|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
""" |
|
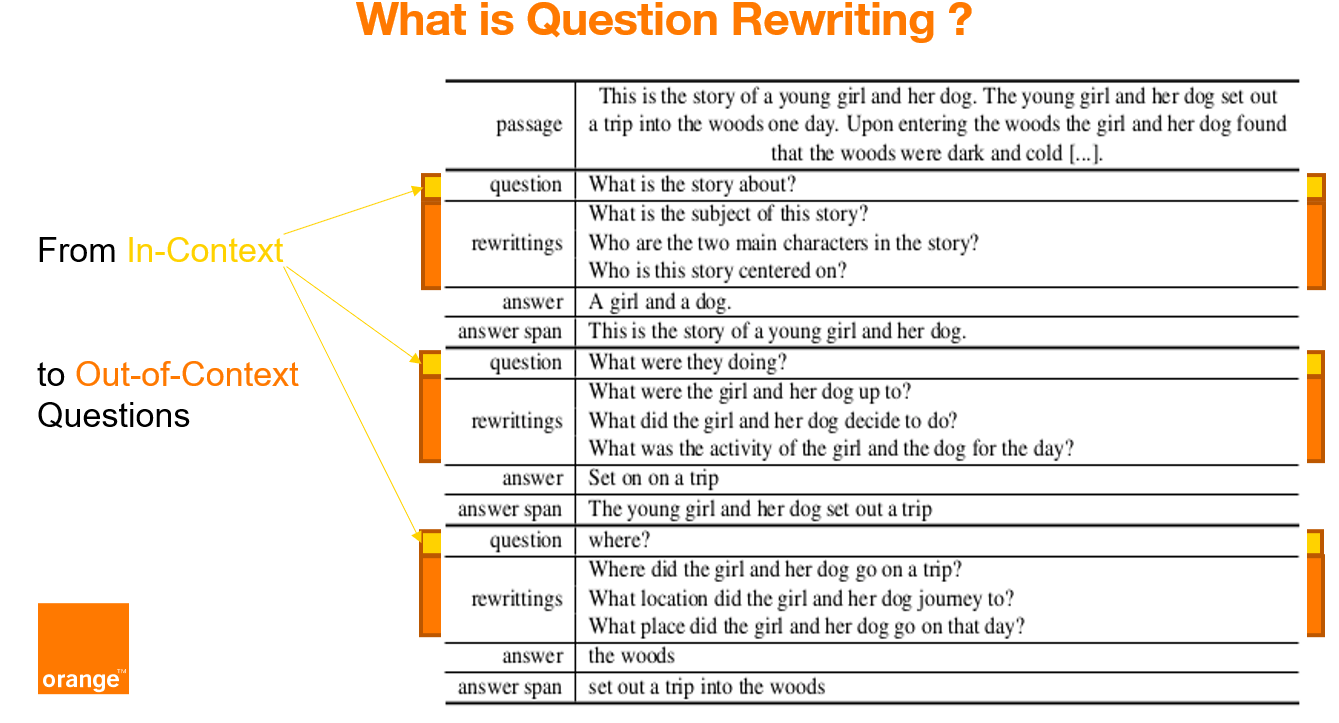
CoQAR is a corpus containing 4.5K conversations from the open-source dataset [Conversational Question-Answering dataset CoQA](https://stanfordnlp.github.io/coqa/), for a total of 53K follow-up question-answer pairs. |
|
In CoQAR each original question was manually annotated with at least 2 at most 3 out-of-context rewritings. |
|
COQAR can be used for (at least) three NLP tasks: question paraphrasing, question rewriting and conversational question answering. |
|
|
|
We annotated each original question of CoQA with at least 2 at most 3 out-of-context rewritings. |
|
|
|
 |
|
|
|
The annotations are published under the licence CC-BY-SA 4.0. |
|
The original content of the dataset CoQA is under the distinct licences described below. |
|
|
|
The corpus CoQA contains passages from seven domains, which are public under the following licenses: |
|
- Literature and Wikipedia passages are shared under CC BY-SA 4.0 license. |
|
- Children's stories are collected from MCTest which comes with MSR-LA license. |
|
- Middle/High school exam passages are collected from RACE which comes with its own license. |
|
- News passages are collected from the DeepMind CNN dataset which comes with Apache license (see [K. M. Hermann, T. Kočiský and E. Grefenstette, L. Espeholt, W. Kay, M. Suleyman, P. Blunsom, Teaching Machines to Read and Comprehend. Advances in Neural Information Processing Systems (NIPS), 2015](http://arxiv.org/abs/1506.03340)). |
|
""" |
|
|
|
|
|
import csv |
|
import json |
|
import os |
|
|
|
import datasets |
|
|
|
_CITATION = """\ |
|
@inproceedings{brabant-etal-2022-coqar, |
|
title = "{C}o{QAR}: Question Rewriting on {C}o{QA}", |
|
author = "Brabant, Quentin and |
|
Lecorv{\'e}, Gw{\'e}nol{\'e} and |
|
Rojas Barahona, Lina M.", |
|
booktitle = "Proceedings of the Thirteenth Language Resources and Evaluation Conference", |
|
month = jun, |
|
year = "2022", |
|
address = "Marseille, France", |
|
publisher = "European Language Resources Association", |
|
url = "https://aclanthology.org/2022.lrec-1.13", |
|
pages = "119--126" |
|
} |
|
""" |
|
|
|
_DESCRIPTION = """\ |
|
CoQAR is a corpus containing 4.5K conversations from the open-source dataset [Conversational Question-Answering dataset CoQA](https://stanfordnlp.github.io/coqa/), for a total of 53K follow-up question-answer pairs. |
|
In CoQAR each original question was manually annotated with at least 2 at most 3 out-of-context rewritings. |
|
COQAR can be used for (at least) three NLP tasks: question paraphrasing, question rewriting and conversational question answering. |
|
|
|
We annotated each original question of CoQA with at least 2 at most 3 out-of-context rewritings. |
|
|
|
 |
|
|
|
The annotations are published under the licence CC-BY-SA 4.0. |
|
The original content of the dataset CoQA is under the distinct licences described below. |
|
|
|
The corpus CoQA contains passages from seven domains, which are public under the following licenses: |
|
- Literature and Wikipedia passages are shared under CC BY-SA 4.0 license. |
|
- Children's stories are collected from MCTest which comes with MSR-LA license. |
|
- Middle/High school exam passages are collected from RACE which comes with its own license. |
|
- News passages are collected from the DeepMind CNN dataset which comes with Apache license (see [K. M. Hermann, T. Kočiský and E. Grefenstette, L. Espeholt, W. Kay, M. Suleyman, P. Blunsom, Teaching Machines to Read and Comprehend. Advances in Neural Information Processing Systems (NIPS), 2015](http://arxiv.org/abs/1506.03340)). |
|
""" |
|
|
|
_HOMEPAGE = "https://github.com/Orange-OpenSource/COQAR/" |
|
|
|
_LICENSE = """ |
|
- Annotations, litterature and Wikipedia passages: licence CC-BY-SA 4.0. |
|
- Children's stories are from MCTest (MSR-LA license). |
|
- Exam passages come from RACE which has its own license. |
|
- News passages are from the DeepMind CNN dataset (Apache license). |
|
""" |
|
|
|
_URLS = { |
|
"train": "https://raw.githubusercontent.com/Orange-OpenSource/COQAR/master/data/CoQAR/train/coqar-train-v1.0.json", |
|
"dev": "https://raw.githubusercontent.com/Orange-OpenSource/COQAR/master/data/CoQAR/dev/coqar-dev-v1.0.json" |
|
} |
|
|
|
|
|
class CoQAR(datasets.GeneratorBasedBuilder): |
|
""" |
|
CoQAR is a corpus containing 4.5K conversations from the open-source dataset [Conversational Question-Answering dataset CoQA](https://stanfordnlp.github.io/coqa/), for a total of 53K follow-up question-answer pairs. |
|
In CoQAR each original question was manually annotated with at least 2 at most 3 out-of-context rewritings. |
|
COQAR can be used for (at least) three NLP tasks: question paraphrasing, question rewriting and conversational question answering. |
|
""" |
|
|
|
VERSION = datasets.Version("1.1.0") |
|
|
|
def _info(self): |
|
features = datasets.Features( |
|
{ |
|
'conversation_id' : datasets.Value("string"), |
|
'turn_id': datasets.Value("int16"), |
|
'original_question' : datasets.Value("string"), |
|
'question_paraphrases' : datasets.Sequence(feature=datasets.Value("string")), |
|
'answer' : datasets.Value("string"), |
|
'answer_span_start' : datasets.Value("int32"), |
|
'answer_span_end' : datasets.Value("int32"), |
|
'answer_span_text' : datasets.Value("string"), |
|
'conversation_history' : datasets.Sequence(feature=datasets.Value("string")), |
|
'file_name' : datasets.Value("string"), |
|
'story': datasets.Value("string"), |
|
'name': datasets.Value("string"), |
|
} |
|
) |
|
|
|
return datasets.DatasetInfo( |
|
|
|
description=_DESCRIPTION, |
|
|
|
features=features, |
|
homepage=_HOMEPAGE, |
|
|
|
license=_LICENSE, |
|
|
|
citation=_CITATION, |
|
) |
|
|
|
def _split_generators(self, dl_manager): |
|
data_dir = dl_manager.download_and_extract(_URLS) |
|
|
|
return [ |
|
datasets.SplitGenerator( |
|
name=datasets.Split.TRAIN, |
|
gen_kwargs={ |
|
"filepath": data_dir['train'], |
|
"split": "train", |
|
}, |
|
), |
|
datasets.SplitGenerator( |
|
name=datasets.Split.VALIDATION, |
|
gen_kwargs={ |
|
"filepath": data_dir['dev'], |
|
"split": "dev", |
|
}, |
|
) |
|
] |
|
|
|
|
|
def _generate_examples(self, filepath, split): |
|
with open(filepath, 'r') as f: |
|
dic = json.load(f) |
|
i = 0 |
|
for datum in dic['data']: |
|
history = [] |
|
for question, answer in zip(datum['questions'], datum['answers']): |
|
yield i, { |
|
'conversation_id' : datum['id'], |
|
'turn_id': question['turn_id'], |
|
'original_question' :question['input_text'], |
|
'question_paraphrases' : question['paraphrase'], |
|
'answer' : answer['input_text'], |
|
'answer_span_start' : answer['span_start'], |
|
'answer_span_end' : answer['span_end'], |
|
'answer_span_text' : answer['span_text'], |
|
'conversation_history' : list(history), |
|
'file_name' : datum['filename'], |
|
'story': datum['story'], |
|
'name': datum['name'] |
|
} |
|
history.append(question['input_text']) |
|
history.append(answer['input_text']) |
|
i+=1 |

