LLM Course documentation
マスク言語モデルの微調整
マスク言語モデルの微調整

Transformerモデルを含む多くのNLPアプリケーションでは、ハギング フェイス ハブから事前学習済みのモデルを取り出し、自分が実行したいタスク用のデータを直接使って微調整を行うだけでよいのです。事前学習に使われたコーパスと微調整に使うコーパスがあまり違わない限り、転移学習は通常良い結果を生み出します。
しかし、モデルのヘッド部だけを対象にタスクに特化したトレーニング行う前に、まずデータを使って言語モデルを微調整したいケースもいくつかあります。例えば、データセットに法的契約や科学論文が含まれている場合、BERTのような素のTransformerモデルは通常、コーパス内のドメイン特有の単語を稀なトークンとして扱うため、結果として満足のいく性能が得られない可能性があります。ドメイン内データで言語モデルを微調整することで、多くの下流タスクのパフォーマンスを向上させることができ、このステップは通常一度だけ行えばよいことになります。
このように、事前に学習した言語モデルをドメイン内データで微調整するプロセスは、通常ドメイン適応と呼ばれます。これは2018年にULMFiTによって普及しました。転移学習をNLPで本当に使えるようにした最初のニューラルアーキテクチャ(LSTMがベース)の1つです。ULMFiTによるドメイン適応の例を下の画像に示します。このセクションでは、LSTMの代わりにTransformerを使って、同様のことを行います!


このセクションの終わりには、以下のような文章を自動補完できるマスク言語モデルがHub上にできていることでしょう。
それでは始めましょう!
🙋 「マスク言語モデリング」や「事前学習済みモデル」という言葉に聞き覚えがない方は、第1章でこれらの主要な概念をすべて動画付きで説明していますので、ぜひご覧になってください。
マスク言語モデリング用の事前学習済みモデルの選択
まず、マスク言語モデリングに適した事前学習済みモデルを選びましょう。以下のスクリーンショットのように、ハギング フェイス ハブの “Fill-Mask “フィルタを適用すると、候補のリストが表示されます。
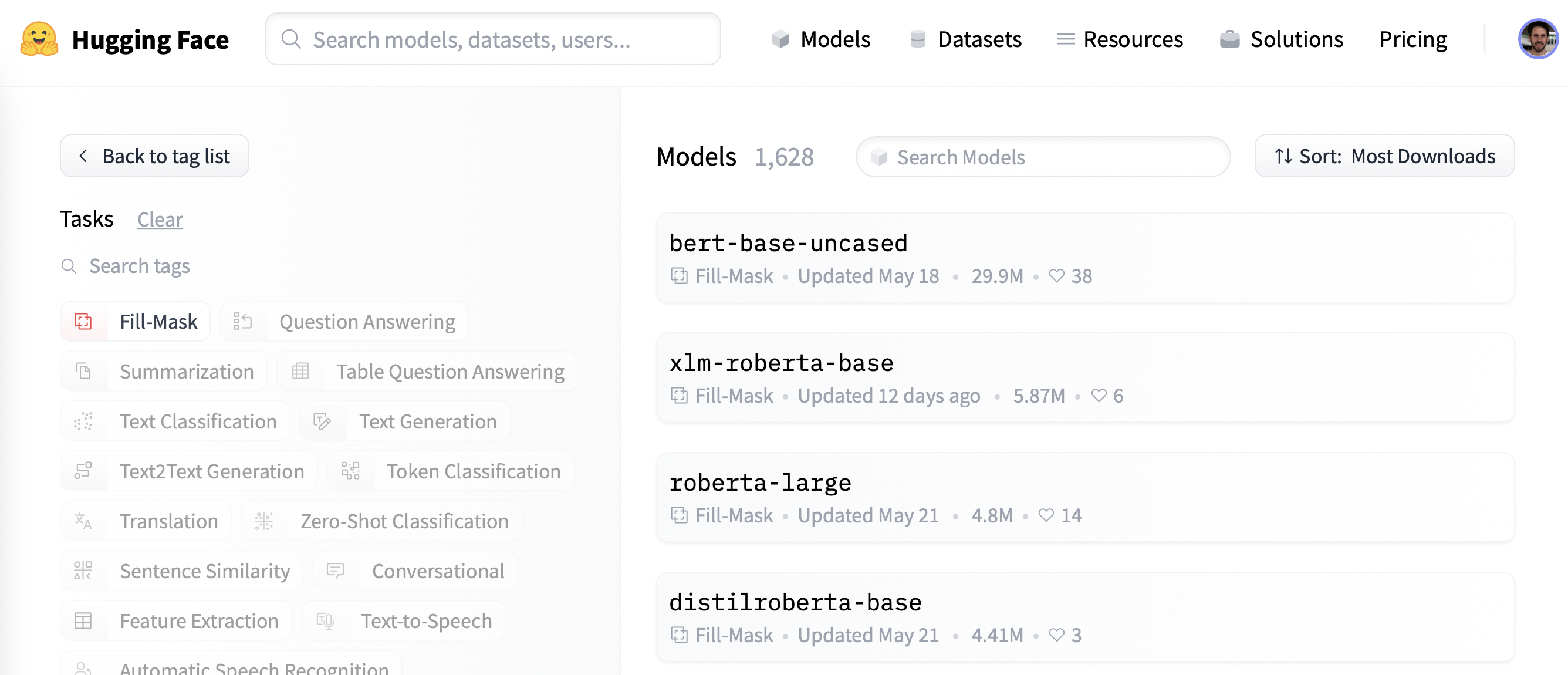
BERT と RoBERTa モデルのファミリーが最もダウンロードされていますが、ここでは DistilBERT と呼ばれるモデルを使用することにします。このモデルは、下流タスクの性能をほとんど損なうことなく、より高速に学習させることができます。
このモデルは、知識蒸留と呼ばれる特別な技術を使用して訓練されました。この手法は、BERTのような大きな「教師モデル」が、それよりはるかに少ないパラメータを持つ「生徒モデル」の訓練を導くために使用されています。
知識蒸溜の詳細を説明すると、この章の内容から離れすぎてしまいますが、もし興味があれば、Natural Language Processing with Transformers(通称Transformers教科書)でそれについてすべて読むことができます。
それでは、AutoModelForMaskedLMクラスを使ってDistilBERTをダウンロードしてみましょう。
from transformers import AutoModelForMaskedLM
model_checkpoint = "distilbert-base-uncased"
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)このモデルがいくつのパラメータを持っているかは、num_parameters() メソッドを呼び出すことで確認することができます。
distilbert_num_parameters = model.num_parameters() / 1_000_000
print(f"'>>> DistilBERT number of parameters: {round(distilbert_num_parameters)}M'")
print(f"'>>> BERT number of parameters: 110M'")'>>> DistilBERT number of parameters: 67M'
'>>> BERT number of parameters: 110M'約6,700万パラメータを持つDistilBERTは、BERTの基本モデルよりも約2倍小さく、これは、学習時に約2倍のスピードアップに相当します(素晴らしい!)。それでは、このモデルが予測する、小さなテキストサンプルの最も可能性の高い完成形はどのような種類のトークンであるかを見てみましょう。
text = "This is a great [MASK]."人間なら [MASK] トークンに対して、“day”, “ride”, “painting” などの多くの可能性を想像することができます。事前学習済みモデルの場合、予測値はモデルが学習したコーパスに依存します。なぜなら、モデルはデータに存在する統計的パターンを選択するように学習するからです。BERTと同様に、DistilBERTはEnglish Wikipedia と BookCorpus のデータセットで事前学習されているので、[MASK]の予測はこれらのドメインを反映すると予想されます。マスクを予測するためには、モデルの入力生成用にDistilBERTのtokenizerが必要なので、これもHubからダウンロードしましょう。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)tokenizerモデルがあれば、テキストサンプルをモデルに渡し、ロジットを抽出し、上位5つの候補を出力することができます。
import torch
inputs = tokenizer(text, return_tensors="pt")
token_logits = model(**inputs).logits
# Find the location of [MASK] and extract its logits
mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
mask_token_logits = token_logits[0, mask_token_index, :]
# Pick the [MASK] candidates with the highest logits
top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist()
for token in top_5_tokens:
print(f"'>>> {text.replace(tokenizer.mask_token, tokenizer.decode([token]))}'")'>>> This is a great deal.'
'>>> This is a great success.'
'>>> This is a great adventure.'
'>>> This is a great idea.'
'>>> This is a great feat.'出力から、モデルの予測は日常的な用語に言及していることがわかりますが、これは英語版ウィキペディアが基盤となっている事を考えれば驚くことではありません。では、この領域をもう少しニッチなもの、つまり、分裂している映画評価データセットに変えてみましょう。
データセット
ドメイン適応の例を示すために、私たちは有名なLarge Movie Review Dataset (略してIMDb)を使用します。これは、感情分析モデルのベンチマークによく使われる、映画のレビューのコーパスです。このコーパスでDistilBERTを微調整することで、言語モデルが事前学習したWikipediaの事実に基づくデータから、映画レビューのより主観的な要素に語彙を適応させることが期待されます。ハギング フェイス ハブのデータは、🤗 Datasetsの load_dataset() 関数で取得することができます。
from datasets import load_dataset
imdb_dataset = load_dataset("imdb")
imdb_datasetDatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['text', 'label'],
num_rows: 50000
})
})train と test 用のデータ分割にはそれぞれ25,000件のレビューから構成され、ラベル付けされていない unsupervised という分割には50,000件のレビューが含まれていることがわかります。どのようなテキストを扱っているか知るために、いくつかのサンプルを見てみましょう。このコースの前の章で行ったように、 Dataset.shuffle() と Dataset.select() 関数を連鎖させて、ランダムなサンプルを作成しましょう。
sample = imdb_dataset["train"].shuffle(seed=42).select(range(3))
for row in sample:
print(f"\n'>>> Review: {row['text']}'")
print(f"'>>> Label: {row['label']}'")
'>>> Review: This is your typical Priyadarshan movie--a bunch of loony characters out on some silly mission. His signature climax has the entire cast of the film coming together and fighting each other in some crazy moshpit over hidden money. Whether it is a winning lottery ticket in Malamaal Weekly, black money in Hera Pheri, "kodokoo" in Phir Hera Pheri, etc., etc., the director is becoming ridiculously predictable. Don\'t get me wrong; as clichéd and preposterous his movies may be, I usually end up enjoying the comedy. However, in most his previous movies there has actually been some good humor, (Hungama and Hera Pheri being noteworthy ones). Now, the hilarity of his films is fading as he is using the same formula over and over again.<br /><br />Songs are good. Tanushree Datta looks awesome. Rajpal Yadav is irritating, and Tusshar is not a whole lot better. Kunal Khemu is OK, and Sharman Joshi is the best.'
'>>> Label: 0'
'>>> Review: Okay, the story makes no sense, the characters lack any dimensionally, the best dialogue is ad-libs about the low quality of movie, the cinematography is dismal, and only editing saves a bit of the muddle, but Sam" Peckinpah directed the film. Somehow, his direction is not enough. For those who appreciate Peckinpah and his great work, this movie is a disappointment. Even a great cast cannot redeem the time the viewer wastes with this minimal effort.<br /><br />The proper response to the movie is the contempt that the director San Peckinpah, James Caan, Robert Duvall, Burt Young, Bo Hopkins, Arthur Hill, and even Gig Young bring to their work. Watch the great Peckinpah films. Skip this mess.'
'>>> Label: 0'
'>>> Review: I saw this movie at the theaters when I was about 6 or 7 years old. I loved it then, and have recently come to own a VHS version. <br /><br />My 4 and 6 year old children love this movie and have been asking again and again to watch it. <br /><br />I have enjoyed watching it again too. Though I have to admit it is not as good on a little TV.<br /><br />I do not have older children so I do not know what they would think of it. <br /><br />The songs are very cute. My daughter keeps singing them over and over.<br /><br />Hope this helps.'
'>>> Label: 1'そう、これらは確かに映画のレビューです。もしあなたが十分に年を取っているなら、最後のレビューにあるVHS版を所有しているというコメントさえ理解できるかもしれません😜! 言語モデリングにはラベルは必要ありませんが、0は否定的なレビュー、1は肯定的なレビューに対応することがもうわかりました。
✏️ 挑戦してみましょう! unsupervised のラベルがついた分割データのランダムサンプルを作成し、ラベルが 0 や 1 でないことを確認してみましょう。また、train と test 用の分割データのラベルが本当に 0 か 1 のみかを確認することもできます。これはすべての自然言語処理の実践者が新しいプロジェクトの開始時に実行すべき、有用なサニティチェックです!
さて、データをざっと見たところで、マスク言語モデリングのための準備に取りかかりましょう。第3章で見たシーケンス分類のタスクと比較すると、いくつかの追加ステップが必要であることがわかるでしょう。さあ、始めましょう!
データの前処理
自己回帰言語モデリングでもマスク言語モデリングでも、共通の前処理として、すべての用例を連結し、コーパス全体を同じ大きさの断片に分割することが行われます。これは、個々のサンプルを単純にトークン化するという、私達の通常のアプローチとは全く異なるものです。なぜすべてを連結するのでしょうか?それは、個々の例文が長すぎると切り捨てられる可能性があり、言語モデリングタスクに役立つかもしれない情報が失われてしまうからです!
そこで、まずいつものようにコーパスをトークン化します。ただし、トークン化する際に truncation=True オプションをtokenizerに設定しないようにします。また、単語IDがあればそれを取得します(6章で説明した高速tokenizerを使用している場合はそうなります)。後で単語全体をマスキングするために必要になるからです。これをシンプルな関数にまとめ、ついでに text と label カラムも不要になったので削除してしまいましょう。
def tokenize_function(examples):
result = tokenizer(examples["text"])
if tokenizer.is_fast:
result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))]
return result
# Use batched=True to activate fast multithreading!
tokenized_datasets = imdb_dataset.map(
tokenize_function, batched=True, remove_columns=["text", "label"]
)
tokenized_datasetsDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 25000
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 50000
})
})DistilBERTはBERTに似たモデルなので、エンコードされたテキストは、他の章で見た input_ids と attention_mask に加え、私達が追加した word_ids で構成されていることがわかります。
さて、映画のレビューをトークン化したので、次のステップはそれらをすべてグループ化して、結果を断片に分割することです。しかし、この断片の大きさはどの程度にすべきでしょうか?これは最終的には利用可能な GPU メモリの量によって決まりますが、良い出発点はモデルの最大コンテキストサイズが何であるかを見ることです。これはtokenizerの model_max_length 属性を調べることで推測することができます。
tokenizer.model_max_length
512この値は、チェックポイントに関連付けられた tokenizer_config.json ファイルから取得します。この場合、BERT と同様に、コンテキストサイズが 512 トークンであることが分かります。
✏️ あなたの番です! BigBird や Longformer などのいくつかの Transformer モデルは、BERT や他の初期の Transformer モデルよりずっと長いコンテキスト長を持っています。これらのチェックポイントのトークナイザーをインスタンス化して、model_max_length がそのモデルカード内に記載されているものと一致することを検証してください。
され、Google Colab内で利用可能なGPUで実験を行うために、メモリに収まるような少し小さめのものを選ぶことにします。
chunk_size = 128なお、小さな断片サイズを使用すると、実際のシナリオでは不利になることがあるので、モデルを適用するユースケースに対応したサイズを使用する必要があります。
さて、ここからが楽しいところです。連結がどのように機能するかを示すために、トークン化されたトレーニングセットからいくつかのレビューを取り出し、レビュー毎のトークン数を出力してみましょう。
# Slicing produces a list of lists for each feature
tokenized_samples = tokenized_datasets["train"][:3]
for idx, sample in enumerate(tokenized_samples["input_ids"]):
print(f"'>>> Review {idx} length: {len(sample)}'")'>>> Review 0 length: 200'
'>>> Review 1 length: 559'
'>>> Review 2 length: 192'そして、これらの例をすべてをシンプルな辞書内包表記を使って連結すると、次のようになります。
concatenated_examples = {
k: sum(tokenized_samples[k], []) for k in tokenized_samples.keys()
}
total_length = len(concatenated_examples["input_ids"])
print(f"'>>> Concatenated reviews length: {total_length}'")'>>> Concatenated reviews length: 951'素晴らしい!全体の長さの裏付けがとれました。
では、連結されたレビューを block_size で指定されたサイズの断片に分割してみましょう。そのために、 concatenated_examples を繰り返し処理し、リスト内包表記を使用して各特徴のスライスを作成します。その結果、断片の辞書ができあがります。
chunks = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
for chunk in chunks["input_ids"]:
print(f"'>>> Chunk length: {len(chunk)}'")'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 55'この例でわかるように、一般的に最後の断片は最大断片サイズより小さくなります。これを扱うには、主に 2 つの方法があります。
- 最後の断片が
chunk_sizeよりも小さければ削除する - 最後の断片の長さが
chunk_sizeと等しくなるまで、最後の断片にダミーデータを詰め込む
ここでは、最初のアプローチをとります。上記のロジックをすべてひとつの関数にまとめ、トークン化されたデータセットに適用してみましょう。
def group_texts(examples):
# Concatenate all texts
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
# Compute length of concatenated texts
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the last chunk if it's smaller than chunk_size
total_length = (total_length // chunk_size) * chunk_size
# Split by chunks of max_len
result = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
# Create a new labels column
result["labels"] = result["input_ids"].copy()
return resultgroup_texts() の最後のステップでは、 input_ids 列のコピーである新しい labels 列を作成していることに注意してください。これから説明するように、マスク言語モデリングでは、入力部に含まれるランダムなマスクトークンを予測することが目的です。 labels 列は、言語モデルが学習の際に参考する真実の値を提供するために使用します。
それでは、信頼できる Dataset.map() 関数を使って、トークン化されたデータセットに group_texts() を適用してみましょう。
lm_datasets = tokenized_datasets.map(group_texts, batched=True)
lm_datasetsDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 61289
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 59905
})
unsupervised: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 122963
})
})テキストをグループ化し、断片に分けたことでtrainとtestのデータセットで25,000よりも多くのサンプルが生成されていることがわかります。これは、元のコーパスに複数のレビューを含むものがあるため 連続トークン を含むサンプルができたからです。このことは、断片の1つにある特別な [SEP] と [CLS] トークンを探すことで明確にわかります。
tokenizer.decode(lm_datasets["train"][1]["input_ids"])".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"上の例では、高校に関する映画とホームレスに関する映画のレビューが2つ重複しているのがわかります。また、マスク言語モデリングのラベルがどのように見えるか確認してみましょう。
tokenizer.decode(lm_datasets["train"][1]["labels"])".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"上の group_texts() 関数から予想されるように、これはデコードされた input_ids と同じに見えます。しかし、それではこのモデルはどうやって何かを学習するのでしょうか?入力のランダムな位置に [MASK] トークンを挿入する、という重要なステップが抜けているのです。それでは、特別なデータコレーターを使って、微調整の際にどのようにこれを行うか見てみましょう。
DistilBERTを Trainer APIで微調整する
マスク言語モデルの微調整は、第3章で行ったようなシーケンス分類モデルの微調整とほぼ同じです。唯一の違いは、各バッチのテキストに含まれるいくつかのトークンをランダムにマスクすることができる特別なデータコレーターが必要であることです。幸いなことに、🤗 Transformersにはこのタスクのために専用の DataCollatorForLanguageModeling が用意されています。私たちはtokenizerと、マスクするトークンの割合を指定する mlm_probability 引数を渡すだけでよいのです。ここでは、BERTで使用され、文献上でも一般的な選択である15%を選びます。
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)ランダムマスクがどのように機能するかを見るために、いくつかの例を data_collator に与えてみましょう。コレーターは辞書型 のリストを想定しており、各 辞書は連続したテキストの塊を表すので、まずデータセットを繰り返し処理してからコレーターにバッチを渡します。このデータコレーターは "word_ids" キーを必要としないので、これを削除します。
samples = [lm_datasets["train"][i] for i in range(2)]
for sample in samples:
_ = sample.pop("word_ids")
for chunk in data_collator(samples)["input_ids"]:
print(f"\n'>>> {tokenizer.decode(chunk)}'")'>>> [CLS] bromwell [MASK] is a cartoon comedy. it ran at the same [MASK] as some other [MASK] about school life, [MASK] as " teachers ". [MASK] [MASK] [MASK] in the teaching [MASK] lead [MASK] to believe that bromwell high\'[MASK] satire is much closer to reality than is " teachers ". the scramble [MASK] [MASK] financially, the [MASK]ful students whogn [MASK] right through [MASK] pathetic teachers\'pomp, the pettiness of the whole situation, distinction remind me of the schools i knew and their students. when i saw [MASK] episode in [MASK] a student repeatedly tried to burn down the school, [MASK] immediately recalled. [MASK]...'
'>>> .... at.. [MASK]... [MASK]... high. a classic line plucked inspector : i\'[MASK] here to [MASK] one of your [MASK]. student : welcome to bromwell [MASK]. i expect that many adults of my age think that [MASK]mwell [MASK] is [MASK] fetched. what a pity that it isn\'t! [SEP] [CLS] [MASK]ness ( or [MASK]lessness as george 宇in stated )公 been an issue for years but never [MASK] plan to help those on the street that were once considered human [MASK] did everything from going to school, [MASK], [MASK] vote for the matter. most people think [MASK] the homeless'いいですね、うまくいきました!
[MASK]トークンがテキストの様々な場所にランダムに挿入されていることがわかります。
これらが学習中にモデルが予測しなければならないトークンになります。そしてデータコレーターの素晴らしいところは、バッチごとに[MASK]の挿入をランダムにすることです!
✏️ あなたの番です! 上のコードを何度か実行して、ランダムなマスキングがあなたの目の前で起こるのを見ましょう! また、tokenizer.decode() メソッドを tokenizer.convert_ids_to_tokens() に置き換えると、与えた単語内から一つのトークンが選択されてマスクされ、他の単語がマスクされないことを見ることができます。
ランダムマスキングの副作用として、Trainerを使用する場合、評価指標が確定的でなくなることが挙げられます。
これはトレーニングセットとテストセットに同じデータコレーターを使用するためです。後ほど、🤗 Accelerateで微調整を行う際に、カスタム評価ループの柔軟性を利用してランダム性をなくす方法について説明します。
マスク言語モデルをトレーニングする場合、個々のトークンではなく、単語全体をマスキングする手法があります。この手法は whole word masking と呼ばれます。単語全体をマスキングする場合、データコレーターを自作する必要があります。データコレーターとは、サンプルのリストを受け取り、それをバッチ変換する関数のことです。
今からやってみましょう!
先ほど計算した単語IDを使って、単語のインデックスと対応するトークンのマップを作る事にします。どの単語をマスクするかをランダムに決めて、そのマスクを入力に適用します。なお、ラベルはマスクする単語を除いて全て-100です。
import collections
import numpy as np
from transformers import default_data_collator
wwm_probability = 0.2
def whole_word_masking_data_collator(features):
for feature in features:
word_ids = feature.pop("word_ids")
# Create a map between words and corresponding token indices
mapping = collections.defaultdict(list)
current_word_index = -1
current_word = None
for idx, word_id in enumerate(word_ids):
if word_id is not None:
if word_id != current_word:
current_word = word_id
current_word_index += 1
mapping[current_word_index].append(idx)
# Randomly mask words
mask = np.random.binomial(1, wwm_probability, (len(mapping),))
input_ids = feature["input_ids"]
labels = feature["labels"]
new_labels = [-100] * len(labels)
for word_id in np.where(mask)[0]:
word_id = word_id.item()
for idx in mapping[word_id]:
new_labels[idx] = labels[idx]
input_ids[idx] = tokenizer.mask_token_id
feature["labels"] = new_labels
return default_data_collator(features)次に、先ほどと同じサンプルで試してみます。
samples = [lm_datasets["train"][i] for i in range(2)]
batch = whole_word_masking_data_collator(samples)
for chunk in batch["input_ids"]:
print(f"\n'>>> {tokenizer.decode(chunk)}'")'>>> [CLS] bromwell high is a cartoon comedy [MASK] it ran at the same time as some other programs about school life, such as " teachers ". my 35 years in the teaching profession lead me to believe that bromwell high\'s satire is much closer to reality than is " teachers ". the scramble to survive financially, the insightful students who can see right through their pathetic teachers\'pomp, the pettiness of the whole situation, all remind me of the schools i knew and their students. when i saw the episode in which a student repeatedly tried to burn down the school, i immediately recalled.....'
'>>> .... [MASK] [MASK] [MASK] [MASK]....... high. a classic line : inspector : i\'m here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn\'t! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless'✏️ あなたの番です! 上のコードを何度か実行して、ランダムなマスキングがあなたの目の前で起こるのを見ましょう! また、tokenizer.decode() メソッドを tokenizer.convert_ids_to_tokens() に置き換えると、与えられた単語からのトークンが常に一緒にマスクされることを確認できます。
これで2つのデータコレーターが揃いましたので、残りの微調整ステップは標準的なものです。Google Colabで、神話に出てくるP100 GPUを運良く割り当てられなかった場合、学習に時間がかかることがあります😭そこで、まず学習セットのサイズを数千事例までダウンサンプルします。心配しないでください、それでもかなりまともな言語モデルができますよ。🤗 Datasets 内のデータセットは第5章で紹介した Dataset.train_test_split() 関数で簡単にダウンサンプリングすることができます。
train_size = 10_000
test_size = int(0.1 * train_size)
downsampled_dataset = lm_datasets["train"].train_test_split(
train_size=train_size, test_size=test_size, seed=42
)
downsampled_datasetDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 10000
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 1000
})
})これは自動的に新しい train と test にデータを分割し、トレーニングセットのサイズを 10,000 事例に、検証セットをその 10%に設定しました。もし強力なGPUをお持ちなら、この値を自由に増やしてください!
次に必要なことは、ハギング フェイス ハブにログインすることです。このコードをnotebookで実行する場合は、次のユーティリティ関数で実行できます。
from huggingface_hub import notebook_login
notebook_login()上記を実行すると、入力ウィジェットが表示され、認証情報を入力することができます。また実行することもできます。
huggingface-cli login好みに応じて、ターミナルを起動し、そこからログインしてください。
一度ログインしたら、Trainer の引数を指定できます。
from transformers import TrainingArguments
batch_size = 64
# Show the training loss with every epoch
logging_steps = len(downsampled_dataset["train"]) // batch_size
model_name = model_checkpoint.split("/")[-1]
training_args = TrainingArguments(
output_dir=f"{model_name}-finetuned-imdb",
overwrite_output_dir=True,
evaluation_strategy="epoch",
learning_rate=2e-5,
weight_decay=0.01,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
push_to_hub=True,
fp16=True,
logging_steps=logging_steps,
)ここでは、各エポックでの学習損失を確実に追跡するために logging_steps を含むデフォルトのオプションを少し調整しました。また、 fp16=True を使用して、混合精度の学習を有効にし、さらに高速化しました。デフォルトでは、 Trainer はモデルの forward() メソッドに含まれない列をすべて削除します。つまり、全単語マスク用のデータコレーターを使用している場合は、 remove_unused_columns=False を設定して、学習時に word_ids カラムが失われないようにする必要があります。
なお、 hub_model_id 引数でプッシュ先のリポジトリ名を指定することができます (特に、組織にプッシュする場合はこの引数を使用する必要があります)。例えば、モデルを huggingface-course organization にプッシュする場合、 TrainingArguments に hub_model_id="huggingface-course/distilbert-finetuned-imdb" を追加しています。デフォルトでは、使用するリポジトリはあなたの名前空間内にあり、設定した出力ディレクトリにちなんだ名前になるので、私たちの場合は "lewtun/distilbert-finetuned-imdb" となります。
これで Trainer のインスタンスを作成するための材料が揃いました。ここでは、標準的な data_collator を使用しますが、練習として全単語マスキングのデータコレーターを試して、結果を比較することができます。
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=downsampled_dataset["train"],
eval_dataset=downsampled_dataset["test"],
data_collator=data_collator,
tokenizer=tokenizer,
)これで trainer.train() を実行する準備ができました。しかしその前に、言語モデルの性能を評価する一般的な指標である パープレキシティ について簡単に見ておきましょう。
言語モデルのパープレキシティ
テキストの分類や質問応答のように、ラベル付けされたコーパスを用いて学習する他のタスクとは異なり、言語モデリングでは明示的なラベルを一切持ちません。では、何が良い言語モデルなのか、どのように判断すればよいのでしょうか?
携帯電話の自動補正機能のように、文法的に正しい文には高い確率で、無意味な文には低い確率で割り当てることができるものが良い言語モデルです。自動補正の失敗例として、携帯電話に搭載された自動補正モデルが、おかしな(そして往々にして不適切な)文章を生成している例がネット上に多数紹介されています。
テストセットのほとんどが文法的に正しい文であると仮定すると、言語モデルの品質を測る一つの方法は、テストセットのすべての文において、次に出現する単語を正しく割り当てる確率を計算することです。確率が高いということは、モデルが未知の例文に「驚き」や「当惑」を感じていないことを示し、その言語の文法の基本パターンを学習していることを示唆しています。パープレキシティには様々な数学的定義がありますが、私達が使うのはクロスエントロピー損失の指数として定義するものです。したがって、Trainer.evaluate()関数を使ってテスト集合のクロスエントロピー損失を計算し、その結果の指数を取ることで事前学習済みモデルのパープレキシティを計算することができるのです。
import math
eval_results = trainer.evaluate()
print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")>>> Perplexity: 21.75パープレキシティスコアが低いほど、良い言語モデルということになります。 私達の開始時のモデルの値はやや大きいことがわかります。 では、微調整によってこの値を下げられるか見てみましょう。そのために、まず学習ループを実行します。
trainer.train()
それから計算を実行し、その結果得られたテストセットに対するパープレキシティを先ほどと同様に計算します。
eval_results = trainer.evaluate()
print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")>>> Perplexity: 11.32素敵!かなりパープレキシティを減らすことができました。 これは、モデルが映画レビューの領域について何かを学んだことを示しています。
一度、トレーニングが終了したら、トレーニング情報が入ったモデルカードをHubにプッシュする事ができます。(チェックポイントはトレーニングの最中に保存されます)。
trainer.push_to_hub()
✏️ あなたの番です! データコレーターを全単語マスキングコレーターに変えて、上記のトレーニングを実行してみましょう。より良い結果が得られましたか?
今回の使用例では、トレーニングループに特別なことをする必要はありませんでしたが、場合によってはカスタムロジックを実装する必要があるかもしれません。そのようなアプリケーションでは、🤗 Accelerateを使用することができます。 見てみましょう!
DistilBERTを🤗 Accelerateを使って微調整する
Trainerで見たように、マスクされた言語モデルの微調整は第3章のテキスト分類の例と非常によく似ています。実際、唯一のわずかな違いは特別なデータコレーターを使うことで、それはこのセクションの前半ですでに取り上げました!
しかし、DataCollatorForLanguageModelingは評価ごとにランダムなマスキングを行うので、学習実行ごとにパープレキシティスコアに多少の変動が見られることがわかりました。このランダム性を排除する一つの方法は、テストセット全体に 一度だけ マスキングを適用し、その後🤗 Transformersのデフォルトのデータコレーターを使用して、評価中にバッチを収集することです。これがどのように機能するかを見るために、DataCollatorForLanguageModeling を最初に使った時と同様に、バッチにマスキングを適用する簡単な関数を実装してみましょう。
def insert_random_mask(batch):
features = [dict(zip(batch, t)) for t in zip(*batch.values())]
masked_inputs = data_collator(features)
# Create a new "masked" column for each column in the dataset
return {"masked_" + k: v.numpy() for k, v in masked_inputs.items()}次に、この関数をテストセットに適用して、マスクされていないカラムを削除し、マスクされたカラムに置き換えることができるようにします。上の data_collator を適切なものに置き換えることで、全単語単位でのマスキングを行うことができます。
その場合は、以下の最初の行を削除してください。
downsampled_dataset = downsampled_dataset.remove_columns(["word_ids"])
eval_dataset = downsampled_dataset["test"].map(
insert_random_mask,
batched=True,
remove_columns=downsampled_dataset["test"].column_names,
)
eval_dataset = eval_dataset.rename_columns(
{
"masked_input_ids": "input_ids",
"masked_attention_mask": "attention_mask",
"masked_labels": "labels",
}
)あとは通常通りデータローダーをセットアップしますが、ここでは評価セットに 🤗 Transformers の default_data_collator を使用します。
from torch.utils.data import DataLoader
from transformers import default_data_collator
batch_size = 64
train_dataloader = DataLoader(
downsampled_dataset["train"],
shuffle=True,
batch_size=batch_size,
collate_fn=data_collator,
)
eval_dataloader = DataLoader(
eval_dataset, batch_size=batch_size, collate_fn=default_data_collator
)ここでは、🤗 Accelerateを使った標準的なステップに従います。最初にやる事は、事前学習したモデルの新しいバージョンをロードすることです。
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)次に、オプティマイザを指定します。ここでは、標準的な AdamW を使用します。
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)これらのオブジェクトがあれば、あとは Accelerator オブジェクトを使ってトレーニングのためのすべてを準備することができます。
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)モデル、オプティマイザー、データローダーが設定されたので、学習率スケジューラーを以下のように指定することができます。
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)トレーニングの前に最後にすることがあります。ハギング フェイス ハブにモデルリポジトリを作成することです。🤗 Hub ライブラリを使って、まずレポジトリのフルネームを生成します。
from huggingface_hub import get_full_repo_name
model_name = "distilbert-base-uncased-finetuned-imdb-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name'lewtun/distilbert-base-uncased-finetuned-imdb-accelerate'それから、🤗 Hub の Repository クラスを使用してリポジトリを作成し、クローンします。
from huggingface_hub import Repository
output_dir = model_name
repo = Repository(output_dir, clone_from=repo_name)これができれば、あとはトレーニングと評価のループをすべて書き出すだけです。
from tqdm.auto import tqdm
import torch
import math
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Training
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
losses.append(accelerator.gather(loss.repeat(batch_size)))
losses = torch.cat(losses)
losses = losses[: len(eval_dataset)]
try:
perplexity = math.exp(torch.mean(losses))
except OverflowError:
perplexity = float("inf")
print(f">>> Epoch {epoch}: Perplexity: {perplexity}")
# Save and upload
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)>>> Epoch 0: Perplexity: 11.397545307900472
>>> Epoch 1: Perplexity: 10.904909330983092
>>> Epoch 2: Perplexity: 10.729503505340409イケてる! エポックごとにパープレキシティを評価し、複数回のトレーニングを実行した際の再現性を確保することができました
微調整したモデルを使う
微調整したモデルは、Hub上のウィジェットを使うか、🤗 Transformersの pipeline を使ってローカル環境で操作することができます。それでは後者に挑戦してみましょう。fill-maskパイプラインを使用してモデルをダウンロードします。
from transformers import pipeline
mask_filler = pipeline(
"fill-mask", model="huggingface-course/distilbert-base-uncased-finetuned-imdb"
)そして「これは素晴らしい[MASK]です」というサンプルテキストをパイプラインに送り、上位5つの予測を確認することができます。
preds = mask_filler(text)
for pred in preds:
print(f">>> {pred['sequence']}")'>>> this is a great movie.'
'>>> this is a great film.'
'>>> this is a great story.'
'>>> this is a great movies.'
'>>> this is a great character.'すっきりしました。 このモデルは、映画と関連する単語をより強く予測するように、明らかに重みを適応させていますね!
これで、言語モデルを学習するための最初の実験を終えました。セクション6では、GPT-2のような自己回帰モデルをゼロから学習する方法を学びます。もし、あなた自身のTransformerモデルをどうやって事前学習するか見たいなら、そちらに向かってください
✏️ あなたの番です! ドメイン適応の利点を定量化するために、IMDbラベルの分類器を、訓練前と微調整したDistilBERTチェックポイントの両方で微調整してください。テキスト分類について復習が必要な場合は、第3章をチェックしてみてください。