
Hervé BREDIN
commited on
Commit
•
e4aa6b9
1
Parent(s):
dba06d0
feat: update README
Browse files- README.md +23 -4
- example.png +0 -0
README.md
CHANGED
|
@@ -15,7 +15,7 @@ tags:
|
|
| 15 |
- resegmentation
|
| 16 |
license: mit
|
| 17 |
inference: false
|
| 18 |
-
extra_gated_prompt: "The collected information will help acquire a better knowledge of pyannote.audio userbase and help its maintainers
|
| 19 |
extra_gated_fields:
|
| 20 |
Company/university: text
|
| 21 |
Website: text
|
|
@@ -24,14 +24,33 @@ extra_gated_fields:
|
|
| 24 |
|
| 25 |
We propose (paid) scientific [consulting services](https://herve.niderb.fr/consulting.html) to companies willing to make the most of their data and open-source speech processing toolkits (and `pyannote` in particular).
|
| 26 |
|
| 27 |
-
# 🎹
|
| 28 |
|
| 29 |
The various concepts behind this model are described in details in this [paper](https://www.isca-speech.org/archive/interspeech_2023/plaquet23_interspeech.html).
|
| 30 |
|
| 31 |
-
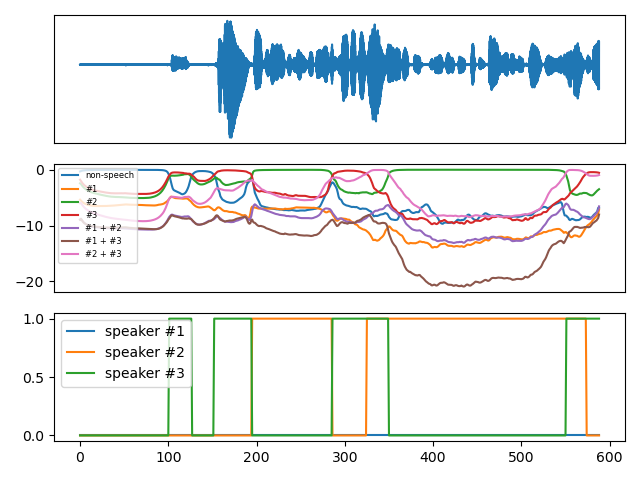
It ingests (ideally 10s of) mono audio sampled at 16kHz and outputs speaker diarization as a (num_frames, num_classes) matrix where the 7 classes are _non-speech_, _speaker #1_, _speaker #2_, _speaker #3_, _speakers #1 and #2_, _speakers #1 and #3_, and s_peakers #2 and #3_
|
| 32 |
-
|
| 33 |
It has been trained by Séverin Baroudi with [pyannote.audio](https://github.com/pyannote/pyannote-audio) `3.0.0` using the combination of the training sets of AISHELL, AliMeeting, AMI, AVA-AVD, DIHARD, Ego4D, MSDWild, REPERE, and VoxConverse.
|
| 34 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 35 |
## Usage
|
| 36 |
|
| 37 |
```python
|
|
|
|
| 15 |
- resegmentation
|
| 16 |
license: mit
|
| 17 |
inference: false
|
| 18 |
+
extra_gated_prompt: "The collected information will help acquire a better knowledge of pyannote.audio userbase and help its maintainers improve it further. If you are an academic researcher, please cite the relevant papers in your own publications using the model. If you work for a company, please consider contributing back to pyannote.audio development (e.g. through unrestricted gifts). We also provide scientific consulting services around speaker diarization and machine listening."
|
| 19 |
extra_gated_fields:
|
| 20 |
Company/university: text
|
| 21 |
Website: text
|
|
|
|
| 24 |
|
| 25 |
We propose (paid) scientific [consulting services](https://herve.niderb.fr/consulting.html) to companies willing to make the most of their data and open-source speech processing toolkits (and `pyannote` in particular).
|
| 26 |
|
| 27 |
+
# 🎹 "Powerset" speaker segmentation
|
| 28 |
|
| 29 |
The various concepts behind this model are described in details in this [paper](https://www.isca-speech.org/archive/interspeech_2023/plaquet23_interspeech.html).
|
| 30 |
|
|
|
|
|
|
|
| 31 |
It has been trained by Séverin Baroudi with [pyannote.audio](https://github.com/pyannote/pyannote-audio) `3.0.0` using the combination of the training sets of AISHELL, AliMeeting, AMI, AVA-AVD, DIHARD, Ego4D, MSDWild, REPERE, and VoxConverse.
|
| 32 |
|
| 33 |
+
It ingests (ideally 10s of) mono audio sampled at 16kHz and outputs speaker diarization as a (num_frames, num_classes) matrix where the 7 classes are _non-speech_, _speaker #1_, _speaker #2_, _speaker #3_, _speakers #1 and #2_, _speakers #1 and #3_, and _speakers #2 and #3_.
|
| 34 |
+
|
| 35 |
+

|
| 36 |
+
|
| 37 |
+
```python
|
| 38 |
+
# waveform (first row)
|
| 39 |
+
duration, sample_rate, num_channels = 10, 16000, 1
|
| 40 |
+
waveform = torch.randn(batch_size, num_channels, duration * sample_rate
|
| 41 |
+
|
| 42 |
+
# powerset multi-class encoding (second row)
|
| 43 |
+
powerset_encoding = model(waveform)
|
| 44 |
+
|
| 45 |
+
# multi-label encoding (third row)
|
| 46 |
+
from pyannote.audio.utils.powerset import Powerset
|
| 47 |
+
max_speakers_per_chunk, max_speakers_per_frame = 3, 2
|
| 48 |
+
to_multilabel = Powerset(
|
| 49 |
+
max_speakers_per_chunk,
|
| 50 |
+
max_speakers_per_frame).to_multilabel
|
| 51 |
+
multilabel_encoding = to_multilabel(powerset_encoding)
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
## Usage
|
| 55 |
|
| 56 |
```python
|
example.png
ADDED
|