

Update markdown/unit1/01_introduction_to_diffusers_CN.md
Browse files
markdown/unit1/01_introduction_to_diffusers_CN.md
CHANGED
|
@@ -8,9 +8,9 @@
|
|
| 8 |
|
| 9 |
## 你将学习到
|
| 10 |
|
| 11 |
-
在这个 Notebook
|
| 12 |
|
| 13 |
-
-
|
| 14 |
- 通过以下方式创建你自己的迷你管线:
|
| 15 |
- 复习扩散模型的核心概念
|
| 16 |
- 从 Hub 中加载数据以进行训练
|
|
@@ -131,7 +131,7 @@ allowfullscreen
|
|
| 131 |
|
| 132 |
这是一个使用了 [这个模型](https://huggingface.co/sd-dreambooth-library/mr-potato-head) 的例子。该模型的训练仅仅使用了 5 张著名的儿童玩具 "Mr Potato Head"的照片。
|
| 133 |
|
| 134 |
-
|
| 135 |
|
| 136 |
|
| 137 |
```python
|
|
@@ -150,7 +150,7 @@ pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float
|
|
| 150 |
Fetching 15 files: 0%| | 0/15 [00:00<?, ?it/s]
|
| 151 |
|
| 152 |
|
| 153 |
-
|
| 154 |
|
| 155 |
|
| 156 |
```python
|
|
@@ -172,17 +172,17 @@ image
|
|
| 172 |
|
| 173 |
|
| 174 |
|
| 175 |
-
**练习:** 你可以使用不同的提示 (prompt)
|
| 176 |
|
| 177 |
-
|
| 178 |
|
| 179 |
-
## MVP (
|
| 180 |
🤗 Diffusers 的核心 API 被分为三个主要部分:
|
| 181 |
-
1.
|
| 182 |
2. **模型**: 训练新的扩散模型时用到的主流网络架构,*e.g.* [UNet](https://arxiv.org/abs/1505.04597).
|
| 183 |
3. **管理器 (or 调度器)**: 在 *推理* 中使用多种不同的技巧来从噪声中生成图像,同时也可以生成在 *训练* 中所需的带噪图像。
|
| 184 |
|
| 185 |
-
|
| 186 |
|
| 187 |
|
| 188 |
```python
|
|
@@ -217,19 +217,21 @@ make_grid(images)
|
|
| 217 |
|
| 218 |
|
| 219 |
|
| 220 |
-
|
|
|
|
|
|
|
| 221 |
|
| 222 |
1. 从训练集中加载一些图像
|
| 223 |
-
2.
|
| 224 |
-
3.
|
| 225 |
4. 评估模型在对这些数据做增强去噪时的表现
|
| 226 |
5. 使用这个信息来更新模型权重,然后重��此步骤
|
| 227 |
|
| 228 |
-
|
| 229 |
|
| 230 |
## 步骤 2:下载一个训练数据集
|
| 231 |
|
| 232 |
-
在这个例子中,我们会用到一个来自 Hugging Face Hub 的图像集。具体来说,[是个 1000 张蝴蝶图像收藏集](https://huggingface.co/datasets/huggan/smithsonian_butterflies_subset).
|
| 233 |
|
| 234 |
|
| 235 |
```python
|
|
@@ -271,7 +273,7 @@ train_dataloader = torch.utils.data.DataLoader(
|
|
| 271 |
)
|
| 272 |
```
|
| 273 |
|
| 274 |
-
|
| 275 |
|
| 276 |
|
| 277 |
```python
|
|
@@ -295,14 +297,13 @@ show_images(xb).resize((8 * 64, 64), resample=Image.NEAREST)
|
|
| 295 |
|
| 296 |
|
| 297 |
|
| 298 |
-
|
| 299 |
-
我们在此篇笔记中使用一个只有 32 像素的小图片集来保证训练时长是可控的。
|
| 300 |
|
| 301 |
## 步骤 3:定义管理器
|
| 302 |
|
| 303 |
-
|
| 304 |
|
| 305 |
-
|
| 306 |
|
| 307 |
|
| 308 |
```python
|
|
@@ -311,7 +312,7 @@ from diffusers import DDPMScheduler
|
|
| 311 |
noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
|
| 312 |
```
|
| 313 |
|
| 314 |
-
DDPM
|
| 315 |
|
| 316 |
$q (\mathbf {x}_t \vert \mathbf {x}_{t-1}) = \mathcal {N}(\mathbf {x}_t; \sqrt {1 - \beta_t} \mathbf {x}_{t-1}, \beta_t\mathbf {I}) \quad
|
| 317 |
q (\mathbf {x}_{1:T} \vert \mathbf {x}_0) = \prod^T_{t=1} q (\mathbf {x}_t \vert \mathbf {x}_{t-1})$<br><br>
|
|
@@ -323,7 +324,7 @@ $\begin {aligned}
|
|
| 323 |
q (\mathbf {x}_t \vert \mathbf {x}_0) &= \mathcal {N}(\mathbf {x}_t; \sqrt {\bar {\alpha}_t} \mathbf {x}_0, {(1 - \bar {\alpha}_t)} \mathbf {I})
|
| 324 |
\end {aligned}$ where $\bar {\alpha}_t = \prod_{i=1}^T \alpha_i$ and $\alpha_i = 1-\beta_i$<br><br>
|
| 325 |
|
| 326 |
-
|
| 327 |
|
| 328 |
|
| 329 |
```python
|
|
@@ -332,7 +333,7 @@ plt.plot((1 - noise_scheduler.alphas_cumprod.cpu()) ** 0.5, label=r"$\sqrt{(1 -
|
|
| 332 |
plt.legend(fontsize="x-large");
|
| 333 |
```
|
| 334 |
|
| 335 |
-
**练习:** 你可以探索一下使用不同的 beta_start 时曲线是如何变化的,beta_end 与 beta_schedule
|
| 336 |
|
| 337 |
|
| 338 |
```python
|
|
@@ -342,7 +343,7 @@ plt.legend(fontsize="x-large");
|
|
| 342 |
# noise_scheduler = DDPMScheduler(num_train_timesteps=1000, beta_schedule='squaredcos_cap_v2')
|
| 343 |
```
|
| 344 |
|
| 345 |
-
|
| 346 |
|
| 347 |
|
| 348 |
```python
|
|
@@ -365,27 +366,27 @@ show_images(noisy_xb).resize((8 * 64, 64), resample=Image.NEAREST)
|
|
| 365 |
|
| 366 |
|
| 367 |
|
| 368 |
-
|
| 369 |
|
| 370 |
## 步骤 4:定义模型
|
| 371 |
|
| 372 |
-
|
| 373 |
|
| 374 |
-
大多数扩散模型使用的模型结构都是一些 [U-net]
|
| 375 |
|
| 376 |
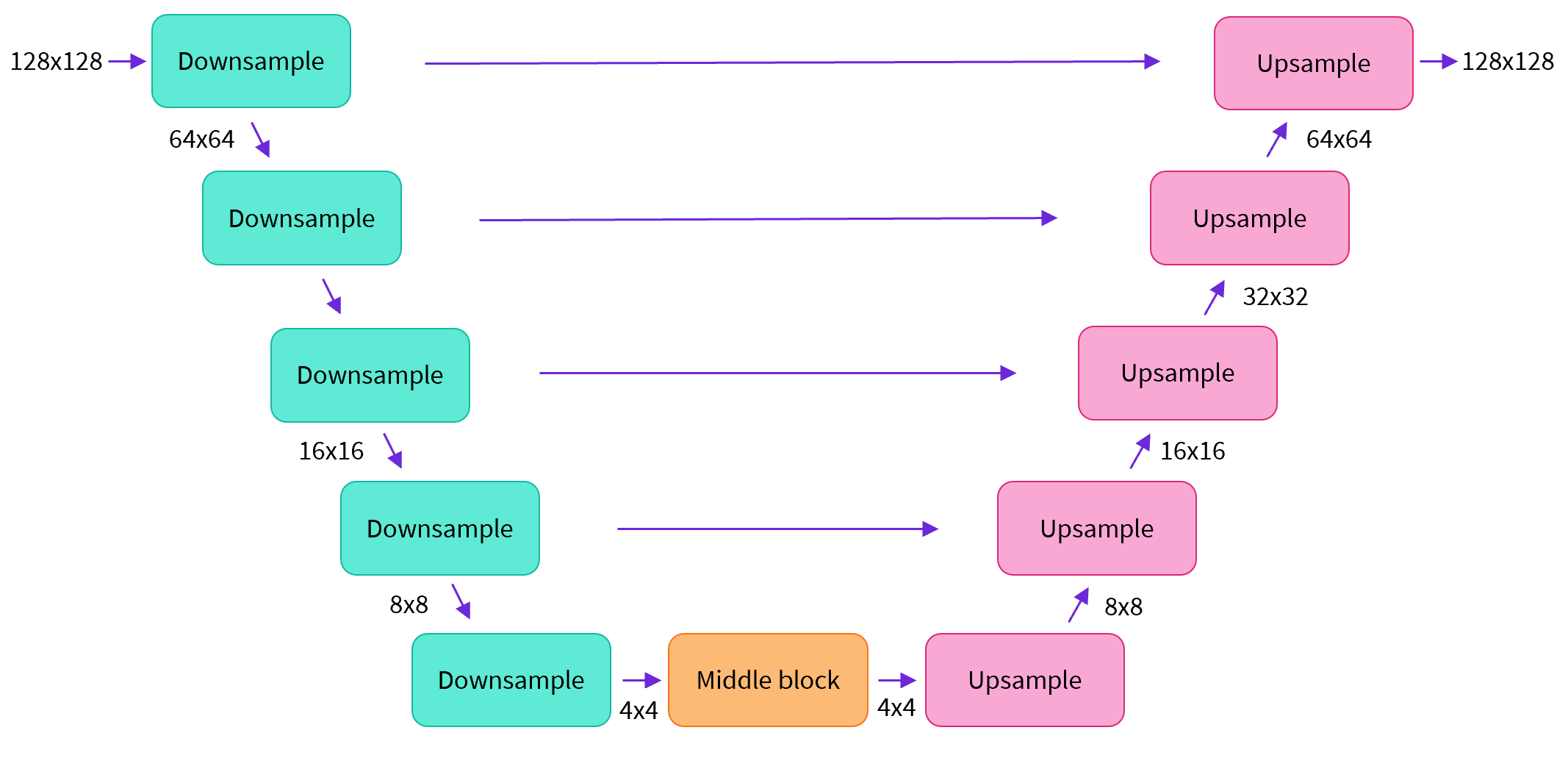
|
| 377 |
|
| 378 |
-
|
| 379 |
-
-
|
| 380 |
-
-
|
| 381 |
-
-
|
| 382 |
|
| 383 |
-
|
| 384 |
|
| 385 |
-
Diffusers 为我们提供了一个易用的`UNet2DModel`类,用来在 PyTorch
|
| 386 |
|
| 387 |
我们来使用 U-net 为我们生成目标大小的图片吧。
|
| 388 |
-
|
| 389 |
|
| 390 |
|
| 391 |
```python
|
|
@@ -414,9 +415,9 @@ model = UNet2DModel(
|
|
| 414 |
model.to(device);
|
| 415 |
```
|
| 416 |
|
| 417 |
-
|
| 418 |
|
| 419 |
-
|
| 420 |
|
| 421 |
|
| 422 |
```python
|
|
@@ -432,24 +433,24 @@ model_prediction.shape
|
|
| 432 |
|
| 433 |
|
| 434 |
|
| 435 |
-
|
| 436 |
|
| 437 |
## 步骤 5:创建训练循环
|
| 438 |
|
| 439 |
-
|
| 440 |
|
| 441 |
-
|
| 442 |
- 随机取样几个迭代周期
|
| 443 |
-
-
|
| 444 |
-
-
|
| 445 |
-
- 使用 MSE
|
| 446 |
- 通过`loss.backward ()`与`optimizer.step ()`来更新模型参数
|
| 447 |
|
| 448 |
-
|
| 449 |
|
| 450 |
-
NB:
|
| 451 |
|
| 452 |
-
|
| 453 |
|
| 454 |
|
| 455 |
```python
|
|
@@ -503,7 +504,7 @@ for epoch in range(30):
|
|
| 503 |
Epoch:30, loss: 0.07474562455900013
|
| 504 |
|
| 505 |
|
| 506 |
-
|
| 507 |
|
| 508 |
|
| 509 |
```python
|
|
@@ -526,7 +527,7 @@ plt.show()
|
|
| 526 |
|
| 527 |
|
| 528 |
|
| 529 |
-
|
| 530 |
|
| 531 |
|
| 532 |
```python
|
|
@@ -536,7 +537,7 @@ plt.show()
|
|
| 536 |
|
| 537 |
## 步骤 6:生成图像
|
| 538 |
|
| 539 |
-
|
| 540 |
|
| 541 |
### 方法 1:建立一个管道:
|
| 542 |
|
|
@@ -566,7 +567,7 @@ pipeline_output.images[0]
|
|
| 566 |
|
| 567 |
|
| 568 |
|
| 569 |
-
|
| 570 |
|
| 571 |
|
| 572 |
```python
|
|
@@ -593,18 +594,17 @@ image_pipe.save_pretrained("my_pipeline")
|
|
| 593 |
config.json diffusion_pytorch_model.bin
|
| 594 |
|
| 595 |
|
| 596 |
-
|
| 597 |
|
| 598 |
### 方法 2:写一个取样循环
|
| 599 |
-
|
| 600 |
|
| 601 |
|
| 602 |
```python
|
| 603 |
# ??image_pipe.forward
|
| 604 |
```
|
| 605 |
|
| 606 |
-
|
| 607 |
-
|
| 608 |
|
| 609 |
```python
|
| 610 |
# Random starting point (8 random images):
|
|
@@ -632,11 +632,11 @@ show_images(sample)
|
|
| 632 |
|
| 633 |
|
| 634 |
|
| 635 |
-
`noise_scheduler.step ()`
|
| 636 |
|
| 637 |
## 步骤 7:把你的模型 Push 到 Hub
|
| 638 |
|
| 639 |
-
|
| 640 |
|
| 641 |
|
| 642 |
```python
|
|
@@ -654,7 +654,7 @@ hub_model_id
|
|
| 654 |
|
| 655 |
|
| 656 |
|
| 657 |
-
|
| 658 |
|
| 659 |
|
| 660 |
```python
|
|
@@ -680,7 +680,7 @@ api.upload_file(
|
|
| 680 |
|
| 681 |
|
| 682 |
|
| 683 |
-
|
| 684 |
|
| 685 |
|
| 686 |
```python
|
|
@@ -715,7 +715,7 @@ card = ModelCard(content)
|
|
| 715 |
card.push_to_hub(hub_model_id)
|
| 716 |
```
|
| 717 |
|
| 718 |
-
现在模型已经在 Hub
|
| 719 |
|
| 720 |
|
| 721 |
```python
|
|
@@ -743,11 +743,11 @@ pipeline_output.images[0]
|
|
| 743 |
|
| 744 |
|
| 745 |
|
| 746 |
-
|
| 747 |
|
| 748 |
# 使用 🤗 Accelerate 来扩大规模
|
| 749 |
|
| 750 |
-
|
| 751 |
|
| 752 |
你可以这样下载该文件:
|
| 753 |
|
|
@@ -787,7 +787,7 @@ hub_model_id
|
|
| 787 |
--mixed_precision="no"
|
| 788 |
```
|
| 789 |
|
| 790 |
-
如之前一样,把模型 push 到 hub
|
| 791 |
|
| 792 |
|
| 793 |
```python
|
|
@@ -841,7 +841,7 @@ card.push_to_hub(hub_model_id)
|
|
| 841 |
|
| 842 |
|
| 843 |
|
| 844 |
-
大概 45
|
| 845 |
|
| 846 |
|
| 847 |
```python
|
|
@@ -863,15 +863,15 @@ make_grid(images)
|
|
| 863 |
|
| 864 |
|
| 865 |
|
| 866 |
-
**练习:**
|
| 867 |
|
| 868 |
# 更高阶的探索之路
|
| 869 |
|
| 870 |
-
|
| 871 |
|
| 872 |
-
-
|
| 873 |
-
- 试试用 DreamBooth
|
| 874 |
-
-
|
| 875 |
- 来瞧瞧 [Diffusion Models from Scratch](https://github.com/huggingface/diffusion-models-class/blob/main/unit1/02_diffusion_models_from_scratch.ipynb) 在本单元的核心思想之上的一些不同看法。
|
| 876 |
|
| 877 |
祝好,敬请关注第 2 单元!
|
|
|
|
| 8 |
|
| 9 |
## 你将学习到
|
| 10 |
|
| 11 |
+
在这个 Notebook 中,你将能够:
|
| 12 |
|
| 13 |
+
- 学习如何使用一个功能强大的自定义扩散模型管线(Pipeline),并了解如何制作一个自己的版本
|
| 14 |
- 通过以下方式创建你自己的迷你管线:
|
| 15 |
- 复习扩散模型的核心概念
|
| 16 |
- 从 Hub 中加载数据以进行训练
|
|
|
|
| 131 |
|
| 132 |
这是一个使用了 [这个模型](https://huggingface.co/sd-dreambooth-library/mr-potato-head) 的例子。该模型的训练仅仅使用了 5 张著名的儿童玩具 "Mr Potato Head"的照片。
|
| 133 |
|
| 134 |
+
首先让我们来加载这个管道。这些代码会自动从 Hub 下载模型权重等需要的文件。这个 demo 需要下载数 GB 的数据,所以如果你不想等待也可以跳过此单元格,只需欣赏样例输出即可!
|
| 135 |
|
| 136 |
|
| 137 |
```python
|
|
|
|
| 150 |
Fetching 15 files: 0%| | 0/15 [00:00<?, ?it/s]
|
| 151 |
|
| 152 |
|
| 153 |
+
管道加载完成后,我们可以使用以下代码生成图像:
|
| 154 |
|
| 155 |
|
| 156 |
```python
|
|
|
|
| 172 |
|
| 173 |
|
| 174 |
|
| 175 |
+
**练习:** 你可以使用不同的提示 (prompt) 自行进行尝试。在这个 demo 中,`sks`是一个新概念的唯一标识符 (UID) - 那么如果把它留空的话会发生什么事呢?你还可以尝试改变`num_inference_steps`和`guidance_scale`。这两个参数分别代表了采样步骤的数量(试试最多可以设为多低?)和模型的输出与提示的匹配程度。
|
| 176 |
|
| 177 |
+
有许多复杂而又神奇的事情发生在这条管线之中!在我们的课程结束之后,你就会清晰的了解这一切是如何运作的。现在,让我们先看看如何从头开始训练扩散模型。
|
| 178 |
|
| 179 |
+
## MVP (最简可实行管线)
|
| 180 |
🤗 Diffusers 的核心 API 被分为三个主要部分:
|
| 181 |
+
1. **管线**: 从高层出发设计的多种类函数,旨在以易部署的方式,能够做到快速通过主流预训练好的扩散模型来生成样本。
|
| 182 |
2. **模型**: 训练新的扩散模型时用到的主流网络架构,*e.g.* [UNet](https://arxiv.org/abs/1505.04597).
|
| 183 |
3. **管理器 (or 调度器)**: 在 *推理* 中使用多种不同的技巧来从噪声中生成图像,同时也可以生成在 *训练* 中所需的带噪图像。
|
| 184 |
|
| 185 |
+
管线对于终端使用者来说已经非常棒,但你既然已经参加了这门课程,我们就假定你想了解更多其中的机制!在此篇笔记结束之后,我们会来构建属于你自己的、能够生成小蝴蝶图片的管线。下面这里会是最终的结果:
|
| 186 |
|
| 187 |
|
| 188 |
```python
|
|
|
|
| 217 |
|
| 218 |
|
| 219 |
|
| 220 |
+
也许这里看起来还不如 DreamBooth 所展示的样例那样惊艳,但要知道我们在训练这些图画时只用了不到训练稳定扩散模型用到数据的 0.0001%。
|
| 221 |
+
|
| 222 |
+
到目前为止,训练一个扩散模型的流程看起来像是这样:
|
| 223 |
|
| 224 |
1. 从训练集中加载一些图像
|
| 225 |
+
2. 加入各种不同级别的噪声
|
| 226 |
+
3. 将已经被引入了不同级别噪声的数据输入模型中
|
| 227 |
4. 评估模型在对这些数据做增强去噪时的表现
|
| 228 |
5. 使用这个信息来更新模型权重,然后重��此步骤
|
| 229 |
|
| 230 |
+
我们会在接下来几节中逐一实现这些步骤,直至训练循环可以完整的运行,在这之后我们会来探索如何使用训练好的模型来生成样本,还有如何封装模型到管道中,从而可以轻松的分享给别人。下面让我我们先从从数据开始入手吧。
|
| 231 |
|
| 232 |
## 步骤 2:下载一个训练数据集
|
| 233 |
|
| 234 |
+
在这个例子中,我们会用到一个来自 Hugging Face Hub 的图像集。具体来说,[是个 1000 张蝴蝶图像收藏集](https://huggingface.co/datasets/huggan/smithsonian_butterflies_subset). 请注意,这是个非常小的数据集。我们在下面的单元格中中注释掉的几行指向了一些规模更大的数据集。你也可以使用这里被注释掉的示例代码,从一个指定的路径来装载图片,从而使用你自己收藏的图像数据。
|
| 235 |
|
| 236 |
|
| 237 |
```python
|
|
|
|
| 273 |
)
|
| 274 |
```
|
| 275 |
|
| 276 |
+
我们可以从中取出一批图像数据来做一下可视化:
|
| 277 |
|
| 278 |
|
| 279 |
```python
|
|
|
|
| 297 |
|
| 298 |
|
| 299 |
|
| 300 |
+
在这篇笔记中,我们使用的是一个图像尺寸为 32 像素的小数据集,从而保证训练时长在可接受的范围内。
|
|
|
|
| 301 |
|
| 302 |
## 步骤 3:定义管理器
|
| 303 |
|
| 304 |
+
我们计划取出这些输入图片然后对它们增添噪声,然后把带噪的图像送入模型。在推理阶段,我们将用模型的预测结果来不断迭代的去除这些噪声。在`diffusers`中,这两个步骤都是由 **调度器(scheduler)** 来处理的。
|
| 305 |
|
| 306 |
+
噪声管理器决定在不同的迭代周期时分别加入多少噪声。下面是我们如何使用 'DDPM' 训练和采样的默认设置创建调度程序。 (基于此篇论文 ["Denoising Diffusion Probabalistic Models"](https://arxiv.org/abs/2006.11239):
|
| 307 |
|
| 308 |
|
| 309 |
```python
|
|
|
|
| 312 |
noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
|
| 313 |
```
|
| 314 |
|
| 315 |
+
DDPM论文描述了一个为每个”时间步“添加少量噪音的退化过程。假设在某个迭代周期,带噪的图像数据为 $x_{t-1}$, 我们可以通过以下方式获得 $x_t$ (比之前更多一点点噪声):<br><br>
|
| 316 |
|
| 317 |
$q (\mathbf {x}_t \vert \mathbf {x}_{t-1}) = \mathcal {N}(\mathbf {x}_t; \sqrt {1 - \beta_t} \mathbf {x}_{t-1}, \beta_t\mathbf {I}) \quad
|
| 318 |
q (\mathbf {x}_{1:T} \vert \mathbf {x}_0) = \prod^T_{t=1} q (\mathbf {x}_t \vert \mathbf {x}_{t-1})$<br><br>
|
|
|
|
| 324 |
q (\mathbf {x}_t \vert \mathbf {x}_0) &= \mathcal {N}(\mathbf {x}_t; \sqrt {\bar {\alpha}_t} \mathbf {x}_0, {(1 - \bar {\alpha}_t)} \mathbf {I})
|
| 325 |
\end {aligned}$ where $\bar {\alpha}_t = \prod_{i=1}^T \alpha_i$ and $\alpha_i = 1-\beta_i$<br><br>
|
| 326 |
|
| 327 |
+
这些数学过程看起来真是可怕!好在有调度器来为我们完成这些运算。我们可以画出 $\sqrt {\bar {\alpha}_t}$ (标记为`sqrt_alpha_prod`) 和 $\sqrt {(1 - \bar {\alpha}_t)}$ (标记为`sqrt_one_minus_alpha_prod`) 来看一下���入 (x) 与噪声是如何在不同迭代周期中量化和叠加的:
|
| 328 |
|
| 329 |
|
| 330 |
```python
|
|
|
|
| 333 |
plt.legend(fontsize="x-large");
|
| 334 |
```
|
| 335 |
|
| 336 |
+
**练习:** 你可以探索一下使用不同的 beta_start 时曲线是如何变化的,beta_end 与 beta_schedule 可以通过以下被注释掉的内容来修改:
|
| 337 |
|
| 338 |
|
| 339 |
```python
|
|
|
|
| 343 |
# noise_scheduler = DDPMScheduler(num_train_timesteps=1000, beta_schedule='squaredcos_cap_v2')
|
| 344 |
```
|
| 345 |
|
| 346 |
+
不论你选择了哪一个调度器,我们现在都可以使用 `noise_scheduler.add_noise` 功能来添加不同程度的噪声,就像这样:
|
| 347 |
|
| 348 |
|
| 349 |
```python
|
|
|
|
| 366 |
|
| 367 |
|
| 368 |
|
| 369 |
+
你可以在这里反复探索使用不同噪声调度器和预设参数带来的效果。 [这个视频](https://www.youtube.com/watch?v=fbLgFrlTnGU) 很好的解释了一些上述数学运算的细节,同时也是对此类概念的一个很好引入介绍。
|
| 370 |
|
| 371 |
## 步骤 4:定义模型
|
| 372 |
|
| 373 |
+
现在我们来到了本章节的核心部分:模型。
|
| 374 |
|
| 375 |
+
大多数扩散模型使用的模型结构都是一些 [U-net] 的变种 (https://arxiv.org/abs/1505.04597) 也是我们在这里会用到的结构。
|
| 376 |
|
| 377 |

|
| 378 |
|
| 379 |
+
简单来说,一个U-net模型大致会有以下三个特征:
|
| 380 |
+
- 输入模型中的图片会经过几个由 ResNetLayer 构成的层,其中每层都使图片的尺寸减半。
|
| 381 |
+
- 在这之后,同样数量的上采样层会将图片的尺寸恢复到原始规模。
|
| 382 |
+
- 残差连接模块会将特征图分辨率相同的上采样层和下采样层连接起来。
|
| 383 |
|
| 384 |
+
U-net模型一个关键特征是输出图片的尺寸与输入图片相同,而这正是我们在扩散模型中所需要的。
|
| 385 |
|
| 386 |
+
Diffusers 为我们提供了一个易用的`UNet2DModel`类,用来在 PyTorch 中创建我们所需要的结构。
|
| 387 |
|
| 388 |
我们来使用 U-net 为我们生成目标大小的图片吧。
|
| 389 |
+
注意这里 `down_block_types` 对应下采样模块 (上图中绿色部分), 而 `up_block_types` 对应上采样模块 (上图中红色部分):
|
| 390 |
|
| 391 |
|
| 392 |
```python
|
|
|
|
| 415 |
model.to(device);
|
| 416 |
```
|
| 417 |
|
| 418 |
+
当我们在处理更高分辨率的图像时,你可能会想尝试使用更多的下、上采样模块,并只在分辨率最低的(最底)层处保留注意力模块,从而降低内存负担。我们会在这之后讨论如何通过实验来找到最适合数据场景的配置方法。
|
| 419 |
|
| 420 |
+
我们可以通过输入一批数据和随机的迭代周期数来看看输出是否与输入尺寸相同:
|
| 421 |
|
| 422 |
|
| 423 |
```python
|
|
|
|
| 433 |
|
| 434 |
|
| 435 |
|
| 436 |
+
接下来让我们来看看如何训练这个模型。
|
| 437 |
|
| 438 |
## 步骤 5:创建训练循环
|
| 439 |
|
| 440 |
+
做完了准备工作以后,我们终于可以开始训练了!下面是PyTorch��的一个典型的迭代优化循环过程的步骤,我们在其中逐批(batch)的输入数据,并使用优化器一步步更新模型的参数 - 在这个样例中我们使用学习率为 0.0004 的 AdamW 优化器。
|
| 441 |
|
| 442 |
+
对于每一批的数据,我们会:
|
| 443 |
- 随机取样几个迭代周期
|
| 444 |
+
- 对数据进行相应的噪声处理
|
| 445 |
+
- 把带噪数据输入模型
|
| 446 |
+
- 使用 MSE 作为损失函数来比较目标结果与模型预测结果,在这个样例中,即是比较真实噪声和模型预测的噪声之间的差距。
|
| 447 |
- 通过`loss.backward ()`与`optimizer.step ()`来更新模型参数
|
| 448 |
|
| 449 |
+
在这个过程中我们需要记录下每一步中的损失函数的值,用来后续绘制损失的曲线图。
|
| 450 |
|
| 451 |
+
NB: 这段代码大概需要十分钟左右来运行 - 如果你想节省时间,你也可以跳过以下两块操作直接使用预训练好的模型。或者,您可以探索如何通过上面的模型定义来减少每一层中的通道数量,从而加快训练速度。
|
| 452 |
|
| 453 |
+
官方的扩散器训练示例 [official diffusers training example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb) 以更高的分辨率在这个数据集上训练一个更大的模型,方便大家了解一个不那么小的训练过程是什么样子:
|
| 454 |
|
| 455 |
|
| 456 |
```python
|
|
|
|
| 504 |
Epoch:30, loss: 0.07474562455900013
|
| 505 |
|
| 506 |
|
| 507 |
+
上面就是绘制出来的损失函数的曲线,我们能看到模型在一开始快速的收敛,接下来以一个较慢的速度持续优化(我们用右边 log 坐标轴的视图可以看的更清楚):
|
| 508 |
|
| 509 |
|
| 510 |
```python
|
|
|
|
| 527 |
|
| 528 |
|
| 529 |
|
| 530 |
+
作为运行上述训练代码的替代方案,你可以像这样使用管道中的模型:
|
| 531 |
|
| 532 |
|
| 533 |
```python
|
|
|
|
| 537 |
|
| 538 |
## 步骤 6:生成图像
|
| 539 |
|
| 540 |
+
接下来的问题是,我们怎么通过这个模型生成图像呢?
|
| 541 |
|
| 542 |
### 方法 1:建立一个管道:
|
| 543 |
|
|
|
|
| 567 |
|
| 568 |
|
| 569 |
|
| 570 |
+
我们可以像这样将管线保存到本地文件夹:
|
| 571 |
|
| 572 |
|
| 573 |
```python
|
|
|
|
| 594 |
config.json diffusion_pytorch_model.bin
|
| 595 |
|
| 596 |
|
| 597 |
+
这些文件包含了重新创建管线所需的所有内容。您可以手动将它们上传到 Hub 以与其他人共享管线,或者在下一节中通过 API 检查代码来完成此操作。
|
| 598 |
|
| 599 |
### 方法 2:写一个取样循环
|
| 600 |
+
如果你观察了管道中的 forward 方法,你可以看到在运行`image_pipe ()`时发生了什么:
|
| 601 |
|
| 602 |
|
| 603 |
```python
|
| 604 |
# ??image_pipe.forward
|
| 605 |
```
|
| 606 |
|
| 607 |
+
我们从完全随机的噪声图像开始,从最大噪声往最小噪声方向运行调度器,根据模型的预测每一步去除少量噪声:
|
|
|
|
| 608 |
|
| 609 |
```python
|
| 610 |
# Random starting point (8 random images):
|
|
|
|
| 632 |
|
| 633 |
|
| 634 |
|
| 635 |
+
`noise_scheduler.step ()` 执行更新”样本“所需的数学运算。事实上有很多种不同的采样方法 - 在下一单元中,我们将看到如何通过使用不同的采样器,来加速现有模型中的图像生成过程,并更多地讨论从扩散���型中采样背后的理论。
|
| 636 |
|
| 637 |
## 步骤 7:把你的模型 Push 到 Hub
|
| 638 |
|
| 639 |
+
在上面的例子中,我们将管道保存到本地文件夹中。为了将模型推送到 Hub,我们需要将文件推送到模型存储库中。我们根据你的选择(模型 ID)来决定仓库的名字(您可以随意替换 model_name;它只需要包含您的用户名,而这就是函数get_full_repo_name()所做的):
|
| 640 |
|
| 641 |
|
| 642 |
```python
|
|
|
|
| 654 |
|
| 655 |
|
| 656 |
|
| 657 |
+
接下来,在 🤗 Hub 上创建模型仓库并 push 它吧:
|
| 658 |
|
| 659 |
|
| 660 |
```python
|
|
|
|
| 680 |
|
| 681 |
|
| 682 |
|
| 683 |
+
最后一件事是创建一个超棒的模型卡,如此,我们的蝴蝶生成器就可以轻松的在 Hub 上被找到(请在描述中随意发挥!):
|
| 684 |
|
| 685 |
|
| 686 |
```python
|
|
|
|
| 715 |
card.push_to_hub(hub_model_id)
|
| 716 |
```
|
| 717 |
|
| 718 |
+
现在模型已经在 Hub 上了,你可以这样从任何地方使用 `DDPMPipeline` 的 `from_pretrained ()` 方法来下载它:
|
| 719 |
|
| 720 |
|
| 721 |
```python
|
|
|
|
| 743 |
|
| 744 |
|
| 745 |
|
| 746 |
+
太棒了,我们成功了!
|
| 747 |
|
| 748 |
# 使用 🤗 Accelerate 来扩大规模
|
| 749 |
|
| 750 |
+
这个笔记本是为了学习而制作的,因此我尽量保持代码的简洁。正因如此,我们省略了一些能让你在更多数据上训练更大模型的内容,比如多gpu支持、进度记录和示例图像、支持更大批量的梯度检查点、自动上传模型等等。好在这些特性在示例训练代码中都有。 [here](https://github.com/huggingface/diffusers/raw/main/examples/unconditional_image_generation/train_unconditional.py).
|
| 751 |
|
| 752 |
你可以这样下载该文件:
|
| 753 |
|
|
|
|
| 787 |
--mixed_precision="no"
|
| 788 |
```
|
| 789 |
|
| 790 |
+
如之前一样,把模型 push 到 hub,并且创建一个超酷的模型卡(请按你的想法随意填写!):
|
| 791 |
|
| 792 |
|
| 793 |
```python
|
|
|
|
| 841 |
|
| 842 |
|
| 843 |
|
| 844 |
+
大概 45 分钟之后,我们将得到这样的结果:
|
| 845 |
|
| 846 |
|
| 847 |
```python
|
|
|
|
| 863 |
|
| 864 |
|
| 865 |
|
| 866 |
+
**练习:** 看看你是否能在尽可能短的时间内找到优秀好用的训练/模型设置,并与社区分享你的发现。阅读这些脚本看看你能不能理解它们,如果遇到了一些看上去令人迷惑的地方,你可以向大家提问来寻求解答。
|
| 867 |
|
| 868 |
# 更高阶的探索之路
|
| 869 |
|
| 870 |
+
希望这些能够让你初步了解如何使用 🤗 Diffusers library !这里有一些你接下来可以尝试的东西:
|
| 871 |
|
| 872 |
+
- 尝试在新的数据集上训练一个无条件扩散模型 - 如果你能直接自己完成那就太好了 [create one yourself](https://huggingface.co/docs/datasets/image_dataset). 你可以在 Hub 这里找到一些能完成这个任务的超棒图像数据集 [HugGan organization](https://huggingface.co/huggan). 如果你不想等待模型训练太久的话,一定记得对图片做下采样!
|
| 873 |
+
- 试试用 DreamBooth 来创建你自己定制的扩散模型管线,看看 [这个 Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) 或者 [这个 notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb)
|
| 874 |
+
- 修改训练脚本来探索不同的 UNet 超参数(例如层数、深度或者通道数),不同的噪声管理器等等。
|
| 875 |
- 来瞧瞧 [Diffusion Models from Scratch](https://github.com/huggingface/diffusion-models-class/blob/main/unit1/02_diffusion_models_from_scratch.ipynb) 在本单元的核心思想之上的一些不同看法。
|
| 876 |
|
| 877 |
祝好,敬请关注第 2 单元!
|