

Replace with clean markdown card
Browse files
README.md
CHANGED
|
@@ -9,18 +9,16 @@ tags:
|
|
| 9 |
- neuroscience
|
| 10 |
- braindecode
|
| 11 |
- convolutional
|
| 12 |
-
- transformer
|
| 13 |
---
|
| 14 |
|
| 15 |
# FBLightConvNet
|
| 16 |
|
| 17 |
-
LightConvNet from Ma, X et al (2023) .
|
| 18 |
|
| 19 |
-
> **Architecture-only repository.**
|
| 20 |
> `braindecode.models.FBLightConvNet` class. **No pretrained weights are
|
| 21 |
-
> distributed here**
|
| 22 |
-
> data
|
| 23 |
-
> separately.
|
| 24 |
|
| 25 |
## Quick start
|
| 26 |
|
|
@@ -39,169 +37,46 @@ model = FBLightConvNet(
|
|
| 39 |
)
|
| 40 |
```
|
| 41 |
|
| 42 |
-
The signal-shape arguments above are
|
| 43 |
-
|
| 44 |
|
| 45 |
## Documentation
|
| 46 |
-
|
| 47 |
-
-
|
| 48 |
-
<https://braindecode.org/stable/generated/braindecode.models.FBLightConvNet.html>
|
| 49 |
-
- Interactive browser with live instantiation:
|
| 50 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 51 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/fblightconvnet.py#L18>
|
| 52 |
|
| 53 |
-
## Architecture description
|
| 54 |
-
|
| 55 |
-
The block below is the rendered class docstring (parameters,
|
| 56 |
-
references, architecture figure where available).
|
| 57 |
-
|
| 58 |
-
<div class='bd-doc'><main>
|
| 59 |
-
<p>LightConvNet from Ma, X et al (2023) [lightconvnet]_.</p>
|
| 60 |
-
<span style="display:inline-block;padding:2px 8px;border-radius:4px;background:#5cb85c;color:white;font-size:11px;font-weight:600;margin-right:4px;">Convolution</span><span style="display:inline-block;padding:2px 8px;border-radius:4px;background:#0072B2;color:white;font-size:11px;font-weight:600;margin-right:4px;">Filterbank</span>
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
.. figure:: https://raw.githubusercontent.com/Ma-Xinzhi/LightConvNet/refs/heads/main/network_architecture.png
|
| 65 |
-
:align: center
|
| 66 |
-
:alt: LightConvNet Neural Network
|
| 67 |
-
|
| 68 |
-
A lightweight convolutional neural network incorporating temporal
|
| 69 |
-
dependency learning and attention mechanisms. The architecture is
|
| 70 |
-
designed to efficiently capture spatial and temporal features through
|
| 71 |
-
specialized convolutional layers and **multi-head attention**.
|
| 72 |
-
|
| 73 |
-
The network architecture consists of four main modules:
|
| 74 |
-
|
| 75 |
-
1. **Spatial and Spectral Information Learning**:
|
| 76 |
-
Applies filterbank and spatial convolutions.
|
| 77 |
-
This module is followed by batch normalization and
|
| 78 |
-
an activation function to enhance feature representation.
|
| 79 |
-
|
| 80 |
-
2. **Temporal Segmentation and Feature Extraction**:
|
| 81 |
-
Divides the processed data into non-overlapping temporal windows.
|
| 82 |
-
Within each window, a variance-based layer extracts discriminative features,
|
| 83 |
-
which are then log-transformed to stabilize variance before being
|
| 84 |
-
passed to the attention module.
|
| 85 |
-
|
| 86 |
-
3. **Temporal Attention Module**: Utilizes a multi-head attention
|
| 87 |
-
mechanism with depthwise separable convolutions to capture dependencies
|
| 88 |
-
across different temporal segments. The attention weights are normalized
|
| 89 |
-
using softmax and aggregated to form a comprehensive temporal
|
| 90 |
-
representation.
|
| 91 |
-
|
| 92 |
-
4. **Final Layer**: Flattens the aggregated features and passes them
|
| 93 |
-
through a linear layer to with kernel sizes matching the input
|
| 94 |
-
dimensions to integrate features across different channels generate the
|
| 95 |
-
final output predictions.
|
| 96 |
-
|
| 97 |
-
Notes
|
| 98 |
-
-----
|
| 99 |
-
This implementation is not guaranteed to be correct and has not been checked
|
| 100 |
-
by the original authors; it is a braindecode adaptation from the Pytorch
|
| 101 |
-
source-code [lightconvnetcode]_.
|
| 102 |
|
| 103 |
-
|
| 104 |
-
----------
|
| 105 |
-
n_bands : int or None or list of tuple of int, default=8
|
| 106 |
-
Number of frequency bands or a list of frequency band tuples. If a list of tuples is provided,
|
| 107 |
-
each tuple defines the lower and upper bounds of a frequency band.
|
| 108 |
-
n_filters_spat : int, default=32
|
| 109 |
-
Number of spatial filters in the depthwise convolutional layer.
|
| 110 |
-
n_dim : int, default=3
|
| 111 |
-
Number of dimensions for the temporal reduction layer.
|
| 112 |
-
stride_factor : int, default=4
|
| 113 |
-
Stride factor used for reshaping the temporal dimension.
|
| 114 |
-
activation : nn.Module, default=nn.ELU
|
| 115 |
-
Activation function class to apply after convolutional layers.
|
| 116 |
-
verbose : bool, default=False
|
| 117 |
-
If True, enables verbose output during filter creation using mne.
|
| 118 |
-
filter_parameters : dict, default={}
|
| 119 |
-
Additional parameters for the FilterBankLayer.
|
| 120 |
-
heads : int, default=8
|
| 121 |
-
Number of attention heads in the multi-head attention mechanism.
|
| 122 |
-
weight_softmax : bool, default=True
|
| 123 |
-
If True, applies softmax to the attention weights.
|
| 124 |
-
bias : bool, default=False
|
| 125 |
-
If True, includes a bias term in the convolutional layers.
|
| 126 |
|
| 127 |
-
|
| 128 |
-
----------
|
| 129 |
-
.. [lightconvnet] Ma, X., Chen, W., Pei, Z., Liu, J., Huang, B., & Chen, J.
|
| 130 |
-
(2023). A temporal dependency learning CNN with attention mechanism
|
| 131 |
-
for MI-EEG decoding. IEEE Transactions on Neural Systems and
|
| 132 |
-
Rehabilitation Engineering.
|
| 133 |
-
.. [lightconvnetcode] Link to source-code:
|
| 134 |
-
https://github.com/Ma-Xinzhi/LightConvNet
|
| 135 |
|
| 136 |
-
.. rubric:: Hugging Face Hub integration
|
| 137 |
|
| 138 |
-
|
| 139 |
-
automatically gain the ability to be pushed to and loaded from the
|
| 140 |
-
Hugging Face Hub. Install with::
|
| 141 |
|
| 142 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 143 |
|
| 144 |
-
**Pushing a model to the Hub:**
|
| 145 |
|
| 146 |
-
|
| 147 |
-
from braindecode.models import FBLightConvNet
|
| 148 |
|
| 149 |
-
|
| 150 |
-
|
| 151 |
-
# ... training code ...
|
| 152 |
|
| 153 |
-
# Push to the Hub
|
| 154 |
-
model.push_to_hub(
|
| 155 |
-
repo_id="username/my-fblightconvnet-model",
|
| 156 |
-
commit_message="Initial model upload",
|
| 157 |
-
)
|
| 158 |
-
|
| 159 |
-
**Loading a model from the Hub:**
|
| 160 |
-
|
| 161 |
-
.. code::
|
| 162 |
-
from braindecode.models import FBLightConvNet
|
| 163 |
-
|
| 164 |
-
# Load pretrained model
|
| 165 |
-
model = FBLightConvNet.from_pretrained("username/my-fblightconvnet-model")
|
| 166 |
-
|
| 167 |
-
# Load with a different number of outputs (head is rebuilt automatically)
|
| 168 |
-
model = FBLightConvNet.from_pretrained("username/my-fblightconvnet-model", n_outputs=4)
|
| 169 |
-
|
| 170 |
-
**Extracting features and replacing the head:**
|
| 171 |
-
|
| 172 |
-
.. code::
|
| 173 |
-
import torch
|
| 174 |
-
|
| 175 |
-
x = torch.randn(1, model.n_chans, model.n_times)
|
| 176 |
-
# Extract encoder features (consistent dict across all models)
|
| 177 |
-
out = model(x, return_features=True)
|
| 178 |
-
features = out["features"]
|
| 179 |
-
|
| 180 |
-
# Replace the classification head
|
| 181 |
-
model.reset_head(n_outputs=10)
|
| 182 |
-
|
| 183 |
-
**Saving and restoring full configuration:**
|
| 184 |
-
|
| 185 |
-
.. code::
|
| 186 |
-
import json
|
| 187 |
-
|
| 188 |
-
config = model.get_config() # all __init__ params
|
| 189 |
-
with open("config.json", "w") as f:
|
| 190 |
-
json.dump(config, f)
|
| 191 |
-
|
| 192 |
-
model2 = FBLightConvNet.from_config(config) # reconstruct (no weights)
|
| 193 |
-
|
| 194 |
-
All model parameters (both EEG-specific and model-specific such as
|
| 195 |
-
dropout rates, activation functions, number of filters) are automatically
|
| 196 |
-
saved to the Hub and restored when loading.
|
| 197 |
-
|
| 198 |
-
See :ref:`load-pretrained-models` for a complete tutorial.</main>
|
| 199 |
-
</div>
|
| 200 |
|
| 201 |
## Citation
|
| 202 |
|
| 203 |
-
|
| 204 |
-
*References* section above) and braindecode:
|
| 205 |
|
| 206 |
```bibtex
|
| 207 |
@article{aristimunha2025braindecode,
|
|
|
|
| 9 |
- neuroscience
|
| 10 |
- braindecode
|
| 11 |
- convolutional
|
|
|
|
| 12 |
---
|
| 13 |
|
| 14 |
# FBLightConvNet
|
| 15 |
|
| 16 |
+
LightConvNet from Ma, X et al (2023) [lightconvnet].
|
| 17 |
|
| 18 |
+
> **Architecture-only repository.** Documents the
|
| 19 |
> `braindecode.models.FBLightConvNet` class. **No pretrained weights are
|
| 20 |
+
> distributed here.** Instantiate the model and train it on your own
|
| 21 |
+
> data.
|
|
|
|
| 22 |
|
| 23 |
## Quick start
|
| 24 |
|
|
|
|
| 37 |
)
|
| 38 |
```
|
| 39 |
|
| 40 |
+
The signal-shape arguments above are illustrative defaults — adjust to
|
| 41 |
+
match your recording.
|
| 42 |
|
| 43 |
## Documentation
|
| 44 |
+
- Full API reference: <https://braindecode.org/stable/generated/braindecode.models.FBLightConvNet.html>
|
| 45 |
+
- Interactive browser (live instantiation, parameter counts):
|
|
|
|
|
|
|
| 46 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 47 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/fblightconvnet.py#L18>
|
| 48 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 49 |
|
| 50 |
+
## Architecture
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 51 |
|
| 52 |
+
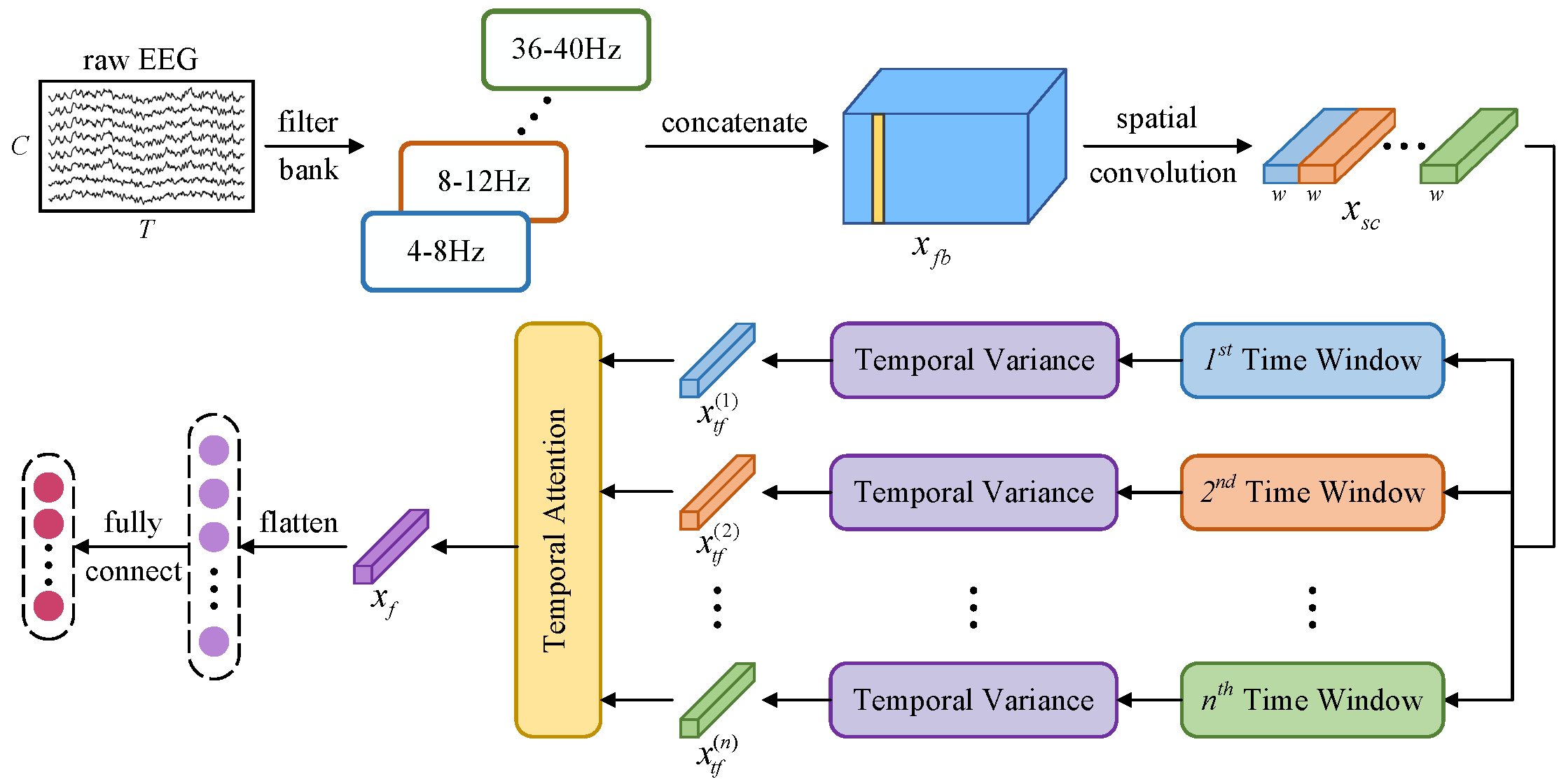
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 53 |
|
|
|
|
| 54 |
|
| 55 |
+
## Parameters
|
|
|
|
|
|
|
| 56 |
|
| 57 |
+
| Parameter | Type | Description |
|
| 58 |
+
|---|---|---|
|
| 59 |
+
| `n_bands` | int or None or list of tuple of int, default=8 | Number of frequency bands or a list of frequency band tuples. If a list of tuples is provided, each tuple defines the lower and upper bounds of a frequency band. |
|
| 60 |
+
| `n_filters_spat` | int, default=32 | Number of spatial filters in the depthwise convolutional layer. |
|
| 61 |
+
| `n_dim` | int, default=3 | Number of dimensions for the temporal reduction layer. |
|
| 62 |
+
| `stride_factor` | int, default=4 | Stride factor used for reshaping the temporal dimension. |
|
| 63 |
+
| `activation` | nn.Module, default=nn.ELU | Activation function class to apply after convolutional layers. |
|
| 64 |
+
| `verbose` | bool, default=False | If True, enables verbose output during filter creation using mne. |
|
| 65 |
+
| `filter_parameters` | dict, default={} | Additional parameters for the FilterBankLayer. |
|
| 66 |
+
| `heads` | int, default=8 | Number of attention heads in the multi-head attention mechanism. |
|
| 67 |
+
| `weight_softmax` | bool, default=True | If True, applies softmax to the attention weights. |
|
| 68 |
+
| `bias` | bool, default=False | If True, includes a bias term in the convolutional layers. |
|
| 69 |
|
|
|
|
| 70 |
|
| 71 |
+
## References
|
|
|
|
| 72 |
|
| 73 |
+
1. Ma, X., Chen, W., Pei, Z., Liu, J., Huang, B., & Chen, J. (2023). A temporal dependency learning CNN with attention mechanism for MI-EEG decoding. IEEE Transactions on Neural Systems and Rehabilitation Engineering.
|
| 74 |
+
2. Link to source-code: https://github.com/Ma-Xinzhi/LightConvNet
|
|
|
|
| 75 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 76 |
|
| 77 |
## Citation
|
| 78 |
|
| 79 |
+
Cite the original architecture paper (see *References* above) and braindecode:
|
|
|
|
| 80 |
|
| 81 |
```bibtex
|
| 82 |
@article{aristimunha2025braindecode,
|