0.560727 / 0.323480 (0.237247) | 0.006563 / 0.007986 (-0.001423) | 0.004078 / 0.004328 (-0.000251) | 0.086383 / 0.004250 (0.082133) | 0.065915 / 0.037052 (0.028862) | 0.521871 / 0.258489 (0.263382) | 0.582281 / 0.293841 (0.288440) | 0.057189 / 0.128546 (-0.071357) | 0.015514 / 0.075646 (-0.060133) | 0.102574 / 0.419271 (-0.316697) | 0.069155 / 0.043533 (0.025622) | 0.525000 / 0.255139 (0.269861) | 0.557968 / 0.283200 (0.274769) | 0.036934 / 0.141683 (-0.104749) | 1.919335 / 1.452155 (0.467181) | 1.870948 / 1.492716 (0.378231) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.241932 / 0.018006 (0.223926) | 0.560136 / 0.000490 (0.559646) | 0.006438 / 0.000200 (0.006238) | 0.000108 / 0.000054 (0.000053) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.036192 / 0.037411 (-0.001220) | 0.106829 / 0.014526 (0.092303) | 0.128667 / 0.176557 (-0.047890) | 0.200514 / 0.737135 (-0.536621) | 0.127542 / 0.296338 (-0.168797) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.754556 / 0.215209 (0.539347) | 7.237324 / 2.077655 (5.159670) | 3.267424 / 1.504120 (1.763304) | 2.789601 / 1.541195 (1.248407) | 2.875728 / 1.468490 (1.407238) | 0.894274 / 4.584777 (-3.690503) | 5.394556 / 3.745712 (1.648844) | 4.818523 / 5.269862 (-0.451338) | 2.965827 / 4.565676 (-1.599850) | 0.101967 / 0.424275 (-0.322308) | 0.008506 / 0.007607 (0.000899) | 0.803476 / 0.226044 (0.577432) | 8.614426 / 2.268929 (6.345497) | 4.169113 / 55.444624 (-51.275511) | 3.346346 / 6.876477 (-3.530130) | 3.418206 / 2.142072 (1.276134) | 1.111718 / 4.805227 (-3.693509) | 0.211302 / 6.500664 (-6.289362) | 0.072524 / 0.075469 (-0.002945) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.792705 / 1.841788 (-0.049083) | 24.442484 / 8.074308 (16.368176) | 23.375008 / 10.191392 (13.183616) | 0.227946 / 0.680424 (-0.452478) | 0.034376 / 0.534201 (-0.499825) | 0.489260 / 0.579283 (-0.090023) | 0.563220 / 0.434364 (0.128856) | 0.617405 / 0.540337 (0.077068) | 0.850577 / 1.386936 (-0.536359) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006594 / 0.011353 (-0.004759) | 0.004366 / 0.011008 (-0.006642) | 0.084241 / 0.038508 (0.045733) | 0.071876 / 0.023109 (0.048767) | 0.321604 / 0.275898 (0.045706) | 0.343501 / 0.323480 (0.020021) | 0.004069 / 0.007986 (-0.003917) | 0.003311 / 0.004328 (-0.001017) | 0.065079 / 0.004250 (0.060829) | 0.053754 / 0.037052 (0.016702) | 0.326199 / 0.258489 (0.067710) | 0.356552 / 0.293841 (0.062711) | 0.031568 / 0.128546 (-0.096979) | 0.008581 / 0.075646 (-0.067065) | 0.289170 / 0.419271 (-0.130101) | 0.053097 / 0.043533 (0.009564) | 0.309678 / 0.255139 (0.054539) | 0.345717 / 0.283200 (0.062517) | 0.024144 / 0.141683 (-0.117539) | 1.497351 / 1.452155 (0.045196) | 1.584691 / 1.492716 (0.091975) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.206357 / 0.018006 (0.188351) | 0.459611 / 0.000490 (0.459121) | 0.002586 / 0.000200 (0.002386) | 0.000079 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027459 / 0.037411 (-0.009952) | 0.082197 / 0.014526 (0.067671) | 0.095004 / 0.176557 (-0.081553) | 0.151063 / 0.737135 (-0.586072) | 0.095107 / 0.296338 (-0.201231) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.384363 / 0.215209 (0.169154) | 3.836187 / 2.077655 (1.758533) | 1.898312 / 1.504120 (0.394192) | 1.727310 / 1.541195 (0.186115) | 1.803579 / 1.468490 (0.335089) | 0.485946 / 4.584777 (-4.098831) | 3.619134 / 3.745712 (-0.126578) | 3.255274 / 5.269862 (-2.014588) | 2.004603 / 4.565676 (-2.561074) | 0.057107 / 0.424275 (-0.367168) | 0.007601 / 0.007607 (-0.000006) | 0.456545 / 0.226044 (0.230500) | 4.556857 / 2.268929 (2.287929) | 2.379954 / 55.444624 (-53.064671) | 2.045874 / 6.876477 (-4.830603) | 2.203090 / 2.142072 (0.061018) | 0.585400 / 4.805227 (-4.219827) | 0.133018 / 6.500664 (-6.367646) | 0.059457 / 0.075469 (-0.016012) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.292581 / 1.841788 (-0.549207) | 19.360057 / 8.074308 (11.285749) | 14.105359 / 10.191392 (3.913967) | 0.166028 / 0.680424 (-0.514396) | 0.018243 / 0.534201 (-0.515958) | 0.392026 / 0.579283 (-0.187257) | 0.412735 / 0.434364 (-0.021629) | 0.459791 / 0.540337 (-0.080547) | 0.624539 / 1.386936 (-0.762397) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006677 / 0.011353 (-0.004676) | 0.003897 / 0.011008 (-0.007111) | 0.064139 / 0.038508 (0.025631) | 0.071346 / 0.023109 (0.048237) | 0.431180 / 0.275898 (0.155282) | 0.470870 / 0.323480 (0.147390) | 0.005562 / 0.007986 (-0.002423) | 0.003405 / 0.004328 (-0.000924) | 0.064532 / 0.004250 (0.060282) | 0.055317 / 0.037052 (0.018265) | 0.434667 / 0.258489 (0.176178) | 0.475765 / 0.293841 (0.181924) | 0.032392 / 0.128546 (-0.096154) | 0.008418 / 0.075646 (-0.067228) | 0.071069 / 0.419271 (-0.348203) | 0.047963 / 0.043533 (0.004430) | 0.440225 / 0.255139 (0.185086) | 0.454860 / 0.283200 (0.171661) | 0.022653 / 0.141683 (-0.119029) | 1.489444 / 1.452155 (0.037289) | 1.556913 / 1.492716 (0.064196) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226733 / 0.018006 (0.208727) | 0.452005 / 0.000490 (0.451516) | 0.004715 / 0.000200 (0.004515) | 0.000099 / 0.000054 (0.000044) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032042 / 0.037411 (-0.005369) | 0.091226 / 0.014526 (0.076700) | 0.103639 / 0.176557 (-0.072917) | 0.157772 / 0.737135 (-0.579363) | 0.105466 / 0.296338 (-0.190872) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.439751 / 0.215209 (0.224542) | 4.357102 / 2.077655 (2.279448) | 2.362857 / 1.504120 (0.858737) | 2.180559 / 1.541195 (0.639364) | 2.279601 / 1.468490 (0.811111) | 0.495161 / 4.584777 (-4.089616) | 3.729199 / 3.745712 (-0.016513) | 3.334839 / 5.269862 (-1.935023) | 2.099315 / 4.565676 (-2.466362) | 0.058178 / 0.424275 (-0.366097) | 0.007303 / 0.007607 (-0.000304) | 0.506968 / 0.226044 (0.280924) | 5.078600 / 2.268929 (2.809671) | 2.846420 / 55.444624 (-52.598204) | 2.480644 / 6.876477 (-4.395833) | 2.693204 / 2.142072 (0.551132) | 0.590118 / 4.805227 (-4.215109) | 0.132900 / 6.500664 (-6.367764) | 0.060053 / 0.075469 (-0.015416) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.356713 / 1.841788 (-0.485075) | 20.380573 / 8.074308 (12.306265) | 15.066507 / 10.191392 (4.875115) | 0.180655 / 0.680424 (-0.499769) | 0.020954 / 0.534201 (-0.513247) | 0.399638 / 0.579283 (-0.179645) | 0.420694 / 0.434364 (-0.013670) | 0.476124 / 0.540337 (-0.064213) | 0.647192 / 1.386936 (-0.739744) |\n\n</details>\n</details>\n\n\n"
] | 2023-08-31T09:45:17Z
| 2023-08-31T10:33:24Z
| 2023-08-31T10:24:38Z
|
MEMBER
| null | null | null |
Temporarily pin `pandas` < 2.1.0 until permanent solution is found.
Hot fix #6197.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6200/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6200/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6200.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6200",
"merged_at": "2023-08-31T10:24:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6200.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6200"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5972
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5972/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5972/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5972/events
|
https://github.com/huggingface/datasets/pull/5972
| 1,767,897,485
|
PR_kwDODunzps5TkE7K
| 5,972
|
Filter unsupported extensions
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006983 / 0.011353 (-0.004369) | 0.004473 / 0.011008 (-0.006535) | 0.105158 / 0.038508 (0.066650) | 0.048973 / 0.023109 (0.025864) | 0.358771 / 0.275898 (0.082873) | 0.432389 / 0.323480 (0.108909) | 0.005689 / 0.007986 (-0.002297) | 0.003584 / 0.004328 (-0.000744) | 0.080852 / 0.004250 (0.076601) | 0.066133 / 0.037052 (0.029081) | 0.370981 / 0.258489 (0.112492) | 0.406942 / 0.293841 (0.113101) | 0.032123 / 0.128546 (-0.096424) | 0.009313 / 0.075646 (-0.066333) | 0.355220 / 0.419271 (-0.064051) | 0.055768 / 0.043533 (0.012235) | 0.370545 / 0.255139 (0.115406) | 0.375619 / 0.283200 (0.092419) | 0.024258 / 0.141683 (-0.117425) | 1.559073 / 1.452155 (0.106918) | 1.616520 / 1.492716 (0.123804) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.277893 / 0.018006 (0.259887) | 0.535447 / 0.000490 (0.534957) | 0.004877 / 0.000200 (0.004677) | 0.000092 / 0.000054 (0.000037) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029444 / 0.037411 (-0.007968) | 0.114366 / 0.014526 (0.099841) | 0.130957 / 0.176557 (-0.045599) | 0.189604 / 0.737135 (-0.547531) | 0.131682 / 0.296338 (-0.164656) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.412315 / 0.215209 (0.197106) | 4.093879 / 2.077655 (2.016225) | 1.856169 / 1.504120 (0.352050) | 1.655358 / 1.541195 (0.114164) | 1.758190 / 1.468490 (0.289699) | 0.545829 / 4.584777 (-4.038948) | 3.871436 / 3.745712 (0.125724) | 1.938244 / 5.269862 (-3.331618) | 1.122727 / 4.565676 (-3.442950) | 0.067107 / 0.424275 (-0.357168) | 0.012012 / 0.007607 (0.004405) | 0.518868 / 0.226044 (0.292824) | 5.235081 / 2.268929 (2.966153) | 2.335115 / 55.444624 (-53.109509) | 2.013074 / 6.876477 (-4.863402) | 2.219808 / 2.142072 (0.077735) | 0.674602 / 4.805227 (-4.130626) | 0.147051 / 6.500664 (-6.353613) | 0.068444 / 0.075469 (-0.007025) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.245600 / 1.841788 (-0.596188) | 15.537727 / 8.074308 (7.463419) | 15.074300 / 10.191392 (4.882908) | 0.194217 / 0.680424 (-0.486207) | 0.018536 / 0.534201 (-0.515665) | 0.437085 / 0.579283 (-0.142198) | 0.441123 / 0.434364 (0.006759) | 0.530681 / 0.540337 (-0.009657) | 0.649154 / 1.386936 (-0.737782) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007243 / 0.011353 (-0.004110) | 0.004688 / 0.011008 (-0.006320) | 0.079809 / 0.038508 (0.041301) | 0.046915 / 0.023109 (0.023805) | 0.415144 / 0.275898 (0.139246) | 0.474867 / 0.323480 (0.151388) | 0.004550 / 0.007986 (-0.003435) | 0.004585 / 0.004328 (0.000257) | 0.080837 / 0.004250 (0.076587) | 0.061667 / 0.037052 (0.024614) | 0.411321 / 0.258489 (0.152832) | 0.464195 / 0.293841 (0.170354) | 0.032510 / 0.128546 (-0.096037) | 0.009306 / 0.075646 (-0.066340) | 0.086637 / 0.419271 (-0.332635) | 0.053335 / 0.043533 (0.009802) | 0.402302 / 0.255139 (0.147163) | 0.424864 / 0.283200 (0.141664) | 0.026573 / 0.141683 (-0.115110) | 1.566793 / 1.452155 (0.114639) | 1.628118 / 1.492716 (0.135401) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.317802 / 0.018006 (0.299796) | 0.544593 / 0.000490 (0.544103) | 0.005690 / 0.000200 (0.005490) | 0.000107 / 0.000054 (0.000053) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033015 / 0.037411 (-0.004397) | 0.121940 / 0.014526 (0.107414) | 0.132920 / 0.176557 (-0.043637) | 0.191481 / 0.737135 (-0.545655) | 0.139139 / 0.296338 (-0.157199) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.460382 / 0.215209 (0.245173) | 4.610046 / 2.077655 (2.532392) | 2.296573 / 1.504120 (0.792453) | 2.099735 / 1.541195 (0.558540) | 2.213913 / 1.468490 (0.745423) | 0.544871 / 4.584777 (-4.039906) | 3.814174 / 3.745712 (0.068462) | 3.246397 / 5.269862 (-2.023464) | 1.480236 / 4.565676 (-3.085440) | 0.068464 / 0.424275 (-0.355811) | 0.012651 / 0.007607 (0.005043) | 0.564989 / 0.226044 (0.338944) | 5.639188 / 2.268929 (3.370259) | 2.827601 / 55.444624 (-52.617023) | 2.473743 / 6.876477 (-4.402734) | 2.567413 / 2.142072 (0.425340) | 0.674351 / 4.805227 (-4.130876) | 0.146248 / 6.500664 (-6.354416) | 0.067553 / 0.075469 (-0.007916) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.346703 / 1.841788 (-0.495085) | 16.494787 / 8.074308 (8.420479) | 15.179487 / 10.191392 (4.988095) | 0.181864 / 0.680424 (-0.498560) | 0.018857 / 0.534201 (-0.515344) | 0.437787 / 0.579283 (-0.141496) | 0.431770 / 0.434364 (-0.002594) | 0.507116 / 0.540337 (-0.033221) | 0.608899 / 1.386936 (-0.778037) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005963 / 0.011353 (-0.005390) | 0.003743 / 0.011008 (-0.007265) | 0.098519 / 0.038508 (0.060011) | 0.037392 / 0.023109 (0.014283) | 0.322706 / 0.275898 (0.046808) | 0.380032 / 0.323480 (0.056552) | 0.004694 / 0.007986 (-0.003292) | 0.002897 / 0.004328 (-0.001432) | 0.078664 / 0.004250 (0.074414) | 0.052646 / 0.037052 (0.015594) | 0.335523 / 0.258489 (0.077034) | 0.375464 / 0.293841 (0.081623) | 0.027537 / 0.128546 (-0.101010) | 0.008452 / 0.075646 (-0.067194) | 0.313844 / 0.419271 (-0.105427) | 0.047368 / 0.043533 (0.003835) | 0.313833 / 0.255139 (0.058694) | 0.342284 / 0.283200 (0.059085) | 0.021136 / 0.141683 (-0.120547) | 1.544764 / 1.452155 (0.092610) | 1.563850 / 1.492716 (0.071134) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.188609 / 0.018006 (0.170603) | 0.421686 / 0.000490 (0.421196) | 0.003336 / 0.000200 (0.003136) | 0.000077 / 0.000054 (0.000023) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023678 / 0.037411 (-0.013733) | 0.099191 / 0.014526 (0.084665) | 0.105819 / 0.176557 (-0.070738) | 0.169654 / 0.737135 (-0.567481) | 0.110240 / 0.296338 (-0.186099) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.425497 / 0.215209 (0.210288) | 4.237165 / 2.077655 (2.159510) | 1.902953 / 1.504120 (0.398833) | 1.699012 / 1.541195 (0.157818) | 1.751107 / 1.468490 (0.282617) | 0.563326 / 4.584777 (-4.021451) | 3.394189 / 3.745712 (-0.351523) | 2.706129 / 5.269862 (-2.563732) | 1.361522 / 4.565676 (-3.204155) | 0.067776 / 0.424275 (-0.356499) | 0.010959 / 0.007607 (0.003352) | 0.530905 / 0.226044 (0.304860) | 5.322467 / 2.268929 (3.053538) | 2.384356 / 55.444624 (-53.060269) | 2.044196 / 6.876477 (-4.832281) | 2.119837 / 2.142072 (-0.022235) | 0.682236 / 4.805227 (-4.122991) | 0.136921 / 6.500664 (-6.363743) | 0.066784 / 0.075469 (-0.008685) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.210642 / 1.841788 (-0.631146) | 13.804572 / 8.074308 (5.730264) | 13.309229 / 10.191392 (3.117837) | 0.154356 / 0.680424 (-0.526068) | 0.016833 / 0.534201 (-0.517368) | 0.366503 / 0.579283 (-0.212780) | 0.385201 / 0.434364 (-0.049163) | 0.426713 / 0.540337 (-0.113624) | 0.516795 / 1.386936 (-0.870141) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006144 / 0.011353 (-0.005209) | 0.003723 / 0.011008 (-0.007285) | 0.077427 / 0.038508 (0.038919) | 0.037636 / 0.023109 (0.014527) | 0.375048 / 0.275898 (0.099150) | 0.442254 / 0.323480 (0.118774) | 0.003506 / 0.007986 (-0.004480) | 0.003751 / 0.004328 (-0.000577) | 0.076771 / 0.004250 (0.072521) | 0.047915 / 0.037052 (0.010862) | 0.378918 / 0.258489 (0.120429) | 0.435300 / 0.293841 (0.141459) | 0.028317 / 0.128546 (-0.100230) | 0.008413 / 0.075646 (-0.067233) | 0.082774 / 0.419271 (-0.336497) | 0.043211 / 0.043533 (-0.000321) | 0.362022 / 0.255139 (0.106883) | 0.404928 / 0.283200 (0.121728) | 0.020692 / 0.141683 (-0.120991) | 1.527303 / 1.452155 (0.075148) | 1.596091 / 1.492716 (0.103375) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.225537 / 0.018006 (0.207530) | 0.399901 / 0.000490 (0.399412) | 0.000424 / 0.000200 (0.000224) | 0.000058 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026483 / 0.037411 (-0.010928) | 0.104373 / 0.014526 (0.089847) | 0.111271 / 0.176557 (-0.065286) | 0.163872 / 0.737135 (-0.573264) | 0.113991 / 0.296338 (-0.182347) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.456484 / 0.215209 (0.241275) | 4.572652 / 2.077655 (2.494998) | 2.374908 / 1.504120 (0.870788) | 2.207855 / 1.541195 (0.666661) | 2.260009 / 1.468490 (0.791519) | 0.562678 / 4.584777 (-4.022099) | 3.441778 / 3.745712 (-0.303934) | 1.729006 / 5.269862 (-3.540855) | 1.024937 / 4.565676 (-3.540739) | 0.068707 / 0.424275 (-0.355568) | 0.011334 / 0.007607 (0.003727) | 0.564293 / 0.226044 (0.338248) | 5.638367 / 2.268929 (3.369438) | 2.665654 / 55.444624 (-52.778970) | 2.320033 / 6.876477 (-4.556444) | 2.328706 / 2.142072 (0.186634) | 0.677433 / 4.805227 (-4.127794) | 0.137190 / 6.500664 (-6.363474) | 0.068585 / 0.075469 (-0.006885) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.312476 / 1.841788 (-0.529312) | 14.206685 / 8.074308 (6.132377) | 14.217928 / 10.191392 (4.026536) | 0.143416 / 0.680424 (-0.537007) | 0.016647 / 0.534201 (-0.517554) | 0.361228 / 0.579283 (-0.218055) | 0.396185 / 0.434364 (-0.038178) | 0.423275 / 0.540337 (-0.117063) | 0.512966 / 1.386936 (-0.873970) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008913 / 0.011353 (-0.002440) | 0.005142 / 0.011008 (-0.005866) | 0.133958 / 0.038508 (0.095449) | 0.049180 / 0.023109 (0.026071) | 0.389169 / 0.275898 (0.113270) | 0.481513 / 0.323480 (0.158033) | 0.006555 / 0.007986 (-0.001430) | 0.003806 / 0.004328 (-0.000522) | 0.102056 / 0.004250 (0.097806) | 0.083259 / 0.037052 (0.046207) | 0.392536 / 0.258489 (0.134047) | 0.447503 / 0.293841 (0.153662) | 0.047472 / 0.128546 (-0.081074) | 0.014748 / 0.075646 (-0.060899) | 0.475619 / 0.419271 (0.056348) | 0.107306 / 0.043533 (0.063773) | 0.421942 / 0.255139 (0.166803) | 0.419736 / 0.283200 (0.136536) | 0.044195 / 0.141683 (-0.097488) | 1.793840 / 1.452155 (0.341686) | 1.960204 / 1.492716 (0.467488) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.252046 / 0.018006 (0.234040) | 0.627725 / 0.000490 (0.627236) | 0.007435 / 0.000200 (0.007235) | 0.000526 / 0.000054 (0.000472) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034656 / 0.037411 (-0.002755) | 0.114534 / 0.014526 (0.100008) | 0.135804 / 0.176557 (-0.040753) | 0.209309 / 0.737135 (-0.527826) | 0.140369 / 0.296338 (-0.155969) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.636736 / 0.215209 (0.421527) | 6.039985 / 2.077655 (3.962330) | 2.640141 / 1.504120 (1.136021) | 2.284492 / 1.541195 (0.743297) | 2.324956 / 1.468490 (0.856466) | 0.934499 / 4.584777 (-3.650278) | 5.673415 / 3.745712 (1.927703) | 5.184584 / 5.269862 (-0.085278) | 2.661911 / 4.565676 (-1.903766) | 0.150420 / 0.424275 (-0.273855) | 0.015655 / 0.007607 (0.008048) | 0.748290 / 0.226044 (0.522246) | 7.579755 / 2.268929 (5.310827) | 3.346732 / 55.444624 (-52.097892) | 2.708212 / 6.876477 (-4.168264) | 2.682423 / 2.142072 (0.540351) | 1.170389 / 4.805227 (-3.634838) | 0.215775 / 6.500664 (-6.284889) | 0.076360 / 0.075469 (0.000891) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.516794 / 1.841788 (-0.324993) | 18.709117 / 8.074308 (10.634809) | 22.492542 / 10.191392 (12.301150) | 0.237978 / 0.680424 (-0.442446) | 0.027828 / 0.534201 (-0.506373) | 0.499968 / 0.579283 (-0.079315) | 0.645899 / 0.434364 (0.211535) | 0.548599 / 0.540337 (0.008262) | 0.675428 / 1.386936 (-0.711508) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008469 / 0.011353 (-0.002884) | 0.005420 / 0.011008 (-0.005589) | 0.093340 / 0.038508 (0.054832) | 0.045896 / 0.023109 (0.022786) | 0.533267 / 0.275898 (0.257369) | 0.596034 / 0.323480 (0.272555) | 0.004816 / 0.007986 (-0.003170) | 0.004379 / 0.004328 (0.000051) | 0.096356 / 0.004250 (0.092106) | 0.058339 / 0.037052 (0.021287) | 0.574464 / 0.258489 (0.315975) | 0.649301 / 0.293841 (0.355461) | 0.047599 / 0.128546 (-0.080947) | 0.013759 / 0.075646 (-0.061887) | 0.104672 / 0.419271 (-0.314599) | 0.061658 / 0.043533 (0.018125) | 0.560956 / 0.255139 (0.305817) | 0.585328 / 0.283200 (0.302128) | 0.034137 / 0.141683 (-0.107546) | 1.844528 / 1.452155 (0.392373) | 1.971398 / 1.492716 (0.478682) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.278666 / 0.018006 (0.260660) | 0.577342 / 0.000490 (0.576853) | 0.005496 / 0.000200 (0.005296) | 0.000131 / 0.000054 (0.000076) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029863 / 0.037411 (-0.007549) | 0.161703 / 0.014526 (0.147177) | 0.132279 / 0.176557 (-0.044277) | 0.227345 / 0.737135 (-0.509791) | 0.138047 / 0.296338 (-0.158291) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.651535 / 0.215209 (0.436326) | 7.077949 / 2.077655 (5.000295) | 2.926990 / 1.504120 (1.422871) | 2.598872 / 1.541195 (1.057678) | 2.614192 / 1.468490 (1.145702) | 0.913845 / 4.584777 (-3.670932) | 5.704301 / 3.745712 (1.958589) | 2.796914 / 5.269862 (-2.472948) | 1.836096 / 4.565676 (-2.729580) | 0.106294 / 0.424275 (-0.317981) | 0.012705 / 0.007607 (0.005098) | 0.836336 / 0.226044 (0.610291) | 8.234079 / 2.268929 (5.965150) | 3.836410 / 55.444624 (-51.608215) | 3.116752 / 6.876477 (-3.759724) | 3.154258 / 2.142072 (1.012186) | 1.195794 / 4.805227 (-3.609434) | 0.240491 / 6.500664 (-6.260173) | 0.087913 / 0.075469 (0.012444) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.724723 / 1.841788 (-0.117064) | 19.492194 / 8.074308 (11.417885) | 21.443341 / 10.191392 (11.251949) | 0.245819 / 0.680424 (-0.434605) | 0.027024 / 0.534201 (-0.507177) | 0.481071 / 0.579283 (-0.098212) | 0.596359 / 0.434364 (0.161995) | 0.646462 / 0.540337 (0.106124) | 0.706380 / 1.386936 (-0.680556) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006634 / 0.011353 (-0.004719) | 0.004003 / 0.011008 (-0.007005) | 0.097874 / 0.038508 (0.059365) | 0.043528 / 0.023109 (0.020419) | 0.302293 / 0.275898 (0.026395) | 0.357041 / 0.323480 (0.033561) | 0.003761 / 0.007986 (-0.004225) | 0.004312 / 0.004328 (-0.000016) | 0.076253 / 0.004250 (0.072003) | 0.062807 / 0.037052 (0.025755) | 0.316737 / 0.258489 (0.058248) | 0.356722 / 0.293841 (0.062881) | 0.030816 / 0.128546 (-0.097730) | 0.008691 / 0.075646 (-0.066955) | 0.328366 / 0.419271 (-0.090906) | 0.062299 / 0.043533 (0.018766) | 0.293877 / 0.255139 (0.038738) | 0.319832 / 0.283200 (0.036632) | 0.024996 / 0.141683 (-0.116687) | 1.473912 / 1.452155 (0.021758) | 1.565439 / 1.492716 (0.072723) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.208428 / 0.018006 (0.190422) | 0.435618 / 0.000490 (0.435128) | 0.000695 / 0.000200 (0.000495) | 0.000056 / 0.000054 (0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026253 / 0.037411 (-0.011158) | 0.106908 / 0.014526 (0.092382) | 0.117075 / 0.176557 (-0.059482) | 0.177969 / 0.737135 (-0.559166) | 0.123400 / 0.296338 (-0.172938) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424970 / 0.215209 (0.209761) | 4.203233 / 2.077655 (2.125578) | 2.009679 / 1.504120 (0.505559) | 1.825691 / 1.541195 (0.284496) | 1.870639 / 1.468490 (0.402149) | 0.530758 / 4.584777 (-4.054019) | 3.718791 / 3.745712 (-0.026921) | 1.800206 / 5.269862 (-3.469656) | 1.071651 / 4.565676 (-3.494025) | 0.065126 / 0.424275 (-0.359149) | 0.011312 / 0.007607 (0.003704) | 0.532503 / 0.226044 (0.306458) | 5.353950 / 2.268929 (3.085021) | 2.463548 / 55.444624 (-52.981076) | 2.139832 / 6.876477 (-4.736645) | 2.238722 / 2.142072 (0.096650) | 0.655736 / 4.805227 (-4.149492) | 0.141689 / 6.500664 (-6.358975) | 0.063282 / 0.075469 (-0.012187) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.183523 / 1.841788 (-0.658265) | 14.146428 / 8.074308 (6.072120) | 14.312883 / 10.191392 (4.121491) | 0.169286 / 0.680424 (-0.511138) | 0.017343 / 0.534201 (-0.516858) | 0.397934 / 0.579283 (-0.181349) | 0.417791 / 0.434364 (-0.016573) | 0.463639 / 0.540337 (-0.076698) | 0.562787 / 1.386936 (-0.824149) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006594 / 0.011353 (-0.004759) | 0.004086 / 0.011008 (-0.006922) | 0.075122 / 0.038508 (0.036614) | 0.041849 / 0.023109 (0.018740) | 0.362645 / 0.275898 (0.086747) | 0.464350 / 0.323480 (0.140870) | 0.003760 / 0.007986 (-0.004226) | 0.003327 / 0.004328 (-0.001001) | 0.076154 / 0.004250 (0.071904) | 0.053232 / 0.037052 (0.016180) | 0.407863 / 0.258489 (0.149374) | 0.460787 / 0.293841 (0.166946) | 0.031917 / 0.128546 (-0.096630) | 0.008770 / 0.075646 (-0.066876) | 0.082612 / 0.419271 (-0.336660) | 0.051311 / 0.043533 (0.007779) | 0.354508 / 0.255139 (0.099369) | 0.419533 / 0.283200 (0.136334) | 0.023980 / 0.141683 (-0.117703) | 1.491255 / 1.452155 (0.039100) | 1.536101 / 1.492716 (0.043384) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.178261 / 0.018006 (0.160255) | 0.444680 / 0.000490 (0.444190) | 0.013761 / 0.000200 (0.013561) | 0.000117 / 0.000054 (0.000063) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027875 / 0.037411 (-0.009536) | 0.111269 / 0.014526 (0.096744) | 0.121096 / 0.176557 (-0.055461) | 0.174387 / 0.737135 (-0.562749) | 0.124714 / 0.296338 (-0.171624) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.445422 / 0.215209 (0.230213) | 4.435877 / 2.077655 (2.358222) | 2.221895 / 1.504120 (0.717775) | 2.030571 / 1.541195 (0.489376) | 2.074863 / 1.468490 (0.606373) | 0.543331 / 4.584777 (-4.041446) | 3.753615 / 3.745712 (0.007903) | 3.317074 / 5.269862 (-1.952787) | 1.630390 / 4.565676 (-2.935286) | 0.066726 / 0.424275 (-0.357549) | 0.011556 / 0.007607 (0.003949) | 0.546985 / 0.226044 (0.320941) | 5.460634 / 2.268929 (3.191705) | 2.705945 / 55.444624 (-52.738679) | 2.373425 / 6.876477 (-4.503052) | 2.401472 / 2.142072 (0.259399) | 0.663225 / 4.805227 (-4.142002) | 0.143694 / 6.500664 (-6.356970) | 0.065283 / 0.075469 (-0.010186) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.264804 / 1.841788 (-0.576983) | 14.803228 / 8.074308 (6.728919) | 14.178514 / 10.191392 (3.987122) | 0.162651 / 0.680424 (-0.517772) | 0.017586 / 0.534201 (-0.516615) | 0.398740 / 0.579283 (-0.180543) | 0.414478 / 0.434364 (-0.019886) | 0.465442 / 0.540337 (-0.074895) | 0.563450 / 1.386936 (-0.823486) |\n\n</details>\n</details>\n\n\n"
] | 2023-06-21T15:43:01Z
| 2023-06-22T14:23:29Z
| 2023-06-22T14:16:26Z
|
MEMBER
| null | null | null |
I used a regex to filter the data files based on their extension for packaged builders.
I tried and a regex is 10x faster that using `in` to check if the extension is in the list of supported extensions.
Supersedes https://github.com/huggingface/datasets/pull/5850
Close https://github.com/huggingface/datasets/issues/5849
I also did a small change to favor the parquet module in case of a draw in the extension counter.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5972/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5972/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5972.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5972",
"merged_at": "2023-06-22T14:16:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5972.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5972"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6485
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6485/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6485/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6485/events
|
https://github.com/huggingface/datasets/issues/6485
| 2,035,141,884
|
I_kwDODunzps55Tcz8
| 6,485
|
FileNotFoundError: [Errno 2] No such file or directory: 'nul'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/73683903?v=4",
"events_url": "https://api.github.com/users/amanyara/events{/privacy}",
"followers_url": "https://api.github.com/users/amanyara/followers",
"following_url": "https://api.github.com/users/amanyara/following{/other_user}",
"gists_url": "https://api.github.com/users/amanyara/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/amanyara",
"id": 73683903,
"login": "amanyara",
"node_id": "MDQ6VXNlcjczNjgzOTAz",
"organizations_url": "https://api.github.com/users/amanyara/orgs",
"received_events_url": "https://api.github.com/users/amanyara/received_events",
"repos_url": "https://api.github.com/users/amanyara/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/amanyara/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amanyara/subscriptions",
"type": "User",
"url": "https://api.github.com/users/amanyara",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi! It seems like the problem is your environment. Maybe this issue can help: https://github.com/pytest-dev/pytest/issues/9519. "
] | 2023-12-11T08:52:13Z
| 2023-12-14T08:09:08Z
| 2023-12-14T08:09:08Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
it seems that sth wrong with my terrible "bug body" life, When i run this code, "import datasets"
i meet this error FileNotFoundError: [Errno 2] No such file or directory: 'nul'


### Steps to reproduce the bug
1.import datasets
### Expected behavior
i just run a single line code and stuct in this bug
### Environment info
OS: Windows10
Datasets==2.15.0
python=3.10
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/73683903?v=4",
"events_url": "https://api.github.com/users/amanyara/events{/privacy}",
"followers_url": "https://api.github.com/users/amanyara/followers",
"following_url": "https://api.github.com/users/amanyara/following{/other_user}",
"gists_url": "https://api.github.com/users/amanyara/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/amanyara",
"id": 73683903,
"login": "amanyara",
"node_id": "MDQ6VXNlcjczNjgzOTAz",
"organizations_url": "https://api.github.com/users/amanyara/orgs",
"received_events_url": "https://api.github.com/users/amanyara/received_events",
"repos_url": "https://api.github.com/users/amanyara/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/amanyara/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amanyara/subscriptions",
"type": "User",
"url": "https://api.github.com/users/amanyara",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6485/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6485/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5255
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5255/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5255/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5255/events
|
https://github.com/huggingface/datasets/issues/5255
| 1,452,631,517
|
I_kwDODunzps5WlWXd
| 5,255
|
Add a Depth Estimation dataset - DIODE / NYUDepth / KITTI
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul",
"user_view_type": "public"
}
|
[
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul",
"user_view_type": "public"
}
] | null |
[
"Also cc @mariosasko and @lhoestq ",
"Cool ! Let us know if you have questions or if we can help :)\r\n\r\nI guess we'll also have to create the NYU CS Department on the Hub ?",
"> I guess we'll also have to create the NYU CS Department on the Hub ?\r\n\r\nYes, you're right! Let me add it to my profile first, and then we can transfer. Meanwhile, if it's recommended to loop the dataset author in here, let me know. \r\n\r\nAlso, the NYU Depth dataset seems big. Any example scripts for creating image datasets that I could refer? ",
"You can check the imagenet-1k one.\r\n\r\nPS: If the licenses allows it, it'b be nice to host the dataset as sharded TAR archives (like imagenet-1k) instead of the ZIP format they use:\r\n- it will make streaming much faster\r\n- ZIP compression is not well suited for images\r\n- it will allow parallel processing of the dataset (you can pass a subset of shards to each worker)\r\n\r\n> if it's recommended to loop the dataset author in here, let me know.\r\n\r\nIt's recommended indeed, you can send them an email once you have the dataset ready and invite them to the org on the Hub",
"> You can check the imagenet-1k one.\r\n\r\nWhere can I find the script? Are you referring to https://huggingface.co/docs/datasets/image_process ? Or is there anything more specific? ",
"You can find it here: https://huggingface.co/datasets/imagenet-1k/blob/main/imagenet-1k.py",
"Update: started working on it here: https://huggingface.co/datasets/sayakpaul/nyu_depth_v2. \r\n\r\nI am facing an issue and I have detailed it here: https://huggingface.co/datasets/sayakpaul/nyu_depth_v2/discussions/1\r\n\r\nEdit: The issue is gone. \r\n\r\nHowever, since the dataset is distributed as a single TAR archive (following the [URL used in TensorFlow Datasets](https://github.com/tensorflow/datasets/tree/master/tensorflow_datasets/datasets/nyu_depth_v2/nyu_depth_v2_dataset_builder.py)) the loading is taking longer. How would suggest to shard the single TAR archive? \r\n\r\n@lhoestq \r\n\r\n",
"A Colab Notebook demonstrating the dataset loading part: \r\n\r\nhttps://colab.research.google.com/gist/sayakpaul/aa0958c8d4ad8518d52a78f28044d871/scratchpad.ipynb\r\n\r\n@osanseviero @lhoestq \r\n\r\nI will work on a notebook to work with the dataset including data visualization.",
"@osanseviero @lhoestq things seem to work fine with the current version of the dataset [here](https://huggingface.co/datasets/sayakpaul/nyu_depth_v2). Here's a notebook I developed to help with visualization: https://colab.research.google.com/drive/1K3ZU8XUPRDOYD38MQS9nreQXJYitlKSW?usp=sharing. \r\n\r\n@lhoestq I need your help with the following:\r\n\r\n> However, since the dataset is distributed as a single TAR archive (following the [URL used in TensorFlow Datasets](https://github.com/tensorflow/datasets/tree/master/tensorflow_datasets/datasets/nyu_depth_v2/nyu_depth_v2_dataset_builder.py)) the loading is taking longer. How would suggest to shard the single TAR archive?\r\n\r\n@osanseviero @lhoestq question for you:\r\n\r\nWhere should we host the dataset? I think hosting it under hf.co/datasets (that is HF is the org) is fine as we have ImageNet-1k hosted similarly. We could then reach out to Diana Wofk (author of [Fast Depth](https://github.com/dwofk/fast-depth) and the owner of the repo on which TFDS NYU Depth V2 is based) for a review. WDYT? ",
"> However, since the dataset is distributed as a single TAR archive (following the [URL used in TensorFlow Datasets](https://github.com/tensorflow/datasets/tree/master/tensorflow_datasets/datasets/nyu_depth_v2/nyu_depth_v2_dataset_builder.py)) the loading is taking longer. How would suggest to shard the single TAR archive?\r\n\r\nFirst you can separate the train data and the validation data.\r\n\r\nThen since the dataset is quite big, you can even shard the train split and the validation split in multiple TAR archives. Something around 16 archives for train and 4 for validation would be fine for example.\r\n\r\nAlso no need to gzip the TAR archives, the images are already compressed in png or jpeg.",
"> Then since the dataset is quite big, you can even shard the train split and the validation split in multiple TAR archives. Something around 16 archives for train and 4 for validation would be fine for example.\r\n\r\nYes, I got you. But this process seems to be manual and should be tailored for the given dataset. Do you have any script that you used to create the ImageNet-1k shards? \r\n\r\n> Also no need to gzip the TAR archives, the images are already compressed in png or jpeg.\r\n\r\nI was not going to do that. Not sure what brought it up. ",
"> Yes, I got you. But this process seems to be manual and should be tailored for the given dataset. Do you have any script that you used to create the ImageNet-1k shards?\r\n\r\nI don't, but I agree it'd be nice to have a script for that !\r\n\r\n> I was not going to do that. Not sure what brought it up.\r\n\r\nThe original dataset is gzipped for some reason",
"Oh, I am using this URL for the download: https://github.com/tensorflow/datasets/blob/master/tensorflow_datasets/datasets/nyu_depth_v2/nyu_depth_v2_dataset_builder.py#L24. ",
"> Where should we host the dataset? I think hosting it under hf.co/datasets (that is HF is the org) is fine as we have ImageNet-1k hosted similarly.\r\n\r\nMaybe you can create an org for NYU Courant (this is the institute of the lab of the main author of the dataset if I'm not mistaken), and invite the authors to join.\r\n\r\nWe don't add datasets without namespace anymore",
"Updates: https://huggingface.co/datasets/sayakpaul/nyu_depth_v2/discussions/5\r\n\r\nThe entire process (preparing multiple archives, preparing data loading script, etc.) was fun and engaging, thanks to the documentation. I believe we could work on a small blog post that would work as a reference for the future contributors following this path. What say? \r\n\r\nCc: @lhoestq @osanseviero ",
"> I believe we could work on a small blog post that would work as a reference for the future contributors following this path. What say?\r\n\r\n@polinaeterna already mentioned it would be nice to present this process for audio (it's exactly the same), I believe it can be useful to many people",
"Cool. Let's work on that after the NYU Depth Dataset is fully in on Hub (under the appropriate org). 🤗",
"@lhoestq need to discuss something while I am adding the dataset card to https://huggingface.co/datasets/sayakpaul/nyu_depth_v2/. \r\n\r\nAs per [Papers With Code](https://paperswithcode.com/dataset/nyuv2), NYU Depth v2 is used for many different tasks:\r\n\r\n* Monocular depth estimation\r\n* Depth estimation \r\n* Semantic segmentation\r\n* Plane instance segmentation \r\n* ...\r\n\r\nSo, while writing the supported task part of the dataset card, should we focus on all these? IMO, we could focus on just depth estimation and semantic segmentation for now since we have supported models for these two. WDYT?\r\n\r\nAlso, I am getting: \r\n\r\n\r\n```\r\nremote: Your push was accepted, but with warnings:\r\nremote: - Warning: The task_ids \"depth-estimation\" is not in the official list: acceptability-classification, entity-linking-classification, fact-checking, intent-classification, multi-class-classification, multi-label-classification, multi-input-text-classification, natural-language-inference, semantic-similarity-classification, sentiment-classification, topic-classification, semantic-similarity-scoring, sentiment-scoring, sentiment-analysis, hate-speech-detection, text-scoring, named-entity-recognition, part-of-speech, parsing, lemmatization, word-sense-disambiguation, coreference-resolution, extractive-qa, open-domain-qa, closed-domain-qa, news-articles-summarization, news-articles-headline-generation, dialogue-generation, dialogue-modeling, language-modeling, text-simplification, explanation-generation, abstractive-qa, open-domain-abstractive-qa, closed-domain-qa, open-book-qa, closed-book-qa, slot-filling, masked-language-modeling, keyword-spotting, speaker-identification, audio-intent-classification, audio-emotion-recognition, audio-language-identification, multi-label-image-classification, multi-class-image-classification, face-detection, vehicle-detection, instance-segmentation, semantic-segmentation, panoptic-segmentation, image-captioning, grasping, task-planning, tabular-multi-class-classification, tabular-multi-label-classification, tabular-single-column-regression, rdf-to-text, multiple-choice-qa, multiple-choice-coreference-resolution, document-retrieval, utterance-retrieval, entity-linking-retrieval, fact-checking-retrieval, univariate-time-series-forecasting, multivariate-time-series-forecasting, visual-question-answering, document-question-answering\r\nremote: ----------------------------------------------------------\r\nremote: Please find the documentation at:\r\nremote: https://huggingface.co/docs/hub/model-cards#model-card-metadata\r\n```\r\n\r\nWhat should be the plan of action for this?\r\n\r\nCc: @osanseviero \r\n\r\n",
"> What should be the plan of action for this?\r\n\r\nWhen you merged https://github.com/huggingface/hub-docs/pull/488, there is a JS Interfaces GitHub Actions workflow that runs https://github.com/huggingface/hub-docs/actions/workflows/js-interfaces-tests.yml. It has a step called [export-task scripts](https://github.com/huggingface/hub-docs/actions/runs/3622479064/jobs/6107238948) which exports an interface you can use in `dataset`. If you look at the logs, it prints out a map. This map can replace https://github.com/huggingface/datasets/blob/main/src/datasets/utils/resources/tasks.json (tasks.json was generated with this script), which should add depth estimation\r\n",
"Thanks @osanseviero. \r\n\r\nhttps://github.com/huggingface/datasets/pull/5335",
"Closing the issue as the dataset has been successfully added: https://huggingface.co/datasets/sayakpaul/nyu_depth_v2"
] | 2022-11-17T03:22:22Z
| 2022-12-17T12:20:38Z
| 2022-12-17T12:20:37Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Name
NYUDepth
### Paper
http://cs.nyu.edu/~silberman/papers/indoor_seg_support.pdf
### Data
https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
### Motivation
Depth estimation is an important problem in computer vision. We have a couple of Depth Estimation models on Hub as well:
* [GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)
* [DPT](https://huggingface.co/docs/transformers/model_doc/dpt)
Would be nice to have a dataset for depth estimation. These datasets usually have three things: input image, depth map image, and depth mask (validity mask to indicate if a reading for a pixel is valid or not). Since we already have [semantic segmentation datasets on the Hub](https://huggingface.co/datasets?task_categories=task_categories:image-segmentation&sort=downloads), I don't think we need any extended utilities to support this addition.
Having this dataset would also allow us to author data preprocessing guides for depth estimation, particularly like the ones we have for other tasks ([example](https://huggingface.co/docs/datasets/image_classification)).
Ccing @osanseviero @nateraw @NielsRogge
Happy to work on adding it.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5255/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5255/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6584
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6584/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6584/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6584/events
|
https://github.com/huggingface/datasets/issues/6584
| 2,078,454,878
|
I_kwDODunzps574rRe
| 6,584
|
np.fromfile not supported
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12895488?v=4",
"events_url": "https://api.github.com/users/d710055071/events{/privacy}",
"followers_url": "https://api.github.com/users/d710055071/followers",
"following_url": "https://api.github.com/users/d710055071/following{/other_user}",
"gists_url": "https://api.github.com/users/d710055071/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/d710055071",
"id": 12895488,
"login": "d710055071",
"node_id": "MDQ6VXNlcjEyODk1NDg4",
"organizations_url": "https://api.github.com/users/d710055071/orgs",
"received_events_url": "https://api.github.com/users/d710055071/received_events",
"repos_url": "https://api.github.com/users/d710055071/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/d710055071/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/d710055071/subscriptions",
"type": "User",
"url": "https://api.github.com/users/d710055071",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"@lhoestq\r\nCan you provide me with some ideas?",
"Hi ! What's the error ?",
"@lhoestq \r\n```\r\nTraceback (most recent call last):\r\n File \"/home/dongzf/miniconda3/envs/dataset_ai/lib/python3.11/runpy.py\", line 198, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/home/dongzf/miniconda3/envs/dataset_ai/lib/python3.11/runpy.py\", line 88, in _run_code\r\n exec(code, run_globals)\r\n File \"/home/dongzf/.vscode/extensions/ms-python.python-2023.22.1/pythonFiles/lib/python/debugpy/adapter/../../debugpy/launcher/../../debugpy/__main__.py\", line 39, in <module>\r\n cli.main()\r\n File \"/home/dongzf/.vscode/extensions/ms-python.python-2023.22.1/pythonFiles/lib/python/debugpy/adapter/../../debugpy/launcher/../../debugpy/../debugpy/server/cli.py\", line 430, in main\r\n run()\r\n File \"/home/dongzf/.vscode/extensions/ms-python.python-2023.22.1/pythonFiles/lib/python/debugpy/adapter/../../debugpy/launcher/../../debugpy/../debugpy/server/cli.py\", line 284, in run_file\r\n runpy.run_path(target, run_name=\"__main__\")\r\n File \"/home/dongzf/.vscode/extensions/ms-python.python-2023.22.1/pythonFiles/lib/python/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py\", line 321, in run_path\r\n return _run_module_code(code, init_globals, run_name,\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/home/dongzf/.vscode/extensions/ms-python.python-2023.22.1/pythonFiles/lib/python/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py\", line 135, in _run_module_code\r\n _run_code(code, mod_globals, init_globals,\r\n File \"/home/dongzf/.vscode/extensions/ms-python.python-2023.22.1/pythonFiles/lib/python/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py\", line 124, in _run_code\r\n exec(code, run_globals)\r\n File \"/mnt/sda/code/dataset_ai/dataset_ai/example/test.py\", line 83, in <module>\r\n data = xnumpy_fromfile(current_dir, download_config=config,dtype=numpy.float32,)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/mnt/sda/code/dataset_ai/dataset_ai/src/datasets/download/streaming_download_manager.py\", line 765, in xnumpy_fromfile\r\n return np.fromfile(xopen(filepath_or_buffer, \"rb\", download_config=download_config).read(), *args, **kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\nValueError: embedded null byte\r\n```",
" not add read() \r\nthe error is \r\n\r\nreturn np.fromfile(xopen(filepath_or_buffer, \"rb\", download_config=download_config), *args, **kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\nio.UnsupportedOperation: fileno",
"xopen return obj do not have fileno function\r\nI don't know why?",
"I used this method to read point cloud data in the script\r\n\r\n\r\n```python\r\nwith open(velodyne_filepath,\"rb\") as obj:\r\n velodyne_data = numpy.frombuffer(obj.read(), dtype=numpy.float32).reshape([-1, 4])\r\n```"
] | 2024-01-12T09:46:17Z
| 2024-01-15T05:20:50Z
| null |
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
How to do np.fromfile to use it like np.load
```python
def xnumpy_fromfile(filepath_or_buffer, *args, download_config: Optional[DownloadConfig] = None, **kwargs):
import numpy as np
if hasattr(filepath_or_buffer, "read"):
return np.fromfile(filepath_or_buffer, *args, **kwargs)
else:
filepath_or_buffer = str(filepath_or_buffer)
return np.fromfile(xopen(filepath_or_buffer, "rb", download_config=download_config).read(), *args, **kwargs)
```
this is not work
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6584/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6584/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6100
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6100/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6100/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6100/events
|
https://github.com/huggingface/datasets/issues/6100
| 1,828,118,930
|
I_kwDODunzps5s9uGS
| 6,100
|
TypeError when loading from GCP bucket
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16692099?v=4",
"events_url": "https://api.github.com/users/bilelomrani1/events{/privacy}",
"followers_url": "https://api.github.com/users/bilelomrani1/followers",
"following_url": "https://api.github.com/users/bilelomrani1/following{/other_user}",
"gists_url": "https://api.github.com/users/bilelomrani1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bilelomrani1",
"id": 16692099,
"login": "bilelomrani1",
"node_id": "MDQ6VXNlcjE2NjkyMDk5",
"organizations_url": "https://api.github.com/users/bilelomrani1/orgs",
"received_events_url": "https://api.github.com/users/bilelomrani1/received_events",
"repos_url": "https://api.github.com/users/bilelomrani1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bilelomrani1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bilelomrani1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bilelomrani1",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[
"Thanks for reporting, @bilelomrani1.\r\n\r\nWe are fixing it. ",
"We have fixed it. We are planning to do a patch release today."
] | 2023-07-30T23:03:00Z
| 2023-08-03T10:00:48Z
| 2023-08-01T10:38:55Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Loading a dataset from a GCP bucket raises a type error. This bug was introduced recently (either in 2.14 or 2.14.1), and appeared during a migration from 2.13.1.
### Steps to reproduce the bug
Load any file from a GCP bucket:
```python
import datasets
datasets.load_dataset("json", data_files=["gs://..."])
```
The following exception is raised:
```python
Traceback (most recent call last):
...
packages/datasets/data_files.py", line 335, in resolve_pattern
protocol_prefix = fs.protocol + "://" if fs.protocol != "file" else ""
TypeError: can only concatenate tuple (not "str") to tuple
```
With a `GoogleFileSystem`, the attribute `fs.protocol` is a tuple `('gs', 'gcs')` and hence cannot be concatenated with a string.
### Expected behavior
The file should be loaded without exception.
### Environment info
- `datasets` version: 2.14.1
- Platform: macOS-13.2.1-x86_64-i386-64bit
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- PyArrow version: 12.0.1
- Pandas version: 2.0.3
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6100/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6100/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5920
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5920/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5920/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5920/events
|
https://github.com/huggingface/datasets/pull/5920
| 1,736,196,991
|
PR_kwDODunzps5R5TRB
| 5,920
|
Optimize IterableDataset.from_file using ArrowExamplesIterable
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007439 / 0.011353 (-0.003914) | 0.004884 / 0.011008 (-0.006124) | 0.098750 / 0.038508 (0.060242) | 0.040723 / 0.023109 (0.017613) | 0.347242 / 0.275898 (0.071344) | 0.381202 / 0.323480 (0.057722) | 0.006814 / 0.007986 (-0.001171) | 0.004543 / 0.004328 (0.000215) | 0.075338 / 0.004250 (0.071088) | 0.058976 / 0.037052 (0.021924) | 0.344746 / 0.258489 (0.086257) | 0.406761 / 0.293841 (0.112920) | 0.028961 / 0.128546 (-0.099585) | 0.009531 / 0.075646 (-0.066115) | 0.337324 / 0.419271 (-0.081947) | 0.051071 / 0.043533 (0.007538) | 0.341251 / 0.255139 (0.086112) | 0.362773 / 0.283200 (0.079573) | 0.109423 / 0.141683 (-0.032260) | 1.457420 / 1.452155 (0.005266) | 1.588824 / 1.492716 (0.096108) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.288620 / 0.018006 (0.270614) | 0.568975 / 0.000490 (0.568485) | 0.003350 / 0.000200 (0.003150) | 0.000088 / 0.000054 (0.000034) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028732 / 0.037411 (-0.008680) | 0.117820 / 0.014526 (0.103294) | 0.120180 / 0.176557 (-0.056376) | 0.178736 / 0.737135 (-0.558399) | 0.126399 / 0.296338 (-0.169939) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.428357 / 0.215209 (0.213148) | 4.251989 / 2.077655 (2.174334) | 2.005239 / 1.504120 (0.501119) | 1.784009 / 1.541195 (0.242815) | 1.883763 / 1.468490 (0.415272) | 0.555429 / 4.584777 (-4.029348) | 3.868146 / 3.745712 (0.122434) | 2.081896 / 5.269862 (-3.187965) | 1.126047 / 4.565676 (-3.439629) | 0.069496 / 0.424275 (-0.354779) | 0.012926 / 0.007607 (0.005318) | 0.536989 / 0.226044 (0.310944) | 5.256052 / 2.268929 (2.987124) | 2.526802 / 55.444624 (-52.917822) | 2.233346 / 6.876477 (-4.643131) | 2.389063 / 2.142072 (0.246990) | 0.677107 / 4.805227 (-4.128120) | 0.147212 / 6.500664 (-6.353452) | 0.067061 / 0.075469 (-0.008408) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.210651 / 1.841788 (-0.631137) | 17.236898 / 8.074308 (9.162589) | 14.427301 / 10.191392 (4.235909) | 0.207194 / 0.680424 (-0.473229) | 0.018079 / 0.534201 (-0.516122) | 0.398355 / 0.579283 (-0.180929) | 0.462453 / 0.434364 (0.028089) | 0.484544 / 0.540337 (-0.055794) | 0.590119 / 1.386936 (-0.796817) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007392 / 0.011353 (-0.003961) | 0.005614 / 0.011008 (-0.005394) | 0.075587 / 0.038508 (0.037079) | 0.040429 / 0.023109 (0.017320) | 0.389901 / 0.275898 (0.114003) | 0.429466 / 0.323480 (0.105986) | 0.006790 / 0.007986 (-0.001196) | 0.006627 / 0.004328 (0.002299) | 0.075227 / 0.004250 (0.070976) | 0.060298 / 0.037052 (0.023246) | 0.391905 / 0.258489 (0.133416) | 0.449385 / 0.293841 (0.155544) | 0.028794 / 0.128546 (-0.099753) | 0.009461 / 0.075646 (-0.066185) | 0.083386 / 0.419271 (-0.335886) | 0.057968 / 0.043533 (0.014435) | 0.377327 / 0.255139 (0.122188) | 0.402825 / 0.283200 (0.119626) | 0.125477 / 0.141683 (-0.016206) | 1.462986 / 1.452155 (0.010832) | 1.595959 / 1.492716 (0.103243) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.304179 / 0.018006 (0.286173) | 0.543113 / 0.000490 (0.542623) | 0.004136 / 0.000200 (0.003936) | 0.000109 / 0.000054 (0.000054) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032617 / 0.037411 (-0.004794) | 0.123596 / 0.014526 (0.109070) | 0.128714 / 0.176557 (-0.047842) | 0.176344 / 0.737135 (-0.560792) | 0.132525 / 0.296338 (-0.163813) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.446041 / 0.215209 (0.230832) | 4.438799 / 2.077655 (2.361144) | 2.210815 / 1.504120 (0.706695) | 2.052025 / 1.541195 (0.510830) | 2.204687 / 1.468490 (0.736197) | 0.535219 / 4.584777 (-4.049558) | 3.858407 / 3.745712 (0.112695) | 3.826043 / 5.269862 (-1.443819) | 1.334149 / 4.565676 (-3.231527) | 0.067454 / 0.424275 (-0.356821) | 0.012566 / 0.007607 (0.004958) | 0.551597 / 0.226044 (0.325553) | 5.520054 / 2.268929 (3.251126) | 2.817976 / 55.444624 (-52.626649) | 2.528074 / 6.876477 (-4.348403) | 2.622391 / 2.142072 (0.480319) | 0.657632 / 4.805227 (-4.147595) | 0.147039 / 6.500664 (-6.353625) | 0.069603 / 0.075469 (-0.005866) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.300140 / 1.841788 (-0.541648) | 17.303907 / 8.074308 (9.229599) | 15.657887 / 10.191392 (5.466495) | 0.168991 / 0.680424 (-0.511433) | 0.021332 / 0.534201 (-0.512869) | 0.487261 / 0.579283 (-0.092022) | 0.450073 / 0.434364 (0.015709) | 0.465865 / 0.540337 (-0.074473) | 0.565501 / 1.386936 (-0.821435) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006536 / 0.011353 (-0.004817) | 0.004254 / 0.011008 (-0.006755) | 0.095387 / 0.038508 (0.056878) | 0.032885 / 0.023109 (0.009776) | 0.298580 / 0.275898 (0.022682) | 0.319771 / 0.323480 (-0.003709) | 0.005510 / 0.007986 (-0.002476) | 0.003891 / 0.004328 (-0.000437) | 0.073763 / 0.004250 (0.069513) | 0.041625 / 0.037052 (0.004573) | 0.294896 / 0.258489 (0.036407) | 0.341308 / 0.293841 (0.047467) | 0.027898 / 0.128546 (-0.100648) | 0.008837 / 0.075646 (-0.066809) | 0.325055 / 0.419271 (-0.094216) | 0.050652 / 0.043533 (0.007119) | 0.298756 / 0.255139 (0.043617) | 0.318261 / 0.283200 (0.035061) | 0.098927 / 0.141683 (-0.042756) | 1.450356 / 1.452155 (-0.001798) | 1.508034 / 1.492716 (0.015318) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.209009 / 0.018006 (0.191003) | 0.439154 / 0.000490 (0.438665) | 0.004299 / 0.000200 (0.004099) | 0.000142 / 0.000054 (0.000087) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025938 / 0.037411 (-0.011473) | 0.105954 / 0.014526 (0.091429) | 0.113858 / 0.176557 (-0.062698) | 0.168887 / 0.737135 (-0.568249) | 0.121292 / 0.296338 (-0.175046) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.402050 / 0.215209 (0.186841) | 4.002310 / 2.077655 (1.924655) | 1.816190 / 1.504120 (0.312070) | 1.634404 / 1.541195 (0.093209) | 1.713632 / 1.468490 (0.245142) | 0.519633 / 4.584777 (-4.065144) | 3.740291 / 3.745712 (-0.005421) | 1.787602 / 5.269862 (-3.482260) | 1.038844 / 4.565676 (-3.526833) | 0.064973 / 0.424275 (-0.359302) | 0.012475 / 0.007607 (0.004868) | 0.498152 / 0.226044 (0.272108) | 4.970941 / 2.268929 (2.702013) | 2.287429 / 55.444624 (-53.157195) | 1.998050 / 6.876477 (-4.878427) | 2.091903 / 2.142072 (-0.050169) | 0.630363 / 4.805227 (-4.174864) | 0.138623 / 6.500664 (-6.362041) | 0.063293 / 0.075469 (-0.012176) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.201802 / 1.841788 (-0.639986) | 14.073836 / 8.074308 (5.999528) | 12.968665 / 10.191392 (2.777273) | 0.144653 / 0.680424 (-0.535771) | 0.017613 / 0.534201 (-0.516588) | 0.392067 / 0.579283 (-0.187216) | 0.416955 / 0.434364 (-0.017409) | 0.471492 / 0.540337 (-0.068845) | 0.554576 / 1.386936 (-0.832360) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006408 / 0.011353 (-0.004945) | 0.004452 / 0.011008 (-0.006556) | 0.073648 / 0.038508 (0.035140) | 0.032536 / 0.023109 (0.009427) | 0.358546 / 0.275898 (0.082648) | 0.387330 / 0.323480 (0.063850) | 0.005542 / 0.007986 (-0.002444) | 0.003882 / 0.004328 (-0.000447) | 0.073867 / 0.004250 (0.069617) | 0.044798 / 0.037052 (0.007746) | 0.362303 / 0.258489 (0.103814) | 0.400496 / 0.293841 (0.106655) | 0.028244 / 0.128546 (-0.100302) | 0.008931 / 0.075646 (-0.066715) | 0.080617 / 0.419271 (-0.338654) | 0.046575 / 0.043533 (0.003043) | 0.364283 / 0.255139 (0.109145) | 0.373215 / 0.283200 (0.090015) | 0.100080 / 0.141683 (-0.041603) | 1.430047 / 1.452155 (-0.022108) | 1.530957 / 1.492716 (0.038240) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.221061 / 0.018006 (0.203055) | 0.441753 / 0.000490 (0.441263) | 0.003626 / 0.000200 (0.003426) | 0.000088 / 0.000054 (0.000033) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029509 / 0.037411 (-0.007902) | 0.109578 / 0.014526 (0.095053) | 0.121009 / 0.176557 (-0.055548) | 0.168950 / 0.737135 (-0.568185) | 0.124475 / 0.296338 (-0.171864) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.431355 / 0.215209 (0.216146) | 4.295507 / 2.077655 (2.217852) | 2.167514 / 1.504120 (0.663394) | 2.013073 / 1.541195 (0.471879) | 1.973730 / 1.468490 (0.505240) | 0.529778 / 4.584777 (-4.054999) | 3.794702 / 3.745712 (0.048989) | 3.062940 / 5.269862 (-2.206922) | 1.503426 / 4.565676 (-3.062251) | 0.066692 / 0.424275 (-0.357583) | 0.011682 / 0.007607 (0.004075) | 0.539311 / 0.226044 (0.313266) | 5.406342 / 2.268929 (3.137414) | 2.652709 / 55.444624 (-52.791916) | 2.260066 / 6.876477 (-4.616410) | 2.295752 / 2.142072 (0.153680) | 0.647199 / 4.805227 (-4.158029) | 0.142981 / 6.500664 (-6.357683) | 0.065082 / 0.075469 (-0.010387) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.279788 / 1.841788 (-0.562000) | 14.982845 / 8.074308 (6.908536) | 14.277166 / 10.191392 (4.085774) | 0.145082 / 0.680424 (-0.535342) | 0.017885 / 0.534201 (-0.516316) | 0.392071 / 0.579283 (-0.187212) | 0.420425 / 0.434364 (-0.013939) | 0.461244 / 0.540337 (-0.079093) | 0.559956 / 1.386936 (-0.826980) |\n\n</details>\n</details>\n\n\n"
] | 2023-06-01T12:14:36Z
| 2023-06-01T12:42:10Z
| 2023-06-01T12:35:14Z
|
MEMBER
| null | null | null |
following https://github.com/huggingface/datasets/pull/5893
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5920/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5920/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5920.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5920",
"merged_at": "2023-06-01T12:35:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5920.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5920"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7226
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7226/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7226/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7226/events
|
https://github.com/huggingface/datasets/issues/7226
| 2,586,920,351
|
I_kwDODunzps6aMUWf
| 7,226
|
Add R as a How to use from the Polars (R) Library as an option
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/45013044?v=4",
"events_url": "https://api.github.com/users/ran-codes/events{/privacy}",
"followers_url": "https://api.github.com/users/ran-codes/followers",
"following_url": "https://api.github.com/users/ran-codes/following{/other_user}",
"gists_url": "https://api.github.com/users/ran-codes/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ran-codes",
"id": 45013044,
"login": "ran-codes",
"node_id": "MDQ6VXNlcjQ1MDEzMDQ0",
"organizations_url": "https://api.github.com/users/ran-codes/orgs",
"received_events_url": "https://api.github.com/users/ran-codes/received_events",
"repos_url": "https://api.github.com/users/ran-codes/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ran-codes/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ran-codes/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ran-codes",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
| null |
[] | null |
[] | 2024-10-14T19:56:07Z
| 2024-10-14T19:57:13Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
The boiler plate code to access a dataset via the hugging face file system is very useful. Please addd
## Add Polars (R) option
The equivailent code works, because the [Polars-R](https://github.com/pola-rs/r-polars) wrapper has hugging faces funcitonaliy as well.
```r
library(polars)
df <- pl$read_parquet("hf://datasets/SALURBAL/core__admin_cube_public/core__admin_cube_public.parquet")
```
## Polars (python) option

## Libraries Currently

### Motivation
There are many data/analysis/research/statistics teams (particularly in academia and pharma) that use R as the default language. R has great integration with most of the newer data techs (arrow, parquet, polars) and having this included could really help in bringing this community into the hugging faces ecosystem.
**This is a small/low-hanging-fruit front end change but would make a big impact expanding the community**
### Your contribution
I am not sure which repositroy this should be in, but I have experience in R, Python and JS and happy to submit a PR in the appropriate repository.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7226/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7226/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5684
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5684/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5684/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5684/events
|
https://github.com/huggingface/datasets/pull/5684
| 1,646,013,226
|
PR_kwDODunzps5NLXWm
| 5,684
|
Release: 2.11.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007017 / 0.011353 (-0.004335) | 0.004917 / 0.011008 (-0.006091) | 0.098391 / 0.038508 (0.059883) | 0.032677 / 0.023109 (0.009568) | 0.312126 / 0.275898 (0.036227) | 0.352477 / 0.323480 (0.028998) | 0.005960 / 0.007986 (-0.002025) | 0.003801 / 0.004328 (-0.000528) | 0.073916 / 0.004250 (0.069666) | 0.045610 / 0.037052 (0.008557) | 0.319626 / 0.258489 (0.061137) | 0.370575 / 0.293841 (0.076734) | 0.035888 / 0.128546 (-0.092658) | 0.012012 / 0.075646 (-0.063635) | 0.338290 / 0.419271 (-0.080982) | 0.049452 / 0.043533 (0.005919) | 0.301226 / 0.255139 (0.046087) | 0.336744 / 0.283200 (0.053545) | 0.100835 / 0.141683 (-0.040847) | 1.500008 / 1.452155 (0.047853) | 1.566757 / 1.492716 (0.074041) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220668 / 0.018006 (0.202662) | 0.449273 / 0.000490 (0.448784) | 0.003861 / 0.000200 (0.003661) | 0.000126 / 0.000054 (0.000072) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026847 / 0.037411 (-0.010565) | 0.105916 / 0.014526 (0.091390) | 0.116245 / 0.176557 (-0.060312) | 0.172617 / 0.737135 (-0.564519) | 0.122846 / 0.296338 (-0.173492) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.417906 / 0.215209 (0.202697) | 4.169092 / 2.077655 (2.091437) | 1.934439 / 1.504120 (0.430319) | 1.735718 / 1.541195 (0.194523) | 1.828205 / 1.468490 (0.359715) | 0.697446 / 4.584777 (-3.887331) | 3.802830 / 3.745712 (0.057118) | 3.686464 / 5.269862 (-1.583398) | 1.863924 / 4.565676 (-2.701752) | 0.086520 / 0.424275 (-0.337755) | 0.012101 / 0.007607 (0.004493) | 0.521252 / 0.226044 (0.295208) | 5.200937 / 2.268929 (2.932009) | 2.414290 / 55.444624 (-53.030334) | 2.070890 / 6.876477 (-4.805587) | 2.237693 / 2.142072 (0.095621) | 0.843417 / 4.805227 (-3.961811) | 0.167856 / 6.500664 (-6.332809) | 0.064997 / 0.075469 (-0.010472) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.212334 / 1.841788 (-0.629454) | 14.710632 / 8.074308 (6.636324) | 14.877489 / 10.191392 (4.686097) | 0.151268 / 0.680424 (-0.529156) | 0.018663 / 0.534201 (-0.515538) | 0.429678 / 0.579283 (-0.149605) | 0.425054 / 0.434364 (-0.009310) | 0.502804 / 0.540337 (-0.037533) | 0.587932 / 1.386936 (-0.799004) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007462 / 0.011353 (-0.003891) | 0.005307 / 0.011008 (-0.005701) | 0.074309 / 0.038508 (0.035801) | 0.033437 / 0.023109 (0.010328) | 0.355087 / 0.275898 (0.079189) | 0.391417 / 0.323480 (0.067937) | 0.005904 / 0.007986 (-0.002082) | 0.004062 / 0.004328 (-0.000266) | 0.073801 / 0.004250 (0.069550) | 0.048503 / 0.037052 (0.011451) | 0.359547 / 0.258489 (0.101058) | 0.405325 / 0.293841 (0.111484) | 0.036615 / 0.128546 (-0.091931) | 0.012185 / 0.075646 (-0.063461) | 0.086829 / 0.419271 (-0.332443) | 0.049101 / 0.043533 (0.005569) | 0.334259 / 0.255139 (0.079120) | 0.376317 / 0.283200 (0.093117) | 0.099935 / 0.141683 (-0.041748) | 1.483166 / 1.452155 (0.031011) | 1.569092 / 1.492716 (0.076375) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.207528 / 0.018006 (0.189521) | 0.437473 / 0.000490 (0.436983) | 0.004915 / 0.000200 (0.004715) | 0.000097 / 0.000054 (0.000043) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028632 / 0.037411 (-0.008780) | 0.111782 / 0.014526 (0.097256) | 0.122545 / 0.176557 (-0.054011) | 0.171191 / 0.737135 (-0.565945) | 0.128999 / 0.296338 (-0.167339) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424422 / 0.215209 (0.209213) | 4.239488 / 2.077655 (2.161833) | 2.027969 / 1.504120 (0.523849) | 1.800667 / 1.541195 (0.259473) | 1.898701 / 1.468490 (0.430211) | 0.711453 / 4.584777 (-3.873324) | 3.766696 / 3.745712 (0.020984) | 2.107530 / 5.269862 (-3.162331) | 1.347137 / 4.565676 (-3.218540) | 0.086823 / 0.424275 (-0.337452) | 0.012137 / 0.007607 (0.004530) | 0.523143 / 0.226044 (0.297099) | 5.273434 / 2.268929 (3.004505) | 2.545463 / 55.444624 (-52.899161) | 2.246683 / 6.876477 (-4.629793) | 2.296862 / 2.142072 (0.154789) | 0.855690 / 4.805227 (-3.949538) | 0.168526 / 6.500664 (-6.332138) | 0.063392 / 0.075469 (-0.012078) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.248926 / 1.841788 (-0.592862) | 14.676308 / 8.074308 (6.602000) | 14.524364 / 10.191392 (4.332972) | 0.184138 / 0.680424 (-0.496286) | 0.017259 / 0.534201 (-0.516942) | 0.433875 / 0.579283 (-0.145408) | 0.416787 / 0.434364 (-0.017577) | 0.532391 / 0.540337 (-0.007947) | 0.628572 / 1.386936 (-0.758364) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006469 / 0.011353 (-0.004884) | 0.004499 / 0.011008 (-0.006510) | 0.098856 / 0.038508 (0.060348) | 0.027753 / 0.023109 (0.004644) | 0.321348 / 0.275898 (0.045450) | 0.351480 / 0.323480 (0.028000) | 0.004949 / 0.007986 (-0.003036) | 0.004655 / 0.004328 (0.000327) | 0.076732 / 0.004250 (0.072482) | 0.036175 / 0.037052 (-0.000878) | 0.310111 / 0.258489 (0.051622) | 0.372427 / 0.293841 (0.078586) | 0.031947 / 0.128546 (-0.096599) | 0.011669 / 0.075646 (-0.063977) | 0.323086 / 0.419271 (-0.096186) | 0.043578 / 0.043533 (0.000045) | 0.325549 / 0.255139 (0.070410) | 0.363827 / 0.283200 (0.080627) | 0.087819 / 0.141683 (-0.053864) | 1.479429 / 1.452155 (0.027274) | 1.549797 / 1.492716 (0.057080) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.178502 / 0.018006 (0.160496) | 0.415954 / 0.000490 (0.415465) | 0.008767 / 0.000200 (0.008567) | 0.000429 / 0.000054 (0.000375) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023639 / 0.037411 (-0.013772) | 0.096266 / 0.014526 (0.081740) | 0.106406 / 0.176557 (-0.070151) | 0.168819 / 0.737135 (-0.568317) | 0.109158 / 0.296338 (-0.187181) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.420729 / 0.215209 (0.205520) | 4.219469 / 2.077655 (2.141814) | 1.885673 / 1.504120 (0.381553) | 1.681868 / 1.541195 (0.140674) | 1.709240 / 1.468490 (0.240749) | 0.694763 / 4.584777 (-3.890014) | 3.395377 / 3.745712 (-0.350335) | 1.846811 / 5.269862 (-3.423051) | 1.158381 / 4.565676 (-3.407296) | 0.082717 / 0.424275 (-0.341558) | 0.012302 / 0.007607 (0.004695) | 0.518148 / 0.226044 (0.292103) | 5.189590 / 2.268929 (2.920661) | 2.294127 / 55.444624 (-53.150498) | 1.960080 / 6.876477 (-4.916397) | 2.045359 / 2.142072 (-0.096713) | 0.803739 / 4.805227 (-4.001488) | 0.152322 / 6.500664 (-6.348342) | 0.067051 / 0.075469 (-0.008418) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.206582 / 1.841788 (-0.635206) | 13.590515 / 8.074308 (5.516207) | 14.083739 / 10.191392 (3.892347) | 0.128738 / 0.680424 (-0.551686) | 0.016577 / 0.534201 (-0.517624) | 0.375499 / 0.579283 (-0.203784) | 0.383256 / 0.434364 (-0.051108) | 0.439441 / 0.540337 (-0.100896) | 0.518102 / 1.386936 (-0.868834) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006708 / 0.011353 (-0.004645) | 0.004591 / 0.011008 (-0.006417) | 0.076512 / 0.038508 (0.038004) | 0.027977 / 0.023109 (0.004868) | 0.341915 / 0.275898 (0.066017) | 0.374381 / 0.323480 (0.050901) | 0.004985 / 0.007986 (-0.003001) | 0.003374 / 0.004328 (-0.000954) | 0.075334 / 0.004250 (0.071083) | 0.037522 / 0.037052 (0.000470) | 0.341702 / 0.258489 (0.083213) | 0.384342 / 0.293841 (0.090501) | 0.032231 / 0.128546 (-0.096315) | 0.011494 / 0.075646 (-0.064153) | 0.084897 / 0.419271 (-0.334375) | 0.041914 / 0.043533 (-0.001619) | 0.342030 / 0.255139 (0.086891) | 0.371024 / 0.283200 (0.087825) | 0.089936 / 0.141683 (-0.051746) | 1.497242 / 1.452155 (0.045087) | 1.585203 / 1.492716 (0.092486) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.227681 / 0.018006 (0.209674) | 0.398995 / 0.000490 (0.398505) | 0.003232 / 0.000200 (0.003032) | 0.000073 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024705 / 0.037411 (-0.012706) | 0.099906 / 0.014526 (0.085380) | 0.106806 / 0.176557 (-0.069750) | 0.157521 / 0.737135 (-0.579614) | 0.110803 / 0.296338 (-0.185535) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.457442 / 0.215209 (0.242233) | 4.580101 / 2.077655 (2.502446) | 2.094687 / 1.504120 (0.590567) | 1.880722 / 1.541195 (0.339528) | 1.938746 / 1.468490 (0.470256) | 0.700933 / 4.584777 (-3.883844) | 3.416278 / 3.745712 (-0.329434) | 2.852183 / 5.269862 (-2.417679) | 1.602659 / 4.565676 (-2.963017) | 0.083949 / 0.424275 (-0.340326) | 0.012255 / 0.007607 (0.004648) | 0.551631 / 0.226044 (0.325586) | 5.539225 / 2.268929 (3.270296) | 2.707298 / 55.444624 (-52.737326) | 2.354720 / 6.876477 (-4.521757) | 2.320790 / 2.142072 (0.178717) | 0.807152 / 4.805227 (-3.998075) | 0.152048 / 6.500664 (-6.348616) | 0.067723 / 0.075469 (-0.007746) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.295690 / 1.841788 (-0.546097) | 13.738082 / 8.074308 (5.663774) | 14.129549 / 10.191392 (3.938157) | 0.161568 / 0.680424 (-0.518855) | 0.016678 / 0.534201 (-0.517522) | 0.386609 / 0.579283 (-0.192674) | 0.383538 / 0.434364 (-0.050826) | 0.477872 / 0.540337 (-0.062465) | 0.564547 / 1.386936 (-0.822389) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007247 / 0.011353 (-0.004106) | 0.005044 / 0.011008 (-0.005964) | 0.095135 / 0.038508 (0.056627) | 0.033622 / 0.023109 (0.010513) | 0.309969 / 0.275898 (0.034071) | 0.340354 / 0.323480 (0.016875) | 0.005635 / 0.007986 (-0.002351) | 0.003938 / 0.004328 (-0.000391) | 0.072089 / 0.004250 (0.067838) | 0.045592 / 0.037052 (0.008539) | 0.316620 / 0.258489 (0.058131) | 0.358174 / 0.293841 (0.064333) | 0.036446 / 0.128546 (-0.092100) | 0.011961 / 0.075646 (-0.063685) | 0.332299 / 0.419271 (-0.086973) | 0.049955 / 0.043533 (0.006422) | 0.307638 / 0.255139 (0.052499) | 0.331719 / 0.283200 (0.048519) | 0.095115 / 0.141683 (-0.046568) | 1.457960 / 1.452155 (0.005806) | 1.502812 / 1.492716 (0.010096) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.223747 / 0.018006 (0.205740) | 0.444837 / 0.000490 (0.444347) | 0.002583 / 0.000200 (0.002383) | 0.000084 / 0.000054 (0.000030) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026461 / 0.037411 (-0.010951) | 0.103946 / 0.014526 (0.089420) | 0.114355 / 0.176557 (-0.062201) | 0.170076 / 0.737135 (-0.567059) | 0.121087 / 0.296338 (-0.175252) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.403252 / 0.215209 (0.188043) | 4.016911 / 2.077655 (1.939257) | 1.787168 / 1.504120 (0.283048) | 1.605206 / 1.541195 (0.064012) | 1.657012 / 1.468490 (0.188522) | 0.701425 / 4.584777 (-3.883352) | 3.818308 / 3.745712 (0.072596) | 3.493757 / 5.269862 (-1.776105) | 1.860534 / 4.565676 (-2.705142) | 0.084994 / 0.424275 (-0.339281) | 0.011904 / 0.007607 (0.004297) | 0.534199 / 0.226044 (0.308155) | 4.992703 / 2.268929 (2.723774) | 2.286231 / 55.444624 (-53.158393) | 1.918163 / 6.876477 (-4.958314) | 2.029811 / 2.142072 (-0.112262) | 0.837532 / 4.805227 (-3.967695) | 0.168545 / 6.500664 (-6.332119) | 0.062866 / 0.075469 (-0.012604) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.172862 / 1.841788 (-0.668926) | 14.966793 / 8.074308 (6.892485) | 14.202079 / 10.191392 (4.010687) | 0.144688 / 0.680424 (-0.535736) | 0.017499 / 0.534201 (-0.516702) | 0.443081 / 0.579283 (-0.136202) | 0.427496 / 0.434364 (-0.006868) | 0.525182 / 0.540337 (-0.015155) | 0.611849 / 1.386936 (-0.775087) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007264 / 0.011353 (-0.004089) | 0.005106 / 0.011008 (-0.005902) | 0.074101 / 0.038508 (0.035593) | 0.033388 / 0.023109 (0.010279) | 0.337108 / 0.275898 (0.061210) | 0.369820 / 0.323480 (0.046340) | 0.005701 / 0.007986 (-0.002284) | 0.003976 / 0.004328 (-0.000353) | 0.073517 / 0.004250 (0.069267) | 0.048741 / 0.037052 (0.011688) | 0.339118 / 0.258489 (0.080629) | 0.398687 / 0.293841 (0.104846) | 0.036661 / 0.128546 (-0.091886) | 0.012082 / 0.075646 (-0.063564) | 0.086743 / 0.419271 (-0.332529) | 0.050150 / 0.043533 (0.006617) | 0.335572 / 0.255139 (0.080433) | 0.354306 / 0.283200 (0.071107) | 0.102074 / 0.141683 (-0.039609) | 1.442911 / 1.452155 (-0.009244) | 1.531564 / 1.492716 (0.038848) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.183163 / 0.018006 (0.165157) | 0.439273 / 0.000490 (0.438783) | 0.002765 / 0.000200 (0.002565) | 0.000225 / 0.000054 (0.000171) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028185 / 0.037411 (-0.009227) | 0.107337 / 0.014526 (0.092811) | 0.119925 / 0.176557 (-0.056631) | 0.172120 / 0.737135 (-0.565015) | 0.124332 / 0.296338 (-0.172007) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.428750 / 0.215209 (0.213541) | 4.268933 / 2.077655 (2.191279) | 2.050135 / 1.504120 (0.546015) | 1.837567 / 1.541195 (0.296372) | 1.907040 / 1.468490 (0.438549) | 0.694162 / 4.584777 (-3.890615) | 3.831542 / 3.745712 (0.085830) | 3.476580 / 5.269862 (-1.793281) | 1.855097 / 4.565676 (-2.710580) | 0.085816 / 0.424275 (-0.338459) | 0.012195 / 0.007607 (0.004588) | 0.544920 / 0.226044 (0.318876) | 5.332977 / 2.268929 (3.064049) | 2.592097 / 55.444624 (-52.852527) | 2.295411 / 6.876477 (-4.581065) | 2.330803 / 2.142072 (0.188730) | 0.833268 / 4.805227 (-3.971959) | 0.177698 / 6.500664 (-6.322966) | 0.063780 / 0.075469 (-0.011689) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.273361 / 1.841788 (-0.568427) | 14.981380 / 8.074308 (6.907072) | 14.395166 / 10.191392 (4.203774) | 0.186590 / 0.680424 (-0.493834) | 0.017676 / 0.534201 (-0.516525) | 0.432100 / 0.579283 (-0.147183) | 0.422490 / 0.434364 (-0.011874) | 0.531421 / 0.540337 (-0.008916) | 0.628548 / 1.386936 (-0.758388) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009005 / 0.011353 (-0.002348) | 0.005803 / 0.011008 (-0.005205) | 0.103491 / 0.038508 (0.064983) | 0.048099 / 0.023109 (0.024990) | 0.304026 / 0.275898 (0.028128) | 0.340840 / 0.323480 (0.017360) | 0.006782 / 0.007986 (-0.001204) | 0.004625 / 0.004328 (0.000296) | 0.076695 / 0.004250 (0.072445) | 0.057541 / 0.037052 (0.020489) | 0.304015 / 0.258489 (0.045526) | 0.347822 / 0.293841 (0.053981) | 0.037904 / 0.128546 (-0.090642) | 0.012686 / 0.075646 (-0.062960) | 0.368093 / 0.419271 (-0.051179) | 0.051795 / 0.043533 (0.008262) | 0.302553 / 0.255139 (0.047415) | 0.328581 / 0.283200 (0.045381) | 0.108947 / 0.141683 (-0.032736) | 1.449770 / 1.452155 (-0.002385) | 1.541944 / 1.492716 (0.049227) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.207529 / 0.018006 (0.189523) | 0.455313 / 0.000490 (0.454823) | 0.008276 / 0.000200 (0.008076) | 0.000322 / 0.000054 (0.000268) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030564 / 0.037411 (-0.006848) | 0.122790 / 0.014526 (0.108264) | 0.126981 / 0.176557 (-0.049576) | 0.187203 / 0.737135 (-0.549932) | 0.129931 / 0.296338 (-0.166408) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.402680 / 0.215209 (0.187471) | 4.017505 / 2.077655 (1.939850) | 1.801480 / 1.504120 (0.297360) | 1.647984 / 1.541195 (0.106790) | 1.702596 / 1.468490 (0.234106) | 0.717469 / 4.584777 (-3.867308) | 3.793813 / 3.745712 (0.048101) | 2.288014 / 5.269862 (-2.981848) | 1.497545 / 4.565676 (-3.068132) | 0.091241 / 0.424275 (-0.333034) | 0.013115 / 0.007607 (0.005508) | 0.498567 / 0.226044 (0.272522) | 4.990203 / 2.268929 (2.721275) | 2.334983 / 55.444624 (-53.109642) | 2.047888 / 6.876477 (-4.828589) | 2.167825 / 2.142072 (0.025753) | 0.863769 / 4.805227 (-3.941459) | 0.172699 / 6.500664 (-6.327965) | 0.069285 / 0.075469 (-0.006184) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.397331 / 1.841788 (-0.444457) | 16.678240 / 8.074308 (8.603932) | 16.665143 / 10.191392 (6.473751) | 0.151011 / 0.680424 (-0.529412) | 0.018303 / 0.534201 (-0.515898) | 0.445389 / 0.579283 (-0.133894) | 0.444644 / 0.434364 (0.010280) | 0.524647 / 0.540337 (-0.015690) | 0.629747 / 1.386936 (-0.757189) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008853 / 0.011353 (-0.002499) | 0.006196 / 0.011008 (-0.004813) | 0.078595 / 0.038508 (0.040087) | 0.048348 / 0.023109 (0.025239) | 0.347038 / 0.275898 (0.071140) | 0.385807 / 0.323480 (0.062327) | 0.007047 / 0.007986 (-0.000938) | 0.004772 / 0.004328 (0.000443) | 0.076116 / 0.004250 (0.071866) | 0.058805 / 0.037052 (0.021752) | 0.345731 / 0.258489 (0.087242) | 0.401589 / 0.293841 (0.107748) | 0.039349 / 0.128546 (-0.089197) | 0.012949 / 0.075646 (-0.062697) | 0.089761 / 0.419271 (-0.329511) | 0.060001 / 0.043533 (0.016468) | 0.351587 / 0.255139 (0.096448) | 0.377708 / 0.283200 (0.094509) | 0.117391 / 0.141683 (-0.024292) | 1.471622 / 1.452155 (0.019467) | 1.568759 / 1.492716 (0.076042) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.191390 / 0.018006 (0.173384) | 0.469033 / 0.000490 (0.468544) | 0.003615 / 0.000200 (0.003415) | 0.000113 / 0.000054 (0.000059) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032706 / 0.037411 (-0.004706) | 0.127095 / 0.014526 (0.112569) | 0.128755 / 0.176557 (-0.047801) | 0.182590 / 0.737135 (-0.554545) | 0.136939 / 0.296338 (-0.159400) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.427392 / 0.215209 (0.212183) | 4.246708 / 2.077655 (2.169053) | 2.115557 / 1.504120 (0.611437) | 2.021221 / 1.541195 (0.480026) | 2.177559 / 1.468490 (0.709069) | 0.713930 / 4.584777 (-3.870847) | 4.192467 / 3.745712 (0.446755) | 3.645437 / 5.269862 (-1.624424) | 1.964986 / 4.565676 (-2.600690) | 0.089436 / 0.424275 (-0.334839) | 0.012917 / 0.007607 (0.005310) | 0.530468 / 0.226044 (0.304423) | 5.310759 / 2.268929 (3.041831) | 2.613566 / 55.444624 (-52.831058) | 2.350443 / 6.876477 (-4.526034) | 2.385278 / 2.142072 (0.243205) | 0.862838 / 4.805227 (-3.942389) | 0.172246 / 6.500664 (-6.328418) | 0.069570 / 0.075469 (-0.005899) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.310008 / 1.841788 (-0.531780) | 16.557079 / 8.074308 (8.482771) | 15.818145 / 10.191392 (5.626752) | 0.180337 / 0.680424 (-0.500087) | 0.018117 / 0.534201 (-0.516083) | 0.433189 / 0.579283 (-0.146095) | 0.429276 / 0.434364 (-0.005088) | 0.539757 / 0.540337 (-0.000580) | 0.640905 / 1.386936 (-0.746031) |\n\n</details>\n</details>\n\n\n"
] | 2023-03-29T15:06:07Z
| 2023-03-29T18:30:34Z
| 2023-03-29T18:15:54Z
|
MEMBER
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5684/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5684/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5684.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5684",
"merged_at": "2023-03-29T18:15:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5684.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5684"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4720
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4720/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4720/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4720/events
|
https://github.com/huggingface/datasets/issues/4720
| 1,309,980,195
|
I_kwDODunzps5OFLYj
| 4,720
|
Dataset Viewer issue for shamikbose89/lancaster_newsbooks
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/50837285?v=4",
"events_url": "https://api.github.com/users/shamikbose/events{/privacy}",
"followers_url": "https://api.github.com/users/shamikbose/followers",
"following_url": "https://api.github.com/users/shamikbose/following{/other_user}",
"gists_url": "https://api.github.com/users/shamikbose/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shamikbose",
"id": 50837285,
"login": "shamikbose",
"node_id": "MDQ6VXNlcjUwODM3Mjg1",
"organizations_url": "https://api.github.com/users/shamikbose/orgs",
"received_events_url": "https://api.github.com/users/shamikbose/received_events",
"repos_url": "https://api.github.com/users/shamikbose/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shamikbose/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shamikbose/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shamikbose",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"It seems like the list of splits could not be obtained:\r\n\r\n```python\r\n>>> from datasets import get_dataset_split_names\r\n>>> get_dataset_split_names(\"shamikbose89/lancaster_newsbooks\", \"default\")\r\nUsing custom data configuration default\r\nTraceback (most recent call last):\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py\", line 354, in get_dataset_config_info\r\n for split_generator in builder._split_generators(\r\n File \"/home/slesage/.cache/huggingface/modules/datasets_modules/datasets/shamikbose89--lancaster_newsbooks/2d1c63d269bf7b9342accce0a95960b1710ab4bc774248878bd80eb96c1afaf7/lancaster_newsbooks.py\", line 73, in _split_generators\r\n data_dir = dl_manager.download_and_extract(_URL)\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 916, in download_and_extract\r\n return self.extract(self.download(url_or_urls))\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 879, in extract\r\n urlpaths = map_nested(self._extract, path_or_paths, map_tuple=True)\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 348, in map_nested\r\n return function(data_struct)\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 884, in _extract\r\n protocol = _get_extraction_protocol(urlpath, use_auth_token=self.download_config.use_auth_token)\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 388, in _get_extraction_protocol\r\n return _get_extraction_protocol_with_magic_number(f)\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 354, in _get_extraction_protocol_with_magic_number\r\n f.seek(0)\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py\", line 684, in seek\r\n raise ValueError(\"Cannot seek streaming HTTP file\")\r\nValueError: Cannot seek streaming HTTP file\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py\", line 404, in get_dataset_split_names\r\n info = get_dataset_config_info(\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py\", line 359, in get_dataset_config_info\r\n raise SplitsNotFoundError(\"The split names could not be parsed from the dataset config.\") from err\r\ndatasets.inspect.SplitsNotFoundError: The split names could not be parsed from the dataset config.\r\n```\r\n\r\nping @huggingface/datasets ",
"Oh, I removed the 'split' key from `kwargs`. I put it back in, but there's still the same error",
"It looks like the data host doesn't support http range requests, which is necessary to glob inside a ZIP archive in streaming mode. Can you try hosting the dataset elsewhere ? Or download each file separately from https://ota.bodleian.ox.ac.uk/repository/xmlui/handle/20.500.12024/2531 ?",
"@lhoestq Thanks! That seems to have solved it. I can get the splits with the `get_dataset_split_names()` function. The dataset viewer is still not loading properly, though. The new error is\r\n```\r\nStatus code: 400\r\nException: BadZipFile\r\nMessage: File is not a zip file\r\n```\r\n\r\nPS. The dataset loads properly and can be accessed"
] | 2022-07-19T20:00:07Z
| 2022-09-08T16:47:21Z
| 2022-09-08T16:47:21Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Link
https://huggingface.co/datasets/shamikbose89/lancaster_newsbooks
### Description
Status code: 400
Exception: ValueError
Message: Cannot seek streaming HTTP file
I am able to use the dataset loading script locally and it also runs when I'm using the one from the hub, but the viewer still doesn't load
### Owner
Yes
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4720/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4720/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5408
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5408/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5408/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5408/events
|
https://github.com/huggingface/datasets/issues/5408
| 1,519,890,752
|
I_kwDODunzps5al7FA
| 5,408
|
dataset map function could not be hash properly
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/68179274?v=4",
"events_url": "https://api.github.com/users/Tungway1990/events{/privacy}",
"followers_url": "https://api.github.com/users/Tungway1990/followers",
"following_url": "https://api.github.com/users/Tungway1990/following{/other_user}",
"gists_url": "https://api.github.com/users/Tungway1990/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Tungway1990",
"id": 68179274,
"login": "Tungway1990",
"node_id": "MDQ6VXNlcjY4MTc5Mjc0",
"organizations_url": "https://api.github.com/users/Tungway1990/orgs",
"received_events_url": "https://api.github.com/users/Tungway1990/received_events",
"repos_url": "https://api.github.com/users/Tungway1990/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Tungway1990/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Tungway1990/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Tungway1990",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi ! On macos I tried with\r\n- py 3.9.11\r\n- datasets 2.8.0\r\n- transformers 4.25.1\r\n- dill 0.3.4\r\n\r\nand I was able to hash `prepare_dataset` correctly:\r\n```python\r\nfrom datasets.fingerprint import Hasher\r\nHasher.hash(prepare_dataset)\r\n```\r\n\r\nWhat version of transformers do you have ? Can you try to call `Hasher.hash` on the the tokenizer and the feature extractor to see which one can't be hashed ?",
"Thanks for your prompt reply.\r\n\r\nI update datasets version to 2.8.0 and the warning is gong."
] | 2023-01-05T01:59:59Z
| 2023-01-06T13:22:19Z
| 2023-01-06T13:22:18Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
I follow the [blog post](https://huggingface.co/blog/fine-tune-whisper#building-a-demo) to finetune a Cantonese transcribe model.
When using map function to prepare dataset, following warning pop out:
`common_voice = common_voice.map(prepare_dataset,
remove_columns=common_voice.column_names["train"], num_proc=1)`
> Parameter 'function'=<function prepare_dataset at 0x000001D1D9D79A60> of the transform datasets.arrow_dataset.Dataset._map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed.
I read https://github.com/huggingface/datasets/issues/4521 and https://github.com/huggingface/datasets/issues/3178 but cannot solve the issue.
### Steps to reproduce the bug
```python
from datasets import load_dataset, DatasetDict
common_voice = DatasetDict()
common_voice["train"] = load_dataset("mozilla-foundation/common_voice_11_0", "zh-HK",
split="train+validation")
common_voice["test"] = load_dataset("mozilla-foundation/common_voice_11_0", "zh-HK",
split="test")
common_voice = common_voice.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "path", "segment", "up_votes"])
from transformers import WhisperFeatureExtractor, WhisperTokenizer, WhisperProcessor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
tokenizer = WhisperTokenizer.from_pretrained("openai/whisper-small", language="chinese", task="transcribe")
processor = WhisperProcessor.from_pretrained("openai/whisper-small", language="chinese", task="transcribe")
from datasets import Audio
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=16000))
def prepare_dataset(batch):
# load and resample audio data from 48 to 16kHz
audio = batch["audio"]
# compute log-Mel input features from input audio array
batch["input_features"] = feature_extractor(audio["array"],
sampling_rate=audio["sampling_rate"]).input_features[0]
# encode target text to label ids
batch["labels"] = tokenizer(batch["sentence"]).input_ids
return batch
common_voice = common_voice.map(prepare_dataset,
remove_columns=common_voice.column_names["train"], num_proc=1)
```
### Expected behavior
Should be no warning shown.
### Environment info
- `datasets` version: 2.7.0
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.9.12
- PyArrow version: 8.0.0
- Pandas version: 1.3.5
- dill version: 0.3.4
- multiprocess version: 0.70.12.2
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/68179274?v=4",
"events_url": "https://api.github.com/users/Tungway1990/events{/privacy}",
"followers_url": "https://api.github.com/users/Tungway1990/followers",
"following_url": "https://api.github.com/users/Tungway1990/following{/other_user}",
"gists_url": "https://api.github.com/users/Tungway1990/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Tungway1990",
"id": 68179274,
"login": "Tungway1990",
"node_id": "MDQ6VXNlcjY4MTc5Mjc0",
"organizations_url": "https://api.github.com/users/Tungway1990/orgs",
"received_events_url": "https://api.github.com/users/Tungway1990/received_events",
"repos_url": "https://api.github.com/users/Tungway1990/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Tungway1990/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Tungway1990/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Tungway1990",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5408/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5408/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5530
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5530/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5530/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5530/events
|
https://github.com/huggingface/datasets/pull/5530
| 1,582,938,241
|
PR_kwDODunzps5J4W_4
| 5,530
|
Add missing license in `NumpyFormatter`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_url": "https://api.github.com/users/alvarobartt/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/alvarobartt",
"id": 36760800,
"login": "alvarobartt",
"node_id": "MDQ6VXNlcjM2NzYwODAw",
"organizations_url": "https://api.github.com/users/alvarobartt/orgs",
"received_events_url": "https://api.github.com/users/alvarobartt/received_events",
"repos_url": "https://api.github.com/users/alvarobartt/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/alvarobartt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alvarobartt/subscriptions",
"type": "User",
"url": "https://api.github.com/users/alvarobartt",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008837 / 0.011353 (-0.002516) | 0.004608 / 0.011008 (-0.006400) | 0.101821 / 0.038508 (0.063312) | 0.030300 / 0.023109 (0.007191) | 0.301275 / 0.275898 (0.025377) | 0.365027 / 0.323480 (0.041547) | 0.007043 / 0.007986 (-0.000943) | 0.003493 / 0.004328 (-0.000835) | 0.078444 / 0.004250 (0.074194) | 0.036963 / 0.037052 (-0.000089) | 0.310510 / 0.258489 (0.052020) | 0.343769 / 0.293841 (0.049928) | 0.033560 / 0.128546 (-0.094986) | 0.011427 / 0.075646 (-0.064220) | 0.323542 / 0.419271 (-0.095730) | 0.043063 / 0.043533 (-0.000470) | 0.308869 / 0.255139 (0.053730) | 0.326436 / 0.283200 (0.043236) | 0.091775 / 0.141683 (-0.049908) | 1.471020 / 1.452155 (0.018865) | 1.494328 / 1.492716 (0.001612) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.009299 / 0.018006 (-0.008707) | 0.415705 / 0.000490 (0.415215) | 0.002406 / 0.000200 (0.002206) | 0.000066 / 0.000054 (0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022959 / 0.037411 (-0.014452) | 0.097111 / 0.014526 (0.082585) | 0.103399 / 0.176557 (-0.073157) | 0.144385 / 0.737135 (-0.592750) | 0.109069 / 0.296338 (-0.187269) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.417796 / 0.215209 (0.202587) | 4.158198 / 2.077655 (2.080543) | 1.862036 / 1.504120 (0.357916) | 1.650130 / 1.541195 (0.108936) | 1.717150 / 1.468490 (0.248660) | 0.691704 / 4.584777 (-3.893073) | 3.328254 / 3.745712 (-0.417458) | 1.850070 / 5.269862 (-3.419792) | 1.154331 / 4.565676 (-3.411346) | 0.082199 / 0.424275 (-0.342076) | 0.012226 / 0.007607 (0.004619) | 0.522491 / 0.226044 (0.296446) | 5.244181 / 2.268929 (2.975253) | 2.286651 / 55.444624 (-53.157973) | 1.954439 / 6.876477 (-4.922038) | 1.992052 / 2.142072 (-0.150020) | 0.804779 / 4.805227 (-4.000449) | 0.147341 / 6.500664 (-6.353323) | 0.063863 / 0.075469 (-0.011606) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.270778 / 1.841788 (-0.571010) | 13.676378 / 8.074308 (5.602070) | 14.253498 / 10.191392 (4.062106) | 0.170748 / 0.680424 (-0.509676) | 0.028451 / 0.534201 (-0.505750) | 0.395034 / 0.579283 (-0.184249) | 0.407512 / 0.434364 (-0.026852) | 0.466740 / 0.540337 (-0.073598) | 0.564338 / 1.386936 (-0.822598) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006733 / 0.011353 (-0.004620) | 0.004635 / 0.011008 (-0.006373) | 0.075464 / 0.038508 (0.036956) | 0.027732 / 0.023109 (0.004623) | 0.343622 / 0.275898 (0.067724) | 0.380388 / 0.323480 (0.056908) | 0.005177 / 0.007986 (-0.002808) | 0.003435 / 0.004328 (-0.000893) | 0.074546 / 0.004250 (0.070296) | 0.039115 / 0.037052 (0.002063) | 0.342207 / 0.258489 (0.083718) | 0.390324 / 0.293841 (0.096483) | 0.031665 / 0.128546 (-0.096882) | 0.011695 / 0.075646 (-0.063951) | 0.085788 / 0.419271 (-0.333484) | 0.042423 / 0.043533 (-0.001110) | 0.340748 / 0.255139 (0.085609) | 0.372813 / 0.283200 (0.089614) | 0.092395 / 0.141683 (-0.049288) | 1.502158 / 1.452155 (0.050004) | 1.618233 / 1.492716 (0.125516) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224451 / 0.018006 (0.206444) | 0.398712 / 0.000490 (0.398222) | 0.002739 / 0.000200 (0.002539) | 0.000074 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025393 / 0.037411 (-0.012018) | 0.100480 / 0.014526 (0.085954) | 0.106913 / 0.176557 (-0.069644) | 0.148639 / 0.737135 (-0.588496) | 0.110098 / 0.296338 (-0.186240) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.439359 / 0.215209 (0.224150) | 4.396801 / 2.077655 (2.319146) | 2.069809 / 1.504120 (0.565689) | 1.851014 / 1.541195 (0.309820) | 1.885003 / 1.468490 (0.416513) | 0.701387 / 4.584777 (-3.883390) | 3.404943 / 3.745712 (-0.340769) | 1.874506 / 5.269862 (-3.395355) | 1.174925 / 4.565676 (-3.390752) | 0.083282 / 0.424275 (-0.340993) | 0.012352 / 0.007607 (0.004745) | 0.543058 / 0.226044 (0.317013) | 5.458186 / 2.268929 (3.189258) | 2.562159 / 55.444624 (-52.882466) | 2.198810 / 6.876477 (-4.677667) | 2.238976 / 2.142072 (0.096903) | 0.810958 / 4.805227 (-3.994269) | 0.153341 / 6.500664 (-6.347323) | 0.067773 / 0.075469 (-0.007696) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.303938 / 1.841788 (-0.537850) | 14.170363 / 8.074308 (6.096055) | 13.727012 / 10.191392 (3.535620) | 0.129118 / 0.680424 (-0.551306) | 0.016746 / 0.534201 (-0.517455) | 0.382759 / 0.579283 (-0.196524) | 0.391070 / 0.434364 (-0.043294) | 0.461197 / 0.540337 (-0.079141) | 0.557641 / 1.386936 (-0.829295) |\n\n</details>\n</details>\n\n\n"
] | 2023-02-13T19:33:23Z
| 2023-02-14T14:40:41Z
| 2023-02-14T12:23:58Z
|
MEMBER
| null | null | null |
## What's in this PR?
As discussed with @lhoestq in https://github.com/huggingface/datasets/pull/5522, the license for `NumpyFormatter` at `datasets/formatting/np_formatter.py` was missing, but present on the rest of the `formatting/*.py` files. So this PR is basically to include it there.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5530/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5530/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5530.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5530",
"merged_at": "2023-02-14T12:23:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5530.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5530"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6486
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6486/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6486/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6486/events
|
https://github.com/huggingface/datasets/pull/6486
| 2,035,206,206
|
PR_kwDODunzps5hqCSc
| 6,486
|
Fix docs phrasing about supported formats when sharing a dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6486). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005042 / 0.011353 (-0.006311) | 0.003452 / 0.011008 (-0.007557) | 0.061845 / 0.038508 (0.023337) | 0.052042 / 0.023109 (0.028933) | 0.241791 / 0.275898 (-0.034107) | 0.264639 / 0.323480 (-0.058841) | 0.003940 / 0.007986 (-0.004045) | 0.002768 / 0.004328 (-0.001560) | 0.047851 / 0.004250 (0.043600) | 0.037599 / 0.037052 (0.000547) | 0.251462 / 0.258489 (-0.007028) | 0.274737 / 0.293841 (-0.019104) | 0.027723 / 0.128546 (-0.100823) | 0.010510 / 0.075646 (-0.065137) | 0.205581 / 0.419271 (-0.213691) | 0.035504 / 0.043533 (-0.008029) | 0.242380 / 0.255139 (-0.012759) | 0.259791 / 0.283200 (-0.023409) | 0.017752 / 0.141683 (-0.123931) | 1.089289 / 1.452155 (-0.362865) | 1.161958 / 1.492716 (-0.330759) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.094288 / 0.018006 (0.076282) | 0.303253 / 0.000490 (0.302763) | 0.000216 / 0.000200 (0.000016) | 0.000042 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018496 / 0.037411 (-0.018915) | 0.060411 / 0.014526 (0.045885) | 0.074294 / 0.176557 (-0.102262) | 0.122934 / 0.737135 (-0.614201) | 0.074710 / 0.296338 (-0.221629) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.286394 / 0.215209 (0.071185) | 2.806145 / 2.077655 (0.728490) | 1.497071 / 1.504120 (-0.007049) | 1.362254 / 1.541195 (-0.178940) | 1.389642 / 1.468490 (-0.078848) | 0.554503 / 4.584777 (-4.030274) | 2.348029 / 3.745712 (-1.397684) | 2.780862 / 5.269862 (-2.489000) | 1.728058 / 4.565676 (-2.837619) | 0.062617 / 0.424275 (-0.361658) | 0.004901 / 0.007607 (-0.002707) | 0.346267 / 0.226044 (0.120223) | 3.363744 / 2.268929 (1.094815) | 1.826994 / 55.444624 (-53.617630) | 1.560656 / 6.876477 (-5.315820) | 1.561083 / 2.142072 (-0.580990) | 0.643395 / 4.805227 (-4.161832) | 0.116206 / 6.500664 (-6.384458) | 0.042008 / 0.075469 (-0.033461) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.953416 / 1.841788 (-0.888371) | 11.461665 / 8.074308 (3.387357) | 10.623865 / 10.191392 (0.432473) | 0.128071 / 0.680424 (-0.552353) | 0.014277 / 0.534201 (-0.519924) | 0.288810 / 0.579283 (-0.290474) | 0.267575 / 0.434364 (-0.166788) | 0.327422 / 0.540337 (-0.212916) | 0.435151 / 1.386936 (-0.951785) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005242 / 0.011353 (-0.006111) | 0.003515 / 0.011008 (-0.007493) | 0.048483 / 0.038508 (0.009975) | 0.051684 / 0.023109 (0.028575) | 0.276564 / 0.275898 (0.000666) | 0.297582 / 0.323480 (-0.025898) | 0.004117 / 0.007986 (-0.003869) | 0.002610 / 0.004328 (-0.001719) | 0.047811 / 0.004250 (0.043561) | 0.040622 / 0.037052 (0.003569) | 0.280265 / 0.258489 (0.021776) | 0.311719 / 0.293841 (0.017878) | 0.028811 / 0.128546 (-0.099735) | 0.010600 / 0.075646 (-0.065047) | 0.056660 / 0.419271 (-0.362611) | 0.032638 / 0.043533 (-0.010894) | 0.276434 / 0.255139 (0.021295) | 0.299095 / 0.283200 (0.015896) | 0.018483 / 0.141683 (-0.123200) | 1.156382 / 1.452155 (-0.295773) | 1.252205 / 1.492716 (-0.240511) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.097868 / 0.018006 (0.079862) | 0.309438 / 0.000490 (0.308948) | 0.000229 / 0.000200 (0.000029) | 0.000043 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021838 / 0.037411 (-0.015573) | 0.068358 / 0.014526 (0.053832) | 0.080432 / 0.176557 (-0.096125) | 0.119788 / 0.737135 (-0.617348) | 0.081742 / 0.296338 (-0.214597) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.301239 / 0.215209 (0.086030) | 2.962242 / 2.077655 (0.884587) | 1.693918 / 1.504120 (0.189798) | 1.573663 / 1.541195 (0.032468) | 1.583125 / 1.468490 (0.114635) | 0.557267 / 4.584777 (-4.027510) | 2.440048 / 3.745712 (-1.305664) | 2.727572 / 5.269862 (-2.542290) | 1.713557 / 4.565676 (-2.852120) | 0.062526 / 0.424275 (-0.361749) | 0.004982 / 0.007607 (-0.002625) | 0.353850 / 0.226044 (0.127806) | 3.530887 / 2.268929 (1.261958) | 2.047864 / 55.444624 (-53.396761) | 1.770776 / 6.876477 (-5.105701) | 1.757621 / 2.142072 (-0.384451) | 0.633847 / 4.805227 (-4.171381) | 0.114055 / 6.500664 (-6.386609) | 0.040078 / 0.075469 (-0.035391) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.983721 / 1.841788 (-0.858066) | 11.896537 / 8.074308 (3.822229) | 10.529883 / 10.191392 (0.338491) | 0.129593 / 0.680424 (-0.550831) | 0.016213 / 0.534201 (-0.517988) | 0.289623 / 0.579283 (-0.289660) | 0.280073 / 0.434364 (-0.154291) | 0.327446 / 0.540337 (-0.212892) | 0.574847 / 1.386936 (-0.812089) |\n\n</details>\n</details>\n\n\n"
] | 2023-12-11T09:21:22Z
| 2023-12-13T14:21:29Z
| 2023-12-13T14:15:21Z
|
MEMBER
| null | null | null |
Fix docs phrasing.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6486/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6486/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6486.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6486",
"merged_at": "2023-12-13T14:15:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6486.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6486"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6626
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6626/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6626/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6626/events
|
https://github.com/huggingface/datasets/pull/6626
| 2,105,482,522
|
PR_kwDODunzps5lU0I2
| 6,626
|
Raise error on bad split name
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6626). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005085 / 0.011353 (-0.006268) | 0.003592 / 0.011008 (-0.007417) | 0.062591 / 0.038508 (0.024083) | 0.031063 / 0.023109 (0.007954) | 0.247029 / 0.275898 (-0.028869) | 0.273706 / 0.323480 (-0.049774) | 0.004034 / 0.007986 (-0.003951) | 0.002672 / 0.004328 (-0.001657) | 0.048407 / 0.004250 (0.044156) | 0.049229 / 0.037052 (0.012177) | 0.264316 / 0.258489 (0.005827) | 0.284953 / 0.293841 (-0.008888) | 0.027712 / 0.128546 (-0.100834) | 0.010619 / 0.075646 (-0.065027) | 0.210017 / 0.419271 (-0.209254) | 0.035636 / 0.043533 (-0.007897) | 0.252830 / 0.255139 (-0.002309) | 0.278772 / 0.283200 (-0.004428) | 0.017356 / 0.141683 (-0.124326) | 1.140202 / 1.452155 (-0.311953) | 1.204807 / 1.492716 (-0.287909) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.089130 / 0.018006 (0.071123) | 0.300115 / 0.000490 (0.299626) | 0.000213 / 0.000200 (0.000013) | 0.000042 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018352 / 0.037411 (-0.019059) | 0.061431 / 0.014526 (0.046905) | 0.073911 / 0.176557 (-0.102646) | 0.121230 / 0.737135 (-0.615906) | 0.074867 / 0.296338 (-0.221471) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282272 / 0.215209 (0.067063) | 2.737413 / 2.077655 (0.659759) | 1.446651 / 1.504120 (-0.057469) | 1.319686 / 1.541195 (-0.221508) | 1.327479 / 1.468490 (-0.141011) | 0.558003 / 4.584777 (-4.026774) | 2.361623 / 3.745712 (-1.384089) | 2.770436 / 5.269862 (-2.499425) | 1.703450 / 4.565676 (-2.862227) | 0.062034 / 0.424275 (-0.362241) | 0.005070 / 0.007607 (-0.002537) | 0.337265 / 0.226044 (0.111221) | 3.299438 / 2.268929 (1.030509) | 1.781273 / 55.444624 (-53.663351) | 1.512743 / 6.876477 (-5.363734) | 1.530995 / 2.142072 (-0.611077) | 0.630210 / 4.805227 (-4.175017) | 0.116219 / 6.500664 (-6.384445) | 0.042220 / 0.075469 (-0.033249) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.946341 / 1.841788 (-0.895446) | 11.462179 / 8.074308 (3.387871) | 10.603314 / 10.191392 (0.411922) | 0.128826 / 0.680424 (-0.551598) | 0.013994 / 0.534201 (-0.520207) | 0.288142 / 0.579283 (-0.291141) | 0.266941 / 0.434364 (-0.167422) | 0.329392 / 0.540337 (-0.210946) | 0.431720 / 1.386936 (-0.955216) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005303 / 0.011353 (-0.006050) | 0.003587 / 0.011008 (-0.007422) | 0.049437 / 0.038508 (0.010929) | 0.031940 / 0.023109 (0.008831) | 0.276651 / 0.275898 (0.000752) | 0.297240 / 0.323480 (-0.026240) | 0.004202 / 0.007986 (-0.003784) | 0.002709 / 0.004328 (-0.001619) | 0.048647 / 0.004250 (0.044397) | 0.044147 / 0.037052 (0.007095) | 0.291171 / 0.258489 (0.032682) | 0.319297 / 0.293841 (0.025456) | 0.048167 / 0.128546 (-0.080379) | 0.010630 / 0.075646 (-0.065016) | 0.058402 / 0.419271 (-0.360869) | 0.033817 / 0.043533 (-0.009716) | 0.300546 / 0.255139 (0.045407) | 0.319396 / 0.283200 (0.036197) | 0.017736 / 0.141683 (-0.123946) | 1.159590 / 1.452155 (-0.292565) | 1.191778 / 1.492716 (-0.300939) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.088971 / 0.018006 (0.070965) | 0.299721 / 0.000490 (0.299231) | 0.000219 / 0.000200 (0.000019) | 0.000043 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021895 / 0.037411 (-0.015516) | 0.075388 / 0.014526 (0.060862) | 0.087446 / 0.176557 (-0.089111) | 0.126339 / 0.737135 (-0.610796) | 0.089329 / 0.296338 (-0.207010) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.296642 / 0.215209 (0.081433) | 2.916023 / 2.077655 (0.838368) | 1.593180 / 1.504120 (0.089060) | 1.470491 / 1.541195 (-0.070704) | 1.485713 / 1.468490 (0.017223) | 0.577204 / 4.584777 (-4.007573) | 2.436463 / 3.745712 (-1.309249) | 2.651004 / 5.269862 (-2.618858) | 1.754026 / 4.565676 (-2.811651) | 0.064943 / 0.424275 (-0.359332) | 0.005115 / 0.007607 (-0.002492) | 0.362082 / 0.226044 (0.136038) | 3.498198 / 2.268929 (1.229270) | 1.951936 / 55.444624 (-53.492688) | 1.682027 / 6.876477 (-5.194450) | 1.751768 / 2.142072 (-0.390304) | 0.668479 / 4.805227 (-4.136748) | 0.119934 / 6.500664 (-6.380730) | 0.041419 / 0.075469 (-0.034050) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.978145 / 1.841788 (-0.863643) | 11.984984 / 8.074308 (3.910676) | 10.732377 / 10.191392 (0.540985) | 0.141868 / 0.680424 (-0.538555) | 0.015256 / 0.534201 (-0.518945) | 0.288488 / 0.579283 (-0.290795) | 0.276091 / 0.434364 (-0.158273) | 0.330429 / 0.540337 (-0.209908) | 0.423964 / 1.386936 (-0.962972) |\n\n</details>\n</details>\n\n\n"
] | 2024-01-29T13:17:41Z
| 2024-01-29T15:18:25Z
| 2024-01-29T15:12:18Z
|
MEMBER
| null | null | null |
e.g. dashes '-' are not allowed in split names
This should add an error message on datasets with unsupported split names like https://huggingface.co/datasets/open-source-metrics/test
cc @AndreaFrancis
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6626/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6626/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6626.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6626",
"merged_at": "2024-01-29T15:12:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6626.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6626"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4997
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4997/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4997/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4997/events
|
https://github.com/huggingface/datasets/pull/4997
| 1,379,430,711
|
PR_kwDODunzps4_RrBU
| 4,997
|
Add support for parsing JSON files in array form
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-20T13:31:26Z
| 2022-09-20T15:42:40Z
| 2022-09-20T15:40:06Z
|
COLLABORATOR
| null | null | null |
Support parsing JSON files in the array form (top-level object is an array). For simplicity, `json.load` is used for decoding. This means the entire file is loaded into memory. If requested, we can optimize this by introducing a param similar to `lines` in [`pandas.read_json`](https://pandas.pydata.org/docs/reference/api/pandas.read_json.html), which, if set to `True`, would allow us to read in chunks.
Fixes https://github.com/huggingface/datasets/issues/4963
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4997/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4997/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4997.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4997",
"merged_at": "2022-09-20T15:40:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4997.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4997"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6604
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6604/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6604/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6604/events
|
https://github.com/huggingface/datasets/issues/6604
| 2,089,713,945
|
I_kwDODunzps58joEZ
| 6,604
|
Transform fingerprint collisions due to setting fixed random seed
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6687910?v=4",
"events_url": "https://api.github.com/users/normster/events{/privacy}",
"followers_url": "https://api.github.com/users/normster/followers",
"following_url": "https://api.github.com/users/normster/following{/other_user}",
"gists_url": "https://api.github.com/users/normster/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/normster",
"id": 6687910,
"login": "normster",
"node_id": "MDQ6VXNlcjY2ODc5MTA=",
"organizations_url": "https://api.github.com/users/normster/orgs",
"received_events_url": "https://api.github.com/users/normster/received_events",
"repos_url": "https://api.github.com/users/normster/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/normster/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/normster/subscriptions",
"type": "User",
"url": "https://api.github.com/users/normster",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"I've opened a PR with a fix.",
"I don't think the PR fixes the root cause, since it still relies on the `random` library which will often have its seed fixed. I think the builtin `uuid.uuid4()` is a better choice: https://docs.python.org/3/library/uuid.html"
] | 2024-01-19T06:32:25Z
| 2024-01-26T15:05:35Z
| 2024-01-26T15:05:35Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
The transform fingerprinting logic relies on the `random` library for random bits when the function is not hashable (e.g. bound methods as used in `trl`: https://github.com/huggingface/trl/blob/main/trl/trainer/dpo_trainer.py#L356). This causes collisions when the training code sets a fixed random seed, which is common practice: https://github.com/huggingface/alignment-handbook/blob/main/recipes/zephyr-7b-beta/sft/config_full.yaml#L45.
This results in fingerprint collisions which leads to silently loading incorrect cache files corresponding to completely different datasets.
### Steps to reproduce the bug
n/a
### Expected behavior
Use `uuid` v4 instead of `random.getrandbits()`
### Environment info
`datasets` main branch
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6604/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6604/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6031
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6031/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6031/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6031/events
|
https://github.com/huggingface/datasets/issues/6031
| 1,804,183,858
|
I_kwDODunzps5riaky
| 6,031
|
Argument type for map function changes when using `input_columns` for `IterableDataset`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8953934?v=4",
"events_url": "https://api.github.com/users/kwonmha/events{/privacy}",
"followers_url": "https://api.github.com/users/kwonmha/followers",
"following_url": "https://api.github.com/users/kwonmha/following{/other_user}",
"gists_url": "https://api.github.com/users/kwonmha/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kwonmha",
"id": 8953934,
"login": "kwonmha",
"node_id": "MDQ6VXNlcjg5NTM5MzQ=",
"organizations_url": "https://api.github.com/users/kwonmha/orgs",
"received_events_url": "https://api.github.com/users/kwonmha/received_events",
"repos_url": "https://api.github.com/users/kwonmha/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kwonmha/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kwonmha/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kwonmha",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Yes, this is intended."
] | 2023-07-14T05:11:14Z
| 2023-07-14T14:44:15Z
| 2023-07-14T14:44:15Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
I wrote `tokenize(examples)` function as an argument for `map` function for `IterableDataset`.
It process dictionary type `examples` as a parameter.
It is used in `train_dataset = train_dataset.map(tokenize, batched=True)`
No error is raised.
And then, I found some unnecessary keys and values in `examples` so I added `input_columns` argument to `map` function to select keys and values.
It gives me an error saying
```
TypeError: tokenize() takes 1 positional argument but 3 were given.
```
The code below matters.
https://github.com/huggingface/datasets/blob/406b2212263c0d33f267e35b917f410ff6b3bc00/src/datasets/iterable_dataset.py#L687
For example, `inputs = {"a":1, "b":2, "c":3}`.
If `self.input_coluns` is `None`,
`inputs` is a dictionary type variable and `function_args` becomes a `list` of a single `dict` variable.
`function_args` becomes `[{"a":1, "b":2, "c":3}]`
Otherwise, lets say `self.input_columns = ["a", "c"]`
`[inputs[col] for col in self.input_columns]` results in `[1, 3]`.
I think it should be `[{"a":1, "c":3}]`.
I want to ask if the resulting format is intended.
Maybe I can modify `tokenize()` to have 2 parameters in this case instead of having 1 dictionary.
But this is confusing to me.
Or it should be fixed as `[{col:inputs[col] for col in self.input_columns}]`
### Steps to reproduce the bug
Run `map` function of `IterableDataset` with `input_columns` argument.
### Expected behavior
`function_args` looks better to have same format.
I think it should be `[{"a":1, "c":3}]`.
### Environment info
dataset version: 2.12
python: 3.8
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6031/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6031/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6892
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6892/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6892/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6892/events
|
https://github.com/huggingface/datasets/pull/6892
| 2,291,201,347
|
PR_kwDODunzps5vLIlp
| 6,892
|
Add support for categorical/dictionary types
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/342233?v=4",
"events_url": "https://api.github.com/users/EthanSteinberg/events{/privacy}",
"followers_url": "https://api.github.com/users/EthanSteinberg/followers",
"following_url": "https://api.github.com/users/EthanSteinberg/following{/other_user}",
"gists_url": "https://api.github.com/users/EthanSteinberg/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/EthanSteinberg",
"id": 342233,
"login": "EthanSteinberg",
"node_id": "MDQ6VXNlcjM0MjIzMw==",
"organizations_url": "https://api.github.com/users/EthanSteinberg/orgs",
"received_events_url": "https://api.github.com/users/EthanSteinberg/received_events",
"repos_url": "https://api.github.com/users/EthanSteinberg/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/EthanSteinberg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/EthanSteinberg/subscriptions",
"type": "User",
"url": "https://api.github.com/users/EthanSteinberg",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6892). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005388 / 0.011353 (-0.005965) | 0.004004 / 0.011008 (-0.007005) | 0.064037 / 0.038508 (0.025529) | 0.031666 / 0.023109 (0.008557) | 0.236493 / 0.275898 (-0.039405) | 0.269047 / 0.323480 (-0.054432) | 0.005008 / 0.007986 (-0.002977) | 0.002964 / 0.004328 (-0.001364) | 0.049926 / 0.004250 (0.045675) | 0.048092 / 0.037052 (0.011039) | 0.245563 / 0.258489 (-0.012926) | 0.282614 / 0.293841 (-0.011227) | 0.027488 / 0.128546 (-0.101058) | 0.010904 / 0.075646 (-0.064742) | 0.204892 / 0.419271 (-0.214379) | 0.037161 / 0.043533 (-0.006372) | 0.238488 / 0.255139 (-0.016651) | 0.258192 / 0.283200 (-0.025008) | 0.018819 / 0.141683 (-0.122864) | 1.131573 / 1.452155 (-0.320582) | 1.204084 / 1.492716 (-0.288632) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095852 / 0.018006 (0.077846) | 0.300225 / 0.000490 (0.299735) | 0.000217 / 0.000200 (0.000017) | 0.000052 / 0.000054 (-0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018592 / 0.037411 (-0.018819) | 0.062297 / 0.014526 (0.047772) | 0.074344 / 0.176557 (-0.102212) | 0.120654 / 0.737135 (-0.616481) | 0.075567 / 0.296338 (-0.220772) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.287700 / 0.215209 (0.072491) | 2.829536 / 2.077655 (0.751882) | 1.446296 / 1.504120 (-0.057824) | 1.320912 / 1.541195 (-0.220283) | 1.362744 / 1.468490 (-0.105746) | 0.563732 / 4.584777 (-4.021045) | 2.399904 / 3.745712 (-1.345808) | 2.676706 / 5.269862 (-2.593156) | 1.744780 / 4.565676 (-2.820896) | 0.062884 / 0.424275 (-0.361391) | 0.004936 / 0.007607 (-0.002671) | 0.338084 / 0.226044 (0.112040) | 3.309532 / 2.268929 (1.040603) | 1.792791 / 55.444624 (-53.651833) | 1.502038 / 6.876477 (-5.374439) | 1.662417 / 2.142072 (-0.479655) | 0.642835 / 4.805227 (-4.162393) | 0.117002 / 6.500664 (-6.383662) | 0.041880 / 0.075469 (-0.033589) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.974814 / 1.841788 (-0.866974) | 11.430883 / 8.074308 (3.356575) | 10.314734 / 10.191392 (0.123342) | 0.139838 / 0.680424 (-0.540586) | 0.014939 / 0.534201 (-0.519262) | 0.288048 / 0.579283 (-0.291235) | 0.269146 / 0.434364 (-0.165218) | 0.324300 / 0.540337 (-0.216037) | 0.421612 / 1.386936 (-0.965324) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005660 / 0.011353 (-0.005692) | 0.003723 / 0.011008 (-0.007285) | 0.049909 / 0.038508 (0.011401) | 0.033079 / 0.023109 (0.009970) | 0.270940 / 0.275898 (-0.004958) | 0.291173 / 0.323480 (-0.032307) | 0.004336 / 0.007986 (-0.003650) | 0.002793 / 0.004328 (-0.001535) | 0.049619 / 0.004250 (0.045368) | 0.041062 / 0.037052 (0.004010) | 0.285026 / 0.258489 (0.026537) | 0.322119 / 0.293841 (0.028278) | 0.029653 / 0.128546 (-0.098894) | 0.010785 / 0.075646 (-0.064861) | 0.058680 / 0.419271 (-0.360591) | 0.033300 / 0.043533 (-0.010233) | 0.269452 / 0.255139 (0.014313) | 0.285426 / 0.283200 (0.002226) | 0.017655 / 0.141683 (-0.124028) | 1.144713 / 1.452155 (-0.307442) | 1.196828 / 1.492716 (-0.295888) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.096719 / 0.018006 (0.078713) | 0.303532 / 0.000490 (0.303042) | 0.000223 / 0.000200 (0.000023) | 0.000049 / 0.000054 (-0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022620 / 0.037411 (-0.014791) | 0.077057 / 0.014526 (0.062532) | 0.088570 / 0.176557 (-0.087987) | 0.128715 / 0.737135 (-0.608421) | 0.090844 / 0.296338 (-0.205494) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.298101 / 0.215209 (0.082892) | 2.919861 / 2.077655 (0.842206) | 1.608945 / 1.504120 (0.104825) | 1.487756 / 1.541195 (-0.053439) | 1.520800 / 1.468490 (0.052310) | 0.576615 / 4.584777 (-4.008162) | 0.964250 / 3.745712 (-2.781462) | 2.852968 / 5.269862 (-2.416893) | 1.868768 / 4.565676 (-2.696908) | 0.063934 / 0.424275 (-0.360341) | 0.005093 / 0.007607 (-0.002514) | 0.352984 / 0.226044 (0.126939) | 3.507441 / 2.268929 (1.238513) | 1.944467 / 55.444624 (-53.500158) | 1.663985 / 6.876477 (-5.212492) | 1.847029 / 2.142072 (-0.295043) | 0.669228 / 4.805227 (-4.136000) | 0.118990 / 6.500664 (-6.381675) | 0.041788 / 0.075469 (-0.033681) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.004541 / 1.841788 (-0.837247) | 12.525181 / 8.074308 (4.450873) | 10.488167 / 10.191392 (0.296775) | 0.141182 / 0.680424 (-0.539242) | 0.016432 / 0.534201 (-0.517769) | 0.283682 / 0.579283 (-0.295601) | 0.128277 / 0.434364 (-0.306087) | 0.321933 / 0.540337 (-0.218404) | 0.416430 / 1.386936 (-0.970506) |\n\n</details>\n</details>\n\n\n",
"@lhoestq Thanks a ton for helping this get merged!"
] | 2024-05-12T07:15:08Z
| 2024-06-07T15:01:39Z
| 2024-06-07T12:20:42Z
|
CONTRIBUTOR
| null | null | null |
Arrow has a very useful dictionary/categorical type (https://arrow.apache.org/docs/python/generated/pyarrow.dictionary.html). This data type has significant speed, memory and disk benefits over pa.string() when there are only a few unique text strings in a column.
Unfortunately, huggingface datasets currently does not support this type. So huggingface datasets cannot natively read many parquet files that use this datatype .This PR adds support for Huggingface Datasets to read categorical/dictionary data.
Note: This PR functions by simply converting those dictionary/categorical types to strings. This means that huggingface datasets cannot take advantage of the compute benefits of categoricals, but it significantly simplifies logic. At this time, I do not think it makes sense to optimize categorical support within huggingface datasets and that we should only try to optimize later, if necessary.
Closes #5706
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6892/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6892/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6892.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6892",
"merged_at": "2024-06-07T12:20:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6892.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6892"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5444
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5444/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5444/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5444/events
|
https://github.com/huggingface/datasets/issues/5444
| 1,550,185,071
|
I_kwDODunzps5cZfJv
| 5,444
|
info messages logged as warnings
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",
"gists_url": "https://api.github.com/users/davidgilbertson/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/davidgilbertson",
"id": 4443482,
"login": "davidgilbertson",
"node_id": "MDQ6VXNlcjQ0NDM0ODI=",
"organizations_url": "https://api.github.com/users/davidgilbertson/orgs",
"received_events_url": "https://api.github.com/users/davidgilbertson/received_events",
"repos_url": "https://api.github.com/users/davidgilbertson/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/davidgilbertson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davidgilbertson/subscriptions",
"type": "User",
"url": "https://api.github.com/users/davidgilbertson",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Looks like a duplicate of https://github.com/huggingface/datasets/issues/1948. \r\n\r\nI also think these should be logged as INFO messages, but let's see what @lhoestq thinks.",
"It can be considered unexpected to see a `map` function return instantaneously. The warning is here to explain this case by mentioning that the cache was used. I don't expect first time users (only seeing warnings) to guess that the cache works this way",
"Oh, so it's intentional? Do all Hugging Face packages use `warning` when using cache?\r\nI guess feel free to close this issue then.",
"Yes it's intentional for `map`. For `load_dataset` it's also intentional but for a different reason: it shows where in the cache the dataset is located, in case the user wants to clear the cache.",
"OK I see. It's surprising to me that these are considered \"something unexpected happened\", the concept of cache is pretty common.\r\n\r\nHas a user every actually complained that they ran their code once, and it took a minute while the data downloaded, then ran their code again and it ran really fast (and completed successfully) but they were so baffled by the fact that it ran quickly, _and_ didn't set the log level to INFO, _and_ hadn't read the docs (or thought about it) to know that datasets are cached, that they logged an issue asking that this information be output as a warning every time they run their code?\r\n\r\nThat seems like a very niche scenario to cater for, given that the side effect is to flood the console with irrelevant warnings for every other user every other time they run a bit of `datasets` code. And the real world impact is that people TURN OFF warnings, which is a pretty bad habit to get into.\r\n\r\nAnyhoo, if there's no chance I'm going to change your mind, please close the issue :)",
"I see your point and I'm not closed to switching to INFO, but I think those logs are important to make the library less opaque. I also just checked `transformers` scripts and they default to INFO which is nice. However for colab users the default is still WARNING iirc, and it counts as one of the main env where `datasets` is used.\r\n\r\nWe also use progress bars a lot in `datasets`, that are shown if the logger is at the WARNING level. But we offer a function to disable the progress bars if necessary.",
"These kinds of messages are logged as INFO in Transformers, so we should probably be consistent with them"
] | 2023-01-20T01:19:18Z
| 2023-07-12T17:19:31Z
| 2023-07-12T17:19:31Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Code in `datasets` is using `logger.warning` when it should be using `logger.info`.
Some of these are probably a matter of opinion, but I think anything starting with `logger.warning(f"Loading chached` clearly falls into the info category.
Definitions from the Python docs for reference:
* INFO: Confirmation that things are working as expected.
* WARNING: An indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected.
In theory, a user should be able to resolve things such that there are no warnings.
### Steps to reproduce the bug
Load any dataset that's already cached.
### Expected behavior
No output when log level is at the default WARNING level.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.10.102.1-microsoft-standard-WSL2-x86_64-with-glibc2.31
- Python version: 3.10.8
- PyArrow version: 9.0.0
- Pandas version: 1.5.2
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5444/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5444/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/4820
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4820/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4820/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4820/events
|
https://github.com/huggingface/datasets/issues/4820
| 1,335,117,132
|
I_kwDODunzps5PlEVM
| 4,820
|
Terminating: fork() called from a process already using GNU OpenMP, this is unsafe.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/37379131?v=4",
"events_url": "https://api.github.com/users/talhaanwarch/events{/privacy}",
"followers_url": "https://api.github.com/users/talhaanwarch/followers",
"following_url": "https://api.github.com/users/talhaanwarch/following{/other_user}",
"gists_url": "https://api.github.com/users/talhaanwarch/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/talhaanwarch",
"id": 37379131,
"login": "talhaanwarch",
"node_id": "MDQ6VXNlcjM3Mzc5MTMx",
"organizations_url": "https://api.github.com/users/talhaanwarch/orgs",
"received_events_url": "https://api.github.com/users/talhaanwarch/received_events",
"repos_url": "https://api.github.com/users/talhaanwarch/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/talhaanwarch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/talhaanwarch/subscriptions",
"type": "User",
"url": "https://api.github.com/users/talhaanwarch",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
| null |
[] | null |
[
"Fixed by installing either resampy<3 or resampy>=4"
] | 2022-08-10T19:42:33Z
| 2022-08-10T19:53:10Z
| 2022-08-10T19:53:10Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
Hi, when i try to run prepare_dataset function in [fine tuning ASR tutorial 4](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tuning_Wav2Vec2_for_English_ASR.ipynb) , i got this error.
I got this error
Terminating: fork() called from a process already using GNU OpenMP, this is unsafe.
There is no other logs available, so i have no clue what is the cause of it.
```
def prepare_dataset(batch):
audio = batch["path"]
# batched output is "un-batched"
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
batch["input_length"] = len(batch["input_values"])
with processor.as_target_processor():
batch["labels"] = processor(batch["text"]).input_ids
return batch
data = data.map(prepare_dataset, remove_columns=data.column_names["train"],
num_proc=4)
```
Specify the actual results or traceback.
There is no traceback except
`Terminating: fork() called from a process already using GNU OpenMP, this is unsafe.`
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.4.0
- Platform: Linux-5.15.0-43-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 9.0.0
- Pandas version: 1.4.3
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/37379131?v=4",
"events_url": "https://api.github.com/users/talhaanwarch/events{/privacy}",
"followers_url": "https://api.github.com/users/talhaanwarch/followers",
"following_url": "https://api.github.com/users/talhaanwarch/following{/other_user}",
"gists_url": "https://api.github.com/users/talhaanwarch/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/talhaanwarch",
"id": 37379131,
"login": "talhaanwarch",
"node_id": "MDQ6VXNlcjM3Mzc5MTMx",
"organizations_url": "https://api.github.com/users/talhaanwarch/orgs",
"received_events_url": "https://api.github.com/users/talhaanwarch/received_events",
"repos_url": "https://api.github.com/users/talhaanwarch/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/talhaanwarch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/talhaanwarch/subscriptions",
"type": "User",
"url": "https://api.github.com/users/talhaanwarch",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4820/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4820/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6515
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6515/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6515/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6515/events
|
https://github.com/huggingface/datasets/issues/6515
| 2,049,724,251
|
I_kwDODunzps56LE9b
| 6,515
|
Why call http_head() when fsspec_head() succeeds
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12895488?v=4",
"events_url": "https://api.github.com/users/d710055071/events{/privacy}",
"followers_url": "https://api.github.com/users/d710055071/followers",
"following_url": "https://api.github.com/users/d710055071/following{/other_user}",
"gists_url": "https://api.github.com/users/d710055071/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/d710055071",
"id": 12895488,
"login": "d710055071",
"node_id": "MDQ6VXNlcjEyODk1NDg4",
"organizations_url": "https://api.github.com/users/d710055071/orgs",
"received_events_url": "https://api.github.com/users/d710055071/received_events",
"repos_url": "https://api.github.com/users/d710055071/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/d710055071/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/d710055071/subscriptions",
"type": "User",
"url": "https://api.github.com/users/d710055071",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[] | 2023-12-20T02:25:51Z
| 2023-12-26T05:35:46Z
| 2023-12-26T05:35:46Z
|
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
https://github.com/huggingface/datasets/blob/a91582de288d98e94bcb5ab634ca1cfeeff544c5/src/datasets/utils/file_utils.py#L510C1-L523C14
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/12895488?v=4",
"events_url": "https://api.github.com/users/d710055071/events{/privacy}",
"followers_url": "https://api.github.com/users/d710055071/followers",
"following_url": "https://api.github.com/users/d710055071/following{/other_user}",
"gists_url": "https://api.github.com/users/d710055071/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/d710055071",
"id": 12895488,
"login": "d710055071",
"node_id": "MDQ6VXNlcjEyODk1NDg4",
"organizations_url": "https://api.github.com/users/d710055071/orgs",
"received_events_url": "https://api.github.com/users/d710055071/received_events",
"repos_url": "https://api.github.com/users/d710055071/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/d710055071/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/d710055071/subscriptions",
"type": "User",
"url": "https://api.github.com/users/d710055071",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6515/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6515/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5422
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5422/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5422/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5422/events
|
https://github.com/huggingface/datasets/issues/5422
| 1,533,385,239
|
I_kwDODunzps5bZZoX
| 5,422
|
Datasets load error for saved github issues
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7360564?v=4",
"events_url": "https://api.github.com/users/folterj/events{/privacy}",
"followers_url": "https://api.github.com/users/folterj/followers",
"following_url": "https://api.github.com/users/folterj/following{/other_user}",
"gists_url": "https://api.github.com/users/folterj/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/folterj",
"id": 7360564,
"login": "folterj",
"node_id": "MDQ6VXNlcjczNjA1NjQ=",
"organizations_url": "https://api.github.com/users/folterj/orgs",
"received_events_url": "https://api.github.com/users/folterj/received_events",
"repos_url": "https://api.github.com/users/folterj/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/folterj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/folterj/subscriptions",
"type": "User",
"url": "https://api.github.com/users/folterj",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"I can confirm that the error exists!\r\nI'm trying to read 3 parquet files locally:\r\n```python\r\nfrom datasets import load_dataset, Features, Value, ClassLabel\r\n\r\nreview_dataset = load_dataset(\r\n \"parquet\",\r\n data_files={\r\n \"train\": os.path.join(sentiment_analysis_data_path, \"train.parquet\"),\r\n \"validation\": os.path.join(sentiment_analysis_data_path, \"validation.parquet\"),\r\n \"test\": os.path.join(sentiment_analysis_data_path, \"test.parquet\"),\r\n },\r\n)\r\n```\r\n\r\nBut you can fix it, by specifying `features` for `load_dataset()` function like this:\r\n```python\r\nfrom datasets import load_dataset, Features, Value, ClassLabel\r\n\r\nfeatures = Features(\r\n {\r\n \"label\": ClassLabel(\r\n num_classes=3,\r\n names=[\"negative\", \"neutral\", \"positive\"],\r\n ),\r\n \"text\": Value(dtype=\"string\"),\r\n }\r\n)\r\n\r\nreview_dataset = load_dataset(\r\n \"parquet\",\r\n data_files={\r\n \"train\": os.path.join(sentiment_analysis_data_path, \"train.parquet\"),\r\n \"validation\": os.path.join(sentiment_analysis_data_path, \"validation.parquet\"),\r\n \"test\": os.path.join(sentiment_analysis_data_path, \"test.parquet\"),\r\n },\r\n features=features,\r\n)\r\n\r\nprint(review_dataset)\r\n```",
"@Extremesarova I think this is a different issue, but understand using features could be a work-around.\r\nIt seems the field `closed_at` is `null` in many cases.\r\n\r\nI've not found a way to specify only a single feature without (succesfully) specifiying the full and quite detailed set of expected features. Using this features set gives an error the column names don't match.\r\n`features = Features({'closed_at': Value(dtype='timestamp[s]', id=None)})`\r\n\r\n",
"Found this when searching for the same error, looks like based on #3965 it's just an issue with the data. I found that changing `df = pd.DataFrame.from_records(all_issues)` to `df = pd.DataFrame.from_records(all_issues).dropna(axis=1, how='all').drop(['milestone'], axis=1)` from the fetch_issues function fixed the issue. \r\nThe \"milestone\" column seemed to be problematic (only ~50 non null rows) and dropped any columns that were all null as well just in case.",
"I have this same issue. I saved a dataset to disk and now I can't load it.",
"Ok the solution was to use load_from_disk instead of load_dataset.",
"Hi @folterj , I faced same issue while creating `issues_dataset` (https://huggingface.co/learn/nlp-course/chapter5/5?fw=pt). The fix which worked for me was loading the *.jsonl file as pd.read_json and then converting it into a Dataset using datasets API.\r\n```\r\nimport pandas as pd\r\ndf=pd.read_json(\"datasets-issues.jsonl\", lines=True)\r\ndf.head()\r\n\r\nfrom datasets import Dataset\r\nissues_dataset = Dataset.from_pandas(df)\r\nissues_dataset\r\nsample = issues_dataset.shuffle(seed=666).select(range(3))\r\nsample[0]\r\n```",
"I understand some work-around suggestions would be to not use load_dataset(), and instead using a different API function. Another alternative would be using the same function using streaming, as I had already suggested in my original post.\r\nHowever, the fact remains that there is an issue in this function as reported."
] | 2023-01-14T17:29:38Z
| 2023-09-14T11:39:57Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Loading a previously downloaded & saved dataset as described in the HuggingFace course:
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
Gives this error:
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
A work-around I found was to use streaming.
### Steps to reproduce the bug
Reproduce by executing the code provided:
https://huggingface.co/course/chapter5/5?fw=pt
From the heading:
'let’s create a function that can download all the issues from a GitHub repository'
### Expected behavior
No error
### Environment info
Datasets version 2.8.0. Note that version 2.6.1 gives the same error (related to null timestamp).
**[EDIT]**
This is the complete error trace confirming the issue is related to the timestamp (`Couldn't cast array of type timestamp[s] to null`)
```
Using custom data configuration default-950028611d2860c8
Downloading and preparing dataset json/default to [...]/.cache/huggingface/datasets/json/default-950028611d2860c8/0.0.0/0f7e3662623656454fcd2b650f34e886a7db4b9104504885bd462096cc7a9f51...
Downloading data files: 100%|██████████| 1/1 [00:00<?, ?it/s]
Extracting data files: 100%|██████████| 1/1 [00:00<00:00, 500.63it/s]
Generating train split: 2619 examples [00:00, 7155.72 examples/s]Traceback (most recent call last):
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 1831, in _prepare_split_single
writer.write_table(table)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\arrow_writer.py", line 567, in write_table
pa_table = table_cast(pa_table, self._schema)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2282, in table_cast
return cast_table_to_schema(table, schema)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2241, in cast_table_to_schema
arrays = [cast_array_to_feature(table[name], feature) for name, feature in features.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2241, in <listcomp>
arrays = [cast_array_to_feature(table[name], feature) for name, feature in features.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1807, in wrapper
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1807, in <listcomp>
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2035, in cast_array_to_feature
arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2035, in <listcomp>
arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1809, in wrapper
return func(array, *args, **kwargs)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2101, in cast_array_to_feature
return array_cast(array, feature(), allow_number_to_str=allow_number_to_str)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1809, in wrapper
return func(array, *args, **kwargs)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1990, in array_cast
raise TypeError(f"Couldn't cast array of type {array.type} to {pa_type}")
TypeError: Couldn't cast array of type timestamp[s] to null
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Program Files\JetBrains\PyCharm 2022.1.3\plugins\python\helpers\pydev\pydevconsole.py", line 364, in runcode
coro = func()
File "<input>", line 1, in <module>
File "C:\Program Files\JetBrains\PyCharm 2022.1.3\plugins\python\helpers\pydev\_pydev_bundle\pydev_umd.py", line 198, in runfile
pydev_imports.execfile(filename, global_vars, local_vars) # execute the script
File "C:\Program Files\JetBrains\PyCharm 2022.1.3\plugins\python\helpers\pydev\_pydev_imps\_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "[...]\PycharmProjects\TransformersTesting\dataset_issues.py", line 20, in <module>
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\load.py", line 1757, in load_dataset
builder_instance.download_and_prepare(
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 860, in download_and_prepare
self._download_and_prepare(
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 953, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 1706, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 1849, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
Generating train split: 2619 examples [00:19, 7155.72 examples/s]
```
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5422/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5422/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5171
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5171/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5171/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5171/events
|
https://github.com/huggingface/datasets/pull/5171
| 1,425,355,111
|
PR_kwDODunzps5BpsXf
| 5,171
|
Add PB and TB in convert_file_size_to_int
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-27T09:50:31Z
| 2022-10-27T12:14:27Z
| 2022-10-27T12:12:30Z
|
MEMBER
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5171/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5171/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5171.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5171",
"merged_at": "2022-10-27T12:12:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5171.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5171"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5320
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5320/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5320/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5320/events
|
https://github.com/huggingface/datasets/pull/5320
| 1,471,360,910
|
PR_kwDODunzps5ED_UQ
| 5,320
|
[Extract] Place the lock file next to the destination directory
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-01T13:55:49Z
| 2022-12-01T15:36:44Z
| 2022-12-01T15:33:58Z
|
MEMBER
| null | null | null |
Previously it was placed next to the archive to extract, but the archive can be in a read-only directory as noticed in https://github.com/huggingface/datasets/issues/5295
Therefore I moved the lock location to be next to the destination directory, which is required to have write permissions
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5320/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5320/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5320.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5320",
"merged_at": "2022-12-01T15:33:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5320.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5320"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6074
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6074/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6074/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6074/events
|
https://github.com/huggingface/datasets/pull/6074
| 1,822,299,128
|
PR_kwDODunzps5Wb8O_
| 6,074
|
Misc doc improvements
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006616 / 0.011353 (-0.004737) | 0.003915 / 0.011008 (-0.007093) | 0.083271 / 0.038508 (0.044763) | 0.072595 / 0.023109 (0.049485) | 0.307224 / 0.275898 (0.031326) | 0.337244 / 0.323480 (0.013764) | 0.005296 / 0.007986 (-0.002690) | 0.003325 / 0.004328 (-0.001003) | 0.064589 / 0.004250 (0.060339) | 0.056369 / 0.037052 (0.019316) | 0.310829 / 0.258489 (0.052340) | 0.345563 / 0.293841 (0.051722) | 0.030551 / 0.128546 (-0.097995) | 0.008519 / 0.075646 (-0.067127) | 0.286368 / 0.419271 (-0.132903) | 0.052498 / 0.043533 (0.008966) | 0.308735 / 0.255139 (0.053596) | 0.329234 / 0.283200 (0.046034) | 0.022588 / 0.141683 (-0.119095) | 1.453135 / 1.452155 (0.000981) | 1.525956 / 1.492716 (0.033239) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.199417 / 0.018006 (0.181410) | 0.454621 / 0.000490 (0.454131) | 0.004928 / 0.000200 (0.004728) | 0.000079 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028436 / 0.037411 (-0.008975) | 0.083722 / 0.014526 (0.069196) | 0.095162 / 0.176557 (-0.081395) | 0.153434 / 0.737135 (-0.583702) | 0.099480 / 0.296338 (-0.196859) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.384647 / 0.215209 (0.169438) | 3.838406 / 2.077655 (1.760751) | 1.891267 / 1.504120 (0.387148) | 1.751432 / 1.541195 (0.210238) | 1.737443 / 1.468490 (0.268953) | 0.487758 / 4.584777 (-4.097019) | 3.635925 / 3.745712 (-0.109787) | 5.208718 / 5.269862 (-0.061144) | 3.029374 / 4.565676 (-1.536302) | 0.057613 / 0.424275 (-0.366662) | 0.007177 / 0.007607 (-0.000430) | 0.455596 / 0.226044 (0.229552) | 4.559969 / 2.268929 (2.291040) | 2.325321 / 55.444624 (-53.119303) | 2.034924 / 6.876477 (-4.841552) | 2.163869 / 2.142072 (0.021796) | 0.583477 / 4.805227 (-4.221750) | 0.132870 / 6.500664 (-6.367795) | 0.059618 / 0.075469 (-0.015851) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.263751 / 1.841788 (-0.578037) | 19.740004 / 8.074308 (11.665696) | 14.410980 / 10.191392 (4.219588) | 0.170367 / 0.680424 (-0.510057) | 0.018225 / 0.534201 (-0.515976) | 0.390101 / 0.579283 (-0.189182) | 0.404298 / 0.434364 (-0.030066) | 0.455295 / 0.540337 (-0.085043) | 0.621179 / 1.386936 (-0.765757) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006580 / 0.011353 (-0.004773) | 0.004078 / 0.011008 (-0.006930) | 0.065842 / 0.038508 (0.027334) | 0.074494 / 0.023109 (0.051385) | 0.403644 / 0.275898 (0.127746) | 0.430204 / 0.323480 (0.106724) | 0.005343 / 0.007986 (-0.002643) | 0.003366 / 0.004328 (-0.000963) | 0.064858 / 0.004250 (0.060607) | 0.056252 / 0.037052 (0.019200) | 0.412556 / 0.258489 (0.154067) | 0.434099 / 0.293841 (0.140258) | 0.031518 / 0.128546 (-0.097028) | 0.008543 / 0.075646 (-0.067104) | 0.071658 / 0.419271 (-0.347613) | 0.049962 / 0.043533 (0.006430) | 0.398511 / 0.255139 (0.143372) | 0.415908 / 0.283200 (0.132708) | 0.025011 / 0.141683 (-0.116672) | 1.492350 / 1.452155 (0.040195) | 1.552996 / 1.492716 (0.060280) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.204971 / 0.018006 (0.186964) | 0.439965 / 0.000490 (0.439475) | 0.002071 / 0.000200 (0.001872) | 0.000084 / 0.000054 (0.000029) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031673 / 0.037411 (-0.005738) | 0.087529 / 0.014526 (0.073004) | 0.099882 / 0.176557 (-0.076675) | 0.156994 / 0.737135 (-0.580141) | 0.101421 / 0.296338 (-0.194918) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.407480 / 0.215209 (0.192271) | 4.069123 / 2.077655 (1.991468) | 2.081288 / 1.504120 (0.577169) | 1.920367 / 1.541195 (0.379172) | 1.981053 / 1.468490 (0.512563) | 0.481995 / 4.584777 (-4.102782) | 3.546486 / 3.745712 (-0.199226) | 5.133150 / 5.269862 (-0.136712) | 3.056444 / 4.565676 (-1.509232) | 0.056650 / 0.424275 (-0.367625) | 0.007746 / 0.007607 (0.000139) | 0.490891 / 0.226044 (0.264847) | 4.902160 / 2.268929 (2.633232) | 2.564726 / 55.444624 (-52.879899) | 2.234988 / 6.876477 (-4.641489) | 2.387656 / 2.142072 (0.245583) | 0.576315 / 4.805227 (-4.228912) | 0.132065 / 6.500664 (-6.368599) | 0.060728 / 0.075469 (-0.014741) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.370568 / 1.841788 (-0.471220) | 19.883159 / 8.074308 (11.808851) | 14.442066 / 10.191392 (4.250674) | 0.150119 / 0.680424 (-0.530305) | 0.018359 / 0.534201 (-0.515842) | 0.394128 / 0.579283 (-0.185155) | 0.411697 / 0.434364 (-0.022667) | 0.460580 / 0.540337 (-0.079757) | 0.608490 / 1.386936 (-0.778446) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"merging now if you don't mind - this way I can make a patch release"
] | 2023-07-26T12:20:54Z
| 2023-07-27T16:16:28Z
| 2023-07-27T16:16:02Z
|
COLLABORATOR
| null | null | null |
Removes the warning about requiring to write a dataset loading script to define multiple configurations, as the README YAML can be used instead (for simple cases). Also, deletes the section about using the `BatchSampler` in `torch<=1.12.1` to speed up loading, as `torch 1.12.1` is over a year old (and `torch 2.0` has been out for a while).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6074/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6074/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6074.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6074",
"merged_at": "2023-07-27T16:16:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6074.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6074"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5618
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5618/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5618/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5618/events
|
https://github.com/huggingface/datasets/issues/5618
| 1,612,977,934
|
I_kwDODunzps5gJBcO
| 5,618
|
Unpin fsspec < 2023.3.0 once issue fixed
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[] | 2023-03-07T08:41:51Z
| 2023-03-07T13:39:03Z
| 2023-03-07T13:39:03Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
Unpin `fsspec` upper version once root cause of our CI break is fixed.
See:
- #5614
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5618/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5618/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5701
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5701/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5701/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5701/events
|
https://github.com/huggingface/datasets/pull/5701
| 1,652,931,399
|
PR_kwDODunzps5NiSCy
| 5,701
|
Add Dataset.from_spark
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/106995444?v=4",
"events_url": "https://api.github.com/users/maddiedawson/events{/privacy}",
"followers_url": "https://api.github.com/users/maddiedawson/followers",
"following_url": "https://api.github.com/users/maddiedawson/following{/other_user}",
"gists_url": "https://api.github.com/users/maddiedawson/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/maddiedawson",
"id": 106995444,
"login": "maddiedawson",
"node_id": "U_kgDOBmCe9A",
"organizations_url": "https://api.github.com/users/maddiedawson/orgs",
"received_events_url": "https://api.github.com/users/maddiedawson/received_events",
"repos_url": "https://api.github.com/users/maddiedawson/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/maddiedawson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/maddiedawson/subscriptions",
"type": "User",
"url": "https://api.github.com/users/maddiedawson",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"@mariosasko Would you or another HF datasets maintainer be able to review this, please?",
"Amazing ! Great job @maddiedawson \r\n\r\nDo you know if it's possible to also support writing to Parquet using the HF ParquetWriter if `file_format=\"parquet\"` ?\r\n\r\nParquet is often used when people want to stream the data to train models - which is suitable for big datasets. On the other hand Arrow is generally used for local memory mapping with random access.\r\n\r\n> Please note there was a previous PR adding this functionality\r\n\r\nAm I right to say that it uses the spark workers to prepare the Arrow files ? If so this should make the data preparation fast and won't fill up the executor's memory as in the previously proposed PR",
"Thanks for taking a look! Unlike the previous PR's approach, this implementation takes advantage of Spark mapping to distribute file writing over multiple tasks. (Also it doesn't load the entire dataset into memory :) )\r\n\r\nSupporting Parquet here sgtm; I'll modify the PR.\r\n\r\nI also updated the PR description with a common Spark-HF use case that we want to improve.",
"Hey @albertvillanova @lhoestq , would one of you be able to re-review please? Thank you!",
"@lhoestq this is ready for another pass! Thanks so much 🙏 ",
"Friendly ping @lhoestq , also cc @polinaeterna who may be able to help take a look?",
"Merging `main` into this branch should fix the CI",
"Just rebased @lhoestq ",
"Thanks @lhoestq ! Is there a way for me to trigger the github workflow myself to triage the test failure? I'm not able to repro the test failures locally.",
"There were two test issues in the workflow that I wasn't able to reproduce locally:\r\n\r\n- Python 3.7: createDataFrame fails due to a pickling error. I modified the tests to instead write and read from json files\r\n- Python 3.10: A worker crashes for unknown reasons. I modified the spark setup to explicitly specify local mode in case it was trying to do something else; let's see if that fixes the issue",
"Also one more question @lhoestq when is the next datasets release? We're hoping this can make it in",
"I just re-ran the CI.\r\nI think we can do a release right after this PR is merged ;)",
"Thanks all! @lhoestq could we re-run CI again please? I think we have to disable this feature on python 3.7 due to the pickling error. The other failure was due to https://issues.apache.org/jira/browse/SPARK-30952 so I rewrote the df processing",
"Thanks @lhoestq , this is ready for another CI run. I pinned the pyspark version to see if that fixes the pickling issue",
"The remaining CI issues have been addressed! They were\r\n\r\n- dill=0.3.1.1 is incompatible with cloudpickle, used by Spark. The min-dependency tests use this dill version, and those were failing. I added a skip-test annotation to skip Spark tests when using this dill version. This shouldn't be a production issue since if users are using that version of dill, they won't really be able to do anything with Spark anyway.\r\n- One of the Spark APIs used in this feature (mapInArrow) is incompatible with Windows. I filed a Spark ticket for the team to investigate. For the tests, I added another annotation to skip Spark tests on Windows. In the next PR (adding streaming mode), we should be able to support Windows since that won't use mapInArrow.\r\n\r\nI ran the CI on my forked branch: https://github.com/maddiedawson/datasets/pull/2 Everything passes except one instance of tests/test_metric_common.py::LocalMetricTest::test_load_metric_frugalscore; it looks like a flake.\r\n\r\n@lhoestq granted that the CI passes here, is this ok to merge and release? We'd like to put out a blog post tomorrow to broadcast this to Spark users!",
"Thanks @lhoestq ! Could you help take a look at the error please? Seems unrelated...\r\n\r\nFAILED tests/test_arrow_dataset.py::BaseDatasetTest::test_map_multiprocessing_on_disk - NotADirectoryError: [WinError 267] The directory name is invalid: 'C:\\\\Users\\\\RUNNER~1\\\\AppData\\\\Local\\\\Temp\\\\tmptfnrdj4x\\\\cache-5c5687cf5629c97a_00000_of_00002.arrow'\r\n===== 1 failed, 2152 passed, 23 skipped, 20 warnings in 461.68s (0:07:41) =====",
"The blog is live btw! https://www.databricks.com/blog/contributing-spark-loader-for-hugging-face-datasets Hopefully there can be a release today?",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012686 / 0.011353 (0.001333) | 0.006051 / 0.011008 (-0.004957) | 0.123057 / 0.038508 (0.084549) | 0.033238 / 0.023109 (0.010128) | 0.388207 / 0.275898 (0.112309) | 0.393972 / 0.323480 (0.070492) | 0.006645 / 0.007986 (-0.001340) | 0.006715 / 0.004328 (0.002386) | 0.098348 / 0.004250 (0.094097) | 0.041410 / 0.037052 (0.004358) | 0.380123 / 0.258489 (0.121634) | 0.427982 / 0.293841 (0.134141) | 0.052194 / 0.128546 (-0.076352) | 0.018775 / 0.075646 (-0.056871) | 0.399063 / 0.419271 (-0.020209) | 0.061019 / 0.043533 (0.017487) | 0.370943 / 0.255139 (0.115804) | 0.398326 / 0.283200 (0.115127) | 0.136893 / 0.141683 (-0.004790) | 1.777431 / 1.452155 (0.325276) | 1.844354 / 1.492716 (0.351638) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.267296 / 0.018006 (0.249289) | 0.565133 / 0.000490 (0.564643) | 0.005811 / 0.000200 (0.005611) | 0.000122 / 0.000054 (0.000068) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027009 / 0.037411 (-0.010402) | 0.125907 / 0.014526 (0.111381) | 0.122111 / 0.176557 (-0.054445) | 0.189023 / 0.737135 (-0.548112) | 0.140510 / 0.296338 (-0.155829) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.589269 / 0.215209 (0.374060) | 6.038038 / 2.077655 (3.960384) | 2.394681 / 1.504120 (0.890561) | 2.099268 / 1.541195 (0.558073) | 2.105146 / 1.468490 (0.636656) | 1.216304 / 4.584777 (-3.368473) | 5.823110 / 3.745712 (2.077397) | 4.999323 / 5.269862 (-0.270539) | 2.781554 / 4.565676 (-1.784122) | 0.148370 / 0.424275 (-0.275905) | 0.015163 / 0.007607 (0.007556) | 0.775153 / 0.226044 (0.549109) | 7.425314 / 2.268929 (5.156385) | 3.320254 / 55.444624 (-52.124370) | 2.718595 / 6.876477 (-4.157881) | 2.696215 / 2.142072 (0.554142) | 1.452249 / 4.805227 (-3.352978) | 0.281355 / 6.500664 (-6.219309) | 0.088146 / 0.075469 (0.012677) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.495718 / 1.841788 (-0.346070) | 17.498714 / 8.074308 (9.424405) | 20.109705 / 10.191392 (9.918313) | 0.233053 / 0.680424 (-0.447371) | 0.028336 / 0.534201 (-0.505865) | 0.538146 / 0.579283 (-0.041137) | 0.642106 / 0.434364 (0.207742) | 0.597214 / 0.540337 (0.056876) | 0.732219 / 1.386936 (-0.654717) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008153 / 0.011353 (-0.003200) | 0.005605 / 0.011008 (-0.005403) | 0.096159 / 0.038508 (0.057651) | 0.034102 / 0.023109 (0.010992) | 0.428091 / 0.275898 (0.152193) | 0.476535 / 0.323480 (0.153056) | 0.006278 / 0.007986 (-0.001708) | 0.006752 / 0.004328 (0.002424) | 0.100553 / 0.004250 (0.096302) | 0.045546 / 0.037052 (0.008494) | 0.463236 / 0.258489 (0.204747) | 0.502512 / 0.293841 (0.208671) | 0.051014 / 0.128546 (-0.077533) | 0.018499 / 0.075646 (-0.057148) | 0.127587 / 0.419271 (-0.291685) | 0.059254 / 0.043533 (0.015722) | 0.432248 / 0.255139 (0.177109) | 0.462002 / 0.283200 (0.178802) | 0.124918 / 0.141683 (-0.016765) | 1.689740 / 1.452155 (0.237585) | 1.871546 / 1.492716 (0.378830) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.274844 / 0.018006 (0.256838) | 0.570522 / 0.000490 (0.570032) | 0.004008 / 0.000200 (0.003808) | 0.000146 / 0.000054 (0.000091) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025323 / 0.037411 (-0.012088) | 0.116323 / 0.014526 (0.101797) | 0.129434 / 0.176557 (-0.047122) | 0.187069 / 0.737135 (-0.550067) | 0.134459 / 0.296338 (-0.161880) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.633551 / 0.215209 (0.418341) | 6.290078 / 2.077655 (4.212423) | 2.692071 / 1.504120 (1.187951) | 2.354344 / 1.541195 (0.813149) | 2.409260 / 1.468490 (0.940770) | 1.270515 / 4.584777 (-3.314261) | 5.552982 / 3.745712 (1.807270) | 3.041417 / 5.269862 (-2.228444) | 1.920634 / 4.565676 (-2.645043) | 0.142500 / 0.424275 (-0.281775) | 0.014378 / 0.007607 (0.006770) | 0.786444 / 0.226044 (0.560399) | 7.711558 / 2.268929 (5.442630) | 3.439688 / 55.444624 (-52.004936) | 2.742314 / 6.876477 (-4.134163) | 2.800531 / 2.142072 (0.658458) | 1.405843 / 4.805227 (-3.399385) | 0.245322 / 6.500664 (-6.255342) | 0.076662 / 0.075469 (0.001193) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.592961 / 1.841788 (-0.248827) | 18.165647 / 8.074308 (10.091339) | 20.011433 / 10.191392 (9.820041) | 0.240558 / 0.680424 (-0.439866) | 0.026045 / 0.534201 (-0.508156) | 0.529610 / 0.579283 (-0.049674) | 0.652494 / 0.434364 (0.218130) | 0.612284 / 0.540337 (0.071947) | 0.733180 / 1.386936 (-0.653756) |\n\n</details>\n</details>\n\n\n",
"python 3.9.2\r\nGot an error _pickle.PicklingError use Dataset.from_spark.\r\n\r\nDid the dataset import load data from spark dataframe using multi-node Spark cluster\r\ndf = spark.read.parquet(args.input_data).repartition(50)\r\nds = Dataset.from_spark(df, keep_in_memory=True,\r\n cache_dir=\"/pnc-data/data/nuplan/t5_spark/cache_data\")\r\nds.save_to_disk(args.output_data)\r\n\r\nError : \r\n_pickle.PicklingError: Could not serialize object: RuntimeError: It appears that you are attempting to reference SparkContext from a broadcast variable, action, or transforma\r\ntion. SparkContext can only be used on the driver, not in code that it run on workers. For more information, see SPARK-5063.\r\n23/06/16 21:17:20 WARN ExecutorPodsWatchSnapshotSource: Kubernetes client has been closed (this is expected if the application is shutting down.)\r\n",
"Hi @yanzia12138 ! Could you open a new issue please and share the full stack trace ? This will help to know what happened exactly"
] | 2023-04-03T23:51:29Z
| 2023-06-16T16:39:32Z
| 2023-04-26T15:43:39Z
|
CONTRIBUTOR
| null | null | null |
Adds static method Dataset.from_spark to create datasets from Spark DataFrames.
This approach alleviates users of the need to materialize their dataframe---a common use case is that the user loads their dataset into a dataframe, uses Spark to apply some transformation to some of the columns, and then wants to train on the dataset.
Related issue: https://github.com/huggingface/datasets/issues/5678
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 4,
"laugh": 0,
"rocket": 0,
"total_count": 6,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5701/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5701/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5701.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5701",
"merged_at": "2023-04-26T15:43:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5701.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5701"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7536
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7536/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7536/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7536/events
|
https://github.com/huggingface/datasets/issues/7536
| 3,018,425,549
|
I_kwDODunzps6z6YTN
| 7,536
|
[Errno 13] Permission denied: on `.incomplete` file
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1282383?v=4",
"events_url": "https://api.github.com/users/ryan-clancy/events{/privacy}",
"followers_url": "https://api.github.com/users/ryan-clancy/followers",
"following_url": "https://api.github.com/users/ryan-clancy/following{/other_user}",
"gists_url": "https://api.github.com/users/ryan-clancy/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ryan-clancy",
"id": 1282383,
"login": "ryan-clancy",
"node_id": "MDQ6VXNlcjEyODIzODM=",
"organizations_url": "https://api.github.com/users/ryan-clancy/orgs",
"received_events_url": "https://api.github.com/users/ryan-clancy/received_events",
"repos_url": "https://api.github.com/users/ryan-clancy/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ryan-clancy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ryan-clancy/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ryan-clancy",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"It must be an issue with umask being used by multiple threads indeed. Maybe we can try to make a thread safe function to apply the umask (using filelock for example)"
] | 2025-04-24T20:52:45Z
| 2025-04-26T12:40:25Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
When downloading a dataset, we frequently hit the below Permission Denied error. This looks to happen (at least) across datasets in from HF, S3, and GCS.
It looks like the `temp_file` being passed [here](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/file_utils.py#L412) can sometimes be created with `000` permissions leading to the permission denied error (the user running the code is still the owner of the file). Deleting that particular file and re-running the code with 0 changes will usually succeed.
Is there some race condition happening with the [umask](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/file_utils.py#L416), which is process global, and the [file creation](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/file_utils.py#L404)?
```
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
.venv/lib/python3.12/site-packages/datasets/load.py:2084: in load_dataset
builder_instance.download_and_prepare(
.venv/lib/python3.12/site-packages/datasets/builder.py:925: in download_and_prepare
self._download_and_prepare(
.venv/lib/python3.12/site-packages/datasets/builder.py:1649: in _download_and_prepare
super()._download_and_prepare(
.venv/lib/python3.12/site-packages/datasets/builder.py:979: in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
.venv/lib/python3.12/site-packages/datasets/packaged_modules/folder_based_builder/folder_based_builder.py:120: in _split_generators
downloaded_files = dl_manager.download(files)
.venv/lib/python3.12/site-packages/datasets/download/download_manager.py:159: in download
downloaded_path_or_paths = map_nested(
.venv/lib/python3.12/site-packages/datasets/utils/py_utils.py:514: in map_nested
_single_map_nested((function, obj, batched, batch_size, types, None, True, None))
.venv/lib/python3.12/site-packages/datasets/utils/py_utils.py:382: in _single_map_nested
return [mapped_item for batch in iter_batched(data_struct, batch_size) for mapped_item in function(batch)]
.venv/lib/python3.12/site-packages/datasets/download/download_manager.py:206: in _download_batched
return thread_map(
.venv/lib/python3.12/site-packages/tqdm/contrib/concurrent.py:69: in thread_map
return _executor_map(ThreadPoolExecutor, fn, *iterables, **tqdm_kwargs)
.venv/lib/python3.12/site-packages/tqdm/contrib/concurrent.py:51: in _executor_map
return list(tqdm_class(ex.map(fn, *iterables, chunksize=chunksize), **kwargs))
.venv/lib/python3.12/site-packages/tqdm/std.py:1181: in __iter__
for obj in iterable:
../../../_tool/Python/3.12.10/x64/lib/python3.12/concurrent/futures/_base.py:619: in result_iterator
yield _result_or_cancel(fs.pop())
../../../_tool/Python/3.12.10/x64/lib/python3.12/concurrent/futures/_base.py:317: in _result_or_cancel
return fut.result(timeout)
../../../_tool/Python/3.12.10/x64/lib/python3.12/concurrent/futures/_base.py:449: in result
return self.__get_result()
../../../_tool/Python/3.12.10/x64/lib/python3.12/concurrent/futures/_base.py:401: in __get_result
raise self._exception
../../../_tool/Python/3.12.10/x64/lib/python3.12/concurrent/futures/thread.py:59: in run
result = self.fn(*self.args, **self.kwargs)
.venv/lib/python3.12/site-packages/datasets/download/download_manager.py:229: in _download_single
out = cached_path(url_or_filename, download_config=download_config)
.venv/lib/python3.12/site-packages/datasets/utils/file_utils.py:206: in cached_path
output_path = get_from_cache(
.venv/lib/python3.12/site-packages/datasets/utils/file_utils.py:412: in get_from_cache
fsspec_get(url, temp_file, storage_options=storage_options, desc=download_desc, disable_tqdm=disable_tqdm)
.venv/lib/python3.12/site-packages/datasets/utils/file_utils.py:331: in fsspec_get
fs.get_file(path, temp_file.name, callback=callback)
.venv/lib/python3.12/site-packages/fsspec/asyn.py:118: in wrapper
return sync(self.loop, func, *args, **kwargs)
.venv/lib/python3.12/site-packages/fsspec/asyn.py:103: in sync
raise return_result
.venv/lib/python3.12/site-packages/fsspec/asyn.py:56: in _runner
result[0] = await coro
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <s3fs.core.S3FileSystem object at 0x7f27c18b2e70>
rpath = '<my-bucket>/<my-prefix>/img_1.jpg'
lpath = '/home/runner/_work/_temp/hf_cache/downloads/6c97983efa4e24e534557724655df8247a0bd04326cdfc4a95b638c11e78222d.incomplete'
callback = <datasets.utils.file_utils.TqdmCallback object at 0x7f27c00cdbe0>
version_id = None, kwargs = {}
_open_file = <function S3FileSystem._get_file.<locals>._open_file at 0x7f27628d1120>
body = <StreamingBody at 0x7f276344fa80 for ClientResponse at 0x7f27c015fce0>
content_length = 521923, failed_reads = 0, bytes_read = 0
async def _get_file(
self, rpath, lpath, callback=_DEFAULT_CALLBACK, version_id=None, **kwargs
):
if os.path.isdir(lpath):
return
bucket, key, vers = self.split_path(rpath)
async def _open_file(range: int):
kw = self.req_kw.copy()
if range:
kw["Range"] = f"bytes={range}-"
resp = await self._call_s3(
"get_object",
Bucket=bucket,
Key=key,
**version_id_kw(version_id or vers),
**kw,
)
return resp["Body"], resp.get("ContentLength", None)
body, content_length = await _open_file(range=0)
callback.set_size(content_length)
failed_reads = 0
bytes_read = 0
try:
> with open(lpath, "wb") as f0:
E PermissionError: [Errno 13] Permission denied: '/home/runner/_work/_temp/hf_cache/downloads/6c97983efa4e24e534557724655df8247a0bd04326cdfc4a95b638c11e78222d.incomplete'
.venv/lib/python3.12/site-packages/s3fs/core.py:1355: PermissionError
```
### Steps to reproduce the bug
I believe this is a race condition and cannot reliably re-produce it, but it happens fairly frequently in our GitHub Actions tests and can also be re-produced (with lesser frequency) on cloud VMs.
### Expected behavior
The dataset loads properly with no permission denied error.
### Environment info
- `datasets` version: 3.5.0
- Platform: Linux-5.10.0-34-cloud-amd64-x86_64-with-glibc2.31
- Python version: 3.12.10
- `huggingface_hub` version: 0.30.2
- PyArrow version: 19.0.1
- Pandas version: 2.2.3
- `fsspec` version: 2024.12.0
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7536/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7536/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4874
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4874/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4874/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4874/events
|
https://github.com/huggingface/datasets/pull/4874
| 1,347,618,197
|
PR_kwDODunzps49n_nI
| 4,874
|
[docs] Some tiny doc tweaks
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/julien-c",
"id": 326577,
"login": "julien-c",
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"repos_url": "https://api.github.com/users/julien-c/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"type": "User",
"url": "https://api.github.com/users/julien-c",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4874). All of your documentation changes will be reflected on that endpoint."
] | 2022-08-23T09:19:40Z
| 2022-08-24T17:27:57Z
| 2022-08-24T17:27:56Z
|
MEMBER
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/julien-c",
"id": 326577,
"login": "julien-c",
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"repos_url": "https://api.github.com/users/julien-c/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"type": "User",
"url": "https://api.github.com/users/julien-c",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4874/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4874/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4874.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4874",
"merged_at": "2022-08-24T17:27:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4874.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4874"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5566
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5566/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5566/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5566/events
|
https://github.com/huggingface/datasets/issues/5566
| 1,595,916,674
|
I_kwDODunzps5fH8GC
| 5,566
|
Directly reading parquet files in a s3 bucket from the load_dataset method
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/16892570?v=4",
"events_url": "https://api.github.com/users/shamanez/events{/privacy}",
"followers_url": "https://api.github.com/users/shamanez/followers",
"following_url": "https://api.github.com/users/shamanez/following{/other_user}",
"gists_url": "https://api.github.com/users/shamanez/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shamanez",
"id": 16892570,
"login": "shamanez",
"node_id": "MDQ6VXNlcjE2ODkyNTcw",
"organizations_url": "https://api.github.com/users/shamanez/orgs",
"received_events_url": "https://api.github.com/users/shamanez/received_events",
"repos_url": "https://api.github.com/users/shamanez/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shamanez/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shamanez/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shamanez",
"user_view_type": "public"
}
|
[
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
},
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
| null |
[] | null |
[
"Hi ! I think is in the scope of this other issue: to https://github.com/huggingface/datasets/issues/5281 "
] | 2023-02-22T22:13:40Z
| 2023-02-23T11:03:29Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
Right now, we have to read the get the parquet file to the local storage. So having ability to read given the bucket directly address would be benificial
### Motivation
In a production set up, this feature can help us a lot. So we do not need move training datafiles in between storage.
### Your contribution
I am willing to help if there's anyway.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5566/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5566/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4816
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4816/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4816/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4816/events
|
https://github.com/huggingface/datasets/pull/4816
| 1,334,099,454
|
PR_kwDODunzps487kpq
| 4,816
|
Update version of opus_paracrawl dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-08-10T05:39:44Z
| 2022-08-12T14:32:29Z
| 2022-08-12T14:17:56Z
|
MEMBER
| null | null | null |
This PR updates OPUS ParaCrawl from 7.1 to 9 version.
Fix #4815.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4816/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4816/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4816.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4816",
"merged_at": "2022-08-12T14:17:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4816.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4816"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6229
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6229/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6229/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6229/events
|
https://github.com/huggingface/datasets/issues/6229
| 1,889,050,954
|
I_kwDODunzps5wmKFK
| 6,229
|
Apply inference on all images in the dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20493493?v=4",
"events_url": "https://api.github.com/users/andysingal/events{/privacy}",
"followers_url": "https://api.github.com/users/andysingal/followers",
"following_url": "https://api.github.com/users/andysingal/following{/other_user}",
"gists_url": "https://api.github.com/users/andysingal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/andysingal",
"id": 20493493,
"login": "andysingal",
"node_id": "MDQ6VXNlcjIwNDkzNDkz",
"organizations_url": "https://api.github.com/users/andysingal/orgs",
"received_events_url": "https://api.github.com/users/andysingal/received_events",
"repos_url": "https://api.github.com/users/andysingal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/andysingal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/andysingal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/andysingal",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"From what I see, `MMSegInferencer` supports NumPy arrays, so replace the line `image_path = example['image']` with `image_path = np.array(example['image'])` to fix the issue (`example[\"image\"]` is a `PIL.Image` object). ",
"> From what I see, `MMSegInferencer` supports NumPy arrays, so replace the line `image_path = example['image']` with `image_path = np.array(example['image'])` to fix the issue (`example[\"image\"]` is a `PIL.Image` object).\r\n\r\nThanks @mariosasko for your reply...\r\ni tried :\r\n```\r\n# Define a function to apply the code to each image in the dataset\r\ndef process_image(image_path):\r\n print(\"Processing image:\", image_path)\r\n result = inferencer(image_path)['predictions']\r\n mask = np.where(result == 12, 255, 0).astype('uint8')\r\n return Image.fromarray(mask)\r\n\r\n# Process and save masks for each image in the dataset\r\nfor idx, example in enumerate(dataset['train']):\r\n image_path = np.array(example['image'])\r\n mask_image = process_image(image_path)\r\n mask_image.save(f\"mask_{idx}.png\")\r\n```\r\nand got\r\n```\r\nProcessing image: [[[202 165 87]\r\n [203 166 88]\r\n [207 168 91]\r\n ...\r\n [243 205 122]\r\n [244 202 120]\r\n [242 200 118]]\r\n\r\n [[202 165 87]\r\n [203 166 88]\r\n [207 168 91]\r\n ...\r\n [244 206 123]\r\n [245 203 121]\r\n [243 201 119]]\r\n\r\n [[203 164 87]\r\n [204 165 88]\r\n [207 168 91]\r\n ...\r\n [245 207 126]\r\n [246 204 122]\r\n [245 203 121]]\r\n\r\n ...\r\n\r\n [[154 123 56]\r\n [155 124 57]\r\n [158 125 56]\r\n ...\r\n [ 3 3 1]\r\n [ 3 3 1]\r\n [ 3 3 1]]\r\n\r\n [[154 123 56]\r\n [154 123 56]\r\n [155 124 57]\r\n ...\r\n [ 2 2 0]\r\n [ 2 2 0]\r\n [ 2 2 0]]\r\n\r\n [[152 121 54]\r\n [152 121 54]\r\n [153 122 55]\r\n ...\r\n [ 2 2 0]\r\n [ 2 2 0]\r\n [ 2 2 0]]]\r\nInference ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ \r\nProcessing image: [[[ 39 44 40]\r\n [ 39 44 40]\r\n [ 39 43 44]\r\n ...\r\n [187 185 164]\r\n [208 204 175]\r\n [203 198 166]]\r\n\r\n [[ 42 47 43]\r\n [ 40 45 41]\r\n [ 40 44 45]\r\n ...\r\n [188 186 165]\r\n [202 198 169]\r\n [201 196 164]]\r\n\r\n [[ 41 46 42]\r\n [ 39 44 40]\r\n [ 40 44 45]\r\n ...\r\n [187 184 165]\r\n [197 193 166]\r\n [201 196 166]]\r\n\r\n ...\r\n\r\n [[ 29 27 30]\r\n [ 28 26 29]\r\n [ 25 23 26]\r\n ...\r\n [ 48 33 28]\r\n [ 44 31 25]\r\n [ 39 26 20]]\r\n\r\n [[ 34 29 33]\r\n [ 32 27 31]\r\n [ 29 24 28]\r\n ...\r\n [ 30 17 11]\r\n [ 36 23 15]\r\n [ 41 28 20]]\r\n\r\n [[ 35 30 34]\r\n [ 33 28 32]\r\n [ 28 23 27]\r\n ...\r\n [ 28 15 9]\r\n [ 41 28 20]\r\n [ 46 33 25]]]\r\nInference ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ \r\nProcessing image: [[[ 65 53 55]\r\n [ 65 53 55]\r\n [ 51 39 41]\r\n ...\r\n [133 127 111]\r\n [150 141 124]\r\n [133 124 107]]\r\n\r\n [[ 58 45 52]\r\n [ 61 48 55]\r\n [ 51 38 45]\r\n ...\r\n [148 141 123]\r\n [178 169 152]\r\n [144 135 118]]\r\n\r\n [[ 79 66 83]\r\n [ 73 60 77]\r\n [ 65 51 66]\r\n ...\r\n [140 131 114]\r\n [142 133 116]\r\n [147 136 118]]\r\n\r\n ...\r\n\r\n [[132 122 133]\r\n [ 95 85 94]\r\n [ 61 51 60]\r\n ...\r\n [ 39 28 42]\r\n [ 46 36 45]\r\n [ 25 16 21]]\r\n\r\n [[150 143 151]\r\n [114 107 115]\r\n [ 64 54 63]\r\n ...\r\n [ 47 35 47]\r\n [ 38 27 35]\r\n [140 129 133]]\r\n\r\n [[145 138 146]\r\n [115 108 116]\r\n [ 69 59 67]\r\n ...\r\n [ 31 19 31]\r\n [128 117 123]\r\n [196 185 189]]]\r\nInference ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ \r\nProcessing image: [[[159 151 140]\r\n [171 163 152]\r\n [161 148 142]\r\n ...\r\n [198 184 171]\r\n [189 175 162]\r\n [183 169 156]]\r\n\r\n [[128 118 106]\r\n [138 128 116]\r\n [138 125 116]\r\n ...\r\n [200 186 173]\r\n [190 176 163]\r\n [187 173 160]]\r\n\r\n [[165 153 137]\r\n [170 158 142]\r\n [174 162 148]\r\n ...\r\n [200 187 171]\r\n [188 175 159]\r\n [182 169 153]]\r\n```\r\nHowever , when trying to add to:\r\n```\r\nfrom datasets import load_dataset\r\ndataset = load_dataset('Andyrasika/cat_kingdom')\r\ndataset\r\n```\r\ni did \r\n```\r\nnew_column = [\"mask\"] * len(dataset[\"train\"])\r\nnew_column\r\ndataset = dataset.add_column(\"/workspace/data\", new_column)\r\n\r\nprint(dataset)\r\n```\r\ngot error:\r\n```\r\n---------------------------------------------------------------------------\r\nAttributeError Traceback (most recent call last)\r\nCell In[11], line 3\r\n 1 new_column = [\"mask\"] * len(dataset[\"train\"])\r\n 2 new_column\r\n----> 3 dataset = dataset.add_column(\"/workspace/data\", new_column)\r\n 5 print(dataset)\r\n\r\nAttributeError: 'DatasetDict' object has no attribute 'add_column'\r\n```",
"https://github.com/huggingface/datasets/issues/6246 resolved the `add_column` error, so I'm closing this issue :) "
] | 2023-09-10T08:36:12Z
| 2023-09-20T16:11:53Z
| 2023-09-20T16:11:52Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
```
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
Cell In[14], line 11
9 for idx, example in enumerate(dataset['train']):
10 image_path = example['image']
---> 11 mask_image = process_image(image_path)
12 mask_image.save(f"mask_{idx}.png")
Cell In[14], line 4, in process_image(image_path)
2 def process_image(image_path):
3 print("Processing image:", image_path)
----> 4 result = inferencer(image_path)['predictions']
5 mask = np.where(result == 12, 255, 0).astype('uint8')
6 return Image.fromarray(mask)
File /usr/local/lib/python3.10/dist-packages/mmseg/apis/mmseg_inferencer.py:183, in MMSegInferencer.__call__(self, inputs, return_datasamples, batch_size, show, wait_time, out_dir, img_out_dir, pred_out_dir, **kwargs)
180 pred_out_dir = ''
181 img_out_dir = ''
--> 183 return super().__call__(
184 inputs=inputs,
185 return_datasamples=return_datasamples,
186 batch_size=batch_size,
187 show=show,
188 wait_time=wait_time,
189 img_out_dir=img_out_dir,
190 pred_out_dir=pred_out_dir,
191 **kwargs)
File /usr/local/lib/python3.10/dist-packages/mmengine/infer/infer.py:221, in BaseInferencer.__call__(self, inputs, return_datasamples, batch_size, **kwargs)
218 inputs = self.preprocess(
219 ori_inputs, batch_size=batch_size, **preprocess_kwargs)
220 preds = []
--> 221 for data in (track(inputs, description='Inference')
222 if self.show_progress else inputs):
223 preds.extend(self.forward(data, **forward_kwargs))
224 visualization = self.visualize(
225 ori_inputs, preds,
226 **visualize_kwargs) # type: ignore # noqa: E501
File /usr/local/lib/python3.10/dist-packages/rich/progress.py:168, in track(sequence, description, total, auto_refresh, console, transient, get_time, refresh_per_second, style, complete_style, finished_style, pulse_style, update_period, disable, show_speed)
157 progress = Progress(
158 *columns,
159 auto_refresh=auto_refresh,
(...)
164 disable=disable,
165 )
167 with progress:
--> 168 yield from progress.track(
169 sequence, total=total, description=description, update_period=update_period
170 )
File /usr/local/lib/python3.10/dist-packages/rich/progress.py:1210, in Progress.track(self, sequence, total, task_id, description, update_period)
1208 if self.live.auto_refresh:
1209 with _TrackThread(self, task_id, update_period) as track_thread:
-> 1210 for value in sequence:
1211 yield value
1212 track_thread.completed += 1
File /usr/local/lib/python3.10/dist-packages/mmengine/infer/infer.py:291, in BaseInferencer.preprocess(self, inputs, batch_size, **kwargs)
266 """Process the inputs into a model-feedable format.
267
268 Customize your preprocess by overriding this method. Preprocess should
(...)
287 Any: Data processed by the ``pipeline`` and ``collate_fn``.
288 """
289 chunked_data = self._get_chunk_data(
290 map(self.pipeline, inputs), batch_size)
--> 291 yield from map(self.collate_fn, chunked_data)
File /usr/local/lib/python3.10/dist-packages/mmengine/infer/infer.py:588, in BaseInferencer._get_chunk_data(self, inputs, chunk_size)
586 chunk_data = []
587 for _ in range(chunk_size):
--> 588 processed_data = next(inputs_iter)
589 chunk_data.append(processed_data)
590 yield chunk_data
File /usr/local/lib/python3.10/dist-packages/mmcv/transforms/base.py:12, in BaseTransform.__call__(self, results)
9 def __call__(self,
10 results: Dict) -> Optional[Union[Dict, Tuple[List, List]]]:
---> 12 return self.transform(results)
File /usr/local/lib/python3.10/dist-packages/mmcv/transforms/wrappers.py:88, in Compose.transform(self, results)
79 """Call function to apply transforms sequentially.
80
81 Args:
(...)
85 dict or None: Transformed results.
86 """
87 for t in self.transforms:
---> 88 results = t(results) # type: ignore
89 if results is None:
90 return None
File /usr/local/lib/python3.10/dist-packages/mmcv/transforms/base.py:12, in BaseTransform.__call__(self, results)
9 def __call__(self,
10 results: Dict) -> Optional[Union[Dict, Tuple[List, List]]]:
---> 12 return self.transform(results)
File /usr/local/lib/python3.10/dist-packages/mmseg/datasets/transforms/loading.py:496, in InferencerLoader.transform(self, single_input)
494 inputs = single_input
495 else:
--> 496 raise NotImplementedError
498 if 'img' in inputs:
499 return self.from_ndarray(inputs)
NotImplementedError:
````
### Steps to reproduce the bug
```
from datasets import load_dataset
dataset = load_dataset('Andyrasika/cat_kingdom')
dataset
from mmseg.apis import MMSegInferencer
checkpoint_name = 'segformer_mit-b5_8xb2-160k_ade20k-640x640'
inferencer = MMSegInferencer(model=checkpoint_name)
# Define a function to apply the code to each image in the dataset
def process_image(image_path):
print("Processing image:", image_path)
result = inferencer(image_path)['predictions']
mask = np.where(result == 12, 255, 0).astype('uint8')
return Image.fromarray(mask)
# Process and save masks for each image in the dataset
for idx, example in enumerate(dataset['train']):
image_path = example['image']
mask_image = process_image(image_path)
mask_image.save(f"mask_{idx}.png")
```
### Expected behavior
create a separate column with masks in the dataset and further shows as a separate column in hub
### Environment info
jupyter notebook RTX 3090
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6229/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6229/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6556
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6556/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6556/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6556/events
|
https://github.com/huggingface/datasets/pull/6556
| 2,064,018,208
|
PR_kwDODunzps5jI0nN
| 6,556
|
Fix imagefolder with one image
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6556). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"Fixed in dataset viewer: https://huggingface.co/datasets/multimodalart/repro_1_image\r\n\r\n<img width=\"682\" alt=\"Capture d’écran 2024-02-12 à 22 57 08\" src=\"https://github.com/huggingface/datasets/assets/1676121/be9a8dbc-2d78-4ffc-aed4-293a7c57bc0d\">\r\n"
] | 2024-01-03T13:13:02Z
| 2024-02-12T21:57:34Z
| 2024-01-09T13:06:30Z
|
MEMBER
| null | null | null |
A dataset repository with one image and one metadata file was considered a JSON dataset instead of an ImageFolder dataset. This is because we pick the dataset type with the most compatible data file extensions present in the repository and it results in a tie in this case.
e.g. for https://huggingface.co/datasets/multimodalart/repro_1_image
I fixed this by deprioritizing metadata files in the count.
fix https://github.com/huggingface/datasets/issues/6545
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6556/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6556/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6556.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6556",
"merged_at": "2024-01-09T13:06:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6556.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6556"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5955
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5955/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5955/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5955/events
|
https://github.com/huggingface/datasets/issues/5955
| 1,756,827,133
|
I_kwDODunzps5otw39
| 5,955
|
Strange bug in loading local JSON files, using load_dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/73934131?v=4",
"events_url": "https://api.github.com/users/Night-Quiet/events{/privacy}",
"followers_url": "https://api.github.com/users/Night-Quiet/followers",
"following_url": "https://api.github.com/users/Night-Quiet/following{/other_user}",
"gists_url": "https://api.github.com/users/Night-Quiet/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Night-Quiet",
"id": 73934131,
"login": "Night-Quiet",
"node_id": "MDQ6VXNlcjczOTM0MTMx",
"organizations_url": "https://api.github.com/users/Night-Quiet/orgs",
"received_events_url": "https://api.github.com/users/Night-Quiet/received_events",
"repos_url": "https://api.github.com/users/Night-Quiet/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Night-Quiet/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Night-Quiet/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Night-Quiet",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"This is the actual error:\r\n```\r\nFailed to read file '/home/lakala/hjc/code/pycode/glm/temp.json' with error <class 'pyarrow.lib.ArrowInvalid'>: cannot mix list and non-list, non-null values\r\n```\r\nWhich means some samples are incorrectly formatted.\r\n\r\nPyArrow, a storage backend that we use under the hood, requires that all the list elements have the same level of nesting (same number of dimensions) or are `None`.\r\n```python\r\nimport pyarrow as pa\r\npa.array([[1, 2, 3], 2]) # ArrowInvalid: cannot mix list and non-list, non-null values\r\npa.array([[1, 2, 3], [2]]) # works\r\n``` ",
"@mariosasko \r\nI used the same operation to check the original data before and after slicing.\r\nThis is reflected in my code.\r\n160000 is not a specific number.\r\nI can also get output using 150000.\r\nThis doesn't seem to align very well with what you said.\r\nBecause if only some sample formats are incorrect.\r\nSo there should be an error in one of the front and back slices.\r\nthank you for your reply.",
"Our JSON loader does the following in your case:\r\n\r\n```python\r\nimport json\r\nimport pyarrow as pa\r\n\r\nwith open(file, encoding=\"utf-8\") as f:\r\n dataset = json.load(f)\r\nkeys = set().union(*[row.keys() for row in dataset])\r\nmapping = {col: [row.get(col) for row in dataset] for col in keys}\r\npa_table = pa.Table.from_pydict(mapping) # the ArrowInvalid error comes from here\r\n```\r\n\r\nSo if this code throws an error with correctly-formatted JSON, then this is an Arrow bug and should be reported in their repo.\r\n\r\n> I used the same operation to check the original data before and after slicing.\r\nThis is reflected in my code.\r\n160000 is not a specific number.\r\nI can also get output using 150000.\r\nThis doesn't seem to align very well with what you said.\r\nBecause if only some sample formats are incorrect.\r\nSo there should be an error in one of the front and back slices.\r\n\r\nYou should shuffle the data to make sure that's not the case",
"@mariosasko \r\nThank you.\r\nI will try again."
] | 2023-06-14T12:46:00Z
| 2023-06-21T14:42:15Z
| 2023-06-21T14:42:15Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
I am using 'load_dataset 'loads a JSON file, but I found a strange bug: an error will be reported when the length of the JSON file exceeds 160000 (uncertain exact number). I have checked the data through the following code and there are no issues. So I cannot determine the true reason for this error.
The data is a list containing a dictionary. As follows:
[
{'input': 'someting...', 'target': 'someting...', 'type': 'someting...', 'history': ['someting...', ...]},
...
]
### Steps to reproduce the bug
```
import json
from datasets import load_dataset
path = "target.json"
temp_path = "temp.json"
with open(path, "r") as f:
data = json.load(f)
print(f"\n-------the JSON file length is: {len(data)}-------\n")
with open(temp_path, "w") as f:
json.dump(data[:160000], f)
dataset = load_dataset("json", data_files=temp_path)
print("\n-------This works when the JSON file length is 160000-------\n")
with open(temp_path, "w") as f:
json.dump(data[160000:], f)
dataset = load_dataset("json", data_files=temp_path)
print("\n-------This works and eliminates data issues-------\n")
with open(temp_path, "w") as f:
json.dump(data[:170000], f)
dataset = load_dataset("json", data_files=temp_path)
```
### Expected behavior
```
-------the JSON file length is: 173049-------
Downloading and preparing dataset json/default to /root/.cache/huggingface/datasets/json/default-acf3c7f418c5f4b4/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4...
Downloading data files: 100%|███████████████████| 1/1 [00:00<00:00, 3328.81it/s]
Extracting data files: 100%|█████████████████████| 1/1 [00:00<00:00, 639.47it/s]
Dataset json downloaded and prepared to /root/.cache/huggingface/datasets/json/default-acf3c7f418c5f4b4/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4. Subsequent calls will reuse this data.
100%|████████████████████████████████████████████| 1/1 [00:00<00:00, 265.85it/s]
-------This works when the JSON file length is 160000-------
Downloading and preparing dataset json/default to /root/.cache/huggingface/datasets/json/default-a42f04b263ceea6a/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4...
Downloading data files: 100%|███████████████████| 1/1 [00:00<00:00, 2038.05it/s]
Extracting data files: 100%|█████████████████████| 1/1 [00:00<00:00, 794.83it/s]
Dataset json downloaded and prepared to /root/.cache/huggingface/datasets/json/default-a42f04b263ceea6a/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4. Subsequent calls will reuse this data.
100%|████████████████████████████████████████████| 1/1 [00:00<00:00, 681.00it/s]
-------This works and eliminates data issues-------
Downloading and preparing dataset json/default to /root/.cache/huggingface/datasets/json/default-63f391c89599c7b0/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4...
Downloading data files: 100%|███████████████████| 1/1 [00:00<00:00, 3682.44it/s]
Extracting data files: 100%|█████████████████████| 1/1 [00:00<00:00, 788.70it/s]
Generating train split: 0 examples [00:00, ? examples/s]Failed to read file '/home/lakala/hjc/code/pycode/glm/temp.json' with error <class 'pyarrow.lib.ArrowInvalid'>: cannot mix list and non-list, non-null values
Traceback (most recent call last):
File "/home/lakala/conda/envs/glm/lib/python3.8/site-packages/datasets/builder.py", line 1858, in _prepare_split_single
for _, table in generator:
File "/home/lakala/conda/envs/glm/lib/python3.8/site-packages/datasets/packaged_modules/json/json.py", line 146, in _generate_tables
raise ValueError(f"Not able to read records in the JSON file at {file}.") from None
ValueError: Not able to read records in the JSON file at /home/lakala/hjc/code/pycode/glm/temp.json.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/lakala/hjc/code/pycode/glm/test.py", line 22, in <module>
dataset = load_dataset("json", data_files=temp_path)
File "/home/lakala/conda/envs/glm/lib/python3.8/site-packages/datasets/load.py", line 1797, in load_dataset
builder_instance.download_and_prepare(
File "/home/lakala/conda/envs/glm/lib/python3.8/site-packages/datasets/builder.py", line 890, in download_and_prepare
self._download_and_prepare(
File "/home/lakala/conda/envs/glm/lib/python3.8/site-packages/datasets/builder.py", line 985, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/lakala/conda/envs/glm/lib/python3.8/site-packages/datasets/builder.py", line 1746, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/home/lakala/conda/envs/glm/lib/python3.8/site-packages/datasets/builder.py", line 1891, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
```
### Environment info
```
Ubuntu==22.04
python==3.8
pytorch-transformers==1.2.0
transformers== 4.27.1
datasets==2.12.0
numpy==1.24.3
pandas==1.5.3
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5955/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5955/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5827
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5827/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5827/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5827/events
|
https://github.com/huggingface/datasets/issues/5827
| 1,698,891,246
|
I_kwDODunzps5lQwXu
| 5,827
|
load json dataset interrupt when dtype cast problem occured
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/46060451?v=4",
"events_url": "https://api.github.com/users/1014661165/events{/privacy}",
"followers_url": "https://api.github.com/users/1014661165/followers",
"following_url": "https://api.github.com/users/1014661165/following{/other_user}",
"gists_url": "https://api.github.com/users/1014661165/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/1014661165",
"id": 46060451,
"login": "1014661165",
"node_id": "MDQ6VXNlcjQ2MDYwNDUx",
"organizations_url": "https://api.github.com/users/1014661165/orgs",
"received_events_url": "https://api.github.com/users/1014661165/received_events",
"repos_url": "https://api.github.com/users/1014661165/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/1014661165/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/1014661165/subscriptions",
"type": "User",
"url": "https://api.github.com/users/1014661165",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"Indeed the JSON dataset builder raises an error when it encounters an unexpected type.\r\n\r\nThere's an old PR open to add away to ignore such elements though, if it can help: https://github.com/huggingface/datasets/pull/2838"
] | 2023-05-07T04:52:09Z
| 2023-05-10T12:32:28Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
i have a json like this:
[
{"id": 1, "name": 1},
{"id": 2, "name": "Nan"},
{"id": 3, "name": 3},
....
]
,which have several problematic rows data like row 2, then i load it with datasets.load_dataset('json', data_files=['xx.json'], split='train'), it will report like this:
Generating train split: 0 examples [00:00, ? examples/s]Failed to read file 'C:\Users\gawinjunwu\Downloads\test\data\a.json' with error <class 'pyarrow.lib.ArrowInvalid'>: Could not convert '2' with type str: tried to convert to int64
Traceback (most recent call last):
File "D:\Python3.9\lib\site-packages\datasets\builder.py", line 1858, in _prepare_split_single
for _, table in generator:
File "D:\Python3.9\lib\site-packages\datasets\packaged_modules\json\json.py", line 146, in _generate_tables
raise ValueError(f"Not able to read records in the JSON file at {file}.") from None
ValueError: Not able to read records in the JSON file at C:\Users\gawinjunwu\Downloads\test\data\a.json.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "c:\Users\gawinjunwu\Downloads\test\scripts\a.py", line 4, in <module>
ds = load_dataset('json', data_dir='data', split='train')
File "D:\Python3.9\lib\site-packages\datasets\load.py", line 1797, in load_dataset
builder_instance.download_and_prepare(
File "D:\Python3.9\lib\site-packages\datasets\builder.py", line 890, in download_and_prepare
self._download_and_prepare(
File "D:\Python3.9\lib\site-packages\datasets\builder.py", line 985, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "D:\Python3.9\lib\site-packages\datasets\builder.py", line 1746, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "D:\Python3.9\lib\site-packages\datasets\builder.py", line 1891, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset.
Could datasets skip those problematic data row?
### Steps to reproduce the bug
prepare a json file like this:
[
{"id": 1, "name": 1},
{"id": 2, "name": "Nan"},
{"id": 3, "name": 3}
]
then use datasets.load_dataset('json', dir_files=['xxx.json']) to load the json file
### Expected behavior
skip the problematic data row and load row1 and row3
### Environment info
python3.9
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5827/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5827/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5968
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5968/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5968/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5968/events
|
https://github.com/huggingface/datasets/issues/5968
| 1,765,252,561
|
I_kwDODunzps5pN53R
| 5,968
|
Common Voice datasets still need `use_auth_token=True`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"cc @pcuenca as well. \r\n\r\nNot super urgent btw",
"The issue commes from the dataset itself and is not related to the `datasets` lib\r\n\r\nsee https://huggingface.co/datasets/mozilla-foundation/common_voice_6_1/blob/2c475b3b88e0f2e5828f830a4b91618a25ff20b7/common_voice_6_1.py#L148-L152",
"Let's remove these lines in the dataset no? cc @anton-l @Vaibhavs10 ",
"Addressed in:\r\n\r\n* `mozilla-foundation/common_voice_1_0` [PR](https://huggingface.co/datasets/mozilla-foundation/common_voice_1_0/discussions/4)\r\n* `mozilla-foundation/common_voice_2_0` [PR](https://huggingface.co/datasets/mozilla-foundation/common_voice_2_0/discussions/3)\r\n* `mozilla-foundation/common_voice_3_0` [PR](https://huggingface.co/datasets/mozilla-foundation/common_voice_3_0/discussions/3)\r\n* `mozilla-foundation/common_voice_4_0` [PR](https://huggingface.co/datasets/mozilla-foundation/common_voice_4_0/discussions/3)\r\n* `mozilla-foundation/common_voice_5_0` [PR](https://huggingface.co/datasets/mozilla-foundation/common_voice_5_0/discussions/3)\r\n* `mozilla-foundation/common_voice_5_1` [PR](https://huggingface.co/datasets/mozilla-foundation/common_voice_5_1/discussions/3)\r\n* `mozilla-foundation/common_voice_6_0` [PR](https://huggingface.co/datasets/mozilla-foundation/common_voice_6_0/discussions/3)\r\n* `mozilla-foundation/common_voice_6_1` [PR](https://huggingface.co/datasets/mozilla-foundation/common_voice_6_1/discussions/3)\r\n* `mozilla-foundation/common_voice_7_0` [PR](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0/discussions/3)\r\n* `mozilla-foundation/common_voice_8_0` [PR](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0/discussions/7)\r\n* `mozilla-foundation/common_voice_9_0` [PR](https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0/discussions/8)\r\n* `mozilla-foundation/common_voice_10_0` [PR](https://huggingface.co/datasets/mozilla-foundation/common_voice_10_0/discussions/7)"
] | 2023-06-20T11:58:37Z
| 2023-07-29T16:08:59Z
| 2023-07-29T16:08:58Z
|
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
We don't need to pass `use_auth_token=True` anymore to download gated datasets or models, so the following should work if correctly logged in.
```py
from datasets import load_dataset
load_dataset("mozilla-foundation/common_voice_6_1", "tr", split="train+validation")
```
However it throws an error - probably because something weird is hardcoded into the dataset loading script.
### Steps to reproduce the bug
1.)
```
huggingface-cli login
```
2.) Make sure that you have accepted the license here:
https://huggingface.co/datasets/mozilla-foundation/common_voice_6_1
3.) Run:
```py
from datasets import load_dataset
load_dataset("mozilla-foundation/common_voice_6_1", "tr", split="train+validation")
```
4.) You'll get:
```
File ~/hf/lib/python3.10/site-packages/datasets/builder.py:963, in DatasetBuilder._download_and_prepare(self, dl_manager, verification_mode, **prepare_split_kwargs)
961 split_dict = SplitDict(dataset_name=self.name)
962 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 963 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
965 # Checksums verification
966 if verification_mode == VerificationMode.ALL_CHECKS and dl_manager.record_checksums:
File ~/.cache/huggingface/modules/datasets_modules/datasets/mozilla-foundation--common_voice_6_1/f4d7854c466f5bd4908988dbd39044ec4fc634d89e0515ab0c51715c0127ffe3/common_voice_6_1.py:150, in CommonVoice._split_generators(self, dl_manager)
148 hf_auth_token = dl_manager.download_config.use_auth_token
149 if hf_auth_token is None:
--> 150 raise ConnectionError(
151 "Please set use_auth_token=True or use_auth_token='<TOKEN>' to download this dataset"
152 )
154 bundle_url_template = STATS["bundleURLTemplate"]
155 bundle_version = bundle_url_template.split("/")[0]
ConnectionError: Please set use_auth_token=True or use_auth_token='<TOKEN>' to download this dataset
```
### Expected behavior
One should not have to pass `use_auth_token=True`. Also see discussion here: https://github.com/huggingface/blog/pull/1243#discussion_r1235131150
### Environment info
```
- `datasets` version: 2.13.0
- Platform: Linux-6.2.0-76060200-generic-x86_64-with-glibc2.35
- Python version: 3.10.6
- Huggingface_hub version: 0.16.0.dev0
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5968/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5968/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5736
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5736/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5736/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5736/events
|
https://github.com/huggingface/datasets/issues/5736
| 1,662,286,061
|
I_kwDODunzps5jFHjt
| 5,736
|
FORCE_REDOWNLOAD raises "Directory not empty" exception on second run
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1219084?v=4",
"events_url": "https://api.github.com/users/rcasero/events{/privacy}",
"followers_url": "https://api.github.com/users/rcasero/followers",
"following_url": "https://api.github.com/users/rcasero/following{/other_user}",
"gists_url": "https://api.github.com/users/rcasero/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rcasero",
"id": 1219084,
"login": "rcasero",
"node_id": "MDQ6VXNlcjEyMTkwODQ=",
"organizations_url": "https://api.github.com/users/rcasero/orgs",
"received_events_url": "https://api.github.com/users/rcasero/received_events",
"repos_url": "https://api.github.com/users/rcasero/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rcasero/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rcasero/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rcasero",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"Hi ! I couldn't reproduce your issue :/\r\n\r\nIt seems that `shutil.rmtree` failed. It is supposed to work even if the directory is not empty, but you still end up with `OSError: [Errno 39] Directory not empty:`. Can you make sure another process is not using this directory at the same time ?",
"I have the same error with `datasets==2.14.5` and `pyarrow==13.0.0`. Python 3.10.13",
"I have same error. Any workaround?"
] | 2023-04-11T11:29:15Z
| 2023-11-30T07:16:58Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Running `load_dataset(..., download_mode=datasets.DownloadMode.FORCE_REDOWNLOAD)` twice raises a `Directory not empty` exception on the second run.
### Steps to reproduce the bug
I cannot test this on datasets v2.11.0 due to #5711, but this happens in v2.10.1.
1. Set up a script `my_dataset.py` to generate and load an offline dataset.
2. Load it with
```python
ds = datasets.load_dataset(path=/path/to/my_dataset.py,
name='toy',
data_dir=/path/to/my_dataset.py,
cache_dir=cache_dir,
download_mode=datasets.DownloadMode.FORCE_REDOWNLOAD,
)
```
It loads fine
```
Dataset my_dataset downloaded and prepared to /path/to/cache/toy-..e05e/1.0.0/...5b4c. Subsequent calls will reuse this data.
```
3. Try to load it again with the same snippet and the splits are generated, but at the end of the loading process it raises the error
```
2023-04-11 12:10:19,965: DEBUG: open file: /path/to/cache/toy-..e05e/1.0.0/...5b4c.incomplete/dataset_info.json
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "/path/to/conda/environment/lib/python3.10/site-packages/datasets/load.py", line 1782, in load_dataset
builder_instance.download_and_prepare(
File "/path/to/conda/environment/lib/python3.10/site-packages/datasets/builder.py", line 852, in download_and_prepare
with incomplete_dir(self._output_dir) as tmp_output_dir:
File "/path/to/conda/environment/lib/python3.10/contextlib.py", line 142, in __exit__
next(self.gen)
File "/path/to/conda/environment/lib/python3.10/site-packages/datasets/builder.py", line 826, in incomplete_dir
shutil.rmtree(dirname)
File "/path/to/conda/environment/lib/python3.10/shutil.py", line 730, in rmtree
onerror(os.rmdir, path, sys.exc_info())
File "/path/to/conda/environment/lib/python3.10/shutil.py", line 728, in rmtree
os.rmdir(path)
OSError: [Errno 39] Directory not empty: '/path/to/cache/toy-..e05e/1.0.0/...5b4c'
```
### Expected behavior
Regenerate the dataset from scratch and reload it.
### Environment info
- `datasets` version: 2.10.1
- Platform: Linux-4.18.0-483.el8.x86_64-x86_64-with-glibc2.28
- Python version: 3.10.8
- PyArrow version: 11.0.0
- Pandas version: 1.5.2
| null |
{
"+1": 4,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5736/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5736/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5375
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5375/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5375/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5375/events
|
https://github.com/huggingface/datasets/pull/5375
| 1,502,720,404
|
PR_kwDODunzps5FxUbG
| 5,375
|
Release: 2.8.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-19T10:48:26Z
| 2022-12-19T10:55:43Z
| 2022-12-19T10:53:15Z
|
MEMBER
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5375/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5375/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5375.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5375",
"merged_at": "2022-12-19T10:53:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5375.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5375"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4847
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4847/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4847/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4847/events
|
https://github.com/huggingface/datasets/pull/4847
| 1,338,270,636
|
PR_kwDODunzps49JNWX
| 4,847
|
Test win ci
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/49282718?v=4",
"events_url": "https://api.github.com/users/Mr-Robot-001/events{/privacy}",
"followers_url": "https://api.github.com/users/Mr-Robot-001/followers",
"following_url": "https://api.github.com/users/Mr-Robot-001/following{/other_user}",
"gists_url": "https://api.github.com/users/Mr-Robot-001/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Mr-Robot-001",
"id": 49282718,
"login": "Mr-Robot-001",
"node_id": "MDQ6VXNlcjQ5MjgyNzE4",
"organizations_url": "https://api.github.com/users/Mr-Robot-001/orgs",
"received_events_url": "https://api.github.com/users/Mr-Robot-001/received_events",
"repos_url": "https://api.github.com/users/Mr-Robot-001/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Mr-Robot-001/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mr-Robot-001/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Mr-Robot-001",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[] | 2022-08-14T14:57:00Z
| 2023-09-24T10:04:13Z
| 2022-08-14T14:57:45Z
|
NONE
| null | null | null |
aa
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/49282718?v=4",
"events_url": "https://api.github.com/users/Mr-Robot-001/events{/privacy}",
"followers_url": "https://api.github.com/users/Mr-Robot-001/followers",
"following_url": "https://api.github.com/users/Mr-Robot-001/following{/other_user}",
"gists_url": "https://api.github.com/users/Mr-Robot-001/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Mr-Robot-001",
"id": 49282718,
"login": "Mr-Robot-001",
"node_id": "MDQ6VXNlcjQ5MjgyNzE4",
"organizations_url": "https://api.github.com/users/Mr-Robot-001/orgs",
"received_events_url": "https://api.github.com/users/Mr-Robot-001/received_events",
"repos_url": "https://api.github.com/users/Mr-Robot-001/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Mr-Robot-001/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mr-Robot-001/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Mr-Robot-001",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4847/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4847/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4847.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4847",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4847.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4847"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7483
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7483/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7483/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7483/events
|
https://github.com/huggingface/datasets/pull/7483
| 2,951,856,468
|
PR_kwDODunzps6QVInB
| 7,483
|
Support skip_trying_type
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11156001?v=4",
"events_url": "https://api.github.com/users/yoshitomo-matsubara/events{/privacy}",
"followers_url": "https://api.github.com/users/yoshitomo-matsubara/followers",
"following_url": "https://api.github.com/users/yoshitomo-matsubara/following{/other_user}",
"gists_url": "https://api.github.com/users/yoshitomo-matsubara/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yoshitomo-matsubara",
"id": 11156001,
"login": "yoshitomo-matsubara",
"node_id": "MDQ6VXNlcjExMTU2MDAx",
"organizations_url": "https://api.github.com/users/yoshitomo-matsubara/orgs",
"received_events_url": "https://api.github.com/users/yoshitomo-matsubara/received_events",
"repos_url": "https://api.github.com/users/yoshitomo-matsubara/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yoshitomo-matsubara/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yoshitomo-matsubara/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yoshitomo-matsubara",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7483). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"Cool ! Can you run `make style` to fix code formatting ?\r\n\r\nI was also thinking of naming the argument `try_original_type` and have it `True` by default",
"@lhoestq \r\n\r\nThank you for the suggestion! I renamed the argument with `True` by default and ran `make style`\r\nDoes it look good?",
"Thanks @lhoestq !\r\n\r\nLet me know if there are anything that I can do for this PR. Otherwise, looking forward to seeing this update in the package soon!",
"CI failures are unrelated, merging :)",
"Great, thanks for your support!\r\nI can't wait for the next release :)"
] | 2025-03-27T07:07:20Z
| 2025-04-09T19:46:46Z
| 2025-04-09T09:53:10Z
|
CONTRIBUTOR
| null | null | null |
This PR addresses Issue #7472
cc: @lhoestq
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7483/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7483/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7483.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7483",
"merged_at": "2025-04-09T09:53:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7483.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7483"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5925
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5925/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5925/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5925/events
|
https://github.com/huggingface/datasets/issues/5925
| 1,741,941,436
|
I_kwDODunzps5n0-q8
| 5,925
|
Breaking API change in datasets.list_datasets caused by change in HfApi.list_datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/78868366?v=4",
"events_url": "https://api.github.com/users/mtkinit/events{/privacy}",
"followers_url": "https://api.github.com/users/mtkinit/followers",
"following_url": "https://api.github.com/users/mtkinit/following{/other_user}",
"gists_url": "https://api.github.com/users/mtkinit/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mtkinit",
"id": 78868366,
"login": "mtkinit",
"node_id": "MDQ6VXNlcjc4ODY4MzY2",
"organizations_url": "https://api.github.com/users/mtkinit/orgs",
"received_events_url": "https://api.github.com/users/mtkinit/received_events",
"repos_url": "https://api.github.com/users/mtkinit/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mtkinit/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mtkinit/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mtkinit",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[] | 2023-06-05T14:46:04Z
| 2023-06-19T17:22:43Z
| 2023-06-19T17:22:43Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Hi all,
after an update of the `datasets` library, we observer crashes in our code. We relied on `datasets.list_datasets` returning a `list`. Now, after the API of the HfApi.list_datasets was changed and it returns a `list` instead of an `Iterable`, the `datasets.list_datasets` now sometimes returns a `list` and somesimes an `Iterable`.
It would be helpful to indicate that by the return type of the `datasets.list_datasets` function.
Thanks,
Martin
### Steps to reproduce the bug
Here, the code crashed after we updated the `datasets` library:
```python
# list_datasets no longer returns a list, which leads to an error when one tries to slice it
for datasets.list_datasets(with_details=True)[:limit]:
...
```
### Expected behavior
It would be helpful to indicate that by the return type of the `datasets.list_datasets` function.
### Environment info
Ubuntu 22.04
datasets 2.12.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5925/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5925/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/7004
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7004/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7004/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7004/events
|
https://github.com/huggingface/datasets/pull/7004
| 2,376,064,264
|
PR_kwDODunzps5zrIYR
| 7,004
|
Fix WebDatasets KeyError for user-defined Features when a field is missing in an example
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/10626398?v=4",
"events_url": "https://api.github.com/users/ProGamerGov/events{/privacy}",
"followers_url": "https://api.github.com/users/ProGamerGov/followers",
"following_url": "https://api.github.com/users/ProGamerGov/following{/other_user}",
"gists_url": "https://api.github.com/users/ProGamerGov/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ProGamerGov",
"id": 10626398,
"login": "ProGamerGov",
"node_id": "MDQ6VXNlcjEwNjI2Mzk4",
"organizations_url": "https://api.github.com/users/ProGamerGov/orgs",
"received_events_url": "https://api.github.com/users/ProGamerGov/received_events",
"repos_url": "https://api.github.com/users/ProGamerGov/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ProGamerGov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ProGamerGov/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ProGamerGov",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7004). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005188 / 0.011353 (-0.006165) | 0.003812 / 0.011008 (-0.007196) | 0.062408 / 0.038508 (0.023900) | 0.030734 / 0.023109 (0.007625) | 0.236528 / 0.275898 (-0.039370) | 0.267684 / 0.323480 (-0.055796) | 0.003182 / 0.007986 (-0.004804) | 0.004009 / 0.004328 (-0.000319) | 0.048966 / 0.004250 (0.044715) | 0.045259 / 0.037052 (0.008207) | 0.250586 / 0.258489 (-0.007903) | 0.287079 / 0.293841 (-0.006762) | 0.029235 / 0.128546 (-0.099311) | 0.012216 / 0.075646 (-0.063431) | 0.203864 / 0.419271 (-0.215408) | 0.036324 / 0.043533 (-0.007209) | 0.245180 / 0.255139 (-0.009959) | 0.270327 / 0.283200 (-0.012872) | 0.018676 / 0.141683 (-0.123007) | 1.115568 / 1.452155 (-0.336586) | 1.183267 / 1.492716 (-0.309449) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.094307 / 0.018006 (0.076301) | 0.299071 / 0.000490 (0.298581) | 0.000219 / 0.000200 (0.000019) | 0.000042 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018336 / 0.037411 (-0.019076) | 0.062973 / 0.014526 (0.048447) | 0.074137 / 0.176557 (-0.102420) | 0.120553 / 0.737135 (-0.616582) | 0.075411 / 0.296338 (-0.220927) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.284751 / 0.215209 (0.069542) | 2.789294 / 2.077655 (0.711640) | 1.457789 / 1.504120 (-0.046331) | 1.339140 / 1.541195 (-0.202055) | 1.341685 / 1.468490 (-0.126805) | 0.714928 / 4.584777 (-3.869849) | 2.361197 / 3.745712 (-1.384516) | 2.791569 / 5.269862 (-2.478293) | 1.892261 / 4.565676 (-2.673416) | 0.077954 / 0.424275 (-0.346321) | 0.005454 / 0.007607 (-0.002153) | 0.350766 / 0.226044 (0.124721) | 3.416749 / 2.268929 (1.147820) | 1.835377 / 55.444624 (-53.609247) | 1.506456 / 6.876477 (-5.370020) | 1.642728 / 2.142072 (-0.499344) | 0.791543 / 4.805227 (-4.013684) | 0.133102 / 6.500664 (-6.367562) | 0.042572 / 0.075469 (-0.032897) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.977958 / 1.841788 (-0.863830) | 11.438271 / 8.074308 (3.363963) | 9.305719 / 10.191392 (-0.885673) | 0.141239 / 0.680424 (-0.539185) | 0.014330 / 0.534201 (-0.519871) | 0.302201 / 0.579283 (-0.277082) | 0.261688 / 0.434364 (-0.172676) | 0.338752 / 0.540337 (-0.201586) | 0.468466 / 1.386936 (-0.918470) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005629 / 0.011353 (-0.005723) | 0.003997 / 0.011008 (-0.007011) | 0.050447 / 0.038508 (0.011939) | 0.031694 / 0.023109 (0.008585) | 0.277392 / 0.275898 (0.001494) | 0.290440 / 0.323480 (-0.033040) | 0.004403 / 0.007986 (-0.003583) | 0.002851 / 0.004328 (-0.001478) | 0.048593 / 0.004250 (0.044343) | 0.040622 / 0.037052 (0.003570) | 0.282640 / 0.258489 (0.024151) | 0.309390 / 0.293841 (0.015549) | 0.031453 / 0.128546 (-0.097094) | 0.012424 / 0.075646 (-0.063223) | 0.060311 / 0.419271 (-0.358960) | 0.033195 / 0.043533 (-0.010338) | 0.266867 / 0.255139 (0.011728) | 0.281966 / 0.283200 (-0.001234) | 0.018026 / 0.141683 (-0.123657) | 1.136273 / 1.452155 (-0.315882) | 1.141643 / 1.492716 (-0.351073) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095011 / 0.018006 (0.077005) | 0.300571 / 0.000490 (0.300082) | 0.000220 / 0.000200 (0.000020) | 0.000044 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022903 / 0.037411 (-0.014508) | 0.077130 / 0.014526 (0.062604) | 0.089576 / 0.176557 (-0.086980) | 0.127156 / 0.737135 (-0.609980) | 0.090008 / 0.296338 (-0.206331) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.289270 / 0.215209 (0.074061) | 2.848239 / 2.077655 (0.770585) | 1.546788 / 1.504120 (0.042668) | 1.417275 / 1.541195 (-0.123920) | 1.456214 / 1.468490 (-0.012276) | 0.716688 / 4.584777 (-3.868088) | 0.940242 / 3.745712 (-2.805470) | 2.911956 / 5.269862 (-2.357906) | 1.871358 / 4.565676 (-2.694318) | 0.077553 / 0.424275 (-0.346722) | 0.005279 / 0.007607 (-0.002328) | 0.343338 / 0.226044 (0.117294) | 3.368694 / 2.268929 (1.099766) | 1.896765 / 55.444624 (-53.547859) | 1.612414 / 6.876477 (-5.264063) | 1.615934 / 2.142072 (-0.526138) | 0.794016 / 4.805227 (-4.011212) | 0.131821 / 6.500664 (-6.368843) | 0.041495 / 0.075469 (-0.033975) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.003418 / 1.841788 (-0.838370) | 12.073906 / 8.074308 (3.999598) | 10.166291 / 10.191392 (-0.025101) | 0.131224 / 0.680424 (-0.549200) | 0.015246 / 0.534201 (-0.518955) | 0.299835 / 0.579283 (-0.279448) | 0.124308 / 0.434364 (-0.310056) | 0.336414 / 0.540337 (-0.203924) | 0.429569 / 1.386936 (-0.957367) |\n\n</details>\n</details>\n\n\n",
"@lhoestq Thank you!"
] | 2024-06-26T18:58:05Z
| 2024-06-29T00:15:49Z
| 2024-06-28T09:30:12Z
|
CONTRIBUTOR
| null | null | null |
Fixes: https://github.com/huggingface/datasets/issues/6900
Not sure if this needs any addition stuff before merging
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7004/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7004/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7004.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7004",
"merged_at": "2024-06-28T09:30:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7004.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7004"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6583
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6583/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6583/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6583/events
|
https://github.com/huggingface/datasets/pull/6583
| 2,077,049,491
|
PR_kwDODunzps5j1DzY
| 6,583
|
remove eli5 test
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6583). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005024 / 0.011353 (-0.006329) | 0.003172 / 0.011008 (-0.007836) | 0.062934 / 0.038508 (0.024426) | 0.031737 / 0.023109 (0.008628) | 0.249251 / 0.275898 (-0.026647) | 0.273084 / 0.323480 (-0.050396) | 0.002958 / 0.007986 (-0.005027) | 0.002726 / 0.004328 (-0.001603) | 0.048519 / 0.004250 (0.044269) | 0.043608 / 0.037052 (0.006556) | 0.253648 / 0.258489 (-0.004841) | 0.280095 / 0.293841 (-0.013746) | 0.027500 / 0.128546 (-0.101046) | 0.010545 / 0.075646 (-0.065101) | 0.206781 / 0.419271 (-0.212490) | 0.035515 / 0.043533 (-0.008018) | 0.259449 / 0.255139 (0.004310) | 0.271488 / 0.283200 (-0.011712) | 0.019352 / 0.141683 (-0.122331) | 1.152002 / 1.452155 (-0.300153) | 1.190325 / 1.492716 (-0.302391) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093253 / 0.018006 (0.075247) | 0.302182 / 0.000490 (0.301692) | 0.000216 / 0.000200 (0.000016) | 0.000047 / 0.000054 (-0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.017889 / 0.037411 (-0.019523) | 0.060292 / 0.014526 (0.045766) | 0.072640 / 0.176557 (-0.103917) | 0.121320 / 0.737135 (-0.615815) | 0.073866 / 0.296338 (-0.222472) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282910 / 0.215209 (0.067701) | 2.779815 / 2.077655 (0.702160) | 1.537929 / 1.504120 (0.033809) | 1.405990 / 1.541195 (-0.135205) | 1.407911 / 1.468490 (-0.060579) | 0.561551 / 4.584777 (-4.023226) | 2.368053 / 3.745712 (-1.377659) | 2.732608 / 5.269862 (-2.537254) | 1.710274 / 4.565676 (-2.855402) | 0.061925 / 0.424275 (-0.362350) | 0.004975 / 0.007607 (-0.002632) | 0.338843 / 0.226044 (0.112799) | 3.328579 / 2.268929 (1.059650) | 1.865994 / 55.444624 (-53.578631) | 1.603145 / 6.876477 (-5.273332) | 1.615440 / 2.142072 (-0.526633) | 0.635646 / 4.805227 (-4.169581) | 0.116185 / 6.500664 (-6.384479) | 0.041964 / 0.075469 (-0.033505) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.956977 / 1.841788 (-0.884811) | 11.539802 / 8.074308 (3.465494) | 10.048855 / 10.191392 (-0.142537) | 0.128758 / 0.680424 (-0.551666) | 0.013491 / 0.534201 (-0.520710) | 0.287330 / 0.579283 (-0.291953) | 0.262416 / 0.434364 (-0.171947) | 0.327327 / 0.540337 (-0.213011) | 0.418423 / 1.386936 (-0.968513) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004963 / 0.011353 (-0.006390) | 0.003335 / 0.011008 (-0.007673) | 0.052082 / 0.038508 (0.013574) | 0.029302 / 0.023109 (0.006192) | 0.284986 / 0.275898 (0.009088) | 0.304082 / 0.323480 (-0.019398) | 0.004065 / 0.007986 (-0.003921) | 0.002643 / 0.004328 (-0.001685) | 0.049504 / 0.004250 (0.045253) | 0.044514 / 0.037052 (0.007461) | 0.287064 / 0.258489 (0.028575) | 0.312921 / 0.293841 (0.019080) | 0.029195 / 0.128546 (-0.099351) | 0.010471 / 0.075646 (-0.065175) | 0.057620 / 0.419271 (-0.361651) | 0.050221 / 0.043533 (0.006689) | 0.285392 / 0.255139 (0.030253) | 0.302111 / 0.283200 (0.018912) | 0.018690 / 0.141683 (-0.122993) | 1.165637 / 1.452155 (-0.286518) | 1.203757 / 1.492716 (-0.288959) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095035 / 0.018006 (0.077028) | 0.304447 / 0.000490 (0.303957) | 0.000231 / 0.000200 (0.000031) | 0.000051 / 0.000054 (-0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022345 / 0.037411 (-0.015066) | 0.077195 / 0.014526 (0.062669) | 0.089564 / 0.176557 (-0.086992) | 0.129248 / 0.737135 (-0.607887) | 0.091974 / 0.296338 (-0.204365) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.300641 / 0.215209 (0.085432) | 2.936669 / 2.077655 (0.859014) | 1.649100 / 1.504120 (0.144980) | 1.510693 / 1.541195 (-0.030502) | 1.517011 / 1.468490 (0.048521) | 0.572511 / 4.584777 (-4.012266) | 2.442704 / 3.745712 (-1.303009) | 2.833089 / 5.269862 (-2.436772) | 1.762668 / 4.565676 (-2.803008) | 0.063754 / 0.424275 (-0.360521) | 0.005034 / 0.007607 (-0.002573) | 0.401631 / 0.226044 (0.175586) | 3.418986 / 2.268929 (1.150057) | 1.989639 / 55.444624 (-53.454986) | 1.695776 / 6.876477 (-5.180701) | 1.712822 / 2.142072 (-0.429250) | 0.654029 / 4.805227 (-4.151198) | 0.117624 / 6.500664 (-6.383040) | 0.041058 / 0.075469 (-0.034411) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.986008 / 1.841788 (-0.855779) | 12.146838 / 8.074308 (4.072530) | 11.105900 / 10.191392 (0.914508) | 0.139938 / 0.680424 (-0.540486) | 0.015117 / 0.534201 (-0.519084) | 0.286151 / 0.579283 (-0.293132) | 0.272960 / 0.434364 (-0.161404) | 0.323370 / 0.540337 (-0.216967) | 0.427379 / 1.386936 (-0.959557) |\n\n</details>\n</details>\n\n\n"
] | 2024-01-11T16:05:20Z
| 2024-01-11T16:15:34Z
| 2024-01-11T16:09:24Z
|
MEMBER
| null | null | null |
since the dataset is defunct
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6583/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6583/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6583.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6583",
"merged_at": "2024-01-11T16:09:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6583.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6583"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5964
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5964/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5964/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5964/events
|
https://github.com/huggingface/datasets/pull/5964
| 1,763,513,574
|
PR_kwDODunzps5TVweZ
| 5,964
|
Always return list in `list_datasets`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006795 / 0.011353 (-0.004558) | 0.004170 / 0.011008 (-0.006838) | 0.098698 / 0.038508 (0.060190) | 0.045393 / 0.023109 (0.022284) | 0.309205 / 0.275898 (0.033307) | 0.361333 / 0.323480 (0.037853) | 0.006009 / 0.007986 (-0.001977) | 0.003334 / 0.004328 (-0.000995) | 0.075071 / 0.004250 (0.070821) | 0.062587 / 0.037052 (0.025535) | 0.322395 / 0.258489 (0.063906) | 0.360499 / 0.293841 (0.066659) | 0.032243 / 0.128546 (-0.096303) | 0.008768 / 0.075646 (-0.066878) | 0.329799 / 0.419271 (-0.089472) | 0.062261 / 0.043533 (0.018728) | 0.298112 / 0.255139 (0.042973) | 0.322815 / 0.283200 (0.039615) | 0.032348 / 0.141683 (-0.109335) | 1.445807 / 1.452155 (-0.006347) | 1.528768 / 1.492716 (0.036051) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.195701 / 0.018006 (0.177695) | 0.437042 / 0.000490 (0.436552) | 0.003867 / 0.000200 (0.003667) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026713 / 0.037411 (-0.010698) | 0.109548 / 0.014526 (0.095022) | 0.119216 / 0.176557 (-0.057341) | 0.178947 / 0.737135 (-0.558188) | 0.125224 / 0.296338 (-0.171114) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.400885 / 0.215209 (0.185676) | 3.991223 / 2.077655 (1.913568) | 1.818449 / 1.504120 (0.314329) | 1.609285 / 1.541195 (0.068090) | 1.666675 / 1.468490 (0.198184) | 0.531486 / 4.584777 (-4.053291) | 3.770142 / 3.745712 (0.024430) | 3.057189 / 5.269862 (-2.212673) | 1.517491 / 4.565676 (-3.048186) | 0.065782 / 0.424275 (-0.358493) | 0.011251 / 0.007607 (0.003644) | 0.504277 / 0.226044 (0.278233) | 5.038979 / 2.268929 (2.770050) | 2.254717 / 55.444624 (-53.189908) | 1.929743 / 6.876477 (-4.946734) | 2.080051 / 2.142072 (-0.062022) | 0.656831 / 4.805227 (-4.148396) | 0.142860 / 6.500664 (-6.357804) | 0.063057 / 0.075469 (-0.012412) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.208819 / 1.841788 (-0.632969) | 14.456966 / 8.074308 (6.382658) | 12.839799 / 10.191392 (2.648407) | 0.164361 / 0.680424 (-0.516063) | 0.017330 / 0.534201 (-0.516871) | 0.397384 / 0.579283 (-0.181899) | 0.422704 / 0.434364 (-0.011660) | 0.472065 / 0.540337 (-0.068273) | 0.576960 / 1.386936 (-0.809976) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006950 / 0.011353 (-0.004403) | 0.004012 / 0.011008 (-0.006997) | 0.076050 / 0.038508 (0.037542) | 0.046646 / 0.023109 (0.023537) | 0.353813 / 0.275898 (0.077915) | 0.417111 / 0.323480 (0.093631) | 0.005422 / 0.007986 (-0.002564) | 0.003356 / 0.004328 (-0.000972) | 0.076662 / 0.004250 (0.072411) | 0.055018 / 0.037052 (0.017966) | 0.371561 / 0.258489 (0.113072) | 0.410471 / 0.293841 (0.116630) | 0.031860 / 0.128546 (-0.096686) | 0.008754 / 0.075646 (-0.066893) | 0.083192 / 0.419271 (-0.336079) | 0.050479 / 0.043533 (0.006946) | 0.351725 / 0.255139 (0.096586) | 0.371596 / 0.283200 (0.088396) | 0.023042 / 0.141683 (-0.118641) | 1.480533 / 1.452155 (0.028379) | 1.545970 / 1.492716 (0.053254) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220095 / 0.018006 (0.202089) | 0.441550 / 0.000490 (0.441061) | 0.000375 / 0.000200 (0.000175) | 0.000056 / 0.000054 (0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029527 / 0.037411 (-0.007884) | 0.111645 / 0.014526 (0.097119) | 0.125732 / 0.176557 (-0.050825) | 0.177322 / 0.737135 (-0.559813) | 0.128620 / 0.296338 (-0.167718) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.432415 / 0.215209 (0.217206) | 4.314381 / 2.077655 (2.236726) | 2.079450 / 1.504120 (0.575331) | 1.893139 / 1.541195 (0.351944) | 1.951363 / 1.468490 (0.482873) | 0.531466 / 4.584777 (-4.053311) | 3.716860 / 3.745712 (-0.028852) | 1.850111 / 5.269862 (-3.419750) | 1.100676 / 4.565676 (-3.465000) | 0.066247 / 0.424275 (-0.358028) | 0.011503 / 0.007607 (0.003896) | 0.537208 / 0.226044 (0.311164) | 5.367560 / 2.268929 (3.098631) | 2.543697 / 55.444624 (-52.900927) | 2.221670 / 6.876477 (-4.654806) | 2.252009 / 2.142072 (0.109937) | 0.658509 / 4.805227 (-4.146718) | 0.142345 / 6.500664 (-6.358319) | 0.064701 / 0.075469 (-0.010768) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.266442 / 1.841788 (-0.575346) | 15.105953 / 8.074308 (7.031645) | 14.288229 / 10.191392 (4.096837) | 0.161182 / 0.680424 (-0.519242) | 0.017074 / 0.534201 (-0.517127) | 0.399464 / 0.579283 (-0.179819) | 0.419459 / 0.434364 (-0.014905) | 0.467553 / 0.540337 (-0.072784) | 0.566337 / 1.386936 (-0.820599) |\n\n</details>\n</details>\n\n\n"
] | 2023-06-19T13:07:08Z
| 2023-06-19T17:29:37Z
| 2023-06-19T17:22:41Z
|
COLLABORATOR
| null | null | null |
Fix #5925
Plus, deprecate `list_datasets`/`inspect_dataset` in favor of `huggingface_hub.list_datasets`/"git clone workflow" (downloads data files)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5964/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5964/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5964.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5964",
"merged_at": "2023-06-19T17:22:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5964.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5964"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4788
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4788/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4788/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4788/events
|
https://github.com/huggingface/datasets/pull/4788
| 1,328,246,021
|
PR_kwDODunzps48oUNx
| 4,788
|
Fix NonMatchingChecksumError in mbpp dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Thank you for the quick response! Before noticing that you already had implemented the fix, I already had implemened my own version. I'd also suggest bumping the major version because the contents of the dataset changed, even if only slightly.\r\nI'll attach my version of the affected files: [mbpp-checksum-changes.zip](https://github.com/huggingface/datasets/files/9258161/mbpp-checksum-changes.zip).",
"Hi @stadlerb, thanks for your feedback.\r\n\r\nWe normally update the major version whenever there is a new dataset release, usually with a breaking change in schema. The patch version is updated whenever there is a small correction in the dataset that does not change its schema.\r\n\r\nAs a side note for future contributions, please note that this dataset is hosted in our library GitHub repository. Therefore, the PRs to GitHub-hosted datasets needs being done through GitHub.\r\n\r\nCurrently added datasets are hosted on the Hub and for them, PRs can be done through the Hub.",
"I just noticed another problem with the dataset: The [GitHub page](https://github.com/google-research/google-research/tree/master/mbpp) and the [paper](http://arxiv.org/abs/2108.07732) mention a train-test split, which is not reflected in the dataloader. I'll open a new issue regarding this later."
] | 2022-08-04T08:17:40Z
| 2022-08-04T17:34:00Z
| 2022-08-04T17:21:01Z
|
MEMBER
| null | null | null |
Fix issue reported on the Hub: https://huggingface.co/datasets/mbpp/discussions/1
Fix #4787.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4788/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4788/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4788.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4788",
"merged_at": "2022-08-04T17:21:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4788.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4788"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7488
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7488/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7488/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7488/events
|
https://github.com/huggingface/datasets/pull/7488
| 2,956,559,358
|
PR_kwDODunzps6QlLmn
| 7,488
|
Support underscore int read instruction
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7488). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"you rock, Quentin - thank you!"
] | 2025-03-28T16:01:15Z
| 2025-03-28T16:20:44Z
| 2025-03-28T16:20:43Z
|
MEMBER
| null | null | null |
close https://github.com/huggingface/datasets/issues/7481
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7488/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7488/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7488.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7488",
"merged_at": "2025-03-28T16:20:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7488.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7488"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7304
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7304/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7304/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7304/events
|
https://github.com/huggingface/datasets/pull/7304
| 2,715,179,811
|
PR_kwDODunzps6D5saw
| 7,304
|
Update iterable_dataset.py
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7304). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update."
] | 2024-12-03T14:25:42Z
| 2024-12-03T14:28:10Z
| 2024-12-03T14:27:02Z
|
MEMBER
| null | null | null |
close https://github.com/huggingface/datasets/issues/7297
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7304/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7304/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7304.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7304",
"merged_at": "2024-12-03T14:27:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7304.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7304"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6577
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6577/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6577/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6577/events
|
https://github.com/huggingface/datasets/issues/6577
| 2,074,790,848
|
I_kwDODunzps57qsvA
| 6,577
|
502 Server Errors when streaming large dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sanchit-gandhi",
"id": 93869735,
"login": "sanchit-gandhi",
"node_id": "U_kgDOBZhWpw",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sanchit-gandhi",
"user_view_type": "public"
}
|
[
{
"color": "fef2c0",
"default": false,
"description": "",
"id": 3287858981,
"name": "streaming",
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming"
}
] |
closed
| false
| null |
[] | null |
[
"cc @mariosasko @lhoestq ",
"Hi! We should be able to avoid this error by retrying to read the data when it happens. I'll open a PR in `huggingface_hub` to address this.",
"Thanks for the fix @mariosasko! Just wondering whether \"500 error\" should also be excluded? I got these errors overnight:\r\n\r\n```\r\nhuggingface_hub.utils._errors.HfHubHTTPError: 500 Server Error: Internal Server Error for url: https://huggingface.co/da\r\ntasets/sanchit-gandhi/concatenated-train-set-label-length-256/resolve/91e6a0cd0356605b021384ded813cfcf356a221c/train/tra\r\nin-02618-of-04012.parquet (Request ID: Root=1-65b18b81-627f2c2943bbb8ab68d19ee2;129537bd-1934-4257-a4d8-1cb774f8e1f8) \r\n \r\nInternal Error - We're working hard to fix this as soon as possible! \r\n```",
"Gently pining @mariosasko and @Wauplin - when trying to stream this large dataset from the HF Hub, I'm running into `500 Internal Server Errors` as described above. I'd love to be able to use the Hub exclusively to stream data when training, but this error pops up a few times a week, terminating training runs and causing me to have to rewind to the last saved checkpoint. Do we reckon there's a way we can protect Datasets' streaming against these errors? The same reproducer as the [original comment](https://github.com/huggingface/datasets/issues/6577#issue-2074790848) can be used, but it's somewhat random whether we hit a 500 error. Leaving the full traceback below: \r\n\r\n```\r\nTraceback (most recent call last): \r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/utils/data/_utils/worker.py\", line 308, in _worker_loo\r\np \r\n data = fetcher.fetch(index) \r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py\", line 32, in fetch \r\n data.append(next(self.dataset_iter)) \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 1367, in __iter__ \r\n yield from self._iter_pytorch() \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 1302, in _iter_pytorch \r\n for key, example in ex_iterable: \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 987, in __iter__ \r\n for x in self.ex_iterable: \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 867, in __iter__ \r\n yield from self._iter() \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 904, in _iter \r\n for key, example in iterator: \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 679, in __iter__ \r\n yield from self._iter() \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 741, in _iter [235/1892]\r\n for key, example in iterator: \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 1119, in __iter__ \r\n for key, example in self.ex_iterable: \r\n File \"/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py\", line 282, in __iter__ \r\n for key, pa_table in self.generate_tables_fn(**self.kwargs): \r\n File \"/home/sanchitgandhi/datasets/src/datasets/packaged_modules/parquet/parquet.py\", line 87, in _generate_tables \r\n for batch_idx, record_batch in enumerate( \r\n File \"pyarrow/_parquet.pyx\", line 1587, in iter_batches \r\n File \"pyarrow/types.pxi\", line 88, in pyarrow.lib._datatype_to_pep3118 \r\n File \"/home/sanchitgandhi/datasets/src/datasets/download/streaming_download_manager.py\", line 342, in read_with_retrie\r\ns \r\n out = read(*args, **kwargs) \r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/fsspec/spec.py\", line 1856, in read \r\n out = self.cache._fetch(self.loc, self.loc + length) \r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/fsspec/caching.py\", line 189, in _fetch \r\n self.cache = self.fetcher(start, end) # new block replaces old \r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/huggingface_hub/hf_file_system.py\", line 629, in _fetch_rang\r\ne \r\n hf_raise_for_status(r) \r\n File \"/home/sanchitgandhi/hf/lib/python3.10/site-packages/huggingface_hub/utils/_errors.py\", line 362, in hf_raise_for\r\n_status \r\n raise HfHubHTTPError(str(e), response=response) from e \r\nhuggingface_hub.utils._errors.HfHubHTTPError: 500 Server Error: Internal Server Error for url: https://huggingface.co/da\r\ntasets/sanchit-gandhi/concatenated-train-set-label-length-256-conditioned/resolve/3c3c0cce51df9f9d2e75968bb2a1851894f504\r\n0d/train/train-03515-of-04010.parquet (Request ID: Root=1-65c7c4c4-153fe71401558c8c2d272c8a;fec3ec68-4a0a-4bfd-95ba-b0a0\r\n5684d612) \r\n \r\nInternal Error - We're working hard to fix this as soon as possible! ",
"@sanchit-gandhi thanks for the feedback. I've opened https://github.com/huggingface/huggingface_hub/pull/2026 to make the download process more robust. I believe that you've witness this problem on Saturday due to the Hub outage. Hope the PR will make your life easier though :)",
"Awesome, thanks @Wauplin! Makes sense re the Hub outage"
] | 2024-01-10T16:59:36Z
| 2024-02-12T11:46:03Z
| 2024-01-15T16:05:44Z
|
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
When streaming a [large ASR dataset](https://huggingface.co/datasets/sanchit-gandhi/concatenated-train-set) from the Hug (~3TB) I often encounter 502 Server Errors seemingly randomly during streaming:
```
huggingface_hub.utils._errors.HfHubHTTPError: 502 Server Error: Bad Gateway for url: https://huggingface.co/datasets/sanchit-gandhi/concatenated-train-set/resolve/7d2acc5c59de848e456e951a76e805304d6fb350/train/train-00288-of-07135.parquet
```
This is despite the parquet file definitely existing on the Hub: https://huggingface.co/datasets/sanchit-gandhi/concatenated-train-set/blob/main/train/train-00228-of-07135.parquet
And having the correct commit id: [7d2acc5c59de848e456e951a76e805304d6fb350](https://huggingface.co/datasets/sanchit-gandhi/concatenated-train-set/commits/main/train)
I’m wondering whether this is coming from datasets? Or from the Hub side?
### Steps to reproduce the bug
Reproducer:
```python
from datasets import load_dataset
from torch.utils.data import DataLoader
from tqdm import tqdm
NUM_EPOCHS = 20
dataset = load_dataset("sanchit-gandhi/concatenated-train-set", "train", streaming=True)
dataset = dataset.with_format("torch")
dataloader = DataLoader(dataset["train"], batch_size=256, drop_last=True, pin_memory=True, num_workers=16)
for epoch in tqdm(range(NUM_EPOCHS), desc="Epoch", position=0):
for batch in tqdm(dataloader, desc="Batch", position=1):
continue
```
Running the above script tends to fail within about 2 hours with a traceback like the following:
<details>
<summary> Traceback: </summary>
```python
1029 for batch in train_loader:
1030 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 630, in __next__
1031 data = self._next_data()
1032 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1325, in _next_data
1033 return self._process_data(data)
1034 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1371, in _process_data
1035 data.reraise()
1036 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/_utils.py", line 694, in reraise
1037 raise exception
1038 huggingface_hub.utils._errors.HfHubHTTPError: Caught HfHubHTTPError in DataLoader worker process 10.
1039 Original Traceback (most recent call last):
1040 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/huggingface_hub/utils/_errors.py", line 286, in hf_raise_for_status
1041 response.raise_for_status()
1042 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/requests/models.py", line 1021, in raise_for_status
1043 raise HTTPError(http_error_msg, response=self)
1044 requests.exceptions.HTTPError: 502 Server Error: Bad Gateway for url: https://huggingface.co/datasets/sanchit-gandhi/concatenated-train-set/resolve/7d2acc5c59de848e456e951a76e805304d6fb350/train/train-00288-of-07135.parquet
1045 The above exception was the direct cause of the following exception:
1046 Traceback (most recent call last):
1047 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/utils/data/_utils/worker.py", line 308, in _worker_loop
1048 data = fetcher.fetch(index)
1049 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py", line 32, in fetch
1050 data.append(next(self.dataset_iter))
1051 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 1363, in __iter__
1052 yield from self._iter_pytorch()
1053 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 1298, in _iter_pytorch
1054 for key, example in ex_iterable:
1055 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 983, in __iter__
1056 for x in self.ex_iterable:
1057 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 863, in __iter__
1058 yield from self._iter()
1059 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 900, in _iter
1060 for key, example in iterator:
1061 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 679, in __iter__
1062 yield from self._iter()
1063 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 741, in _iter
1064 for key, example in iterator:
1065 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 863, in __iter__
1066 yield from self._iter()
1067 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 900, in _iter
1068 for key, example in iterator:
1069 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 1115, in __iter__
1070 for key, example in self.ex_iterable:
1071 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 679, in __iter__
1072 yield from self._iter()
1073 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 741, in _iter
1074 for key, example in iterator:
1075 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 1115, in __iter__
1076 for key, example in self.ex_iterable:
1077 File "/home/sanchitgandhi/datasets/src/datasets/iterable_dataset.py", line 282, in __iter__
1078 for key, pa_table in self.generate_tables_fn(**self.kwargs):
1079 File "/home/sanchitgandhi/datasets/src/datasets/packaged_modules/parquet/parquet.py", line 87, in _generate_tables
1080 for batch_idx, record_batch in enumerate(
1081 File "pyarrow/_parquet.pyx", line 1367, in iter_batches
1082 File "pyarrow/types.pxi", line 88, in pyarrow.lib._datatype_to_pep3118
1083 File "/home/sanchitgandhi/datasets/src/datasets/download/streaming_download_manager.py", line 341, in read_with_retries
1084 out = read(*args, **kwargs)
1085 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/fsspec/spec.py", line 1856, in read
1086 out = self.cache._fetch(self.loc, self.loc + length)
1087 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/fsspec/caching.py", line 189, in _fetch
1088 self.cache = self.fetcher(start, end) # new block replaces old
1089 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/huggingface_hub/hf_file_system.py", line 626, in _fetch_range
1090 hf_raise_for_status(r)
1091 File "/home/sanchitgandhi/hf/lib/python3.8/site-packages/huggingface_hub/utils/_errors.py", line 333, in hf_raise_for_status
1092 raise HfHubHTTPError(str(e), response=response) from e
1093 huggingface_hub.utils._errors.HfHubHTTPError: 502 Server Error: Bad Gateway for url: https://huggingface.co/datasets/sanchit-gandhi/concatenated-train-set/resolve/7d2acc5c59de848e456e951a76e805304d6fb350/train/train-00288-of-07135.parquet
```
</details>
### Expected behavior
Should be able to stream the dataset without any 502 error.
### Environment info
- `datasets` version: 2.16.2.dev0
- Platform: Linux-5.13.0-1023-gcp-x86_64-with-glibc2.29
- Python version: 3.8.10
- `huggingface_hub` version: 0.20.1
- PyArrow version: 14.0.2
- Pandas version: 2.0.3
- `fsspec` version: 2023.10.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11801849?v=4",
"events_url": "https://api.github.com/users/Wauplin/events{/privacy}",
"followers_url": "https://api.github.com/users/Wauplin/followers",
"following_url": "https://api.github.com/users/Wauplin/following{/other_user}",
"gists_url": "https://api.github.com/users/Wauplin/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Wauplin",
"id": 11801849,
"login": "Wauplin",
"node_id": "MDQ6VXNlcjExODAxODQ5",
"organizations_url": "https://api.github.com/users/Wauplin/orgs",
"received_events_url": "https://api.github.com/users/Wauplin/received_events",
"repos_url": "https://api.github.com/users/Wauplin/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Wauplin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Wauplin/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Wauplin",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6577/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6577/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/4845
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4845/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4845/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4845/events
|
https://github.com/huggingface/datasets/pull/4845
| 1,337,928,283
|
PR_kwDODunzps49IOjf
| 4,845
|
Mark CI tests as xfail if Hub HTTP error
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-08-13T10:45:11Z
| 2022-08-23T04:57:12Z
| 2022-08-23T04:42:26Z
|
MEMBER
| null | null | null |
In order to make testing more robust (and avoid merges to master with red tests), we could mark tests as xfailed (instead of failed) when the Hub raises some temporary HTTP errors.
This PR:
- marks tests as xfailed only if the Hub raises a 500 error for:
- test_upstream_hub
- makes pytest report the xfailed/xpassed tests.
More tests could also be marked if needed.
Examples of CI failures due to temporary Hub HTTP errors:
- FAILED tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_multiple_files
- https://github.com/huggingface/datasets/runs/7806855399?check_suite_focus=true
`requests.exceptions.HTTPError: 500 Server Error: Internal Server Error for url: https://hub-ci.huggingface.co/api/datasets/__DUMMY_TRANSFORMERS_USER__/test-16603108028233/commit/main (Request ID: aZeAQ5yLktoGHQYBcJ3zo)`
- FAILED tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_no_token
- https://github.com/huggingface/datasets/runs/7840022996?check_suite_focus=true
`requests.exceptions.HTTPError: 500 Server Error: Internal Server Error for url: https://s3.us-east-1.amazonaws.com/lfs-staging.huggingface.co/repos/81/e3/81e3b831fa9bf23190ec041f26ef7ff6d6b71c1a937b8ec1ef1f1f05b508c089/caae596caa179cf45e7c9ac0c6d9a9cb0fe2d305291bfbb2d8b648ae26ed38b6?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20220815%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20220815T144713Z&X-Amz-Expires=900&X-Amz-Signature=5ddddfe8ef2b0601e80ab41c78a4d77d921942b0d8160bcab40ff894095e6823&X-Amz-SignedHeaders=host&x-id=PutObject`
- FAILED tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_private
- https://github.com/huggingface/datasets/runs/7835921082?check_suite_focus=true
`requests.exceptions.HTTPError: 500 Server Error: Internal Server Error for url: https://hub-ci.huggingface.co/api/repos/create (Request ID: gL_1I7i2dii9leBhlZen-) - Internal Error - We're working hard to fix that as soon as possible!`
- FAILED tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_to_hub_custom_features_image_list
- https://github.com/huggingface/datasets/runs/7835920900?check_suite_focus=true
- This is not 500, but 404:
`requests.exceptions.HTTPError: 404 Client Error: Not Found for url: [https://hub-ci.huggingface.co/datasets/__DUMMY_TRANSFORMERS_USER__/test-16605586458339.git/info/lfs/objects](https://hub-ci.huggingface.co/datasets/__DUMMY_TRANSFORMERS_USER__/test-16605586458339.git/info/lfs/objects/batch)`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4845/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4845/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4845.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4845",
"merged_at": "2022-08-23T04:42:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4845.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4845"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6862
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6862/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6862/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6862/events
|
https://github.com/huggingface/datasets/pull/6862
| 2,276,763,745
|
PR_kwDODunzps5ubOoL
| 6,862
|
Fix load_dataset for data_files with protocols other than HF
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/544843?v=4",
"events_url": "https://api.github.com/users/matstrand/events{/privacy}",
"followers_url": "https://api.github.com/users/matstrand/followers",
"following_url": "https://api.github.com/users/matstrand/following{/other_user}",
"gists_url": "https://api.github.com/users/matstrand/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/matstrand",
"id": 544843,
"login": "matstrand",
"node_id": "MDQ6VXNlcjU0NDg0Mw==",
"organizations_url": "https://api.github.com/users/matstrand/orgs",
"received_events_url": "https://api.github.com/users/matstrand/received_events",
"repos_url": "https://api.github.com/users/matstrand/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/matstrand/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/matstrand/subscriptions",
"type": "User",
"url": "https://api.github.com/users/matstrand",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6862). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005615 / 0.011353 (-0.005738) | 0.004015 / 0.011008 (-0.006994) | 0.066769 / 0.038508 (0.028261) | 0.032983 / 0.023109 (0.009874) | 0.246301 / 0.275898 (-0.029597) | 0.266463 / 0.323480 (-0.057017) | 0.003291 / 0.007986 (-0.004695) | 0.002905 / 0.004328 (-0.001424) | 0.049913 / 0.004250 (0.045663) | 0.046186 / 0.037052 (0.009134) | 0.248971 / 0.258489 (-0.009518) | 0.288066 / 0.293841 (-0.005775) | 0.029638 / 0.128546 (-0.098908) | 0.012454 / 0.075646 (-0.063192) | 0.225397 / 0.419271 (-0.193875) | 0.036075 / 0.043533 (-0.007458) | 0.250110 / 0.255139 (-0.005029) | 0.267968 / 0.283200 (-0.015232) | 0.020943 / 0.141683 (-0.120740) | 1.116938 / 1.452155 (-0.335216) | 1.159617 / 1.492716 (-0.333099) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.099813 / 0.018006 (0.081807) | 0.310770 / 0.000490 (0.310280) | 0.000223 / 0.000200 (0.000023) | 0.000043 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018909 / 0.037411 (-0.018503) | 0.062833 / 0.014526 (0.048307) | 0.074895 / 0.176557 (-0.101662) | 0.121213 / 0.737135 (-0.615922) | 0.076984 / 0.296338 (-0.219355) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282026 / 0.215209 (0.066817) | 2.775044 / 2.077655 (0.697390) | 1.485574 / 1.504120 (-0.018546) | 1.356639 / 1.541195 (-0.184556) | 1.378677 / 1.468490 (-0.089813) | 0.724739 / 4.584777 (-3.860038) | 2.379279 / 3.745712 (-1.366433) | 3.030104 / 5.269862 (-2.239758) | 1.981636 / 4.565676 (-2.584041) | 0.078758 / 0.424275 (-0.345517) | 0.005188 / 0.007607 (-0.002419) | 0.336284 / 0.226044 (0.110240) | 3.261649 / 2.268929 (0.992720) | 1.849333 / 55.444624 (-53.595292) | 1.564988 / 6.876477 (-5.311489) | 1.598720 / 2.142072 (-0.543353) | 0.793190 / 4.805227 (-4.012038) | 0.135384 / 6.500664 (-6.365280) | 0.043597 / 0.075469 (-0.031872) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.976428 / 1.841788 (-0.865359) | 12.087446 / 8.074308 (4.013138) | 9.756592 / 10.191392 (-0.434800) | 0.140836 / 0.680424 (-0.539588) | 0.015193 / 0.534201 (-0.519008) | 0.327789 / 0.579283 (-0.251494) | 0.265418 / 0.434364 (-0.168945) | 0.356548 / 0.540337 (-0.183790) | 0.451014 / 1.386936 (-0.935922) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005879 / 0.011353 (-0.005474) | 0.004001 / 0.011008 (-0.007008) | 0.051066 / 0.038508 (0.012558) | 0.033824 / 0.023109 (0.010714) | 0.275303 / 0.275898 (-0.000595) | 0.301223 / 0.323480 (-0.022257) | 0.004456 / 0.007986 (-0.003530) | 0.002930 / 0.004328 (-0.001399) | 0.050674 / 0.004250 (0.046423) | 0.040798 / 0.037052 (0.003746) | 0.288702 / 0.258489 (0.030213) | 0.324865 / 0.293841 (0.031024) | 0.032935 / 0.128546 (-0.095611) | 0.012372 / 0.075646 (-0.063274) | 0.060778 / 0.419271 (-0.358493) | 0.034369 / 0.043533 (-0.009164) | 0.277240 / 0.255139 (0.022101) | 0.300027 / 0.283200 (0.016828) | 0.018586 / 0.141683 (-0.123097) | 1.148498 / 1.452155 (-0.303657) | 1.256665 / 1.492716 (-0.236052) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.105616 / 0.018006 (0.087610) | 0.328206 / 0.000490 (0.327716) | 0.000229 / 0.000200 (0.000029) | 0.000052 / 0.000054 (-0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023759 / 0.037411 (-0.013652) | 0.077709 / 0.014526 (0.063183) | 0.089840 / 0.176557 (-0.086717) | 0.129891 / 0.737135 (-0.607244) | 0.091533 / 0.296338 (-0.204805) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.308228 / 0.215209 (0.093019) | 2.966868 / 2.077655 (0.889213) | 1.589914 / 1.504120 (0.085794) | 1.463263 / 1.541195 (-0.077932) | 1.508233 / 1.468490 (0.039743) | 0.722289 / 4.584777 (-3.862488) | 0.961580 / 3.745712 (-2.784132) | 2.897209 / 5.269862 (-2.372653) | 1.969601 / 4.565676 (-2.596076) | 0.079850 / 0.424275 (-0.344425) | 0.005394 / 0.007607 (-0.002213) | 0.355451 / 0.226044 (0.129406) | 3.486822 / 2.268929 (1.217893) | 1.987236 / 55.444624 (-53.457388) | 1.701017 / 6.876477 (-5.175460) | 1.849909 / 2.142072 (-0.292163) | 0.785358 / 4.805227 (-4.019870) | 0.135085 / 6.500664 (-6.365579) | 0.042056 / 0.075469 (-0.033413) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.055287 / 1.841788 (-0.786501) | 13.696916 / 8.074308 (5.622608) | 10.801396 / 10.191392 (0.610004) | 0.134642 / 0.680424 (-0.545782) | 0.016007 / 0.534201 (-0.518194) | 0.304163 / 0.579283 (-0.275120) | 0.124530 / 0.434364 (-0.309834) | 0.344002 / 0.540337 (-0.196335) | 0.445138 / 1.386936 (-0.941798) |\n\n</details>\n</details>\n\n\n"
] | 2024-05-03T01:43:47Z
| 2024-07-23T14:37:08Z
| 2024-07-23T14:30:09Z
|
CONTRIBUTOR
| null | null | null |
Fixes huggingface/datasets/issues/6598
I've added a new test case and a solution. Before applying the solution the test case was failing with the same error described in the linked issue.
MRE:
```
pip install "datasets[s3]"
python -c "from datasets import load_dataset; load_dataset('csv', data_files={'train': 's3://noaa-gsod-pds/2024/A5125600451.csv'})"
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6862/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6862/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6862.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6862",
"merged_at": "2024-07-23T14:30:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6862.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6862"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6727
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6727/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6727/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6727/events
|
https://github.com/huggingface/datasets/pull/6727
| 2,177,826,110
|
PR_kwDODunzps5pLJyE
| 6,727
|
Using a registry instead of calling globals for fetching feature types
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11325244?v=4",
"events_url": "https://api.github.com/users/psmyth94/events{/privacy}",
"followers_url": "https://api.github.com/users/psmyth94/followers",
"following_url": "https://api.github.com/users/psmyth94/following{/other_user}",
"gists_url": "https://api.github.com/users/psmyth94/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/psmyth94",
"id": 11325244,
"login": "psmyth94",
"node_id": "MDQ6VXNlcjExMzI1MjQ0",
"organizations_url": "https://api.github.com/users/psmyth94/orgs",
"received_events_url": "https://api.github.com/users/psmyth94/received_events",
"repos_url": "https://api.github.com/users/psmyth94/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/psmyth94/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/psmyth94/subscriptions",
"type": "User",
"url": "https://api.github.com/users/psmyth94",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6727). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"looks like some files are missing in your google storage",
"cc @mariosasko is it related to https://github.com/huggingface/datasets/pull/6474 ? The files should ideally not move for backward compatibility anyway",
"@lhoestq All the files are still there.\r\n\r\nThe problem is that the `natural_questions` is now a no-code dataset, so the test's paths are no longer correct (unless the revision is pinned to the previous version). \r\n\r\n@psmyth94 This has been fixed on `main`, so you can make the CI tests green with the following:\r\n```python\r\ngit remote add upstream https://github.com/huggingface/datasets.git\r\ngit pull upstream main\r\ngit push\r\n```",
"Thank you @mariosasko ! I'm updating this branch if you don't mind @psmyth94 ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004903 / 0.011353 (-0.006450) | 0.003105 / 0.011008 (-0.007903) | 0.061980 / 0.038508 (0.023471) | 0.029726 / 0.023109 (0.006617) | 0.243406 / 0.275898 (-0.032492) | 0.262530 / 0.323480 (-0.060950) | 0.003905 / 0.007986 (-0.004081) | 0.002617 / 0.004328 (-0.001712) | 0.047851 / 0.004250 (0.043601) | 0.040397 / 0.037052 (0.003345) | 0.259461 / 0.258489 (0.000972) | 0.285059 / 0.293841 (-0.008782) | 0.027321 / 0.128546 (-0.101225) | 0.009876 / 0.075646 (-0.065770) | 0.206999 / 0.419271 (-0.212273) | 0.034906 / 0.043533 (-0.008626) | 0.245120 / 0.255139 (-0.010019) | 0.270490 / 0.283200 (-0.012710) | 0.017341 / 0.141683 (-0.124342) | 1.128182 / 1.452155 (-0.323973) | 1.173024 / 1.492716 (-0.319693) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.089337 / 0.018006 (0.071331) | 0.298256 / 0.000490 (0.297767) | 0.000216 / 0.000200 (0.000016) | 0.000047 / 0.000054 (-0.000007) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018179 / 0.037411 (-0.019233) | 0.061275 / 0.014526 (0.046749) | 0.073137 / 0.176557 (-0.103419) | 0.119603 / 0.737135 (-0.617532) | 0.073969 / 0.296338 (-0.222370) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.283109 / 0.215209 (0.067900) | 2.765441 / 2.077655 (0.687787) | 1.471276 / 1.504120 (-0.032844) | 1.346365 / 1.541195 (-0.194830) | 1.360668 / 1.468490 (-0.107822) | 0.549947 / 4.584777 (-4.034830) | 2.344213 / 3.745712 (-1.401499) | 2.700905 / 5.269862 (-2.568956) | 1.689936 / 4.565676 (-2.875741) | 0.061985 / 0.424275 (-0.362290) | 0.004923 / 0.007607 (-0.002684) | 0.329833 / 0.226044 (0.103788) | 3.277580 / 2.268929 (1.008652) | 1.833987 / 55.444624 (-53.610638) | 1.571023 / 6.876477 (-5.305454) | 1.573259 / 2.142072 (-0.568813) | 0.627504 / 4.805227 (-4.177723) | 0.114106 / 6.500664 (-6.386558) | 0.041197 / 0.075469 (-0.034272) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.967400 / 1.841788 (-0.874388) | 11.046527 / 8.074308 (2.972219) | 9.542214 / 10.191392 (-0.649178) | 0.140745 / 0.680424 (-0.539679) | 0.013627 / 0.534201 (-0.520574) | 0.288429 / 0.579283 (-0.290855) | 0.260509 / 0.434364 (-0.173855) | 0.324704 / 0.540337 (-0.215633) | 0.419366 / 1.386936 (-0.967570) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005123 / 0.011353 (-0.006230) | 0.003119 / 0.011008 (-0.007890) | 0.048931 / 0.038508 (0.010423) | 0.032067 / 0.023109 (0.008958) | 0.276825 / 0.275898 (0.000927) | 0.297589 / 0.323480 (-0.025890) | 0.004075 / 0.007986 (-0.003911) | 0.002579 / 0.004328 (-0.001750) | 0.047862 / 0.004250 (0.043612) | 0.044032 / 0.037052 (0.006980) | 0.289469 / 0.258489 (0.030980) | 0.327269 / 0.293841 (0.033428) | 0.029369 / 0.128546 (-0.099177) | 0.010180 / 0.075646 (-0.065466) | 0.057111 / 0.419271 (-0.362161) | 0.051046 / 0.043533 (0.007513) | 0.276758 / 0.255139 (0.021619) | 0.296084 / 0.283200 (0.012884) | 0.017376 / 0.141683 (-0.124306) | 1.154486 / 1.452155 (-0.297669) | 1.192699 / 1.492716 (-0.300018) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.085981 / 0.018006 (0.067974) | 0.296956 / 0.000490 (0.296466) | 0.000211 / 0.000200 (0.000011) | 0.000050 / 0.000054 (-0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021239 / 0.037411 (-0.016172) | 0.074851 / 0.014526 (0.060326) | 0.085676 / 0.176557 (-0.090881) | 0.125876 / 0.737135 (-0.611259) | 0.087573 / 0.296338 (-0.208765) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.289220 / 0.215209 (0.074011) | 2.812342 / 2.077655 (0.734688) | 1.572886 / 1.504120 (0.068766) | 1.446442 / 1.541195 (-0.094752) | 1.458737 / 1.468490 (-0.009753) | 0.562010 / 4.584777 (-4.022767) | 2.422896 / 3.745712 (-1.322816) | 2.578408 / 5.269862 (-2.691454) | 1.689998 / 4.565676 (-2.875678) | 0.064782 / 0.424275 (-0.359493) | 0.005051 / 0.007607 (-0.002556) | 0.339982 / 0.226044 (0.113938) | 3.309882 / 2.268929 (1.040953) | 1.910273 / 55.444624 (-53.534351) | 1.649723 / 6.876477 (-5.226753) | 1.744073 / 2.142072 (-0.397999) | 0.651905 / 4.805227 (-4.153323) | 0.114606 / 6.500664 (-6.386058) | 0.040030 / 0.075469 (-0.035439) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.008374 / 1.841788 (-0.833414) | 11.547300 / 8.074308 (3.472992) | 9.966061 / 10.191392 (-0.225331) | 0.144874 / 0.680424 (-0.535550) | 0.014400 / 0.534201 (-0.519801) | 0.285435 / 0.579283 (-0.293848) | 0.274755 / 0.434364 (-0.159609) | 0.323105 / 0.540337 (-0.217232) | 0.439172 / 1.386936 (-0.947764) |\n\n</details>\n</details>\n\n\n"
] | 2024-03-10T17:47:51Z
| 2024-03-13T12:08:49Z
| 2024-03-13T10:46:02Z
|
CONTRIBUTOR
| null | null | null |
Hello,
When working with bio-data, each feature often has metadata associated with it (e.g. species, lineage, snp position, etc). To store this, I like to use the feature classes with the added `metadata` attribute. However, when saving or loading with custom features, you get an error since that class doesn't exist in the global namespace in `datasets.features.features`. Take for example,
```python
from dataclasses import dataclass, field
from datasets import Dataset
from datasets.features.features import Value, Features
@dataclass
class FeatureA(Value):
metadata: dict = field(default=dict)
_type: str = field(default="FeatureA", init=False, repr=False)
@dataclass
class FeatureB(Value):
metadata: dict = field(default_factory=dict)
_type: str = field(default="FeatureB", init=False, repr=False)
test_data = {
"a": [1, 2, 3],
"b": [4, 5, 6],
}
test_data = Dataset.from_dict(
test_data,
features=Features({
"a": FeatureA("int32", metadata={"species": "lactobacillus acetotolerans"}),
"b": FeatureB("int32", metadata={"species": "lactobacillus iners"}),
})
)
# returns an error since FeatureA and FeatureB are not in the global namespace
test_data.save_to_disk('./test_data')
```
Saving the dataset (0/1 shards): 0%| | 0/3 [00:00<?, ? examples/s]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[2], line 28
19 test_data = Dataset.from_dict(
20 test_data,
21 features=Features({
(...)
24 })
25 )
27 # returns an error since FeatureA and FeatureB are not in the global namespace
---> 28 test_data.save_to_disk('./test_data')
...
File ~\Documents\datasets\src\datasets\features\features.py:1361, in generate_from_dict(obj)
1359 return {key: generate_from_dict(value) for key, value in obj.items()}
1360 obj = dict(obj)
-> 1361 class_type = globals()[obj.pop("_type")]
1363 if class_type == Sequence:
1364 return Sequence(feature=generate_from_dict(obj["feature"]), length=obj.get("length", -1))
KeyError: 'FeatureA'
We can avoid this by having a registry (like formatters) and doing
```python
from datasets.features.features import register_feature
register_feature(FeatureA, "FeatureA")
register_feature(FeatureB, "FeatureB")
test_data.save_to_disk('./test_data')
```
Saving the dataset (1/1 shards): 100%|------| 3/3 [00:00<00:00, 211.13 examples/s]
and loading from disk returns with all metadata information
```python
from datasets import load_from_disk
test_data = load_from_disk('./test_data')
test_data.features
```
{'a': FeatureA(dtype='int32', id=None, metadata={'species': 'lactobacillus acetotolerans'}),
'b': FeatureB(dtype='int32', id=None, metadata={'species': 'lactobacillus iners'})}
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6727/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6727/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6727.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6727",
"merged_at": "2024-03-13T10:46:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6727.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6727"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5615
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5615/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5615/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5615/events
|
https://github.com/huggingface/datasets/issues/5615
| 1,612,552,653
|
I_kwDODunzps5gHZnN
| 5,615
|
IterableDataset.add_column is unable to accept another IterableDataset as a parameter.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/6466389?v=4",
"events_url": "https://api.github.com/users/zsaladin/events{/privacy}",
"followers_url": "https://api.github.com/users/zsaladin/followers",
"following_url": "https://api.github.com/users/zsaladin/following{/other_user}",
"gists_url": "https://api.github.com/users/zsaladin/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zsaladin",
"id": 6466389,
"login": "zsaladin",
"node_id": "MDQ6VXNlcjY0NjYzODk=",
"organizations_url": "https://api.github.com/users/zsaladin/orgs",
"received_events_url": "https://api.github.com/users/zsaladin/received_events",
"repos_url": "https://api.github.com/users/zsaladin/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zsaladin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zsaladin/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zsaladin",
"user_view_type": "public"
}
|
[
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] |
closed
| false
| null |
[] | null |
[
"Hi! You can use `concatenate_datasets([ids1, ids2], axis=1)` to do this."
] | 2023-03-07T01:52:00Z
| 2023-03-09T15:24:05Z
| 2023-03-09T15:23:54Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
`IterableDataset.add_column` occurs an exception when passing another `IterableDataset` as a parameter.
The method seems to accept only eager evaluated values.
https://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/iterable_dataset.py#L1388-L1391
I wrote codes below to make it.
```py
def add_column(dataset: IterableDataset, name: str, add_dataset: IterableDataset, key: str) -> IterableDataset:
iter_add_dataset = iter(add_dataset)
def add_column_fn(example):
if name in example:
raise ValueError(f"Error when adding {name}: column {name} is already in the dataset.")
return {name: next(iter_add_dataset)[key]}
return dataset.map(add_column_fn)
```
Is there other way to do it? Or is it intended?
### Steps to reproduce the bug
Thie codes below occurs `NotImplementedError`
```py
from datasets import IterableDataset
def gen(num):
yield {f"col{num}": 1}
yield {f"col{num}": 2}
yield {f"col{num}": 3}
ids1 = IterableDataset.from_generator(gen, gen_kwargs={"num": 1})
ids2 = IterableDataset.from_generator(gen, gen_kwargs={"num": 2})
new_ids = ids1.add_column("new_col", ids1)
for row in new_ids:
print(row)
```
### Expected behavior
`IterableDataset.add_column` is able to task `IterableDataset` and lazy evaluated values as a parameter since IterableDataset is lazy evalued.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-3.10.0-1160.36.2.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.9.7
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5615/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5615/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6072
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6072/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6072/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6072/events
|
https://github.com/huggingface/datasets/pull/6072
| 1,822,123,560
|
PR_kwDODunzps5WbWFN
| 6,072
|
Fix fsspec storage_options from load_dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007617 / 0.011353 (-0.003736) | 0.004580 / 0.011008 (-0.006428) | 0.100913 / 0.038508 (0.062405) | 0.087703 / 0.023109 (0.064594) | 0.424159 / 0.275898 (0.148261) | 0.467195 / 0.323480 (0.143715) | 0.006890 / 0.007986 (-0.001096) | 0.003765 / 0.004328 (-0.000564) | 0.077513 / 0.004250 (0.073262) | 0.064889 / 0.037052 (0.027837) | 0.422349 / 0.258489 (0.163860) | 0.477391 / 0.293841 (0.183550) | 0.036025 / 0.128546 (-0.092522) | 0.009939 / 0.075646 (-0.065707) | 0.342409 / 0.419271 (-0.076862) | 0.061568 / 0.043533 (0.018035) | 0.431070 / 0.255139 (0.175931) | 0.462008 / 0.283200 (0.178809) | 0.027480 / 0.141683 (-0.114203) | 1.802271 / 1.452155 (0.350116) | 1.861336 / 1.492716 (0.368620) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.255806 / 0.018006 (0.237800) | 0.507969 / 0.000490 (0.507479) | 0.010060 / 0.000200 (0.009860) | 0.000112 / 0.000054 (0.000058) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032286 / 0.037411 (-0.005125) | 0.104468 / 0.014526 (0.089942) | 0.112707 / 0.176557 (-0.063850) | 0.181285 / 0.737135 (-0.555850) | 0.113180 / 0.296338 (-0.183158) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.449265 / 0.215209 (0.234056) | 4.465941 / 2.077655 (2.388287) | 2.177889 / 1.504120 (0.673769) | 1.969864 / 1.541195 (0.428669) | 2.077502 / 1.468490 (0.609011) | 0.561607 / 4.584777 (-4.023170) | 4.281873 / 3.745712 (0.536161) | 4.975352 / 5.269862 (-0.294510) | 2.907121 / 4.565676 (-1.658555) | 0.070205 / 0.424275 (-0.354070) | 0.009164 / 0.007607 (0.001557) | 0.581921 / 0.226044 (0.355876) | 5.538667 / 2.268929 (3.269739) | 2.798853 / 55.444624 (-52.645771) | 2.314015 / 6.876477 (-4.562462) | 2.584836 / 2.142072 (0.442763) | 0.672333 / 4.805227 (-4.132894) | 0.153828 / 6.500664 (-6.346836) | 0.069757 / 0.075469 (-0.005712) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.559670 / 1.841788 (-0.282118) | 23.994639 / 8.074308 (15.920331) | 16.856160 / 10.191392 (6.664768) | 0.195555 / 0.680424 (-0.484869) | 0.021586 / 0.534201 (-0.512615) | 0.469295 / 0.579283 (-0.109989) | 0.481582 / 0.434364 (0.047218) | 0.588667 / 0.540337 (0.048329) | 0.734347 / 1.386936 (-0.652589) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009614 / 0.011353 (-0.001739) | 0.004616 / 0.011008 (-0.006392) | 0.077223 / 0.038508 (0.038715) | 0.103074 / 0.023109 (0.079965) | 0.447834 / 0.275898 (0.171936) | 0.524696 / 0.323480 (0.201216) | 0.007120 / 0.007986 (-0.000866) | 0.003890 / 0.004328 (-0.000438) | 0.076406 / 0.004250 (0.072156) | 0.073488 / 0.037052 (0.036436) | 0.466221 / 0.258489 (0.207732) | 0.532206 / 0.293841 (0.238365) | 0.037596 / 0.128546 (-0.090950) | 0.010029 / 0.075646 (-0.065617) | 0.084313 / 0.419271 (-0.334959) | 0.060088 / 0.043533 (0.016555) | 0.437792 / 0.255139 (0.182653) | 0.512850 / 0.283200 (0.229650) | 0.032424 / 0.141683 (-0.109259) | 1.762130 / 1.452155 (0.309975) | 1.946097 / 1.492716 (0.453381) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.250774 / 0.018006 (0.232768) | 0.506869 / 0.000490 (0.506379) | 0.008232 / 0.000200 (0.008032) | 0.000164 / 0.000054 (0.000110) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.037779 / 0.037411 (0.000368) | 0.111933 / 0.014526 (0.097407) | 0.122385 / 0.176557 (-0.054172) | 0.190372 / 0.737135 (-0.546763) | 0.122472 / 0.296338 (-0.173866) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.488502 / 0.215209 (0.273293) | 4.878114 / 2.077655 (2.800459) | 2.504144 / 1.504120 (1.000024) | 2.321077 / 1.541195 (0.779883) | 2.416797 / 1.468490 (0.948307) | 0.583582 / 4.584777 (-4.001195) | 4.277896 / 3.745712 (0.532184) | 3.874780 / 5.269862 (-1.395082) | 2.540099 / 4.565676 (-2.025577) | 0.068734 / 0.424275 (-0.355541) | 0.009158 / 0.007607 (0.001550) | 0.578401 / 0.226044 (0.352357) | 5.763354 / 2.268929 (3.494426) | 3.167771 / 55.444624 (-52.276853) | 2.675220 / 6.876477 (-4.201257) | 2.920927 / 2.142072 (0.778855) | 0.673948 / 4.805227 (-4.131280) | 0.157908 / 6.500664 (-6.342756) | 0.071672 / 0.075469 (-0.003797) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.635120 / 1.841788 (-0.206668) | 24.853480 / 8.074308 (16.779172) | 17.162978 / 10.191392 (6.971586) | 0.209577 / 0.680424 (-0.470847) | 0.030110 / 0.534201 (-0.504091) | 0.546970 / 0.579283 (-0.032313) | 0.581912 / 0.434364 (0.147548) | 0.571460 / 0.540337 (0.031123) | 0.823411 / 1.386936 (-0.563525) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006674 / 0.011353 (-0.004679) | 0.004198 / 0.011008 (-0.006810) | 0.084859 / 0.038508 (0.046351) | 0.076065 / 0.023109 (0.052955) | 0.316065 / 0.275898 (0.040167) | 0.352097 / 0.323480 (0.028617) | 0.005610 / 0.007986 (-0.002376) | 0.003600 / 0.004328 (-0.000729) | 0.064921 / 0.004250 (0.060671) | 0.054493 / 0.037052 (0.017441) | 0.318125 / 0.258489 (0.059636) | 0.370183 / 0.293841 (0.076342) | 0.031141 / 0.128546 (-0.097405) | 0.008755 / 0.075646 (-0.066891) | 0.288241 / 0.419271 (-0.131030) | 0.052379 / 0.043533 (0.008846) | 0.328147 / 0.255139 (0.073008) | 0.347548 / 0.283200 (0.064348) | 0.024393 / 0.141683 (-0.117290) | 1.480646 / 1.452155 (0.028492) | 1.575867 / 1.492716 (0.083151) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.268978 / 0.018006 (0.250971) | 0.586470 / 0.000490 (0.585980) | 0.003190 / 0.000200 (0.002990) | 0.000081 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030595 / 0.037411 (-0.006816) | 0.083037 / 0.014526 (0.068511) | 0.103706 / 0.176557 (-0.072850) | 0.164104 / 0.737135 (-0.573031) | 0.104536 / 0.296338 (-0.191802) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.382274 / 0.215209 (0.167065) | 3.811878 / 2.077655 (1.734223) | 1.840098 / 1.504120 (0.335978) | 1.670949 / 1.541195 (0.129754) | 1.763755 / 1.468490 (0.295264) | 0.479526 / 4.584777 (-4.105251) | 3.544443 / 3.745712 (-0.201269) | 3.263004 / 5.269862 (-2.006858) | 2.092801 / 4.565676 (-2.472875) | 0.057167 / 0.424275 (-0.367108) | 0.007450 / 0.007607 (-0.000157) | 0.463731 / 0.226044 (0.237686) | 4.624630 / 2.268929 (2.355701) | 2.327078 / 55.444624 (-53.117546) | 1.977734 / 6.876477 (-4.898743) | 2.237152 / 2.142072 (0.095079) | 0.573210 / 4.805227 (-4.232018) | 0.132095 / 6.500664 (-6.368569) | 0.060283 / 0.075469 (-0.015186) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.243404 / 1.841788 (-0.598384) | 20.306778 / 8.074308 (12.232470) | 14.561660 / 10.191392 (4.370268) | 0.170826 / 0.680424 (-0.509598) | 0.018574 / 0.534201 (-0.515627) | 0.392367 / 0.579283 (-0.186916) | 0.402918 / 0.434364 (-0.031446) | 0.476629 / 0.540337 (-0.063708) | 0.653709 / 1.386936 (-0.733227) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006562 / 0.011353 (-0.004791) | 0.004092 / 0.011008 (-0.006916) | 0.065951 / 0.038508 (0.027443) | 0.078090 / 0.023109 (0.054981) | 0.369679 / 0.275898 (0.093781) | 0.411442 / 0.323480 (0.087962) | 0.005646 / 0.007986 (-0.002339) | 0.003537 / 0.004328 (-0.000791) | 0.066024 / 0.004250 (0.061773) | 0.058947 / 0.037052 (0.021895) | 0.389219 / 0.258489 (0.130730) | 0.414200 / 0.293841 (0.120359) | 0.030372 / 0.128546 (-0.098174) | 0.008631 / 0.075646 (-0.067015) | 0.071692 / 0.419271 (-0.347580) | 0.048035 / 0.043533 (0.004502) | 0.376960 / 0.255139 (0.121821) | 0.389847 / 0.283200 (0.106648) | 0.023940 / 0.141683 (-0.117743) | 1.487633 / 1.452155 (0.035479) | 1.561680 / 1.492716 (0.068964) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.301467 / 0.018006 (0.283461) | 0.544159 / 0.000490 (0.543669) | 0.000408 / 0.000200 (0.000208) | 0.000055 / 0.000054 (0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030939 / 0.037411 (-0.006472) | 0.087432 / 0.014526 (0.072906) | 0.103263 / 0.176557 (-0.073293) | 0.154551 / 0.737135 (-0.582585) | 0.104631 / 0.296338 (-0.191707) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422348 / 0.215209 (0.207139) | 4.206003 / 2.077655 (2.128348) | 2.212619 / 1.504120 (0.708499) | 2.049616 / 1.541195 (0.508421) | 2.139093 / 1.468490 (0.670603) | 0.489647 / 4.584777 (-4.095130) | 3.523291 / 3.745712 (-0.222422) | 3.277657 / 5.269862 (-1.992205) | 2.111353 / 4.565676 (-2.454324) | 0.057597 / 0.424275 (-0.366679) | 0.007675 / 0.007607 (0.000068) | 0.493068 / 0.226044 (0.267023) | 4.939493 / 2.268929 (2.670565) | 2.695995 / 55.444624 (-52.748630) | 2.374904 / 6.876477 (-4.501573) | 2.600110 / 2.142072 (0.458038) | 0.586306 / 4.805227 (-4.218921) | 0.134137 / 6.500664 (-6.366527) | 0.061897 / 0.075469 (-0.013572) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.330628 / 1.841788 (-0.511160) | 20.557964 / 8.074308 (12.483656) | 14.251632 / 10.191392 (4.060240) | 0.148772 / 0.680424 (-0.531652) | 0.018383 / 0.534201 (-0.515817) | 0.392552 / 0.579283 (-0.186731) | 0.403959 / 0.434364 (-0.030405) | 0.462154 / 0.540337 (-0.078184) | 0.608832 / 1.386936 (-0.778104) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007659 / 0.011353 (-0.003694) | 0.004500 / 0.011008 (-0.006508) | 0.100379 / 0.038508 (0.061871) | 0.079731 / 0.023109 (0.056622) | 0.381788 / 0.275898 (0.105890) | 0.416524 / 0.323480 (0.093044) | 0.004446 / 0.007986 (-0.003539) | 0.003752 / 0.004328 (-0.000577) | 0.074956 / 0.004250 (0.070706) | 0.062885 / 0.037052 (0.025832) | 0.383849 / 0.258489 (0.125360) | 0.433906 / 0.293841 (0.140065) | 0.036079 / 0.128546 (-0.092468) | 0.009927 / 0.075646 (-0.065719) | 0.343879 / 0.419271 (-0.075393) | 0.061055 / 0.043533 (0.017523) | 0.376703 / 0.255139 (0.121564) | 0.428111 / 0.283200 (0.144911) | 0.028667 / 0.141683 (-0.113016) | 1.777755 / 1.452155 (0.325600) | 1.878283 / 1.492716 (0.385567) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220829 / 0.018006 (0.202823) | 0.506406 / 0.000490 (0.505916) | 0.005550 / 0.000200 (0.005350) | 0.000123 / 0.000054 (0.000069) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034928 / 0.037411 (-0.002483) | 0.103873 / 0.014526 (0.089347) | 0.114352 / 0.176557 (-0.062204) | 0.188218 / 0.737135 (-0.548918) | 0.117343 / 0.296338 (-0.178995) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.459148 / 0.215209 (0.243939) | 4.582092 / 2.077655 (2.504437) | 2.275603 / 1.504120 (0.771483) | 2.058155 / 1.541195 (0.516960) | 2.163886 / 1.468490 (0.695396) | 0.573033 / 4.584777 (-4.011744) | 4.414891 / 3.745712 (0.669178) | 7.280433 / 5.269862 (2.010572) | 4.119414 / 4.565676 (-0.446262) | 0.067432 / 0.424275 (-0.356843) | 0.008687 / 0.007607 (0.001080) | 0.556029 / 0.226044 (0.329984) | 5.557192 / 2.268929 (3.288264) | 2.921596 / 55.444624 (-52.523028) | 2.520249 / 6.876477 (-4.356228) | 2.778965 / 2.142072 (0.636893) | 0.684765 / 4.805227 (-4.120462) | 0.159228 / 6.500664 (-6.341436) | 0.074015 / 0.075469 (-0.001454) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.534470 / 1.841788 (-0.307318) | 23.630693 / 8.074308 (15.556385) | 17.058142 / 10.191392 (6.866750) | 0.200909 / 0.680424 (-0.479515) | 0.021637 / 0.534201 (-0.512564) | 0.467417 / 0.579283 (-0.111866) | 0.460456 / 0.434364 (0.026092) | 0.541131 / 0.540337 (0.000793) | 0.728560 / 1.386936 (-0.658376) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007625 / 0.011353 (-0.003727) | 0.004495 / 0.011008 (-0.006513) | 0.076373 / 0.038508 (0.037865) | 0.085260 / 0.023109 (0.062151) | 0.475778 / 0.275898 (0.199880) | 0.504604 / 0.323480 (0.181124) | 0.006733 / 0.007986 (-0.001253) | 0.003751 / 0.004328 (-0.000578) | 0.074993 / 0.004250 (0.070743) | 0.064704 / 0.037052 (0.027652) | 0.490072 / 0.258489 (0.231583) | 0.507560 / 0.293841 (0.213719) | 0.036765 / 0.128546 (-0.091781) | 0.009955 / 0.075646 (-0.065692) | 0.082452 / 0.419271 (-0.336820) | 0.057131 / 0.043533 (0.013598) | 0.467664 / 0.255139 (0.212525) | 0.482143 / 0.283200 (0.198943) | 0.025396 / 0.141683 (-0.116287) | 1.807587 / 1.452155 (0.355433) | 1.853355 / 1.492716 (0.360639) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.250543 / 0.018006 (0.232537) | 0.495685 / 0.000490 (0.495196) | 0.000415 / 0.000200 (0.000215) | 0.000063 / 0.000054 (0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035795 / 0.037411 (-0.001616) | 0.105954 / 0.014526 (0.091428) | 0.120158 / 0.176557 (-0.056399) | 0.181714 / 0.737135 (-0.555422) | 0.121242 / 0.296338 (-0.175097) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.488241 / 0.215209 (0.273032) | 4.866916 / 2.077655 (2.789262) | 2.531530 / 1.504120 (1.027410) | 2.360642 / 1.541195 (0.819448) | 2.457320 / 1.468490 (0.988830) | 0.571224 / 4.584777 (-4.013553) | 4.339042 / 3.745712 (0.593330) | 3.672812 / 5.269862 (-1.597050) | 2.364535 / 4.565676 (-2.201142) | 0.067004 / 0.424275 (-0.357271) | 0.009019 / 0.007607 (0.001412) | 0.563751 / 0.226044 (0.337707) | 5.664917 / 2.268929 (3.395989) | 3.043316 / 55.444624 (-52.401308) | 2.682722 / 6.876477 (-4.193755) | 2.863482 / 2.142072 (0.721409) | 0.666171 / 4.805227 (-4.139056) | 0.151862 / 6.500664 (-6.348802) | 0.071199 / 0.075469 (-0.004271) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.601880 / 1.841788 (-0.239907) | 23.069073 / 8.074308 (14.994765) | 16.918377 / 10.191392 (6.726985) | 0.173614 / 0.680424 (-0.506810) | 0.021843 / 0.534201 (-0.512358) | 0.470531 / 0.579283 (-0.108753) | 0.471152 / 0.434364 (0.036788) | 0.550968 / 0.540337 (0.010631) | 0.718869 / 1.386936 (-0.668067) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007530 / 0.011353 (-0.003823) | 0.004151 / 0.011008 (-0.006858) | 0.098490 / 0.038508 (0.059982) | 0.086955 / 0.023109 (0.063846) | 0.362133 / 0.275898 (0.086235) | 0.391402 / 0.323480 (0.067922) | 0.006274 / 0.007986 (-0.001712) | 0.003711 / 0.004328 (-0.000618) | 0.073519 / 0.004250 (0.069269) | 0.066170 / 0.037052 (0.029118) | 0.379057 / 0.258489 (0.120568) | 0.398132 / 0.293841 (0.104291) | 0.033936 / 0.128546 (-0.094610) | 0.009977 / 0.075646 (-0.065670) | 0.323766 / 0.419271 (-0.095505) | 0.078615 / 0.043533 (0.035082) | 0.352403 / 0.255139 (0.097264) | 0.386607 / 0.283200 (0.103407) | 0.036579 / 0.141683 (-0.105103) | 1.691899 / 1.452155 (0.239745) | 1.819396 / 1.492716 (0.326680) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.216888 / 0.018006 (0.198882) | 0.465781 / 0.000490 (0.465291) | 0.006197 / 0.000200 (0.005997) | 0.000086 / 0.000054 (0.000031) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032870 / 0.037411 (-0.004542) | 0.096026 / 0.014526 (0.081500) | 0.111093 / 0.176557 (-0.065464) | 0.185982 / 0.737135 (-0.551154) | 0.106967 / 0.296338 (-0.189371) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441567 / 0.215209 (0.226358) | 4.353813 / 2.077655 (2.276158) | 2.176034 / 1.504120 (0.671914) | 1.969631 / 1.541195 (0.428437) | 2.048821 / 1.468490 (0.580330) | 0.549144 / 4.584777 (-4.035633) | 4.016166 / 3.745712 (0.270453) | 3.764249 / 5.269862 (-1.505613) | 2.293995 / 4.565676 (-2.271681) | 0.065227 / 0.424275 (-0.359048) | 0.008303 / 0.007607 (0.000695) | 0.513783 / 0.226044 (0.287738) | 5.247617 / 2.268929 (2.978689) | 2.782114 / 55.444624 (-52.662510) | 2.342776 / 6.876477 (-4.533701) | 2.621569 / 2.142072 (0.479497) | 0.679336 / 4.805227 (-4.125891) | 0.152061 / 6.500664 (-6.348603) | 0.070294 / 0.075469 (-0.005175) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.471778 / 1.841788 (-0.370010) | 22.714904 / 8.074308 (14.640596) | 15.607991 / 10.191392 (5.416599) | 0.172592 / 0.680424 (-0.507832) | 0.021799 / 0.534201 (-0.512402) | 0.462740 / 0.579283 (-0.116543) | 0.490885 / 0.434364 (0.056521) | 0.552997 / 0.540337 (0.012660) | 0.763784 / 1.386936 (-0.623152) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007466 / 0.011353 (-0.003886) | 0.004322 / 0.011008 (-0.006686) | 0.074331 / 0.038508 (0.035823) | 0.085315 / 0.023109 (0.062206) | 0.409284 / 0.275898 (0.133386) | 0.464584 / 0.323480 (0.141104) | 0.005651 / 0.007986 (-0.002335) | 0.003577 / 0.004328 (-0.000751) | 0.070250 / 0.004250 (0.066000) | 0.059780 / 0.037052 (0.022727) | 0.419668 / 0.258489 (0.161179) | 0.462984 / 0.293841 (0.169143) | 0.034159 / 0.128546 (-0.094387) | 0.008999 / 0.075646 (-0.066647) | 0.076302 / 0.419271 (-0.342969) | 0.052274 / 0.043533 (0.008741) | 0.425938 / 0.255139 (0.170799) | 0.430399 / 0.283200 (0.147200) | 0.025017 / 0.141683 (-0.116666) | 1.680697 / 1.452155 (0.228542) | 1.774677 / 1.492716 (0.281960) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.291514 / 0.018006 (0.273508) | 0.461175 / 0.000490 (0.460685) | 0.023061 / 0.000200 (0.022861) | 0.000120 / 0.000054 (0.000065) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033950 / 0.037411 (-0.003462) | 0.100032 / 0.014526 (0.085506) | 0.118308 / 0.176557 (-0.058249) | 0.183601 / 0.737135 (-0.553535) | 0.116936 / 0.296338 (-0.179402) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.478779 / 0.215209 (0.263570) | 4.709505 / 2.077655 (2.631850) | 2.457442 / 1.504120 (0.953322) | 2.213737 / 1.541195 (0.672542) | 2.340642 / 1.468490 (0.872152) | 0.567187 / 4.584777 (-4.017590) | 3.923061 / 3.745712 (0.177349) | 3.752989 / 5.269862 (-1.516873) | 2.324028 / 4.565676 (-2.241649) | 0.064471 / 0.424275 (-0.359804) | 0.008845 / 0.007607 (0.001238) | 0.547447 / 0.226044 (0.321402) | 5.599435 / 2.268929 (3.330506) | 2.980547 / 55.444624 (-52.464077) | 2.754908 / 6.876477 (-4.121569) | 2.832978 / 2.142072 (0.690906) | 0.635059 / 4.805227 (-4.170168) | 0.153478 / 6.500664 (-6.347187) | 0.067146 / 0.075469 (-0.008323) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.555588 / 1.841788 (-0.286200) | 22.828906 / 8.074308 (14.754597) | 16.211008 / 10.191392 (6.019616) | 0.168009 / 0.680424 (-0.512415) | 0.021966 / 0.534201 (-0.512235) | 0.464872 / 0.579283 (-0.114411) | 0.460429 / 0.434364 (0.026065) | 0.530498 / 0.540337 (-0.009839) | 0.705020 / 1.386936 (-0.681916) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005964 / 0.011353 (-0.005389) | 0.003644 / 0.011008 (-0.007364) | 0.079607 / 0.038508 (0.041099) | 0.058387 / 0.023109 (0.035278) | 0.312226 / 0.275898 (0.036328) | 0.349206 / 0.323480 (0.025726) | 0.004715 / 0.007986 (-0.003271) | 0.002869 / 0.004328 (-0.001460) | 0.061668 / 0.004250 (0.057417) | 0.045694 / 0.037052 (0.008642) | 0.313516 / 0.258489 (0.055027) | 0.357543 / 0.293841 (0.063702) | 0.027179 / 0.128546 (-0.101367) | 0.007961 / 0.075646 (-0.067686) | 0.262473 / 0.419271 (-0.156798) | 0.045588 / 0.043533 (0.002055) | 0.313102 / 0.255139 (0.057963) | 0.368686 / 0.283200 (0.085486) | 0.020556 / 0.141683 (-0.121127) | 1.447258 / 1.452155 (-0.004897) | 1.527319 / 1.492716 (0.034602) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.199417 / 0.018006 (0.181411) | 0.422155 / 0.000490 (0.421665) | 0.004972 / 0.000200 (0.004772) | 0.000073 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023539 / 0.037411 (-0.013872) | 0.073055 / 0.014526 (0.058529) | 0.083631 / 0.176557 (-0.092926) | 0.145923 / 0.737135 (-0.591212) | 0.083820 / 0.296338 (-0.212518) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.396305 / 0.215209 (0.181096) | 3.967065 / 2.077655 (1.889410) | 2.101109 / 1.504120 (0.596989) | 1.958817 / 1.541195 (0.417622) | 2.037894 / 1.468490 (0.569404) | 0.496955 / 4.584777 (-4.087822) | 3.078948 / 3.745712 (-0.666764) | 3.363655 / 5.269862 (-1.906207) | 2.087659 / 4.565676 (-2.478018) | 0.057171 / 0.424275 (-0.367104) | 0.006410 / 0.007607 (-0.001197) | 0.470535 / 0.226044 (0.244491) | 4.715259 / 2.268929 (2.446330) | 2.355510 / 55.444624 (-53.089114) | 2.025270 / 6.876477 (-4.851207) | 2.210401 / 2.142072 (0.068329) | 0.580538 / 4.805227 (-4.224689) | 0.125068 / 6.500664 (-6.375596) | 0.059871 / 0.075469 (-0.015598) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.245468 / 1.841788 (-0.596320) | 18.322042 / 8.074308 (10.247734) | 13.609726 / 10.191392 (3.418334) | 0.143623 / 0.680424 (-0.536801) | 0.017068 / 0.534201 (-0.517133) | 0.330758 / 0.579283 (-0.248525) | 0.339946 / 0.434364 (-0.094418) | 0.377861 / 0.540337 (-0.162476) | 0.524593 / 1.386936 (-0.862343) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006049 / 0.011353 (-0.005304) | 0.003737 / 0.011008 (-0.007271) | 0.062816 / 0.038508 (0.024308) | 0.063768 / 0.023109 (0.040658) | 0.362001 / 0.275898 (0.086103) | 0.395251 / 0.323480 (0.071772) | 0.004823 / 0.007986 (-0.003163) | 0.002881 / 0.004328 (-0.001447) | 0.061987 / 0.004250 (0.057737) | 0.049950 / 0.037052 (0.012898) | 0.362442 / 0.258489 (0.103953) | 0.399321 / 0.293841 (0.105480) | 0.027616 / 0.128546 (-0.100930) | 0.007965 / 0.075646 (-0.067681) | 0.068584 / 0.419271 (-0.350687) | 0.044700 / 0.043533 (0.001168) | 0.361011 / 0.255139 (0.105872) | 0.386007 / 0.283200 (0.102807) | 0.024621 / 0.141683 (-0.117061) | 1.441497 / 1.452155 (-0.010657) | 1.533145 / 1.492716 (0.040429) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.223446 / 0.018006 (0.205440) | 0.411147 / 0.000490 (0.410657) | 0.001821 / 0.000200 (0.001621) | 0.000081 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025661 / 0.037411 (-0.011751) | 0.077838 / 0.014526 (0.063313) | 0.086148 / 0.176557 (-0.090408) | 0.140386 / 0.737135 (-0.596750) | 0.088793 / 0.296338 (-0.207546) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.425209 / 0.215209 (0.210000) | 4.250723 / 2.077655 (2.173068) | 2.403437 / 1.504120 (0.899317) | 2.283584 / 1.541195 (0.742390) | 2.326870 / 1.468490 (0.858380) | 0.504781 / 4.584777 (-4.079996) | 3.017042 / 3.745712 (-0.728670) | 4.643068 / 5.269862 (-0.626794) | 2.535710 / 4.565676 (-2.029967) | 0.058520 / 0.424275 (-0.365755) | 0.006766 / 0.007607 (-0.000841) | 0.500664 / 0.226044 (0.274620) | 5.017073 / 2.268929 (2.748145) | 2.668661 / 55.444624 (-52.775963) | 2.335486 / 6.876477 (-4.540991) | 2.486518 / 2.142072 (0.344445) | 0.598795 / 4.805227 (-4.206432) | 0.126395 / 6.500664 (-6.374269) | 0.063154 / 0.075469 (-0.012315) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.358059 / 1.841788 (-0.483728) | 18.615724 / 8.074308 (10.541416) | 13.670934 / 10.191392 (3.479542) | 0.134650 / 0.680424 (-0.545774) | 0.016941 / 0.534201 (-0.517260) | 0.335215 / 0.579283 (-0.244068) | 0.356118 / 0.434364 (-0.078246) | 0.393109 / 0.540337 (-0.147228) | 0.534165 / 1.386936 (-0.852771) |\n\n</details>\n</details>\n\n\n"
] | 2023-07-26T10:44:23Z
| 2023-07-27T12:51:51Z
| 2023-07-27T12:42:57Z
|
MEMBER
| null | null | null |
close https://github.com/huggingface/datasets/issues/6071
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6072/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6072/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6072.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6072",
"merged_at": "2023-07-27T12:42:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6072.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6072"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5986
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5986/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5986/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5986/events
|
https://github.com/huggingface/datasets/pull/5986
| 1,772,233,111
|
PR_kwDODunzps5TygOZ
| 5,986
|
Make IterableDataset.from_spark more efficient
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/134338709?v=4",
"events_url": "https://api.github.com/users/mathewjacob1002/events{/privacy}",
"followers_url": "https://api.github.com/users/mathewjacob1002/followers",
"following_url": "https://api.github.com/users/mathewjacob1002/following{/other_user}",
"gists_url": "https://api.github.com/users/mathewjacob1002/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mathewjacob1002",
"id": 134338709,
"login": "mathewjacob1002",
"node_id": "U_kgDOCAHYlQ",
"organizations_url": "https://api.github.com/users/mathewjacob1002/orgs",
"received_events_url": "https://api.github.com/users/mathewjacob1002/received_events",
"repos_url": "https://api.github.com/users/mathewjacob1002/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mathewjacob1002/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mathewjacob1002/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mathewjacob1002",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"@lhoestq would you be able to review this please and also approve the workflow?",
"Sounds good to me :) feel free to run `make style` to apply code formatting",
"_The documentation is not available anymore as the PR was closed or merged._",
"cool ! I think we can merge once all comments have been addressed",
"@lhoestq I just addressed the comments and I think we can move ahead with this! \r\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007734 / 0.011353 (-0.003619) | 0.004608 / 0.011008 (-0.006400) | 0.094466 / 0.038508 (0.055958) | 0.086477 / 0.023109 (0.063368) | 0.410311 / 0.275898 (0.134413) | 0.455560 / 0.323480 (0.132080) | 0.006112 / 0.007986 (-0.001874) | 0.003845 / 0.004328 (-0.000483) | 0.072506 / 0.004250 (0.068256) | 0.066721 / 0.037052 (0.029669) | 0.409967 / 0.258489 (0.151478) | 0.460480 / 0.293841 (0.166639) | 0.036700 / 0.128546 (-0.091847) | 0.009854 / 0.075646 (-0.065792) | 0.320936 / 0.419271 (-0.098335) | 0.061002 / 0.043533 (0.017469) | 0.413963 / 0.255139 (0.158824) | 0.426787 / 0.283200 (0.143588) | 0.029182 / 0.141683 (-0.112501) | 1.685136 / 1.452155 (0.232981) | 1.754590 / 1.492716 (0.261873) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.222698 / 0.018006 (0.204692) | 0.505929 / 0.000490 (0.505440) | 0.005291 / 0.000200 (0.005091) | 0.000097 / 0.000054 (0.000042) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032527 / 0.037411 (-0.004884) | 0.094842 / 0.014526 (0.080317) | 0.110138 / 0.176557 (-0.066418) | 0.193786 / 0.737135 (-0.543349) | 0.112593 / 0.296338 (-0.183745) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441671 / 0.215209 (0.226461) | 4.392961 / 2.077655 (2.315306) | 2.161111 / 1.504120 (0.656991) | 1.967080 / 1.541195 (0.425885) | 2.065411 / 1.468490 (0.596920) | 0.561080 / 4.584777 (-4.023697) | 4.159612 / 3.745712 (0.413900) | 6.435248 / 5.269862 (1.165386) | 3.732338 / 4.565676 (-0.833339) | 0.066156 / 0.424275 (-0.358119) | 0.008030 / 0.007607 (0.000423) | 0.532182 / 0.226044 (0.306137) | 5.315142 / 2.268929 (3.046213) | 2.680157 / 55.444624 (-52.764467) | 2.303799 / 6.876477 (-4.572677) | 2.530911 / 2.142072 (0.388838) | 0.669504 / 4.805227 (-4.135723) | 0.151940 / 6.500664 (-6.348724) | 0.066999 / 0.075469 (-0.008470) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.424275 / 1.841788 (-0.417513) | 21.550742 / 8.074308 (13.476434) | 16.031414 / 10.191392 (5.840022) | 0.194681 / 0.680424 (-0.485743) | 0.020389 / 0.534201 (-0.513812) | 0.429808 / 0.579283 (-0.149475) | 0.457503 / 0.434364 (0.023139) | 0.511522 / 0.540337 (-0.028816) | 0.682621 / 1.386936 (-0.704315) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007519 / 0.011353 (-0.003834) | 0.004445 / 0.011008 (-0.006563) | 0.071946 / 0.038508 (0.033438) | 0.082982 / 0.023109 (0.059873) | 0.459938 / 0.275898 (0.184040) | 0.504875 / 0.323480 (0.181395) | 0.005805 / 0.007986 (-0.002181) | 0.003740 / 0.004328 (-0.000589) | 0.071998 / 0.004250 (0.067747) | 0.062580 / 0.037052 (0.025527) | 0.462263 / 0.258489 (0.203774) | 0.506355 / 0.293841 (0.212514) | 0.036321 / 0.128546 (-0.092225) | 0.009830 / 0.075646 (-0.065816) | 0.079810 / 0.419271 (-0.339461) | 0.055291 / 0.043533 (0.011758) | 0.464093 / 0.255139 (0.208954) | 0.481109 / 0.283200 (0.197910) | 0.026909 / 0.141683 (-0.114774) | 1.652538 / 1.452155 (0.200383) | 1.750713 / 1.492716 (0.257997) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.267552 / 0.018006 (0.249546) | 0.502021 / 0.000490 (0.501531) | 0.001635 / 0.000200 (0.001435) | 0.000099 / 0.000054 (0.000044) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033747 / 0.037411 (-0.003665) | 0.104242 / 0.014526 (0.089716) | 0.113829 / 0.176557 (-0.062728) | 0.176242 / 0.737135 (-0.560893) | 0.117002 / 0.296338 (-0.179336) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.476731 / 0.215209 (0.261522) | 4.727054 / 2.077655 (2.649399) | 2.589396 / 1.504120 (1.085276) | 2.511180 / 1.541195 (0.969985) | 2.634122 / 1.468490 (1.165632) | 0.563840 / 4.584777 (-4.020937) | 4.140212 / 3.745712 (0.394500) | 6.188789 / 5.269862 (0.918928) | 3.716897 / 4.565676 (-0.848780) | 0.065823 / 0.424275 (-0.358452) | 0.007705 / 0.007607 (0.000098) | 0.566580 / 0.226044 (0.340535) | 5.653306 / 2.268929 (3.384377) | 3.028756 / 55.444624 (-52.415868) | 2.592319 / 6.876477 (-4.284158) | 2.614250 / 2.142072 (0.472178) | 0.667135 / 4.805227 (-4.138093) | 0.153455 / 6.500664 (-6.347209) | 0.069321 / 0.075469 (-0.006148) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.541978 / 1.841788 (-0.299810) | 21.747360 / 8.074308 (13.673052) | 15.963657 / 10.191392 (5.772265) | 0.192843 / 0.680424 (-0.487581) | 0.020702 / 0.534201 (-0.513499) | 0.433620 / 0.579283 (-0.145663) | 0.467327 / 0.434364 (0.032963) | 0.507398 / 0.540337 (-0.032940) | 0.692797 / 1.386936 (-0.694140) |\n\n</details>\n</details>\n\n\n"
] | 2023-06-23T22:18:20Z
| 2023-07-07T10:05:58Z
| 2023-07-07T09:56:09Z
|
CONTRIBUTOR
| null | null | null |
Moved the code from using collect() to using toLocalIterator, which allows for prefetching partitions that will be selected next, thus allowing for better performance when iterating.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5986/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5986/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5986.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5986",
"merged_at": "2023-07-07T09:56:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5986.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5986"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5633
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5633/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5633/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5633/events
|
https://github.com/huggingface/datasets/issues/5633
| 1,621,469,970
|
I_kwDODunzps5gpasS
| 5,633
|
Cannot import datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11250555?v=4",
"events_url": "https://api.github.com/users/eerio/events{/privacy}",
"followers_url": "https://api.github.com/users/eerio/followers",
"following_url": "https://api.github.com/users/eerio/following{/other_user}",
"gists_url": "https://api.github.com/users/eerio/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/eerio",
"id": 11250555,
"login": "eerio",
"node_id": "MDQ6VXNlcjExMjUwNTU1",
"organizations_url": "https://api.github.com/users/eerio/orgs",
"received_events_url": "https://api.github.com/users/eerio/received_events",
"repos_url": "https://api.github.com/users/eerio/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/eerio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eerio/subscriptions",
"type": "User",
"url": "https://api.github.com/users/eerio",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Okay, the issue was likely caused by mixing `conda` and `pip` usage - I forgot that I have already used `pip` in this environment previously and that it was 'spoiled' because of it. Creating another environment and installing `datasets` by pip with other packages from the `requirements.txt` file solved the problem."
] | 2023-03-13T13:14:44Z
| 2023-03-13T17:54:19Z
| 2023-03-13T17:54:19Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Hi,
I cannot even import the library :( I installed it by running:
```
$ conda install datasets
```
Then I realized I should maybe use the huggingface channel, because I encountered the error below, so I ran:
```
$ conda remove datasets
$ conda install -c huggingface datasets
```
Please see 'steps to reproduce the bug' for the specific error, as steps to reproduce is just importing the library
### Steps to reproduce the bug
```
$ python3
Python 3.8.15 (default, Nov 24 2022, 15:19:38)
[GCC 11.2.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import datasets
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jack/.conda/envs/jack_zpp/lib/python3.8/site-packages/datasets/__init__.py", line 33, in <module>
from .arrow_dataset import Dataset, concatenate_datasets
File "/home/jack/.conda/envs/jack_zpp/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 59, in <module>
from .arrow_reader import ArrowReader
File "/home/jack/.conda/envs/jack_zpp/lib/python3.8/site-packages/datasets/arrow_reader.py", line 27, in <module>
import pyarrow.parquet as pq
File "/home/jack/.conda/envs/jack_zpp/lib/python3.8/site-packages/pyarrow/parquet/__init__.py", line 20, in <module>
from .core import *
File "/home/jack/.conda/envs/jack_zpp/lib/python3.8/site-packages/pyarrow/parquet/core.py", line 37, in <module>
from pyarrow._parquet import (ParquetReader, Statistics, # noqa
ImportError: cannot import name 'FileEncryptionProperties' from 'pyarrow._parquet' (/home/jack/.conda/envs/jack_zpp/lib/python3.8/site-packages/pyarrow/_parquet.cpython-38-x86_64-linux-gnu.so)
```
### Expected behavior
I would expect for the statement `import datasets` to cause no error
### Environment info
Output of `conda list`:
```
# packages in environment at /home/jack/.conda/envs/pbalawender_zpp:
#
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 1_gnu
abseil-cpp 20210324.2 h2531618_0
advertools 0.13.2 pypi_0 pypi
aiofiles 0.8.0 pypi_0 pypi
aiohttp 3.8.3 py38h5eee18b_0
aiosignal 1.2.0 pyhd3eb1b0_0
aiosqlite 0.17.0 pypi_0 pypi
anyio 3.6.2 pypi_0 pypi
aquirdturtle-collapsible-headings 3.1.0 pypi_0 pypi
argon2-cffi 21.3.0 pypi_0 pypi
argon2-cffi-bindings 21.2.0 pypi_0 pypi
arrow 1.2.3 pypi_0 pypi
arrow-cpp 3.0.0 py38h6b21186_4
asttokens 2.2.0 pypi_0 pypi
async-timeout 4.0.2 py38h06a4308_0
attrs 22.1.0 py38h06a4308_0
automat 22.10.0 pypi_0 pypi
aws-c-common 0.4.57 he6710b0_1
aws-c-event-stream 0.1.6 h2531618_5
aws-checksums 0.1.9 he6710b0_0
aws-sdk-cpp 1.8.185 hce553d0_0
babel 2.11.0 pypi_0 pypi
backcall 0.2.0 pyhd3eb1b0_0
beautifulsoup4 4.11.1 pypi_0 pypi
blas 1.0 mkl
bleach 5.0.1 pypi_0 pypi
boost-cpp 1.73.0 h27cfd23_11
bottleneck 1.3.5 py38h7deecbd_0
brotli 1.0.9 h5eee18b_7
brotli-bin 1.0.9 h5eee18b_7
brotlipy 0.7.0 py38h27cfd23_1003
bzip2 1.0.8 h7b6447c_0
c-ares 1.18.1 h7f8727e_0
ca-certificates 2023.01.10 h06a4308_0
certifi 2022.9.24 pypi_0 pypi
cffi 1.15.1 py38h5eee18b_3
charset-normalizer 2.1.1 pypi_0 pypi
click 8.1.3 pypi_0 pypi
constantly 15.1.0 pypi_0 pypi
contourpy 1.0.6 pypi_0 pypi
cryptography 38.0.4 pypi_0 pypi
cssselect 1.2.0 pypi_0 pypi
cudatoolkit 10.1.243 h8cb64d8_10 conda-forge
cycler 0.11.0 pypi_0 pypi
dacite 1.6.0 pypi_0 pypi
dataclasses 0.8 pyh6d0b6a4_7
datasets 1.18.4 py_0 huggingface
datetime 4.7 pypi_0 pypi
debugpy 1.6.4 pypi_0 pypi
decorator 5.1.1 pyhd3eb1b0_0
defusedxml 0.7.1 pypi_0 pypi
dill 0.3.6 py38h06a4308_0
docker-pycreds 0.4.0 pypi_0 pypi
double-conversion 3.1.5 he6710b0_1
entrypoints 0.4 py38h06a4308_0
executing 0.8.3 pyhd3eb1b0_0
filelock 3.8.0 pypi_0 pypi
flake8 6.0.0 pypi_0 pypi
flask 2.1.3 py38h06a4308_0
flit-core 3.6.0 pyhd3eb1b0_0
fonttools 4.38.0 pypi_0 pypi
fqdn 1.5.1 pypi_0 pypi
freetype 2.12.1 h4a9f257_0
frozenlist 1.3.3 py38h5eee18b_0
fsspec 2022.11.0 py38h06a4308_0
gensim 4.2.0 pypi_0 pypi
gflags 2.2.2 he6710b0_0
giflib 5.2.1 h5eee18b_3
gitdb 4.0.10 pypi_0 pypi
gitpython 3.1.30 pypi_0 pypi
glog 0.5.0 h2531618_0
grpc-cpp 1.39.0 hae934f6_5
huggingface-hub 0.11.1 pypi_0 pypi
huggingface_hub 0.13.1 py_0 huggingface
hyperlink 21.0.0 pypi_0 pypi
icu 58.2 he6710b0_3
idna 3.4 py38h06a4308_0
importlib-metadata 5.1.0 pypi_0 pypi
importlib_metadata 4.11.3 hd3eb1b0_0
importlib_resources 5.2.0 pyhd3eb1b0_1
incremental 22.10.0 pypi_0 pypi
intel-openmp 2021.4.0 h06a4308_3561
ipykernel 6.17.1 pyh210e3f2_0 conda-forge
ipython 8.7.0 pypi_0 pypi
ipython-genutils 0.2.0 pypi_0 pypi
ipywidgets 8.0.2 pyhd8ed1ab_1 conda-forge
isoduration 20.11.0 pypi_0 pypi
itemadapter 0.7.0 pypi_0 pypi
itemloaders 1.0.6 pypi_0 pypi
itsdangerous 2.0.1 pyhd3eb1b0_0
jedi 0.18.2 pypi_0 pypi
jinja2 3.1.2 py38h06a4308_0
jmespath 1.0.1 pypi_0 pypi
joblib 1.2.0 pypi_0 pypi
jpeg 9b h024ee3a_2
json5 0.9.10 pypi_0 pypi
jsonpickle 3.0.0 pypi_0 pypi
jsonpointer 2.3 pypi_0 pypi
jsonschema 4.17.3 py38h06a4308_0
jupyter-core 5.1.0 pypi_0 pypi
jupyter-events 0.5.0 pypi_0 pypi
jupyter-server 1.23.3 pypi_0 pypi
jupyter-server-fileid 0.6.0 pypi_0 pypi
jupyter-server-ydoc 0.4.0 pypi_0 pypi
jupyter-ydoc 0.2.2 pypi_0 pypi
jupyter_client 7.4.9 py38h06a4308_0
jupyter_core 5.2.0 py38h06a4308_0
jupyterlab 3.6.0a4 pypi_0 pypi
jupyterlab-pygments 0.2.2 pypi_0 pypi
jupyterlab-server 2.16.3 pypi_0 pypi
jupyterlab_widgets 3.0.3 pyhd8ed1ab_0 conda-forge
kiwisolver 1.4.4 pypi_0 pypi
krb5 1.19.4 h568e23c_0
lcms2 2.12 h3be6417_0
ld_impl_linux-64 2.38 h1181459_1
libboost 1.73.0 h3ff78a5_11
libbrotlicommon 1.0.9 h5eee18b_7
libbrotlidec 1.0.9 h5eee18b_7
libbrotlienc 1.0.9 h5eee18b_7
libcurl 7.88.1 h91b91d3_0
libedit 3.1.20221030 h5eee18b_0
libev 4.33 h7f8727e_1
libevent 2.1.12 h8f2d780_0
libffi 3.4.2 h6a678d5_6
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libnghttp2 1.46.0 hce63b2e_0
libpng 1.6.39 h5eee18b_0
libprotobuf 3.17.2 h4ff587b_1
libsodium 1.0.18 h7b6447c_0
libssh2 1.10.0 h8f2d780_0
libstdcxx-ng 11.2.0 h1234567_1
libthrift 0.14.2 hcc01f38_0
libtiff 4.1.0 h2733197_1
libuv 1.44.2 h5eee18b_0
libwebp 1.2.0 h89dd481_0
lz4-c 1.9.4 h6a678d5_0
markupsafe 2.1.1 py38h7f8727e_0
matplotlib 3.6.2 pypi_0 pypi
matplotlib-inline 0.1.6 py38h06a4308_0
mccabe 0.7.0 pypi_0 pypi
mistune 2.0.4 pypi_0 pypi
mkl 2021.4.0 h06a4308_640
mkl-service 2.4.0 py38h7f8727e_0
mkl_fft 1.3.1 py38hd3c417c_0
mkl_random 1.2.2 py38h51133e4_0
morfeusz2 1.99.6 pypi_0 pypi
multidict 6.0.2 py38h5eee18b_0
multiprocess 0.70.14 py38h06a4308_0
nbclassic 0.4.8 pypi_0 pypi
nbclient 0.7.2 pypi_0 pypi
nbconvert 7.2.5 pypi_0 pypi
nbformat 5.7.0 py38h06a4308_0
ncurses 6.4 h6a678d5_0
nest-asyncio 1.5.6 py38h06a4308_0
ninja 1.10.2 h06a4308_5
ninja-base 1.10.2 hd09550d_5
notebook 6.5.2 pypi_0 pypi
notebook-shim 0.2.2 pypi_0 pypi
numexpr 2.8.4 py38he184ba9_0
numpy 1.23.5 py38h14f4228_0
numpy-base 1.23.5 py38h31eccc5_0
oauthlib 3.2.2 pypi_0 pypi
opencv-python 4.6.0.66 pypi_0 pypi
openssl 1.1.1t h7f8727e_0
orc 1.6.9 ha97a36c_3
packaging 22.0 py38h06a4308_0
pandas 1.5.2 pypi_0 pypi
pandocfilters 1.5.0 pypi_0 pypi
parsel 1.7.0 pypi_0 pypi
parso 0.8.3 pyhd3eb1b0_0
pathlib 1.0.1 pypi_0 pypi
pathtools 0.1.2 pypi_0 pypi
pexpect 4.8.0 pyhd3eb1b0_3
pickleshare 0.7.5 pyhd3eb1b0_1003
pillow 9.3.0 pypi_0 pypi
pip 22.2.2 py38h06a4308_0
pkgutil-resolve-name 1.3.10 py38h06a4308_0
platformdirs 2.5.4 pypi_0 pypi
prometheus-client 0.15.0 pypi_0 pypi
promise 2.3 pypi_0 pypi
prompt-toolkit 3.0.33 pypi_0 pypi
protego 0.2.1 pypi_0 pypi
protobuf 4.21.12 pypi_0 pypi
psutil 5.9.0 py38h5eee18b_0
ptyprocess 0.7.0 pyhd3eb1b0_2
pure_eval 0.2.2 pyhd3eb1b0_0
pyarrow 10.0.1 pypi_0 pypi
pyasn1 0.4.8 pypi_0 pypi
pyasn1-modules 0.2.8 pypi_0 pypi
pycodestyle 2.10.0 pypi_0 pypi
pycparser 2.21 pyhd3eb1b0_0
pydispatcher 2.0.6 pypi_0 pypi
pyflakes 3.0.1 pypi_0 pypi
pygments 2.11.2 pyhd3eb1b0_0
pyopenssl 22.1.0 pypi_0 pypi
pyrsistent 0.18.0 py38heee7806_0
pysocks 1.7.1 py38h06a4308_0
python 3.8.15 h7a1cb2a_2
python-dateutil 2.8.2 pyhd3eb1b0_0
python-dotenv 0.21.0 pypi_0 pypi
python-fastjsonschema 2.16.2 py38h06a4308_0
python-json-logger 2.0.4 pypi_0 pypi
python-xxhash 2.0.2 py38h5eee18b_1
pytorch 1.7.1 py3.8_cuda10.1.243_cudnn7.6.3_0 pytorch
pytz 2022.6 pypi_0 pypi
pyyaml 6.0 py38h5eee18b_1
pyzmq 23.2.0 py38h6a678d5_0
queuelib 1.6.2 pypi_0 pypi
re2 2022.04.01 h295c915_0
readline 8.2 h5eee18b_0
regex 2022.10.31 pypi_0 pypi
requests 2.28.1 py38h06a4308_0
requests-file 1.5.1 pypi_0 pypi
requests-oauthlib 1.3.1 pypi_0 pypi
rfc3339-validator 0.1.4 pypi_0 pypi
rfc3986-validator 0.1.1 pypi_0 pypi
scikit-learn 1.1.3 pypi_0 pypi
scipy 1.9.3 pypi_0 pypi
scrapy 2.7.1 pypi_0 pypi
seaborn 0.12.1 pypi_0 pypi
send2trash 1.8.0 pypi_0 pypi
sentry-sdk 1.12.1 pypi_0 pypi
service-identity 21.1.0 pypi_0 pypi
setproctitle 1.3.2 pypi_0 pypi
setuptools 65.6.3 pypi_0 pypi
shortuuid 1.0.11 pypi_0 pypi
six 1.16.0 pyhd3eb1b0_1
smart-open 6.2.0 pypi_0 pypi
smmap 5.0.0 pypi_0 pypi
snappy 1.1.9 h295c915_0
sniffio 1.3.0 pypi_0 pypi
soupsieve 2.3.2.post1 pypi_0 pypi
sqlite 3.40.1 h5082296_0
stack-data 0.6.2 pypi_0 pypi
stack_data 0.2.0 pyhd3eb1b0_0
terminado 0.17.0 pypi_0 pypi
threadpoolctl 3.1.0 pypi_0 pypi
tinycss2 1.2.1 pypi_0 pypi
tk 8.6.12 h1ccaba5_0
tldextract 3.4.0 pypi_0 pypi
tokenizers 0.13.2 pypi_0 pypi
tomli 2.0.1 pypi_0 pypi
torchvision 0.8.2 py38_cu101 pytorch
tornado 6.2 py38h5eee18b_0
tqdm 4.64.1 py38h06a4308_0
traitlets 5.6.0 pypi_0 pypi
transformers 4.25.1 pypi_0 pypi
tweepy 4.12.1 pypi_0 pypi
twisted 22.10.0 pypi_0 pypi
twython 3.9.1 pypi_0 pypi
typing-extensions 4.4.0 py38h06a4308_0
typing_extensions 4.4.0 py38h06a4308_0
uri-template 1.2.0 pypi_0 pypi
uriparser 0.9.3 he6710b0_1
urllib3 1.26.13 pypi_0 pypi
utf8proc 2.6.1 h27cfd23_0
w3lib 2.1.0 pypi_0 pypi
wandb 0.13.7 pypi_0 pypi
wcwidth 0.2.5 pyhd3eb1b0_0
webcolors 1.12 pypi_0 pypi
webencodings 0.5.1 pypi_0 pypi
websocket-client 1.4.2 pypi_0 pypi
werkzeug 2.2.2 py38h06a4308_0
wheel 0.38.4 py38h06a4308_0
widgetsnbextension 4.0.3 py38h06a4308_0
xxhash 0.8.0 h7f8727e_3
xz 5.2.10 h5eee18b_1
y-py 0.5.4 pypi_0 pypi
yaml 0.2.5 h7b6447c_0
yarl 1.8.1 py38h5eee18b_0
ypy-websocket 0.5.0 pypi_0 pypi
zeromq 4.3.4 h2531618_0
zipp 3.11.0 py38h06a4308_0
zlib 1.2.13 h5eee18b_0
zope-interface 5.5.2 pypi_0 pypi
zstd 1.4.9 haebb681_0
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5633/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5633/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5898
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5898/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5898/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5898/events
|
https://github.com/huggingface/datasets/issues/5898
| 1,726,190,481
|
I_kwDODunzps5m45OR
| 5,898
|
Loading The flores data set for specific language
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/36159918?v=4",
"events_url": "https://api.github.com/users/106AbdulBasit/events{/privacy}",
"followers_url": "https://api.github.com/users/106AbdulBasit/followers",
"following_url": "https://api.github.com/users/106AbdulBasit/following{/other_user}",
"gists_url": "https://api.github.com/users/106AbdulBasit/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/106AbdulBasit",
"id": 36159918,
"login": "106AbdulBasit",
"node_id": "MDQ6VXNlcjM2MTU5OTE4",
"organizations_url": "https://api.github.com/users/106AbdulBasit/orgs",
"received_events_url": "https://api.github.com/users/106AbdulBasit/received_events",
"repos_url": "https://api.github.com/users/106AbdulBasit/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/106AbdulBasit/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/106AbdulBasit/subscriptions",
"type": "User",
"url": "https://api.github.com/users/106AbdulBasit",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"got that the syntax is like this\r\n\r\ndataset = load_dataset(\"facebook/flores\", \"ace_Arab\")"
] | 2023-05-25T17:08:55Z
| 2023-05-25T17:21:38Z
| 2023-05-25T17:21:37Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
I am trying to load the Flores data set
the code which is given is
```
from datasets import load_dataset
dataset = load_dataset("facebook/flores")
```
This gives the error of config name
""ValueError: Config name is missing"
Now if I add some config it gives me the some error
"HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: 'facebook/flores, 'ace_Arab''.
"
How I can load the data of the specific language ?
Couldn't find any tutorial
any one can help me out?
### Steps to reproduce the bug
step one load the data set
`from datasets import load_dataset
dataset = load_dataset("facebook/flores")`
it gives the error of config
once config is given
it gives the error of
"HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: 'facebook/flores, 'ace_Arab''.
"
### Expected behavior
Data set should be loaded but I am receiving error
### Environment info
Datasets , python ,
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/36159918?v=4",
"events_url": "https://api.github.com/users/106AbdulBasit/events{/privacy}",
"followers_url": "https://api.github.com/users/106AbdulBasit/followers",
"following_url": "https://api.github.com/users/106AbdulBasit/following{/other_user}",
"gists_url": "https://api.github.com/users/106AbdulBasit/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/106AbdulBasit",
"id": 36159918,
"login": "106AbdulBasit",
"node_id": "MDQ6VXNlcjM2MTU5OTE4",
"organizations_url": "https://api.github.com/users/106AbdulBasit/orgs",
"received_events_url": "https://api.github.com/users/106AbdulBasit/received_events",
"repos_url": "https://api.github.com/users/106AbdulBasit/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/106AbdulBasit/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/106AbdulBasit/subscriptions",
"type": "User",
"url": "https://api.github.com/users/106AbdulBasit",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5898/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5898/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5296
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5296/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5296/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5296/events
|
https://github.com/huggingface/datasets/issues/5296
| 1,464,553,580
|
I_kwDODunzps5XS1Bs
| 5,296
|
Bug in xjoin with Windows pathnames
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[] | 2022-11-25T13:29:33Z
| 2022-11-29T08:05:13Z
| 2022-11-29T08:05:13Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
Currently, `xjoin` function has a bug with local Windows pathnames: instead of returning the OS-dependent join pathname, it always returns it in POSIX format.
```python
from datasets.download.streaming_download_manager import xjoin
path = xjoin("C:\\Users\\USERNAME", "filename.txt")
```
Join path should be:
```python
"C:\\Users\\USERNAME\\filename.txt"
```
However it is:
```python
"C:/Users/USERNAME/filename.txt"
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5296/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5296/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5735
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5735/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5735/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5735/events
|
https://github.com/huggingface/datasets/pull/5735
| 1,662,150,903
|
PR_kwDODunzps5OAY3A
| 5,735
|
Implement sharding on merged iterable datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"events_url": "https://api.github.com/users/bruno-hays/events{/privacy}",
"followers_url": "https://api.github.com/users/bruno-hays/followers",
"following_url": "https://api.github.com/users/bruno-hays/following{/other_user}",
"gists_url": "https://api.github.com/users/bruno-hays/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bruno-hays",
"id": 48770768,
"login": "bruno-hays",
"node_id": "MDQ6VXNlcjQ4NzcwNzY4",
"organizations_url": "https://api.github.com/users/bruno-hays/orgs",
"received_events_url": "https://api.github.com/users/bruno-hays/received_events",
"repos_url": "https://api.github.com/users/bruno-hays/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bruno-hays/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bruno-hays/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bruno-hays",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi ! What if one of the sub-iterables only has one shard ? In that case I don't think we'd end up with a correctly interleaved dataset, since only rank 0 would yield examples from this sub-iterable",
"Hi ! \r\nI just tested this out with the code below and it seems to be ok. Both datasets are alternating and we get all the examples with no duplicates.\r\n\r\nOn thing to keep in mind is that the max amount of workers is equal to the lowest amount of shard amongst the datasets to be merged (1 in this example).\r\n\r\n ```python\r\nfrom torch.utils.data import DataLoader\r\n\r\nfrom datasets import load_dataset, interleave_datasets\r\n\r\n\r\ndef process_dataset_train(batch):\r\n return {\"input\": f'train: {batch[\"review\"][:20]}'}\r\n\r\n\r\ndef process_dataset_test(batch):\r\n return {\"input\": f'test: {batch[\"review\"][:20]}'}\r\n\r\n\r\ndef identity_collator(x):\r\n return x\r\n\r\n\r\nif __name__ == \"__main__\":\r\n ds = load_dataset(\"lhoestq/demo1\")\r\n ds[\"train\"] = ds[\"train\"].map(process_dataset_train, remove_columns=ds[\"train\"].column_names)\r\n ds[\"test\"] = ds[\"test\"].map(process_dataset_test, remove_columns=ds[\"test\"].column_names)\r\n\r\n ds1 = ds[\"train\"].to_iterable_dataset(num_shards=5)\r\n ds2 = ds[\"test\"].to_iterable_dataset(num_shards=1)\r\n\r\n ds_merged = interleave_datasets([ds1, ds2], stopping_strategy=\"all_exhausted\")\r\n\r\n dataloader = DataLoader(ds_merged, collate_fn=identity_collator, num_workers=1, batch_size=1)\r\n\r\n for i, element in enumerate(dataloader):\r\n print(i, element)\r\n\r\n```\r\n\r\n```\r\n0 [{'input': 'train: Great app! The new v'}]\r\n1 [{'input': 'test: Works with RTL and N'}]\r\n2 [{'input': \"train: Great It's not fully\"}]\r\n3 [{'input': 'test: Works with RTL SDR W'}]\r\n4 [{'input': 'train: Works on a Nexus 6p '}]\r\n5 [{'input': 'test: Awsome App! Easy to '}]\r\n6 [{'input': 'train: The bandwidth seemed'}]\r\n7 [{'input': \"test: I'll forgo the refun\"}]\r\n8 [{'input': 'train: Works well with my H'}]\r\n9 [{'input': 'test: looks like a great p'}]\r\n```",
"<s> Could you try with `num_workers>1` ? </s>\r\n\r\nedit: Oh I see\r\n\r\n> On thing to keep in mind is that the max amount of workers is equal to the lowest amount of shard amongst the datasets to be merged (1 in this example).",
"Great ! It's ok to have the max amount of workers is equal to the lowest amount of shard :)\r\n\r\nSo in the case of `num_workers>min(n_shards_per_dataset)` maybe some workers should turn off, and a warning can probably be shown. This is already the case if you use a single dataset with a single shard and `num_workers>1`.\r\n\r\n\r\nRight now it seems to raise an error:\r\n\r\n```python\r\n File \"/Users/quentinlhoest/hf/datasets/src/datasets/iterable_dataset.py\", line 979, in __iter__\r\n yield from self._iter_pytorch(ex_iterable)\r\n File \"/Users/quentinlhoest/hf/datasets/src/datasets/iterable_dataset.py\", line 912, in _iter_pytorch\r\n for key, example in ex_iterable.shard_data_sources(worker_info.id, worker_info.num_workers):\r\n File \"/Users/quentinlhoest/hf/datasets/src/datasets/iterable_dataset.py\", line 259, in shard_data_sources\r\n [iterable.shard_data_sources(worker_id, num_workers) for iterable in self.ex_iterables],\r\n File \"/Users/quentinlhoest/hf/datasets/src/datasets/iterable_dataset.py\", line 259, in <listcomp>\r\n [iterable.shard_data_sources(worker_id, num_workers) for iterable in self.ex_iterables],\r\n File \"/Users/quentinlhoest/hf/datasets/src/datasets/iterable_dataset.py\", line 125, in shard_data_sources\r\n requested_gen_kwargs = _merge_gen_kwargs([gen_kwargs_list[i] for i in shard_indices])\r\n File \"/Users/quentinlhoest/hf/datasets/src/datasets/utils/sharding.py\", line 76, in _merge_gen_kwargs\r\n for key in gen_kwargs_list[0]\r\nIndexError: list index out of range\r\n```",
"Good point. I have fixed the n_shards property of merged iterable datasets so that this warning is raised properly",
"Hey @lhoestq, what do you think of the last modifications ? ",
"Hello! No problem :)\r\n\r\n- About HorizontallyConcatenatedMultiSourcesExamplesIterable, I've haven't been able to create a bug with sharding. So either I missed something or it's working somehow:\r\n\r\n```python\r\nfrom torch.utils.data import DataLoader\r\n\r\nfrom datasets import load_dataset, interleave_datasets, concatenate_datasets\r\n\r\n\r\ndef process_dataset_train(batch):\r\n return {\"input\": f'train: {batch[\"review\"][:20]}'}\r\n\r\n\r\ndef process_dataset_test(batch):\r\n return {\"input\": f'test: {batch[\"review\"][:20]}'}\r\n\r\n\r\ndef identity_collator(x):\r\n return x\r\n\r\n\r\nif __name__ == \"__main__\":\r\n ds = load_dataset(\"lhoestq/demo1\")\r\n ds[\"train\"] = ds[\"train\"].map(process_dataset_train, remove_columns=ds[\"train\"].column_names)\r\n ds[\"test\"] = ds[\"test\"].map(process_dataset_test, remove_columns=ds[\"test\"].column_names)\r\n ds[\"test\"] = ds[\"test\"].rename_columns({\"input\": \"input2\"})\r\n\r\n ds1 = ds[\"train\"].to_iterable_dataset(num_shards=5)\r\n ds2 = ds[\"test\"].to_iterable_dataset(num_shards=3)\r\n\r\n ds_merged = concatenate_datasets([ds1, ds2], axis=1)\r\n\r\n #n_shards is always 1 for HorizontallyConcatenatedMultiSourcesExamplesIterable\r\n dataloader = DataLoader(ds_merged, collate_fn=identity_collator, num_workers=1, batch_size=1)\r\n\r\n for i, element in enumerate(dataloader):\r\n print(i, element)\r\n```\r\n\r\n```\r\n0 [{'input': 'train: Great app! The new v', 'input2': 'test: Works with RTL and N'}]\r\n1 [{'input': \"train: Great It's not fully\", 'input2': 'test: Works with RTL SDR W'}]\r\n2 [{'input': 'train: Works on a Nexus 6p ', 'input2': 'test: Awsome App! Easy to '}]\r\n3 [{'input': 'train: The bandwidth seemed', 'input2': \"test: I'll forgo the refun\"}]\r\n4 [{'input': 'train: Works well with my H', 'input2': 'test: looks like a great p'}]\r\n```\r\n\r\n- I've added a test but I'm not completely happy with it. My issue is that multiprocessing makes interleaving not completely deterministic as samples are yielded whenever ready by each process, if I'm correct.\r\nAs a result I opted to check for the amount of samples yielded and make that they are all unique, which should be equivalent.\r\nBut now my issue is that the \"first_exhausted\" method breaks the loop when one of the datasets of one of the shards is empty which means that all shards stop yielding and we could be missing up to n_workers samples. I don't know if this is the behaviour expected, but I had to modify the test to accomodate this.\r\n\r\nWhat are your thoughts about this ?",
"Ah indeed it works because it's set to be only 1 shard - my bad :)",
"> But now my issue is that the \"first_exhausted\" method breaks the loop when one of the datasets of one of the shards is empty which means that all shards stop yielding and we could be missing up to n_workers samples. I don't know if this is the behaviour expected, but I had to modify the test to accomodate this.\r\n\r\nThis looks reasonable, maybe this can be documented in the `interleave_datasets` docstring ?\r\n```\r\nNote for iterable datasets:\r\n\r\nIn a distributed setup or in PyTorch DataLoader workers, the stopping strategy is applied per process.\r\nTherefore the \"first_exhausted\" strategy on an sharded iterable dataset can generate less samples in total (up to 1 missing sample per subdataset per worker).\r\n```",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006441 / 0.011353 (-0.004912) | 0.004551 / 0.011008 (-0.006457) | 0.099144 / 0.038508 (0.060636) | 0.028163 / 0.023109 (0.005054) | 0.386342 / 0.275898 (0.110444) | 0.398347 / 0.323480 (0.074867) | 0.004836 / 0.007986 (-0.003150) | 0.004724 / 0.004328 (0.000395) | 0.076277 / 0.004250 (0.072027) | 0.036305 / 0.037052 (-0.000747) | 0.377179 / 0.258489 (0.118690) | 0.410694 / 0.293841 (0.116853) | 0.030196 / 0.128546 (-0.098351) | 0.011436 / 0.075646 (-0.064211) | 0.325911 / 0.419271 (-0.093360) | 0.043709 / 0.043533 (0.000177) | 0.375801 / 0.255139 (0.120662) | 0.396511 / 0.283200 (0.113311) | 0.088346 / 0.141683 (-0.053337) | 1.483427 / 1.452155 (0.031272) | 1.553708 / 1.492716 (0.060992) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.190974 / 0.018006 (0.172968) | 0.451309 / 0.000490 (0.450819) | 0.004045 / 0.000200 (0.003845) | 0.000077 / 0.000054 (0.000022) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023814 / 0.037411 (-0.013597) | 0.096922 / 0.014526 (0.082396) | 0.101506 / 0.176557 (-0.075050) | 0.164694 / 0.737135 (-0.572441) | 0.106899 / 0.296338 (-0.189439) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.432164 / 0.215209 (0.216954) | 4.308076 / 2.077655 (2.230421) | 2.092434 / 1.504120 (0.588314) | 1.937405 / 1.541195 (0.396210) | 1.988030 / 1.468490 (0.519540) | 0.695476 / 4.584777 (-3.889301) | 3.436413 / 3.745712 (-0.309299) | 2.892954 / 5.269862 (-2.376908) | 1.519906 / 4.565676 (-3.045771) | 0.082579 / 0.424275 (-0.341696) | 0.012233 / 0.007607 (0.004626) | 0.531329 / 0.226044 (0.305284) | 5.365272 / 2.268929 (3.096344) | 2.391452 / 55.444624 (-53.053172) | 2.051116 / 6.876477 (-4.825361) | 2.140663 / 2.142072 (-0.001410) | 0.807262 / 4.805227 (-3.997966) | 0.151290 / 6.500664 (-6.349374) | 0.066137 / 0.075469 (-0.009333) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.193106 / 1.841788 (-0.648682) | 13.577240 / 8.074308 (5.502932) | 14.280126 / 10.191392 (4.088734) | 0.142538 / 0.680424 (-0.537886) | 0.016641 / 0.534201 (-0.517560) | 0.386318 / 0.579283 (-0.192965) | 0.385991 / 0.434364 (-0.048373) | 0.440712 / 0.540337 (-0.099625) | 0.524189 / 1.386936 (-0.862747) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006628 / 0.011353 (-0.004725) | 0.004664 / 0.011008 (-0.006344) | 0.077254 / 0.038508 (0.038746) | 0.028369 / 0.023109 (0.005259) | 0.343076 / 0.275898 (0.067178) | 0.376491 / 0.323480 (0.053011) | 0.005298 / 0.007986 (-0.002687) | 0.004853 / 0.004328 (0.000524) | 0.075927 / 0.004250 (0.071677) | 0.039951 / 0.037052 (0.002899) | 0.346225 / 0.258489 (0.087736) | 0.382367 / 0.293841 (0.088526) | 0.031133 / 0.128546 (-0.097413) | 0.011666 / 0.075646 (-0.063981) | 0.086383 / 0.419271 (-0.332889) | 0.042885 / 0.043533 (-0.000647) | 0.343885 / 0.255139 (0.088746) | 0.366840 / 0.283200 (0.083640) | 0.095942 / 0.141683 (-0.045741) | 1.528972 / 1.452155 (0.076817) | 1.586392 / 1.492716 (0.093676) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.223952 / 0.018006 (0.205946) | 0.410767 / 0.000490 (0.410277) | 0.001014 / 0.000200 (0.000814) | 0.000067 / 0.000054 (0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024210 / 0.037411 (-0.013201) | 0.100308 / 0.014526 (0.085782) | 0.106899 / 0.176557 (-0.069658) | 0.156514 / 0.737135 (-0.580621) | 0.109548 / 0.296338 (-0.186790) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.434763 / 0.215209 (0.219554) | 4.348485 / 2.077655 (2.270831) | 2.064255 / 1.504120 (0.560135) | 1.864394 / 1.541195 (0.323199) | 1.899732 / 1.468490 (0.431242) | 0.694147 / 4.584777 (-3.890630) | 3.357898 / 3.745712 (-0.387815) | 2.909155 / 5.269862 (-2.360707) | 1.424790 / 4.565676 (-3.140886) | 0.082597 / 0.424275 (-0.341678) | 0.012442 / 0.007607 (0.004835) | 0.538758 / 0.226044 (0.312713) | 5.390288 / 2.268929 (3.121359) | 2.532016 / 55.444624 (-52.912609) | 2.185724 / 6.876477 (-4.690753) | 2.274176 / 2.142072 (0.132104) | 0.804785 / 4.805227 (-4.000442) | 0.152649 / 6.500664 (-6.348015) | 0.067707 / 0.075469 (-0.007762) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.285219 / 1.841788 (-0.556568) | 13.958098 / 8.074308 (5.883790) | 14.043653 / 10.191392 (3.852261) | 0.144526 / 0.680424 (-0.535898) | 0.016813 / 0.534201 (-0.517388) | 0.390286 / 0.579283 (-0.188997) | 0.389184 / 0.434364 (-0.045180) | 0.470810 / 0.540337 (-0.069527) | 0.562391 / 1.386936 (-0.824545) |\n\n</details>\n</details>\n\n\n"
] | 2023-04-11T10:02:25Z
| 2023-04-27T16:39:04Z
| 2023-04-27T16:32:09Z
|
CONTRIBUTOR
| null | null | null |
This PR allows sharding of merged iterable datasets.
Merged iterable datasets with for instance the `interleave_datasets` command are comprised of multiple sub-iterable, one for each dataset that has been merged.
With this PR, sharding a merged iterable will result in multiple merged datasets each comprised of sharded sub-iterable, ensuring that there is no duplication of data.
As a result it is now possible to set any amount of workers in the dataloader as long as it is lower or equal to the lowest amount of shards amongst the datasets. Before it had to be set to 0.
I previously talked about this issue on the forum [here](https://discuss.huggingface.co/t/interleaving-iterable-dataset-with-num-workers-0/35801)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5735/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5735/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5735.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5735",
"merged_at": "2023-04-27T16:32:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5735.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5735"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6292
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6292/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6292/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6292/events
|
https://github.com/huggingface/datasets/issues/6292
| 1,937,050,470
|
I_kwDODunzps5zdQtm
| 6,292
|
how to load the image of dtype float32 or float64
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26437644?v=4",
"events_url": "https://api.github.com/users/wanglaofei/events{/privacy}",
"followers_url": "https://api.github.com/users/wanglaofei/followers",
"following_url": "https://api.github.com/users/wanglaofei/following{/other_user}",
"gists_url": "https://api.github.com/users/wanglaofei/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/wanglaofei",
"id": 26437644,
"login": "wanglaofei",
"node_id": "MDQ6VXNlcjI2NDM3NjQ0",
"organizations_url": "https://api.github.com/users/wanglaofei/orgs",
"received_events_url": "https://api.github.com/users/wanglaofei/received_events",
"repos_url": "https://api.github.com/users/wanglaofei/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/wanglaofei/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wanglaofei/subscriptions",
"type": "User",
"url": "https://api.github.com/users/wanglaofei",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"Hi! Can you provide a code that reproduces the issue?\r\n\r\nAlso, which version of `datasets` are you using? You can check this by running `python -c \"import datasets; print(datasets.__version__)\"` inside the env. We added support for \"float images\" in `datasets 2.9`."
] | 2023-10-11T07:27:16Z
| 2023-10-11T13:19:11Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
_FEATURES = datasets.Features(
{
"image": datasets.Image(),
"text": datasets.Value("string"),
},
)
The datasets builder seems only support the unit8 data. How to load the float dtype data?
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6292/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6292/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7496
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7496/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7496/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7496/events
|
https://github.com/huggingface/datasets/issues/7496
| 2,967,345,522
|
I_kwDODunzps6w3hly
| 7,496
|
Json builder: Allow features to override problematic Arrow types
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1017189?v=4",
"events_url": "https://api.github.com/users/edmcman/events{/privacy}",
"followers_url": "https://api.github.com/users/edmcman/followers",
"following_url": "https://api.github.com/users/edmcman/following{/other_user}",
"gists_url": "https://api.github.com/users/edmcman/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/edmcman",
"id": 1017189,
"login": "edmcman",
"node_id": "MDQ6VXNlcjEwMTcxODk=",
"organizations_url": "https://api.github.com/users/edmcman/orgs",
"received_events_url": "https://api.github.com/users/edmcman/received_events",
"repos_url": "https://api.github.com/users/edmcman/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/edmcman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/edmcman/subscriptions",
"type": "User",
"url": "https://api.github.com/users/edmcman",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
| null |
[] | null |
[
"Hi ! It would be cool indeed, currently the JSON data are generally loaded here: \n\nhttps://github.com/huggingface/datasets/blob/90e5bf8a8599b625d6103ee5ac83b98269991141/src/datasets/packaged_modules/json/json.py#L137-L140\n\nMaybe we can pass a Arrow `schema` to avoid errors ?"
] | 2025-04-02T19:27:16Z
| 2025-04-15T13:06:09Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
In the JSON builder, use explicitly requested feature types before or while converting to Arrow.
### Motivation
Working with JSON datasets is really hard because of Arrow. At the very least, it seems like it should be possible to work-around these problems by explicitly setting problematic columns's types. But it seems like this is not possible because the features are only used *after* converting to arrow.
Here's a simple example where the Arrow error could potentially be avoided by converting the column to a string: https://colab.research.google.com/drive/16QHRdbUwKSrpwVfGwu8V8AHr8v2dv0dt?usp=sharing
### Your contribution
Maybe with some guidance. I'm not very familiar with arrow or pandas.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7496/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7496/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6909
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6909/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6909/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6909/events
|
https://github.com/huggingface/datasets/pull/6909
| 2,307,508,120
|
PR_kwDODunzps5wCoiE
| 6,909
|
Update requests >=2.32.1 to fix vulnerability
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6909). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005375 / 0.011353 (-0.005978) | 0.004005 / 0.011008 (-0.007003) | 0.062407 / 0.038508 (0.023899) | 0.032241 / 0.023109 (0.009131) | 0.256092 / 0.275898 (-0.019806) | 0.285740 / 0.323480 (-0.037740) | 0.004146 / 0.007986 (-0.003839) | 0.002831 / 0.004328 (-0.001497) | 0.049179 / 0.004250 (0.044928) | 0.048303 / 0.037052 (0.011251) | 0.270841 / 0.258489 (0.012352) | 0.303209 / 0.293841 (0.009368) | 0.027642 / 0.128546 (-0.100905) | 0.010661 / 0.075646 (-0.064985) | 0.201999 / 0.419271 (-0.217272) | 0.036532 / 0.043533 (-0.007001) | 0.262441 / 0.255139 (0.007302) | 0.280944 / 0.283200 (-0.002256) | 0.018369 / 0.141683 (-0.123314) | 1.122249 / 1.452155 (-0.329906) | 1.171352 / 1.492716 (-0.321364) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.096433 / 0.018006 (0.078427) | 0.297272 / 0.000490 (0.296782) | 0.000222 / 0.000200 (0.000023) | 0.000043 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019645 / 0.037411 (-0.017766) | 0.062744 / 0.014526 (0.048219) | 0.076096 / 0.176557 (-0.100460) | 0.121882 / 0.737135 (-0.615253) | 0.076267 / 0.296338 (-0.220072) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.274159 / 0.215209 (0.058950) | 2.729371 / 2.077655 (0.651716) | 1.454328 / 1.504120 (-0.049792) | 1.330517 / 1.541195 (-0.210678) | 1.338832 / 1.468490 (-0.129658) | 0.600252 / 4.584777 (-3.984525) | 2.388658 / 3.745712 (-1.357054) | 2.837717 / 5.269862 (-2.432145) | 1.747329 / 4.565676 (-2.818347) | 0.064620 / 0.424275 (-0.359655) | 0.004955 / 0.007607 (-0.002653) | 0.340253 / 0.226044 (0.114209) | 3.351559 / 2.268929 (1.082630) | 1.822718 / 55.444624 (-53.621907) | 1.518663 / 6.876477 (-5.357814) | 1.548066 / 2.142072 (-0.594006) | 0.663525 / 4.805227 (-4.141702) | 0.118334 / 6.500664 (-6.382331) | 0.042060 / 0.075469 (-0.033410) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.976509 / 1.841788 (-0.865278) | 11.703321 / 8.074308 (3.629013) | 9.305605 / 10.191392 (-0.885787) | 0.131016 / 0.680424 (-0.549408) | 0.014299 / 0.534201 (-0.519902) | 0.293963 / 0.579283 (-0.285320) | 0.264018 / 0.434364 (-0.170345) | 0.330265 / 0.540337 (-0.210073) | 0.427239 / 1.386936 (-0.959697) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005437 / 0.011353 (-0.005916) | 0.003774 / 0.011008 (-0.007234) | 0.049927 / 0.038508 (0.011419) | 0.032246 / 0.023109 (0.009137) | 0.271808 / 0.275898 (-0.004090) | 0.295652 / 0.323480 (-0.027828) | 0.004220 / 0.007986 (-0.003766) | 0.002803 / 0.004328 (-0.001525) | 0.049656 / 0.004250 (0.045406) | 0.041938 / 0.037052 (0.004885) | 0.282199 / 0.258489 (0.023710) | 0.310206 / 0.293841 (0.016365) | 0.030389 / 0.128546 (-0.098157) | 0.010593 / 0.075646 (-0.065054) | 0.057862 / 0.419271 (-0.361409) | 0.033937 / 0.043533 (-0.009596) | 0.268920 / 0.255139 (0.013781) | 0.286000 / 0.283200 (0.002800) | 0.018766 / 0.141683 (-0.122917) | 1.118556 / 1.452155 (-0.333599) | 1.175083 / 1.492716 (-0.317633) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.095135 / 0.018006 (0.077129) | 0.304735 / 0.000490 (0.304245) | 0.000210 / 0.000200 (0.000010) | 0.000054 / 0.000054 (-0.000000) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022971 / 0.037411 (-0.014441) | 0.076204 / 0.014526 (0.061678) | 0.090801 / 0.176557 (-0.085756) | 0.130149 / 0.737135 (-0.606987) | 0.090986 / 0.296338 (-0.205352) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.298535 / 0.215209 (0.083326) | 2.882959 / 2.077655 (0.805304) | 1.574018 / 1.504120 (0.069899) | 1.445251 / 1.541195 (-0.095944) | 1.483651 / 1.468490 (0.015160) | 0.572012 / 4.584777 (-4.012765) | 0.972223 / 3.745712 (-2.773489) | 2.745776 / 5.269862 (-2.524085) | 1.783980 / 4.565676 (-2.781697) | 0.063910 / 0.424275 (-0.360365) | 0.005397 / 0.007607 (-0.002210) | 0.349104 / 0.226044 (0.123059) | 3.433303 / 2.268929 (1.164374) | 1.961506 / 55.444624 (-53.483119) | 1.665905 / 6.876477 (-5.210571) | 1.800977 / 2.142072 (-0.341095) | 0.655843 / 4.805227 (-4.149384) | 0.118320 / 6.500664 (-6.382345) | 0.041748 / 0.075469 (-0.033722) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.006835 / 1.841788 (-0.834952) | 12.506123 / 8.074308 (4.431815) | 10.564310 / 10.191392 (0.372918) | 0.143121 / 0.680424 (-0.537303) | 0.016340 / 0.534201 (-0.517861) | 0.284181 / 0.579283 (-0.295102) | 0.125975 / 0.434364 (-0.308389) | 0.324369 / 0.540337 (-0.215969) | 0.443713 / 1.386936 (-0.943223) |\n\n</details>\n</details>\n\n\n"
] | 2024-05-21T07:11:20Z
| 2024-05-21T07:45:58Z
| 2024-05-21T07:38:25Z
|
MEMBER
| null | null | null |
Update requests >=2.32.1 to fix vulnerability.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6909/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6909/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6909.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6909",
"merged_at": "2024-05-21T07:38:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6909.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6909"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6119
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6119/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6119/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6119/events
|
https://github.com/huggingface/datasets/pull/6119
| 1,835,996,350
|
PR_kwDODunzps5XKI19
| 6,119
|
[Docs] Add description of `select_columns` to guide
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/18213435?v=4",
"events_url": "https://api.github.com/users/unifyh/events{/privacy}",
"followers_url": "https://api.github.com/users/unifyh/followers",
"following_url": "https://api.github.com/users/unifyh/following{/other_user}",
"gists_url": "https://api.github.com/users/unifyh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/unifyh",
"id": 18213435,
"login": "unifyh",
"node_id": "MDQ6VXNlcjE4MjEzNDM1",
"organizations_url": "https://api.github.com/users/unifyh/orgs",
"received_events_url": "https://api.github.com/users/unifyh/received_events",
"repos_url": "https://api.github.com/users/unifyh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/unifyh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/unifyh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/unifyh",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007755 / 0.011353 (-0.003598) | 0.004618 / 0.011008 (-0.006391) | 0.098132 / 0.038508 (0.059624) | 0.086759 / 0.023109 (0.063650) | 0.374668 / 0.275898 (0.098770) | 0.417131 / 0.323480 (0.093651) | 0.004604 / 0.007986 (-0.003382) | 0.005461 / 0.004328 (0.001132) | 0.077249 / 0.004250 (0.072999) | 0.063247 / 0.037052 (0.026195) | 0.391801 / 0.258489 (0.133312) | 0.432139 / 0.293841 (0.138298) | 0.036755 / 0.128546 (-0.091791) | 0.010011 / 0.075646 (-0.065636) | 0.346175 / 0.419271 (-0.073097) | 0.061503 / 0.043533 (0.017971) | 0.374063 / 0.255139 (0.118924) | 0.435873 / 0.283200 (0.152673) | 0.029476 / 0.141683 (-0.112207) | 1.786945 / 1.452155 (0.334790) | 1.857190 / 1.492716 (0.364474) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.253939 / 0.018006 (0.235933) | 0.506847 / 0.000490 (0.506358) | 0.007278 / 0.000200 (0.007079) | 0.000451 / 0.000054 (0.000397) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032938 / 0.037411 (-0.004474) | 0.097493 / 0.014526 (0.082967) | 0.112090 / 0.176557 (-0.064467) | 0.177986 / 0.737135 (-0.559149) | 0.112060 / 0.296338 (-0.184278) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.481858 / 0.215209 (0.266649) | 4.814894 / 2.077655 (2.737239) | 2.496428 / 1.504120 (0.992308) | 2.309965 / 1.541195 (0.768770) | 2.393819 / 1.468490 (0.925329) | 0.564670 / 4.584777 (-4.020107) | 4.151222 / 3.745712 (0.405510) | 3.676115 / 5.269862 (-1.593747) | 2.346165 / 4.565676 (-2.219512) | 0.066344 / 0.424275 (-0.357931) | 0.009006 / 0.007607 (0.001399) | 0.567699 / 0.226044 (0.341654) | 5.686799 / 2.268929 (3.417871) | 3.031044 / 55.444624 (-52.413580) | 2.606259 / 6.876477 (-4.270217) | 2.864876 / 2.142072 (0.722804) | 0.681730 / 4.805227 (-4.123498) | 0.155405 / 6.500664 (-6.345259) | 0.071492 / 0.075469 (-0.003977) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.514446 / 1.841788 (-0.327341) | 22.624912 / 8.074308 (14.550604) | 16.754145 / 10.191392 (6.562753) | 0.193113 / 0.680424 (-0.487311) | 0.021808 / 0.534201 (-0.512393) | 0.468241 / 0.579283 (-0.111042) | 0.499647 / 0.434364 (0.065283) | 0.539571 / 0.540337 (-0.000766) | 0.771268 / 1.386936 (-0.615668) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007562 / 0.011353 (-0.003791) | 0.004548 / 0.011008 (-0.006460) | 0.075998 / 0.038508 (0.037490) | 0.081648 / 0.023109 (0.058539) | 0.462876 / 0.275898 (0.186978) | 0.499366 / 0.323480 (0.175886) | 0.005839 / 0.007986 (-0.002147) | 0.003753 / 0.004328 (-0.000576) | 0.075918 / 0.004250 (0.071668) | 0.063233 / 0.037052 (0.026181) | 0.459024 / 0.258489 (0.200535) | 0.506388 / 0.293841 (0.212547) | 0.036179 / 0.128546 (-0.092367) | 0.009961 / 0.075646 (-0.065685) | 0.082061 / 0.419271 (-0.337211) | 0.056469 / 0.043533 (0.012936) | 0.459567 / 0.255139 (0.204428) | 0.482578 / 0.283200 (0.199378) | 0.026363 / 0.141683 (-0.115320) | 1.742247 / 1.452155 (0.290092) | 1.807166 / 1.492716 (0.314450) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.330526 / 0.018006 (0.312520) | 0.511674 / 0.000490 (0.511184) | 0.040969 / 0.000200 (0.040769) | 0.000176 / 0.000054 (0.000121) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035492 / 0.037411 (-0.001920) | 0.104338 / 0.014526 (0.089813) | 0.116973 / 0.176557 (-0.059583) | 0.180218 / 0.737135 (-0.556917) | 0.118801 / 0.296338 (-0.177538) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.492196 / 0.215209 (0.276987) | 4.910271 / 2.077655 (2.832616) | 2.542562 / 1.504120 (1.038442) | 2.333516 / 1.541195 (0.792321) | 2.439682 / 1.468490 (0.971192) | 0.571966 / 4.584777 (-4.012811) | 4.089801 / 3.745712 (0.344089) | 3.732129 / 5.269862 (-1.537733) | 2.375887 / 4.565676 (-2.189789) | 0.067376 / 0.424275 (-0.356900) | 0.008350 / 0.007607 (0.000743) | 0.583942 / 0.226044 (0.357897) | 5.840002 / 2.268929 (3.571074) | 3.062520 / 55.444624 (-52.382104) | 2.722512 / 6.876477 (-4.153965) | 2.938307 / 2.142072 (0.796234) | 0.689459 / 4.805227 (-4.115769) | 0.155632 / 6.500664 (-6.345032) | 0.072387 / 0.075469 (-0.003082) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.595587 / 1.841788 (-0.246201) | 23.035478 / 8.074308 (14.961170) | 16.457675 / 10.191392 (6.266283) | 0.170819 / 0.680424 (-0.509605) | 0.022042 / 0.534201 (-0.512159) | 0.466824 / 0.579283 (-0.112459) | 0.486350 / 0.434364 (0.051986) | 0.574330 / 0.540337 (0.033993) | 0.764913 / 1.386936 (-0.622023) |\n\n</details>\n</details>\n\n\n"
] | 2023-08-04T03:13:30Z
| 2023-08-16T10:13:02Z
| 2023-08-16T10:02:52Z
|
CONTRIBUTOR
| null | null | null |
Closes #6116
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6119/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6119/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6119.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6119",
"merged_at": "2023-08-16T10:02:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6119.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6119"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6264
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6264/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6264/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6264/events
|
https://github.com/huggingface/datasets/pull/6264
| 1,914,958,781
|
PR_kwDODunzps5bTvzh
| 6,264
|
Temporarily pin tensorflow < 2.14.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008356 / 0.011353 (-0.002997) | 0.004553 / 0.011008 (-0.006455) | 0.101025 / 0.038508 (0.062517) | 0.090194 / 0.023109 (0.067085) | 0.427127 / 0.275898 (0.151229) | 0.469116 / 0.323480 (0.145636) | 0.007593 / 0.007986 (-0.000393) | 0.003751 / 0.004328 (-0.000578) | 0.077432 / 0.004250 (0.073182) | 0.082744 / 0.037052 (0.045692) | 0.433638 / 0.258489 (0.175149) | 0.482387 / 0.293841 (0.188546) | 0.040658 / 0.128546 (-0.087888) | 0.009799 / 0.075646 (-0.065848) | 0.345274 / 0.419271 (-0.073998) | 0.076642 / 0.043533 (0.033109) | 0.424417 / 0.255139 (0.169278) | 0.457045 / 0.283200 (0.173846) | 0.033642 / 0.141683 (-0.108041) | 1.765446 / 1.452155 (0.313291) | 1.859279 / 1.492716 (0.366562) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.273629 / 0.018006 (0.255623) | 0.505743 / 0.000490 (0.505253) | 0.009300 / 0.000200 (0.009100) | 0.000359 / 0.000054 (0.000305) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032510 / 0.037411 (-0.004901) | 0.099628 / 0.014526 (0.085103) | 0.112904 / 0.176557 (-0.063652) | 0.179118 / 0.737135 (-0.558018) | 0.115946 / 0.296338 (-0.180393) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.456431 / 0.215209 (0.241222) | 4.556559 / 2.077655 (2.478904) | 2.207893 / 1.504120 (0.703773) | 2.024706 / 1.541195 (0.483512) | 2.165424 / 1.468490 (0.696934) | 0.571745 / 4.584777 (-4.013031) | 4.341017 / 3.745712 (0.595305) | 3.980520 / 5.269862 (-1.289342) | 2.333077 / 4.565676 (-2.232599) | 0.067200 / 0.424275 (-0.357075) | 0.008563 / 0.007607 (0.000956) | 0.545294 / 0.226044 (0.319250) | 5.445152 / 2.268929 (3.176224) | 2.740657 / 55.444624 (-52.703968) | 2.370635 / 6.876477 (-4.505842) | 2.451642 / 2.142072 (0.309570) | 0.679385 / 4.805227 (-4.125842) | 0.155967 / 6.500664 (-6.344697) | 0.072812 / 0.075469 (-0.002657) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.494483 / 1.841788 (-0.347305) | 23.673700 / 8.074308 (15.599392) | 16.608529 / 10.191392 (6.417137) | 0.170220 / 0.680424 (-0.510204) | 0.021630 / 0.534201 (-0.512571) | 0.470771 / 0.579283 (-0.108512) | 0.535874 / 0.434364 (0.101510) | 0.550376 / 0.540337 (0.010039) | 0.776633 / 1.386936 (-0.610303) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007899 / 0.011353 (-0.003454) | 0.004581 / 0.011008 (-0.006427) | 0.076520 / 0.038508 (0.038012) | 0.090374 / 0.023109 (0.067265) | 0.495016 / 0.275898 (0.219118) | 0.532384 / 0.323480 (0.208904) | 0.006160 / 0.007986 (-0.001825) | 0.003780 / 0.004328 (-0.000548) | 0.077164 / 0.004250 (0.072914) | 0.064444 / 0.037052 (0.027391) | 0.501642 / 0.258489 (0.243153) | 0.549170 / 0.293841 (0.255329) | 0.038051 / 0.128546 (-0.090495) | 0.010081 / 0.075646 (-0.065565) | 0.083752 / 0.419271 (-0.335520) | 0.061334 / 0.043533 (0.017801) | 0.493502 / 0.255139 (0.238363) | 0.518018 / 0.283200 (0.234818) | 0.029534 / 0.141683 (-0.112149) | 1.929432 / 1.452155 (0.477277) | 1.889985 / 1.492716 (0.397268) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.254802 / 0.018006 (0.236795) | 0.494463 / 0.000490 (0.493974) | 0.005040 / 0.000200 (0.004840) | 0.000120 / 0.000054 (0.000065) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.038372 / 0.037411 (0.000960) | 0.112247 / 0.014526 (0.097721) | 0.124365 / 0.176557 (-0.052191) | 0.187142 / 0.737135 (-0.549993) | 0.126070 / 0.296338 (-0.170269) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.513418 / 0.215209 (0.298209) | 5.132267 / 2.077655 (3.054613) | 2.773676 / 1.504120 (1.269556) | 2.576840 / 1.541195 (1.035645) | 2.681729 / 1.468490 (1.213238) | 0.581809 / 4.584777 (-4.002968) | 4.327075 / 3.745712 (0.581363) | 4.040264 / 5.269862 (-1.229598) | 2.436192 / 4.565676 (-2.129484) | 0.067819 / 0.424275 (-0.356456) | 0.008760 / 0.007607 (0.001153) | 0.610765 / 0.226044 (0.384720) | 6.105679 / 2.268929 (3.836750) | 3.341341 / 55.444624 (-52.103284) | 2.926695 / 6.876477 (-3.949781) | 3.017269 / 2.142072 (0.875196) | 0.707289 / 4.805227 (-4.097938) | 0.157379 / 6.500664 (-6.343285) | 0.072549 / 0.075469 (-0.002920) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.666738 / 1.841788 (-0.175050) | 23.698567 / 8.074308 (15.624259) | 17.806437 / 10.191392 (7.615045) | 0.172103 / 0.680424 (-0.508321) | 0.023508 / 0.534201 (-0.510693) | 0.473171 / 0.579283 (-0.106112) | 0.524834 / 0.434364 (0.090470) | 0.562562 / 0.540337 (0.022224) | 0.788667 / 1.386936 (-0.598269) |\n\n</details>\n</details>\n\n\n",
"CI 404 errors are unrelated. See:\r\n- #6262 ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006657 / 0.011353 (-0.004696) | 0.003975 / 0.011008 (-0.007033) | 0.084614 / 0.038508 (0.046106) | 0.074557 / 0.023109 (0.051448) | 0.309213 / 0.275898 (0.033315) | 0.338245 / 0.323480 (0.014765) | 0.005375 / 0.007986 (-0.002610) | 0.003355 / 0.004328 (-0.000973) | 0.064406 / 0.004250 (0.060156) | 0.061763 / 0.037052 (0.024711) | 0.313405 / 0.258489 (0.054916) | 0.352149 / 0.293841 (0.058308) | 0.031597 / 0.128546 (-0.096949) | 0.008499 / 0.075646 (-0.067147) | 0.289098 / 0.419271 (-0.130174) | 0.054415 / 0.043533 (0.010882) | 0.313210 / 0.255139 (0.058071) | 0.326728 / 0.283200 (0.043528) | 0.024597 / 0.141683 (-0.117086) | 1.449916 / 1.452155 (-0.002239) | 1.526314 / 1.492716 (0.033598) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.231435 / 0.018006 (0.213429) | 0.537224 / 0.000490 (0.536734) | 0.007287 / 0.000200 (0.007088) | 0.000227 / 0.000054 (0.000172) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028340 / 0.037411 (-0.009071) | 0.084085 / 0.014526 (0.069560) | 0.428211 / 0.176557 (0.251655) | 0.157360 / 0.737135 (-0.579775) | 0.139470 / 0.296338 (-0.156868) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.389311 / 0.215209 (0.174102) | 3.871329 / 2.077655 (1.793674) | 1.861533 / 1.504120 (0.357413) | 1.688082 / 1.541195 (0.146887) | 1.804036 / 1.468490 (0.335546) | 0.489154 / 4.584777 (-4.095623) | 3.603843 / 3.745712 (-0.141869) | 3.424868 / 5.269862 (-1.844994) | 2.013525 / 4.565676 (-2.552152) | 0.057387 / 0.424275 (-0.366888) | 0.007274 / 0.007607 (-0.000333) | 0.462340 / 0.226044 (0.236295) | 4.620095 / 2.268929 (2.351167) | 2.326641 / 55.444624 (-53.117984) | 1.990082 / 6.876477 (-4.886395) | 2.037841 / 2.142072 (-0.104232) | 0.581973 / 4.805227 (-4.223254) | 0.135932 / 6.500664 (-6.364732) | 0.061092 / 0.075469 (-0.014377) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.249586 / 1.841788 (-0.592202) | 19.036233 / 8.074308 (10.961925) | 14.083365 / 10.191392 (3.891973) | 0.169802 / 0.680424 (-0.510622) | 0.018547 / 0.534201 (-0.515654) | 0.392926 / 0.579283 (-0.186357) | 0.409993 / 0.434364 (-0.024371) | 0.460081 / 0.540337 (-0.080257) | 0.643836 / 1.386936 (-0.743100) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006889 / 0.011353 (-0.004464) | 0.004060 / 0.011008 (-0.006948) | 0.064332 / 0.038508 (0.025824) | 0.077067 / 0.023109 (0.053958) | 0.401235 / 0.275898 (0.125337) | 0.437139 / 0.323480 (0.113659) | 0.005510 / 0.007986 (-0.002476) | 0.003338 / 0.004328 (-0.000991) | 0.064446 / 0.004250 (0.060195) | 0.055537 / 0.037052 (0.018485) | 0.432689 / 0.258489 (0.174200) | 0.460005 / 0.293841 (0.166164) | 0.033122 / 0.128546 (-0.095424) | 0.008637 / 0.075646 (-0.067010) | 0.071088 / 0.419271 (-0.348183) | 0.049024 / 0.043533 (0.005491) | 0.400258 / 0.255139 (0.145119) | 0.419324 / 0.283200 (0.136124) | 0.022050 / 0.141683 (-0.119632) | 1.475744 / 1.452155 (0.023589) | 1.546565 / 1.492716 (0.053848) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226241 / 0.018006 (0.208235) | 0.448574 / 0.000490 (0.448085) | 0.004732 / 0.000200 (0.004533) | 0.000097 / 0.000054 (0.000042) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033260 / 0.037411 (-0.004151) | 0.092622 / 0.014526 (0.078096) | 0.105501 / 0.176557 (-0.071056) | 0.157981 / 0.737135 (-0.579155) | 0.105993 / 0.296338 (-0.190345) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.445716 / 0.215209 (0.230507) | 4.451848 / 2.077655 (2.374194) | 2.404769 / 1.504120 (0.900649) | 2.232594 / 1.541195 (0.691399) | 2.312735 / 1.468490 (0.844245) | 0.491208 / 4.584777 (-4.093569) | 3.561629 / 3.745712 (-0.184083) | 3.444269 / 5.269862 (-1.825592) | 2.060365 / 4.565676 (-2.505311) | 0.057723 / 0.424275 (-0.366552) | 0.007392 / 0.007607 (-0.000215) | 0.526447 / 0.226044 (0.300403) | 5.264307 / 2.268929 (2.995379) | 2.951481 / 55.444624 (-52.493143) | 2.593178 / 6.876477 (-4.283299) | 2.689780 / 2.142072 (0.547707) | 0.588649 / 4.805227 (-4.216579) | 0.133566 / 6.500664 (-6.367098) | 0.060462 / 0.075469 (-0.015008) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.381008 / 1.841788 (-0.460780) | 19.452394 / 8.074308 (11.378086) | 15.255912 / 10.191392 (5.064520) | 0.171043 / 0.680424 (-0.509381) | 0.020395 / 0.534201 (-0.513806) | 0.396429 / 0.579283 (-0.182854) | 0.422820 / 0.434364 (-0.011544) | 0.477305 / 0.540337 (-0.063032) | 0.658274 / 1.386936 (-0.728663) |\n\n</details>\n</details>\n\n\n"
] | 2023-09-27T08:16:06Z
| 2023-09-27T08:45:24Z
| 2023-09-27T08:36:39Z
|
MEMBER
| null | null | null |
Temporarily pin tensorflow < 2.14.0 until permanent solution is found.
Hot fix #6263.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6264/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6264/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6264.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6264",
"merged_at": "2023-09-27T08:36:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6264.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6264"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4569
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4569/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4569/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4569/events
|
https://github.com/huggingface/datasets/issues/4569
| 1,284,833,694
|
I_kwDODunzps5MlQGe
| 4,569
|
Dataset Viewer issue for sst2
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun",
"user_view_type": "public"
}
|
[
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[
"Hi @lewtun, thanks for reporting.\r\n\r\nI have checked locally and refreshed the preview and it seems working smooth now:\r\n```python\r\nIn [8]: ds\r\nOut[8]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['idx', 'sentence', 'label'],\r\n num_rows: 67349\r\n })\r\n validation: Dataset({\r\n features: ['idx', 'sentence', 'label'],\r\n num_rows: 872\r\n })\r\n test: Dataset({\r\n features: ['idx', 'sentence', 'label'],\r\n num_rows: 1821\r\n })\r\n})\r\n```\r\n\r\nCould you confirm? ",
"Thanks @albertvillanova - it is indeed working now (not sure what caused the error in the first place). Closing this :)"
] | 2022-06-26T07:32:54Z
| 2022-06-27T06:37:48Z
| 2022-06-27T06:37:48Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Link
https://huggingface.co/datasets/sst2
### Description
Not sure what is causing this, however it seems that `load_dataset("sst2")` also hangs (even though it downloads the files without problem):
```
Status code: 400
Exception: Exception
Message: Give up after 5 attempts with ConnectionError
```
### Owner
No
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4569/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4569/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5483
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5483/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5483/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5483/events
|
https://github.com/huggingface/datasets/issues/5483
| 1,560,894,690
|
I_kwDODunzps5dCVzi
| 5,483
|
Unable to upload dataset
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/57996478?v=4",
"events_url": "https://api.github.com/users/yuvalkirstain/events{/privacy}",
"followers_url": "https://api.github.com/users/yuvalkirstain/followers",
"following_url": "https://api.github.com/users/yuvalkirstain/following{/other_user}",
"gists_url": "https://api.github.com/users/yuvalkirstain/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yuvalkirstain",
"id": 57996478,
"login": "yuvalkirstain",
"node_id": "MDQ6VXNlcjU3OTk2NDc4",
"organizations_url": "https://api.github.com/users/yuvalkirstain/orgs",
"received_events_url": "https://api.github.com/users/yuvalkirstain/received_events",
"repos_url": "https://api.github.com/users/yuvalkirstain/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yuvalkirstain/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yuvalkirstain/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yuvalkirstain",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Seems to work now, perhaps it was something internal with our university's network."
] | 2023-01-28T15:18:26Z
| 2023-01-29T08:09:49Z
| 2023-01-29T08:09:49Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Uploading a simple dataset ends with an exception
### Steps to reproduce the bug
I created a new conda env with python 3.10, pip installed datasets and:
```python
>>> from datasets import load_dataset, load_from_disk, Dataset
>>> d = Dataset.from_dict({"text": ["hello"] * 2})
>>> d.push_to_hub("ttt111")
/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_hf_folder.py:92: UserWarning: A token has been found in `/a/home/cc/students/cs/kirstain/.huggingface/token`. This is the old path where tokens were stored. The new location is `/home/olab/kirstain/.cache/huggingface/token` which is configurable using `HF_HOME` environment variable. Your token has been copied to this new location. You can now safely delete the old token file manually or use `huggingface-cli logout`.
warnings.warn(
Creating parquet from Arrow format: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 279.94ba/s]
Upload 1 LFS files: 0%| | 0/1 [00:02<?, ?it/s]
Pushing dataset shards to the dataset hub: 0%| | 0/1 [00:04<?, ?it/s]
Traceback (most recent call last):
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_errors.py", line 264, in hf_raise_for_status
response.raise_for_status()
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/requests/models.py", line 1021, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://s3.us-east-1.amazonaws.com/lfs.huggingface.co/repos/cf/0c/cf0c5ab8a3f729e5f57a8b79a36ecea64a31126f13218591c27ed9a1c7bd9b41/ece885a4bb6bbc8c1bb51b45542b805283d74590f72cd4c45d3ba76628570386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIA4N7VTDGO27GPWFUO%2F20230128%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20230128T151640Z&X-Amz-Expires=900&X-Amz-Signature=89e78e9a9d70add7ed93d453334f4f93c6f29d889d46750a1f2da04af73978db&X-Amz-SignedHeaders=host&x-amz-storage-class=INTELLIGENT_TIERING&x-id=PutObject
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 334, in _inner_upload_lfs_object
return _upload_lfs_object(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 391, in _upload_lfs_object
lfs_upload(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/lfs.py", line 273, in lfs_upload
_upload_single_part(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/lfs.py", line 305, in _upload_single_part
hf_raise_for_status(upload_res)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_errors.py", line 318, in hf_raise_for_status
raise HfHubHTTPError(str(e), response=response) from e
huggingface_hub.utils._errors.HfHubHTTPError: 403 Client Error: Forbidden for url: https://s3.us-east-1.amazonaws.com/lfs.huggingface.co/repos/cf/0c/cf0c5ab8a3f729e5f57a8b79a36ecea64a31126f13218591c27ed9a1c7bd9b41/ece885a4bb6bbc8c1bb51b45542b805283d74590f72cd4c45d3ba76628570386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIA4N7VTDGO27GPWFUO%2F20230128%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20230128T151640Z&X-Amz-Expires=900&X-Amz-Signature=89e78e9a9d70add7ed93d453334f4f93c6f29d889d46750a1f2da04af73978db&X-Amz-SignedHeaders=host&x-amz-storage-class=INTELLIGENT_TIERING&x-id=PutObject
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 4909, in push_to_hub
repo_id, split, uploaded_size, dataset_nbytes, repo_files, deleted_size = self._push_parquet_shards_to_hub(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 4804, in _push_parquet_shards_to_hub
_retry(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 281, in _retry
return func(*func_args, **func_kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 124, in _inner_fn
return fn(*args, **kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/hf_api.py", line 2537, in upload_file
commit_info = self.create_commit(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 124, in _inner_fn
return fn(*args, **kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/hf_api.py", line 2346, in create_commit
upload_lfs_files(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 124, in _inner_fn
return fn(*args, **kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 346, in upload_lfs_files
thread_map(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/tqdm/contrib/concurrent.py", line 94, in thread_map
return _executor_map(ThreadPoolExecutor, fn, *iterables, **tqdm_kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/tqdm/contrib/concurrent.py", line 76, in _executor_map
return list(tqdm_class(ex.map(fn, *iterables, **map_args), **kwargs))
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/tqdm/std.py", line 1195, in __iter__
for obj in iterable:
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 621, in result_iterator
yield _result_or_cancel(fs.pop())
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 319, in _result_or_cancel
return fut.result(timeout)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 458, in result
return self.__get_result()
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 403, in __get_result
raise self._exception
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/thread.py", line 58, in run
result = self.fn(*self.args, **self.kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 338, in _inner_upload_lfs_object
raise RuntimeError(
RuntimeError: Error while uploading 'data/train-00000-of-00001-6df93048e66df326.parquet' to the Hub.
```
### Expected behavior
The dataset should be uploaded without any exceptions
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-4.15.0-65-generic-x86_64-with-glibc2.27
- Python version: 3.10.9
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/57996478?v=4",
"events_url": "https://api.github.com/users/yuvalkirstain/events{/privacy}",
"followers_url": "https://api.github.com/users/yuvalkirstain/followers",
"following_url": "https://api.github.com/users/yuvalkirstain/following{/other_user}",
"gists_url": "https://api.github.com/users/yuvalkirstain/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yuvalkirstain",
"id": 57996478,
"login": "yuvalkirstain",
"node_id": "MDQ6VXNlcjU3OTk2NDc4",
"organizations_url": "https://api.github.com/users/yuvalkirstain/orgs",
"received_events_url": "https://api.github.com/users/yuvalkirstain/received_events",
"repos_url": "https://api.github.com/users/yuvalkirstain/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yuvalkirstain/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yuvalkirstain/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yuvalkirstain",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5483/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5483/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6941
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6941/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6941/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6941/events
|
https://github.com/huggingface/datasets/issues/6941
| 2,328,930,165
|
I_kwDODunzps6K0Kd1
| 6,941
|
Supporting FFCV: Fast Forward Computer Vision
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/20135317?v=4",
"events_url": "https://api.github.com/users/Luciennnnnnn/events{/privacy}",
"followers_url": "https://api.github.com/users/Luciennnnnnn/followers",
"following_url": "https://api.github.com/users/Luciennnnnnn/following{/other_user}",
"gists_url": "https://api.github.com/users/Luciennnnnnn/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Luciennnnnnn",
"id": 20135317,
"login": "Luciennnnnnn",
"node_id": "MDQ6VXNlcjIwMTM1MzE3",
"organizations_url": "https://api.github.com/users/Luciennnnnnn/orgs",
"received_events_url": "https://api.github.com/users/Luciennnnnnn/received_events",
"repos_url": "https://api.github.com/users/Luciennnnnnn/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Luciennnnnnn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Luciennnnnnn/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Luciennnnnnn",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
open
| false
| null |
[] | null |
[] | 2024-06-01T05:34:52Z
| 2024-06-01T05:34:52Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
Supporting FFCV, https://github.com/libffcv/ffcv
### Motivation
According to the benchmark, FFCV seems to be fastest image loading method.
### Your contribution
no
| null |
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6941/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6941/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5630
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5630/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5630/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5630/events
|
https://github.com/huggingface/datasets/pull/5630
| 1,620,327,510
|
PR_kwDODunzps5L1ahF
| 5,630
|
adds early exit if url is `PathLike`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/44398246?v=4",
"events_url": "https://api.github.com/users/vvvm23/events{/privacy}",
"followers_url": "https://api.github.com/users/vvvm23/followers",
"following_url": "https://api.github.com/users/vvvm23/following{/other_user}",
"gists_url": "https://api.github.com/users/vvvm23/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vvvm23",
"id": 44398246,
"login": "vvvm23",
"node_id": "MDQ6VXNlcjQ0Mzk4MjQ2",
"organizations_url": "https://api.github.com/users/vvvm23/orgs",
"received_events_url": "https://api.github.com/users/vvvm23/received_events",
"repos_url": "https://api.github.com/users/vvvm23/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vvvm23/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vvvm23/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vvvm23",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5630). All of your documentation changes will be reflected on that endpoint."
] | 2023-03-12T11:23:28Z
| 2023-03-15T11:58:38Z
| null |
NONE
| null | null | null |
Closes #4864
Should fix errors thrown when attempting to load `json` dataset using `pathlib.Path` in `data_files` argument.
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5630/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5630/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5630.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5630",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5630.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5630"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5782
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5782/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5782/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5782/events
|
https://github.com/huggingface/datasets/issues/5782
| 1,679,622,367
|
I_kwDODunzps5kHQDf
| 5,782
|
Support for various audio-loading backends instead of always relying on SoundFile
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/129098876?v=4",
"events_url": "https://api.github.com/users/BoringDonut/events{/privacy}",
"followers_url": "https://api.github.com/users/BoringDonut/followers",
"following_url": "https://api.github.com/users/BoringDonut/following{/other_user}",
"gists_url": "https://api.github.com/users/BoringDonut/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/BoringDonut",
"id": 129098876,
"login": "BoringDonut",
"node_id": "U_kgDOB7HkfA",
"organizations_url": "https://api.github.com/users/BoringDonut/orgs",
"received_events_url": "https://api.github.com/users/BoringDonut/received_events",
"repos_url": "https://api.github.com/users/BoringDonut/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/BoringDonut/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BoringDonut/subscriptions",
"type": "User",
"url": "https://api.github.com/users/BoringDonut",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
| null |
[] | null |
[
"Hi! \r\n\r\nYou can use `set_transform`/`with_transform` to define a custom decoding for audio formats not supported by `soundfile`:\r\n```python\r\naudio_dataset_amr = Dataset.from_dict({\"audio\": [\"audio_samples/audio.amr\"]})\r\n\r\ndef decode_audio(batch):\r\n batch[\"audio\"] = [read_ffmpeg(audio_path) for audio_path in batch[\"audio\"]]\r\n return batch\r\n\r\naudio_dataset_amr.set_transform(decode_amr) \r\n```\r\n\r\nSupporting multiple backends is more work to maintain, but we could consider this if we get more requests such as this one.",
"Could it be put somewhere as an example tip or something?",
"Considering the number of times a custom decoding transform has been suggested as a solution, an example in the [docs](https://huggingface.co/docs/datasets/process#format-transform) would be nice.\r\n\r\ncc @stevhliu "
] | 2023-04-22T17:09:25Z
| 2023-05-10T20:23:04Z
| 2023-05-10T20:23:04Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
Introduce an option to select from a variety of audio-loading backends rather than solely relying on the SoundFile library. For instance, if the ffmpeg library is installed, it can serve as a fallback loading option.
### Motivation
- The SoundFile library, used in [features/audio.py](https://github.com/huggingface/datasets/blob/649d5a3315f9e7666713b6affe318ee00c7163a0/src/datasets/features/audio.py#L185), supports only a [limited number of audio formats](https://pysoundfile.readthedocs.io/en/latest/index.html?highlight=supported#soundfile.available_formats).
- However, current methods for creating audio datasets permit the inclusion of audio files in formats not supported by SoundFile.
- As a result, developers may potentially create a dataset they cannot read back.
In my most recent project, I dealt with phone call recordings in `.amr` or `.gsm` formats and was genuinely surprised when I couldn't read the dataset I had just packaged a minute prior. Nonetheless, I can still accurately read these files using the librosa library, which employs the audioread library that internally leverages ffmpeg to read such files.
Example:
```python
audio_dataset_amr = Dataset.from_dict({"audio": ["audio_samples/audio.amr"]}).cast_column("audio", Audio())
audio_dataset_amr.save_to_disk("audio_dataset_amr")
audio_dataset_amr = Dataset.load_from_disk("audio_dataset_amr")
print(audio_dataset_amr[0])
```
Results in:
```
Traceback (most recent call last):
...
raise LibsndfileError(err, prefix="Error opening {0!r}: ".format(self.name))
soundfile.LibsndfileError: Error opening <_io.BytesIO object at 0x7f316323e4d0>: Format not recognised.
```
While I acknowledge that support for these rare file types may not be a priority, I believe it's quite unfortunate that it's possible to create an unreadable dataset in this manner.
### Your contribution
I've created a [simple demo repository](https://github.com/BoringDonut/hf-datasets-ffmpeg-audio) that highlights the mentioned issue. It demonstrates how to create an .amr dataset that results in an error when attempting to read it just a few lines later.
Additionally, I've made a [fork with a rudimentary solution](https://github.com/BoringDonut/datasets/blob/fea73a8fbbc8876467c7e6422c9360546c6372d8/src/datasets/features/audio.py#L189) that utilizes ffmpeg to load files not supported by SoundFile.
Here you may see github actions fails to read `.amr` dataset using the version of the current dataset, but will work with the patched version:
- https://github.com/BoringDonut/hf-datasets-ffmpeg-audio/actions/runs/4773780420/jobs/8487063785
- https://github.com/BoringDonut/hf-datasets-ffmpeg-audio/actions/runs/4773780420/jobs/8487063829
As evident from the GitHub action above, this solution resolves the previously mentioned problem.
I'd be happy to create a proper pull request, provide runtime benchmarks and tests if you could offer some guidance on the following:
- Where should I incorporate the ffmpeg (or other backends) code? For example, should I create a new file or simply add a function within the Audio class?
- Is it feasible to pass the audio-loading function as an argument within the current architecture? This would be useful if I know in advance that I'll be reading files not supported by SoundFile.
A few more notes:
- In theory, it's possible to load audio using librosa/audioread since librosa is already expected to be installed. However, librosa [will soon discontinue audioread support](https://github.com/librosa/librosa/blob/aacb4c134002903ae56bbd4b4a330519a5abacc0/librosa/core/audio.py#L227). Moreover, using audioread on its own seems inconvenient because it requires a file [path as input](https://github.com/beetbox/audioread/blob/ff9535df934c48038af7be9617fdebb12078cc07/audioread/__init__.py#L108) and cannot work with bytes already loaded into memory or an open file descriptor (as mentioned in [librosa docs](https://librosa.org/doc/main/generated/librosa.load.html#librosa.load), only SoundFile backend supports an open file descriptor as an input).
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5782/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5782/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6058
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6058/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6058/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6058/events
|
https://github.com/huggingface/datasets/issues/6058
| 1,815,131,397
|
I_kwDODunzps5sMLUF
| 6,058
|
laion-coco download error
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/54424110?v=4",
"events_url": "https://api.github.com/users/yangyijune/events{/privacy}",
"followers_url": "https://api.github.com/users/yangyijune/followers",
"following_url": "https://api.github.com/users/yangyijune/following{/other_user}",
"gists_url": "https://api.github.com/users/yangyijune/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yangyijune",
"id": 54424110,
"login": "yangyijune",
"node_id": "MDQ6VXNlcjU0NDI0MTEw",
"organizations_url": "https://api.github.com/users/yangyijune/orgs",
"received_events_url": "https://api.github.com/users/yangyijune/received_events",
"repos_url": "https://api.github.com/users/yangyijune/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yangyijune/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yangyijune/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yangyijune",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"This can also mean one of the files was not downloaded correctly.\r\n\r\nWe log an erroneous file's name before raising the reader's error, so this is how you can find the problematic file. Then, you should delete it and call `load_dataset` again.\r\n\r\n(I checked all the uploaded files, and they seem to be valid Parquet files, so I don't think this is a bug on their side)\r\n"
] | 2023-07-21T04:24:15Z
| 2023-07-22T01:42:06Z
| 2023-07-22T01:42:06Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
The full trace:
```
/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/datasets/load.py:1744: FutureWarning: 'ignore_verifications' was de
precated in favor of 'verification_mode' in version 2.9.1 and will be removed in 3.0.0.
You can remove this warning by passing 'verification_mode=no_checks' instead.
warnings.warn(
Downloading and preparing dataset parquet/laion--laion-coco to /home/bian/.cache/huggingface/datasets/laion___parquet/laion--
laion-coco-cb4205d7f1863066/0.0.0/bcacc8bdaa0614a5d73d0344c813275e590940c6ea8bc569da462847103a1afd...
Downloading data: 100%|█| 1.89G/1.89G [04:57<00:00,
Downloading data files: 100%|█| 1/1 [04:59<00:00, 2
Extracting data files: 100%|█| 1/1 [00:00<00:00, 13
Generating train split: 0 examples [00:00, ? examples/s]<_io.BufferedReader
name='/home/bian/.cache/huggingface/datasets/downlo
ads/26d7a016d25bbd9443115cfa3092136e8eb2f1f5bcd4154
0cb9234572927f04c'>
Traceback (most recent call last):
File "/home/bian/data/ZOC/download_laion_coco.py", line 4, in <module>
dataset = load_dataset("laion/laion-coco", ignore_verifications=True)
File "/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/datasets/load.py", line 1791, in load_dataset
builder_instance.download_and_prepare(
File "/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/datasets/builder.py", line 891, in download_and_prepare
self._download_and_prepare(
File "/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/datasets/builder.py", line 986, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/datasets/builder.py", line 1748, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/datasets/builder.py", line 1842, in _prepare_split_single
generator = self._generate_tables(**gen_kwargs)
File "/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/datasets/packaged_modules/parquet/parquet.py", line 67, in
_generate_tables
parquet_file = pq.ParquetFile(f)
File "/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/pyarrow/parquet/core.py", line 323, in __init__
self.reader.open(
File "pyarrow/_parquet.pyx", line 1227, in pyarrow._parquet.ParquetReader.open
File "pyarrow/error.pxi", line 100, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file
.
```
I have carefully followed the instructions in #5264 but still get the same error.
Other helpful information:
```
ds = load_dataset("parquet", data_files=
...: "https://huggingface.co/datasets/laion/l
...: aion-coco/resolve/d22869de3ccd39dfec1507
...: f7ded32e4a518dad24/part-00000-2256f782-1
...: 26f-4dc6-b9c6-e6757637749d-c000.snappy.p
...: arquet")
Found cached dataset parquet (/home/bian/.cache/huggingface/datasets/parquet/default-a02eea00aeb08b0e/0.0.0/bb8ccf89d9ee38581ff5e51506d721a9b37f14df8090dc9b2d8fb4a40957833f)
100%|██████████████| 1/1 [00:00<00:00, 4.55it/s]
```
### Steps to reproduce the bug
```
from datasets import load_dataset
dataset = load_dataset("laion/laion-coco", ignore_verifications=True/False)
```
### Expected behavior
Properly load Laion-coco dataset
### Environment info
datasets==2.11.0 torch==1.12.1 python 3.10
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/54424110?v=4",
"events_url": "https://api.github.com/users/yangyijune/events{/privacy}",
"followers_url": "https://api.github.com/users/yangyijune/followers",
"following_url": "https://api.github.com/users/yangyijune/following{/other_user}",
"gists_url": "https://api.github.com/users/yangyijune/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yangyijune",
"id": 54424110,
"login": "yangyijune",
"node_id": "MDQ6VXNlcjU0NDI0MTEw",
"organizations_url": "https://api.github.com/users/yangyijune/orgs",
"received_events_url": "https://api.github.com/users/yangyijune/received_events",
"repos_url": "https://api.github.com/users/yangyijune/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yangyijune/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yangyijune/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yangyijune",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6058/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6058/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6324
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6324/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6324/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6324/events
|
https://github.com/huggingface/datasets/issues/6324
| 1,955,126,687
|
I_kwDODunzps50iN2f
| 6,324
|
Conversion to Arrow fails due to wrong type heuristic
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2862336?v=4",
"events_url": "https://api.github.com/users/jphme/events{/privacy}",
"followers_url": "https://api.github.com/users/jphme/followers",
"following_url": "https://api.github.com/users/jphme/following{/other_user}",
"gists_url": "https://api.github.com/users/jphme/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jphme",
"id": 2862336,
"login": "jphme",
"node_id": "MDQ6VXNlcjI4NjIzMzY=",
"organizations_url": "https://api.github.com/users/jphme/orgs",
"received_events_url": "https://api.github.com/users/jphme/received_events",
"repos_url": "https://api.github.com/users/jphme/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jphme/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jphme/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jphme",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Unlike Pandas, Arrow is strict with types, so converting the problematic strings to ints (or ints to strings) to ensure all the values have the same type is the only fix. \r\n\r\nJSON support has been requested in Arrow [here](https://github.com/apache/arrow/issues/32538), but I don't expect this to be implemented soon. \r\n\r\nAlso, this type could be represented with the Arrow Union type. However, due to low usage, the Union type has limited support in the Arrow ecosystem (e.g., IIRC Parquet still does not support it). So, we should probably wait a bit more before adding support for it in `datasets`",
"> Unlike Pandas, Arrow is strict with types, so converting the problematic strings to ints (or ints to strings) to ensure all the values have the same type is the only fix.\r\n> \r\n> JSON support has been requested in Arrow [here](https://github.com/apache/arrow/issues/32538), but I don't expect this to be implemented soon.\r\n> \r\n> Also, this type could be represented with the Arrow Union type. However, due to low usage, the Union type has limited support in the Arrow ecosystem (e.g., IIRC Parquet still does not support it). So, we should probably wait a bit more before adding support for it in `datasets`\r\n\r\nOk many thanks, I was able to mitigate the problem by manually checking and converting all problematic fields now."
] | 2023-10-20T23:20:58Z
| 2023-10-23T20:52:57Z
| 2023-10-23T20:52:57Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
I have a list of dictionaries with valid/JSON-serializable values.
One key is the denominator for a paragraph. In 99.9% of cases its a number, but there are some occurences of '1a', '2b' and so on.
If trying to convert this list to a dataset with `Dataset.from_list()`, I always get
`ArrowInvalid: Could not convert '1' with type str: tried to convert to int64`, presumably because pyarrow tries to convert the keys to integers.
Is there any way to circumvent this and fix dtypes? I didn't find anything in the documentation.
### Steps to reproduce the bug
* create a list of dicts with one key being a string of an integer for the first few thousand occurences and try to convert to dataset.
### Expected behavior
There shouldn't be an error (e.g. some flag to turn off automatic str to numeric conversion).
### Environment info
- `datasets` version: 2.14.5
- Platform: Linux-5.15.0-84-generic-x86_64-with-glibc2.35
- Python version: 3.9.18
- Huggingface_hub version: 0.17.3
- PyArrow version: 13.0.0
- Pandas version: 2.1.1
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/2862336?v=4",
"events_url": "https://api.github.com/users/jphme/events{/privacy}",
"followers_url": "https://api.github.com/users/jphme/followers",
"following_url": "https://api.github.com/users/jphme/following{/other_user}",
"gists_url": "https://api.github.com/users/jphme/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jphme",
"id": 2862336,
"login": "jphme",
"node_id": "MDQ6VXNlcjI4NjIzMzY=",
"organizations_url": "https://api.github.com/users/jphme/orgs",
"received_events_url": "https://api.github.com/users/jphme/received_events",
"repos_url": "https://api.github.com/users/jphme/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jphme/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jphme/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jphme",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6324/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6324/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6658
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6658/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6658/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6658/events
|
https://github.com/huggingface/datasets/pull/6658
| 2,129,158,371
|
PR_kwDODunzps5mlZyb
| 6,658
|
[Resumable IterableDataset] Add IterableDataset state_dict
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6658). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"would be nice to have this feature in the new dataset release!",
"Before finalising this this I'd like to make sure this philosophy makes sense for other libs like `accelerate` for example.\r\n\r\ncc @muellerzr I'd love your feedback on this one\r\ncc @LysandreJik also if you think other people should take a look",
"> One design question though: what's the logic behind self._state_dict rather than having it all be state_dict?\r\n\r\nThe `_state_dict` is the internal object that is updated in-place while you iterate on the dataset.\r\n\r\nWe need to copy it every time the user accesses it.\r\n\r\nOtherwise we would get\r\n```python\r\nstate_dict = ds.state_dict()\r\nfor x in ds:\r\n assert ds.state_dict() == state_dict # and actually `assert ds.state_dict() is state_dict`\r\n```\r\n\r\nThe state is updated in-place since it's made of dictionaries that are shared with the steps in the IterableDataset pipeline.",
"What do you think of making it a full property with a docstring explicitly stating users shouldn’t call/modify it directly?\r\n\r\nI can imagine some exploratory users getting curious",
"I don't think users read docstrings of properties that often. What about explaining the logic in the `.state_dict()` docstring ? This also feels aligned with the way `.state_dict()` and `.load_state_dict()` works in pytorch (you should use load_state_dict to load a modified copy of the state dict)",
"Sure, I can agree with that!",
"Just a small note mentioning returns a copy of the state dict should be enough imo",
"looking forward as well for this PR to be merge",
"> I don't think users read docstrings of properties that often. What about explaining the logic in the `.state_dict()` docstring ? This also feels aligned with the way `.state_dict()` and `.load_state_dict()` works in pytorch (you should use load_state_dict to load a modified copy of the state dict)\r\n\r\nHi, I'm experimenting with LLM pretraining using your code. I found that the time of resuming an iterable dataset can be reduced to 5% (my streaming process includes tokenization), but I'm not sure if I'm using it correctly. Could you help me check it? Thanks.\r\n\r\n```\r\nclass CustomTrainer(Trainer):\r\n def _save_rng_state(self, output_dir):\r\n super()._save_rng_state(output_dir)\r\n if self.args.should_save:\r\n with open(os.path.join(output_dir, f'iterable_data_state_dict.json'), 'w', encoding='utf-8') as fo:\r\n json.dump(self.train_dataset.state_dict(), fo, ensure_ascii=False)\r\n```\r\n\r\n```\r\n dataset = <A IterableDataset constructed by (interleave, map(tokenization))>\r\n lask_ckpt_iterable_data_state_dict_file_path = os.path.join(training_args.resume_from_checkpoint, f'iterable_data_state_dict.json')\r\n if os.path.exists(lask_ckpt_iterable_data_state_dict_file_path) and finetuning_args.load_iteratable_state_dict:\r\n if not training_args.ignore_data_skip:\r\n raise ValueError(f'Found `iterable_data_state_dict_file_path`: `{lask_ckpt_iterable_data_state_dict_file_path}`. Please set `ignore_data_skip`=True to skip tokenization.')\r\n with open(lask_ckpt_iterable_data_state_dict_file_path) as f:\r\n lask_ckpt_iterable_data_state_dict = json.load(f)\r\n dataset.load_state_dict(lask_ckpt_iterable_data_state_dict)\r\n logger.info(f'Loading `iterable_data_state_dict` from {lask_ckpt_iterable_data_state_dict_file_path}')\r\n```\r\n",
"it sounds good to me :)",
"@lhoestq Hi, if I set `prefetch`, does this dataset work well?",
"It does work well if you prefetch and then resume from a state, but you might lose the samples that were in the prefetch buffer of the DataLoader (which could be acceptable in some circumstances).\r\n\r\nFortunately we're about to ship an integration with the new StatefulDataLoader from torchdata which can help on this matter :)",
"yeah, what I meant is that prefetch might drop a few data entries. really looking forward to the new StatefulDataLoader. :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005788 / 0.011353 (-0.005564) | 0.004036 / 0.011008 (-0.006972) | 0.064720 / 0.038508 (0.026212) | 0.034990 / 0.023109 (0.011881) | 0.245488 / 0.275898 (-0.030410) | 0.272596 / 0.323480 (-0.050884) | 0.003170 / 0.007986 (-0.004815) | 0.002867 / 0.004328 (-0.001461) | 0.049961 / 0.004250 (0.045711) | 0.050951 / 0.037052 (0.013899) | 0.257757 / 0.258489 (-0.000732) | 0.292957 / 0.293841 (-0.000884) | 0.027739 / 0.128546 (-0.100807) | 0.010942 / 0.075646 (-0.064705) | 0.205153 / 0.419271 (-0.214118) | 0.037892 / 0.043533 (-0.005641) | 0.247536 / 0.255139 (-0.007603) | 0.267239 / 0.283200 (-0.015960) | 0.021490 / 0.141683 (-0.120193) | 1.107306 / 1.452155 (-0.344848) | 1.144675 / 1.492716 (-0.348041) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.103212 / 0.018006 (0.085205) | 0.315174 / 0.000490 (0.314684) | 0.000229 / 0.000200 (0.000029) | 0.000044 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019771 / 0.037411 (-0.017641) | 0.064033 / 0.014526 (0.049507) | 0.076751 / 0.176557 (-0.099805) | 0.122615 / 0.737135 (-0.614521) | 0.078490 / 0.296338 (-0.217848) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.286236 / 0.215209 (0.071027) | 2.841469 / 2.077655 (0.763814) | 1.514079 / 1.504120 (0.009959) | 1.393792 / 1.541195 (-0.147403) | 1.432741 / 1.468490 (-0.035749) | 0.571003 / 4.584777 (-4.013774) | 2.369031 / 3.745712 (-1.376681) | 2.825246 / 5.269862 (-2.444616) | 1.858524 / 4.565676 (-2.707153) | 0.065366 / 0.424275 (-0.358909) | 0.005107 / 0.007607 (-0.002500) | 0.341010 / 0.226044 (0.114965) | 3.443894 / 2.268929 (1.174966) | 1.879192 / 55.444624 (-53.565433) | 1.603046 / 6.876477 (-5.273431) | 1.807639 / 2.142072 (-0.334433) | 0.646726 / 4.805227 (-4.158502) | 0.119409 / 6.500664 (-6.381255) | 0.044564 / 0.075469 (-0.030905) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.971026 / 1.841788 (-0.870762) | 12.593884 / 8.074308 (4.519576) | 10.305243 / 10.191392 (0.113851) | 0.132018 / 0.680424 (-0.548406) | 0.014387 / 0.534201 (-0.519814) | 0.288597 / 0.579283 (-0.290686) | 0.267373 / 0.434364 (-0.166991) | 0.325626 / 0.540337 (-0.214711) | 0.488808 / 1.386936 (-0.898128) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005991 / 0.011353 (-0.005362) | 0.004028 / 0.011008 (-0.006980) | 0.051951 / 0.038508 (0.013443) | 0.036870 / 0.023109 (0.013761) | 0.263777 / 0.275898 (-0.012122) | 0.290914 / 0.323480 (-0.032566) | 0.004594 / 0.007986 (-0.003392) | 0.002971 / 0.004328 (-0.001357) | 0.049699 / 0.004250 (0.045449) | 0.044939 / 0.037052 (0.007887) | 0.275055 / 0.258489 (0.016566) | 0.316244 / 0.293841 (0.022403) | 0.030501 / 0.128546 (-0.098045) | 0.011197 / 0.075646 (-0.064449) | 0.058718 / 0.419271 (-0.360554) | 0.034926 / 0.043533 (-0.008607) | 0.259172 / 0.255139 (0.004033) | 0.280127 / 0.283200 (-0.003072) | 0.019775 / 0.141683 (-0.121908) | 1.169468 / 1.452155 (-0.282687) | 1.178098 / 1.492716 (-0.314619) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.101633 / 0.018006 (0.083626) | 0.314684 / 0.000490 (0.314194) | 0.000224 / 0.000200 (0.000024) | 0.000055 / 0.000054 (0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024071 / 0.037411 (-0.013341) | 0.079894 / 0.014526 (0.065368) | 0.090915 / 0.176557 (-0.085642) | 0.132397 / 0.737135 (-0.604738) | 0.091919 / 0.296338 (-0.204419) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.296237 / 0.215209 (0.081028) | 2.891752 / 2.077655 (0.814097) | 1.551937 / 1.504120 (0.047817) | 1.414179 / 1.541195 (-0.127016) | 1.450192 / 1.468490 (-0.018298) | 0.556272 / 4.584777 (-4.028504) | 0.952374 / 3.745712 (-2.793339) | 2.709450 / 5.269862 (-2.560411) | 1.771251 / 4.565676 (-2.794426) | 0.061873 / 0.424275 (-0.362402) | 0.005058 / 0.007607 (-0.002549) | 0.344790 / 0.226044 (0.118746) | 3.398982 / 2.268929 (1.130053) | 1.905832 / 55.444624 (-53.538792) | 1.632357 / 6.876477 (-5.244120) | 1.822913 / 2.142072 (-0.319160) | 0.643426 / 4.805227 (-4.161802) | 0.117321 / 6.500664 (-6.383343) | 0.042107 / 0.075469 (-0.033363) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.974921 / 1.841788 (-0.866867) | 12.497801 / 8.074308 (4.423493) | 11.216174 / 10.191392 (1.024782) | 0.135288 / 0.680424 (-0.545136) | 0.016731 / 0.534201 (-0.517470) | 0.287987 / 0.579283 (-0.291296) | 0.130246 / 0.434364 (-0.304117) | 0.323282 / 0.540337 (-0.217055) | 0.414595 / 1.386936 (-0.972341) |\n\n</details>\n</details>\n\n\n",
"@lhoestq Hello, I'm wondering if there are any solutions to work with shuffle now. I've noticed the caveats in docs, \r\n> examples from shuffle buffers are lost when resuming and the buffers are refilled with new data ",
"Hi ! I haven't experimented with implementing state_dict for the shuffle buffer. Not sure if this is a good idea to add this, given a shuffle buffer can be quite big and poses serialization challenges.\r\n\r\nIt shouldn't be difficult to experiment with a simple implementation in `BufferShuffledExamplesIterable` though",
"@lhoestq thank you for your quick response! I'll try it :}",
"@lhoestq Hi, just revise the `BufferShuffledExamplesIterable` and it works\r\n```py\r\n\r\nclass BufferShuffledExamplesIterable(datasets.iterable_dataset.BufferShuffledExamplesIterable):\r\n\r\n def __init__(self, *args, **kwargs):\r\n super().__init__(*args, **kwargs)\r\n\r\n def _init_state_dict(self) -> dict:\r\n self._state_dict = self.ex_iterable._init_state_dict()\r\n self._state_dict['mem_buffer'] = ([],)\r\n self._state_dict['gloabl_example_index'] = 0\r\n return self._state_dict\r\n\r\n def __iter__(self):\r\n buffer_size = self.buffer_size\r\n rng = deepcopy(self.generator)\r\n indices_iterator = self._iter_random_indices(rng, buffer_size)\r\n # this is the shuffle buffer that we keep in memory\r\n mem_buffer = self._state_dict['mem_buffer'][0]\r\n gloabl_example_index_start = self._state_dict[\"gloabl_example_index\"] if self._state_dict else 0\r\n # skip already consumed ones\r\n for i in range(gloabl_example_index_start):\r\n _ = next(indices_iterator)\r\n for x in self.ex_iterable:\r\n if len(mem_buffer) == buffer_size: # if the buffer is full, pick and example from it\r\n i = next(indices_iterator)\r\n if self._state_dict:\r\n self._state_dict['gloabl_example_index'] += 1\r\n yield mem_buffer[i]\r\n mem_buffer[i] = x # replace the picked example by a new one\r\n else: # otherwise, keep filling the buffer\r\n mem_buffer.append(x)\r\n # when we run out of examples, we shuffle the remaining examples in the buffer and yield them\r\n rng.shuffle(mem_buffer)\r\n yield from mem_buffer\r\n\r\n def shuffle_data_sources(self, generator: np.random.Generator) -> BufferShuffledExamplesIterable:\r\n \"\"\"Shuffle the wrapped examples iterable as well as the shuffling buffer.\"\"\"\r\n return BufferShuffledExamplesIterable(\r\n self.ex_iterable.shuffle_data_sources(generator), buffer_size=self.buffer_size, generator=generator\r\n )\r\n\r\n def shard_data_sources(self, worker_id: int, num_workers: int) -> BufferShuffledExamplesIterable:\r\n \"\"\"Keep only the requested shard.\"\"\"\r\n return BufferShuffledExamplesIterable(\r\n self.ex_iterable.shard_data_sources(worker_id, num_workers),\r\n buffer_size=self.buffer_size,\r\n generator=self.generator,\r\n )\r\n\r\n def load_state_dict(self, state_dict: dict) -> dict:\r\n def _inner_load_state_dict(state, new_state):\r\n if new_state is not None and isinstance(state, dict):\r\n for key in state:\r\n state[key] = _inner_load_state_dict(state[key], new_state[key])\r\n return state\r\n elif new_state is not None and isinstance(state, list):\r\n for i in range(len(state)):\r\n state[i] = _inner_load_state_dict(state[i], new_state[i])\r\n return state\r\n return new_state\r\n\r\n return _inner_load_state_dict(self._state_dict, state_dict)\r\n```\r\n\r\nI've noticed that it uses significantly more RAM than the original version and experiences a considerable decrease in GPU utilization. Could you offer some suggestions to address this issue?\r\n\r\nor **is it prohibited** to maintain sth except for simple indices that small enough for each worker 😢 \r\n\r\n",
"Some ExamplesIterable copy and store old versions of the state_dict of parent ExamplesIterable. It is the case for example for batched `map()` (state_dict of beginning of the batch) or `interleave_dataset()` (state_dict of the previous step since it buffers one example to know if the iterable is exhausted).\r\n\r\nCopying a shuffle buffer takes some RAM and some time, which can slow down the data loading pipeline.\r\nMaybe the examples in the shuffle buffer shouldn't not be copied (only do a shallow copy of the list), this would surely help."
] | 2024-02-11T20:35:52Z
| 2024-10-01T10:19:38Z
| 2024-06-03T19:15:39Z
|
MEMBER
| null | null | null |
A simple implementation of a mechanism to resume an IterableDataset.
It works by restarting at the latest shard and skip samples. It provides fast resuming (though not instantaneous).
Example:
```python
from datasets import Dataset, concatenate_datasets
ds = Dataset.from_dict({"a": range(5)}).to_iterable_dataset(num_shards=3)
ds = concatenate_datasets([ds] * 2)
print(f"{ds.state_dict()=}")
for i, example in enumerate(ds):
print(example)
if i == 6:
state_dict = ds.state_dict()
print("checkpoint")
ds.load_state_dict(state_dict)
print(f"resuming from checkpoint {ds.state_dict()=}")
for example in ds:
print(example)
```
returns
```
ds.state_dict()={'ex_iterable_idx': 0, 'ex_iterables': [{'shard_idx': 0, 'shard_example_idx': 0}, {'shard_idx': 0, 'shard_example_idx': 0}]}
{'a': 0}
{'a': 1}
{'a': 2}
{'a': 3}
{'a': 4}
{'a': 0}
{'a': 1}
checkpoint
{'a': 2}
{'a': 3}
{'a': 4}
resuming from checkpoint ds.state_dict()={'ex_iterable_idx': 1, 'ex_iterables': [{'shard_idx': 3, 'shard_example_idx': 0}, {'shard_idx': 0, 'shard_example_idx': 2}]}
{'a': 2}
{'a': 3}
{'a': 4}
```
using torchdata:
```python
from datasets import load_dataset
from torchdata.stateful_dataloader import StatefulDataLoader
my_iterable_dataset = load_dataset("deepmind/code_contests", streaming=True, split="train")
dataloader = StatefulDataLoader(my_iterable_dataset, batch_size=32, num_workers=4)
# save in the middle of training
state_dict = dataloader.state_dict()
# and resume later
dataloader.load_state_dict(state_dict)
```
docs: https://huggingface.co/docs/datasets/main/en/use_with_pytorch#checkpoint-and-resume
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6658/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6658/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6658.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6658",
"merged_at": "2024-06-03T19:15:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6658.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6658"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6282
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6282/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6282/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6282/events
|
https://github.com/huggingface/datasets/pull/6282
| 1,928,473,630
|
PR_kwDODunzps5cBT5p
| 6,282
|
Drop data_files duplicates
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006934 / 0.011353 (-0.004419) | 0.004097 / 0.011008 (-0.006911) | 0.084662 / 0.038508 (0.046154) | 0.077106 / 0.023109 (0.053996) | 0.355035 / 0.275898 (0.079137) | 0.381466 / 0.323480 (0.057986) | 0.004182 / 0.007986 (-0.003803) | 0.003411 / 0.004328 (-0.000917) | 0.065279 / 0.004250 (0.061029) | 0.058192 / 0.037052 (0.021140) | 0.372363 / 0.258489 (0.113874) | 0.401621 / 0.293841 (0.107780) | 0.031719 / 0.128546 (-0.096827) | 0.008753 / 0.075646 (-0.066893) | 0.287125 / 0.419271 (-0.132146) | 0.052943 / 0.043533 (0.009410) | 0.349680 / 0.255139 (0.094541) | 0.364004 / 0.283200 (0.080805) | 0.026705 / 0.141683 (-0.114977) | 1.472708 / 1.452155 (0.020553) | 1.556559 / 1.492716 (0.063842) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224868 / 0.018006 (0.206862) | 0.458793 / 0.000490 (0.458304) | 0.009434 / 0.000200 (0.009234) | 0.000356 / 0.000054 (0.000301) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029670 / 0.037411 (-0.007741) | 0.086517 / 0.014526 (0.071991) | 0.097342 / 0.176557 (-0.079215) | 0.153722 / 0.737135 (-0.583413) | 0.098465 / 0.296338 (-0.197874) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.400739 / 0.215209 (0.185530) | 3.998087 / 2.077655 (1.920432) | 2.025772 / 1.504120 (0.521652) | 1.858679 / 1.541195 (0.317485) | 1.951573 / 1.468490 (0.483083) | 0.483028 / 4.584777 (-4.101749) | 3.554085 / 3.745712 (-0.191627) | 3.306983 / 5.269862 (-1.962879) | 2.087043 / 4.565676 (-2.478633) | 0.057127 / 0.424275 (-0.367148) | 0.007252 / 0.007607 (-0.000355) | 0.480180 / 0.226044 (0.254136) | 4.787183 / 2.268929 (2.518255) | 2.489667 / 55.444624 (-52.954957) | 2.150774 / 6.876477 (-4.725703) | 2.403197 / 2.142072 (0.261124) | 0.581843 / 4.805227 (-4.223384) | 0.134915 / 6.500664 (-6.365749) | 0.061283 / 0.075469 (-0.014186) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.285700 / 1.841788 (-0.556088) | 19.474093 / 8.074308 (11.399785) | 14.336349 / 10.191392 (4.144957) | 0.170932 / 0.680424 (-0.509492) | 0.018348 / 0.534201 (-0.515853) | 0.391909 / 0.579283 (-0.187374) | 0.414706 / 0.434364 (-0.019658) | 0.458156 / 0.540337 (-0.082182) | 0.656303 / 1.386936 (-0.730633) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006738 / 0.011353 (-0.004615) | 0.004029 / 0.011008 (-0.006979) | 0.064411 / 0.038508 (0.025903) | 0.078225 / 0.023109 (0.055116) | 0.408468 / 0.275898 (0.132569) | 0.445585 / 0.323480 (0.122105) | 0.005490 / 0.007986 (-0.002495) | 0.003419 / 0.004328 (-0.000910) | 0.063966 / 0.004250 (0.059715) | 0.056779 / 0.037052 (0.019727) | 0.415258 / 0.258489 (0.156769) | 0.461258 / 0.293841 (0.167418) | 0.032051 / 0.128546 (-0.096495) | 0.008471 / 0.075646 (-0.067176) | 0.071004 / 0.419271 (-0.348267) | 0.049068 / 0.043533 (0.005536) | 0.409575 / 0.255139 (0.154436) | 0.430748 / 0.283200 (0.147548) | 0.023784 / 0.141683 (-0.117899) | 1.507894 / 1.452155 (0.055739) | 1.586575 / 1.492716 (0.093859) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.228574 / 0.018006 (0.210568) | 0.451389 / 0.000490 (0.450900) | 0.006312 / 0.000200 (0.006112) | 0.000100 / 0.000054 (0.000045) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033391 / 0.037411 (-0.004020) | 0.096816 / 0.014526 (0.082290) | 0.107269 / 0.176557 (-0.069288) | 0.159749 / 0.737135 (-0.577387) | 0.108240 / 0.296338 (-0.188098) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.437643 / 0.215209 (0.222434) | 4.378173 / 2.077655 (2.300518) | 2.367218 / 1.504120 (0.863098) | 2.229493 / 1.541195 (0.688298) | 2.329849 / 1.468490 (0.861359) | 0.494985 / 4.584777 (-4.089792) | 3.578540 / 3.745712 (-0.167172) | 3.338220 / 5.269862 (-1.931642) | 2.092482 / 4.565676 (-2.473194) | 0.058495 / 0.424275 (-0.365780) | 0.007396 / 0.007607 (-0.000211) | 0.511001 / 0.226044 (0.284957) | 5.113497 / 2.268929 (2.844568) | 2.806215 / 55.444624 (-52.638409) | 2.485428 / 6.876477 (-4.391048) | 2.764907 / 2.142072 (0.622835) | 0.598824 / 4.805227 (-4.206404) | 0.134988 / 6.500664 (-6.365676) | 0.061752 / 0.075469 (-0.013717) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.365583 / 1.841788 (-0.476205) | 20.270297 / 8.074308 (12.195989) | 15.331673 / 10.191392 (5.140281) | 0.166152 / 0.680424 (-0.514272) | 0.020678 / 0.534201 (-0.513523) | 0.394821 / 0.579283 (-0.184462) | 0.420493 / 0.434364 (-0.013871) | 0.468551 / 0.540337 (-0.071787) | 0.654903 / 1.386936 (-0.732033) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007803 / 0.011353 (-0.003550) | 0.004664 / 0.011008 (-0.006344) | 0.099908 / 0.038508 (0.061400) | 0.090674 / 0.023109 (0.067565) | 0.406009 / 0.275898 (0.130111) | 0.465098 / 0.323480 (0.141618) | 0.004667 / 0.007986 (-0.003319) | 0.003880 / 0.004328 (-0.000449) | 0.076552 / 0.004250 (0.072301) | 0.066345 / 0.037052 (0.029292) | 0.419195 / 0.258489 (0.160706) | 0.478581 / 0.293841 (0.184741) | 0.036967 / 0.128546 (-0.091579) | 0.010000 / 0.075646 (-0.065647) | 0.347126 / 0.419271 (-0.072145) | 0.062265 / 0.043533 (0.018733) | 0.406653 / 0.255139 (0.151514) | 0.439044 / 0.283200 (0.155845) | 0.031289 / 0.141683 (-0.110394) | 1.797674 / 1.452155 (0.345520) | 1.835183 / 1.492716 (0.342467) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.268194 / 0.018006 (0.250187) | 0.493614 / 0.000490 (0.493124) | 0.015636 / 0.000200 (0.015436) | 0.000417 / 0.000054 (0.000362) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034188 / 0.037411 (-0.003223) | 0.099127 / 0.014526 (0.084601) | 0.113949 / 0.176557 (-0.062607) | 0.181209 / 0.737135 (-0.555926) | 0.114943 / 0.296338 (-0.181395) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.455767 / 0.215209 (0.240558) | 4.542947 / 2.077655 (2.465293) | 2.214605 / 1.504120 (0.710485) | 2.015163 / 1.541195 (0.473969) | 2.084945 / 1.468490 (0.616455) | 0.583827 / 4.584777 (-4.000950) | 4.187009 / 3.745712 (0.441297) | 3.920841 / 5.269862 (-1.349020) | 2.447260 / 4.565676 (-2.118417) | 0.069139 / 0.424275 (-0.355137) | 0.008734 / 0.007607 (0.001127) | 0.544673 / 0.226044 (0.318629) | 5.445094 / 2.268929 (3.176165) | 2.788284 / 55.444624 (-52.656340) | 2.395863 / 6.876477 (-4.480614) | 2.622632 / 2.142072 (0.480560) | 0.703931 / 4.805227 (-4.101297) | 0.160502 / 6.500664 (-6.340162) | 0.073734 / 0.075469 (-0.001735) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.498992 / 1.841788 (-0.342795) | 22.761476 / 8.074308 (14.687168) | 17.123919 / 10.191392 (6.932527) | 0.170272 / 0.680424 (-0.510151) | 0.021307 / 0.534201 (-0.512894) | 0.467548 / 0.579283 (-0.111735) | 0.480777 / 0.434364 (0.046413) | 0.542168 / 0.540337 (0.001830) | 0.771092 / 1.386936 (-0.615844) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007923 / 0.011353 (-0.003430) | 0.004664 / 0.011008 (-0.006344) | 0.077795 / 0.038508 (0.039286) | 0.090293 / 0.023109 (0.067184) | 0.494682 / 0.275898 (0.218784) | 0.539973 / 0.323480 (0.216494) | 0.006302 / 0.007986 (-0.001684) | 0.003794 / 0.004328 (-0.000535) | 0.076567 / 0.004250 (0.072317) | 0.067141 / 0.037052 (0.030089) | 0.501279 / 0.258489 (0.242790) | 0.555670 / 0.293841 (0.261829) | 0.037773 / 0.128546 (-0.090773) | 0.009930 / 0.075646 (-0.065716) | 0.084839 / 0.419271 (-0.334433) | 0.056876 / 0.043533 (0.013344) | 0.499329 / 0.255139 (0.244190) | 0.518449 / 0.283200 (0.235249) | 0.026041 / 0.141683 (-0.115642) | 1.787259 / 1.452155 (0.335105) | 1.853505 / 1.492716 (0.360788) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.238413 / 0.018006 (0.220407) | 0.488889 / 0.000490 (0.488399) | 0.007476 / 0.000200 (0.007277) | 0.000141 / 0.000054 (0.000087) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.038701 / 0.037411 (0.001290) | 0.115391 / 0.014526 (0.100865) | 0.125553 / 0.176557 (-0.051004) | 0.190267 / 0.737135 (-0.546868) | 0.126401 / 0.296338 (-0.169937) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.509270 / 0.215209 (0.294061) | 5.087631 / 2.077655 (3.009976) | 2.745863 / 1.504120 (1.241743) | 2.560259 / 1.541195 (1.019064) | 2.653124 / 1.468490 (1.184634) | 0.582118 / 4.584777 (-4.002659) | 4.181144 / 3.745712 (0.435431) | 3.871179 / 5.269862 (-1.398683) | 2.459849 / 4.565676 (-2.105827) | 0.068844 / 0.424275 (-0.355431) | 0.008672 / 0.007607 (0.001065) | 0.604898 / 0.226044 (0.378854) | 6.073263 / 2.268929 (3.804334) | 3.366638 / 55.444624 (-52.077986) | 2.937261 / 6.876477 (-3.939215) | 3.181173 / 2.142072 (1.039100) | 0.700478 / 4.805227 (-4.104750) | 0.158361 / 6.500664 (-6.342303) | 0.072860 / 0.075469 (-0.002609) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.621363 / 1.841788 (-0.220425) | 23.614315 / 8.074308 (15.540007) | 17.607213 / 10.191392 (7.415821) | 0.198031 / 0.680424 (-0.482393) | 0.023859 / 0.534201 (-0.510342) | 0.474674 / 0.579283 (-0.104609) | 0.491173 / 0.434364 (0.056809) | 0.581995 / 0.540337 (0.041658) | 0.792168 / 1.386936 (-0.594768) |\n\n</details>\n</details>\n\n\n",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6282). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004779 / 0.011353 (-0.006574) | 0.002916 / 0.011008 (-0.008092) | 0.061962 / 0.038508 (0.023454) | 0.029537 / 0.023109 (0.006428) | 0.242574 / 0.275898 (-0.033324) | 0.268585 / 0.323480 (-0.054894) | 0.004006 / 0.007986 (-0.003979) | 0.002434 / 0.004328 (-0.001895) | 0.048289 / 0.004250 (0.044039) | 0.045534 / 0.037052 (0.008481) | 0.248251 / 0.258489 (-0.010239) | 0.277037 / 0.293841 (-0.016804) | 0.023728 / 0.128546 (-0.104818) | 0.007295 / 0.075646 (-0.068351) | 0.205813 / 0.419271 (-0.213459) | 0.059093 / 0.043533 (0.015560) | 0.244336 / 0.255139 (-0.010803) | 0.262865 / 0.283200 (-0.020335) | 0.017232 / 0.141683 (-0.124451) | 1.126729 / 1.452155 (-0.325426) | 1.198987 / 1.492716 (-0.293729) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091246 / 0.018006 (0.073240) | 0.300747 / 0.000490 (0.300258) | 0.000202 / 0.000200 (0.000003) | 0.000041 / 0.000054 (-0.000013) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018681 / 0.037411 (-0.018731) | 0.063567 / 0.014526 (0.049041) | 0.074019 / 0.176557 (-0.102538) | 0.120856 / 0.737135 (-0.616279) | 0.076525 / 0.296338 (-0.219814) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282230 / 0.215209 (0.067021) | 2.731502 / 2.077655 (0.653847) | 1.473901 / 1.504120 (-0.030219) | 1.351165 / 1.541195 (-0.190030) | 1.390582 / 1.468490 (-0.077908) | 0.398443 / 4.584777 (-4.186334) | 2.360497 / 3.745712 (-1.385215) | 2.548158 / 5.269862 (-2.721703) | 1.552416 / 4.565676 (-3.013260) | 0.045659 / 0.424275 (-0.378616) | 0.004778 / 0.007607 (-0.002829) | 0.330191 / 0.226044 (0.104146) | 3.262510 / 2.268929 (0.993582) | 1.823076 / 55.444624 (-53.621549) | 1.541206 / 6.876477 (-5.335271) | 1.589069 / 2.142072 (-0.553004) | 0.472265 / 4.805227 (-4.332963) | 0.099712 / 6.500664 (-6.400952) | 0.042803 / 0.075469 (-0.032666) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.963022 / 1.841788 (-0.878766) | 11.998807 / 8.074308 (3.924499) | 10.526006 / 10.191392 (0.334614) | 0.140965 / 0.680424 (-0.539459) | 0.014197 / 0.534201 (-0.520004) | 0.271668 / 0.579283 (-0.307615) | 0.263993 / 0.434364 (-0.170371) | 0.307213 / 0.540337 (-0.233124) | 0.427411 / 1.386936 (-0.959525) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004761 / 0.011353 (-0.006592) | 0.002652 / 0.011008 (-0.008357) | 0.047949 / 0.038508 (0.009441) | 0.049714 / 0.023109 (0.026604) | 0.274021 / 0.275898 (-0.001877) | 0.292413 / 0.323480 (-0.031067) | 0.003912 / 0.007986 (-0.004074) | 0.002290 / 0.004328 (-0.002038) | 0.047320 / 0.004250 (0.043069) | 0.038061 / 0.037052 (0.001009) | 0.279318 / 0.258489 (0.020829) | 0.305167 / 0.293841 (0.011326) | 0.024595 / 0.128546 (-0.103952) | 0.006976 / 0.075646 (-0.068671) | 0.052987 / 0.419271 (-0.366285) | 0.032454 / 0.043533 (-0.011079) | 0.273986 / 0.255139 (0.018847) | 0.297641 / 0.283200 (0.014442) | 0.017680 / 0.141683 (-0.124003) | 1.141218 / 1.452155 (-0.310937) | 1.222543 / 1.492716 (-0.270173) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092880 / 0.018006 (0.074873) | 0.305080 / 0.000490 (0.304590) | 0.000215 / 0.000200 (0.000016) | 0.000051 / 0.000054 (-0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021050 / 0.037411 (-0.016362) | 0.069676 / 0.014526 (0.055150) | 0.081082 / 0.176557 (-0.095475) | 0.119234 / 0.737135 (-0.617902) | 0.081242 / 0.296338 (-0.215096) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.295916 / 0.215209 (0.080707) | 2.909769 / 2.077655 (0.832115) | 1.623118 / 1.504120 (0.118998) | 1.502297 / 1.541195 (-0.038898) | 1.540290 / 1.468490 (0.071800) | 0.401176 / 4.584777 (-4.183601) | 2.427764 / 3.745712 (-1.317948) | 2.568610 / 5.269862 (-2.701252) | 1.550486 / 4.565676 (-3.015190) | 0.046895 / 0.424275 (-0.377380) | 0.004800 / 0.007607 (-0.002807) | 0.344524 / 0.226044 (0.118479) | 3.429189 / 2.268929 (1.160261) | 1.949738 / 55.444624 (-53.494887) | 1.681440 / 6.876477 (-5.195037) | 1.675304 / 2.142072 (-0.466769) | 0.469663 / 4.805227 (-4.335564) | 0.097470 / 6.500664 (-6.403194) | 0.040121 / 0.075469 (-0.035348) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.957947 / 1.841788 (-0.883841) | 11.968455 / 8.074308 (3.894147) | 10.809763 / 10.191392 (0.618371) | 0.140603 / 0.680424 (-0.539820) | 0.015562 / 0.534201 (-0.518638) | 0.276406 / 0.579283 (-0.302877) | 0.295267 / 0.434364 (-0.139097) | 0.315744 / 0.540337 (-0.224593) | 0.417985 / 1.386936 (-0.968951) |\n\n</details>\n</details>\n\n\n",
"I've opened #6704 with a cleaner fix for the issue :)"
] | 2023-10-05T14:43:08Z
| 2024-09-02T14:08:35Z
| 2024-09-02T14:08:35Z
|
MEMBER
| null | null | null |
I just added drop_duplicates=True to `.from_patterns`. I used a dict to deduplicate and preserve the order
close https://github.com/huggingface/datasets/issues/6259
close https://github.com/huggingface/datasets/issues/6272
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6282/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6282/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6282.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6282",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6282.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6282"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5412
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5412/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5412/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5412/events
|
https://github.com/huggingface/datasets/issues/5412
| 1,524,250,269
|
I_kwDODunzps5a2jad
| 5,412
|
load_dataset() cannot find dataset_info.json with multiple training runs in parallel
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7139344?v=4",
"events_url": "https://api.github.com/users/mtoles/events{/privacy}",
"followers_url": "https://api.github.com/users/mtoles/followers",
"following_url": "https://api.github.com/users/mtoles/following{/other_user}",
"gists_url": "https://api.github.com/users/mtoles/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mtoles",
"id": 7139344,
"login": "mtoles",
"node_id": "MDQ6VXNlcjcxMzkzNDQ=",
"organizations_url": "https://api.github.com/users/mtoles/orgs",
"received_events_url": "https://api.github.com/users/mtoles/received_events",
"repos_url": "https://api.github.com/users/mtoles/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mtoles/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mtoles/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mtoles",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi ! It fails because the dataset is already being prepared by your first run. I'd encourage you to prepare your dataset before using it for multiple trainings.\r\n\r\nYou can also specify another cache directory by passing `cache_dir=` to `load_dataset()`.",
"Thank you! What do you mean by prepare it beforehand? I am unclear how to conduct dataset preparation outside of using the `load_dataset` function.",
"You can have a separate script that does load_dataset + map + save_to_disk to save your prepared dataset somewhere. Then in your training script you can reload the dataset with load_from_disk",
"Thank you! I believe I was running additional map steps after loading, resulting in the cache conflict. "
] | 2023-01-08T00:44:32Z
| 2023-01-19T20:28:43Z
| 2023-01-19T20:28:43Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
I have a custom local dataset in JSON form. I am trying to do multiple training runs in parallel. The first training run runs with no issue. However, when I start another run on another GPU, the following code throws this error.
If there is a workaround to ignore the cache I think that would solve my problem too.
I am using datasets version 2.8.0.
### Steps to reproduce the bug
1. Start training run of GPU 0 loading dataset from
```
load_dataset(
"json",
data_files=tr_dataset_path,
split=f"train",
download_mode="force_redownload",
)
```
2. While GPU 0 is training, start an identical run on GPU 1. GPU 1 will produce the following error:
```
Traceback (most recent call last):
File "/local-scratch1/data/mt/code/qq/train.py", line 198, in <module>
main()
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 1055, in main
rv = self.invoke(ctx)
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "/local-scratch1/data/mt/code/qq/train.py", line 113, in main
load_dataset(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/load.py", line 1734, in load_dataset
builder_instance = load_dataset_builder(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/load.py", line 1518, in load_dataset_builder
builder_instance: DatasetBuilder = builder_cls(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/builder.py", line 366, in __init__
self.info = DatasetInfo.from_directory(self._cache_dir)
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/info.py", line 313, in from_directory
with fs.open(path_join(dataset_info_dir, config.DATASET_INFO_FILENAME), "r", encoding="utf-8") as f:
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/spec.py", line 1094, in open
self.open(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/spec.py", line 1106, in open
f = self._open(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/implementations/local.py", line 175, in _open
return LocalFileOpener(path, mode, fs=self, **kwargs)
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/implementations/local.py", line 273, in __init__
self._open()
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/implementations/local.py", line 278, in _open
self.f = open(self.path, mode=self.mode)
FileNotFoundError: [Errno 2] No such file or directory: '/home/username/.cache/huggingface/datasets/json/default-43d06a4aedb25e6d/0.0.0/0f7e3662623656454fcd2b650f34e886a7db4b9104504885bd462096cc7a9f51/dataset_info.json'
```
### Expected behavior
Expected behavior: 2nd GPU training run should run the same as 1st GPU training run.
### Environment info
Copy-and-paste the text below in your GitHub issue.
- `datasets` version: 2.8.0
- Platform: Linux-5.4.0-120-generic-x86_64-with-glibc2.10
- Python version: 3.8.15
- PyArrow version: 9.0.0
- Pandas version: 1.5.2
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/7139344?v=4",
"events_url": "https://api.github.com/users/mtoles/events{/privacy}",
"followers_url": "https://api.github.com/users/mtoles/followers",
"following_url": "https://api.github.com/users/mtoles/following{/other_user}",
"gists_url": "https://api.github.com/users/mtoles/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mtoles",
"id": 7139344,
"login": "mtoles",
"node_id": "MDQ6VXNlcjcxMzkzNDQ=",
"organizations_url": "https://api.github.com/users/mtoles/orgs",
"received_events_url": "https://api.github.com/users/mtoles/received_events",
"repos_url": "https://api.github.com/users/mtoles/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mtoles/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mtoles/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mtoles",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5412/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5412/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6844
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6844/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6844/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6844/events
|
https://github.com/huggingface/datasets/pull/6844
| 2,265,870,546
|
PR_kwDODunzps5t2PRA
| 6,844
|
Retry on HF Hub error when streaming
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6844). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"@Wauplin This PR is indeed not needed as explained in https://github.com/huggingface/datasets/issues/6843#issuecomment-2079630389. \r\n\r\nSo, I'm closing it."
] | 2024-04-26T14:09:04Z
| 2024-04-26T15:37:42Z
| 2024-04-26T15:37:42Z
|
COLLABORATOR
| null | null | null |
Retry on the `huggingface_hub`'s `HfHubHTTPError` in the streaming mode.
Fix #6843
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6844/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6844/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6844.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6844",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6844.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6844"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6054
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6054/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6054/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6054/events
|
https://github.com/huggingface/datasets/issues/6054
| 1,813,271,304
|
I_kwDODunzps5sFFMI
| 6,054
|
Multi-processed `Dataset.map` slows down a lot when `import torch`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47121592?v=4",
"events_url": "https://api.github.com/users/ShinoharaHare/events{/privacy}",
"followers_url": "https://api.github.com/users/ShinoharaHare/followers",
"following_url": "https://api.github.com/users/ShinoharaHare/following{/other_user}",
"gists_url": "https://api.github.com/users/ShinoharaHare/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ShinoharaHare",
"id": 47121592,
"login": "ShinoharaHare",
"node_id": "MDQ6VXNlcjQ3MTIxNTky",
"organizations_url": "https://api.github.com/users/ShinoharaHare/orgs",
"received_events_url": "https://api.github.com/users/ShinoharaHare/received_events",
"repos_url": "https://api.github.com/users/ShinoharaHare/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ShinoharaHare/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ShinoharaHare/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ShinoharaHare",
"user_view_type": "public"
}
|
[
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
}
] |
closed
| false
| null |
[] | null |
[
"A duplicate of https://github.com/huggingface/datasets/issues/5929"
] | 2023-07-20T06:36:14Z
| 2023-07-21T15:19:37Z
| 2023-07-21T15:19:37Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
When using `Dataset.map` with `num_proc > 1`, the speed slows down much if I add `import torch` to the start of the script even though I don't use it.
I'm not sure if it's `torch` only or if any other package that is "large" will also cause the same result.
BTW, `import lightning` also slows it down.
Below are the progress bars of `Dataset.map`, the only difference between them is with or without `import torch`, but the speed varies by 6-7 times.
- without `import torch` 
- with `import torch` 
### Steps to reproduce the bug
Below is the code I used, but I don't think the dataset and the mapping function have much to do with the phenomenon.
```python3
from datasets import load_from_disk, disable_caching
from transformers import AutoTokenizer
# import torch
# import lightning
def rearrange_datapoints(
batch,
tokenizer,
sequence_length,
):
datapoints = []
input_ids = []
for x in batch['input_ids']:
input_ids += x
while len(input_ids) >= sequence_length:
datapoint = input_ids[:sequence_length]
datapoints.append(datapoint)
input_ids[:sequence_length] = []
if input_ids:
paddings = [-1] * (sequence_length - len(input_ids))
datapoint = paddings + input_ids if tokenizer.padding_side == 'left' else input_ids + paddings
datapoints.append(datapoint)
batch['input_ids'] = datapoints
return batch
if __name__ == '__main__':
disable_caching()
tokenizer = AutoTokenizer.from_pretrained('...', use_fast=False)
dataset = load_from_disk('...')
dataset = dataset.map(
rearrange_datapoints,
fn_kwargs=dict(
tokenizer=tokenizer,
sequence_length=2048,
),
batched=True,
num_proc=8,
)
```
### Expected behavior
The multi-processed `Dataset.map` function speed between with and without `import torch` should be the same.
### Environment info
- `datasets` version: 2.13.1
- Platform: Linux-3.10.0-1127.el7.x86_64-x86_64-with-glibc2.31
- Python version: 3.10.11
- Huggingface_hub version: 0.14.1
- PyArrow version: 12.0.0
- Pandas version: 2.0.1
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47121592?v=4",
"events_url": "https://api.github.com/users/ShinoharaHare/events{/privacy}",
"followers_url": "https://api.github.com/users/ShinoharaHare/followers",
"following_url": "https://api.github.com/users/ShinoharaHare/following{/other_user}",
"gists_url": "https://api.github.com/users/ShinoharaHare/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ShinoharaHare",
"id": 47121592,
"login": "ShinoharaHare",
"node_id": "MDQ6VXNlcjQ3MTIxNTky",
"organizations_url": "https://api.github.com/users/ShinoharaHare/orgs",
"received_events_url": "https://api.github.com/users/ShinoharaHare/received_events",
"repos_url": "https://api.github.com/users/ShinoharaHare/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ShinoharaHare/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ShinoharaHare/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ShinoharaHare",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6054/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6054/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/4558
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4558/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4558/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4558/events
|
https://github.com/huggingface/datasets/pull/4558
| 1,283,479,650
|
PR_kwDODunzps46THl_
| 4,558
|
Add evaluation metadata to wmt14
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun",
"user_view_type": "public"
}
|
[
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4558). All of your documentation changes will be reflected on that endpoint.",
"As discussed with @lewtun, we are closing this PR, because it requires first the task names to be aligned between AutoTrain and datasets."
] | 2022-06-24T09:08:54Z
| 2023-09-24T09:35:39Z
| 2022-09-23T09:36:50Z
|
MEMBER
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4558/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4558/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4558.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4558",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4558.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4558"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5150
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5150/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5150/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5150/events
|
https://github.com/huggingface/datasets/issues/5150
| 1,420,684,999
|
I_kwDODunzps5Ure7H
| 5,150
|
Problems after upgrading to 2.6.1
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_url": "https://api.github.com/users/pietrolesci/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/pietrolesci",
"id": 61748653,
"login": "pietrolesci",
"node_id": "MDQ6VXNlcjYxNzQ4NjUz",
"organizations_url": "https://api.github.com/users/pietrolesci/orgs",
"received_events_url": "https://api.github.com/users/pietrolesci/received_events",
"repos_url": "https://api.github.com/users/pietrolesci/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/pietrolesci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pietrolesci/subscriptions",
"type": "User",
"url": "https://api.github.com/users/pietrolesci",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"Hi! I can't reproduce the error following these steps. Can you please provide a reproducible example?",
"I faced the same issue:\r\n\r\n### Repro\r\n```\r\n!pip install datasets==2.6.1\r\nimport datasets as Dataset\r\ndataset = Dataset.from_pandas(dataframe)\r\ndataset.save_to_disk(local)\r\n\r\n!pip install datasets==2.5.2\r\nimport datasets as Dataset\r\ndataset = Dataset.load_from_disk(local)\r\n```\r\n\r\n",
"@Lokiiiiii And what are the contents of the \"dataframe\" in your example?",
"I bumped into the issue too. @Lokiiiiii thanks for steps. I \"solved\" if for now by `pip install datasets>=2.6.1` everywhere.",
"Hi all, \r\nI experienced the same issue. \r\nPlease note that the pull request is related to the IMDB example provided in the doc, and is a fix for that, in that context, to make sure that people can follow the doc example and have a working system. \r\nIt does not provide a fix for Datasets itself. ",
"im getting the same error.\r\n- using the base AWS HF container that uses a datasets <2.\r\n- updating the AWS HF container to use dataset 2.4\r\n",
"Same here, running on our SageMaker pipelines. It's only happening for some but not all of our saved Datasets.",
"I am also receiving this error on Sagemaker but not locally, I have noticed that this occurs when the `.dataset/` folder does not contain a single file like:\r\n\r\n`dataset.arrow`\r\n\r\nbut instead contains multiple files like:\r\n\r\n`data-00000-of-00002.arrow`\r\n`data-00001-of-00002.arrow`\r\n\r\nI think that it may have something to do with this recent PR that updated the behaviour of `dataset.save_to_disk` by introducing sharding: https://github.com/huggingface/datasets/pull/5268\r\n\r\nFor now I can get around this by forcing datasets==2.8.0 on machine that creates dataset and in the huggingface instance for training (by running this at the start of training script `os.system(\"pip install datasets==2.8.0\")`)\r\n\r\nTo ensure the dataset is a single shard when saving the dataset locally:\r\n\r\n```python3\r\ndataset.flatten_indices().save_to_disk('path/to/dataset', num_shards=1)\r\n```\r\n\r\n and then manually changing the name afterwards from `path/to/dataset/data-00000-of-00001.arrow` to `path/to/dataset/dataset.arrow` and updating the `path/to/dataset/state.json` to reflect this name change. i.e. by changing `state.json` to this:\r\n\r\n```javascript\r\n{\r\n \"_data_files\": [\r\n {\r\n \"filename\": \"dataset.arrow\"\r\n }\r\n ],\r\n \"_fingerprint\": \"420086f0636f8727\",\r\n \"_format_columns\": null,\r\n \"_format_kwargs\": {},\r\n \"_format_type\": null,\r\n \"_output_all_columns\": false,\r\n \"_split\": null\r\n}\r\n```",
"Does anyone know if this has been resolved?",
"I have the same issue in datasets version 2.3.2"
] | 2022-10-24T11:32:36Z
| 2024-05-12T07:40:03Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Loading a dataset_dict from disk with `load_from_disk` is now creating a `KeyError "length"` that was not occurring in v2.5.2.
Context:
- Each individual dataset in the dict is created with `Dataset.from_pandas`
- The dataset_dict is create from a dict of `Dataset`s, e.g., `DatasetDict({"train": train_ds, "validation": val_ds})
- The pandas dataframe, besides text columns, has a column with a dictionary inside and potentially different keys in each row. Correctly the `Dataset.from_pandas` function adds `key: None` to all dictionaries in each row so that the schema can be correctly inferred.
### Steps to reproduce the bug
Steps to reproduce:
- Upgrade to datasets==2.6.1
- Create a dataset from pandas dataframe with `Dataset.from_pandas`
- Create a dataset_dict from a dict of `Dataset`s, e.g., `DatasetDict({"train": train_ds, "validation": val_ds})
- Save to disk with the `save` function
### Expected behavior
Same as in v2.5.2, that is load from disk without errors
### Environment info
- `datasets` version: 2.6.1
- Platform: Linux-5.4.209-129.367.amzn2int.x86_64-x86_64-with-glibc2.26
- Python version: 3.9.13
- PyArrow version: 9.0.0
- Pandas version: 1.5.1
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5150/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5150/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5418
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5418/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5418/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5418/events
|
https://github.com/huggingface/datasets/issues/5418
| 1,530,111,184
|
I_kwDODunzps5bM6TQ
| 5,418
|
Add ProgressBar for `to_parquet`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url": "https://api.github.com/users/zanussbaum/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zanussbaum",
"id": 33707069,
"login": "zanussbaum",
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"organizations_url": "https://api.github.com/users/zanussbaum/orgs",
"received_events_url": "https://api.github.com/users/zanussbaum/received_events",
"repos_url": "https://api.github.com/users/zanussbaum/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zanussbaum/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zanussbaum/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zanussbaum",
"user_view_type": "public"
}
|
[
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url": "https://api.github.com/users/zanussbaum/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zanussbaum",
"id": 33707069,
"login": "zanussbaum",
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"organizations_url": "https://api.github.com/users/zanussbaum/orgs",
"received_events_url": "https://api.github.com/users/zanussbaum/received_events",
"repos_url": "https://api.github.com/users/zanussbaum/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zanussbaum/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zanussbaum/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zanussbaum",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url": "https://api.github.com/users/zanussbaum/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zanussbaum",
"id": 33707069,
"login": "zanussbaum",
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"organizations_url": "https://api.github.com/users/zanussbaum/orgs",
"received_events_url": "https://api.github.com/users/zanussbaum/received_events",
"repos_url": "https://api.github.com/users/zanussbaum/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zanussbaum/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zanussbaum/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zanussbaum",
"user_view_type": "public"
}
] | null |
[
"Thanks for your proposal, @zanussbaum. Yes, I agree that would definitely be a nice feature to have!",
"@albertvillanova I’m happy to make a quick PR for the feature! let me know ",
"That would be awesome ! You can comment `#self-assign` to assign you to this issue and open a PR :) Will be happy to review",
"Closing as this has been merged @lhoestq "
] | 2023-01-12T05:06:20Z
| 2023-01-24T18:18:24Z
| 2023-01-24T18:18:24Z
|
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Feature request
Add a progress bar for `Dataset.to_parquet`, similar to how `to_json` works.
### Motivation
It's a bit frustrating to not know how long a dataset will take to write to file and if it's stuck or not without a progress bar
### Your contribution
Sure I can help if needed
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url": "https://api.github.com/users/zanussbaum/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zanussbaum",
"id": 33707069,
"login": "zanussbaum",
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"organizations_url": "https://api.github.com/users/zanussbaum/orgs",
"received_events_url": "https://api.github.com/users/zanussbaum/received_events",
"repos_url": "https://api.github.com/users/zanussbaum/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zanussbaum/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zanussbaum/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zanussbaum",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5418/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5418/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5604
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5604/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5604/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5604/events
|
https://github.com/huggingface/datasets/issues/5604
| 1,608,304,775
|
I_kwDODunzps5f3MiH
| 5,604
|
Problems with downloading The Pile
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11065386?v=4",
"events_url": "https://api.github.com/users/sentialx/events{/privacy}",
"followers_url": "https://api.github.com/users/sentialx/followers",
"following_url": "https://api.github.com/users/sentialx/following{/other_user}",
"gists_url": "https://api.github.com/users/sentialx/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sentialx",
"id": 11065386,
"login": "sentialx",
"node_id": "MDQ6VXNlcjExMDY1Mzg2",
"organizations_url": "https://api.github.com/users/sentialx/orgs",
"received_events_url": "https://api.github.com/users/sentialx/received_events",
"repos_url": "https://api.github.com/users/sentialx/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sentialx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sentialx/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sentialx",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi! \r\n\r\n\r\nYou can specify `download_config=DownloadConfig(resume_download=True))` in `load_dataset` to resume the download when re-running the code after the timeout error:\r\n```python\r\nfrom datasets import load_dataset, DownloadConfig\r\ndataset = load_dataset('the_pile', split='train', cache_dir='F:\\datasets', download_config=DownloadConfig(resume_download=True))\r\n```\r\n\r\n",
"@mariosasko , I used your suggestion but its not saving anything , just stops and runs from the same point .\r\nbelow is the script to download and save on disk .\r\n\r\n```\r\nfrom datasets import load_dataset, DownloadConfig\r\n\r\n\r\n#load the Pile dataset from Hugging Face Datasets\r\n#dataset = load_dataset('the_pile')\r\ndataset = load_dataset('the_pile', split='train', cache_dir='datasets', download_config=DownloadConfig(resume_download=True))\r\n\r\n\r\n# save each file in the dataset to disk\r\nfor i, example in enumerate(dataset['train']):\r\n filename = f'pile_file_{i}.json'\r\n with open(filename, 'w') as f:\r\n f.write(str(example))\r\n\r\nprint(\"Finished saving Pile dataset files to disk.\")\r\n```\r\n",
"@mariosasko , it shows nothing in dataset folder\r\n\r\n```\r\n du -sh /mnt/nlp/hugging_face/*\r\n20K /mnt/nlp/hugging_face/datasets\r\n4.0K /mnt/nlp/hugging_face/download_pile.py\r\n```\r\n",
"@mariosasko \r\n\r\n```\r\nroot@d20f0ab8f4f8:/mnt/hugging_face# python3 download_pile.py\r\nNo config specified, defaulting to: the_pile/all\r\nDownloading and preparing dataset the_pile/all to /mnt/hugging_face/datasets/the_pile/all/0.0.0/6fadc480ecb32470826cbf5900a9558b791ce55d5e9a0fdc8ad653e7b64bb349...\r\nDownloading data files: 0%| | 0/3 [00:00<?, ?it/s]\r\n\r\n\r\n\r\n\r\n\r\nDownloading data: 70%|████████████████████████████████████████████████████████████████████▊ | 10.7G/15.2G [12:09<11:53, 6.36MB/s]\r\nDownloading data: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████| 15.2G/15.2G [22:15<00:00, 7.25MB/s]\r\nDownloading data: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████| 15.2G/15.2G [46:17<00:00, 5.48MB/s]\r\nDownloading data: 40%|██████████████████████████████████████▏ | 6.07G/15.3G [50:49<1:17:02, 1.99MB/s]\r\nTraceback (most recent call last):██████████████████████████▊ | 6.07G/15.3G [50:49<25:35:23, 99.9kB/s]\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 444, in _error_catcher\r\n yield\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 567, in read\r\n data = self._fp_read(amt) if not fp_closed else b\"\"\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 525, in _fp_read\r\n data = self._fp.read(chunk_amt)\r\n File \"/usr/lib/python3.8/http/client.py\", line 459, in read\r\n n = self.readinto(b)\r\n File \"/usr/lib/python3.8/http/client.py\", line 503, in readinto\r\n n = self.fp.readinto(b)\r\n File \"/usr/lib/python3.8/socket.py\", line 669, in readinto\r\n return self._sock.recv_into(b)\r\n File \"/usr/lib/python3.8/ssl.py\", line 1241, in recv_into\r\n return self.read(nbytes, buffer)\r\n File \"/usr/lib/python3.8/ssl.py\", line 1099, in read\r\n return self._sslobj.read(len, buffer)\r\nConnectionResetError: [Errno 104] Connection reset by peer\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.8/dist-packages/requests/models.py\", line 816, in generate\r\n yield from self.raw.stream(chunk_size, decode_content=True)\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 628, in stream\r\n data = self.read(amt=amt, decode_content=decode_content)\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 593, in read\r\n raise IncompleteRead(self._fp_bytes_read, self.length_remaining)\r\n File \"/usr/lib/python3.8/contextlib.py\", line 131, in __exit__\r\n self.gen.throw(type, value, traceback)\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 461, in _error_catcher\r\n raise ProtocolError(\"Connection broken: %r\" % e, e)\r\nurllib3.exceptions.ProtocolError: (\"Connection broken: ConnectionResetError(104, 'Connection reset by peer')\", ConnectionResetError(104, 'Connection reset by peer'))\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"download_pile.py\", line 6, in <module>\r\n dataset = load_dataset('the_pile', split='train', cache_dir='datasets', download_config=DownloadConfig(resume_download=True))\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/load.py\", line 1782, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/builder.py\", line 872, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/builder.py\", line 1649, in _download_and_prepare\r\n super()._download_and_prepare(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/builder.py\", line 945, in _download_and_prepare\r\n split_generators = self._split_generators(dl_manager, **split_generators_kwargs)\r\n File \"/root/.cache/huggingface/modules/datasets_modules/datasets/the_pile/6fadc480ecb32470826cbf5900a9558b791ce55d5e9a0fdc8ad653e7b64bb349/the_pile.py\", line 192, in _split_generators\r\n data_dir = dl_manager.download(_DATA_URLS[self.config.name])\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/download/download_manager.py\", line 427, in download\r\n downloaded_path_or_paths = map_nested(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py\", line 443, in map_nested\r\n mapped = [\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py\", line 444, in <listcomp>\r\n _single_map_nested((function, obj, types, None, True, None))\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py\", line 363, in _single_map_nested\r\n mapped = [_single_map_nested((function, v, types, None, True, None)) for v in pbar]\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py\", line 363, in <listcomp>\r\n mapped = [_single_map_nested((function, v, types, None, True, None)) for v in pbar]\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py\", line 346, in _single_map_nested\r\n return function(data_struct)\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/download/download_manager.py\", line 453, in _download\r\n return cached_path(url_or_filename, download_config=download_config)\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/file_utils.py\", line 182, in cached_path\r\n output_path = get_from_cache(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/file_utils.py\", line 575, in get_from_cache\r\n http_get(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/file_utils.py\", line 379, in http_get\r\n for chunk in response.iter_content(chunk_size=1024):\r\n File \"/usr/local/lib/python3.8/dist-packages/requests/models.py\", line 818, in generate\r\n raise ChunkedEncodingError(e)\r\nrequests.exceptions.ChunkedEncodingError: (\"Connection broken: ConnectionResetError(104, 'Connection reset by peer')\", ConnectionResetError(104, 'Connection reset by peer'))\r\n```\r\n",
"Users with slow internet speed are doomed (4MB/s). The dataset downloads fine at minimum speed 10MB/s.\n\nAlso, when the train splits were generated and then I removed the downloads folder to save up disk space, it started redownloading the whole dataset. Is there any way to use the already generated splits instead?",
"@sentialx @mariosasko , anytime on my above script , am I downloading and saving dataset correctly . Please suggest :)",
"@sentialx probably worth noting that `resume_download=True` doesn't directly save the dataset to disk, but instead just helps in resuming the dataset resume on interruption as @mariosasko mentions. resolving resumptions after a crash is [an open issue](https://github.com/huggingface/datasets/issues/5380) at the moment."
] | 2023-03-03T09:52:08Z
| 2023-10-14T02:15:52Z
| 2023-03-24T12:44:25Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
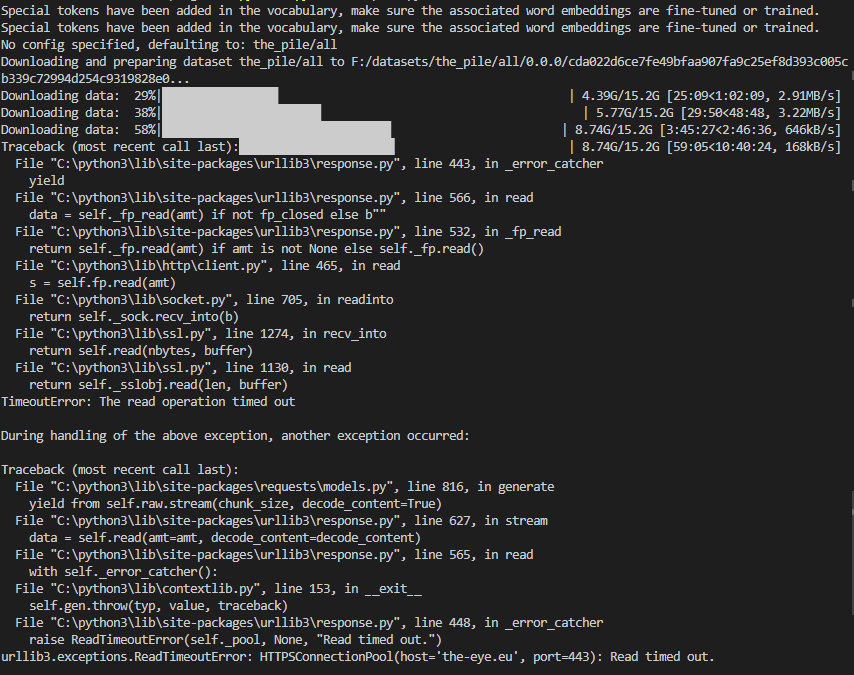
Here are the downloaded files:
They should be all 14GB like here (https://the-eye.eu/public/AI/pile/train/).
Alternatively, can I somehow download the files by myself and use the datasets preparing script?
### Steps to reproduce the bug
dataset = load_dataset('the_pile', split='train', cache_dir='F:\datasets')
### Expected behavior
The files should be downloaded correctly.
### Environment info
- `datasets` version: 2.10.1
- Platform: Windows-10-10.0.22623-SP0
- Python version: 3.10.5
- PyArrow version: 9.0.0
- Pandas version: 1.4.2
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5604/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5604/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6423
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6423/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6423/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6423/events
|
https://github.com/huggingface/datasets/pull/6423
| 1,994,946,847
|
PR_kwDODunzps5fhzD6
| 6,423
|
Fix conda release by adding pyarrow-hotfix dependency
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004476 / 0.011353 (-0.006877) | 0.002691 / 0.011008 (-0.008317) | 0.061400 / 0.038508 (0.022892) | 0.030096 / 0.023109 (0.006986) | 0.279868 / 0.275898 (0.003970) | 0.310320 / 0.323480 (-0.013159) | 0.003873 / 0.007986 (-0.004112) | 0.002394 / 0.004328 (-0.001935) | 0.048307 / 0.004250 (0.044056) | 0.043326 / 0.037052 (0.006273) | 0.288256 / 0.258489 (0.029767) | 0.311449 / 0.293841 (0.017609) | 0.022970 / 0.128546 (-0.105576) | 0.006714 / 0.075646 (-0.068932) | 0.201656 / 0.419271 (-0.217615) | 0.052811 / 0.043533 (0.009278) | 0.285123 / 0.255139 (0.029984) | 0.301495 / 0.283200 (0.018295) | 0.017531 / 0.141683 (-0.124152) | 1.097660 / 1.452155 (-0.354494) | 1.161986 / 1.492716 (-0.330731) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.089223 / 0.018006 (0.071217) | 0.297815 / 0.000490 (0.297326) | 0.000205 / 0.000200 (0.000005) | 0.000042 / 0.000054 (-0.000013) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018679 / 0.037411 (-0.018732) | 0.062742 / 0.014526 (0.048216) | 0.072869 / 0.176557 (-0.103687) | 0.120730 / 0.737135 (-0.616406) | 0.074526 / 0.296338 (-0.221813) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.299977 / 0.215209 (0.084768) | 2.921029 / 2.077655 (0.843375) | 1.632283 / 1.504120 (0.128163) | 1.508008 / 1.541195 (-0.033187) | 1.513967 / 1.468490 (0.045477) | 0.403056 / 4.584777 (-4.181721) | 2.340011 / 3.745712 (-1.405701) | 2.552319 / 5.269862 (-2.717543) | 1.549741 / 4.565676 (-3.015935) | 0.046303 / 0.424275 (-0.377972) | 0.004768 / 0.007607 (-0.002839) | 0.356921 / 0.226044 (0.130877) | 3.506410 / 2.268929 (1.237482) | 1.975394 / 55.444624 (-53.469230) | 1.688683 / 6.876477 (-5.187794) | 1.715502 / 2.142072 (-0.426571) | 0.471016 / 4.805227 (-4.334212) | 0.099552 / 6.500664 (-6.401112) | 0.042095 / 0.075469 (-0.033374) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.955784 / 1.841788 (-0.886004) | 11.191802 / 8.074308 (3.117494) | 10.127818 / 10.191392 (-0.063574) | 0.141225 / 0.680424 (-0.539199) | 0.014486 / 0.534201 (-0.519715) | 0.267204 / 0.579283 (-0.312079) | 0.289108 / 0.434364 (-0.145256) | 0.309458 / 0.540337 (-0.230880) | 0.422802 / 1.386936 (-0.964134) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004797 / 0.011353 (-0.006556) | 0.002907 / 0.011008 (-0.008101) | 0.047666 / 0.038508 (0.009158) | 0.051183 / 0.023109 (0.028074) | 0.266315 / 0.275898 (-0.009583) | 0.286429 / 0.323480 (-0.037051) | 0.003954 / 0.007986 (-0.004031) | 0.002041 / 0.004328 (-0.002288) | 0.047652 / 0.004250 (0.043401) | 0.038211 / 0.037052 (0.001158) | 0.272210 / 0.258489 (0.013721) | 0.299425 / 0.293841 (0.005584) | 0.024266 / 0.128546 (-0.104280) | 0.006747 / 0.075646 (-0.068900) | 0.052959 / 0.419271 (-0.366312) | 0.032094 / 0.043533 (-0.011439) | 0.265677 / 0.255139 (0.010538) | 0.285373 / 0.283200 (0.002174) | 0.017577 / 0.141683 (-0.124106) | 1.114514 / 1.452155 (-0.337640) | 1.212970 / 1.492716 (-0.279746) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.088347 / 0.018006 (0.070341) | 0.296678 / 0.000490 (0.296188) | 0.000209 / 0.000200 (0.000009) | 0.000044 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021159 / 0.037411 (-0.016253) | 0.069886 / 0.014526 (0.055360) | 0.079832 / 0.176557 (-0.096725) | 0.115512 / 0.737135 (-0.621623) | 0.081600 / 0.296338 (-0.214739) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.292659 / 0.215209 (0.077450) | 2.872556 / 2.077655 (0.794901) | 1.573017 / 1.504120 (0.068897) | 1.445122 / 1.541195 (-0.096072) | 1.485584 / 1.468490 (0.017094) | 0.388638 / 4.584777 (-4.196139) | 2.434847 / 3.745712 (-1.310865) | 2.518167 / 5.269862 (-2.751695) | 1.503000 / 4.565676 (-3.062676) | 0.045123 / 0.424275 (-0.379153) | 0.004778 / 0.007607 (-0.002829) | 0.347955 / 0.226044 (0.121910) | 3.384819 / 2.268929 (1.115891) | 1.920185 / 55.444624 (-53.524439) | 1.646910 / 6.876477 (-5.229567) | 1.638092 / 2.142072 (-0.503980) | 0.450535 / 4.805227 (-4.354692) | 0.095301 / 6.500664 (-6.405363) | 0.040275 / 0.075469 (-0.035194) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.956088 / 1.841788 (-0.885700) | 11.776642 / 8.074308 (3.702334) | 10.651063 / 10.191392 (0.459671) | 0.127079 / 0.680424 (-0.553345) | 0.015080 / 0.534201 (-0.519121) | 0.273737 / 0.579283 (-0.305546) | 0.271434 / 0.434364 (-0.162929) | 0.308448 / 0.540337 (-0.231889) | 0.412467 / 1.386936 (-0.974469) |\n\n</details>\n</details>\n\n\n",
"Once this PR is merged, we should upload the missing version to conda.\r\n\r\n@lhoestq you did this in the past. If you tell me your approach (I see a tag called `VERSION`...), I could do it myself.",
"Maybe open a PR against the 2.14 branch and update `release-conda.yml` like this ?\r\n\r\n```diff\r\n- on:\r\n- push:\r\n- tags:\r\n- - \"[0-9]+.[0-9]+.[0-9]+*\"\r\n+ on: push\r\n```\r\n\r\nand then set it back to normal after the release is done",
"After having cherry-picked the commit in this PR, I have released the conda package. See: \r\n- https://github.com/huggingface/datasets/actions/runs/6880182419/job/18713812449\r\n- https://anaconda.org/HuggingFace/datasets/files?version=2.14.7\r\n\r\nI am merging this PR.\r\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004993 / 0.011353 (-0.006360) | 0.002964 / 0.011008 (-0.008044) | 0.062588 / 0.038508 (0.024080) | 0.030794 / 0.023109 (0.007685) | 0.234856 / 0.275898 (-0.041042) | 0.264807 / 0.323480 (-0.058673) | 0.003139 / 0.007986 (-0.004847) | 0.002498 / 0.004328 (-0.001831) | 0.048058 / 0.004250 (0.043807) | 0.048349 / 0.037052 (0.011296) | 0.238210 / 0.258489 (-0.020279) | 0.278144 / 0.293841 (-0.015697) | 0.023219 / 0.128546 (-0.105327) | 0.007296 / 0.075646 (-0.068351) | 0.203263 / 0.419271 (-0.216008) | 0.058844 / 0.043533 (0.015311) | 0.246330 / 0.255139 (-0.008809) | 0.264550 / 0.283200 (-0.018649) | 0.018580 / 0.141683 (-0.123103) | 1.084163 / 1.452155 (-0.367992) | 1.154891 / 1.492716 (-0.337825) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092393 / 0.018006 (0.074387) | 0.300545 / 0.000490 (0.300055) | 0.000203 / 0.000200 (0.000003) | 0.000047 / 0.000054 (-0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018648 / 0.037411 (-0.018763) | 0.063151 / 0.014526 (0.048625) | 0.074206 / 0.176557 (-0.102350) | 0.120929 / 0.737135 (-0.616207) | 0.075970 / 0.296338 (-0.220368) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.278489 / 0.215209 (0.063279) | 2.664804 / 2.077655 (0.587150) | 1.433040 / 1.504120 (-0.071080) | 1.321416 / 1.541195 (-0.219779) | 1.320964 / 1.468490 (-0.147526) | 0.401289 / 4.584777 (-4.183488) | 2.365310 / 3.745712 (-1.380402) | 2.635798 / 5.269862 (-2.634063) | 1.584384 / 4.565676 (-2.981293) | 0.045675 / 0.424275 (-0.378600) | 0.004854 / 0.007607 (-0.002753) | 0.337592 / 0.226044 (0.111548) | 3.330462 / 2.268929 (1.061534) | 1.794507 / 55.444624 (-53.650117) | 1.531284 / 6.876477 (-5.345193) | 1.507165 / 2.142072 (-0.634908) | 0.478622 / 4.805227 (-4.326606) | 0.099105 / 6.500664 (-6.401560) | 0.041575 / 0.075469 (-0.033894) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.941790 / 1.841788 (-0.899997) | 11.609871 / 8.074308 (3.535563) | 10.770869 / 10.191392 (0.579477) | 0.138931 / 0.680424 (-0.541493) | 0.014406 / 0.534201 (-0.519795) | 0.269681 / 0.579283 (-0.309602) | 0.260556 / 0.434364 (-0.173808) | 0.308244 / 0.540337 (-0.232093) | 0.428867 / 1.386936 (-0.958069) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004803 / 0.011353 (-0.006550) | 0.003263 / 0.011008 (-0.007745) | 0.049143 / 0.038508 (0.010635) | 0.052033 / 0.023109 (0.028924) | 0.267815 / 0.275898 (-0.008083) | 0.288733 / 0.323480 (-0.034747) | 0.004159 / 0.007986 (-0.003826) | 0.002407 / 0.004328 (-0.001921) | 0.048978 / 0.004250 (0.044728) | 0.038994 / 0.037052 (0.001942) | 0.264028 / 0.258489 (0.005539) | 0.303930 / 0.293841 (0.010090) | 0.024283 / 0.128546 (-0.104263) | 0.007201 / 0.075646 (-0.068446) | 0.053810 / 0.419271 (-0.365461) | 0.032611 / 0.043533 (-0.010922) | 0.266730 / 0.255139 (0.011591) | 0.281564 / 0.283200 (-0.001635) | 0.018720 / 0.141683 (-0.122963) | 1.140676 / 1.452155 (-0.311479) | 1.206604 / 1.492716 (-0.286113) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.109390 / 0.018006 (0.091384) | 0.313783 / 0.000490 (0.313294) | 0.000228 / 0.000200 (0.000028) | 0.000050 / 0.000054 (-0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021228 / 0.037411 (-0.016183) | 0.070505 / 0.014526 (0.055979) | 0.081961 / 0.176557 (-0.094595) | 0.119943 / 0.737135 (-0.617193) | 0.083582 / 0.296338 (-0.212757) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.295702 / 0.215209 (0.080493) | 2.886865 / 2.077655 (0.809210) | 1.583206 / 1.504120 (0.079086) | 1.451129 / 1.541195 (-0.090065) | 1.486253 / 1.468490 (0.017763) | 0.403207 / 4.584777 (-4.181570) | 2.408889 / 3.745712 (-1.336824) | 2.578480 / 5.269862 (-2.691381) | 1.533066 / 4.565676 (-3.032610) | 0.046075 / 0.424275 (-0.378200) | 0.004877 / 0.007607 (-0.002730) | 0.345995 / 0.226044 (0.119950) | 3.377039 / 2.268929 (1.108110) | 1.944614 / 55.444624 (-53.500010) | 1.677691 / 6.876477 (-5.198786) | 1.672828 / 2.142072 (-0.469244) | 0.468426 / 4.805227 (-4.336802) | 0.097290 / 6.500664 (-6.403374) | 0.040695 / 0.075469 (-0.034774) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.965778 / 1.841788 (-0.876010) | 12.092639 / 8.074308 (4.018331) | 11.210968 / 10.191392 (1.019576) | 0.131212 / 0.680424 (-0.549212) | 0.015865 / 0.534201 (-0.518336) | 0.285702 / 0.579283 (-0.293581) | 0.278319 / 0.434364 (-0.156045) | 0.336063 / 0.540337 (-0.204275) | 0.426265 / 1.386936 (-0.960671) |\n\n</details>\n</details>\n\n\n"
] | 2023-11-15T14:57:12Z
| 2023-11-15T17:15:33Z
| 2023-11-15T17:09:24Z
|
MEMBER
| null | null | null |
Fix conda release by adding pyarrow-hotfix dependency.
Note that conda release failed in latest 2.14.7 release: https://github.com/huggingface/datasets/actions/runs/6874667214/job/18696761723
```
Traceback (most recent call last):
File "/usr/share/miniconda/envs/build-datasets/conda-bld/datasets_1700036460222/test_tmp/run_test.py", line 2, in <module>
import datasets
File "/usr/share/miniconda/envs/build-datasets/conda-bld/datasets_1700036460222/_test_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold/lib/python3.12/site-packages/datasets/__init__.py", line 22, in <module>
from .arrow_dataset import Dataset
File "/usr/share/miniconda/envs/build-datasets/conda-bld/datasets_1700036460222/_test_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold/lib/python3.12/site-packages/datasets/arrow_dataset.py", line 67, in <module>
from .arrow_writer import ArrowWriter, OptimizedTypedSequence
File "/usr/share/miniconda/envs/build-datasets/conda-bld/datasets_1700036460222/_test_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold/lib/python3.12/site-packages/datasets/arrow_writer.py", line 27, in <module>
from .features import Features, Image, Value
File "/usr/share/miniconda/envs/build-datasets/conda-bld/datasets_1700036460222/_test_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold/lib/python3.12/site-packages/datasets/features/__init__.py", line 18, in <module>
from .features import Array2D, Array3D, Array4D, Array5D, ClassLabel, Features, Sequence, Value
File "/usr/share/miniconda/envs/build-datasets/conda-bld/datasets_1700036460222/_test_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold/lib/python3.12/site-packages/datasets/features/features.py", line 34, in <module>
import pyarrow_hotfix # noqa: F401 # to fix vulnerability on pyarrow<14.0.1
^^^^^^^^^^^^^^^^^^^^^
ModuleNotFoundError: No module named 'pyarrow_hotfix'
```
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6423/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6423/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6423.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6423",
"merged_at": "2023-11-15T17:09:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6423.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6423"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6322
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6322/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6322/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6322/events
|
https://github.com/huggingface/datasets/pull/6322
| 1,952,947,461
|
PR_kwDODunzps5dT5vG
| 6,322
|
Fix regex `get_data_files` formatting for base paths
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1981179?v=4",
"events_url": "https://api.github.com/users/ZachNagengast/events{/privacy}",
"followers_url": "https://api.github.com/users/ZachNagengast/followers",
"following_url": "https://api.github.com/users/ZachNagengast/following{/other_user}",
"gists_url": "https://api.github.com/users/ZachNagengast/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ZachNagengast",
"id": 1981179,
"login": "ZachNagengast",
"node_id": "MDQ6VXNlcjE5ODExNzk=",
"organizations_url": "https://api.github.com/users/ZachNagengast/orgs",
"received_events_url": "https://api.github.com/users/ZachNagengast/received_events",
"repos_url": "https://api.github.com/users/ZachNagengast/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ZachNagengast/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZachNagengast/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ZachNagengast",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"> The reason why I used the the glob_pattern_to_regex in the entire pattern is because otherwise I got an error for Windows local paths: a base_path like 'C:\\\\Users\\\\runneradmin... made the function string_to_dict raise re.error: incomplete escape \\U at position 2\r\n\r\nWhat is the expected inputs and outputs for the windows `base_path`\r\n\r\n> That issue was fixed once we pass the base_path as POSIX.\r\n\r\nI'm not sure what you meant by that, are there still changes needed?\r\n",
"We took the liberty of continuing this PR to include it in today's patch release :)\r\nI hope you don't mind",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007109 / 0.011353 (-0.004244) | 0.004209 / 0.011008 (-0.006799) | 0.097401 / 0.038508 (0.058892) | 0.079532 / 0.023109 (0.056423) | 0.341300 / 0.275898 (0.065402) | 0.402165 / 0.323480 (0.078685) | 0.005838 / 0.007986 (-0.002148) | 0.003310 / 0.004328 (-0.001018) | 0.072804 / 0.004250 (0.068553) | 0.059418 / 0.037052 (0.022366) | 0.339277 / 0.258489 (0.080788) | 0.418495 / 0.293841 (0.124654) | 0.035975 / 0.128546 (-0.092571) | 0.008101 / 0.075646 (-0.067546) | 0.339236 / 0.419271 (-0.080035) | 0.059326 / 0.043533 (0.015794) | 0.326880 / 0.255139 (0.071741) | 0.393614 / 0.283200 (0.110414) | 0.025830 / 0.141683 (-0.115852) | 1.657726 / 1.452155 (0.205571) | 1.817250 / 1.492716 (0.324534) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.256015 / 0.018006 (0.238008) | 0.482447 / 0.000490 (0.481957) | 0.012166 / 0.000200 (0.011966) | 0.000343 / 0.000054 (0.000288) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029898 / 0.037411 (-0.007514) | 0.088218 / 0.014526 (0.073692) | 0.102353 / 0.176557 (-0.074203) | 0.165863 / 0.737135 (-0.571272) | 0.100342 / 0.296338 (-0.195996) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.429362 / 0.215209 (0.214153) | 4.147327 / 2.077655 (2.069672) | 2.014653 / 1.504120 (0.510533) | 1.824394 / 1.541195 (0.283199) | 1.936408 / 1.468490 (0.467917) | 0.542960 / 4.584777 (-4.041817) | 3.917215 / 3.745712 (0.171503) | 3.714825 / 5.269862 (-1.555036) | 2.180279 / 4.565676 (-2.385398) | 0.057808 / 0.424275 (-0.366467) | 0.008426 / 0.007607 (0.000819) | 0.472372 / 0.226044 (0.246327) | 4.879656 / 2.268929 (2.610728) | 2.602729 / 55.444624 (-52.841896) | 2.142593 / 6.876477 (-4.733884) | 2.206070 / 2.142072 (0.063997) | 0.635591 / 4.805227 (-4.169636) | 0.140928 / 6.500664 (-6.359736) | 0.065119 / 0.075469 (-0.010350) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.455909 / 1.841788 (-0.385879) | 20.803592 / 8.074308 (12.729284) | 14.788713 / 10.191392 (4.597321) | 0.170546 / 0.680424 (-0.509878) | 0.021189 / 0.534201 (-0.513012) | 0.432368 / 0.579283 (-0.146915) | 0.444664 / 0.434364 (0.010300) | 0.517744 / 0.540337 (-0.022593) | 0.699265 / 1.386936 (-0.687671) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007592 / 0.011353 (-0.003760) | 0.004045 / 0.011008 (-0.006964) | 0.073434 / 0.038508 (0.034926) | 0.076962 / 0.023109 (0.053853) | 0.468873 / 0.275898 (0.192975) | 0.479968 / 0.323480 (0.156488) | 0.006270 / 0.007986 (-0.001716) | 0.003652 / 0.004328 (-0.000677) | 0.069893 / 0.004250 (0.065643) | 0.061902 / 0.037052 (0.024850) | 0.443379 / 0.258489 (0.184890) | 0.492627 / 0.293841 (0.198786) | 0.035967 / 0.128546 (-0.092579) | 0.009276 / 0.075646 (-0.066370) | 0.083060 / 0.419271 (-0.336212) | 0.050870 / 0.043533 (0.007337) | 0.438246 / 0.255139 (0.183107) | 0.472074 / 0.283200 (0.188874) | 0.023724 / 0.141683 (-0.117959) | 1.677178 / 1.452155 (0.225023) | 1.732273 / 1.492716 (0.239557) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.244693 / 0.018006 (0.226687) | 0.470067 / 0.000490 (0.469577) | 0.005574 / 0.000200 (0.005374) | 0.000105 / 0.000054 (0.000051) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.036242 / 0.037411 (-0.001169) | 0.099166 / 0.014526 (0.084641) | 0.116785 / 0.176557 (-0.059772) | 0.174986 / 0.737135 (-0.562149) | 0.118130 / 0.296338 (-0.178209) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.475907 / 0.215209 (0.260698) | 4.708125 / 2.077655 (2.630470) | 2.600855 / 1.504120 (1.096735) | 2.446498 / 1.541195 (0.905303) | 2.538786 / 1.468490 (1.070296) | 0.566787 / 4.584777 (-4.017990) | 4.066187 / 3.745712 (0.320475) | 3.743632 / 5.269862 (-1.526229) | 2.337737 / 4.565676 (-2.227939) | 0.068402 / 0.424275 (-0.355873) | 0.008674 / 0.007607 (0.001067) | 0.593428 / 0.226044 (0.367384) | 5.840687 / 2.268929 (3.571759) | 3.194937 / 55.444624 (-52.249688) | 2.899033 / 6.876477 (-3.977444) | 2.977870 / 2.142072 (0.835797) | 0.683673 / 4.805227 (-4.121554) | 0.154933 / 6.500664 (-6.345731) | 0.071619 / 0.075469 (-0.003850) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.501895 / 1.841788 (-0.339893) | 21.709792 / 8.074308 (13.635484) | 15.679556 / 10.191392 (5.488164) | 0.188028 / 0.680424 (-0.492396) | 0.022555 / 0.534201 (-0.511646) | 0.439840 / 0.579283 (-0.139443) | 0.452140 / 0.434364 (0.017776) | 0.526421 / 0.540337 (-0.013916) | 0.731692 / 1.386936 (-0.655244) |\n\n</details>\n</details>\n\n\n"
] | 2023-10-19T19:45:10Z
| 2023-10-23T14:40:45Z
| 2023-10-23T14:31:21Z
|
CONTRIBUTOR
| null | null | null |
With this pr https://github.com/huggingface/datasets/pull/6309, it is formatting the entire base path into regex, which results in the undesired formatting error `doesn't match the pattern` because of the line in `glob_pattern_to_regex`: `.replace("//", "/")`:
- Input: `hf://datasets/...`
- Output: `hf:/datasets/...`
This fix will only convert the `split_pattern` to regex and keep the `base_path` unchanged.
cc @albertvillanova hopefully this still works with your implementation
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6322/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6322/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6322.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6322",
"merged_at": "2023-10-23T14:31:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6322.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6322"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7207
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7207/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7207/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7207/events
|
https://github.com/huggingface/datasets/pull/7207
| 2,573,582,335
|
PR_kwDODunzps59-Dms
| 7,207
|
apply formatting after iter_arrow to speed up format -> map, filter for iterable datasets
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/5719745?v=4",
"events_url": "https://api.github.com/users/alex-hh/events{/privacy}",
"followers_url": "https://api.github.com/users/alex-hh/followers",
"following_url": "https://api.github.com/users/alex-hh/following{/other_user}",
"gists_url": "https://api.github.com/users/alex-hh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/alex-hh",
"id": 5719745,
"login": "alex-hh",
"node_id": "MDQ6VXNlcjU3MTk3NDU=",
"organizations_url": "https://api.github.com/users/alex-hh/orgs",
"received_events_url": "https://api.github.com/users/alex-hh/received_events",
"repos_url": "https://api.github.com/users/alex-hh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/alex-hh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alex-hh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/alex-hh",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"I think the problem is that the underlying ex_iterable will not use iter_arrow unless the formatting type is arrow, which leads to conversion from arrow -> python -> numpy in this case rather than arrow -> numpy.\r\n\r\nIdea of updated fix is to use the ex_iterable's iter_arrow in any case where it's available and any formatting is specified. The formatter then works directly on arrow tables; the outputs of the formatter get passed to the function to be mapped.\r\n\r\nWith updated version:\r\n\r\n```python\r\nimport numpy as np\r\nimport time\r\nfrom datasets import Dataset, Features, Array3D\r\n\r\nfeatures=Features(**{\"array0\": Array3D((None, 10, 10), dtype=\"float32\"), \"array1\": Array3D((None,10,10), dtype=\"float32\")})\r\ndataset = Dataset.from_dict({f\"array{i}\": [np.zeros((x,10,10), dtype=np.float32) for x in [2000,1000]*25] for i in range(2)}, features=features)\r\n```\r\n\r\n```python\r\nds = dataset.to_iterable_dataset()\r\nds = ds.with_format(\"numpy\").map(lambda x: x, batched=True, batch_size=10)\r\nt0 = time.time()\r\nfor ex in ds:\r\n pass\r\nt1 = time.time()\r\n```\r\nTotal time: < 0.01s (~30s on main)\r\n\r\n```python\r\nds = dataset.to_iterable_dataset()\r\nds = ds.with_format(\"numpy\").map(lambda x: x, batched=False)\r\nt0 = time.time()\r\nfor ex in ds:\r\n pass\r\nt1 = time.time()\r\n```\r\nTime: ~0.02 s (~30s on main)\r\n\r\n```python\r\nds = dataset.to_iterable_dataset()\r\nds = ds.with_format(\"numpy\")\r\nt0 = time.time()\r\nfor ex in ds:\r\n pass\r\nt1 = time.time()\r\n```\r\nTime: ~0.02s",
"also now working for filter with similar performance improvements:\r\n\r\n```python\r\nfiltered_examples = []\r\nds = dataset.to_iterable_dataset()\r\nds = ds.with_format(\"numpy\").filter(lambda x: [arr.shape[0]==2000 for arr in x[\"array0\"]], batch_size=10, batched=True)\r\nt0 = time.time()\r\nfor ex in ds:\r\n filtered_examples.append(ex)\r\nt1 = time.time()\r\nassert len(filtered_examples) == 25\r\n```\r\n0.01s vs 50s on main\r\n\r\n\r\n```python\r\nfiltered_examples = []\r\nds = dataset.to_iterable_dataset()\r\nds = ds.with_format(\"numpy\").filter(lambda x: x[\"array0\"].shape[0]==2000, batched=False)\r\nt0 = time.time()\r\nfor ex in ds:\r\n filtered_examples.append(ex)\r\nt1 = time.time()\r\nassert len(filtered_examples) == 25\r\n```\r\n0.04s vs 50s on main\r\n",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7207). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"(the distributed tests failing in the CI are unrelated)",
"There also appears to be a separate? issue with chaining filter and map bc filter iter_arrow only returns _iter_arrow if arrow formatting is applied (and vv presumably)\r\n\r\nI don't have a good minimal example atm",
"> issue with chaining filter and map bc filter iter_arrow only returns _iter_arrow if arrow formatting is applied (and vv presumably)\r\n\r\nMaybe related to this issue ?\r\n\r\n```python\r\nds = Dataset.from_dict({\"a\": range(10)}).to_iterable_dataset()\r\nds = ds.with_format(\"arrow\").map(lambda x: x, features=Features({\"a\": Value(\"string\")})).with_format(None)\r\nprint(list(ds)) # yields integers instead of strings\r\n```",
"I feel like we could get rid of TypedExampleIterable altogether and apply formatting with feature conversion with `formatted_python_examples_iterator ` and `formatted_arrow_examples_iterator`\r\n\r\nbtw you can pass `features=` in `get_formatter()` to get a formatter that does the feature conversion at the same time as formatting\r\n\r\n(edit:\r\n\r\nexcept maybe the arrow formatter doesn't use `features` yet, we can fix it like this if it's really needed\r\n```diff\r\nclass ArrowFormatter(Formatter[pa.Table, pa.Array, pa.Table]):\r\n def format_row(self, pa_table: pa.Table) -> pa.Table:\r\n- return self.simple_arrow_extractor().extract_row(pa_table)\r\n+ pa_table = self.simple_arrow_extractor().extract_row(pa_table)\r\n+. return cast_table_to_features(pa_table, self.features) if self.features else pa_table\r\n \r\n```\r\n\r\n\r\n)",
"> I feel like we could get rid of TypedExampleIterable altogether and apply formatting with feature conversion with formatted_python_examples_iterator and formatted_arrow_examples_iterator\r\n\r\nOh nice didn't know about the feature support in get_formatter. Haven't thought through whether this works but would a FormattedExampleIterable (with feature conversion) be able to solve this and fit the API better?",
"> Oh nice didn't know about the feature support in get_formatter. Haven't thought through whether this works but would a FormattedExampleIterable (with feature conversion) be able to solve this and fit the API better?\r\n\r\nYes this is surely the way to go actually !",
"ok i've fixed the chaining issue with my last two commits.\r\n\r\nWill see if I can refactor into a FormattedExampleIterable\r\n\r\nThe other issue you posted seems to be unrelated (maybe something to do with feature decoding?)",
"updated with FormattedExamplesIterable.\r\n\r\nthere might be a few unnecessary format calls once the data is already formatted - doesn't seem like a big performance bottleneck but could maybe be fixed with e.g. an is_formatted property\r\n\r\nIt also might be possible to do a wider refactor and use FormattedExamplesIterable elsewhere. But I'd personally prefer not to try that rn.",
"Thinking about this in the context of #7210 - am wondering if it would make sense for Features to define their own extraction arrow->object logic? e.g. Arrays should *always* be extracted with NumpyArrowExtractor, not only in case with_format is set to numpy (which a user can easily forget or not know to do)\r\n",
"> Thinking about this in the context of https://github.com/huggingface/datasets/issues/7210 - am wondering if it would make sense for Features to define their own extraction arrow->object logic? e.g. Arrays should always be extracted with NumpyArrowExtractor, not only in case with_format is set to numpy (which a user can easily forget or not know to do)\r\n\r\nFor `ArrayND` they already implement `to_pylist` to decode arrow data and it can be updated to return a numpy array (see the `ArrayExtensionArray` class for more details)",
"@lhoestq im no longer sure my specific concern about with_format(None) was well-founded - I didn't appreciate that the python formatter tries to do nothing to python objects including numpy arrays, so the existing with_format(None) should I *think* do what I want. Do you think with_format(None) is ok as is after all? If so think this is hopefully ready for final review!",
"@lhoestq I've updated to make compatible with latest changes on main, and think the current with_format None behaviour is probably fine - please let me know if there's anything else I can do!",
"Hi Alex, I will be less available from today and for a week. I'll review your PR and play with it once I come back if you don't mind !",
"thanks for the reviews and extensions, happy to see this merged :)"
] | 2024-10-08T15:44:53Z
| 2025-01-14T18:36:03Z
| 2025-01-14T16:59:30Z
|
CONTRIBUTOR
| null | null | null |
I got to this by hacking around a bit but it seems to solve #7206
I have no idea if this approach makes sense or would break something else?
Could maybe work on a full pr if this looks reasonable @lhoestq ? I imagine the same issue might affect other iterable dataset methods?
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7207/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7207/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7207.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7207",
"merged_at": "2025-01-14T16:59:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7207.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7207"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6838
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6838/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6838/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6838/events
|
https://github.com/huggingface/datasets/issues/6838
| 2,263,674,843
|
I_kwDODunzps6G7O_b
| 6,838
|
Remove token arg from CLI examples
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[] | 2024-04-25T14:00:38Z
| 2024-04-26T16:57:41Z
| 2024-04-26T16:57:41Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
As suggested by @Wauplin, see: https://github.com/huggingface/datasets/pull/6831#discussion_r1579492603
> I would not advertise the --token arg in the example as this shouldn't be the recommended way (best to login with env variable or huggingface-cli login)
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6838/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6838/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6706
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6706/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6706/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6706/events
|
https://github.com/huggingface/datasets/pull/6706
| 2,163,783,123
|
PR_kwDODunzps5obgt-
| 6,706
|
Update ruff
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6706). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005014 / 0.011353 (-0.006339) | 0.003324 / 0.011008 (-0.007685) | 0.062501 / 0.038508 (0.023993) | 0.027633 / 0.023109 (0.004524) | 0.245693 / 0.275898 (-0.030205) | 0.271963 / 0.323480 (-0.051517) | 0.003062 / 0.007986 (-0.004923) | 0.002646 / 0.004328 (-0.001683) | 0.049020 / 0.004250 (0.044769) | 0.042381 / 0.037052 (0.005328) | 0.269729 / 0.258489 (0.011240) | 0.289052 / 0.293841 (-0.004789) | 0.027138 / 0.128546 (-0.101408) | 0.010246 / 0.075646 (-0.065400) | 0.205378 / 0.419271 (-0.213893) | 0.035792 / 0.043533 (-0.007741) | 0.247204 / 0.255139 (-0.007935) | 0.271805 / 0.283200 (-0.011394) | 0.019541 / 0.141683 (-0.122142) | 1.129335 / 1.452155 (-0.322820) | 1.174088 / 1.492716 (-0.318629) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091340 / 0.018006 (0.073334) | 0.300037 / 0.000490 (0.299547) | 0.000214 / 0.000200 (0.000014) | 0.000046 / 0.000054 (-0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018360 / 0.037411 (-0.019051) | 0.061239 / 0.014526 (0.046713) | 0.072304 / 0.176557 (-0.104253) | 0.118883 / 0.737135 (-0.618253) | 0.073562 / 0.296338 (-0.222777) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.284478 / 0.215209 (0.069269) | 2.761819 / 2.077655 (0.684165) | 1.443757 / 1.504120 (-0.060363) | 1.315221 / 1.541195 (-0.225974) | 1.333930 / 1.468490 (-0.134560) | 0.581470 / 4.584777 (-4.003307) | 2.422530 / 3.745712 (-1.323183) | 2.869898 / 5.269862 (-2.399963) | 1.789159 / 4.565676 (-2.776517) | 0.063708 / 0.424275 (-0.360567) | 0.004922 / 0.007607 (-0.002685) | 0.337352 / 0.226044 (0.111307) | 3.290192 / 2.268929 (1.021263) | 1.840192 / 55.444624 (-53.604432) | 1.543008 / 6.876477 (-5.333469) | 1.548947 / 2.142072 (-0.593125) | 0.655129 / 4.805227 (-4.150098) | 0.119010 / 6.500664 (-6.381654) | 0.042583 / 0.075469 (-0.032886) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.981333 / 1.841788 (-0.860455) | 11.349564 / 8.074308 (3.275256) | 9.397603 / 10.191392 (-0.793789) | 0.142151 / 0.680424 (-0.538273) | 0.013850 / 0.534201 (-0.520351) | 0.286323 / 0.579283 (-0.292960) | 0.265223 / 0.434364 (-0.169141) | 0.335322 / 0.540337 (-0.205015) | 0.441727 / 1.386936 (-0.945209) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005134 / 0.011353 (-0.006219) | 0.003216 / 0.011008 (-0.007792) | 0.049401 / 0.038508 (0.010893) | 0.031509 / 0.023109 (0.008400) | 0.262211 / 0.275898 (-0.013687) | 0.284814 / 0.323480 (-0.038665) | 0.004165 / 0.007986 (-0.003821) | 0.002693 / 0.004328 (-0.001636) | 0.048088 / 0.004250 (0.043838) | 0.043609 / 0.037052 (0.006557) | 0.271126 / 0.258489 (0.012637) | 0.301374 / 0.293841 (0.007533) | 0.028891 / 0.128546 (-0.099655) | 0.009911 / 0.075646 (-0.065735) | 0.057334 / 0.419271 (-0.361938) | 0.050936 / 0.043533 (0.007403) | 0.258883 / 0.255139 (0.003744) | 0.282884 / 0.283200 (-0.000315) | 0.017475 / 0.141683 (-0.124208) | 1.167562 / 1.452155 (-0.284593) | 1.214081 / 1.492716 (-0.278636) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.096890 / 0.018006 (0.078884) | 0.315819 / 0.000490 (0.315329) | 0.000218 / 0.000200 (0.000018) | 0.000054 / 0.000054 (0.000000) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021775 / 0.037411 (-0.015637) | 0.075816 / 0.014526 (0.061290) | 0.086992 / 0.176557 (-0.089564) | 0.125816 / 0.737135 (-0.611319) | 0.090343 / 0.296338 (-0.205995) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.295204 / 0.215209 (0.079995) | 2.903129 / 2.077655 (0.825475) | 1.629838 / 1.504120 (0.125718) | 1.531862 / 1.541195 (-0.009332) | 1.504614 / 1.468490 (0.036123) | 0.572910 / 4.584777 (-4.011867) | 2.482555 / 3.745712 (-1.263157) | 2.637259 / 5.269862 (-2.632603) | 1.733049 / 4.565676 (-2.832628) | 0.063239 / 0.424275 (-0.361036) | 0.005037 / 0.007607 (-0.002570) | 0.346657 / 0.226044 (0.120612) | 3.446469 / 2.268929 (1.177540) | 2.017864 / 55.444624 (-53.426761) | 1.688704 / 6.876477 (-5.187773) | 1.790813 / 2.142072 (-0.351259) | 0.660769 / 4.805227 (-4.144458) | 0.115582 / 6.500664 (-6.385082) | 0.040111 / 0.075469 (-0.035358) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.058089 / 1.841788 (-0.783699) | 11.998171 / 8.074308 (3.923863) | 10.459128 / 10.191392 (0.267736) | 0.149653 / 0.680424 (-0.530771) | 0.015015 / 0.534201 (-0.519186) | 0.289973 / 0.579283 (-0.289310) | 0.274217 / 0.434364 (-0.160147) | 0.351057 / 0.540337 (-0.189281) | 0.434295 / 1.386936 (-0.952641) |\n\n</details>\n</details>\n\n\n"
] | 2024-03-01T16:44:58Z
| 2024-03-01T17:02:13Z
| 2024-03-01T16:52:17Z
|
MEMBER
| null | null | null | null |
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6706/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6706/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6706.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6706",
"merged_at": "2024-03-01T16:52:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6706.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6706"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6630
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6630/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6630/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6630/events
|
https://github.com/huggingface/datasets/pull/6630
| 2,106,478,275
|
PR_kwDODunzps5lYPi3
| 6,630
|
Bump max range of dill to 0.3.8
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/27844407?v=4",
"events_url": "https://api.github.com/users/ringohoffman/events{/privacy}",
"followers_url": "https://api.github.com/users/ringohoffman/followers",
"following_url": "https://api.github.com/users/ringohoffman/following{/other_user}",
"gists_url": "https://api.github.com/users/ringohoffman/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ringohoffman",
"id": 27844407,
"login": "ringohoffman",
"node_id": "MDQ6VXNlcjI3ODQ0NDA3",
"organizations_url": "https://api.github.com/users/ringohoffman/orgs",
"received_events_url": "https://api.github.com/users/ringohoffman/received_events",
"repos_url": "https://api.github.com/users/ringohoffman/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ringohoffman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ringohoffman/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ringohoffman",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6630). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"Hmm these errors look pretty weird... can they be retried?",
"Hi, thanks for working on this! To fix the errors, you also need to update [this file](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/_dill.py) (by adding `version.parse(\"0.3.8\").release` to the lists)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005068 / 0.011353 (-0.006285) | 0.003657 / 0.011008 (-0.007351) | 0.062914 / 0.038508 (0.024406) | 0.027965 / 0.023109 (0.004855) | 0.241804 / 0.275898 (-0.034094) | 0.268069 / 0.323480 (-0.055411) | 0.004066 / 0.007986 (-0.003920) | 0.002704 / 0.004328 (-0.001624) | 0.048745 / 0.004250 (0.044495) | 0.042158 / 0.037052 (0.005106) | 0.257670 / 0.258489 (-0.000819) | 0.279419 / 0.293841 (-0.014422) | 0.027193 / 0.128546 (-0.101353) | 0.010379 / 0.075646 (-0.065267) | 0.207009 / 0.419271 (-0.212262) | 0.035494 / 0.043533 (-0.008039) | 0.246025 / 0.255139 (-0.009114) | 0.265906 / 0.283200 (-0.017294) | 0.017335 / 0.141683 (-0.124348) | 1.134052 / 1.452155 (-0.318103) | 1.184668 / 1.492716 (-0.308049) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093137 / 0.018006 (0.075130) | 0.302279 / 0.000490 (0.301789) | 0.000210 / 0.000200 (0.000010) | 0.000047 / 0.000054 (-0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018190 / 0.037411 (-0.019221) | 0.061436 / 0.014526 (0.046910) | 0.073102 / 0.176557 (-0.103454) | 0.119782 / 0.737135 (-0.617354) | 0.074292 / 0.296338 (-0.222046) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.285905 / 0.215209 (0.070696) | 2.809051 / 2.077655 (0.731397) | 1.470305 / 1.504120 (-0.033814) | 1.350457 / 1.541195 (-0.190738) | 1.349111 / 1.468490 (-0.119379) | 0.568277 / 4.584777 (-4.016500) | 2.353046 / 3.745712 (-1.392666) | 2.805862 / 5.269862 (-2.463999) | 1.750275 / 4.565676 (-2.815401) | 0.062370 / 0.424275 (-0.361905) | 0.004954 / 0.007607 (-0.002653) | 0.335609 / 0.226044 (0.109564) | 3.367200 / 2.268929 (1.098271) | 1.829431 / 55.444624 (-53.615193) | 1.545093 / 6.876477 (-5.331384) | 1.571107 / 2.142072 (-0.570966) | 0.640279 / 4.805227 (-4.164949) | 0.116209 / 6.500664 (-6.384455) | 0.042308 / 0.075469 (-0.033161) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.982972 / 1.841788 (-0.858816) | 11.424370 / 8.074308 (3.350062) | 10.427111 / 10.191392 (0.235719) | 0.129477 / 0.680424 (-0.550946) | 0.014166 / 0.534201 (-0.520035) | 0.287597 / 0.579283 (-0.291686) | 0.265588 / 0.434364 (-0.168776) | 0.324007 / 0.540337 (-0.216330) | 0.430766 / 1.386936 (-0.956170) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005347 / 0.011353 (-0.006005) | 0.003733 / 0.011008 (-0.007275) | 0.049520 / 0.038508 (0.011011) | 0.031177 / 0.023109 (0.008068) | 0.281854 / 0.275898 (0.005956) | 0.300937 / 0.323480 (-0.022543) | 0.004385 / 0.007986 (-0.003601) | 0.002841 / 0.004328 (-0.001488) | 0.048661 / 0.004250 (0.044411) | 0.044258 / 0.037052 (0.007205) | 0.295651 / 0.258489 (0.037162) | 0.322872 / 0.293841 (0.029031) | 0.048924 / 0.128546 (-0.079622) | 0.010742 / 0.075646 (-0.064905) | 0.059327 / 0.419271 (-0.359944) | 0.033938 / 0.043533 (-0.009595) | 0.282235 / 0.255139 (0.027096) | 0.297432 / 0.283200 (0.014233) | 0.018295 / 0.141683 (-0.123388) | 1.164459 / 1.452155 (-0.287696) | 1.214511 / 1.492716 (-0.278205) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091441 / 0.018006 (0.073435) | 0.303023 / 0.000490 (0.302533) | 0.000211 / 0.000200 (0.000011) | 0.000051 / 0.000054 (-0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022024 / 0.037411 (-0.015388) | 0.075570 / 0.014526 (0.061044) | 0.086761 / 0.176557 (-0.089796) | 0.126437 / 0.737135 (-0.610698) | 0.088354 / 0.296338 (-0.207984) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.289360 / 0.215209 (0.074151) | 2.816433 / 2.077655 (0.738779) | 1.561442 / 1.504120 (0.057322) | 1.438168 / 1.541195 (-0.103027) | 1.453398 / 1.468490 (-0.015092) | 0.579474 / 4.584777 (-4.005303) | 2.458640 / 3.745712 (-1.287072) | 2.638572 / 5.269862 (-2.631290) | 1.725218 / 4.565676 (-2.840458) | 0.063550 / 0.424275 (-0.360725) | 0.005220 / 0.007607 (-0.002387) | 0.338883 / 0.226044 (0.112838) | 3.353585 / 2.268929 (1.084656) | 1.913186 / 55.444624 (-53.531438) | 1.667445 / 6.876477 (-5.209032) | 1.740085 / 2.142072 (-0.401987) | 0.646369 / 4.805227 (-4.158859) | 0.116737 / 6.500664 (-6.383927) | 0.041052 / 0.075469 (-0.034417) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.023180 / 1.841788 (-0.818608) | 12.078398 / 8.074308 (4.004090) | 10.952012 / 10.191392 (0.760620) | 0.131335 / 0.680424 (-0.549089) | 0.015701 / 0.534201 (-0.518499) | 0.289709 / 0.579283 (-0.289574) | 0.270495 / 0.434364 (-0.163869) | 0.331773 / 0.540337 (-0.208565) | 0.417660 / 1.386936 (-0.969276) |\n\n</details>\n</details>\n\n\n"
] | 2024-01-29T21:35:55Z
| 2024-01-30T16:19:45Z
| 2024-01-30T15:12:25Z
|
CONTRIBUTOR
| null | null | null |
Release on Jan 27, 2024: https://pypi.org/project/dill/0.3.8/#history
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6630/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6630/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/6630.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6630",
"merged_at": "2024-01-30T15:12:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6630.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6630"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5748
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5748/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5748/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5748/events
|
https://github.com/huggingface/datasets/pull/5748
| 1,667,517,024
|
PR_kwDODunzps5OSgNH
| 5,748
|
[BUG FIX] Issue 5739
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/1772912?v=4",
"events_url": "https://api.github.com/users/airlsyn/events{/privacy}",
"followers_url": "https://api.github.com/users/airlsyn/followers",
"following_url": "https://api.github.com/users/airlsyn/following{/other_user}",
"gists_url": "https://api.github.com/users/airlsyn/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/airlsyn",
"id": 1772912,
"login": "airlsyn",
"node_id": "MDQ6VXNlcjE3NzI5MTI=",
"organizations_url": "https://api.github.com/users/airlsyn/orgs",
"received_events_url": "https://api.github.com/users/airlsyn/received_events",
"repos_url": "https://api.github.com/users/airlsyn/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/airlsyn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/airlsyn/subscriptions",
"type": "User",
"url": "https://api.github.com/users/airlsyn",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[] | 2023-04-14T05:07:31Z
| 2023-04-14T05:07:31Z
| null |
NONE
| null | null | null |
A fix for https://github.com/huggingface/datasets/issues/5739
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5748/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5748/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5748.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5748",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5748.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5748"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5017
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5017/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5017/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5017/events
|
https://github.com/huggingface/datasets/issues/5017
| 1,384,022,463
|
I_kwDODunzps5SfoG_
| 5,017
|
xcsr: X-CSQA simply uses english for all alleged non-english data
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/26286291?v=4",
"events_url": "https://api.github.com/users/thesofakillers/events{/privacy}",
"followers_url": "https://api.github.com/users/thesofakillers/followers",
"following_url": "https://api.github.com/users/thesofakillers/following{/other_user}",
"gists_url": "https://api.github.com/users/thesofakillers/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thesofakillers",
"id": 26286291,
"login": "thesofakillers",
"node_id": "MDQ6VXNlcjI2Mjg2Mjkx",
"organizations_url": "https://api.github.com/users/thesofakillers/orgs",
"received_events_url": "https://api.github.com/users/thesofakillers/received_events",
"repos_url": "https://api.github.com/users/thesofakillers/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thesofakillers/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thesofakillers/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thesofakillers",
"user_view_type": "public"
}
|
[
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[
"Thanks for reporting, @thesofakillers. Good catch. We are fixing this. "
] | 2022-09-23T16:11:54Z
| 2022-09-26T10:57:31Z
| 2022-09-26T10:57:31Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
## Describe the bug
All the alleged non-english subcollections for the X-CSQA task in the [xcsr benchmark dataset ](https://huggingface.co/datasets/xcsr) seem to be copies of the english subcollection, rather than translations. This is in contrast to the data description:
> we automatically translate the original CSQA and CODAH datasets, which only have English versions, to 15 other languages, forming development and test sets for studying X-CSR
## Steps to reproduce the bug
```python
# let's say you want to load the french X-CSQA subcollection
french = datasets.load_dataset("xcsr", "X-CSQA-fr")
# for good measure, let's load english too
english = datasets.load_dataset("xcsr", "X-CSQA-en")
# let's inspect
"".join(english['test'][0]['question']['stem'])
# output: 'The people wanted to stop the parade, so what did they set up to thwart it?'
"".join(french['test'][0]['question']['stem'])
# output: 'The people wanted to stop the parade, so what did they set up to thwart it?'
# what? Why are they both in english?
# I've checked this for validation and train splits too, across many datapoints. It's all the same english dataset
# maybe i need to look better?
french['test'].unique('lang')
# output: ['en']
# no, it's all english
```
## Expected results
Accessing a subcollection in language X should return a subcollection containg samples in language X
## Actual results
Accessing a subcollection in language X returns a subcollection containing samples in English.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.5.1
- Platform: macOS-10.15.7-x86_64-i386-64bit
- Python version: 3.8.13
- PyArrow version: 9.0.0
- Pandas version: 1.4.3
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5017/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5017/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/7346
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7346/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7346/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7346/events
|
https://github.com/huggingface/datasets/issues/7346
| 2,758,752,118
|
I_kwDODunzps6kbzd2
| 7,346
|
OSError: Invalid flatbuffers message.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/46232487?v=4",
"events_url": "https://api.github.com/users/antecede/events{/privacy}",
"followers_url": "https://api.github.com/users/antecede/followers",
"following_url": "https://api.github.com/users/antecede/following{/other_user}",
"gists_url": "https://api.github.com/users/antecede/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/antecede",
"id": 46232487,
"login": "antecede",
"node_id": "MDQ6VXNlcjQ2MjMyNDg3",
"organizations_url": "https://api.github.com/users/antecede/orgs",
"received_events_url": "https://api.github.com/users/antecede/received_events",
"repos_url": "https://api.github.com/users/antecede/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/antecede/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/antecede/subscriptions",
"type": "User",
"url": "https://api.github.com/users/antecede",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Thanks for reporting, it looks like an issue with `pyarrow.ipc.open_stream`\r\n\r\nCan you try installing `datasets` from this pull request and see if it helps ? https://github.com/huggingface/datasets/pull/7348",
"> Thanks for reporting, it looks like an issue with `pyarrow.ipc.open_stream`\r\n> \r\n> Can you try installing `datasets` from this pull request and see if it helps ? #7348\r\n\r\nThank you very much. Here, it also needed to be changed to `except (OSError, pa.lib.ArrowInvalid):`. And then the bug was fixed.\r\nhttps://github.com/huggingface/datasets/blob/2826a040a05e19fca894253b78a932d4fcb4a584/src/datasets/packaged_modules/arrow/arrow.py#L48",
"Cool ! we will do a new release soon :) in the meantime you can use `datasets` from `main`"
] | 2024-12-25T11:38:52Z
| 2025-01-09T14:25:29Z
| 2025-01-09T14:25:05Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
When loading a large 2D data (1000 × 1152) with a large number of (2,000 data in this case) in `load_dataset`, the error message `OSError: Invalid flatbuffers message` is reported.
When only 300 pieces of data of this size (1000 × 1152) are stored, they can be loaded correctly.
When 2,000 2D arrays are stored in each file, about 100 files are generated, each with a file size of about 5-6GB. But when 300 2D arrays are stored in each file, **about 600 files are generated, which is too many files**.
### Steps to reproduce the bug
error:
```python
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
Cell In[2], line 4
1 from datasets import Dataset
2 from datasets import load_dataset
----> 4 real_dataset = load_dataset("arrow", data_files='tensorData/real_ResidueTensor/*', split="train")#.with_format("torch") # , split="train"
5 # sim_dataset = load_dataset("arrow", data_files='tensorData/sim_ResidueTensor/*', split="train").with_format("torch")
6 real_dataset
File [~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/datasets/load.py:2151](http://localhost:8899/lab/tree/RTC%3Anew_world/esm3/~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/datasets/load.py#line=2150), in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, verification_mode, keep_in_memory, save_infos, revision, token, streaming, num_proc, storage_options, trust_remote_code, **config_kwargs)
2148 return builder_instance.as_streaming_dataset(split=split)
2150 # Download and prepare data
-> 2151 builder_instance.download_and_prepare(
2152 download_config=download_config,
2153 download_mode=download_mode,
2154 verification_mode=verification_mode,
2155 num_proc=num_proc,
2156 storage_options=storage_options,
2157 )
2159 # Build dataset for splits
2160 keep_in_memory = (
2161 keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)
2162 )
File [~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/datasets/builder.py:924](http://localhost:8899/lab/tree/RTC%3Anew_world/esm3/~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/datasets/builder.py#line=923), in DatasetBuilder.download_and_prepare(self, output_dir, download_config, download_mode, verification_mode, dl_manager, base_path, file_format, max_shard_size, num_proc, storage_options, **download_and_prepare_kwargs)
922 if num_proc is not None:
923 prepare_split_kwargs["num_proc"] = num_proc
--> 924 self._download_and_prepare(
925 dl_manager=dl_manager,
926 verification_mode=verification_mode,
927 **prepare_split_kwargs,
928 **download_and_prepare_kwargs,
929 )
930 # Sync info
931 self.info.dataset_size = sum(split.num_bytes for split in self.info.splits.values())
File [~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/datasets/builder.py:978](http://localhost:8899/lab/tree/RTC%3Anew_world/esm3/~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/datasets/builder.py#line=977), in DatasetBuilder._download_and_prepare(self, dl_manager, verification_mode, **prepare_split_kwargs)
976 split_dict = SplitDict(dataset_name=self.dataset_name)
977 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 978 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
980 # Checksums verification
981 if verification_mode == VerificationMode.ALL_CHECKS and dl_manager.record_checksums:
File [~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/datasets/packaged_modules/arrow/arrow.py:47](http://localhost:8899/lab/tree/RTC%3Anew_world/esm3/~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/datasets/packaged_modules/arrow/arrow.py#line=46), in Arrow._split_generators(self, dl_manager)
45 with open(file, "rb") as f:
46 try:
---> 47 reader = pa.ipc.open_stream(f)
48 except pa.lib.ArrowInvalid:
49 reader = pa.ipc.open_file(f)
File [~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/pyarrow/ipc.py:190](http://localhost:8899/lab/tree/RTC%3Anew_world/esm3/~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/pyarrow/ipc.py#line=189), in open_stream(source, options, memory_pool)
171 def open_stream(source, *, options=None, memory_pool=None):
172 """
173 Create reader for Arrow streaming format.
174
(...)
188 A reader for the given source
189 """
--> 190 return RecordBatchStreamReader(source, options=options,
191 memory_pool=memory_pool)
File [~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/pyarrow/ipc.py:52](http://localhost:8899/lab/tree/RTC%3Anew_world/esm3/~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/pyarrow/ipc.py#line=51), in RecordBatchStreamReader.__init__(self, source, options, memory_pool)
50 def __init__(self, source, *, options=None, memory_pool=None):
51 options = _ensure_default_ipc_read_options(options)
---> 52 self._open(source, options=options, memory_pool=memory_pool)
File [~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/pyarrow/ipc.pxi:1006](http://localhost:8899/lab/tree/RTC%3Anew_world/esm3/~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/pyarrow/ipc.pxi#line=1005), in pyarrow.lib._RecordBatchStreamReader._open()
File [~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/pyarrow/error.pxi:155](http://localhost:8899/lab/tree/RTC%3Anew_world/esm3/~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/pyarrow/error.pxi#line=154), in pyarrow.lib.pyarrow_internal_check_status()
File [~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/pyarrow/error.pxi:92](http://localhost:8899/lab/tree/RTC%3Anew_world/esm3/~/miniforge3/envs/esmIne3/lib/python3.12/site-packages/pyarrow/error.pxi#line=91), in pyarrow.lib.check_status()
OSError: Invalid flatbuffers message.
```
reproduce:Here is just an example result, the real 2D matrix is the output of the ESM large model, and the matrix size is approximate
```python
import numpy as np
import pyarrow as pa
random_arrays_list = [np.random.rand(1000, 1152) for _ in range(2000)]
table = pa.Table.from_pydict({
'tensor': [tensor.tolist() for tensor in random_arrays_list]
})
import pyarrow.feather as feather
feather.write_feather(table, 'test.arrow')
from datasets import load_dataset
dataset = load_dataset("arrow", data_files='test.arrow', split="train")
```
### Expected behavior
`load_dataset` load the dataset as normal as `feather.read_feather`
```python
import pyarrow.feather as feather
feather.read_feather('tensorData/real_ResidueTensor/real_tensor_1.arrow')
```
Plus `load_dataset("parquet", data_files='test.arrow', split="train")` works fine
### Environment info
- `datasets` version: 3.2.0
- Platform: Linux-6.8.0-49-generic-x86_64-with-glibc2.39
- Python version: 3.12.3
- `huggingface_hub` version: 0.26.5
- PyArrow version: 18.1.0
- Pandas version: 2.2.3
- `fsspec` version: 2024.9.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7346/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7346/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/7161
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7161/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7161/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7161/events
|
https://github.com/huggingface/datasets/issues/7161
| 2,541,971,931
|
I_kwDODunzps6Xg2nb
| 7,161
|
JSON lines with empty struct raise ArrowTypeError
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] |
closed
| false
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
[
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
] | null |
[] | 2024-09-23T08:48:56Z
| 2024-09-25T04:43:44Z
| 2024-09-23T11:30:07Z
|
MEMBER
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
JSON lines with empty struct raise ArrowTypeError: struct fields don't match or are in the wrong order
See example: https://huggingface.co/datasets/wikimedia/structured-wikipedia/discussions/5
> ArrowTypeError: struct fields don't match or are in the wrong order: Input fields: struct<> output fields: struct<pov_count: int64, update_count: int64, citation_needed_count: int64>
Related to:
- #7159
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7161/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7161/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/5680
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5680/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5680/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5680/events
|
https://github.com/huggingface/datasets/pull/5680
| 1,645,430,103
|
PR_kwDODunzps5NJYNz
| 5,680
|
Fix a description error for interleave_datasets.
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/55624066?v=4",
"events_url": "https://api.github.com/users/QizhiPei/events{/privacy}",
"followers_url": "https://api.github.com/users/QizhiPei/followers",
"following_url": "https://api.github.com/users/QizhiPei/following{/other_user}",
"gists_url": "https://api.github.com/users/QizhiPei/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/QizhiPei",
"id": 55624066,
"login": "QizhiPei",
"node_id": "MDQ6VXNlcjU1NjI0MDY2",
"organizations_url": "https://api.github.com/users/QizhiPei/orgs",
"received_events_url": "https://api.github.com/users/QizhiPei/received_events",
"repos_url": "https://api.github.com/users/QizhiPei/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/QizhiPei/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/QizhiPei/subscriptions",
"type": "User",
"url": "https://api.github.com/users/QizhiPei",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006772 / 0.011353 (-0.004581) | 0.004674 / 0.011008 (-0.006335) | 0.098702 / 0.038508 (0.060194) | 0.028257 / 0.023109 (0.005148) | 0.368008 / 0.275898 (0.092110) | 0.402825 / 0.323480 (0.079345) | 0.005158 / 0.007986 (-0.002828) | 0.003470 / 0.004328 (-0.000858) | 0.075541 / 0.004250 (0.071291) | 0.039755 / 0.037052 (0.002702) | 0.373431 / 0.258489 (0.114942) | 0.410159 / 0.293841 (0.116318) | 0.031355 / 0.128546 (-0.097192) | 0.011632 / 0.075646 (-0.064014) | 0.325475 / 0.419271 (-0.093797) | 0.042574 / 0.043533 (-0.000958) | 0.373629 / 0.255139 (0.118490) | 0.393921 / 0.283200 (0.110721) | 0.084669 / 0.141683 (-0.057013) | 1.459947 / 1.452155 (0.007792) | 1.529593 / 1.492716 (0.036877) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.189994 / 0.018006 (0.171988) | 0.409091 / 0.000490 (0.408602) | 0.003693 / 0.000200 (0.003493) | 0.000072 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024649 / 0.037411 (-0.012762) | 0.097702 / 0.014526 (0.083177) | 0.103650 / 0.176557 (-0.072906) | 0.167141 / 0.737135 (-0.569994) | 0.108460 / 0.296338 (-0.187879) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.429544 / 0.215209 (0.214335) | 4.277106 / 2.077655 (2.199451) | 2.018745 / 1.504120 (0.514625) | 1.814782 / 1.541195 (0.273587) | 1.897030 / 1.468490 (0.428540) | 0.700332 / 4.584777 (-3.884445) | 3.421761 / 3.745712 (-0.323951) | 3.008281 / 5.269862 (-2.261581) | 1.554230 / 4.565676 (-3.011446) | 0.082922 / 0.424275 (-0.341353) | 0.012312 / 0.007607 (0.004705) | 0.527757 / 0.226044 (0.301713) | 5.287450 / 2.268929 (3.018522) | 2.329083 / 55.444624 (-53.115542) | 2.016651 / 6.876477 (-4.859826) | 2.214510 / 2.142072 (0.072437) | 0.807676 / 4.805227 (-3.997551) | 0.151752 / 6.500664 (-6.348912) | 0.066819 / 0.075469 (-0.008651) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.239522 / 1.841788 (-0.602266) | 13.923672 / 8.074308 (5.849364) | 14.317394 / 10.191392 (4.126002) | 0.159379 / 0.680424 (-0.521045) | 0.016537 / 0.534201 (-0.517664) | 0.376808 / 0.579283 (-0.202475) | 0.376351 / 0.434364 (-0.058012) | 0.437124 / 0.540337 (-0.103213) | 0.520589 / 1.386936 (-0.866347) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006892 / 0.011353 (-0.004461) | 0.004671 / 0.011008 (-0.006337) | 0.075841 / 0.038508 (0.037333) | 0.028713 / 0.023109 (0.005604) | 0.345105 / 0.275898 (0.069207) | 0.380694 / 0.323480 (0.057214) | 0.005155 / 0.007986 (-0.002830) | 0.003379 / 0.004328 (-0.000949) | 0.075134 / 0.004250 (0.070883) | 0.039990 / 0.037052 (0.002938) | 0.345540 / 0.258489 (0.087051) | 0.389913 / 0.293841 (0.096072) | 0.032089 / 0.128546 (-0.096458) | 0.011583 / 0.075646 (-0.064063) | 0.085169 / 0.419271 (-0.334102) | 0.041847 / 0.043533 (-0.001686) | 0.341504 / 0.255139 (0.086365) | 0.367582 / 0.283200 (0.084382) | 0.092684 / 0.141683 (-0.048999) | 1.498647 / 1.452155 (0.046492) | 1.549056 / 1.492716 (0.056339) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.228643 / 0.018006 (0.210637) | 0.410680 / 0.000490 (0.410191) | 0.000398 / 0.000200 (0.000198) | 0.000059 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025354 / 0.037411 (-0.012057) | 0.101567 / 0.014526 (0.087041) | 0.108340 / 0.176557 (-0.068217) | 0.157804 / 0.737135 (-0.579332) | 0.113985 / 0.296338 (-0.182354) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.436427 / 0.215209 (0.221218) | 4.359331 / 2.077655 (2.281676) | 2.047877 / 1.504120 (0.543757) | 1.844242 / 1.541195 (0.303047) | 1.924553 / 1.468490 (0.456063) | 0.695986 / 4.584777 (-3.888791) | 3.435571 / 3.745712 (-0.310141) | 1.905189 / 5.269862 (-3.364673) | 1.198542 / 4.565676 (-3.367134) | 0.083386 / 0.424275 (-0.340889) | 0.012442 / 0.007607 (0.004835) | 0.542562 / 0.226044 (0.316517) | 5.416554 / 2.268929 (3.147625) | 2.499496 / 55.444624 (-52.945128) | 2.160658 / 6.876477 (-4.715819) | 2.210535 / 2.142072 (0.068462) | 0.803324 / 4.805227 (-4.001903) | 0.151735 / 6.500664 (-6.348929) | 0.068392 / 0.075469 (-0.007078) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.319915 / 1.841788 (-0.521873) | 14.176755 / 8.074308 (6.102446) | 14.376366 / 10.191392 (4.184974) | 0.141219 / 0.680424 (-0.539204) | 0.017181 / 0.534201 (-0.517020) | 0.383589 / 0.579283 (-0.195694) | 0.389352 / 0.434364 (-0.045012) | 0.474465 / 0.540337 (-0.065873) | 0.563047 / 1.386936 (-0.823889) |\n\n</details>\n</details>\n\n\n"
] | 2023-03-29T09:50:23Z
| 2023-03-30T13:14:19Z
| 2023-03-30T13:07:18Z
|
CONTRIBUTOR
| null | null | null |
There is a description mistake in the annotation of interleave_dataset with "all_exhausted" stopping_strategy.
``` python
d1 = Dataset.from_dict({"a": [0, 1, 2]})
d2 = Dataset.from_dict({"a": [10, 11, 12, 13]})
d3 = Dataset.from_dict({"a": [20, 21, 22, 23, 24]})
dataset = interleave_datasets([d1, d2, d3], stopping_strategy="all_exhausted")
```
According to the interleave way, the correct output of `dataset["a"]` is `[0, 10, 20, 1, 11, 21, 2, 12, 22, 0, 13, 23, 1, 10, 24]`, not `[0, 10, 20, 1, 11, 21, 2, 12, 22, 0, 13, 23, 1, 0, 24]`
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5680/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5680/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/5680.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5680",
"merged_at": "2023-03-30T13:07:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5680.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5680"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7015
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/7015/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/7015/comments
|
https://api.github.com/repos/huggingface/datasets/issues/7015/events
|
https://github.com/huggingface/datasets/pull/7015
| 2,383,151,220
|
PR_kwDODunzps50CJuE
| 7,015
|
add split argument to Generator
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/156736?v=4",
"events_url": "https://api.github.com/users/piercus/events{/privacy}",
"followers_url": "https://api.github.com/users/piercus/followers",
"following_url": "https://api.github.com/users/piercus/following{/other_user}",
"gists_url": "https://api.github.com/users/piercus/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/piercus",
"id": 156736,
"login": "piercus",
"node_id": "MDQ6VXNlcjE1NjczNg==",
"organizations_url": "https://api.github.com/users/piercus/orgs",
"received_events_url": "https://api.github.com/users/piercus/received_events",
"repos_url": "https://api.github.com/users/piercus/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/piercus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/piercus/subscriptions",
"type": "User",
"url": "https://api.github.com/users/piercus",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7015). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"@albertvillanova thanks for the review, please take a look",
"@albertvillanova please take a look",
"Thank you again! Your PR is merged.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005267 / 0.011353 (-0.006086) | 0.003711 / 0.011008 (-0.007297) | 0.062288 / 0.038508 (0.023780) | 0.031357 / 0.023109 (0.008248) | 0.233592 / 0.275898 (-0.042306) | 0.257722 / 0.323480 (-0.065758) | 0.003124 / 0.007986 (-0.004861) | 0.003335 / 0.004328 (-0.000994) | 0.048594 / 0.004250 (0.044344) | 0.043853 / 0.037052 (0.006801) | 0.248589 / 0.258489 (-0.009900) | 0.278474 / 0.293841 (-0.015367) | 0.029573 / 0.128546 (-0.098973) | 0.011779 / 0.075646 (-0.063868) | 0.204989 / 0.419271 (-0.214282) | 0.035734 / 0.043533 (-0.007799) | 0.240064 / 0.255139 (-0.015075) | 0.263105 / 0.283200 (-0.020094) | 0.018764 / 0.141683 (-0.122919) | 1.115705 / 1.452155 (-0.336449) | 1.175457 / 1.492716 (-0.317260) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092664 / 0.018006 (0.074657) | 0.297893 / 0.000490 (0.297403) | 0.000217 / 0.000200 (0.000017) | 0.000047 / 0.000054 (-0.000007) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019056 / 0.037411 (-0.018355) | 0.062472 / 0.014526 (0.047946) | 0.073462 / 0.176557 (-0.103094) | 0.119723 / 0.737135 (-0.617412) | 0.074420 / 0.296338 (-0.221919) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.283131 / 0.215209 (0.067922) | 2.776694 / 2.077655 (0.699039) | 1.455586 / 1.504120 (-0.048534) | 1.323902 / 1.541195 (-0.217293) | 1.333169 / 1.468490 (-0.135321) | 0.723921 / 4.584777 (-3.860856) | 2.385842 / 3.745712 (-1.359870) | 2.926843 / 5.269862 (-2.343018) | 1.896773 / 4.565676 (-2.668903) | 0.079754 / 0.424275 (-0.344521) | 0.005188 / 0.007607 (-0.002419) | 0.342466 / 0.226044 (0.116421) | 3.404204 / 2.268929 (1.135275) | 1.856575 / 55.444624 (-53.588049) | 1.554507 / 6.876477 (-5.321970) | 1.564065 / 2.142072 (-0.578007) | 0.810363 / 4.805227 (-3.994864) | 0.135537 / 6.500664 (-6.365127) | 0.041987 / 0.075469 (-0.033482) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.962288 / 1.841788 (-0.879500) | 11.310837 / 8.074308 (3.236529) | 9.630034 / 10.191392 (-0.561358) | 0.131108 / 0.680424 (-0.549316) | 0.015225 / 0.534201 (-0.518976) | 0.304211 / 0.579283 (-0.275072) | 0.272707 / 0.434364 (-0.161657) | 0.341550 / 0.540337 (-0.198787) | 0.444528 / 1.386936 (-0.942408) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005665 / 0.011353 (-0.005688) | 0.003916 / 0.011008 (-0.007092) | 0.049946 / 0.038508 (0.011438) | 0.031760 / 0.023109 (0.008651) | 0.273826 / 0.275898 (-0.002072) | 0.300193 / 0.323480 (-0.023287) | 0.004350 / 0.007986 (-0.003635) | 0.002749 / 0.004328 (-0.001579) | 0.048451 / 0.004250 (0.044201) | 0.039798 / 0.037052 (0.002746) | 0.284570 / 0.258489 (0.026081) | 0.318855 / 0.293841 (0.025014) | 0.032724 / 0.128546 (-0.095822) | 0.012103 / 0.075646 (-0.063543) | 0.059857 / 0.419271 (-0.359414) | 0.034185 / 0.043533 (-0.009348) | 0.276079 / 0.255139 (0.020940) | 0.294070 / 0.283200 (0.010871) | 0.018168 / 0.141683 (-0.123515) | 1.149681 / 1.452155 (-0.302473) | 1.191349 / 1.492716 (-0.301367) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092676 / 0.018006 (0.074669) | 0.304971 / 0.000490 (0.304481) | 0.000203 / 0.000200 (0.000003) | 0.000050 / 0.000054 (-0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023110 / 0.037411 (-0.014301) | 0.079117 / 0.014526 (0.064591) | 0.087457 / 0.176557 (-0.089099) | 0.128295 / 0.737135 (-0.608840) | 0.089747 / 0.296338 (-0.206592) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.305158 / 0.215209 (0.089949) | 2.992277 / 2.077655 (0.914623) | 1.595369 / 1.504120 (0.091249) | 1.462955 / 1.541195 (-0.078240) | 1.476269 / 1.468490 (0.007779) | 0.731652 / 4.584777 (-3.853124) | 0.961053 / 3.745712 (-2.784659) | 2.800259 / 5.269862 (-2.469602) | 1.881249 / 4.565676 (-2.684428) | 0.079503 / 0.424275 (-0.344772) | 0.005252 / 0.007607 (-0.002355) | 0.354921 / 0.226044 (0.128877) | 3.495272 / 2.268929 (1.226343) | 1.956419 / 55.444624 (-53.488205) | 1.654941 / 6.876477 (-5.221536) | 1.782506 / 2.142072 (-0.359567) | 0.816487 / 4.805227 (-3.988741) | 0.135870 / 6.500664 (-6.364794) | 0.041114 / 0.075469 (-0.034355) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.050346 / 1.841788 (-0.791442) | 12.510129 / 8.074308 (4.435821) | 10.524835 / 10.191392 (0.333443) | 0.152388 / 0.680424 (-0.528036) | 0.016073 / 0.534201 (-0.518128) | 0.301956 / 0.579283 (-0.277327) | 0.126871 / 0.434364 (-0.307493) | 0.339554 / 0.540337 (-0.200783) | 0.435873 / 1.386936 (-0.951064) |\n\n</details>\n</details>\n\n\n"
] | 2024-07-01T08:09:25Z
| 2024-07-26T09:37:51Z
| 2024-07-26T09:31:56Z
|
CONTRIBUTOR
| null | null | null |
## Actual
When creating a multi-split dataset using generators like
```python
datasets.DatasetDict({
"val": datasets.Dataset.from_generator(
generator=generator_val,
features=features
),
"test": datasets.Dataset.from_generator(
generator=generator_test,
features=features,
)
})
```
It displays (for both test and val)
```
Generating train split
```
## Expected
I would like to be able to improve this behavior by doing
```python
datasets.DatasetDict({
"val": datasets.Dataset.from_generator(
generator=generator_val,
features=features,
split="val"
),
"test": datasets.Dataset.from_generator(
generator=generator_test,
features=features,
split="test"
)
})
```
It would display
```
Generating val split
```
and
```
Generating test split
```
## Proposal
Current PR is adding an explicit `split` argument and replace the implicit "train" split in the following classes/function :
* Generator
* from_generator
* AbstractDatasetInputStream
* GeneratorDatasetInputStream
Please share your feedbacks
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7015/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/7015/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/7015.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7015",
"merged_at": "2024-07-26T09:31:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7015.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7015"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5713
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5713/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5713/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5713/events
|
https://github.com/huggingface/datasets/issues/5713
| 1,657,141,251
|
I_kwDODunzps5ixfgD
| 5,713
|
ArrowNotImplementedError when loading dataset from the hub
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi Julien ! This sounds related to https://github.com/huggingface/datasets/issues/5695 - TL;DR: you need to have shards smaller than 2GB to avoid this issue\r\n\r\nThe number of rows per shard is computed using an estimated size of the full dataset, which can sometimes lead to shards bigger than `max_shard_size`. The estimation is currently done using the first samples of the dataset (which can surely be improved). We should probably open an issue to fix this once and for all.\r\n\r\nAnyway for your specific dataset I'd suggest you to pass `num_shards` instead of `max_shard_size` for now, and make sure to have enough shards to end up with shards smaller than 2GB",
"Hi Quentin! Thanks a lot! Using `num_shards` instead of `max_shard_size` works as expected.\r\n\r\nIndeed the way you describe how the size is computed cannot really work with the dataset I'm building as all the image doesn't have the same resolution and then size. Opening an issue on this might be a good idea."
] | 2023-04-06T10:27:22Z
| 2023-04-06T13:06:22Z
| 2023-04-06T13:06:21Z
|
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Hello,
I have created a dataset by using the image loader. Once the dataset is created I try to download it and I get the error:
```
Traceback (most recent call last):
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/builder.py", line 1860, in _prepare_split_single
for _, table in generator:
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/packaged_modules/parquet/parquet.py", line 69, in _generate_tables
for batch_idx, record_batch in enumerate(
File "pyarrow/_parquet.pyx", line 1323, in iter_batches
File "pyarrow/error.pxi", line 121, in pyarrow.lib.check_status
pyarrow.lib.ArrowNotImplementedError: Nested data conversions not implemented for chunked array outputs
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/load.py", line 1791, in load_dataset
builder_instance.download_and_prepare(
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/builder.py", line 891, in download_and_prepare
self._download_and_prepare(
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/builder.py", line 986, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/builder.py", line 1748, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/builder.py", line 1893, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
```
### Steps to reproduce the bug
Create the dataset and push it to the hub:
```python
from datasets import load_dataset
dataset = load_dataset("imagefolder", data_dir="/path/to/dataset")
dataset.push_to_hub("org/dataset-name", private=True, max_shard_size="1GB")
```
Then use it:
```python
from datasets import load_dataset
dataset = load_dataset("org/dataset-name")
```
### Expected behavior
To properly download and use the pushed dataset.
Something else to note is that I specified to have shards of 1GB max, but at the end, for the train set, it is an almost 7GB single file that is pushed.
### Environment info
- `datasets` version: 2.11.0
- Platform: Linux-5.15.90.1-microsoft-standard-WSL2-x86_64-with-glibc2.35
- Python version: 3.10.10
- Huggingface_hub version: 0.13.3
- PyArrow version: 11.0.0
- Pandas version: 2.0.0
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5713/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5713/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6132
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6132/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6132/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6132/events
|
https://github.com/huggingface/datasets/issues/6132
| 1,843,491,020
|
I_kwDODunzps5t4XDM
| 6,132
|
to_iterable_dataset is missing in document
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11533479?v=4",
"events_url": "https://api.github.com/users/npuichigo/events{/privacy}",
"followers_url": "https://api.github.com/users/npuichigo/followers",
"following_url": "https://api.github.com/users/npuichigo/following{/other_user}",
"gists_url": "https://api.github.com/users/npuichigo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/npuichigo",
"id": 11533479,
"login": "npuichigo",
"node_id": "MDQ6VXNlcjExNTMzNDc5",
"organizations_url": "https://api.github.com/users/npuichigo/orgs",
"received_events_url": "https://api.github.com/users/npuichigo/received_events",
"repos_url": "https://api.github.com/users/npuichigo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/npuichigo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/npuichigo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/npuichigo",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Fixed with PR"
] | 2023-08-09T15:15:03Z
| 2023-08-16T04:43:36Z
| 2023-08-16T04:43:29Z
|
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
to_iterable_dataset is missing in document
### Steps to reproduce the bug
to_iterable_dataset is missing in document
### Expected behavior
document enhancement
### Environment info
unrelated
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/11533479?v=4",
"events_url": "https://api.github.com/users/npuichigo/events{/privacy}",
"followers_url": "https://api.github.com/users/npuichigo/followers",
"following_url": "https://api.github.com/users/npuichigo/following{/other_user}",
"gists_url": "https://api.github.com/users/npuichigo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/npuichigo",
"id": 11533479,
"login": "npuichigo",
"node_id": "MDQ6VXNlcjExNTMzNDc5",
"organizations_url": "https://api.github.com/users/npuichigo/orgs",
"received_events_url": "https://api.github.com/users/npuichigo/received_events",
"repos_url": "https://api.github.com/users/npuichigo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/npuichigo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/npuichigo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/npuichigo",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6132/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6132/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6077
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6077/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6077/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6077/events
|
https://github.com/huggingface/datasets/issues/6077
| 1,822,486,810
|
I_kwDODunzps5soPEa
| 6,077
|
Mapping gets stuck at 99%
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/21087104?v=4",
"events_url": "https://api.github.com/users/Laurent2916/events{/privacy}",
"followers_url": "https://api.github.com/users/Laurent2916/followers",
"following_url": "https://api.github.com/users/Laurent2916/following{/other_user}",
"gists_url": "https://api.github.com/users/Laurent2916/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Laurent2916",
"id": 21087104,
"login": "Laurent2916",
"node_id": "MDQ6VXNlcjIxMDg3MTA0",
"organizations_url": "https://api.github.com/users/Laurent2916/orgs",
"received_events_url": "https://api.github.com/users/Laurent2916/received_events",
"repos_url": "https://api.github.com/users/Laurent2916/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Laurent2916/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Laurent2916/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Laurent2916",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"The `MAX_MAP_BATCH_SIZE = 1_000_000_000` hack is bad as it loads the entire dataset into RAM when performing `.map`. Instead, it's best to use `.iter(batch_size)` to iterate over the data batches and compute `mean` for each column. (`stddev` can be computed in another pass).\r\n\r\nAlso, these arrays are big, so it makes sense to reduce `batch_size`/`writer_batch_size` to avoid RAM issues and slow IO.",
"Hi @mariosasko !\r\n\r\nI agree, it's an ugly hack, but it was convenient since the resulting `mean_std` could be cached by the library. For my large dataset (which doesn't fit in RAM), I'm actually using something similar to what you suggested. I got rid of the first mapping in the above scripts and replaced it with an iterator, but the issue with the second mapping still persists.",
"Have you tried to reduce `batch_size`/`writer_batch_size` in the 2nd `.map`? Also, can you interrupt the process when it gets stuck and share the error stack trace?",
"I think `batch_size/writer_batch_size` is already at its lowest in the 2nd `.map` since `batched=False` implies `batch_size=1` and `len(ds) = 1000 = writer_batch_size`.\r\n\r\nHere is also a bunch of stack traces when I interrupted the process:\r\n\r\n<details>\r\n <summary>stack trace 1</summary>\r\n\r\n```python\r\n(pyg)[d623204@rosetta-bigviz01 stage-laurent-f]$ python src/random_scripts/uses_random_data.py \r\nFound cached dataset random_data (/local_scratch/lfainsin/.cache/huggingface/datasets/random_data/default/0.0.0/444e214e1d0e6298cfd3f2368323ec37073dc1439f618e19395b1f421c69b066)\r\nApplying mean/std: 97%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ | 967/1000 [00:01<00:00, 534.87 examples/s]Traceback (most recent call last): \r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 179, in __arrow_array__\r\n storage = to_pyarrow_listarray(data, pa_type)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 1466, in to_pyarrow_listarray\r\n return pa.array(data, pa_type.storage_dtype)\r\n File \"pyarrow/array.pxi\", line 320, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 39, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow/error.pxi\", line 144, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 123, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowTypeError: Could not convert tensor([[-1.0273, -0.8037, -0.6860],\r\n [-0.5034, -1.2685, -0.0558],\r\n [-1.0908, -1.1820, -0.3178],\r\n ...,\r\n [-0.8171, 0.1781, -0.5903],\r\n [ 0.4370, 1.9305, 0.5899],\r\n [-0.1426, 0.9053, -1.7559]]) with type Tensor: was not a sequence or recognized null for conversion to list type\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3449, in _map_single\r\n writer.write(example)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 490, in write\r\n self.write_examples_on_file()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 448, in write_examples_on_file\r\n self.write_batch(batch_examples=batch_examples)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 553, in write_batch\r\n arrays.append(pa.array(typed_sequence))\r\n File \"pyarrow/array.pxi\", line 236, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 110, in pyarrow.lib._handle_arrow_array_protocol\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 223, in __arrow_array__\r\n return pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 446, in cast_to_python_objects\r\n return _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 407, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 408, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 319, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 320, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 263, in _cast_to_python_objects\r\n def _cast_to_python_objects(obj: Any, only_1d_for_numpy: bool, optimize_list_casting: bool) -> Tuple[Any, bool]:\r\nKeyboardInterrupt\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 179, in __arrow_array__\r\n storage = to_pyarrow_listarray(data, pa_type)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 1466, in to_pyarrow_listarray\r\n return pa.array(data, pa_type.storage_dtype)\r\n File \"pyarrow/array.pxi\", line 320, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 39, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow/error.pxi\", line 144, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 123, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowTypeError: Could not convert tensor([[-1.0273, -0.8037, -0.6860],\r\n [-0.5034, -1.2685, -0.0558],\r\n [-1.0908, -1.1820, -0.3178],\r\n ...,\r\n [-0.8171, 0.1781, -0.5903],\r\n [ 0.4370, 1.9305, 0.5899],\r\n [-0.1426, 0.9053, -1.7559]]) with type Tensor: was not a sequence or recognized null for conversion to list type\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/gpfs_new/data/users/lfainsin/stage-laurent-f/src/random_scripts/uses_random_data.py\", line 62, in <module>\r\n ds_normalized = ds.map(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 580, in wrapper\r\n out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 545, in wrapper\r\n out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3087, in map\r\n for rank, done, content in Dataset._map_single(**dataset_kwargs):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3492, in _map_single\r\n writer.finalize()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 584, in finalize\r\n self.write_examples_on_file()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 448, in write_examples_on_file\r\n self.write_batch(batch_examples=batch_examples)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 553, in write_batch\r\n arrays.append(pa.array(typed_sequence))\r\n File \"pyarrow/array.pxi\", line 236, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 110, in pyarrow.lib._handle_arrow_array_protocol\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 223, in __arrow_array__\r\n return pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 446, in cast_to_python_objects\r\n return _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 407, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 408, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 319, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 319, in <listcomp>\r\n [\r\nKeyboardInterrupt\r\n```\r\n\r\n</details>\r\n\r\n<details>\r\n <summary>stack trace 2</summary>\r\n\r\n```python\r\n(pyg)[d623204@rosetta-bigviz01 stage-laurent-f]$ python src/random_scripts/uses_random_data.py \r\nFound cached dataset random_data (/local_scratch/lfainsin/.cache/huggingface/datasets/random_data/default/0.0.0/444e214e1d0e6298cfd3f2368323ec37073dc1439f618e19395b1f421c69b066)\r\nApplying mean/std: 99%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 988/1000 [00:20<00:00, 526.19 examples/s]Applying mean/std: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▊| 999/1000 [00:21<00:00, 9.66 examples/s]Traceback (most recent call last): \r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 179, in __arrow_array__\r\n storage = to_pyarrow_listarray(data, pa_type)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 1466, in to_pyarrow_listarray\r\n return pa.array(data, pa_type.storage_dtype)\r\n File \"pyarrow/array.pxi\", line 320, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 39, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow/error.pxi\", line 144, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 123, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowTypeError: Could not convert tensor([[-1.0273, -0.8037, -0.6860],\r\n [-0.5034, -1.2685, -0.0558],\r\n [-1.0908, -1.1820, -0.3178],\r\n ...,\r\n [-0.8171, 0.1781, -0.5903],\r\n [ 0.4370, 1.9305, 0.5899],\r\n [-0.1426, 0.9053, -1.7559]]) with type Tensor: was not a sequence or recognized null for conversion to list type\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3449, in _map_single\r\n writer.write(example)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 490, in write\r\n self.write_examples_on_file()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 448, in write_examples_on_file\r\n self.write_batch(batch_examples=batch_examples)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 553, in write_batch\r\n arrays.append(pa.array(typed_sequence))\r\n File \"pyarrow/array.pxi\", line 236, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 110, in pyarrow.lib._handle_arrow_array_protocol\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 223, in __arrow_array__\r\n return pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 446, in cast_to_python_objects\r\n return _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 407, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 408, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 319, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 320, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 263, in _cast_to_python_objects\r\n def _cast_to_python_objects(obj: Any, only_1d_for_numpy: bool, optimize_list_casting: bool) -> Tuple[Any, bool]:\r\nKeyboardInterrupt\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 179, in __arrow_array__\r\n storage = to_pyarrow_listarray(data, pa_type)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 1466, in to_pyarrow_listarray\r\n return pa.array(data, pa_type.storage_dtype)\r\n File \"pyarrow/array.pxi\", line 320, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 39, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow/error.pxi\", line 144, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 123, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowTypeError: Could not convert tensor([[-1.0273, -0.8037, -0.6860],\r\n [-0.5034, -1.2685, -0.0558],\r\n [-1.0908, -1.1820, -0.3178],\r\n ...,\r\n [-0.8171, 0.1781, -0.5903],\r\n [ 0.4370, 1.9305, 0.5899],\r\n [-0.1426, 0.9053, -1.7559]]) with type Tensor: was not a sequence or recognized null for conversion to list type\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/gpfs_new/data/users/lfainsin/stage-laurent-f/src/random_scripts/uses_random_data.py\", line 62, in <module>\r\n ds_normalized = ds.map(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 580, in wrapper\r\n out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 545, in wrapper\r\n out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3087, in map\r\n for rank, done, content in Dataset._map_single(**dataset_kwargs):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3492, in _map_single\r\n writer.finalize()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 584, in finalize\r\n self.write_examples_on_file()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 448, in write_examples_on_file\r\n self.write_batch(batch_examples=batch_examples)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 553, in write_batch\r\n arrays.append(pa.array(typed_sequence))\r\n File \"pyarrow/array.pxi\", line 236, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 110, in pyarrow.lib._handle_arrow_array_protocol\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 223, in __arrow_array__\r\n return pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 446, in cast_to_python_objects\r\n return _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 407, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 408, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 319, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 320, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 291, in _cast_to_python_objects\r\n if config.JAX_AVAILABLE and \"jax\" in sys.modules:\r\nKeyboardInterrupt\r\n```\r\n\r\n</details>\r\n\r\n<details>\r\n <summary>stack trace 3</summary>\r\n\r\n```python\r\n(pyg)[d623204@rosetta-bigviz01 stage-laurent-f]$ python src/random_scripts/uses_random_data.py \r\nFound cached dataset random_data (/local_scratch/lfainsin/.cache/huggingface/datasets/random_data/default/0.0.0/444e214e1d0e6298cfd3f2368323ec37073dc1439f618e19395b1f421c69b066)\r\nApplying mean/std: 99%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▎ | 989/1000 [00:01<00:00, 504.80 examples/s]Traceback (most recent call last): \r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 179, in __arrow_array__\r\n storage = to_pyarrow_listarray(data, pa_type)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 1466, in to_pyarrow_listarray\r\n return pa.array(data, pa_type.storage_dtype)\r\n File \"pyarrow/array.pxi\", line 320, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 39, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow/error.pxi\", line 144, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 123, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowTypeError: Could not convert tensor([[-1.0273, -0.8037, -0.6860],\r\n [-0.5034, -1.2685, -0.0558],\r\n [-1.0908, -1.1820, -0.3178],\r\n ...,\r\n [-0.8171, 0.1781, -0.5903],\r\n [ 0.4370, 1.9305, 0.5899],\r\n [-0.1426, 0.9053, -1.7559]]) with type Tensor: was not a sequence or recognized null for conversion to list type\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3449, in _map_single\r\n writer.write(example)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 490, in write\r\n self.write_examples_on_file()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 448, in write_examples_on_file\r\n self.write_batch(batch_examples=batch_examples)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 553, in write_batch\r\n arrays.append(pa.array(typed_sequence))\r\n File \"pyarrow/array.pxi\", line 236, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 110, in pyarrow.lib._handle_arrow_array_protocol\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 223, in __arrow_array__\r\n return pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 446, in cast_to_python_objects\r\n return _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 407, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 408, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 319, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 320, in <listcomp>\r\n _cast_to_python_objects(\r\nKeyboardInterrupt\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 179, in __arrow_array__\r\n storage = to_pyarrow_listarray(data, pa_type)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 1466, in to_pyarrow_listarray\r\n return pa.array(data, pa_type.storage_dtype)\r\n File \"pyarrow/array.pxi\", line 320, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 39, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow/error.pxi\", line 144, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 123, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowTypeError: Could not convert tensor([[-1.0273, -0.8037, -0.6860],\r\n [-0.5034, -1.2685, -0.0558],\r\n [-1.0908, -1.1820, -0.3178],\r\n ...,\r\n [-0.8171, 0.1781, -0.5903],\r\n [ 0.4370, 1.9305, 0.5899],\r\n [-0.1426, 0.9053, -1.7559]]) with type Tensor: was not a sequence or recognized null for conversion to list type\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/gpfs_new/data/users/lfainsin/stage-laurent-f/src/random_scripts/uses_random_data.py\", line 62, in <module>\r\n ds_normalized = ds.map(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 580, in wrapper\r\n out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 545, in wrapper\r\n out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3087, in map\r\n for rank, done, content in Dataset._map_single(**dataset_kwargs):\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_dataset.py\", line 3492, in _map_single\r\n writer.finalize()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 584, in finalize\r\n self.write_examples_on_file()\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 448, in write_examples_on_file\r\n self.write_batch(batch_examples=batch_examples)\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 553, in write_batch\r\n arrays.append(pa.array(typed_sequence))\r\n File \"pyarrow/array.pxi\", line 236, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 110, in pyarrow.lib._handle_arrow_array_protocol\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/arrow_writer.py\", line 223, in __arrow_array__\r\n return pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 446, in cast_to_python_objects\r\n return _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 407, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 408, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 319, in _cast_to_python_objects\r\n [\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 320, in <listcomp>\r\n _cast_to_python_objects(\r\n File \"/local_scratch/lfainsin/.conda/envs/pyg/lib/python3.10/site-packages/datasets/features/features.py\", line 298, in _cast_to_python_objects\r\n if obj.ndim == 0:\r\nKeyboardInterrupt\r\n```\r\n\r\n</details>\r\n",
"Same issue by following code:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\nfrom torchvision.transforms import transforms\r\n\r\npath = \"~/dataset/diffusiondb50k\" # path maybe not necessary\r\ndataset = load_dataset(\"poloclub/diffusiondb\", \"2m_first_1k\", data_dir=path)\r\n\r\ntransform = transforms.Compose([transforms.ToTensor()])\r\ndataset = dataset.map(\r\n lambda x: {\r\n 'image': transform(x['image']),\r\n 'prompt': x['prompt'],\r\n 'width': x['width'],\r\n 'height': x['height'],\r\n }, \r\n # num_proc=4,\r\n)\r\ndataset\r\n```\r\n\r\nAnd the `dataset.map()` stucks at `Map: 99% 986/1000 [00:07<00:00, 145.72 examples/s]`.\r\n\r\nAlso, there is 1 process left in `htop` with 100% CPU usage. And if I add `num_proc=4,`, there will be 4 same processes left.\r\n\r\n### Environment Info\r\n\r\n- `datasets` version: 2.15.0\r\n- Python version: 3.12.2\r\n- Platform: Linux-6.8.0-36-generic-x86_64-with-glibc2.39",
"Hi @zmoki688, I've noticed since that it's pretty common for disk writes to lag behind the operations performed by the `map` operator (especially when the data is large and the operations are cheap). Since the progress bar doesn't seem to account for the writes, it speeds up to 99% but wait until all writes are done. At least that's what I think happens when monitoring my disks I/O (with `iotop` and the likes)"
] | 2023-07-26T14:00:40Z
| 2024-07-22T12:28:06Z
| null |
CONTRIBUTOR
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
Hi !
I'm currently working with a large (~150GB) unnormalized dataset at work.
The dataset is available on a read-only filesystem internally, and I use a [loading script](https://huggingface.co/docs/datasets/dataset_script) to retreive it.
I want to normalize the features of the dataset, meaning I need to compute the mean and standard deviation metric for each feature of the entire dataset. I cannot load the entire dataset to RAM as it is too big, so following [this discussion on the huggingface discourse](https://discuss.huggingface.co/t/copy-columns-in-a-dataset-and-compute-statistics-for-a-column/22157) I am using a [map operation](https://huggingface.co/docs/datasets/v2.14.0/en/package_reference/main_classes#datasets.Dataset.map) to first compute the metrics and a second map operation to apply them on the dataset.
The problem lies in the second mapping, as it gets stuck at ~99%. By checking what the process does (using `htop` and `strace`) it seems to be doing a lot of I/O operations, and I'm not sure why.
Obviously, I could always normalize the dataset externally and then load it using a loading script. However, since the internal dataset is updated fairly frequently, using the library to perform normalization automatically would make it much easier for me.
### Steps to reproduce the bug
I'm able to reproduce the problem using the following scripts:
```python
# random_data.py
import datasets
import torch
_VERSION = "1.0.0"
class RandomDataset(datasets.GeneratorBasedBuilder):
def _info(self):
return datasets.DatasetInfo(
version=_VERSION,
supervised_keys=None,
features=datasets.Features(
{
"positions": datasets.Array2D(
shape=(30000, 3),
dtype="float32",
),
"normals": datasets.Array2D(
shape=(30000, 3),
dtype="float32",
),
"features": datasets.Array2D(
shape=(30000, 6),
dtype="float32",
),
"scalars": datasets.Sequence(
feature=datasets.Value("float32"),
length=20,
),
},
),
)
def _split_generators(self, dl_manager):
return [
datasets.SplitGenerator(
name=datasets.Split.TRAIN, # type: ignore
gen_kwargs={"nb_samples": 1000},
),
datasets.SplitGenerator(
name=datasets.Split.TEST, # type: ignore
gen_kwargs={"nb_samples": 100},
),
]
def _generate_examples(self, nb_samples: int):
for idx in range(nb_samples):
yield idx, {
"positions": torch.randn(30000, 3),
"normals": torch.randn(30000, 3),
"features": torch.randn(30000, 6),
"scalars": torch.randn(20),
}
```
```python
# main.py
import datasets
import torch
def apply_mean_std(
dataset: datasets.Dataset,
means: dict[str, torch.Tensor],
stds: dict[str, torch.Tensor],
) -> dict[str, torch.Tensor]:
"""Normalize the dataset using the mean and standard deviation of each feature.
Args:
dataset (`Dataset`): A huggingface dataset.
mean (`dict[str, Tensor]`): A dictionary containing the mean of each feature.
std (`dict[str, Tensor]`): A dictionary containing the standard deviation of each feature.
Returns:
dict: A dictionary containing the normalized dataset.
"""
result = {}
for key in means.keys():
# extract data from dataset
data: torch.Tensor = dataset[key] # type: ignore
# extract mean and std from dict
mean = means[key] # type: ignore
std = stds[key] # type: ignore
# normalize data
normalized_data = (data - mean) / std
result[key] = normalized_data
return result
# get dataset
ds = datasets.load_dataset(
path="random_data.py",
split="train",
).with_format("torch")
# compute mean (along last axis)
means = {key: torch.zeros(ds[key][0].shape[-1]) for key in ds.column_names}
means_sq = {key: torch.zeros(ds[key][0].shape[-1]) for key in ds.column_names}
for batch in ds.iter(batch_size=8):
for key in ds.column_names:
data = batch[key]
batch_size = data.shape[0]
data = data.reshape(-1, data.shape[-1])
means[key] += data.mean(dim=0) / len(ds) * batch_size
means_sq[key] += (data**2).mean(dim=0) / len(ds) * batch_size
# compute std (along last axis)
stds = {key: torch.sqrt(means_sq[key] - means[key] ** 2) for key in ds.column_names}
# normalize each feature of the dataset
ds_normalized = ds.map(
desc="Applying mean/std", # type: ignore
function=apply_mean_std,
batched=False,
fn_kwargs={
"means": means,
"stds": stds,
},
)
```
### Expected behavior
Using the previous scripts, the `ds_normalized` mapping completes in ~5 minutes, but any subsequent use of `ds_normalized` is really really slow, for example reapplying `apply_mean_std` to `ds_normalized` takes forever. This is very strange, I'm sure I must be missing something, but I would still expect this to be faster.
### Environment info
- `datasets` version: 2.13.1
- Platform: Linux-3.10.0-1160.66.1.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.10.12
- Huggingface_hub version: 0.15.1
- PyArrow version: 12.0.0
- Pandas version: 2.0.2
| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6077/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6077/timeline
| null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5778
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5778/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5778/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5778/events
|
https://github.com/huggingface/datasets/issues/5778
| 1,678,125,951
|
I_kwDODunzps5kBit_
| 5,778
|
Schrödinger's dataset_dict
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/902005?v=4",
"events_url": "https://api.github.com/users/liujuncn/events{/privacy}",
"followers_url": "https://api.github.com/users/liujuncn/followers",
"following_url": "https://api.github.com/users/liujuncn/following{/other_user}",
"gists_url": "https://api.github.com/users/liujuncn/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/liujuncn",
"id": 902005,
"login": "liujuncn",
"node_id": "MDQ6VXNlcjkwMjAwNQ==",
"organizations_url": "https://api.github.com/users/liujuncn/orgs",
"received_events_url": "https://api.github.com/users/liujuncn/received_events",
"repos_url": "https://api.github.com/users/liujuncn/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/liujuncn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/liujuncn/subscriptions",
"type": "User",
"url": "https://api.github.com/users/liujuncn",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Hi ! Passing `data_files=\"path/test.json\"` is equivalent to `data_files={\"train\": [\"path/test.json\"]}`, that's why you end up with a train split. If you don't pass `data_files=`, then split names are inferred from the data files names"
] | 2023-04-21T08:38:12Z
| 2023-07-24T15:15:14Z
| 2023-07-24T15:15:14Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
If you use load_dataset('json', data_files="path/test.json"), it will return DatasetDict({train:...}).
And if you use load_dataset("path"), it will return DatasetDict({test:...}).
Why can't the output behavior be unified?
### Steps to reproduce the bug
as description above.
### Expected behavior
consistent predictable output.
### Environment info
'2.11.0'
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5778/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5778/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/6440
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/6440/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/6440/comments
|
https://api.github.com/repos/huggingface/datasets/issues/6440/events
|
https://github.com/huggingface/datasets/issues/6440
| 2,004,509,301
|
I_kwDODunzps53emJ1
| 6,440
|
`.map` not hashing under python 3.9
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/9058204?v=4",
"events_url": "https://api.github.com/users/changyeli/events{/privacy}",
"followers_url": "https://api.github.com/users/changyeli/followers",
"following_url": "https://api.github.com/users/changyeli/following{/other_user}",
"gists_url": "https://api.github.com/users/changyeli/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/changyeli",
"id": 9058204,
"login": "changyeli",
"node_id": "MDQ6VXNlcjkwNTgyMDQ=",
"organizations_url": "https://api.github.com/users/changyeli/orgs",
"received_events_url": "https://api.github.com/users/changyeli/received_events",
"repos_url": "https://api.github.com/users/changyeli/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/changyeli/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/changyeli/subscriptions",
"type": "User",
"url": "https://api.github.com/users/changyeli",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"Tried to upgrade Python to 3.11 - still get this message. A partial solution is to NOT use `num_proc` at all. It will be considerably longer to finish the job.",
"Hi! The `model = torch.compile(model)` line is problematic for our hashing logic. We would have to merge https://github.com/huggingface/datasets/pull/5867 to support hashing `torch.compile`-ed models/functions. \r\n\r\nI've started refactoring the hashing logic and plan to incorporate a fix for `torch.compile` as part of it, so this should be addressed soon (probably this or next week). "
] | 2023-11-21T15:14:54Z
| 2023-11-28T16:29:33Z
| 2023-11-28T16:29:33Z
|
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
### Describe the bug
The `.map` function cannot hash under python 3.9. Tried to use [the solution here](https://github.com/huggingface/datasets/issues/4521#issuecomment-1205166653), but still get the same message:
`Parameter 'function'=<function map_to_pred at 0x7fa0b49ead30> of the transform datasets.arrow_dataset.Dataset._map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed.`
### Steps to reproduce the bug
```python
def map_to_pred(batch):
"""
Perform inference on an audio batch
Parameters:
batch (dict): A dictionary containing audio data and other related information.
Returns:
dict: The input batch dictionary with added prediction and transcription fields.
"""
audio = batch['audio']
input_features = processor(
audio['array'], sampling_rate=audio['sampling_rate'], return_tensors="pt").input_features
input_features = input_features.to('cuda')
with torch.no_grad():
predicted_ids = model.generate(input_features)
preds = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
batch['prediction'] = processor.tokenizer._normalize(preds)
batch["transcription"] = processor.tokenizer._normalize(batch['transcription'])
return batch
MODEL_CARD = "openai/whisper-small"
MODEL_NAME = MODEL_CARD.rsplit('/', maxsplit=1)[-1]
model = WhisperForConditionalGeneration.from_pretrained(MODEL_CARD)
processor = AutoProcessor.from_pretrained(
MODEL_CARD, language="english", task="transcribe")
model = torch.compile(model)
dt = load_dataset("audiofolder", data_dir=config['DATA']['dataset'], split="test")
dt = dt.cast_column("audio", Audio(sampling_rate=16000))
result = coraal_dt.map(map_to_pred, num_proc=16)
```
### Expected behavior
Hashed and cached dataset starts inferencing
### Environment info
- `transformers` version: 4.35.0
- Platform: Linux-5.14.0-284.30.1.el9_2.x86_64-x86_64-with-glibc2.34
- Python version: 3.9.18
- Huggingface_hub version: 0.17.3
- Safetensors version: 0.4.0
- Accelerate version: 0.24.1
- Accelerate config: not found
- PyTorch version (GPU?): 2.1.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6440/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/6440/timeline
| null |
completed
| null | null |
https://api.github.com/repos/huggingface/datasets/issues/4541
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4541/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4541/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4541/events
|
https://github.com/huggingface/datasets/pull/4541
| 1,280,161,436
|
PR_kwDODunzps46HyPK
| 4,541
|
Fix timestamp conversion from Pandas to Python datetime in streaming mode
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
[] |
closed
| false
| null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"CI failures are unrelated to this PR, merging"
] | 2022-06-22T13:40:01Z
| 2022-06-22T16:39:27Z
| 2022-06-22T16:29:09Z
|
MEMBER
| null | null | null |
Arrow accepts both pd.Timestamp and datetime.datetime objects to create timestamp arrays.
However a timestamp array is always converted to datetime.datetime objects.
This created an inconsistency between streaming in non-streaming. e.g. the `ett` dataset outputs datetime.datetime objects in non-streaming but pd.timestamp in streaming.
I fixed this by always converting pd.Timestamp to datetime.datetime during the example encoding step.
I fixed the same issue for pd.Timedelta as well. Finally I added an extra step of conversion for Series and DataFrame to take this into account in case such data are passed as Series or DataFrame.
Fix https://github.com/huggingface/datasets/issues/4533
Related to https://github.com/huggingface/datasets-server/issues/397
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
}
|
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4541/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/4541/timeline
| null | null | 0
|
{
"diff_url": "https://github.com/huggingface/datasets/pull/4541.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4541",
"merged_at": "2022-06-22T16:29:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4541.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4541"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5242
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5242/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5242/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5242/events
|
https://github.com/huggingface/datasets/issues/5242
| 1,449,069,382
|
I_kwDODunzps5WXwtG
| 5,242
|
Failed Data Processing upon upload with zip file full of images
|
{
"avatar_url": "https://avatars.githubusercontent.com/u/82735473?v=4",
"events_url": "https://api.github.com/users/scrambled2/events{/privacy}",
"followers_url": "https://api.github.com/users/scrambled2/followers",
"following_url": "https://api.github.com/users/scrambled2/following{/other_user}",
"gists_url": "https://api.github.com/users/scrambled2/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/scrambled2",
"id": 82735473,
"login": "scrambled2",
"node_id": "MDQ6VXNlcjgyNzM1NDcz",
"organizations_url": "https://api.github.com/users/scrambled2/orgs",
"received_events_url": "https://api.github.com/users/scrambled2/received_events",
"repos_url": "https://api.github.com/users/scrambled2/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/scrambled2/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/scrambled2/subscriptions",
"type": "User",
"url": "https://api.github.com/users/scrambled2",
"user_view_type": "public"
}
|
[] |
open
| false
| null |
[] | null |
[
"cc @abhishekkrthakur @SBrandeis "
] | 2022-11-15T02:47:52Z
| 2022-11-15T17:59:23Z
| null |
NONE
| null | null |
{
"completed": 0,
"percent_completed": 0,
"total": 0
}
|
I went to autotrain and under image classification arrived where it was time to prepare my dataset. Screenshot below

I chose the method 2 option. I have a csv file with two columns. ~23,000 files.
I uploaded this and chose the image_relpath, and target columns.
The image uploader said that I could only upload 10,000 singular images at a time so the 2nd option was to zip the images up and upload a zip archive which I did.
That all uploaded.
Now I have the message below. It appears the zip archive does just uncompress on the Hugging Face end?
What am I missing here?

| null |
{
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5242/reactions"
}
|
https://api.github.com/repos/huggingface/datasets/issues/5242/timeline
| null | null | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.