

Replace with clean markdown card
Browse files
README.md
CHANGED
|
@@ -14,13 +14,12 @@ tags:
|
|
| 14 |
|
| 15 |
# MetaNeuromotorHand
|
| 16 |
|
| 17 |
-
Generic neuromotor interface for handwriting from Meta (2025) .
|
| 18 |
|
| 19 |
-
> **Architecture-only repository.**
|
| 20 |
> `braindecode.models.MetaNeuromotorHand` class. **No pretrained weights are
|
| 21 |
-
> distributed here**
|
| 22 |
-
> data
|
| 23 |
-
> separately.
|
| 24 |
|
| 25 |
## Quick start
|
| 26 |
|
|
@@ -39,394 +38,67 @@ model = MetaNeuromotorHand(
|
|
| 39 |
)
|
| 40 |
```
|
| 41 |
|
| 42 |
-
The signal-shape arguments above are
|
| 43 |
-
|
| 44 |
|
| 45 |
## Documentation
|
| 46 |
-
|
| 47 |
-
-
|
| 48 |
-
<https://braindecode.org/stable/generated/braindecode.models.MetaNeuromotorHand.html>
|
| 49 |
-
- Interactive browser with live instantiation:
|
| 50 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 51 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/meta_neuromotor.py#L34>
|
| 52 |
|
| 53 |
-
## Architecture description
|
| 54 |
-
|
| 55 |
-
The block below is the rendered class docstring (parameters,
|
| 56 |
-
references, architecture figure where available).
|
| 57 |
-
|
| 58 |
-
<div class='bd-doc'><main>
|
| 59 |
-
<p>Generic neuromotor interface for handwriting from Meta (2025) [gni2025]_.</p>
|
| 60 |
-
<span style="display:inline-block;padding:2px 8px;border-radius:4px;background:#56B4E9;color:white;font-size:11px;font-weight:600;margin-right:4px;">Attention/Transformer</span><span style="display:inline-block;padding:2px 8px;border-radius:4px;background:#5cb85c;color:white;font-size:11px;font-weight:600;margin-right:4px;">Convolution</span>
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
.. figure:: https://media.springernature.com/full/springer-static/image/art%3A10.1038%2Fs41586-025-09255-w/MediaObjects/41586_2025_9255_Fig1_HTML.png
|
| 65 |
-
:align: center
|
| 66 |
-
:alt: Platform and decoding pipeline from the Nature paper (Figure 1).
|
| 67 |
-
:width: 700px
|
| 68 |
-
|
| 69 |
-
Figure 1 from the paper [gni2025]_ - *"A hardware and software
|
| 70 |
-
platform for high-throughput recording and real-time decoding of
|
| 71 |
-
sEMG at the wrist."* Shows the 16-channel sEMG-RD wristband, the
|
| 72 |
-
three tasks (handwriting, gestures, wrist control) and the
|
| 73 |
-
per-task decoding pipeline at a block level.
|
| 74 |
-
|
| 75 |
-
Conformer-based surface-EMG-to-character decoder for the handwriting
|
| 76 |
-
task of Meta's generic neuromotor interface (CTRL-labs at Reality
|
| 77 |
-
Labs, Nature 2025). Takes raw 16-channel surface EMG recorded at the
|
| 78 |
-
wrist and emits a per-token score sequence for CTC decoding
|
| 79 |
-
[graves2006ctc]_. The upstream repository
|
| 80 |
-
(`facebookresearch/generic-neuromotor-interface
|
| 81 |
-
<https://github.com/facebookresearch/generic-neuromotor-interface>`_)
|
| 82 |
-
ships one architecture per task: 1-DOF wrist control, discrete
|
| 83 |
-
gestures and handwriting. Only the handwriting head is ported here.
|
| 84 |
-
|
| 85 |
-
.. rubric:: Macro Components
|
| 86 |
-
|
| 87 |
-
The forward pass is a strict sequence of five modules, in order:
|
| 88 |
-
|
| 89 |
-
1. ``_MultivariatePowerFrequencyFeatures`` (MPF features, fixed
|
| 90 |
-
signal-processing stage, no trainable parameters).
|
| 91 |
-
|
| 92 |
-
- Channel-wise STFT (:func:`torch.stft`) -- ``n_fft=64`` (32 ms),
|
| 93 |
-
hop ``10`` (5 ms), Hann window.
|
| 94 |
-
- Strided windowing of consecutive STFT bins into
|
| 95 |
-
``mpf_window_length`` (80 ms) windows sliding every
|
| 96 |
-
``mpf_stride`` (20 ms).
|
| 97 |
-
- Per-pair cross-spectral density across channels, squared
|
| 98 |
-
magnitude.
|
| 99 |
-
- Frequency-band averaging over 6 bands
|
| 100 |
-
(0-50, 30-100, 100-225, 225-375, 375-700, 700-1000 Hz).
|
| 101 |
-
- SPD matrix logarithm via eigendecomposition
|
| 102 |
-
(Barachant et al. 2012; [pyriemann]_).
|
| 103 |
-
|
| 104 |
-
Output shape ``(batch, num_freq_bins, n_chans, n_chans, time')``
|
| 105 |
-
at 50 Hz (= ``sfreq / mpf_stride``).
|
| 106 |
-
|
| 107 |
-
2. ``_MaskAug`` -- SpecAugment [park2019specaug]_ on the MPF
|
| 108 |
-
features during training, no-op at eval. Zero parameters.
|
| 109 |
-
Hyperparameters ``mask_max_num_masks=(3, 2)`` and
|
| 110 |
-
``mask_max_lengths=(5, 1)`` match the released checkpoints.
|
| 111 |
-
|
| 112 |
-
3. ``_RotationInvariantMPFMLP`` -- armband-rotation invariance.
|
| 113 |
-
|
| 114 |
-
- Circular roll of the 16-channel cross-spectral matrix by each
|
| 115 |
-
offset in ``invariance_offsets`` (default ``{-1, 0, +1}``).
|
| 116 |
-
- Vectorize upper triangle keeping only ``num_adjacent_cov``
|
| 117 |
-
off-diagonals (assumes circular adjacency of the armband).
|
| 118 |
-
- Shared MLP applied to each rotated vector.
|
| 119 |
-
- Mean-pool across rotations -- enforces approximate invariance
|
| 120 |
-
to rigid rotations of the armband around the wrist.
|
| 121 |
-
|
| 122 |
-
Output shape ``(batch, hidden_dim, time')`` with
|
| 123 |
-
``hidden_dim = 64`` by default.
|
| 124 |
-
|
| 125 |
-
4. Causal conformer encoder [gulati2020conformer]_.
|
| 126 |
-
|
| 127 |
-
- Block structure: FF(half) -> windowed causal multi-head
|
| 128 |
-
attention -> depthwise convolution -> FF(half) ->
|
| 129 |
-
:class:`torch.nn.LayerNorm`.
|
| 130 |
-
- Depth: 15 blocks. The paper's schedule has stride ``2`` at
|
| 131 |
-
blocks 5 and 10 (total 4x temporal downsampling) and attention
|
| 132 |
-
window ``16`` for blocks 1-10 then ``8`` for blocks 11-15.
|
| 133 |
-
- Causality: attention is restricted to a fixed local window
|
| 134 |
-
ending at the current frame, so the encoder runs as a streaming
|
| 135 |
-
causal decoder. A frame-stacking step before the stack halves
|
| 136 |
-
the frame rate once more.
|
| 137 |
-
|
| 138 |
-
5. :class:`torch.nn.Linear` classification head, optionally followed
|
| 139 |
-
by :func:`torch.nn.functional.log_softmax`. The final linear
|
| 140 |
-
projects to ``n_outputs`` (vocabulary size, default ``100``).
|
| 141 |
-
Log-softmax is gated by ``log_softmax``; disabled by default
|
| 142 |
-
since braindecode models conventionally return logits.
|
| 143 |
-
|
| 144 |
-
.. rubric:: Hardware, signal and training corpus
|
| 145 |
-
|
| 146 |
-
The upstream sEMG-RD research wristband has 48 electrode pins
|
| 147 |
-
arranged as 16 bipolar channels aligned with the proximal-distal
|
| 148 |
-
forearm axis, a 2 kHz sample rate, a ~2.46 uVrms noise floor, and
|
| 149 |
-
an analog front-end with a 20 Hz high-pass and 850 Hz low-pass.
|
| 150 |
-
Before featurization the raw signal is rescaled by ``2.46e-6``
|
| 151 |
-
(to unit noise s.d.) and digitally high-passed at 40 Hz (4th-order
|
| 152 |
-
Butterworth) to suppress motion artifacts.
|
| 153 |
-
|
| 154 |
-
The published handwriting decoder was trained on recordings from
|
| 155 |
-
~6,627 participants (~1 h 15 min each) prompted to "write" text
|
| 156 |
-
sampled from Simple English Wikipedia, the Google Schema-guided
|
| 157 |
-
Dialogue dataset and Reddit, in three postures (seated on surface,
|
| 158 |
-
seated on leg, standing on leg). Participants wrote letters, digits,
|
| 159 |
-
words and phrases; spaces were either implicit or prompted by a
|
| 160 |
-
right-dash token produced via a right-index swipe. Training sizes
|
| 161 |
-
scale geometrically from 25 to 6,527 participants; validation and
|
| 162 |
-
test sets hold 50 participants each.
|
| 163 |
-
|
| 164 |
-
.. rubric:: MPF featurizer (paper defaults)
|
| 165 |
-
|
| 166 |
-
``sEMG (2 kHz)`` ->
|
| 167 |
-
``STFT(n_fft=64 samples / 32 ms, hop=10 samples / 5 ms)`` ->
|
| 168 |
-
per-pair complex cross-spectrum -> squared magnitude, band-averaged
|
| 169 |
-
into 6 bins, then matrix-log on each 16x16 SPD matrix, produced
|
| 170 |
-
every ``mpf_stride = 40 samples (20 ms)`` over a
|
| 171 |
-
``mpf_window_length = 160 samples (80 ms)`` window. Output rate:
|
| 172 |
-
50 Hz before the conformer's ``time_reduction_stride`` and the
|
| 173 |
-
2x internal strides.
|
| 174 |
-
|
| 175 |
-
The paper's frequency bins are non-overlapping (0-62.5, 62.5-125,
|
| 176 |
-
125-250, 250-375, 375-687.5, 687.5-1000 Hz), but the upstream
|
| 177 |
-
training config -- matched by the ``mpf_frequency_bins`` default --
|
| 178 |
-
uses slightly overlapping bins (0-50, 30-100, 100-225, 225-375,
|
| 179 |
-
375-700, 700-1000 Hz); the code default reproduces the released
|
| 180 |
-
checkpoints.
|
| 181 |
-
|
| 182 |
-
.. rubric:: Training recipe (paper values, not defaults of this class)
|
| 183 |
-
|
| 184 |
-
- **Loss**: CTC [graves2006ctc]_ with FastEmit regularization
|
| 185 |
-
[fastemit2021]_ to reduce streaming latency.
|
| 186 |
-
- **Vocabulary**: lowercase ``[a-z]``, digits ``[0-9]``, punctuation
|
| 187 |
-
``[,.?'!]`` and four control gestures (``space``, ``dash``,
|
| 188 |
-
``backspace``, ``pinch``); the deployed networks used
|
| 189 |
-
``vocab_size = 100`` (the default) to reserve blank / unused
|
| 190 |
-
slots. Greedy CTC decoding (collapse repeats) was used at test.
|
| 191 |
-
- **Optimizer**: AdamW, ``weight_decay = 5e-2``.
|
| 192 |
-
- **Learning rate**: cosine annealing from ``6e-4`` (1 M-parameter
|
| 193 |
-
model) or ``3e-4`` (60 M) with a 1,500-step warmup and
|
| 194 |
-
``min_lr = 0``.
|
| 195 |
-
- **Batching**: global batch size 512 (= 32 processes x 16),
|
| 196 |
-
prompts zero-padded to the longest in the batch; gradient
|
| 197 |
-
clipping at norm ``0.1``; 200 epochs. Training the largest model
|
| 198 |
-
took ~4 d 17 h on 4 x NVIDIA A10G GPUs.
|
| 199 |
-
- **Augmentation**: SpecAugment on the MPF features (time and
|
| 200 |
-
frequency masks; ``mask_max_num_masks=(3, 2)``,
|
| 201 |
-
``mask_max_lengths=(5, 1)``) plus random circular channel
|
| 202 |
-
rotations of ``{-1, 0, +1}``.
|
| 203 |
-
|
| 204 |
-
Reported closed-loop performance: ``20.9 WPM`` on held-out naive
|
| 205 |
-
users (n = 20), compared with ``25.1 WPM`` on a pen-and-paper
|
| 206 |
-
baseline and ``36 WPM`` on a mobile keyboard; personalization with
|
| 207 |
-
20 min of data improves offline CER by ~16 %.
|
| 208 |
-
|
| 209 |
-
.. rubric:: Output shape and CTC usage
|
| 210 |
-
|
| 211 |
-
The forward pass returns a tensor of shape
|
| 212 |
-
``(batch, T_out, n_outputs)``, the natural layout for CTC.
|
| 213 |
-
``T_out`` is the downsampled emission sequence length and can be
|
| 214 |
-
obtained from the input length via :meth:`compute_output_lengths`.
|
| 215 |
-
For :class:`torch.nn.CTCLoss`, move the time dimension first:
|
| 216 |
-
``emissions.transpose(0, 1)``.
|
| 217 |
-
|
| 218 |
-
.. warning::
|
| 219 |
-
The rotation-invariant MLP assumes circular channel adjacency
|
| 220 |
-
(the 16-electrode EMG armband used in the paper). For arbitrary
|
| 221 |
-
EEG montages the rotation invariance is not meaningful and this
|
| 222 |
-
model should not be used as-is.
|
| 223 |
-
|
| 224 |
-
.. warning::
|
| 225 |
-
**License -- noncommercial use only.** This module is a
|
| 226 |
-
derivative of Meta's reference implementation and is released
|
| 227 |
-
under `CC BY-NC 4.0
|
| 228 |
-
<https://creativecommons.org/licenses/by-nc/4.0/>`_, the same
|
| 229 |
-
license as the upstream repository. The paper itself is
|
| 230 |
-
distributed under CC BY-NC-ND 4.0. Neither is covered by
|
| 231 |
-
braindecode's BSD-3 license, and both must not be used in
|
| 232 |
-
commercial products or services. Using the pretrained weights
|
| 233 |
-
carries the same restriction.
|
| 234 |
-
|
| 235 |
-
.. versionadded:: 1.5
|
| 236 |
-
|
| 237 |
-
Parameters
|
| 238 |
-
----------
|
| 239 |
-
n_outputs : int
|
| 240 |
-
Vocabulary size for CTC. Defaults to ``100`` (handwriting
|
| 241 |
-
charset).
|
| 242 |
-
n_chans : int
|
| 243 |
-
Number of EMG channels. Defaults to ``16`` (one armband).
|
| 244 |
-
sfreq : float
|
| 245 |
-
Sampling frequency in Hz. Defaults to ``2000``.
|
| 246 |
-
mpf_window_length : int
|
| 247 |
-
MPF window length in samples.
|
| 248 |
-
mpf_stride : int
|
| 249 |
-
MPF frame stride in samples.
|
| 250 |
-
mpf_n_fft : int
|
| 251 |
-
STFT window / FFT size.
|
| 252 |
-
mpf_fft_stride : int
|
| 253 |
-
STFT hop size. Must divide ``mpf_stride`` and be
|
| 254 |
-
``<= mpf_n_fft``.
|
| 255 |
-
mpf_frequency_bins : sequence of (float, float) or None
|
| 256 |
-
``(low, high)`` Hz bands to average the cross-spectrum over.
|
| 257 |
-
If ``None``, all FFT frequency bins are used.
|
| 258 |
-
mask_max_num_masks : sequence of int
|
| 259 |
-
Max number of SpecAugment masks per dim (order matches
|
| 260 |
-
``mask_dims``).
|
| 261 |
-
mask_max_lengths : sequence of int
|
| 262 |
-
Max mask length per dim (order matches ``mask_dims``).
|
| 263 |
-
mask_dims : str
|
| 264 |
-
Axes to mask, among ``"CFT"``. Defaults to ``"TF"``.
|
| 265 |
-
mask_value : float
|
| 266 |
-
Filler value for masked regions.
|
| 267 |
-
invariance_hidden_dims : sequence of int
|
| 268 |
-
Hidden layer sizes of the per-rotation MLP. Output feature dim
|
| 269 |
-
is ``invariance_hidden_dims[-1]``.
|
| 270 |
-
invariance_offsets : sequence of int
|
| 271 |
-
Circular channel rotations to average over.
|
| 272 |
-
num_adjacent_cov : int
|
| 273 |
-
Number of adjacent off-diagonals of the cross-channel
|
| 274 |
-
covariance matrix to keep.
|
| 275 |
-
conformer_input_dim : int
|
| 276 |
-
Conformer embedding dimension ``D``.
|
| 277 |
-
conformer_ffn_dim : int
|
| 278 |
-
Feed-forward hidden dim inside each block.
|
| 279 |
-
conformer_kernel_size : int or sequence of int
|
| 280 |
-
Depthwise-conv kernel size per block.
|
| 281 |
-
conformer_stride : int or sequence of int
|
| 282 |
-
Depthwise-conv stride per block. As a scalar, applied only to
|
| 283 |
-
the last block (entire encoder downsamples by ``stride``); as a
|
| 284 |
-
sequence of length ``conformer_num_layers``, applied per block.
|
| 285 |
-
Defaults to the paper's 15-layer schedule
|
| 286 |
-
``(1, 1, 1, 1, 2) * 2 + (1,) * 5`` (2x downsampling at blocks 5
|
| 287 |
-
and 10). When overriding ``conformer_num_layers``, also pass a
|
| 288 |
-
matching schedule or a scalar.
|
| 289 |
-
conformer_num_heads : int
|
| 290 |
-
Number of attention heads.
|
| 291 |
-
conformer_attn_window_size : int or sequence of int
|
| 292 |
-
Attention receptive field per block. Defaults to the paper's
|
| 293 |
-
15-layer schedule ``(16,) * 10 + (8,) * 5``. When overriding
|
| 294 |
-
``conformer_num_layers``, also pass a matching schedule or a
|
| 295 |
-
scalar.
|
| 296 |
-
conformer_num_layers : int
|
| 297 |
-
Number of conformer blocks.
|
| 298 |
-
drop_prob : float
|
| 299 |
-
Dropout probability applied throughout the conformer (FFN,
|
| 300 |
-
conv and attention blocks).
|
| 301 |
-
time_reduction_stride : int
|
| 302 |
-
Frame-stacking stride applied **before** the conformer.
|
| 303 |
-
``1`` disables it.
|
| 304 |
-
log_softmax : bool
|
| 305 |
-
If ``True``, apply :func:`torch.nn.functional.log_softmax` to
|
| 306 |
-
the emissions. Disabled by default (braindecode models return
|
| 307 |
-
logits).
|
| 308 |
-
activation : type of nn.Module
|
| 309 |
-
Activation class used inside the conformer feed-forward and
|
| 310 |
-
convolution blocks. Defaults to :class:`torch.nn.SiLU`.
|
| 311 |
-
invariance_activation : type of nn.Module
|
| 312 |
-
Activation class used inside the rotation-invariant MLP.
|
| 313 |
-
Defaults to :class:`torch.nn.LeakyReLU`.
|
| 314 |
-
|
| 315 |
-
Examples
|
| 316 |
-
--------
|
| 317 |
-
Load Meta's pretrained handwriting checkpoint (`download script`_
|
| 318 |
-
in the upstream repo)::
|
| 319 |
-
|
| 320 |
-
import torch
|
| 321 |
-
from braindecode.models import MetaNeuromotorHand
|
| 322 |
-
|
| 323 |
-
ckpt = torch.load("model_checkpoint.ckpt", weights_only=False)
|
| 324 |
-
sd = {
|
| 325 |
-
k[len("network."):]: v
|
| 326 |
-
for k, v in ckpt["state_dict"].items()
|
| 327 |
-
if k.startswith("network.")
|
| 328 |
-
}
|
| 329 |
-
|
| 330 |
-
model = MetaNeuromotorHand(n_times=32000, log_softmax=True)
|
| 331 |
-
# load_state_dict applies the class-level ``mapping`` for
|
| 332 |
-
# upstream keys.
|
| 333 |
-
model.load_state_dict(sd, strict=True)
|
| 334 |
-
|
| 335 |
-
.. _download script: https://github.com/facebookresearch/generic-neuromotor-interface#download-the-data-and-models
|
| 336 |
-
|
| 337 |
-
References
|
| 338 |
-
----------
|
| 339 |
-
.. [gni2025] CTRL-labs at Reality Labs (Kaifosh, P., Reardon, T. R.
|
| 340 |
-
et al.), 2025. A generic non-invasive neuromotor interface for
|
| 341 |
-
human-computer interaction. Nature 645, 702-710.
|
| 342 |
-
https://doi.org/10.1038/s41586-025-09255-w
|
| 343 |
-
.. [gulati2020conformer] Gulati, A. et al., 2020. Conformer:
|
| 344 |
-
convolution-augmented transformer for speech recognition.
|
| 345 |
-
Proc. Interspeech, 5036-5040.
|
| 346 |
-
.. [graves2006ctc] Graves, A., Fernandez, S., Gomez, F.,
|
| 347 |
-
Schmidhuber, J., 2006. Connectionist temporal classification:
|
| 348 |
-
labelling unsegmented sequence data with recurrent neural
|
| 349 |
-
networks. Proc. ICML, 369-376.
|
| 350 |
-
.. [park2019specaug] Park, D. S. et al., 2019. SpecAugment:
|
| 351 |
-
a simple data augmentation method for automatic speech
|
| 352 |
-
recognition. Proc. Interspeech, 2613-2617.
|
| 353 |
-
.. [fastemit2021] Yu, J. et al., 2021. FastEmit: low-latency
|
| 354 |
-
streaming ASR with sequence-level emission regularization.
|
| 355 |
-
Proc. ICASSP.
|
| 356 |
-
.. [pyriemann] Barachant, A., Barthelemy, Q., King, J.-R., Gramfort,
|
| 357 |
-
A., Chevallier, S., Rodrigues, P. L. C., ... Aristimunha, B.,
|
| 358 |
-
2026. pyRiemann (v0.10). Zenodo.
|
| 359 |
-
https://doi.org/10.5281/zenodo.593816
|
| 360 |
-
|
| 361 |
-
.. rubric:: Hugging Face Hub integration
|
| 362 |
-
|
| 363 |
-
When the optional ``huggingface_hub`` package is installed, all models
|
| 364 |
-
automatically gain the ability to be pushed to and loaded from the
|
| 365 |
-
Hugging Face Hub. Install with::
|
| 366 |
-
|
| 367 |
-
pip install braindecode[hub]
|
| 368 |
-
|
| 369 |
-
**Pushing a model to the Hub:**
|
| 370 |
-
|
| 371 |
-
.. code::
|
| 372 |
-
from braindecode.models import MetaNeuromotorHand
|
| 373 |
-
|
| 374 |
-
# Train your model
|
| 375 |
-
model = MetaNeuromotorHand(n_chans=22, n_outputs=4, n_times=1000)
|
| 376 |
-
# ... training code ...
|
| 377 |
-
|
| 378 |
-
# Push to the Hub
|
| 379 |
-
model.push_to_hub(
|
| 380 |
-
repo_id="username/my-metaneuromotorhand-model",
|
| 381 |
-
commit_message="Initial model upload",
|
| 382 |
-
)
|
| 383 |
-
|
| 384 |
-
**Loading a model from the Hub:**
|
| 385 |
-
|
| 386 |
-
.. code::
|
| 387 |
-
from braindecode.models import MetaNeuromotorHand
|
| 388 |
-
|
| 389 |
-
# Load pretrained model
|
| 390 |
-
model = MetaNeuromotorHand.from_pretrained("username/my-metaneuromotorhand-model")
|
| 391 |
-
|
| 392 |
-
# Load with a different number of outputs (head is rebuilt automatically)
|
| 393 |
-
model = MetaNeuromotorHand.from_pretrained("username/my-metaneuromotorhand-model", n_outputs=4)
|
| 394 |
-
|
| 395 |
-
**Extracting features and replacing the head:**
|
| 396 |
-
|
| 397 |
-
.. code::
|
| 398 |
-
import torch
|
| 399 |
-
|
| 400 |
-
x = torch.randn(1, model.n_chans, model.n_times)
|
| 401 |
-
# Extract encoder features (consistent dict across all models)
|
| 402 |
-
out = model(x, return_features=True)
|
| 403 |
-
features = out["features"]
|
| 404 |
-
|
| 405 |
-
# Replace the classification head
|
| 406 |
-
model.reset_head(n_outputs=10)
|
| 407 |
-
|
| 408 |
-
**Saving and restoring full configuration:**
|
| 409 |
-
|
| 410 |
-
.. code::
|
| 411 |
-
import json
|
| 412 |
-
|
| 413 |
-
config = model.get_config() # all __init__ params
|
| 414 |
-
with open("config.json", "w") as f:
|
| 415 |
-
json.dump(config, f)
|
| 416 |
-
|
| 417 |
-
model2 = MetaNeuromotorHand.from_config(config) # reconstruct (no weights)
|
| 418 |
|
| 419 |
-
|
| 420 |
-
|
| 421 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 422 |
|
| 423 |
-
See :ref:`load-pretrained-models` for a complete tutorial.</main>
|
| 424 |
-
</div>
|
| 425 |
|
| 426 |
## Citation
|
| 427 |
|
| 428 |
-
|
| 429 |
-
*References* section above) and braindecode:
|
| 430 |
|
| 431 |
```bibtex
|
| 432 |
@article{aristimunha2025braindecode,
|
|
|
|
| 14 |
|
| 15 |
# MetaNeuromotorHand
|
| 16 |
|
| 17 |
+
Generic neuromotor interface for handwriting from Meta (2025) [gni2025].
|
| 18 |
|
| 19 |
+
> **Architecture-only repository.** Documents the
|
| 20 |
> `braindecode.models.MetaNeuromotorHand` class. **No pretrained weights are
|
| 21 |
+
> distributed here.** Instantiate the model and train it on your own
|
| 22 |
+
> data.
|
|
|
|
| 23 |
|
| 24 |
## Quick start
|
| 25 |
|
|
|
|
| 38 |
)
|
| 39 |
```
|
| 40 |
|
| 41 |
+
The signal-shape arguments above are illustrative defaults — adjust to
|
| 42 |
+
match your recording.
|
| 43 |
|
| 44 |
## Documentation
|
| 45 |
+
- Full API reference: <https://braindecode.org/stable/generated/braindecode.models.MetaNeuromotorHand.html>
|
| 46 |
+
- Interactive browser (live instantiation, parameter counts):
|
|
|
|
|
|
|
| 47 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 48 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/meta_neuromotor.py#L34>
|
| 49 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 50 |
|
| 51 |
+
## Architecture
|
| 52 |
+
|
| 53 |
+
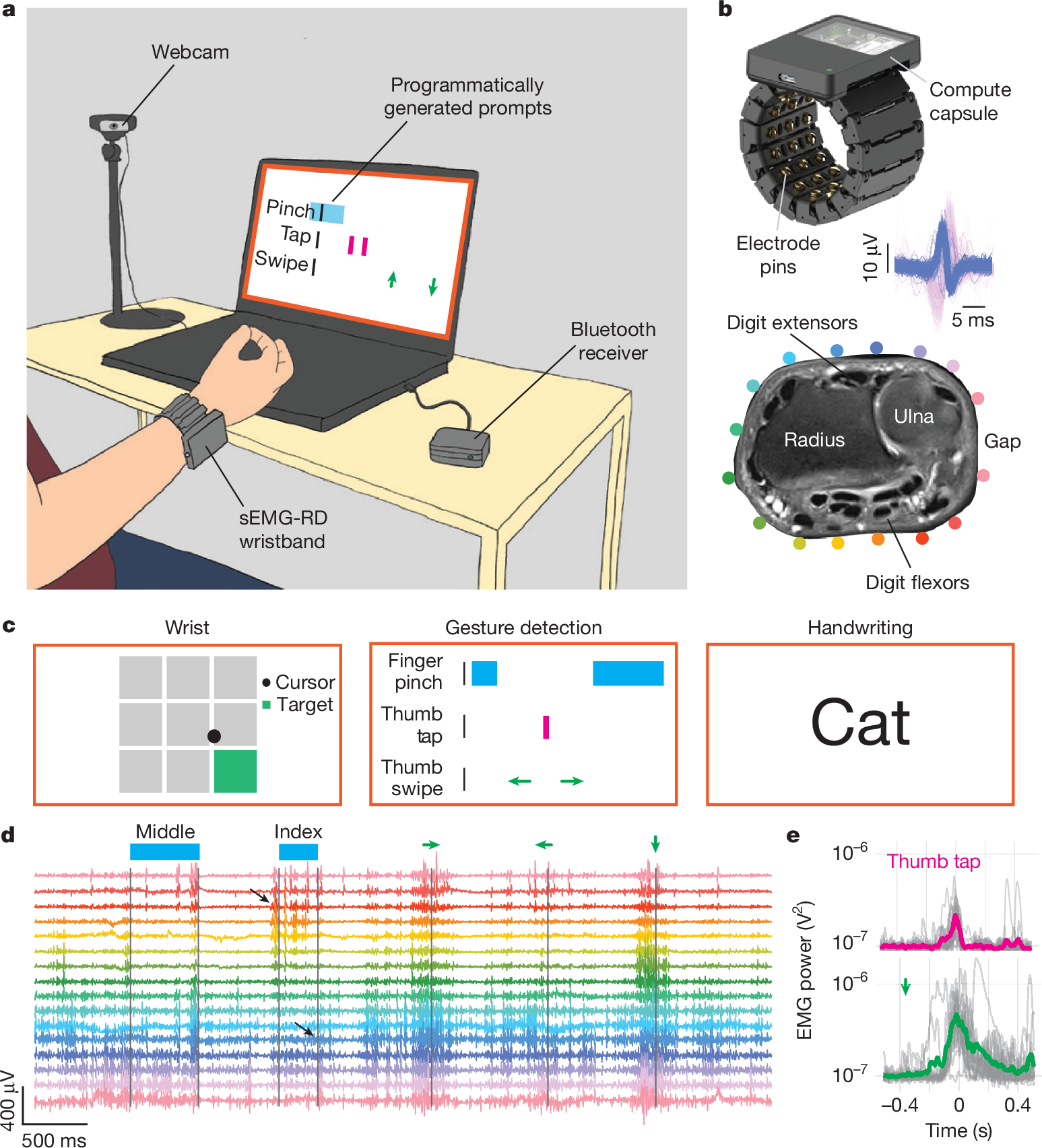
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
## Parameters
|
| 57 |
+
|
| 58 |
+
| Parameter | Type | Description |
|
| 59 |
+
|---|---|---|
|
| 60 |
+
| `n_outputs` | int | Vocabulary size for CTC. Defaults to `100` (handwriting charset). |
|
| 61 |
+
| `n_chans` | int | Number of EMG channels. Defaults to `16` (one armband). |
|
| 62 |
+
| `sfreq` | float | Sampling frequency in Hz. Defaults to `2000`. |
|
| 63 |
+
| `mpf_window_length` | int | MPF window length in samples. |
|
| 64 |
+
| `mpf_stride` | int | MPF frame stride in samples. |
|
| 65 |
+
| `mpf_n_fft` | int | STFT window / FFT size. |
|
| 66 |
+
| `mpf_fft_stride` | int | STFT hop size. Must divide `mpf_stride` and be `<= mpf_n_fft`. |
|
| 67 |
+
| `mpf_frequency_bins` | sequence of (float, float) or None | `(low, high)` Hz bands to average the cross-spectrum over. If `None`, all FFT frequency bins are used. |
|
| 68 |
+
| `mask_max_num_masks` | sequence of int | Max number of SpecAugment masks per dim (order matches `mask_dims`). |
|
| 69 |
+
| `mask_max_lengths` | sequence of int | Max mask length per dim (order matches `mask_dims`). |
|
| 70 |
+
| `mask_dims` | str | Axes to mask, among `"CFT"`. Defaults to `"TF"`. |
|
| 71 |
+
| `mask_value` | float | Filler value for masked regions. |
|
| 72 |
+
| `invariance_hidden_dims` | sequence of int | Hidden layer sizes of the per-rotation MLP. Output feature dim is `invariance_hidden_dims[-1]`. |
|
| 73 |
+
| `invariance_offsets` | sequence of int | Circular channel rotations to average over. |
|
| 74 |
+
| `num_adjacent_cov` | int | Number of adjacent off-diagonals of the cross-channel covariance matrix to keep. |
|
| 75 |
+
| `conformer_input_dim` | int | Conformer embedding dimension `D`. |
|
| 76 |
+
| `conformer_ffn_dim` | int | Feed-forward hidden dim inside each block. |
|
| 77 |
+
| `conformer_kernel_size` | int or sequence of int | Depthwise-conv kernel size per block. |
|
| 78 |
+
| `conformer_stride` | int or sequence of int | Depthwise-conv stride per block. As a scalar, applied only to the last block (entire encoder downsamples by `stride`); as a sequence of length `conformer_num_layers`, applied per block. Defaults to the paper's 15-layer schedule `(1, 1, 1, 1, 2) * 2 + (1,) * 5` (2x downsampling at blocks 5 and 10). When overriding `conformer_num_layers`, also pass a matching schedule or a scalar. |
|
| 79 |
+
| `conformer_num_heads` | int | Number of attention heads. |
|
| 80 |
+
| `conformer_attn_window_size` | int or sequence of int | Attention receptive field per block. Defaults to the paper's 15-layer schedule `(16,) * 10 + (8,) * 5`. When overriding `conformer_num_layers`, also pass a matching schedule or a scalar. |
|
| 81 |
+
| `conformer_num_layers` | int | Number of conformer blocks. |
|
| 82 |
+
| `drop_prob` | float | Dropout probability applied throughout the conformer (FFN, conv and attention blocks). |
|
| 83 |
+
| `time_reduction_stride` | int | Frame-stacking stride applied **before** the conformer. `1` disables it. |
|
| 84 |
+
| `log_softmax` | bool | If `True`, apply :func:`torch.nn.functional.log_softmax` to the emissions. Disabled by default (braindecode models return logits). |
|
| 85 |
+
| `activation` | type of nn.Module | Activation class used inside the conformer feed-forward and convolution blocks. Defaults to :class:`torch.nn.SiLU`. |
|
| 86 |
+
| `invariance_activation` | type of nn.Module | Activation class used inside the rotation-invariant MLP. Defaults to :class:`torch.nn.LeakyReLU`. |
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
## References
|
| 90 |
+
|
| 91 |
+
1. CTRL-labs at Reality Labs (Kaifosh, P., Reardon, T. R. et al.), 2025. A generic non-invasive neuromotor interface for human-computer interaction. Nature 645, 702-710. https://doi.org/10.1038/s41586-025-09255-w
|
| 92 |
+
2. Gulati, A. et al., 2020. Conformer: convolution-augmented transformer for speech recognition. Proc. Interspeech, 5036-5040.
|
| 93 |
+
3. Graves, A., Fernandez, S., Gomez, F., Schmidhuber, J., 2006. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. Proc. ICML, 369-376.
|
| 94 |
+
4. Park, D. S. et al., 2019. SpecAugment: a simple data augmentation method for automatic speech recognition. Proc. Interspeech, 2613-2617.
|
| 95 |
+
5. Yu, J. et al., 2021. FastEmit: low-latency streaming ASR with sequence-level emission regularization. Proc. ICASSP.
|
| 96 |
+
6. Barachant, A., Barthelemy, Q., King, J.-R., Gramfort, A., Chevallier, S., Rodrigues, P. L. C., ... Aristimunha, B., 2026. pyRiemann (v0.10). Zenodo. https://doi.org/10.5281/zenodo.593816
|
| 97 |
|
|
|
|
|
|
|
| 98 |
|
| 99 |
## Citation
|
| 100 |
|
| 101 |
+
Cite the original architecture paper (see *References* above) and braindecode:
|
|
|
|
| 102 |
|
| 103 |
```bibtex
|
| 104 |
@article{aristimunha2025braindecode,
|