
End of training
Browse files- README.md +3 -3
- all_results.json +20 -20
- eval_results.json +15 -15
- train_results.json +6 -6
- trainer_state.json +0 -0
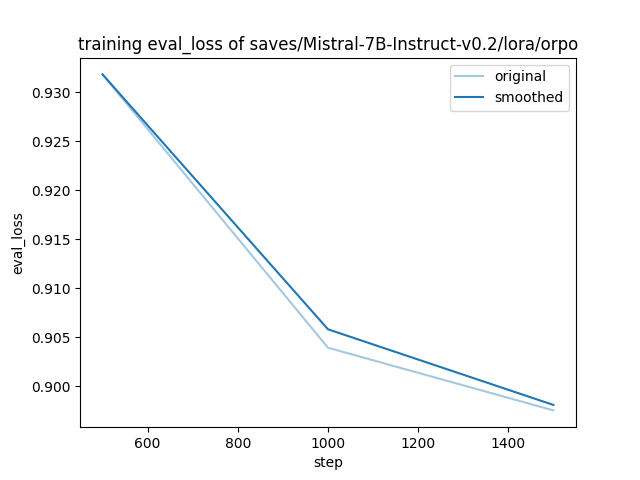
- training_eval_loss.png +0 -0
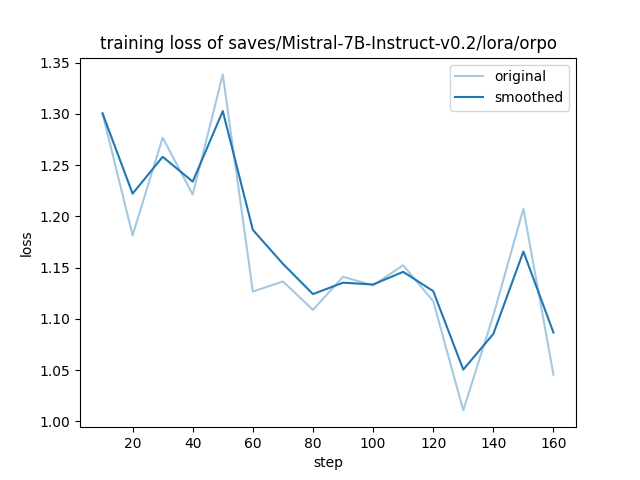
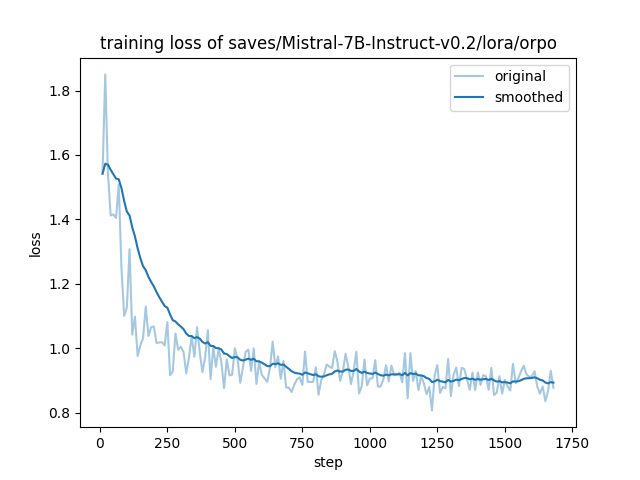
- training_loss.png +0 -0
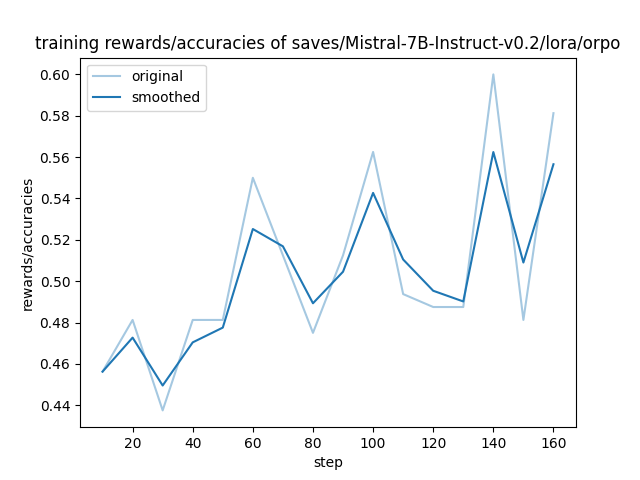
- training_rewards_accuracies.png +0 -0
- training_sft_loss.png +0 -0
README.md
CHANGED
|
@@ -2,10 +2,10 @@
|
|
| 2 |
license: apache-2.0
|
| 3 |
library_name: peft
|
| 4 |
tags:
|
| 5 |
-
- trl
|
| 6 |
-
- dpo
|
| 7 |
- llama-factory
|
| 8 |
- lora
|
|
|
|
|
|
|
| 9 |
- generated_from_trainer
|
| 10 |
base_model: mistralai/Mistral-7B-Instruct-v0.2
|
| 11 |
model-index:
|
|
@@ -18,7 +18,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 18 |
|
| 19 |
# Mistral-7B-Instruct-v0.2-ORPO
|
| 20 |
|
| 21 |
-
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on
|
| 22 |
It achieves the following results on the evaluation set:
|
| 23 |
- Loss: 0.8975
|
| 24 |
- Rewards/chosen: -0.0835
|
|
|
|
| 2 |
license: apache-2.0
|
| 3 |
library_name: peft
|
| 4 |
tags:
|
|
|
|
|
|
|
| 5 |
- llama-factory
|
| 6 |
- lora
|
| 7 |
+
- trl
|
| 8 |
+
- dpo
|
| 9 |
- generated_from_trainer
|
| 10 |
base_model: mistralai/Mistral-7B-Instruct-v0.2
|
| 11 |
model-index:
|
|
|
|
| 18 |
|
| 19 |
# Mistral-7B-Instruct-v0.2-ORPO
|
| 20 |
|
| 21 |
+
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on the dpo_mix_en dataset.
|
| 22 |
It achieves the following results on the evaluation set:
|
| 23 |
- Loss: 0.8975
|
| 24 |
- Rewards/chosen: -0.0835
|
all_results.json
CHANGED
|
@@ -1,22 +1,22 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch": 2.
|
| 3 |
-
"eval_logits/chosen": -2.
|
| 4 |
-
"eval_logits/rejected": -2.
|
| 5 |
-
"eval_logps/chosen": -
|
| 6 |
-
"eval_logps/rejected": -1.
|
| 7 |
-
"eval_loss":
|
| 8 |
-
"eval_odds_ratio_loss": 0.
|
| 9 |
-
"eval_rewards/accuracies": 0.
|
| 10 |
-
"eval_rewards/chosen": -0.
|
| 11 |
-
"eval_rewards/margins": 0.
|
| 12 |
-
"eval_rewards/rejected": -0.
|
| 13 |
-
"eval_runtime":
|
| 14 |
-
"eval_samples_per_second":
|
| 15 |
-
"eval_sft_loss":
|
| 16 |
-
"eval_steps_per_second":
|
| 17 |
-
"total_flos":
|
| 18 |
-
"train_loss":
|
| 19 |
-
"train_runtime":
|
| 20 |
-
"train_samples_per_second":
|
| 21 |
-
"train_steps_per_second": 0.
|
| 22 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 2.997999555456768,
|
| 3 |
+
"eval_logits/chosen": -2.8460819721221924,
|
| 4 |
+
"eval_logits/rejected": -2.8720545768737793,
|
| 5 |
+
"eval_logps/chosen": -0.8352006673812866,
|
| 6 |
+
"eval_logps/rejected": -1.0736578702926636,
|
| 7 |
+
"eval_loss": 0.8975116014480591,
|
| 8 |
+
"eval_odds_ratio_loss": 0.6231085658073425,
|
| 9 |
+
"eval_rewards/accuracies": 0.5899999737739563,
|
| 10 |
+
"eval_rewards/chosen": -0.0835200697183609,
|
| 11 |
+
"eval_rewards/margins": 0.023845719173550606,
|
| 12 |
+
"eval_rewards/rejected": -0.10736579447984695,
|
| 13 |
+
"eval_runtime": 189.1831,
|
| 14 |
+
"eval_samples_per_second": 5.286,
|
| 15 |
+
"eval_sft_loss": 0.8352006673812866,
|
| 16 |
+
"eval_steps_per_second": 2.643,
|
| 17 |
+
"total_flos": 1.985199772705751e+18,
|
| 18 |
+
"train_loss": 0.9645641791862949,
|
| 19 |
+
"train_runtime": 17170.3123,
|
| 20 |
+
"train_samples_per_second": 1.572,
|
| 21 |
+
"train_steps_per_second": 0.098
|
| 22 |
}
|
eval_results.json
CHANGED
|
@@ -1,17 +1,17 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch": 2.
|
| 3 |
-
"eval_logits/chosen": -2.
|
| 4 |
-
"eval_logits/rejected": -2.
|
| 5 |
-
"eval_logps/chosen": -
|
| 6 |
-
"eval_logps/rejected": -1.
|
| 7 |
-
"eval_loss":
|
| 8 |
-
"eval_odds_ratio_loss": 0.
|
| 9 |
-
"eval_rewards/accuracies": 0.
|
| 10 |
-
"eval_rewards/chosen": -0.
|
| 11 |
-
"eval_rewards/margins": 0.
|
| 12 |
-
"eval_rewards/rejected": -0.
|
| 13 |
-
"eval_runtime":
|
| 14 |
-
"eval_samples_per_second":
|
| 15 |
-
"eval_sft_loss":
|
| 16 |
-
"eval_steps_per_second":
|
| 17 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 2.997999555456768,
|
| 3 |
+
"eval_logits/chosen": -2.8460819721221924,
|
| 4 |
+
"eval_logits/rejected": -2.8720545768737793,
|
| 5 |
+
"eval_logps/chosen": -0.8352006673812866,
|
| 6 |
+
"eval_logps/rejected": -1.0736578702926636,
|
| 7 |
+
"eval_loss": 0.8975116014480591,
|
| 8 |
+
"eval_odds_ratio_loss": 0.6231085658073425,
|
| 9 |
+
"eval_rewards/accuracies": 0.5899999737739563,
|
| 10 |
+
"eval_rewards/chosen": -0.0835200697183609,
|
| 11 |
+
"eval_rewards/margins": 0.023845719173550606,
|
| 12 |
+
"eval_rewards/rejected": -0.10736579447984695,
|
| 13 |
+
"eval_runtime": 189.1831,
|
| 14 |
+
"eval_samples_per_second": 5.286,
|
| 15 |
+
"eval_sft_loss": 0.8352006673812866,
|
| 16 |
+
"eval_steps_per_second": 2.643
|
| 17 |
}
|
train_results.json
CHANGED
|
@@ -1,8 +1,8 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch": 2.
|
| 3 |
-
"total_flos":
|
| 4 |
-
"train_loss":
|
| 5 |
-
"train_runtime":
|
| 6 |
-
"train_samples_per_second":
|
| 7 |
-
"train_steps_per_second": 0.
|
| 8 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 2.997999555456768,
|
| 3 |
+
"total_flos": 1.985199772705751e+18,
|
| 4 |
+
"train_loss": 0.9645641791862949,
|
| 5 |
+
"train_runtime": 17170.3123,
|
| 6 |
+
"train_samples_per_second": 1.572,
|
| 7 |
+
"train_steps_per_second": 0.098
|
| 8 |
}
|
trainer_state.json
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_eval_loss.png
ADDED
|
training_loss.png
CHANGED
|
|
training_rewards_accuracies.png
CHANGED
|
|
training_sft_loss.png
CHANGED

|

|