
thanks to damo ❤
Browse files- .gitattributes +2 -0
- anytext_v1.1.ckpt +3 -0
- clip-vit-large-patch14/.gitattributes +28 -0
- clip-vit-large-patch14/README.md +145 -0
- clip-vit-large-patch14/config.json +171 -0
- clip-vit-large-patch14/merges.txt +0 -0
- clip-vit-large-patch14/preprocessor_config.json +19 -0
- clip-vit-large-patch14/pytorch_model.bin +3 -0
- clip-vit-large-patch14/special_tokens_map.json +1 -0
- clip-vit-large-patch14/tokenizer.json +0 -0
- clip-vit-large-patch14/tokenizer_config.json +34 -0
- clip-vit-large-patch14/vocab.json +0 -0
- configuration.json +1 -0
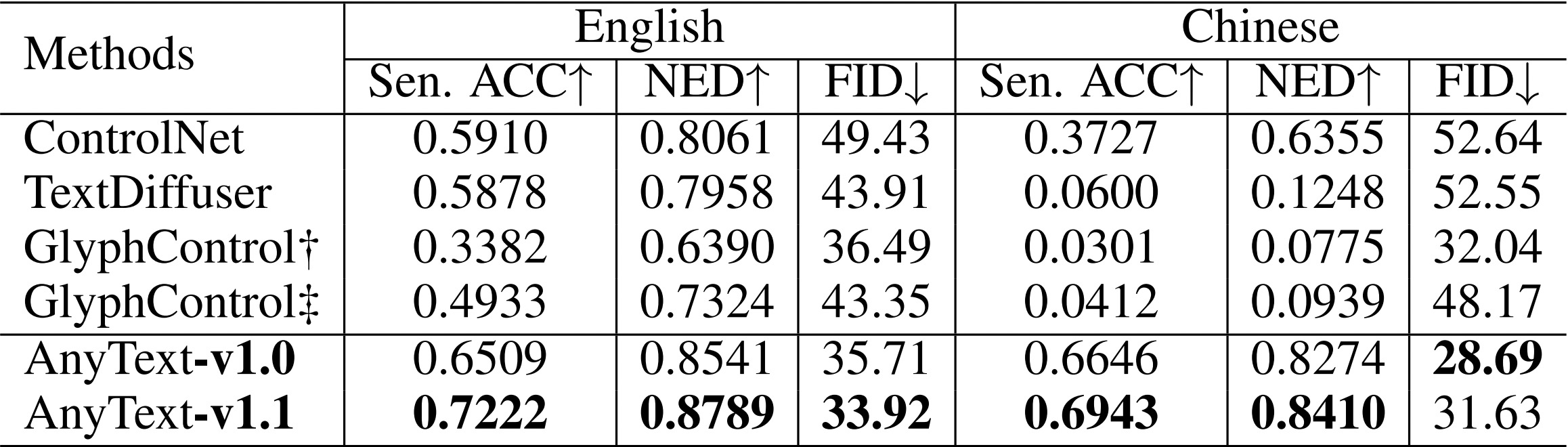
- description/eval.jpg +0 -0
- description/sample.jpg +0 -0
- ms_wrapper.py +385 -0
- nlp_csanmt_translation_zh2en/README.md +228 -0
- nlp_csanmt_translation_zh2en/bpe.en +0 -0
- nlp_csanmt_translation_zh2en/bpe.zh +0 -0
- nlp_csanmt_translation_zh2en/configuration.json +79 -0
- nlp_csanmt_translation_zh2en/resources/csanmt-model.png +0 -0
- nlp_csanmt_translation_zh2en/resources/ctl.png +0 -0
- nlp_csanmt_translation_zh2en/resources/sampling.png +0 -0
- nlp_csanmt_translation_zh2en/src_vocab.txt +0 -0
- nlp_csanmt_translation_zh2en/tf_ckpts/checkpoint +2 -0
- nlp_csanmt_translation_zh2en/tf_ckpts/ckpt-0.data-00000-of-00001 +3 -0
- nlp_csanmt_translation_zh2en/tf_ckpts/ckpt-0.index +0 -0
- nlp_csanmt_translation_zh2en/tf_ckpts/ckpt-0.meta +3 -0
- nlp_csanmt_translation_zh2en/train.en +0 -0
- nlp_csanmt_translation_zh2en/train.zh +0 -0
- nlp_csanmt_translation_zh2en/trg_vocab.txt +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
nlp_csanmt_translation_zh2en/tf_ckpts/ckpt-0.data-00000-of-00001 filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
nlp_csanmt_translation_zh2en/tf_ckpts/ckpt-0.meta filter=lfs diff=lfs merge=lfs -text
|
anytext_v1.1.ckpt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:09c88d145aa08f067641dc1d10c8890855939fa756d4cdc991e781a5f3918f59
|
| 3 |
+
size 5730281759
|
clip-vit-large-patch14/.gitattributes
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bin.* filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
model.safetensors filter=lfs diff=lfs merge=lfs -text
|
clip-vit-large-patch14/README.md
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tags:
|
| 3 |
+
- vision
|
| 4 |
+
widget:
|
| 5 |
+
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
|
| 6 |
+
candidate_labels: playing music, playing sports
|
| 7 |
+
example_title: Cat & Dog
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# Model Card: CLIP
|
| 11 |
+
|
| 12 |
+
Disclaimer: The model card is taken and modified from the official CLIP repository, it can be found [here](https://github.com/openai/CLIP/blob/main/model-card.md).
|
| 13 |
+
|
| 14 |
+
## Model Details
|
| 15 |
+
|
| 16 |
+
The CLIP model was developed by researchers at OpenAI to learn about what contributes to robustness in computer vision tasks. The model was also developed to test the ability of models to generalize to arbitrary image classification tasks in a zero-shot manner. It was not developed for general model deployment - to deploy models like CLIP, researchers will first need to carefully study their capabilities in relation to the specific context they’re being deployed within.
|
| 17 |
+
|
| 18 |
+
### Model Date
|
| 19 |
+
|
| 20 |
+
January 2021
|
| 21 |
+
|
| 22 |
+
### Model Type
|
| 23 |
+
|
| 24 |
+
The base model uses a ViT-L/14 Transformer architecture as an image encoder and uses a masked self-attention Transformer as a text encoder. These encoders are trained to maximize the similarity of (image, text) pairs via a contrastive loss.
|
| 25 |
+
|
| 26 |
+
The original implementation had two variants: one using a ResNet image encoder and the other using a Vision Transformer. This repository has the variant with the Vision Transformer.
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
### Documents
|
| 30 |
+
|
| 31 |
+
- [Blog Post](https://openai.com/blog/clip/)
|
| 32 |
+
- [CLIP Paper](https://arxiv.org/abs/2103.00020)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
### Use with Transformers
|
| 36 |
+
|
| 37 |
+
```python
|
| 38 |
+
from PIL import Image
|
| 39 |
+
import requests
|
| 40 |
+
|
| 41 |
+
from transformers import CLIPProcessor, CLIPModel
|
| 42 |
+
|
| 43 |
+
model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14")
|
| 44 |
+
processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14")
|
| 45 |
+
|
| 46 |
+
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
| 47 |
+
image = Image.open(requests.get(url, stream=True).raw)
|
| 48 |
+
|
| 49 |
+
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
|
| 50 |
+
|
| 51 |
+
outputs = model(**inputs)
|
| 52 |
+
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
|
| 53 |
+
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
## Model Use
|
| 58 |
+
|
| 59 |
+
### Intended Use
|
| 60 |
+
|
| 61 |
+
The model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such models - the CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis.
|
| 62 |
+
|
| 63 |
+
#### Primary intended uses
|
| 64 |
+
|
| 65 |
+
The primary intended users of these models are AI researchers.
|
| 66 |
+
|
| 67 |
+
We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
|
| 68 |
+
|
| 69 |
+
### Out-of-Scope Use Cases
|
| 70 |
+
|
| 71 |
+
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
|
| 72 |
+
|
| 73 |
+
Certain use cases which would fall under the domain of surveillance and facial recognition are always out-of-scope regardless of performance of the model. This is because the use of artificial intelligence for tasks such as these can be premature currently given the lack of testing norms and checks to ensure its fair use.
|
| 74 |
+
|
| 75 |
+
Since the model has not been purposefully trained in or evaluated on any languages other than English, its use should be limited to English language use cases.
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
## Data
|
| 80 |
+
|
| 81 |
+
The model was trained on publicly available image-caption data. This was done through a combination of crawling a handful of websites and using commonly-used pre-existing image datasets such as [YFCC100M](http://projects.dfki.uni-kl.de/yfcc100m/). A large portion of the data comes from our crawling of the internet. This means that the data is more representative of people and societies most connected to the internet which tend to skew towards more developed nations, and younger, male users.
|
| 82 |
+
|
| 83 |
+
### Data Mission Statement
|
| 84 |
+
|
| 85 |
+
Our goal with building this dataset was to test out robustness and generalizability in computer vision tasks. As a result, the focus was on gathering large quantities of data from different publicly-available internet data sources. The data was gathered in a mostly non-interventionist manner. However, we only crawled websites that had policies against excessively violent and adult images and allowed us to filter out such content. We do not intend for this dataset to be used as the basis for any commercial or deployed model and will not be releasing the dataset.
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
## Performance and Limitations
|
| 90 |
+
|
| 91 |
+
### Performance
|
| 92 |
+
|
| 93 |
+
We have evaluated the performance of CLIP on a wide range of benchmarks across a variety of computer vision datasets such as OCR to texture recognition to fine-grained classification. The paper describes model performance on the following datasets:
|
| 94 |
+
|
| 95 |
+
- Food101
|
| 96 |
+
- CIFAR10
|
| 97 |
+
- CIFAR100
|
| 98 |
+
- Birdsnap
|
| 99 |
+
- SUN397
|
| 100 |
+
- Stanford Cars
|
| 101 |
+
- FGVC Aircraft
|
| 102 |
+
- VOC2007
|
| 103 |
+
- DTD
|
| 104 |
+
- Oxford-IIIT Pet dataset
|
| 105 |
+
- Caltech101
|
| 106 |
+
- Flowers102
|
| 107 |
+
- MNIST
|
| 108 |
+
- SVHN
|
| 109 |
+
- IIIT5K
|
| 110 |
+
- Hateful Memes
|
| 111 |
+
- SST-2
|
| 112 |
+
- UCF101
|
| 113 |
+
- Kinetics700
|
| 114 |
+
- Country211
|
| 115 |
+
- CLEVR Counting
|
| 116 |
+
- KITTI Distance
|
| 117 |
+
- STL-10
|
| 118 |
+
- RareAct
|
| 119 |
+
- Flickr30
|
| 120 |
+
- MSCOCO
|
| 121 |
+
- ImageNet
|
| 122 |
+
- ImageNet-A
|
| 123 |
+
- ImageNet-R
|
| 124 |
+
- ImageNet Sketch
|
| 125 |
+
- ObjectNet (ImageNet Overlap)
|
| 126 |
+
- Youtube-BB
|
| 127 |
+
- ImageNet-Vid
|
| 128 |
+
|
| 129 |
+
## Limitations
|
| 130 |
+
|
| 131 |
+
CLIP and our analysis of it have a number of limitations. CLIP currently struggles with respect to certain tasks such as fine grained classification and counting objects. CLIP also poses issues with regards to fairness and bias which we discuss in the paper and briefly in the next section. Additionally, our approach to testing CLIP also has an important limitation- in many cases we have used linear probes to evaluate the performance of CLIP and there is evidence suggesting that linear probes can underestimate model performance.
|
| 132 |
+
|
| 133 |
+
### Bias and Fairness
|
| 134 |
+
|
| 135 |
+
We find that the performance of CLIP - and the specific biases it exhibits - can depend significantly on class design and the choices one makes for categories to include and exclude. We tested the risk of certain kinds of denigration with CLIP by classifying images of people from [Fairface](https://arxiv.org/abs/1908.04913) into crime-related and non-human animal categories. We found significant disparities with respect to race and gender. Additionally, we found that these disparities could shift based on how the classes were constructed. (Details captured in the Broader Impacts Section in the paper).
|
| 136 |
+
|
| 137 |
+
We also tested the performance of CLIP on gender, race and age classification using the Fairface dataset (We default to using race categories as they are constructed in the Fairface dataset.) in order to assess quality of performance across different demographics. We found accuracy >96% across all races for gender classification with ‘Middle Eastern’ having the highest accuracy (98.4%) and ‘White’ having the lowest (96.5%). Additionally, CLIP averaged ~93% for racial classification and ~63% for age classification. Our use of evaluations to test for gender, race and age classification as well as denigration harms is simply to evaluate performance of the model across people and surface potential risks and not to demonstrate an endorsement/enthusiasm for such tasks.
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
## Feedback
|
| 142 |
+
|
| 143 |
+
### Where to send questions or comments about the model
|
| 144 |
+
|
| 145 |
+
Please use [this Google Form](https://forms.gle/Uv7afRH5dvY34ZEs9)
|
clip-vit-large-patch14/config.json
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "clip-vit-large-patch14/",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"CLIPModel"
|
| 5 |
+
],
|
| 6 |
+
"initializer_factor": 1.0,
|
| 7 |
+
"logit_scale_init_value": 2.6592,
|
| 8 |
+
"model_type": "clip",
|
| 9 |
+
"projection_dim": 768,
|
| 10 |
+
"text_config": {
|
| 11 |
+
"_name_or_path": "",
|
| 12 |
+
"add_cross_attention": false,
|
| 13 |
+
"architectures": null,
|
| 14 |
+
"attention_dropout": 0.0,
|
| 15 |
+
"bad_words_ids": null,
|
| 16 |
+
"bos_token_id": 0,
|
| 17 |
+
"chunk_size_feed_forward": 0,
|
| 18 |
+
"cross_attention_hidden_size": null,
|
| 19 |
+
"decoder_start_token_id": null,
|
| 20 |
+
"diversity_penalty": 0.0,
|
| 21 |
+
"do_sample": false,
|
| 22 |
+
"dropout": 0.0,
|
| 23 |
+
"early_stopping": false,
|
| 24 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 25 |
+
"eos_token_id": 2,
|
| 26 |
+
"finetuning_task": null,
|
| 27 |
+
"forced_bos_token_id": null,
|
| 28 |
+
"forced_eos_token_id": null,
|
| 29 |
+
"hidden_act": "quick_gelu",
|
| 30 |
+
"hidden_size": 768,
|
| 31 |
+
"id2label": {
|
| 32 |
+
"0": "LABEL_0",
|
| 33 |
+
"1": "LABEL_1"
|
| 34 |
+
},
|
| 35 |
+
"initializer_factor": 1.0,
|
| 36 |
+
"initializer_range": 0.02,
|
| 37 |
+
"intermediate_size": 3072,
|
| 38 |
+
"is_decoder": false,
|
| 39 |
+
"is_encoder_decoder": false,
|
| 40 |
+
"label2id": {
|
| 41 |
+
"LABEL_0": 0,
|
| 42 |
+
"LABEL_1": 1
|
| 43 |
+
},
|
| 44 |
+
"layer_norm_eps": 1e-05,
|
| 45 |
+
"length_penalty": 1.0,
|
| 46 |
+
"max_length": 20,
|
| 47 |
+
"max_position_embeddings": 77,
|
| 48 |
+
"min_length": 0,
|
| 49 |
+
"model_type": "clip_text_model",
|
| 50 |
+
"no_repeat_ngram_size": 0,
|
| 51 |
+
"num_attention_heads": 12,
|
| 52 |
+
"num_beam_groups": 1,
|
| 53 |
+
"num_beams": 1,
|
| 54 |
+
"num_hidden_layers": 12,
|
| 55 |
+
"num_return_sequences": 1,
|
| 56 |
+
"output_attentions": false,
|
| 57 |
+
"output_hidden_states": false,
|
| 58 |
+
"output_scores": false,
|
| 59 |
+
"pad_token_id": 1,
|
| 60 |
+
"prefix": null,
|
| 61 |
+
"problem_type": null,
|
| 62 |
+
"projection_dim" : 768,
|
| 63 |
+
"pruned_heads": {},
|
| 64 |
+
"remove_invalid_values": false,
|
| 65 |
+
"repetition_penalty": 1.0,
|
| 66 |
+
"return_dict": true,
|
| 67 |
+
"return_dict_in_generate": false,
|
| 68 |
+
"sep_token_id": null,
|
| 69 |
+
"task_specific_params": null,
|
| 70 |
+
"temperature": 1.0,
|
| 71 |
+
"tie_encoder_decoder": false,
|
| 72 |
+
"tie_word_embeddings": true,
|
| 73 |
+
"tokenizer_class": null,
|
| 74 |
+
"top_k": 50,
|
| 75 |
+
"top_p": 1.0,
|
| 76 |
+
"torch_dtype": null,
|
| 77 |
+
"torchscript": false,
|
| 78 |
+
"transformers_version": "4.16.0.dev0",
|
| 79 |
+
"use_bfloat16": false,
|
| 80 |
+
"vocab_size": 49408
|
| 81 |
+
},
|
| 82 |
+
"text_config_dict": {
|
| 83 |
+
"hidden_size": 768,
|
| 84 |
+
"intermediate_size": 3072,
|
| 85 |
+
"num_attention_heads": 12,
|
| 86 |
+
"num_hidden_layers": 12,
|
| 87 |
+
"projection_dim": 768
|
| 88 |
+
},
|
| 89 |
+
"torch_dtype": "float32",
|
| 90 |
+
"transformers_version": null,
|
| 91 |
+
"vision_config": {
|
| 92 |
+
"_name_or_path": "",
|
| 93 |
+
"add_cross_attention": false,
|
| 94 |
+
"architectures": null,
|
| 95 |
+
"attention_dropout": 0.0,
|
| 96 |
+
"bad_words_ids": null,
|
| 97 |
+
"bos_token_id": null,
|
| 98 |
+
"chunk_size_feed_forward": 0,
|
| 99 |
+
"cross_attention_hidden_size": null,
|
| 100 |
+
"decoder_start_token_id": null,
|
| 101 |
+
"diversity_penalty": 0.0,
|
| 102 |
+
"do_sample": false,
|
| 103 |
+
"dropout": 0.0,
|
| 104 |
+
"early_stopping": false,
|
| 105 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 106 |
+
"eos_token_id": null,
|
| 107 |
+
"finetuning_task": null,
|
| 108 |
+
"forced_bos_token_id": null,
|
| 109 |
+
"forced_eos_token_id": null,
|
| 110 |
+
"hidden_act": "quick_gelu",
|
| 111 |
+
"hidden_size": 1024,
|
| 112 |
+
"id2label": {
|
| 113 |
+
"0": "LABEL_0",
|
| 114 |
+
"1": "LABEL_1"
|
| 115 |
+
},
|
| 116 |
+
"image_size": 224,
|
| 117 |
+
"initializer_factor": 1.0,
|
| 118 |
+
"initializer_range": 0.02,
|
| 119 |
+
"intermediate_size": 4096,
|
| 120 |
+
"is_decoder": false,
|
| 121 |
+
"is_encoder_decoder": false,
|
| 122 |
+
"label2id": {
|
| 123 |
+
"LABEL_0": 0,
|
| 124 |
+
"LABEL_1": 1
|
| 125 |
+
},
|
| 126 |
+
"layer_norm_eps": 1e-05,
|
| 127 |
+
"length_penalty": 1.0,
|
| 128 |
+
"max_length": 20,
|
| 129 |
+
"min_length": 0,
|
| 130 |
+
"model_type": "clip_vision_model",
|
| 131 |
+
"no_repeat_ngram_size": 0,
|
| 132 |
+
"num_attention_heads": 16,
|
| 133 |
+
"num_beam_groups": 1,
|
| 134 |
+
"num_beams": 1,
|
| 135 |
+
"num_hidden_layers": 24,
|
| 136 |
+
"num_return_sequences": 1,
|
| 137 |
+
"output_attentions": false,
|
| 138 |
+
"output_hidden_states": false,
|
| 139 |
+
"output_scores": false,
|
| 140 |
+
"pad_token_id": null,
|
| 141 |
+
"patch_size": 14,
|
| 142 |
+
"prefix": null,
|
| 143 |
+
"problem_type": null,
|
| 144 |
+
"projection_dim" : 768,
|
| 145 |
+
"pruned_heads": {},
|
| 146 |
+
"remove_invalid_values": false,
|
| 147 |
+
"repetition_penalty": 1.0,
|
| 148 |
+
"return_dict": true,
|
| 149 |
+
"return_dict_in_generate": false,
|
| 150 |
+
"sep_token_id": null,
|
| 151 |
+
"task_specific_params": null,
|
| 152 |
+
"temperature": 1.0,
|
| 153 |
+
"tie_encoder_decoder": false,
|
| 154 |
+
"tie_word_embeddings": true,
|
| 155 |
+
"tokenizer_class": null,
|
| 156 |
+
"top_k": 50,
|
| 157 |
+
"top_p": 1.0,
|
| 158 |
+
"torch_dtype": null,
|
| 159 |
+
"torchscript": false,
|
| 160 |
+
"transformers_version": "4.16.0.dev0",
|
| 161 |
+
"use_bfloat16": false
|
| 162 |
+
},
|
| 163 |
+
"vision_config_dict": {
|
| 164 |
+
"hidden_size": 1024,
|
| 165 |
+
"intermediate_size": 4096,
|
| 166 |
+
"num_attention_heads": 16,
|
| 167 |
+
"num_hidden_layers": 24,
|
| 168 |
+
"patch_size": 14,
|
| 169 |
+
"projection_dim": 768
|
| 170 |
+
}
|
| 171 |
+
}
|
clip-vit-large-patch14/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
clip-vit-large-patch14/preprocessor_config.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"crop_size": 224,
|
| 3 |
+
"do_center_crop": true,
|
| 4 |
+
"do_normalize": true,
|
| 5 |
+
"do_resize": true,
|
| 6 |
+
"feature_extractor_type": "CLIPFeatureExtractor",
|
| 7 |
+
"image_mean": [
|
| 8 |
+
0.48145466,
|
| 9 |
+
0.4578275,
|
| 10 |
+
0.40821073
|
| 11 |
+
],
|
| 12 |
+
"image_std": [
|
| 13 |
+
0.26862954,
|
| 14 |
+
0.26130258,
|
| 15 |
+
0.27577711
|
| 16 |
+
],
|
| 17 |
+
"resample": 3,
|
| 18 |
+
"size": 224
|
| 19 |
+
}
|
clip-vit-large-patch14/pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f1a17cdbe0f36fec524f5cafb1c261ea3bbbc13e346e0f74fc9eb0460dedd0d3
|
| 3 |
+
size 1710671599
|
clip-vit-large-patch14/special_tokens_map.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"bos_token": {"content": "<|startoftext|>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "eos_token": {"content": "<|endoftext|>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "unk_token": {"content": "<|endoftext|>", "single_word": false, "lstrip": false, "rstrip": false, "normalized": true}, "pad_token": "<|endoftext|>"}
|
clip-vit-large-patch14/tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
clip-vit-large-patch14/tokenizer_config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"unk_token": {
|
| 3 |
+
"content": "<|endoftext|>",
|
| 4 |
+
"single_word": false,
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"normalized": true,
|
| 8 |
+
"__type": "AddedToken"
|
| 9 |
+
},
|
| 10 |
+
"bos_token": {
|
| 11 |
+
"content": "<|startoftext|>",
|
| 12 |
+
"single_word": false,
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"rstrip": false,
|
| 15 |
+
"normalized": true,
|
| 16 |
+
"__type": "AddedToken"
|
| 17 |
+
},
|
| 18 |
+
"eos_token": {
|
| 19 |
+
"content": "<|endoftext|>",
|
| 20 |
+
"single_word": false,
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"rstrip": false,
|
| 23 |
+
"normalized": true,
|
| 24 |
+
"__type": "AddedToken"
|
| 25 |
+
},
|
| 26 |
+
"pad_token": "<|endoftext|>",
|
| 27 |
+
"add_prefix_space": false,
|
| 28 |
+
"errors": "replace",
|
| 29 |
+
"do_lower_case": true,
|
| 30 |
+
"name_or_path": "openai/clip-vit-base-patch32",
|
| 31 |
+
"model_max_length": 77,
|
| 32 |
+
"special_tokens_map_file": "./special_tokens_map.json",
|
| 33 |
+
"tokenizer_class": "CLIPTokenizer"
|
| 34 |
+
}
|
clip-vit-large-patch14/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
configuration.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"framework":"pytorch","task":"my-anytext-task","model":{"type":"my-custom-model"},"pipeline":{"type":"my-custom-pipeline"},"allow_remote":true}
|
description/eval.jpg
ADDED
|
description/sample.jpg
ADDED

|
ms_wrapper.py
ADDED
|
@@ -0,0 +1,385 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
AnyText: Multilingual Visual Text Generation And Editing
|
| 3 |
+
Paper: https://arxiv.org/abs/2311.03054
|
| 4 |
+
Code: https://github.com/tyxsspa/AnyText
|
| 5 |
+
Copyright (c) Alibaba, Inc. and its affiliates.
|
| 6 |
+
'''
|
| 7 |
+
import os
|
| 8 |
+
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
|
| 9 |
+
import torch
|
| 10 |
+
import random
|
| 11 |
+
import re
|
| 12 |
+
import numpy as np
|
| 13 |
+
import cv2
|
| 14 |
+
import einops
|
| 15 |
+
import time
|
| 16 |
+
from PIL import ImageFont
|
| 17 |
+
from cldm.model import create_model, load_state_dict
|
| 18 |
+
from cldm.ddim_hacked import DDIMSampler
|
| 19 |
+
from t3_dataset import draw_glyph, draw_glyph2
|
| 20 |
+
from util import check_channels, resize_image, save_images
|
| 21 |
+
from pytorch_lightning import seed_everything
|
| 22 |
+
from modelscope.pipelines import pipeline
|
| 23 |
+
from modelscope.utils.constant import Tasks
|
| 24 |
+
from modelscope.models.base import TorchModel
|
| 25 |
+
from modelscope.preprocessors.base import Preprocessor
|
| 26 |
+
from modelscope.pipelines.base import Model, Pipeline
|
| 27 |
+
from modelscope.utils.config import Config
|
| 28 |
+
from modelscope.pipelines.builder import PIPELINES
|
| 29 |
+
from modelscope.preprocessors.builder import PREPROCESSORS
|
| 30 |
+
from modelscope.models.builder import MODELS
|
| 31 |
+
from bert_tokenizer import BasicTokenizer
|
| 32 |
+
checker = BasicTokenizer()
|
| 33 |
+
BBOX_MAX_NUM = 8
|
| 34 |
+
PLACE_HOLDER = '*'
|
| 35 |
+
max_chars = 20
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
@MODELS.register_module('my-anytext-task', module_name='my-custom-model')
|
| 39 |
+
class MyCustomModel(TorchModel):
|
| 40 |
+
|
| 41 |
+
def __init__(self, model_dir, *args, **kwargs):
|
| 42 |
+
super().__init__(model_dir, *args, **kwargs)
|
| 43 |
+
self.init_model(**kwargs)
|
| 44 |
+
|
| 45 |
+
'''
|
| 46 |
+
return:
|
| 47 |
+
result: list of images in numpy.ndarray format
|
| 48 |
+
rst_code: 0: normal -1: error 1:warning
|
| 49 |
+
rst_info: string of error or warning
|
| 50 |
+
debug_info: string for debug, only valid if show_debug=True
|
| 51 |
+
'''
|
| 52 |
+
def forward(self, input_tensor, **forward_params):
|
| 53 |
+
tic = time.time()
|
| 54 |
+
str_warning = ''
|
| 55 |
+
# get inputs
|
| 56 |
+
seed = input_tensor.get('seed', -1)
|
| 57 |
+
if seed == -1:
|
| 58 |
+
seed = random.randint(0, 99999999)
|
| 59 |
+
seed_everything(seed)
|
| 60 |
+
prompt = input_tensor.get('prompt')
|
| 61 |
+
draw_pos = input_tensor.get('draw_pos')
|
| 62 |
+
ori_image = input_tensor.get('ori_image')
|
| 63 |
+
|
| 64 |
+
mode = forward_params.get('mode')
|
| 65 |
+
sort_priority = forward_params.get('sort_priority', '↕')
|
| 66 |
+
show_debug = forward_params.get('show_debug', False)
|
| 67 |
+
revise_pos = forward_params.get('revise_pos', False)
|
| 68 |
+
img_count = forward_params.get('image_count', 4)
|
| 69 |
+
ddim_steps = forward_params.get('ddim_steps', 20)
|
| 70 |
+
w = forward_params.get('image_width', 512)
|
| 71 |
+
h = forward_params.get('image_height', 512)
|
| 72 |
+
strength = forward_params.get('strength', 1.0)
|
| 73 |
+
cfg_scale = forward_params.get('cfg_scale', 9.0)
|
| 74 |
+
eta = forward_params.get('eta', 0.0)
|
| 75 |
+
a_prompt = forward_params.get('a_prompt', 'best quality, extremely detailed,4k, HD, supper legible text, clear text edges, clear strokes, neat writing, no watermarks')
|
| 76 |
+
n_prompt = forward_params.get('n_prompt', 'low-res, bad anatomy, extra digit, fewer digits, cropped, worst quality, low quality, watermark, unreadable text, messy words, distorted text, disorganized writing, advertising picture')
|
| 77 |
+
|
| 78 |
+
prompt, texts = self.modify_prompt(prompt)
|
| 79 |
+
n_lines = len(texts)
|
| 80 |
+
if mode in ['text-generation', 'gen']:
|
| 81 |
+
edit_image = np.ones((h, w, 3)) * 127.5 # empty mask image
|
| 82 |
+
elif mode in ['text-editing', 'edit']:
|
| 83 |
+
if draw_pos is None or ori_image is None:
|
| 84 |
+
return None, -1, "Reference image and position image are needed for text editing!", ""
|
| 85 |
+
if isinstance(ori_image, str):
|
| 86 |
+
ori_image = cv2.imread(ori_image)[..., ::-1]
|
| 87 |
+
assert ori_image is not None, f"Can't read ori_image image from{ori_image}!"
|
| 88 |
+
elif isinstance(ori_image, torch.Tensor):
|
| 89 |
+
ori_image = ori_image.cpu().numpy()
|
| 90 |
+
else:
|
| 91 |
+
assert isinstance(ori_image, np.ndarray), f'Unknown format of ori_image: {type(ori_image)}'
|
| 92 |
+
edit_image = ori_image.clip(1, 255) # for mask reason
|
| 93 |
+
edit_image = check_channels(edit_image)
|
| 94 |
+
edit_image = resize_image(edit_image, max_length=768) # make w h multiple of 64, resize if w or h > max_length
|
| 95 |
+
h, w = edit_image.shape[:2] # change h, w by input ref_img
|
| 96 |
+
# preprocess pos_imgs(if numpy, make sure it's white pos in black bg)
|
| 97 |
+
if draw_pos is None:
|
| 98 |
+
pos_imgs = np.zeros((w, h, 1))
|
| 99 |
+
if isinstance(draw_pos, str):
|
| 100 |
+
draw_pos = cv2.imread(draw_pos)[..., ::-1]
|
| 101 |
+
assert draw_pos is not None, f"Can't read draw_pos image from{draw_pos}!"
|
| 102 |
+
pos_imgs = 255-draw_pos
|
| 103 |
+
elif isinstance(draw_pos, torch.Tensor):
|
| 104 |
+
pos_imgs = draw_pos.cpu().numpy()
|
| 105 |
+
else:
|
| 106 |
+
assert isinstance(draw_pos, np.ndarray), f'Unknown format of draw_pos: {type(draw_pos)}'
|
| 107 |
+
pos_imgs = pos_imgs[..., 0:1]
|
| 108 |
+
pos_imgs = cv2.convertScaleAbs(pos_imgs)
|
| 109 |
+
_, pos_imgs = cv2.threshold(pos_imgs, 254, 255, cv2.THRESH_BINARY)
|
| 110 |
+
# seprate pos_imgs
|
| 111 |
+
pos_imgs = self.separate_pos_imgs(pos_imgs, sort_priority)
|
| 112 |
+
if len(pos_imgs) == 0:
|
| 113 |
+
pos_imgs = [np.zeros((h, w, 1))]
|
| 114 |
+
if len(pos_imgs) < n_lines:
|
| 115 |
+
if n_lines == 1 and texts[0] == ' ':
|
| 116 |
+
pass # text-to-image without text
|
| 117 |
+
else:
|
| 118 |
+
return None, -1, f'Found {len(pos_imgs)} positions that < needed {n_lines} from prompt, check and try again!', ''
|
| 119 |
+
elif len(pos_imgs) > n_lines:
|
| 120 |
+
str_warning = f'Warning: found {len(pos_imgs)} positions that > needed {n_lines} from prompt.'
|
| 121 |
+
# get pre_pos, poly_list, hint that needed for anytext
|
| 122 |
+
pre_pos = []
|
| 123 |
+
poly_list = []
|
| 124 |
+
for input_pos in pos_imgs:
|
| 125 |
+
if input_pos.mean() != 0:
|
| 126 |
+
input_pos = input_pos[..., np.newaxis] if len(input_pos.shape) == 2 else input_pos
|
| 127 |
+
poly, pos_img = self.find_polygon(input_pos)
|
| 128 |
+
pre_pos += [pos_img/255.]
|
| 129 |
+
poly_list += [poly]
|
| 130 |
+
else:
|
| 131 |
+
pre_pos += [np.zeros((h, w, 1))]
|
| 132 |
+
poly_list += [None]
|
| 133 |
+
np_hint = np.sum(pre_pos, axis=0).clip(0, 1)
|
| 134 |
+
# prepare info dict
|
| 135 |
+
info = {}
|
| 136 |
+
info['glyphs'] = []
|
| 137 |
+
info['gly_line'] = []
|
| 138 |
+
info['positions'] = []
|
| 139 |
+
info['n_lines'] = [len(texts)]*img_count
|
| 140 |
+
gly_pos_imgs = []
|
| 141 |
+
for i in range(len(texts)):
|
| 142 |
+
text = texts[i]
|
| 143 |
+
if len(text) > max_chars:
|
| 144 |
+
str_warning = f'"{text}" length > max_chars: {max_chars}, will be cut off...'
|
| 145 |
+
text = text[:max_chars]
|
| 146 |
+
gly_scale = 2
|
| 147 |
+
if pre_pos[i].mean() != 0:
|
| 148 |
+
gly_line = draw_glyph(self.font, text)
|
| 149 |
+
glyphs = draw_glyph2(self.font, text, poly_list[i], scale=gly_scale, width=w, height=h, add_space=False)
|
| 150 |
+
gly_pos_img = cv2.drawContours(glyphs*255, [poly_list[i]*gly_scale], 0, (255, 255, 255), 1)
|
| 151 |
+
if revise_pos:
|
| 152 |
+
resize_gly = cv2.resize(glyphs, (pre_pos[i].shape[1], pre_pos[i].shape[0]))
|
| 153 |
+
new_pos = cv2.morphologyEx((resize_gly*255).astype(np.uint8), cv2.MORPH_CLOSE, kernel=np.ones((resize_gly.shape[0]//10, resize_gly.shape[1]//10), dtype=np.uint8), iterations=1)
|
| 154 |
+
new_pos = new_pos[..., np.newaxis] if len(new_pos.shape) == 2 else new_pos
|
| 155 |
+
contours, _ = cv2.findContours(new_pos, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
|
| 156 |
+
if len(contours) != 1:
|
| 157 |
+
str_warning = f'Fail to revise position {i} to bounding rect, remain position unchanged...'
|
| 158 |
+
else:
|
| 159 |
+
rect = cv2.minAreaRect(contours[0])
|
| 160 |
+
poly = np.int0(cv2.boxPoints(rect))
|
| 161 |
+
pre_pos[i] = cv2.drawContours(new_pos, [poly], -1, 255, -1) / 255.
|
| 162 |
+
gly_pos_img = cv2.drawContours(glyphs*255, [poly*gly_scale], 0, (255, 255, 255), 1)
|
| 163 |
+
gly_pos_imgs += [gly_pos_img] # for show
|
| 164 |
+
else:
|
| 165 |
+
glyphs = np.zeros((h*gly_scale, w*gly_scale, 1))
|
| 166 |
+
gly_line = np.zeros((80, 512, 1))
|
| 167 |
+
gly_pos_imgs += [np.zeros((h*gly_scale, w*gly_scale, 1))] # for show
|
| 168 |
+
pos = pre_pos[i]
|
| 169 |
+
info['glyphs'] += [self.arr2tensor(glyphs, img_count)]
|
| 170 |
+
info['gly_line'] += [self.arr2tensor(gly_line, img_count)]
|
| 171 |
+
info['positions'] += [self.arr2tensor(pos, img_count)]
|
| 172 |
+
# get masked_x
|
| 173 |
+
masked_img = ((edit_image.astype(np.float32) / 127.5) - 1.0)*(1-np_hint)
|
| 174 |
+
masked_img = np.transpose(masked_img, (2, 0, 1))
|
| 175 |
+
masked_img = torch.from_numpy(masked_img.copy()).float().cuda()
|
| 176 |
+
encoder_posterior = self.model.encode_first_stage(masked_img[None, ...])
|
| 177 |
+
masked_x = self.model.get_first_stage_encoding(encoder_posterior).detach()
|
| 178 |
+
info['masked_x'] = torch.cat([masked_x for _ in range(img_count)], dim=0)
|
| 179 |
+
|
| 180 |
+
hint = self.arr2tensor(np_hint, img_count)
|
| 181 |
+
|
| 182 |
+
cond = self.model.get_learned_conditioning(dict(c_concat=[hint], c_crossattn=[[prompt + ' , ' + a_prompt] * img_count], text_info=info))
|
| 183 |
+
un_cond = self.model.get_learned_conditioning(dict(c_concat=[hint], c_crossattn=[[n_prompt] * img_count], text_info=info))
|
| 184 |
+
shape = (4, h // 8, w // 8)
|
| 185 |
+
self.model.control_scales = ([strength] * 13)
|
| 186 |
+
samples, intermediates = self.ddim_sampler.sample(ddim_steps, img_count,
|
| 187 |
+
shape, cond, verbose=False, eta=eta,
|
| 188 |
+
unconditional_guidance_scale=cfg_scale,
|
| 189 |
+
unconditional_conditioning=un_cond)
|
| 190 |
+
x_samples = self.model.decode_first_stage(samples)
|
| 191 |
+
x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cpu().numpy().clip(0, 255).astype(np.uint8)
|
| 192 |
+
results = [x_samples[i] for i in range(img_count)]
|
| 193 |
+
if mode == 'edit' and False: # replace backgound in text editing but not ideal yet
|
| 194 |
+
results = [r*np_hint+edit_image*(1-np_hint) for r in results]
|
| 195 |
+
results = [r.clip(0, 255).astype(np.uint8) for r in results]
|
| 196 |
+
if len(gly_pos_imgs) > 0 and show_debug:
|
| 197 |
+
glyph_bs = np.stack(gly_pos_imgs, axis=2)
|
| 198 |
+
glyph_img = np.sum(glyph_bs, axis=2) * 255
|
| 199 |
+
glyph_img = glyph_img.clip(0, 255).astype(np.uint8)
|
| 200 |
+
results += [np.repeat(glyph_img, 3, axis=2)]
|
| 201 |
+
# debug_info
|
| 202 |
+
if not show_debug:
|
| 203 |
+
debug_info = ''
|
| 204 |
+
else:
|
| 205 |
+
input_prompt = prompt
|
| 206 |
+
for t in texts:
|
| 207 |
+
input_prompt = input_prompt.replace('*', f'"{t}"', 1)
|
| 208 |
+
debug_info = f'<span style="color:black;font-size:18px">Prompt: </span>{input_prompt}<br> \
|
| 209 |
+
<span style="color:black;font-size:18px">Size: </span>{w}x{h}<br> \
|
| 210 |
+
<span style="color:black;font-size:18px">Image Count: </span>{img_count}<br> \
|
| 211 |
+
<span style="color:black;font-size:18px">Seed: </span>{seed}<br> \
|
| 212 |
+
<span style="color:black;font-size:18px">Cost Time: </span>{(time.time()-tic):.2f}s'
|
| 213 |
+
rst_code = 1 if str_warning else 0
|
| 214 |
+
return results, rst_code, str_warning, debug_info
|
| 215 |
+
|
| 216 |
+
def init_model(self, **kwargs):
|
| 217 |
+
font_path = kwargs.get('font_path', 'font/Arial_Unicode.ttf')
|
| 218 |
+
self.font = ImageFont.truetype(font_path, size=60)
|
| 219 |
+
cfg_path = kwargs.get('cfg_path', 'models_yaml/anytext_sd15.yaml')
|
| 220 |
+
ckpt_path = kwargs.get('model_path', os.path.join(self.model_dir, 'anytext_v1.1.ckpt'))
|
| 221 |
+
clip_path = os.path.join(self.model_dir, 'clip-vit-large-patch14')
|
| 222 |
+
self.model = create_model(cfg_path, cond_stage_path=clip_path).cuda().eval()
|
| 223 |
+
self.model.load_state_dict(load_state_dict(ckpt_path, location='cuda'), strict=False)
|
| 224 |
+
self.ddim_sampler = DDIMSampler(self.model)
|
| 225 |
+
self.trans_pipe = pipeline(task=Tasks.translation, model=os.path.join(self.model_dir, 'nlp_csanmt_translation_zh2en'))
|
| 226 |
+
|
| 227 |
+
def modify_prompt(self, prompt):
|
| 228 |
+
prompt = prompt.replace('“', '"')
|
| 229 |
+
prompt = prompt.replace('”', '"')
|
| 230 |
+
p = '"(.*?)"'
|
| 231 |
+
strs = re.findall(p, prompt)
|
| 232 |
+
if len(strs) == 0:
|
| 233 |
+
strs = [' ']
|
| 234 |
+
else:
|
| 235 |
+
for s in strs:
|
| 236 |
+
prompt = prompt.replace(f'"{s}"', f' {PLACE_HOLDER} ', 1)
|
| 237 |
+
if self.is_chinese(prompt):
|
| 238 |
+
old_prompt = prompt
|
| 239 |
+
prompt = self.trans_pipe(input=prompt + ' .')['translation'][:-1]
|
| 240 |
+
print(f'Translate: {old_prompt} --> {prompt}')
|
| 241 |
+
return prompt, strs
|
| 242 |
+
|
| 243 |
+
def is_chinese(self, text):
|
| 244 |
+
text = checker._clean_text(text)
|
| 245 |
+
for char in text:
|
| 246 |
+
cp = ord(char)
|
| 247 |
+
if checker._is_chinese_char(cp):
|
| 248 |
+
return True
|
| 249 |
+
return False
|
| 250 |
+
|
| 251 |
+
def separate_pos_imgs(self, img, sort_priority, gap=102):
|
| 252 |
+
num_labels, labels, stats, centroids = cv2.connectedComponentsWithStats(img)
|
| 253 |
+
components = []
|
| 254 |
+
for label in range(1, num_labels):
|
| 255 |
+
component = np.zeros_like(img)
|
| 256 |
+
component[labels == label] = 255
|
| 257 |
+
components.append((component, centroids[label]))
|
| 258 |
+
if sort_priority == '↕':
|
| 259 |
+
fir, sec = 1, 0 # top-down first
|
| 260 |
+
elif sort_priority == '↔':
|
| 261 |
+
fir, sec = 0, 1 # left-right first
|
| 262 |
+
components.sort(key=lambda c: (c[1][fir]//gap, c[1][sec]//gap))
|
| 263 |
+
sorted_components = [c[0] for c in components]
|
| 264 |
+
return sorted_components
|
| 265 |
+
|
| 266 |
+
def find_polygon(self, image, min_rect=False):
|
| 267 |
+
contours, hierarchy = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
|
| 268 |
+
max_contour = max(contours, key=cv2.contourArea) # get contour with max area
|
| 269 |
+
if min_rect:
|
| 270 |
+
# get minimum enclosing rectangle
|
| 271 |
+
rect = cv2.minAreaRect(max_contour)
|
| 272 |
+
poly = np.int0(cv2.boxPoints(rect))
|
| 273 |
+
else:
|
| 274 |
+
# get approximate polygon
|
| 275 |
+
epsilon = 0.01 * cv2.arcLength(max_contour, True)
|
| 276 |
+
poly = cv2.approxPolyDP(max_contour, epsilon, True)
|
| 277 |
+
n, _, xy = poly.shape
|
| 278 |
+
poly = poly.reshape(n, xy)
|
| 279 |
+
cv2.drawContours(image, [poly], -1, 255, -1)
|
| 280 |
+
return poly, image
|
| 281 |
+
|
| 282 |
+
def arr2tensor(self, arr, bs):
|
| 283 |
+
arr = np.transpose(arr, (2, 0, 1))
|
| 284 |
+
_arr = torch.from_numpy(arr.copy()).float().cuda()
|
| 285 |
+
_arr = torch.stack([_arr for _ in range(bs)], dim=0)
|
| 286 |
+
return _arr
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
@PREPROCESSORS.register_module('my-anytext-task', module_name='my-custom-preprocessor')
|
| 290 |
+
class MyCustomPreprocessor(Preprocessor):
|
| 291 |
+
|
| 292 |
+
def __init__(self, *args, **kwargs):
|
| 293 |
+
super().__init__(*args, **kwargs)
|
| 294 |
+
self.trainsforms = self.init_preprocessor(**kwargs)
|
| 295 |
+
|
| 296 |
+
def __call__(self, results):
|
| 297 |
+
return self.trainsforms(results)
|
| 298 |
+
|
| 299 |
+
def init_preprocessor(self, **kwarg):
|
| 300 |
+
""" Provide default implementation based on preprocess_cfg and user can reimplement it.
|
| 301 |
+
if nothing to do, then return lambda x: x
|
| 302 |
+
"""
|
| 303 |
+
return lambda x: x
|
| 304 |
+
|
| 305 |
+
|
| 306 |
+
@PIPELINES.register_module('my-anytext-task', module_name='my-custom-pipeline')
|
| 307 |
+
class MyCustomPipeline(Pipeline):
|
| 308 |
+
""" Give simple introduction to this pipeline.
|
| 309 |
+
|
| 310 |
+
Examples:
|
| 311 |
+
|
| 312 |
+
>>> from modelscope.pipelines import pipeline
|
| 313 |
+
>>> input = "Hello, ModelScope!"
|
| 314 |
+
>>> my_pipeline = pipeline('my-task', 'my-model-id')
|
| 315 |
+
>>> result = my_pipeline(input)
|
| 316 |
+
|
| 317 |
+
"""
|
| 318 |
+
|
| 319 |
+
def __init__(self, model, preprocessor=None, **kwargs):
|
| 320 |
+
super().__init__(model=model, auto_collate=False)
|
| 321 |
+
assert isinstance(model, str) or isinstance(model, Model), \
|
| 322 |
+
'model must be a single str or Model'
|
| 323 |
+
pipe_model = self.model
|
| 324 |
+
pipe_model.eval()
|
| 325 |
+
if preprocessor is None:
|
| 326 |
+
preprocessor = MyCustomPreprocessor()
|
| 327 |
+
super().__init__(model=pipe_model, preprocessor=preprocessor, **kwargs)
|
| 328 |
+
|
| 329 |
+
def _sanitize_parameters(self, **pipeline_parameters):
|
| 330 |
+
return {}, pipeline_parameters, {}
|
| 331 |
+
|
| 332 |
+
def _check_input(self, inputs):
|
| 333 |
+
pass
|
| 334 |
+
|
| 335 |
+
def _check_output(self, outputs):
|
| 336 |
+
pass
|
| 337 |
+
|
| 338 |
+
def forward(self, inputs, **forward_params):
|
| 339 |
+
return super().forward(inputs, **forward_params)
|
| 340 |
+
|
| 341 |
+
def postprocess(self, inputs):
|
| 342 |
+
return inputs
|
| 343 |
+
|
| 344 |
+
|
| 345 |
+
usr_config_path = 'models'
|
| 346 |
+
config = Config({
|
| 347 |
+
"framework": 'pytorch',
|
| 348 |
+
"task": 'my-anytext-task',
|
| 349 |
+
"model": {'type': 'my-custom-model'},
|
| 350 |
+
"pipeline": {"type": "my-custom-pipeline"},
|
| 351 |
+
"allow_remote": True
|
| 352 |
+
})
|
| 353 |
+
# config.dump('models/' + 'configuration.json')
|
| 354 |
+
|
| 355 |
+
if __name__ == "__main__":
|
| 356 |
+
img_save_folder = "SaveImages"
|
| 357 |
+
inference = pipeline('my-anytext-task', model=usr_config_path)
|
| 358 |
+
params = {
|
| 359 |
+
"show_debug": True,
|
| 360 |
+
"image_count": 2,
|
| 361 |
+
"ddim_steps": 20,
|
| 362 |
+
}
|
| 363 |
+
|
| 364 |
+
# 1. text generation
|
| 365 |
+
mode = 'text-generation'
|
| 366 |
+
input_data = {
|
| 367 |
+
"prompt": 'photo of caramel macchiato coffee on the table, top-down perspective, with "Any" "Text" written on it using cream',
|
| 368 |
+
"seed": 66273235,
|
| 369 |
+
"draw_pos": 'example_images/gen9.png'
|
| 370 |
+
}
|
| 371 |
+
results, rtn_code, rtn_warning, debug_info = inference(input_data, mode=mode, **params)
|
| 372 |
+
if rtn_code >= 0:
|
| 373 |
+
save_images(results, img_save_folder)
|
| 374 |
+
# 2. text editing
|
| 375 |
+
mode = 'text-editing'
|
| 376 |
+
input_data = {
|
| 377 |
+
"prompt": 'A cake with colorful characters that reads "EVERYDAY"',
|
| 378 |
+
"seed": 8943410,
|
| 379 |
+
"draw_pos": 'example_images/edit7.png',
|
| 380 |
+
"ori_image": 'example_images/ref7.jpg'
|
| 381 |
+
}
|
| 382 |
+
results, rtn_code, rtn_warning, debug_info = inference(input_data, mode=mode, **params)
|
| 383 |
+
if rtn_code >= 0:
|
| 384 |
+
save_images(results, img_save_folder)
|
| 385 |
+
print(f'Done, result images are saved in: {img_save_folder}')
|
nlp_csanmt_translation_zh2en/README.md
ADDED
|
@@ -0,0 +1,228 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tasks:
|
| 3 |
+
- translation
|
| 4 |
+
|
| 5 |
+
widgets:
|
| 6 |
+
- task: translation
|
| 7 |
+
inputs:
|
| 8 |
+
- type: text
|
| 9 |
+
name: input
|
| 10 |
+
title: 输入文字
|
| 11 |
+
validator:
|
| 12 |
+
max_words: 128
|
| 13 |
+
examples:
|
| 14 |
+
- name: 1
|
| 15 |
+
title: 示例1
|
| 16 |
+
inputs:
|
| 17 |
+
- name: text
|
| 18 |
+
data: 阿里巴巴集团的使命是让天下没有难做的生意
|
| 19 |
+
- name: 2
|
| 20 |
+
title: 示例2
|
| 21 |
+
inputs:
|
| 22 |
+
- name: text
|
| 23 |
+
data: 今天天气真不错!
|
| 24 |
+
|
| 25 |
+
model-type:
|
| 26 |
+
- csanmt
|
| 27 |
+
|
| 28 |
+
domain:
|
| 29 |
+
- nlp
|
| 30 |
+
|
| 31 |
+
frameworks:
|
| 32 |
+
- tensorflow
|
| 33 |
+
|
| 34 |
+
backbone:
|
| 35 |
+
- transformer
|
| 36 |
+
|
| 37 |
+
metrics:
|
| 38 |
+
- bleu
|
| 39 |
+
|
| 40 |
+
license: Apache License 2.0
|
| 41 |
+
|
| 42 |
+
finetune-support: True
|
| 43 |
+
|
| 44 |
+
language:
|
| 45 |
+
- zh-en
|
| 46 |
+
|
| 47 |
+
finetune-support: True
|
| 48 |
+
|
| 49 |
+
tags:
|
| 50 |
+
- CSANMT
|
| 51 |
+
- Neural Machine Translation
|
| 52 |
+
- Continuous Semantic Augmentation
|
| 53 |
+
- ACL2022
|
| 54 |
+
|
| 55 |
+
datasets:
|
| 56 |
+
train:
|
| 57 |
+
- damo/WMT-Chinese-to-English-Machine-Translation-Training-Corpus
|
| 58 |
+
test:
|
| 59 |
+
- damo/WMT-Chinese-to-English-Machine-Translation-newstest
|
| 60 |
+
- damo/IWSLT-Chinese-to-English-Machine-Translation-Spoken
|
| 61 |
+
- damo/WMT-Chinese-to-English-Machine-Translation-Medical
|
| 62 |
+
---
|
| 63 |
+
# 基于连续语义增强的神经机器翻译模型介绍
|
| 64 |
+
本模型基于邻域最小风险优化策略,backbone选用先进的transformer-large模型,编码器和解码器深度分别为24和6,相关论文已发表于ACL 2022,并获得Outstanding Paper Award。
|
| 65 |
+
|
| 66 |
+
## 模型描述
|
| 67 |
+
基于连续语义增强的神经机器翻译模型【[论文链接](https://arxiv.org/abs/2204.06812)】由编码器、解码器以及语义编码器三者构成。其中,语义编码器以大规模多语言预训练模型为基底,结合自适应对比学习,构建跨语言连续语义表征空间。此外,设计混合高斯循环采样策略,融合拒绝采样机制和马尔可夫链,提升采样效率的同时兼顾自然语言句子在离散空间中固有的分布特性。最后,结合邻域风险最小化策略优化翻译模型,能够有效提升数据的利用效率,显著改善模型的泛化能力和鲁棒性。模型结构如下图所示。
|
| 68 |
+
|
| 69 |
+
<center> <img src="./resources/csanmt-model.png" alt="csanmt_translation_model" width="400"/> <br> <div style="color:orange; border-bottom: 1px solid #d9d9d9; display: inline-block; color: #999; padding: 2px;">CSANMT连续语义增强机器翻译</div> </center>
|
| 70 |
+
|
| 71 |
+
具体来说,我们将双语句子对两个点作为球心,两点之间的欧氏距离作为半径,构造邻接语义区域(即邻域),邻域内的任意一点均与双语句子对语义等价。为了达到这一点,我们引入切线式对比学习,通过线性插值方法构造困难负样例,其中负样本的游走范围介于随机负样本和切点之间。然后,基于混合高斯循环采样策略,从邻接语义分布中采样增强样本,通过对差值向量进行方向变换和尺度缩放,可以将采样目标退化为选择一系列的尺度向量。
|
| 72 |
+
|
| 73 |
+
<div> <center> <img src="./resources/ctl.png" alt="tangential_ctl" width="300"/> <br> <div style="color:orange; border-bottom: 1px solid #d9d9d9; display: inline-block; color: #999; padding: 2px;">切线式对比学习</div> </center> </div> <div> <center> <img src="./resources/sampling.png" alt="sampling" width="300"/> <br> <div style="color:orange; border-bottom: 1px solid #d9d9d9; display: inline-block; color: #999; padding: 2px;">混合高斯循环采样</div> </center> </div>
|
| 74 |
+
|
| 75 |
+
## 期望模型使用方式以及适用范围
|
| 76 |
+
本模型适用于具有一定数据规模(百万级以上)的所有翻译语向,同时能够与离散式数据增强方法(如back-translation)结合使用。
|
| 77 |
+
|
| 78 |
+
### 如何使用
|
| 79 |
+
在ModelScope框架上,提供输入源文,即可通过简单的Pipeline调用来使用。
|
| 80 |
+
|
| 81 |
+
### 代码范例
|
| 82 |
+
```python
|
| 83 |
+
# Chinese-to-English
|
| 84 |
+
|
| 85 |
+
from modelscope.pipelines import pipeline
|
| 86 |
+
from modelscope.utils.constant import Tasks
|
| 87 |
+
|
| 88 |
+
input_sequence = '声明补充说,沃伦的同事都深感震惊,并且希望他能够投案自首。'
|
| 89 |
+
|
| 90 |
+
pipeline_ins = pipeline(task=Tasks.translation, model="damo/nlp_csanmt_translation_zh2en")
|
| 91 |
+
outputs = pipeline_ins(input=input_sequence)
|
| 92 |
+
|
| 93 |
+
print(outputs['translation']) # 'The statement added that Warren's colleagues were deeply shocked and expected him to turn himself in.'
|
| 94 |
+
```
|
| 95 |
+
|
| 96 |
+
## 模型局限性以及可能的偏差
|
| 97 |
+
1. 模型在通用数据集上训练,部分垂直领域有可能产生一些偏差,请用户自行评测后决定如何使用。
|
| 98 |
+
2. 当前版本在tensorflow 2.3和1.14环境测试通过,其他环境下可用性待测试。
|
| 99 |
+
3. 当前版本fine-tune在cpu和单机单gpu环境测试通过,单机多gpu等其他环境待测试。
|
| 100 |
+
|
| 101 |
+
## 训练数据介绍
|
| 102 |
+
1. [WMT21](https://arxiv.org/abs/2204.06812)数据集,系WMT官方提供的新闻领域双语数据集。
|
| 103 |
+
2. [Opensubtitles2018](https://www.opensubtitles.org),偏口语化(字幕)的双语数据集。
|
| 104 |
+
3. [OPUS](https://www.opensubtitles.org),众包数据集。
|
| 105 |
+
|
| 106 |
+
## 模型训练流程
|
| 107 |
+
|
| 108 |
+
### 数据准备
|
| 109 |
+
|
| 110 |
+
使用中英双语语料作为训练数据,准备两个文件:train.zh和train.en,其中每一行一一对应,例如:
|
| 111 |
+
|
| 112 |
+
```
|
| 113 |
+
#train.zh
|
| 114 |
+
这只是一个例子。
|
| 115 |
+
今天天气怎么样?
|
| 116 |
+
...
|
| 117 |
+
```
|
| 118 |
+
|
| 119 |
+
```
|
| 120 |
+
# train.en
|
| 121 |
+
This is just an example.
|
| 122 |
+
What's the weather like today?
|
| 123 |
+
...
|
| 124 |
+
```
|
| 125 |
+
|
| 126 |
+
### 预处理
|
| 127 |
+
训练数据预处理流程如下:
|
| 128 |
+
|
| 129 |
+
1. Tokenization
|
| 130 |
+
|
| 131 |
+
英文通过[mosesdecoder](https://github.com/moses-smt/mosesdecoder)进行Tokenization
|
| 132 |
+
```
|
| 133 |
+
perl tokenizer.perl -l en < train.en > train.en.tok
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
中文通过[jieba](https://github.com/fxsjy/jieba)进行中文分词
|
| 137 |
+
```
|
| 138 |
+
import jieba
|
| 139 |
+
|
| 140 |
+
fR = open('train.zh', 'r', encoding='UTF-8')
|
| 141 |
+
fW = open('train.zh.tok', 'w', encoding='UTF-8')
|
| 142 |
+
|
| 143 |
+
for sent in fR:
|
| 144 |
+
sent = fR.read()
|
| 145 |
+
sent_list = jieba.cut(sent)
|
| 146 |
+
fW.write(' '.join(sent_list))
|
| 147 |
+
|
| 148 |
+
fR.close()
|
| 149 |
+
fW.close()
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
2. [Byte-Pair-Encoding](https://github.com/rsennrich/subword-nmt)
|
| 153 |
+
|
| 154 |
+
```
|
| 155 |
+
subword-nmt apply-bpe -c bpe.en < train.en.tok > train.en.tok.bpe
|
| 156 |
+
|
| 157 |
+
subword-nmt apply-bpe -c bpe.zh < train.zh.tok > train.zh.tok.bpe
|
| 158 |
+
```
|
| 159 |
+
|
| 160 |
+
### 参数配置
|
| 161 |
+
|
| 162 |
+
修改Configuration.json相关训练配置,根据用户定制数据进行微调。参数介绍如下:
|
| 163 |
+
|
| 164 |
+
```
|
| 165 |
+
"train": {
|
| 166 |
+
"num_gpus": 0, # 指定GPU数量,0表示CPU运行
|
| 167 |
+
"warmup_steps": 4000, # 冷启动所需要的迭代步数,默认为4000
|
| 168 |
+
"update_cycle": 1, # 累积update_cycle个step的梯度进行一次参数更新,默认为1
|
| 169 |
+
"keep_checkpoint_max": 1, # 训练过程中保留的checkpoint数量
|
| 170 |
+
"confidence": 0.9, # label smoothing权重
|
| 171 |
+
"optimizer": "adam",
|
| 172 |
+
"adam_beta1": 0.9,
|
| 173 |
+
"adam_beta2": 0.98,
|
| 174 |
+
"adam_epsilon": 1e-9,
|
| 175 |
+
"gradient_clip_norm": 0.0,
|
| 176 |
+
"learning_rate_decay": "linear_warmup_rsqrt_decay", # 学习衰减策略,可选模式包括[none, linear_warmup_rsqrt_decay, piecewise_constant]
|
| 177 |
+
"initializer": "uniform_unit_scaling", # 参数初始化策略,可选模式包括[uniform, normal, normal_unit_scaling, uniform_unit_scaling]
|
| 178 |
+
"initializer_scale": 0.1,
|
| 179 |
+
"learning_rate": 1.0, # 学习率的缩放系数,即根据step值确定学习率以后,再根据模型的大小对学习率进行缩放
|
| 180 |
+
"train_batch_size_words": 1024, # 单训练batch所包含的token数量
|
| 181 |
+
"scale_l1": 0.0,
|
| 182 |
+
"scale_l2": 0.0,
|
| 183 |
+
"train_max_len": 100, # 默认情况下,限制训练数据的长度为100,用户可自行调整
|
| 184 |
+
"max_training_steps": 5, # 最大训练步数
|
| 185 |
+
"save_checkpoints_steps": 1000, # 间隔多少steps保存一次模型
|
| 186 |
+
"num_of_samples": 4, # 连续语义采样的样本数量
|
| 187 |
+
"eta": 0.6
|
| 188 |
+
},
|
| 189 |
+
"dataset": {
|
| 190 |
+
"train_src": "train.zh", # 指定源语言数据文件
|
| 191 |
+
"train_trg": "train.en", # 指定目标语言数据文件
|
| 192 |
+
"src_vocab": {
|
| 193 |
+
"file": "src_vocab.txt" # 指定源语言词典
|
| 194 |
+
},
|
| 195 |
+
"trg_vocab": {
|
| 196 |
+
"file": "trg_vocab.txt" # 指定目标语言词典
|
| 197 |
+
}
|
| 198 |
+
}
|
| 199 |
+
```
|
| 200 |
+
|
| 201 |
+
### 模型训练
|
| 202 |
+
```python
|
| 203 |
+
# Chinese-to-English
|
| 204 |
+
|
| 205 |
+
from modelscope.trainers.nlp import CsanmtTranslationTrainer
|
| 206 |
+
|
| 207 |
+
trainer = CsanmtTranslationTrainer(model="damo/nlp_csanmt_translation_zh2en")
|
| 208 |
+
trainer.train()
|
| 209 |
+
|
| 210 |
+
```
|
| 211 |
+
|
| 212 |
+
## 数据评估及结果
|
| 213 |
+
| Backbone |#Params| WMT18-20 (NLTK_BLEU)| IWSLT 16-17 (NLTK_BLEU) | Remark |
|
| 214 |
+
|:---------:|:-----:|:--------------------:|:-----------------------:|:-----------:|
|
| 215 |
+
| - | - | 35.8 | 27.8 | Google |
|
| 216 |
+
| 24-6-1024 | 570M | 34.9 | 28.4 | ModelScope |
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
## 论文引用
|
| 220 |
+
如果你觉得这个该模型对有所帮助,请考虑引用下面的相关的论文:
|
| 221 |
+
``` bibtex
|
| 222 |
+
@inproceedings{wei-etal-2022-learning,
|
| 223 |
+
title = {Learning to Generalize to More: Continuous Semantic Augmentation for Neural Machine Translation},
|
| 224 |
+
author = {Xiangpeng Wei and Heng Yu and Yue Hu and Rongxiang Weng and Weihua Luo and Rong Jin},
|
| 225 |
+
booktitle = {Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, ACL 2022},
|
| 226 |
+
year = {2022},
|
| 227 |
+
}
|
| 228 |
+
```
|
nlp_csanmt_translation_zh2en/bpe.en
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
nlp_csanmt_translation_zh2en/bpe.zh
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
nlp_csanmt_translation_zh2en/configuration.json
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"framework": "tensorflow",
|
| 3 |
+
"task": "translation",
|
| 4 |
+
"pipeline": {
|
| 5 |
+
"type": "csanmt-translation"
|
| 6 |
+
},
|
| 7 |
+
"model": {
|
| 8 |
+
"type": "csanmt-translation",
|
| 9 |
+
"hidden_size": 1024,
|
| 10 |
+
"filter_size": 4096,
|
| 11 |
+
"num_heads": 16,
|
| 12 |
+
"num_encoder_layers": 24,
|
| 13 |
+
"num_decoder_layers": 6,
|
| 14 |
+
"attention_dropout": 0.0,
|
| 15 |
+
"residual_dropout": 0.0,
|
| 16 |
+
"relu_dropout": 0.0,
|
| 17 |
+
"layer_preproc": "layer_norm",
|
| 18 |
+
"layer_postproc": "none",
|
| 19 |
+
"shared_embedding_and_softmax_weights": true,
|
| 20 |
+
"shared_source_target_embedding": true,
|
| 21 |
+
"initializer_scale": 0.1,
|
| 22 |
+
"position_info_type": "absolute",
|
| 23 |
+
"max_relative_dis": 16,
|
| 24 |
+
"num_semantic_encoder_layers": 4,
|
| 25 |
+
"src_vocab_size": 50000,
|
| 26 |
+
"trg_vocab_size": 50000,
|
| 27 |
+
"seed": 1234,
|
| 28 |
+
"beam_size": 4,
|
| 29 |
+
"lp_rate": 0.6,
|
| 30 |
+
"max_decoded_trg_len": 100
|
| 31 |
+
},
|
| 32 |
+
"dataset": {
|
| 33 |
+
"train_src": "train.zh",
|
| 34 |
+
"train_trg": "train.en",
|
| 35 |
+
"src_vocab": {
|
| 36 |
+
"file": "src_vocab.txt"
|
| 37 |
+
},
|
| 38 |
+
"trg_vocab": {
|
| 39 |
+
"file": "trg_vocab.txt"
|
| 40 |
+
}
|
| 41 |
+
},
|
| 42 |
+
"preprocessor": {
|
| 43 |
+
"src_lang": "zh",
|
| 44 |
+
"tgt_lang": "en",
|
| 45 |
+
"src_bpe": {
|
| 46 |
+
"file": "bpe.zh"
|
| 47 |
+
}
|
| 48 |
+
},
|
| 49 |
+
"train": {
|
| 50 |
+
"num_gpus": 0,
|
| 51 |
+
"warmup_steps": 4000,
|
| 52 |
+
"update_cycle": 1,
|
| 53 |
+
"keep_checkpoint_max": 1,
|
| 54 |
+
"confidence": 0.9,
|
| 55 |
+
"optimizer": "adam",
|
| 56 |
+
"adam_beta1": 0.9,
|
| 57 |
+
"adam_beta2": 0.98,
|
| 58 |
+
"adam_epsilon": 1e-9,
|
| 59 |
+
"gradient_clip_norm": 0.0,
|
| 60 |
+
"learning_rate_decay": "linear_warmup_rsqrt_decay",
|
| 61 |
+
"initializer": "uniform_unit_scaling",
|
| 62 |
+
"initializer_scale": 0.1,
|
| 63 |
+
"learning_rate": 1.0,
|
| 64 |
+
"train_batch_size_words": 1024,
|
| 65 |
+
"scale_l1": 0.0,
|
| 66 |
+
"scale_l2": 0.0,
|
| 67 |
+
"train_max_len": 100,
|
| 68 |
+
"num_of_epochs": 2,
|
| 69 |
+
"save_checkpoints_steps": 1000,
|
| 70 |
+
"num_of_samples": 4,
|
| 71 |
+
"eta": 0.6
|
| 72 |
+
},
|
| 73 |
+
"evaluation": {
|
| 74 |
+
"beam_size": 4,
|
| 75 |
+
"lp_rate": 0.6,
|
| 76 |
+
"max_decoded_trg_len": 100
|
| 77 |
+
}
|
| 78 |
+
|
| 79 |
+
}
|
nlp_csanmt_translation_zh2en/resources/csanmt-model.png
ADDED
|
nlp_csanmt_translation_zh2en/resources/ctl.png
ADDED
|
nlp_csanmt_translation_zh2en/resources/sampling.png
ADDED
|
nlp_csanmt_translation_zh2en/src_vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
nlp_csanmt_translation_zh2en/tf_ckpts/checkpoint
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_checkpoint_path: "ckpt-0"
|
| 2 |
+
all_model_checkpoint_paths: "ckpt-0"
|
nlp_csanmt_translation_zh2en/tf_ckpts/ckpt-0.data-00000-of-00001
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:078a794d1bd12ed16868a582abcf55b9d2b49ee70dec6d3f5b86687c94b90c92
|
| 3 |
+
size 7881046036
|
nlp_csanmt_translation_zh2en/tf_ckpts/ckpt-0.index
ADDED
|
Binary file (87.9 kB). View file
|
|
|
nlp_csanmt_translation_zh2en/tf_ckpts/ckpt-0.meta
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:489ff5e7dc03f938bce5d781c8c90eb3961d62b47a468a4d0bfdd7c1254718ab
|
| 3 |
+
size 10480829
|
nlp_csanmt_translation_zh2en/train.en
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
nlp_csanmt_translation_zh2en/train.zh
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
nlp_csanmt_translation_zh2en/trg_vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|