

Replace with clean markdown card
Browse files
README.md
CHANGED
|
@@ -10,18 +10,16 @@ tags:
|
|
| 10 |
- braindecode
|
| 11 |
- foundation-model
|
| 12 |
- convolutional
|
| 13 |
-
- transformer
|
| 14 |
---
|
| 15 |
|
| 16 |
# InterpolatedLaBraM
|
| 17 |
|
| 18 |
Channel-interpolating wrapper around :class:`Labram`.
|
| 19 |
|
| 20 |
-
> **Architecture-only repository.**
|
| 21 |
> `braindecode.models.InterpolatedLaBraM` class. **No pretrained weights are
|
| 22 |
-
> distributed here**
|
| 23 |
-
> data
|
| 24 |
-
> separately.
|
| 25 |
|
| 26 |
## Quick start
|
| 27 |
|
|
@@ -40,248 +38,59 @@ model = InterpolatedLaBraM(
|
|
| 40 |
)
|
| 41 |
```
|
| 42 |
|
| 43 |
-
The signal-shape arguments above are
|
| 44 |
-
|
| 45 |
|
| 46 |
## Documentation
|
| 47 |
-
|
| 48 |
-
-
|
| 49 |
-
<https://braindecode.org/stable/generated/braindecode.models.InterpolatedLaBraM.html>
|
| 50 |
-
- Interactive browser with live instantiation:
|
| 51 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 52 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/interpolated.py#L1>
|
| 53 |
|
| 54 |
-
## Architecture description
|
| 55 |
-
|
| 56 |
-
The block below is the rendered class docstring (parameters,
|
| 57 |
-
references, architecture figure where available).
|
| 58 |
-
|
| 59 |
-
<div class='bd-doc'><main>
|
| 60 |
-
<p>Channel-interpolating wrapper around :class:`Labram`.</p>
|
| 61 |
-
<p>:bdg-dark-line:`Channel`</p>
|
| 62 |
-
<p>Accepts arbitrary user <span class="docutils literal">chs_info</span> and projects them to the
|
| 63 |
-
backbone's canonical channel set via
|
| 64 |
-
:class:`~braindecode.modules.ChannelInterpolationLayer`.</p>
|
| 65 |
-
<p>For all other parameters and behavior see the backbone
|
| 66 |
-
documentation reproduced below.</p>
|
| 67 |
-
<p>Labram from Jiang, W B et al (2024) [Jiang2024]_.</p>
|
| 68 |
-
<span style="display:inline-block;padding:2px 8px;border-radius:4px;background:#5cb85c;color:white;font-size:11px;font-weight:600;margin-right:4px;">Convolution</span><span style="display:inline-block;padding:2px 8px;border-radius:4px;background:#d9534f;color:white;font-size:11px;font-weight:600;margin-right:4px;">Foundation Model</span>
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
.. figure:: https://arxiv.org/html/2405.18765v1/x1.png
|
| 73 |
-
:align: center
|
| 74 |
-
:alt: Labram Architecture.
|
| 75 |
-
|
| 76 |
-
Large Brain Model for Learning Generic Representations with Tremendous
|
| 77 |
-
EEG Data in BCI from [Jiang2024]_.
|
| 78 |
-
|
| 79 |
-
This is an **adaptation** of the code [Code2024]_ from the Labram model.
|
| 80 |
-
|
| 81 |
-
The model is transformer architecture with **strong** inspiration from
|
| 82 |
-
BEiTv2 [BeiTv2]_.
|
| 83 |
-
|
| 84 |
-
The models can be used in two modes:
|
| 85 |
-
|
| 86 |
-
- Neural Tokenizer: Design to get an embedding layers (e.g. classification).
|
| 87 |
-
- Neural Decoder: To extract the ampliture and phase outputs with a VQSNP.
|
| 88 |
-
|
| 89 |
-
The braindecode's modification is to allow the model to be used in
|
| 90 |
-
with an input shape of (batch, n_chans, n_times), if neural tokenizer
|
| 91 |
-
equals True. The original implementation uses (batch, n_chans, n_patches,
|
| 92 |
-
patch_size) as input with static segmentation of the input data.
|
| 93 |
-
|
| 94 |
-
The models have the following sequence of steps::
|
| 95 |
-
|
| 96 |
-
if neural tokenizer:
|
| 97 |
-
- SegmentPatch: Segment the input data in patches;
|
| 98 |
-
- TemporalConv: Apply a temporal convolution to the segmented data;
|
| 99 |
-
- Residual adding cls, temporal and position embeddings (optional);
|
| 100 |
-
- WindowsAttentionBlock: Apply a windows attention block to the data;
|
| 101 |
-
- LayerNorm: Apply layer normalization to the data;
|
| 102 |
-
- Linear: An head linear layer to transformer the data into classes.
|
| 103 |
-
|
| 104 |
-
else:
|
| 105 |
-
- PatchEmbed: Apply a patch embedding to the input data;
|
| 106 |
-
- Residual adding cls, temporal and position embeddings (optional);
|
| 107 |
-
- WindowsAttentionBlock: Apply a windows attention block to the data;
|
| 108 |
-
- LayerNorm: Apply layer normalization to the data;
|
| 109 |
-
- Linear: An head linear layer to transformer the data into classes.
|
| 110 |
-
|
| 111 |
-
.. important::
|
| 112 |
-
**Pre-trained Weights Available**
|
| 113 |
-
|
| 114 |
-
This model has pre-trained weights available on the Hugging Face Hub.
|
| 115 |
-
You can load them using:
|
| 116 |
-
|
| 117 |
-
.. code:: python
|
| 118 |
-
from braindecode.models import Labram
|
| 119 |
-
|
| 120 |
-
# Load pre-trained model from Hugging Face Hub
|
| 121 |
-
model = Labram.from_pretrained("braindecode/labram-pretrained")
|
| 122 |
-
|
| 123 |
-
To push your own trained model to the Hub:
|
| 124 |
-
|
| 125 |
-
.. code:: python
|
| 126 |
-
# After training your model
|
| 127 |
-
model.push_to_hub(
|
| 128 |
-
repo_id="username/my-labram-model", commit_message="Upload trained Labram model"
|
| 129 |
-
)
|
| 130 |
-
|
| 131 |
-
Requires installing ``braindecode[hug]`` for Hub integration.
|
| 132 |
-
|
| 133 |
-
.. versionadded:: 0.9
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
Examples
|
| 137 |
-
--------
|
| 138 |
-
Load pre-trained weights::
|
| 139 |
-
|
| 140 |
-
>>> import torch
|
| 141 |
-
>>> from braindecode.models import Labram
|
| 142 |
-
>>> model = Labram(n_times=1600, n_chans=64, n_outputs=4)
|
| 143 |
-
>>> url = "https://huggingface.co/braindecode/Labram-Braindecode/blob/main/braindecode_labram_base.pt"
|
| 144 |
-
>>> state = torch.hub.load_state_dict_from_url(url, progress=True)
|
| 145 |
-
>>> model.load_state_dict(state)
|
| 146 |
-
|
| 147 |
-
|
| 148 |
-
Parameters
|
| 149 |
-
----------
|
| 150 |
-
patch_size : int
|
| 151 |
-
The size of the patch to be used in the patch embedding.
|
| 152 |
-
learned_patcher : bool
|
| 153 |
-
Whether to use a learned patch embedding (via a convolutional layer) or a fixed patch embedding (via rearrangement).
|
| 154 |
-
embed_dim : int
|
| 155 |
-
The dimension of the embedding.
|
| 156 |
-
conv_in_channels : int
|
| 157 |
-
The number of convolutional input channels.
|
| 158 |
-
conv_out_channels : int
|
| 159 |
-
The number of convolutional output channels.
|
| 160 |
-
num_layers : int (default=12)
|
| 161 |
-
The number of attention layers of the model.
|
| 162 |
-
num_heads : int (default=10)
|
| 163 |
-
The number of attention heads.
|
| 164 |
-
mlp_ratio : float (default=4.0)
|
| 165 |
-
The expansion ratio of the mlp layer
|
| 166 |
-
qkv_bias : bool (default=False)
|
| 167 |
-
If True, add a learnable bias to the query, key, and value tensors.
|
| 168 |
-
qk_norm : Pytorch Normalize layer (default=nn.LayerNorm)
|
| 169 |
-
If not None, apply LayerNorm to the query and key tensors.
|
| 170 |
-
Default is nn.LayerNorm for better weight transfer from original LaBraM.
|
| 171 |
-
Set to None to disable Q,K normalization.
|
| 172 |
-
qk_scale : float (default=None)
|
| 173 |
-
If not None, use this value as the scale factor. If None,
|
| 174 |
-
use head_dim**-0.5, where head_dim = dim // num_heads.
|
| 175 |
-
drop_prob : float (default=0.0)
|
| 176 |
-
Dropout rate for the attention weights.
|
| 177 |
-
attn_drop_prob : float (default=0.0)
|
| 178 |
-
Dropout rate for the attention weights.
|
| 179 |
-
drop_path_prob : float (default=0.0)
|
| 180 |
-
Dropout rate for the attention weights used on DropPath.
|
| 181 |
-
norm_layer : Pytorch Normalize layer (default=nn.LayerNorm)
|
| 182 |
-
The normalization layer to be used.
|
| 183 |
-
init_values : float (default=0.1)
|
| 184 |
-
If not None, use this value to initialize the gamma_1 and gamma_2
|
| 185 |
-
parameters for residual scaling. Default is 0.1 for better weight
|
| 186 |
-
transfer from original LaBraM. Set to None to disable.
|
| 187 |
-
use_abs_pos_emb : bool (default=True)
|
| 188 |
-
If True, use absolute position embedding.
|
| 189 |
-
use_mean_pooling : bool (default=True)
|
| 190 |
-
If True, use mean pooling.
|
| 191 |
-
init_scale : float (default=0.001)
|
| 192 |
-
The initial scale to be used in the parameters of the model.
|
| 193 |
-
neural_tokenizer : bool (default=True)
|
| 194 |
-
The model can be used in two modes: Neural Tokenizer or Neural Decoder.
|
| 195 |
-
attn_head_dim : bool (default=None)
|
| 196 |
-
The head dimension to be used in the attention layer, to be used only
|
| 197 |
-
during pre-training.
|
| 198 |
-
activation: nn.Module, default=nn.GELU
|
| 199 |
-
Activation function class to apply. Should be a PyTorch activation
|
| 200 |
-
module class like ``nn.ReLU`` or ``nn.ELU``. Default is ``nn.GELU``.
|
| 201 |
-
|
| 202 |
-
References
|
| 203 |
-
----------
|
| 204 |
-
.. [Jiang2024] Wei-Bang Jiang, Li-Ming Zhao, Bao-Liang Lu. 2024, May.
|
| 205 |
-
Large Brain Model for Learning Generic Representations with Tremendous
|
| 206 |
-
EEG Data in BCI. The Twelfth International Conference on Learning
|
| 207 |
-
Representations, ICLR.
|
| 208 |
-
.. [Code2024] Wei-Bang Jiang, Li-Ming Zhao, Bao-Liang Lu. 2024. Labram
|
| 209 |
-
Large Brain Model for Learning Generic Representations with Tremendous
|
| 210 |
-
EEG Data in BCI. GitHub https://github.com/935963004/LaBraM
|
| 211 |
-
(accessed 2024-03-02)
|
| 212 |
-
.. [BeiTv2] Zhiliang Peng, Li Dong, Hangbo Bao, Qixiang Ye, Furu Wei. 2024.
|
| 213 |
-
BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers.
|
| 214 |
-
arXiv:2208.06366 [cs.CV]
|
| 215 |
-
|
| 216 |
-
.. rubric:: Hugging Face Hub integration
|
| 217 |
-
|
| 218 |
-
When the optional ``huggingface_hub`` package is installed, all models
|
| 219 |
-
automatically gain the ability to be pushed to and loaded from the
|
| 220 |
-
Hugging Face Hub. Install with::
|
| 221 |
-
|
| 222 |
-
pip install braindecode[hub]
|
| 223 |
-
|
| 224 |
-
**Pushing a model to the Hub:**
|
| 225 |
-
|
| 226 |
-
.. code::
|
| 227 |
-
from braindecode.models import Labram
|
| 228 |
-
|
| 229 |
-
# Train your model
|
| 230 |
-
model = Labram(n_chans=22, n_outputs=4, n_times=1000)
|
| 231 |
-
# ... training code ...
|
| 232 |
-
|
| 233 |
-
# Push to the Hub
|
| 234 |
-
model.push_to_hub(
|
| 235 |
-
repo_id="username/my-labram-model",
|
| 236 |
-
commit_message="Initial model upload",
|
| 237 |
-
)
|
| 238 |
-
|
| 239 |
-
**Loading a model from the Hub:**
|
| 240 |
-
|
| 241 |
-
.. code::
|
| 242 |
-
from braindecode.models import Labram
|
| 243 |
-
|
| 244 |
-
# Load pretrained model
|
| 245 |
-
model = Labram.from_pretrained("username/my-labram-model")
|
| 246 |
-
|
| 247 |
-
# Load with a different number of outputs (head is rebuilt automatically)
|
| 248 |
-
model = Labram.from_pretrained("username/my-labram-model", n_outputs=4)
|
| 249 |
-
|
| 250 |
-
**Extracting features and replacing the head:**
|
| 251 |
|
| 252 |
-
|
| 253 |
-
import torch
|
| 254 |
|
| 255 |
-
|
| 256 |
-
# Extract encoder features (consistent dict across all models)
|
| 257 |
-
out = model(x, return_features=True)
|
| 258 |
-
features = out["features"]
|
| 259 |
|
| 260 |
-
# Replace the classification head
|
| 261 |
-
model.reset_head(n_outputs=10)
|
| 262 |
|
| 263 |
-
|
| 264 |
|
| 265 |
-
|
| 266 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 267 |
|
| 268 |
-
config = model.get_config() # all __init__ params
|
| 269 |
-
with open("config.json", "w") as f:
|
| 270 |
-
json.dump(config, f)
|
| 271 |
|
| 272 |
-
|
| 273 |
|
| 274 |
-
|
| 275 |
-
|
| 276 |
-
|
| 277 |
|
| 278 |
-
See :ref:`load-pretrained-models` for a complete tutorial.</main>
|
| 279 |
-
</div>
|
| 280 |
|
| 281 |
## Citation
|
| 282 |
|
| 283 |
-
|
| 284 |
-
*References* section above) and braindecode:
|
| 285 |
|
| 286 |
```bibtex
|
| 287 |
@article{aristimunha2025braindecode,
|
|
|
|
| 10 |
- braindecode
|
| 11 |
- foundation-model
|
| 12 |
- convolutional
|
|
|
|
| 13 |
---
|
| 14 |
|
| 15 |
# InterpolatedLaBraM
|
| 16 |
|
| 17 |
Channel-interpolating wrapper around :class:`Labram`.
|
| 18 |
|
| 19 |
+
> **Architecture-only repository.** Documents the
|
| 20 |
> `braindecode.models.InterpolatedLaBraM` class. **No pretrained weights are
|
| 21 |
+
> distributed here.** Instantiate the model and train it on your own
|
| 22 |
+
> data.
|
|
|
|
| 23 |
|
| 24 |
## Quick start
|
| 25 |
|
|
|
|
| 38 |
)
|
| 39 |
```
|
| 40 |
|
| 41 |
+
The signal-shape arguments above are illustrative defaults — adjust to
|
| 42 |
+
match your recording.
|
| 43 |
|
| 44 |
## Documentation
|
| 45 |
+
- Full API reference: <https://braindecode.org/stable/generated/braindecode.models.InterpolatedLaBraM.html>
|
| 46 |
+
- Interactive browser (live instantiation, parameter counts):
|
|
|
|
|
|
|
| 47 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 48 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/interpolated.py#L1>
|
| 49 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 50 |
|
| 51 |
+
## Architecture
|
|
|
|
| 52 |
|
| 53 |
+
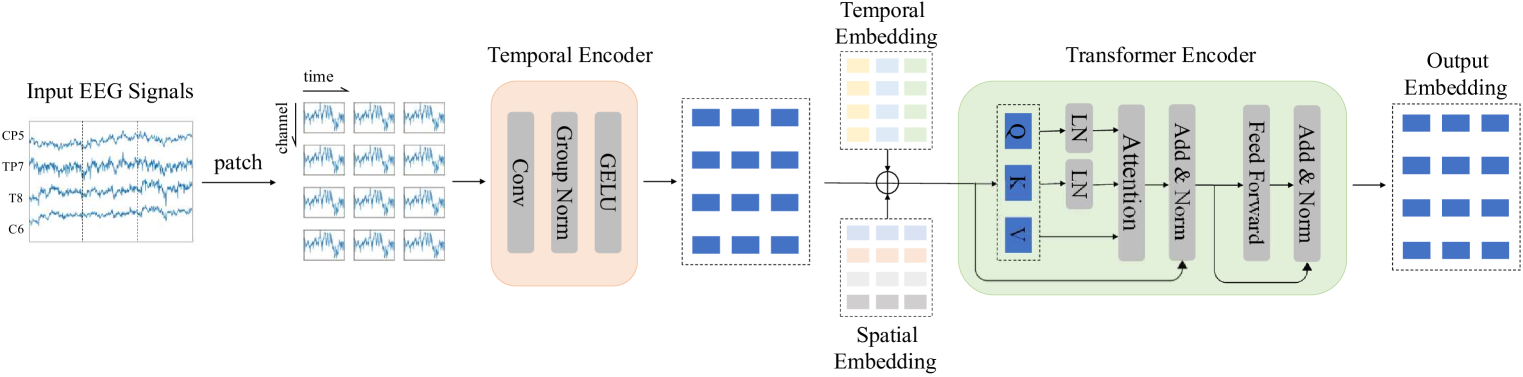
|
|
|
|
|
|
|
|
|
|
| 54 |
|
|
|
|
|
|
|
| 55 |
|
| 56 |
+
## Parameters
|
| 57 |
|
| 58 |
+
| Parameter | Type | Description |
|
| 59 |
+
|---|---|---|
|
| 60 |
+
| `patch_size` | int | The size of the patch to be used in the patch embedding. |
|
| 61 |
+
| `learned_patcher` | bool | Whether to use a learned patch embedding (via a convolutional layer) or a fixed patch embedding (via rearrangement). |
|
| 62 |
+
| `embed_dim` | int | The dimension of the embedding. |
|
| 63 |
+
| `conv_in_channels` | int | The number of convolutional input channels. |
|
| 64 |
+
| `conv_out_channels` | int | The number of convolutional output channels. |
|
| 65 |
+
| `num_layers` | int (default=12) | The number of attention layers of the model. |
|
| 66 |
+
| `num_heads` | int (default=10) | The number of attention heads. |
|
| 67 |
+
| `mlp_ratio` | float (default=4.0) | The expansion ratio of the mlp layer |
|
| 68 |
+
| `qkv_bias` | bool (default=False) | If True, add a learnable bias to the query, key, and value tensors. |
|
| 69 |
+
| `qk_norm` | Pytorch Normalize layer (default=nn.LayerNorm) | If not None, apply LayerNorm to the query and key tensors. Default is nn.LayerNorm for better weight transfer from original LaBraM. Set to None to disable Q,K normalization. |
|
| 70 |
+
| `qk_scale` | float (default=None) | If not None, use this value as the scale factor. If None, use head_dim**-0.5, where head_dim = dim // num_heads. |
|
| 71 |
+
| `drop_prob` | float (default=0.0) | Dropout rate for the attention weights. |
|
| 72 |
+
| `attn_drop_prob` | float (default=0.0) | Dropout rate for the attention weights. |
|
| 73 |
+
| `drop_path_prob` | float (default=0.0) | Dropout rate for the attention weights used on DropPath. |
|
| 74 |
+
| `norm_layer` | Pytorch Normalize layer (default=nn.LayerNorm) | The normalization layer to be used. |
|
| 75 |
+
| `init_values` | float (default=0.1) | If not None, use this value to initialize the gamma_1 and gamma_2 parameters for residual scaling. Default is 0.1 for better weight transfer from original LaBraM. Set to None to disable. |
|
| 76 |
+
| `use_abs_pos_emb` | bool (default=True) | If True, use absolute position embedding. |
|
| 77 |
+
| `use_mean_pooling` | bool (default=True) | If True, use mean pooling. |
|
| 78 |
+
| `init_scale` | float (default=0.001) | The initial scale to be used in the parameters of the model. |
|
| 79 |
+
| `neural_tokenizer` | bool (default=True) | The model can be used in two modes: Neural Tokenizer or Neural Decoder. |
|
| 80 |
+
| `attn_head_dim` | bool (default=None) | The head dimension to be used in the attention layer, to be used only during pre-training. |
|
| 81 |
+
| `activation: nn.Module, default=nn.GELU` | — | Activation function class to apply. Should be a PyTorch activation module class like `nn.ReLU` or `nn.ELU`. Default is `nn.GELU`. |
|
| 82 |
|
|
|
|
|
|
|
|
|
|
| 83 |
|
| 84 |
+
## References
|
| 85 |
|
| 86 |
+
1. Wei-Bang Jiang, Li-Ming Zhao, Bao-Liang Lu. 2024, May. Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI. The Twelfth International Conference on Learning Representations, ICLR.
|
| 87 |
+
2. Wei-Bang Jiang, Li-Ming Zhao, Bao-Liang Lu. 2024. Labram Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI. GitHub https://github.com/935963004/LaBraM (accessed 2024-03-02)
|
| 88 |
+
3. Zhiliang Peng, Li Dong, Hangbo Bao, Qixiang Ye, Furu Wei. 2024. BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers. arXiv:2208.06366 [cs.CV]
|
| 89 |
|
|
|
|
|
|
|
| 90 |
|
| 91 |
## Citation
|
| 92 |
|
| 93 |
+
Cite the original architecture paper (see *References* above) and braindecode:
|
|
|
|
| 94 |
|
| 95 |
```bibtex
|
| 96 |
@article{aristimunha2025braindecode,
|