

thanks to SimianLuo ❤
Browse files- .gitattributes +1 -0
- LCM_Dreamshaper_v7_4k.safetensors +3 -0
- README.md +74 -0
- feature_extractor/preprocessor_config.json +28 -0
- inference.py +68 -0
- lcm_pipeline.py +273 -0
- lcm_scheduler.py +479 -0
- model_index.json +32 -0
- safety_checker/config.json +30 -0
- safety_checker/model.safetensors +3 -0
- scheduler/scheduler_config.json +19 -0
- speed_fid.png +0 -0
- teaser.png +3 -0
- text_encoder/config.json +25 -0
- text_encoder/model.safetensors +3 -0
- tokenizer/added_tokens.json +4 -0
- tokenizer/merges.txt +0 -0
- tokenizer/special_tokens_map.json +6 -0
- tokenizer/tokenizer_config.json +32 -0
- tokenizer/vocab.json +0 -0
- unet/config.json +66 -0
- unet/diffusion_pytorch_model.safetensors +3 -0
- vae/config.json +32 -0
- vae/diffusion_pytorch_model.safetensors +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
teaser.png filter=lfs diff=lfs merge=lfs -text
|
LCM_Dreamshaper_v7_4k.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:84feab3a32f1d36108b762b25dad483ca9e37f719b23e0cfd0fdc4ad3fd5409b
|
| 3 |
+
size 3438495296
|
README.md
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
pipeline_tag: text-to-image
|
| 6 |
+
tags:
|
| 7 |
+
- text-to-image
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# Latent Consistency Models
|
| 11 |
+
|
| 12 |
+
Official Repository of the paper: *[Latent Consistency Models](https://arxiv.org/abs/2310.04378)*.
|
| 13 |
+
|
| 14 |
+
Project Page: https://latent-consistency-models.github.io
|
| 15 |
+
|
| 16 |
+
## Try our Hugging Face demos:
|
| 17 |
+
[](https://huggingface.co/spaces/SimianLuo/Latent_Consistency_Model)
|
| 18 |
+
|
| 19 |
+
## Model Descriptions:
|
| 20 |
+
Distilled from [Dreamshaper v7](https://huggingface.co/Lykon/dreamshaper-7) fine-tune of [Stable-Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) with only 4,000 training iterations (~32 A100 GPU Hours).
|
| 21 |
+
|
| 22 |
+
## Generation Results:
|
| 23 |
+
|
| 24 |
+
<p align="center">
|
| 25 |
+
<img src="teaser.png">
|
| 26 |
+
</p>
|
| 27 |
+
|
| 28 |
+
By distilling classifier-free guidance into the model's input, LCM can generate high-quality images in very short inference time. We compare the inference time at the setting of 768 x 768 resolution, CFG scale w=8, batchsize=4, using a A800 GPU.
|
| 29 |
+
|
| 30 |
+
<p align="center">
|
| 31 |
+
<img src="speed_fid.png">
|
| 32 |
+
</p>
|
| 33 |
+
|
| 34 |
+
## Usage
|
| 35 |
+
|
| 36 |
+
You can try out Latency Consistency Models directly on:
|
| 37 |
+
[](https://huggingface.co/spaces/SimianLuo/Latent_Consistency_Model)
|
| 38 |
+
|
| 39 |
+
To run the model yourself, you can leverage the 🧨 Diffusers library:
|
| 40 |
+
1. Install the library:
|
| 41 |
+
```
|
| 42 |
+
pip install diffusers transformers accelerate
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
2. Run the model:
|
| 46 |
+
```py
|
| 47 |
+
from diffusers import DiffusionPipeline
|
| 48 |
+
import torch
|
| 49 |
+
|
| 50 |
+
pipe = DiffusionPipeline.from_pretrained("SimianLuo/LCM_Dreamshaper_v7", custom_pipeline="latent_consistency_txt2img", custom_revision="main")
|
| 51 |
+
|
| 52 |
+
# To save GPU memory, torch.float16 can be used, but it may compromise image quality.
|
| 53 |
+
pipe.to(torch_device="cuda", torch_dtype=torch.float32)
|
| 54 |
+
|
| 55 |
+
prompt = "Self-portrait oil painting, a beautiful cyborg with golden hair, 8k"
|
| 56 |
+
|
| 57 |
+
# Can be set to 1~50 steps. LCM support fast inference even <= 4 steps. Recommend: 1~8 steps.
|
| 58 |
+
num_inference_steps = 4
|
| 59 |
+
|
| 60 |
+
images = pipe(prompt=prompt, num_inference_steps=num_inference_steps, guidance_scale=8.0, lcm_origin_steps=50, output_type="pil").images
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
## BibTeX
|
| 64 |
+
|
| 65 |
+
```bibtex
|
| 66 |
+
@misc{luo2023latent,
|
| 67 |
+
title={Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference},
|
| 68 |
+
author={Simian Luo and Yiqin Tan and Longbo Huang and Jian Li and Hang Zhao},
|
| 69 |
+
year={2023},
|
| 70 |
+
eprint={2310.04378},
|
| 71 |
+
archivePrefix={arXiv},
|
| 72 |
+
primaryClass={cs.CV}
|
| 73 |
+
}
|
| 74 |
+
```
|
feature_extractor/preprocessor_config.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"crop_size": {
|
| 3 |
+
"height": 224,
|
| 4 |
+
"width": 224
|
| 5 |
+
},
|
| 6 |
+
"do_center_crop": true,
|
| 7 |
+
"do_convert_rgb": true,
|
| 8 |
+
"do_normalize": true,
|
| 9 |
+
"do_rescale": true,
|
| 10 |
+
"do_resize": true,
|
| 11 |
+
"feature_extractor_type": "CLIPFeatureExtractor",
|
| 12 |
+
"image_mean": [
|
| 13 |
+
0.48145466,
|
| 14 |
+
0.4578275,
|
| 15 |
+
0.40821073
|
| 16 |
+
],
|
| 17 |
+
"image_processor_type": "CLIPImageProcessor",
|
| 18 |
+
"image_std": [
|
| 19 |
+
0.26862954,
|
| 20 |
+
0.26130258,
|
| 21 |
+
0.27577711
|
| 22 |
+
],
|
| 23 |
+
"resample": 3,
|
| 24 |
+
"rescale_factor": 0.00392156862745098,
|
| 25 |
+
"size": {
|
| 26 |
+
"shortest_edge": 224
|
| 27 |
+
}
|
| 28 |
+
}
|
inference.py
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from lcm_pipeline import LatentConsistencyModelPipeline
|
| 2 |
+
from lcm_scheduler import LCMScheduler
|
| 3 |
+
|
| 4 |
+
from diffusers import AutoencoderKL, UNet2DConditionModel
|
| 5 |
+
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
| 6 |
+
from transformers import CLIPTokenizer, CLIPTextModel, CLIPImageProcessor
|
| 7 |
+
|
| 8 |
+
import os
|
| 9 |
+
import torch
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
from safetensors.torch import load_file
|
| 12 |
+
|
| 13 |
+
# Input Prompt:
|
| 14 |
+
prompt = "Self-portrait oil painting, a beautiful cyborg with golden hair"
|
| 15 |
+
|
| 16 |
+
# Save Path:
|
| 17 |
+
save_path = "./lcm_images"
|
| 18 |
+
os.makedirs(save_path, exist_ok=True)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
# Origin SD Model ID:
|
| 22 |
+
model_id = "digiplay/DreamShaper_7"
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
# Initalize Diffusers Model:
|
| 26 |
+
vae = AutoencoderKL.from_pretrained(model_id, subfolder="vae")
|
| 27 |
+
text_encoder = CLIPTextModel.from_pretrained(model_id, subfolder="text_encoder")
|
| 28 |
+
tokenizer = CLIPTokenizer.from_pretrained(model_id, subfolder="tokenizer")
|
| 29 |
+
unet = UNet2DConditionModel.from_pretrained(model_id, subfolder="unet", device_map=None, low_cpu_mem_usage=False, local_files_only=True)
|
| 30 |
+
safety_checker = StableDiffusionSafetyChecker.from_pretrained(model_id, subfolder="safety_checker")
|
| 31 |
+
feature_extractor = CLIPImageProcessor.from_pretrained(model_id, subfolder="feature_extractor")
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
# Initalize Scheduler:
|
| 35 |
+
scheduler = LCMScheduler(beta_start=0.00085, beta_end=0.0120, beta_schedule="scaled_linear", prediction_type="epsilon")
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
# Replace the unet with LCM:
|
| 39 |
+
lcm_unet_ckpt = "./LCM_Dreamshaper_v7_4k.safetensors"
|
| 40 |
+
ckpt = load_file(lcm_unet_ckpt)
|
| 41 |
+
m, u = unet.load_state_dict(ckpt, strict=False)
|
| 42 |
+
if len(m) > 0:
|
| 43 |
+
print("missing keys:")
|
| 44 |
+
print(m)
|
| 45 |
+
if len(u) > 0:
|
| 46 |
+
print("unexpected keys:")
|
| 47 |
+
print(u)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
# LCM Pipeline:
|
| 51 |
+
pipe = LatentConsistencyModelPipeline(vae=vae, text_encoder=text_encoder, tokenizer=tokenizer, unet=unet, scheduler=scheduler, safety_checker=safety_checker, feature_extractor=feature_extractor)
|
| 52 |
+
pipe = pipe.to("cuda")
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
# Output Images:
|
| 56 |
+
images = pipe(prompt=prompt, num_images_per_prompt=4, num_inference_steps=4, guidance_scale=8.0, lcm_origin_steps=50).images
|
| 57 |
+
|
| 58 |
+
# Save Images:
|
| 59 |
+
for i in tqdm(range(len(images))):
|
| 60 |
+
output_path = os.path.join(save_path, "{}.png".format(i))
|
| 61 |
+
image = images[i]
|
| 62 |
+
image.save(output_path)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
|
lcm_pipeline.py
ADDED
|
@@ -0,0 +1,273 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from diffusers import DiffusionPipeline, AutoencoderKL, UNet2DConditionModel
|
| 3 |
+
from transformers import CLIPTokenizer, CLIPTextModel, CLIPImageProcessor
|
| 4 |
+
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
| 5 |
+
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
|
| 6 |
+
from diffusers.image_processor import VaeImageProcessor
|
| 7 |
+
|
| 8 |
+
from typing import List, Optional, Tuple, Union, Dict, Any
|
| 9 |
+
|
| 10 |
+
from diffusers import logging
|
| 11 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 12 |
+
|
| 13 |
+
class LatentConsistencyModelPipeline(DiffusionPipeline):
|
| 14 |
+
def __init__(
|
| 15 |
+
self,
|
| 16 |
+
vae: AutoencoderKL,
|
| 17 |
+
text_encoder: CLIPTextModel,
|
| 18 |
+
tokenizer: CLIPTokenizer,
|
| 19 |
+
unet: UNet2DConditionModel,
|
| 20 |
+
scheduler: None,
|
| 21 |
+
safety_checker: StableDiffusionSafetyChecker,
|
| 22 |
+
feature_extractor: CLIPImageProcessor,
|
| 23 |
+
requires_safety_checker: bool = True
|
| 24 |
+
):
|
| 25 |
+
super().__init__()
|
| 26 |
+
|
| 27 |
+
self.register_modules(
|
| 28 |
+
vae=vae,
|
| 29 |
+
text_encoder=text_encoder,
|
| 30 |
+
tokenizer=tokenizer,
|
| 31 |
+
unet=unet,
|
| 32 |
+
scheduler=scheduler,
|
| 33 |
+
safety_checker=safety_checker,
|
| 34 |
+
feature_extractor=feature_extractor,
|
| 35 |
+
)
|
| 36 |
+
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
|
| 37 |
+
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def _encode_prompt(
|
| 41 |
+
self,
|
| 42 |
+
prompt,
|
| 43 |
+
device,
|
| 44 |
+
num_images_per_prompt,
|
| 45 |
+
prompt_embeds: None,
|
| 46 |
+
):
|
| 47 |
+
r"""
|
| 48 |
+
Encodes the prompt into text encoder hidden states.
|
| 49 |
+
|
| 50 |
+
Args:
|
| 51 |
+
prompt (`str` or `List[str]`, *optional*):
|
| 52 |
+
prompt to be encoded
|
| 53 |
+
device: (`torch.device`):
|
| 54 |
+
torch device
|
| 55 |
+
num_images_per_prompt (`int`):
|
| 56 |
+
number of images that should be generated per prompt
|
| 57 |
+
prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 58 |
+
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
|
| 59 |
+
provided, text embeddings will be generated from `prompt` input argument.
|
| 60 |
+
"""
|
| 61 |
+
|
| 62 |
+
if prompt is not None and isinstance(prompt, str):
|
| 63 |
+
batch_size = 1
|
| 64 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 65 |
+
batch_size = len(prompt)
|
| 66 |
+
else:
|
| 67 |
+
batch_size = prompt_embeds.shape[0]
|
| 68 |
+
|
| 69 |
+
if prompt_embeds is None:
|
| 70 |
+
|
| 71 |
+
text_inputs = self.tokenizer(
|
| 72 |
+
prompt,
|
| 73 |
+
padding="max_length",
|
| 74 |
+
max_length=self.tokenizer.model_max_length,
|
| 75 |
+
truncation=True,
|
| 76 |
+
return_tensors="pt",
|
| 77 |
+
)
|
| 78 |
+
text_input_ids = text_inputs.input_ids
|
| 79 |
+
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
|
| 80 |
+
|
| 81 |
+
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
|
| 82 |
+
text_input_ids, untruncated_ids
|
| 83 |
+
):
|
| 84 |
+
removed_text = self.tokenizer.batch_decode(
|
| 85 |
+
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
|
| 86 |
+
)
|
| 87 |
+
logger.warning(
|
| 88 |
+
"The following part of your input was truncated because CLIP can only handle sequences up to"
|
| 89 |
+
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
|
| 93 |
+
attention_mask = text_inputs.attention_mask.to(device)
|
| 94 |
+
else:
|
| 95 |
+
attention_mask = None
|
| 96 |
+
|
| 97 |
+
prompt_embeds = self.text_encoder(
|
| 98 |
+
text_input_ids.to(device),
|
| 99 |
+
attention_mask=attention_mask,
|
| 100 |
+
)
|
| 101 |
+
prompt_embeds = prompt_embeds[0]
|
| 102 |
+
|
| 103 |
+
if self.text_encoder is not None:
|
| 104 |
+
prompt_embeds_dtype = self.text_encoder.dtype
|
| 105 |
+
elif self.unet is not None:
|
| 106 |
+
prompt_embeds_dtype = self.unet.dtype
|
| 107 |
+
else:
|
| 108 |
+
prompt_embeds_dtype = prompt_embeds.dtype
|
| 109 |
+
|
| 110 |
+
prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
|
| 111 |
+
|
| 112 |
+
bs_embed, seq_len, _ = prompt_embeds.shape
|
| 113 |
+
# duplicate text embeddings for each generation per prompt, using mps friendly method
|
| 114 |
+
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
|
| 115 |
+
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
|
| 116 |
+
|
| 117 |
+
# Don't need to get uncond prompt embedding because of LCM Guided Distillation
|
| 118 |
+
return prompt_embeds
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def run_safety_checker(self, image, device, dtype):
|
| 122 |
+
if self.safety_checker is None:
|
| 123 |
+
has_nsfw_concept = None
|
| 124 |
+
else:
|
| 125 |
+
if torch.is_tensor(image):
|
| 126 |
+
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
|
| 127 |
+
else:
|
| 128 |
+
feature_extractor_input = self.image_processor.numpy_to_pil(image)
|
| 129 |
+
safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
|
| 130 |
+
image, has_nsfw_concept = self.safety_checker(
|
| 131 |
+
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
|
| 132 |
+
)
|
| 133 |
+
return image, has_nsfw_concept
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, latents=None):
|
| 137 |
+
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
|
| 138 |
+
if latents is None:
|
| 139 |
+
latents = torch.randn(shape, dtype=dtype).to(device)
|
| 140 |
+
else:
|
| 141 |
+
latents = latents.to(device)
|
| 142 |
+
# scale the initial noise by the standard deviation required by the scheduler
|
| 143 |
+
latents = latents * self.scheduler.init_noise_sigma
|
| 144 |
+
return latents
|
| 145 |
+
|
| 146 |
+
def get_w_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
| 147 |
+
"""
|
| 148 |
+
see https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
|
| 149 |
+
Args:
|
| 150 |
+
timesteps: torch.Tensor: generate embedding vectors at these timesteps
|
| 151 |
+
embedding_dim: int: dimension of the embeddings to generate
|
| 152 |
+
dtype: data type of the generated embeddings
|
| 153 |
+
|
| 154 |
+
Returns:
|
| 155 |
+
embedding vectors with shape `(len(timesteps), embedding_dim)`
|
| 156 |
+
"""
|
| 157 |
+
assert len(w.shape) == 1
|
| 158 |
+
w = w * 1000.
|
| 159 |
+
|
| 160 |
+
half_dim = embedding_dim // 2
|
| 161 |
+
emb = torch.log(torch.tensor(10000.)) / (half_dim - 1)
|
| 162 |
+
emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
|
| 163 |
+
emb = w.to(dtype)[:, None] * emb[None, :]
|
| 164 |
+
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
|
| 165 |
+
if embedding_dim % 2 == 1: # zero pad
|
| 166 |
+
emb = torch.nn.functional.pad(emb, (0, 1))
|
| 167 |
+
assert emb.shape == (w.shape[0], embedding_dim)
|
| 168 |
+
return emb
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
@torch.no_grad()
|
| 172 |
+
def __call__(
|
| 173 |
+
self,
|
| 174 |
+
prompt: Union[str, List[str]] = None,
|
| 175 |
+
height: Optional[int] = 768,
|
| 176 |
+
width: Optional[int] = 768,
|
| 177 |
+
guidance_scale: float = 7.5,
|
| 178 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 179 |
+
latents: Optional[torch.FloatTensor] = None,
|
| 180 |
+
num_inference_steps: int = 4,
|
| 181 |
+
lcm_origin_steps: int = 50,
|
| 182 |
+
prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 183 |
+
output_type: Optional[str] = "pil",
|
| 184 |
+
return_dict: bool = True,
|
| 185 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 186 |
+
):
|
| 187 |
+
|
| 188 |
+
# 0. Default height and width to unet
|
| 189 |
+
height = height or self.unet.config.sample_size * self.vae_scale_factor
|
| 190 |
+
width = width or self.unet.config.sample_size * self.vae_scale_factor
|
| 191 |
+
|
| 192 |
+
# 2. Define call parameters
|
| 193 |
+
if prompt is not None and isinstance(prompt, str):
|
| 194 |
+
batch_size = 1
|
| 195 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 196 |
+
batch_size = len(prompt)
|
| 197 |
+
else:
|
| 198 |
+
batch_size = prompt_embeds.shape[0]
|
| 199 |
+
|
| 200 |
+
device = self._execution_device
|
| 201 |
+
# do_classifier_free_guidance = guidance_scale > 0.0 # In LCM Implementation: cfg_noise = noise_cond + cfg_scale * (noise_cond - noise_uncond) , (cfg_scale > 0.0 using CFG)
|
| 202 |
+
|
| 203 |
+
# 3. Encode input prompt
|
| 204 |
+
prompt_embeds = self._encode_prompt(
|
| 205 |
+
prompt,
|
| 206 |
+
device,
|
| 207 |
+
num_images_per_prompt,
|
| 208 |
+
prompt_embeds=prompt_embeds,
|
| 209 |
+
)
|
| 210 |
+
|
| 211 |
+
# 4. Prepare timesteps
|
| 212 |
+
self.scheduler.set_timesteps(num_inference_steps, lcm_origin_steps)
|
| 213 |
+
timesteps = self.scheduler.timesteps
|
| 214 |
+
|
| 215 |
+
# 5. Prepare latent variable
|
| 216 |
+
num_channels_latents = self.unet.config.in_channels
|
| 217 |
+
latents = self.prepare_latents(
|
| 218 |
+
batch_size * num_images_per_prompt,
|
| 219 |
+
num_channels_latents,
|
| 220 |
+
height,
|
| 221 |
+
width,
|
| 222 |
+
prompt_embeds.dtype,
|
| 223 |
+
device,
|
| 224 |
+
latents,
|
| 225 |
+
)
|
| 226 |
+
|
| 227 |
+
bs = batch_size * num_images_per_prompt
|
| 228 |
+
|
| 229 |
+
# 6. Get Guidance Scale Embedding
|
| 230 |
+
w = torch.tensor(guidance_scale).repeat(bs)
|
| 231 |
+
w_embedding = self.get_w_embedding(w, embedding_dim=256).to(device)
|
| 232 |
+
|
| 233 |
+
# 7. LCM MultiStep Sampling Loop:
|
| 234 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 235 |
+
for i, t in enumerate(timesteps):
|
| 236 |
+
|
| 237 |
+
ts = torch.full((bs,), t, device=device, dtype=torch.long)
|
| 238 |
+
|
| 239 |
+
# model prediction (v-prediction, eps, x)
|
| 240 |
+
model_pred = self.unet(
|
| 241 |
+
latents,
|
| 242 |
+
ts,
|
| 243 |
+
timestep_cond=w_embedding,
|
| 244 |
+
encoder_hidden_states=prompt_embeds,
|
| 245 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 246 |
+
return_dict=False)[0]
|
| 247 |
+
|
| 248 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 249 |
+
latents, denoised = self.scheduler.step(model_pred, i, t, latents, return_dict=False)
|
| 250 |
+
|
| 251 |
+
# # call the callback, if provided
|
| 252 |
+
# if i == len(timesteps) - 1:
|
| 253 |
+
progress_bar.update()
|
| 254 |
+
|
| 255 |
+
if not output_type == "latent":
|
| 256 |
+
image = self.vae.decode(denoised / self.vae.config.scaling_factor, return_dict=False)[0]
|
| 257 |
+
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
|
| 258 |
+
else:
|
| 259 |
+
image = denoised
|
| 260 |
+
has_nsfw_concept = None
|
| 261 |
+
|
| 262 |
+
if has_nsfw_concept is None:
|
| 263 |
+
do_denormalize = [True] * image.shape[0]
|
| 264 |
+
else:
|
| 265 |
+
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
|
| 266 |
+
|
| 267 |
+
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
if not return_dict:
|
| 271 |
+
return (image, has_nsfw_concept)
|
| 272 |
+
|
| 273 |
+
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
|
lcm_scheduler.py
ADDED
|
@@ -0,0 +1,479 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 Stanford University Team and The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pytorch_diffusion
|
| 16 |
+
# and https://github.com/hojonathanho/diffusion
|
| 17 |
+
|
| 18 |
+
import math
|
| 19 |
+
from dataclasses import dataclass
|
| 20 |
+
from typing import List, Optional, Tuple, Union
|
| 21 |
+
|
| 22 |
+
import numpy as np
|
| 23 |
+
import torch
|
| 24 |
+
|
| 25 |
+
from diffusers import ConfigMixin, SchedulerMixin
|
| 26 |
+
from diffusers.configuration_utils import register_to_config
|
| 27 |
+
from diffusers.utils import BaseOutput
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
@dataclass
|
| 31 |
+
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->DDIM
|
| 32 |
+
class LCMSchedulerOutput(BaseOutput):
|
| 33 |
+
"""
|
| 34 |
+
Output class for the scheduler's `step` function output.
|
| 35 |
+
|
| 36 |
+
Args:
|
| 37 |
+
prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
|
| 38 |
+
Computed sample `(x_{t-1})` of previous timestep. `prev_sample` should be used as next model input in the
|
| 39 |
+
denoising loop.
|
| 40 |
+
pred_original_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
|
| 41 |
+
The predicted denoised sample `(x_{0})` based on the model output from the current timestep.
|
| 42 |
+
`pred_original_sample` can be used to preview progress or for guidance.
|
| 43 |
+
"""
|
| 44 |
+
|
| 45 |
+
prev_sample: torch.FloatTensor
|
| 46 |
+
denoised: Optional[torch.FloatTensor] = None
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
|
| 50 |
+
def betas_for_alpha_bar(
|
| 51 |
+
num_diffusion_timesteps,
|
| 52 |
+
max_beta=0.999,
|
| 53 |
+
alpha_transform_type="cosine",
|
| 54 |
+
):
|
| 55 |
+
"""
|
| 56 |
+
Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
|
| 57 |
+
(1-beta) over time from t = [0,1].
|
| 58 |
+
|
| 59 |
+
Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
|
| 60 |
+
to that part of the diffusion process.
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
Args:
|
| 64 |
+
num_diffusion_timesteps (`int`): the number of betas to produce.
|
| 65 |
+
max_beta (`float`): the maximum beta to use; use values lower than 1 to
|
| 66 |
+
prevent singularities.
|
| 67 |
+
alpha_transform_type (`str`, *optional*, default to `cosine`): the type of noise schedule for alpha_bar.
|
| 68 |
+
Choose from `cosine` or `exp`
|
| 69 |
+
|
| 70 |
+
Returns:
|
| 71 |
+
betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
|
| 72 |
+
"""
|
| 73 |
+
if alpha_transform_type == "cosine":
|
| 74 |
+
|
| 75 |
+
def alpha_bar_fn(t):
|
| 76 |
+
return math.cos((t + 0.008) / 1.008 * math.pi / 2) ** 2
|
| 77 |
+
|
| 78 |
+
elif alpha_transform_type == "exp":
|
| 79 |
+
|
| 80 |
+
def alpha_bar_fn(t):
|
| 81 |
+
return math.exp(t * -12.0)
|
| 82 |
+
|
| 83 |
+
else:
|
| 84 |
+
raise ValueError(f"Unsupported alpha_tranform_type: {alpha_transform_type}")
|
| 85 |
+
|
| 86 |
+
betas = []
|
| 87 |
+
for i in range(num_diffusion_timesteps):
|
| 88 |
+
t1 = i / num_diffusion_timesteps
|
| 89 |
+
t2 = (i + 1) / num_diffusion_timesteps
|
| 90 |
+
betas.append(min(1 - alpha_bar_fn(t2) / alpha_bar_fn(t1), max_beta))
|
| 91 |
+
return torch.tensor(betas, dtype=torch.float32)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def rescale_zero_terminal_snr(betas):
|
| 95 |
+
"""
|
| 96 |
+
Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
Args:
|
| 100 |
+
betas (`torch.FloatTensor`):
|
| 101 |
+
the betas that the scheduler is being initialized with.
|
| 102 |
+
|
| 103 |
+
Returns:
|
| 104 |
+
`torch.FloatTensor`: rescaled betas with zero terminal SNR
|
| 105 |
+
"""
|
| 106 |
+
# Convert betas to alphas_bar_sqrt
|
| 107 |
+
alphas = 1.0 - betas
|
| 108 |
+
alphas_cumprod = torch.cumprod(alphas, dim=0)
|
| 109 |
+
alphas_bar_sqrt = alphas_cumprod.sqrt()
|
| 110 |
+
|
| 111 |
+
# Store old values.
|
| 112 |
+
alphas_bar_sqrt_0 = alphas_bar_sqrt[0].clone()
|
| 113 |
+
alphas_bar_sqrt_T = alphas_bar_sqrt[-1].clone()
|
| 114 |
+
|
| 115 |
+
# Shift so the last timestep is zero.
|
| 116 |
+
alphas_bar_sqrt -= alphas_bar_sqrt_T
|
| 117 |
+
|
| 118 |
+
# Scale so the first timestep is back to the old value.
|
| 119 |
+
alphas_bar_sqrt *= alphas_bar_sqrt_0 / (alphas_bar_sqrt_0 - alphas_bar_sqrt_T)
|
| 120 |
+
|
| 121 |
+
# Convert alphas_bar_sqrt to betas
|
| 122 |
+
alphas_bar = alphas_bar_sqrt**2 # Revert sqrt
|
| 123 |
+
alphas = alphas_bar[1:] / alphas_bar[:-1] # Revert cumprod
|
| 124 |
+
alphas = torch.cat([alphas_bar[0:1], alphas])
|
| 125 |
+
betas = 1 - alphas
|
| 126 |
+
|
| 127 |
+
return betas
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
class LCMScheduler(SchedulerMixin, ConfigMixin):
|
| 131 |
+
"""
|
| 132 |
+
`LCMScheduler` extends the denoising procedure introduced in denoising diffusion probabilistic models (DDPMs) with
|
| 133 |
+
non-Markovian guidance.
|
| 134 |
+
|
| 135 |
+
This model inherits from [`SchedulerMixin`] and [`ConfigMixin`]. Check the superclass documentation for the generic
|
| 136 |
+
methods the library implements for all schedulers such as loading and saving.
|
| 137 |
+
|
| 138 |
+
Args:
|
| 139 |
+
num_train_timesteps (`int`, defaults to 1000):
|
| 140 |
+
The number of diffusion steps to train the model.
|
| 141 |
+
beta_start (`float`, defaults to 0.0001):
|
| 142 |
+
The starting `beta` value of inference.
|
| 143 |
+
beta_end (`float`, defaults to 0.02):
|
| 144 |
+
The final `beta` value.
|
| 145 |
+
beta_schedule (`str`, defaults to `"linear"`):
|
| 146 |
+
The beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
|
| 147 |
+
`linear`, `scaled_linear`, or `squaredcos_cap_v2`.
|
| 148 |
+
trained_betas (`np.ndarray`, *optional*):
|
| 149 |
+
Pass an array of betas directly to the constructor to bypass `beta_start` and `beta_end`.
|
| 150 |
+
clip_sample (`bool`, defaults to `True`):
|
| 151 |
+
Clip the predicted sample for numerical stability.
|
| 152 |
+
clip_sample_range (`float`, defaults to 1.0):
|
| 153 |
+
The maximum magnitude for sample clipping. Valid only when `clip_sample=True`.
|
| 154 |
+
set_alpha_to_one (`bool`, defaults to `True`):
|
| 155 |
+
Each diffusion step uses the alphas product value at that step and at the previous one. For the final step
|
| 156 |
+
there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
|
| 157 |
+
otherwise it uses the alpha value at step 0.
|
| 158 |
+
steps_offset (`int`, defaults to 0):
|
| 159 |
+
An offset added to the inference steps. You can use a combination of `offset=1` and
|
| 160 |
+
`set_alpha_to_one=False` to make the last step use step 0 for the previous alpha product like in Stable
|
| 161 |
+
Diffusion.
|
| 162 |
+
prediction_type (`str`, defaults to `epsilon`, *optional*):
|
| 163 |
+
Prediction type of the scheduler function; can be `epsilon` (predicts the noise of the diffusion process),
|
| 164 |
+
`sample` (directly predicts the noisy sample`) or `v_prediction` (see section 2.4 of [Imagen
|
| 165 |
+
Video](https://imagen.research.google/video/paper.pdf) paper).
|
| 166 |
+
thresholding (`bool`, defaults to `False`):
|
| 167 |
+
Whether to use the "dynamic thresholding" method. This is unsuitable for latent-space diffusion models such
|
| 168 |
+
as Stable Diffusion.
|
| 169 |
+
dynamic_thresholding_ratio (`float`, defaults to 0.995):
|
| 170 |
+
The ratio for the dynamic thresholding method. Valid only when `thresholding=True`.
|
| 171 |
+
sample_max_value (`float`, defaults to 1.0):
|
| 172 |
+
The threshold value for dynamic thresholding. Valid only when `thresholding=True`.
|
| 173 |
+
timestep_spacing (`str`, defaults to `"leading"`):
|
| 174 |
+
The way the timesteps should be scaled. Refer to Table 2 of the [Common Diffusion Noise Schedules and
|
| 175 |
+
Sample Steps are Flawed](https://huggingface.co/papers/2305.08891) for more information.
|
| 176 |
+
rescale_betas_zero_snr (`bool`, defaults to `False`):
|
| 177 |
+
Whether to rescale the betas to have zero terminal SNR. This enables the model to generate very bright and
|
| 178 |
+
dark samples instead of limiting it to samples with medium brightness. Loosely related to
|
| 179 |
+
[`--offset_noise`](https://github.com/huggingface/diffusers/blob/74fd735eb073eb1d774b1ab4154a0876eb82f055/examples/dreambooth/train_dreambooth.py#L506).
|
| 180 |
+
"""
|
| 181 |
+
|
| 182 |
+
# _compatibles = [e.name for e in KarrasDiffusionSchedulers]
|
| 183 |
+
order = 1
|
| 184 |
+
|
| 185 |
+
@register_to_config
|
| 186 |
+
def __init__(
|
| 187 |
+
self,
|
| 188 |
+
num_train_timesteps: int = 1000,
|
| 189 |
+
beta_start: float = 0.0001,
|
| 190 |
+
beta_end: float = 0.02,
|
| 191 |
+
beta_schedule: str = "linear",
|
| 192 |
+
trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
|
| 193 |
+
clip_sample: bool = True,
|
| 194 |
+
set_alpha_to_one: bool = True,
|
| 195 |
+
steps_offset: int = 0,
|
| 196 |
+
prediction_type: str = "epsilon",
|
| 197 |
+
thresholding: bool = False,
|
| 198 |
+
dynamic_thresholding_ratio: float = 0.995,
|
| 199 |
+
clip_sample_range: float = 1.0,
|
| 200 |
+
sample_max_value: float = 1.0,
|
| 201 |
+
timestep_spacing: str = "leading",
|
| 202 |
+
rescale_betas_zero_snr: bool = False,
|
| 203 |
+
):
|
| 204 |
+
if trained_betas is not None:
|
| 205 |
+
self.betas = torch.tensor(trained_betas, dtype=torch.float32)
|
| 206 |
+
elif beta_schedule == "linear":
|
| 207 |
+
self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
|
| 208 |
+
elif beta_schedule == "scaled_linear":
|
| 209 |
+
# this schedule is very specific to the latent diffusion model.
|
| 210 |
+
self.betas = (
|
| 211 |
+
torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
|
| 212 |
+
)
|
| 213 |
+
elif beta_schedule == "squaredcos_cap_v2":
|
| 214 |
+
# Glide cosine schedule
|
| 215 |
+
self.betas = betas_for_alpha_bar(num_train_timesteps)
|
| 216 |
+
else:
|
| 217 |
+
raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
|
| 218 |
+
|
| 219 |
+
# Rescale for zero SNR
|
| 220 |
+
if rescale_betas_zero_snr:
|
| 221 |
+
self.betas = rescale_zero_terminal_snr(self.betas)
|
| 222 |
+
|
| 223 |
+
self.alphas = 1.0 - self.betas
|
| 224 |
+
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
|
| 225 |
+
|
| 226 |
+
# At every step in ddim, we are looking into the previous alphas_cumprod
|
| 227 |
+
# For the final step, there is no previous alphas_cumprod because we are already at 0
|
| 228 |
+
# `set_alpha_to_one` decides whether we set this parameter simply to one or
|
| 229 |
+
# whether we use the final alpha of the "non-previous" one.
|
| 230 |
+
self.final_alpha_cumprod = torch.tensor(1.0) if set_alpha_to_one else self.alphas_cumprod[0]
|
| 231 |
+
|
| 232 |
+
# standard deviation of the initial noise distribution
|
| 233 |
+
self.init_noise_sigma = 1.0
|
| 234 |
+
|
| 235 |
+
# setable values
|
| 236 |
+
self.num_inference_steps = None
|
| 237 |
+
self.timesteps = torch.from_numpy(np.arange(0, num_train_timesteps)[::-1].copy().astype(np.int64))
|
| 238 |
+
|
| 239 |
+
def scale_model_input(self, sample: torch.FloatTensor, timestep: Optional[int] = None) -> torch.FloatTensor:
|
| 240 |
+
"""
|
| 241 |
+
Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
|
| 242 |
+
current timestep.
|
| 243 |
+
|
| 244 |
+
Args:
|
| 245 |
+
sample (`torch.FloatTensor`):
|
| 246 |
+
The input sample.
|
| 247 |
+
timestep (`int`, *optional*):
|
| 248 |
+
The current timestep in the diffusion chain.
|
| 249 |
+
|
| 250 |
+
Returns:
|
| 251 |
+
`torch.FloatTensor`:
|
| 252 |
+
A scaled input sample.
|
| 253 |
+
"""
|
| 254 |
+
return sample
|
| 255 |
+
|
| 256 |
+
def _get_variance(self, timestep, prev_timestep):
|
| 257 |
+
alpha_prod_t = self.alphas_cumprod[timestep]
|
| 258 |
+
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
|
| 259 |
+
beta_prod_t = 1 - alpha_prod_t
|
| 260 |
+
beta_prod_t_prev = 1 - alpha_prod_t_prev
|
| 261 |
+
|
| 262 |
+
variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
|
| 263 |
+
|
| 264 |
+
return variance
|
| 265 |
+
|
| 266 |
+
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler._threshold_sample
|
| 267 |
+
def _threshold_sample(self, sample: torch.FloatTensor) -> torch.FloatTensor:
|
| 268 |
+
"""
|
| 269 |
+
"Dynamic thresholding: At each sampling step we set s to a certain percentile absolute pixel value in xt0 (the
|
| 270 |
+
prediction of x_0 at timestep t), and if s > 1, then we threshold xt0 to the range [-s, s] and then divide by
|
| 271 |
+
s. Dynamic thresholding pushes saturated pixels (those near -1 and 1) inwards, thereby actively preventing
|
| 272 |
+
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
|
| 273 |
+
photorealism as well as better image-text alignment, especially when using very large guidance weights."
|
| 274 |
+
|
| 275 |
+
https://arxiv.org/abs/2205.11487
|
| 276 |
+
"""
|
| 277 |
+
dtype = sample.dtype
|
| 278 |
+
batch_size, channels, height, width = sample.shape
|
| 279 |
+
|
| 280 |
+
if dtype not in (torch.float32, torch.float64):
|
| 281 |
+
sample = sample.float() # upcast for quantile calculation, and clamp not implemented for cpu half
|
| 282 |
+
|
| 283 |
+
# Flatten sample for doing quantile calculation along each image
|
| 284 |
+
sample = sample.reshape(batch_size, channels * height * width)
|
| 285 |
+
|
| 286 |
+
abs_sample = sample.abs() # "a certain percentile absolute pixel value"
|
| 287 |
+
|
| 288 |
+
s = torch.quantile(abs_sample, self.config.dynamic_thresholding_ratio, dim=1)
|
| 289 |
+
s = torch.clamp(
|
| 290 |
+
s, min=1, max=self.config.sample_max_value
|
| 291 |
+
) # When clamped to min=1, equivalent to standard clipping to [-1, 1]
|
| 292 |
+
|
| 293 |
+
s = s.unsqueeze(1) # (batch_size, 1) because clamp will broadcast along dim=0
|
| 294 |
+
sample = torch.clamp(sample, -s, s) / s # "we threshold xt0 to the range [-s, s] and then divide by s"
|
| 295 |
+
|
| 296 |
+
sample = sample.reshape(batch_size, channels, height, width)
|
| 297 |
+
sample = sample.to(dtype)
|
| 298 |
+
|
| 299 |
+
return sample
|
| 300 |
+
|
| 301 |
+
def set_timesteps(self, num_inference_steps: int, lcm_origin_steps: int, device: Union[str, torch.device] = None):
|
| 302 |
+
"""
|
| 303 |
+
Sets the discrete timesteps used for the diffusion chain (to be run before inference).
|
| 304 |
+
|
| 305 |
+
Args:
|
| 306 |
+
num_inference_steps (`int`):
|
| 307 |
+
The number of diffusion steps used when generating samples with a pre-trained model.
|
| 308 |
+
"""
|
| 309 |
+
|
| 310 |
+
if num_inference_steps > self.config.num_train_timesteps:
|
| 311 |
+
raise ValueError(
|
| 312 |
+
f"`num_inference_steps`: {num_inference_steps} cannot be larger than `self.config.train_timesteps`:"
|
| 313 |
+
f" {self.config.num_train_timesteps} as the unet model trained with this scheduler can only handle"
|
| 314 |
+
f" maximal {self.config.num_train_timesteps} timesteps."
|
| 315 |
+
)
|
| 316 |
+
|
| 317 |
+
self.num_inference_steps = num_inference_steps
|
| 318 |
+
|
| 319 |
+
# LCM Timesteps Setting: # Linear Spacing
|
| 320 |
+
c = self.config.num_train_timesteps // lcm_origin_steps
|
| 321 |
+
lcm_origin_timesteps = np.asarray(list(range(1, lcm_origin_steps + 1))) * c - 1 # LCM Training Steps Schedule
|
| 322 |
+
skipping_step = len(lcm_origin_timesteps) // num_inference_steps
|
| 323 |
+
timesteps = lcm_origin_timesteps[::-skipping_step][:num_inference_steps] # LCM Inference Steps Schedule
|
| 324 |
+
|
| 325 |
+
self.timesteps = torch.from_numpy(timesteps.copy()).to(device)
|
| 326 |
+
|
| 327 |
+
def get_scalings_for_boundary_condition_discrete(self, t):
|
| 328 |
+
self.sigma_data = 0.5 # Default: 0.5
|
| 329 |
+
|
| 330 |
+
# By dividing 0.1: This is almost a delta function at t=0.
|
| 331 |
+
c_skip = self.sigma_data**2 / (
|
| 332 |
+
(t / 0.1) ** 2 + self.sigma_data**2
|
| 333 |
+
)
|
| 334 |
+
c_out = (( t / 0.1) / ((t / 0.1) **2 + self.sigma_data**2) ** 0.5)
|
| 335 |
+
return c_skip, c_out
|
| 336 |
+
|
| 337 |
+
|
| 338 |
+
def step(
|
| 339 |
+
self,
|
| 340 |
+
model_output: torch.FloatTensor,
|
| 341 |
+
timeindex: int,
|
| 342 |
+
timestep: int,
|
| 343 |
+
sample: torch.FloatTensor,
|
| 344 |
+
eta: float = 0.0,
|
| 345 |
+
use_clipped_model_output: bool = False,
|
| 346 |
+
generator=None,
|
| 347 |
+
variance_noise: Optional[torch.FloatTensor] = None,
|
| 348 |
+
return_dict: bool = True,
|
| 349 |
+
) -> Union[LCMSchedulerOutput, Tuple]:
|
| 350 |
+
"""
|
| 351 |
+
Predict the sample from the previous timestep by reversing the SDE. This function propagates the diffusion
|
| 352 |
+
process from the learned model outputs (most often the predicted noise).
|
| 353 |
+
|
| 354 |
+
Args:
|
| 355 |
+
model_output (`torch.FloatTensor`):
|
| 356 |
+
The direct output from learned diffusion model.
|
| 357 |
+
timestep (`float`):
|
| 358 |
+
The current discrete timestep in the diffusion chain.
|
| 359 |
+
sample (`torch.FloatTensor`):
|
| 360 |
+
A current instance of a sample created by the diffusion process.
|
| 361 |
+
eta (`float`):
|
| 362 |
+
The weight of noise for added noise in diffusion step.
|
| 363 |
+
use_clipped_model_output (`bool`, defaults to `False`):
|
| 364 |
+
If `True`, computes "corrected" `model_output` from the clipped predicted original sample. Necessary
|
| 365 |
+
because predicted original sample is clipped to [-1, 1] when `self.config.clip_sample` is `True`. If no
|
| 366 |
+
clipping has happened, "corrected" `model_output` would coincide with the one provided as input and
|
| 367 |
+
`use_clipped_model_output` has no effect.
|
| 368 |
+
generator (`torch.Generator`, *optional*):
|
| 369 |
+
A random number generator.
|
| 370 |
+
variance_noise (`torch.FloatTensor`):
|
| 371 |
+
Alternative to generating noise with `generator` by directly providing the noise for the variance
|
| 372 |
+
itself. Useful for methods such as [`CycleDiffusion`].
|
| 373 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 374 |
+
Whether or not to return a [`~schedulers.scheduling_lcm.LCMSchedulerOutput`] or `tuple`.
|
| 375 |
+
|
| 376 |
+
Returns:
|
| 377 |
+
[`~schedulers.scheduling_utils.LCMSchedulerOutput`] or `tuple`:
|
| 378 |
+
If return_dict is `True`, [`~schedulers.scheduling_lcm.LCMSchedulerOutput`] is returned, otherwise a
|
| 379 |
+
tuple is returned where the first element is the sample tensor.
|
| 380 |
+
|
| 381 |
+
"""
|
| 382 |
+
if self.num_inference_steps is None:
|
| 383 |
+
raise ValueError(
|
| 384 |
+
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
|
| 385 |
+
)
|
| 386 |
+
|
| 387 |
+
# 1. get previous step value
|
| 388 |
+
prev_timeindex = timeindex + 1
|
| 389 |
+
if prev_timeindex < len(self.timesteps):
|
| 390 |
+
prev_timestep = self.timesteps[prev_timeindex]
|
| 391 |
+
else:
|
| 392 |
+
prev_timestep = timestep
|
| 393 |
+
|
| 394 |
+
# 2. compute alphas, betas
|
| 395 |
+
alpha_prod_t = self.alphas_cumprod[timestep]
|
| 396 |
+
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
|
| 397 |
+
|
| 398 |
+
beta_prod_t = 1 - alpha_prod_t
|
| 399 |
+
beta_prod_t_prev = 1 - alpha_prod_t_prev
|
| 400 |
+
|
| 401 |
+
# 3. Get scalings for boundary conditions
|
| 402 |
+
c_skip, c_out = self.get_scalings_for_boundary_condition_discrete(timestep)
|
| 403 |
+
|
| 404 |
+
# 4. Different Parameterization:
|
| 405 |
+
parameterization = self.config.prediction_type
|
| 406 |
+
|
| 407 |
+
if parameterization == "epsilon": # noise-prediction
|
| 408 |
+
pred_x0 = (sample - beta_prod_t.sqrt() * model_output) / alpha_prod_t.sqrt()
|
| 409 |
+
|
| 410 |
+
elif parameterization == "sample": # x-prediction
|
| 411 |
+
pred_x0 = model_output
|
| 412 |
+
|
| 413 |
+
elif parameterization == "v_prediction": # v-prediction
|
| 414 |
+
pred_x0 = alpha_prod_t.sqrt() * sample - beta_prod_t.sqrt() * model_output
|
| 415 |
+
|
| 416 |
+
# 4. Denoise model output using boundary conditions
|
| 417 |
+
denoised = c_out * pred_x0 + c_skip * sample
|
| 418 |
+
|
| 419 |
+
# 5. Sample z ~ N(0, I), For MultiStep Inference
|
| 420 |
+
# Noise is not used for one-step sampling.
|
| 421 |
+
if len(self.timesteps) > 1:
|
| 422 |
+
noise = torch.randn(model_output.shape).to(model_output.device)
|
| 423 |
+
prev_sample = alpha_prod_t_prev.sqrt() * denoised + beta_prod_t_prev.sqrt() * noise
|
| 424 |
+
else:
|
| 425 |
+
prev_sample = denoised
|
| 426 |
+
|
| 427 |
+
if not return_dict:
|
| 428 |
+
return (prev_sample, denoised)
|
| 429 |
+
|
| 430 |
+
return LCMSchedulerOutput(prev_sample=prev_sample, denoised=denoised)
|
| 431 |
+
|
| 432 |
+
|
| 433 |
+
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.add_noise
|
| 434 |
+
def add_noise(
|
| 435 |
+
self,
|
| 436 |
+
original_samples: torch.FloatTensor,
|
| 437 |
+
noise: torch.FloatTensor,
|
| 438 |
+
timesteps: torch.IntTensor,
|
| 439 |
+
) -> torch.FloatTensor:
|
| 440 |
+
# Make sure alphas_cumprod and timestep have same device and dtype as original_samples
|
| 441 |
+
alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
|
| 442 |
+
timesteps = timesteps.to(original_samples.device)
|
| 443 |
+
|
| 444 |
+
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
|
| 445 |
+
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
|
| 446 |
+
while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
|
| 447 |
+
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
|
| 448 |
+
|
| 449 |
+
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
|
| 450 |
+
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
|
| 451 |
+
while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
|
| 452 |
+
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
|
| 453 |
+
|
| 454 |
+
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
|
| 455 |
+
return noisy_samples
|
| 456 |
+
|
| 457 |
+
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.get_velocity
|
| 458 |
+
def get_velocity(
|
| 459 |
+
self, sample: torch.FloatTensor, noise: torch.FloatTensor, timesteps: torch.IntTensor
|
| 460 |
+
) -> torch.FloatTensor:
|
| 461 |
+
# Make sure alphas_cumprod and timestep have same device and dtype as sample
|
| 462 |
+
alphas_cumprod = self.alphas_cumprod.to(device=sample.device, dtype=sample.dtype)
|
| 463 |
+
timesteps = timesteps.to(sample.device)
|
| 464 |
+
|
| 465 |
+
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
|
| 466 |
+
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
|
| 467 |
+
while len(sqrt_alpha_prod.shape) < len(sample.shape):
|
| 468 |
+
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
|
| 469 |
+
|
| 470 |
+
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
|
| 471 |
+
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
|
| 472 |
+
while len(sqrt_one_minus_alpha_prod.shape) < len(sample.shape):
|
| 473 |
+
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
|
| 474 |
+
|
| 475 |
+
velocity = sqrt_alpha_prod * noise - sqrt_one_minus_alpha_prod * sample
|
| 476 |
+
return velocity
|
| 477 |
+
|
| 478 |
+
def __len__(self):
|
| 479 |
+
return self.config.num_train_timesteps
|
model_index.json
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "LatentConsistencyModelPipeline",
|
| 3 |
+
"_diffusers_version": "0.22.0.dev0",
|
| 4 |
+
"feature_extractor": [
|
| 5 |
+
"transformers",
|
| 6 |
+
"CLIPImageProcessor"
|
| 7 |
+
],
|
| 8 |
+
"safety_checker": [
|
| 9 |
+
"stable_diffusion",
|
| 10 |
+
"StableDiffusionSafetyChecker"
|
| 11 |
+
],
|
| 12 |
+
"scheduler": [
|
| 13 |
+
null,
|
| 14 |
+
null
|
| 15 |
+
],
|
| 16 |
+
"text_encoder": [
|
| 17 |
+
"transformers",
|
| 18 |
+
"CLIPTextModel"
|
| 19 |
+
],
|
| 20 |
+
"tokenizer": [
|
| 21 |
+
"transformers",
|
| 22 |
+
"CLIPTokenizer"
|
| 23 |
+
],
|
| 24 |
+
"unet": [
|
| 25 |
+
"diffusers",
|
| 26 |
+
"UNet2DConditionModel"
|
| 27 |
+
],
|
| 28 |
+
"vae": [
|
| 29 |
+
"diffusers",
|
| 30 |
+
"AutoencoderKL"
|
| 31 |
+
]
|
| 32 |
+
}
|
safety_checker/config.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "digiplay/DreamShaper_7",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"StableDiffusionSafetyChecker"
|
| 5 |
+
],
|
| 6 |
+
"initializer_factor": 1.0,
|
| 7 |
+
"logit_scale_init_value": 2.6592,
|
| 8 |
+
"model_type": "clip",
|
| 9 |
+
"projection_dim": 768,
|
| 10 |
+
"text_config": {
|
| 11 |
+
"bos_token_id": 0,
|
| 12 |
+
"dropout": 0.0,
|
| 13 |
+
"eos_token_id": 2,
|
| 14 |
+
"hidden_size": 768,
|
| 15 |
+
"intermediate_size": 3072,
|
| 16 |
+
"model_type": "clip_text_model",
|
| 17 |
+
"num_attention_heads": 12
|
| 18 |
+
},
|
| 19 |
+
"torch_dtype": "float32",
|
| 20 |
+
"transformers_version": "4.35.0.dev0",
|
| 21 |
+
"vision_config": {
|
| 22 |
+
"dropout": 0.0,
|
| 23 |
+
"hidden_size": 1024,
|
| 24 |
+
"intermediate_size": 4096,
|
| 25 |
+
"model_type": "clip_vision_model",
|
| 26 |
+
"num_attention_heads": 16,
|
| 27 |
+
"num_hidden_layers": 24,
|
| 28 |
+
"patch_size": 14
|
| 29 |
+
}
|
| 30 |
+
}
|
safety_checker/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fb351a5ded815c3ff744968ad9c6b218d071b9d313d04f35e813b84b4c0ffde8
|
| 3 |
+
size 1215979664
|
scheduler/scheduler_config.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "LCMScheduler",
|
| 3 |
+
"_diffusers_version": "0.22.0.dev0",
|
| 4 |
+
"beta_end": 0.012,
|
| 5 |
+
"beta_schedule": "scaled_linear",
|
| 6 |
+
"beta_start": 0.00085,
|
| 7 |
+
"clip_sample": true,
|
| 8 |
+
"clip_sample_range": 1.0,
|
| 9 |
+
"dynamic_thresholding_ratio": 0.995,
|
| 10 |
+
"num_train_timesteps": 1000,
|
| 11 |
+
"prediction_type": "epsilon",
|
| 12 |
+
"rescale_betas_zero_snr": false,
|
| 13 |
+
"sample_max_value": 1.0,
|
| 14 |
+
"set_alpha_to_one": true,
|
| 15 |
+
"steps_offset": 0,
|
| 16 |
+
"thresholding": false,
|
| 17 |
+
"timestep_spacing": "leading",
|
| 18 |
+
"trained_betas": null
|
| 19 |
+
}
|
speed_fid.png
ADDED
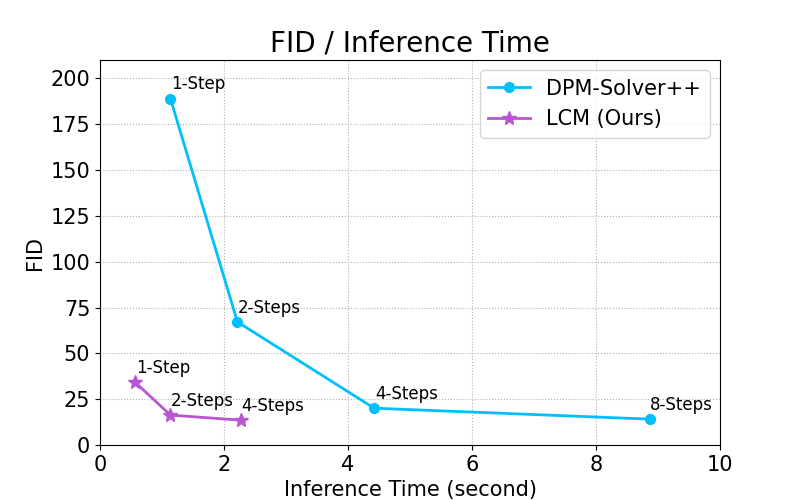
|
teaser.png
ADDED

|
Git LFS Details
|
text_encoder/config.json
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "digiplay/DreamShaper_7",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"CLIPTextModel"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 0,
|
| 8 |
+
"dropout": 0.0,
|
| 9 |
+
"eos_token_id": 2,
|
| 10 |
+
"hidden_act": "quick_gelu",
|
| 11 |
+
"hidden_size": 768,
|
| 12 |
+
"initializer_factor": 1.0,
|
| 13 |
+
"initializer_range": 0.02,
|
| 14 |
+
"intermediate_size": 3072,
|
| 15 |
+
"layer_norm_eps": 1e-05,
|
| 16 |
+
"max_position_embeddings": 77,
|
| 17 |
+
"model_type": "clip_text_model",
|
| 18 |
+
"num_attention_heads": 12,
|
| 19 |
+
"num_hidden_layers": 12,
|
| 20 |
+
"pad_token_id": 1,
|
| 21 |
+
"projection_dim": 768,
|
| 22 |
+
"torch_dtype": "float32",
|
| 23 |
+
"transformers_version": "4.35.0.dev0",
|
| 24 |
+
"vocab_size": 49408
|
| 25 |
+
}
|
text_encoder/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:66262104f5099c84ad0e6ec156acae57b2292caebd4d7b8699327fa745145b76
|
| 3 |
+
size 492265168
|
tokenizer/added_tokens.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<|endoftext|>": 49407,
|
| 3 |
+
"<|startoftext|>": 49406
|
| 4 |
+
}
|
tokenizer/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer/special_tokens_map.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": "<|startoftext|>",
|
| 3 |
+
"eos_token": "<|endoftext|>",
|
| 4 |
+
"pad_token": "<|endoftext|>",
|
| 5 |
+
"unk_token": "<|endoftext|>"
|
| 6 |
+
}
|
tokenizer/tokenizer_config.json
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"49406": {
|
| 5 |
+
"content": "<|startoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": true,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"49407": {
|
| 13 |
+
"content": "<|endoftext|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": true,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
}
|
| 20 |
+
},
|
| 21 |
+
"additional_special_tokens": [],
|
| 22 |
+
"bos_token": "<|startoftext|>",
|
| 23 |
+
"clean_up_tokenization_spaces": true,
|
| 24 |
+
"do_lower_case": true,
|
| 25 |
+
"eos_token": "<|endoftext|>",
|
| 26 |
+
"errors": "replace",
|
| 27 |
+
"model_max_length": 77,
|
| 28 |
+
"pad_token": "<|endoftext|>",
|
| 29 |
+
"tokenizer_class": "CLIPTokenizer",
|
| 30 |
+
"tokenizer_file": null,
|
| 31 |
+
"unk_token": "<|endoftext|>"
|
| 32 |
+
}
|
tokenizer/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
unet/config.json
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "UNet2DConditionModel",
|
| 3 |
+
"_diffusers_version": "0.22.0.dev0",
|
| 4 |
+
"act_fn": "silu",
|
| 5 |
+
"addition_embed_type": null,
|
| 6 |
+
"addition_embed_type_num_heads": 64,
|
| 7 |
+
"addition_time_embed_dim": null,
|
| 8 |
+
"attention_head_dim": 8,
|
| 9 |
+
"attention_type": "default",
|
| 10 |
+
"block_out_channels": [
|
| 11 |
+
320,
|
| 12 |
+
640,
|
| 13 |
+
1280,
|
| 14 |
+
1280
|
| 15 |
+
],
|
| 16 |
+
"center_input_sample": false,
|
| 17 |
+
"class_embed_type": null,
|
| 18 |
+
"class_embeddings_concat": false,
|
| 19 |
+
"conv_in_kernel": 3,
|
| 20 |
+
"conv_out_kernel": 3,
|
| 21 |
+
"cross_attention_dim": 768,
|
| 22 |
+
"cross_attention_norm": null,
|
| 23 |
+
"down_block_types": [
|
| 24 |
+
"CrossAttnDownBlock2D",
|
| 25 |
+
"CrossAttnDownBlock2D",
|
| 26 |
+
"CrossAttnDownBlock2D",
|
| 27 |
+
"DownBlock2D"
|
| 28 |
+
],
|
| 29 |
+
"downsample_padding": 1,
|
| 30 |
+
"dropout": 0.0,
|
| 31 |
+
"dual_cross_attention": false,
|
| 32 |
+
"encoder_hid_dim": null,
|
| 33 |
+
"encoder_hid_dim_type": null,
|
| 34 |
+
"flip_sin_to_cos": true,
|
| 35 |
+
"freq_shift": 0,
|
| 36 |
+
"in_channels": 4,
|
| 37 |
+
"layers_per_block": 2,
|
| 38 |
+
"mid_block_only_cross_attention": null,
|
| 39 |
+
"mid_block_scale_factor": 1,
|
| 40 |
+
"mid_block_type": "UNetMidBlock2DCrossAttn",
|
| 41 |
+
"norm_eps": 1e-05,
|
| 42 |
+
"norm_num_groups": 32,
|
| 43 |
+
"num_attention_heads": null,
|
| 44 |
+
"num_class_embeds": null,
|
| 45 |
+
"only_cross_attention": false,
|
| 46 |
+
"out_channels": 4,
|
| 47 |
+
"projection_class_embeddings_input_dim": null,
|
| 48 |
+
"resnet_out_scale_factor": 1.0,
|
| 49 |
+
"resnet_skip_time_act": false,
|
| 50 |
+
"resnet_time_scale_shift": "default",
|
| 51 |
+
"sample_size": 96,
|
| 52 |
+
"time_cond_proj_dim": 256,
|
| 53 |
+
"time_embedding_act_fn": null,
|
| 54 |
+
"time_embedding_dim": null,
|
| 55 |
+
"time_embedding_type": "positional",
|
| 56 |
+
"timestep_post_act": null,
|
| 57 |
+
"transformer_layers_per_block": 1,
|
| 58 |
+
"up_block_types": [
|
| 59 |
+
"UpBlock2D",
|
| 60 |
+
"CrossAttnUpBlock2D",
|
| 61 |
+
"CrossAttnUpBlock2D",
|
| 62 |
+
"CrossAttnUpBlock2D"
|
| 63 |
+
],
|
| 64 |
+
"upcast_attention": null,
|
| 65 |
+
"use_linear_projection": false
|
| 66 |
+
}
|
unet/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7be468469c513f8614a73423aa009581295fbd8c903703450632b2275c0145a9
|
| 3 |
+
size 3438495328
|
vae/config.json
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "AutoencoderKL",
|
| 3 |
+
"_diffusers_version": "0.22.0.dev0",
|
| 4 |
+
"_name_or_path": "digiplay/DreamShaper_7",
|
| 5 |
+
"act_fn": "silu",
|
| 6 |
+
"block_out_channels": [
|
| 7 |
+
128,
|
| 8 |
+
256,
|
| 9 |
+
512,
|
| 10 |
+
512
|
| 11 |
+
],
|
| 12 |
+
"down_block_types": [
|
| 13 |
+
"DownEncoderBlock2D",
|
| 14 |
+
"DownEncoderBlock2D",
|
| 15 |
+
"DownEncoderBlock2D",
|
| 16 |
+
"DownEncoderBlock2D"
|
| 17 |
+
],
|
| 18 |
+
"force_upcast": true,
|
| 19 |
+
"in_channels": 3,
|
| 20 |
+
"latent_channels": 4,
|
| 21 |
+
"layers_per_block": 2,
|
| 22 |
+
"norm_num_groups": 32,
|
| 23 |
+
"out_channels": 3,
|
| 24 |
+
"sample_size": 768,
|
| 25 |
+
"scaling_factor": 0.18215,
|
| 26 |
+
"up_block_types": [
|
| 27 |
+
"UpDecoderBlock2D",
|
| 28 |
+
"UpDecoderBlock2D",
|
| 29 |
+
"UpDecoderBlock2D",
|
| 30 |
+
"UpDecoderBlock2D"
|
| 31 |
+
]
|
| 32 |
+
}
|
vae/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6bb865b3478d73053007b8a76f114010e26f1a1d2ea02dc0261464caa4289c2d
|
| 3 |
+
size 334643268
|