
Corentin
commited on
Commit
·
c4c2296
1
Parent(s):
1f1ccf4
new models & events & docs
Browse files- README.md +26 -11
- runs/sdh16k_normal_resize_20220830-083856/validation/events.out.tfevents.1661848941.561a638614d6.77.1.v2 → history.pickle +2 -2
- model.h5 +2 -2
- myoquant-sdh-train.ipynb +509 -0
- runs/{sdh16k_normal_resize_20220830-083856/train/events.out.tfevents.1661848752.561a638614d6.77.0.v2 → SDH16K_wandb_20230406-214521/train/events.out.tfevents.1680810371.guepe.1458055.0.v2} +2 -2
- runs/SDH16K_wandb_20230406-214521/validation/events.out.tfevents.1680810475.guepe.1458055.1.v2 +3 -0
- training_curve.png +0 -0
README.md
CHANGED
|
@@ -60,16 +60,17 @@ Full model code:
|
|
| 60 |
|
| 61 |
```python
|
| 62 |
data_augmentation = tf.keras.Sequential([
|
| 63 |
-
layers.
|
| 64 |
-
layers.Rescaling(scale=1./127.5, offset=-1),
|
| 65 |
-
RandomBrightness(factor=0.2, value_range=(-1.0, 1.0)), # Not avaliable in tensorflow 2.8
|
| 66 |
layers.RandomContrast(factor=0.2),
|
| 67 |
layers.RandomFlip("horizontal_and_vertical"),
|
| 68 |
layers.RandomRotation(0.3, fill_mode="constant"),
|
| 69 |
layers.RandomZoom(.2, .2, fill_mode="constant"),
|
| 70 |
layers.RandomTranslation(0.2, .2,fill_mode="constant"),
|
| 71 |
-
|
|
|
|
| 72 |
])
|
|
|
|
|
|
|
| 73 |
model = models.Sequential()
|
| 74 |
model.add(data_augmentation)
|
| 75 |
model.add(
|
|
@@ -80,7 +81,7 @@ model.add(
|
|
| 80 |
)
|
| 81 |
)
|
| 82 |
model.add(layers.Flatten())
|
| 83 |
-
model.add(layers.Dense(
|
| 84 |
```
|
| 85 |
|
| 86 |
```
|
|
@@ -110,28 +111,41 @@ Class imbalance was handled by using the class\_-weight attribute during trainin
|
|
| 110 |
The following hyperparameters were used during training:
|
| 111 |
|
| 112 |
- optimizer: Adam
|
| 113 |
-
- Learning Rate Schedule: `ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=5, min_lr=
|
| 114 |
- Loss Function: SparseCategoricalCrossentropy
|
| 115 |
- Metric: Accuracy
|
| 116 |
|
|
|
|
|
|
|
| 117 |
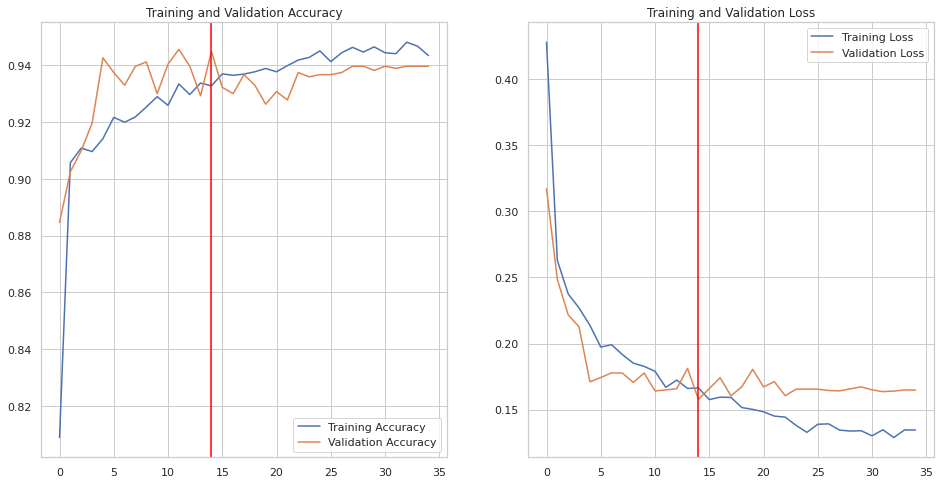
## Training Curve
|
| 118 |
|
|
|
|
| 119 |
Plot of the accuracy vs epoch and loss vs epoch for training and validation set.
|
| 120 |

|
| 121 |
|
| 122 |
## Test Results
|
| 123 |
|
| 124 |
-
Results for accuracy metrics on the test split of the [corentinm7/MyoQuant-SDH-Data](https://huggingface.co/datasets/corentinm7/MyoQuant-SDH-Data) dataset.
|
| 125 |
|
| 126 |
```
|
| 127 |
-
105/105 -
|
| 128 |
Test data results:
|
| 129 |
-
0.
|
|
|
|
|
|
|
|
|
|
| 130 |
```
|
| 131 |
|
| 132 |
# How to Import the Model
|
| 133 |
|
| 134 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 135 |
Then the model can easily be imported in Tensorflow/Keras using:
|
| 136 |
|
| 137 |
```python
|
|
@@ -144,6 +158,7 @@ model_sdh = keras.models.load_model(
|
|
| 144 |
## The Team Behind this Dataset
|
| 145 |
|
| 146 |
**The creator, uploader and main maintainer of this model, associated dataset and MyoQuant is:**
|
|
|
|
| 147 |
- **[Corentin Meyer, 3rd year PhD Student in the CSTB Team, ICube — CNRS — Unistra](https://cmeyer.fr) Email: <corentin.meyer@etu.unistra.fr> Github: [@lambda-science](https://github.com/lambda-science)**
|
| 148 |
|
| 149 |
Special thanks to the experts that created the data for the dataset and all the time they spend counting cells :
|
|
@@ -161,4 +176,4 @@ Last but not least thanks to Bertrand Vernay being at the origin of this project
|
|
| 161 |
<img src="https://i.imgur.com/m5OGthE.png" alt="Partner Banner" style="border-radius: 25px;" />
|
| 162 |
</p>
|
| 163 |
|
| 164 |
-
MyoQuant-SDH-Model is born within the collaboration between the [CSTB Team @ ICube](https://cstb.icube.unistra.fr/en/index.php/Home) led by Julie D. Thompson, the [Morphological Unit of the Institute of Myology of Paris](https://www.institut-myologie.org/en/recherche-2/neuromuscular-investigation-center/morphological-unit/) led by Teresinha Evangelista, the [imagery platform MyoImage of Center of Research in Myology](https://recherche-myologie.fr/technologies/myoimage/) led by Bruno Cadot, [the photonic microscopy platform of the IGMBC](https://www.igbmc.fr/en/plateformes-technologiques/photonic-microscopy) led by Bertrand Vernay and the [Pathophysiology of neuromuscular diseases team @ IGBMC](https://www.igbmc.fr/en/igbmc/a-propos-de-ligbmc/directory/jocelyn-laporte) led by Jocelyn Laporte
|
|
|
|
| 60 |
|
| 61 |
```python
|
| 62 |
data_augmentation = tf.keras.Sequential([
|
| 63 |
+
layers.RandomBrightness(factor=0.2, input_shape=(None, None, 3)), # Not avaliable in tensorflow 2.8
|
|
|
|
|
|
|
| 64 |
layers.RandomContrast(factor=0.2),
|
| 65 |
layers.RandomFlip("horizontal_and_vertical"),
|
| 66 |
layers.RandomRotation(0.3, fill_mode="constant"),
|
| 67 |
layers.RandomZoom(.2, .2, fill_mode="constant"),
|
| 68 |
layers.RandomTranslation(0.2, .2,fill_mode="constant"),
|
| 69 |
+
layers.Resizing(256, 256, interpolation="bilinear", crop_to_aspect_ratio=True),
|
| 70 |
+
layers.Rescaling(scale=1./127.5, offset=-1), # For [-1, 1] scaling
|
| 71 |
])
|
| 72 |
+
|
| 73 |
+
# My ResNet50V2
|
| 74 |
model = models.Sequential()
|
| 75 |
model.add(data_augmentation)
|
| 76 |
model.add(
|
|
|
|
| 81 |
)
|
| 82 |
)
|
| 83 |
model.add(layers.Flatten())
|
| 84 |
+
model.add(layers.Dense(len(config.SUB_FOLDERS), activation='softmax'))
|
| 85 |
```
|
| 86 |
|
| 87 |
```
|
|
|
|
| 111 |
The following hyperparameters were used during training:
|
| 112 |
|
| 113 |
- optimizer: Adam
|
| 114 |
+
- Learning Rate Schedule: `ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=5, min_lr=1e-7` with START_LR = 1e-5 and MIN_LR = 1e-7
|
| 115 |
- Loss Function: SparseCategoricalCrossentropy
|
| 116 |
- Metric: Accuracy
|
| 117 |
|
| 118 |
+
For more details please see the training notebook associated.
|
| 119 |
+
|
| 120 |
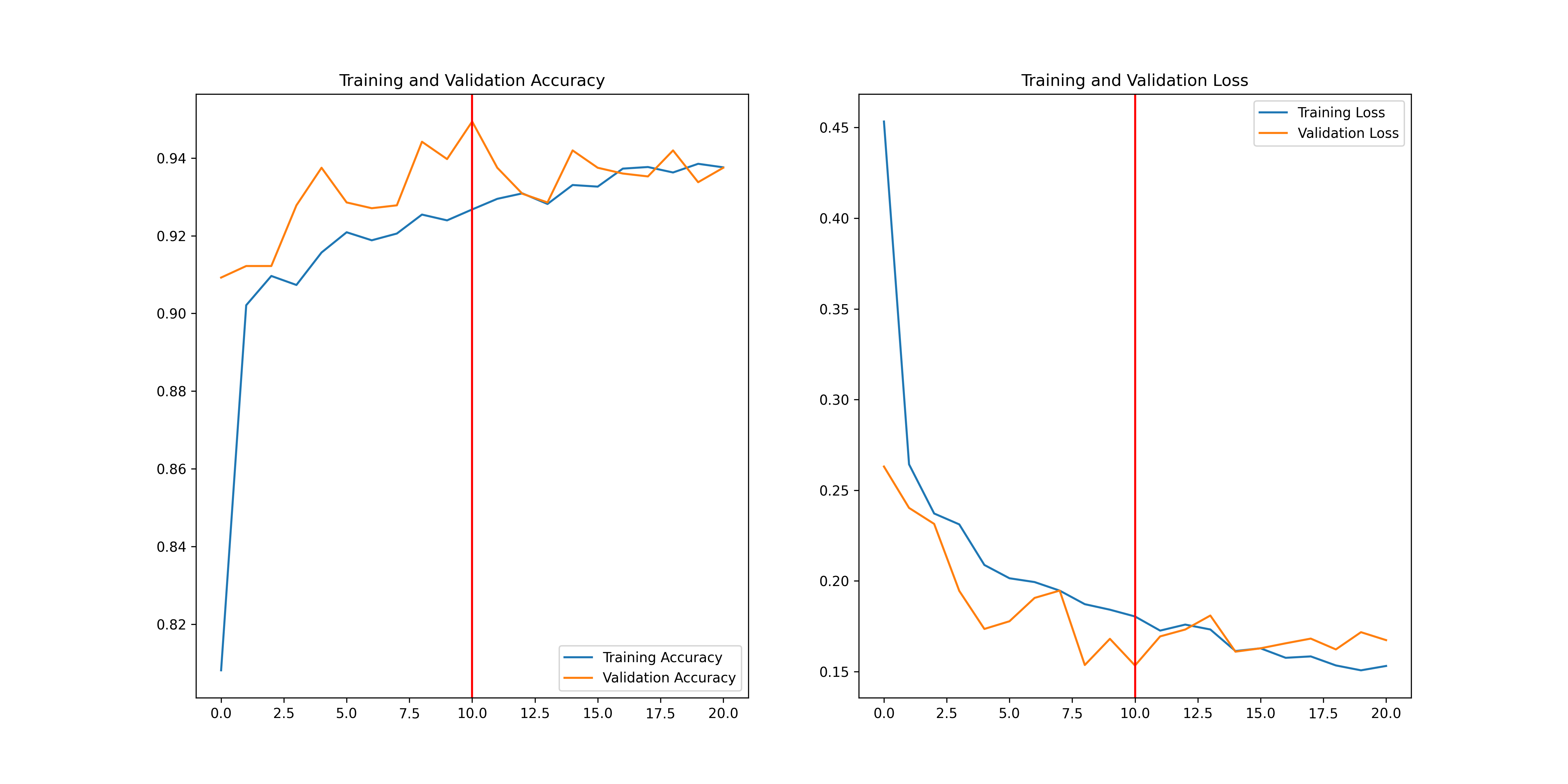
## Training Curve
|
| 121 |
|
| 122 |
+
Full training results are avaliable on `Weights and Biases` here: [https://api.wandb.ai/links/lambda-science/ka0iw3b6](https://api.wandb.ai/links/lambda-science/ka0iw3b6)
|
| 123 |
Plot of the accuracy vs epoch and loss vs epoch for training and validation set.
|
| 124 |

|
| 125 |
|
| 126 |
## Test Results
|
| 127 |
|
| 128 |
+
Results for accuracy and balanced accuracy metrics on the test split of the [corentinm7/MyoQuant-SDH-Data](https://huggingface.co/datasets/corentinm7/MyoQuant-SDH-Data) dataset.
|
| 129 |
|
| 130 |
```
|
| 131 |
+
105/105 - 11s - loss: 0.1574 - accuracy: 0.9321 - 11s/epoch - 102ms/step
|
| 132 |
Test data results:
|
| 133 |
+
0.9321024417877197
|
| 134 |
+
105/105 [==============================] - 6s 44ms/step
|
| 135 |
+
Test data results:
|
| 136 |
+
0.9166411912436779
|
| 137 |
```
|
| 138 |
|
| 139 |
# How to Import the Model
|
| 140 |
|
| 141 |
+
With Tensorflow 2.10 and over:
|
| 142 |
+
|
| 143 |
+
```python
|
| 144 |
+
model_sdh = keras.models.load_model("model.h5")
|
| 145 |
+
```
|
| 146 |
+
|
| 147 |
+
With Tensorflow <2.10:
|
| 148 |
+
To import this model RandomBrightness layer had to be added by hand (it was only introduced in Tensorflow 2.10.). So you will need to download the `random_brightness.py` fille in addition to the model.
|
| 149 |
Then the model can easily be imported in Tensorflow/Keras using:
|
| 150 |
|
| 151 |
```python
|
|
|
|
| 158 |
## The Team Behind this Dataset
|
| 159 |
|
| 160 |
**The creator, uploader and main maintainer of this model, associated dataset and MyoQuant is:**
|
| 161 |
+
|
| 162 |
- **[Corentin Meyer, 3rd year PhD Student in the CSTB Team, ICube — CNRS — Unistra](https://cmeyer.fr) Email: <corentin.meyer@etu.unistra.fr> Github: [@lambda-science](https://github.com/lambda-science)**
|
| 163 |
|
| 164 |
Special thanks to the experts that created the data for the dataset and all the time they spend counting cells :
|
|
|
|
| 176 |
<img src="https://i.imgur.com/m5OGthE.png" alt="Partner Banner" style="border-radius: 25px;" />
|
| 177 |
</p>
|
| 178 |
|
| 179 |
+
MyoQuant-SDH-Model is born within the collaboration between the [CSTB Team @ ICube](https://cstb.icube.unistra.fr/en/index.php/Home) led by Julie D. Thompson, the [Morphological Unit of the Institute of Myology of Paris](https://www.institut-myologie.org/en/recherche-2/neuromuscular-investigation-center/morphological-unit/) led by Teresinha Evangelista, the [imagery platform MyoImage of Center of Research in Myology](https://recherche-myologie.fr/technologies/myoimage/) led by Bruno Cadot, [the photonic microscopy platform of the IGMBC](https://www.igbmc.fr/en/plateformes-technologiques/photonic-microscopy) led by Bertrand Vernay and the [Pathophysiology of neuromuscular diseases team @ IGBMC](https://www.igbmc.fr/en/igbmc/a-propos-de-ligbmc/directory/jocelyn-laporte) led by Jocelyn Laporte
|
runs/sdh16k_normal_resize_20220830-083856/validation/events.out.tfevents.1661848941.561a638614d6.77.1.v2 → history.pickle
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c222fe72b84d6acd03fcf393efb8a41201bdbace8df399c2050409fc53a5c595
|
| 3 |
+
size 1241
|
model.h5
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d9b858710ae2756424f7c4df0edcee9549e6f57b81e89c5227fbbb1201081514
|
| 3 |
+
size 283136344
|
myoquant-sdh-train.ipynb
ADDED
|
@@ -0,0 +1,509 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"import os\n",
|
| 10 |
+
"os.environ[\"TF_CPP_MIN_LOG_LEVEL\"] = \"3\"\n",
|
| 11 |
+
"import tensorflow as tf\n",
|
| 12 |
+
"tf.get_logger().setLevel('ERROR')\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"if tf.test.gpu_device_name()=='':\n",
|
| 15 |
+
" print('You do not have GPU access.') \n",
|
| 16 |
+
" print('Did you change your runtime ?') \n",
|
| 17 |
+
" print('If the runtime setting is correct then Google did not allocate a GPU for your session')\n",
|
| 18 |
+
" print('Expect slow performance. To access GPU try reconnecting later')\n",
|
| 19 |
+
"\n",
|
| 20 |
+
"else:\n",
|
| 21 |
+
" print('You have GPU access')\n",
|
| 22 |
+
" !nvidia-smi\n",
|
| 23 |
+
"\n",
|
| 24 |
+
"# from tensorflow.python.client import device_lib \n",
|
| 25 |
+
"# device_lib.list_local_devices()\n",
|
| 26 |
+
"\n",
|
| 27 |
+
"# print the tensorflow version\n",
|
| 28 |
+
"print('Tensorflow version is ' + str(tf.__version__))"
|
| 29 |
+
]
|
| 30 |
+
},
|
| 31 |
+
{
|
| 32 |
+
"cell_type": "code",
|
| 33 |
+
"execution_count": null,
|
| 34 |
+
"metadata": {},
|
| 35 |
+
"outputs": [],
|
| 36 |
+
"source": [
|
| 37 |
+
"import wandb\n",
|
| 38 |
+
"from wandb.keras import WandbMetricsLogger\n",
|
| 39 |
+
"\n",
|
| 40 |
+
"run = wandb.init(project='myoquant-sdh',\n",
|
| 41 |
+
" config={\n",
|
| 42 |
+
" \"BATCH_SIZE\": 32,\n",
|
| 43 |
+
" \"CLASS_WEIGHTS\": True,\n",
|
| 44 |
+
" \"EARLY_STOPPING_PATIENCE\": 10,\n",
|
| 45 |
+
" \"EPOCH\": 1000,\n",
|
| 46 |
+
" \"EPOCH_OPTI_LR\": 100,\n",
|
| 47 |
+
" \"LOSS\": \"SparseCategoricalCrossentropy\",\n",
|
| 48 |
+
" \"LR_PATIENCE\":5,\n",
|
| 49 |
+
" \"LR_PLATEAU_RATIO\":0.2,\n",
|
| 50 |
+
" \"MAX_LR\":0.00001,\n",
|
| 51 |
+
" \"METRIC\":\"accuracy\",\n",
|
| 52 |
+
" \"MIN_LR\":1e-7,\n",
|
| 53 |
+
" \"MODEL_NAME\":\"SDH16K_wandb\",\n",
|
| 54 |
+
" \"OPTIMIZER\":\"adam\",\n",
|
| 55 |
+
" \"OPTI_START_LR\":1e-7,\n",
|
| 56 |
+
" \"RELOAD_MODEL\":False,\n",
|
| 57 |
+
" \"SUB_FOLDERS\":{0:\"control\", 1:\"sick\"},\n",
|
| 58 |
+
" \"UPLOAD_LOGS\":True,\n",
|
| 59 |
+
" }\n",
|
| 60 |
+
" )\n",
|
| 61 |
+
"\n",
|
| 62 |
+
"config = wandb.config\n",
|
| 63 |
+
"BASE_FOLDER=\"/home/meyer/code-project/AI-dev-playground/data/\"\n",
|
| 64 |
+
"LOG_DIR=\"/home/meyer/code-project/AI-dev-playground/logs\""
|
| 65 |
+
]
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"cell_type": "code",
|
| 69 |
+
"execution_count": null,
|
| 70 |
+
"metadata": {},
|
| 71 |
+
"outputs": [],
|
| 72 |
+
"source": [
|
| 73 |
+
"import tensorflow as tf\n",
|
| 74 |
+
"from tensorflow.image import resize_with_crop_or_pad\n",
|
| 75 |
+
"from tensorflow.keras import layers, models, callbacks\n",
|
| 76 |
+
"from tensorflow.keras.preprocessing import image\n",
|
| 77 |
+
"from tensorflow.keras.utils import load_img, img_to_array\n",
|
| 78 |
+
"# import tensorflow_addons as tfa\n",
|
| 79 |
+
"\n",
|
| 80 |
+
"import tensorboard as tb\n",
|
| 81 |
+
"from tensorflow.keras.applications.resnet_v2 import ResNet50V2, preprocess_input\n",
|
| 82 |
+
"from sklearn.metrics import balanced_accuracy_score\n",
|
| 83 |
+
"\n",
|
| 84 |
+
"import matplotlib.cm as cm\n",
|
| 85 |
+
"from IPython.display import Image, display\n",
|
| 86 |
+
"\n",
|
| 87 |
+
"from pathlib import Path\n",
|
| 88 |
+
"import pickle\n",
|
| 89 |
+
"import numpy as np\n",
|
| 90 |
+
"import datetime, os\n",
|
| 91 |
+
"import glob\n",
|
| 92 |
+
"from math import exp, log, pow\n",
|
| 93 |
+
"# from PIL import Image\n",
|
| 94 |
+
"from matplotlib import pyplot as plt\n",
|
| 95 |
+
"from scipy import stats\n",
|
| 96 |
+
"import pandas as pd\n",
|
| 97 |
+
"\n",
|
| 98 |
+
"tf.random.set_seed(42)\n",
|
| 99 |
+
"np.random.seed(42)\n",
|
| 100 |
+
"\n",
|
| 101 |
+
"MODEL_PATH = os.path.join(BASE_FOLDER, \"results\", config.MODEL_NAME)\n",
|
| 102 |
+
"Path(MODEL_PATH).mkdir(parents=True, exist_ok=True)\n",
|
| 103 |
+
"\n",
|
| 104 |
+
"logdir = os.path.join(LOG_DIR, datetime.datetime.now().strftime(config.MODEL_NAME+\"_%Y%m%d-%H%M%S\"))\n",
|
| 105 |
+
"tensorboard_cb = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)\n",
|
| 106 |
+
"\n",
|
| 107 |
+
"def generate_dataset(folder, sub_folders=[\"control\", \"inter\", \"sick\"]):\n",
|
| 108 |
+
" n_elem = 0\n",
|
| 109 |
+
" for sub_folder in sub_folders:\n",
|
| 110 |
+
" n_elem += len(glob.glob(os.path.join(folder, sub_folder, \"*.tif\")))\n",
|
| 111 |
+
" \n",
|
| 112 |
+
" images_array = np.empty(shape=(n_elem, 256, 256, 3), dtype=np.uint8)\n",
|
| 113 |
+
" labels_array = np.empty(shape=n_elem, dtype=np.uint8)\n",
|
| 114 |
+
" counter = 0\n",
|
| 115 |
+
" for index, sub_folder in enumerate(sub_folders):\n",
|
| 116 |
+
" path_files = os.path.join(folder, sub_folder, \"*.tif\")\n",
|
| 117 |
+
" for img in glob.glob(path_files):\n",
|
| 118 |
+
" im = img_to_array(image.load_img(img))\n",
|
| 119 |
+
" # im_resized = image.smart_resize(im, (256, 256))\n",
|
| 120 |
+
" im_resized = tf.image.resize(im, (256,256))\n",
|
| 121 |
+
" images_array[counter] = im_resized\n",
|
| 122 |
+
" labels_array[counter] = index\n",
|
| 123 |
+
" counter += 1\n",
|
| 124 |
+
" return images_array, labels_array\n",
|
| 125 |
+
"\n",
|
| 126 |
+
"def scale_fn(x):\n",
|
| 127 |
+
" # return 1.0 # Triangular Scaling Method\n",
|
| 128 |
+
" return 1 / (2.0 ** (x - 1)) # Triangular2 Scaling method\n",
|
| 129 |
+
"\n",
|
| 130 |
+
"\n",
|
| 131 |
+
"def get_inter_unsure_img(BASE_FOLDER):\n",
|
| 132 |
+
" n_unsure = len(glob.glob(BASE_FOLDER+\"Unsure/*.tif\"))\n",
|
| 133 |
+
" n_intermediate = len(glob.glob(BASE_FOLDER+\"Intermediate/*.tif\"))\n",
|
| 134 |
+
" \n",
|
| 135 |
+
" unsure_images = np.empty(shape=(n_unsure, 256, 256, 3), dtype=np.uint8)\n",
|
| 136 |
+
" intermediate_images = np.empty(shape=(n_intermediate, 256, 256, 3), dtype=np.uint8)\n",
|
| 137 |
+
"\n",
|
| 138 |
+
" counter = 0\n",
|
| 139 |
+
" for img in glob.glob(BASE_FOLDER+\"Unsure/*.tif\"):\n",
|
| 140 |
+
" im = img_to_array(image.load_img(img))\n",
|
| 141 |
+
" # im_resized = image.smart_resize(im, (256, 256))\n",
|
| 142 |
+
" im_resized = tf.image.resize(im, (256,256))\n",
|
| 143 |
+
" unsure_images[counter] = im_resized\n",
|
| 144 |
+
" counter += 1\n",
|
| 145 |
+
" \n",
|
| 146 |
+
" counter = 0\n",
|
| 147 |
+
" for img in glob.glob(BASE_FOLDER+\"Intermediate/*.tif\"):\n",
|
| 148 |
+
" im = img_to_array(image.load_img(img))\n",
|
| 149 |
+
" # im_resized = image.smart_resize(im, (256, 256))\n",
|
| 150 |
+
" im_resized = tf.image.resize(im, (256,256))\n",
|
| 151 |
+
" intermediate_images[counter] = im_resized\n",
|
| 152 |
+
" counter += 1\n",
|
| 153 |
+
"\n",
|
| 154 |
+
"\n",
|
| 155 |
+
" return unsure_images, intermediate_images\n",
|
| 156 |
+
"\n",
|
| 157 |
+
"# GRAD-CAM\n",
|
| 158 |
+
"def get_img_array(img_path, size):\n",
|
| 159 |
+
" # `img` is a PIL image of size 299x299\n",
|
| 160 |
+
" img = tf.keras.preprocessing.image.load_img(img_path, target_size=size)\n",
|
| 161 |
+
" # `array` is a float32 Numpy array of shape (299, 299, 3)\n",
|
| 162 |
+
" array = tf.keras.preprocessing.image.img_to_array(img)\n",
|
| 163 |
+
" # We add a dimension to transform our array into a \"batch\"\n",
|
| 164 |
+
" # of size (1, 299, 299, 3)\n",
|
| 165 |
+
" array = np.expand_dims(array, axis=0)\n",
|
| 166 |
+
" return array\n",
|
| 167 |
+
"\n",
|
| 168 |
+
"\n",
|
| 169 |
+
"def make_gradcam_heatmap(img_array, model, last_conv_layer_name, pred_index=None):\n",
|
| 170 |
+
" # First, we create a model that maps the input image to the activations\n",
|
| 171 |
+
" # of the last conv layer as well as the output predictions\n",
|
| 172 |
+
" grad_model = tf.keras.models.Model(\n",
|
| 173 |
+
" [model.inputs], [model.get_layer(last_conv_layer_name).output, model.output]\n",
|
| 174 |
+
" )\n",
|
| 175 |
+
"\n",
|
| 176 |
+
" # Then, we compute the gradient of the top predicted class for our input image\n",
|
| 177 |
+
" # with respect to the activations of the last conv layer\n",
|
| 178 |
+
" with tf.GradientTape() as tape:\n",
|
| 179 |
+
" last_conv_layer_output, preds = grad_model(img_array)\n",
|
| 180 |
+
" if pred_index is None:\n",
|
| 181 |
+
" pred_index = tf.argmax(preds[0])\n",
|
| 182 |
+
" class_channel = preds[:, pred_index]\n",
|
| 183 |
+
"\n",
|
| 184 |
+
" # This is the gradient of the output neuron (top predicted or chosen)\n",
|
| 185 |
+
" # with regard to the output feature map of the last conv layer\n",
|
| 186 |
+
" grads = tape.gradient(class_channel, last_conv_layer_output)\n",
|
| 187 |
+
"\n",
|
| 188 |
+
" # This is a vector where each entry is the mean intensity of the gradient\n",
|
| 189 |
+
" # over a specific feature map channel\n",
|
| 190 |
+
" pooled_grads = tf.reduce_mean(grads, axis=(0, 1, 2))\n",
|
| 191 |
+
"\n",
|
| 192 |
+
" # We multiply each channel in the feature map array\n",
|
| 193 |
+
" # by \"how important this channel is\" with regard to the top predicted class\n",
|
| 194 |
+
" # then sum all the channels to obtain the heatmap class activation\n",
|
| 195 |
+
" last_conv_layer_output = last_conv_layer_output[0]\n",
|
| 196 |
+
" heatmap = last_conv_layer_output @ pooled_grads[..., tf.newaxis]\n",
|
| 197 |
+
" heatmap = tf.squeeze(heatmap)\n",
|
| 198 |
+
"\n",
|
| 199 |
+
" # For visualization purpose, we will also normalize the heatmap between 0 & 1\n",
|
| 200 |
+
" heatmap = tf.maximum(heatmap, 0) / tf.math.reduce_max(heatmap)\n",
|
| 201 |
+
" return heatmap.numpy()\n",
|
| 202 |
+
"\n",
|
| 203 |
+
"def save_and_display_gradcam(img, heatmap, cam_path=\"cam.jpg\", alpha=0.5):\n",
|
| 204 |
+
" # Rescale heatmap to a range 0-255\n",
|
| 205 |
+
" heatmap = np.uint8(255 * heatmap)\n",
|
| 206 |
+
"\n",
|
| 207 |
+
" # Use jet colormap to colorize heatmap\n",
|
| 208 |
+
" jet = cm.get_cmap(\"jet\")\n",
|
| 209 |
+
"\n",
|
| 210 |
+
" # Use RGB values of the colormap\n",
|
| 211 |
+
" jet_colors = jet(np.arange(256))[:, :3]\n",
|
| 212 |
+
" jet_heatmap = jet_colors[heatmap]\n",
|
| 213 |
+
"\n",
|
| 214 |
+
" # Create an image with RGB colorized heatmap\n",
|
| 215 |
+
" jet_heatmap = tf.keras.preprocessing.image.array_to_img(jet_heatmap)\n",
|
| 216 |
+
" jet_heatmap = jet_heatmap.resize((img.shape[1], img.shape[0]))\n",
|
| 217 |
+
" jet_heatmap = tf.keras.preprocessing.image.img_to_array(jet_heatmap)\n",
|
| 218 |
+
"\n",
|
| 219 |
+
" # Superimpose the heatmap on original image\n",
|
| 220 |
+
" superimposed_img = jet_heatmap * alpha + img*255\n",
|
| 221 |
+
" superimposed_img = tf.keras.preprocessing.image.array_to_img(superimposed_img)\n",
|
| 222 |
+
" return superimposed_img"
|
| 223 |
+
]
|
| 224 |
+
},
|
| 225 |
+
{
|
| 226 |
+
"cell_type": "code",
|
| 227 |
+
"execution_count": null,
|
| 228 |
+
"metadata": {},
|
| 229 |
+
"outputs": [],
|
| 230 |
+
"source": [
|
| 231 |
+
"train_images, train_labels = generate_dataset(os.path.join(BASE_FOLDER, \"train\"), sub_folders=list(config.SUB_FOLDERS.values()))\n",
|
| 232 |
+
"val_images, val_labels = generate_dataset(os.path.join(BASE_FOLDER, \"validation\"), sub_folders=list(config.SUB_FOLDERS.values()))\n",
|
| 233 |
+
"test_images, test_labels = generate_dataset(os.path.join(BASE_FOLDER, \"test\"), sub_folders=list(config.SUB_FOLDERS.values()))\n",
|
| 234 |
+
"\n",
|
| 235 |
+
"train_dataset = tf.data.Dataset.from_tensor_slices((train_images, train_labels)).shuffle(10000).repeat(1)\n",
|
| 236 |
+
"val_dataset = tf.data.Dataset.from_tensor_slices((val_images, val_labels)).shuffle(10000).repeat(1)\n",
|
| 237 |
+
"test_dataset = tf.data.Dataset.from_tensor_slices((test_images, test_labels)).shuffle(10000).repeat(1) \n",
|
| 238 |
+
"\n",
|
| 239 |
+
"data_augmentation = tf.keras.Sequential([\n",
|
| 240 |
+
" layers.RandomBrightness(factor=0.2), # Not avaliable in tensorflow 2.8\n",
|
| 241 |
+
" layers.RandomContrast(factor=0.2),\n",
|
| 242 |
+
" layers.RandomFlip(\"horizontal_and_vertical\"),\n",
|
| 243 |
+
" layers.RandomRotation(0.3, fill_mode=\"constant\"),\n",
|
| 244 |
+
" layers.RandomZoom(.2, .2, fill_mode=\"constant\"),\n",
|
| 245 |
+
" layers.RandomTranslation(0.2, .2,fill_mode=\"constant\"),\n",
|
| 246 |
+
"])\n",
|
| 247 |
+
"\n",
|
| 248 |
+
"train_dataset = train_dataset.batch(config.BATCH_SIZE).prefetch(1)\n",
|
| 249 |
+
"val_dataset = val_dataset.batch(config.BATCH_SIZE).prefetch(1)\n",
|
| 250 |
+
"test_dataset = test_dataset.batch(config.BATCH_SIZE).prefetch(1)\n",
|
| 251 |
+
"\n",
|
| 252 |
+
"# Scaling by total/2 helps keep the loss to a similar magnitude.\n",
|
| 253 |
+
"# The sum of the weights of all examples stays the same.\n",
|
| 254 |
+
"if config.CLASS_WEIGHTS:\n",
|
| 255 |
+
" class_weights_numpy = np.unique(train_labels, return_counts=True)\n",
|
| 256 |
+
" n_train = len(train_labels)\n",
|
| 257 |
+
" class_weights = dict()\n",
|
| 258 |
+
" for index, folder in enumerate(config.SUB_FOLDERS):\n",
|
| 259 |
+
" class_weights[class_weights_numpy[0][index]] = (1/class_weights_numpy[1][index])*(n_train/2.0)\n",
|
| 260 |
+
"else:\n",
|
| 261 |
+
" class_weights = None\n",
|
| 262 |
+
" \n",
|
| 263 |
+
" print(class_weights)\n",
|
| 264 |
+
"\n",
|
| 265 |
+
"plt.figure(figsize=(10,10))\n",
|
| 266 |
+
"counter = 0\n",
|
| 267 |
+
"for i in np.random.choice(range(len(train_images)),25):\n",
|
| 268 |
+
" plt.subplot(5,5,counter+1)\n",
|
| 269 |
+
" plt.xticks([])\n",
|
| 270 |
+
" plt.yticks([])\n",
|
| 271 |
+
" plt.grid(False)\n",
|
| 272 |
+
" plt.imshow(train_images[i])\n",
|
| 273 |
+
" plt.xlabel(list(config.SUB_FOLDERS.values())[train_labels[i]])\n",
|
| 274 |
+
" counter +=1\n",
|
| 275 |
+
"plt.show()\n"
|
| 276 |
+
]
|
| 277 |
+
},
|
| 278 |
+
{
|
| 279 |
+
"cell_type": "code",
|
| 280 |
+
"execution_count": null,
|
| 281 |
+
"metadata": {},
|
| 282 |
+
"outputs": [],
|
| 283 |
+
"source": [
|
| 284 |
+
"data_augmentation = tf.keras.Sequential([\n",
|
| 285 |
+
" layers.RandomBrightness(factor=0.2, input_shape=(None, None, 3)), # Not avaliable in tensorflow 2.8\n",
|
| 286 |
+
" layers.RandomContrast(factor=0.2),\n",
|
| 287 |
+
" layers.RandomFlip(\"horizontal_and_vertical\"),\n",
|
| 288 |
+
" layers.RandomRotation(0.3, fill_mode=\"constant\"),\n",
|
| 289 |
+
" layers.RandomZoom(.2, .2, fill_mode=\"constant\"),\n",
|
| 290 |
+
" layers.RandomTranslation(0.2, .2,fill_mode=\"constant\"),\n",
|
| 291 |
+
" layers.Resizing(256, 256, interpolation=\"bilinear\", crop_to_aspect_ratio=True), \n",
|
| 292 |
+
" layers.Rescaling(scale=1./127.5, offset=-1), # For [-1, 1] scaling\n",
|
| 293 |
+
"])\n",
|
| 294 |
+
"\n",
|
| 295 |
+
"# My ResNet50V2\n",
|
| 296 |
+
"model = models.Sequential()\n",
|
| 297 |
+
"model.add(data_augmentation)\n",
|
| 298 |
+
"model.add(\n",
|
| 299 |
+
" ResNet50V2(\n",
|
| 300 |
+
" include_top=False,\n",
|
| 301 |
+
" input_shape=(256,256,3),\n",
|
| 302 |
+
" pooling=\"avg\",\n",
|
| 303 |
+
" )\n",
|
| 304 |
+
")\n",
|
| 305 |
+
"model.add(layers.Flatten())\n",
|
| 306 |
+
"model.add(layers.Dense(len(config.SUB_FOLDERS), activation='softmax'))\n",
|
| 307 |
+
"\n",
|
| 308 |
+
"model.summary()"
|
| 309 |
+
]
|
| 310 |
+
},
|
| 311 |
+
{
|
| 312 |
+
"cell_type": "code",
|
| 313 |
+
"execution_count": null,
|
| 314 |
+
"metadata": {},
|
| 315 |
+
"outputs": [],
|
| 316 |
+
"source": [
|
| 317 |
+
"# Find min max LR\n",
|
| 318 |
+
"\"\"\"\n",
|
| 319 |
+
"def scheduler(epoch, lr):\n",
|
| 320 |
+
" return lr*exp(log(pow(10,8))/EPOCH_OPTI_LR)\n",
|
| 321 |
+
"\n",
|
| 322 |
+
"model.compile(optimizer=tf.keras.optimizers.Nadam(learning_rate=OPTI_START_LR),\n",
|
| 323 |
+
" loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n",
|
| 324 |
+
" metrics=['accuracy'])\n",
|
| 325 |
+
"\n",
|
| 326 |
+
"lr_cb = tf.keras.callbacks.LearningRateScheduler(scheduler)\n",
|
| 327 |
+
"history = model.fit(train_images, train_labels, epochs=EPOCH_OPTI_LR, batch_size=BATCH_SIZE,\n",
|
| 328 |
+
" validation_data=(val_images, val_labels), shuffle=True, class_weight=class_weights, \n",
|
| 329 |
+
" callbacks=[lr_cb, tensorboard_cb])\n",
|
| 330 |
+
"\n",
|
| 331 |
+
"loss = history.history['loss']\n",
|
| 332 |
+
"val_loss = history.history['val_loss']\n",
|
| 333 |
+
"\n",
|
| 334 |
+
"learning_rate_range = [OPTI_START_LR]\n",
|
| 335 |
+
"for epoch in range(EPOCH_OPTI_LR-1):\n",
|
| 336 |
+
" learning_rate_range.append(learning_rate_range[epoch] * exp(log(pow(10,8))/EPOCH_OPTI_LR))\n",
|
| 337 |
+
"\n",
|
| 338 |
+
"plt.figure(figsize=(16, 8))\n",
|
| 339 |
+
"\n",
|
| 340 |
+
"plt.subplot(1, 1, 1)\n",
|
| 341 |
+
"plt.plot(learning_rate_range, loss, label='Training Loss')\n",
|
| 342 |
+
"plt.plot(learning_rate_range, val_loss, label='Validation Loss')\n",
|
| 343 |
+
"plt.legend(loc='upper right')\n",
|
| 344 |
+
"plt.title('Training and Validation Loss')\n",
|
| 345 |
+
"plt.xscale('log')\n",
|
| 346 |
+
"plt.savefig(os.path.join(MODEL_PATH, \"curve_findLR.png\"), dpi=300)\n",
|
| 347 |
+
"plt.show()\n",
|
| 348 |
+
"\"\"\""
|
| 349 |
+
]
|
| 350 |
+
},
|
| 351 |
+
{
|
| 352 |
+
"cell_type": "code",
|
| 353 |
+
"execution_count": null,
|
| 354 |
+
"metadata": {},
|
| 355 |
+
"outputs": [],
|
| 356 |
+
"source": [
|
| 357 |
+
"steps_per_epoch = len(train_images) // config.BATCH_SIZE # Batch size is 32\n",
|
| 358 |
+
"\n",
|
| 359 |
+
"# Triangular 1Cycle Scheduler and Cosine Scheduler\n",
|
| 360 |
+
"# clr = tfa.optimizers.CyclicalLearningRate(initial_learning_rate=MIN_LR,\n",
|
| 361 |
+
"# maximal_learning_rate=MAX_LR,\n",
|
| 362 |
+
"# scale_fn=scale_fn,\n",
|
| 363 |
+
"# step_size= 8 * steps_per_epoch\n",
|
| 364 |
+
"# )\n",
|
| 365 |
+
"# cosine_decay = tf.keras.optimizers.schedules.CosineDecayRestarts(\n",
|
| 366 |
+
"# TRAIN_LR, 10 * steps_per_epoch, t_mul=1.0, m_mul=1.0, alpha=0.005)\n",
|
| 367 |
+
"\n",
|
| 368 |
+
"if config.RELOAD_MODEL:\n",
|
| 369 |
+
" print(config.MODEL_NAME, \" reloaded as starting point!\")\n",
|
| 370 |
+
" model = models.load_model(os.path.join(MODEL_PATH, \"model.h5\"))\n",
|
| 371 |
+
"\n",
|
| 372 |
+
"\n",
|
| 373 |
+
"reduce_lr = callbacks.ReduceLROnPlateau(monitor='val_loss', factor=config.LR_PLATEAU_RATIO,\n",
|
| 374 |
+
" patience=config.LR_PATIENCE, min_lr=config.MIN_LR)\n",
|
| 375 |
+
"\n",
|
| 376 |
+
"checkpoint_cb = callbacks.ModelCheckpoint(os.path.join(MODEL_PATH, \"model.h5\"), save_best_only=True)\n",
|
| 377 |
+
"early_stopping_cb = callbacks.EarlyStopping(patience=config.EARLY_STOPPING_PATIENCE, restore_best_weights=True)\n",
|
| 378 |
+
"wandb_metrics = WandbMetricsLogger(log_freq=\"epoch\")\n",
|
| 379 |
+
"\n",
|
| 380 |
+
"model.compile(\n",
|
| 381 |
+
" optimizer=tf.keras.optimizers.Adam(learning_rate=config.MAX_LR),\n",
|
| 382 |
+
" loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),\n",
|
| 383 |
+
" metrics=[config.METRIC]\n",
|
| 384 |
+
" )\n",
|
| 385 |
+
"\n",
|
| 386 |
+
"history = model.fit(train_dataset, epochs=config.EPOCH, batch_size=config.BATCH_SIZE,\n",
|
| 387 |
+
" validation_data=val_dataset, shuffle=True, class_weight=class_weights, \n",
|
| 388 |
+
" callbacks=[reduce_lr, checkpoint_cb, early_stopping_cb, tensorboard_cb, wandb_metrics])\n",
|
| 389 |
+
"\n",
|
| 390 |
+
"art = wandb.Artifact(\"myoquant-sdh-classifier\", type=\"model\")\n",
|
| 391 |
+
"art.add_file(os.path.join(MODEL_PATH, \"model.h5\"))\n",
|
| 392 |
+
"wandb.log_artifact(art)\n",
|
| 393 |
+
"wandb.finish()\n",
|
| 394 |
+
"\n",
|
| 395 |
+
"model = models.load_model(os.path.join(MODEL_PATH, \"model.h5\"))\n",
|
| 396 |
+
"with open(os.path.join(MODEL_PATH, \"history.pickle\"), 'wb') as file_pi:\n",
|
| 397 |
+
" pickle.dump(history.history, file_pi)"
|
| 398 |
+
]
|
| 399 |
+
},
|
| 400 |
+
{
|
| 401 |
+
"cell_type": "code",
|
| 402 |
+
"execution_count": null,
|
| 403 |
+
"metadata": {},
|
| 404 |
+
"outputs": [],
|
| 405 |
+
"source": [
|
| 406 |
+
"# Acc and Loss Plot\n",
|
| 407 |
+
"acc = history.history['accuracy']\n",
|
| 408 |
+
"val_acc = history.history['val_accuracy']\n",
|
| 409 |
+
"\n",
|
| 410 |
+
"loss = history.history['loss']\n",
|
| 411 |
+
"val_loss = history.history['val_loss']\n",
|
| 412 |
+
"\n",
|
| 413 |
+
"epochs_range = range(len(acc))\n",
|
| 414 |
+
"\n",
|
| 415 |
+
"plt.figure(figsize=(16, 8))\n",
|
| 416 |
+
"plt.subplot(1, 2, 1)\n",
|
| 417 |
+
"plt.plot(epochs_range, acc, label='Training Accuracy')\n",
|
| 418 |
+
"plt.plot(epochs_range, val_acc, label='Validation Accuracy')\n",
|
| 419 |
+
"plt.axvline(x=len(acc)-config.EARLY_STOPPING_PATIENCE-1, color=\"red\")\n",
|
| 420 |
+
"plt.legend(loc='lower right')\n",
|
| 421 |
+
"plt.title('Training and Validation Accuracy')\n",
|
| 422 |
+
"\n",
|
| 423 |
+
"plt.subplot(1, 2, 2)\n",
|
| 424 |
+
"plt.plot(epochs_range, loss, label='Training Loss')\n",
|
| 425 |
+
"plt.plot(epochs_range, val_loss, label='Validation Loss')\n",
|
| 426 |
+
"plt.axvline(x=len(acc)-config.EARLY_STOPPING_PATIENCE-1, color=\"red\")\n",
|
| 427 |
+
"plt.legend(loc='upper right')\n",
|
| 428 |
+
"plt.title('Training and Validation Loss')\n",
|
| 429 |
+
"plt.savefig(os.path.join(MODEL_PATH, \"training_curve.png\"), dpi=300)\n",
|
| 430 |
+
"plt.show()"
|
| 431 |
+
]
|
| 432 |
+
},
|
| 433 |
+
{
|
| 434 |
+
"cell_type": "code",
|
| 435 |
+
"execution_count": null,
|
| 436 |
+
"metadata": {},
|
| 437 |
+
"outputs": [],
|
| 438 |
+
"source": [
|
| 439 |
+
"# Test Evaluation\n",
|
| 440 |
+
"model = models.load_model(os.path.join(MODEL_PATH, \"model.h5\"))\n",
|
| 441 |
+
"\n",
|
| 442 |
+
"test_loss, test_acc = model.evaluate(test_dataset, verbose=2)\n",
|
| 443 |
+
"print(\"Test data results: \")\n",
|
| 444 |
+
"print(test_acc)\n",
|
| 445 |
+
"\n",
|
| 446 |
+
"test_proba = model.predict(test_images)\n",
|
| 447 |
+
"test_classes = test_proba.argmax(axis=-1)\n",
|
| 448 |
+
"print(\"Test data results: \")\n",
|
| 449 |
+
"print(balanced_accuracy_score(test_labels, test_classes))"
|
| 450 |
+
]
|
| 451 |
+
},
|
| 452 |
+
{
|
| 453 |
+
"cell_type": "code",
|
| 454 |
+
"execution_count": null,
|
| 455 |
+
"metadata": {},
|
| 456 |
+
"outputs": [],
|
| 457 |
+
"source": [
|
| 458 |
+
"# Generate class activation heatmap\n",
|
| 459 |
+
"model = models.load_model(os.path.join(MODEL_PATH, \"model.h5\"))\n",
|
| 460 |
+
"counter = 0\n",
|
| 461 |
+
"plt.figure(figsize=(10,10))\n",
|
| 462 |
+
"\n",
|
| 463 |
+
"for i in np.random.choice(range(len(test_images)),25):\n",
|
| 464 |
+
" img_array = np.empty((1, 256, 256, 3))\n",
|
| 465 |
+
" img_array[0]=test_images[i]/255.\n",
|
| 466 |
+
" predicted_class = model.predict(img_array*255).argmax()\n",
|
| 467 |
+
" predicted_proba = round(np.amax(model.predict(img_array*255)), 2)\n",
|
| 468 |
+
" heatmap = make_gradcam_heatmap(img_array, model.get_layer(\"resnet50v2\"), \"conv5_block3_3_conv\") \n",
|
| 469 |
+
" plt.subplot(5,5,counter+1)\n",
|
| 470 |
+
" plt.xticks([])\n",
|
| 471 |
+
" plt.yticks([])\n",
|
| 472 |
+
" plt.grid(False)\n",
|
| 473 |
+
" grad_cam_img = save_and_display_gradcam(img_array[0], heatmap)\n",
|
| 474 |
+
" plt.imshow(grad_cam_img)\n",
|
| 475 |
+
" xlabel = config.SUB_FOLDERS[test_labels[i]]+\" (\" + str(predicted_class) + \" \" + str(predicted_proba) + \")\"\n",
|
| 476 |
+
" plt.xlabel(xlabel)\n",
|
| 477 |
+
" counter +=1\n",
|
| 478 |
+
"plt.show()"
|
| 479 |
+
]
|
| 480 |
+
}
|
| 481 |
+
],
|
| 482 |
+
"metadata": {
|
| 483 |
+
"kernelspec": {
|
| 484 |
+
"display_name": ".venv",
|
| 485 |
+
"language": "python",
|
| 486 |
+
"name": "python3"
|
| 487 |
+
},
|
| 488 |
+
"language_info": {
|
| 489 |
+
"codemirror_mode": {
|
| 490 |
+
"name": "ipython",
|
| 491 |
+
"version": 3
|
| 492 |
+
},
|
| 493 |
+
"file_extension": ".py",
|
| 494 |
+
"mimetype": "text/x-python",
|
| 495 |
+
"name": "python",
|
| 496 |
+
"nbconvert_exporter": "python",
|
| 497 |
+
"pygments_lexer": "ipython3",
|
| 498 |
+
"version": "3.8.10"
|
| 499 |
+
},
|
| 500 |
+
"orig_nbformat": 4,
|
| 501 |
+
"vscode": {
|
| 502 |
+
"interpreter": {
|
| 503 |
+
"hash": "7dcfd37d9fc7b622fbfef8254b45067d70c57a3c50902cea4f6ef7a4affc9af0"
|
| 504 |
+
}
|
| 505 |
+
}
|
| 506 |
+
},
|
| 507 |
+
"nbformat": 4,
|
| 508 |
+
"nbformat_minor": 2
|
| 509 |
+
}
|
runs/{sdh16k_normal_resize_20220830-083856/train/events.out.tfevents.1661848752.561a638614d6.77.0.v2 → SDH16K_wandb_20230406-214521/train/events.out.tfevents.1680810371.guepe.1458055.0.v2}
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:12877dd526c458d4e602f3cb8cf202a32f98d184a1c694bb94fe100207b9add9
|
| 3 |
+
size 6359090
|
runs/SDH16K_wandb_20230406-214521/validation/events.out.tfevents.1680810475.guepe.1458055.1.v2
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:69374377fd4d689f90e78fced0042c8c454bc3b0a978ff5a76e6ed091a8a236c
|
| 3 |
+
size 6794
|
training_curve.png
CHANGED
|
|